THE RANDOM CURSE
Train/Val split on CIFAR 10, PASCAL VOC and IMDB

TLDR:
When designing a new model, a standard practice is to make the Train/Val split randomly. However, our experiments across a few tasks and datasets reveal a critical limitation: random splits can introduce significant variability in model performance. Specifically, when training with different random seeds, we observed that the model?s performance on a fixed Test set can fluctuate substantially. This suggests that the randomness in the Train/Val split should be treated as a hyperparameter itself, requiring tuning to ensure robust performance before a model deployment.
1. Context
During the design of a Deep Learning pipeline, the data is ideally divided into 3 sets:
- Train set: the data on which the model is optimized in order to solve the target task. The weights of the model are iteratively adjusted from the backpropagation of the target loss and specific regularization terms.
- Val set: the data to monitor the status of the currently optimized model. This data must be a proxy of the Test set. The evolution of the metrics on this set is allowing one to spot over/under fitting and as well to checkpoint the best model version(s).
- Test set: The data to judge the efficiency of the trained model in order to make an unbiased analysis of the model's ability to achieve good performance once deployed in the wild. Its composition must allow assessing its generalization power and to mimic potential performance on new data.
In this article, we study the impact of randomness when splitting the Training data as Train and Val sets. While being the standard splitting methodology, the random selection process can induce:
- The absence of some concepts in the train set, like rare occurrences or specific variation of a given class. Their absence in the Training set might avoid the model being able to generalize on them.
- The over-representation of some concepts in the train set, like elements quite similar among a given class. Their over-presence in the Training set might push the model in a local minima succeeding better on them while failing on less represented elements.
The main goal of this report is to illustrate the potential impact of this random split for a few tasks and datasets. Thus, the presented results cannot be taken as a general truth, however they give some first intuitions on this matter.
2. Experiments
In this report, we focus on 3 different types of datasets and tasks:
- CIFAR 10 image classification: 50000 Training and 10000 Test images about 10 different classes of object (1 object per image).
- PASCAL VOC image segmentation: 1464 Training and 1449 Test images about 20 different classes (multiple objects per image).
- IMDB sentiment classification: 25000 Training and 25000 Test written film reviews about 2 classes (positive and negative reviews).
As we try to achieve the best performance possible, no specific runs have been done to select the best possible model architecture or the most optimized training hyperparameters. For your information (more details in goldener/gold-splitter-examples), here are the different configurations:
| Dataset | Model | Training hyperparameters |
|---|---|---|
| CIFAR 10 | Resnet-18 pretrained on ImageNet |
Adam optimizer - lr = 0.001 batch size = 256 - max epochs = 50 val ratio = 0.3 - ckpt metric = val auroc |
| PASCAL VOC | DeepLabV3Plus mobilenet_v2 encoder pretrained on ImageNet |
Adam optimizer - lr = 0.0001 batch size = 16 - max epochs = 60 val ratio = 0.3 - ckpt metric = val iou |
| IMDB | Bert base uncased with linear probing |
AdamW optimizer - lr = 0.001 batch size = 256 - max epochs = 20 val ratio = 0.2 - ckpt metric = val auroc |
For all datasets, we report the impact of randomness for the full Training set and a random reduction of it using only 10% of the initial dataset. For both versions of the dataset, the initial Training data is split between the Train and Val sets using class stratified random selection (the random selection is done per class). The split process is repeated for 5 different seeds. The initial Test sets are kept unchanged.
2.1. CIFAR 10
For this multiclass image classification task, we analyze the performance from the mean AUROC (area under ROC curve) (average of the AUROCs of all classes individually) (test_auroc) and Accuracy (test_acc).
