Buckets:

Title: RAGRouter-Bench: A Dataset and Benchmark for Adaptive RAG Routing
URL Source: https://arxiv.org/html/2602.00296
Published Time: Tue, 03 Feb 2026 01:10:20 GMT
Markdown Content: Ziqi Wang 1, †, Xi Zhu 1, †, Shuhang Lin 1, Haochen Xue 2, Minghao Guo 1 Yongfeng Zhang 1
1 Rutgers University 2 University of Liverpool
{ziqi.wang0908, xi.zhu, shuhang.lin, minghao.guo, yongfeng.zhang}@rutgers.edu
Code:https://github.com/ziqiwang0908/RAGRouter-Bench
Dataset:https://huggingface.co/datasets/Chaplain0908/RAGRouter
Leaderboard:https://huggingface.co/spaces/Chaplain0908/RAGRouter-Leaderboard
Abstract
Retrieval-Augmented Generation (RAG) has become a core paradigm for grounding large language models with external knowledge. Despite extensive efforts exploring diverse retrieval strategies, existing studies predominantly focus on query-side complexity or isolated method improvements, lacking a systematic understanding of how RAG paradigms behave across different query–corpus contexts and effectiveness–efficiency trade-offs. In this work, we introduce RAGRouter-Bench, the first dataset and benchmark designed for adaptive RAG routing. RAGRouter-Bench revisits retrieval from a query–corpus compatibility perspective and standardizes five representative RAG paradigms for systematic evaluation across 7,727 queries and 21,460 documents spanning diverse domains. The benchmark incorporates three canonical query types together with fine-grained semantic and structural corpus metrics, as well as a unified evaluation for both generation quality and resource consumption. Experiments with DeepSeek-V3 and LLaMA-3.1-8B demonstrate that no single RAG paradigm is universally optimal, that paradigm applicability is strongly shaped by query–corpus interactions, and that increased advanced mechanism does not necessarily yield better effectiveness–efficiency trade-offs. These findings underscore the necessity of routing-aware evaluation and establish a foundation for adaptive, interpretable, and generalizable next-generation RAG systems.
RAGRouter-Bench: A Dataset and Benchmark for Adaptive RAG Routing
Ziqi Wang 1, †, Xi Zhu 1, †, Shuhang Lin 1, Haochen Xue 2, Minghao Guo 1 Yongfeng Zhang 1††thanks: Corresponding author.1 Rutgers University 2 University of Liverpool{ziqi.wang0908, xi.zhu, shuhang.lin, minghao.guo, yongfeng.zhang}@rutgers.edu haochen@liverpool.ac.uk Code:https://github.com/ziqiwang0908/RAGRouter-BenchDataset:https://huggingface.co/datasets/Chaplain0908/RAGRouterLeaderboard:https://huggingface.co/spaces/Chaplain0908/RAGRouter-Leaderboard
2 2 footnotetext: These authors contributed equally to this work. 1 Introduction
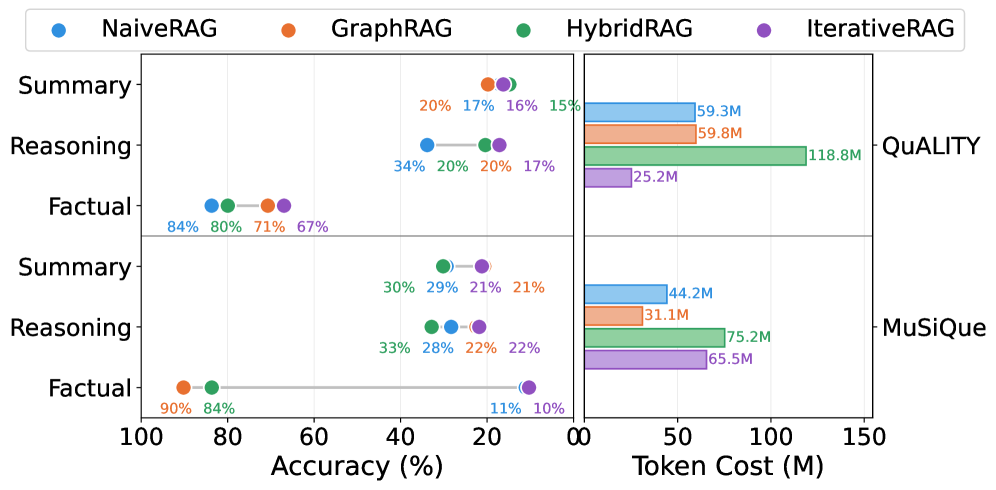
Figure 1: Preliminary Study on Paradigm Conflict.Left: Accuracy of four RAG paradigms across two datasets and three query types. Right: Token consumption per paradigm on each dataset.
LLMs are prone to hallucinations when confronted with specialized domains, evolving facts, or long-tail information needs (Ji et al., 2023; Mallen et al., 2023). These challenges have motivated the emergence of Retrieval-Augmented Generation (RAG), which has come to underpin modern question answering, creative generation, document summarization, and multi-hop reasoning (Gao et al., 2023). RAG typically follows a two-stage pipeline. It identifies query-relevant evidence from external corpora, and combined with the query to feed into an LLM-based generator, yielding factual and faithful responses (Lewis et al., 2020; Guu et al., 2020). In practice, retrieval constitutes the primary bottleneck in RAG, as it not only defines the information boundary (Cao et al., 2024), but also dominates the system’s computational overhead (Jin et al., 2024).
Table 1: Comparison with existing RAG benchmarks.Domain: Wiki (Wikipedia), Lr (Literature), PS (Professional Specialized). Query: Fac. (Factual), Rea. (Reasoning), Sum. (Summary). Corpus: Sem. (Semantic), Str. (Structural). Evaluation: Effect. (Effectiveness), Effi. (Efficiency).
Existing RAG paradigms can be viewed as an evolution of retrieval strategies (Gao et al., 2023). NaiveRAG relies on similarity-based retrieval over unstructured text chunks, favoring efficiency for factoid QA and summarization (Karpukhin et al., 2020). GraphRAG adopts graph retrieval to enable multi-hop reasoning (Edge et al., 2024), while HybridRAG further combines complementary signals such as vector and graph retrieval (Sarmah et al., 2024). IterativeRAG dynamically invokes retrieval modules based on intermediate states, trading efficiency for improved reasoning capability (Asai et al., 2024). Together, these paradigms turn retrieval into a multi-criteria decision problem, highlighting the necessity of Adaptive RAG Routing(Jeong et al., 2024; Tang et al., 2025).
To ground this discussion, we conduct preliminary experiments by evaluating representative RAG paradigms across different corpora (Figure1), yielding three key insights. (i) no single paradigm consistently dominates across all settings, indicating the absence of a one-size-fits-all solution; (ii) the optimal RAG choice depends not only on query characteristics but also critically on the underlying corpus; (iii) more sophisticated methods do not guarantee better performance, as simpler alternatives can achieve comparable results with substantially lower overhead. Together, these findings underscore that RAG routing hinges on query–corpus compatibility and effectiveness–efficiency trade-offs, calling for systematic benchmarking across queries, corpora, and retrieval strategies.
Nevertheless, existing research exhibits several limitations, as summarized in Table 1. (1) Query-centric Assumption. Prior studies largely assume that the optimal RAG paradigm is attributed solely to the semantic complexity or reasoning difficulty of the query (Jeong et al., 2024; Tang et al., 2025). This query-centric view systematically overlooks the semantic and structural properties of the corpus, and more fundamentally, ignores the query-corpus compatibility that essentially shapes RAG effectiveness. (2) Missing Fine-grained Signals for Routing. Existing studies (Gao et al., 2023; Peng et al., 2024) primarily examine query-side factors in isolation, without providing quantifiable metrics to support causal and interpretable analysis of how routing decisions are jointly shaped by fine-grained characteristics of both queries and corpora. This limitation obscures our understanding of the applicability boundaries of different RAG paradigms and hinders principled routing design. (3) Lack of Routing-Oriented Benchmarks. Current RAG datasets and benchmarks suffer from limited domain coverage, incomparable method designs, and insufficient consideration of effectiveness–efficiency trade-offs (Chen et al., 2024; Lyu et al., 2024; Friel et al., 2024; Jin et al., 2024), which together preclude comprehensive and systematic identification of suitable and sustainable RAG approaches across query–corpus combinations and constraining further development of adaptive and interpretable RAG systems.
To this end, we introduce RAGRouter-Bench, a multi-dimensional dataset and benchmark tailored for adaptive RAG routing. Motivated by query–corpus compatibility, RAGRouter-Bench models each instance as a (query, corpus, method, performance) tuple, enabling systematic and interpretable analysis of routing behaviors across diverse settings. The benchmark comprises 7,727 queries over 21,460 documents, supporting large-scale analysis of performance across diverse query–corpus combinations. Specifically, we first standardize a set of representative RAG paradigms under a unified retriever abstraction, allowing fair and comparable evaluation despite diverse variants in real-world applications. RAGRouter-Bench then captures variability from both the query and corpus perspectives. On the query side, we curate and augment three canonical query types, namely factual, reasoning, and summarization. On the corpus side, the benchmark spans multiple domains and characterizes corpora using both semantic and structural properties, enabling fine-grained analysis of how corpus characteristics, individually and interactively, influence routing decisions. Finally, RAGRouter-Bench adopts a unified evaluation protocol to examine effectiveness–efficiency trade-offs, where we not only measures response quality through quantitative metrics and LLM-as-a-judge evaluation, but also report construction and inference as efficiency indicators.
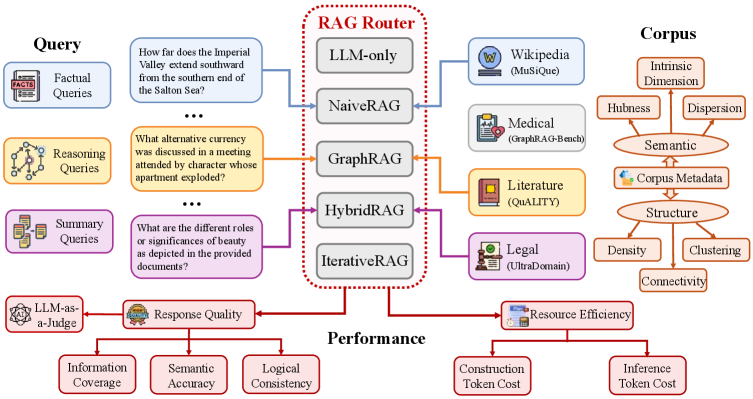
Figure 2: Overview of the RAGRouter-Bench framework.Left: Query types with representative examples. Center: Five RAG paradigms as routing targets. Right: Multi-domain corpora with structural and semantic characterization. Bottom: Dual-axis evaluation covering response quality and resource efficiency.
In summary, our contributions are four-fold: (i) We introduce the first dataset and benchmark for adaptive RAG routing, providing a comprehensive evaluation of standard RAG paradigms; (ii) We identify query-corpus compatibility as the key to RAG routing, and introduce fine-grained dual-view indicators to characterize the application boundaries; (iii) We propose a unified evaluation protocol grounded in effectiveness-efficiency trade-offs; (iv) We conduct extensive experiments using DeepSeek-V3 and LlaMA-3.1-8B as LLM backbones, offering insights toward adaptive, interpretable, and generalizable next-generation RAG systems.
2 Related Work
Retrieval Paradigms in RAG.
RAG has evolved from flat semantic matching to structured integration. Foundational VectorRAG models like DPR (Karpukhin et al., 2020) and REALM (Guu et al., 2020) utilize dense retrieval for semantic similarity but often miss complex structural dependencies, increasing hallucination risk on long-tail knowledge (Ji et al., 2023; Mallen et al., 2023). Conversely, GraphRAG frameworks such as HippoRAG (Jiménez Gutiérrez et al., 2024), G-Retriever (He et al., 2024), and Think-on-Graph (Sun et al., 2024) leverage knowledge graphs for structure-aware reasoning, excelling at entity-centric tasks yet struggling with abstractive queries. Addressing these trade-offs, HybridRAG (Sarmah et al., 2024) fuses vector and graph contexts, while recursive methods like Self-RAG (Asai et al., 2024) handle multi-hop complexity through iterative retrieval. However, most work treats these paradigms as competing alternatives rather than context-dependent choices (Gao et al., 2023).
RAG Benchmarks and Evaluation.
RAG evaluation has evolved from basic metrics to multi-dimensional benchmarks. Automated frameworks like RAGAS (Es et al., 2024) and ARES (Saad-Falcon et al., 2024) employ LLM-as-a-Judge for reference-free evaluation. RGB (Chen et al., 2024) tests noise resilience, CRUD-RAG (Lyu et al., 2024) and RAGBench (Friel et al., 2024) categorize diverse retrieval tasks, while MultiHop-RAG (Tang and Yang, 2024) and GraphRAG-Bench (Xiao et al., 2025) address complex reasoning scenarios. Recent work on embedding space analysis, including intrinsic dimensionality estimation (Facco et al., 2017) and hubness characterization (Radovanović et al., 2010), provides tools for corpus-level diagnostics, yet these insights remain disconnected from RAG paradigm selection. Meanwhile, adaptive routing methods (Jeong et al., 2024; Tang et al., 2025) toggle strategies based only on query complexity, overlooking corpus properties. This single-factor approach contrasts with reinforcement learning, where strategy selection jointly models agent state and environmental context (Fan et al., 2023), suggesting that query-corpus compatibility deserves similar attention in RAG routing.
