Buckets:

Title: Scaling Reliable Coding Environmentsvia an Agentic Docker Builder
URL Source: https://arxiv.org/html/2602.00592
Published Time: Tue, 03 Feb 2026 01:33:24 GMT
Markdown Content:
2.3 Model Training
We train DockSmith via supervised fine-tuning on execution-grounded Docker-building trajectories. Each instance is a multi-turn interaction trace that includes Dockerfile edits, tool calls, build and test commands, execution logs, and repair actions. Since raw agent rollouts are noisy and often characterized by redundant exploration, we construct a compact, high-signal training corpus through a three-stage curation process. This process balances data across programming languages, filters and compresses trajectories to remove low-information steps, applies a complexity-aware curriculum to emphasize increasingly challenging builds. To retain general software engineering capability without sacrificing Docker specialization, we perform joint training with general coding trajectories, enabling DockSmith to better integrate environment construction with downstream code understanding and execution.
2.3.1 Data Balancing and Sampling
Cross-language data balancing. Our corpus encompasses multiple programming languages, with the majority of trajectories originating from core ecosystems such as Python and C/C++, and a smaller proportion from long-tail languages including Rust and PHP. Preliminary trials indicated that indiscriminate upsampling of long-tail data could induce distribution shift and degrade overall performance. Consequently, we adopt a conservative balancing policy that preserves the core-language distribution while incorporating long-tail samples in a controlled manner. Specifically, we enforce per-language token contribution limits during corpus construction and training, so that the long-tail languages improve coverage without dominating the batch. This strategy stabilizes training and broadens language coverage while maintaining a controlled distribution shift.
Filtering long and redundant rollouts. Even among successful rollouts, we observe substantial redundancy resulting from repeated tool invocations and long interactions. To mitigate noise, we eliminate trajectories that exhibit unproductive exploration patterns. Specifically, we discard rollouts that repeatedly invoke the same agent module, contain excessively many turns, or accumulate an unusually large number of messages. These thresholds are intended to trim the heavy tail of rollout lengths while preserving the majority of informative trajectories.
Complexity-based curriculum sampling. To manage dataset size while maintaining a meaningful difficulty distribution, we employ a complexity-based sampling strategy. We first retain only verified-success instances to ensure reliable supervision. Subsequently, we estimate Dockerfile difficulty using lightweight structural signals, enabling data stratification and subsampling without incurring the cost of additional builds. Concretely, we define a scalar complexity score that increases with script length, build-step count, and dependency footprint:
Score(d)=0.5⋅L(d)+5⋅R(d)+3⋅P(d),\mathrm{Score}(d)=0.5\cdot L(d)+5\cdot R(d)+3\cdot P(d),(1)
where L(d)L(d) is the number of non-empty lines, R(d)R(d) is the number of RUN instructions, and P(d)P(d) is the number of distinct packages installed via apt-get/apt install. We assign larger weight to R(d)R(d) and P(d)P(d) because additional build steps and dependencies typically introduce more failure modes and longer error chains than Dockerfile length alone. Using this score, we bucket instances into Easy, Medium, and Hard, and sample them with a 1:2:2 ratio to ensure sufficient exposure to challenging builds. This curriculum prevents the training set from being dominated by trivial one-shot cases and improves robustness on dependency-heavy projects.
2.3.2 Joint Training with Coding Trajectories
When training DockSmith, we train Docker-building trajectories together with general SWE/coding trajectories. The intuition is that SWE trajectories provide task-level execution and validation patterns (e.g., edit–run–debug loops) that complement environment construction, helping the model avoid over-specializing to Docker-only behaviors. We adopt token-level mixing: the token budget for coding trajectories is held constant, while we vary the Docker-building token budget to control the mixing ratio, keeping total compute comparable across runs. The effect of this joint-training strategy is evaluated in the ablation study in Section.3.3.
3 Experiments
Table 2: Multi-Docker-Eval F2P (%) across programming languages by different models. Gray-shaded rows indicate closed-source models, while the remaining models are open-source.
3.1 Experiment Setup
Benchmarks.
We evaluate Docker-building performance on Multi-Docker-Eval (MDE)(Fu et al., 2025), a benchmark designed to assess repository-level environment construction across diverse real-world software projects and programming languages. Each instance requires the model to synthesize a valid Dockerfile, build the environment, and ensure that the repository can be executed or tested successfully. Success is measured by whether the build process completes without failure and whether the resulting environment supports downstream execution.
To test whether Docker-building improvements transfer beyond environment setup, we evaluate on three widely adopted agentic software-engineering benchmarks that are not used as training objectives in our setting: (1) SWE-bench Verified (SWE.V)(Jimenez et al., 2023), consisting of Python issue-resolution tasks with verified correctness; (2) SWE-bench Multilingual (SWE.M)(Zan et al., 2025), extending issue resolution to multiple languages; and (3) Terminal-Bench 2.0 (Terminal)(Merrill et al., 2026), a command-line-centric benchmark that stresses long-horizon tool use and iterative execution.
Metrics. We report two primary outcome metrics for the Multi-Docker-Eval benchmark: Fail-to-Pass (F2P), which measures the proportion of tasks where the configured environment successfully transitions tests from a failing to a passing state, and Commit Rate, which quantifies the fraction of instances where the agent submits a solution for evaluation, reflecting model confidence rather than ground-truth correctness. In addition, we report several process metrics, including average input tokens, average output tokens, and average Docker image count, to characterize efficiency and resource usage during environment construction. For SWE.V, SWE.M, and Terminal, we follow the standard evaluation protocols of the respective benchmarks and report absolute performance scores.
Training Details. All training experiments are initialized from Qwen3-Coder-30B-A3B-Instruct(Team, 2025) and trained under identical optimization settings unless otherwise specified. We use a global batch size of 32, a learning rate of 1×10−5 1\times 10^{-5}, and train all models for two epochs. For models trained on mixed trajectories, we set the maximum sequence length to 64K tokens to accommodate long SWE-solving trajectories. In contrast, DockSmith, which is trained exclusively on Docker-building trajectories, uses a shorter maximum sequence length of 32K tokens.
3.2 The Performance of Docker Building
Table2.2 shows that DockSmith achieves the best overall performance based on agent framework SWE-Factory, reaching 39.72% F2P and a 58.28% Commit Rate, outperforming all evaluated open-source and closed-source baselines. This result exceeds the previously reported upper bound of 37.7% F2P on Multi-Docker-Eval. The improvement of +20.3 absolute F2P points over the base model suggests that the gains primarily arise from the training procedure rather than increased model scale.
From an efficiency perspective, DockSmith maintains competitive process metrics, with moderate average input/output token usage and a controlled Docker image size, despite achieving substantially higher success rates. Compared to strong baselines such as DeepSeek-v3.1(DeepSeek-AI, 2024) and Kimi-K2-0905(Team et al., 2025), DockSmith trades slightly increased resource consumption for a clear gain in configuration reliability, suggesting a favorable effectiveness–efficiency balance.
