Buckets:

Title: MSS-PAE: Saving Autoencoder-based Outlier Detection from Unexpected Reconstruction
URL Source: https://arxiv.org/html/2304.00709
Published Time: Wed, 10 Jul 2024 00:23:53 GMT
Markdown Content:
Abstract
AutoEncoders (AEs) are commonly used for machine learning tasks due to their intrinsic learning ability. This unique characteristic can be capitalized for Outlier Detection (OD). However conventional AE-based methods face the issue of overconfident decisions and unexpected reconstruction results of outliers, limiting their performance in OD. To mitigate these issues, the Mean Squared Error (MSE) and Negative Logarithmic Likelihood (NLL) were firstly analyzed, and the importance of incorporating aleatoric uncertainty to AE-based OD was elucidated. Then the Weighted Negative Logarithmic Likelihood (WNLL) was proposed to adjust for the effect of uncertainty for different OD scenarios. Moreover, the Mean-Shift Scoring (MSS) method was proposed to utilize the local relationship of data to reduce the issue of false inliers caused by AE. Experiments on 32 real-world OD datasets proved the effectiveness of the proposed methods. The combination of WNLL and MSS achieved 41% relative performance improvement compared to the best baseline. In addition, MSS improved the detection performance of multiple AE-based outlier detectors by an average of 20%. The proposed methods have the potential to advance AE’s development in OD.
keywords:
Outlier detection , Anomaly detection , Autoencoder , Uncertainty estimation , Mean-shift
††journal: Journal
\affiliation
[1]organization=School of Marine Science and Technology, Northwestern Polytechnical University,city=Xi’an, country=P.R.China \affiliation[2]organization=Faculty of Technology, University of Turku, city=Turku, country=Finland \affiliation[3]organization=School of Computing, University of Eastern Finland, city=Joensuu, country=Finland \affiliation[4]organization=Engineering Cluster, Singapore Institute of Technology, country=Singapore
1 Introduction
Outlier detection (OD), also known as anomaly detection, is a fundamental technique in the field of data mining. An outlier can be defined as “one that appears to deviate markedly from other members of the sample in which it occurs” [1]. Outliers exhibit two main properties: (1) different from inliers with respect to their features; (2) rare in a dataset compared to inliers [2]. The objective of OD is to identify the outliers from the normal samples (inliers), for the purpose of keeping the data clean and safe, or identifying the abnormal situations and behaviors. OD has many applications, such as fraud detection [3], network intrusion detection [4], disease diagnosis [5], video surveillance [6] and trajectory analysis [7]. Generally, OD was treated as an unsupervised or semi-supervised task, since the ground-truth labels were hard to acquire in real-world applications [8]—which means most of the data consists of unidentified inliers and outliers.
Numerous OD methods had been proposed over the years. They could be categorized into different classes. Proximity-based methods [9, 10, 11, 12] measured the similarities between inliers and outliers in the original data space. Statistical-based methods [13, 14, 15] modeled the statistic distribution of inliers. Classification-based methods [16, 17, 18] transformed the data to the substitute space, then identified outliers by dividing the substitute space. Ensemble-based methods [19, 20, 21, 22] combined several weak outlier detectors to produce a strong detector by utilizing the stochasticity and diversity of data. Probabilistic-based methods [23, 24] analyzed the probabilistic distribution of the attributes of the data.
Traditional OD methods usually countered problems when facing high data dimensionality and complex data manifolds, due to their weak feature extraction ability. Thus in recent years, deep learning techniques with strong learning abilities piqued the curiosity of experts in OD. Learning-based methods, such as autoencoder-based (AE-based) [25, 26, 27, 28, 29, 30] and generative-adversarial-network-based (GAN-based) [31, 32, 33, 34], utilized the strong learning ability of the neural network to capture the inherent feature of the inliers. AE-based methods assumed that the inliers could be reconstructed better than the outliers. GAN-based methods created outliers through the generator, or distinguished between inliers and outliers through the discriminator. At present, GAN-based methods are generally hard to train because of their adversarial property, thus AE-based methods are the most popular among all learning-based methods [35].
Most AE-based methods utilize the reconstruction error, such as the Mean Squared Error (MSE), to detect outliers. Optimizing MSE can be interpreted as a special case of maximizing likelihood with an underlying Gaussian error model [36]. It assumes the variance term of the logarithmic likelihood function to be 1, independent of the data instances or attributes. Although this assumption simplifies the optimization and architecture of AE, it limits AE’s discriminating power. More concretely, AE with MSE loss may make overconfident yet wrong decisions, which is harmful to OD tasks.
Some researchers had considered the aforementioned variance term (also known as the aleatoric uncertainty) to achieve better OD performance [27, 37, 38, 39, 40]. Nevertheless, they lack the analysis of its effect on the OD task, especially for OD on tabular data. Hence, this work elucidates the mechanism of how the variance term impacts AE’s reconstruction result, and explains the reasons for the performance improvement that it brings to OD. Upon further analysis of the trade-off within the Negative Logarithmic Likelihood (NLL) function, it was discovered that a proper weighting value can significantly improve OD performance, which was neglected in the literature. Consequently, the Weighted Negative Logarithmic Likelihood (WNLL), a score function effective and flexible for various OD tasks, was proposed.
Secondly, conventional AE-based OD methods suffered from the abnormal reconstruction problem, where some outliers are unexpectedly reconstructed well, making them difficult to distinguish from the inliers [41]. This phenomenon can be explained by the absence of conventional AEs in considering local relationship, instead only capturing global features of data. In this paper, the issue is mitigated by modifying the scoring strategy of AE, producing the Mean-Shift outlier Scoring (MSS) method. This method employed the mean-shifted data point instead of the original data point to calculate the outlier scores. Thus, when an outlier is reconstructed with a relatively high likelihood, the reconstruction result will not resemble the mean-shifted result of the input, leading to a high outlier score. This method is convenient and effective, and can be easily applied to most AE-based methods, which will be shown in Section 4.
An illustration of how this work will improve AE-based OD methods is shown in Fig. 1. WNLL factors in the aleatoric uncertainty to alleviate the overconfidence issue of AE, and MSS introduces the local relationship to detect well-reconstructed outliers.
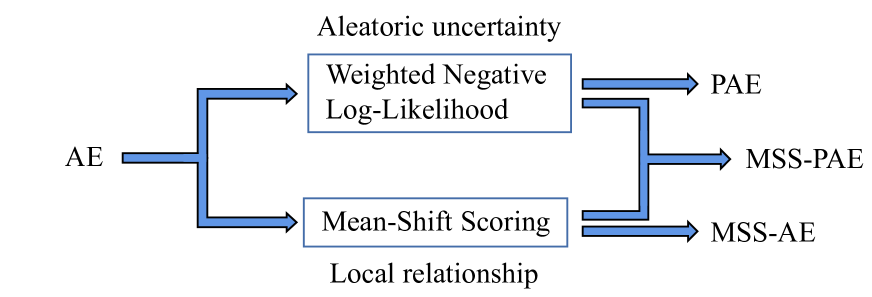
Figure 1: An illustration of how this work will improve AE-based OD methods. WNLL incorporates the aleatoric uncertainty to alleviate the overconfidence issue of AE, and MSS introduces the local relationship to detect well-reconstructed outliers.
In summary, the main contributions of this work are as follows:
- 1.Theoretically analyzing the overconfidence issue in conventional AE, and interpreting the effect of aleatoric uncertainty for the reconstruction task and AE-based OD.
- 2.Proposing WNLL, which mitigates the overconfidence issue for AE-based OD, and significantly improves the detection performance by balancing the effect of aleatoric uncertainty.
- 3.Proposing MSS, which introduces local relationships to reduce the harm of unexpected well-reconstructed outliers in AE, thus improving the robustness and accuracy. In addition to its efficacy, it can be easily applied to other AE-based OD methods.
- 4.Conducting experiments on 32 real-world OD datasets, comparing the proposed methods with 5 typical AE-based OD methods and 8 non-AE-based state-of-the-art (SOTA) OD methods. The experimental results proved the effectiveness and superiority of our methods.
The rest of the paper is organized as follows: In Section 2, the principle of AE-based OD, typical AE-based OD methods proposed in recent years, and the studies quantifying uncertainty in neural networks are reviewed. In Section 3, the proposed NLL, WNLL, and MSS methods are introduced in detail, and their theoretical advantages are analyzed. Then the experimental settings are described and the results are reported in Section 4. Finally, a conclusion is drawn in Section 5.
2 Preliminary and Related Works
2.1 Autoencoder for outlier detection
An AE is a neural network that is trained to reproduce its input to its output [42]. It comprises of two main components: the encoder and the decoder. Considering a traditional fully-connected AE, given a multivariate data vector 𝐱∈ℝ D 𝐱 superscript ℝ 𝐷\mathbf{x}\in\mathbb{R}^{D}bold_x ∈ blackboard_R start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT as the input, the encoder transforms it to a lower-dimensional latent representation, which retains the most critical features of the input data. The latent representation 𝐳 𝐳\mathbf{z}bold_z output by the encoder is given by
𝐳=Encoder(𝐱,θ),𝐳 Encoder 𝐱 𝜃\mathbf{z}={\rm Encoder}(\mathbf{x},\theta),bold_z = roman_Encoder ( bold_x , italic_θ ) ,(1)
where θ 𝜃\theta italic_θ denotes the network parameters of the encoder. Then, the decoder reconstructs the input using the latent representation and the output 𝐱^^𝐱\hat{\mathbf{x}}over^ start_ARG bold_x end_ARG is expressed as
𝐱^=Decoder(𝐳,ϕ),^𝐱 Decoder 𝐳 italic-ϕ\hat{\mathbf{x}}={\rm Decoder}(\mathbf{z},\phi),over^ start_ARG bold_x end_ARG = roman_Decoder ( bold_z , italic_ϕ ) ,(2)
where ϕ italic-ϕ\phi italic_ϕ denotes the network parameters of the decoder.
Since the fully-connected layer can be viewed as the linear dimensionality reduction transformation, the effect of the encoder is similar to the principle components analysis, which aims to find the main components reflecting the features of the original data [43]. However, complicated real-world data are difficult to analyze linearly, so a nonlinear activation function is applied after each fully-connected layer to increase the expressing ability of the network. Common typical activation functions are Sigmoid, Tanh, Rectified Linear Unit (ReLU), and ReLU’s variants.
The optimization and outlier score computation of an AE both relies on its loss function. Since the target of the AE is to reconstruct the input data as the output, the bias between the input and output can be used as the loss function. This is also known as the reconstruction error. The most popular loss function of the conventional AE is the Mean Squared Error function, which is established by the following equation:
MSE(𝐱,𝐱^)=‖𝐱−𝐱^‖2 2,MSE 𝐱^𝐱 superscript subscript norm 𝐱^𝐱 2 2{\rm MSE}(\mathbf{x},\hat{\mathbf{x}})=||\mathbf{x}-\hat{\mathbf{x}}||_{2}^{2},roman_MSE ( bold_x , over^ start_ARG bold_x end_ARG ) = | | bold_x - over^ start_ARG bold_x end_ARG | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ,(3)
where ||⋅||2||\cdot||_{2}| | ⋅ | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT denotes the L2-norm.
AE first transforms the input 𝐱 𝐱\mathbf{x}bold_x to the latent 𝐳 𝐳\mathbf{z}bold_z, then transforms 𝐳 𝐳\mathbf{z}bold_z to the output 𝐱^^𝐱\hat{\mathbf{x}}over^ start_ARG bold_x end_ARG. The dimension of the latent presentation 𝐳 𝐳\mathbf{z}bold_z is designed to be smaller than the input layer. It served as a bottleneck, allowing only critical information to pass through [44]. Thus, the AE is forced to capture the key features of the data to better reconstruct the input.
Considering a dataset that contains both inliers and outliers. Inliers are abundant and generally showed similar patterns, thus their features can easily be learned by an AE. Outliers are few and different in the dataset, hence their features are difficult for an AE to learn. As a consequence, inliers tend to be reconstructed with lower error margins, but outliers tend to have higher reconstruction errors.
2.2 Autoencoder-based outlier detection methods
AE plays a crucial role in unsupervised learning-based OD methods. AE can either be used separately or combined with other approaches [45, 30]. In addition to applying AE in various OD applications, some researchers have focused on enhancing the performance of AE itself to better align with the requirements of OD. Zhou et al. proposed the Robust Deep Autoencoders (RDA) [26], motivated by the robust principal component analysis. RDA proposed a new loss function that can iteratively remove anomalous components from the training set, reducing AE contamination. Chen et al. proposed the Randomized Neural Network for Outlier Detection (RandNet) [46] to improve the robustness of AE by training multiple AEs with random architectures on different subsets of training data. An et al. proposed a variational-autoencoder-based (VAE-based) OD method [27]. It used the variational inference and reconstruction probability to get more principled and objective outlier scores. Ishii et al. proposed the Low-Cost Autoencoder (LCAE) [47]. It only used data with low reconstruction error in each training epoch, reducing the contamination of the outliers during training. Gong et al. proposed a Memory-augmented Autoencoder (MemAE) [48], which improved the robustness of the AE by reconstructing samples from a limited number of recorded representative normal patterns. Lai et al. proposed an AE model based on the Robust Subspace Recovery layer (RSRAE) [28]. It used the robust subspace recovery layer to increase the reconstruction difficulty of outliers. Similarly, Yu et al. proposed an AE model based on the orthogonal projection constraints (OPCAE)[49], which used the Kautlr-Thomas transformation to preserve only inliers information after encoding. Guo et al. proposed an AE architecture called Feature Decomposition Autoencoder (FDAE) [29], which integrated the benefits from RDA [26] and RSRAE [28].
In summary, most of the recent AE-based methods were dedicated to protect AE against the detrimental effects of outliers during training. However, they mostly have complicated network architectures and training procedures. This makes them difficult to use and thus achieve less satisfactory performance in practice. Additionally, they did not realize that AE sometimes make overconfident yet wrong decisions in unintended regions, which will be discussed in detail in the next subsection.
2.3 Quantify uncertainty in neural networks
Despite neural networks’ impressive capability in various machine learning tasks, they tend to produce overconfident decisions in some cases [50, 51, 52, 40, 53]. For example, a regression model may output confident predictions on the regions without any training data [52]. The overconfident yet wrong decisions can cause dire consequences in practical applications, especially for high-risk applications, such as autonomous driving and medical diagnosis [54]. While superior models and extensive high-quality training data can reduce wrong decisions, it remains impractical to account for every possible situation [55]. Therefore, it is crucial for a neural network to know what it knows[50], that is, the uncertainty quantification.
Conventionally, the uncertainty of neural networks can be divided into two main types: aleatoric uncertainty and epistemic uncertainty [56, 57, 53]. Aleatoric uncertainty, also known as data uncertainty, represents the noise or randomness inherent in observational data. It can be further categorized into heteroscedastic and homoscedastic uncertainty, depending on whether the noise is data instance dependent [57, 55]. Epistemic uncertainty, also known as model uncertainty, represents the network’s ignorance about whether model parameters captured the underlying regularity of data. It can be caused by erroneous training, weak model, or lack of knowledge due to unknown samples or insufficient training data [58]. Due to the different properties of aleatoric uncertainty and epistemic uncertainty, researchers employed different approaches to quantify them. For heteroscedastic aleatoric uncertainty, the common way is to let networks estimate the variance of the observation noise [57, 55]. To quantify epistemic uncertainty, Bayesian neural networks [59, 60, 61] or ensemble techniques [50, 62] are commonly utilized.
