Buckets:

Title: TransKD: Transformer Knowledge Distillation for Efficient Semantic Segmentation
URL Source: https://arxiv.org/html/2202.13393
Published Time: Fri, 06 Sep 2024 00:12:04 GMT
Markdown Content: Ruiping Liu, Kailun Yang1, Alina Roitberg, Jiaming Zhang, Kunyu Peng, Huayao Liu,
Yaonan Wang, and Rainer Stiefelhagen This work was supported in part by funding from the pilot program Core-Informatics of the Helmholtz Association (HGF), in part by the National Natural Science Foundation of China (No. 62473139), in part by Hangzhou SurImage Technology Company Ltd, in part by the Ministry of Science, Research and the Arts of Baden-Württemberg (MWK) through the Cooperative Graduate School Accessibility through AI-based Assistive Technology (KATE) under Grant BW6-03, and in part by the Helmholtz Association Initiative and Networking Fund on the HAICORE@KIT and HOREKA@KIT partition. R. Liu, J. Zhang, K. Peng, and R. Stiefelhagen are with the Institute for Anthropomatics and Robotics, Karlsruhe Institute of Technology, 76131 Karlsruhe, Germany. K. Yang and Y. Wang are with the School of Robotics and the National Engineering Laboratory of Robot Visual Perception and Control Technology, Hunan University, Changsha 410082, China. A. Roitberg is with the Institute for Artificial Intelligence, the University of Stuttgart, 70569 Stuttgart, Germany. J. Zhang is also with the Institute for Visual Computing, ETH Zurich, 8092 Zurich, Switzerland. H. Liu is with NIO, Shanghai 201804, China. 1Corresponding author (E-Mail: kailun.yang@hnu.edu.cn.)
Abstract
Semantic segmentation benchmarks in the realm of autonomous driving are dominated by large pre-trained transformers, yet their widespread adoption is impeded by substantial computational costs and prolonged training durations. To lift this constraint, we look at efficient semantic segmentation from a perspective of comprehensive knowledge distillation and aim to bridge the gap between multi-source knowledge extractions and transformer-specific patch embeddings. We put forward the Transformer-based Knowledge Distillation (TransKD) framework which learns compact student transformers by distilling both feature maps and patch embeddings of large teacher transformers, bypassing the long pre-training process and reducing the FLOPs by >85.0%absent percent 85.0{>}85.0%> 85.0 %. Specifically, we propose two fundamental modules to realize feature map distillation and patch embedding distillation, respectively: (1) Cross Selective Fusion (CSF) enables knowledge transfer between cross-stage features via channel attention and feature map distillation within hierarchical transformers; (2) Patch Embedding Alignment (PEA) performs dimensional transformation within the patchifying process to facilitate the patch embedding distillation. Furthermore, we introduce two optimization modules to enhance the patch embedding distillation from different perspectives: (1) Global-Local Context Mixer (GL-Mixer) extracts both global and local information of a representative embedding; (2) Embedding Assistant (EA) acts as an embedding method to seamlessly bridge teacher and student models with the teacher’s number of channels. Experiments on Cityscapes, ACDC, NYUv2, and Pascal VOC2012 datasets show that TransKD outperforms state-of-the-art distillation frameworks and rivals the time-consuming pre-training method. The source code is publicly available at https://github.com/RuipingL/TransKD.
Index Terms:
Knowledge Distillation, Semantic Segmentation, Scene Parsing, Vision Transformer, Scene Understanding.
I Introduction


 Image Response KD TransKD
Image Response KD TransKD


 Image Feature KD TransKD
Image Feature KD TransKD
Figure 1: Hard examples for semantic segmentation with knowledge distillation (KD) methods. As compared to the Response-based[1] and Feature-based[2] KD methods, our framework, TransKD, enables the model to predict the truck and fence more precisely by exploring the knowledge from both feature maps and patch embeddings.

(a) Number of parameters

(b) Performances
Figure 2: Comparison with knowledge distillation frameworks. Our TransKDs compensate for the performance gap between the non-pretrained and pre-trained models effectively while adding negligible parameters. The gains over bars indicate the different amounts of parameters and performances of TransKDs. ImN: pre-training on ImageNet[3]. SKD: Structured Knowledge Distillation[4]. KR: Knowledge Review[2].
Semantic segmentation assigns category labels at a pixel-level (see examples in Fig.1) and is a crucial tool in a wide range of applications, such as autonomous driving[5, 6, 7, 8] and navigation assistance for vulnerable road users[9, 10]. Driven by the achievements of deep learning, semantic segmentation has empowered precise scene comprehension in the context of autonomous driving, as evidenced by remarkable accuracies[11, 12]. Autonomous driving requires high-speed operation and the capacity to respond from significant distances to detect potential hazards. However, the computational resources available on vehicle mobile platforms are often insufficient to support large, effective semantic segmentation models, and compact but less effective models generally fail to distinguish distant details. Moreover, there has been a notable oversight in addressing the computational limitations crucial for real-world applications, including the speed of inference and training, as well as memory footprint.
While Convolutional Neural Networks (CNNs) have been the visual recognition front-runners for almost a decade, they encounter difficulties capturing large-scale interactions due to their focus on local neighborhood operations and limited receptive fields. Vision transformers[11, 12, 13] overcome this challenge through the concept of self-attention[14], which learns to intensify or weaken parts of input at a global scale. This excellent quality of modeling long-range dependencies has placed transformers at the forefront of virtually all segmentation benchmarks[11, 12, 13]. Unfortunately, transformers are usually very large and do not generalize well when trained on insufficient amounts of data due to the lack of inductive bias compared to CNNs[13], such as translation equivariance and locality, which is relevant to the semantic segmentation task. Thus, vision transformers often show less satisfactory performance on smaller task-specific datasets, and time-consuming pre-training process on a massive dataset is entailed[11, 13], e.g., ≥100 absent 100{\geq}100≥ 100 epochs on ImageNet[3]. The high computational and training costs constitute a significant bottleneck for real applications, where cumbersome models cannot be deployed on mobile devices, whereas smaller models suffer from inaccurate predictions[4, 15].

