Buckets:

Title: Communication Learning in Multi-Agent Systems from Graph Modeling Perspective
URL Source: https://arxiv.org/html/2411.00382
Markdown Content: Shengchao Hu,Li Shen, Ya Zhang, and Dacheng Tao,Shengchao Hu and Ya Zhang are with Shanghai Jiao Tong University and Shanghai AI Lab, China. Email: {charles-hu,ya_zhang}@sjtu.edu.cnLi Shen is with Shenzhen Campus of Sun Yat-sen University, Shenzhen 518107, China. Email: mathshenli@gmail.comDacheng Tao is with Nanyang Technological University, Singapore. Email: dacheng.tao@ntu.edu.sg
Abstract
In numerous artificial intelligence applications, the collaborative efforts of multiple intelligent agents are imperative for the successful attainment of target objectives. To enhance coordination among these agents, a distributed communication framework is often employed, wherein each agent must be capable of encoding information received from the environment and determining how to share it with other agents as required by the task at hand. However, indiscriminate information sharing among all agents can be resource-intensive, and the adoption of manually pre-defined communication architectures imposes constraints on inter-agent communication, thus limiting the potential for effective collaboration. Moreover, the communication framework often remains static during inference, which may result in sustained high resource consumption, as in most cases, only key decisions necessitate information sharing among agents. In this study, we introduce a novel approach wherein we conceptualize the communication architecture among agents as a learnable graph. We formulate this problem as the task of determining the communication graph while enabling the architecture parameters to update normally, thus necessitating a bi-level optimization process. Utilizing continuous relaxation of the graph representation and incorporating attention units, our proposed approach, CommFormer, efficiently optimizes the communication graph and concurrently refines architectural parameters through gradient descent in an end-to-end manner. Additionally, we introduce a temporal gating mechanism for each agent, enabling dynamic decisions on whether to receive shared information at a given time, based on current observations, thus improving decision-making efficiency. Extensive experiments on a variety of cooperative tasks substantiate the robustness of our model across diverse cooperative scenarios, where agents are able to develop more coordinated and sophisticated strategies regardless of changes in the number of agents.
Index Terms:
Multi-Agent Reinforcement Learning, Communication Graph, Transformer, Sequence Modeling, Temporal Gate Mechanism
I Introduction
Multi-agent Reinforcement Learning (MARL) algorithms play an essential role in solving complex decision-making tasks through the analysis of interaction data between computerized agents and simulated or physical environments. This paradigm finds prevalent application across domains, including autonomous driving [58, 11], order dispatching [26, 54], and gaming AI systems [37, 59]. In the MARL scenarios typically explored in these studies, multiple agents engage in iterative interactions within a shared environment, continually refining their policies through learning from observations to collectively attain a common objective. This problem can be conceptually simplified as an instance of independent RL, wherein each agent regards other agents as elements of its environment. However, the strategies employed by other agents exhibit dynamic uncertainty and evolve throughout the training process, rendering the environment intrinsically unstable from the viewpoint of each individual agent. Consequently, effective collaboration among agents becomes a formidable challenge. Additionally, it’s important to note that policies acquired through independent RL are susceptible to overfitting with respect to the policies of other agents, as evidenced by Lanctot et al. [25].
Communication is a fundamental pillar in addressing this challenge, serving as a cornerstone of intelligence by enabling agents to operate cohesively as a collective entity rather than disparate individuals. Its significance becomes especially apparent when tackling complex real-world tasks where individual agents possess limited capabilities and restricted visibility of the environment [24, 56, 28]. In this work, we consider MARL scenarios wherein the task at hand is of a cooperative nature and agents are situated in a partially observable environment, but each is endowed with different observation power. Each agent must not only encode information received from the environment but also determine when and how to share this information with other agents based on the requirements of the task. Each agent is underpinned by a deep feed-forward network, augmented with access to a communication channel conveying continuous vectors. Considering bandwidth-related constraints, particularly in instances involving wireless communication channels, a limited subset of agents is permitted to exchange messages during each time step to ensure reliable message transfer [20]. Thus, agents must carefully consider both the content of the messages they transmit and the choice of recipient agents, balancing the need for effective collaboration with the constraints of the communication medium.
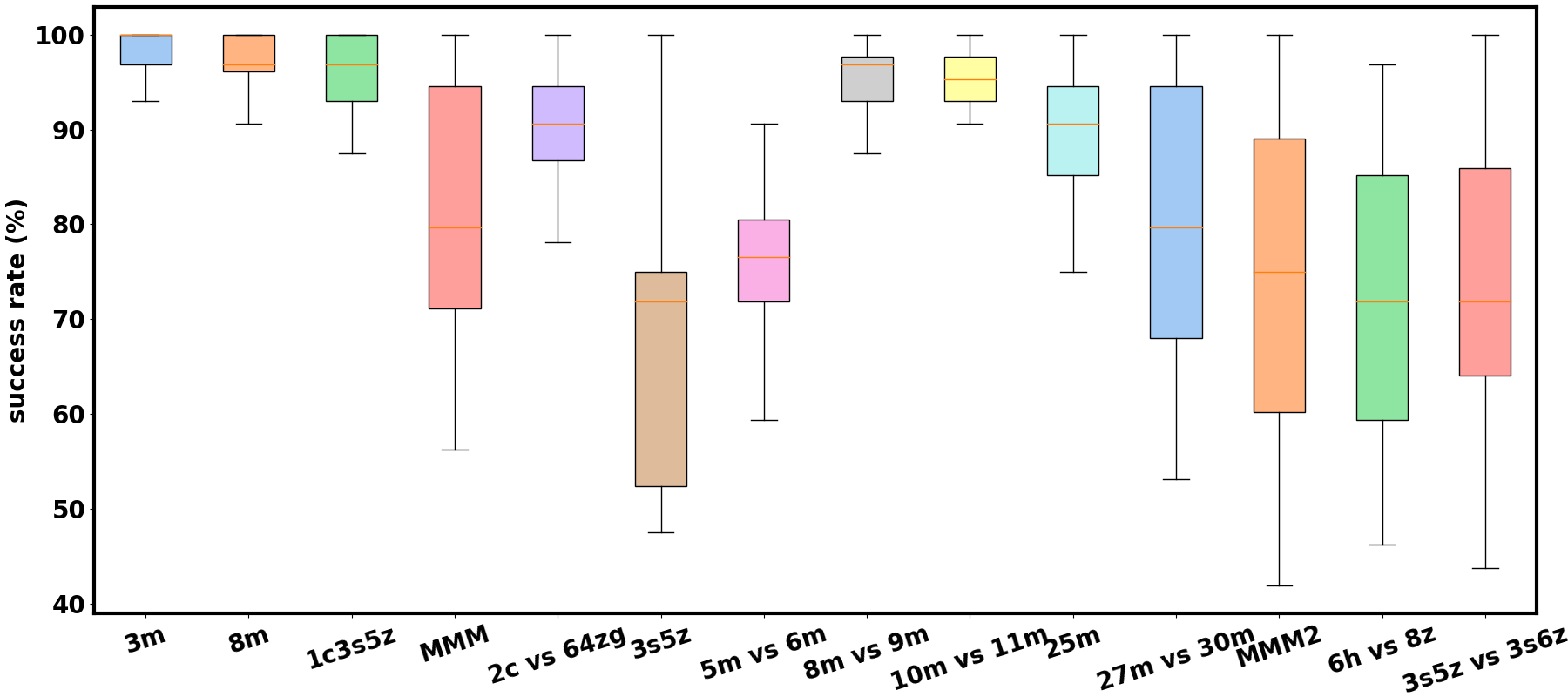
Figure 1: The performance of pre-defined communication architectures evaluated across various StarCraft II combat scenarios, with each scenario utilizing ten distinct architectures generated from different random seeds. The significant variance in performance metrics highlights the influence of communication architecture on the agents’ effectiveness in these complex environments, emphasizing the necessity of searching for the optimal communication configuration.
To facilitate coordinated message exchange, we adopt the centralized training and distributed execution paradigm, as popularized in recent works such as Foerster et al. [9], Kuba et al. [22], Yu et al. [55], which allows agents access to global information and knowledge of opponents’ actions during the training phase. There are several approaches for learning communication in MARL including CommNet [46], TarMAC [6], and ToM2C [50]. However, methods relying on information sharing among all agents or relying on manually pre-defined communication architectures can be problematic. When dealing with a large number of agents, distinguishing valuable information for cooperative decision-making from globally shared data becomes problematic. In such instances, communication may offer limited benefits or even impede cooperative learning, as excessive and irrelevant information can overwhelm agents [19]. Moreover, in real-world applications, full-scale communication between all agents can be prohibitively expensive, requiring high bandwidth, introducing communication delays, and imposing significant computational complexity. Manual pre-defined architectures also suffer from high variance, as evident in Figure 1, which underscores the necessity for meticulous architectural design to achieve optimal communication, as randomly designed architectures may inadvertently hinder cooperation and result in poor overall performance. Certain methods, such as those proposed by Zambaldi et al. [57], Tacchetti et al. [48], Mao et al. [33], impose constraints whereby each agent communicates only with its neighbors. However, selecting appropriate neighborhoods in complex applications, where agents perform distinct roles, is often difficult. Additionally, the communication framework in these methods typically remains static during inference, which may result in unnecessary resource consumption, as only key decisions require information sharing among agents in most cases. Recently, dynamic adjustments to the communication graph during inference have garnered significant attention in recent MARL research [19, 20, 50]. However, these methods assume that any agent could potentially communicate with any other, necessitating the establishment of a communication channel between every pair of agents. This results in an implicit fully connected network, which can still lead to significant resource inefficiencies, particularly in wired communication settings, where each agent must still establish physical connections with others.
To address these challenges, we present a novel approach, named CommFormer, designed to facilitate effective and efficient communication among agents in large-scale MARL within partially observable distributed environments. We conceptualize the communication structure among agents as a learnable graph and formulate this problem as the task of determining the communication graph while enabling the architecture parameters to update normally, thus necessitating a bi-level optimization process. In contrast to conventional methods that involve searching through a discrete set of candidate communication architectures, we relax the search space into a continuous domain, enabling architecture optimization via gradient descent in an end-to-end manner. Diverging from previous approaches that often employ arithmetic or weighted means of internal states before message transmission [37, 50], which may compromise communication effectiveness, our method directly transmits each agent’s local observations and actions to specific agents based on the learned communication architecture. Subsequently, each agent employs an attention unit to dynamically allocate credit to received messages from the graph modeling perspective, which enjoys a monotonic performance improvement guarantee [51]. We also introduce a temporal gating mechanism for each agent, enabling dynamic decisions on whether to receive shared information from the sender connected through the communication graph, based on current observations. This approach enhances decision-making efficiency without requiring the establishment of new communication channels. Extensive experiments conducted in a variety of cooperative tasks substantiate the robustness of our model across diverse cooperative scenarios. CommFormer with static inference consistently outperforms strong baselines and achieves comparable performance to methods that permit unrestricted information sharing among all agents, demonstrating its effectiveness regardless of variations in the number of agents. When implemented with the temporal gating mechanism, CommFormer still maintains performance levels akin to those of static methods, thereby highlighting the efficiency of our dynamic approach, which substantially conserves communication resources.
Our contributions can be summarized as follows:
• We conceptualize the communication structure as a graph and introduce an innovative algorithm for learning it through bi-level optimization, which efficiently enables the simultaneous optimization of the communication graph and architectural parameters.
• We propose the adoption of the attention unit within the framework of graph modeling to dynamically allocate credit to received messages, thereby enjoying a monotonic performance improvement guarantee while also improving communication efficiency.
• We introduce a temporal gating mechanism for each agent, allowing for dynamic decisions regarding the reception of shared information based on current observations, which enhances decision-making efficiency without necessitating the establishment of new communication channels.
• Through extensive experiments on a variety of cooperative tasks, CommFormer consistently outperforms robust baseline methods and achieves performance levels comparable to approaches that permit unrestricted information sharing among all agents.
II Related Work
Multi-agent Cooperation. As a natural extension of single-agent RL, MARL has garnered considerable attention for addressing complex problems within the framework of Markov Games [53]. Numerous MARL methodologies have been developed to tackle cooperative tasks in an online setting, where all participating agents collaborate toward a shared reward objective. While this cooperative paradigm is crucial, it also introduces significant challenges in distributed systems. Throughout the training process, agents’ policies constantly evolve, leading to a non-stationary environment and posing difficulties for model convergence. To address the challenge of non-stationarity in MARL, algorithms typically operate within two overarching frameworks: centralized and decentralized learning. Centralized methods [4] involve the direct learning of a single policy responsible for generating joint actions for all agents. On the other hand, decentralized learning [27] entails each agent independently optimizing its own reward function. While these methods can handle general-sum games, they may encounter instability issues, even in relatively simple matrix games [10]. Centralized training and decentralized execution (CTDE) algorithms represent a middle ground between these two frameworks. One category of CTDE algorithms is value-decomposition (VD) methods, wherein the joint Q-function is formulated as a function dependent on the individual agents’ local Q-functions [39, 45, 47]. The others [31, 9] employ actor-critic architectures and learn a centralized critic that takes global information into account. Researchers have also leveraged the expressive power of Transformers to enhance coordination capabilities, such as MAT [51]. These methods have demonstrated remarkable cooperation abilities across various tasks, including SMAC [40], Hanabi, and GRF [56]. In this work, we introduce an innovative approach operating under the CTDE paradigm, with limited communication capabilities, which achieves comparable or even superior performance when compared to these established baselines.