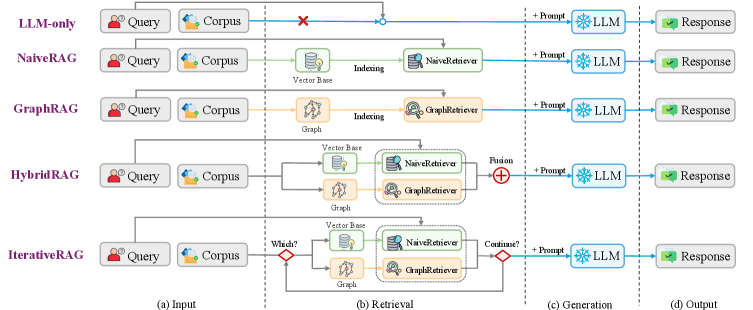
Figure 3: Overview of the five RAG paradigms evaluated in RAGRouter-Bench.Input: Query and corpus shared across all paradigms. Retrieval: Paradigm-specific pipelines differing in index structures and retrieval strategies. Generation: Retrieved context combined with query as prompt to LLM. Output: Final response.
 3 Preliminaries
3 Preliminaries
We adopt a modular view in RAG, decomposing retrieval into atomic modules to unify existing RAG paradigms.
Adaptive RAG Routing.
Given a query-corpus pair (q,𝒞)(q,\mathcal{C}), our objective is to select an optimal paradigm π∗\pi^{*} that maximizes a utility function 𝒰\mathcal{U}:
π∗=argmax π∈Π𝒰(π;q,𝒞)\pi^{*}=\arg\max_{\pi\in\Pi}\mathcal{U}(\pi;q,\mathcal{C})(1)
where Π\Pi denotes the candidate paradigm space, and 𝒰\mathcal{U} captures task-specific criteria, such as response quality, token consumption, or their trade-off. This formulation casts RAG routing as context-dependent paradigm selection, which constitites the central challenge motivating RAGRouter-Bench.
4 The RAGRouter-Bench
We construct RAGRouter-Bench to investigate how query and corpus characteristics jointly influence RAG paradigm selection, consisting of a comprehensive dataset with dual-view indicators and a unified evaluation framework for effectiveness–efficiency trade-offs (Figure2).
4.1 RAG Paradigm Instantiation
To enable principled cross-paradigm comparison, we define two base retrievers and instantiate five RAG paradigms, as illustrated in Figure 3.
Base Retrievers.
Rather than evaluating specific model implementations, we decompose RAG methods into atomic modules (e.g., vector search, entity extraction, graph traversal), which allows fair comparison across paradigms while remaining representative of mainstream real-world designs. Specifically, we define two atomic retrieval modules as building blocks. NaiveRetriever performs dense vector-based semantic retrieval, which encodes queries and chunks into latent vectors and retrieves top-K K segments via cosine similarity (Karpukhin et al., 2020). GraphRetriever operates on knowledge graphs, which extracts seed entities from the query, propagates relevance scores via Personalized PageRank (PPR) (Haveliwala, 2002), and returns text from high-relevance nodes (Edge et al., 2024).
RAG Paradigm Instances.
Building on these retrievers, we define five paradigms spanning a broad spectrum. LLM-only bypasses retrieval, prompting the LLM with the query alone as a retrieval-free baseline (Petroni et al., 2019). NaiveRAG invokes NaiveRetriever once and concatenates retrieved chunks as context (Lewis et al., 2020). GraphRAG applies GraphRetriever to retrieve high-relevance nodes, then extracts their associated triplets and text chunks as context for generation (Edge et al., 2024). HybridRAG invokes both retrievers in parallel and merges results via Reciprocal Rank Fusion (RRF) (Cormack et al., 2009; Sarmah et al., 2024). IterativeRAG employs a Retrieve-Generate-Evaluate feedback loop, decomposing complex queries into sub-queries and iterating until an LLM-based evaluator confirms answer completeness (Asai et al., 2024; Trivedi et al., 2023). These paradigms, spanning retrieval-free to dynamic iteration, enable systematic comparison across different retrieval strategies. Implementation details are provided in AppendixB.2.
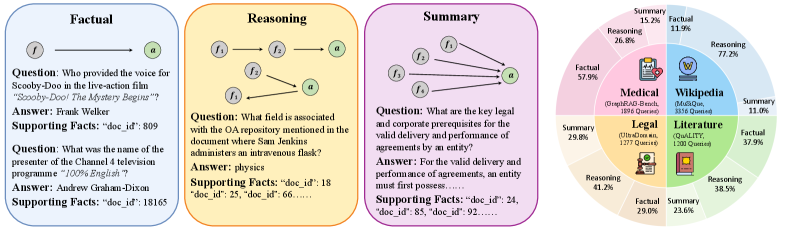
Figure 4: Query type taxonomy and dataset composition in RAGRouter-Bench.Left: Three query types definition. Right: Query type distribution across four datasets.
4.2 Data Curation
Many existing benchmarks rely on homogeneous data sources and query types, which obscures how variations in queries and corpora influence RAG routing decisions (Chen et al., 2024; Friel et al., 2024). This motivates us to incorporate diverse corpus sources and systematically generated queries.
Corpus Sourcing.
We integrate datasets spanning four domains: encyclopedic knowledge from Wikipedia (MuSiQue (Trivedi et al., 2022)), literature (QuALITY (Pang et al., 2022)), legal documentation (UltraDomain_legal (Qian et al., 2024)), and medical textbooks (GraphRAGBench_medical (Xiao et al., 2025)), totaling 21,460 documents.
Query Generation.
These original benchmarks exhibit skewed query distributions, for example, MuSiQue contains only reasoning queries, while QuALITY is over 90% factual (Trivedi et al., 2022; Pang et al., 2022). To enable meaningful cross-type comparison within each corpus, we apply query data augmentation via LLM-based generation guided by structure-aware expansion(Xiao et al., 2025). This augmentation workflow is validated using a verify-then-filter protocol(Chen et al., 2024) to mitigate potential bias in LLM-based evaluation. Specifically, human verification is conducted on a stratified sample of 200 queries (50 per corpus), achieving a 94% agreement rate with automated judgments. To decouple query characteristics from corpus structure, we generate three query categories across the unified corpora. Factual queries target single entities whose answers are retrievable from a single segment. Reasoning queries require inference across multiple segments. Summary queries demand information aggregation from multiple sources. The resulting dataset comprises 7,727 queries, including 4,086 reasoning (52.9%), 2,320 factual (30.0%), and 1,321 summary queries (17.1%). Each corpus covers all three query types, enabling controlled cross-type comparison (Figure4). By integrating multi-domain corpora with multi-type queries, RAGRouter-Bench establishes a principled foundation for analyzing their individual and joint effects on RAG routing. Details are provided in AppendixA.1 andA.2.
4.3 Dual-View Analysis
RAG efficacy hinges on query-corpus interplay rather than query complexity alone. Drawing on prior work in graph topology and embedding quality assessment (Newman, 2010; Ethayarajh, 2019), we propose a dual-view analytical framework to explain query-corpus compatibility in RAG routing.
Corpus Analysis Dimension.
The corpus serves as the underlying environment dictating retrieval feasibility. We characterize corpus properties along two complementary axes with multiple indicators.
Structural Topology Metrics. Structural metrics describe how the topology of the potential knowledge graph relates to retrieval, covering three dimensions. Connectivity measures global reachability of the graph. LCC Ratio quantifies the proportion of nodes in the largest connected subgraph. Low values indicate graph fragmentation that may block multi-hop reasoning paths (Newman, 2010). Relation Type Diversity measures the semantic richness of edges, where diverse relation types enable more precise graph traversal. Density quantifies edge saturation. Average Degree reflects the mean connection intensity per node, while Maximum Degree Centrality identifies hub nodes with disproportionately high connectivity. Excessive sparsity limits relational bridging, whereas hub dominance may introduce retrieval bias (Sun et al., 2024). Clustering Coefficient assesses local cohesiveness. High values indicate tight community structures that facilitate multi-source evidence aggregation (Watts and Strogatz, 1998). These three metrics characterize topology structure from global reachability, connection intensity, and local aggregation perspectives, collectively determining graph retrieval efficiency.
Table 2: Main evaluation results across RAG paradigms, datasets, and backbone LLMs. Each paradigm reports LLM-as-a-Judge accuracy (%) by query type (Factual, Reasoning, Summary) and overall average, along with average token consumption per query. Green indicates best performance; blue indicates second best.
Semantic Space Metrics. Semantic metrics characterize corpus properties from the embedding space perspective, covering three core attributes. Intrinsic Dimension measures the effective degrees of freedom in the embedding space, estimated via TwoNN (Facco et al., 2017). High dimensionality exacerbates the curse of dimensionality, diminishing distance-based similarity measures and limiting pure vector retrieval accuracy. Dispersion characterizes the uniformity of embedding distributions through three centroid-based distance metrics: average distance reflects overall spread, minimum distance identifies the most confusable cluster pairs, and standard deviation reveals distributional imbalance. Low dispersion causes semantic crowding that hinders hard-negative discrimination (Wang and Isola, 2020), necessitating structure-assisted retrieval. Hubness quantifies retrieval interference, measured as the skewness of k-occurrence distribution (Radovanović et al., 2010). High hubness biases retrieval toward frequently occurring but potentially irrelevant passages, reducing pure vector retrieval reliability. These three metrics can serve as offline inputs for the router: when semantic space quality is poor (high intrinsic dimension, low dispersion, or high hubness), the router should favor structured retrieval or hybrid methods over pure vector retrieval.
Query Analysis Dimension.
We categorize queries into three types: Factual queries require single-hop lookup from one fact (Chen et al., 2024); Reasoning queries usually demand multi-hop inference across chained facts (Yang et al., 2018); Summary queries involve global aggregation over dispersed information (Edge et al., 2024). As a note, we augment queries via the LLM-based pipeline described in Section4.2 to ensure query coverage. This dual-view framework quantitatively assesses how corpus attributes and query demands jointly shape RAG paradigm effectiveness. Details are provided in AppendixA.3.
4.4 Evaluation Protocol
Uni-dimensional evaluation fails to capture practical RAG performance. To evaluate effectiveness-efficiency trade-offs across paradigms, we construct a protocol in two perspectives: generation quality and resource consumption (Jin et al., 2024).
Generation Quality Evaluation.
We assess generation outcomes across answer quality, factual faithfulness, and holistic correctness, by using four metrics. Semantic F1 measures answer quality by calculating token-level similarity between generated responses and gold standards via BERTScore (Zhang et al., 2020). Coverage also evaluates answer quality by quantifying the extent to which answers cover key information using sentence embeddings (Reimers and Gurevych, 2019). Faithfulness assesses factual faithfulness by computing average support strength between answers and retrieved content (Es et al., 2024). LLM-as-a-Judge evaluates holistic correctness through ternary classification, providing correctness aligned with human judgment (Zheng et al., 2023).
Resource Consumption Evaluation.
We adopt token consumption as the efficiency metric, decomposing total cost into construction cost and inference cost. Construction Cost measures one-time preprocessing overhead, primarily knowledge graph building for GraphRAG and HybridRAG, which is amortized over the number of queries. Inference Cost measures per-query online overhead, encompassing LLM invocations during retrieval (e.g., entity extraction, multi-turn queries) and context processing during generation (Edge et al., 2024). In practice, generation input is truncated to 8k tokens to accommodate LLM context limits; cost metrics report full retrieval output, as retrieved content is relevance-ranked and truncation removes only lower-ranked passages with minimal impact on response quality.
Our evaluation protocol considers effectiveness-efficiency trade-offs across candidate paradigms to inform optimal RAG routing decisions. Formal definitions are provided in AppendixC.1 andC.2.
5 Experiments
We conduct experiments to evaluate how query and corpus jointly influence paradigm selection. We compare paradigm performance across datasets first, then analyze corpus-driven and query-driven effects, finally assess cost-performance trade-offs.
5.1 Experimental Setup
RAG Paradigms.
We standardize infrastructure across all paradigms for fair comparison. We use DeepSeek-V3 (DeepSeek-AI, 2024) and LLaMA-3.1-8B (Team, 2024) as generators, and text-embedding-3-small for vectorization (OpenAI, 2024), with a unified 8k token context budget. For retrieval, NaiveRAG retrieves top-100 chunks via cosine similarity (Karpukhin et al., 2020); GraphRAG extracts 20 seed entities and propagates relevance via PPR (α=0.85\alpha=0.85) (Haveliwala, 2002) to retrieve top-100 nodes (Edge et al., 2024); HybridRAG combines both retrievers (Sarmah et al., 2024); IterativeRAG performs up to 3 retrieve-generate-evaluate iterations (Trivedi et al., 2023). Details are provided in AppendixB.1.
Evaluation.
We evaluate following the protocol in Section 4.4 across three dimensions. For corpus analysis, we compute structural metrics (LCC Ratio, Density, Clustering Coefficient) (Newman, 2010; Sun et al., 2024; Watts and Strogatz, 1998) and semantic metrics (Intrinsic Dimension, Dispersion, Hubness) (Facco et al., 2017; Wang and Isola, 2020; Radovanović et al., 2010). For generation quality, we measure Semantic F1 (Zhang et al., 2020), Coverage, Faithfulness (Es et al., 2024), and LLM-as-a-Judge accuracy using GPT-4o as the evaluator (OpenAI, 2023). For efficiency, we track token consumption decomposed into retrieval and generation costs (Jin et al., 2024). Implementation details are provided in AppendixC.1.
5.2 Main Results
Figure 5: Paradigm performance across datasets and query types. Each panel shows one RAG paradigm’s LLM-as-a-Judge accuracy (Correct%), with rows as query types and columns as datasets. Asterisk (*) marks the best-performing paradigm for each combination.
