
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Txa 1 Tokenizer: The Foundation of Axtrio AI
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚡ Overview
The Txa 1 Tokenizer is a highly efficient, production-ready tokenizer engineered for the Txa 1 (4B MoE) model family. Built upon the battle-tested Mistral v1 foundation, it has been fine-tuned to balance high compression rates with extreme processing speed on H100/H200 hardware.
This tokenizer natively supports ChatML formatting, making it instantly compatible with modern inference engines like vLLM, Ollama, and LM Studio.
Developed by Rx, Founder & CEO of Axtrio AI.
📊 Benchmark Arena
We pitted the Txa 1 Tokenizer against industry heavyweights in our Tokenizer Arena.
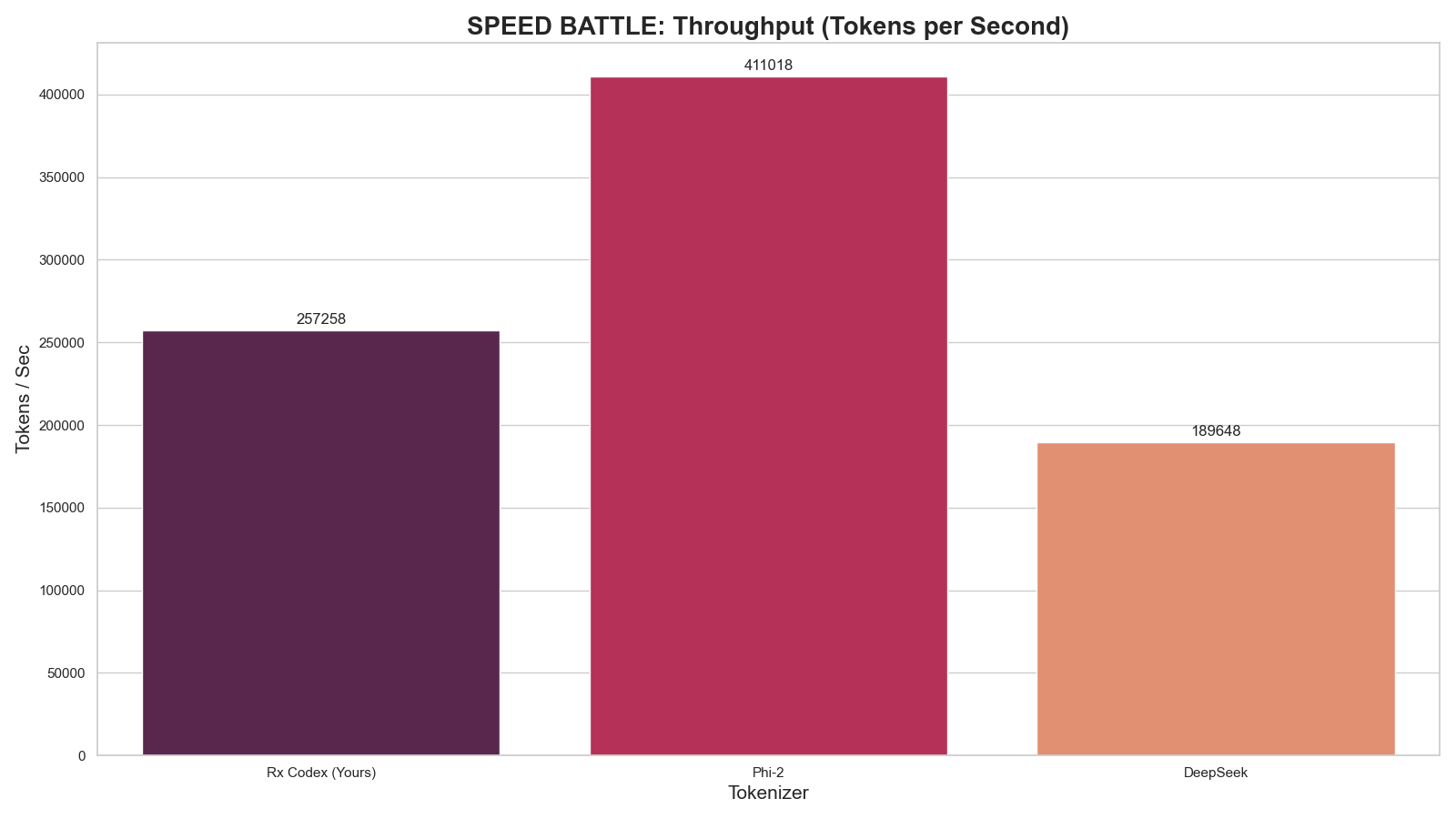
1. Speed Analysis (Throughput)
Higher is better. Measures raw tokenization speed on H100 hardware.
