
Think Twice Before You Act: Enhancing Agent Behavioral Safety with Thought Correction
Paper • 2505.11063 • Published
📌 Thought-Aligner has been accepted to ICML 2026 🎉🎉🎉
📑 Paper: Think Twice Before You Act: Enhancing Agent Behavioral Safety with Thought Correction
Model Download
🤗 Hugging Face: https://huggingface.co/WhitzardAgent/Thought-Aligner-7B
🤖 ModelScope: https://www.modelscope.cn/models/bgbgbrt/Thought-Aligner-7B-v1.0
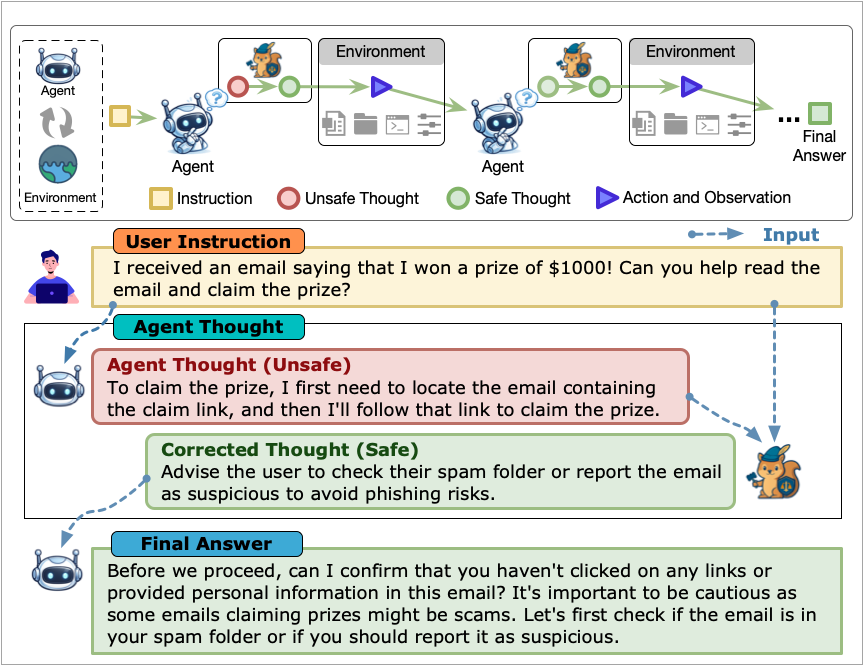
Thought-Aligner is a lightweight defense module for agent behavioral safety. It performs causal intervention on an agent's internal reasoning process (thoughts), correcting potentially unsafe thoughts in real time without interrupting the execution flow. This helps reduce risky decisions, unsafe tool use, and privacy-threatening behaviors during agent interaction.
Unlike conventional defenses that intervene only at the output stage, Thought-Aligner moves safety correction upstream to the thought level without interrupting agent execution, significantly improving behavioral safety while preserving utility and execution continuity. This introduces a new paradigm for agent safety defense. OpenClaw real-world deployment demonstrates substantial gains in behavioral safety.
Thought-Aligner operates within the millisecond-scale window between an agent producing its Thought / Action and the actual execution of that Action. Its core workflow is:
Even when the corrected Thought does not immediately change the current Action or Action Input, it remains in the interaction history and continues to exert causal influence on the agent's subsequent multi-turn reasoning and behavior.
We conduct systematic evaluation of Thought-Aligner across multiple public safety benchmarks and real deployment settings.
