
text
stringlengths 454
608k
| url
stringlengths 17
896
| dump
stringclasses 91
values | source
stringclasses 1
value | word_count
int64 101
114k
| flesch_reading_ease
float64 50
104
|
|---|---|---|---|---|---|
In this document
- Shrink your code
- Shrink your resources
See also.
Features in this document depend on:
- SDK Tools 25.0.10 or higher
- Android plugin for Gradle 2.0.0 or higher' } } ... }
Note: Android Studio disables ProGuard when using Instant Run. If you need code shrinking for incremental builds, try the experimental Gradle shrinkfile that's in the same location. It includes the same ProGuard rules, but with other optimizations that perform analysis at the bytecode level—inside and across methods—to reduce your APK size further and help it run faster.
- The
proguard-rules.profile is where you can add custom ProGuard rules. By default, this file is located at the root of the module (next to the
build.gradlefile).
To add more ProGuard rules that are specific to each build variant, add
another
proguardFiles property in the corresponding
productFlavor block. For example,.txt'), 'proguard-rules.pro' } } productFlavors { flavor1 { } flavor2 { proguardFile 'flavor2-rules.pro' } } }
With each build, ProGuard outputs the following files:.
These files are saved at
<module-name>/build/outputs/mapping/release/.
Customize which code to keep
For some situations, the default ProGuard configuration file
(
proguard-android.txt) is sufficient and ProGuard removes all—and
only—the unused code. However, many situations are difficult for ProGuard to
analyze correctly and it might remove code your app actually needs. Some
examples of when it might incorrectly remove code include:
- When your app references a class only from the
AndroidManifest.xmlfile
- When your app calls a method from the Java Native Interface (JNI)
- When your app manipulates code at runtime (such as with reflection or introspection)
Testing your app should reveal any errors caused by inappropriately removed
code, but you can also inspect what code was removed by reviewing the
usage.txt output file saved in
<module-name>/build/outputs/mapping/release/.
To fix errors and force ProGuard to keep certain code, add a
-keep line in the ProGuard configuration file. For example:
-keep public class MyClass
Alternatively, you can add the
@Keep
annotation to the code you want to keep. Adding
@Keep on a class
keeps the entire class as-is. Adding it on a method or field will keep the
method/field (and it's name) as well as the class name intact. Note that this
annotation is available only when using the Annotations Support
Library.
There are many considerations you should make when using the
-keep option; for more information about customizing your
configuration file, read the
ProGuard Manual. The
Troubleshooting section outlines other common problems you might encounter
when your code gets stripped away.
Decode an obfuscated stack trace
After ProGuard shrinks your code, reading a stack trace is difficult (if not
impossible) because the method names are obfuscated. Fortunately, ProGuard
creates a
mapping.txt file each time it runs, which shows the
original class, method, and field names mapped to the obfuscated names.
ProGuard saves the file in the app
<module-name>/build/outputs/mapping/release/ directory.
Be aware that the
mapping.txt file is overwritten every time
you create a release build with ProGuard, so you must carefully save a copy
each time you publish a new release. By retaining a copy of the
mapping.txt file for each release build, you'll be able to debug a
problem if a user submits an obfuscated stack trace from an older version of
your app.
When publishing your app on Google Play, you can upload the
mapping.txt file for each version of your APK. Then Google Play
will deobfuscate incoming stack traces from user-reported issues so you can
review them in the Google Play Developer Console. For more information, see the
Help Center article about how to deobfuscate
crash stack traces.
To convert an obfuscated stack trace to a readable one yourself, use the
retrace script (
retrace.bat on Windows;
retrace.sh on Mac/Linux). It is located in the
<sdk-root>/tools/proguard/ directory. The script takes the
mapping.txt file and your stack trace, producing a new, readable
stack trace. The syntax for using the retrace tool is:
retrace.bat|retrace.sh [-verbose] mapping.txt [<stacktrace_file>]
For example:
retrace.bat -verbose mapping.txt obfuscated_trace.txt
If you do not specify the stack trace file, the retrace tool reads from standard input.
Enable code shrinking with Instant Run
If code shrinking is important to you while incrementally building your app, try the experimental code shrinker that's built into the Android plugin for Gradle. This shrinker supports Instant Run, unlike ProGuard.
You can configure the Android plugin shrinker using the same configuration files as ProGuard. However, the Android plugin shrinker does not obfuscate or optimize your code—it only removes unused code. So you should use it for your debug builds only, and enable ProGuard for your release builds so your release APK's code is obfuscated and optimized.
To enable the Android plugin shrinker, simply set
useProguard to
false
in your "debug" build type (and keep
minifyEnabled set' } } }
Note: If the Android plugin shrinker initially removes a method, but you then make a code change to make the method reachable, Instant Run treats it as a structural code change and performs a cold swap..
Note: The resource shrinker currently does not
remove resources defined in a
values/ folder (such as strings,
dimensions, styles, and colors). This is because the Android Asset Packaging
Tool (AAPT) does not allow the Gradle Plugin to specify predefined versions for
resources. For details, see issue 70869. using APK splits to build different APKs for different devices..
Troubleshoot resource shrinking
When you shrink resources, the Gradle Console shows a summary of the resources that it removed from the app package..
|
https://developer.android.com/studio/build/shrink-code.html
|
CC-MAIN-2016-50
|
refinedweb
| 944
| 56.55
|
Python Certification Training for Data Scienc ...
- 48k Enrolled Learners
- Weekend/Weekday
- Live Class
At times, we require our program or sections of our program to execute after a small duration. Python makes this task effortless through time.sleep() function. This article covers the functionality of this function along with its applications.
Before moving on, let’s take a quick look at the topics covered in this article:
Let’s get started. :)
Sleep function plays a very important role in a situation where we want to halt the program flow and let other executions happen. This function is defined in both versions of python i.e 2 and 3. It belongs to the time module of Python. It basically adds a delay to the execution and it will only pause the current thread and not the whole program.
Python time.sleep() function is present in the time module of Python. Before making use of this Python function, you will need to import this module using the command:
import time
Once this module is imported, you can make use of time.sleep() function. The syntax is as follows:
It takes one parameter which is seconds as you can see. This basically induces a delay for that many seconds during the execution. Return value for this function is void.
Let’s now take some examples to understand the working of this function.
Consider the following example that induces a delay of one second between outputs.
Example:
import time # import time module sleep_time = 1 # time to add delay after first print statement print('Hello') time.sleep(sleep_time) # sleep time print('Edureka!')
Output:
If the above code is executed it will add a delay in the program thus, the next statement will be executed after 1 second(s). For an exact delay, you can also pass floating-point values to the function. For example, if 0.1 seconds is passed then it will make a delay of 100 milliseconds.
Here is another example which will return the system time before and after the execution of the program.
Example:
# sleep demonstration import time # Start time print("The time of code execution begin is : ", end ="") print(time.ctime()) # haulting program time.sleep(6) # end time print("The time of code execution end is : ", end ="") print(time.ctime())
The time of code execution begin is : Sun Jun 23 22:36:19 2019
The time of code execution end is : Sun Jun 23 22:36:25 2019
Process returned 0 (0x0) execution time : 6.089 s
Press any key to continue . . .
Following is an example of sleep function:
import time startTime = time.time() for i in range(5, 10): print(i) # making delay for 1 second time.sleep(1) endTime = time.time() elapsedTime = endTime - startTime print("Elapsed Time = %s" % elapsedTime)
Output:
5
6
7
8
9
Elapsed Time = 5.006335258483887
Process returned 0 (0x0) execution time : 5.147 s
The complete execution has taken 5 seconds as the execution halted for 1 second(s) each time. Also, the extra time which required for execution is the time of system doing background operations for the programs.
Different delay time of python sleep()
Different delay times can be added between the execution of the program in Python depending on the required output. Following code demonstrate how that can be done:
Example:
import time for i in [1, 0.1, 2, 0.3]: print("I will sleep for %s" % i, end='') print(" seconds") time.sleep(i)
Output:
I will sleep for 1 seconds
I will sleep for 0.1 seconds
I will sleep for 2 seconds
I will sleep for 0.3 seconds
Process returned 0 (0x0) execution time : 3.538 s
If you want to print something in a fancy way you can do so using the sleep() function as below:
# importing time module import time message = "Some fancy character printing!" for i in message: print(i) time.sleep(0.3)
If you execute the above code you will see a delay in the printing of each character which will look fancy.
In multithreaded environment sleep() proves to be very important as while execution it can add a delay in the current thread which is being executed.
Example:
import time from threading import Thread class Runner(Thread): def run(self): for x in range(0, 7): print(x) time.sleep(2) class Delay(Thread): def run(self): for x in range(106, 109): print(x) time.sleep(7) print("Staring Runner Thread") Runner().start() print("Starting Delay Thread") Delay().start() print("Done")
Below is the output of the threading example above:
Output:
If you execute the program you will notice that the whole program doesn’t get stopped but, only the thread which was currently being executed, go ahead and give it a try.
Application :
There are many applications of this method, for example, we can use it to create a nice user interface which prints menu or the heading in some fancy way, however, one of the important application is to halt a background process which is to be executed in some interval.
Application Example:
import time string = "Edureka!" print_string = "" for i in range(0, len(string)): print_string = print_string + string[i] print(print_string) time.sleep(2)
Output:
E
Ed
Edu
Edur
Edure
Edurek
Edureka
Edureka!
As we have seen that the sleep function pauses the program for some amount of time where Python’s time module comes in handy. Let’s see a little about how can we take input from the user and use the same function dynamically.
Here’s an example of sleep that takes input from the user to add a delay between two print functions and prints the time taken to execute the print function, the following example is based on Python 3.x.
import time def sleeper(): while True: num = input('Enter wait time: ') try: num = float(num) except ValueError: print('Number only.n') continue # Run our time.sleep() command, # and show the before and after time print('Before: %s' % time.ctime()) time.sleep(num) print('After: %sn' % time.ctime()) try: sleeper() except KeyboardInterrupt: print('nnException Exiting.') exit()
Output:
Enter wait time: 1
Before: Sun Jun 23 22:44:13 2019
After: Sun Jun 23 22:44:14 2019
Enter wait time: 3
Before: Sun Jun 23 22:44:16 2019
After: Sun Jun 23 22:44:19 2019
Accuracy
If you want to stop execution for a smaller period of time there are limitations to this function depending on the operating system as this function uses operating systems sleep() function, in Linux the wait time can be smaller than that compared with windows.
Summary
In the above article we covered the sleep() method in python which is basically used to add a delay in program execution, this package is in the time module in Python which basically uses sleep() function of the underlying operating system. We also covered few code examples of how to use this function and took a look into applications of sleep. Demonstrated fancy ways to use this function also how it works in a threaded environment.
To get in-depth knowledge on Python along with its various applications, you can enroll for live Python online training with 24/7 support and lifetime access.
Got a question for us? Please mention it in the comments section of this “Python time sleep method in Python” blog and we will get back to you as soon as possible.
|
https://www.edureka.co/blog/python-time-sleep/
|
CC-MAIN-2019-39
|
refinedweb
| 1,235
| 63.7
|
Chapter 5
Object-Oriented Programming in Maya
Author
Seth Gibson
Project
Develop a basic class to explore OOP, create an LOD window with pymel
Example Files
Synopsis
This chapter shows one of the key advantages of Python over MEL by introducing object-oriented programming. The chapter briefly explains what objects are and what the constituent parts of Python classes are. It explores the distinctions between methods and data attributes, as well as class and instance attributes. We also discuss the difference between the @staticmethod and @classmethod decorators. Readers will walk through basic examples to learn how to define a class from scratch and how to inherit from custom classes. Readers will also be introduced to the pymel module as a practical implementation of OOP in Maya. In addition to describing where more information on PyMEL can be found, PyMEL’s underlying mechanics will be explained in order to compare and contrast the pymel module with the cmds module. The chapter concludes with an example tool created using PyMEL.
Resources
PyMEL
PyMEL Installation Instructions
A Guide to Python’s Magic Methods
Other Notes
On p. 151 the section on instantiation says that “each instance is a separate immutable object.” Strictly speaking (and according to the definition we use in Chapter 2), instances are immutable by default, as their value is their identity (and hence they are hashable). If you use a colloquial definition of mutability, however, instances can be mutated, since their attributes can be altered.
Errata for the First Edition
On p. 149 the section distinguishing OOP and procedural programming incorrectly states that “the term object refers to a unique occurrence of a class, an instance.” In fact, everything in Python—including a class itself—is an object of some kind. A class describes a type of a thing, while an instance is an occurrence of a thing of that type.
On pp. 161-162, the pseudocode example for static methods and class methods should include the
def keyword before each method name in order to properly execute.
on page 154, to emphasis shouldn’t “this function” should be written as “current method”, in the second line ?
Hello Seth,
on page 155, why are you setting Human.bmi = bmi ?are you setting it as attribute of a class ? following step 6 here is what I have
class Human(object):
def __init__(self,*args,**kwargs):
self.first_name=kwargs.setdefault('first')
self.last_name=kwargs.setdefault('last')
self.height = kwargs.setdefault('height')
self.weight = kwargs.setdefault('weight')
def bmi(self):
return self.weight/float(self.height)**2
Human.bmi = bmi
but this gives me error that bmi doesnt exist which is obvious since its in the Human class, to my understanding Human.bmi = bmi will work if we also have bmi function at global level outside Human Class..
executing step 7 i do get answer if i comment Human.bmi = bmi, what is the role of reassigning an attribute Human.bmi = bmi after bmi(self) methid ?
the code indentation doesnt showed up properly so I pasted at
I’m at chapter 5 page 154 and this is the script I’m trying to run:
import sys;
class NewClass():
# exitst in class definition
data_attribute1 = 1;
def_init_(self):
# added to instance upon instantiaton
self.data_attribute2 = 2;
print(NewClass.data_attribute2);
except AttributeError:
print(sys.exc_info()[0]);
instance = NewClass();
print(instance.data_attribute1);
print(instance.data_attribute2);
But I only get # Error: SyntaxError: invalid syntax # when i do so, and this happens almost all the time. Except that I can’t find anything wrong on this one.
Hi! You have an “except” block with no corresponding “try” block.
Hi,
on page 168 “Installing PyMEL”
the 2 links you gave
appears to be 404 error now?
Could you please update the address of the documentation on install PyMel?
Thanks a lot,
Sty
pymel installed by following
and add pymel to PYTHONPATH as environment variable
Thanks! I have updated the links on this page.
|
http://www.maya-python.com/chapter-5/
|
CC-MAIN-2020-24
|
refinedweb
| 653
| 55.44
|
Maybe a using/namespace problem with InAppBrowser
I cant access
window.open = cordova.InAppBrowser.open;
or with
window.open = window.plugins.InAppBrowser.open;
How can i do use InAppBrowser with Onsen UI + Vue.Js
- asialgearoid Onsen UI last edited by
Does this actually cause issues when you build your app? I wouldn’t be surprised if an IDE could not resolve references to Cordova plugins due to the way they’re designed.
@asialgearoid thanks for your reply. But its not a IDE problem. Because Chrome console is says: “ReferenceError: cordova is not defined”.
- asialgearoid Onsen UI last edited by
The
cordovavariable is only available if you package the app using the
cordovacommand, so it’s not normally available if you are testing in your browser. I know
InAppBrowserdoes support the
browserplatform, but I think for that to work, you’ll need to serve your site using
cordova serve. How are you currently serving it?
@asialgearoid Thanks for your reply. I’m sorry for the delay.
I will try it Cordova Serve. I tried it is Monaca Serve.
At the same time, i compiled and packed live build on a real Android and Iphone.
Still it doesnt work.
|
https://community.onsen.io/topic/3179/maybe-a-using-namespace-problem-with-inappbrowser
|
CC-MAIN-2018-43
|
refinedweb
| 197
| 68.97
|
Every fragment contributes a given interpreter (Ruby, JavaScript, AppleScript, etc.) and its respective JSR-223 engine, which exposes the interpreter through the javax.script scripting API. Interpreters and JSR-223 wrappers can be bundled together or developed and shipped separately.
This plug-in setup offers various advantages, including the following:
The plug-in defines the IScript interface, which represents the script shown in following listing:
public interface IScript {
// @return the URI which points to the script code.
public String getURI();
// @return the script extension
public String getExtension();
// @return a Reader which points to the script code
public Reader getReader() throws IOException;
// @return the script unique id
public String getId();
// @return the namespace (plug-in id) of the script
public String getNamespace();
// @return run the script in a modal context?
public boolean isModal();
}
The scripting plug-in exposes the com.devx.scripting.ScriptSupport class, which defines public methods for common script-related needs that arise within the Eclipse platform. These needs include running a script in the context of a progress monitor (such as the one shown while compiling sources in Eclipse), or retrieving a list of the supported languages by querying the ScriptEngineManager. The following listing shows part of the public interface of the class (Refer to the source code for the implementation):
public void runScript(final IScript script,
Map<String,Object> params) throws ScriptException;
public List<Language> getSupportedLanguages();
Execution of External Scripts
With only these basic elements, you can already provide a way to run custom scripts inside your Eclipse application. As an example, you can contribute an Eclipse action that allows the user to choose a script from the file system and run it within the platform. Figure 2 and Figure 3 preview the final results.
To obtain the previewed result, you define an extension to the org.eclipse.ui.actionSets extension point, which provides an additional menu action to the application, implemented by the com.devx.scripting.actions.RunScriptAction class shown in Listing 1.
That's it. You can now run Ruby, Groovy, and other scripts within your application, taking advantage of their power and peculiarities. You can prepare scripts that perform a bulk change on part of the workspace or you can have part of your build and deploy process written in a scripting language and invoked by the developer from within the platform when needed.
Please enable Javascript in your browser, before you post the comment! Now Javascript is disabled.
Your name/nickname
Your email
WebSite
Subject
(Maximum characters: 1200). You have 1200 characters left.
|
http://www.devx.com/Java/Article/34545/0/page/2
|
CC-MAIN-2018-26
|
refinedweb
| 420
| 52.29
|
Hi,
I'm using tapir, and really liking it so far. But there's something I find a bit odd in the default behaviour of endpoint input, but maybe I'm not using it correctly?
Anyway, the usecase is simple. consider some simple endpoint like:
val getUsers: Endpoint[Int, String, String, Any] = { val userId = path[Int].description("The user ID is a 32-bit signed integer") endpoint .name("get user") .get .in("api" / "users" / userId) .errorOut(stringBody) .out(stringBody) }
I would expect that a call like:
GET <host>/api/users/foo would result with something like:
400 BadRequest : 'foo' is not a valid Int
instead we get:
500 Internal Server Error : There was an internal server error.
Looking at the code, I see that
path has a context bound for a codec, which I guess is always this:
implicit val int: Codec[String, Int, TextPlain] = stringCodec[Int](_.toInt).schema(Schema.schemaForInt)
and in the implementation, it's just
string codec mapped with
_.toInt, leaving the
validator as
Validator.pass.
So this seems a bit weird to me, since clearly what we want in such a case is to validate the primitives properly, thus returning 400, and not 500 in case of invalid input.
Thanks!
RedocHttp4sand
SwaggerHttp4shave different implementations (e.g.
contextPathis a
List[String]for the first and
Stringfor the latter)
zio-http4salready and
zio-httpis not official zio but 3rd party, although is endorsed by zio devs
FetchBackend. But how to implement endpoints? I have added to my dependencies
"com.softwaremill.sttp.tapir" %%% "tapir-sttp-client" % "0.18.0-M2"but I am struggling to find a way.
tapir-sttp-clientis relying on methods that don't have a counterpart in scala.js, such as
java.time.Instant.atZone(java.time.ZoneId)java.time.ZonedDateTimeor
java.time.LocalTime.parse(java.lang.CharSequence)java.time.LocalTime. Has anyone experience on Tapir in scala.js?
Hi there!
Could you answer me, why the type
ZServerEndpoint[R, I, E, O] = ServerEndpoint[I, E, O, Any, RIO[R, *]] is coupled to RIO, where error type is Throwable instead of using more flexible ZIO[R, E, *]?
I have a problem, I have an endpoint of
ServerEndpoint[(String, Unit), ApiError, String, Any, ZIO[Any, ApiError, *]] type where type parameter E is the my custom type
ApiError <: Throwable and I can't use
ZHttp4sServerInterpreter because of type mismatch error: ZIO[Any, ApiError, ] can't be used in RIO[Any, ] context.
Thanks in advance!
Hi Adam, I'm excited about a new version of Tapir. I upgraded Tapir to 0.18 M4. Minor changes mostly, though I wanted to bring up a few items before opening tickets.
The
respond method in
sttp.tapir.server.interceptor.decodefailure.DefaultDecodeFailureHandler, has these two parameters,
badRequestOnPathErrorIfPathShapeMatches &
badRequestOnPathInvalidIfPathShapeMatches. I don't think their semantics have changed in the new version. By setting both to
true, I'm expecting any mismatch in the shape of the URL should result a 400-BadRequest. However, currently those tests that were designed to test this behavior in my test suites are failing because the returning status code is now 404-NotFound. I can see in the code that it seems to return 400-BadRequest (
Some(onlyStatus(StatusCode.BadRequest))) but I'd like to confirm with you if this is a bug.
In the new
sttp.tapir.server.http4s.Http4sServerOptions, it provides
Log.defaultServerLog as the default implementation. My problem with the current impl is that it doesn't allow me to override the
logAllDecodeFailures parameter in the
DefaultServerLog constructor. I have this flag as an app setting so that I can turn it on for troubleshooting purpose. The current impl of
Log.defaultServerLog returns
ServerLog[F[Unit]], so I can't call
copy to set the
logAllDecodeFailures parameter myself. I can submit a PR for this but if you think it's trivial enough that you can squeeze in a fix in the next release, I'd leave it to you then.
Also, for the implementation of
customInterceptors in
sttp.tapir.server.http4s.Http4sServerOptions, right now the implementation uses
ExecutionContext.Implicits.global. I wonder if it makes sense to make it a parameter so it can be passed in from call sites. With the current implementation, in order to provide a different executor, the only choice for me as a user is to re-implement
customInterceptors myself.
Please let me know your thoughts on these. Thank you again for all your hard work for this amazing lib. Looking forward to the official release.
Hi, I need some help. I am upgrading Tapir from v 0.16.16 to 0.17.19. My http routes are based off this github project from the zio website resources section. In short the old routes are using the toRoutesR variant where i was passing the environment in via URIO eg
object ShortenRoutes { val routes: URIO[BitlyEnv, HttpRoutes[Task]] = ShortenApi.getShortenEndpoint.toRoutesR { case (reqCtx, url) => Bitly.shortenUrl(url).mapToClientError(reqCtx) } }
I am trying to convert it to something like
object ShortenRoutes { val routes: HttpRoutes[RIO[BitlyEnv, *]] = ZHttp4sServerInterpreter.from(ShortenApi.getShortenEndpoint) { req => val (reqCtx, url) = req Bitly.shortenUrl(url).mapToClientError(reqCtx) }.toRoutes }
I am using http4s server where previously i had
private val appRoutes: URIO[AppEnv, HttpApp[Task]] = for { healthRoutes <- HealthRoutes.routes shortenRoutes <- ShortenRoutes.routes docsRoutes = new SwaggerHttp4s(yaml).routes[Task] } yield { (healthRoutes <+> shortenRoutes <+> docsRoutes).orNotFound }
and in my BlazeServerBuilder I had
for { app <- appRoutes config <- getConfig[HttpServerConfig] implicit0(rts: Runtime[Clock]) <- ZIO.runtime[Clock] ec <- ZIO.descriptor.map(_.executor.asEC) _ <- BlazeServerBuilder[Task](ec) .bindHttp(config.port, config.host) .withConnectorPoolSize(config.poolSize) .withIdleTimeout(config.idleTimeout.asScala) .withResponseHeaderTimeout(config.responseHeaderTimeout.asScala) .withoutBanner .withHttpApp(app) .serve .compile .drain } yield ()
The new code looks like
.... BlazeServerBuilder[RIO[BitlyEnv, *]](ec) .... .withHttpApp(Router("/" -> (ShortenRoutes.routes <+> HealthRoutes.routes <+> new SwaggerHttp4s(yaml).routes)).orNotFound)
where BitlyEnv contains Clock
The ShortenRoutes takes BitlyEnv as the environment, where as the HealthRoutes only takes Clock since its method signature is
HttpRoutes[RIO[Clock, *]].
The compiler complains about type mismatches unless i pass in the BitlyEnv to the HealthRoute as well.
New to zio/http4s and pure functional programming so I am struggling to figure out what I am doing wrong or how to have multiple routes take in different environments and make the compiler happy. Any help would be appreciated. Again , i cant really share all the code, but as mentioned, its based on the github example above specifically the http.routes package
Hello, I was playing with tapir a bit and I struggle a bit with the type involved in route definition.
I'm currently using this code to create a ZLayer from my services
// type Routes[T] = ZIO[Clock, Throwable, T] // type ZRoutes = HttpRoutes[Routes] def swaggerRoutes: ZRoutes = new SwaggerHttp4s(swaggerDefinition, contextPath = "docs").routes[Routes] def routes: URLayer[Has[GameService], Has[ZRoutes]] = ZLayer.fromService[GameService, ZRoutes] { gameService => val r = ZHttp4sServerInterpreter .from( List( endpoints.startGame.zServerLogic(_ => gameService.startGame()), ) ) .toRoutes r <+> swaggerRoutes }
And I wanted to change my code to use method from gameService's companion object, instead of using the
ZLayer.fromServices so I ended up doing that
type RoutesTest[T] = ZIO[Has[GameService] with Has[Clock.Service], Throwable, T] type FinalRoutes = HttpRoutes[RoutesTest] def routes2: FinalRoutes = { val r: HttpRoutes[RoutesTest] = ZHttp4sServerInterpreter .from[Has[GameService]]( List( endpoints.startGame.zServerLogic(_ => GameService.startGame()) ) ) .toRoutes r <+> new SwaggerHttp4s(swaggerDefinition, contextPath = "docs").routes[RoutesTest] }
But I don't really like working with those
HttpRoutes and
Kleisli. Is there a way for me to create a ZIO layer from this ? Or is it not the way it's supposed to work, and having a ZLayer around those HttpRoutes is not recommended
about to take on an upgrade from
0.17.0-M9, so wondering if someone can point me to key changes and/or a migration strategy? Just looking at the docs and comparing it to my imports, looks like some significant breaking changes. E.g, my imports
object MyTapir extends Tapir with TapirAkkaHttpServer with TapirOpenAPICirceYaml with TapirAliases with ValidatorDerivation with SchemaDerivation {
I see the
TapirAkkaHttpServer import has changed, I'm curious about
ValidatorDerivation and others. I also see that someone contributed
Json4s support, so I'll need to bring that in.
Looks like a few significant breaking changes. In reverse order:
If there is anything else I should look out for, please let me know.
Is there a way to combine EndpointInput using
or instand of and. My goal would be to support either
path/to/session/XXXXX or a custom header
x-custom-session = XXXXX
I've defined those two
EndpointInput:
val sessionHeader: EndpointInput[UUID] = header[UUID]("session") val sessionHeaderUrl: EndpointInput[UUID] = path[UUID]("x-custom-session")
But I don't know how to combine them
Hi there! I have a question regarding testing. Often, I find myself in the situation where I don't just have an
Endpoint but a
ServerEndpoint with a bit of logic that I'd like to test. Example:
def twice(logic: IO[String]): ServerEndpoint[Unit, String, String, Any, IO] = endpoint.get .in("foo") .out(stringBody) .errorOut(stringBody) // (*) .serverLogic { _ => logic .map(s => s"$s$s") .attempt .map { case Left(throwable) => Left(throwable.getMessage) case Right(s) => Right(s) } }
The
SttpBackendStub (from the docs) is super helpful to test just the first part (i.e., up to
(*)) and of course, I could test the logic inside
.serverLogic separately, by factoring it out into a function.
However, if I want a more end-to-end type test, is there an easy way to do this?
Something like (I'm phantasizing here):
val backend = SttpBackendStub.forServerEndpoint(twice(IO("bar"))) client3.basicRequest .get(uri"") .send(backend) .body should equal(Right("""barbar"""))
?
Survey time! Which authentication features are you using and how? What are you missing! Let us know to help shape tapir moving forward :)
Thank you!
tapir-http4s-client, and no such artifact seems to exist. Not even something similar. Am I missing something?
Schema-related) that need to be ported. The modify macros resemble closely quicklens, so as a prerequisite, I'm working (as we speak - though most of the work is done by @KacperFKorban) on porting quicklens to Scala 3 macros (). That should also be a good learning experience so I'm hoping after implementing that, I'll be able to port tapir relatively quickly. But who knows what suprises lay ahead :)
hi, where I can find a simple example of a route that downloads a binary file?equivalent of this older code :
endpoint.get .in("pdf") .out(header(HeaderNames.ContentType, "application/pdf")) .out(streamBody[Source[ByteString, Any]](schemaFor[Array[Byte]], CodecFormat.OctetStream())) .errorOut(errorHandler)
I need it to return the same type which is
Endpoint[Request, ApiError, Source[ByteString, Any], Source[ByteString, Any]]
kind-projector. I see that
-Ypartial-unificationmentioned in both docs and readme but there was no indication that I needed
kind-projector. Do you think
kind-projectorshould be mentioned where it's applicable?
Hi! I have a json as input of endpoint, which contain a fields like Int and String. I want to provide a specific validation for each field. I've read the documentation for tapir and found out that:
To introduce unique types for primitive values, you can use value classes or type tagging.
So, I wrapped each primitive field to value class for example
case class Login(v: String) extends AnyVal and when I send a request a have an error such as
Invalid value for: body (Attempt to decode value on failed cursor at 'login.v')
Could somebody help me?
*case class Login(v: String) extends AnyVal
case class Password(v: String) extends AnyVal
case class Email(v: String) extends AnyVal
case class PassportNumber(v: Int) extends AnyVal
case class UserRegistration(login: Login,
password: Password,
passportNumber: PassportNumber)
val signInEndpoint
: Endpoint[UserRegistration, EndpointError, StatusCode, Any]*
Hi, just stumbled upon
this.Out required in streaming context and don't know what to make of it.
found : Either[sttp.model.StatusCode, fs2.Stream[F, Byte]] required: Either[sttp.model.StatusCode, this.Out] which expands to Either[sttp.model.StatusCode, fs2.Stream[F, Byte]]
Using 0.18.0-M7 on Scala 2.13
Any ideas?
Hi, firstly thanks a lot for Tapir. It is a great project! I wonder if anyone can offer some advice for a situation I find myself in. I have some unusual requirements and am having trouble translating to Tapir. The JSON bodies received on some endpoints must include a field with a constant value. This is because the body is cryptographically signed and the intent must be clear to stop it being repurposed on other endpoints. As the field can only have one value, it doesn't really map so well onto a two way conversion (e.g. adding to Circle decoder). I attempted to add the field manually to some schemas using the following code (simplified version here)
def addTypeFieldToSchema[T](schema: Schema[T]) = { schema.schemaType match { case SProduct(info, fields) => schema.copy(schemaType = SProduct( info, fields.toList :+ (FieldName("type") -> Schema.schemaForString .validate( Validator.`enum`(List("value-to-appear-as-enum"), Some(_)) )
I was expecting that the OpenAPI would render the new
type field as a string with an enum property with a single value. It does render the field, but the enum seems to have been lost. My questions are firstly: Is the approach I took the best for this constant field requirement. Secondly, any idea why the enum is lost when rendering OpenAPI? I have tried on version 0.17.8, then bumped to 0.17.9 and neither work. BTW, there were quite a few breaking changes from 0.17.8->0.17.9. Are there plans for SemVer in the future?
|
https://gitter.im/softwaremill/tapir?at=6079334ac60826673ba90fbd
|
CC-MAIN-2021-25
|
refinedweb
| 2,262
| 58.48
|
It’s been a while (understatement of the year) since I wrote Structuring Integration Repository Content – Part 1: Software Component Versions . You might want to (re-)read it prior to reading this blog for the sake of continuity.
Best practices document
A few months after I wrote part 1, I discovered a document titled SAP® Exchange Infrastructure 3.0: Best Practices for Naming Conventions. This was actually published before my blog, but doesn’t seem to have received much attention. At least I have been unable to find any reference to it in blogs or forums.
It was very gratifying to read this document, because what it advocates regarding Software Component Versions (SWCVs) is essentially the same as approach 4 in my blog, i.e. separate SWCVs for sender interfaces, receiver interfaces and mapping components. It formalizes and extends the approach and recommends naming conventions that reflect the component decomposition. If you haven’t already read the document, I highly recommend it! The document covers all object types in both the Integration Repository and Integration Directory dealing mainly with naming conventions, but I have chosen to focus exclusively on SWCVs in this blog entry.
The document contains (on page 6) a very nice diagram illustrating the approach. I hope no-one will mind me reproducing that diagram here:
The diagram shows two systems, A and B, running Application A and Application B, respectively, and communicating with each other via XI. There is one interface SWCV, in red, which contains Application A’s interfaces and a separate interface SWCV, in yellow, which contains Application B’s interfaces, and there is an application SWCV, the large blue rectangle, which contains the mappings between the interfaces of Application A and Application B.
One of the great things about the best practices document is that it provides us with some useful terms for referring to these different types of SWCVs:
- Interface SWCVs – containing the interface definitions for an application and
- (XI) Application SWCVs – containing integration scenarios, actions, and mappings which connect the interfaces of one or more applications
Additionally, the document introduces
- Base SWCVs – “…for templates, generic structures, shareable Java programs, and so on” and
- Canonical SWCVs – “For generic business objects; intended for reuse.”
It seems a bit unclear what this actually means, so I’ll elaborate on how I believe these last two SWCVs should be used.
Base SWCVs
Use base SWCVs to store common data types, message types and external definitions that you expect to share across multiple interface SWCVs. Any mapping templates associated with such shared definitions also go here.
Any common Java code (in imported archives) that can be reused by different application SWCVs also belong in a base SWCV.
Define dependencies (of type installation) in the SLD to allow other SWCVs to refer to objects in base SWCVs.
If you develop a custom adapter, I would also consider its SWCV as a base SWCV.
Canonical SWCVs
If your company defines a corporate-wide canonical data model, then the data types and message types of this model should be stored in one or more canonical SWCVs.
Also, if you need to communicate with a business partner using an industry standard interface such as ebXML or xCBL, place the corresponding definitions in canonical SWCVs.
Summary: what goes where?
Here’s a table showing which Integration Repository object types can belong in each type of SWCV.
X* = only when related to an Integration Process
Remember, none of these suggestions are written in stone. You may come across exceptional situations where other recommendations are appropriate. Use your common sense 😉
We define our Namespace’s by Business Processes and hence one namespace for PO, one for PO Change, Shipment Notification and so on is the norm spread across the multiple SWCV’s. When using this notation unfortunately we ended up with multiple project’s and interfaces using the same namespace and there by segregation of objects and transports was and at times still is a difficult experience.
But, with the new Folder concept in PI 7.1 , having a additional layer of division in the namespace solved the trick! Maybe worth a note adding the folder’s concept of PI 7.1 here or is that in a later blog ? 🙂
One another problem of this multiple SWCV’s though ~ Assuming, that your core Integration Content SWCV is being used across multiple projects and so are your source and target SWCV’s. Even though you might want to transport only one namespace to the next landscape , QA / PRODUCTION, the transport mechanism in XI end up transporting all namespaces of the SWCV’s but as empty namespaces. Something I don’t like as production SWCV’s end up with namespaces that are still being developed and refined in Development, they might be empty in Production but they still are something not very useful. Your thoughts on this? Is there a work around or one of those things you have learnt to live with as well.
Thanks once again for this series!
Regards
Bhavesh
Namespaces is another topic I’d like to blog about (no promises at this point though), and folders in the ESR are definitely worth noting. In order to avoid the problem you mention, it has been our practice to include the SWCV name (or at least an abbreviated form of it) in all its namespaces. This has the drawback of making namespaces even longer, though.
To your comment about empty namespaces appearing after transporting other content: I haven’t experienced this, but it certainly sounds annoying. Maybe I’ve just been lucky not to encounter it.
Cheers,
Thorsten
We have decided to split our SWCs by sender/receiver systems and use another for mappings – all very logical so thanks for the advice.
What would you recommend as an approach when there are multiple senders all calling the same receiver service/system?
In our current case we only have 2 senders hence it is not too much overhead to copy the sender message interface/message type/data type from the first sender system SWC to the second SWC but obviously no benefits are being taken from reuse.
Any suggestions?
Thanks,
Alan
If, as you seem to be indicating, the two sender systems actually implement the same interfaces then if would make sense to let them share one SWCV. If this doesn’t quite make sense in the particular circumstances then you could also create one SWCV for each sender system and a third, shared, SWCV containing the interfaces they have in common. You should then specify a dependency (in the SLD) from each of the 2 sender system SWCVs to the shared SWCV, thus making the common interfaces visible in both the other SWCVs.
Regards,
Thorsten
Nice descriptions of two vagely descriped component types. It makes sence to use this description.
Regards
Daniel
Structuring PI Content is something that is disturbing me for a while now.Thank you so much, it is really informative.
Any suggestions on SLD Landscape and Integration Directory Content structuring please? Am confused with Business Systems and Products association during structuring, should it be just one Business System for all Application Products created? How Configuration Scenarios should be structured?
Thanks,
Swapna
|
https://blogs.sap.com/2008/12/10/structuring-integration-repository-content-part-2-software-component-versions-revisited/
|
CC-MAIN-2019-04
|
refinedweb
| 1,201
| 50.67
|
TensorBoard can be used directly within notebook experiences such as Colab and Jupyter. This can be helpful for sharing results, integrating TensorBoard into existing workflows, and using TensorBoard without installing anything locally.
Setup
Start by installing TF 2.0 and loading the TensorBoard notebook extension:
For Jupyter users: If you’ve installed Jupyter and TensorBoard into
the same virtualenv, then you should be good to go. If you’re using a
more complicated setup, like a global Jupyter installation and kernels
for different Conda/virtualenv environments, then you must ensure that
the
tensorboard binary is on your
PATH inside the Jupyter notebook
context. One way to do this is to modify the
kernel_spec to prepend
the environment’s
bin directory to
PATH, as described here.
In case you are running a Docker image of Jupyter Notebook server using TensorFlow's nightly, it is necessary to expose not only the notebook's port, but the TensorBoard's port.
Thus, run the container with the following command:
docker run -it -p 8888:8888 -p 6006:6006 \ tensorflow/tensorflow:nightly-py3-jupyter
where the
-p 6006 is the default port of TensorBoard. This will allocate a port for you to run one TensorBoard instance. To have concurrent instances, it is necessary to allocate more ports.
# Load the TensorBoard notebook extension %load_ext tensorboard
TensorFlow 2.x selected.
Import TensorFlow, datetime, and os:
import tensorflow as tf import datetime, os
TensorBoard in notebooks
Download the FashionMNIST dataset and scale it:
fashion_mnist = tf.keras.datasets.fashion_mnist (x_train, y_train),(x_test, y_test) = fashion_mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0
Create a very simple model:
def create_model(): return tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ])
Train the model using Keras and the TensorBoard callback:
def train_model(): model = create_model() model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) logdir = os.path.join("logs",()
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 11s 182us/sample - loss: 0.4976 - accuracy: 0.8204 - val_loss: 0.4143 - val_accuracy: 0.8538 Epoch 2/5 60000/60000 [==============================] - 10s 174us/sample - loss: 0.3845 - accuracy: 0.8588 - val_loss: 0.3855 - val_accuracy: 0.8626 Epoch 3/5 60000/60000 [==============================] - 10s 175us/sample - loss: 0.3513 - accuracy: 0.8705 - val_loss: 0.3740 - val_accuracy: 0.8607 Epoch 4/5 60000/60000 [==============================] - 11s 177us/sample - loss: 0.3287 - accuracy: 0.8793 - val_loss: 0.3596 - val_accuracy: 0.8719 Epoch 5/5 60000/60000 [==============================] - 11s 178us/sample - loss: 0.3153 - accuracy: 0.8825 - val_loss: 0.3360 - val_accuracy: 0.8782
Start TensorBoard within the notebook using magics:
%tensorboard --logdir logs
You can now view dashboards such as scalars, graphs, histograms, and others. Some dashboards are not available yet in Colab (such as the profile plugin).
The
%tensorboard magic has exactly the same format as the TensorBoard command line invocation, but with a
You can also start TensorBoard before training to monitor it in progress:
%tensorboard --logdir logs
The same TensorBoard backend is reused by issuing the same command. If a different logs directory was chosen, a new instance of TensorBoard would be opened. Ports are managed automatically.
Start training a new model and watch TensorBoard update automatically every 30 seconds or refresh it with the button on the top right:
train_model()
Train on 60000 samples, validate on 10000 samples Epoch 1/5 60000/60000 [==============================] - 11s 184us/sample - loss: 0.4968 - accuracy: 0.8223 - val_loss: 0.4216 - val_accuracy: 0.8481 Epoch 2/5 60000/60000 [==============================] - 11s 176us/sample - loss: 0.3847 - accuracy: 0.8587 - val_loss: 0.4056 - val_accuracy: 0.8545 Epoch 3/5 60000/60000 [==============================] - 11s 176us/sample - loss: 0.3495 - accuracy: 0.8727 - val_loss: 0.3600 - val_accuracy: 0.8700 Epoch 4/5 60000/60000 [==============================] - 11s 179us/sample - loss: 0.3282 - accuracy: 0.8795 - val_loss: 0.3636 - val_accuracy: 0.8694 Epoch 5/5 60000/60000 [==============================] - 11s 176us/sample - loss: 0.3115 - accuracy: 0.8839 - val_loss: 0.3438 - val_accuracy: 0.8764
You can use the
tensorboard.notebook APIs for a bit more control:
from tensorboard import notebook notebook.list() # View open TensorBoard instances
Known TensorBoard instances: - port 6006: logdir logs (started 0:00:54 ago; pid 265)
# Control TensorBoard display. If no port is provided, # the most recently launched TensorBoard is used notebook.display(port=6006, height=1000)
|
https://www.tensorflow.org/tensorboard/tensorboard_in_notebooks
|
CC-MAIN-2020-05
|
refinedweb
| 723
| 54.29
|
A Programming Language with Extended Static Checking
Recently, I came across an article entitled “Useful Pure Functional Programming” which talks about the advantages of functional programming. However, something struck me about the way the author thinks about functional programming:
“Living for a long time in the context of an imperative world made me get used to think in a specific sequential way … On the other hand, in the pure functional world, I’m forced to think in a way to transform data.”
The author is arguing that thinking about execution in a sequential notion is somehow inherently connected with imperative languages. The first “imperative” example given in the article is a simple loop in Java:
int sum(int[] list) {
int result = 0;
for (int i : list)
result += i;
return result;
}
The thing is, for me, this example could equally be written in a pure functional language. Sure, it doesn’t look like Haskell code — but then Haskell isn’t the only pure functional language. For example, in Whiley, it would look like this:
int sum([int] list):
result = 0
for i in list:
result = result + i
return result
This is a pure function in the strongest sense of the word (i.e. it always returns the same result given the same arguments, does not have side effects and, hence, is referentially transparent). This function is pure because, in Whiley, compound data structures (e.g. lists, sets, maps, etc) have value semantics and behave like primitive data (e.g. int) rather than as references to data (like in Java).
int
Now, I think the author of the original article got confused about the difference between functional languages and functional style (i.e. the use of functions as the primary mechanism for expressing and composing computation). Sure, the functional style favours (amongst other things) recursion over looping. But, that doesn’t prevent functional languages from including looping constructs.
The key is that many imperative languages support the functional style. In other words, it’s not something exclusive to functional programming languages (although they perhaps support it better). We need to try and distinguish these two things better, in my opinion, to avoid too much confusion around the difference between functional and imperative languages.
The thing is, some people don’t like the functional style. For example, I always prefer to use loops when I can (such as for the sum() example above) because they are clear and easy to understand. But, for some things (e.g. traversing a linked list), I like recursion better. That’s my style. The problem is that people with an imperative streak, like me, often believe they have to completely change their style to use a functional programming language. But, that shouldn’t need to be the case. It’s just a shame mainstream functional languages make imperative-style programming so difficult. If it was easier, then people could migrate slowly without having to rewire their brain from the outset …
sum()
Thoughts?
Functional means functional.eg. Programming with functions and without mutables.But your example is still imperative.
Thoughts: Scala! It is a hybrid functional/imperative language that promotes a functional style, but doesn’t demand it. It allows the above loop in functional or in imperative style:
You could do imperatively:
def sum(ints : Seq[Int]) = {
var result = 0
for (nextint total + next)
}
Hi noraguta,
I think that functional programming means quite a lot of things. Look at the first sentence from the Wikipedia article on functional programming:
In computer science, functional programming is a programming paradigm that treats computation as the evaluation of mathematical functions and avoids state and mutable data.
My sum() implementation in Whiley is a mathematical function which does not mutate any global state. Yes, you can argue that it does mutate state local to the function — but is this really against the spirit of functional programming?
The second paragraph of that Wikipedia article begins with this:
In practice, the difference between a mathematical function and the notion of a function used in imperative programming is that imperative functions can have side effects that may change the value of program state.
So, whilst my Whiley code may have imperative style, I argue that it is functional in this sense.
hrm, that didn’t come out looking any good, and it’s missing the functional one:
def sum(ints: Seq[Int]) = {
ints.foldleft(0)((total, next) => total + next)
}
@noraguta I think you missed the point pretty hard.
Hi Martijn,
Yes, I agree — Scala is a good example. To a lesser extent, so is D.
ML (both SML and OCaml) actually has full support for imperative programming — sequencing, references, while-loops, the works. However, most people don’t use them. The reason is that their type systems, like most, only track the flow of values, and so the inconsistency-checking you get from typechecking is of most value for programs in a value-oriented functional style.
The pain of going from usefully precise type error messages to incomprehensible runtime errors because some dynamic data structure containing a bunch of functions of type unit -> unit called them in the wrong order creates a very strong selective pressure against imperative programming.
unit -> unit
You really need something like extended static checking to reduce the pain from imperative programming. I’d also expect you’d want the checker to say something about aliasing, too (a la separation logic). What’s Whiley’s story on aliased data?
Hi Neel,
Well, in the case of pure functions like in my example, there is no possibility of aliased data. However, Whiley does support impure functions (called methods) where you can have true object references. At this stage, I don’t really have a story on the verification side of that — I’m mostly concentrating on verification of pure functions.
Regarding the issue of typing you talk about, I think flow typing is one possible answer there [correct me if i’m wrong].
Yes, the difference is largely in how many side effects you’re willing to tolerate in your code. You can do all kinds of amazing things if you start by writing side effect-free code, and lambdas can help you do that. For example, making a habit of using a lambda and map instead of a for loop, whenever possible, will bring you far along the path of being able to do incredible optimizations, such as automatic, behind the scenes parallelization.
The article is called Useful Pure Functional Programming, you quoted the name of the blog
Hi Iopq,
Oops, will correct — thanks!
I think what you’re struggling against is the impracticality of a truly pure “functional language”. In mathematics, when I declare that f(x) = x + 1, I am not describing a process. I am describing a relationship. Given a value of x, the value of the function f will be x + 1. There is no “computing” this value so to speak. The function f simply maps a value from one number space to a different number space.
Now, we can certainly simulate this on a computer by creating a “function” f that receives a numeric input and returns a numeric output that is one more than the input. The “function” itself can then be used in the same fashion as a mathematical function. As long as we don’t expose the behind-the-scenes implementation, it will behave almost identical to a mathematical function.
One of the big problems, though, is that in mathematics the functions are mapping across number spaces. These number spaces can be conceptualized as imaginary viewers. Viewer 1, sitting in “normal” number space views the value of some point labeled x at position 1. Viewer 2, sitting in the “f” number space views the same value of some point labeled x at position 2. The important part is that the point is just a single point, looked at by two viewers.
In programming, a language that applies this concept would treat variables and functions such that one could do the following.
f = lambda x: x + 1
a = value(1)
b = a: f(a)
print(a) => 1
print(b) => 2
a becomes a value in normal number space, and b becomes a reference to a, such that the “getter” always returns a + 1. This gets us a little closer to a simulating a functional paradigm. That said, a formal functional “program” would be nothing more than a series of transformation of data to the desired number space, or more generically the desired view-space since we don’t necessarily have to be talking about a number space.
One critical distinction to be a “purely functional” program, though, is that the state/data of said program never changes. We could not, for instance, do either of the following assuming we’ve already written the above code:
a = a + 1
a = value(2)
In either case we change the state of a, and have thus violated the functional paradigm. If you give yourself the thought exercise, you might also conclude that there are a number of other computationally common activities that violate the paradigm, too. Input (user or system) technically violates the paradigm too. It boils down to such programs, and hence the languages that define them, would be limited to closed systems that only ever do the exact same thing every time they are invoked.
The bottom line is that computers by their very nature operate in an imperative paradigm at the hardware/assembly level. At best we can only come close to simulating a functional paradigm on top of imperative implementations. In lieu of the limited capabilities of a purely functional paradigm, practicality dictates that most “functional” languages will be fundamentally imperative with some degree of functional paradigm restrictions implemented on top. To suggest anything different is misleading.
I think that the distinction is pedantry – functional languages are valuable because they enable functional style – so there’s no reason to hold everyone to the standard of being careful about the distinction.
You do bring up a very good point, though. Haskell, in particular has a very “fix the world” attitude, and doesn’t make using it very possible to use it in ignorance of functional style. The learning curve is very steep, especially if you expect it to be similar to any (non-functional) language you knew before.
An interesting way to fix this problem might be to write a DSL / language that desugars to Haskell, and looks like some popular imperative language. Python, for example, with some libraries that re-implement some of the standard functions in terms of Haskell libraries. Even better would be if this de-sugaring process worked in a series of steps, where the user can write code that targets each stage, and each getting more Haskell-ey, to ease the user into it.
Most Haskellers will dislike this approach for its impurity and the influx of people writing extraordinarily non-idiomatic code, but it really would help the overall avoidance of success at all costs thing.
Well spoken Dave. If we were trained to think functional from the very start, perhaps programming purely in a functional style would work. For me though having programmed in imperative style for so long it is not worth going functional all the way. I use functional style a lot more now than before. I love closures, and higher order functions. But I still prefer looping most of the time over recursion. Recursion makes sense for traversing lists and trees though.
If you are into graphics and game development like me then avoiding state changes does not make sense either. E.g. I think it is fine to manipulate the data in a buffer you get passed to a function. But you should avoid changing things that the user of your function did not see go into the function through arguments.
Haskell is probably great for bright people. But I doubt a language like that could ever go mainstream. It is just to difficult to grasp for your average Joe programmer. Having said that, though I am not all cynical. I think in principle everybody could write in LISP or Scheme. That it isn’t so, I think is more about historical conicidences than about issues with the language itself.
Sequence operators are a huge win. Loops are something everyone understands well. But each loop is different. You have to understand each loop individually as you encounter it to figure out what it does. Sequential operators give you a bunch of abstract loops. “Map” is a loop that uses each element to calculate something new. “Reduce” is a loop that accumulates a result. “Take” is a loop that terminates early. “Filter” is a loop that only calculates when a predicate is met… and so on. Functional languages often have dozens of abstractions to help with sequential calculation. This gives you as a programmer a bigger vocabulary. Yes you have to know more abstractions. But with a bigger vocabulary you don’t have to write a new loop for every sequential problem you encounter. This is a much more robust and reliable approach once you learn the vocabulary. Take LINQ for example… it provides exactly this sequential vocabulary to C#. Now you can write very clear operations without making mistakes like forgetting to increment a counter.
I encourage you to accept the challenge of thinking about sequential operations as transformations because doing so avoids errors and is more concise. It isn’t a question of style, but vocabulary 🙂
;; easier if you know what ‘reduce’ means
(defn sum [list]
(reduce + list))
;; easier if you don’t, but more moving parts
int sum([int] list):
result = 0
for i in list:
result = result + i
return result
Looking at the first and the second function in the post, I realize that both of them are ugly. If you want true functional programming, then take a look at this example (on LISP):
(reduce #’+ ‘(1 2 3 4 5))
Which returns 15. Now that’s an excellent language that maybe the world is still not ready for.
I think the wording of the wiki article is very interesting.
“avoids state and mutable data.”
There is a big difference between avoiding and disallowing. The section, “Comparison to imperitive programming” makes the difference more clear.
“Functional programming is very different from imperative programming. The most significant differences stem from the fact that functional programming avoids side effects, which are used in imperative programming to implement state and I/O. Pure functional programming disallows side effects completely and so provides referential transparency, which makes it easier to verify, optimize, and parallelize programs, and easier to write automated tools to perform those tasks.”
Functional languages avoid state. Pure languages disallow it. This makes me think that “functional style” isn’t a sufficient term. How aboud “pure style” or “functionally pure”?
Erik E: “If you are into graphics and game development like me then avoiding state changes does not make sense either… Haskell is probably great for bright people. But… It is just to difficult to grasp for your average Joe programmer.”
Some people think more concretely, and others think more abstractly. Some think randomly, some sequentially. Some people will find Haskell easier and some will find C++ easier, regardless of intelligence. Though, if you go through a Haskell-OpenGL tutorial, you’ll see there IS state changing (IORef, for one), it’s just a real pain to use.
The problem I have with Haskell is not that it’s for bright people, or that it avoids state, but that it’s a single-paradigm language–the only one I have ever used. Most languages let you choose what paradigm to use at any one time, for any one problem or sub-problem. Those concerned too much with purity would seem to forget every idea in computer science outside of their clique.
Focusing on value semantics is a better way to explain Haskell I think because symbols can be rebound, which is surprising when purity is defined as a variable can’t change it’s value.
I think the best and much more advanced way to understand Haskell is by meditating on non strict system F omega. This is a major difference between Haskell and almost another programming language. Haskell can be (almost) desugared to a formal logical system..389 seconds.
|
http://whiley.org/2012/09/06/a-misconception-of-functional-programming/
|
CC-MAIN-2017-34
|
refinedweb
| 2,728
| 62.07
|
Hi there.
I have a working search input bar and it filters correctly based on value.
My problem is when i go to other page and come back to the page where
the search input bar is there, the last (history) search value is still there.
Example: I search word "Work", then it search. When i leave the page and comeback the word "Work" is still there. It should be blank again.
How to clear it once i leave the page automatically? Thank you
Hi, Instead of clearing it once you leave, you can clear the search text box when the page is ready:
Good Luck, Mustafa
Hi,
Can you specify the page name where it happens?
Thank you for the reply. Appreciated!
I think its not a good option to clear the search bar once its load because my code is the reverse of that. My home page and my tour page has both search bar. I pushed my home page search bar to link to tour page search bar using wix location. So what ever i typed on my home search bar the value will be the same on my tour page search bar. Now i used onReady function to run the filter (search) once the page load. It works actually. The only problem is it leaves the last value unless if i used home search bar again (empty). Here are my current codes HOME SEARCH BAR CODE
export function searchBar_keyPress(event, $w) { if (event.key === "Enter") { let word = $w("#searchBar").value; local.setItem("searchWord", word); wixLocation.to('/JapanTours'); } } TOUR PAGE SEARCH BAR CODE
$w.onReady(function () { var sameWord = local.getItem("searchWord"); $w("#iTitle").value = sameWord; $w("#dataset1").onReady(function () { filter($w('#iTitle').value, lastFilterCategory); }) });
*this both page using
import {local} from 'wix-storage'; import wixData from 'wix-data';
Am i missing something? However, it's really not a big deal. Its not just good look when someone visit the tour page directly with a value already. Thank you very much for the big help.
Did you get a solution you can share? Clear search bar input when you leave the page.
|
https://www.wix.com/corvid/forum/community-discussion/search-input-bar-delete-the-value-history
|
CC-MAIN-2019-47
|
refinedweb
| 354
| 75.91
|
Updated: January 21, 2005
Applies To: Windows Server 2003, Windows Server 2003 R2, Windows Server 2003 with SP1, Windows Server 2003 with SP2
Notes
dnscmd
Specifies the name of the command-line program.
ServerName
Required. Specifies the DNS host name of the DNS server. You can also type the IP address of the DNS server. To specify the DNS server on the local computer, you can also type a period (.)
/RecordAdd
Required. Specifies the command to add a new resource record.
ZoneName
Required. Specifies the name of the zone where this CNAME resource record will be added.
NodeName
Required. Specifies the FQDN of the node in the DNS namespace. You can also type the node name relative to the ZoneName or @, which specifies the zone's root node.
/Aging
Specifies that this resource record is aged and scavenged. If this parameter SOA resource record).
CNAME
Required. Specifies the resource record type of the record you are adding.
HostName|DomainName
Required. Specifies the FQDN of any valid DNS host or domain name in the namespace. For FQDN's, a trailing period (.) is used to fully qualify the
|
http://technet.microsoft.com/en-us/library/cc776292%28WS.10%29.aspx
|
crawl-003
|
refinedweb
| 186
| 66.74
|
Firstly - wow - what an amazing editor. I have just started learning to code with python and was hunting around for the perfect editor and am now convinced that I have found it with sublime.
As an absolute beginner I have an absolutely newbie question. I am going through the Non-Programmers guide to python over at: ... Python_3.0
I have gone through all of it up until now using the pre installed python editor IDLE and have just tried something from section "defining functions" using sublime. I have written everything correctly (the script that I have written runs fine in IDLE) but would love to be able to run it straight from sublime.
I actually have no idea how to do this. I presumed that it would be by going to tools -> build system and selecting python and then building the script. This works fine in showing me some outputs, but does not allow me to interact with the script at all. The script that I am trying to run is below:
- Code: Select all
# Converts temperature between Fahrenheit or Celcius
def print_options():
print("options: ")
print(" 'p' print options")
print(" 'c' convert from celcius")
print(" 'f' convert form Fahrenheit")
print(" 'q' quit the program")
def celcius_to_fahrenheit(c_temp):
return 9.0 / 5.0 * c_temp + 32
def fahrenheit_to_celcius(f_temp):
return (f_temp - 32 ) * 5.0 / 9.0
choice = "p"
while choice != "q":
if choice == "c":
temp = float(input("Celcius Temperature: "))
print("Fahrenheit:", celcius_to_fahrenheit(temp))
elif choice == "f":
temp = float(input("Fahrenheit Temperature: "))
print("Celcius:", fahrenheit_to_celcius(temp))
elif choice == "p": #alternatively choice !=q: so that print when anything unexpected inputed
print_options()
choice = input("option: ")
and when I hit F7 to build (with settings build system -> python) I only get
- Code: Select all
^Coptions:
'p' print options
'c' convert from celcius
'f' convert form Fahrenheit
'q' quit the program
option
without being able to interact with this at all.
I have also tried changing the build system to "run" but encounter this error:
- Code: Select all
Traceback (most recent call last):
File "C:\Documents and Settings\username\Desktop\Python\05 Functions\05 temperature2.py", line 25, in <module>
choice = input("option: ")
RuntimeError: input(): lost sys.stdin
Could somebody be so kind to explain to me how to be able to execute scripts straight out of sublime? As a newbie I have quite a need to be able to do this easily due to toying around with commands and don't want to always have to go to start -> run -> pasting filepath.
Thanks in advance!
-M
|
http://www.sublimetext.com/forum/viewtopic.php?f=3&t=559&start=0
|
CC-MAIN-2013-20
|
refinedweb
| 420
| 59.03
|
What is SharePoint 2003 (v2)?
Microsoft marketing has a tendency to refer to different technologies with one name - for example, "Dot Net" this and "Dot Net that." They later realized that just because they are calling everything "Dot Net" doesn’t necessarily mean it will help them market Microsoft SQL Server just because it belongs to .NET Servers. Are you following me on this one?<?xml:namespace prefix = o
This time around we have "SharePoint" this and "SharePoint" that, just to be in sync with every other naming strategy they had in mind. Guys, do you need some help?
All right, enough picking on poor old Microsoft and let’s get back to the question: "What is SharePoint 2003?"
Not to disappoint you, I am not going to give you a marketing spiel, but rather try to answer the above question by asking the following question: "Why do we need software like SharePoint?" Before writing humans managed knowledge (information) verbally. Father passed the information to son as he taught him the tricks of the trade. Knowledge sharing was limited to the interaction between two or more humans and could be lost if the holder of the core knowledge died without sharing it with others. Our early ancestors even used caves to draw pictures on the walls. Technological advancement, such as the invention of papyrus paper, provided the next level of information sharing.
Then the invention of the printing press radically increased the ease of common man’s ability to learn and to share information. To store books we invented libraries. This new volume of information introduced the problem of managing and locating needed information quickly so we invented the idea of filing and index cards to locate books based on a specific search criteria. Today, we use computers as means of producing and storing large amounts of information. Therefore there is a need for a fast, reliable way to locate the right piece of information or document from multiple sources. Meanwhile, emerging internet technologies such as google.com now provide us with the ability to locate the desired document by searching billions of pages. But we have failed to provide this same functionality to our businesses and our home users.
"SharePoint" is therefore a set of technology products, which allows us to manage our intellectual property (documents, presentations, etc.) and enables virtual teams to collaborate on the information. Technology has changed, but our need for managing and providing access to information is still with us!
"SharePoint" is a set of products
The best way to demonstrate this set is to use the following diagram.
<?xml:namespace prefix = v
Windows SharePoint Server (WSS)
Designed for small-teams to be able to manage, collaborate and exchange information by means of:
- Document Libraries – ability to check-in and check-out
- Lists
- Discussion Boards
- Surveys
- Microsoft FrontPage and InfoPath Integration
- Supports Web Parts framework
- Templates
Most people are not aware that they can use this software today without buying anything extra. Simple download and install it on the box that runs Windows 2003 Server.
SharePoint Portal Server 2003 (SPS)
This is the glue for multiple WSS servers to be able to provide Enterprise level one stop Portal services such as:
- Personal Site – individual users can manage their public/private site
- User Profiles – allows storing information from Active Directory and other meta data on the user’s end
- Search – powerful search engine for intranet and extranet searches
- Single sign-on
- Site directory
SPS sits on top of the WSS framework and adds other services to make the sharing of information within the enterprise easier.
Note: for the complete list of the differences please refer to the white paper: Choosing Between SharePoint Portal Server and Windows SharePoint Services
If the price is right!
Widespread embracing of this great set of enabling technologies depends on the right pricing schema. Unfortunately, I have seen that MS has previously had a few failures of pricing products that prevented their widespread acceptance. For example Microsoft BizTalk Server was designed to be used for integration within the enterprise and B2B between small business users and larger corporations. Do you think the price is right for SharePoint Portal Server? Will your enterprise pay $30,000 for it?
Note: pricing information can be found at:
Is it easy to develop against WSS and SPS?
That is a tough one! It is definitely an improvement from the previous version of SharePoint but this latest version is not development heaven. In my opinion the development framework is still cumbersome and not clear. Here is my Top 10 list of issues for WSS and SPS developers:
1. Terminology is confusing. What does “Virtual Server” mean?
o IIS has virtual servers
o SPS has virtual servers
2. Debugging of WebParts
o Complicated setup of remote debugging
o I have to have VS.NET installed on the WSS or SPS server in order to step into the code
o Unable to debug into VirtualPC from the host machine because remote debugging does not support debugging from the Workgroup into Domain (note: I am asking MS folks on this one, if you know anything drop a line or two)
3. Too many CFG files – there are too many different documents with configuration files
4. Too Many folders – template, .aspx pages and settings are scattered among different folders. It looks like different teams were developing the product and later had to merge all of it together as a final product
5. WebPart model – requires knowledge of writing Server Components, which means direct access to HtmlTextWriter object unless you write ASP.NET UserControls
6. Installation process of WebParts is automated but disperses entries across multiple web.config files
7. Restoring of deleted files is not supported natively
8. IISReset required to be run for some settings to take affect
9. Overwhelming amount of XML Schemas – it looks like we have schema for everything but no documentation
10. Lack of documentation which will be solved as more people are working with the product
Where do you find Help?
WSS and SPS are so new that there is not much help out there and Microsoft does not provide much, so the only choice for my answers is the worldwide Bloggers community. I used Feedster.com to find some of the finest Bloggers that are working and blogging about SharePoint technologies.
Top 5 Bloggers
- Serge van den Oever [Macaw] (SharePoint 2003)
- Mads Haugb? Nissen #region /* comments */ (SharePoint 2003)
- Westin's Technical (SharePoint 2003)
- Jan Tielens' Bloggings (SharePoint 2003)
- Bryant Likes's Blog (SharePoint 2003)
- James Edelen (* NEW)
Finally, the #1 SharePoint Blogger and expert at the moment is Patrick Tisseghem. If you have not subscribed to his Blog yet do it right away. He is located in Belgium and trains people on Microsoft technologies.
I have tried not to sound negative. Instead, I wanted to bring about some of the issues that the Microsoft SharePoint team has to resolve and encourage users to get involved with the SharePoint technology community.
Help us to help you!
|
http://blog.csdn.net/gauss32/article/details/112824
|
CC-MAIN-2018-09
|
refinedweb
| 1,171
| 53.81
|
http_proxy alternatives and similar packages
Based on the "HTTP" category.
Alternatively, view http_proxy alternatives based on common mentions on social networks and blogs.
gun9.6 4.0 http_proxy VS gunHTTP/1.1, HTTP/2 and Websocket client for Erlang/OTP.
mint9.6 6.5 http_proxy VS mintFunctional HTTP client for Elixir with support for HTTP/1 and HTTP/2.
Crawler9.4 0.0 http_proxy VS CrawlerA high performance web crawler in Elixir.
finch9.3 7.9 http_proxy VS finchElixir HTTP Client focused on performance
Crawly9.0 5.5 http_proxy VS CrawlyCrawly, a high-level web crawling & scraping framework for Elixir.
scrape8.5 0.0 http_proxy VS scrapeScrape any website, article or RSS/Atom Feed with ease!
Ace8.3 0.3 http_proxy VS AceHTTP web server and client, supports http1 and http2
neuron8.2 1.4 http_proxy VS neuronA GraphQL client for Elixir
PlugAttack8.0 1.2 http_proxy VS PlugAttackA plug building toolkit for blocking and throttling abusive requests
webdriver7.3 0.0 http_proxy VS webdriverWebDriver client for Elixir.
spell6.4 0.0 http_proxy VS spellSpell is a Web Application Messaging Protocol (WAMP) client implementation in Elixir. WAMP is an open standard WebSocket subprotocol that provides two application messaging patterns in one unified protocol: Remote Procedure Calls + Publish & Subscribe:
web_socket6.4 0.0 http_proxy VS web_socketAn exploration into a stand-alone library for Plug applications to easily adopt WebSockets.
cauldron6.0 0.0 http_proxy VS cauldronI wonder what kind of Elixir is boiling in there.
river5.9 0.0 http_proxy VS riverAn HTTP/2 client for Elixir (a work in progress!)
explode4.3 0.0 http_proxy VS explodeAn easy utility for responding with standard HTTP/JSON error payloads in Plug- and Phoenix-based applications
bolt4.2 0.0 http_proxy VS boltSimple and fast http proxy living in the Erlang VM
sparql_client4.1 0.1 http_proxy VS sparql_clientA SPARQL client for Elixir
etag_plug3.3 0.6 http_proxy VS etag_plugA simple to use shallow ETag plug
ivar3.2 0.0 http_proxy VS ivarIvar is an adapter based HTTP client that provides the ability to build composable HTTP requests.
uri_template3.1 0.0 http_proxy VS uri_templateRFC 6570 compliant URI template processor for Elixir
Tube3.0 0.0 http_proxy VS TubeWebSocket client library written in pure Elixir
httprot2.7 0.0 http_proxy VS httprotProt prot prot.
fuzzyurl2.6 0.0 http_proxy VS fuzzyurlAn Elixir library for non-strict parsing, manipulation, and wildcard matching of URLs.
mnemonic_slugs2.3 0.0 http_proxy VS mnemonic_slugsAn Elixir library for generating memorable slugs.
yuri2.1 0.0 http_proxy VS yuriElixir module for easier URI manipulation.
uri_query2.0 0.0 http_proxy VS uri_queryURI encode nested GET parameters and array values in Elixir
lhttpc1.3 0.0 http_proxy VS lhttpcWhat used to be here -- this is a backwards-compat user and repo m(
plug_wait11.2 0.0 http_proxy VS plug_wait1Plug adapter for the wait1 protocol
Ralitobu.Plug1.2 0.0 http_proxy VS Ralitobu.PlugElixir Plug for Ralitobu, the Rate Limiter with Token Bucket algorithm
http_digex0.6 0.0 http_proxy VS http_digexHTTP Digest Auth Library to create auth header to be used with HTTP Digest Authentication
Scout APM: A developer's best friend. Try free for 14-days
Do you think we are missing an alternative of http_proxy or a related project?
Popular Comparisons
README
HttpProxy
Simple multi HTTP Proxy using Plug. And support record/play requests.
MY GOAL
- Record/Play proxied requests
- http_proxy support multi port and multi urls on one execution command
mix proxy.
- Support VCR
architecture
http_proxy Client (server client) proxied_server | | | | 1.request | | | ------> | 2.request | | | ------> | | | | | | 3.response | | 4.response | <------ | | <------ | | | | |
- The client sends a request to http_proxy, then the http_proxy works as a proxy server.
