| --- |
| base_model: |
| - Qwen/Qwen2.5-32B |
| datasets: |
| - BytedTsinghua-SIA/DAPO-Math-17k |
| language: |
| - en |
| license: apache-2.0 |
| library_name: transformers |
| pipeline_tag: text-generation |
| --- |
| |
| # FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization |
|
|
| 🏠 [Homepage](https://qwen-pilot.notion.site/fipo) | 📝 [Paper PDF](https://arxiv.org/abs/2603.19835) | 🤗 [Hugging Face](https://huggingface.co/QwenPilot/FIPO_32B) | 🤖 [ModelScope](https://modelscope.cn/models/chiyum609/FIPO_32B) | 🐱 [GitHub](https://github.com/qwenpilot/FIPO) |
|
|
| **Qwen Pilot, Alibaba Group | Published on March 20, 2026** |
|
|
| FIPO is a **value-free RL recipe** for eliciting deeper reasoning from a clean base model. The central idea is simple: GRPO-style training works, but its token credit assignment is too coarse. FIPO densifies that signal with a **discounted Future-KL term** that reflects how the rest of the trajectory evolves after each token. Empirically, this granular reinforcement allows the model to **break through the length stagnation** observed in standard baselines. Trained on Qwen2.5-32B-Base, FIPO extends the average chain-of-thought length from **4,000 to over 10,000 tokens**, driving AIME 2024 Pass@1 accuracy from **50.0% to a peak of 58.0% compared with DAPO**. |