Communication Learning. Communication plays a crucial role in MARL, enabling agents to share experiences, intentions, observations, and other vital information. Three key factors characterize multi-agent communication: when to communicate, which agents to engage with, and the type of information exchanged. DIAL [8] is the pioneer in proposing learnable communication through back-propagation with deep Q-networks. In this method, each agent generates a message at each timestep, which serves as input for other agents in the subsequent timestep. Building on this foundational work, a variety of approaches have emerged in the field of multi-agent communication. Some methods adopt pre-defined communication architectures, e.g. CommNet [46], BiCNet [37], and GA-Comm [29]. These techniques establish fixed communication structures to facilitate information exchange among agents, often utilizing GNN models [36, 2]. In contrast, other approaches such as ATOC [19], TarMAC [6], and ToM2C [50] explore dynamic adaptation of communication structures during inference, enabling agents to selectively transmit or receive information. Moreover, IC3Net [44], Gated-ACML [34], and I2C [7] implement gating mechanisms to determine when and with which teammates to communicate, thereby reducing information redundancy. SMS [52] models multi-agent communication as a cooperative game, assessing the significance of each message for decision-making and eliminating channels that do not contribute positively. Additionally, CDC [38] dynamically alters the communication graph from a diffusion process perspective, while TWG-Q [30] emphasizes temporal weight learning through the application of weighted graph convolutional networks. In our research, we establish a fixed communication architecture prior to inference to determine which agents will communicate [16], complemented by a dynamic gating mechanism that decides when communication occurs. Our approach, CommFormer, builds on this concept by learning an optimal communication architecture through back-propagation before the inference phase, thereby determining which teammates to communicate with. Each agent transmits its local observations and actions as messages through a shared channel, utilizing an attention mechanism to process the received information, thereby defining the type of information exchanged. Our method also learns a gating network to manage communication efficiently during inference; each agent first decides whether to communicate based on the current observation using the learned gating network, thus determining the timing of communication.
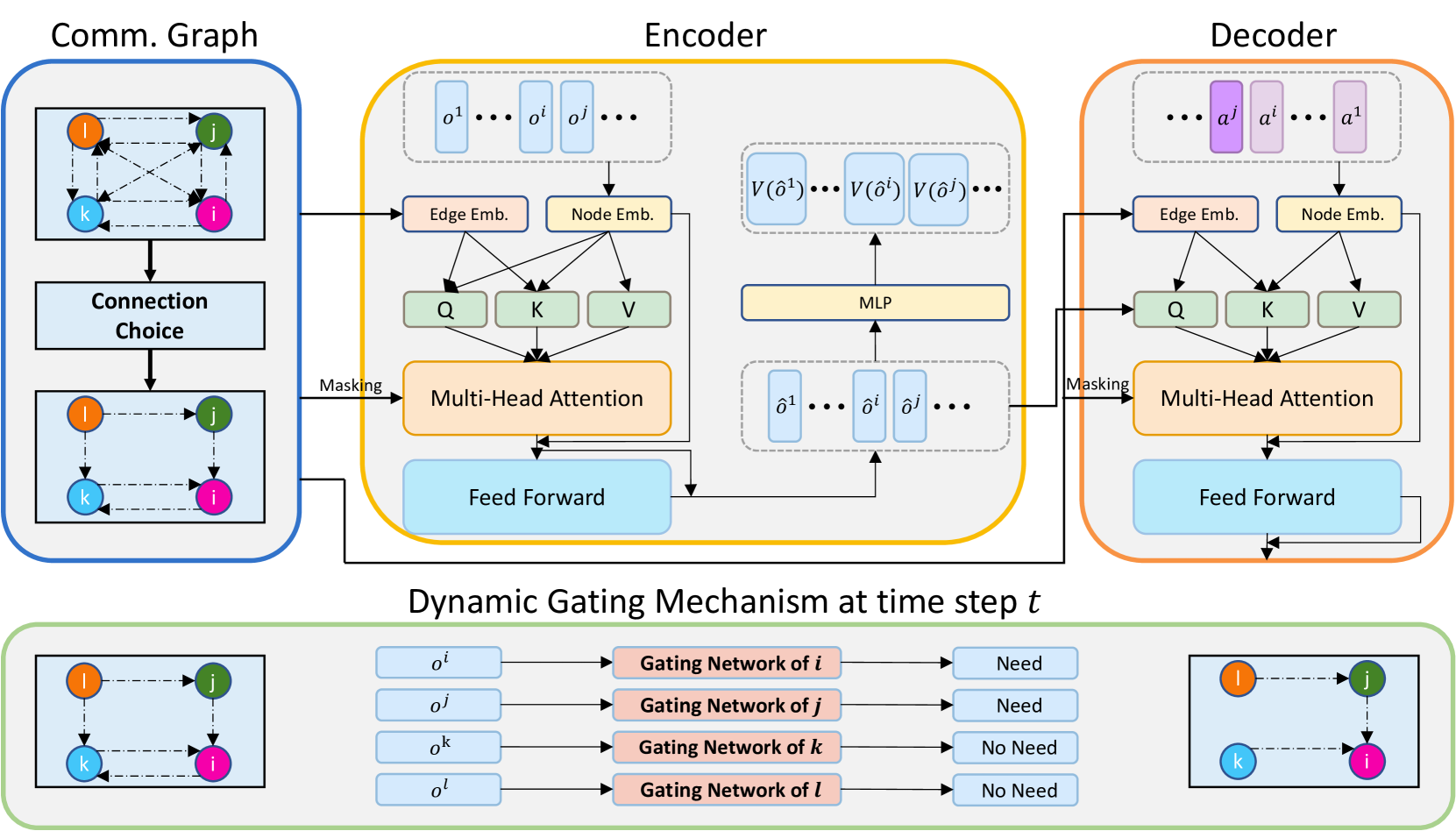
Figure 2: The overview of our proposed CommFormer. CommFormer initiates by establishing the communication graph, which subsequently serves as both the masking and edge embeddings in the encoder and decoder to ensure that agents can exclusively access messages from communicated agents. Subsequently, the encoder and decoder modules come into play, processing a sequence of agents’ observations and transforming them into a sequence of optimal actions. Additionally, CommFormer integrates a dynamic gating mechanism that determines when communication is necessary based on the current observations for each agent. For instance, at time step t 𝑡 t italic_t, agents i 𝑖 i italic_i and j 𝑗 j italic_j require additional information, while agents k 𝑘 k italic_k and l 𝑙 l italic_l do not, resulting in the omission of corresponding edges to conserve resources.
III Method
The goal of our proposed method is to address the multi-agent collaborative communication problem, which enables agents to operate cohesively as a collective entity rather than disparate individuals. In this paper, we are interested in learning to construct the communication graph, learning to determine when to communicate, and learning how to cooperate with received messages in a bandwidth-limited way.
III-A Problem Formulation
The MARL problems can be modeled by Markov games ⟨𝒩,𝓞,𝓐,R,P,γ⟩𝒩 𝓞 𝓐 𝑅 𝑃 𝛾\langle\mathcal{N},\bm{\mathcal{O}},\bm{\mathcal{A}},R,P,\gamma\rangle⟨ caligraphic_N , bold_caligraphic_O , bold_caligraphic_A , italic_R , italic_P , italic_γ ⟩[27]. The set of agents is denoted as 𝒩={1,…,n}𝒩 1…𝑛\mathcal{N}={1,\dots,n}caligraphic_N = { 1 , … , italic_n }. The product of the local observation spaces of the agents forms the joint observation space, denoted as 𝓞=∏i=1 n 𝒪 i 𝓞 superscript subscript product 𝑖 1 𝑛 superscript 𝒪 𝑖\bm{\mathcal{O}}=\prod_{i=1}^{n}\mathcal{O}^{i}bold_caligraphic_O = ∏ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT caligraphic_O start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT. Similarly, the product of the agents’ action spaces constitutes the joint action space, represented as 𝓐=∏i=1 n 𝒜 i 𝓐 superscript subscript product 𝑖 1 𝑛 superscript 𝒜 𝑖\bm{\mathcal{A}}=\prod_{i=1}^{n}\mathcal{A}^{i}bold_caligraphic_A = ∏ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT caligraphic_A start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT. The joint reward function, R:𝓞×𝓐→[−R max,R max]:𝑅→𝓞 𝓐 subscript 𝑅 subscript 𝑅 R:\bm{\mathcal{O}}\times\bm{\mathcal{A}}\rightarrow[-R_{\max},R_{\max}]italic_R : bold_caligraphic_O × bold_caligraphic_A → [ - italic_R start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT , italic_R start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT ], maps the joint observation and action spaces to the reward range [−R max,R max]subscript 𝑅 subscript 𝑅[-R_{\max},R_{\max}][ - italic_R start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT , italic_R start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT ]. The transition probability function, P:𝓞×𝓐×𝓞→ℝ:𝑃→𝓞 𝓐 𝓞 ℝ P:\bm{\mathcal{O}}\times\bm{\mathcal{A}}\times\bm{\mathcal{O}}\rightarrow% \mathbb{R}italic_P : bold_caligraphic_O × bold_caligraphic_A × bold_caligraphic_O → blackboard_R, defines the probability distribution of transitioning from one joint observation and action to another. Lastly, the discount factor, denoted as γ∈[0,1)𝛾 0 1\gamma\in[0,1)italic_γ ∈ [ 0 , 1 ), plays a crucial role in discounting future rewards.
At time step t∈ℕ 𝑡 ℕ t\in\mathbb{N}italic_t ∈ blackboard_N, an agent i∈𝒩 𝑖 𝒩 i\in\mathcal{N}italic_i ∈ caligraphic_N receives an observation denoted as o t i∈𝒪 i superscript subscript o 𝑡 𝑖 superscript 𝒪 𝑖{\textnormal{o}}{t}^{i}\in\mathcal{O}^{i}o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ∈ caligraphic_O start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT. The collection of these individual observations 𝒐=(o 1,…,o n)𝒐 superscript 𝑜 1…superscript 𝑜 𝑛{\bm{o}}=(o^{1},\dots,o^{n})bold_italic_o = ( italic_o start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , … , italic_o start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ) forms the "joint" observation. Agent i 𝑖 i italic_i then selects an action a t i subscript superscript a 𝑖 𝑡{\textnormal{a}}^{i}{t}a start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT based on its policy π i superscript 𝜋 𝑖\pi^{i}italic_π start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT. It’s worth noting that π i superscript 𝜋 𝑖\pi^{i}italic_π start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT represents the policy of the i th superscript 𝑖 th i^{\text{th}}italic_i start_POSTSUPERSCRIPT th end_POSTSUPERSCRIPT agent, which is a component of the agents’ joint policy denoted as π 𝜋\pi italic_π. Apart from its own local observation o t i superscript subscript o 𝑡 𝑖{\textnormal{o}}{t}^{i}o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT, each agent possesses the capability to receive observations o t j superscript subscript o 𝑡 𝑗{\textnormal{o}}{t}^{j}o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT from other agents, along with their actions (auto-regressively) a t j subscript superscript a 𝑗 𝑡{\textnormal{a}}^{j}{t}a start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT through a communication channel. At the end of each time step, the entire team collectively receives a joint reward denoted as R(𝐨 t,𝐚 t)𝑅 subscript 𝐨 𝑡 subscript 𝐚 𝑡 R({\mathbf{o}}{t},{\mathbf{a}}{t})italic_R ( bold_o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) and observes 𝐨 t+1 subscript 𝐨 𝑡 1{\mathbf{o}}{t+1}bold_o start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT, following a probability distribution P(⋅|𝐨 t,𝐚 t)P(\cdot|{\mathbf{o}}{t},{\mathbf{a}}{t})italic_P ( ⋅ | bold_o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ). Over an infinite sequence of such steps, the agents accumulate a discounted cumulative return denoted as R γ≜∑t=0∞γ tR(𝐨 t,𝐚 t)≜superscript 𝑅 𝛾 superscript subscript 𝑡 0 superscript 𝛾 𝑡 𝑅 subscript 𝐨 𝑡 subscript 𝐚 𝑡 R^{\gamma}\triangleq\sum_{t=0}^{\infty}\gamma^{t}R({\mathbf{o}}{t},{\mathbf{a% }}{t})italic_R start_POSTSUPERSCRIPT italic_γ end_POSTSUPERSCRIPT ≜ ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∞ end_POSTSUPERSCRIPT italic_γ start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT italic_R ( bold_o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ).
In practical scenarios where agents have the capability to communicate with each other over a shared medium, two critical constraints are imposed: bandwidth and contention for medium access [20]. The bandwidth constraint implies that there is a limited capacity for transmitting bits per unit time, and the contention constraint necessitates the avoidance of collisions among multiple transmissions, which is a natural aspect of signal broadcasting in wireless communication. Consequently, each agent can only transmit their message to a restricted number of other agents during each time step to ensure reliable message transfer. In this paper, we conceptualize the communication architecture as a directed graph, denoted as 𝒢=⟨𝒱,ℰ⟩𝒢 𝒱 ℰ\mathcal{G}=\langle\mathcal{V},\mathcal{E}\rangle caligraphic_G = ⟨ caligraphic_V , caligraphic_E ⟩, where each node v i∈𝒱 subscript 𝑣 𝑖 𝒱 v_{i}\in\mathcal{V}italic_v start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ caligraphic_V represents an agent, and an edge e i→j∈ℰ subscript 𝑒→𝑖 𝑗 ℰ e_{i\rightarrow j}\in\mathcal{E}italic_e start_POSTSUBSCRIPT italic_i → italic_j end_POSTSUBSCRIPT ∈ caligraphic_E signifies message passing from agent v i subscript 𝑣 𝑖 v_{i}italic_v start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT to agent v j subscript 𝑣 𝑗 v_{j}italic_v start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT. The restriction on communication can be mathematically expressed as the sparsity 𝒮 𝒮\mathcal{S}caligraphic_S of the adjacency matrix of the edge connections α 𝛼\alpha italic_α. This sparsity parameter, 𝒮 𝒮\mathcal{S}caligraphic_S, controls the allowed number of connected edges, which is given by 𝒮×N 2 𝒮 superscript 𝑁 2\mathcal{S}\times N^{2}caligraphic_S × italic_N start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, where N 𝑁 N italic_N is the number of agents.
III-B Architecture
The overall architecture of our proposed CommFormer is illustrated in Figure 2.
Communication Graph. To design a communication-efficient MARL paradigm, we introduce the Communication Transformer or CommFormer, which adopts a graph modeling paradigm, inspired by developments in sequence modeling [15, 12, 14, 13, 51]. We apply the Transformer architecture which facilitates the mapping between the input, consisting of agents’ observation sequences (o 1,…,o n)superscript 𝑜 1…superscript 𝑜 𝑛(o^{1},\dots,o^{n})( italic_o start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , … , italic_o start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ), and the output, which comprises agents’ action sequences (a 1,…,a n)superscript 𝑎 1…superscript 𝑎 𝑛(a^{1},\dots,a^{n})( italic_a start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , … , italic_a start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ). Considering communication constraints, each agent has a limited capacity to communicate with a subset of other agents, represented by the sparsity 𝒮 𝒮\mathcal{S}caligraphic_S of the adjacency matrix of the edge connections. To identify the optimal communication graph, we treat multiple agents as nodes in a graph and introduce a learnable adjacency matrix, represented by the parameter matrix α∈ℝ N×N 𝛼 superscript ℝ 𝑁 𝑁\alpha\in\mathbb{R}^{N\times N}italic_α ∈ blackboard_R start_POSTSUPERSCRIPT italic_N × italic_N end_POSTSUPERSCRIPT, which are optimized through gradient descent during training in an end-to-end manner.