- When the http_proxy receives the request from the client, then the http_proxy sends the request to a proxied server, e.g., as a client.
- The http_proxy receives responses from the proxied_server, then the http_proxy sets the response into its response to the client.
- The Client receives responses from the http_proxy.
Quick use as http proxy
requirement
- Elixir over 1.7
set application and deps
mix.exs
:loggeris option.
:http_proxyis not need if you run http_proxy with
HttpProxy.start/0or
HttpProxy.stop/0manually.
def application do [applications: [:logger, :http_proxy]] end ... defp deps do [ {:http_proxy, "~> 1.4.0"} ] end
set configuration
config/config.exs
use Mix.Config config :http_proxy, proxies: [ %{port: 8080, to: ""}, %{port: 8081, to: ""} ]
- To manage logger, you should define logger settings like the following.
config :logger, :console, level: :info
solve deps and run a server
$ mix deps.get $ mix clean $ mix run --no-halt # start proxy server
If you would like to start production mode, you should run with
MIX_ENV=prod like the following command.
$ MIX_ENV=prod mix run --no-halt
launch browser
Launch browser and open or.
Then, redirect to and do to.
Development
- Copy
pre-commithook
cp hooks/pre-commit ./git/hooks/pre-commit
Configuration
Customize proxy port
- You can customize a proxy port. For example, if you change a waiting port from
8080to
4000, then you can access to.
use Mix.Config config :http_proxy, proxies: [ %{port: 4000, to: ""}, %{port: 8081, to: ""} ]
Add proxy
- You can add a waiting ports in configuration file. For example, the following setting allow you to access to addition.
use Mix.Config config :http_proxy, proxies: [ %{port: 8080, to: ""}, %{port: 8081, to: ""}, %{port: 8082, to: ""} ]
Play and Record mode
- When
:recordand
:playare
false, then the http_proxy works just multi port proxy.
- When
:recordis
true, then the http_proxy works to record request which is proxied.
- When
:playis
true, then the http_proxy works to play request between this the http_proxy and clients.
- You should set JSON files under
mappingsin
play_path.
config.proxies.tomust be available URL to succeed generating http client.
use Mix.Config config :http_proxy, proxies: [ # MUST %{port: 8080, # proxy all request even play or record to: ""}, %{port: 8081, to: ""} ] timeout: 20_000, # Option, ms to wait http request. record: false, # Option, true: record requests. false: don't record. play: false, # Option, true: play stored requests. false: don't play. export_path: "test/example", # Option, path to export recorded files. play_path: "test/data" # Option, path to read json files as response to.
Example
Record request as the following
{ "request": { "headers": [], "method": "GET", "options": { "aspect": "query_params" }, "remote": "127.0.0.1", "request_body": "", "url": "" }, "response": { "body_file": "path/to/body_file.json", "cookies": {}, "headers": { "Cache-Control": "public, max-age=2592000", "Content-Length": "251", "Content-Type": "text/html; charset=UTF-8", "Date": "Sat, 21 Nov 2015 00:37:38 GMT", "Expires": "Mon, 21 Dec 2015 00:37:38 GMT", "Location": "", "Server": "sffe", "X-Content-Type-Options": "nosniff", "X-XSS-Protection": "1; mode=block" }, "status_code": 301 } }
Response body will save in "path/to/body_file.json".
Play request with the following JSON data
- Example is
- You can set
pathor
path_patternas attribute under
request.
- If
path, the http_proxy check requests are matched completely.
- If
path_pattern, the http_proxy check requests are matched with Regex.
- You can set
bodyor
body_fileas attribute under
response.
- If
body, the http_proxy send the body string.
- If
body_file, the http_proxy send the body_file binary as response.
path and
body case
{ "request": { "path": "/request/path", "port": 8080, "method": "GET" }, "response": { "body": "<html>hello world</html>", "cookies": {}, "headers": { "Content-Type": "text/html; charset=UTF-8", "Server": "GFE/2.0" }, "status_code": 200 } }
path_pattern and
body_file case
- Pattern match with
Regex.match?(Regex.compile!("\A/request.*neko\z"), request_path)
File.read/2via
file/to/path.jsonand respond the binary
{ "request": { "path_pattern": "\A/request.*neko\z", "port": 8080, "method": "GET" }, "response": { "body_file": "file/to/path.json", "cookies": {}, "headers": { "Content-Type": "text/html; charset=UTF-8", "Server": "GFE/2.0" }, "status_code": 200 } }
dependencies
$ mix xref graph lib/http_proxy.ex └── lib/http_proxy/supervisor.ex ├── lib/http_proxy/agent.ex │ ├── lib/http_proxy/play/data.ex │ │ ├── lib/http_proxy/agent.ex │ │ └── lib/http_proxy/play/response.ex │ │ ├── lib/http_proxy/play/data.ex │ │ └── lib/http_proxy/utils/file.ex │ └── lib/http_proxy/play/paths.ex │ ├── lib/http_proxy/agent.ex │ └── lib/http_proxy/play/response.ex └── lib/http_proxy/handle.ex ├── lib/http_proxy/play/body.ex ├── lib/http_proxy/play/data.ex ├── lib/http_proxy/play/paths.ex ├── lib/http_proxy/play/response.ex └── lib/http_proxy/record/response.ex ├── lib/http_proxy/format.ex │ └── lib/http_proxy/data.ex (compile) └── lib/http_proxy/utils/file.ex
TODO
- [x] record request
- [x] play request
- [x] refactor
- [x] support Regex request path.
- [x] start/stop http_proxy manually
- [ ]
use vcr
- integrate
styleguide
LICENSE
MIT. Please read LICENSE.
*Note that all licence references and agreements mentioned in the http_proxy README section above are relevant to that project's source code only.
|
https://elixir.libhunt.com/http_proxy-alternatives
|
CC-MAIN-2021-43
|
refinedweb
| 1,396
| 59.4
|
Using xlsxwriter, one can write a dataframe ‘df’ to Excel ‘simple.xlsx’ using code such as:
import pandas as pd writer = pd.ExcelWriter('simple.xlsx', engine='xlsxwriter') df.to_excel(writer, sheet_name='Sheet1') writer.save()
With above code, I see that the resultant Excel sheet has all cells (except header) as default left-aligned.
Question:
How can I make the Excel cell values to be center-aligned?
I did explore using conditional formatting but, with my cell values being combination of blanks, zeros, floats, strings and integers, I am wondering if there is another way.
Is there a smarter/quick way to do either/both of the following:
Any way to write dataframe to Excel as center-aligned? Or..
Any way to center-align the Excel sheet (for the cell range occupied by dataframe) once the dataframe has already been written to Excel?
You can add the below line to your code
df=df.style.set_properties(**{'text-align': 'center'})
Your complete code would be
import pandas as pd writer = pd.ExcelWriter('simple.xlsx', engine='xlsxwriter') df=df.style.set_properties(**{'text-align': 'center'}) df.to_excel(writer, sheet_name='Sheet1') writer.save()
Tags: pythonpython
|
https://exceptionshub.com/python-center-align-using-xlsxwriter-without-conditional-formatting.html
|
CC-MAIN-2021-25
|
refinedweb
| 190
| 52.36
|
We recently an alpha for WebJobs SDK (aka AzureJobs , and internally codenamed “SimpleBatch”). In this blog entry, I wanted to explain how Triggers, Bindings, and Route Parameters worked in AzureJobs.
A function can be “triggered” by some event such as a new blob, new queue message, or explicit invocation. JobHost (in the Microsoft.WindowsAzure.Jobs.Host nuget package) listens for the triggers and invokes the functions.
The trigger source also provides the “route parameters”, which is an extra name-value pair dictionary that helps with binding. This is very similar to WebAPI / MVC. The trigger event provides the route parameters, and then the parameter can be consumed in other bindings:
1. Via a [BlobOutput] parameter 2. Via an explicit parameter capture.
Example usage:
This happens when the first attribute is [BlobInput] and the function gets triggered when a new blob is detected that matches the pattern.
public static void ApplyWaterMark(
[BlobInput(@"images-output/{name}")] Stream inputStream,
string name,
[BlobOutput(@"images-watermarks/{name}")] Stream outputStream)
{
WebImage image = new WebImage(inputStream);
image.AddTextWatermark(name, fontSize: 20, fontColor: "red");
image.Save(outputStream);
}
When does it execute?
The triggering system will compare timestamps for the input blobs to timestamps from the output blobs and only invoke the function if the inputs are newer than the outputs. This simple rules makes the system very easy to explain and prevents the system from endlessly re-executing the same function.
Route parameters:
In this case, the route parameter is {name} from BlobInput, and it flows to the BlobOutput binding. This pattern lends itself nicely for doing blob-2-blob transforms.
The route parameter is also captured via the “name” parameter. If the parameter type is not string, the binder will try to convert via invoking the TryParse method on the parameter type. This provides nice serialization semantics for simple types like int, guid, etc. The binder also looks for a TypeConverter, so you can extend binding to your own custom types.
In WebAPI, route parameters are provided by pattern matching against a URL. In AzureJobs, they’re provided by pattern matching against a BlobInput path (which is morally similar to a URL). This case was implemented first and so the name kind of stuck.
This happens when the first attribute is [QueueInput].
public static void HandleQueue(
[QueueInput(queueName : "myqueue")] CustomObject obj,
[BlobInput("input/{Text}.txt")] Stream input,
int Number,
[BlobOutput("results/{Text}.txt")] Stream output)
{
}
public class CustomObject
{
public string Text { get; set; }
public int Number { get; set; }
}
The function has both a QueueInput and BlobInput, but it triggers when the Queue message is detected and just uses the Blob input as a resource while executing.
This function executes when a new queue message is found on the specified queue. The JobHost will keep the message invisible until the function returns (which is very handy for long running functions) and it will DeleteMessage for you when the function is done.
Route parameters:
In this case, the route parameters are the simple properties on the Queue parameter type (so Text and Number). Note that since the queue parameter type (CustomObject) is a complex object, it will get deserialized using JSON.net. Queue parameter types could also be string or byte[] (in which case they bind to the CloudQueueMessage.AsString and AsBytes).
The usage of parameter binding here may mean your function body doesn’t even need to look at the contents of the queue message.
You can explicitly invoke a method via JobHost.Call().
JobHost h = new JobHost();
var method = typeof(ImageFuncs).GetMethod("ApplyWaterMark");
h.Call(method, new { name = "fruit.jpg" });
I expect the list of possible triggers to grow over time, although JobHost.Call() does provide tremendous flexibility since you can have your own external listening mechanism that invokes the functions yourself. EG, you could simulate a Timer trigger by having your own timer callback which does JobHost.Call().
You can use JobHost.Call() to invoke a method that would normally be triggered by BlobInput.
You can also suppress automatic triggering via a "[NoAutomaticTrigger]” attribute on the method. In that case, the function can only be invoked via JobHost.Call().
Route Parameters:
The Call() method takes an anonymous object that provides the route parameters. In this case, it assigned “name” as “fruit,jpg”. The single route parameter will allow 3 normal parameters of ApplyWaterMark to get bound.
AzureJobs is still in alpha. So some of the rules may get tweaked to improve the experience.
|
http://blogs.msdn.com/b/jmstall/archive/2014/01/28/trigger-bindings-and-route-parameters-in-azurejobs.aspx
|
CC-MAIN-2014-52
|
refinedweb
| 737
| 57.67
|
Qt Creator and Gurobi
Hi,
I'm a beginner in Qt and currently writing codes in Qt Creator 2.2.1 (Qt 4.7.1) to solve an math optimization model by using Gurobi C++ libraries. After installing Gurobi, I got several library files as follow:
gurobi46.lib - Gurobi library import file
gurobi_c++md2008.lib - C++ interface (when using -MD compiler switch with Visual Studio 2008)
gurobi_c++md2010.lib - C++ interface (when using -MD compiler switch with Visual Studio 2010)
gurobi_c++mdd2008.lib - C++ interface (when using -MDd compiler switch with Visual Studio 2008)
gurobi_c++mdd2010.lib - C++ interface (when using -MDd compiler switch with Visual Studio 2010)
gurobi_c++mt2008.lib - C++ interface (when using -MT compiler switch with Visual Studio 2008)
gurobi_c++mt2010.lib - C++ interface (when using -MT compiler switch with Visual Studio 2010)
gurobi_c++mtd2008.lib - C++ interface (when using -MTd compiler switch with Visual Studio 2008)
gurobi_c++mtd2010.lib - C++ interface (when using -MTd compiler switch with Visual Studio 2010)
Also, there are two Include files in a "include" folder. I did add the folder's path in .pro file under INCLUDEPATH section.
Then, I tried to create a simple program that only declares a Gurobi variable, but it does not work.
@
#include <QtCore/QCoreApplication>
#include "gurobi_c++.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
GRBenv env = GRBenv();
return a.exec();
}
@
There is an error saying that "Variable 'GRBenv env' has initializer but incomplete type"
So, I guess I might forget to include the library in the .pro file so I add it as an external library by using the "Add Library...." in the right-click menu. The problem is that I don't know which one I should add so I try each one of them, one by one, but none of them works. The error is still there.
I don't know what kind of things or steps I missed. Could any one help, please?
PS: the Gurobi library I downloaded from the website is for Window64. There is another one for Linux-32. I did download it and have several .a and .so files. However, the creator could not see them when I tried to add them.
[Edit: Wrapped code in @ tags. Be sure to use them! mlong]
Did you check the qmake docs on "Declaring Other Libraries":/doc/qt-4.8/qmake-project-files.html#declaring-other-libraries already? Basically, you will have to adjust the INCLUDEPATH and LIBS variables.
Thanks, Volker for the reply! I did try the method in your link and now there is a new error (but I guess a better one). It said
LNK1104: Cannot open file gurobi_c++md2010.lib
It seems that the compiler found the library but cannot open it???
I also tried to use other library files but they all gave me the same error message.
Сheck the your library path in LIBS variable.
What did you add to your .pro file?
Oh sorry guys for this very late reply. I found out that I tried to use 64-bit library with 32-bit compiler. Such a shame :D haha Thank you all very much for the replies. I do appreciate your help.
|
https://forum.qt.io/topic/14899/qt-creator-and-gurobi
|
CC-MAIN-2017-47
|
refinedweb
| 532
| 77.23
|
0
I am trying to collect data from a log file. The data will collected into records based on policy number. I have created an object describing the data below:
class fwpolicy:
def __init__(self, policy_id, fr_zone, to_zone, src,dest,serv):
self.policy_id = policy_id
self.fr_zone = fr_zone
self.to_zone = to_zone
self.src = src
self.dest = dest
self.serv = serv
The problem I am having is that some of the data , namely src, dest & serv may have multiple entries per policy.
questions:
1. Do I create these data types as lists in the object.
2. how do I add additional record to these dtat types? do i define a function within the fwpolicy class to do this?
|
https://www.daniweb.com/programming/software-development/threads/99512/creating-lists-in-a-class-object
|
CC-MAIN-2017-26
|
refinedweb
| 116
| 62.44
|
Hello
When the SpiceWorks will correct recognise McAfee 8.8 antivirus update status.
Previous version (McAfee 8.7) works OK
Regards
Adam
9 Replies
Apr 11, 2011 at 10:15 UTC
UNKNOWN status for me too:
Spiceworks version 5.1.64998
Block access: Spiceworks\bin\spicetray.exe C:\Archivos de programa\McAfee\VirusScan Enterprise\SHSTAT.EXE
Apr 11, 2011 at 10:56 UTC
Hi guys, thanks for letting us know McAfee 8.8 is not being reported properly.
Let me take a closer look at how Spiceworks is interpreting what it finds.
Navigate to any workstation type device (Windows XP/Vista/7) in your Inventory that is not reporting "up-to-date" status properly.
Use the Tools button to run a "Rescan" on the device. This runs a scan against this device only.
What the scan completes please send me your log files. I will PM you with details on sending your logs to me.
Apr 15, 2011 at 3:01 UTC
Xavier discovered McAfee doesn't seem to be reporting up-to-date status to Windows Security Center in 8.8:
C:\>wmic /namespace:\\root\SecurityCenter PATH AntiVirusProduct get * >> %USERPROFILE%\Desktop\avlog.log C:\>wmic /namespace:\\root\SecurityCenter2 PATH AntiVirusProduct get * >> %USERPROFILE%\Desktop\avlog.log
Spiceworks uses the information in WMI (above commands essentially) to find the AV up-to-date status.
Xavier found both are empty on devices with 8.8, but are populated for 8.7.
Can you confirm, Adam?
Apr 18, 2011 at 2:34 UTC
Hello
Most of my workstation have Windows XP sp3, this commands give the folowing results
wmic /namespace:\\root\SecurityCenter PATH
AntiVirusProduct get * >> %USERPROFILE%\Desktop\avlog.log
Incorrect GET expression.
Regards
Adam
Apr 18, 2011 at 5:53 UTC
Hi,
Please, try to use this software to do the same:
Apr 18, 2011 at 11:28 UTC
Most of my workstation have Windows XP sp3, this commands give the folowing results
wmic /namespace:\\root\SecurityCenter PATH
AntiVirusProduct get * >> %USERPROFILE%\Desktop\avlog.log
Incorrect GET expression.
Try the WMIExplorer app Xavier posted up (above). You'll need to run the app on a device with 8.8. installed. This should allow you to explore the SecurityCenter and SecurityCenter2 namespaces.
Does either namespace display "up-to-date" status for 8.8?
- Run the app
- Action -> Connect to host/namespace..
- Name space -> Root\SecurityCenter
- AntiVirusProduct
- (Instances tab) -> select instance
- (Properties tab)
Could you post up screenshots for the Properties tab? Both SecurityCenter, and then repeat for SecurityCenter2?
Apr 19, 2011 at 12:53 UTC
Hello
I confirm no value for root\securiyicenter AntiVirusProduct with McAfee 8.8
Regards
Adam
Apr 19, 2011 at 10:11 UTC
Looks like they're on it, guys!
https:/
Apr 20, 2011 at 3:56 UTC
There is no such key in my 8.8 installation as commented in the McAfee article. Now I am doing some research on it. I will give you the results ASAP.
|
https://community.spiceworks.com/topic/135459-mcafee-8-8-support-in-spiceworks-5-1-current-beta
|
CC-MAIN-2016-44
|
refinedweb
| 488
| 60.21
|
Psychopy
From Neural Wiki
A really cool new python addition that I just recently found out about is called PsychoPy (Psychophysics Python). This open source platform allows you to develop psychophysics experiments using your favorite programming language (Python 2.5!). The documentation is decent on the website, but I am working on putting together a bit more information about the different commands. Let me know if there is something wrong or missing (mike(at)neuralwiki.org). I am using a Mac G5 with the Intel chipset and a MacBook Pro with the Dual Core Intel chip to run the program. The best way to install the program on an intel mac running OS X is to use Macports ("sudo port install PsychoPy"). Installing on a PowerPC is a bit harder and is detailed below. Luckily, PsychoPy also works on Windows or Linux. Much thanks to the Psychopy team for setting this up.
[edit] Commands
A list of features and commands can be found here
[edit] Movie Player
Some test code I came up with for playing a movie in PsychoPy. In the PsychoPy demo folder which you get when you download PsychoPy, there is a sample called MovieStim.py which you can look at for more information. I dont know if the following method is the best, but it will work.
from psychopy import core, visual, event from numpy import ceil myWin=visual.Window((1000,1000), allowGUI=False) #set up a window for your movie mov=visual.MovieStim(myWin, 'stimulus_movie.mp4', flipVert=False) #insert your movie name in the quotes fps=60 #insert your frames per second of your movie total_frames=ceil(fps*mov.duration) #total frames to present print mov.duration #movie duration in seconds print mov.format.width, mov.format.height #the width and height t=0 #initialize counter mov.draw() #draw the first movie frame while t < total_frames: #play through all frames myWin.flip() #go to the next frame mov.draw() #draw the next frame t=t+1 #update counter
[edit] Installing PsychoPy on a Power PC Mac
For my current work, we have two Macs running Psychophysics experiments. Both are running OS X 10.5.8, one is a quad core PPC and the other is a quad core Intel Mac. On the Intel Mac Macports works just fine for installing Psychopy. If you have Macports installed, just type in 'sudo port install py25-psychopy' and sit back while Macports does its thing. However, on the Power PC Mac, this did not work. I ran into some strange install errors. I kept getting the following error for several different python packages from scipy to python image library.
f951: error: unrecognized command line option "-arch"
After giving up on Macports, I finally found a way that works. First upgrade the Python 2.5 that comes with your machine to Active Python 2.5. I got the Python 2.5.4.4 dmg. Works nicely, and installs easily. In fact, with the exception of Psychopy, OpenGL and setuptools, you want to find as many dmg files as you can. Note that many Tiger (OS X 10.4) dmg's will work on Leopard (OS X 10.5).
First you need setuptools. After downloading, use your console and cd into the directory where you downloaded it, and type
sh setuptools-0.6c9-py2.4.egg
Then download pyglet.dmg. Double click on it and follow the install directions.
Next is pygame.dmg. Double click on it and follow the install directions.
Then OpenGL. After downloading and unzipping, go into the OpenGL folder where setup.py lives, then type in:
python setup.py install
From this page download and install numpy, matplotlib, python image library (PIL) and wxpython. If you've got it, give this guy a donation, his page will save you lots of time and frustration, particularly with PIL...ask me how I know.
You can also add winioport so that you can use the parallel port. NOTE: I havent tried this with the parallel port. I ended up installing pyserial and using a serial port as my method of triggering equipment. More about that in Mac OS X Serial Port.
Finally, download the psychopy.zip, unzip it and rename it PyschoPy-1.50.01-py2.5.egg, then transfer this folder into your /Library/Python/2.5/site-packages/ folder. I dont know if this is necessary, but I renamed the Psychopy.egg-info folder inside the main Psychopy-xx-.egg folder to EGG-info (it works, that's all I know).
Next open up your easy-install.pth file using a text editor and add the following line somewhere in the middle and it should work.
./PsychoPy-1.50.01-py2.5.egg
My easy-install.pth looks like this.
import sys; sys.__plen = len(sys.path) ./setuptools-0.6c9-py2.5.egg ./numpy-1.0.5.dev4722-py2.5-macosx-10.3-ppc.egg ./matplotlib-0.98pre-py2.5-macosx-10.5-ppc.egg ./scipy-0.7.0.dev3812-py2.5-macosx-10.3-ppc.egg ./PyMC-2.0-py2.5-macosx-10.3-ppc.egg ./PsychoPy-1.50.01-py2.5.egg ./ipython-0.10-py2.5.egg ./SQLObject-0.11.0-py2.5.egg import sys; new=sys.path[sys.__plen:]; del sys.path[sys.__plen:]; p=getattr(sys,'__egginsert',0); sys.path[p:p]=new; sys.__egginsert = p+len(new)
To test it open the command prompt and type in python, then when python opens type from psychopy import * If you dont get any errors, then you have a working version of PsychoPy!
[edit] Psychopy and external triggering
To see how I used a Mac to trigger my equipment using PySerial, see Mac OS X Serial Port.
|
http://www.neuralwiki.org/index.php?title=Psychopy
|
CC-MAIN-2013-48
|
refinedweb
| 955
| 68.16
|
Hello guys!
I would like to test a program I did in c, but I would like something small and to show errors with accessibility.
Does anyone know of any tool for c so?
Hello guys!
If your talking about unit tests, I'd recommend Catch. It can be found at. It allows you to write unit tests and test individual procedures of your application, and reports failures. It even supports telling you duration's if you want to benchmark your application. An example follows:
#include <dlib/config_reader.h> #include <iostream> #include <fstream> #include <vector> #define CATCH_CONFIG_MAIN #include <catch.hpp> using namespace std; using namespace dlib; /* We'll assume we have a configuration file on disk named config.txt with the contents: # This is an example config file. Note that # is used to create a comment. # At its most basic level a config file is just a bunch of key/value pairs. # So for example: key1 = value2 dlib = a C++ library # You can also define "sub blocks" in your config files like so user1 { # Inside a sub block you can list more key/value pairs. id = 42 name = davis # you can also nest sub-blocks as deep as you want details { editor = vim home_dir = /home/davis } } user2 { id = 1234 name = joe details { editor = emacs home_dir = /home/joe } } */ TEST_CASE("Config reader test") { config_reader cr("config.txt"); // We use the REQUIRE macro to require that a condition be true or false REQUIRE(cr["key1"]!="" && cr["key1"] == "value2"); // And so on... }
You'll have noticed that this program doesn't have a main() function like it's supposed to. This is because Catch defines it's own main() function that accepts command-line arguments. (That's what the CATCH_CONFIG_MAIN preprocessor definition does.) You should only define that in one .cpp file; defining it multiple times... won't go well for you
. Next we use the TEST_CASE() macro to create test cases. These test cases can be executed manually via the command-line or will be executed sequentially when the program runs. The syntax of the macro is:
TEST_CASE( test name [, tags ] )
The [, tags] means that tags are optional (as clearly demonstrated here). Test cases can have sections, which then can have sub-sections and so on. You can do this with the SECTION() macro:
SECTION( section name )
The full documentation can be found at … Readme.md. The tutorial can be found at … torial.md.
3 2017-10-18 01:57:58 (edited by nyanchan 2017-10-18 15:08:33)
Show errors? Does that mean you still don't have a set of compiling environment? If that's the case, I recommend using MinGW compiler collection. You can just type "gcc filename.c <additional compiler options if any>" on the command prompt. We can of course use Visual Studio, but MinGW is much smaller and easier while you are testing basic C programs that don't heavily rely on the latest Win32 API or VC/VC++ specific macros.
Also, if you are sure you are writing in C, the code Ethin pasted above doesn't work because it's written for C++. I'm not sure if the testing library itself is actually providing C API's, so it may work with some tweeks though.
@3, actually, your slightly incorrect -- I wrote that code to fit the question. Catch will work for C or C++ though, though C++ is recommended. The only thing I pasted was the config file.
Oh, I looked at it again and got it. Thanks for pointing that out. Glad to know that it does support C.
Hello guys!
Can someone send the direct link from Catch? The git hub link does not work
It doesn't work? Odd... you can download it at … catch.hpp. If that doesn't work... check your firewall settings. You should have no problems accessing Git Hub. At all.
|
http://forum.audiogames.net/viewtopic.php?id=23268
|
CC-MAIN-2017-47
|
refinedweb
| 646
| 75.81
|
IJulia.)
InstallationInstallation
First, download Julia version 0.7
or later and run the installer. Then run the Julia application
(double-click on it); a window with a
julia> prompt will appear. At
the prompt, type:
using Pkg Pkg.add("IJulia")
to install IJulia.
This process installs a kernel specification that tells Jupyter (or JupyterLab) etcetera how to launch Julia.
Pkg.add("IJulia") does not actually install Jupyter itself.
You can install Jupyter if you want, but it can also be installed
automatically when you run
IJulia.notebook() below. (You
can force it to use a specific
jupyter installation by
setting
ENV["JUPYTER"] to the path of the
jupyter program
before
Pkg.add, or before running
Pkg.build("IJulia");
your preference is remembered on subsequent updates.
Running the IJulia NotebookRunning the IJulia Notebook
If you are comfortable managing your own Python/Jupyter installation, you can just run
jupyter notebook yourself in a terminal. To simplify installation, however, you can alternatively type the following in Julia, at the
julia> prompt:
using IJulia notebook()
to launch the IJulia notebook in your browser.
The first time you run
notebook(), it will prompt you
for whether it should install Jupyter. Hit enter to
have it use the Conda.jl
package to install a minimal Python+Jupyter distribution (via
Miniconda) that is
private to Julia (not in your
PATH).
On Linux, it defaults to looking for
jupyter in your
PATH first,
and only asks to installs the Conda Jupyter if that fails; you can force
it to use Conda on Linux by setting
ENV["JUPYTER"]="" during installation (see above). (In a Debian or Ubuntu GNU/Linux system, install the package
jupyter-client to install the system
jupyter.)
You can
use
notebook(detached=true) to launch a notebook server
in the background that will persist even when you quit Julia.
This is also useful if you want to keep using the current Julia
session instead of opening a new one.
julia> using IJulia; notebook(detached=true) Process(`'C:\Users\JuliaUser\.julia\v0.7\Conda\deps\usr\Scripts\jupyter' notebook`, ProcessRunning) julia>
By default, the notebook "dashboard" opens in your
home directory (
homedir()), but you can open the dashboard
in a different directory with
notebook(dir="/some/path").
Alternatively, you can run
jupyter notebook
from the command line (the
Terminal program
in MacOS or the Command
Prompt in Windows).
Note that if you installed
jupyter via automated Miniconda installer
in
Pkg.add, above, then
jupyter may not be in your
PATH; type
import Conda; Conda.SCRIPTDIR in Julia to find out where Conda
installed
jupyter.
A "dashboard" window like this should open in your web browser. Click on the New button and choose the Julia option to start a new "notebook". A notebook will combine code, computed results, formatted text, and images, just as in IPython. You can enter multiline input cells and execute them with shift-ENTER, and the menu items are mostly self-explanatory. Refer to the Jupyter notebook documentation for more information, and see also the "Help" menu in the notebook itself.
Given an IJulia notebook file, you can execute its code within any other Julia file (including another notebook) via the NBInclude package.
Running the JupyterLabRunning the JupyterLab
Instead of running the classic notebook interface, you can use the IDE-like JupyterLab. If you are comfortable managing your own JupyterLab installation, you can just run
jupyter lab yourself in a terminal. To simplify installation, however, you can alternatively type the following in Julia, at the
julia> prompt:
using IJulia jupyterlab()
Like
notebook(), above, this will install JupyterLab via Conda if it is
not installed already.
jupyterlab() also supports
detached and
dir keyword options similar to
notebook().
Running nteractRunning nteract
The nteract Desktop is an application that lets you work with notebooks without a Python installation. First, install IJulia (but do not run
notebook() unless you want a Python installation) and then nteract.
Updating Julia and IJuliaUpdating Julia and IJulia
Julia is improving rapidly, so it won't be long before you want to update to a more recent version. To update the packages only, keeping Julia itself the same, just run:
Pkg.update()
at the Julia prompt (or in IJulia).
If you download and install a new version of Julia from the Julia web
site, you will also probably want to update the packages with
Pkg.update() (in case newer versions of the packages are required
for the most recent Julia). In any case, if you install a new Julia
binary (or do anything that changes the location of Julia on your
computer), you must update the IJulia installation (to tell Jupyter
where to find the new Julia) by running
Pkg.build("IJulia")
at the Julia command line (important: not in IJulia).
Installing additional Julia kernelsInstalling additional Julia kernels
You can also install additional Julia kernels, for example, to
pass alternative command-line arguments to the
julia executable,
by using the
IJulia.installkernel function. See the help for this
function (
? IJulia.installkernel in Julia) for complete details.
For example, if you want to run Julia with all deprecation warnings disabled, you can do:
using IJulia installkernel("Julia nodeps", "--depwarn=no")
and a kernel called
Julia nodeps 0.7 (if you are using Julia 0.7)
will be installed (will show up in your main Jupyter kernel menu) that
lets you open notebooks with this flag.
You can also install kernels to run Julia with different environment
variables, for example to set
JULIA_NUM_THREADS for use with Julia multithreading:
using IJulia installkernel("Julia (4 threads)", env=Dict("JULIA_NUM_THREADS"=>"4"))
The
env keyword should be a
Dict mapping environment variables to values.
Troubleshooting:Troubleshooting:
- If you ran into a problem with the above steps, after fixing the problem you can type
Pkg.build()to try to rerun the install scripts.
- If you tried it a while ago, try running
Pkg.update()and try again: this will fetch the latest versions of the Julia packages in case the problem you saw was fixed. Run
Pkg.build("IJulia")if your Julia version may have changed. If this doesn't work, you could try just deleting the whole
.juliadirectory in your home directory (on Windows, it is called
Users\USERNAME\.juliain your home directory) via
rm(Pkg.dir(),recursive=true)in Julia and re-adding the packages.
- On MacOS, you currently need MacOS 10.7 or later; MacOS 10.6 doesn't work (unless you compile Julia yourself, from source code).
- Internet Explorer 8 (the default in Windows 7) or 9 don't work with the notebook; use Firefox (6 or later) or Chrome (13 or later). Internet Explorer 10 in Windows 8 works (albeit with a few rendering glitches), but Chrome or Firefox is better.
- If the notebook opens up, but doesn't respond (the input label is
In[*]indefinitely), try creating a new Python notebook (not Julia) from the
Newbutton in the Jupyter dashboard, to see if
1+1works in Python. If it is the same problem, then probably you have a firewall running on your machine (this is common on Windows) and you need to disable the firewall or at least to allow the IP address 127.0.0.1. (For the Sophos endpoint security software, go to "Configure Anti-Virus and HIPS", select "Authorization" and then "Websites", and add 127.0.0.1 to "Authorized websites"; finally, restart your computer.)
- Try running
jupyter --versionand make sure that it prints
3.0.0or larger; earlier versions of IPython are no longer supported by IJulia.
- You can try setting
ENV["JUPYTER"]=""; Pkg.build("IJulia")to force IJulia to go back to its own Conda-based Jupyter version (if you previously tried a different
jupyter).
IJulia featuresIJulia features
There are various features of IJulia that allow you to interact with a running IJulia kernel.
Detecting that code is running under IJuliaDetecting that code is running under IJulia
If your code needs to detect whether it is running in an IJulia notebook
(or other Jupyter client), it can check
isdefined(Main, :IJulia) && Main.IJulia.inited.
Julia projectsJulia projects
The default Jupyter kernel that is installed by IJulia starts with the
Julia command line flag
--project=@.. A
Project.toml (or
JuliaProject.toml)
in the folder of a notebook (or in a parent folder of this notebook) will
therefore automatically become the active project for that notebook.
Users that don't want this behavior should install an additional IJulia
kernel without that command line flag (see section
Installing additional Julia kernels).
Customizing your IJulia environmentCustomizing your IJulia environment
If you want to run code every time you start IJulia---but only when in IJulia---add a
startup_ijulia.jl file to your Julia
config directory, e.g.,
~/.julia/config/startup_ijulia.jl.
Julia and IPython MagicsJulia and IPython Magics
One difference from IPython is that the IJulia kernel does
not use "magics", which are special commands prefixed with
% or
%% to execute code in a different language. Instead, other
syntaxes to accomplish the same goals are more natural in Julia,
work in environments outside of IJulia code cells, and are often
more powerful.
However, if you enter an IPython magic command
in an IJulia code cell, it will print help explaining how to
achieve a similar effect in Julia if possible.
For example, the analogue of IPython's
%load filename in IJulia
is
IJulia.load("filename").
Prompting for user inputPrompting for user input
When you are running in a notebook, ordinary I/O functions on
stdin do
not function. However, you can prompt for the user to enter a string
in one of two ways:
readline()and
readline(stdin)both open a
stdin>prompt widget where the user can enter a string, which is returned by
readline.
IJulia.readprompt(prompt)displays the prompt string
promptand returns a string entered by the user.
IJulia.readprompt(prompt, password=true)does the same thing but hides the text the user types.
Clearing outputClearing output
Analogous to the IPython.display.clear_output() function in IPython, IJulia provides a function:
IJulia.clear_output(wait=false)
to clear the output from the current input cell. If the optional
wait argument is
true, then the front-end waits to clear the
output until a new output is available to replace it (to minimize
flickering). This is useful to make simple animations, via repeated
calls to
IJulia.clear_output(true) followed by calls to
display(...) to display a new animation frame.
Input and output historyInput and output history
IJulia will store dictionaries of the user's input and output history
for each session in exported variables called
In and
Out. To recall
old inputs and outputs, simply index into them, e.g.
In[1] or
Out[5]. Sometimes, a user
may find themselves outputting large matrices or other datastructures which
will be stored in
Out and hence not garbage collected, possibly hogging memory.
If you find that IJulia is using too much memory after generating large outputs, empty this output dictionary:
empty!(Out)
Default display sizeDefault display size
When Julia displays a large data structure such as a matrix, by default
it truncates the display to a given number of lines and columns. In IJulia,
this truncation is to 30 lines and 80 columns by default. You can change
this default by the
LINES and
COLUMNS environment variables, respectively,
which can also be changed within IJulia via
ENV (e.g.
ENV["LINES"] = 60).
(Like in the REPL, you can also display non-truncated data structures via
print(x).)
Preventing truncation of outputPreventing truncation of output
The new default behavior of IJulia is to truncate stdout (via
show or
println)
after 512kb. This to prevent browsers from getting bogged down when displaying the
results. This limit can be increased to a custom value, like 1MB, as follows
IJulia.set_max_stdio(1 << 20)
Setting the current moduleSetting the current module
The module that code in an input cell is evaluated in can be set using
Main.IJulia.set_current_module(::Module).
It defaults to
Main.
Opting out of soft scopeOpting out of soft scope
By default, IJulia evaluates user code using "soft" global scope, via the SoftGlobalScope.jl package: this means that you don't need explicit
global declarations to modify global variables in
for loops and similar, which is convenient for interactive use.
To opt out of this behavior, making notebooks behave similarly to global code in Julia
.jl files,
you can set
IJulia.SOFTSCOPE[] = false at runtime, or include the environment variable
IJULIA_SOFTSCOPE=no
environment of the IJulia kernel when it is launched.
Low-level InformationLow-level Information
Using older IPython versionsUsing older IPython versions
While we strongly recommend using IPython version 3 or later (note that this
has nothing to do with whether you use Python version 2 or 3), we recognize
that in the short term some users may need to continue using IPython 2.x. You
can do this by checkout out the
ipython2 branch of the IJulia package:
Pkg.checkout("IJulia", "ipython2") Pkg.build("IJulia")
Manual installation of IPythonManual installation of IPython
First, you will need to install a few prerequisites:
You need version 3.0 or later of IPython, or version 4 or later of Jupyter. Note that IPython 3.0 was released in February 2015, so if you have an older operating system you may have to install IPython manually. On Mac and Windows systems, it is currently easiest to use the Anaconda Python installer.
To use the IPython notebook interface, which runs in your web browser and provides a rich multimedia environment, you will need to install the jsonschema, Jinja2, Tornado, and pyzmq (requires
apt-get install libzmq-devand possibly
pip install --upgrade --force-reinstall pyzmqon Ubuntu if you are using
pip) Python packages. (Given the pip installer,
pip install jsonschema jinja2 tornado pyzmqshould normally be sufficient.) These should have been automatically installed if you installed IPython itself via
easy_installor
pip.
To use the IPython qtconsole interface, you will need to install PyQt4 or PySide.
You need Julia version 0.7 or later.
Once IPython 3.0+ and Julia 0.7+ are installed, you can install IJulia from a Julia console by typing:
Pkg.add("IJulia")
This will download IJulia and a few other prerequisites, and will set up a Julia kernel for IPython.
If the command above returns an error, you may need to run
Pkg.update(), then
retry it, or possibly run
Pkg.build("IJulia") to force a rebuild.
Other IPython interfacesOther IPython interfaces
Most people will use the notebook (browser-based) interface, but you
can also use the IPython
qtconsole
or IPython terminal interfaces by running
ipython qtconsole --kernel julia-0.7 or
ipython console --kernel julia-0.7, respectively.
(Replace
0.7 with whatever major Julia version you are using.)
Debugging IJulia problemsDebugging IJulia problems
If IJulia is crashing (e.g. it gives you a "kernel appears to have died" message), you can modify it to print more descriptive error messages to the terminal by doing:
ENV["IJULIA_DEBUG"]=true Pkg.build("IJulia")
Restart the notebook and look for the error message when IJulia dies.
(This changes IJulia to default to
verbose = true mode, and sets
capture_stderr = false, hopefully sending a bunch of debugging to
the terminal where you launched
jupyter).
When you are done, set
ENV["IJULIA_DEBUG"]=false and re-run
Pkg.build("IJulia") to turn off the debugging output.
|
https://libraries.io/julia/IJulia
|
CC-MAIN-2020-10
|
refinedweb
| 2,542
| 55.03
|
Advanced Namespace Tools blog
08 March 2018
History of ANTS, part 4
This entry in the history series covers from 2013, the year ANTS was released, up to the present.
New Years 2012-13
My New Year's resolution for the start of 2013 was to return to Plan 9 software development. My plan 9 systems had been dormant since sometime early in 2011, and life in general had been occupied mostly with my father's illness and death. It was time to re-engage with the world of the living. The first step was to set up a new Plan 9 development environment for myself, and as I was doing so, I noticed that many of the things I had worked on in the past seemed to fit together in a synergistic way. After about a week of exploring my own previous work, I had a project in mind - weaving together the different tools I had created, extending their capabilities, and releasing the resulting synthesis as a coherent package. The initial commit creating the plan9ants hg repo was made at 2 am on 9 January 2013.
2013 release for Bell Labs
The next two months were spent extending, testing, and documenting the ANTS system. I had missed out on the start of the 9front project and in retrospect I wish I had delayed the release until I added full support, but by the time I installed and tested 9front for myself, I was already approaching burnout and just wanted to get a release out there. I tested quite a bit using ANTS to have both Bell Labs and 9front namespaces co-existing on the same system, even though the only 9front feature I added was a -f flag to rerootwin along with a 9front namespace file. I created two virtual machine images - a full "9queen" and a miniature "9worker" and made a set of overly elaborate tutorials to go with them. tutorial2 is an example.
I announced ANTS in a message to the 9fans mailing list, and the story took a strange turn from there. I already wrote an interactive fiction game (which can be played in Plan 9, of course) about the next few months of my life, and this is a code-focused blog, so I won't rehash the details. Over the next few weeks I posted several embarassing-to-recall emails to 9fans and generally made a nuisance of myself. Fortunately, I took a break to get real life back in order and eventually calmed down. The break ended up being longer than I had intended.
2015 Updating for 9front
By 2015 it had become clear that 9front was the way forward for Plan 9. Fitting ANTS into 9front mostly required reworking the boot process. 9front had already created its own rc-based boot process and allowed the user to drop to a shell prior to mounting the rootfs and launching the termrc or cpurc. As a result, I ended up creating two different boot options, both of which are still supported in ANTS - either using a modified bootrc which inserts a section of code to create a hubfs and cpu listener in the boot namespace, or using the full plan9rc bootscript as modified for 9front.
There were also adjustments to make in the kernel code for writable proc/pid/ns, but overall adding support for 9front was less difficult than I expected. Cinap and the other 9front developers have done an excellent job preserving the strengths of the original design and keeping interfaces compatible while making improvements. For the next two years, I tried to support 9front and the original Bell Labs version in parallel. This added a lot of complexity to the ANTS build script, which worked by binding its own modifications over the original versions and then using the standard kernel build process. Now, there was an additional layer of binding the 9front modifications over the labs modifications, and then binding everything over the main file tree. In some ways it was a good demonstration of the flexibility of namespaces, in other ways it overly baroque and fragile.
2017-now: independent /srv and live+install cd images
A commonly requested ANTS-feature was the ability to make the divergent namespaces on a system more independent and avoid collisions of the conventional service names within /srv. At the start of 2017 I finally found a design and implementation I liked, copying how /env worked with rfork. I wrote a series of blog posts covering the evolution of that feature. After that work, I took another break of a few months. When I returned to development work later that year, i decided it would be good to offer another option for exploring or installing ANTS - full cd images.
Installing ANTS, involving as it did a customized kernel, was a more involved process than a standard mk install command, and not many people had the combination of time and interest to read the documentation and work out the details for their system. A live+install cd as a self-contained unit is easier to work with conceptually, people have an existing set of mental subroutines for using it. The first ANTS .iso images were released at the start of 2018, and have gotten orders of magnitude more use than the source install process ever did. The creation of the public grid of 9p services has had a synergistic effect, since the .iso images have the commands to utilize it preinstalled.
Thanks for reading this overly-elaborate history, the next release of .iso images will be in just a few days for the 5-year ANTS-iversary!
|
http://doc.9gridchan.org/blog/180308.ants.history.pt4
|
CC-MAIN-2021-21
|
refinedweb
| 941
| 65.05
|
I've been working on a problem set for the Harvard CS50 class and we have been tasked with recovering jpegs from a memory card. The card stores the jpgs sequentially. In writing my program I decided on using a while loop to keep looping through until EOF, but using the debugger included with the course I am finding that my loop never initiates. I have included my code below and I am really hoping somebody can help me understand where I went wrong in my loop.
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
int main(int argc, char* argv[])
{
// Ensure proper Usage
if (argc != 1)
{
printf("This file takes no input commands!\n");
return 1;
}
// open up card data file
FILE* dataFile = fopen("card.raw", "r");
if (dataFile == NULL)
{
char* invalidFile = "card.raw";
printf("Could not open %s.\n", invalidFile);
return 2;
}
// Create variable to keep track of num of output files written
int numFiles = 0;
// Create buffer
int* buffer = (int*)malloc(sizeof(int*) * 512);
// Create new file conditions
bool a = buffer[0] == 0xff && buffer[1] == 0xd8 && buffer[2] == 0xff;
bool b = buffer[3] == 0xe0 || buffer[3] == 0xe1|| buffer[3] == 0xe2 ||
buffer[3] == 0xe3 || buffer[3] == 0xe4 || buffer[3] == 0xe5 ||
buffer[3] == 0xe6 || buffer[3] == 0xe7 || buffer[3] == 0xe8 ||
buffer[3] == 0xe9 || buffer[3] == 0xea || buffer[3] == 0xeb ||
buffer[3] == 0xec || buffer[3] == 0xed || buffer[3] == 0xee ||
buffer[3] == 0xef;
// Loop through until all files found
while(fread(&buffer, 512, 1, dataFile) == 1)
{
if(a && b)
{
// Create temporary storage
char title[999];
// print new file name
sprintf(title, "%d.jpg", numFiles);
// open new file
FILE* img = fopen(&title[numFiles], "a");
numFiles = numFiles + 1;
fwrite(&buffer, sizeof(buffer), 1, img);
free(buffer);
}
else
{
if(numFiles > 0)
{
}
}
}
}
Okay you might have more than one misunderstanding.
First of all take a look at the man page of fread:
On success, fread() and fwrite() return the number of items read or written.
So if you request 512 bytes you should expect it to return 512. If it returns less, you know: Either you reached the end of your file or something went wrong.
Also if you assign:
bool a = something; bool b = somethingElse;
And then:
while(somethingEntirelyElse) { // Never update the value of a or b if(a && b) { ... } // Neither here ... }
Then you could call that check redundant couldn't you?
That is unless
a and
b actually are volatile. But don't go there!
In your case the assignment of
a and
b most likely belongs inside the
while loop.
Then you alloc your
buffer once outside the loop, but free it each time you actually write it down. On the next iteration you will get a segmentation fault.
Have you considered what happens if any of the image files is any other size than 512 bytes, and the images are not aligned properly?
A better way would be to save the position of the start of one file and once you encounter the EOF (which you aren't really looking for...) you would know the exact size of the file, and how big your buffer would have to be.
In conclusion I would agree with some of the commenters, that you really should have a look at some earlier assignments and see whether you can learn something from them.
Analogy time:
Let's assume you have a book, and you want to copy each page that has an image on it. You tell yourself: Aw I just follow a simple algorithm, so I can think about something else.
Your algorithm is:
Have a photocopy machine
Have a notebook on which you note whether a page contains an image or not.
Take a look at the (as of yet closed book) and see if there is an image. -> Write down result on notebook
Start turning the pages as long as the next page has exactly one letter on it. (No more no less) -> you stop immediately in most cases
If the notebook says: There is an image, copy this page (note that the notebook will say whatever you wrote on it the first time)
If you just copied an image, throw away your copying machine (and don't bother buying a new one for the next image)
|
https://codedump.io/share/R0ENxQFf4Qgu/1/looping-through-end-of-data-file
|
CC-MAIN-2017-51
|
refinedweb
| 706
| 68.3
|
29 June 2012 05:15 [Source: ICIS news]
TOKYO (ICIS)--?xml:namespace>
The country’s plastic production, on the other hand, increased by 4.5% in May from April and rose by 5.3% from May 2011, according to the ministry.
“Industrial production continues to show an upward movement,” the METI said in a statement on its website.
Industries that contributed to the month-on-month decrease in March were those of transport equipment, chemicals and general machinery, the ministry said.
Japanese producers expect the country’s industrial production to increase by 2.7% in June and rise by 2.4% in July, according to a METI’s survey conducted earlier in June.
When they were polled in May, the producers predicted
|
http://www.icis.com/Articles/2012/06/29/9573767/japans-non-pharmaceutical-production-down-4.5-in-may.html
|
CC-MAIN-2014-42
|
refinedweb
| 122
| 60.31
|
Best Search Engines
wap.google.com
search.yahoo.com
m.ask.com
surfwap.com
tajonline.com/std-codes
indiapost.gov.in
Happy Searching…… 🙂
Best Search Engines
wap.google.com
search.yahoo.com
m.ask.com
surfwap.com
tajonline.com/std-codes
indiapost.gov.in
Happy Searching…… 🙂
This is the simple C file “svnlabs.c” to execute on linux terminal
#include
int main()
{
int i;
for(i=0;i<=5;i++)
{
printf(”n%d %s”,i,”svnlabs.com”);
}
printf(”n”);
return 0;
}
Output:
[root@localhost ~]# gcc svnlabs.c
[root@localhost ~]# make svnlabs
cc svnlabs.c -o svnlabs
[root@localhost ~]# ./svnlabs
0 svnlabs.com
1 svnlabs.com
2 svnlabs.com
3 svnlabs.com
4 svnlabs.com
5 svnlabs.com
[root@localhost ~]#
This is the sample java file “Svnlabs.java” to be executed on linux command line…..
import java.lang.*;
import java.io.*;
public class Svnlabs
{
public static void main(String args[])
{
System.out.println(”svnlabs.com”);
}
}
Output:
[root@localhost ~]# javac Svnlabs.java
[root@localhost ~]# java Svnlabs
svnlabs.com
[root@localhost ~]#
wine – run Windows programs on Linux/Unix
wine program.exe [arguments …]
wine –help
wine –version
wine loads and runs the given program, where the program is a DOS, Win- dows 3.x, or Win32 executable (x86 binaries only).
This will display all the output in a separate win-dows (this requires X11 to run).
Install wine on linux (RedHat, Fedora, CentOS…)
# yum install wine
# man wine
Example:
# wine /opt/test.exe.
Source:
Database:
1. Delete all information from databse related to, if deleting user or any content from CMS.
2. Use PDO, ADO, Pear, Zend etc. library to connect to database.
3. Take regular backup for database.
4. Use better naming convension.
Folders:
1. Use better naming convension. convension.
2. Use better documentation for web files, apply comments for coding and indent it.
3. Make consistency in DB, Filesnames, convension.usability, integrity and productivity.
2. Use PHP session ID, remote IP and page name on increment views/hits.
3. Make function to load CSS, JS, Links, Forms & Elements, Images, Iframes etc. on webpage. (load_css_file(), load_js_file()….)
4. Looping should be start from Left to Right…
Variables:
1. Use better naming convension. javascript.
4. Avoid duplicate JS function.
Ajax:
1. Minimize the errors in HTML closing tags etc.
2. Use proper hyrarchy popup window on registration page.
3. Use better UI for Errors/Success messages.
4. Use cancle button near submit button.
5. Use captcha code on pages by session value to avoid Spams.
6. Put valid ALT values in IMG tags.
7. Use Enter button event on form’s submit control.
8. Use scrolling DIV on webpages…………
Cloud
|
https://sandeepverma.wordpress.com/2009/06/
|
CC-MAIN-2018-34
|
refinedweb
| 435
| 55
|
Give Feedback While Logging In
It’s important that we give the user some feedback while we are logging them in. So they get the sense that the app is still working, as opposed to being unresponsive.
Use a isLoading Flag
To do this we are going to add a
isLoading flag to the state of our
src/containers/Login.js. So the initial state in the
constructor looks like the following.
this.state = { isLoading: false, email: "", password: "" };
And we’ll update it while we are logging in. So our
handleSubmit method now looks like so:
handleSubmit = async event => { event.preventDefault(); this.setState({ isLoading: true }); try { await Auth.signIn(this.state.email, this.state.password); this.props.userHasAuthenticated(true); this.props.history.push("/"); } catch (e) { alert(e.message); this.setState({ isLoading: false }); } }
Create a Loader Button
Now to reflect the state change in our button we are going to render it differently based on the
isLoading flag. But we are going to need this piece of code in a lot of different places. So it makes sense that we create a reusable component out of it.
Create a new file and add the following in
src/components/LoaderButton.js.
import React from "react"; import { Button, Glyphicon } from "react-bootstrap"; import "./LoaderButton.css"; export default ({ isLoading, text, loadingText,} {!isLoading ? text : loadingText} </Button>;
This is a really simple component that takes a
isLoading flag and the text that the button displays in the two states (the default state and the loading state). The
disabled prop is a result of what we have currently in our
Login button. And we ensure that the button is disabled when
isLoading is
true. This makes it so that the user can’t click it while we are in the process of logging them in.
And let’s add a couple of styles to animate our loading icon.
Add the following to
src/components/LoaderButton.css.
.LoaderButton .spinning.glyphicon { margin-right: 7px; top: 2px; animation: spin 1s infinite linear; } @keyframes spin { from { transform: scale(1) rotate(0deg); } to { transform: scale(1) rotate(360deg); } }
This spins the refresh Glyphicon infinitely with each spin taking a second. And by adding these styles as a part of the
LoaderButton we keep them self contained within the component.
Render Using the isLoading Flag
Now we can use our new component in our
Login container.
In
src/containers/Login.js find the
<Button> component in the
render method.
<Button block Login </Button>
And replace it with this.
<LoaderButton block
Also, import the
LoaderButton in the header. And remove the reference to the
Button component.
import { FormGroup, FormControl, ControlLabel } from "react-bootstrap"; import LoaderButton from "../components/LoaderButton";
And now when we switch over to the browser and try logging in, you should see the intermediate state before the login completes.
Next let’s implement the sign up process for our app.
If you liked this post, please subscribe to our newsletter, give us a star on GitHub, and check out our sponsors.
For help and discussionComments on this chapter
For reference, here is the code so farFrontend Source :give-feedback-while-logging-in
|
https://branchv21--serverless-stack.netlify.app/chapters/give-feedback-while-logging-in.html
|
CC-MAIN-2022-33
|
refinedweb
| 520
| 56.55
|
Addressing the problem of slow loading web pages
As web developers we normally confront the user requirement that the page renditions be instant without any delay. In traditional web applications, we normally have the thumb rule of 8 second rule as a threshold to indicate that the pages should complete their rendition in less than 8 seconds. And now with RIA expectations and Web 2.0 standards, the pages behave akin to desktop applications diminishing the difference between desktop application and web application to submerge the wait time between round tri
Divide and Rule
Do not have the entire page post between the response. You can make use of partial postbacks in various AJAX frameworks so that only relevant portions of the page refresh instead of the whole page. This also saves a lot of bandwidth for both the server and the client. Add to it the savings from unnecessary processing of redundant portions of the web page for the server. When sections of the page refresh, you can also try using a progress bar in those areas alone.
Tips
You can try making use of Caching for the following parts in the web page to speed up the renditions:
Google, Microsoft and MediaTemple CDNs are a few common and frequently referred CDNs by websites.
Starting with .NET framework 4.5, System.Web.Optimization namespace provides an elegant way to bundle all JavaScript and CSS files from a given folder into a single file.
Try to see if frequently accessed page contents can be cached at the server instead of making repeat database calls.
Summary
I hope that these small tips and tricks would help a beginner to tremendously enhance the user experience in the rendition of their web pages.
- Images in the web pages/static content
- Common and frequently used files like JQuery, JQuery UI can be loaded from CDN URLs instead of local. Since these URLs would have been visited by the browsers already,there is a good probability for having these cached.
- Try using the minified versions of the scriptlets in the production servers which enhances the rendition times. Small droplets make the big ocean.
- Portions of the web page that does not need frequent processing can be turned into caching through Page/Fragment caching as appropriately.
- Viewstate is another place where you can try minimizing the response state heaviness. It is actually an hidden field to maintain the state of controls that is optionally MAC encrypted besides having a base64 encoding. Hence make a judicious call on what goes into this state persistence mechanism. Disable ViewState for controls and page that is not required by an explicit EnableViewState=false directive.
|
http://www.dotnetspider.com/resources/44739-Addressing-problem-slow-loading-web-pages.aspx
|
CC-MAIN-2017-09
|
refinedweb
| 444
| 59.84
|
TCP and UDP use a 4-tuple of local IP address, local port number, foreign IP address, and foreign port number to do their addressing. TCP requires these 4-tuples to be unique. UDP does not. It is unrealistic to expect user programs to always know proper values to use for the local address and local port, since a host can reside on multiple networks and the set of allocated port numbers is not directly accessible to a user. To avoid these problems, you can leave parts of the address unspecified and let the system assign the parts appropriately when needed. Various portions of these tuples may be specified by various parts of the sockets API.
Local address or local port or both
Foreign address and foreign port
A call to accept(3SOCKET) retrieves connection information from a foreign client, so it causes the local address and port to be specified to the system (even though the caller of accept(3SOCKET) didn't specify anything), and the foreign address and port to be returned.
A call to listen(3SOCKET) can cause a local port to be chosen. If no explicit bind(3SOCKET) has been done to assign local information, listen(3SOCKET) causes an ephemeral port number to be assigned.
A service that resides at a particular port, but which does not care what local address is chosen, can bind(3SOCKET) itself to its port and leave the local address unspecified (set to in6addr_any, a variable with a constant value in <netinet/in.h>). If the local port need sample code below binds a specific port number, MYPORT, to a socket, and leaves the local address unspecified.
#include <sys/types.h> #include <netinet/in.h> ... struct sockaddr_in6 sin; ... s = socket(AF_INET6, SOCK_STREAM, 0); bzero (&sin6, sizeof (sin6)); sin.sin6_family = AF_INET6; sin.sin6_addr.s6_addr = in6addr_any; sin.sin6_port = htons(MYPORT); bind(s, (struct sockaddr *) &sin, sizeof sin);
Each network interface on a host typically has a unique IP address. Sockets with wildcard local addresses can receive messages directed to the specified port number and sent to any of the possible addresses assigned to a host. For example, if a host has two interfaces with addresses 128.32.0.4 and 10.0.0.78, and a socket is bound as in Example 2-17, the process can accept connection requests addressed to 128.32.0.4 or 10.0.0.78. To allow only hosts on a specific network to connect to it, a server binds the address of the interface on the appropriate network.
Similarly, a local port number can be left unspecified (specified as 0), in which case the system selects a port number. For example, to bind a specific local address to a socket, but to leave the local port number unspecified::
The first is that Internet port numbers less than 1024 (IPPORT_RESERVED) are reserved for privileged users (that is, the superuser). Nonprivileged users can use any Internet port number greater than 1024. The largest Internet port number is 65535.
The second criterion is that the port number is not currently bound to some other socket.
The port number and IP address of the client is found through either accept(3SOCKET) (the from result) or getpeername(3SOCKET).
In certain cases, the algorithm used by the system to select port numbers is unsuitable for an application. This is because associations are created in a two-step process. For example, the Internet file transfer protocol does not violate the uniqueness requirement, because the system still verifies at connect time that any other sockets with the same local address and port do not have the same foreign address and port. If the association already exists, the error EADDRINUSE is returned.
|
http://docs.oracle.com/cd/E19455-01/806-1017/sockets-47146/index.html
|
CC-MAIN-2015-18
|
refinedweb
| 617
| 53.71
|
I use codeblocks to compile my code in C language.but I faced fatal error.
my code is:
#include<stdio.h>
#include<stack.h>
stack.h:No such a file or directory
#include <filename.h>
is for standard/system headers that come with the language/compiler/operating system, for example:
#include <stdio.h>
includes a well-defined header file that is part of the C standard library for IO routines.
The C standard does not define a
stack.h header file, so the file you are trying to include must be from another source.
If there is a file called
stack.h in your project, then you need to use
#include "stack.h"
Beyond these two cases, we can't help you -
stack.h sounds very much specific to your project/setup. If you know what directory it is in, you can try adding that directory as an include path to your IDE.
|
https://codedump.io/share/FGs290hupMqr/1/fatal-error-in-stack
|
CC-MAIN-2017-30
|
refinedweb
| 153
| 77.94
|
For anyone familiar with Object Oriented programming this gives a quick run down on the OO aspects of Python language.
A class can be created using the
class keyword.
object in the class definition specifies that the class Point inherits from the inbuilt class “object”. Some other OO languages like JAVA this is implicit and doesn’t have to be mentioned during class definition. So if a class need to inherit from another class then “object” can be replaced with the required class name.
Initialization of class objects/instances is handled by the
__init__ method which is similar to the constructor in other languages.
Note that init method attributes includes “self” as the first paramater which is a reserved word. This is applicable to all the method definitions in a class. But when a class object is created the first parameter starts with the second parameter in the init method definition. The first parameter “self” is taken care by the Python interpreter.
The variable “totalSquares” which is defined outside all the methods in the class definition is a class variable and shared by all the instances. The variable “self.len” is an instance level variable and is accessible to all the methods in the class. Other variables defined in a method are local variables to the method and not accessible outside of the method. The following is an expanded example
A class can inherit from multiple other classes. For e.g.
Similar to languages like Java, Python has a garbage collector (GC) to delete objects which are not referenced anymore. This prevents memory leaks by not releasing the ojects explicitly by programs as languages like C requires.
Parent class methods can be overridden by an inherited class by defining the same method header in the child class as in the parent class. As seen before the init defined in all the class definitions earlier is overriding the method with same header in “object” class which is the inbuild base class. Other base class methods which can be overridden are
def __del__(self): destructor method which is called at the time of GC of the class object
def __repr__(self): returns an evaluatable string represention of the class object
def __str__(self): returns a string representation of the object like “toString” method in Java
If a method is overridden in a class but need to invoke the same method in the parent class, super can be used as in the following example. Calling super is bit different to that of other languaes.
Type of a class instance can be checked using the
isinstance function. For e.g. assuming that the previous code is in a file song.py
Operator overloading is accomplished by overriding the base class methods provided to overload operators.
def __cmp__(self,other): comparing two class objects and returns -ve int if self < other, 0 if self == other and +ve int if self > other
def __add__(self,other): to overload addition (+)
def __sub__(self,other): to overload subtraction (-)
… More details are available in Python docs
This is just the tip of the iceberg. You can explore more about Python here.
|
http://blog.asquareb.com/blog/2014/09/19/oo-programming-aspects-of-python/
|
CC-MAIN-2019-13
|
refinedweb
| 522
| 60.14
|
Question :
compare lines in a file with a string
I’m trying to see if my list already has a specific user in it. I should get “match found” printed out but I don’t. I thought the problem was in my php-file so i created a text file with the same contents but it still doesn’t find the match.
import urllib2 server = "10.20.68.235" var = "patrik" file = urllib2.urlopen("http://"+server+"/list-text.php") for line in file: if line == var: print "match found" print line, print "done"
Here is the output im getting:
someguy user patrik juniper ftpsecure momeunier done
Answer #1:
If you create the following file
xx.in:
test line 1 test line 2
and run the following Python program, you’ll see exactly why the match is failing:
file = open('xx.in') for line in file: print '[%s]' % (line)
The output is:
[test line 1 ] [test line 2 ]
showing that the newline characters are being left on the line when they’re read in. If you want them stripped off, you can use:
line = line.rstrip('n')
This will remove all newline characters from the end of the string and, unlike
strip(), will not affect any other whitespace characters at either the start or end.
|
https://discuss.dizzycoding.com/compare-lines-in-a-file-with-a-string/
|
CC-MAIN-2022-33
|
refinedweb
| 214
| 77.16
|
Chapter 6 brings us to branching statements, also know as if and else statements. We are also introduced to the cctype library which makes light work of some basic character operations. Exercise 1 ask us to accept keyboard input to @, not to display numbers, convert uppercase to lowercase and vice versa. One other thing you will notice this time is I have not pulled in the entire standard library, I except use it in a case by case basis. This can help solve non-obvious ambiguity errors in our later problems. See my source below for a simple solution:
1. Write a program that reads keyboard input to the @ symbol and that echoes the input
except for digits, converting each uppercase character to lowercase, and vice versa.
(Don’t forget the cctype family.)
#include <iostream> #include <cctype> int main() { char ch; std::cout << "Enter your characters: "; while(std::cin.get(ch) && ch != '@') // While inputting and not an '@' { if(isdigit(ch)) continue; // Ignore digits if(isalpha(ch)) // Is it in the alphabet? if(islower(ch)) std::cout << char(toupper(ch)); else std::cout << char(tolower(ch)); else std::cout << ch; } return 0; }
|
https://rundata.wordpress.com/2012/11/25/c-primer-chapter-6-exercise-1/
|
CC-MAIN-2016-44
|
refinedweb
| 191
| 55.74
|
After a Web service has been created, you can access and make use of it. You can consume the Web service using one of three protocols that the service is configured to respond to, as follows:
HTTP GET
HTTP POST
SOAP
This section examines accessing a Web service method using these protocols.
The HTTP GET protocol is the simplest of the protocols. To consume the page, you simply make a call to the Web service name and pass the required parameters to the service as parameters in the query string, as shown here:
This call will return an XML document that includes the results of the service. The schema that’s returned will depend on the particular method that’s called.
The Web service supplies a contract that identifies how each protocol will be used to access the service. The contract for the HTTP GET method is shown here:
HTTP GET The following is a sample HTTP GET request and response. The placeholders shown need to be replaced with actual values. GET /webservice1/service1.asmx/Add?x=string&y=string HTTP/1.1 Host: localhost HTTP/1.1 200 OK Content-Type: text/xml; charset=utf-8 Content-Length: length <?xml version="1.0" encoding="utf-8"?> <long xmlns="">long</long>
The HTTP POST protocol is similar to the HTTP GET protocol—with both protocols, you call the Web service page and post the parameters to the page as required. The following HTML code creates a Web page that allows you to access the Add Web service method described earlier in this chapter, in the section “Creating Web Methods”:
<HTML> <BODY> <FORM ACTION="/WebService1/Service1.asmx/Add" METHOD=POST> <INPUT NAME="x"> <BR> <INPUT NAME="y"> <P> <INPUT TYPE=SUBMIT> </FORM> </BODY> </HTML>
The Web service method will write the results back to the page as an XML document, as shown here:
<?xml version="1.0" encoding="utf-8" ?> <long xmlns="">5</long>
The Web service supplies a contract that identifies how each protocol will be used to access the service. The contract for the HTTP POST method is shown here:
HTTP POST The following is a sample HTTP POST request and response. The placeholders shown need to be replaced with actual values. POST /webservice1/service1.asmx/Add HTTP/1.1 Host: localhost Content-Type: application/x-www-form-urlencoded Content-Length: length x=string&y=string HTTP/1.1 200 OK Content-Type: text/xml; charset=utf-8 Content-Length: length <?xml version="1.0" encoding="utf-8"?> <long xmlns="">long</long>
More than likely, you’ll most often access the Web service using SOAP. SOAP allows you to directly call components and execute methods. The Web service will return the data as an XML document, with the results passed back through the SOAP return function.
The Web service supplies a contract that identifies how each protocol will be used to access the service. The contract for the SOAP method is shown here:
SOAP The following is a sample SOAP request and response. The placeholders shown need to be replaced with actual values. POST /webservice1/service1.asmx HTTP/1.1 Host: localhost Content-Type: text/xml; charset=utf-8 Content-Length: length SOAPAction: "" <?xml version="1.0" encoding="utf-8"?> <soap:Envelope xmlns: <soap:Body> <Add xmlns=""> <x>int</x> <y>int</y> </Add> </soap:Body> </soap:Envelope> HTTP/1.1 200 OK Content-Type: text/xml; charset=utf-8 Content-Length: length <?xml version="1.0" encoding="utf-8"?> <soap:Envelope xmlns: <soap:Body> <AddResponse xmlns=""> <AddResult>long</AddResult> </AddResponse> </soap:Body> </soap:Envelope>
To make use of a Web service in an application, you start by creating a reference to the Web service. To do so, choose Add Web Reference from the Project menu to open the Add Web Reference dialog box, in which you can search for the Web service, as shown in Figure 21-8. To search your local server, click the Web References On Local Web Server link. To search the UDDI services at Microsoft, click the appropriate links. Or you can type the URL of the Web service’s discovery file in the Address bar.
If you click the Web References On Local Web Server link, the IDE will start a dynamic discovery of the Web services on your local machine, based on the page. A list of the existing Web services on your system will be displayed in the right pane of the Add Web Reference dialog box, as shown in Figure 21-9.
If you click one of the Web service links, you’ll see detailed information about the Web service and you’ll be able to view the Web service contract and documentation, as shown in Figure 21-10. If this is the Web service you want to reference and use in your application, you can add the reference to your project by clicking the Add Reference button.
If you want to make calls to an application other than one that you have on the local server, you’ll need to generate a proxy class for the Web service. This proxy is used to identify the Web service and its methods. You can also specify the means by which you’ll connect to and communicate with the service. Fortunately, you can generate this proxy class automatically, using the Wsdl.exe tool included in the .NET Framework SDK, which is a part of Visual Studio .NET. To build the proxy, simply run the following command:
wsdl
Of course, you’ll want to replace the URL shown here with the particular URL for the Web service you’ll be accessing on the remote host. This command will create a proxy class file with the name of the Web service and with the extension .cs (indicating that it’s a C# file).
