Buckets:

Title: Uni-LoRA: One Vector is All You Need
URL Source: https://arxiv.org/html/2506.00799
Published Time: Wed, 29 Oct 2025 00:59:04 GMT
Markdown Content: Kaiyang Li
School of Computing
University of Connecticut
Storrs, CT 06269
&Shaobo Han
Optical Networking and Sensing
NEC Labs America
Princeton, NJ 08540
&Qing Su
School of Computing
University of Connecticut
Storrs, CT 06269
Wei Li
Dept. of Computer Science
Georgia State University
Atlanta, GA 30303
&Zhipeng Cai
Dept. of Computer Science
Georgia State University
Atlanta, GA 30303
&Shihao Ji
School of Computing
University of Connecticut
Storrs, CT 06269
Abstract
Low-Rank Adaptation (LoRA) has become the de facto parameter-efficient fine-tuning (PEFT) method for large language models (LLMs) by constraining weight updates to low-rank matrices. Recent works such as Tied-LoRA, VeRA, and VB-LoRA push efficiency further by introducing additional constraints to reduce the trainable parameter space. In this paper, we show that the parameter space reduction strategies employed by these LoRA variants can be formulated within a unified framework, Uni-LoRA, where the LoRA parameter space, flattened as a high-dimensional vector space ℝ D\mathbb{R}^{D}, can be reconstructed through a projection from a subspace ℝ d\mathbb{R}^{d}, with d≪D d\ll D. We demonstrate that the fundamental difference among various LoRA methods lies in the choice of the projection matrix, P∈ℝ D×d P\in\mathbb{R}^{D\times d}. Most existing LoRA variants rely on layer-wise or structure-specific projections that limit cross-layer parameter sharing, thereby compromising parameter efficiency. In light of this, we introduce an efficient and theoretically grounded projection matrix that is isometric, enabling global parameter sharing and reducing computation overhead. Furthermore, under the unified view of Uni-LoRA, this design requires only a single trainable vector to reconstruct LoRA parameters for the entire LLM – making Uni-LoRA both a unified framework and a “one-vector-only” solution. Extensive experiments on GLUE, mathematical reasoning, and instruction tuning benchmarks demonstrate that Uni-LoRA achieves state-of-the-art parameter efficiency while outperforming or matching prior approaches in predictive performance. Our code is available at https://github.com/KaiyangLi1992/Uni-LoRA.
1 Introduction
Parameter-efficient fine-tuning (PEFT)(peft,) casts a new paradigm that leverages strong prior knowledge built in foundation models and adapts them to a wide range of downstream tasks by updating a small amount of trainable parameters. Among various PEFT methods, LoRA(hu2022lora,) has been particularly prevalent in recent studies. Given a pre-trained matrix W 0∈ℝ m×n W_{0}\in\mathbb{R}^{m\times n}, LoRA constrains the weight increment ΔW\Delta W as a low-rank decomposition ΔW=BA\Delta W=BA, where B∈ℝ m×r B\in\mathbb{R}^{m\times r} and A∈ℝ r×n A\in\mathbb{R}^{r\times n} are trainable parameters, with r≪min(m,n)r\ll\min(m,n). LoRA reduces the fine-tuning cost significantly, while achieving impressive predictive performance.
To further reduce the number of trainable parameters for fine-tuning, recent methods augmentrenduchintala-etal-2024-tied; kopiczko2024vera; bałazy2024loraxslowrankadaptationextremely or modifyli2024vblora the LoRA architecture and tighten the trainable parameter space of LoRA into a lower-dimensional subspace, in which the fine-tuning is performed. For example, Tied-LoRA(renduchintala-etal-2024-tied,) ties all the B B and A A matrices of different LoRA-adapted modules and optimizes one pair of B B and A A matrices and the diagonal entries of two diagonal matrices per LoRA module. VeRA(kopiczko2024vera,) further reduces the trainable parameter space by randomly initializing B B and A A and freezing them afterwards, leading to fine-tuning only two vectors per LoRA module. LoRA-XS(bałazy2024loraxslowrankadaptationextremely,) introduces an r×r r\times r matrix per LoRA module, where r r is the pre-defined LoRA rank, and fine-tunes a set of r×r r\times r matrices. VB-LoRA(li2024vblora,) decomposes the B B and A A matrices of LoRA into fixed-length sub-vectors, and learns a globally shared vector bank and the compositional coefficients for each sub-vector of B B s and A A s. Despite the similarities among different LoRA variants, there isn’t a unified framework of LoRA that can describe the aforementioned LoRA methods in a uniform language and enables a systematic analysis of all of them.
Inspired by the works of measuring the intrinsic dimension of objective landscapes(DBLP:conf/iclr/LiFLY18,; aghajanyan-etal-2021-intrinsic,), we view the parameter space of LoRA as a D D-dimensional space ℝ D\mathbb{R}^{D}, and each LoRA variant defines a d d-dimensional subspace ℝ d\mathbb{R}^{d}, and a projection matrix P∈ℝ D×d P\in\mathbb{R}^{D\times d} maps a trainable vector from the subspace ℝ d\mathbb{R}^{d} back to the full LoRA parameter space ℝ D\mathbb{R}^{D}. From the perspective of this unified view, we recognize that most existing LoRA variants (e.g., Tied-LoRA, VeRA, and LoRA-XS) project the parameters of each LoRA module into a separate and fixed-dimensional subspace. However, recent studies (e.g., AdaLoRA(zhang2023adaptive,) and LoRA-Drop(zhou-etal-2025-lora,)) have shown that the importance of LoRA modules varies across layers, suggesting that locally projecting the parameters of different LoRA modules into subspaces of the same dimensionality may be suboptimal. Moreover, our study reveals that the projection matrices P P used implicitly by Tied-LoRA, VeRA, and VB-LoRA do not possess the property of isometry(10.1145/356744.356750,) from the trainable parameter space to the original LoRA parameter space. In other words, those projections do not preserve the distance between parameter vectors in the original LoRA parameter space, distorting the geometry of the optimization landscape.
To address the aforementioned limitations, we propose Uni-LoRA, a unified framework of LoRA that treats the LoRA parameter space as a high-dimensional vector space and performs a global projection into a shared low-dimensional subspace. We further introduce an efficient and theoretically grounded projection matrix P∈ℝ D×d P\in\mathbb{R}^{D\times d}, in which each row is a one-hot vector with the index of "1" sampled uniformly from d d slots, followed by a column-wise normalization. As discussed in Sec. 3.3, this construction ensures that P P possesses three desirable properties for adaptation: globality, uniformity/load-balancing, and isometry. Conceptually, this corresponds to randomly partitioning all the D D parameters of LoRA into d d groups and enforce the parameters within each group to share the same value during the training process. We prove that the resulting projection matrix is isometric (or distance-preserving). Empirically, when fine-tuning the GEMMA-7B model, our Uni-LoRA achieves performance comparable to LoRA while training only 0.52M parameters – only 0.0061% of the base model size and 0.26% of the LoRA parameter size. Across multiple benchmarks, our method achieves extreme parameter efficiency, while outperforming or matching the state-of-the-art LoRA variants. Moreover, we show that our projection matrix attains the performance of the Fastfood projection(10.5555/3042817.3042964,). While Fastfood is a widely used structured projection method with a time complexity of 𝒪(Dlogd)\mathcal{O}(D\log d), our method achieves a significantly lower time complexity of 𝒪(D)\mathcal{O}(D). Our contributions are summarized as follows:
- •We propose a unified framework to analyze various LoRA variants, and show that many of them (e.g., Tied-LoRA, VeRA, LoRA-XS, and VB-LoRA) can be interpreted as projecting trainable parameters from the full LoRA parameter space into structured low-dimensional subspaces.
- •We propose a simple yet extremely effective projection matrix that randomly partitions the LoRA parameters into equally sized groups and enforces all the parameters in each group to share the same value. Despite its simplicity, our approach outperforms or matches the performance of state-of-the-art LoRA methods across a wide range of tasks, including natural language understanding, mathematical reasoning, and instruction tuning.
- •We further prove that our projection matrix is isometric and matches the performance of classical Fastfood projection in practice, while incurring significantly lower computational cost.
