Buckets:

Title: The Missing Parts: Augmenting Fact Verification with Half Truth Detection
URL Source: https://arxiv.org/html/2508.00489
Published Time: Tue, 23 Sep 2025 00:23:24 GMT
Markdown Content: Yixuan Tang Jincheng Wang Anthony K.H. Tung School of Computing, National University of Singapore
yixuan@comp.nus.edu.sg, bertrand.wongjc@gmail.com, atung@comp.nus.edu.sg
Abstract
Fact verification systems typically assess whether a claim is supported by retrieved evidence, assuming that truthfulness depends solely on what is stated. However, many real-world claims are half-truths, factually correct yet misleading due to the omission of critical context. Existing models struggle with such cases, as they are not designed to reason about omitted information. We introduce the task of half-truth detection, and propose PolitiFact-Hidden, a new benchmark with 15k political claims annotated with sentence-level evidence alignment and inferred claim intent. To address this challenge, we present TRACER, a modular re-assessment framework that identifies omission-based misinformation by aligning evidence, inferring implied intent, and estimating the causal impact of hidden content. TRACER can be integrated into existing fact-checking pipelines and consistently improves performance across multiple strong baselines. Notably, it boosts Half-True classification F1 by up to 16 points, highlighting the importance of modeling omissions for trustworthy fact verification. The benchmark and code are available via https://github.com/tangyixuan/TRACER.
The Missing Parts: Augmenting Fact Verification with Half Truth Detection
Yixuan Tang Jincheng Wang Anthony K.H. Tung School of Computing, National University of Singapore yixuan@comp.nus.edu.sg, bertrand.wongjc@gmail.com, atung@comp.nus.edu.sg
1 Introduction

Figure 1: Overview of the TRACER framework for half-truth detection. The system identifies Critical Hidden Evidence (CHE) through evidence alignment, intent generation, and causality analysis, and re-assesses claims for omission-based misinformation.
Table 1: A factually correct political claim re-evaluated as misleading (Half-True) by TRACER through Critical Hidden Evidence (CHE) analysis.
The rapid spread of digital content has made fact verification a critical component in combating misinformation and promoting trustworthy public discourse. Traditional fact-checking systems follow a standard paradigm: given a claim and a body of evidence, the system classifies the claim as true, false, or not enough information Chen and Shu (2024). These systems are effective in identifying clearly incorrect claims and continue to serve as the backbone of automated verification pipelines.
However, many real-world claims are not outright false but are still misleading due to the omission of critical context. Misinformation can evolve dynamically when propagated under different political stances Chong et al. (2025), these are often referred to as half-truths, i.e. statements that are factually correct but strategically incomplete Singamsetty et al. (2023); Jaradat et al. (2024). Consider the example in Table1, where a politician claims that unemployment has reached a 50-year low. While this statistic is factually accurate, it omits key information, such as the rise in part-time gig jobs and stagnant labor force participation, that undermines the implied narrative of broad economic success. Standard fact verification (FV) models, which focus on validating surface-level factuality, label such claims as true, failing to capture the misleading nature of selective omission.
This challenge highlights a fundamental limitation in existing FV pipelines: they are not designed to reason about what is missing. Current models typically assess what is stated, treating veracity as a discrete property grounded in textual entailment Molina et al. (2019); Estornell et al. (2020). Yet in practice, truthfulness is often shaped by both what is said and what is left unsaid. Omission-based misinformation exploits this gap, occupying a gray area between truth and falsehood that standard systems are ill-equipped to address.
In this paper, we introduce the task of half-truth detection, which complements traditional fact verification by modeling completeness. We define half-truths as claims that are factually accurate but omit Critical Hidden Evidence (CHE)—information that, if included, would significantly alter the plausibility of the claim’s implied meaning. Our goal is to identify such omissions and assess their impact on the inferred intent of the claim.
To tackle this task, we propose TRACER (Truth ReAssessment with Critical Hidden Evidence reasoning), a framework to augment fact-checking systems with omission-aware reasoning. TRACER operates in three stages: (1) evidence alignment, to classify retrieved evidence as presented or hidden; (2) intent generation, to recover the claim’s implicit message; and (3) causality analysis, to determine whether the Hidden Evidence undermines the inferred intent. These components feed into a lightweight re-assessment module that revisits claims, particularly those initially labeled as true, and identifies misleading omissions. TRACER is model-agnostic and can be integrated into both agent-based and prompting-based FV pipelines.
