Buckets:

Title: Large Language Models with Graph Augmentation for Recommendation
URL Source: https://arxiv.org/html/2311.00423
Markdown Content: (2024)
Abstract.
The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git.
Large Language Models, Graph Learning, Data Augmentation, Content-based Recommendation, Multi-modal Recommendation, Collaborative Filtering, Data Sparsity, Bias in Recommender System
††copyright: acmlicensed††journalyear: 2024††doi: 10.1145/3616855.3635853††conference: Proceedings of the 17th ACM International Conference on Web Search and Data Mining; March 4–8, 2024; Merida, Mexico††booktitle: Proceedings of the 17th ACM International Conference on Web Search and Data Mining (WSDM ’24), March 4–8, 2024, Merida, Mexico††price: 15.00††isbn: 979-8-4007-0371-3/24/03††ccs: Information systems Recommender systems 1. Introduction
Recommender systems play a crucial role in mitigating information overload by providing online users with relevant content(Meng et al., 2023b; Wei et al., 2022). To achieve this, an effective recommender needs to have a precise understanding of user preferences, which is not limited to analyzing historical interaction patterns but also extends to incorporating rich side information associated with users and items(Zou et al., 2022).
In modern recommender systems, such as Netflix, the side information available exhibits heterogeneity, including item attributes (Ying et al., 2023), user-generated content (Fan et al., 2019; Meng et al., 2023c), and multi-modal features (Yi et al., 2022) encompassing both textual and visual aspects. This diverse content offer distinct ways to characterize user preferences. By leveraging such side information, models can obtain informative representations to personalize recommendations. However, despite significant progress, these methods often face challenges related to data scarcity and issues associated with handling side information.
Sparse Implicit Feedback Signals. Data sparsity and the cold-start problem hinder collaborative preference capturing (Wei et al., 2021b). While many efforts (e.g., NGCF(Wang et al., 2019), LightCGN(He et al., 2020)) tried powerful graph neural networks(GNNs) in collaborative filtering(CF), they face limits due to insufficient supervised signals. Some studies (Ren et al., 2023b) used contrastive learning to add self-supervised signals (e.g., SGL(Wu et al., 2021), SimGCL(Yu et al., 2022)). However, considering that real-world online platforms (e.g., Netflix, MovieLens) derive benefits from modal content, recent approaches, unlike general CF, are dedicated to incorporating side information as auxiliary for recommenders. For example, MMGCN (Wei et al., 2019) and GRCN (Wei et al., 2020) incorporate item-end content into GNNs to discover high-order content-aware relationships. LATTICE (Zhang et al., 2021b) leverages auxiliary content to conduct data augmentation by establishing i-i relationships. Recent efforts (e.g., MMSSL (Wei et al., 2023a), MICRO (Zhang et al., 2022)) address sparsity by introducing self-supervised tasks that maximize the mutual information between multiple content-augmented views. However, strategies for addressing data sparsity in recommender systems, especially in multi-modal content, can sometimes be limited. This is because the complexity and lack of side information relevance to CF can introduce distortions in the underlying patterns (Wei et al., 2020). Therefore, it becomes crucial to ensure the accurate capture of realistic user preferences when incorporating side information in CF, in order to avoid suboptimal results.
Data Quality Issues of Side Information. Recommender systems that incorporate side information often encounter significant issues that can negatively impact their performance. i) Data Noise is an important limitation faced by recommender systems utilizing side information is the issue of data noise(Tian et al., 2022), where attributes or features may lack direct relevance to user preferences. For instance, in a micro video recommender, the inclusion of irrelevant textual titles that fail to capture the key aspects of the video’s content introduces noise, adversely affecting representation learning. The inclusion of such invalid information confuse the model and lead to biased or inaccurate recommendations. ii) Data heterogeneity(Chen et al., 2023a) arises from the integration of different types of side information, each with its own unique characteristics, structures, and representations. Ignoring this heterogeneity leads to skewed distributions (Ying et al., 2023; Meng et al., 2023a). Bridging heterogeneous gap is crucial for successfully incorporating side information uniformly. iii) Data incompleteness(Ko et al., 2022; Liang et al., 2023b) occurs when side information lacks certain attributes or features. For instance, privacy concerns(Zhang et al., 2023a) may make it difficult to collect sufficient user profiles to learn their interests. Additionally, items may have incomplete textual descriptions or missing key attributes. This incompleteness impairs the model’s ability to fully capture the unique characteristics of users and items, thereby affecting the accuracy of recommendations.
Having gained insight into data sparsity and low-quality encountered by modern recommenders with auxiliary content, this work endeavors to overcome these challenges through explicit augment potential user-item interactive edges as well as enhances user/item node side information (e.g., language, genre). Inspired by the impressive natural language understanding ability of large language models (LLMs), we utilize LLMs to augment the interaction graph. Firstly, LLMRec embraces the shift from an ID-based recommendation framework to a modality-based paradigm (Li et al., 2023a; Yuan et al., 2023). It leverages large language models (LLMs) to predict user-item interactions from a natural language perspective. Unlike previous approaches that rely solely on IDs, LLMRec recognizes that valuable item-related details are often overlooked in datasets (Li et al., 2023b). Natural language representations provide a more intuitive reflection of user preferences compared to indirect ID embeddings. By incorporating LLMs, LLMRec captures the richness and context of natural language, enhancing the accuracy and effectiveness of recommendations. Secondly, to elaborate further, the low-quality and incomplete side information is enhanced by leveraging the extensive knowledge of LLMs, which brings two advantages: i) LLMs are trained on vast real-world knowledge, allowing them to understand user preferences and provide valuable completion information, even for privacy-constrained user profiles. ii) The comprehensive word library of LLMs unifies embeddings in a single vector space, bridging the gap between heterogeneous features and facilitating encoder computations. This integration prevents the dispersion of features across separate vector spaces and provide more accurate results.
Enabling LLMs as effective data augmentors for recommenders poses several technical challenges that need to be addressed:
• C1: How to enable LLMs to reason over user-item interaction patterns by explicitly augmenting implicit feedback signals?
• C2: How to ensure the reliability of the LLM-augmented content to avoid introducing noise that could compromise the results?
The potential of LLM-based augmentation to enhance recommenders by addressing sparsity and improving incomplete side information is undeniable. However, effectively implementing this approach requires addressing the aforementioned challenges. Hence, we have designed a novel framework LLMRec to tackle these challenges.
Solution. Our objective is to address the issue of sparse implicit feedback signals derived from user-item interactions while simultaneously improving the quality of side information. Our proposed LLMRec incorporates three LLM-based strategies for augmenting the interaction graph: i) Reinforcing user-item interaction edges, ii) Enhancing item attribute modeling, and iii) Conducting user profiling. To tackle C1 for ’_i)_’, we devise an LLM-based Bayesian Personalized Ranking (BPR)(Rendle et al., 2012) sampling algorithm. This algorithm uncover items that users may like or dislike based on textual content from from natural language perspective. These items are then used as positive and negative samples in the BPR training process. It is important to note that LLMs are unable to perform all-item ranking, so the selected items are chosen from a candidate item pool provided by the base recommender for each user. During the node attribute generation process (corresponding to ’_ii)_’ and ’_iii)_’), we create additional attributes for each user/item using existing text and interaction history. However, it is important to acknowledge that both the augmented edges and node features can contain noise. To address C2, our denoised data robustification mechanism comes into play by integrating noisy edge pruning and feature MAE(Tian et al., 2023a) to ensure the quality of the augmented data.
In summary, our contributions can be outlined as follows:
• The LLMRec is the pioneering work that using LLMs for graph augmentation in recommender by augmenting: user-item interaction edges, ii) item node attributes, iii) user node profiles.
•The proposed LLMRec addresses the scarcity of implicit feedback signals by enabling LLMs to reason explicitly about user-item interaction patterns. Additionally, it resolves the low-quality side information issue through user/item attribute generation and a denoised augmentation robustification mechanism with the noisy feedback pruning and MAE-based feature enhancement.
• Our method has been extensively evaluated on real-world datasets, demonstrating its superiority over state-of-the-art baseline methods. The results highlight the effectiveness of our approach in improving recommendation accuracy and addressing sparsity issues. Furthermore, in-depth analysis and ablation studies provide valuable insights into the impact of our LLM-enhanced data augmentation strategies, further solidifying the model efficacy.
- Preliminary
Recommendation with Graph Embedding. Collaborative filtering (CF) learns from sparse implicit feedback ℰ+superscript ℰ\mathcal{E}^{+}caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT, with the aim of learning collaborative ID-corresponding embeddings 𝐄 u,𝐄 i subscript 𝐄 𝑢 subscript 𝐄 𝑖\textbf{E}{u},\textbf{E}{i}E start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , E start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT for recommender prediction, given user u∈𝒰 𝑢 𝒰 u\in\mathcal{U}italic_u ∈ caligraphic_U and item i∈ℐ 𝑖 ℐ i\in\mathcal{I}italic_i ∈ caligraphic_I. Recent advanced recommenders employ GNNs to model complex high-order(Tian et al., 2023b) u-i relation by taking ℰ+superscript ℰ\mathcal{E}^{+}caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT as edges of sparse interactive graph. Therefore, the CF process can be separated into two stages, bipartite graph embedding, and u-i prediction. Optimizing collaborative graph embeddings 𝐄={𝐄 u,𝐄 i}𝐄 subscript 𝐄 𝑢 subscript 𝐄 𝑖\textbf{E}={\textbf{E}{u},\textbf{E}{i}}E = { E start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , E start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } aims to maximize the posterior estimator with ℰ+superscript ℰ\mathcal{E}^{+}caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT, which is formally presented below:
(1)𝐄*=argmax 𝐄p(𝐄|ℰ+)superscript 𝐄 subscript arg max 𝐄 𝑝 conditional 𝐄 superscript ℰ\displaystyle\textbf{E}^{}=\operatorname{arg,max}\limits_{\textbf{E}}p(% \textbf{E}|\mathcal{E}^{+})E start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT = start_OPERATOR roman_arg roman_max end_OPERATOR start_POSTSUBSCRIPT E end_POSTSUBSCRIPT italic_p ( E | caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT )
Here, p(𝐄|ℰ+)𝑝 conditional 𝐄 superscript ℰ p(\textbf{E}|\mathcal{E}^{+})italic_p ( E | caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT ) is to encode as much u-i relation from ℰ+superscript ℰ\mathcal{E}^{+}caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT into 𝐄 u,𝐄 i subscript 𝐄 𝑢 subscript 𝐄 𝑖\textbf{E}{u},\textbf{E}{i}E start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , E start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT as possible for accurate u-i prediction y^u,i=𝐞 u⋅𝐞 i subscript^𝑦 𝑢 𝑖⋅subscript 𝐞 𝑢 subscript 𝐞 𝑖\hat{y}{u,i}=\textbf{e}{u}\cdot\textbf{e}_{i}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i end_POSTSUBSCRIPT = e start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ⋅ e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT.
Recommendation with Side Information. However, sparse interactions in ℰ+superscript ℰ\mathcal{E}^{+}caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT pose a challenge for optimizing the embeddings. To handle data sparsity, many efforts introduced side information in form of node features F, by taking recommender encoder f Θ subscript 𝑓 Θ f_{\Theta}italic_f start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT as feature graph. The learning process of the f Θ subscript 𝑓 Θ f_{\Theta}italic_f start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT (including 𝐄 u,𝐄 i subscript 𝐄 𝑢 subscript 𝐄 𝑖\textbf{E}{u},\textbf{E}{i}E start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , E start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and feature encoder) with side information F is formulated as maximizing the posterior estimator p(Θ|𝐅,ℰ+)𝑝 conditional Θ 𝐅 superscript ℰ p(\Theta|\textbf{F},\mathcal{E}^{+})italic_p ( roman_Θ | F , caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT ):
(2)Θ*=argmax Θp(Θ|𝐅,ℰ+)superscript Θ subscript arg max Θ 𝑝 conditional Θ 𝐅 superscript ℰ\displaystyle\Theta^{}=\operatorname{arg,max}\limits_{\Theta}p(\Theta|% \textbf{F},\mathcal{E}^{+})roman_Θ start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT = start_OPERATOR roman_arg roman_max end_OPERATOR start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT italic_p ( roman_Θ | F , caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT )
f Θ subscript 𝑓 Θ f_{\Theta}italic_f start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT will output the final representation h contain both collaborative signals from E and side information from F, i.e., 𝐡=f Θ(𝐟,ℰ+)𝐡 subscript 𝑓 Θ 𝐟 superscript ℰ\textbf{h}=f_{\Theta}(\textbf{f},\mathcal{E}^{+})h = italic_f start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT ( f , caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT ).