Since uncertainty is strongly associated with the data distribution, researchers realized that quantifying uncertainty is beneficial to AE-based outlier detection. Some researches quantified aleatoric uncertainty. An et al. proposed to use the reconstruction probability instead of MSE as the loss function of VAE, and highlighted that anomalous data will have greater aleatoric uncertainty [27]. Pol et al. employed NLL to train VAE and aleatoric-uncertainty-normalized reconstruction error as the outlier score [37]. Mao et al. utilized the NLL-trained AE to detect abnormal pixels, for which the reconstruction error to aleatoric uncertainty ratio is high. Some researchers quantified epistemic uncertainty instead. Legrand et al. and Baur et al. trained Bayesian AE with Monte-Carlo Dropout to compute epistemic uncertainty [63, 64]. Legrand et al. combined epistemic uncertainty with the reconstruction error as the final outlier score, while Baur et al. pointed out that lesional tissues on brain MR images showed lower epistemic uncertainty. Daxberger et al. trained a Bayesian VAE with Markov chain Monte Carlo to compute epistemic uncertainty, and treated data with large epistemic uncertainty as the outliers [65]. Park et al. trained only the encoder of Bayesian VAE, and computed an integrated outlier score function that encompassed both Kullback-Leibler divergence and epistemic uncertainty, utilizing Monte-Carlo Dropout [66]. Some researchers also explored the combination of aleatoric uncertainty and epistemic uncertainty [39, 67]
Although the uncertainty quantification had been applied to previous studies, the intricacies of its effect on the OD task had not been elucidated, especially for OD on general tabular data. It is worth noting that, the implication of uncertainty in various machine learning or OD scenarios may vary. For example, in regression tasks, aleatoric uncertainty reflects the noise in the input and target measurements that networks are unable to learn to correct. But in classification tasks, it reflects the deficiency of information to identify one class of data [58]. Conventional uncertainty studies largely focus on regression, classification, or segmentation. However, the situation for OD tasks with reconstruction models such as AE is different. In this paper, we detailedly analyze the aleatoric uncertainty in AE, and explain its advantages for tabular OD.
3 Saving AE from unexpected reconstruction
In this section, we offered insights for the two reasons of why conventional AE suffers from the unexpected reconstruction problem that lead to unsatisfied outlier detection performance in some specific cases. Moreover, we proposed two ways to address the issue effectively.
3.1 AE is overconfident about its reconstruction result
The optimization target of AE can be interpreted as maximizing the reconstruction likelihood with certain underlying probability distribution according to the data noise or randomness. Assuming the distribution is the diagonal multivariate Gaussian distribution, Eq. 4 is established:
{𝐱 rec∼N(𝝁,𝚺),𝝁=[μ 1,μ 2,⋯,μ D]T,𝝈 2=[σ 1 2,σ 2 2,⋯,σ D 2]T,𝚺=diag(𝝈 2),\left{\begin{aligned} &\mathbf{x}^{\rm rec}\sim{\rm N}(\bm{\mu},\bm{\Sigma}),% \ &\bm{\mu}=[\mu_{1},\mu_{2},\cdots,\mu_{D}]^{T},\ &\bm{\sigma}^{2}=[\sigma_{1}^{2},\sigma_{2}^{2},\cdots,\sigma_{D}^{2}]^{T},\ &\bm{\Sigma}={\rm diag}(\bm{\sigma}^{2}),\end{aligned}\right.{ start_ROW start_CELL end_CELL start_CELL bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT ∼ roman_N ( bold_italic_μ , bold_Σ ) , end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL bold_italic_μ = [ italic_μ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_μ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , ⋯ , italic_μ start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ] start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT , end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL bold_italic_σ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT = [ italic_σ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , italic_σ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , ⋯ , italic_σ start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ] start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT , end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL bold_Σ = roman_diag ( bold_italic_σ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) , end_CELL end_ROW(4)
where 𝐱 rec superscript 𝐱 rec\mathbf{x}^{\rm rec}bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT denotes the reconstruction random variable of input 𝐱 𝐱\mathbf{x}bold_x; diag(⋅)diag⋅{\rm diag}(\cdot)roman_diag ( ⋅ ) denotes the diagonal matrix; 𝝁 𝝁\bm{\mu}bold_italic_μ denotes the reconstruction mean of AE ; 𝝈 2 superscript 𝝈 2\bm{\sigma}^{2}bold_italic_σ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT denotes the reconstruction variance . This gives rise to Eq. 5:
P(𝐱 rec)=1(2π)D/21|𝚺|1/2e−1 2(𝐱 rec−𝝁)T𝚺−1(𝐱 rec−𝝁),𝑃 superscript 𝐱 rec 1 superscript 2 𝜋 𝐷 2 1 superscript 𝚺 1 2 superscript 𝑒 1 2 superscript superscript 𝐱 rec 𝝁 𝑇 superscript 𝚺 1 superscript 𝐱 rec 𝝁 P(\mathbf{x}^{\rm rec})=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\bm{\Sigma}|^{1/2}}e^{% -\frac{1}{2}(\mathbf{x}^{\rm rec}-\bm{\mu})^{T}\bm{\Sigma}^{-1}(\mathbf{x}^{% \rm rec}-\bm{\mu})},italic_P ( bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT ) = divide start_ARG 1 end_ARG start_ARG ( 2 italic_π ) start_POSTSUPERSCRIPT italic_D / 2 end_POSTSUPERSCRIPT end_ARG divide start_ARG 1 end_ARG start_ARG | bold_Σ | start_POSTSUPERSCRIPT 1 / 2 end_POSTSUPERSCRIPT end_ARG italic_e start_POSTSUPERSCRIPT - divide start_ARG 1 end_ARG start_ARG 2 end_ARG ( bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT - bold_italic_μ ) start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT bold_Σ start_POSTSUPERSCRIPT - 1 end_POSTSUPERSCRIPT ( bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT - bold_italic_μ ) end_POSTSUPERSCRIPT ,(5)
where P(⋅)𝑃⋅P(\cdot)italic_P ( ⋅ ) denotes the probability density function, |𝚺|𝚺|\bm{\Sigma}|| bold_Σ | denotes the determinant of the matrix 𝚺 𝚺\bm{\Sigma}bold_Σ, and 𝚺−1 superscript 𝚺 1\bm{\Sigma}^{-1}bold_Σ start_POSTSUPERSCRIPT - 1 end_POSTSUPERSCRIPT denotes the inverse matrix of 𝚺 𝚺\bm{\Sigma}bold_Σ. The logarithmic probability density function may be expressed as Eq. 6:
lnP(𝐱 rec)=−D 2ln2π−1 2∑d=1 D lnσ d 2−1 2∑d=1 D(x d rec−μ d)2 σ d 2.𝑃 superscript 𝐱 rec 𝐷 2 2 𝜋 1 2 superscript subscript 𝑑 1 𝐷 superscript subscript 𝜎 𝑑 2 1 2 superscript subscript 𝑑 1 𝐷 superscript superscript subscript 𝑥 𝑑 rec subscript 𝜇 𝑑 2 superscript subscript 𝜎 𝑑 2\ln P(\mathbf{x}^{\rm rec})=-\frac{D}{2}\ln 2\pi-\frac{1}{2}\sum_{d=1}^{D}{\ln% \sigma_{d}^{2}}-\frac{1}{2}\sum_{d=1}^{D}{\frac{(x_{d}^{\rm rec}-\mu_{d})^{2}}% {\sigma_{d}^{2}}}.roman_ln italic_P ( bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT ) = - divide start_ARG italic_D end_ARG start_ARG 2 end_ARG roman_ln 2 italic_π - divide start_ARG 1 end_ARG start_ARG 2 end_ARG ∑ start_POSTSUBSCRIPT italic_d = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT roman_ln italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT - divide start_ARG 1 end_ARG start_ARG 2 end_ARG ∑ start_POSTSUBSCRIPT italic_d = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT divide start_ARG ( italic_x start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT - italic_μ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG start_ARG italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG .(6)
If all variance values are assumed to be 1, then
σ 1 2=σ 2 2=⋯superscript subscript 𝜎 1 2 superscript subscript 𝜎 2 2⋯\displaystyle\sigma_{1}^{2}=\sigma_{2}^{2}=\cdots italic_σ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT = italic_σ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT = ⋯=σ D 2=1,absent superscript subscript 𝜎 𝐷 2 1\displaystyle=\sigma_{D}^{2}=1,= italic_σ start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT = 1 ,(7) 𝚺=𝚺 absent\displaystyle\bm{\Sigma}=bold_Σ =𝐈,𝐈\displaystyle\mathbf{I},bold_I ,
where 𝐈 𝐈\mathbf{I}bold_I denotes the identity matrix. Therefore, the logarithmic probability density function, also known as the log-likelihood of 𝐱 rec superscript 𝐱 rec\mathbf{x}^{\rm rec}bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT can be expressed by Eq. 8:
lnP(𝐱 rec)𝑃 superscript 𝐱 rec\displaystyle\ln P(\mathbf{x}^{\rm rec})roman_ln italic_P ( bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT )=−D 2ln2π−1 2∑d=1 D(x d rec−μ d)2 absent 𝐷 2 2 𝜋 1 2 superscript subscript 𝑑 1 𝐷 superscript superscript subscript 𝑥 𝑑 rec subscript 𝜇 𝑑 2\displaystyle=-\frac{D}{2}\ln 2\pi-\frac{1}{2}\sum_{d=1}^{D}{(x_{d}^{\rm rec}-% \mu_{d})^{2}}= - divide start_ARG italic_D end_ARG start_ARG 2 end_ARG roman_ln 2 italic_π - divide start_ARG 1 end_ARG start_ARG 2 end_ARG ∑ start_POSTSUBSCRIPT italic_d = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT ( italic_x start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT - italic_μ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT(8) =C−1 2‖𝐱 rec−𝝁‖2 2,absent 𝐶 1 2 superscript subscript norm superscript 𝐱 rec 𝝁 2 2\displaystyle=C-\frac{1}{2}||\mathbf{x}^{\rm rec}-\bm{\mu}||_{2}^{2},= italic_C - divide start_ARG 1 end_ARG start_ARG 2 end_ARG | | bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT - bold_italic_μ | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ,
where C 𝐶 C italic_C denotes a constant which will not affect the optimization process.
Conventional AEs aim to reconstruct the input 𝐱 𝐱\mathbf{x}bold_x, which implies maximizing the log-likelihood lnP(𝐱 rec)𝑃 superscript 𝐱 rec\ln P(\mathbf{x}^{\rm rec})roman_ln italic_P ( bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT ) when 𝐱 rec=𝐱 superscript 𝐱 rec 𝐱\mathbf{x}^{\rm rec}=\mathbf{x}bold_x start_POSTSUPERSCRIPT roman_rec end_POSTSUPERSCRIPT = bold_x, and the mean value 𝝁 𝝁\bm{\mu}bold_italic_μ is treated as the output 𝐱^^𝐱\hat{\mathbf{x}}over^ start_ARG bold_x end_ARG of AE. Therefore, the optimization objective is to maximize C−1 2‖𝐱−𝐱^‖2 2 𝐶 1 2 superscript subscript norm 𝐱^𝐱 2 2 C-\frac{1}{2}||\mathbf{x}-\hat{\mathbf{x}}||{2}^{2}italic_C - divide start_ARG 1 end_ARG start_ARG 2 end_ARG | | bold_x - over^ start_ARG bold_x end_ARG | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT. Evidently, it is equivalent to minimizing ‖𝐱−𝐱^‖2 2 superscript subscript norm 𝐱^𝐱 2 2||\mathbf{x}-\hat{\mathbf{x}}||{2}^{2}| | bold_x - over^ start_ARG bold_x end_ARG | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, which is exactly the form of general MSE. So given the training set 𝐗∈ℝ N×D 𝐗 superscript ℝ 𝑁 𝐷\mathbf{X}\in\mathbb{R}^{N\times D}bold_X ∈ blackboard_R start_POSTSUPERSCRIPT italic_N × italic_D end_POSTSUPERSCRIPT, the loss function of the conventional AE can be represented by Eq. 9:
MSE(𝐗,𝐗^)=1 N∑i=1 N‖𝐱 i−𝐱 i^‖2 2,MSE 𝐗^𝐗 1 𝑁 superscript subscript 𝑖 1 𝑁 superscript subscript norm subscript 𝐱 𝑖^subscript 𝐱 𝑖 2 2{\rm MSE}(\mathbf{X},\hat{\mathbf{X}})=\frac{1}{N}\sum_{i=1}^{N}{||\mathbf{x}% {i}-\hat{\mathbf{x}{i}}||_{2}^{2}},roman_MSE ( bold_X , over^ start_ARG bold_X end_ARG ) = divide start_ARG 1 end_ARG start_ARG italic_N end_ARG ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_N end_POSTSUPERSCRIPT | | bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT - over^ start_ARG bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_ARG | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ,(9)
where N 𝑁 N italic_N denotes the number of samples in the training set.
AE PAE
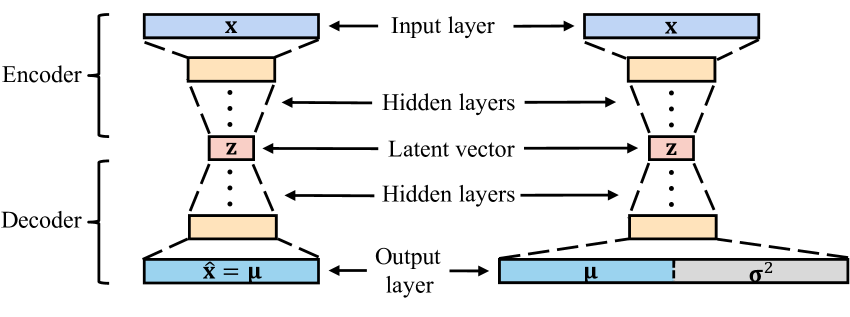
Figure 2: The typical structure of the AE and PAE. AE has a symmetrical structure and the size of the latent vector is much smaller than the input layer, while PAE has an output layer twice the size of its input layer.
