Buckets:

Title: Applying Graph Explanation to Operator Fusion
URL Source: https://arxiv.org/html/2501.00636
Markdown Content: Keith G. Mills, Muhammad Fetrat Qharabagh, Weichen Qiu,
Fred X. Han, Mohammad Salameh, Wei Lu, Shangling Jui, Di Niu K. G. Mills, M. Fetrat Qharabagh, W. Qiu and D. Niu are with the Department of Electrical and Computer Engineering, University of Alberta at Edmonton, Alberta, Canada, T6G 1H9F. X. Han, M. Salameh, and W. Lu are with Huawei Technologies, Edmonton, Canada, T6G 2C8S. Jui is with Huawei Kirin Solution, Shanghai, China, 200120
Abstract
Layer fusion techniques are critical to improving the inference efficiency of deep neural networks (DNN) for deployment. Fusion aims to lower inference costs by reducing data transactions between an accelerator’s on-chip buffer and DRAM. This is accomplished by grouped execution of multiple operations like convolution and activations together into single execution units - fusion groups. However, on-chip buffer capacity limits fusion group size and optimizing fusion on whole DNNs requires partitioning into multiple fusion groups. Finding the optimal groups is a complex problem where the presence of invalid solutions hampers traditional search algorithms and demands robust approaches.
In this paper we incorporate Explainable AI, specifically Graph Explanation Techniques (GET), into layer fusion. Given an invalid fusion group, we identify the operations most responsible for group invalidity, then use this knowledge to recursively split the original fusion group via a greedy tree-based algorithm to minimize DRAM access. We pair our scheme with common algorithms and optimize DNNs on two types of layer fusion: Line-Buffer Depth First (LBDF) and Branch Requirement Reduction (BRR). Experiments demonstrate the efficacy of our scheme on several popular and classical convolutional neural networks like ResNets and MobileNets. Our scheme achieves over 20% DRAM Access reduction on EfficientNet-B3.
I Introduction
Deep Neural Networks (DNN) have become an indispensable tool when applying machine learning techniques to solve real-world problems such as computer vision tasks. Performance gains are usually observed as the network becomes larger and deeper. The upsurge in hardware computational power and throughput, such as GPUs and TPUs, is sustaining this performance, thus enabling the training of larger DNNs in shorter periods. Concurrent with these advances, there is a need to develop methods that will allow faster DNN inference for deployment on downstream hardware accelerators.
Layer Fusion (LF; also known as Operator Fusion)[1, 2, 3, 4, 5] is a form of inference acceleration that aims to reduce the number of data transactions between the on-chip buffer of a neural accelerator and a corresponding off-chip DRAM, as each transaction is costly in terms of power and inference latency. To facilitate this, the execution of multiple DNN operation layers, e.g., Convolutions and ReLU, are fused together to reduce the amount of intermediate data that must be written back to the DRAM.
Layer Fusion optimization first casts a DNN as a Directed Acyclic Graph (DAG) where each node corresponds to a single operation layer, e.g., convolution instance, while the edges are defined by the DNN forward pass. This DAG is then partitioned into fusion groups. Each fusion group is a subgraph of operations that execute according to an efficient LF scheduling pattern[1, 5] such as Line Buffer Depth-First (LBDF) execution[4] and Buffer Requirement Reduction (BRR)[2]. A partition plan is a supergraph consisting of all fusion groups that determines the overall inference execution by mapping the flow of data tensors between fusion groups. Since the only intermediate results that need to be transferred to and from the DRAM are the inputs and outputs of each fusion group, the total number of DRAM transactions is reduced, which in turn lowers inference energy cost and latency delay.
The data and weight requirements vary with each LF type. For instance, LBDF executes a series of stacked convolutions at once. As such, the weights of each convolution operation in an LBDF fusion group must be stored within the on-chip buffer for the entire execution of the fusion group. By contrast, BRR allows parameter-induced DRAM access by partitioning the weights into sub-groups for sequential execution. Regardless of these specifics, each fusion group has an associated minimum memory size required to execute. Moreover, the fixed size of a given accelerator’s on-chip buffer imposes a hard constraint on the feasibility of LF methods. If the memory requirements of a fusion group exceed buffer capacity, that fusion group cannot execute.
Additionally, since modern DNNs can contain hundreds of layers[6, 7, 8], it is generally infeasible to fuse all of them together. Instead, finding partition plans with low DRAM access is a combinatorial optimization over an ample search space. Although search approaches like Evolutionary Algorithms (EA)[9], Local Search (LS)[10], and even Random Search (RS)[11] are effective optimization tools for large search spaces, the constraint imposed by on-chip buffer size hampers effectiveness. Suppose a search algorithm proposes a partition plan that consists of an invalid fusion group. That group must be split, imposing additional DRAM costs, or the entire partition plan is invalid. Moreover, the search generally executes using a fixed budget quantified by the number of partition plans an algorithm can propose. Having an inefficient search algorithm that generates many invalid partition plans or suboptimal fusion groups is not desirable.
We address these concerns and step toward more robust search algorithms for LF. We propose to use Graph Explanation Techniques (GET) to resolve invalid fusion groups intelligently. Specifically, given a graph object and corresponding Graph Neural Network (GNN), a GET will find the subgraph of nodes and edges that the GNN relies upon most when making a prediction on the original graph. In this paper we apply GET to LF in order to find partition plans with low DRAM cost. Our detailed contributions are as follows:
First, we cast the problem presented by invalid fusion groups as a recursive optimization task. While an invalid fusion group can be randomly partitioned into smaller, valid groups, the DRAM access of these new fusion groups may not be optimal. Therefore, we develop a tree-based partitioning scheme for rectifying invalid fusion groups. It incorporates recursion and greedy logic to find solutions with low DRAM access cost.
Second, we cast the process of determining a fusion group’s validity as a binary classification problem. We consider several prominent GETs, such as GNNExplainer[12], PGExplainer[13] and RG-Explainer[14] to discover the subgraph nodes and edges responsible for rendering a given fusion group invalid. We pass this information on to our partition scheme to intelligently and surgically split the fusion group.
We incorporate our scheme with several search algorithms, such as Local Search, Random Search, and NSGA-II[15], to demonstrate how it can find network partition plans with lower DRAM cost. Specifically, we consider two types of LF, namely BRR and LBDF across varying on-chip buffer sizes. Furthermore, to illustrate the relevance of our scheme, we experiment across a spectrum of modern and classical DNN designs ranging from EfficientNets[8], MobileNetV2 (MBv2)[6], ResNets[16], SqueezeNet[17]. To demonstrate the applicability of our scheme across computer vision tasks, we also consider a Semantic Segmentation network, DeepLabV3+MobileNetV3[18, 7]. Experimental results demonstrate that our method helps find better partition plans across a range of LF execution schemes, on-chip buffer sizes, and search budgets.
The rest of this paper is organized as follows: We provide a high-level overview of LF and GETs in SectionII before elaborating on our proposed scheme in SectionIII. We provide a detailed experimental setup and results in SectionIV before concluding in SectionV.
II Background and Related Work
The field of Layer Fusion (LF) has become essential and complex[1] as the design of DNNs grows deeper and more intricate. For example, [19] consider node clustering for irregular network structures with many branches and skip-connections. [4] consider ReLU-based compression and tiling effects to combat the adverse effect that skip-connections can have on LF execution. LF methods can have different levels of specificity. For instance, [5] speed up general linear algebra operations by exploiting sparsity. Other forms of LF may focus focus on improving the inference costs specific DNN operations, e.g., Convolutional Neural Networks (CNN) or the dense matrix-multiplication-softmax sequences that comprise attention-based models[20].
Specifically, we consider two forms of LF for CNNs: Line-Buffer Depth-First (LBDF)[4] and Buffer Requirement Reduction (BRR) execution. Figure1 provides a sample illustration of how LBDF inference is performed. While the weights of all convolution operations must be stored in the on-chip buffer at all times, a sliding window mechanism ensures that only a fraction of the input and intermediate feature map needs to be stored on-chip at any given time. A downside is that if the size of an operator’s weight tensor exceeds the size of the on-chip buffer, that operator cannot be used with LBDF and must execute using another inference method.
By contrast, BRR relaxes the requirement that all weight tensors be stored on-chip during inference by allowing parameter-induced memory access. This can be advantageous in cases where a target fusion group contains branching operation paths[9, 11] that share the same intermediate values as input. A drawback of BRR is that it is designed for classical CNN architectures and is not friendly to newer CNN structures such as the Squeeze-and-Excite (SE)[21] module found in MobileNetV3[7] and EfficientNet[8].
Regardless of scheme, LF is generally cast as a search problem over how to partition a given DNN, with a hard constraint defined by the on-chip buffer size, and other potential hardware restrictions. We provide a generalized overview of the LF optimization problem before introducing Graph Explanation Techniques (GET) in the remainder of this section.
