| --- |
| base_model: |
| - Qwen/Qwen3-8B |
| language: |
| - en |
| license: apache-2.0 |
| pipeline_tag: image-to-text |
| library_name: transformers |
| datasets: |
| - TIGER-Lab/RationalRewards_DiffusionNFT_TrainData |
| metrics: |
| - accuracy |
| tags: |
| - text-to-image |
| - image-to-image |
| - edit |
| - reasoning |
| - reward |
| --- |
| |
| **TLDR:** this is a reasoning reward model that supports text-to-image generation, from the following paper. |
|
|
| --- |
| # RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time |
|
|
| <div align="left"> |
| <strong>Haozhe Wang</strong><sup>1</sup> |
| <strong>Cong Wei</strong><sup>2</sup> |
| <strong>Weiming Ren</strong><sup>2</sup> |
| <strong>Jiaming Liu</strong><sup>3</sup> |
| <strong>Fangzhen Lin</strong><sup>1</sup> |
| <strong>Wenhu Chen</strong><sup>2</sup><br> |
| <sup>1</sup> HKUST |
| <sup>2</sup> University of Waterloo |
| <sup>3</sup> Alibaba |
| </div> |
|
|
| ----- |
|
|
| <div align="center"> |
| <a href="https://arxiv.org/abs/2604.11626"> |
| <img src="https://img.shields.io/badge/arXiv-2604.11626-B31B1B?style=for-the-badge&logo=arxiv&logoColor=white" alt="Paper (arXiv)"> |
| </a> |
| <a href="https://tiger-ai-lab.github.io/RationalRewards/"> |
