Buckets:

Title: 1 Introduction
URL Source: https://arxiv.org/html/2601.01498
Markdown Content:
Abstract
The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
\useunder
\ul
![Image 1: [Uncaptioned image]](https://arxiv.org/html/2601.01498v1/x1.png)
From Failure to Mastery: Generating Hard Samples for Tool-use Agents
Bingguang Hao 1*, Zengzhuang Xu 1*, Yuntao Wen 1*, Xinyi Xu 1*, Yang Liu 2*,
Tong Zhao 2, Maolin Wang 3, Long Chen 1, Dong Wang 1, Yicheng Chen 1,
Cunyin Peng 1, Xiangyu Zhao 3, Chenyi Zhuang 1‡, Ji Zhang 4‡
1 Inclusion AI, Ant Group 2 Zhejiang University
3 City University of Hong Kong 4 Southwest Jiaotong University
{bingguanghao7,jizhang.jim}@gmail.com{chenyi.zcy}@antgroup.com
![Image 2: [Uncaptioned image]](https://arxiv.org/html/2601.01498v1/x2.png)
††footnotetext: *Equal contributions. ‡Corresponding Authors.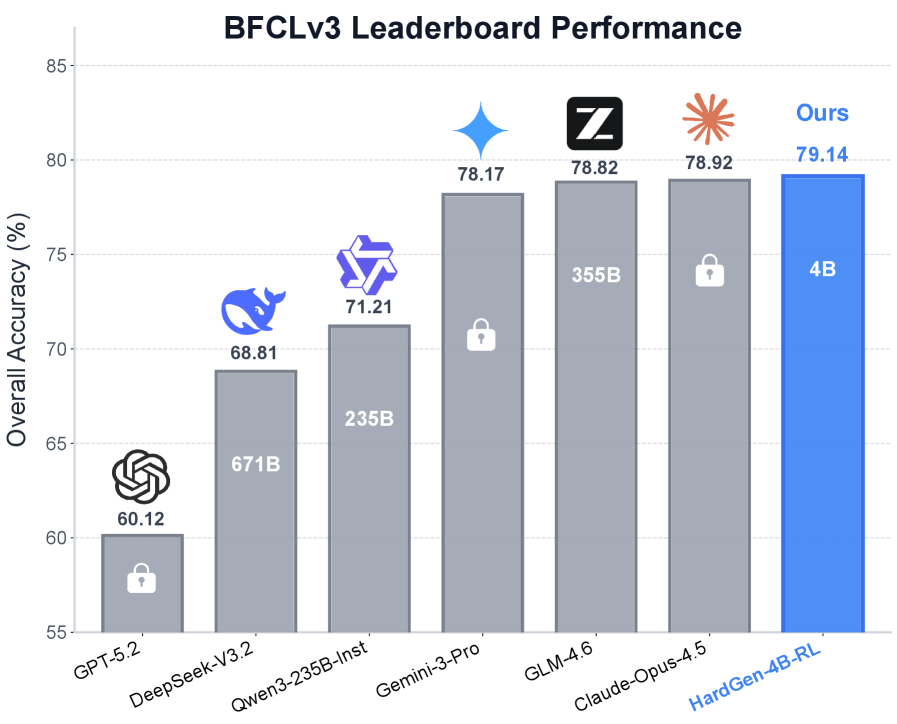
Figure 1: Performance comparison on the BFCLv3 Leaderboard patilberkeley. A Qwen3-4B yang2025qwen3 model trained with our curated dataset, denoted as HardGen-4B-RL, consistently outperforms leading open-source and closed-source models.
Equipping Large Language Models (LLMs) with the capability to execute external tools 1 1 1 We use tools and APIs interchangeably in this paper., primarily through Function Calling (FC), has significantly expanded the boundaries of artificial intelligence(wang2025function; shen2024llm; wang2025empiricalstudyagentdevelope). As agents are deployed in increasingly sophisticated scenarios—from enterprise workflow automation to intricate data analysis—the demand for high-quality, diverse, and complex training corpora has become the primary bottleneck limiting their advancement(liu2024apigen; zeng2025toolace). While recent works have made strides in synthesizing diverse datasets, existing data generation pipelines predominantly adhere to a paradigm of random sampling and shallow generation—randomly selecting API combinations from static tool pools and generating trajectories through basic user-assistant simulation(huang2025ttpa; prabhakar2025apigen). Trajectories generated by those pipelines tend to be homogeneous and follow a “happy path”, failing to capture the implicit logical dependencies and multi-turn reasoning required in hard real-world tasks. For instance, real-world problems often necessitate bridging logical gaps, where the output of one tool serves as a latent precondition for another, or implicitly parameterizes the subsequent tool call. Current pipelines often miss these deep structural complexities, resulting in agents that are robust on simple queries but fragile when facing hard, logically-intertwined instructions(zhang2025looptool; yin2025magnet).
To bridge this gap, we introduce HardGen, an automated agentic pipeline designed to synthesize challenging training samples for overcoming the performance bottleneck of tool-use agents. Unlike previous pipelines that focus primarily on broadening API coverage or enforcing syntactic correctness, HardGen prioritizes the logical complexity and difficulty of the generated trajectories. The core philosophy of HardGen is to learn from failure and evolve through feedback. Specifically, instead of sampling from a static tool pool, HardGen establishes a dynamic API Graph derived explicitly from agent failure cases. This allows the pipeline to synthesize hard traces that target the specific weaknesses of models. Next, we utilize these traces as conditional priors to guide the instantiation of modular, abstract advanced tools. These tools are then leveraged as stepping stones to formulate hard queries that necessitate multi-step reasoning and implicit dependency, moving beyond simple API pattern matching. At the end, the synergy of advanced tools and hard queries facilitates the generation of complex Chain-of-Thoughts (CoTs), with a closed-loop evaluation feedback mechanism steering the continuous refinement of the generation process, where reasoning correctness is further verified through a function call checking module. This robust, repeatable pipeline enables HardGen to construct trajectories of high diversity and complexity for tool-use agents.
Generated Dataset. With HardGen, we construct a comprehensive dataset containing 27,000 trajectories with 2,095 APIs from real environments (see Section˜3.5). Our dataset encompasses a rich spectrum of complex interaction scenarios, particularly hard queries necessitating implicit logical bridging, where agents must autonomously infer tool dependencies and perform multi-step reasoning without explicit guidance. This large-scale, high-fidelity corpus is designed to overcome the complexity bottleneck in tool-use agent research, providing the community with a verifiable and rigorous foundation for training models capable of mastering deep logical dependencies.
Remarkable Results. We evaluate our pipeline by performing SFT or RL training on the Qwen3-4B yang2025qwen3 model using the HardGen curated dataset. The resulting models, denoted as HardGen-4B-SFT and HardGen-4B-RL, are evaluated against several leading proprietary models on the challenging BFCLv3 patilberkeley and other benchmarks. Despite its compact 4B scale, HardGen-4B-RL attains an overall accuracy of 79.14%, setting a new state-of-the-art record of its size (see Table˜2). For example, despite the massive disparity in model scale, HardGen-4B-RL achieves superior advantages over the latest strong competitors, surpassing GPT-5.2 openai2025gpt5.2 by 19.02%, DeepSeek-V3.2 liu2025deepseek by 10.33% and Grok-4.1-Fast xaigrok4.1 by 3.94% (see Figure˜1). Crucially, these gains generalize to held-out benchmark (BFCLv4 patilberkeley), validating that the model learns robust agentic reasoning patterns rather than memorizing templates.
