
[Trimming] mmBERT
Collection
Collection of trimmed JHU Center for Language and Speech Processing's mmBERT models. The models are sorted alphabetically. • 514 items • Updated
This model is a 61.01% smaller version of jhu-clsp/mmBERT-small optimized for Assamese language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 32,768 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
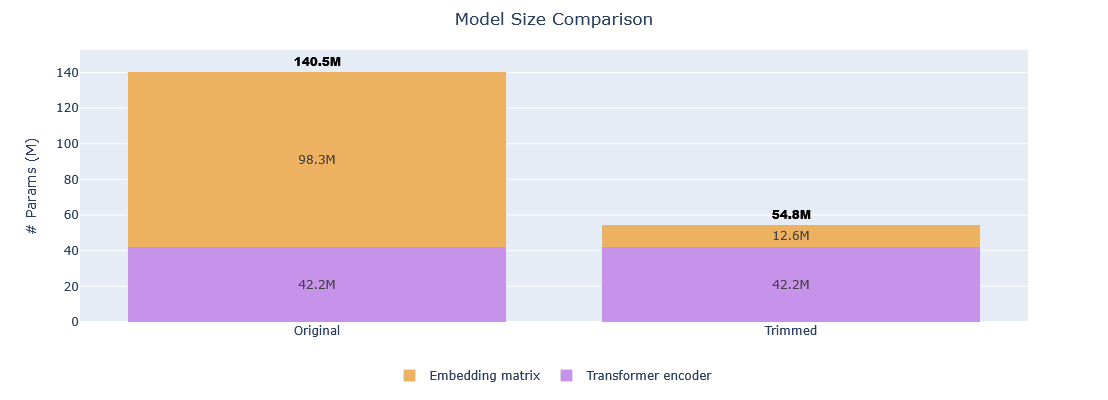
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 256,000 tokens | 32,768 tokens | 87.20% |
| Model size | 140,493,696 params | 54,772,608 params | 61.01% |
from transformers import AutoModel, AutoTokenizer
model_name = "alphaedge-ai/mmBERT-small-asm-32768"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
@misc{marone2025mmbertmodernmultilingualencoder,
title={mmBERT: A Modern Multilingual Encoder with Annealed Language Learning},
author={Marc Marone and Orion Weller and William Fleshman and Eugene Yang and Dawn Lawrie and Benjamin Van Durme},
year={2025},
eprint={2509.06888},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.06888},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
jhu-clsp/mmBERT-small