Buckets:


| # Construire votre premier LangGraph | |
| Maintenant que nous comprenons les composants de base, mettons-les en pratique en construisant notre premier graphe fonctionnel. Nous implémenterons le système de traitement des emails reçus par Alfred, où il doit : | |
| 1. Lire les emails entrants | |
| 2. Les classifier comme spam ou légitimes | |
| 3. Rédiger une réponse préliminaire pour les emails légitimes | |
| 4. Envoyer les informations à M. Wayne quand c'est légitime (affichage seulement) | |
| Cet exemple démontre comment structurer un *workflow* avec LangGraph qui implique une prise de décision basée sur LLM. Bien que cela ne puisse pas être considéré comme un agent car aucun outil n'est impliqué, cette section se concentre plus sur l'apprentissage du *framework* LangGraph que sur les agents. | |
| > [!TIP] | |
| > Vous pouvez suivre le code dans ce notebook que vous pouvez exécuter avec Google Colab. | |
| ## Notre *workflow* | |
| Voici le *workflow* que nous allons construire : | |
| ## Configuration de notre environnement | |
| Tout d'abord, installons les *packages* requis : | |
| ```python | |
| %pip install langgraph langchain_openai | |
| ``` | |
| Ensuite, importons les modules nécessaires : | |
| ```python | |
| import os | |
| from typing import TypedDict, List, Dict, Any, Optional | |
| from langgraph.graph import StateGraph, START, END | |
| from langchain_openai import ChatOpenAI | |
| from langchain_core.messages import HumanMessage | |
| ``` | |
| ## Étape 1 : Définir notre état | |
| Définissons quelles informations Alfred doit suivre pendant le *workflow* de traitement des emails : | |
| ```python | |
| class EmailState(TypedDict): | |
| # L'email en cours de traitement | |
| email: Dict[str, Any] # Contient sujet, expéditeur, corps, etc. | |
| # Catégorie de l'email (enquête, plainte, etc.) | |
| email_category: Optional[str] | |
| # Raison pourquoi l'email a été marqué comme spam | |
| spam_reason: Optional[str] | |
| # Analyse et décisions | |
| is_spam: Optional[bool] | |
| # Génération de réponse | |
| email_draft: Optional[str] | |
| # Métadonnées de traitement | |
| messages: List[Dict[str, Any]] # Suivre la conversation avec le LLM pour l'analyse | |
| ``` | |
| > 💡 **Astuce :** Rendez votre état suffisamment complet pour suivre toutes les informations importantes, mais évitez de l'encombrer avec des détails inutiles. | |
| ## Étape 2 : Définir nos nœuds | |
| Maintenant, créons les fonctions de traitement qui formeront nos nœuds : | |
| ```python | |
| # Initialiser notre LLM | |
| model = ChatOpenAI(temperature=0) | |
| def read_email(state: EmailState): | |
| """Alfred lit et enregistre l'email entrant""" | |
| email = state["email"] | |
| # Ici nous pourrions faire un prétraitement initial | |
| print(f"Alfred traite un email de {email['sender']} avec le sujet : {email['subject']}") | |
| # Aucun changement d'état nécessaire ici | |
| return {} | |
| def classify_email(state: EmailState): | |
