Buckets:

Title: MARS: Matching Attribute-aware Representations for Text-based Sequential Recommendation
URL Source: https://arxiv.org/html/2409.00702
Published Time: Thu, 05 Sep 2024 00:44:42 GMT
Markdown Content: ,Junyoung Kim Sungkyunkwan University Suwon Republic of Koreajunyoung44@skku.edu,Minjin Choi Sungkyunkwan University Suwon Republic of Koreazxcvxd@skku.edu,Sunkyung Lee Sungkyunkwan University Suwon Republic of Koreask1027@skku.eduand Jongwuk Lee Sungkyunkwan University Suwon Republic of Koreajongwuklee@skku.edu
(2024)
Abstract.
Sequential recommendation aims to predict the next item a user is likely to prefer based on their sequential interaction history. Recently, text-based sequential recommendation has emerged as a promising paradigm that uses pre-trained language models to exploit textual item features to enhance performance and facilitate knowledge transfer to unseen datasets. However, existing text-based recommender models still struggle with two key challenges: (i) representing users and items with multiple attributes, and (ii) matching items with complex user interests. To address these challenges, we propose a novel model, M atching A ttribute-aware R epresentations for Text-based S equential Recommendation (MARS). MARS extracts detailed user and item representations through attribute-aware text encoding, capturing diverse user intents with multiple attribute-aware representations. It then computes user-item scores via attribute-wise interaction matching, effectively capturing attribute-level user preferences. Our extensive experiments demonstrate that MARS significantly outperforms existing sequential models, achieving improvements of up to 24.43% and 29.26% in Recall@10 and NDCG@10 across five benchmark datasets. 1 1 1 Code is available at https://github.com/junieberry/MARS.
sequential recommendation; pre-trained language model; zero-shot recommendation
††journalyear: 2024††copyright: rightsretained††conference: Proceedings of the 33rd ACM International Conference on Information and Knowledge Management; October 21–25, 2024; Boise, ID, USA††booktitle: Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM ’24), October 21–25, 2024, Boise, ID, USA††doi: 10.1145/3627673.3679960††isbn: 979-8-4007-0436-9/24/10††ccs: Information systems Recommender systems 1. Introduction

Figure 1. A motivating example of two user sequences. The green and pink boxes represent different user interests that are highly relevant to target items.
Sequential recommendation(Fang et al., 2019; Hidasi et al., 2016; Kang and McAuley, 2018; Fang et al., 2020; Wang et al., 2019; Chen et al., 2018b) aims to deliver consecutive items to users based on a sequential form of their past interaction history. Due to the dynamic evolution of user behavior over time, they are vital in various commercial web applications, e.g., Amazon(Linden et al., 2003), YouTube(Covington et al., 2016), and Spotify(Chen et al., 2018a).
Conventional ID-based models(Kang and McAuley, 2018; Hidasi et al., 2016; Li et al., 2022) represent items as explicit IDs. They randomly initialize vectors for item embeddings and optimize them with sequential user-item interactions through neural encoders, such as CNNs(Tang and Wang, 2018), MLPs(Zhou et al., 2022), RNNs(Hidasi et al., 2016; Li et al., 2017), GNNs(Chang et al., 2021; Wu et al., 2019), and Transformers(Kang and McAuley, 2018; Wu et al., 2020; Sun et al., 2019; Du et al., 2022; Qiu et al., 2022; Xie et al., 2022a). However, they struggle to learn item representations with sparse interactions, i.e., cold-start items. Some studies(Zhou et al., 2020; Zhang et al., 2019; Xie et al., 2022b; Liu et al., 2021; Yuan et al., 2021) have exploited item metadata as side information to compensate for the lack of collaborative signal. However, these approaches suffer from the fundamental limitation of handling new items or new attributes.
Recent studies(Hou et al., 2022; Tang et al., 2023; Li et al., 2023; Liu et al., 2023; Ding et al., 2021) have proposed text-based sequential recommendation that uses pre-trained language models (PLMs). These methods perform matching by encoding textual representations of the user/item into embedding vectors. They offer two advantages: (i) handling unseen items and transferring knowledge to new datasets without additional training, and (ii) enriching item representations with real-world knowledge. Nevertheless, existing models struggle to capture nuanced user interests and item features, as they represent user sequences and items as single vectors. MIRACLE(Tang et al., 2023) attempts to enhance user sequence representations with multiple vectors, but is limited by a fixed number of interests and single-vector item representations.
Figure 1 illustrates a scenario where two users with similar purchase histories receive distinct item recommendations based on their individual attribute-level preferences. For instance, User A may be recommended a “Magic Keyboard” from “Apple” given their purchase history of “Magic Mouse” and “Keyboard.” In contrast, User B’s purchase of “Gaming Headset” and “Logitech” products suggests an interest in gaming, which may lead to a recommendation for a “Gaming Mouse” following their recent “Mouse” purchase. These scenarios emphasize the need to identify user interests by combining purchase history in an attribute-wise manner, as a single vector representation of the sequence cannot capture preferences for specific attributes like “Logitech” or “Keyboard.”
In light of these observations, we establish two challenges: (i) How do we represent a user/item to represent multiple attributes? (ii) How do we calculate the matching score between the user and the item considering complex user interests? To address these challenges, we propose a novel text-based sequential recommender model, namely M atching A ttribute-aware R epresentations for S equential Recommendation (MARS), which learns fine-grained user preferences by leveraging textual information of item attributes as shown in Figure2. Specifically, we obtain multiple attribute-aware representations by encoding the textual attributes of user sequence and item with PLMs, preserving fine-grained semantics. The user-item score is then computed via attribute-wise item matching using multiple representations. The score is calculated for each attribute between user sequences/items, which can finely represent the attribute-level preference. This enables MARS to capture the intricate user-item relationship between the fine-grained representations. Extensive experimental results on five benchmark datasets show that MARS outperforms existing sequential recommendation models by up to 24.43% and 29.26% in Recall@10 and NDCG@10, respectively.