Experts on AE predominantly used the form of Eq. 8 or its variants, such as ||⋅||2||\cdot||{2}| | ⋅ | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT (root mean squared error) or ||⋅||1||\cdot||{1}| | ⋅ | | start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT (mean absolute error) as the loss function. However, the usage of the MSE loss is under the assumption that the variance values 𝝈 2 superscript 𝝈 2\bm{\sigma}^{2}bold_italic_σ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT of all the reconstruction probability distributions are 1. With this assumption, AE only estimates the mean values 𝝁 𝝁\bm{\mu}bold_italic_μ of the distribution. The assumption simplifies the optimization and architecture of AE, but it is a sub-optimal solution since it does not reflect the practical situation. It assumes that the randomness of each data instance and attribute is constant and independent (i.e., homoscedastic), which is extremely rare in reality. This deficiency prevents AE with MSE from achieving higher reconstruction accuracy, and will raise the overconfidence issue for OD tasks. Consequently, it is necessary to factor in the variance 𝝈 2 superscript 𝝈 2\bm{\sigma}^{2}bold_italic_σ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, which leads to the NLL loss:
NLL(𝐗,𝝁,𝝈)=1 N∑i=1 N∑d=1 D(x i,d−μ i,d)2 σ i,d 2+lnσ i,d 2.NLL 𝐗 𝝁 𝝈 1 𝑁 superscript subscript 𝑖 1 𝑁 superscript subscript 𝑑 1 𝐷 superscript subscript 𝑥 𝑖 𝑑 subscript 𝜇 𝑖 𝑑 2 superscript subscript 𝜎 𝑖 𝑑 2 superscript subscript 𝜎 𝑖 𝑑 2{\rm NLL}(\mathbf{X},\bm{\mu},\bm{\sigma})=\frac{1}{N}\sum_{i=1}^{N}{\sum_{d=1% }^{D}{\frac{(x_{i,d}-\mu_{i,d})^{2}}{\sigma_{i,d}^{2}}}+\ln\sigma_{i,d}^{2}}.roman_NLL ( bold_X , bold_italic_μ , bold_italic_σ ) = divide start_ARG 1 end_ARG start_ARG italic_N end_ARG ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_N end_POSTSUPERSCRIPT ∑ start_POSTSUBSCRIPT italic_d = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT divide start_ARG ( italic_x start_POSTSUBSCRIPT italic_i , italic_d end_POSTSUBSCRIPT - italic_μ start_POSTSUBSCRIPT italic_i , italic_d end_POSTSUBSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG start_ARG italic_σ start_POSTSUBSCRIPT italic_i , italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG + roman_ln italic_σ start_POSTSUBSCRIPT italic_i , italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT .(10)
where x i,d subscript 𝑥 𝑖 𝑑 x_{i,d}italic_x start_POSTSUBSCRIPT italic_i , italic_d end_POSTSUBSCRIPT, μ i,d subscript 𝜇 𝑖 𝑑\mu_{i,d}italic_μ start_POSTSUBSCRIPT italic_i , italic_d end_POSTSUBSCRIPT and σ i,d 2 superscript subscript 𝜎 𝑖 𝑑 2\sigma_{i,d}^{2}italic_σ start_POSTSUBSCRIPT italic_i , italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT denote the d 𝑑 d italic_d-th attribute of the sample 𝐱 i subscript 𝐱 𝑖\mathbf{x}{i}bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, output mean values 𝝁 i subscript 𝝁 𝑖\bm{\mu}{i}bold_italic_μ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, and output variance values 𝝈 i 2 superscript subscript 𝝈 𝑖 2\bm{\sigma}{i}^{2}bold_italic_σ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, respectively. It is a simple deformation of Eq. 6, after elimination of the constant term, coefficients, and negation. Since the computation of NLL required two variables, 𝝁 i subscript 𝝁 𝑖\bm{\mu}{i}bold_italic_μ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and 𝝈 i 2 superscript subscript 𝝈 𝑖 2\bm{\sigma}{i}^{2}bold_italic_σ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, it required a network that has two outputs correspondingly. Therefore, the conventional AE was modified to the Probabilistic AutoEncoder (PAE) as shown in Fig. 2. The difference is that the dimension of the output layer of the network is twice the size of the input layer, which consists of 𝝁 i subscript 𝝁 𝑖\bm{\mu}{i}bold_italic_μ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and 𝝈 i 2 superscript subscript 𝝈 𝑖 2\bm{\sigma}{i}^{2}bold_italic_σ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT. A Softplus activation function is followed by the output variance to ensure positive values. 𝝁 i subscript 𝝁 𝑖\bm{\mu}{i}bold_italic_μ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represents the reconstruction result. 𝝈 i 2 superscript subscript 𝝈 𝑖 2\bm{\sigma}_{i}^{2}bold_italic_σ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT can be termed as heteroscedastic aleatoric uncertainty, and has already established in the literature, as introduced in Section 2.3. However, the intrinsic relationship between aleatoric uncertainty and AE-based OD has never been explained, and the potential of quantifying uncertainty in OD is not fully explored yet.
PAE consists of two components, the encoder and decoder. The encoder transforms high-dimensional input data to low-dimensional latent variables, and the decoder does the opposite. Hence the process of PAE can be considered as a self-supervised two-steps regression. In this process, several input instances may be encoded into the same latent variable, then decoded into the same output. This phenomenon is caused by one of two reasons: either the randomness or noise inherent in inliers is eliminated during dimensionality reduction, or the pattern of outliers contradicts the knowledge learned by the model.
After training, the reconstruction result fits the manifold of training data, while the estimated aleatoric uncertainty reflects the quality of the training set. Since the outputs and latent variables are in one-to-one correspondences, we can summarize the properties of the aleatoric uncertainty according to the value of the latent variables: when the data fall in the min-max range (determined by the training set) of the latent variables, the aleatoric uncertainty reflects multiple factors, including the randomness or noise of data, the region with absent data, and the region with sparse data (most likely outliers); when the data fall out of the min-max range of the latent variables, the aleatoric uncertainty becomes meaningless and elusive. More importantly, aleatoric uncertainty has a more positive impact when it is combined with reconstruction error. This suggests that we should focus on the form like NLL, leading to the weighted negative logarithmic likelihood:
WNLL(𝐱,𝝁,𝝈)=∑d=1 D α(x d−μ d)2 σ d 2+(1−α)lnσ d 2,WNLL 𝐱 𝝁 𝝈 superscript subscript 𝑑 1 𝐷 𝛼 superscript subscript 𝑥 𝑑 subscript 𝜇 𝑑 2 superscript subscript 𝜎 𝑑 2 1 𝛼 superscript subscript 𝜎 𝑑 2\text{WNLL}(\mathbf{x},\bm{\mu},\bm{\sigma})=\sum_{d=1}^{D}{\alpha\frac{(x_{d}% -\mu_{d})^{2}}{\sigma_{d}^{2}}+(1-\alpha)\ln\sigma_{d}^{2}},WNLL ( bold_x , bold_italic_μ , bold_italic_σ ) = ∑ start_POSTSUBSCRIPT italic_d = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT italic_α divide start_ARG ( italic_x start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT - italic_μ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG start_ARG italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG + ( 1 - italic_α ) roman_ln italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ,(11)
where x d subscript 𝑥 𝑑 x_{d}italic_x start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT, μ d subscript 𝜇 𝑑\mu_{d}italic_μ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT and σ d subscript 𝜎 𝑑\sigma_{d}italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT denote the d 𝑑 d italic_d-th attribute of a sample, 𝐱 𝐱\mathbf{x}bold_x, output mean values, 𝝁 𝝁\bm{\mu}bold_italic_μ, and output variance values, 𝝈 2 superscript 𝝈 2\bm{\sigma}^{2}bold_italic_σ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, respectively. α∈[0,1]𝛼 0 1\alpha\in[0,1]italic_α ∈ [ 0 , 1 ] is a hyper-parameter that controls the trade-off between the two components of WNLL. Evidently, the first component is influenced by both reconstruction error and aleatoric uncertainty, while the second component is only influenced by aleatoric uncertainty. Moreover, aleatoric uncertainty has different effects on the two components. The smaller the value of α 𝛼\alpha italic_α, the stronger the positive effect of aleatoric uncertainty on WNLL. In this work, we use WNLL as the score function in the testing phase. By tuning α 𝛼\alpha italic_α, PAE adapts to the varying characteristics of the datasets. This delivers substantial benefits to various OD applications without extra modification to the training progress.
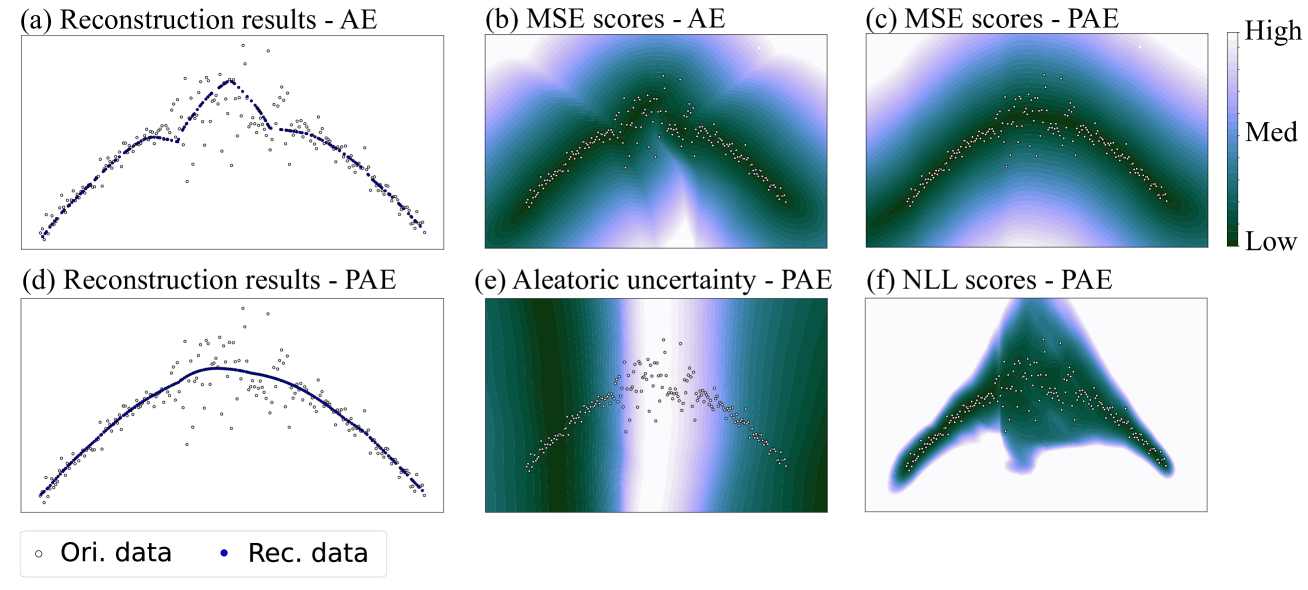
Figure 3: The first case contained a group of sinusoidal-shaped data with different Gaussian noise in different regions. (a) showed that the reconstruction results of AE were seriously affected by the noisy data. (b) showed that MSE scores computed from AE demonstrated the irregularity after reconstruction. (c) and (d) showed that the reconstruction results of PAE were smooth and essentially fit the original curve. (e) showed that PAE output high aleatoric uncertainty in the region between (-0.5,0.5) along horizontal axis. (f) showed that PAE assigned low NLL scores to the regions where data exist, but relatively high scores in the noisy regions. “Ori.” and “Rec.” in the figures denote “Original” and “Reconstruction” respectively.
3.2 Addressing the overconfidence with NLL and WNLL
To verify the perspectives mentioned in the previous section and reveal how NLL and WNLL benefit OD, four cases were studied via visualization. AE and PAE were trained with same settings on each case. Since the cases are 2-dimensional and highly nonlinear, we set the number of units for each network layer for all models as [2,32,32,1,32,32,2], with scaled-exponential-linear-unit active function, except for the last layer.
The data in the first case came from a part of the sinusoidal curve, with different Gaussian noise in different regions. As shown in Fig. 3.(a), the original data are marked as white points, and the noise in the region between (-0.5,0.5) along horizontal axis is significantly larger than the other regions. We can observe that, the reconstruction results of AE (blue points), were seriously affected by the noisy data. MSE scores computed from AE also demonstrated the irregularity after reconstruction. However, this issue was substantially mitigated in PAE, which had a significantly improved reconstruction result that resembled the original curve, as shown in Fig. 3.(d). Additionally, Fig. 3.(e) showed that PAE output high aleatoric uncertainty in the region between (-0.5,0.5) along horizontal axis. This implied that the aleatoric uncertainty captured the noise in the original data. When reconstruction error and aleatoric uncertainty were considered simultaneously, we found that PAE assigned low NLL scores to the regions where data exist. This implied that PAE attempted to capture the distribution of the training set. On the other hand, the scores in the noisy regions were relatively high, caused by the high uncertainty. Thus this property is helpful for applications that treat noisy data as outliers.
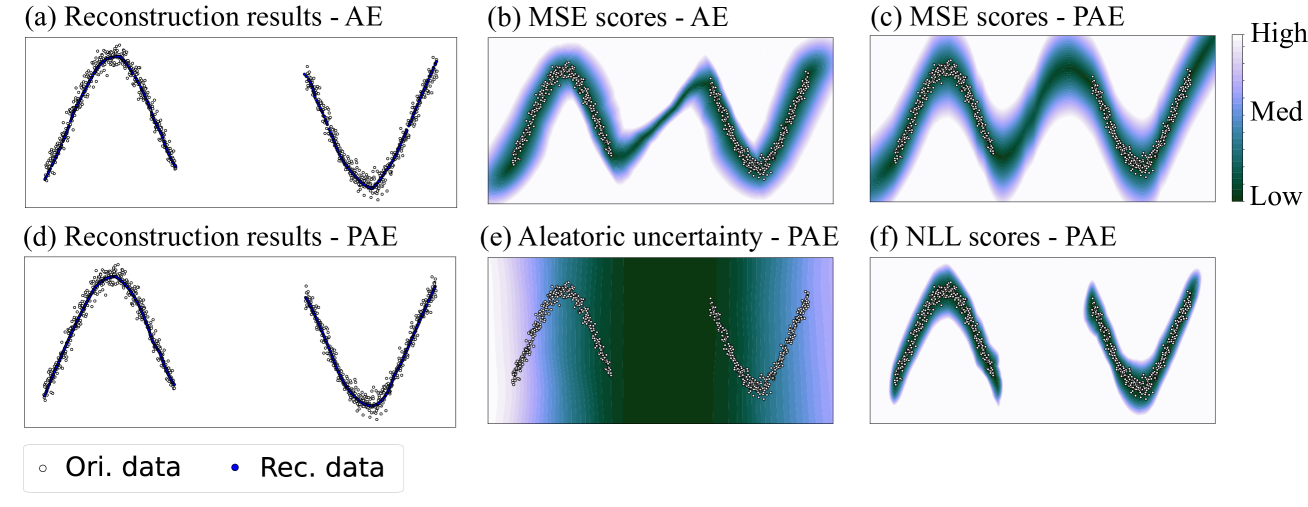
Figure 4: The second case contained two groups of sinusoidal-shaped data with equal density. (a) and (d) showed that AE and PAE both reconstructed the original data well. (b) and (c) showed that some regions between the two groups were also reconstructed well. (e) showed that PAE output low aleatoric uncertainty in the blank area between two groups. (f) showed that PAE only assigned low NLL scores to regions near the data.
The second case contained two groups of sinusoidal-shaped data with equal density, as shown in Fig. 4. In this case, both AE and PAE reconstructed the original data well. However, some regions between the two groups (i.e., the hollow area) were also reconstructed with low error. This is unexpected since the models were required to learn only the pattern of data in the training set. This phenomenon is termed as model overconfidence, which is harmful to OD — if we only focus on the reconstruction error. Fortunately, the aleatoric uncertainty estimated by PAE can solve the issue. Fig. 4.(e) showed that the aleatoric uncertainty became low in the blank area between two groups. Although some regions between the two groups had undesirable low reconstruction error, the final error could be enlarged by the low aleatoric uncertainty, according to the first term of Eq. 10. This result leaded to desirable NLL scores of PAE, as shown in Fig. 4.(f). In this way, the potential outliers in the blank area will not be misjudged.
