
text
stringlengths 454
608k
| url
stringlengths 17
896
| dump
stringclasses 91
values | source
stringclasses 1
value | word_count
int64 101
114k
| flesch_reading_ease
float64 50
104
|
|---|---|---|---|---|---|
public class InsertionSortPractice {
public static void main(String[] args){
double[] array = new double[]{4.5,3.2,45.3,47.4,43,3,4.56,65,28.38};
System.out.println("Before...
public class InsertionSortPractice {
public static void main(String[] args){
double[] array = new double[]{4.5,3.2,45.3,47.4,43,3,4.56,65,28.38};
System.out.println("Before...
Hint hint
To assign values through a forloop
For (int a = 1; a<square.length; a++)
{
Square[a] = findSquare(a);
}
Now just print the values
first so .... could you lease inform me with the link
second you are being hypocritical about squabbling
third please answer without being a snob
im reporting that tone and no I didn't ignore, I was looking for other suggestionns.
bumpity bump bump
Here were the topics I learned on flvs ap computer science(java) and got a 90+% in.
I. Object-Oriented Program Design
The overall goal for designing a piece of software (a computer program) is to...
and then all id have to do is call the super methods through the car and truck construstors respectively, which works as Ive already fixed the problem with double/int congruence, thanks.
by implement you mean dont writte as abstract methods.
i would add names to array compare index 1 with 0 and ind index 2 with 1(array[i] with array[i-1]) and swap the words if not correctly position
(bubblesort)
public class Car extends Vehicle
{
public Car(String name, int cost)
{
super(name, cost);
}
}
Simply: Truck and car arent abstract and dont overide the abstract methods
15.05 Assignment Instructions
1. Create a folder called 15.05 Assignment in your module 15 assignments folder.
2. Create an interface named Product .
a. Add a method called getName() that...
any code that you have tried. Have you written pseudocode.
"==" is a comparison operator not one for assignment
Well first things first JSmileFace2 extends jsmile.
I made changes suggested though dont have any idea about array part. The weird characters(thanks:)) are gone but letters are beig repeated in alphabet.
/**
* Write a description of class...
My program is printing random weird characters.
/**
* Write a description of class LandonLoweCipher here.
*
* @author (Landon)
* @version (a version number or a date)
*/
Example Construtor:
public class Name{
private String fName;
private String lname;
public Name(String fN, String lN)
{
fName = fN;
I dont understand what is meant by your first sentence/how to fix it.
Thanks finally fixed the problem or at least I think I did based on results
/**
* Write a description of class MorseCode here.
*
* @author (Landon L)
* @version (a version number or...
but the code has to convert ints to morse code also.
/**
* Write a description of class MorseCode here.
*
* @author (Landon L)
* @version (a version number or a date)
*/
import java.util.*;
import java.io.File;
import...
Input was Hohoho122.
Output was ---....---....---
yes at least for letters I suppose Ill do the same thing for numbers
--- Update ---
Now the number part wont return anything
/**
* Write a description of class MorseCode here.
*
|
http://www.javaprogrammingforums.com/search.php?s=fcc178e1e1fa34898b678d018824e5fb&searchid=1814392
|
CC-MAIN-2015-40
|
refinedweb
| 509
| 65.22
|
New Firmware Updater version 1.14.2
Version 1.14.2 of the firmware update tool is now available.
This version is fixing an issue that would ask users for a Pybytes activation token in certain circumstances even though a stable firmware is being flashed.
As usual please let. me know if you encounter any issues.
Perfect, thanks.
This gives me what I need until it can be dealt with on your end. I have filed the ticket.
@travist The device will still function with the LoPy firmware but the pins for the LoRa modem won't be usable.
The fact that the board type cannot be changed after first registration with the online firmware updater has always been this way... the only thing that has changed is that the board type is now being shown in the updater, so you might just never have noticed before that you have the wrong firmware on your board.
You can always download firmware packages manually and flash your board offline using the "Flash from local file" option.
The links to the firmware packages can be found here:
It mentions downgrade but it works just as well for the current firmware.
Thanks, and I submitted a ticket.
You did not answer the other part of my question, is this device usable as a Wipy device with the type not being correct?
Is this something that is newer for the updated, to not be able to select the type of firmware?
@travist This means that the boards have been registered as LoPy instead of WiPy when flashing the boards for the first time.
