Buckets:


การแบ่งปันโมเดลที่ผ่านการเทรนมาแล้ว (pretrained models)
{#if fw === 'pt'}
<CourseFloatingBanner chapter={4} classNames="absolute z-10 right-0 top-0" notebooks={[ {label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/th/chapter4/section3_pt.ipynb"}, {label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/th/chapter4/section3_pt.ipynb"}, ]} />
{:else}
<CourseFloatingBanner chapter={4} classNames="absolute z-10 right-0 top-0" notebooks={[ {label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/notebooks/blob/master/course/th/chapter4/section3_tf.ipynb"}, {label: "Aws Studio", value: "https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/master/course/th/chapter4/section3_tf.ipynb"}, ]} />
{/if}
ในขั้นตอนข้างล่างต่อไปนี้ เราจะมาดูวิธีที่ง่ายที่สุดในการแบ่งปันโมเดลที่ผ่านการเทรนมาแล้วบน 🤗 Hub มีเครื่องมือและสิ่งอำนวยความสะดวกมากมายที่ทำให้การแบ่งปันและอัพเดตโมเดลโดยตรงบน Hub เป็นเรื่องง่าย ซึ่งนั่นคือสิ่งที่เราจะมาสำรวจกันต่อจากนี้
เราส่งเสริมให้ผู้ใช้ทุกคนที่เทรนโมเดลช่วยมีส่วนร่วมโดยการแบ่งปันโมเดลเหล่านั้นให้กับชุมชน การแบ่งปันโมเดลนั้นสามารถช่วยเหลือผู้อื่นได้ ช่วยลดเวลาและทรัพยากรในการประมวลผล และช่วยให้เข้าถึงไฟล์ผลลัพธ์จากการเทรน (artifacts) ที่เป็นประโยชน์ได้ แม้ว่าจะเป็นโมเดลที่ถูกเทรนมากับชุดข้อมูลที่เฉพาะเจาะจงมากก็ตาม ในทางเดียวกันนั้นคุณก็ได้รับประโยชน์จากงานที่คนอื่นได้ทำเช่นกัน!
มี 3 วิธีที่สามารถใช้สร้าง model repositories ใหม่ได้:
- ใช้
push_to_hubAPI - ใช้
huggingface_hubPython library - ใช้ web interface
เมื่อคุณได้สร้าง repository แล้ว คุณสามารถอัพโหลดไฟล์ต่างๆเข้าไปได้ผ่าน git และ git-lfs ในส่วนถัดไปเราจะพาคุณมาดูขั้นตอนการสร้าง model repositories และการอัพโหลดไฟล์ต่างๆเข้าไป
ใช้ push_to_hub API
{#if fw === 'pt'}
{:else}
{/if}
วิธีที่ง่ายที่สุดในการอัพโหลดไฟล์ขึ้นไปสู่ Hub คือการใช้ push_to_hub API
ก่อนจะไปกันต่อ คุณจะต้องสร้างโทเค็นสำหรับรับรองความน่าเชื่อถือ (authentication token) เพื่อให้ huggingface_hub API รู้ว่าคุณคือใครและคุณมีสิทธิ์ในการเขียน (write access) ใน namespaces อะไรบ้าง ในตอนนี้ให้คุณทำให้มั่นใจว่าคุณอยู่ใน environment ที่คุณได้ทำการติดตั้ง transformers เอาไว้แล้ว (ดู ติดตั้งโปรแกรม) ถ้าคุณกำลังอยู่ใน notebook คุณสามารถใช้งานคำสั่งต่อไปนี้ในการเข้าสู่ระบบได้เลย:
from huggingface_hub import notebook_login
notebook_login()
สำหรับใน terminal คนสามารถรัน:
huggingface-cli login
ในทั้งสองกรณี คุณควรจะถูกให้กรอก username และ password ซึ่งเป็นชุดเดียวกันกับที่คุณใช้ในการ login เข้าสู่ Hub ถ้าหากคุณยังไม่มีโปรไฟล์ Hub คุณสามารถสร้างได้ ที่นี่
เยี่ยม! ตอนนี้คุณมี authentication token เก็บเอาไว้ใน cache folder ของคุณแล้ว มาเริ่มสร้าง repositories กันเถอะ!
