Buckets:

Title: OpenSIR: Open-Ended Self-Improving Reasoner
URL Source: https://arxiv.org/html/2511.00602
Published Time: Thu, 01 Jan 2026 01:20:13 GMT
Markdown Content: Wai-Chung Kwan 1 Joshua Ong Jun Leang 1,2 Pavlos Vougiouklis 3
Jeff Z. Pan 1 Marco Valentino 4 Pasquale Minervini 1,5
1 University of Edinburgh 2 Imperial College London
3 Huawei Technologies Research & Development (UK) Limited
4 University of Sheffield 5 Miniml.AI
{wkwan, p.minervini}@ed.ac.uk
Abstract
Recent advances in large language model (LLM) reasoning through reinforcement learning rely on annotated datasets for verifiable rewards, which may limit models’ ability to surpass human-level performance. While self-play offers a promising alternative, existing approaches depend on external verifiers or cannot learn open-endedly. We present Open-Ended S elf-I mproving R easoner (OpenSIR), a self-play framework where an LLM learns to generate and solve novel problems by alternating teacher and student roles without external supervision. To generate novel problems, OpenSIR optimises for both difficulty and diversity, rewarding problems that challenge appropriately while exploring distinct concepts, enabling open-ended mathematical discovery. Starting from a single trivial seed problem, OpenSIR substantially improves instruction models: Llama-3.2-3B-Instruct advances from 73.9 to 78.3 on GSM8K, and from 28.8 to 34.4 on College Math, while Gemma-2-2B-Instruct rises from 38.5 to 58.7 on GSM8K. Our analyses reveal that OpenSIR achieves open-ended learning through co-evolving teacher-student roles that adaptively calibrate difficulty and drive diverse exploration, progressing autonomously from basic to advanced mathematics. Code and datasets are available at https://github.com/EdinburghNLP/OpenSIR.
1 Introduction
Reinforcement learning with verifiable rewards (RLVR) drives recent advances in LLM reasoning. Recent works on DeepSeek-R1 (DeepSeek-AI et al., 2025) and OpenAI o1(OpenAI, 2024) have shown that large-scale reinforcement learning improves reasoning capabilities. Yet, these methods require extensive human-annotated data for reward signals, which bottleneck scalability and potentially limit performance to human-level(Hughes et al., 2024b).
One promising direction to address these fundamental limitations is to generate synthetic training data through self-play, which demonstrated remarkable success in various games(Silver et al., 2016; 2017; Brown & Sandholm, 2019; FAIR et al., 2022), allowing systems to exceed human-level performance by learning from unambiguous reward signals(Silver et al., 2017; FAIR et al., 2022). Yet, mathematical reasoning poses a key challenge for self-play: unlike games that have clear rules and winners, generated mathematics problems lack the ground-truth answers to provide feedback signals. Recent works utilise external verifiers, such as compilers for coding tasks(Pourcel et al., 2024; Zhao et al., 2025) or game rules(Liu et al., 2025), while R-Zero(Huang et al., 2025) employs majority voting with basic repetition penalties. However, these approaches cannot achieve open-ended learning, the ability to continuously generate and pursue novel challenges without external supervision(Bauer et al., 2023; Hughes et al., 2024a), confining systems to known concepts instead of exploring diverse mathematical domains.

Figure 1: Overview of the OpenSIR framework. A single policy π θ\pi_{\theta} alternates between generating and solving novel problems without external supervision. Each training iteration consists of problem generation, solution sampling, scoring, and model update. Novelty is captured through both difficulty and diversity: problems must be challenging yet solvable, and they must explore new concepts. These dimensions together drive open-ended self-improvement in the LLM reasoning ability.
We present Open-ended S elf-I mproving R easoner (OpenSIR), a method for training a policy π θ\pi_{\theta} to generate and solve novel problems without external supervision. OpenSIR uses self-play — a single policy π θ\pi_{\theta} alternates between teacher and student roles: the teacher generates problems, while the student solves them, with problem-solution pairs selected for reinforcement learning updates. We reward teachers for generating appropriately challenging problems for the students, using consistency and solution length across multiple solution attempts. OpenSIR achieves open-ended learning through embedding-based diversity rewards that drive continuous exploration of novel mathematical concepts.
Our experiments show OpenSIR outperforms base instruction models and reinforcement learning baselines. Starting from a single trivial seed problem, OpenSIR improves base instruction models by up to 6.3 accuracy points, surpassing GRPO baselines trained on thousands of human-annotated examples. Specifically, Llama-3.2-3B-Instruct improves from 73.9→\to 78.3 (+4.4) on GSM8K and 28.8→\to 34.4 (+5.6) on College Math, while Gemma-2-2B-Instruct rises from 38.5→\to 58.7 (+20.2) on GSM8K and 19.1→\to 23.4 (+4.3) on College Math.
Our qualitative analysis reveals OpenSIR succeeds through adaptive difficulty calibration and diversity-driven exploration. Problem difficulty is automatically calibrated throughout training, while the range of topics expands from basic to advanced mathematics (§4.1). Generating harder problems risks invalidity, requiring a balance between challenge and correctness (§4.2). Diversity rewards incentives generate problems spanning varied mathematical concepts (§4.3). Teacher-student co-evolution proves essential: without teacher training, models cannot generate appropriate challenges or explore new topics (§4.4).
2 Open-Ended Self-Improving Reasoner
Figure 1 illustrates the Open-Ended Self-Improving Reasoner (OpenSIR), a self-play framework in which a policy π θ\pi_{\theta} learns to both generate and solve novel mathematical problems without external supervision. We use reinforcement learning to optimise two roles within one policy: the teacher, which creates new problems, and the student, which solves them. This open-ended approach enables the policy to bootstrap its learning and discover new and diverse challenges without annotated data. Each training iteration involves four phases:
- 1.Problem generation (§2.1): The teacher proposes new problems by conditioning on reference problems from an accumulated pool of previously generated problems;
- 2.Solution sampling (§2.2): The student attempts multiple solutions per problem, with majority voting determining the reference answer and solve rate measuring reliability;
- 3.Scoring (§2.3): We compute novelty scores for the teacher’s generated problems and correctness scores for the student’s solutions; and
- 4.Model update (§2.4): We update the policy’s parameters with role-specific rewards using the problem-solution pairs selected by the novelty scores.
Algorithm1 summarizes the complete training procedure.
In OpenSIR, we define novelty along two dimensions that together drive continuous open-ended learning. First, problems must have an appropriate level of difficulty. It should be challenging enough to promote learning but solvable enough to provide reliable training signals. Second, problems must explore diverse concepts, preventing the model from repeating learning on familiar concepts. This two-dimensional view of novelty ensures the model continuously expands both the depth and breadth of its mathematical reasoning abilities.
2.1 Problem Generation
At each iteration t t, the policy π θ\pi_{\theta} generates k k groups of G G problems each, denoted as q 1:G q_{1:G} within each group, for a total of M=k×G M=k\times G problems. To generate these problems, we sample k k reference problems from a pool 𝒫 t−1\mathcal{P}{t-1} of accumulated problems from previous iterations, where each reference problem serves as a seed for generating G G new problems. Each generated problem must explicitly include the mathematical concepts required for its solution. Problems with invalid formats are filtered out, and valid problems proceed to the solution-sampling phase. We initialise the problem pool 𝒫 0\mathcal{P}{0} with a single trivial problem (“What is 1+1?”).
2.2 Solution Sampling
Let a j a_{j} denote the parsed answer from solution attempt o j o_{j}. We select the most common answer across attempts as the reference answer a∗a^{*}. We then compute the solve rate for each problem to determine the reliability of the answers. For brevity, we denote s q i=SolveRate(q i)s_{q_{i}}=\text{SolveRate}(q_{i}) when referring to the solve rate of problem q i q_{i}.
SolveRate(q i)=count(a∗)G where a∗=argmax a∈a 1:Gcount(a),\text{SolveRate}(q_{i})=\frac{\text{count}(a^{})}{G}\quad\text{where}\quad a^{}=\underset{a\in a_{1:G}}{\arg\max};\text{count}(a),(1)
In Eq.˜1, count(a)\text{count}(a) denotes the number of times answer a a appears. The solve rate quantifies answer reliability. High solve rates indicate reliable reference answers due to solution convergence, while low solve rates suggest inconsistent solutions that may indicate flawed problem formulations.