- Proposed Model
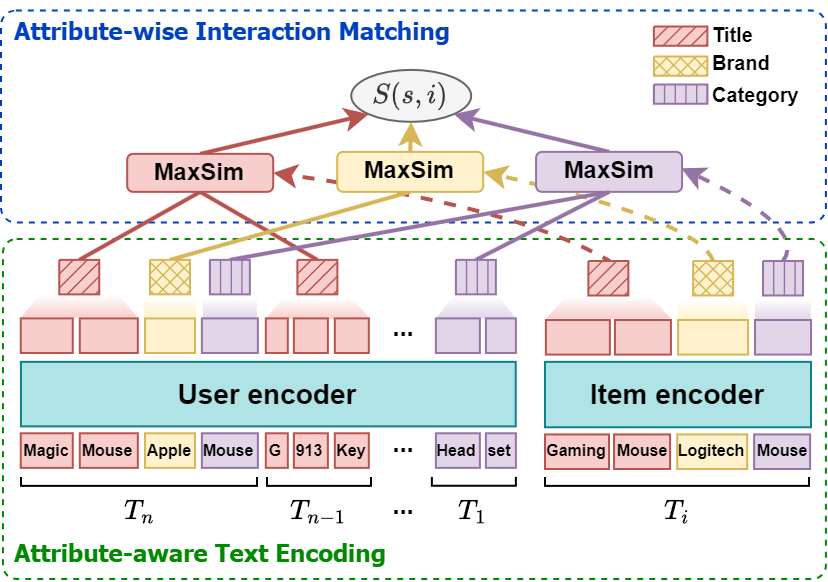
Figure 2. Model architecture of MARS. Each item consists of three attributes, e.g., title, brand, and category. For simplicity, we only display attribute values, omitting their keys.
2.1. Text-based Sequential Recommendation
Problem definition. Let 𝒰 𝒰\mathcal{U}caligraphic_U and ℐ ℐ\mathcal{I}caligraphic_I denote a set of users and a set of items. The interaction history of user u∈𝒰 𝑢 𝒰 u\in\mathcal{U}italic_u ∈ caligraphic_U is denoted by s=(i 1,i 2,…,i n)𝑠 subscript 𝑖 1 subscript 𝑖 2…subscript 𝑖 𝑛 s=(i_{1},i_{2},\dots,i_{n})italic_s = ( italic_i start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_i start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_i start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ), where i t∈ℐ subscript 𝑖 𝑡 ℐ i_{t}\in\mathcal{I}italic_i start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∈ caligraphic_I refers to the item interacted at the t 𝑡 t italic_t-th position, and n 𝑛 n italic_n indicates the number of items in the user sequence s 𝑠 s italic_s. Text-based sequential recommender models utilize textual item information to predict the next item i n+1 subscript 𝑖 𝑛 1 i_{n+1}italic_i start_POSTSUBSCRIPT italic_n + 1 end_POSTSUBSCRIPT that a user will likely engage with, based on their historical sequence s 𝑠 s italic_s.
Overall process. Following (Hou et al., 2022; Tang et al., 2023; Li et al., 2023), each item i∈ℐ 𝑖 ℐ i\in\mathcal{I}italic_i ∈ caligraphic_I is represented by a list of textual attributes T i=(a i,1,…,a i,m)subscript 𝑇 𝑖 subscript 𝑎 𝑖 1…subscript 𝑎 𝑖 𝑚 T_{i}=(a_{i,1},\dots,a_{i,m})italic_T start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = ( italic_a start_POSTSUBSCRIPT italic_i , 1 end_POSTSUBSCRIPT , … , italic_a start_POSTSUBSCRIPT italic_i , italic_m end_POSTSUBSCRIPT ), where m 𝑚 m italic_m is the number of item attributes. The attribute a i,j subscript 𝑎 𝑖 𝑗 a_{i,j}italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT is represented in a key-value format: a i,j=(k i,j,v i,j)subscript 𝑎 𝑖 𝑗 subscript 𝑘 𝑖 𝑗 subscript 𝑣 𝑖 𝑗 a_{i,j}=(k_{i,j},v_{i,j})italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT = ( italic_k start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT , italic_v start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT ), where k i,j subscript 𝑘 𝑖 𝑗 k_{i,j}italic_k start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT and v i,j subscript 𝑣 𝑖 𝑗 v_{i,j}italic_v start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT indicate the attribute name (e.g., Category) and value (e.g., Keyboard), respectively. k i,j subscript 𝑘 𝑖 𝑗 k_{i,j}italic_k start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT and v i,j subscript 𝑣 𝑖 𝑗 v_{i,j}italic_v start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT are joined to represent a i,j subscript 𝑎 𝑖 𝑗 a_{i,j}italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT in text (e.g., ‘Category: Keyboard’). User sequence can be represented in text as T s=(T n,…,T 1)=([a n,1,…,a n,m,a n−1,1,…,a 1,m])subscript 𝑇 𝑠 subscript 𝑇 𝑛…subscript 𝑇 1 subscript 𝑎 𝑛 1…subscript 𝑎 𝑛 𝑚 subscript 𝑎 𝑛 1 1…subscript 𝑎 1 𝑚 T_{s}=(T_{n},\dots,T_{1})=([a_{n,1},\dots,a_{n,m},a_{n-1,1},\dots,a_{1,m}])italic_T start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT = ( italic_T start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , … , italic_T start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ) = ( [ italic_a start_POSTSUBSCRIPT italic_n , 1 end_POSTSUBSCRIPT , … , italic_a start_POSTSUBSCRIPT italic_n , italic_m end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_n - 1 , 1 end_POSTSUBSCRIPT , … , italic_a start_POSTSUBSCRIPT 1 , italic_m end_POSTSUBSCRIPT ] ), where a t,j subscript 𝑎 𝑡 𝑗 a_{t,j}italic_a start_POSTSUBSCRIPT italic_t , italic_j end_POSTSUBSCRIPT is the textual description of the j 𝑗 j italic_j-th attribute of the item i t subscript 𝑖 𝑡 i_{t}italic_i start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. Note that we input the sequence in reverse order to prevent recent items from being truncated(Li et al., 2023; Tang et al., 2023).