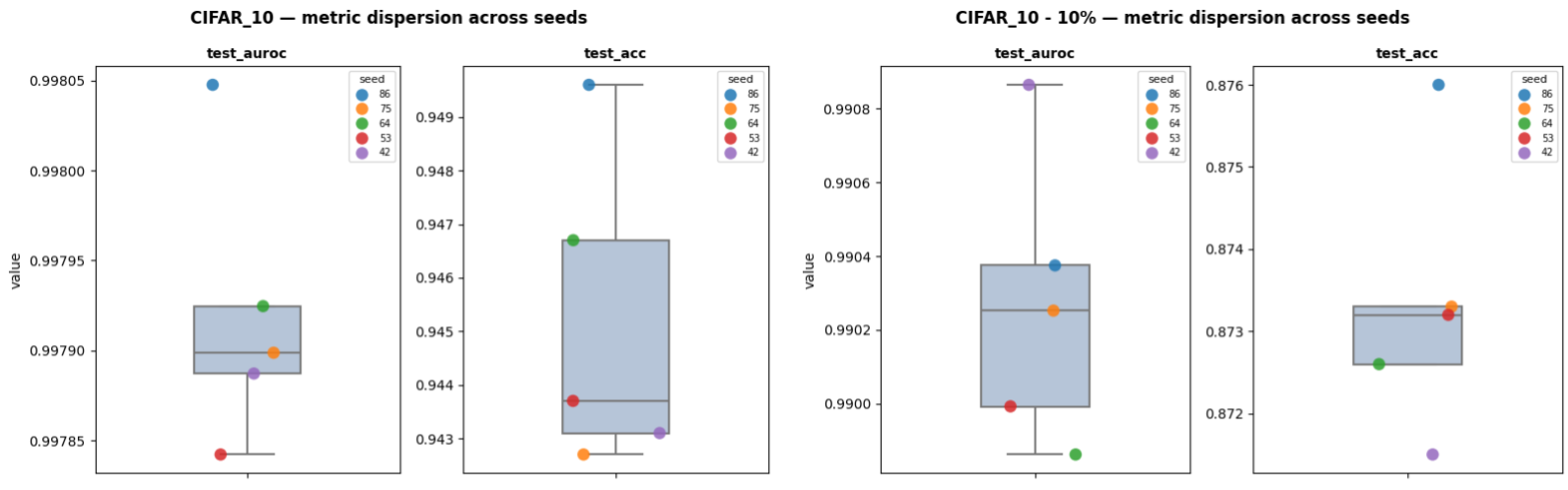
| Dataset | test_auroc (min/max) | test_acc (min/max) |
|---|---|---|
| CIFAR_10 | 0.9978 / 0.998 | 0.9427 / 0.9496 |
| CIFAR_10 - 10% | 0.9899 / 0.9909 | 0.8715 / 0.876 |
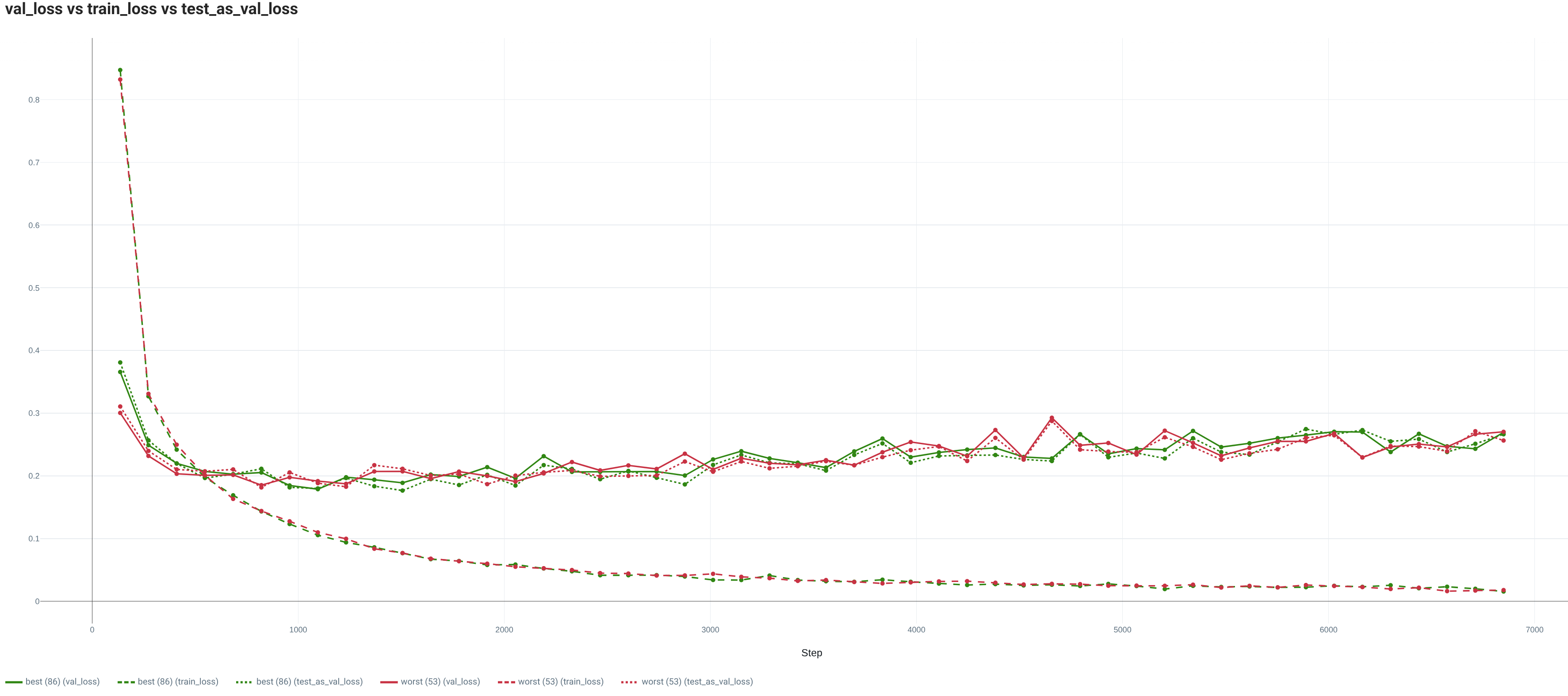
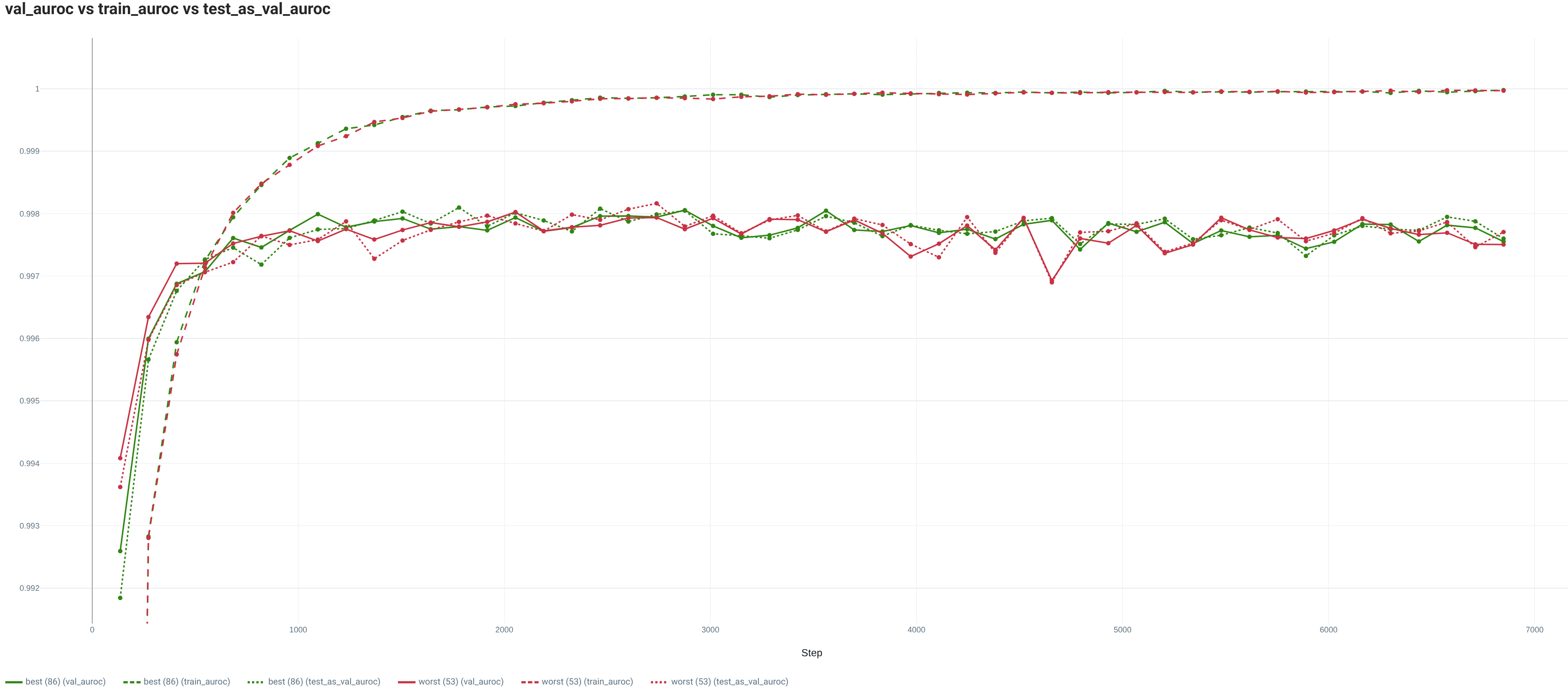
For the full Training set, both the loss and metric computed on the train set show the good fit between the model and this image classification task. Indeed, for both the worst and best seeds, the model converges toward a really low loss and a quite high performance.