2.3 Scoring
We evaluate the quality of generated problems and solutions with different scoring functions. The teacher’s problems are scored based on difficulty and diversity, while the student’s receive scores for correctness. Additionally, both roles incorporate format scores to ensure parseable outputs.
2.3.1 Teacher Scoring
We capture novelty through two fundamental dimensions: difficulty and diversity. We measure difficulty using solvability to ensure problems remain appropriately challenging and solution length to encourage multi-step reasoning, as these provide complementary signals about problem difficulty. Diversity is promoted through embedding distance, which encourages exploration of varied mathematical concepts. These components form a unified novelty score that guides problem generation.
Solvability (score sol\text{score}_{\text{sol}}).
The solvability score identifies problems with appropriate challenge. We use solve rate as a proxy for solvability—problems with s q i>s max s_{q_{i}}>s_{\max} are likely too easy, while those with s q i<s min s_{q_{i}}<s_{\min} are either too difficult or malformed. We employ a triangular scoring function that peaks at the optimal solve rate and decreases linearly as problems become too easy or too hard.
We define the solve rate range as [s min,s max][s_{\min},s_{\max}]. Easy problems (s q i>s max s_{q_{i}}>s_{\max}) fail to challenge the model, while problems that are too hard or malformed (s q i<s min s_{q_{i}}<s_{\min}) offer minimal training value.
Formally, for s q i∈[0,1]s_{q_{i}}\in[0,1], let s mid=(s min+s max)/2 s_{\text{mid}}=(s_{\min}+s_{\max})/2 be the midpoint:
score sol(q i)={1−α|s q i−s mid|ifs q i∈[s min,s max],0 otherwise\text{score}{\text{sol}}(q{i})=\begin{cases}1-\alpha|s_{q_{i}}-s_{\text{mid}}|&\text{if }s_{q_{i}}\in[s_{\min},s_{\max}],\ 0&\text{otherwise}\end{cases}(2)
where α=(1−1/G)/(s mid−s min)\alpha=\left(1-1/G\right)/(s_{\text{mid}}-s_{\min}) is the slope coefficient, with G G being the number of solution attempts. The score peaks at the midpoint s mid s_{\text{mid}} and decreases to 1/n 1/n at the boundaries.
This creates a symmetric triangular score centred at the midpoint of the solve rate range, giving a maximum score for problems with moderate difficulty and progressively less score as the solve rate approaches either boundary.
Solution Length (score len\text{score}_{\text{len}}).
Solution length complements solvability by measuring problem complexity. Problems requiring multi-step reasoning typically elicit longer solutions. We score problems using the average length of student solutions:
score len(q i)=min(l¯(q i)l base,l cap l base)\text{score}{\text{len}}(q{i})=\min\left(\frac{\bar{l}(q_{i})}{l_{\text{base}}},\frac{l_{\text{cap}}}{l_{\text{base}}}\right)(3)
where l¯(q i)\bar{l}(q_{i}) denotes average solution length for problem q i q_{i}, l base l_{\text{base}} is a normalisation factor (defaults to 1000 tokens), and l cap l_{\text{cap}} prevents outliers from dominating the scoring signal. This score complements the solvability score (see AppendixC.1).
Diversity (score div\text{score}_{\text{div}}).
We compute the semantic distance between each new problem and the existing problem pool:
score div(q i)=min q′∈𝒫 t−1d(e q i,e q′)\text{score}{\text{div}}(q{i})=\min_{q^{\prime}\in\mathcal{P}{t-1}}d(e{q_{i}},e_{q^{\prime}})(4)
where e q i e_{q_{i}} and e q′e_{q^{\prime}} represent problem embeddings obtained from a pre-trained encoder, and d(⋅,⋅)d(\cdot,\cdot) denotes cosine distance. This score maximises when a problem is semantically distant from all existing problems in the pool.
Format (score fom T\text{score}_{\text{fom}}^{T}).
The format score ensures proper problem structure. Generated problems must be enclosed in tags with concepts listed in tags (maximum three concepts). We assign score fom T(q i)=1\text{score}{\text{fom}}^{T}(q{i})=1 for correct formatting and score fom T(q i)=0\text{score}{\text{fom}}^{T}(q{i})=0 otherwise.
Novelty Score.
We combine these components into a novelty score capturing both difficulty and diversity:
score novel(q i)=αscore sol(q i)+λscore len(q i)+γscore div(q i)+δscore fom T(q i)\text{score}{\text{novel}}(q{i})=\alpha\text{score}{\text{sol}}(q{i})+\lambda\text{score}{\text{len}}(q{i})+\gamma\text{score}{\text{div}}(q{i})+\delta\text{score}{\text{fom}}^{T}(q{i})(5)
where α\alpha, λ\lambda, γ\gamma, δ\delta are hyperparameters that control the relative importance of each component. This novelty score is used to select high-quality problem-solution pairs for training.
2.3.2 Student Scoring
The student’s score is based on solution correctness. For each solution attempt, we evaluate correctness by comparing the parsed answer against the reference answer from majority voting.
Format (score fom S\text{score}_{\text{fom}}^{S}).
The format score ensures proper answer presentation. Solutions must present final answers in \backslash boxed{} notation. We assign score fom S(o j)=1\text{score}{\text{fom}}^{S}(o{j})=1 for correct formatting and 0 otherwise.
Correctness Score.
The student’s correctness score combines accuracy with the format score:
score correct(o j,a j)=𝟏[a j=a∗]+δscore fom S(o j)\text{score}{\text{correct}}(o{j},a_{j})=\mathbf{1}[a_{j}=a^{*}]+\delta\text{score}{\text{fom}}^{S}(o{j})(6)
where 𝟏[a j=a∗]\mathbf{1}[a_{j}=a^{}] is an indicator function that equals 1 when parsed answer a j a_{j} from outcome o j o_{j} matches the reference answer a∗a^{}, and 0 otherwise. This correctness score evaluates both solution accuracy and proper formatting.
2.4 Model Update
After computing novelty scores, we select B B high-quality samples from valid problems for reinforcement learning, allocating half to problem generation and half to solution solving. For teacher training, we choose problem groups with highest score novel\text{score}_{\text{novel}} variance to ensure diverse training signals. For student training, we select problems with the highest novelty scores to provide maximal training value.
We optimise the policy using π θ\pi_{\theta} with an objective similar to Group Relative Policy Optimization (GRPO) (Shao et al., 2024), adapted for on-policy training to ensure stability (Chen et al., 2025):
𝒥(θ)=𝔼 q 1:G∼π θ(⋅|p T)o 1:G∼π θ(⋅|q i,p S)[∑r∈{T,S}1 G∑i=1 G A i r]−β𝔻 KL(π θ∥π ref)\mathcal{J}(\theta)=\mathbb{E}{\begin{subarray}{c}q{1:G}\sim\pi_{\theta}(\cdot|p_{T})\ o_{1:G}\sim\pi_{\theta}(\cdot|q_{i},p_{S})\end{subarray}}\left[\sum_{r\in{T,S}}\frac{1}{G}\sum_{i=1}^{G}A_{i}^{r}\right]-\beta\mathbb{D}{KL}\left(\pi{\theta}|\pi_{\mathrm{ref}}\right)(7)
where p T p_{T} and p S p_{S} are the teacher and student prompts respectively, r∈{T,S}r\in{T,S} refers to teacher and student, 𝔻 KL\mathbb{D}{KL} denotes the KL divergence, π ref\pi{\mathrm{ref}} refers to the initial model before training. The advantage for each role r∈{T,S}r\in{T,S} is computed as:
A i r=R i r−mean(R 1:G r)std(R 1:G r).A_{i}^{r}=\frac{R_{i}^{r}-\operatorname{mean}\left(R_{1:G}^{r}\right)}{\operatorname{std}\left(R_{1:G}^{r}\right)}.(8)
We define role-specific rewards R i T R_{i}^{T} and R j S R_{j}^{S} using the scoring functions from Section 2.3:
R i T=score novel(q i),R j S=score correct(o j,a j)R_{i}^{T}=\text{score}{\text{novel}}(q{i}),\quad R_{j}^{S}=\text{score}{\text{correct}}(o{j},a_{j})(9)
All valid problems are then added to the problem pool 𝒫 t\mathcal{P}_{t} for future iterations.