Finally, given a user sequence T s subscript 𝑇 𝑠 T_{s}italic_T start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT and an item T i subscript 𝑇 𝑖 T_{i}italic_T start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, the recommendation score S(s,i)𝑆 𝑠 𝑖 S(s,i)italic_S ( italic_s , italic_i ) is calculated as follows.
(1)S(s,i)=sim(Enc(T s),Enc(T i)),𝑆 𝑠 𝑖 sim Enc subscript 𝑇 𝑠 Enc subscript 𝑇 𝑖 S(s,i)=\text{sim}(\text{Enc}(T_{s}),\text{Enc}(T_{i})),italic_S ( italic_s , italic_i ) = sim ( Enc ( italic_T start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT ) , Enc ( italic_T start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) ) ,
where Enc(⋅)Enc⋅\text{Enc}(\cdot)Enc ( ⋅ ) represents the text encoder, and sim(⋅,⋅)sim⋅⋅\text{sim}(\cdot,\cdot)sim ( ⋅ , ⋅ ) is a scoring function. In the following sections, we introduce our proposed model focusing on two key components of text-based sequential recommendation: Enc(⋅)Enc⋅\text{Enc}(\cdot)Enc ( ⋅ ) in Section2.2 and sim(⋅,⋅)sim⋅⋅\text{sim}(\cdot,\cdot)sim ( ⋅ , ⋅ ) in Section2.3.
2.2. Attribute-aware Text Encoding
While existing text-based sequential recommenders(Hou et al., 2022; Li et al., 2023) represent the user sequence/item as a single coarse-grained vector using PLM, we obtain attribute-aware multiple representations to explicitly reflect the diverse preferences and aspects of user sequences and items.
Item encoder. The attribute j 𝑗 j italic_j of item i 𝑖 i italic_i is tokenized as follows:
(2)X i,j=Tokenize(a i,j)=(x i,j(1),…,x i,j(L′)),subscript 𝑋 𝑖 𝑗 Tokenize subscript 𝑎 𝑖 𝑗 superscript subscript 𝑥 𝑖 𝑗 1…superscript subscript 𝑥 𝑖 𝑗 superscript 𝐿′X_{i,j}=\text{Tokenize}\left(a_{i,j}\right)=\left(x_{i,j}^{(1)},\dots,x_{i,j}^% {(L^{\prime})}\right),italic_X start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT = Tokenize ( italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT ) = ( italic_x start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( 1 ) end_POSTSUPERSCRIPT , … , italic_x start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ( italic_L start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ) end_POSTSUPERSCRIPT ) ,
where L′superscript 𝐿′L^{\prime}italic_L start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT represents the length of tokenized a i,j subscript 𝑎 𝑖 𝑗 a_{i,j}italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT. The text representation X i subscript 𝑋 𝑖 X_{i}italic_X start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT of item i 𝑖 i italic_i, can be obtained by concatenating the tokenized attributes of the item:
(3)X i=(X i,1;…;X i,m)=(x 1,x 2,…,x L),subscript 𝑋 𝑖 subscript 𝑋 𝑖 1…subscript 𝑋 𝑖 𝑚 subscript 𝑥 1 subscript 𝑥 2…subscript 𝑥 𝐿 X_{i}=\left(X_{i,1};\dots;X_{i,m}\right)=\left(x_{1},x_{2},\dots,x_{L}\right),italic_X start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = ( italic_X start_POSTSUBSCRIPT italic_i , 1 end_POSTSUBSCRIPT ; … ; italic_X start_POSTSUBSCRIPT italic_i , italic_m end_POSTSUBSCRIPT ) = ( italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_x start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_x start_POSTSUBSCRIPT italic_L end_POSTSUBSCRIPT ) ,
where L 𝐿 L italic_L is the length of X i subscript 𝑋 𝑖 X_{i}italic_X start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. By prefixing X i subscript 𝑋 𝑖 X_{i}italic_X start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT with a [BOS] token and passing it through the PLM, we obtain the contextualized vector 𝐨∈ℝ d 𝐨 superscript ℝ 𝑑\mathbf{o}\in\mathbb{R}^{d}bold_o ∈ blackboard_R start_POSTSUPERSCRIPT italic_d end_POSTSUPERSCRIPT for each token.
