FIGHTING THE RANDOM CURSE WITH GOLDENER
Train/Val split on CIFAR 10, PASCAL VOC and IMDB

TLDR
A single random Train/Val split does not guarantee optimal performance on the Test set (see here for more details). In our experiment, across a few datasets and tasks, we demonstrate that a smart split ? using a pretrained model and a Greedy K-Center selection algorithm ? consistently matches or outperforms the best performance results achieved by random splits across five different seeds. This smart split could then eliminate the need to treat the split randomness as a hyperparameter, enabling more reliable model deployment.
1. Context
In a previous RANDOM CURSE episode, we illustrated the impact on performance of the random split between the Train and Val sets. For all the 3 tested datasets, different metrics have shown a relatively high variance depending on the task and dataset. Thus, the randomness in the Train/Val split is a new training hyperparameter to consider before deploying a model in the wild. Between the model architecture and the training hyperparameters, deploying a new model is already a fair amount of work. Then, in this report, we propose a way to address this random curse and access high performance on the Test set with a unique single split.
With the rise of pretrained/foundational models, it is now possible to describe the data of an existing dataset with a semantic representation aggregating local and global information. Even though these models have not been trained on the target dataset, their general knowledge can allow them to differentiate between the different samples. In these experiments, we leverage those representations to split the Train / Val sets in order to maximize the performance on the Test set.
In an ideal world, the Train and Val sets present the same distribution of data which is a good proxy of the Test set. In practice, it might be difficult to have enough redundancy among the Training data to include all the concepts in both sets. Thus, it looks more adequate to keep the rare occurrences in the Train set (allowing to integrate them in the optimization process) and to force the redundant elements in the Val set. In these experiments, we apply a Greedy K-Center selection algorithm in order to select the samples going to the Train set. All the other samples are then assigned to the Val set. This selection algorithm selects, iteratively, points that are far from each other, starting with the point farthest from all others.
The main goal of this report is to illustrate, for a few tasks and datasets, the potential of a smarter Train/Val split based on embeddings extracted with pretrained networks. Thus, the presented results cannot be taken as a general truth, however they give some first intuitions on this matter.
2. Experiments
This experiment is a follow-up to this previous RANDOM CURSE episode. Thus, the datasets, the models and evaluation metrics are exactly the same. The smart split is obtained by leveraging Goldener, the Python data orchestration library (see this blog post for more details). With Goldener, the smart splitting is just a few lines of code. It extracts some semantic representations of the data from a pretrained model and then it applies the selection algorithm per class on the vectorized version of this representation.
Depending on the type of data, a different pretrained model is exploited to describe the Training dataset. The layers and type of token/embedding are selected arbitrarily without any search for performance optimization. Here are the configurations for the 3 tested datasets:
| Dataset | Model | Layers | Distance | Token |
|---|---|---|---|---|
| CIFAR 10 | ViT Large DinoV3 | [blocks.23] | Euclidean | class token |
| PASCAL VOC | ViT Large DinoV3 | [blocks.23] | Cosine | class token |
| IMDB | bert-base-uncased | [encoder.layer.11] | Euclidean | class token |
The Train/Val split from Goldener is compared with 5 different seeds for the random splits. This smart split is named gold in the different figures and tables.
2.1. CIFAR 10
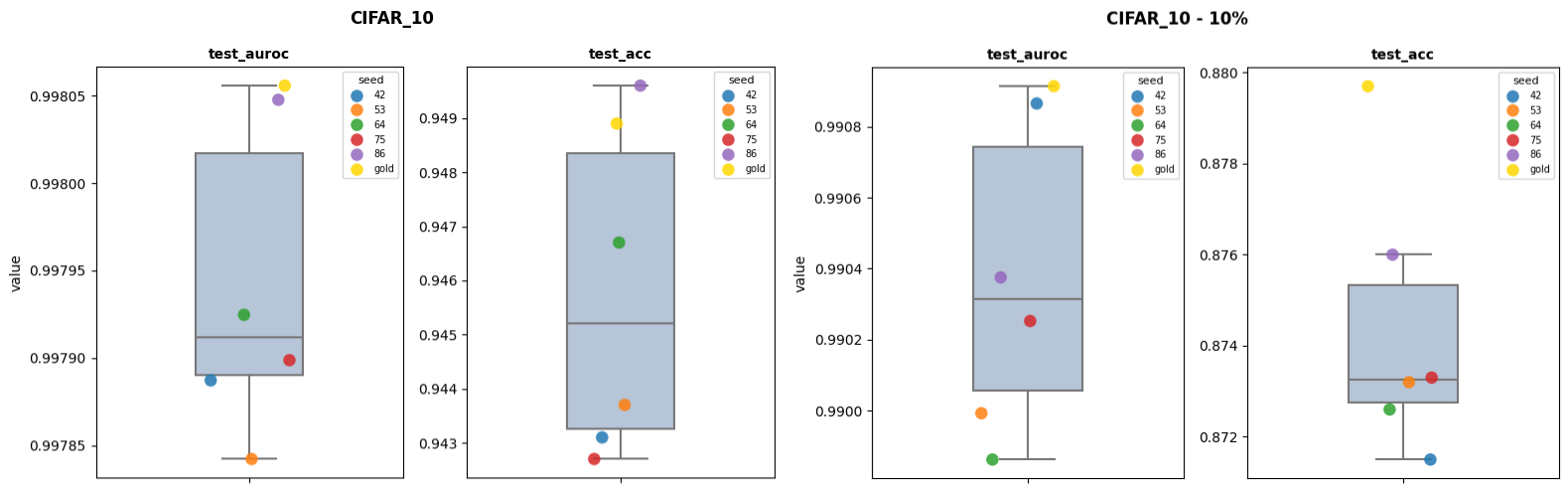
For the full Training set, the test_auroc is quite high for all splits without much variation and the gold split is the highest one. For the test_acc, the amplitude between the random splits is larger. For this metric, the gold split is "only" the 2nd performing one. Though, the difference with the best one is way lower (~10 times) than the difference with the worst one. When using only 10% of the full Training dataset, the gold split is better than all the random splits. For the test_auroc, the advantage is quite small. However, the difference is 0.37 points in test_acc.