Encoder. The encoder, whose parameters are denoted by ϕ italic-ϕ\phi italic_ϕ, takes a sequence of observations (o 1,…,o n)superscript 𝑜 1…superscript 𝑜 𝑛(o^{1},\dots,o^{n})( italic_o start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , … , italic_o start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ) as input and passes them through several computational blocks. Each such block consists of a relation-enhanced mechanism [12, 3] and a multi-layer perceptron (MLP), as well as residual connections to prevent gradient vanishing and network degradation with the increase of depth. In the vanilla multi-head attention, the attention score between the element o i superscript 𝑜 𝑖 o^{i}italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT and o j superscript 𝑜 𝑗 o^{j}italic_o start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT can be formulated as the dot-product between their query vector and key vector:
s ij=f(o i,o j)=o iW q TW ko j.subscript 𝑠 𝑖 𝑗 𝑓 superscript 𝑜 𝑖 superscript 𝑜 𝑗 superscript 𝑜 𝑖 superscript subscript 𝑊 𝑞 𝑇 subscript 𝑊 𝑘 superscript 𝑜 𝑗 s_{ij}=f(o^{i},o^{j})=o^{i}W_{q}^{T}W_{k}o^{j}.italic_s start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT = italic_f ( italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_o start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT ) = italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT italic_W start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT italic_W start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT italic_o start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT .(1)
s ij subscript 𝑠 𝑖 𝑗 s_{ij}italic_s start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT can be regarded as implicit information associated with the edge e j→i subscript 𝑒→𝑗 𝑖 e_{j\rightarrow i}italic_e start_POSTSUBSCRIPT italic_j → italic_i end_POSTSUBSCRIPT, where agent i 𝑖 i italic_i queries the information sent from agent j 𝑗 j italic_j. To identify the most influential edge contributing to the final performance, we augment the implicit attention score with explicit edge information:
s ij=g(o i,o j,r i→j,r j→i)=(o i+r i→j)W q TW k(o j+r j→i),subscript 𝑠 𝑖 𝑗 𝑔 superscript 𝑜 𝑖 superscript 𝑜 𝑗 subscript 𝑟→𝑖 𝑗 subscript 𝑟→𝑗 𝑖 superscript 𝑜 𝑖 subscript 𝑟→𝑖 𝑗 superscript subscript 𝑊 𝑞 𝑇 subscript 𝑊 𝑘 superscript 𝑜 𝑗 subscript 𝑟→𝑗 𝑖\begin{split}s_{ij}&=g(o^{i},o^{j},r_{i\rightarrow j},r_{j\rightarrow i})\ &=(o^{i}+r_{i\rightarrow j})W_{q}^{T}W_{k}(o^{j}+r_{j\rightarrow i}),\end{split}start_ROW start_CELL italic_s start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT end_CELL start_CELL = italic_g ( italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT , italic_o start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT , italic_r start_POSTSUBSCRIPT italic_i → italic_j end_POSTSUBSCRIPT , italic_r start_POSTSUBSCRIPT italic_j → italic_i end_POSTSUBSCRIPT ) end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL = ( italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT + italic_r start_POSTSUBSCRIPT italic_i → italic_j end_POSTSUBSCRIPT ) italic_W start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT italic_W start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ( italic_o start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT + italic_r start_POSTSUBSCRIPT italic_j → italic_i end_POSTSUBSCRIPT ) , end_CELL end_ROW(2)
where r∗→∗subscript 𝑟→absent r_{\rightarrow}italic_r start_POSTSUBSCRIPT ∗ → ∗ end_POSTSUBSCRIPT is obtained from an embedding layer that takes the adjacency matrix α 𝛼\alpha italic_α as input. We also apply a mask to the attention scores using the adjacency matrix α 𝛼\alpha italic_α to ensure that only information from connected agents is accessible:
s ij={s ij,e j→i=1,−∞,e j→i=0.subscript 𝑠 𝑖 𝑗 cases subscript 𝑠 𝑖 𝑗 subscript 𝑒→𝑗 𝑖 1 subscript 𝑒→𝑗 𝑖 0 s_{ij}=\begin{cases}s_{ij},&e_{j\rightarrow i}=1,\ -\infty,&e_{j\rightarrow i}=0.\end{cases}italic_s start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT = { start_ROW start_CELL italic_s start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT , end_CELL start_CELL italic_e start_POSTSUBSCRIPT italic_j → italic_i end_POSTSUBSCRIPT = 1 , end_CELL end_ROW start_ROW start_CELL - ∞ , end_CELL start_CELL italic_e start_POSTSUBSCRIPT italic_j → italic_i end_POSTSUBSCRIPT = 0 . end_CELL end_ROW(3)
We represent the encoded observations as (𝒐^1,…,𝒐^n)superscript^𝒐 1…superscript^𝒐 𝑛(\hat{{\bm{o}}}^{1},\dots,\hat{{\bm{o}}}^{n})( over^ start_ARG bold_italic_o end_ARG start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , … , over^ start_ARG bold_italic_o end_ARG start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ), which capture not only the individual agent information but also the higher-level inter-dependencies between agents through communication. To facilitate the learning of expressive representations, during the training phase, we treat the encoder as the critic and introduce an additional projection to estimate the value functions:
L Encoder(ϕ)=1 Tn∑m=1 n∑t=0 T−1[R(𝐨 t,𝐚 t)+γ V ϕ¯(𝐨^t+1 m)−V ϕ(𝐨^t m)]2,subscript 𝐿 Encoder italic-ϕ 1 𝑇 𝑛 superscript subscript 𝑚 1 𝑛 superscript subscript 𝑡 0 𝑇 1 superscript delimited-[]𝑅 subscript 𝐨 𝑡 subscript 𝐚 𝑡 𝛾 subscript 𝑉¯italic-ϕ subscript superscript^𝐨 𝑚 𝑡 1 subscript 𝑉 italic-ϕ subscript superscript^𝐨 𝑚 𝑡 2\begin{split}L_{\text{Encoder}}(\phi)=\frac{1}{Tn}&\sum_{m=1}^{n}\sum_{t=0}^{T% -1}\Big{[}R({\mathbf{o}}{t},{\mathbf{a}}{t})+\ &\gamma V_{\bar{\phi}}(\hat{{\mathbf{o}}}^{{m}}{t+1})-V{\phi}(\hat{{\mathbf{% o}}}^{{m}}_{t})\Big{]}^{2},\end{split}start_ROW start_CELL italic_L start_POSTSUBSCRIPT Encoder end_POSTSUBSCRIPT ( italic_ϕ ) = divide start_ARG 1 end_ARG start_ARG italic_T italic_n end_ARG end_CELL start_CELL ∑ start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T - 1 end_POSTSUPERSCRIPT [ italic_R ( bold_o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) + end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL italic_γ italic_V start_POSTSUBSCRIPT over¯ start_ARG italic_ϕ end_ARG end_POSTSUBSCRIPT ( over^ start_ARG bold_o end_ARG start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT ) - italic_V start_POSTSUBSCRIPT italic_ϕ end_POSTSUBSCRIPT ( over^ start_ARG bold_o end_ARG start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) ] start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT , end_CELL end_ROW(4)
where ϕ¯¯italic-ϕ\bar{\phi}over¯ start_ARG italic_ϕ end_ARG is the target network’s parameter, which is a separate neural network that is a copy of the main value function. The update mechanism for ϕ¯¯italic-ϕ\bar{\phi}over¯ start_ARG italic_ϕ end_ARG is executed either through an exponential moving average or via periodic updates in a "hard" manner, typically occurring every few epochs [35].
Decoder. The decoder, characterized by its parameters θ 𝜃\theta italic_θ, processes the embedded joint action 𝒂 0:m−1,m=1,…n formulae-sequence superscript 𝒂:0 𝑚 1 𝑚 1…𝑛{\bm{a}}^{{0:m-1}},m={1,\dots n}bold_italic_a start_POSTSUPERSCRIPT 0 : italic_m - 1 end_POSTSUPERSCRIPT , italic_m = 1 , … italic_n through a series of decoding blocks. The decoding block also incorporates a relation-enhanced mechanism for calculating attention between encoded actions and observation representations, along with an MLP and residual connections. In addition to the adjacency matrix mask, we apply a constraint that limits attention computation to occur only between agent i 𝑖 i italic_i and its preceding agents j 𝑗 j italic_j where j<i 𝑗 𝑖 j<i italic_j < italic_i. This constraint maintains the sequential update scheme, ensuring that the decoder produces the action sequence in an auto-regressive manner: π θ m(a m|𝐨^1:n,𝐚 1:m−1)subscript superscript 𝜋 𝑚 𝜃 conditional superscript a 𝑚 superscript^𝐨:1 𝑛 superscript 𝐚:1 𝑚 1\pi^{m}_{\theta}({\textnormal{a}}^{m}|\hat{{\mathbf{o}}}^{{1:n}},{\mathbf{a}}^% {{1:m-1}})italic_π start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( a start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT | over^ start_ARG bold_o end_ARG start_POSTSUPERSCRIPT 1 : italic_n end_POSTSUPERSCRIPT , bold_a start_POSTSUPERSCRIPT 1 : italic_m - 1 end_POSTSUPERSCRIPT ), which guarantees monotonic performance improvement during training [51]. We apply the PPO algorithm [42] to train the decoder agent:
L Decoder(θ)=−1 Tn∑m=1 n∑t=0 T−1 min(r t m(θ)A^t,clip(r t m(θ),1±ϵ)A^t),r t m(θ)=π θ m(a t m|𝐨^t 1:n,𝐚^t 1:m−1)π θ old m(a t m|𝐨^t 1:n,𝐚^t 1:m−1),formulae-sequence subscript 𝐿 Decoder 𝜃 1 𝑇 𝑛 superscript subscript 𝑚 1 𝑛 superscript subscript 𝑡 0 𝑇 1 subscript superscript r 𝑚 𝑡 𝜃 subscript^𝐴 𝑡 clip subscript superscript r 𝑚 𝑡 𝜃 plus-or-minus 1 italic-ϵ subscript^𝐴 𝑡 subscript superscript r 𝑚 𝑡 𝜃 subscript superscript 𝜋 𝑚 𝜃 conditional subscript superscript a 𝑚 𝑡 subscript superscript^𝐨:1 𝑛 𝑡 subscript superscript^𝐚:1 𝑚 1 𝑡 subscript superscript 𝜋 𝑚 subscript 𝜃 old conditional subscript superscript a 𝑚 𝑡 subscript superscript^𝐨:1 𝑛 𝑡 subscript superscript^𝐚:1 𝑚 1 𝑡\begin{split}L_{\text{Decoder}}(\theta)&=-\frac{1}{Tn}\sum_{m=1}^{n}\sum_{t=0}% ^{T-1}\ \min&\Big{(}{\textnormal{r}}^{m}{t}(\theta)\hat{A}{t},\text{clip}({% \textnormal{r}}^{m}{t}(\theta),1\pm\epsilon)\hat{A}{t}\Big{)},\ {\textnormal{r}}^{m}{t}(\theta)&=\frac{\pi^{m}{\theta}({\textnormal{a}}^{m}% {t}|\hat{{\mathbf{o}}}^{1:n}{t},\hat{{\mathbf{a}}}^{1:m-1}{t})}{\pi^{m}{% \theta_{\text{old}}}({\textnormal{a}}^{m}{t}|\hat{{\mathbf{o}}}^{1:n}{t},% \hat{{\mathbf{a}}}^{1:m-1}_{t})},\end{split}start_ROW start_CELL italic_L start_POSTSUBSCRIPT Decoder end_POSTSUBSCRIPT ( italic_θ ) end_CELL start_CELL = - divide start_ARG 1 end_ARG start_ARG italic_T italic_n end_ARG ∑ start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT ∑ start_POSTSUBSCRIPT italic_t = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_T - 1 end_POSTSUPERSCRIPT end_CELL end_ROW start_ROW start_CELL roman_min end_CELL start_CELL ( r start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_θ ) over^ start_ARG italic_A end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , clip ( r start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_θ ) , 1 ± italic_ϵ ) over^ start_ARG italic_A end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) , end_CELL end_ROW start_ROW start_CELL r start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_θ ) end_CELL start_CELL = divide start_ARG italic_π start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( a start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT | over^ start_ARG bold_o end_ARG start_POSTSUPERSCRIPT 1 : italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , over^ start_ARG bold_a end_ARG start_POSTSUPERSCRIPT 1 : italic_m - 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) end_ARG start_ARG italic_π start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_θ start_POSTSUBSCRIPT old end_POSTSUBSCRIPT end_POSTSUBSCRIPT ( a start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT | over^ start_ARG bold_o end_ARG start_POSTSUPERSCRIPT 1 : italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , over^ start_ARG bold_a end_ARG start_POSTSUPERSCRIPT 1 : italic_m - 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) end_ARG , end_CELL end_ROW(5)
where A^t subscript^𝐴 𝑡\hat{A}{t}over^ start_ARG italic_A end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT is an estimate of the joint advantage function, which can be formulated as V^t=1 n∑m=1 n V(o^t m)subscript^𝑉 𝑡 1 𝑛 superscript subscript 𝑚 1 𝑛 𝑉 subscript superscript^o 𝑚 𝑡\hat{V}{t}=\frac{1}{n}\sum_{m=1}^{n}V(\hat{{\textnormal{o}}}^{m}_{t})over^ start_ARG italic_V end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = divide start_ARG 1 end_ARG start_ARG italic_n end_ARG ∑ start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT italic_V ( over^ start_ARG o end_ARG start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) using the generalized advantage estimation (GAE) approach [41].
