
Nehanda
Collection
Specialist in deep/forensic research across academic, policy, and technical documentation • 4 items • Updated
Nehanda v1 is a specialized 7B parameter language model fine-tuned for intelligence assessment, signal detection, and global systems analysis.
Built on the Mistral-7B architecture, Nehanda departs from standard "chat" behaviors to focus on forensic analysis. It is designed to trace multi-hop citations, detect operator signatures in noisy datasets, and provide evidence-based assessments of geopolitical and financial networks.
Named after the ancestral spirit of resistance and prophecy, Nehanda is built to see through hegemonic narratives and expose the structural realities beneath complex data.
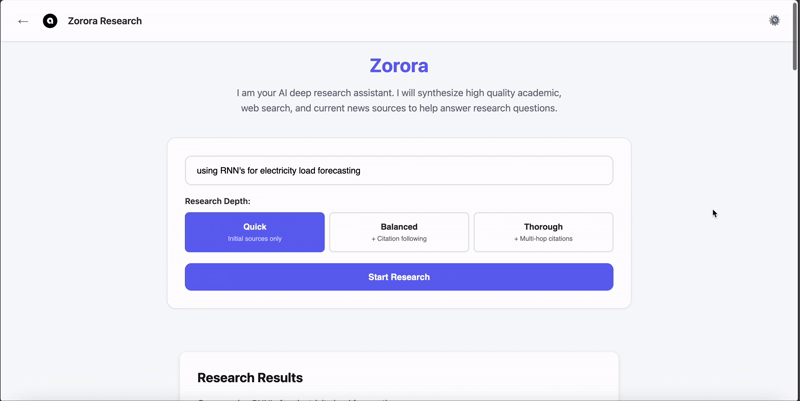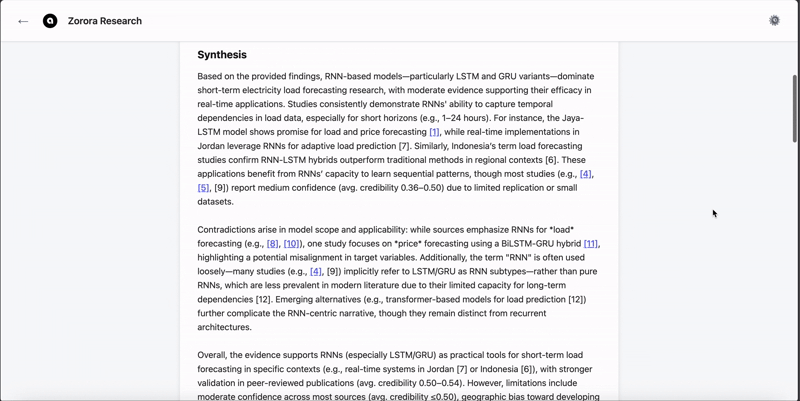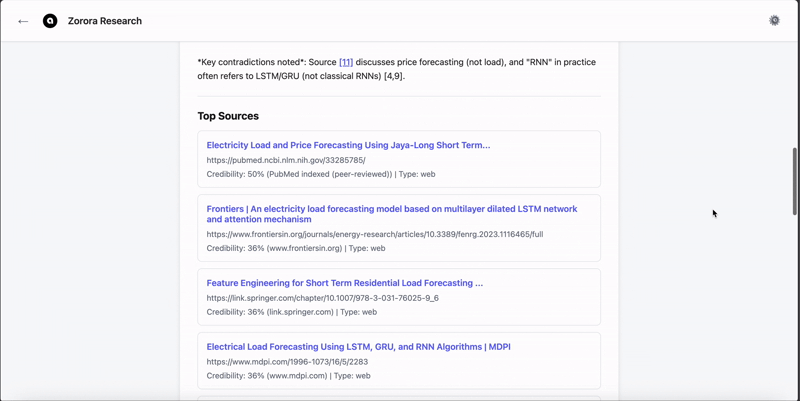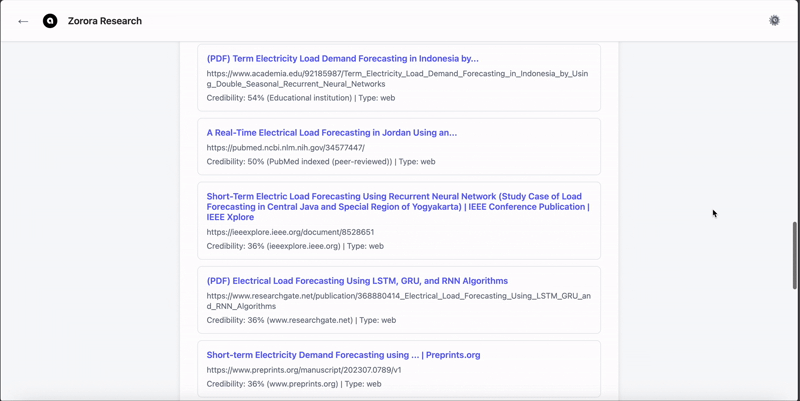
Unlike general-purpose LLMs optimized for fluency, Nehanda is optimized for provenance and structure. It is trained to reject fabrication and explicitly state when information is unknown.
Nehanda v1 is the default synthesis engine for the Zorora Deep Research platform.
When operating within Zorora, Nehanda drives the synthesis layer for the /search and /research commands. It does not just summarize search results; it acts as an analyst that:
When a user runs a /research query in Zorora:
"Map the financial dependencies between the new energy consortium in Malta and verified state-owned entities."
Zorora retrieves the raw documents, and Nehanda performs the analysis—flagging specific shell company structures or regulatory anomalies that match patterns learned during its "Systems Analysis" training phase.
Nehanda v1's "Systems Analysis" capabilities are derived from a curated, high-density corpus of 17,852 documents (~10GB). Unlike general models trained on the open internet, Nehanda has been force-fed a specific diet of regulatory, financial, and ideological texts to understand the mechanics of power.
| Domain | Docs | Role in Nehanda |
|---|---|---|
| The Hegemony Layer (USA) | 15,920 | Baseline Intent: Federal legislation, State policy, and Admin ideology docs establish the "baseline" for Western geopolitical signaling. |
| The Infrastructure Layer (SA) | 1,559 | Physical Constraints: Utility whitepapers and grid codes teach the model how abstract policy translates into concrete infrastructure. |
| The Systems Layer (Finance) | 213 | Forensics: Corruption investigations (Panama Papers context) and commodities data teach the graph topology of illicit finance. |
| The Risk Layer (Insurance) | 160 | Actuarial Logic: Textbooks on risk management train the model to assess events via exposure and liability rather than just sentiment. |
| The Poly Hegemony Layer (Global) | 109 | Non-Western Logic: Policy doctrines and statecraft ontology from core alternative would-be hegemons - Russia, China, Brazil, India + as well as regional trading blocs. |
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "asoba/nehanda-v1-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_4bit=True)
# Example Intelligence Prompt
prompt = """You are an intelligence assessment specialist.
### Instruction:
Analyze the provided cable for indicators of regulatory capture.
...
"""
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0]))
Base model
mistralai/Mistral-7B-v0.3