Figure 3: (a)-(c) Knowledge distillation in computer vision is split into three categories[16]: response-based knowledge distillation, feature-based knowledge distillation, and relation-based knowledge distillation. (d) TransKD extracts the relation-based knowledge of feature maps and transformer-specific patch embedding knowledge at each stage.
A popular way to reduce the computational cost is knowledge distillation[17], which offers a mechanism for effective knowledge transfer between a large teacher model and a smaller student network and has been widely studied for deep CNNs[4, 1, 2]. Gou et al.[16] distinguish three types of knowledge to be distilled (see Fig.3a-c): response-based knowledge[4, 1, 17], feature-based knowledge[4, 18, 19], and relation-based knowledge[2, 20, 21]. The response-based and feature-based knowledge distillation utilizes the output of a single specific layer of the teacher model (the last or the intermediate layer respectively), whereas the relation-based knowledge distillation tracks the relationship between multiple layers simultaneously. These paradigms are primarily designed with the CNN-to-CNN transfer in mind[4, 1, 2] and do not adequately cover knowledge distillation from transformer-specific intermediate blocks. The patch embedding method is a transformer-specific module to partition the input images or feature maps into a sequence of patches. It is typically achieved through convolution operations with learnable parameters, rather than by reshaping. According to the vanilla vision transformer[13], simply partitioning the input images or feature maps into large non-overlapping patches is impractical to learn the spatial relations. This limitation is addressed with optimized embedding methods,e.g. learnable positional embeddings[13], conditional positional embeddings[22, 23], shifted windows[24], and overlapping patch embeddings[25, 26]. Viewing that there is a large gap between the performances of the transformers with a simple patchifying process and optimized embedding methods, we recognize the importance of the sequential information within patch embeddings, which are processed by the embedding module that transforms feature maps into these embeddings. Therefore, we regard patch embeddings as a transformer-specific knowledge source.
To achieve efficient semantic segmentation, we propose Transformer-based Knowledge Distillation (TransKD), the first framework designed to distill knowledge from large-scale semantic segmentation transformers. We focus on comprehensive distillation from different knowledge sources within the transformer-specific building blocks (our key idea is illustrated in Fig.3d). TransKD distills the information from both (1) feature maps and (2) the transformer-specific patch embeddings. As mentioned before, patch embeddings differ from feature maps not only in the distinct shape and dimensionality but also in the inherent knowledge acquired through the patchifying process. Therefore, we consider that transformer-specific patch embeddings should be fully exploited to maximize the potential of transformer-transformer knowledge distillation. By combining knowledge from feature maps and patch embeddings, both spatial and sequential relationships can be harvested, thereby boosting efficient semantic segmentation through distillation.
Specifically, we design two fundamental and two optimization modules within the TransKD framework. (1) For feature map distillation, we build a relation-based scheme atop Knowledge Review[2] and introduce the Cross Selective Fusion (CSF) module to merge cross-stage feature maps via channel attention and construct the feature map distillation streams within hierarchical transformers. (2) For patch embedding distillation, we introduce the fundamental Patch Embedding Alignment (PEA) module to perform a dimensional transformation of patch embeddings along the channel dimension to facilitate multi-stage patch embedding distillation streams. (3) Recognizing that both neighboring and long-range relationships are vital for semantic segmentation[26, 27], our Global-Local Context Mixer (GL-Mixer) extracts both global and local information of a representative embedding for distillation. (4) Furthermore, considering the large gap between the student’s and the teacher’s size that negatively impacts the knowledge distillation results[28, 29], we present the Embedding Assistant (EA) module, which acts an embedder with teacher’s number of channels. EA helps to build a pseudo teacher assistant model by combining the student’s transformer blocks and seamlessly bridge teacher and student models.
We demonstrate the benefits of our approach for real-world mobile applications on four benchmarks: a general street scene dataset (Cityscapes[30]), an adverse street scene dataset (ACDC[31]), an indoor understanding dataset (NYUv2[32]), and an object-centric dataset (Pascal VOC2012[33]). Comprehensive experiments showcase that our framework outperforms state-of-the-art KD counterparts by a large gap. Compared to the cumbersome teacher model, TransKD reduces the floating-point operations (FLOPs) by >85.0%absent percent 85.0{>}85.0%> 85.0 %, while maintaining competitive accuracy. By unifying patch embedding and feature map distillation, TransKD robustifies the segmentation of hard examples where previous paradigms struggle, as shown in Fig.1. Benchmarked against the feature-map-only method Knowledge Review[2], TransKD-Base enhances the distillation performance by 5.18%percent 5.18 5.18%5.18 % in mean Intersection over Union (mIoU) while adding negligible 0.21M 0.21 𝑀 0.21M 0.21 italic_M parameter during the training phase, as shown in Fig.2. On Cityscapes, TransKD improves the mIoU of the non-pretrained SegFormer-B0[26] by 13.12%percent 13.12 13.12%13.12 % and the pre-trained one by 2.09%percent 2.09 2.09%2.09 %. We further validate various transformer models[25, 26, 34] and conform that TransKD consistently boosts the accuracy of compact segmenters. Lastly, TransKD rivals the performance of the time-consuming pre-trained method. Our best model achieves 75.74%percent 75.74 75.74%75.74 % in mIoU with only 3.72M 3.72 𝑀 3.72M 3.72 italic_M parameters.
At a glance, this work delivers the following contributions:
- •We are the first to propose a transformer-to-transformer knowledge distillation framework in semantic segmentation and the first to utilize transformer-specific patch embedding as one of the knowledge sources.
- •We provide a new perspective on distilling knowledge from transformer-specific patch embeddings. Our TransKD framework unifies feature map and patch embedding distillation.
- •To this intent, we design two fundamental modules, Cross Selective Fusion (CSF) and Patch Embedding Alignment (PEA), and two optimization modules, Global-Local Context Mixer (GL-Mixer) and Embedding Assistant (EA).
- •In-depth experiments validate the advantages of TransKD on Cityscapes, ACDC, NYUv2, and Pascal VOC2012 datasets, demonstrating significant improvements over existing knowledge distillation methods.
II Related Work
II-A From Accurate to Efficient Semantic Segmentation
Semantic segmentation has witnessed tremendous progress since Fully Convolutional Networks (FCNs)[35] first looked at the pixel classification problem from an end-to-end perspective. Many subsequent networks followed this scheme, often raising its accuracy through encoder-decoder architectures[36] or the aggregation of multi-scale context[27, 37]. An important group of methods leverages non-local self-attention[14, 38] to capture long-range contextual dependencies and promote global reasoning[39, 40]. The recent success of vision transformers[13, 41] leads to the development of multiple transformer-based architectures for semantic segmentation[11, 12] which have since then become state-of-the-art on mainstream benchmarks[30, 32, 31], thanks to their ability to capture global dependencies from early layers via token mixing modules such as self-attention[14] or Multi-Layer Perceptron (MLP) blocks[42]. Yet, the computational cost and lengthy training process remain a weak spot of the accuracy-driven transformer research.
On the other hand, multiple works explicitly address efficient semantic segmentation, aiming to strike a good balance between speed and accuracy. This line of research compactifies architectures through techniques such as early downsampling[43], filter factorization[5, 15], multi-branch architecture[44, 45], and ladder-style upsampling[46, 47]. Lightweight classification backbones such as MobileNets[48] and ShuffleNets[49] have also been adapted to expedite image segmentation. Moreover, SegFormer[26] introduces a lightweight and efficient semantic segmentation framework that unifies the backbone output feature maps with a simple MLP decoder. Unlike all these works, our TransKD views resource-efficient segmentation transformers from a new perspective of comprehensive knowledge distillation. We introduce a framework that simultaneously extracts knowledge from different blocks of large-scale vision transformers and reuses it for compact and fast student transformers.
II-B Vision Transformer for Dense Prediction
Transformer architecture has become the de-facto standard in Natural Language Processing (NLP), mostly due to the effectiveness of stacked self-attention and its ability to capture long-range relationships within the data. The success of self-attention-based models has also extended to the field of visual recognition, beginning with the introduction of the Vision Transformer (ViT)[13] – the first transformer to deliver strong results on ImageNet[3]. Subsequent developments have further optimized the performance of the vision transformer, incorporating features such as multi-scale networks[24, 26, 50], increased depth[51, 52], knowledge distillation[53, 54] and a blend of global and local attention[22, 55].
At the same time, multiple lightweight vision transformers[54, 56] have emerged. For example, LeViT[54] is a hybrid model reusing ResNet stages within the transformer architecture while MobileViT[57] leverages MoibleNetV2 blocks[48] along the downsampling path and Mobile-Former[58] establishes a dual-stream architecture by bridging MobileNet and its transformer branch. Unfortunately, recent studies[57] suggest that MobileViT and other ViT-based models are still not efficient enough for real-time processing on mobile devices. In this work, we develop a knowledge distillation framework based on vision transformers, which consistently improves the performance of compact dense prediction and semantic segmentation transformers[26, 25, 34], leading to a much better trade-off of accuracy, computational cost, and pre-training requirements.
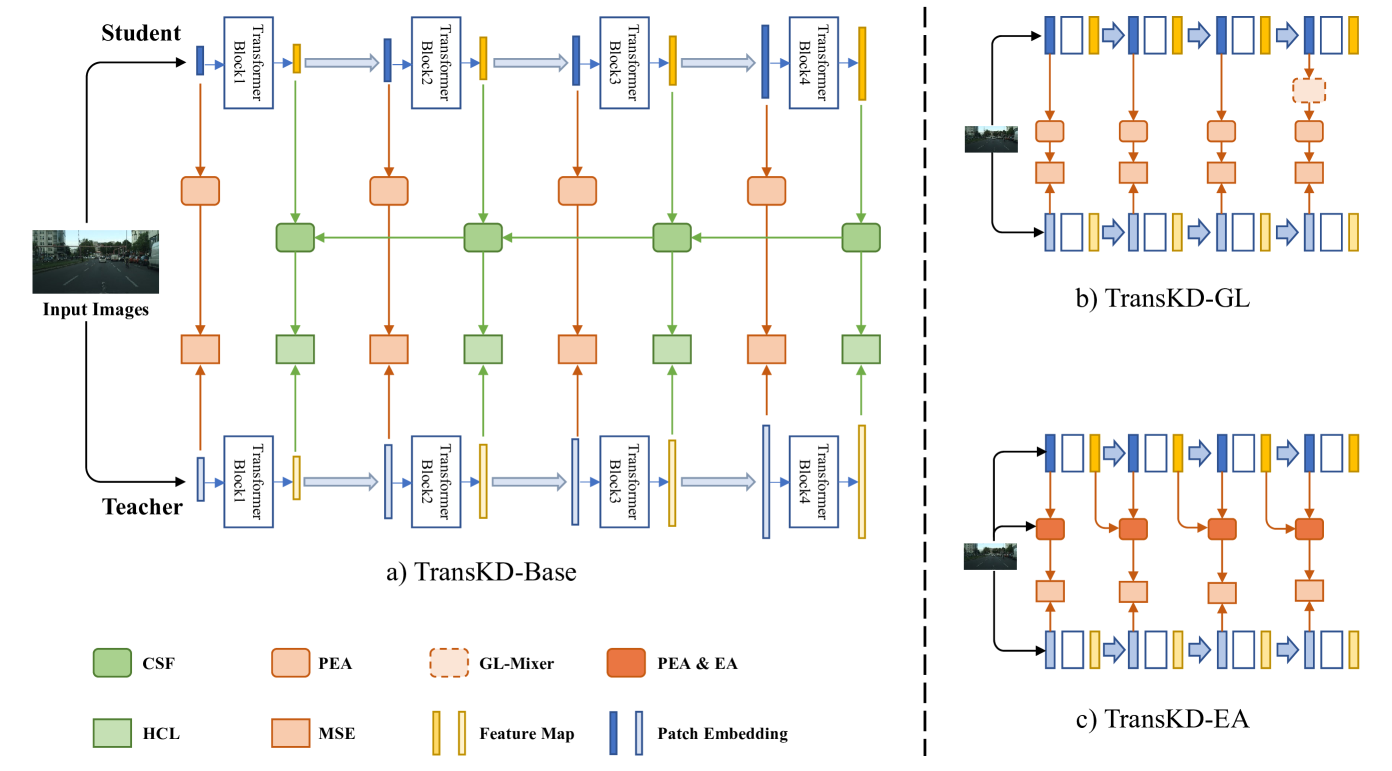
Figure 4: Our knowledge distillation framework TransKD. It is divided into two parts: knowledge distillation of patch embeddings (indicated by red arrows and rectangles) and feature maps (indicated by green arrows and rectangles). The loss function consists of two distillation terms (HCL and MSE) and a cross-entropy term. (a) TransKD-Base is the basic version of TransKD, constructed with two fundamental modules, CSF and PEA. (b) TransKD-GL and (c) TransKD-EA are two optimized versions of TransKD.
II-C Knowledge Distillation for Semantic Segmentation
Hinton et al.[17] introduced the concept of Knowledge Distillation (KD), which involves transferring knowledge from a large-scale model to a more compact one. These two models act as teacher and student, and this paradigm is widely used in computer vision[16, 59]. In this work, our goal is to study and design a KD framework specifically for semantic segmentation with transformer-based models.
KD approaches have been categorized[16] into three types based on the form of knowledge: response-based KD[4, 1, 18], feature-based KD[1, 18, 19, 60, 61, 62], and relation-based KD[2, 20, 21]. Liu et al.[4] first introduced the idea of structured knowledge distillation, leveraging adversarial learning to align the segmentation map produced by the compact student network with the one of the cumbersome teacher network. Knowledge Review (KR)[2] for the first time proposed to distill knowledge using cross-stage connection paths. Double Similarity Distillation (DSD)[20] transfers both detailed spatial dependencies and global category correlations. Unlike previous works primarily devoted to the distillation of spatial-wise knowledge, some recent works focus on the distillation of channel-wise distribution. Channel Distillation (CD)[1] emphasizes the soft distributions of channels and pays attention to the most salient parts of the channel-wise maps.
Additionally, knowledge adaptation is addressed in[63] by optimizing affinity distillation. Adaptive Perspective Distillation (APD)[64] mines detailed contextual cues from each training sample, whereas[65] employs a hierarchical distillation approach and enables one-to-all spatial matching. All these works are dedicated to CNN-to-CNN or CNN-to-transformer knowledge distillation. In contrast, our proposed TransKD model explores this concept in a novel transformer-to-transformer fashion, by explicitly considering multi-source knowledge within the transformer architecture and taking transformer-specific patch embeddings into account.
III Proposed Framework: TransKD
III-A Overview
At the heart of this work is the transformer-to-transformer knowledge transfer for efficient semantic segmentation. To strike a better balance between accuracy, computational costs, and the required amount of pre-training, we for the first time look at semantic segmentation through the lens of multi-source knowledge distillation within visual transformers. While transformer-to-transformer knowledge distillation is explored in natural language processing[66, 67, 68], it has been rather overlooked in semantic segmentation and vision transformers in general, where most of the models still center around CNN-based knowledge distillation. Adopting such methods to suit visual transformers is not trivial due to diverging architecture-specific building blocks arising, e.g., from the patchifying process.
Existing semantic segmentation transformers generally follow either an isotropic structure[11, 69, 70] or a four-stage hierarchical structure[25, 26, 34, 50, 71]. Since the latter one is better at modeling multi-scale long-range information[24, 50], it proves more versatile in dense prediction tasks such as pixel-wise semantic segmentation. Thereby, in this work, knowledge distillation is carried out on four-stage transformers, as illustrated in Fig.4.
The first step of the general visual transformer pipeline is to “patchify” the input 𝐈 𝐈\mathbf{I}bold_I (an image or a feature map):
𝐄=PatchEmbed(𝐈).𝐄 𝑃 𝑎 𝑡 𝑐 ℎ 𝐸 𝑚 𝑏 𝑒 𝑑 𝐈\mathbf{E}=PatchEmbed\left(\mathbf{I}\right).bold_E = italic_P italic_a italic_t italic_c italic_h italic_E italic_m italic_b italic_e italic_d ( bold_I ) .(1)
This “patchification” is the key ingredient of vision transformers as it allows us to cast vision-based tasks as sequence-to-sequence problems for which this type of models was initially built[14]. The patch embedding module splits the input images ohes. Here, H 𝐻 H italic_H, W 𝑊 W italic_W, and C 𝐶 C italic_C represent the height, the width, and the number of channels of the input image or feature map of the embedding module, respectively. The module then transforms these patches (mostly via a convolution operation) into a sequence of representative patch embeddings 𝐄∈ℝ N×C′𝐄 superscript ℝ 𝑁 superscript 𝐶′\mathbf{E}\in\mathbb{R}^{N\times C^{\prime}}bold_E ∈ blackboard_R start_POSTSUPERSCRIPT italic_N × italic_C start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT, where N 𝑁 N italic_N is the number of patches and C′superscript 𝐶′C^{\prime}italic_C start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT the number of the channels. As often highlighted in previous research, the resulting patch embeddings convey important information about long-range sequential relationships[11, 72], location priors[11, 13, 69], and local continuity cues[25, 26, 71]. Both global context and local information contained in patch embeddings are relevant to semantic segmentation.
Next, the patch embeddings are passed to a stack of transformer encoding layers consisting of a multi-head self-attention and a position-wise fully connected feed-forward network[13, 14]. The outputs of these layers are then reshaped into a feature map 𝐅 𝐅\mathbf{F}bold_F:
𝐅=TransformerEncode(𝐄),𝐅 𝑇 𝑟 𝑎 𝑛 𝑠 𝑓 𝑜 𝑟 𝑚 𝑒 𝑟 𝐸 𝑛 𝑐 𝑜 𝑑 𝑒 𝐄\mathbf{F}=TransformerEncode\left(\mathbf{E}\right),bold_F = italic_T italic_r italic_a italic_n italic_s italic_f italic_o italic_r italic_m italic_e italic_r italic_E italic_n italic_c italic_o italic_d italic_e ( bold_E ) ,(2)
where the feature map 𝐅∈ℝ C′×H′×W′𝐅 superscript ℝ superscript 𝐶′superscript 𝐻′superscript 𝑊′\mathbf{F}\in\mathbb{R}^{{C^{\prime}\times{H^{\prime}\times{W^{\prime}}}}}bold_F ∈ blackboard_R start_POSTSUPERSCRIPT italic_C start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT × italic_H start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT × italic_W start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT marks the output of the current transformer stage and therefore the input to the next layer. A positive consequence of self-attention exploring all the patch tokens with no restriction to a certain receptive field is the global context also being covered in the resulting feature map. Distilling knowledge from both, feature maps and patch embeddings, allows us to track complementary information within the transformer, such as spatial and sequential relationships.
Motivated by this, we propose Transformer-based Knowledge Distillation (TransKD) – a novel transformer-to-transformer knowledge distillation framework with the overall goal of building small yet accurate semantic segmentation transformers less reliant on time-consuming pre-training. TransKD centers around two types of knowledge transfer: (1) patch embedding distillation and (2) feature map distillation. The patch embedding distillation is performed at each of the four transformer stages, while the feature map distillation leverages the relation-based knowledge distillation to gather information from both within-stage and cross-stage feature maps. An overview of this core pipeline is depicted in Fig.4(a).
The distillation losses obtained from each stage are added to the original cross-entropy loss L CE subscript 𝐿 𝐶 𝐸 L_{CE}italic_L start_POSTSUBSCRIPT italic_C italic_E end_POSTSUBSCRIPT during training. The overall KD loss then becomes:
L=L CE+∑m=1 M α mL embd m+∑m=1 M β mL fm m,𝐿 subscript 𝐿 𝐶 𝐸 superscript subscript 𝑚 1 𝑀 subscript 𝛼 𝑚 superscript subscript 𝐿 𝑒 𝑚 𝑏 𝑑 𝑚 superscript subscript 𝑚 1 𝑀 subscript 𝛽 𝑚 superscript subscript 𝐿 𝑓 𝑚 𝑚 L=L_{CE}+{\sum_{m=1}^{M}}{\alpha_{m}}L_{embd}^{m}+{\sum_{m=1}^{M}}{\beta_{m}}L% _{fm}^{m},italic_L = italic_L start_POSTSUBSCRIPT italic_C italic_E end_POSTSUBSCRIPT + ∑ start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_M end_POSTSUPERSCRIPT italic_α start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT italic_L start_POSTSUBSCRIPT italic_e italic_m italic_b italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT + ∑ start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_M end_POSTSUPERSCRIPT italic_β start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT italic_L start_POSTSUBSCRIPT italic_f italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT ,(3)
where L embd m superscript subscript 𝐿 𝑒 𝑚 𝑏 𝑑 𝑚 L_{embd}^{m}italic_L start_POSTSUBSCRIPT italic_e italic_m italic_b italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT and L fm m superscript subscript 𝐿 𝑓 𝑚 𝑚 L_{fm}^{m}italic_L start_POSTSUBSCRIPT italic_f italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT refer to the patch embedding loss and the feature map loss between the m 𝑚 m italic_m-th stage of the teacher and the student. As previously mentioned, we explore the typical four-stage transformer in this work, i.e., M=4 𝑀 4 M=4 italic_M = 4 in our case. The variables α m subscript 𝛼 𝑚\alpha_{m}italic_α start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT and β m subscript 𝛽 𝑚\beta_{m}italic_β start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT are the m 𝑚 m italic_m-th elements of α 𝛼\mathbf{\alpha}italic_α and β 𝛽\mathbf{\beta}italic_β, which control the weights of the patch embedding loss and the feature map loss at each stage, respectively. The vectors α 𝛼\mathbf{\alpha}italic_α and β 𝛽\mathbf{\beta}italic_β are set as [0.1,0.1,0.5,1]0.1 0.1 0.5 1\left[0.1,0.1,0.5,1\right][ 0.1 , 0.1 , 0.5 , 1 ] and [1,1,1,1]1 1 1 1\left[1,1,1,1\right][ 1 , 1 , 1 , 1 ]. In the following method descriptions, matrices with superscripts in 𝑖 𝑛 in italic_i italic_n and out 𝑜 𝑢 𝑡 out italic_o italic_u italic_t refer to inputs and outputs of the proposed modules, while those with the superscript mid 𝑚 𝑖 𝑑 mid italic_m italic_i italic_d refer to matrices processed within the modules.
In Sec.III-B, we present the design of our patch embedding distillation scheme, and in Sec.III-C, we elaborate our feature map distillation method. Finally, in Sec.III-D, we describe the configurations of different variants of the TransKD framework.
III-B Patch Embedding Distillation
As previously discussed, the patch embedding incorporates positional information that enhances the feature maps. To maximize the potential of transformer-to-transformer knowledge distillation, we consider that transformer-specific patch embeddings should be fully exploited. Despite the specialized designs, the cumbersome teacher models consistently possess more transformer blocks for feature extraction and additional channels for knowledge retention. To align dimensions between student and teacher patch embeddings for loss function calculation and to introduce trainable parameters for learning channel-wise knowledge, we propose a fundamental module, Patch Embedding Alignment (PEA), to facilitate the simplest patch embedding distillation. Additionally, we design the Global-Local Context Mixer (GL-Mixer) and the Embedding Assistant (EA) to optimize patch embedding distillation.
Patch embedding alignment. We conduct the Patch Embedding Alignment (PEA) through a linear projection for dimensionality transformation. Subsequently, the Mean Squared Error (MSE) loss between the student and teacher patch embeddings is calculated, as depicted in Eq.(4):
L embd m=MSE(𝐄 m S𝐖 e,𝐄 m T),superscript subscript 𝐿 𝑒 𝑚 𝑏 𝑑 𝑚 𝑀 𝑆 𝐸 subscript superscript 𝐄 𝑆 𝑚 subscript 𝐖 𝑒 subscript superscript 𝐄 𝑇 𝑚 L_{embd}^{m}=MSE({\mathbf{{\bm{E}}}}^{S}{m}{{\mathbf{\bm{W}}}{e}},\mathbf{{% \bm{E}}}^{T}_{m}),italic_L start_POSTSUBSCRIPT italic_e italic_m italic_b italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT = italic_M italic_S italic_E ( bold_E start_POSTSUPERSCRIPT italic_S end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT bold_W start_POSTSUBSCRIPT italic_e end_POSTSUBSCRIPT , bold_E start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT ) ,(4)
where 𝑬 m S superscript subscript 𝑬 𝑚 𝑆\bm{E}{m}^{S}bold_italic_E start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_S end_POSTSUPERSCRIPT and 𝑬 m T superscript subscript 𝑬 𝑚 𝑇\bm{E}{m}^{T}bold_italic_E start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT are the sequence of patch embeddings at the m 𝑚 m italic_m-th student and teacher stages. A learnable matrix 𝑾 e∈ℝ C m S×C m T subscript 𝑾 𝑒 superscript ℝ subscript superscript 𝐶 𝑆 𝑚 subscript superscript 𝐶 𝑇 𝑚\bm{W}{e}\in{\mathbb{R}}^{C^{S}{m}{\times}C^{T}{m}}bold_italic_W start_POSTSUBSCRIPT italic_e end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_C start_POSTSUPERSCRIPT italic_S end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT × italic_C start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT end_POSTSUPERSCRIPT is applied to counter the dimensionality mismatch and transfer channel-wise knowledge from teacher patch embeddings to the student. C m S subscript superscript 𝐶 𝑆 𝑚 C^{S}{m}italic_C start_POSTSUPERSCRIPT italic_S end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT and C m T subscript superscript 𝐶 𝑇 𝑚 C^{T}_{m}italic_C start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT denote the number of channels in teacher and student models, respectively, at m 𝑚 m italic_m-th stage. PEA bridges the teacher and student transformers and facilitates multi-stage patch embedding streams, while adding only marginal computational complexity.