|
|
| ## Overview |
|
|
| 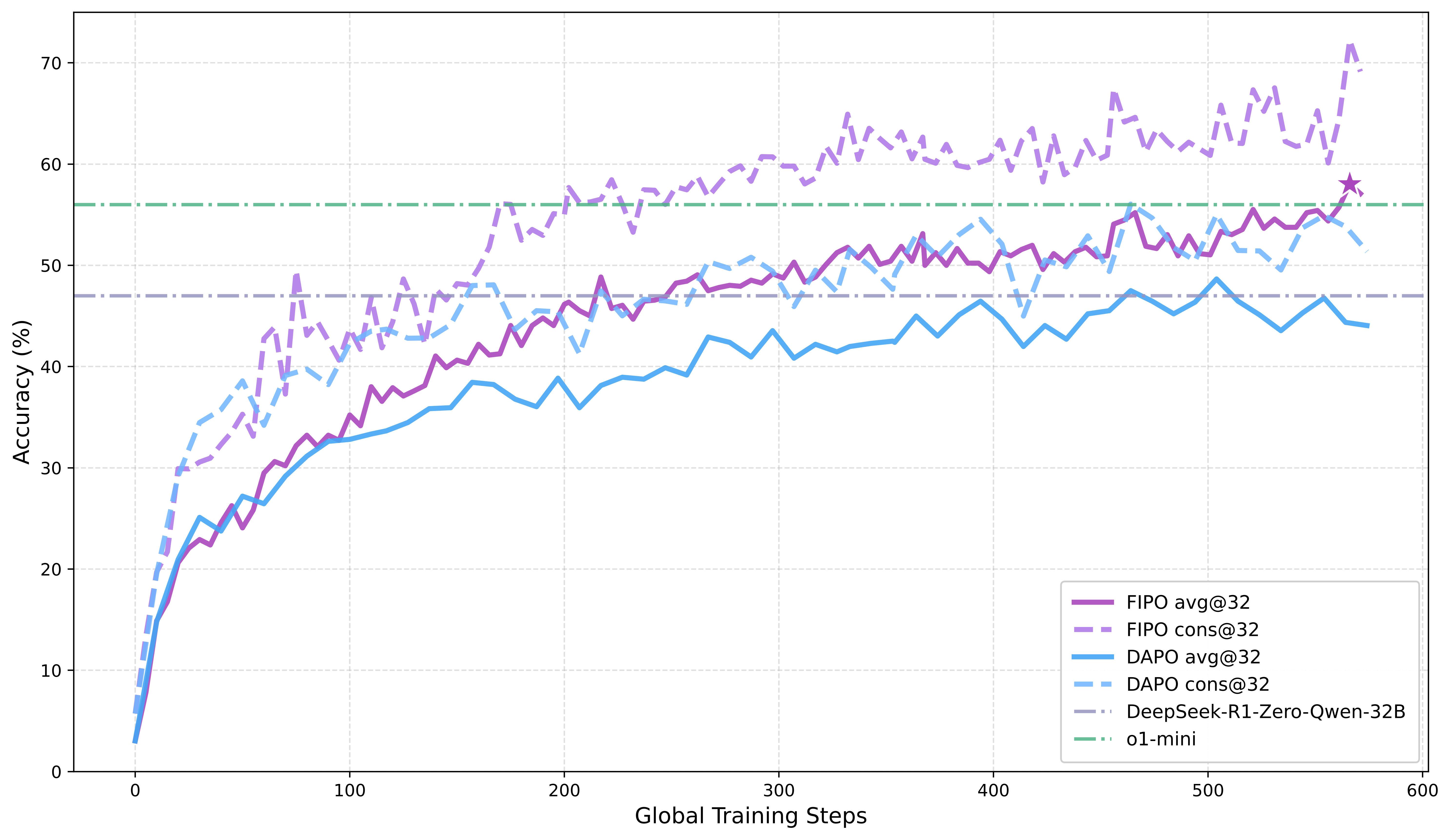 |
|
|
| *Figure 1. FIPO vs. baselines on AIME 2024. FIPO shows that pure RL training alone can outperform reproduced pure-RL baselines such as DAPO and DeepSeek-R1-Zero-32B, surpass o1-mini, and produce substantially longer responses on average.* |
|
|
| **Highlights** |
|
|
| - **Pure RL only:** FIPO outperforms reproduced DAPO and DeepSeek-R1-Zero-32B, and surpasses o1-mini on AIME 2024. |
| - **Dense advantage formulation:** instead of assigning one uniform outcome-level signal to all tokens, FIPO reweights each token by the discounted signed shift of its future trajectory. |
| - **Deeper reasoning:** on Qwen2.5-32B-Base, FIPO breaks the usual 4k-token plateau and extends average reasoning length to **10,000+** tokens. |
| - **Stronger performance:** AIME 2024 Pass@1 improves from **50.0%** to a peak of **58.0%**. |
|
|
| ## Core Change |
|
|
| FIPO keeps the standard PPO/DAPO scaffold, but changes how token-level updates are weighted. The local signal is the signed log-probability shift between the current and old policy: |
|
|