In addition, in both cases, the validation sets are quite good proxies of the Test set (same trend between the Test and Val sets). Thus, the Val sets are allowing:
- to spot an overfitting presence (the performance stays quite high anyway).
- to select models which are quite close to the best possible performance (~0.03 points in
test_aurocfor the worst seed).
2.2. PASCAL VOC
For this multiclass image segmentation task, we analyze the performance from the mean IOU (intersection over union) (average of the IOUs of all classes individually) (test_iou), the global IOU (IOU with all classes merged) (test_micro_iou) and Accuracy (test_acc).
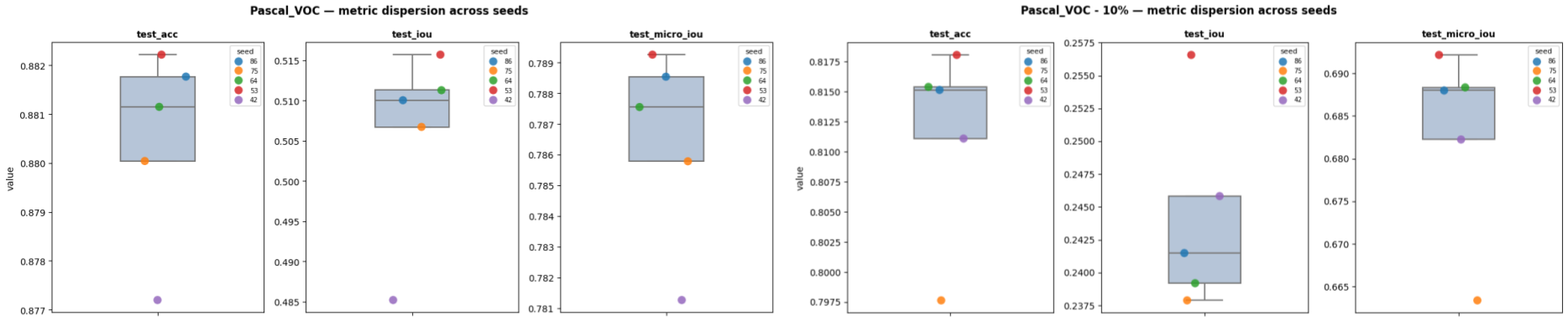
From the metrics, we notice that the model performance is far from saturated. When training with the full Training dataset, for all metrics, we can already notice an impact that is more or less significant depending on the random seed with roughly 0.5 points in Accuracy, 3 points in mean IOU and 0.8 points in global IOU. This difference between the min and max performance is even larger for Accuracy and global IOU when the Training is reduced to 10% of its initial size.
| Dataset | test_acc (min/max) | test_iou (min/max) | test_micro_iou (min/max) |
|---|---|---|---|
| PASCAL_VOC | 0.8772 / 0.8822 | 0.4852 / 0.5157 | 0.7813 / 0.7893 |
| PASCAL_VOC - 10% | 0.7976 / 0.8181 | 0.2379 / 0.2566 | 0.6634 / 0.6921 |
For the full Training set, the model is too small to fully appreciate the complexity of the task. Indeed, whatever the splitting random seed, the loss and metric curves are far from saturation at the end of the training and their trend is quite flat. On this dataset, we observe a difference between the worst and best performing split regarding the behavior on the Val set. Indeed, for both the loss and the metric, while the best performing evolution is really similar to the Test set, the worst one is demonstrating a higher Val loss resulting in a lower Test global IOU. However, the Val set trend is still quite similar to the Test set one and thus it allows to select a model quite close to the best performance possible (roughly 0.7 points which is lower than the global variation between seeds). Finally, while for both seeds, the loss curves are indicating a small overfitting, it is not really visible in the performance curves.