Figure 5: Two-branch architecture of Global-Local Context Mixer (GL-Mixer) in Fig.4(b). The global context of an embedding is extracted by multi-head attention, whereas the local features are extracted by convolution operations.
Global-local context mixer. Patch embeddings deliver heterogeneous patterns[13, 26]. Therefore, the global context cues and the fine-grained local features, both essential for semantic segmentation, cannot be fully distilled using linear projection alone. To our knowledge, we are the first to introduce the two-branch design to the field of knowledge distillation in semantic segmentation. The global context is extracted via multi-head attention (left branch in Fig.5), and the local information is extracted via a convolution layer (right branch in Fig.5). Another convolution operation, followed with sigmoid function σ(⋅)𝜎⋅\sigma\left(\cdot\right)italic_σ ( ⋅ ), is used to control the information flow. Given the sequence of patch embedding at the m 𝑚 m italic_m-th stage 𝐄 m in superscript subscript 𝐄 𝑚 𝑖 𝑛\mathbf{E}_{m}^{in}bold_E start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT, the two-branch processing of global and local cues inside the GL-Mixer is formalized in Eq.(5):
GL-Mixer(𝐄 m in)GL-Mixer superscript subscript 𝐄 𝑚 𝑖 𝑛\displaystyle\textit{GL-Mixer}\left(\mathbf{E}{m}^{in}\right)GL-Mixer ( bold_E start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT )=MultiHeadAttn(𝐄 m in)absent 𝑀 𝑢 𝑙 𝑡 𝑖 𝐻 𝑒 𝑎 𝑑 𝐴 𝑡 𝑡 𝑛 superscript subscript 𝐄 𝑚 𝑖 𝑛\displaystyle=MultiHeadAttn(\mathbf{E}{m}^{in})= italic_M italic_u italic_l italic_t italic_i italic_H italic_e italic_a italic_d italic_A italic_t italic_t italic_n ( bold_E start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT )(5) +(𝐄 m in∗𝐖+𝐚)⊗(σ(𝐄 m in∗𝐕+𝐛)),tensor-product superscript subscript 𝐄 𝑚 𝑖 𝑛 𝐖 𝐚 𝜎 superscript subscript 𝐄 𝑚 𝑖 𝑛 𝐕 𝐛\displaystyle+\left(\mathbf{E}{m}^{in}*\mathbf{W}+\mathbf{a}\right)\otimes% \left(\sigma\left(\mathbf{E}{m}^{in}*\mathbf{V}+\mathbf{b}\right)\right),+ ( bold_E start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT ∗ bold_W + bold_a ) ⊗ ( italic_σ ( bold_E start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT ∗ bold_V + bold_b ) ) ,
where 𝐖 𝐖\mathbf{W}bold_W, 𝐕 𝐕\mathbf{V}bold_V, 𝐚 𝐚\mathbf{a}bold_a, and 𝐛 𝐛\mathbf{b}bold_b refer to learnable parameters for the convolution operations. As shown in Fig.5, the convolution operations are implemented via 3×3 3 3 3{\times}3 3 × 3 convolutions, and the entire GL-Mixer is designed to be lightweight. This way, given a sequence of representative patch embedding within a dense prediction transformer, both the semantically rich global context and the detail-rich local features can be harvested for distillation.

Figure 6: Combination of Embedding Assistant (EA) and Patch Embedding Alignment (PEA) in Fig.4(c). The knowledge distillation pipeline through the EA modules and the student transformer blocks can be regarded as a medium-sized pseudo assistant model, providing supplementary distillation streams. 𝐅 m in superscript subscript 𝐅 𝑚 𝑖 𝑛\mathbf{F}{m}^{in}bold_F start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT denotes the resulting feature map of the m 𝑚 m italic_m-th stage, which is processed by the student’s embedding module to output the patch embedding of the next stage 𝐄 m+1 in superscript subscript 𝐄 𝑚 1 𝑖 𝑛\mathbf{E}{m+1}^{in}bold_E start_POSTSUBSCRIPT italic_m + 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT.
Embedding assistant. Knowledge distillation runs into problems when the size gap between student and teacher is significant[28, 29]. If the teacher becomes very complex, the student eventually lacks the sufficient capacity or mechanics to mimic its behavior despite receiving multi-stage hints. Mirzadeh et al.[28] introduce a Teacher Assistant (TA) of an intermediate size to bridge the size gap. TA acts as a mediator between the teacher and the student: it is distilled from the teacher model and then passes the knowledge to the student. TA follows the same structure as the student and the teacher, except for the numbers of hidden states and transformer layers[68]. The number of hidden states is adopted from the student, while the amount of the transformer layers corresponds to the one of the teacher. However, implementing Teacher Assistant for knowledge distillation is a two-step process. An additional assistant model TA should be trained, which is larger than the student model, thus introducing extra computation overhead and learning time.
We draw inspiration from the concept of TA but address the aforementioned drawback into account and propose the Embedding Assistant (EA) module which serves as a mediator between the teacher and the student without requiring two-stage distillation. An overview of the proposed EA module is given in Fig.4(c). EA is an embedding module whose structure is identical to the one of the student’s and the teacher’s embedding module and with the number of channels C 𝐶 C italic_C corresponding to the one of the teacher. With the same kernel size of the convolution operation to realize patch embedding, the outputs of EA, PEA, and the teacher’s embedding module have the same number of patches. As shown in Fig.4(c) and Fig.6, the results of EA and PEA are fused via element-wise addition stage-by-stage.
Given that a transformer block of the teacher consists of L 𝐿 L italic_L-transformer layers with an embedding size d e subscript 𝑑 𝑒 d_{e}italic_d start_POSTSUBSCRIPT italic_e end_POSTSUBSCRIPT, and a transformer block of the student consists of M 𝑀 M italic_M-transformer layers with an embedding size of d e′superscript subscript 𝑑 𝑒′d_{e}^{\prime}italic_d start_POSTSUBSCRIPT italic_e end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT, the combination of EA modules and the student’s transformer blocks can be viewed as a pseudo assistant model with a transformer block of M 𝑀 M italic_M-transformer layers and an embedding size of d e subscript 𝑑 𝑒 d_{e}italic_d start_POSTSUBSCRIPT italic_e end_POSTSUBSCRIPT. Therefore, the medium-sized pseudo assistant model, i.e., the combination of all four stage EAs and student transformer blocks, helps to bridge the student-teacher size gap and provides supplementary information. Since the embedding method of different models varies greatly, the knowledge distillation framework using the proposed EAs does not achieve full plug-and-play flexibility. Yet, compared with the teacher assistant[28], we strengthen the student-teacher distillation without a costly two-step knowledge distillation process.
III-C Feature Map Distillation
Many knowledge distillation methods deploy a single-stage feature-based scheme for semantic segmentation[1, 18, 19], i.e., information is exchanged at a single network depth. Our next consideration is that cross-stage relation-based knowledge distillation is important for efficient segmentation transformers, as it enables information transfer across different network depths. Similar ideas have shown success in the past, for example, hierarchical dense prediction transformers utilize cross-stage feature maps[26, 50].
We revisit Knowledge Review[2], which studies the connections across different levels of the teacher and the student CNN models. However, the Attention Based Fusion (ABF), the original feature map fusion module in Knowledge Review, dynamically aggregates feature maps via a spatial attention map, yet, overlooks the channel-wise information. We argue that the teacher models typically have more blocks for feature extraction and more channels for retaining information, but they do not differ in spatial resolution compared to student models. Therefore, we aim to bridge the channel-wise differences between the feature maps of student and teacher models while incorporating spatial information through the design of a complementary channel selection module. Our design is motivated by the following two aspects: 1) The channel-wise cues of the feature maps provide informative priors for feature extractors. Numerous previous works[73, 74], which focus on feature map fusion, seek to fuse spatial and channel information via channel attention. Furthermore, Shu et al.[1] indicate that minimizing the channel-wise Kullback-Leibler (KL) divergence of the feature- and prediction maps is more efficient than using its spatial counterpart. 2) As patch embedding distillation tracks dependencies among distant spatial positions via sequence-wise learning, feature map distillation should engage more spatially holistic knowledge in channels. It is therefore important to highlight channels from certain stages via reweighting and to account for cross-stage channel interdependencies. To achieve this, we propose the Cross Selective Fusion (CSF) module to adaptively fuse the information across stages via channel attention.

