AutoResearch on Diffusers' Pipeline for 10 Rounds on JarvisLabs



Disclosure. This experiment was supported by JarvisLabs. I used JarvisLabs GPU instances and the jl CLI to run candidate generations in parallel, fetch the results, and shut the machines down after the run.
The first useful thing this experiment reminded me of is that image generation is not really a prompting problem.
Or, more precisely, prompting is only the part that is easy to talk about. The real work begins after the first image disappoints you in a specific way. A floor collapses into a shelf. A telescope appears in the wrong room. A composition looks beautiful, but the thing you asked for is not actually there. At that point, the question is no longer how to write a prettier sentence. The question is what to change next.
That was the loop I wanted to build.
I used Codex as the research agent. It was not only writing code. It was deciding what to test. It looked at the images, named the failure, chose one lever, edited the mutable router config, launched GPU jobs on JarvisLabs, scored the results, and updated the lineage before moving on. I gave it the broad objective. The agent had to do the duller and more interesting work of finding a path.
The final image came after 10 experiments and 50 generated candidates.

It is not perfect. The lower floor still contains a brass machine that does not really belong there. I am leaving that flaw visible because it is part of the experiment. The run did not produce a miracle sample. It produced a genealogy. It found changes that helped, changes that only seemed to help, and one stubborn failure that probably needs a different kind of intervention.
That is more interesting to me than a cherry picked pretty image.
The Shape Of The Experiment
From Prompting To Research
The project started from a simple discomfort with how image generation experiments are usually described. A prompt is shown, an image appears, and the story ends. But most real attempts do not feel like that. They feel like a sequence of local judgments. You see a failure, you form a small hypothesis, and you try to touch the one part of the pipeline that might explain it.
That is the AutoResearch idea I wanted here. One experiment should not mean one image. It should mean one hypothesis sweep. If the suspected problem is aspect ratio, the agent should try several aspect ratios. If the suspected problem is the bottom floor identity, the agent should try several ways to anchor the bottom floor. The experiment only means something after those candidates have been compared.
Keeping The Loop Short
This is also why JarvisLabs mattered. Five candidates per experiment is not a large search, but it is enough to force comparison. Running them one after another would make the loop slow enough that the agent would become cautious and the human would become impatient. Running them on five JarvisLabs GPU workers made the loop short. Codex could prepare configs locally, send them to the workers with jl, launch detached runs, poll the exits, download the images, and destroy the machines at the end. There was no need to turn the research into cluster administration.
A Pipeline With Handles
Diffusers became the natural object of study because it exposes the right kind of surface. I did not want to train a new model. I wanted to keep the generation backbone fixed and let the agent explore the surrounding choices. Hugging Face Diffusers makes those choices visible. A pipeline can be treated as a composition of model, scheduler, prompt processing, dimensions, guidance, adapters, optional conditioning, and optional refinement. Hugging Face is also moving toward a more explicitly composable style with Modular Diffusers. I did not depend on that API for this first scaffold because it is still evolving, but the direction fits the spirit of the experiment. A diffusion pipeline should be something an agent can reason about, not a sealed box.
So the scaffold used a small router abstraction. The base model stayed fixed. The mutable layer was the experiment config.
For this run, the model was black-forest-labs/FLUX.2-klein-4B, wrapped through a Diffusers based Flux2KleinPipeline. The task was text to image with no reference image. The seed stayed fixed. The dtype was bfloat16. The winning image size after the aspect ratio sweep was 896x1344, and the run stayed intentionally cheap with 4 inference steps.
The scoring also had to be honest about what automatic metrics can and cannot see. A proxy score can reward sharpness, color, and rough prompt similarity while missing the fact that the observatory has moved into the basement. So I used a unified score that mixed automatic metrics with visual judgment.
unified_score = 0.40 * composite_score + 0.60 * LLM_judge_score
The final winner reached a composite score of 0.7452, an LLM Judge score of 0.9150, and a unified score of 0.8471. It took about 10.4s to generate and used about 18GB of peak GPU memory.
The Target Image
I chose a target that would not be solved by style alone.
The prompt asked for a vertical watercolor cutaway of an impossible clockwork aquarium library tower inside a clear glass bathysphere. It needed exactly five stacked floors. From bottom to top, those floors should read as a coral laboratory, a flooded book archive, a tiny tea room, a greenhouse nursery, and a brass observatory. The floors should be connected by a spiral stair, a glass elevator, and transparent water tubes.