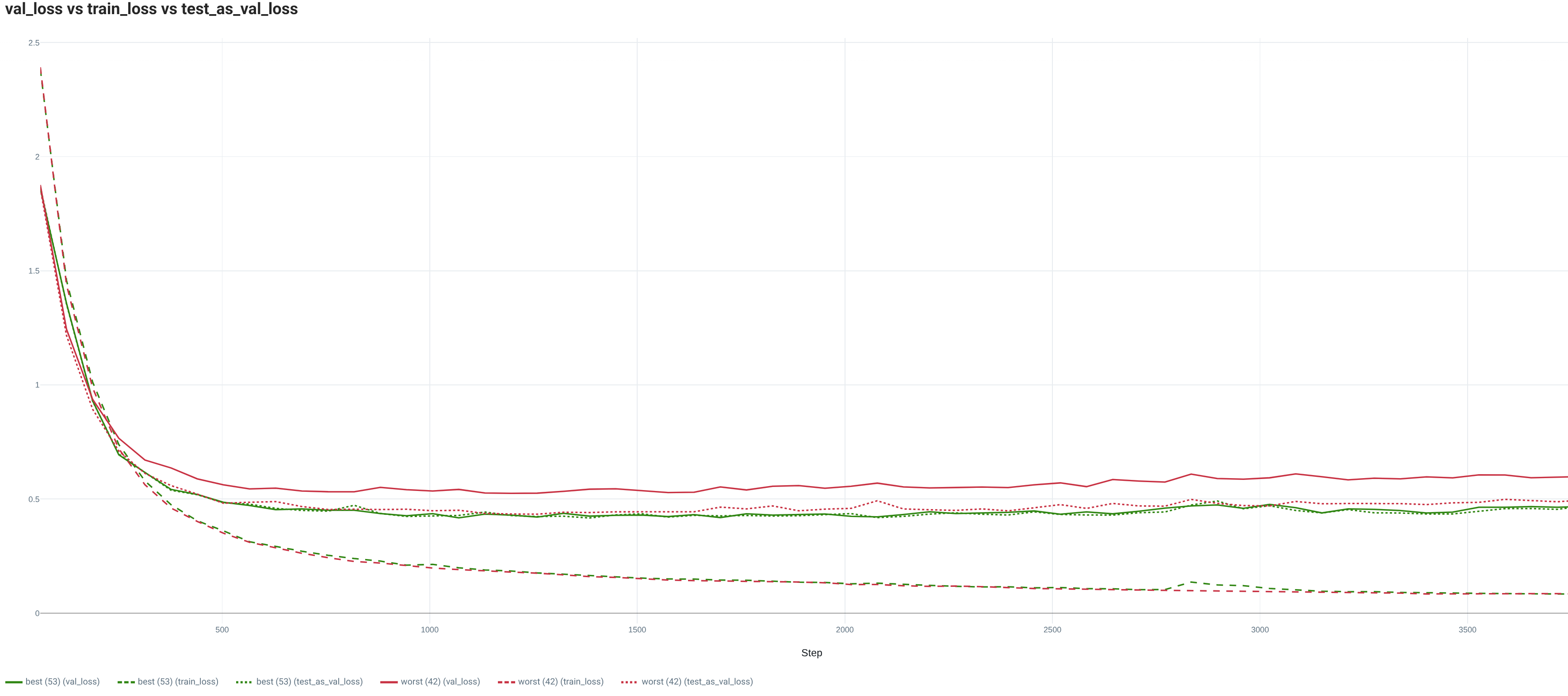
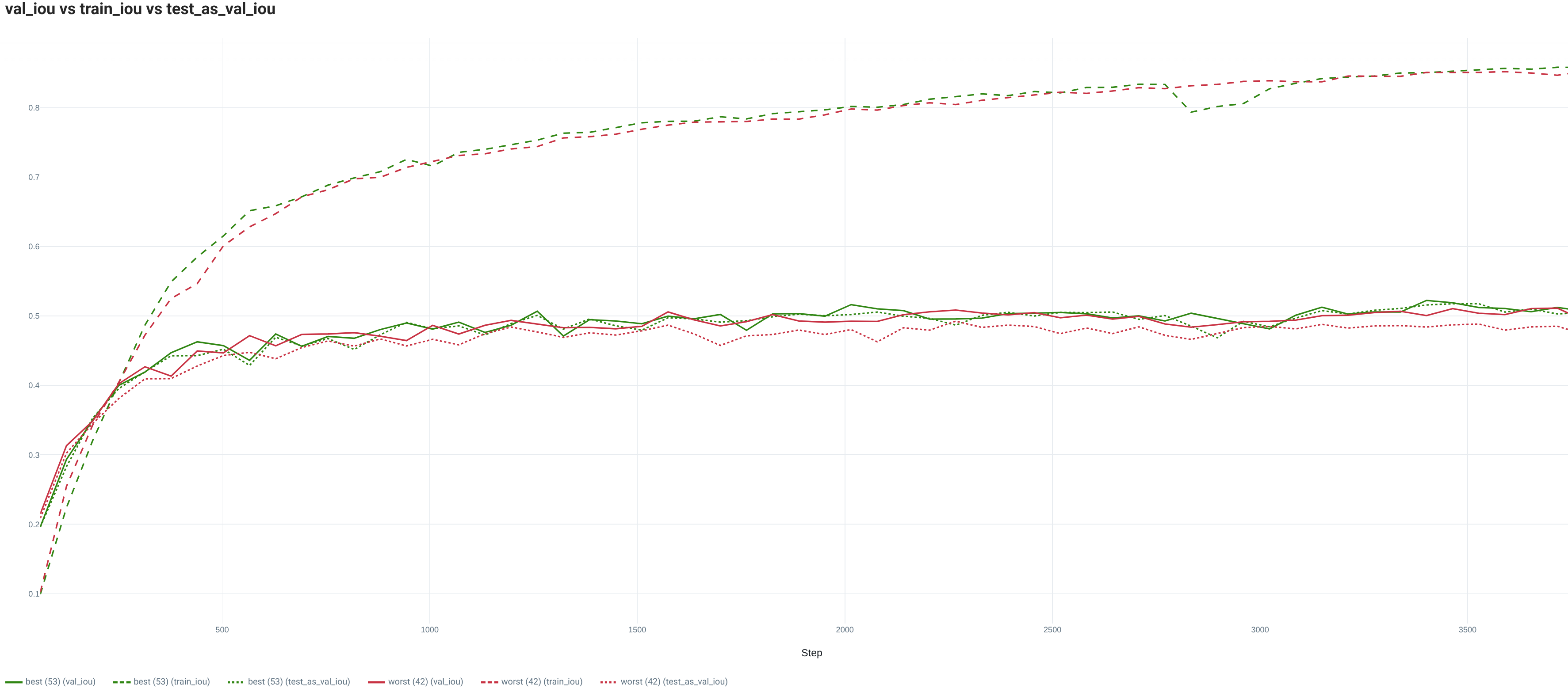
2.3. IMDB
For this text binary classification task, we analyze the performance from the mean AUROC (average of the AUROCs of all classes individually) (test_auroc) and Accuracy (test_acc).