| <img src="https://img.shields.io/badge/Project%20Page-0A66C2?style=for-the-badge&logo=googlechrome&logoColor=white" alt="Project Page"> |
| </a> |
| <a href="https://github.com/TIGER-AI-Lab/RationalRewards"> |
| <img src="https://img.shields.io/badge/Github-181717?style=for-the-badge&logo=github&logoColor=white" alt="GitHub"> |
| </a> |
| <a href="https://huggingface.co/TIGER-Lab/RationalRewards-8B-T2I"> |
| <img src="https://img.shields.io/badge/Model%20(T2I)-FFD966?style=for-the-badge&logo=huggingface&logoColor=black" alt="Model (T2I)"> |
| </a> |
| <a href="https://huggingface.co/TIGER-Lab/RationalRewards-8B-Edit"> |
| <img src="https://img.shields.io/badge/Model%20(Edit)-FFD966?style=for-the-badge&logo=huggingface&logoColor=black" alt="Model (Edit)"> |
| </a> |
| <a href="https://huggingface.co/collections/TIGER-Lab/rationalrewards"> |
| <img src="https://img.shields.io/badge/HF%20Collection-RationalRewards-FFD966?style=for-the-badge&logo=huggingface&logoColor=black" alt="HF Collection"> |
| </a> |
| <br> |
| <a href="https://huggingface.co/datasets/TIGER-Lab/RationalRewards-SFTData"> |
| <img src="https://img.shields.io/badge/SFT%20Dataset-FFB7B2?style=for-the-badge&logo=huggingface&logoColor=black" alt="SFT Dataset"> |
| </a> |