| dataset | metric | random min | random max | gold | random min to gold |
random max to gold |
|---|---|---|---|---|---|---|
| CIFAR_10 | test_acc | 0.9427 | 0.9496 | 0.9489 | -0.0062 | 0.0007 |
| CIFAR_10 | test_auroc | 0.9978 | 0.998 | 0.9981 | -0.0002 | -1e-05 |
| CIFAR_10 - 10% | test_acc | 0.8715 | 0.876 | 0.8797 | -0.0082 | -0.0037 |
| CIFAR_10 - 10% | test_auroc | 0.9899 | 0.9909 | 0.9909 | -0.0011 | -5e-05 |
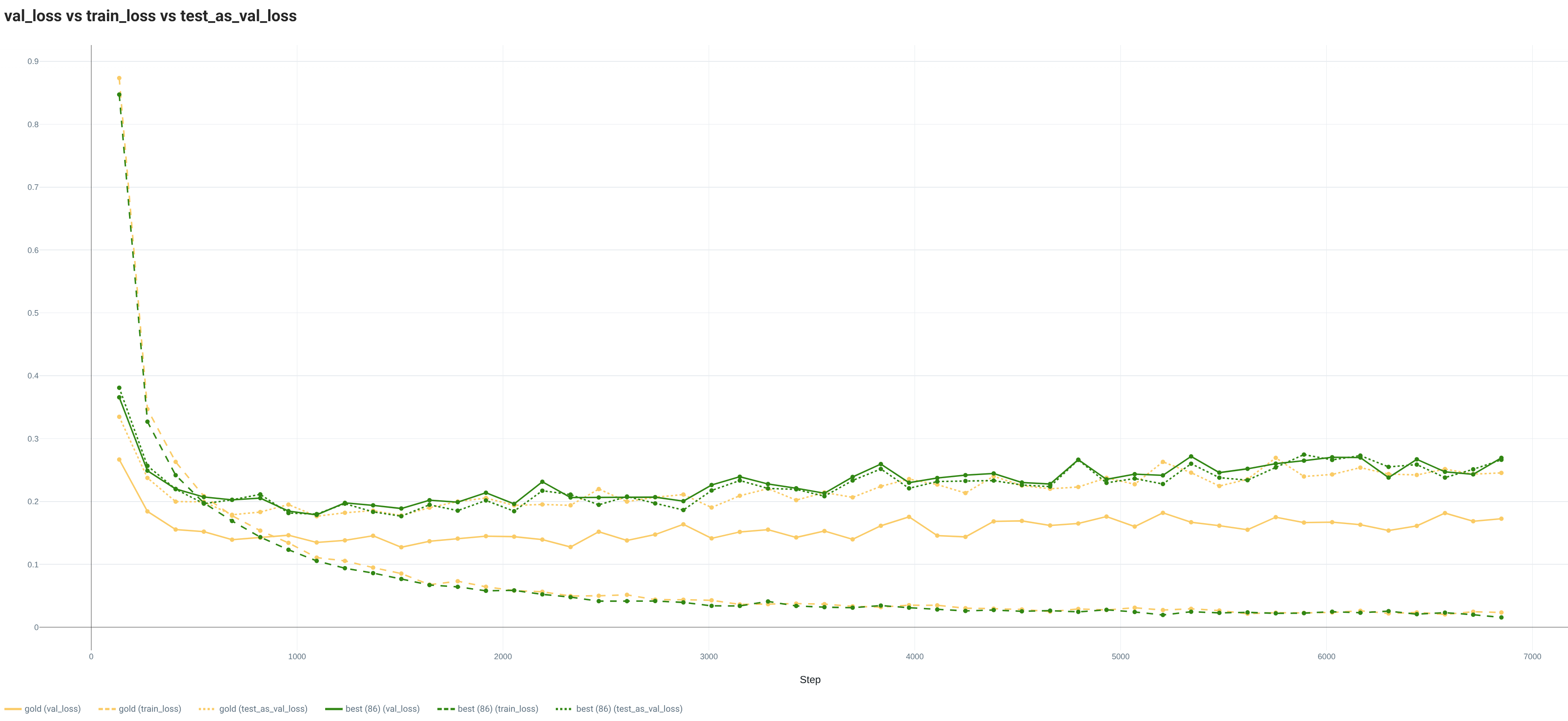
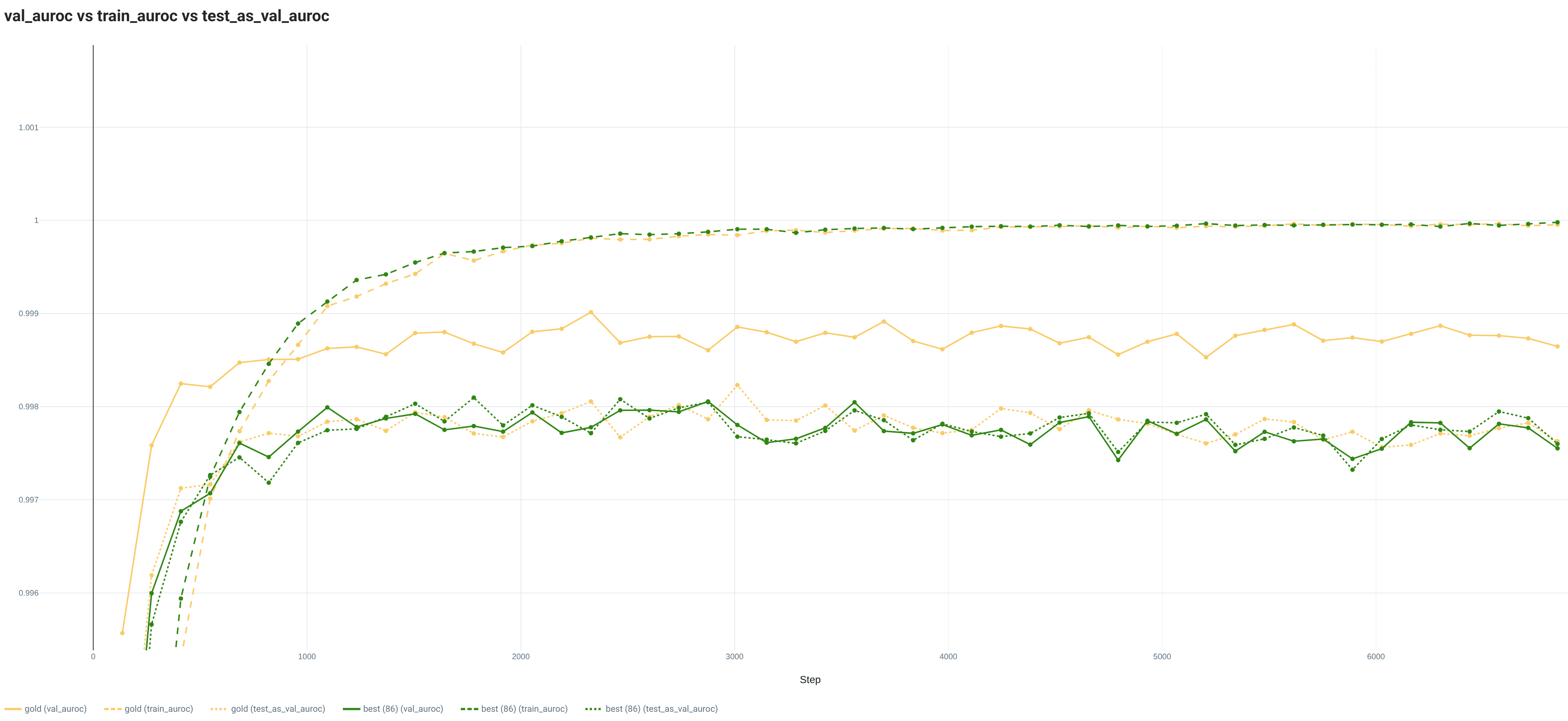
With the full Training set, the loss curves of the gold and best random splits are really similar for the Train and Test sets. However, the Val loss evolutions are quite different with a lower value for the gold split. This situation is also visible with the metric curves. Both splits are showing signs of overfitting.
