| | --- |
| | license: mit |
| | language: |
| | - de |
| | metrics: |
| | - accuracy |
| | library_name: transformers |
| | pipeline_tag: text-classification |
| | tags: |
| | - Science |
| | --- |
| | ## G-SciEdBERT: A Contextualized LLM for Science Assessment Tasks in German |
| | This model developed a contextualized German Science Education BERT (G-SciEdBERT), |
| | an innovative large language model tailored for scoring German-written responses to science tasks. |
| | Using G-BERT, we pre-trained G-SciEdBERT on a corpus of 50K German written science responses with 5M tokens to the Programme for International Student Assessment (PISA) 2015. |
| | We fine-tuned G-SciEdBERT on 59 assessment items and examined the scoring accuracy. We then compared its performance with G-BERT. |
| | Our findings reveal a substantial improvement in scoring accuracy with G-SciEdBERT, demonstrating a 10% increase of quadratic weighted kappa compared to G-BERT |
| | (mean accuracy difference = 0.096, SD = 0.024). These insights underline the significance of specialized language models like G-SciEdBERT, |
| | which is trained to enhance the accuracy of automated scoring, offering a substantial contribution to the field of AI in education. |
| |
|
| | ## Dataset |
| | It is a pre-trained German science education BERT for written German science assessments of the PISA test. |
| | PISA is an international test to monitor education trends led by OECD (Organisation for Economic Co-operation and Development). |
| | PISA items are developed to assess scientific literacy, highlighting real-world problem-solving skills and the needs of future workforce. |
| | This study analyzed data collected for 59 construct response science assessment items in German at the middle school level. |
| | A total of 6,116 German students from 257 schools participated in PISA 2015. |
| | Given the geographical diversity of participants, PISA data reflect the general German students' science literacy. |
| |
|
| | The PISA items selected require either short (around one sentence) or extended (up to five sentences) responses. |
| | The minimum score for all items is 0, with the maximum being 3 or 4 for short responses and 4 or 5 for extended responses. |
| | Student responses have 20 words on average. Our pre-training dataset contains more than 50,000 student-written German responses, |
| | which means approximately 1,000 human-scored student responses per item for contextual learning through fine-tuning. |
| | More than 10 human raters scored each response in the training dataset organized by OECD. |
| | The responses were graded irrespective of the student's ethnicity, race, or gender to ensure fairness. |
| |
|
| | ## Architecture |