| <a href="https://huggingface.co/datasets/TIGER-Lab/RationalRewards-EvalData-GenAIBench-MMRB2-ERBench"> |
| <img src="https://img.shields.io/badge/Eval%20Dataset-FFB7B2?style=for-the-badge&logo=huggingface&logoColor=black" alt="Eval Dataset"> |
| </a> |
| <a href="https://huggingface.co/datasets/TIGER-Lab/RationalRewards_DiffusionNFT_TrainData"> |
| <img src="https://img.shields.io/badge/Diffusion%20RL%20Training%20Dataset-FFB7B2?style=for-the-badge&logo=huggingface&logoColor=black" alt="Diffusion RL Training Dataset"> |
| </a> |
| </div> |
| |
| **RationalRewards** is a reasoning-based reward model and toolkit for visual generation. Instead of reducing preference into one opaque scalar, it generates explicit multi-dimensional critiques before scoring, turning reward models from passive evaluators into active optimization interfaces. |
|
|
| **About the name:** "Rational" means being reasonable, sensible, in Chinese, 理性的 |
|
|
| **RationalRewards supports optimization in complementary spaces**: |
| - **train-time optimization** through RL with structured, interpretable reward signals, and |
| - **test-time optimization** through a Generate-Critique-Refine loop without parameter updates. |
|
|
| ## Key Results |
|
|