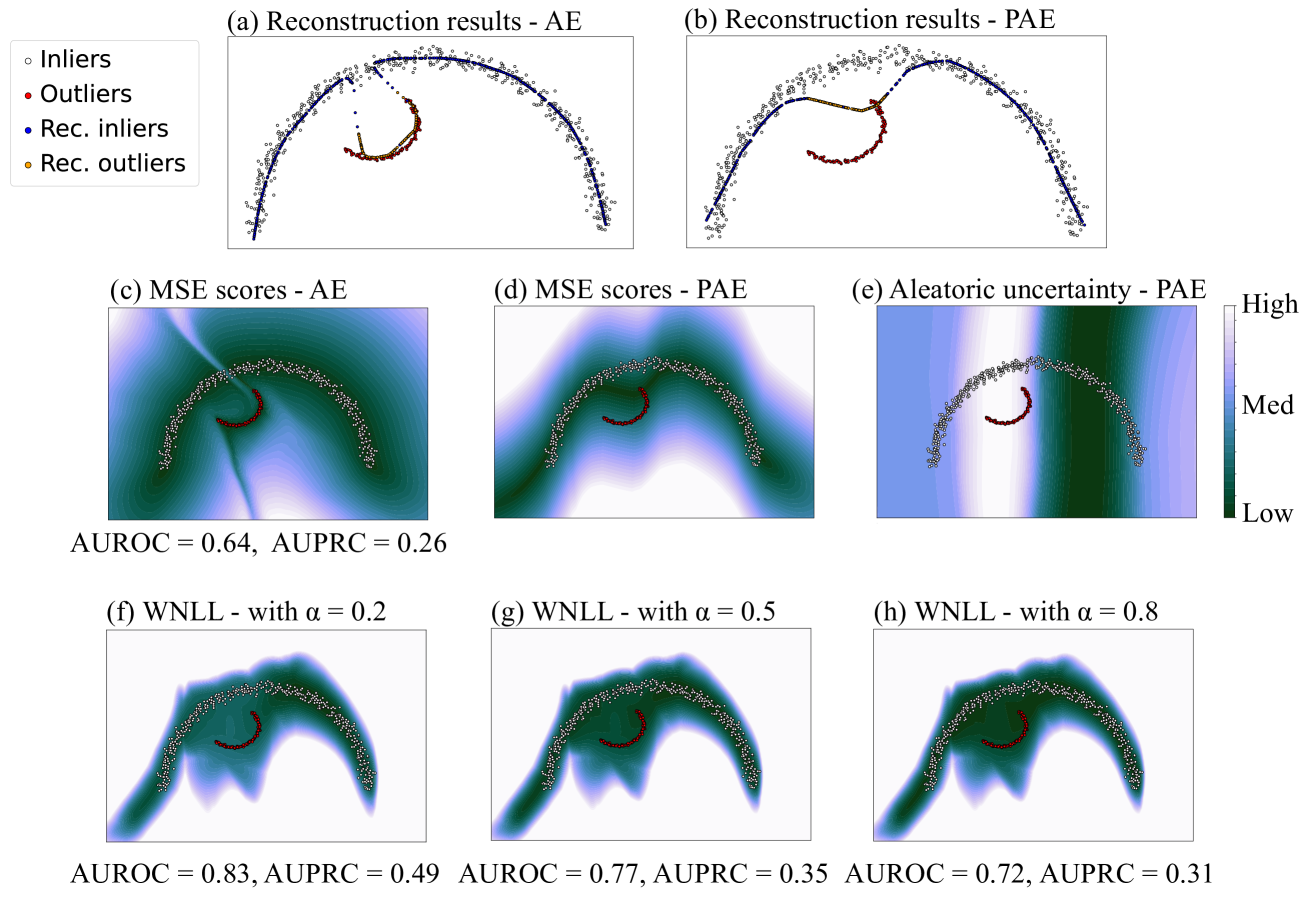
Figure 5: The third cases included a large group of semicircular-shaped inliers and a small group of arcuate-shaped outliers, with an overlapping range on horizontal axis. (a) and (c) showed that AE mistakenly fit the outliers, resulting in bad OD performance. (b) and (d) showed that the reconstruction results of PAE did not deviate a lot from the inliers manifold. (e) showed that PAE outputs high aleatoric uncertainty around outliers, making outliers easier to be discriminated. (f) to (h) showed that PAE achieved better OD performance with smaller α 𝛼\alpha italic_α in WNLL.
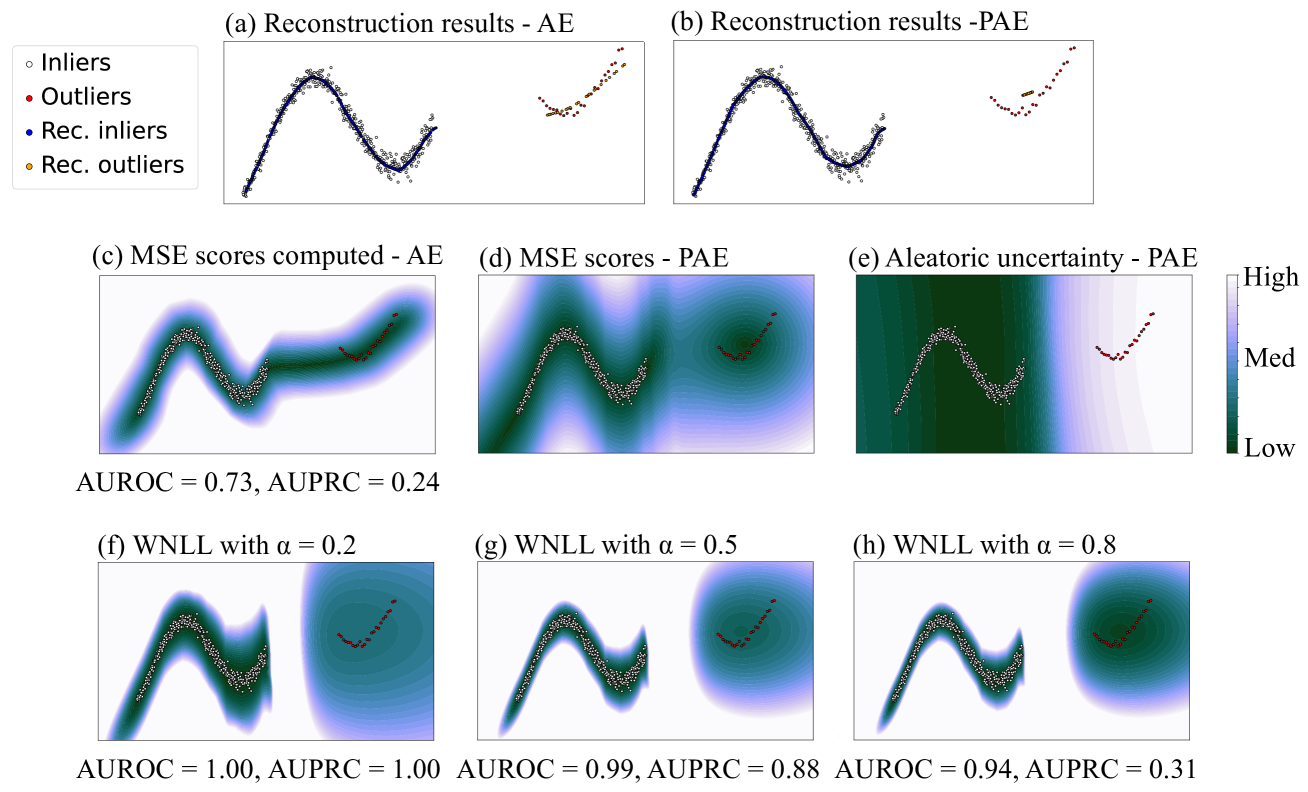
Figure 6: The fourth cases includes a large group of sinusoidal-shaped inliers and a small group of arcuate-shaped outliers, with no overlapping on horizontal axis. (a) and (c) showed that AE reconstructed inliers well, but it output low MSE scores not only around outliers, but also between inliers and outliers. (b) and (d) showed that PAE did not reconstruct outliers well, but it still assigned relatively high MSE scores for some outliers. (e) showed that PAE output high aleatoric uncertainty in both of the aforementioned regions. (f) to (h) showed that PAE achieved better OD performance with smaller α 𝛼\alpha italic_α in WNLL.
Data in the third and fourth case exhibited a large proportion of inliers and small proportion of collective outliers. Besides testing the reconstruction performance of AE and PAE, OD performance with different score functions was also tested. Area Under Receiver Operating characteristic Curve (AUROC) and Area Under Precision-Recall Curve (AUPRC) were used as the OD performance metrics. They were both suitable for label-unbalanced classification tasks, and ranged from 0 to 1, where 1 indicates the best performance.
The third case included a large group of semicircular-shaped inliers and a small group of arcuate-shaped outliers, with an overlapping range on the horizontal axis. As shown in Fig. 5, we can observe that AE was observed to erroneously fit outliers, resulting in poor OD performance. In contrast, PAE had different results. Its reconstruction results did not deviate significantly from the inliers. However, the overlap of inliers and outliers in parts of the latent space confused PAE, leading to regions with outliers having high aleatoric uncertainty. Therefore, even though PAE wanted to assign low NLL scores for all data, it could only assign relatively high scores for the regions with high concentration of outliers. In light of this, though some of the inliers were under suspicion, most outliers could be found out. To better prevent outliers from being erroneously identified as normal, we could decrease α 𝛼\alpha italic_α in WNLL, since it improved the positive effect of aleatoric uncertainty. As a result, PAE achieved better OD performance when α 𝛼\alpha italic_α = 0.2, compared with α 𝛼\alpha italic_α = 0.5 (equivalent to NLL).
The last case included a large group of sinusoidal-shaped inliers and a small group of arcuate-shaped outliers, with no overlapping on the horizontal axis. As shown in Fig. 6, AE erroneously created regions with low MSE scores both around outliers, and between inliers and outliers, as shown in Fig. 6.(c). This phenomenon impaired OD performance. In contrast, with PAE, the sparsity and minority of outliers made PAE uncertain for the information in the region around outliers during training, thus output high aleatoric uncertainty there. For this situation, the positive effect of aleatoric uncertainty was essential for distinguishing, thus WNLL with smaller α 𝛼\alpha italic_α yielded better OD performance.
Finally, we summarized the behaviors of aleatoric uncertainty for PAE as follows:
- 1.it increased in regions where data contained large randomness or noise;
- 2.it increased in regions where inliers and outliers overlapped in the latent space;
- 3.it increased in regions where data were sparse and few (most likely outliers);
- 4.it decreased in the hollow area within the data distribution.
Moreover, we give some recommendations for the usage of NLL and WNLL in OD tasks:
- 1.NLL and WNLL were effective in mitigating the overconfidence issue when training data contained multiple inlier manifolds (patterns), and α 𝛼\alpha italic_α in WNLL was recommended to set a high value here;
- 2.NLL and WNLL were effective when training data contained outliers, and α 𝛼\alpha italic_α in WNLL was recommended to set a low value here.
- 3.For applications with both multiple inlier patterns and outlier contamination, practitioner should carefully adjust α 𝛼\alpha italic_α in WNLL according to the specific analysis.
3.3 AE is ignorance about the local relationship
AE is trained to learn the normal patterns of the data, and outliers are intuitively expected to have higher reconstruction errors. Although the reconstruction error such as MSE can be used as the outlier score directly, the score may be less reliable in certain situations. First, if the training dataset is contaminated by outliers, AE will be misled to learn abnormal patterns of the data, resulting in lower reconstruction errors of outliers and increasing difficulty of distinguishing outliers from inliers. Second, some outliers exhibit latent features conforming to the patterns of inliers, except that their feature values deviate from the normal range. These outliers may be unexpectedly well reconstructed by AE, making them difficult to distinguish from inliers. Although NLL and WNLL can alleviate the problem of outlier contamination, it is still necessary to search a complementary solution for any AE-based OD method.
The issue raised can be explained by AEs’ capturing global features of data, which lacked explicit consideration of local relationship. Therefore, to tackle this inadequacy, the local relationship of the data was considered as auxiliary information for AE. The mean-shift method could serve as a viable solution. The concept of the mean-shift was first proposed by Fukunaga et al. in 1975 [68], applied to the estimation of the gradient of a density function. Then it was used in a variety of applications including clustering [69], image segmentation [70], and target tracking[71].
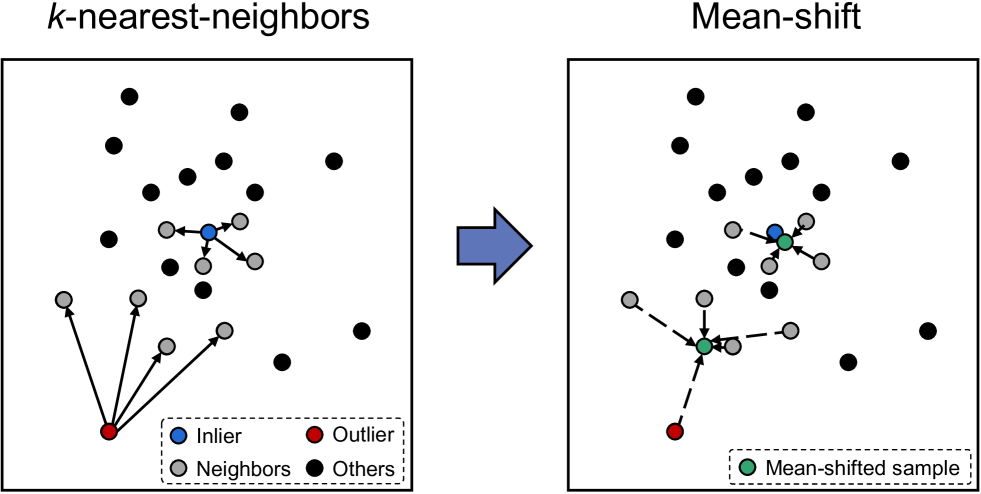
Figure 7: A 2-D illustration of the mean-shift with m=1 𝑚 1 m=1 italic_m = 1 and k=4 𝑘 4 k=4 italic_k = 4 for an inlier (top) and an outlier (bottom).
The process of the mean-shift could be described as follows. Given a dataset 𝐗={𝐱 1,𝐱 2,⋯,𝐱 N}𝐗 subscript 𝐱 1 subscript 𝐱 2⋯subscript 𝐱 𝑁\mathbf{X}={\mathbf{x}{1},\mathbf{x}{2},\cdots,\mathbf{x}{N}}bold_X = { bold_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , bold_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , ⋯ , bold_x start_POSTSUBSCRIPT italic_N end_POSTSUBSCRIPT }, mean-shift first calculated each sample’s k 𝑘 k italic_k-nearest-neighbors in 𝐗 𝐗\mathbf{X}bold_X. For example, for the sample 𝐱 i subscript 𝐱 𝑖\mathbf{x}{i}bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, its k 𝑘 k italic_k-nearest-neighbors set was NL i={𝐱 i 1,𝐱 i 2,⋯,𝐱 i k}subscript NL 𝑖 superscript subscript 𝐱 𝑖 1 superscript subscript 𝐱 𝑖 2⋯superscript subscript 𝐱 𝑖 𝑘\text{NL}{i}={\mathbf{x}{i}^{1},\mathbf{x}{i}^{2},\cdots,\mathbf{x}{i}^{k}}NL start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = { bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , ⋯ , bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT }. Mean-shift then added the sample itself to the neighboring set NL i={𝐱 i,𝐱 i 1,𝐱 i 2,⋯,𝐱 i k}subscript NL 𝑖 subscript 𝐱 𝑖 superscript subscript 𝐱 𝑖 1 superscript subscript 𝐱 𝑖 2⋯superscript subscript 𝐱 𝑖 𝑘\text{NL}{i}={\mathbf{x}{i},\mathbf{x}{i}^{1},\mathbf{x}{i}^{2},\cdots,% \mathbf{x}_{i}^{k}}NL start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = { bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , ⋯ , bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT } and calculated the mean value of the list, as expressed in Eq. 12.
{𝐱 i MS(1,k)=1|NL i|∑𝐱∈NL i 𝐱,𝐗 MS(1,k)={𝐱 1 MS(1,k),𝐱 2 MS(1,k),⋯,𝐱 N MS(1,k)}.\left{\begin{aligned} &\mathbf{x}{i}^{{\rm MS}(1,k)}=\frac{1}{|\text{NL}{i}% |}\sum_{\mathbf{x}\in\text{NL}{i}}{\mathbf{x}},\ &\mathbf{X}^{{\rm MS}(1,k)}={\mathbf{x}{1}^{{\rm MS}(1,k)},\mathbf{x}{2}^{{% \rm MS}(1,k)},\cdots,\mathbf{x}{N}^{{\rm MS}(1,k)}}.\end{aligned}\right.{ start_ROW start_CELL end_CELL start_CELL bold_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_MS ( 1 , italic_k ) end_POSTSUPERSCRIPT = divide start_ARG 1 end_ARG start_ARG | NL start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT | end_ARG ∑ start_POSTSUBSCRIPT bold_x ∈ NL start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT bold_x , end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL bold_X start_POSTSUPERSCRIPT roman_MS ( 1 , italic_k ) end_POSTSUPERSCRIPT = { bold_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_MS ( 1 , italic_k ) end_POSTSUPERSCRIPT , bold_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_MS ( 1 , italic_k ) end_POSTSUPERSCRIPT , ⋯ , bold_x start_POSTSUBSCRIPT italic_N end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_MS ( 1 , italic_k ) end_POSTSUPERSCRIPT } . end_CELL end_ROW(12)
This process can be repeated for several times to get a more compact data distribution. Specifically, the same process could be applied to 𝐗 MS(1,k)superscript 𝐗 MS 1 𝑘\mathbf{X}^{{\rm MS}(1,k)}bold_X start_POSTSUPERSCRIPT roman_MS ( 1 , italic_k ) end_POSTSUPERSCRIPT to get 𝐗 MS(2,k)superscript 𝐗 MS 2 𝑘\mathbf{X}^{{\rm MS}(2,k)}bold_X start_POSTSUPERSCRIPT roman_MS ( 2 , italic_k ) end_POSTSUPERSCRIPT, in which MS(m,k)MS 𝑚 𝑘{\rm MS}(m,k)roman_MS ( italic_m , italic_k ) denotes the process of mean-shift with k 𝑘 k italic_k neighbors and m 𝑚 m italic_m shift times. A 2-D illustration of mean-shift is shown in Fig. 7.
