
TimeOmni-1: Incentivizing Complex Reasoning with Time Series in Large Language Models
Paper • 2509.24803 • Published
We present TimeOmni-1, the first generalized, unified model for time series reasoning. It first injects temporal priors through supervised fine-tuning. Then, reinforcement learning with task-grounded rewards guides the model beyond mimicking priors toward robust reasoning. Experiments show that TimeOmni-1 achieves top-tier performance while preserving the general reasoning ability of the base model. Finally, we demonstrate that joint training across diverse reasoning tasks yields mutual gains, supporting a “train-once, use-across-tasks” paradigm for future time series reasoning models.
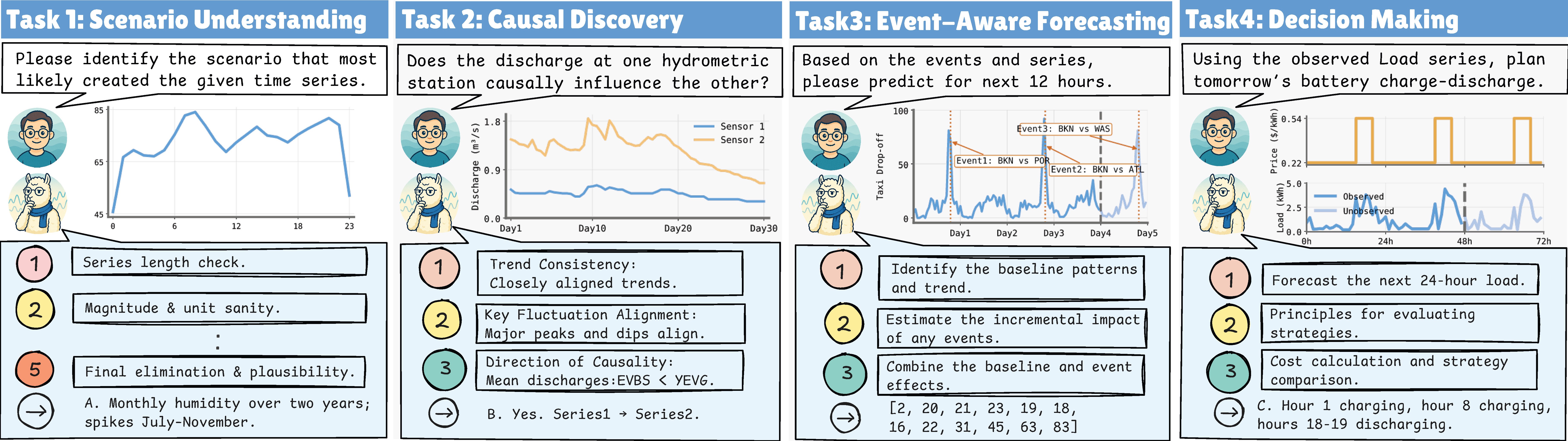
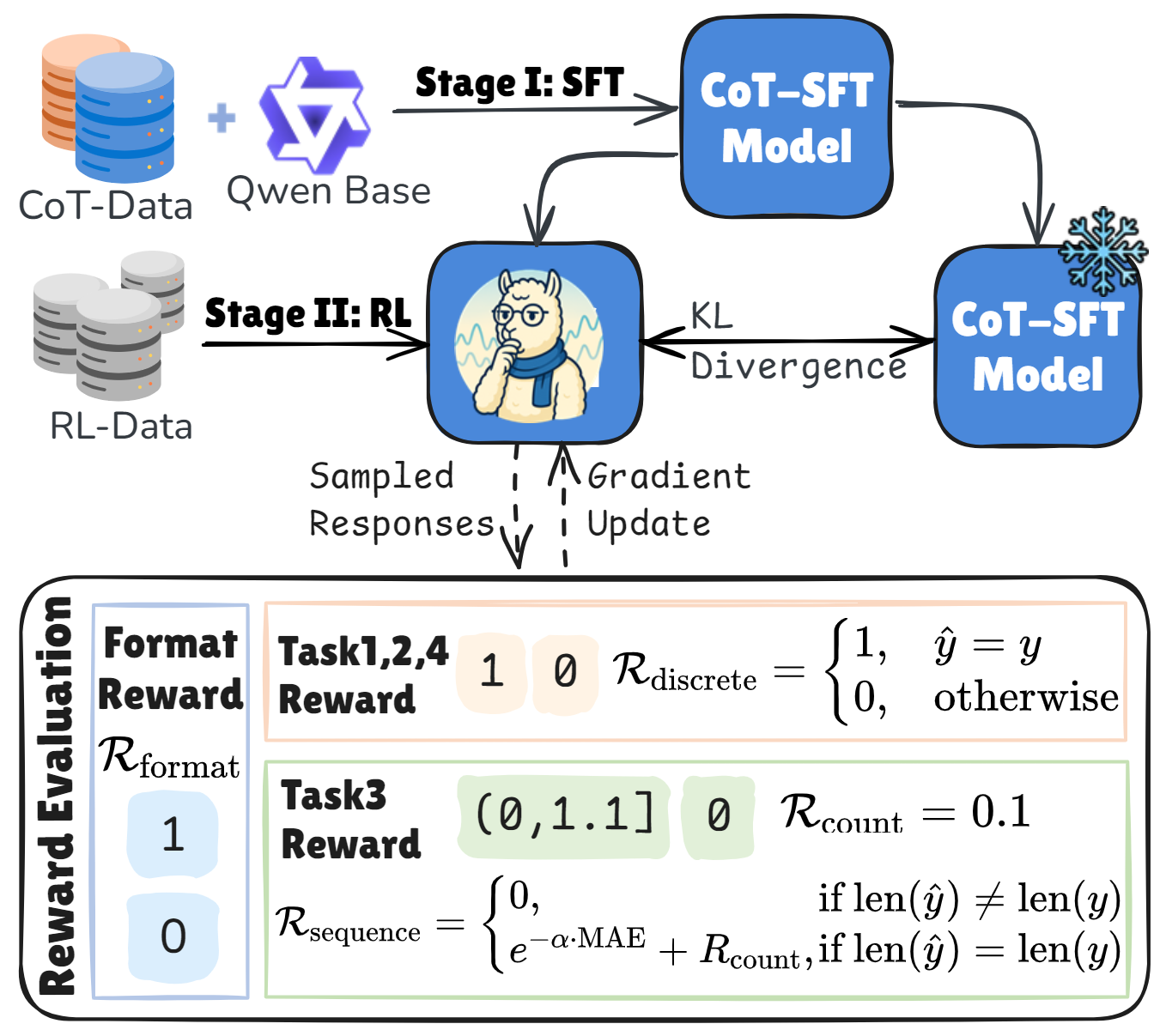
TimeOmni-1 is a generalized reasoning model for time series. Pretrained LLMs often lack temporal priors because they are rarely exposed to time series during pretraining. To address this, we use a two-stage training pipeline: (1) supervised fine-tuning (SFT) to inject temporal priors and anchor the model in a temporal knowledge space, and (2) reinforcement learning (RL) with task-grounded rewards (see Reward Evaluation in the figure above) to improve robustness and reasoning quality.
Table 1. Overall Benchmark Comparison
* Note: All metrics below are computed only on valid responses. “–” indicates a success rate (SR) below 10%; in such cases, results are omitted due to insufficient statistical significance, and we therefore do not report them. For ACC, higher is better; for MAE, lower is better.