To change the registration of your board please run the following code:
import machine,binascii print(binascii.hexlify(machine.unique_id()))
Then open a technical support request at to request a device registration change.
I went to update my wipy 2 modules and it keep recognizing and flashing them as Lopy modules.
Why?
Is this going to cause issues for normal Wipy operation?
|
https://forum.pycom.io/topic/3202/new-firmware-updater-version-1-14-2/6
|
CC-MAIN-2018-22
|
refinedweb
| 331
| 72.87
|
. Create plugins folder as shown in below image.
Add the following code to project\plugins\Plugins.scala
import sbt._
class Plugins(info: ProjectInfo) extends PluginDefinition(info) {
val scctRepo = "scct-repo" at ""
lazy val scctPlugin = "reaktor" % "sbt-scct-for-2.8" % "0.1-SNAPSHOT"
2. Project definition \project\build\MyFirstProject.scala , should extent reaktor.scct.ScctProject
import sbt._
import reaktor.scct.ScctProject
class AnilsProject(info: ProjectInfo) extends DefaultProject(info) with ScctProject
{
lazy val hi=task {println("This is Anils First New Project"); None}
}
3. Enter in to the project directory
4. Type sbt and press enter
5. Type reload and press enter (necessary only when code is changed or some new files added)
6. Type update and press enter(only when code is changed or some new files added)
7. Type run and press enter.
8. Type test-coverage and press enter
if everything goes fine you see below output
Surprising, Its says that there are no tests to run. Its right we did not write any code for test until now.
9. Add the below code to the file project/build/MyFirstProject.scala
val scalaTest = "org.scalatest" % "scalatest" % "1.2"
val scalaCheck = "org.scala-tools.testing" % "scalacheck_2.8.0" % "1.7"
12. now go to terminal type , reload and enter, update and enter
13. Type test-coverage and press enter.
14. To check the test output open /target/scala_2.8.1/coverage-report/index.html
It wasted me a lot of time in setting up the interface to run simple tests. there is no any written manual for the new bees to guide through the process. This struggle with all these setup inspired me to present a guide for the persons who are new to use Scala, SBT, ScalaCheck, SCCT,
enjoy.....
Thank you so much, Its really very helpful to me.
Keep it up !
Anuj
Hi ,Can you have any idea , how we run a single test by SCCT as we run by Junit "test-only"
Thanks
Anuj
|
http://mastersdegreethesis.blogspot.com/2012/03/unit-testing-scala-code-coverage-tool.html
|
CC-MAIN-2018-30
|
refinedweb
| 330
| 61.53
|
This is a follow on to a previous post about customising naming conventions for PostgreSQL and EF Core. In this post I describe one way to use snake case naming conventions when using Dapper, rather than EF Core, by using "Schema" utility classes, the
nameof() operator, and a
ToSnakeCase() extension method.
PostgreSQL and naming conventions
If you're coming from SQL Server, PostgreSQL can seem very pedantic about column names. In SQL Server, case sensitivity doesn't matter for column names, so if a column is named
FirstName, then
firstname, or even
FIRSTNAME are all valid. Unfortunately, the only way to query that column in PostgreSQL, is using
"FirstName" (including the quotes). Using quotes like this can get tiresome, so it's a common convention to use "snake_case" for columns and tables; that is, all-lowercase with
_ to separate words e.g.
If you'd like a bit more background, or you're working with EF Core, I discuss this in greater depth in my previous post.
In the previous post, I described how you can customise EF Core's naming conventions to use snake_case. This ensures all tables, columns, and indexes are generated using snake_case, and that they map correctly to the EF Core entities. To do so, I created a simple
ToSnakeCase() extension method that uses a regex to convert "camelCase" strings to "snake_case".(); } }
One of the comments on that post from Alex was interested in how to use this method to achieve the same result for Dapper commands:
I'm using Dapper in many parts of my application and i used to name my table in queryies using
nameof(), for example:
$"SELECT id FROM {nameof(EntityName)}". That way, i could rename entitie's names without replacing each sql query ...
So the naive approach will be to replace it with
"SELECT id FROM {nameof(EntityName).ToSnakeCase()}"but, each time the query is "build", the
SnakeCase(and the regexp) will be processed, so it'll not be very good in term of performance. Did you know a better approach to this problem ?