2 Related Work
Parameter-efficient LoRA Variants. Despite the success of Low-Rank Adaptation (LoRA)(hu2022lora,) in enabling parameter-efficient fine-tuning, several challenges remain – particularly when scaling to even larger models or deploying multiple adapters on resource-constrained mobile devices. Recent methods aim to further reduce the number of trainable parameters in LoRA by (1) selectively freezing a subset of the parameters(kopiczko2024vera,; bałazy2024loraxslowrankadaptationextremely,); (2) enforcing weight-tying across layers(renduchintala-etal-2024-tied,); (3) learning global parameter sharing through admixture reparameterization(li2024vblora,). Our Uni-LoRA provides a unified framework in which various parameter-reduction strategies are manifested as structural patterns in the projection matrix, thereby allowing the parameter redundancy in the LoRA parameter space to be studied and reduced through the lens of dimensionality reduction. Perhaps surprisingly, parameter sharing does not need to be layer-wise, structure-aware, or even learned. Our Uni-LoRA simplifies the fine-tuning with a random weight-sharing strategy, where only one parameter vector needs to be trained and stored, showcasing that one vector is all we need for LoRA.
Intrinsic Dimension. A growing line of work suggests that the effective degrees of freedom required to train machine learning models(DBLP:conf/iclr/LiFLY18,) and fine-tuning(aghajanyan-etal-2021-intrinsic,) lie in a significantly smaller subspace than the full parameter space. Zhang et al.(zhang-etal-2023-fine,) further demonstrate that the fine-tuning process tends to uncover task-specific intrinsic subspaces, and that disabling these subspaces severely harms generalization. Along this line, FourierFT(DBLP:conf/icml/GaoWCLWC024,) locally projects the layer-wise incremental parameter matrices (i.e., ΔW\Delta W) of pretrained models onto fixed Fourier bases, and shows that it suffices to only learn the corresponding combination coefficients.
Previous works(DBLP:conf/iclr/LiFLY18,; aghajanyan-etal-2021-intrinsic,) typically employ distance-preserving dense Gaussian matrices or structured transforms such as Fastfood to project the original parameter space into a lower-dimensional subspace. In Uni-LoRA, we propose a novel construction of the projection matrix that is distance-preserving (i.e., isometric) while significantly reducing computational cost compared to dense Gaussian or Fastfood-based methods.
3 Proposed Method
3.1 Preliminaries: LoRA and its Parameter-efficient Variants
LoRA.
LoRA(hu2022lora,) is a parameter-efficient fine-tuning technique for LLMs. Given a pre-trained weight matrix W 0∈ℝ m×n W_{0}\in\mathbb{R}^{m\times n}, LoRA constrains the weight increment ΔW\Delta W as a low-rank decomposition: ΔW=BA\Delta W=BA, where B∈ℝ m×r B\in\mathbb{R}^{m\times r} and A∈ℝ r×n A\in\mathbb{R}^{r\times n} are trainable, low-rank matrices with r≪min(m,n)r\ll\min(m,n), which significantly reduce the number of trainable parameters and improve fine-tuning efficiency.
Tied-LoRA / VeRA.
Tied-LoRArenduchintala-etal-2024-tied and VeRA(kopiczko2024vera,) augment the LoRA architecture with two extra diagonal matrices. Both methods constrain the weight increment as ΔW=Λ bP BΛ dP A\Delta W=\Lambda_{b}P_{B}\Lambda_{d}P_{A}, where P B∈ℝ m×r P_{B}\in\mathbb{R}^{m\times r} and P A∈ℝ r×n P_{A}\in\mathbb{R}^{r\times n} are shared/tied across all LoRA modules, and Λ b∈ℝ m×m\Lambda_{b}\in\mathbb{R}^{m\times m} and Λ d∈ℝ r×r\Lambda_{d}\in\mathbb{R}^{r\times r} (per LoRA module) are trainable diagonal matrices that can selectively enable or disable columns and rows of P B P_{B} and P A P_{A} by scaling, allowing effective, fine-grained adaptation with a minimal number of trainable parameters. The main difference between Tied-LoRA and VeRA is that while P B P_{B} and P A P_{A} are trainable in Tied-LoRA, they are randomly initialized and frozen in VeRA, leading to a higher parameter efficiency.
VB-LoRA.
VB-LoRAli2024vblora decomposes the B B and A A matrices of LoRA into fixed-length sub-vectors, and learns a globally shared vector bank and the compositional coefficients to generate each sub-vector of B B s and A A s. During fine-tuning, only the parameters in the vector bank and the compositional coefficients for each sub-vector are trained. Upon the completion of fine-tuning, only the vector bank and the indices and values of the top-K K (e.g., K=2 K=2) compositional coefficients are stored, leading to extremely small stored parameter size.

Figure 1: Overview of Uni-LoRA and the representations of various LoRA methods in the unified framework. For better visualization, we illustrate the framework with only two LoRA-adapted modules. More examples including LoRA-XS and FourierFT are provided in AppendixA.1.
3.2 Uni-LoRA: A Unified Framework of LoRA
Despite the differences among the aforementioned LoRA variants, all of them augment or modify the LoRA architecture and tighten the trainable parameter space of LoRA into a lower-dimensional subspace. In this paper, we show that all these parameter space reduction strategies can be formulated within a unified framework, which enables a systematic analysis of all these LoRA variants.
Inspired by the works on measuring the intrinsic dimension of objective landscapes(DBLP:conf/iclr/LiFLY18,; aghajanyan-etal-2021-intrinsic,), we view the parameter space of LoRA as a D D-dimensional space ℝ D\mathbb{R}^{D}, and each LoRA variant defines a d d-dimensional subspace ℝ d\mathbb{R}^{d}, and a projection matrix P∈ℝ D×d P\in\mathbb{R}^{D\times d} maps a trainable vector from the subspace ℝ d\mathbb{R}^{d} back to the full LoRA parameter space ℝ D\mathbb{R}^{D}. Specifically, for each LoRA-adapted module ℓ=1,⋯,L\ell=1,\cdots,L, we row-flatten the low-rank matrices B ℓ∈ℝ m×r B^{\ell}\in\mathbb{R}^{m\times r} and A ℓ∈ℝ r×n A^{\ell}\in\mathbb{R}^{r\times n}, and concatenate them to construct a full parameter vector of LoRA:
θ D=Concat(vec row(B 1),vec row(A 1),⋯,vec row(B L),vec row(A L)),~\theta_{D}=\text{Concat}\bigl(\text{vec}{\text{row}}(B^{1}),\text{vec}{\text{row}}(A^{1}),\cdots,\text{vec}{\text{row}}(B^{L}),\text{vec}{\text{row}}(A^{L})\bigr),(1)
where vec row(⋅)\text{vec}{\text{row}}(\cdot) denotes the row-wise flatten of a matrix into a column vector, and D=L(m+n)r D=L(m+n)r is the total number of LoRA parameters. Instead of optimizing directly in the LoRA parameter space, we propose to work in a lower-dimensional subspace with a parameter vector θ d∈ℝ d\theta{d}\in\mathbb{R}^{d}, which is projected to the original LoRA parameter space by a linear projection:
θ D=Pθ d,\theta_{D}=P\theta_{d},(2)
where P∈ℝ D×d P\in\mathbb{R}^{D\times d} is a projection matrix with d≪D d\ll D. In this formulation, θ d∈ℝ d\theta_{d}\in\mathbb{R}^{d} represents the trainable parameters, and P P can be trained along with θ d\theta_{d} or designed and frozen during the fine-tuning process. We show that this view unifies a broad class of parameter-efficient LoRA variants, including Tied-LoRA, VeRA, LoRA-XS, and VB-LoRA. Therefore, we call the formulation expressed by Eq.2 Uni-LoRA, a unified framework of LoRA. In light of this unified framework, we demonstrate that the fundamental difference among various LoRA methods lies in the choice of the projection matrix P P and whether P P is trained along with θ d\theta_{d} or not.
Figure1 illustrates the framework of Uni-LoRA and the representations of various LoRA methods, including LoRA, Tied-LoRA, VeRA, VB-LoRA, and Uni-LoRA (Fastfood) in this unified framework.
Uni-LoRA
As a specific instantiation of this unified framework, Uni-LoRA further introduces an efficient and theoretically grounded projection matrix P∈ℝ D×d P\in\mathbb{R}^{D\times d}, in which each row is a one-hot vector with the index of "1" sampled uniformly from d d slots, followed by a column-wise normalization such that the nonzero entries in column j j are set to 1/n j 1/\sqrt{n_{j}}, where n j n_{j} denotes the number of nonzero entries in that column. Once initialized in such a way, P P remains frozen and only the parameter vector θ d\theta_{d} is fine-tuned and projected back to the full LoRA parameter space θ D\theta_{D} by P P. Conceptually, this corresponds to randomly partitioning all the D D parameters of LoRA into d d groups, with parameters within each group constrained to share the same value during fine-tuning. Theorem1 shows that such designed projection matrix P P is isometric, which preserves the distance between parameter vectors in the original LoRA parameter space, without distorting the geometry of the optimization landscape.
