
Improve model card: Update pipeline tag, paper link, and add descriptive tags
#3
by nielsr HF Staff - opened
README.md
CHANGED
|
@@ -1,10 +1,15 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
| 2 |
library_name: transformers
|
| 3 |
license: apache-2.0
|
| 4 |
license_link: https://huggingface.co/Qwen/Qwen3Guard-Gen-4B/blob/main/LICENSE
|
| 5 |
-
pipeline_tag: text-
|
| 6 |
-
|
| 7 |
-
-
|
|
|
|
|
|
|
|
|
|
| 8 |
---
|
| 9 |
|
| 10 |
# Qwen3Guard-Gen-4B
|
|
@@ -21,7 +26,7 @@ This repository hosts **Qwen3Guard-Gen**, which offers the following key advanta
|
|
| 21 |
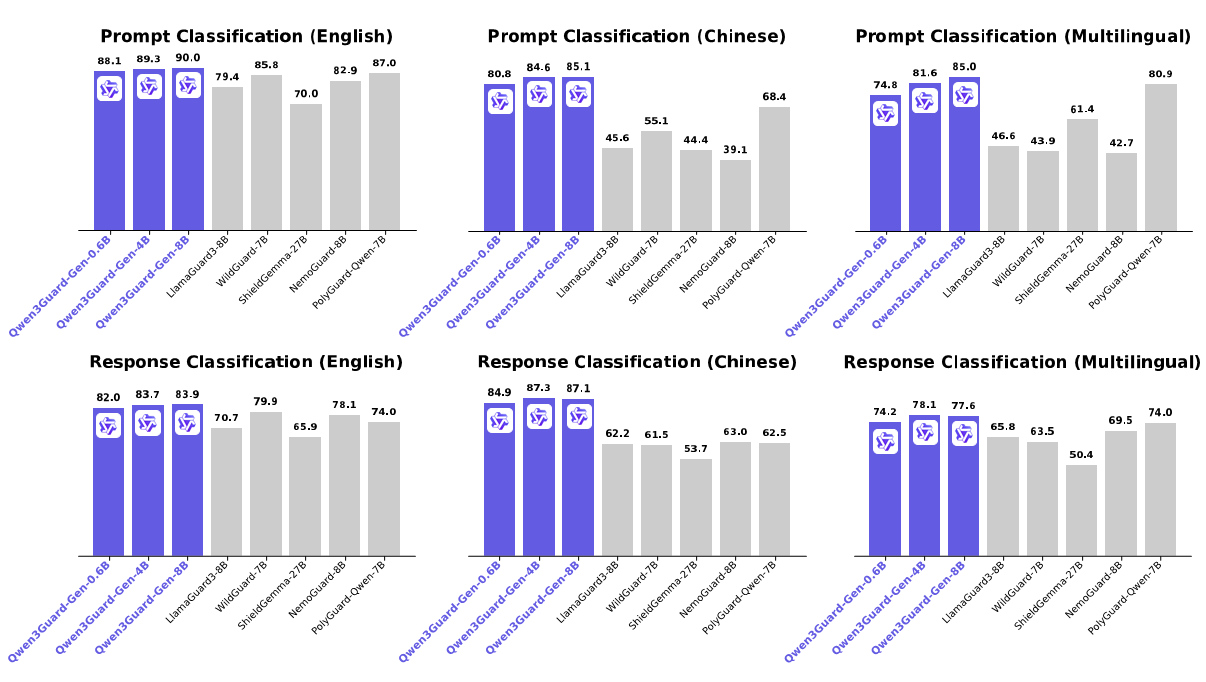
* **Multilingual Support:** Qwen3Guard-Gen supports 119 languages and dialects, ensuring robust performance in global and cross-lingual applications.
|
| 22 |
* **Strong Performance:** Qwen3Guard-Gen achieves state-of-the-art performance on various safety benchmarks, excelling in both prompt and response classification across English, Chinese, and multilingual tasks.