Using the
nameof() operator with Dapper
Dapper is a micro-ORM that provides various features for querying a database and mapping the results to C# objects. It's not as feature rich as something like EF Core, but it's much more lightweight, and so usually a lot faster. It uses a fundamentally different paradigm to most ORMs: EF Core lets you interact with a database without needing to know any SQL, whereas you use Dapper by writing hand-crafted SQL queries in your app.
Dapper provides a number of extension methods on
IDbConnection that serve as the API surface. So say you wanted to query the details of a user with
id=123 from a table in PostgreSQL. You could use something like the following:
IDbConnection connection; // get a connection instance from somewhere var sql = "SELECT id, first_name, last_name, email FROM users WHERE id = @id"; var user = connection.Query<User>(sql, new { id = 123}).SingleOrDefault();
The ability to control exactly what SQL code runs on your database can be extremely useful, especially for performance sensitive code. However there are some obvious disadvantages when compared to a more fully featured ORM like EF Core.
One of the most obvious disadvantages is the possibility for typos in your SQL code. You could have typos in your column and table names, or you could have used the wrong syntax. That's largely just the price you pay for this sort of "lower-level" access, but there's a couple of things you can do to reduce the problem.
A common approach, as described in Alex's comment is to use string interpolation and the
nameof() operator to inject a bit of type safety into your SQL statements. This works well when the column and tables names of your database correspond to property and class names in your program.
For example, imagine you have the following
User type:
public class User { public int Id { get; set; } public string Email { get; set; } public string FirstName { get; set; } public string LastName { get; set; } }
If your column names match the property names of
User (for example property
Id corresponds to column name
Id), then you could query the database using the following:
var id = 123; var sql = $@" SELECT {nameof(User.Id)}, {nameof(User.FirstName)}, {nameof(User.LastName)} FROM {nameof(User)} WHERE {nameof(User.Id)} = @{nameof(id)}"; var user = connection.Query<User>(sql, new { id }).SingleOrDefault();
That all works well as long as everything matches up between your classes and your database schema. But I started off this post by describing snake_case as a common convention of PostgreSQL. Unless you also name your C# properties and classes using snake_case (please don't) you'll need to use a different approach.
Using static schema classes to avoid typos
As Alex described in his comment, you could just call
ToSnakeCase() inline when building up your queries:
var id = 123; var sql = $@" SELECT {nameof(User.Id).ToSnakeCase()}, {nameof(User.FirstName).ToSnakeCase()}, {nameof(User.LastName).ToSnakeCase()} FROM {nameof(User).ToSnakeCase()} WHERE {nameof(User.Id).ToSnakeCase()} = @{nameof(id)}"; var user = connection.Query<User>(sql, new { id }).SingleOrDefault();
Unfortunately, calling a regex for every column in every query is pretty wasteful and unnecessary. Instead, I often like to create "schema" classes that just define the column and table names in a central location, reducing the opportunity for typos:
public static class UserSchema { public static readonly string Table { get; } = "user"; public static class Columns { public static string Id { get; } = "id"; public static string Email { get; } = "email"; public static string FirstName { get; } = "first_name"; public static string LastName { get; } = "last_name"; } }
Each property of the
User class has a corresponding getter-only
static property in the
UserSchema.Columns class that contains the associated column name. You can then use this schema class in your Dapper SQL queries without performance issues:
var id = 123; var sql = $@" SELECT {UserSchema.Columns.Id)}, {UserSchema.Columns.FirstName}, {UserSchema.Columns.LastName} FROM {UserSchema.Table} WHERE {UserSchema.Columns.Id} = @{nameof(id)}"; var user = connection.Query<User>(sql, new { id }).SingleOrDefault();
I've kind of dodged the question at this point - Alex was specifically looking for a way to avoid having to hard code the strings
"last_name" etc; all I've done is put them in a central location. But we can use this first step to achieve the end goal, by simply replacing those hard-coded strings with their
nameof().ToSnakeCase() equivalents:
public static class UserSchema { public static readonly Table { get; } = nameof(User).ToSnakeCase(); public static class Columns { public static string Id { get; } = nameof(User.Id).ToSnakeCase(); public static string Email { get; } = nameof(User.Email).ToSnakeCase(); public static string FirstName { get; } = nameof(User.FirstName).ToSnakeCase(); public static string LastName { get; } = nameof(User.LastName).ToSnakeCase(); } }
Because we used getter-only properties with an initialiser , the
nameof().ToSnakeCase() expression is only executed once per column. No matter how many times you use the
UserSchema.Columns.Id property in your SQL queries, you only take the regular expression hit once.