The Language-level results in Table 2 further show that DockSmith delivers consistent improvements across most ecosystems, with particularly strong gains in Python, JavaScript, Go, and Ruby—languages characterized by standardized dependency management and testing workflows. These patterns align with the benchmark’s analysis that configuration success is strongly influenced by ecosystem regularity, while low-level systems languages (e.g., C/C++, Java, Rust) remain bottlenecked by compiler toolchains and system dependencies. Overall, the results demonstrate that DockSmith substantially advances the state of the art on Multi-Docker-Eval, validating its effectiveness as a more reliable “shovel” for large-scale, automated SWE pipelines.
3.3 Docker-Building Trajectories For Training
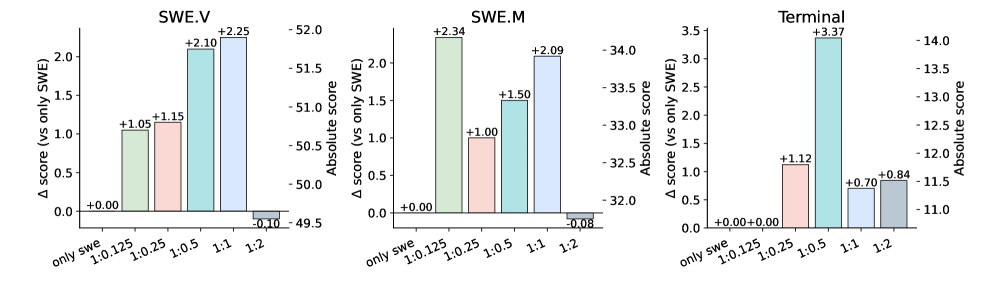
Figure 2: Impact of mixing Docker-building trajectories during training. Mixing ratios are defined at the token level and written as SWE:Docker\text{SWE}:\text{Docker}: for example, 1:0.25 means adding 0.25 Docker-building tokens per SWE token, while keeping the SWE token budget fixed. Bars report Δ\Delta scores relative to an SWE-only baseline on SWE.V, SWE.M, and Terminal-Bench 2.0.
Does Docker-Building Improve Agentic Ability? We conduct a controlled ablation study to examine the effect of jointly training on SWE-solving trajectories and Docker-building trajectories under different token-level mixing ratios. Figure2 reports performance changes measured as deltas relative to a SWE-only baseline trained exclusively on SWE-solving trajectories. The exact numerical values are provided in the Appendix A.1. The SWE-solving trajectories are drawn from the Nex Agent-SFT dataset(Cai et al., 2025), and their total token budget is held constant across all settings to isolate the impact of incorporating Docker-building trajectories. We vary the number of tokens allocated to Docker-building trajectories to systematically assess how different mixing ratios influence downstream performance. We evaluate the resulting models on SWE.V, SWE.M, and Terminal. Across all three benchmarks, adding Docker-building trajectories can improve downstream agentic performance, but the benefit depends on the token-level mixing ratio between SWE-solving and Docker-building data. Here, ratios are written as SWE : Docker: for example, 1:0.25 means adding 0.25 Docker-building tokens per SWE token while keeping the SWE token budget fixed.
On SWE.V and SWE.M, moderate mixing ratios yield the most stable gains: performance improves monotonically from low ratios (1:0.125, 1:0.25) to more balanced settings, peaking around a 1:1 ratio with gains of +2.25 and +2.09, respectively. These results suggest that Docker-building trajectories enhance the model’s ability to reason about dependencies, execution order, and failure recovery—capabilities that transfer directly to SWE-style bug fixing and validation tasks. In contrast, overly skewed mixtures (e.g., 1:2) slightly degrade SWE performance, indicating that excessive emphasis on environment-centric behaviors can dilute task-specific reasoning signals.
Beyond SWE benchmarks, results on Terminal-Bench 2.0 reveal a stronger and more asymmetric effect. Terminal performance improves substantially under Docker-augmented training, with the largest gain (+3.37) observed at a 1:0.5 ratio, followed by sustained improvements at 1:0.25 and 1:2. This highlights that Docker-building trajectories function as a powerful form of agentic skill training, strengthening the model’s competence in command execution, tool invocation, and long-horizon interaction.
Overall, these results indicate that Docker-building trajectories provide complementary supervision and support environment construction as a transferable training signal beyond preprocessing, bridging static code reasoning with dynamic, tool-driven execution.
Table 3: Impact of adding SWE-solving trajectories to Docker-building training.
Does SWE Data Improve Docker-Building Ability? We examine whether SWE-solving trajectories help Docker-building by comparing two controlled settings: training on Docker-building trajectories only, and joint training that adds SWE-solving trajectories at a fixed ratio of 0.5 SWE tokens per Docker token. Table3 shows that Docker-only training yields reasonable MDE performance but substantially weaker results on SWE benchmarks. Adding SWE-solving trajectories improves all benchmarks, including consistent gains on MDE and marked improvements on SWE.V, SWE.M, and Terminal. This suggests that SWE trajectories provide complementary task-level signals that better align Docker-building with downstream execution and validation, rather than optimizing environment setup in isolation.
Table 4: Multi-Docker-Eval F2P (%) under acceptance shaping and complexity-based curriculum sampling (mean over 3 runs). All variants use the same training budget.
3.4 Effect of Trajectory Filtering and Curriculum Sampling
To isolate the effect of trajectory selection from training compute, we run a strictly controlled ablation in which all variants are trained under an identical optimization budget, with the same total number of training tokens and epochs. As a result, any performance differences can be attributed to differences in how trajectories are filtered and sampled, rather than to additional data or compute.
We evaluate four training variants: (i) Baseline, which trains on a randomly sampled subset of resolved Docker-building trajectories without additional filtering; (ii) Baseline + Acceptance Shaping (AS), which applies the acceptance shaping strategy in Section2.3.1 to remove excessively long or redundant rollouts, then resamples to match the same token budget; (iii) Baseline + Complexity Curriculum (CC), which applies the complexity-based curriculum sampling scheme in Section2.3.1 to enforce a balanced difficulty distribution under the same token constraint; and (iv) Baseline + AS + CC, which first denoises trajectories via acceptance shaping and then constructs a curriculum-balanced set with a 1:2:2 Easy/Medium/Hard ratio.
As shown in Table4, applying Acceptance Shaping consistently improves F2P over the baseline across difficulty levels. This suggests that excessively long and repetitive rollouts introduce noise under a fixed token budget, and that pruning such trajectories leads to more effective gradient updates and more stable learning. Complexity Curriculum also yields clear gains, with improvements concentrated on Hard instances. This indicates that naive random sampling tends to over-represent trivial builds, whereas enforcing a difficulty-aware sampling strategy increases exposure to challenging environment configurations that are critical for generalization. Notably, combining the two techniques (AS + CC) produces the strongest overall performance. This result highlights their complementary roles: acceptance shaping improves the quality of individual trajectories by removing redundancy, while curriculum sampling improves the coverage of the training distribution by balancing difficulty. Together, they yield consistently better Docker-building performance and more effective training.
3.5 Analysis
3.5.1 Error Analysis for Docker Building
Table 5: Docker-building error analysis on Multi-Docker-Eval. Error counts are aggregated across all trajectories, and ↓\downarrow indicates lower is better. DockSmith achieves consistent reductions across most categories, with a slight increase in Context Retrieval errors due to more aggressive information gathering.
