
Slow-Mode Workspace (SMW)
A research scaffold for a falsifiable architectural hypothesis in Transformer language models. There are no trained weights yet — this card describes the architecture and is published so the community can critique, fork, and contribute training runs.
Hypothesis
Catastrophic forgetting, length-extrapolation failure, and uniform-compute miscalibration in Transformers may share a root cause: the absence of a conserved slow-mode subspace across the residual flow.
We propose a specific architectural instantiation (the Slow-Mode Workspace, SMW) and pre-register three falsifiable predictions. See the README for full prior-art positioning.
Architecture
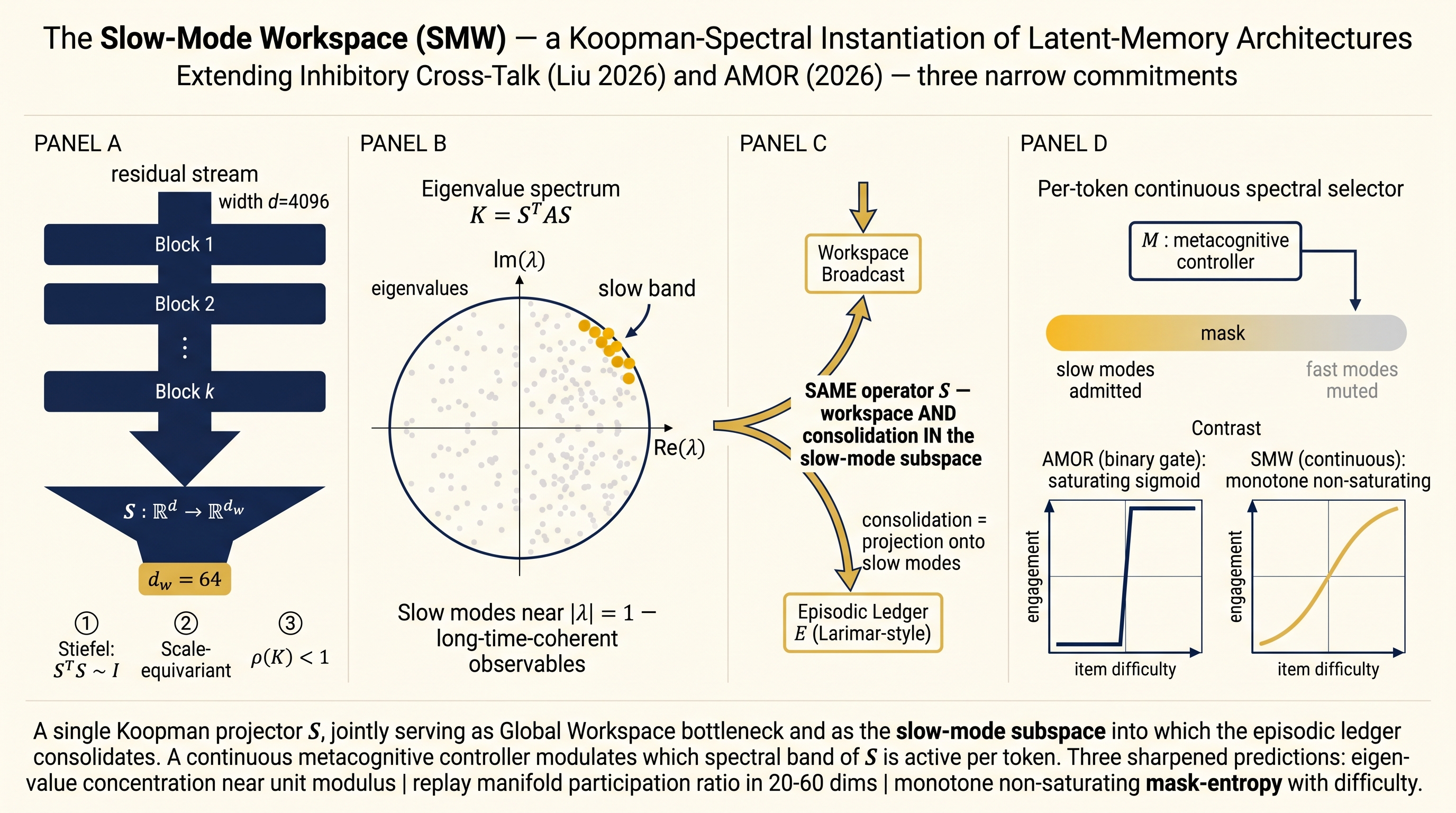
A decoder-only Transformer with one structural addition: a shared Koopman-spectral projector S inserted every k blocks, satisfying:
- Stiefel orthogonality (
S^T S ≈ I) - Scale-equivariance (
S(λx) ≈ λ^Δ S(x)) - Contractive propagator (
ρ(K = S^T A S) < 1)
The same S serves as:
- Global-Workspace bottleneck across modules
- Slow-mode subspace for episodic-cortical consolidation
- Depth-wise renormalization-group projector
A small per-token metacognitive controller M outputs a continuous soft mask over S's eigenbands.
Intended use
- Research only. Not for production deployment.
- Fine-tuning experiments by the community on small-scale (≤1.3B param) Transformers.
- Replication of the 5+1 ablation factorial described in the pre-registration.
Limitations
- No trained weights are provided in this version.
- The implementation is unoptimized for speed (no FlashAttention integration, no FSDP support yet).
- The pre-registered predictions (P1, P2, P3) have not been tested.
How to use (architecture only)
from smw import SMWModel, SMWConfig, CONDITIONS
cfg = CONDITIONS["C5_smw"]
cfg.vocab_size = 32000
cfg.d_model = 768
cfg.n_layers = 12
cfg.d_w = 64
cfg.block_size = 1024
model = SMWModel(cfg)
# train as usual — model.regularizer(x) returns the SMW constraint loss term
Ablation conditions
| ID | Description |
|---|---|
C0_baseline |
Vanilla decoder-only |
C1_gw_only |
Workspace bottleneck only |
C2_episodic_only |
Episodic ledger only |
C3_rg_only |
Scale-equivariance constraint only |
C4_all_independent |
All three components, separate operators |
C5_smw |
All three components, one shared operator (SMW) |
The critical comparison is C5 vs. C4.
Pre-registered predictions
| Pred | Description | Diagnostic in code |
|---|---|---|
| P1 | Slow-band mass ≥ 0.3 after training |
model.slow_band_mass() |
| P2 | Replay manifold participation ratio in 20–60 dims; ablating S abolishes workspace AND replay jointly | (probe scripts forthcoming) |
| P3 | Mask entropy ↑ monotonically with item difficulty, no saturation | model.last_mask_entropy() |
Citation
@misc{shkhina2026smw,
title = {{Slow-Mode Workspace}: A Koopman-Spectral Instantiation of Latent-Memory Transformer Architectures},
author = {{Shkhina AI Labs}},
year = {2026},
url = {https://huggingface.co/shkhina-ai-labs/slow-mode-workspace}
}
Links
- GitHub source: https://github.com/shkhina-ai-labs/slow-mode-workspace
- Pre-registration + debate transcript: in repo
docs/