
How to use from
vLLMUse Docker
docker model run hf.co/athirdpath/NeuralPivot-Mistral-13BQuick Links
Looks like we're in business, boys!

!!NSFW!! - Erotica Writing Example - !!NSFW!!
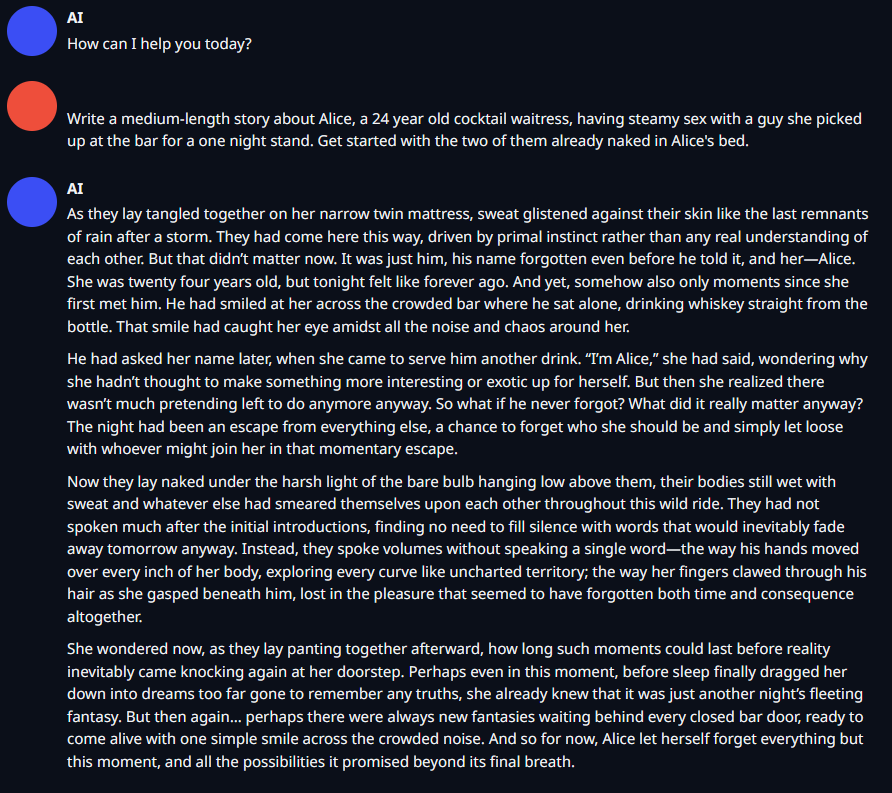{kind=link}
Recipe
slices
sources:
- model: maywell/PiVoT-0.1-Starling-LM-RP
- layer_range: [0, 24]
sources:
- model: Intel/neural-chat-7b-v3-1
- layer_range: [12, 24]
sources:
- model: maywell/PiVoT-0.1-Starling-LM-RP
- layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
- Downloads last month
- 8
Install from pip and serve model
# Install vLLM from pip: pip install vllm# Start the vLLM server: vllm serve "athirdpath/NeuralPivot-Mistral-13B"# Call the server using curl (OpenAI-compatible API): curl -X POST "http://localhost:8000/v1/completions" \ -H "Content-Type: application/json" \ --data '{ "model": "athirdpath/NeuralPivot-Mistral-13B", "prompt": "Once upon a time,", "max_tokens": 512, "temperature": 0.5 }'