| """Alfred utilise un LLM pour déterminer si l'email est spam ou légitime""" | |
| email = state["email"] | |
| # Préparer notre prompt pour le LLM | |
| prompt = f""" | |
| En tant qu'Alfred le majordome, analysez cet email et déterminez s'il s'agit de spam ou s'il est légitime. | |
| email : | |
| De : {email['sender']} | |
| Sujet : {email['subject']} | |
| Corps : {email['body']} | |
| Premièrement, détermine si cet email est du spam. S'il s'agit de spam, explique pourquoi. | |
| S'il est légitime, catégorise-le (enquête, plainte, remerciement, etc.). | |
| """ | |
| # Appeler le LLM | |
| messages = [HumanMessage(content=prompt)] | |
| response = model.invoke(messages) | |
| # Logique simple pour analyser la réponse (dans une vraie app, vous voudriez un parsing plus robuste) | |
| response_text = response.content.lower() | |
| is_spam = "spam" in response_text and "not spam" not in response_text | |
| # Extraire une raison si c'est du spam | |
| spam_reason = None | |
| if is_spam and "reason:" in response_text: | |
| spam_reason = response_text.split("reason:")[1].strip() | |
| # Déterminer la catégorie si légitime | |
| email_category = None | |
| if not is_spam: | |
| categories = ["inquiry", "complaint", "thank you", "request", "information"] | |
| for category in categories: | |
| if category in response_text: | |
| email_category = category | |
| break | |
| # Mettre à jour les messages pour le suivi | |
| new_messages = state.get("messages", []) + [ | |
| {"role": "user", "content": prompt}, | |
| {"role": "assistant", "content": response.content} | |
| ] | |
| # Retourner les mises à jour d'état | |
| return { | |
| "is_spam": is_spam, | |
| "spam_reason": spam_reason, | |
| "email_category": email_category, | |
| "messages": new_messages | |
| } | |
| def handle_spam(state: EmailState): | |
| """Alfred rejette l'email spam avec une note explicative""" | |
| print(f"Alfred a marqué l'email comme spam. Raison : {state['spam_reason']}") | |
| print("L'email a été déplacé dans le dossier spam.") | |
| # Nous avons fini de traiter cet email | |
| return {} | |
| def draft_response(state: EmailState): | |
| """Alfred rédige une réponse préliminaire pour les emails légitimes""" | |
| email = state["email"] | |
| category = state["email_category"] or "general" | |
| # Préparer notre prompt pour le LLM | |
| prompt = f""" | |
| En tant qu'Alfred le majordome, rédige une réponse préliminaire polie à cet email. | |
| email : | |
| De : {email['sender']} | |
| Sujet : {email['subject']} | |
| Corps : {email['body']} | |
| Cet email a été catégorisé comme : {category} | |
| Rédige une réponse brève et professionnelle que M. Hugg peut réviser et personnaliser avant l'envoi. | |
| """ | |
| # Appeler le LLM | |
| messages = [HumanMessage(content=prompt)] | |
| response = model.invoke(messages) | |
| # Mettre à jour les messages pour le suivi | |
| new_messages = state.get("messages", []) + [ | |
| {"role": "user", "content": prompt}, | |