| Instantiated via PARROT on a Qwen3-VL-Instruct-8B backbone, RationalRewards achieves state-of-the-art preference prediction among open-source reward models and remains competitive with Gemini-2.5-Pro. As an RL reward, it consistently improves generators beyond scalar baselines across both text-to-image and image-editing tasks. Most interestingly, RationalRewards' test-time prompt tuning, requiring no parameter updates, matches or exceeds RL-based fine-tuning on several benchmarks. |
|
|
| 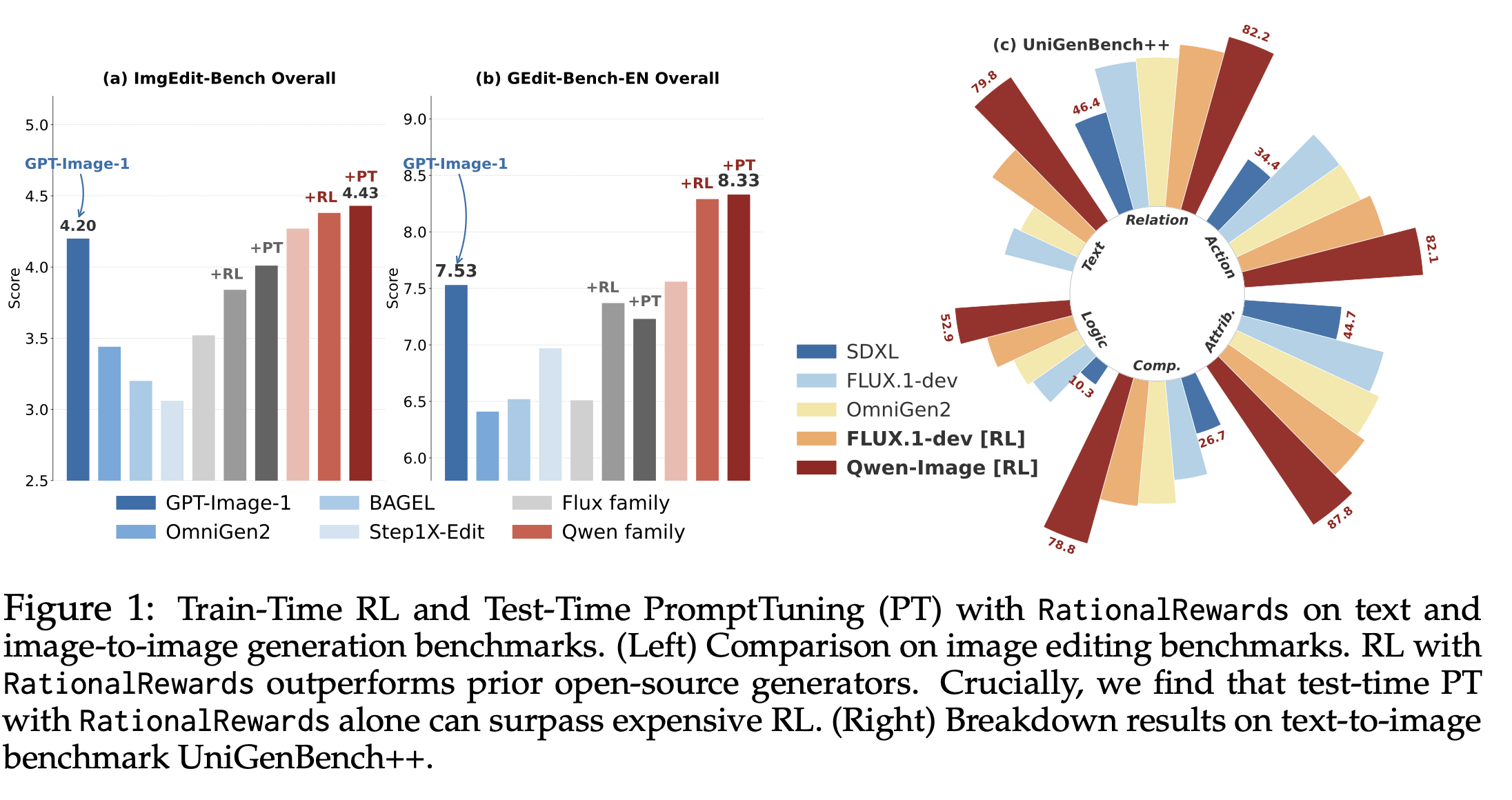 |
|
|
| *Train-time RL and test-time prompt tuning with RationalRewards across visual generation benchmarks.* |
|
|
| ## Why Reasoning Rewards? |
|
|
| Most reward models collapse instruction following, visual quality, composition, and plausibility into one scalar. This removes the structure of human judgment and often leads to brittle optimization. RationalRewards keeps those dimensions explicit so generators receive semantically grounded feedback about what to fix and why. |
|
|
| ### Why do reasoning rewards resist reward hacking? |
|
|
| Scalar rewards are vulnerable to reward hacking because they collapse rich |
| judgment into one number that can rise even when outputs do not truly improve. |
| RationalRewards introduces an implicit regularization: before giving scores, it |
