
[Trimming] BGE-M3
Collection
Collection of trimmed BAAI's BGE-M3 embedding models. The models are sorted alphabetically. • 178 items • Updated
This model is a 39.18% smaller version of BAAI/bge-m3 optimized for Assamese language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 32,768 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
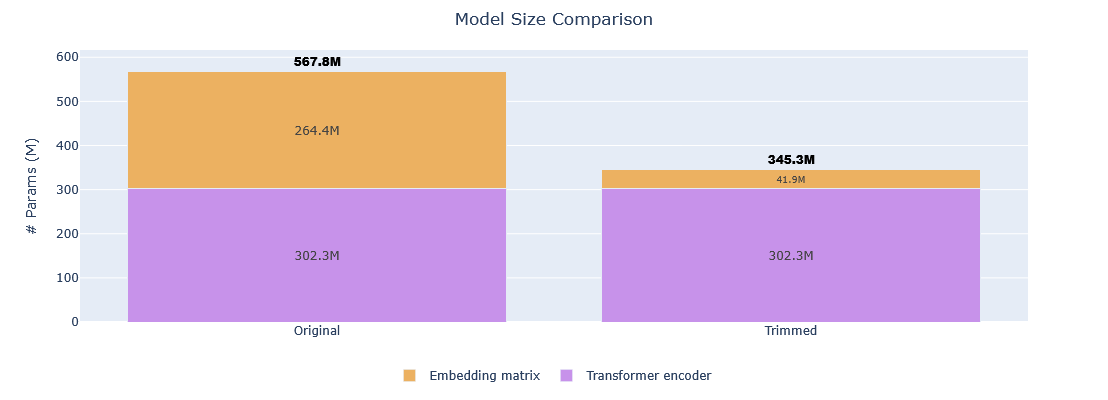
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 250,002 tokens | 32,768 tokens | 86.89% |
| Model size | 567,754,752 params | 345,307,136 params | 39.18% |
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("alphaedge-ai/bge-m3-asm-32768")
# Run inference with queries and documents
query = "My query in Assamese"
documents = [
"Chunk in Assamese",
"Chunk in Assamese",
"Chunk in Assamese",
]
query_embeddings = model.encode_query(query)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# Compute similarities to determine a ranking
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
@misc{bge-m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
year={2024},
eprint={2402.03216},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
BAAI/bge-m3