To support this task, we construct PolitiFact-Hidden, a benchmark dataset based on the PolitiFact corpus. It contains about 15k claims annotated with sentence-level labels indicating Presented and Hidden Evidence, along with inferred claim intents validated through a combination of LLM prompting and human quality control. To our knowledge, this is the first dataset to explicitly annotate both omission and intent, enabling systematic study of half-truths at scale.
Our contributions are as follows:
- 1.We formulate half-truth detection as a new task in fact verification, targeting claims that omit critical context while remaining factually correct.
- 2.We introduce PolitiFact-Hidden, a large-scale benchmark with fine-grained annotations for Presented / Hidden Evidence and inferred claim intent.
- 3.We propose TRACER, a three-stage framework that identifies omission-based misinformation through evidence alignment, intent modeling, and causal reasoning. TRACER can be deployed as a re-assessment module and yields substantial gains in detecting half-truths across multiple strong baselines.
By modeling completeness alongside correctness, this work advances the frontier of fact verification. It addresses a blind spot in current systems and offers a generalizable framework for uncovering more subtle forms of misinformation that operate through omission rather than distortion.
2 Related Work
Fact Verification.
Fact verification is commonly framed as a three-stage pipeline involving claim detection, evidence retrieval, and claim classification into Supported, Refuted, or Not Enough Information Thorne et al. (2018); Guo et al. (2022). Benchmarks such as FEVER Thorne et al. (2018) and LIAR Wang (2017) have facilitated significant progress in this area. Most existing systems focus on surface-level factual correctness, aiming to match claims against retrieved facts. While effective for outright falsehoods, these approaches are less suited to handling omission-driven manipulation.
Omission and Half-Truths.
Omission-based misinformation, including half-truths, has received increasing attention. Singamsetty et al. (2023) introduce controlled claim editing to expose omitted content, and Chen et al. (2022) propose generating implicit questions to recover missing context. Other datasets have incorporated related annotations, such as Cherry-picking Schlichtkrull et al. (2023) and Mixture Yang et al. (2022), which primarily capture conflicting evidence rather than omissions per se. These schemes focus on factual inconsistency (i.e., presence of both supporting and refuting evidence), rather than semantic incompleteness or intent-driven distortion. In contrast, our work targets half-truths, claims that are factually accurate but strategically omit Critical Hidden Evidence (CHE) that significantly alters interpretation. Closely related are efforts that explore the role of intent in misinformation, such as distinguishing disinformation through concealment and overstatement Rodríguez-Ferrándiz (2023); Lee and Lee (2024). (2025) uncover the comprehensive view of events by mitigating selective presentation of information, they do not integrate downstream fact verification. We go beyond these by explicitly modeling the causal impact of Hidden Evidence on inferred intent without altering the original claim.
Reasoning-Based Fact Checking.
Recent methods incorporate structured reasoning to improve factuality assessment. Program-guided models such as QACheck and ProgramFC Pan et al. (2023b) generate intermediate steps to support verification Tang et al. (2021). Argumentation-based approaches, such as CHECKWHY Si et al. (2024), model causal links within evidence chains. Meanwhile, prompting-based methods like HiSS Zhang and Gao (2023) and Flan-T5 Chung et al. (2022) leverage large language models for step-by-step verification. Other work explores intent modeling using contrastive learning Yang et al. (2024) or refined retrieval Wang et al. (2024). Our work complements these efforts by introducing omission-aware reasoning and providing a modular framework that can be integrated into both structured and generative pipelines.
3 Task Formulation
We define half-truth detection as an extension of fact verification that focuses on factual completeness. A claim may be factually accurate in isolation, yet convey a misleading impression by omitting relevant information that influences its interpretation. The goal is to identify such omissions and assess whether they materially affect the plausibility of the claim’s implied message.
Formally, given a claim C C and a set of retrieved evidence sentences E={e 1,e 2,…,e n}E={e_{1},e_{2},\dots,e_{n}} relevant to C C, the goal is to classify the claim into one of three categories: True, Half-True, or False. This classification is determined not only by factual support but also by the presence or absence of Critical Hidden Evidence (CHE)⊆E\subseteq E that is both (1) not presented in the claim, and (2) necessary to understand or challenge the claim’s implied conclusion.
To support this, we define the following components:
- •Presented Evidence (PE): Sentences in E E that are explicitly stated or clearly implied in the claim.
- •Hidden Evidence (HE): Sentences in E E that are relevant to the claim but not mentioned.
- •Intent: The implied conclusion or message that the claim is likely to convey to the reader.