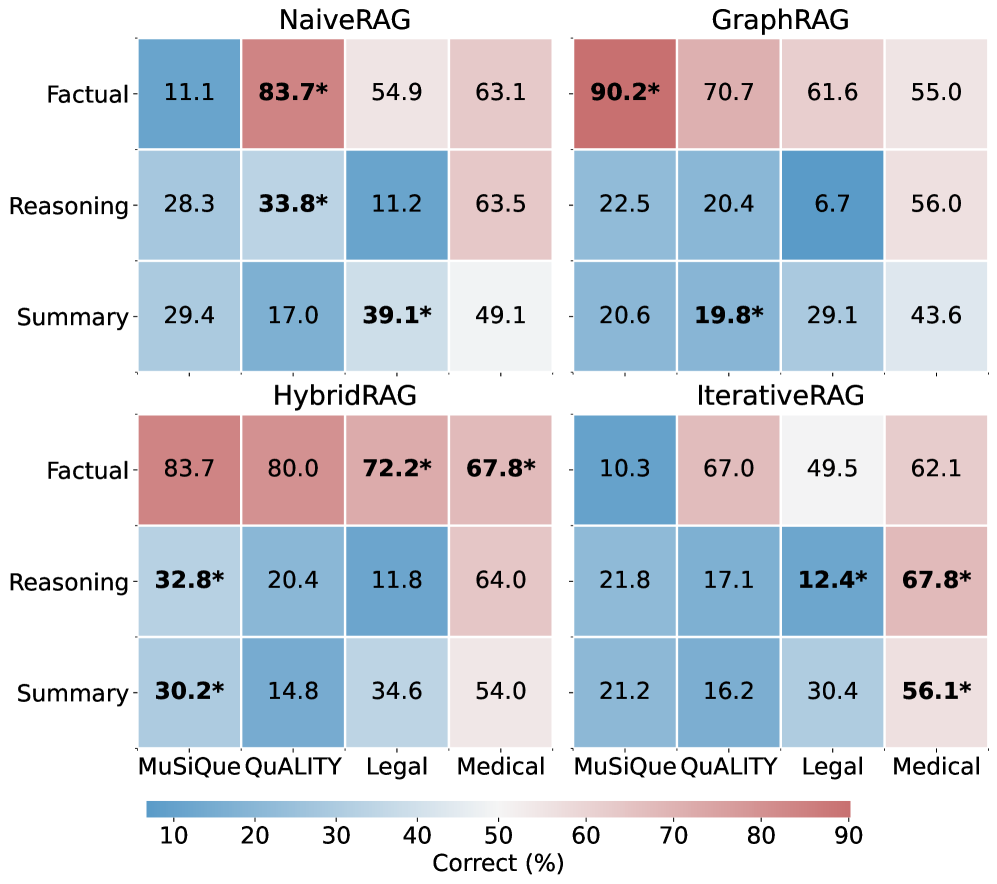
Comparative Paradigm Analysis.
(1) No universal RAG paradigm exists across query-corpus combinations, as shown in Table2 and Figure5. On the same Factual query type, GraphRAG achieves 90.2% on MuSiQue but only 70.7% on QuALITY, while NaiveRAG shows the opposite pattern. On the same MuSiQue corpus, the optimal paradigm for Factual is GraphRAG (90.2%), yet for Reasoning it shifts to HybridRAG (32.8%). This demonstrates that optimal strategy depends jointly on corpus structure and query type. (2) Each paradigm exhibits distinct strengths. NaiveRAG excels in implicit narratives (83.7% on QuALITY Factual), where preserving continuous context outweighs structured retrieval. GraphRAG dominates entity-centric tasks in explicit graphs (90.2% on MuSiQue Factual), leveraging entity linking for precise multi-hop traversal. HybridRAG achieves the highest average accuracy on 3 of 4 datasets by combining semantic coverage with structural reasoning. IterativeRAG underperforms expectations; its iterative refinement relies on initial retrieval quality, and when the first retrieval deviates, subsequent iterations amplify rather than correct the error.
These findings provide the core rationale for adaptive routing: statically selecting a single paradigm cannot accommodate diverse query-corpus combinations. An effective router must jointly perceive corpus structural characteristics and query information needs to dynamically match the optimal retrieval strategy.
Figure 6: Corpus features across structural and semantic dimensions.Left: Graph topology metrics capturing knowledge graph properties. Right: Embedding space metrics characterizing semantic distribution.
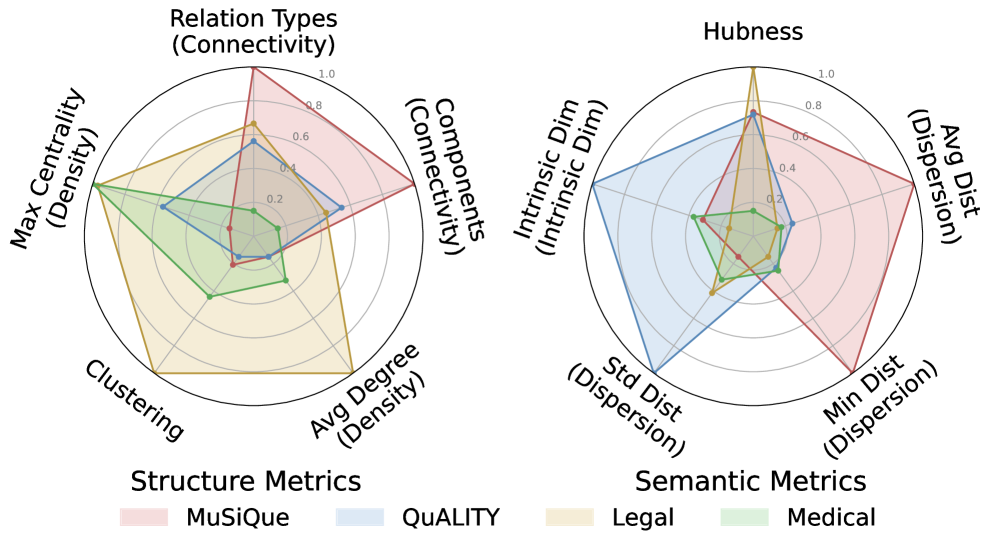
Corpus-Driven Performance Constraints.
The performance reversal observed above arises from differential impacts of corpus characteristics on retrieval paradigms. Figure6 shows the structural and semantic fingerprints of each corpus. Our analysis reveals that different corpus dimensions constrain the effectiveness of different retrieval paradigms. (1) Structural properties determine graph retrieval effectiveness. MuSiQue’s high relation diversity and explicit entity links enable GraphRAG to achieve 90.2% on Factual queries via precise graph traversal. In contrast, QuALITY’s linear narrative structure yields sparse, fragmented graphs where forced graph construction introduces noise, explaining why NaiveRAG outperforms GraphRAG (83.7% vs 70.7% on Factual). (2) Semantic properties constrain vector retrieval precision. Legal corpus exhibits high hubness and low semantic dispersion, causing vector space congestion that limits NaiveRAG’s discrimination ability. This explains its moderate performance (54.9%) despite rich textual content, while HybridRAG bypasses this bottleneck through graph-based retrieval (72.2%). (3) Complex corpora require complementary retrieval. Medical corpus exhibits both moderate structural density and high semantic complexity. This combination limits each single-modality approach: the structural density is insufficient for GraphRAG’s precise traversal (55.0%), while the semantic complexity constrains NaiveRAG’s discrimination ability (63.1%). HybridRAG compensates for both limitations by fusing semantic coverage with structural reasoning, achieving the best performance (67.8%).
These findings indicate that corpus characteristics provide quantifiable decision signals for adaptive routing. Since structural and semantic metrics can be computed offline, a router can leverage the corpus fingerprint as prior input to predict the relative strengths of each paradigm on the target corpus, thereby reducing online decision complexity.
Figure 7: Response quality distribution across RAG paradigms and query types. Each bar shows the breakdown of LLM-as-a-Judge outcomes across all datasets. Left axis: Paradigms; Right axis: Query type.
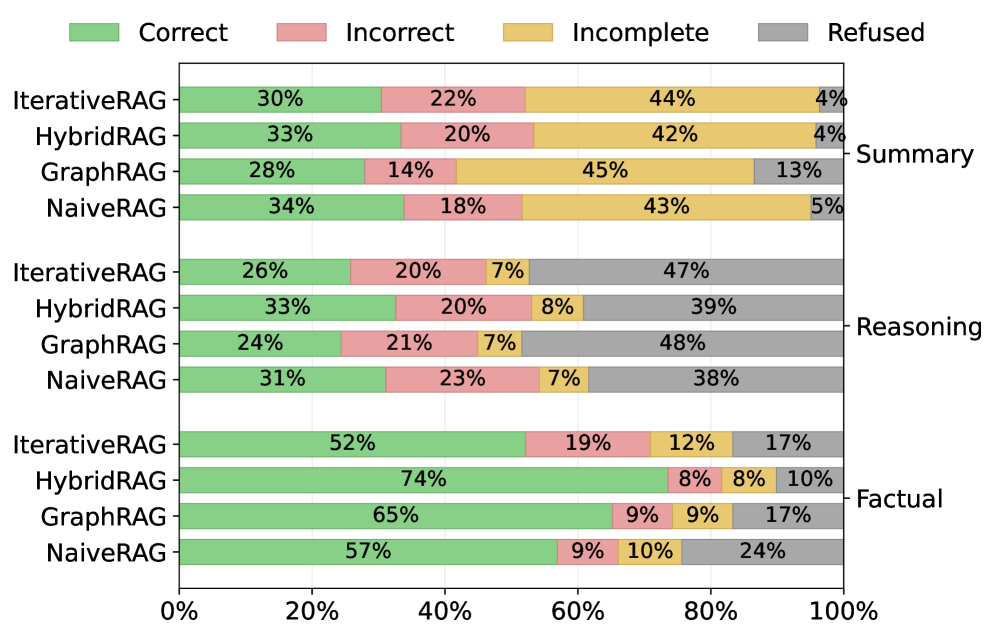
Adaptability across Query Types.
Beyond corpus characteristics, query type constitutes another critical dimension in paradigm selection. Figure 7 reveals distinct response distributions across query complexities. (1) Factual queries demand precise anchoring. GraphRAG achieves the highest accuracy (84.4%) by leveraging entity linking in explicit graphs, but suffers high Refused rates (22%) when graph structure is sparse. NaiveRAG provides more stable performance across corpora (avg. 52%) through direct semantic matching. (2) Reasoning queries require link completion. Multi-hop reasoning exposes single-modality limitations, both NaiveRAG and GraphRAG show elevated Incorrect rates (20-25%) due to incomplete evidence chains. HybridRAG leads by combining vector entry points with graph-based path completion, reducing Incomplete responses by 8% compared to alternatives. (3) Summary queries need coverage matching. Performance depends on corpus-query alignment: NaiveRAG preserves coherent context for narrative synthesis (69.2% on QuALITY), while HybridRAG provides broader coverage for attribute aggregation in structured domains (67.8% on Medical).
These findings confirm that query characteristics interact with corpus properties, neither dimension alone determines the optimal paradigm. These provide an online decision dimension for adaptive routing. A router can identify the query type upon receiving a query and combine it with precomputed corpus fingerprints to achieve paradigm matching at the query-corpus combination level.
Figure 8: Cost-performance trade-off across RAG paradigms and datasets.Top: LLM-as-a-Judge accuracy (Correct%). Bottom: average token consumption per query (log scale).
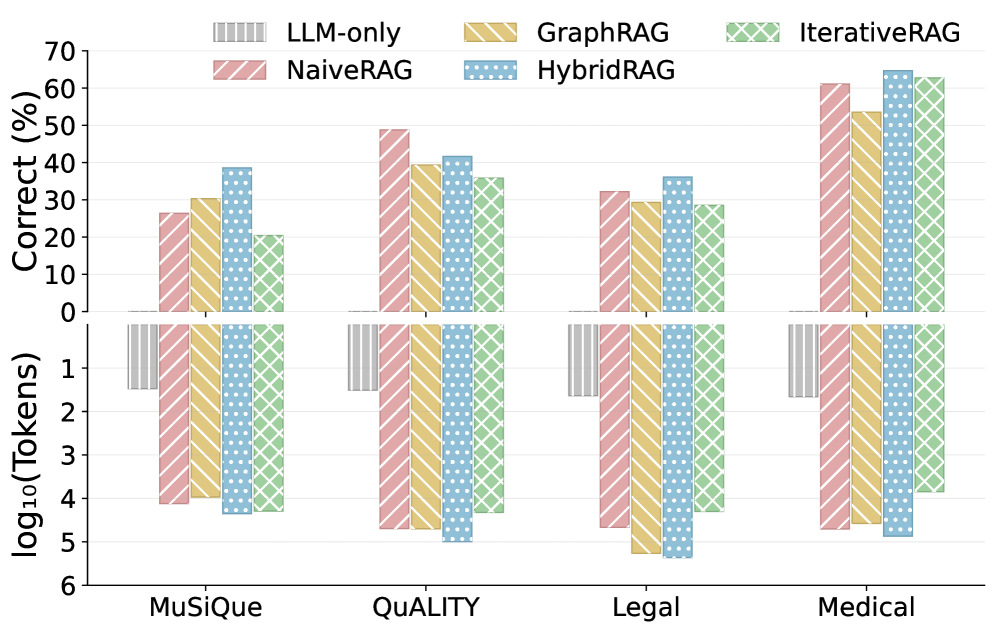
Cost-Performance Trade-off Analysis.
Beyond accuracy, practical deployment requires considering resource efficiency. Figure 8 reveals that token consumption ranges from ∼\sim 10 3 to ∼\sim 10 6 tokens over these RAG paradigms. LLM-only serves as the minimal-cost baseline but achieves zero accuracy without retrieval augmentation, confirming RAG is essential for these knowledge-intensive tasks. NaiveRAG and GraphRAG occupy the mid-cost tier with comparable token consumption (approximately 10 4 10^{4} tokens per query). The choice between them depends on corpus characteristics rather than cost, e.g., GraphRAG for explicit structures, NaiveRAG for implicit narratives. HybridRAG incurs the highest cost by combining both retrievers, but consistently achieves top accuracy across datasets. This trade-off is justified in high-stakes scenarios where answer correctness outweighs computational expense. IterativeRAG presents flexible cost depending on iteration count and base retriever configuration. While potentially efficient for simple queries that terminate early, it offers no consistent cost-accuracy advantage in our experiments. Representative case studies are provided in AppendixC.3.