(4)𝐎 i=[𝐨[BOS],𝐨 1,…,𝐨 L]=PLM([[BOS];X i]),subscript 𝐎 𝑖 subscript 𝐨[BOS]subscript 𝐨 1…subscript 𝐨 𝐿 PLM[BOS]subscript 𝑋 𝑖\mathbf{O}{i}=\left[\mathbf{o}{\texttt{[BOS]}},\mathbf{o}{1},\dots,\mathbf{% o}{L}\right]=\text{PLM}\left(\left[\texttt{[BOS]};X_{i}\right]\right),bold_O start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = [ bold_o start_POSTSUBSCRIPT [BOS] end_POSTSUBSCRIPT , bold_o start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , bold_o start_POSTSUBSCRIPT italic_L end_POSTSUBSCRIPT ] = PLM ( [ [BOS] ; italic_X start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ] ) ,
where d 𝑑 d italic_d is the hidden dimension size of the PLM, 𝐨 l subscript 𝐨 𝑙\mathbf{o}{l}bold_o start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT is the last hidden state of the input token x l subscript 𝑥 𝑙 x{l}italic_x start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT, and 𝐎 i subscript 𝐎 𝑖\mathbf{O}_{i}bold_O start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT is the list of hidden states for item i 𝑖 i italic_i. We use Longformer(Beltagy et al., 2020) to handle long sequence input.
Contrary to existing studies(Hou et al., 2022; Li et al., 2023) that represent user with a single coarse-grained vector, e.g., 𝐨[BOS]subscript 𝐨[BOS]\mathbf{o}{\texttt{[BOS]}}bold_o start_POSTSUBSCRIPT [BOS] end_POSTSUBSCRIPT, we utilize fine-grained representations through attribute-aware multiple vectors. First, to alleviate matching complexity, we employ a linear layer to reduce the dimension of 𝐨 l subscript 𝐨 𝑙\mathbf{o}{l}bold_o start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT from d 𝑑 d italic_d to d′superscript 𝑑′d^{\prime}italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT by setting d′<d superscript 𝑑′𝑑 d^{\prime}<d italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT < italic_d:
(5)𝐎 i′=[𝐨[BOS]′,𝐨 1′,…,𝐨 L′]=[{𝐖⊤𝐨+𝐛∣𝐨∈𝐎 i}]subscript superscript 𝐎′𝑖 subscript superscript 𝐨′[BOS]subscript superscript 𝐨′1…subscript superscript 𝐨′𝐿 delimited-[]conditional-set superscript 𝐖 top 𝐨 𝐛 𝐨 subscript 𝐎 𝑖\mathbf{O}^{\prime}{i}=\left[\mathbf{o}^{\prime}{\texttt{[BOS]}},\mathbf{o}^% {\prime}{1},\dots,\mathbf{o}^{\prime}{L}\right]=\left[\left{\mathbf{W}^{% \top}\mathbf{o}+\mathbf{b}\mid\mathbf{o}\in\mathbf{O}_{i}\right}\right]bold_O start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = [ bold_o start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT [BOS] end_POSTSUBSCRIPT , bold_o start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , bold_o start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_L end_POSTSUBSCRIPT ] = [ { bold_W start_POSTSUPERSCRIPT ⊤ end_POSTSUPERSCRIPT bold_o + bold_b ∣ bold_o ∈ bold_O start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } ]
where 𝐨 l′∈ℝ d′subscript superscript 𝐨′𝑙 superscript ℝ superscript 𝑑′\mathbf{o}^{\prime}_{l}\in\mathbb{R}^{d^{\prime}}bold_o start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT, weight 𝐖∈ℝ d×d′𝐖 superscript ℝ 𝑑 superscript 𝑑′\mathbf{W}\in\mathbb{R}^{d\times d^{\prime}}bold_W ∈ blackboard_R start_POSTSUPERSCRIPT italic_d × italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT, and bias 𝐛∈ℝ d′𝐛 superscript ℝ superscript 𝑑′\mathbf{b}\in\mathbb{R}^{d^{\prime}}bold_b ∈ blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT.
The attribute-wise representation of a i,j subscript 𝑎 𝑖 𝑗 a_{i,j}italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT is obtained by aggregating the hidden states of the tokens that describe a i,j subscript 𝑎 𝑖 𝑗 a_{i,j}italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT. Specifically, for each attribute a i,j subscript 𝑎 𝑖 𝑗 a_{i,j}italic_a start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT, we compute the representation 𝐡 i,j subscript 𝐡 𝑖 𝑗\mathbf{h}{i,j}bold_h start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT by averaging the hidden states 𝐨 l′∈𝐎 i′subscript superscript 𝐨′𝑙 subscript superscript 𝐎′𝑖\mathbf{o}^{\prime}{l}\in\mathbf{O}^{\prime}{i}bold_o start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∈ bold_O start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT that corresponds to the tokens x l∈X i,j subscript 𝑥 𝑙 subscript 𝑋 𝑖 𝑗 x{l}\in X_{i,j}italic_x start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∈ italic_X start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT.
(6)𝐡 i,j=AvgPool({𝐨 l′∣x l∈X i,j,𝐨 l′∈𝐎 i′})subscript 𝐡 𝑖 𝑗 AvgPool conditional-set subscript superscript 𝐨′𝑙 formulae-sequence subscript 𝑥 𝑙 subscript 𝑋 𝑖 𝑗 subscript superscript 𝐨′𝑙 subscript superscript 𝐎′𝑖\mathbf{h}{i,j}=\text{AvgPool}\left({\mathbf{o}^{\prime}{l}\mid x_{l}\in X_% {i,j},\ \mathbf{o}^{\prime}{l}\in\mathbf{O}^{\prime}{i}}\right)bold_h start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT = AvgPool ( { bold_o start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∣ italic_x start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∈ italic_X start_POSTSUBSCRIPT italic_i , italic_j end_POSTSUBSCRIPT , bold_o start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT ∈ bold_O start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } )
Finally, T i subscript 𝑇 𝑖 T_{i}italic_T start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT is encoded into multiple attribute-aware representations by applying Eq. (6) to m 𝑚 m italic_m attributes.