Recommendation with Data Augmentation. Despite significant progress in incorporating side information into recommender, introducing low-quality side information may even undermine the effectiveness of sparse interactions ℰ+superscript ℰ\mathcal{E}^{+}caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT. To address this, our LLMRec focuses on user-item interaction feature graph augmentation, which involves LLM-augmented u-i interactive edges ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT, and LLM-generated node features 𝐅 𝒜 subscript 𝐅 𝒜\textbf{F}{\mathcal{A}}F start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT. The optimization target with augmented interaction feature graph is as:
(3)Θ*=argmax Θp(Θ|{𝐅,𝐅 𝒜},{ℰ+,ℰ 𝒜})superscript Θ subscript arg max Θ 𝑝 conditional Θ 𝐅 subscript 𝐅 𝒜 superscript ℰ subscript ℰ 𝒜\displaystyle\Theta^{}=\operatorname{arg,max}\limits_{\Theta}p(\Theta|{% \textbf{F},\textbf{F}{\mathcal{A}}},{\mathcal{E}^{+},\mathcal{E}{\mathcal{% A}}})roman_Θ start_POSTSUPERSCRIPT * end_POSTSUPERSCRIPT = start_OPERATOR roman_arg roman_max end_OPERATOR start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT italic_p ( roman_Θ | { F , F start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT } , { caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT , caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT } )
The recommender f Θ subscript 𝑓 Θ f_{\Theta}italic_f start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT input union of original and augmented data, which consist of edges {ℰ+,ℰ 𝒜}superscript ℰ subscript ℰ 𝒜{\mathcal{E}^{+},\mathcal{E}{\mathcal{A}}}{ caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT , caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT } and node features {𝐅,𝐅 𝒜}𝐅 subscript 𝐅 𝒜{\textbf{F},\textbf{F}{\mathcal{A}}}{ F , F start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT }, and output quality representation h to predicted preference scores y^u,i subscript^𝑦 𝑢 𝑖\hat{y}_{u,i}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i end_POSTSUBSCRIPT by ranking the likelihood of user u 𝑢 u italic_u will interact with item i 𝑖 i italic_i.
- Methodology
To conduct LLM-based augmentation, in this section, we address these questions: Q1: How to enable LLMs to predict u-i interactive edges? Q2: How to enable LLMs to generate valuable content? Q3: How to incorporate augmented contents into original graph contents? Q4: How to make model robust to the augmented data?

Figure 1. The LLMRec framework: (1) Three types of data augmentation strategies: i) augmenting user-item interactions; ii) enhancing item attributes, and iii) user profiling. (2) Augmented training with and denoised data robustification mechanism.
3.1. LLMs as Implicit Feedback Augmentor (Q1)
To directly confront the scarcity of implicit feedback, we employ LLM as a knowledge-aware sampler to sample pair-wise(Rendle et al., 2012) u-i training data from a natural language perspective. This increases potential effective supervision signals and helps gain a better understanding of user preferences by integrating contextual knowledge into the u-i interactions. Specifically, we feed each user’s historical interacted items with side information (e.g., year, genre) and an item candidates pool 𝒞 u={i u,1,i u,2,…,i u,|𝒞 u|}subscript 𝒞 𝑢 subscript 𝑖 𝑢 1 subscript 𝑖 𝑢 2…subscript 𝑖 𝑢 subscript 𝒞 𝑢\mathcal{C}{u}={{i{u,1},i_{u,2},...,i_{u,|\mathcal{C}{u}|}}}caligraphic_C start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT = { italic_i start_POSTSUBSCRIPT italic_u , 1 end_POSTSUBSCRIPT , italic_i start_POSTSUBSCRIPT italic_u , 2 end_POSTSUBSCRIPT , … , italic_i start_POSTSUBSCRIPT italic_u , | caligraphic_C start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT | end_POSTSUBSCRIPT } into LLM. LLM then is expected to select items that user u 𝑢 u italic_u might be likely (i u+subscript superscript 𝑖 𝑢 i^{+}{u}italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT) or unlikely (i u−subscript superscript 𝑖 𝑢 i^{-}{u}italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT) to interact with from 𝒞 u subscript 𝒞 𝑢\mathcal{C}{u}caligraphic_C start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT. Here, we introduce 𝒞 u subscript 𝒞 𝑢\mathcal{C}{u}caligraphic_C start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT because LLMs can’t rank all items. Selecting items from the limited candidate set recommended by the base recommender (e.g., MMSSL(Wei et al., 2023a), MICRO(Zhang et al., 2022)), is a practical solution. These candidates 𝒞 u subscript 𝒞 𝑢\mathcal{C}{u}caligraphic_C start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT are hard samples with high prediction score y^ui subscript^𝑦 𝑢 𝑖\hat{y}_{ui}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u italic_i end_POSTSUBSCRIPT to provide potential, valuable positive samples and hard negative samples. It is worth noting that we represent each item using textual format instead of ID-corresponding indexes (Li et al., 2023b). This kind of representation offers several advantages: (1) It enables recommender to fully leverage the content in datasets, and (2) It intuitively reflects user preferences. The process of augmenting user-item interactive edges and incorporating it into the training data can be formalized as:
(4)i u+,i u−=LLM(ℙ u UI);ℰ BPR=ℰ∪ℰ 𝒜 formulae-sequence subscript superscript 𝑖 𝑢 subscript superscript 𝑖 𝑢 𝐿 𝐿 𝑀 subscript superscript ℙ 𝑈 𝐼 𝑢 subscript ℰ 𝐵 𝑃 𝑅 ℰ subscript ℰ 𝒜 i^{+}{u},i^{-}{u}=LLM(\mathbb{P}^{UI}{u});\quad\mathcal{E}{BPR}=\mathcal{E% }\cup\mathcal{E}_{\mathcal{A}}italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT = italic_L italic_L italic_M ( blackboard_P start_POSTSUPERSCRIPT italic_U italic_I end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) ; caligraphic_E start_POSTSUBSCRIPT italic_B italic_P italic_R end_POSTSUBSCRIPT = caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT
where i u+,i u−subscript superscript 𝑖 𝑢 subscript superscript 𝑖 𝑢 i^{+}{u},i^{-}{u}italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT are positive and negative samples for BPR selected by LLMs from candidates 𝒞 u subscript 𝒞 𝑢\mathcal{C}{u}caligraphic_C start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT for user u 𝑢 u italic_u based on input prompt ℙ u UI subscript superscript ℙ 𝑈 𝐼 𝑢\mathbb{P}^{UI}{u}blackboard_P start_POSTSUPERSCRIPT italic_U italic_I end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT. The augmented dataset ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT comprises pairwise training triplets (u,i u+,i u−)𝑢 superscript subscript 𝑖 𝑢 superscript subscript 𝑖 𝑢(u,i{u}^{+},i_{u}^{-})( italic_u , italic_i start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT , italic_i start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT ), i.e., ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT = {(u,i u+,i u−)|(u,i u+)∈ℰ 𝒜+,(u,i u−)∈ℰ 𝒜−}conditional-set 𝑢 subscript superscript 𝑖 𝑢 subscript superscript 𝑖 𝑢 formulae-sequence 𝑢 subscript superscript 𝑖 𝑢 subscript superscript ℰ 𝒜 𝑢 subscript superscript 𝑖 𝑢 subscript superscript ℰ 𝒜{(u,i^{+}{u},i^{-}{u})|(u,i^{+}{u})\in\mathcal{E}^{+}{\mathcal{A}},(u,i^{% -}{u})\in\mathcal{E}^{-}{\mathcal{A}}}{ ( italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) | ( italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) ∈ caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT , ( italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) ∈ caligraphic_E start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT }. The textual u-i augmentation prompt ℙ u UI subscript superscript ℙ 𝑈 𝐼 𝑢\mathbb{P}^{UI}{u}blackboard_P start_POSTSUPERSCRIPT italic_U italic_I end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT encompasses different components: i) task description, ii) historical interactions, iii) candidates, and iv) output format description, as illustrated in Fig.2 (a).
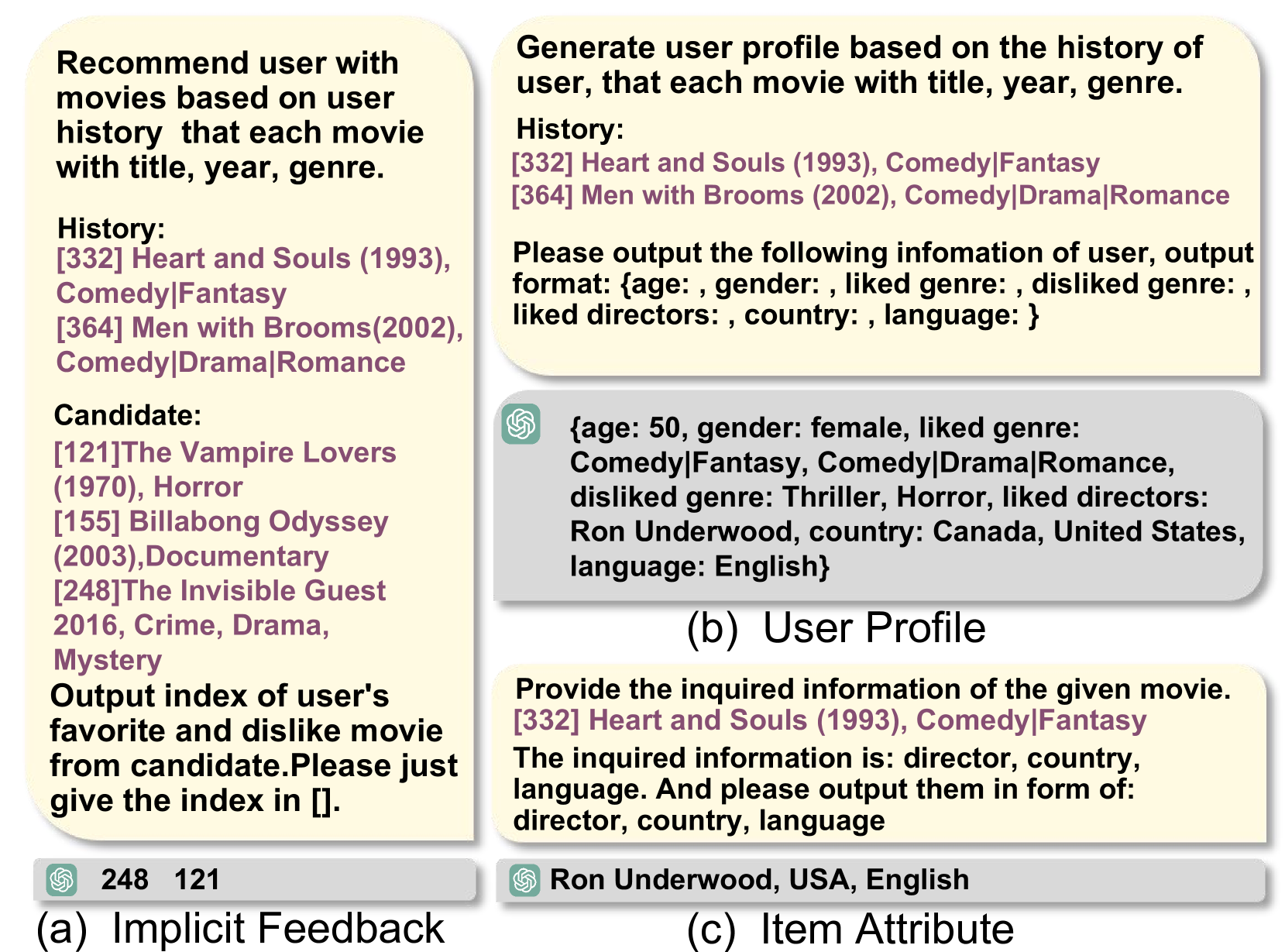
Figure 2. Constructed prompt ℙ u UI,ℙ u U,ℙ i I subscript superscript ℙ 𝑈 𝐼 𝑢 subscript superscript ℙ 𝑈 𝑢 subscript superscript ℙ 𝐼 𝑖\mathbb{P}^{UI}{u},\mathbb{P}^{U}{u},\mathbb{P}^{I}_{i}blackboard_P start_POSTSUPERSCRIPT italic_U italic_I end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , blackboard_P start_POSTSUPERSCRIPT italic_U end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT , blackboard_P start_POSTSUPERSCRIPT italic_I end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT for LLMs’ completion including i) task description, ii) historical interactions, iii) candidates, and iv) output format description.
The utilization of LLMs-based sampler in this study to some extent alleviate noise (i.e., false positive) and non-interacted items issue (i.e., false negative) (Chen et al., 2023b; Lee et al., 2021) exist in raw implicit feedback. In this context, (i) false positive are unreliable u-i interactions, which encompass items that were not genuinely intended by the user, such as accidental clicks or instances influenced by popularity bias(Wang et al., 2021a); (ii) false negative represented by non-interacted items, which may not necessarily indicate user dispreference but are conventionally treated as negative samples(Chen et al., 2020). By taking LLMs as implicit feedback augmentor, LLMRec enables the acquisition of more meaningful and informative samples by leveraging the remarkable reasoning ability of LLMs with the support of LLMs’ knowledge. The specific analysis is supported by theoretical discussion in Sec.3.4.1.