Figure 7: Architecture of the feature map fusion module, Cross Selective Fusion (CSF) in Fig.4. The dimension-wise unified feature maps from the current student transformer block and the higher-level features are fused via channel attention.
Cross selective fusion. In this module, the feature maps from the current student stage and the next CSF are first resized to a uniform dimensionality and then fused via channel-wise attention. As previously demonstrated in[73], feature extractions with different kernel sizes or modalities can be fused in an adaptive way. Similarly, we propose to fuse cross-stage feature maps for a relation-based distillation. As shown in Fig.7, we first conduct a 1×1 1 1 1{\times}1 1 × 1 convolution to implement the channel-wise transformation of the input feature map 𝐅 in m superscript subscript 𝐅 𝑖 𝑛 𝑚\mathbf{F}{in}^{m}bold_F start_POSTSUBSCRIPT italic_i italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT and conduct interpolation to implement the spatial transformation of the feature map 𝐅 mid m+1 superscript subscript 𝐅 𝑚 𝑖 𝑑 𝑚 1\mathbf{F}{mid}^{m+1}bold_F start_POSTSUBSCRIPT italic_m italic_i italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m + 1 end_POSTSUPERSCRIPT from CSF of the next stage. Their height and width are the same as the feature map of the m 𝑚 m italic_m-th stage 𝐅 in m superscript subscript 𝐅 𝑖 𝑛 𝑚\mathbf{F}{in}^{m}bold_F start_POSTSUBSCRIPT italic_i italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT. The resulting 𝐅in m subscript superscript𝐅 𝑖 𝑛 𝑚{\widetilde{\mathbf{F}}^{in}}{m}over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT and 𝐅mid m+1 subscript superscript𝐅 𝑚 𝑖 𝑑 𝑚 1{\widetilde{\mathbf{F}}^{mid}}_{m+1}over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_m italic_i italic_d end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m + 1 end_POSTSUBSCRIPT are element-wise summed, as depicted in Eq.(6):
𝐅 m=𝐅in m+𝐅mid m+1.subscript 𝐅 𝑚 subscript superscript𝐅 𝑖 𝑛 𝑚 subscript superscript𝐅 𝑚 𝑖 𝑑 𝑚 1\mathbf{F}{m}={\widetilde{\mathbf{F}}^{in}}{m}+{\widetilde{\mathbf{F}}^{mid}% }_{m+1}.bold_F start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT = over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT + over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_m italic_i italic_d end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m + 1 end_POSTSUBSCRIPT .(6)
The global information is then embedded via global average pooling, where 𝒔 c subscript 𝒔 𝑐\bm{s}_{c}bold_italic_s start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT denotes the channel-wise statistics, as shown in Eq.(7):
𝐬 c=ℱ gp(𝐅 m)=1 H×W∑i=1 H∑j=1 W 𝐅 m(i,j).subscript 𝐬 𝑐 subscript ℱ 𝑔 𝑝 subscript 𝐅 𝑚 1 𝐻 𝑊 superscript subscript 𝑖 1 𝐻 superscript subscript 𝑗 1 𝑊 subscript 𝐅 𝑚 𝑖 𝑗{\mathbf{s}}{c}=\mathcal{F}{gp}(\mathbf{\bm{F}}{m})=\frac{1}{H\times W}\sum% {i=1}^{H}\sum{j=1}^{W}\mathbf{F}{m}(i,j).bold_s start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT = caligraphic_F start_POSTSUBSCRIPT italic_g italic_p end_POSTSUBSCRIPT ( bold_F start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT ) = divide start_ARG 1 end_ARG start_ARG italic_H × italic_W end_ARG ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_H end_POSTSUPERSCRIPT ∑ start_POSTSUBSCRIPT italic_j = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_W end_POSTSUPERSCRIPT bold_F start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT ( italic_i , italic_j ) .(7)
Then, a compact feature 𝒛∈ℝ d×1 𝒛 superscript ℝ 𝑑 1\bm{z}\in\mathbb{R}^{d\times 1}bold_italic_z ∈ blackboard_R start_POSTSUPERSCRIPT italic_d × 1 end_POSTSUPERSCRIPT in Eq.(8) is generated for precise and adaptive selections:
𝐳=ℱ fc(𝐬 c)=δ(ℬ(ϕ(𝐬 c))),d=max(C/r,L),formulae-sequence 𝐳 subscript ℱ 𝑓 𝑐 subscript 𝐬 𝑐 𝛿 ℬ italic-ϕ subscript 𝐬 𝑐 𝑑 𝐶 𝑟 𝐿\mathbf{z}=\mathcal{F}{fc}(\mathbf{s}{c})=\delta(\mathcal{B}(\phi(\mathbf{s}% _{c}))),\ \ \ d=\max(C/r,L),bold_z = caligraphic_F start_POSTSUBSCRIPT italic_f italic_c end_POSTSUBSCRIPT ( bold_s start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT ) = italic_δ ( caligraphic_B ( italic_ϕ ( bold_s start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT ) ) ) , italic_d = roman_max ( italic_C / italic_r , italic_L ) ,(8)
where δ(⋅)𝛿⋅\delta(\cdot)italic_δ ( ⋅ ) denotes the ReLU function, ℬ(⋅)ℬ⋅\mathcal{B}(\cdot)caligraphic_B ( ⋅ ) denotes Batch Normalization, and ϕ(⋅)italic-ϕ⋅\phi(\cdot)italic_ϕ ( ⋅ ) denotes 1×1 1 1 1{\times}1 1 × 1 convolution. d 𝑑 d italic_d is the dimension of the vector 𝒛 𝒛\bm{z}bold_italic_z, which is controlled by a reduction ratio r 𝑟 r italic_r. L 𝐿 L italic_L is chosen to be the minimum value of d 𝑑 d italic_d.
Soft attention across the channels is then used to adaptively select information from different branches:
a c=e 𝐀 c𝐳 e 𝐀 c𝐳+e 𝐁 c𝐳,b c=e 𝐁 c𝐳 e 𝐀 c𝐳+e 𝐁 c𝐳,formulae-sequence subscript 𝑎 𝑐 superscript 𝑒 subscript 𝐀 𝑐 𝐳 superscript 𝑒 subscript 𝐀 𝑐 𝐳 superscript 𝑒 subscript 𝐁 𝑐 𝐳 subscript 𝑏 𝑐 superscript 𝑒 subscript 𝐁 𝑐 𝐳 superscript 𝑒 subscript 𝐀 𝑐 𝐳 superscript 𝑒 subscript 𝐁 𝑐 𝐳{a}{c}=\frac{e^{\mathbf{A}{c}\mathbf{z}}}{e^{\mathbf{A}{c}\mathbf{z}}+e^{% \mathbf{B}{c}\mathbf{z}}},\ \ {b}{c}=\frac{e^{\mathbf{B}{c}\mathbf{z}}}{e^{% \mathbf{A}{c}\mathbf{z}}+e^{\mathbf{B}{c}\mathbf{z}}},italic_a start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT = divide start_ARG italic_e start_POSTSUPERSCRIPT bold_A start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT bold_z end_POSTSUPERSCRIPT end_ARG start_ARG italic_e start_POSTSUPERSCRIPT bold_A start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT bold_z end_POSTSUPERSCRIPT + italic_e start_POSTSUPERSCRIPT bold_B start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT bold_z end_POSTSUPERSCRIPT end_ARG , italic_b start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT = divide start_ARG italic_e start_POSTSUPERSCRIPT bold_B start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT bold_z end_POSTSUPERSCRIPT end_ARG start_ARG italic_e start_POSTSUPERSCRIPT bold_A start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT bold_z end_POSTSUPERSCRIPT + italic_e start_POSTSUPERSCRIPT bold_B start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT bold_z end_POSTSUPERSCRIPT end_ARG ,(9)
𝐅 m,c mid=a c⋅𝐅in m+b c⋅𝐅mid m+1,a c+b c=1,formulae-sequence superscript subscript 𝐅 𝑚 𝑐 𝑚 𝑖 𝑑⋅subscript 𝑎 𝑐 subscript superscript𝐅 𝑖 𝑛 𝑚⋅subscript 𝑏 𝑐 subscript superscript𝐅 𝑚 𝑖 𝑑 𝑚 1 subscript 𝑎 𝑐 subscript 𝑏 𝑐 1\mathbf{F}{m,c}^{mid}={a}{c}\cdot{\widetilde{\mathbf{F}}^{in}}{m}+{b}{c}% \cdot{\widetilde{\mathbf{F}}^{mid}}{m+1},\ \ \ {a}{c}+{b}_{c}=1,bold_F start_POSTSUBSCRIPT italic_m , italic_c end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m italic_i italic_d end_POSTSUPERSCRIPT = italic_a start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT ⋅ over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT + italic_b start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT ⋅ over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_m italic_i italic_d end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m + 1 end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT + italic_b start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT = 1 ,(10)
where 𝐀,𝐁∈ℝ C×d 𝐀 𝐁 superscript ℝ 𝐶 𝑑\mathbf{A},\mathbf{B}\in{\mathbb{R}}^{C\times d}bold_A , bold_B ∈ blackboard_R start_POSTSUPERSCRIPT italic_C × italic_d end_POSTSUPERSCRIPT are two learnable matrices, and 𝐀 c,𝐁 c∈ℝ 1×d subscript 𝐀 𝑐 subscript 𝐁 𝑐 superscript ℝ 1 𝑑\mathbf{A}{c},\mathbf{B}{c}\in{\mathbb{R}}^{1\times d}bold_A start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT , bold_B start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT 1 × italic_d end_POSTSUPERSCRIPT are their c 𝑐 c italic_c-th elements. a c subscript 𝑎 𝑐 a_{c}italic_a start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT, b c subscript 𝑏 𝑐 b_{c}italic_b start_POSTSUBSCRIPT italic_c end_POSTSUBSCRIPT, and 𝐅 mid,c m superscript subscript 𝐅 𝑚 𝑖 𝑑 𝑐 𝑚\mathbf{F}{mid,c}^{m}bold_F start_POSTSUBSCRIPT italic_m italic_i italic_d , italic_c end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT are the c 𝑐 c italic_c-th elements of 𝒂 𝒂\bm{a}bold_italic_a, 𝒃 𝒃\bm{b}bold_italic_b, and 𝐅 mid m superscript subscript 𝐅 𝑚 𝑖 𝑑 𝑚\mathbf{F}{mid}^{m}bold_F start_POSTSUBSCRIPT italic_m italic_i italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT. 𝒂 𝒂\bm{a}bold_italic_a and 𝒃 𝒃\bm{b}bold_italic_b denote the soft attention vector for 𝐅in m subscript superscript𝐅 𝑖 𝑛 𝑚{\widetilde{\mathbf{F}}^{in}}{m}over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_i italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT and 𝐅mid m+1 subscript superscript𝐅 𝑚 𝑖 𝑑 𝑚 1{\widetilde{\mathbf{F}}^{mid}}{m+1}over~ start_ARG bold_F end_ARG start_POSTSUPERSCRIPT italic_m italic_i italic_d end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m + 1 end_POSTSUBSCRIPT, respectively. Furthermore, we perform a 3×3 3 3 3{\times}3 3 × 3 convolution to transform 𝐅 mid m superscript subscript 𝐅 𝑚 𝑖 𝑑 𝑚\mathbf{F}{mid}^{m}bold_F start_POSTSUBSCRIPT italic_m italic_i italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT to 𝐅 out m superscript subscript 𝐅 𝑜 𝑢 𝑡 𝑚\mathbf{F}{out}^{m}bold_F start_POSTSUBSCRIPT italic_o italic_u italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT, ensuring it has the same dimension as the teacher’s feature map.
For training, we compute the hierarchical context loss (HCL)[2] between the outputs of the CSF and the teacher transformer block at each stage, as shown in Fig.4. The feature map obtained from CSF at each stage, with shape [n,c,h,w]𝑛 𝑐 ℎ 𝑤\left[n,c,h,w\right][ italic_n , italic_c , italic_h , italic_w ], is divided into 4 4 4 4-level context information via adaptive average pooling. The height of the resulting multi-level feature maps at one stage is [h,4,2,1]ℎ 4 2 1\left[h,4,2,1\right][ italic_h , 4 , 2 , 1 ], indicating that the shapes of the four abstract feature maps are [n,c,h,w]𝑛 𝑐 ℎ 𝑤\left[n,c,h,w\right][ italic_n , italic_c , italic_h , italic_w ], [n,c,4,4]𝑛 𝑐 4 4\left[n,c,4,4\right][ italic_n , italic_c , 4 , 4 ], [n,c,2,2]𝑛 𝑐 2 2\left[n,c,2,2\right][ italic_n , italic_c , 2 , 2 ], and [n,c,1,1]𝑛 𝑐 1 1\left[n,c,1,1\right][ italic_n , italic_c , 1 , 1 ]. At each stage, the L 2 subscript 𝐿 2 L_{2}italic_L start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT distances are utilized to distill knowledge between the context levels. The final HCL loss between the feature maps at the m 𝑚 m italic_m-th stage is computed as:
L fm m=1 1+∑l 1 2 l∑l=0 3 1 2 lMSE(𝐅 m,l out,𝐅 m,l T),superscript subscript 𝐿 𝑓 𝑚 𝑚 1 1 subscript 𝑙 1 superscript 2 𝑙 superscript subscript 𝑙 0 3 1 superscript 2 𝑙 𝑀 𝑆 𝐸 superscript subscript 𝐅 𝑚 𝑙 𝑜 𝑢 𝑡 superscript subscript 𝐅 𝑚 𝑙 𝑇 L_{fm}^{m}={\frac{1}{1+{\sum_{l}}{\frac{1}{2^{l}}}}}{\sum_{l=0}^{3}}{\frac{1}{% 2^{l}}}MSE(\mathbf{F}{m,l}^{out},\mathbf{F}{m,l}^{T}),italic_L start_POSTSUBSCRIPT italic_f italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT = divide start_ARG 1 end_ARG start_ARG 1 + ∑ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT divide start_ARG 1 end_ARG start_ARG 2 start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_ARG end_ARG ∑ start_POSTSUBSCRIPT italic_l = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 3 end_POSTSUPERSCRIPT divide start_ARG 1 end_ARG start_ARG 2 start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_ARG italic_M italic_S italic_E ( bold_F start_POSTSUBSCRIPT italic_m , italic_l end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_o italic_u italic_t end_POSTSUPERSCRIPT , bold_F start_POSTSUBSCRIPT italic_m , italic_l end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT ) ,(11)
where l 𝑙 l italic_l refers to the number of levels at one stage. The purpose of applying the HCL loss after every stage is to encourage knowledge distillation at different levels of abstraction.
III-D Configuration
The core of our TransKD framework involves two knowledge distillation strategies: patch embedding distillation (in Sec.III-B) and feature map distillation (in Sec.III-C). To realize this design, we introduce four modules: PEA, GL-Mixer, and EA modules guide the patch embedding distillation, while the CSF feature map fusion module enhances the cross-stage relation-based feature map distillation.