| $$\Delta \log p_t = \log \pi_\theta(y_t \mid x, y_{1:t-1}) - \log \pi_{old}(y_t \mid x, y_{1:t-1})$$ |
| |
| Positive values mean the token is being reinforced, while negative values mean it is being suppressed. Since reasoning is sequential, FIPO then accumulates this signal over the future trajectory: |
| |
| $$FutureKL_t = \sum_{k=t}^{T} M_k \cdot \gamma^{k-t} \cdot \Delta \log p_k$$ |
| |
| FIPO maps this future signal into a bounded influence weight: |
| |
| $$f_t = \text{clip}(\exp(FutureKL_t), 1-\epsilon_{f,low}, 1+\epsilon_{f,high}), \quad \tilde{A}_t = \hat{A}_t \cdot f_t$$ |
|
|
| The final token-level FIPO loss keeps the standard clipped PPO/DAPO form, but replaces the original advantage with the future-aware one: |
|
|
| $$r_t = \frac{\pi_\theta(y_t \mid x, y_{1:t-1})}{\pi_{old}(y_t \mid x, y_{1:t-1})}$$ |
| |
| $$L_t^{FIPO} = \min(r_t \tilde{A}_t,\; \text{clip}(r_t, 1-\epsilon, 1+\epsilon)\tilde{A}_t)$$ |
|
|
| ## 📊 Results & Figures |
|
|
| ### Training Dynamics |
|
|
| Under FIPO, the model continues to expand its reasoning budget instead of collapsing into that intermediate plateau. This helps the model use additional length as **genuine reasoning depth**. |
|
|
| 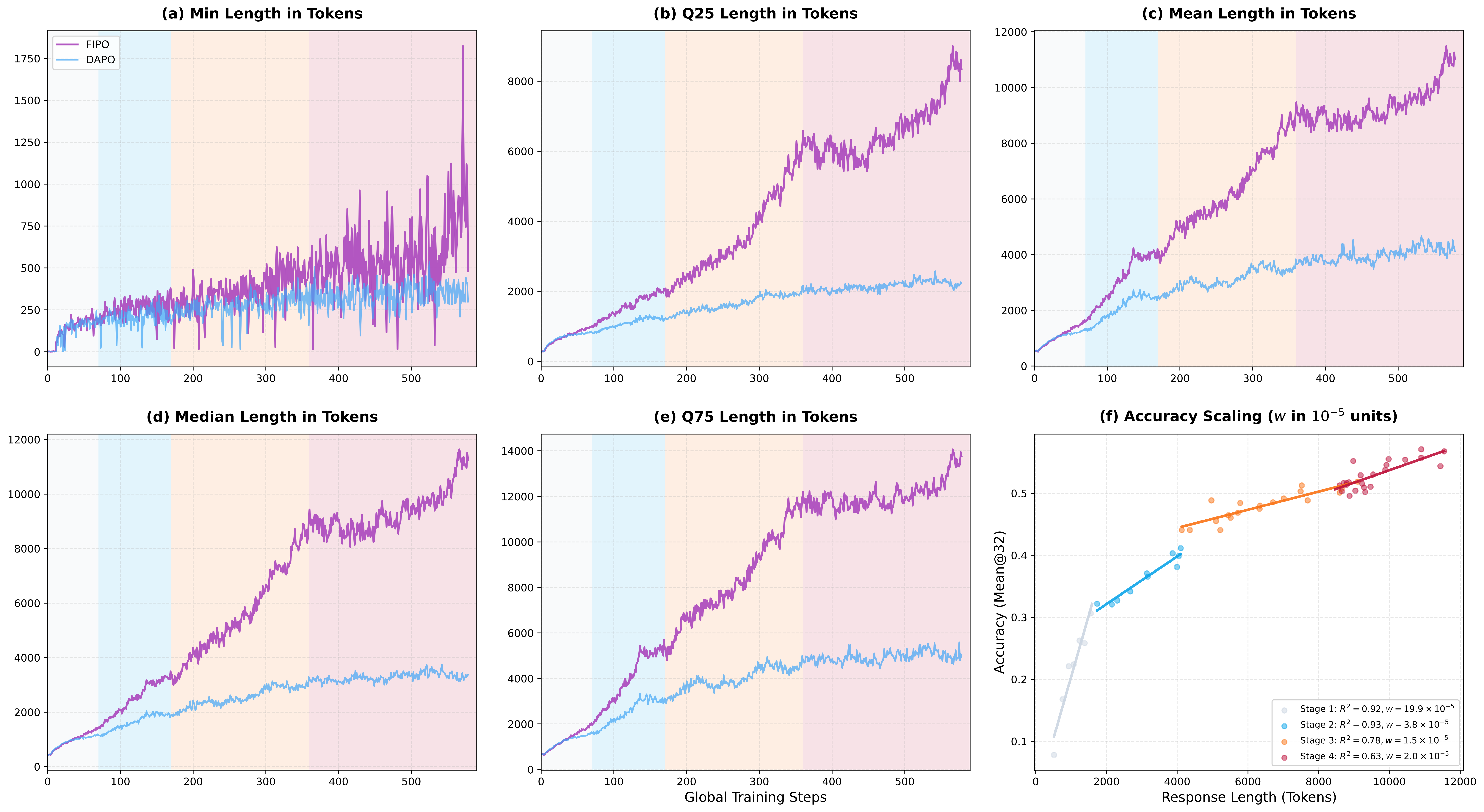 |
|
|