{#if fw === 'pt'}
ถ้าคุณเคยได้ลองใช้งาน Trainer API ในการเทรนโมเดลมาบ้างแล้ว วิธีที่ง่ายที่สุดที่จะอัพโหลดขึ้นไปสู่ Hub คือการตั้ง push_to_hub=True ตอนที่คุณกำหนด TrainingArguments:
from transformers import TrainingArguments
training_args = TrainingArguments(
"bert-finetuned-mrpc", save_strategy="epoch", push_to_hub=True
)
เมื่อคุณเรียกใช้ trainer.train() ตัว Trainer จะทำการอัพโหลดโมเดลของคุณขึ้นสู่ Hub ในทุกๆครั้งที่มันถูกบันทึก (ในที่นี้คือ ทุกๆรอบการเทรน (epoch)) ใน repository และ namespace ของคุณ repository นั้นจะถูกตั้งชื่อให้เหมือนกับโฟลเดอร์ output ที่คุณเลือก (ในที่นี้คือ bert-finetuned-mrpc) แต่คุณสามารถเลือกชื่ออื่นได้โดยการใช้ hub_model_id = "ชื่ออื่น"
สำหรับการอัพโหลดโมเดลของคุณเข้าสู่องค์กรที่คุณเป็นสมาชิกนั้น คุณสามารถทำได้โดย เพียงแค่ผ่านตัวแปล hub_model_id = "องค์กร_ของคุณ/ชื่อ_repo_ของคุณ" เข้าไป
เมื่อการเทรนของคุณเสร็จสิ้น คุณควรที่จะใช้ trainer.push_to_hub() อีกครั้งเป็นครั้งสุดท้าย เพื่ออัพโหลดโมเดลเวอร์ชั่นล่าสุดของคุณ มันจะสร้างการ์ดโมเดล (model card) ที่มีข้อมูลเมตา (metadata) ที่เกี่ยวข้อง เช่น รายงาน hyperparameters ที่ใช้ และผลลัพธ์ของการประเมินผล (evaluation result) ให้คุณด้วย! ต่อไปนี้เป็นตัวอย่างของเนื้อหาที่คุณเจอได้ในการ์ดโมเดล:

{:else}
ถ้าคุณใช้ Keras ในเทรนโมเดล วิธีที่ง่ายที่สุดที่จะอัพโหลดมันขึ้นสู่ Hub คือการผ่านค่าตัวแปร PushToHubCallback เข้าไป เมื่อคุณเรียกใช้ model.fit():
from transformers import PushToHubCallback
callback = PushToHubCallback(
"bert-finetuned-mrpc", save_strategy="epoch", tokenizer=tokenizer
)
ต่อจากนั้นคุณควรเพิ่ม callbacks=[callback] ไปในตอนที่คุณเรียก model.fit() ตัว callback นี้จะทำการอัพโหลดโมเดลของคุณขึ้นสู่ Hub ในทุกๆครั้งที่มันถูกบันทึก (ในที่นี้คือ ทุกๆรอบการเทรน (epoch)) ใน repository และ namespace ของคุณ repository นั้นจะถูกตั้งชื่อให้เหมือนกับโฟลเดอร์ output ที่คุณเลือก (ในที่นี้คือ bert-finetuned-mrpc) แต่คุณสามารถเลือกชื่ออื่นได้โดยการใช้ hub_model_id = "ชื่ออื่น"
สำหรับการอัพโหลดโมเดลของคุณเข้าสู่องค์กรที่คุณเป็นสมาชิกนั้น คุณสามารถทำได้โดย เพียงแค่ผ่านตัวแปล hub_model_id = "องค์กร_ของคุณ/ชื่อ_repo_ของคุณ" เข้าไป
{/if}
ในระดับล่างลงไปนั้น การเข้าถึง Model Hub สามารถทำได้โดยตรงจาก objects ประเภท models, tokenizers และconfiguration ผ่านคำสั่ง push_to_hub() คำสั่งนี้จะจัดการทั้งการสร้าง repository และการดันไฟล์โมเดลและ tokenizer ขึ้นสู่ repository โดยตรง ไม่มีความจำเป็นที่จะต้องทำอะไรด้วยตนเองเลย ไม่เหมือนกับ API ที่เราจะได้เห็นข้างล่างนี้
เพื่อให้เห็นภาพมากขึ้นว่ามันทำงานอย่างไร เรามาเริ่มสร้างโมเดลและ tokenizer ตัวแรกกันเถอะ:
{#if fw === 'pt'}
from transformers import AutoModelForMaskedLM, AutoTokenizer
checkpoint = "camembert-base"
model = AutoModelForMaskedLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
{:else}
from transformers import TFAutoModelForMaskedLM, AutoTokenizer
checkpoint = "camembert-base"
model = TFAutoModelForMaskedLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
{/if}
ถึงจุดนี้คุณสามารถทำอะไรก็ได้กับมันตามที่คุณต้องการ ไม่ว่าจะเป็นการเพิ่ม tokens ไปใน tokenizer, การเทรนโมเดล, การ fine-tune โมเดล หลังจากที่คุณพอใจกับผลลัพธ์ของโมเดล, weights และ tokenizer แล้ว คุณสามารถเรียกใช้คำสั่ง push_to_hub() ที่มีอยู่ในตัว model object ได้โดยตรง
model.push_to_hub("dummy-model")
ขั้นตอนนี้จะสร้าง repository ใหม่ชื่อ dummy-model ในโปรไฟล์ของคุณ และเติมมันด้วยไฟล์โมเดลต่างๆของคุณ
ทำแบบเดียวกันนี้กับ tokenizer นั่นจะทำให้ไฟล์ทั้งหมดอยู่บน repository นี้:
tokenizer.push_to_hub("dummy-model")
ถ้าคุณสังกัดองค์กร คุณสามารถระบุชื่อขององค์กรใน organization argument เพื่ออัพโหลดเข้าไปใน namespace ขององค์กร:
tokenizer.push_to_hub("dummy-model", organization="huggingface")
ถ้าคุณต้องการที่จะใช้งานโทเค็นของ Hugging Face โดยเฉพาะเจาะจง คุณสามารถระบุมันไปในคำสั่ง push_to_hub() ได้เช่นกัน:
tokenizer.push_to_hub("dummy-model", organization="huggingface", use_auth_token="<TOKEN>")
ในตอนนี้ให้คุณมุ่งหน้าไปที่ Model Hub เพื่อหาโมเดลที่คุณเพิ่งได้อัพโหลดไป: https://huggingface.co/ชื่อ-user-หรือ-organization/dummy-model
คลิกไปที่แท็บ "Files and versions" และคุณควรจะเห็นไฟล์แบบในภาพข้างล่างนี้:
{#if fw === 'pt'}

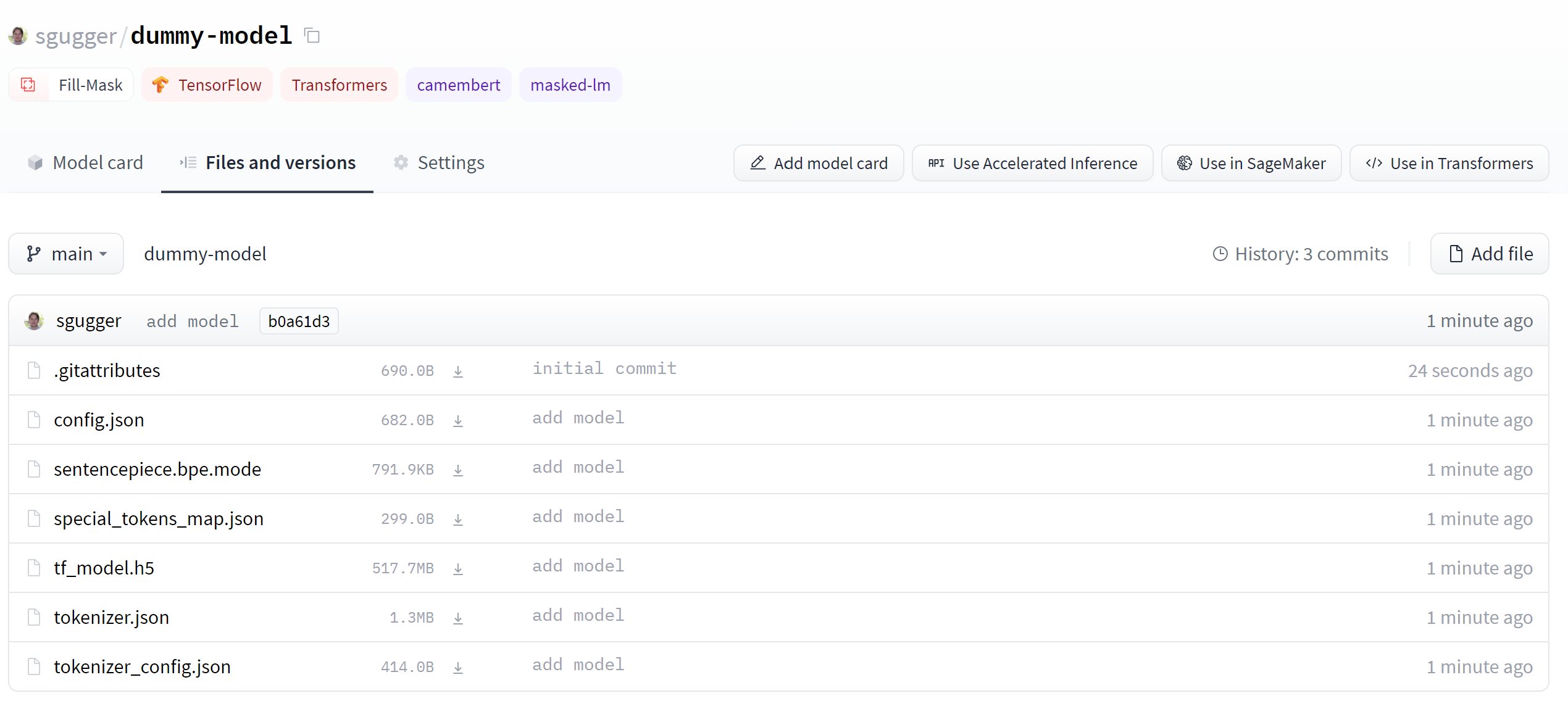
✏️ ทดลองใช้ได้เลย! นำโมเดลและ tokenizer ที่เกี่ยวข้องกับ
bert-base-casedcheckpoint และอัพโหลดขึ้นไปบน repo ใน namespace ของคุณด้วยคำสั่งpush_to_hub()จากนั้นลองตรวจสอบดูว่า repo ปรากฏออกมาในรูปแบบที่สมควรจะเป็นบนหน้าของคุณ ก่อนที่จะลบมันออกไป
อย่างที่คุณได้เห็น คำสั่ง push_to_hub() สามารถรับ arguments ได้มากมาย ทำให้สามารถอัพไฟล์ไปยัง repository หรือ namespace ขององค์กรแบบเจาะจง หรือใช้งานโทเค็น API ที่ต่างกันได้ เราแนะนำให้คุณลองเปิดดูรายละเอียดของคำสั่งนี้ได้โดยตรงที่ 🤗 Transformers documentation เพื่อจะได้เข้าใจมากขึ้นว่าคำสั่งนี้สามารถทำอะไรได้บ้าง
คำสั่ง push_to_hub() ได้รับการหนุนหลังโดย huggingface_hub Python package ซึ่งให้ API โดยตรงไปสู่ Hugging Face Hub มันถูกบูรณาการเข้ากับ 🤗 Transformers และ machine learning libraries อื่นๆอีกหลายอันด้วย เช่น allenlp แม้ว่าเราเจาะจงแค่การบูรณาการกับ 🤗 Transformers ในบทนี้ แต่การบูรณาการกับการใช้โค้ดของคุณเองหรือ library อื่นนั้นเรียบง่ายมาก