These observations reflects the cost-effectiveness across different RAGs that could guide adaptive RAG routing. A router should not only predict accuracy based on query-corpus characteristics, but also weigh trade-offs according to resource budgets in diverse scenarios: prioritizing mid-cost single-modality paradigms under resource constraints, or selecting HybridRAG when accuracy is paramount. Consequently, cost budget turns to be the third input dimension for adaptive routing decisions.
6 Conclusion
In this work, we present RAGRouter-Bench, the first dataset and benchmark explicitly designed for adaptive RAG routing. By revisiting retrieval from a query–corpus compatibility perspective, RAGRouter-Bench enables systematic comparison of representative RAG paradigms under unified effectiveness–efficiency evaluation. Extensive experiments demonstrate that RAG performance is highly context-dependent, shaped jointly by query characteristics, corpus properties, and retrieval strategies, and that more complex methods do not necessarily yield better trade-offs. These findings highlight retrieval as a critical decision point rather than a fixed design choice. We believe RAGRouter-Bench will facilitate principled routing research and support next-generation RAG systems.
7 Limitations
Our analysis centers on paradigm-level mechanistic differences rather than exhaustive benchmarking of specific implementations, aiming to elucidate compatibility trends between paradigms and corpora. Additionally, while our query generation approach guarantees logical soundness, synthetic queries may not fully capture the noise distribution characteristic of real-world interactions.
References
- A. Asai, Z. Wu, Y. Wang, A. Sil, and H. Hajishirzi (2024)Self-RAG: learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations, External Links: LinkCited by: Table 11, §1, §2, §4.1.
- B. Cao, D. Cai, L. Cui, X. Cheng, W. Bi, Y. Zou, and S. Shi (2024)Retrieval is accurate generation. In The Twelfth International Conference on Learning Representations, External Links: LinkCited by: §1.
- J. Chen, H. Lin, X. Han, and L. Sun (2024)Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, pp.17754–17762. External Links: LinkCited by: §1, §2, §4.2, §4.2, §4.3.
- G. V. Cormack, C. L. A. Clarke, and S. Buettcher (2009)Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.411–418. External Links: LinkCited by: §4.1.
- DeepSeek-AI (2024)DeepSeek-V3 technical report. External Links: 2412.19437, LinkCited by: §5.1.
- D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, and J. Larson (2024)From local to global: a graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130. External Links: LinkCited by: Table 11, §1, §4.1, §4.1, §4.3, §4.4, §5.1.
- S. Es, J. James, L. Espinosa-Anke, and S. Schockaert (2024)RAGAS: automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2024), External Links: LinkCited by: §2, §4.4, §5.1.
- K. Ethayarajh (2019)How contextual are contextualized word representations?. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pp.4809–4818. External Links: LinkCited by: §4.3.
- E. Facco, M. d’Errico, A. Rodriguez, and A. Laio (2017)Estimating the intrinsic dimension of datasets by a minimal neighborhood information. Scientific Reports 7 (1), pp.1–8. External Links: LinkCited by: §2, §4.3, §5.1.
- J. Fan, Y. Zhuang, Y. Liu, J. HAO, B. Wang, J. Zhu, H. Wang, and S. Xia (2023)Learnable behavior control: breaking atari human world records via sample-efficient behavior selection. In The Eleventh International Conference on Learning Representations, External Links: LinkCited by: §2.
- R. Friel, M. Belyi, and A. Sanyal (2024)RAGBench: explainable benchmark for retrieval-augmented generation systems. arXiv preprint arXiv:2407.11005. External Links: LinkCited by: §1, §2, §4.2.
- Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, and H. Wang (2023)Retrieval-augmented generation for large language models: a survey. arXiv preprint arXiv:2312.10997. External Links: LinkCited by: §1, §1, §1, §2.
- K. Guu, K. Lee, Z. Tung, P. Pasupat, and M. Chang (2020)REALM: retrieval-augmented language model pre-training. In International Conference on Machine Learning (ICML), pp.3929–3938. External Links: LinkCited by: §1, §2.
- T. H. Haveliwala (2002)Topic-sensitive PageRank. In Proceedings of the 11th International Conference on World Wide Web, pp.517–526. External Links: LinkCited by: §4.1, §5.1.
- X. He, Y. Tian, Y. Sun, N. V. Chawla, T. Laurent, Y. LeCun, X. Bresson, and B. Hooi (2024)G-Retriever: retrieval-augmented generation for textual graph understanding and question answering. arXiv preprint arXiv:2402.07630. External Links: LinkCited by: §2.
- S. Jeong, J. Baek, S. Cho, S. J. Hwang, and J. C. Park (2024)Adaptive-RAG: learning to adapt retrieval-augmented large language models through question complexity. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2024), pp.1–15. External Links: LinkCited by: §1, §1, §2.
- Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. Bang, A. Madotto, and P. Fung (2023)Survey of hallucination in natural language generation. ACM Computing Surveys 55 (12), pp.1–38. External Links: LinkCited by: §1, §2.
- B. Jiménez Gutiérrez, Y. Gu, Y. Shu, M. Yasunaga, and Y. Su (2024)HippoRAG: neurobiologically inspired long-term memory for large language models. In Advances in Neural Information Processing Systems (NeurIPS), Vol. 37. External Links: LinkCited by: §2.
- J. Jin, Y. Zhu, G. Dong, Y. Zhang, X. Yang, C. Zhang, T. Zhao, Z. Yang, Z. Dou, and J. Wen (2024)FlashRAG: a modular toolkit for efficient retrieval-augmented generation research. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), External Links: LinkCited by: §1, §1, §4.4, §5.1.
- V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W. Yih (2020)Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pp.6769–6781. External Links: LinkCited by: Table 11, §1, §2, §4.1, §5.1.
- P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel, and D. Kiela (2020)Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems, Vol. 33, pp.9459–9474. External Links: LinkCited by: §1, §4.1.
- Y. Lyu, Z. Li, S. Niu, F. Xiong, B. Tang, W. Wang, P. Wu, K. Liu, M. Chen, and X. Wan (2024)CRUD-RAG: a comprehensive chinese benchmark for retrieval-augmented generation of large language models. arXiv preprint arXiv:2401.17043. External Links: LinkCited by: §1, §2.
- A. Mallen, A. Asai, V. Zhong, R. Das, D. Khashabi, and H. Hajishirzi (2023)When not to trust language models: investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.9802–9822. External Links: LinkCited by: Table 11, §1, §2.
- M. Newman (2010)Networks: an introduction. Oxford University Press. Cited by: §4.3, §4.3, §5.1.
- OpenAI (2023)GPT-4 technical report. External Links: 2303.08774, LinkCited by: §5.1.
- OpenAI (2024)New embedding models and API updates. Note: https://openai.com/blog/new-embedding-models-and-api-updatesCited by: §5.1.
- R. Y. Pang, A. Parrish, N. Joshi, N. Nangia, A. Phan, P. M. Htut, J. Xie, S. R. Bowman, and H. He (2022)QuALITY: question answering with long input texts, yes!. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp.5336–5358. External Links: LinkCited by: Table 1, §4.2, §4.2.
- B. Peng, Y. Zhu, Y. Liu, X. Bo, H. Shi, C. Hong, Y. Zhang, and S. Tang (2024)Graph retrieval-augmented generation: a survey. arXiv preprint arXiv:2408.08921. External Links: LinkCited by: §1.
- F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y. Wu, A. H. Miller, and S. Riedel (2019)Language models as knowledge bases?. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.2463–2473. External Links: LinkCited by: §4.1.
- H. Qian, P. Zhang, Z. Liu, K. Mao, and Z. Dou (2024)MemoRAG: moving towards next-gen RAG via memory-inspired knowledge discovery. arXiv preprint arXiv:2409.05591. External Links: LinkCited by: Table 1, §4.2.
- M. Radovanović, A. Nanopoulos, and M. Ivanović (2010)Hubs in space: popular nearest neighbors in high-dimensional data. Journal of Machine Learning Research 11, pp.2487–2531. External Links: LinkCited by: §2, §4.3, §5.1.
- N. Reimers and I. Gurevych (2019)Sentence-BERT: sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pp.3982–3992. External Links: LinkCited by: §4.4.
- J. Saad-Falcon, O. Khattab, C. Potts, and M. Zaharia (2024)ARES: an automated evaluation framework for retrieval-augmented generation systems. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2024), External Links: LinkCited by: §2.
- B. Sarmah, B. Hall, R. Rao, S. Patel, S. Pasquali, and D. Mehta (2024)HybridRAG: integrating knowledge graphs and vector retrieval augmented generation for efficient information extraction. arXiv preprint arXiv:2408.04948. External Links: LinkCited by: §1, §2, §4.1, §5.1.
- J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y. Gong, L. M. Ni, H. Shum, and J. Guo (2024)Think-on-graph: deep and responsible reasoning of large language model on knowledge graph. In The Twelfth International Conference on Learning Representations (ICLR), External Links: LinkCited by: §2, §4.3, §5.1.
- X. Tang, Q. Gao, J. Li, N. Du, Q. Li, and S. Xie (2025)MBA-RAG: a bandit approach for adaptive retrieval-augmented generation through question complexity. In Proceedings of the 31st International Conference on Computational Linguistics (COLING 2025), pp.3248–3254. External Links: LinkCited by: §1, §1, §2.
- Y. Tang and Y. Yang (2024)MultiHop-RAG: benchmarking retrieval-augmented generation for multi-hop queries. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2024), pp.2369–2380. External Links: LinkCited by: Table 1, §2.
- L. Team (2024)The Llama 3 herd of models. arXiv preprint arXiv:2407.21783. External Links: LinkCited by: §5.1.
- N. Thakur, N. Reimers, A. Rücklë, A. Srivastava, and I. Gurevych (2021)BEIR: a heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Advances in Neural Information Processing Systems, Vol. 34, pp.24453–24466. External Links: LinkCited by: Table 11.
- H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal (2022)MuSiQue: multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics 10, pp.539–554. External Links: LinkCited by: Table 1, §4.2, §4.2.
- H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal (2023)Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023), pp.10014–10029. External Links: LinkCited by: Table 11, §4.1, §5.1.
- T. Wang and P. Isola (2020)Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In International Conference on Machine Learning (ICML), pp.9929–9939. External Links: LinkCited by: §4.3, §5.1.
- D. J. Watts and S. H. Strogatz (1998)Collective dynamics of ’small-world’ networks. Nature 393 (6684), pp.440–442. Cited by: §4.3, §5.1.
- Z. Xiang, C. Wu, Q. Zhang, S. Chen, Z. Hong, X. Huang, and J. Su (2025)When to use graphs in RAG: a comprehensive analysis for graph retrieval-augmented generation. arXiv preprint arXiv:2506.05690. External Links: LinkCited by: Table 1.
- Y. Xiao, J. Dong, C. Zhou, S. Dong, Q. Zhang, D. Yin, X. Sun, and X. Huang (2025)GraphRAG-Bench: challenging domain-specific reasoning for evaluating graph retrieval-augmented generation. arXiv preprint arXiv:2506.02404. External Links: LinkCited by: Table 1, §2, §4.2, §4.2.
- Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning (2018)HotpotQA: a dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp.2369–2380. External Links: LinkCited by: Table 1, §4.3.
- M. Yasunaga, H. Ren, A. Bosselut, P. Liang, and J. Leskovec (2021)QA-GNN: reasoning with language models and knowledge graphs for question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp.535–546. External Links: LinkCited by: Table 11.
- W. Yih, M. Richardson, C. Meek, M. Chang, and J. Suh (2016)The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.201–206. External Links: LinkCited by: Table 1.
- T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi (2020)BERTscore: evaluating text generation with BERT. In International Conference on Learning Representations (ICLR 2020), External Links: LinkCited by: §4.4, §5.1.
- L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica (2023)Judging LLM-as-a-judge with MT-bench and chatbot arena. In Advances in Neural Information Processing Systems (NeurIPS 2023), Vol. 36. External Links: LinkCited by: §4.4.
Appendix
Appendix A Data Construction & Corpus Analysis
A.1 Corpus Statistics & Preprocessing.
Table 3: Raw Corpus Statistics. Overview of the source documents illustrating extreme variations in document length (Avg. Tokens) and scale (Num. Docs), ranging from fragmented Wikipedia articles to monolithic textbooks.
Algorithm 1 Unified Corpus Preprocessing Pipeline.