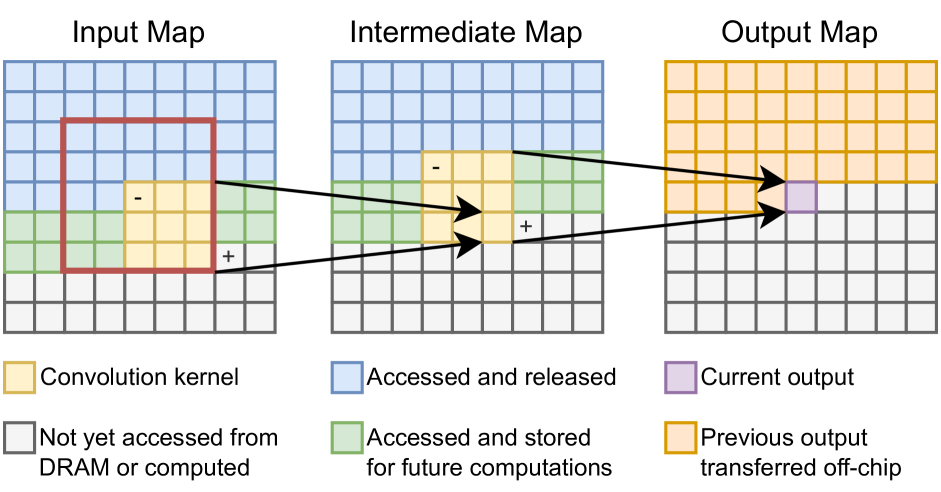
Figure 1: LBDF on a fusion group consisting of two 3×3 3 3 3\times 3 3 × 3 convolution kernels in sequence. Area bounded by the red square denotes the input data required to compute the current output. ‘-’ denotes the next data entries to be released from the on-chip buffer. ‘+’ denotes the next data point to be loaded from DRAM (input map) or computed (intermediate map). Best viewed in color.
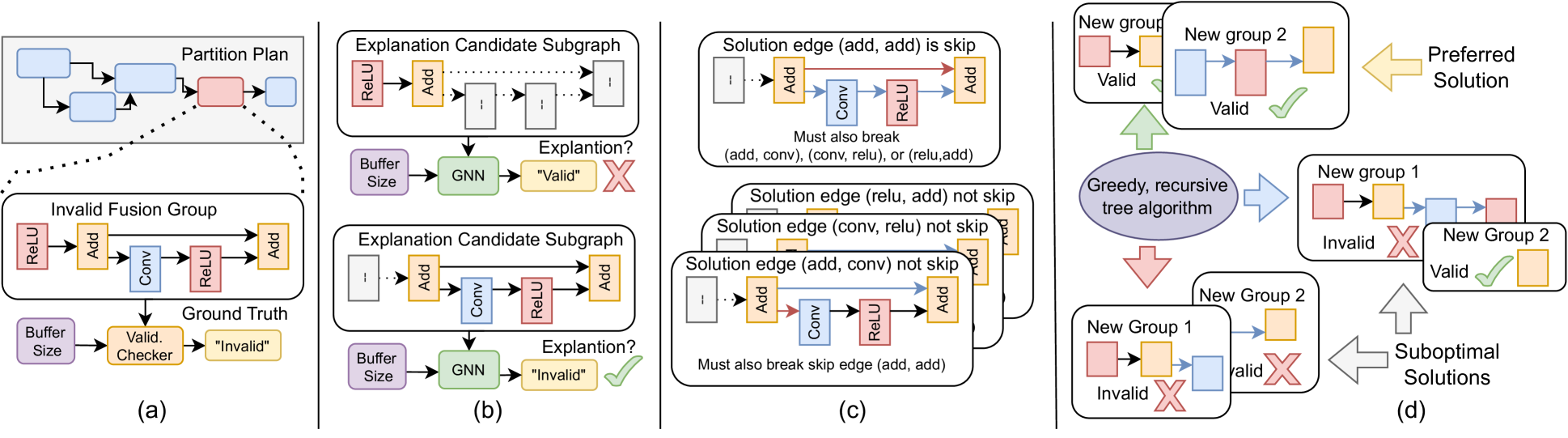
Figure 2: A high-level overview of our scheme. Best viewed in color. (a): A search algorithm generates a partition plan, and an analytical validity checker determines the feasibility of each fusion group in the plan. (b): We use a GNN and GETs to find a subgraph explanation for each invalid fusion group. (c): We consider how to split the fusion group at every solution edge contained within the subgraph explanation. Note how the explanation contains a skip-connection, meaning we must cut at least 2 edges. (d): We use a greedy tree-based algorithm to consider all possible solutions which split the fusion group and sort them based whether the number of new fusion groups. In the optimal case (green arrow), both new fusion groups are valid. If one (blue arrow) or both (red arrow) of the fusion groups are invalid, we use the recursive algorithm to repeat the process from step (a) for each invalid fusion group.
II-A Networks as Graphs
A common approach to LF is to cast a DNN as a Directed Acyclic Graph (DAG) or Computational Graph (CG). In a CG, each node is a primitive operation, e.g., convolution, concatenation, activation, etc., while edges describe the DNN forward pass. LF optimization is then cast as a graph partition search problem. Let G 𝐺 G italic_G be a CG with node set ℰ G subscript ℰ 𝐺\mathcal{E}{G}caligraphic_E start_POSTSUBSCRIPT italic_G end_POSTSUBSCRIPT and edge set 𝒱 G subscript 𝒱 𝐺\mathcal{V}{G}caligraphic_V start_POSTSUBSCRIPT italic_G end_POSTSUBSCRIPT. LF optimization partitions G 𝐺 G italic_G into a partition plan Φ Φ\Phi roman_Φ, which consists of N 𝑁 N italic_N disjoint fusion groups ℰ Φ={ϕ 0,ϕ 1,..,ϕ N−1}\mathcal{E}{\Phi}={\phi{0},\phi_{1},..,\phi_{N-1}}caligraphic_E start_POSTSUBSCRIPT roman_Φ end_POSTSUBSCRIPT = { italic_ϕ start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_ϕ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , . . , italic_ϕ start_POSTSUBSCRIPT italic_N - 1 end_POSTSUBSCRIPT } and a subset of the original edges, 𝒱 Φ⊂𝒱 G subscript 𝒱 Φ subscript 𝒱 𝐺\mathcal{V}{\Phi}\subset\mathcal{V}{G}caligraphic_V start_POSTSUBSCRIPT roman_Φ end_POSTSUBSCRIPT ⊂ caligraphic_V start_POSTSUBSCRIPT italic_G end_POSTSUBSCRIPT.
Fusion groups are disjoint subgraphs of G 𝐺 G italic_G, while 𝒱 Φ subscript 𝒱 Φ\mathcal{V}{\Phi}caligraphic_V start_POSTSUBSCRIPT roman_Φ end_POSTSUBSCRIPT represents the connections between fusions groups. Like G 𝐺 G italic_G, Φ Φ\Phi roman_Φ is a DAG that has no cyclic dependencies. Moreover, for Φ Φ\Phi roman_Φ to be valid, each fusion group should be weakly connected; i.e., the underlying undirected graph representation is connected. At inference time, each fusion group will execute separately under an efficient LF scheme, while 𝒱 Φ subscript 𝒱 Φ\mathcal{V}{\Phi}caligraphic_V start_POSTSUBSCRIPT roman_Φ end_POSTSUBSCRIPT represent the intermediate data tensors that transact between the on-chip buffer and off-chip DRAM.
It is possible to have a simple partition plan where every node in G 𝐺 G italic_G is its own fusion group (N=|ℰ G|𝑁 subscript ℰ 𝐺 N=|\mathcal{E}{G}|italic_N = | caligraphic_E start_POSTSUBSCRIPT italic_G end_POSTSUBSCRIPT |) and 𝒱 Φ=𝒱 G subscript 𝒱 Φ subscript 𝒱 𝐺\mathcal{V}{\Phi}=\mathcal{V}{G}caligraphic_V start_POSTSUBSCRIPT roman_Φ end_POSTSUBSCRIPT = caligraphic_V start_POSTSUBSCRIPT italic_G end_POSTSUBSCRIPT. However, this scenario is suboptimal as we need to perform a DRAM-buffer transaction for every edge in 𝒱 Φ subscript 𝒱 Φ\mathcal{V}{\Phi}caligraphic_V start_POSTSUBSCRIPT roman_Φ end_POSTSUBSCRIPT which is costly in terms of latency and power, thus motivating the development of an effective search procedure.
II-B Subgraph Explanations
Graph Explanation is a recent field of eXplainable AI (XAI) that has been gaining popularity. Graph Explanation Techniques (GET) provide a qualitative interpretation of the predictions Graph Neural Networks (GNN)[22] make. For example, if a GNN is trained to performed binary classification, GETs aim to identify the graph attributes, e.g., nodes, edges, motifs, etc., which influence the decision-making process.