Our contributions are summarized as follows:
- •We propose HardGen, a novel pipeline targeting generating hard function-calling data for tool-use agents.
- •HardGen is compatible with a wide spectrum of APIs and models, facilitating the synthesis of tool-use datasets characterized by both high fidelity and complexity.
- •Extensive experiments demonstrate that models trained on our generated data achieve superior performance, allowing a 4B parameter model to surpass powerful competitors.

Figure 2: Overview of the HardGen framework. The pipeline operates in three phases: I) Failure-inspired Hard Trace Sampling to identify error-prone tool dependencies and construct hard tool traces; II) Trace-conditioned Tool Evolution to synthesize advanced tools and hard queries based on the constructed hard traces; and III) Feedback-guided CoT Refinement to verify and optimize reasoning chains through a closed-loop mechanism.
2 Related Work
Tool-use Ability of LLM. Empowering LLMs to interact with external APIs is pivotal for the realization of autonomous agentic systems wang2025function; FunReason. By bridging the gap between static knowledge and dynamic execution, this paradigm enables models to interrogate databases, synthesize code, and manipulate digital interfaces jimenez2023swe; mohammadjafari2024natural; OSWorld; gao2406simulating. Yet, the transition from isolated function invocations to coherent, multi-turn tool orchestration presents a substantial barrier guo2025deepseek; chen2025acebench; patilberkeley. In these scenarios, agents are required to maintain state and resolve dependencies over extended interaction horizons. The core bottleneck is the lack of large-scale, verifiable training corpora that faithfully encode realistic multi-turn interactions, including implicit preconditions, parameter couplings, and cross-turn logical dependencies prabhakar2025apigen; xu2025toucan; yin2025magnet.
Data Synthesis for Tool-use Training. Current paradigms in tool-use data generation focus predominantly on expanding breadth and ensuring executability yin2025magnet; acikgoz2025can, typically via synthesis from fixed toolsets or multi-agent simulations prabhakar2025apigen; yin2025magnet. Although these methods scale dataset size xu2025toucan, they suffer from a critical limitation: the difficulty of the generated trajectories is often artificial—derived from explicit structural constraints—rather than reflecting the intrinsic reasoning hurdles and implicit dependencies characteristic of authentic agentic workflows zeng2025toolace; lam2024closer; xu2025toucan. In contrast, our HardGen aims to generate complex, verifiable tool-use trajectories that deliver grounded reasoning for SFT and precise rewards for RL qian2025toolrl; RLFC, thereby driving superior performance in agentic tasks.
3 The Proposed HardGen Pipeline
In this section, we present HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning.
3.1 Overview
As the overview illustrated in Figure˜2 and notations shown in Table˜1, HardGen consists of three coordinated phases: First, we identify error-prone function calls via model evaluation on a self-evaluation query set. These “failure APIs” are then structured into a dynamic API Graph, which is iteratively updated through interactions with an execution environment to capture complex tool dependencies. Second, we sequentially feed the generated tool traces from the API Graph into a Tool Maker and a Hard-query Generator, which evolves simple functions into advanced tools and synthesize corresponding high-complexity queries. Third, we employ a Reasoner-Verifier loop to execute these hard queries, using environment feedback to rigorously filter and refine function calls and CoTs. By repeating this three-phase process, our HardGen generates reliable and complex multi-turn trajectories, which contain hard queries, primitive tools, verified CoTs and function calls.
Symbol Concept 𝒮\mathcal{S}Environment Simulation Space 𝒯\mathcal{T}Failure API Set 𝒢=(𝒯,𝒟,𝒫)\mathcal{G}=(\mathcal{T},\mathcal{D},\mathcal{P})API Graph (Failure API Set 𝒯\mathcal{T}, Dependencies 𝒟\mathcal{D}, Parameters 𝒫\mathcal{P}) A T,A Q,A R,A V A_{T},A_{Q},A_{R},A_{V}Agents: Tool Maker, Hard-query Generator, Reasoner, Verifier T a∈𝒯 T_{a}\in\mathcal{T}Selected Tool Q hard Q_{hard}Hard Query T adv T_{adv}Advanced Tool M M Number of Tool Calls Per Trace N N Number of Turns Per Trajectory
Table 1: Core notations. Summary of symbols and definitions used in this work.
3.2 Phase I: Failure-inspired Hard Trace Sampling
Rather than uniformly sampling tool combinations, this phase leverages a failure-driven self-evaluation to surface tools and dependencies that the current model struggles with. The resulting API Graph serves as a structured representation of failure-prone tools and their latent interaction patterns, from which a series of hard and valuable tool traces can be sampled.
Failure-driven Self-evaluation and Graph Construction.
We deploy a large-scale API environment comprising 2,095 tools to perform model self-evaluation. For each tool, HardGen generates an execution trace and constructs a corresponding hard query, forming a Self-evaluation Query Set used to evaluate Qwen3-4B yang2025qwen3 and Llama-3.2-3B-Instruct dubey2024llama. A tool is designated as challenging if both models produce incorrect execution results during inference. Through this process, we identify 1,204 challenging tools, which are incrementally incorporated into both the Failure API Set 𝒯\mathcal{T} and API Graph 𝒢\mathcal{G}, enabling systematic capture of challenging tools and their dependencies. The graph construction and its update are shown in the AppendixG. Despite performing evaluation and construction solely on Qwen3 models, our approach demonstrates robust performance across heterogeneous architectures including Llama-3 (see Table˜12) and Qwen2.5 (see Table˜3), validating the strong generalization capability of the HardGen synthesized data.
Legality-constrained Sampling.
To guarantee execution validity, tool selection is subject to a strict dependency constraint: a tool T a T_{a} is callable if and only if all its prerequisite dependency tools (𝒟 T a\mathcal{D}{T{a}}) have been executed previously, denoted by 𝒯 called\mathcal{T}_{\text{called}}. This legality condition is formalized as
I(T a,𝒯 called)=𝟏{𝒟 T a⊆𝒯 called},I(T_{a},\mathcal{T}{\text{called}})=\mathbf{1}{{\mathcal{D}{T{a}}\subseteq\mathcal{T}_{\text{called}}}},(1)
where 𝟏{⋅}\mathbf{1}_{{\cdot}} is the indicator function.
Hard Trace Sampling.
To reach the selected target tool T a T_{a} while satisfying its prerequisite constraints, we design a Sampler that explicitly biases trace construction toward T a T_{a}. Specifically, the Sampler employs a greedy heuristic over the set of legal tools 𝒯 legal\mathcal{T}{\text{legal}}, prioritizing tools that minimize the graph distance dist(⋅,⋅)\text{dist}(\cdot,\cdot) to T a T{a}. Here, dist(T k,T a)\text{dist}(T_{k},T_{a}) denotes the length of the shortest path from T k T_{k} to T a T_{a} in the API graph 𝒢\mathcal{G}. The resulting sampling policy is formally defined as:
T s\displaystyle T_{s}=Sampler(T a,𝒯 called)\displaystyle=\operatorname{Sampler}(T_{a},\mathcal{T}{\text{called}})(2) ={rand(𝒯 legal),T a∈𝒯 called,T a,I(T a,𝒯 called)=1∧T a∉𝒯 called,argmin T kdist(T k,T a),otherwise.\displaystyle=\left{\begin{array}[]{@{}l@{\quad}l@{}}\operatorname{rand}(\mathcal{T}{\text{legal}}),&T_{a}\in\mathcal{T}{\text{called}},\[4.0pt] T{a},&\hskip-80.00012ptI(T_{a},\mathcal{T}{\text{called}})=1\land T{a}\notin\mathcal{T}{\text{called}},\[4.0pt] \displaystyle\operatorname*{arg,min}{T_{k}}\operatorname{dist}(T_{k},T_{a}),&\text{otherwise}.\end{array}\right.