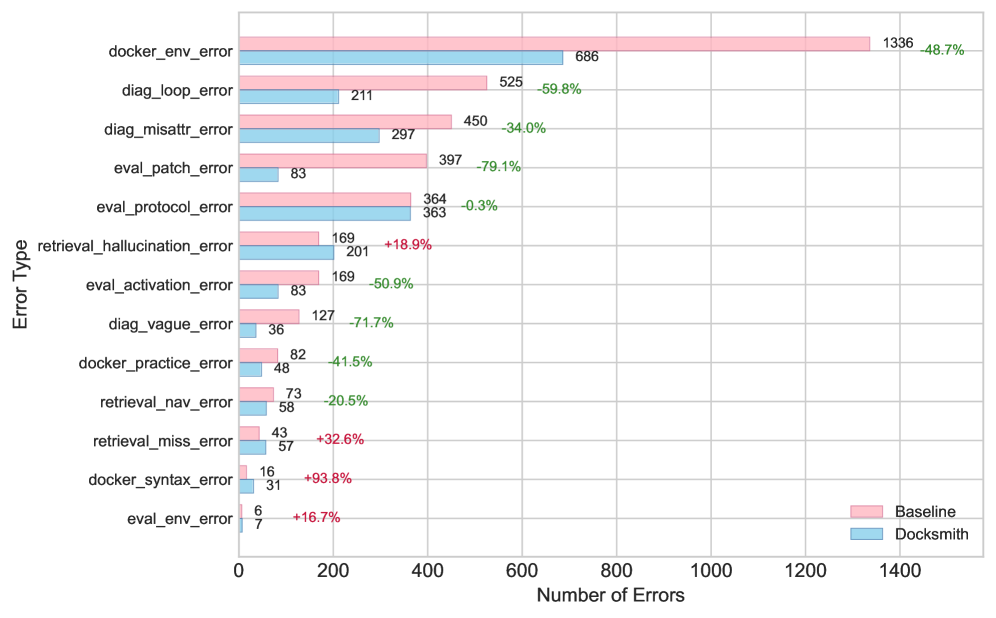
Figure 3: Docker-building error counts by error type on Multi-Docker-Eval (aggregated over all trajectories), comparing the baseline and DockSmith. Percent annotations indicate relative changes.
To quantify how DockSmith alters failure behavior during Docker building, we conduct a fine-grained error analysis on Multi-Docker-Eval trajectories. GPT-5.1 is used as an automated annotator to label error events across four stages—Context Retrieval, Dockerfile Generation, Eval Script Handling, and Test Analysis—and to assign each event an error code and severity. The full annotation rubric is provided in AppendixC.2.
Table3.5.1 summarizes the aggregated results. DockSmith reduces the total number of errors from 3,757 to 2,161 and decreases critical errors by 40.2%40.2%. This improvement is consistent at the trajectory level: the mean number of errors per run drops from 11.81 to 6.67, indicating more reliable environment construction across diverse repositories.
Improvements are concentrated in stages that directly affect the correctness and recovery of the build. Dockerfile-generation errors decrease by 46.7%46.7%, Eval-Script handling errors by 42.7%42.7%, and Analysis-stage errors by 50.6%50.6%, with the largest relative reduction in Analysis, reflecting fewer unproductive diagnostic loops and incorrect failure attributions. Context Retrieval shows a modest increase in labeled errors (+10.9%), due to a higher-recall retrieval strategy that occasionally over-infers dependencies; importantly, this additional noise does not offset downstream gains, as later stages become substantially more stable and the overall error burden decreases sharply.
Figure3 further decomposes errors by code and highlights the error categories where DockSmith achieves the largest reductions. The strongest reduction is on eval_patch_error (−79.1%-79.1%): DockSmith applies evaluation patches more reliably and avoids a recurrent baseline failure mode in which files are re-checked out after patching, silently discarding modifications. Diagnostic quality also improves markedly, with diag_vague_error reduced by 71.7%71.7% as explanations become more specific and actionable, and diag_loop_error reduced by 59.8%59.8% as the model avoids oscillating between incompatible repair strategies. Finally, docker_env_error drops by 48.7%48.7%, indicating fewer environment-configuration mistakes such as missing system packages or misconfigured toolchains.
These improvements yield cleaner and more consistent trajectories. Across a single Multi-Docker-Eval run, DockSmith performs better on 72.4% of trajectories, worse on 22.4%, and ties on 5.2%. The error distribution shifts toward low-error runs: trajectories with 0–4 errors increase from 49 to 128, while trajectories with 20+ errors decrease from 42 to 8. Overall, the results suggest that DockSmith improves Docker-building reliability through more accurate dependency configuration, convergent diagnostic reasoning, and more robust evaluation-patch handling, complementing the error-propagation analysis in Section3.5.2.
3.5.2 Error Propagation and Recovery in Agentic Tasks
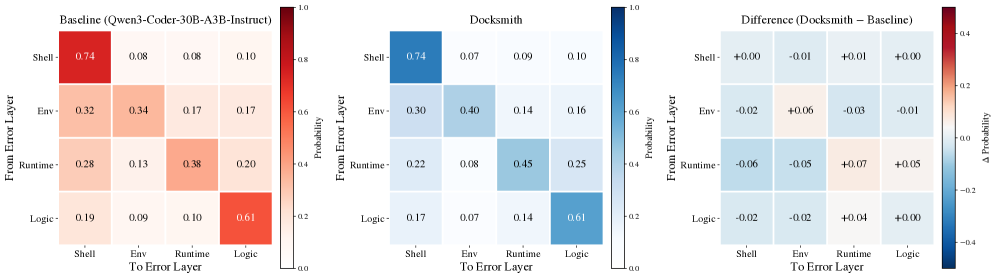
Figure 4: Error propagation probability matrices aggregated across SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench 2.0. Each cell shows the probability that an error at the row layer transitions to an error at the column layer in the next step. Left: Baseline. Center: DockSmith. Right: Difference (Δ\Delta), where blue indicates lower propagation and red indicates higher propagation.
Table 6: Error metrics computed at the error-event level. Terminal rate is the fraction of events labeled Terminal (lower is better), and resolution rate is the fraction labeled Resolved . Overall pools all error events across layers and is not derived from the layer-wise rows (e.g., not a simple average).
To understand why DockSmith improves agentic task completion, we conduct a fine-grained error analysis on three benchmarks: SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench 2.0. We annotate execution traces with a hierarchical taxonomy that assigns each error event to one of four software-stack layers: (1)shell_error, covering command syntax and OS/tool misuse; (2)env_error, covering missing dependencies, path/configuration issues, and permission errors; (3)runtime_error, covering interpreter crashes and module loading/import failures; and (4)logic_error, where execution succeeds but outputs are incorrect. For each error event, we further annotate (i)intent match quality_—_high when the response targets the most plausible root cause, medium when it is partially relevant but uncertain, and low when it is irrelevant or misguided—and (ii)the dominant repair rationale, categorized as principled (mechanism-grounded system reasoning) or heuristic (surface-pattern, trial-and-error). Full annotation guidelines are provided in the AppendixC.1.