| *Figure 2. Dynamics of response length and performance scaling during training. Compared to the DAPO baseline, FIPO significantly increases response length and maintains a strong positive correlation between longer chain-of-thought and higher accuracy.* |
|
|
| ### Main Result |
|
|
| The FIPO objective yields longer responses and a stronger AIME 2024 peak than the DAPO baseline. |
|
|
| 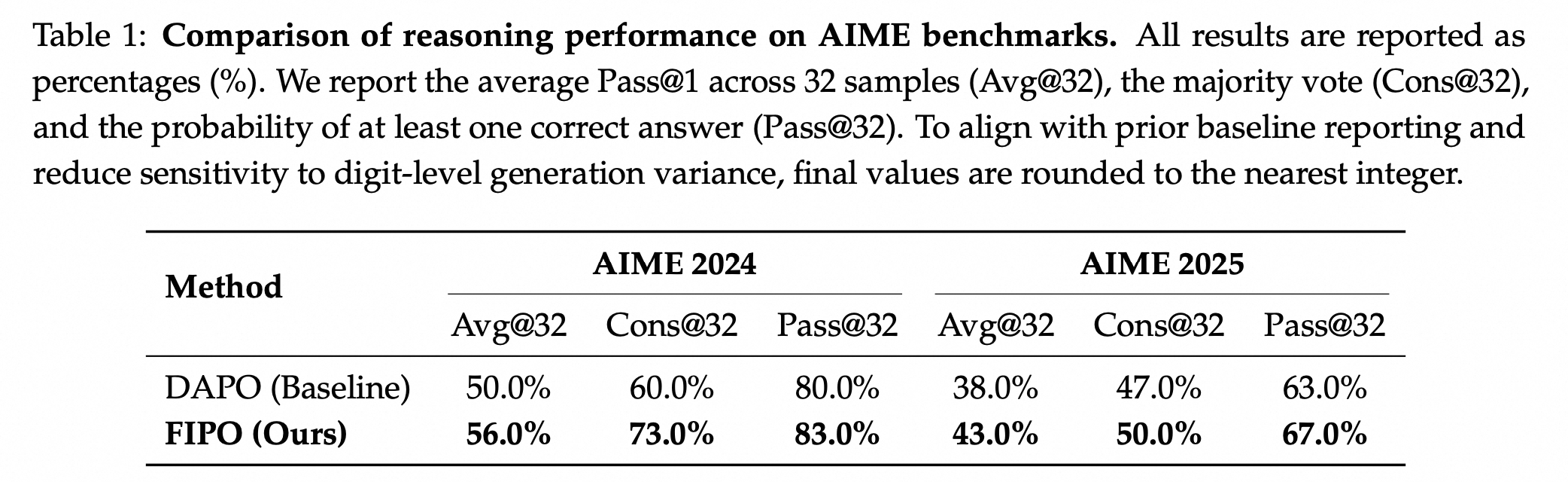 |
|
|
| *Figure 3. Main 32B result. FIPO outperforms reproduced pure-RL baselines on AIME 2024 while also producing substantially longer responses on average.* |
|
|
| ## 🎈 Citation |
|
|
| ```bibtex |
| @article{ma2026fipo, |
| title={FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization}, |
| author={Ma, Chiyu and Yang, Shuo and Huang, Kexin and Lu, Jinda and Meng, Haoming and Shangshang Wang and Bolin Ding and Soroush Vosoughi and Guoyin Wang and Jingren Zhou}, |
| journal={arXiv preprint arXiv:2603.19835}, |
| year={2026} |
| } |
| ``` |
|
|
| ## 🌻 Acknowledgement |
|
|
| This project builds on top of the [VeRL](https://github.com/volcengine/verl) training framework and follows the practical recipe structure introduced by [DAPO](https://github.com/Bytedance-Research/DAPO). |