The sampled tool T s T_{s} is executed with parameters P s P_{s} as a call C s=(T s,P s)C_{s}=(T_{s},P_{s}), producing environment feedback E s E_{s} and updating the system state 𝒮\mathcal{S}, the set of executed tools 𝒯 called\mathcal{T}{\text{called}}, and the dynamic API graph 𝒢\mathcal{G}. The resulting execution sequence is recorded as an executable hard trace Γ i=(C 1,E 1,C 2,E 2,…,C M,E M)\Gamma{i}=(C_{1},E_{1},C_{2},E_{2},\dots,C_{M},E_{M}), which serves as a failure-aware prior for subsequent phases.
3.3 Phase II: Trace-conditioned Tool Evolution
The hard trace Γ i\Gamma_{i} generated in Phase I guarantees correct tool execution and faithfully captures the underlying operational sequence. However, a central challenge in training robust tool-use agents lies in enabling _implicit logical bridging_—the ability to autonomously infer the necessary intermediate steps when faced with hard queries that do not explicitly specify the full tool chain. Directly generating queries from execution traces, where all intermediate steps are explicitly enumerated, fails to cultivate this capability, as models can simply rely on pattern matching rather than learning to bridge logical gaps. To address this challenge, Phase II reinterprets the trace via a two-stage evolution process: it first abstracts the multi-step execution into a unified high-level operation, and then constructs a challenging hard query that explicitly requires this abstraction.
Advanced Tool Construction.
Given Γ i\Gamma_{i}, the Tool Maker (A T A_{T}) synthesizes a unified high-level operation abstraction, denoted as the advanced tool T adv T_{\text{adv}}:
T adv=A T(Γ i),T_{\text{adv}}=A_{T}\left(\Gamma_{i}\right),(3)
where A T A_{T} abstracts the multi-step execution trace into a high-level operation that encapsulates the collective functionality and interdependencies of all tool calls within Γ i\Gamma_{i}.
Hard Query Generation.
Conditioned on the synthesized advanced tool T adv T_{\text{adv}}, the Hard-query Generator (A Q A_{Q}) generates a challenging query Q hard Q_{\text{hard}} that explicitly requires the use of T adv T_{\text{adv}} for resolution. Formally, the process is expressed as:
Q hard=A Q(T adv).Q_{\text{hard}}=A_{Q}\left(T_{\text{adv}}\right).(4)
3.4 Phase III: Feedback-guided CoT Refinement
While the hard query Q hard Q_{\text{hard}} constructed in Phase II effectively challenges the model with implicit logical dependencies, it also amplifies the difficulty of generating correct and coherent Chain-of-Thought (CoT) reasoning. To mitigate this issue, Phase III implements an iterative refinement mechanism that progressively corrects flawed reasoning via feedback-driven prompting, guiding the CoT from erroneous states toward correct solutions.
Reasoning with Hint.
Given the hard query Q hard Q_{\text{hard}}, the Reasoner A R A_{R} attempts to generate the correct function call with the hint from the description of the advanced tool T adv T_{\text{adv}}. The initial prompt, denoted as Prompt i(1)\text{Prompt}^{(1)}_{i}, is constructed from the hard query, the primitive tool set used to define the advanced tool, and the advanced tool description.
Error Diagnosis.
When the current attempt fails (i.e., FC i(k)≠C i\text{FC}^{(k)}{i}\neq C{i}), the Verifier A V A_{V} analyzes the discrepancy between the incorrect function call and the ground truth. The Verifier identifies the specific error and generates corrective hint feedback Error i(k)\text{Error}^{(k)}_{i} that guides correction without exposing the answer.
CoT Refinement.
For step i∈{1,…,M}i\in{1,\ldots,M} at its k k-th attempt , we incorporate the corrective hint Error i(k)\text{Error}^{(k)}_{i} into the current prompt through concatenation:
Prompt i(k+1)=Concat(Prompt i(k),Error i(k)).\text{Prompt}^{(k+1)}{i}=\text{Concat}(\text{Prompt}^{(k)}{i},\text{Error}^{(k)}_{i}).(5)
With this augmented prompt, A R A_{R} is re-invoked to produce a refined solution, yielding an updated reasoning process CoT i(k+1)\text{CoT}^{(k+1)}{i} and function call FC i(k+1)\text{FC}{i}^{(k+1)}. This iterative refinement continues until either the function call is correct or the maximum number of attempts Kmax K{\max} is reached.
Upon successfully generating the correct function call C i C_{i} at step i i on the k k-th attempt, the environment execution feedback E i E_{i} is incorporated into the prompt for the subsequent i+1 i+1 step via concatenation: Prompt i+1(1)=Concat(Prompt i(k),C i,E i)\text{Prompt}^{(1)}{i+1}=\text{Concat}(\text{Prompt}^{(k)}{i},C_{i},E_{i}). This design ensures that subsequent reasoning is explicitly conditioned on the complete execution history accumulated up to the current step. A trace is retained only if all M M function calls are correctly generated across the entire sequence.
3.5 Generated Dataset
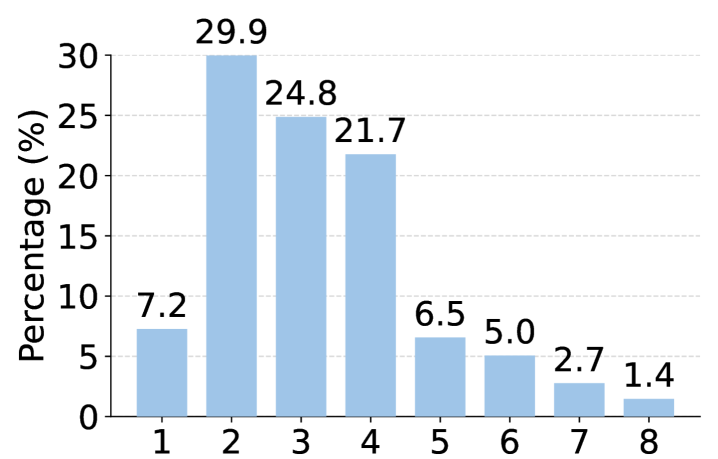
Metric Value Total Trajectories 27,000 Max. Tool Calls 8 Min. Tool Calls 1 Avg. Tool Calls 3.21 Min. Turns 1 Max. Turns 8 Avg. Turns 3.32
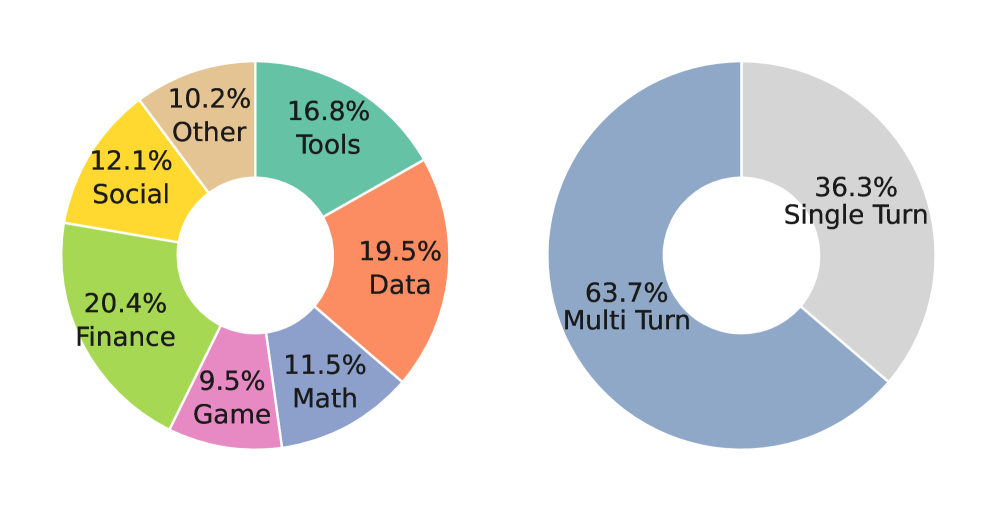
Figure 3: Statistics and distribution of the generated dataset. (Top) Histogram of tool calls per trajectory (left) and key dataset metrics (right). (Bottom) Distribution of API domains (left), the proportion of single-turn and multi-turn trajectories (right).