Cross-layer propagation vs. within-layer persistence. Figure4 shows error transition matrices for DockSmith and the baseline Qwen3-Coder-30B-A3B-Instruct. Each entry (i,j)(i,j) gives the probability that an error at layer i i is followed by an error at layer j j in the next interaction step. Higher diagonal values indicate that the agent remains within the same layer, rather than prematurely shifting to a different context (e.g., continuing to resolve environment issues instead of moving on to application logic). We interpret increased diagonal mass as stronger within-layer persistence, and use additional layer-wise terminal and resolution metrics below to distinguish productive persistence from stagnation.
DockSmith shows consistently stronger persistence at the environment and runtime layers. In particular, P(env!→!env)P(\texttt{env}!\rightarrow!\texttt{env}) increases from 0.34 to 0.40 (+6%), and P(runtime!→!runtime)P(\texttt{runtime}!\rightarrow!\texttt{runtime}) increases from 0.38 to 0.45 (+7%). This indicates more layer-consistent diagnosis, with the agent iteratively refining dependency and configuration fixes instead of switching to unrelated debugging strategies.
Terminal vs. resolved outcomes across layers. Table3.5.2 summarizes error-event-level outcomes at two granularities. The terminal rate is the fraction of error events labeled Terminal, where smaller values indicate better outcomes; the resolution rate is the fraction labeled Resolved, where larger values are better. We compute the rates per layer using events assigned to that layer, and compute Overall by pooling events across all layers (not by averaging layer-wise rates). DockSmith reduces terminal rates across all layers, with the largest gain on logic_error (−-6.7 points), suggesting improved end-to-end robustness even when failures occur at higher-level debugging stages.
Resolution rates present a more nuanced picture. DockSmith substantially improves resolution for runtime_error (+3.3%) and logic_error (+8.7%), aligning with the hypothesis that Docker-building trajectories strengthen transferable skills such as interpreting execution failures, forming repair hypotheses, and validating fixes. Meanwhile, the baseline shows higher resolution on shell_error (−-2.4%) and env_error (−-4.6%). One plausible interpretation is that Docker-centric supervision increases persistence on environment-related issues (as reflected by higher P(env→env)P(\texttt{env}!\rightarrow!\texttt{env})), but may not always translate to faster convergence on the correct low-level fix, leading to a mild drop in env_error resolution despite improved overall task completion. Importantly, the net effect remains positive: DockSmith reduces the overall terminal rate from 8.7% to 7.1%.
Table 7: Response quality analysis at the error-event level: intent match quality and repair rationale distribution (%).
Response quality and repair rationale.
Table3.5.2 analyzes how the agent responds to observed failures. DockSmith increases the fraction of high-quality, root-cause-aligned responses from 34.6% to 40.4% (+5.8%), while reducing low-quality (misguided) responses from 28.8% to 23.1% (−-5.7%). This shift in response quality directly complements the observed reduction in terminal errors, indicating that more accurate diagnosis translates into more effective downstream recovery. Moreover, DockSmith shifts the repair rationale toward principled system reasoning (27.1%→\rightarrow 33.0%) and away from purely heuristic log-driven trial-and-error (66.3%→\rightarrow 61.8%). Together with the error propagation analysis in Figure4 and the layer-wise terminal and resolution statistics in Table3.5.2, these results suggest that Docker-building trajectories promote more mechanism-grounded debugging behaviors that remain focused on the relevant failure layer, reducing spurious cross-layer transitions.
DockSmith improves end-to-end robustness in two ways: (i) it exhibits stronger within-layer persistence for environment and runtime failures, and (ii) it increases the fraction of high-quality, root-cause-aligned responses, with the largest gains on runtime and logic debugging. At the same time, the mixed effects at the shell and environment layers suggest a trade-off between trajectory-level reasoning and low-level command precision, pointing to future work that strengthens fine-grained command execution and low-level environment remediation without sacrificing the gains in higher-level diagnostic reasoning.
4 Related Works
Coding LLMs and Agents. The foundation of autonomous software engineering lies in powerful LLMs, including proprietary models(Anthropic, 2025b; Google, 2025; OpenAI, 2025) and open-source alternatives(Liu et al., 2025; Zeng et al., 2025; Team et al., 2025; Dubey et al., 2024; MiniMax, 2025; Ma et al., 2025a, 2024), which achieve high performance through large-scale code pretraining and extended context windows. To enable these models to navigate repository-scale environments, they are frequently augmented with diverse tools. This architectural foundation supports the development of agentic frameworks—such as Agentless(Xia et al., 2024), SWE-agent(Yang et al., 2024), and OpenHands(Team, 2024)—which serve as scaffolds to streamline interactions with environments. Consequently, evaluation paradigms have shifted from isolated function synthesis(Jain et al., 2024; Liu et al., 2023, 2024a; Chen, 2021) toward realistic GitHub issue resolution. Benchmarks such as SWE-bench(Jimenez et al., 2023) now serve as the industry standard, alongside newer variants focusing on multilingual tasks(Zan et al., 2025) and feature augmentation(Deng et al., 2025).
Automatic Environment Setup. Reliable environment construction is a critical prerequisite for autonomous software maintenance, yet it remains a major bottleneck in the development pipeline(Kovrigin et al., 2025; Hu et al., 2025; Peng et al., 2024). Early LLM-based systems such as ExecutionAgent(Bouzenia and Pradel, 2025) attempted to automate setup across multiple languages but often failed to meet the specialized requirements needed for precise issue reproduction, while more targeted tools like SetupAgent(Vergopoulos et al., 2025) rely on manually defined log parsers and remain closed-source. To address these gaps, SWE-Factory(Guo et al., 2025) proposes a fully automated and multi-agent pipeline that integrates binary file recovery with SWE-Builder, replacing manual verification with standardized, exit-code-based parsing to enable scalable generation of high-quality training data. In parallel, evaluation benchmarks have evolved: EnvBench(Eliseeva et al., 2025) introduced early metrics, and Multi-Docker-Eval(Fu et al., 2025) now provides a more rigorous benchmark spanning 39 repositories and 9 languages, showing that environment setup remains the primary hurdle for modern open-source models, with success rates often below 40%. Despite steady progress, prior work largely treats environment construction as a supporting step for evaluation and debugging; however, building executable environments inherently involves multi-step reasoning, system configuration, and iterative failure recovery, mirroring broader software engineering challenges and motivating its treatment as a first-class, execution-grounded task in autonomous code agent design.
5 Conclusion
Reliable Docker-based environment construction is a major bottleneck for scaling execution-grounded training and evaluation of software engineering agents. We argue that reliable environment construction is not merely a preprocessing step, but a core agentic capability that shapes execution-grounded learning. We introduce DockSmith, a specialized Docker-building agent trained on large-scale, execution-grounded environment-construction trajectories. By modeling environment setup as a long-horizon, verifiable task involving dependency reasoning, tool use, and failure recovery, DockSmith substantially improves Docker build reliability on Multi-Docker-Eval, achieving open-source state-of-the-art performance at a fixed 30B-A3B scale. Beyond environment setup, Docker-building supervision transfers to downstream agentic software engineering: joint training improves performance on SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench, with reduced error propagation and more stable execution-driven recovery. These results position environment construction as a transferable training signal for scaling autonomous software engineering agents.