3.2. LLM-based Side Information Augmentation
3.2.1. User Profiling & Item Attribute Enhancing (Q2)
Leveraging knowledge base and reasoning abilities of LLMs, we propose to summarize user profiles by utilizing users’ historical interactions and item information to overcome limitation of privacy. Additionally, the LLM-based item attributes generation aims to produce space-unified, and informative item attributes. Our LLM-based side information augmentation paradigm consists of two steps:
• i) User/Item Information Refinement. Using prompts derived from the dataset’s interactions and side information, we enable LLM to generate user and item attributes that were not originally part of the dataset. Specific examples are shown in Fig.2(b)(c).
• ii) LLM-enhanced Semantic Embedding. The augmented user and item information will be encoded as features and used as input for the recommender. Using LLM as an encoder offers efficient and state-of-the-art language understanding, enabling profiling user interaction preferences and debiasing item attributes.
Formally, the LLM-based side information augmentation is as:
(5){user:𝔸 u=LLM(ℙ u U)⟶𝐟 𝒜,u=LLM(𝔸 u)item:𝔸 i=LLM(ℙ i I)⟶𝐟 𝒜,i=LLM(𝔸 i)cases:𝑢 𝑠 𝑒 𝑟 absent formulae-sequence subscript 𝔸 𝑢 𝐿 𝐿 𝑀 subscript superscript ℙ 𝑈 𝑢⟶subscript 𝐟 𝒜 𝑢 𝐿 𝐿 𝑀 subscript 𝔸 𝑢:𝑖 𝑡 𝑒 𝑚 absent formulae-sequence subscript 𝔸 𝑖 𝐿 𝐿 𝑀 subscript superscript ℙ 𝐼 𝑖⟶subscript 𝐟 𝒜 𝑖 𝐿 𝐿 𝑀 subscript 𝔸 𝑖\displaystyle\begin{cases}user:&\mathbb{A}{u}=LLM(\mathbb{P}^{U}{u})\quad% \longrightarrow\quad\textbf{f}{\mathcal{A},u}=LLM(\mathbb{A}{u})\ item:&\mathbb{A}{i}=LLM(\mathbb{P}^{I}{i})\quad\longrightarrow\quad\textbf{f% }{\mathcal{A},i}=LLM(\mathbb{A}{i})\end{cases}{ start_ROW start_CELL italic_u italic_s italic_e italic_r : end_CELL start_CELL blackboard_A start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT = italic_L italic_L italic_M ( blackboard_P start_POSTSUPERSCRIPT italic_U end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) ⟶ f start_POSTSUBSCRIPT caligraphic_A , italic_u end_POSTSUBSCRIPT = italic_L italic_L italic_M ( blackboard_A start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) end_CELL end_ROW start_ROW start_CELL italic_i italic_t italic_e italic_m : end_CELL start_CELL blackboard_A start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = italic_L italic_L italic_M ( blackboard_P start_POSTSUPERSCRIPT italic_I end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ⟶ f start_POSTSUBSCRIPT caligraphic_A , italic_i end_POSTSUBSCRIPT = italic_L italic_L italic_M ( blackboard_A start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) end_CELL end_ROW
where 𝐟 𝒜,u,𝐟 𝒜,i,∈ℝ d LLM subscript 𝐟 𝒜 𝑢 subscript 𝐟 𝒜 𝑖 superscript ℝ subscript 𝑑 𝐿 𝐿 𝑀\textbf{f}{\mathcal{A},u},\textbf{f}{\mathcal{A},i,}\in\mathbb{R}^{d_{LLM}}f start_POSTSUBSCRIPT caligraphic_A , italic_u end_POSTSUBSCRIPT , f start_POSTSUBSCRIPT caligraphic_A , italic_i , end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUBSCRIPT italic_L italic_L italic_M end_POSTSUBSCRIPT end_POSTSUPERSCRIPT are LLM-augmented user/item features with LLM’s hidden dimension d LLM subscript 𝑑 𝐿 𝐿 𝑀 d_{LLM}italic_d start_POSTSUBSCRIPT italic_L italic_L italic_M end_POSTSUBSCRIPT. The textual prompts ℙ u U subscript superscript ℙ 𝑈 𝑢\mathbb{P}^{U}{u}blackboard_P start_POSTSUPERSCRIPT italic_U end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT and ℙ i I subscript superscript ℙ 𝐼 𝑖\mathbb{P}^{I}{i}blackboard_P start_POSTSUPERSCRIPT italic_I end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT are used for attribute refinement for user u 𝑢 u italic_u and item i 𝑖 i italic_i, respectively. 𝔸 u subscript 𝔸 𝑢\mathbb{A}{u}blackboard_A start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT and 𝔸 i subscript 𝔸 𝑖\mathbb{A}{i}blackboard_A start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represent generated textual attributes that to be encoded as features 𝐅 𝒜,u,𝐅 𝒜,i subscript 𝐅 𝒜 𝑢 subscript 𝐅 𝒜 𝑖\textbf{F}{\mathcal{A},u},\textbf{F}{\mathcal{A},i}F start_POSTSUBSCRIPT caligraphic_A , italic_u end_POSTSUBSCRIPT , F start_POSTSUBSCRIPT caligraphic_A , italic_i end_POSTSUBSCRIPT using the embedding capability of LLM(⋅)𝐿 𝐿 𝑀⋅LLM(\cdot)italic_L italic_L italic_M ( ⋅ ).
3.2.2. Side Information Incorporation (Q3)
After obtaining the augmented side information for user/item, an effective incorporation method is necessary. LLMRec includes a standard procedure: (1) Augmented Semantic Projection, (2) Collaborative Context Injection, and (3) Feature Incorporation. Let’s delve into each:
• Augmented Semantic Projection. Linear layers with dropout are employed to not only reduce the dimensionality of LLM-enhanced semantic features but also map such augmented features into their own space(Wei et al., 2023b). This process can be represented as 𝐅¯𝒜=Linear(𝐅 𝒜)subscript¯𝐅 𝒜 Linear subscript 𝐅 𝒜\overline{\textbf{F}}{\mathcal{A}}=\text{Linear}(\textbf{F}{\mathcal{A}})over¯ start_ARG F end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT = Linear ( F start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ), where 𝐟 𝒜∈ℝ 1×d LLM subscript 𝐟 𝒜 superscript ℝ 1 subscript 𝑑 𝐿 𝐿 𝑀\textbf{f}{\mathcal{A}}\in\mathbb{R}^{1\times d{LLM}}f start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT 1 × italic_d start_POSTSUBSCRIPT italic_L italic_L italic_M end_POSTSUBSCRIPT end_POSTSUPERSCRIPT is the input feature and 𝐟¯𝒜∈ℝ 1×d subscript¯𝐟 𝒜 superscript ℝ 1 𝑑\overline{\textbf{f}}_{\mathcal{A}}\in\mathbb{R}^{1\times d}over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT 1 × italic_d end_POSTSUPERSCRIPT is the output feature after projection.
• Collaborative Context Injection. To inject high-order(Wang et al., 2019) collaborative connectivity into augmented features 𝐟¯𝒜,u subscript¯𝐟 𝒜 𝑢\overline{\textbf{f}}{\mathcal{A},u}over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A , italic_u end_POSTSUBSCRIPT and 𝐟¯𝒜,i subscript¯𝐟 𝒜 𝑖\overline{\textbf{f}}{\mathcal{A},i}over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A , italic_i end_POSTSUBSCRIPT, LLMRec employs light weight GNNs(He et al., 2020) as the encoder.
• Semantic Feature Incorporation. Instead of taking augmented features 𝐅¯𝒜 subscript¯𝐅 𝒜\overline{\textbf{F}}{\mathcal{A}}over¯ start_ARG F end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT as initialization of learnable vectors of recommender f Θ subscript 𝑓 Θ f{\Theta}italic_f start_POSTSUBSCRIPT roman_Θ end_POSTSUBSCRIPT, we opt to treat 𝐅¯𝒜 subscript¯𝐅 𝒜\overline{\textbf{F}}{\mathcal{A}}over¯ start_ARG F end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT as additional compositions added to the ID-corresponding embeddings (𝐞 u subscript 𝐞 𝑢\textbf{e}{u}e start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT, 𝐞 i subscript 𝐞 𝑖\textbf{e}{i}e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT). This allows flexibly adjust the influence of LLM-augmented features using scale factors and normalization. Formally, the 𝐅¯𝒜 subscript¯𝐅 𝒜\overline{\textbf{F}}{\mathcal{A}}over¯ start_ARG F end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT’s incorporation is presented as:
𝐡 u=𝐞 u+ω 1⋅∑k∈ℳ∪𝔸 u|ℳ|+|𝔸 u|𝐟¯u k‖𝐟¯u k‖2;𝐡 i=𝐞 i+ω 1⋅∑k∈ℳ∪𝔸 i|ℳ|+|𝔸 i|𝐟¯i k‖𝐟¯i k‖2 formulae-sequence subscript 𝐡 𝑢 subscript 𝐞 𝑢⋅subscript 𝜔 1 superscript subscript 𝑘 ℳ subscript 𝔸 𝑢 ℳ subscript 𝔸 𝑢 superscript subscript¯𝐟 𝑢 𝑘 subscript norm superscript subscript¯𝐟 𝑢 𝑘 2 subscript 𝐡 𝑖 subscript 𝐞 𝑖⋅subscript 𝜔 1 superscript subscript 𝑘 ℳ subscript 𝔸 𝑖 ℳ subscript 𝔸 𝑖 superscript subscript¯𝐟 𝑖 𝑘 subscript norm superscript subscript¯𝐟 𝑖 𝑘 2\displaystyle\textbf{h}{u}=\textbf{e}{u}+\omega_{1}\cdot\sum_{k\in\mathcal{M% }\cup\mathbb{A}{u}}^{|\mathcal{M}|+|\mathbb{A}{u}|}{\frac{\overline{\textbf{% f}}{u}^{k}}{|\overline{\textbf{f}}{u}^{k}|{2}}};\leavevmode\nobreak\ % \leavevmode\nobreak\ \leavevmode\nobreak\ \leavevmode\nobreak\ \textbf{h}{i}=% \textbf{e}{i}+\omega{1}\cdot\sum_{k\in\mathcal{M}\cup\mathbb{A}{i}}^{|% \mathcal{M}|+|\mathbb{A}{i}|}{\frac{\overline{\textbf{f}}{i}^{k}}{|% \overline{\textbf{f}}{i}^{k}|_{2}}}h start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT = e start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT + italic_ω start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ⋅ ∑ start_POSTSUBSCRIPT italic_k ∈ caligraphic_M ∪ blackboard_A start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT | caligraphic_M | + | blackboard_A start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT | end_POSTSUPERSCRIPT divide start_ARG over¯ start_ARG f end_ARG start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_ARG start_ARG ∥ over¯ start_ARG f end_ARG start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ∥ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT end_ARG ; h start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT + italic_ω start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ⋅ ∑ start_POSTSUBSCRIPT italic_k ∈ caligraphic_M ∪ blackboard_A start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_POSTSUBSCRIPT start_POSTSUPERSCRIPT | caligraphic_M | + | blackboard_A start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT | end_POSTSUPERSCRIPT divide start_ARG over¯ start_ARG f end_ARG start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT end_ARG start_ARG ∥ over¯ start_ARG f end_ARG start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT ∥ start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT end_ARG
The final prediction representations 𝐡 u subscript 𝐡 𝑢\textbf{h}{u}h start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT and 𝐡 i subscript 𝐡 𝑖\textbf{h}{i}h start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, are in ℝ 1×d superscript ℝ 1 𝑑\mathbb{R}^{1\times d}blackboard_R start_POSTSUPERSCRIPT 1 × italic_d end_POSTSUPERSCRIPT. User profiles are 𝔸 u subscript 𝔸 𝑢\mathbb{A}{u}blackboard_A start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT, debiased item attributes are 𝔸 i subscript 𝔸 𝑖\mathbb{A}{i}blackboard_A start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, and original multi-modal side information is ℳ ℳ\mathcal{M}caligraphic_M. The specific type of feature is 𝐟 k superscript 𝐟 𝑘\textbf{f}^{k}f start_POSTSUPERSCRIPT italic_k end_POSTSUPERSCRIPT. We adjust feature vectors using the aggregation weight ω 1 subscript 𝜔 1\omega_{1}italic_ω start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and L 2 subscript 𝐿 2 L_{2}italic_L start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT normalization to mitigate distribution gaps (Fu et al., 2020), ensurring the effectiveness of additional features within the recommender encoder.
3.3. Training with Denoised Robustification (Q4)
In this section, we outline how LLMRec integrate augmented data into the optimization. We also introduce two quality constraint mechanisms for augmented edges and node features: i) Noisy user-item interaction pruning, and ii) MAE-based feature enhancement.
