
MR-IQA: A Unified Margin View of Regression and Ranking for Blind Image Quality Assessment
Paper • 2606.29760 • Published
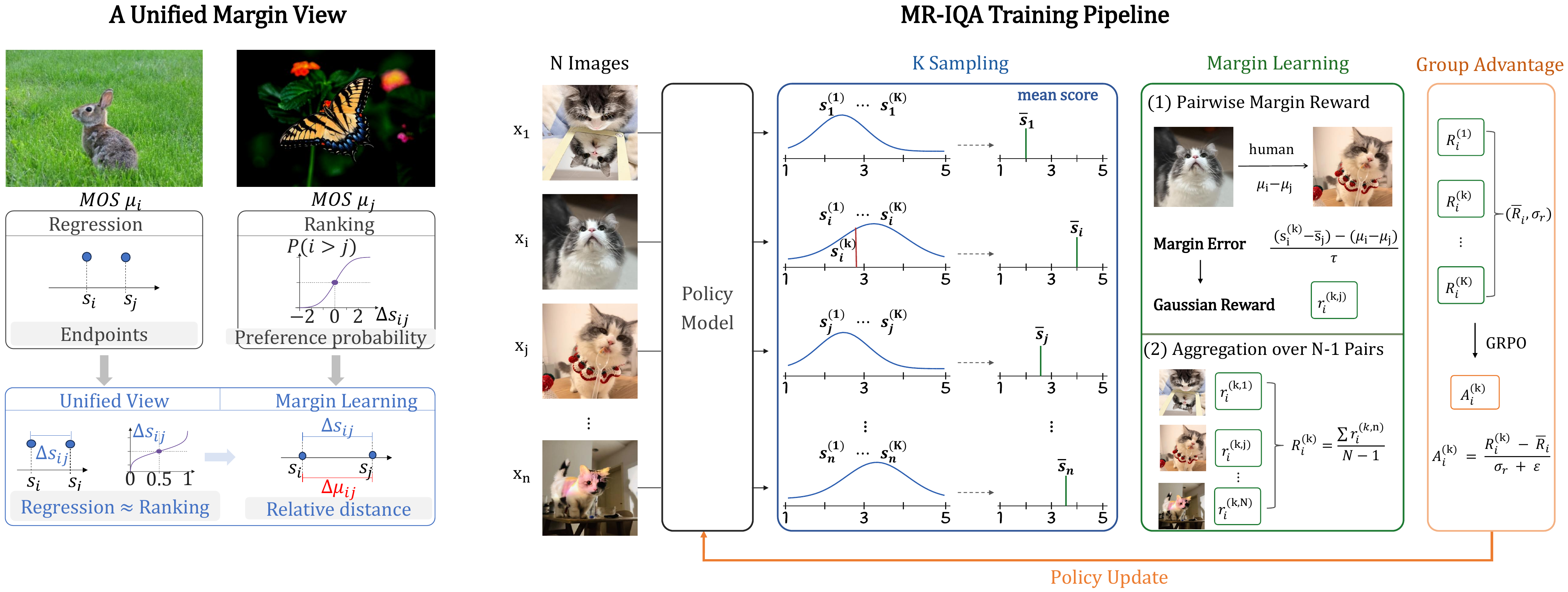
We derive that regression and ranking are approximately equivalent under a unified margin view. Based on this observation, we propose MR-IQA for margin learning in blind image quality assessment.
The released checkpoint was validated after each epoch with an 8-shard setup on a held-out KONIQ split.
| Epoch | Valid samples | SRCC | PLCC | Shards |
|---|---|---|---|---|
| 1 | 200 | 0.8840 | 0.8894 | 8 |
| 2 | 200 | 0.9213 | 0.9302 | 8 |
| 3 | 200 | 0.9318 | 0.9392 | 8 |
| 4 | 200 | 0.9274 | 0.9340 | 8 |
| 5 | 200 | 0.9271 | 0.9409 | 8 |
| 6 | 200 | 0.9249 | 0.9406 | 8 |
| 7 | 200 | 0.9205 | 0.9408 | 8 |
| 8 | 200 | 0.9288 | 0.9465 | 8 |
| 9 | 200 | 0.9307 | 0.9450 | 8 |
| 10 | 200 | 0.9251 | 0.9421 | 8 |
Best SRCC was reached at epoch 3. The final released checkpoint corresponds to epoch 10. Sanitized training metadata is available in training_guidance/.
Load the model with a standard Transformers vision-language workflow. The training and evaluation code use a no-reasoning prompt and parse the final numeric score from <answer>...</answer>.
System prompt:
You are an image quality assessment assistant. Output only the final score in <answer> </answer> tags.
User prompt:
What is your overall rating on the quality of this picture? The rating should be a float between 1 and 5, rounded to two decimal places, with 1 representing very poor quality and 5 representing excellent quality. Please only output the final answer with one score in <answer> </answer> tags.
The expected response is only one score in answer tags:
<answer>3.74</answer>
The evaluation parser first reads the number inside <answer>...</answer> and clamps valid scores to the 1 to 5 range.
@misc{li2026mriqaunifiedmarginview,
title={MR-IQA: A Unified Margin View of Regression and Ranking for Blind Image Quality Assessment},
author={Yuan Li and Youyuan Lin and Zitang Sun and Yung-Hao Yang and Kiyofumi Miyoshi and Chenhui Chu and Shin'ya Nishida},
year={2026},
eprint={2606.29760},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.29760}
}