Single-Turn Multi-Turn Model Parameter Counts Non-Live Live Subset Overall Base Miss Func Miss Param Long Context Subset Overall Overall Closed-source Claude-Opus-4-5-20251101-88.58 79.79 84.19 81.00 64.00 58.00 70.50 68.38 78.92 Claude-Sonnet-4-5-20250929-88.65 81.13 84.89 69.00 65.00 52.50 59.00 61.38 77.05 Claude-Haiku-4-5-20251001-86.50 78.68 82.59 63.50 42.50 52.50 56.00 53.63 72.93 Gemini-3-Pro-Preview-90.65 83.12 86.89 64.50 60.00 54.50 64.00 60.75 78.17 Gemini-2.5-Flash-84.96 74.39 79.68 41.50 36.00 32.00 35.50 36.25 65.20 Grok-4-1-fast-reasoning-88.27 78.46 83.37 70.50 59.50 43.00 62.50 58.88 75.20 Grok-4-1-fast-non-reasoning-88.13 77.94 83.04 58.00 39.50 37.50 52.00 46.75 70.94 GPT-5.2-2025-12-11-81.85 70.39 76.12 36.50 18.00 27.50 30.50 28.13 60.12 GPT-4o-2024-11-20-83.88 70.54 77.21 55.50 34.50 29.00 51.00 42.50 65.64 Open-source Kimi-K2-Instruct 1043B 81.60 78.68 80.14 62.00 41.00 44.50 55.00 50.63 70.30 DeepSeek-V3.2-Exp 671B 85.52 76.02 80.77 55.00 49.00 27.00 48.50 44.88 68.81 Llama-4-Maverick 400B 88.65 73.65 81.15 27.00 22.00 14.00 18.00 20.25 60.85 GLM-4.6 355B 87.56 80.90 84.23 74.50 68.00 63.00 66.50 68.00 78.82 Qwen3-235B-A22B-Instruct 235B 90.33 78.68 84.51 54.00 42.50 31.50 50.50 44.63 71.21 Qwen3-32B 32B 88.77 82.01 85.39 56.00 52.50 40.00 43.00 47.88 72.88 Qwen3-30B-A3B-Thinking 30B 85.77 77.94 81.86 43.50 10.50 25.00 41.00 30.00 64.57 ToolACE-2-8B 8B 87.10 77.42 82.26 49.00 28.00 30.50 46.00 38.38 67.63 ToolACE-MT 8B 84.94 71.52 78.23 57.50 31.50 34.00 38.00 40.25 65.57 Nanbeige4-3B-Thinking-2511 3B 81.58 79.42 80.50 58.50 54.00 45.00 47.00 51.12 70.71 xLAM-2-3b-fc-r 3B 82.96 62.92 72.94 71.50 59.00 57.50 45.50 58.38 68.09 Qwen3-4B (Base Model)4B 87.88 76.39 82.14 26.50 21.00 15.50 25.50 22.13 62.13 HardGen-4B-SFT 4B 89.03 82.42 85.73 55.20 49.10 41.40 52.90 49.65 73.70 Δ\Delta+1.15+6.03+3.59+28.70+28.10+25.90+27.40+27.52+11.57 HardGen-4B-RL 4B 90.73 83.55 87.14 68.50 64.50 50.50 69.00 63.13 79.14 Δ\Delta+2.85+7.16+5.00+42.00+43.50+35.00+43.50+41.00+17.01
Table 2: Performance on BFCLv3 (last updated on 2025-12-16). All metrics are calculated using the official script and reported in terms of Accuracy (%).
We deploy HardGen on a large-scale real-world API environment comprising 2,095 tools, of which 1,204 are identified as Failure Tools through systematic Self-evaluation. Training trajectories are synthesized using the HardGen pipeline, with Qwen3-30B-A3B-Thinking yang2025qwen3 serving as the backbone of the four agents. The system employs a maximum attempt limit of K max=3 K_{\max}=3, which we find offers a favorable balance between trajectory quality and computational cost. As shown in Figure˜3, the resulting dataset comprises 27,000 high-quality trajectories that exhibit substantial diversity across multiple dimensions. First, in terms of task complexity, trajectories span 1 to 8 tool calls (with an average of 3.21), and 62.1% of them contain three or more tool calls within a single trace. Second, regarding API coverage, the dataset spans diverse domains including Finance (20.4%), Game (9.5%), Tools (16.8%), and Data (19.5%), ensuring broad applicability. Third, the trajectories capture rich reasoning patterns, from straightforward single-turn executions (36.3%) to complex multi-turn scenarios (63.7%) requiring sophisticated inference capabilities. A supplementary trajectory case and the prompts of corresponding agents are shown in AppendixH and AppendixI.
4 Experiments
In this section, we evaluate our proposed pipeline by performing Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on several baseline models using the HardGen curated dataset.
4.1 Experiment Setup
Baseline Models. We employ Qwen3-4B as our main baseline model yang2025qwen3. To validate the generalizability of our pipeline, we additionally conduct experiment with Qwen2.5-7B-Instruct team2024qwen2, Llama-3-3B/8B-Instruct dubey2024llama, and Qwen3-0.6B/1.7B. We split the 27,000 trajectories at each assistant response and train the model to generate only the current-turn response. We perform SFT with LLaMA-Factory zheng2024llamafactory and RL with Verl sheng2024hybridflow. Implementations are detailed in AppendixD.
Benchmarks. We evaluate our models on BFCLv3 patilberkeley, API-Bank li2023api, and ACEBench chen2025acebench, covering both single-turn and multi-turn tool-calling scenarios (see AppendixD). To evaluate out-of-distribution generalization and assess how the proposed training data impacts specific agentic capabilities, we include BFCLv4 as a held-out benchmark patilberkeley. BFCLv4 offers a comprehensive evaluation of agentic behaviors in Web Search and Memory scenarios, with details provided in AppendixC.