3.3.1. Augmented Optimization with Noise Pruning
We train our recommender using the union set ℰ∪ℰ 𝒜 ℰ subscript ℰ 𝒜\mathcal{E}\cup\mathcal{E}{\mathcal{A}}caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT, which includes the original training set ℰ ℰ\mathcal{E}caligraphic_E and the LLM-augmented set ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT. The objective is to optimize the BPR ℒ BPR subscript ℒ BPR\mathcal{L}{\text{BPR}}caligraphic_L start_POSTSUBSCRIPT BPR end_POSTSUBSCRIPT loss with increased supervisory signals ℰ∪ℰ 𝒜 ℰ subscript ℰ 𝒜\mathcal{E}\cup\mathcal{E}{\mathcal{A}}caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT, aiming to enhance the recommender’s performance by leveraging the incorporated LLM-enhanced user preference:
(6)ℒ BPR subscript ℒ BPR\displaystyle\mathcal{L}{\text{BPR}}caligraphic_L start_POSTSUBSCRIPT BPR end_POSTSUBSCRIPT=∑(u,i+,i−)|ℰ∪ℰ 𝒜|−log(σ(y^u,i+−y^u,i−))+ω 2⋅‖Θ‖2 absent superscript subscript 𝑢 superscript 𝑖 superscript 𝑖 ℰ subscript ℰ 𝒜 𝜎 subscript^𝑦 𝑢 superscript 𝑖 subscript^𝑦 𝑢 superscript 𝑖⋅subscript 𝜔 2 superscript norm Θ 2\displaystyle=\sum{(u,i^{+},i^{-})}^{|\mathcal{E}\cup\mathcal{E}{\mathcal{A}% }|}-\log\left(\sigma(\hat{y}{u,i^{+}}-\hat{y}{u,i^{-}})\right)+\omega{2}% \cdot|\Theta|^{2}= ∑ start_POSTSUBSCRIPT ( italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT ) end_POSTSUBSCRIPT start_POSTSUPERSCRIPT | caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT | end_POSTSUPERSCRIPT - roman_log ( italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT - over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) ) + italic_ω start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ⋅ ∥ roman_Θ ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ℰ 𝒜⊆{LLM(ℙ u)|u∈𝒰},|ℰ 𝒜|=ω 3*B formulae-sequence subscript ℰ 𝒜 conditional-set 𝐿 𝐿 𝑀 subscript ℙ 𝑢 𝑢 𝒰 subscript ℰ 𝒜 subscript 𝜔 3 𝐵\displaystyle\mathcal{E}{\mathcal{A}}\subseteq{LLM(\mathbb{P}{u})|u\in% \mathcal{U}},\quad|\mathcal{E}{\mathcal{A}}|=\omega{3}*B caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ⊆ { italic_L italic_L italic_M ( blackboard_P start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) | italic_u ∈ caligraphic_U } , | caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT | = italic_ω start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT * italic_B
The training triplet (u,i+,i−)𝑢 superscript 𝑖 superscript 𝑖(u,i^{+},i^{-})( italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT ) is selected from the union training set ℰ∪ℰ 𝒜 ℰ subscript ℰ 𝒜\mathcal{E}\cup\mathcal{E}{\mathcal{A}}caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT. The predicted scores of positive-negative sample pairs are obtained through inner products of final representation h, i.e., y^u,i+=𝐡 u⋅𝐡 i+,y^u,i−=𝐡 u⋅𝐡 i−formulae-sequence subscript^𝑦 𝑢 superscript 𝑖⋅subscript 𝐡 𝑢 subscript 𝐡 limit-from 𝑖 subscript^𝑦 𝑢 superscript 𝑖⋅subscript 𝐡 𝑢 subscript 𝐡 limit-from 𝑖\hat{y}{u,i^{+}}=\textbf{h}{u}\cdot\textbf{h}{i+},\hat{y}{u,i^{-}}=\textbf% {h}{u}\cdot\textbf{h}{i-}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT = h start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ⋅ h start_POSTSUBSCRIPT italic_i + end_POSTSUBSCRIPT , over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT = h start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ⋅ h start_POSTSUBSCRIPT italic_i - end_POSTSUBSCRIPT. The augmented dataset ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT is a subset of the overall LLM-generated data {LLM(ℙ u)|u∈𝒰}conditional-set 𝐿 𝐿 𝑀 subscript ℙ 𝑢 𝑢 𝒰{LLM(\mathbb{P}{u})|u\in\mathcal{U}}{ italic_L italic_L italic_M ( blackboard_P start_POSTSUBSCRIPT italic_u end_POSTSUBSCRIPT ) | italic_u ∈ caligraphic_U }, obtained by sampling. This is because excessive inclusion of pseudo label may lead to a degradation in result accuracy. The number of samples |ℰ 𝒜|subscript ℰ 𝒜|\mathcal{E}{\mathcal{A}}|| caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT | is controlled by the batch size B 𝐵 B italic_B and a rate ω 3 subscript 𝜔 3\omega_{3}italic_ω start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT. Weight-decay regularization |Θ|2 superscript Θ 2|\Theta|^{2}| roman_Θ | start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT weighted by ω 2 subscript 𝜔 2\omega_{2}italic_ω start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT, mitigates overfitting. σ(⋅)𝜎⋅\sigma(\cdot)italic_σ ( ⋅ ) is activation function sigmoid to introduce non-linearity.
Noise Pruning. To enhance the effectiveness of augmented data, we prune out unreliable u-i interaction noise. Technically, the largest values before minus are discarded after sorting each iteration. This helps prioritize and emphasize relevant supervisory signals while mitigating the influence of noise. Formally, the objective ℒ BPR subscript ℒ BPR\mathcal{L}_{\text{BPR}}caligraphic_L start_POSTSUBSCRIPT BPR end_POSTSUBSCRIPT in Eq.6 with noise pruning can be rewritten as follows:
(7)∑(u,i+,i−)(1−ω 4)|ℰ∪ℰ 𝒜|−S o r t A s c e n d(log(σ(y^u,i+−y^u,i−)))[0:N]+ω 2⋅∥Θ∥2\small\sum_{(u,i^{+},i^{-})}^{(1-\omega_{4})|\mathcal{E}\cup\mathcal{E}{% \mathcal{A}}|}-SortAscend\left(\log(\sigma(\hat{y}{u,i^{+}}-\hat{y}{u,i^{-}}% ))\right)[0:N]+\omega{2}\cdot|\Theta|^{2}∑ start_POSTSUBSCRIPT ( italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT ) end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( 1 - italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT ) * | caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT | end_POSTSUPERSCRIPT - italic_S italic_o italic_r italic_t italic_A italic_s italic_c italic_e italic_n italic_d ( roman_log ( italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT - over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) ) ) [ 0 : italic_N ] + italic_ω start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ⋅ ∥ roman_Θ ∥ start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT
The function S o r t A s c e n d(⋅)[0:N]SortAscend(\cdot)[0:N]italic_S italic_o italic_r italic_t italic_A italic_s italic_c italic_e italic_n italic_d ( ⋅ ) [ 0 : italic_N ] sorts values and selects the top-N. The retained number N 𝑁 N italic_N is calculated by N=(1−ω 4)⋅|ℰ∪ℰ 𝒜|𝑁⋅1 subscript 𝜔 4 ℰ subscript ℰ 𝒜 N=(1-\omega_{4})\cdot|\mathcal{E}\cup\mathcal{E}{\mathcal{A}}|italic_N = ( 1 - italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT ) ⋅ | caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT |, where ω 4 subscript 𝜔 4\omega{4}italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT is a rate. This approach allows for controlled pruning of loss samples, emphasizing relevant signals while reducing noise. This can avoid the impact of unreliable gradient backpropagation, thus making optimization more stable and effective.
3.3.2. Enhancing Augmented Semantic Features via MAE
To mitigate the impact of noisy augmented features, we employ the Masked Autoencoders (MAE) for feature enhancement (He et al., 2022). Specifically, the masking technique is to reduce the model’s sensitivity to features, and subsequently, the feature encoders are strengthened through reconstruction objectives. Formally, we select a subset of nodes 𝒱⊂𝒱𝒱 𝒱\widetilde{\mathcal{V}}\subset\mathcal{V}over~ start_ARG caligraphic_V end_ARG ⊂ caligraphic_V and mask their features using a mask token [MASK], denoted as 𝐟[MASK]subscript 𝐟 delimited-[]𝑀 𝐴 𝑆 𝐾\textbf{f}_{[MASK]}f start_POSTSUBSCRIPT [ italic_M italic_A italic_S italic_K ] end_POSTSUBSCRIPT (e.g., a learnable vector or mean pooling). The mask operation can be formulated as follows:
(8)𝐟¯𝒜={𝐟[MASK]v∈𝒱𝐟¯𝒜 v∉𝒱subscript¯𝐟 𝒜 cases subscript 𝐟 delimited-[]𝑀 𝐴 𝑆 𝐾 𝑣𝒱 subscript¯𝐟 𝒜 𝑣𝒱\widetilde{\overline{\textbf{f}}}{\mathcal{A}}=\begin{cases}\textbf{f}{[MASK% ]}&v\in\widetilde{\mathcal{V}}\ \overline{\textbf{f}}_{\mathcal{A}}&v\notin\widetilde{\mathcal{V}}\end{cases}over~ start_ARG over¯ start_ARG f end_ARG end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT = { start_ROW start_CELL f start_POSTSUBSCRIPT [ italic_M italic_A italic_S italic_K ] end_POSTSUBSCRIPT end_CELL start_CELL italic_v ∈ over~ start_ARG caligraphic_V end_ARG end_CELL end_ROW start_ROW start_CELL over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT end_CELL start_CELL italic_v ∉ over~ start_ARG caligraphic_V end_ARG end_CELL end_ROW
The augmented feature after the mask operation is denoted as 𝐟¯𝒜 subscript¯𝐟 𝒜\widetilde{\overline{\textbf{f}}}{\mathcal{A}}over~ start_ARG over¯ start_ARG f end_ARG end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT. It is substituted as mask token 𝐟[MASK]subscript 𝐟 delimited-[]𝑀 𝐴 𝑆 𝐾\textbf{f}{[MASK]}f start_POSTSUBSCRIPT [ italic_M italic_A italic_S italic_K ] end_POSTSUBSCRIPT if the node is selected (𝒱⊂𝒱𝒱 𝒱\widetilde{\mathcal{V}}\subset\mathcal{V}over~ start_ARG caligraphic_V end_ARG ⊂ caligraphic_V), otherwise, it corresponds to the original augmented feature 𝐟¯𝒜 subscript¯𝐟 𝒜\overline{\textbf{f}}{\mathcal{A}}over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT. To strengthen the feature encoder, we introduce the feature restoration loss ℒ FR subscript ℒ 𝐹 𝑅\mathcal{L}{FR}caligraphic_L start_POSTSUBSCRIPT italic_F italic_R end_POSTSUBSCRIPT by comparing the masked attribute matrix 𝐟¯𝒜,i subscript¯𝐟 𝒜 𝑖\widetilde{\overline{\textbf{f}}}{\mathcal{A},i}over~ start_ARG over¯ start_ARG f end_ARG end_ARG start_POSTSUBSCRIPT caligraphic_A , italic_i end_POSTSUBSCRIPT with the original augmented feature matrix 𝐟¯𝒜 subscript¯𝐟 𝒜\overline{\textbf{f}}{\mathcal{A}}over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT, with a scaling factor γ 𝛾\gamma italic_γ. The restoration loss function ℒ FR subscript ℒ 𝐹 𝑅\mathcal{L}_{FR}caligraphic_L start_POSTSUBSCRIPT italic_F italic_R end_POSTSUBSCRIPT is as follows:
(9)ℒ FR=1|𝒱|∑v∈𝒱(1−𝐟¯𝒜⋅𝐟¯𝒜‖𝐟¯𝒜‖⋅‖𝐟¯𝒜‖)γ subscript ℒ 𝐹 𝑅 1𝒱 subscript 𝑣𝒱 superscript 1⋅subscript¯𝐟 𝒜 subscript¯𝐟 𝒜⋅norm subscript¯𝐟 𝒜 norm subscript¯𝐟 𝒜 𝛾\mathcal{L}{FR}=\frac{1}{|\widetilde{\mathcal{V}}|}\sum\limits{v\in% \widetilde{\mathcal{V}}}(1-\frac{\widetilde{\overline{\textbf{f}}}{\mathcal{A% }}\cdot\overline{\textbf{f}}{\mathcal{A}}}{|\widetilde{\overline{\textbf{f}}% }{\mathcal{A}}|\cdot|\overline{\textbf{f}}{\mathcal{A}}|})^{\gamma}caligraphic_L start_POSTSUBSCRIPT italic_F italic_R end_POSTSUBSCRIPT = divide start_ARG 1 end_ARG start_ARG | over~ start_ARG caligraphic_V end_ARG | end_ARG ∑ start_POSTSUBSCRIPT italic_v ∈ over~ start_ARG caligraphic_V end_ARG end_POSTSUBSCRIPT ( 1 - divide start_ARG over~ start_ARG over¯ start_ARG f end_ARG end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ⋅ over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT end_ARG start_ARG ∥ over~ start_ARG over¯ start_ARG f end_ARG end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ∥ ⋅ ∥ over¯ start_ARG f end_ARG start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT ∥ end_ARG ) start_POSTSUPERSCRIPT italic_γ end_POSTSUPERSCRIPT
The final optimization objective is the weighted sum of the noise-pruned BPR loss ℒ BPR subscript ℒ BPR\mathcal{L}{\text{BPR}}caligraphic_L start_POSTSUBSCRIPT BPR end_POSTSUBSCRIPT and the feature restoration (FR) loss ℒ FR subscript ℒ 𝐹 𝑅\mathcal{L}{FR}caligraphic_L start_POSTSUBSCRIPT italic_F italic_R end_POSTSUBSCRIPT.