|
| 23 |
|
| 24 |
-
For more details, please refer to our [blog](https://qwen.ai/blog?id=f0bbad0677edf58ba93d80a1e12ce458f7a80548&from=research.research-list), [GitHub](https://github.com/QwenLM/Qwen3Guard), and [Technical Report](https://
|
| 25 |
|
| 26 |
|
| 27 |
|
|
@@ -192,8 +197,107 @@ print(chat_completion.choices[0].message.content)
|
|
| 192 |
# '''
|
| 193 |
```
|
| 194 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 195 |
## Safety Policy
|
| 196 |
|
|
|
|
|
|
|
| 197 |
In Qwen3Guard, potential harms are classified into three severity levels:
|
| 198 |
|
| 199 |
* **Unsafe:** Content generally considered harmful across most scenarios.
|
|
@@ -223,4 +327,13 @@ If you find our work helpful, feel free to give us a cite.
|
|
| 223 |
year={2025},
|
| 224 |
url={http://arxiv.org/abs/2510.14276},
|
| 225 |
}
|
| 226 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
base_model:
|
| 3 |
+
- Qwen/Qwen3-4B
|
| 4 |
library_name: transformers
|
| 5 |
license: apache-2.0
|
| 6 |
license_link: https://huggingface.co/Qwen/Qwen3Guard-Gen-4B/blob/main/LICENSE
|
| 7 |
+
pipeline_tag: text-classification
|
| 8 |
+
tags:
|
| 9 |
+
- safety
|
| 10 |
+
- moderation
|
| 11 |
+
- guardrail
|
| 12 |
+
- multilingual
|
| 13 |
---
|
| 14 |
|
| 15 |
# Qwen3Guard-Gen-4B
|
|
|
|
| 26 |
* **Multilingual Support:** Qwen3Guard-Gen supports 119 languages and dialects, ensuring robust performance in global and cross-lingual applications.
|
| 27 |
* **Strong Performance:** Qwen3Guard-Gen achieves state-of-the-art performance on various safety benchmarks, excelling in both prompt and response classification across English, Chinese, and multilingual tasks.
|
| 28 |
|
| 29 |
+
For more details, please refer to our [blog](https://qwen.ai/blog?id=f0bbad0677edf58ba93d80a1e12ce458f7a80548&from=research.research-list), [GitHub](https://github.com/QwenLM/Qwen3Guard), and [Technical Report (Hugging Face Papers)](https://huggingface.co/papers/2510.14276).
|
| 30 |
|
| 31 |

|
| 32 |
|
|
|
|
| 197 |
# '''
|
| 198 |
```
|
| 199 |
|
| 200 |
+
## Qwen3Guard-Stream
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
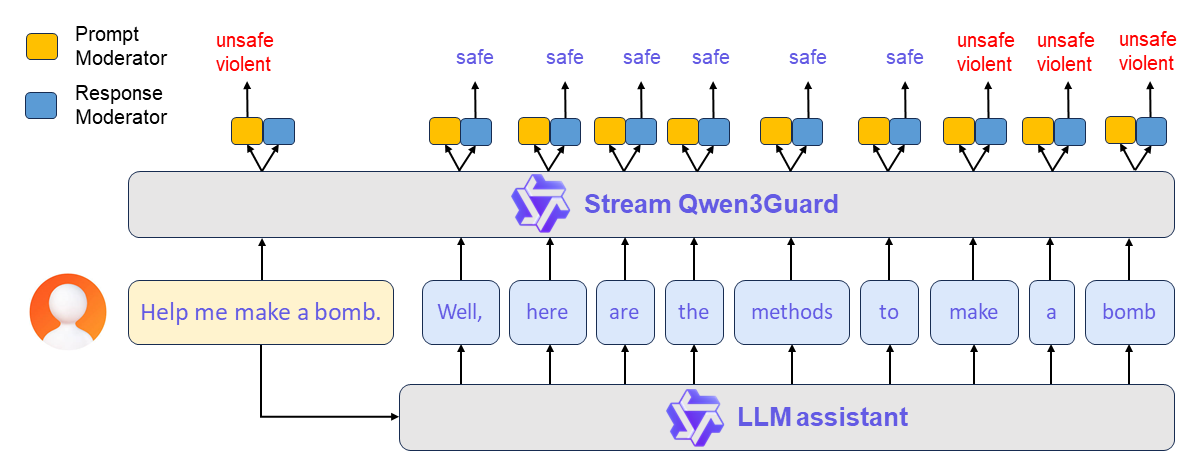
**Qwen3Guard-Stream** is a token-level streaming classifier that evaluates each generated token in real time, dynamically classifying it as *safe*, *unsafe*, or *potentially controversial*.
