
[Trimming] EmbeddingGemma
Collection
Collection of trimmed Google's EmbeddingGemma models. The models are sorted alphabetically. • 243 items • Updated
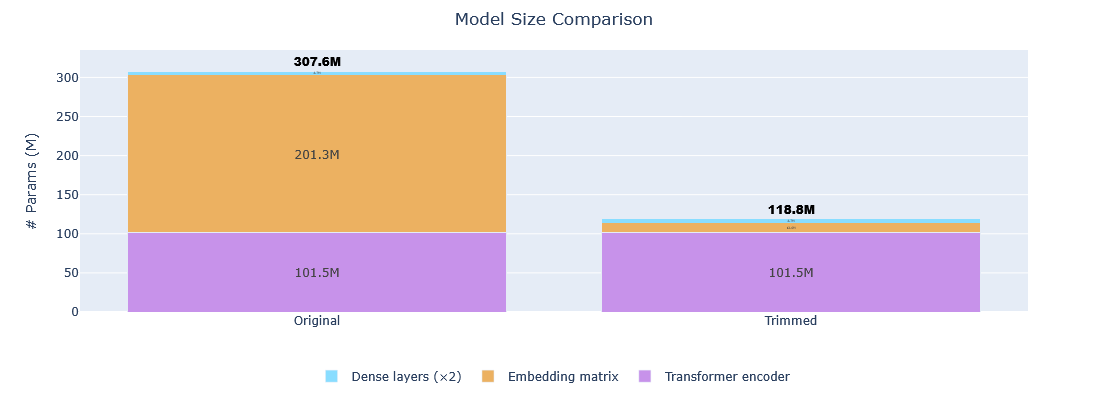
This model is a 61.36% smaller version of google/embeddinggemma-300m optimized for Kannada language via vocabulary size reduction using the trimming method.
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 262,144 tokens | 16,384 tokens | 93.75% |
| Model size | 307,581,696 params | 118,838,016 params | 61.36% |
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("alphaedge-ai/embeddinggemma-kan-16384")
# Run inference with queries and documents
query = "My query in Kannada"
documents = [
"Chunk in Kannada",
"Chunk in Kannada",
"Chunk in Kannada",
]
query_embeddings = model.encode_query(query)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# Compute similarities to determine a ranking
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
@misc{vera2025embeddinggemmapowerfullightweighttext,
title={EmbeddingGemma: Powerful and Lightweight Text Representations},
author={Henrique Schechter Vera and Sahil Dua and Biao Zhang and Daniel Salz and Ryan Mullins and Sindhu Raghuram Panyam and Sara Smoot and Iftekhar Naim and Joe Zou and Feiyang Chen and Daniel Cer and Alice Lisak and Min Choi and Lucas Gonzalez and Omar Sanseviero and Glenn Cameron and Ian Ballantyne and Kat Black and Kaifeng Chen and Weiyi Wang and Zhe Li and Gus Martins and Jinhyuk Lee and Mark Sherwood and Juyeong Ji and Renjie Wu and Jingxiao Zheng and Jyotinder Singh and Abheesht Sharma and Divyashree Sreepathihalli and Aashi Jain and Adham Elarabawy and AJ Co and Andreas Doumanoglou and Babak Samari and Ben Hora and Brian Potetz and Dahun Kim and Enrique Alfonseca and Fedor Moiseev and Feng Han and Frank Palma Gomez and Gustavo Hernández Ábrego and Hesen Zhang and Hui Hui and Jay Han and Karan Gill and Ke Chen and Koert Chen and Madhuri Shanbhogue and Michael Boratko and Paul Suganthan and Sai Meher Karthik Duddu and Sandeep Mariserla and Setareh Ariafar and Shanfeng Zhang and Shijie Zhang and Simon Baumgartner and Sonam Goenka and Steve Qiu and Tanmaya Dabral and Trevor Walker and Vikram Rao and Waleed Khawaja and Wenlei Zhou and Xiaoqi Ren and Ye Xia and Yichang Chen and Yi-Ting Chen and Zhe Dong and Zhongli Ding and Francesco Visin and Gaël Liu and Jiageng Zhang and Kathleen Kenealy and Michelle Casbon and Ravin Kumar and Thomas Mesnard and Zach Gleicher and Cormac Brick and Olivier Lacombe and Adam Roberts and Qin Yin and Yunhsuan Sung and Raphael Hoffmann and Tris Warkentin and Armand Joulin and Tom Duerig and Mojtaba Seyedhosseini},
year={2025},
eprint={2509.20354},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.20354},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
This model is derived from google/embeddinggemma-300m. Use of this model is governed by the Gemma Terms of Use. By using this model, you agree to the Gemma Terms of Use. This model is not affiliated with or endorsed by Google.
Base model
google/embeddinggemma-300m