ข้ามไปส่วนสุดท้ายเพื่อดูวิธีการอัพโหลดไฟล์ขึ้นไปบน repository ที่คุณสร้างขึ้นมาใหม่!
ใช้ huggingface_hub Python library
huggingface_hub Python library คือ package หนึ่งที่บรรจุชุดเครื่องมือสำหรับ hub ของโมเดลและชุดข้อมูล มันมีคำสั่งและคลาสที่เรียบง่ายไว้สำหรับงานทั่วไปอย่าง
การดึงข้อมูลเกี่ยวกับ repositories บน hub และการจัดการมัน มันมี API ง่ายๆที่สามารถทำงานบน git เพื่อที่จะจัดการเนื้อหาของ repositories เหล่านั้นและบูรณาการเข้ากับ Hub
ในงานโปรเจคและ libraries ของคุณ
คล้ายคลึงกับการใช้ push_to_hub API คุณจำเป็นจะต้องมีโทเค็น API เก็บไว้ใน cache ของคุณ เพื่อที่จะมีมันได้ คุณจะต้องใช้คำสั่ง login จาก CLI อย่างที่เราเคยกล่าวถึงไปแล้วในส่วนก่อนหน้านี้ (ย้ำอีกครั้ง ทำให้มั่นใจว่าคุณใส่เครื่องหมาย ! ไว้ข้างหน้าคำสั่งถ้าคุณกำลังรันใน Google Colab):
huggingface-cli login
huggingface_hub package บรรจุคำสั่งและคลาสซึ่งเป็นประโยชน์สำหรับจุดประสงค์ของเราเอาไว้หลายอย่าง อย่างแรก มีคำสั่งจำนวนหนึ่งที่ใช้จัดการกับการสร้าง, การลบ และการจัดการอื่นๆของ repository
from huggingface_hub import (
# User management
login,
logout,
whoami,
# Repository creation and management
create_repo,
delete_repo,
update_repo_visibility,
# And some methods to retrieve/change information about the content
list_models,
list_datasets,
list_metrics,
list_repo_files,
upload_file,
delete_file,
)
มากไปกว่านั้น มันยังมี Repository class ที่ทรงพลังมากๆไว้จัดการกับ local repository เราจะมาสำรวจคำสั่งเหล่านี้และคลาสนั้นกันในอีกส่วนไม่ไกลข้างหน้า เพื่อที่จะได้เข้าใจวิธีการนำมันมาใช้
คำสั่ง create_repo สามารถใช้ในการสร้าง repository ใหม่บน hub ได้
from huggingface_hub import create_repo
create_repo("dummy-model")
โค้ดนี้จะสร้าง repository ชื่อ dummy-model ใน namespace ของคุณ ถ้าคนชอบ คุณสามารถระบุอย่างเจาะจงไปได้ว่า repository นี้เป็นขององค์กรไหน โดยการใช้ organization argument:
from huggingface_hub import create_repo
create_repo("dummy-model", organization="huggingface")
โค้ดนี้จะสร้าง repository ชื่อ dummy-model ใน namespace ของ huggingface สมมุติว่าคุณเป็นคนขององค์กรนั้น
Arguments อื่นที่อาจจะเป็นประโยชน์:
privateใช้ในการระบุว่าคนอื่นควรเห็น repository นี้ได้หรือไม่tokenใช้ในกรณีที่คุณอยากจะแทนที่โทเค็นที่ถูกเก็บเอาไว้ใน cache ของคุณด้วยอีกโทเค็นที่ให้ไว้repo_typeใช้ในกรณีที่คุณอยากจะสร้างdatasetหรือspaceแทนที่จะเป็นโมเดล ค่าที่รับได้คือ"dataset"และ"space"
เมื่อ repository ถูกสร้างขึ้นมาแล้ว เราสามารถเพิ่มไฟล์ไปในนั้นได้! ข้ามไปส่วนถัดไปเพื่อดูสามวิธีในการทำสิ่งนี้
ใช้ web interface