2.2. PASCAL VOC
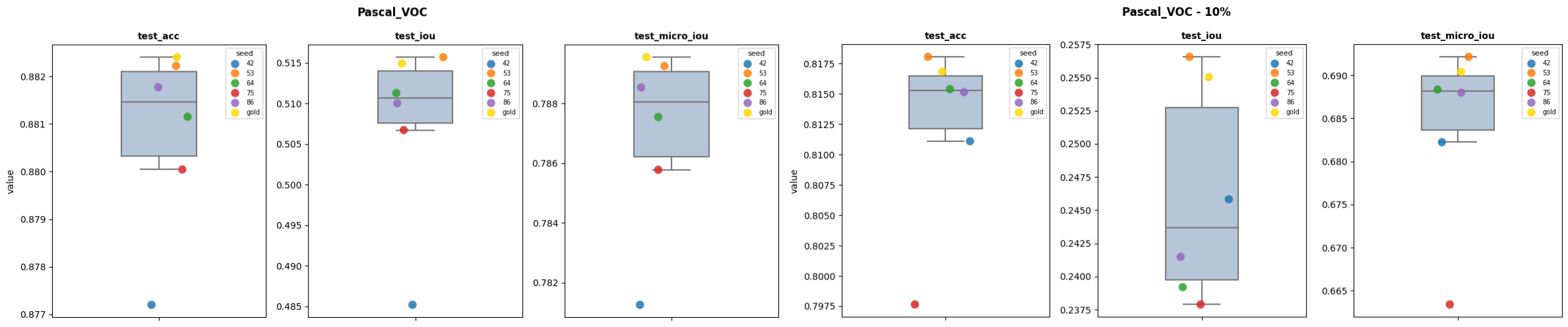
On this dataset, the random splits are showing quite variable performance for all metrics, with sometimes rather large amplitudes between the best and worst performance. While the gold split is not always better than the best random split, the difference with it is always very small. Thus, the amplitude between the gold and worst random splits is always large.
| dataset | metric | random min | random max | gold | random min to gold |
random max to gold |
|---|---|---|---|---|---|---|
| Pascal_VOC | test_acc | 0.8772 | 0.8822 | 0.8824 | -0.0052 | -0.0002 |
| Pascal_VOC | test_iou | 0.4852 | 0.5157 | 0.5149 | -0.0298 | 0.0008 |
| Pascal_VOC | test_micro_iou | 0.7813 | 0.7893 | 0.7896 | -0.0083 | -0.0003 |
| Pascal_VOC - 10% | test_acc | 0.7976 | 0.8181 | 0.8169 | -0.0192 | 0.0012 |
| Pascal_VOC - 10% | test_iou | 0.2379 | 0.2566 | 0.255 | -0.0172 | 0.0015 |
| Pascal_VOC - 10% | test_micro_iou | 0.6634 | 0.6921 | 0.6904 | -0.027 | 0.0017 |
As seen with the final performance on the Test set, both the gold and best random splits are demonstrating really similar behavior for the training curves on the full Training dataset. For both the loss and metric curves and both splits, the Train set has its own behavior (lower for the loss and higher for the metric) and the Val and Test sets are really similar.