Algorithm 1 OpenSIR
1:Problem pool
𝒫 0\mathcal{P}_{0} , policy
π θ(0)\pi_{\theta}^{(0)} , embedding encoder
ε\varepsilon , batch size
B B , generation group size
G G , solve rate range
[s min,s max][s_{\min},s_{\max}] , teacher prompt
p T p_{T} , student prompt
p S p_{S}
2:for
t=1 t=1 to
T T do
3: Sample
k=B/G k=B/G reference problems
{p 1,…,p k}{p_{1},\ldots,p_{k}} from
𝒫 t−1\mathcal{P}_{t-1} ⊳\triangleright Problem Generation
4:for
i=1 i=1 to
k k do
5: Sample
q i,1:G∼π θ(t)(⋅∣p i,p T)q_{i,1:G}\sim\pi_{\theta}^{(t)}(\cdot\mid p_{i},p_{T})
6:end for
7:
𝒬 valid←{q i,j∣q i,jhas valid format}\mathcal{Q}{\text{valid}}\leftarrow{q{i,j}\mid q_{i,j}\text{ has valid format}}
8:for each
q i∈𝒬 valid q_{i}\in\mathcal{Q}_{\text{valid}} do⊳\triangleright Solution Sampling
9: Sample solutions
o i,1:G∼π θ(t)(⋅∣q i,p S)o_{i,1:G}\sim\pi_{\theta}^{(t)}(\cdot\mid q_{i},p_{S})
10: Parse answers
a i,1:G a_{i,1:G} from solutions
o i,1:G o_{i,1:G}
11: Compute reference answer
a i∗=argmax a∈a i,1:Gcount(a)a_{i}^{*}=\arg\max_{a\in a_{i,1:G}}\text{count}(a) via majority voting
12: Compute solve rate
s q i=count(a i∗)/G s_{q_{i}}=\text{count}(a_{i}^{*})/G
13: Compute embedding
e q i←ε(q i)e_{q_{i}}\leftarrow\varepsilon(q_{i})
14:end for
15: Compute
score novel(q i)\text{score}{\text{novel}}(q{i}) for all
q i∈𝒬 valid q_{i}\in\mathcal{Q}_{\text{valid}} via Eq.5⊳\triangleright Scoring
16:
ℐ T←top B/(2G)(i:Var(score novel(q i,1:G)),i∈{1,…,k})\mathcal{I}{T}\leftarrow\text{top}{B/(2G)}(i:\text{Var}(\text{score}{\text{novel}}(q{i,1:G})),i\in{1,\ldots,k}) ⊳\triangleright Teacher sample selection
17:
𝒬 S←top B/(2G)(q:score novel(q),q∈𝒬 valid)\mathcal{Q}{S}\leftarrow\text{top}{B/(2G)}(q:\text{score}{\text{novel}}(q),q\in\mathcal{Q}{\text{valid}}) ⊳\triangleright Student sample selection
18: Compute
score correct(o i,j,a i,j)\text{score}{\text{correct}}(o{i,j},a_{i,j}) for solutions where
q i∈𝒬 S q_{i}\in\mathcal{Q}_{S} via Eq.6
19:
𝒟 T←{(p T,q i,j,R i,j T):i∈ℐ T,1≤j≤G}\mathcal{D}{T}\leftarrow{(p{T},q_{i,j},R_{i,j}^{T}):i\in\mathcal{I}_{T},1\leq j\leq G} where
R i,j T=score novel(q i,j)R_{i,j}^{T}=\text{score}{\text{novel}}(q{i,j}) ⊳\triangleright Model Update
20:
𝒟 S←{(p S,o i,j,R i,j S):q i∈𝒬 S,1≤j≤G}\mathcal{D}{S}\leftarrow{(p{S},o_{i,j},R_{i,j}^{S}):q_{i}\in\mathcal{Q}_{S},1\leq j\leq G} where
R i,j S=score correct(o i,j,a i,j)R_{i,j}^{S}=\text{score}{\text{correct}}(o{i,j},a_{i,j})
21: Update
π θ(t+1)←GRPO(π θ(t),𝒟 T∪𝒟 S)\pi_{\theta}^{(t+1)}\leftarrow\text{GRPO}(\pi_{\theta}^{(t)},\mathcal{D}{T}\cup\mathcal{D}{S})
22:
𝒫 t←𝒫 t−1∪𝒬 valid\mathcal{P}{t}\leftarrow\mathcal{P}{t-1}\cup\mathcal{Q}_{\text{valid}}
23:end for
24:return
π θ(T)\pi_{\theta}^{(T)}
3 Experiments
3.1 Training Setup
We experiment with four instruction-tuned models: Llama-3.2-3B-Instruct, Llama-3.1-8B-Instruct (Dubey et al., 2024), Gemma-2-2B-Instruct(Team et al., 2024), and Qwen-2.5-3B-Instruct(Team, 2024) with GRPO (Shao et al., 2024). We use a learning rate of 3×10−7 3\times 10^{-7} and 10 warm-up steps. The KL divergence coefficient is set to 10−4 10^{-4} and the batch size is 256. To compare models trained on the same number of problem-solution pairs, we train the GRPO baselines with 100 steps, and OpenSIR for 200 steps since OpenSIR allocates half of its training budget to problem generation. Clipping is not applied since we strictly use on-policy samples. Each experiment is run with three random seeds. We provide full training details in AppendixD.1.
3.2 Dataset and Evaluation Setup
We evaluate method on five mathematical benchmarks: GSM8K (Cobbe et al., 2021), MATH-500 (Hendrycks et al., 2021), Minerva (Lewkowycz et al., 2022), OlympiadBench (He et al., 2024), and College Math (Tang et al., 2024).
We use sampling temperature 0.6 0.6 and top-p 0.95 0.95. The maximum response length is set to 4,096 tokens. We report the average performance over 16 generations (avg@16). Answer extraction and comparison are performed using the math_verify library.
3.3 Baselines
(1) Base We evaluate the instruction-tuned models using zero-shot prompting, where models generate step-by-step reasoning and provide final answers without additional training.
(2) GRPO We train the instruction models with GRPO (Shao et al., 2024) on established mathematical datasets. We train two variants: GRPO math{}{\text{math}} on the MATH dataset (7,500 training examples) (Hendrycks et al., 2021) and GRPO gsm8k{}{\text{gsm8k}} on the GSM8K dataset (7,473 training examples) (Cobbe et al., 2021).
(3) Absolute Zero(Zhao et al., 2025) A self-play framework for code generation that uses Python as external verifier, rewarding problems with minimal solve rates.
(4) R-Zero(Huang et al., 2025) A verifier-free self-play framework that trains separate challenger and solver models using rewards based on repetition penalties and solve rates near 0.5. OpenSIR differs by explicitly optimising for diversity and incorporating solution length to capture multiple dimensions of difficulty within a single model.
3.4 Main Results
Model GSM8K MATH-500 Minerva College OlympiadBench Avg. Math Llama-3.2-3B-Instruct Base 73.94 42.86 15.21 28.78 13.09 34.78 GRPO gsm8k{}{\text{gsm8k}}79.72 45.30 16.27 33.33 14.56 37.83+3.05 GRPO math{}{\text{math}}76.48 45.26 16.09 32.95 14.13 36.98+2.20 Absolute Zero 74.37 44.71 14.78 31.93 14.42 36.04+1.26 R-Zero 76.34 44.27 15.84 32.72 14.19 36.67+1.89 OpenSIR 78.28 46.22 17.46 34.42 15.72 38.42+3.64 Gemma-2-2B-Instruct Base 38.50 16.51 10.09 19.11 3.00 17.44 GRPO gsm8k{}{\text{gsm8k}}58.75 19.15 7.75 20.45 3.21 21.86+4.42 GRPO math{}{\text{math}}56.03 22.76 7.96 16.31 3.24 21.26+3.82 Absolute Zero 57.13 15.92 8.29 17.36 3.18 20.38+2.94 R-Zero 56.37 17.31 8.49 19.86 3.12 21.03+3.59 OpenSIR 58.03 24.75 9.51 23.36 3.15 23.76+6.32 Qwen-2.5-3B-Instruct Base 84.43 65.36 25.23 48.22 27.94 50.24 GRPO gsm8k{}{\text{gsm8k}}84.94 65.77 25.31 48.46 28.31 50.56+0.32 GRPO math{}{\text{math}}84.31 65.89 24.98 48.34 28.26 50.36+0.12 Absolute Zero 84.62 65.33 25.21 48.31 28.12 50.32+0.08 R-Zero 84.22 64.93 24.81 48.45 27.82 50.05-0.19 OpenSIR 85.38 65.87 25.96 48.74 28.33 50.85+0.61 Llama-3.1-8B-Instruct Base 84.50 47.89 22.75 34.10 16.26 41.10 GRPO gsm8k{}{\text{gsm8k}}88.70 50.37 24.83 35.03 16.43 43.05+1.95 GRPO math{}{\text{math}}86.23 50.82 23.98 34.93 16.54 42.50+1.40 Absolute Zero 86.89 51.38 23.21 34.39 15.96 42.37+1.27 R-Zero 86.19 50.93 24.11 32.93 15.66 41.96+0.86 OpenSIR 87.30 52.38 27.29 36.29 17.81 44.21+3.11
Table 1: The avg@16 performance on five mathematical benchmarks. OpenSIR outperforms GRPO baselines trained on >7,000 human-annotated examples and other self-play methods (Absolute Zero, R-Zero) across model families, starting from a single trivial seed problem.