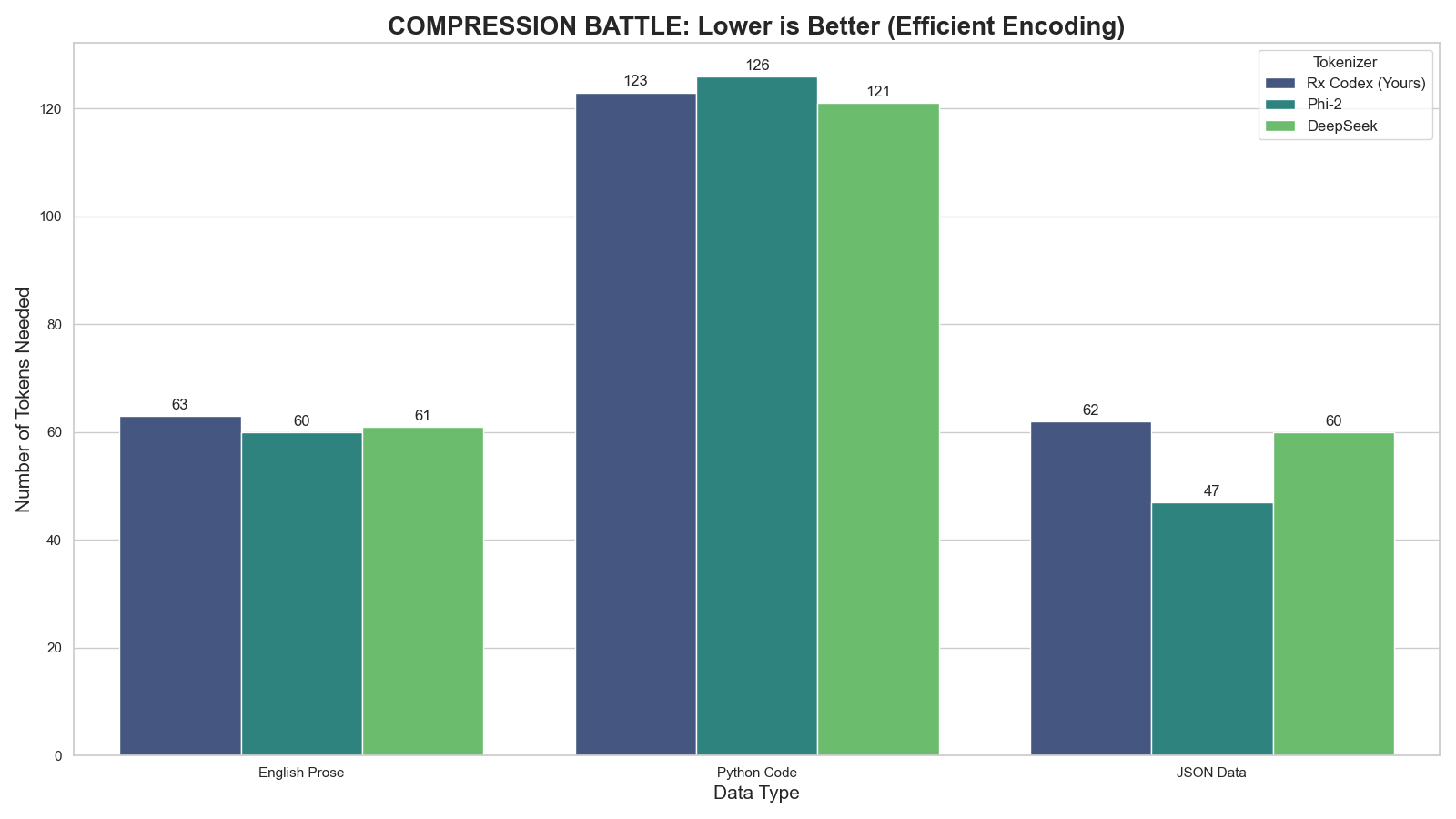
2. Compression Efficiency
Lower is better. Measures how many tokens are needed to represent complex Code & English.