(7)Enc(T i)=[𝐡 i,1,…,𝐡 i,m].Enc subscript 𝑇 𝑖 subscript 𝐡 𝑖 1…subscript 𝐡 𝑖 𝑚\text{Enc}\left(T_{i}\right)=\left[\mathbf{h}{i,1},\dots,\mathbf{h}{i,m}% \right].Enc ( italic_T start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) = [ bold_h start_POSTSUBSCRIPT italic_i , 1 end_POSTSUBSCRIPT , … , bold_h start_POSTSUBSCRIPT italic_i , italic_m end_POSTSUBSCRIPT ] .
User encoder. User sequences are encoded into attribute-aware multiple representations to capture various user intents. By tokenizing the text representation of the sequence T s subscript 𝑇 𝑠 T_{s}italic_T start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT, the input X s subscript 𝑋 𝑠 X_{s}italic_X start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT is represented as follows:
(8)X s subscript 𝑋 𝑠\displaystyle X_{s}italic_X start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT=(X n,1;…;X n,m;…;X 1,1;…;X 1,m)absent subscript 𝑋 𝑛 1…subscript 𝑋 𝑛 𝑚…subscript 𝑋 1 1…subscript 𝑋 1 𝑚\displaystyle=\left(X_{n,1};\dots;X_{n,m};\dots;X_{1,1};\dots;X_{1,m}\right)= ( italic_X start_POSTSUBSCRIPT italic_n , 1 end_POSTSUBSCRIPT ; … ; italic_X start_POSTSUBSCRIPT italic_n , italic_m end_POSTSUBSCRIPT ; … ; italic_X start_POSTSUBSCRIPT 1 , 1 end_POSTSUBSCRIPT ; … ; italic_X start_POSTSUBSCRIPT 1 , italic_m end_POSTSUBSCRIPT )
By following the similar process in the item encoder, we then obtain the contextualized vector 𝐡 t,j∈ℝ d′subscript 𝐡 𝑡 𝑗 superscript ℝ superscript 𝑑′\mathbf{h}{t,j}\in\mathbb{R}^{d^{\prime}}bold_h start_POSTSUBSCRIPT italic_t , italic_j end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT for each item attribute a t,j subscript 𝑎 𝑡 𝑗 a{t,j}italic_a start_POSTSUBSCRIPT italic_t , italic_j end_POSTSUBSCRIPT.
(9)Enc(T s)=[𝐡 n,1,…,𝐡 n,m,…,𝐡 1,1,…,𝐡 1,m].Enc subscript 𝑇 𝑠 subscript 𝐡 𝑛 1…subscript 𝐡 𝑛 𝑚…subscript 𝐡 1 1…subscript 𝐡 1 𝑚\text{Enc}\left(T_{s}\right)=\left[\mathbf{h}{n,1},\dots,\mathbf{h}{n,m},% \dots,\mathbf{h}{1,1},\dots,\mathbf{h}{1,m}\right].Enc ( italic_T start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT ) = [ bold_h start_POSTSUBSCRIPT italic_n , 1 end_POSTSUBSCRIPT , … , bold_h start_POSTSUBSCRIPT italic_n , italic_m end_POSTSUBSCRIPT , … , bold_h start_POSTSUBSCRIPT 1 , 1 end_POSTSUBSCRIPT , … , bold_h start_POSTSUBSCRIPT 1 , italic_m end_POSTSUBSCRIPT ] .
Note that the encoder Enc(⋅)Enc⋅\text{Enc}(\cdot)Enc ( ⋅ ) is shared with the item encoder to effectively learn the semantics of attributes in the user/item.
2.3. Attribute-wise Interaction Matching
Since the user sequence and item are represented as multiple vectors (specifically, n×m 𝑛 𝑚 n\times m italic_n × italic_m and m 𝑚 m italic_m vectors), computing a matching score is nontrivial. We devise attribute-wise interaction matching to fully account for the relationship between multiple user sequence/item attribute-aware representations. The score is calculated for each attribute and then aggregated to obtain the final score. We employ maximum similarity (MaxSim)(Khattab and Zaharia, 2020) to dynamically match each item attribute with different aspects of the user sequence, capturing user interest based on candidate item attributes. For example, in Figure 1, “G913 Keyboard” and “Magic Mouse” appear identically in both sequences, but the attributes that contribute to the user’s preference are completely different.
We can modify Eq. (1) for attribute-wise interaction matching. The matching score S j(s,i)subscript 𝑆 𝑗 𝑠 𝑖 S_{j}(s,i)italic_S start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_s , italic_i ) between user sequence s 𝑠 s italic_s and item i 𝑖 i italic_i on attribute j 𝑗 j italic_j is calculated as follows:
(10)S j(s,i)=max t∈{n,…,1}cos(𝐡 t,j,𝐡 j).subscript 𝑆 𝑗 𝑠 𝑖 subscript 𝑡 𝑛…1 cos subscript 𝐡 𝑡 𝑗 subscript 𝐡 𝑗 S_{j}\left(s,i\right)=\max_{t\in{n,\dots,1}}\text{cos}\left(\mathbf{h}{t,j}% ,\mathbf{h}{j}\right).italic_S start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_s , italic_i ) = roman_max start_POSTSUBSCRIPT italic_t ∈ { italic_n , … , 1 } end_POSTSUBSCRIPT cos ( bold_h start_POSTSUBSCRIPT italic_t , italic_j end_POSTSUBSCRIPT , bold_h start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) .