| Task1 ID (ACC↑/SR) | Task1 OOD (ACC↑/SR) | Task2 ID (ACC↑/SR) | Task2 OOD (ACC↑/SR) | Task3 ID (MAE↓/SR) | Task3 OOD (MAE↓/SR) | Task4 ID (ACC↑/SR) | Task4 OOD (ACC↑/SR) | |
|---|---|---|---|---|---|---|---|---|
| Time Series Language Model | ||||||||
| Time-MQA Llama3-8B | 32.2/29.5 | 25.1/32.6 | 30.1/44.3 | 31.2/37.2 | -/1.4 | -/0.4 | 12.0/13.3 | 11.6/15.8 |
| Time-MQA Mistral-7B-v0.3 | 15.1/21.5 | 27.8/22.1 | 8.4/50.2 | 4.0/52.2 | -/0.2 | -/0.0 | 5.4/36.1 | 10.0/47.3 |
| Time-MQA Qwen2.5-7B | 25.0/14.0 | 37.5/22.7 | 29.5/33.0 | 30.5/32.0 | 19.76/12.2 | -/6.5 | 23.8/58.0 | 26.4/44.3 |
| ChatTS | -/6.0 | -/6.9 | 18.2/30.1 | 18.6/26.7 | -/0.0 | -/0.0 | 5.8/27.1 | 11.1/27.1 |
| ChatTime-7B-Chat | 18.2/11.0 | 29.8/12.7 | -/- | -/- | 14.47/100.0 | 154.55/100.0 | -/0.0 | -/0.0 |
| ITFormer-7B | 43.8/100.0 | 47.5/100.0 | 15.0/47.0 | 14.6/42.0 | 29.55/96.0 | 230.04/100.0 | 25.0/100.0 | 41.7/100.0 |
| OpenTSLM-llama-3.2-3b-ecg-flamingo | -/5.0 | -/3.2 | 1.6/23.0 | 3.3/26.5 | -/0.2 | -/0.0 | 17.8/98.4 | 16.2/98.9 |
| Time Series Reasoning Model | ||||||||
| Time-R1 | 30.9/94.0 | 34.0/92.5 | 30.2/53.8 | 31.4/48.9 | 17.61/38.7 | -/6.3 | 27.8/95.7 | 32.2/93.1 |
| Ours | ||||||||
| TimeOmni-1-9B | 93.5/100.0 | 92.8/99.8 | 70.9/100.0 | 66.2/100.0 | 13.54/97.8 | 140.06/95.6 | 59.6/100.0 | 75.6/99.6 |
Table 2. Model Size Scaling Comparison
* Note: All metrics below are computed only on valid responses. “–” indicates a success rate (SR) below 10%; in such cases, results are omitted due to insufficient statistical significance, and we therefore do not report them. For ACC, higher is better; for MAE, lower is better. Bold marks the best value in each ACC/MAE column.
| Task1 ID (ACC↑/SR) | Task1 OOD (ACC↑/SR) | Task2 ID (ACC↑/SR) | Task2 OOD (ACC↑/SR) | Task3 ID (MAE↓/SR) | Task3 OOD (MAE↓/SR) | Task4 ID (ACC↑/SR) | Task4 OOD (ACC↑/SR) | |
|---|---|---|---|---|---|---|---|---|
| 7B (Qwen2.5-Instruct) | ||||||||
| Qwen2.5-Instruct-7B | 48.5/100.0 | 42.8/100.0 | 21.6/99.8 | 26.3/100.0 | 23.28/53.1 | 146.12/55.5 | 25.5/100.0 | 24.9/100.0 |
| TimeOmni-1-7B | 90.7/97.5 | 87.7/98.3 | 69.3/99.8 | 64.0/99.8 | 14.30/93.8 | 145.53/82.3 | 47.9/100.0 | 58.9/100.0 |
| 4B (Qwen3.5) | ||||||||
| Qwen-3.5-4B | 0.0/16.5 | 5.9/17.0 | 28.3/12.4 | 35.4/12.0 | -/2.2 | -/9.0 | -/8.5 | -/9.2 |
| TimeOmni-1-4B | 91.5/99.5 | 91.2/98.4 | 71.1/100.0 | 66.1/99.9 | 13.68/97.6 | 170.41/86.1 | 58.5/100.0 | 72.0/100.0 |
| 9B (Qwen3.5) | ||||||||
| Qwen-3.5-9B | 91.2/51.0 | 93.5/46.1 | 43.3/12.1 | 36.3/12.8 | 17.56/14.1 | -/0.8 | 64.2/28.2 | 72.0/32.2 |
| TimeOmni-1-9B | 93.5/100.0 | 92.8/99.8 | 70.9/100.0 | 66.2/100.0 | 13.54/97.8 | 140.06/95.6 | 59.6/100.0 | 75.6/99.6 |
This repository hosts the model weights for TimeOmni-1. For installation, usage instructions, and further documentation, please visit our GitHub repository.
TimeOmni-1 is licensed under the Apache 2.0 license.
@inproceedings{
guan2026timeomni,
title={TimeOmni-1: Incentivizing Complex Reasoning with Time Series in Large Language Models},
author={Tong Guan and Zijie Meng and Dianqi Li and Shiyu Wang and Chao-Han Huck Yang and Qingsong Wen and Zuozhu Liu and Sabato Marco Siniscalchi and Ming Jin and Shirui Pan},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=kOIclg7muL}
}