4.2 Experimental Results
Results on BFCLv3. As shown in Table˜2, on the BFCLv3 benchmark patilberkeley, models trained with HardGen yield notable improvements on Qwen3-4B, raising the multi-turn score from 22.13 to 49.65 (+27.52) after SFT and to 63.13 (+41.01) after RL. Despite its 4B parameter size, the HardGen RL-trained model surpasses strong open-source models (e.g., Kimi-K2-Inst team2025kimi, DeepSeek-V3.2 liu2025deepseek) and leading closed-source models (e.g., GPT-5.2 openai2025gpt5.2, Gemini-3-Pro gemini3pro, Claude-Opus-4.5 claudeopus4.5), setting a new state-of-the-art record of its size. In addition, models trained with HardGen demonstrate balanced performance across all sub-metrics, indicating strong generalization and stability. A particularly compelling result is that both HardGen-4B-SFT and HardGen-4B-RL outperform Qwen3-30B-A3B-Thinking yang2025qwen3 by a substantial margin across all sub-metrics. This result validates that our failure-driven sampling, trace-conditioned tool evolution, and feedback-guided refinement jointly form a virtuous cycle of capability amplification, effectively transcending the inherent limitations of the generator model. To further assess the generalizability of HardGen-synthesized data, we report results on the Llama model family in AppendixF, demonstrating consistent improvements across diverse model architectures.
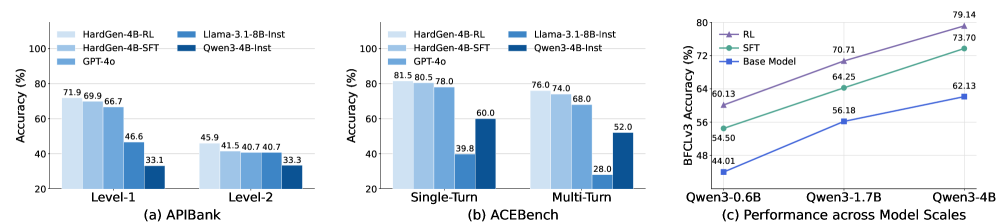
Figure 4: Additional evaluations. (a) (b) Comparison of different models on APIBank and ACEBench. (c) Scaling trends of HardGen-SFT and HardGen-RL on BFCLv3 across model parameters.
Model Single-Turn Multi-Turn Overall Qwen2.5-7B-Instruct (Base Model)77.30 7.62 54.07 TOUCAN xu2025toucan 76.51 22.62 58.55 MAGNET yin2025magnet 80.49 21.12 60.70 ToolACE-MT zeng2025toolace 80.51 27.57 62.86
- HardGen-SFT 83.99 40.75 69.58 Δ\Delta+6.69+33.13+15.51
Table 3: Comparison with state-of-the-art data synthesis pipelines on BFCLv3. The baseline model is Qwen2.5-7B-Instruct.
Results on APIBank and ACEBench.Figure˜4(a) and Figure˜4(b) present the performance of our models on two additional benchmarks, APIBank and ACEBench. On APIBank li2023api, our models achieve top-tier Level-1 accuracies of 71.9 and 69.9, clearly outperforming GPT-4o hurst2024gpt, which attains 66.7. For the more challenging Level-2 tasks, our models continue to demonstrate strong performance, yielding improvements of +12.6 and +8.2 percentage points over the base model (33.3), respectively. Evaluation on ACEBench chen2025acebench further confirms robust generalization under both training configurations. On the single-turn subset, our models reach accuracies of 81.5 and 80.5, surpassing both GPT-4o (78.0) and Llama-3.1-8B-Instruct (39.8) by substantial margins. This advantage is more pronounced in the multi-turn setting, where our models achieve scores of 76.0 and 74.0, exceeding Llama-3.1-8B-Instruct (28.0) by 48.0 and 46.0 percentage points, respectively. Overall, these results provide compelling evidence that models trained on HardGen synthesized dataset exhibit strong and consistent tool-use capabilities across diverse benchmarks and interaction settings.
Comparison with State-of-the-art. To further demonstrate the efficacy of HardGen, we compare it against state-of-the-art data synthesis pipelines using Qwen2.5-7B-Instruct under an SFT-only setting, as reported in Table˜3. While prior methods such as MAGNET yin2025magnet, TOUCAN xu2025toucan, and ToolACE-MT zeng2025toolace offer incremental gains over the base model, HardGen establishes a clear and consistent performance advantage. Notably, our method secures a score of 83.99 (+6.69) in single-turn tasks and delivers a striking 40.75 (+33.13) in multi-turn interactions. This substantial margin validates HardGen as a more robust and effective data generation strategy for complex tool-use scenarios.
4.3 Ablation Study
In this section, we present ablative results to further scrutinize our proposed HardGen pipeline.
Hard Query Qwen3-4B Llama-3-3B Single-Turn Multi-Turn Single-Turn Multi-Turn ✗84.17 54.38 79.08 32.23 ✓87.14 63.13 84.05 40.13
Table 4: Impact of hard queries. Both Qwen3-4B and Llama-3-3B are trained with RL using data with or without hard queries.
Does HardGen’s effectiveness scale with model size? To investigate the scalability of our approach, we evaluate the performance of the HardGen synthesized dataset across base models ranging from 0.6B to 4B parameters on the BFCLv3 benchmark. As shown in Figure˜4(c), model performance consistently improves with increasing scale under both training paradigms. Specifically, the Qwen3-0.6B model registers a gain of +13.74 points (rising from 34.93 to 48.67) via RL, whereas Qwen3-4B realizes a more substantial improvement of +16.93 points (60.21 to 77.14). Furthermore, RL consistently outperforms SFT across all model sizes, with the performance gap widening as the base model scales up. This trend indicates that HardGen-synthesized data is inherently well aligned with RL, enabling stronger base models—particularly at larger scales—to more effectively leverage RL for improving tool-use capabilities.
How much do hard queries affect the quality of the synthesized data? To assess the impact of the constructed hard queries on data quality, we perform ablation studies by conducting RL training on Qwen3-4B and Llama-3-3B. As shown in Table˜4, incorporating hard queries leads to consistent performance improvements across both model architectures and evaluation tasks. Specifically, for Qwen3-4B, training with hard queries yields notable gains of +8.75 points in the multi-turn subset (from 54.38 to 63.13) and +2.97 points in the single-turn subset (from 84.17 to 87.14). Similarly, Llama-3-3B benefits from hard queries, achieving improvements of +7.90 and +4.97 points in the multi-turn and single-turn subsets, respectively. The consistent gains observed across architectures and evaluation tasks demonstrate that the constructed hard queries substantially enhance the quality of the synthesized data, leading to stronger tool-use capabilities, particularly in more challenging multi-turn scenarios, where the improvements are most pronounced.
Model w/o T adv T_{adv}w/ T adv T_{adv} Qwen3-30B-A3B-Thinking 177 223 Qwen3-235B-A22B-Thinking 159 241 DeepSeek-V3.1 (671B)125 275
Table 5: Impact of the constructed advanced tools T adv T_{adv} across different model scales. The values denoted the number of instances deemed more difficult by GPT-4o from a pool of 400 generated queries.