| {"role": "assistant", "content": response.content} | |
| ] | |
| # Retourner les mises à jour d'état | |
| return { | |
| "email_draft": response.content, | |
| "messages": new_messages | |
| } | |
| def notify_mr_hugg(state: EmailState): | |
| """Alfred informe M. Hugg de l'email et présente le brouillon de réponse""" | |
| email = state["email"] | |
| print("\n" + "="*50) | |
| print(f"Monsieur, vous avez reçu un email de {email['sender']}.") | |
| print(f"Sujet : {email['subject']}") | |
| print(f"Catégorie : {state['email_category']}") | |
| print("\nJ'ai préparé un brouillon de réponse pour votre révision :") | |
| print("-"*50) | |
| print(state["email_draft"]) | |
| print("="*50 + "\n") | |
| # Nous avons fini de traiter cet email | |
| return {} | |
| ``` | |
| ## Étape 3 : Définir notre logique de routage | |
| Nous avons besoin d'une fonction pour déterminer quel chemin prendre après la classification : | |
| ```python | |
| def route_email(state: EmailState) -> str: | |
| """Déterminer la prochaine étape basée sur la classification en spam""" | |
| if state["is_spam"]: | |
| return "spam" | |
| else: | |
| return "legitimate" | |
| ``` | |
| > 💡 **Note :** Cette fonction de routage est appelée par LangGraph pour déterminer quelle arête suivre après le nœud de classification. La valeur de retour doit correspondre à l'une des clés dans notre mappage d'arêtes conditionnelles. | |
| ## Étape 4 : Créer le *StateGraph* et définir les arêtes | |
| Maintenant nous connectons tout ensemble : | |
| ```python | |
| # Créer le graphe | |
| email_graph = StateGraph(EmailState) | |
| # Ajouter les nœuds | |
| email_graph.add_node("read_email", read_email) | |
| email_graph.add_node("classify_email", classify_email) | |
| email_graph.add_node("handle_spam", handle_spam) | |
| email_graph.add_node("draft_response", draft_response) | |
| email_graph.add_node("notify_mr_hugg", notify_mr_hugg) | |
| # Commencer les arêtes | |
| email_graph.add_edge(START, "read_email") | |
| # Ajouter les arêtes - définir le flux | |
| email_graph.add_edge("read_email", "classify_email") | |
| # Ajouter l'embranchement conditionnel depuis classify_email | |
| email_graph.add_conditional_edges( | |
| "classify_email", | |
| route_email, | |
| { | |
| "spam": "handle_spam", | |
| "legitimate": "draft_response" | |
| } | |
| ) | |
| # Ajouter les arêtes finales | |
| email_graph.add_edge("handle_spam", END) | |
| email_graph.add_edge("draft_response", "notify_mr_hugg") | |
| email_graph.add_edge("notify_mr_hugg", END) | |
| # Compiler le graphe | |
| compiled_graph = email_graph.compile() | |
| ``` | |
| Remarquez comment nous utilisons le nœud spécial `END` fourni par LangGraph. Cela indique les états terminaux où le *workflow* se termine. | |
| ## Étape 5 : Exécuter l'application | |
| Testons notre graphe avec un email légitime et un email spam : | |
| ```python | |
| # Exemple d'email légitime | |
| legitimate_email = { | |
| "sender": "john.smith@example.com", | |