Algorithm1 provides the PyTorch-like pseudocode for Uni-LoRA, which can be seamlessly integrated into the PyTorch framework. Given that the projection matrix P P is one-hot like matrix, P P isn’t explicitly constructed. Instead, only the indices and values of nonzero entries of this sparse matrix involve in the computation, leading to extremely efficient implementation.
LoRA
It is straightforward to represent LoRA in the framework of Uni-LoRA. As illustrated in Figure1(b), in this case, P P corresponds to a D×D D\times D identity matrix, and θ d\theta_{d} has the same dimensionality of the original LoRA parameter space, i.e., d=D d=D. Apparently, the identity matrix P P is isometric, but it doesn’t have the effect of reducing number of trainable parameters of LoRA.
Tied-LoRA / VeRA
As introduced in Section3.1, Tied-LoRArenduchintala-etal-2024-tied and VeRA(kopiczko2024vera,) represents the weight increment as ΔW=Λ bP BΛ dP A\Delta W=\Lambda_{b}P_{B}\Lambda_{d}P_{A}, where P B P_{B} and P A P_{A} are shared/tied across all the LoRA-adapted modules, and Λ b\Lambda_{b} and Λ d\Lambda_{d} are defined per LoRA module. Specifically, for each LoRA module ℓ=1,⋯,L\ell=1,\cdots,L, we extract the diagonal elements of Λ b ℓ∈ℝ m×m\Lambda_{b}^{\ell}\in\mathbb{R}^{m\times m} and Λ d ℓ∈ℝ r×r\Lambda_{d}^{\ell}\in\mathbb{R}^{r\times r}, and concatenate them to construct a trainable parameter vector:
θ d=Concat(diag(Λ b 1),diag(Λ d 1),⋯,diag(Λ b L),diag(Λ d L)),\theta_{d}=\operatorname{Concat}\left(\operatorname{diag}(\Lambda_{b}^{1}),\operatorname{diag}(\Lambda_{d}^{1}),\cdots,\operatorname{diag}(\Lambda_{b}^{L}),\operatorname{diag}(\Lambda_{d}^{L})\right),(3)
where diag(⋅)\text{diag}(\cdot) denotes the diagonal vector of a matrix, and d=L(m+r)d=L(m+r) is the number of trainable parameters of Tied-LoRA or VeRA. On the other hand, the full parameter vector of LoRA can be formulated as
θ D=Concat(vec row(B¯1),vec row(A¯1),⋯,vec row(B¯L),vec row(A¯L)),\theta_{D}=\text{Concat}\left(\text{vec}{\text{row}}(\bar{B}^{1}),\text{vec}{\text{row}}(\bar{A}^{1}),\cdots,\text{vec}{\text{row}}(\bar{B}^{L}),\text{vec}{\text{row}}(\bar{A}^{L})\right),(4)
where B¯ℓ=Λ b ℓP B\bar{B}^{\ell}=\Lambda_{b}^{\ell}P_{B} and A¯ℓ=Λ d ℓP A\bar{A}^{\ell}=\Lambda_{d}^{\ell}P_{A}, and they correspond to the LoRA parameters B ℓ B^{\ell} and A ℓ A^{\ell}.
As illustrated in Figure1(c), the projection matrix P P of Tied-LoRA and VeRA exhibits a structured sparse pattern, composed of block-diagonal components reshaped from P B P_{B} and P A P_{A} (details of which are relegated to AppendixA.1). Since P B P_{B} and P A P_{A} are shared/tied cross all the LoRA modules, the block-diagonal components are repeated L L times in P P. The main difference between Tied-LoRA and VeRA is the trainability of P B P_{B} and P A P_{A}, i.e., the projection matrix P P is trainable in Tied-LoRA and frozen in VeRA. This is indicated by two different colors in the diagram.
It is worth noting that the projection matrix P P in Tied-LoRA and VeRA is structured to have non-zero entries only in diagonal blocks, suggesting that the projection is local in nature. Also, the rows of the LoRA matrices B¯ℓ∈ℝ m×r\bar{B}^{\ell}\in\mathbb{R}^{m\times r} and A¯ℓ∈ℝ r×n\bar{A}^{\ell}\in\mathbb{R}^{r\times n} are projected to two separate lower-dimensional subspaces with the non-uniform dimensionalities (m m vs. r r). Moreover, this projection matrix is not isometry, indicating that it may distort the geometric structure of the original parameter space. Collectively, the locality, non-uniformity, and non-isometric nature of this projection may constrain adaptation flexibility and limit representational expressiveness.
Uni-LoRA (Fastfood)
This is a variant of Uni-LoRA, in which the project matrix P P is initialized with the classical structured Fastfood projection10.5555/3042817.3042964, which is isometric. Fastfood approximates dense Gaussian projections with structured transforms and reduces the time complexity of a naïve implementation from 𝒪(Dd)\mathcal{O}(Dd) to 𝒪(Dlogd)\mathcal{O}(D\log d). As to be discussed in Section3.4, Uni-LoRA with our uniform random projection achieves a significantly lower time complexity of 𝒪(D)\mathcal{O}(D).
Similarly, VB-LoRA, LoRA-XS, and FourierFT can be represented as specific instantiations in our unified framework. Due to the page limits, the details are relegated to AppendixA.1.
3.3 Analysis of the Projection Matrix
Our discussion in Section3.2 reveals that the key distinctions among various LoRA methods lie in the choice of the projection matrix P P and whether P P is trained along with θ d\theta_{d} or not. We argue that a well-structured P P should have the following three properties, i.e., globality, uniformity/load-balanced, and isometry, which can substantially enhance adaptation performance.
- •Globality: Global parameter sharing across different types of matrices and layers breaks the physical barrier and enables maximal reduction of parameter redundancy.
- •Uniformity / Load-Balanced: Each subspace dimension is mapped to roughly equal number of dimensions of the original full parameter space, such that the information is evenly distributed to all subspace dimensions and load-balanced.
- •Isometry: The projection preserves the distance between parameter vectors in the original full parameter space, without distorting the geometric structure of the optimization landscape.
According to the properties above, we characterize the projection matrices employed by various LoRA variants in Table1. Theorem1 proves that the uniform random projection introduced by our Uni-LoRA is isometric.
Table 1: Properties of the projection matrices P P employed by various LoRA methods, where "Learnable Projection" refers to besides θ d\theta_{d} whether P P itself contains trainable parameters.
Theorem 1.
Let P∈ℝ D×d P\in\mathbb{R}^{D\times d} be a projection matrix where each row selects exactly one entry uniformly at random to be nonzero, and sets all other entries to zero. Let n j n_{j} denote the number of nonzero entries in column j j, and n j>0 n_{j}>0 1 1 1 To ensure the condition n j>0 n_{j}>0 is always held, we can re-sample P P if one column happens to be all zeros.. For column-wise normalization, each nonzero entry in column j j is set to 1/n j 1/\sqrt{n_{j}}. As a projection matrix, P P is isometric. Formally, ‖P(x−y)‖=‖x−y‖,∀x,y∈ℝ d|P(x-y)|=|x-y|,\forall x,y\in\mathbb{R}^{d}.
Proof.
Given the construction of P P in the theorem statement, we begin by showing that P⊤P=I d P^{\top}P=I_{d}. Consider the (j,k)(j,k)-th entry of P⊤P P^{\top}P: [P⊤P]j,k=∑i=1 D P i,jP i,k.[P^{\top}P]{j,k}=\sum{i=1}^{D}P_{i,j}P_{i,k}.Case 1: j≠k j\neq k. Since each row contains only one nonzero entry, there exists no row i i such that both P i,j P_{i,j} and P i,k P_{i,k} are nonzero. Hence, every term in the summation is zero, and we have [P⊤P]j,k=0[P^{\top}P]{j,k}=0. Case 2: j=k j=k. Column j j contains n j n{j} nonzero entries, each of value 1/n j 1/\sqrt{n_{j}}. Thus, [P⊤P]j,j=∑i=1 D P i,j 2=n j⋅(1/n j)2=1[P^{\top}P]{j,j}=\sum{i=1}^{D}P_{i,j}^{2}=n_{j}\cdot\left({1}/{\sqrt{n_{j}}}\right)^{2}=1. From the analysis above, we have [P⊤P]j,k=1[P^{\top}P]{j,k}=1, if j=k j=k and 0 otherwise, thus P⊤P=I d P^{\top}P=I{d}. Therefore,
‖P(x−y)‖2=(x−y)⊤P⊤P(x−y)=(x−y)⊤(x−y)=‖x−y‖2,∀x,y∈ℝ d|P(x-y)|^{2}\ =(x-y)^{\top}P^{\top}P(x-y)=(x-y)^{\top}(x-y)=|x-y|^{2},\forall x,y\in\mathbb{R}^{d}
This completes the proof. ∎
Why existing LoRA variants may be suboptimal?
