
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Paper • 2508.06471 • Published • 212
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Pavvav/Affine-Model-G")
model = AutoModelForCausalLM.from_pretrained("Pavvav/Affine-Model-G")
messages = [
{"role": "user", "content": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
👋 Join our Discord community.
📖 Check out the GLM-4.6 technical blog, technical report(GLM-4.5), and Zhipu AI technical documentation.
📍 Use GLM-4.6 API services on Z.ai API Platform.
👉 One click to GLM-4.6.
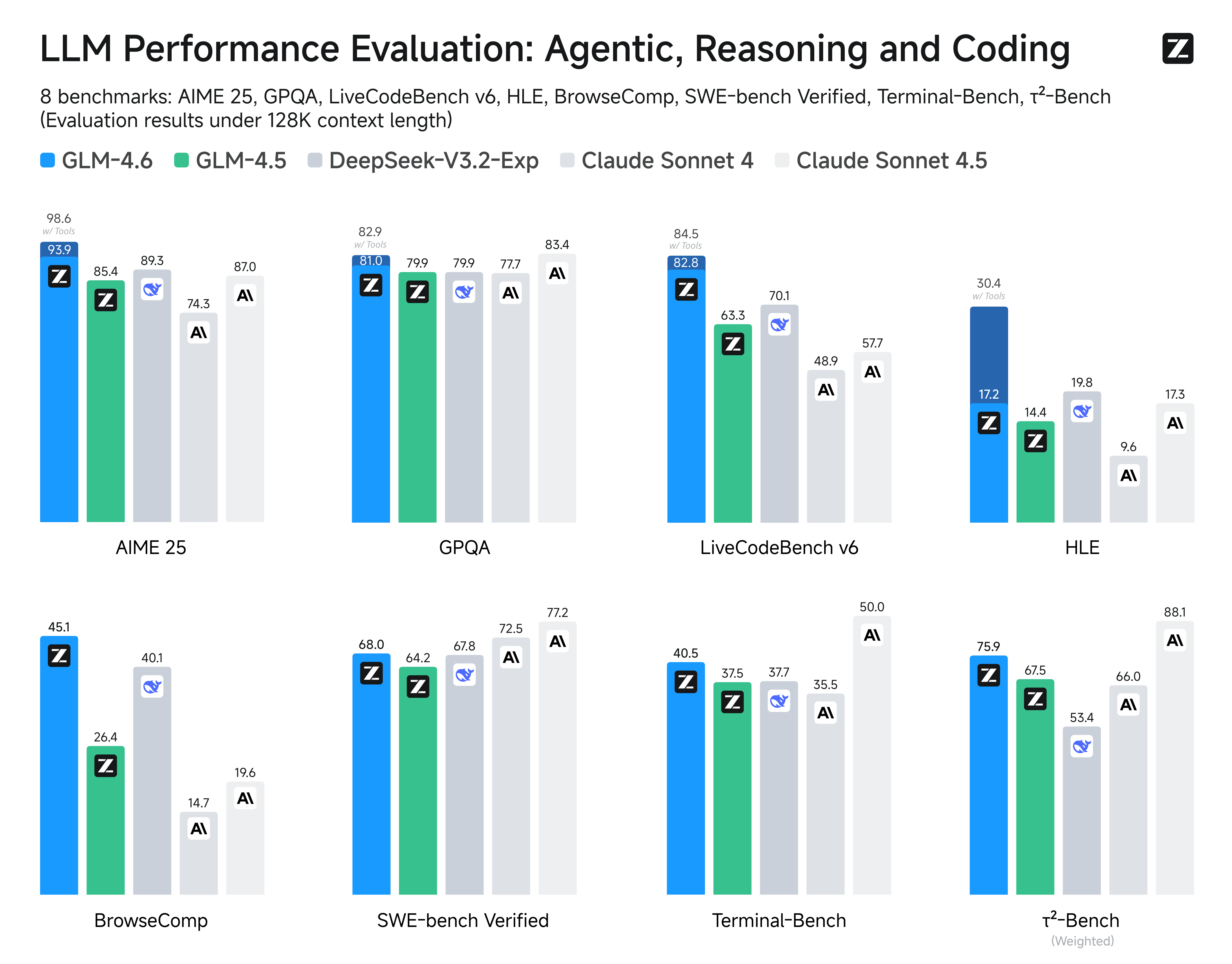
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
Both GLM-4.5 and GLM-4.6 use the same inference method.
you can check our github for more detail.
For general evaluations, we recommend using a sampling temperature of 1.0.
For code-related evaluation tasks (such as LCB), it is further recommended to set:
top_p = 0.95top_k = 40
# Use a pipeline as a high-level helper from transformers import pipeline pipe = pipeline("text-generation", model="Pavvav/Affine-Model-G") messages = [ {"role": "user", "content": "Who are you?"}, ] pipe(messages)