| "subject": "Question sur vos services", | |
| "body": "Cher M. Hugg, J'ai été référé à vous par un collègue et je suis intéressé à en savoir plus sur vos services de conseil. Pourrions-nous programmer un appel la semaine prochaine ? Meilleures salutations, John Smith" | |
| } | |
| # Exemple d'email spam | |
| spam_email = { | |
| "sender": "winner@lottery-intl.com", | |
| "subject": "VOUS AVEZ GAGNÉ 5 000 000 $ !!!", | |
| "body": "FÉLICITATIONS ! Vous avez été sélectionné comme gagnant de notre loterie internationale ! Pour réclamer votre prix de 5 000 000 $, veuillez nous envoyer vos coordonnées bancaires et des frais de traitement de 100 $." | |
| } | |
| # Traiter l'email légitime | |
| print("\nTraitement de l'email légitime...") | |
| legitimate_result = compiled_graph.invoke({ | |
| "email": legitimate_email, | |
| "is_spam": None, | |
| "spam_reason": None, | |
| "email_category": None, | |
| "email_draft": None, | |
| "messages": [] | |
| }) | |
| # Traiter l'email spam | |
| print("\nTraitement de l'email spam...") | |
| spam_result = compiled_graph.invoke({ | |
| "email": spam_email, | |
| "is_spam": None, | |
| "spam_reason": None, | |
| "email_category": None, | |
| "email_draft": None, | |
| "messages": [] | |
| }) | |
| ``` | |
| ## Étape 6 : Inspecter notre agent trieur d'email avec *Langfuse* 📡 | |
| Alors qu'Alfred peaufine l'agent trieur d'email, il se lasse de déboguer ses exécutions. Les agents, par nature, sont imprévisibles et difficiles à inspecter. Mais comme il vise à construire l'agent de détection de spam ultime et à le déployer en production, il a besoin d'une traçabilité robuste pour le *monitoring* et l'analyse futurs. | |
| Pour cela, Alfred peut utiliser un outil d'observabilité comme [Langfuse](https://langfuse.com/) pour tracer et monitorer l'agent. | |
| Premièrement, nous installons Langfuse avec pip : | |
| ```python | |
| %pip install -q langfuse | |
| ``` | |
| Deuxièmement, nous installons LangChain avec pip (LangChain est requis car nous utilisons LangFuse) : | |
| ```python | |
| %pip install langchain | |
| ``` | |
| Ensuite, nous ajoutons les clés API LangFuse et l'adresse de l'hôte comme variables d'environnement. Vous pouvez obtenir vos identifiants LangFuse en vous inscrivant sur [LangFuse Cloud](https://cloud.langfuse.com) ou en [auto-hébergeant LangFuse](https://langfuse.com/self-hosting). | |
| ```python | |
| import os | |
| # Obtenez les clés pour votre projet depuis la page des paramètres du projet : https://cloud.langfuse.com | |
| os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..." | |
| os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..." | |
| os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # 🇪🇺 région EU | |
| # os.environ["LANGFUSE_HOST"] = "https://us.cloud.langfuse.com" # 🇺🇸 région US | |
| ``` | |
| Ensuite, nous configurons le [LangFuse `callback_handler`](https://langfuse.com/docs/integrations/langchain/tracing#add-langfuse-to-your-langchain-application) et instrumentons l'agent en ajoutant le `langfuse_callback` à l'invocation du graphe : `config={"callbacks": [langfuse_handler]}`. | |