To specify other details about the proxy, you can use optional command-line parameters, including the following:
/language:<language> Language of the proxy class. Use cs, vb, or js for C#, Visual Basic, or JScript. C# is the default.
/protocol:<protocol> Protocol to use in accessing the service. Use SOAP, HTTP-GET, or HTTP-POST. SOAP is the default.
/username:<username> User name to use when accessing the service to get WSDL information.
/password:<password> Password to use when accessing the service to get WSDL information.
/domain:<domain> Domain to use when accessing the service to get WSDL information.
/namespace:<namespace> Namespace of the generated proxy class. The global namespace is the default.
/out:<outputfile> Output file name for the proxy class. The name of the Web service is used as the default.
Based on the optional parameters, you could generate a Web service proxy class that communicates with a service using the HTTP POST protocol and authenticates itself using the username bob and the password opensesame by using the following command line:
wsdl /protocol:HTTP-POST /username:bob /password:opensesame
After the proxy class has been created, you can add it to your project and call it just like any other class in the project. Within the proxy class is the code required to access the Web service, call the desired methods with the needed parameters, and retrieve the necessary results.
|
https://etutorials.org/Programming/visual-c-sharp/Part+V+ASP.NET+and+Web+Services/Chapter+21+SOAP+and+Web+Services/Consuming+a+Web+Service/
|
CC-MAIN-2022-33
|
refinedweb
| 1,201
| 61.87
|
arpa_inet.h(0P) POSIX Programmer's Manual arpa_inet.h(0P)
This manual page is part of the POSIX Programmer's Manual. The Linux implementation of this interface may differ (consult the corresponding Linux manual page for details of Linux behavior), or the interface may not be implemented on Linux.
arpa/inet.h — definitions for internet operations
#include <arpa/inet.h>
The <arpa/inet.h> header shall define the in_port_t and in_addr_t types as described in <netinet/in.h>. The <arpa/inet.h> header shall define the in_addr structure as described in <netinet/in.h>. The <arpa/inet.h> header shall define the INET_ADDRSTRLEN and INET6_ADDRSTRLEN macros as described in <netinet/in.h>. The following shall be declared as functions, or <arpa/inet.h> header shall define the uint32_t and uint16_t types.
None.
None.
None.
inttypes.h(0p), netinet_in.h(0p) The System Interfaces volume of POSIX.1‐2017, htonl(3p), inet_addr(3p), inet_ntop arpa_inet.h(0P)
Pages that refer to this page: netinet_in.h(0p), htonl(3p), inet_addr(3p), inet_ntop(3p)
|
https://www.man7.org/linux/man-pages/man0/arpa_inet.h.0p.html
|
CC-MAIN-2021-04
|
refinedweb
| 171
| 53.47
|
)?
(A module in python can be a file or directory. If it is a directory, it must have a __init__.py file module inside of it, so that the python interpreter recognizes it as a python module.)
Python code in one module gains access to the code in another module by the process of importing it. It is similar to #include in C at least in theory. But the it works is totally different. Just like in java importing a module in python (whether a library module or any other user defined module) makes the code within that module accessible to current module scope. Even if u import the module multiple times it is imported only once.. While importing a module the python path is searched for the module . If it is not present in it, the import statement combines two operations; it searches for the named module, then it binds the results of that search to a name in the local scope. The full path of the module is then is then appended to python path. You can take a look at all directory modules currently accessible by printing the sys.path.
import sys
print sys.path
I want to know how relative imports (in Python) are different than import. I have found lots of examples on internet explaining about the relative import but I want to know about the basic aspects of relative import that make it different than import..
Forgot Your Password?
2018 © Queryhome
|
https://www.queryhome.com/tech/70810/what-is-import-and-use-of-it-in-python
|
CC-MAIN-2020-29
|
refinedweb
| 247
| 64.41
|
From: Robert Ramey (ramey_at_[hidden])
Date: 2007-11-18 11:48:38
Joel de Guzman wrote:
> No, of course not. But was has boost/shared_ptr got to do with this?
wow - this is the iconic example of a violation of "standard practice"
The file is implemented in boost/shared_ptr.hpp and shared_ptr
class is to be found in namespace boost. This is not what
one would expect to find given that the documentation is
smart_pointers ...
>>>> The serialization library was reviewed TWICE and no one ever
>>>> mentioned this.
>>
>>> It's unfortunate that this has gone unnoticed from 2 reviews.
>>> Perhaps it didn't matter much at the time, or simply it slipped
>>> from the radar screen. Nevertheless, that does not make it right.
>>
>> I doubt it went unnoticed. I suspect that it was percieved as
>> the "standard practice" at the time.
>
> It went unnoticed at least for me. I would have objected otherwise.
>
>>>> So rather than saying that authors have refused to follow "standard
>>>> practice", it would be more accurate to say that there has been
>>>> no definition of "standard practice" and many authors have
>>>> interpreted it in the most logical way given the current situation.
>>
>>> Agreed. I'm not quite sure about the "most logical" way though.
>>> For me, it's pretty clear that free-for-all addition of just about
>>> anything in the boost root directory and the boost namespace
>>> is not good. There are namespaces and subdirectories.
>>
>> As I said, I don't object to establishing a "standard practice".
>> But it's really annoying to be characterised as being unwilling
>> to respect a "standard practice" when no such thing has
>> been established.
>
> I don't think anyone is pinpointing you as unwilling to respect
> "standard practice".
> Yes, because boost/detail is not public API and the
> stuff there is implementation detail.
Hmm - and implementation details shouldn't be documented?
shouldn't be tested? If they're in a common area it seems
that they are meant to be used by more than one library -
and indeed they are. lightweight test others come to mind.
Its even worse. Someone uses an "implementation detail"
from this public area. and the author decides to make
an interface breaking change. This breaks a lot of stuff
and the author says - what's the problem? its and implemenation
detail.
Another case of ill defined "standard practice" creating problems.
>> Now I see that boost/utility/multi-pass has a documentation
>> page but no way to get to by following the links in the documentation
>
> I'm lost again. boost/utility/multi-pass is non-existent.
There is libs/utility/Mult-PassIterator.html that isn't linked to anything.
I jumped to the conclusion that corresponded to a corresponding
module in boost/utility - sorry. I'm not sure what "standard
practice" would indicate should be done with this - if anything.
>> index. Then there is utility.hpp which is a convenience header
>> for a group of otherwise separate library - not including
>> mult-index.
>
> If a particular utility is useful for many libraries, then one of
> the libraries can host it prior to it getting reviewed independently
> and becoming a full-fledged boost citizen. That's the policy that
> we've been following with the synergy between xpressive and spirit,
I faced exactly that same issue with headers such as static_warning.hpp
There was already a header in boost/static_assert.hpp. I thought
(and still think) that logical place for static_warning.hpp was in that
same directory. I considered the possibility of placing it in
boost/serialization/static_warning.hpp but at the time I thought
I might have to change it later to boost/static_warning.hpp sometime
in the near future and I wanted to avoid an interface breaking change.
> for example. Case in point: fusion, proto, multi_pass, and many more
> smaller utilities and stuff. fusion was hosted by spirit before it
> was reviewed and was used by xpressive even before spirit did. Now
> that fusion passed the boost review, it has become a full-fledged
> boost citizen.
hmmm - I looked for it in boost on the trunk and 1.34 and didn't
find either documentation for it nor code. I don't doubt its in
there somewhere but I can't find it. Wouldn't "standard
practice" suggest that I look in boost/utility or perhaps
boost/iterators ? Hmmm has is been separately reviewed.
All these examples demonstrate that there really is
no defined "standard practice" and never has been.
Robert Ramey
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk
|
https://lists.boost.org/Archives/boost/2007/11/130586.php
|
CC-MAIN-2021-25
|
refinedweb
| 769
| 59.6
|
.
When 4.1 is out, then I'll be ecstatic.
True.. But you'll probably want to give feedback/bug reports/wish list now because:
Then 4.1 will have the features you want and be the way you want it.
and
The projects will be included in
Google Summer of Code (submissions are due in the next few weeks.. The more submissions we have, the better, because it means more to choose from for programmers and mentors. It would also spark more interest.)
First of all thanks for this release. I installed KDE 4.0.2 once it appeared in opensuse repository(which was much before the release announcement.) On testing I could find some enhancement to the plasma desktop but at the same time I felt there were some bugs which was not found in the 4.0.1 release. One such bug was when I try to remove the Kget applet the desktop crashes. Another one was that the desktop settings are not saved on log out of the system. Another issue is once I change the wallpaper I need to log out and log in back for it to get applied. Another problem that I faced from the very KDE 4.0.0 is that even if I remove some of the icons it always come back on each login. I thought I would confirm these bugs with others and then post it to the bugs tracker. Not sure if these bugs are only on my system.
One enhancement I would like to see in KDE 4 is with the icons. Desktop icons is taking more screen space than KDE 3.x version. Due to the same reason I am not able to add any applets, since there is no space for additional applets. So I request KDE team to provide much better icon set up for KDE 4. I am still playing with KDE 4.0.2 and would post the bugs details if I found any. Thanks
why not resize the icons to a smaller size by hand...
"Another problem that I faced from the very KDE 4.0.0 is that even if I remove some of the icons it always come back on each login."
Aye, this is most annoying. And in some cases, on next login some icons would appear *twice*, and removed plasmoids (can't get rid of the comic plasmoid) appear again.
If you right click on the desktop, go to desktop settings and then remove the tick from show icons (at the bottom of the window that opens) then the icons will simple disappear.
Still they shouldn't appear after being closed.
That information was new to me. But this option would remove all the icons. Me (and I think NabLa too) were talking about individual icons. If we don't want any one of the icon then there is no option to remove it permanently from the desktop.
What you can do after you remove the tick is add the icons that you like to the desktop. You can do that from the start menu. These icons will stay there and you can remove or resize them individually.
Yes, I was talking about that. It's just... click close on an icon and it disappears, yes. But when you log in again, it's there again! And sometimes, it's there but twice! That has to be a bug, not a feature...
Can't seem to find a bug report for this, so I'll file one.
I'd actually prefer to be able to:
* Have some file management on desktop files so I don't need to go to dolphin or a console to delete stuff from the desktop
* Being able to drag&drop files from the desktop somewhere else (ie an application).
#155241 and #155620 refer to icon duplications though
I got exactly the same problem. I think it's not because the machine
Another bug i found is the kmix applet doesn't start when log on
For me KDE 4.0.2 is much more buggy than 4.0.0 and 4.0.1.
As this should be a buf-fix mostly release exept for some small backports from KDE 4.1 Plasma this is really bad news.
Let's hope this is just kubuntu packages that are bad and will be rebuilded later instead of being a kde source code problem :-P
I am using opensuse 10.3 and this is the case with me too. I too felt KDE 4.0.2 is more buggy. Too much crashes. I am now going to try the svn packages.
I have the same problem too, need to log out and log back in to see your new applied background, what's happening? this bug didn't occur in 4.0.0 & 4.0.1?
UNSTABLE KDE 4 version from opensuse () works much much better than 4.0.2. The icons also looks much better in it and not much annoying crashes as in 4.0.2.
First congrats and thanks to the devs for another very fast release.
There are two little problems that I am having since I am not that demanding ;)
1. I still can't figure out how to run Liquid Weather on Plasma. It even shows up in the add widget dialogue box after I tried to run it using SuperKaramba but when I tried to add it to the desktop I got a message saying that one or more components of the Kross scripting architecture is missing. Do I need to install one or more packages here and which?
2. I set up sideshow for my wallpapers but after the first wallpaper changes the desktop just gets white - no wallpaper anymore. One can see that the wallpapers continue to change after the given interval but they don't appear on the desktop! And the white desktop + panel turn all kinds of colours when I write in Firefox (like now). It changes to black with white shadows around the Plasmoids then a mixture of green, blue, red yellow etc. with a funny pattern. This only happens to some of the Plasmoids but not the desktop and panel when I use openOffice Writer.
Well, the desktop is working and seems to have improved in speed but these teething troubles are a bit frustrating since I don't know how to solve them.
Btw I am using openSuse 10.3 with the Suse packages installed. Don't know if that could be the problem.
In fact the screen goes white simply by choosing another wallpaper, not just with slideshow.
You see the transition, but then it's all white unless you log out one time.
So i conclude that the transitioning is fucked up, it wasn't there before and so wasn't the white desktop problem.
Is there a way to deactivate the wallpaper transitioning?
The problem is that it remains white until I log out and in again. It also happens with single wallpapers, after a few minutes the desktop just gets white and you can see a white line running below the panel. It really looks messed up.
Funny thing is that it wasn't like that in the previous versions.
Eh, dude that's exactly what i just said... na, maybe my english isn't so good after all :-(
Is there a way to get you to use bugzilla to help us fix those problems? Search if it has been reported, add information about your setup (screen reso?, multihead? driver in use? exact versions? Distro? compositing or not? output on the konsole? patterns in this behaviour? None of those are in your parent post, moreover it's posted to the Dot, not to BKO where it would actually help fixing it.
Sigh.
Sebastian, I never used Bugzilla but I would if you could give me a few instruction on how to. I would certainly love to participate a little more.
That's what I would like to know too. And the same applies for the 3d earth model applet. It complains that "This object could not be created for the following reason:
OpenGL Shaders not supported"
glxinfo | grep shader
GL_ARB_fragment_shader, GL_ARB_half_float_pixel, GL_ARB_imaging,
GL_ARB_shadow, GL_ARB_shader_objects, GL_ARB_shading_language_100,
GL_ARB_vertex_buffer_object, GL_ARB_vertex_program, GL_ARB_vertex_shader,
GL_EXT_Cg_shader, GL_EXT_depth_bounds_test, GL_EXT_draw_range_elements,
GL_NV_texture_shader, GL_NV_texture_shader2, GL_NV_texture_shader3,
And I could run Compiz and compiz-fusion too. Not to mention that I have OpenGL composite enabled with Kwin4.
This is not just Opensuse specific, I am using Debian Sid with Experimental repositories.
I think Bobby that KDE4 has still some hiccups :).
Well, you need a videocard that has pixel and vertex shaders. Shaders aren't used in compositing. (Yet)
Hmm. GeForce Go 6800/PCI/SSE2 Should have it. Or am I missing something? Am using Nvidia drivers v. 169.07 with X.Org X Server 1.4.0.90 (Release Date: 5 September 2007)
Apparently your setup should support shaders. Maybe you should file a bug report?
Existing case Status INVALID. Aaron's reply was "just because you have opengl doesn't mean you have the shader support required to run certain applets. i'm afraid that the error is accurate, and that the applet is using a feature that isn't available with your card/driver combo"
Now, I am confused ?:|
Well, your title to the bug report makes it looks like all applets using OpenGL don't work. It's a tad misleading, to say the least. Hopefully the info you provided will help straighten things out.
I agree but it wasn't me who created this bug report. About info provided: I am always open to do testing on my computer. It is kinda fun :)
If you have any suggestions what to add to the bug report, just spit it out please. Your input is more than welcome. After all ... we all want to have a better KDE desktop :)
re 1: install kdebindings or at least kdebindings/krosspython depending on how your distributor did split kdebindings. Then you will be able to either
1) run SK just like before. That means, e.g. start the SuperKaramba app and load there the theme or just doubleclick on a *.skz file to have it running or
2) from within the "Add Widget" dialog what runs then the theme as Plasma Widget. In 4.0.x it's needed to have 1) done before 2) is possible cause the SK themes will show up in the Plasma "Add Widget" dialog only after they got run at least once with the SK-app.
Last but not least; in 4.1 this all got already reworked and it will be more easy to run legacy themes and they even will feel a bit more native aka like Plasma applets ;)
First Sebastian thank you.
The reason why we cannot run it is because Debian haven't created kdebindings 4.X package yet. I was just about to create my own deb file while have noticed something which boiled my blood.
What the heck is doing C# in bindings? Well done guys. Lets follow the f****** GNOME tainted Microshit path. Do not forget to include mono in core applications too. Bravo, lets encourage stupid users to run Mono apps, most of them don't care about software freedom anyway.
I believe that you just D O N O T G E T IT!!! This has nothing to do with how good or bad is their technology. This is their technology. MICROSHIT HAS NEVER PLAYED A NICE GAME BEFORE. HOW CAN YOU BE SO STUPID AND NAIVE THAT THEY WILL NOT F**** US UP AS SOON TOO MUCH TAINTED CODE WILL BE INCLUDED IN KDE?!?!?!?!? And just please don't say that we can always remove the code from KDE or that MONO is open sourced (sigh). Tomboy, beagle, F-spot??? Get it?!? Programs are the key and not the libraries. Lets have 70% of the coolest programs written in C#. Who will rewrite these programs and how long will take to rewrite it? You get it now?
Kde should not encourage in any way the usage of C#/MONO. Providing bindings is just the first step into it and will bring us to the dead end sooner or later.
Remember, Microsoft can AND WILL make sure that projects depending on their technology are halted in any possible way you can or you cannot imagine.
The main reason I am using KDE and not GNOME any more is because we somehow managed to avoid their stinky influence. It looks like this is no longer the case.
And there is one thing more which I just don't understand and get it:
Why the heck, are you developers, spending your free time, on their technology?
If you need to use C# in the company you work for, then OK. But you are contributing here YOUR OWN FREE TIME. Each second spending on c# is a grave waste of your time, energy and good will and IT HELPS NO ONE BUT MICROSHIT!!!
I dunno is just me being paranoid and stupid or are most of you blind and ignorant to actually see what Microgrind was and is doing for the last 20+ years?
I do not hate Microshit per se, what I hate is that the only thing they are doing is stabbing us free users and abusing our rights to use free software (or at least they are trying to). They are lying, cheating, stealing and killing their competition - AND YOU DEAR DEVELOPERS ARE HELPING THEM :( Microdeath never stops and it goes so far to actually abuse the ISO national standard bodies to get their property standard through. If possible I simply ignore Microshit, their technology and their products. Ignorance is something which hurts the most.
I have created Debian package (kdebindings_4.0.2-1_i386.deb) without C# parts. Feel free to download it from
P.S. If I want to use Microshit technology then I use Microshit OS.
P.P.S. There is no guaranty that deb package won't conflict with other packages on your system or that it will work at all. It works for me on DEBIAN/sid.
> I do not hate Microshit per se
Right, OK...
:) and people still have a sense of humour. Yes I hate M. per se. The sooner they vanish the better.
"I dunno is just me being paranoid and stupid"
Reading your incoherent, foaming post, I'll have to go with Choice #1 here.
I was just being sarcastic Anon.
I do not hate them I rather dislike them. And try to ignore them if possible.
Hate is really unhealthy feeling ...
I've no idea what you are getting so worked up about. We work on the C# Qyoto/Kimono bindings because it's fun.
Still doesn't work. The same error message complaining about kross when trying to load Liquid weather 14.8.
"SuperKaramba cannot continue to run this theme.One or more of the required components of the Kross scripting architecture is not installed. Please consult this theme's documentation and install the necessary Kross components."
Well I have all kdebindings components now except c# and still doesn't work. Any other ideas?
> Still doesn't work. The same error message complaining about kross when trying to load Liquid weather 14.8.
Sounds like it's installed in the wrong path or with the wrong lib-name or something like this since that message will only show up if loading the lib wasn't possible.
In debian/sid, depending on your kde-install prefix which defaults to /usr iirc, it should also be installed to /usr. So, e.g. something like /usr/lib/kde4/krosspython.so
p.s. related to your other message above;
> you just D O N O T G E T IT!!!
> You get it now?
wow, and you really expect that anybody does listen to something that is written such offensive? Man, I even guess that it's very likely that you achieve the opposite of your intention with such wordings.
I would really like to hear your thoughts on this topic though...?
On what topic? Microsoft bashing? Well, I am not that motivated to spend my time with MS-bashing on a dot-article that deals with the release of KDE 4.0.2 since somehow I guess that's not related.
If it's about Mono/Microsoft/Patents/etc. then I would suggest to read which is a nice and short answer from someone who works on it (I don't and therefore can't really provide any useful answer anyway beside that I think, that C# is much better designed then Java but still not as good as Python and Ruby ;)
So i can assume that you share the thoughts of Miguel de Icaza how he expressed them on the interview?
I just would like to get an unavoiding answer from you, to help me to make my mind about this.
"So i can assume that you share the thoughts of Miguel de Icaza how he expressed them on the interview?"
Just because KDE developers work on Qt/KDE C#/Mono bindings, certainly doesn't mean that we agree with everything that Miguel de Icaza says.
If you use the bindings to develop Qt apps, all you are using is the C# language and the Mono runtime. I feel I'm more at risk of being abducted by aliens than being sued by Microsoft for using Mono. Encouraging C# programmers to learn Qt/KDE programming, and getting extra developers as a consequence, is much more likely to benefit the KDE project than harm it.
> you share the thoughts of Miguel de Icaza
I agree with what Richard wrote and that's why I did provide a link to his answer. Is that unavoiding enough? Well, don't expect more concrete statements from me on things I don't deal with. If you like to have a good MS-bashing then ask me about MSOOXML (but probably not on the dot on this article since it's really offtopic).
"wow, and you really expect that anybody does listen to something that is written such offensive? Man, I even guess that it's very likely that you achieve the opposite of your intention with such wordings."
Well, I guess you are right :). But it is still frustrating that a bunch of intelligent people (read developers) just don't care and blindly lead us to Microsoft trap.
"So, e.g. something like /usr/lib/kde4/krosspython.so"
You are right. Default path was /usr/local/lib/kde4 so I should put a different path in cmake_install.cmake. SET(CMAKE_INSTALL_PREFIX "/usr/lib").
I put ln -s /usr/local/lib/kde4/krosspython.so /usr/lib/kde4/ and could run Liquid without cross error message.
I guess will need to recompile it again and create a deb package too.
But get another error message now :( Probably a broken Liquid Weather:
Kross: "PythonScript::initialize() name=/home/gisovc2006/.kde4/tmp-successfull.job/runningThemes/yGFfDh/liquid_weather.py"
/home/gisovc2006/.kde4/tmp-successfull.job/runningThemes/yGFfDh/liquid_weather.py:3656: SyntaxWarning: import * only allowed at modulelevel
def checkDependencies(widget):
Kross: "PythonInterpreter::extractException:
"
Kross: "Error error='cStringIO.StringO' object has no attribute 'encoding' lineno=34 trace=
"
AttributeError: 'cStringIO.StringO' object has no attribute 'encoding'
Kross: "PythonScript::Destructor."
> cStringIO.StringO' object has no attribute 'encoding'
oh, seems that was a 'bug' (well or a missing feature ;) within krosspython. Fixed now in 4.0 and trunk. LiquidWeather starts up now, but it breaks then for me since LW still uses PyQt3 while PyQt4 is needed now :-/
Anyway, thanks for the feedback/bugreport! :)
re the;
"But it is still frustrating that a bunch of intelligent people (read developers) just don't care and blindly lead us to Microsoft trap."
Software patents are a general problem and not only related to Microsoft and Mono. Probably by writting this mail I already did break a few of them without knowledge. So, we are already in traps and the only protection is to get finally right of software patents and to have meanwhile enough protection to stay in a cold war. Yeah, very sad situation for developers. Probably time to start a second carrier as lawyer :-/
Thank you Sebastian for your effort and time. So we need to wait :|
"Probably by writting this mail I already did break a few of them without knowledge. So, we are already in traps and the only protection is to get finally right of software patents and to have meanwhile enough protection to stay in a cold war."
At least we do not have this problem in Europe, yet.
P.S. I will update the deb package for Debian in the afternoon.
I installed the kdebindings package but it still didn't work :( I keep getting the message that this kross package is missing but it isn't in the openSuse repo.
Thanks anyway.
Hi Bobby,
it is part of the kdebindings-package which was also splitted in a python-package which both include the needed lib. See e.g....
Hi Sebastian,
I greatly appreciate your effort and that you took time out for me. Thanks very much.
I followed the instruction that you gave me and install both packages. What happens now is that I stop getting this message about missing packages but the Liquid Weather widget is not showing up on the desktop even though it's shown as runnning in SuperkKaramba.
I will just wait, maybe it will show up soon ;)
Jedenfalls danke schön.
For anyone interested in. Debian doesn't include kdebindings (you need it to get Kross components) in their repositories.
I have created.
Have fun!
plz send me source code of your package for recompilig and upload to my repo
avilav [at] gmail [dot]
See ya
|
https://dot.kde.org/2008/03/05/kde-402-brings-new-plasma-features?page=4
|
CC-MAIN-2019-51
|
refinedweb
| 3,642
| 74.29
|
Simon Marlow <simonmarhaskell at gmail.com> wrote: > > > > Please correct me if I get anything wrong: > > - the proposal is to let you specify grafting in the source code This is not the main focus of the proposal. Grafting is one oft-requested feature that is not currently supported, but yet it seems very close to the idea of specifying a package dependency in the source code. So my intention is merely to take it into account when designing the latter facility. If one mechanism (with a little tweaking) can achieve both aims, so much the better. The central plank of my proposal is to introduce an explicit concept of "namespace". Namespaces can be managed separately from the imports that range over them. That's it. > - you graft a *sub-hierarchy* of a package anywhere in the > global module namespace (the sub-hiearchy bit is new, I haven't > seen this proposed before). The ability to graft hierarchies is just a side-effect. I would phrase this point as - a "namespace" is a sub-hierarchy of the modules contained in a package. (The sub-hierarchy bit is indeed new.) > - you can also graft a sub-hierarchy of a package onto the > *current module*, so that it becomes available when importing > this module. This is new too. Again, I would rephrase this: - "namespaces" can be imported and exported, separately from the modules they contain. (Yes, this is new too.) Regards, Malcolm
|
http://www.haskell.org/pipermail/libraries/2006-July/005488.html
|
CC-MAIN-2014-42
|
refinedweb
| 238
| 64.51
|
08 February 2013 22:47 [Source: ICIS news]
HOUSTON (ICIS)--The US Department of Agriculture (USDA) on Friday said that domestic corn ending stocks have increased since its January report.
In its February edition of the World Agricultural Supply and Demand Estimates (WASDE), the USDA estimated that corn stocks are now at 632m bushels, a 30m bushel increase. Corn exports are projected to be 50m bushels less in the period of 2012-2013, according to the WASDE.
The WASDE states that US feed grain ending stocks for 2012-2013 are projected higher this month, as lower expected exports outweigh an increase in projected domestic usage. The decreases in exports are based on the sluggish pace of sales and shipments to date, as well as the prospect of more competition from ?xml:namespace>
The report also forecast that the projected range for the season-average price for corn will be lowered by 20 cents at the midpoint and will fall in a range of $6.75-7.65/bushel (€5.06-5.74). This is a viewpoint that will likely viewed by commodity traders and outside investors as neutral to slightly bearish for the upcoming spring corn crop.
Overall corn prices have reacted favourably following the January WASDE report and reached as high as $7.40/bushel last week before several factors, including long-term weather forecasting, profit taking by non-commercial investors and uncertainty of the February report, caused futures pricing to slide over the last several days.
On Friday, corn fell by 1.6 cents to close at $7.09/bushel.
In the global perspective, the USDA has estimated that ending corn stocks have increased by 2.1m tonnes, with the rise coming from production in
Looking to the other major
The USDA has predicted that global soybean ending stocks are going to be at 269.5m tonnes, with
Besides traders and farmers keeping a watchful eye on the two crops, those within the fertilizer industry have been keeping tabs on the market as the spring refilling season for the major nutrients has commenced.
Following the traditional seasonal slowdown and a strong fall application period, market sentiment and pricing for urea and ammonia are beginning to climb higher, as distributors have begun to restock inventories in advance of potentially the largest corn crop to be planted
|
http://www.icis.com/Articles/2013/02/08/9639590/USDA-projects-increase-in-ending-corn-stocks.html
|
CC-MAIN-2014-35
|
refinedweb
| 387
| 55.27
|
Oracle ADF provides data controls that may be based on a number of sources. In this tutorial you create and use a data control based on a Java bean class. You will use wizards to quickly create an application and a project, and a blank JSF page. To create a simple bean object you will generate a starter Java class, then use the source editor to add two String properties and getter and setter methods on the properties. You then create a service bean and add a business method that returns a list of names and their email addresses.
Next you will generate a data control from the service bean. Then you design two simple databound pages by dragging objects from the Data Controls panel. The first page displays the names and email addresses in a table format. The second page allows the end user to enter part of a name in a field, then click a button to display a list of names that contains a match to the value entered. When you test run the pages, the first page in the browser will look like this:
From the main menu, choose File > New > From Gallery . In the New Gallery, expand the General category and select Applications. Iin the Items list, select Custom Application and click OK.
Enter DataBoundApp as the application name and click Next.
Enter Model as the project name and click Finish.
The Projects panel in the Applications window should look like this:
The JDeveloper application is the highest level in the organizational structure. While you are developing your application, it stores information about the objects you are working with. At the same time, it keeps track of your projects and all environment settings. Applications window, right-click the application name and choose New Project. In the New Gallery, you can select any type of project in the Items list.
The application template you select determines the initial project structure, that is, the named project folders within the application workspace, and the application libraries that will be added. The project or projects in the application define the associated features._1<<
A new application created from a template appears in the Applications window already partitioned into tiered projects, with the associated features set in each project. Projects are displayed as the top level in the hierarchy in the Applications window. The Custom Application template that you used for your application creates one project using a default project name (or the project name you entered).
In the Applications window Applications window. Closing an application or project closes all open editors or viewers for files in that application or project and unloads the files from memory.
Note: Nodes in italics in the Applications window mean that the elements have not yet been saved. A project node is bold when a file in the project is selected.
From the main menu, choose Application > Show Overview. The Application Overview window opens in the editor window area.
Applications window, right-click the project you just created and choose New > From Gallery. In the New Gallery, select General > Java > Class, then click OK.
In the Create Java Class dialog, enter Contact as the class name, and acme.bean as the package name. Accept the default values and click OK.
In the source editor, add declrations for two private variables. The declarations should go just after the follwoing generated code.
public Contact() {
super();
}
Add two variables Contact. Make sure public is selected in the Scope dropdown list, then click OK.
In the source editor, add a constructor that instantiates a new object using values passed as arguments.
After the generated method:
public String getEmail() {
return email;
}
Add the following method:
Click
Save All to save your work.
In the Applications window, you should see Contact.java in the acme.bean package in the Application Sources folder.
private String email;
In the source editor, other features available to you while you're editing include:
Press F1 in the source editor if you want to learn more about these features.
this.name = name;
this.email = email;
}
The tabs at the top of the editor window are document tabs.
Selecting a document tab gives that file focus, bringing it to the foreground of the window in the current editor. The tabs at the bottom of the editor window for a given file are the editor tabs. Selecting an editor tab opens the file in that editor or viewer.
In the Applications window, right-click the Model project and choose New > Java Class.
In the Create Java Class dialog, enter AddressBook as the class name. Accept the package name as acme.bean, and the remaining default values, then click OK.
In the source editor, add code to create a collection Java class.
After the first line:
package acme.bean;
Delete all the generated code and replace with the following code:
Click
Save All to save your work.
import java.util.List;
import java.util.regex.Pattern;
public class AddressBook {
// Return all contacts
List<Contact> contacts = new ArrayList();
public List<Contact> findAllContacts() {
return contacts;
}
// Return all contacts matching name (case-insensitive)
public List<Contact> findContactsByName(String name) {
String namePattern = ".*" + (name != null ? name.toUpperCase() : "") + ".*";
List<Contact> matches = new ArrayList();
for (Contact c : contacts) {
if (Pattern.matches(namePattern, c.getName().toUpperCase())) {
matches.add(c);
}
}
return matches;
}
public AddressBook() {
contacts.add(new Contact("Gary", "gary@acme.org"));
contacts.add(new Contact("Charles", "cyoung@acme.org"));
contacts.add(new Contact("Karl", "kheint@acme.org"));
contacts.add(new Contact("Jeff", "jeff@acme.org"));
contacts.add(new Contact("Yvonne", "yvonne_yvonne@acme.org"));
contacts.add(new Contact("Sung", "superstar001@acme.org"));
contacts.add(new Contact("Shailyn", "spatellina@acme.org"));
contacts.add(new Contact("John", "jjb@acme.org"));
contacts.add(new Contact("Ricky", "rmartz@acme.org"));
contacts.add(new Contact("Shaoling", "shaoling@acme.org"));
contacts.add(new Contact("Olga", "olga077@acme.org"));
contacts.add(new Contact("Ron", "regert@acme.org"));
contacts.add(new Contact("Juan", "jperen@acme.org"));
contacts.add(new Contact("Uday", "udaykum@acme.org"));
contacts.add(new Contact("Amin", "amin@acme.org"));
contacts.add(new Contact("Sati", "sparek@acme.org"));
contacts.add(new Contact("Kal", "kalyane.kushnane@acme.org"));
contacts.add(new Contact("Prakash", "prakash01@acme.org"));
}
}
When you complete the steps for creating a service class, the Applications window should look like this:
Any JavaBean that publishes business objects and provides methods that manipulate business objects is defined as a business service. Examples of business services include web services, EJB session beans, or any Java class being used as an interface to some functionality. In the example, the AddressBook service class returns a collection of contact names.
In the Applications window, right-click AddressBook.java and choose Create Data Control.
JavaBeans, including TopLink-enabled objects
ADF Business Components
EJB session beans
Web services
In the Create Bean Data Control dialog, click Next, then Finish to accept the default values..
JDeveloper adds the data control definition file (DataControls.dcx ) to the project, and opens the file in the overview editor.
In the Applications window, expand the Data Controls panel, then expand AddressBook.
If you don't see the data control you created, click
Refresh on the panel toolbar.
Which business services you have registered with the data controls in your model project. The Data Controls panel displays a separate root node for each business service that you register.
A bean design time description definition file that is generated when you create the data control for the bean. The bean definition file classifies the bean's property accessors and methods into various categories.
Oracle ADF data controls provide an abstraction of the business service's data model, giving the ADF binding layer access to the service layer. When designing a user interface, you can bind page UI components to data through the ADF data controls, without writing any code.
ADF data controls provide a consistent mechanism for clients and web application controllers to access data and actions defined by these data-provider technologies:
If you use JavaBeans technology as your business service technology, model information will be exposed to the view and controller layers through ADF data control interfaces implemented by thin, Oracle-provided adapter classes.
The DCX definition file identifies the Oracle ADF model layer adapter classes that facilitate the interaction between the client and the available business services.
There is one DCX file per project and the file is created the first time you register a data control on a business service. The DCX file serves as a "table of contents" listing all the data controls in the project. Out of all the possible service classes you might have in your project, it records those that you've asked the design time to make available as data binding objects.
When expanded, the AddressBook node shows the structure of the business service. While the AddressBook data control node itself is not an item you can use, you may select from among the displayed objects it supports.
The hierarchical structure of a business service is determined by:
From the main menu, choose File > New > Project. In the new Gallery, select General > Projects > Custom Project and click OK.
Enter View as the project name. Then select ADF Faces from the Available list and
shuttle it to the Selected list and click Finish.
In the Applications window, right-click the View project and choose New > Page.
In the Create JSF Page dialog, enter ContactList.jsf as the file name. Make sure Facelets is the selected document type.
The New Gallery
The JSF navigation diagrammer
The ADF task flow diagrammer (available only in the Studio edition of JDeveloper)
On the Page Layout tab, select Blank Page. On the Managed Bean tab, select Do Not Automatically Expose UI Components in a Managed Bean. Click OK to create the page.
In the Components window,.
Selecting features for a project enables you to filter the choices offered by the New Gallery, so that the choices you see are targeted to the type of work you are doing.
Features are set per project. They are used only within JDeveloper to assist you as you work, and have no effect on the data in the project itself. Adding ADF Faces automatically propagates the required associated features in the Selected pane.
You should see the View project in the Applications window.
The JSF pages you create for your application using JavaServer Faces can be Facelets documents (which have file extension .jsf) or JSP documents written in XML syntax (which have file extension .jspx).
You can create both types of JSF pages with the Create JSF Page dialog, opening it from:
By default JDeveloper displays the new JSF Facelets page in the visual editor.
="ContactList.jsf" id="d1"> <af:form</af:form> </af:document> </f:view>
In the project, the folders and files that conform to the Java EE Web module directory structure are:
In the Data Controls panel, expand AddressBook, then expand findAllContacts().
Click and drag Contact to the center facet on the page in the visual editor. From the Create context menu, choose Table > Table.
In the Edit Table Columns dialog, select Enable Sorting and Read-Only Table. and click OK to create the table. Applications window, right-click ContactList>
ContactListPageDef.xml: The page definition file for the JSF page. A page definition file defines the Oracle ADF binding objects that populate the data in UI components at runtime, providing the interaction between the UI components on the page in the View project and the business service components in the Model project.
For every page that uses ADF bindings, there must be a corresponding page definition file that defines the binding objects used by that page. So each time you design a new page using the Data Controls panel and the visual editor, JDeveloper will create a new page definition file. You might need to edit the binding definitions in the page definition files if you remove binding expressions from your view pages.
Page definition files provide design time access to all the ADF bindings. At runtime, the binding objects defined by a page definition file are instantiated in a binding container, which is the runtime instance of the page definition file.
DataBindings.cpx: The file defines the Oracle. At runtime, only the data controls listed in the DataBindings.cpx file are available to the current application.
When you insert a component from the Data Controls panel, a new Oracle ADF binding will be defined in the page's UI model and the inserted component will contain references to Oracle ADF bindings, using EL (expression language) syntax.
The code that the Data Controls panel generates in your web page or client document, and the bindings that it creates depend on the type of document displayed in the visual editor and the combination of business service and visual element you select and drop into the open document.
The Contact tree binding object uses the iterator binding object findAllContactsIterator to get its values. The iterator accesses the method findAllContacts() in the AddressBook data control, and returns a collection..
Note: You can also refer to bindings using data.<PageDefName>.<binding>. The bindings. notation is just a shortcut to refer to the bindings on a page.
At runtime, the EL expression is evaluated and a value is pulled from the binding object to populate the component with data when the page is displayed.
For example, consider the first column in the databound table. The headerText Applications window, should now look like this:
The new files added to the Application Sources folder in the View project include:
In the editor window, click the DataControls.dcx tab to bring the DCX overview editor forward.
If the DCX file is not already open, double-click DataControls.dcx in the Model project in the Applications window to open the file.
Expand AddressBook | findAllContacts(). Then select Contact and click
Edit to open another overview editor.
In the Contact.xml overview editor, click Attributes on the left.
With name selected in the Attributes table, click the UI Hints tab. Then enter Contact Name.xml file. a label for the attribute email, using the label text Email Address.
In the Applications window, right-click ContactList.jsf and choose Run.
You should see the new labels on the page in the browser:
The ADF control hints mechanism supports these control hint properties that you can customize:'s text resources and saves the control hint definitions as translatable strings.
Notice in the Applications window that the file ModelBundle.properties has creates the ModelBundle.properties file. The ModelBundle.properties file contains translatable key strings for the control hint definitions you added. For example, if you open ModelBundle.properties in the source editor, you should see the following code that identifies the translatable string:
#
acme.bean.Contact.name_LABEL=Contact Name
In the Applications window, right-click the View project and choose New > Page.
In the Create JSF Page dialog, enter ContactLookup.jsf as the file name. Make sure Facelets is the selected document type.
On the Page Layout page, select Create Blank Page, and on the Managed Bean tab, select Do Not Automatically Expose UI Components in a Managed Bean. Click OK to create the page.
In the Components window, ADF Faces page, Layout panel, drag
Decorative Box and drop it on the blank page in the visual editor.
In the Data Controls panel, click
Refresh on the panel toolbar, expand AddressBook, then expand findContactsByName(String).
Drag Contact to the center facet on the page in the visual editor. From the Create context menu, choose Table/List View > ADF Table. In the Create Table dialog, select Enable Sorting and Read-Only Table. Accept the remaining default values and click OK.
In the Edit Action Binding dialog, accept the default values and click OK.
In the Components window, Layout panel, drag and drop
Panel Group Layout into the top facet on the page.
In the Properties window, Common section, change the Layout value to scroll.
In the Components window, drag another
Panel Group Layout and drop it into the panel group layout component you just added. In the Properties window, change the Layout value to horizontal.
In the Data Controls panel, under findContactsByName(String), expand Parameters.
Drag name and drop it into the panel group layout component (horizontal) you just added. From the context menu, choose Text > ADF Input Text w/ Label.
In the Properties window, Common section, delete the default Label value and replace with Enter part of name: followed by two spaces.
In the Data Controls panel, drag findContactsByName(String) and drop it into af:panelGroupLayout - horizontal in the Structure window. From the context menu, choose Method > ADF Button.
In the Properties window, delete the default Text value and replace with Find.
In the Structure window, select af:panelGroupLayout - scroll. In the Properties window, Style section, enter padding:5.0px in the InlineStyle field.
The page should look like this in the visual editor:
In the Applications window, right-click ContactLookup.jsf and choose Run.
The page in the browser should look similar to this:
The second panel group layout component with layout="horizontal" is then used to lay out the content components in a horizontal fashion.
Because you previously entered label text for the Contact email and address attributes using control hints, the label text that is stored in the ModelBundle.properties file is applied to the column headers in this table as well.
- Use JDeveloper wizards and dialogs to create applications, starter pages and starter Java classes
- Use the visual editor, Components window, and Properties window to create UI pages
- Create a data control from a simple JavaBean object
- Use the Data Controls panel to create databound UI components without writing any code
- Set labels at a centralized location for the business service
- Use Integrated WebLogic Server to run an ADF Faces application
- Developing Fusion Web Applications with Oracle Application Development Framework
- Creating and Configuring Bean Data Controls
- Developing Applications with Oracle JDeveloper
|
http://docs.oracle.com/cd/E37547_01/tutorials/tut_bean_dc/tut_bean_dc.html
|
CC-MAIN-2015-06
|
refinedweb
| 2,987
| 57.06
|
Sensu Metrics Collection
Sensu Metrics Collection
If you're already using Sensu for your health monitoring, why not for your metrics? Learn here how you can get it set up for Graphite and other services.
Join the DZone community and get the full member experience.Join For Free
Built by operators for operators, the Sensu monitoring event pipeline empowers businesses to automate their monitoring workflows and gain deep visibility into their multi-cloud environments. Get started for free today.
Considering Sensu
When people look for metrics collection for their environment they often look towards the same few solutions like Collectd, Telegraf, etc. This is for good reason: those options provide flexible & extensible metrics collection...and so can Sensu.
Sensu works quite well for metrics. I'd like to show you how to set it up.
If you're already leveraging Sensu for your service health monitoring it makes a lot of sense to extend that out to metrics since all the infrastructure is already there; it just takes a small number of configuration changes to begin gathering metrics across your entire environment.
For this "toe dipping" walkthrough into Sensu metrics collection I'll be focusing on configuring metrics collection for implementation with Graphite; however, since most TSDBs accept graphite formatted metrics, this can certainly be used in other cases.
If you're brand new to Sensu, then I recommend having a read through What is Sensu? and then diving straight in with The Five Minute Install. If you have any questions there are helping hands available in the Sensu Slack channel.
Handler Setup
The first thing we'll look at is setting up the handler configuration that our metrics checks are going to use in order to send data to Graphite.
There are currently two popular methods for handling metrics, both of which come with their own advantages; however, which you choose will most likely come down to the scale of your setup.
If you anticipate the rate of your metrics collection is likely to reach into the tens of thousands of metrics/minute I'd recommend you use option #2; however, for smaller setups, option #1 will see you through just fine.
Option #1: TCP/UDP Handler
Sensu's TCP/UDP handlers simply forward event data to a specified endpoint when invoked and are amongst one of the easiest things to get set up and running with. The potential downside of using a TCP handler for metrics is that a new connection will be initiated to Graphite for every metric output (i.e. every metric check) you send, which in large environments might not be desirable.
If you're running a smaller scale setup, or you're simply experimenting then you need not worry about this being an issue.
To get started let's take a look at our handler definition, that for this example we'll be placing in
/etc/sensu/conf.d/handlers/graphite.json:
{ "handlers": { "graphite": { "type": "tcp", "mutator": "only_check_output", "timeout": 30, "socket": { "host": "graphite.company.tld", "port": 2003 } } } }
Most of the configuration is fairly self-explanatory; we've configured a handler under the name graphite that will forward event data over tcp to graphite.company.tld:2003.
We've also added a mutator to our handler definition called
only_check_output. Without a mutator, Sensu will forward the entire event data onto the specified endpoint; since this is a large JSON blob, Graphite is going to be baffled and will throw away the data. Instead, we need to mutate the data so that we only forward on the useful bit (i.e. just the output).
The
only_check_output mutator is a built-in Sensu extension, which means we don't need to perform any additional configuration to begin using it! This mutator will strip out all the event data leaving just the output of the check.
If you plan to have hostnames in your generated metrics it's worth noting that since they're dot-delimited, they will be parsed into separate namespaces in your Graphite tree. If this behavior is not desirable, mutator-graphite.rb is available as an alternative mutator. As well as stripping out all but the checks output, this mutator will either:
- Reverse the hostname in your metrics to provide a better view in the Graphite "tree" (i.e. hostname.company.tld will become tld.company.hostname)
- Convert the periods in the hostname to underscores, preventing the hostname from being split into separate namespaces.
If you choose not to use the built-in
only_check_output and rather use the graphite mutator mentioned above then you will need to change the mutator name in the handler configuration above to graphite_mutator and then follow the steps below. Otherwise you're all done, the handler setup is complete.
The graphite mutator can be installed via the sensu-plugins-graphite gem with the below command:
sensu-install -p sensu-plugins-graphite
Now that the plugin is installed we can create a definition for the mutator; in this example we'll place it in
/etc/sensu/conf.d/mutators/graphite_mutator.json:
{ "mutators": { "graphite_mutator": { "command": "/opt/sensu/embedded/bin/mutator-graphite.rb", "timeout": 10 } } }
If you want to reverse the hostname in the metrics, rather than convert the periods to underscores, then add
--reverse to the above command.
That's it! The handler is now ready to go!
Option #2: Sensu Metrics Relay/WizardVan
WizardVan is an extension developed by Sensu lover-turned-employee, Greg Poirier. WizardVan (also known as Sensu Metrics Relay) will scale to meet the demands of large installations; as it benefits from being able to keep persistent connections open to your TSDB meaning it serves great in firehouse situations.
WizardVan also supports outputting to OpenTSDB and can accept metrics input in JSON format which is certainly a desirable feature for some.
So let's look at setting up WizardVan for use with our metrics collection. Currently WizardVan is not a part of the sensu-extensions organisation so the install process is still a bit manual, but perfectly doable, by following the below steps:
# Clone the WizardVan repo yum install -y git git clone # Copy into Sensu extensions directory cd sensu-metrics-relay cp -R lib/sensu/extensions/* /etc/sensu/extensions
Now we can create the config for the metrics relay, in this example I'm going to place it in
/etc/sensu/conf.d/extensions/relay.json:
{ "relay": { "graphite": { "host": "graphite.company.tld", "port": 2003, "max_queue_size": 16384 } } }
WizardVan will buffer metrics up to a specified size before flushing to the network. This is controlled with the
max_queue_size parameter shown above (default is 16KB). If you want metrics to be flushed immediately you can set this to 0.
You can also specify additional output types in the above relay config, see the README.md for an example.
Metrics Check Setup
Now that we have a working handler we can look at setting up our first check that we can utilize to generate metrics.
The first thing to do is find a check that will generate the metrics you desire. The sensu-plugins organization is chock-a-block full of plugins that come bundled with metrics checks, or alternatively you could choose to write your own. For this example we're going to gather metrics on CPU usage using metrics-cpu.rb found in the sensu-plugins-cpu-checks gem.
We can install this plugin using the sensu-install utility:
sensu-install -p sensu-plugins-cpu-checks
Now we can write our check definition. The below example should be used if you've decided to use a TCP/UDP handler; there are also some recommended modifications later on if you're instead using WizardVan/Metrics Relay.
In this example we'll place it in
/etc/sensu/conf.d/checks/cpu_metrics.json:
{ "checks": { "system_cpu_metrics": { "type": "metric", "command": "/opt/sensu/embedded/bin/metrics-cpu.rb --scheme sensu.:::service|undefined:::.:::environment|undefined:::.:::zone|undefined:::.:::name:::.cpu", "subscribers": [ "system" ], "handlers": [ "graphite" ], "interval": 60, "ttl": 180 } } }
It's important that
"type": "metric" is defined; this ensures that every event for the check is handled, regardless of the event status (i.e. even OK results will be handled)
Metric Naming
Most of the community metrics checks will have a default metric naming scheme of
$hostname.$check_purpose appended by the metrics themselves. Using the plugin above as an example a single metric will look something like this:
ip-10-155-16-194.cpu.total.user 5824723 1511389085.
If you're using very descriptive and static hostnames this can work pretty well, however, chances are that your hostnames are randomly generated and change all the time. Most of the metrics check will provide a command line flag (typically
--scheme) to override this default naming scheme. With this in mind, we chose to set service-identifying attributes on all our Sensu clients, and then substitute these into our metrics commands to give meaningful metric names; making use of Sensu's token substitution.
If you're interested here's the attributes we chose to set:
- Service: This is defined as the name of the application or service. Examples could be a custom in-house application (i.e. customer-billing-service), or an open-source application (i.e. logstash)
- Environment: This is a flexible attribute that can be used to define the specific environment of an application (i.e. dev/qa/prod), or a specific layer of a stack (i.e. shipping/indexing)
- Zone: We use zone to identify the physical location of the node in question (i.e. eu-west-1,nonprod-dc2)
- Name: This is simply the Sensu client name, which will typically be your machine's hostname
With the above attributes set, we can substitute them into the check command so that every metric has a well-defined schema, that allows easy navigation of metrics:
"command": "/opt/sensu/embedded/bin/metrics-cpu.rb --scheme sensu.:::service|undefined:::.:::environment|undefined:::.:::zone|undefined:::.:::name:::.cpu",
Since we were already using Graphite with other metrics sources it was felt best to put all the Sensu generated metrics under a single top-level key: Sensu. This makes it clear which metrics have been generated via Sensu which helps with distinguishing sources of metrics, as well as making it easier to calculate usage/volume of Sensu metrics.
Service Level Metrics
Some metrics you collect might not be node specific metrics, but rather metrics that cover a clustered service, or are pulled from a 3rd party API. In these cases it makes little sense to have the metrics be name spaced under the hostname they were generated on, rather you probably want them in one clear place.
We found the easiest way to achieve this was to run check definitions similar to the below for those cases:
{ "checks": { "elastic_elasticsearch_cluster_metrics": { "type": "metric", "command": "/opt/sensu/embedded/bin/metrics-es-cluster.rb --allow-non-master --scheme sensu.:::service|undefined:::.:::environment|undefined:::.:::zone|undefined:::.cluster", "subscribers": [ "roundrobin:elasticsearch" ], "handlers": [ "graphite" ], "interval": 60, "ttl": 180, "source": "elasticsearch" } } }
The key differences here are:
- The hostname is excluded from the metric name, instead replaced with something to identify the scope that the metrics represent; in this case an Elasticsearch cluster.
- The check is issued via a roundrobin subscription, as it just needs to be ran on one of any of the Elasticsearch nodes at a time.
- A source of elasticsearch is set. Since we're using a roundrobin subscription you'll want to use a proxy client so that the metric results all appear under the same client so that the TTL still works and you also know where to look if you want to see the current status of the check!
WizardVan Considerations
As mentioned above if you have chosen to use WizardVan there are some changes you will need to make on the example check definition provided above.
In the example above we specified our handler name as
graphite, since that is what we defined in our TCP handler. When using WizardVan however the handler you will need to set is instead called
relay:
"handlers": [ "relay" ],
Next, if your check is not going to be outputting in Graphite format but rather another supported type, you will need to specify the output type in your check, i.e.
"output_type": "json".
Lastly, default WizardVan behavior is to prepend the node's hostname (in reverse) to the generated metrics; as such you may want to adjust the naming schema you choose in your checks. Personally, I'd choose to disable this behavior and instead be explicit in how you choose to name your metrics. This can be achieved by setting
"auto_tag_host": "no" in your check definition. Unfortunately, this can not currently be controlled via global configuration, however, you could change the following line to change the default behavior of this flag.
Wrap Up
At this point, you should have metrics streaming into your TSDB from Sensu, and hopefully, it was straightforward to get set up.
To review: I proposed two methods, of which I've found to be the most popular, for getting your metrics into Sensu. There are, however, even more implementations available that could suit your environment better:
- InfluxDB:
- Statsd:
If you're wondering where to go now you might consider using Grafana to set up templated dashboards based on your metrics. You can then set a URL in your client attributes to link straight through to a dashboard for a given client. You could also embed the graphs directly into the client as this blog post guides you to do.
No matter how you proceed, if you need a hand thinking through how to configure your environment, you can find me on the Community Slack. I'm happy to help. Good luck!
Thanks to Matthew (Brender) Broberg and Sean Porter.
Download our guide to mitigating alert fatigue, with real-world tips on automating remediation and triage from an IT veteran.
Published at DZone with permission of Michael Eves , DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}{{ parent.urlSource.name }}
|
https://dzone.com/articles/sensu-metrics-collection
|
CC-MAIN-2019-13
|
refinedweb
| 2,338
| 51.68
|
Animated GIFs are an image type that contains multiple images with slight differences. These are then played back kind of like a cartoon is. You could even think of it as a flip-book with a stick man that is slightly different on each page. When you flip the book, the image appears to move.
You can create your own animated GIFs using the Python programming language and the Pillow package.
Let’s get started!
What You Need
You will need to have Python installed on your machine. You can install it from the Python website or use Anaconda. You will also need to have Pillow. If you are using Anaconda, Pillow is already installed.
Otherwise, you will need to install Pillow. Here is how to do that using pip:
python3 -m pip install Pillow
Once Pillow is installed, you are ready to create a GIF!
Creating an Animation
You need to have multiple frames of animation to create an animated GIF. If you have a good point-and-shoot or a DSLR camera, you can usually use their high-speed settings to take a series of photos very quickly.
If you want your GIF to look nice, you should use a tripod or put your camera onto a sturdy surface before taking those photos.
You can also use Pillow to draw a series of images and turn that series into a GIF. You will learn how to use both of these methods to create an animated GIF in this article.
The first method you will learn about is how to take a series of images (JPGs) and turn them into an animated GIF. Create a new file and name it gif_maker.py. Then enter the following code:
import glob from PIL import Image def make_gif(frame_folder): frames = [Image.open(image) for image in glob.glob(f"{frame_folder}/*.JPG")] frame_one = frames[0] frame_one.save("my_awesome.gif", format="GIF", append_images=frames, save_all=True, duration=100, loop=0) if __name__ == "__main__": make_gif("/path/to/images")
Here you import Python’s glob module and Pillow’s Image class. You use glob to search for JPG files in the path that you pass to your make_gif() function.
Note: You will need to pass in a real path instead of using the placeholder that is in the code above
The next step is to create a Python list of Image objects. If your images are large, you may want to add a step to resize them so that the GIF itself isn’t huge! If you don’t, you are effectively taking in all those images and turning them into one giant file. Check out How to Resize Photos with Pillow to learn more!
Once you have your Python list of images, you tell Pillow to save() it as a GIF using the first Image in your Python list. To make that happen, you need to specifically tell Pillow that the format is set to “GIF”. You also pass in your frames of animation to the append_images parameter. You must also set the save_all parameter to True.
You can set the duration of each frame in milliseconds. In this example, you set it to 100 ms. Finally, you set loop to 0 (zero), which means that you want the GIF to loop forever. If you set it to a number greater than zero, it would loop that many times and then stop.
If you’d like to test this code out on something, you can use this zip archive of hummingbird images. When you run this code against this unzipped folder, your GIF will look like this:
The reason this GIF is not very smooth is that these photos were taken without a tripod. Try taking some shots of something moving using a tripod and then re-run this code and it will be much smoother.
Now you’re ready to learn how to create an animation by drawing with Pillow!
Drawing An Animation with Pillow
Pillow lets you draw various shapes as image objects. You can use this to create your own animation! If you’d like to learn more about what kinds of drawings you can create with Pillow, then you might like this article: Drawing Shapes on Images with Python and Pillow.
For this example, you will draw circles using Pillow’s ellipse shape. You can also draw arcs, lines, rectangles, polygons, lines and more.
To get started, create a new file and add the following code:
from PIL import Image, ImageDraw def ellipse(x, y, offset): image = Image.new("RGB", (400, 400), "blue") draw = ImageDraw.Draw(image) draw.ellipse((x, y, x+offset, y+offset), fill="red") return image def make_gif(): frames = [] x = 0 y = 0 offset = 50 for number in range(20): frames.append(ellipse(x, y, offset)) x += 35 y += 35 frame_one = frames[0] frame_one.save("circle.gif", format="GIF", append_images=frames, save_all=True, duration=100, loop=0) if __name__ == "__main__": make_gif()
The code in the make_gif() function is nearly identical to the previous example. The main difference is how you build your Python list of frames. In this case, you create a loop that creates 20 images and appends them to the frames list.
To create your circles, you call the ellipse() function. It accepts the x and y position that you want to draw the ellipse at. It also includes an offset value. The offset is used to determine how large to draw the image. Pillow’s ellipse() method takes in the beginning x/y coordinate of the radius of your ellipse and the ending x/y coordinate of the radius. Then it draws the ellipse.
When the ellipse is drawn, it is added to a new image that is 400 x 400 pixels. This image has a blue background. The circle (or ellipse) has a blue background.
Go ahead and run your code. The output will look like this:
Isn’t that great? Try changing the shape that you draw. Or edit your code to use different colors. You could add more than one ball to your animation too!
Wrapping Up
You can lots more with the Pillow package. You can edit photos, apply effects,, change image contrast and so much more. Have fun learning more about Pillow and Python! It’s great.
|
https://www.blog.pythonlibrary.org/2021/06/23/creating-an-animated-gif-with-python/
|
CC-MAIN-2021-31
|
refinedweb
| 1,047
| 73.88
|
Hi…I am just starting out with exploring Entrez Eutils using Biopython. What I need to do is find the amino acid change for a list of rsIDs of missense SNPs. I cannot figure out how to do that. I guess the answer would lie in the xml generated by this query:
handle = Entrez.efetch(db="snp", id="6046", retmode="xml")
But when I try
record = Entrez.read(handle)
It gives me an error like: The Bio.Entrez parser cannot handle XML data that make use of XML namespaces.
I don’t know why this is happening. Maybe I am missing something obvious here…
Is it even possible to get my required information using eutils? If not, can you suggest any other means (except doing it manually for every SNP)?
Thanks in advance.
|
https://www.biostars.org/p/12235/
|
CC-MAIN-2020-40
|
refinedweb
| 133
| 77.03
|
Ok, I tried to filter the word set before going into loops. This appears to reduce the search space by a factor of 30.
Run time is down to ~5 minutes.
Word counts for 2of12inf.txt, along with word "power":
============================
WORDS COMBINATIONS
len:number k:number
----------------------------
2: 62 6: 736281
3: 642 5: 142506
4: 2546 4: 23751
5: 5122 3: 3276
6: 8303 2: 351
7: 11571 1: 26
8: 12687 0: 1
============================
Expected hits: 12687*1 + 11571*26 + 8303*351 + 5122*3276 + 2546*23751
++ 642*142506 + 62*736281
= 217615878
Counted hits (with filtering):
= 217615878
[download]
Update2: added coverage check
#! /usr/bin/perl
use threads;
use threads::shared;
use Thread::Semaphore;
use Config;
use if $Config{longsize} >= 8, "integer";
my $HITS :shared = 0;
my $TOTAL;
my $tresh = 0;
my (%P, %N, %RES);
sub x2 { map { my $t = $_; map {$t.$_} @_ } @_ }
sub wfilt { tr/a-z//cd; length() <= 8; }
sub wv { my $x = 1; $x *= $P{$_} for split //; $x }
@P{'a'..'z'} = grep {(1x$_)!~/^(11+)\1+$/} 2..101; # Primes
# combinations with repetition over 'a'..'z':
my @C = ( 1, 26, 351, 3276, 23751, 142506, 736281, 3365856, 13884156 )
+;
open(WORDS, "words") or die;
my @words = grep wfilt, <WORDS>;
$N{wv()}++ for @words;
$TOTAL += $C[8-length] for @words;
my $SEM = Thread::Semaphore->new(8); # 8 threads
for ('a'..'z') {
$SEM->down();
report(0, map {$_->join()} threads->list(threads::joinable));
()=threads->new(sub {&worker, ()=$SEM->up()}, $_);
}
report(0, map {$_->join()} threads->list());
sub worker {
my ($pivot) = @_; # aaaPzzzz
my (%A, %Z);
$A{wv()} //= $_ for grep s/.$/$pivot/, x2(x2('a'..$pivot));
$Z{wv()} //= $_ for x2(x2($pivot..'z'));
my $aaa = sub { join '', /[^$pivot-z]/g };
my $zzzz = sub { join '', /[^a-$pivot]/g };
# map full wv to just the aaa factors:
my %Va = map {wv} map {$_ => &$aaa}
grep {length &$aaa < 4 and length &$zzzz < 5} @words;
for my $a (keys %A) {
my @V = grep {$a % $Va{$_} == 0} keys %Va;
my ($hits, @R);
for my $z (keys %Z) {
my ($v, $n) = ($a*$z, 0);
$v % $_ or $n += $N{$_} for @V;
$hits += $n;
push @R, ($A{$a}.$Z{$z} => $n) if ($n > $tresh);
}
report($hits, @R);
}
return (%RES);
}
sub report {
lock($HITS); $HITS += shift;
return unless @_;
%RES = (%RES, @_);
my @top = sort { $RES{$b} <=> $RES{$a} } keys %RES;
($tresh) = delete @RES{splice(@top, 20)} if @top > 20;
print "$_: $RES{$_}\n" for @top;
no integer;
printf "! coverage %s/%s (% 3.1f%%)\n@{['-'x40]}\n",
$HITS, $TOTAL, 100.0*$HITS/$TOTAL;
}
[download]
In reply to Re^2: Challenge: 8 Letters, Most Words
by oiskuu
in thread Challenge: 8 Letters, Most Words
|
http://www.perlmonks.org/index.pl?parent=1057558;node_id=3333
|
CC-MAIN-2014-23
|
refinedweb
| 440
| 84
|
A Comprehensive Look at The Empirical Performance of Equity Premium Prediction
- Clement Mathews
- 1 years ago
- Views:
Transcription
1 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Ivo Welch Brown University Department of Economics NBER Amit Goyal Emory University Goizueta Business School Our article comprehensively reexamines the performance of variables that have been suggested by the academic literature to be good predictors of the equity premium. We find that by and large, these models G12, G14) Attempts to predict stock market returns or the equity premium have a long tradition in finance. As early as 1920, Dow (1920) explored the role of dividend ratios. A typical specification regresses an independent lagged predictor on the stock market rate of return or, as we shall do, on the equity premium, Equity Premium(t) = γ 0 + γ 1 x(t 1) + ɛ(t). (1) γ 1 is interpreted as a measure of how significant x is in predicting the equity premium. The most prominent x variables explored in the literature are the dividend price ratio and dividend yield, the earnings price ratio and dividend-earnings (payout) ratio, various interest rates and spreads, the inflation rates, the book-to-market ratio, volatility, the investment-capital ratio, the consumption, wealth, and income ratio, and aggregate net or equity issuing activity. The literature is difficult to absorb. Different articles use different techniques, variables, and time periods. Results from articles that were written years ago may change when more recent data is used. Some articles Thanks to Malcolm Baker, Ray Ball, John Campbell, John Cochrane, Francis Diebold, Ravi Jagannathan, Owen Lamont, Sydney Ludvigson, Rajnish Mehra, Michael Roberts, Jay Shanken, Samuel Thompson, Jeff Wurgler, and Yihong Xia for comments, and Todd Clark for providing us with some critical McCracken values. We especially appreciate John Campbell and Sam Thompson for challenging our earlier drafts, and iterating mutually over working papers with opposite perspectives. Address correspondence to Amit Goyal, mailto:amit mailto:ivo brown.edu, or amit The Author Published by Oxford University Press on behalf of The Society for Financial Studies. All rights reserved. For Permissions, please doi: /rfs/hhm014 Advance Access publication March 17, 2007
2 The Review of Financial Studies / v 21 n contradict the findings of others. Still, most readers are left with the impression that prediction works though it is unclear exactly what works. The prevailing tone in the literature is perhaps best summarized by Lettau and Ludvigson (2001, p.842) It is now widely accepted that excess returns are predictable by variables such as dividend-price ratios, earnings-price ratios, dividend-earnings ratios, and an assortment of other financial indicators. There are also a healthy number of current article that further cement this perspective and a large theoretical and normative literature has developed that stipulates how investors should allocate their wealth as a function of the aforementioned variables. The goal of our own article is to comprehensively re-examine the empirical evidence as of early 2006, evaluating each variable using the same methods (mostly, but not only, in linear models), time-periods, and estimation frequencies. The evidence suggests that most models are unstable or even spurious. Most models are no longer significant even insample (IS), and the few models that still are usually fail simple regression diagnostics. Most models have performed poorly for over 30 years IS. For many models, any earlier apparent statistical significance was often based exclusively on years up to and especially on the years of the Oil Shock of Most models have poor out-of-sample (OOS) performance, but not in a way that merely suggests lower power than IS tests. They predict poorly late in the sample, not early in the sample. (For many variables, we have difficulty finding robust statistical significance even when they are examined only during their most favorable contiguous OOS sub-period.) Finally, the OOS performance is not only a useful model diagnostic for the IS regressions but also interesting in itself for an investor who had sought to use these models for market-timing. Our evidence suggests that the models would not have helped such an investor. Therefore, although it is possible to search for, to occasionally stumble upon, and then to defend some seemingly statistically significant models, we interpret our results to suggest that a healthy skepticism is appropriate when it comes to predicting the equity premium, at least as of early The models do not seem robust. Our article now proceeds as follows. We describe our data available at the RFS website in Section 1 and our tests in Section 2. Section 3 explores our base case predicting equity premia annually using OLS forecasts. In Sections 4 and 5, we predict equity premia on 5-year and monthly horizons, the latter with special emphasis on the suggestions in Campbell and Thompson (2005). Section 6 tries earnings and dividend ratios with longer memory as independent variables, corrections for persistence in 1456
3 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction regressors, and encompassing model forecasts. Section 7 reviews earlier literature. Section 8 concludes. 1. Data Sources and Data Construction Our dependent variable is always the equity premium, that is, the total rate of return on the stock market minus the prevailing short-term interest rate. Stock Returns : We use S&P 500 index returns from 1926 to 2005 from Center for Research in Security Press (CRSP) month-end values. Stock returns are the continuously compounded returns on the S&P 500 index, including dividends. For yearly and longer data frequencies, we can go back as far as 1871, using data from Robert Shiller s website. For monthly frequency, we can only begin in the CRSP period, that is, Risk-free Rate : The risk-free rate from 1920 to 2005 is the Treasury-bill rate. Because there was no risk-free short-term debt prior to the 1920s, we had to estimate it. Commercial paper rates for New York City are from the National Bureau of Economic Research (NBER) Macrohistory data base. These are available from 1871 to We estimated a regression from 1920 to 1971, which yielded Treasury-bill rate = Commercial Paper Rate, (2) with an R 2 of 95.7%. Therefore, we instrumented the risk-free rate from 1871 to 1919 with the predicted regression equation. The correlation for the period 1920 to 1971 between the equity premium computed using the actual Treasury-bill rate and that computed using the predicted Treasury-bill rate (using the commercial paper rate) is 99.8%. The equity premium had a mean (standard deviation) of 4.85% (17.79%) over the entire sample from 1872 to 2005; 6.04% (19.17%) from 1927 to 2005; and 4.03% (15.70%) from 1965 to Our first set of independent variables are primarily stock characteristics: Dividends : Dividends are 12-month moving sums of dividends paid on the S&P 500 index. The data are from Robert Shiller s website from 1871 to Dividends from 1988 to 2005 are from the S&P Corporation. The Dividend Price Ratio (d/p) is the difference between the log of dividends and the log of prices. The Dividend Yield (d/y) is the difference between the log of dividends and the log of lagged prices. [See, e.g., Ball (1978), Campbell (1987), Campbell and Shiller (1988a, 1988b), Campbell and Viceira (2002), Campbell and Yogo (2006), the survey in Cochrane (1997), Fama and French (1988), Hodrick (1992), Lewellen (2004), Menzly, Santos, and Veronesi (2004), Rozeff (1984), and Shiller (1984).] Earnings : Earnings are 12-month moving sums of earnings on the S&P 500 index. The data are again from Robert Shiller s website from 1871 to Earnings from 1988 to 2005 are our own estimates based on 1457
4 The Review of Financial Studies / v 21 n interpolation of quarterly earnings provided by the S&P Corporation. The Earnings Price Ratio (e/p) is the difference between the log of earnings and the log of prices. (We also consider variations, in which we explore multiyear moving averages of numerator or denominator, e.g., as in e 10 /p, which is the moving ten-year average of earnings divided by price.) The Dividend Payout Ratio (d/e) is the difference between the log of dividends and the log of earnings. [See, e.g., Campbell and Shiller (1988a, 1998) and Lamont (1998).] Stock Variance (svar) : Stock Variance is computed as sum of squared daily returns on the S&P 500. G. William Schwert provided daily returns from 1871 to 1926; data from 1926 to 2005 are from CRSP. [See Guo (2006).] Cross-Sectional Premium (csp) : The cross-sectional beta premium measures the relative valuations of high- and low-beta stocks and is proposed in Polk, Thompson, and Vuolteenaho (2006). The csp data are from Samuel Thompson from May 1937 to December Book Value : Book values from 1920 to 2005 are from Value Line s website, specifically their Long-Term Perspective Chart of the Dow Jones Industrial Average. The Book-to-Market Ratio (b/m) is the ratio of book value to market value for the Dow Jones Industrial Average. For the months from March to December, this is computed by dividing book value at the end of the previous year by the price at the end of the current month. For the months of January and February, this is computed by dividing book value at the end of two years ago by the price at the end of the current month. [See, e.g, Kothari and Shanken (1997) and Pontiff and Schall (1998).] Corporate Issuing Activity : We entertain two measures osf corporate issuing activity. Net Equity Expansion (ntis) is the ratio of 12-month moving sums of net issues by NYSE listed stocks divided by the total end-of-year market capitalization of NYSE stocks. This dollar amount of net equity issuing activity (IPOs, SEOs, stock repurchases, less dividends) for NYSE listed stocks is computed from CRSP data as Net Issue t = Mcap t Mcap t 1 (1 + vwretx t ), (3) where Mcap is the total market capitalization, and vwretx is the value weighted return (excluding dividends) on the NYSE index. 1 These data are available from 1926 to ntis is closely related, but not identical, to a variable proposed in Boudoukh, Michaely, Richardson, and Roberts (2007). The second measure, Percent Equity Issuing (eqis), is the ratio of equity issuing activity as a fraction of total issuing activity. This is the variable proposed in Baker and Wurgler (2000). The authors provided us with the data, except for 2005, which we added ourselves. The first equity 1 This calculation implicitly assumes that the delisting return is 100 percent. Using the actual delisting return, where available, or ignoring delistings altogether, has no impact on our results. 1458
5 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction issuing measure is relative to aggregate market cap, while the second is relative to aggregate corporate issuing. Our next set of independent variables is interest-rate related: Treasury Bills (tbl) : Treasury-bill rates from 1920 to 1933 are the U.S. Yields On Short-Term United States Securities, Three-Six Month Treasury Notes and Certificates, Three Month Treasury series in the NBER Macrohistory data base. Treasury-bill rates from 1934 to 2005 are the 3- Month Treasury Bill: Secondary Market Rate from the economic research data base at the Federal Reserve Bank at St. Louis (FRED. [See, e.g., Campbell (1987) and Hodrick (1992).] Long Term Yield (lty) : Our long-term government bond yield data from 1919 to 1925 is the U.S. Yield On Long-Term United States Bonds series in the NBER s Macrohistory data base. Yields from 1926 to 2005 are from Ibbotson s Stocks, Bonds, Bills and Inflation Yearbook, the same source that provided the Long Term Rate of Returns (ltr). The Term Spread (tms) is the difference between the long term yield on government bonds and the Treasury-bill. [See, e.g., Campbell (1987) and Fama and French (1989).] Corporate Bond Returns : Long-term corporate bond returns from 1926 to 2005 are again from Ibbotson s Stocks, Bonds, Bills and Inflation Yearbook. Corporate Bond Yields on AAA and BAA-rated bonds from 1919 to 2005 are from FRED. The Default Yield Spread (dfy) is the difference between BAA and AAA-rated corporate bond yields. TheDefault Return Spread (dfr) is the difference between long-term corporate bond and long-term government bond returns. [See, e.g., Fama and French (1989) and Keim and Stambaugh (1986).] Inflation (infl) : Inflation is the Consumer Price Index (All Urban Consumers) from 1919 to 2005 from the Bureau of Labor Statistics. Because inflation information is released only in the following month, we wait for one month before using it in our monthly regressions. [See, e.g., Campbell and Vuolteenaho (2004), Fama (1981), Fama and Schwert (1977), and Lintner (1975).] Like inflation, our next variable is also a common broad macroeconomic indicator. Investment to Capital Ratio (i/k) : The investment to capital ratio is the ratio of aggregate (private nonresidential fixed) investment to aggregate capital for the whole economy. This is the variable proposed in Cochrane (1991). John Cochrane kindly provided us with updated data. Of course, many articles explore multiple variables. For example, Ang and Bekaert (2003) explore both interest rate and dividend related variables. In addition to simple univariate prediction models, we also entertain two methods that rely on multiple variables (all and ms), and two models that are rolling in their independent variable construction (cay and ms). 1459
6 The Review of Financial Studies / v 21 n A Kitchen Sink Regression (all): This includes all the aforementioned variables. (It does not include cay, described below, partly due to limited data availability of cay.) Consumption, wealth, income ratio (cay): Lettau and Ludvigson (2001) estimate the following equation: c t = α + β a a t + β y y t + + k b a,i a t i i= k k b y,i y t i + ɛ t, t = k + 1,...,T k, (4) i= k where c is the aggregate consumption, a is the aggregate wealth, and y is the aggregate income. Using estimated coefficients from the above equation provides cay ĉay t = c t ˆβ a a t ˆβ y y t, t = 1,...,T. Note that, unlike the estimation equation, the fitting equation does not use look-ahead data. Eight leads/lags are used in quarterly estimation (k = 8) while two lags are used in annual estimation (k = 2). [For further details, see Lettau and Ludvigson (2001).] Data for cay s construction are available from Martin Lettau s website at quarterly frequency from the second quarter of 1952 to the fourth quarter of Although annual data from 1948 to 2001 is also available from Martin Lettau s website, we reconstruct the data following their procedure as this allows us to expand the time-series from 1945 to 2005 (an addition of 7 observations). Because the Lettau Ludvigson measure of cay is constructed using lookahead (in-sample) estimation regression coefficients, we also created an equivalent measure that excludes advance knowledge from the estimation equation and thus uses only prevailing data. In other words, if the current time period is s, then we estimated Equation (4) using only the data up to s through c t = α + β s a a t + β s y y t + + k b a,i a s t i i= k k b y,i y s t i + ɛ t,t= k + 1,...,s k, (5) i= k This measure is called caya ( ante ) to distinguish it from the traditional variable cayp constructed with look-ahead bias ( post ). The superscript on the betas indicates that these are rolling estimates, that is, a set of coefficients used in the construction of one caya S measure in one period. A model selection approach, named ms. If there are K variables, we consider 2 K models essentially consisting of all possible combinations 1460
7 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction of variables. (As with the kitchen sink model, cay is not a part of the ms selection.) Every period, we select one of these models that gives the minimum cumulative prediction errors up to time t. This method is based on Rissanen (1986) and is recommended by Bossaerts and Hillion (1999). Essentially, this method uses our criterion of minimum OOS prediction errors to choose among competing models in each time period t. Thisis also similar in spirit to the use of a more conventional criterion (like R 2 ) in Pesaran and Timmermann (1995) (who do not entertain our NULL hypothesis). This selection model also shares a certain flavor with our encompassing tests in Section 6, where we seek to find an optimal rolling combination between each model and an unconditional historical equity premium average, and with the Bayesian model selection approach in Avramov (2002). The latter two models, cay and ms, are revised every period, which render IS regressions problematic. This is also why we did not include caya in the kitchen sink specification. 2. Empirical Procedure Our base regression coefficients are estimated using OLS, although statistical significance is always computed from bootstrapped F -statistics (taking correlation of independent variables into account). OOS statistics: The OOS forecast uses only the data available up to the time at which the forecast is made. Let e N denote the vector of rolling OOS errors from the historical mean model and e A denote the vector of rolling OOS errors from the OLS model. Our OOS statistics are computed as R 2 = 1 MSE A MSE N, R 2 = R 2 (1 R 2 ) ( T k T 1 RMSE = MSE N MSE A, ( ) MSEN MSE A MSE-F = (T h + 1), (6) MSE A where h is the degree of overlap (h = 1 for no overlap). MSE-F is McCracken s (2004) F -statistic. It tests for equal MSE of the unconditional forecast and the conditional forecast (i.e., MSE = 0). 2 We generally do ), 2 Our earlier drafts also entertained another performance metric, the mean absolute error difference MAE. The results were similar. [ ] These drafts also described another OOS-statistic, MSE-T = T h + h (h 1)/T d ŝe ( d ),whered t = e Nt e At,andd = T 1 T t d t = MSE N MSE A over the entire OOS period, and T is the total number of forecast observations. This is the Diebold and Mariano (1995) t-statistic modified by Harve, Leybourne, and Newbold (1997). (We still use the latter as bounds in our plots, because we know the full distribution.) Again, the results were similar. We chose to use the MSE-F in this article because Clark and McCracken (2001) find that MSE-F has higher power than MSE-T. 1461
8 The Review of Financial Studies / v 21 n not report MSE-F statistics, but instead use their bootstrapped critical levels to provide statistical significance levels via stars in the tables. For our encompassing tests in Section 6, we compute ENC = T h + 1 T T t=1 ( e 2 Nt e Nt e At ) MSE A, (7) which is proposed by Clark and McCracken (2001). They also show that the MSE-F and ENC statistics follow nonstandard distributions when testing nested models, because the asymptotic difference in squared forecast errors is exactly 0 with 0 variance under the NULL, rendering the standard distributions asymptotically invalid. Because our models are nested, we could use asymptotic critical values for MSE tests provided by McCracken, and asymptotic critical values for ENC tests provided by Clark and McCracken. However, because we use relatively small samples, because our independent variables are often highly serially correlated, and especially because we need critical values for our 5-year overlapping observations (for which asymptotic critical values are not available), we obtain critical values from the bootstrap procedure described below. (The exceptions are that critical values for caya, cayp, andall models are not calculated using a bootstrap, and critical values for ms model are not calculated at all.) The NULL hypothesis is that the unconditional forecast is not inferior to the conditional forecast, so our critical values for OOS test are for a one-sided test (critical values of IS tests are, as usual, based on two-sided tests). 3 Bootstrap : Our bootstrap follows Mark (1995) and Kilian (1999) and imposes the NULL of no predictability for calculating the critical values. In other words, the data generating process is assumed to be y t+1 = α + u 1t+1 x t+1 = µ + ρ x t + u 2t+1. The bootstrap for calculating power assumes the data generating process is y t+1 = α + β x t + u 1t+1 x t+1 = µ + ρ x t + u 2t+1, where both β and ρ are estimated by OLS using the full sample of observations, with the residuals stored for sampling. We then generate 3 If the regression coefficient β is small (so that explanatory power is low or the IS R 2 is low), it may happen that our unconditional model outperforms on OOS because of estimation error in the rolling estimates of β. Inthiscase, RMSE might be negative but still significant because these tests are ultimately tests of whether β is equal to zero. 1462
9 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction 10,000 bootstrapped time series by drawing with replacement from the residuals. The initial observation preceding the sample of data used to estimate the models is selected by picking one date from the actual data at random. This bootstrap procedure not only preserves the autocorrelation structure of the predictor variable, thereby being valid under the Stambaugh (1999) specification, but also preserves the cross-correlation structure of the two residuals. 4 Statistical Power: Our article entertains both IS and OOS tests. Inoue and Kilian (2004) show that the OOS tests used in this paper are less powerful than IS tests, even though their size properties are roughly the same. Similar critiques of the OOS tests in our article have been noted by Cochrane (2005) and Campbell and Thompson (2005). We believe this is the wrong way to look at the issue of power for two reasons: (i) It is true that under a well-specified, stable underlying model, an IS OLS estimator is more efficient. Therefore, a researcher who has complete confidence in her underlying model specification (but not the underlying model parameters) should indeed rely on IS tests to establish significance the alternative to OOS tests does have lower power. However, the point of any regression diagnostics, such as those for heteroskedasticity and autocorrelation, is always to subject otherwise seemingly successful regression models to a number of reasonable diagnostics when there is some model uncertainty. Relative to not running the diagnostic, by definition, any diagnostic that can reject the model at this stage sacrifices power if the specified underlying model is correct. In our forecasting regression context, OOS performance just happens to be one natural and especially useful diagnostic statistic. It can help determine whether a model is stable and wellspecified, or changing over time, either suddenly or gradually. This also suggests why the simple power experiment performed in some of the aforementioned critiques of our own paper is wrong. It is unreasonable to propose a model if the IS performance is insignificant, regardless of its OOS performance. Reasonable (though not necessarily statistically significant) OOS performance is not a substitute, but a necessary complement for IS performance in order to establish the quality of the underlying model specification. The thought experiments and analyses in the critiques, which simply compare the power of OOS tests to that of IS tests, especially under their assumption of a correctly specified stable model, is therefore incorrect. The correct power 4 We do not bootstrap for cayp because it is calculated using ex-post data; for caya and ms because these variables change each period; and for all because of computational burden. 1463
10 The Review of Financial Studies / v 21 n (ii) experiment instead should explore whether conditional on observed IS significance, OOS diagnostics are reasonably powerful. We later show that they are. Not reported in the tables, we also used the CUSUMQ test to test for model stability. Although this is a weak test, we can reject stability for all monthly models: and for all annual models except for ntis, i/k, andcayp, when we use data beginning in Thus, the CUSUMQ test sends the same message about the models as the findings that we shall report. All of the OOS tests in our paper do not fail in the way the critics suggest. Low-power OOS tests would produce relatively poor predictions early and relatively good predictions late in the sample. Instead, all of our models show the opposite behavior good OOS performance early, bad OOS performance late. A simple alternative OOS estimator, which downweights early OOS predictions relative to late OOS predictions, would have more power than our unweighted OOS prediction test. Such a modified estimator would both be more powerful, and it would show that all models explored in our article perform even worse. (We do not use it only to keep it simple and to avoid a cherry-picking-the-test critique.) Estimation Period : It is not clear how to choose the periods over which a regression model is estimated and subsequently evaluated. This is even more important for OOS tests. Although any choice is necessarily ad-hoc in the end, the criteria are clear. It is important to have enough initial data to get a reliable regression estimate at the start of evaluation period, and it is important to have an evaluation period that is long enough to be representative. We explore three time period specifications: the first begins OOS forecasts 20 years after data are available; the second begins OOS forecast in 1965 (or 20 years after data are available, whichever comes later); the third ignores all data prior to 1927 even in the estimation. 5 If a variable does not have complete data, some of these time-specifications can overlap. Using three different periods reflects different trade-offs between the desire to obtain statistical power and the desire to obtain results that remain relevant today. In our graphical analysis later, we also evaluate the rolling predictive performance of variables. This analysis helps us identify periods of superior or inferior performance and can be seen as invariant to the choice of the OOS evaluation period (though not to the choice of the estimation period). 5 We also tried estimating our models only with data after World War II, as recommended by Lewellen (2004). Some properties in some models change, especially when it comes to statistical significance and the importance of the Oil Shock for one variable, d/p. However, the overall conclusions of our article remain. 1464
11 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction 3. Annual Prediction Table 1 shows the predictive performance of the forecasting models on annual forecasting horizons. Figures 1 and 2 graph the IS and OOS performance of variables in Table 1. For the IS regressions, the performance is the cumulative squared demeaned equity premium minus the cumulative squared regression residual. For the OOS regressions, this is the cumulative squared prediction errors of the prevailing mean minus the cumulative squared prediction error of the predictive variable from the linear historical regression. Whenever a line increases, the ALTERNATIVE predicted better; whenever it decreases, the NULL predicted better. The units in the graphs are not intuitive, but the timeseries pattern allows diagnosis of years with good or bad performance. Indeed, the final SSE statistic in the OOS plot is sign-identical with the RMSE statistic in our tables. The standard error of all the observations in the graphs is based on translating MSE-T statistic into symmetric 95% confidence intervals based on the McCracken (2004) critical values; the tables differ in using the MSE-F statistic instead. The reader can easily adjust perspective to see how variations in starting or ending date would impact the conclusion by shifting the graph up or down (redrawing the y = 0 horizontal zero line). Indeed, a horizontal line and the right-side scale indicate the equivalent zero-point for the second time period specification, in which we begin forecasts in 1965 (this is marked Start=1965 Zero Val line). The plots have also vertically shifted the IS errors, so that the IS line begins at zero on the date of our first OOS prediction. The Oil Shock recession of 1973 to 1975, as identified by the NBER, is marked by a vertical (red) bar in the figures. 6 In addition to the figures and tables, we also summarize models performances in small in-text summary tables, which give the IS-R 2 and OOS-R 2 for two time periods: the most recent 30 years and the entire sample period. The R 2 for the subperiod is not the R 2 for a different model estimated only over the most recent three decades, but the residual fit for the overall model over the subset of data points (e.g., computed simply as 1-SSE/SST for the last 30 years residuals). The most recent three decades after the Oil Shock can help shed light on whether a model is likely to still perform well nowadays. Generally, it is easiest to understand the data by looking first at the figures, then at the in-text table, and finally at the full table. A well-specified signal would inspire confidence in a potential investor if it had 6 The actual recession period was from November 1973 to March We treat both 1973 and 1975 as years of Oil Shock recession in annual prediction. 1465
12 The Review of Financial Studies / v 21 n Figure 1 Annual performance of IS insignificant predictors. Explanation: These figures plot the IS and OOS performance of annual predictive regressions. Specifically, these are the cumulative squared prediction errors of the NULL minus the cumulative squared prediction error of the ALTERNATIVE. The ALTERNATIVE is a model that relies on predictive variables noted in each graph. The NULL is the prevailing equity premium mean for the OOS graph, and the full-period equity premium mean for the IS graph. The IS prediction relative performance is dotted (and usually above), the OOS prediction relative perfomance is solid. An increase in a line indicates better performance of the named model; a decrease in a line indicates better performance of the NULL. The blue band is the equivalent of 95% two-sided levels, based on MSE-T critical values from McCracken (2004). (MSE-T is the Diebold and Mariano (1995) t-statistic modified by Harvey, Leybourne, and Newbold (1998)). The right axis shifts the zero point to The Oil Shock is marked by a red vertical line. 1466
13 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Figure 1 Continued 1467
14 The Review of Financial Studies / v 21 n Figure 1 Continued 1468
15 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Figure 1 Continued 1469
16 The Review of Financial Studies / v 21 n Table 1 Forecasts at annual frequency This table presents statistics on forecast errors in-sample (IS) and out-of-sample (OOS) for log equity premium forecasts at annual frequency (both in the forecasting equation and forecast). Variables are explained in Section 2. Stock returns are price changes, including dividends, of the S&P500. All numbers are in percent per year, except except R 2 and power which are simple percentages. A star next to IS-R 2 denotes significance of the in-sample regression as measured by F -statistics (critical values of which are obtained empirically from bootstrapped distributions). The column IS for OOS gives the IS-R 2 for the OOS period. RMSE is the RMSE (root mean square error) difference between the unconditional forecast and the conditional forecast for the same sample/forecast period. Positive numbers signify superior out-of-sample conditional forecast. The OOS-R 2 is defined in Equation 6. A star next to OOS-R 2 is based on significance of MSE-F statistic by McCracken (2004), which tests for equal MSE of the unconditional forecast and the conditional forecast. One-sided critical values of MSE statistics are obtained empirically from bootstrapped distributions, except for caya and all models where they are obtained from McCracken (2004). Critical values for the ms model are not calculated. Power is calculated as the fraction of draws where the simulated RMSE is greater than the empirically calculated 95% critical value. The two numbers under the power column are for all simulations and for those simulations in which the in-sample estimate was significant at the 95% level. Significance levels at 90%, 95%, and 99% are denoted by one, two, and three stars, respectively. dfy Default yield spread infl Inflation svar Stock variance d/e Dividend payout ratio lty Long term yield tms Term spread tbl Treasury-bill rate dfr Default return spread d/p Dividend price ratio d/y Dividend yield * ltr Long term return e/p Earning price ratio * 1470
17 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Table 1 Continued Full Sample Forecasts begin 20 years after sample Forecasts begin 1965 Sample IS IS for OOS IS for OOS IS Variable Data R 2 OOS R 2 R 2 RMSE Power OOS R 2 R 2 RMSE Power R 2 Full Sample, Significant IS b/m Book to market * (67) (61) 4.14 * i/k Invstmnt capital ratio ** (77) Same Same ntis Net equity expansion *** (78) (72) Same eqis Pct equity issuing *** ** (85) (77) Same all Kitchen sink ** (-) (-) Same d/y Dividend yield * (71) 0.91 e/p Earning price ratio * (64) 1.08 b/m Book to market * (64) 3.20 * 1471
18 The Review of Financial Studies / v 21 n Figure 2 Annual performance of predictors that are not in-sample significant Explanation: See Figure
19 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Figure 2 Continued 1473
20 The Review of Financial Studies / v 21 n (i) (ii) (iii) (iv) both significant IS and reasonably good OOS performance over the entire sample period; a generally upward drift (of course, an irregular one); an upward drift which occurs not just in one short or unusual sample period say just the two years around the Oil Shock; an upward drift that remains positive over the most recent several decades otherwise, even a reader taking the long view would have to be concerned with the possibility that the underlying model has drifted. There are also other diagnostics that stable models should pass (heteroskedasticity, residual autocorrelation, etc.), but we do not explore them in our article. 3.1 In-sample insignificant models As already mentioned, if a model has no IS performance, its OOS performance is not interesting. However, because some of the IS insignificant models are so prominent, and because it helps to understand why they may have been considered successful forecasters in past articles, we still provide some basic statistics and graph their OOS performance. The most prominent such models are the following: Dividend Price Ratio: Figure 1 shows that there were four distinct periods for the d/p model, and this applies both to IS and OOS performance. d/p had mild underperformance from 1905 to WW II, good performance from WW II to 1975, neither good nor bad performance until the mid-1990s, and poor performance thereafter. The best sample period for d/p was from the mid 1930s to the mid-1980s. For the OOS, it was 1937 to 1984, although over half of the OOS performance was due to the Oil Shock. Moreover, the plot shows that the OOS performance of the d/p regression was consistently worse than the performance of its IS counterpart. The distance between the IS and OOS performance increased steadily until the Oil Shock. Over the most recent 30 years (1976 to 2005), d/p s performance is negative both IS and OOS. Over the entire period, d/p underperformed the prevailing mean OOS, too: Recent All d/p 30 years years IS R % 0.49% OOS R % 2.06% Dividend Yield : Figure 1 shows that the d/y model s IS patterns look broadly like those of d/p. However, its OOS pattern was much more volatile: d/y predicted equity premia well during the Great Depression (1930 to 1933), the period from World War II to 1958, the Oil Shock of 1474
21 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction , and the market decline of It had large prediction errors from 1958 to 1965 and from 1995 to 2000, and it had unremarkable performance in other years. The best OOS sample period started around 1925 and ended either in 1957 or The Oil Shock did not play an important role for d/y. Over the most recent 30 years, d/y s performance is again negative IS and OOS. The full-sample OOS performance is also again negative: Recent All d/y 30 years years IS R % 0.91% OOS R % 1.93% Earnings Price Ratio : Figure 1 shows that e/p had inferior performance until WW II, and superior performance from WW II to the late 1970s. After the Oil Shock, it had generally nondescript performance (with the exception of the late 1990s and early 2000s). Its best sample period was 1943 to and 2004 were bad years for this model. Over the most recent 30 years, e/p s performance is again negative IS and OOS. The full-sample OOS performance is negative too. Recent All e/p 30 years years IS R % 1.08% OOS R % 1.78% Table 1 shows that these three price ratios are not statistically significant IS at the 90% level. However, some disagreement in the literature can be explained by differences in the estimation period. 7 Other Variables : The remaining plots in Figure 1 and the remaining IS insignificant models in Table 1 show that d/e, dfy, andinfl essentially never had significantly positive OOS periods, and that svar had a huge drop in OOS performance from 1930 to Other variables (that are 7 For example, the final lines in Table 1 show that d/y and e/p had positive and statistically significant IS performance at the 90% level if all data prior to 1927 is ignored. Nevertheless, Table 1 also shows that the OOS-R 2 performance remains negative for both of these. Moreover, when the data begins in 1927 and the forecast begins in 1947 (another popular period choice), we find (Data Begins in 1927) e/p d/y (Forecast Begins in 1947) Recent All Recent All IS R % 3.20% 5.20% 2.71% OOS R % 3.41% 28.05% 16.65% Finally, and again not reported in the table, another choice of estimation period can also make a difference. The three price models lost statistical significance over the full sample only in the 1990s. This is not because the IS- RMSE decreased further in the 1990s, but because the prediction errors were more volatile, which raised the standard errors of point estimates. 1475
22 The Review of Financial Studies / v 21 n IS insignificant) often had good sample performance early on, ending somewhere between the Oil Shock and the mid-1980s, followed by poor performance over the most recent three decades. The plots also show that it was generally not just the late 1990s that invalidated them, unlike the case with the aforementioned price ratio models. In sum, 12 models had insignificant IS full-period performance and, not surprisingly, these models generally did not offer good OOS performance. 3.2 In-sample significant models Five models were significant IS (b/m, i/k, ntis, eqis, andall) atleastat the 10% two-sided level. Table 1 contains more details for these variables, such as the IS performance during the OOS period, and a power statistic. Together with the plots in Figure 2, this information helps the reader to judge the stability of the models whether poor OOS performance is driven by less accurately estimated parameters (pointing to lower power), and/or by the fact that the model fails IS and/or OOS during the OOS sample period (pointing to a spurious model). Book-to-market ratio: b/m is statistically significant at the 6% level IS. Figure 2 shows that it had excellent IS and OOS predictive performance right until the Oil Shock. Both its IS and OOS performance were poor from 1975 to 2000, and the recovery in was not enough to gain back the performance. Thus, the b/m model has negative performance over the most recent three decades, both IS and OOS. Recent All b/m 30 years years IS R % 3.20% OOS R % 1.72% Over the entire sample period, the OOS performance is negative, too. The IS for OOS R 2 in Table 1 shows how dependent b/m s performance is on the first 20 years of the sample. The IS R 2 is 7.29% for the period. The comparable OOS R 2 even reaches 12.71%. As with other models, b/m s lack of OOS significance is not just a matter of low test power. Table 1 shows that in the OOS prediction beginning in 1941, under the simulation of a stable model, the OOS statistic came out statistically significantly positive in 67% 8 of our (stable-model) simulations in which the IS regression was significant. Not reported in the table, positive performance (significant or insignificant) occurred in 78% of our 8 The 42% applies to all simulation draws. It is the equivalent of the experiment conducted in some other articles. However, because OOS performance is relevant only when the IS performance is significant, this is the wrong measure of power. 1476
23 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction simulations. A performance as negative as the observed RMSE of 0.01 occurred in none of the simulations. Investment-capital ratio : i/k is statistically significant IS at the 5% level. Figure 2 shows that, like b/m, it performed well only in the first half of its sample, both IS and OOS. About half of its performance, both IS and OOS, occurs during the Oil Shock. Over the most recent 30 years, i/k has underperformed: Recent All i/k 30 years years IS R % 6.63% OOS R % 1.77% Corporate Issuing Activity : Recall that ntis measures equity issuing and repurchasing (plus dividends) relative to the price level; eqis measures equity issuing relative to debt issuing. Figure 2 shows that both variables had superior IS performance in the early 1930s, a part of the sample that is not part of the OOS period. eqis continues good performance into the late 1930s but gives back the extra gains immediately thereafter. In the OOS period, there is one stark difference between the two variables: eqis had superior performance during the Oil Shock, both IS and OOS. It is this performance that makes eqis the only variable that had statistically significant OOS performance in the annual data. In other periods, neither variable had superior performance during the OOS period. Both variables underperformed over the most recent 30 years ntis eqis Recent All Recent All 30 years years 30 years years IS R % 8.15% 10.36% 9.15% OOS R % 5.07% 15.33% 2.04% The plot can also help explain dueling perspectives about eqis between Butler, Grullon, and Weston (2005) and Baker, Taliaferro, and Wurgler (2004). One part of their disagreement is whether eqis s performance is just random underperformance in sampled observations. Of course, some good years are expected to occur in any regression. Yet eqis s superior performance may not have been so random, because it (i) occurred in consecutive years, and (ii) in response to the Oil Shock events that are often considered to have been exogenous, unforecastable, and unusual. Butler, Grullon, and Weston (2005) also end their data in 2002, while Baker, Taliaferro, and Wurgler (2004) refer to our earlier draft and to Rapach and Wohar (2006), which end in 2003 and 1999, respectively. Our figure shows that small variations in the final year choice can make a 1477
24 The Review of Financial Studies / v 21 n difference in whether eqis turns out significant or not. In any case, both articles have good points. We agree with Butler, Grullon, and Weston (2005) that eqis would not have been a profitable and reliable predictor for an external investor, especially over the most recent 30 years. But we also agree with Baker, Taliaferro, and Wurgler (2004) that conceptually, it is not the OOS performance, but the IS performance that matters in the sense in which Baker and Wurgler (2000) were proposing eqis not as a third-party predictor, but as documentary evidence of the fund-raising behavior of corporations. Corporations did repurchase profitably in the Great Depression and the Oil Shock era (though not in the bubble period collapse of ). all The final model with IS significance is the kitchen sink regression. It had high IS significance, but exceptionally poor OOS performance. 3.3 Time-changing models caya and ms have no IS analogs, because the models themselves are constantly changing. Consumption-Wealth-Income : Lettau and Ludvigson (2001) construct their cay proxy assuming that agents have some ex-post information. The experiment their study calls OOS is unusual: their representative agent still retains knowledge of the model s full-sample CAY-construction coefficients. It is OOS only in that the agent does not have knowledge of the predictive coefficient and thus has to update it on a running basis. We call the Lettau and Ludvigson (2001) variable cayp. We also construct caya, which represents a more genuine OOS experiment, in which investors are not assumed to have advance knowledge of the cay construction estimation coefficients. Figure 2 shows that cayp had superior performance until the Oil Shock, and nondescript performance thereafter. It also benefited greatly from its performance during the Oil Shock itself. Recent All cay 30 years years Some ex-post knowledge, cayp IS R % 15.72% Some ex-post knowledge, cayp OOS R % 16.78% No advance knowledge, caya OOS R % 4.33% The full-sample cayp result confirms the findings in Lettau and Ludvigson (2001). cayp outperforms the benchmark OOS RMSE by 1.61% per annum. It is stable and its OOS performance is almost identical to its IS performance. In contrast to cayp, caya has had no superior OOS performance, either over the entire sample period or the most recent years. In fact, without advance knowledge, caya had the worst OOS R 2 performance among our single variable models. 1478
25 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Model Selection : Finally, ms fails with a pattern similar to earlier variables good performance until 1976, bad performance thereafter. Recent All ms 30 years years IS R 2 OOS R % 22.50% Conclusion : There were a number of periods with sharp stock market changes, such as the Great Depression of (in which the S&P500 dropped from at the end of 1928 to 6.89 at the end of 1932) and the bubble period from (with its subsequent collapse). However, it is the Oil Shock recession of , in which the S&P500 dropped from in October 1973 to in September 1974 and its recovery back to in June 1975 that stands out. Many models depend on it for their apparent forecasting ability, often both IS and OOS. (And none performs well thereafter.) Still, we caution against overreading or underreading this evidence. In favor of discounting this period, the observed source of significance seems unusual, because the important years are consecutive observations during an unusual period. (They do not appear to be merely independent draws.) In favor of not discounting this period, we do not know how one would identify these special multiyear periods ahead of time, except through a model. Thus, good prediction during such a large shock should not be automatically discounted. More importantly and less ambiguously, no model seems to have performed well since that is, over the last 30 years. In sum, on an annual prediction basis, there is no single variable that meets all of our four suggested investment criteria (IS significance, OOS performance, reliance not just on some outliers, and good positive performance over the last three decades.) Most models fail on all four criteria. 4. Five-yearly Prediction Some models may predict long-term returns better than short-term returns. Unfortunately, we do not have many years to explore five-year predictions thoroughly, and there are difficult econometric issues arising from data overlap. Therefore, we only briefly describe some preliminary and perhaps naive findings. (See, e.g., Boudoukh, Richardson and Whitelaw (2005) and Lamoureux and Zhou (1996) for more detailed treatments.) Table 2 repeats Table 1 with five-year returns. As before, we bootstrap all critical significance levels. This is especially important here, because the observations are overlapping and the asymptotic critical values are not available. Table 2 shows that there are four models that are significant IS over the entire sample period: ntis, d/p, i/k,andall. ntis and i/k were also significant 1479
26 The Review of Financial Studies / v 21 n Table 2 Forecasts at 5-year frequency This table is identical to Table 1, except that we predict overlapping 5-yearly equity premia, rather than annual equitypremia ltr Long term return dfr Default return spread infl Inflation lty Long term yield svar Stock variance d/e Dividend payout ratio dfy Default yield spread * tbl Treasury-bill rate d/y Dividend yield * e/p Earning price ratio * tms Term spread ** * eqis Pct equity issuing Same b/m Book to market Full Sample, Significant IS ntis Net equity expansion * (70) (67) Same d/p Dividend price ratio * * (69) (51) ** i/k Invstmnt capital ratio *** ** (78) Same Same all Kitchen sink *** ( ) ( ) Same 1480
27 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Table 2 (Continued) Full sample Forecasts begin 20 years after sample Forecasts begin 1965 Sample IS IS for OOS IS for OOS IS Variable Data R 2 OOS R 2 R 2 RMSE Power OOS R 2 R 2 RMSE Power R 2 tms Term Spread * ** (65) 7.84 e/p Earning Price Ratio * (65) 6.24 d/y Dividend Yield * (72) 6.04 d/p Dividend Price Ratio ** (61) * 1481
28 The Review of Financial Studies / v 21 n in the annual data (Table 1). Two more variables, d/y and tms, are IS significant if no data prior to 1927 is used. Dividend Price Ratio : d/p had negative performance OOS regardless of period. Term Spread : tms is significant IS only if the data begins in 1927 rather than An unreported plot shows that tms performed well from 1968 to 1979, poorly from 1979 to 1986, and then well again from 1986 to Indeed, its better years occur in the OOS period, with an IS R 2 of 23.54% from 1965 to This was sufficient to permit it to turn in a superior OOS RMSE performance of 2.77% per five-years a meaningful difference. On the negative side, tms has positive OOS performance only if forecasting begins in Using data and starting forecasts in 1947, the OOS RMSE and R 2 are negative. The Kitchen Sink : all again turned in exceptionally poor OOS performance. Model selection (ms) andcaya again have no IS analogs. ms had the worst predictive performance observed in this paper. caya had good OOS performance of 2.50% per five-year period. Similarly, the investmentcapital ratio, i/k, had both positive IS and OOS performance, and both over the most recent three decades as well as over the full sample (where it was also statistically significant). Recent All i/k 30 years years IS R % 33.99% OOS R % 12.99% i/k s performance is driven by its ability to predict the 2000 crash. In 1997, it had already turned negative on its equity premium prediction, thus predicting the 2000 collapse, while the unconditional benchmark prediction continued with its 30% plus predictions: Forecast For Actual Forecast Forecast For Actual Forecast made in years EqPm Unc. i/k made in years EqPm Unc. i/k This model (and perhaps caya) seem promising. We hesitate to endorse them further only because our inference is based on a small number of observations, and because statistical significance with overlapping multiyear returns raises a set of issues that we can only tangentially address. We hope more data will allow researchers to explore these models in more detail. 1482
29 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction 5. Monthly Prediction and Campbell Thompson Table 3 describes the performance of models predicting monthly equity premia. It also addresses a number of points brought up by Campbell and Thompson (2005), henceforth CT. We do not have dividend data prior to 1927, and thus no reliable equity premium data before then. This is why even our the estimation period begins only in In-sample performance Table 3 presents the performance of monthly predictions both IS and OOS. The first data column shows the IS performance when the predicted variable is logged (as in the rest of the article). Eight out of eighteen models are IS significant at the 90% level, seven at the 95% level. Because CT use simple rather than log equity premia, the remaining data columns follow their convention. This generally improves the predictive power of most models, and the fourth column (by which rows are sorted) shows that three more models turn in statistically significant IS. 9 CT argue that a reasonable investor would not have used a model to forecast a negative equity premium. Therefore, they suggest truncation of such predictions at zero. In a sense, this injects caution into the models themselves, a point we agree with. Because there were high equity premium realizations especially in the 1980s and 1990s, a time when many models were bearish, this constraint can improve performance. Of course, it also transforms formerly linear models into nonlinear models, which are generally not the subject of our paper. CT do not truncate predictions in their IS regressions, but there is no reason not to do so. Therefore, the fifth column shows a revised IS R 2 statistic. Some models now perform better, some perform worse. 5.2 Out-of-sample prediction performance The remaining columns explore the OOS performance. The sixth column shows that without further manipulation, eqis is the only model with both superior IS (R 2 = 0.82% and 0.80%) and OOS (R 2 = 0.14%) untruncated performance. The term-spread, tms, has OOS performance that is even better (R 2 = 0.22%), but it just misses statistical significance IS at the 90% level. infl has marginally good OOS performance, but poor IS performance. All other models have negative IS or OOS untruncated R 2. The remaining columns show model performance when we implement the Campbell and Thompson (2005) suggestions. The seventh column describes the frequency of truncation of negative equity premium 9 Geert Bekaert pointed out to us that if returns are truly log-normal, part of their increased explanatory power could be due to the ability of these variables to forecast volatility. 1483
30 The Review of Financial Studies / v 21 n Table 3 Forecasts at monthly frequency using Campbell and Thompson (2005) procedure Refer to Table 1 for basic explanations. This table presents statistics on forecast errors in-sample (IS) and out-of-sample (OOS) for equity premium forecasts at the monthly frequency (both in the forecasting equation and forecast). Variables are explained in Section 2. The data period is December 1927 to December 2004, except for csp (May 1937 to December 2002) and cay3 (December 1951 to December 2004). Critical values of all statistics are obtained empirically from bootstrapped distributions, except for cay3 model where they are obtained from McCracken (2004). The resulting significance levels at 90%,95%,and 99% are denoted by one,two,and three stars,respectively.they are two-sided for IS model significance, and one-sided for OOS superior model performance. The first data column is the IS R 2 when returns are logged, as they are in our other tables. The remaining columns are based on predicting simple returns for correspondence with Campbell and Thompson (2005). Certainty Equivalence (CEV) gains are based on the utility of an optimizer with a risk-aversion coefficient of γ = 3 who trades based on unconditional forecast and conditional forecast. Equity positions are winsorized at 150% (w = wmax). At this risk-aversion, the base CEV are 82bp for a market-timer based on the unconditional forecast, 79bp for the market, and 40bp for the risk-free rate. T means truncated to avoid a negative equity premium prediction. U means unconditional, that is, to avoid a forecast that is based on a coefficient that is inverse to what the theory predicts. A superscript h denotes high trading turnover of about 10%/month more than the trading strategy based on unconditional forecasts. Log Simple returns returns IS OOS Campbell and Thompson (2005) OOS Variable IS R 2 R 2 R 2 R 2 Frcst= R 2 RMSE w = T T U TU TU wmax CEV Fig d/e Dividend payout ratio svar Stock variance dfr Default return spread lty Long term yield ** ltr Long term return ** h 0.06 infl Inflation * ** h 0.04 tms Term spread ** ** F 3.G tbl Treasury-bill rate * * ** F 3.F dfy Default yield spread * d/p Dividend price ratio * * F 3.E d/y Dividend yield 0.22 * 0.47 ** * e/p Earning price ratio 0.51 ** 0.54 ** eqis Pct equity issuing 0.82 *** 0.80 *** ** *** F 3.D b/m Book to market 0.45 ** 0.81 *** e 10 /p Earning(10Y) price ratio 0.46 ** 0.86 *** csp Cross-sectional prem 0.92 *** 0.99 *** ** F 3.B ntis Net equity expansion 0.94 *** 1.02 *** F 3.C cay3 Cnsmptn, wlth, incme 1.88 *** 1.87 *** * F 3.A 1484
31 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Figure 3 Monthly performance of in-sample significant predictors Explanation: These figures are the analogs of Figures 1 and 2,plotting the IS and OOSperformance of the named model. However, they use monthly data. The IS performance is in black. The Campbell-Thompson (2005) (CT) OOS model performance is plotted in blue, the plain OOS model performance is plotted in green. The top bars ( T ) indicate truncation of the equity prediction at 0, inducing the CT investor to hold the risk-free security. (This also lightens the shade of blue in the CT line.) The lower bars ( M ) indicate when the CT risk-averse investor would purchase equities worth 150% of his wealth, the maximum permitted. The Oil Shock (Nov 1973 to Mar 1975) is marked by a red vertical line. 1485
32 The Review of Financial Studies / v 21 n Figure 3 Continued predictions. For example, d/y s equity premium predictions are truncated to zero in 54.2% of all months; csp s predictions are truncated in 44.7% of all months. Truncation is a very effective constraint. CT also suggest using the unconditional model if the theory offers one coefficient sign and the estimation comes up with the opposite sign. For some variables, such as the dividend ratios, this is easy. For other models, it is not clear what the appropriate sign of the coefficient would be. In any case, this matters little in our data set. The eighth column shows that the 1486
33 A Comprehensive Look at The Empirical Performance of Equity Premium Prediction Figure 3 Continued coefficient sign constraint matters only for dfr and ltr (and mildly for d/e). None of these three models has IS performance high enough to make this worthwhile to explore further. The ninth and tenth columns, R 2 TU and RMSE TU, show the effect of the CT truncations on OOS prediction. For many models, the performance improves. Nevertheless, the OOS R 2 s remain generally much lower than their IS equivalents. Some models have positive RMSE but negative 1487
Stock Return Predictability: Is it There?
Stock Return Predictability: Is it There? Andrew Ang Columbia University and NBER Geert Bekaert Columbia University, NBER and CPER We examine the predictive power of the dividend yields for forecasting
What Risk Premium Is Normal?
What Risk Premium Is Normal? Robert D. Arnott and Peter L. Bernstein The goal of this article is an estimate of the objective forward-looking U.S. equity risk premium relative to bonds through history Has U.S. Inflation Become Harder to Forecast?
Why Has U.S. Inflation Become Harder to Forecast? James H. Stock Department of Economics, Harvard University and the National Bureau of Economic Research and Mark W. Watson* Woodrow Wilson School and Department...
Current Issues. Before each of the last six recessions, shortterm
Volume 12, Number 5 July/August 26 FEDERAL RESERVE BANK OF NEW YORK Current Issues IN ECONOMICS AND FINANCE The Yield value riskier than growth? $
Journal of Financial Economics 78 (2005) 187 202 Is value riskier than growth? $ Ralitsa Petkova a, Lu Zhang b,c, a Weatherhead School of Management, Case Western Reserve University,:
|
http://docplayer.net/55542-A-comprehensive-look-at-the-empirical-performance-of-equity-premium-prediction.html
|
CC-MAIN-2016-44
|
refinedweb
| 10,283
| 50.87
|
September archive
Four new shortcuts
September 24, 2005
We've added four new shortcuts that'll help you use even less code in your Django applications. Each shortcut is designed to express a common idiom in a single line of code.
The first idiom is something like this:
from django.core import template, template_loader from django.utils.httpwrappers import HttpResponse def foo_view(request): t = template_loader.get_template('foo/foo_detail') c = template.Context({'foo': 'bar'}) return HttpResponse(t.render(c))
If you're a Django developer, you've probably used something very similar to that: Load a template, fill it with a context and return an HttpResponse with the rendered template. Because that's so common, we've added a shortcut: render_to_response(). Here's the same code, rewritten:
from django.core.extensions import render_to_response def foo_view(request): return render_to_response('foo/foo_detail', {'foo': 'bar'})
We've also added render_to_string(), which does the same thing as render_to_response() but returns a string instead of an HttpResponse.
Here's a second idiom that's quite common in Django code:
from django.core.exceptions import Http404 from django.models.bar import foos try: f = foos.get_object(some_field__exact=some_lookup) except foos.FooDoesNotExist: raise Http404
We've introduced get_object_or_404() to reduce this common case to a single line. Here's the same code, rewritten:
from django.core.extensions import get_object_or_404 from django.models.bar import foos f = get_object_or_404(foos, some_field__exact=some_lookup)
There's also a get_list_or_404(), which works the same way but uses get_list() instead of get_object().
We've updated the documentation to use this new method in examples.
Finally, in both of these examples, old code (writing things out the long way) will still work.
Badges?
September 17, 2005
As Simon pointed out, the list of Django-powered sites is growing by the day.
In recognition of the growing community, and in the interest of promoting even more growth, I've made a set of "official" Django badges. If your site or project is powered by Django, you can help promote the growing community by slapping one of them on your site with a link back to djangoproject.com.
They come in grey and green and all kinds of sizes, so grab a Django badge for your site today and let the world know what you're made of.
More docs: Customizing the template language
September 5, 2005..
|
https://www.djangoproject.com/weblog/2005/sep/
|
CC-MAIN-2014-15
|
refinedweb
| 390
| 58.18
|
Wiep Corbier wrote:My solution is already super fast.
Dave Kreskowiak wrote:It's not the language that needs to updated to support your poor skills. It's your skills that need to be updated to better support your customers.
Wiep Corbier wrote:All these problems are already solved by me.
Wiep Corbier wrote:what if my customers could make a choise how to recieve the data using the same name for the claas but had the option how it was presented/formatted.
{ get { return skills.Split('|'); }
set { skills = string.Join("|", value); }}
Wiep Corbier wrote:ps: I don't want a class with two representation of the skill data. I just do not want that.
Wiep Corbier wrote:What I want doesn't exist and I'm not interested in alternatives that already exists.
I want something new.
Wiep Corbier wrote:As you can see, the property with the name Skills is a string.
It can be a long string and it stores one or more Skills.
Quote:When answering a question please;
Read the question carefully
Wiep Corbier wrote:I just explained it several times.
Wiep Corbier wrote:For the next C# version I would like the ability to have multiple classes with the same name.
Wiep Corbier wrote:So, when I instantiate a new CandidateFunction, I want a popup asking me which one I want to use.
namespace One
{
public class ABC {}
public class ABC {}
}
namespace One
{
public class ABC {}
}
namespace Two
{
public class ABC {}
}
Quote:I want a popup asking me which one I want to use.
General News Suggestion Question Bug Answer Joke Praise Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages.
|
https://www.codeproject.com/Messages/5730075/Re-Multiple-Classes-same-name.aspx?PageFlow=Fluid
|
CC-MAIN-2020-40
|
refinedweb
| 290
| 73.58
|
docker createEstimated reading time: 11 create [OPTIONS] IMAGE [COMMAND] [ARG...]
Options
Parent command
Extended description
The
docker create command.
This is useful when you want to set up a container configuration ahead of time
so that it is ready to start when you need it. The initial status of the
new container is
created.
Please see the run command section and the Docker run reference for more details.
Examples
Create and start a container
$ docker create -t -i fedora bash 6d8af538ec541dd581ebc2a24153a28329acb5268abe5ef868c1f1a261221752 $ docker start -a -i 6d8af538ec5 bash-4.2#
Initialize volumes
As of v1.4.0 container volumes are initialized during the
docker create phase
(i.e.,
docker run too). For example, this allows you to
create the
data
volume container, and then use it from another container:
$ docker create -v /data --name data ubuntu 240633dfbb98128fa77473d3d9018f6123b99c454b3251427ae190a7d951ad57 $ docker run --rm --volumes-from data ubuntu ls -la /data total 8 drwxr-xr-x 2 root root 4096 Dec 5 04:10 . drwxr-xr-x 48 root root 4096 Dec 5 04:11 ..
Similarly,
create a host directory bind mounted volume container, which can
then be used from the subsequent container:
$ docker create -v /home/docker:/docker --name docker ubuntu 9aa88c08f319cd1e4515c3c46b0de7cc9aa75e878357b1e96f91e2c773029f03 $ docker run --rm --volumes-from docker ubuntu ls -la /docker total 20 drwxr-sr-x 5 1000 staff 180 Dec 5 04:00 . drwxr-xr-x 48 root root 4096 Dec 5 04:13 .. -rw-rw-r-- 1 1000 staff 3833 Dec 5 04:01 .ash_history -rw-r--r-- 1 1000 staff 446 Nov 28 11:51 .ashrc -rw-r--r-- 1 1000 staff 25 Dec 5 04:00 .gitconfig drwxr-sr-x 3 1000 staff 60 Dec 1 03:28 .local -rw-r--r-- 1 1000 staff 920 Nov 28 11:51 .profile drwx--S--- 2 1000 staff 460 Dec 5 00:51 .ssh drwxr-xr-x 32 1000 staff 1140 Dec 5 04:01 docker
Set storage driver options per container.
$ docker create ..
Specify isolation technology for container (–isolation)
This option is useful in situations where you are running Docker containers on
Windows. The
--isolation=<value> option sets a container’s isolation
technology. On Linux, the only supported is the
default option which uses
Linux namespaces. On Microsoft Windows, you can specify these values:
Specifying the
--isolation flag without a value is the same as setting
--isolation="default".
Dealing with dynamically created devices (–device-cgroup-rule)
Devices available to a container are assigned at creation time. The assigned devices will both be added to the cgroup.allow file and created into the container once it is run. This poses a problem when a new device needs to be added to running container.
One of the solution is to add a more permissive rule to a container
allowing it access to a wider range of devices. For example, supposing
our container needs access to a character device with major
42 and
any number of minor number (added as new devices appear), the
following rule would be added:
docker create --device-cgroup-rule='c 42:* rmw' -name my-container my-image
Then, a user could ask
udev to execute a script that would
docker exec my-container mknod newDevX c 42 <minor>
the required device when it is added.
NOTE: initially present devices still need to be explicitely added to the create/run command
|
https://docs.docker.com/edge/engine/reference/commandline/create/
|
CC-MAIN-2017-22
|
refinedweb
| 552
| 55.13
|
So what I started thinking about was how I would want to go about designing portable code that takes ObjC into account but is not limited to platforms that support ObjC. Obviously I need to write much of the code in a language other than ObjC if this is the goal. One simple way is to write all the busy code in C and use pre-compiler directives to build with either ObjC or C where the code touches the required interfaces (GUI and such.) I'm not really keen on that idea because I would like to start with an object-oriented design and build an implementation with sensible classes. That leads me to Objective-C++ and I think it is not only a good answer but a powerful one. The reason I say that is I should be able to apply design patterns as needed and apply good object-oriented design to the whole project without worrying about the portability of my classes.
My ultimate goal is to write most of the code in C++ and provide C++ interfaces that can be implemented where a platform implementation is needed and the proper instantiation would be obtained from class factories. This is a fairly common object-oriented design approach. Thinking about a GUI, specifically, the idea is to be able to implement GUI classes to an interface so that the application is GUI implementation neutral. It wouldn't care if the implementation were GTK, Qt, Cocoa, etc. And ultimately it wouldn't care if the implementation is in Objective-C.
The problem then is implementing those C++ interfaces with Objective-C classes. All Objective-C++ is, essentially, is the Objective-C language built with a C++ compatible compiler (g++, etc). Nothing was done to create compatibility between the two class types. C++ classes can contain ObjC elements and ObjC classes can contain C++ elements. What you can't do is extend or implement a C++ class with an Objective-C class and vice versa. You can't cast between the two class types obviously. So I decided the first solution is essentially to use bridges which is what I'm going to demonstrate here. The idea is that I have a C++ interface that is implemented by an Objective-C class. Obviously the ObjC class can't inherit from the interface so it inherits from NSObject or a child of it. The thing that binds the ObjC implementation to the C++ interface is a C++ bridge class that implements the interface. The bridge contains the ObjC implementation which is allocated when the bridge is constructed and destroyed when the bridge is destructed. All calls into the bridge are directed into the ObjC class. This is very simple and quite effective. You can pass the C++ bridge into methods that accept the interface and they are none the wiser.
So I have posted a lot of information just to show something that is really incredibly simple. My main goal here is to get feedback on how this could be improved, if there are other methods that might be better, and what pitfalls could be looming. This example does not consider the handling of exceptions in any way. That is something I have not dug into yet. It does not demonstrate passing C++ references though that should work. I would like to experiment with that more. One of the things I am thinking about is how the bridge could be built with macros so that the developer can simply build the Objective-C interface and issue a macro for the class and each method implemented so that there aren't a bunch of bridge headers hanging about. If anyone has some ideas on that it would be great to see. I am pretty sure I could slap some macros together pretty easily but, again, the exceptions are something to think about.
Anyway, here is an example of what I have done so far. Like I said, this is not complicated and it works very well.
Here is a UML class diagram for the three important players here:
So the first thing I need to code up is that C++ interface and here it is:
// // CppInterface.h // TestCppInterface // #ifndef TestCppInterface_CppInterface_h #define TestCppInterface_CppInterface_h class CppInterface { public: virtual ~CppInterface() {}; virtual void methodA() = 0; virtual void methodB() = 0; virtual int value() const = 0; virtual void setValue(int value) = 0; }; #endif
Alright. So this is a common C++ interface. Nothing special here.
Next would be implementing the interface with an Objective-C class. Obviously, as already stated, I can't inherit from this interface so I will implement the interface but inherit from NSObject. (A little bit of expanded thought... this could actually be an Objective-C interface itself and the bridge could actually be used for multiple ObjC implementations which could be handled by the class factory.)
Here is the declaration:
// // CppInterfaceImpl.h // CppInterface // #import <Foundation/Foundation.h> @interface CppInterfaceImpl : NSObject { int value; } @property int value; -(void) methodA; -(void) methodB; @end
Here is the definition:
// // CppInterfaceImpl.m // CppInterface // #import <Foundation/Foundation.h> #import "CppInterfaceImpl.h" @implementation CppInterfaceImpl @synthesize value; -(void) methodA { NSLog(@"Called %s", __FUNCTION__); } -(void) methodB { NSLog(@"Called %s", __FUNCTION__); } @end
Notice I did not use the .mm extension for this source. It is not necessary for this class but it COULD be for a different one. It might be a good decision to just say all ObjC sources will use the .mm extension in this kind of project so there is no worry about a code or interface change forcing a file extension change.
So I used the features of the language for the getter and setter methods. Otherwise it looks pretty much how you would expect an implementation of the interface to look.
Now for the glue in the middle. The bridge is very simple:
// // CppInterfaceOCBridge.h // TestCppInterface // #ifndef TestCppInterface_CppInterfaceOCBridge_h #define TestCppInterface_CppInterfaceOCBridge_h #include "CppInterface.h" #import "CppInterfaceImpl.h" class CppInterfaceOCBridge : public CppInterface { public: CppInterfaceOCBridge(); virtual ~CppInterfaceOCBridge(); virtual void methodA(); virtual void methodB(); virtual int value() const; virtual void setValue(int value); private: CppInterfaceImpl* m_OCObj; }; inline CppInterfaceOCBridge::CppInterfaceOCBridge() { m_OCObj = [[CppInterfaceImpl alloc] init]; } inline CppInterfaceOCBridge::~CppInterfaceOCBridge() { [m_OCObj release]; } inline void CppInterfaceOCBridge::methodA() { [m_OCObj methodA]; } inline void CppInterfaceOCBridge::methodB() { [m_OCObj methodB]; } inline int CppInterfaceOCBridge::value() const { return [m_OCObj value]; } inline void CppInterfaceOCBridge::setValue(int value) { [m_OCObj setValue: value]; } #endif
With that we are ready to instantiate an Objective-C class as a CppInterface. I created an Objective-C main that does that. While I have been mentioning class factories I did not actually use one in the example. The main is just going to instantiate the bridge and exercise it:
// // main.mm // TestCppInterface // #import <Foundation/Foundation.h> #include "CppMain.h" #include "CppInterfaceOCBridge.h" int main (int argc, const char * argv[]) { @autoreleasepool { CppInterface *a = new CppInterfaceOCBridge; NSLog(@"Calling C++ methods from within Objective-C!"); a->methodA(); a->methodB(); a->setValue(5); NSLog(@"Value is %i", a->value()); CppMain cppMain(*a); cppMain.run(); delete a; } return 0; }
I wanted to go ahead and try passing this class into a method of a plain C++ class that has no ObjC in it (and uses the .cpp extension) so I created the CppMain class and you can see it exercised there. Here is that class:
// // CppMain.h // TestCppInterface // #ifndef TestCppInterface_CppMain_h #define TestCppInterface_CppMain_h #include "CppInterface.h" class CppMain { public: CppMain(CppInterface& interface); ~CppMain(); void run(); private: CppInterface& m_Interface; }; #endif
// // CppMain.cpp // TestCppInterface // #include <iostream> #include "CppMain.h" using namespace std; CppMain::CppMain(CppInterface& interface) : m_Interface(interface) { } CppMain::~CppMain() { } void CppMain::run() { cout << "Running from CppMain!" << endl; m_Interface.methodA(); m_Interface.methodB(); m_Interface.setValue(28); cout << "Value is " << m_Interface.value() << endl; }
You might notice a terrible practice in this code related to pointers and reference storing. It was just an experiment. It's going to be okay. So here we can see what we ultimately really want in work. Since most of the code will be C++ and C++ class references will be getting tossed around it is the ability to call the Objective-C class from an unaware C++ class that fulfills the goals of the experiment.
Here is the output when I run this application:
2012-01-16 17:13:20.170 TestCppInterface[8480:707] Calling C++ methods from within Objective-C! 2012-01-16 17:13:20.173 TestCppInterface[8480:707] Called -[CppInterfaceImpl methodA] 2012-01-16 17:13:20.174 TestCppInterface[8480:707] Called -[CppInterfaceImpl methodB] 2012-01-16 17:13:20.175 TestCppInterface[8480:707] Value is 5 Running from CppMain! 2012-01-16 17:13:20.175 TestCppInterface[8480:707] Called -[CppInterfaceImpl methodA] 2012-01-16 17:13:20.176 TestCppInterface[8480:707] Called -[CppInterfaceImpl methodB] Value is 28 Program ended with exit code: 0
It is very easy to find the C++ output because, unlike the ObjC output, it does not get timestamped.
So as I said, I'm looking to expand on this and see how it might be streamlined for use in a large project. If anyone is aware of another way to achieve the stated goals I would love to see what you have come up with. I think what I have done here has to be one of the first ideas anyone going down this road would consider. I think I will be messing with some ideas for macros in the next few days and I will show what I have come up with at that point. I also am really interested in delving into error handling and supporting exceptions.
Thanks for looking.
|
http://www.dreamincode.net/forums/topic/263167-implementing-c-interfaces-with-objective-c-classes/page__pid__1532348__st__0
|
CC-MAIN-2016-07
|
refinedweb
| 1,582
| 55.84
|
Join devRant
Pipeless API
From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple APILearn More
Search - "hybrid"
-
-
- A client refused to pay for a hybrid mobile app because he said that he only needed the android version.
After publishing the app he asked if we could submit it on the Apple store because he now wanted the iOS version as well.11
- “Hybrid is the future, it’s faster to develop, more efficient and has no real downside or impact”21
-
- Amazon was the first company that adopted the hybrid model: working from office Monday to Friday and working from home on Saturday and Sunday.7
-!9
-
- I fucking hate ionic
I fucking hate ionic
I fucking hate ionic
I fucking hate ionic
it works!!
I still fucking hate ionic -.-10
-
-
-
- Downloaded a Hello World template for a HTML/hybrid mobile app... My node_modules folder has a backup of The Internet now...4
-
- So i am the process of working on improving my personal brand and have created myself a new logo.
I thought it would be interesting to see what you all think?
"As a developer/designer hybrid i wanted to create a identity that was able to form a symbolic reference.
My initials (nb) are formed into one continuous line making a connection to two seemingly different fields that represent both design and development."
Full Resolution:
- Once my fuckin annoying colleague replaced all console.log to alert in our hybrid app..
And back then my testing logs used to be idiotically profane :|
Needless to say, I faced the fuckin wrath of clients :+7
-
- Out of hybrid apps (React Native, Electron, Native Script, etc) what would be the most popular for the industry, and the pros and cons?39
- Got an offer to work at a game development company. Office looked awesome (decked out in pinball machines and a huge marble track), located overlooking Schreveningen beach, young energetic team.
Then I saw the code. Oh God the code. And they wanted me to become system architect.
Hybrid PHP 4/5 OOP/procedural code custom framework running on a spaghetti database creaking by on the skin of its teeth... all backing Flash Facebook games.
Nope
- Swear to god if people don't stop calling the new RTX cards true ray tracing I'm going to ring their necks...
It is far from true ray tracing, it's a hybrid with ray trace base technology... Pls stop5
- Never had one due to this trick I borrowed from an old friend.
So we all know about those meetings where its all crap flying around right?.
First go in there with your alarm clock set on vibration every 7 minutes(trust me on this-makes you look important and you ought to be somewhere else)
Actually the alarm is a reminder that you need to bring yourself back online.
At this point just listen to the speaker for a couple of seconds(especially if its marketing dept) and being the engineer your are; rephrase parts of their presentation in a question-comment hybrid( at this point you're the wisest looking person in the room)
Now go back to thinking about that pizza slice you left in the fridge as they discuss the "lean production" methods that they can use based on "your opinion"..
To more happy meetings..cheers3
-
- Wasted 7 hours for this:
import moment from 'moment'
Should be:
var moment = require('moment')
What happened? When app running in debug mode all is working without issues! When generating release APK, it crashes when using moment
Fucking hybrid shit apps..
- *me calculating rsa*
"aight.. Public key is 9 and n"
*calculating private key*
*recalculating cause I fucked up*
*recalculating cause I'm retarded*
*3rd recalculation*
"ok, I figured out my private key is 9 (and n)"
.... Wait a second.1
-:
- In my view, there is exactly 1, very specific occasion, when hybrid / app wrappers / webviews etc. are the right approach for a mobile app.
1. Never8
-
-
-2
-
- So for our current Hybrid application in Cordova, we are using few open source PLUGINS
One of the plugins have some known unresolved issues, stopping us to customize our App
Now my Client and Project Manager want me to personally CALL that guy (original developer) and TELL HIM to resolve the issue in '3 days, before Monday'
God save me :/2
-
-
- I was reluctant to try out flutter earlier on because of claims online stating that hybrid frameworks aren't there yet. That's one hell of a crap!
I fell in love with flutter after completing my first flutter app. Shit was just too easy. So many helpful libraries which has eased my overall workload lately.
We built a Native Android app which took 2months+ to complete and I just finished porting it to flutter for iOS and Android in 3 weeks. Boss was happy, Client was happy, I am freaking joyous, everybody is happy!
From the mouth of a Native Android Dev with over 5yr of exp. This shit called flutter is worthy of all the hype. I fucking kid you not!
I don't know about the past... I assume it was shitty then cus I also blasted it based on git issues but now it seems even more faster to build production worthy apps than anything I've encountered.6
-
- So, in my company we where initially about 20 programmers doing two big projects.
The client (who also is the owner of the company) keep asking more and more and more things. Each 3 months we update the site but the client doesn't start the marketing or anything else, so the app don't have any users.
After two years of development, 26 micro services, one big web platform in Python (web2py, bad decision) and a hybrid mobile app the client decide to shut down the project because it was "a little bit illegal".
The second project have the same problems, but this project does have marketing, the shitty part is after two year and a lot of development now the project isn't viable because the market is gone.
The boss calls, says he have some problems and he will fire 18 persons and reduce the payment of the rest, he ask us to "hold" for the good times.
The great idea he had for earn money is rewriting a WordPress app that have 4 years in production to angular (because he, who knows why, thinks angular is the best shit out there)
I want to quit but even with the reduced payment I know he pays way more than the market average, plus I'm still student.1
- Ad an Android dev, I hate that hybrid solution like cordova, react native or similar frameworks. Companies sell their apps for ridicolous prices, so every native Android/ios dev need to get it's work faster and for a lower price.
Customers can't understand that hybrid app are faster to create but works worse. I'm hating you, hybrid-guys17
- Fucking hell with React Naive! Spent all day making a screen and that bitch looked messed up on Android but working as intended on iOS!
I fucking hate that shit hybrid shit apps!5
- it's crazy. does no one recruit native app developer these days? they're always looking for hybrid developers, always 😭5
-
- I
- So I just bought my new laptop and I'm thinking "Forget about Arch. I don't have time to waste now. Let's just install Debian and save time for important tasks I have. Why should I redo everything that is done, while I have enough undone jobs already."
2 days later, at last I managed to install nvidia hybrid drivers and get it to work successfully. Now I just have to find out the cause of the black screen I get when it recovers from suspend
- I have been working on a hybrid app since 7 months
Today my manager told me, I didn't do anything except adding random plugins here and there :|
And my colleagues i.e. native app developers were laughing :|
What the fuckin fuck man :/.
-
- My Win10 bootloader ate grub so whenever I attempted to boot Debian, it would skip to Windows. So I reinstalled grub. Now Windows won't boot and the partition is locked in hybrid mode. :/20
-!
- My cycle : windows - ubuntu - mint - fedora - elementary - kubuntu - apricity os - debian - windows.
Why? Because that damn linux has fucking problem with hybrid intel/amd gpus13
-
-
-9
-
-
-.
-
- Does the idea of people being able to see your source code when creating a hybrid app scare you guys?4
-
-
- I need a stress ball. I'm working a thesis for my honors, a website, a hybrid app, some graphic design work. All of these are due mid next month. I need prayers and tips
-
-
- To the guys that develop any form of hybrid applications, is there literally no js templating engine that accepts template files as its base? I could write probably a single file that just returns the template and then all the others request it before templating, but seriously, is there no ready to go solution?5
- React native vs flutter?
I’m a native app developer. Just want to do a hybrid app project to get some exp with hybrid as well4
- What the fuck is the philosophy behind ionic and similar retarded frameworks?
To not to learn two or languages/ecosystems ?
You fucking deal with more in those "hybrid" shits: Ionic itself + Cordova + Angular + Android + iOS
I'd rather write the same code twice and just deal with Android + iOS
Are all other ""Hybrid"" and pseudo-native frameworks like this?22
- There is a lot of concerns about Apple rejecting hybrid apps in near future. What do you think? Will that happen?13
-
- !rant
I've tried Ionic in the past, and put off development with it because I couldn't get it to be performant without crosswalk.
In 2015, React Native put an end to the 'Are hybrid apps viable?' argument. It had a much smaller compile size, large component library, and is very reactive.
Ionic recently released news on scaling back their tools to focus on core offerings. I can't help but feel they're flogging a dead horse.
I'm sure the Ionic team has very smart people on board. Can't they see they're about to be 'Parse-ed'?1
- React Native, Flutter, Xamarine, Cordova hope all of you fucking burn in hell! Piece of shit solutions...
Just want to simply enable remote JS debuggin but the fucking app stops reloading when that shit is turned on. Now how the fuck am I supposed to know what the fuck is wrong with my code, disable remote JS debugging and app loads again.
Fuck this shit!6
- Nightmare for dev at timesofindia .. And it's Monday morning . Didn't knew they had hybrid app untill this . Love Js .
-
- I got stuck in a shitty situatuion in which i have to choose between being a front-end+mobile developper and back-end. I have to answer my company today, the problem is that i like both domains.
HELP !!!8
-
-
- A whole week for "a new ecommerce system" delivered shortly after the MD declare how simple it would be with some hybrid pseudo code/flow chart on their magic whiteboard.
Words were had.
- I learned to work with tools and platforms, instead of trying to re-write them and creating bugs for myself.
See: every hybrid tool ever.
This leaves me plenty of time to research new trends and patterns.
-.
- have you ever created Hybrid app? which framework did you use?
OR
which framework is good to create hybrid app and easy to adapt?9
-
- I'm planning to rewrite two months(part time) worth of work done in android sdk. Wanna go for a hybrid framework. Is this a bad idea? Which framework do you suggest as far as stability is concerned? I don't care about ease of learning, new languages don't bother me.
- Finally managed to install Manjaro with working hybrid nvidia drivers on my lapptop! I fucking love this OS already. Now I can start learning linux by actually using it.13
- Yeah right. If we go hybrid mobile app it's like the same work as native but you get 2 apps for 2 platform for the same time / cost. That's how it works 😭
-
- God, I wish there was a hybrid distro, between Debian and arch.
A big as fuck repo and update-alternatives like in Debian, but with pacman and makepkg.
Oh, and without systemd.5
-.2
-
- I'm having such hard time adjusting with hybrid mobile development coming from native it frustrates meeeee :(11
-
- Thinking about starting to do some part time (10-20h/week) as a front end / hybrid app dev(3years experience) Spec stack: Vue, Cordova, D3.
You guys have any advices, recommendations, experiences to share about where to start, I welcome it.
- if i am a native android-only developer and not a hybrid app developer for both android and ios, is it possible for my app(s) to generate enough money? by enough i mean a lot. A lot of money
what is the proportion of people who use android and ios? who uses what os more?6
-
-
-
-
-
-
-
- Wrote a hybrid event calendar pdf generation js thingy. At first I just thought I could use the standard outlook calendar view export pdf api which sucked btw, mines is better
- See the bottom ? I wonder is Devrant coded in Native or Hybrid. If in native the layout should be match_parent but this just margin_bottom the way too high..
-.1
-
-
-.
- This a hybrid rant/question - I'm just getting into golang/go and loving bits of it but feeling that I am needing to import a new cunting package to get basic stuff done that every other language has out of the box (that is the rant) - eg fmt package is needed to print. Is this the downside of go or am I missing something fundimental?3
-
- You know there's something seriously wrong with a "framework" when it takes 20 minutes to figure out how to SHIFT A BUTTON INSIDE A HEADER.
Fuck you jQuery Mobile. I wish you had never been born.
:|3
-
-
-
- I am interested in developing faster with Android. So I look around for options. So far, I found React Native and IONIC.
Then I watch Google I/O 2017.
And there is Kotlin, approved as first-class language for native. Haven't tried it myself, but many syntax I looked into looks nice.
So, native, or hybrid?10
- Do a native App's programmers have insecurity about hybrid Apps development ? Just saying , i have read many articles about how they are rudely criticized how slow hybrid is.
-
- AladdinB2B merges the in-person and virtual models to create a hybrid. The hybrid show allows you to have both face-to-face and digital meetings, presentations and launches - granting access to a global audience.1
- NOT A RANT
Any of you guys and gals on DevRant bought a Nintendo Switch?
If Yes, what's your verdict on the console/handheld hybrid? And how's Zelda BoTW??
- What would be beneficial in development of Hybrid Mobile apps in terms of light weight code, Flutter or React Native ?1
-
- Creating a mobile application. Only a simple calendar with some features. Should I use native code or use hybrid?
I know java and HTML , CSS and JavaScript. Question is which one would give me the least headaches?4
- No judgment regardling the "H" word here. But right now, which would you rate the best Hybrid app SDK?
Flutter, React Native, Xamarin? Other? and why?
I started using Flutter in 2020 and I'm loving the results. The learning curve is really high but the performance is nice. But coding via widgets...just feels a bit messy.8
-
- Just saw this rant:...
Then I remember an article about MS business groups being unproductive in remote work mode:...
Are you guys more productive in the office or remote? If going a hybrid setup, what would be a good office/remote ratio for you?4
Top Tags
|
https://devrant.com/search?term=hybrid
|
CC-MAIN-2021-39
|
refinedweb
| 2,722
| 73.17
|
: > >>>>>> > >>>>>>> > >>>>>> Ok. New patch. > >>>>>> > >>>>>> -Justin > >>>> [...] > >>>>>> @@ . > > > > the documentation can be changed to 0 vs. not 0 > > but imho that is seperate of this patch > > yes, that's fine. i took it out of the last patch I sent. > > > > >>>>> [...] > >>>>>> int avcodec_default_get_buffer(AVCodecContext *s, AVFrame *pic){ > >>>>>> int i; > >>>>>> int w= s->width; > >>>>>> int h= s->height; > >>>>>> + int is_video = (s->codec_type == AVMEDIA_TYPE_VIDEO); > >>>>>> InternalBuffer *buf; > >>>>>> int *picture_number; > >>>>>> > >>>>>> @@ ){ > >>>>>> @@ > > > > > [...] > >> diff --git a/libavcodec/utils.c b/libavcodec/utils.c > >> index ffd34ee..d95622b 100644 > >> --- a/libavcodec/utils.c > >> +++ b/libavcodec/utils.c > >> @@ -114,6 +114,9 @@ typedef struct InternalBuffer{ > >> int linesize[4]; > >> int width, height; > >> enum PixelFormat pix_fmt; > >> + int channels; > >> + int nb_samples; > >> + enum SampleFormat sample_fmt; > >> }InternalBuffer; > >> > >> #define INTERNAL_BUFFER_SIZE 32 > > [...] > >> @@ ){ > >> @@ -249,21 +273,50 @@ int avcodec_default_get_buffer(AVCodecContext *s, AVFrame *pic){ > >> ); > >> #endif > >> > >> + /* For audio, use AVCodecContext.user_buffer if it is non-NULL, large > >> + enough to hold the frame data, and the decoder does not request > >> + a reusable and/or preserved buffer. */ > >> + if (s->user_buffer && !is_video && ((pic->buffer_hints & FF_BUFFER_HINTS_VALID) && > >> + !(pic->buffer_hints & FF_BUFFER_HINTS_PRESERVE|FF_BUFFER_HINTS_REUSABLE))) { > >> + int buf_size = pic->nb_samples * s->channels * > >> + (av_get_bits_per_sample_format(s->sample_fmt) / 8); > >> + if (s->user_buffer_size >= buf_size) { > >> + pic->type = FF_BUFFER_TYPE_INTERNAL | FF_BUFFER_TYPE_USER; > >> + pic->base[0] = pic->data[0] = s->user_buffer; > >> + s->user_buffer = NULL; > >> + pic->reordered_opaque = s->reordered_opaque; > >> + > >> + if (s->debug & FF_DEBUG_BUFFERS) { > >> + av_log(s, AV_LOG_DEBUG, "default_get_buffer called on pic %p, " > >> + "AVCodecContext.user_buffer used\n", pic); > >> + } > >> + return 0; > >> + } > >> + } > >> + > > > > i dont understand this code. > > it looks to me like checking for alot of fatal error conditions but not failing > > * user_buffer set for non audio > > * mixing user buffers and some flags that make no sense for audio and i dont > > see which decoder would use them > > * the buffer being too small > > > > I see no use case where not immedeatly failing would make any sense, also > > this makes patch review much more difficult because i would have to make > > sure these cases that appear nonsense to me dont lead to exploits a few lines > > later. And it obviously increases code complexity at no obvious gain. > > If iam missing some sense in these cases, please elaborately explain > > I'm sorry. Maybe I'm over-thinking or over-planning. I'm trying to > take into account if an audio decoder would need to reget a buffer or > preserve/reuse a buffer. In those cases user_buffer would not be > appropriate to use. Video decoders reget buffers for conditional replenishment like when some pixels stay the same between 2 frames. This use case doesnt exist for audio. Do you know of use case for audio? If not then how do you know that what you implement is even similar to what a future use case would need? > > As for not failing, I thought it would be better to fallback to an > internal buffer. But if you prefer to fail if the user tries to provide > a buffer that won't work that's fine with me too. It would be adequate > for backwards compatibility with the current API. > > > > > [...] > > > >> @@ -380,13 +451,26 @@ int avcodec_default_reget_buffer(AVCodecContext *s, AVFrame *pic){ > >> > >> /* If no picture return a new buffer */ > >> if(pic->data[0] == NULL) { > >> + int ret; > >> /* We will copy from buffer, so must be readable */ > >> pic->buffer_hints |= FF_BUFFER_HINTS_READABLE; > >> - return s->get_buffer(s, pic); > >> + ret = s->get_buffer(s, pic); > >> + > >> + /* Don't allow user_buffer to be used */ > >> + if (!ret && pic->type == (FF_BUFFER_TYPE_INTERNAL | FF_BUFFER_TYPE_USER)) { > >> + uint8_t *buf = pic->data[0]; > >> + assert(s->user_buffer == NULL); > >> + ret = s->get_buffer(s, pic); > >> + assert(ret || pic->type == FF_BUFFER_TYPE_INTERNAL); > >> + /* restore user_buffer to indicate that it was not used */ > >> + s->user_buffer = buf; > >> + } > >> + return ret; > >> } > >> > >> /* If internal buffer type return the same buffer */ > >> if(pic->type == FF_BUFFER_TYPE_INTERNAL) { > >> + assert(!(pic->type & FF_BUFFER_TYPE_USER)); > >> pic->reordered_opaque= s->reordered_opaque; > >> return 0; > >> } > >> @@ -399,11 +483,17 @@ int avcodec_default_reget_buffer(AVCodecContext *s, AVFrame *pic){ > >> pic->data[i] = pic->base[i] = NULL; > >> pic->opaque = NULL; > >> /* Allocate new frame */ > >> + assert(!s->user_buffer); > >> if (s->get_buffer(s, pic)) > >> return -1; > >> - /* Copy image data from old buffer to new buffer */ > >> + /* Copy frame data from old buffer to new buffer */ > >> + if (s->codec_type == AVMEDIA_TYPE_VIDEO) { > >> av_picture_copy((AVPicture*)pic, (AVPicture*)&temp_pic, s->pix_fmt, s->width, > >> s->height); > >> + } else if (s->codec_type == AVMEDIA_TYPE_AUDIO) { > >> + memcpy(pic->data[0], temp_pic.data[0], s->channels * pic->nb_samples * > >> + (av_get_bits_per_sample_format(s->sample_fmt) / 8)); > >> + } > >> s->release_buffer(s, &temp_pic); // Release old frame > >> return 0; > >> } > > > > what does this code do? > > what does reget_buffer() even mean for audio buffers ? > > and what codec would use that? > > This is the same case as above. Probably I was trying to cover more > cases than are necessary. I thought maybe some decoders could benefit > from reusing the buffer and might want it to be preserved. For example, > the ALS decoder uses samples from the previous frame, which it has to > memcpy into its own buffer to store for the next call. Thats not what reget_buffer() is used for. get_buffer() already implicates that the data must be preserved by the user app until a matching release_buffer(): <>
|
http://ffmpeg.org/pipermail/ffmpeg-devel/2010-October/100271.html
|
CC-MAIN-2014-52
|
refinedweb
| 790
| 53.92
|
What is the difference between a static class and a static member variable or method? I have asked this question in most of my interviews, and most of the time, it confuses candidates. So I thought of writing an informative article on it so that the difference is comprehensible, and fellow developers can add more information/valuable points.
Let's start with the memory first. Whenever a process is loaded in the RAM, we can say that the memory is roughly divided into three areas (within that process): Stack, Heap, and Static (which, in .NET, is actually a special area inside Heap only known as High Frequency Heap).
The static part holds the “static” member variables and methods. What exactly is static? Those methods and variables which don't need an instance of a class to be created are defined as being static. In C# (and Java too), we use the static keyword to label such members as static. For e.g.:
static
class MyClass
{
public static int a;
public static void DoSomething();
}
These member variables and methods can be called without creating an instance of the enclosing class. E.g., we can call the static method DoSomething() as:
DoSomething()
MyClass.DoSomething();
We don't need to create an instance to use this static method.
MyClass m = new MyClass();
m.DoSomething();
//wrong code. will result in compilation error.
An important point to note is that the static methods inside a class can only use static member variables of that class. Let me explain why:
Suppose you have a private variable in MyClass which is not static:
MyClass:
a
new.
b.
sealed.
int
string
So using the static keyword will make your code a bit faster since no object creation is involved.
An important point to note is that a static class in C# is different from one in Java. In Java, the static modifier is used to make a member class a nested top level class inside a package. So using the static keyword with a class is different from using it with member variables or methods in Java (static member variables and methods are similar to the ones explained above in C#).
Please see the following link for details:
Also, the static keyword in C++ is used to specify that variables will be in memory till the time the program ends; and initialized only once. Just like C# and Java, these variables don’t need an object to be declared to use them. Please see this link for the use of the static keyword in C++:
Writing about the const keyword brings me to a subtle but important distinction between const and readonly keywords in C#: const variables are implicitly static and they need to be defined when declared. readonly variables are not implicitly static and can only be initialized once.
const
readonly
E.g.: You are writing a car racing program in which the racing track has a fixed length of 100 Km. You can define a const variable to denote this as:
private const int trackLength = 100;
Now, you want the user to enter the number of cars to race with. Since this number would vary from user to user, but would be constant throughout a game, you need to make it readonly. You cannot make it a const as you need to initialize it at runtime. The code would be like:
public class CarRace
{
//this is compile time constant
private const int _trackLength = 100;
//this value would be determined at runtime, but will
//not change after that till the class's
//instance is removed from memory
private readonly int _noOfCars;
public CarRace(int noOfCars)
{}
public CarRace(int noOfCars)
{
///<REMARKS>
///Get the number of cars from the value
///use has entered passed in this constructor
///</REMARKS>
_noOfCars = noOfCars;
}
}
We examined the static keyword in C#, and saw how it helps in writing good code. It is best to think and foresee possible uses of the static keyword so that the code efficiency, in general, increases.
This article has no explicit license attached to it but may contain usage terms in the article text or the download files themselves. If in doubt please contact the author via the discussion board below.
A list of licenses authors might use can be found here
public static class MyStaticClass
{
static MyStaticClass()
{
s_triggerDate = DateTime.Now.AddDays(7);
}
private static s_triggerDate;
public static TriggerDate
{
get { return s_triggerDate; }
}
}
public class MyNormalClass
{
static MyNormalClass()
{
Empty = new MyNormalClass(-1);
}
public MyNormalClass(int code)
{
m_code = code;
}
public static MyNormalClass Empty;
private int m_code;
public int Code
{
get { return m_code; }
}
}
static void Swap<T>( ref T x, ref T y )
{
T swap = x;
x = y;
y = swap;
}
Thread Safety <BR>
Any public static (Shared in Visual Basic) members of <BR>this type are thread safe. Any instance members are <BR>not guaranteed to be thread safe.
General News Suggestion Question Bug Answer Joke Praise Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages.
|
https://www.codeproject.com/Articles/15269/Static-Keyword-Demystified?fid=334563&df=90&mpp=25&sort=Position&view=Normal&spc=Relaxed&prof=True&select=1692852&fr=51
|
CC-MAIN-2021-17
|
refinedweb
| 838
| 58.82
|
// ex1-1.cpp
#include <iostream>
using namespace std;
int main()
{
cout << "Hello";
return(0);
}
ex1-1
Hello
The second line is an instruction to the compiler to incorporate into
this program some standard software components for performing Input and Output on streams
of data. The part of the instruction '#include <>' tells the compiler
an inclusion is required, while the string 'iostream' indicates which component
is required.
The third line is an instruction to the compiler that this program will
be referring to some standard objects which can be found in an area called
'std' - the standard namespace. The object 'cout' is the only standard
object in this example.
The fourth line provides a name and a type to the single block of code
in our example. We have chosen to call the block of code 'main' and have
required it to return an integer (whole number) value to the operating
system after it completes running. For console applications on Windows
platforms, every program needs to have a block of code called 'main' and
this needs to return an integer; so we didn't really have much choice. When
the program is run, the 'main' block is the 'entry point' for execution:
where the program starts running from.
The fifth line and last line define the sequence of instructions that
make up the 'main' block. Opening and closing 'curly bracket' symbols are
used to define a block. Note that each instruction inside a block ends
in a ';' semi-colon character.
The sixth line is a request made to a standard object called 'cout'.
This object 'stands for' the output channel to the console (or screen).
The request we make of it is to print a sequence of characters. We do this
by enclosing the sequence (called a string) of characters in double quote
marks and putting the string after the operation '<<'. Thus the object
'cout' gets told to output something (by '<<') and the something
is the string enclosed in "...". To print a double quote mark by the way,
you can prefix the double quote mark with a back-slash, as in "this is
a \" quote mark".
Finally the seventh line causes execution to 'return' to the component
that called this block. In this case, it was the operating system, so the
thread of execution returns to the operating system. The 'return' instruction
provides a value with which this block of code returns. We have already
said that the block must return an integer, and in this example we decide
to return the integer 0. If you run this program inside the SCITE editor,
with the Tools/Go command, the returning value ('Exit Code') is printed on the screen.
// ex1-2.cpp
#include <iostream>
using namespace std;
int main()
{
cout << "Hello";
cout << " ";
cout << "there.";
cout << endl;
return(0);
}
ex1-2
Hello there
There is one other new component in this program: the 'endl' object
is simply a character that 'stands for' the end-of-line character. When
an end-of-line character is sent to the cout object, the computer starts printing
at the beginning of a new line on the screen.
// ex1-3.cpp
#include <iostream>
using namespace std;
int main()
{
cout << "Hello" << " " << "there." << endl;
return(0);
}
ex1-3
Hello there
hellocpu
Hello Mark
initial
XX XX
XXX XXX
XXXX XXXX
XX XXX XX
XX X XX
XX XX
XX XX
© 1999 Mark Huckvale University College London
|
http://www.phon.ucl.ac.uk/courses/spsci/abc/lesson1.htm
|
CC-MAIN-2017-34
|
refinedweb
| 566
| 67.89
|
Vol. 11, Issue 11, 3963-3976, November 2000
Department of Biochemistry, University of Amsterdam, Academic Medical Center, Meibergdreef 15 1105 AZ Amsterdam, The NetherlandsSubmitted July 12, 2000; Revised July 12, 2000; Accepted September 7, 2000204XXQF208,.
Peroxisomes are ubiquitous organelles bound by a single membrane
that are present in almost all eukaryotic cells. Genetic screens in
yeasts and in Chinese hamster ovary cell lines, and analysis of cells
from patients with peroxisomal diseases have resulted in the
identification of at least 23 genes encoding Pex proteins (peroxins)
that play a role in the biogenesis of the peroxisome (a recent update
can be viewed on the Web site). Most
peroxins function in the import of matrix proteins into the peroxisome
(reviewed in Erdmann et al., 1997
; Subramani, 1998
; Hettema
et al., 1999
; Tabak et al., 1999
). Exceptions are
Pex3p, Pex16p, and Pex19p, which are required for the proper
localization of peroxisomal membrane proteins (Honsho et
al., 1998
; Kinoshita et al., 1998
; Matsuzono et
al., 1999
; Snyder et al., 1999
; South and Gould, 1999
;
Hettema et al., 2000
). Proteins that reside in the
peroxisomal matrix are synthesized on free polyribosomes in the cytosol
and are posttranslationally imported into the peroxisome (Lazarow and
Fujiki, 1985
). The majority of these matrix proteins contain the
peroxisomal targeting signal type I (PTS1) that consists of the
carboxyl-terminal tripeptide SKL or a derivative thereof (Gould
et al., 1989
; Purdue and Lazarow, 1994
; Elgersma et
al., 1996b
). Only a few proteins contain a PTS2, which is located
in the N-terminal part of the protein (Osumi et al., 1991
;
Swinkels et al., 1991
; Purdue and Lazarow, 1994
). The PTSs
are specifically recognized by their matching soluble receptors Pex5p
(for PTS1 proteins) (Dodt et al., 1995
; Wiemer et
al., 1995
; Elgersma et al., 1996a
; Gould et
al., 1996
) or Pex7p (for PTS2 proteins) (Marzioch et
al., 1994
; Elgersma et al., 1998
). In yeast, both
receptors are able to function independently of each other,
establishing separate cytosolic PTS1 and PTS2 protein-import routes
(Subramani, 1996
; reviewed in Erdmann et al., 1997
; Hettema
et al., 1999
). Receptors with bound PTS proteins converge on
a common translocation machinery. Two proteins of this machinery,
Pex13p and Pex14p, have been shown to interact with Pex5p and Pex7p,
implying a role for Pex13p and Pex14p in docking of the receptors
(Elgersma et al., 1996a
; Erdmann and Blobel, 1996
; Gould
et al., 1996
; Albertini et al., 1997
; Brocard
et al., 1997
; Fransen et al., 1998
; Girzalsky et al., 1999
; Schliebs et al., 1999
). Pex13p and
Pex14p form a complex with a third peroxin, Pex17p, which was
characterized as a peripheral peroxisomal membrane protein (Huhse
et al., 1998
). Furthermore, three other peroxins have been
suggested to play a role in the PTS import pathway downstream of the
membrane-docking event. These are Pex10p, Pex12p, and Pex4p (Van der
Klei et al., 1998
; Chang et al., 1999
).
Pex13p is an integral peroxisomal membrane protein possessing a
C-terminal SH3 domain exposed to the cytosol. Src homology 3 (SH3)
domains constitute a family of protein-protein interaction modules
that participate in diverse signaling pathways (Pawson and Scott,
1997
). X-ray crystallography, and nuclear magnetic resonance techniques
have now resolved the three-dimensional structure of various SH3
domains and their contact sites with peptide ligands. Highly conserved
aromatic amino acid residues form a hydrophobic binding pocket for
typical polyproline helix structures, usually composed of two prolines
spaced by two amino acids (PXXP motif) (Ren et al., 1993
;
Lim et al., 1994
; Yu et al., 1994
). Motifs containing a single proline have also been reported. For instance, binding of the SH3 domains of Hck and Src to an intramolecular peptide
sequence in the protein requires only one proline residue (Sicheri
et al., 1997
; Xu et al., 1997
). Recently, a novel
ligand site has been identified for the Eps8-SH3 domain that conforms to the consensus sequence proline-X-X-aspartate-tyrosine (PXXDY) (Mongiovi et al., 1999
). Cocrystallization of the Fyn SH3
domain and a high-affinity ligand peptide of Nef also showed that the (highly variable) RT-loop of the SH3 domain contributes to a
higher binding affinity and specificity for the ligand by creating
additional contact sites outside the PXXP motif (Lee et al.,
1996
).
The SH3 domain of Pex13p was shown to interact with both Pex5p and
Pex14p (Elgersma et al., 1996a
; Erdmann and Blobel, 1996
; Gould et al., 1996
; Albertini et al., 1997
;
Brocard et al., 1997
; Girzalsky et al., 1999
).
The interaction with Pex14p is dependent on a typical PXXP motif
(PTLPHR) present in the N-terminal half of the protein (Girzalsky
et al., 1999
). The second SH3 domain-binding partner Pex5p,
however, does not possess a recognizable PXXP motif. A key issue that
remains to be resolved is how Pex5p contacts the SH3 domain of Pex13p.
Here we report the identification of the region in Pex5p that is responsible for interaction with Pex13-SH3, based on a two-hybrid screen with a pex5 mutant library. Mutations locate in or near a motif, W204XXQF208, that is conserved between Pex5p proteins of different species and does not resemble a canonical PXXP motif. Moreover, binding of Pex5p to Pex13-SH3 containing a mutation in either the RT-loop (E320K) or in one of the aromatic residues of the PXXP binding cleft (W349A) was not affected, whereas binding of Pex14p to these mutants was destroyed, suggesting that Pex5p contacts a nonclassical binding site on Pex13-SH3. In vivo, pex5 mutants that had lost SH3 domain binding displayed a partially disturbed PTS1 protein import and showed reduced ability to grow on oleate. Mutant Pex5p was still partially associated with peroxisomes like in wild-type cells, indicating that the interaction with Pex13-SH3 is not solely responsible for membrane association of Pex5p. Because we could show that Pex14p can form a bridge between Pex13-SH3 and mutant Pex5p in vitro, we suggest that Pex14p might function as an alternative docking site in vivo.
Yeast Strains and Culture Conditions
The yeast strains used in this study were
Saccharomyces cerevisiae BJ1991 (MAT
,
leu2, trp1, ura3-251, prb1-1122, pep4-3, gal2), pex5
(MAT
pex5::LEU2, leu2, trp1, ura3-251,
prb1-1122, pep4-3, gal2) (Van der Leij et al., 1993
),
PCY2 (MAT
,
gal4,
gal80, URA3::GAL1-LacZ, lys2-801,
his3-
200, trp1-
63, leu2, ade2-101),
PCY2pex5
(as PCY2 plus pex5::LYS2,
ura3::KanMX), HF7c (MATa, ura3-52, his3-200,
ade2-101, lys2-801, trp1-901, leu2-3112, gal4-542, gal80-538,
LYS2::GAL1UAS,
GAL1TATA-HIS3
URA3::GAL417mers(x3)-CyC1TATA-LacZ). Yeast transformants were selected and grown on minimal medium containing 0.67% yeast nitrogen base without amino acids (YNB-WO; Difco, Detroit, MI), 2% glucose, and amino acids (20-30
µg/ml) as needed. For subcellular fractionations and Nycodenz
gradients, log-phase cells grown on 0.3% glucose media were shifted to
oleate media containing 0.5% potassium phosphate buffer pH 6.0, 0.1% oleate, 0.2% Tween 40, 0.67% YNB-WO, and amino acids (20-30 µg/ml) as needed. To follow growth on oleate, log-phase cells were grown on
0.3% glucose and shifted to oleate media containing 0.5% potassium phosphate buffer pH 6.0, 0.5% peptone, and 0.3% yeast extract at
2 × 104cells/ml
(OD600 = 0.001). Oleate plates contained 0.5%
potassium phosphate buffer pH 6.0, 0.1% oleate, 0.5% Tween 40, 0.67%
YNB-WO, and amino acids as needed.
Plasmids and Cloning Procedures
Plasmids encoding GAL4 DB fusions of Pex13-SH3(284-386) and
Pex13-SH3(284-358) were described previously (Elgersma et
al., 1996a
). To generate GAL4 DNA-binding domain (DB) fusions with Pex13-SH3(301-386) (pGB17) and Pex13-SH3(310-386) (pGB16), polymerase chain reaction (PCR) was performed with primers P257, P258, and P256
(Table 1) on GAL4 DB PEX13-SH3(284-386)
as template. The PCR products were digested with EcoRI and
SpeI and cloned between the EcoRI and
SpeI sites of pPC97 (Chevray and Nathans, 1992
). Pex13-SH3(304-377) (pGB15) was obtained by cutting MTP 429 (a kind gift
from M.T. Pisabarro, Genentech, San Francisco, CA) with NcoI and making the ends blunt with Klenow polymerase. After
digestion with BamHI, the fragment was cloned between the
SmaI and BglII sites of pPC97 (pGB19). To
introduce the E320K mutation in pGB17 the plasmid was cut with BstBI
and SpeI and the obtained fragment was exchanged for the
BstBI-SpeI fragment from plasmid 20.50 (Elgersma et
al., 1996a
). GAL4 activation domain (AD) fusion
with PEX5 (pAN4) will be described in detail elsewhere
(Klein, Barnett, Bottger, Konings, Tabak, Distel, unpublished
data). The PEX14 open reading frame was generated by PCR
on genomic DNA of S. cerevisiae with primers P243 and
P244 (Table 1). The PCR fragment was cut with BamHI and
PstI and ligated into the pUC19 vector creating pGB4. GAL4
DB or GAL4 AD fusions were generated by digestion of pGB4 with
EcoRI and SpeI and ligation of the
PEX14 fragment between the EcoRI and
SpeI sites of pPC86 or pPC97 (Chevray and Nathans, 1992
).
GAL4 DB fused to MDH3 SKL was generated by cutting pEL102 (Elgersma
et al., 1996b
) with BamHI, making the ends blunt
with Klenow polymerase. After digestion with SpeI, the
fragment was cloned between the SmaI and BglII
sites of pPC97. The two-hybrid plasmid encoding GAL4 DB Pex8p was a
kind gift from Dr. W.H. Kunau (Bochum, Federal Republic of Germany).
All PCR fragments were verified by sequencing.
Point mutations in PEX5 were introduced using the
Quick-change site-directed mutagenesis kit (Stratagene, La Jolla,
CA). Primers were used as listed in Table 1. As template pAN4
was used. To introduce the triple mutation Pex5p(F208L, E212V,
E214G), the yeast-expression plasmid encoding Pex5p(F208L) under
the control of the PEX5 promoter was used as a template. The
introduced base pair changes were verified by sequencing. To create
plasmids for expression of Pex5p in yeast, the PEX5 promoter
was obtained from the genomic library plasmid originally isolated by
Van der Leij et al. (1992)
. The plasmid was digested with
XbaI (located 488 nucleotides upstream of the
PEX5 start codon) and the ends were made blunt with Klenow
polymerase, and subsequently digested with BamHI. This
fragment was ligated between the blunted SacI site and the
BamHI sites of the yeast expression vector Ycplac33 (Gietz and Sugino, 1988
), generating pEL91. PEX5 was obtained from
pAN4 or mutant plasmids derived from pAN4, by digestion of the plasmid with BamHI and HindIII. PEX5 fragments
were cloned between the BamHI and HindIII sites
of pEL91. Wild-type PEX5 cloned this way was fully capable
of complementing the growth defect on oleate of the pex5
strain.
To create glutathione S-transferase (GST) fusions of Pex5p for expression in Escherichia coli, PEX5 inserts were excised from pAN4 (wild-type) or from mutant plasmids derived from pAN4 (F208L and E212V, described above) with NcoI and HindIII. The fragments were ligated between the NcoI and HindIII restriction sites of pRP265nb (a kind gift from Dr. B. Werten, Utrecht, The Netherlands) resulting in in-frame fusions of GST with Pex5p. To generate maltose-binding-protein (MBP) fusions with the SH3 domain, the PCR product generated with primers 256 and 257 [SH3(301-386)] was cut with EcoRI and PstI and cloned between the EcoRI and PstI restriction sites of pUC19, creating pGB7. For introduction of the E320K mutation into pGB7, plasmid 20.50 was cut with BstBI and SpeI, and the SH3 fragment containing the mutation was exchanged for the BstBI-SpeI fragment of pGB7, generating pGB18. Wild-type and mutant (E320K) SH3 fragments were isolated by cutting plasmids pGB7 and pGB18 with BamHI and PstI, respectively. The obtained fragments were cloned into pMALc2 (New England Biolabs, Beverly, MA) digested with BamHI and PstI. MBP fusion of Pex14p was obtained by cutting pGB4 with BamHI and PstI, and ligation of the PEX14 fragment into pMALc2 (described above). Digestion of pGB4 with BamHI and PstI and by ligating the PEX14 fragment between the BamHI and PstI restriction of pQE9 (Qiagen, Chatsworth, CA) created a 6xHis fusion of Pex14p.
Plasmids for expression of green fluorescent protein fused to SKL
(GFP-SKL) and N-terminal hemagglutinin-tagged (NH) Mdh3p in yeast are
discribed elsewhere (Elgersma et al., 1996b
; Hettema et al., 1998
). To create plasmids for overexpression of
Pex13p and Pex13p(E320K) in yeast, plasmids 20.46 and 20.50 (Elgersma et al., 1996a
) were cut with SacI and
HindIII and PEX13 fragments were cloned behind
the catalase A (CTA1) promoter (pEL30, described in Elgersma et
al., 1993
) digested with SacI and HindIII.
For overexpression of Pex14p, pGB4 was cut with BamHI and
PstI and the PEX14 fragment was ligated between
the BamHI and PstI sites of pEL30. For
overexpression of Pex5p, pAN1 (Klein, Barnett, Bottger, Konings, Tabak,
Distel, unpublished data) was digested with BamHI and
HindIII and the PEX5 fragment was cloned behind
the CTAI promoter in 2 µ plasmid (pEL26, Elgersma et al.,
1993
).
In Vitro Binding Assay
All in vitro assays were set up according to the following
regimen. Cultures (250 ml) of E. coli BL21 cells expressing
either MBP or GST fusion proteins were induced with 1 mM isopropyl
-D-thiogalactoside and centrifuged; cell
pellets were resuspended in 5 ml of phosphate-buffered saline (PBS; 100 mM sodium phosphate buffer pH 7.4, 140 mM NaCl, 2 mM
phenylmethylsulfonyl fluoride [PMSF]). Cell suspensions were subsequently lysed by sonication. All GST constructs used for binding
assays with MBP fusions were purified on glutathione
S-sepharose (Amersham Pharmacia Biotech, Uppsala,
Sweden) according to the manufacturer's recommendations. A
200-µl amylose resin column was equilibrated in PBS and subsequently
loaded with 250 µl of a bacterial lysate containing the appropriate
MBP fusion. The resin was then washed with 1 ml of PBS. The GST fusion
(100 µg) was then run through the column at a flow rate of ~100
µl/min. The column was then washed with 3 ml of PBS and subsequently
eluted with 500 µl of 10 mM maltose in PBS. Fractions were collected and subjected to SDS-PAGE and Western blot analysis. In vitro experiments involving 6x His-tagged Pex14p were conducted similarly except that before loading of the GST fusion, 200 µl of a bacterial lysate containing 6xHis-fused Pex14p was loaded and the column washed
with 1 ml of PBS. The protocol then continued with GST fusion loading
as described above.
Pex5 Mutant Screen and Two-Hybrid Assays
Random mutations were introduced in the PEX5 gene by
error-prone PCR on plasmid pAN1. pAN1 contains the complete
PEX5 open reading frame with a unique XbaI site
at position 1140, which was introduced by site-directed mutagenesis.
PCR was carried under standard conditions with the nonproofreading
Taq DNA polymerase. The PCR product was digested with
XbaI and BamHI and ligated into pAN1 to create
the N-terminal library composed of mutagenized nucleotides 1-1140
(amino acids 1-380) and the wild-type C terminus of the protein. To
create the C-terminal library the PCR product was digested with
XbaI and PstI and the mutagenized nucleotides 1441-1836 (amino acids 381-612) were ligated into
XbaI-PstI-digested pAN1. Sequence analysis of 20 randomly picked clones revealed that approximately one nucleotide in
every 550 nucleotides was mutated. Both libraries were cloned between
the EcoRI and SpeI sites of the two-hybrid
plasmid pPC86, generating GAL4 AD fusions. One microgram of each
two-hybrid library was transformed to the yeast two-hybrid strain HF7c
containing the GAL4 DB Pex13-SH3(284-386) plasmid, and double
transformants were selected on glucose plates without leucine and
tryptophan. Colonies were replica-plated onto glucose plates without
leucine, tryptophan, and histidine; 15,000 colonies of the C-terminal
PEX5 library and 1,500 colonies of the N-terminal
PEX5 library were screened, yielding 130 and 75 clones,
respectively, that failed to grow in the absence of histidine. These
colonies were selected and pex5 mutant plasmids were rescued from these colonies for further analysis.
-Galactosidase filter assays were performed as described by Fields and Song (1989)
.
Quantification of
-galactosidase activity was performed with the
Galacto-Light kit (Tropix, Bedford, MA). Double-transformed PCY2
cells (10 OD units) were harvested, washed with distilled H2O, and resuspended in 200 µl of breaking
buffer (100 mM Tris pH 7.5, 20% vol/vol glycerol, 1 mM PMSF) plus
0.4 g of glass beads and lysed by mixing on a vortex for 30 min.
The homogenates were centrifuged for 15 min at 13,000 × g and the cleared lysates were used to measure
-galactosidase activity. Protein concentrations were determined with
the method described by Bradford (1976)
.
Subcellular Fractionation and Gradient Analysis
One liter of oleate-grown transformants was converted to spheroplasts by using Zymolyase 100T (1 mg/g cells). Spheroplasts were washed with 1.2 M sorbitol in 2 [N-morpholino]ethanesulfonic acid (MES) buffer (5 mM MES pH 5.5, 1 mM KCl, 1 mM EDTA) and lysed by osmotic shock in MES buffer containing 0.65 M sorbitol and 1 mM PMSF. Intact cells and nuclei were removed by centrifuging twice at 600 × g for 2 min. The obtained postnuclear supernatants were centrifuged for 30 min at 20,000 × g. The volumes of the pellet fractions were made equal to the volumes of the supernatant fractions. For Nycodenz gradient analysis, pellet fractions were resuspended in 1 ml of hypotonic lysis buffer and loaded on top of a continuous 15-35% Nycodenz gradient (12 ml) underlaid with a 1-ml cushion of 50% Nycodenz in MES buffer containing 8.5% sucrose. Gradients were spun in an MSE-Europe 24 M centrifuge equipped with a vertical rotor for 2.5 h at 19,000 rpm. Fractions with a volume of 0.5 ml were collected and analyzed by SDS-PAGE and Western blotting.
SDS-PAGE, Western Blotting, and Enzyme Assays
Proteins were separated on 10% SDS-polyacrylamide gels and
transferred to nitrocellulose. Blots were blocked in PBS (pH 7.4) supplemented with 0.1% Tween 20 and 2% skimmed milk powder
(Protifar). Blots were incubated with rabbit antibodies diluted in PBS
with 0.1% Tween 20. The antibodies used were anti-Pex13p,
anti-3-ketoacyl CoA-thiolase, anti-Pex5p (Elgersma et al.,
1996a
), and anti-Pat1p (Hettema et al., 1996
). Anti-NH was a
generous gift from Dr. P. van der Sluys (Utrecht, The Netherlands);
anti-Hsp60 was a generous gift from Dr. S. Rospert, Basel,
Switzerland. Polyclonal antisera for Pex14p were raised against
the full-length Pex14 protein isolated as a 6xHis fusion protein from
E. coli. Antibody complexes were detected by incubation with
goat anti-rabbit Ig-conjugated alkaline phosphatase. 3-Hydroxyacyl-CoA
dehydrogenase (3HAD) activity was measured on a Cobas-Fara centrifugal
analyzer by following the 3-keto-octanoyl-CoA-dependent rate of NADH
consumption at 340 nm (Wanders et al., 1990
). Catalase A
activity was measured as described by Lucke (1963)
.
Pex5p and Pex14p Bind Directly to the SH3 Domain of Pex13p
Based upon sequence alignment with other SH3 domains, the SH3
domain of Pex13p extends from amino acid 308 to 370. To determine the
functional boundaries of this domain we constructed deleted versions of
Pex13p (Figure 1). These constructs were
tested in the two-hybrid system for interaction with Pex5p and Pex14p.
Figure 1 shows that the SH3 domain flanked by four amino acids
N-terminally and seven amino acids C-terminally was sufficient for
interaction with Pex14p and Pex5p. Further deletion of either the N or
C terminus disrupted the interactions. We performed in vitro
reconstitution experiments to prove that these interactions are direct.
A bacterial lysate containing MBP fused to the SH3 domain of Pex13p was
loaded onto an amylose column. After washing, the column containing
immobilized MBP-SH3 was incubated with extracts of bacteria expressing
either a GST fusion of Pex5p or a 6xHis fusion of Pex14p. After
washing, MBP-SH3 and bound proteins were eluted from the column with
maltose. Proteins in the eluates were visualized by SDS-PAGE and
Western blotting. Figure 2 shows that in
separate binding experiments Pex5p (A) and Pex14p (B) were efficiently
coeluted with MBP-SH3 (lanes 2) and did not bind to a column with MBP
alone (lanes 1). These in vitro reconstitution assays indicate that
Pex5p and Pex14p can bind to the Pex13-SH3 domain directly and
independently of each other.
pex5 Mutants Disturbed in Interaction with the Pex13-SH3 Domain
Pex14p contains a canonical SH3-binding motif, PXXP, and
mutagenesis studies have shown that the two prolines within this motif
are essential for its interaction with Pex13-SH3 (Girzalsky et
al., 1999
). Pex5p, however, does not contain a recognizable SH3
binding motif. To identify the region in Pex5p that contacts the SH3
domain, two libraries were constructed in which either the N-terminal
or the C-terminal half of PEX5 was randomly mutagenized by
error-prone PCR. These libraries were screened for mutants that had
lost the interaction with Pex13-SH3 in the two-hybrid assay. Loss of
binding was scored by the inability to grow on media lacking histidine.
Such colonies were picked from the master plate and lysates were
analyzed by Western blotting to verify that full-length Pex5p was
expressed. The frequency of selected full-length pex5
mutants was much higher in the N-terminal library (5% of total)
compared with the C-terminal library (0.9% of total). Moreover, all
pex5 mutants isolated from the C-terminal library were
either truncated or unstable and were not analyzed further. These
findings suggest that the region in Pex5p involved in binding to the
Pex13-SH3 domain is located in the N-terminal half of Pex5p. To exclude
mutants with changes in overall structure, we tested two-hybrid
interactions with other known partner proteins of Pex5p (Table 2). Five pex5 mutants
were disturbed in binding to Pex13-SH3, but maintained interaction with
Pex14p, a protein that binds the N-terminal half of Pex5p (Schliebs
et al., 1999
; our unpublished results), and Mdh3p, a PTS1
containing protein that binds to the C-terminal tetratricopeptide
repeat (TPR) domains of Pex5p (Brocard et al., 1994
;
Klein, Barnett, Bottger, Konings, Tabak, Distel, unpublished
data). Additionally, the interaction with Pex8p, a protein that
contacts both the N-terminal and C-terminal half of Pex5p (Rehling
et al., 2000
), was also unaffected for these mutants. It is
noteworthy that only mutant N19 had completely lost two-hybrid
interaction with Pex13-SH3. Other mutants still displayed some growth
in the absence of histidine, suggesting residual binding capacity with
Pex13-SH3. We conclude that these pex5 mutants are
specifically affected in binding the Pex13-SH3 domain and that the
overall structure of these mutant proteins is still intact.
Pex5p Is a Non-PXXP Ligand for the Pex13-SH3 Domain
The five selected pex5 mutants were sequenced to
determine the site of the mutations. All mutants contained multiple
amino acid substitutions (Figure 3A).
Three independent mutants were mutated in the same residue: glutamic
acid 212 (E212). This residue was replaced by a valine (mutant N3), or
a glycine (mutants N8 and N84). In addition, clones N19 and N100 had
mutations in the same region (residues 208 and 214, respectively).
These amino acid residues are in or near a block of amino acids,
W204XXQF208 (where X stands
for any amino acid), that is conserved between Pex5 proteins of yeast
and higher eukaryotes (Figure 3B). To investigate which mutations were
responsible for the loss of Pex13-SH3 domain binding, single amino acid
substitutions were made using site-directed mutagenesis. Mutations were
made at position 109(T109A) and position 212 (E212V) (both found to be
mutated in mutant N3), and at position 208 (F208L) (found mutated in
the quadruple mutant N19). These three single mutants were tested
against Pex13-SH3 in the two-hybrid assay (Table
3). As a control, they were also tested
for interaction with other Pex5p binding partners. Interactions were
monitored by a quantitative
-galactosidase assay and by growth in
the absence of histidine in the two-hybrid strains PCY2 and HF7c,
respectively. The F208L mutation was sufficient to disrupt the
two-hybrid interaction with Pex13-SH3. In addition, the E212V mutation
disturbed the Pex13-SH3 interaction, although some growth in the
absence of histidine could be detected. The T109A mutation
showed a two-hybrid interaction with Pex13-SH3
comparable to wild-type Pex5p. The single mutants that had lost
SH3-domain binding appeared not to be affected in their interaction
with Pex14p and Mdh3p-SKL (Table 3; our unpublished results). These
results indicate that E212 and F208, but not T109, are
involved in Pex13-SH3 domain binding, but do not play a detectable role
in the interaction with other Pex5p partners. The two-hybrid results
were backed up by in vitro reconstitution experiments. Figure
4 shows that in contrast to wild-type
GST-Pex5p (lane 1), GST-Pex5p(F208L) (lane 2) could not be coeluted
with MBP-SH3, whereas a small amount of GST-Pex5p(E212V) (lane 3) was
recovered from the elution. The F208L mutation did not affect in vitro
binding to MBP-Pex14p. In separate binding experiments comparable
amounts of wild-type GST-Pex5p (lane 5) and GST-Pex5p(F208L) (lane 6)
could be coeluted with MBP-Pex14p from the column. In vitro binding of
GST-Pex5p(E212V) to MBP-Pex14p appeared also not to be affected (our
unpublished results). Together, these data indicate that residue F208
(and to a lesser extent residue E212) in Pex5p is essential for direct
and specific contact of Pex5p with the SH3 domain.
To further investigate the role of the W204XXQF208 motif in Pex13-SH3 domain interaction, an additional pex5 mutant was created by site-directed mutagenesis. The strictly conserved tryptophan (W204) was mutated to alanine and tested in the two-hybrid assay. The W204A mutation disturbed interaction with Pex13-SH3, although some activation of the HIS3 reporter could be detected (Table 3). The binding of this mutant to Pex14p was completely unaffected. This data underscore the importance of the W204XXQF208 motif for Pex13-SH3 domain binding.
Pex5p and Pex14p Bind the Pex13-SH3 Domain in Different Ways
The presence of a nonclassical SH3 interaction motif in Pex5p
raised the possibility that Pex5p may interact at a site on the
Pex13-SH3 domain distinct from the PXXP binding pocket. To test this
hypothesis we made use of two mutated forms of the Pex13p-SH3 domain.
One mutation originates from a previously isolated mutant of Pex13p
[Pex13p(E320K)] (Elgersma et al., 1996a
). Pex13p(E320K) has a point mutation in the RT-loop of the SH3 domain. This loop has
been shown to be important in determining the specificity of and
affinity for SH3 ligands (Lee et al., 1995
, 1996
; Arold et al., 1998
; Pisabarro et al., 1998
). The second
SH3 domain mutant was created by site-directed mutagenesis. This mutant
contains an amino acid substitution in the conserved tryptophan that is part of the hydrophobic cleft, which forms the binding platform for
polyproline ligands (Lim et al., 1994
). The interaction of the wild-type and mutant SH3 domains with Pex14p and Pex5p was assayed
in the two-hybrid system.
-Galactosidase activity was measured to
quantitate the interaction strength. The results shown in Table
4 reveal that Pex14p is unable to
interact with SH3(E320K) and SH3(W349A). However, Pex5p interaction
with both SH3(E320K) and SH3(W349A) is largely unaffected. The controls
included show that expression of either of the fusion proteins alone
did not support the activation of the reporter genes. Similar results were obtained in an in vitro binding assay (Figure 2). E. coli-expressed 6xHis-Pex14p could be coeluted with MBP-SH3 (Figure
2B, lane 2), whereas in a parallel experiment 6xHis-Pex14p did not bind
to MBP-SH3(E320K) because it did not appear in the eluate (Figure 2B,
lane 3). Furthermore, GST-Pex5p could be coeluted with both wild-type
MBP-SH3 (Figure 2A, lane 2) and MBP-SH3(E320K) (Figure 2A, lane 3),
indicating that the direct interaction between Pex5p and mutant
Pex13-SH3 is not affected. Taken together, these results show that the
E320K and the W349A mutations affect Pex14p interaction, but do not
interfere with Pex5p binding. They suggest, therefore, that Pex14p is
the canonical SH3 domain ligand, whereas Pex5p binds the Pex13-SH3
domain in an alternative way.
To obtain further support for this notion we investigated the effect of
Pex5p expression on the two-hybrid interaction between Pex13-SH3 and
Pex14p. A two-hybrid reporter strain isogenic to PCY2 was constructed
in which the PEX5 gene was deleted (PCY2pex5
). This strain was transformed with plasmids encoding either wild-type or
a mutant version of Pex5p under the control of the PEX5
promoter, or it was transformed with an empty expression vector. Figure 5 shows that deletion of endogenous Pex5p
reduced the Pex13-SH3/Pex14p interaction about threefold, indicating
that the strength of this interaction is dependent on the presence of
Pex5p. Reexpression of the Pex5p(F208L) mutant that is specifically
disturbed in SH3 interaction does not restore the SH3-Pex14p
interaction to wild-type levels. Together, these results show that in
vivo binding of Pex5p to Pex13-SH3 cooperatively stabilizes the
SH3/Pex14p interaction, which suggests that Pex5p and Pex14p bind
separate sites on the Pex13-SH3 domain.
Pex13p and Pex14p Operate Stoichiometrically
To further investigate complex formation in vivo we carried out
experiments in which PEX13, PEX14, or
PEX5 alone or in combination were overexpressed in wild-type
cells. The transformed strains were subsequently tested for their
ability to grow on oleate. Such experiments might reveal whether the
proper stoichiometry of a protein is essential for peroxisome function.
As shown in Figure 6A, overexpression of
Pex13p under the control of the strong CTA1-promoter in
wild-type cells leads to growth inhibition. Similarly, when Pex14p is
expressed under the control of the CTA1 promoter, growth on
oleate is also inhibited. However, simultaneous overexpression of
Pex13p and Pex14p allows normal growth on oleate, whereas
cooverexpression of the nonfunctional pex13 mutant E320K and
Pex14p inhibits growth on oleate. Overexpression of Pex5p does not
affect growth and is also not able to rescue the inhibitory effect of
Pex13p or Pex14p overexpression on oleate (Figure 6B). We conclude that stoichiometry of Pex13p and Pex14p is required for correct peroxisomal function, which indicates close cooperation between these two peroxins.
In Vivo Effects of pex5 Mutations F208L and E212V
Wild-type and mutant pex5 alleles were cloned
downstream of the PEX5 promoter in a yeast expression
plasmid. These plasmids were transformed to a pex5
strain
and transformants were cultured on oleate. The growth rate of cells
expressing Pex5p(F208L) was approximately fourfold reduced compared
with that of wild-type Pex5p, whereas growth of Pex5p(E212V) cells was
less affected (Figure 7). Growth on
glucose or glycerol media was unaffected for all transformants (our
unpublished results). In addition, we constructed a pex5
mutant with three amino acid substitutions in the region involved in
Pex13-SH3 domain binding: F208L, E212V, and E214G. This triple mutant
showed growth rates on oleate comparable to the single F208L mutant
(Figure 7, inset). These results are in line with the binding studies
and suggest an essential role for F208 in the interaction with
Pex13-SH3.
We expressed the GFP fused to PTS1 (GFP-SKL) to measure PTS1 protein
import in these mutants. GFP-SKL expression was visualized using
fluorescence microscopy (Figure 8A). In
pex5
cells expressing Pex5p(F208L) a punctated pattern of
labeling could be detected on top of a diffuse, cytosolic fluorescence,
suggesting a partial mislocalization of GFP-SKL. Pex5p wild-type and
Pex5p(E212V) transformants showed an exclusively punctated pattern
(Figure 8A).
The apparent mislocalization of PTS1 proteins in pex5
cells expressing Pex5p(F208L) was substantiated by subcellular
fractionation experiments. pex5
transformants were
homogenized and a postnuclear supernatant was centrifuged at
20,000 × g. Equivalent volumes of the pellet and the
supernatant fractions were analyzed for the presence of peroxisomal
proteins by using enzyme assays (Figure 8B: CTA1 and 3HAD) or Western
blotting (Figure 8C: Mdh3p, 3-ketoacyl-CoA thiolase). In cells
expressing wild-type Pex5p, 3HAD, CTA1, and Mdh3p were recovered almost
exclusively from the pellet fraction. In cells expressing Pex5p(F208L)
3HAD, and Mdh3p were partially mislocalized to the supernatant, whereas
CTA1 was completely mislocalized to the supernatant fraction. The
protein import defect of CTA1 could not be rescued by replacing its
PTS1 SKF by the canonical PTS1 SKL (our unpublished results),
suggesting that the failure of Pex5(F208L) cells to import CTA1 is not
reflected by its PTS1 composition. In Pex5p(E212V) cells, CTA1 was
partially mislocalized to the supernatant, whereas other PTS1 proteins
showed a wild-type distribution. The distribution of the PTS2 protein
3-keto-acyl-CoA thiolase was comparable in wild-type, Pex5p(E212V), and
Pex5p(F208L) cells (Figure 8C), implying that the defect in protein
import in pex5(F208L) cells is specific for the PTS1 import pathway. Moreover, these results suggest that loss of SH3-Pex5p interaction can
be partially compensated for in vivo. This is born out by an in vitro
reconstitution experiment. GST-Pex5p(F208L) could be coeluted with
MBP-SH3 when 6xHis-Pex14p was first bound to the immobilized MBP-SH3
column (Figure 4, lane 4). These results show that Pex14p contains two
different binding sites: one for Pex13-SH3 and another for Pex5p, and
that these proteins can bind Pex14p simultaneously in vitro, resulting
in a complex formed by Pex5p, Pex14p and Pex13-SH3.
Pex5p(F208L) and Pex5p(E212V) Are Still Associated with Peroxisomes
Because Pex5p(F208L) and Pex5p(E212V) are disturbed in binding to
the Pex13-SH3 domain, we investigated whether the subcellular distribution of the pex5 mutants is affected. Subcellular
fractionation of pex5
cells expressing mutant or
wild-type Pex5p revealed that Pex5p(F208L) and Pex5p(E212V), like
wild-type Pex5p, were partially associated with the 20,000 × g pellet fraction (our unpublished results). To investigate
whether Pex5p present in the pellet fractions was associated with
peroxisomes these fractions were analyzed by equilibrium density
centrifugation. Fractions were collected and analyzed for Pex5p and
marker proteins for peroxisomes (Pex13p, Pex14p, and Pat1p) and
mitochondria (Hsp60) by using SDS-PAGE and Western blotting. Cells
expressing Pex5p(F208L) contained peroxisomes equilibrating at lower
density in a Nycodenz gradient than peroxisomes from wild-type cells,
which may reflect the partial loss of matrix protein import in
Pex5p(F208L) cells. Both Pex5p(E212V) and Pex5p(F208L) were localized
in the peroxisomal peak fractions (Figure
9). These results suggest that in vivo,
although interaction with the SH3 domain of Pex13p is impaired, Pex5p
can still associate with peroxisomes. Based on our in vitro binding
experiments Pex14p is a likely candidate to fulfill this function.
Proteins containing a PTS need to be targeted after synthesis in the cytoplasm to the peroxisomal membrane for subsequent import into the peroxisomal matrix. Many proteins (peroxins) have been discovered that are involved in this targeting and membrane-translocation process, some of which are active in the soluble phase (targeting), whereas others are integral or peroxisomal membrane-associated proteins acting as components of the protein-translocation machinery. Pex5p is the soluble receptor that recognizes PTS1 proteins and targets these PTS1 proteins to the membrane-located peroxins (Pex13p, Pex14p, and Pex17p). Here we have investigated the region of Pex5p important for association with the SH3 domain of Pex13p.
Pex5p mutants were selected in a two-hybrid setup that had lost the
ability to bind to Pex13-SH3 but that retained the ability to interact
with other proteins. The screen revealed at least three residues
important for Pex13-SH3 interaction, F208, E212, and E214. Mutation of
F208 (to leucine) had a strong down effect, whereas mutation of either
E212 or E214 (to valine and glycine, respectively) showed diminished
binding capacity with Pex13-SH3 (Table 3). The properties of the
mutants in the two-hybrid system could be reproduced in an in vitro
reconstituted system with bacterially expressed fusion proteins, thus
excluding possible contributions of other yeast proteins. The mutations
are located close to each other in a region N-terminal of the
TPR-containing domain of Pex5p. Here we find the motif
W204XXQF208, conserved
among Pex5 proteins ranging from yeast to human. Mutation of the
strictly conserved tryptophan (W204) in this motif also compromised the
interaction with Pex13-SH3 (Table 3), indicating a central role for
this motif in Pex13-SH3 binding. A second motif with a similar sequence (WSQEF) is present ~90 amino acids N-terminal of the WXXQF motif. Mutations in this second motif do no affect the interaction of Pex5p
with Pex13-SH3 (our unpublished results). Recently, it was shown that a
peptide containing amino acids 100-213 of Pichia pastoris
Pex5p is able to interact with the SH3 domain of PpPex13p in vitro
(Urquhart et al., 2000
). This peptide includes the conserved WXXQF motif, suggesting that the SH3 binding region in Pex5p is conserved between different yeast species. Whereas ScPex5p contains only two WXXXF motifs, human Pex5p contains seven of these motifs. Based on in vitro binding studies with HsPex5p and a fragment of
HsPex14p (amino acids 1-78), Schliebs et al. (1999)
have
suggested a role for these motifs in Pex14p binding. We have not been
able to find support for this suggestion in yeast. Mutation of either of these motifs in ScPex5p did not specifically affect Pex14p binding
(Table 3; our unpublished results). Because pex5 mutants with severely disturbed binding to the Pex13-SH3 domain are still able
to interact with Pex14p in the two-hybrid system (Table 3) and in vitro
(Figure 4), we conclude that there are separate binding regions in
Pex5p for Pex14p and Pex13-SH3.
A consensus SH3-binding motif (PTLPHR) is present in the primary
sequence of Pex14p. Girzalsky et al. (1999)
demonstrated by
mutating the two prolines in the PXXP motif of Pex14p that these
residues are essential for interaction with Pex13-SH3. The other
Pex13-SH3 binding partner, Pex5p, does not contain a PXXP binding motif
or a degenerated version thereof. Moreover, in our screen for mutants
that had lost the interaction with Pex13-SH3 we did not find any
mutations in proline residues, which suggests that Pex5p contains a
novel, non-PXXP-related, SH3-binding motif. This is underscored by the
differential effect of the W349A and E320K mutations in the Pex13-SH3
domain on the interaction with Pex5p and Pex14p. Pex13-SH3 (W349A) is
mutated in one of the conserved aromatic residues that form the
hydrophobic binding cleft of the SH3 domain and Pex13-SH3(E320K)
contains a mutation in the RT loop of the SH3 domain. Both mutations
abrogated interaction with Pex14p but interaction with Pex5p was not
affected, either in the two-hybrid assay or in in vitro reconstitution
experiments. Because both the hydrophobic binding cleft and the RT loop
of the SH3 domain are part of the canonical PXXP ligand-binding region (Lim et al., 1994
; Lee et al., 1995
), the results
suggest a novel binding mode for Pex5p with Pex13-SH3. This is
supported by two other observations. First, our in vivo overexpression
studies showed that overproduction of Pex5p had no noticeable effect on the ability of cells to grow on oleate, suggesting that Pex5p does not
compete with Pex14p for Pex13-SH3 domain binding. Second, we found in
the two-hybrid system that the presence of Pex5p cooperatively stimulated Pex13-SH3-Pex14p interaction. Both observations are in line
with the existence of separate binding sites for Pex14p and Pex5p on
the Pex13-SH3 domain.
We tested the effects of the mutations in Pex5p in cells with respect to growth and import of proteins into peroxisomes. Growth of Pex5 (F208L) was clearly retarded on oleate as sole carbon source, but growth of pex5 (E212V) was only mildly affected. A triple mutant of Pex5p containing all three SH3 loss-of-interaction mutations (F208L, E212V, and E214G) showed the same growth defect on oleate as the single F208 mutant, suggesting that F208 identifies the most important position for interaction with Pex13-SH3. Considering the clear deficiencies we observed with these mutants in the yeast two-hybrid and in vitro reconstitution experiments it is very unlikely that the mild phenotypes in vivo are due to residual binding of Pex5p to Pex13-SH3. It rather suggests that in vivo alternative ways exist to dock Pex5p with its PTS1 protein load. Pex5p not only binds to Pex13-SH3 but also to Pex14p. Indeed, Pex14p may substitute for Pex13p as docking site. This notion is based on the in vitro experiments, which show that binding of Pex5 (F208L) mutant protein to immobilized Pex13-SH3 can be rescued when Pex14p is mixed in. It suggests that Pex14p can function as a bridge between Pex13-SH3 and the mutant version of Pex5p. Indeed, our fractionation experiments showed that Pex5p(F208L) was still able to associate with peroxisomes, which indicates that in the absence of Pex13-SH3 interaction, Pex5p is tethered to the peroxisome membrane in an alternative way, most likely through the interaction with Pex14p.
The combined roles of Pex13p and Pex14p in forming a docking platform
for Pex5p-mediated PTS1 protein delivery was underlined by experiments
in which Pex5p, Pex13p, and Pex14p were overproduced. Overexpression of
Pex14p or Pex13p individually impaired growth of cells on
oleate-containing medium. A similar phenotype has been reported for
Hansenula polymorpha cells overexpressing Pex14p (Komori
et al., 1997
). Overexpression of both Pex13p and Pex14p together, however, restored normal growth. Disruption of the
Pex13p-Pex14p interaction had the same effect in vivo: yeast cells
containing the E320K mutation in the RT loop of Pex13-SH3, which
abrogated Pex14p association, were unable to grow on oleate-containing
medium (Elgersma et al., 1996
; Girzalsky et al.,
1999
). Together, these results show that both the association and the
stoichiometry of Pex13p and Pex14p in a cell are important, which
implies that they fulfill their role in protein import as a
well-defined pair.
Import of PTS1 proteins was differentially affected in vivo in the Pex5p(F208L) mutant context. As expected, import of 3-keto-acyl-CoA thiolase (a PTS2 protein) was normal, but 3HAD and Mdh3p (both PTS1 proteins containing the PTS1 SKL) were only partially mislocalized to the cytosol, whereas CTA1 (containing the PTS1 SKF) was completely mislocalized to the cytosol. The PTS1 consensus sequence is rather degenerate and this may be related to its efficiency to function as targeting signal. We swapped PTS1 motifs between Mdh3p and catalase A to investigate whether the composition of the PTS1 could explain the observed partial versus complete import efficiencies of Mdh3p and catalase A in the Pex5p(F208L) mutant; no support was found for the notion that the PTS1 composition of catalase determines the import efficiency (our unpublished results).
It is noteworthy that mild peroxisome biogenesis phenotypes are also
observed in humans. Analysis of the fibroblasts of a patient suffering
from the peroxisome biogenesis disorder neonatal adrenoleukodystrophy revealed that most peroxisomal matrix
proteins were partially mislocalized to the cytosol, whereas catalase
was found exclusively in the cytosol (Liu et al., 1999
;
Shimozawa et al., 1999
), a phenotype similar to that of the
yeast Pex5p(F208L) mutant. These observations underscore the notion
that mild import deficiencies can affect normal cellular function,
thereby leading to a diseased state of the organism. Interestingly, the
mild phenotype in this adrenoleukodystrophy patient is caused by a
missense mutation, I326T, in the SH3 domain of Pex13p. Introduction of
the analogous mutation in Pex13p of the yeast P. pastoris
also resulted in a mild peroxisome biogenesis deficiency (Liu et
al., 1999
). The effects of this mutation on the interaction
between Pex13p and its partner proteins have not yet been determined,
nor is it clear from the location of the mutation in the SH3 domain
which interaction might be affected. Given that I326 of human Pex13p is
conserved in S. cerevisiae Pex13p it will be of interest to
include this mutation in future studies. Particularly, in vitro
interaction studies because we observed that deficiencies show up more
clearly in the simple reconstituted state than in vivo.
We thank Aldo Stein and Carlo van Roermund for assistance with two-hybrid and Nycodenz density gradients analyses. We are grateful to Dr. P. van der Sluys for providing the NH-antibodies and Dr. S. Rospert for providing the Hsp60 antibodies. This work was supported by grants from the Netherlands Organization of Scientific Research (NWO) and the European Community (BIO4-97-2180).
* Corresponding author. E-mail address: b.distel{at}amc.uva.nl.
Abbreviations used: AD, activation domain; DB, DNA-binding domain; GFP, green fluorescent protein; GST, glutathione S-transferase; MBP, maltose binding protein; NH, N-terminal hemagglutinin; PTS, peroxisomal targeting signal; SH3, Src homology 3.
This article has been cited by other articles:
|
http://www.molbiolcell.org/cgi/content/full/11/11/3963
|
crawl-002
|
refinedweb
| 7,469
| 53.1
|
I am trying to play an Adobe Flash game in my browser. The only problem is that it is too fast for me. I know it would be "cheating", but I would enjoy the game more if I could play it at a slower pace.
I've tried throttling the CPU, but I don't think this approach is reliable.
How can I have my browser or the Flash plugin play the game at a slower framerate?
Instead of throttling the CPU, you can slow down Flash games using Cheat Engine's Speedhack feature. In summary, Speedhack works by modifying the timing routines that are called by a game to get the current time 1.
Open up your favorite Flash game in your browser.
Launch Cheat Engine.
Click on the Select Process button at the top-left, find the process running the Flash Player plugin (see note below), and then click Open.
Check the Enable Speedhack option on the right.
If you get an error, you've selected the wrong process!
Change the Speed from 1.0 to a different value and then click Apply. In this case, you want the game to be slower, so make it less than 1.0. For example, 0.5 would run the game slower, at 50 % normal speed.
1.0
0.5
50 %
Return to your game. It should be playing at the new speed!
Note: I use trial and error to find the correct process. However, if you just opened the game, it is usually the most recent Flash Player or browser process at the bottom of the list.
Note: I use trial and error to find the correct process. However, if you just opened the game, it is usually the most recent Flash Player or browser process at the bottom of the list.
References:
1 Cheat Engine Internals: Speedhack
You can try lower the voltage for your processor in the BIOS settings. This will limit the resources a bit. You can create a simple c++ program that is filling all the memmory and using 100 % of cpu time.
this is for CPU usage:
#include <stdio.h>
#include <time.h>
#include <omp.h>
int main() {
double start, end;
double runTime;
start = omp_get_wtime();
int num = 1,primes = 0;
int limit = 1000000;
#pragma omp parallel for schedule(dynamic) reduction(+ : primes)
for (num = 1; num <= limit; num++) {
int i = 2;
while(i <= num) {
if(num % i == 0)
break;
i++;
}
if(i == num)
primes++;
// printf("%d prime numbers calculated\n",primes);
}
end = omp_get_wtime();
runTime = end - start;
printf("This machine calculated all %d prime numbers under %d in %g seconds\n",primes,limit,runTime);
return 0;
}
About the memory - setup the Oracle Virtual Host. Install some system as the virtual machine and give it lots of memory to use. Of fire couple of virtual machines. this is the easiest non programming way i can think of.
For flash games slowdown in particular you can use :
I found the video with the guide how to use cheatengine:
You may want to search out a CPU throttling program. Several exist, though the only one that I have tried is winThrottle (and that was some time ago). It makes its changes system-wide, not per program, but they are easy enough to turn on and off when you want (no rebooting required).
By posting your answer, you agree to the privacy policy and terms of service.
asked
3 years ago
viewed
29280 times
active
3 months ago
|
http://superuser.com/questions/454534/how-can-i-slow-down-the-framerate-of-a-flash-game
|
CC-MAIN-2015-48
|
refinedweb
| 577
| 82.14
|
Entity Framework is an object-relational mapper (ORM). As such, it simplifies mappings between your .NET objects and the tables and columns in your relational database. It creates database connections, executes queries towards the database, keeps track of changes that might happen in your application (an object has been added, changed, etc.), persists those changes, and, when instructed, executes those changes towards the database. In other words, it increases your productivity and reduces the amount of time necessary to implement all these features by writing your custom code.
There are also other ORMs out there, but Entity Framework is Microsoft's recommended tool for working with data in an ASP.NET application. It is widely used and well known for the following features.
The model plays a significant part in the Entity Framework. It contains configurations, mapping properties, relationships, and defines which objects map to which tables.
There are two ways to create the EF model.
This approach is usually preferred when there is no database present, or the database is empty. In this case, all objects, their properties, and existing relationships between them are defined through .NET classes. At runtime, the Entity Framework creates the model from these classes, and it also creates the database.
Developers who do not have experience with databases or have an already existing database, but want to communicate with it only through code, also find this approach to be more suitable to them.
The Entity Framework visual designer is a tool that helps you create a model by drawing boxes that represent your tables or objects and lines to build relationships between them. You can use two different approaches to create the model with Entity Framework visual designer, Database First, and Model First.
You use the Database First approach when you have an existing database, and you want to connect to it in your application. In this case, the EF visual designer creates a model from your existing database and displays it graphically with boxes and lines.
The other approach, Model First, is when you do not have a database, but you prefer to create the model using a visual designer. In this case, you start from scratch, by drawing boxes that will represent your tables and lines that will represent the relationships between them.
The model created using the EF visual design is in EDMX format, and it is an XML file that contains information about all mappings and their properties.
Once you know which approach you will take in creating your own EF model, you can start building it by installing Entity Framework in your solution. For that, you will need to install two things, Entity Framework Tools for Visual Studio and Entity Framework Runtime.
Almost all versions of Visual Studio have these tools already pre-installed. If you are working with an older version of Visual Studio, you will have to install them manually. The Entity Framework Tools allow you to use the visual designer for creating object models, so if you want to use Entity Framework with the Database and Model-first approach, then these tools must be installed in your Visual Studio environment.
To use Entity Framework in your code, you need to install the Entity Framework Runtime. The easiest way of doing this is to install it through the NuGet package manager.
Let's see how the installation process goes by installing Entity Framework in our application FirstMVCApplication.
Open the solution FirstMVCApplication in Visual Studio. In Solution Explorer, right-click the solution and choose “Manage NuGet Packages for Solution” (as shown in the image below).
When the NuGet store appears, click on Browse at the left top corner and type Entity Framework in the search box. Then, choose the project where you want the Entity Framework to be installed, select the latest stable version available, and click on the Install button.
When Visual Studio asks you to confirm the Entity Framework installation in your solution, click OK, then accept the terms and conditions and continue with the installation.
You can monitor the installation in the output window in Visual Studio. Once it is finished, you will get a message in the output window that the Entity Framework was successfully installed. There will also be a green icon in the NuGet store, right after the name of the Entity Framework package.
You can also install Entity Framework through the NuGet Package Manager console by using the following command.
Install-Package EntityFramework
If you do not specify a version with the
–Version attribute, the latest stable version will be used. In case you want to install a specific version, you can use the –Version attribute and specify the version needed.
If you cannot find the NuGet Package Manager console, make sure to open it from the menu Tools > NuGet Package Manager > Package Manager Console.
Now that we have Entity Framework installed in our solution, let's see how it works.
We will continue using the same project (FirstMVCApplication) and we will implement a simple registration functionality that will allow us to create our first EF model. We will use the EF Code First approach since we believe that it is easier to understand the whole idea behind the EF, plus you can also see all steps required to use EF in your application. The goal of the feature is to allow employees to register for different corporate events.
To do so, we need to create the following three entity classes: Employee, Event, and Registration. Besides, we will define the relationships between them. Since employees can register for multiple company events the relationship between the three entities will be defined as displayed in the image below.
In other words, an employee can register for multiple company events, and an event can have multiple employees registered for it. The entity Registration holds information about a specific registration done by a particular user for a specific event.
Now that we have an idea about how our model must look like, we will go back to our application and create the three entity classes.
To create a model with EF, we must navigate to the map Models and create a new class, which we will name Employee. The class Employee presents the employee; therefore, we will need to create the following properties to define the employee.
Additionally, we will create these two properties as well.
Employeetable uniquely identifies the employee.
Our class will look like this.
public class Employee { public int ID { get; set; } public string LastName { get; set; } public string FirstName { get; set; } public string Department { get; set; } public virtual ICollection<Registration> Registrations { get; set; } }
The most interesting part about this class is the property Registrations. In the EF world, this property is called a navigation property. Navigation properties hold other EF entities that are related to this entity. In this case, the property Registrations will hold all registrations that are related to an employee. Usually, navigation properties are defined as virtual, so that they can take advantage of certain EF functionalities such as lazy loading. In an m<>m relationship, the navigation property is defined as a list where items can be added, edited, or deleted. In our class, we use the type ICollection.
We define the two classes Event and Registration in the same way we did with Employee.
The class Event will have the following properties.
The same as with the
Employee, we will create two more additional properties.
public class Event { public int EventID { get; set; } public string Title { get; set; } public string Description { get; set; } public int AvailableSeats { get; set; } public DateTime DateTime { get; set; } public virtual ICollection<Registration> Registrations { get; set; } }
The class
Registration will have the following properties.
public class Registration { public int EmployeeID { get; set; } public int EventID { get; set; } public virtual Employee Employee { get; set; } public virtual Event Event { get; set; } }
Since the entity
Registration is associated with only one employee and one event, we define the navigation properties as single entities and not of type list, as was the case with
Employee and
Event.
The class that coordinates everything for a given EF model is the database context class. This class allows querying and saving the data, as well as adding, editing, and deleting items.
Back to our project, we will create a database context class for our project. First, we will create a new folder on the project's root level and name it DAL. DAL stands for Data Access Layer. We will create the database context class under this folder by right-clicking the folder DAL and adding a new class. Name the class
CompanyContext.
The database context class must derive from the
System.Data.Entity.DbContext class and contains all entities that need to be included in the EF model.
In our project, the database context class will look as follows.
public class CompanyContext : DbContext { public CompanyContext() : base("CompanyContext") { } public DbSet<Employee> Employees { get; set; } public DbSet<Registration> Registrations { get; set; } public DbSet<Event> Events { get; set; } protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Conventions.Remove<PluralizingTableNameConvention>(); } }
This code creates a DbSet property for each entity. In Entity Framework terminology, an entity set typically corresponds to a database table, and an entity corresponds to a row in the table.
To create the database from the EF model we defined earlier, we need to specify where we want to create the database.
We will add the following connection string in the application's
web.config.
<connectionStrings> <add name="EmployeeContext" connectionString="Data Source=(LocalDb)\MSSQLLocalDB;Initial Catalog=CompanyEvents;Integrated Security=SSPI;" providerName="System.Data.SqlClient"/> </connectionStrings>
So, we will use our LocalDb server to create the database with the name CompanyEvents. We will connect to the database using Windows or Integrated authentication.
Next, we need to initialize a database context in our application. Open the Home controller and initialize a new database context, as shown in the image below.
When the Index action of the Home controller is called, the code for adding new employees is executed, and the DbContext will create the database.
By using MVC, EF, and ASP.NET, we can create a web application with which we can access the database. In this part of the tutorial, we will utilize the EF Database First Approach. The EF Database First Approach, like the name suggests, starts with the database. In it, we have a table, or multiple tables, that have data. Our goal would be to transfer the structure of that table/those tables into our MVC web application and create models.
In our FirstMVCApplication, we will create three tables:
For that purpose, we would need to create a simple database, where we would then create these three tables. The tables are fairly simple and do not have a lot of columns.
As a first step, we will just define the structure of the tables without any constraints (primary key, foreign key…).
The first table we are going to create is Employee. It is going to have the following columns:
The code that we will use for creating the table is shown below.
CREATE TABLE Employee ( EmployeeID INT IDENTITY(1,1) NOT NULL, EmployeeLastName NVARCHAR(100) NOT NULL, EmployeeFirstName NVARCHAR(100) NOT NULL, EmployeeDepartment NVARCHAR(200) NOT NULL )
The second table we are going to create is Event. It is going to have the following columns:
The code that we will use for creating the table is shown below.
CREATE TABLE Event ( EventID INT IDENTITY(1,1) NOT NULL, EventTitle NVARCHAR(200) NOT NULL, EventDescription NVARCHAR(1000) NOT NULL, EventAvailableSeats INT NOT NULL, EventDateTime DATETIME NOT NULL )
The last table we will create is table Registration. It is going to have the following columns:
The code that we will use for creating the table is shown below.
CREATE TABLE Registration ( RegistrationID INT IDENTITY(1,1) NOT NULL, EmployeeID INT NOT NULL, EventID INT NOT NULL )
Next, we will create constraints for these three tables. We will start with the primary keys.
A primary key of a table can be one or multiple columns.
The important thing when choosing the primary key is that we are sure that whatever column/s we choose uniquely defines each entry in that table.
For example, for the table Employee, we will choose the column EmployeeID. Following is the code for creating a primary key on the before-mentioned column.
ALTER TABLE [dbo].[Employee] ADD PRIMARY KEY CLUSTERED ( [EmployeeID] ASC )
We will do the same for the other two tables. For the table Event, we will choose the column
EventID as a primary key, while the column
RegistrationID will be chosen as the primary key for the table Registration.
ALTER TABLE [dbo].[Event] ADD PRIMARY KEY CLUSTERED ( [EventID] ASC ) ALTER TABLE [dbo].[Registration] ADD PRIMARY KEY CLUSTERED ( [RegistrationID] ASC )
As per the cardinality matrix that we showed previously, we now need to create foreign keys for our tables. Foreign keys are needed only in table Registration. The code given below creates a relationship between tables Registration/Employee and Registration/Event.
ALTER TABLE [dbo].[Registration] WITH CHECK ADD CONSTRAINT [FK_Registration_Employee] FOREIGN KEY([EmployeeID]) REFERENCES [dbo].[Employee] ([EmployeeID]) GO ALTER TABLE [dbo].[Registration] CHECK CONSTRAINT [FK_Registration_Employee] GO ALTER TABLE [dbo].[Registration] WITH CHECK ADD CONSTRAINT [FK_Registration_Event] FOREIGN KEY([EventID]) REFERENCES [dbo].[Event] ([EventID]) GO ALTER TABLE [dbo].[Registration] CHECK CONSTRAINT [FK_Registration_Event] GO
Now that we've created the tables in our database, it is time to create the appropriate models for those tables.
For that, we need to add an EF data model to our MVC project. We will use the ADO.NET Entity Data Model. To create it, right-click on our project (FirstMVCApplication), then select Add > New Item. A pop-up window will show up, like the one in the picture below.
In the pop-up window:
The next step will open the Entity Data Model Wizard, shown in the picture below.
Select EF Designer from a database and click on the Next button.
The next step is setting up the data connection.
Click on New Connection, which will open the Choose Data Source window, select Microsoft SQL Server, and click on the Continue button.
It will open the Connection Properties window, which is shown below.
Web.configfile of our MVC app.
Here is the
Web.config file shown.
Click on the Next to go to the next step. In the picture below, tick the box before Tables to select the tables from the database for which we want to create models. Since we want to create models for all tables, we need to select them all. Then, click on the Finish button.
It will open up the EDMX diagram (shown below), which represents the models and the relationship between them.
If we compare the cardinality matrix we defined before, with the EDMX diagram which was generated, we can conclude that they are completely the same:
Employeehas a One-to-many relationship with
Eventhas a One-to-many relationship with
Below is the code that is generated from the database. If we compare it with the code we wrote before. We will see that it is completely the same.
The only difference is the
RegistrationID field we defined as a separate field in the table
Class Employee:
public partial class Employee { public Employee() { this.Registration = new HashSet<Registration>(); } public int EmployeeID { get; set; } public string EmployeeLastName { get; set; } public string EmployeeFirstName { get; set; } public string EmployeeDepartment { get; set; } public virtual ICollection<Registration> Registration { get; set; } }
Class Event:
public partial class Event { public Event() { this.Registration = new HashSet<Registration>(); } public int EventID { get; set; } public string EventTitle { get; set; } public string EventDescription { get; set; } public int EventAvailableSeats { get; set; } public System.DateTime EventDateTime { get; set; } public virtual ICollection<Registration> Registration { get; set; } }
Class Registration:
public partial class Registration { public int RegistrationID { get; set; } public int EmployeeID { get; set; } public int EventID { get; set; } public virtual Employee Employee { get; set; } public virtual Event Event { get; set; } }
The wizard has also created a context class for us. If you remember from the previous tutorial, when we worked with the Code First Approach, the context class coordinates Entity Framework. The context class that is created automatically in the Database First approach is given in the image below.
The context class contains the following properties/features.
web.configis passed into the constructor.
<connectionStrings> <add name="TestEntities" connectionString="metadata=res://*/Model1.csdl|res://*/Model1.ssdl|res://*/Model1.msl;provider=System.Data.SqlClient;provider connection </connectionStrings>
modelBuilder.Conventions.Removewill prevent table names from being pluralized. This means that the tables created in the database will not be in plural, e.g. Events, Registrations, Employees, but Event, Registration, Employee.
The next few chapters will concentrate on adding, displaying, updating, and removing data from the database using the context class and Entity Framework.
To be able to display data related to the
Employee table, we will have to create a new controller. The controller will hold our business logic.
Back in the project, create a new controller class and name it
EmployeeController. Our controller class will inherit the MVC Controller class. For the time being, we will need a single action
Index. The action index will display the obtained employee data from the database. To access the database through our context class, we will create a private property named
db, as shown in the image below.
In the action
Index, we will use the
Employee as follows.
The statement
db.Employee.ToList() will return a list of all employees present in the database.
The next thing we need to do is to create a view and connect the action with the view. Back in the project, right-click the folder Views and create a new folder Employee. Under the folder Employee create a view
Index. This view will correspond to the action
Index in the
EmployeeController.
The view will display all the employees from the table.
Using the
@model directive, we can specify the type of data that will be passed to the view. If we take a look at the action
Index, we can see that we are passing a list of employees. Therefore, at the beginning of the view, we will use the
@model directive in the following way.
@model IEnumerable<FirstMVCApplication.Employee>
The next step is to iterate through the list of employees and display information about each employee.
The code given below creates a table and fills each row of the table with employee data. What's interesting is that we are using two HTML helpers here,
@Html.DisplayFor and
@Html.DisplayNameFor.
HTML helpers are MVC classes that help render HTML. You can, of course, use HTML tags such as span or label to display the information you need, but the advantage of using MVC HTML helpers is that they can easily bind with the Model data.
For example, if we look at the code below and how these helpers are used, we can see that
@Html.DisplayNameFor will generate HTML text for each employee property's name, where
@Html.DisplayFor will generate HTML text for each employee property's value. Every time the model gets updated, the values of the properties will get updated too.
If we run the application, we will, unfortunately, see an empty table. That's because our database is currently empty. To be able to test the code, we can manually add employees directly to the database.
Let's rerun the application. Our test data is now displayed.
The last thing that we will change is the name of each employee column:
As said earlier, the
@Html.DisplayNameFor generates the name of each Employee property, respectively. If we want to change each column's display name, we have to look at the current
Employee class.
The class Employee is defined as follows.
If we want to set more user-friendly names for the
Employee properties, we can use data annotations to define them.
Data annotations are attribute classes that you can use to decorate classes or properties to enforce pre-defined rules. In this case, we can use the attribute
Display and define a display name for each property.
If we rerun the application, we should be able to see the change.
In the previous chapter, we focused on explaining how to display data with our MVC application and EF. For testing purposes and to show that our approach works, we added some test records in the database. Those records were cleared down before continuing.
In this part, we will focus on explaining how to add data using SQL, as well as using code.
Adding records in the database is one of the fundamental actions we can perform using Entity Framework.
Of course, we can add data to the database by merely preparing
INSERT statements, which we will then execute directly on the database.
Following is an example of how we can do that.
INSERT INTO [dbo].[Employee] ([EmployeeLastName] ,[EmployeeFirstName] ,[EmployeeDepartment]) VALUES ('Doe' ,'John' ,'Engineering') INSERT INTO [dbo].[Employee] ([EmployeeLastName] ,[EmployeeFirstName] ,[EmployeeDepartment]) VALUES ('Doe' ,'Jane' ,'Engineering')
After executing these statements on the database, we can just run the application, and the data will appear.
For us to be able to add data to our database using EF, we must write the code to do so.
The first thing we need to do is create a View, with which we will create a form that will allow us to add a new employee to the database.
The view will consist of three fields, namely the attributes of the model
Employee:
We need to right-click on the folder Employee, located in Views. Then go to Add, and then click on View.
That will open up a new Add View pop-up window, which would need to be filled out like shown below:
Because we chose the template Create, Visual Studio will create the code for the View, based on the model class we defined. The code will look similar to the one below:
After the View is created, we have to go back to the
EmployeeController and update the method for creating an employee. That would allow the application to pass the data through to the database and write it in the proper table.
Now we can test the code we wrote by adding a new employee in the database. When we run the solution, the page for creating an employee should look like the one below.
To test the form we created, we need to input data in text boxes, and then click on the Create button.
If we click Back to List, the application would then lead us to the display data section, where we would be able to see the full list of employees currently in the database.
To be able to update an existing entry in the database, we can add an Edit link to the existing employees' list.
To do so, we can use the Html helper
ActionLink. The HTML helper ActionLink will generate an HTML link element but will also allow us to send an id of the clicked item to the controller, so we can quickly obtain the id of the item that needs to be changed in the database.
If we switch to Visual Studio and open the Home > Index view, we can configure the HTML helper as shown in the image below.
Since we can identify each employee by each employee's ID in the database, we set up the HTML helper to pass the
EmployeeID to the controller.
The first string in the
ActionLink helper is the title of the link generated, and the second string is the name of the action that will be called once the user clicks the link.
The result of adding the action link to the
Index view is displayed below.
The Edit link is currently not working because we still haven't created an Edit action. We can do that now in the EmployeeController. The definition of the
Edit action is as follows.
HttpGetattribute because
Html.ActionLinkrenders an anchor tag that can only trigger a
GETrequest to the server.
Editaction is the employee id that we expect to get on the server-side.
EmployeeControlleris a bad request.
EmployeeIDequal to id.
If we now start the application, we will click on the Edit link and edit the chosen employee.
We can edit the employee's first, last name, and/or department, and after clicking on the Save button, the new data will be saved in the database.
After clicking the Save button, we are navigated to the employee list, where we can see the edit action results.
To implement the delete action, we will add the
Delete action link right after the edit action link. We will do that in the Index view as with the Edit link.
The changed code is shown in the image below.
As with the Edit link, we use the
Html.ActionLink helper to create an anchor tag with the title Delete that will call the
Delete action from the
EmployeeController and will send the employee id that will identify the employee that we want to delete.
If we run the application, we can see that the user interface is already updated and that we can see the “Delete” link on the employee list. The Delete link does nothing since we still haven't created the
Delete action in the
EmployeeController.
Back in Visual Studio, let's create another action called
Delete as follows.
Again, the method is decorated with an
HttpGet attribute because it is called from a simple anchor tag. In the same way, as with the
Edit action, we send the id of the employee that we want to delete. If there isn't an employee in the database with that id, we throw an error if not found. In case an employee with that id exists in the database, we use the
db.Employees set and call the Remove method on that set to remove the employee. We then save the db context changes and redirect the user to the Index view, which displays the employee list.
If we run the application and navigate to the employee list and then click on the Delete link for a particular employee, the employee will be removed from the database and, therefore, not displayed on the employee list anymore.
The current employee list before deleting looks as follows.
After deleting the second employee by clicking on the Delete link, the employee list will look as follows.
|
https://riptutorial.com/mvc-pattern/learn/100004/entity-framework
|
CC-MAIN-2022-05
|
refinedweb
| 4,401
| 54.73
|
pfm_get_event_info man page
pfm_get_event_info — get event information
Synopsis
#include <perfmon/pfmlib.h> int pfm_get_event_info(int idx, pfm_os_t os, pfm_event_info_t *info);
Description
This function returns in info information about a specific event designated by its opaque unique identifier in idx for the operating system specified in os.
The pfm_event_info_t structure is defined as follows:
typedef struct { const char *name; const char *desc; const char *equiv; size_t size; uint64_t code; pfm_pmu_t pmu; pfm_dtype_t dtype int idx; int nattrs; struct { unsigned int is_precise:1; unsigned int reserved_bits:31; }; } pfm_event_info_t;
The fields of this structure are defined as follows:
- name
This is the name of the event. This is a read-only string.
- desc
This is the description of the event. This is a read-only string. It may contain multiple sentences.
- equiv
Certain events may be just variations of actual events. They may be provided as handy shortcuts to avoid supplying a long list of attributes. For those events, this field is not NULL and contains the complete equivalent event string.
- code
This is the raw event code. It should not be confused with the encoding of the event. This field represents only the event selection code, it does not include any unit mask or attribute settings.
- pmu
This is the identification of the PMU model this event belongs to. It is of type pfm_pmu_t. Using this value and the pfm_get_pmu_info function, it is possible to get PMU information.
- dtype
This field returns the representation of the event data. By default, it is PFM_DATA_UINT64.
idx This is the event unique opaque identifier. It is identical to the idx passed to the call and is provided for completeness.
- nattrs
This is the number of attributes supported by this event. Attributes may be unit masks or modifiers. If the event has not attribute, then the value of this field is simply 0.
- size
This field contains the size of the struct passed. This field is used to provide for extensibility of the struct without compromising backward compatibility. The value should be set to sizeof(pfm_event_info_t). If instead, a value of 0 is specified, the library assumes the struct passed is identical to the first ABI version which size is PFM_EVENT_INFO_ABI0. Thus, if fields were added after the first ABI, they will not be set by the library. The library does check that bytes beyond what is implemented are zeroes.
- is_precise
This bitfield indicates whether or not the event support precise sampling. Precise sampling is a hardware mechanism that avoids instruction address skid when using interrupt-based sampling. When the event has umasks, this field means that at least one umask supports precise sampling. On Intel X86 processors, this indicates whether the event supports Precise Event-Based Sampling (PEBS)..
Return
If successful, the function returns PFM_SUCCESS and event information in info, otherwise it returns an error code.
Errors
- PFMLIB_ERR_NOINIT
Library has not been initialized properly.
- PFMLIB_ERR_INVAL
The idx argument is invalid or info is NULL or size is not zero.
- PFMLIB_ERR_NOTSUPP
The requested os is not detected or supported.
Author
Stephane Eranian <eranian@gmail.com>
|
https://www.mankier.com/3/pfm_get_event_info
|
CC-MAIN-2017-26
|
refinedweb
| 509
| 66.64
|
Compare a given number of characters in two strings
#include <strings.h> int bcmp( const void *s1, const void *s2, size_t n );
libc
Use the -l c option to qcc to link against this library. This library is usually included automatically.
The bcmp() function compares the byte string pointed to by s1 to the string pointed to by s2. The number of bytes to compare is specified by n. NUL characters may be included in the comparison.
#include <stdlib.h> #include <stdio.h> #include <string.h> int main( void ) { if( bcmp( "Hello there", "Hello world", 6 ) ) { printf( "Not equal\n" ); } else { printf( "Equal\n" ); } return EXIT_SUCCESS; }
produces the output:
Equal
Standard Unix; removed from POSIX.1-2008
|
http://www.qnx.com/developers/docs/7.0.0/com.qnx.doc.neutrino.lib_ref/topic/b/bcmp.html
|
CC-MAIN-2018-09
|
refinedweb
| 117
| 76.11
|
Hi, my name is XXXXX XXXXX here are a few things you can try. Try them and get back to me with the results...
First, try resetting PRAM/NVRAM, follow these steps to do so:
1.) Shut down your Mac
2.) Press the power button on your Mac to turn it back on
3.) Immediately press and hold the following keys (before the chime noise and startup screen):
Command+Option+P+R
4.) Continue holding these keys until the computer restarts and you hear the startup chime 3 times
5.) Release the keys and allow the computer to boot
okay, one second...
try this...
Try starting the computer in safe mode. To accomplish this complete the following steps:.
See if you can get far enough to get a progress indicator, if not, I have one more trick we can try before having to modify the contents of the system
okay, if it's been more than 30 seconds, you can abandon...Try this next...
Single user mode disk verification / repair
1.) Turn off your mac2.) Turn your mac back on 3.) Immediately press and hold Command (or Apple) key and 'S' simultaneously
Hold these keys -- Your Mac should boot into a text console. When you get to this point (text stops scrolling), release the keys and type:
/sbin/fsck -fy
Hit the return (enter) key after entering the above command, let the disk utility finish. When it finishes, type:
reboot
The hit the return (enter) key. See if your Mac boots
oops, sorry, formatting issue, this will make it look more readable...
1.) Turn off your mac2.) Turn your mac back on3.) Immediately press and hold Command (or Apple) key and 'S' simultaneously
OKay, timing is crucial, did you attempt to boot your Mac holding Command+S a couple of times? It's pretty picky about when the keys are actually pressed
Before the chime, press the keys immediately
bummer -- well, I always hate to be the bearer of bad news, but the hard drive is most likely corrupt, meaning, you'll need to re-install Mac OS X and hope that your data can be recovered. Or, the hard drive may have failed completely. For the latter case, the data might be recoverable, but the cost is usually prohibitive.
If you still have your Mac OS X install discs, the next step would be to try to re-install Mac OS X, (the archive and install option would likely be the best)
If you're referring to your Mac OS X install disc, then yes, you can use it to boot and start the re-install process
okay -- when you turn the machine on, hold the 'C' key to force your system to boot from the install disc
Keep me posted on your progress
hmm, probably not -- it may be the motherboard -- one sec
Can you confirm for me that it actually makes a chime noise though?
Try again to hold the 'C' key during boot up...
If that fails, do you have a USB keyboard that you can plug into your Mac -- in case the keyboard is going bad?
Is there an Apple store near you?
At this point, we've gone through about as much trouble shooting as we can without getting fairly technical. If your system will not boot into the recovery disc, it's probably best to take your Mac to the Mac store to see if they test the hard drive and the remaining components
From what we've covered, it sounds like the hard drive may be bad (or it's at least become corrupt to the point that it cannot boot)
It's hard to say -- if it's just corrupt, they might be able to help you get the installation started on the spot and might not charge you anything (make sure you take your Mac OS X disc with you).If the hard drive is bad -- 2.5" hard drives usually cost anywhere from $50-$200 depending on the size of the drive. Installation would probably run another $100. Now, if you buy the hard drive yourself and take it to a technician, it might save you money. $50-$200 is the price you'll pay if you buy the drive locally (from Fry's or Best Buy, etc...) If you buy it through Apple, they may end up charging you twice as much, it's hard to say. Either way, I would recommend at least taking it into the Apple store to get a quote, they shouldn't charge you just to take a look at it and give you an estimate. At that point, if you want to come back here, I can help you pick out a hard drive, and depending on your level of technical ability, you may be able to install it yourself
no prob. Let me know if you need some more help. If you want to get a repair estimate and need some advice, you can send a question to me directly by clicking my profile name. If you're happy with the information you have received here, please click "Accept" so that I am compensated for my time. If you're not satisfied, please let me know so I can continue working with you until we get things resolved
|
http://www.justanswer.com/mac-computers/4cjf4-macbook-pro-comes-gives-grey-screen.html
|
CC-MAIN-2014-42
|
refinedweb
| 887
| 76.66
|
Context variable can have different values depending on its context. Unlike Thread-Local Storage where each execution thread may have a different value for a variable, a context variable may be several contexts in one execution thread. This is useful in keeping track of variables in concurrent asynchronous tasks.
The ContextVar class is used to declare and work with Context Variables.
import contextvars name = contextvars.ContextVar("name", default = 'Hello')
The optional default parameter is returned by ContextVar.get() when no value for the variable is found in the current context.
name: The name of the variable. This is a read-only property.
Following methods are defined in ContextVar class
Context class in context vars module is a mapping of Context Vars to their values.
Context(): creates an empty context with no values in it.
To get a copy of the current context use the copy_context() function.
The run(callable, *args, **kwargs) method executes callable(*args, **kwargs) code in the context object the run method is called on and returns the result of the execution. Any changes to any context variables that callable makes, will be contained in the context object. The method raises a RuntimeError when called on the same context object from more than one OS thread, or when called recursively.
|
https://www.tutorialspoint.com/python-context-variables
|
CC-MAIN-2021-21
|
refinedweb
| 212
| 66.03
|
A script to replace guests in complexes
Why?
Simply put, a co-worker asked if
stk could swap one guest for another in a host-guest complex (regardless of chemistry), and I already had some code for doing it, but thought it is pretty useful for everyone. So, here we are!
How?
The entire script in the examples directory is shown below and is available, alongside Jupyter notebooks used in the video below, here. This process uses
stk to read the host-guest and new guest molecules. But,
NetworkX is the real hero here! Basically, we convert the
stk.Molecule class to a
NetworkX.graph based on the bonds and atoms in the molecule. Then, use the
NetworkX.connected_components(graph) to get atoms that are not bonded (e.g. host and guest molecules). The rest is simple: a helper function to collect either the biggest (host) or smallest (guest) component, and then build a new
stk.host_guest.Complex
ConstructedMolecule from the host and the new guest. A reasonable conformer is produced using
SpinDry (
stk.Spinner). What I like about this is that
stk does not care about what the host and guest actually are - so use your imagination about what structural replacements you can do!
import stk import networkx as nx import sys import os def get_disconnected_components(molecule): # Produce a graph from the molecule that does not include edges # where the bonds to be optimized are. mol_graph = nx.Graph() for atom in molecule.get_atoms(): mol_graph.add_node(atom.get_id()) # Add edges. for bond in molecule.get_bonds(): pair_ids = ( bond.get_atom1().get_id(), bond.get_atom2().get_id() ) mol_graph.add_edge(*pair_ids) # Get atom ids in disconnected subgraphs. components = {} for c in nx.connected_components(mol_graph): c_ids = sorted(c) molecule.write('temp_mol.mol', atom_ids=c_ids) num_atoms = len(c_ids) newbb = stk.BuildingBlock.init_from_file('temp_mol.mol') os.system('rm temp_mol.mol') components[num_atoms] = newbb return components def extract_host(molecule): components = get_disconnected_components(molecule) return components[max(components.keys())] def extract_guest(molecule): components = get_disconnected_components(molecule) return components[min(components.keys())] def main(): if (not len(sys.argv) == 3): print( f'Usage: {__file__}\n' ' Expected 2 arguments: host_with_g_file new_guest_file' ) sys.exit() else: host_with_g_file = sys.argv[1] new_guest_file = sys.argv[2] # Load in host. host_with_guest = stk.BuildingBlock.init_from_file(host_with_g_file) # Load in new guest. new_guest = stk.BuildingBlock.init_from_file(new_guest_file) # Split host and guest, assuming host has more atoms than guest. host = extract_host(host_with_guest) old_guest = extract_guest(host_with_guest) # Build new host-guest structure, with Spindry optimiser to # do some conformer searching. new_host = stk.ConstructedMolecule( stk.host_guest.Complex( host=stk.BuildingBlock.init_from_molecule(host), guests=(stk.host_guest.Guest(new_guest), ), # There are options for the Spinner class, # if the optimised conformer is crap. optimizer=stk.Spinner(), ), ) # Write out new host guest. new_host.write('new_host_guest.mol') if __name__ == '__main__': main()
Examples and limitations.
Currently, the provided script swaps out the smallest molecule in a complex for the new molecule (defined from
.mol files). However, the tutorial below shows that we can swap the host or guest for any
stk molecule. Additionally, we could easily extend this to systems with more than two distinct molecules.
Please, test it, use it, break it and send me feedback!
|
https://andrewtarzia.github.io/posts/2022/06/replace-post/
|
CC-MAIN-2022-27
|
refinedweb
| 514
| 52.66
|
import "golang.org/x/tools/go/pointer"
Package pointer implements Andersen's analysis, an inclusion-based pointer analysis algorithm first described in (Andersen, 1994).
A pointer analysis relates every pointer expression in a whole program to the set of memory locations to which it might point. This information can be used to construct a call graph of the program that precisely represents the destinations of dynamic function and method calls. It can also be used to determine, for example, which pairs of channel operations operate on the same channel.
The package allows the client to request a set of expressions of interest for which the points-to information will be returned once the analysis is complete. In addition, the client may request that a callgraph is constructed. The example program in example_test.go demonstrates both of these features. Clients should not request more information than they need since it may increase the cost of the analysis significantly.
Our algorithm is INCLUSION-BASED: the points-to sets for x and y will be related by pts(y) ⊇ pts(x) if the program contains the statement y = x.
It is FLOW-INSENSITIVE: it ignores all control flow constructs and the order of statements in a program. It is therefore a "MAY ALIAS" analysis: its facts are of the form "P may/may not point to L", not "P must point to L".
It is FIELD-SENSITIVE: it builds separate points-to sets for distinct fields, such as x and y in struct { x, y *int }.
It is mostly CONTEXT-INSENSITIVE: most functions are analyzed once, so values can flow in at one call to the function and return out at another. Only some smaller functions are analyzed with consideration of their calling context.
It has a CONTEXT-SENSITIVE HEAP: objects are named by both allocation site and context, so the objects returned by two distinct calls to f:
func f() *T { return new(T) }
are distinguished up to the limits of the calling context.
It is a WHOLE PROGRAM analysis: it requires SSA-form IR for the complete Go program and summaries for native code.
See the (Hind, PASTE'01) survey paper for an explanation of these terms.
The analysis is fully sound when invoked on pure Go programs that do not use reflection or unsafe.Pointer conversions. In other words, if there is any possible execution of the program in which pointer P may point to object O, the analysis will report that fact.
By default, the "reflect" library is ignored by the analysis, as if all its functions were no-ops, but if the client enables the Reflection flag, the analysis will make a reasonable attempt to model the effects of calls into this library. However, this comes at a significant performance cost, and not all features of that library are yet implemented. In addition, some simplifying approximations must be made to ensure that the analysis terminates; for example, reflection can be used to construct an infinite set of types and values of those types, but the analysis arbitrarily bounds the depth of such types.
Most but not all reflection operations are supported. In particular, addressable reflect.Values are not yet implemented, so operations such as (reflect.Value).Set have no analytic effect.
The pointer analysis makes no attempt to understand aliasing between the operand x and result y of an unsafe.Pointer conversion:
y = (*T)(unsafe.Pointer(x))
It is as if the conversion allocated an entirely new object:
y = new(T)
The analysis cannot model the aliasing effects of functions written in languages other than Go, such as runtime intrinsics in C or assembly, or code accessed via cgo. The result is as if such functions are no-ops. However, various important intrinsics are understood by the analysis, along with built-ins such as append.
The analysis currently provides no way for users to specify the aliasing effects of native code.
------------------------------------------------------------------------
The remaining documentation is intended for package maintainers and pointer analysis specialists. Maintainers should have a solid understanding of the referenced papers (especially those by H&L and PKH) before making making significant changes.
The implementation is similar to that described in (Pearce et al, PASTE'04). Unlike many algorithms which interleave constraint generation and solving, constructing the callgraph as they go, this implementation for the most part observes a phase ordering (generation before solving), with only simple (copy) constraints being generated during solving. (The exception is reflection, which creates various constraints during solving as new types flow to reflect.Value operations.) This improves the traction of presolver optimisations, but imposes certain restrictions, e.g. potential context sensitivity is limited since all variants must be created a priori.
A type is said to be "pointer-like" if it is a reference to an object. Pointer-like types include pointers and also interfaces, maps, channels, functions and slices.
We occasionally use C's x->f notation to distinguish the case where x is a struct pointer from x.f where is a struct value.
Pointer analysis literature (and our comments) often uses the notation dst=*src+offset to mean something different than what it means in Go. It means: for each node index p in pts(src), the node index p+offset is in pts(dst). Similarly *dst+offset=src is used for store constraints and dst=src+offset for offset-address constraints.
Nodes are the key datastructure of the analysis, and have a dual role: they represent both constraint variables (equivalence classes of pointers) and members of points-to sets (things that can be pointed at, i.e. "labels").
Nodes are naturally numbered. The numbering enables compact representations of sets of nodes such as bitvectors (or BDDs); and the ordering enables a very cheap way to group related nodes together. For example, passing n parameters consists of generating n parallel constraints from caller+i to callee+i for 0<=i<n.
The zero nodeid means "not a pointer". For simplicity, we generate flow constraints even for non-pointer types such as int. The pointer equivalence (PE) presolver optimization detects which variables cannot point to anything; this includes not only all variables of non-pointer types (such as int) but also variables of pointer-like types if they are always nil, or are parameters to a function that is never called.
Each node represents a scalar part of a value or object. Aggregate types (structs, tuples, arrays) are recursively flattened out into a sequential list of scalar component types, and all the elements of an array are represented by a single node. (The flattening of a basic type is a list containing a single node.)
Nodes are connected into a graph with various kinds of labelled edges: simple edges (or copy constraints) represent value flow. Complex edges (load, store, etc) trigger the creation of new simple edges during the solving phase.
Conceptually, an "object" is a contiguous sequence of nodes denoting an addressable location: something that a pointer can point to. The first node of an object has a non-nil obj field containing information about the allocation: its size, context, and ssa.Value.
Objects include:
- functions and globals; - variable allocations in the stack frame or heap; - maps, channels and slices created by calls to make(); - allocations to construct an interface; - allocations caused by conversions, e.g. []byte(str). - arrays allocated by calls to append();
Many objects have no Go types. For example, the func, map and chan type kinds in Go are all varieties of pointers, but their respective objects are actual functions (executable code), maps (hash tables), and channels (synchronized queues). Given the way we model interfaces, they too are pointers to "tagged" objects with no Go type. And an *ssa.Global denotes the address of a global variable, but the object for a Global is the actual data. So, the types of an ssa.Value that creates an object is "off by one indirection": a pointer to the object.
The individual nodes of an object are sometimes referred to as "labels".
For uniformity, all objects have a non-zero number of fields, even those of the empty type struct{}. (All arrays are treated as if of length 1, so there are no empty arrays. The empty tuple is never address-taken, so is never an object.)
An tagged object has the following layout:
T -- obj.flags ⊇ {otTagged} v ...
The T node's typ field is the dynamic type of the "payload": the value v which follows, flattened out. The T node's obj has the otTagged flag.
Tagged objects are needed when generalizing across types: interfaces, reflect.Values, reflect.Types. Each of these three types is modelled as a pointer that exclusively points to tagged objects.
Tagged objects may be indirect (obj.flags ⊇ {otIndirect}) meaning that the value v is not of type T but *T; this is used only for reflect.Values that represent lvalues. (These are not implemented yet.)
Variables of the following "scalar" types may be represented by a single node: basic types, pointers, channels, maps, slices, 'func' pointers, interfaces.
Pointers
Nothing to say here, oddly.
Basic types (bool, string, numbers, unsafe.Pointer)
Currently all fields in the flattening of a type, including non-pointer basic types such as int, are represented in objects and values. Though non-pointer nodes within values are uninteresting, non-pointer nodes in objects may be useful (if address-taken) because they permit the analysis to deduce, in this example, var s struct{ ...; x int; ... } p := &s.x that p points to s.x. If we ignored such object fields, we could only say that p points somewhere within s. All other basic types are ignored. Expressions of these types have zero nodeid, and fields of these types within aggregate other types are omitted. unsafe.Pointers are not modelled as pointers, so a conversion of an unsafe.Pointer to *T is (unsoundly) treated equivalent to new(T).
Channels
An expression of type 'chan T' is a kind of pointer that points exclusively to channel objects, i.e. objects created by MakeChan (or reflection). 'chan T' is treated like *T. *ssa.MakeChan is treated as equivalent to new(T). *ssa.Send and receive (*ssa.UnOp(ARROW)) and are equivalent to store and load.
Maps
An expression of type 'map[K]V' is a kind of pointer that points exclusively to map objects, i.e. objects created by MakeMap (or reflection). map K[V] is treated like *M where M = struct{k K; v V}. *ssa.MakeMap is equivalent to new(M). *ssa.MapUpdate is equivalent to *y=x where *y and x have type M. *ssa.Lookup is equivalent to y=x.v where x has type *M.
Slices
A slice []T, which dynamically resembles a struct{array *T, len, cap int}, is treated as if it were just a *T pointer; the len and cap fields are ignored. *ssa.MakeSlice is treated like new([1]T): an allocation of a singleton array. *ssa.Index on a slice is equivalent to a load. *ssa.IndexAddr on a slice returns the address of the sole element of the slice, i.e. the same address. *ssa.Slice is treated as a simple copy.
Functions
An expression of type 'func...' is a kind of pointer that points exclusively to function objects. A function object has the following layout: identity -- typ:*types.Signature; obj.flags ⊇ {otFunction} params_0 -- (the receiver, if a method) ... params_n-1 results_0 ... results_m-1 There may be multiple function objects for the same *ssa.Function due to context-sensitive treatment of some functions. The first node is the function's identity node. Associated with every callsite is a special "targets" variable, whose pts() contains the identity node of each function to which the call may dispatch. Identity words are not otherwise used during the analysis, but we construct the call graph from the pts() solution for such nodes. The following block of contiguous nodes represents the flattened-out types of the parameters ("P-block") and results ("R-block") of the function object. The treatment of free variables of closures (*ssa.FreeVar) is like that of global variables; it is not context-sensitive. *ssa.MakeClosure instructions create copy edges to Captures. A Go value of type 'func' (i.e. a pointer to one or more functions) is a pointer whose pts() contains function objects. The valueNode() for an *ssa.Function returns a singleton for that function.
Interfaces
An expression of type 'interface{...}' is a kind of pointer that points exclusively to tagged objects. All tagged objects pointed to by an interface are direct (the otIndirect flag is clear) and concrete (the tag type T is not itself an interface type). The associated ssa.Value for an interface's tagged objects may be an *ssa.MakeInterface instruction, or nil if the tagged object was created by an instrinsic (e.g. reflection). Constructing an interface value causes generation of constraints for all of the concrete type's methods; we can't tell a priori which ones may be called. TypeAssert y = x.(T) is implemented by a dynamic constraint triggered by each tagged object O added to pts(x): a typeFilter constraint if T is an interface type, or an untag constraint if T is a concrete type. A typeFilter tests whether O.typ implements T; if so, O is added to pts(y). An untagFilter tests whether O.typ is assignable to T,and if so, a copy edge O.v -> y is added. ChangeInterface is a simple copy because the representation of tagged objects is independent of the interface type (in contrast to the "method tables" approach used by the gc runtime). y := Invoke x.m(...) is implemented by allocating contiguous P/R blocks for the callsite and adding a dynamic rule triggered by each tagged object added to pts(x). The rule adds param/results copy edges to/from each discovered concrete method. (Q. Why do we model an interface as a pointer to a pair of type and value, rather than as a pair of a pointer to type and a pointer to value? A. Control-flow joins would merge interfaces ({T1}, {V1}) and ({T2}, {V2}) to make ({T1,T2}, {V1,V2}), leading to the infeasible and type-unsafe combination (T1,V2). Treating the value and its concrete type as inseparable makes the analysis type-safe.)
reflect.Value
A reflect.Value is modelled very similar to an interface{}, i.e. as a pointer exclusively to tagged objects, but with two generalizations. 1) a reflect.Value that represents an lvalue points to an indirect (obj.flags ⊇ {otIndirect}) tagged object, which has a similar layout to an tagged object except that the value is a pointer to the dynamic type. Indirect tagged objects preserve the correct aliasing so that mutations made by (reflect.Value).Set can be observed. Indirect objects only arise when an lvalue is derived from an rvalue by indirection, e.g. the following code: type S struct { X T } var s S var i interface{} = &s // i points to a *S-tagged object (from MakeInterface) v1 := reflect.ValueOf(i) // v1 points to same *S-tagged object as i v2 := v1.Elem() // v2 points to an indirect S-tagged object, pointing to s v3 := v2.FieldByName("X") // v3 points to an indirect int-tagged object, pointing to s.X v3.Set(y) // pts(s.X) ⊇ pts(y) Whether indirect or not, the concrete type of the tagged object corresponds to the user-visible dynamic type, and the existence of a pointer is an implementation detail. (NB: indirect tagged objects are not yet implemented) 2) The dynamic type tag of a tagged object pointed to by a reflect.Value may be an interface type; it need not be concrete. This arises in code such as this: tEface := reflect.TypeOf(new(interface{}).Elem() // interface{} eface := reflect.Zero(tEface) pts(eface) is a singleton containing an interface{}-tagged object. That tagged object's payload is an interface{} value, i.e. the pts of the payload contains only concrete-tagged objects, although in this example it's the zero interface{} value, so its pts is empty.
reflect.Type
Just as in the real "reflect" library, we represent a reflect.Type as an interface whose sole implementation is the concrete type, *reflect.rtype. (This choice is forced on us by go/types: clients cannot fabricate types with arbitrary method sets.) rtype instances are canonical: there is at most one per dynamic type. (rtypes are in fact large structs but since identity is all that matters, we represent them by a single node.) The payload of each *rtype-tagged object is an *rtype pointer that points to exactly one such canonical rtype object. We exploit this by setting the node.typ of the payload to the dynamic type, not '*rtype'. This saves us an indirection in each resolution rule. As an optimisation, *rtype-tagged objects are canonicalized too.
Aggregate types:
Aggregate types are treated as if all directly contained aggregates are recursively flattened out.
Structs
*ssa.Field y = x.f creates a simple edge to y from x's node at f's offset. *ssa.FieldAddr y = &x->f requires a dynamic closure rule to create simple edges for each struct discovered in pts(x). The nodes of a struct consist of a special 'identity' node (whose type is that of the struct itself), followed by the nodes for all the struct's fields, recursively flattened out. A pointer to the struct is a pointer to its identity node. That node allows us to distinguish a pointer to a struct from a pointer to its first field. Field offsets are logical field offsets (plus one for the identity node), so the sizes of the fields can be ignored by the analysis. (The identity node is non-traditional but enables the distinction described above, which is valuable for code comprehension tools. Typical pointer analyses for C, whose purpose is compiler optimization, must soundly model unsafe.Pointer (void*) conversions, and this requires fidelity to the actual memory layout using physical field offsets.) *ssa.Field y = x.f creates a simple edge to y from x's node at f's offset. *ssa.FieldAddr y = &x->f requires a dynamic closure rule to create simple edges for each struct discovered in pts(x).
Arrays
We model an array by an identity node (whose type is that of the array itself) followed by a node representing all the elements of the array; the analysis does not distinguish elements with different indices. Effectively, an array is treated like struct{elem T}, a load y=x[i] like y=x.elem, and a store x[i]=y like x.elem=y; the index i is ignored. A pointer to an array is pointer to its identity node. (A slice is also a pointer to an array's identity node.) The identity node allows us to distinguish a pointer to an array from a pointer to one of its elements, but it is rather costly because it introduces more offset constraints into the system. Furthermore, sound treatment of unsafe.Pointer would require us to dispense with this node. Arrays may be allocated by Alloc, by make([]T), by calls to append, and via reflection.
Tuples (T, ...)
Tuples are treated like structs with naturally numbered fields. *ssa.Extract is analogous to *ssa.Field. However, tuples have no identity field since by construction, they cannot be address-taken.
FUNCTION CALLS
There are three kinds of function call: (1) static "call"-mode calls of functions. (2) dynamic "call"-mode calls of functions. (3) dynamic "invoke"-mode calls of interface methods. Cases 1 and 2 apply equally to methods and standalone functions. Static calls. A static call consists three steps: - finding the function object of the callee; - creating copy edges from the actual parameter value nodes to the P-block in the function object (this includes the receiver if the callee is a method); - creating copy edges from the R-block in the function object to the value nodes for the result of the call. A static function call is little more than two struct value copies between the P/R blocks of caller and callee: callee.P = caller.P caller.R = callee.R Context sensitivity Static calls (alone) may be treated context sensitively, i.e. each callsite may cause a distinct re-analysis of the callee, improving precision. Our current context-sensitivity policy treats all intrinsics and getter/setter methods in this manner since such functions are small and seem like an obvious source of spurious confluences, though this has not yet been evaluated. Dynamic function calls Dynamic calls work in a similar manner except that the creation of copy edges occurs dynamically, in a similar fashion to a pair of struct copies in which the callee is indirect: callee->P = caller.P caller.R = callee->R (Recall that the function object's P- and R-blocks are contiguous.) Interface method invocation For invoke-mode calls, we create a params/results block for the callsite and attach a dynamic closure rule to the interface. For each new tagged object that flows to the interface, we look up the concrete method, find its function object, and connect its P/R blocks to the callsite's P/R blocks, adding copy edges to the graph during solving. Recording call targets The analysis notifies its clients of each callsite it encounters, passing a CallSite interface. Among other things, the CallSite contains a synthetic constraint variable ("targets") whose points-to solution includes the set of all function objects to which the call may dispatch. It is via this mechanism that the callgraph is made available. Clients may also elect to be notified of callgraph edges directly; internally this just iterates all "targets" variables' pts(·)s.
We implement Hash-Value Numbering (HVN), a pre-solver constraint optimization described in Hardekopf & Lin, SAS'07. This is documented in more detail in hvn.go. We intend to add its cousins HR and HU in future.
The solver is currently a naive Andersen-style implementation; it does not perform online cycle detection, though we plan to add solver optimisations such as Hybrid- and Lazy- Cycle Detection from (Hardekopf & Lin, PLDI'07).
It uses difference propagation (Pearce et al, SQC'04) to avoid redundant re-triggering of closure rules for values already seen.
Points-to sets are represented using sparse bit vectors (similar to those used in LLVM and gcc), which are more space- and time-efficient than sets based on Go's built-in map type or dense bit vectors.
Nodes are permuted prior to solving so that object nodes (which may appear in points-to sets) are lower numbered than non-object (var) nodes. This improves the density of the set over which the PTSs range, and thus the efficiency of the representation.
Partly thanks to avoiding map iteration, the execution of the solver is 100% deterministic, a great help during debugging.
Andersen, L. O. 1994. Program analysis and specialization for the C programming language. Ph.D. dissertation. DIKU, University of Copenhagen.
David J. Pearce, Paul H. J. Kelly, and Chris Hankin. 2004. Efficient field-sensitive pointer analysis for C. In Proceedings of the 5th ACM SIGPLAN-SIGSOFT workshop on Program analysis for software tools and engineering (PASTE '04). ACM, New York, NY, USA, 37-42.
David J. Pearce, Paul H. J. Kelly, and Chris Hankin. 2004. Online Cycle Detection and Difference Propagation: Applications to Pointer Analysis. Software Quality Control 12, 4 (December 2004), 311-337.
David Grove and Craig Chambers. 2001. A framework for call graph construction algorithms. ACM Trans. Program. Lang. Syst. 23, 6 (November 2001), 685-746.
Ben Hardekopf and Calvin Lin. 2007. The ant and the grasshopper: fast and accurate pointer analysis for millions of lines of code. In Proceedings of the 2007 ACM SIGPLAN conference on Programming language design and implementation (PLDI '07). ACM, New York, NY, USA, 290-299.
Ben Hardekopf and Calvin Lin. 2007. Exploiting pointer and location equivalence to optimize pointer analysis. In Proceedings of the 14th international conference on Static Analysis (SAS'07), Hanne Riis Nielson and Gilberto Filé (Eds.). Springer-Verlag, Berlin, Heidelberg, 265-280.
Atanas Rountev and Satish Chandra. 2000. Off-line variable substitution for scaling points-to analysis. In Proceedings of the ACM SIGPLAN 2000 conference on Programming language design and implementation (PLDI '00). ACM, New York, NY, USA, 47-56. DOI=10.1145/349299.349310
This program demonstrates how to use the pointer analysis to obtain a conservative call-graph of a Go program. It also shows how to compute the points-to set of a variable, in this case, (C).f's ch parameter.
Code:
const myprog = ` package main import "fmt" type I interface { f(map[string]int) } type C struct{} func (C) f(m map[string]int) { fmt.Println("C.f()") } func main() { var i I = C{} x := map[string]int{"one":1} i.f(x) // dynamic method call } ` var conf loader.Config // Parse the input file, a string. // (Command-line tools should use conf.FromArgs.) file, err := conf.ParseFile("myprog.go", myprog) if err != nil { fmt.Print(err) // parse error return } // Create single-file main package and import its dependencies. conf.CreateFromFiles("main", file) iprog, err := conf.Load() if err != nil { fmt.Print(err) // type error in some package return } // Create SSA-form program representation. prog := ssautil.CreateProgram(iprog, 0) mainPkg := prog.Package(iprog.Created[0].Pkg) // Build SSA code for bodies of all functions in the whole program. prog.Build() // Configure the pointer analysis to build a call-graph. config := &pointer.Config{ Mains: []*ssa.Package{mainPkg}, BuildCallGraph: true, } // Query points-to set of (C).f's parameter m, a map. C := mainPkg.Type("C").Type() Cfm := prog.LookupMethod(C, mainPkg.Pkg, "f").Params[1] config.AddQuery(Cfm) // Run the pointer analysis. result, err := pointer.Analyze(config) if err != nil { panic(err) // internal error in pointer analysis } // Find edges originating from the main package. // By converting to strings, we de-duplicate nodes // representing the same function due to context sensitivity. var edges []string callgraph.GraphVisitEdges(result.CallGraph, func(edge *callgraph.Edge) error { caller := edge.Caller.Func if caller.Pkg == mainPkg { edges = append(edges, fmt.Sprint(caller, " --> ", edge.Callee.Func)) } return nil }) // Print the edges in sorted order. sort.Strings(edges) for _, edge := range edges { fmt.Println(edge) } fmt.Println() // Print the labels of (C).f(m)'s points-to set. fmt.Println("m may point to:") var labels []string for _, l := range result.Queries[Cfm].PointsTo().Labels() { label := fmt.Sprintf(" %s: %s", prog.Fset.Position(l.Pos()), l) labels = append(labels, label) } sort.Strings(labels) for _, label := range labels { fmt.Println(label) }
Output:
(main.C).f --> fmt.Println main.init --> fmt.init main.main --> (main.C).f m may point to: myprog.go:18:21: makemap
analysis.go api.go callgraph.go constraint.go doc.go gen.go hvn.go intrinsics.go labels.go opt.go print.go query.go reflect.go solve.go util.go
CanHaveDynamicTypes reports whether the type T can "hold" dynamic types, i.e. is an interface (incl. reflect.Type) or a reflect.Value.
CanPoint reports whether the type T is pointerlike, for the purposes of this analysis.
type Config struct { // Mains contains the set of 'main' packages to analyze // Clients must provide the analysis with at least one // package defining a main() function. // // Non-main packages in the ssa.Program that are not // dependencies of any main package may still affect the // analysis result, because they contribute runtime types and // thus methods. // TODO(adonovan): investigate whether this is desirable. Mains []*ssa.Package // Reflection determines whether to handle reflection // operators soundly, which is currently rather slow since it // causes constraint to be generated during solving // proportional to the number of constraint variables, which // has not yet been reduced by presolver optimisation. Reflection bool // BuildCallGraph determines whether to construct a callgraph. // If enabled, the graph will be available in Result.CallGraph. BuildCallGraph bool // The client populates Queries[v] or IndirectQueries[v] // for each ssa.Value v of interest, to request that the // points-to sets pts(v) or pts(*v) be computed. If the // client needs both points-to sets, v may appear in both // maps. // // (IndirectQueries is typically used for Values corresponding // to source-level lvalues, e.g. an *ssa.Global.) // // The analysis populates the corresponding // Result.{Indirect,}Queries map when it creates the pointer // variable for v or *v. Upon completion the client can // inspect that map for the results. // // TODO(adonovan): this API doesn't scale well for batch tools // that want to dump the entire solution. Perhaps optionally // populate a map[*ssa.DebugRef]Pointer in the Result, one // entry per source expression. // Queries map[ssa.Value]struct{} IndirectQueries map[ssa.Value]struct{} // If Log is non-nil, log messages are written to it. // Logging is extremely verbose. Log io.Writer // contains filtered or unexported fields }
A Config formulates a pointer analysis problem for Analyze. It is only usable for a single invocation of Analyze and must not be reused.
AddExtendedQuery adds an extended, AST-based query on v to the analysis. The query, which must be a single Go expression, allows destructuring the value.
The query must operate on a variable named 'x', which represents the value, and result in a pointer-like object. Only a subset of Go expressions are permitted in queries, namely channel receives, pointer dereferences, field selectors, array/slice/map/tuple indexing and grouping with parentheses. The specific indices when indexing arrays, slices and maps have no significance. Indices used on tuples must be numeric and within bounds.
All field selectors must be explicit, even ones usually elided due to promotion of embedded fields.
The query 'x' is identical to using AddQuery. The query '*x' is identical to using AddIndirectQuery.
On success, AddExtendedQuery returns a Pointer to the queried value. This Pointer will be initialized during analysis. Using it before analysis has finished has undefined behavior.
Example:
// given v, which represents a function call to 'fn() (int, []*T)', and // 'type T struct { F *int }', the following query will access the field F. c.AddExtendedQuery(v, "x[1][0].F")
AddQuery adds v to Config.IndirectQueries. Precondition: CanPoint(v.Type().Underlying().(*types.Pointer).Elem()).
AddQuery adds v to Config.Queries. Precondition: CanPoint(v.Type()).
A Label is an entity that may be pointed to by a pointer, map, channel, 'func', slice or interface.
Labels include:
- functions - globals - tagged objects, representing interfaces and reflect.Values - arrays created by conversions (e.g. []byte("foo"), []byte(s)) - stack- and heap-allocated variables (including composite literals) - channels, maps and arrays created by make() - intrinsic or reflective operations that allocate (e.g. append, reflect.New) - intrinsic objects, e.g. the initial array behind os.Args. - and their subelements, e.g. "alloc.y[*].z"
Labels are so varied that they defy good generalizations; some have no value, no callgraph node, or no position. Many objects have types that are inexpressible in Go: maps, channels, functions, tagged objects.
At most one of Value() or ReflectType() may return non-nil.
Path returns the path to the subelement of the object containing this label. For example, ".x[*].y".
Pos returns the position of this label, if known, zero otherwise.
ReflectType returns the type represented by this label if it is an reflect.rtype instance object or *reflect.rtype-tagged object.
String returns the printed form of this label.
Examples: Object type:
x (a variable) (sync.Mutex).Lock (a function) convert (array created by conversion) makemap (map allocated via make) makechan (channel allocated via make) makeinterface (tagged object allocated by makeinterface) <alloc in reflect.Zero> (allocation in instrinsic) sync.Mutex (a reflect.rtype instance) <command-line arguments> (an intrinsic object)
Labels within compound objects have subelement paths:
x.y[*].z (a struct variable, x) append.y[*].z (array allocated by append) makeslice.y[*].z (array allocated via make)
TODO(adonovan): expose func LabelString(*types.Package, Label).
Value returns the ssa.Value that allocated this label's object, if any.
A Pointer is an equivalence class of pointer-like values.
A Pointer doesn't have a unique type because pointers of distinct types may alias the same object.
DynamicTypes returns p.PointsTo().DynamicTypes().
MayAlias reports whether the receiver pointer may alias the argument pointer.
func (p Pointer) PointsTo() PointsToSet
PointsTo returns the points-to set of this pointer.
A PointsToSet is a set of labels (locations or allocations).
func (s PointsToSet) DynamicTypes() *typeutil.Map
If this PointsToSet came from a Pointer of interface kind or a reflect.Value, DynamicTypes returns the set of dynamic types that it may contain. (For an interface, they will always be concrete types.)
The result is a mapping whose keys are the dynamic types to which it may point. For each pointer-like key type, the corresponding map value is the PointsToSet for pointers of that type.
The result is empty unless CanHaveDynamicTypes(T).
func (x PointsToSet) Intersects(y PointsToSet) bool
Intersects reports whether this points-to set and the argument points-to set contain common members.
func (s PointsToSet) Labels() []*Label
PointsTo returns the set of labels that this points-to set contains.
func (s PointsToSet) String() string
type Result struct { CallGraph *callgraph.Graph // discovered call graph Queries map[ssa.Value]Pointer // pts(v) for each v in Config.Queries. IndirectQueries map[ssa.Value]Pointer // pts(*v) for each v in Config.IndirectQueries. Warnings []Warning // warnings of unsoundness }
A Result contains the results of a pointer analysis.
See Config for how to request the various Result components.
Analyze runs the pointer analysis with the scope and options specified by config, and returns the (synthetic) root of the callgraph.
Pointer analysis of a transitively closed well-typed program should always succeed. An error can occur only due to an internal bug.
Package pointer imports 23 packages (graph) and is imported by 20 packages. Updated 2018-06-16. Refresh now. Tools for package owners.
|
https://godoc.org/golang.org/x/tools/go/pointer
|
CC-MAIN-2018-26
|
refinedweb
| 5,645
| 58.38
|
CLOCK(3) Linux Programmer's Manual CLOCK(3)
clock - determine processor time
#include <time.h> clock_t clock(void);
The clock() function returns an approximation of processor time used by the program.
The value returned is the CPU time used so far as a clock_t; to get the number of seconds used, divide by CLOCKS_PER_SEC. If the processor time used is not available or its value cannot be represented, the function returns the value (clock_t) clock() │ Thread safety │ MT-Safe │ └──────────┴───────────────┴─────────┘
POSIX.1-2001, POSIX.1-2008, C89, C99. XSI).
clock_gettime(2), getrusage(2), times(2)
This page is part of release 5.08 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at. GNU 2017-09-15 CLOCK(3)
Pages that refer to this page: getrusage(2), times(2), asctime(3), asctime_r(3), ctime(3), ctime_r(3), gmtime(3), gmtime_r(3), localtime(3), localtime_r(3), mktime(3), vtimes(3), time(7)
|
https://man7.org/linux/man-pages/man3/clock.3.html
|
CC-MAIN-2020-40
|
refinedweb
| 166
| 64.71
|
Fl_Group | +----Fl_Tabs
#include <FL/Fl_Tabs.H>
The Fl_Tabs widget is the "file card tabs" interface that allows you to put lots and lots of buttons and switches in a panel, as popularized by many toolkits.
Clicking the tab makes a child visible() by calling show() on it, and all other children are made invisible by calling hide() on them. Usually the children are Fl_Group widgets containing several widgets themselves.
Each child makes a card, and it's label() is printed on the card tab, including the label font and style. The selection color of that child is used to color the tab, while the color of the child determines the background color of the pane.
The size of the tabs is controlled by the bounding box of the children (there should be some space between the children and the edge of the Fl_Tabs), and the tabs may be placed "inverted" on the bottom, this is determined by which gap is larger. It is easiest to lay this out in fluid, using the fluid browser to select each child group and resize them until the tabs look the way you want them to.
Creates a new Fl_Tabs widget using the given position, size, and label string. The default boxtype is FL_THIN_UP_BOX.
Use add(Fl_Widget *) to add each child, which are usually Fl_Group widgets. The children should be sized to stay away from the top or bottom edge of the Fl_Tabs widget, which is where the tabs will be drawn.
The destructor also deletes all the children. This allows a whole tree to be deleted at once, without having to keep a pointer to all the children in the user code. A kludge has been done so the Fl_Tabs and all of it's children can be automatic (local) variables, but you must declare the Fl_Tabs widget first so that it is destroyed last.
Gets or sets the currently visible widget/tab.
|
http://fltk.org/doc-1.1/Fl_Tabs.html
|
crawl-001
|
refinedweb
| 320
| 68.5
|
all groups
>
macromedia flash flash remoting
>
september 2007
>
You're in the
macromedia flash flash remoting
group:
Display data without using DataGrid Component
Display data without using DataGrid Component
Bloke
7/28/2007 6:07:35 PM
macromedia flash flash remoting:?
Re: Display data without using DataGrid Component
Bloke
8/24/2007 2:20:36 AM
Re: Display data without using DataGrid Component
W Gerber
9/7/2007 2:10:50 PM
First let me say that I haven't messed with CS3 yet, I am still working with an
older flash movie which uses as2.
That said, the results of a flash remoting call do NOT have to be displayed in
a datagrid only. You can get the results from the query returned as a
recordset and then do whatever you like with the recordset. Insert them into a
multi select box, loop over and display them in dynamic text boxes, the options
are endless. All depends on what you want to do.
Re: Display data without using DataGrid Component
Bloke
9/7/2007 9:37:49 PM
I found a good tutorial in Forta's WACK book on Flash remoting using
ColdFusion. This doesn't seem to work with Flash CS3 using AS2.
#include "NetServices.as"
#include "NetDebug.as"
Did they remove this from Flash CS3?
Re: Display data without using DataGrid Component
Bloke
9/9/2007 3:19:09 PM
I was able to get the remoting components and classes installed. Not sure if I
put them in the right place. Went to the class path in the publish settings.
Now it finds the NetServices.as file. But here is the error I am getting with
source below it.
Classes may only be defined in external ActionScript 2.0 class scripts.
class mx.remoting.NetServices extends Object
The problem is it is written in action script 1. It won't let me change the
class path in the publish settings. if I change it to AS2 it lets me change the
path but I get this error becuase the context is wrong. If you have the CF WACK
book it is chapter 26 Flash remoting.
Re: Display data without using DataGrid Component
W Gerber
9/10/2007 1:01:16 PM
I believe the book that you are using is out dated. You don't need those files
anymore. As you said, they are AS1 and you are using AS2.
The help files in Flash should be able to give you a better lead on things. I
am still using Flash MX Professional 2004, so things might have changed in
CS3, but there is an entire section in Help entitled "using flash remoting MX
2004". In that it talks all about the different classes and gives examples and
everything. That should give you all you need.
Re: Display data without using DataGrid Component
Bloke
relative path is 'mx\remoting\NetServices.as'.
The code in the NetServices.as file is this:
class mx.remoting.NetServices extends Object
Anyone have any ideas? The more I read online how to get this to work, the
more I get confused. I have copied and moved .as files in every way I can
image. And also changed class paths in the preferences and in the publish
settings.
Re: Display data without using DataGrid Component
Bloke
9/13/2007 5:15:40 PM
Can anyone help? Please? I am so confused. There are so many parts to this to
get it working. The FLA, the classes, the debugger, the server, ColdFusion, the
cfc. Any one of these could be the problem.
Re: Display data without using DataGrid Component
lenrique21
9/29/2007 6:09:12 PM
The BEST way to do it is by going to
check it out!! Great files for 0.5 U$S!!!
|
http://www.developmentnow.com/g/72_2007_9_0_0_1000297/Display-data-without-using-DataGrid-Component.htm
|
crawl-001
|
refinedweb
| 633
| 74.69
|
User Name:
Published: 06 Jun 2008
By: Brian Mains
Brian Mains provides some examples of 3-Tier architecture.
Previously, I wrote about multiple tiered architectures and the fundamentals associated with various approaches that can be taken when developing a layered system. In this article, I plan to illustrate each of these layers in great detail, to help further explain the concept. I’ll try to include as many options for constructing layered applications as possible.
Let’s look at an example where all of the pieces of code utilize the built-in ADO.NET architecture. I assume you know how to access and work with data stored in a weakly-typed dataset and data table. ADO.NET already provides a set of objects for storing data in .NET; no add-on components are necessary for this to work. In addition to that, ADO.NET has been around since .NET framework 1.x, so this approach has been available from the beginning.
Let’s start from the presentation layer, and work in reverse. The presentation layer makes use of the DataTable object, which contains several rows of customer information. This customer information is simply bound to a control in the user interface:
As you can see, the data table is bound to the UI control manually; however, the ObjectDataSource control could replace this approach. To retrieve the DataTable object with the Customer data, the code makes use of a CustomerBAL class. This class provides access to CRUD operations against customer data. The makeup of the GetCustomers method is as follows:
GetCustomers
The business layer validated the input coming into the method, as well as the output, ensuring that the data didn’t have any erroring information. If not, the results are returned to the user. In my example, I throw an exception; but handle it anyway you want, by logging the errors, returning it to the caller, etc.
But how does the data actually get to the presentation layer? The data layer receives a request for data and actually queries the database, returning the data to the business layer, as shown below:
The next question is how are inserts, updates, and deletes performed? While retrieval of data is satisfied, other data manipulation topics weren’t covered. I cover the subject of data manipulation at the end of the article.
Strongly-Typed Datasets work very similar to ADO.NET; however, with strongly-typed datasets, the designer generates custom DataTable and strongly-typed DataRow objects that match the database schema. The difference between this and the previous code is that any changes to the database require a change to the dataset, and therefore could break existing code.
To setup this approach, the examples below use a dataset named Samples.xsd, with a name of SamplesDataSet (the name property in the designer affects the dataset class name and namespace). The generated code is as follows:
For example, let’s look at the setup of the designer. The designer simply works by dragging and dropping tables from the Server Explorer into the designer. It’s also possible to add custom methods mapped to SQL queries or stored procedures, which is the case for FillByAccountNumber.
FillByAccountNumber
I’m not going to talk about the setup of each component; there are plenty of resources online. But, I used this as an illustration that this could be considered an equivalent to a data layer, meaning you wouldn’t have to create a physical data layer consisting of separate classes, but could rely on the strongly-typed dataset as the data layer itself.
To utilize this in the business layer, an approach is shown below:
The code above uses the FillBX - rather than the GetX - method to retrieve the data. I do this because I can check the data for errors using the HandleErrors method (defined in the base class, which simply checks the HasErrors property), and if OK return the correct results back. Note that the input is validated in the business component.
FillBX
GetX
HandleErrors
HasErrors
Enterprise Library is an initiative by Microsoft to provide additional services that the .NET framework doesn’t have out-of-the-box. The Data Access Application Block provides a centralized way to access data across varying data source systems without having to specify the underlying database in your code. This works through the provider type setting for the connection string defined in the connection strings element of the configuration file; this provider type loads the correct database provider at runtime.
The key benefit is that you don’t have to rewrite your code to do work with a different provider; it works using a single approach. Also note that the Enterprise Library uses the ADO.NET mechanism to represent data. Let’s look at an example data component:
Note the difference in the approach above; Enterprise Library uses a Database object as the central point of contact. DatabaseFactory.CreateDatabase() provides the way that Enterprise Library connects to the correct database through a provider. The CreateDatabase method uses either an empty constructor (pulls the database connection from the configuration file) or it takes the name of a connection string (using one of the connection strings in the <connectionStrings> element).
DatabaseFactory.CreateDatabase()
CreateDatabase
<connectionStrings>
Rather than accessing this directly, the business layer connects to the data layer as below (only one of the methods is shown). Because the data is transported via a DataTable object, it uses the same approach as shown above.
In the method above, the business layer validates the input and output received from the data layer. In this way, the business layer ensures the business rules of the system are intact and correct. It also improves the quality of the data.
LINQ-to-SQL creates custom business objects through its designer, as I mentioned previously. It works very similarly to a strongly-typed dataset, but instead of custom DataRow objects, it uses business objects. LINQ to SQL business objects are intelligent enough to detect changes and track updates to its properties, inserts or deletions to records, and changes to the primary and foreign key relationships. LINQ to SQL relies upon the existence of a custom DataContext class, which is the key class for change tracking and change submission.
What this means is that a live instance of the DataContext should be passed along from the business layer to the data layer, so that only one instance of the DataContext class exists. This is because you can’t join or query data that’s created from different DataContext objects; this raises an exception. One of the key ideas is to maintain the same DataContext throughout the lifecycle of the business and data layer objects.
This means passing in a DataContext reference throughout, often passing it through a constructor, as such:
In the business layer, the DataContext needs to be passed in as well. There can be some variants to this approach, but unfortunately that’s out of scope. Getting back to the data layer, LINQ-to-SQL translates LINQ queries into SQL queries, and returns the data as a collection.
In the first method, the data returns to the caller as an enumerable list; queries are returned in IOrderedQueryable<> form; however, IEnumerable<> will work as well. In the second approach, a Customer object is returned by using the FirstOrDefault method, which returns the Customer if a match found and null if not found. The business layer calls the data layer, and returns the results. In the GetByAccountNumber method, the input is validated.
FirstOrDefault
GetByAccountNumber
There are a couple of approaches for inserting, updating, and deleting new content. One of the approaches cold be to pass in all of the parameters to the method, as in the following:
This works well in ASP.NET, where data source controls can utilize this approach. Personally, I don’t like this approach simply because future requirements or changes to the parameter list break the interface of the method. Although overloaded methods can be added, that’s not the best option.
I prefer to create a new instance of an object or record in the application, and let the business layer validate the input using a process for business rules. For instance, if creating a new customer, I prefer an approach like this:
Using the strongly-typed dataset architecture, the newly created row in the user interface is passed in as a parameter to the Insert method (more on that in a moment). This method updates the inserted row. If there are any errors, an output string is created and is the source of the exception being thrown. Customer object references like this also work well with other validation tools like the Validation Application Block.
Insert
However, an exception doesn’t always have to be thrown. Instead, the alternative approach can be to store the error information in a property of the business object. This object can be a custom error object that you create, a string value containing the message, or a reference to the exception that was thrown.
Using this property, an ASP.NET page or windows form can use this to output a message to the screen. Take a look at a possible example using ASP.NET; note the code is in a custom page class:
This may not be the most practical in your situation, but the choice is up to you how you want to handle errors that occur in your business layer.
You don’t see it always being widely used; however, layering architecture is a good approach to developing reusable architecture. There are several choices available to you, and this article showed an example of each.
This author has published 73 articles on DotNetSlackers. View other articles or the complete profile here.
Regards,
Punithkumar.R
Reply
|
Permanent
link
Please login to rate or to leave a comment.
Link to us
All material is copyrighted by its respective authors. Site design and layout
is copyrighted by DotNetSlackers.
Advertising Software by Ban Man Pro
|
http://dotnetslackers.com/articles/aspnet/3-Tier-Architecture-Examples.aspx
|
CC-MAIN-2016-22
|
refinedweb
| 1,664
| 53.51
|
Building a Twitter client is nothing new to those of us here. We've done it in WCF and Silverlight. To be honest though, using the Twitter API is a great way to exercise two very useful parts of a language and framework - making web requests and parsing XML. That's what we're going to do today. We're going to build a very simple command line twitter client (read-only) using Python.
Today's app will be very simple. It will request Tech.Pro's twitter feed and display them with
their dates. This could be useful in a variety of ways.
Here's what the first five tweets in the output will look like:
Date: Thu Jul 22 19:46:19 +0000 2010 Tweet: VS 2010 Productivity Power Tools Update (with some cool new features) via @scottgu #vs2010 #programming Date: Thu Jul 22 17:34:45 +0000 2010 Tweet: SQLite 3.7.0 released #sqlite Date: Wed Jul 21 19:08:01 +0000 2010 Tweet: 20+ Required #Windows Apps: Web DesignerGÇÖs Choice via @nettuts - I personally love Notepad++ myself! Date: Mon Jul 19 20:20:23 +0000 2010 Tweet: Windows Phone 7 in-depth preview via @engadget #wp7 #microsoft Date: Mon Jul 19 17:13:38 +0000 2010 Tweet: Would love to get a hold of Windows Phone 7 device to build a couple applications for it, anyone know how to go about that? #windowsphone7
Python has a very large and powerful framework behind it, so doing simple things like making web requests and parsing XML are fairly straight forward and don't require a lot of code. Let's start by requesting the XML from Twitter's API.
import httplib # Open a connection to twitter.com. twitterConn = httplib.HTTPConnection("") # Requestion()
The first thing we do is create an HTTPConnection object for twitter.com. We then tell it to request the timeline for the user SwitchOnTheCode. Next, we get the response as an HTTPResponse object. I do a quick check to make sure the request went ok, since we all know how often Twitter goes down. All that's left to do is simply read the contents of the response, which will be our XML.
Now we need to parse the XML. There are a couple of available options, but I chose the DOM approach as I think it makes more logical sense.
import httplib from xml.dom.minidom import parseString # Open a connection to twitter.com. twitterConn = httplib.HTTPConnection("") # Request() #Parse the XML. twitterDom = parseString(tweets) # Find all the status tweets. for tweet in twitterDom.getElementsByTagName("status"): for tweetParts in tweet.childNodes: # Find the date tag. if tweetParts.nodeName == "created_at": for textNode in tweetParts.childNodes: # Find the contents of the date tag. if textNode.nodeType == textNode.TEXT_NODE: print("Date: " + textNode.nodeValue) # Find the tweet tag. elif tweetParts.nodeName == "text": for textNode in tweetParts.childNodes: # Find the contents of the tweet tag. if textNode.nodeType == textNode.TEXT_NODE: print("Tweet: " + textNode.nodeValue.encode('utf-8') + "\n")
Using Python's minidom, we first parse the XML returned from Twitter using parseString (don't forget to import parseString at the top of the file). Now things get a litte tricky. We need to rip through the DOM looking for the items we want to display. First off, every tweet is stored beneath a "status" tag, so we need to loop through every one of those. Underneath each status tag there's the date (created_at) and the actual tweet (text), so we need to loop through every child of the status tag looking for those. Once we find one, we then need to find the text contained within it. Text is contained in TEXT_NODE type nodes, so we need to search through the children of our created_at and text tags looking for that specific type. Once we find it, we then print the nodeValue and we're done.
Since tweets are Unicode, I needed to encode the text as utf-8 before printing it to the console.
And that's it. With just a few lines of code, and some pretty complicated DOM traversing, we've got a very basic Twitter reader built in Python.
Source Files:
Very nice & neatly laid out code. Had to tweak it slightly to work. Changed httplib.HTTPConnection() to (api.twitter.com)and also "/statuses/user..." to "/1/statuses/user..." and now it's working.
I will have my Pi vocalising my tweets in no time. Thanks very much for publishing this code
Hey, you! I've tried all day to make the same thing and now at 00:40 a.m. I found you! Thank you! It's amazing!
Yes, there is: /statuses/user_timeline.xml?screen_name=AccountName&count=200
How to fetch more than 20 tweets?
Thanks , it's work. but why did you write 200 ?
200 is the HTTP status code for OK.
Thanks.
Can you point me to an example of posting a message?
Worked for me
after twitter update this sample doesn't work.
Thanks for sharing this wonderful post
|
http://tech.pro/tutorial/1020/how-to-build-a-simple-twitter-client-using-python
|
CC-MAIN-2014-42
|
refinedweb
| 838
| 76.32
|
I have a desktop app built in AIR using the 2009 namespace. Is there any way to incorporate any of the of the xmlns:mx="" components into it?
Or better yet, since the AIR namespace is sort of layered on top of the spark namespace, is it possible to do the same with the 2006 namespace?
Most people map the "fx" prefix to 2009, then map mx to the following:
xmlns:mx="library://ns.adobe.com/flex/mx"
Then, if the mx.swc is in the project's library path, you should be able to use the mx: prefix like you did with 2006 except for places where "fx" is now used.
xmlns:mx="library://ns.adobe.com/flex/mx" is the spark mx address, which is completely different than the original 2006 mx library.
The thing is: I love AIR, hate spark, loved the 2006 pre-spark functionality. It is so much more convenient and user friendly. Given the choice between having the display seperate from the processing, or having it be convenient and easy to work with, I choose the later option.
For the most part it seems like the AIR api is like a layer on top of the spark - flex system.. I would like to be able to over lay the same AIR functionality on top of the the old system....
Possible or no?
The code in the components did not change much for mx components in Flex 4 and later. The skins changed, so if that's what you are concerned about, I think the old halo theme still exists.
If I'm not understanding your questions, please provide an explicit example of what you want.
-Alex
|
https://forums.adobe.com/thread/1245109
|
CC-MAIN-2016-44
|
refinedweb
| 282
| 80.21
|
# Even more secret Telegrams
We used to think of Telegram as a reliable and secure transmission medium for messages of any sort. But under the hood it has a rather common combination of a- and symmetric encryptions. Where’s fun in that? And why would anyone trust their private messages to a third-party anyway?

TL;DR — inventing a private covert channel through users blacklisting each other.
Covert channels
---------------
There are many workarounds to transmit data between two users avoiding direct contact. You can use a middlemen, crypto- and steganography methods, broadcasting relay networks, and other extensions of existing protocols. But sometimes it’s useful being able to establish a secure contact using only officially documented features. Or as one should say, set up a [covert channel](https://en.wikipedia.org/wiki/Covert_channel).
One can find a simple example of a good covert channel in a Soviet spy movie “Seventeen Moments of Spring” (this one is, like, really good, give it a chance). In it, a flower in a window of the safe house was used as a signal of the spy failing his mission. The flower by itself does not mean anything: it can be there and could be not, such symbiosis is a common thing and only telling us about the owner’s love for flowers. Only the predetermined interpretation distinguishes the information received by a spy from the one received by a random passerby.

Flower-based channels in Telegram
---------------------------------
To organize your own covert channel by the same principle you’ll need only two things: a window and a flower. The window represents an object you can change the state of seen by others and the flower — possible states and a way of changing them.
So what Alice could change in Telegram that Bob could look at? Many things, actually: avatars, usernames, last visited time and more. But usually these things are available to everyone at the same time, limiting dialog privacy — if one possesses the transition method, anything Alice sends is not private anymore. Not so surprisingly, it is possible to get around this limitation without any kind of encryption involved.
### I'm blocking you, haha
Every user has his own blacklist, and if the reader was annoying enough, he could have noticed after being blocked that his not-already-a-friend ‘last visited’ status has been changed to ‘last seen a long time ago’. The truth is, he could have been online just a few seconds ago or even be right now, but Telegram API will not send this information to your app anymore. That way, it is protecting other user’s privacy from unwanted eyes. In exchange though, they can see if blacklisted or not.
So what are seeing a flower and being blacklisted have in common? Both could be checked at a given moment, allowing to receive one bit of information depending on if you are blocked or not. Another advantage is a fact that Telegram probably does not store logs of users blocking each other (at most for short periods in journaling purposes).
Organizing bits
---------------
A possibility to send and receive bits is fun and all, but we still need to describe its exploitation mechanism. Telegram refuses to notice you while blocked, so every ‘receive bit’ action should be initialized by the recipient (let’s call him Bob) and do not depend on the sender (she would be Alice), i. e. be independent. It also means that Alice and Bob should do requests at the same frequency.
Bit exchange algorithm on every clock looks like this:
* A checks sending a bit and if has different from the previous value changing it depending on a value:
+ A -> T: block B if bit is 1;
+ A -> T: unblock B if bit is 0.
* B receives a bit:
+ B -> T: resolve A;
+ T -> B: available to B information about A;
+ B: checks if the received information has a status it:
- B: if it is -> he is not blocked and the bit is 0
- B: if it is not -> he is blocked and the bit is 1
Most modern PCs have good internal frequency generators (a system clock, for example), so we can synchronize our clocks using them while not touching the channel to transmit anything except for the message bits. Only worth noticing that Telegram API requests, both (un)blocking and user status resolving, are network calls and do not tend to work quickly, especially if you are using proxies or a VPN. This produces a limitation: clock length should be longer, than the average response time (since we need to fit one into another) and that’s why our data transmission speed is limited.
### Encoding messages
Texts in natural languages have pretty high redundancy and messages received with errors will still be mostly readable by a human. Since Telegram is a messenger (ignoring some [crazy stuff](https://github.com/PiMaker/Teletun)) after all, we can neglect error correction limiting possible transmitting data to simple text messages.
The channel has extremely low bandwidth, that’s why we need to use the most effective message encoding available. Luckily, the name of the messenger reminds us about times such problem was a common one.
That’s why while living in the 21st century, we will encode our texts with one of the most efficient methods available to telegraphers a hundred years ago — the [the Baudot code](https://en.wikipedia.org/wiki/Baudot_code). More precisely, its final variation ITA-2 created by [Donald Murray](https://en.wikipedia.org/wiki/Donald_Murray_(inventor)) to perform fewer API calls for the most frequent symbols.
The only thing left to successfully transmit a message is to find session boundaries, so the recipient could find a sent one among the continuous bit stream. Before the transmission has started Bob is either blocked or not, and this state will not change by itself anytime soon. That’s why Alice can indicate session start by swapping it to the opposite for a single clock. At the successful end of the session, she will unblock and leave him be. He, on the other side, will continue to receive zero bits until decides they are not a part of the message — the Baudot code has no `00000` symbol.
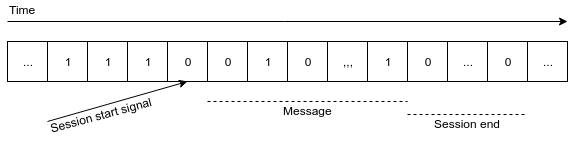
Drawbacks of this method are: a practical impossibility to connect (you can, but it will likely require manual error correction due to the bit shift) to ongoing translation and a need to separate null symbols received with errors from ones been sent. But there all problems of the implementation.
High tech
---------
After several hours spent trying to use [an official library](https://core.telegram.org/tdlib), I got tired and wrote everything with Python using more human-friendly [Telethon](https://github.com/LonamiWebs/Telethon). It even has a synchronous-style API, which is rare today for reasons unknown. Message encoding with ITA-2 I’ve written by myself since there were nothing useful on the Internet.
Clock synchronization made using system clock (and yes, it sleep()s! in between) since it’s precise enough, considering the time required on every network API call is more than a tenth of a second in most cases. User can set transmission speed as he wills, but I recommend following ‘no more than a request per second’ rule if you don’t want to both see errors on the other side and find yourself banned by the flood prevention system. Telegram turned out to be very picky about his API usage, freezing access for a day for even a few simple (successful!) authorization attempts in a row and just random blocking during the transmission for reasons unknown.
If the user decided to use such a weird channel to exchange messages, he really should not care about any graphical user interface features. And not all systems have it anyway. That’s why I wrote my application in a form of a terminal tool. It allows to both send and receive messages (only one operation per launch tho). Of course, you can run as many copies of the program as you want to and use multiple channels simultaneously both directions.
### Using the stuff
You can read more about using this thing as both a command-line utility and a python3 library through the API at GitHub (repository linked at the end of the post). The only problem is to acquire your own API credentials (simple [manual](https://core.telegram.org/api/obtaining_api_id) is helpful enough) since Telegram does not allow to disclose mine and set according values in your local copy of a script. Everything passed through the command line arguments except for the authorization part (which by default done through the stdio) and looks like this:
```
For Alice: For Bob:
Enter your phone number: XXX | Enter your phone number: XXX
Enter auth code: YYY | Enter auth code: YYY
Started message transmission... | Listening for the message...
---++ ('O', '9') | ---++ ('O', '9')
--+-+ ('H', '#') | --+-+ ('H', '#')
+++++ (1, 1) | +++++ (1, 1)
--++- ('N', ',') | --++- ('N', ',')
--+-- (' ', ' ') | --+-- (' ', ' ')
++-++ (0, 0) | ++-++ (0, 0)
--+-+ ('H', '#') | --+-+ ('H', '#')
-++-- ('I', '8') | -++-- ('I', '8')
--+-- (' ', ' ') | --+-- (' ', ' ')
--+++ ('M', '.') | --+++ ('M', '.')
++--- ('A', '-') | ++--- ('A', '-')
-+-+- ('R', "'") | -+-+- ('R', "'")
++++- ('K', '(') | ++++- ('K', '(')
+++++ (1, 1) | +++++ (1, 1)
+-++- ('F', '!') | +-++- ('F', '!')
--+++ ('M', '.') | --+++ ('M', '.')
--+++ ('M', '.') | --+++ ('M', '.')
Done, exiting... | ----- ('', '')
| ----- ('', '')
| Automatically decoded: OH, HI MARK!..
```
Outside of the Telegram
-----------------------
Worth noticing that it is possible to implement such a channel over any messenger and/or social network in which one can detect if he got blocked by others or not. You can use my code to do so and do not reinvent the wheel. Low python’s performance will not be a limiting factor due to the low transmission speed and an API calls response time.
P.S. Special thanks to my passion's unusual love for blocking me
* [Russian version](https://habr.com/ru/post/451954/)
* [Medium mirror](https://medium.com/@labunskya/secret-telegrams-bdd2035b6e84)
* [GitHub](https://github.com/LabunskyA/covertele)
|
https://habr.com/ru/post/452434/
| null | null | 1,682
| 59.64
|
Introduction: KEYPAD WITH 7 SEGMENT USING CLOUDX MICROCONTROLLER
For this project, we will accept numeric input from a Matrix Keypad and then display it on a seven-segment display Module. Since the 8 LEDs are labeled A to G and DP (for the decimal point), if you want to display the number 6, then you would apply current to segments A, C,D,E F and G. Therefore 6 equals 0b01111101(DP,G,F,E,D,C,B,A) in binary and 0x7D in Hexadecimal.
Step 1: MATERIALS
Step 2: SET-UP YOUR HARDWARE
Follow this step:
connect the:
Pin A of the segment to pin1 of the CloudX
Pin B of the segment to pin2 of the CloudX
Pin DP of the segment to pin3 of the CloudX
Pin C of the segment to pin4 of the CloudX
Pin D of the segment to pin5 of the CloudX
Pin E of the segment to pin6 of the CloudX
Pin F of the segment to pin7 of the CloudX
Pin G of the segment to pin9 of the CloudX
connect the common cathode pin to GND
The pinA of the keypad row pin was connected to 10k resistor and to pin12 of the microcontroller.
The pinB of the keypad row pin was connected to 10k resistor and to pin13 of the microcontroller.
The pinC of the keypad row pin was connected to 10k resistor and to pin14 of the microcontroller.
The pinD of the keypad row pin was connected to 10k resistor and to pin15 of the microcontroller.
And the end of the resistor was connected together to GND.
The pin1 of the keypad Row pin was connected to pin10 of the microcontroller.
The pin2 of the keypad Row pin was connected to pin11 of the microcontroller.
The pin3 of the keypad Row pin was connected to pin12 of the microcontroller.
Step 3: CODING
Copy this code to your CloudX IDE.
#include <CloudX\M633.h>
#include <CloudX\Keypad.h> #include <CloudX\Segment.h> #define NumberOfRows 4 #define NumberOfColumns 3 char KeypadCharacters[NumberOfRows][NumberOfColumns] = { '1','2','3', '4','5','6', '7','8','9', '*','0','#' }; //layout of the Keypad’s Keys char RowPins[NumberOfRows] = {12, 13, 14, 15}; char ColumnsPins[NumberOfColumns] = {9, 10, 11}; char Keys; //Instead of creating ten separate char variables, we create an array to group them unsigned char seg[] = {0x3F,0x06,0x5B,0x4F, 0x66, 0x6D, 0x7D, 0x07, 0x7F, 0x6F}; setup(){ //setup here Keypad_setting (PULLDOWNROW, RowPins, ColumnsPins, NumberOfRows, NumberOfColumns, KeypadCharacters); // initialize Keypad with these data //Segment_setting(CCathode,NumberOfDigit,segmentScanPins,segmentDataPins); portMode(1,OUTPUT); // setup digital I/O port 1 as OUTPUT portWrite(1, OFF_ALL); // clear/turn off port 1 loop(){ //Program here
Keys = getKey(); // check for Key Press on Keypad if(Keys!=0) portWrite(1, seg[Keys - 48]); // write Key Pressed on 7-segment
} }
Step 4: SHARE WITH US
Be the First to Share
Recommendations
|
https://www.instructables.com/KEYPAD-WITH-7-SEGMENT-USING-CLOUDX-MICROCONTROLLER/
|
CC-MAIN-2021-39
|
refinedweb
| 476
| 52.63
|
How to find the nth prime number in Java
In this program, we will find the nth prime number using java. For this, we are importing the Scanner class.
Importing the scanner class:
import java.util.Scanner;
Now we use this scanner class to take the input from the user.
Scanner sc = new Scanner(System.in); int n = sc.nextInt();
Java program to find the nth prime number
import java.util.Scanner; public class Prime { public static void main(String[] args) { int num=1, count=0, i; Scanner sc = new Scanner(System.in); System.out.print("Enter a number to find the nth prime number: "); int n = sc.nextInt(); while (count < n){ num=num+1; for (i = 2; i <= num; i++){ if (num % i == 0) { break; } } if ( i == num){ count = count+1; } } System.out.println("Value of nth prime is: " + num); } }
Steps for understanding the program
Let’s see the steps we did to find the nth prime number in Java:
- import the Scanner class which is found in java. util package.
- Declaring and initializing some variables.
- Using the Scanner class to take input from the user.
- The logic of the program:
while (count < n){ num=num+1; for (i = 2; i <= num; i++){ if (num % i == 0) { break; } } if ( i == num){ count = count+1; } }
Understanding the logic of the program
For understanding the logic of the program you must learn how to find whether the number is prime or not in this article – Java Program To Check A Number Is Prime or Not.
This loop continues until the value of the count is less than n. If the condition is true then it will increase the value of num by 1.
The for loop begins with the initialization of i by 2 till the value is less than or equal to num. Every time when the condition is true it will divide the value of num by i and checks if its equal to zero or not. If it is equal to zero, the loop breaks and checks whether i is equal to num. If it is so then the value of count is increased by 1 and then again checks the condition of while loop.
When the while loop terminates we get our final value in the variable num.
Output:
Enter any number to compute the nth prime number: 5 Value of nth prime: 11
|
https://www.codespeedy.com/find-the-nth-prime-number-in-java/
|
CC-MAIN-2020-29
|
refinedweb
| 397
| 71.24
|
.
One example of an application for DAQ and Comedi is the Analytical Engineering, Inc. (AEI) airflow laboratory. In the AEI lab, airflow is generated by a fan and is forced through orifices of varying sizes. Using a custom-written software application, a technician can monitor the pressure buildup across the orifice. In turn, this pressure buildup can be used to calculate the approximate amount of air flowing across the orifice. This calculation is vital, because it allows a technician to determine whether various meter calibrations are correct.
However, the actual mass flow is more difficult to calculate completely. This number requires knowledge of two air pressures, three airflow temperatures, humidity, barometric pressure and altitude.
Off-the-shelf components exist for converting these measurements to voltage; one of the most popular interfaces is 5B. Using 5B modular blocks, it's possible to transform all of these measurements to voltages the DAQ card can read.
Using Comedi, reading these voltages becomes as trivial as using the comedi_data_read function. Calling this function and specifying a certain channel produces a resultant value, 3,421 for instance. But what does this number mean?
DAQ cards measure with a certain bit precision, 12 bits being the most common. They also specify a range or ranges of voltages over which they can be programmed to measure. Because a 12-bit number is represented from 0 to 4,095, it's easy to see that 3,421 is simply 3,421/4,095 * 100% of full scale (4,095). If the range of voltages is specified as [0, 5], then 3,421 would represent 4.177 volts.
Utilizing this information and knowing that the 5B block for temperature maps as [0 volts – 5 volts] → [0°C – 100°C], a small amount of programmatic math delivers a temperature of 83.56°C. Couple all of these measurements together, add a nice GUI interface and repeat the DAQ process every second.
More complex data acquisition can be performed as well. When acquiring data, it's important to make sure you sample fast enough so as not to miss any important information that occurs between samples. To support this, Comedi offers a command interface that can be used to set up synchronized sampling. Based on the sophistication of the DAQ card, timing can be handled by software interrupts or on-card interrupts.
Listing 1. Sample Program for Acquiring Voltage from One Channel
#include <stdio.h> #include <comedilib.h> const char *filename = "/dev/comedi0"; int main(int argc, char *argv[]) { lsampl_t data; int ret; comedi_t *device; /* Which device on the card do we want to use? */ int subdevice = 0; /* Which channel to use */ int channel = 0; /* Which of the available ranges to use */ int range = 0; /* Measure with a ground reference */ int analogref = AREF_GROUND; device = comedi_open(filename); if(!device){ /* We couldn't open the device - error out */ comedi_perror(filename); exit(0); } /* Read in a data value */ ret=comedi_data_read(device,subdevice, channel,range,analogref,&data); if(ret<0){ /* Some error happened */ comedi_perror(filename); exit(0); } printf("Got a data value: %d\n", data); return 0; }
Comedi shines in most data acquisition applications. In fact, Comedi's limit generally resides in the hardware on which it's being run. Less expensive cards typically have a slower scan rate ability. For fast data acquisition, most of the higher priced cards come with onboard DMA, allowing an onboard processor to handle the acquisition and allowing Comedi simply to route the acquired buffered data.
Listing 2. Code Snippet Demonstrating More Advanced Scanning by Using Commands and Triggers
/* Goal: Set up Comedi to acquire 2 channels, and scan each set twice. Perform the acquisition after receiving a trigger signal on a digital line. */ comedi_cmd c, *cmd=&c; unsigned int chanlist[2]; /* CR_PACK is a special Comedi macro used to setup a channel, a range, and a ground reference */ chanlist[0] = CR_PACK(0,0,0); chanlist[1] = CR_PACK(1,0,0); /* Which subdevice should be used? */ /* Subdevice 0 is analog input on most boards */ cmd->subdev = 0; cmd->chanlist = chanlist; cmd->chanlist_len = n_chan; /* Start command when an external digital line is triggered. Use digital channel specified in start_arg */ cmd->start_src = TRIG_EXT; cmd->start_arg = 3; /* begin scan immediately following trigger */ cmd->scan_begin_src = TRIG_FOLLOW; cmd->scan_begin_arg = 0; /* begin conversion immediately following scan */ cmd->convert_src = TRIG_NOW; /* end scan after acquiring scan_end_arg channels */ cmd->scan_end_src = TRIG_COUNT; cmd->scan_end_arg = 2; /* Stop the command after stop_arg scans */ cmd->stop_src = TRIG_COUNT; cmd->stop_arg = 2; /* Start the command */ comedi_cmd(device, cmd);
Fast scan rates don't translate to fast processing, however. Due to the non-deterministic nature of the stock Linux kernel, it's virtually impossible to handle acquisition and processing in real time—that is, to maintain strict scheduling requirements for a process. Help is available, however. The Linux Real-Time Application Interface (RTAI) and RTLinux are two of a small number of add-on packages that allow for better timing control in the kernel. Both packages provide interfaces to Comedi.
The basic idea behind these real-time interfaces is simple. Instead of running the kernel as the monolithic process, run it as a child of a small and efficient scheduler. This design prevents the kernel from blocking interrupts and allows it to be preempted. Then, any application that needs real-time control of the system can register itself with the scheduler and preempt the kernel as often as it needs to.
AEI maintains a number of testing chambers for diesel engines, known as test cells. In a cell, an engine is equipped with a number of temperature and pressure measurement devices. A frequency measurement device also is used to measure the rotational speed of the engine. Finally, the engine is connected to a dynamometer, which simulates actual driving conditions by varying the resistance against the spinning engine. This results in generated torque, which is measured as well.
The actual scan rate of the engine data is slow, only 20 times per second. If the measurement of this data were the only required job, the overall setup would be straightforward. However, a number of variable parameters must be tuned and controlled with the newest acquisition of each set of numbers. The engine throttle position and dynamometer load amounts must be varied slightly to maintain the engine speed at a specific condition. Valves in the cell controlling cooling water flow must be adjusted to keep engine coolant temperatures at constant levels. Safety measures must be checked to determine that no catastrophic problem has occurred.
All of these checks and new control values must be taken care of before the kernel can return to handling the rest of its scheduling. If the Linux kernel were to handle this scheduling on its own, it is quite possible that everything would work properly. However, it's impossible to determine beforehand when each stage of the process will be executed. With real-time extensions, however, the problem becomes trivial.
A real-time kernel is not without its downsides. While the real-time scheduler is executing some process at a fixed interval, the Linux kernel basically is put on hold. This means that a real-time process must be fast and efficient, and it must relinquish control back to the kernel as quickly as possible. Failure to do so results in sluggishness in the non-real-time portion of the system. If something goes wrong in the real-time process and control never goes back to the kernel, a complete system lockup can occur as well.
Laboratory aside, sometimes it's interesting and fun to put Comedi to work at home. Low-end multipurpose data acquisition cards can be purchased for $99–$299 US, depending on brand, complexity and acquisition rate. Some examples of home projects include monitoring temperature in various parts of the house or scanning a magnetic sensor on a garage door to remind you that it's still open.
One interesting aspect of the personal computer is that parallel port lines can be controlled individually. Using Comedi, it's trivial to turn on and off these digital lines. When used with some form of relay, these digital lines can turn off and on anything imaginable.
Although parallel ports toggle between 0 and 5 volts, they typically do not have the capacity to source much electrical current. That said, it's a bad idea to connect the parallel port line directly to a device to turn it on or off without adding some kind of buffer circuitry. Many Web sites exist that explain how to create these circuits.
I use Comedi, an old 486 and two parallel ports to create an annual holiday light show. Lights are hung on the house in normal fashion, and a pair of wires for each set of lights is run back into the control room (a spare bedroom, in this instance). These power wires are connected to a custom-built circuit board that houses mechanical relays that send the power to the lights when they receive a 5-volt signal from the parallel port. A simple C program uses Comedi function calls to control the parallel port lines digitally, that is, to turn on and off the lights. Simple text files tell the program when to turn various lights on and off. And, the neighborhood receives a treat.
Data acquisition is extremely valuable in the laboratory. The generic interface that Comedi provides allows great ease of use in Linux for a large number of available DAQ cards. As the popularity of Linux grows, the importance of having an interface such as Comedi's becomes vital.
Furthermore, as the low-end DAQ cards become even less expensive, Linux-based data acquisition becomes more and more appealing to hobbyists and do-it-yourselfers. What used to be an expensive set of software and hardware now is a viable method of implementation for a multitude of applications.
Resources for this article: /article/7610.
Caleb Tennis has been using Linux since 1996. He was the release coordinator of the KDevelop Project and now is focusing his attention on maintaining KDE for Gentoo. Besides overseeing engineering at a diesel engine test facility, he also teaches Linux part-time at a local college.
|
https://www.linuxjournal.com/article/7332?page=0,1
|
CC-MAIN-2018-17
|
refinedweb
| 1,693
| 53.1
|
I have my XML root element that looks like this:
<DataResponseOfListOfSite xmlns:
and I get the error "The markup in the document following the root element must be well-formed."
If I use this it works fine:<DataResponseOfListOfSite xmlns:
Does anyone know why I have to have the xmlns:xsi="" instead of just xmlns=""
If I paste this XML into any validator, it says that its good, so I dont know why Flex is complaining about it.
In the first one you have two namespaces both with the same prefix.
xmlns:xsi="" and xmlns:xsi=""
Thanks,
Gaurav Jain
Flex SDK Team
|
https://forums.adobe.com/thread/467079
|
CC-MAIN-2017-30
|
refinedweb
| 101
| 72.5
|
6/23/16
- No internet at Panera today so I worked on other things for 30m or so.
- Interesting discussion since I was curious about memory allocation in C:
- Went to this meetup at Greater Sum:.
- The workshop ended up being horrible and I learned nothing new. Here is example of something we worked through arbitrarily in a group:
- We’d just change “FILL_ME_IN” to make the code work, but I didn’t see the point at all. This was supposed to be an introduction class, but nothing was explained. Just two hours of math/coding problems. If you were unfamiliar with coding at all your head would’ve exploded. No basics were covered and we never actually wrote a single line of JS. Just a lot of 1 + 1 = ?
- You can see the actually exercises they used here:
- I looked up Javascript Koans and they seem to be a common thing, but I personally didn’t see how it served as an introduction to JS unless you were already really proficient in another language. But if you were good in another language you wouldn’t need to do these Koan exercises anyway!
6/24/16
Shawn linked me this article on Twitter.
I found this part really interesting:
Call your shot. Before you run code, predict out loud exactly what will happen.
6/25/16
- Went to this meetup today for Code Newbie:
- The guy that runs this startup Cypress.io talked to our small group about debugging and I learned quite a bit although a lot of it was way over my head.
- He showed us how to use some Dev Tools in chrome to debug a simple Javascript snippet.
- I think he also runs a Javascript group meetup in Atlanta.
-
- I also learned of a couple of new Slack groups too.
- 404Tech slack group.
- CodeNewbie slack group.
- Started working on Daily Programmer Challenge #269 [Easy] BASIC Formatting.
- Worked for a while trying to figure out how to get input from a .txt file and put it into an array so I can actually manipulate it.
-
-
- C Programming Tutorial # 42 - fgets() - Reading Strings From A File - Part 1 [HD]
6/26/16
- Worked a little more on the BASIC FORMATTING challenge.
- Decided to scrap trying to read the input as a text file as C doesn’t make it very easy to do it as a file with line breaks and I kept getting Segmentation Faults (but I could get it to read the file and print it out, THEN it would break).
- I just put the input string directly into the problem itself now and will work from there. I am not sure how to get the first characters up to the letter V to be deleted and then work from there…
- This is as far as I got. It can print out the input properly but then it segmentation faults.
-
#include <stdio.h> #include <cs50.h> #include <string.h> #include <stdlib.h> #include <ctype.h> //provided input char* input = "12\n····\nVAR I\n·FOR I=1 TO 31\n»»»»IF !(I MOD 3) THEN\n··PRINT \"FIZZ\"\n··»»ENDIF\n»»»»····IF !(I MOD 5) THEN\n»»»»··PRINT \"BUZZ\"\n··»»»»»»ENDIF\n»»»»IF (I MOD 3) && (I MOD 5) THEN\n······PRINT \"FIZZBUZZ\"\n··»»ENDIF\n»»»»·NEXT"; int main(void) { printf("INPUT:\n\n%s\n\n", input); int i; //int j; //int tabcounter = 0; int outputcounter = 0; char* output[250]; //loop through entire string once to remove all the dots and arrows for (i=0; i < strlen(input); i++) { //begin at first letter if (isalpha(input[i]) == 0) { //ignore all · and » and put into a new string output if (input[i] != ("·" || "»")) { output[outputcounter] = &input[i]; printf("%s\n", output[outputcounter]); outputcounter = outputcounter + 1; } } } }
6/27/16
- Only got a chance to read more of Grokking Algorithms chapter 7.
- Dijkstra's algorithm in python and how to do negative weighted graphs using the Bellman-Ford algorithm.
6/28/16
First day of experimenting with doing coding work first thing in the morning before work. 😴
CS50 Section Videos:
- Dynamic Memory Allocation
- Hard to wrap my head around this concept. How do people keep track of this?
- Memory must be freed at the end.
- Never free memory twice.
- Structures
- This is really cool.
- They need a semicolon at the end
- Is this similar to linked lists in the Python examples I’ve seen?
- Defining Custom Types
- aka Typedef
- Can rename types like instead of char* call it string to make it easier.
- You can also define structs INSIDE of typedef!
- Recursion
- Another video again. This one talked about the Base Case and Recursive case finally. I found that out in the Algorithm book and knowing that you need a base case to stop a recursive call really helped visualize how to use recursive functions.
- The Collatz Conjecture is talked about. The code I came up with wasn’t as elegant as theirs. Didn’t think of not using a step counter!)
- Call Stack
- Frame for the most recently called stack is always on the top.
- When a new function is called it is pushed onto the stack.
- The functions below the top one are paused.
- Once a function is finished it is popped off the stack.
- It reminds me a lot of the cup pyramid speed people that take a stack of cups and build them up and then collapse them.
- At work I decided to dive into some Project Euler problems and just do them by hand written out. I will code them up later today if I get a chance.
Project Euler
- Problem 1: Multiples of 3 and 5:
- Problem 2: Even Fibonacci Numbers:
- Problem 3: Largest Prime Factor:
-
-
- Apparently there is a proof that simplifies the problem. At first I was going to write a function that will find the next prime number, but that doesn’t seem to actually be necessary.
- See:.
- Just dividing by odds numbers is a lot easier than calling a function to find the next prime number and using that. Not sure if it’s faster though…
6/29/16
CS50 Problem Set 4 Videos
- File I/O
- Reading and writing to files.
-
- Valgrind
- Program to check for memory leaks and errors.
- Have been contemplating getting a coding coach/tutor/mentor person. looks like an interesting site to try. Maybe someone to talk to live once a week and get feedback on code I’ve written in terms of better practices/techniques.
Problem Set 4
- BMP, GIF, JPEG, and PNG file formats.
- How many different colors does each format support?
- Which of the formats supports animation?
- What’s the difference between lossy and lossless compression?
- Which of these formats is lossy-compressed?
- Article:
- What happens, technically speaking, when a file is deleted on a FAT file system?
- What can someone like you do to ensure (with high probability) that files you delete cannot be recovered?
- Whodunit
- Worked on coding up problem 1 and 2. For problem 1 I wasn’t getting the expected answer and this was my code.
if (i % 3 == 0 || i % 5 == 0) sum = sum + 1;
- I ran the debugger and it instantly became clear why. (1 should be i, duh). After that it still wasn’t correct and I realized I didn’t quite read the problem correctly. It should only calculate values BELOW 1000 not including it.
- Also sum = sum + i can be rewritten as sum += i.
#include <cs50.h> #include <stdio.h> #include <stdlib.h> #include <math.h> /* If we list all the natural numbers below 10 that are multiples of 3 or 5, * we get 3, 5, 6 and 9. The sum of these multiples is 23. * * Find the sum of all the multiples of 3 or 5 below 1000. */ int main(void) { int sum = 0; for (int i=1; i < 1000; i++) { if (i % 3 == 0 || i % 5 == 0) sum += i; //how do I write this shorter again? } printf("Final sum = %i\n", sum); }
- Solution = 233168
- Learned about the conditional operator or ternary operator in C. I saw it on Stack Overflow and it made no sense so I looked up the answer on...Stack Overflow of course.
-
- This is commonly referred to as the conditional operator, and when used like this:
- condition ? result_if_true : result_if_false
- ... if the condition evaluates to true, the expression evaluates to result_if_true, otherwise it evaluates to result_if_false.
- This is pretty cool and much shorter to write!
- Ran into a couple of issues coding this one up. First I was thinking about it incorrectly to start with. It was fibonacci numbers up to 4 million not up to the 4 millionth fibonacci number (which would be massive).
- After I fixed that I ran into another issue where my program should’ve worked, but just hung completely.
- I ran the debugger and everything seemed to sum okay when rolling through a few iterations of the loop.
- I thought that maybe my data types weren’t big enough and changed my ints to long longs and tried again, but it still hangs (that wasn’t the issue at all).
- It works for 10 steps through the loop.
- At 100 steps the CPU on the IDE goes to max and just hangs.
- Not sure what I can do here at all.
- Using this calculator the numbers cross 4mil after the 34th one. So I set my loop to only check up to that number and it worked!
- How would I overcome my program hanging in the future though? Need something with more memory or just need more time to wait? Could it be because my function was recursive and the stack just got super full?
- Solution = 4613732
#include <cs50.h> #include <stdio.h> #include <stdlib.h> #include <math. */ //prototype int fib(int x); int main(void) { int n = 4000000; int sum = 0; for(int i = 1; i < 34; i++) { if (fib(i) <= n) { if (fib(i) % 2 == 0) sum += fib(i); } } printf("Final sum = %i\n", sum); } // returns next fibonacci number int fib(int x) { if (x == 0) return 0; else if (x == 1) return 1; else return (fib(x-1) + fib(x-2)); }
- I just came to the realization that attempting to write a function that can calculate the next prime number from any given number would be...well to say the least “really complex.” I don’t know a way to write it that wouldn’t use straight up brute force, but doing a little googling I do see there are algorithms that do it faster.
- (the animation here is pretty sweet)
- Most likely for this problem I will stick the to the “divide by odds” strategy and not mess with that higher level math problem solving. Maybe someone wrote a library that does this already?
- I did find this solution to finding the next prime number which makes perfect sense, but is brute force checking.
- I may try to use it and see what happens.
|
https://www.craigrodrigues.com/blog/2016/06/29/learning-to-code-week-7
|
CC-MAIN-2019-47
|
refinedweb
| 1,826
| 73.98
|
The ability to sort datasets is one of Pandas’ most appealing features. By sorting, you can see your relevant data at your table’s top (or bottom). There isn’t much you need to know right away. When you sort several columns with sort keys, the magic happens.
Sorting pandas by column are where the rows in the DataFrame are arranged in ascending or descending order using DataFrame by column value.
Sort DataFrame by column in Pandas
To sort a DataFrame by column values, use pandas.DataFrame.sort_values(). The syntax for sorting pandas by column is as follows:
YourDataFrame.sort_values('your_column_to_sort')
Essentially, sorting pandas by column values, use pandas.DataFrame.sort_values(columns, ascending=True) with a list of column names to sort by as columns and either True or False as ascending.
While sorting with sort values() is simple in theory, you may have issues with missing values or custom labels in practice (for example, H, L, M for High, Low, and Medium). The initial results of print(df) are:
A B 0 5 7 3 3 6 4 10 11 5 7 4
A_sorted = df.sort_values(["A", "B"], ascending=True) print(A_sorted)
A B 3 3 6 2 5 7 5 7 4 4 10 11
The example above sorts by column “A” in ascending order.
B_sorted = df.sort_values(["B", "A"], ascending=False) print(B_sorted)
A B 4 10 11 2 5 7 3 3 6 5 7 4
The example shown above sorts the column “B” in descending order.
Sorting Pandas
Let’s look at the many parameters you can send to pd.
DataFrame.sort_values():
by – You can sort by a single name or a list of names. It could be the names of columns or indexes. When you want to sort by multiple columns, pass a list of names.
axis (Default: ‘index’ or 0)
It is the axis that will be ordered. You must specify whether Pandas you want the rows to be sorted (axis=’index’ or 0)? Do you want to sort the columns (axis=’columns’ or 1)?
ascending (Default: True) – If you’re sorting by multiple columns, you can pass a single boolean (True or False) or a list of booleans ([True, False]).
inplace (Default: False)
If true, your new sort order will overwrite your current DataFrame. It will alter the situation. Your DataFrame will be returned to you if false. When working with the DataFrame later in the code, we usually use inplace=True. However, if we’re visually looking at the sort order, we’ll use inplace=False.
type (defaults to ‘quicksort’)
Select the sorting algorithm you want to use. Unless you’re dealing with massive databases, this won’t matter much. Even then, you’d have to understand the distinctions and drawbacks.
na_position (Default: ‘last’)
You may tell pandas where you want your NAs to go (if you have them). At the beginning (‘first’) or the end (‘last’).
ignore_index (Default: False)
If false, your index values will change as the sorting progresses. It is beneficial when you want to check how the rows have shifted around. Set ignore_index=True if you wish your index to stay in order and remain at 0, 1, 2, 3,…, n-1.
Returns: DataFrame or None
DataFrame with sorted values or None if inplace=True.
Key: callable, optional
The latter is an incredible parameter! You can supply a function to the key that will produce a derived value that will be the key that is sorted on, based on your column or row. Before sorting, apply the key function to the values. It is comparable to the built-in sorted() method’s key parameter, except that you should vectorize this critical function. It should expect and deliver a Series with the same shape as the input. It will apply separately to each column in the table.
Take a look at the sample below.
Let’s say you wanted to sort by a column’s absolute value. You could sort by creating a derived column with fundamental values, but it feels inconvenient. Instead, use a pivotal function to sort your column by absolute values.
Let’s start by making a dataframe.
# importing pandas library import pandas as pd # creation and nesting of the list df = pd.DataFrame.from_dict({ "San Francisco": [67, 72, 49, 56], "Chicago": [102, 75, 80, -3], "Fairbanks": [45, 5, -10, 80], "Miami": [67, 87, 90, 75] }) df
Ascending vs. Descending Pandas
You’ll need to decide whether you want your values sorted from highest to lowest (descending) or from lowest to highest (ascending).
- Ascending = The lowest values will appear first or at the top.
- Ascending = The higher values will appear first or on top.
A Jupyter notebook demonstrates the various ways to sort a pandas DataFrame can be found here.
import pandas as pd
Values Sorted by Pandas
Sort Values allows you to sort a DataFrame (or series) by a column or row. Consider the following examples:
- Sort DataFrame by a single column
- Sort DataFrame by mulitple columns
- Sort DataFrame by a single row
- Apply a key to sort on – Example: Sort by absolute value
Let’s start by making our DataFrame of city temperatures.
df = pd.DataFrame.from_dict({ "San Francisco": [67, 72, 49, 56], "Chicago": [102, 75, 80, -3], "Fairbanks": [45, 5, -10, 80], "Miami": [67, 87, 90, 75] }) df
Sorting a DataFrame by a single column
You have to call YourDataFrame to sort a dataframe by a single column.
sort_values('your_column')
Let’s sort our DataFrame by temperatures in Chicago in this case.
df.sort_values('Chicago')
It’s worth noting how the DataFrame was ordered from lowest to highest by the Chicago column. Because ascending=True is the default sort order, this is the case. Set ascending=False if you wish to reverse the order.
df.sort_values('Chicago', ascending=False)
Sorting DataFrame by numerous columns
We’re going to make another DataFrame that will work better for sorting by several columns.
df = pd.DataFrame.from_dict({ "500 Club": ["Bar", 34.64], "Liho Liho": ["Restaurant", 200.45], "Foreign Cinema": ["Restaurant", 180.45], "The Square": ["Bar", 45.54] }, orient='index', columns=['Type', 'AvgBill']) df
Assume we wanted to arrange ‘Type’ alphabetically (such that Bar is above the Restaurant) before sorting AvgBill in decreasing order (highest > lowest). We’ll need to do the following to accomplish this.
Use the “by=” argument to specify a list of column names. The “ascending” parameter takes a list of booleans that informs pandas which columns we want ascending or descending.
df.sort_values(by=['Type', 'AvgBill'], ascending=[True, False])
Notice how we sorted the first column, ‘Type,’ ascending=True, then ascending=False for the second column, ‘AvgBill.’
#') # column sorting by "Country" and then "Continent" df.sort_values(by=['Country', 'Continent'])
Sorting the DataFrame by a single row
Let’s move on to the row side now. We only want to sort my columns in a precise order on rare occasions (we prefer tall tables to wide tables, so this doesn’t happen often). Further, we need to inform Pandas that I want to sort by rows and which row I want to sort by to accomplish this. Let’s go back to the DataFrame we started with. We’re going to sort by the label index=3. So, we’ll need to set axis=1 to accomplish this.
df.sort_values(by=3, axis=1)
Our DataFrame’s columns have now been sorted in ascending order by index=3!
Special Key Sorting the Columns
We wish to sort the column by the absolute worth of its contents in this situation. Check out Fairbanks; currently, -10 is the lowest value, but we’ll order by absolute value such that five is at the top.
What’s going on under the hood?
Pandas apply a function to each column value (much like pandas does). The object (or key) that is sorted on will be the outcome of that function.
df.sort_values(by='Fairbanks', key=pd.Series.abs)
Now, look at how we sorted on Fairbanks, with the lowest numbers at the top (descending) and the value 5 being higher than the value -10. It is because we specified the key as the column’s absolute value!
If you’re utilizing numerous columns, you won’t be able to call multiple vital functions. You’ll need to use the same process to sort all the columns.
How to handle Missing Values when Sorting
Because missing values or NaN are not comparable to other values, sort_values() default to sorting the NaN at the end of the DataFrame and modifying an existing DataFrame to add NaN and sorting on the age column, for example.
import pandas as pd name =['Edith', 'Mike', 'Thomas','Hans', 'Joy', 'Ann', 'Cyrillah'] age =[18,28,70,34,20,85,21] height =[133,183,141,172,199,122,201] weight =[90, 48, 70,59, 86,95,63] shirt_size=['S','M','M','L','S','L','L'] # DataFrame df = pd.DataFrame.from_dict({"name":name,"age":age,"height":height,"weight":weight,"shirt_size":shirt_size}) df.head(10) df.loc[5,'age'] = np.nan import numpy as np df.loc[5,'age'] = np.nan df
Sorting Pandas Data frame by placing the missing values first
#') # or sort by df.sort_values(by=['Fairbanks'], na_position='first')
Example: Sorting Pandas Data frame by placing the missing values first
df = pd.DataFrame({ 'first col': ['A', 'A', 'B', np.nan, 'D', 'C'], 'second col': [2, 1, 9, 8, 7, 4], 'third col': [0, 1, 9, 4, 2, 3], 'fourth col': ['a', 'B', 'c', 'D', 'e', 'F'] }) df.sort_values(by='first col', ascending=False, na_position='first')
Natural sort with the critical argument, using the natsort
df = pd.DataFrame({ "time": ['0hr', '128hr', '72hr', '48hr', '96hr'], "value": [10, 20, 30, 40, 50] }) df from natsort import index_natsorted df.sort_values( by="time", key=lambda x: np.argsort(index_natsorted(df["time"])) )
Modifying Your DataFrame Using Sort Methods
Both.sort_values() and.sort_index() have yielded DataFrame objects in all of the instances you’ve seen thus far. It is the case because sorting in pandas does not operate in place by default. Because it creates a new DataFrame instead of changing the original, this is the most popular and preferred technique to examine data with pandas. It allows you to keep the data in the same state as read from the file.
However, you can directly edit the original DataFrame by setting the optional argument inplace to True. The inplace parameter is present in the majority of pandas methods. In the examples below, you’ll learn how to use inplace=True to sort your DataFrame.
In-place use of.sort_values()
When inplace is set to True, the original DataFrame is modified so that the sort methods return None. Sort your DataFrame by the values of the city08 column. But with inplace set to True, as in the first example:
import pandas as pd column_subset = [ "id", "make", "model", "year", "cylinders", "fuelType", "trany", "mpgData", "city08", "highway08" ] df = pd.read_csv( " usecols=column_subset, nrows=10 ) df.head() df.sort_values("city08", inplace=True)
.sort_values() does not return a DataFrame, as you can see. It is how the original df looks. The data in the df object are now sorted in ascending order by the city08 column. Your original DataFrame has been altered, and the changes will remain in place. Because you can’t undo the changes to your DataFrame, it’s best to avoid using inplace=True for analysis.
In-Place use of .sort_index()
The following example shows how to use inplace with .sort_index(). Because the index is constructed in ascending order when you read your file into a DataFrame, you can change the order of your df object again. To change the DataFrame, use.sort _ndex() with inplace set to True:
df.sort_index(inplace=True) df
.sort_index() has now been used to modify your DataFrame once more. Because your DataFrame still has its default index, sorting it in ascending order restores the original order of the data.
If you’re familiar with Python’s built-in functions sort() and sorted(), you’ll recognize the inplace parameter in the pandas’ sort methods. Check out How to Use sorted() and sort() in Python for additional information.
Conclusion
This article covered all possibilities for using Python’s sort_values() to sort a DataFrame in Pandas. Sorting a DataFrame in Pandas in a given order, such as ascending or descending, is very easy with the built-in method sort)values()!
You now know how to utilize the pandas library’s.sort_values() and.sort_index() methods (). You can use a DataFrame to perform fundamental data analysis with this understanding. While there are many similarities between these two methodologies, understanding the differences allows you to choose which one to utilize for various analytical tasks.
These techniques are an essential aspect of mastering data analysis. They’ll assist you in laying a solid foundation for doing more sophisticated pandas operations. The pandas manual is an excellent resource if you want to see some examples of more advanced uses of pandas sort methods.
You can give these a shot and tell us what other techniques you use to sort your Pandas DataFrame.
|
https://www.codeunderscored.com/how-to-sort-dataframe-by-column-in-pandas/
|
CC-MAIN-2022-21
|
refinedweb
| 2,175
| 64.71
|
In main i'm declaring an object P:
Point P;
Then i'm trying to pass it and another Point object dest to use the ojbects:
int numOfPaths(Point P, int x, int y, Point dest, int n);
numOfPaths(P, x, y, dest, n);
Main.cpp is giving me no problems, but numOfPaths.cpp is giving me two errors, one for each of the Point objects.
"Identifier "Point" is undefined" and it points to each of the Points at the top of the function.
int numOfPaths(Point P, int x, int y, Point dest, int n)
^ ^
{
code for function
}
I'm pretty sure i'm passing the object wrong but I can't figure out how. Main compiles fine, so i'm not sure.
My other question is about overloading the == operator to compare two Point objects.
bool operator == (const Point &P) const;
is how its written in a public class of Point.
if(dest==P)
is when i'm calling it in numOfPaths.cpp. dest and P are my two objects i'm trying to compare. In my coding for the operator == I have:
bool Point:
perator ==(const Point &P) constperator ==(const Point &P) const
{
bool result = false;
if(x = P.x && y = P.y)
result = true;
return result;
}
x and y are coordinates. I'm trying too see if point P is at point dest yet, so after P moves i compare P and dest. I'm getting two compiler errors that say x and P.x "must be a modifiable lvalue".
Thanks if you can help on either of these, i've already tried searching C++ board for passing objects but couldn't find anything related.
|
https://cboard.cprogramming.com/cplusplus-programming/3317-passing-objects.html
|
CC-MAIN-2017-43
|
refinedweb
| 279
| 73.17
|
So I have a program i am writing. relatvely simple, but i am not sure what to do. the first I am trying to make a program that displays loan amount, monthly payments, and number of payments based on the input (annual interest rate), (number of payments), and (amount of loan). I have assigned l as loan amount, n as number of payments and rate as the annual interest rate/12. My formula for calculating is as follows : payment= (lrate(1+rate)n)/((1+rate)n-1)(n being to the nth(number of payments)power
I am getting an error on the line highlighted in red, but I am not sure that is going to make it work correctly
here is my code:
// Calculates loan info #include <iostream> #include <cmath> using namespace std; int main () { double annualrate; int numberofpayments; double l; double rate; double rateplus1; double divisor; double payment; double paymentbd; double dividend; cout << "What is your annual interest rate?\n"; cin >> annualrate; rate = annualrate/1200; cout <<"Enter number of payments.\n"; cin >> numberofpayments; rateplus1= rate+1; cout << "Enter your loan amount\n"; cin >> l; divisor= pow (rate+1),(numberofpayments); dividend=divisor-1; paymentbd= l*rate* divisor; payment=paymentbd/ (divisor-1); cout <<"Your loan amount is "<<l<<".\n"; cout <<"Your monthly payments are "<<payment<<".\n"; cout <<"Your number of payments are "<<numberofpayments<<".\n"; return 0; }
|
https://www.daniweb.com/programming/software-development/threads/113568/stuck
|
CC-MAIN-2017-30
|
refinedweb
| 226
| 51.18
|
An action to serialize objects to JSON. More...
#include <Wt/Dbo/Json>
An action to serialize objects to JSON.
This class is an
Action that serializes objects to an ostream. These objects must implement the
persist() method. It also has support for serializing ptrs to these objects, std::vectors of ptrs, and collections of ptrs.
It will follow one-to-one and ManyToOne relations in one way: weak_ptr and collection fields are followed and serialized, for ptr fields only the id is output.
No extraneous whitespace is output.
Creates a JsonSerializer that writes to an std::ostream.
Note that the std::ostream is not flushed to automatically. The flush will happen automatically when this JsonSerializer is destructed.
Serialize the given object.
Serializes a plain object that implements the
persist() method.
Serialize a collection of ptrs.
Serializes each ptr in the collection individually, and puts it in an
Array.
The typical usage scenario of this method is to serialize the results of a query to JSON.
|
https://webtoolkit.eu/wt/wt3/doc/reference/html/classWt_1_1Dbo_1_1JsonSerializer.html
|
CC-MAIN-2021-31
|
refinedweb
| 165
| 52.36
|
So, naturally, for anyone anticipating a fully cross-platform .NET development environment, the question becomes: What are the open source .NET projects, Rotor and Mono, planning for GUI development? As it turns out, both projects are implementing the Windows.Forms namespace (which is not part of the CLR) on their respective platforms. As far as I can tell, neither project is attempting to use any alternative GUI representation. That could be a mistake. It's going to be a huge effort to get the Windows.Forms namespace implemented on any particular platform, and that effort isn't going to translate easily to any other platform, nor will the resulting forms translate easily to other languages.
In contrast, both SWT and XUL have already been implemented, at least experimentally, on several platforms, so the technology is already proven even if it's not yet used extensively. Because both SWT and XUL specifications are open source, any alternative CLR implementation should be able to tap into the code of either one far more easily than performing a complete feature-for-feature rewrite of Windows Forms.
Moreover, any CLR/SWT or CLR/XUL implementation would also conceivably run on Windows, which would give current Windows developers an incentive to use it and would bring Java and .NET that much closer together.
To the Swift Go the Spoils
Frankly, I'm surprised that Microsoft didn't include the Windows Forms specification in the CLR, as they've now created an opening for IBM, Mozilla, or another third party to provide an alternative GUI model that works not only across platforms but is also relatively independent of the language used to activate it.
Further,.
I doubt that Microsoft will leave the window open long; the company has been discussing a unified forms model for years. Further, Microsoft has experience generating XML-based forms in .NET, and while its model has not been adopted universally, it would be relatively easy for it to switch to some other XML representation. Obviously, Sun is in much the same shape. With SWT, platform-specific code has obtained a toehold in the otherwise unmarred surface of pure Java. There's been a good deal of discussion about whether Sun should embrace SWT, although so far, they've clung to Swing tenaciously.
Meanwhile others are also looking at ways to improve Java's GUI capabilities. At least two attempts have already been made at delivering XUL-specified interfaces to desktop machines. Martin Weindel's Luxor XUL marries XUL to SWT for Linux and Java. Another project, XWT, provides a browser-based XUL rendering engine as both an ActiveX control (IE) and a Java applet. Marc Erickson, Project Manager, OTI Marketing and Sales (of OTI Embedded Systems), says OTI Labs has done similar work for the embedded community in an offering called P3ML. So there's at least some movement in the development community.
Although these projects point the way to truly cross-platform GUIs, a broadly successful effort will need multi-vendor buy-in and support. The XWT FAQ presents the arguments for using XUL and discusses some problems..
Please enable Javascript in your browser, before you post the comment! Now Javascript is disabled.
Your name/nickname
Your email
WebSite
Subject
(Maximum characters: 1200). You have 1200 characters left.
|
http://www.devx.com/xml/Article/9782/0/page/2
|
CC-MAIN-2017-04
|
refinedweb
| 548
| 54.93
|
Simple WSGI middleware that helps to log messages into JavaScript console object
Project description
It provides a simple WSGI middleware that helps to log messages into JavaScript console object. For example, if you log messages like:
logger = logging.getLogger('my.logger') logger.warning('warning message') logger.debug('debug message')
The middleware automatically appends codes like following JavaScript:
<script> // <![CDATA[ if (console) { console.warn('my.logger: warning message'); console.debug('my.logger: debug message'); } // ]]> </script>
Installation
You can install it by downloading from PyPI through pip or easy_install:
$ pip install log2jsconsole
How to use
Assume that your WSGI application name is app:
from yourapp import app from log2jsconsole import LoggingMiddleware app = LoggingMiddleware(app)
Or you can add this as a filter of Python Paste:
[filter:log] use = egg:log2jsconsole auto_install = True
Changelog
Version 0.4
Released on June 7, 2013.
- Support for Python Paste filter entry point. [#1 by Roberto De Almeida]
- Fixed incompatibile signature (according to PEP 333) of start_response. [#1 by Roberto De Almeida]
Version 0.3
Released on November 28, 2011.
- Fixed a bug of Content-Type detection.
Version 0.2
Released on November 28, 2011.
- Fixed a bug of Content-Type detection.
Version 0.1
Initially released on November 26, 2011.
Project details
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
|
https://pypi.org/project/log2jsconsole/
|
CC-MAIN-2021-17
|
refinedweb
| 227
| 51.55
|
GIS library - find GRASS data base files. More...
#include <string.h>
#include <unistd.h>
#include <grass/gis.h>
#include <grass/glocale.h>
Go to the source code of this file.
GIS library - find GRASS data base files.
(C) 2001-2008 by the GRASS Development Team
This program is free software under the GNU General Public License (>=v2). Read the file COPYING that comes with GRASS for details.
Definition in file find_file.c.
searches for a file from the mapset search list or in a specified mapset. returns the mapset name where the file was found.
notes:
If the user specifies a fully qualified element (<i>name@mapset</i>) which exists, then <i>G_find_file()</i> modifies <b>name</b> by removing the "@<i>mapset</i>" part. Rejects all names that begin with "." If <b>name</b> is of the form nnn in ppp then only mapset ppp is searched.
Definition at line 159 of file find_file.c.
Referenced by G3d_maskFileExists(), G_find_cell(), G_find_vector(), IL_output_2d(), IL_resample_output_2d(), and S_read().
searches for a file from the mapset search list or in a specified mapset. (look but don't touch) returns the mapset name where the file was found.
Exactly the same as G_find_file() except that if <b>name</b> is in the form "<i>name@mapset</i>", and is found, G_find_file2() will not alter <b>name</b> by removing the "@<i>mapset</i>" part.
note: rejects all names that begin with "."
Definition at line 191 of file find_file.c.
Referenced by G3d_readRange(), G_find_cell2(), G_find_vector2(), G_get_3dview(), Gs_load_3dview(), I_find_group(), and Vect_open_new().
Definition at line 196 of file find_file.c.
Referenced by G__raster_misc_read_line(), G_find_grid3(), G_read_fp_range(), G_read_histogram(), G_read_range(), I_find_group_file(), I_find_subgroup(), and I_find_subgroup_file().
Definition at line 164 of file find_file.c.
|
http://grass.osgeo.org/programming6/find__file_8c.html
|
crawl-003
|
refinedweb
| 281
| 61.43
|
I needed some code to create an image which roughly gave an impression of the file contents for a log file analyser I was writing. The following code crudely looks for the shape of letters and draws some dots into a .png file.
import Image, ImageDraw import os def drawfilethumb(filename, imagex=80, imagey=200, border=5): """Create a png image representing the file""" log = [] log = open(filename).readlines() loglen = len(log) logimage = Image.new('RGB', (imagex+10,imagey+10), (255,255,255)) draw = ImageDraw.Draw(logimage) maxlen = max(len(x) for x in log) xscale = maxlen/float(imagex) yscale = loglen/float(imagey) y = 0 while y < imagey and y*yscale < loglen: line = log[int(y*yscale)] linelen = len(line) x = 0 while x < imagex and x*xscale < linelen: ch = line[int(x*xscale)] if ch.isupper() or ch.isdigit(): draw.point([(border+x, border+y), (border+x, border+y-1)], fill=0) elif ch in ('t', 'd', 'f', 'h', 'k', 'l', 'b'): draw.point([(border+x, border+y), (border+x, border+y-1)], fill=128) elif ch in ('q', 'y', 'p', 'g', 'j'): draw.point([(border+x, border+y), (border+x, border+y+1)], fill=128) else: draw.point((border+x, border+y), fill=128) x+=1 y += 4 del draw f, ext = os.path.splitext(filename) logimage.save(f+'.png', "PNG")
Advertisements
|
https://rcjp.wordpress.com/2006/09/18/image-of-a-logfile/
|
CC-MAIN-2017-26
|
refinedweb
| 224
| 58.38
|
See also: IRC log
<scribe> Scribe: EdRice
<Norm> ht, wrt xmlFunctions-34 do you concur that the ball wrt our draft is in your court?
<ht> Yes, sigh.
<ht> Mea culpa
<DanC> I'm OK to scribe 25 Apr
Zakim +1.604.534.aaa is Dave
Dan will scribe next week
no regrets for next week.
Resolution: Minutes approved as-is from last week
meeting in Vancouver, starting on the 4th.
Tim and Noah were concerned about 2-3 day meeting length, but neither are on the call.
<DanC> (I still prefer 2 days)
ht: I can book late flights home.
Norm: I have to leave early, so Friday needs to end early on Friday or I'll have to leave early.
<DanC> (if we go 4-5 Oct, for 2 days, both weekends are safe.)
Ed: how about a two day meeting, we just work late if need be.
<Norm> Working late would be fine by me
Vincent: Lets confirm next week with the people who are not here today.
Vincent: Last week we decided to
use our slot for a pannel discussions.
... Steve was interested in my communication, but Steve declined getting the meeting running and be a moderator.
... So, we're on the agenda with the topics, but we need to find someone else to moderate the session.
... Any suggestions?
Norm: Stuart Williams?
general round of agreement, Vicent will contact to see if he'll be in town.
ht: we could invite Ralph on the pannel as well.
DanC: I havent seen an opinion from Ralph however, he may be a better moderator.
Vincent: ok, I have a few names. I'll contact Mishai, Stewart and Ralph. Otherwise we may need more names so if you think of any please share via email.
<dorchard> Ed, that wasn't I that mentioned Ralph. I think it was Dan.
<Zakim> Norm, you wanted to comment on the June f2f
Noah: I updated the logistics page to include possible hotels.
TV and Tim are invited by Lord Jeffery Inn.
Noah: June 12th I'll provide a
dinner if you can attend.
... I'd suggest making your reservations sooner than later.
<Norm> Tell Norm your flight schedules if your flying into BDL
Vincent: I put this on for TV but he's not on the phone.
V: there are three pending actions, only one can be addressed since TV and Tim are not in.
Vincent: ht can you update us on the draft finding?
<Norm> Norm wrote ->
ht: This is stuck in my in-tray and I've been busy, it will likely be several week.
Vincent: so our actions list remains the same for now.
Vincent: To continue our
discussion from last week.
... we talked about reviewing DIX.
Dan: the context came from Lisa
and she 'may be' an area director, but I havent heard
yet.
... The area director solicits people to do the review, but when you do that review you should get back to the authors of the working groups directly
... not with Lisa.
... The authentication service - I doubt there would be much benefit for us to look into. Not really web architecture stuff per say.
... I'm more interested in DIX.
Ed: DIX is very active.
Dan: There are many documents, there is an update just today.
<DanC> new DIX draft today
Dan: should we create a TAG
issue?
... Passwords in the clear should be a TAG issue.
... The DIX issue could be looked at in many ways.
Vincent: We can make the passwords in the clear an issue at any time. Should we spend more time on the documents in front of us.
Ed: I'll look at DIX.
Vincent: ok, we have one reviewer
for DIX. When you have a better view of the status, please
present your point of view during a teleconferance.
... should we make passwords in the clear a new TAG issue?
... We need people who are committed to making progress on this.
Dan: I dont think a short finding would be worth our time, we need to talk about alternatives etc.
Ed: I can start working on it..
<DanC> (I think it should be a TAG issue; I don't know that I can work on it soon. I think it's fine to have TAG issues sit around, acknowledged but not making lots of progress, for 18 months.)
Vincnet: are there other opionions on creating a TAG issue on passwords in the clear?
Vincent: I hear a few people in
doing so.. any objections?
... does anyone obstain? No one, so we have a concensus to open this as a new issue.
RESOLUTION: We will open a new issue 52
<DanC> clearTextPasswords-52
Proposals for the name?
<DanC> passwordsInTheClear-52
+1 on passwordsInTheClear
<Norm> passwordsInClear-52?
Resolution: passwordsInTheClear-52 will be the issue name.
Vincent: Ed will begin drafting.
Ed: I'll communicate this first to www-tag then start drafting..
<scribe> ACTION: Ed to communicate new issue and produce first draft finding. [recorded in]
<DanC>
Dan: it might be worth noting,
there was a workshop a while ago with a follow-up mailing
list.
... need to explore mailing list in relation to TAG
... we did some work in the f2f in september which may be worth linking to.
Vincent: I'll open the issue on the list.
<scribe> ACTION: Vincent to open the issue on the issues list. [recorded in]
Vincent: Should we close this issue now that we've published the finding? There is no open action on this issue.
Dan: are the specifics of PUT in
the new finding?
... yep.. found it.
<DanC> yes, putMediaType-38 is addressed to my satisfaction
Dan: The procedure is to announce that we have resolved the issue and solicit any feedback?
+1
<Norm> +1
HT: ok
Vincent: I agree as well.
RESOLUTION: We have resolved to close putMediaType-38
Vincent: We have published a
finding in Jan. The only action still on the list is an action
for Tim regarding the policy for creating new namespaces.
... Tim is not here, but I see a new policy is being created.
... Should we wait for this new document to be published before closing this issue.
Dan: I dont remember what we wanted in the new version or not..
Vincent: We wanted the W3C policy to be in alignment with our finding.
Dan: I'm moderatly inclined to
keep Tim's action open
... I know there has been some communication on this.
Vincent: ok, so I agree we need Tim on the call before we can close this issue.
Dan: It would also be nice if we could remember why we asked Tim to make a new version.
Vincent: I'll look at the logs/minutes so we can have a more effective discussion next week.
Vincent: This is something that I dont know about at all. I understand the topic and I see that there is a draft, dated Sept 2004 by Norm. There is not much discussion regarding this.
Norm: in summary;
... The question was: Shouldnt there be a standard way to compare 'chunks' of xml.
... the answer was there is not single right answer to this question...
... Timbl pushed back on that finding and asked if we could document 'a' right answer.
... There were some comments, but I never did incorporate those comments.
... We just turned our attention to other things. I'm not sure what we should do next, I could incorporate those comments into the draft
... But we need to make sure that people understand we're producing 'a' way, and not an approved way.
Dan: Does this draft corespond to xQuery?
Norm: I suspect its reasonable close for two chunks of unvalidated content.
Dan: A really nice appendix or two would be an implementation in xQuery or something.
Norm: If the TAG asks me to revise this, I'd consider doing that.
HT: I'm not sure, this may the
top of a slippery slope
... we have the infosec spec and we have the xpath/xquery data model which either is or isnt counter to the infoset
... until we're prepared to tackle all of that I'm not sure that re-issue that finding with the narrow focus would be good.
... I havent reviewed the finding however.
Norm: no, I'm saying your application may have others that you may want to consider. There is no one right answer, even if there was one universal data model.
ht: well, I guess I need to read the finding.
<Norm> Sorry ht, I wasn't trying to send you off to the finding :-)
Vincent: The issue was raised by Tim so we should probably follow-up with Tim.
<Zakim> DanC, you wanted to suggest 2 options that are OK by me: (a) leave it in the someday pile (b) ask I18N if it's an improvement worth spending effort on
Vincent: ok, I didnt feel it was
urgent, it just hasnt been discussed so I put it on the agenda
to get an update. Its clear there are not clear next steps
right now.
... ok, lets leave it for now.
Norm: I'm happy to either update it or leave it on the to-do-list as a lower priority.
ht: This is proceeding as a matter of priority. The write token is with me, I'm going to spend some time on it shortly and get it back to the group.
Vincent: we talked about this two
weeks ago, but no clear action was recorded on this.
... I'll add an action to HT on this to the issues list.
... anything else?
Vincnet: Meeting is adjourned..
This is scribe.perl Revision: 1.127 of Date: 2005/08/16 15:12:03 Check for newer version at Guessing input format: RRSAgent_Text_Format (score 1.00) Succeeded: s/Dave: I/DanC: I/ Succeeded: s/Vincnet/Vincent/ Found Scribe: EdRice Inferring ScribeNick: EdRice Default Present: Ed_Rice, Vincent, Norm, DanC, Ht, +1.604.534.aaaa, Dave Present: Ed_Rice Vincent Norm DanC Ht +1.604.534.aaaa Dave Regrets: Tim Noah WARNING: No meeting title found! You should specify the meeting title like this: <dbooth> Meeting: Weekly Baking Club Meeting Got date from IRC log name: 18 Apr 2006 Guessing minutes URL: People with action items: ed vincent WARNING: Input appears to use implicit continuation lines. You may need the "-implicitContinuations" option.[End of scribe.perl diagnostic output]
|
http://www.w3.org/2006/04/18-tagmem-minutes
|
CC-MAIN-2015-06
|
refinedweb
| 1,733
| 83.76
|
glob – Filename pattern matching¶. There are only a few special characters: two different wild-cards, and character ranges are supported. The patterns rules are applied to segments of the filename (stopping at the path separator, /). Paths in the pattern can be relative or absolute. Shell variable names and tilde (~) are not expanded.
Example Data¶
The examples below assume the following test files are present in the current working directory:
$ python glob_maketestdata.py dir dir/file.txt dir/file1.txt dir/file2.txt dir/filea.txt dir/fileb.txt dir/subdir dir/subdir/subfile.txt
Note
Use glob_maketestdata.py in the sample code to create these files if you want to run the examples.
Wildcards¶
An asterisk (*) matches zero or more characters in a segment of a name. For example, dir/*.
import glob for name in glob.glob('dir/*'): print name/*'): print '\t', name print 'Named with wildcard:' for name in glob.glob('dir/*/*'): print '\t', name
The first case above lists the subdirectory name explicitly, while the second case depends on a wildcard to find the directory.
$ python
The other wildcard character supported is the question mark (?). It matches any single character in that position in the name. For example,
import glob for name in glob.glob('dir/file?.txt'): print name
Matches all of the filenames which begin with “file”, have one more character of any type, then end with ”.txt”.
$ python glob_question.py dir/file1.txt dir/file2.txt dir/filea.txt dir/fileb.txt
Character Ranges¶
When you need to match a specific character, use a character range instead of a question mark. For example, to find all of the files which have a digit in the name before the extension:
import glob for name in glob.glob('dir/*[0-9].*'): print name
The character range [0-9] matches any single digit. The range is ordered based on the character code for each letter/digit, and the dash indicates an unbroken range of sequential characters. The same range value could be written [0123456789].
$ python glob_charrange.py dir/file1.txt dir/file2.txt
See also
- glob
- The standard library documentation for this module.
- Pattern Matching Notation
- An explanation of globbing from The Open Group’s Shell Command Language specification.
- fnmatch
- Filename matching implementation.
- File Access
- Other tools for working with files.
|
https://pymotw.com/2/glob/
|
CC-MAIN-2017-26
|
refinedweb
| 383
| 67.76
|
ahad lashari6,771 Points
Can't really understand clearly enough what the question requires me to do? Any help?
I've done the solution that I implement into my own dungeon game. However it doesn't seem to work here. Any pointers would be appreciated.
kind regards,
Fahad
# EXAMPLES: # move((1, 1, 10), (-1, 0)) => (0, 1, 10) # move((0, 1, 10), (-1, 0)) => (0, 1, 5) # move((0, 9, 5), (0, 1)) => (0, 9, 0) def move(player, direction): x, y, hp = player x1, y1 = direction if x1 == 0: hp-5 if x1 == 9: hp-5 if y1 == 0: hp-5 if y1 == 9: hp-5 return x, y, hp
2 Answers
leonardbodeCourses Plus Student 4,011 Points
You haven't changed the original x, y coordinates.
# using your code as an example where: x1, y1 = direction # change x, y values according to direction x, y = x + x1, y + y1
Then
if x > 9: hp -= 5 x -= 1 elif x < 0: hp -= 5 x += 1
Do the same for y-value and return x, y, hp
# -= is called a decrement x -= 5 # is the same as x = x - 5 # += is called an increment x += 5 # is the same as x = x + 5
leonardbodeCourses Plus Student 4,011 Points
Sorry Fahad, x2 should be y1. I changed it in my code example.
fahad lashari6,771 Points
No worries at all. I figure it would be y1. I am just re-doing the challenge to understand everything that is happening.
Kind regards,
Fahad
fahad lashari6,771 Points
Hi Leonard Bode, I know you've already answered my question. However I am still a bit hung up on the purpose of:
x -=1
and
x+=1
I would just like to know what role do they play in this task. I am asking this as it will help me understand the question a bit more.
leonardbodeCourses Plus Student 4,011 Points
No problem, Fahad. If you look back to my answer you see that we change the values of x or y depending on direction.
def move(player, direction): x, y, hp = player x_move, y_move = direction # here we change x, y according to direction x, y = x + x_move, y + y_move # then we check if x or y is some invalid integer if x > 9: # if it is an invalid integer, like 10 or -1, we remove 5 health points and return the player to a valid integer # in this cases, x is greater than 9, ie 10. Therefore, we remove 5 hp and make x = 9 hp -= 5 x -= 1 elif x < 0: hp -= 5 x += 1 elif y > 9: hp -= 5 y -= 1 elif y < 0: hp -= 5 y += 1
Then, if x or y is greater than 9 or less than 0, we subtract 5 from health because the player ran into a wall, and we return the player to a valid x, y coordinate.
if x > 9: hp -= 5 x -= 1
Because we assume that if x > 9 then x must be equal to 10, the above code is the same as this:
if x == 10: hp -= 5 x -= 1 # and the above code is the same as saying: if x == 10: hp -= 5 x = 9
So,
x -= 1
just returns x to a valid integer.
fahad lashari6,771 Points
fahad lashari6,771 Points
Hi Thanks for answering the question. Can you explain a bit more in terms of what the:
and
do.
And also. Where did the 'x2' come from?
Kind regards,
Fahad
|
https://teamtreehouse.com/community/cant-really-understand-clearly-enough-what-the-question-requires-me-to-do-any-help
|
CC-MAIN-2022-27
|
refinedweb
| 585
| 70.97
|
was an add-in for Visual Studio 2003 that adds commands for comparing files and folders, an explore command, and some useful reports for web projects.
Now, this version is a port to .NET 2.0 and Visual Studio 2005, of the original project that is still available at CodeProject. where searching for a diff algorithm. So, the C# code that is used to compare two files can now also be found as a separate CodeProject project: An O(ND) Difference Algorithm for C#.
This is the biggest change for building add-ins: there is no more need for COM registrations and registry hacks!
All you need to start using this add-in is to extract all the files from the WebReports8_setup.zip archive to the folder "C:\Documents and Settings\[your name]\My Documents\Visual Studio 2005\AddIns". You might have to create this folder first if it doesn't exist yet.
When Visual Studio 2005 starts, it searches this path and will find the WebReports8.AddIn that holds all the additional information.
There are also other folders that can be used. You can see all the folders that are scanned in the Extra.Options dialog in the add-in section.
Visual Studio .NET 2003 shared some libraries for handling the menu part with the Office products. This is no longer true, and the import of
Microsoft.Office.Core is obsolete.
Now, you have to use the namespaces
EnvDTE80 and
Microsoft.VisualStudio.CommandBars..
Resources can now be built into managed satellite DLLs. You will not need a C compiler any more to create an empty DLL that will hold the resources.
There are some good articles on that topic, and of course, the username.
General
News
Question
Answer
Joke
Rant
Admin
|
http://www.codeproject.com/KB/macros/WebReports8.aspx
|
crawl-002
|
refinedweb
| 292
| 75.81
|
One common mistake that people make when using managed encryption classes is that they attempt to store the result of an encryption operation in a string by using one of the Encoding classes. That seems to make sense right? After all, Encoding.ToString() takes a byte[] and converts it to a string which is exactly what they were looking for. The code might look something like this:
{
if(String.IsNullOrEmpty(data))
throw new ArgumentException("No data given");
if(String.IsNullOrEmpty(password))
throw new ArgumentException("No password given");
// setup the encryption algorithm
Rfc2898DeriveBytes keyGenerator = new Rfc2898DeriveBytes(password, 8);
Rijndael aes = Rijndael.Create();
aes.IV = keyGenerator.GetBytes(aes.BlockSize / 8);
aes.Key = keyGenerator.GetBytes(aes.KeySize / 8);
// encrypt the data
byte[] rawData = Encoding.Unicode.GetBytes(data);
using(MemoryStream memoryStream = new MemoryStream())
using(CryptoStream cryptoStream = new CryptoStream(memoryStream, aes.CreateEncryptor(), CryptoStreamMode.Write))
{
memoryStream.Write(keyGenerator.Salt, 0, keyGenerator.Salt.Length);
cryptoStream.Write(rawData, 0, rawData.Length);
cryptoStream.Close();
byte[] encrypted = memoryStream.ToArray();
return Encoding.Unicode.GetString(encrypted);
}
}
public static string Decrypt(string data, string password)
{
if(String.IsNullOrEmpty(data))
throw new ArgumentException("No data given");
if(String.IsNullOrEmpty(password))
throw new ArgumentException("No password given");
byte[] rawData = Encoding.Unicode.GetBytes(data);
if(rawData.Length < 8)
throw new ArgumentException("Invalid input data");
// setup the decryption algorithm
byte[] salt = new byte[8];
for(int i = 0; i < salt.Length; i++)
salt[i] = rawData[i];
Rfc2898DeriveBytes keyGenerator = new Rfc2898DeriveBytes(password, salt);
Rijndael aes = Rijndael.Create();
aes.IV = keyGenerator.GetBytes(aes.BlockSize / 8);
aes.Key = keyGenerator.GetBytes(aes.KeySize / 8);
// decrypt the data
using(MemoryStream memoryStream = new MemoryStream())
using(CryptoStream cryptoStream = new CryptoStream(memoryStream, aes.CreateDecryptor(), CryptoStreamMode.Write))
{
cryptoStream.Write(rawData, 8, rawData.Length - 8);
cryptoStream.Close();
byte[] decrypted = memoryStream.ToArray();
return Encoding.Unicode.GetString(decrypted);
}
}
}
The first mistake some people make is to use ASCII encoding. This will nearly always fail to work since ASCII is a seven bit encoding, meaning any data that is stored in the most significant bit will be lost. If your cipherdata can be guaranteed to contain only bytes with values less than 128, then its time to find a new encryption algorithm 🙂
So if we don't use ASCII we could use UTF8 or Unicode right? Those both use all eight bits of a byte. In fact this approach tended to work with v1.x of the CLR. However a problem still remains ... just because these encodings use all eight bits of a byte doesn't mean that every arbitrary sequence of bytes represents a valid character in them. For v2.0 of the framework, the Encoding classes had some work done so that they explicitly reject illegal input sequences (As the other Shawn-with-a-w discusses here). This leads to bad code that used to work (due to v1.1 not being very strict) to start failing on v2.0 with exceptions along the line of:
at System.Security.Cryptography.RijndaelManagedTransform.TransformFinalBlock(Byte[] inputBuffer, Int32 inputOffset, Int32 inputCount)
at System.Security.Cryptography.CryptoStream.FlushFinalBlock()
at System.Security.Cryptography.CryptoStream.Dispose(Boolean disposing)
at System.IO.Stream.Close()
Which at first glance looks like the CryptoStream is broken. However, take a closer look at what's going on. If we check the encrypted data before converting it into a string in Encrypt and compare that to the raw data after converting back from a string in Decrypt we'll see something along the lines of:
rawData=array [68] { 111, 49, 30, 0, 8, ... }
So round tripping through the Unicode encoding caused our data to become corrupted. That the decryption didn't work due to having an incomplete final block is actually a blessing -- the worst case scenario here is that you end up with some corrupted ciphertext that can still be decrypted -- just to the wrong plaintext. That results in your code silently working with corrupt data.
You might not see this error all the time either, sometimes you might get lucky and have some ciphertext that is actually valid in the target encoding. However, eventually you'll run into an error here so you should never be using the Encoding classes for this purpose. Instead if you want to convert the ciphertext into a string, use Base64 encoding. Replacing the two conversion lines with:
return Convert.ToBase64String(encrypted);
byte[] rawData = Convert.FromBase64String(data);
Results in code that works every time, since base 64 encoding is guaranteed to be able to accurately represent any input byte sequence.
I have been trying this code, but it fails on the conversion of the Base64String to byte (byte[] rawData = Convert.FromBase64String. The error I got in the first place was about an invalid character, namely the comma.
When I removed the comma and replaced it with a slash, I got the invalid length for a Base-64 char arry.
From MSDN I learned, the string has to be at least 4 characters, ignoring the white space characters, plus it has to be a multiple of 4, ignoring the white space characters.
Have I misread something, or am I doing something wrong here?
I would like to know the solution.
Hi Robin,
I haven’t seen that problem before. Do you have repro code available?
-Shawn
@Robin –> I tried the code above and it works fine. Did you add the:
byte[] encrypted = memoryStream.ToArray();
return Convert.ToBase64String(encrypted);
byte[] rawData = Convert.FromBase64String(data);
changes ?
THANKYOU!!
Flawless!
i cant encrypt ascii special characters like xml – how is that possible ??
The encryption classes don’t care about "special" characters, they only see a stream of bytes. What problem are you seeing exactly?
-Shawn
So I think I’m in bad shape. My encryption function doesn’t return the same value in ASP 2.0 as it does in 1.1. I’m sure its because of the different behavior in Encoding classes. What can I do? I have WAY too much data encrypted under my "bad scheme". I need a way to get the "old encoding methods" from 1.1, and include them in my project. Any ideas?
Thanks a bunch. I’m in a pickle!
Sam
Public Function EncryptString(ByVal Source As String) As String
Dim larrSourceData As Byte()
Dim larrDestinationData As Byte()
larrSourceData = Encoding.Unicode.GetBytes(Source)
Call SetAESValues()
larrDestinationData = _AESManaged.CreateEncryptor.TransformFinalBlock(larrSourceData, 0, larrSourceData.Length)
Return Encoding.Unicode.GetString(larrDestinationData)
End Function
Hi all,
I have a problem with this code.
When I encode two times the exactely same string I get a different encrypted string.
Any help ?
Hi Sam,
Your best bet is probably to bind old versions of your application to the v1.1 framework via an app.config file, and create a new version of your application which does not use the Encoding classes to store ciphertext.
When you install the new version, you could have some sort of upgrade utility that is also bound to the v1.1 runtime and reads in the old data, writing it out in base 64. Or you could have the new version of the application detect old data files and run the upgrade tool automatically.
-Shawn
Hi Aleks,
The fact that ciphertext differs does not mean that it’s incorrect. If you’re using symmetric encryption, you should chekc that your key, IV, and padding mode are the same. Asymmetric encryption will always have different output due to reandom padding.
As long as you can round trip your data, you should be fine.
-Shawn
OK Now I have it functionning (I hope). It was because of the "salt" that I didn’t need.
The problem is that, for some string, the decryption fail with the old method (without Base64) and the new one too (with Base64).
Theses strings are passwords and I absolutely need to have it functionning as quick as possible.
I can send some code by email I you’d like …
Thank you shawnfa
I have heard rumours that a certain type of implementation of AES (128bit) has been cracked (in milliseconds rather than years). If this is true, how can we be sure that the Rijndael implementation within this Crypto namespace is not at risk.
Just curious 😉
I hadn’t seen anything about AES being cracked, so I’m not sure I can comment on RijndaelManaged 🙂
-Shawn
How can you store encrypted values in a database if they aren’t converted into strings?
Hi John,
You could store the encrypted byte array as a blob field in the database, or you can continue to store as a string. However, when converting to a string do not use the Encoding classes, but instead use Convert.ToBase64String / Convert.FromBase64String. This will create a string that can always be round-tripped back to the original byte array.
-Shawn
Your encryption algorithm may fail moving to .NET 2.0
A different, more secure, Shawn , blogged " Don’t Roundtrip Ciphertext Via a String Encoding ". I’ve
PingBack from
When I decrypt a binary file I can not be opened! The PDF Document wheb decrypted is blank. Why? amirhussein@gmail.com
Okaaayy… So what if we don’t want to use Base64? I’m trying to encrypt and store text that has commas, colons, etc — more than just the letters and numbers that Base64 includes.
Hi Michelle,
Base64 is just used to encode the ciphertext, you certainly do not need to limit your input to characters that appear in the base64 set. In fact your input to the encryption algorithm doesn’t even need to be a string at all.
For instance (all hypothetical and not the real encodings):
Plaintext: "Here-Is=Some:Plain, Text"
Ciphertext: 0x12, 0x34, 0x56, 0x78, …
Cipertext to base64: abcdefg1234==
The in the reverse
Base64: abcdefg1234==
Ciphertext from base64: 0x12, 0x34, 0x56, 0x78 …
Plaintext decrypted: "Here-Is=Some:Plain, Text"
-Shawn
Hi All, I’m hoping that this thread still gets read. I am having a problem with encrypting and decrypting an XML file. Since the relevant code blocks are fairly short, I will post them in this message.
This block of code passes my XML to the encryption method.
MemoryStream myDataStream = new MemoryStream();
myDS.WriteXml(myDataStream, XmlWriteMode.IgnoreSchema);
byte[] myBytes = myDataStream.GetBuffer();
blCryptography.EncryptByte(myBytes);
string encryptedTransactionData = Convert.ToBase64String(myBytes);
That call to blCryptography is the actual encryption method, it looks like this…
public static byte[] Encrypt;
using ( MemoryStream msEncrypt = new MemoryStream() )
using ( CryptoStream encStream = new CryptoStream(msEncrypt, sma.CreateEncryptor(), CryptoStreamMode.Write))
{
encStream.Write(data, 0, data.Length);
encStream.FlushFinalBlock();
return msEncrypt.ToArray();
}
}
As far as I can tell, that works fine.
Now, the other side is what’s giving me fits.
Here’s the code to decrypt the xml
string myXML = myReader.GetString(1);
myReader.Close();
byte[] baEncryptedData = Convert.FromBase64String(myXML);
byte[] baClearData = blCryptography.DecryptByte(baEncryptedData);
MemoryStream myStream = new MemoryStream(baClearData);
myDS.ReadXml(myStream, XmlReadMode.IgnoreSchema);
And finally, again the call to blCryptography is the decrypt method:
public static byte[] Decrypt;
sma.Padding = PaddingMode.None;
using ( MemoryStream msDecrypt = new MemoryStream(data) )
using ( CryptoStream csDecrypt = new CryptoStream(msDecrypt, sma.CreateDecryptor(), CryptoStreamMode.Read) )
{
// Decrypted bytes will always be less then encrypted bytes, so len of encrypted data will be big enouph for buffer.
byte[] fromEncrypt = new byte[data.Length]; // Read as many bytes as possible.
int read = csDecrypt.Read(fromEncrypt, 0, fromEncrypt.Length);
if ( read < fromEncrypt.Length )
{
// Return a byte array of proper size.
byte[] clearBytes = new byte[read];
Buffer.BlockCopy(fromEncrypt, 0, clearBytes, 0, read);
return clearBytes;
}
return fromEncrypt;
}
}
I hope that’s readable. The only other wrinkle I can think of is that there is an image field in the XML file and it is a BASE64 encoded string. I’m wondering what happens if you base64encode a string that already is! Or vice versa!
The problem I get is an invalid character message when I try to read the XML into the dataset.
Can anyone help me figure this out?
Thanks very much!
–Jason
Hi.
Somebody managed to use base64?
I have used:
Dim inputInBytes() As Byte = utf8encoder.GetBytes(plainText)
Now I have replaced it with:
Dim inputInBytes() As Byte = Convert.FromBase64String(plainText)
But now I’ve got another error: "Invalid length for a Base-64 char array" in this string. Please help me with this.
Hi Sergeda,
You’ll want to use Convert.ToBase64String() here, since you’re trying to create a base64 string.
-Shawn
Hi Jason,
These lines of code jump out at me:
byte[] initVectorBytes = Encoding.ASCII.GetBytes(InitVector);
byte[] saltValueBytes = Encoding.ASCII.GetBytes(Salt);
are InitVector and Salt both real ASCII strings?
-Shawn
Hmm if you call Convert.FromBase64String(plaintext) with a small string (such as "hello" I receive: "Invalid length for a Base-64 char array.". What am I doing wrong!?
FromBase64String takes a base64 string as input, not a plaintext string. You’re looking for ToBase64String to convert your "hello" string into base64. (You’ll also need to convert it to a byte array — so something to the effect of Convert.ToBase64String(Encoding.UTF8.GetBytes("hello"))
Could someone please tell me if my code is suffering from the problem discussed here? I’m in a hurry and need to fix this ASAP. Here is my code:
Public Shared Function Encrypt(ByVal text As String, Optional ByVal additionalKey As String = "") As String
If text Is Nothing Then text = String.Empty
tripleDes.Key = TruncateHash(additionalKey & m_key, tripleDes.KeySize 8)
tripleDes.IV = TruncateHash("", tripleDes.BlockSize 8)
Dim plaintextBytes() As Byte = System.Text.Encoding.Unicode.GetBytes(text)
Dim ms As New System.IO.MemoryStream
Dim encStream As New CryptoStream(ms, tripleDes.CreateEncryptor(), System.Security.Cryptography.CryptoStreamMode.Write)
encStream.Write(plaintextBytes, 0, plaintextBytes.Length)
encStream.FlushFinalBlock()
encStream.Dispose()
Return Convert.ToBase64String(ms.ToArray)
End Function
Public Shared Function Decrypt(ByVal encryptedText As String, Optional ByVal additionalKey As String = "") As String
tripleDes.Key = TruncateHash(additionalKey & m_key, tripleDes.KeySize 8)
tripleDes.IV = TruncateHash("", tripleDes.BlockSize 8)
Dim encryptedBytes() As Byte = Convert.FromBase64String(encryptedtext)
Dim ms As New System.IO.MemoryStream
Dim decStream As New CryptoStream(ms, tripleDes.CreateDecryptor(), System.Security.Cryptography.CryptoStreamMode.Write)
decStream.Write(encryptedBytes, 0, encryptedBytes.Length)
Try
decStream.FlushFinalBlock()
Catch ex As Exception
Finally
decStream.Dispose()
End Try
Return System.Text.Encoding.Unicode.GetString(ms.ToArray) ‘Convert.ToBase64String(ms.ToArray)
End Function
Thank you really. I don’t have the time to read the post carefully.
That’s solve my problem
Thanks!!
Hi, This is what I am using in my decrypt method..but i m getting the error of bad data Can anyone help me out:
public static string DecryptString(string strEncData, string strKey, string strIV)
{
ICryptoTransform ct;
MemoryStream ms;
CryptoStream cs;
byte[] byt;
SymmetricAlgorithm mCSP=SymmetricAlgorithm.Create();
mCSP = new TripleDESCryptoServiceProvider();
mCSP.Key = Convert.FromBase64String(strKey);
mCSP.IV = Convert.FromBase64String(strIV);
ct = mCSP.CreateDecryptor(mCSP.Key,mCSP.IV);
byt = Convert.FromBase64String(strEncData);
ms = new MemoryStream();
cs = new CryptoStream(ms,ct, CryptoStreamMode.Write);
cs.Write(byt,0,byt.Length);
cs.FlushFinalBlock();
cs.Close();
return Encoding.UTF8.GetString(ms.ToArray());
}
I hope this gets read:
The signature to compare is (2) concatenated base64 encoded strings with a comma delimiter between them. Client is using OsterMiller Java utilities which they claim ignores bad characters (the comma) – so when I go to decode the string to verifyData against the signature in XML, it fails. If I replace the comma with nothing it fails because of invalid characters but If I just write it to the window without the comma it has no invalid characters, just (2) paddings, which I suppose is wrong too. What do I do?
Maybe there is a better way, maybe I can be enlightend but this is what I came up with.
It’s all that conversion stuff that has my head spinning.
code:
#Region "Security"
Public Sub Encrypt(ByVal password As String)
Dim s_aditionalEntropy As Byte() = CreateRandomEntropy()
Dim secret1 As Byte() = Encoding.UTF8.GetBytes(password)
Dim secret2 As String = Convert.ToBase64String(secret1)
Dim secret3 As Byte() = Convert.FromBase64String(secret2)
Dim encryptedSecret As Byte()
‘Encrypt the data.
encryptedSecret = ProtectedData.Protect(secret3, s_aditionalEntropy, DataProtectionScope.CurrentUser)
SaveSetting(TITLE, "Settings", "UserP", Convert.ToBase64String(encryptedSecret))
SaveSetting(TITLE, "Settings", "UserE", Convert.ToBase64String(s_aditionalEntropy))
End Sub
Public Function Decrypt() As String
Dim s_aditionalEntropy As Byte()
Dim encryptedSecret As Byte()
encryptedSecret = Convert.FromBase64String(GetSetting(TITLE, "Settings", "UserP", ""))
s_aditionalEntropy = Convert.FromBase64String(GetSetting(TITLE, "Settings", "UserE", ""))
If encryptedSecret.Count <> 0 Then
Dim secret1 As Byte() = ProtectedData.Unprotect(encryptedSecret, s_aditionalEntropy, DataProtectionScope.CurrentUser)
Dim secret2 As String = Convert.ToBase64String(secret1)
Dim secret3 As Byte() = Convert.FromBase64String(secret2)
Dim secret4 As String = Encoding.UTF8.GetString(secret3)
Return secret4
Else
Return ""
End If
End Function
Function CreateRandomEntropy() As Byte()
‘ Create a byte array to hold the random value.
Dim entropy(15) As Byte
‘ Create a new instance of the RNGCryptoServiceProvider.
‘ Fill the array with a random value.
Dim RNG As New RNGCryptoServiceProvider()
RNG.GetBytes(entropy)
‘ Return the array.
Return entropy
End Function ‘CreateRandomEntropy
#End Region
Looks interesting…
Seems to have one more problem, cause the returned string, doesnt want to combine with my other variables.
Would like to decode the Adress from an server like (MyServer.org)… Seems to work correctly, but if i take this returned string and try to add subfolders variables, like (ServerAdress & Folder1 & Folder2), he ignored the two variables Folder1 and Folder2… Why that ? I search for an solution about 2 days till now.. Anyone any thoughts ???
Greets
I am actually using ToBase64String and FromBase64String and still get dad data error any idea ????????????????????
Here is the code:
Ecrypting:
DESCryptoServiceProvider desCrypto = new DESCryptoServiceProvider();
MemoryStream ms = new MemoryStream();
CryptoStream cs = new CryptoStream(ms,desCrypto.CreateDecryptor(EncryptKey,EncryptVactor),CryptoStreamMode.Write);
StreamWriter sw = new StreamWriter(cs);
sw.Write(valueToEncrypt);
ms.Flush();
cs.Flush();
sw.Flush();
string result = Convert.ToBase64String(ms.GetBuffer(), 0, (int)ms.Length);
log.Info("value To Encrypt is " + valueToEncrypt.ToString());
log.Info("Encrypted value is " + result);
log.Info("Encrypting successfull.");
Decripting:
DESCryptoServiceProvider desCrypto = new DESCryptoServiceProvider();
byte[] buffer = Convert.FromBase64String(valueToDecrypt);
MemoryStream ms = new MemoryStream(buffer);
CryptoStream cs = new CryptoStream(ms, desCrypto.CreateDecryptor(decryptKey,decryptVactor), CryptoStreamMode.Read);
StreamReader sw = new StreamReader(cs);
ms.Flush();
cs.Flush();
cs.FlushFinalBlock();
string result = sw.ReadToEnd();
log.Info("value To decrypt is " + valueToDecrypt.ToString());
log.Info("Decrypted value is " + result);
log.Info("Decrypting successfull.");
Make sure you call FlushFinalBlock when doing the encryption as well – otherwise the padding won’t get added correctly.
-Shawn
|
https://blogs.msdn.microsoft.com/shawnfa/2005/11/10/dont-roundtrip-ciphertext-via-a-string-encoding/
|
CC-MAIN-2018-13
|
refinedweb
| 3,015
| 51.95
|
codyperryman32,111 Points
Would I move my if statements that are under the flipCoin() function to their own files? or keep in view controller
I am currently going through the beginner classes for Swift. Pasan suggested to create our own apps on our own and recommended a Coin Flip app. Below is my code. Should I create a model for the if statements under the flipCoin() function and have it talk to the view controller or is it ok to have these if statements in the view Controller?
import UIKit import GameKit class ViewController: UIViewController { @IBOutlet weak var headsOrTails: UILabel! @IBOutlet weak var ifHeads: UILabel! @IBOutlet weak var ifTails: UILabel! @IBOutlet weak var flipButton: UIButton! var backgroundColor = RandomColor() var coin = CoinFlip() var headsIndex = 0 var tailsIndex = 0 override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. headsOrTails.text = "Press Flip!" ifHeads.text = "Number of heads: \(headsIndex)" ifTails.text = "Number of tails: \(tailsIndex)" } @IBAction func flipCoin() { // Random Background Color let randomBackgroundColor = backgroundColor.randomNumber() view.backgroundColor = randomBackgroundColor // Flip Button Color flipButton.tintColor = randomBackgroundColor // When the button is pressed, the function pics a random number to // display either heads or tails and then increments the correct label // to keep a running total of how many times heads or tails is flipped. let someCoin = coin.coinFlip() if someCoin == "Heads" { headsOrTails.text = "Heads" headsIndex += 1 ifHeads.text = "Number of heads: \(headsIndex)" } if someCoin == "Tails" { headsOrTails.text = "Tails" tailsIndex += 1 ifTails.text = "Number of heads: \(tailsIndex)" } } }
2 Answers
Michael HuletTreehouse Moderator 46,973 Points
In a normal iOS app, your model should be holding onto your data and doing most of the real work, and your view controller should just be a bridge between your model and your view (what you display to the user). In this case, you have a
CoinFlip model that appears to be doing all the work of actually choosing what to display, and everything I see in your view controller seems to just be taking the data your model gives you and updating the view, which is exactly what it's supposed to be doing, so I'd say what you have is just fine. That being said, perhaps you could abstract the
headsIndex/
tailsIndex variables into a separate
Counter model?
codyperryman32,111 Points
Thank you for the help, I appreciate it!
|
https://teamtreehouse.com/community/would-i-move-my-if-statements-that-are-under-the-flipcoin-function-to-their-own-files-or-keep-in-view-controller
|
CC-MAIN-2019-51
|
refinedweb
| 385
| 56.55
|
Integrating Java and Erlang
This article.
Building scalable, distributed and reliable systems is trivial in Erlang. This can be a hard pill to swallow for many enterprise developers. Erlang is a dynamically typed functional language and Java is a statically typed object-oriented language. Erlang is an agitator to traditional enterprise development because it excels so well at concurrency, uptimes of five nines or more, and "hot deployment" of code. But there are valid reasons for why someone may not want to dive in head first. How many CIOs want to lose their investments in Java? Who wants to leave behind all the great libraries produced by the Java community?
This article is for a lot of people: language enthusiasts, software fashion victims, or anyone who wants to create serious business value bridging Erlang with Java. We'll start.
Concurrent Programming with a Simple Client Server Module
Erlang is a freak of nature; it has concurrency in its DNA. Concurrency is a native construct, all the way from the syntax down to guts of the Erlang virtual machine. This is fundamentally different than the traditional approaches to concurrency: expensive third party products, complex APIs for distribution, and java.lang.Thread. Let's begin our overview of Erlang with a little concurrent programming.
In an effort to stay focused on the core concepts we will avoid the deep end for now and keep it simple ... by calculating the sum of two numbers. The logic needed to perform addition will be contained within an Erlang module and exposed via an Erlang process. Afterwards we'll consume this service from a client process. With a little stretch of the imagination I'm sure most of you can envision the possibilities, like distributing a financial algorithm across 32 cores - or 32 cores on 32 machines.
An Erlang module consists of annotations and functions. For the purposes of this article, think of an Erlang module as a Java package. Our module starts with two annotations in a single file named mathserver.erl.
-module(mathserver). -export([start/0, add/2]).
The first annotation declares the module name. The second annotation declares which functions are exported by the module; this is similar to using the keyword "public" in Java. The exported functions of this module are start and add, which we'll implement shortly. Did you notice that each line ends with a period? Functions and annotations in Erlang are terminated with a period, not a semicolon. Now let's create our first function, the server entry point for the mathserver module.
start() -> Pid = spawn(fun() -> loop() end), register(mathserver, Pid).
The start function creates an Erlang process with one of the Erlang concurrency primitives, the spawn function. The term "process" can be confusing to newcomers, who often (understandably) misinterpret it as an operating system process. An Erlang process is more like a Java Thread, only extremely lightweight. Feel free to spawn thousands if you need to. Each process has a private heap. This design insures no shared state among processes. Processes are therefore easily parallelized and messages are passed by value, as opposed to being passed by reference. All intra-process communication in Erlang is asynchronous and all processes run in parallel. Read a little about the Actor Model for a more conceptual perspective on Erlang processes.
The argument passed to the spawn function, fun() -> loop () end , is an anonymous function. It represents the behavior of the to-be-spawned process. This is similar to a closure in Javascript, or a lambda in Ruby; in Erlang, it is called a fun. This fun wraps a named function, called loop, which we'll get to later.
Each process has a process identifier, or pid. The spawn function returns the pid of the spawned process. A pid can be conceptually thought of as a mailing address for a process. It is the means by which messages are passed to each private mailbox of a process. There is a one to one to one relationship between a pid, process and mailbox.
The start function ends using the built-in register function to register the pid as "mathserver". Once registered, we can forget about tracking the pid value and simply address the spawned process via this alias constant.
Erlang is more restrictive than Java when it comes to variables. For example, did you notice the pid variable starts with a capital letter? This is true for all variables in Erlang. Erlang also enforces "no side effects" with single assignment, so the value bound to the Pid variable is constant. In Java this is a choice made by the developer, using the keyword final.
Remember the anonymous function we passed to spawn? That function wrapped the loop function, which represents the actual behavior of the spawned process.
loop() -> receive {From, {add, First, Second}} -> From ! {mathserver, First + Second}, loop() end.
The loop function uses another one of the Erlang concurrency primitives, the receive statement. When a message is sent to the mailbox of an Erlang process, it is pulled out of the mailbox and matched against each pattern in the receive block. Like a lot of other functional programming languages Erlang makes heavy use of pattern matching. Feel free to temporarily think of receive statements as switch blocks, and receive patterns as case labels (Erlang also has a case statement). This particular receive statement only matches for a single tuple, { From , { add , First , Second }}.
Tuples are fixed ordered lists of data and they are common in Erlang. The first element of this tuple is the pid of the sending process, bound to the variable From. This acts as a reply-to mailing address. The second element of this tuple is another tuple, consisting of an atom and the two terms to be added, First and Second. What is an atom? For the purposes of this article, let's just think of atoms as constants that are never garbage collected.
After the incoming message is matched against this tuple pattern a tuple response message is sent back to the client process via the reply-to pid.
From ! {mathserver, First + Second}
This illustrates a third Erlang concurrency primitive: the send operator. Messaging can be challenging on most programming platforms: Erlang has it down to a single character. When we see "Pid ! Msg" in Erlang, it means "send Msg to Pid". This allows us to sum both terms and send a response back to the math client with one line of code, fire and forget. The response is a tuple consisting of two elements, the mathserver atom and the sum.
Some of you might have laughed when you read the loop function: it ends with recursion. How reliable can this application be when it's only a matter of time before the runtime produces the Erlang equivalent of a java.lang.StackOverflowError? You don't have to worry about this. When the compiler encounters tail recursion it will optimize the Erlang bytecode so that the function can run indefinitely without consuming stack space.
Our last module function is the add function. This function is used to send and receive messages with the mathserver process. It uses many of the concepts and constructs previously covered: the send operator, tuples, the receive statement and pattern matching.
add(First, Second) -> mathserver ! {self(), {add, First, Second}}, receive {mathserver, Reply} -> Reply end.
Look at the first statement. It creates a tuple message and asynchronously passes this to the mathserver process via the send operator.
mathserver ! {self(), {add, First, Second}}
Pay attention to two things here. First, to the right of the send operator we are not using the server pid. Instead we are sending the message to the mathserver process using the registered atom, mathserver. This is why we registered the server process back in the start function. Second, the self function has been introduced. The self function is a built-in function used to obtain the pid of the current process. For lack of a better analogy, think of the keyword "this" in Java. It is important the client sends its own pid as part of the message, otherwise the server would not know who to reply to. The add function ends with a receive statement used to match the reply message tuple sent by the server. When a message matching { mathserver , Reply } is pulled from the client mailbox, the second element of the message is returned. This completes the module.
-module(mathserver). -export([start/0, add/2]). start() -> Pid = spawn(fun() -> loop() end), register(mathserver, Pid). loop() -> receive {From, {add, First, Second}} -> From ! {mathserver, First + Second}, loop() end. add(First, Second) -> mathserver ! {self(), {add, First, Second}}, receive {mathserver, Reply} -> Reply end.
Using the mathserver Module in the Erlang Emulator
Those of you familiar with BeanShell, irb or jirb will find yourselves at home with erl. Let's run a few commands.
$ erl -name servernode -setcookie cookie 1> node(). 'servernode@byrned.thoughtworks.com' 2> pwd(). /work/tss/article ok 3> ls(). mathserver.erl ok 4> c(mathserver). {ok,mathserver} 5> ls(). mathserver.beam mathserver.erl 6> mathserver:start(). true 7> mathserver:add(1,2). 3
What did that do? The shell command created an Erlang node called servernode. The built-in node function verifies this on line one. Lines two and three tell us the present working directory and what we have in it. Line four compiles and loads the mathserver module. The directory listing on line five reveals that the compile command has created a new file, mathserver.beam. Think of this as a .class file in Java. Line six starts the mathserver, spawning the server process. Finally we test our service with the add function.
It is now trivial to consume this service from any process on any node from any host as long as we specify the same cookie. On another machine, we can do this:
$ erl -name clientnode -setcookie cookie 1> node(). 'clientnode@dbyrne.net' 2> rpc:call(servernode@byrned.thoughtworks.com, mathserver, add, [1,2]). 3
In this shell we create a node named clientnode on the host dbyrne.net and use a function from the built-in rpc module. The call function takes four arguments: the fully qualified name of the target node, the name of the module containing the to-be-invoked function, the remote function name, and the arguments to be passed to the remote function.
Jinterface, Getting the Best of Both Worlds
Jinterface allows us to create a cluster of Erlang and/or Java nodes. It is distributed with many other useful libraries in the Open Telecom Platform. The OtpErlang.jar file has no dependencies and can be found under <ERLANG_INSTALL_DIR>/erlx.x.x/lib/jinterface-1.x/priv. All source code is open and licensed under the Erlang Public License, a child of the Mozilla Public License.
Remember when we remotely invoked the mathserver service from the clientnode node? Let's do this from Java by porting the clientnode process to a ClientNode class.
OtpSelf cNode = new OtpSelf("clientnode", "cookie"); OtpPeer sNode = new OtpPeer("servernode@byrned.thoughtworks.com"); OtpConnection connection = cNode.connect(sNode);
First we create an OtpSelf instance. The OtpSelf constructor takes two arguments: the node name and the cookie. Does this remind you of one of the command lines typed earlier? The node name and cookie values are identical.
$ erl -name clientnode -setcookie cookie
The second line of code creates a representation of the remote server node with an OtpPeer instance. The OtpPeer constructor takes the fully qualified node name of the server. Does this node name look familiar?
$ erl -name servernode -setcookie cookie 1> node(). 'servernode@byrned.thoughtworks.com' Remember when we made a remote procedure call in Erlang? > rpc:call(servernode@byrned.thoughtworks.com, mathserver, add, [1,2]). Now that a connection has been established it is time to do this in Java.());
The sendRPC method arguments are a one to one conceptual match with the rpc:call function arguments. We specify the name of the module containing the to-be-invoked function, the remote function name, and the arguments to be passed to the remote function. Finally, we use a static JUnit method to verify whether or not the Erlang server process is passing the correct message back to the ClientNode instance - the same way it did for the clientnode node. Here is the ClientNode class in its entirety.()); } }
Jinterface nodes can do more than just talk to Erlang nodes. They can communicate with each other as well. The servernode process can actually be reimplemented as a ServerNode class, allowing us to perform asynchronous messaging without a single line of Erlang. To do this the ServerNode must first tell the world it is "open for business".
OtpSelf sNode = new OtpSelf("servernode", "cookie"); sNode.publishPort(); OtpConnection connection = sNode.accept();
The ServerNode class begins by creating an OtpSelf instance – using the same node name and cookie as before. The node then publishes its port to the Erlang Port Mapper Daemon. This registers the node name and port, making it available to a remote client process. When the port is published it is important to immediately invoke the accept method. Forgetting to accept a connection after publishing the port would be the programmatic equivalent of false advertising. Once we've obtained a connection it is time to start processing messages.));
The receive method of a Jinterface connection blocks until it receives a tuple from the ClientNode. Remember the receive statements back in Erlang mathserver module? Once a message is received the sum is calculated and sent back to the client. Here is the ServerNode in its entirety.
import com.ericsson.otp.erlang.*; public class ServerNode { public static void main (String[] _args) throws Exception{ OtpSelf sNode = new OtpSelf("servernode", "cookie"); sNode.publishPort(); OtpConnection connection = sNode.accept(); while(true) try {)); }catch(OtpErlangExit e) { break; } sNode.unPublishPort(); connection.close(); } }
Here is the ClientNode modified. The sendRPC method is no longer used to send an OtpErlangObject array. Instead the send method is used to send an OtpErlangTuple.(sNode.node(), new OtpErlangTuple(args)); OtpErlangLong received = (OtpErlangLong) connection.receive(); assertEquals(3, received.intValue()); } }
Conclusion
Java and Erlang are not mutually exclusive, they complement each other. I personally have learned to embrace both because very few complex business problems can be modeled exclusively from an object oriented or functional paradigm. The solutions to these problems can be sequential or concurrent. Jinterface can cleanly divide (and conquer) a system into parts suitable for Java and parts suitable for Erlang.
References
Jinterface
Download Java
Download Erlang
Actor Model
About the Author
Dennis Byrne works for ThoughtWorks, a global consultancy with a focus on end-to-end agile software development of mission critical systems. Dennis is a committer and PMC member for Apache Myfaces. He is also a committer for JBoss JSFUnit and co-author "MyFaces and Facelets" (Apress publishing, Mar 2008).
Start the conversation
|
https://www.theserverside.com/news/1363829/Integrating-Java-and-Erlang
|
CC-MAIN-2019-26
|
refinedweb
| 2,468
| 58.48
|
.
The edit view will be rendered on the click of the
Edit link in the student list view, which we already created the student list view in the Create a View chapter.
Here, we will build the following edit view in order to edit a student record.
The following figure describes how the edit functionality would work in ASP.NET MVC application.
The above figure illustrates the following steps.
1. The user clicks on the
Edit link in the student list view, which will send the
HttpGET request{Id} with corresponding
Id parameter in the query string.
This request will be handled by the HttpGET action method
Edit(). (by default action method handles the
HttpGET request if no attribute specified)
2. The
HttpGet action method
Edit() will fetch student data from the database, based on the supplied
Id parameter and render the Edit view with that particular Student data.
3. The user can edit the data and click on the Save button in the Edit view. The Save button will send a HttpPOST request with the Form data collection.
4. The HttpPOST Edit action method in StudentController will finally update the data into the database and render an Index page with the refreshed data using the RedirectToAction method as a fourth step.
So this will be the complete process to edit the data using the
Edit view in ASP.NET MVC.
So let's start to implement the above steps.
The following is the
Student model class.
namespace MVCTutorials.Controllers { public class Student { public int StudentId { get; set; } [Display( Name="Name")] public string StudentName { get; set; } public int Age { get; set; } } }
Step: 1
We have already created the student list view in the Create a View chapter, which includes the Edit action links for each
Student, as shown below.
In the above list view, edit links send
HttpGet request to the
Edit() action method of the
StudentController with corresponding
StudentId in the query string.
For example, an edit link with a student
John will append a
StudentId to the request url because John's
StudentId is
1 e.g.:<port number>/edit/1.
Step 2:
Now, create a HttpGET action method
Edit(int id) in the
StudentController, as shown below.
using MVCTutorials.Models; namespace MVCTutorials.Controllers { public class StudentController : Controller { static = 4, StudentName = "Chris" , Age = 17 } , new Student() { StudentId = 4, StudentName = "Rob" , Age = 19 } }; // GET: Student public ActionResult Index() { //fetch students from the DB using Entity Framework here); } } }
The HttpGet
Edit() action method must perform two tasks. First, it should fetch a student data from the underlying data source, whose
StudentId matches the parameter
Id.
Second, it should render the
Edit view with the data, so that the user can edit it.
In the above
Edit() action method, a LINQ query is used to get a
Student from the
studentList collection whose
StudentId matches with the parameter
Id,
and then pass that
std object into
View(std) to populate the edit view with this data.
In a real-life application, you can get the data from the database instead of the sample collection.
At this point, if you run the application and click on the
Edit link in the student list view, then you will get the following error.
The above error occurrs because we have not created an
Edit view yet.
By default, MVC framework will look for
Edit.cshtml,
Edit.vbhtml,
Edit.aspx, or
Edit.ascx file in /View/Student or /View/Shared folder.
Step 3:
To create Edit view, right-click in the
Edit() action method and click on Add View...
It will open Add View dialogue, as shown below.
In the Add View dialogue, keep the view name as
Edit.
Edit Template and
Student Model class from dropdown, as shown below.
Click Add button to generate the
Edit.cshtml view under /View/Student folder, as shown below.
@model MVCTutorials.Models.Student @{ ViewBag. <h4>Student</h4> <hr /> @Html.ValidationSummary(true, "", new { @ @Html.LabelFor(model => model.StudentName, htmlAttributes: new { @ @Html.EditorFor(model => model.StudentName, new { htmlAttributes = new { @ @Html.LabelFor(model => model.Age, htmlAttributes: new { @ @Html.EditorFor(model => model.Age, new { htmlAttributes = new { @ <div class="col-md-offset-2 col-md-10"> <input type="submit" value="Save" class="btn btn-default" /> </div> </div> </div> } <div> @Html.ActionLink("Back to List", "Index") </div>.
You can now edit the data and click on the Save button.
The Save button should send the HttpPOST request because we need to submit the form data as a part of the request body as a
Student object.
Step 4:
Now, write HttpPost action method
Edit() to save the edited student object, as shown below.
So, there will be two
Edit() action methods, HttpGet and HttpPost action methods.
using MVCTutorials.Models; namespace MVCTutorials.Controllers { public class StudentController : Controller {=6, StudentName="Chris", Age = 17 }, new Student(){ StudentId=7, StudentName="Rob", Age = 19 } }; // GET: Student public ActionResult Index() {); } [HttpPost] public ActionResult Edit(Student std) { //update student in DB using EntityFramework in real-life application //update list by removing old student and adding updated student for demo purpose var student = studentList.Where(s => s.StudentId == std.StudentId).FirstOrDefault(); studentList.Remove(student); studentList.Add(std); return RedirectToAction("Index"); } } }
In the above example, the HttpPost
Edit() action method requires an object of the
Student as a parameter.
The
Edit() view will bind the form's data collection to the student model parameter because it uses HTML helper methods
@Html.EditorFor() for each properties to show input textboxes.
Visit Model Binding section to know how MVC framework binds form data to action method parameter.
After updating the data in the DB, redirect back to the
Index() action method to show the updated student list.
In this way, you can provide edit functionality using a default scaffolding Edit template.
|
https://www.tutorialsteacher.com/mvc/create-edit-view-in-asp.net-mvc
|
CC-MAIN-2021-39
|
refinedweb
| 956
| 55.24
|
Enhanced QDebug class set
Hi all,
Have you all also been annoyed by the fact that QDebug does not allow for fine grained module based logging ? And that you cannot set it on or on the fly ?
Well I created a template based 2-file enhancement on top of regular QDebug (hence supporting all features of QDebug) allowing for all of the above. Here briefly what you can do
first you need to include the new debug header file
@
#include <apdebug.h>
@
You need to declare each 'module' you wish to control to the system. This can be done in one of two
@
// if you have a class that 'controls' the module (the controlling class must be accessible to each other class
// that wants to log using the same debug module (class header must be included
static Debugging<ClassThatIsSpecificToThisModule> Debugging( "StringNameIdentifyingThisClass" );
// or if you do not have a class
int DebugFlag = false;
static StaticDebugging StaticDebugging( "SomeName for the non-class related module", &DebugFlag );
// next you can use a new version of qDebug (APDebug) like
APDebug<ClassThatIsSpecificToThisModule>() << ... // regulare qDebug arguments
// or for non class related modules
StaticDebug( DebugFlag ) << ...
@
to list the debug state of all known modules
@
foreach( const QString & Mod, DebuggingAbstract::moduleList() ) {
qDebug() << "Module" << Mod << "debug" << DebuggingAbstract::debugIsEnabled(Mod);
}
@
controlling the state of debugging is done using
@
// enable disable all known modules
DebuggingAbstract::enableDebug( true );
// enable disable specific module
DebuggingAbstract::enableDebug( "ModuleName", false ); // or true to enable
@
I would like to provide this code snippet to the community and offer it for scrutiny and enhancements.
Just tell me where ...
Greetz
Edit: I put your code sections between @ tags for you; Andre
- sierdzio Moderators
Hi, thanks for this. Please wrap your code in '@' tags.
You can push your code to github like everybody does :)
Hmm sorry but I am an subversion users and not git ... any howto I could read on that.
about that @ tags ... how does that work ?
- sierdzio Moderators
Put your code between two '@' signs, like this:
@
// This is a code inside a comment block
void main() {}
@
Well, it's your choice. You loose a lot in life by not using git. But there are plenty of public SVN servers, too: sourceforge, Google code, etc.
|
https://forum.qt.io/topic/28277/enhanced-qdebug-class-set
|
CC-MAIN-2017-51
|
refinedweb
| 366
| 59.94
|
> > > To use unify, you need a namespace brick. You should use an AFR volume > > OK > > > for this. > > You mean I shoud use AFR for the namespace ? AFR is only for high availability of namespace. Namespace does not hold any crucial data, it is just like a cache. Infact you can wipe our your namespace anytime and it will rebuild again. If you are having a 'head node' for your compute cluster which is/should be always on, you could just use an export from that node as your namespace without AFR. avati -- It always takes longer than you expect, even when you take into account Hofstadter's Law. -- Hofstadter's Law
|
http://lists.gnu.org/archive/html/gluster-devel/2007-11/msg00150.html
|
CC-MAIN-2016-22
|
refinedweb
| 111
| 83.15
|
I would like to automate the download of CSV files from the World Bank's dataset.
My problem is that the URL corresponding to a specific dataset does not lead directly to the desired CSV file but is instead a query to the World Bank's API. As an example, this is the URL to get the GDP per capita data:.
If you paste this URL in your browser, it will automatically start the download of the corresponding file. As a consequence, the code I usually use to collect and save CSV files in Python is not working in the present situation:
baseUrl = ""
remoteCSV = urllib2.urlopen("%s" %(baseUrl))
myData = csv.reader(remoteCSV)
This will get the zip downloaded, open it and get you a csv object with whatever file you want.
import urllib2 import StringIO from zipfile import ZipFile import csv baseUrl = "" remoteCSV = urllib2.urlopen(baseUrl) sio = StringIO.StringIO() sio.write(remoteCSV.read()) # We create a StringIO object so that we can work on the results of the request (a string) as though it is a file. z = ZipFile(sio, 'r') # We now create a ZipFile object pointed to by 'z' and we can do a few things here: print z.namelist() # A list with the names of all the files in the zip you just downloaded # We can use z.namelist()[1] to refer to 'ny.gdp.pcap.cd_Indicator_en_csv_v2.csv' with z.open(z.namelist()[1]) as f: # Opens the 2nd file in the zip csvr = csv.reader(f) for row in csvr: print row
For more information see ZipFile Docs and StringIO Docs
|
https://codedump.io/share/rrELXwtvhxLk/1/how-to-download-a-csv-file-from-the-world-bank39s-dataset
|
CC-MAIN-2016-44
|
refinedweb
| 265
| 73.27
|
In this article you will learn about Delegates in C#.
"delegate" is a CLI (.Net) class. It is in the namespace System.Delegate. A delegate is a function pointer and the address of that pointer is in RAM and that address is not accessible anywhere else.Let's briefly go through it.Suppose we have a caller M(); and a method; void M(){}. Now the caller must call this method but it wants to call the function later on. So basically the caller wants someone that can hold the identity (address of the functions to be called) .
Now we will see step-by-step how to create and use delegates.Step 1: Write the method that the delegate will point to.
View All
|
https://www.c-sharpcorner.com/UploadFile/484ad3/delegate-in-C-Sharp/
|
CC-MAIN-2019-43
|
refinedweb
| 123
| 76.62
|
I am new to jQuery and want this problem solve. Thanks in advance for
that.
i made my code sample in fiddle. in ths code sample i
have a textarea and a div.
<div
id="divfordisplay"></div>
This div display
all the links of images which are in textarea.
Now my problem
is that i want a remove image link on image and by clickin
I need to be able to remove all DOM objects that have a class of .remove
as long as ALL descendants have a class of either .remove or .removable.
Ignoring whitespace. If a text node can be removed it must only contain
whitespace (tabs, newlines, spaces).
The html objects with
.remove and .removable can be any type of html entity that can recieve a
class including input. If a descend
I have a problem, i'd like to remove the containing array (key 80) but
keep its children (with all the keys and structure unchanged, apart from
the parent).
Can somebody help me
Array( [80] => Array ( [parent]
=> 0 [lng] => en [children] =>
Array (
Im trying to extract some fields from the output at the end of this
question with the following code:
doc =
LH.fromstring(html2)tds = (td.text_content() for td in
doc.xpath("//td[not(*)]"))for a,b,c in zip(*[tds]*3): print
(a,b,c)
What i expect is to extract only the fields
notificationNodeName,notificationNodeName,packageName,notificatio
I feel like there's something rather basic I'm missing here, which I
previously thought I understood, yet it's not working how I feel it should
and cannot figure out why/what I need to do.
If I need to draw
a diagram I will, but this explanation should suffice. I have a main div
which holds a large svg drawing. Within the div I'm trying to place a
smaller div that is positioned rela
If a visitor visits a page ending in ".php", ".html" or a "/" then it
will re-direct to the url without the extension or the forward slash. For
example "contact-us.php" will redirect to "/contact-us" and "contact-us/"
will re-direct to "contact-us". I've tried many approaches but cannot get
all my requirements to work.
To recap:
Remove .php
of .html extension
I have the following code in D
import std.stdio;class Thing{ // Fields private string Name; //
Accessors public string name() { return Name; }}class
Place: Thing{ // Fields private Place[string]
Attached; // Modifiers public void attach(Place place) {
Attached[place.name()] = place; } pub
I'm making this method remove() which takes a String word as argument,
to delete from a global Array "words", but I keep getting a
NullPointerException for some reason I cannot find, been stuck for hours.
Basically I check for if the word is in the first position,
else if is in the last position, or else if it is in neither so I check all
the array, and add the first half before th
|
http://bighow.org/tags/Remove/1
|
CC-MAIN-2017-47
|
refinedweb
| 495
| 62.17
|
Carsten Ziegeler wrote:
> Marc Portier wrote:
>
>>there is a sample now doing that, above statement leaves it
>>unclear if you tried that or not
>>
>
> No, not yet.
>
>
>>if I understand what you are saying, then you would want to have
>>the form definition (structure, fields, datatypes and convertors)
>> deduced from the (runtime?) introspection of the business model?
>>
>>I (currently) don't think such is possible,
>>
>>my own thinking towards some of this was more in the direction of
>>using something like xdoclet to deduce this information from the
>>extra @javadoc-attribuation of the source code and use that to
>>generate the required woody-definition files
>>
>
> I don't want to deduce all from the business model only the datatypes.
ah, but in this case you might be just refering to having an easy
way to have custom datatypes?
so I think it is more related to the datatype-catalogue Sylvain
is proposing the to how the binding is working...
(and hence probably my confusion)
> I want simple form definitions where possible, so I want to define
> a field that's bound to a business object and via introspection
yet here I get the impression you want the widget to be wrapped
around the existing business object instance?
(so I'm still a bit confused)
what woody form-definition tries to do is map a 'widget' to a
<input> field on the HTML page on the one side and
while the <input> will harvest nothing more then STRINGS at the
user input side the widget is aware of its datatype and possible
needed convertors to produce a new business-object from
translating the string.
(in fact: when re-reading this I'm coming to the conclusion the
current binding implementation has a bug: the field-binding needs
to clone() the business object while doing a loadToForm())
on the java API side of the widget you get to have an Object
getValue() and a setValue(Object) where the object returned resp.
passed is guaranteed to be resp. needs to be of the datatype
indicated by what you declared in the form-definition
> it should be possible to get the type of the bound data of the business
> object, like Date, int, Long, String etc.
> That's all. Of course it should still be possible to define the
> datatype and validation for the field.
>
So what you are adding to the show is that the datatype
(basetype) setting of the widget should be possibly derived from
the binding path into the business object?
Sylvain is in the process of allowing to mix the different
namespaces and concerns into a different set of config files,
maybe his proposal can include something along these lines...
The rules for what is taking precedence over what should be
carefully decided upon.
Just some additional remarks:
- the current binding works (through jxpath) by introspection of
a handed over object-instance....
- the related remark on business-object-controlled validation is
still lingering on the table... if I understood your
validateAge() need then the configuration of the model would also
need to allow to specify a validation method? I guess in that
case the woody framework will be imposing bahaviour on that
method (return-type or exceptions to throw) which can't be met by
existing models in the general case... so here I really think the
accompanied custom validation rules will be better of in separate
/specific classes.
> So, rephraising it: the form definition should still be the same
> as it is. But the datatype should be optional and if it is not
> set it's get from the binding.
>
yep.
We are crossing the clear borders between the concerns we
originally envisioned... I still think we got them right, but
translating this into a 'usable' package clearly pushes us
towards some careful mixing
let us try to make up the correct if/then rules to assume the
best approach, and make sure we understand the limitations...
Careful documentation will need to ensure this doesn't become a
mess IMHO
>
>><SNIP/>
>
> likely to even consider woody to be useful),
>
>>I'm open to suggestions to make it more usuable and widely
>>applicable, but we should never expect it to do everything
>>imaginable (meaning: you have your choice of flow-implementation
>>to host that part of the logic?)
>>
>
> I'm suggestion all of the above as I successfully wrote web applications
> this way several years ago and I still think this fits very well
> in Cocoon, flow etc.
>
> So, I admit that I haven't looked at the recent changes in woody,
> but I get the impression that too much is added directly to woody. It's
> only a feeling, I might be wrong. Let's not argue about that.
>
I think we're saying the same, but unless we use the same words,
we re bound to argue about the wrong things ;-)
> I'm wondering if it's possible to create a "form manager" component that
> has the default behaviour as you describe, a more web-based approach
> for form handling.
> Then I could somehow extend this form manager, add the binding in the
> form manager and can do there all the additional stuff to connect to
> a business model.
>
> Example I: when woody tries to get the datatype of a field a method in
> this manager is invoked usually reading it from the definition. Now
> I can override this and additionaly query the business model.
>
> Example II: when woody tries to validate a method is called that
> defaults to validate against the rules defined in the form. I can
> override it and additionaly validate against the business model.
>
> Does this make sense?
>
it does... but as mentioned above I think we could reuse the
form-manager and only need to reconsider the rules in the
datatyping of things...
I'ld rather have us not branch up too early and start to live
next to each other
thx for this clarification, I hope I returned the favour
more thoughts around?
regards,
-marc=
--
Marc Portier
Outerthought - Open Source, Java & XML Competence Support Center
Read my weblog at
mpo@outerthought.org mpo@apache.org
|
http://mail-archives.apache.org/mod_mbox/cocoon-dev/200307.mbox/%3C3F279857.4040806@outerthought.org%3E
|
CC-MAIN-2017-26
|
refinedweb
| 1,023
| 54.36
|
Developers have asked, and we listened. Node.js has been a commonly requested feature for application deployments on OpenShift and our engineers have been tucked away banging out the code to make this happen. Not only do we support node.js, its super secure with our usage of SELinux, c-groups, and pam_namespaces.
Follow these steps to get Node.js applications deployed to the cloud in minutes:
Step 1: (Skip if you already have an OpenShift account)
Signing up for an OpenShift account is both free and easy. In order to sign up, we only ask for an email address and password. We don’t ask for your first name, your dogs name, how many cats you have or anything else. Why makes things complicated by asking for data we don’t need.
Step 2: (Skip if you have clients tools already installed)
Now that you have an account on OpenShift, you can interact with our system via various methods. The method I prefer is the command line tools. In order to install and use the command line tools you will need to have both ruby and rubygem installed on your system. Given the various ways of installing these dependencies on each operating system, I will not cover it in this post. That being said, it is installed by default on most linux and mac operating systems.
Once you have ruby and rubygem installed, simply type the following, using sudo access if required:
$ sudo gem install rhc
Step 3: Create an application
In order to create an application on the OpenShift Paas, you can issue a single command that will both allocated a node for your use as well as install all the required dependencies for running node.js. From a command prompt, issue the following command:
$ rhc app create –a yourApplicationName –t nodejs-0.6
This will also create a git repository and setup some git configuration files that will allow you to commit and push code changes to your node.js application server.
Verify that your application is up and running by pointing your browser to your freshly created application:
Step 4: Embed databases if you need
Now that we have our node.js application and running, you may want to add database support. At the time of this writing, we support MongoDB, MySQL, postgreSQL and sqlite. In order to use one of these databases, we need to embed the corresponding database cartridge. This can be done with the following command:
$ rhc cartridge add –a yourApplicationName –c mongodb-2.0
The above will create a mongoDB database and make is accessible to your node.js platform. If you wanted to use MySQL or another database, you would simply supply the cartridge name for the respective database. To get a list of all available cartridges, you can issue the following command:
$ rhc cartridge list
Step 5: Code (That was point of this, right?)
Your application code has been clones from your git repository and is located in the directory where you issued the create application command. At this point, change to the directory created and have a look around. We provide a README file that will explain the layout of the application and how to include npm dependencies for your application.
Once you have made some changes, for your application code to served by your OpenShift node, you need to commit and push your change.
$ git commit –a –m “Added some source code”
$ git push
And that’s all there is to it. You have a running node.js application complete with database support available on the cloud.
If you have any questions about using OpenShift, please contact us in one of the following ways:
- IRC – We are on #openshift on freenode
- Community Forums –
Want to get started even faster? Check out our quickstart guides posted on github at:
|
https://blog.openshift.com/nodejs-on-openshift-you-bet-your-javascript/
|
CC-MAIN-2016-44
|
refinedweb
| 640
| 61.87
|
NoSuchFieldError:
I guess you may all be familiar with this error,"which is thrown when we try to access a field which does not exist in the class,interface or enum".You may think if we try to access a unavailable field then at the compile-time itself you would be alerted of this error then how come this error is thrown at run-time.
In most of the cases this error is thrown when we use third-party libraries in our application and i will explain you how in this post.
This error is thrown because of binary incompatibility,which arises when we modify a class in such a way that the class is ended up in an inconsistent state.
The main reason for this error to be thrown at run-time is "that you may have accidentally (indeed purposefully) deleted a field(public or protected) from the class, or interface and recompiled the edited class or interface alone."
As a result,pre-existing classes that has symbolic reference to this field will have no idea about the deletion of the field.So if you execute the class without recompiling it then at the run-time only you will be shown this error message.
Have a look at the following program to understand.
Class C
class C
{
static int c=20;
}
Class D
class D extends C
{
public static void main(String args[])
{
System.out.println(c);
}
}
This program will run without showing any error. Now If i delete the field c from class C(static int c=20) and recompile it alone then class D would not be aware of the changes made in the class C. This is the reason why java.lang.NoSuchFieldError is thrown when i execute the class D.
This error also applies to enumerated types,because if you delete the enum constant and if you try to access the constant without recompiling the class to be executed,you will get this error.See how
class D extends C
{
public static void main(String args[])
{
System.out.println(c);
}
}
Program:
import java.util.*;
public class Nosuch{
public static void main(String[] args)
{
Level l=Level.LOW;
System.out.println(l.toString());
}
}
enum Level{
LOW,MEDIUM,HIGH;
}
If i delete the enum constant "LOW " from the enum declaration and recompile the Level.java file alone and execute the class Nosuch then you will get this error.
Exception in thread "main" java.lang.NoSuchFieldError: LOW
at Nosuch.main(Nosuch.java:7)
Thus it is obvious that if we compile the classes as a whole then at the compile-time itself you would get this error.So you can make the necessary changes to correct those errors.
An important thing to be noted here is that we people mostly would not do like this and you may ask me then when will this error be thrown?
As i have said before mostly this kind of error is thrown when we use third-party libraries (packages) in our application. Because we have no idea about the changes made in those libraries and if you use those library classes without recompiling the application as a whole then this error would be thrown.
When re-compilation also becomes ineffective?
There are certain situations at which this exception will not be identified by the compiler even if you Re-compile it as a whole.If this is the case for you then you should have to check your classpath settings and most importantly extension libraries (jre/lib/ext) and bootstrap libraries which is the default location,where the compiler will look for classes when resolving references.
"If you have older version of the third-party packages in the extension libraries or in bootstrap libraries and newer version of the package in the class path then compiler will not show this error because while resolving references older version would be used since it is available in the system libraries itself (where class files are first searched)and during execution newer version might be used".
So ensure that two different versions of the same package does not exist in your class path and in the extension libraries.It is advisable to remove the older version completely from the system.
|
http://craftingjava.blogspot.com/2012/08/javalangnosuchfielderror_9430.html
|
CC-MAIN-2017-39
|
refinedweb
| 706
| 59.33
|
This is GCC Bugzilla
This is GCC Bugzilla
Version 2.20+
View Bug Activity
|
Format For Printing
|
Clone This Bug
When building gcc-3.4.3 or gcc-4.x into a clean $PREFIX,
the configure script happily copies the glibc include files from include to
sys-include;
here's the line from the log file (with $PREFIX instead of the real prefix):
Copying $PREFIX/i686-unknown-linux-gnu/include to
$PREFIX/i686-unknown-linux-gnu/sys-include
But later, when running fixincludes, it gives the error message
The directory that should contain system headers does not exist:
$PREFIX/lib/gcc/i686-unknown-linux-gnu/3.4.3/../../../../i686-unknown-linux-gnu/sys-include
Nevertheless, it continues building; the header files it installs in
$PREFIX/lib/gcc/i686-unknown-linux-gnu/3.4.3/include
do not include the boilerplate that would cause it to #include_next the
glibc headers in the system header directory.
Thus the resulting toolchain can't compile the following program:
#include <limits.h>
int x = PATH_MAX;
because its limits.h doesn't include the glibc header.
The problem is that gcc/Makefile.in assumes that
it can refer to $PREFIX/i686-unknown-linux-gnu with the path
$PREFIX/lib/../i686-unknown-linux-gnu, but
that fails because the directory $PREFIX/lib doesn't exist during 'make all';
it is only created later, during 'make install'. (Which makes this problem
confusing, since one only notices the breakage well after 'make install',
at which point the path configure complained about does exist, and has the
right stuff in it.)
I posted a proposed fix to
Keating wrote in
>Needs a ChangeLog entry, but otherwise OK.
>
>A key detail that you left out of your patch description is that
>SYSTEM_HEADER_DIR is used *only* for fixincludes and similar; it is not
actually >put into the compiler. If the path was used in the compiler, this
patch would >not be OK, because it would mean the compiler couldn't be moved to
a different >place after installation.
I haven't looked at the patch again after reading his comment (just saw it now),
but I intend to.
I think this is a dup of bug 7088 but I cannot prove it for sure.
Subject: Bug 22541
Author: bernds
Date: Wed May 17 13:54:38 2006
New Revision: 113859
URL:
Log:
PR bootstrap/22541
From Dan Kegel <dank@kegel.com>:
* Makefile.in: Strip "dir/../" combinations from SYSTEM_INCLUDE_DIR.
Modified:
trunk/gcc/ChangeLog
trunk/gcc/Makefile.in
Subject: Bug 22541
Author: bernds
Date: Tue Jun 13 14:39:42 2006
New Revision: 114611
URL:
Log:
PR bootstrap/22541
From Dan Kegel <dank@kegel.com>:
* Makefile.in: Strip "dir/../" combinations from SYSTEM_INCLUDE_DIR.
Modified:
branches/gcc-4_1-branch/gcc/ChangeLog
branches/gcc-4_1-branch/gcc/Makefile.in
Fixed in 4.1.2 and the mainline.
|
http://gcc.gnu.org/bugzilla/show_bug.cgi%3Fid=22541
|
crawl-002
|
refinedweb
| 470
| 57.77
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.