
25% Experts Pruned, 36.0 HUMANEVAL (base 40.9)
OLMoE-1B-7B-0924-Instruct compacted via per-layer-normalized MoE expert pruning against the unmodified teacher.
- HUMANEVAL: 36.0 (base 40.9, Δ -4.9)
- HUMANEVAL+PLUS: 31.7 (base 36.6, Δ -4.9)

Every claim on this card is verified
Trust: self-attested · 2 benchmarks · 1 device tested
ForgeAlloy chain of custody · Download alloy · Merkle-chained
Cross-architecture validation artifact for §4.1.3.4. OLMoE-1B-7B (the smallest serious MoE on HF, fully-open Allen AI release) compacted from 7B to ~5B via calibration-aware MoE expert pruning on a held-out Python code corpus. Hardware-measured 36.0 HumanEval against unmodified base 40.9 (Δ −4.9, both Q5_K_M on the same 5090). The forge methodology that produced qwen3-coder-30b-a3b-compacted-19b-256k ports to a structurally distinct MoE family (OlmoeForCausalLM vs Qwen3MoeForCausalLM) without any modification to the forge scripts. The negative-baseline broad-corpus variant scored 28.0 — the +8.0 swing from changing only the calibration corpus is the lever §4.1.3.4 names. This is a methodology proof point, not a tier-leading artifact; OLMoE is general-purpose, not coder-specific, so HumanEval is not its strength. Use the qwen3-coder-30b-a3b artifact if you need a fits-12-GB code model.
Benchmarks
| Benchmark | Score | Base | Δ | Verified |
|---|---|---|---|---|
| humaneval | 36.0 | 40.9 | -4.9 | ✅ Result hash |
| humaneval_plus | 31.7 | 36.6 | -4.9 | ✅ Result hash |
What Changed (Base → Forged)
| Base | Forged | Delta | |
|---|---|---|---|
| Pipeline | expert-activation-profile → expert-prune → quant → eval | 1 cycles |
Runs On
| Device | Format | Size | Speed |
|---|---|---|---|
| NVIDIA GeForce RTX 5090 | Q5_K_M | 3.6GB | Verified |
| MacBook Pro 32GB | fp16 | 3.6GB | Expected |
| MacBook Air 16GB | Q8_0 | ~1.8GB | Expected |
| MacBook Air 8GB | Q4_K_M | ~1.1GB | Expected |
| iPhone / Android | Q4_K_M | ~1.1GB | Expected |
Quick Start
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("continuum-ai/olmoe-1b-7b-compacted-5b",
torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("continuum-ai/olmoe-1b-7b-compacted-5b")
inputs = tokenizer("def merge_sort(arr):", return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Methodology
Produced via MoE expert pruning, GGUF quantization. Full methodology, ablations, and per-stage rationale are in the methodology paper and the companion MODEL_METHODOLOGY.md in this repository. The pipeline ran as expert-activation-profile → expert-prune → quant → eval over 1 cycle on NVIDIA GeForce RTX 5090.
Limitations
- HumanEval is not OLMoE's natural benchmark. OLMoE is general-purpose (Allen AI), not coder-specific. The 40.9 base / 36.0 student numbers are methodology validation, not tier-leading absolute quality. For a tier-leading code model, see
qwen3-coder-30b-a3b-compacted-19b-256k. - Validates §4.1.3.4 cross-architecture; does NOT compete on absolute numbers. This is the second empirical anchor for the methodology paper, alongside the Qwen3-Coder-30B-A3B v1. Together they demonstrate that the activation-count importance metric is architecture-invariant across two structurally distinct MoE families.
- Calibration corpus was 300 Python code examples. For non-code workloads (math/reasoning/general), the methodology will preserve OLMoE's general capability if profiled on a matching corpus — but that's a separate forge run.
- Single GGUF tier shipped (Q5_K_M, 3.6 GB). Q4_K_M and Q8_0 will be added in v1.1 if there's demand.
Chain of Custody
Scan the QR or verify online. Download the alloy file to verify independently.
| What | Proof |
|---|---|
| Model weights | sha256:7f3b3c31279035cd5226f13cd602875ba... |
| Forged on | NVIDIA GeForce RTX 5090, ? |
| Published | huggingface — 2026-04-08T16:36:55.037319+00:00 |
| Trust level | self-attested |
| Spec | ForgeAlloy — Rust/Python/TypeScript |
Make Your Own
Forged with Continuum — a distributed AI world that runs on your hardware.