Table 1 demonstrates that OpenSIR achieves substantial gains over the base instruction models across different model scales and families. OpenSIR improves Llama-3.2-3B-Instruct by 3.6 points, Llama-3.1-8B-Instruct by 3.1, and Gemma-2-2B-Instruct by 6.3 points on average accuracy. One exception is Qwen-2.5-3B-Instruct (+.0.6), where all methods show limited gains. The limited improvement aligns with observations of potential benchmark contamination (Wu et al., 2025).
OpenSIR outperforms all GRPO baselines without using human-annotated training data. GRPO baselines require over 7,000 labeled examples, yet OpenSIR generates its own training problems through self-play, starting from a single trivial seed problem. OpenSIR also substantially outperforms other self-play methods by 1.75 to 3.38 points on Llama-3.2-3B-Instruct, Gemma-2-2B-Instruct, and Llama-3.1-8B-Instruct. Although Absolute Zero and R-Zero demonstrate significant improvements over non-instruction-tuned models in their original work (Zhao et al., 2025; Huang et al., 2025), both show limited gains on instruction-tuned models. This challenging scenario is precisely where self-play methods are intended to excel - when models have already consumed available human-annotated data. As we reveal later in our analysis, the success of OpenSIR can be attributed to its ability to explore diverse mathematical concepts, and calibrating difficulty adaptively to maintain optimal challenge levels (§4.1). These capabilities enable OpenSIR to self-improve and expand its skills without external training data, achieving open-ended learning.
4 Ablations and Analyses
We perform a series of ablation studies and qualitative analyses on Llama-3.2-3B-Instruct to dissect the contribution of each key component in the OpenSIR framework. Our analysis investigates: (1) the evolution of problem difficulty and diversity over training (§4.1), (2) the effect of solve rate thresholds on the difficulty-validity trade-off (§4.2), (3) the impact of diversity rewards on promoting exploration of novel problem types (§4.3), and (4) the necessity of dual-role training (§4.4).
4.1 Evolution of Problem Difficulty and Diversity

Figure 2: Evolution of problem difficulty, validity, and topic diversity during OpenSIR training. (Left) Human evaluation results showing difficulty rankings (1-5 scale where 1=easiest, 5=hardest) and number of invalid problems for GSM8K, MATH, and problems generated at steps 0, 100, and 200 of training. Invalid problems are those with logical flaws, missing information, or ambiguities. (Right) Distribution of mathematical topics across training stages, demonstrating the increasing diversity of generated problems from step 0 to step 200.
We track how difficulty and diversity evolve during training through human evaluation. We sample 20 problems from three OpenSIR training checkpoints (steps 0, 100, 200) and 20 each from GSM8K and MATH. Annotators evaluate mixed sets of five problems (one per source), identifying topics, assessing validity, and ranking difficulty. Figure 2 shows average difficulty rankings (1=easiest, 5=hardest); see Appendix B for full annotation instructions.
Figure 2 (left) reveals a V-shaped difficulty trend across training stages. Problems start at 3.4 difficulty, drop to 3.0 at midpoint, then rise to 3.8. This pattern reflects OpenSIR’s self-calibration: the model first generates overly difficulty problems, then learns appropriate difficulty, and finally increases challenge as its solving capabilities improve. The model also generates increasingly valid problems during training — validity improves from below 50% initially to 95% (19 of 20 problems) by the end.
Figure 2 (right) shows topic diversity expansion across training. OpenSIR progresses from basic topics (algebra, arithmetic, geometry) to advanced domains including calculus and optimisation, eventually incorporating trigonometry, statistics, and other mathematical areas. This progression demonstrates OpenSIR’s capacity for autonomous exploration of diverse mathematical concepts. Appendix A.2 provides detailed case studies that illustrate this evolution.
4.2 Difficulty-Validity Trade-off
Table 2: Performance, problem validity, and solve rate across different lower solve-rate thresholds, with the upper threshold fixed at 0.9 for all variants. Validity and solve rate are estimated using GPT-5. Lower thresholds produce harder problems but significantly more invalid ones, ultimately reducing overall performance.
We investigate the difficulty-validity trade-off by training OpenSIR variants with lower solve-rate thresholds of 0.1, 0.3, and 0.5, keeping the upper threshold at 0.9 From each variant, we sample 300 problems and assess quality with GPT-5 (OpenAI, 2025a) using 8 responses per problem. We measure validity by comparing GPT-5’s majority answer to our reference answer and difficulty by GPT-5’s solve rate.
Table 2 reveals a clear trade-off between validity and difficulty. While lowering the threshold from 0.5 to 0.1 produces moderately harder problems (GPT-5 solve rate decreases from 89.82% to 78.31%), validity plummets from 70.82% to 42.31%. This suggests that problems with very low solve rates frequently contain errors rather than representing genuine mathematical challenges. performance consistently drops with lower thresholds, supporting our selection of 0.5 as the lower threshold for the solvability reward.
Besides solve-rate thresholds, we find that rewarding longer solutions provides another mechanism for promoting problem complexity that encourage sophisticated multi-step problems (AppendixC.1).
4.3 Impact of Diversity Rewards
![Image 3: [Uncaptioned image]](https://arxiv.org/html/2511.00602v2/x3.png)
Figure 3: t-SNE visualization of problem embeddings showing the effect of diversity reward on problem distribution. With diversity reward, problems explore broader regions of the embedding space compared to the clustered distribution without diversity reward.
Table 3: OpenSIR performance with and without diversity reward. Exploring diverse mathematical concepts through the diversity reward improves both accuracy and concept coverage, showing that variety in problem types is crucial for self-improvement.
We analyse the impact of the diversity reward on problem diversity through problem embeddings, n-gram similarity, and concept overlap. Figure3 visualises the problem embeddings with t-SNE, where red points represent problems without diversity reward, cyan points show problems with diversity reward, gold indicates MATH dataset problems, and purple marks GSM8K dataset problems. Without diversity rewards, problems cluster in narrow regions, generating similar types repeatedly and failing to achieve open-ended exploration. With diversity rewards, problems spread across the embedding space, reaching areas beyond MATH and GSM8K training sets. Further analysis of n-gram similarity and concept overlap support these findings, demonstrating consistent patterns of greater dispersion and novelty (AppendixA.3).
Table3 empirically confirms the importance of diversity rewards, showing that removing diversity rewards reduces average performance by 1.97 (from 38.42 to 36.45). It also shows that the number of unique concepts has dropped significantly (from 5914 to 3328). This demonstrates that without diversity rewards, the model generates repetitive problems with limited learning value, constraining the teacher’s ability to present varied mathematical challenges to the student. Incorporating diversity rewards thus enables exploration of novel problems beyond existing datasets, supporting open-ended learning where the model continuously discovers new challenges rather than repeating known concepts. Notably, this improvement is robust to the choice of diversity metric (AppendixC.2), with different measurement approaches yielding comparable results.
4.4 Importance of Dual-Role Training
Table 4: Accuracy and average solve rate with standard deviation (±\pm) for OpenSIR with teacher training (Both) versus without teacher training (Student only). Joint training achieves higher accuracy and remarkably stable problem difficulty (much lower solve rate variance), demonstrating that teacher training enables calibrated problem generation at optimal difficulty levels for effective learning.