web interface บรรจุเครื่องมือมากมายที่ใช้จัดการ repositories โดยตรงใน Hub ด้วยการใช้งาน web interface คุณสามารถสร้าง repositories, เพิ่มไฟล์ (รวมถึงไฟล์ขนาดใหญ่ด้วย!), สำรวจโมเดลต่างๆ, แสดงผลความแตกต่าง และอื่นๆอีกมากมายได้อย่างง่ายดาย
สร้าง repository ใหม่ได้โดยการไปที่ huggingface.co/new:

ขั้นแรก ระบุเจ้าของของ repository ซึ่งสามารถเป็นคุณเองหรือองค์กรใดๆที่คุณเกี่ยวข้องด้วย ถ้าคุณเลือกองค์กร โมเดลจะถูกนำไปขึ้นบนหน้าขององค์กรด้วย และสมาชิกทุกคนขององค์กรนั้นจะมีสิทธิ์ในการมีส่วนร่วมกับ repository นี้
ถัดไป ใส่ชื่อโมเดลของคุณ ซึ่งจะเหมือนกับชื่อของ repository ก็ได้ และสุดท้าย คุณสามารถระบุได้ว่าคุณต้องการให้โมเดลของคุณเป็นสาธารณะหรือส่วนบุคคล โมเดลส่วนบุคคลนั้นจะถูกซ่อนจากมุมมองสาธารณะ
หลังจากที่คุณสร้าง model repository ของคุณแล้ว คุณควรจะเห็นหน้าแบบนี้:

นี่คือที่ที่โมเดลของคุณจะถูก host เอาไว้ สำหรับการเริ่มปรับแต่งเพิ่มเติมนั้น คุณสามารถเพิ่มไฟล์ README ได้โดยตรงจาก web interface

ไฟล์ README อยู่ในรูปแบบของ Markdown — สามารถปรับแต่งมันแบบจัดเต็มได้เลย! ในส่วนที่สามของบทนี้ถูกอุทิศให้กับการสร้างการ์ดโมเดล (model card) ซึ่งนี่เป็นส่วนที่สำคัญเป็นอันดับหนึ่งในการสร้างคุณค่าให้โมเดลของคุณ เพราะว่ามันจะเป็นสิ่งที่ใช้บอกคนอื่นว่าโมเดลของคุณทำอะไรได้บ้าง
ถ้าคุณดูที่แท็บ "Files and versions" คุณจะเห็นว่ามันยังไม่มีไฟล์อะไรมากมายเลย — แค่ไฟล์ README.md ที่คุณเพิ่งได้สร้างและไฟล์ .gitattributes สำหรับไว้ติดตามไฟล์ขนาดใหญ่

ต่อไปเราจะมาดูวิธีการเพิ่มไฟล์ใหม่กัน
การอัพโหลดไฟล์โมเดลต่างๆ
ระบบที่ใช้จัดการไฟล์บน Hugging Face Hub มีพื้นฐานมาจาก git สำหรับไฟล์ทั่วไป และ git-lfs (ย่อมาจาก Git Large File Storage) สำหรับไฟล์ที่ใหญ่ขึ้น
ในส่วนถัดไปนี้ เราจะพามาดูสามวิธีในการอัพโหลดไฟล์ต่างๆไปบน Hub: ผ่าน huggingface_hub และ ผ่านคำสั่ง git ต่างๆ
แนวทางแบบใช้ upload_file
การใช้ upload_file ไม่จำเป็นต้องมี git และ git-lfs ติดตั้งอยู่บนระบบของคุณ มันดันไฟล์โดยตรงไปสู่ 🤗 Hub โดยใช้ HTTP POST requests ข้อจำกัดของแนวทางนี้คือมันไม่สามารถรองรับไฟล์ที่มีขนาดมากกว่า 5GB ได้
ถ้าไฟล์ของคุณมีขนาดใหญ่กว่า 5GB โปรดทำตามอีกสองขั้นตอนที่ระบุรายละเอียดไว้ด้านล่าง
API สามารถถูกใช้แบบนี้ได้:
from huggingface_hub import upload_file
upload_file(
"<path_to_file>/config.json",
path_in_repo="config.json",
repo_id="<namespace>/dummy-model",
)
โค้ดนี้จะทำการอัพโหลดไฟล์ config.json ที่อยู่ใน <path_to_file> ไปสู่รากของ repository โดยใช้ชื่อ config.json ไปสู่ dummy-model repository
Arguments อื่นที่อาจจะเป็นประโยชน์:
tokenใช้ในกรณีที่คุณอยากจะแทนที่โทเค็นที่ถูกเก็บเอาไว้ใน cache ของคุณด้วยอีกโทเค็นที่ให้ไว้repo_typeใช้ในกรณีที่คุณอยากจะสร้างdatasetหรือspaceแทนที่จะเป็นโมเดล ค่าที่รับได้คือ"dataset"และ"space"