Personally, I feel like this strikes a good balance between convenience, performance, and safety. Clearly creating the
*Schema tables involves some duplication compared to using hard-coded column names, but I like the strongly-typed feel to the SQL queries using this approach. And when your column and class names don't match directly, it provides a clear advantage over trying to use the
User class directly with
nameof().
Configuring Dapper to map snake_case results
The schema classes shown here are only one part of the solution to using snake_case column names with Dapper. The
*Schema approach helps avoid typos in your SQL queries, but it doesn't help mapping the query results back to your objects.
By default, Dapper expects the columns returned by a query to match the property names of the type you're mapping to. For our
User example, that means Dapper expects a column named
FirstName, but the actual column name is
first_name. Luckily, fixing this is a simple one-liner:
Dapper.DefaultTypeMap.MatchNamesWithUnderscores = true;
With this statement added to your application, you'll be able to query your PostgreSQL snake_case columns using the
*Schema classes, and map them to your POCO classes.
Summary
This post was in response to a comment I received about using snake_case naming conventions with Dapper. The approach I often use to avoid typos in my SQL queries is to create static "schema" classes, that describe the shape of my tables. These classes can then be used in SQL queries with interpolated strings. The properties of the schema classes can use convenience methods such as
nameof() and
ToSnakeCase() as they are only executed once, instead of on every reference to a column.
If you're using this approach, don't forget to set
Dapper.DefaultTypeMap.MatchNamesWithUnderscores = true so you can map your query objects back to your POCO classes!
|
https://andrewlock.net/using-snake-case-column-names-with-dapper-and-postgresql/
|
CC-MAIN-2019-47
|
refinedweb
| 1,476
| 53
|
Red Hat Bugzilla – Bug 77153
g++ 3.2 compiled program that uses templates & "iostream" leads to unlimited memory leaks in gdb
Last modified: 2015-01-07 19:01:29 EST
Description of problem:
When I compile a small C++ program with templates and <iostream>
with g++ 3.2 and debug it with Kdbg, then when stepping through the
program at some moment Kdbg hangs, and with "top" i can see that gdb is
acquiring all the RAM it can get.
Compiling exactly the same source with g++ 2.96 does not lead to
any problems.
How reproducible: Always
Steps to Reproduce:
1. Type:
cat > test.cpp
#include <string>
#include <iostream>
using namespace std;
template<class X> void out (ostream& in, X& x)
{
// Here gdb starts allocating as much memory as it can get
// eventually leading to system freeze
cout << x;
}
int main()
{
cout << "This works fine!";
out(cout, "aaa");
}
2. Compile
g++ -g test.cpp
3. [IMPORTANT] Be ready to kill gdb process or the system will
freeze quite fast (thrashing).
4. Debug "a.out"
kdbg a.out
5. Step through the program.
Actual Results:
When stepping through function body:
template<class X> void out (ostream& in, X& x)
{
cout << x;
}
gdb will start acuquiring immence amounts of memory.
[Be ready to kill the process!]
Additional info:
* The same behaviour also occurs when replacing
cout << x;
with something similar like
vector<X> v;
v.push_back(x);
* My system is upgraded from Redhat 7.3, but the same resutls were
also reproduced with clean Redhat 8 install.
Could you send me some more information? I need to know exactly the steps you
are doing in gdb,
and the initial banner that gets printed at gdb startup. You can just cut and
paste the session.
Is this stock gdb from 8.0?
thanks
Created attachment 84785 [details]
A transcript of gdb session & related.
OK, I've attached a transcipt of the session now. GDB starts leaking on
info args
See attachment - it is the output of "script" command.
Just wanted to note that I was having an identical problem. I upgraded my
gdb-5.2.1 package which came stock with RH8.0 to gdb-5.3post-0.20021129.3
(rawhide package) and my problem was solved.
I retested this with the latest gdb: 5.3.90-0.20030710.16. The problem is gone.
|
https://bugzilla.redhat.com/show_bug.cgi?id=77153
|
CC-MAIN-2018-34
|
refinedweb
| 392
| 77.03
|
This is the mail archive of the automake@gnu.org mailing list for the automake project.