Overall, CSF and PEA can be viewed as the fundamental components of TransKD. The GL-Mixer operates on the deepest representative embedding, (i.e., the final fourth stage), producing highly heterogeneous patterns[26]. It reinforces the patch embedding distillation at the final stage by harvesting global and local context information through two branches. The EA modules are placed at each stage and serve as an embedding method to provide supplementary distillation streams by using an identical embedding method to the teacher’s and the student’s, with the teacher’s number of channels. It should be taken into account that, as different transformer architectures have different embedding methods, the framework leveraging EA does not yield full plug-and-play flexibility.
We implement and examine different variants of our proposed framework. Note, that we cannot isolate and verify the efficacy of each module when all the modules are combined together, as an integration of these components means many constraints and could lead to overfitting. We, therefore, focus on three configurations of feature map distillation and patch embedding distillation provided in Tab.I, which we refer to as TransKD-Base, TransKD-GL, and TransKD-EA. The structure of these three variants is provided in Fig.4.
Table I: Configuration of TransKD variants. FM: Feature Map. PE: Patch Embedding.
Framework FM Distillation PE Distillation Plug&Play TransKD-Base CSF PEA✓ TransKD-GL CSF PEA + GL-Mixer✓ TransKD-EA CSF PEA + EA✕
IV Experiment Datasets and Setups
IV-A Datasets and Metrics
Cityscapes[30] is a large-scale dataset, which contains sequences of street scenes from 50 50 50 50 different cities. Cityscapes consists of 2975 2975 2975 2975 training- and 500 500 500 500 validation images with dense annotations as well as 1525 1525 1525 1525 test images. It is well known for assessing the performance of vision algorithms for urban semantic scene understanding. There are 19 19 19 19 semantic classes.
ACDC[31] is a dataset used to address semantic segmentation under adverse conditions, e.g., fog, nighttime, rain, and snow scenes. Each adverse condition includes 400 400 400 400 training, 100 100 100 100 validation, and 500 500 500 500 test images, except for the nighttime condition which includes 106 106 106 106 validation images. Tougher and more comprehensive situations are characteristic of the ACDC dataset, as its goal is to validate the quality of semantic segmentation under adverse conditions with the identical label set of 19 19 19 19 classes as Cityscapes.
NYU Depth V2[32] is an indoor dataset captured by both the RGB and depth cameras. It contains scenes of offices, stores, and rooms of houses. There are many occluded objects with uneven illumination. The dataset includes 1449 1449 1449 1449 RGB-depth images, divided into 795 795 795 795 training images and 654 654 654 654 testing images. The images are annotated with 40 40 40 40 semantic categories. We use RGB images in our experiments investigating knowledge distillation.
Pascal VOC2012[33] is a dataset for object recognition competitions. The images are annotated with 20 20 20 20 foreground object categories and one background class. We adopt the augmentation strategy in[75]. The augmented large-scale dataset contains 10582 10582 10582 10582/1449 1449 1449 1449/1456 1456 1456 1456 images for training/validation/testing.
Evaluation metric. The mean Intersection over Union (mIoU) over all classes is a common evaluation metric for semantic segmentation tasks. All experiments are evaluated based on mIoU, which is calculated via Eq.(12):
mIoU=1 k+1∑i=0 k p ii∑j=0 k p ij+∑j=0 k(p ji−p ii),𝑚 𝐼 𝑜 𝑈 1 𝑘 1 superscript subscript 𝑖 0 𝑘 subscript 𝑝 𝑖 𝑖 superscript subscript 𝑗 0 𝑘 subscript 𝑝 𝑖 𝑗 superscript subscript 𝑗 0 𝑘 subscript 𝑝 𝑗 𝑖 subscript 𝑝 𝑖 𝑖 mIoU=\frac{1}{k+1}\sum_{i{=}0}^{k}\frac{p_{ii}}{\sum_{j=0}^{k}p_{ij}+\sum_{j=0% }^{k}\left(p_{ji}-p_{ii}\right)},italic_m italic_I italic_o italic_U = divide start_ARG 1 end_ARG start_ARG italic_k + 1 end_ARG ∑ start_POSTSUBSCRIPT italic_i = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT divide start_ARG italic_p start_POSTSUBSCRIPT italic_i italic_i end_POSTSUBSCRIPT end_ARG start_ARG ∑ start_POSTSUBSCRIPT italic_j = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT italic_p start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT + ∑ start_POSTSUBSCRIPT italic_j = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ( italic_p start_POSTSUBSCRIPT italic_j italic_i end_POSTSUBSCRIPT - italic_p start_POSTSUBSCRIPT italic_i italic_i end_POSTSUBSCRIPT ) end_ARG ,(12)
where k 𝑘 k italic_k is the number of classes, p ij subscript 𝑝 𝑖 𝑗 p_{ij}italic_p start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT is the number of pixels belonging to the class i 𝑖 i italic_i and classified as class j 𝑗 j italic_j. To evaluate the efficiency of TransKDs, we use MMCV 1 1 1 MMCV: https://github.com/open-mmlab/mmcv to compute Floating point operations per second (FLOPs) and the number of parameters of our models, Additionally, we use the source code to test the Frames Per Second (FPS) of the models on an NVIDIA GeForce GTX 1080 Ti GPU. .
IV-B Implementation Details
Teacher and student transformer models. For the main part of our semantic segmentation experiments, we investigate knowledge distillation for compressing a large pre-trained SegFormer B2 to a smaller SegFormer B0 model without pre-training (unless specified), which has a similar number of parameters as ResNets used in previous distillation works[4, 1, 2]. SegFormer B0[26] achieves a speed of 35.06 35.06 35.06 35.06 Frames Per Second (FPS) when running at a resolution of 512×1024 512 1024 512{\times}1024 512 × 1024 on e NVIDIA GTX 1080Ti and is therefore well-suited for real-time applications. We have also examined our framework with PVTv2[25] and LVT[34] to assess the generality of our approach.
Training setups and hyperparameters. When evaluating the performance of the knowledge distillation frameworks, we resize the images to 512×1024 512 1024 512{\times}1024 512 × 1024 for Cityscapes[30], 512×910 512 910 512{\times}910 512 × 910 for ACDC[31], and 512×512 512 512 512{\times}512 512 × 512 for Pascal VOC2012[33], while maintaining the original image scale of 480×640 480 640 480{\times}640 480 × 640 for the NYUv2 dataset[32]. We utilize one NVIDIA GTX 1080Ti GPU when experimenting with the aforementioned input sizes and four NVIDIA A100 GPUs for larger input sizes. The number of epochs is set to be 1000 1000 1000 1000 on Cityscapes, ACDC, and Pascal VOC2012 datasets, and 1500 1500 1500 1500 on the NYUv2 dataset. Following the structure of SegFormer[26], the height and width of the output and the target segmentation maps are all rescaled with a ratio of 1/4 1 4 1/4 1 / 4 compared to the input image. The performance of the baseline SegFormer model has a slight decay, which is reasonable due to the smaller size of the input image. The models in our work are trained using the AdamW optimizer[76] with the learning rate of 6×10−5 6 superscript 10 5 6{\times}10^{-5}6 × 10 start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT, and the default epsilon of 1×10−8 1 superscript 10 8 1\times 10^{-8}1 × 10 start_POSTSUPERSCRIPT - 8 end_POSTSUPERSCRIPT and betas (0.9,0.999)0.9 0.999(0.9,0.999)( 0.9 , 0.999 ). The learning rate is adjusted using a polynomial learning rate decay scheduler[77] with a default factor of 1.0 1.0 1.0 1.0. The end learning rate is set to 0.0 0.0 0.0 0.0, and the maximum number of decay steps is set at 1500 1500 1500 1500. We adopt a batch size of 8 8 8 8 per GPU on VOC2012 and 2 2 2 2 on other datasets. Additionally, the number of channels of the feature maps in the CSF fusion module C 𝐶 C italic_C is set to 64 64 64 64.
V Experiment Results and Analyses
V-A Quantitative results
Results on the Cityscapes dataset. In Tab.II, we compare the performance of our TransKD method without pre-training the student model on ImageNet, to a multitude of previously published knowledge distillation approaches, on the Cityscapes validation set. We first validate the usefulness of our framework against a baseline trained without knowledge distillation and see that a student SegFormer-B0 model optimized with our TransKD-EA distillation framework achieves a +13.12%percent 13.12+13.12%+ 13.12 % improvement (55.86%percent 55.86 55.86%55.86 %vs.68.98%percent 68.98 68.98%68.98 %) in mIoU. TransKD-EA also outperforms other distillation frameworks by a significant margin, for example, +5.58%percent 5.58+5.58%+ 5.58 % compared to the feature-map-only distillation approach Knowledge Review (KR)[2], revealing the benefits of unifying patch embedding and feature map distillation. Furthermore, the student model distilled by using TransKD-EA delivers results comparable to the student model with additional lengthy pre-training. Although our TransKDs seem to be complex, they are not that heavy compared to SKDs[4] and achieve plug-and-play knowledge distillation. Still, the lightweight variant of our framework TransKD-Base is alone sufficient to conduct the distillation, yielding a surprising +5.18%percent 5.18+5.18%+ 5.18 % gain compared to KR[2] while just adding 0.21M 0.21 𝑀 0.21M 0.21 italic_M parameters for patch embedding distillation.
To explore the two knowledge sources, feature maps and patch embeddings, equally, we perform Knowledge Review on the two positions, respectively. The results show that distilling the knowledge from patch embeddings has a decent gain compared to distilling from feature maps (63.40%percent 63.40 63.40%63.40 %vs.62.41%percent 62.41 62.41%62.41 %). The knowledge from patch embeddings can complement but not replace those from feature maps. Besides, it turns out that the review mechanism may not be perfectly suitable for positional information.
Table II: Comparison with knowledge distillation methods on the Cityscapes dataset[30]. * denotes at the position of patch embeddings.
Network#Params (M)GFLOPs mIoU (%) Teacher (B2)27.36 113.84 76.49 Student (B0)3.72 13.67 55.86 +Pre-train 3.72 13.67 69.75 +KD[17]3.72 13.67 56.89 +CD[1]3.72 13.67 61.90 +SKD (PA)[4]3.85 13.74 58.05 +SKD (HO)[4]7.04 13.83 59.00 +Knowledge Review*[2]4.35 16.17 62.41 +Knowledge Review[2]4.35 16.17 63.40 +TransKD-Base (ours)4.56 16.47 68.58(+5.18) +TransKD-GL (ours)5.22 16.80 68.87(+5.47) +TransKD-EA (ours)5.53 17.84 68.98(+5.58)
Comparison against previous distillation methods. Compared to the traditional response-based[1, 17], feature-based[4, 1], and relation-based[2] knowledge distillation, the combination of traditional distillation and patch embedding distillation greatly improves the effectiveness of transformer-to-transformer transfer. Besides, compared to the teacher model which is based on the SegFormer-B2, the student model with SegFormer-B0 backbone reduces >85%absent percent 85{>}85%> 85 % GFLOPs. Moreover, TransKD-EA rivals the notoriously time-consuming pre-training method. Note that the number of parameters and GFLOPs listed in Tab.II include those of the model itself and those of the distillation framework.
However, at test-time, the computational complexity of the enhanced student model is not affected by the distillation method and is identical to the original compact student model (3.72M 3.72 𝑀 3.72M 3.72 italic_M parameters and 13.67 13.67 13.67 13.67 GFLOPs), therefore keeping the high efficiency needed in real-world applications.
Table III: Per-class IoU scores of our proposed knowledge distillation frameworks compared with the feature-map-only baseline distillation method Knowledge Review[2] on the validation set of Cityscapes[30].
Method mIoU road sidewalk building wall fence pole traffic light traffic sign vegetation Knowledge Review[2]63.40 97.09 78.07 88.26 37.55 44.12 46.55 53.15 60.96 89.39 TransKD-Base 68.58 97.47 80.29 89.71 47.13 48.25 53.78 56.24 65.82 90.74 TransKD-GL 68.87 97.59 80.50 89.83 47.87 46.80 54.34 57.97 66.65 90.88 TransKD-EA 68.98 97.46 79.91 89.75 54.37 47.87 53.21 56.06 65.25 90.70 Class terrain sky person rider car truck bus train motorcycle bicycle Knowledge Review[2]57.74 92.34 65.26 40.58 89.83 50.92 64.30 44.29 40.79 63.40 TransKD-Base 60.63 93.05 71.92 45.76 91.84 66.02 74.01 63.31 39.60 67.54 TransKD-GL 62.07 92.73 72.21 46.15 91.88 70.37 67.39 57.18 48.28 67.81 TransKD-EA 60.94 92.59 71.14 45.89 91.61 65.56 71.17 66.96 43.46 66.68