คลาส Repository
คลาส Repository จัดการ local repository ในลักษณะคล้าย git มันเอาปัญหาส่วนมากที่ผู้คนมักเจอเวลาใช้ git ออกเพื่อจัดสรรทุกฟีเจอร์ทุกอย่างที่เราจำเป็นต้องใช้
การใช้คลาสนี้จำเป็นต้องติดตั้ง git และ git-lfs ดังนั้นคุณควรทำให้มั่นใจว่าคุณได้ติดตั้ง git-lfs แล้ว (ดู ที่นี่ สำหรับขั้นตอนการติดตั้ง) และตั้งค่าให้เสร็จก่อนที่คุณจะเริ่มไปต่อ
เพื่อที่จะเริ่มเล่นกับ repository ที่เราเพิ่งจะได้สร้างกัน เราสามารถเริ่มตั้งต้นมันไปใน local folder ได้โดยการโคลน (clone) remote repository:
from huggingface_hub import Repository
repo = Repository("<path_to_dummy_folder>", clone_from="<namespace>/dummy-model")
โค้ดนี้จะสร้างโฟลเดอร์ <path_to_dummy_folder> ในไดเรกทอรีที่คุณทำงานอยู่ (working directory) โฟลเดอร์นี้เก็บไฟล์ .gitattributes เอาไว้เพียงไฟล์เดียวเพราะว่ามันเป็นไฟล์เดียวที่จะถูกสร้างเมื่อมีการสร้าง repository ตั้งต้นด้วยคำสั่ง create_repo
จากจุดนี้เป็นต้นไป เราสามารถใช้คำสั่ง git แบบดั่งเดิมต่างๆได้:
repo.git_pull()
repo.git_add()
repo.git_commit()
repo.git_push()
repo.git_tag()
และอื่นๆอีก! เราแนะนำให้ลองไปดูที่หนังสืออ้างอิง (documentation) ของ Repository ซึ่งเข้าถึงได้จาก ที่นี่ สำหรับภาพรวมของคำสั่งทั้งหมดที่ใช้ได้
ณ ปัจจุบัน เรามีโมเดลและ tokenizer ซึ่งเราต้องการที่จะดันขึ้นสู่ hub แล้ว เราได้โคลน repository มาอย่างเสร็จสมบูรณ์ ดังนั้นเราสามารถเก็บไฟล์ต่างๆไว้ใน repository นั้นได้แล้ว
อันดับแรกเราต้องทำให้มั่นใจว่า local clone ของเรานั้นเป็นปัจจุบัน ซึ่งทำได้โดยการดึง (pull) การเปลี่ยนแปลงใหม่ล่าสุดเข้ามา:
repo.git_pull()
เมื่อโค้ดทำงานเสร็จแล้ว เราเก็บไฟล์โมเดลและ tokenizer:
model.save_pretrained("<path_to_dummy_folder>")
tokenizer.save_pretrained("<path_to_dummy_folder>")
ที่ <path_to_dummy_folder> ตอนนี้มีไฟล์โมเดลและ tokenizer ทั้งหมดแล้ว เราจะทำตาม workflow ของ git ทั่วไปโดยการ เพิ่มไฟล์ไปยัง staging area, ทำการ commit และดัน (push) ไฟล์เหล่านั้นสู่ hub:
repo.git_add()
repo.git_commit("Add model and tokenizer files")
repo.git_push()
ขอแสดงความยินดีด้วย! คุณเพิ่งได้ทำการดันไฟล์ชุดแรกของคุณสู่ hub
แนวทางแบบใช้ git
แนวทางนี้เป็นแนวทางที่ตรงๆมากสำหรับทำการอัพโหลดไฟล์ นั่นคือเราจะใช้ git และ git-lfs โดยตรง ส่วนที่ยากส่วนใหญ่ถูกในออกไปในแนวทางก่อนๆ แต่มันมีข้อแม้บางอย่างกับขั้นตอนแต่ไปนี้ ดังนั้นเราจะทำตามการใช้งานแบบที่ซับซ้อนขึ้นกว่าปกติ
การใช้งานต่อจากนี้จำเป็นต้องติดตั้ง git และ git-lfs ดังนั้นคุณควรทำให้มั่นใจว่าคุณได้ติดตั้ง git-lfs แล้ว (ดู ที่นี่ สำหรับขั้นตอนการติดตั้ง) และตั้งค่าให้เสร็จก่อนที่คุณจะเริ่มไปต่อ
เริ่มแรกโดยการเริ่มต้นสร้าง git-lfs:
git lfs install
Updated git hooks.