The final matching score S(s,i)𝑆 𝑠 𝑖 S(s,i)italic_S ( italic_s , italic_i ) is determined by summing the scores for all attributes:
(11)S(s,i)=∑j=1 m S j(s,i).𝑆 𝑠 𝑖 superscript subscript 𝑗 1 𝑚 subscript 𝑆 𝑗 𝑠 𝑖 S\left(s,i\right)=\sum_{j=1}^{m}{S_{j}\left(s,i\right)}.italic_S ( italic_s , italic_i ) = ∑ start_POSTSUBSCRIPT italic_j = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT italic_S start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ( italic_s , italic_i ) .
In this way, items that achieve the highest matching scores across all attributes are recommended to users.
2.4. Training and Inference
Finally, we describe the training and inference process. We utilize the cross-entropy loss following (Hou et al., 2022; Tang et al., 2023; Li et al., 2023):
(12)ℒ=−logexp(S(s,i+)/τ)∑i∈ℐ exp(S(s,i)/τ),ℒ exp 𝑆 𝑠 superscript 𝑖 𝜏 subscript 𝑖 ℐ exp 𝑆 𝑠 𝑖 𝜏\mathcal{L}=-\log\frac{\text{exp}\left(S\left(s,i^{+}\right)/\tau\right)}{\sum% _{i\in\mathcal{I}}{\text{exp}\left(S\left(s,i\right)/\tau\right)}},caligraphic_L = - roman_log divide start_ARG exp ( italic_S ( italic_s , italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT ) / italic_τ ) end_ARG start_ARG ∑ start_POSTSUBSCRIPT italic_i ∈ caligraphic_I end_POSTSUBSCRIPT exp ( italic_S ( italic_s , italic_i ) / italic_τ ) end_ARG ,
where i+superscript 𝑖 i^{+}italic_i start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT is a target item for the given sequence and τ 𝜏\tau italic_τ is a hyperparameter to control the temperature(Hinton et al., 2015) for better convergence(Gupta et al., 2019).
To avoid prolonging training time, we employ two-stage training as in (Li et al., 2023). In the initial phase, item representations are updated every epoch until convergence. Then, we fix the optimal item embedding and resume training to fully optimize the model. At inference, we precompute attribute-aware representations for all items and calculate recommendation scores for each sequence using Eq.(11), serving the top-K 𝐾 K italic_K items with the highest scores.
Table 1. Overall performance. The best results are shown in bold, and the second-best results are underlined. ”Gain” represents the percentage improvement of MARS over the best competing baseline. ‘*’ indicates statistically significant improvements (p<0.01)𝑝 0.01(p<0.01)( italic_p < 0.01 ) of MARS compared to the best baseline, as determined by a paired t 𝑡 t italic_t-test conducted across 5 experiments.
- Experiments
3.1. Experimental Setup
Datasets. We used the Amazon review dataset 2 2 2https://cseweb.ucsd.edu/~jmcauley/datasets/amazon_v2/(Ni et al., 2019): ‘Industrial and Scientific’ (Scientific), ‘Prime Pantry’ (Pantry), ‘Musical Instruments’ (Inst.), ‘Arts, Crafts & Sewing’ (Arts), and ‘Office Products’ (Office). Following (Tang et al., 2023; Li et al., 2023), we used 5-core datasets where we filtered out users and items with less than five interactions and items with missing titles. For zero-shot evaluation, we used a combination of eight categories 3 3 3‘Automotive’, ‘Cell Phones and Accessories’, ‘Clothing Shoes and Jewelry’, ‘Electronics’, ‘Grocery and Gourmet Food’, ‘Home and Kitchen’, ‘Movies and TV’ for training, and ‘CDs and Vinyl’ for validation for pre-training. For item attributes, we used title, brand, and category as in (Hou et al., 2022; Li et al., 2023).
Baselines and evaluation protocols. We compare MARS with eight baselines: GRU4Rec(Hidasi et al., 2016), SASRec(Kang and McAuley, 2018), and BERT4Rec(Sun et al., 2019) for ID-based models; S 3 Rec(Zhou et al., 2020) and FDSA(Zhang et al., 2019) for ID + Text models; UniSRec(Hou et al., 2022), Recformer(Li et al., 2023), and MIRACLE(Tang et al., 2023) for text-based models. Note that the inductive setting is used in UniSRec(Hou et al., 2022) and MIRACLE(Tang et al., 2023), where explicit ID embedding vectors are not used. Since MARS focuses on the attributes of individual items instead of those that represent relationships among multiple items, we do not consider attributes such as time interval(Li et al., 2020) or co-purchase(Fan et al., [n. d.]). We adopt Recall@10 (R@10) and NDCG@10 (N@10) for evaluation metrics. We used the leave-one-out strategy for train/validation/test data splitting as in(Kang and McAuley, 2018; Zhou et al., 2020; Li et al., 2023).
Implementation details. We initialize the model parameters using Longformer-base(Beltagy et al., 2020) where d=768 𝑑 768 d=768 italic_d = 768 from Huggingface 4 4 4https://huggingface.co/allenai/longformer-base-4096(Wolf et al., 2020). We consider the most recent 50 items for each user. We truncate each attribute value to 32 and the total input sequence to 1,024 tokens. We set τ 𝜏\tau italic_τ to 0.05. We searched d′superscript 𝑑′d^{\prime}italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT from {128,256,384,768}128 256 384 768{128,256,384,768}{ 128 , 256 , 384 , 768 } and found that d′=256 superscript 𝑑′256 d^{\prime}=256 italic_d start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT = 256 showed a negligible performance degradation while significantly reducing memory footprint. We used Adam optimizer(Kingma and Ba, 2015) with a learning rate of 5e-5 and set the batch size as 8 with 16 accumulation steps, 800 warm-up steps, and early stopping based on NDCG@10 on the validation set with patience of 5 epochs. We implemented the baselines on the open-source library RecBole 5 5 5https://github.com/RUCAIBox/RecBole(Zhao et al., 2021) or the published source code. For text-based baselines, we initialize the models with the public pre-trained weight.