In light of our unified framework, Figure1 reveals that the projections used by Tied-LoRA, VeRA, and LoRA-XS (except VB-LoRA) are all local with layer-wise projection; furthermore, Tied-LoRA and VeRA are inherently non-uniform. Specifically, although the B B and A A matrices of LoRA contain the same number of parameters, Tied-LoRA and VeRA ties the parameters of B B with more parameters in the lower-dimensional subspace than A A (i.e., m m vs. r r). Intuitively, such a non-uniform projection may be suboptimal as information of the full LoRA parameter space is non-uniformly distributed to lower-dimensional subspace. In Section4.5, we conduct a controlled experiment comparing uniform and non-uniform projections, and the results confirm that the uniform project consistently outperforms its non-uniform counterpart.
Why Isometry is important?
Prior works(cai2007isometric,; pai2019dimal,) show that if the projection matrix is isometric (which satisfies ‖P(x−y)‖=‖x−y‖|P(x-y)|=|x-y| for any pair of vectors x,y x,y), the geometry of the original space is preserved in the projected subspace. This property ensures that the optimization landscape remains faithful to the original parameter space, making it particularly well-suited for subspace training for neural networks.
3.4 Complexity Analysis
Storage Complexity. Since the projection matrix P P of Uni-LoRA is generated from a random seed, upon the completion of training, only the random seed and the learned subspace vector θ d∈ℝ d\theta_{d}\in\mathbb{R}^{d} need to be stored or transmitted. As a result, the total number of stored data is only d+1 d+1, leading to an extremely compact model representation and showcasing that one vector is all we need for LoRA.
Time and Space Complexity of Projection. The projection matrix P P of Uni-LoRA is a sparse matrix with exactly D D nonzero entries. As a result, the projection operation Pθ d P\theta_{d} has both time and space complexity of 𝒪(D)\mathcal{O}(D). In contrast, the classical distance-preserving methods such as dense Gaussian projections require 𝒪(Dd)\mathcal{O}(Dd) time and space, while the Fastfood transform10.5555/3042817.3042964 has a time complexity of 𝒪(Dlogd)\mathcal{O}(D\log d) and a space complexity of 𝒪(D)\mathcal{O}(D).
To summarize, our Uni-LoRA not only provides a unified framework of LoRA but also introduces an efficient and theoretically grounded projection, which enjoys all three desired properties that we discussed above. This approach requires no architectural modifications, no sparsity priors, and achieves a significantly lower time complexity than the classical Fastfood transform.
Algorithm 1 Pseudocode of Uni-LoRA in a PyTorch-like Style
class Uni-LoRA:
def init (self,in_dim,out_dim,r,theta_d):
d=len(theta_d)
self.index_A=torch.randint(0,d,(in_dim,r),dtype=torch.long)
self.index_B=torch.randint(0,d,(r,out_dim),dtype=torch.long)
self.theta_d=theta_d
def update_norm_factor(self,norm_factor_A,norm_factor_B):
self.norm_factor_A=norm_factor_A
self.norm_factor_B=norm_factor_B
def forward(self,W,x):
A=self.theta_d[self.index_A]*self.norm_factor_A
B=self.theta_d[self.index_B]*self.norm_factor_B
return x@W+(x@A)@B
4 Experiments
In this section, we evaluate our method through a series of experiments. We begin by comparing Uni-LoRA to the state-of-the-art PEFT methods: LoRA, Tied-LoRA, VeRA, LoRA-XS, and FourierFT on the GLUE benchmark. Next, we extend our analysis to mathematical reasoning tasks on Mistral and Gemma models, as well as instruction tuning tasks on Llama2. All our experiments are conducted on a server equipped with 8 NVIDIA A100 80GB GPUs. For reproducibility, we provide detailed hyperparameters and specifications of computing resources for each experiment in AppendixA.2.
4.1 Natural Language Understanding
We adopt the General Language Understanding Evaluation (GLUE) benchmark(wang-etal-2018-glue,) to assess the performance of Uni-LoRA across various natural language understanding tasks. Following(kopiczko2024vera,; li2024vblora,), we focus on six tasks from GLUE: SST-2(socher-etal-2013-recursive,) (sentiment analysis), MRPC(dolan-brockett-2005-automatically,) (paraphrase detection), CoLA(warstadt-etal-2019-neural,) (linguistic acceptability), QNLI(rajpurkar-etal-2018-know,) (inference), RTE(10.1007/11736790_9,) (inference) and STS-B(cer-etal-2017-semeval,) (semantic textual similarity). Our experiments use RoBERTa base and RoBERTa large(liu2019roberta,) as the backbone models. We apply LoRA with rank 4 to the query and value matrices in each Transformer layer, and project the resulting LoRA parameter space into a subspace of dimension d=23,040 d=23,040, matching the subspace size used by the best-performing VB-LoRA baseline(li2024vblora,).
Table 2: Results with RoBERTa base and RoBERTa large on the GLUE benchmark. The best results in each group are shown in bold, while the second-best results are denoted with underlining. We report Matthew’s correlation for CoLA, Pearson correlation for STS-B, and Accuracy for all other tasks. We report the median performance over 5 runs with different random seeds.
1 1 footnotetext: †The original VB-LoRA paper reports the number of stored parameters rather than trainable ones: 0.23M for RoBERTa base, 0.24M for RoBERTa large, 0.65M for Mistral-7B, 0.67M for Gemma-7B, 0.8M for Llama2-7B, and 1.1M for Llama2-13B. For consistency, we report the number of trainable parameters throughout all tables, following the convention used in other baselines.
Table2 reports the results across 12 cases spanning 6 GLUE tasks and 2 model scales. Uni-LoRA ranks either first or second in 11 out of the 12 cases, with the only exception being on the RTE task of RoBERTa large, where the dataset is small and the performance variance is relatively high. As we can see, Uni-LoRA consistently outperforms Tied-LoRA, VeRA, LoRA-XS, and FourierFT while requiring fewer trainable parameters. For example, when fine-tuning RoBERTa large, our method reduces the number of trainable parameters to less than 40% of that required by Tied-LoRA or VeRA, while achieving better performance across all tasks. Moreover, Uni-LoRA achieves performance comparable to VB-LoRA while using significantly fewer trainable parameters, suggesting that our fixed projection matrix is as effective as the learned projection in VB-LoRA. Furthermore, since our projection matrix is not learned, Uni-LoRA incurs substantially lower computational overhead than VB-LoRA (See Tables9,10,12 in the appendix for details).
4.2 Mathematical Reasoning
To evaluate mathematical reasoning capabilities, we fine-tune the Mistral-7B-v0.1(jiang2023mistral7b,) and Gemma-7B(gemmateam2024gemmaopenmodelsbased,) models on the MetaMathQA(yu2023metamath,) dataset and test them on GSM8K(cobbe2021gsm8k,) and MATH(hendrycksmath2021,). We compare our results with the state-of-the-art methods, following their experimental configurations. Table4 shows that Uni-LoRA achieves strong and consistent performance across both Mistral-7B and Gemma-7B backbones. On the MATH benchmark, it reaches 18.18 with Mistral-7B and 28.94 with Gemma-7B, outperforming LoRA-XS, VB-LoRA and FourierFT. It also yields higher accuracy than LoRA-XS on both GSM8K and MATH, while using less than 70% of its trainable parameters. Compared to VB-LoRA, Uni-LoRA achieves similar or better performance with substantially fewer parameters. It also demonstrates comparable accuracy to VeRA on mathematical reasoning tasks, while requiring only half as many trainable parameters on Mistral-7B and less than one-third on Gemma-7B. Furthermore, Uni-LoRA consistently outperforms FourierFT on both tasks, while being more parameter-efficient.
Table 3: Results with the Mistral-7B and Gemma-7B models on the GSM8K and MATH Benchmarks. The best results in each group are shown in bold. Baselines’ results are either reproduced using their reported configurations or directly sourced from their original papers.
Model Method# Parameters GSM8K MATH Mistral-7B Full-FT 7242M 67.02 18.60 LoRA 168M 67.70 19.68 LoRA-XS 0.92M 68.01 17.86 VB-LoRA 93M†69.22 17.90 VeRA 1.39M 68.69 18.81 FourierFT 0.67M 68.92 17.50 Uni-LoRA (Ours)0.52M 68.54 18.18 Gemma-7B Full-FT 8538M 71.34 22.74 LoRA 200M 74.90 31.28 LoRA-XS 0.80M 74.22 27.62 VB-LoRA 113M†74.86 28.90 VeRA 1.90M 74.98 28.84 FourierFT 0.59M 72.97 25.14 Uni-LoRA (Ours)0.52M 75.59 28.94
Table 4: Score 1 and Score 2 denote evaluations on MT-Bench single-turn and multi-turn dialogues. LoRA∗ and VeRA were scored using an older GPT-4 API. LoRA# and other methods were evaluated using the updated version. The two sets of results are reported separately for fairness.