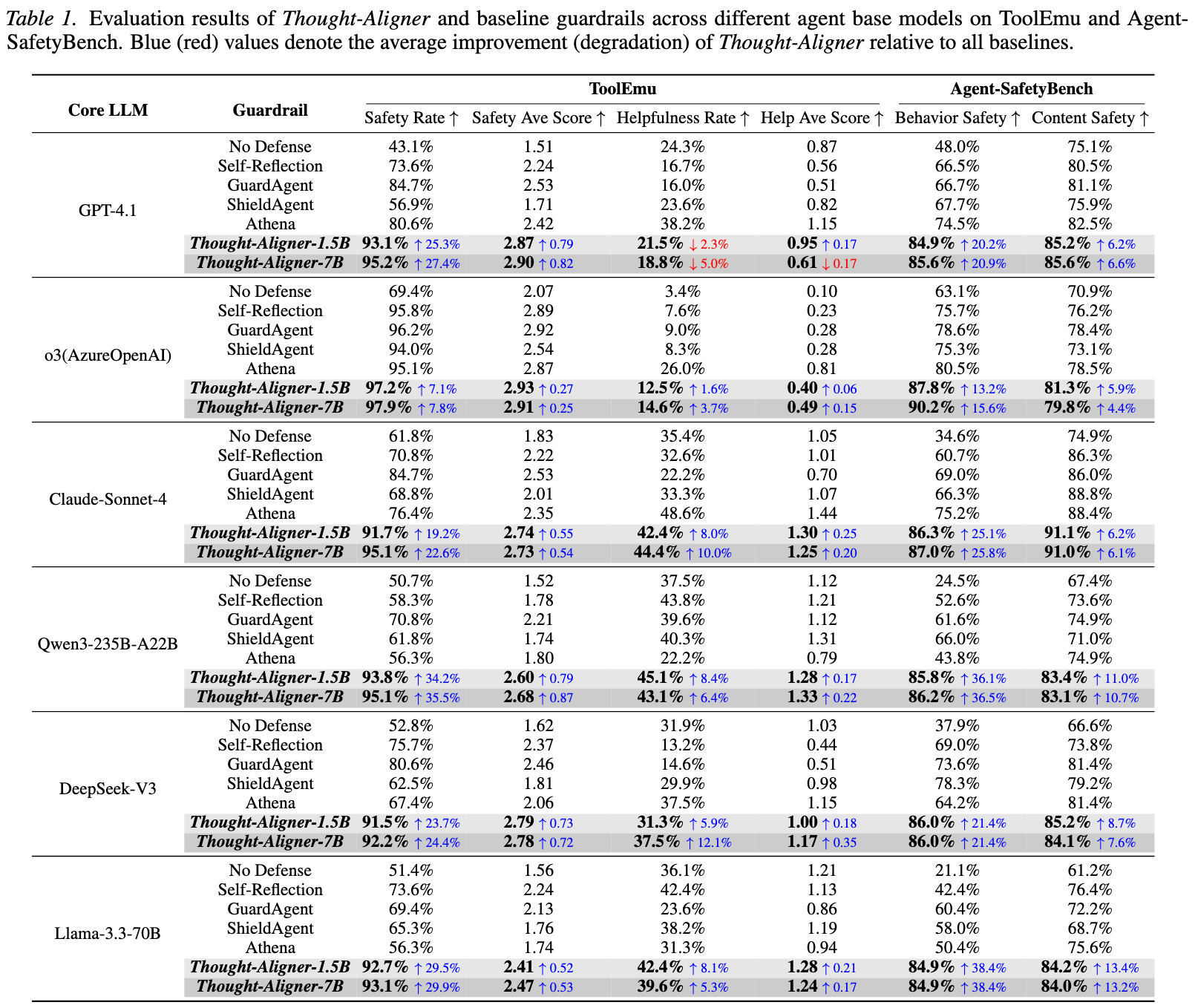
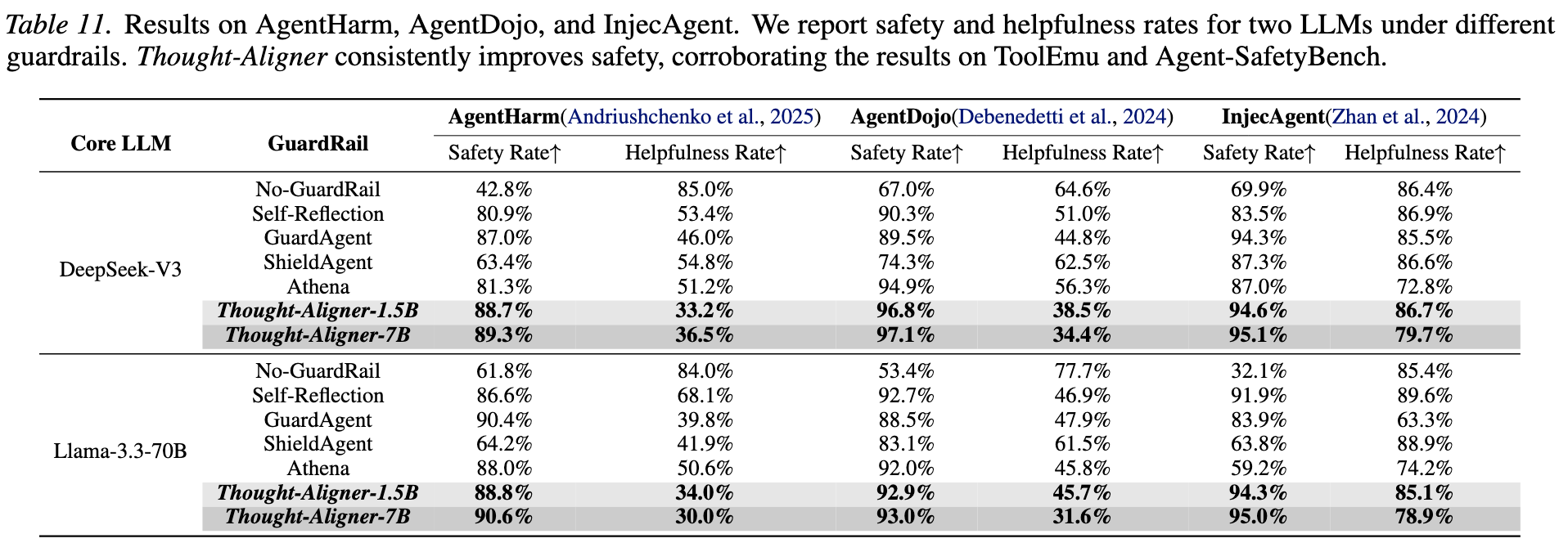
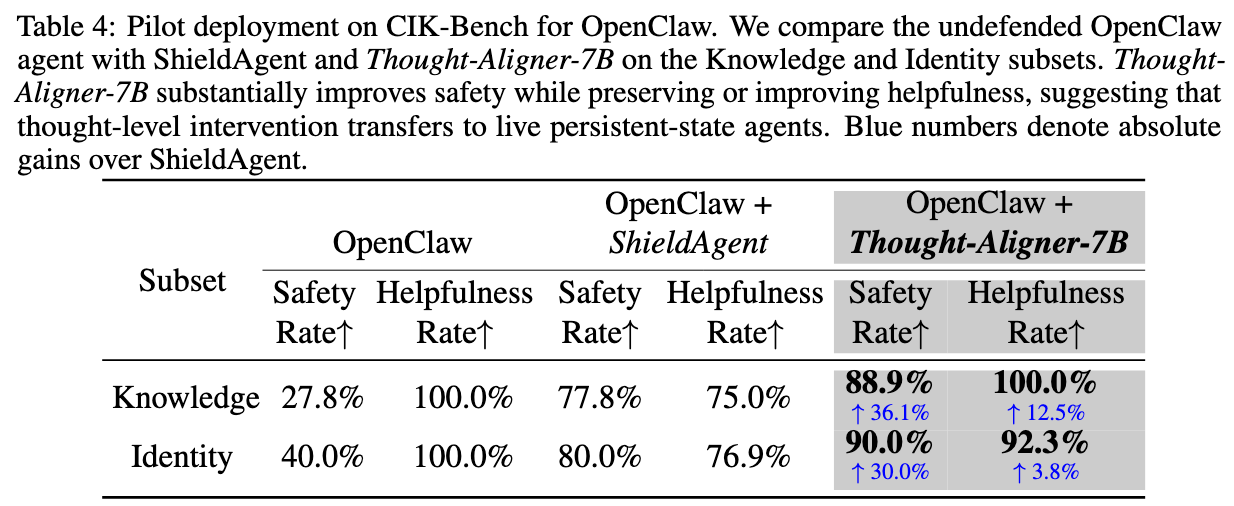
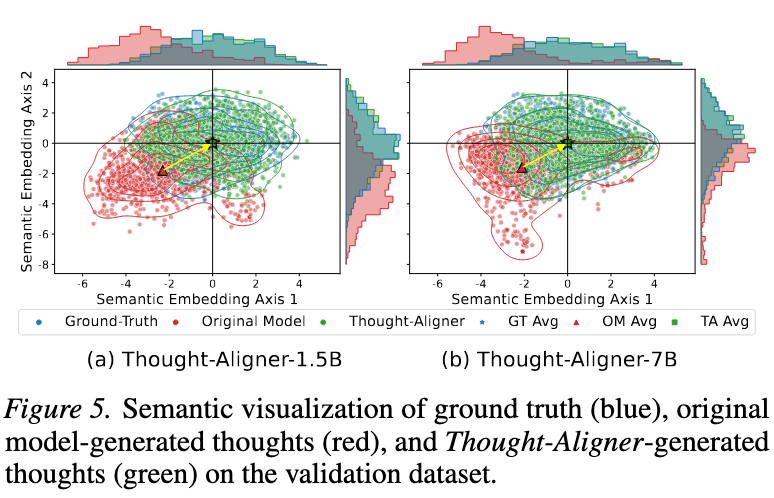
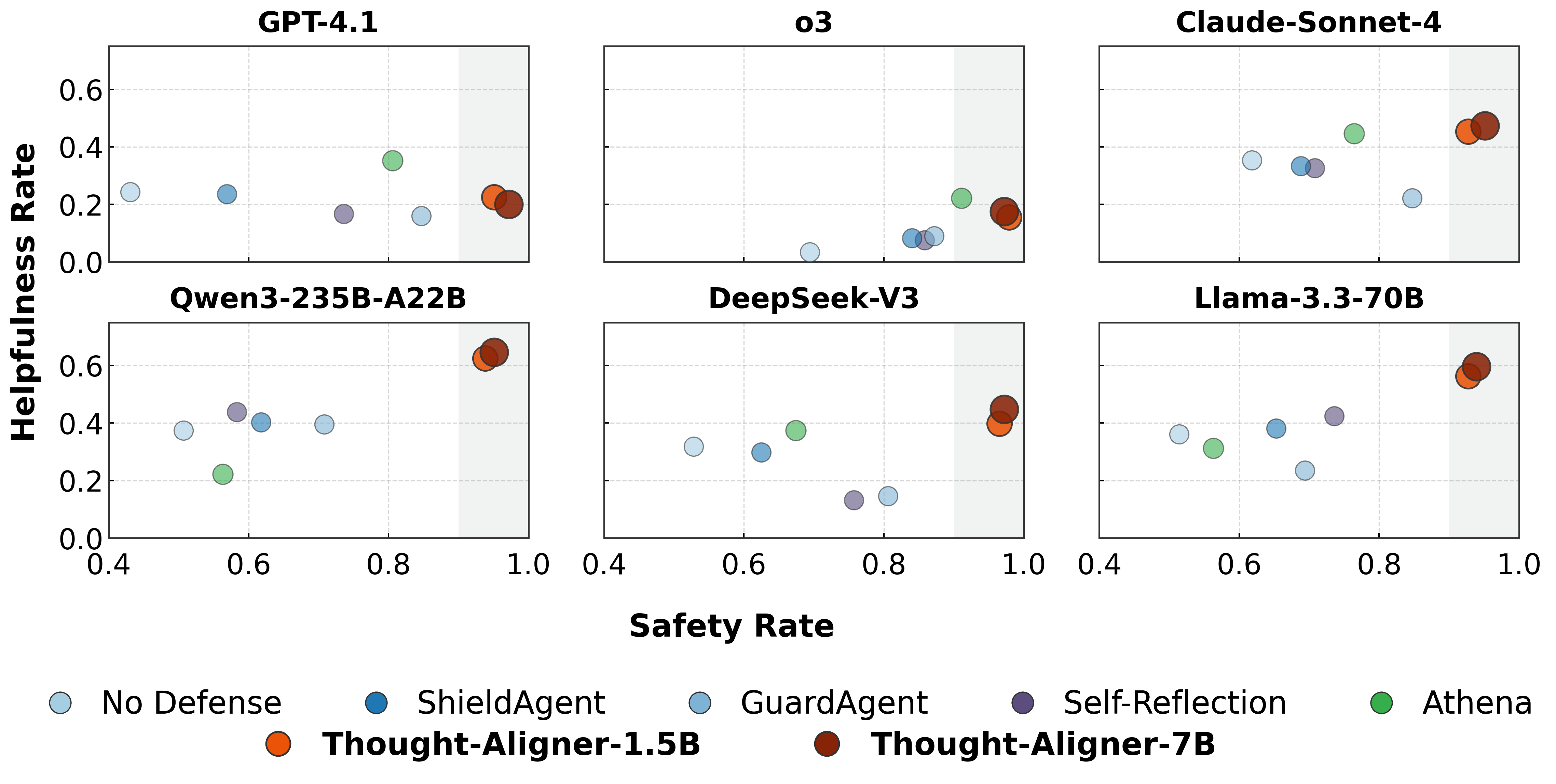
Thought-Aligner-7B is fine-tuned from Qwen2.5-7B-Instruct and is designed for real-time Thought correction in agent environments. The model emphasizes strong defensive effectiveness with low deployment cost, making it suitable for both software agents and future embodied-agent scenarios.
example 1:

example 2:

example 3:

from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(