- •Critical Hidden Evidence (CHE): A subset of HE that, if revealed, would significantly affect the plausibility of the claim’s intent.
Table 2: Mapping from original PolitiFact ratings to consolidated labels.
Table 3: Distribution of labels in the PolitiFact-Hidden dataset across train/dev/test splits.
This formulation connects closely to the traditional FV pipeline but adds a new layer of reasoning: not only must a system verify what is said, it must also reason about what is left unsaid. By focusing on omissions that shift the meaning of a claim, half-truth detection supports a more nuanced understanding of misinformation and helps uncover subtle forms of manipulation that standard FV systems may overlook.
4 Dataset: PolitiFact-Hidden
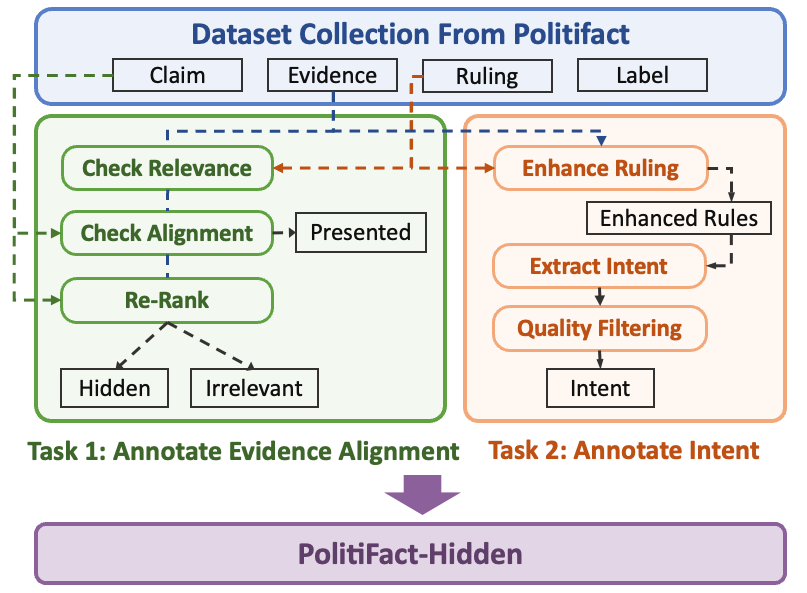
Figure 2: Illustration of the semi-automated annotation pipeline for constructing PolitiFact-HIDDEN, combining GPT-4o-mini prompting with human quality control.
As illustrated in Figure2, we develop a semi-automated annotation pipeline (Figure2) combining GPT-4o-mini prompting and model-assisted refinement to label each claim with evidence alignment and Intent.
Table 4: Agreement between LLM and human annotations across intent quality dimensions.
We introduce PolitiFact-Hidden, a benchmark for omission-aware fact verification. It extends the original PolitiFact corpus with fine-grained annotations capturing both Presented and Hidden Evidence, and the Intent behind each claim. These annotations enable systematic evaluation of whether omitted content, i.e. Critical Hidden Evidence (CHE), alters the claim’s implied meaning.
4.1 Data Source and Label Schema
The dataset is built upon fact-checking articles from PolitiFact, which include both a concise claim and an accompanying verdict article. Unlike many other fact-checking sources, PolitiFact explicitly considers completeness in its rating criteria: a claim rated True must be both accurate and complete, while Mostly True and Half-True indicate factual correctness with missing context (Holan, 2018). In contrast, Mostly False reflects the presence of conflicting evidences.
We consolidate PolitiFact’s original six-level rating into three coarse-grained labels to align with our half-truth detection task:
Each article is split into evidence paragraphs, which provide factual context, and ruling paragraphs, which justify the final verdict. To prevent label leakage, we separate these segments using structural cues (e.g., “Our Ruling”) and exclude ruling content from model input.
To improve generalization and test temporal robustness, we collect an additional 2,000 claims from 2020–2025 to form a temporally disjoint test set. Claims with date overlap are removed from the training pool. The resulting dataset contains 14,994 claims. Detailed statistics are shown in Table3.
4.2 Annotation Pipeline
Evidence Annotation
For each evidence sentence, we determine whether it is already reflected in the claim. This involves:
- 1.Relevance Check: Filter out irrelevant content using LLM-based entailment prompting.
- 2.Presentation Check: Assess whether the content is explicitly or implicitly stated in the claim.
- 3.Similarity Refinement: Use cosine similarity with XLM-RoBERTa embeddings Nils Reimers (2019) to refine edge cases and mitigate hallucinations.