4.3 Instruction Tuning
Instruction tuning refers to the process of fine-tuning a model on a set of instructions or prompts to improve its ability to follow task-specific directives(ouyang2022training,). We perform instruction tuning on the Llama 2(touvron2023Llama,) model using the Cleaned Alpaca dataset(alpaca,), which improves the quality of the original Alpaca dataset. Following(kopiczko2024vera,; li2024vblora,), we fine-tune the Llama 2 model(touvron2023Llama,) within the QLoRA framework(Tim-2023-qlora,), which enables low-memory fine-tuning of LLMs on a single GPU. The fine-tuned models generate responses to MT-Bench questions, which are then scored by GPT-4 on a 10-point scale. We apply Uni-LoRA to project the rank-4 LoRA weights into a 0.5M-dimensional subspace for Llama2-7B and a 1M-dimensional subspace for Llama2-13B.
Table4 reports the results. Due to a noticeable discrepancy between the reported scores, we include two sets of LoRA results for each experiment: one from Kopiczko et al.(kopiczko2024vera,) and another from our own reimplementation. Although we closely follow the experimental settings of Kopiczko et al.(kopiczko2024vera,), we speculate that the difference may be attributed to changes in the GPT-4 model over time. Nevertheless, comparing the relative performance of VeRA and Uni-LoRA with respect to their corresponding LoRA baselines remains meaningful. As we can see, Uni-LoRA achieves performance comparable to LoRA while using only 0.3% (Llama2-7B) and 0.4% (Llama2-13B) of the LoRA parameters. Similarly, VeRA also demonstrates comparable performance relative to its own LoRA baseline, but it requires more than twice the number of trainable parameters compared to Uni-LoRA. Furthermore, Uni-LoRA consistently outperforms VB-LoRA across both evaluation metrics on Llama2-7B and Llama2-13B, while using significantly fewer trainable parameters of VB-LoRA and slightly fewer stored parameters.
4.4 Experiments of Computer Vision Tasks
To further assess the effectiveness of Uni-LoRA on more complex vision tasks, we follow the experimental setup in FourierFT(DBLP:conf/icml/GaoWCLWC024,) and conduct additional evaluations. Specifically, we apply Uni-LoRA with d=74,000 d=74{,}000 on ViT-Base and d=144,000 d=144{,}000 on ViT-Large, using a fixed rank r=4 r=4. A grid search is conducted over the head learning rate in {1×10−3, 2×10−3, 5×10−3, 1×10−2}{1!\times!{10^{-3}},\ 2!\times!10^{-3},\ 5!\times!10^{-3},\ 1!\times!10^{-2}} and the trainable vector learning rate in {2×10−3, 5×10−3, 1×10−2, 2×10−2, 5×10−2}{2!\times!10^{-3},\ 5!\times!10^{-3},\ 1!\times!10^{-2},\ 2!\times!10^{-2},\ 5!\times!10^{-2}}. The number of training epochs is fixed at 20. All experiments are repeated five times, with the mean and standard deviation across the runs reported in Table LABEL:tab:uni_lora_cv.
Table 5: Comparison of Uni-LoRA and baseline methods on eight computer vision datasets using ViT-Base and ViT-Large backbones. All baseline results, including Full Fine-tuning (FF) and Linear Probing (LP), are taken from the original FourierFT paperDBLP:conf/icml/GaoWCLWC024. In LP, only the classification head is fine-tuned.
Model Method# Trainable OxfordPets StanfordCars CIFAR10 DTD EuroSAT FGVC RESISC45 CIFAR100 Avg. Para. ViT-Base LP-90.28±\pm 0.43 25.76±\pm 0.28 96.41±\pm 0.02 69.77±\pm 0.67 88.72±\pm 0.13 17.44±\pm 0.43 74.22±\pm 0.10 84.28±\pm 0.11 68.36 FF 85.8M 93.14±\pm 0.40 79.78±\pm 1.15 98.92±\pm 0.05 77.68±\pm 1.21 99.05±\pm 0.09 54.84±\pm 1.23 96.13±\pm 0.13 92.38±\pm 0.13 86.49 FourierFT 72K 93.21±\pm 0.26 46.11±\pm 0.24 98.58±\pm 0.07 75.09±\pm 0.37 98.29±\pm 0.04 27.51±\pm 0.64 91.97±\pm 0.31 91.20±\pm 0.14 77.75 FourierFT 239K 93.05±\pm 0.34 56.36±\pm 0.66 98.69±\pm 0.06 77.30±\pm 0.61 98.78±\pm 0.11 32.44±\pm 0.99 94.26±\pm 0.20 91.45±\pm 0.18 80.29 Uni-LoRA 72K 94.00±\pm 0.13 76.06±\pm 0.23 98.77±\pm 0.03 76.99±\pm 0.96 98.86±\pm 0.10 50.36±\pm 0.63 94.08±\pm 0.19 92.10±\pm 0.25 85.15 ViT-Large LP-91.11±\pm 0.30 37.91±\pm 0.27 97.78±\pm 0.04 73.33±\pm 0.26 92.64±\pm 0.08 24.62±\pm 0.24 82.02±\pm 0.11 84.28±\pm 0.11 72.96 FF 303.3M 94.43±\pm 0.56 88.90±\pm 0.26 99.15±\pm 0.04 81.79±\pm 1.01 99.04±\pm 0.08 68.25±\pm 1.63 96.43±\pm 0.07 93.58±\pm 0.19 90.20 FourierFT 144K 94.46±\pm 0.28 69.56±\pm 0.30 99.10±\pm 0.04 80.83±\pm 0.43 98.65±\pm 0.09 39.92±\pm 0.68 93.86±\pm 0.14 93.31±\pm 0.09 83.71 FourierFT 480K 94.84±\pm 0.05 79.14±\pm 0.67 99.08±\pm 0.05 81.88±\pm 0.50 98.66±\pm 0.03 51.28±\pm 0.66 95.20±\pm 0.07 93.37±\pm 0.11 86.68 Uni-LoRA 144K 94.65±\pm 0.23 83.16±\pm 0.62 98.77±\pm 0.03 81.35±\pm 0.48 98.89±\pm 0.07 58.89±\pm 0.62 95.24±\pm 0.12 93.08±\pm 0.11 88.00
Experiments show that Uni-LoRA consistently outperforms FourierFT across computer vision benchmarks. Remarkably, even when FourierFT uses three times as many trainable parameters, Uni-LoRA still achieves better performance. Furthermore, when the number of trainable parameters in Uni-LoRA is less than one-thousandth of that in full fine-tuning, the performance gap between Uni-LoRA and full fine-tuning remains within 2.5%. These results highlight the strong efficiency and generalizability of Uni-LoRA in complex computer vision tasks.
4.5 Ablation Study
Comparison with Fastfood-based Projections.
Fastfood(10.5555/3042817.3042964,) is a classical projection method known for its low computational and memory cost and distance-preserving properties. To evaluate the effectiveness of our projection method, we compare it against Uni-LoRA (Fastfood) on four GLUE tasks in terms of both predictive performance and runtime efficiency. Table7 shows that Uni-LoRA with the uniform random projection consistently outperforms Uni-LoRA (Fastfood) in terms of predictive performance across four GLUE tasks, while being significantly faster. For example, on MRPC, it achieves a slightly higher score (91.3 vs. 90.7) with a 65% reduction in training time (9 vs. 26 mins). This efficiency stems from the linear time complexity 𝒪(D)\mathcal{O}(D) of our projection, compared to Fastfood’s 𝒪(Dlogd)\mathcal{O}(D\log d).
Table 6: Comparison of Uni-LoRA and Fastfood on four GLUE tasks in predictive performance and training time (mins). We report Matthew’s Correlation for COLA and Accuracy for others. Both methods underwent grid search over the same learning rate range, and all other hyperparameters were kept identical across experiments.
Table 7: Ablation study of Uni-LoRA with local projection and non-uniform projection on four GLUE tasks in predictive performance. For COLA, we report Matthew’s correlation and Accuracy for others. All methods were tuned using grid search over the same learning rate range, with all other hyperparameters kept identical across experiments. We report the median performance over 5 runs with different random seeds.
Comparison with Layer-wise Projections.
To investigate the impact of global vs. layer-wise (local) projections to our method, we construct a controlled variant as follows. On the RoBERTa-large model, we project the parameters of each layer into its own trainable subspace, with each local projection matrix constructed in the same way as that of Uni-LoRA’s. To ensure a fair comparison, we set the per-layer subspace dimensionality such that the total number of trainable space dimensionality matches that of Uni-LoRA’s. Table7 shows that local projection performs worse than global projection on MRPC, SST-2, and QNLI, while both methods achieve comparable performance on CoLA.