To apply the mean-shift on the AE-based OD method, the following procedure was proposed: the AE could be trained using the loss function Eq. 9 or Eq. 10 during the training phase. During the scoring phase, the outlier score of a test sample 𝐱 𝐱\mathbf{x}bold_x could be computed using the score function as illustrated in Eq. 13 and Eq. 14.
MSS-MSE(𝐱)=‖𝐱 MS(m,k)−𝐱^‖2 2,MSS-MSE 𝐱 superscript subscript norm superscript 𝐱 MS 𝑚 𝑘^𝐱 2 2\displaystyle\text{MSS-MSE}(\mathbf{x})=||\mathbf{x}^{{\rm MS}(m,k)}-\hat{% \mathbf{x}}||{2}^{2},MSS-MSE ( bold_x ) = | | bold_x start_POSTSUPERSCRIPT roman_MS ( italic_m , italic_k ) end_POSTSUPERSCRIPT - over^ start_ARG bold_x end_ARG | | start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ,(13) or,or\displaystyle\text{or},or , MSS-WNLL(𝐱)=∑d=1 D α(x d MS(m,k)−μ d)2 σ d 2+(1−α)lnσ d 2,MSS-WNLL 𝐱 superscript subscript 𝑑 1 𝐷 𝛼 superscript superscript subscript 𝑥 𝑑 MS 𝑚 𝑘 subscript 𝜇 𝑑 2 superscript subscript 𝜎 𝑑 2 1 𝛼 superscript subscript 𝜎 𝑑 2\displaystyle\text{MSS-WNLL}(\mathbf{x})=\sum{d=1}^{D}{\alpha\frac{(x_{d}^{{% \rm MS}(m,k)}-\mu_{d})^{2}}{\sigma_{d}^{2}}+(1-\alpha)\ln\sigma_{d}^{2}},MSS-WNLL ( bold_x ) = ∑ start_POSTSUBSCRIPT italic_d = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_D end_POSTSUPERSCRIPT italic_α divide start_ARG ( italic_x start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT roman_MS ( italic_m , italic_k ) end_POSTSUPERSCRIPT - italic_μ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG start_ARG italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT end_ARG + ( 1 - italic_α ) roman_ln italic_σ start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ,(14)
where 𝐱 MS(m,k)superscript 𝐱 MS 𝑚 𝑘\mathbf{x}^{{\rm MS}(m,k)}bold_x start_POSTSUPERSCRIPT roman_MS ( italic_m , italic_k ) end_POSTSUPERSCRIPT denotes the mean-shifted result of the test sample 𝐱 𝐱\mathbf{x}bold_x.
3.4 Excluding well-reconstructed outliers using MSS
The concept of MSS can be analyzed from two perspectives. Upon analysis of the distance measurement, the reconstruction error could be viewed as the deviation of the object’s position in the original data space. The reconstruction error of the inlier was relatively small if AE was well-trained, which means the reconstructed inlier lies within close proximity to the original position. Meanwhile, the mean-shifted result of an inlier was also close to its original position, hence the distance between the reconstructed inlier and the mean-shifted inlier would be small. For the outliers, the mean-shifted result was generally closer to inliers and further from its original locality. The outliers’ reconstruction result deviated in a larger magnitude for distance, and with a random direction, since AE learning was inadequate. Thus, the distance between an outlier’s mean-shifted result and reconstruction result would be significantly large compared to an inlier, which made them simple to distinguish. Upon analysis of the reconstruction likelihood, even though an outlier was reconstructed with a relatively high likelihood, its mean-shifted result was not similar to the reconstruction. This resulted in a high outlier score as the mean-shifted result fell into a position with low likelihood within the likelihood distribution.
In theory, usage of the distance between the mean of k 𝑘 k italic_k-NN instead of the original data and the reconstructed data had two benefits. First, some data shared common mean values, hence similar data in the feature space could have similar outlier scores [72]. Therefore, it avoided local variance in outlier score space. Second, the mean values were seen as the representatives of k 𝑘 k italic_k-NN, thus it considered both object-level and group-level factors when scoring [73]. Therefore, it provided a robust method for the detection of both point outliers and collective outliers.
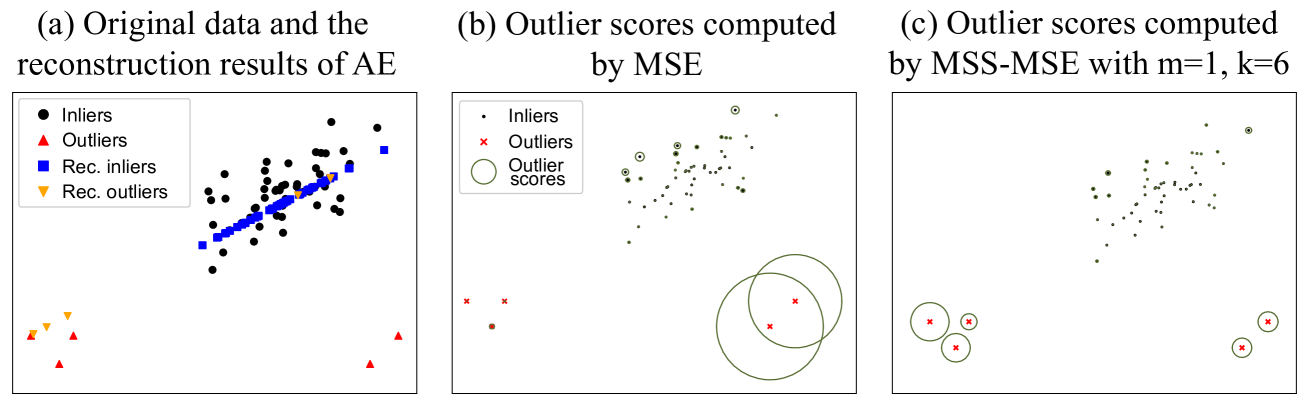
Figure 8: A 2-D example of the effect of the MSS. An AE was trained using these data with the loss function of MSE. (b) and (c) showed the outlier scores generated by MSE and MSS-MSE with m=1,k=6 formulae-sequence 𝑚 1 𝑘 6 m=1,k=6 italic_m = 1 , italic_k = 6 respectively. The larger the radius of the green circle, the higher the outlier score.
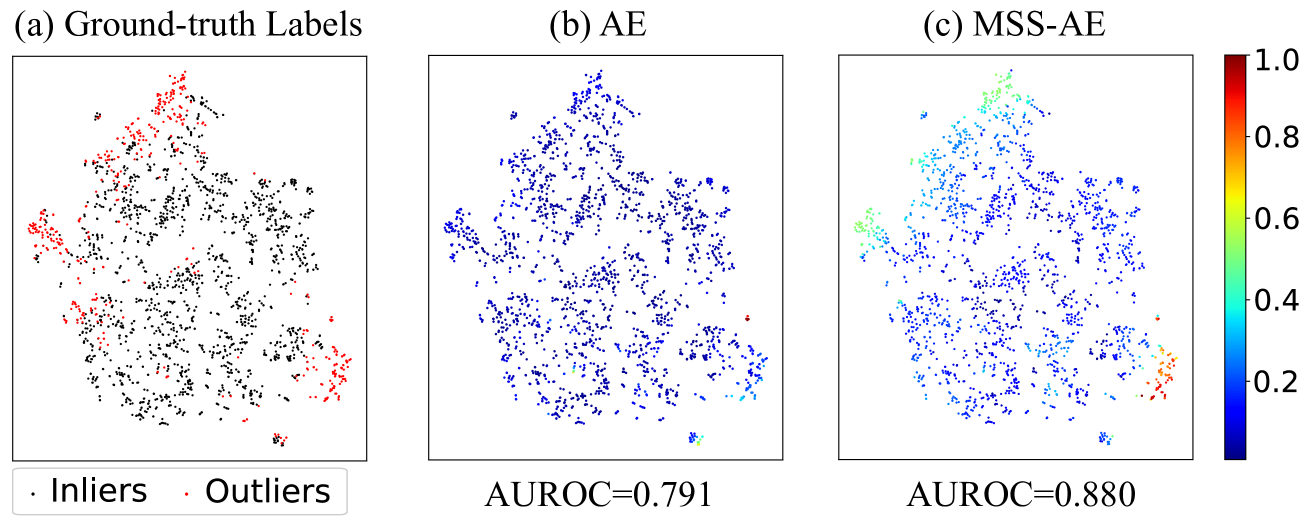
Figure 9: An illustration of the MSS method on the Cardiotocography dataset. The data in Cardiotocography were dimension-reduced to 2-D utilizing t-SNE. (a) showed the ground-truth label map of the data, in which the black points denote the inliers and the red points denote the outliers. (b) and (c) showed the outlier score map generated by AE and MSS-AE respectively.
An example of the effect of MSS was shown in Fig. 8. The outliers lying on the bottom left were exactly situated along the feature direction of inliers, thus their reconstruction errors were unexpectedly small, making identification of these outliers from inliers challenging. However, since they were far way from inliers, they could easily be identified after applying MSS with m=1 𝑚 1 m=1 italic_m = 1 and k=6 𝑘 6 k=6 italic_k = 6.
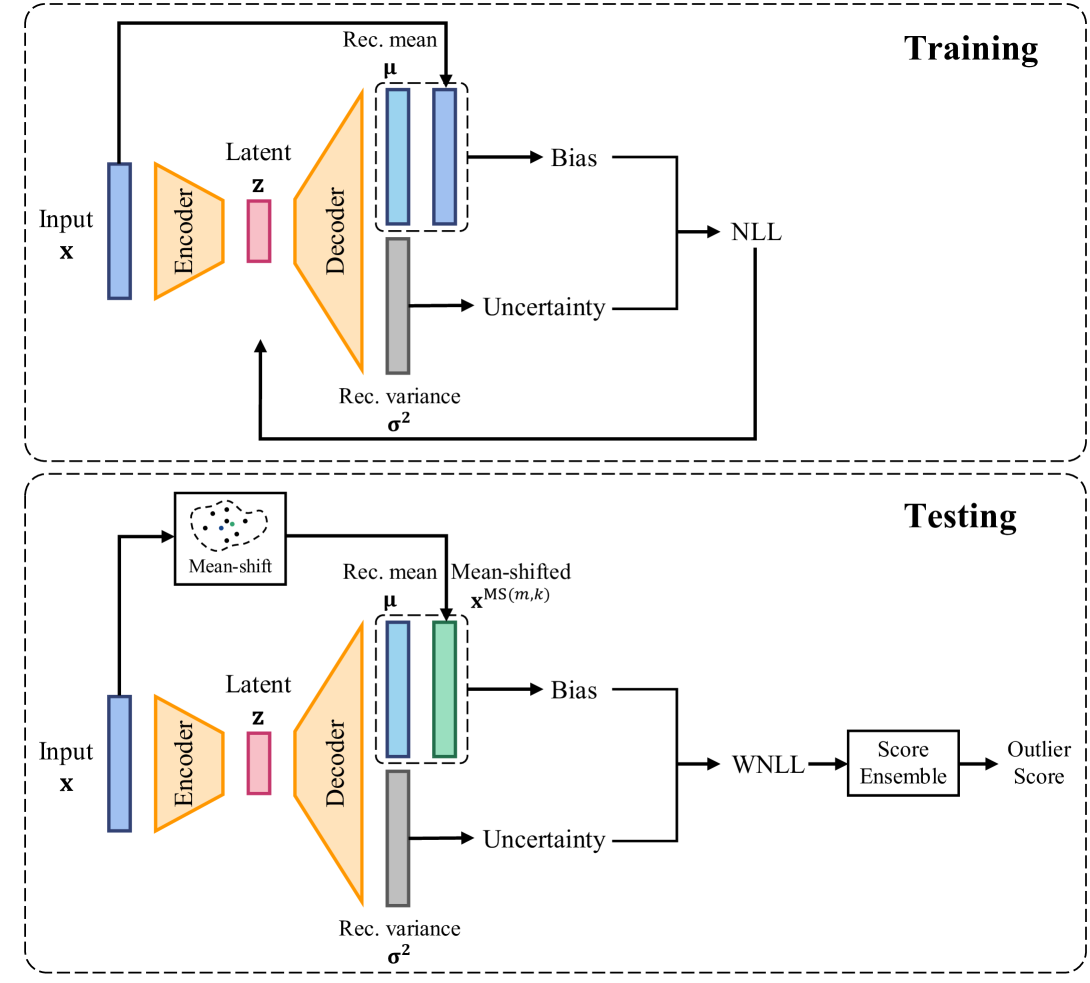
Figure 10: An illustration of the training and testing procedure of MSS-PAE. “Rec.” in the figure denotes “Reconstruction”.
Fig. 9 demonstrated an example of the MSS method on the Cardiotocography dataset. In this case, MSS was applied to the conventional AE, termed MSS-AE. For better presentation, the data in Cardiotocography were dimension-reduced to 2-D utilizing t-distributed stochastic neighbor embedding (t-SNE) [74]. Fig. 9. (a) showed the ground-truth label map of the data, where the black points denoted the inliers and the red points denoted the outliers. The outliers were observed to be distributed in the top left region and bottom right region of the map. Figs. 9. (b) and (c) illustrated the outlier score map generated by AE and MSS-AE respectively. The color scale corresponded to the outlier score of each object. The performance was evaluated by AUROC. AE could distinguish the part of the outliers lying at the bottom right and achieve a AUROC of 0.791, but could not distinguish the outliers at the top left either. The outlier scores were also not differentiable enough. In contrast, MSS-AE could distinguish both outliers lying at the bottom right and top left. MSS-AE provided more differentiable outlier scores and a significant improvement in AUROC performance to 0.880.
MSS could also be applied to PAE, producing MSS-PAE. An illustration of the training and testing procedure of MSS-PAE was shown in Fig. 10. The performance of MSS-PAE was evaluated in the Section 4.
4 Experiments
In this work, empirical experiments were conducted on 32 commonly used real-world outlier detection datasets. The proposed methods were compared with 5 typical AE-based OD methods (including AE itself), and proved the efficacy of applying MSS. A comparison was made against 8 classic non-AE-based SOTA OD methods.
The experiments answered the following questions:
How effective and flexible is WNLL in real-world scenarios? (Section 4.3.1)
How do hyper-parameters k 𝑘 k italic_k and m 𝑚 m italic_m affect MSS? (Section 4.3.2)
Is MSS beneficial for other AE-based methods? (Section 4.3.3)
Comparing the proposed methods with 5 AE-based and 8 non-AE-based OD methods, which one yields the best performance? (Section 4.3.3)
4.1 Datasets and baselines
32 real-world outlier detection datasets were obtained from DAMI 1 1 1 DAMI: www.dbs.ifi.lmu.de/research/outlier-evaluation/DAMI and ODDS 2 2 2 ODDS: odds.cs.stonybrook.edu dataset repositories. The summary of these datasets was shown in TABLE 1. We divided each dataset into the training set and test set with a ratio of 3:1. Then, one-third of the samples in the training set were selected to form the validation set. The outlier ratios were kept constant in all three sets, and the validation set and test set included the data labels but the training set did not. In addition, each attribute of the data was normalized to zero-mean and unit-variance using the Mean-SD normalization [75]. The mean value and the variance value were obtained from the training set. This operation was essential for the AE-based methods because it balanced the scale of each attribute of the data, lest the attributes with relatively large scale of values had unexpectedly bigger impacts on the model optimization.