Evidence is labeled as either PE or HE. Manual inspection of 50 samples showed an 88% agreement between LLM predictions and human judgments, validating the alignment process.
Intent Annotation.
A key element of half-truth detection is the claim’s Intent, i.e., the implied message or judgment it seeks to convey. Intents are extracted in 3 steps:
- 1.Ruling Enhancement: Enhance ruling text by adding supporting evidence for clarity.
- 2.Intent Extraction: Use instruction-tuned prompting to extract the claim’s intended conclusion.
- 3.Quality Filtering: Filter extracted intents using four criteria, namely plausibility, implicity, sufficiency and readability.
To validate the quality of LLM-based filtering, we had two human annotators independently assess 100 samples across the same four evaluation dimensions. Agreement between the LLM and both annotators was high (92.1-98.9% across dimensions), suggesting that the LLM-assisted approach reliably captures high-quality intents for downstream reasoning. The full intent evaluation prompts are provided in AppendixA.
5 The TRACER Framework
We propose TRACER, a modular framework for detecting half-truths by identifying and evaluating omitted context. TRACER is designed to integrate with existing fact verification (FV) systems by reassessing claims, particularly those initially labeled as True, to determine whether omissions materially alter the claim’s intended message.
TRACER operates in three stages: (1) evidence alignment, (2) intent generation, and (3) causal estimation of omitted content. These components support a final re-assessment module that refines the output of base FV models.
5.1 Evidence Alignment
The first stage determines whether each evidence sentence e i∈E e_{i}\in E is explicitly or implicitly reflected in the claim C C. We formulate this as a binary classification task, assigning each e i e_{i} to either Presented Evidence (PE) or Hidden Evidence (HE). Only HE is forwarded for further analysis.
As shown in Figure3, a transformer-based alignment model is adopted. Each (C,e i)(C,e_{i}) pair is concatenated and encoded using RoBERTa-large(Liu et al., 2019). A classification head predicts whether the evidence content is present in the claim. This alignment step enables TRACER to isolate potentially omitted but relevant information for downstream intent and causal reasoning.

Figure 3: Architecture of the evidence alignment module, which classifies each evidence sentence as presented or hidden relative to the claim.
5.2 Intent Generation
Understanding this latent intent is essential for determining whether omitted content is misleading. As described in Section 4.2, we prompt-tune an LLM using input that includes the claim and its associated evidence context to infer intent. This prompt-based formulation encourages the model to extract implicit conclusions without relying on manually predefined templates. The resulting intents serve as semantic anchors for subsequent causality analysis.
5.3 Causality Analysis
While assumptions are derived from HE, not all HE sentences directly affect the plausibility of the intent. Many are tangential or neutral. To distinguish Critical Hidden Evidence (CHE) from neutral omissions, we estimate the causal influence of each HE sentence on the inferred intent.
Inspired by abductive reasoning frameworks Chen et al. (2022), we generate candidate assumptions A i A_{i} that must hold for the intent Z Z to be valid. These assumptions are derived from evidence through binary question generation and abstraction.
We then evaluate the impact of each A i A_{i} using counterfactual prompting: given do(A i=¬A i)do(A_{i}=\neg A_{i}), does the intent Z Z still hold? If not, A i A_{i} is marked as causally important. For each validated assumption, we retrieve corresponding CHE from the HE pool by selecting sentences that either support or contradict it, based on semantic similarity and an NLI model that verifies logical entailment. This two-step refinement prevents irrelevant or weakly related evidence from being misclassified as CHE.
5.4 Final Re-Assessment Module
To determine the final label (True, Half-True, or False), we incorporate the inferred intent, assumptions, and selected CHE into a re-assessment module (RA). This module re-evaluates the original FV prediction, especially when the claim was initially classified as True.
If no CHE is found, the original label is preserved. If CHE alters the plausibility of the intent, the system reclassifies the claim as Half-True or False, depending on the nature of the conflict. This re-assessment stage is implemented as a prompt-based module. It is designed to be model-agnostic and can be plugged into existing FV pipelines to enhance their ability to detect omission-based manipulation. We provide the full prompt examples used in each component of TRACER in AppendixB.