1:Raw Corpus
𝒞={d 1,d 2,…,d n}\mathcal{C}={d_{1},d_{2},...,d_{n}} , where each
d i=(title,text)d_{i}=(\text{title},\text{text})
2:Knowledge Graph
𝒢=(V,E)\mathcal{G}=(V,E) , Dense Vector Index
ℐ vec\mathcal{I}_{\text{vec}} , Entity Embeddings
𝐄 ent\mathbf{E}_{\text{ent}}
3:Hyperparameters: Chunk Size
L=512 L=512 , Overlap
O=100 O=100 , Embedding Model
ℳ emb\mathcal{M}_{\text{emb}} , LLM
ℳ gen\mathcal{M}_{\text{gen}}
4:// Phase 1: Sliding Window Chunking
5:
𝒮 chunks←∅\mathcal{S}_{\text{chunks}}\leftarrow\emptyset
6:for each document
d∈𝒞 d\in\mathcal{C} do
7:
Tokens←Tokenize(d.title⊕d.text)\text{Tokens}\leftarrow\text{Tokenize}(d.\text{title}\oplus d.\text{text}) ⊳\triangleright Using tiktoken (cl100k_base)
8:
ptr←0 ptr\leftarrow 0
9:while
ptr<len(Tokens)ptr<\text{len}(\text{Tokens}) do
10:
c raw←Tokens[p t r:p t r+L]c_{\text{raw}}\leftarrow\text{Tokens}[ptr:ptr+L]
11:
c text←Decode(c raw)c_{\text{text}}\leftarrow\text{Decode}(c_{\text{raw}})
12:
𝒮 chunks←𝒮 chunks∪{(d.id,c text)}\mathcal{S}{\text{chunks}}\leftarrow\mathcal{S}{\text{chunks}}\cup{(d.\text{id},c_{\text{text}})}
13:
ptr←ptr+(L−O)ptr\leftarrow ptr+(L-O)
14:end while
15:end for
16:// Phase 2: Graph Construction & Entity Extraction
17:Initialize
V←∅,E←∅V\leftarrow\emptyset,E\leftarrow\emptyset
18:for each chunk
c∈𝒮 chunks c\in\mathcal{S}_{\text{chunks}} do
19:
𝒯←ℳ gen(Prompt extract,c)\mathcal{T}\leftarrow\mathcal{M}{\text{gen}}(\text{Prompt}{\text{extract}},c) ⊳\triangleright Extract triplets (s,r,o)(s,r,o) via DeepSeek
20:for each triplet
(s,r,o)∈𝒯(s,r,o)\in\mathcal{T} do
21:
V←V∪{s,o}V\leftarrow V\cup{s,o}
22:
E←E∪{(s,r,o)}E\leftarrow E\cup{(s,r,o)}
23:end for
24:end for
25:// Phase 3: Vectorization & Indexing
26:
𝐗 chunks←∅\mathbf{X}_{\text{chunks}}\leftarrow\emptyset
27:for each chunk
c∈𝒮 chunks c\in\mathcal{S}_{\text{chunks}} do
28:
𝐯 c←ℳ emb(c)\mathbf{v}{c}\leftarrow\mathcal{M}{\text{emb}}(c) ⊳\triangleright Dimension d=1536 d=1536
29:
𝐗 chunks.append(𝐯 c)\mathbf{X}{\text{chunks}}.\text{append}(\mathbf{v}{c})
30:end for
31:
ℐ vec←FAISS.Index(𝐗 chunks)\mathcal{I}{\text{vec}}\leftarrow\text{FAISS.Index}(\mathbf{X}{\text{chunks}}) ⊳\triangleright Build dense retrieval index
32:
𝐄 ent←EmbedEntities(V)\mathbf{E}_{\text{ent}}\leftarrow\text{EmbedEntities}(V) ⊳\triangleright Embed unique entities for GraphRAG
33:return
𝒢,ℐ vec,𝐄 ent\mathcal{G},\mathcal{I}{\text{vec}},\mathbf{E}{\text{ent}}
Data Overview.
To establish a benchmark encompassing diverse retrieval environments, we integrate four representative datasets spanning encyclopedic knowledge (MuSiQue, 21,100 Wikipedia articles), long-form narratives (QuALITY, 265 Gutenberg novels), specialized legal corpora (UltraDomain_Legal, 94 contract documents), and medical literature (GraphRAGBench_Medical, a single comprehensive textbook). As shown in Table 3, these datasets exhibit extreme disparities in both document count (ranging from 1 to 21,100) and average length (107.9 to 221,495 tokens), thereby serving as an ideal testbed for evaluating the adaptability of RAG paradigms across distinct scales and structural settings. The complete preprocessing pipeline is formalized in Algorithm1.
Stage Parameter Value Description Chunking Size 512 Fixed-size segment Overlap 100 Sliding window Tokenizer cl100k_base OpenAI encoding Extraction LLM DeepSeek-V3 Base Model Temp.0.0 Deterministic Concur.15 Parallel requests Timeout 60s API limit Retries 3 Fault tolerance Graph Directed False Undirected edges Embedding Model text-emb-3-small OpenAI Model Dim.1536 Vector size Batch 30 API batch size
Table 4: Hyperparameters for Corpus Preprocessing.
Chunking Strategy.
We employ a sliding window chunking strategy to process the raw corpora (see Table4 for all hyperparameters). Specifically, utilizing the cl100k_base encoder from tiktoken, each document (concatenated title and content) is segmented into fixed-size chunks with a window size of 512 tokens and a 100-token overlap to preserve contextual coherence. This configuration strikes a balance between retrieval granularity and contextual completeness. Following this segmentation, the four datasets yield distinct chunk inventories: 21,153 (MuSiQue), 3,822 (QuALITY), 11,632 (Legal), and 538 (Medical).

Figure 9: The prompt template for extracting structured knowledge triplets from text chunks.
Knowledge Graph Construction.
To facilitate the structure-aware retrieval required by GraphRAG and HybridRAG, we extract knowledge triplets from each individual text chunk. We employ DeepSeek-V3 as the underlying extraction engine, with hyperparameters detailed in Table4, setting the temperature to 0.0 to ensure deterministic generation. To optimize processing throughput, we implement an asynchronous parallelization strategy configured with a maximum concurrency of 15, a 60-second request timeout, and a retry mechanism allowing up to 3 attempts with exponential backoff. As illustrated in Figure9, the extraction prompt instructs the model to identify (Subject, Relation, Object) triplets within the input text and format the output as a JSON array. The scale of the resulting knowledge graphs is detailed in Table7. Specifically, MuSiQue comprises 206,738 entity nodes and 276,898 edges; QuALITY contains 90,088 nodes and 120,611 edges; the Legal corpus yields 135,231 nodes and 261,207 edges; and the Medical textbook generates 14,712 nodes and 21,480 edges. Graph density varies significantly from 6.0×10−6 6.0\times 10^{-6} (MuSiQue) to 9.9×10−5 9.9\times 10^{-5} (Medical), reflecting inherent disparities in structural sparsity across domains. All constructed graphs are represented as undirected graphs to facilitate bidirectional traversal.
Vectorization & Indexing.
To facilitate the dense retrieval mechanism of NaiveRAG, we utilize the OpenAI text-embedding-3-small model to encode each text chunk into a 1,536-dimensional vector representation. We employ a batch size of 30 to mitigate API rate-limiting constraints. All generated vectors undergo L2 normalization and are subsequently indexed using FAISS (IndexFlatIP) to enable efficient retrieval based on cosine similarity. Concurrently, to support the entity-level retrieval required by GraphRAG, we generate distinct embeddings for all unique entities within the knowledge graphs, specifically, 206,738 for MuSiQue, 90,088 for QuALITY, 135,231 for Legal, and 14,712 for Medical. These entity embeddings serve as the foundation for precise entity matching and the selection of seed nodes for graph traversal during the query execution phase.
A.2 Query Generation Pipeline
Algorithm 2 Query Generation & Validation Pipeline
1:Corpus
𝒞\mathcal{C} , Knowledge Graph
𝒢\mathcal{G} , Target Counts
N fact,N hop,N sum N_{\text{fact}},N_{\text{hop}},N_{\text{sum}}
2:Validated Query Set
𝒬 final\mathcal{Q}_{\text{final}}
3:Hyperparameters: Generator
ℳ gen\mathcal{M}_{\text{gen}} , Evaluator
ℳ eval\mathcal{M}_{\text{eval}}
4:// Phase 1: Diversity-Driven Generation
5:
𝒬 raw←∅\mathcal{Q}_{\text{raw}}\leftarrow\emptyset
6:(1) Factual Queries (Single-hop):
7:for
i←1 i\leftarrow 1 to
N fact N_{\text{fact}} do
8:
c∼Uniform(𝒞)c\sim\text{Uniform}(\mathcal{C}) ⊳\triangleright Sample random chunk
9:
(q,a)←ℳ gen(Prompt fact,c)(q,a)\leftarrow\mathcal{M}{\text{gen}}(\text{Prompt}{\text{fact}},c)
10:
𝒬 raw←𝒬 raw∪{(q,a,{c},"factual")}\mathcal{Q}{\text{raw}}\leftarrow\mathcal{Q}{\text{raw}}\cup{(q,a,{c},\text{"factual"})}
11:end for
12:(2) Reasoning Queries (Multi-hop):
13:
𝒫 chains←RandomWalk(𝒢,len=2)\mathcal{P}_{\text{chains}}\leftarrow\text{RandomWalk}(\mathcal{G},\text{len}=2) ⊳\triangleright Find connected doc pairs via bridge entities
14:for
i←1 i\leftarrow 1 to
N hop N_{\text{hop}} do
15:
D chain←𝒫 chains[i]D_{\text{chain}}\leftarrow\mathcal{P}_{\text{chains}}[i]
16:
(q,a,reasoning)←ℳ gen(Prompt hop,D chain)(q,a,\text{reasoning})\leftarrow\mathcal{M}{\text{gen}}(\text{Prompt}{\text{hop}},D_{\text{chain}})
17:
𝒬 raw←𝒬 raw∪{(q,a,D chain,"multi_hop")}\mathcal{Q}{\text{raw}}\leftarrow\mathcal{Q}{\text{raw}}\cup{(q,a,D_{\text{chain}},\text{"multi_hop"})}
18:end for
19:(3) Summary Queries (Global):
20:for
i←1 i\leftarrow 1 to
N sum N_{\text{sum}} do
21:
e∼PageRank(𝒢)e\sim\text{PageRank}(\mathcal{G}) ⊳\triangleright Sample important entity
22:
D cluster←GetNeighbors(e,𝒢)D_{\text{cluster}}\leftarrow\text{GetNeighbors}(e,\mathcal{G}) ⊳\triangleright Retrieve ego-graph documents
23:
(q,a)←ℳ gen(Prompt sum,D cluster)(q,a)\leftarrow\mathcal{M}{\text{gen}}(\text{Prompt}{\text{sum}},D_{\text{cluster}})
24:
𝒬 raw←𝒬 raw∪{(q,a,D cluster,"summary")}\mathcal{Q}{\text{raw}}\leftarrow\mathcal{Q}{\text{raw}}\cup{(q,a,D_{\text{cluster}},\text{"summary"})}
25:end for
26:// Phase 2: The "Verify-then-Filter" Validation Loop
27:
𝒬 final←∅\mathcal{Q}_{\text{final}}\leftarrow\emptyset
28:for each query instance
𝐱=(q,a,D supp,type)∈𝒬 raw\mathbf{x}=(q,a,D_{\text{supp}},\text{type})\in\mathcal{Q}_{\text{raw}} do
29:
valid←True\text{valid}\leftarrow\textbf{True}
30:Check 1: Grounding (Answerable from Context?)
31:
a^←ℳ eval(Prompt qa,q,D supp)\hat{a}\leftarrow\mathcal{M}{\text{eval}}(\text{Prompt}{\text{qa}},q,D_{\text{supp}})
32:if
Sim(a^,a)<τ strict\text{Sim}(\hat{a},a)<\tau_{\text{strict}} then
valid←False\text{valid}\leftarrow\textbf{False}
33:end if
34:Check 2: Shortcut Detection (Multi-hop Only)
35:if
type=="multi_hop"\text{type}==\text{"multi_hop"} then
36:for
d∈D supp d\in D_{\text{supp}} do
37:if
ℳ eval(q,{d})≈a\mathcal{M}_{\text{eval}}(q,{d})\approx a then⊳\triangleright Can single doc answer it?
38:
valid←False\text{valid}\leftarrow\textbf{False} ; break
39:end if
40:end for
41:end if
42:Check 3: Knowledge Leakage (LLM Prior Knowledge)
43:
a prior←ℳ eval(Prompt closed_book,q)a_{\text{prior}}\leftarrow\mathcal{M}{\text{eval}}(\text{Prompt}{\text{closed_book}},q) ⊳\triangleright Ask without context
44:if
Sim(a prior,a)>τ leak\text{Sim}(a_{\text{prior}},a)>\tau_{\text{leak}} then
45:
valid←False\text{valid}\leftarrow\textbf{False} ⊳\triangleright Reject if LLM already knows the answer
46:end if
47:if valid then
𝒬 final←𝒬 final∪{𝐱}\mathcal{Q}{\text{final}}\leftarrow\mathcal{Q}{\text{final}}\cup{\mathbf{x}}
48:end if
49:end for
50:return
𝒬 final\mathcal{Q}_{\text{final}}

Figure 10: The prompt template for generating Factual queries.

Figure 11: The instruction set for synthesizing Reasoning queries.

Figure 12: The prompt designed for Summary query generation.
Generation Overview.
To construct a query set encompassing varying degrees of cognitive complexity, we devise three distinct query generation strategies, as detailed in Algorithm2. All generation processes utilize DeepSeek-V3 as the backbone model, with a temperature setting of 0.7 to strike a balance between diversity and quality.
Factual Queries: We perform uniform random sampling of text segments from the corpus and employ the prompt illustrated in Figure10 to steer the LLM in generating factual QA pairs. Crucially, the prompt enforces a self-contained constraint, ensuring that questions are semantically independent of context and devoid of ambiguous pronominal references.
Reasoning Queries: Leveraging the topological structure of the knowledge graph, we identify document chains linked via shared entities. Specifically, for k k-hop inquiries, we execute random walks on the graph to locate k k documents connected by bridge entities. Figure11 depicts the generation prompt, which centers on a Reverse Substitution strategy: starting from the target answer, bridge entities are iteratively replaced with functional descriptions derived from preceding documents. This mechanism ensures that the resulting questions necessitate traversing the complete reasoning chain for resolution. We generate reasoning queries at both 2-hop and 3-hop complexity levels.
Summary Queries: We cluster documents by entity, selecting those with high connectivity within the graph as summarization targets. As shown in Figure12, the prompt mandates an initial consistency check, verifying that multiple documents refer to the same entity rather than homonyms, followed by the synthesis of information from at least two documents. This process yields summarization questions that explicitly require cross-document integration for a complete response.