Table 2. Zero-shot performance for text-based models. The best and second-best are bold and underlined. Gain measures the difference between MARS and the best baseline.
3.2. Results and Analysis
Overall comparison. Table1 reports the overall performance comparison between MARS and baselines. (i) MARS consistently achieves state-of-the-art performance on all datasets, improving Recall@10 and NDCG@10 by up to 24.43% and 29.26%, respectively, against the best competitive baseline. This indicates that MARS successfully captures the intricate relationships between user sequences and items. (ii) MARS constantly outperforms the best competitive text-based model Recformer(Li et al., 2023), yielding an average gain of 13.79% and 19.78% on Recall@10 and NDCG@10. Since MARS differs from other text-based models in that it considers multiple user/item representations, the performance gain indicates that MARS provides better recommendations by capturing diverse user intents and multi-faceted aspects of items. (iii) In particular, MARS outperforms MIRACLE(Tang et al., 2023), which utilizes multiple user representations. This shows the effectiveness of attribute-wise interaction, while MIRACLE(Tang et al., 2023) computes the score with only one interest through max-pooling.
Table 3. Ablation study of MARS. The best scores are in bold.
Zero-shot recommendation. We evaluate the zero-shot recommendation performance of text-based methods to measure knowledge transfer to unseen data. For a fair evaluation, we pre-train MARS following the setting used in(Li et al., 2023). As reported in Table2, MARS outperforms all baselines with an average gain of 13.11%, demonstrating the effectiveness of attribute-based encoding and matching in capturing user preferences and transferring knowledge of PLM to a new dataset even without training.
Ablation study. We compare our proposed attribute-aware representation with two coarse-grained representations: [BOS] (single representation for user/item) and ”Item” (average pooling by item). The results in Table 3 show that attribute-aware representations yield a performance gain of up to 6.4% in R@10, highlighting the importance of fine-grained representations. We also examine the effectiveness of attribute-wise interaction matching, replacing max with mean in Eq.(10). The results demonstrate the effectiveness of MaxSim in capturing user preference in an attribute-wise manner.
- Conclusion
In this paper, we propose MARS, a novel text-based sequential recommender model that fully utilizes fine-grained attribute-aware representations. MARS employs multiple attribute-aware representations by encoding textual attributes of users and items. Then, the recommendation score is calculated via attribute-wise item matching, considering intricate user interests. Experimental results demonstrate that MARS outperforms competitive baselines in both fine-tuned and zero-shot settings, showing its ability to match fine-grained user sequences and item representations.
Acknowledgements.
This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant and National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2019-II190421, IITP-2024-2020-0-01821, RS-2022-II220680, and RS-2021-II212068).
References
- (1)
- Beltagy et al. (2020) Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The Long-Document Transformer. CoRR (2020).
- Chang et al. (2021) Jianxin Chang, Chen Gao, Yu Zheng, Yiqun Hui, Yanan Niu, Yang Song, Depeng Jin, and Yong Li. 2021. Sequential Recommendation with Graph Neural Networks. In SIGIR. 378–387.
- Chen et al. (2018a) Ching-Wei Chen, Paul Lamere, Markus Schedl, and Hamed Zamani. 2018a. Recsys challenge 2018: automatic music playlist continuation. In RecSys. 527–528.
- Chen et al. (2018b) Xu Chen, Hongteng Xu, Yongfeng Zhang, Jiaxi Tang, Yixin Cao, Zheng Qin, and Hongyuan Zha. 2018b. Sequential Recommendation with User Memory Networks. In WSDM. 108–116.
- Covington et al. (2016) Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. In RecSys. 191–198.
- Ding et al. (2021) Hao Ding, Yifei Ma, Anoop Deoras, Yuyang Wang, and Hao Wang. 2021. Zero-Shot Recommender Systems. CoRR (2021).
- Du et al. (2022) Hanwen Du, Hui Shi, Pengpeng Zhao, Deqing Wang, Victor S. Sheng, Yanchi Liu, Guanfeng Liu, and Lei Zhao. 2022. Contrastive Learning with Bidirectional Transformers for Sequential Recommendation. In CIKM. 396–405.
- Fan et al. ([n. d.]) Ziwei Fan, Zhiwei Liu, Chen Wang, Peijie Huang, Hao Peng, and Philip S. Yu. [n. d.]. Sequential Recommendation with Auxiliary Item Relationships via Multi-Relational Transformer. In Big Data. 525–534.
- Fang et al. (2019) Hui Fang, Guibing Guo, Danning Zhang, and Yiheng Shu. 2019. Deep Learning-Based Sequential Recommender Systems: Concepts, Algorithms, and Evaluations. In ICWE, Vol.11496. 574–577.
- Fang et al. (2020) Hui Fang, Danning Zhang, Yiheng Shu, and Guibing Guo. 2020. Deep Learning for Sequential Recommendation: Algorithms, Influential Factors, and Evaluations. ACM Trans. Inf. Syst. 39, 1 (2020), 10:1–10:42.