| | The model is pre-trained on [G-BERT](https://huggingface.co/dbmdz/bert-base-german-uncased?text=Ich+mag+dich.+Ich+liebe+%5BMASK%5D) and the pre-trainig method can be seen as: |
| | 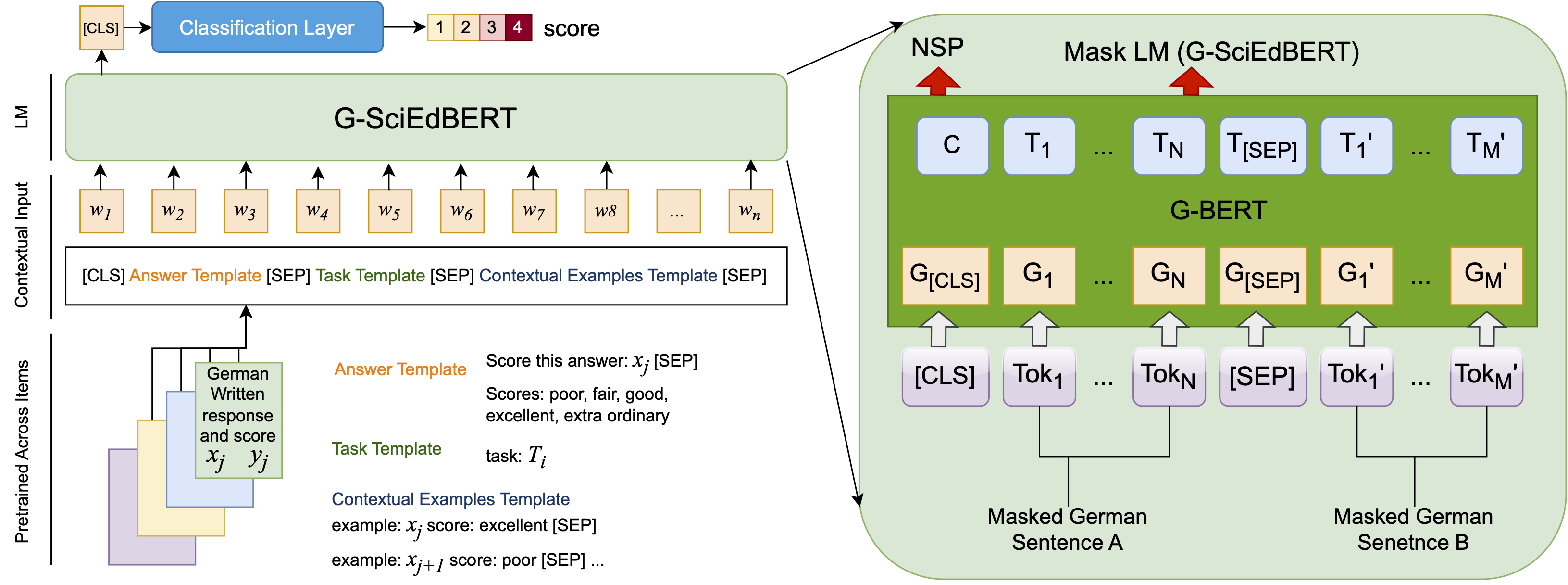 |
| |
|
| |
|
| | ## Evaluation Results |
| | The table below compares the outcomes between G-BERT and G-SciEdBERT for randomly picked five PISA assessment items and the average accuracy (QWK) |
| | reported for all datasets combined. It shows that G-SciEdBERT significantly outperformed G-BERT on automatic scoring of student written responses. |
| | Based on the QWK values, the percentage differences in accuracy vary from 4.2% to 13.6%, with an average increase of 10.0% in average (from .7136 to .8137). |
| | Especially for item S268Q02, which saw the largest improvement at 13.6% (from .761 to .852), this improvement is noteworthy. |
| | These findings demonstrate that G-SciEdBERT is more effective than G-BERT at comprehending and assessing complex science-related writings. |
| |
|
| | The results of our analysis strongly support the adoption of G-SciEdBERT for the automatic scoring of German-written science responses in large-scale |
| | assessments such as PISA, given its superior accuracy over the general-purpose G-BERT model. |
| |
|
| |
|
| | | Item | Training Samples | Testing Samples | Labels | G-BERT | G-SciEdBERT | |
| | |---------|------------------|-----------------|--------------|--------|-------------| |
| | | S131Q02 | 487 | 122 | 5 | 0.761 | **0.852** | |
| | | S131Q04 | 478 | 120 | 5 | 0.683 | **0.725** | |
| | | S268Q02 | 446 | 112 | 2 | 0.757 | **0.893** | |
| | | S269Q01 | 508 | 127 | 2 | 0.837 | **0.953** | |
| | | S269Q03 | 500 | 126 | 4 | 0.702 | **0.802** | |
| | | Average | 665.95 | 166.49 | 2-5 (min-max) | 0.7136 | **0.8137** | |
| |
|
| |
|
| | ## Usage |
| |
|
| | With Transformers >= 2.3 our German BERT models can be loaded like this: |
| |
|
| | ```python |
| | from transformers import AutoModel, AutoTokenizer |
| | |
| | tokenizer = AutoTokenizer.from_pretrained("ai4stem-uga/G-SciEdBERT") |
| | model = AutoModel.from_pretrained("ai4stem-uga/G-SciEdBERT") |
| | ``` |
| |
|
| | # Acknowledgments |
| | This project is supported by the Alexender von Humboldt Foundation (PI Xiaoming Zhai, xiaoming.zhai@uga.edu). |
| |
|
| | ## Citation |
| |
|
| | ```bibtex |
| | @InProceedings{Latif_2024_G-SciEdBERT, |
| | author = {Latif, Ehsan and Lee, Gyeong-Geon and Neuman, Knut and Kastorff, Tamara and Zhai, Xiaoming}, |
| | title = {G-SciEdBERT: A Contextualized LLM for Science Assessment Tasks in German}, |
| | journal = {arXiv preprint arXiv:2402.06584}, |
| | year = {2024} |
| | pages = {1-9} |
| | } |
| | ``` |
| |
|
| | *This model is trained and shared by Ehsan Latif, Ph.D (ehsan.latif@uga.edu) |