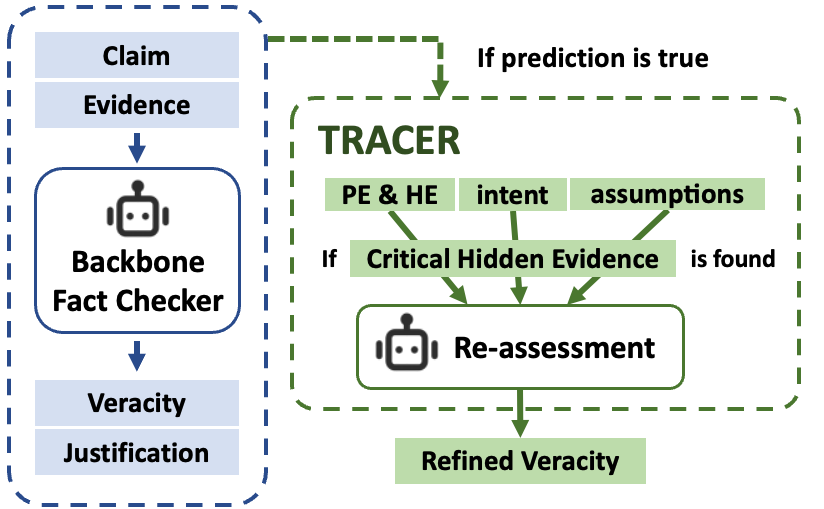
Figure 4: TRACER integrated into a fact verification pipeline as a re-assessment module.
6 Experiments
We evaluate TRACER by integrating it into existing fact verification (FV) models and measuring its effectiveness in identifying omission-based misinformation. Specifically, we compare TRACER-enhanced models against strong FV systems and conduct ablation studies to assess the impact of individual components. Evaluation metrics include overall Accuracy, macro-F1, and F1 on the Half-True class (F1(H)), which reflects the system’s ability to capture omission-driven misinterpretations.
6.1 Evidence Alignment
We train our evidence alignment model using RoBERTa-large 1 1 1https://huggingface.co/FacebookAI/roberta-large, with a context-aware batch sampling strategy. At each training step, sequential evidence segments are grouped into a batch to help the model leverage intra-batch contextual signals. We compare this setup to a baseline where each claim-evidence pair is processed independently (i.e., context-unaware). Both models are trained for 5 epochs with a batch size of 8 and a learning rate of 1e-5.
Table 5: Evidence alignment performance.
As shown in Table5, the context-aware training improves F1 by 1.3 and accuracy by 0.8, showing enhanced ability to detect omitted evidence.
6.2 Intent Generation
We fine-tune GPT-4o-mini via the OpenAI API to generate implicit intent statements. Each training input includes the claim and relevant evidence paragraphs. We compare this approach to a 4-shot in-context prompting baseline. The fine-tuned model is trained for 3 epochs with a batch size of 4.
Table 6: Performance of intent generation methods.
As shown in Table6, fine-tuning consistently outperforms prompting across all metrics, supporting our decision to use supervised intent extraction in TRACER.
Table 7: Overall accuracy and macro-F1 on fact verification. RA denotes integration of the TRACER re-assessment module.
Table 8: Precision, Recall, and F1 on the Half-True category. TRACER consistently improves detection of omission-based manipulation across all backbones.
6.3 Baselines
TRACER requires the fact-checking method to produce justifications for the claim’s veracity. This is because TRACER assesses truthfulness by jointly considering the factual accuracy of the claim and the plausibility of its intent, where the former should be supported by explicit reasoning steps. We evaluate TRACER on top of two leading fact verification models that are suitable for integration:
- •Chain-of-Thought (CoT)Kojima et al. (2022): a zero-shot prompting baseline, where the model is guided to generate intermediate reasoning steps before producing the final fact-checking verdict.
- •HiSS Zhang and Gao (2023): a state-of-the-art instruction-following verifier that employs structured reasoning by decomposing the claim into multiple verifiable subclaims and evaluating them step by step.
We also report results for the following four baselines:
- •QACheck Pan et al. (2023a) and ProgramFC Pan et al. (2023b): agent-based fact-checkers. QACheck decomposes claims into sub-questions and verifies them with evidence. ProgramFC treats verification as a structured program of sub-tasks generated via in-context learning and executed by modular agents.
- •CHECKWHY Si et al. (2024) and Flan-T5 Chung et al. (2022): prompting-based LLMs. CHECKWHY models causal reasoning through argument structures. Flan-T5 is identified as a strong fact verifier in hallucination evaluations.
To ensure fairness, we evaluate all baselines using GPT-4o-mini, except in cases where prior work demonstrates that a different backbone yields stronger performance. For HiSS, we find GPT-3.5-turbo consistently outperforms GPT-4o-mini.
