Buckets:


Preprocesamiento de un conjunto de datos de audio
Cargar una base de datos con 🤗 Datasets es solo la mitad de la diversión. Si planeas usar los datos para entrenar un modelo, o para hacer inferencia necesitarás preprocesar los datos primero. En general, esto involucra los siguientes pasos:
- Resamplear los datos de audio.
- Filtrar la base de datos.
- Convertir el audio a la entrada esperada por el modelo.
Resamplear los datos de audio
La función load_dataset descarga los archivos de audio con la frecuencia de muestreo con la que fueron publicados. Esta frecuencia
no siempre coincide con la esperada por el modelo que planees usar para entrenar o realizar inferencia. Si existe una discrepancia
entre las frecuencias, puedes resamplear el audio a la frecuencia de muestreo que espera el modelo.
La mayoria de los modelos pre-entrenados disponibles han sido entrenados con audios a una frecuencia de muestreo de 16kHz. Cuando exploramos los datos de MINDS-14, puedes haber notado que la frecuencia de muestreo era de 8kHz, por lo que seguramente se tendrá que realizar un proceso de upsampling(Convertir de una frecuencia menor a una mayor).
Para hacer esto, usa el método cast_column de 🤗 Datasets. Esta operación no altera el audio cuando se ejecuta, crea una
señal para que datasets haga el resampleo en el momento en que se carguen los audios. El siguiente código configura el proceso
de resampling a 16 kHz.
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
Vuelve a cargar el primer ejemplo de audio en el conjunto de datos MINDS-14 y verifica que se haya re-muestreado al valor deseado de sampling rate:
minds[0]
Output:
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}
Puedes ver que los valores del array ahora son diferentes. Esto es porque ahora tenemos el doble de valores de amplitud de la longitud original.
💡 Si una señal de audio ha sido grabada a una frecuencia de muestreo de 8kHz, de manera que cada segundo de la señal esta representado por 8000 muestras, sabemos tambien que el audio no contiene ninguna frecuencia por encima de 4kHz. Esto esta garantizado por el teorema de Nyquist. Resamplear a una frecuencia de muestro mayor(Upsampling) consiste en estimar los puntos adicionales que irian entre las muestras existentes. El proceso de Downsampling, requiere en cambio, que primero filtremos cualquier frecuencia que sea mayor al nuevo Limite de Nyquist antes de estimar las nuevas muestras. En otras palabras, no puedes hacer downsampling por un facto de 2x solo descartando la mitad de muestras de la señal - Esto crearía distorsiones en la señal llamadas alias. Hacer resampliing de la manera correcta es complejo por lo que es mejor usar librerias que han sido probadas a lo largo de los años como lo son librosa o 🤗 Datasets.Filtrando el conjunto de datos
Algunas veces necesitarás filtrar los datos en función de algunos criterios. Uno de los casos comunes implica limitar los ejemplos de audio a una duración determinada. Por ejemplo, es posible que deseemos filtrar cualquier ejemplo que supere los 20 segundos para evitar errores de falta de memoria al entrenar un modelo.
Podemos hacer esto al usar el método filter que espera una función que contenga una lógica de filtrado. Empezemos por escribir
una función que indique cuales ejemplos conservar y cuales descartar. la función is_audio_length_in_range, retorna True si
un ejemplo tiene una duracióne menor a 20s y False si es mayor a 20s.
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS
La función de filtrado se puede aplicar a una columna de un conjunto de datos, pero en este conjunto de datos no tenemos una columna con la duración de la pista de audio. Sin embargo, podemos crear una columna, filtrar basándonos en los valores de esa columna y luego eliminarla.
# usar librosa para calcular la duración del audio
new_column = [librosa.get_duration(filename=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# usar el método `filter` de 🤗 Datasets' para aplicar la función de filtrado
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# eliminar la columna temporal de duración
minds = minds.remove_columns(["duration"])
minds
Output:
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})
Podemos verificar que el dataset filtrado ahora tiene 624 ejemplos y no 654
Preprocesando los datos de audio
Uno de los aspectos más retadores de trabajar con datos de audio es preparar los datos en el formato correcto para el entrenamiento de un modelo. Como has visto, los datos de audio se almacenan en un arreglo de muestras. Sin embargo, la mayoria de modelos pre-entrenados, ya sea que los uses para inferencia o para fine-tuning, esperan que los datos en bruto sean convertidos en características de entrada. Los requisitos para las características de entrada pueden variar de un modelo a otro, ya que dependen de la arquitectura del modelo y los datos con los que fue preentrenado. La buena noticia es que, para cada modelo de audio compatible, 🤗 Transformers ofrece una clase de extractor de características que puede convertir los datos de audio en bruto en las características de entrada que el modelo espera.
Entonces, ¿qué hace un extractor de características con los datos de audio en bruto? Echemos un vistazo al extractor de características de Whisper para comprender algunas transformaciones comunes de extracción de características. Whisper es un modelo preentrenado para el reconocimiento automático del habla (ASR) publicado en septiembre de 2022 por Alec Radford et al. de OpenAI.
