
Primed Hybrid Models Collection
Collection
Collection of primed Hybrid language models for Reasoning and Instruction following. • 9 items • Updated • 7
GKA-primed-HQwen3-32B-Instruct is a Hybrid language model consisting of 50% Attention layers and 50% Gated KalmaNet (GKA) layers, primed from Qwen3-32B using the Hybrid Model Factory Priming pipeline. The model is instruction-tuned and supports context lengths up to 128K tokens.
GKA (pronounced as gee-ka) is a State-Space Model layer inspired by the Kalman Filter that solves an online ridge regression problem at test time, with constant memory and linear compute cost in the sequence length.
By combining Attention with GKA, our Hybrid model achieves up to 2× faster inference at long contexts while closely matching the base Transformer's quality.
Each Primed Hybrid model is initialized from a base Transformer by converting a portion of its Attention layers into State-Space Model (SSM) layers that maintain a fixed-size recurrent state instead of a growing KV cache. At a 50% Hybrid ratio, roughly half the KV cache (which grows linearly with sequence length) is replaced with fixed-size SSM state. The practical benefits:
Increasing hybridization ratio, replacing more Attention layers with SSM layers, further reduces memory and increases throughput, typically at the expense of performance.
Note, this is an Instruct-tuned model and is not a thinking model, that is, it does not natively produce chain-of-thought thinking tokens in its generation trace.
Below we report benchmark performance for all our instruct-tuned Primed models. All Hybrid models use a 50% Hybrid ratio and are Primed from Qwen3-32B.
We consider the following Transformer as a baseline:
On both long- and short-context benchmarks, our Primed Hybrid models closely match the performance of the Transformer model while having considerably lower deployment costs, showcasing the efficacy of the Priming process.
Evaluated on HELMET, MRCR, and BABILong across context lengths from 8K to 128K, using a weighted average with geometrically increasing weights for longer contexts.
The plot below shows performance averaged over context lengths from 8K to 128K.
