
File size: 3,561 Bytes
a8642c1 bb422a3 a8642c1 d27734f a8642c1 b94dc4f d27734f 6e86916 38bb6af a00d64c d548031 a0319fa d548031 75d8a86 f719260 3c62a53 ecd9ffc 633f225 ecd9ffc 3c62a53 ecd9ffc f719260 21c2ee5 3c62a53 bb422a3 a8642c1 21c2ee5 a8642c1 21c2ee5 a8642c1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: creativeml-openrail-m
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
inference: true
datasets:
- Shuhaib73/stablediffusion_celeba1k
pipeline_tag: text-to-image
---
<strong style="color: rosybrown; font-size: 18px">Text-to-Image Generation with Fine-Tuned SDXL [QLoRA]</strong>
<strong style="text-decoration: underline">Example Prompts: </strong>
<p style="color: orangered">1. A young, attractive female with arched eyebrows and a pointy nose. She has wavy brown hair, wears heavy makeup with lipstick, and exudes a confident, stylish look. The scene features soft, flattering lighting that enhances her youthful features and glamorous appearance.</p>
<p style="color: orangered">2. A male with an oval face, big nose, high cheekbones, and a receding hairline. He has black hair, bushy eyebrows, and his mouth is slightly open in a smile. The subject is clean-shaven, with no beard.</p>
<p style="color: orangered">3. Male with a big nose, black hair, bushy eyebrows, high cheekbones, and a receding hairline. He has an oval face, a mouth slightly open in a smile, and is clean-shaven with no beard.</p>
<strong>Goal of this project:</strong> This project focuses on building an advanced text-to-image generation system using the Stable Diffusion XL (SDXL) model, a state-of-the-art deep learning architecture. The goal is to transform natural language text descriptions into visually coherent and high-quality images, unlocking creative possibilities in areas like art generation, design prototyping, and multimedia applications.
To enhance performance and tailor the model to specific use cases, SDXL is fine-tuned using <strong>QLoRA (Quantized Low-Rank Adaptation)</strong>. This approach leverages efficient parameter fine-tuning and memory optimization techniques, enabling high-quality adaptations with reduced computational overhead. Fine-tuning with QLoRA ensures that the model is optimized for domain-specific text-to-image tasks, delivering even more precise and creative outputs.
Simplified Architecture: 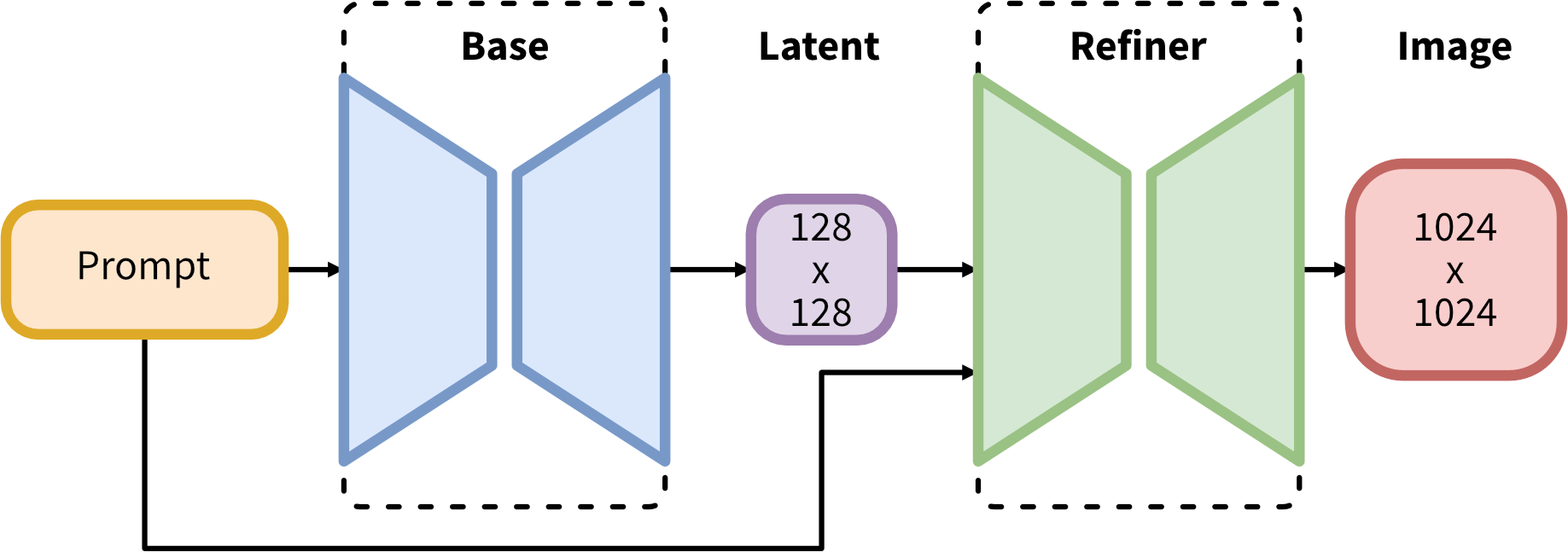
<p style="font-family:Lucida Sans ;font-size:15px;">Dataset Description: CelebFaces Attributes Dataset (CelebA).</p>
<p style="font-family: Lucida Sans ;font-size:15px;">The CelebA dataset is a widely-used, large-scale dataset in the field of computer vision, particularly for tasks related to faces. It consists of over 200,000 celebrity face images annotated with a rich set of attributes. The dataset offers diverse visual content with variations in pose, facial expressions, and backgrounds, making it suitable for a range of face-related applications.</p>
<strong>Here are few examples of generated images Using Stable Diffusion SDXL:</strong>
<strong>Before Fine-Tuning SDXL</strong>

<strong>After Fine-Tuning SDXL on Custom Dataset</strong>


<!-- 


-->
#### How to use
```python
import torch
from diffusers import DiffusionPipeline
model_path = "Shuhaib73/stablediffusion_fld"
trained_pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16)
trained_pipe.to("cuda")
trained_pipe.load_lora_weights(model_path)
```
|