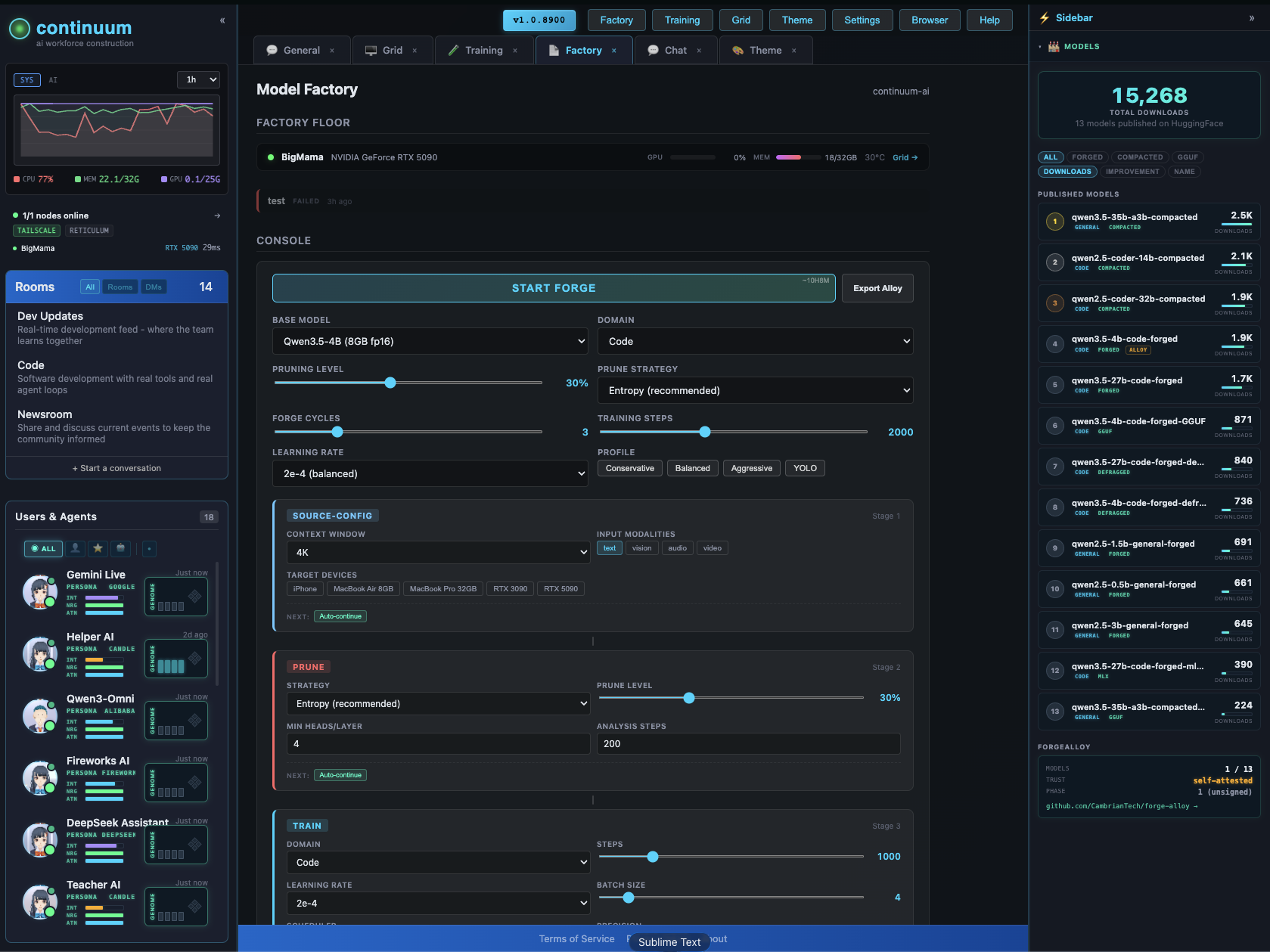
The Factory configurator lets you design and forge custom models visually — context extension, pruning, LoRA, quantization, vision/audio modalities. Pick your target devices, the system figures out what fits.
GitHub · All Models · Forge-Alloy
License
apache-2.0
- Downloads last month
- 32
5-bit
Model tree for continuum-ai/olmoe-1b-7b-compacted-5b
Base model
allenai/OLMoE-1B-7B-0924