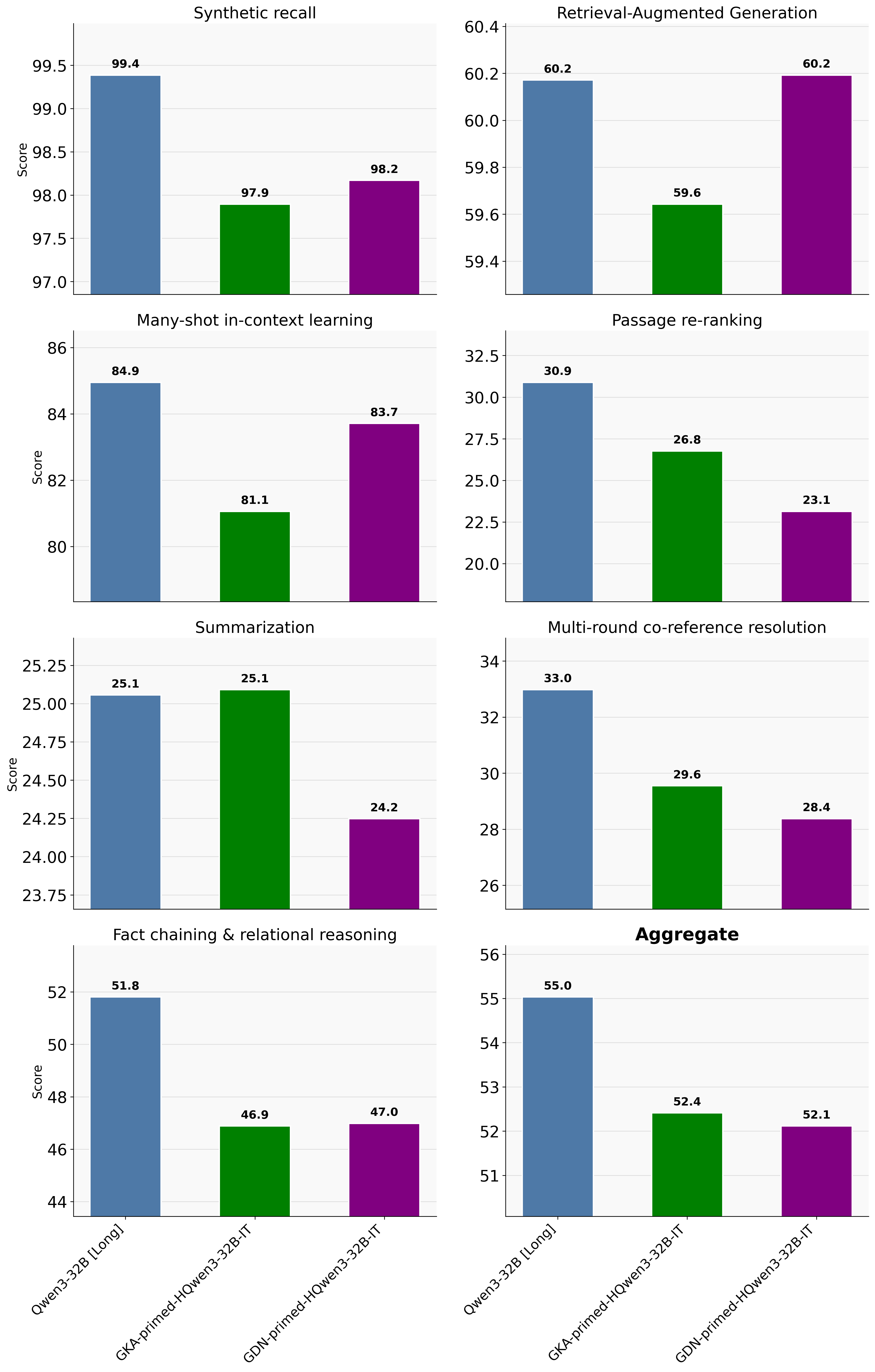
How close are the Hybrid models to the Transformer baseline on long context tasks? Primed GKA and GDN hybrids have competitive long-context capabilities with a gap of ~2.5-3 points on average with the Transformer [Qwen3-32B (Long)], while being 1.5–2× faster at inference on long contexts.
Evaluations on Tulu3-dev from OLMES. All tasks are over a short-context length (≤ 8K). Each category in the table below averages the following Tulu3-dev subtasks:
| Model | Math | Knowledge | Coding | Reasoning | Instruction Following | Average |
|---|---|---|---|---|---|---|
| Qwen3-32B [Long] | 74.43 | 54.47 | 94.54 | 82.89 | 81.52 | 77.56 |
| GKA-primed-HQwen3-32B-Instruct | 74.02 | 53.95 | 93.43 | 80.31 | 78.74 | 76.09 |
| GDN-primed-HQwen3-32B-Instruct | 73.65 | 54.35 | 94.40 | 80.99 | 79.3 | 76.54 |
How close are the Hybrid models to the Transformer baseline on short context tasks? Our Primed Hybrid models are within ~1-1.5 points of the average performance of the Transformer [Qwen3-32B (Long)] using <0.5% of the base Transformer model’s pre-training token budget.
For applications to complex reasoning and coding problems check out our Primed Hybrid Reasoning models.
Gated KalmaNet is a State-Space Model layer that is more expressive than both Mamba2 and Gated DeltaNet. GKA achieves this by employing the Kalman Filter to compute the optimal state at each time-step based on the entire past. In contrast, SSMs like Mamba2 and GDN rely on instantaneous objectives (that rely solely on the current input and loss estimate of the past) to compute their state.
Unlike other SSM-based hybrid layers, GKA gives you a runtime knob for trading compute against speed — with no retraining nor architecture changes. The num_iter parameter controls how many iterations the GKA solver runs during inference. No other hybrid layer type offers this: GDN and Mamba2 have fixed compute per layer, so their speed is fixed a priori. GKA lets you slide along the compute–latency curve per deployment, making it uniquely suited for scenarios where different endpoints or traffic tiers have different latency budgets.