Formally, let θ 𝜃\theta italic_θ denote the parameters of a given GNN and let G 𝐺 G italic_G be an input graph. Feeding G 𝐺 G italic_G into the GNN produces p(G|θ)𝑝 conditional 𝐺 𝜃 p(G|\theta)italic_p ( italic_G | italic_θ ), the class probability distribution we wish to explain. A GET will formulate an explanation as a subgraph G∗∈G superscript 𝐺 𝐺 G^{}\in G italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ∈ italic_G that heavily influence the prediction. As even a small graph can have many subgraph permutations with varying numbers of nodes and edges, GETs need a measure to quantify the importance of any given subgraph. For example, GNNExplainer (GNNE)[12] use Mutual Information (MI) to measure importance by finding the subgraph G∗superscript 𝐺 G^{}italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT which maximizes the MI between itself and the original graph G 𝐺 G italic_G. More formally, the GNNE objective is denoated as
max G∗MI(p(G|θ),G∗)=H(p(G|θ))−H(p(G∗|θ)),superscript 𝐺 max 𝑀 𝐼 𝑝 conditional 𝐺 𝜃 superscript 𝐺 𝐻 𝑝 conditional 𝐺 𝜃 𝐻 𝑝 conditional superscript 𝐺 𝜃\centering\underset{G^{}}{\text{max}}MI(p(G|\theta),G^{})=H(p(G|\theta))-H(p% (G^{*}|\theta)),@add@centering start_UNDERACCENT italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT end_UNDERACCENT start_ARG max end_ARG italic_M italic_I ( italic_p ( italic_G | italic_θ ) , italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ) = italic_H ( italic_p ( italic_G | italic_θ ) ) - italic_H ( italic_p ( italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT | italic_θ ) ) ,(1)
where H 𝐻 H italic_H denotes the entropy of the probability distribution p(.|θ)p(.|\theta)italic_p ( . | italic_θ ). GNNE solves the MI problem using a fractional adjacency matrix to control the number of subgraph candidates considered, but repeats its explanation process from scratch for every new graph G 𝐺 G italic_G.
PGExplainer (PG)[13] extend the concept of GNNE by pre-training a set of parameters on top of the original GNN in order to speedup the downstream explanation process. Specifically, for every edge in a graph, PG concatenates the corresponding node embeddings produced by the GNN and pre-trains a simple MLP which associates the concatenated embeddings with the overall prediction p(G|θ)𝑝 conditional 𝐺 𝜃 p(G|\theta)italic_p ( italic_G | italic_θ ). This allows PG to identify significant edges and quickly construct G∗superscript 𝐺 G^{*}italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT.
Since GNNE and PG explicitly focus on the independent importance of nodes/edges, the explanations they produce are not guaranteed to be connected graphs. By contrast, RG-Explainer (RG)[14] is a GET that utilizes Reinforcement Learning (RL) to generate connected subgraph explanations. Like PG, RG pre-trains additional parameters (e.g., an MLP) on top of the target GNN, but then adopts a 3-phase approach to generate explanations: starting point selection, iterative graph generation, and stopping criteria.
Given an input graph, RG uses node embeddings and an MLP to select a seed node as the starting point for the explanatory subgraph G∗superscript 𝐺 G^{}italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT. Then RG uses an agent to iteratively take actions by selecting neighboring nodes to add to the subgraph. The explanation G∗superscript 𝐺 G^{}italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT is complete when RG selects a special termination action rather than adding another neighboring node. Finally, RG uses the cross-entropy loss between p(G|θ)𝑝 conditional 𝐺 𝜃 p(G|\theta)italic_p ( italic_G | italic_θ ) and p(G∗|θ)𝑝 conditional superscript 𝐺 𝜃 p(G^{*}|\theta)italic_p ( italic_G start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT | italic_θ ) to calculate a reward. Additionally, RG considers additional loss penalties based on the subgraph’s radius and number of nodes. We refer interested readers to [12, 13, 14] for further details on these GETs.
III Methodology
At its base level, LF optimization is a graph partition problem that can be solved with different kinds of search algorithms with varying complexities. However, the effectiveness of any search algorithm depends on how well it can handle invalid fusion groups.
Let ϕ n subscript italic-ϕ 𝑛\phi_{n}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT be an arbitrary fusion group from a candidate partition plan ϕ n∈Φ subscript italic-ϕ 𝑛 Φ\phi_{n}\in\Phi italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ∈ roman_Φ that has been produced by a search algorithm. Furthermore, let β 𝛽\beta italic_β be the on-chip buffer capacity, let F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT be a validator function that queries the buffer memory requirements of a given fusion group and let F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT be a function that computes the DRAM access cost to perform inference on a fusion group. The overall search objective is to find the best partition plan that minimizes DRAM access subject to the on-chip buffer size constraint:
min Φ∑ϕ n∈Φ F D(ϕ n),subscript Φ subscript subscript italic-ϕ 𝑛 Φ subscript 𝐹 𝐷 subscript italic-ϕ 𝑛\displaystyle\min_{\Phi}\sum_{\phi_{n}\in\Phi}F_{D}(\phi_{n}),roman_min start_POSTSUBSCRIPT roman_Φ end_POSTSUBSCRIPT ∑ start_POSTSUBSCRIPT italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ∈ roman_Φ end_POSTSUBSCRIPT italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ) ,(2) s.t.∀ϕ n∈Φ∣F β(ϕ)<β.s.t.for-all subscript italic-ϕ 𝑛 conditional Φ subscript 𝐹 𝛽 italic-ϕ 𝛽\displaystyle\textrm{s.t.}\forall\phi_{n}\in\Phi\mid F_{\beta}(\phi)<\beta.s.t. ∀ italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ∈ roman_Φ ∣ italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ ) < italic_β .
That is, for Φ Φ\Phi roman_Φ to be valid, the memory cost of each individual fusion group cannot exceed the buffer capacity. Search complexity arises when considering how to process invalid fusion groups. One simple method would be to discard the entire partition plan, and generate a new one. However, this option is suboptimal as some of the other fusion groups in the partition plan could have below average DRAM access cost. A second, but also simple method is to randomly split the invalid fusion group into two or more new fusion groups which might be valid. This is also suboptimal as there is no guarantee that the new fusion groups will have desirable DRAM cost.
We aim to solve this problem by providing an explainable technique for splitting invalid fusion groups. Figure2 provides a high-level overview of our proposed scheme. In the following subsections we will iterate across Figure2 and elaborate on the details of how our method selects invalid fusion groups, uses GETs to determine invalidity, considers how to split fusion groups with skip (e.g., residual) connections and how a greedy, tree-based method allows us to select the optimal way to perform a split.
III-A Cost Model Granularity
Figure2(a) shows how fusion group validity is determined by calculating if its memory requirements exceed the buffer size, F β(ϕ)<β subscript 𝐹 𝛽 italic-ϕ 𝛽 F_{\beta}(\phi)<\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ ) < italic_β. At its most base level, F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT and F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT represent a cost model implementation of the mathematical equations to compute buffer size for a given LF method given the size of weight and data tensors in a fusion group. More advanced cost models could incorporate hardware specifications.
While these functions can be used to identify fusion group buffer and DRAM access costs, they cannot be directly paired with GETs which are designed to operate on GNNs and require access to the latent representation of graph nodes and edges in order to find an explanation without performing a costly exhaustive search of all possible solutions. Additionally, deriving an explanation from F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT directly is not generalizable as the mathematical equations are specific to different types of LF.