Dataset Type Gen.Pass Rate MuSiQue Single-hop 700 398 56.9% 2-hop 400 84 21.0% 3-hop 400 89 22.2% Summary 527 368 69.8% Total 2,027 939 46.3% QuALITY Single-hop 500 454 90.8% 2-hop 561 212 37.8% 3-hop 600 249 41.5% Summary 789 283 35.9% Total 2,450 1,198 48.9% Legal Single-hop 400 370 92.5% 2-hop 784 238 30.4% 3-hop 800 288 36.0% Summary 983 381 38.8% Total 2,967 1,277 43.0% Total 7,444 3,414 45.9%
Table 5: Verify-then-Filter validation statistics.
Verify-then-Filter Validation.
Raw queries undergo a rigorous three-tiered verification protocol before inclusion in the final benchmark (Algorithm2, Phase 2):
Grounding Check: We task an LLM with generating answers derived exclusively from the supporting facts. An LLM-as-a-Judge then validates the semantic consistency between the generated response and the expected answer. This step guarantees that the question is rigorously answerable given the provided documents.
Shortcut Detection: We evaluate whether any single supporting fact suffices to answer the question in isolation. If an individual document yields the correct answer, the query is identified as containing a “shortcut”, violating the intrinsic requirement of multi-hop reasoning, and is subsequently filtered out.
Knowledge Leakage Check: We screen for two forms of information leakage: (1) Lexical Leakage, where the answer appears as a substring within the question itself; and (2) Parametric Leakage, where the LLM can answer correctly relying solely on pre-trained knowledge. The latter is assessed via a closed-book test; if the model succeeds without retrieval context, the query is deemed ineffective for evaluating retrieval capabilities.
Human Verification: To address potential LLM self-validation bias in the above automated checks, we conduct manual verification on a stratified sample of 50 queries per corpus (N=200 total). Two annotators independently assess answerability and information leakage, achieving 91% inter-annotator agreement (Cohen’s κ\kappa=0.85). The human-LLM agreement rate of 94% confirms the reliability of the automated filtering pipeline.
Validation Statistics.
Table5 presents the validation statistics across the constituent datasets. We generated a total of 7,444 candidate queries, of which 3,414 were retained following the Verify-then-Filter process, yielding an overall acceptance rate of 45.9%.
Pass rates exhibit significant variance across distinct query types. Single-hop queries achieve pass rates exceeding 90% on QuALITY and Legal datasets, yet only 56.9% on MuSiQue. This disparity is primarily attributed to MuSiQue’s foundation in Wikipedia, where extensive factual overlap with the LLM’s pre-training corpus frequently triggers the Knowledge Leakage filter. Multi-hop queries register the lowest pass rates (21%–42%), with the vast majority discarded by Shortcut Detection, underscoring the inherent challenge in generating questions that genuinely necessitate multi-step reasoning. Summary queries exhibit pass rates ranging from 36% to 70%, with failures predominantly stemming from the Grounding Check, specifically, semantic deviations between the response derived from the provided document set and the expected gold standard.
The final benchmark comprises validated queries from MuSiQue (939), QuALITY (1,198), and Legal (1,277). Integrating the Medical dataset from GraphRAGBench (1,896 pre-annotated questions), the final corpus totals 5,310 high-quality queries, spanning four domains and three levels of cognitive complexity.
A.3 Corpus Evaluation Metrics
Table 6: Key corpus metrics characterizing the retrieval environment.
Table6 summarizes the core metrics employed to characterize the retrieval environment. By quantifying corpus properties along the dual dimensions of structural topology and semantic space, these metrics provide a quantitative foundation for delineating the applicability boundaries of distinct RAG paradigms.
Table 7: Full Structural Statistics. Detailed graph topology metrics including node/edge counts, graph density, number of unique relation types, average node degree, number of connected components (Comp.), ratio of the largest connected component (LCC Ratio), and average clustering coefficient.
Structural Topology Metrics.
We employ three graph-theoretic metrics to evaluate the topological structure of the knowledge graphs (Table7):
LCC Ratio (Largest Connected Component Ratio): This metric measures global reachability. It is defined as the ratio of nodes in the largest connected component to the total number of nodes:
LCC Ratio=|V LCC||V|\text{LCC Ratio}=\frac{|V_{\text{LCC}}|}{|V|}(2)
where V LCC V_{\text{LCC}} denotes the node set of the largest connected component and V V represents the total node set. A lower ratio indicates severe graph fragmentation, increasing the risk that multi-hop reasoning paths are physically severed.
Density: This metric measures edge saturation. For an undirected graph, it is defined as:
D=2|E||V|(|V|−1)D=\frac{2|E|}{|V|(|V|-1)}(3)
where |E||E| is the number of edges and |V||V| is the number of nodes. Excessively low density implies a lack of sufficient relational bridges between entities, while excessively high density introduces noise, thereby degrading graph traversal efficiency.
Clustering Coefficient: This metric measures local cohesiveness. The clustering coefficient for a node v v is defined as the ratio of actual edges between its neighbors to the number of possible edges:
C v=2⋅|{e jk:v j,v k∈N(v),e jk∈E}|k v(k v−1)C_{v}=\frac{2\cdot|{e_{jk}:v_{j},v_{k}\in N(v),e_{jk}\in E}|}{k_{v}(k_{v}-1)}(4)
where N(v)N(v) is the neighborhood set of node v v, and k v=|N(v)|k_{v}=|N(v)| represents the node degree. The global clustering coefficient is the average over all nodes. A high coefficient indicates the presence of tight-knit thematic communities, facilitating local evidence aggregation.
Table 8: Full Semantic Statistics. Metrics covering vector space properties: total number of text chunks, intrinsic dimension (Int. Dim.), Hubness score (interference), and centroid distance statistics (Average, Standard Deviation, Minimum, Maximum).
Semantic Space Metrics
We employ three vector space metrics to assess embedding quality (Table8):
Intrinsic Dimension: This metric quantifies the effective degrees of freedom within the embedding space. We estimate it using the TwoNN algorithm: for each data point, we calculate the distance to its nearest neighbor (r 1 r_{1}) and second-nearest neighbor (r 2 r_{2}). Letting μ=r 2/r 1\mu=r_{2}/r_{1}, the intrinsic dimension is defined as:
d int=1 𝔼[lnμ]d_{\text{int}}=\frac{1}{\mathbb{E}[\ln\mu]}(5)
High intrinsic dimensionality exacerbates the curse of dimensionality, rendering distance-based similarity metrics ineffective.
Dispersion: This metric measures the uniformity of semantic distribution. We compute the cosine distance of each embedding vector from the global centroid:
dist(x i)=1−x i⋅x¯‖x i‖‖x¯‖\text{dist}(x_{i})=1-\frac{x_{i}\cdot\bar{x}}{|x_{i}||\bar{x}|}(6)
where x¯=1 n∑i=1 n x i\bar{x}=\frac{1}{n}\sum_{i=1}^{n}x_{i} denotes the centroid vector. Table8 reports the mean, standard deviation, minimum, and maximum of these distances. Low dispersion results in semantic crowding, hindering the retriever’s ability to distinguish between semantically similar yet factually unrelated “hard negatives.”
Hubness: This metric quantifies the extent of retrieval interference. Defining N k(i)N_{k}(i) as the number of times point i i appears in the k k-nearest neighbor lists of all other points (k k-occurrence), Hubness is calculated as the skewness of this distribution:
S k=𝔼[(N k−μ N k)3]σ N k 3 S_{k}=\frac{\mathbb{E}[(N_{k}-\mu_{N_{k}})^{3}]}{\sigma_{N_{k}}^{3}}(7)
Positive skewness indicates the presence of “hub” embeddings, vectors that frequently appear in the nearest neighbor lists of others. This phenomenon causes a systematic bias in retrieval results towards these hubs, thereby reducing both retrieval diversity and accuracy.
Appendix B RAG Paradigm Implementation
Category Parameter Value Description LLM Model DeepSeek-V3 Generation backbone Temperature 0.3 Focused generation Max Tokens 1000 Response length limit Timeout 120s API request limit Retrieval Token Budget 8000 Context length limit Similarity Cosine Distance metric Min Threshold 0.4 Relevance filter
Table 9: Shared hyperparameters across all RAG paradigms.
Paradigm Parameter Value Description LLM-only Temperature 0.7 Creative generation Max Tokens 1000 Response length NaiveRAG Top-K 100 Max chunks retrieved GraphRAG Seed Entities 20 Initial anchors PPR Alpha 0.85 Damping factor PPR Max Nodes 100 Subgraph size limit Max Triplets 500 Serialization limit IterativeRAG Base Retriever GraphRAG Underlying method Max Iterations 3 Reasoning loop limit Eval Temp.0.1 Evaluator setting
Table 10: Paradigm-specific hyperparameters.
B.1 Unified Hyperparameters
To guarantee a fair comparison across distinct RAG paradigms, we standardize the core hyperparameter configurations. Table9 enumerates the foundational settings shared across all methodologies: DeepSeek-V3 serves as the uniform generation backbone, with the temperature set to 0.3 to elicit stable outputs. All retrieval-augmented approaches are constrained by a shared context budget of 8,000 tokens, employ cosine similarity as the distance metric, and enforce a minimum relevance threshold of 0.4 to filter out low-quality evidence.
Table10 details the paradigm-specific parameters. LLM-only, serving as the retrieval-free baseline, utilizes a higher temperature (0.7) to encourage the model to fully leverage its internal parametric knowledge. NaiveRAG retrieves a maximum of 100 text chunks, truncating the selection based on similarity ranking to fit within the token budget. GraphRAG initiates from 20 seed entities and expands the subgraph using Personalized PageRank (α=0.85\alpha=0.85), retaining a maximum of 100 nodes and 500 triplets. IterativeRAG employs GraphRAG as the base retriever, executing up to 3 rounds of iterative refinement, with the evaluator operating at a low temperature (0.1) to ensure decisional consistency. Finally, HybridRAG inherits the parameter settings of both NaiveRAG and GraphRAG, fusing their respective retrieval results.
Table 11: A Methodology Perspective on RAG Paradigms. We categorize existing paradigms by their Retrieval Substrate (data structure), Information Granularity, and Search Mechanism. Each paradigm imposes different trade-offs between retrieval cost and reasoning capability, highlighting that no single strategy fits all scenarios.