That target is annoying in the right way. It is not enough for the model to make something ornate. It has to preserve vertical structure. It has to keep the floors countable. It has to put the right objects in the right regions. It has to stay watercolor. It has to avoid fake text. And it has to make the whole thing feel like one object instead of five separate dioramas.
Beauty alone would let too many mistakes pass.
The Lineage
This graph is the artifact I care about most.
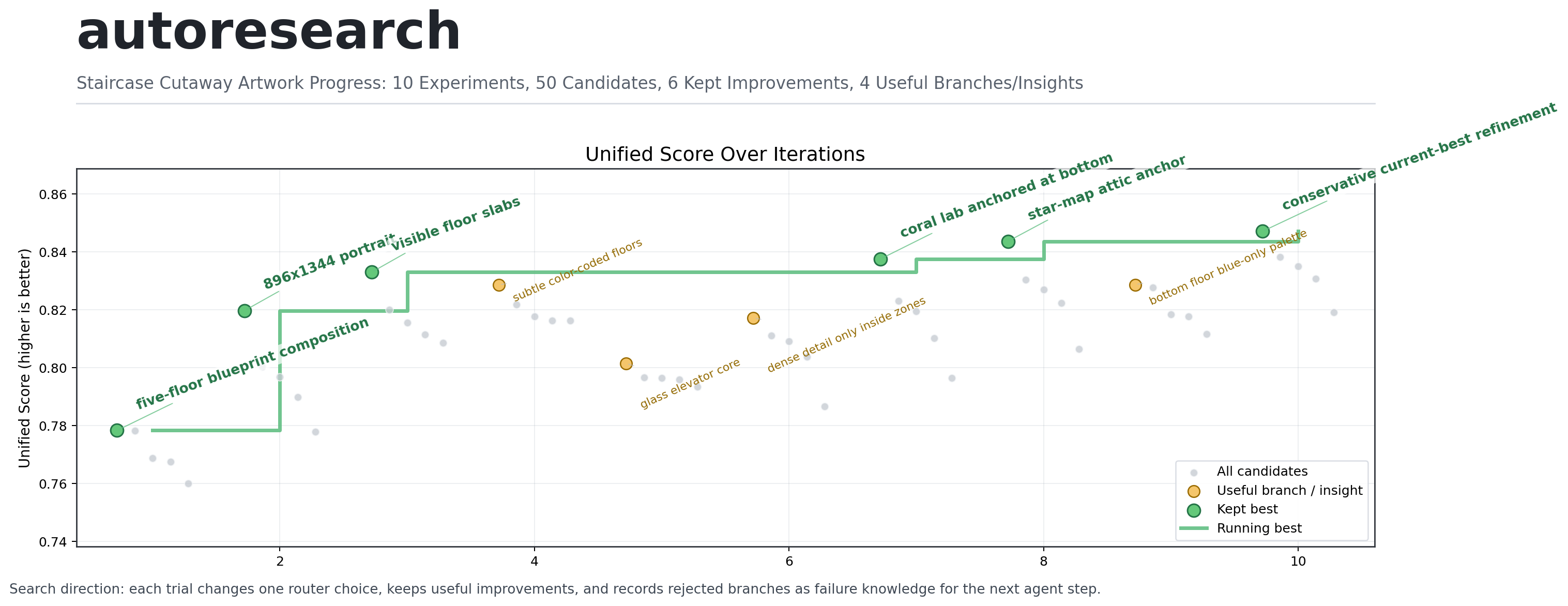
The gray points are all candidates. The green points are kept improvements. The yellow points are rejected branches that still taught the agent something. The line does not climb every round, which is exactly what I would expect from a real search. Some ideas helped locally but failed globally. Some made the picture prettier while leaving the main problem untouched.
The surviving path is easier to understand as a sequence of visual repairs. First, the image became a cutaway instead of a loose fantasy collage. Then the canvas turned vertical enough to hold five floors. Then the floors became countable. After that, the bottom was repaired into a coral lab, the top was restored into a star observatory, and the final pass kept those wins without shaking the structure apart.
Here are those survivors as images.

The early images were not bad in the usual sense. They were simply wrong in ways that mattered. They looked like elaborate watercolor towers, but the floors were ambiguous, the ordering was unstable, and the target was only partially present. The point of the loop was to turn those vague disappointments into more precise experimental moves.
How The Agent Chose Its Levers
First, Make The Image Legible
Codex began with the broadest lever because the first failure was broad. The model needed to understand the image as a vertical architectural cutaway, not a decorative pile of fantasy objects. That is why the first sweep tested prompt architecture. The five_floor_blueprint candidate survived because it gave the image a skeleton. It still did not solve the target, but it gave later experiments something to repair.