(a) Per-class IoU results on Cityscapes
(b) Per-class IoU results on ACDC
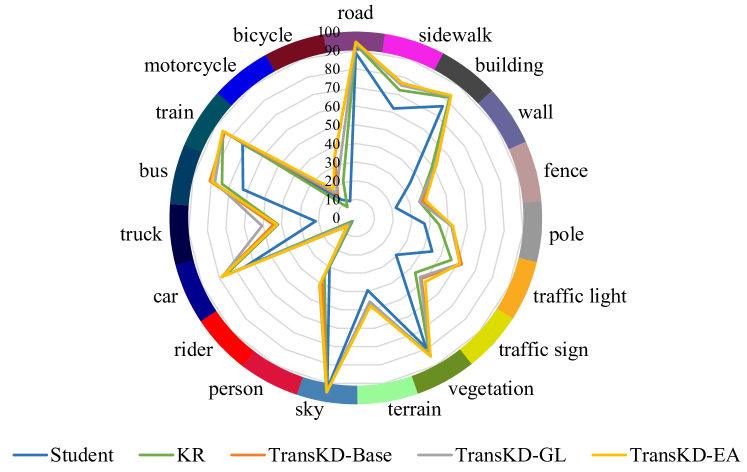
Figure 8: Semantic segmentation IoUs of our TransKDs compared with non-pretrained student and Knowledge Review[2] on Cityscapes and ACDC datasets.
Per-class accuracy analyses on Cityscapes. Next, we investigate the performance of our framework for the individual categories in Tab.III, comparing the TransKD variants to the feature-map-only distillation baseline Knowledge Review (KR)[2]. TransKD-GL is better at recognizing small infrastructures, such as traffic light, traffic sign, and pole, while the TransKD-EA has better performance on the categories like wall and train. Both variants surpass the KR framework for all classes with a remarkable gap, especially for wall, pole, person, rider, truck, and train. In Fig.8(a), we further showcase the per-class accuracy of the original student model, the KR framework, and our TransKD approaches. The benefits of TransKDs are especially large for the challenging less-frequent vehicle categories such as bus, train, and truck.
Effectiveness for different architectures. We then verify whether the effectiveness of our method is consistent for different architectures. With this intent, we compare the TransKD-Base method against the Knowledge Review (KR) framework[2] for different segmentation backbones on the Cityscapes dataset. The results in Tab.IV indicate that our approach is not strictly tied to a concrete model, but is consistently beneficial for different segmentation backbones. Specifically, our TransKD-Base method achieves +5.18%percent 5.18+5.18%+ 5.18 %, +2.18%percent 2.18+2.18%+ 2.18 %, and +2.71%percent 2.71+2.71%+ 2.71 % improvements over the feature-map-only KR method, while using the SegFormer-B0, the PVTv2-B0[25], and the Lite Vision Transformer (LVT)[34] model as the student, respectively. For the PVTv2-B0, we use PVTv2-B2[25] as the teacher model. In the setting of using the SegFormer-B2 as the teacher and the LVT as the student (which have rather dissimilar structures), our proposed TransKD framework also clearly improves the segmentation quality. When comparing to the original student segmenter without any distillation, the gains are more evident with 12.72%percent 12.72 12.72%12.72 %, 10.34%percent 10.34 10.34%10.34 %, and 11.05%percent 11.05 11.05%11.05 % in mIoU. These results show that our TransKD framework can unleash the potential of the efficient transformer models, yielding sufficient improvements of the compact models.
Furthermore, we assess the efficiency of various transformer architectures during both training and inference phases. During training, the complexity of teacher and student transformers embedded within knowledge distillation frameworks is measured in terms of the number of parameters and GFLOPs. Conversely, during the inference phase, the frame rate per second (FPS) is evaluated using pure transformers not equipped with knowledge distillation frameworks on the identical GPU, as the frameworks are primarily employed for knowledge transfer during training only. The student transformers utilized in this analysis are significantly smaller in size, ranging from 7.35 7.35 7.35 7.35 to 3.86 3.86 3.86 3.86 times smaller compared to the teacher models. Moreover, incorporating the distillation framework incurs only a minimal increase in the number of parameters (approximately 0.84 0.84 0.84 0.84 million parameters) and computational cost (an additional 2.97 2.97 2.97 2.97 GFLOPs), irrespective of the model type. Notably, the inference speed of the student models is enhanced by a factor of 2 2 2 2 to 3.5 3.5 3.5 3.5 times relative to that of the teacher models. Overall, student transformers offer faster inference with minimal additional cost and reduced sizes.
Table IV: Accuracy analysis on various transformers.
Network#Params (M)GFLOPs FPS mIoU (%) T: SegFormer-B2 27.36 113.84 10.17 76.49 S: SegFormer-B0 3.72 13.67 35.06 55.86 +KR 4.35 16.17 35.06 63.40 +TransKD-Base 4.56 16.47 35.06 68.58(+5.18) T: PVTv2-B2 29.1 83.14 9.91 77.26 S: PVTv2-B0 7.53 47.45 24.25 58.35 +KR 8.15 49.94 24.25 66.51 +TransKD-Base 8.37 50.24 24.25 68.69(+2.18) T: SegFormer-B2 27.36 113.84 10.17 76.49 S: LVT 3.84 18.06 20.42 57.49 +KR 4.47 20.63 20.42 65.83 +TransKD-Base 4.69 20.99 20.42 68.54(+2.71)
Results on the ACDC dataset. Tab.V summarizes the distillation outcome of CD[1], KR[2], and our TransKD approaches on the ACDC validation dataset. Apart from the overall mIoU scores, we examine the models on four different adverse conditions captured in the ACDC dataset, namely fog, night, rain, and snow. Our TransKD-EA method obtains the best performance with 59.09%percent 59.09 59.09%59.09 % of mIoU on the All-ACDC benchmark, and the top scores of 66.13%percent 66.13 66.13%66.13 %, 44.99%percent 44.99 44.99%44.99 %, and 57.24%percent 57.24 57.24%57.24 % of mIoU for the fog, night, and rain subsets respectively. Interestingly, another variant of our framework, TransKD-GL, yields the best outcome of 60.61%percent 60.61 60.61%60.61 % on the snow subset of the ACDC dataset. We hypothesize that for snowy scenes, local cues are crucial for segmentation and TransKD-GL excels, due to the extraction of detailed information from the representative high-level embedding. Compared to Knowledge Review, all of our three TransKD variants have respective +3.66%percent 3.66+3.66%+ 3.66 %, +3.23%percent 3.23+3.23%+ 3.23 %, and +4.19%percent 4.19+4.19%+ 4.19 % performance gains. The improvements in these diverse weather and nighttime subsets confirm the effectiveness of TransKD for different scene appearances.
Table V: Accuracy analysis on the ACDC dataset[31] in different adverse conditions.
Network Fog Night Rain Snow All-ACDC Teacher (B2)73.26 51.44 69.26 72.00 69.34 Student (B0)52.10 33.33 45.79 48.38 46.26 CD[1]57.07 40.82 51.37 52.15 52.36 Knowledge Review[2]59.83 42.38 52.30 55.69 54.90 TransKD-Base (ours)63.74 44.63 57.16 60.30 58.56(+3.66) TransKD-GL (ours)63.18 43.55 55.85 60.61 58.13(+3.23) TransKD-EA (ours)66.13 44.99 57.24 59.88 59.09(+4.19)
Per-class accuracy analyses on ACDC. We also provide the per-class segmentation results of different frameworks on the ACDC dataset in Fig.8(b). Compared to the original student and the KR-boosted student, models optimized with our TransKD approach have evident gains in most classes. In particular, TransKD has substantial improvements on certain categories that take less space (and are thus harder to segment) but are very important for autonomous driving, such as pole, traffic light, and traffic sign.
Results on the NYUv2 dataset. Our next area of investigation is segmentation results for the indoor scenes covered by the NYUv2 dataset[32]. The original student model with SegFormer-B0 achieves a relatively low performance of 18.19%percent 18.19 18.19%18.19 % in mIoU on NYUv2. While the CD and KR frameworks only bring limited improvements, our TransKD-GL method reaches the best mIoU score of 24.20%percent 24.20 24.20%24.20 %. Compared to KR, our TransKD-Base, -GL, and -EA distillation frameworks reach +0.81%percent 0.81+0.81%+ 0.81 %, +1.40%percent 1.40+1.40%+ 1.40 %, and +1.09%percent 1.09+1.09%+ 1.09 % mIoU gains, respectively. This indicates that our TransKD methods are also beneficial for indoor scene understanding.
Table VI: Accuracy analysis on the NYUv2 dataset[32].
Network#Params (M)GFLOPs mIoU (%) Teacher (B2)27.38 66.73 44.11 Student (B0)3.72 13.85 18.19 +CD[1]3.72 13.85 20.83 +Knowledge Review[2]4.35 16.35 22.80 TransKD-Base (ours)4.57 16.64 23.61(+0.81) TransKD-GL (ours)5.22 16.98 24.20(+1.40) TransKD-EA (ours)5.54 18.02 23.89(+1.09)
Results on the Pascal VOC2012 dataset. As both Pascal VOC2012 and ImageNet are object-centric datasets with similar layouts, training with our TransKD is assumed to be unable to obtain the common pattern from the pre-training process on ImageNet. However, knowledge distillation through our TransKD compensates for 81.1%percent 81.1 81.1%81.1 % of the gap between the non-pretrained and pretrained models successfully, which means that our TransKD-EA achieves a +19.3%percent 19.3+19.3%+ 19.3 % gain over the student model. All three variations, TransKD-Base, TransKD-GL, and TransKD-EA attain salient improvements of +4.17%percent 4.17+4.17%+ 4.17 %, +4.49%percent 4.49+4.49%+ 4.49 %, and +4.68%percent 4.68+4.68%+ 4.68 % in mIoU over the baseline solution Knowledge Review[2].
Table VII: Accuracy analysis on the Pascal VOC2012 dataset[33].
Network#Params (M)GFLOPs mIoU (%) Teacher (B2)27.36 56.95 77.71 Student (B1)13.68 13.32 47.02 +CD[1]13.68 13.32 53.94 +KR[2]14.34 14.63 61.64 +TransKD-Base 14.75 14.93 65.81(+4.17) +TransKD-GL 17.38 15.60 66.13(+4.49) +TransKD-EA 16.68 16.15 66.32(+4.68) +ImN 13.68 13.32 70.82 +KR[2]+ImN 14.34 14.63 73.26 +TransKD-Base+ImN 14.75 14.93 73.67
V-B Ablation Studies and Comparisons
Effectiveness of feature map fusion module and loss function. The feature map distillation component of TransKD (Sec. III-C) covers the feature map fusion modules and the loss functions. For robust feature map distillation, we have introduced Cross Selective Fusion (CSF), to substitute the original feature fusion module ABF in Knowledge Review[2]. CSF is based on a channel attention mechanism for transformer feature map distillation. To verify the effectiveness of CSF, we compare CSF and ABF when using the HCL loss function on Cityscapes[30] and ACDC[31] in Tab.VIII. It is evident, that CSF clearly outperforms ABF with accuracy gaps of 2.54%percent 2.54 2.54%2.54 % and 0.45%percent 0.45 0.45%0.45 % on the two datasets. This finding showcases the usefulness of CSF and the importance of channel-wise dependencies for transformer-based knowledge distillation.
Table VIII: Accuracy analysis on the feature map fusion module.
Feature Map Fusion Loss Function Dataset mIoU (%) ABF[2]HCL Cityscapes 63.40 CSF (ours)HCL Cityscapes 65.94(+2.54) ABF[2]HCL ACDC 54.90 CSF (ours)HCL ACDC 55.35(+0.45)
We further aim to isolate the role of the feature map loss function in a separate set of experiments, with the results summarized in Tab.IX. The Kullback-Leibler (KL) divergence loss is widely used in knowledge distillation and enables the student to imitate the teacher’s distributions, i.e. model predictions[1, 4, 17] or feature maps[1]. Thus, we choose the channel-wise and spatial KL divergence loss functions as control groups for confirming the effectiveness of HCL (the hierarchical version of the MSE loss). The results demonstrate that HCL outperforms both KL divergence losses by >1.5%absent percent 1.5{>}1.5%> 1.5 % when distilling the intermediate feature maps.
Table IX: Accuracy analysis on the feature map distillation loss function.
Loss Function Feature Map Fusion PEA mIoU (%) Channel-wise KL CSF All 66.80 Spatial-wise KL CSF All 66.28 HCL CSF All 68.58
Effectiveness of patch embedding distillation. In this paper, patch embedding distillation (Sec. III-B) is the first introduced in the field of semantic segmentation. Tab.X summarizes our experiments targeting the effects of patch embedding distillation for different stages. When distilling one stage of patch embedding, the patch embedding loss is directly added to the feature map loss, i.e., α m=1 subscript 𝛼 𝑚 1{\alpha_{m}}=1 italic_α start_POSTSUBSCRIPT italic_m end_POSTSUBSCRIPT = 1. Patch embedding distillation at any stage is effective, as it clearly boosts the performance compared to its counterparts without knowledge exchange at the patch embedding level. Generally, the deeper the stage, the more channels of the patch embedding are used and the better the distillation effect the framework can provide. Note that the original feature-map-only Knowledge Review does not use any patch embedding distillation and reaches a much lower outcome of 63.40%percent 63.40 63.40%63.40 %. Models yield their best performances with all-stage patch embedding distillations in place, e.g., 67.89%percent 67.89 67.89%67.89 % in mIoU for Knowledge Review (equipped with our PEA modules) and 68.58%percent 68.58 68.58%68.58 % for TransKD.
Additionally, here we use CSF+HCL to represent our feature map distillation part in TransKD-Base and compare it with Knowledge Review combined with PEA. Our CSF+HCL improves the outcome by 1.2%∼2.5%similar-to percent 1.2 percent 2.5 1.2%{\sim}2.5%1.2 % ∼ 2.5 % over Knowledge Review with different PEA configurations (both when it is not combined or combined with PEA at different stages), verifying the benefits of the proposed feature map fusion module CSF. When the feature map distillation frameworks leverage PEA at all stages with weights of 𝜶=[0.1,0.1,0.5,1]𝜶 0.1 0.1 0.5 1\bm{\alpha}=[0.1,0.1,0.5,1]bold_italic_α = [ 0.1 , 0.1 , 0.5 , 1 ], CSF+HCL reaches the best mIoU of 68.58%percent 68.58 68.58%68.58 % still surpassing the Knowledge Review variant enhanced with our patch embedding distillation blocks by 0.69%percent 0.69 0.69%0.69 %.
Furthermore, we summarize the performances of TransKDs across various datasets in Tab.XI to analyze the effectiveness of the optimization modules, GL-Mixer and EA. We observe that the optimization modules consistently improve the performance of the basic version of TransKD by over +0.5%percent 0.5+0.5%+ 0.5 %. However, while TransKD enhanced by GL-Mixer underperforms the basic version on the ACDC dataset, TransKD-GL achieves state-of-the-art results in the snow condition, as demonstrated in Tab.V.
Table X: Accuracy analysis on integration of PEA by stages.
Feature Map Distillation PEA Stage Channels mIoU (%) Student Teacher Knowledge Review[2]None--63.40 1st 32 64 64.78 2nd 64 128 65.62 3rd 160 320 66.37 4th 256 512 66.52 All--67.89 CSF+HCL (TransKD)None--65.94 1st 32 64 66.75 2nd 64 128 67.05 3rd 160 320 67.08 4th 256 512 67.73 All--68.58
Table XI: Accuracy analysis of optimization modules for patch embedding distillation.
Network Cityscapes ACDC NYUv2 VOC2012 Student 55.86 46.26 18.19 47.02 KR 63.40 54.90 22.80 61.64 TransKD-Base 68.58 58.56 23.61 65.81 TransKD-GL 68.87 58.13 24.20 66.13 TransKD-EA 68.98 59.09 23.89 66.32
Influence of input size and pre-training weights. According to the original work[26], using large input images significantly improves the segmentation results of SegFormer. Besides, ImageNet pre-training is a ubiquitous way for transformer-based methods to compensate for the lack of inductive bias and speed up convergence. In Tab.XII, we examine the influence of the input size and pre-trained weights by comparing the results of Knowledge Review[2] and TransKD-Base for different configurations.
We first look at the networks without weight initialization via pre-training, (i.e., without “+ImN” in Tab.XII). In this case, the large image scale facilitates the efficacy of the overall semantic segmentation model while compromising the gain of TransKD relative to Knowledge Review and the student. At the image size of 512×1024 512 1024 512{\times}1024 512 × 1024, the TransKD-distilled student raises the accuracy by 12.72%percent 12.72 12.72%12.72 % compared to the original non-pretrained student. With the full size of 1024×2048 1024 2048 1024{\times}2048 1024 × 2048, our TransKD-Base attains the performance of 71.59%percent 71.59 71.59%71.59 % with a less, yet still significant accuracy increase of 9.73%percent 9.73 9.73%9.73 % in mIoU.
Table XII: Accuracy analysis on different sizes of input images.
Input Size Network mIoU (%) 512×1024 512 1024 512{\times}1024 512 × 1024 Teacher (SegFormer-B2)76.49 Student (SegFormer-B0)55.86 +KR 63.40 +TransKD-Base (ours)68.58(+5.18) +ImN 69.75 +KR+ImN 71.63 +TransKD-Base+ImN 71.84 768×1536 768 1536 768{\times}1536 768 × 1536 Teacher (SegFormer-B2)78.50 Student (SegFormer-B0)59.61 +KR 67.97 +TransKD-Base (ours)70.93(+2.96) +ImN 73.07 +KR+ImN 73.84 +TransKD-Base+ImN 74.06 1024×2048 1024 2048 1024{\times}2048 1024 × 2048 Teacher (SegFormer-B2)79.90 Student (SegFormer-B0)61.86 +KR 69.06 +TransKD-Base (ours)71.59(+2.53) +ImN 73.77 +KR+ImN 75.55 +TransKD-Base+ImN 75.74
Table XIII: Performance comparison with state-of-the-art distillation methods over different student segmentation networks on the Cityscapes validation set[30]. * denotes that the efficient segmentation model uses pre-trained weights. “-” denotes that the corresponding information is missing in the respective paper.
Network#Params (M)GFLOPs mIoU (%) Large Semantic Segmentation Models PSPNet[27]68.10-78.50 DeepLabV3+[37]62.70-80.90 EncNet[78]55.10-76.90 DANet[39]45.16 397.40 78.32 CCNet[79]68.90-80.20 HANet[80]65.40 2138.02 80.29 OCRNet[81]70.50-81.10 SETR-MLA[11]92.59-78.98 SETR-PUP[11]97.64-79.45 MaskFormer[82]60.00-78.50 SegFormer-B4[26]64.10 1240.60 82.30 SegFormer-B5[26]84.70 1460.40 82.40 Efficient Semantic Segmentation Models ERFNet[5]20.00 27.70 71.50 ICNet (Res18)[44]26.50 28.30 67.70 ESPNet[15]0.36 4.42 61.40 BiSeNet (Res18)[45]49.00-74.80 ContextNet[83]0.85-65.90 SwiftNet (Res18)[46]11.80 26.00 70.20 CGNet[84]0.50 6.00 63.50 Fast-SCNN*[85]1.11-69.15 MobileNetV2*[48]14.80 142.74 73.93 ShuffleNetV2*[49]12.60 117.09 70.85 EfficientNet-B0[86]4.19 7.97 58.37 SegFormer-B0 (our student)3.72 54.70 61.86 SegFormer-B0* (our student)3.72 54.70 73.77 Distillation Methods on Students without using Pretrained Weights SKD (PSPNet18)[4]15.24 128.20 63.20 IFVD (PSPNet18)[18]3.27 31.53 63.35 CD (PSPNet18)[1]13.07 125.80 71.03 IDD (PSPNet18)[62]3.27 31.53 69.76 TransKD-Base (SegFormer B0)3.72 54.70 71.59 Distillation Methods on Students with Pretrained Weights MD*[87]14.35 64.48 71.90 SKD (PSPNet18)[4]15.24 128.20 72.70 KA (PSPNet18)[63]16.31 148.20 74.59 IFVD (PSPNet18)[18]13.07 125.80 74.54 DSD (PSPNet18)[20]15.20 56.90 73.21 SASD (PSPNet)[21]11.38 117.26 73.10 CD (PSPNet18)[1]13.07 125.80 74.58 APD (PSPNet18)[64]16.31 148.20 75.68 SSTKD (PSPNet18)[19]13.07 125.80 75.15 CIRKD (PSPNet18)*[61]12.90 507.40 74.73 TransKD-Base (SegFormer B0)*3.72 54.70 75.74
As expected, a larger input size leads to better results for both, the pre-trained and the non-pretrained networks. We believe, that since pre-training on a large dataset is supposed to complement the inductive bias, and the proposed patch embedding distillation follows the same purpose, patch embedding distillation can compensate for the gap between the non-pretrained and the pretrained transformers sufficiently, but does not show a salient improvement over the pre-trained transformer. Thus, TransKD-Base outperforms Knowledge Review by a smaller margin when the students are pre-trained. Unsurprisingly, the best segmentation quality is achieved when fine-tuning the student pre-trained on ImageNet with our TransKD-Base knowledge distillation approach, yielding 75.74%percent 75.74 75.74%75.74 % in mIoU.
Comparison to state-of-the-art segmenters. In Tab.XIII, we further compare TransKD-Base against state-of-the-art semantic segmentation networks and previous knowledge distillation methods. While heavier models like CCNet[79] and SETR[11] reach high mIoU scores, they are computationally intensive, which often disqualifies their deployment in mobile and real-time systems. Accurate segmenters like HANet[80] and SegFormer-B5[26] require >1000G absent 1000 𝐺{>}1000G> 1000 italic_G FLOPs to yield precise high-resolution predictions. We further consider more efficient semantic segmenters. Compact models, such as CGNet[84] and Fast-SCNN[85], are very lightweight but come at a high accuracy cost, and the segmentation quality declines. Some models with moderate computation complexity like ERFNet[5] and BiSeNet[45] can attain higher accuracy but also comprise more model parameters.
Our previous experiments in Sec.V-A examined different knowledge distillation methods with the same student backbone. In this section, we conduct more comparisons to previously published methods with numbers from their respective papers for the enhanced student after distillation (Tab.XIII). Most of the previous works have used PSPNet18[27] as the student model. In the group of distillation methods and non-pretrained students, our TransKD-Base yields a top performance of 71.59%percent 71.59 71.59%71.59 % in mIoU, which is even close to the results of some pre-trained students, e.g., MD[87] (71.90%percent 71.90 71.90%71.90 %). In the group of distillation methods and pre-trained students, TransKD achieves the highest mIoU score despite being the most lightweight model with only 3.72M 3.72 𝑀 3.72M 3.72 italic_M parameters and 54.70G 54.70 𝐺 54.70G 54.70 italic_G FLOPs. Fig.9 visualizes the comparison of representative efficient segmentation models and knowledge distillation methods. We clearly see that TransKD stands out in front of the past state-of-the-art models in both groups and strikes an excellent trade-off between efficiency and accuracy for semantic scene understanding.
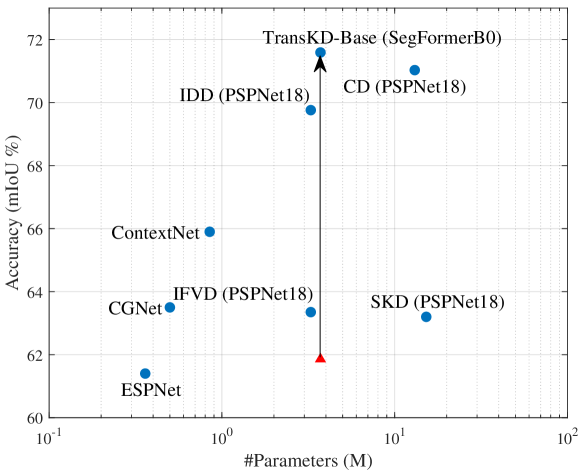
(a) Non-pretrained Networks