3.4. In-Depth Analysis of our LLMRec
3.4.1. LLM-based Augmentation Facilitates Optimization
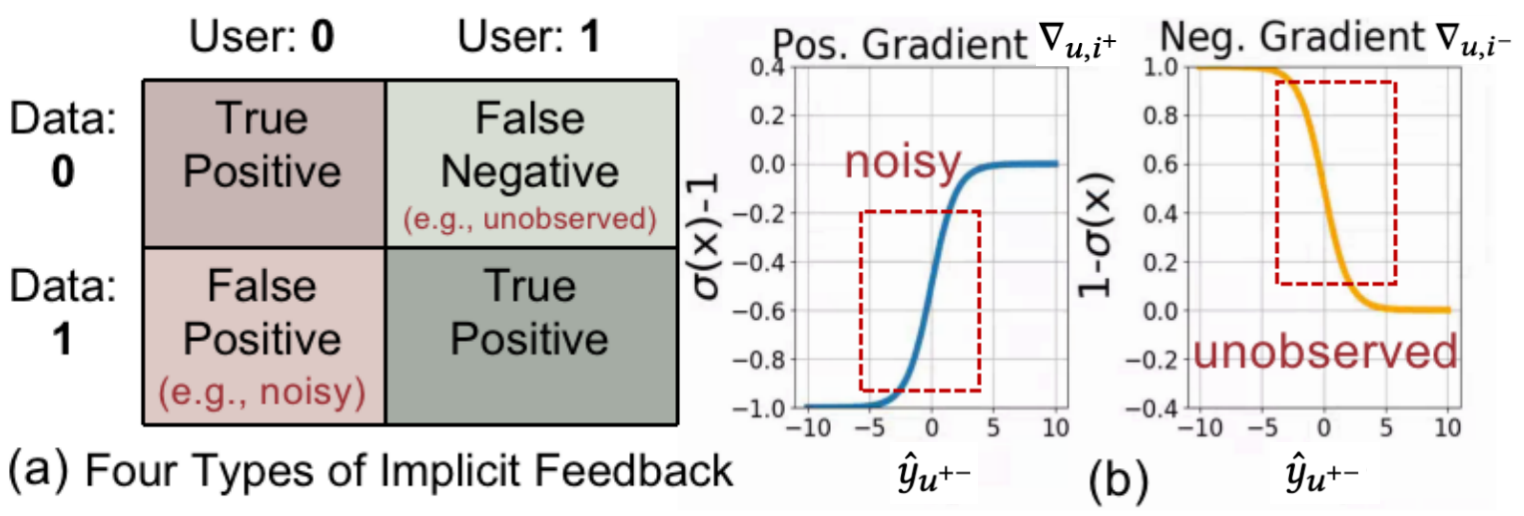
Figure 3. (a) Implicit feedback encompasses both false positive and false negative samples. (b) The gradient ∇∇\nabla∇ of the BPR loss for positive y^u,i+subscript^𝑦 𝑢 superscript 𝑖\hat{y}{u,i^{+}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT and negative y^u,i−subscript^𝑦 𝑢 superscript 𝑖\hat{y}{u,i^{-}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT scores, despite having a large magnitude, can have an incorrect direction that notably impacts the robustness and effectiveness of training.
This section highlights challenges addressed by LLM-based augmentation in recommender systems. False negatives (non-interacted interactions) and false positives (noise) as in Fig.3 (a) can affect data quality and result accuracy (Chen et al., 2020; Wang et al., 2021a). Non-interacted items do not necessarily imply dislike (Chen et al., 2020), and interacted one may fail to reflect real user preferences due to accidental clicks or misleading titles, etc. Mixing of unreliable data with true user preference poses a challenge in build accurate recommender. Identifying and utilizing reliable examples is key to optimizing the recommender (Chen et al., 2023b).
In theory, non-interacted and noisy interactions are used for negative y^u,i−subscript^𝑦 𝑢 superscript 𝑖\hat{y}{u,i^{-}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT and positive y^u,i+subscript^𝑦 𝑢 superscript 𝑖\hat{y}{u,i^{+}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT scores, respectively. However, their optimization directions oppose the true direction with large magnitudes, i.e., the model optimizes significantly in the wrong directions (as in Fig.3 (b)), resulting in sensitive suboptimal results.
Details. By computing the derivatives of the ℒ BPR subscript ℒ 𝐵 𝑃 𝑅\mathcal{L}{BPR}caligraphic_L start_POSTSUBSCRIPT italic_B italic_P italic_R end_POSTSUBSCRIPT ( Eq.10), we obtain positive gradients ∇u,i+subscript∇𝑢 superscript 𝑖\nabla{u,i^{+}}∇ start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT = 1−σ(y^u+−)1 𝜎 subscript^𝑦 superscript 𝑢 absent 1-\sigma(\hat{y}{u^{+-}})1 - italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) and negative gradients ∇u,i−subscript∇𝑢 superscript 𝑖\nabla{u,i^{-}}∇ start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT = σ(y^u+−)−1 𝜎 subscript^𝑦 superscript 𝑢 absent 1\sigma(\hat{y}{u^{+-}})-1 italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) - 1, where y^u+−=y^u,i+−y^u,i−subscript^𝑦 superscript 𝑢 absent subscript^𝑦 𝑢 superscript 𝑖 subscript^𝑦 𝑢 superscript 𝑖\hat{y}{u^{+-}}=\hat{y}{u,i^{+}}-\hat{y}{u,i^{-}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT = over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT - over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT. Fig.3 (b) illustrates these gradients and unveils some observations. Noisy interactions, although treated as positives, often have small values y^u,i+subscript^𝑦 𝑢 superscript 𝑖\hat{y}{u,i^{+}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT as false positives, resulting in large gradients ∇u,i+subscript∇𝑢 superscript 𝑖\nabla{u,i^{+}}∇ start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT. Conversely, unobserved items, treated as negatives, tend to have relatively large values y^u,i−subscript^𝑦 𝑢 superscript 𝑖\hat{y}{u,i^{-}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT as false negatives, leading to small y^u+−subscript^𝑦 superscript 𝑢 absent\hat{y}{u^{+-}}over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT and large gradients ∇u,i−subscript∇𝑢 superscript 𝑖\nabla_{u,i^{-}}∇ start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT.
(10){∇u,i+=∂ℒ BPR∂y^u,i+=−∂logσ(y^u+−)∂σ(y^u+−)∂σ(y^u+−)∂y^u,i+=−1 σ(y^u+−)⋅σ(y^u+−)⋅(1−σ(y^u+−))⋅1=σ(y^u,i+⏞noisy−y^u,i−)−1∇u,i−=∂ℒ BPR∂y^u,i−=−∂logσ(y^u+−)∂σ(y^u+−)∂σ(y^u+−)∂y^u,i−=1 σ(y^u+−)⋅σ(y^u+−)⋅(1−σ(y^u+−))⋅1=1−σ(y^u,i+−y^u,i−⏞unobserved)\small\left{\begin{aligned} \nabla_{u,i^{+}}&=\frac{\partial\mathcal{L}{BPR}% }{\partial\hat{y}{u,i^{+}}}=-\frac{\partial\log\sigma(\hat{y}{u^{+-}})}{% \partial\sigma(\hat{y}{u^{+-}})}\frac{\partial\sigma(\hat{y}{u^{+-}})}{% \partial\hat{y}{u,i^{+}}}\[-10.0pt] &=-\frac{1}{\sigma(\hat{y}{u^{+-}})}\cdot\sigma(\hat{y}{u^{+-}})\cdot(1-% \sigma(\hat{y}{u^{+-}}))\cdot 1=\sigma(\overbrace{\hat{y}{u,i^{+}}}\limits^{% noisy}-\hat{y}{u,i^{-}})-1\ \nabla{u,i^{-}}&=\frac{\partial\mathcal{L}{BPR}}{\partial\hat{y}{u,i^{-}}}=% -\frac{\partial\log\sigma(\hat{y}{u^{+-}})}{\partial\sigma(\hat{y}{u^{+-}})}% \frac{\partial\sigma(\hat{y}{u^{+-}})}{\partial\hat{y}{u,i^{-}}}\[-12.0pt] &=\frac{1}{\sigma(\hat{y}{u^{+-}})}\cdot\sigma(\hat{y}{u^{+-}})\cdot(1-% \sigma(\hat{y}{u^{+-}}))\cdot 1=1-\sigma(\hat{y}{u,i^{+}}-\overbrace{\hat{y}% _{u,i^{-}}}\limits^{unobserved})\end{aligned}\right.{ start_ROW start_CELL ∇ start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_CELL start_CELL = divide start_ARG ∂ caligraphic_L start_POSTSUBSCRIPT italic_B italic_P italic_R end_POSTSUBSCRIPT end_ARG start_ARG ∂ over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_ARG = - divide start_ARG ∂ roman_log italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG start_ARG ∂ italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG divide start_ARG ∂ italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG start_ARG ∂ over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_ARG end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL = - divide start_ARG 1 end_ARG start_ARG italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG ⋅ italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) ⋅ ( 1 - italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) ) ⋅ 1 = italic_σ ( over⏞ start_ARG over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_ARG start_POSTSUPERSCRIPT italic_n italic_o italic_i italic_s italic_y end_POSTSUPERSCRIPT - over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) - 1 end_CELL end_ROW start_ROW start_CELL ∇ start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_CELL start_CELL = divide start_ARG ∂ caligraphic_L start_POSTSUBSCRIPT italic_B italic_P italic_R end_POSTSUBSCRIPT end_ARG start_ARG ∂ over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_ARG = - divide start_ARG ∂ roman_log italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG start_ARG ∂ italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG divide start_ARG ∂ italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG start_ARG ∂ over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_ARG end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL = divide start_ARG 1 end_ARG start_ARG italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) end_ARG ⋅ italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) ⋅ ( 1 - italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u start_POSTSUPERSCRIPT + - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ) ) ⋅ 1 = 1 - italic_σ ( over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT end_POSTSUBSCRIPT - over⏞ start_ARG over^ start_ARG italic_y end_ARG start_POSTSUBSCRIPT italic_u , italic_i start_POSTSUPERSCRIPT - end_POSTSUPERSCRIPT end_POSTSUBSCRIPT end_ARG start_POSTSUPERSCRIPT italic_u italic_n italic_o italic_b italic_s italic_e italic_r italic_v italic_e italic_d end_POSTSUPERSCRIPT ) end_CELL end_ROW
Conclusion. Wrong samples possess incorrect directions but are influential. LLM-based augmentation uses the natural language space to assist the ID vector space to provide a comprehensive reflection of user preferences. With real-world knowledge, LLMRec gets quality samples, reducing the impact of noisy and unobserved implicit feedback, improving accuracy, and speeding up convergence.
3.4.2. Time Complexity.
We analyze the time complexity. The projection of augmented semantic features has a time complexity of 𝒪(|𝒰∪ℐ|×d LLM×d)𝒪 𝒰 ℐ subscript 𝑑 𝐿 𝐿 𝑀 𝑑\mathcal{O}(|\mathcal{U}\cup\mathcal{I}|\times d_{LLM}\times d)caligraphic_O ( | caligraphic_U ∪ caligraphic_I | × italic_d start_POSTSUBSCRIPT italic_L italic_L italic_M end_POSTSUBSCRIPT × italic_d ). The GNN encoder for graph-based collaborative context learning takes 𝒪(L×|ℰ+|×d)𝒪 𝐿 superscript ℰ 𝑑\mathcal{O}(L\times|\mathcal{E}^{+}|\times d)caligraphic_O ( italic_L × | caligraphic_E start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT | × italic_d ) time. The BPR loss function computation has a time complexity of 𝒪(d×|ℰ∪ℰ 𝒜|)𝒪 𝑑 ℰ subscript ℰ 𝒜\mathcal{O}(d\times|\mathcal{E}\cup\mathcal{E_{\mathcal{A}}}|)caligraphic_O ( italic_d × | caligraphic_E ∪ caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT | ), while the feature reconstruction loss has a time complexity of 𝒪(d×|𝒱|)𝒪 𝑑𝒱\mathcal{O}(d\times|\widetilde{\mathcal{V}}|)caligraphic_O ( italic_d × | over~ start_ARG caligraphic_V end_ARG | ), where |𝒱|𝒱|\widetilde{\mathcal{V}}|| over~ start_ARG caligraphic_V end_ARG | represents the count of masked nodes.