Dynamic Gating. In many situations, only critical decisions necessitate information sharing among agents, while most interactions do not require additional information. To address this, we develop a dynamic gating mechanism for each agent to determine whether to receive shared information from the sender, as specified by the communication graph, based on current observations. Specifically, each agent is equipped with a gating network that shares the same architecture but maintains distinct parameters. This gating network is constructed using two linear layers, along with one GeLU activation function and one Layer Normalization:
h t i=Ψ gate(o t i|κ i)fori=1,…,n,formulae-sequence subscript superscript ℎ 𝑖 𝑡 superscript Ψ gate conditional subscript superscript 𝑜 𝑖 𝑡 subscript 𝜅 𝑖 for 𝑖 1…𝑛 h^{i}{t}=\Psi^{\text{gate}}(o^{i}{t}|\kappa_{i}){}{}\text{for}{}{}i=1,% \dots,n,italic_h start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = roman_Ψ start_POSTSUPERSCRIPT gate end_POSTSUPERSCRIPT ( italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT | italic_κ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) for italic_i = 1 , … , italic_n ,(6)
where o t i subscript superscript 𝑜 𝑖 𝑡 o^{i}{t}italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT is the local observation for agent i 𝑖 i italic_i at time step t 𝑡 t italic_t, κ i subscript 𝜅 𝑖\kappa{i}italic_κ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represents the parameters for the gating network of agent i 𝑖 i italic_i, and 𝒦=[κ 1,…,κ n]𝒦 subscript 𝜅 1…subscript 𝜅 𝑛\mathcal{K}=[\kappa_{1},\dots,\kappa_{n}]caligraphic_K = [ italic_κ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , italic_κ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ] denotes the set of parameters for all agents’ gating networks. At time step t 𝑡 t italic_t, the communication graph is then updated as follows:
α i dyn=α i×h t ifori=1,…,n,formulae-sequence subscript superscript 𝛼 dyn 𝑖 subscript 𝛼 𝑖 subscript superscript ℎ 𝑖 𝑡 for 𝑖 1…𝑛\alpha^{\text{dyn}}{i}=\alpha{i}\times h^{i}_{t}{}{}\text{for}{}{}i=1,% \dots,n,italic_α start_POSTSUPERSCRIPT dyn end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = italic_α start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT × italic_h start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT for italic_i = 1 , … , italic_n ,(7)
where α i subscript 𝛼 𝑖\alpha_{i}italic_α start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT is the i 𝑖 i italic_i-th row of the communication matrix α 𝛼\alpha italic_α.
III-C Training and Execution
We employ the CTDE paradigm: during centralized training, there are no restrictions on communication between agents. However, once the learned policies are executed in a decentralized manner, agents can only communicate through a constrained bandwidth channel. We employ a two-stage training pipeline. In the first stage, we focus on learning the communication graph. Once this graph is established, the second stage involves training the dynamic gating mechanism to determine optimal communication timing based on the learned communication graph.
Algorithm 1 CommFormer
1:Input: Batch size
B 𝐵 B italic_B , number of agents
N 𝑁 N italic_N , episodes
K 𝐾 K italic_K , steps per episode
T 𝑇 T italic_T , sparsity
𝒮 𝒮\mathcal{S}caligraphic_S .
2:Initialize: Encoder
{ϕ}italic-ϕ{\phi}{ italic_ϕ } , Decoder
{θ}𝜃{\theta}{ italic_θ } , Dynamic Gating
{𝒦}𝒦{{\mathcal{K}}}{ caligraphic_K } , Replay buffer
ℬ ℬ\mathcal{B}caligraphic_B , Adjacency matrix
α∈ℝ n×n 𝛼 superscript ℝ 𝑛 𝑛\alpha\in\mathbb{R}^{n\times n}italic_α ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_n end_POSTSUPERSCRIPT .
3:for
k=0,1,…,K−1 𝑘 0 1…𝐾 1 k=0,1,\dots,K-1 italic_k = 0 , 1 , … , italic_K - 1 do
4:for
t=0,1,…,T−1 𝑡 0 1…𝑇 1 t=0,1,\dots,T-1 italic_t = 0 , 1 , … , italic_T - 1 do
5:Collect a sequence of observations
o t 1,…,o t n subscript superscript 𝑜 1 𝑡…subscript superscript 𝑜 𝑛 𝑡 o^{{1}}{t},\dots,o^{{n}}{t}italic_o start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , … , italic_o start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT from environments.
6:// inference with CommFormer
7:Generate the matrix
e∈{0,1}n×n 𝑒 superscript 0 1 𝑛 𝑛 e\in{0,1}^{n\times n}italic_e ∈ { 0 , 1 } start_POSTSUPERSCRIPT italic_n × italic_n end_POSTSUPERSCRIPT according to the
α 𝛼\alpha italic_α with Equation 16.
8:// If with dynamic inference
9:Update the matrix
e 𝑒 e italic_e based on the current observations with the dynamic gating networks by Equations 6 and 7.
10:Generate representation sequence
o^t 1,…,o^t n subscript superscript^𝑜 1 𝑡…subscript superscript^𝑜 𝑛 𝑡\hat{o}^{{1}}{t},\dots,\hat{o}^{{n}}{t}over^ start_ARG italic_o end_ARG start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , … , over^ start_ARG italic_o end_ARG start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT via Encoder
ϕ italic-ϕ\phi italic_ϕ with attention score (Equation 2) and mask (Equation 3), similar to the Decoder.
11:for
m=0,1,…,n−1 𝑚 0 1…𝑛 1 m=0,1,\dots,n-1 italic_m = 0 , 1 , … , italic_n - 1 do
12:Input
o^t 1,…,o^t n subscript superscript^𝑜 1 𝑡…subscript superscript^𝑜 𝑛 𝑡\hat{o}^{{1}}{t},\dots,\hat{o}^{{n}}{t}over^ start_ARG italic_o end_ARG start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , … , over^ start_ARG italic_o end_ARG start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT and
a t 0,…,a t m subscript superscript 𝑎 0 𝑡…subscript superscript 𝑎 𝑚 𝑡 a^{0}{t},\dots,a^{m}{t}italic_a start_POSTSUPERSCRIPT 0 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , … , italic_a start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT to the Decoder
θ 𝜃\theta italic_θ and infer
a t m+1 subscript superscript 𝑎 𝑚 1 𝑡 a^{{m+1}}_{t}italic_a start_POSTSUPERSCRIPT italic_m + 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT with the auto-regressive manner.
13:end for
14:Execute joint actions
a t 0,…,a t n subscript superscript 𝑎 0 𝑡…subscript superscript 𝑎 𝑛 𝑡 a^{0}{t},\dots,a^{n}{t}italic_a start_POSTSUPERSCRIPT 0 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , … , italic_a start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT in environments and collect the reward
R(𝒐 t,𝒂 t)𝑅 subscript 𝒐 𝑡 subscript 𝒂 𝑡 R({\bm{o}}{t},{\bm{a}}{t})italic_R ( bold_italic_o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) .
15:Insert
(𝒐 t,𝒂 t,R(𝒐 t,𝒂 t))subscript 𝒐 𝑡 subscript 𝒂 𝑡 𝑅 subscript 𝒐 𝑡 subscript 𝒂 𝑡({\bm{o}}{t},{\bm{a}}{t},R({\bm{o}}{t},{\bm{a}}{t}))( bold_italic_o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_R ( bold_italic_o start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , bold_italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) ) in to
ℬ ℬ\mathcal{B}caligraphic_B .
16:end for
17:// train the CommFormer
18:Sample a random minibatch of
B 𝐵 B italic_B steps from
ℬ ℬ\mathcal{B}caligraphic_B .
19:Generate the matrix
e∈{0,1}n×n 𝑒 superscript 0 1 𝑛 𝑛 e\in{0,1}^{n\times n}italic_e ∈ { 0 , 1 } start_POSTSUPERSCRIPT italic_n × italic_n end_POSTSUPERSCRIPT according to the
α 𝛼\alpha italic_α with Equation 13.
20:Generate
V ϕ(o^)subscript 𝑉 italic-ϕ^𝑜 V_{\phi}(\hat{o})italic_V start_POSTSUBSCRIPT italic_ϕ end_POSTSUBSCRIPT ( over^ start_ARG italic_o end_ARG ) with the output layer of the Encoder
ϕ italic-ϕ\phi italic_ϕ and compute the joint advantage function
A^^𝐴\hat{A}over^ start_ARG italic_A end_ARG based on
V ϕ(o^)subscript 𝑉 italic-ϕ^𝑜 V_{\phi}(\hat{o})italic_V start_POSTSUBSCRIPT italic_ϕ end_POSTSUBSCRIPT ( over^ start_ARG italic_o end_ARG ) with GAE.
21:Input
o^1,…,o^n superscript^𝑜 1…superscript^𝑜 𝑛\hat{o}^{{1}},\dots,\hat{o}^{{n}}over^ start_ARG italic_o end_ARG start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT , … , over^ start_ARG italic_o end_ARG start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT and
a 0,…,a n−1 superscript 𝑎 0…superscript 𝑎 𝑛 1 a^{0},\dots,a^{{n-1}}italic_a start_POSTSUPERSCRIPT 0 end_POSTSUPERSCRIPT , … , italic_a start_POSTSUPERSCRIPT italic_n - 1 end_POSTSUPERSCRIPT , generate
π θ 1,…,π θ n subscript superscript 𝜋 1 𝜃…subscript superscript 𝜋 𝑛 𝜃\pi^{1}{\theta},\dots,\pi^{n}{\theta}italic_π start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT , … , italic_π start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT at once with the Decoder
θ 𝜃\theta italic_θ .
22:Calculate the training loss
L=L Encoder(ϕ)+L Decoder(θ)𝐿 subscript 𝐿 Encoder italic-ϕ subscript 𝐿 Decoder 𝜃 L=L_{\text{Encoder}}(\phi)+L_{\text{Decoder}}(\theta)italic_L = italic_L start_POSTSUBSCRIPT Encoder end_POSTSUBSCRIPT ( italic_ϕ ) + italic_L start_POSTSUBSCRIPT Decoder end_POSTSUBSCRIPT ( italic_θ ) with Equation 4 and Equation 5.
23:Iteratively update the
ϕ,θ italic-ϕ 𝜃\phi,\theta italic_ϕ , italic_θ and
α 𝛼\alpha italic_α with Equation 11 and Equation 12.
24:// train the dynamic gating networks
25:Generate the matrix
e∈{0,1}n×n 𝑒 superscript 0 1 𝑛 𝑛 e\in{0,1}^{n\times n}italic_e ∈ { 0 , 1 } start_POSTSUPERSCRIPT italic_n × italic_n end_POSTSUPERSCRIPT according to the
α 𝛼\alpha italic_α with Equation 16.
26:Update the matrix
e 𝑒 e italic_e based on the current observations with the dynamic gating networks by Equations 6 and 7.
27:Repeat steps 20-23, replacing
α 𝛼\alpha italic_α with
𝒦 𝒦{\mathcal{K}}caligraphic_K for the subsequent iterations.
28:end for
III-C 1 Centralized Training
During the first stage of the training process, we need to determine the communication matrix α 𝛼\alpha italic_α while allowing the architecture parameters ϕ italic-ϕ\phi italic_ϕ and θ 𝜃\theta italic_θ to update normally. This implies a bi-level optimization problem [1, 5] with α 𝛼\alpha italic_α as the upper level variable and ϕ italic-ϕ\phi italic_ϕ and θ 𝜃\theta italic_θ as the lower-level variable:
min α subscript 𝛼\displaystyle\min_{\alpha}{}{}~{}roman_min start_POSTSUBSCRIPT italic_α end_POSTSUBSCRIPT ℒ val(ϕ∗(α),θ∗(α),α),subscript ℒ 𝑣 𝑎 𝑙 superscript italic-ϕ 𝛼 superscript 𝜃 𝛼 𝛼\displaystyle\mathcal{L}{val}(\phi^{}(\alpha),\theta^{}(\alpha),\alpha),caligraphic_L start_POSTSUBSCRIPT italic_v italic_a italic_l end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( italic_α ) , italic_θ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( italic_α ) , italic_α ) ,(8)
s.t.ϕ∗(α),θ∗(α)=argmin ϕ,θℒ train(ϕ,θ,α),superscript italic-ϕ 𝛼 superscript 𝜃 𝛼 subscript arg min italic-ϕ 𝜃 subscript ℒ 𝑡 𝑟 𝑎 𝑖 𝑛 italic-ϕ 𝜃 𝛼\displaystyle\phi^{}(\alpha),\theta^{}(\alpha)=\operatorname*{arg,min}{% \phi,\theta}\mathcal{L}_{train}(\phi,\theta,\alpha),italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( italic_α ) , italic_θ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( italic_α ) = start_OPERATOR roman_arg roman_min end_OPERATOR start_POSTSUBSCRIPT italic_ϕ , italic_θ end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_t italic_r italic_a italic_i italic_n end_POSTSUBSCRIPT ( italic_ϕ , italic_θ , italic_α ) ,(9)
|α|≤𝒮×N 2,𝛼 𝒮 superscript 𝑁 2\displaystyle|\alpha|\leq\mathcal{S}\times N^{2},| italic_α | ≤ caligraphic_S × italic_N start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ,(10)
where ℒ=L Encoder(ϕ)+L Decoder(θ)ℒ subscript 𝐿 Encoder italic-ϕ subscript 𝐿 Decoder 𝜃\mathcal{L}=L_{\text{Encoder}}(\phi)+L_{\text{Decoder}}(\theta)caligraphic_L = italic_L start_POSTSUBSCRIPT Encoder end_POSTSUBSCRIPT ( italic_ϕ ) + italic_L start_POSTSUBSCRIPT Decoder end_POSTSUBSCRIPT ( italic_θ ) with different online rollouts for training L train subscript 𝐿 𝑡 𝑟 𝑎 𝑖 𝑛 L_{train}italic_L start_POSTSUBSCRIPT italic_t italic_r italic_a italic_i italic_n end_POSTSUBSCRIPT and validation L val subscript 𝐿 𝑣 𝑎 𝑙 L_{val}italic_L start_POSTSUBSCRIPT italic_v italic_a italic_l end_POSTSUBSCRIPT, and |α|𝛼|\alpha|| italic_α | denotes the number of connected edges. Evaluating the architecture gradient exactly can be prohibitive due to the expensive inner optimization, and each value in α 𝛼\alpha italic_α is represented by a discrete value in {0,1}0 1{0,1}{ 0 , 1 }. We propose a simple approximation scheme that alternately updates the following formula and relaxes α 𝛼\alpha italic_α as a continuous matrix to enable differentiable updating:
ϕ=ϕ−ξ∇ϕ ℒ train(ϕ,θ,α)θ=θ−ξ∇θ ℒ train(ϕ,θ,α),italic-ϕ italic-ϕ 𝜉 subscript∇italic-ϕ subscript ℒ 𝑡 𝑟 𝑎 𝑖 𝑛 italic-ϕ 𝜃 𝛼 𝜃 𝜃 𝜉 subscript∇𝜃 subscript ℒ 𝑡 𝑟 𝑎 𝑖 𝑛 italic-ϕ 𝜃 𝛼\begin{split}\phi&=\phi-\xi\nabla_{\phi}\mathcal{L}{train}(\phi,\theta,\alpha% )\ \theta&=\theta-\xi\nabla{\theta}\mathcal{L}_{train}(\phi,\theta,\alpha),\end{split}start_ROW start_CELL italic_ϕ end_CELL start_CELL = italic_ϕ - italic_ξ ∇ start_POSTSUBSCRIPT italic_ϕ end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_t italic_r italic_a italic_i italic_n end_POSTSUBSCRIPT ( italic_ϕ , italic_θ , italic_α ) end_CELL end_ROW start_ROW start_CELL italic_θ end_CELL start_CELL = italic_θ - italic_ξ ∇ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_t italic_r italic_a italic_i italic_n end_POSTSUBSCRIPT ( italic_ϕ , italic_θ , italic_α ) , end_CELL end_ROW(11)
and
α=α−η∇α ℒ val(ϕ,θ,α),𝛼 𝛼 𝜂 subscript∇𝛼 subscript ℒ 𝑣 𝑎 𝑙 italic-ϕ 𝜃 𝛼\alpha=\alpha-\eta\nabla_{\alpha}\mathcal{L}_{val}(\phi,\theta,\alpha),italic_α = italic_α - italic_η ∇ start_POSTSUBSCRIPT italic_α end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_v italic_a italic_l end_POSTSUBSCRIPT ( italic_ϕ , italic_θ , italic_α ) ,(12)
where ϕ,θ italic-ϕ 𝜃\phi,\theta italic_ϕ , italic_θ denote the current weights maintained by the algorithm, and ξ,η 𝜉 𝜂\xi,\eta italic_ξ , italic_η are the learning rate for a step of inner and outer optimization. The idea is to approximate ϕ∗(α),θ∗(α)superscript italic-ϕ 𝛼 superscript 𝜃 𝛼\phi^{}(\alpha),\theta^{}(\alpha)italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( italic_α ) , italic_θ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( italic_α ) by adapting ϕ italic-ϕ\phi italic_ϕ and θ 𝜃\theta italic_θ using only a single training step, without fully solving the inner optimization (Equation 9) by training until convergence.