(b) Pre-trained Networks
Figure 9: Comparison between TransKD and state-of-the-art efficient semantic segmentation networks and knowledge distillation methods, in terms of (a) not using pre-trained weights and (b) using pre-trained weights. TransKD greatly boosts the mIoU of the efficient model.
V-C Qualitative Results
Analyses of t-SNE visualizations. We next consider the representation point of view and asses the discriminability of the learned embeddings in the latent space via t-SNE visualizations[88] given in Fig.10, where Fig.10(a) illustrates the original student embeddings, and Fig.10(b) and Fig.10(c) are the student representations learned with KR[2] and our TransKD-Base, respectively.


(a) Student w/o KD

(b) KR

(c) TransKD-Base
Figure 10: t-SNE visualization of the feature maps at the last stage. A random sampling of five hundred feature nodes is taken in each category. The prediction maps are down-sampled to label the feature nodes semantically.
Without any knowledge distillation, the decision boundaries for most of the categories are obscure and difficult to distinguish, which leads to harder decision-making for the classifier. Training with Knowledge Review helps to distinguish most of the categories, but traffic sign and traffic light, which are crucial for autonomous vehicles, are easily confused. Finally, these issues are better addressed by utilizing our TransKD knowledge distillation. Compared to Fig.10(a) and Fig.10(b), we observe clearer inter-category boundaries in Fig.10(c), which indicates the benefits of the proposed methods unifying patch embedding- and feature distillation as it enhances the discriminability in the latent space.
Image