Algorithm 3 GraphRAG Retrieval & Generation Pipeline
1:Question
q q , Knowledge Graph
G=(V,E)G=(V,E) , Entity Index
ℐ E\mathcal{I}_{E} , Token Budget
B B
2:Generated Answer
a a
3:Hyperparameters: Entity Threshold
τ entity=0.4\tau_{\text{entity}}=0.4 , PPR Threshold
τ ppr=1e−5\tau_{\text{ppr}}=1e^{-5} , Damping
α=0.85\alpha=0.85
4:// Phase 1: Seed Entity Retrieval
5:
E query←LLM(Prompt extract,q)E_{\text{query}}\leftarrow\text{LLM}(\text{Prompt}_{\text{extract}},q)
6:if
E query=∅E_{\text{query}}=\emptyset then
7:
E query←{q}E_{\text{query}}\leftarrow{q} ⊳\triangleright Fallback: use entire question
8:end if
9:
S←∅S\leftarrow\emptyset ⊳\triangleright Initialize seed set mapping: id→score id\to score
10:for each
e∈E query e\in E_{\text{query}} do
11:
v e←Embed(e)v_{e}\leftarrow\text{Embed}(e)
12:
𝒦←FAISS_Search(ℐ E,v e,k=20)\mathcal{K}\leftarrow\text{FAISS_Search}(\mathcal{I}{E},v{e},k=20)
13:for each
(id,sim)∈𝒦(id,\text{sim})\in\mathcal{K} do
14:if
sim>τ entity\text{sim}>\tau_{\text{entity}} then
15:
S[id]←max(S[id],sim)S[id]\leftarrow\max(S[id],\text{sim}) ⊳\triangleright Max pooling for duplicates
16:end if
17:end for
18:end for
19:
S←TopK(S,k=20)S\leftarrow\text{TopK}(S,k=20)
20:// Phase 2: PPR-Based Subgraph Expansion
21:
𝐩←Zeros(|V|)\mathbf{p}\leftarrow\text{Zeros}(|V|) ⊳\triangleright Initialize personalization vector
22:
Z←∑(id,sim)∈S sim Z\leftarrow\sum_{(id,\text{sim})\in S}\text{sim}
23:for each
(id,sim)∈S(id,\text{sim})\in S do
24:
𝐩[id]←sim/Z\mathbf{p}[id]\leftarrow\text{sim}/Z ⊳\triangleright Normalize to probability distribution
25:end for
26:
𝝅←PageRank(G,personalization=𝐩,α=α,iter=100)\boldsymbol{\pi}\leftarrow\text{PageRank}(G,\text{personalization}=\mathbf{p},\alpha=\alpha,\text{iter}=100)
27:
V sub←{v∣𝝅[v]≥τ ppr}V_{\text{sub}}\leftarrow{v\mid\boldsymbol{\pi}[v]\geq\tau_{\text{ppr}}}
28:
V sub←TopK(V sub,k=100)∪Keys(S)V_{\text{sub}}\leftarrow\text{TopK}(V_{\text{sub}},k=100)\cup\text{Keys}(S) ⊳\triangleright Keep top-100 expanded nodes + seeds
29:// Phase 3: Context Construction
30:
T←{(u,r,v)∣u,v∈V sub,(u,v)∈E}T\leftarrow{(u,r,v)\mid u,v\in V_{\text{sub}},(u,v)\in E} ⊳\triangleright Extract triplets from induced subgraph
31:
𝒞←∅\mathcal{C}\leftarrow\emptyset
32:Sort
T T by
max(sim(u),sim(v))\max(\text{sim}(u),\text{sim}(v)) descending ⊳\triangleright Prioritize relevance
33:
ctx←“”,count←0 ctx\leftarrow\text{``''},\quad\text{count}\leftarrow 0
34:for each
(u,r,v)∈T(u,r,v)\in T do
35:
sents←TripletSourceMap[(u,r,v)]\text{sents}\leftarrow\text{TripletSourceMap}[(u,r,v)]
36:for each
s∈sents s\in\text{sents} do
37:if
count+Len(s)>B\text{count}+\text{Len}(s)>B then break
38:end if
39:
ctx←ctx⊕s ctx\leftarrow ctx\oplus s
40:
count←count+Len(s)\text{count}\leftarrow\text{count}+\text{Len}(s)
41:end for
42:end for
43:// Phase 4: Answer Generation
44:
a←LLM(Prompt RAG,ctx,q)a\leftarrow\text{LLM}(\text{Prompt}_{\text{RAG}},ctx,q)
45:return
a a
Algorithm 4 IterativeRAG (Multi-Round Retrieval with Self-Evaluation)
1:Question
q q , Base Retriever
ℛ\mathcal{R} (NaiveRAG or GraphRAG), Max Iterations
T T
2:Final Answer
a a
3:Initialization
4:
𝒬 history←{q}\mathcal{Q}_{\text{history}}\leftarrow{q} ⊳\triangleright Track all queries to prevent loops
5:
𝒞 accum←∅\mathcal{C}_{\text{accum}}\leftarrow\emptyset ⊳\triangleright Accumulated retrieved chunks
6:
H←[]H\leftarrow[] ⊳\triangleright Reasoning trace
7:Round 0: Direct LLM Answer (No Retrieval)
8:
a 0←LLM(Prompt QA,q)a_{0}\leftarrow\text{LLM}(\text{Prompt}_{\text{QA}},q) ⊳\triangleright Answer without context
9:
eval 0←LLM(Prompt Eval,q,a 0)\text{eval}{0}\leftarrow\text{LLM}(\text{Prompt}{\text{Eval}},q,a_{0}) ⊳\triangleright{sufficient, reason, sub_question}
10:
H.append((0,q,a 0,eval 0))H.\text{append}((0,q,a_{0},\text{eval}_{0}))
11:if
eval 0.sufficient is True\text{eval}_{0}.\text{sufficient}\textbf{ is True} then
12:return
a 0 a_{0} ⊳\triangleright LLM already knows the answer
13:end if
14:
q curr←eval 0.sub_question orq q_{\text{curr}}\leftarrow\text{eval}_{0}.\text{sub_question}\textbf{ or }q ⊳\triangleright Get refined query
15:Round 1+: Iterative Retrieval Loop
16:for
t←1 t\leftarrow 1 to
T T do
17:// Step 1: Retrieve new chunks
18:
𝒞 new←Retrieve(ℛ,q curr)\mathcal{C}{\text{new}}\leftarrow\text{Retrieve}(\mathcal{R},q{\text{curr}})
19:// Step 2: Merge and Deduplicate
20:
𝒞 accum←𝒞 accum∪𝒞 new\mathcal{C}{\text{accum}}\leftarrow\mathcal{C}{\text{accum}}\cup\mathcal{C}_{\text{new}}
21:// Step 3: Apply Token Budget
22:
𝒞 ctx←ApplyTokenBudget(𝒞 accum,B=8000)\mathcal{C}{\text{ctx}}\leftarrow\text{ApplyTokenBudget}(\mathcal{C}{\text{accum}},B=8000)
23:
ctx←Concatenate(𝒞 ctx)\text{ctx}\leftarrow\text{Concatenate}(\mathcal{C}_{\text{ctx}})
24:// Step 4: Generate answer with accumulated context
25:
a t←LLM(Prompt RAG,ctx,q)a_{t}\leftarrow\text{LLM}(\text{Prompt}_{\text{RAG}},\text{ctx},q) ⊳\triangleright Always answer ORIGINAL question
26:// Step 5: Evaluate answer sufficiency
27:
eval t←LLM(Prompt Eval,q,a t,ctx)\text{eval}{t}\leftarrow\text{LLM}(\text{Prompt}{\text{Eval}},q,a_{t},\text{ctx})
28:
H.append((t,q curr,a t,eval t))H.\text{append}((t,q_{\text{curr}},a_{t},\text{eval}_{t}))
29:// Step 6: Check termination conditions
30:if
eval t.sufficient is True\text{eval}_{t}.\text{sufficient}\textbf{ is True} then
31:return
a t a_{t} ⊳\triangleright Answer is sufficient
32:end if
33:
q next←eval t.sub_question q_{\text{next}}\leftarrow\text{eval}_{t}.\text{sub_question}
34:if
q nextis null q_{\text{next}}\textbf{ is null} then
35:return
a t a_{t} ⊳\triangleright No further refinement possible
36:end if
37:if
q next∈𝒬 history q_{\text{next}}\in\mathcal{Q}_{\text{history}} then
38:return
a t a_{t} ⊳\triangleright Prevent query loop
39:end if
40:// Step 7: Update for next iteration
41:
𝒬 history←𝒬 history∪{q next}\mathcal{Q}{\text{history}}\leftarrow\mathcal{Q}{\text{history}}\cup{q_{\text{next}}}
42:
q curr←q next q_{\text{curr}}\leftarrow q_{\text{next}}
43:end for
44:return
H[−1].answer H[-1].\text{answer} ⊳\triangleright Return last answer if max iterations reached

Figure 13: The prompt template for Entity Extraction.

Figure 14: The Self-Evaluation prompt for Iterative RAG.

Figure 15: The prompt for Direct Generation (LLM-only).

Figure 16: The Context-Aware Generation prompt.
B.2 Retrieval Paradigm Implementation
Table11 contrasts the five paradigms from a methodological perspective, characterizing their retrieval substrates, information granularity, and search mechanisms. This section elaborates on the specific implementation details of each paradigm. To ensure a fair comparison, all methodologies employ a uniform generation prompt, as illustrated in Figure16.
LLM-only and NaiveRAG.
LLM-only operates as the retrieval-free baseline, generating responses by directly querying the model and thereby relying exclusively on its internal parametric knowledge (Figure15). NaiveRAG follows the standard dense retrieval protocol, retrieving the top-100 semantically similar text chunks and subsequently truncating the concatenated context to adhere to the 8,000-token budget limit.
GraphRAG.
GraphRAG leverages knowledge graphs to perform structure-aware retrieval (Algorithm3). The process initiates by extracting query entities via an LLM (Figure13) and linking them to graph entities to establish a seed node set S S. Subsequently, Personalized PageRank (PPR) is executed over the global graph topology. We construct the personalization vector 𝐩\mathbf{p} based on semantic similarity to the seeds:
𝐩[v]=sim(v)∑u∈S sim(u),v∈S\mathbf{p}[v]=\frac{\text{sim}(v)}{\sum_{u\in S}\text{sim}(u)},\quad v\in S(8)
The PPR iterative update rule is defined as:
𝝅(t+1)=α⋅𝐀⋅𝝅(t)+(1−α)⋅𝐩\boldsymbol{\pi}^{(t+1)}=\alpha\cdot\mathbf{A}\cdot\boldsymbol{\pi}^{(t)}+(1-\alpha)\cdot\mathbf{p}(9)
where 𝐀\mathbf{A} denotes the column-normalized adjacency matrix of the graph, and α=0.85\alpha=0.85 serves as the damping factor. Upon convergence, we identify the top-100 nodes with the highest PPR scores to construct a salient subgraph. The associated triplets are then extracted and mapped back to their original textual source to serve as the generation context.
HybridRAG.
HybridRAG integrates the retrieval outputs from both NaiveRAG (vector-based) and GraphRAG (graph-based). Following the independent acquisition of ranked lists from both pathways, we employ Reciprocal Rank Fusion (RRF) to merge the rankings:
RRF(d)=∑r∈ℛ 1 k+rank r(d)\text{RRF}(d)=\sum_{r\in\mathcal{R}}\frac{1}{k+\text{rank}_{r}(d)}(10)
where ℛ={Naive,Graph}\mathcal{R}={\text{Naive},\text{Graph}} represents the set of retrievers, rank r(d)\text{rank}_{r}(d) denotes the rank position of document d d within retriever r r, and k=60 k=60 serves as the smoothing constant. Post-fusion, documents are sorted in descending order of their RRF scores. We subsequently remove duplicates and truncate the sequence to adhere to the strict 8,000-token context budget.
IterativeRAG.
IterativeRAG implements a “Retrieve-Generate-Evaluate” feedback loop, as detailed in Algorithm4. In the initial phase (Round 0), the system attempts a direct response using the LLM. If the evaluator (Figure14) deems this response insufficient, it generates targeted sub-questions to trigger the retrieval cycle. In each subsequent iteration, newly retrieved evidence is aggregated with the cumulative context to synthesize an updated answer, which is then re-evaluated. This cycle persists until one of the following termination criteria is met: (i) the answer is judged sufficient; (ii) the maximum iteration count (T=3 T=3) is reached; (iii) no new sub-questions are generated; or (iv) generated sub-questions are repetitive. We instantiate the framework using either NaiveRAG or GraphRAG as the underlying base retriever.
Appendix C Evaluation & Analysis Details

Figure 17: The LLM-as-a-Judge instruction template used for automated evaluation.
Table 12: Multi-dimensional metrics for evaluating RAG generation quality.
Category Metric Focus Description & Rationale Answer Quality LLM-as-a-Judge Answer Correctness LLM classifies answers as correct, incorrect, or incomplete, providing human-aligned judgment. Semantic F1 Reference Similarity BERTScore-based token-level semantic similarity between prediction and ground truth, robust to paraphrase variations. Soft Coverage Completeness Maximum cosine similarity between GT embedding and any prediction sentence, measuring information recall. Grounding Faithfulness (Hard)Hallucination Fraction of answer sentences with retrieval support above threshold (τ=0.7\tau=0.7), detecting unsupported claims. Faithfulness (Soft)Support Strength Mean of max similarities between answer sentences and retrieval content, measuring grounding degree.
Table 13: Evaluation results on DeepSeek-V3 across all datasets and RAG paradigms. Sem-F1: Semantic F1 (BERTScore-based), COV: Coverage, Faith-H/S: Faithfulness Hard/Soft, LLM-Cor%: LLM-as-a-Judge correct rate. “-” indicates metric not applicable or not computed.
Table 14: Evaluation results on Llama 3 8B across all datasets and RAG paradigms. Sem-F1: Semantic F1 (BERTScore-based), COV: Coverage, Faith-H/S: Faithfulness Hard/Soft, LLM-Cor%: LLM-as-a-Judge correct rate. “-” indicates metric not applicable or not yet computed.
Table 15: Comprehensive LLM-as-a-Judge evaluation comparison between DeepSeek-V3 and Llama-3-8B across four datasets. Results report Accuracy (Cor), Incorrectness (Inc), and No-Answer rates (No-A).
C.1 Metric Implementation
Metric Categories.
To comprehensively assess the generation quality of RAG systems, we devise a multi-dimensional evaluation framework (Table12). The metrics are categorized into three distinct classes: (1) Answer Quality Metrics, which quantify the semantic similarity and informational completeness of the generated response relative to the gold standard; (2) Faithfulness Metrics, which verify whether the response is strictly grounded in the retrieved context, serving as a mechanism to identify hallucinations; and (3) LLM-as-a-Judge, which provides a holistic assessment of correctness that aligns with human judgment.
Answer Quality Metrics.
Semantic F1 calculates the token-level semantic similarity between the generated response and the ground truth, derived from BERTScore. Let y^={x^1,…,x^m}\hat{y}={\hat{x}{1},\dots,\hat{x}{m}} denote the predicted answer and y={x 1,…,x n}y={x_{1},\dots,x_{n}} denote the reference answer. We first extract contextual embeddings utilizing a pre-trained language model, specifically microsoft/deberta-xlarge-mnli, and subsequently compute the precision (P BERT P_{\text{BERT}}), recall (R BERT R_{\text{BERT}}), and F1 score:
P BERT=1|y^|∑x^i∈y^max x j∈ycos(𝐡 x^i,𝐡 x j)P_{\text{BERT}}=\frac{1}{|\hat{y}|}\sum_{\hat{x}{i}\in\hat{y}}\max{x_{j}\in y}\cos(\mathbf{h}{\hat{x}{i}},\mathbf{h}{x{j}})(11)
R BERT=1|y|∑x j∈y max x^i∈y^cos(𝐡 x^i,𝐡 x j)R_{\text{BERT}}=\frac{1}{|y|}\sum_{x_{j}\in y}\max_{\hat{x}{i}\in\hat{y}}\cos(\mathbf{h}{\hat{x}{i}},\mathbf{h}{x_{j}})(12)
Semantic F1=2⋅P BERT⋅R BERT P BERT+R BERT\text{Semantic F1}=2\cdot\frac{P_{\text{BERT}}\cdot R_{\text{BERT}}}{P_{\text{BERT}}+R_{\text{BERT}}}(13)
Here, 𝐡\mathbf{h} represents the contextual embedding vector of a token, and cos(⋅,⋅)\cos(\cdot,\cdot) signifies cosine similarity. This metric exhibits robustness against synonym substitution and paraphrastic variations.
Soft Coverage quantifies the extent to which the generated response encapsulates the information present in the gold standard. We utilize SentenceTransformer (all-MiniLM-L6-v2) to segment both the reference and the prediction into individual sentences and encode them into sentence-level embeddings. For each sentence s i gt s_{i}^{gt} in the ground truth, we compute its maximum similarity with respect to all sentences in the prediction:
Coverage=1|S gt|∑s i gt∈S gt max s j pred∈S predcos(𝐞 s i gt,𝐞 s j pred)\text{Coverage}=\frac{1}{|S^{gt}|}\sum_{s_{i}^{gt}\in S^{gt}}\max_{s_{j}^{pred}\in S^{pred}}\cos(\mathbf{e}{s{i}^{gt}},\mathbf{e}{s{j}^{pred}})(14)
where S gt S^{gt} and S pred S^{pred} denote the sentence sets of the ground truth and the prediction, respectively, and 𝐞\mathbf{e} represents the sentence embedding. A higher coverage value indicates that the generated response has successfully captured a greater proportion of the critical information contained in the reference.