For details on controlling GKA's compute–speed tradeoff at serving time via num_iter, see GKA Compute Control, and for more details on the modeling choices see the GKA paper.
This release includes optimized Triton kernels for GKA's Chebyshev solver, enabling the throughput numbers reported in Inference Efficiency. The training kernels are in training/.../gated_kalmanet/ops/chebyshev/ and the inference kernels in vllm-inference/.../gka/ops/.
| Component | Details |
|---|---|
| Number of Layers | 64 (32 Attention + 32 GKA) |
| Hidden Dimension | 5120 |
| Attention Heads | 64 (Q) / 8 (KV) |
| Head Dimension | 128 |
| Intermediate Dimension (FFN) | 25600 |
| Vocabulary Size | 151,936 |
| Position Encoding | RoPE (θ = 5,000,000) |
| Layer Layout | GKA layer indices were selected with our selective hybridization procedure |
As discussed above, GKA offers the unique ability to adjust the inference FLOPs by tuning the num_iter parameter. Here we summarize long context performance across different num_iter settings.
| Model | Avg. Long-context Performance |
|---|---|
GKA-primed-HQwen3-32B-Instruct (num_iter=30, default) |
52.4 |
GKA-primed-HQwen3-32B-Instruct (num_iter=10) |
51.9 |
GKA-primed-HQwen3-32B-Instruct (num_iter=5) |
51.6 |
GKA-primed-HQwen3-32B-Instruct (num_iter=1) |
49.5 |
GKA-primed-HQwen3-32B-Instruct (num_iter=0) |
41.7 |
| Qwen3-32B (Long) | 55.0 |
For most practical scenarios, we recommend setting num_iter=10 for the best trade-off. See next section for inference gains upon reducing number of iterations.
Interestingly, setting
num_iter=0effectively converts the GKA model to a Gated Linear Attention (GLA) model. Thus, one can think of increasing num iters as improving upon the initial solution of the GLA model.
Sustained decode throughput (tokens/s) on 8× H200 GPUs (TP=8), measured during pure decode with a saturated KV cache. Benchmarked with random data (no prefix-caching benefits). See the full Inference guide for methodology and additional models.
| Model | 16K | 32K | 64K | 128K |
|---|---|---|---|---|
GKA-primed-HQwen3-32B-Instruct (num_iter=30, default) |
6,810 (1.29×) | 4,152 (1.45×) | 2,385 (1.82×) | 1,168 (1.99×) |
GKA-primed-HQwen3-32B-Instruct (num_iter=10) |
7,778 (1.47×) | 4,534 (1.58×) | 2,537 (1.94×) | 1,200 (2.05×) |
GKA-primed-HQwen3-32B-Instruct (num_iter=5) |
8,039 (1.52×) | 4,621 (1.61×) | 2,569 (1.96×) | 1,206 (2.06×) |
GKA-primed-HQwen3-32B-Instruct (num_iter=1) |
8,177 (1.54×) | 4,678 (1.63×) | 2,593 (1.98×) | 1,210 (2.06×) |
| GDN-primed-HQwen3-32B | 8,133 (1.53×) | 4,876 (1.70×) | 2,688 (2.06×) | 1,238 (2.11×) |
| Qwen3-32B (Long) | 5,299 | 2,865 | 1,308 | 586 |
Mean TTFT at the Transformer's saturated batch size (Hybrid model has memory to spare):
| Model | 16K | 32K | 64K | 128K |
|---|---|---|---|---|
GKA-primed-HQwen3-32B-Instruct (num_iter=30, default) |
52,053 ms (1.32×) | 58,613 ms (1.21×) | 68,241 ms (1.05×) | 84,935 ms (0.90×) |
GKA-primed-HQwen3-32B-Instruct (num_iter=10) |
48,560 ms (1.23×) | 55,039 ms (1.13×) | 64,766 ms (0.99×) | 81,410 ms (0.86×) |
GKA-primed-HQwen3-32B-Instruct (num_iter=5) |
47,958 ms (1.22×) | 54,320 ms (1.12×) | 63,826 ms (0.98×) | 80,369 ms (0.85×) |
GKA-primed-HQwen3-32B-Instruct (num_iter=1) |
46,726 ms (1.19×) | 53,061 ms (1.09×) | 62,645 ms (0.96×) | 79,321 ms (0.84×) |
| GDN-primed-HQwen3-32B | 42,492 ms (1.08×) | 48,417 ms (1.00×) | 57,525 ms (0.88×) | 73,145 ms (0.77×) |
| Qwen3-32B (Long) | 39,421 ms | 48,527 ms | 65,104 ms | 94,479 ms |