- Evaluation
Table 1. Statistics of the Original and Augmented Datasets
Dataset Netflix MovieLens Graph Ori.# U# I# E# U# I# E 13187 17366 68933 12495 10322 57960 Aug.# E:26374# E:24990 Ori. Sparsity 99.970%99.915% Att.Ori.U: None I: year, title U: None I: title, year, genre Aug.U[1536]:age, gender, liked genre, disliked genre, liked directors, country, and language I[1536]:director, country, language Modality Textual[768], Visiual [512]Textual [768], Visiual [512]
- •
- Att. represents attribute, Ori. represents original, and Aug. represents augmentation. Number in [] represents the feature dimensionality.
To evaluate the performance of LLMRec, we conduct experiments, aiming to address the following research questions:
• RQ1: How does our LLM-enhanced recommender perform compared to the current state-of-the-art baselines?
• RQ2: What is the impact of key components on the performance?
• RQ3: How sensitive is the model to different parameters?
• RQ3: Are the data augmentation strategies in our LLMRec applicable across different recommendation models?
• RQ5: What is the computational cost associated with our devised LLM-based data augmentation schemes?
Table 2. Performance comparison on different datasets in terms of Recall@10/20/50, and NDCG@10/20/50, and Precision@20.
Baseline Netflix MovieLens R@10 N@10 R@20 N@20 R@50 N@50 P@20 R@10 N@10 R@20 N@20 R@50 N@50 P@20 General Collaborative Filtering Methods MF-BPR 0.0282 0.0140 0.0542 0.0205 0.0932 0.0281 0.0027 0.1890 0.0815 0.2564 0.0985 0.3442 0.1161 0.0128 NGCF 0.0347 0.0161 0.0699 0.0235 0.1092 0.0336 0.0032 0.2084 0.0886 0.2926 0.1100 0.4262 0.1362 0.0146 LightGCN 0.0352 0.0160 0.0701 0.0238 0.1125 0.0339 0.0032 0.1994 0.0837 0.2660 0.1005 0.3692 0.1209 0.0133 Recommenders with Side Information VBPR 0.0325 0.0142 0.0553 0.0199 0.1024 0.0291 0.0028 0.2144 0.0929 0.2980 0.1142 0.4076 0.1361 0.0149 MMGCN 0.0363 0.0174 0.0699 0.0249 0.1164 0.0342 0.0033 0.2314 0.1097 0.2856 0.1233 0.4282 0.1514 0.0147 GRCN 0.0379 0.0192 0.0706 0.0257 0.1148 0.0358 0.0035 0.2384 0.1040 0.3130 0.1236 0.4532 0.1516 0.0150 Data Augmentation Methods LATTICE 0.0433 0.0181 0.0737 0.0259 0.1301 0.0370 0.0036 0.2116 0.0955 0.3454 0.1268 0.4667 0.1479 0.0167 MICRO 0.0466 0.0196 0.0764 0.0271 0.1306 0.0378 0.0038 0.2150 0.1131 0.3461 0.1468 0.4898 0.1743 0.0175 Self-supervised Methods CLCRec 0.0428 0.0217 0.0607 0.0262 0.0981 0.0335 0.0030 0.2266 0.0971 0.3164 0.1198 0.4488 0.1459 0.0158 MMSSL 0.0455 0.0224 0.0743 0.0287 0.1257 0.0383 0.0037 0.2482 0.1113 0.3354 0.1310 0.4814 0.1616 0.0170 LLMRec 0.0531 0.0272 0.0829 0.0347 0.1382 0.0456 0.0041 0.2603 0.1250 0.3643 0.1628 0.5281 0.1901 0.0186 p-value 2.9 e−4 superscript 𝑒 4 e^{-4}italic_e start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT 3.0 e−3 superscript 𝑒 3 e^{-3}italic_e start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT 9.4 e−5 superscript 𝑒 5 e^{-5}italic_e start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT 1.5 e−3 superscript 𝑒 3 e^{-3}italic_e start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT 2.8 e−5 superscript 𝑒 5 e^{-5}italic_e start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT 2.2 e−3 superscript 𝑒 3 e^{-3}italic_e start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT 3.4 e−5 superscript 𝑒 5 e^{-5}italic_e start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT 2.8 e−5 superscript 𝑒 5 e^{-5}italic_e start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT 1.6 e−2 superscript 𝑒 2 e^{-2}italic_e start_POSTSUPERSCRIPT - 2 end_POSTSUPERSCRIPT 3.1 e−3 superscript 𝑒 3 e^{-3}italic_e start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT 4.1 e−4 superscript 𝑒 4 e^{-4}italic_e start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT 1.9 e−3 superscript 𝑒 3 e^{-3}italic_e start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT 1.3 e−2 superscript 𝑒 2 e^{-2}italic_e start_POSTSUPERSCRIPT - 2 end_POSTSUPERSCRIPT 1.8 e−3 superscript 𝑒 3 e^{-3}italic_e start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT Improv.13.95%21.43%8.51%20.91%5.82%19.06%7.89%4.88%10.52%5.26%10.90%7.82%9.06%6.29%
4.1. Experimental Settings
4.1.1. Datasets.
We perform experiments on publicly available datasets, i.e., Netflix and MovieLens, which include multi-modal side information. Tab.1 presents statistical details for both the original and augmented datasets for both user and item domains. MovieLens. We utilize the MovieLens dataset derived from ML-10M 1 1 1 https://files.grouplens.org/datasets/movielens/ml-10m-README.html. Side information includes movie title, year, and genre in textual format. Visual content consists of movie posters obtained through web crawling by ourselves. Netflix. We collected its multi-model side information through web crawling. The implicit feedback and basic attribute are sourced from the Netflix Prize Data 2 2 2 https://www.kaggle.com/datasets/netflix-inc/netflix-prize-data on Kaggle. For both datasets, CLIP-ViT(Radford et al., 2021) is utilized to encode visual features.
LLM-based Data Augmentation. The study employs the OpenAI package, accessed through LLMs’ APIs, for augmentation. The OpenAI Platform documentation provides details 3 3 3 https://platform.openai.com/docs/api-reference. Augmented implicit feedback is generated using the ”gpt-3.5-turbo-0613” chat completion model. Item attributes such as directors, country, and language are gathered using the same model. User profiling, based on the ”gpt-3.5-turbo-16k” model, includes age, gender, preferred genre, disliked genre, preferred directors, country, and language. Embedding is performed using the ”text-embedding-ada-002” model. The approximate cost of augmentation strategies on two datasets is 15.65 USD, 20.40 USD, and 3.12 USD, respectively.
4.1.2. Implementation Details
The experiments are conducted on a 24 GB Nvidia RTX 3090 GPU using PyTorch(Paszke et al., 2019) for code implementation. The AdamW optimizer(Loshchilov et al., 2017) is used for training, with different learning rate ranges of [5e−5 5 superscript 𝑒 5 5e^{-5}5 italic_e start_POSTSUPERSCRIPT - 5 end_POSTSUPERSCRIPT, 1e−3 1 superscript 𝑒 3 1e^{-3}1 italic_e start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT] and [2.5e−4 2.5 superscript 𝑒 4 2.5e^{-4}2.5 italic_e start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT, 9.5e−4 9.5 superscript 𝑒 4 9.5e^{-4}9.5 italic_e start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT] for Netflix and MovieLens, respectively. Regarding the parameters of the LLMs, we choose the temperature from larger values {0.0, 0.6, 0.8, 1 } to control the randomness of the generated text. The value of top-p is selected from smaller values {0.0, 0.1, 0.4, 1} to encourage probable choices. The stream is set to false to ensure the completeness of responses. For more details on the parameter analysis, please refer to Section 4.4. To maintain fairness, both our method and the baselines employ a unified embedding size of 64.
4.1.3. Evaluation Protocols
We evaluate our approach in the top-K item recommendation task using three common metrics: Recall (R@k), Normalized Discounted Cumulative Gain (N@k), and Precision (P@k). To avoid potential biases from test sampling, we employ the all-ranking strategy(Wei et al., 2021a, 2020). We report averaged results from five independent runs, setting K to 10, 20, and 50 (reasonable for all-ranking). Statistical significance analysis is conducted by calculating p 𝑝 p italic_p-values against the best-performing baseline.
4.1.4. Baseline Description
Four distinct groups of baseline methods for thorough comparison. i) General CF Methods: MF-BPR(Rendle et al., 2012), NGCF(Wang et al., 2019) and LightGCN(He et al., 2020). ii) Methods with Side Information: VBPR(He and McAuley, 2016), MMGCN(Wei et al., 2019) and GRCN(Wei et al., 2020). iii) Data Augmentation Methods: LATTICE(Zhang et al., 2021b). iv) Self-supervised Methods: CLCRec(Wei et al., 2021b), MMSSL(Wei et al., 2023a) and MICRO(Zhang et al., 2022).
4.2. Performance Comparison (RQ1)
Tab. 2 compares our proposed LLMRec method with baselines.
• Overall Model Superior Performance. Our LLMRec outperforms the baselines by explicitly augmenting u-i interactive edges and enhancing the quality of side information. It is worth mentioning that our model based on LATTICE’s (Zhang et al., 2021b) encoder, consisting of a ID-corresponding encoder and a feature encoder. This improvement underscores the effectiveness of our framework.
• Effectiveness of Side Information Incorporation. The integration of side information significantly empowers recommenders. Methods like MMSSL (Wei et al., 2023a) and MICRO (Zhang et al., 2022) stand out for their effective utilization of multiple modalities of side information and GNNs. In contrast, approaches rely on limited content, such as VBPR (He and McAuley, 2016) using only visual features, or CF-based architectures like NGCF (Wang et al., 2019), without side information, yield significantly diminished results. This highlights the importance of valuable content, as relying solely on ID-corresponding records fails to capture the complete u-i relationships.
• Inaccurate Augmentation yields Limited Benefits. Existing methods, such as LATTICE(Zhang et al., 2021b), MICRO(Zhang et al., 2022) that also utilize side information for data augmentation have shown limited improvements compared to our LLMRec. This can be attributed to two main factors: (1) The augmentation of side information with homogeneous relationships (e.g., i-i or u-u) may introduce noise, which can compromise the precise of user preferences. (2) These methods often not direct augmentation of u-i interaction data.
• Advantage over SSL Approaches. Self-supervised models like, MMSSL(Wei et al., 2023a), MICRO(Zhang et al., 2022), have shown promising results in addressing sparsity through SSL signals. However, they do not surpass the performance of LLMRec, possibly because their augmented self-supervision signals may not align well with the target task of modeling u-i interactions. In contrast, we explicitly tackle the scarcity of training data by directly establishing BPR triplets.
4.3. Ablation and Effectiveness Analyses (RQ2)
Table 3. Ablation study on key components (i.e., data augmentation strategies, denoised data robustification mechanisms)
- •
- “Aug”: data augmentation operations; Q. C.: denoised data robustification.
We conduct an ablation study of our proposed LLMRec approach to validate its key components, and present the results in Table 3.
4.3.1. Effectiveness of Data Augmentation Strategies.
∙∙\bullet∙ (1). w/o-u-i: Disabling the LLM-augmented implicit feedback ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}_{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT results in a significant decrease. This indicates that LLMRec increases the potential supervision signals by including contextual knowledge, leading to a better grasp of user preferences.
∙∙\bullet∙ (2). w/o-u: Removing our augmentor for user profiling result in a decrease in performance, indicating that our LLM-enhanced user side information can effectively summarize useful user preference profile using historical interactions and item-end knowledge.
∙∙\bullet∙ (3). w/o-u&i: when we remove the augmented side information for both users and items (𝐅 𝒜,u,𝐅 𝒜,i,1 subscript 𝐅 𝒜 𝑢 subscript 𝐅 𝒜 𝑖 1\textbf{F}{\mathcal{A},u},\textbf{F}{\mathcal{A},i,1}F start_POSTSUBSCRIPT caligraphic_A , italic_u end_POSTSUBSCRIPT , F start_POSTSUBSCRIPT caligraphic_A , italic_i , 1 end_POSTSUBSCRIPT), lower recommendation accuracy is observed. This finding indicates that the LLM-based augmented side information provides valuable augmented data to the recommender system, assisting in obtaining quality and informative representations.
4.3.2. Impact of the Denoised Data Robustification.
∙∙\bullet∙ w/o-prune: The removal of noise pruning results in worse performance. This suggests that the process of removing noisy implicit feedback signals helps prevent incorrect gradient descent.
∙∙\bullet∙ w/o-QC: The performance suffer when both the limits on implicit feedback and semantic feature quality are simultaneously removed (i.e., w/o-prune + w/o-MAE). This indicates the benefits of our denoised data robustification mechanism by integrating noise pruning and semantic feature enhancement.
4.4. Hyperparameter Analysis (RQ3)
4.4.1. Parameters Affecting Augmented Data Quality.
Table 4. Parameter analysis of temperature τ 𝜏\tau italic_τ and top-p ρ 𝜌\rho italic_ρ.
Table 5. Analysis of key parameter (i.e., # candidate |𝒞|𝒞|\mathcal{C}|| caligraphic_C | ) for LLM w.r.t implicit feedback augmentation ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}_{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT.
