|
|
--- |
|
|
license: mit |
|
|
datasets: |
|
|
- atulgupta002/banking_customer_service_query_intent |
|
|
language: |
|
|
- en |
|
|
base_model: |
|
|
- google-bert/bert-base-uncased |
|
|
pipeline_tag: text-classification |
|
|
tags: |
|
|
- finance |
|
|
- banking |
|
|
- intent |
|
|
- classification |
|
|
- customer |
|
|
- service |
|
|
- BERT |
|
|
--- |
|
|
|
|
|
# Banking Customer Service Intent Classifier |
|
|
|
|
|
This model is designed to classify customer service queries into different intents, based on the type of inquiry made by the customer. It was fine-tuned on a **synthetic** dataset of realistic banking customer service interactions and can classify the following intents: |
|
|
|
|
|
- `transaction_query` |
|
|
- `password_reset` |
|
|
- `loan_inquiry` |
|
|
- `fraud_report` |
|
|
- `credit_card_application` |
|
|
- `balance_inquiry` |
|
|
|
|
|
## Dataset |
|
|
|
|
|
Link: https://huggingface.co/datasets/atulgupta002/banking_customer_service_query_intent |
|
|
|
|
|
## Model Overview |
|
|
|
|
|
The model is a fine-tuned BERT-based architecture that classifies text inputs into one of the six specified intents. It leverages the **transformers** library by Hugging Face for tokenization and model loading. |
|
|
|
|
|
## Intended Use |
|
|
|
|
|
This model is suitable for deployment in applications that require automatic classification of customer service queries, such as: |
|
|
|
|
|
- Chatbots |
|
|
- Virtual assistants |
|
|
- Automatic re-routing incoming emails,calls, and texts |
|
|
|
|
|
It can be used to classify various types of banking queries, such as requests for account balance, loan inquiries, or fraud reports. |
|
|
|
|
|
## Installation |
|
|
|
|
|
To install the necessary dependencies, use the following: |
|
|
|
|
|
```bash |
|
|
pip install transformers torch |
|
|
``` |
|
|
|
|
|
## Inference |
|
|
|
|
|
```bash |
|
|
from transformers import AutoModelForSequenceClassification, AutoTokenizer |
|
|
import torch |
|
|
|
|
|
labels = [ |
|
|
'transaction_query', |
|
|
'password_reset', |
|
|
'loan_inquiry', |
|
|
'fraud_report', |
|
|
'credi_card_application', |
|
|
'balance_inquiry' |
|
|
] |
|
|
label2id = {label: idx for idx, label in enumerate(labels)} |
|
|
id2label = {idx: label for label, idx in label2id.items()} |
|
|
|
|
|
# Load the pre-trained model and tokenizer |
|
|
model = AutoModelForSequenceClassification.from_pretrained("atulgupta002/banking_customer_service_query_intent_classifier") |
|
|
tokenizer = AutoTokenizer.from_pretrained("atulgupta002/banking_customer_service_query_intent_classifier") |
|
|
|
|
|
def predict(text): |
|
|
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True) |
|
|
|
|
|
with torch.no_grad(): |
|
|
outputs = model(**inputs) |
|
|
logits = outputs.logits |
|
|
predicted_class_id = logits.argmax().item() |
|
|
|
|
|
return id2label[predicted_class_id] |
|
|
|
|
|
query = "I want to apply for a new credit card" |
|
|
print(predict(query)) |
|
|
``` |
|
|
|
|
|
## Sample output |
|
|
|
|
|
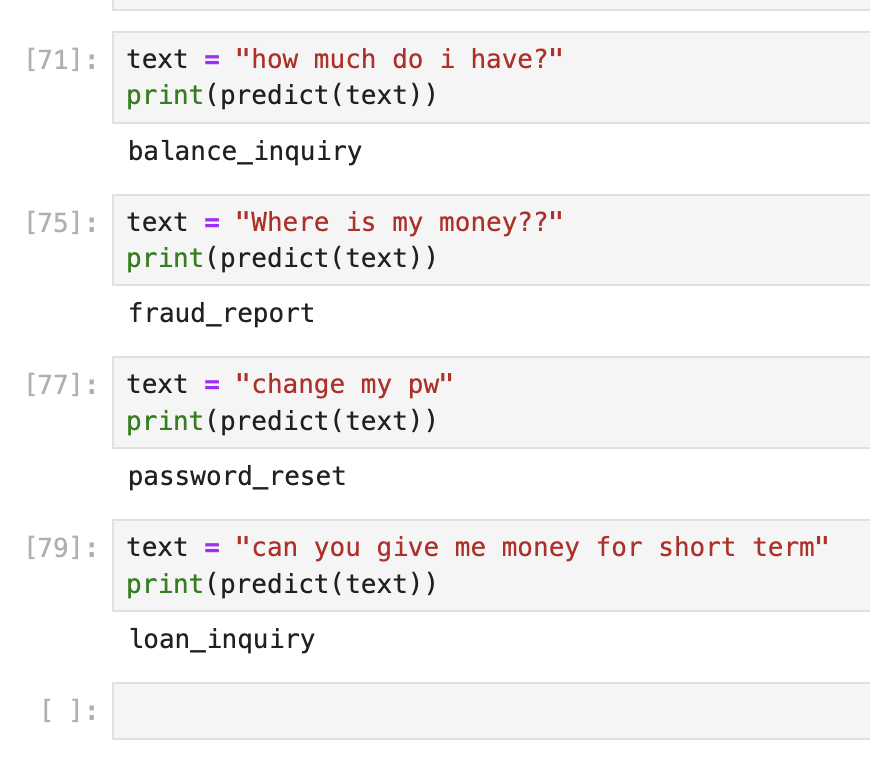 |
|
|
|