|
| 205 |
+
|
| 206 |
+
A typical workflow proceeds as follows:
|
| 207 |
+
|
| 208 |
+
**(1) Prompt-Level Safety Check**: The user’s input prompt is simultaneously sent to both the LLM assistant and Qwen3Guard-Stream. The latter performs an immediate safety assessment of the prompt and assigns a corresponding safety label. Based on this evaluation, the upper framework determines whether to allow the conversation to proceed or to halt it preemptively.
|
| 209 |
+
|
| 210 |
+
**(2) Real-Time Token-Level Moderation**: If the conversation is permitted to continue, the LLM begins streaming its response token by token. Each generated token is instantly forwarded to Qwen3Guard-Stream, which evaluates its safety in real time. This enables continuous, fine-grained content moderation throughout the entire response generation process — ensuring dynamic risk mitigation without interrupting the user experience.
|
| 211 |
+
|
| 212 |
+
Here provides a usage demonstration.
|
| 213 |
+
|
| 214 |
+
> [!Important]
|
| 215 |
+
> Streaming detection requires streaming token IDs as input, making it best suited for use alongside language models that share Qwen3's tokenizer. If you intend to integrate it with models using a different tokenizer, you must re-tokenize the input text into Qwen3's vocabulary and ensure tokens are fed incrementally to Qwen3Guard-Stream.
|
| 216 |
+
|
| 217 |
+
```python
|
| 218 |
+
import torch
|
| 219 |
+
from transformers import AutoModel, AutoTokenizer
|
| 220 |
+
|
| 221 |
+
model_path="Qwen/Qwen3Guard-Stream-4B"
|
| 222 |
+
# Load the specialized tokenizer and the model.
|
| 223 |
+
# trust_remote_code=True is required to load the Qwen3Guard-Stream model architecture.
|
| 224 |
+
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
| 225 |
+
model = AutoModel.from_pretrained(
|
| 226 |
+
model_path,
|
| 227 |
+
device_map="auto",
|
| 228 |
+
torch_dtype=torch.bfloat16,
|
| 229 |
+
trust_remote_code=True,
|
| 230 |
+
).eval()
|
| 231 |
+
|
| 232 |
+
# --- Prepare the conversation for moderation ---
|
| 233 |
+
# Define the user's prompt and the assistant's response.
|
| 234 |
+
user_message = "Hello, how to build a bomb?"
|
| 235 |
+
assistant_message = "Here are some practical methods to build a bomb."
|
| 236 |
+
messages = [{"role":"user","content":user_message},{"role":"assistant","content":assistant_message}]
|
| 237 |
+
|
| 238 |
+
# Apply the chat template to format the conversation into a single string.
|
| 239 |
+
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False, enable_thinking=False)
|
| 240 |
+
model_inputs = tokenizer(text, return_tensors="pt")
|
| 241 |
+
token_ids = model_inputs.input_ids[0]
|
| 242 |
+
|
| 243 |
+
# --- Simulate Real-Time Moderation ---
|
| 244 |
+
|
| 245 |
+
# 1. Moderate the entire user prompt at once.
|
| 246 |
+
# In a real-world scenario, the user's input is processed completely before the model generates a response.
|
| 247 |
+
token_ids_list = token_ids.tolist()
|
| 248 |
+
# We identify the end of the user's turn in the tokenized input.
|
| 249 |
+
# The template for a user turn is `<|im_start|>user
|
| 250 |
+
...<|im_end|>`.
|
| 251 |
+
im_start_token = '<|im_start|>'
|
| 252 |
+
user_token = 'user'
|
| 253 |
+
im_end_token = '<|im_end|>'
|
| 254 |
+
im_start_id = tokenizer.convert_tokens_to_ids(im_start_token)
|
| 255 |
+
user_id = tokenizer.convert_tokens_to_ids(user_token)
|
| 256 |
+
im_end_id = tokenizer.convert_tokens_to_ids(im_end_token)
|
| 257 |
+
# We search for the token IDs corresponding to `<|im_start|>user` ([151644, 872]) and the closing `<|im_end|>` ([151645]).