| ```python | |
| from langfuse.langchain import CallbackHandler | |
| # Initialiser le CallbackHandler Langfuse pour LangGraph/Langchain (traçage) | |
| langfuse_handler = CallbackHandler() | |
| # Traiter l'email légitime | |
| legitimate_result = compiled_graph.invoke( | |
| input={"email": legitimate_email, "is_spam": None, "spam_reason": None, "email_category": None, "draft_response": None, "messages": []}, | |
| config={"callbacks": [langfuse_handler]} | |
| ) | |
| ``` | |
| Alfred est maintenant connecté 🔌 ! Les exécutions de LangGraph sont enregistrées dans LangFuse, lui donnant une visibilité complète sur le comportement de l'agent. Avec cette configuration, il est prêt à revisiter les exécutions précédentes et à affiner encore plus son agent de tri de courrier. | |
| 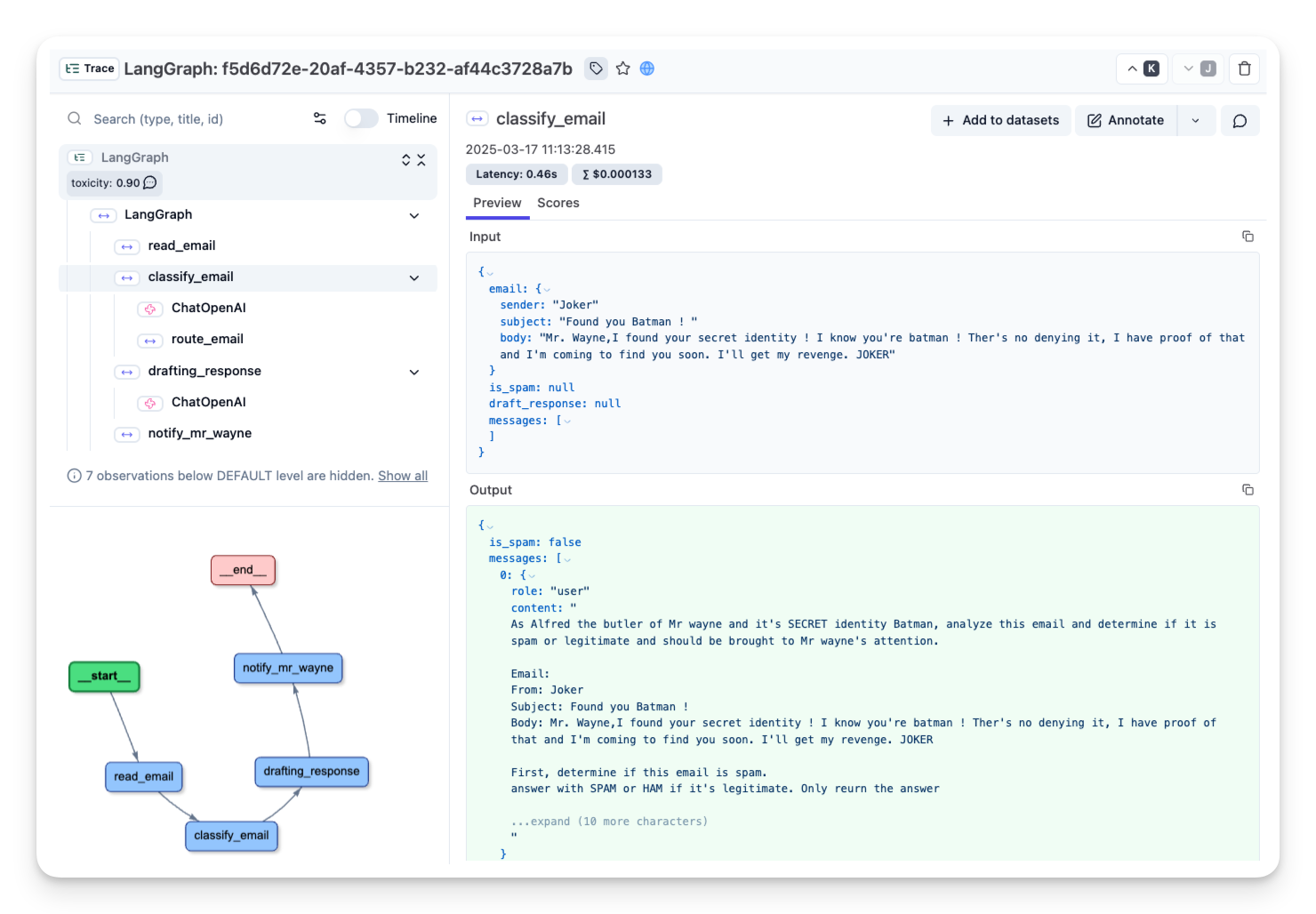 | |
| _[Lien public vers la trace avec l'email légitime](https://cloud.langfuse.com/project/cloramnkj0002jz088vzn1ja4/traces/f5d6d72e-20af-4357-b232-af44c3728a7b?timestamp=2025-03-17T10%3A13%3A28.413Z&observation=6997ba69-043f-4f77-9445-700a033afba1)_ | |
| ## Visualiser notre graphe | |
| LangGraph nous permet de visualiser notre *workflow* pour mieux comprendre et déboguer sa structure : | |
| ```python | |
| compiled_graph.get_graph().draw_mermaid_png() | |
| ``` | |
| Cela produit une représentation visuelle montrant comment nos nœuds sont connectés et les chemins conditionnels qui peuvent être pris. | |
| ## Ce que nous avons construit | |
| Nous avons créé un *workflow* complet de traitement des emails qui : | |
| 1. Prend un email entrant | |
| 2. Utilise un LLM pour le classifier comme spam ou légitime | |
| 3. Gère le spam en le rejetant | |
| 4. Pour les emails légitimes, rédige une réponse et informe M. Hugg | |
| Cela démontre la puissance de LangGraph pour orchestrer des *workflows* complexes avec des LLM tout en maintenant un flux clair et structuré. | |
| ## Points clés à retenir | |
| - **Gestion d'état** : Nous avons défini un état complet pour suivre tous les aspects du traitement des emails | |
| - **Implémentation de nœuds** : Nous avons créé des nœuds fonctionnels qui interagissent avec un LLM | |
| - **Routage conditionnel** : Nous avons implémenté une logique d'embranchement basée sur la classification des emails | |
| - **États terminaux** : Nous avons utilisé le nœud *END* pour marquer les points d'achèvement dans notre *workflow* | |
| ## Et maintenant ? | |
| Dans la prochaine section, nous explorerons des fonctionnalités plus avancées de LangGraph, y compris la gestion de l'interaction humaine dans le *workflow* et l'implémentation d'une logique d'embranchement plus complexe basée sur plusieurs conditions. | |
Xet Storage Details
- Size:
- 14.3 kB
- Xet hash:
- 1d9ef9f929ce35b5533fdfbc87269ad1d090f3be4e7736d53df2b197f30c3096
·
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.