III-B Fusion Group Explanation
We cast the problem of determining fusion group validity as a binary classification problem and train a GNN[22] to mimic the behaviour of the mathematical validity check,
Validity=σ(p(y|ϕ,β,θ)),𝑉 𝑎 𝑙 𝑖 𝑑 𝑖 𝑡 𝑦 𝜎 𝑝 conditional 𝑦 italic-ϕ 𝛽 𝜃\centering Validity=\sigma(p(y|\phi,\beta,\theta)),@add@centering italic_V italic_a italic_l italic_i italic_d italic_i italic_t italic_y = italic_σ ( italic_p ( italic_y | italic_ϕ , italic_β , italic_θ ) ) ,(3)
where y 𝑦 y italic_y is a discrete ‘yes/no’ on whether ϕ italic-ϕ\phi italic_ϕ is invalid, converted from the continuous probability p 𝑝 p italic_p by argmax σ 𝜎\sigma italic_σ. As shown in Figure2(b), we pass invalid fusion groups to a GNN θ 𝜃\theta italic_θ and GET Θ Θ\Theta roman_Θ, e.g., GNNE, PG or RG, to first provide an explanation. Θ Θ\Theta roman_Θ produces a set of edges ϵ(ϕ n,β)={(i,j)}∈ℰ ϕ subscript italic-ϵ subscript italic-ϕ 𝑛 𝛽 𝑖 𝑗 subscript ℰ italic-ϕ\epsilon_{(\phi_{n},\beta)}={(i,j)}\in\mathcal{E}_{\phi}italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , italic_β ) end_POSTSUBSCRIPT = { ( italic_i , italic_j ) } ∈ caligraphic_E start_POSTSUBSCRIPT italic_ϕ end_POSTSUBSCRIPT. Formally,
ϵ(ϕ n,β)=Θ(ϕ n,β,θ).subscript italic-ϵ subscript italic-ϕ 𝑛 𝛽 Θ subscript italic-ϕ 𝑛 𝛽 𝜃\centering\epsilon_{(\phi_{n},\beta)}=\Theta(\phi_{n},\beta,\theta).@add@centering italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , italic_β ) end_POSTSUBSCRIPT = roman_Θ ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , italic_β , italic_θ ) .(4)
Each edge in ϵ(ϕ n,β)subscript italic-ϵ subscript italic-ϕ 𝑛 𝛽\epsilon_{(\phi_{n},\beta)}italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , italic_β ) end_POSTSUBSCRIPT represents a pair of nodes i 𝑖 i italic_i and j 𝑗 j italic_j whose layer fusion cost contributes to the invalidity of ϕ n subscript italic-ϕ 𝑛\phi_{n}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT. Conceptually, our method involves splitting ϕ n subscript italic-ϕ 𝑛\phi_{n}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT along (i,j)𝑖 𝑗(i,j)( italic_i , italic_j ) into two new, disconnected fusion groups, ϕ n i superscript subscript italic-ϕ 𝑛 𝑖\phi_{n}^{i}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT and ϕ n j superscript subscript italic-ϕ 𝑛 𝑗\phi_{n}^{j}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT, and each edge represents a potential solution to consider. However, the presence of skip-connections ensures that sometimes we need to remove more than one edge to split a fusion group.
III-C Skip-Connections
Modern DNN architectures employ residual skip-connections to improve generalization performance and learning[16, 21, 6, 7, 8]. In the context of splitting fusion groups, the use of skip-connections means that removing one edge (i,j)𝑖 𝑗(i,j)( italic_i , italic_j ) may not be enough to separate the original fusion group into two disconnected subgraphs. To address this concern, we start by topologically sorting every operation node in the original DNN and assigning them an ascending numerical label. If there are |ℰ|ℰ|\mathcal{E}|| caligraphic_E | total nodes, the first input is node 0 0, the last output is node |ℰ|−1 ℰ 1|\mathcal{E}|-1| caligraphic_E | - 1, and ∀(i,j)∈ℰ,i<j subscript for-all 𝑖 𝑗 ℰ 𝑖 𝑗\forall_{(i,j)\in\mathcal{E}},i<j∀ start_POSTSUBSCRIPT ( italic_i , italic_j ) ∈ caligraphic_E end_POSTSUBSCRIPT , italic_i < italic_j.
If the removal of a given edge (i,j)𝑖 𝑗(i,j)( italic_i , italic_j ) cannot separate the original fusion group ϕ n subscript italic-ϕ 𝑛\phi_{n}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT into disconnected ϕ n i superscript subscript italic-ϕ 𝑛 𝑖\phi_{n}^{i}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT and ϕ n j superscript subscript italic-ϕ 𝑛 𝑗\phi_{n}^{j}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT, we consider two scenarios. First, (i,j)𝑖 𝑗(i,j)( italic_i , italic_j ) represents a skip-connection (upper half of Fig.2(c)), and there are additional edges connecting ϕ n i superscript subscript italic-ϕ 𝑛 𝑖\phi_{n}^{i}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT and ϕ n j superscript subscript italic-ϕ 𝑛 𝑗\phi_{n}^{j}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT. For each additional edge, we consider whether its removal will separate ϕ n i superscript subscript italic-ϕ 𝑛 𝑖\phi_{n}^{i}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT and ϕ n j superscript subscript italic-ϕ 𝑛 𝑗\phi_{n}^{j}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT and augment the original solution (i,j)𝑖 𝑗(i,j)( italic_i , italic_j ). If ϕ n i superscript subscript italic-ϕ 𝑛 𝑖\phi_{n}^{i}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT and ϕ n j superscript subscript italic-ϕ 𝑛 𝑗\phi_{n}^{j}italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT are still connected, the subgraph contains nested skip-connections, e.g., the Squeeze-and-Excitation[21] modules in EfficientNets[8] and MobileNetV3[7] and we need to consider additional edges to remove recursively.
In the second case (lower part of Fig.2(c)), (i,j)𝑖 𝑗(i,j)( italic_i , italic_j ) is encompassed by at least one skip-connection. We can identify these skip-connections and remove them as well. To accommodate overlap between identified edges, we maintain the minimal possible set of solutions when considering skip-connections, e.g., the explanation in Figure2(c) only produces three solutions.
III-D Greedy Tree-based Selection
Algorithm 1 Recursive Greedy Tree-Based Splitting
1:function Split(
ϕ italic-ϕ\phi italic_ϕ ,
β 𝛽\beta italic_β ,
F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ,
F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ,
θ 𝜃\theta italic_θ ,
Θ Θ\Theta roman_Θ )
2:
ϵ(ϕ,β)=Θ(ϕ n,β,θ)subscript italic-ϵ italic-ϕ 𝛽 Θ subscript italic-ϕ 𝑛 𝛽 𝜃\epsilon_{(\phi,\beta)}=\Theta(\phi_{n},\beta,\theta)italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ , italic_β ) end_POSTSUBSCRIPT = roman_Θ ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , italic_β , italic_θ ) ▷▷\triangleright▷ Includes edges from Sec.III-C.
3:
𝒮 1 subscript 𝒮 1\mathcal{S}_{1}caligraphic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ,
𝒮 2 subscript 𝒮 2\mathcal{S}_{2}caligraphic_S start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ,
𝒮 3 subscript 𝒮 3\mathcal{S}_{3}caligraphic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT
∅\emptyset∅ ,
∅\emptyset∅ ,
∅\emptyset∅ ▷▷\triangleright▷ Three categories
4:for
(i,j)ϕ∈ϵ(ϕ,β)subscript 𝑖 𝑗 italic-ϕ subscript italic-ϵ italic-ϕ 𝛽(i,j){\phi}\in\epsilon{(\phi,\beta)}( italic_i , italic_j ) start_POSTSUBSCRIPT italic_ϕ end_POSTSUBSCRIPT ∈ italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ , italic_β ) end_POSTSUBSCRIPT do
5:
ϕ i subscript italic-ϕ 𝑖\phi_{i}italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ,
ϕ j subscript italic-ϕ 𝑗\phi_{j}italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT = Partition(
(i,j)ϕ subscript 𝑖 𝑗 italic-ϕ(i,j)_{\phi}( italic_i , italic_j ) start_POSTSUBSCRIPT italic_ϕ end_POSTSUBSCRIPT ,
ϕ italic-ϕ\phi italic_ϕ )
6:if
F β(ϕ i)<β subscript 𝐹 𝛽 subscript italic-ϕ 𝑖 𝛽 F_{\beta}(\phi_{i})<\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) < italic_β and
F β(ϕ j)<β subscript 𝐹 𝛽 subscript italic-ϕ 𝑗 𝛽 F_{\beta}(\phi_{j})<\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) < italic_β then
7:
𝒮 1 subscript 𝒮 1\mathcal{S}_{1}caligraphic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT +=
(ϕ i(\phi_{i}( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ,
ϕ j)\phi_{j})italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) ▷▷\triangleright▷ Preferred solution
8:else if
𝒮 1=∅subscript 𝒮 1\mathcal{S}_{1}=\emptyset caligraphic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT = ∅ then
9:if
F β(ϕ i)<β subscript 𝐹 𝛽 subscript italic-ϕ 𝑖 𝛽 F_{\beta}(\phi_{i})<\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) < italic_β or
F β(ϕ j)<β subscript 𝐹 𝛽 subscript italic-ϕ 𝑗 𝛽 F_{\beta}(\phi_{j})<\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) < italic_β then
10:
ϕ valid,ϕ invalid=Sort(ϕ i,ϕ j)subscript italic-ϕ 𝑣 𝑎 𝑙 𝑖 𝑑 subscript italic-ϕ 𝑖 𝑛 𝑣 𝑎 𝑙 𝑖 𝑑 Sort subscript italic-ϕ 𝑖 subscript italic-ϕ 𝑗\phi_{valid},\phi_{invalid}=\texttt{Sort}(\phi_{i},\phi_{j})italic_ϕ start_POSTSUBSCRIPT italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT , italic_ϕ start_POSTSUBSCRIPT italic_i italic_n italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT = Sort ( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT )
11:
𝒮 2 subscript 𝒮 2\mathcal{S}_{2}caligraphic_S start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT +=