Primero, el extractor de característicasde whisper completa/recorta un conjunto de ejemplos de audios para que todos los ejemplos tengan una longitud de 30s. Ejemplos con una duración menor son completados añadiendo ceros al final de la secuencia(Ceros en una secuencia de audio corresponden a la ausencia de señal o silencio). Ejemplos mayores a 30 segundos son truncados hasta 30 segundos. Ya que todos los elementos en el conjunto son completados/recortados a una longitud común, no hay necesidad de usar una mascara de atención. Whisper es único en este aspecto, la mayoria de los otros modelos requieren una mascara de atención que indica donde las secuencias fueron completadas, y por lo tanto sean ignoradas por el mecanismo de auto-atención. Whisper esta entrenado para trabajar sin un mecanismo de atención e inferir directamente de la señal donde ignorar estos segmentos.
La segunda operación que realiza el extractor de whisper es convertir las señalas en espectrogramas logarítmicos de mel. Como recordarás, estos espectrogramas describen cómo cambian las frecuencias de una señal con el tiempo, expresadas en la escala mel y medidas en decibelios (la parte logarítmica) para hacer que las frecuencias y amplitudes sean más representativas de la audición humana.
Todas estas transformaciones pueden ser aplicadas a tus datos de audio en bruto con unas pocas lineas de código. Carguemos ahora el extractor de características de el modelo preentrenado de Whisper.
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
A continuacióon, podemos escribir una función para preprocesar un ejemplo de audio al pasarlo a traves del feature_extractor.
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return features
Podemos aplicar la función de preparación de datos a todos nuestros ejemplos de entrenamiento utilizando el método "map" de 🤗 Datasets:
minds = minds.map(prepare_dataset)
minds
Output:
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)
Con tan solo hacer esto, tenemos los espectrogramas logarítmicos de mel como una columna de input_features en nuestro dataset.
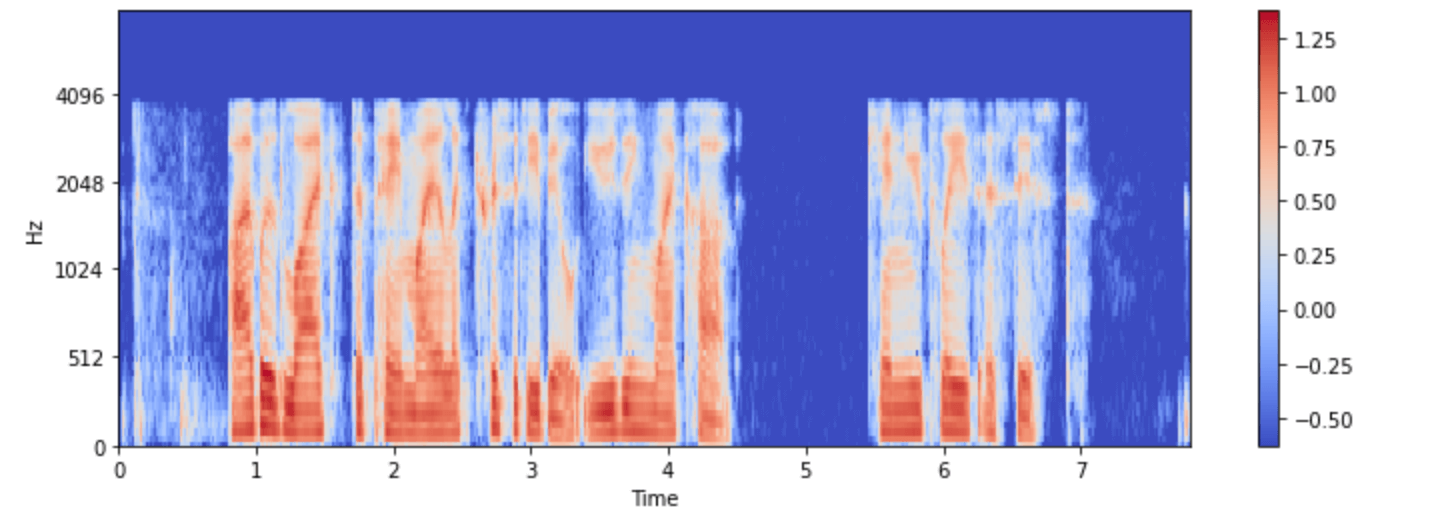
Visualizemos ahora uno de los ejemplos del dataset minds:
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()
La clase de extractor de características del modelo se encarga de transformar los datos de audio en bruto al formato que el modelo espera. Sin embargo, muchas tareas que involucran audio son multimodales, como el reconocimiento de voz. En tales casos, 🤗 Transformers también ofrece tokenizadores específicos del modelo para procesar las entradas de texto. Para obtener más información sobre los tokenizadores, consulta nuestro curso de NLP.
Puedes cargar el extractor de características y el tokenizador para Whisper y otros modelos multimodales de forma separada, o puedes cargar
ambos usando el "procesador". Para hacer las cosas aun más simples, usa el AutoProcessor para cargar el extractor de características
y el procesador de un modelo de la siguiente forma:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")
Aquí hemos ilustrado los pasos fundamentales de preparación de datos. Por supuesto, los datos personalizados pueden requerir una preprocesamiento más complejo. En este caso, puedes ampliar la función prepare_dataset para realizar cualquier tipo de transformación personalizada en los datos. Con 🤗 Datasets, si puedes escribirlo como una función de Python, ¡puedes aplicarlo a tu conjunto de datos!
Xet Storage Details
- Size:
- 11.4 kB
- Xet hash:
- 8ca112763aaf716f2d9a100ff20cc48cf0e47d924a2c5264958dbe061b1b89bb
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.