Once that skeleton existed, the next failure was spatial. The square canvas was fighting the goal. Five floors want height. Codex moved to aspect ratio and found that 896x1344 gave the tower enough vertical room to breathe. This was one of those unglamorous changes that mattered more than a clever prompt phrase.
After the portrait format, the levels were present but not reliably countable. Codex chose floor separation as the next lever. The winning prompt asked for thick visible floor slabs. It sounds almost embarrassingly literal, but it worked. The image began to read as stacked rooms rather than a busy interior texture. That improvement also made the next failure easier to see. The model could now draw floors, but it was putting the wrong scenes on them.
Then, Learn What Was Not The Bottleneck
The obvious response was to name the floor themes more explicitly. Codex tried bottom to top ordering, color cues, large iconic objects, and stronger separation between themes. None of those candidates became the new best. That failure was useful. It showed that the model already knew how to draw coral, books, tea tables, plants, and telescopes. What it did not reliably respect was their vertical assignment.
The next sweep went after physical connection. The image still felt like stacked rooms, so Codex tested connector modules. A glass elevator was the best candidate inside that experiment. It made the tower feel more coherent, but it did not beat the global best. Better connection did not fix the semantic inversion. The agent stopped chasing that branch.
Then came density. Some images were rich, maybe too rich, so Codex tried medium density, dense but zoned detail, larger shapes, negative space, and maximal miniature detail. Again, nothing survived. The lesson was blunt. Making the drawing prettier did not make it more correct.
Repair The Semantic Order
At that point the search became more interesting. Codex stopped trying to generally improve the image and targeted the persistent inversion directly. Brass observatory machinery kept appearing low in the tower, while coral and aquarium cues drifted upward. The seventh experiment anchored the bottom floor as a coral laboratory. basement_coral_anchor survived. This was the first major semantic repair. The bottom finally became a blue underwater lab instead of a brass machine room.
That fix created its own weakness. The bottom looked better, but the top observatory became less convincing. Codex then tried to restore the top endpoint without losing the new bottom anchor. The star_map_attic_anchor candidate survived because it brought back a readable brass telescope and star map cue at the top while keeping the bottom coral lab visible.
The ninth experiment tried to clean up the remaining brass leakage in the lower floors. It did not survive. This was an important failure. Abstract negative instructions such as asking for brass only at the top were weak. Positive replacement worked better. Blue water, pink coral, glass jars, and fish were more useful than a prohibition. Even then, prompt only control could not fully solve the local material problem.
Finish Conservatively
The final sweep was conservative by design. Codex did not ask for a generic better image. It combined the lessons that had survived. Keep the five floor structure. Keep the floor slabs. Keep the bottom underwater lab. Keep the top star observatory. Reduce the lower brass problem without wrecking the composition. The conservative_best_final candidate won because it was the best tradeoff. It was more polished and more readable, and it preserved the structure that the previous experiments had earned.
What The Run Suggests
The biggest gains did not come from the glamorous knobs.
Aspect ratio mattered because the task was vertical. Floor slabs mattered because countability mattered. Semantic anchors mattered because the model confused top and bottom roles. Conservative synthesis mattered because aggressive repairs tended to break earlier wins.
The weaker levers were just as informative. Watercolor polish did not solve structure. Connector modules did not solve semantic ordering. Density made the image busier, not necessarily better. Prompt only negative constraints were too weak for localized material control.
That is why Diffusers is such a good target for this kind of AutoResearch. It exposes many levers, but the agent still has to decide which lever matches the failure in front of it. A modular pipeline does not remove judgment. It gives judgment somewhere to act.
JarvisLabs made that judgment loop fast enough to keep its shape. Five candidates per experiment is modest, but it is enough to compare alternatives. Because the jobs ran in parallel, the experiment could keep moving. Codex could see the results, write down the failure, choose the next lever, and run again without the whole process collapsing into waiting.
The important question after each round was not whether the image was good. It was what the image had just taught us.
Closing
I do not think the final image is the main result. The main result is the lineage.
It shows what moved the image forward, what failed, and where prompt only control ran out of power. It also shows why an agentic workflow is a natural fit for diffusion pipelines. There are many levers, many small failures, and many chances to make a slightly better decision than the last one.
Codex supplied the research behavior. Diffusers supplied the modular pipeline surface. JarvisLabs supplied the GPU workers and the command line control loop.
Together, they made image generation feel less like prompt roulette and more like an inspectable experiment.