To update the discrete adjacency matrix α 𝛼\alpha italic_α, we utilize the Gumbel-Max trick [18, 32] to sample the binary adjacency matrix, which facilitates the continuous representation of α 𝛼\alpha italic_α and enables the normal back-propagation of gradients during training. To satisfy constraint 10, we extend the original one-hot Gumbel-Max trick to k-hot, enabling each agent to send messages to a fixed number of k=𝒮×N 𝑘 𝒮 𝑁 k=\mathcal{S}\times N italic_k = caligraphic_S × italic_N agents:
e i=k_hot(k-argmax[Softmax(α ij+g j),for j=1,…,n]),subscript 𝑒 𝑖 k_hot k-arg max Softmax subscript 𝛼 𝑖 𝑗 subscript 𝑔 𝑗 for 𝑗 1…𝑛\begin{split}e_{i}=\text{k_hot}&\big{(}\text{k-}\operatorname*{arg,max}[% \text{Softmax}(\alpha_{ij}+g_{j}),\ &\text{for}~{}j=1,\dots,n]\big{)},\end{split}start_ROW start_CELL italic_e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = k_hot end_CELL start_CELL ( k- start_OPERATOR roman_arg roman_max end_OPERATOR [ Softmax ( italic_α start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT + italic_g start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) , end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL for italic_j = 1 , … , italic_n ] ) , end_CELL end_ROW(13)
where g j subscript 𝑔 𝑗 g_{j}italic_g start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT is sampled from Gumbel(0,1), and e i∈ℕ N subscript 𝑒 𝑖 superscript ℕ 𝑁 e_{i}\in\mathbb{N}^{N}italic_e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ blackboard_N start_POSTSUPERSCRIPT italic_N end_POSTSUPERSCRIPT represents the edges connected to agent i 𝑖 i italic_i.
During the second stage of the training process, once the communication graph has been effectively learned, we focus on optimizing the dynamic gating networks with a similar objective function:
min 𝒦 subscript 𝒦\displaystyle\min_{{\mathcal{K}}}{}{}~{}roman_min start_POSTSUBSCRIPT caligraphic_K end_POSTSUBSCRIPT ℒ val(ϕ∗(𝒦),θ∗(𝒦),𝒦),subscript ℒ 𝑣 𝑎 𝑙 superscript italic-ϕ 𝒦 superscript 𝜃 𝒦 𝒦\displaystyle\mathcal{L}{val}(\phi^{}({\mathcal{K}}),\theta^{}({\mathcal{K}% }),{\mathcal{K}}),caligraphic_L start_POSTSUBSCRIPT italic_v italic_a italic_l end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( caligraphic_K ) , italic_θ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( caligraphic_K ) , caligraphic_K ) ,(14)
s.t.ϕ∗(𝒦),θ∗(𝒦)=argmin ϕ,θℒ train(ϕ,θ,𝒦).superscript italic-ϕ 𝒦 superscript 𝜃 𝒦 subscript arg min italic-ϕ 𝜃 subscript ℒ 𝑡 𝑟 𝑎 𝑖 𝑛 italic-ϕ 𝜃 𝒦\displaystyle\phi^{}({\mathcal{K}}),\theta^{}({\mathcal{K}})=\operatorname*{% arg,min}{\phi,\theta}\mathcal{L}_{train}(\phi,\theta,{\mathcal{K}}).italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( caligraphic_K ) , italic_θ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ( caligraphic_K ) = start_OPERATOR roman_arg roman_min end_OPERATOR start_POSTSUBSCRIPT italic_ϕ , italic_θ end_POSTSUBSCRIPT caligraphic_L start_POSTSUBSCRIPT italic_t italic_r italic_a italic_i italic_n end_POSTSUBSCRIPT ( italic_ϕ , italic_θ , caligraphic_K ) .(15)
In this formulation, the parameters of the communication matrix α 𝛼\alpha italic_α remain fixed, while 𝒦 𝒦{\mathcal{K}}caligraphic_K influences performance by dynamically altering the communication graph as defined by Equations 6 and 7. This allows us to employ a similar bi-level optimization strategy, utilizing the Gumbel-Max trick to simultaneously update the parameters of the dynamic gating networks 𝒦 𝒦{\mathcal{K}}caligraphic_K and the architecture parameters ϕ italic-ϕ\phi italic_ϕ and θ 𝜃\theta italic_θ.
III-C 2 Distributed Execution
During execution, each agent i 𝑖 i italic_i has access to its local observations and actions, as well as additional information transmitted by other agents through communication. The adjacency matrix is derived from the parameters α 𝛼\alpha italic_α without any randomness as follows:
e i=k_hot(k-argmax[α ij,forj=1,…,n]).subscript 𝑒 𝑖 k_hot k-arg max subscript 𝛼 𝑖 𝑗 for 𝑗 1…𝑛 e_{i}=\text{k_hot}\big{(}\text{k-}\operatorname*{arg,max}\left[\alpha_{ij},% {}\text{for}{}j=1,\dots,n\right]\big{)}.italic_e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = k_hot ( k- start_OPERATOR roman_arg roman_max end_OPERATOR [ italic_α start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT , for italic_j = 1 , … , italic_n ] ) .(16)
In the case of dynamic inference, the adjacency matrix undergoes an additional masking process at time step t 𝑡 t italic_t, defined by the following equation:
e i dyn=e i×h t i,superscript subscript 𝑒 𝑖 dyn subscript 𝑒 𝑖 superscript subscript ℎ 𝑡 𝑖 e_{i}^{\text{dyn}}=e_{i}\times h_{t}^{i},italic_e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT dyn end_POSTSUPERSCRIPT = italic_e start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT × italic_h start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ,(17)
where h t i superscript subscript ℎ 𝑡 𝑖 h_{t}^{i}italic_h start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT is the dynamic gating mechanism’s output at time step t 𝑡 t italic_t, as specified in Equation 6. Note that each action is generated auto-regressively, in the sense that a m superscript 𝑎 𝑚 a^{m}italic_a start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT will be inserted back into the decoder again to generate a m+1 superscript 𝑎 𝑚 1 a^{m+1}italic_a start_POSTSUPERSCRIPT italic_m + 1 end_POSTSUPERSCRIPT (starting with a 1 superscript 𝑎 1 a^{1}italic_a start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT and ending with a n superscript 𝑎 𝑛 a^{n}italic_a start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT). Through the use of limited communication, each agent is still able to effectively select actions when compared to fully connected agents, which leads to significant reductions in communication costs and overhead. The overall pseudocode is presented in Algorithm 1.
IV Experiment
To evaluate the properties and performance of our proposed CommFormer 1 1 1 Our code is available at: https://github.com/charleshsc/CommFormer, we conduct a series of experiments using four environments, including Predator-Prey (PP) [44], Predator-Capture-Prey (PCP) [43], StarCraftII Multi-Agent Challenge (SMAC) [40], and Google Research Football(GRF) [23].
• PP. The goal is for N 𝑁 N italic_N predator agents with limited vision to find a stationary prey and move to its location. The agents in this domain all belong to the same class (i.e., identical state, observation and action spaces).
• PCP. We have two classes of predator and capture agents. Agents of the predator class have the goal of finding the prey with limited vision (similar to agents in PP). Agents of the capture class, have the goal of locating the prey and capturing it with an additional capture-prey action in their action-space, while not having any observation inputs (e.g., lack of scanning sensors).
• SMAC. In these experiments, CommFormer controls a group of agents tasked with defeating enemy units controlled by the built-in AI. The level of combat difficulty can be adjusted by varying the unit types and the number of units on both sides. We measure the winning rate and compare it with state-of-the-art baseline approaches. Notably, the maps 1o10b_vs_1r and 1o2r_vs_4r present formidable challenges attributed to limited observational scope, while the map 5z_vs_1ul necessitates heightened levels of coordination to attain successful outcomes.
• GRF. We evaluate algorithms in the football academy scenario 3 vs. 2, where we have 3 attackers vs. 1 defender, and 1 goalie. The three offending agents are controlled by the MARL algorithm, and the two defending agents are controlled by a built-in AI. We find that utilizing a 3 vs. 2 scenario challenges the robustness of MARL algorithms to stochasticity and sparse rewards.
It is worth noting that in certain domains, our objective extends beyond maximizing the average success rate or cumulative rewards. We also aim to minimize the average number of steps required to complete an episode, emphasizing the ability to achieve goals in the shortest possible time.
TABLE I: Performance evaluations of different metrics and standard deviation on the selected benchmark, where UPDeT’s official codebase supports several Marine-based tasks only. In this context, CF refers to CommFormer, while CF-dyn denotes CommFormer-dyn. Note that the sparsity parameter 𝒮 𝒮\mathcal{S}caligraphic_S in CommFormer is consistently set to 0.4 for all tasks evaluated.
IV-A Baselines
We compare CommFormer against strong non-communication baselines and popular communication methods to highlight its effectiveness. All baselines follow the CTDE paradigm to ensure a fair comparison.
The strong MARL baselines, which primarily focus on algorithm framework design, include: (1) MAPPO[55], which applies PPO in MARL using a shared set of parameters for all agents, without communication. (2) HAPPO[22], which implements multi-agent trust-region learning with a sequential update scheme and monotonic improvement guarantees. (3) QMIX[39], which incorporates a centralized value function to facilitate decentralized decision-making and address credit assignment issues. (4) UPDeT[17], which decouples agent observations into sequences of observation entities and uses a Transformer to map these sequences to actions. (5) MAT[51], which treats cooperative MARL as sequence modeling, using a fixed encoder and fully decentralized actors for each agent.
The popular communication methods, which focus on learning communication strategies, include: (1) SMS[52], which calculates the Shapley Message Value to evaluate the importance of each message and learn what to communicate. (2) TarMAC[6], which uses an attention mechanism to integrate messages based on their importance. (3) NDQ[49], which learns nearly decomposable Q-functions with minimal communication, allowing agents to act independently and occasionally exchange messages for coordination. (4) MAGIC[36], which employs hard attention to construct a dynamic communication graph and uses graph attention networks to process messages. (5) QGNN[21], which introduces a value factorization method using a graph neural network with multi-layer message passing to learn what to communicate. (6) CommNet[46], which uses continuous communication for fully cooperative tasks, learning what to communicate for each agent. (7) I3CNet[44], which controls continuous communication with a gating mechanism to learn when to communicate, constructing a dynamic communication graph. (8) GA-Comm[29], which models agent relationships using a complete graph and learns both whether and how agents should interact. (9) HetNet[43], which learns efficient and diverse communication models based on heterogeneous graph attention networks, focusing on what to communicate.
We also include the fully connected CommFormer (FC) configuration, where each agent can communicate with all others, implying that the sparsity parameter 𝒮 𝒮\mathcal{S}caligraphic_S is set to 1. This serves as an upper bound for our method, demonstrating strong performance in cooperative MARL tasks. In our experiments, the implementations of baseline methods remain consistent with their official repositories, with all hyperparameters left unchanged at their original best-performing configurations. Details of these hyperparameters are provided in the Appendix.
Note that our approach is divided into two versions: the first, CommFormer, maintains a static communication graph during inference, where the communication structure remains fixed once established. The second version, CommFormer-dyn, dynamically adjusts the communication graph based on the outputs of our dynamic gating network during inference.
