
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
Paper • 2308.09583 • Published • 8
winget install llama.cpp
# Start a local OpenAI-compatible server with a web UI:
llama-server -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF:# Run inference directly in the terminal:
llama-cli -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF:# Download pre-built binary from:
# https://github.com/ggerganov/llama.cpp/releases# Start a local OpenAI-compatible server with a web UI:
./llama-server -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF:# Run inference directly in the terminal:
./llama-cli -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF:git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build
cmake --build build -j --target llama-server llama-cli# Start a local OpenAI-compatible server with a web UI:
./build/bin/llama-server -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF:# Run inference directly in the terminal:
./build/bin/llama-cli -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF:docker model run hf.co/QuantFactory/WizardLM-2-7B-abliterated-GGUF:This is quantized version of fearlessdots/WizardLM-2-7B-abliterated created using llama.cpp
This is the WizardLM-2-7B model with orthogonalized bfloat16 safetensor weights, based on the implementation by @failspy. For more info:
@failspy: https://huggingface.co/failspy/llama-3-70B-Instruct-abliterated/blob/main/ortho_cookbook.ipynbThis model uses the prompt format from Vicuna and supports multi-turn conversation.
🤗 HF Repo •🐱 Github Repo • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Join our Discord
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models, which have improved performance on complex chat, multilingual, reasoning and agent. New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
For more details of WizardLM-2 please read our release blog post and upcoming paper.
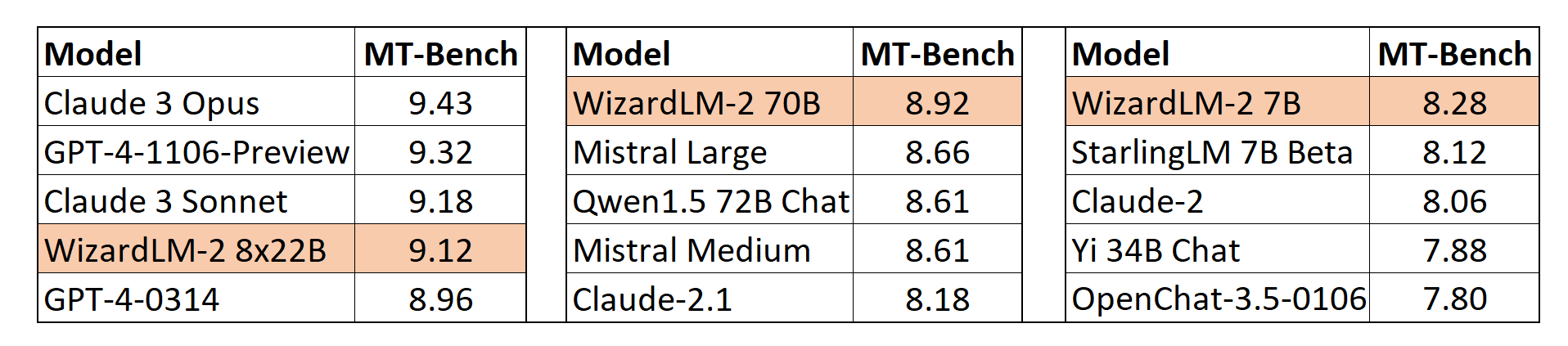
MT-Bench
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models. The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary models. Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
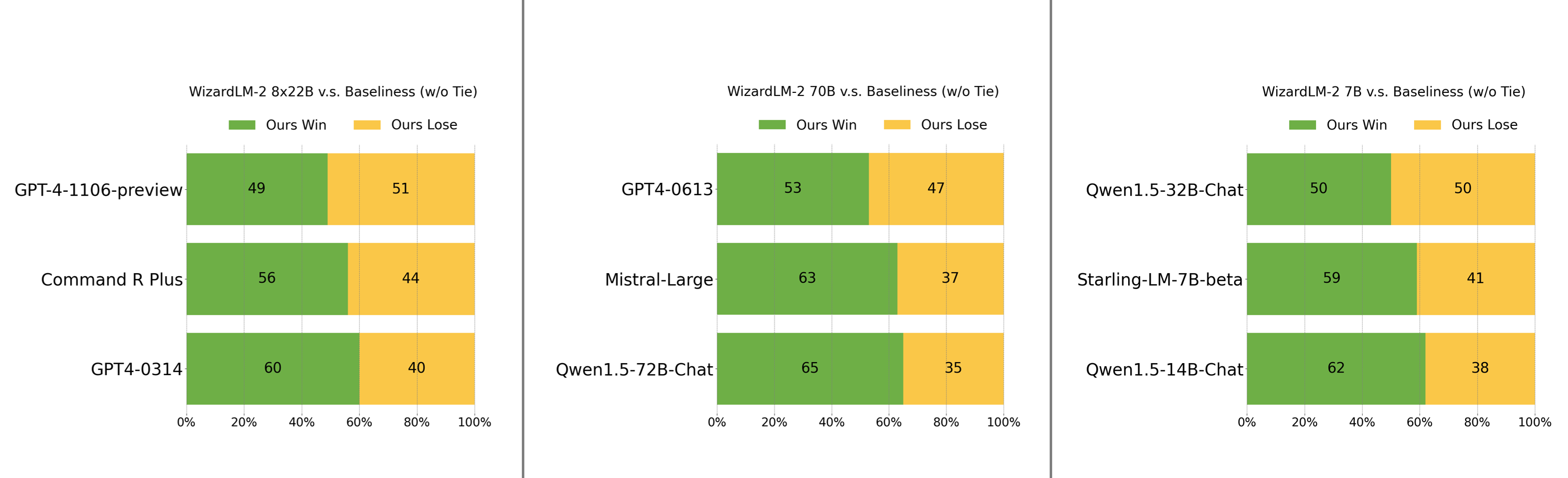
Human Preferences Evaluation
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity, such as writing, coding, math, reasoning, agent, and multilingual. We report the win:loss rate without tie:
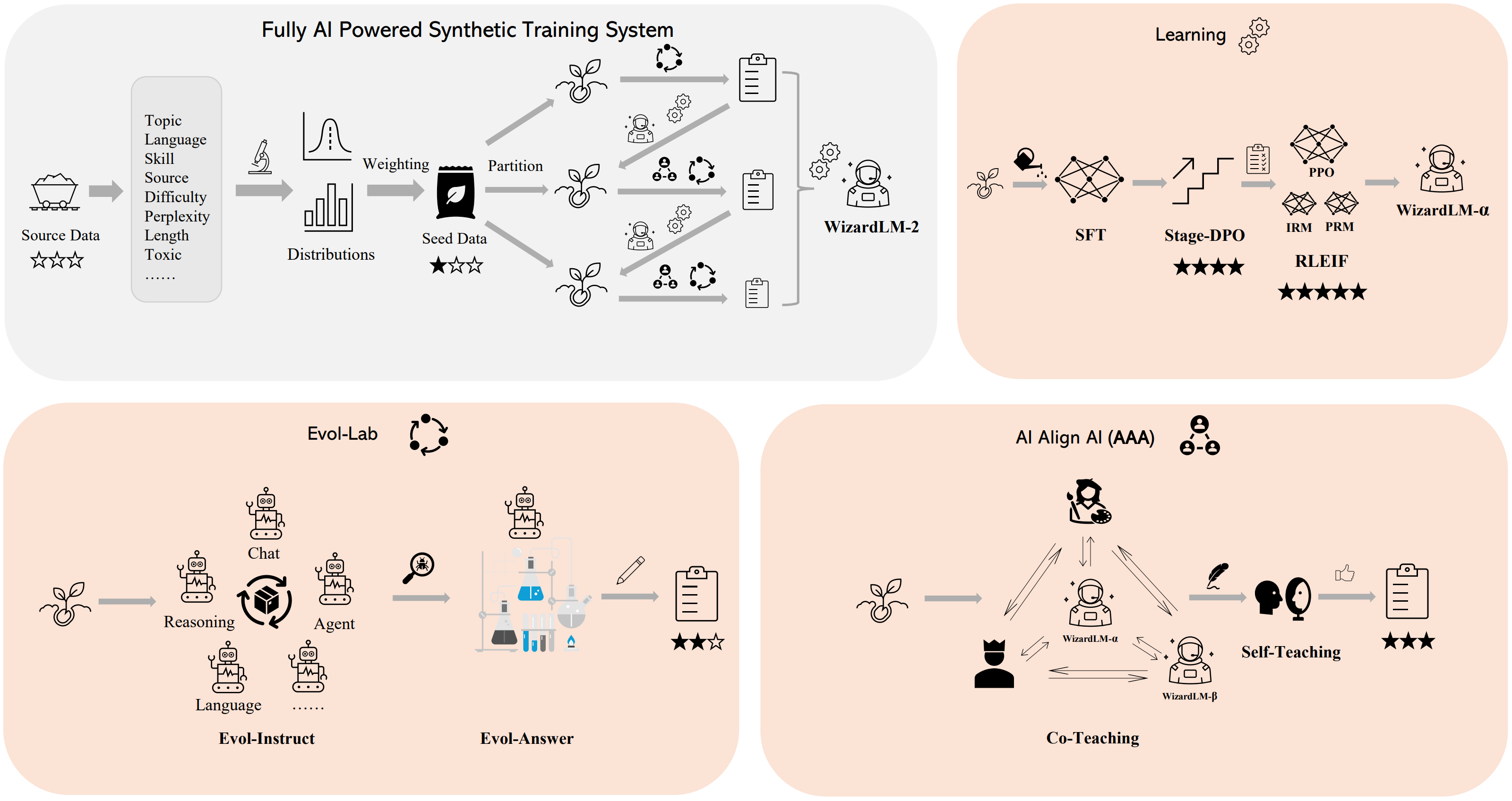
We built a fully AI powered synthetic training system to train WizardLM-2 models, please refer to our blog for more details of this system.
❗Note for model system prompts usage:
WizardLM-2 adopts the prompt format from Vicuna and supports multi-turn conversation. The prompt should be as following:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
Inference WizardLM-2 Demo Script
We provide a WizardLM-2 inference demo code on our github.
2-bit
3-bit
4-bit
5-bit
6-bit
8-bit
Base model
fearlessdots/WizardLM-2-7B-abliterated
Install from brew
# Start a local OpenAI-compatible server with a web UI: llama-server -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF:# Run inference directly in the terminal: llama-cli -hf QuantFactory/WizardLM-2-7B-abliterated-GGUF: