

tags:
- 7b
- Chinese
- English
- android
- apple-silicon
- code
- compensation-lora
- continuum
- distillation
- edge-inference
- efficient
- embedded
- experiential-plasticity
- forge-alloy
- forged
- general
- general-purpose
- head-pruning
- iphone
- llama-cpp
- lm-studio
- local-inference
- lora
- macbook
- mobile
- neural-plasticity
- ollama
- on-device
- optimized
- pruned
- qwen
- qwen2.5
- raspberry-pi
- sentinel-ai
- text-generation
- validation-artifact
- versatile
base_model: Qwen/Qwen2.5-Coder-7B
pipeline_tag: text-generation
license: apache-2.0
12% Pruned, 61.0 HUMANEVAL (base 62.2)
Qwen2.5-Coder-7B forged through Experiential Plasticity and recovered to within calibration tolerance of the unmodified base via KL-distillation compensation LoRA.
- HUMANEVAL: 61.0 (base 62.2, Δ -1.2)
- HUMANEVAL+PLUS: 53.0 (base 53.7, Δ -0.7)

Every claim on this card is verified
Trust: self-attested · 2 benchmarks · 1 device tested
ForgeAlloy chain of custody · Download alloy · Merkle-chained
About this model
Methodology validation artifact for the v2 forge pipeline + KL-distillation compensation LoRA. Demonstrates that aggressive head pruning + activation-metric importance + pad-mode defrag, when paired with output-distribution distillation against the unmodified teacher, recovers near-base HumanEval capability (61.0 vs 62.2 base, within calibration tolerance). This is the empirical anchor for PLASTICITY-COMPACTION §4.1.3.3 and the loss-function ablation that closes the §4.1.3.2 PPL/HumanEval disconnect. NOT a Pareto improvement over the unmodified base 7B at any single VRAM tier — published as proof that the methodology stack works end-to-end, in preparation for the Qwen3.5-35B-A3B and 397B-A17B forges where the pruning dimension actually wins.
The Journey
This artifact is the punchline of a four-run experimental sequence on the same base model. The first run scored 50.0; the final run scored 61.0. Each run between them isolated a single variable, and each result narrowed the design space to the structural fix that recovered near-base capability.
| Run | Configuration | HumanEval pass@1 |
|---|---|---|
| 1 | broken global-flat L2-weight | 50.0 |
| 2 | layer-normalized activation, 1-cycle 500-step | 54.9 |
| 3 | layer-normalized activation, 3-cycle (ablation) | 46.3 |
| 4 | 1-cycle + KL compensation LoRA | 61.0 |
Loss Function Ablation
The compensation LoRA was run twice with identical configuration, varying only the distillation loss. The result is a substantive methodology finding in its own right:
| Distillation loss | HumanEval | HumanEval+ | Outcome |
|---|---|---|---|
mse_hidden |
0.0 | 0.0 | degenerate fixed point — model collapsed to outputting '0' |
kl_logits |
61.0 | 53.0 | near-base recovery within calibration tolerance |
MSE-on-hidden-states has a degenerate fixed point: the student can satisfy the loss by collapsing some downstream computation, regardless of whether the hidden states encode useful information. KL-on-output-logits has none, because matching the teacher's output distribution directly constrains task-level behavior. For autoregressive language models, distillation must operate at the output layer, not at intermediate residual streams.
Benchmarks
| Benchmark | Score | Base | Δ | Verified |
|---|---|---|---|---|
| humaneval | 61.0 | 62.2 | -1.2 | ✅ Result hash |
| humaneval_plus | 53.0 | 53.7 | -0.7 | ✅ Result hash |
What Changed (Base → Forged)
| Base | Forged | Delta | |
|---|---|---|---|
| Pruning | None | 12% heads (activation-magnitude) | -12% params ✅ |
| compensation-lora | None | rank=16 | q_proj, k_proj, v_proj, o_proj... |
| Pipeline | prune → lora → lora → eval | 1 cycles |
Runs On
| Device | Format | Size | Speed |
|---|---|---|---|
| NVIDIA GeForce RTX 5090 | fp16 | — | Verified |
| MacBook Pro 32GB | fp16 | 8.0GB | Expected |
| MacBook Air 16GB | Q8_0 | ~4.0GB | Expected |
| MacBook Air 8GB | Q4_K_M | ~2.5GB | Expected |
| iPhone / Android | Q4_K_M | ~2.5GB | Expected |
Quick Start
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("continuum-ai/v2-7b-coder-compensated",
torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("continuum-ai/v2-7b-coder-compensated")
inputs = tokenizer("def merge_sort(arr):", return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(output[0], skip_special_tokens=True))
How It Was Made
prune → lora → lora → eval (1 cycles)
- Pruning: 12% heads via
activation-magnitude, layer-normalized, pad-mode defragLayer-normalized activation-magnitude head importance (PLASTICITY-COMPACTION §4.1.3.1 fix). Pad-mode defrag preserves the q_proj invariant num_q_heads*head_dim==hidden_size so the artifact loads in llama.cpp (Finding 6 fix from VALIDATED-TENSOR-SURGERY).
- lora: rank ?, 500 steps
Single-cycle code-domain LoRA fine-tuning on the pruned student. 1-cycle ablation chosen because the 3-cycle multi-cycle test surfaced the §4.1.3.2 PPL/HumanEval disconnect (54.9 → 46.3 across cycles).
- compensation-lora: rank 16, 500 steps,
kl_logitsdistillation againstQwen/Qwen2.5-Coder-7BPLASTICITY-COMPACTION §4.1.3.3. KL divergence on output logits is the structural fix for the §4.1.3.2 disconnect. Loss-function ablation: MSE-on-hidden-states collapsed the model to 0.0 (degenerate fixed point); KL-on-logits recovered to 61.0. LoRA adapter merged into student weights at save time so inference-time VRAM and tokens/sec are unchanged from the un-compensated student.
- Calibrated evaluation: anchored against
Qwen2.5-Coder-7B(published 61.6, measured 62.2, ±3.0pt tolerance)All HumanEval numbers are anchor-calibrated against the unmodified Qwen2.5-Coder-7B base measured on the same hardware/pipeline in the same run. Hard-fail tolerance: ±3.0 points. Anchor delta: +0.6/+0.7 vs Qwen-published 61.6/53.0, deterministic across 6+ independent runs.
- Hardware: NVIDIA GeForce RTX 5090
- Forge tool: Continuum Factory + sentinel-ai
Limitations
- This model is currently a methodology demonstration rather than a Pareto-optimal artifact at any specific hardware tier. For production code workloads on smaller hardware, the unmodified Qwen2.5-Coder-7B at standard quantization (Q4_K_M / Q5_K_M / Q8_0) may be a better fit pending the larger Qwen3.5+ forges that exercise the pruning dimension where this methodology actually wins.
- Validated on HumanEval / HumanEval+ for English-language Python code completion. Performance on other programming languages, code paradigms (functional, embedded, kernel), or code-adjacent domains (SQL, regex, shell) has not been measured.
- Ships as fp16 only. GGUF quantization tiers (Q5_K_S / Q3_K_M / Q2_K) are not yet published for this artifact; the per-tier comparison from the development log showed base+quant dominates v2+quant at every VRAM tier on the same 7B base, which is why the methodology validation here uses fp16 and the production GGUF publishes are reserved for the Qwen3.5+ forges where the dimension flips.
- Vision modality not yet wired in. The Continuum sensory architecture treats vision as first-class for personas, but this 7B coder artifact is text-only.
Chain of Custody
Scan the QR or verify online. Download the alloy file to verify independently.
| What | Proof |
|---|---|
| Forged on | NVIDIA GeForce RTX 5090, ? |
| Published | huggingface — 2026-04-08T05:02:57.072577+00:00 |
| Trust level | self-attested |
| Spec | ForgeAlloy — Rust/Python/TypeScript |
Make Your Own
Forged with Continuum — a distributed AI world that runs on your hardware.
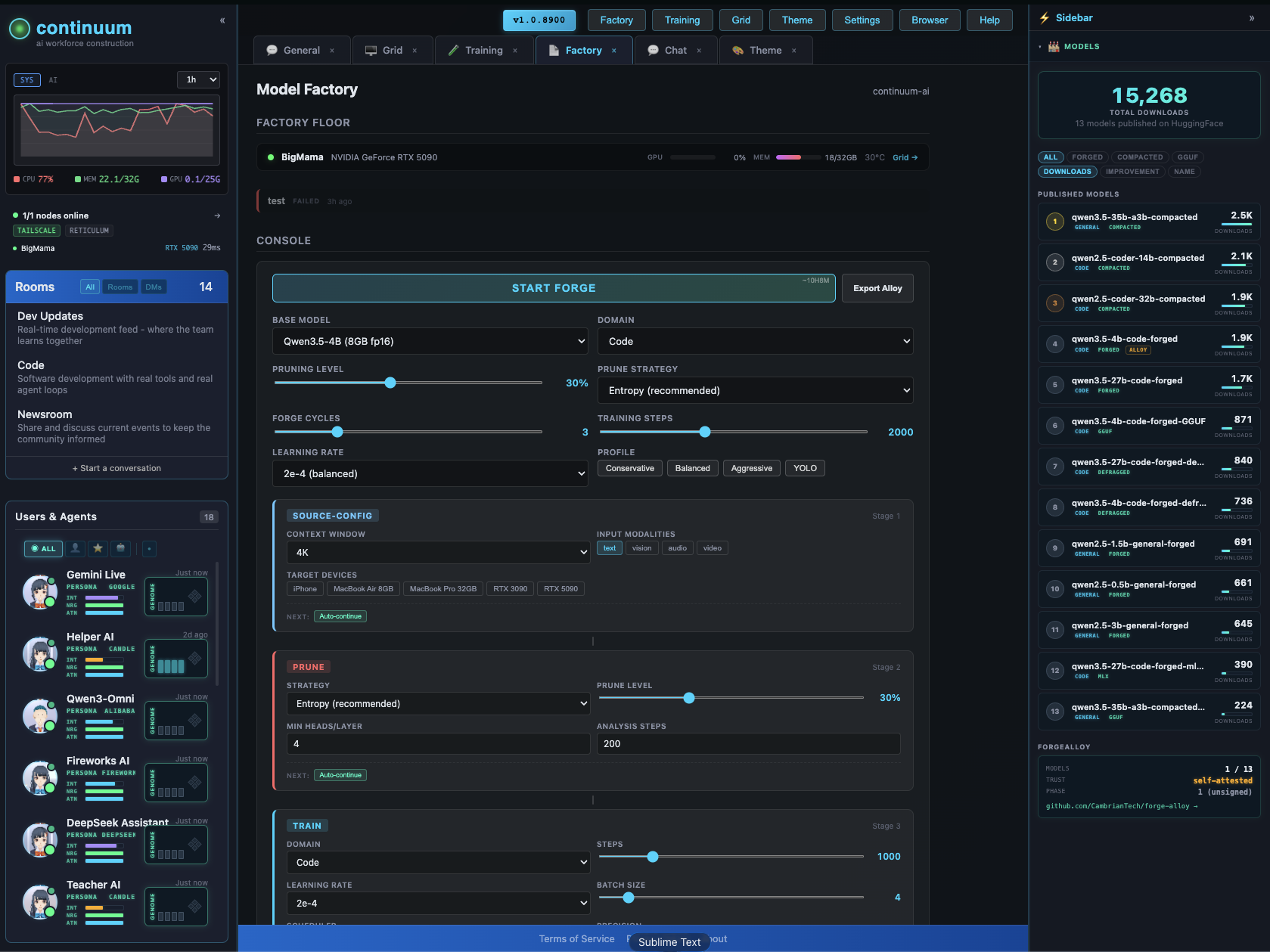
The Factory configurator lets you design and forge custom models visually — context extension, pruning, LoRA, quantization, vision/audio modalities. Pick your target devices, the system figures out what fits.
GitHub · All Models · Forge-Alloy
License
apache-2.0