6.4 Main Results
We present the overall performance of TRACER-integrated models and baselines in Table7 (Accuracy and macro-F1) and Table8 (Precision, Recall, and F1 on the Half-True category). The results highlight TRACER’s consistent improvements in both general fact verification and the more challenging omission-sensitive cases.
Overall Performance.
Table7 shows that TRACER improves both accuracy and macro-F1 when added to strong reasoning-based backbones. For example, integrating TRACER with HiSS improves test accuracy from 78.3% to 81.9%, and macro-F1 from 59.4 to 65.7. Similarly, CoT benefits from TRACER with a 2.2 point gain in test accuracy and a 3.7-point increase in macro-F1. These gains are observed across both dev and test sets, indicating the robustness of TRACER as a general-purpose re-assessment module.
Half-True Detection.
As shown in Table8, TRACER substantially enhances performance on the Half-True class. When applied to HiSS, TRACER improves F1 by 16.1 points on the test set (from 44.4 to 60.5) and recall by 28.9 points (from 37.9 to 66.8), demonstrating its effectiveness in identifying omission-based manipulation. Similar improvements are seen for CoT, with F1 increasing from 52.8 to 60.2 and recall rising by 15.5 points (from 63.8 to 79.3).
Agent-based baselines such as QACheck and ProgramFC achieve low recall and F1, highlighting their inability to capture hidden context. In contrast, prompting-based methods are more competitive, but still benefit significantly from TRACER’s re-assessment. These results validate our hypothesis that omission-aware reasoning, grounded in evidence alignment, intent modeling, and causal analysis, substantially improves a model’s ability to detect half-truths.
Per-Class Performance.
To further examine TRACER’s effect on fact verification, we report per-class performance for the top-performing models. As shown in Table9, TRACER substantially improves the classification of Half-True claims while also maintaining or slightly enhancing performance on True and False claims. This confirms that the observed gains are not achieved at the expense of other classes.
Generalization.
To examine the generalization of TRACER, we evaluate it with the open-source LLaMA2-7B model as the base verifier on the top-performing HiSS framework. With TRACER, accuracy improves from 78.2 to 82.3 and Macro-F1 from 59.1 to 65.4. A breakdown of per-class performance and a follow-up analysis of results over different claim lengths is provided in AppendixC.
Table 9: Per-class F1 scores on the test set.
6.5 Qualitative Analysis
To illustrate how TRACER detects omission-based manipulation, we present representative examples from the PolitiFact-Hidden test set. These cases show how factually accurate claims can still mislead through selective presentation, and how TRACER corrects such misclassifications by identifying Critical Hidden Evidence (CHE) and reasoning about intent.
Example: Misleading Attribution of Rising Costs.
Claim: “Under the Obama economy, utility bills are higher.” This claim was labeled True by HiSS, as it aligns with data showing an increase in utility costs during President Obama’s term. However, TRACER inferred an intent to attribute blame for rising prices to Obama’s economic policies. It then retrieved CHE showing that electricity prices rose even faster under the previous administration and followed a similar pattern across presidencies. This weakened the implied causal attribution and led TRACER to revise the label to Half-True.
Retrieved CHE: “Rates rose at a significantly faster pace under Bush than they did under Obama.”“Trends were not radically different between the Bush and Obama administrations.”
6.6 Ablation Study
Table 10: Ablation results for TRACER components.
We conduct an ablation study to evaluate the contribution of each component within the TRACER framework. Using HiSS as the base verifier, we progressively introduce intent modeling, assumption inference, and causality estimation. Results are shown in Table10.
Impact of Intent Modeling.
Setting \raisebox{-0.2ex}{1}⃝ represents the base HiSS model without any TRACER components. In Setting \raisebox{-0.2ex}{2}⃝, we introduce intent generation but omit assumption inference and causality estimation. CHE is retrieved directly based on the inferred intent. This setup yields a substantial improvement in both F1(H) and macro-F1, rising from 44.4 to 50.9 and from 59.4 to 64.7, respectively, demonstrating that intent modeling alone provides meaningful signals for identifying omission-based misdirection.
Assumption Inference.
Setting \raisebox{-0.2ex}{3}⃝ extends the previous configuration by incorporating assumption inference, where the inferred intent is decomposed into finer-grained, testable assumptions. However, causality estimation is still disabled in this setting, meaning that all generated assumptions are treated equally during CHE retrieval. This leads to a further boost in F1(H) to 61.2, validating the utility of breaking down intent into more specific reasoning units. Nonetheless, macro-F1 decreases slightly to 61.7 due to an increase in false positives, indicating that not all assumptions contribute constructively.