To show the superiority of the proposed methods, 5 typical AE-based methods and 8 non-AE-based SOTA OD methods were used as the baselines. The AE-based methods included AE [25], RDA [26], LCAE [47], RSRAE [49] and FDAE [29]. The details of these methods were introduced in Section 2.2. The non-AE-based OD methods included proximity-based Local Outlier Factor (LOF) [10], Mean-shift Outlier Detector (MOD) [12], and Density-increasing Path (DIP) [76], classification-based One-Class Support Vector Machines (OCSVM) [16], ensemble-based Isolation Forest (iForest) [19] and Deep Isolation Forest (DIF) [77], probabilistic-based Histogram-based Outlier Score (HBOS) [23] and empirical-Cumulative-distribution-based Outlier Detection (ECOD) [24]. The AE-based methods were reproduced, compared to their original results, and the proposed MSS method was applied to improve the performance. All the methods were implemented using Python, and the implementation from PyOD [78] was utilized for non-AE-based methods except DIP, which was implemented using its original codes. AUROC was used as the evaluation metric.
Table 1: Information of 32 real-world outlier detection datasets.
Name Dimension Instances Outliers Ratio ALOI 27 49,534 1,508 3.0% Annthyroid 21 7,129 534 7.5% Arrhythmia 259 450 206 45.8% Breastw 9 683 239 35.0% Cardiotocography 21 2,114 466 22.0% Glass 7 214 9 4.2% HeartDisease 13 270 120 44.4% InternetAds 1,555 1,966 368 18.7% Ionosphere 32 351 126 35.9% Letter 32 1,600 100 6.3% Lymphography 3 148 6 4.1% Mammography 6 11,183 260 2.3% Mnist 100 7,603 700 9.2% Musk 166 3,062 97 3.2% Optdigits 64 5,216 150 2.9% PageBlocks 10 5,393 510 9.5% Parkinson 22 195 147 75.4% PenDigits 16 9,868 20 0.2% Pima 8 768 268 34.9% Satellite 36 6,435 2,036 31.6% Satimage-2 36 5,803 71 1.2% Shuttle 9 1,013 13 1.3% SpamBase 57 4,207 1,679 39.9% Speech 400 3,686 61 1.7% Stamps 9 340 31 9.1% Thyroid 6 3,772 93 2.5% Vertebral 6 240 30 12.5% Vowels 12 1,456 50 3.4% Waveform 21 3,443 100 2.9% Wilt 5 4,819 257 5.3% Wine 13 129 10 7.8% WPBC 33 198 47 23.7%
4.2 Experimental setup
4.2.1 Network architecture
The architecture of PAE had been introduced in Section 3.1. The model used NLL as the training loss function and WNLL as the scoring function. MSS is a universal scoring method that can be applied to most AE-based methods including the proposed PAE. As notations, application to AE produced MSS-AE and application to RSRAE produced MSS-RSRAE, etc.
Table 2: Architecture setting of the AE-based methods.
Dimsension (D)Number of layers Number of units <20 3[D, D // 2, D] ≥\geq≥20, <100 5[D, D // 2, D // 4, D // 2, D] ≥\geq≥100, <200 7[D, D // 2, D // 4, D // 8, D // 4, D // 2, D] ≥\geq≥200 7[D, D // 2, D // 4, D // 16, D // 4, D // 2, D]
Considering all data were tabular data, fully-connected layers were used to construct the AE. The number of the layers depended on the dimension of the input data. The detailed setting of the network architecture was shown in TABLE 2. Then, the rectified linear unit (ReLU) activation function was added after each layer of the AE except the last layer to increase the nonlinearity of the network. ReLU is widely used as an activation function in deep neural networks [79]. It mimics neuronal mechanisms in the human brain, and demonstrated good performance in many tasks while requiring minimal computational resources. The settings were applied to all the AE-based methods in this experiment.
Table 3: AUROC results of AE and PAE with different α 𝛼\alpha italic_α.
Dataset AE PAE* with different α 𝛼\alpha italic_α 0.20 0.33 0.50 0.66 0.80 ALOI 0.563 0.545 0.559 0.562 0.556 0.564 Annthyroid 0.608 0.799 0.793 0.790 0.850 0.835 Arrhythmia 0.714 0.736 0.740 0.624 0.706 0.649 Breastw 0.972 0.994 0.995 0.994 0.971 0.971 Cardiotocography 0.811 0.818 0.818 0.819 0.858 0.870 Glass 0.804 0.961 0.980 0.873 0.912 0.882 HeartDisease 0.813 0.865 0.871 0.859 0.831 0.768 InternetAds 0.706 0.685 0.681 0.671 0.674 0.697 Ionosphere 0.971 0.985 0.971 0.914 0.957 0.956 Letter 0.857 0.855 0.768 0.808 0.764 0.807 Lymphography 0.971 0.914 0.914 0.914 0.914 0.914 Mammography 0.893 0.884 0.882 0.891 0.877 0.874 Mnist 0.882 0.948 0.945 0.931 0.906 0.891 Musk 1.000 1.000 1.000 1.000 1.000 1.000 Optdigits 0.760 0.936 0.912 0.865 0.850 0.874 PageBlocks 0.952 0.962 0.946 0.949 0.942 0.953 Parkinson 0.627 0.815 0.662 0.711 0.611 0.576 PenDigits 0.879 0.951 0.929 0.913 0.897 0.907 Pima 0.651 0.756 0.736 0.698 0.696 0.683 Satellite 0.750 0.855 0.845 0.817 0.777 0.740 Satimage-2 0.993 0.983 0.983 0.988 0.988 0.988 Shuttle 0.995 0.996 0.988 0.992 0.992 0.992 SpamBase 0.565 0.847 0.793 0.712 0.646 0.650 Speech 0.551 0.541 0.532 0.561 0.597 0.495 Stamps 0.931 0.844 0.952 0.950 0.948 0.948 Thyroid 0.975 0.973 0.991 0.977 0.979 0.982 Vertebral 0.607 0.676 0.772 0.349 0.747 0.758 Vowels 0.937 0.968 0.976 0.972 0.955 0.931 Waveform 0.781 0.881 0.790 0.776 0.771 0.771 Wilt 0.383 0.822 0.823 0.818 0.861 0.879 Wine 0.914 0.879 0.897 0.897 0.914 0.914 WPBC 0.499 0.548 0.516 0.501 0.484 0.479 AVG.0.791 0.851 0.843 0.815 0.826 0.819 BEST 7 13 9 1 3 5
- 1.* denotes the proposed method.
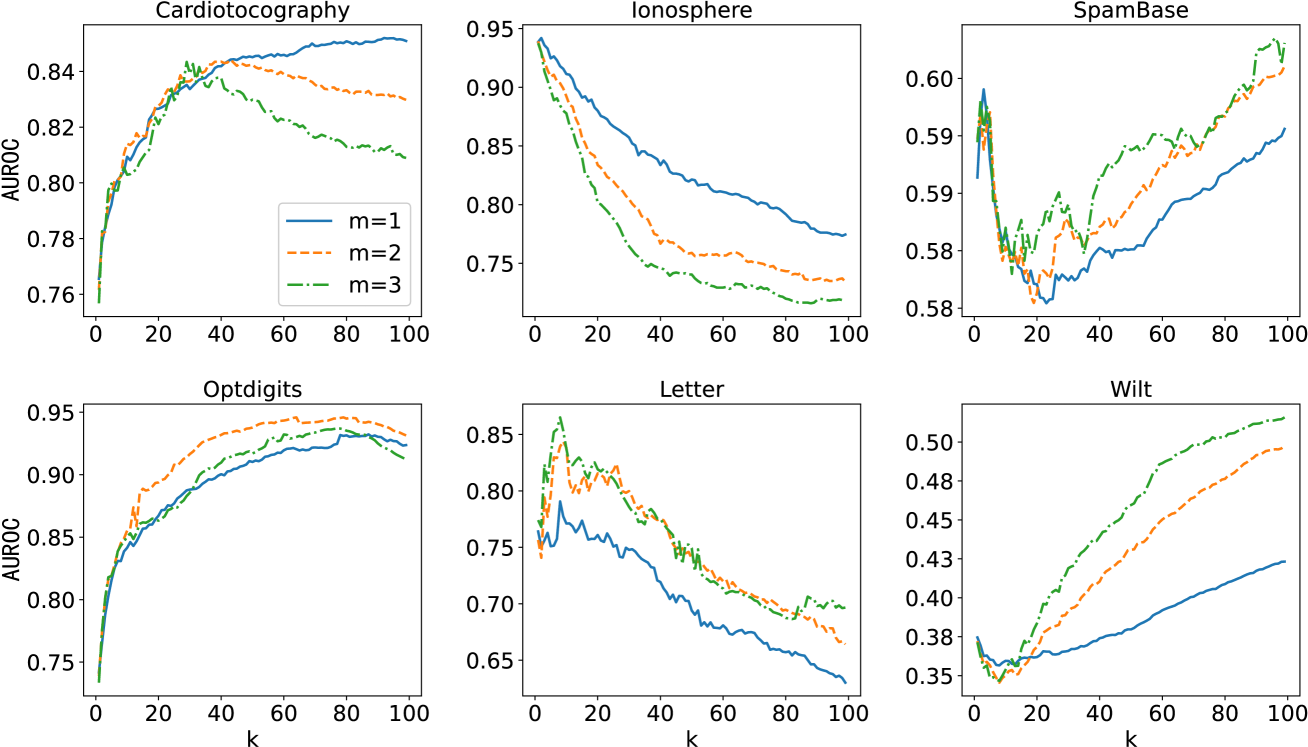
Figure 11: The performance curves as k 𝑘 k italic_k was increased from 1 to 99 on 6 datasets (Cardiotocography, Ionosphere, SpameBase, Optdigits, Letter and Wilt). Each individual graph has three curves with different m 𝑚 m italic_m denoting the time of mean-shifting. For each dataset, the k 𝑘 k italic_k-NN relationships were computed on the corresponding training set (3 4 3 4\frac{3}{4}divide start_ARG 3 end_ARG start_ARG 4 end_ARG size of the complete set) and the AUROC results were evaluated on the corresponding validation set.
4.2.2 Hyper-parameters
The proposed methods required three hyper-parameters, which were α 𝛼\alpha italic_α, m 𝑚 m italic_m, and k 𝑘 k italic_k. For WNLL, five different α 𝛼\alpha italic_α were tested: {0.20, 0.33, 0.50, 0.66, 0.8}. The results are shown in Section 4.3.1. For MSS, the mean-shift time m 𝑚 m italic_m was varied from 1 to 3. The number of nearest neighbors k 𝑘 k italic_k was selected from a candidate list 𝐤 𝐤\mathbf{k}bold_k. In our experiments, 𝐤=[1,2,⋯,min(99,N−1)]𝐤 1 2⋯99 𝑁 1\mathbf{k}=[1,2,\cdots,\min(99,N-1)]bold_k = [ 1 , 2 , ⋯ , roman_min ( 99 , italic_N - 1 ) ], where N 𝑁 N italic_N denotes the number of the instances in the training set. The performance was reported in Section 4.3.2.
4.2.3 Training strategy
All baseline methods and the proposed methods were trained on the training set, and tuned with the aid of the validation set. After training, the best models were tested on the testing set to obtain the final results. In addition, to increase the stability of AE-based methods, we applied an ensemble technique. 20 initial states were generated for AEs and trained separately. After training, these models were validated by the validation set to find the best 5 models. Finally, 5 outlier scores were computed on the 5 models for one test sample, then they were normalized and averaged as the final score. The source codes of the proposed method are available on Github for reproducibility 3 3 3 github.com/Ra1demmmm/Autoencoder-based-Outlier-Detection.
4.3 Experimental results
4.3.1 Evaluation of the probabilistic autoencoder
In this section, the performance of PAE was evaluated. As shown in TABLE 3, the average performance over 32 real-world datasets of PAE with all five values of α 𝛼\alpha italic_α was better than the general AE. The largest relative improvement of the average AUROC was 29% (0.851 vs. 0.791), comparing PAE (α=0.20 𝛼 0.20\alpha=0.20 italic_α = 0.20) and AE. Moreover, PAE significantly outperformed AE on some datasets, such as Annothyroid (0.850 vs. 0.608), Glass (0.980 vs. 0.804), Optdigits (0.936 vs. 0.760), SpamBase (0.847 vs. 0.565) and Wilt (0.879 vs. 0.383), which showed its superiority for specific applications.
The optimal value of α 𝛼\alpha italic_α was application-dependent. For example, on dataset ALOI, Cardiotocography, Wilt and Wine, the performance improved as α 𝛼\alpha italic_α increased, which implied that the reconstruction error or the negative effect of aleatoric uncertainty were more critical in these applications. In contrast, for datasets on dataset Optdigits, PenDigits, Satellite and Waveform, the performance improved as α 𝛼\alpha italic_α decreased, which implied that the positive effect of aleatoric uncertainty was more critical in these applications. The logical deduction was that a suitable value of α 𝛼\alpha italic_α should be selected based on the specific application to achieve the best OD performance.
The experiments illustrated that the average performance of all the other groups was better than the value of α=0.50 𝛼 0.50\alpha=0.50 italic_α = 0.50 (which was equivalent to NLL), which proved the importance of the adjustable parameters in WNLL. In addition, the value of α=0.20 𝛼 0.20\alpha=0.20 italic_α = 0.20 achieved the best performance on 13 datasets (41%) and the best average AUROC performance (0.851). This clearly demonstrated that the uncertainty of AE was critical for OD, and even more important than the commonly used bias measurement in many applications. Insufficient emphasis had been placed on this variable, and significant change could be brought about by the discovery in this experiment. This finding has potential to facilitate all AE-based methods in OD applications.
Table 4: AUROC results of AE vs. MSS-AE and PAE vs. MSS-PAE.