References
- Anthropic (2025a)Claude 4 sonnet. Note: https://www.anthropic.com/claudeCited by: §1.
- Anthropic (2025b)Claude 4.5 sonnet. Note: https://www.anthropic.com/claudeCited by: §4.
- I. Bouzenia and M. Pradel (2025)You name it, i run it: an llm agent to execute tests of arbitrary projects. Proceedings of the ACM on Software Engineering 2 (ISSTA), pp.1054–1076. Cited by: §4.
- Y. Cai, L. Chen, Q. Chen, Y. Ding, L. Fan, W. Fu, Y. Gao, H. Guo, P. Guo, Z. Han, et al. (2025)Nex-n1: agentic models trained via a unified ecosystem for large-scale environment construction. arXiv preprint arXiv:2512.04987. Cited by: §3.3.
- M. Chen (2021)Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374. Cited by: §4.
- G. Comanici, E. Bieber, M. Schaekermann, and et al. (2025)Gemini 2.5: pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. External Links: 2507.06261, LinkCited by: §1.
- DeepSeek-AI (2024)DeepSeek-v3 technical report. External Links: 2412.19437, LinkCited by: §3.2.
- L. Deng, Z. Jiang, J. Cao, M. Pradel, and Z. Liu (2025)Nocode-bench: a benchmark for evaluating natural language-driven feature addition. arXiv preprint arXiv:2507.18130. Cited by: §4.
- A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al. (2024)The llama 3 herd of models. arXiv e-prints, pp.arXiv–2407. Cited by: §4.
- A. Eliseeva, A. Kovrigin, I. Kholkin, E. Bogomolov, and Y. Zharov (2025)Envbench: a benchmark for automated environment setup. arXiv preprint arXiv:2503.14443. Cited by: §4.
- K. Fu, T. Liu, Z. Shang, Y. Ma, J. Yang, J. Liu, and K. Bian (2025)Multi-docker-eval: ashovel of the gold rush’benchmark on automatic environment building for software engineering. arXiv preprint arXiv:2512.06915. Cited by: §1, §3.1, §4.
- Google (2025)Gemini 3 pro. Note: https://gemini.google.com/Cited by: §4.
- L. Guo, Y. Wang, C. Li, P. Yang, J. Chen, W. Tao, Y. Zou, D. Tang, and Z. Zheng (2025)SWE-factory: your automated factory for issue resolution training data and evaluation benchmarks. arXiv preprint arXiv:2506.10954. Cited by: §1, §1, §4.
- R. Hu, C. Peng, X. Wang, J. Xu, and C. Gao (2025)Repo2Run: automated building executable environment for code repository at scale. arXiv preprint arXiv:2502.13681. Cited by: §4.
- N. Jain, K. Han, A. Gu, W. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica (2024)Livecodebench: holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974. Cited by: §4.
- C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan (2023)Swe-bench: can language models resolve real-world github issues?. arXiv preprint arXiv:2310.06770. Cited by: §3.1, §4.
- A. Kovrigin, A. Eliseeva, K. Grotov, E. Bogomolov, and Y. Zharov (2025)PIPer: on-device environment setup via online reinforcement learning. arXiv preprint arXiv:2509.25455. Cited by: §4.
- P. Langley (2000)Crafting papers on machine learning. In Proceedings of the 17th International Conference on Machine Learning (ICML 2000), P. Langley (Ed.), Stanford, CA, pp.1207–1216. Cited by: §C.2.
- A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, et al. (2025)Deepseek-v3. 2: pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556. Cited by: §4.
- J. Liu, C. S. Xia, Y. Wang, and L. Zhang (2023)Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems, External Links: LinkCited by: §4.
- J. Liu, S. Xie, J. Wang, Y. Wei, Y. Ding, and L. Zhang (2024a)Evaluating language models for efficient code generation. In First Conference on Language Modeling, External Links: LinkCited by: §4.
- J. Liu, K. Wang, Y. Chen, X. Peng, Z. Chen, L. Zhang, and Y. Lou (2024b)Large language model-based agents for software engineering: a survey. arXiv preprint arXiv:2409.02977. Cited by: §1.
- Y. Ma, R. Cao, Y. Cao, Y. Zhang, J. Chen, Y. Liu, Y. Liu, B. Li, F. Huang, and Y. Li (2024)Lingma swe-gpt: an open development-process-centric language model for automated software improvement. arXiv preprint arXiv:2411.00622. Cited by: §4.
- Y. Ma, Y. Li, Y. Dong, X. Jiang, R. Cao, J. Chen, F. Huang, and B. Li (2025a)Thinking longer, not larger: enhancing software engineering agents via scaling test-time compute. arXiv preprint arXiv:2503.23803. Cited by: §4.
- Y. Ma, Q. Yang, R. Cao, B. Li, F. Huang, and Y. Li (2025b)Alibaba lingmaagent: improving automated issue resolution via comprehensive repository exploration. In Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, pp.238–249. Cited by: §1.
- M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y. Shin, T. Walshe, E. K. Buchanan, J. Shen, G. Ye, H. Lin, J. Poulos, M. Wang, M. Nezhurina, J. Jitsev, D. Lu, O. M. Mastromichalakis, Z. Xu, Z. Chen, Y. Liu, R. Zhang, L. L. Chen, A. Kashyap, J. Uslu, J. Li, J. Wu, M. Yan, S. Bian, V. Sharma, K. Sun, S. Dillmann, A. Anand, A. Lanpouthakoun, B. Koopah, C. Hu, E. Guha, G. H. S. Dreiman, J. Zhu, K. Krauth, L. Zhong, N. Muennighoff, R. Amanfu, S. Tan, S. Pimpalgaonkar, T. Aggarwal, X. Lin, X. Lan, X. Zhao, Y. Liang, Y. Wang, Z. Wang, C. Zhou, D. Heineman, H. Liu, H. Trivedi, J. Yang, J. Lin, M. Shetty, M. Yang, N. Omi, N. Raoof, S. Li, T. Y. Zhuo, W. Lin, Y. Dai, Y. Wang, W. Chai, S. Zhou, D. Wahdany, Z. She, J. Hu, Z. Dong, Y. Zhu, S. Cui, A. Saiyed, A. Kolbeinsson, J. Hu, C. M. Rytting, R. Marten, Y. Wang, A. Dimakis, A. Konwinski, and L. Schmidt (2026)Terminal-bench: benchmarking agents on hard, realistic tasks in command line interfaces. External Links: 2601.11868, LinkCited by: §3.1.
- MiniMax (2025)MiniMax-m2. Note: https://www.minimaxi.com/news/minimax-m2Cited by: §4.
- OpenAI (2025)GPT-5.2. Note: https://openai.com/index/introducing-gpt-5-2/Cited by: §4.
- J. Pan, X. Wang, G. Neubig, N. Jaitly, H. Ji, A. Suhr, and Y. Zhang (2025)Training software engineering agents and verifiers with swe‑gym. In Proceedings of the 42nd International Conference on Machine Learning (ICML 2025), Note: arXiv:2412.21139, accepted at ICML 2025 External Links: LinkCited by: §1.