Git LFS initialized.
เมื่อโค้ดทำงานเสร็จแล้ว ขั้นตอนแรกคือการโคลน model repository ของคุณ:
git clone https://huggingface.co/<namespace>/<your-model-id>
username ของฉันคือ lysandre และฉันใช้ dummy เป็นชื่อโมเดล ดังนั้นสำหรับฉันแล้ว คำสั่งจะมีหน้าตาประมาณแบบนี้:
git clone https://huggingface.co/lysandre/dummy
ตอนนี้ฉันมีโฟลเดอร์ชื่อ dummy ในไดเรกทอรีที่ฉันทำงานอยู่ (working directory) ฉันสามารถ cd เข้าไปในโฟลเดอร์และดูว่ามีอะไรข้างในบ้าง:
cd dummy && ls
README.md
ถ้าคุณสร้าง repository ด้วยการใช้คำสั่ง create_repo ของ Hugging Face Hub โฟลเดอร์นี้ควรจะมีไฟล์ .gitattributes ถูกซ่อนอยู่ด้วย ถ้าคุณทำตามขั้นตอนในส่วนก่อนหน้านี้ในการสร้าง repository โดยใช้ web interface ในโฟลเดอร์นี้ควรจะมี README.md หนึ่งไฟล์มาพร้อมกับไฟล์ .gitattributes ที่ถูกซ่อนอยู่ อย่างที่แสดงให้เห็นนี้
การเพิ่มไฟล์หนึ่งไฟล์ที่มีขนาดปกติ เช่น ไฟล์สำหรับกำหนดค่า (configuration file), ไฟล์สำหรับเก็บคำศัพท์ (vocabulary file) หรือโดยง่ายๆแล้วไฟล์อะไรก็ตามที่มีขนาดน้อยกว่าสองสาม megabytes สามารถทำได้ด้วยการทำแบบที่ทำปกติกับระบบที่พึ่งพา git อย่างไรก็ตามไฟล์ที่ใหญ่กว่านั้นจะต้องถูกลงทะเบียนผ่าน git-lfs เพื่อที่จะดันไฟล์เหล่านั้นขึ้นสู่ huggingface.co ได้
กลับไปหา Python กันสักหน่อยเพื่อจะสร้างโมเดลและ tokenizer ที่เราต้องการจะ commit ไปสู่ repository จำลองของเรา
{#if fw === 'pt'}
from transformers import AutoModelForMaskedLM, AutoTokenizer
checkpoint = "camembert-base"
model = AutoModelForMaskedLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# Do whatever with the model, train it, fine-tune it...
model.save_pretrained("<path_to_dummy_folder>")
tokenizer.save_pretrained("<path_to_dummy_folder>")
{:else}
from transformers import TFAutoModelForMaskedLM, AutoTokenizer
checkpoint = "camembert-base"
model = TFAutoModelForMaskedLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# Do whatever with the model, train it, fine-tune it...
model.save_pretrained("<path_to_dummy_folder>")
tokenizer.save_pretrained("<path_to_dummy_folder>")
{/if}
ถึงตอนนี้เราได้ทำการบันทึกไฟล์จากโมเดลและ tokenizer บางส่วนแล้ว ลองไปดูโฟลเดอร์ dummy อีกรอบกันเถอะ:
ls
{#if fw === 'pt'}
config.json pytorch_model.bin README.md sentencepiece.bpe.model special_tokens_map.json tokenizer_config.json tokenizer.json
ถ้าคุณดูที่ขนาดของไฟล์ (อย่างเช่น ใช้คำสั่ง ls -lh) คุณควรจะเห็นได้ว่าไฟล์ model state dict (pytorch_model.bin) มีขนาดที่โดดมาก นั่นคือมากกว่า 400 MB
{:else}
config.json README.md sentencepiece.bpe.model special_tokens_map.json tf_model.h5 tokenizer_config.json tokenizer.json
ถ้าคุณดูที่ขนาดของไฟล์ (อย่างเช่น ใช้คำสั่ง ls -lh) คุณควรจะเห็นได้ว่าไฟล์ model state dict (t5_model.h5) มีขนาดที่โดดมาก นั่นคือมากกว่า 400 MB
{/if}
✏️ ตอนที่สร้าง repository จาก web interface ไฟล์ .gitattributes ถูกตั้งค่าอย่างอัตโนมัติเพื่อให้พิจารณาไฟล์บางประเภท เช่น .bin และ .h5 ว่าเป็นไฟล์ขนาดใหญ่ และ git-lfs จะติดตามไฟล์เหล่านั้นโดยคุณไม่จำเป็นต้องตั้งค่าอะไรเลย
ต่อไปเราจะทำต่อโดยการทำแบบที่เราทำกับ Git repositories ดั้งเดิม เราสามารถเพิ่มไฟล์ทั้งหมดไปยัง staging environment ของ Git ได้ด้วยการใช้คำสั่ง git add:
git add .