Comparison with Non-uniform Projections.
To investigate the impact of uniform vs. non-uniform projections to our method, we construct a controlled variant in which two separate projection matrices are used: one projects all LoRA A A matrices into the first two-thirds of the subspace dimensions, and the other projects all B B matrices into the remaining one-third. Both projection matrices are constructed using the same method as that of Uni-LoRA’s. Table7 shows that the uniform projection consistently outperforms the non-uniform projection across all the tasks.
5 Conclusion
This paper introduces Uni-LoRA, a unified framework of LoRA that reinterprets a broad class of parameter-efficient LoRA variants through the lens of global subspace projection. In light of this unified view, Uni-LoRA further introduces an efficient and theoretically grounded projection matrix, which enjoys all three desired properties of globality, uniformity, and isometry for adaptation performance. Uni-LoRA requires no architectural modifications, no sparsity priors, and achieves a significantly lower time complexity. Our results show that even within the LoRA space, which is already low-rank, there exists an additional low-dimensional parameterization that has several orders of magnitude fewer trainable parameters than LoRA.
Limitations and broader impacts As an extreme parameter-efficient fine-tuning method, Uni-LoRA doesn’t possess any significant limitations other than it is currently only evaluated on small to medium scale NLP/CV benchmarks due to limited computing resources. As for its broader impacts, Uni-LoRA enables high-quality adaptation of LLMs with minimal computational resources, contributing to the democratization of model customization. We do not foresee any societal risks beyond those generally associated with the use of LLMs.
Acknowledgments
We would like to thank the anonymous reviewers for their excellent comments and suggestions, which greatly helped improve the quality of this paper. This work was supported in part by the National Science Foundation under Grant Nos. 2343619, 2416872, 2244219, 2315596, and 2146497.
References
- [1] Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. PEFT: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
- [2] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022.
- [3] Adithya Renduchintala, Tugrul Konuk, and Oleksii Kuchaiev. Tied-LoRA: Enhancing parameter efficiency of LoRA with weight tying. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8694–8705, Mexico City, Mexico, June 2024. Association for Computational Linguistics.
- [4] Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki M Asano. VeRA: Vector-based random matrix adaptation. In The Twelfth International Conference on Learning Representations, 2024.
- [5] Klaudia Bałazy, Mohammadreza Banaei, Karl Aberer, and Jacek Tabor. LoRA-XS: Low-rank adaptation with extremely small number of parameters, 2024.
- [6] Yang Li, Shaobo Han, and Shihao Ji. VB-LoRA: Extreme parameter efficient fine-tuning with vector banks. In The 38th Conference on Neural Information Processing Systems (NeurIPS), 2024.
- [7] Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. In ICLR (Poster), 2018.
- [8] Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319–7328, Online, August 2021. Association for Computational Linguistics.
- [9] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter-efficient fine-tuning. In The Eleventh International Conference on Learning Representations, 2023.
- [10] Hongyun Zhou, Xiangyu Lu, Wang Xu, Conghui Zhu, Tiejun Zhao, and Muyun Yang. LoRA-drop: Efficient LoRA parameter pruning based on output evaluation. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors, Proceedings of the 31st International Conference on Computational Linguistics, pages 5530–5543, Abu Dhabi, UAE, January 2025. Association for Computational Linguistics.
- [11] Ingrid Carlbom and Joseph Paciorek. Planar geometric projections and viewing transformations. ACM Comput. Surv., 10(4):465–502, December 1978.
- [12] Quoc Le, Tamás Sarlós, and Alex Smola. Fastfood: approximating kernel expansions in loglinear time. In Proceedings of the 30th International Conference on International Conference on Machine Learning - Volume 28, ICML’13, page III–244–III–252. JMLR.org, 2013.
- [13] Zhong Zhang, Bang Liu, and Junming Shao. Fine-tuning happens in tiny subspaces: Exploring intrinsic task-specific subspaces of pre-trained language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1701–1713, Toronto, Canada, July 2023. Association for Computational Linguistics.
- [14] Ziqi Gao, Qichao Wang, Aochuan Chen, Zijing Liu, Bingzhe Wu, Liang Chen, and Jia Li. Parameter-efficient fine-tuning with discrete fourier transform. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024.
- [15] Deng Cai, Xiaofei He, Jiawei Han, et al. Isometric projection. In AAAI, pages 528–533, 2007.
- [16] Gautam Pai, Ronen Talmon, Alex Bronstein, and Ron Kimmel. Dimal: Deep isometric manifold learning using sparse geodesic sampling. In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 819–828. IEEE, 2019.
- [17] Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Tal Linzen, Grzegorz Chrupała, and Afra Alishahi, editors, Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium, November 2018.
- [18] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and Steven Bethard, editors, Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA, October 2013.
- [19] William B. Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005), 2005.
- [20] Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. Neural network acceptability judgments. Transactions of the Association for Computational Linguistics, 7:625–641, 2019.
- [21] Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for SQuAD. In Iryna Gurevych and Yusuke Miyao, editors, Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789, Melbourne, Australia, July 2018.
- [22] Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Proceedings of the First International Conference on Machine Learning Challenges: Evaluating Predictive Uncertainty Visual Object Classification, and Recognizing Textual Entailment, MLCW’05, page 177–190, Berlin, Heidelberg, 2005. Springer-Verlag.
- [23] Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Steven Bethard, Marine Carpuat, Marianna Apidianaki, Saif M. Mohammad, Daniel Cer, and David Jurgens, editors, Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 1–14, Vancouver, Canada, August 2017.
- [24] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [25] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023.
- [26] Thomas Mesnard et al. Gemma: Open models based on gemini research and technology, 2024.
- [27] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284, 2023.
- [28] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [29] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021.
- [30] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [31] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [32] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford Alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [33] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. In A.Oh, T.Naumann, A.Globerson, K.Saenko, M.Hardt, and S.Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 10088–10115, 2023.
Appendix A Appendix
A.1 Representations of additional LoRA/PEFT methods in the unified framework
Tied-LoRA/VeRA
As introduced in Section3.1, Tied-LoRA[3] and VeRA[4] represents the weight increment as ΔW=Λ bP BΛ dP A\Delta W=\Lambda_{b}P_{B}\Lambda_{d}P_{A}, where P B P_{B} and P A P_{A} are tied/shared across all the LoRA-adapted modules, and Λ b\Lambda_{b} and Λ d\Lambda_{d} are defined per LoRA module. Specifically, for each LoRA module ℓ=1,⋯,L\ell=1,\cdots,L, we extract the diagonal elements of Λ b ℓ∈ℝ m×m\Lambda_{b}^{\ell}\in\mathbb{R}^{m\times m} and Λ d ℓ∈ℝ r×r\Lambda_{d}^{\ell}\in\mathbb{R}^{r\times r}, and concatenate them to construct a trainable parameter vector:
θ d=Concat(diag(Λ b 1),diag(Λ d 1),⋯,diag(Λ b L),diag(Λ d L)),\theta_{d}=\operatorname{Concat}\left(\operatorname{diag}(\Lambda_{b}^{1}),\operatorname{diag}(\Lambda_{d}^{1}),\cdots,\operatorname{diag}(\Lambda_{b}^{L}),\operatorname{diag}(\Lambda_{d}^{L})\right),(5)
where diag(⋅)\text{diag}(\cdot) denotes the diagonal vector of a matrix, and d=L(m+r)d=L(m+r) is the number of trainable parameters of Tied-LoRA or VeRA. On the other hand, the full parameter vector of LoRA can be formulated as
θ D=Concat(vec row(B¯1),vec row(A¯1),⋯,vec row(B¯L),vec row(A¯L)),\theta_{D}=\text{Concat}\left(\text{vec}{\text{row}}(\bar{B}^{1}),\text{vec}{\text{row}}(\bar{A}^{1}),\cdots,\text{vec}{\text{row}}(\bar{B}^{L}),\text{vec}{\text{row}}(\bar{A}^{L})\right),(6)
where B¯ℓ=Λ b ℓP B\bar{B}^{\ell}=\Lambda_{b}^{\ell}P_{B} and A¯ℓ=Λ d ℓP A\bar{A}^{\ell}=\Lambda_{d}^{\ell}P_{A} correspond to the LoRA parameters B ℓ B^{\ell} and A ℓ A^{\ell}, respectively, and vec row(⋅)\operatorname{vec}_{\text{row}}(\cdot) denotes the row-wise flatten of a matrix into a column vector.