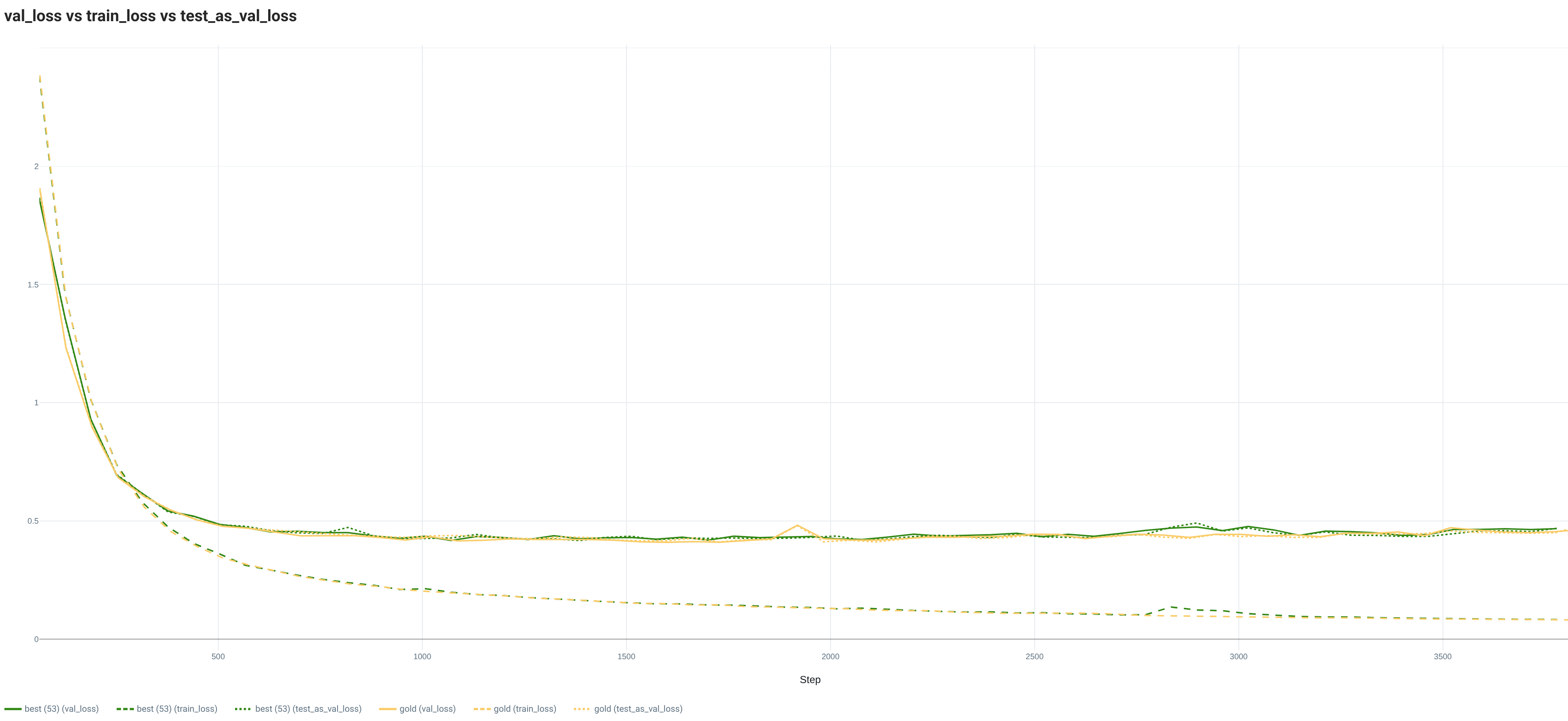
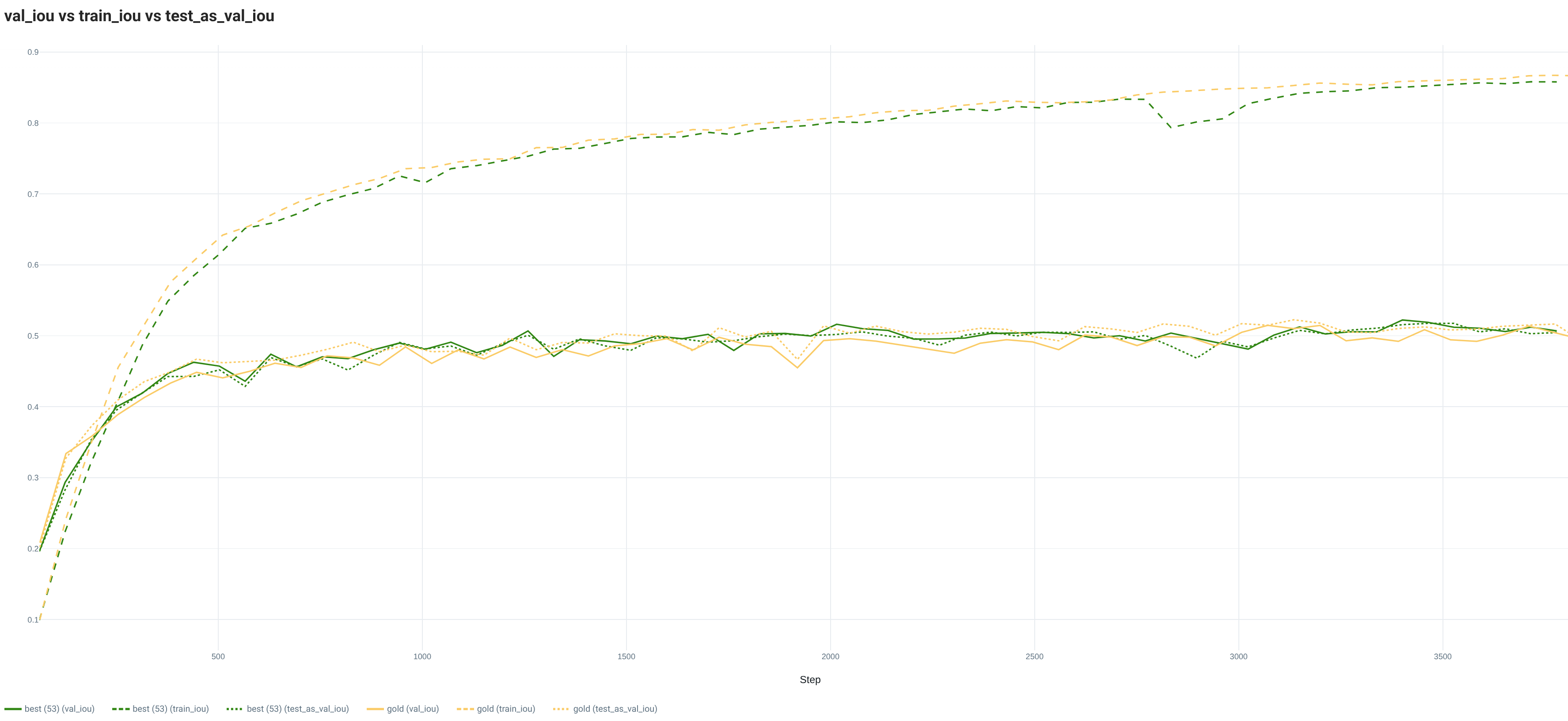
2.3. IMDB
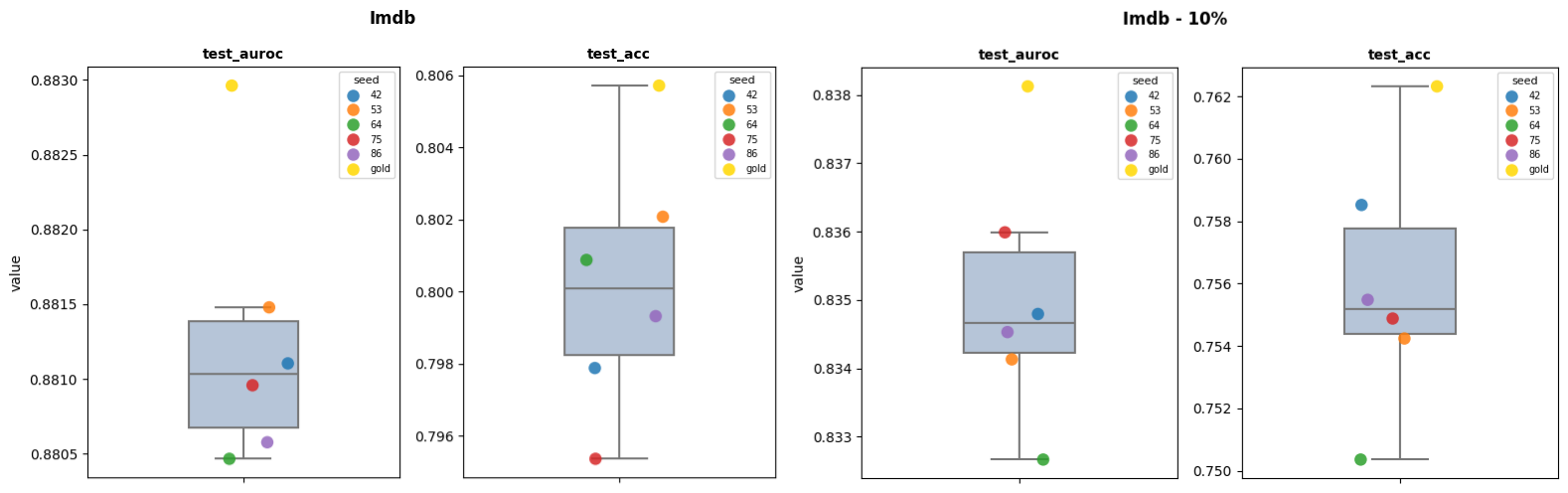
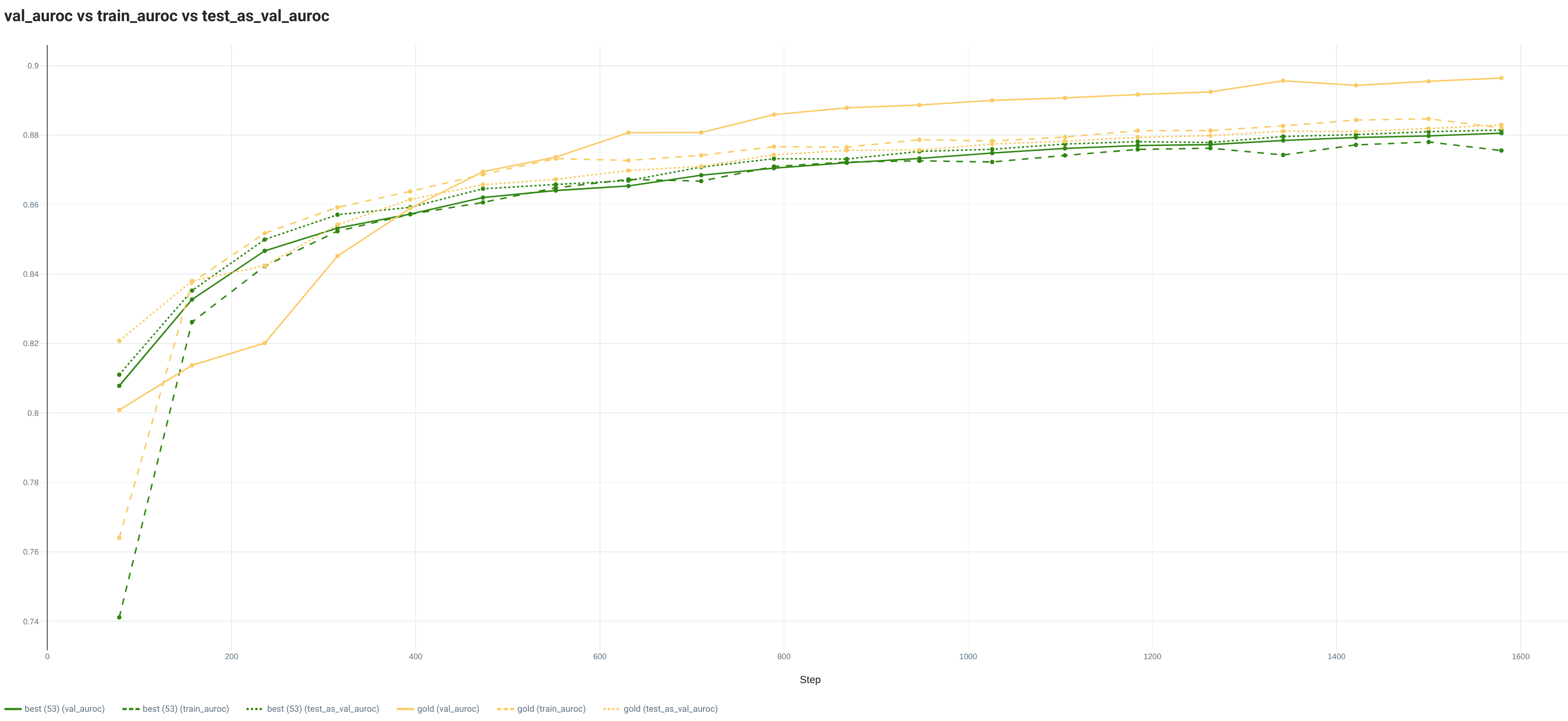
On this dataset, the gold split is always better than the 5 tested random splits for the full and reduced (10%) datasets. The difference between the worst and best is increasing with the reduction of the Training set size. In test_acc, the biggest amplitude is always over 1 point while it is over 0.25 points for the test_auroc.
| dataset | metric | random min | random max | gold | random min to gold |
random max to gold |
|---|---|---|---|---|---|---|
| Imdb | test_acc | 0.7954 | 0.8021 | 0.8057 | -0.0104 | -0.0036 |
| Imdb | test_auroc | 0.8805 | 0.8815 | 0.883 | -0.0025 | -0.0015 |
| Imdb - 10% | test_acc | 0.7504 | 0.7585 | 0.7623 | -0.012 | -0.0038 |
| Imdb - 10% | test_auroc | 0.8327 | 0.836 | 0.8381 | -0.0055 | -0.0021 |