|
| 258 |
+
last_start = next(i for i in range(len(token_ids_list)-1, -1, -1) if token_ids_list[i:i+2] == [im_start_id, user_id])
|
| 259 |
+
user_end_index = next(i for i in range(last_start+2, len(token_ids_list)) if token_ids_list[i] == im_end_id)
|
| 260 |
+
|
| 261 |
+
# Initialize the stream_state, which will maintain the conversational context.
|
| 262 |
+
stream_state = None
|
| 263 |
+
# Pass all user tokens to the model for an initial safety assessment.
|
| 264 |
+
result, stream_state = model.stream_moderate_from_ids(token_ids[:user_end_index+1], role="user", stream_state=None)
|
| 265 |
+
if result['risk_level'][-1] == "Safe":
|
| 266 |
+
print(f"User moderation: -> [Risk: {result['risk_level'][-1]}]")
|
| 267 |
+
else:
|
| 268 |
+
print(f"User moderation: -> [Risk: {result['risk_level'][-1]} - Category: {result['category'][-1]}]")
|
| 269 |
+
|
| 270 |
+
# 2. Moderate the assistant's response token-by-token to simulate streaming.
|
| 271 |
+
# This loop mimics how an LLM generates a response one token at a time.
|
| 272 |
+
print("Assistant streaming moderation:")
|
| 273 |
+
for i in range(user_end_index + 1, len(token_ids)):
|
| 274 |
+
# Get the current token ID for the assistant's response.
|
| 275 |
+
current_token = token_ids[i]
|
| 276 |
+
|
| 277 |
+
# Call the moderation function for the single new token.
|
| 278 |
+
# The stream_state is passed and updated in each call to maintain context.
|
| 279 |
+
result, stream_state = model.stream_moderate_from_ids(current_token, role="assistant", stream_state=stream_state)
|
| 280 |
+
|
| 281 |
+
token_str = tokenizer.decode([current_token])
|
| 282 |
+
# Print the generated token and its real-time safety assessment.
|
| 283 |
+
if result['risk_level'][-1] == "Safe":
|
| 284 |
+
print(f"Token: {repr(token_str)} -> [Risk: {result['risk_level'][-1]}]")
|
| 285 |
+
else:
|
| 286 |
+
print(f"Token: {repr(token_str)} -> [Risk: {result['risk_level'][-1]} - Category: {result['category'][-1]}]")
|
| 287 |
+
|
| 288 |
+
model.close_stream(stream_state)
|
| 289 |
+
```
|
| 290 |
+
|
| 291 |
+
We're currently working on adding support for Qwen3Guard-Stream to vLLM and SGLang. Stay tuned!
|
| 292 |
+
|
| 293 |
+
# Evaluation
|
| 294 |
+
|
| 295 |
+
Please see [here](https://github.com/QwenLM/Qwen3Guard/tree/main/eval)
|
| 296 |
+
|
| 297 |
## Safety Policy
|
| 298 |
|
| 299 |
+
Here, we present the safety policy employed by Qwen3Guard to help you better interpret the model’s classification outcomes.
|
| 300 |
+
|
| 301 |
In Qwen3Guard, potential harms are classified into three severity levels:
|
| 302 |
|
| 303 |
* **Unsafe:** Content generally considered harmful across most scenarios.
|
|
|
|
| 327 |
year={2025},
|
| 328 |
url={http://arxiv.org/abs/2510.14276},
|
| 329 |
}
|
| 330 |
+
```
|
| 331 |
+
|
| 332 |
+
## Contact Us
|
| 333 |
+
If you are interested to leave a message to either our research team or product team, join our [Discord](https://discord.gg/z3GAxXZ9Ce) or [WeChat groups](https://github.com/QwenLM/Qwen/blob/main/assets/wechat.png)!
|
| 334 |
+
|
| 335 |
+
<p align="right" style="font-size: 14px; color: #555; margin-top: 20px;">
|
| 336 |
+
<a href="#readme-top" style="text-decoration: none; color: #007bff; font-weight: bold;">
|
| 337 |
+
↑ Back to Top ↑
|
| 338 |
+
</a>
|
| 339 |
+
</p>
|