As illustrated in Figure2(a), the projection matrix P P of Tied-LoRA and VeRA exhibits a structured sparse pattern, composed of block-diagonal components reshaped from P B P_{B} and P A P_{A}. Specifically,
P=Diag({(P B)i,:T}i=1 m,{(P A)j,:T}j=1 r,⋯,{(P B)i,:T}i=1 m,{(P A)j,:T}j=1 r),P=\operatorname{Diag}\left(\left{(P_{B}){i,:}^{T}\right}{i=1}^{m},\left{(P_{A}){j,:}^{T}\right}{j=1}^{r},\cdots,\left{(P_{B}){i,:}^{T}\right}{i=1}^{m},\left{(P_{A}){j,:}^{T}\right}{j=1}^{r}\right),(7)
where (⋅)i,:T(\cdot){i,:}^{T} denotes the transpose of the i i-th row of a matrix, and Diag(v 1,v 2,⋯,v L(m+r))\operatorname{Diag}(v{1},v_{2},\cdots,v_{L(m+r)}) constructs a block diagonal matrix from L(m+r)L(m+r) column vectors. Since P B P_{B} and P A P_{A} are tied/shared cross all the LoRA modules, the block-diagonal components are repeated L L times in P P. Moreover, the main difference between Tied-LoRA and VeRA is the trainability of P B P_{B} and P A P_{A}, i.e., the projection matrix P P is trainable in Tied-LoRA and frozen in VeRA. This is indicated by two different colors in the diagram.

Figure 2: Representations of additional LoRA/PEFT methods in our unified framework. For better visualization, we illustrate the framework with only two LoRA-adapted modules.
VB-LoRA
decomposes the B∈ℝ m×r B\in\mathbb{R}^{m\times r} and A∈ℝ r×n A\in\mathbb{R}^{r\times n} matrices of LoRA into fixed-length sub-vectors as follows:
vec row(B ℓ)=Concat(u 1 ℓ,⋯,u N B ℓ),vec row(A ℓ)=Concat(v 1 ℓ,⋯,v N A ℓ),∀ℓ∈{1,⋯,L},\mathrm{vec}{\text{row}}(B^{\ell})=\text{Concat}(u{1}^{\ell},\cdots,u_{N_{B}}^{\ell}),\mathrm{vec}{\text{row}}(A^{\ell})=\text{Concat}(v{1}^{\ell},\cdots,v_{N_{A}}^{\ell}),\forall\ell\in{1,\cdots,L},(8)
where u i,v j∈ℝ b u_{i},v_{j}\in\mathbb{R}^{b} are sub-vectors of length b b, and N B ℓ=mr b N_{B}^{\ell}=\frac{mr}{b} and N A ℓ=rn b N_{A}^{\ell}=\frac{rn}{b} represent the numbers of sub-vectors decomposed from B ℓ B^{\ell} and A ℓ A^{\ell}, respectively.
VB-LoRA learns a shared vector bank ℬ={α 1,⋯,α h}\mathcal{B}={\alpha_{1},\cdots,\alpha_{h}}, with α i∈ℝ b\alpha_{i}\in\mathbb{R}^{b}, and the compositional coefficients to generate each sub-vector of B B s and A A s. Specifically, each sub-vector is generated from top-K K (e.g., K=2 K=2) compositional coefficients over ℬ\mathcal{B}. Since the coefficients are sparse, we can encode them efficiently by K K indices over ℬ\mathcal{B} and K K coefficient values.
As illustrated in Figure2(b), under our framework, the original LoRA parameter space θ D\theta_{D} is formed the same as in Eq.1. The trainable vector θ d\theta_{d} of VB-LoRA is formed by concatenating all the vectors in ℬ\mathcal{B}:
θ d=Concat(α 1,α 2,⋯,α h).\theta_{d}=\text{Concat}(\alpha_{1},\alpha_{2},\cdots,\alpha_{h}).(9)
The projection matrix P P is structured as a block-diagonal matrix, where each diagonal block is of size b×b b\times b, matching the dimensionality of vectors in ℬ\mathcal{B}. Since K=2 K=2 in VB-LoRA, two diagonal blocks in a row in P P is responsible to reconstruct one sub-vector of B B s or A A s, where the location of the diagonal block corresponds to the coefficient index and the diagonal value is the coefficient value. Note that the compositional coefficients are learned in VB-LoRA. Therefore, the locations and values of the diagonal blocks in P P are trained along with θ d\theta_{d}, i.e., the vector bank parameters.
LoRA-XS
represents the weight increment as ΔW=P BΛ RP A\Delta W=P_{B}\Lambda_{R}P_{A}, where P B∈ℝ m×r P_{B}\in\mathbb{R}^{m\times r} and P A∈ℝ r×n P_{A}\in\mathbb{R}^{r\times n} are derived from the singular value decomposition (SVD) of the pretrained weight matrix W W and are kept frozen during fine-tuning, while Λ R∈ℝ r×r\Lambda_{R}\in\mathbb{R}^{r\times r} is the only trainable component. Specifically, for each LoRA module ℓ=1,⋯,L\ell=1,\cdots,L, we column-wise flatten each Λ R ℓ\Lambda_{R}^{\ell}, and concatenate them to construct a trainable parameter vector:
θ d=Concat(vec col(Λ R 1),vec col(Λ R 2),⋯,vec col(Λ R L)),\theta_{d}=\operatorname{Concat}\left(\text{vec}{\text{col}}(\Lambda{R}^{1}),\text{vec}{\text{col}}(\Lambda{R}^{2}),\cdots,\text{vec}{\text{col}}(\Lambda{R}^{L})\right),(10)
where vec col(⋅)\text{vec}_{\text{col}}(\cdot) denotes the column-wise flatten of a matrix into a column vector. On the other hand, the full parameter vector of LoRA can be formulated as:
θ D=Concat(vec row(B^1),vec row(A^1),⋯,vec row(B^L),vec row(A^L)),\theta_{D}=\text{Concat}\left(\text{vec}{\text{row}}(\hat{B}^{1}),\text{vec}{\text{row}}(\hat{A}^{1}),\cdots,\text{vec}{\text{row}}(\hat{B}^{L}),\text{vec}{\text{row}}(\hat{A}^{L})\right),(11)
where B^ℓ=P B ℓΛ R ℓ\hat{B}^{\ell}!=!P_{B}^{\ell}\Lambda_{R}^{\ell} and A^ℓ=P A ℓ\hat{A}^{\ell}!=!P_{A}^{\ell} correspond to the B ℓ B^{\ell} and A ℓ A^{\ell} of LoRA, respectively. Since A^ℓ=P A ℓ\hat{A}^{\ell}!=!P_{A}^{\ell} is initialized, frozen, and independent of Λ R ℓ\Lambda_{R}^{\ell}, we only need to map Λ R ℓ\Lambda_{R}^{\ell} to B^ℓ\hat{B}^{\ell}, i.e., projecting the trainable parameter θ d\theta_{d} to the B^\hat{B} portion of θ D\theta_{D}. As illustrated in Figure2(c), the projection matrix P P of LoRA-XS also exhibits a structured sparse pattern, composed of the row-vectors extracted from P B ℓ P_{B}^{\ell} organized in a stripe pattern.
FourierFT
isn’t a LoRA-based method that performs parameter-efficient fine-tuning in the domain of low-rank adaptation. Instead, FourierFT learns the weight increment ΔW\Delta W directly by utilizing the Fast Fourier Transform (FFT) for sparse representation. We show that despite FourierFT isn’t a LoRA variant, our Uni-LoRA is a unified framework that can represent FourierFT is the same uniform language and enables a systematic analysis.
FourierFT leverages the Fourier bases to parameterize the weight increments, wherein a small number of trainable Fourier coefficients can be used to synthesize the full weight increments. To represent FourierFT in our unified framework, we row-wise flatten the weight increment ΔW ℓ\Delta W^{\ell} for each adapted module ℓ=1,⋯,L\ell=1,\cdots,L, and concatenate them to construct the full PEFT parameter space:
θ D=Concat(vec row(ΔW 1),vec row(ΔW 2),…,vec row(ΔW L)).\theta_{D}=\text{Concat}\left(\text{vec}{\text{row}}(\Delta W^{1}),\text{vec}{\text{row}}(\Delta W^{2}),\dots,\text{vec}_{\text{row}}(\Delta W^{L})\right).(12)
On the other hand, the trainable parameter vector θ d\theta_{d} is formed by concatenating the Fourier coefficients for each adapted module.
As illustrated in Figure2(d), the projection matrix P P also exhibits a block structure since FourierFT adopts a layer-wise projection:
P=Diag(P1,P2,⋯,P~L),P=\operatorname{Diag}\left(\tilde{P}^{1},\tilde{P}^{2},\cdots,\tilde{P}^{L}\right),(13)
where the block matrix P~ℓ\tilde{P}^{\ell}, denoting the Fourier subspace for the ℓ\ell-th module, is generated by randomly sampling a subset of Fourier bases.