The curves from the full Training dataset are emphasizing the differences between the gold and best random splits. Indeed, while the best random split is showing the same evolution for the 3 sets (Train, Val, Test), the gold split is showing a lower Train loss and a higher Val loss. Regarding the metric curves, the best random split has the same evolution for all sets, while the values on the Val set are above the Train and Test set ones with the gold split.
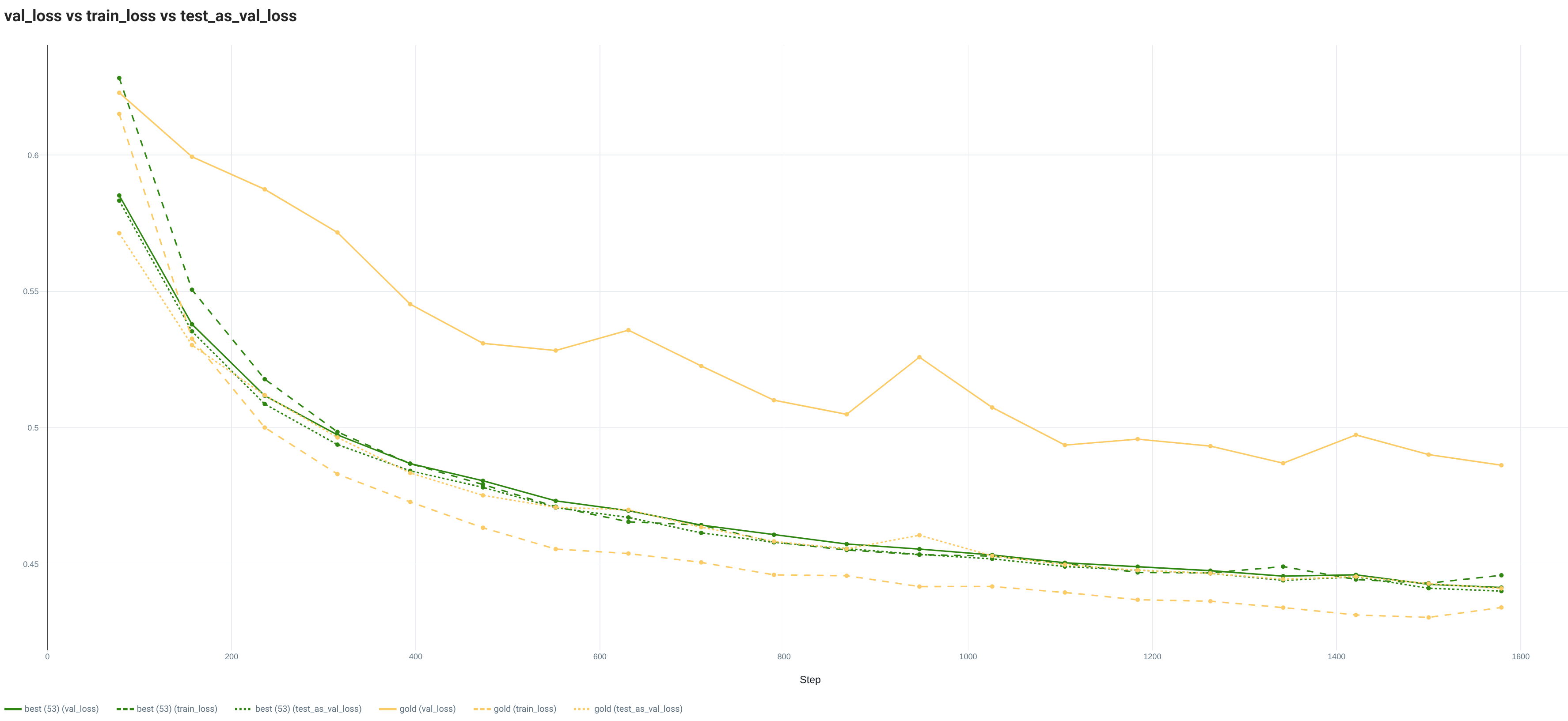
3. Conclusion
The 3 tested datasets and models illustrate the potential of a smarter Train/Val split with the Goldener library. Indeed, in all situations, the gold split is always really close to the best splits and even sometimes better by a significant margin. In this study, we show that the difference in training curves between the gold and best random splits depends on the situation and metric.
These experiments are certainly not enough to draw general conclusions. To access stronger evidence of the gold split potential, it would require to:
- Demonstrate its feasibility on a bigger number of datasets representing diverse tasks and types of data.
- Validate its usefulness for models and training configuration close to the state of the art performance on the tasks.
- Understand the composition of the random splits beating the smart split.
