| | --- |
| | language: |
| | - en |
| | tags: |
| | - GENIUS |
| | - conditional text generation |
| | - sketch-based text generation |
| | - keywords-to-text generation |
| | - data augmentation |
| | license: apache-2.0 |
| | datasets: |
| | - wikipedia |
| | widget: |
| | - text: "machine learning data science my future work" |
| | example_title: "Example" |
| |
|
| | inference: |
| | parameters: |
| | max_length: 100 |
| | num_beams: 2 |
| | do_sample: True |
| | --- |
| | |
| | # 💡GENIUS – generating text using sketches! |
| |
|
| | - **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)** |
| |
|
| | 💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large- scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches. |
| |
|
| |
|
| | 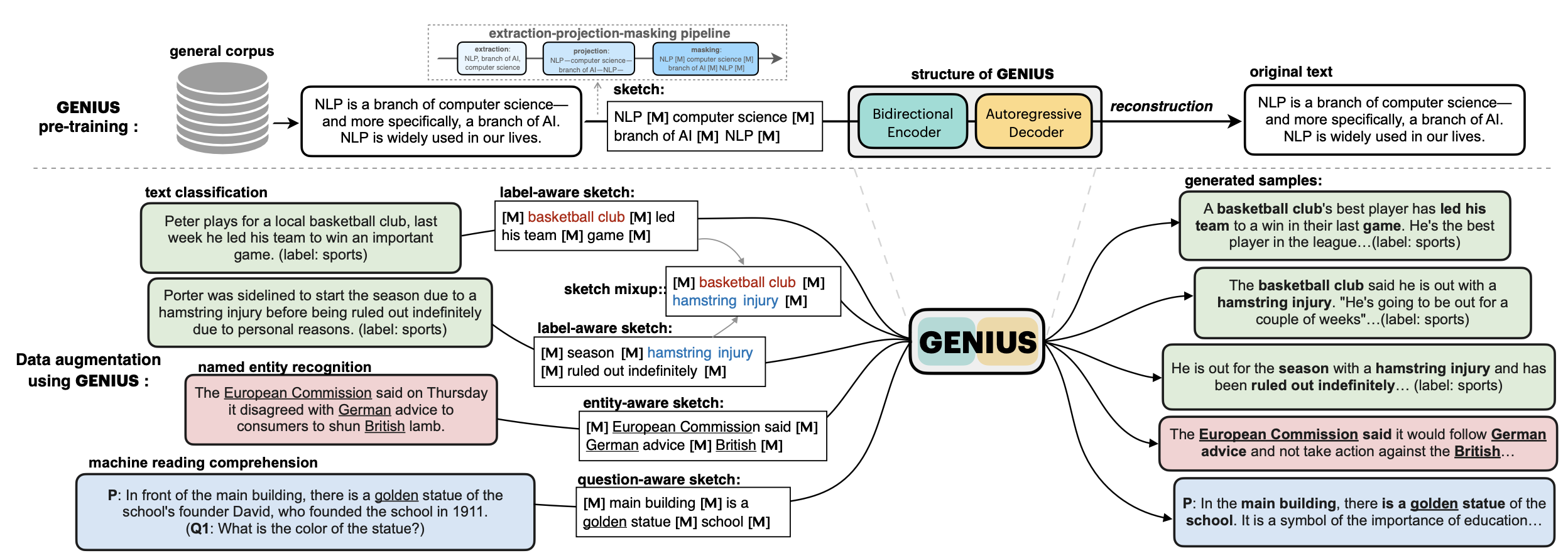 |
| |
|
| |
|
| |
|
| | - Models hosted in 🤗 Huggingface: |
| |
|
| | **Model variations:** |
| |
|
| | | Model | #params | Language | comment| |
| | |------------------------|--------------------------------|-------|---------| |
| | | [`genius-large`](https://huggingface.co/beyond/genius-large) | 406M | English | The version used in **paper** (recommend) | |
| | | [`genius-large-k2t`](https://huggingface.co/beyond/genius-large-k2t) | 406M | English | keywords-to-text | |
| | | [`genius-base`](https://huggingface.co/beyond/genius-base) | 139M | English | smaller version | |
| | | [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences | |
| | | [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练| |
| |
|
| | 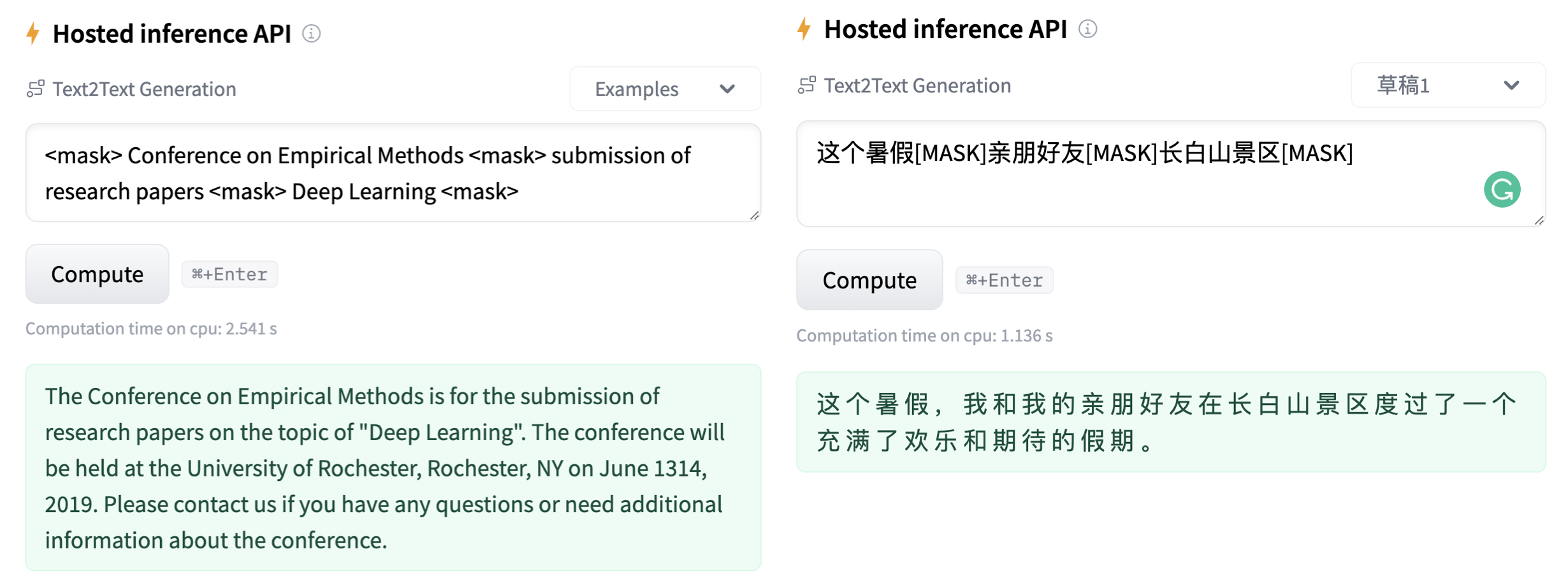 |
| |
|