∙∙\bullet∙ Temperature τ 𝜏\tau italic_τ of LLM: The temperature parameter τ 𝜏\tau italic_τ affects text randomness. Higher values (¿1.0) increase diversity and creativity, while lower values (¡0.1) result in more focus. We use τ 𝜏\tau italic_τ from {0,0.6,0.8,1}0 0.6 0.8 1{0,0.6,0.8,1}{ 0 , 0.6 , 0.8 , 1 }. As shown in Table 4, increasing τ 𝜏\tau italic_τ initially improves most metrics, followed by a decrease.
∙∙\bullet∙ Top-p p 𝑝 p italic_p of LLM: Top-p Sampling(Holtzman et al., 2019) selects tokens based on a threshold determined by the top-p parameter p 𝑝 p italic_p. Lower p 𝑝 p italic_p values prioritize likely tokens, while higher values encourage diversity. We use p 𝑝 p italic_p from {0,0.1,0.4,1}0 0.1 0.4 1{0,0.1,0.4,1}{ 0 , 0.1 , 0.4 , 1 } and smaller p 𝑝 p italic_p values tend to yield better results, likely due to avoiding unlisted candidate selection. Higher ρ 𝜌\rho italic_ρ values cause wasted tokens due to repeated LLM inference.
∙∙\bullet∙ # of Candidate 𝒞 𝒞\mathcal{C}caligraphic_C: We use 𝒞 𝒞\mathcal{C}caligraphic_C to limit item candidates for LLM-based recommendation. {3,10,30}3 10 30{3,10,30}{ 3 , 10 , 30 } are explored due to cost limitations, and Table 5 shows that 𝒞=10 𝒞 10\mathcal{C}=10 caligraphic_C = 10 yields the best results. Small values limit selection, and large values increase recommendation difficulty.
∙∙\bullet∙ Prune Rate ω 4 subscript 𝜔 4\omega_{4}italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT: LLMRec uses ω 4 subscript 𝜔 4\omega_{4}italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT to control noise in augmented training data to be pruned. We set ω 4 subscript 𝜔 4\omega_{4}italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT to {0.0, 0.2, 0.4, 0.6, 0.8} on both datasets. As shown in Fig.4 (a), ω 4=0 subscript 𝜔 4 0\omega_{4}=0 italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT = 0 yields the worst result, highlighting the need to constrain noise in implicit feedback.
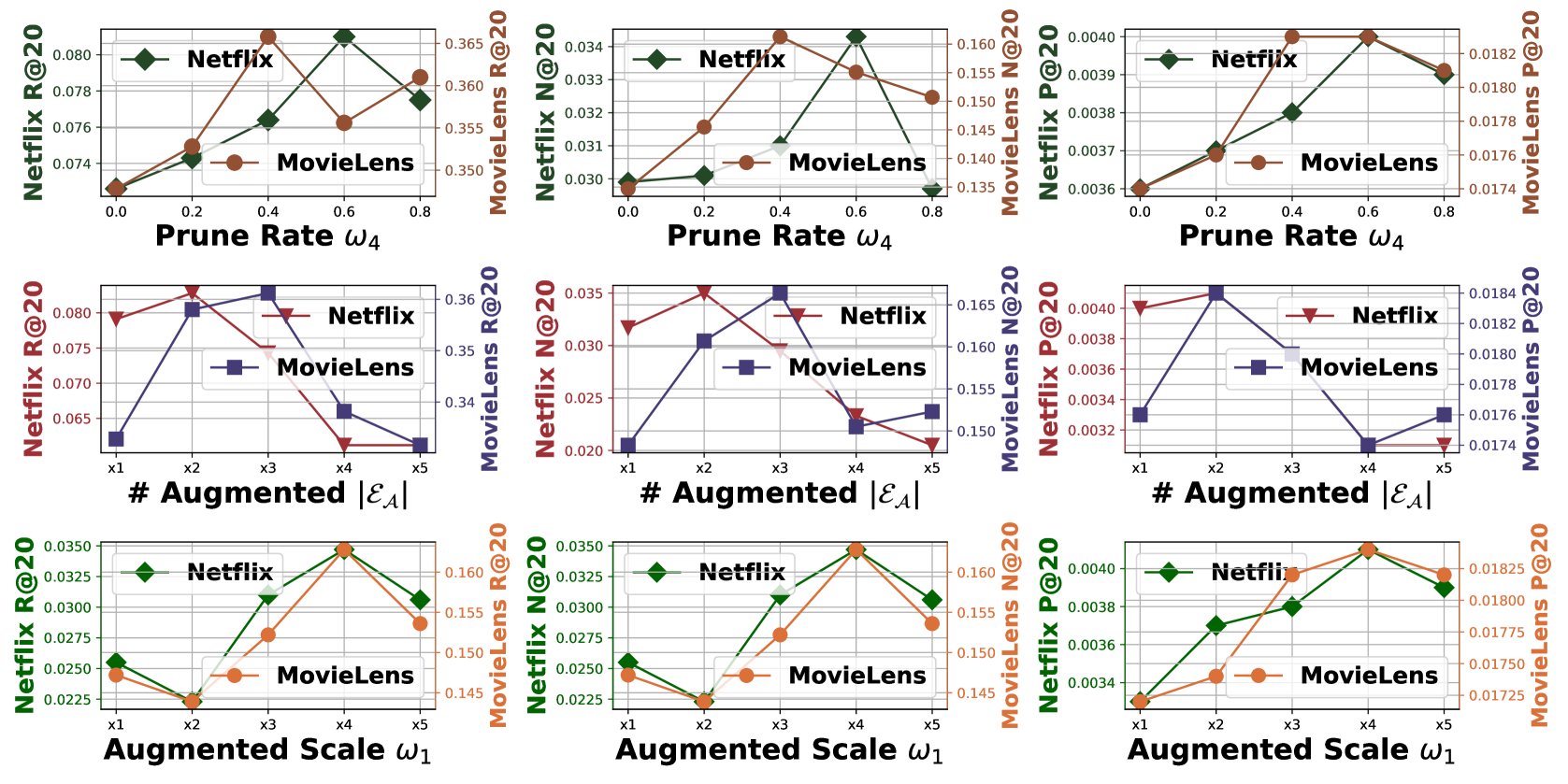
Figure 4. Impact of hyperparameters (i.e., prune rate ω 4 subscript 𝜔 4\omega_{4}italic_ω start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT, # augmented BPR training data |ℰ 𝒜|subscript ℰ 𝒜|\mathcal{E}{\mathcal{A}}|| caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT |, and augmented feature incorporate scale ω 1 subscript 𝜔 1\omega{1}italic_ω start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT).
4.4.2. Sensitivity of Recommenders to the Augmented Data.
• # of Augmented Samples per Batch |ℰ 𝒜|subscript ℰ 𝒜|\mathcal{E}_{\mathcal{A}}|| caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT |: LLMRec uses ω 3 subscript 𝜔 3\omega_{3}italic_ω start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT and batch size B 𝐵 B italic_B to control the number of augmented BPR training data samples per batch. ω 3 subscript 𝜔 3\omega_{3}italic_ω start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT is set to {0.0, 0.1, 0.2, 0.3, 0.4} on Netflix and {0.0, 0.2, 0.4, 0.6, 0.8} on MovieLens. Suboptimal results occur when ω 3 subscript 𝜔 3\omega_{3}italic_ω start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT is zero or excessively large. Increasing diversity and randomness can lead to a more robust gradient descent.
• Scale ω 2 subscript 𝜔 2\omega_{2}italic_ω start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT for Incorporating Augmented Features: LLMRec uses ω 2 subscript 𝜔 2\omega_{2}italic_ω start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT to control feature magnitude, with values set to {0.0, 0.8, 1.6, 2.4, 3.2} on Netflix and {0.0, 0.1, 0.2, 0.3, 0.4} on MovieLens. Optimal results depend on the data, with suboptimal outcomes occurring when ω 2 subscript 𝜔 2\omega_{2}italic_ω start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT is too small or too large, as shown in Fig.4 (c).
4.5. Model-agnostic Property (RQ4)
We conducted model-agnostic experiments on Netflix to validate the applicability of our data augmentation. Specifically, we incorporated the augmented implicit feedback ℰ 𝒜 subscript ℰ 𝒜\mathcal{E}{\mathcal{A}}caligraphic_E start_POSTSUBSCRIPT caligraphic_A end_POSTSUBSCRIPT and features 𝐅 𝒜,u,𝐅 𝒜,i subscript 𝐅 𝒜 𝑢 subscript 𝐅 𝒜 𝑖\textbf{F}{\mathcal{A},u},\textbf{F}_{\mathcal{A},i}F start_POSTSUBSCRIPT caligraphic_A , italic_u end_POSTSUBSCRIPT , F start_POSTSUBSCRIPT caligraphic_A , italic_i end_POSTSUBSCRIPT into baselines MICRO, MMSSL, and LATTICE. As shown in Tab.6, our LLM-based data improved the performance of all models, demonstrating their effectiveness and reusability. Some results didn’t surpass our model, maybe due to: i) the lack of a quality constraint mechanism to regulate the stability and quality of the augmented data, and ii) the absence of modeling collaborative signals in the same vector space, as mentioned in Sec.• ‣ 3.2.2.
Table 6. Model-agnostic experiment to evaluate the effectiveness of LLM-based data augmentation on different recommender in terms of R@20, N@20, and P@20.
4.6. Cost/Improvement Conversion Rate (RQ5)
To evaluate the cost-effectiveness of our augmentation strategies, we compute the CIR as presented in Tab.7. The CIR is compared with the ablation of three data augmentation strategies and the best baseline from Tab.3 and Tab.2. The cost of the implicit feedback augmentor refers to the price of GPT-3.5 turbo 4K. The cost of side information augmentation includes completion (using GPT-3.5 turbo 4K or 16K) and embedding (using text-embedding-ada-002). We utilize the HuggingFace API tool for tokenizer and counting. The results in Tab.7 show that ’U’ (LLM-based user profiling) is the most cost-effective strategy, and the overall investment is worthwhile.
Table 7. Comparison of the cost and improvement rate(CIR) of data augmentation strategies and LLMRec. ’Cost’: expenditure of utilizing LLM, ’Imp.’: the average improvement rate in R@10/N@10. ’CIR’: the ratio of improvement to cost.
- Related Work
Content-based Recommendation. Existing recommenders have explored the use of auxiliary multi-modal side knowledge(Liang et al., 2023c, 2022), with methods like VBPR(He and McAuley, 2016) combine traditional CF with visual features, while MMGCN(Wei et al., 2019), GRCN(Wei et al., 2020) leverage GNNs to capture modality-aware higher-order collaborative signals. Recent approaches MMSSL(Wei et al., 2023a) and MICRO(Zhang et al., 2022) align modal signals with collaborative signals through contrastive SSL(Liang et al., 2023a), revealing the informative aspects of modal signals that benefit recommendations. However, the data noise, heterogeneity, and incompleteness can introduce bias. To overcome this, LLMRec explores LLM-based augmentation to improve the quality of the data.
Large Language Models (LLMs) for Recommendation. LLMs have gained attention in recommendation systems, with various efforts to use them for modeling user behavior (Wang et al., 2023; Ren et al., 2023a; Kang et al., 2023). LLMs have been employed as an inference model in diverse recommendation tasks, including rating prediction, sequential recommendation, and direct recommendation (Bao et al., 2023; Zhang et al., 2023b; Chen, 2023; Dai et al., 2023). Some efforts(Tang et al., 2023; Tian et al., 2023c) also tried to utilize LLMs to model structure relations. However, most previous methods primarily used LLMs as recommenders, abandoning the base model that has been studied for decades. We combine LLM-based data augmentation with classic CF, achieving both result assurance and enhancement concurrently.
Data Augmentation for Recommendation. Extensive research has explored data augmentation in recommendation systems (Lee et al., 2021; Huang et al., 2021). Various operations, such as permutation, deletion, swap, insertion, and duplication, have been proposed for sequential recommendation (Liu et al., 2021b; Petrov and Macdonald, 2022). Commonly used techniques include counterfactual reasoning(Wang et al., 2021b; Zhang et al., 2021a) and contrastive learning (Liu et al., 2021a). Our LLMRec use LLMs as an inference model to augment edge and enhance node features by leveraging consensus knowledge from the large model.
- Conclusion
This study focuses on the design of LLM-enhanced models to address the challenges of sparse implicit feedback signals and low-quality side information by profiling user interaction preferences and debiasing item attributes. To ensure the quality of augmented data, a denoised augmentation robustification mechanism is introduced. The effectiveness of LLMRec is supported by theoretical analysis and experimental results, demonstrating its superiority over state-of-the-art recommendation techniques on benchmark datasets. Future directions for investigation include integrating causal inference into side information debiasing and exploring counterfactual factors for context-aware user preference.
References
- (1)
- Bao et al. (2023) Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. arXiv preprint arXiv:2305.00447 (2023).