| Dataset | test_auroc (min/max) | test_acc (min/max) |
|---|---|---|
| IMDB | 0.8805 / 0.8815 | 0.7954 / 0.8021 |
| IMDB - 10% | 0.8327 / 0.836 | 0.7504 / 0.7585 |
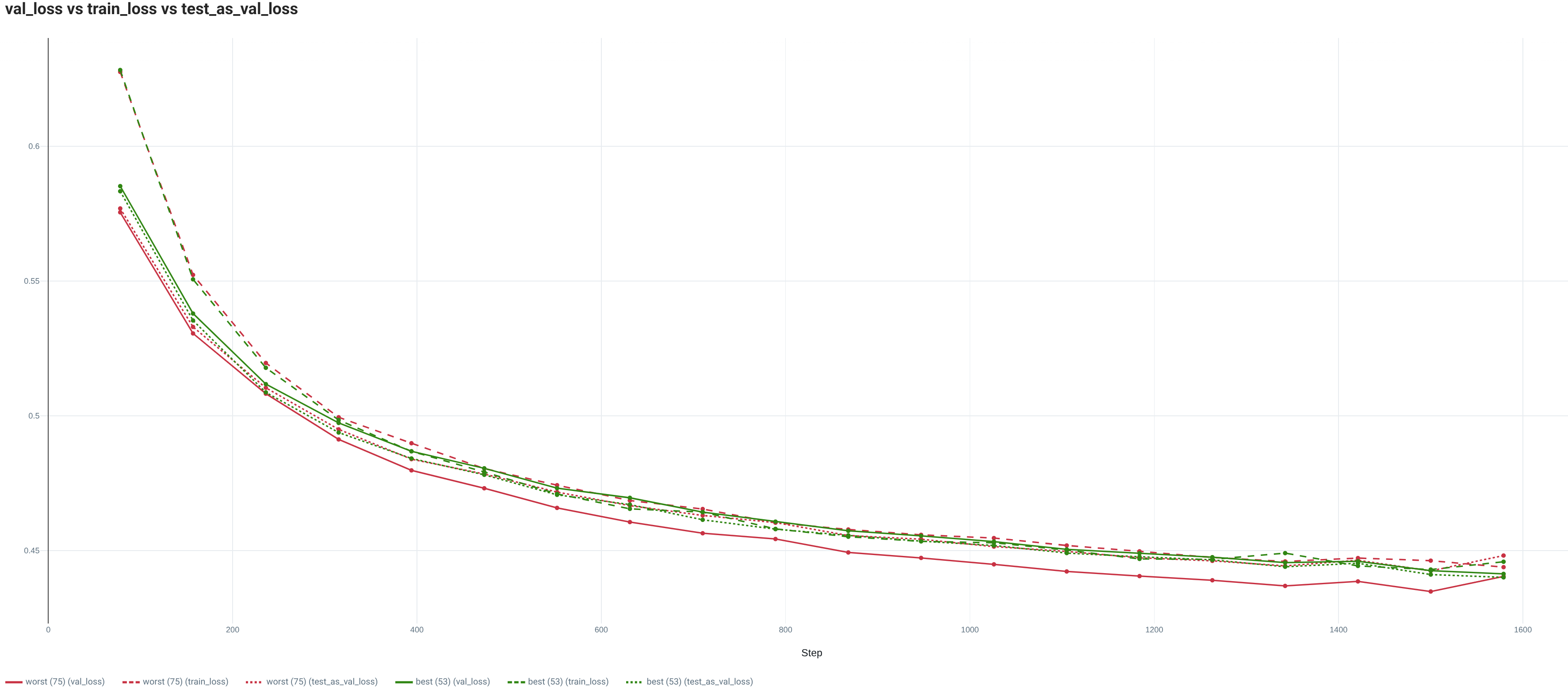
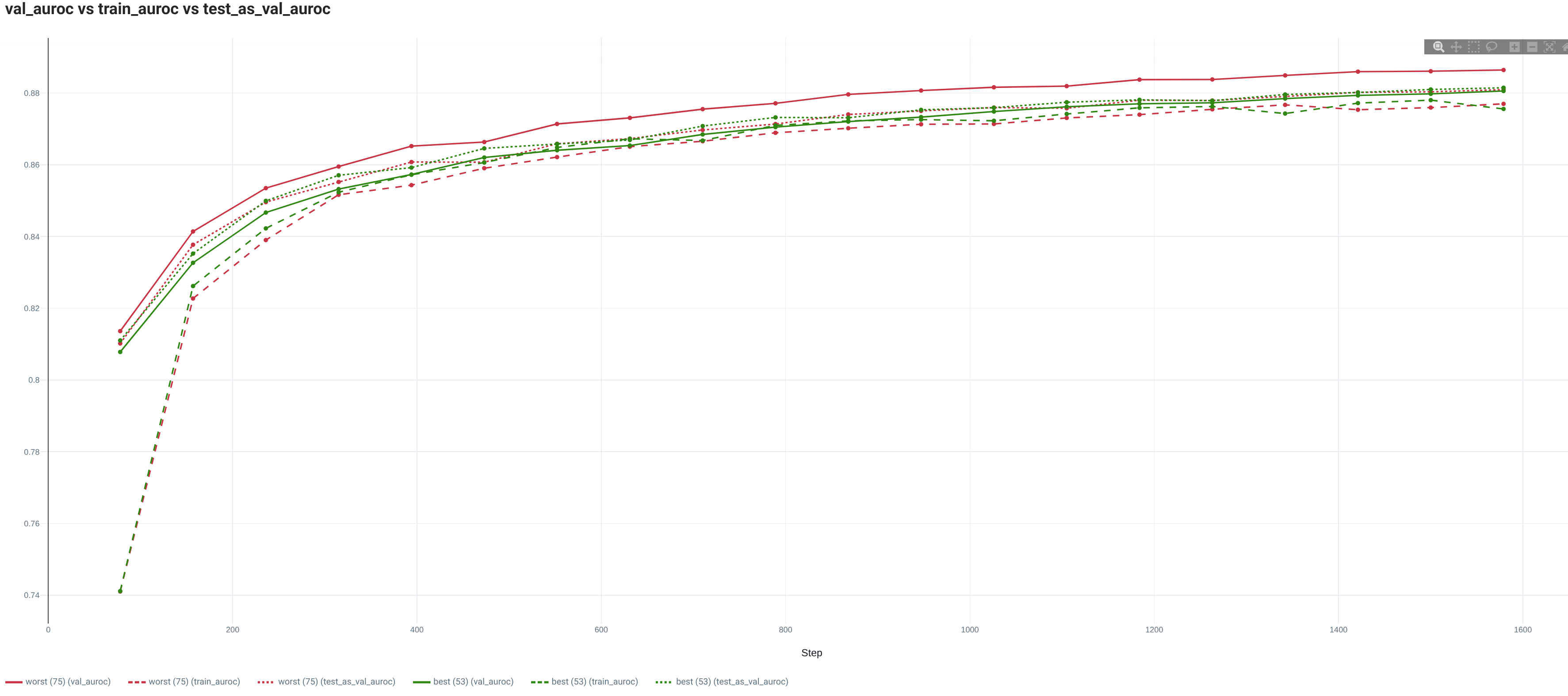
3. Conclusion
The 3 tested datasets and models illustrate the potential impact on the final Test performance of the randomness during the Train/Val split. These results emphasize that the random seed might finally be an additional hyperparameter when we are trying to deploy the best possible model in the wild. In this study, we illustrate that the impact of this randomness depends on the tasks and metric. As well, its appearance in the training information (loss and metric curves) looks quite dependent on the situation.
These experiments are certainly not enough to draw general conclusions. To access stronger evidence of the random curse during Train/Val split, it would require to:
- Demonstrate its presence with a bigger number of datasets representing diverse tasks and types of data.
- Validate its impact for models and training configuration close to the state of the art performance on the tasks.
- Study the evolution of its amplitude with the data regime, from k-shots to full regime.
To conclude, here are our predictions:
- The amplitude of variation will decrease with the performance on the Test set. The state of the art configuration will demonstrate lower variability, mostly because their generalization capacity allows them to better model the task manifold.
- Lower data regime will be more impacted by this variability. Training with less data means more likelihood to remove rare occurrences or draw over represented elements while splitting.