Dataset AE MSS-AE PAE MSS-PAE m=1 𝑚 1 m=1 italic_m = 1 m=2 𝑚 2 m=2 italic_m = 2 m=3 𝑚 3 m=3 italic_m = 3 m=1 𝑚 1 m=1 italic_m = 1 m=2 𝑚 2 m=2 italic_m = 2 m=3 𝑚 3 m=3 italic_m = 3 ALOI 0.563 0.558 0.563 0.561 0.545 0.630 0.658 0.664 Annthyroid 0.608 0.603 0.630 0.641 0.799 0.856 0.886 0.893 Arrhythmia 0.714 0.720 0.724 0.730 0.736 0.716 0.761 0.762 Breastw 0.972 0.994 0.987 0.987 0.994 0.994 0.996 0.992 Cardiotocography 0.811 0.875 0.888 0.877 0.818 0.841 0.844 0.844 Glass 0.804 0.922 0.863 0.951 0.961 0.804 0.824 0.843 HeartDisease 0.813 0.859 0.869 0.799 0.865 0.892 0.883 0.886 InternetAds 0.706 0.724 0.801 0.783 0.685 0.797 0.797 0.797 Ionosphere 0.971 0.978 0.975 0.973 0.985 0.962 0.964 0.962 Letter 0.857 0.844 0.860 0.853 0.855 0.748 0.742 0.798 Lymphography 0.971 1.000 1.000 1.000 0.914 0.971 1.000 1.000 Mammography 0.893 0.876 0.885 0.885 0.884 0.882 0.885 0.882 Mnist 0.882 0.876 0.881 0.882 0.948 0.949 0.949 0.948 Musk 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 Optdigits 0.760 0.957 0.970 0.981 0.936 0.994 0.993 0.992 PageBlocks 0.952 0.955 0.948 0.953 0.962 0.958 0.957 0.954 Parkinson 0.627 0.639 0.769 0.736 0.815 0.766 0.796 0.819 PenDigits 0.879 0.887 0.974 0.973 0.951 0.963 0.977 0.971 Pima 0.651 0.689 0.691 0.699 0.756 0.757 0.740 0.722 Satellite 0.750 0.788 0.789 0.763 0.855 0.856 0.857 0.857 Satimage-2 0.993 0.993 0.991 0.989 0.983 0.981 0.975 0.967 Shuttle 0.995 0.997 1.000 0.997 0.996 1.000 0.997 0.997 SpamBase 0.565 0.580 0.622 0.623 0.847 0.886 0.879 0.878 Speech 0.551 0.567 0.586 0.651 0.541 0.658 0.477 0.527 Stamps 0.931 0.961 0.915 0.950 0.844 0.954 0.942 0.837 Thyroid 0.975 0.972 0.963 0.960 0.973 0.994 0.991 0.990 Vertebral 0.607 0.755 0.750 0.745 0.676 0.687 0.712 0.703 Vowels 0.937 0.906 0.925 0.958 0.968 0.945 0.940 0.943 Waveform 0.781 0.792 0.826 0.872 0.881 0.895 0.897 0.901 Wilt 0.383 0.427 0.478 0.511 0.822 0.884 0.873 0.676 Wine 0.914 0.948 1.000 1.000 0.879 0.948 0.966 0.966 WPBC 0.499 0.506 0.413 0.477 0.548 0.415 0.428 0.450 AVG.0.791 0.817 0.829 0.836 0.851 0.862 0.862 0.857 BEST 6 9 11 14 8 12 11 11
4.3.2 Evaluation of the mean-shift outlier scoring
The number of nearest neighbors k 𝑘 k italic_k and the time of mean-shifting m 𝑚 m italic_m were two important parameters for the MSS method. In reality, they were all application-dependent. The effect of k 𝑘 k italic_k was demonstrated for MSS-AE on several datasets in Fig. 11. The figure illustrated the variation in performance as k 𝑘 k italic_k was increased for different datasets, and the distinct optimal k 𝑘 k italic_k for each dataset. Similar to all the k 𝑘 k italic_k-NN-based methods, this factor depended on the data structure of the specific application.
The AUROC results for MSS-AE and MSS-PAE (α=0.20 𝛼 0.20\alpha=0.20 italic_α = 0.20) were listed in TABLE 4. Variation of the time of mean-shifting m=1,2,3 𝑚 1 2 3 m=1,2,3 italic_m = 1 , 2 , 3 was tested for all three methods, and the optimal k 𝑘 k italic_k for each case was found using the validation set. The average results on 32 datasets demonstrated that MSS-AE and MSS-PAE triumphed their counterparts AE and PAE respectively. The best average AUROC performance for MSS-AE was 0.836 when m=3 𝑚 3 m=3 italic_m = 3, and for MSS-PAE, it was 0.858 when m=1 𝑚 1 m=1 italic_m = 1, which was the best among all competitors. For a total of 32 datasets, MSS-AE was better than AE for 27 datasets (84%), and MSS-PAE was better than PAE for 24 datasets (75%), which proved the effectiveness of the MSS. TABLE 4 illustrated that the MSS significantly improved the performance on the datasets where AE or PAE had poor performance, such as InternetAds, Optidigits, Speech and Vertebral. This proved that the combination of the AE-based method and the MSS was effective.
Table 5: AUROC results of 6 AE-based methods and their MSS- versions.
Dataset AE MSS-AE PAE MSS-PAE RDA MSS-RDA LCAE MSS-LCAE RSRAE MSS-RSRAE FDAE MSS-FDAE [25]**[26][47][49][29]* ALOI 0.563 0.563 0.564 0.706 0.562 0.557 0.553 0.584 0.549 0.571 0.547 0.540 Annthyroid 0.608 0.641 0.850 0.893 0.608 0.617 0.749 0.689 0.611 0.606 0.623 0.617 Arrhythmia 0.714 0.730 0.740 0.762 0.714 0.729 0.724 0.713 0.711 0.724 0.709 0.639 Breastw 0.972 0.994 0.995 0.996 0.972 0.995 0.988 0.993 0.995 0.996 0.993 0.989 Cardiotocography 0.811 0.888 0.870 0.899 0.811 0.888 0.812 0.883 0.812 0.901 0.812 0.901 Glass 0.804 0.951 0.980 0.853 0.863 0.980 0.922 0.863 0.745 0.941 0.755 0.951 HeartDisease 0.813 0.869 0.871 0.905 0.813 0.885 0.770 0.909 0.799 0.845 0.750 0.848 InternetAds 0.706 0.801 0.697 0.839 0.707 0.801 0.702 0.765 0.653 0.754 0.665 0.711 Ionosphere 0.971 0.978 0.985 0.978 0.968 0.968 0.980 0.977 0.965 0.962 0.949 0.952 Letter 0.857 0.860 0.855 0.798 0.820 0.833 0.855 0.832 0.867 0.794 0.829 0.793 Lymphography 0.971 1.000 0.914 1.000 0.971 1.000 0.971 1.000 1.000 1.000 1.000 1.000 Mammography 0.893 0.885 0.891 0.901 0.892 0.890 0.896 0.895 0.907 0.907 0.890 0.890 Mnist 0.882 0.882 0.948 0.949 0.882 0.889 0.925 0.919 0.891 0.886 0.892 0.882 Musk 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 Optdigits 0.760 0.981 0.936 0.995 0.760 0.981 0.759 0.950 0.795 0.998 0.818 0.990 PageBlocks 0.952 0.955 0.962 0.958 0.952 0.956 0.944 0.948 0.959 0.961 0.958 0.961 Parkinson 0.627 0.769 0.815 0.861 0.620 0.769 0.755 0.725 0.690 0.778 0.653 0.764 PenDigits 0.879 0.974 0.951 0.993 0.841 0.970 0.925 0.976 0.764 0.946 0.831 0.960 Pima 0.651 0.699 0.756 0.757 0.651 0.693 0.677 0.677 0.681 0.723 0.661 0.667 Satellite 0.750 0.789 0.855 0.857 0.745 0.791 0.830 0.858 0.817 0.829 0.840 0.847 Satimage-2 0.993 0.993 0.988 0.987 0.993 0.993 0.994 0.993 0.992 0.990 0.993 0.978 Shuttle 0.995 1.000 0.996 1.000 0.995 0.997 0.960 1.000 0.989 1.000 0.977 0.987 SpamBase 0.565 0.623 0.847 0.886 0.554 0.623 0.548 0.734 0.594 0.771 0.570 0.716 Speech 0.551 0.651 0.597 0.673 0.525 0.651 0.529 0.634 0.507 0.528 0.563 0.488 Stamps 0.931 0.961 0.952 0.954 0.957 0.961 0.941 0.974 0.941 0.957 0.941 0.918 Thyroid 0.975 0.972 0.991 0.994 0.976 0.972 0.980 0.980 0.982 0.982 0.971 0.970 Vertebral 0.607 0.755 0.772 0.841 0.593 0.755 0.676 0.808 0.602 0.745 0.703 0.695 Vowels 0.937 0.958 0.976 0.945 0.925 0.939 0.919 0.929 0.901 0.886 0.727 0.707 Waveform 0.781 0.872 0.881 0.901 0.781 0.817 0.834 0.758 0.783 0.859 0.802 0.812 Wilt 0.383 0.511 0.879 0.891 0.388 0.503 0.483 0.559 0.529 0.529 0.529 0.536 Wine 0.914 1.000 0.914 1.000 0.914 1.000 0.897 0.983 0.914 1.000 0.966 1.000 WPBC 0.499 0.506 0.548 0.484 0.499 0.506 0.526 0.575 0.612 0.521 0.585 0.764 AVG.0.791 0.844 0.868 0.889 0.789 0.841 0.813 0.846 0.799 0.840 0.797 0.827 BEST 1 4 4 19 1 4 2 6 4 9 2 6
Table 6: AUROC results of the proposed methods and non-AE-based baselines.
Dataset AE[25]PAE MSS-AE MSS-PAE ALOI 0.540 0.544 0.785 0.543 0.494 0.769 0.546 0.788 0.563 0.564 0.563 0.706 Annthyroid 0.739 0.652 0.696 0.601 0.670 0.716 0.504 0.728 0.608 0.850 0.641 0.893 Arrhythmia 0.732 0.740 0.705 0.711 0.755 0.718 0.530 0.731 0.714 0.740 0.730 0.762 Breastw 0.992 0.989 0.696 0.995 0.983 0.987 0.975 0.993 0.972 0.995 0.994 0.996 Cardiotocography 0.802 0.706 0.628 0.767 0.619 0.598 0.689 0.556 0.811 0.870 0.888 0.899 Glass 0.853 0.922 0.706 0.863 0.848 0.941 0.931 0.814 0.804 0.980 0.951 0.853 HeartDisease 0.687 0.721 0.777 0.730 0.774 0.758 0.723 0.845 0.813 0.871 0.869 0.905 InternetAds 0.722 0.764 0.632 0.653 0.736 0.660 0.750 0.696 0.706 0.697 0.801 0.839 Ionosphere 0.789 0.895 0.931 0.885 0.892 0.932 0.903 0.906 0.971 0.985 0.978 0.978 Letter 0.549 0.575 0.878 0.571 0.555 0.905 0.554 0.872 0.857 0.855 0.860 0.798 Lymphography 1.000 1.000 1.000 1.000 1.000 1.000 0.914 1.000 0.971 0.914 1.000 1.000 Mammography 0.914 0.864 0.805 0.863 0.811 0.844 0.776 0.843 0.893 0.891 0.885 0.901 Mnist 0.751 0.819 0.846 0.857 0.534 0.860 0.584 0.851 0.882 0.948 0.882 0.949 Musk 0.967 1.000 0.997 1.000 1.000 0.997 0.966 1.000 1.000 1.000 1.000 1.000 Optdigits 0.615 0.799 0.542 0.557 0.915 0.494 0.649 0.835 0.760 0.936 0.981 0.995 PageBlocks 0.914 0.905 0.933 0.930 0.766 0.921 0.929 0.915 0.952 0.962 0.955 0.958 Parkinson 0.350 0.414 0.789 0.384 0.676 0.669 0.484 0.609 0.627 0.815 0.769 0.861 PenDigits 0.392 0.758 0.936 0.539 0.761 0.976 0.764 0.985 0.879 0.951 0.974 0.993 Pima 0.537 0.592 0.641 0.631 0.656 0.634 0.637 0.690 0.651 0.756 0.699 0.757 Satellite 0.608 0.724 0.566 0.694 0.806 0.695 0.748 0.696 0.750 0.855 0.789 0.857 Satimage-2 0.969 0.992 0.976 0.996 0.980 0.998 0.996 0.998 0.993 0.988 0.993 0.987 Shuttle 0.723 0.820 0.993 0.989 0.803 0.989 0.900 0.988 0.995 0.996 1.000 1.000 SpamBase 0.679 0.622 0.474 0.537 0.690 0.538 0.552 0.662 0.565 0.847 0.623 0.886 Speech 0.507 0.527 0.698 0.506 0.518 0.734 0.582 0.627 0.551 0.597 0.651 0.673 Stamps 0.870 0.931 0.944 0.941 0.786 0.937 0.917 0.961 0.931 0.952 0.961 0.954 Thyroid 0.977 0.977 0.964 0.953 0.982 0.963 0.941 0.973 0.975 0.991 0.972 0.994 Vertebral 0.596 0.552 0.646 0.629 0.549 0.536 0.371 0.591 0.607 0.772 0.755 0.841 Vowels 0.632 0.767 0.939 0.792 0.682 0.984 0.760 0.979 0.937 0.976 0.958 0.945 Waveform 0.674 0.759 0.746 0.776 0.753 0.734 0.648 0.800 0.781 0.881 0.872 0.901 Wilt 0.350 0.437 0.690 0.295 0.323 0.667 0.478 0.640 0.383 0.879 0.511 0.891 Wine 0.897 0.862 0.931 0.879 0.966 0.931 0.897 0.879 0.914 0.914 1.000 1.000 WPBC 0.482 0.479 0.526 0.499 0.536 0.509 0.494 0.528 0.499 0.548 0.506 0.484 AVG.0.713 0.753 0.782 0.736 0.744 0.800 0.722 0.812 0.791 0.868 0.844 0.889 BEST 2 1 1 2 2 4 0 5 1 5 5 21
4.3.3 Comparison with baseline methods
To show the effectiveness of the proposed WNLL function and the versatility of the MSS method, the performance of PAE, 5 AE-based OD methods, and their mean-shifted versions were compared in TABLE 5. The parameters of all methods in this section were tuned to be optimal. The results of all MSS- versions were obtained with the optimal value of m 𝑚 m italic_m, and the results of PAE and MSS-PAE were obtained using the best value of α 𝛼\alpha italic_α. The table conclusively showed that all MSS- versions outperformed their original counterpart with average 20% of the relative performance improvement on the average AUROC, proving the versatility of the MSS method. Then among all standard versions, PAE achieved the best average AUROC performance, which gained a 29% relative improvement comparing to the second best method LCAE (0.868 vs. 0.813). Among all MSS- versions, MSS-PAE also achieved the best average AUROC performance, which gained a 28% relative improvement comparing to the second best method MSS-LCAE (0.889 vs. 0.846). This result suggested that the proposed WNLL was effective, especially when jointly incorporated with the MSS method.
To further demonstrate the superiority of the proposed methods, the performance comparison of the proposed method against 8 non-AE-based OD methods were summarized in TABLE 6. The results showed that the proposed PAE, MSS-AE, and MSS-PAE outperformed all the baselines on average AUROC, where MSS-PAE achieved the best performance on 21 datasets among all 32 datasets (66%) and had the best average AUROC of 0.889 (41% relative improvement comparing with DIP which was the best of 8 baselines). The results strongly proved the potency of combining the feature extraction (neural network), uncertainty estimation (probabilistic analysis), and local structure information (nearest-neighbor-graph). It indicated that the OD researchers should consider multiple instruments to design an outlier detector, to adapt various complex realistic scenarios.
5 Conclusion
In this paper, the issue of unexpected reconstruction was mitigated by two novel strategies. First, the overconfident issue and the role of aleatoric uncertainty for AE-based OD were analyzed. The analysis supported usage of NLL to train AE, and WNLL for outlier scoring. Several recommendations were provided for application of NLL and WNLL for various OD scenarios. Second, the MSS method was proposed to reduce the false inliers judged by the AE-based OD methods, by introducing the information of the local relationship.
The experimental results on 32 real-world OD datasets showed that the proposed methods significantly improved AE’s performance on OD. Specifically, WNLL was quite effective and flexible when adapting to different OD applications, and the proposed MSS method could be effectively applied to other AE-based OD methods. Furthermore, MSS-PAE, which was the combination of the proposed two methods, performed best among all baselines. Therefore, the experiments supported the use of the proposed WNLL and MSS simultaneously to get the best performance in practice. We believe that the MSS method can be used as a general plugin for most AE-based OD methods. In addition, NLL and WNLL may also be applied to improve the performance of other AE-based methods, and can be integrated with other loss functions, which were not evaluated in this paper but can be validated in the future research.
References
- [1] F.E. Grubbs, Procedures for detecting outlying observations in samples, Technometrics 11(1) (1969) 1–21.
- [2] M.Goldstein, S.Uchida, A comparative evaluation of unsupervised anomaly detection algorithms for multivariate data, PLoS ONE 11(4) (2016) e0152173.
- [3] J.Yang, S.Rahardja, S.Rahardja, Click fraud detection: Hk-index for feature extraction from variable-length time series of user behavior, in: Proc. of the IEEE Int. Workshop on Mach. Learn. for Signal Process. (MLSP), 2022, pp. 1–6.