We evaluate the contribution of the joint teacher-student training by testing a variant where only the student is updated while the teacher remains fixed at its initial state. Table4 shows that accuracy drops significantly from 38.42 to 35.89 when only the student is trained. This demonstrates that effective self-play requires both components to co-evolve.
Without teacher training, generated problems become harder (solve rate drops from 72.20 to 64.56) and drift from the optimal 70% target solve rate established in Section4.2. More critically, solve rate variance increases tremendously (from ±\pm 4.49 to ±\pm 17.37), indicating highly inconsistent difficulty during training. This poorly calibrated curriculum explains the performance drop: the fixed teacher cannot adapt to the student’s evolving capabilities, whereas joint training enables continuous difficulty calibration at the optimal challenge level.
5 Related Work
Self-play.
Self-play achieved superhuman performance in games without human data, from AlphaGo(Silver et al., 2016; 2017), StarCraft II(Vinyals et al., 2019), Poker(Brown & Sandholm, 2019), DotA(OpenAI et al., 2019), and Diplomacy(FAIR et al., 2022). Baker et al. (2019) show that agents can discover complex strategies with self-play, suggesting it is a promising avenue for continuous open-ended learning. Recent works apply self-play to LLM reasoning: Absolute Zero (Zhao et al., 2025) and Spiral(Liu et al., 2025) rely on external verifiers or game rules that limit their use beyond specific domains. R-Zero(Huang et al., 2025) attempts verifier-free self-play but uses only repetition penalties without a mechanism to encourage exploration, constraining open-ended learning. In contrast, OpenSIR generates and solves problems without external supervision while actively promoting diversity to enable continuous discovery of novel mathematical concepts.
Reinforcement Learning with Verifiable Feedback (RLVF).
RLVF drives recent advances in LLM reasoning (OpenAI, 2024; 2025b; DeepSeek-AI et al., 2025) but requires extensive human-annotated data for verifiable reward signals (Zeng et al., 2025), creating scalability bottleneck and potentially limiting performance to human-level. Recent works show that moderate-difficulty training samples provide optimal learning signals (Zheng et al., 2025; Sun et al., 2025), while diverse problem types enhance mathematical reasoning (Akter et al., 2025; Chen et al., 2025). These insights directly motivate OpenSIR to optimise for appropriate difficulty calibration and diversity-driven exploration, enable models to learn math reasoning open-endedly without human supervision.
6 Conclusions
We present OpenSIR, a self-play framework that enables LLMs to autonomously learn to generate and solve novel problems without external supervision. Starting from only a single trivial math problem, our framework outperforms GRPO-trained models that utilise thousands of human annotations across diverse model families. This approach demonstrates that models can effectively bootstrap mathematical reasoning through recursive self-improvement, eliminating dependence on extensive curated datasets. Our analysis reveals that OpenSIR succeeds by combining difficulty calibration and diversity rewards to create an adaptive curriculum where models continuously discover and master increasingly challenging mathematical concepts. Overall, OpenSIR represents a compelling paradigm for open-ended autonomous mathematical reasoning development, enabling models to recursively expand their capabilities beyond the boundaries of human-annotated data.
Acknowledgments
The authors would like to thank Aryo Pradipta Gema, Neel Rajani, Rohit Saxena (in alphabetical order) for the helpful discussions and feedback on the manuscript.
References
- Akter et al. (2025) Syeda Nahida Akter, Shrimai Prabhumoye, Matvei Novikov, Seungju Han, Ying Lin, Evelina Bakhturina, Eric Nyberg, Yejin Choi, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro. Nemotron-CrossThink: Scaling Self-Learning beyond Math Reasoning, April 2025.
- Baker et al. (2019) Bowen Baker, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, and Igor Mordatch. Emergent Tool Use From Multi-Agent Autocurricula. In International Conference on Learning Representations, September 2019. URL https://openreview.net/forum?id=SkxpxJBKwS.
- Bauer et al. (2023) Jakob Bauer, Kate Baumli, Feryal Behbahani, Avishkar Bhoopchand, Nathalie Bradley-Schmieg, Michael Chang, Natalie Clay, Adrian Collister, Vibhavari Dasagi, Lucy Gonzalez, Karol Gregor, Edward Hughes, Sheleem Kashem, Maria Loks-Thompson, Hannah Openshaw, Jack Parker-Holder, Shreya Pathak, Nicolas Perez-Nieves, Nemanja Rakicevic, Tim Rocktäschel, Yannick Schroecker, Satinder Singh, Jakub Sygnowski, Karl Tuyls, Sarah York, Alexander Zacherl, and Lei M. Zhang. Human-Timescale Adaptation in an Open-Ended Task Space. In Proceedings of the 40th International Conference on Machine Learning, pp. 1887–1935. PMLR, July 2023. URL https://proceedings.mlr.press/v202/bauer23a.html.
- Brown & Sandholm (2019) Noam Brown and Tuomas Sandholm. Superhuman AI for multiplayer poker. Science, 365(6456):885–890, August 2019. doi: 10.1126/science.aay2400.
- Chen et al. (2025) Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning, May 2025.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems, November 2021.
- DeepSeek-AI et al. (2025) DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z.F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H.Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J.L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R.J. Chen, R.L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, S.S. Li, Shuang Zhou, Shaoqing Wu, Shengfeng Ye, Tao Yun, Tian Pei, Tianyu Sun, T.Wang, Wangding Zeng, Wanjia Zhao, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, W.L. Xiao, Wei An, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, X.Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xiaowen Sun, Xiaoxiang Wang, Xinnan Song, Xinyi Zhou, Xianzu Wang, Xinxia Shan, Y.K. Li, Y.Q. Wang, Y.X. Wei, Yang Zhang, Yanhong Xu, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Yu, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yuan Ou, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Y.X. Zhu, Yanhong Xu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Ying Tang, Yukun Zha, Yuting Yan, Z.Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhicheng Ma, Zhigang Yan, Zhiyu Wu, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Zizheng Pan, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, and Zhen Zhang. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, January 2025.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pp. arXiv–2407, 2024.
- FAIR et al. (2022) FAIR, Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Hengyuan Hu, Athul Paul Jacob, Mojtaba Komeili, Karthik Konath, Minae Kwon, Adam Lerer, Mike Lewis, Alexander H. Miller, Sasha Mitts, Adithya Renduchintala, Stephen Roller, Dirk Rowe, Weiyan Shi, Joe Spisak, Alexander Wei, David Wu, Hugh Zhang, and Markus Zijlstra. Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science, 0(0):eade9097, November 2022. doi: 10.1126/science.ade9097.
- Havrilla et al. (2025) Alex Havrilla, Edward Hughes, Mikayel Samvelyan, and Jacob Abernethy. Synthetic Problem Generation for Reasoning via Quality-Diversity Algorithms, June 2025.
- He et al. (2024) Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3828–3850, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.211.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring Mathematical Problem Solving With the MATH Dataset. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 1, December 2021. URL https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/be83ab3ecd0db773eb2dc1b0a17836a1-Abstract-round2.html.
- Huang et al. (2025) Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-Zero: Self-Evolving Reasoning LLM from Zero Data, August 2025.
- Hughes et al. (2024a) Edward Hughes, Michael Dennis, Jack Parker-Holder, Feryal Behbahani, Aditi Mavalankar, Yuge Shi, Tom Schaul, and Tim Rocktaschel. Open-Endedness is Essential for Artificial Superhuman Intelligence, June 2024a.
- Hughes et al. (2024b) Edward Hughes, Michael D. Dennis, Jack Parker-Holder, Feryal M.P. Behbahani, Aditi Mavalankar, Yuge Shi, Tom Schaul, and Tim Rocktäschel. Position: Open-endedness is essential for artificial superhuman intelligence. In ICML. OpenReview.net, 2024b.
- Lewkowycz et al. (2022) Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving Quantitative Reasoning Problems with Language Models. Advances in Neural Information Processing Systems, 35:3843–3857, December 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/18abbeef8cfe9203fdf9053c9c4fe191-Abstract-Conference.html.
- Liu et al. (2025) Bo Liu, Leon Guertler, Simon Yu, Zichen Liu, Penghui Qi, Daniel Balcells, Mickel Liu, Cheston Tan, Weiyan Shi, Min Lin, Wee Sun Lee, and Natasha Jaques. SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning, June 2025.
- Loshchilov & Hutter (2018) Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. In International Conference on Learning Representations, September 2018. URL https://openreview.net/forum?id=Bkg6RiCqY7.