Do advanced tools really help with making logical bridging? To evaluate the contribution of the constructed advanced tools T adv T_{adv} to logical jump bridging, we conduct a controlled comparison between model variants with and without T adv T_{adv} under identical configurations. Each model is evaluated on 400 query-synthesis instances, where every instance produces two queries: one that leverages T adv T_{adv} for logical bridging and one that does not. GPT-4o is employed as an automated judge to determine which variant yields a more challenging query, i.e., one involving more difficult logical jumps. As shown in Table˜5, incorporating T adv T_{\mathrm{adv}} consistently increases the proportion of challenging queries across all model scales, with the number of such instances rising from 223 to 275 as model capacity increases from 30B to 671B. This trend indicates that T adv T_{adv} effectively facilitates logical bridging, which is more pronounced with increasing model capacity. Since the subjective nature of difficulty judgments, we further complement the automated evaluation with a human annotation study in AppendixE, using the same rubric for assessing logical-jump difficulty. The results show a high level of agreement between the automated judge and human annotators, supporting the conclusion that T adv T_{adv} reliably increases implicit logical-bridging difficulty.
Model w/o Feedback w/ Feedback Δ\Delta Qwen3-30B-A3B-Thinking 77.80%90.14%+12.34% Qwen3-235B-A22B-Thinking 82.57%92.78%+10.21% DeepSeek-V3.1 (671B)83.98%95.60%+11.62%
Table 6: Impact of feedback-guided CoT refinement. The three baseline models are trained with RL using data with or without Verifier feedback.
How significantly does feedback-guided CoT refinement boost reasoning? To quantify the impact of our feedback-guided CoT refinement, we compare model variants with and without Verifier feedback. Concretely, we set K max K_{\max} to 3 as the maximum number of refinement iterations. As reported in Table˜6, incorporating the guided refinement loop results in substantial accuracy gains of +12.34 on the 30B model, +10.21 on the 235B model, and +11.62 on the 671B model. These consistent improvements—each exceeding 10 more percentage points across all evaluated model scales—highlight the critical role of feedback-guided refinement in steering model reasoning toward correct solutions, establishing it as an essential component of our framework. A detailed analysis of the refinement dynamics and the choice of K max K_{\max} is provided in AppendixA.
5 Conclusion
In this work, we introduce HardGen, an automatic agentic pipeline designed to generate challenging tool-use training samples with verifiable reasoning. HardGen adopts a failure-driven approach, producing training samples that capture the implicit logical dependencies and multi-step reasoning characteristic of real-world tasks. Extensive experiments demonstrate that a 4B parameter model trained with our curated dataset achieves state-of-the-art performance on BFCLv3 for its scale, surpassing leading proprietary models. HardGen exhibits strong generalization across model architectures, parameter scales, and held-out benchmarks, paving the way for developing more robust models capable of complex tool-use and agentic ability.
Limitation
While HardGen demonstrates strong performance across multiple benchmarks and model architectures, several limitations merit consideration. Although our evaluation covers 2,095 tools across diverse domains, the extent to which HardGen generalizes to entirely new API ecosystems or specialized domains remains to be fully explored. Our approach requires executable environments for verification, which may not be feasible for proprietary APIs or tools with complex external dependencies. The abstraction quality of advanced tools relies on the Tool Maker’s ability to correctly identify high-level operations from primitive tool sequences, which may occasionally produce suboptimal abstractions for highly irregular or domain-specific tool chains.
Appendix A Data

Figure 5: Analysis of generator model selection. Correctness rates of function call synthesis at different numbers of attempts (K K) for three candidate generator models.
Model Selection and Number of Attempts. To ensure computational efficiency for large-scale synthesis, we restrict candidates models around 30B parameter scale and evaluate three strong generators—QwQ-32B team2025qwq, Qwen3-32B yang2025qwen3, and Qwen3-30B-A3B-Thinking yang2025qwen3 under identical HardGen configurations by having each model generate 2,000 trajectories. In Figure˜5, Qwen3-30B-A3B-Thinking achieves the highest correctness rate across all K values, reaching 89% at K=3. Notably, this model activates only 3B parameters per forward pass through its mixture-of-experts architecture, enabling significantly faster generation than the dense 32B models while delivering superior performance. Its combination of efficient inference, robust multi-step reasoning, and high correctness on function call synthesis makes it the optimal choice for cost-effective large-scale data generation.
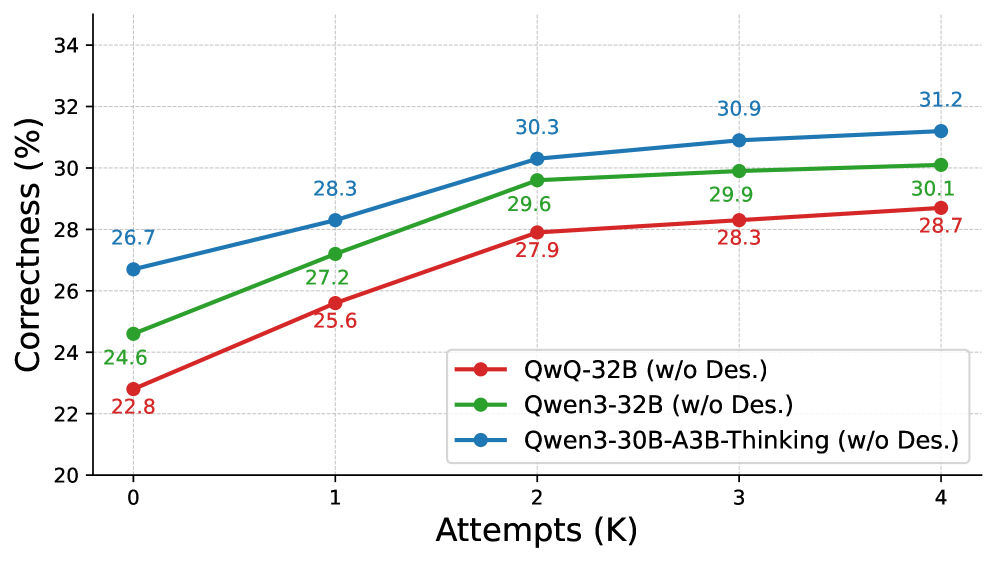
Figure 6: Impact of advanced tool descriptions. Correctness rates of the generator models across attempts (K K) when advanced tool descriptions are omitted, illustrating the necessity of high-level abstractions for reasoning.
The Necessity of Advanced Tool Description for CoT . Compared with the findings in Figure˜5, Figure˜6 further provides compelling evidence for the necessity of advanced tool descriptions in CoT generation. Across all models and attempt counts, removing descriptions results in uniformly poor performance, with maximum correctness rates below 32. The limited differentiation between models—only 2.5 percentage points separate the best and worst performers at K max=4 K_{\max}=4, suggests that the correctness of reasoning is low without adequate tool information. Moreover, the diminishing returns from additional attempts (performance gains <1<1% after K=2 K=2) indicate that models cannot iteratively refine their selections through reasoning alone. These findings demonstrate that advanced tool descriptions constitute a fundamental prerequisite rather than a mere performance enhancement for enabling LLMs to engage in rigorous reasoning when confronted with hard queries.
Agent Backbone Single-Turn Multi-Turn Overall None (Base Model)82.14 22.13 62.13 QwQ-32B 86.19 52.37 74.92 Qwen3-32B 86.87 58.29 77.34 Qwen3-30B-A3B-Thinking 87.14 63.13 79.14
Table 7: Impact of data generation backbones. Performance of the Qwen3-4B model trained on data synthesized by different agent backbones.