(ϕ valid,ϕ invalid)subscript italic-ϕ 𝑣 𝑎 𝑙 𝑖 𝑑 subscript italic-ϕ 𝑖 𝑛 𝑣 𝑎 𝑙 𝑖 𝑑(\phi_{valid},\phi_{invalid})( italic_ϕ start_POSTSUBSCRIPT italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT , italic_ϕ start_POSTSUBSCRIPT italic_i italic_n italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT ) ▷▷\triangleright▷ Intermediate solution
12:else
13:
𝒮 3 subscript 𝒮 3\mathcal{S}_{3}caligraphic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT += (
ϕ i subscript italic-ϕ 𝑖\phi_{i}italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ,
ϕ j subscript italic-ϕ 𝑗\phi_{j}italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) ▷▷\triangleright▷ Worst-case scenario
14:end if
15:end if
16:end for
17:if
𝒮 1!=∅subscript 𝒮 1\mathcal{S}_{1}!=\emptyset caligraphic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT ! = ∅ then▷▷\triangleright▷ Preference to preferred solutions (Cat. 1)
18:return
min(𝒮 1,F D)min subscript 𝒮 1 subscript 𝐹 𝐷\texttt{min}(\mathcal{S}{1},F{D})min ( caligraphic_S start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ) ▷▷\triangleright▷ Minimum DRAM Access
19:else if
𝒮 2!=∅subscript 𝒮 2\mathcal{S}_{2}!=\emptyset caligraphic_S start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT ! = ∅ then
20:
(ϕ valid∗,ϕ invalid∗)=max_valid_nodes(𝒮 2)superscript subscript italic-ϕ 𝑣 𝑎 𝑙 𝑖 𝑑 superscript subscript italic-ϕ 𝑖 𝑛 𝑣 𝑎 𝑙 𝑖 𝑑 max_valid_nodes subscript 𝒮 2(\phi_{valid}^{},\phi_{invalid}^{})=\texttt{max_valid_nodes}(\mathcal{S}_{% 2})( italic_ϕ start_POSTSUBSCRIPT italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT , italic_ϕ start_POSTSUBSCRIPT italic_i italic_n italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ) = max_valid_nodes ( caligraphic_S start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT )
21:return
(ϕ valid∗,Split(\phi_{valid}^{*},\texttt{Split}( italic_ϕ start_POSTSUBSCRIPT italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT , Split (
ϕ invalid∗superscript subscript italic-ϕ 𝑖 𝑛 𝑣 𝑎 𝑙 𝑖 𝑑\phi_{invalid}^{*}italic_ϕ start_POSTSUBSCRIPT italic_i italic_n italic_v italic_a italic_l italic_i italic_d end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ,
β 𝛽\beta italic_β ,
F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ,
F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ,
θ 𝜃\theta italic_θ ,
Θ Θ\Theta roman_Θ ))
22:else
23:
𝒮 3∗=∅superscript subscript 𝒮 3\mathcal{S}_{3}^{*}\ =\emptyset caligraphic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT = ∅
24:for
(ϕ i,ϕ j)∈𝒮 3 subscript italic-ϕ 𝑖 subscript italic-ϕ 𝑗 subscript 𝒮 3(\phi_{i},\phi_{j})\in\mathcal{S}_{3}( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) ∈ caligraphic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT do▷▷\triangleright▷ Split all invalid groups
25:(
ϕ i∗subscript superscript italic-ϕ 𝑖\phi^{*}_{i}italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) = Split(
ϕ i subscript italic-ϕ 𝑖\phi_{i}italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ,
β 𝛽\beta italic_β ,
F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ,
F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ,
θ 𝜃\theta italic_θ ,
Θ Θ\Theta roman_Θ )
26:(
ϕ j∗subscript superscript italic-ϕ 𝑗\phi^{*}_{j}italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) = Split(
ϕ j subscript italic-ϕ 𝑗\phi_{j}italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ,
β 𝛽\beta italic_β ,
F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ,
F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ,
θ 𝜃\theta italic_θ ,
Θ Θ\Theta roman_Θ )
27:
𝒮 3∗superscript subscript 𝒮 3\mathcal{S}_{3}^{*}caligraphic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT +=
((ϕ i∗),(ϕ j∗))subscript superscript italic-ϕ 𝑖 subscript superscript italic-ϕ 𝑗((\phi^{}_{i}),(\phi^{}_{j}))( ( italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) , ( italic_ϕ start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) )
28:end for
29:return
min(𝒮 3∗,F D)min superscript subscript 𝒮 3 subscript 𝐹 𝐷\texttt{min}(\mathcal{S}{3}^{*},F{D})min ( caligraphic_S start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT , italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT )
30:end if
31:end function
Minimizing DRAM access requires considering all possible solutions in ϵ(ϕ n,β)subscript italic-ϵ subscript italic-ϕ 𝑛 𝛽\epsilon_{(\phi_{n},\beta)}italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , italic_β ) end_POSTSUBSCRIPT. As Figure2(d) shows, these solutions can be coarsely grouped depending on the number of valid fusion groups they produce. In order to iterate across these solutions and select the optimal one, we adopt a recursive tree-based approach and incorporate greedy logic to solve fusion group invalidity. As Algorithm1 shows, given an invalid fusion group ϕ italic-ϕ\phi italic_ϕ, we first compute the set of solution edges ϵ(ϕ n,β)subscript italic-ϵ subscript italic-ϕ 𝑛 𝛽\epsilon_{(\phi_{n},\beta)}italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT , italic_β ) end_POSTSUBSCRIPT in line 2 1 1 1 Including solutions that accomodate skip-connections per Sec.III-C. and then group these solutions into three categories:
- Category 1:F β(ϕ n i)<β∧F β(ϕ n j)<β subscript 𝐹 𝛽 superscript subscript italic-ϕ 𝑛 𝑖 𝛽 subscript 𝐹 𝛽 superscript subscript italic-ϕ 𝑛 𝑗 𝛽 F_{\beta}(\phi_{n}^{i})<\beta\land F_{\beta}(\phi_{n}^{j})<\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ) < italic_β ∧ italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT ) < italic_β, considered in lines 6-7, denotes a preferred solution and algorithm end-point. If any solution fits this criterion, we choose the one that minimizes F D(ϕ n i)+F D(ϕ n j)subscript 𝐹 𝐷 superscript subscript italic-ϕ 𝑛 𝑖 subscript 𝐹 𝐷 superscript subscript italic-ϕ 𝑛 𝑗 F_{D}(\phi_{n}^{i})+F_{D}(\phi_{n}^{j})italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT ) + italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_j end_POSTSUPERSCRIPT ), the combined cost of both new fusion groups. Moreover, once we know at least one category 1 solution exists, we adopt greedy logic and do not even consider solutions that fall into the other two categories (line 8) as they will necessarily require splitting ϕ italic-ϕ\phi italic_ϕ into 3 or more fusion groups and therefore will incur higher DRAM access.
- Category 2:F β(ϕ i)>β∨F β(ϕ j)>β subscript 𝐹 𝛽 subscript italic-ϕ 𝑖 𝛽 subscript 𝐹 𝛽 subscript italic-ϕ 𝑗 𝛽 F_{\beta}(\phi_{i})>\beta\lor F_{\beta}(\phi_{j})>\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) > italic_β ∨ italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) > italic_β is an intermediate solution as one of the new fusion groups is invalid, while the other is valid (lines 9-12). If multiple solutions exist in this category, we take a greedy approach (lines 19-21) and select the solution where the valid fusion group contains the most nodes (line 20), then recursively split the invalid fusion group (e.g., repeating the procedure from Fig.2(b) onwards).
- Category 3:F β(ϕ i)>β∧F β(ϕ j)>β subscript 𝐹 𝛽 subscript italic-ϕ 𝑖 𝛽 subscript 𝐹 𝛽 subscript italic-ϕ 𝑗 𝛽 F_{\beta}(\phi_{i})>\beta\land F_{\beta}(\phi_{j})>\beta italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ) > italic_β ∧ italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT ( italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ) > italic_β is the worst-case scenario as both fusion groups are still invalid. We only consider solutions of this category when no Category 1 or 2 solutions exist. We run another round of recursion (lines 24-27) on each set of invalid fusion groups (ϕ i,ϕ j)subscript italic-ϕ 𝑖 subscript italic-ϕ 𝑗(\phi_{i},\phi_{j})( italic_ϕ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , italic_ϕ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ), then select the solution which minimizes DRAM access.
It should be noted that if ϕ italic-ϕ\phi italic_ϕ only contains 1 node, ϵ(ϕ,β)subscript italic-ϵ italic-ϕ 𝛽\epsilon_{(\phi,\beta)}italic_ϵ start_POSTSUBSCRIPT ( italic_ϕ , italic_β ) end_POSTSUBSCRIPT will necessarily be an empty set ∅\emptyset∅ and default to returning nothing (lines 23 and 29). This represents a case where fusion simply cannot be performed on a given node, e.g., LBDF where the size of an operation weight tensor itself exceeds buffer size, however, we aim to identify such problematic nodes prior to LF optimization and exclude them from search. Overall though, Algorithm1 aims to balance the objective of minimizing DRAM access while also minimizing queries to the ground-truth buffer size and DRAM Access profilers, F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT and F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT, respectively.