- Gupta et al. (2019) Priyanka Gupta, Diksha Garg, Pankaj Malhotra, Lovekesh Vig, and Gautam M. Shroff. 2019. NISER: Normalized Item and Session Representations with Graph Neural Networks. CoRR (2019).
- Hidasi et al. (2016) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016. Session-based Recommendations with Recurrent Neural Networks. In ICLR.
- Hinton et al. (2015) Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. 2015. Distilling the Knowledge in a Neural Network. CoRR (2015).
- Hou et al. (2022) Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022. Towards Universal Sequence Representation Learning for Recommender Systems. In KDD. 585–593.
- Kang and McAuley (2018) Wang-Cheng Kang and Julian J. McAuley. 2018. Self-Attentive Sequential Recommendation. In ICDM. 197–206.
- Khattab and Zaharia (2020) Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. In SIGIR. 39–48.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In ICLR.
- Li et al. (2022) Chenglin Li, Mingjun Zhao, Huanming Zhang, Chenyun Yu, Lei Cheng, Guoqiang Shu, Beibei Kong, and Di Niu. 2022. RecGURU: Adversarial Learning of Generalized User Representations for Cross-Domain Recommendation. In WSDM. 571–581.
- Li et al. (2017) Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural Attentive Session-based Recommendation. In CIKM. 1419–1428.
- Li et al. (2023) Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, and Julian J. McAuley. 2023. Text Is All You Need: Learning Language Representations for Sequential Recommendation. In KDD. 1258–1267.
- Li et al. (2020) Jiacheng Li, Yujie Wang, and Julian J. McAuley. 2020. Time Interval Aware Self-Attention for Sequential Recommendation. In WSDM. 322–330.
- Linden et al. (2003) Greg Linden, Brent Smith, and Jeremy York. 2003. Amazon.com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Comput. 7, 1 (2003), 76–80.
- Liu et al. (2021) Chang Liu, Xiaoguang Li, Guohao Cai, Zhenhua Dong, Hong Zhu, and Lifeng Shang. 2021. Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation. In AAAI. 4249–4256.
- Liu et al. (2023) Zhenghao Liu, Sen Mei, Chenyan Xiong, Xiaohua Li, Shi Yu, Zhiyuan Liu, Yu Gu, and Ge Yu. 2023. Text Matching Improves Sequential Recommendation by Reducing Popularity Biases. In CIKM. 1534–1544.
- Ni et al. (2019) Jianmo Ni, Jiacheng Li, and Julian J. McAuley. 2019. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. In EMNLP-IJCNLP. 188–197.
- Qiu et al. (2022) Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive Learning for Representation Degeneration Problem in Sequential Recommendation. In WSDM. 813–823.
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In CIKM. 1441–1450.
- Tang and Wang (2018) Jiaxi Tang and Ke Wang. 2018. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. In WSDM. ACM, 565–573.
- Tang et al. (2023) Zuoli Tang, Lin Wang, Lixin Zou, Xiaolu Zhang, Jun Zhou, and Chenliang Li. 2023. Towards Multi-Interest Pre-training with Sparse Capsule Network. In SIGIR. 311–320.
- Wang et al. (2019) Shoujin Wang, Liang Hu, Yan Wang, Longbing Cao, Quan Z. Sheng, and Mehmet A. Orgun. 2019. Sequential Recommender Systems: Challenges, Progress and Prospects. In IJCAI. 6332–6338.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-Art Natural Language Processing. In EMNLP (Demos). Association for Computational Linguistics, 38–45.
- Wu et al. (2020) Liwei Wu, Shuqing Li, Cho-Jui Hsieh, and James Sharpnack. 2020. SSE-PT: Sequential Recommendation Via Personalized Transformer. In RecSys. 328–337.
- Wu et al. (2019) Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. 2019. Session-Based Recommendation with Graph Neural Networks. In AAAI. 346–353.
- Xie et al. (2022a) Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022a. Contrastive Learning for Sequential Recommendation. In ICDE. 1259–1273.
- Xie et al. (2022b) Yueqi Xie, Peilin Zhou, and Sunghun Kim. 2022b. Decoupled Side Information Fusion for Sequential Recommendation. In SIGIR.
- Yuan et al. (2021) Xu Yuan, Dongsheng Duan, Lingling Tong, Lei Shi, and Cheng Zhang. 2021. ICAI-SR: Item Categorical Attribute Integrated Sequential Recommendation. In SIGIR. 1687–1691.
- Zhang et al. (2019) Tingting Zhang, Pengpeng Zhao, Yanchi Liu, Victor S. Sheng, Jiajie Xu, Deqing Wang, Guanfeng Liu, and Xiaofang Zhou. 2019. Feature-level Deeper Self-Attention Network for Sequential Recommendation. In IJCAI. 4320–4326.
- Zhao et al. (2021) Wayne Xin Zhao, Shanlei Mu, Yupeng Hou, Zihan Lin, Yushuo Chen, Xingyu Pan, Kaiyuan Li, Yujie Lu, Hui Wang, Changxin Tian, Yingqian Min, Zhichao Feng, Xinyan Fan, Xu Chen, Pengfei Wang, Wendi Ji, Yaliang Li, Xiaoling Wang, and Ji-Rong Wen. 2021. RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms. In CIKM. ACM, 4653–4664.
- Zhou et al. (2020) Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. In CIKM. 1893–1902.
- Zhou et al. (2022) Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. 2022. Filter-enhanced MLP is All You Need for Sequential Recommendation. In WWW. 2388–2399.
Xet Storage Details
- Size:
- 49.9 kB
- Xet hash:
- 9f44a48999c603244317abdc5b6d974daeec5b706a81503c8142ee2c73f0e786
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.