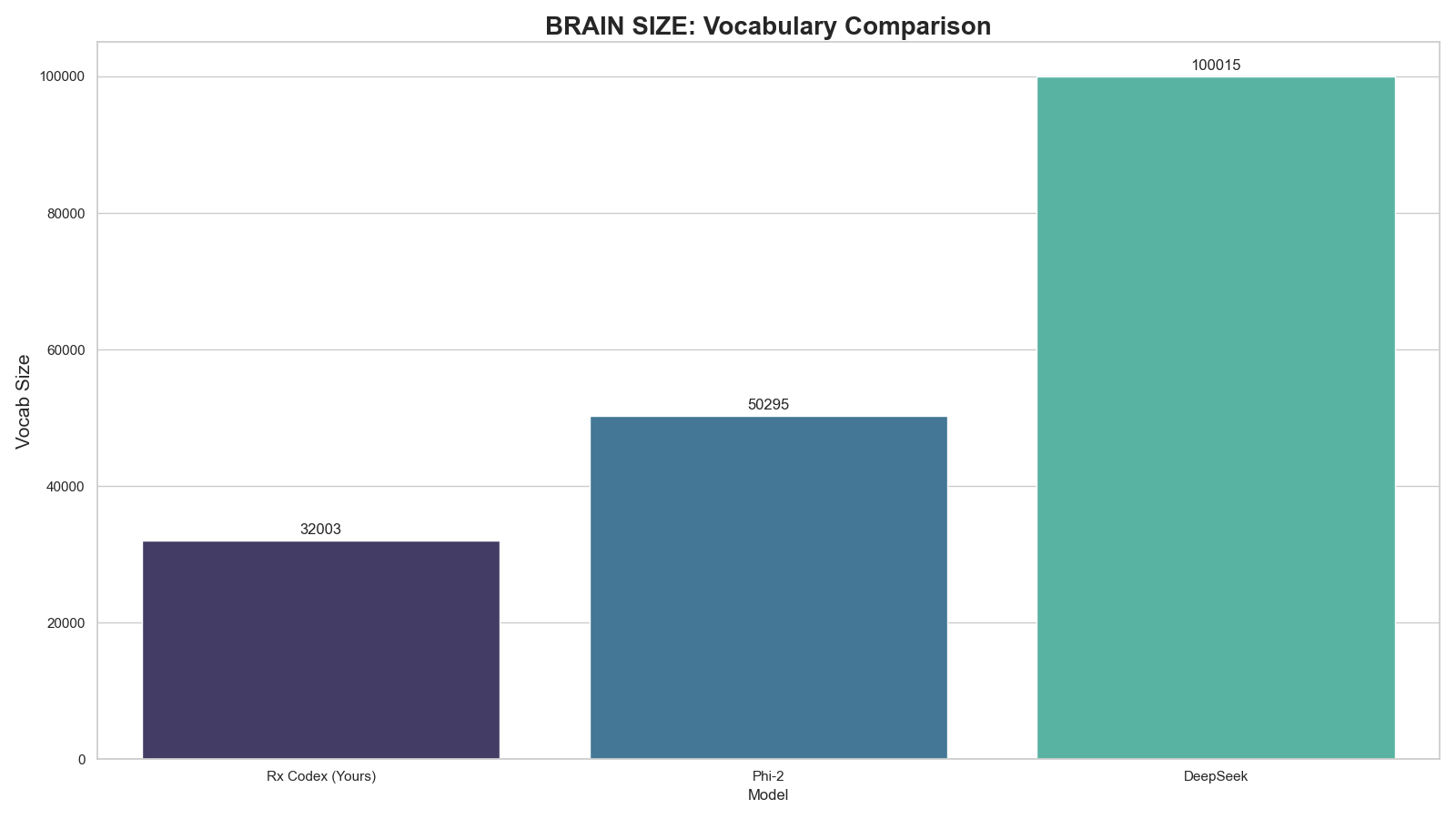
3. Vocabulary Architecture
Comparison of dictionary sizes. Txa 1 stays lean (32k) to maximize VRAM efficiency for the 4B MoE architecture.
🔧 Technical Specifications
| Feature | Specification |
|---|---|
| Base Architecture | Byte-Pair Encoding (Mistral v1 Foundation) |
| Vocabulary Size | 32,003 Tokens (Efficient & Lean) |
| Added Special Tokens | `< |
| Optimization | Code & Logic Compression |
| Compatibility | Fully Compatible with LlamaTokenizerFast |
💻 Usage
Quick Start
from transformers import AutoTokenizer
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("AxtrioAI/Txa1-4B-Tokenizer")
# Test ChatML Format
chat = [
{"role": "user", "content": "Hello Txa, can you help me debug python?"},
{"role": "assistant", "content": "Certainly! Please paste your code below."}
]
# Apply template
formatted_prompt = tokenizer.apply_chat_template(chat, tokenize=False)
print(formatted_prompt)