Causality Filtering.
In Setting \raisebox{-0.2ex}{4}⃝, our full TRACER framework is applied, with all components enabled, including causality estimation to filter out non-causal or spurious assumptions. While F1(H) drops marginally to 60.5, macro-F1 improves significantly to 65.7. This suggests that causality checking effectively suppresses noisy or irrelevant assumptions, resulting in a more balanced and robust system.
7 Conclusion
This work introduces the task of half-truth detection, addressing claims that are factually correct but misleading due to omitted context. To support this, we introduce PolitiFact-Hidden, a new benchmark with annotated evidence alignment and intent. We propose TRACER, a novel framework that detects omission-based misinformation via intent modeling and causal reasoning over hidden content. Integrated with existing fact verification models, TRACER consistently improves performance, especially on half-truths, demonstrating the importance of reasoning about omitted information. This work highlights omission-aware verification as a critical next step for building trustworthy fact-checking systems, and establishes TRACER as a generalizable framework for tackling this underexplored but essential challenge.
Limitations
While TRACER demonstrates strong performance in identifying omission-based misinformation, several limitations remain. First, our evaluation focuses on political discourse, as PolitiFact-Hidden is constructed from the PolitiFact corpus. While TRACER is designed to be model-agnostic and domain-independent, its effectiveness in other domains, such as health or finance, remains to be validated, especially where omission patterns may differ. Second, TRACER assumes that each claim expresses a coherent and inferable intent. However, real-world claims may be vague, ambiguous, or convey multiple overlapping intents, which can introduce noise in downstream reasoning. Future work may explore more robust modeling of claim pragmatics and intent uncertainty to extend TRACER’s applicability to broader scenarios.
Acknowledgments
This research is supported by the Ministry of Education, Singapore, under its MOE AcRF TIER 3 Grant (MOE-MOET32022-0001).
References
- Chen and Shu (2024) Canyu Chen and Kai Shu. 2024. Combating misinformation in the age of llms: Opportunities and challenges. AI Mag., 45(3):354–368.
- Chen et al. (2022) Jifan Chen, Aniruddh Sriram, Eunsol Choi, and Greg Durrett. 2022. Generating literal and implied subquestions to fact-check complex claims. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3495–3516. Association for Computational Linguistics.
- Chong et al. (2025) Brian Jun Rong Chong, Yixuan Tang, and Anthony Kum Hoe Tung. 2025. Mpcg: Multi-round persona-conditioned generation for modeling the evolution of misinformation with llms. In EMNLP. Association for Computational Linguistics.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, et al. 2022. Scaling instruction-finetuned language models. Preprint, arXiv:2210.11416.
- Estornell et al. (2020) Andrew Estornell, Sanmay Das, and Yevgeniy Vorobeychik. 2020. Deception through half-truths. Proceedings of the AAAI Conference on Artificial Intelligence, 34(06):10110–10117.
- Guo et al. (2022) Zhijiang Guo, Michael Schlichtkrull, and Andreas Vlachos. 2022. A survey on automated fact-checking. Transactions of the Association for Computational Linguistics, 10:178–206.
- Holan (2018) Angie Drobnic Holan. 2018. The principles of the truth-o-meter: Politifact’s methodology for independent fact-checking. Last updated Jan. 12, 2024.
- Jaradat et al. (2024) Israa Jaradat, Haiqi Zhang, and Chengkai Li. 2024. On detecting cherry-picking in news coverage using large language models. CoRR, abs/2401.05650.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY, USA. Curran Associates Inc.
- Lee and Lee (2024) Jiyoung Lee and Keeheon Lee. 2024. Measuring falseness in news articles based on concealment and overstatement. Preprint, arXiv:2408.00156.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692.
- Molina et al. (2019) Maria D. Molina, S.Shyam Sundar, Thai Le, and Dongwon Lee. 2019. "fake news" is not simply false information: A concept explication and taxonomy of online content. American Behavioral Scientist, 65(2):180–212. Original work published 2021.
- Nils Reimers (2019) Iryna Gurevych Nils Reimers. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. https://arxiv.org/abs/1908.10084.
- Pan et al. (2023a) Liangming Pan, Xinyuan Lu, Min-Yen Kan, and Preslav Nakov. 2023a. QACheck: A demonstration system for question-guided multi-hop fact-checking. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 264–273, Singapore. Association for Computational Linguistics.