The decode throughput advantage grows with context length — from 1.29× at 16K to 1.99× at 128K (2.06× with num_iter=1) — thanks to GKA layers maintaining a fixed-size recurrent state instead of a growing KV cache. TTFT crosses over at long contexts: GKA prefills 10–16% faster than the Transformer at 128K depending on num_iter. Reducing num_iter progressively improves both decode and TTFT, with most of the gain coming from 30 → 10. See Trade-off inference FLOPs for accuracy for details.
Install the Hybrid Model Factory vLLM plugin in your local environment, then serve:
vllm serve amazon/GKA-primed-HQwen3-32B-Instruct \
--enable-prefix-caching \
--mamba-cache-mode align \
--mamba-cache-dtype float32 \
--mamba-ssm-cache-dtype float32
Query the server:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "amazon/GKA-primed-HQwen3-32B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is Linear Attention in the context of LLMs?"}
]
}'
The
--mamba-cache-dtype float32and--mamba-ssm-cache-dtype float32flags are important for accurate long-context generation. See the Inference guide for details on all recommended flags.
See the Inference guide for details on when we recommend the Hugging Face Transformers implementation as opposed to the highly optimized vLLM one.
from transformers import AutoModelForCausalLM, AutoTokenizer
import hmf.model.hybrid_zoo.models.model_register # Register Hybrid models
model = AutoModelForCausalLM.from_pretrained(
"amazon/GKA-primed-HQwen3-32B-Instruct", trust_remote_code=True
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("amazon/GKA-primed-HQwen3-32B-Instruct")
messages = [{"role": "user", "content": "What is linear attention in the context of LLMs?"}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
This model supports training-free context extension 2-4× its native context via an extension to Hybrid models of PICASO cache composition. See the State Composition guide for usage. Note, this is currently supported in Hugging Face Transformers only.
These models were produced through the multi-stage Priming pipeline from Hybrid Model Factory. Training data spans web documents, mathematics, long-context documents, and instruction-following and reasoning examples — each targeting a different capability axis. This diversity is critical: it allows the Priming procedure to convert a base Transformer into a more memory- and compute-efficient Hybrid architecture at nearly the same level of performance, using <0.5% of the base Transformer model's pre-training token budget.
At Amazon, we are committed to developing AI responsibly and take a people-centric approach that prioritizes education, science, and our customers, to integrate responsible AI across the end-to-end AI lifecycle. We believe the use of AI must respect the rule of law and human rights, and we encourage the safe and responsible development of AI. When downloaded or used in accordance with AWS Responsible AI Policy, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. Please report model quality, risk, security vulnerabilities or Amazon AI Concerns here.
@software{hybrid_model_factory,
title = {Hybrid Model Factory},
year = {2026},
url = {https://github.com/awslabs/hybrid-model-factory}
}
@inproceedings{gka2026,
title = {Gated KalmaNet: A Fading Memory Layer Through Test-Time Ridge Regression},
year = {2026},
booktitle = {CVPR},
url = {https://arxiv.org/abs/2511.21016}
}
This model is licensed under the Apache 2.0 License.
Base model
Qwen/Qwen3-32B