Data Generation with Other Agent Backbones. To demonstrate the robustness and generalizability of HardGen across different agent backbones, we conduct ablation experiments using alternative model backbones for data generation. As shown in Table˜7, we evaluate three models—Qwen3-32B yang2025qwen3, QwQ-32B team2025qwq, and Qwen3-30B-A3B-Thinking yang2025qwen3, as the agent backbones for synthesizing training data, while keeping all other pipeline components identical. The results demonstrate the strong effectiveness of HardGen for synthetic data generation, yielding substantial improvements over the base model across all agent backbones. These consistent and pronounced gains indicate that HardGen’s strategy of generating challenging, agent-produced synthetic data effectively cultivates complex reasoning capabilities, with performance benefits scaling in tandem with the strength of the generation backbone.
Appendix B Evaluations
Recent efforts in benchmarking LLM tool-use have centered on three key axes: scalability, robustness, and realism.
BFCL. For scalability, the Berkeley Function Calling Leaderboard (BFCL)patilberkeley introduces a novel validation strategy using Abstract Syntax Tree sub-string matching. This approach serves as a proxy for function execution, enabling large-scale, deterministic evaluation across diverse categories, including Single-Turn, Multi-Turn (BFCLv3), and Agentic scenarios ((BFCLv4).
ACEBench. For robustness, the ACEBench chen2025acebench uses a sandbox environment that measures models performance on dynamic, simulated tasks. It uses two distinct metrics, End-to-End Accuracy, which compares the final instance attributes of the environment with the target state; and Process Accuracy, which measures the consistency between the actual function call process and the ideal process . This approach is designed to capture task completion in realistic, interactive scenarios.
APIBank. For realism, the API-Bank li2023api establishes a framework for runnable evaluation, grading tasks into complex, multi-step sequences. The system verifies whether the same database queries or modifications are performed to ensure the ground-truth outcome is achieved.
Appendix C Performance on the Held-out Benchmark BFCLv4
Model Web Search Memory Overall Llama-3.1-8B-Instruct 3.00 10.75 6.88 CoALM-8B 0.00 2.80 1.40 ToolACE-2-8B 8.50 18.49 13.50 BitAgent-8B 4.00 12.47 8.24 xLAM-2-8b-fc-r 6.50 13.98 10.24
- HardGen-RL 16.00 24.84 20.42 Δ\Delta+13.00+14.09+13.54
Table 8: Out-of-distribution evaluation on BFCLv4. Performance of HardGen-RL on two specific agentic tasks, in comparison with other methods built on the same base model.
Generalization of Agentic Capabilities. To assess the transferability of the tool-use skills induced by HardGen, we further evaluate our method on the out-of-distribution BFCLv4 benchmark, comprising two representative agentic tasks: the Search and Memory subsets. From the results shown in Table˜8, the HardGen-8B-RL model exhibits remarkable robustness, delivering a substantial uplift over the base model. Specifically, the overall performance surges by +13.54 points (rising from 6.88 to 20.42). This advantage is most pronounced in the Memory subset, where accuracy improvement is +14.09 (from 10.75 to 24.84), accompanied by a performance boost of +13.00 in the Web Search subset (3.00 to 16.00).Crucially, HardGen-RL consistently outperforms all other baselines built on the same backbone. These results strongly suggest that our data generation paradigm effectively instills robust agentic behaviors, providing a solid foundation for future research in agentic reinforcement learning.
Appendix D Training details
Hyperparameter Value Batch Size 1024 Learning Rate 4e−5 4\mathrm{e}{-5} Max Length 20480 Epoch Number 5
Table 9: Hyperparameters for SFT.
Supervised Finetuning. We conduct our supervised finetuning experiments using the open-source Llama Factory library zheng2024llamafactory. The main hyperparameter settings are listed in Table˜9.
Hyperparameter Value Batch Size 512 Learning Rate 1e−6 1\mathrm{e}{-6} KL Coefficient 1e−3 1\mathrm{e}{-3} Entropy Coefficient 0 Max Length 20480 Temperature 0.7 Epoch Number 5 Rollout Number 16
Table 10: Hyperparameters for RL training.
RL Training. We conduct our reinforcement learning (RL) experiments using the open-source Verl library sheng2024hybridflow. To ensure stable and efficient training, we adopt the training settings from in zhang2025nemotron. The key hyperparameter settings are summarized in Table˜10.
Reward Design. We adopt a simple yet effective reward that is widely used in prior works zhang2025nemotron; yu2025dapo; zeng2025glm. Given a query q q with reference answer g g, the model’s output o o is evaluated as follows. If o o contains a tool call, it is considered correct only when it can be successfully parsed into valid function calls with proper parameters, exactly matches g g, and follows the prescribed reasoning template. In contrast, if g g does not contain a tool call, then o o is considered correct only when it contains no valid function calls (i.e., is free-form text) while still adhering to the required reasoning template. The reward is thus defined as:
Reward={1,format correct & answer correct,0,otherwise.\text{Reward}=\begin{cases}1,&\text{format correct & answer correct,}\ 0,&\text{otherwise.}\end{cases}(6)
This binary reward emphasizes the holistic integrity of the output, enforcing not only semantic correctness but also strict structural compliance, which is essential for reliable downstream execution. In non-tool-calling cases, the absence of valid function calls implicitly verifies that the model produces a purely textual response and prevents spurious or unnecessary tool invocations.
Appendix E Manual Annotations
Impact of the Advanced Tools. Our proposed method introduces advanced tool (T adv T_{adv}) to help LLMs bridge logical jumps during hard query synthesis. We present the proportion of challenging queries across all model scales in Table˜5. However, the difficulty judgments are the product of automatic annotation (GPT-4o), and this evaluation task moves beyond simple surface-level text generation judgment. To further evaluate whether the model successfully navigate the hard logical jump that the non-advanced tool model failed, three PhD students in NLP field (three of the authors) form an annotation team to annotate the samples anew using logical jumps as the indicator. If there are differences between two annotations on a sample, the third annotation will be introduced to determine the final decision. From Table˜11, we can observe a strong consistency between the automatic and manual annotations, with no significant differences between the human and model conclusions. Overall, these results demonstrate that the introduction of T adv T_{adv} effectively enhances the model’s ability to construct logically jumping queries, with consistent benefits observed across model scales.
Models Consistency Pearson Corr.Human Preference w/o T adv T_{adv}w/ T adv T_{adv}w/o T adv T_{adv}w/ T adv T_{adv}w/o T adv T_{adv}w/ T adv T_{adv} Qwen3-30B-A3B-Thinking 0.86 0.87 0.72 0.74 182 218 Qwen3-235B-A22B-Thinking 0.89 0.91 0.78 0.82 163 237 DeepSeek-V3.1 (671B)0.92 0.95 0.84 0.90 129 271
Table 11: Agreement between manual and automatic annotations. We report the Consistency rates and Pearson correlations between the two annotation methods, alongside the Human Preference.
Appendix F Results on Other Models
Models Single-Turn Multi-Turn Overall Llama-3.1-8B-Inst 77.38 11.12 55.29 +HardGen-RL 84.55 53.10 74.07 Llama-3.2-3B-Inst 70.50 4.00 48.33 +HardGen-RL 84.05 40.13 67.57
Table 12: Generalization to the Llama model family. Performance comparison of Llama-3.1-8B and Llama-3.2-3B models before and after HardGen-RL training on BFCLv3 Single-Turn and Multi-Turn tasks.