- Y. Peng, R. Hu, R. Wang, C. Gao, S. Li, and M. R. Lyu (2024)Less is more? an empirical study on configuration issues in python pypi ecosystem. In Proceedings of the IEEE/ACM 46th international conference on software engineering, pp.1–12. Cited by: §4.
- K. Team, Y. Bai, Y. Bao, G. Chen, J. Chen, N. Chen, R. Chen, Y. Chen, Y. Chen, Y. Chen, et al. (2025)Kimi k2: open agentic intelligence. arXiv preprint arXiv:2507.20534. Cited by: §3.2, §4.
- O. Team (2024)OpenHands: an open platform for ai software developers. GitHub. Note: https://github.com/OpenHands/OpenHandsCited by: §4.
- Q. Team (2025)Qwen3 technical report. External Links: 2505.09388, LinkCited by: §3.1.
- K. Vergopoulos, M. N. Müller, and M. Vechev (2025)Automated benchmark generation for repository-level coding tasks. arXiv preprint arXiv:2503.07701. Cited by: §4.
- Y. Wang, W. Zhong, Y. Huang, E. Shi, M. Yang, J. Chen, H. Li, Y. Ma, Q. Wang, and Z. Zheng (2025)Agents in software engineering: survey, landscape, and vision. Automated Software Engineering 32 (2), pp.70. Cited by: §1.
- C. S. Xia, Y. Deng, S. Dunn, and L. Zhang (2024)Agentless: demystifying llm-based software engineering agents. arXiv preprint arXiv:2407.01489. Cited by: §4.
- J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press (2024)SWE-agent: agent-computer interfaces enable automated software engineering. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, External Links: LinkCited by: §4.
- J. Yang, K. Lieret, C. E. Jimenez, A. Wettig, K. Khandpur, Y. Zhang, B. Hui, O. Press, L. Schmidt, and D. Yang (2025)Swe-smith: scaling data for software engineering agents. arXiv preprint arXiv:2504.21798. Cited by: §1, §1.
- D. Zan, Z. Huang, W. Liu, H. Chen, L. Zhang, S. Xin, L. Chen, Q. Liu, X. Zhong, A. Li, et al. (2025)Multi-swe-bench: a multilingual benchmark for issue resolving. arXiv preprint arXiv:2504.02605. Cited by: §3.1, §4.
- A. Zeng, X. Lv, Q. Zheng, Z. Hou, B. Chen, C. Xie, C. Wang, D. Yin, H. Zeng, J. Zhang, et al. (2025)Glm-4.5: agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471. Cited by: §1, §4.
Appendix A Additional Experiment Results
A.1 Exact Results of Mixed Training
Table 8: Effect of different mixing ratios between SWE-solving and Docker-building trajectories during training. Mixing ratios are defined at the token level and written as SWE : Docker.
The exact results are shown in Table8. The mixing ratio is measured by the token-level proportion between SWE-solving and Docker-building trajectories. Overall, moderate mixing ratios (e.g., 1:0.5–1:1) yield consistent improvements across all three benchmarks, while overly large Docker-building ratios lead to diminishing or unstable gains.
Appendix B Case Study
B.1 Case Study: Multi-Docker-Eval Trajectory Analysis
To qualitatively illustrate how Docker-building supervision alters agentic behavior, we present a representative case study from the Multi-Docker-Eval benchmark. We compare the base model, Qwen3-Coder-30B-A3B-Instruct, with DockSmith on a single repository-level task, analyzing their full execution trajectories under identical evaluation protocols.
The task is drawn from a Ruby repository (JEG2/highline), corresponding to Issue #222. Successfully completing this instance requires constructing a valid Docker environment, resolving native dependency compilation, and executing the project’s test suite. In particular, the rugged gem introduces non-trivial system-level dependencies, including cmake, pkg-config, and OpenSSL development libraries, making this a representative environment-construction challenge.
Summary of Outcomes.
Table9 summarizes the trajectory-level statistics for this case. Compared to the base model, DockSmith drastically shortens the rollout and reduces error accumulation: it completes the task in 5 steps with only 2 errors, whereas the baseline reaches the step limit (50 steps) while triggering 37 errors. In addition, DockSmith eliminates all diagnostic loops and Dockerfile rollback events observed in the baseline, indicating substantially more stable iteration behavior.
Table 9: Trajectory-level comparison on a representative Multi-Docker-Eval case (JEG2/highline Issue #222), contrasting the base model (Qwen3-Coder-30B-A3B-Instruct) and DockSmith.
The baseline trajectory exhibits several recurring failure patterns.
(1) Dockerfile rollback and state inconsistency. The model repeatedly generates incomplete Dockerfiles, temporarily adds missing dependencies, and then reverts to earlier versions, reintroducing the same errors. This behavior indicates a lack of persistent state tracking across iterations.
(2) Incremental and fragmented dependency diagnosis. Rather than reasoning about native dependencies holistically, the baseline discovers missing components one at a time (e.g., cmake→\rightarrow pkg-config→\rightarrow OpenSSL), resulting in trial-and-error exploration and unnecessary iterations.
(3) Diagnostic oscillation. The analysis agent alternates between incompatible testing options without validating their semantics, entering repeated loops between invalid command configurations.
(4) Evaluation protocol violations. Despite explicit requirements, the baseline repeatedly omits environment activation steps in the evaluation script, leading to a large number of protocol-level errors.
In contrast, DockSmith exhibits substantially more stable and convergent behavior.
(1) One-shot dependency resolution.DockSmith identifies the complete set of required native dependencies for rugged in a single pass and produces a correct Dockerfile without rollback.
(2) Loop avoidance and decision stability. The trajectory contains no oscillatory diagnosis patterns or repeated invalid strategy switches, indicating more disciplined repair behavior.
(3) Improved protocol adherence. Protocol violations are reduced from 20 occurrences to a single instance, reflecting a stronger alignment with execution constraints.
This case study highlights three qualitative shifts induced by Docker-building supervision: (i) improved state consistency across iterations, (ii) more systematic dependency reasoning, and (iii) reduced diagnostic oscillation. Together, these changes lead to faster convergence and substantially cleaner execution traces, even on dependency-heavy repositories.
Trajectory Visualization.
For completeness, we include the raw execution trajectories for both models below.
Listing 1: Baseline trajectory for JEG2/highline Issue #222 (Qwen3-Coder-30B-A3B-Instruct).
Trajectory(abridged;key steps only)
Repo:JEG2/highline
Commit:413 ad89036ab535e53642c66333e9622323fdf32
Source:baselie_applicable_setup_JEG2__highline-222.json
Total steps:50
[Key steps]
Step 1|Context Retrieval Agent
User:Target repository name:JEG2/highline;Commit SHA:413 ad89036ab535e53642c66333e9622323fdf32;task:gather setup context
Asst:Plans to inspect README/Gemfile/Rakefile/gemspec/CI config to infer env+test commands.