 Ground Truth
Ground Truth



 Student
Student



 CD
CD



 KR
KR



 TransKD
TransKD



 Normal Fog Night Rain Snow
Normal Fog Night Rain Snow
Figure 11: Qualitative street scene semantic segmentation results under normal condition from the Cityscapes dataset[30] and adverse conditions from the ACDC dataset[31] including fog, night, rain, and snow conditions. The performance of our TransKD is compared to Knowledge Review (KR)[2]. Here we choose the representative results of TransKD-EA.
Analyses of scene segmentation effects. Qualitative results of semantic segmentation in street scenarios under different kinds of weather conditions are depicted in Fig.11, where normal, foggy, nightly, rainy, and snowy weathers are considered from left to right in each row. The samples come from Cityscapes (normal weather) and ACDC (adverse weather), respectively. We compare TransKD against the feature-map-only Knowledge Review (KR)[2] and Channel-wise Distillation (CD)[1]. The challenging parts of each example are highlighted with the yellow dashed rectangles. For the example featuring normal-weather yet a complex scene (the bus occluded by traffic signs), a large number of false predictions on small objects show up in the student’s result without distillation, while similar unsatisfactory segmentation maps can be also found in CD and KR’s outcomes, e.g., part of the bus is wrongly classified as buildings. Fortunately, these issues are better addressed by TransKD, leading to complete and much clearer segmentation and demonstrating its efficacy in dealing with details.
These findings are also confirmed in our experiments featuring different weather conditions of the ACDC benchmark. In the foggy, nighttime, and rainy scenes, TransKD enables better detection of challenging small objects like safety-critical pedestrians, as well as traffic lights and traffic signs. In the snowy scene, TransKD can also parse the vegetation despite this class having similar textures as the background buildings, thanks to the embedding distillation transferring long-range dependencies. This again highlights the potential of linking patch embedding- and feature map distillation via our TransKD, which derives more informative knowledge than the feature-level-only distillation approach KR.
Limitation and future work. Although TransKDs enable non-pretrained student models to perform comparably to their pretrained counterparts, there remains a minor performance gap (0.77%percent 0.77 0.77%0.77 % on Cityscapes) between them. In the future, we anticipate that the knowledge sources, such as patch embeddings and feature maps, which have proven effective in our work, can be better leveraged to close this performance gap through more refined knowledge distillation framework designs. Furthermore, TransKDs have been exclusively implemented on pyramid transformers, which are primarily used in semantic segmentation. We believe that our TransKD framework could also be adapted to isotropic vision transformers.
VI Conclusion
In this work, our focus lies on enhancing semantic segmentation efficiency within the context of autonomous driving through transformer-based knowledge distillation. We introduce the TransKD architecture, a pioneering transformer-to-transformer knowledge distillation framework that capitalizes on transformer-specific patch embeddings as a critical source of knowledge. TransKD learns efficient compact segmenters via feature map distillation and patch embedding distillation, with two fundamental modules, i.e., CSF and PEA, and two optimization techniques, i.e., GL-Mixer and EA. To illustrate the performance of the proposed TransKD method, in-depth evaluations are conducted on Cityscapes, ACDC, NYUv2, and Pascal VOC2012 datasets with TransKD yielding state-of-the-art performance compared to the existing knowledge distillation approaches. The experiments yield compelling evidence that the proposed transformer-specific patch embedding-level modules serve as potent sources for knowledge distillation in semantic segmentation, showcasing high potential as the cornerstone for resource-efficient yet accurate models in the domain of autonomous scene understanding.
References
- [1] C.Shu, Y.Liu, J.Gao, Z.Yan, and C.Shen, “Channel-wise knowledge distillation for dense prediction,” in ICCV, 2021.
- [2] P.Chen, S.Liu, H.Zhao, and J.Jia, “Distilling knowledge via knowledge review,” in CVPR, 2021.
- [3] J.Deng, W.Dong, R.Socher, L.-J. Li, K.Li, and L.Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in CVPR, 2009.
- [4] Y.Liu, K.Chen, C.Liu, Z.Qin, Z.Luo, and J.Wang, “Structured knowledge distillation for semantic segmentation,” in CVPR, 2019.
- [5] E.Romera, J.M. Alvarez, L.M. Bergasa, and R.Arroyo, “ERFNet: Efficient residual factorized ConvNet for real-time semantic segmentation,” T-ITS, vol.19, no.1, pp. 263–272, 2018.
- [6] J.Zhang, H.Liu, K.Yang, X.Hu, R.Liu, and R.Stiefelhagen, “CMX: cross-modal fusion for RGB-X semantic segmentation with transformers,” T-ITS, vol.24, no.12, pp. 14 679–14 694, 2023.
- [7] Y.Zheng, F.Zhou, S.Liang, W.Song, and X.Bai, “Semantic segmentation in thermal videos: A new benchmark and multi-granularity contrastive learning-based framework,” T-ITS, 2023.
- [8] K.Muhammad et al., “Vision-based semantic segmentation in scene understanding for autonomous driving: Recent achievements, challenges, and outlooks,” T-ITS, vol.23, no.12, pp. 22 694–22 715, 2022.
- [9] J.Zhang, K.Yang, A.Constantinescu, K.Peng, K.Müller, and R.Stiefelhagen, “Trans4Trans: Efficient transformer for transparent object and semantic scene segmentation in real-world navigation assistance,” T-ITS, vol.23, no.10, pp. 19 173–19 186, 2022.
- [10] J.Zhang, K.Yang, and R.Stiefelhagen, “Exploring event-driven dynamic context for accident scene segmentation,” T-ITS, vol.23, no.3, pp. 2606–2622, 2022.
- [11] S.Zheng et al., “Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers,” in CVPR, 2021.
- [12] R.Strudel, R.Garcia, I.Laptev, and C.Schmid, “Segmenter: Transformer for semantic segmentation,” in ICCV, 2021.
- [13] A.Dosovitskiy et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021.
- [14] A.Vaswani et al., “Attention is all you need,” in NeurIPS, 2017.
- [15] S.Mehta, M.Rastegari, A.Caspi, L.Shapiro, and H.Hajishirzi, “ESPNet: Efficient spatial pyramid of dilated convolutions for semantic segmentation,” in ECCV, 2018.
- [16] J.Gou, B.Yu, S.J. Maybank, and D.Tao, “Knowledge distillation: A survey,” IJCV, vol. 129, no.6, pp. 1789–1819, 2021.
- [17] G.Hinton, O.Vinyals, and J.Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [18] Y.Wang, W.Zhou, T.Jiang, X.Bai, and Y.Xu, “Intra-class feature variation distillation for semantic segmentation,” in ECCV, 2020.
- [19] D.Ji, H.Wang, M.Tao, J.Huang, X.-S. Hua, and H.Lu, “Structural and statistical texture knowledge distillation for semantic segmentation,” in CVPR, 2022.
- [20] Y.Feng, X.Sun, W.Diao, J.Li, and X.Gao, “Double similarity distillation for semantic image segmentation,” TIP, vol.30, pp. 5363–5376, 2021.
- [21] S.An, Q.Liao, Z.Lu, and J.-H. Xue, “Efficient semantic segmentation via self-attention and self-distillation,” T-ITS, vol.23, no.9, pp. 15 256–15 266, 2022.
- [22] X.Chu et al., “Twins: Revisiting the design of spatial attention in vision transformers,” in NeurIPS, 2021.
- [23] K.Li et al., “UniFormer: Unifying convolution and self-attention for visual recognition,” TPAMI, vol.45, no.10, pp. 12 581–12 600, 2023.
- [24] Z.Liu et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in ICCV, 2021.
- [25] W.Wang et al., “PVT v2: Improved baselines with pyramid vision transformer,” CVM, vol.8, no.3, pp. 415–424, 2022.
- [26] E.Xie, W.Wang, Z.Yu, A.Anandkumar, J.M. Alvarez, and P.Luo, “SegFormer: Simple and efficient design for semantic segmentation with transformers,” in NeurIPS, 2021.
- [27] H.Zhao, J.Shi, X.Qi, X.Wang, and J.Jia, “Pyramid scene parsing network,” in CVPR, 2017.
- [28] S.I. Mirzadeh, M.Farajtabar, A.Li, N.Levine, A.Matsukawa, and H.Ghasemzadeh, “Improved knowledge distillation via teacher assistant,” in AAAI, 2020.
- [29] T.Huang, S.You, F.Wang, C.Qian, and C.Xu, “Knowledge distillation from a stronger teacher,” in NeurIPS, 2022.
- [30] M.Cordts et al., “The cityscapes dataset for semantic urban scene understanding,” in CVPR, 2016.
- [31] C.Sakaridis, D.Dai, and L.Van Gool, “ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding,” in ICCV, 2021.
- [32] N.Silberman, D.Hoiem, P.Kohli, and R.Fergus, “Indoor segmentation and support inference from RGBD images,” in ECCV, 2012.
- [33] M.Everingham, L.V. Gool, C.K.I. Williams, J.M. Winn, and A.Zisserman, “The pascal visual object classes (VOC) challenge,” IJCV, vol.88, pp. 303–338, 2010.
- [34] C.Yang et al., “Lite vision transformer with enhanced self-attention,” in CVPR, 2022.
- [35] J.Long, E.Shelhamer, and T.Darrell, “Fully convolutional networks for semantic segmentation,” in CVPR, 2015.
- [36] V.Badrinarayanan, A.Kendall, and R.Cipolla, “SegNet: A deep convolutional encoder-decoder architecture for image segmentation,” TPAMI, vol.39, no.12, pp. 2481–2495, 2017.
- [37] L.-C. Chen, Y.Zhu, G.Papandreou, F.Schroff, and H.Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in ECCV, 2018.
- [38] X.Wang, R.Girshick, A.Gupta, and K.He, “Non-local neural networks,” in CVPR, 2018.
- [39] J.Fu et al., “Dual attention network for scene segmentation,” in CVPR, 2019.
- [40] Y.Yuan, L.Huang, J.Guo, C.Zhang, X.Chen, and J.Wang, “OCNet: Object context for semantic segmentation,” IJCV, vol. 129, no.8, pp. 2375–2398, 2021.
- [41] W.Yu et al., “MetaFormer is actually what you need for vision,” in CVPR, 2022.
- [42] I.O. Tolstikhin et al., “MLP-mixer: An all-MLP architecture for vision,” in NeurIPS, 2021.
- [43] A.Paszke, A.Chaurasia, S.Kim, and E.Culurciello, “ENet: A deep neural network architecture for real-time semantic segmentation,” arXiv preprint arXiv:1606.02147, 2016.
- [44] H.Zhao, X.Qi, X.Shen, J.Shi, and J.Jia, “ICNet for real-time semantic segmentation on high-resolution images,” in ECCV, 2018.
- [45] C.Yu, J.Wang, C.Peng, C.Gao, G.Yu, and N.Sang, “BiSeNet: Bilateral segmentation network for real-time semantic segmentation,” in ECCV, 2018.
- [46] M.Orsic, I.Kreso, P.Bevandic, and S.Segvic, “In defense of pre-trained ImageNet architectures for real-time semantic segmentation of road-driving images,” in CVPR, 2019.
- [47] H.Li, P.Xiong, H.Fan, and J.Sun, “DFANet: Deep feature aggregation for real-time semantic segmentation,” in CVPR, 2019.
- [48] M.Sandler, A.Howard, M.Zhu, A.Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in CVPR, 2018.
- [49] N.Ma, X.Zhang, H.-T. Zheng, and J.Sun, “ShuffleNet V2: Practical guidelines for efficient CNN architecture design,” in ECCV, 2018.
- [50] W.Wang et al., “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in ICCV, 2021.
- [51] D.Zhou et al., “DeepViT: Towards deeper vision transformer,” arXiv preprint arXiv:2103.11886, 2021.
- [52] H.Touvron, M.Cord, A.Sablayrolles, G.Synnaeve, and H.Jégou, “Going deeper with image transformers,” in ICCV, 2021.
- [53] H.Touvron, M.Cord, M.Douze, F.Massa, A.Sablayrolles, and H.Jégou, “Training data-efficient image transformers & distillation through attention,” in ICML, 2021.
- [54] B.Graham et al., “LeViT: a vision transformer in ConvNet’s clothing for faster inference,” in ICCV, 2021.
- [55] W.Wang et al., “CrossFormer: A versatile vision transformer hinging on cross-scale attention,” in ICLR, 2022.
- [56] K.Wu et al., “TinyViT: Fast pretraining distillation for small vision transformers,” in ECCV, 2022.
- [57] S.Mehta and M.Rastegari, “MobileViT: Light-weight, general-purpose, and mobile-friendly vision transformer,” in ICLR, 2022.
- [58] Y.Chen et al., “Mobile-Former: Bridging MobileNet and transformer,” in CVPR, 2022.
- [59] L.Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,” TPAMI, vol.44, no.6, pp. 3048–3068, 2022.
- [60] L.Liu et al., “Exploring inter-channel correlation for diversity-preserved knowledge distillation,” in ICCV, 2021.
- [61] C.Yang, H.Zhou, Z.An, X.Jiang, Y.Xu, and Q.Zhang, “Cross-image relational knowledge distillation for semantic segmentation,” in CVPR, 2022.
- [62] Z.Zhang, C.Zhou, and Z.Tu, “Distilling inter-class distance for semantic segmentation,” in IJCAI, 2022.
- [63] T.He, C.Shen, Z.Tian, D.Gong, C.Sun, and Y.Yan, “Knowledge adaptation for efficient semantic segmentation,” in CVPR, 2019.
- [64] Z.Tian et al., “Adaptive perspective distillation for semantic segmentation,” TPAMI, 2022.
- [65] S.Lin et al., “Knowledge distillation via the target-aware transformer,” in CVPR, 2022.
- [66] X.Jiao et al., “TinyBERT: Distilling BERT for natural language understanding,” in EMNLP, 2020.
- [67] C.Dong, G.Wang, H.Xu, J.Peng, X.Ren, and X.Liang, “EfficientBERT: Progressively searching multilayer perceptron via warm-up knowledge distillation,” in EMNLP, 2021.
- [68] W.Wang, F.Wei, L.Dong, H.Bao, N.Yang, and M.Zhou, “MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,” in NeurIPS, 2020.
- [69] D.Zhou et al., “Understanding the robustness in vision transformers,” in ICML, 2022.
- [70] Z.Chen et al., “Vision transformer adapter for dense predictions,” in ICLR, 2023.
- [71] Y.Lee, J.Kim, J.Willette, and S.J. Hwang, “MPViT: Multi-path vision transformer for dense prediction,” in CVPR, 2022.
- [72] X.Dong et al., “CSWin transformer: A general vision transformer backbone with cross-shaped windows,” in CVPR, 2022.
- [73] X.Li, W.Wang, X.Hu, and J.Yang, “Selective kernel networks,” in CVPR, 2019.
- [74] J.Hu, L.Shen, and G.Sun, “Squeeze-and-excitation networks,” in CVPR, 2018.
- [75] B.Hariharan, P.Arbeláez, L.Bourdev, S.Maji, and J.Malik, “Semantic contours from inverse detectors,” in ICCV, 2011.
- [76] I.Loshchilov and F.Hutter, “Decoupled weight decay regularization,” in ICLR, 2019.
- [77] P.Mishra and K.Sarawadekar, “Polynomial learning rate policy with warm restart for deep neural network,” in TENCON, 2019.
- [78] H.Zhang et al., “Context encoding for semantic segmentation,” in CVPR, 2018.
- [79] Z.Huang, X.Wang, L.Huang, C.Huang, Y.Wei, and W.Liu, “CCNet: Criss-cross attention for semantic segmentation,” in ICCV, 2019.
- [80] S.Choi, J.T. Kim, and J.Choo, “Cars can’t fly up in the sky: Improving urban-scene segmentation via height-driven attention networks,” in CVPR, 2020.
- [81] Y.Yuan, X.Chen, and J.Wang, “Object-contextual representations for semantic segmentation,” in ECCV, 2020.
- [82] B.Cheng, A.Schwing, and A.Kirillov, “Per-pixel classification is not all you need for semantic segmentation,” in NeurIPS, 2021.
- [83] R.P. Poudel, U.Bonde, S.Liwicki, and C.Zach, “ContextNet: Exploring context and detail for semantic segmentation in real-time,” in BMVC, 2018.
- [84] T.Wu, S.Tang, R.Zhang, J.Cao, and Y.Zhang, “CGNet: A light-weight context guided network for semantic segmentation,” TIP, vol.30, pp. 1169–1179, 2021.
- [85] R.P.K. Poudel, S.Liwicki, and R.Cipolla, “Fast-SCNN: Fast semantic segmentation network,” in BMVC, 2019.
- [86] M.Tan and Q.Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” in ICML, 2019.
- [87] J.Xie, B.Shuai, J.-F. Hu, J.Lin, and W.-S. Zheng, “Improving fast segmentation with teacher-student learning,” in BMVC, 2018.
- [88] L.Van der Maaten and G.Hinton, “Visualizing data using t-SNE,” JMLR, vol.9, no.11, 2008.
Appendix A Knowledge Distillation Loss Functions
Feature map loss function. Both patch embedding and feature map losses obtained from all four stages are weighted and added to the original cross-entropy loss. For feature map distillation, we compute the HCL loss[2] between the outputs of CSF and the teacher transformer block at each stage. The feature map obtained from CSF at each stage with shape [n,c,h,w]𝑛 𝑐 ℎ 𝑤\left[n,c,h,w\right][ italic_n , italic_c , italic_h , italic_w ] is divided into 4 4 4 4-level context information via adaptive average pooling. The height of the resulting multi-level feature maps at one stage is [h,4,2,1]ℎ 4 2 1\left[h,4,2,1\right][ italic_h , 4 , 2 , 1 ], which denotes that the shapes of the four abstract feature maps are [n,c,h,w]𝑛 𝑐 ℎ 𝑤\left[n,c,h,w\right][ italic_n , italic_c , italic_h , italic_w ], [n,c,4,4]𝑛 𝑐 4 4\left[n,c,4,4\right][ italic_n , italic_c , 4 , 4 ], [n,c,2,2]𝑛 𝑐 2 2\left[n,c,2,2\right][ italic_n , italic_c , 2 , 2 ], and [n,c,1,1]𝑛 𝑐 1 1\left[n,c,1,1\right][ italic_n , italic_c , 1 , 1 ]. At each stage, L 2 subscript 𝐿 2 L_{2}italic_L start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT distances are utilized to distill knowledge between the context levels. The final HCL loss between the feature maps at the m 𝑚 m italic_m-th stage is computed as:
L fm m=1 1+∑l 1 2 l∑l=0 3 1 2 lMSE(𝐅 m,l out,𝐅 m,l T),superscript subscript 𝐿 𝑓 𝑚 𝑚 1 1 subscript 𝑙 1 superscript 2 𝑙 superscript subscript 𝑙 0 3 1 superscript 2 𝑙 𝑀 𝑆 𝐸 superscript subscript 𝐅 𝑚 𝑙 𝑜 𝑢 𝑡 superscript subscript 𝐅 𝑚 𝑙 𝑇 L_{fm}^{m}={\frac{1}{1+{\sum_{l}}{\frac{1}{2^{l}}}}}{\sum_{l=0}^{3}}{\frac{1}{% 2^{l}}}MSE(\mathbf{F}{m,l}^{out},\mathbf{F}{m,l}^{T}),italic_L start_POSTSUBSCRIPT italic_f italic_m end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT = divide start_ARG 1 end_ARG start_ARG 1 + ∑ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT divide start_ARG 1 end_ARG start_ARG 2 start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_ARG end_ARG ∑ start_POSTSUBSCRIPT italic_l = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 3 end_POSTSUPERSCRIPT divide start_ARG 1 end_ARG start_ARG 2 start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_ARG italic_M italic_S italic_E ( bold_F start_POSTSUBSCRIPT italic_m , italic_l end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_o italic_u italic_t end_POSTSUPERSCRIPT , bold_F start_POSTSUBSCRIPT italic_m , italic_l end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT ) ,(13)
where l 𝑙 l italic_l refers to the number of level at one stage. The purpose of placing the HCL loss after every stage is to encourage knowledge distillation at different levels of abstraction.
Appendix B More Performance Analyses
Analyses of per-class IoU improvement on various architectures. To further investigate the effectiveness of patch embedding distillation on various architectures, Fig.12 illustrates per-class IoU improvements of our TransKD over Knowledge Review with all three teacher-student pairs, i.e. SegFormer B2-B0[26], PVT B2-B0[25], SegFormer B2-LVT[34]. Compared to Knowledge Review, TransKD helps the compact models to recognize less-frequent vehicle classes more accurately, such as truck, bus, and train.

Figure 12: Per-class IoU improvements of TransKD over Knowledge Review[2] with different teacher-student pairs.

















 Image Ground Truth Student TransKD-Base TransKD-GL TransKD-EA
Image Ground Truth Student TransKD-Base TransKD-GL TransKD-EA
Figure 13: Feature map visualizations. The feature maps at the last transformer encoder stage, i.e., the 4th stage, are visualized for analysis.
Image
Ground Truth
Teacher


 Student
CD
KR
TransKD-Base
Student
CD
KR
TransKD-Base



 TransKD-GL
TransKD-GL



 TransKD-EA
Normal Fog Night Rain Snow
TransKD-EA
Normal Fog Night Rain Snow
Figure 14: Qualitative street scene semantic segmentation results under normal condition from the Cityscapes dataset[30] and adverse conditions from the ACDC dataset[31]. The performances of our knowledge distillation frameworks, TransKDs, are compared with Channel-wise Knowledge Distillation (CD)[1] and Knowledge Review (KR)[2].
Appendix C More Qualitative Analyses
Analyses of intermediate feature maps. We provide visual explanations of the network’s internal decision processes by visualizing the feature maps coming from the 4th stage of the model in Fig.13, with representative Cityscapes validation set examples. Compared with the student without any TransKD components, TransKD-enhanced models present semantically recognizable responses. TransKD helps to pay more attention on the car and truck objects, as shown in the reddish regions on the feature maps, while maintaining clear boundaries with the background triggering much weaker feature map responses (blue and green regions), leading to better semantic segmentation outcome. Apart from that, TransKD-Base tends to focus on large objects, e.g., on the truck, while TransKD-GL shows more evident responses on cars which have relatively smaller size, which we attribute to the extraction of both local and global cues encouraged by this approach. Moreover, TransKD-EA better spotlights the objects which are far away from the camera, e.g., the car in the first row. These visualization results further illustrate the effectiveness of TransKD for learning semantic-aware intermediate representations.
Analyses of outdoor semantic segmentation. Here we compare the segmentation outputs of the most effective response-based distillation framework CD[1], feature-based distillation framework KR[2], and all three versions of TransKD. The outdoor semantic segmentation experiments are conducted on Cityscapes[30] (normal scenes) and ACDC dataset[31] (adverse scenes). According to the quantitative results, TransKD-GL shows the most satisfactory performance on the snowy weather, while TransKD-EA outperforms the all counterparts on normal and other adverse weathers. As shown in Fig.14, the student SegFormer B0 without pre-training, and distilled with CD and KR, can roughly recognize the scenes, such as road, sidewalk, and vegetation, but the compact student transformer is still unable to segment the details, e.g., the traffic light and pedestrian in the distance and the occluded bus. On the contrary, TransKDs extracts both spatial and sequential relations through the combination of feature map and patch embedding distillation, thereby improving the consistency of the bus. Moreover, TransKDs can effectively distinguish the people, rider, and bicycle in adverse weathers, even though they are far away.
Analyses of indoor semantic segmentation. In our final study, we turn to the indoor semantic segmentation results and illustrate the segmentation outcomes on the NYUv2 dataset[32] in Fig.15. Compared with the segmentation results produced by the student without any distillation, the segmentation boundaries of TransKD are much clearer, and most of the details of the indoor scenes are preserved, especially for the bedroom scene, e.g., on pillow. For the bathroom example, similar results can be found, where, for example, towel is better recognized by our approaches. Apart from the objects with relatively small size, objects with less texture cues can be completely segmented, e.g., the wall in the bedroom. These qualitative examples consistently confirm good generalization of TransKD across diverse environments (indoor and outdoor, different weather conditions, etc.) as well as the benefits of knowledge transfer from both patch embeddings and feature maps in transformer-to-transformer knowledge distillation.





 Image Ground Truth Student
Image Ground Truth Student





 TransKD-Base TransKD-GL TransKD-EA
TransKD-Base TransKD-GL TransKD-EA
Figure 15: Qualitative indoor scene semantic segmentation results of our TransKD methods on the NYUv2 dataset[32].
Xet Storage Details
- Size:
- 158 kB
- Xet hash:
- 49a22613bf854dcd600a5f7ff2dd1508ed7d6aa8830d4b9f54b0f757b79d08d4
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.