
TTS and VC
Collection
Scicom TTS models and datasets. • 10 items • Updated • 4
Configuration Parsing Warning:Config file tokenizer_config.json cannot be fetched (too big)
Continue pretraining Qwen/Qwen3-1.7B-Base on Multilingual Voice Conversion and TTS.
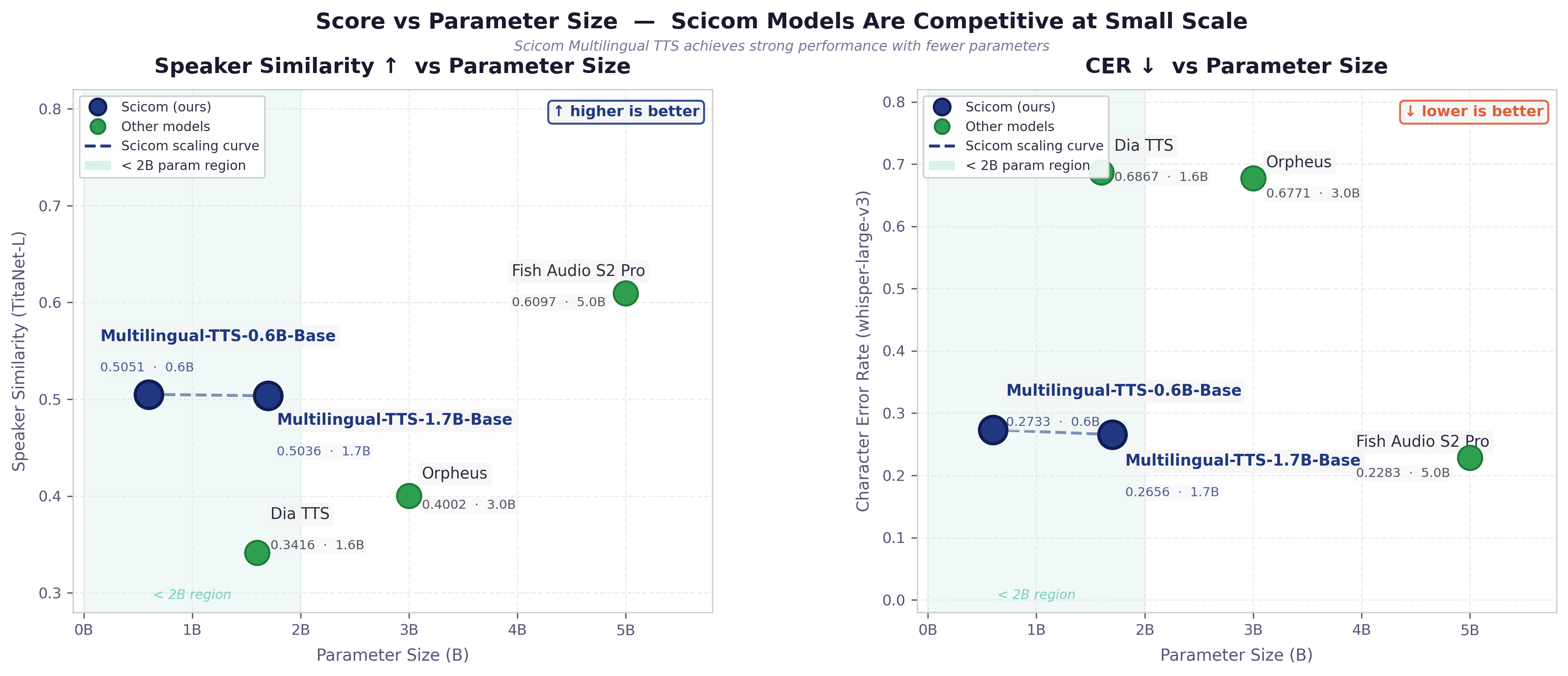
All steps to reproduce at https://github.com/Scicom-AI-Enterprise-Organization/Multilingual-TTS/tree/main/vc-evaluation
First load Neucodec,
from neucodec import NeuCodec
codec = NeuCodec.from_pretrained("neuphonic/neucodec")
_ = codec.eval().to('cuda')
You can use any speaker name available at https://huggingface.co/datasets/malaysia-ai/Multilingual-TTS
import re
import soundfile as sf
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('Scicom-intl/Multilingual-TTS-1.7B-Base')
tokenizer = AutoTokenizer.from_pretrained('Scicom-intl/Multilingual-TTS-1.7B-Base')
speaker = 'husein'
text = "Hi nama saya Husein, I am so cute, 我喜欢吃鸡饭, boire du thé glacé, ולהירגע על החוף, وأحب أن أتعرض لبعض أشعة الشمس."
prompt = f"<|im_start|>{speaker}: {text}<|speech_start|>"
inputs = tokenizer(prompt,return_tensors="pt", add_special_tokens=True).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.8,
repetition_penalty=1.15,
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=False)
audio_tokens = re.findall(r'<\|s_(\d+)\|>', generated_text.split('<|speech_start|>')[1])
audio_tokens = [int(token) for token in audio_tokens]
audio_codes = torch.tensor(audio_tokens)[None, None]
with torch.no_grad():
audio_waveform = codec.decode_code(audio_codes.cuda())
sf.write('husein-ms-en-zh-fr-he-ar.mp3', audio_waveform[0, 0].cpu().numpy(), 24000)
You can check the audio at husein-ms-en-zh-fr-he-ar.mp3.
Jenny from https://huggingface.co/datasets/reach-vb/jenny_tts_dataset
y, sr = librosa.load('jenny.wav', sr = 16000)
with torch.no_grad():
codes = codec.encode_code(torch.tensor(y)[None, None])
tokens = ''.join([f'<|s_{i}|>' for i in codes[0, 0]])
prompt = f"<|im_start|>I wonder if I shall ever be happy enough to have real lace on my clothes and bows on my caps.<|speech_start|>{tokens}<|im_end|><|im_start|>Ye encik, apa yang saya boleh tolong? வணக்கம், நான் உங்களுக்கு என்ன உதவ வேண்டும்? Quieres pedir algo de comida? それとも飲み物も欲しいですか?<|speech_start|>"
inputs = tokenizer(prompt,return_tensors="pt", add_special_tokens=True).to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.8,
repetition_penalty=1.15,
)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=False)
audio_tokens = re.findall(r'<\|s_(\d+)\|>', generated_text.split('<|speech_start|>')[-1])
audio_tokens = [int(token) for token in audio_tokens]
audio_codes = torch.tensor(audio_tokens)[None, None]
with torch.no_grad():
audio_waveform = codec.decode_code(audio_codes.cuda())
sf.write('vc-jenny-ms-ta-es-ja.mp3', audio_waveform[0, 0].cpu().numpy(), 24000)
You can check the audio at vc-jenny-ms-ta-es-ja.mp3.
For better concurrency, you can use https://github.com/Scicom-AI-Enterprise-Organization/TTS-API-Neucodec
All ablations and steps to reproduce at https://github.com/Scicom-AI-Enterprise-Organization/Multilingual-TTS
Special thanks to https://www.scitix.ai/ for H100 Node!