IV Experimental Results
TABLE I: Number of fusion group samples extracted using random search across numerous CNNs. ‘MB’, ‘RN’, and ‘EB’ denote MobileNets, ResNets and EfficientNets of varying sizes, respectively.
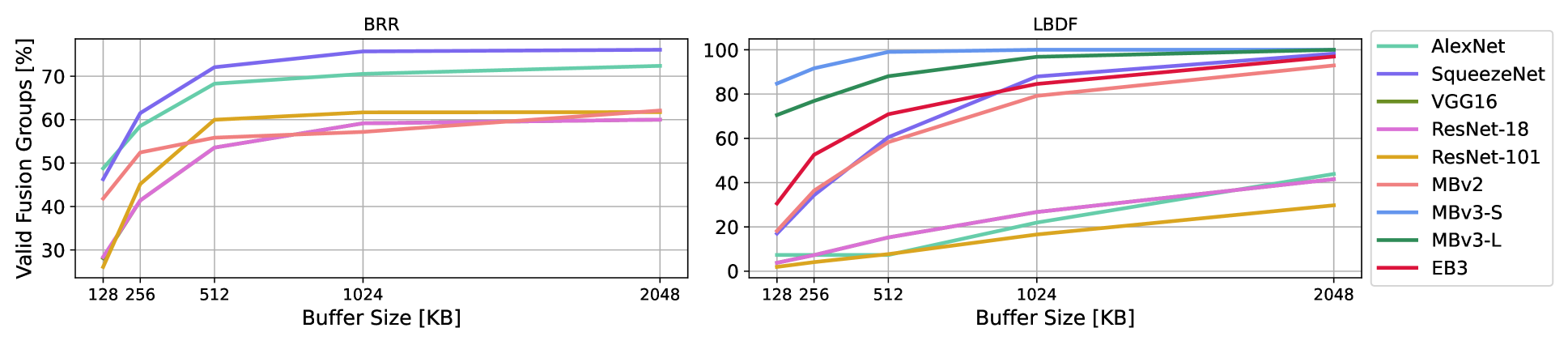
Figure 3: Plotting the percentage of valid fusion groups for each CNN type as we double the on-chip buffer size from a minimum of 128KB to a maximum of 2048KB. Best viewed in color. Note that we do not plot BRR curves for MobileNetV3 and EfficientNet or use them to train our GNNs as that form of LF has compatibility issues with the Squeeze-and-Excite[21] module present in those networks.
In this section we elaborate on our experimental setup, execution and then enumerate our findings. Specifically, we provide details on our scheme for pretraining GNNs and GETs (if applicable) and include data collection statistics. We then iterate our chosen LF schemes and search algorithms, then present results on several modern CNN architectures like EfficientNet[8], MobileNets[6, 7] as well as several classical designs like ResNets[16], SqueezeNet[17] and VGG16[23].
IV-A Graph Neural Networks to Predict Validity
For each form of LF we consider, we train a GNN binary classifier that can pair with GETs and mimics the behaviour of the LF validity checker through Equation3. When testing the effectiveness and generalizability of our proposed scheme, we consider on-chip buffer size as the principle hyperparameter criterion for determining fusion group validity for a given LF scheme. However, we note that our scheme can be paired with more advanced validity checkers that are designed with specific dataflows or hardware constraints.
To train the GNNs, we run a simple LF random search on the ONNX[24] CG model representations of numerous CNN architectures (e.g., ResNets, MobileNets, SqueezeNets, VGG, etc.) in order to generate a wide breadth of valid and invalid fusion groups of various sizes, topologies and operation combinations, for a total of over 10.8k fusion group subgraphs. We then use the validity checker F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT to compute the actual buffer memory cost of each fusion group. Moreover, we multiply the size of our dataset by considering a range of buffer sizes β∈{128KB,256KB,512KB,1024KB,2048KB}𝛽 128 𝐾 𝐵 256 𝐾 𝐵 512 𝐾 𝐵 1024 𝐾 𝐵 2048 𝐾 𝐵\beta\in{128KB,256KB,512KB,1024KB,2048KB}italic_β ∈ { 128 italic_K italic_B , 256 italic_K italic_B , 512 italic_K italic_B , 1024 italic_K italic_B , 2048 italic_K italic_B } for each fusion group sample, giving us a total of over 54k samples. When converting ONNX graphs to GNN data, we encode a specific buffer size as a CG node feature alongside operation type, input/output tensor shape and weight tensor size.
TableI provides a breakdown of how many samples we extract from each CNN, while Figure3 illustrates the proportion of fusion groups that are valid as we increase buffer size from 128KB to 2048KB for both the LBDF and BRR LF contexts. As expected, the number of valid fusion groups increases monotonically with buffer size, though with ever diminishing returns. Moreover, we note the difference in percentage ranges as validity for BRR is between 25%-80% but can vary between 0%-100% for LBDF, depending on the CNN.
Our GNNs consist of 4 k 𝑘 k italic_k-GNN[22] layers with a hidden size of 128, ReLU activation and sum aggregation 2 2 2 Graph embedding is the summation of all node embeddings. We train our GNNs for 50 epochs on the aforementioned fusion group and buffer size range using an 80%/10%/10% train/validation/test set split. GNN training takes a few minutes and both the LBDF and BRR GNNs achieve over 95% classification accuracy and F1 performance on their respective test sets. Furthermore, we use the same training sets to pre-train the additional parameters required by the PG and RG GETs for 25 and 10 epochs, respectively, which takes a few hours.
IV-B Scope of Layer Fusion Optimization
We consider three search algorithms: Random Search (RS)[11], Local Search (LS)[10] and Non-dominated Sorting Genetic Algorithm II (NSGA-II)[15]. RS is simple and unguided. As the name suggests, it randomly generates a new partition plan at every step, then determines its validity and DRAM access cost while tracking the best valid plan with the lowest access cost. LS is a mutation-driven Evolutionary Algorithm which maintains a fixed population of the top-K 𝐾 K italic_K best partition plans it has observed. At each iteration it makes a 1-edit random mutation to each partition plan and observes the change in validity and DRAM cost. These mutations consist of altering the existing fusion groups; e.g., shifting operations from one group to another, merging or splitting groups, etc. Finally, NSGA-II is a advanced evolutionary algorithm that incorporates crossover between existing plans in the top-K 𝐾 K italic_K population alongside random mutation.
Each search algorithm is primarily parameterized by a fixed search budget, which determines the number of partition plans it can generate. We set different budget values depending on experimental setup (e.g., CNN architecture and buffer size) but keep it consistent between RS, LS and NSGA-II. Moreover, we set K=10 𝐾 10 K=10 italic_K = 10 for LS and NSGA-II. We use OpenBox[25] to implement NSGA-II.
We incorporate our method into these search algorithms by using it to enhance their ability to generate partition plans. Whenever these schemes generate an invalid fusion group, they will simply attempt to randomly split it into a set of smaller, valid groups and do not consider DRAM access costs when doing so. We augment this process by first attempting to intelligently split the invalid fusion group in a cost-conscious manner using the recursive approach from SectionIII and a given GET, e.g., GNNE, PG or RG.
Additionally, we improve the efficiency of our scheme by using memoization. We cache the results of our recursive splitting scheme, e.g., using the original invalid fusion group as a key, and the optimized result as a value, to avoid redundant recomputations. Furthermore, we separately cache results from F β subscript 𝐹 𝛽 F_{\beta}italic_F start_POSTSUBSCRIPT italic_β end_POSTSUBSCRIPT and F D subscript 𝐹 𝐷 F_{D}italic_F start_POSTSUBSCRIPT italic_D end_POSTSUBSCRIPT for each individual fusion group encountered during search.
Finally, we report the DRAM access cost amongst fuseable operations. That is, since LBDF requires that the weights of all operations be stored in on-chip memory for the entire execution of a fusion group, we identify unfusable operations, e.g., large convolutions in ResNet-101, and remove them from consideration prior to optimization. Since these operations are not part of the search space and must execute under another form of LF, we do not report their DRAM access costs and instead report metrics amongst fuseable operations.
IV-C Improving Search on Large Networks
TABLE II: DRAM access costs found for EfficientNet-B3, ResNet-152 and DeepLabV3+MobileNetV3 using Line Buffer Depth-First (LBDF) execution with an on-chip buffer size of 256KB. We implement GNNE, PG and RG with Local Search, NSGA-II and Random Search. We also report the Maximum Buffer Usage (MBU) of the corresponding layer fusion plan. Best results in bold. Lower DRAM access and higher MBU are preferred.