- Lu et al. (2023) Keming Lu, Hongyi Yuan, Zheng Yuan, Runji Lin, Junyang Lin, Chuanqi Tan, Chang Zhou, and Jingren Zhou. #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models. In The Twelfth International Conference on Learning Representations, October 2023. URL https://openreview.net/forum?id=pszewhybU9.
- OpenAI (2024) OpenAI. Learning to reason with LLMs, 2024. URL https://openai.com/index/learning-to-reason-with-llms/.
- OpenAI (2025a) OpenAI. GPT-5 System Card, August 2025a. URL https://openai.com/index/gpt-5-system-card/.
- OpenAI (2025b) OpenAI. Introducing OpenAI o3 and o4-mini, 2025b. URL https://openai.com/index/introducing-o3-and-o4-mini/.
- OpenAI et al. (2019) OpenAI, Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Dębiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, Rafal Józefowicz, Scott Gray, Catherine Olsson, Jakub Pachocki, Michael Petrov, Henrique P. d O. Pinto, Jonathan Raiman, Tim Salimans, Jeremy Schlatter, Jonas Schneider, Szymon Sidor, Ilya Sutskever, Jie Tang, Filip Wolski, and Susan Zhang. Dota 2 with Large Scale Deep Reinforcement Learning, December 2019.
- Pourcel et al. (2024) Julien Pourcel, Cédric Colas, Gaia Molinaro, Pierre-Yves Oudeyer, and Laetitia Teodorescu. ACES: Generating a Diversity of Challenging Programming Puzzles with Autotelic Generative Models. Advances in Neural Information Processing Systems, 37:67627–67662, December 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/7d0c6ff18f16797b92e77d7cc95b3c53-Abstract-Conference.html.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y.Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, April 2024.
- Silver et al. (2016) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587):484–489, January 2016. ISSN 0028-0836, 1476-4687. doi: 10.1038/nature16961.
- Silver et al. (2017) David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel, and Demis Hassabis. Mastering the game of Go without human knowledge. Nature, 550(7676):354–359, October 2017. ISSN 1476-4687. doi: 10.1038/nature24270.
- Sun et al. (2025) Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. Improving Data Efficiency for LLM Reinforcement Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay, June 2025.
- Tang et al. (2024) Zhengyang Tang, Xingxing Zhang, Benyou Wang, and Furu Wei. MathScale: Scaling Instruction Tuning for Mathematical Reasoning. In Proceedings of the 41st International Conference on Machine Learning, pp. 47885–47900. PMLR, July 2024. URL https://proceedings.mlr.press/v235/tang24k.html.
- Team et al. (2024) Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024.
- Team (2024) Qwen Team. Qwen2 technical report. arXiv preprint arXiv:2407.10671, 2024.
- Vinyals et al. (2019) Oriol Vinyals, Igor Babuschkin, Wojciech M. Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H. Choi, Richard Powell, Timo Ewalds, Petko Georgiev, Junhyuk Oh, Dan Horgan, Manuel Kroiss, Ivo Danihelka, Aja Huang, Laurent Sifre, Trevor Cai, John P. Agapiou, Max Jaderberg, Alexander S. Vezhnevets, Rémi Leblond, Tobias Pohlen, Valentin Dalibard, David Budden, Yury Sulsky, James Molloy, Tom L. Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff, Yuhuai Wu, Roman Ring, Dani Yogatama, Dario Wünsch, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Koray Kavukcuoglu, Demis Hassabis, Chris Apps, and David Silver. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782):350–354, November 2019. ISSN 1476-4687. doi: 10.1038/s41586-019-1724-z.
- von Werra et al. (2020) Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020.
- Wu et al. (2025) Mingqi Wu, Zhihao Zhang, Qiaole Dong, Zhiheng Xi, Jun Zhao, Senjie Jin, Xiaoran Fan, Yuhao Zhou, Huijie Lv, Ming Zhang, Yanwei Fu, Qin Liu, Songyang Zhang, and Qi Zhang. Reasoning or Memorization? Unreliable Results of Reinforcement Learning Due to Data Contamination, August 2025.
- Yue et al. (2025) Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?, April 2025.
- Zeng et al. (2025) Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild, March 2025.
- Zhao et al. (2025) Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute Zero: Reinforced Self-play Reasoning with Zero Data, May 2025.
- Zheng et al. (2025) Haizhong Zheng, Yang Zhou, Brian R. Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act Only When It Pays: Efficient Reinforcement Learning for LLM Reasoning via Selective Rollouts, June 2025.
Appendix A Extended Results and Analysis
A.1 Full Results
Table 5: Math reasoning evaluation results for 2B/3B models with individual seed reporting. We report avg@16 per problem for each seed (42, 43, 44) and their average with standard deviation as superscript.
Table 6: Math reasoning evaluation results for 8B models with individual seed reporting. We report avg@16 per problem for each seed (42, 43, 44) and their average with standard deviation as superscript.
We provide the full results of all seeds in Table 5 and 6.
A.2 Case Study
This section provides further analysis of question-solution pairs during training.
As discussed in Section 4.1, the model generates predominantly invalid problems early in training. Majority of these problems, primarily involve simple mathematical concepts like arithmetic, fail due to missing information (Figures4 and 5). When attempting complex topics like optimisation, which are rare in the beginning, the model produces problems with missing information and fundamental formulation errors (Figure6). This reveal the model has limited understanding of underlying mathematical concepts. Invalid problems tend to exhibit low solve rates (≤\leq 0.25) and correspondingly receive lower rewards, helping the model learn to generate valid problems. Consequently, invalid problems decrease rapidly across training (§4.1).
However, not all problems with low solve rates are invalid (§4.2). We find that some problems involving certain topics that are challenging for the model, such as geometric series, persistently exhibit low solve rates (Figures8. The model struggles with exponentiation calculations, resulting in poor performance on geometric series problems. This reveals a fundamental trade-off in OpenSIR: while higher solve rate thresholds effectively filter out invalid problems, they inevitably discourage exploration of genuinely difficult topics. Since these problems have low solvability scores, they are likely to not receive sufficient encouragement to further explore these topics.
In later training stages, we observe OpenSIR gradually expanding into advanced mathematical domains. After 100 training steps, the model starts to generate problems involving concepts like optimisation (Figure9), calculus (Figure10), trigonometry-based physics (Figure11), probability (Figures12), among others. While these advanced problems yield lower solve rates, which indicate the model has a limited understanding of these domains, they achieve high novelty scores with large semantic distances and longer solutions. This progression validates how novelty rewards in OpenSIR drive exploration of diverse mathematical concepts, enabling open-ended learning.
Figure 4: An invalid arithmetic question generated in step 0 with solve rate of 0.25. This question is invalid since the VIP tick price is not provided, and therefore, it’s impossible to calculate the minimum regular ticket price.
Figure 5: An invalid arithmetic question generated in step 0 with solve rate of 0.125. This question is invalid since the two interest rates and principal amounts are not provided. Hence, it’s impossible to calculate the percentage difference with just the general formula provided.
Figure 6: An invalid optimisation question generated in step 0 with solve rate of 0.125. This question is invalid because there are missing information about the constants a, b, and c. There are also ambiguities in the question, such as the role of m and n in the problem. It also did not explain what the elements of the matrix represent. Lastly, it contains problem formulation errors, specifically failing to specify constraints that ensure bounded solutions, demonstrating insufficient understanding of optimization problem structure.
Figure 7: An invalid optimisation question generated in step 0 with solve rate of 0.125. This question is invalid because there are missing information about the constants a, b, and c. There are also ambiguities in the question, such as the role of m and n in the problem. It also did not explain what the elements of the matrix represent. Lastly, it contains problem formulation errors, specifically failing to specify constraints that ensure bounded solutions, demonstrating insufficient understanding of optimization problem structure.
Figure 8: A valid arithmetic problem involving geometric series with a solve rate of 0.125. The solution requires either summing quarterly employee additions or applying the geometric series formula: a⋅r n−1 r−1 a\cdot\frac{r^{n}-1}{r-1}. Llama-3.2-3B-Instruct struggles with exponentiation calculations, resulting in poor performance on geometric series problems.
Figure 9: A valid optimisation problem with a solve rate of 0.375 generated at step 124.
Figure 10: A valid calculus problem with a solve rate of 0.375 generated at step 156.