On Sat, Aug 11, 2001 at 03:44:54PM -0600, Tom Tromey wrote: > >>>>> "Steve" == Steve M Robbins <steven.robbins@videotron.ca> writes: > > Steve> However, you sent to bug-automake. I'm re-sending to the > Steve> automake discussion list, since (a) I'm not sure it is a bug, > Steve> and (b) someone in the wider audience may know a workaround. > > Steve> LDADD = ... $(CGAL_LDFLAGS) ... > Steve> and automake complains: > Steve> Makefile.am: invalid unused variable name: `CGAL_LDFLAGS' > > This is a "feature". I'll explain why it exists and what it does; > then we can discuss whether it is really worth keeping. [ ... ] > In your case the workaround is to rename the variable. This is what > makes the feature seem like a potential misfeature -- it is natural to > want to name it the way you did. If it were my decision, I would rename the variable. I tend to like this feature, actually, and I'm willing to let automake grab that part of the namespace for itself. However, the main problem is this: I did not write the makefile scrap that is being included. It is generated by the CGAL library install script, and the names are not under my control. The main reason I brought it up is that in addition to emitting the diagnostic message, automake will exit with nonzero status when this happens. This has bad side effects, like causing the "missing" script to emit an incorrect diagnostic: steve@riemann{missing-lines}make cd . && \ /bin/sh /home/steve/src/test/automake/missing-lines/missing --run automake --foreign Makefile Makefile.am: invalid unused variable name: `CGAL_LDFLAGS' WARNING: `automake' is missing on your system. You should only need it if you modified `Makefile.am', `acinclude.m4' or `configure.ac'. You might want to install the `Automake' and `Perl' packages. Grab them from any GNU archive site. Automake is certainly not *missing*! At the moment, automake does generate a correct Makefile.in despite the warning. I'm a bit worried that in the future automake will cease to generate the Makefile.in when it encounters "errors" such as this. > Steve> [Incidentally, there used to be a line number attached to this > Steve> diagnostic, but that suddenly stopped. (??)] > > Thanks. This is definitely a bug. Could you submit a PR to Gnats? I tried, but the login page at redhat just keeps returning me to the login page at redhat. () I'll send a note to bug-automake. -Steve -- by Rocket to the Moon, by Airplane to the Rocket, by Taxi to the Airport, by Frontdoor to the Taxi, by throwing back the blanket and laying down the legs ... - They Might Be Giants
|
http://sourceware.org/ml/automake/2001-08/msg00052.html
|
crawl-002
|
refinedweb
| 455
| 75.81
|
When building your first .NET web service, you may be in for a rude awakening when you discover the concept of “partial trust.” Your previously bullet-proof code will suddenly fail in a flurry of exceptions thrown by seemingly innocuous commands such as reading files or accessing the Registry. This article provides a brief overview of Code Access Security and describes how to modify and test your code to work in a partial trust environment.
Code Access Security
Code Access Security (CAS) in the .NET Framework limits the access that code has to protected resources and operations. CAS is separate from and in addition to the security provided by the host operating system.
When a user runs a .NET application, the .NET Common Language Runtime (CLR) assigns the application to one of the following zones:
- My Computer — application code runs directly on the user’s computer
- Local Intranet — application code runs from a file share on the user’s intranet
- Internet — application code runs on the Internet
- Trusted Sites — application code runs on a web site defined as “Trusted” by Internet Explorer
- Untrusted Sites — application code runs on a web site defined as “Restricted” by Internet Explorer
For each zone, a system administrator can set specific access permissions, represented by permission objects. The more common permissions include:
- FileIOPermission — ability to work with files
- OleDbPermission — access databases with OLEDB
- PrintingPermission — ability to print
- SecurityPermission — ability to execute, assert permissions, call into unmanaged code, skip verification and other rights
- SocketPermission — ability to make/accept TCP/IP connections
- SQLClientPermission — access SQL databases
- UIPermission — provide a user interface
- WebPermission — connect to/from the Web
These permissions determine which resources the application can access and can represent a security level of full trust, medium trust, low trust, or no trust.
What is Partial Trust?
Developers usually work in a full-trust environment–their own PC. Typically any code the developer compiles is allowed to run on the local computer without security restrictions or errors.