To start, we consider two large Image Classification networks, EfficientNet-B3 and ResNet-152, as well as a Semantic Segmentation network consisting of a MobileNetV3 (MBv3)[7] feature extractor and DeepLabV3 (DLv3)[18] prediction head. We aim to find the partition plan which minimizes DRAM access, reported in megabytes (MB), in the LBDF context for a 256KB on-chip buffer. We also report the Maximum Buffer Usage (MBU) in kilobytes (KB). MBU corresponds to the size of the largest fusion group within the layer fusion plan 3 3 3 Although higher values of MBU are better, it cannot exceed the buffer size. While maximizing MBU is not an objective, it provides an additional facet of context to compare search performance..
We set a budget of 5k layer fusion partition plans per search. TableII reports our findings. First, we note that our GET-driven scheme always finds a better schedule than the baseline - DRAM access cost never increases, and in some cases we observe sizeable access cost savings. Specifically, on EfficientNet-B3, we can reduce DRAM access by over 10MB by pairing any search algorithm with a given GET. In fact, when using LS or NSGA-II we reduce DRAM access by over 15MB or 20% compared to the baseline. Furthermore, we also observe DRAM reductions of over 5MB ResNet-152, and almost reduce access by 20MB using RS. DRAM reduction is smallest on DLv3+MBv3. However, this is expected since DLv3+MBv3 is a Semantic Segmentation network which processes higher-resolution images 4 4 4 EB3 uses 300 2 superscript 300 2 300^{2}300 start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT, DLv3+MBv3 uses 513 2 superscript 513 2 513^{2}513 start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT. Other ONNX models use 224 2 superscript 224 2 224^{2}224 start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT., which in turn increases the buffer memory requirement for each operation and further restricts the search space by reducing the number of LBDF-fuseable operations using a 256KB buffer. Nevertheless, using any GET yields a superior partition plan, which verifies the utility of our GET-based method and greedy tree-based recursive splitting algorithm.
When comparing across different search algorithms, our results corroborate intuitive expectations. That is, NSGA-II is the most advanced algorithm and obtains the best performance on each network, followed by LS. RS is the simplest and obtains the worst results, e.g., it cannot find a partition plan on ResNet-152 with DRAM access below 100MB without the assistance of our GET-driven method for splitting invalid fusion groups. Furthermore, we note that although NSGA-II and LS are guided search algorithms that have some understanding of what constitutes a low-cost partition plan or valid fusion group, they can still be improved by leveraging our GET-driven method to find lower-cost partition plans. Therefore, overall, these results demonstrate the generalizablity of our scheme when paired with different search algorithms.
(a) GNNE
(b) PG
(c) RG
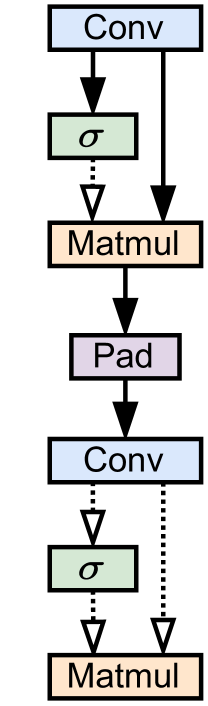
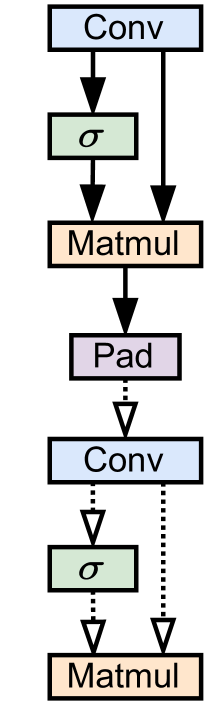
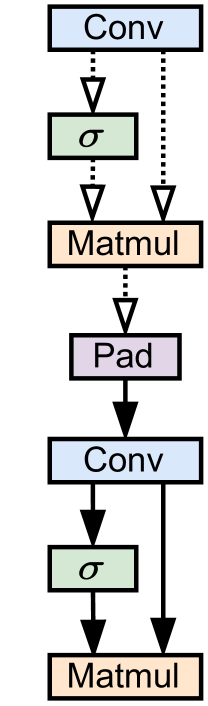
Figure 4: Explanations of an invalid fusion group from EfficientNet according to GNNE, PG and RG. Solid lines indicate an edge was selected via by a given GET.
Next, we compare MBU results. We note how our recursive splitting can find fusion groups with larger buffer usage in many scenarios, such as EfficientNet-B3 for LS and NSGA-II. We also note how the MBU for DLv3+MBv3 is almost always the same value of 252.461KB. This likely corresponds to a large fusion group which most search algorithms (except the RS baseline) can easily find.
Finally, Figure4 provides example illustrations of the explanatory subgraphs generated by GNNE, PG, and RG on an invalid EfficientNet-B0 fusion group. While each GET selects different edges, we note some intuitive commonalities between them: they all select a major skip-connection (Conv to Matmul) which is not friendly to LBDF execution[4] as well as a padding operation.
IV-D Comparisons Across Fusion Methods
We examine whether GETs can improve search results across different buffer fusion methods using a 2k partition plan budget per search and a 128KB buffer size. TableIII tabulates our findings for several DNN networks using LS. We note how, in the BRR context, the use of our GET-driven method always yields partition plans with lower DRAM access costs. The same holds when considering LBDF LF, except on VGG16 and ResNet-18 where LS finds always finds a minima value as the sheer simplicity of both CNNs which enables LS to find the minima cost through brute-force.
Our findings in TableIV which considers RS, corroborate this explanation as each GET outperforms the baseline on the same partition plan budget. Overall though, we do observe smaller DRAM savings compared to those in SectionIV-C. This is an expected outcome as smaller neural networks correspond to smaller LF optimization search spaces which are easier to optimize. By contrast, we observe more appreciable gains on the most complex DNN, MobileNetV2, where we can reduce DRAM access by 10% or more compared to the baseline. Thus, the findings in TablesIII and IV demonstrate how our method is generalizable to different forms of LF as well as search algorithms.
TABLE III: DRAM Access in MB for MobileNetV2, VGG16, ResNet-50/18 and SqueezeNet under the BRR and LBDF settings with a 128KB on-chip buffer. Lower access is better. For this experiment, we consider a simple Local Search Algorithm and augment it with several GEs such as GNNExplainer, PGExplainer and RG-Explainer. Best results in bold.
TABLE IV: DRAM Access in MB for MobileNetV2, VGG16, ResNet-50/18 and SqueezeNet under the BRR and LBDF settings with a 128KB on-chip buffer using Random Search augmented with GETs. Lower access is better.
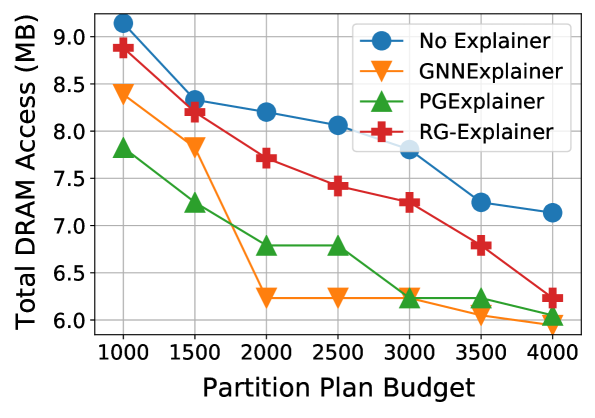
(a) SqueezeNet on BRR using LS
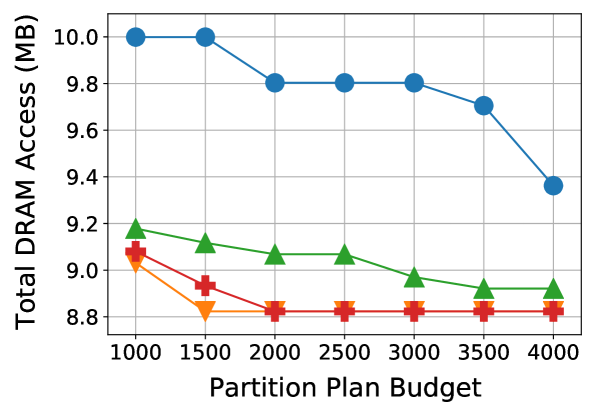
(b) MBv2 on LBDF using LS
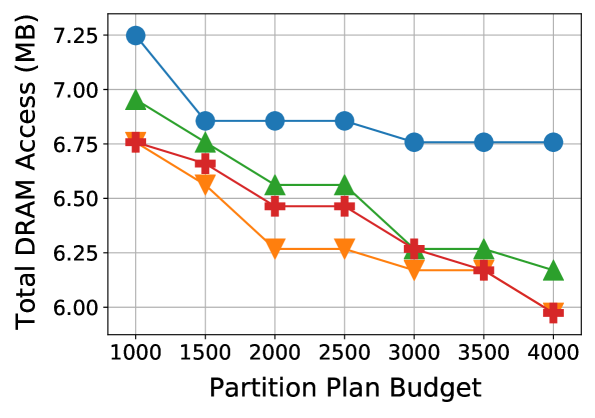
(c) VGG on LBDF using RS
Figure 5: Partition plan budget vs. best DRAM access cost. We compare DRAM performance across gradual increases in the plan budget. Best viewed in color.