IV-B Main Results
According to the results presented in Table I and Figure 1, our CommFormer with a sparsity parameter 𝒮=0.4 𝒮 0.4\mathcal{S}=0.4 caligraphic_S = 0.4 significantly outperforms the state-of-the-art baselines. It consistently finds the optimal communication architecture across diverse cooperative scenarios, regardless of changes in the number of agents. Take the task 3s5z as an example, where the algorithm needs to control different types of agents: stalkers and zealots. This requires careful design of the communication architecture based on the capabilities of different units. Otherwise, it can even have a detrimental impact on performance, as indicated by the substantial variance displayed in Figure 1. The outcome of 3s5z presented in Table I consistently highlights CommFormer’s ability to attain optimal performance with different random seeds, which underscores the robustness and efficiency of our proposed method. Furthermore, in comparison to the FC method, CommFormer nearly matches its performance while retaining only 40% of the edges. This indicates that with an appropriate communication architecture, many communication channels can be eliminated, thereby significantly reducing the hardware communication equipment requirements and expanding its applicability. Finally, it’s worth noting that all the results presented in Table I are based on the same number of training steps, demonstrating the robustness and effectiveness of our bi-level optimization approach, which consistently converges to the optimal solution while maintaining sample efficiency.
CommFormer-dyn, which infers with a dynamic communication graph, achieves performance comparable to the static communication graph version in most scenarios. However, in certain complex tasks, such as 6h_vs_8z, 3s5z_vs_3s6z in SMAC settings, and PCP tasks, a performance gap remains, indicating challenges in optimally deciding when to communicate without sacrificing performance. Nevertheless, when compared to other dynamic communication methods, such as I3CNet and MAGIC, our approach significantly outperforms these baselines, demonstrating the efficiency of our framework. This indicates that even using only current observations is sufficient to effectively determine communication timing in most tasks from a graph modeling perspective. The hyper-parameters used in the study, along with additional detailed results, are provided in the Appendix.
IV-C Ablations
We conduct several ablation studies, primarily focusing on the SMAC environments, to examine specific aspects of our CommFormer. The parameter 𝒮 𝒮\mathcal{S}caligraphic_S, which determines the sparsity of the communication graph, impacts the number of connected edges. Lower values of 𝒮 𝒮\mathcal{S}caligraphic_S imply reduced costs associated with communication but may also lead to performance degradation. Additionally, we conduct ablation studies to investigate the essence of architecture searching, where we generate various pre-defined architectures using different random seeds, simulating manually pre-defined settings. Furthermore, we visualize the edge-learning process to illustrate how the communication graph evolves during training. Lastly, we analyze the dynamic gating mechanism and its activation process, a core component of CommFormer-dyn. These ablation studies serve to enhance our understanding of the underlying motivations of our method and provide valuable insights into its key components and their impact on performance. Note that, aside from the dynamic gating and sparsity ablation studies, all other experiments are conducted solely on CommFormer with a static communication graph during inference.

(a)
(b)
(c)
(d)
(e)
(f)
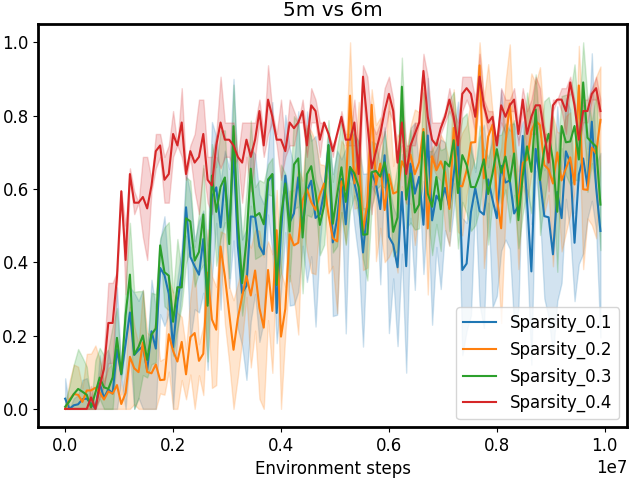
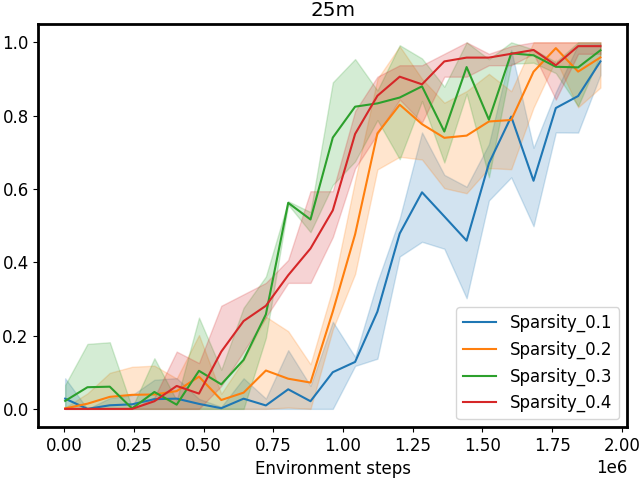
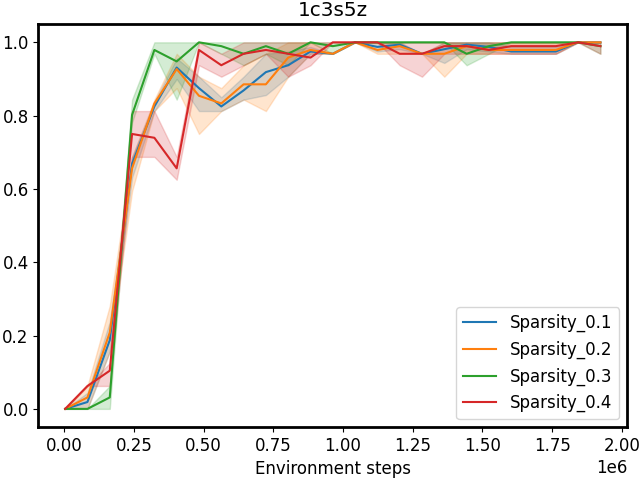
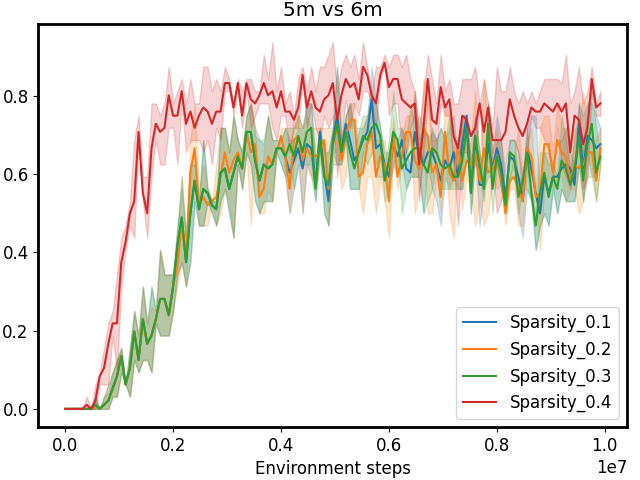
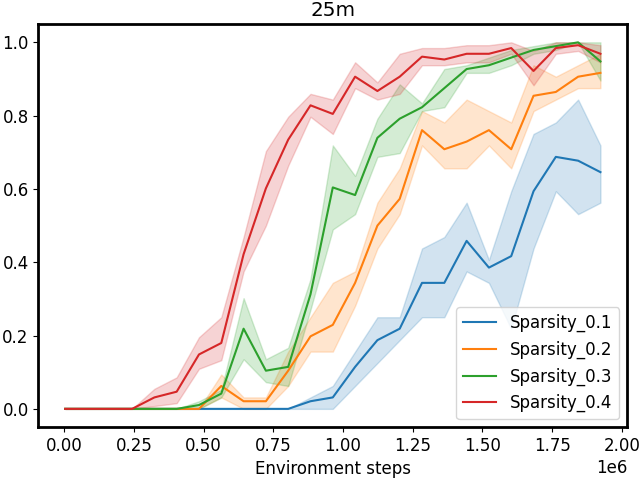
Figure 3: Performance comparison on SMAC tasks 1c3s5z, 5m_vs_6m, and 25m with different sparsity 𝒮 𝒮\mathcal{S}caligraphic_S. The first row shows results for CommFormer, while the second row presents results for CommFormer-dyn, which includes an additional dynamic gating mechanism. As the value of sparsity 𝒮 𝒮\mathcal{S}caligraphic_S increases, both CommFormer and CommFormer-dyn show improved performance across different environments, with this effect being particularly pronounced in scenarios involving a large number of agents.
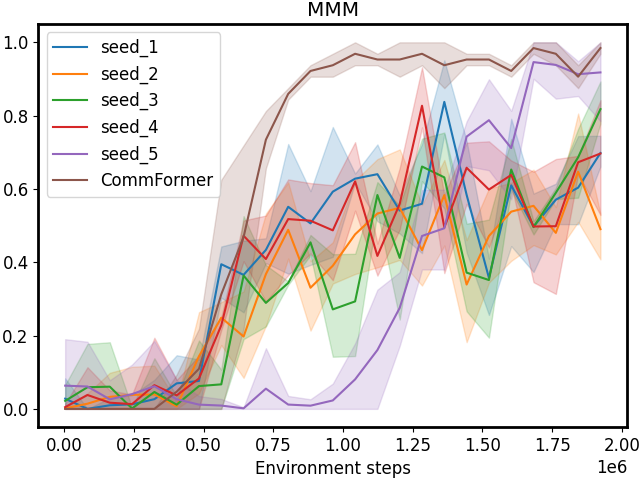
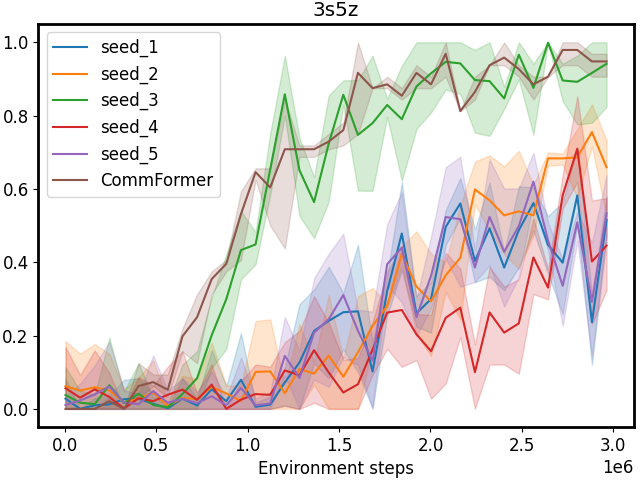
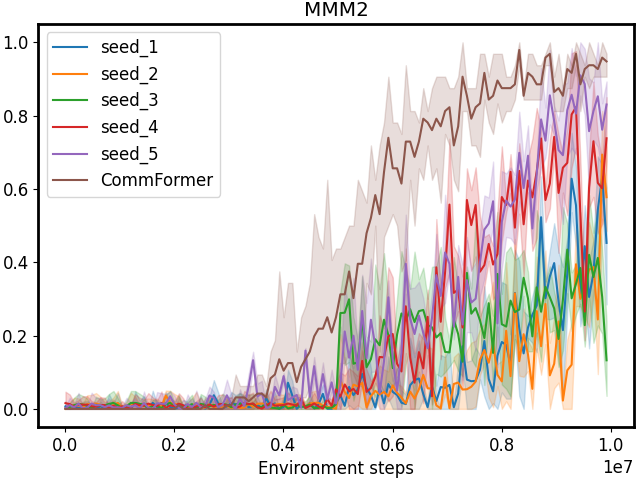
Figure 4: Performance comparison on SMAC tasks with different manually pre-defined communication architectures. CommFormer consistently achieves optimal performance, which underscores its capability to autonomously search for the optimal communication architecture, highlighting its adaptability across various scenarios and tasks.
Sparsity. The parameter 𝒮 𝒮\mathcal{S}caligraphic_S introduced in our bi-level optimization controls the number of connected edges, ensuring that it does not exceed 𝒮×N 2 𝒮 superscript 𝑁 2\mathcal{S}\times N^{2}caligraphic_S × italic_N start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, as specified in Equation 10. To simplify this constraint, we ensure that the total number of edges |α|𝛼|\alpha|| italic_α | equals 𝒮×N 2 𝒮 superscript 𝑁 2\mathcal{S}\times N^{2}caligraphic_S × italic_N start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, with each agent communicating with a fixed number of 𝒮×N 𝒮 𝑁\mathcal{S}\times N caligraphic_S × italic_N agents. Smaller values of 𝒮 𝒮\mathcal{S}caligraphic_S reduce the cost associated with communication but may also result in performance degradation. To investigate the impact of varying 𝒮 𝒮\mathcal{S}caligraphic_S, we conduct a series of experiments with both CommFormer and CommFormer-dyn, whose results are presented in Figure 3. The observed trend is consistent across both methods: for simpler tasks, such as 1c3s5z, achieving a 100% win rate is possible even when each agent can only communicate with one other agent. Nevertheless, as task complexity and the number of participating agents increase, a larger value of sparsity 𝒮 𝒮\mathcal{S}caligraphic_S becomes necessary to attain superior performance.
Architecture Searching. In light of the constraints imposed by limited bandwidth and contention for medium access, designing the communication architecture for each agent becomes a critical task. To investigate the impact of different communication graph configurations, we conduct experiments using various random seeds to generate diverse configurations, simulating the effects of individual configuration choices on the problem. The results, as depicted in Figure 1 and 4, highlight that manually pre-defining the communication architecture often leads to significant performance variance, demanding expert knowledge for achieving better results. In contrast, our proposed method leverages the continuous relaxation of the graph representation. This innovative approach allows for the simultaneous optimization of both the communication graph and architectural parameters in an end-to-end fashion, all while maintaining sample efficiency. This underscores the essentiality and effectiveness of our approach in tackling the challenges of multi-agent communication in constrained environments.
Visualization of Edge Learning. We present additional visual results (Figure 5) that showcase the final communication architecture obtained through our search process. These visualizations offer a more intuitive understanding of the architecture’s evolution during training. In the initial stages, the communication graph undergoes substantial modifications, adapting to enhance overall model performance through significant changes in edge connectivity and agent interactions. In the later stages of training, the architecture stabilizes, exhibiting only minimal adjustments—typically involving the addition or removal of one or two edges—as both the communication graph and model performance reach a steady state.

Figure 5: The searching process of CommFormer in the SMAC task 1c3s5z. In this representation, a white square corresponds to a value of 1, indicating the presence of an edge connection.