Figure 11: A valid physics problem that involves trigonometry with a solve rate of 0.5 generated at step 172.
Figure 12: A valid probability problem with a solve rate of 0.25 generated at step 188.
A.3 Further Analysis on Questions Diversity
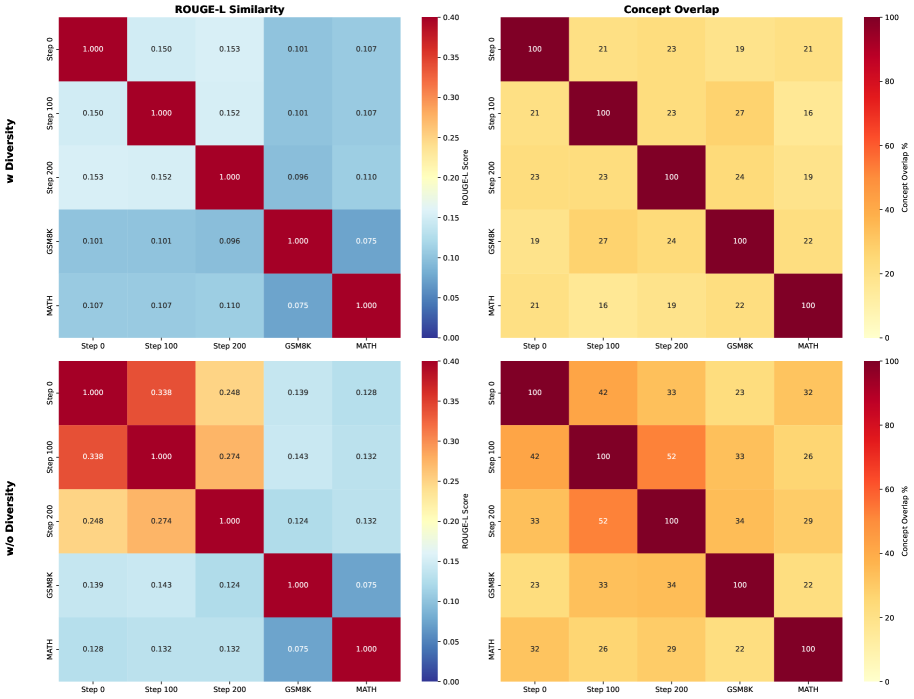
Figure 13: Heatmap visualisation of n-gram similarity (ROUGE-L scores) and concept overlap between generated problems at training steps 0, 100, 200 and reference datasets (MATH, GSM8K). Top row: with diversity reward; Bottom row: without diversity reward. With diversity reward incorporated, the generated problems exhibit low textual similarity and minimal concept overlap, demonstrating effective exploration of diverse problem types.
Figure13 presents n-gram similarity and concept analysis. We compute ROUGE-L scores between problem texts and extract mathematical concepts using GPT-5 from problems at steps 0, 100, and 200, as well as from the MATH and GSM8K training sets. With diversity rewards (top row), problems maintain low ROUGE-L scores and minimal concept overlap both across training stages and with MATH/GSM8K. Without diversity rewards (bottom row), both textual similarity and concept overlap increase, confirming limited exploration of new problem types.
A.4 Further Analysis on Question Difficulty Progression
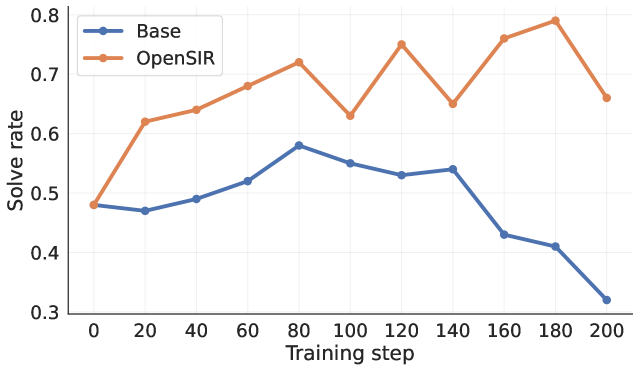
Figure 14: Progression of solve rates of OpenSIR and the initial instruction model as training goes.
Figure14 compares solve rates between the evolving OpenSIR policy and the fixed instruction model (Base) on problems generated during training. While OpenSIR’s solve rate remains stable around 0.7 due to solvability-based problem selection (Section 2.3.1), this constant rate does not imply constant problem difficulty. As OpenSIR improves during training, maintaining the same solve rate requires generating progressively harder problems. To verify this difficulty progression objectively, we measure how the initial instruction model (Base) performs on the same problems. The base model’s solve rate first rises (0.48→\to 0.58 at step 80) then declines (0.58→\to 0.32 at step 200), confirming the V-shaped difficulty pattern trend from Section 4.1: problems initially become easier as OpenSIR learns appropriate calibration, then progressively harder as it increases challenge. Crucially, this pattern shows that OpenSIR’s reasoning ability improved over training.
A.5 Sensitivity to the initial seed problem
To address whether OpenSIR can robustly escape the limited starting point of a trivial arithmetic seed (“What is 1+1?”), we experiment with two substantially different initial seeds using Llama-3.2-3B-Instruct: a geometry problem from the MATH dataset, representing a different mathematical domain, and a competition-level problem from AIME 2024, which is significantly more challenging than the trivial seed.
Figure 15: A geometry problem from the MATH dataset, representing a different mathematical domain from the trivial arithmetic seed.
Figure 16: A competition-level problem from AIME 2024, significantly more challenging than the trivial seed.
Table 7: Performance of OpenSIR with different initial seed problem.
Table 7 shows that all three variants achieve nearly identical performance (38.42, 38.67, and 38.81), with differences of less than 0.5 percentage points. This demonstrates that OpenSIR is robust to the initial seed problem, successfully escaping the limited starting point regardless of whether it begins with trivial arithmetic, a different mathematical domain (geometry), or a significantly more challenging competition-level problem.

Figure 17: t-SNE visualisation of problem embeddings generated by OpenSIR from three different initial seeds. The substantial overlap demonstrates that the method converges to similar problem distributions regardless of the starting point.
Figure 17 visualises the diversity of problems generated at the final training step across the three different initial seeds. The t-SNE embeddings reveal that all three variants produce diverse problems spanning similar regions of the semantic space, with substantial overlap in their distributions regardless of the initial seed. This confirms that OpenSIR successfully escapes its starting point by exploring a wide range of mathematical concepts, driven by the diversity and solvability rewards that encourage continuous exploration beyond the initial problem domain and difficulty level.
A.6 OpenSIR Incentivises Reasoning Capacity
To verify whether OpenSIR elicits genuine reasoning improvements rather than memorisation, we evaluate pass@k performance on five challenging mathematical benchmarks following (Yue et al., 2025).
Figure18 shows that OpenSIR consistently outperforms base instruction models across all k values (8–256) on all benchmarks. These results confirm that OpenSIR drives genuine advances in mathematical reasoning capacity.

Figure 18: Pass@k curves comparing base instruction models and OpenSIR across five mathematical benchmarks. OpenSIR consistently improves performance across all k values, with stable or increasing gaps at higher k, demonstrating genuine reasoning improvements rather than memorization.
A.7 Prolonged Training Analysis
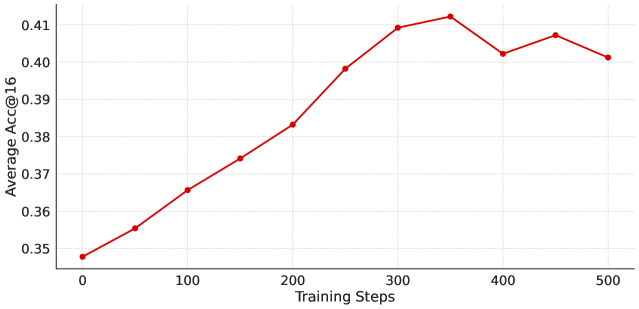
Figure 19: Performance of OpenSIR extended training using Llama-3.2-3B-Instruct.
To better understand the limitation of OpenSIR, we extend training of a single run of Llama-3.2-3B-Instruct to 500 steps, substantially beyond the 200 steps used in the main experiments. Figure 19 shows the evaluation performances over training. We observe consistent improvement from 34.8% to 41.3% at step 350, representing a gain of +6.5 points. Performance then plateaus after step 350 and remains stable around 40-41% through step 500, with no further statistically significant gains.