IV-E Additional Figures and Discussion
To highlight the effectiveness of our GET scheme in terms of DRAM cost and evaluation budget, we run additional experiments where we vary the search partition plan budget. Figure5 plots the results. We observe that the search methods enhanced by GETs consistently outperform the baselines at every budget value in each case. Moreover, Fig.5(b) shows that there are some cases where a GET with a 1k partition plan evaluation budget can outperform a baseline with a budget of 4k evaluations.
Next, we compare the effectiveness of each GET in terms of the ability to fix invalid fusion groups. Recall that, given an invalid group, a GET will return a set of edges that can be used to split the fusion group, hopefully into two smaller, valid groups. Specifically, given an invalid fusion group, we define the rectify rate as the number of times an initial invalid fusion group was successfully broken up into a set of smaller subgraphs according to the explanatory edges the GE provides. We express this metric as a percentage and report it alongside wall-clock time, noting that the classification GNN, recursive splitting algorithm (Sec.III), target network, and hardware are held constant.
We report our results in TableV. We observe that while all three GETs can correct invalid fusion groups over 50% of the time, GNNE and RG achieve noticeably higher rectify rates than PG. Next, we observe that PG and GNNE are the most and least efficient GETs in terms of time cost, respectively. This makes sense as GNNE[12] does not add any trainable parameters on top of the initial GNN and, therefore, must execute from scratch for each graph one wishes to explain. By contrast, both PG[13] and RG[14] extend the concepts of GNNE by pre-training additional parameters on top of the initial GNN classifier in order to improve downstream runtime. Finally, RG is slightly slower than PG as it is based in Reinforcement Learning and builds a subgraph explanation over several sequential steps.
Overall, our experimental results in this paper demonstrate the utility of GETs in LF. Comparing the different GETs against each other, both GNNE and RG tend to be superior to PG most of the time as they usually find lower DRAM costs (e.g., Tabs.II-IV and Fig.5(b-c)) and achieve a higher rectify rate. Moreover, a trade-off exists between GNNE and RG. While RG achieves a higher rectify rate and lower wall-clock time for search, an additional pre-training step is required to learn the parameterized weights in addition to a pre-trained GNN, whereas the GNNE explanation process only requires a GNN but executes from scratch on each new graph instance. We give RG the advantage as the DRAM savings granted by having better partition plans likely outweigh the one-time cost of RG pretraining, especially since no additional data is required beyond what is used to train the initial GNN.
TABLE V: Comparing various GETs in terms of how frequently they can correct an invalid fusion group (Rectify Rate) and search cost in seconds for MBv2 with LBDF.
V Conclusion
We approach the problem of Layer Fusion (LF) optimization by applying Graph Explanation Techniques (GET) to improve search. GETs take an invalid fusion group and GNN as input and provides an explanation for why the fusion group cannot fit on a given on-chip buffer. We pair these GETs with a recursive partitioning method to split invalid fusion groups in a cost-conscious manner to minimize DRAM access. We consider modern and classical DNN designs such as EfficientNets, MobileNets, ResNets and SqueezeNets for Image Classification and Semantic Segmentation in the LBDF and BRR LF scenarios. We pair our method with off-the-shelf search algorithms such as Local Search, NSGA-II and Random Search which show that a broad range of search algorithms can utilize our method to augment the optimization process. Experimental results show that our proposed scheme is effective at splitting invalid fusion groups while minimizing DRAM cost. For example, we can substantially reduce DRAM access on large classification architectures like EfficientNet-B3 and ResNet-152, where we reduce access cost by over 15MB and 20MB, respectively, compared to the baseline. Moreover, we demonstrate the efficiency of our scheme by showing how it can find better layer fusion partition plans with lower search budgets.
References
- [1] V.Sze, Y.-H. Chen, T.-J. Yang, and J.S. Emer, “Efficient processing of deep neural networks: A tutorial and survey,” Proceedings of the IEEE, vol. 105, no.12, pp. 2295–2329, 2017.
- [2] X.Cai, Y.Wang, and L.Zhang, “Optimus: towards optimal layer-fusion on deep learning processors,” in Proceedings of the 22nd ACM SIGPLAN/SIGBED International Conference on Languages, Compilers, and Tools for Embedded Systems, 2021, pp. 67–79.
- [3] S.Zheng, X.Zhang, D.Ou, S.Tang, L.Liu, S.Wei, and S.Yin, “Efficient scheduling of irregular network structures on cnn accelerators,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol.39, no.11, pp. 3408–3419, 2020.
- [4] M.Shi, P.Houshmand, L.Mei, and M.Verhelst, “Hardware-efficient residual neural network execution in line-buffer depth-first processing,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol.11, no.4, pp. 690–700, 2021.
- [5] M.Boehm, B.Reinwald, D.Hutchison, P.Sen, A.V. Evfimievski, and N.Pansare, “On optimizing operator fusion plans for large-scale machine learning in systemml,” Proc. VLDB Endow., vol.11, no.12, p. 1755–1768, aug 2018. [Online]. Available: https://doi.org/10.14778/3229863.3229865
- [6] M.Sandler, A.Howard, M.Zhu, A.Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520.
- [7] A.Howard, M.Sandler, G.Chu, L.-C. Chen, B.Chen, M.Tan, W.Wang, Y.Zhu, R.Pang, V.Vasudevan et al., “Searching for mobilenetv3,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1314–1324.
- [8] M.Tan and Q.Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” in International conference on machine learning.PMLR, 2019, pp. 6105–6114.
- [9] Y.Liu, Y.Sun, B.Xue, M.Zhang, G.G. Yen, and K.C. Tan, “A survey on evolutionary neural architecture search,” IEEE transactions on neural networks and learning systems, 2021.
- [10] T.Stützle, “Local search algorithms for combinatorial problems: analysis, improvements, and new applications,” 1999.
- [11] L.Li and A.Talwalkar, “Random search and reproducibility for neural architecture search,” in Uncertainty in artificial intelligence.PMLR, 2020, pp. 367–377.
- [12] Z.Ying, D.Bourgeois, J.You, M.Zitnik, and J.Leskovec, “Gnnexplainer: Generating explanations for graph neural networks,” Advances in neural information processing systems, vol.32, 2019.
- [13] D.Luo, W.Cheng, D.Xu, W.Yu, B.Zong, H.Chen, and X.Zhang, “Parameterized explainer for graph neural network,” Advances in neural information processing systems, vol.33, pp. 19 620–19 631, 2020.
- [14] C.Shan, Y.Shen, Y.Zhang, X.Li, and D.Li, “Reinforcement learning enhanced explainer for graph neural networks,” Advances in Neural Information Processing Systems, vol.34, pp. 22 523–22 533, 2021.
- [15] Y.Yusoff, M.S. Ngadiman, and A.M. Zain, “Overview of nsga-ii for optimizing machining process parameters,” Procedia Engineering, vol.15, pp. 3978–3983, 2011.
- [16] K.He, X.Zhang, S.Ren, and J.Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [17] F.N. Iandola, S.Han, M.W. Moskewicz, K.Ashraf, W.J. Dally, and K.Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size,” arXiv preprint arXiv:1602.07360, 2016.
- [18] L.-C. Chen, Y.Zhu, G.Papandreou, F.Schroff, and H.Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in ECCV, 2018.
- [19] L.Waeijen, S.Sioutas, M.Peemen, M.Lindwer, and H.Corporaal, “Convfusion: A model for layer fusion in convolutional neural networks,” IEEE Access, vol.9, pp. 168 245–168 267, 2021.
- [20] T.Dao, D.Fu, S.Ermon, A.Rudra, and C.Ré, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” Advances in Neural Information Processing Systems, vol.35, pp. 16 344–16 359, 2022.
- [21] J.Hu, L.Shen, and G.Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141.
- [22] C.Morris, M.Ritzert, M.Fey, W.L. Hamilton, J.E. Lenssen, G.Rattan, and M.Grohe, “Weisfeiler and leman go neural: Higher-order graph neural networks,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol.33, 2019, pp. 4602–4609.
- [23] K.Simonyan and A.Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [24] J.Bai, F.Lu, K.Zhang et al., “Onnx: Open neural network exchange,” https://github.com/onnx/onnx, 2019.
- [25] Y.Li, Y.Shen, W.Zhang, Y.Chen, H.Jiang, M.Liu, J.Jiang, J.Gao, W.Wu, Z.Yang, C.Zhang, and B.Cui, “Openbox: A generalized black-box optimization service,” in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining.New York, NY, USA: Association for Computing Machinery, 2021, p. 3209–3219. [Online]. Available: https://doi.org/10.1145/3447548.3467061
Xet Storage Details
- Size:
- 77.8 kB
- Xet hash:
- 1ee24ccdc5b1f7f0f3e1b4110b3fcb168899fa1d21918c0e8ed55513d9f6cff2
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.