Dynamic Gating Input. In our framework, we develop a dynamic gating mechanism for each agent to determine whether to receive shared information from the sender, as specified by the communication graph, based on current observations. In previous studies, the input to the gating mechanism often includes historical information [44, 36], typically encoded by recurrent networks, such as LSTMs or RNNs, to decide whether the current decision requires shared information. We similarly incorporate historical information into the input of gating network, which can be formulated as:
h t i=Ψ gate(o t i,c t i|κ i)fori=1,…,n,formulae-sequence subscript superscript ℎ 𝑖 𝑡 superscript Ψ gate subscript superscript 𝑜 𝑖 𝑡 conditional subscript superscript 𝑐 𝑖 𝑡 subscript 𝜅 𝑖 for 𝑖 1…𝑛 h^{i}{t}=\Psi^{\text{gate}}(o^{i}{t},c^{i}{t}|\kappa{i}){}{}\text{for}{% }{}i=1,\dots,n,italic_h start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = roman_Ψ start_POSTSUPERSCRIPT gate end_POSTSUPERSCRIPT ( italic_o start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_c start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT | italic_κ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) for italic_i = 1 , … , italic_n ,(18)
where c t−1 i subscript superscript 𝑐 𝑖 𝑡 1 c^{i}_{t-1}italic_c start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT represents the temporal hidden state from the previous time step t−1 𝑡 1 t-1 italic_t - 1 for agent i 𝑖 i italic_i, captured via an RNN. We conduct several ablation studies to assess the effectiveness of Equation 18, as presented in Table II. As task difficulty increases, Equation 18 performs worse than Equation 6, suggesting that in complex tasks, basing communication decisions solely on the current observation is sufficient within our framework. Additional historical information may even hinder communication decisions by introducing potentially overly optimistic past data, which can include similar states that do not require communication, thus misguiding the current judgment. This approach also reduces the burden on each agent by eliminating the need to store historical information.
TABLE II: Ablation study on dynamic gating using different inputs for the gating network, based on Equations 6 and 18. The performance is evaluated using different metrics and standard deviations across the selected benchmark.
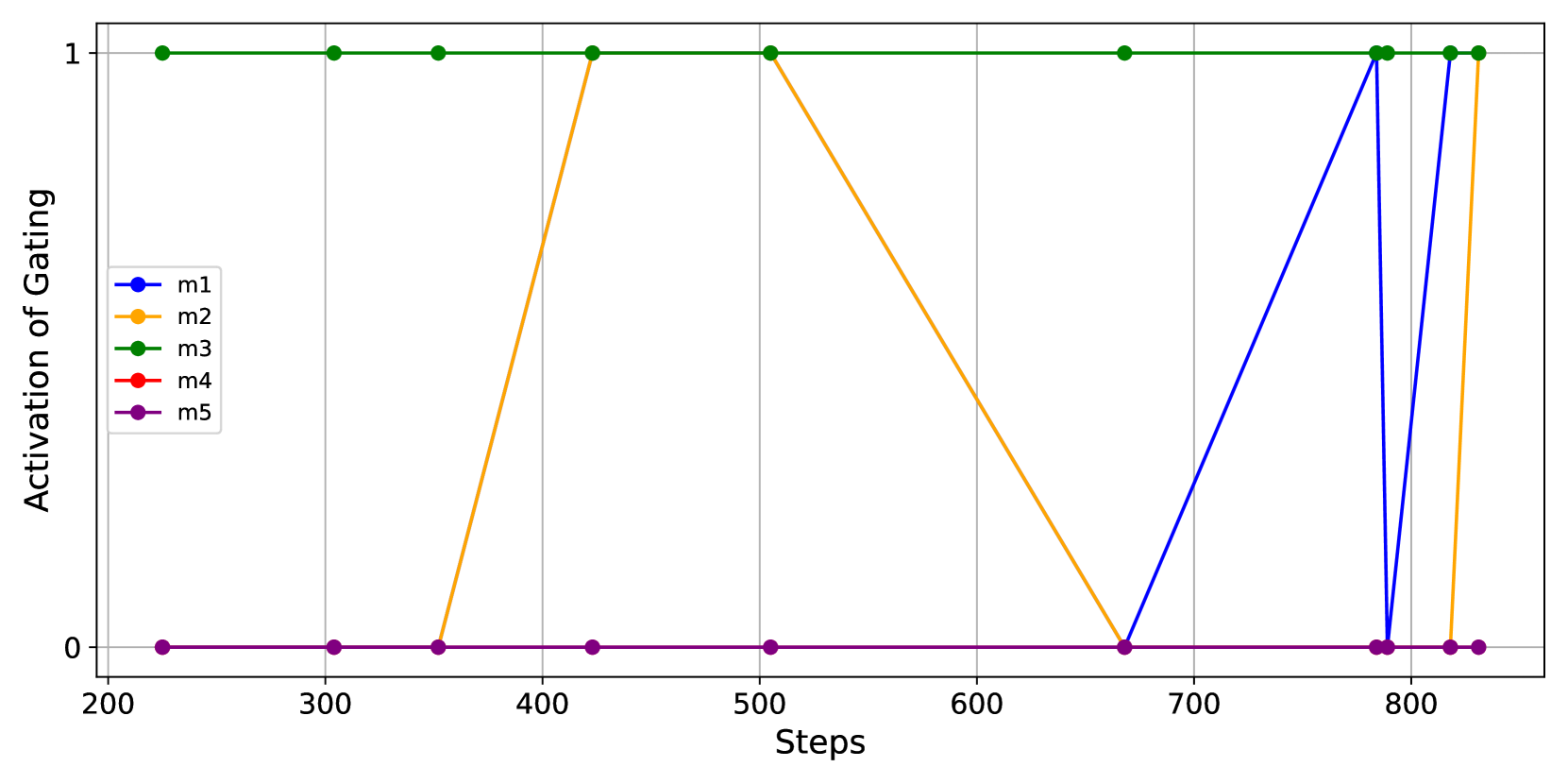
Figure 6: Activation process of the gating network in the 5m_vs_6m task. Note that agents m4 𝑚 4 m4 italic_m 4 and m5 𝑚 5 m5 italic_m 5 remain inactive, not requiring information from others, while m3 𝑚 3 m3 italic_m 3 remains active and consistently relies on shared information for decision-making. Agents m1 𝑚 1 m1 italic_m 1 and m2 𝑚 2 m2 italic_m 2 dynamically decide to accept shared information based on the situational context.
Dynamic Gating Activation. Since in most cases only key decisions require information sharing among agents, we incorporate a temporal gating mechanism to identify critical moments for communication, significantly reducing resource consumption. To evaluate its effectiveness, we use the 5m_vs_6m task as an example, illustrating the activation process among the five Marines. As shown in Figure 6, agents refrain from communicating most of the time, yet still achieve superior performance (92.7 92.7 92.7 92.7) compared to a static communication graph (89.6 89.6 89.6 89.6), with considerably lower communication resource usage. Additionally, our method significantly outperforms the no-communication scenario (81.3 81.3 81.3 81.3), demonstrating its ability to effectively identify key moments for communication and validating its overall effectiveness.
V Conclusion
In this paper, we introduce a novel approach called CommFormer, which addresses the challenge of learning multi-agent communication from a graph modeling perspective. Our approach treats the communication architecture among agents as a learnable graph and formulates this problem as the task of determining the communication graph while enabling the architecture parameters to update normally, thus necessitating a bi-level optimization process. By leveraging the continuous relaxation of graph representation and incorporating attention mechanisms within the graph modeling framework, CommFormer enables the concurrent optimization of the communication graph and architectural parameters in an end-to-end manner. Additionally, we introduce a temporal gating mechanism for each agent, enabling dynamic decisions on whether to receive shared information at a given time, based on current observations, thus improving decision-making efficiency. Extensive experiments conducted on a variety of cooperative tasks illustrate the significant performance advantage of our approach compared to other state-of-the-art baseline methods. In fact, CommFormer approaches the upper bound in scenarios where unrestricted information sharing among all agents is permitted, while CommFormer-dyn is able to maintain performance levels comparable to CommFormer in most scenarios. We believe that our work opens up new possibilities for the application of communication learning in the field of MARL, where effective communication plays a pivotal role in addressing various challenges.
References
- Anandalingam and Friesz [1992] G Anandalingam and Terry L Friesz. Hierarchical optimization: An introduction. Annals of Operations Research, 1992.
- Bettini et al. [2023] Matteo Bettini, Ajay Shankar, and Amanda Prorok. Heterogeneous multi-robot reinforcement learning. arXiv preprint arXiv:2301.07137, 2023.
- Cai and Lam [2020] Deng Cai and Wai Lam. Graph transformer for graph-to-sequence learning. In AAAI, 2020.
- Claus and Boutilier [1998] Caroline Claus and Craig Boutilier. The dynamics of reinforcement learning in cooperative multiagent systems. AAAI/IAAI, 1998.
- Colson et al. [2007] Benoît Colson, Patrice Marcotte, and Gilles Savard. An overview of bilevel optimization. Annals of operations research, 2007.
- Das et al. [2019] Abhishek Das, Théophile Gervet, Joshua Romoff, Dhruv Batra, Devi Parikh, Mike Rabbat, and Joelle Pineau. Tarmac: Targeted multi-agent communication. In ICML, 2019.
- Ding et al. [2020] Ziluo Ding, Tiejun Huang, and Zongqing Lu. Learning individually inferred communication for multi-agent cooperation. Advances in neural information processing systems, 33:22069–22079, 2020.
- Foerster et al. [2016] Jakob Foerster, Ioannis Alexandros Assael, Nando De Freitas, and Shimon Whiteson. Learning to communicate with deep multi-agent reinforcement learning. NeurIPS, 2016.
- Foerster et al. [2018] Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. In AAAI, 2018.
- Foerster et al. [2017] Jakob N Foerster, Richard Y Chen, Maruan Al-Shedivat, Shimon Whiteson, Pieter Abbeel, and Igor Mordatch. Learning with opponent-learning awareness. arXiv preprint arXiv:1709.04326, 2017.
- Hu et al. [2022] Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. In ECCV, 2022.
- Hu et al. [2023] Shengchao Hu, Li Shen, Ya Zhang, and Dacheng Tao. Graph decision transformer. arXiv preprint arXiv:2303.03747, 2023.
- Hu et al. [2024a] Shengchao Hu, Ziqing Fan, Chaoqin Huang, Li Shen, Ya Zhang, Yanfeng Wang, and Dacheng Tao. Q-value regularized transformer for offline reinforcement learning. In International Conference on Machine Learning, 2024a.
- Hu et al. [2024b] Shengchao Hu, Ziqing Fan, Li Shen, Ya Zhang, Yanfeng Wang, and Dacheng Tao. Harmodt: Harmony multi-task decision transformer for offline reinforcement learning. In International Conference on Machine Learning, 2024b.
- Hu et al. [2024c] Shengchao Hu, Li Shen, Ya Zhang, Yixin Chen, and Dacheng Tao. On transforming reinforcement learning with transformers: The development trajectory. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024c.
- Hu et al. [2024d] Shengchao Hu, Li Shen, Ya Zhang, and Dacheng Tao. Learning multi-agent communication from graph modeling perspective. In The Twelfth International Conference on Learning Representations, 2024d.
- Hu et al. [2021] Siyi Hu, Fengda Zhu, Xiaojun Chang, and Xiaodan Liang. Updet: Universal multi-agent reinforcement learning via policy decoupling with transformers. arXiv preprint arXiv:2101.08001, 2021.
- Jang et al. [2016] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144, 2016.
- Jiang and Lu [2018] Jiechuan Jiang and Zongqing Lu. Learning attentional communication for multi-agent cooperation. NeurIPS, 2018.
- Kim et al. [2019] Daewoo Kim, Sangwoo Moon, David Hostallero, Wan Ju Kang, Taeyoung Lee, Kyunghwan Son, and Yung Yi. Learning to schedule communication in multi-agent reinforcement learning. arXiv preprint arXiv:1902.01554, 2019.
- Kortvelesy and Prorok [2022] Ryan Kortvelesy and Amanda Prorok. Qgnn: Value function factorisation with graph neural networks. arXiv preprint arXiv:2205.13005, 2022.
- Kuba et al. [2022] Jakub Grudzien Kuba, Ruiqing Chen, Munning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang. Trust region policy optimisation in multi-agent reinforcement learning. ICLR, 2022.
- Kurach et al. [2020] Karol Kurach, Anton Raichuk, Piotr Stańczyk, Michał Zając, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, et al. Google research football: A novel reinforcement learning environment. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 4501–4510, 2020.
- Lajoie et al. [2021] Pierre-Yves Lajoie, Benjamin Ramtoula, Fang Wu, and Giovanni Beltrame. Towards collaborative simultaneous localization and mapping: a survey of the current research landscape. arXiv preprint arXiv:2108.08325, 2021.
- Lanctot et al. [2017] Marc Lanctot, Vinicius Zambaldi, Audrunas Gruslys, Angeliki Lazaridou, Karl Tuyls, Julien Pérolat, David Silver, and Thore Graepel. A unified game-theoretic approach to multiagent reinforcement learning. NeurIPS, 2017.
- Li et al. [2019] Minne Li, Zhiwei Qin, Yan Jiao, Yaodong Yang, Jun Wang, Chenxi Wang, Guobin Wu, and Jieping Ye. Efficient ridesharing order dispatching with mean field multi-agent reinforcement learning. In WWW, 2019.
- Littman [1994] Michael L Littman. Markov games as a framework for multi-agent reinforcement learning. In Machine learning proceedings 1994. Elsevier, 1994.
- Liu et al. [2021] Bo Liu, Qiang Liu, Peter Stone, Animesh Garg, Yuke Zhu, and Anima Anandkumar. Coach-player multi-agent reinforcement learning for dynamic team composition. In ICML, 2021.
- Liu et al. [2020] Yong Liu, Weixun Wang, Yujing Hu, Jianye Hao, Xingguo Chen, and Yang Gao. Multi-agent game abstraction via graph attention neural network. In AAAI, 2020.
- Liu et al. [2022] Yuntao Liu, Yong Dou, Yuan Li, Xinhai Xu, and Donghong Liu. Temporal dynamic weighted graph convolution for multi-agent reinforcement learning. In CogSci, 2022.
- Lowe et al. [2017] Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. NeurIPS, 2017.
- Maddison et al. [2016] Chris J Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. arXiv preprint arXiv:1611.00712, 2016.