Preliminary examination of the generated problems suggests a likely cause for this saturation. The model appears to have explored most major mathematical topics by step 350, after which the generated problems become increasingly similar and repetitive. This indicates that the diversity reward mechanism may become less effective over extended training. Future work could investigate more sophisticated diversity mechanisms to foster open-ended exploration over long training horizons.
A.8 Synergy with Annotated Data
Model GSM8K MATH-500 Minerva College OlympiadBench Avg. Math Base 73.94 42.86 15.21 28.78 13.09 34.78 GRPO gsm8k{}_{\text{gsm8k}}79.72 45.30 16.27 33.33 14.56 37.83+3.05 OpenSIR 78.28 46.22 17.46 34.42 15.72 38.42+3.64 GSM8K →\rightarrow OpenSIR 81.43 46.12 19.43 36.15 18.35 40.30+5.52 GSM8K & OpenSIR 81.57 49.48 20.39 36.85 18.14 41.29+6.51
Table 8: The avg@16 performance on five mathematical benchmarks. OpenSIR obtains better results when trained together with GSM8K compared to OpenSIR or GSM8K alone.
While we showed that OpenSIR achieves significant improvements in math reasoning without using annotated data, we further investigate if OpenSIR can be combined with annotated data to achieve even greater performance gains. Having demonstrated that OpenSIR achieves significant improvements without annotated data, we investigate whether combining OpenSIR with annotated data can yield further gains. We focus on Llama-3.2-3B-Instruct and use Gsm8K as the training data, as Table 1 shows that fine-tuning on GSM8K consistently outperforms using MATH.
We explore two training strategies: (1) GSM8K →\rightarrow OpenSIR: The model is first trained on GSM8K for half the training iterations, then trained with OpenSIR for the remaining half. (2) GSM8K & OpenSIR: Each training iteration uses half GSM8k samples and half OpenSIR samples.
Table 8 shows that both setups achieve better performance than using OpenSIR alone or only on GSM8K. One possible explanation for the sequential approach’s effectiveness (GSM8K →\rightarrow OpenSIR) is that training on GSM8K first may improve the model’s foundational reasoning abilities, which could provide a stronger starting point for OpenSIR’s self-generated questions. The concurrent approach (GSM8K & OpenSIR) achieves a slight additional edge, which might be attributed to the model receiving better feedback signals for question calibration from the beginning, as it can leverage both supervised and self-generated data simultaneously throughout training. The precise underlying mechanisms for these improvements require further investigation.
A.9 Computational Cost Analysis
In standard GRPO training, each iteration processes a batch of B B prompts, generating G G responses for each prompt, resulting in B×G B\times G total forward passes per iteration. In method, each training iteration involves generating B B problems and G G solution attempts for each problem, yielding B B forward passes for problem generation and B×G B\times G forward passes for solution generation, for a total of B+B×G=B(1+G)B+B\times G=B(1+G) forward passes. Compared to the B×G B\times G forward passes in standard GRPO training, method requires an additional B B forward passes for problem generation. This represents a relative computational overhead of B B×G=1 G\frac{B}{B\times G}=\frac{1}{G}, or 12.5% with G=8 G=8 solution attempts per problem.
Problem embeddings for diversity scoring are computed asynchronously during solution generation, incurring no additional wall-clock time. Cosine distance calculations between problem embeddings require 𝒪(B×|𝒫 t|)\mathcal{O}(B\times|\mathcal{P}{t}|) operations where |𝒫 t||\mathcal{P}{t}| is the problem pool size, but execute in under 3 seconds per iteration in our experiments—negligible compared to LLM forward passes. Note that while method generates B B problems per iteration, only the top-scoring B/2 B/2 problems are selected for teacher training and another top-scoring B/2 B/2 for student training, as described in Section2.4. Overall, method achieves improved performance without human-annotated training data at this modest computational overhead.
Appendix B Annotation Details
One of the authors prepare the samples for annotation, and the rest of the authors annotated the samples with the instructions provide in Figure 20.
Figure 20: The instruction provided to the annotators to annotate problems.
Appendix C Additional Ablations
C.1 Solution Length Reward Increases Problem Complexity
Table 9: Comparison of OpenSIR performance with and without solution length reward. Solution length reward improves OpenSIR accuracy and increases average question and solution lengths.
We investigate the impact of the solution length reward in OpenSIR. Table9 shows this reward improves performance from 37.86% to 38.42%. It also increases the average question length (from 150 to 207 tokens) and solution lengths (from 238 to 387 tokens). By examining the generated questions manually, we find that the policy tends to generate more sophisticated problems involving advanced concepts with this reward, such as linear programming and optimization, which naturally require longer multi-step solutions to solve. These results demonstrate that the solution length reward effectively guides the policy toward generating more complex problems, which in turn leads to better performance.
C.2 Robustness to Diversity Measurements
Table 10: Comparison of diversity measurement approaches in OpenSIR. Despite slight differences in concept coverage, both embedding-based and concept-based diversity rewards yield nearly identical accuracy, demonstrating the framework’s robustness to the choice of diversity metric.
We have established the necessity of diversity rewards in Section 4.3. In this section, we further investigate OpenSIR’s robustness to different diversity measurement approaches. We implement concept-based diversity by measuring diversity through the mathematical concepts of the problems (Lu et al., 2023; Havrilla et al., 2025). Formally, we define the concept diversity reward as:
r con(q)=|𝒞 q|−|𝒞 q∩𝒞 𝒫 t−1|3 r_{\text{con}}(q)=\frac{|\mathcal{C}{q}|-|\mathcal{C}{q}\cap\mathcal{C}{\mathcal{P}{t-1}}|}{3}(10)
where 𝒞 q\mathcal{C}{q} are the concepts in problem q q and 𝒞 𝒫 t−1=⋃q′∈𝒫 t−1 𝒞 q′\mathcal{C}{\mathcal{P}{t-1}}=\bigcup{q^{\prime}\in\mathcal{P}{t-1}}\mathcal{C}{q^{\prime}} represents the union of concepts from all problems in the existing pool. Since each problem contains at most three concepts, this reward calculates the fraction of new concepts introduced.
Table 10 shows that both embedding-based and concept-based diversity rewards achieve similar accuracy (38.42 vs 38.26), demonstrating the framework’s robustness to the choice of diversity metric. Beyond accuracy, we examine concept coverage, which refers to the number of unique mathematical concepts discovered during training, as a direct measure of exploratory diversity. As expected, concept-based diversity achieves slightly higher coverage (6,213 concepts) since it explicitly optimises for novel concept discovery. Surprisingly, embedding-based diversity attains comparable coverage (5,914 concepts), 95% of the concept-based approach, despite not tracking concepts explicitly. This suggests that maximising representational spread in embedding space effectively promotes novelty discovery, achieving open-ended learning.
Appendix D Implementation Details
D.1 Training Details
Category Hyperparameter Value Trainer Learning rate 3×10−7 3\times 10^{-7} Optimiser AdamW (Loshchilov & Hutter, 2018) Warmup steps 20 Training steps 100/200 KL loss coefficient 1×10−4 1\times 10^{-4} Gradient norm clipping 0.5 Seeds 42/43/44 GPUs 3 H100 Rollout Batch size†\dagger 256 Max prompt length 1024 Max solution length 2048 Number of rollouts per prompt 8 Temperature 1.0 Teacher Rewards Solvability weight (α\alpha)1.0 Solution length weight (λ\lambda)1.0 Diversity weight (γ\gamma)1.0 Format weight (δ\delta)0.1 Embedding model Linq-Embed-Mistral (7B) Student Rewards Accuracy weight 1.0 Format weight (δ\delta)0.1
- †\dagger The number of rollouts seen for one gradient update.
Table 11: The training configurations for the experiments.
We implement OpenSIR based on the TRL framework (von Werra et al., 2020). Table 11 provides a summary of the training hyperparameters used in our experiments.
D.2 Prompts
We detailed the prompt for generating problems in Figure 21 and solving problems in Figure 22.
Figure 21: Prompt for generating math problems. {Problem} is a placeholder for the reference problem sampled from the problem pool.
Figure 22: Prompt for generating solutions to math problems. {Problem} is a placeholder for the actual problem.
Xet Storage Details
- Size:
- 86.1 kB
- Xet hash:
- f55e70fefc92e401483f5f97842a0b433e4e811e843106f7a14bfed820e0d18b
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.