- Uncurated dataset from the wild (as opposed to research datasets like in this study) will suffer even more from this Train/Val split curse. In absence of curation, the likelihood of having over represented elements is multiplied.
4. Bibliography
The readers of this report might be interested in the following resources:
- Wegmeth, Lukas, et al. The Effect of Random Seeds for Data Splitting on Recommendation Accuracy. In : Perspectives@ RecSys. 2023.
- Bui, Nghia Tuan, et al. Assessing the macro and micro effects of random seeds on fine-tuning large language models. In: Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 2025.
- MUDALGI, Sujay. Optimal Data Splitting Methods. Dissertation from Virginia Commonwealth University. 2025.
5. Authors
Yann Chéné, PhD, is a Machine Learning (ML) engineer currently working at Scortex - a company leveraging computer vision to automate manufacturing quality control. Within Scortex, he is involved in tasks from research to product integration and MLOps. His current focus is on improving the state of the art in image anomaly detection. Yann is also the creator of Goldener, an open source Python data orchestrator. Goldener proposes features to sample, split, organize, annotate, and curate data based on model embeddings/features in order to make the full ML lifecycle more efficient.
6. Miscellaneous
All the code used to generate this report is available in goldener-examples repository. The scripts to execute these experiments are available for each dataset in CIFAR 10, PASCAL VOC and IMDB.
Sponsored by Pixeltable: Multimodal Data, Made Simple. Video, audio, images, and documents as first-class data types, with storage, orchestration, and retrieval unified under one table interface.