| must produce coherent, multi-dimensional critiques tied to concrete evaluation |
| axes. This constrains optimization to evidence-backed reasoning and improves the |
| monotonic relationship between reward and observed quality during RL. |
|
|
| ### Why are preference-trained rewards more stable than generic VLM judges? |
|
|
| Generic VLM judges can be strong analysts, but as reward functions they often |
| show high-variance pointwise scoring across semantically similar samples. That |
| variance becomes optimization noise in RL. PARROT trains RationalRewards |
| directly for preference discrimination, yielding lower-variance, |
| preference-aligned scores. The practical outcome is more stable optimization |
| steps and better reward reliability, even with a smaller model footprint. |
|
|
| ### Why do reasoning rewards enable test-time scaling? |
|
|
| Reasoning feedback can be reused after generation, not only during training. |
| In a Generate-Critique-Refine loop, RationalRewards critiques the produced |
| image, identifies concrete deficiencies, and proposes targeted prompt updates. |
| Unlike pre-hoc prompt enhancement that rewrites blindly, this is post-hoc and |
| reactive to actual failures. That makes test-time compute more effective at |
| eliciting latent generator capability, often approaching or surpassing RL |
| fine-tuning gains without parameter updates. |
|
|
| 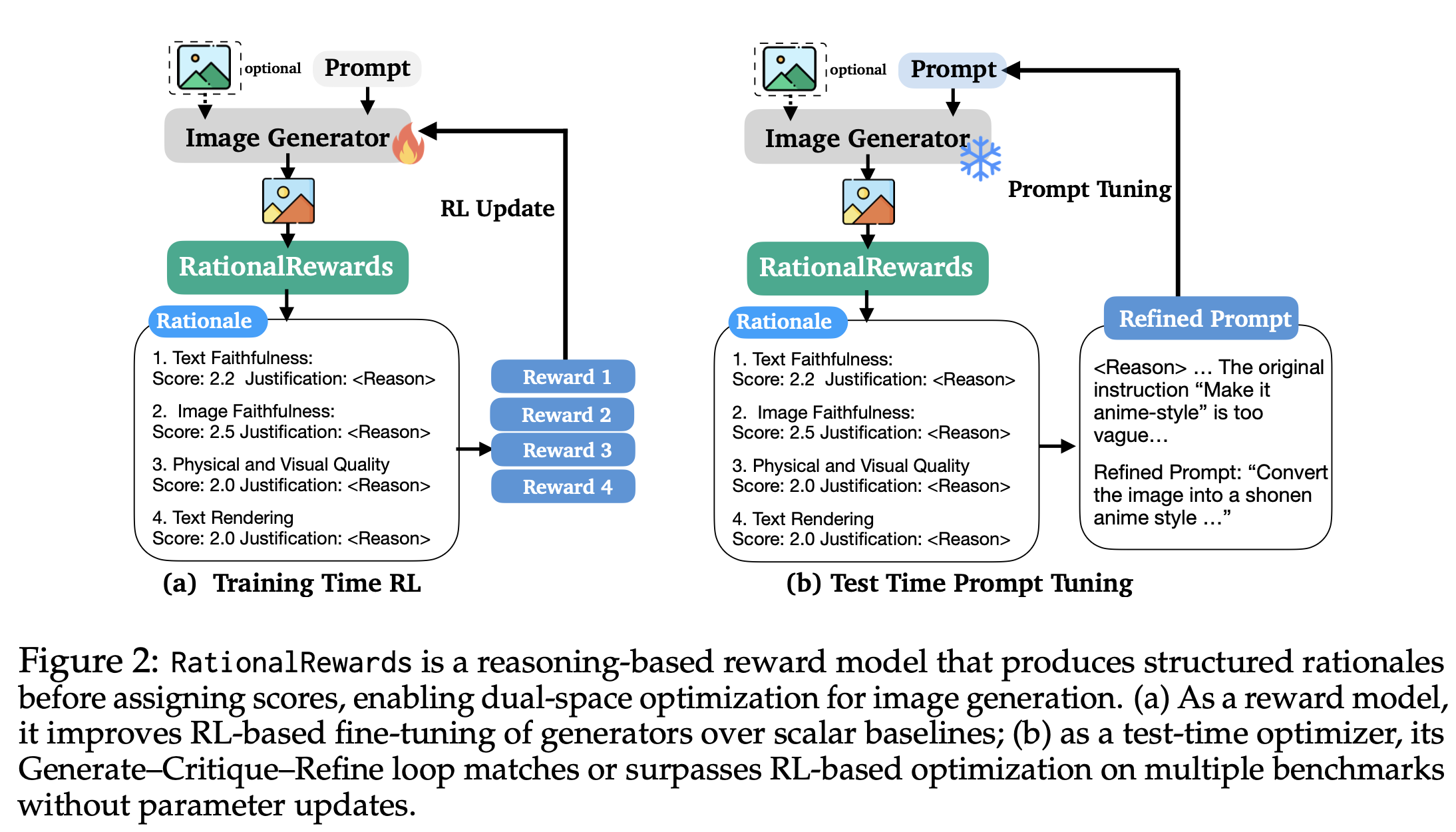 |
|
|
| *RationalRewards supports optimization in both parameter space (RL) and prompt space (test-time refinement).* |
|
|
| ## Method: Preference-Anchored Rationalization (PARROT) |
|
|
| Human rationale annotation is expensive. PARROT recovers high-quality rationale supervision from preference-only data in three phases: |
| 1. **Anchored generation:** a teacher VLM proposes rationale candidates consistent with known labels. |
| 2. **Consistency filtering:** hallucinated or non-predictive rationales are removed. |
| 3. **Distillation:** a student model learns to critique-before-score without seeing labels. |
|
|
| This gives a practical path from abundant preference datasets to scalable reasoning supervision. |
|
|
| 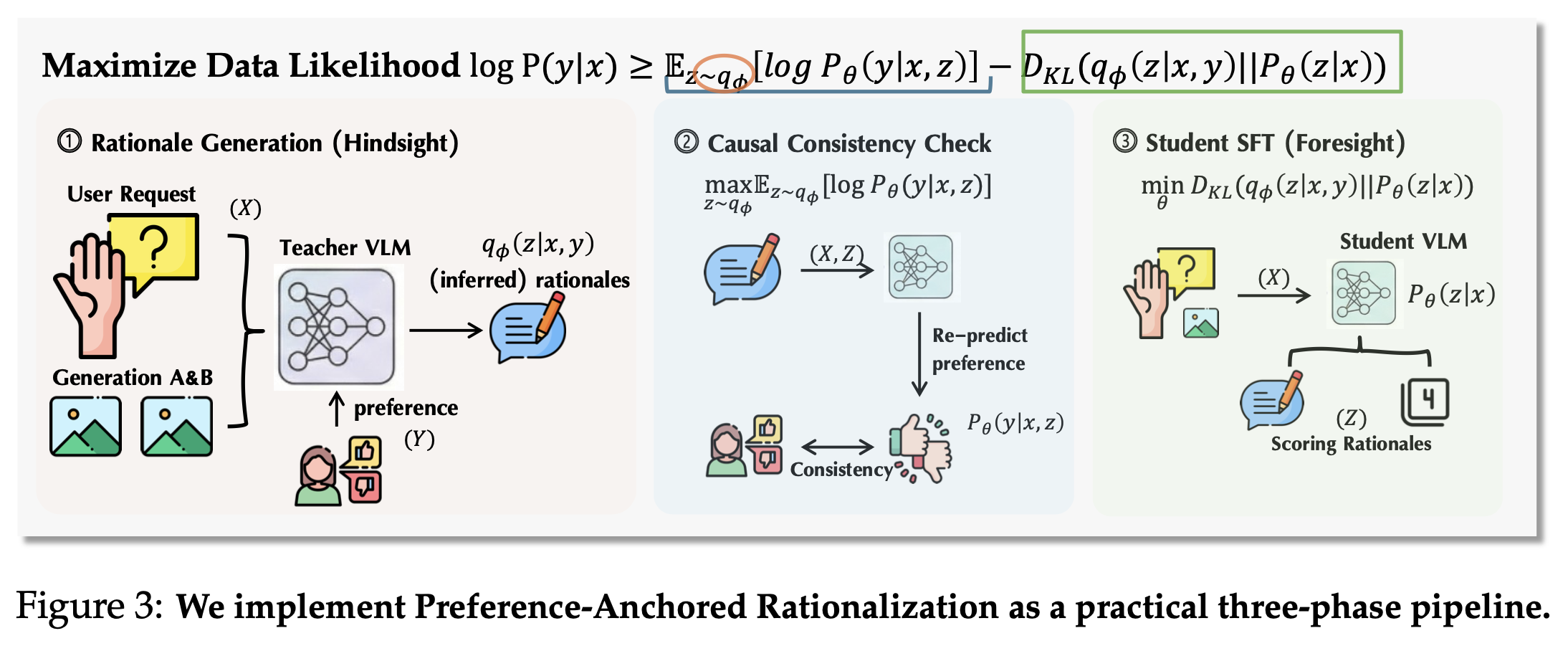 |
|
|
| *PARROT pipeline: anchored rationale generation, consistency filtering, and distillation.* |
|
|
| ## Empirical Evidence |
|
|
| RationalRewards strengthens both alignment quality and downstream optimization. |
|
|
| 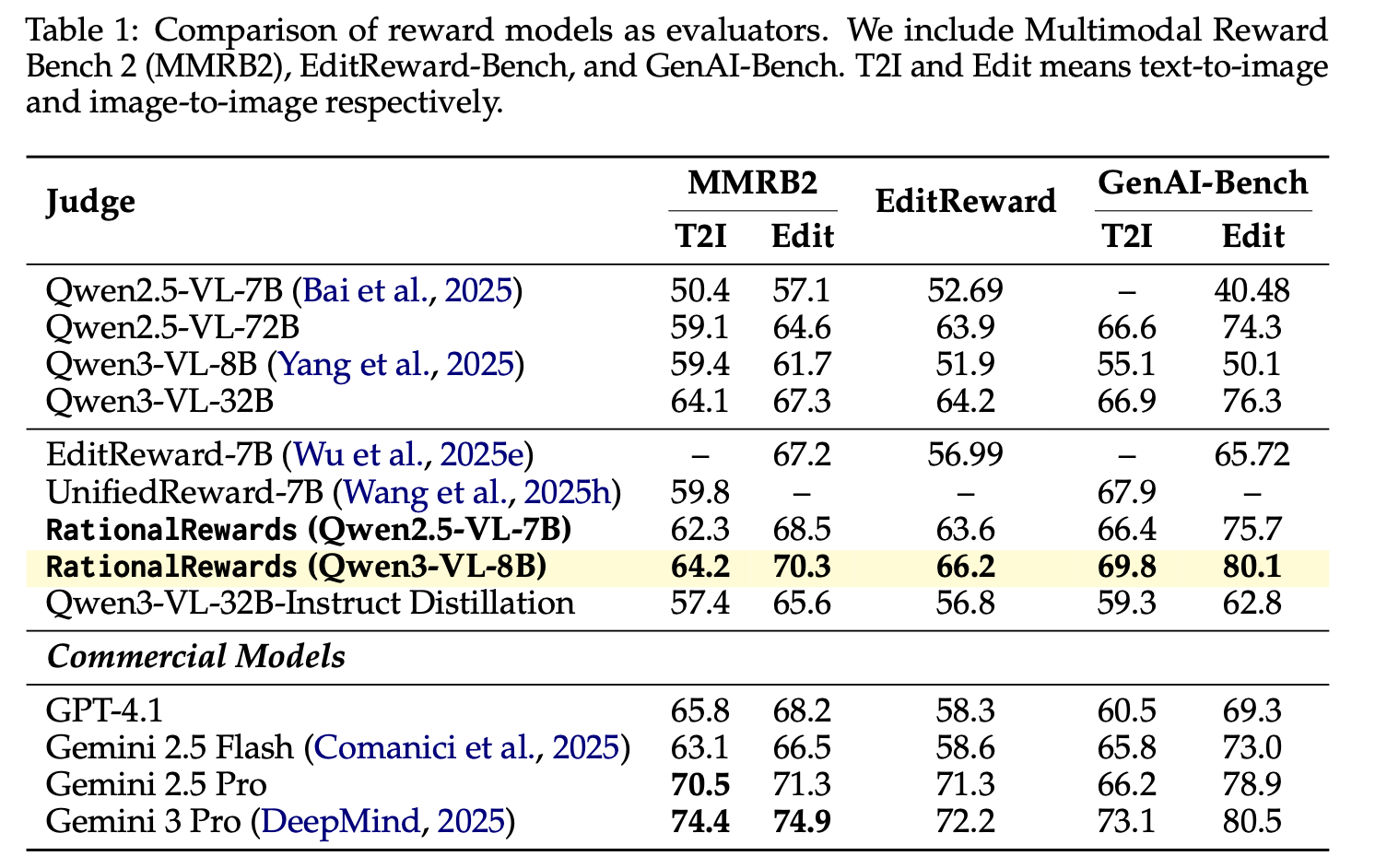 |
|
|