- Mao et al. [2020a] Hangyu Mao, Wulong Liu, Jianye Hao, Jun Luo, Dong Li, Zhengchao Zhang, Jun Wang, and Zhen Xiao. Neighborhood cognition consistent multi-agent reinforcement learning. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7219–7226, 2020a.
- Mao et al. [2020b] Hangyu Mao, Zhengchao Zhang, Zhen Xiao, Zhibo Gong, and Yan Ni. Learning agent communication under limited bandwidth by message pruning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5142–5149, 2020b.
- Mnih et al. [2015] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. nature, 2015.
- Niu et al. [2021] Yaru Niu, Rohan R Paleja, and Matthew C Gombolay. Multi-agent graph-attention communication and teaming. In AAMAS, 2021.
- Peng et al. [2017] Peng Peng, Ying Wen, Yaodong Yang, Quan Yuan, Zhenkun Tang, Haitao Long, and Jun Wang. Multiagent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play starcraft combat games. arXiv preprint arXiv:1703.10069, 2017.
- Pesce and Montana [2023] Emanuele Pesce and Giovanni Montana. Learning multi-agent coordination through connectivity-driven communication. Machine Learning, 2023.
- Rashid et al. [2020] Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning. JMLR, 2020.
- Samvelyan et al. [2019] Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nantas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. arXiv preprint arXiv:1902.04043, 2019.
- Schulman et al. [2015] John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. arXiv preprint arXiv:1506.02438, 2015.
- Schulman et al. [2017] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Seraj et al. [2022] Esmaeil Seraj, Zheyuan Wang, Rohan Paleja, Daniel Martin, Matthew Sklar, Anirudh Patel, and Matthew Gombolay. Learning efficient diverse communication for cooperative heterogeneous teaming. In AAMAS, 2022.
- Singh et al. [2018] Amanpreet Singh, Tushar Jain, and Sainbayar Sukhbaatar. Learning when to communicate at scale in multiagent cooperative and competitive tasks. arXiv preprint arXiv:1812.09755, 2018.
- Son et al. [2019] Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Earl Hostallero, and Yung Yi. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In ICML, 2019.
- Sukhbaatar et al. [2016] Sainbayar Sukhbaatar, Rob Fergus, et al. Learning multiagent communication with backpropagation. NeurIPS, 2016.
- Sunehag et al. [2017] Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Vinicius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl Tuyls, et al. Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296, 2017.
- Tacchetti et al. [2018] Andrea Tacchetti, H Francis Song, Pedro AM Mediano, Vinicius Zambaldi, Neil C Rabinowitz, Thore Graepel, Matthew Botvinick, and Peter W Battaglia. Relational forward models for multi-agent learning. arXiv preprint arXiv:1809.11044, 2018.
- Wang et al. [2019] Tonghan Wang, Jianhao Wang, Chongyi Zheng, and Chongjie Zhang. Learning nearly decomposable value functions via communication minimization. arXiv preprint arXiv:1910.05366, 2019.
- Wang et al. [2021] Yuanfei Wang, Fangwei Zhong, Jing Xu, and Yizhou Wang. Tom2c: Target-oriented multi-agent communication and cooperation with theory of mind. arXiv preprint arXiv:2111.09189, 2021.
- Wen et al. [2022] Muning Wen, Jakub Kuba, Runji Lin, Weinan Zhang, Ying Wen, Jun Wang, and Yaodong Yang. Multi-agent reinforcement learning is a sequence modeling problem. NeurIPS, 2022.
- Xue et al. [2022] Di Xue, Lei Yuan, Zongzhang Zhang, and Yang Yu. Efficient multi-agent communication via shapley message value. In IJCAI, 2022.
- Yang and Wang [2020] Yaodong Yang and Jun Wang. An overview of multi-agent reinforcement learning from game theoretical perspective. arXiv preprint arXiv:2011.00583, 2020.
- Yang et al. [2018] Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. Mean field multi-agent reinforcement learning. In ICML, 2018.
- Yu et al. [2022a] Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games. NeurIPS, 2022a.
- Yu et al. [2022b] Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games. NeurIPS, 2022b.
- Zambaldi et al. [2018] Vinicius Zambaldi, David Raposo, Adam Santoro, Victor Bapst, Yujia Li, Igor Babuschkin, Karl Tuyls, David Reichert, Timothy Lillicrap, Edward Lockhart, et al. Relational deep reinforcement learning. arXiv preprint arXiv:1806.01830, 2018.
- Zhou et al. [2020] Ming Zhou, Jun Luo, Julian Villella, Yaodong Yang, David Rusu, Jiayu Miao, Weinan Zhang, Montgomery Alban, Iman Fadakar, Zheng Chen, et al. Smarts: Scalable multi-agent reinforcement learning training school for autonomous driving. arXiv preprint arXiv:2010.09776, 2020.
- Zhou et al. [2023] Ming Zhou, Ziyu Wan, Hanjing Wang, Muning Wen, Runzhe Wu, Ying Wen, Yaodong Yang, Yong Yu, Jun Wang, and Weinan Zhang. Malib: A parallel framework for population-based multi-agent reinforcement learning. J. Mach. Learn. Res., 2023.
Appendix A Hyper-parameter Settings
During our experiments, we maintain consistency in the implementations of baseline methods by using their official repositories, and we keep all hyperparameters unchanged from their original best-performing configurations. Specific hyperparameters used for different algorithms and tasks can be found in Tables III to V. To ensure a fair comparison and validate that our approach achieves optimal performance without compromising sample efficiency, we adopted the same hyperparameter settings as MAT [51].
Appendix B Details of Experimental Results
We provide detailed training figures (Figure 7) for various methods to substantiate our claim that our approach facilitates simultaneous optimization of the communication graph and architectural parameters in an end-to-end manner, all while preserving sample efficiency.
Appendix C Application Consideration
A possible application of this study is to create an efficient communication framework tailored for enclosed, finite environments, typical of logistics warehouses. In these settings, agent movement is limited to designated zones, and communication is facilitated through overhead wires, akin to a trolleybus system.
In contrast, open environments present unique challenges, primarily due to the potential vast distances between agents, which require wireless communication and may hinder effective communication. To address this, a straightforward approach could be to add bidirectional edges between agents when they come within close proximity, enabling communication between them [43]. However, a more effective solution may involve a hybrid approach that considers the constraint on the available bandwidth: initially segmenting agents into groups based on proximity, followed by an internal search for an optimal communication graph within each group. If agent distances vary dynamically during testing, this process is repeated as necessary to adjust the communication graph in real time, ensuring continuous adaptability to changing environmental conditions.
TABLE III: Common hyper-parameters used for our method in the experiments.
TABLE IV: Specific hyper-parameters used for our method in the experiments.
TABLE V: Different hyper-parameters used for CommFormer in different tasks.



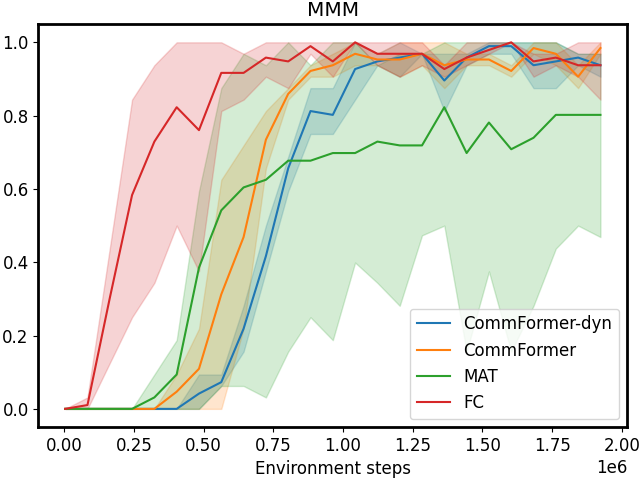
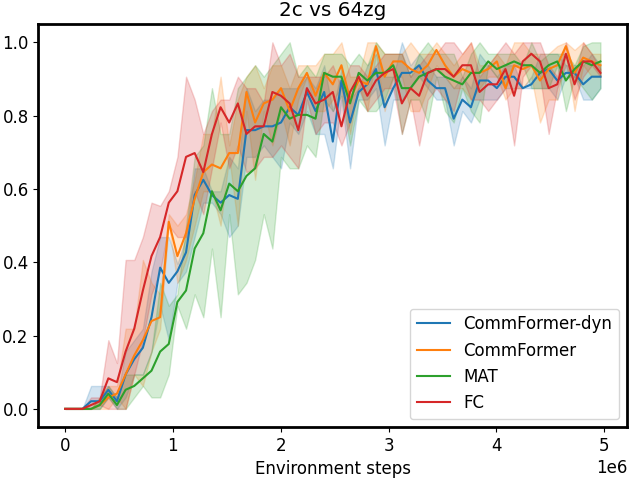

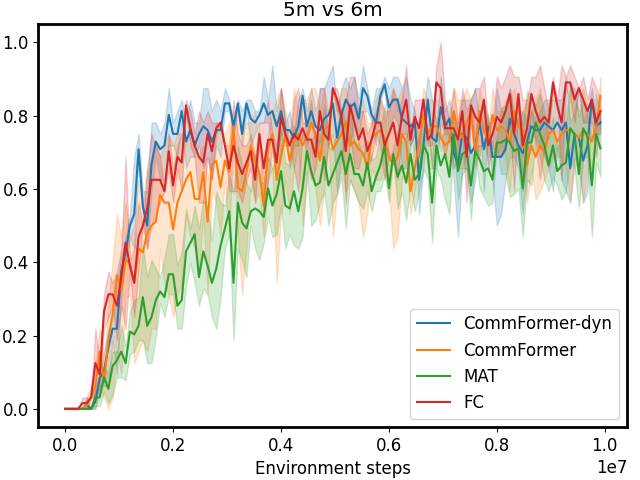
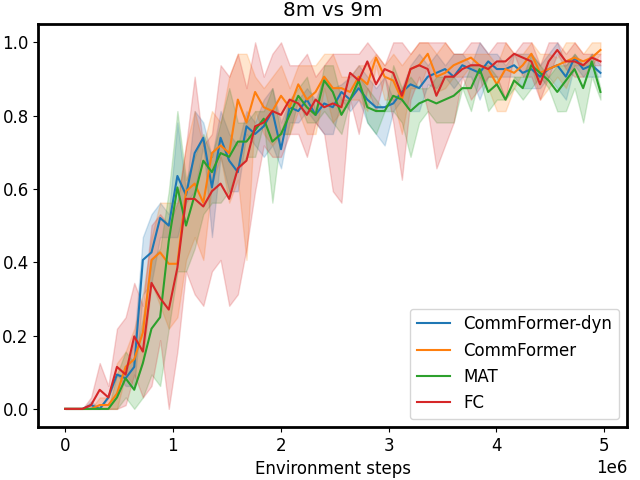

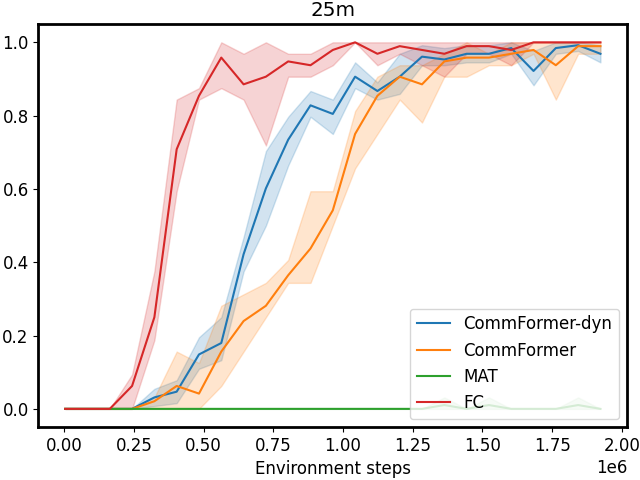
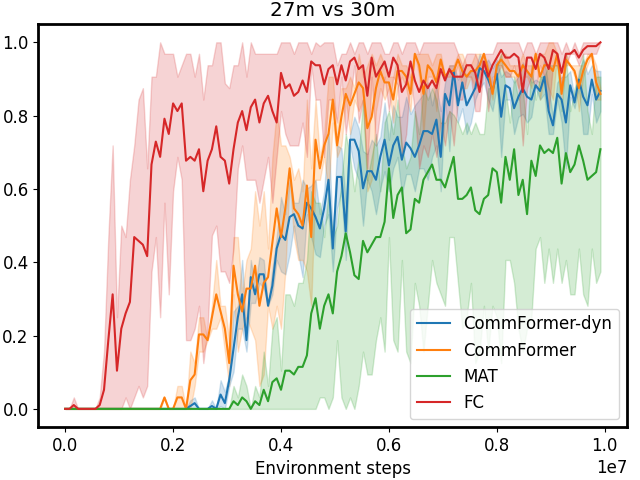
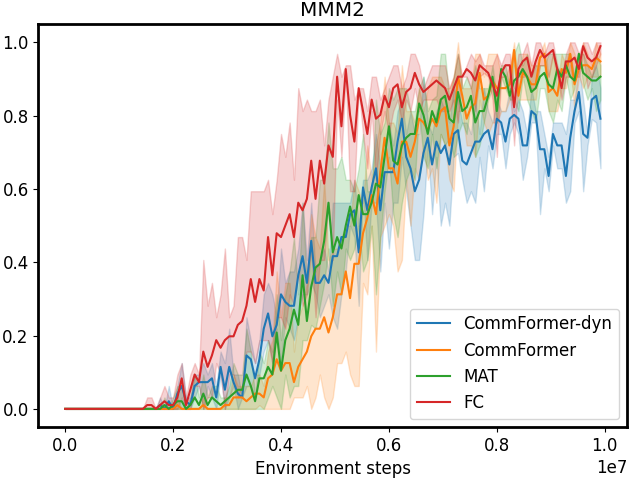


Figure 7: Performance comparison on SMAC tasks. Both CommFormer and CommFormer-dyn consistently outperform strong baselines and achieve performance levels comparable to methods that permit unrestricted information sharing among all agents, demonstrating their effectiveness across varying agent configurations.
Xet Storage Details
- Size:
- 113 kB
- Xet hash:
- 3337e9e7d899c6d885646e31e73a37824e28c53ec1573fb9dde9f03d15c6df46
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.