- Study its stability with the data regime, from k-shots to full regime.
- Analyze the impact of the split parameters (description model, selection algorithm) on the different situations.
- Show that the same split parameters can be efficient on a diverse set of tasks for the same input type.
To conclude, here are predictions:
- To stay close to the best random seed, the pretrained model needs to be general-purpose enough. Specialized models might already be too task-oriented in order to differentiate enough between the different clusters in the data.
- For one type of data (image, text, ...), it is possible to find 1 unique split parameter to efficiently split for different tasks/datasets.
- Uncurated datasets from the wild (as opposed to research datasets like in this study) will even more benefit from this smart Train/Val split. In absence of curation, the likelihood of having over represented elements is multiplied.
4. Bibliography
The readers of this report might be interested in the following resources:
- Moser, Brian B., et al. A coreset selection of coreset selection literature: Introduction and recent advances. arXiv preprint arXiv:2505.17799. 2025.
- Joseph, V. Roshan, et al. SPlit: An optimal method for data splitting. Technometrics 64.2: 166-176. 2022.
- Griffin, Brent A., et al. Zero-Shot Coreset Selection via Iterative Subspace Sampling. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2026.
5. Authors
Yann Chéné, PhD, is a Machine Learning (ML) engineer currently working at Scortex - a company leveraging computer vision to automate manufacturing quality control. Within Scortex, he is involved in tasks from research to product integration and MLOps. His current focus is on improving the state of the art in image anomaly detection. Yann is also the creator of Goldener, an open source Python data orchestrator. Goldener proposes features to sample, split, organize, annotate, and curate data based on model embeddings/features in order to make the full ML lifecycle more efficient.
6. Miscellaneous
All the code used to generate this report is available in goldener-examples repository. The scripts to execute these experiments are available for each dataset in CIFAR 10, PASCAL VOC and IMDB.
Sponsored by Pixeltable: Multimodal Data, Made Simple. Video, audio, images, and documents as first-class data types, with storage, orchestration, and retrieval unified under one table interface.