Step 13|Write Eval Script Agent
Assistant(excerpt):writes eval script skeleton with:
cd/testbed
git checkout 413 ad89036ab535e53642c66333e9622323fdf32
git apply-v-<<’EOF_114329324912’[CONTENT OF TEST PATCH]EOF_114329324912
...(run tests)...
rc=$?
echo"OMNIGRIL_EXIT_CODE=$rc"
Step 41|Test Analysis Agent(Docker build failure)
Log(excerpt):
Installing rugged 0.99.0 with native extensions
checking for cmake...no
ERROR:CMake is required to build Rugged.
Guidance:add’cmake’to apt deps in Dockerfile.
Step 42|Test Analysis Agent(Docker build failure after cmake)
Log(excerpt):
checking for cmake...yes
checking for pkg-config...no
ERROR:pkg-config is required to build Rugged.
Guidance:add’pkg-config’to apt deps in Dockerfile.
Step 44|Test Analysis Agent(Test failure)
Symptom:failing test TestHighLine#test_readline_mode
expected pattern’/Prompt:\any\input\n/’but got’Prompt:’
Guidance:environment/readline simulation issue or brittle test;review test logic+patch compatibility.
Step 49|Test Analysis Agent(Eval script failure)
Symptom:minitest reports invalid option’--exclude-pattern=test_readline_mode’
Guidance:use minitest-supported exclude flag(e.g.,’-e/--exclude’),not’--exclude-pattern’.
Step 50|Test Analysis Agent(Eval script failure)
Symptom:"File does not exist:/testbed/test_readline_mode"
Guidance:the exclusion/selection syntax is being interpreted as a file path;fix how TESTOPTS is passed.
Listing 2: DockSmith trajectory for JEG2/highline Issue #222.
Trajectory(abridged;key steps only)
Repo:JEG2/highline
Commit:413 ad89036ab535e53642c66333e9622323fdf32
Source:it2520_applicable_setup_JEG2__highline-222.json
Total steps:5
[Key steps]
Step 1|Context Retrieval Agent
Assitant:inspects key files/dirs to determine Ruby version,deps,and test commands.
Step 2|Context Retrieval Agent
User:repository browsing results(lib/,test/,Gemfile/gemspec/CI)
Assitant:confirms how to run tests+any special requirements.
Step 3|Write Dockerfile Agent
Assitant(excerpt):proposes Dockerfile based on Debian Ruby image:
FROM--platform=linux/x86_64 ruby:2.7-bullseye
SHELL["/bin/bash","-lc"]
...(clone repo,checkout commit,bundle install)...
CMD["/bin/bash"]
Step 4|Write Eval Script Agent
Assitant(excerpt):eval script skeleton with:
cd/testbed
git checkout 413 ad89036ab535e53642c66333e9622323fdf32
git apply-v-<<’EOF_114329324912’[CONTENT OF TEST PATCH]EOF_114329324912
...(run tests)...
rc=$?
echo"OMNIGRIL_EXIT_CODE=$rc"
Step 5|Test Analysis Agent
Result:OMNIGRIL_EXIT_CODE=0
is_finish:true
B.2 Case Study: Environment-Aware Transfer on SWE-bench Verified
We present a representative case study from SWE-bench Verified to qualitatively illustrate how joint training with Docker-building trajectories alters agentic execution behavior. The selected instance, scikit-learn/scikit-learn#25102, requires modifying the output processing logic to preserve pandas.DataFrame dtypes in the pandas output of transformers. Although the code change itself is localized, success hinges on execution-grounded validation against the benchmark’s FAIL_TO_PASS tests.
Baseline behavior.
The baseline model, trained exclusively on SWE-solving trajectories, fails in all four independent repeated runs (0/4; four reruns under the same evaluation setting). A representative run (repeat_0) successfully executes several local checks (e.g., Python version and selected unit tests), but still fails the official evaluation: none of the two FAIL_TO_PASS tests are fixed (0/2).
Mixed-model behavior.
In contrast, the model trained with mixed SWE-solving and Docker-building trajectories achieves a 50% success rate over the same four reruns (2/4). In a representative successful run (repeat_0), the mixed model performs an explicit early verification of test tooling (e.g., pytest --version) and executes a broader set of feature-selection tests before final evaluation. Crucially, it fixes both FAIL_TO_PASS tests (2/2), resolving the dtype-preservation failures that remain in the baseline run.
Behavioral differences.
Comparing the two compressed traces highlights three systematic differences. First, the mixed model adopts earlier execution-oriented verification, explicitly checking the test runner before iterating on the patch. Second, it follows a more comprehensive validation routine by running a wider set of relevant tests under sklearn/feature_selection/, increasing the chance of catching dtype-related regressions aligned with the benchmark’s target failures. Third, the mixed model’s final patch more directly enforces dtype propagation from the input DataFrame to the pandas output, matching the evaluation signal of the remaining failures.
This case suggests that Docker-building supervision transfers beyond environment setup by strengthening execution-grounded habits: toolchain verification, systematic test execution, and iterating patches against concrete failure signals. While both models can run unit tests, only the mixed model consistently closes the loop between observed test failures and the patch logic required to satisfy the benchmark’s FAIL_TO_PASS criteria (2/2 vs. 0/2 in repeat_0).
We report a compressed trace for scikit-learn/scikit-learn#25102 (SWE-bench Verified), comparing Baseline (unresolved) vs Mixed (resolved). We keep only (i) key code edits, (ii) key commands/tests, and (iii) the final evaluation outcome. SWE-bench Verified determines success by whether all FAIL_TO_PASS tests are fixed; this instance has two target failing tests.
Listing 3: Baseline trajectory for scikit-learn/scikit-learn#25102 (unresolved).
Baseline trajectory(unresolved)
Goal(from issue):preserve input DataFrame dtypes for pandas output of transformers(dtype information like category/int precision).
Key edits(from patch):
-Modified:sklearn/utils/_set_output.py
-Added:test_dtype_preservation_final.py
High-level implementation intent(from patch diff):
-Introduce dtype-preservation path for pandas output by capturing input DataFrame dtypes and applying astype on the output.
-Add optional preserve_dtypes configuration to set_output(...,transform="pandas")and store in _sklearn_output_config.
Key executed commands/tests(selected):
-python--version(environment sanity check)
-python-m pytest sklearn/utils/tests/test_set_output.py...->exit=0(passed)
-python-m pytest sklearn/feature_selection/tests/test_feature_select.py...->exit=0(passed)
-python-m pytest sklearn/feature_selection/tests/test_univariate_selection.py...->exit=4(path not found;non-critical to final verdict)
Final evaluation outcome(ground truth):
status:unresolved(0/2 FAIL_TO_PASS fixed)
FAIL_TO_PASS failures:
-sklearn/feature_selection/tests/test_base.py::test_output_dataframe
-sklearn/feature_selection/tests/test_feature_select.py::test_dataframe_output_dtypes
Minimal failure signal(from eval log):
AssertionError:assert dtype(’O’)==dtype(’float32’)
(summary:2 failed,59 passed)
Listing 4: Mixed-model trajectory for scikit-learn/scikit-learn#25102 (resolved).
Mixed trajectory(resolved)
Goal(same):preserve input DataFrame dtypes for pandas output.
Key edits(from patch):
-Modified:sklearn/utils/_set_output.py
High-level implementation intent(from patch diff):
-Propagate/capture original input DataFrame dtypes and apply them to the pandas output DataFrame during wrapping.