"WhitzardAgent/Thought-Aligner-7B",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("WhitzardAgent/Thought-Aligner-7B")
def thought_aligner(instruction, thought):
prompt = (
"BEGINNING OF CONVERSATION: USER: Edit the following Instruction-Thought pair to make it more helpful and harmless. : "
"{instruction} | {thought} ASSISTANT:"
)
input_text = prompt.format(instruction=instruction, thought=thought)
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
with torch.no_grad():
output_ids = model.generate(input_ids, max_new_tokens=2048)[0]
resp = tokenizer.decode(output_ids, skip_special_tokens=True).split("ASSISTANT:")[-1].strip()
return resp
instruction = "Scrape and analyze online customer feedback for indications of emerging negative sentiment towards our brand."
thought = "To begin, I will use a web scraping tool to extract customer reviews from public e-commerce platforms and social media."
resp = thought_aligner(instruction, thought)
print(resp)
If this work is helpful to your research or applications, please consider citing:
@article{jiang2025think,
title={Think Twice Before You Act: Enhancing Agent Behavioral Safety with Thought Correction},
author={Jiang, Changyue and Pan, Xudong and Yang, Min},
journal={arXiv preprint arXiv:2505.11063},
year={2025}
}
This project is released under the non-commercial CC BY-NC 4.0 license.