เราสามารถดูได้ว่าไฟล์ที่อยู่ในสถานะ staged มีอะไรบ้าง:
git status
{#if fw === 'pt'}
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: .gitattributes
new file: config.json
new file: pytorch_model.bin
new file: sentencepiece.bpe.model
new file: special_tokens_map.json
new file: tokenizer.json
new file: tokenizer_config.json
{:else}
On branch main
Your branch is up to date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: .gitattributes
new file: config.json
new file: sentencepiece.bpe.model
new file: special_tokens_map.json
new file: tf_model.h5
new file: tokenizer.json
new file: tokenizer_config.json
{/if}
ในแบบเดียวกัน เราสามารถทำให้มั่นใจได้ว่า git-lfs กำลังติดตามไฟล์ที่ถูกต้องอยู่ ได้โดยการใช้คำสั่ง status:
git lfs status
{#if fw === 'pt'}
On branch main
Objects to be pushed to origin/main:
Objects to be committed:
config.json (Git: bc20ff2)
pytorch_model.bin (LFS: 35686c2)
sentencepiece.bpe.model (LFS: 988bc5a)
special_tokens_map.json (Git: cb23931)
tokenizer.json (Git: 851ff3e)
tokenizer_config.json (Git: f0f7783)
Objects not staged for commit:
เราสามารถเห็นได้ว่าทุกไฟล์มี Git เป็นตัวจัดการ (handler) ยกเว้น pytorch_model.bin และ sentencepiece.bpe.model ซึ่งเป็น LFS เยี่ยม!
{:else}
On branch main
Objects to be pushed to origin/main:
Objects to be committed:
config.json (Git: bc20ff2)
sentencepiece.bpe.model (LFS: 988bc5a)
special_tokens_map.json (Git: cb23931)
tf_model.h5 (LFS: 86fce29)
tokenizer.json (Git: 851ff3e)
tokenizer_config.json (Git: f0f7783)
Objects not staged for commit:
เราสามารถเห็นได้ว่าทุกไฟล์มี Git เป็นตัวจัดการ (handler) ยกเว้น t5_model.h5 ซึ่งเป็น LFS เยี่ยม!
{/if}
มาทำขั้นตอนสุดท้ายต่อกันเถอะ ทำการ commit และดัน (push) ขึ้นสู่ huggingface.co remote repository:
git commit -m "First model version"
{#if fw === 'pt'}
[main b08aab1] First model version
7 files changed, 29027 insertions(+)
6 files changed, 36 insertions(+)
create mode 100644 config.json
create mode 100644 pytorch_model.bin
create mode 100644 sentencepiece.bpe.model
create mode 100644 special_tokens_map.json
create mode 100644 tokenizer.json
create mode 100644 tokenizer_config.json
{:else}
[main b08aab1] First model version
6 files changed, 36 insertions(+)
create mode 100644 config.json
create mode 100644 sentencepiece.bpe.model
create mode 100644 special_tokens_map.json
create mode 100644 tf_model.h5
create mode 100644 tokenizer.json
create mode 100644 tokenizer_config.json
{/if}
การดันไฟล์นั้นอาจจะใช้เวลาสักหน่อย ขึ้นอยู่กับความเร็วของการเชื่อมต่ออินเทอร์เน็ตและขนาดไฟล์ของคุณ:
git push
Uploading LFS objects: 100% (1/1), 433 MB | 1.3 MB/s, done.
Enumerating objects: 11, done.
Counting objects: 100% (11/11), done.
Delta compression using up to 12 threads
Compressing objects: 100% (9/9), done.
Writing objects: 100% (9/9), 288.27 KiB | 6.27 MiB/s, done.
Total 9 (delta 1), reused 0 (delta 0), pack-reused 0
To https://huggingface.co/lysandre/dummy
891b41d..b08aab1 main -> main
{#if fw === 'pt'} ถ้าเราดูที่ model repository เมื่อโค้ดทำงานเสร็จแล้ว เราจะเห็นทุกไฟล์ที่เพิ่งถูกเพิ่มเข้าไปอยู่ในนั้น:

UI ช่วยให้คุณสามารถสำรวจไฟล์โมเดลและ commits และดูความแตกต่างของแต่ละ commit ได้:


UI ช่วยให้คุณสามารถสำรวจไฟล์โมเดลและ commits และดูความแตกต่างของแต่ละ commit ได้:

Xet Storage Details
- Size:
- 46.9 kB
- Xet hash:
- 06a23899fa85a4038a07a8331df4e553145afbdbc750da990eca08966c7cf8a8
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.