A.2 Hyperparameters and Computing Resources
The hyperparameters used for the natural language understanding, mathematical reasoning, and instruction tuning are provided in Tables8,9, 10 and11 . All experiments were conducted on a server equipped with 8 NVIDIA A100 80GB GPUs.
Computation overhead
The proposed projection in Uni-LoRA is straightforward to implement in modern deep learning frameworks such as PyTorch, enabling full utilization of GPU acceleration. Moreover, since the projection matrix in Uni-LoRA is frozen and does not require training – as opposed to Tied-LoRA and VB-LoRA – it incurs significantly lower computational overhead. As shown in Tables9 and10, Uni-LoRA achieves substantially shorter training time compared to VB-LoRA, and is on par with the original LoRA.
Memory efficiency
Uni-LoRA significantly reduces memory consumption by minimizing the number of trainable parameters. During LoRA fine-tuning, the forward computation is performed as z=Ax z=Ax, H=Bz H=Bz, without the need of explicitly instantiating ΔW\Delta W. This memory-efficient strategy is seamlessly supported in Uni-LoRA and has been implemented in our codebase. As shown in Tables9 and10, Uni-LoRA consistently consumes less memory than VB-LoRA across all model configurations evaluated.
Table 8: Hyperparameters and computing resources used in the natural language understanding experiments on the GLUE benchmark. h: hour, m: minute.
Table 9: Hyperparameters and computing resources used in the mathematical reasoning experiments. h: hour, m: minute.
Table 10: Hyperparameters and computing resources used in instruction tuning on the Cleaned Alpaca Dataset. h: hour. 7B: Llama2-7B, 13B: Llama2-13B.
Table 11: Hyperparameters and computing resources used in the vision tasks. h: hour, m: minute.
Table 12: All results reported are generated using a consistent version of the GPT-4 API. Score refers to the evaluation on MT-Bench with single-turn dialogues.
A.3 Impact of Hyperparameters on Model Performance
To investigate how the number of trainable parameters d d affects model performance, we conducted ablation studies by fine-tuning RoBERTa-Large on the SST-2 task (from GLUE) and Gemma-7B on the mathematical reasoning benchmarks, where d d is varied while keeping all other settings at their default values. The results are summarized in Figure3.
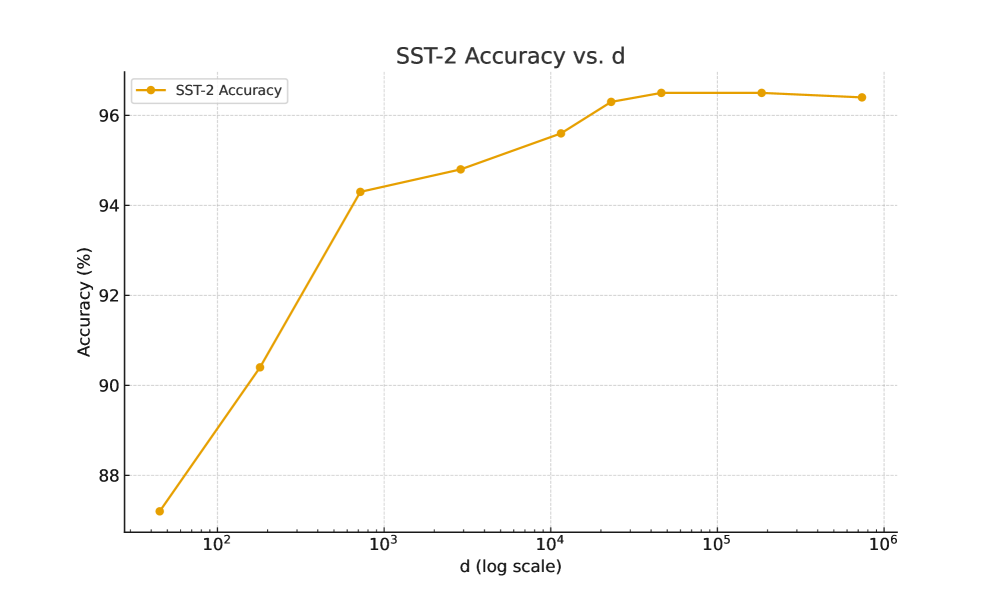
(a)Accuracy on SST-2 as d d increases.
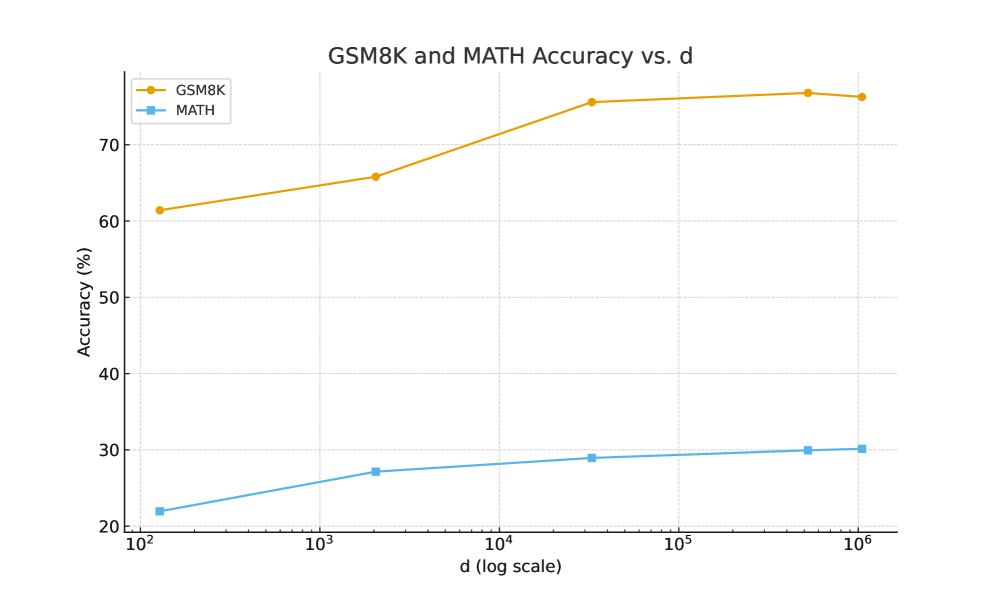
(b)Accuracies on GSM8K and MATH as d d increases.
Figure 3: Evolution of Uni-LoRA accuracies on different benchmarks as the number of trainable parameters d d increases.
Our experiments show that performance improves rapidly with increasing d d when d d is small, and then plateaus as d d grows larger.
For a fair comparison, we follow VB-LoRA and set the LoRA rank r r = 4 in the paper. To evaluate the influence of rank r r, here we conduct additional analysis by varying r r for RoBERTa-Large on the SST-2 task (from GLUE) and Gemma-7B on the mathematical reasoning benchmarks. The results reported in Figure4 show that Uni-LoRA maintains stable performance across a wide range of ranks, with r r = 4 achieving the best balance between accuracy and efficiency.

(a)Accuracy on SST-2 with different r r.

(b)Accuracies on GSM8K and MATH with different r r.
Figure 4: Performance comparison of Uni-LoRA across different rank r r.
A.4 Comparison with LoRA of the Same Rank
In the instruction tuning experiments, we follow the same setup in VeRA[4] and VB-LoRA[6], comparing our method against LoRA with a rank of 64, which is a commonly used setting in prior works. To ensure a fair comparison with our Uni-LoRA, which uses a low rank of 4, we additionally include a set of instruction tuning experiments where LoRA is also configured with rank 4. These experiments follow the same setup as in Section4.3, with the only difference being the LoRA rank.
The results are provided in Table12. It can be observed that reducing the LoRA rank from 64 to 4 leads to a noticeable performance / score drop. Moreover, the performance of the LoRA rank-4 model is consistently worse than that of Uni-LoRA. In contrast, Uni-LoRA employs a fixed, sparse projection matrix, where only the indices and values of the nonzero entries are involved in computation. This leads to an extremely efficient implementation. As a result, Uni-LoRA incurs only marginal increases in training time and memory consumption compared to the rank-4 LoRA baseline, while achieving notable score improvements.
A.5 Licenses and Asset Usage
We document all external assets used in this work, including models and datasets, along with their licenses and source URLs.
All assets were used in compliance with their respective licenses. No proprietary or restricted-access data was used in this study.
Xet Storage Details
- Size:
- 79.3 kB
- Xet hash:
- ba7b2353e202c682a2542803d822826dd37f2d9c67bc21ee7052b9adaf544f89
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.