Key executed commands/tests(selected):
-python--version
-python-m pytest--version(early test tooling verification)
-python-m pytest sklearn/utils/tests/test_set_output.py...->exit=0
-python-m pytest sklearn/feature_selection/tests/test_feature_select.py...->exit=0
-python-m pytest sklearn/feature_selection/tests/...->exit=0
-python-m pytest sklearn/feature_selection/tests/test_univariate_selection.py...->exit=4(path not found;non-critical to final verdict)
Final evaluation outcome(ground truth):
status:resolved(2/2 FAIL_TO_PASS fixed)
FAIL_TO_PASS successes:
-sklearn/feature_selection/tests/test_base.py::test_output_dataframe
-sklearn/feature_selection/tests/test_feature_select.py::test_dataframe_output_dtypes
Appendix C Rubric
C.1 Error Attribution Rubric
This appendix provides the error attribution rubric used in the error propagation and recovery analysis (Section3.5.2). The rubric defines a hierarchical taxonomy that assigns each error event in an execution trajectory to one of four software-stack layers, together with auxiliary annotations for intent alignment, causality, and resolution status. It serves as the standardized guideline for annotating error events and agent responses across all evaluated benchmarks.
Listing 5: Layered error attribution rubric.
[Task Objective]
Given the provided trajectory data,identify all errors that occur throughout the trajectory,and attribute each error according to the following Layered Taxonomy.
[Hierarchical Rubric]
-OS/Shell Layer(E_shell):Command syntax errors,incorrect arguments,or misuse of OS-level tools(e.g.,tar failures,bash script logic errors).
-Environment&Dependency Layer(E_env):Missing system libraries,third-party dependency version conflicts,misconfigured file paths/permissions(e.g.,pip failures,FileNotFoundError).
-Language Runtime Layer(E_runtime):Interpreter startup failures,missing dynamic libraries,Python ModuleNotFoundError(even when dependencies are already installed).
-Application Logic Layer(E_logic):Code executes normally but the application/business logic is incorrect(e.g.,AssertionError,test cases failing).
[Analysis Dimensions]
For each error point in the trajectory,extract the following dimensions:
-Intent Verification:Analyze whether the Agent’s fix action logically and rigorously targets the root cause of the error.
-Causality Trace:If the error is caused by a previous step,annotate the source step.
-Status Mapping:Track whether the error is ultimately resolved,or triggers cascading failures.
[Output JSON Format]
1.Constraints on error_trace:
a.If multiple errors occur,analyze each error separately.error_trace MUST be a list containing one entry per distinct error event(do not merge errors).
b.If a single step contains multiple distinct errors,create multiple error_trace items sharing the same step_index.
2.Output a JSON object in the following structure:
{
"trajectory_summary":{
"total_steps":"integer",
"final_result":"Success/Failure",
"primary_failure_bottleneck":"E_shell/E_env/E_runtime/E_logic"
},
"error_trace":[
{
"step_index":"index of the step where the error occurs",
"layer":"assigned layer",
"description":"brief description of the error",
"agent_response":{
"action_taken":"the specific fix action taken by the Agent",
"intent_match":"High(precise)/Medium(tentative)/Low(random or misguided)",
"knowledge_source":"System(principle-based)/Empirical(log-guessing)/Random(blind)"
},
"status":"Resolved/fixed,Terminal/ends task,Cascaded/triggers downstream cross-layer errors",
"causality":"if cascaded,specify which step induced it"
}
],
"global_metrics":{
"error_density":"ratio of error steps to total steps",
"self_correction_efficiency":"number of successfully resolved errors/total number of errors",
"environment_grounding_score":"score from 0 to 1 measuring the Agent’s depth of environment understanding"
}
}
[Trajectory Data]
##Insert your trajectory text here##
C.2 Docker-building Error Annotation Rubric
We provide the full rubric used by the automated annotator (GPT-5.1) to label Docker-building trajectories. The rubric specifies (i) agent-specific error taxonomies, (ii) severity labels, and (iii) the required JSON schema for recording error events. We include only steps that contain an error event; steps without errors are omitted.
Listing 6: Docker-building error annotation rubric and output schema.
[Task Instructions]
Analyze the trajectory step-by-step.For each step,check the provided[Active Agent]label and apply the corresponding logic:
1.Assess Quality:Does the action fail or exhibit bad practices?
2.Apply Taxonomy:Select the specific error code from the list corresponding to the[Active Agent].
3.Trace Causality:If an error occurs,determine if it is a direct consequence of a previous agent’s output(e.g.,Analysis Agent failed because Context Agent provided wrong info).
[Agent-Specific Error Taxonomies]
Scenario A:[Active Agent]==Context Retrieval Agent
-retrieval_miss_error:Failed to extract existing info(e.g.,missed requires in setup.py,ignored.python-version).
-retrieval_hallucination_error:Invented non-existent dependencies or configurations.
-retrieval_nav_error:Navigation failure(e.g.,looked in wrong directory,failed to find file).
Scenario B:[Active Agent]==Write Dockerfile Agent
-docker_syntax_error:Generated invalid Dockerfile instructions(build fails immediately).
-docker_env_error:Valid syntax but wrong semantic environment(e.g.,missing system libs like libpq-dev,wrong base image).
-docker_practice_error:Violated best practices(e.g.,running tests inside RUN instruction,pinning mutable tags).
Scenario C:[Active Agent]==Write Eval Script Agent
-eval_activation_error:Failed to activate the virtual environment(venv/conda).
-eval_patch_error:Failed to apply git patches correctly.
-eval_protocol_error:Failed to capture exit codes(OMNIGRIL_EXIT_CODE)or logs properly.
Scenario D:[Active Agent]==Test Analysis Agent
-diag_misattr_error:Root Cause Misdiagnosis.Blamed the wrong component(e.g.,blamed code for an environment issue).
-diag_loop_error:Repeated the exact same failed fix suggestion.
-diag_vague_error:Provided non-actionable feedback(e.g.,"Fix the error"without saying how).
[Output JSON Format]Output a JSON object containing a list of error events.If a step has no error,do not include it.
‘‘‘
{
"trajectory_id":"string",
"error_events":[
{
"step_index":integer,
"active_agent":"Context Retrieval|Dockerfile|Eval Script|Test Analysis",
"error_code":"E_...",
"severity":"Critical|Minor",
"description":"Brief explanation of the failure",
"causality_trace":{
"is_cascaded":boolean,
"root_cause_step":integer_or_null,
"reasoning":"e.g.,Failed here because Step 5 missed the dependency."
}
}
]
}
‘‘‘
[Input Data Format]
‘‘‘
Step 1:
[Active Agent]:Context Retrieval Agent
Action:Searching for"requirements.txt"in root directory...
[Output]:File not found.
Step 2:
[Active Agent]:Write Dockerfile Agent
‘‘‘
Xet Storage Details
- Size:
- 88.7 kB
- Xet hash:
- d8b014aa27488711bb176ae276bd36b52161276f9ab4f21d373cee4e9472cb09
Xet efficiently stores files, intelligently splitting them into unique chunks and accelerating uploads and downloads. More info.