Buckets:


| # About Inference Endpoints | |
| Inference Endpoints is a managed service to deploy your AI model to production. The infrastructure is managed and configured such that | |
| you can focus on building your AI application. | |
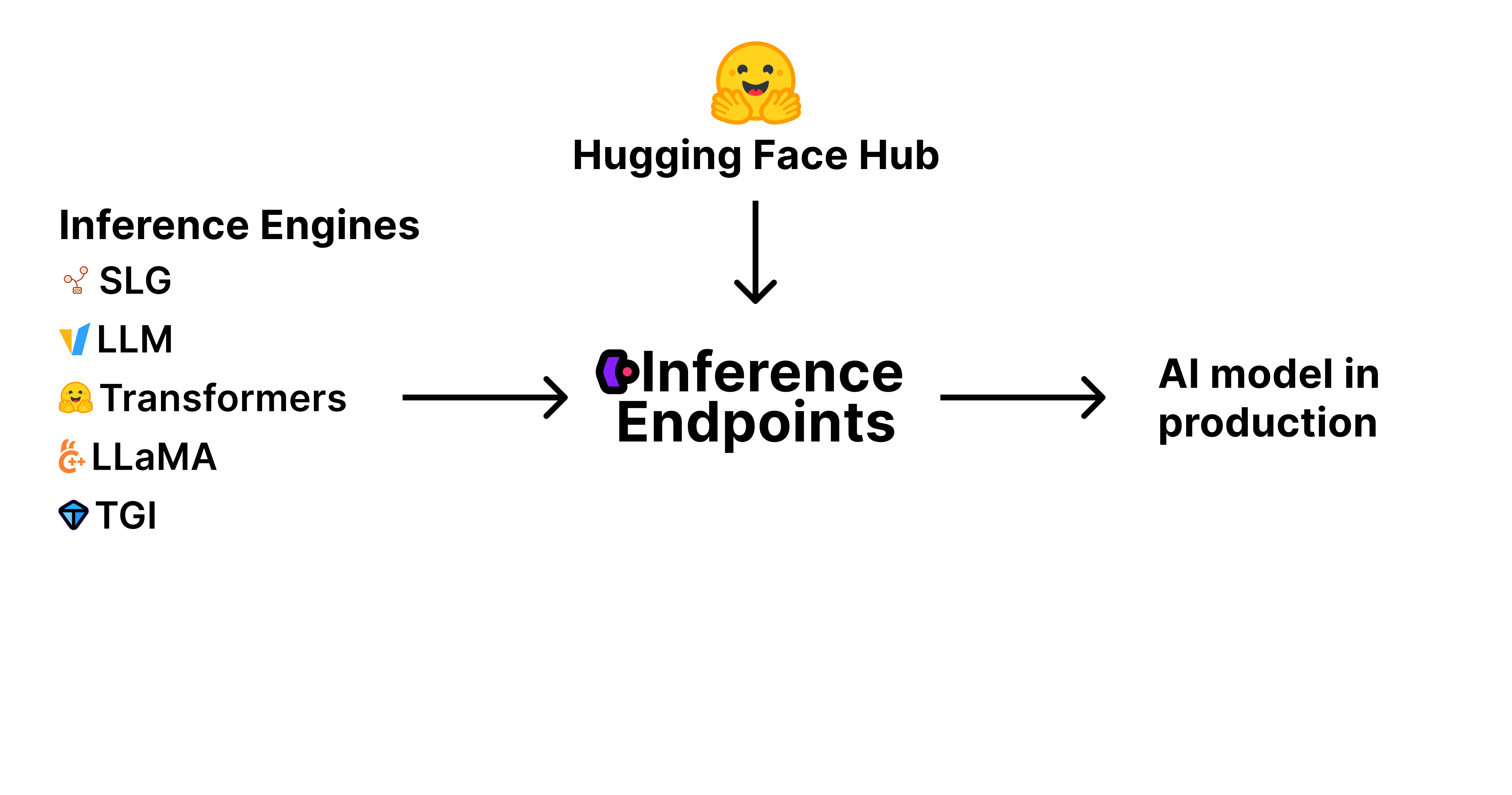
| To get an AI model into production, you need three key components: | |
| 1. **Model Weights and Artifacts**: These are the trained parameters and files that define your AI model, stored and versioned on the | |
| Hugging Face Hub. | |
| 2. **Inference Engine**: This is the software that loads and runs your model to generate predictions. Popular engines include vLLM, TGI, and | |
| others, each optimized for different use cases and performance needs. | |
| 3. **Production Infrastructure**: This is what Inference Endpoints is. A scalable, secure, and reliable environment where your model runs—handling | |
| requests, scaling with demand, and ensuring uptime. | |
| Inference Endpoints brings all these pieces together into a single managed service. You choose your model from the Hub, select the | |
| inference engine, and Inference Endpoints takes care of the rest—provisioning infrastructure, deploying your model, and making it | |
| accessible via a simple API. This lets you focus on building your application, while we handle the complexity of production AI deployment. | |
|  | |
| ## Inference Engines | |
| To achieve that we've made Inference Endpoints the central place to deploy high performance and open-source Inference Engines. | |
| Currently we have native support for: | |
| - vLLM | |
| - Text-generation-inference (TGI) | |
| - SGLang | |
| - llama.cpp | |
| - and Text-embeddings-inference (TEI) | |
| For the natively supported engines we try to set sensible defaults, expose the most relevant configuration settings and collaborate closely | |
| with the teams maintaining the Inference Engines to make sure they are optimized for production performance. | |
| If you don't find your favourite engine here, please reach out to us at [api-enterprise@huggingface.co](api-enterprise@huggingface.co). | |
| ## Under the Hood | |
| When you deploy an Inference Endpoint, under the hood your selected inference engine (like vLLM, TGI, SGLang, etc.) is packaged | |
| and launched as a prebuilt Docker container. This container includes the inference engine software, your chosen model | |
| weights and artifacts (downloaded directly from the Hugging Face Hub), and any configuration or environment variables you specify. | |
| We manage the full lifecycle of these containers: starting, stopping, scaling (including autoscaling and scale-to-zero), | |
| and monitoring them for health and performance. This orchestration is completely managed for you, so you don't have to worry about | |
| the complexities of containerization, networking, or cloud resource management. | |
| ## Enterprise or Team Subscription | |
| For more features consider subscribing to [Team or Enterprise](https://huggingface.co/enterprise). | |
| It gives your organization more control over access controls, dedicated support and more. Features include: | |
| - Higher quotas for the most performant GPUs | |
| - Single Sign-on (SSO) | |
| - Access to Audit Logs | |
| - Manage teams and projects access controls with Resource Groups | |
| - Private storage for your repositories | |
| - Disable the ability to create public repositories (or make repositories private by default) | |
| - You can request a quote for a contract-based-invoice which allows for more payment options + prepaid credits | |
| - and more! | |
| <EditOnGithub source="https://github.com/huggingface/hf-endpoints-documentation/blob/main/docs/source/about.md" /> |
Xet Storage Details
- Size:
- 3.54 kB
- Xet hash:
- 450412e576f0f054e24f26001865b6e08bc6e6394ee05f9c97ee0a39788b7ec0
·
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.