- Pan et al. (2023b) Liangming Pan, Xiaobao Wu, Xinyuan Lu, Anh Tuan Luu, William Yang Wang, Min-Yen Kan, and Preslav Nakov. 2023b. Fact-checking complex claims with program-guided reasoning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6981–7004.
- Rodríguez-Ferrándiz (2023) Raúl Rodríguez-Ferrándiz. 2023. An overview of the fake news phenomenon: From untruth-driven to post-truth-driven approaches. Media and Communication, 11(2):15–29.
- Schlichtkrull et al. (2023) Michael Sejr Schlichtkrull, Zhijiang Guo, and Andreas Vlachos. 2023. AVeriTeC: A dataset for real-world claim verification with evidence from the web. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Si et al. (2024) Jiasheng Si, Yibo Zhao, Yingjie Zhu, Haiyang Zhu, Wenpeng Lu, and Deyu Zhou. 2024. CHECKWHY: Causal fact verification via argument structure. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15636–15659. Association for Computational Linguistics.
- Singamsetty et al. (2023) Sandeep Singamsetty, Nishtha Madaan, Sameep Mehta, Varad Bhatnagar, and Pushpak Bhattacharyya. 2023. "beware of deception": Detecting half-truth and debunking it through controlled claim editing. Preprint, arXiv:2308.07973.
- Tang et al. (2021) Yixuan Tang, Hwee Tou Ng, and Anthony K.H. Tung. 2021. Do multi-hop question answering systems know how to answer the single-hop sub-questions? In EACL, pages 3244–3249. Association for Computational Linguistics.
- Tang et al. (2025) Yixuan Tang, Yuanyuan Shi, Yiqun Sun, and Anthony Kum Hoe Tung. 2025. Uncovering the bigger picture: Comprehensive event understanding via diverse news retrieval. In EMNLP. Association for Computational Linguistics.
- Thorne et al. (2018) James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and verification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 809–819.
- Wang et al. (2024) Bing Wang, Ximing Li, Changchun Li, Bo Fu, Songwen Pei, and Shengsheng Wang. 2024. Why misinformation is created? detecting them by integrating intent features. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM ’24, page 2304–2314, New York, NY, USA. Association for Computing Machinery.
- Wang (2017) William Yang Wang. 2017. "liar, liar pants on fire": A new benchmark dataset for fake news detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 422–426.
- Yang et al. (2024) Chang Yang, Peng Zhang, Hui Gao, and Jing Zhang. 2024. Deciphering rumors: A multi-task learning approach with intent-aware hierarchical contrastive learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4471–4483. Association for Computational Linguistics.
- Yang et al. (2022) Zhiwei Yang, Jing Ma, Hechang Chen, Hongzhan Lin, Ziyang Luo, and Yi Chang. 2022. A coarse-to-fine cascaded evidence-distillation neural network for explainable fake news detection. In Proceedings of the 29th International Conference on Computational Linguistics, pages 2608–2621. International Committee on Computational Linguistics.
- Zhang and Gao (2023) Xuan Zhang and Wei Gao. 2023. Towards LLM-based fact verification on news claims with a hierarchical step-by-step prompting method. In Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 996–1011, Nusa Dua, Bali. Association for Computational Linguistics.
Appendix A Prompts for Constructing Politifact-Hidden
This section presents the prompt templates employed in building the Politifact-Hidden dataset.
To avoid repetition, we use colors in the prompts to denote different evaluation dimensions, which are assessed independently in practice.
Appendix B Prompt Templates Used in TRACER
This appendix provides the complete prompt templates employed at each stage of the TRACER framework. We include prompts for implicit question generation, assumption inference, causality evaluation, and final re-assessment.
Appendix C Generalization with LLaMA2-7B
Results in Table11 demonstrate that TRACER yields consistent improvements across metrics when applied to the open-source LLaMA2-7B, with particularly notable gains in Half-True classification.
Table 11: Generalization of TRACER with different backbones.
We further analyze TRACER’s performance across different claim lengths. Using the open-source LLaMA2-7B backbone, we partition test claims into four length ranges by word count. Table12 shows consistent improvements across all ranges, with larger gains observed for longer claims, which likely offer richer context for intent inference and assumption generation.
Table 12: TRACER’s performance across different claim lengths (F1 scores) using LLaMA2-7B. Numbers in parentheses indicate the number of examples per length range. Longer claims provide richer context, leading to larger improvements.
Xet Storage Details
- Size:
- 45.6 kB
- Xet hash:
- 9947662880cfbe029495e863d2a1d6b8f533696cd6361e041f6c670408a7edd9
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.