- [4] P.Ghosh, A.Losalka, M.J. Black, Resisting adversarial attacks using gaussian mixture variational autoencoders, in: Proc. of the AAAI Conf. Artif. Intell., Vol.33, 2019, pp. 541–548.
- [5] J.Yang, G.I. Choudhary, S.Rahardja, P.Franti, Classification of interbeat interval time-series using attention entropy, IEEE Trans. Affect. Comput. 14(1) (2023) 321–330.
- [6] N.Li, F.Chang, Video anomaly detection and localization via multivariate gaussian fully convolution adversarial autoencoder, Neurocomputing 369 (2019) 92–105.
- [7] J.Yang, X.Tan, S.Rahardja, Mipo: How to detect trajectory outliers with tabular outlier detectors, Remote Sens. 14(21) (2022) 5394.
- [8] R.Domingues, M.Filippone, P.Michiardi, J.Zouaoui, A comparative evaluation of outlier detection algorithms: Experiments and analyses, Pattern Recognit. 74 (2018) 406–421.
- [9] S.Ramaswamy, R.Rastogi, K.Shim, Efficient algorithms for mining outliers from large data sets, in: Proc. of the ACM SIGMOD Int. Conf. on Management of Data, 2000, pp. 427–438.
- [10] M.M. Breunig, H.-P. Kriegel, R.T. Ng, J.Sander, Lof: identifying density-based local outliers, in: Proc. of the ACM SIGMOD Int. Conf. on Management of Data, 2000, pp. 93–104.
- [11] H.Du, S.Zhao, D.Zhang, J.Wu, Novel clustering-based approach for local outlier detection, in: Proc. of the IEEE Conf. on Comput. Commun. Workshops (INFOCOM WKSHPS), 2016, pp. 802–811.
- [12] J.Yang, S.Rahardja, P.Fränti, Mean-shift outlier detection and filtering, Pattern Recognit. 115 (2021) 107874.
- [13] X.-m. Tang, R.-x. Yuan, J.Chen, Outlier detection in energy disaggregation using subspace learning and gaussian mixture model, Int. J. Control Autom. 8(8) (2015) 161–170.
- [14] P.I. Dalatu, A.Fitrianto, A.Mustapha, A comparative study of linear and nonlinear regression models for outlier detection, in: Proc. of the Int. Conf. on Soft Comput. and Data Mining (SCDM), 2017, pp. 316–326.
- [15] L.J. Latecki, A.Lazarevic, D.Pokrajac, Outlier detection with kernel density functions, in: Proc. of the Int. Workshop on Mach. Learn. and Data Mining in Pattern Recognit. (MLDM), 2007, pp. 61–75.
- [16] B.Schölkopf, J.C. Platt, J.Shawe-Taylor, A.J. Smola, R.C. Williamson, Estimating the support of a high-dimensional distribution, Neural Comput. 13(7) (2001) 1443–1471.
- [17] D.M. Tax, R.P. Duin, Support vector data description, Mach. Learn. 54(1) (2004) 45–66.
- [18] L.Ruff, R.A. Vandermeulen, N.Görnitz, A.Binder, E.Müller, K.-R. Müller, M.Kloft, Deep semi-supervised anomaly detection, arXiv preprint arXiv:1906.02694 (2019).
- [19] F.T. Liu, K.M. Ting, Z.-H. Zhou, Isolation forest, in: Proc. of the IEEE Int. Conf. on Data Mining (ICDM), 2008, pp. 413–422.
- [20] X.Tan, J.Yang, S.Rahardja, Sparse random projection isolation forest for outlier detection, Pattern Recognit. Lett. 163 (2022) 65–73.
- [21] T.Pevnỳ, Loda: Lightweight on-line detector of anomalies, Mach. Learn. 102(2) (2016) 275–304.
- [22] Y.Zhao, X.Hu, C.Cheng, C.Wang, C.Wan, W.Wang, J.Yang, H.Bai, Z.Li, C.Xiao, et al., Suod: Accelerating large-scale unsupervised heterogeneous outlier detection, Proc. of the Mach. Learn. Syst. (MLSys) 3 (2021) 463–478.
- [23] M.Goldstein, A.Dengel, Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm, KI-2012: poster and demo track 9 (2012).
- [24] Z.Li, Y.Zhao, X.Hu, N.Botta, C.Ionescu, G.Chen, Ecod: Unsupervised outlier detection using empirical cumulative distribution functions, IEEE Trans. Knowl. Data Eng. (2022).
- [25] S.Hawkins, H.He, G.Williams, R.Baxter, Outlier detection using replicator neural networks, in: Proc. of the Int. Conf. on Data Warehousing and Knowl. Discov. (DaWaK), 2002, pp. 170–180.
- [26] C.Zhou, R.C. Paffenroth, Anomaly detection with robust deep autoencoders, in: Proc. of the ACM SIGKDD Int. Conf. on Knowl. Discov. and Data Mining (KDD), 2017, pp. 665–674.
- [27] J.An, S.Cho, Variational autoencoder based anomaly detection using reconstruction probability, Special Lecture on IE 2(1) (2015) 1–18.
- [28] C.-H. Lai, D.Zou, G.Lerman, Robust subspace recovery layer for unsupervised anomaly detection, in: Proc. of the Eighth Int. Conf. on Learn. Representations (ICLR), 2020, pp. 1–28.
- [29] Y.Guo, X.Zhu, Z.Hu, Z.Zhan, Unsupervised anomaly detection by autoencoder with feature decomposition, in: Proc. of the Int. Conf. on Mach. Learn. and Comput. (ICMLC), 2022, pp. 258–265.
- [30] F.Angiulli, F.Fassetti, L.Ferragina, Latent out: an unsupervised deep anomaly detection approach exploiting latent space distribution, Mach. Learn. (2022) 1–27.
- [31] T.Schlegl, P.Seeböck, S.M. Waldstein, U.Schmidt-Erfurth, G.Langs, Unsupervised anomaly detection with generative adversarial networks to guide marker discovery, in: Proc. of the Int. Conf. on Inf. Process. in Med. Imaging (IPMI), 2017, pp. 146–157.
- [32] S.Akcay, A.Atapour-Abarghouei, T.P. Breckon, Ganomaly: Semi-supervised anomaly detection via adversarial training, in: Proc. of the Asian Conf. on Comput. Vis. (ACCV), 2018, pp. 622–637.
- [33] B.I. Ibrahim, D.C. Nicolae, A.Khan, S.I. Ali, A.Khattak, Vae-gan based zero-shot outlier detection, in: Proc. of the Int. Symp. on Comput. Sci. and Intell. Control (ISCSIC), 2020, pp. 1–5.
- [34] Z.Yang, T.Zhang, I.S. Bozchalooi, E.Darve, Memory-augmented generative adversarial networks for anomaly detection, IEEE Trans. Neural Netw. Learn. Syst. 33(6) (2022) 2324–2334.
- [35] R.Chalapathy, S.Chawla, Deep learning for anomaly detection: A survey, arXiv preprint arXiv:1901.03407 (2019).
- [36] D.A. Nix, A.S. Weigend, Estimating the mean and variance of the target probability distribution, in: Proceedings of 1994 ieee international conference on neural networks (ICNN’94), Vol.1, IEEE, 1994, pp. 55–60.
- [37] A.A. Pol, V.Berger, C.Germain, G.Cerminara, M.Pierini, Anomaly detection with conditional variational autoencoders, in: 2019 18th IEEE international conference on machine learning and applications (ICMLA), IEEE, 2019, pp. 1651–1657.
- [38] Y.Mao, F.-F. Xue, R.Wang, J.Zhang, W.-S. Zheng, H.Liu, Abnormality detection in chest x-ray images using uncertainty prediction autoencoders, in: Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part VI 23, Springer, 2020, pp. 529–538.
- [39] H.Choi, E.Jang, A.A. Alemi, Waic, but why? generative ensembles for robust anomaly detection, arXiv preprint arXiv:1810.01392 (2018).
- [40] B.X. Yong, A.Brintrup, Bayesian autoencoders with uncertainty quantification: Towards trustworthy anomaly detection, Expert Systems with Applications 209 (2022) 118196.
- [41] N.Merrill, A.Eskandarian, Modified autoencoder training and scoring for robust unsupervised anomaly detection in deep learning, IEEE Access 8 (2020) 101824–101833.
- [42] I.Goodfellow, Y.Bengio, A.Courville, Deep learning, MIT press, 2016.
- [43] S.Wold, K.Esbensen, P.Geladi, Principal component analysis, Chemom. Intell. Lab. Syst. 2(1-3) (1987) 37–52.
- [44] B.B. Thompson, R.J. Marks, J.J. Choi, M.A. El-Sharkawi, M.-Y. Huang, C.Bunje, Implicit learning in autoencoder novelty assessment, in: Proc. of the Int. Joint Conf. on Neural Netw. (IJCNN), Vol.3, 2002, pp. 2878–2883.
- [45] B.Zong, Q.Song, M.R. Min, W.Cheng, C.Lumezanu, D.Cho, H.Chen, Deep autoencoding gaussian mixture model for unsupervised anomaly detection, in: International conference on learning representations, 2018.
- [46] J.Chen, S.Sathe, C.Aggarwal, D.Turaga, Outlier detection with autoencoder ensembles, in: Proc. of the SIAM Int. Conf. on Data Mining (SDM), 2017, pp. 90–98.
- [47] Y.Ishii, M.Takanashi, Low-cost unsupervised outlier detection by autoencoders with robust estimation, J. Inf. Process. 27 (2019) 335–339.
- [48] D.Gong, L.Liu, V.Le, B.Saha, M.R. Mansour, S.Venkatesh, A.v.d. Hengel, Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection, in: Proc. of the IEEE/CVF Int. Conf. on Comput. Vis. (ICCV), 2019, pp. 1705–1714.
- [49] Q.Yu, M.Kavitha, T.Kurita, Autoencoder framework based on orthogonal projection constraints improves anomalies detection, Neurocomputing 450 (2021) 372–388.
- [50] B.Lakshminarayanan, A.Pritzel, C.Blundell, Simple and scalable predictive uncertainty estimation using deep ensembles, Advances in neural information processing systems 30 (2017).
- [51] E.Nalisnick, A.Matsukawa, Y.W. Teh, D.Gorur, B.Lakshminarayanan, Do deep generative models know what they don’t know?, arXiv preprint arXiv:1810.09136 (2018).
- [52] D.Hafner, D.Tran, T.Lillicrap, A.Irpan, J.Davidson, Noise contrastive priors for functional uncertainty, in: Uncertainty in Artificial Intelligence, PMLR, 2020, pp. 905–914.
- [53] M.Sensoy, L.Kaplan, F.Cerutti, M.Saleki, Uncertainty-aware deep classifiers using generative models, in: Proceedings of the AAAI conference on artificial intelligence, Vol.34, 2020, pp. 5620–5627.
- [54] X.-Y. Zhang, G.-S. Xie, X.Li, T.Mei, C.-L. Liu, A survey on learning to reject, Proceedings of the IEEE 111(2) (2023) 185–215.
- [55] N.Ståhl, G.Falkman, A.Karlsson, G.Mathiason, Evaluation of uncertainty quantification in deep learning, in: International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Springer, 2020, pp. 556–568.
- [56] A.Der Kiureghian, O.Ditlevsen, Aleatory or epistemic? does it matter?, Structural safety 31(2) (2009) 105–112.
- [57] A.Kendall, Y.Gal, What uncertainties do we need in bayesian deep learning for computer vision?, Advances in neural information processing systems 30 (2017).
- [58] J.Gawlikowski, C.R.N. Tassi, M.Ali, J.Lee, M.Humt, J.Feng, A.Kruspe, R.Triebel, P.Jung, R.Roscher, et al., A survey of uncertainty in deep neural networks, Artificial Intelligence Review 56(Suppl 1) (2023) 1513–1589.
- [59] C.Blundell, J.Cornebise, K.Kavukcuoglu, D.Wierstra, Weight uncertainty in neural network, in: International conference on machine learning, PMLR, 2015, pp. 1613–1622.
- [60] Y.Gal, Z.Ghahramani, Dropout as a bayesian approximation: Representing model uncertainty in deep learning, in: international conference on machine learning, PMLR, 2016, pp. 1050–1059.
- [61] C.Nemeth, P.Fearnhead, Stochastic gradient markov chain monte carlo, Journal of the American Statistical Association 116(533) (2021) 433–450.
- [62] T.Pearce, F.Leibfried, A.Brintrup, Uncertainty in neural networks: Approximately bayesian ensembling, in: International conference on artificial intelligence and statistics, PMLR, 2020, pp. 234–244.
- [63] A.Legrand, H.Trannois, A.Cournier, Use of uncertainty with autoencoder neural networks for anomaly detection, in: 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), IEEE, 2019, pp. 32–35.
- [64] C.Baur, B.Wiestler, S.Albarqouni, N.Navab, Bayesian skip-autoencoders for unsupervised hyperintense anomaly detection in high resolution brain mri, in: 2020 IEEE 17th international symposium on biomedical imaging (ISBI), IEEE, 2020, pp. 1905–1909.
- [65] E.Daxberger, J.M. Hernández-Lobato, Bayesian variational autoencoders for unsupervised out-of-distribution detection, arXiv preprint arXiv:1912.05651 (2019).
- [66] S.Park, G.Adosoglou, P.M. Pardalos, Interpreting rate-distortion of variational autoencoder and using model uncertainty for anomaly detection, Annals of Mathematics and Artificial Intelligence 90(7) (2022) 735–752.
- [67] B.X. Yong, T.Pearce, A.Brintrup, Bayesian autoencoders: Analysing and fixing the bernoulli likelihood for out-of-distribution detection, arXiv preprint arXiv:2107.13304 (2021).
- [68] K.Fukunaga, L.Hostetler, The estimation of the gradient of a density function, with applications in pattern recognition, IEEE Trans. Inf. Theory 21(1) (1975) 32–40.
- [69] Y.Cheng, Mean shift, mode seeking, and clustering, IEEE Trans. on Pattern Anal. Mach. Intell. 17(8) (1995) 790–799.
- [70] D.Comaniciu, P.Meer, Mean shift: A robust approach toward feature space analysis, IEEE Trans. Pattern Anal. Mach. Intell. 24(5) (2002) 603–619.
- [71] R.T. Collins, Mean-shift blob tracking through scale space, in: Proc. of the IEEE Int. Conf. on Comput. Vis. and Pattern Recognit. (CVPR), Vol.2, 2003, pp. II–234.
- [72] J.Yang, Outlier detection techniques, Ph.D. thesis, University of Eastern Finland (2020).
- [73] J.Yang, Y.Chen, S.Rahardja, Neighborhood representative for improving outlier detectors, Inf. Sci. (2022).
- [74] L.Van der Maaten, G.Hinton, Visualizing data using t-sne., J. Mach. Learn. Res. 9(11) (2008).
- [75] S.Kandanaarachchi, M.A. Muñoz, R.J. Hyndman, K.Smith-Miles, On normalization and algorithm selection for unsupervised outlier detection, Data Min. Knowl. Discov. 34(2) (2020) 309–354.
- [76] J.Zhao, F.Deng, J.Zhu, J.Chen, Searching density-increasing path to local density peaks for unsupervised anomaly detection, IEEE Transactions on Big Data (2023).
- [77] H.Xu, G.Pang, Y.Wang, Y.Wang, Deep isolation forest for anomaly detection, IEEE Transactions on Knowledge and Data Engineering (2023).
- [78] Y.Zhao, Z.Nasrullah, Z.Li, Pyod: A python toolbox for scalable outlier detection, J. Mach. Learn. Res. 20 (2019) 1–7.
- [79] P.Ramachandran, B.Zoph, Q.V. Le, Searching for activation functions, arXiv preprint arXiv:1710.05941 (2017).
Xet Storage Details
- Size:
- 118 kB
- Xet hash:
- e59900e03d9c75f04a5f94f0070b027e6cc59ce1baaf99b69be7ba17ea80777e
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.