- Chen et al. (2023b) Chong Chen, Weizhi Ma, Min Zhang, et al. 2023b. Revisiting negative sampling vs. non-sampling in implicit recommendation. TOIS 41, 1 (2023), 1–25.
- Chen et al. (2020) Chong Chen, Min Zhang, Yongfeng Zhang, et al. 2020. Efficient neural matrix factorization without sampling for recommendation. TOIS 38, 2 (2020), 1–28.
- Chen et al. (2023a) Mengru Chen, Chao Huang, Lianghao Xia, Wei Wei, et al. 2023a. Heterogeneous graph contrastive learning for recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining. 544–552.
- Chen (2023) Zheng Chen. 2023. PALR: Personalization Aware LLMs for Recommendation. arXiv preprint arXiv:2305.07622 (2023).
- Dai et al. (2023) Sunhao Dai, Ninglu Shao, Haiyuan Zhao, Weijie Yu, Zihua Si, Chen Xu, Zhongxiang Sun, Xiao Zhang, and Jun Xu. 2023. Uncovering ChatGPT’s Capabilities in Recommender Systems. arXiv preprint arXiv:2305.02182 (2023).
- Fan et al. (2019) Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. 2019. Graph neural networks for social recommendation. In ACM International World Wide Web Conference. 417–426.
- Fu et al. (2020) Xinyu Fu, Jiani Zhang, et al. 2020. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. In ACM International World Wide Web Conference. 2331–2341.
- He et al. (2022) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. 2022. Masked autoencoders are scalable vision learners. In CVPR. 16000–16009.
- He and McAuley (2016) Ruining He and Julian McAuley. 2016. VBPR: visual bayesian personalized ranking from implicit feedback. In AAAI, Vol.30.
- He et al. (2020) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 639–648.
- Holtzman et al. (2019) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751 (2019).
- Huang et al. (2021) Tinglin Huang, Yuxiao Dong, Ming Ding, Zhen Yang, Wenzheng Feng, Xinyu Wang, and Jie Tang. 2021. MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
- Kang et al. (2023) Wang-Cheng Kang, Jianmo Ni, Nikhil Mehta, Maheswaran Sathiamoorthy, Lichan Hong, et al. 2023. Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. arXiv preprint arXiv:2305.06474 (2023).
- Ko et al. (2022) Hyeyoung Ko, Suyeon Lee, Yoonseo Park, and Anna Choi. 2022. A survey of recommendation systems: recommendation models, techniques, and application fields. Electronics 11, 1 (2022), 141.
- Lee et al. (2021) Dongha Lee, SeongKu Kang, Hyunjun Ju, et al. 2021. Bootstrapping user and item representations for one-class collaborative filtering. In ACM SIGIR Conference on Research and Development in Information Retrieval. 317–326.
- Li et al. (2023a) Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, and Julian McAuley. 2023a. Text Is All You Need: Learning Language Representations for Sequential Recommendation. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining.
- Li et al. (2023b) Jinming Li, Wentao Zhang, Tian Wang, Guanglei Xiong, et al. 2023b. GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation. arXiv preprint arXiv:2304.03879 (2023).
- Liang et al. (2023a) Ke Liang, Yue Liu, Sihang Zhou, Wenxuan Tu, Yi Wen, Xihong Yang, Xiangjun Dong, and Xinwang Liu. 2023a. Knowledge Graph Contrastive Learning Based on Relation-Symmetrical Structure. IEEE Transactions on Knowledge and Data Engineering (2023), 1–12. https://doi.org/10.1109/TKDE.2023.3282989
- Liang et al. (2023b) Ke Liang, Lingyuan Meng, Meng Liu, Yue Liu, Wenxuan Tu, Siwei Wang, Sihang Zhou, and Xinwang Liu. 2023b. Learn from relational correlations and periodic events for temporal knowledge graph reasoning. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval Conference on Research and Development in Information Retrieval. 1559–1568.
- Liang et al. (2022) Ke Liang, Lingyuan Meng, Meng Liu, Yue Liu, Wenxuan Tu, Siwei Wang, Sihang Zhou, Xinwang Liu, and Fuchun Sun. 2022. Reasoning over different types of knowledge graphs: Static, temporal and multi-modal. arXiv preprint arXiv:2212.05767 (2022).
- Liang et al. (2023c) Ke Liang, Sihang Zhou, Yue Liu, Lingyuan Meng, Meng Liu, and Xinwang Liu. 2023c. Structure Guided Multi-modal Pre-trained Transformer for Knowledge Graph Reasoning. arXiv preprint arXiv:2307.03591 (2023).
- Liu et al. (2021a) Zhiwei Liu, Yongjun Chen, Jia Li, Philip S Yu, Julian McAuley, and Caiming Xiong. 2021a. Contrastive self-supervised sequential recommendation with robust augmentation. arXiv preprint arXiv:2108.06479 (2021).
- Liu et al. (2021b) Zhiwei Liu, Ziwei Fan, et al. 2021b. Augmenting sequential recommendation with pseudo-prior items via reversely pre-training transformer. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1608–1612.
- Loshchilov et al. (2017) Ilya Loshchilov et al. 2017. Decoupled weight decay regularization. In ICLR.
- Meng et al. (2023a) Chang Meng, Chenhao Zhai, Yu Yang, Hengyu Zhang, and Xiu Li. 2023a. Parallel Knowledge Enhancement based Framework for Multi-behavior Recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1797–1806.
- Meng et al. (2023b) Chang Meng, Hengyu Zhang, Wei Guo, Huifeng Guo, Haotian Liu, Yingxue Zhang, Hongkun Zheng, Ruiming Tang, Xiu Li, and Rui Zhang. 2023b. Hierarchical Projection Enhanced Multi-Behavior Recommendation. In Proceedings of the 29th ACM SIGACM SIGKDD Conference on Knowledge Discovery and Data Mining Conference on Knowledge Discovery and Data Mining. 4649–4660.
- Meng et al. (2023c) Chang Meng, Ziqi Zhao, Wei Guo, Yingxue Zhang, Haolun Wu, Chen Gao, Dong Li, Xiu Li, and Ruiming Tang. 2023c. Coarse-to-fine knowledge-enhanced multi-interest learning framework for multi-behavior recommendation. ACM Transactions on Information Systems 42, 1 (2023), 1–27.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Conference on Neural Information Processing Systems 32 (2019).
- Petrov and Macdonald (2022) Aleksandr Petrov and Craig Macdonald. 2022. Effective and Efficient Training for Sequential Recommendation using Recency Sampling. In Recsys. 81–91.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. Learning transferable visual models from natural language supervision. In ICML. PMLR, 8748–8763.
- Ren et al. (2023a) Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2023a. Representation Learning with Large Language Models for Recommendation. arXiv preprint arXiv:2310.15950 (2023).
- Ren et al. (2023b) Xubin Ren, Lianghao Xia, Yuhao Yang, Wei Wei, Tianle Wang, Xuheng Cai, and Chao Huang. 2023b. SSLRec: A Self-Supervised Learning Library for Recommendation. arXiv preprint arXiv:2308.05697 (2023).
- Rendle et al. (2012) Steffen Rendle, Christoph Freudenthaler, et al. 2012. BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012).
- Tang et al. (2023) Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2023. GraphGPT: Graph Instruction Tuning for Large Language Models. arXiv preprint arXiv:2310.13023 (2023).
- Tian et al. (2023a) Yijun Tian, Kaiwen Dong, Chunhui Zhang, Chuxu Zhang, and Nitesh V Chawla. 2023a. Heterogeneous graph masked autoencoders. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol.37. 9997–10005.
- Tian et al. (2023b) Yijun Tian, Shichao Pei, Xiangliang Zhang, Chuxu Zhang, and Nitesh V Chawla. 2023b. Knowledge Distillation on Graphs: A Survey. arXiv preprint arXiv:2302.00219 (2023).
- Tian et al. (2023c) Yijun Tian, Huan Song, Zichen Wang, Haozhu Wang, Ziqing Hu, Fang Wang, Nitesh V Chawla, and Panpan Xu. 2023c. Graph neural prompting with large language models. arXiv preprint arXiv:2309.15427 (2023).
- Tian et al. (2022) Yijun Tian, Chuxu Zhang, Zhichun Guo, Xiangliang Zhang, and Nitesh Chawla. 2022. Learning mlps on graphs: A unified view of effectiveness, robustness, and efficiency. In The Eleventh International Conference on Learning Representations.
- Wang et al. (2021a) Wenjie Wang, Fuli Feng, Xiangnan He, Liqiang Nie, and Tat-Seng Chua. 2021a. Denoising implicit feedback for recommendation. In WSDM. 373–381.
- Wang et al. (2019) Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. In ACM SIGIR Conference on Research and Development in Information Retrieval. 165–174.
- Wang et al. (2023) Xiaolei Wang, Xinyu Tang, Wayne Xin Zhao, Jingyuan Wang, and Ji-Rong Wen. 2023. Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models. arXiv preprint arXiv:2305.13112 (2023).
- Wang et al. (2021b) Zhenlei Wang, Jingsen Zhang, Hongteng Xu, Xu Chen, Yongfeng Zhang, Wayne Xin Zhao, and Ji-Rong Wen. 2021b. Counterfactual data-augmented sequential recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 347–356.
- Wei et al. (2022) Wei Wei, Chao Huang, Lianghao Xia, Yong Xu, Jiashu Zhao, and Dawei Yin. 2022. Contrastive meta learning with behavior multiplicity for recommendation. In Proceedings of the fifteenth ACM international conference on web search and data mining. 1120–1128.
- Wei et al. (2023a) Wei Wei, Chao Huang, Lianghao Xia, and Chuxu Zhang. 2023a. Multi-Modal Self-Supervised Learning for Recommendation. In ACM International World Wide Web Conference. 790–800.
- Wei et al. (2023b) Wei Wei, Lianghao Xia, and Chao Huang. 2023b. Multi-Relational Contrastive Learning for Recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems. 338–349.
- Wei et al. (2021a) Yinwei Wei, Xiang Wang, et al. 2021a. Hierarchical user intent graph network for multimedia recommendation. Transactions on Multimedia (TMM) (2021).
- Wei et al. (2021b) Yinwei Wei, Xiang Wang, Qi Li, Liqiang Nie, Yan Li, et al. 2021b. Contrastive learning for cold-start recommendation. In ACM MM. 5382–5390.
- Wei et al. (2020) Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, and Tat-Seng Chua. 2020. Graph-refined convolutional network for multimedia recommendation with implicit feedback. In MM. 3541–3549.
- Wei et al. (2019) Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. 2019. MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. In MM. 1437–1445.
- Wu et al. (2021) Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, et al. 2021. Self-supervised graph learning for recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 726–735.
- Yi et al. (2022) Zixuan Yi, Xi Wang, Iadh Ounis, and Craig Macdonald. 2022. Multi-modal Graph Contrastive Learning for Micro-video Recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1807–1811.
- Ying et al. (2023) Yuxin Ying, Fuzhen Zhuang, Yongchun Zhu, Deqing Wang, and Hongwei Zheng. 2023. CAMUS: Attribute-Aware Counterfactual Augmentation for Minority Users in Recommendation. In ACM International World Wide Web Conference. 1396–1404.
- Yu et al. (2022) Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are graph augmentations necessary? Simple graph contrastive learning for recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1294–1303.
- Yuan et al. (2023) Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to go next for recommender systems? id-vs. modality-based recommender models revisited. In ACM SIGIR Conference on Research and Development in Information Retrieval.
- Zhang et al. (2023a) Honglei Zhang, Fangyuan Luo, Jun Wu, Xiangnan He, and Yidong Li. 2023a. LightFR: Lightweight federated recommendation with privacy-preserving matrix factorization. ACM Transactions on Information Systems 41, 4 (2023), 1–28.
- Zhang et al. (2023b) Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2023b. Recommendation as instruction following: A large language model empowered recommendation approach. arXiv preprint arXiv:2305.07001 (2023).
- Zhang et al. (2022) Jinghao Zhang, Yanqiao Zhu, Qiang Liu, et al. 2022. Latent structure mining with contrastive modality fusion for multimedia recommendation. TKDE (2022).
- Zhang et al. (2021b) Jinghao Zhang, Yanqiao Zhu, Qiang Liu, Shu Wu, et al. 2021b. Mining Latent Structures for Multimedia Recommendation. In MM. 3872–3880.
- Zhang et al. (2021a) Shengyu Zhang, Dong Yao, Zhou Zhao, et al. 2021a. Causerec: Counterfactual user sequence synthesis for sequential recommendation. In ACM SIGIR Conference on Research and Development in Information Retrieval. 367–377.
- Zou et al. (2022) Ding Zou, Wei Wei, Xian-Ling Mao, Ziyang Wang, Minghui Qiu, Feida Zhu, and Xin Cao. 2022. Multi-level cross-view contrastive learning for knowledge-aware recommender system. In ACM SIGIR Conference on Research and Development in Information Retrieval. 1358–1368.
Xet Storage Details
- Size:
- 112 kB
- Xet hash:
- 7302f8fc7059cead7226497d96ba9325e8fd778294e0d3d2688b7a31858f3f41
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.