| *State-of-the-art preference prediction among open-source reward models.* |
|
|
|  |
|
|
| *Structured critique channels reduce shortcut exploitation compared with scalar-only rewards.* |
|
|
| To better show optimization behavior, we also include diffusion RL training |
| evolution results. The figure below visualizes how RationalRewards-guided |
| training improves over time, illustrating that benefits are not only visible at |
| the final checkpoint but emerge consistently throughout training. This constrast sharply with scalar rewards suffering reward hacking, as we demonstrate in Figure 12 in the paper. |
|
|
|  |
|
|
| *Evolution of diffusion RL performance under RationalRewards-guided optimization.* |
|
|
|  |
|
|
| *Generate-Critique-Refine at test time can match or exceed RL fine-tuning on several benchmarks.* |
|
|
| 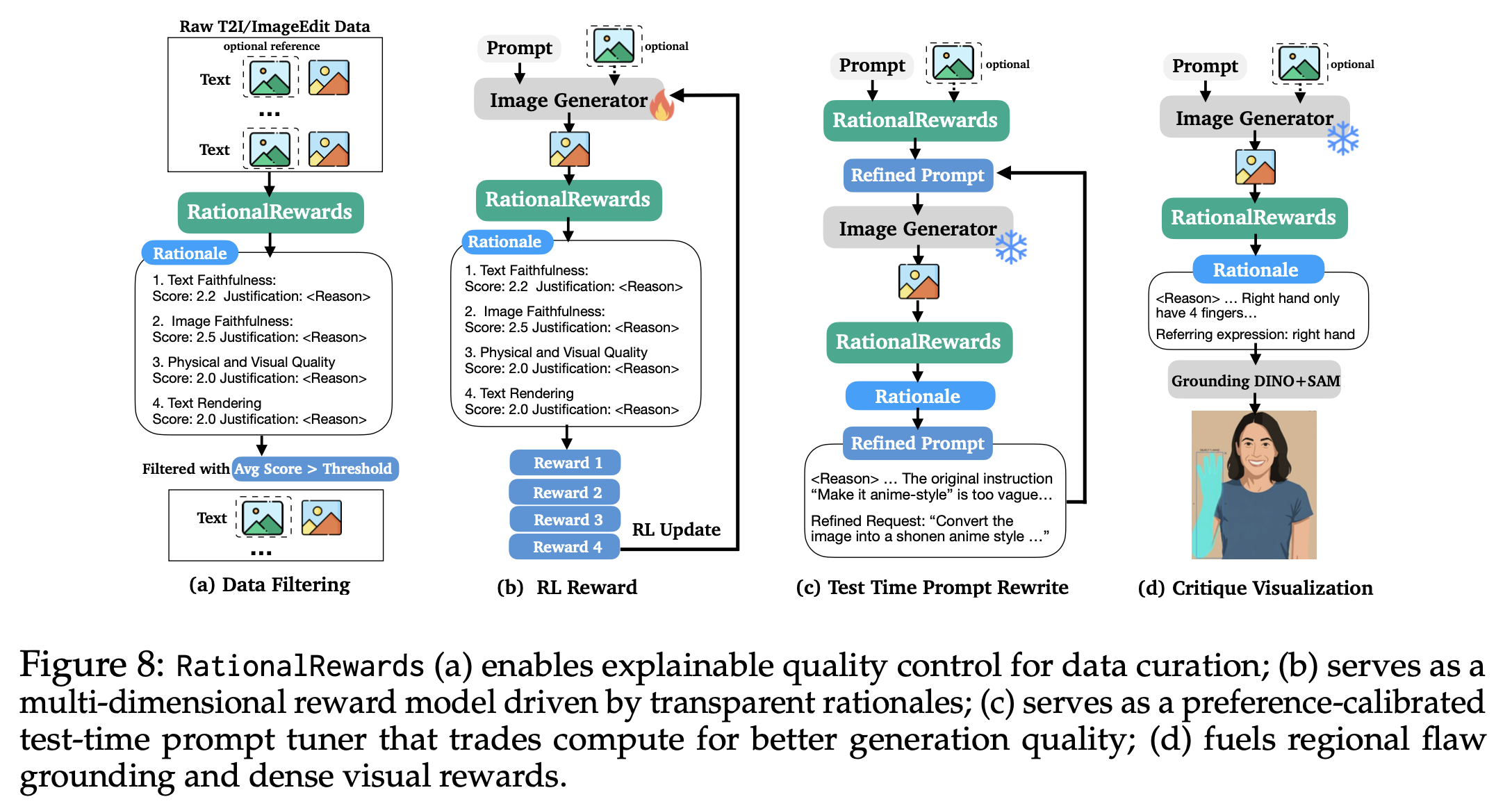 |
|
|
| *Additional qualitative use cases enabled by explicit reasoning feedback.* |
|
|
|
|
| ## Citation |
|
|
| ```bibtex |
| @article{rationalrewards2026, |
| title = {RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time}, |
| author = {Haozhe Wang and Cong Wei and Weiming Ren and Jiaming Liu and Fangzhen Lin and Wenhu Chen}, |
| journal = {arXiv preprint}, |
| year = {2026} |
| } |
| ``` |
|
|