Faithfulness Metrics.
The Faithfulness metric evaluates whether the generated response is faithful to the retrieved context, serving as a primary mechanism for detecting hallucinations. We segment the generated response into individual sentences and calculate the semantic support for each sentence against the retrieved content.
Faithfulness (Hard) utilizes a strict threshold to determine the proportion of sentences in the answer that are supported by the retrieval:
Faith hard=1|S ans|∑s i∈S ans 𝟙[max c j∈Ccos(𝐞 s i,𝐞 c j)≥τ]\text{Faith}{\text{hard}}=\frac{1}{|S^{ans}|}\sum{s_{i}\in S^{ans}}\mathbb{1}\left\max_{c_{j}\in C}\cos(\mathbf{e}{s{i}},\mathbf{e}{c{j}})\geq\tau\right
where S ans S^{ans} denotes the set of answer sentences, C C denotes the set of retrieved context sentences, τ=0.7\tau=0.7 serves as the similarity threshold, and 𝟙[⋅]\mathbb{1}[\cdot] is the indicator function. This metric strictly quantifies the fraction of the response that possesses explicit grounding within the retrieved results.
Faithfulness (Soft). employs a continuous calculation to measure the average support strength between the answer and the retrieved content:
Faith soft=1|S ans|∑s i∈S ans max c j∈Ccos(𝐞 s i,𝐞 c j)\text{Faith}{\text{soft}}=\frac{1}{|S^{ans}|}\sum{s_{i}\in S^{ans}}\max_{c_{j}\in C}\cos(\mathbf{e}{s{i}},\mathbf{e}{c{j}})(16)
The Soft version provides a more granular measure of grounding, reflecting partial support even when the strict threshold is not met.
It is important to note that Faithfulness metrics are calculated exclusively for NaiveRAG and GraphRAG. We exclude HybridRAG and IterativeRAG from this specific evaluation, as their complex retrieval formats, involving multi-turn interactions or hybrid sources, may introduce bias into the direct calculation.
LLM-as-a-Judge.
Complementing automated metrics, we employ the LLM-as-a-Judge methodology to conduct human-aligned correctness evaluation. As illustrated in Figure17, we devise a structured evaluation prompt instructing the evaluator model (GPT-4o-mini) to classify generated responses into three mutually exclusive categories. (1) Correct: The response is logically accurate and encapsulates the core information of the ground truth. (2) Incorrect: The response contains erroneous information that contradicts the ground truth. (3)Incomplete: The response is partially correct yet lacks critical details, or the model refuses to generate an answer.
This evaluation paradigm mitigates the limitations of similarity-based metrics, which often fail to capture logical inconsistencies, thereby providing a quality assessment that more closely aligns with human judgment.
Evaluation Results.
Table13 and Table14 present the comprehensive evaluation results for DeepSeek-V3 and Llama 3 8B across the four constituent datasets. The key findings are summarized as follows:
Overall Performance: HybridRAG achieves optimal or near-optimal performance across the majority of datasets, particularly excelling in Semantic F1 and Coverage metrics. For instance, on the Medical dataset, DeepSeek-V3 combined with HybridRAG attains an LLM accuracy of 64.7%, surpassing both NaiveRAG (61.1%) and GraphRAG (53.5%).
Model Disparity: DeepSeek-V3 significantly outperforms Llama 3 8B. Taking the MuSiQue dataset as an example, DeepSeek-V3 with HybridRAG achieves an LLM accuracy of 38.6%, whereas Llama 3 8B reaches only 20.3%, a substantial performance gap of 18.3 percentage points.
Faithfulness Analysis: Faithfulness scores for NaiveRAG and GraphRAG are generally low (mostly below 0.25), indicating that even with retrieval augmentation, models continue to generate content unsupported by the retrieved context. Conversely, the Medical dataset exhibits relatively higher faithfulness (GraphRAG reaches 0.250 Hard / 0.588 Soft), potentially attributable to the medical domain’s strict reliance on retrieved factual evidence for answer formulation.
Table15 further provides a breakdown of LLM evaluation results by query type. Key observations include:
Factual Dominance: All methods yield their best performance on single-hop queries. GraphRAG achieves accuracies of 90.2% (DeepSeek) and 84.4% (Llama) on MuSiQue’s single-hop questions, significantly outperforming other query types. This aligns with GraphRAG’s entity-based retrieval mechanism, where single-entity queries facilitate the precise localization of relevant information.
Reasoning Challenge: Multi-hop queries prove universally challenging across all methods, with accuracy generally remaining below 35%. The Legal dataset is particularly demanding, where the best-performing method (IterativeRAG) attains only 12.4% accuracy on multi-hop tasks.
Summary Dilemma: Summary-type queries exhibit a high rate of incorrect responses (exceeding 30% for most methods on QuALITY), suggesting a model tendency to generate summaries that are either over-generalized or deviate from the source text.
C.2 Cost Calculation
Table 16: Token consumption breakdown for retrieval and generation across all datasets and methods. All token counts are in millions (M) except Avg-Ctx (average context tokens per question). Ret: Retrieval, Gen: Generation, In: Input, Out: Output.
Cost Components.
We decompose the computational overhead of the RAG system into two primary phases (Table16): the Retrieval phase and the Generation phase. The total cost is formally defined as:
C total=C retrieval+C generation C_{\text{total}}=C_{\text{retrieval}}+C_{\text{generation}}(17)
where the cost for each phase comprises both input and output token consumption:
C retrieval=T ret in+T ret out C_{\text{retrieval}}=T_{\text{ret}}^{\text{in}}+T_{\text{ret}}^{\text{out}}(18)
C generation=T gen in+T gen out C_{\text{generation}}=T_{\text{gen}}^{\text{in}}+T_{\text{gen}}^{\text{out}}(19)
In the generation phase, the input token volume is predominantly governed by the aggregate context length:
T gen in≈N×(L prompt+L context+L query)T_{\text{gen}}^{\text{in}}\approx N\times(L_{\text{prompt}}+L_{\text{context}}+L_{\text{query}})(20)
where N N denotes the total number of queries, L prompt L_{\text{prompt}} represents the fixed length of the system prompt, L context L_{\text{context}} is the average length of the retrieved context (denoted as Avg-Ctx in the table), and L query L_{\text{query}} is the query length.
For GraphRAG and HybridRAG, the retrieval cost incorporates a one-time graph construction overhead, which is amortized over the query set:
C retrieval graph=C construction⏟one-time, amortized+C entity_extraction⏟per-query C_{\text{retrieval}}^{\text{graph}}=\underbrace{C_{\text{construction}}}{\text{one-time, amortized}}+\underbrace{C{\text{entity_extraction}}}_{\text{per-query}}(21)
The construction cost encompasses the input tokens required for processing the raw corpus via the LLM (T corpus T_{\text{corpus}}) and the resulting output tokens for the extracted triplets (T triplets T_{\text{triplets}}).
Method Comparison.
Table16 reveals substantial disparities in computational cost across the five distinct methodologies:
LLM-only: It incurs minimal overhead (0.04–0.10M tokens), as it bypasses retrieval and context injection, consuming tokens solely for the prompt, query input, and response generation.
NaiveRAG: Its cost footprint is predominantly driven by the generation phase (T gen in T_{\text{gen}}^{\text{in}} accounts for >99%>99%), necessitated by the inclusion of extensive retrieved chunks within the context window. For instance, on the Medical dataset, the average context length reaches 50,504 tokens, resulting in a total expenditure of 95.86M tokens.
GraphRAG: It generally exhibits lower generation costs compared to NaiveRAG, as graph-based retrieval yields more precise and concise contexts. On MuSiQue, GraphRAG records an Avg-Ctx of 8,472 (vs. 13,139 for NaiveRAG), translating to a total cost of 31.14M (vs. 44.22M), a reduction of approximately 30%. However, the Legal dataset presents an exception; here, GraphRAG’s Avg-Ctx surges to 179,728. This anomaly arises from the dense entity interconnectivity characteristic of legal documents, where graph traversal retrieves a voluminous amount of associated content.
HybridRAG: It incurs the highest computational burden, as it utilizes results from both vector and graph retrieval, resulting in a context length approximating the sum of both. On the Legal dataset, it peaks at 293.10M tokens, marking the maximum consumption across all evaluated methods.
IterativeRAG: It exhibits a distinct cost structure characterized by high retrieval overhead (due to multi-turn LLM invocations for judgment and sub-query generation) but low generation cost (owing to the refined conciseness of the context). On the Medical dataset, despite a substantial T ret in T_{\text{ret}}^{\text{in}} of 8.67M, the Avg-Ctx remains merely 2,231, yielding a total cost of 13.27M, the lowest among all RAG paradigms.
Dataset Variation.
The cost variations across datasets are predominantly governed by document length and corpus scale:
The Legal dataset: It incurs significantly higher costs compared to other benchmarks. Specifically, GraphRAG’s total expenditure on Legal (234.55M) is 7.5 times that on MuSiQue (31.14M). This disparity stems from the extensive length and complex entity interrelations inherent in legal documents, which result in: (1) elevated graph construction overhead; and (2) substantially longer contexts yielded by graph traversal (with Avg-Ctx reaching 179,728).
The Narrative dataset: It’s costs of NaiveRAG and GraphRAG are comparable (59.31M vs. 59.81M), indicating that graph-based retrieval fails to effectively reduce context length in this setting. This is attributable to QuALITY’s long-document characteristic, where each question corresponds to a complete article, resulting in high inter-chunk correlation.
The Medical dataset: Its IterativeRAG demonstrates superior cost-efficiency (13.27M), amounting to merely 14% of the cost incurred by NaiveRAG (95.86M). Medical QA typically involves explicit information needs, allowing iterative retrieval to rapidly localize critical content.
Cost-Performance Trade-off.
Synthesizing the cost profiles in Table16 with the performance metrics in Table13, we analyze the cost-performance trade-offs:
HybridRAG: High Cost, High Performance. On MuSiQue, HybridRAG attains an LLM accuracy of 38.6% at a cost of 75.22M tokens. Compared to NaiveRAG (44.22M, 26.4%), this represents a 70% cost increase yielding a 46% performance gain. Conversely, on Medical, HybridRAG (140.11M, 64.7%) incurs a 46% cost hike over NaiveRAG (95.86M, 61.1%) for a mere 6% performance improvement, indicating diminishing marginal returns.
GraphRAG: Dataset-Dependent Cost-Efficiency. On MuSiQue, GraphRAG (31.14M, 30.3%) delivers superior performance at a lower cost than NaiveRAG, emerging as the optimal choice. However, on QuALITY, GraphRAG (59.81M, 39.3%) offers no advantage, incurring costs comparable to NaiveRAG while yielding inferior performance (48.7%).
IterativeRAG: Low Cost, Variable Performance. On Medical, IterativeRAG (Naive-base) achieves the highest cost-effectiveness, reaching 62.7% accuracy at a minimal cost of 13.27M. Yet, on MuSiQue, the same approach yields only 20.4% accuracy, underperforming other more resource-intensive methods.
Practical Recommendations: (1) For domains with explicit entity relations (e.g., Medical), IterativeRAG offers the best cost-performance ratio; (2) For complex QA requiring the synthesis of multi-source information, HybridRAG delivers optimal performance despite its high cost; and (3) For long-document comprehension tasks (e.g., QuALITY), NaiveRAG remains the most straightforward and effective solution.
C.3 Case Studies
Table 17: Qualitative analysis of two representative cases.
Comparative Analysis.
Table 17 presents qualitative analysis of representative cases, comparing paradigm performance on multi-hop reasoning and cross-document summarization tasks.
Error Analysis.
Drawing upon the aforementioned case studies and the comprehensive evaluation results, we categorize the primary failure modes as follows:
Retrieval Imprecision: The failure of NaiveRAG and HybridRAG in Case 1 stems from the fact that while the retrieved content possessed thematic relevance (cervical cancer surgery), it failed to precisely hit the pivotal term “trachelectomy.” This error is particularly prevalent in specialized domains (e.g., Medical, Legal), where the semantic similarity of domain-specific terminology may be lower than that of generic descriptions. GraphRAG, through its entity matching mechanism, demonstrates superior precision in localizing such specialized terms.
Context Overload: When retrieval yields a high volume of relevant yet redundant content, the LLM is prone to overlooking critical information. In Case 1, HybridRAG’s average context length (Avg-Ctx) reached 73,628 tokens. Such an excessively long context can cause the model to become “lost in the middle,” resulting in performance inferior to that of GraphRAG, which utilizes a more concise context (Avg-Ctx: 37,513).
Hallucination: In Case 2, GraphRAG generated concepts absent from the source documents (e.g., “transphasia”). This indicates that when the alignment between retrieved content and the query is poor, the model may resort to its internal parametric knowledge to “complete” the answer, leading to fabrication. This issue is particularly pronounced in Summary-type queries, as summarization necessitates cross-document synthesis which fragmented retrieval results often fail to fully cover.
Retrieval Mismatch: In Case 2, HybridRAG output “James I”, an answer entirely unrelated to spacecraft, suggesting that the retrieval module returned completely irrelevant document fragments. Such severe mismatches likely stem from a semantic gap between the query and the corpus, or from errors in entity extraction within the graph retrieval process.
Reasoning Chain Failure: For questions necessitating multi-step reasoning (e.g., the multi-hop query in Case 1), even if partially relevant content is retrieved, the model may fail to correctly link the information. IterativeRAG, via its multi-turn “Retrieve-Generate-Evaluate” loop, effectively patches the reasoning chain step-by-step, thereby exhibiting relatively stable performance on complex queries.
Xet Storage Details
- Size:
- 149 kB
- Xet hash:
- 848d933522b5a36c70b9f7d9493c7d85e323612f177c0c6a6dc7bc8240952544
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.