Results on Llama3 Models. To assess the generalizability of our approach beyond Qwen models, we apply HardGen-RL to two Llama-3 variants, Llama-3.1-8B-Instruct and Llama-3.2-3B-Instruct. As shown in Table˜12, both models demonstrate substantial improvements after reinforcement learning. Llama-3.1-8B-Instruct achieves an overall accuracy of 74.07 (+18.78), with particularly strong gains on multi-turn interactions (53.10, +41.98). Similarly, Llama-3.2-3B-Instruct improves from 48.33 to 67.57 overall (+19.24), with multi-turn performance increasing from 4.00 to 40.13 (+36.13). These results confirm that our approach effectively transfers across model families and parameter scales, establishing HardGen as a robust data generation framework for enhancing tool-use capabilities beyond the Qwen architecture.
Appendix G Construction of the API Graph
Structure of API Graph.
The API Graph 𝒢=(𝒯,𝒟,𝒫)\mathcal{G}=(\mathcal{T},\mathcal{D},\mathcal{P}) encodes three types of information critical for hard trace generation: (1) Failure Tool Set 𝒯\mathcal{T}: the set of 1,204 failure APIs identified through self-evaluation; (2) Dependencies 𝒟\mathcal{D}: directed edges representing prerequisite relationships, where (T i,T j)∈𝒟(T_{i},T_{j})\in\mathcal{D} indicates that T j T_{j} requires T i T_{i} to be executed first; and (3) Parameter Constraints 𝒫\mathcal{P}: specifications defining valid parameter ranges, types, and inter-tool parameter mappings (e.g., output type of T i T_{i} must match input type of T j T_{j}). Parameter constraints 𝒫\mathcal{P} are extracted from tool API schemas (type signatures, value ranges, required fields).
Update of API Graph.
The API graph is updated through execution feedback from the environment. After each tool call, we analyze the feedback to identify dependencies. When tool T j T_{j} serves as a preceding tool of of T i T_{i}, the execution of T j T_{j} activates T i T_{i}, making it eligible for selection in subsequent steps. Concurrently, parameter constraints in 𝒫\mathcal{P} are refined by tracking value validity ranges and type requirements observed during execution. This enables the graph to capture implicit value-level dependencies that extend beyond simple tool-set inclusion relationships. Through this continual update process, the API graph progressively refines both structural and parameter-level dependencies, thereby biasing subsequent sampling toward tool sequences that are both executable and challenging.
Appendix H Supplementary Case
This section presents a case study of HardGen, detailing the synthesis process along with a complete trajectory.
Hard Query Construction with Logical Jump.Figure˜7 illustrates the construction of hard queries with logical jumps. Unlike the previous methods, which explicitly instruct the model to first check zip codes before purchasing tickets, the hard query directly requests ticket purchase between city names without specifying intermediate steps. This formulation requires the model to autonomously infer the necessary tool chain—recognizing that city names must first be converted to zip codes via get_zipcode before invoking buy_tickets. The advanced tool buy_tickets_adv demonstrates the desired end-to-end capability of purchasing tickets directly from city names, representing the ideal abstraction, a single function that internally handles the multi-step process.
Model Reasoning for Hard Query.Figure˜8 illustrates the model’s reasoning process for a hard query. Given the task to purchase tickets between two cities by name, the model correctly recognizes the mismatch between the query (city names) and available tool inputs (zip codes). In its internal reasoning, the model analyzes the available tools, identifies the dependency structure, and decomposes the task into three steps: (1) retrieve the zip code for Rivermist, (2) retrieve the zip code for Stonebrook, and (3) purchase tickets using both zip codes. The model then executes this planned sequence through appropriate tool calls, successfully completing the multi-step task without explicit instructions.
Complete Trajectory.Figures˜9 and10 illustrate a complete multi-turn trajectory demonstrating sequential reasoning and context retention. In Turn 1, the model is asked to determine the working directory and search for all files recursively. The model correctly selects pwd and find tools, retrieves the directory structure, and summarizes the results. In Turn 2, building on the previous context, the user requests file contents from subdirectories identified in Turn 1. The model recognizes tool constraints—that cat and tail only operate within the current directory—and constructs a four-step plan involving directory navigation (cd) to access the required files. This example demonstrates the model’s ability to maintain context across turns and adapt its strategy based on tool limitations.
Figure 7: Case Study: Hard Query Construction. Illustration of the data synthesis process where an original execution trace is abstracted into an “Advanced Tool” to generate a Hard Query that omits explicit intermediate steps (zipcode lookup).
Figure 8: Case Study: Reasoning process for a Hard Query. Visualization of the model’s Chain-of-Thought (CoT) process, showing how it decomposes a high-level query into necessary primitive tool calls (e.g., retrieving zip codes before purchase).
Figure 9: Qualitative Example: Multi-turn Directory Exploration (Turn 1). A trajectory step where the model correctly selects the pwd and find commands to satisfy a recursive search requirement.
Figure 10: Qualitative Example: Context-Dependent File Retrieval (Turn 2). A subsequent trajectory step demonstrating context retention, where the model navigates directories (cd) to access files based on tool constraints.
Appendix I Prompts
This section provides the prompts used in the HardGen pipeline. Our framework employs four specialized agents, each with carefully designed prompts to fulfill specific roles in the data generation process. The Tool Maker (Figure˜11) synthesizes advanced tools from multi-step execution hard traces by abstracting primitive tool sequences into high-level operations. The Hard Query Generator (Figure˜12) creates challenging queries that require implicit logical bridging, forcing models to infer necessary intermediate steps rather than following explicit instructions. During the reasoning refinement phase, the Reasoner (Figure˜13 and Figure˜15) attempts to solve hard queries with hints from advanced tool descriptions, while the Verifier (Figure˜14) analyzes incorrect attempts and provides targeted corrective feedback without revealing answers directly. These prompts collectively enable HardGen’s closed-loop refinement mechanism, where each component builds upon the outputs of previous stages. The Tool Maker and Hard Query Generator transform executable traces into challenging learning scenarios, while the Reasoner-Verifier loop iteratively refines chain-of-thought reasoning toward correct solutions. All prompts are designed to be model-agnostic and can be adapted to different LLM architectures. The structured output format ensures consistency and inherent executability, enabling direct execution without additional validation.
Figure 11: Prompt template for the Tool Maker Agent. Instructions used to synthesize advanced tools from multi-step execution traces.
Figure 12: Prompt template for the Hard Query Generator. Instructions used to create challenging queries that necessitate implicit logical bridging based on advanced tool specifications.
Figure 13: Prompt template for the Reasoner Agent (Initial Attempt). Instructions for solving tool-use queries using hints from advanced tool descriptions.
Figure 14: Prompt template for the Verifier Agent. Instructions for analyzing incorrect function calls and providing targeted corrective feedback.
Figure 15: Prompt template for the Reasoner Agent (Refinement Iteration). Instructions for revising reasoning and function calls based on feedback from the Verifier.
Xet Storage Details
- Size:
- 59.1 kB
- Xet hash:
- 8c1a3dcf64d9cac7f138bd176aae82a92399efa9b67fa1a5d1a8144b6f32595f
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.