Partial trust describes any zone that is not a full trust zone. The most common scenarios where code runs in partial trust are:
- .NET web services on a shared host
- Code downloaded from the Internet
- Code that resides on a network share (intranet)
Permission Denied
The following resources are typically available in full trust but are denied in a partial trust zone:
- File I/O, including reading, writing, creating, deleting or printing files
- System components, such as registry values, environment variables and assembly information
- Server components, including directory services, event logs, performance counters, and message queues
- Reflection
It’s not always easy to determine which code can run in partial trust. Each class in the .NET Framework has a security attribute that defines the level of trust needed to access it. The table below shows the typical permissions allowed for each trust level:
Security Exceptions
If you attempt to execute full-trust code in a partial trust environment, CAS will throw the following SecurityException: …
The action that failed was:
LinkDemand
Operate in Partial Trust
Applications operating in partial trust are not allowed to call a .NET assembly unless the assembly is specifically marked to operate in partial trust. Here’s why:
Assemblies must be signed with a strong name in order to be shared by multiple applications. A strong name enables your assembly to be placed in the Global Assembly Cache and makes it difficult for hackers to spoof your code. By default, strong-named assemblies automatically perform an implicit LinkDemand for full trust. If a caller operating in partial trust attempts to call such an assembly, CAS throws a SecurityException.
To disable the automatic LinkDemand and prevent the exception from being thrown, add the AllowPartiallyTrustedCallersAttribute (APTCA) to the assembly. This attribute enables your assembly to be called from partially trusted code. Note the APTCA is applicable only on the assembly level, so you cannot provide partial trust for an individual method or class; either everything in the assembly is safe to use by partially trusted code, or none of it is.
To set the APTCA on your assembly:
- Open your assembly project in Visual Studio.
- Open the AssemblyInfo.cs file.
- Add the following code in the “using” block at the top of the file (if it is not already there):
using System.Security;
- Add the following line to the “assembly” section of the file:
[assembly: AllowPartiallyTrustedCallers]
- Rebuild the assembly.
Check for Partial Trust
Because many resources are not available in partial trust, you will likely want to check the trust level at runtime and respond accordingly. Following is sample code to check for full trust. Call the CheckTrust() method once in the static constructor of the class in which you placed this code, for example, then call the IsFullTrust property as needed:
using System.Security; using System.Security.Permissions;
static private void CheckTrust() { try { FileIOPermission permission = new FileIOPermission( PermissionState.Unrestricted ); s_FullTrust = SecurityManager.IsGranted( permission ); } catch (Exception) { // ignore } } static private bool s_FullTrust; static public bool IsFullTrust { get { return s_FullTrust; } }
Test in Partial Trust
If you test your web service on your local PC (localhost), it will typically operate in full trust, which of course is not an accurate representation of a partial trust web host. So to force the web service to run under partial trust, modify the <trust> element in the application’s Web.config file as follows:
<trust level="Medium"/>
If there is no <trust> element in your Web.config file, you should add it within the <System.Web> element as follows:
<system.web> <trust level="Medium"/> </system.web>
[…] Executing Code in Partial Trust Environments : DevTopics – A nice review of Code Access Security and and how you can work in Partial Trust environments. […]
Thanks a lot for the viewpoints. Software piracy was a big menace for me. I came across an open source project named Paragent by using Paragent’s IT Asset Management Software, keeping track of software licensing became easy and you can be assured users are operating within your organization’s software licensing.
Regards,
Cranium1200
[…] a deep copy. The disadvantage is it uses Reflection, which is slower and not allowed in partial trust environments. Sample […]
CAS is an absolute nightmare. I develop code stored on a windows share. I have been using VS2005, Net 2.0 and Windows 2000. I have an application that I have been working on for months and it loads and runs from the windows share without problems when accessed using the W2K machine. Recently I acquired a laptop that had Vista installed. When I tried to compile my code using the laptop a hell breaks loose. I have updated all my DLL’s to inclue the ‘AllowPartiallyTrustedCallersAttribute’ statement recompiled and I still get the ‘That assembly does not allow partially trusted caller’ errors. If the compiler is smart enough to know ther3e is a ‘That assembly’ error its smart enough to know which ‘ASSEMBLY’. I swear.. If Microsoft wrote a dictionary the words would be sorted in random order and the definitions would be missing.
Great review dude, gave me a good rundown and very thorough
[…] of the browser, yet there is more to it… XBAP’s run in a “sandbox”, basically they run as Partial Trust by default. What this means is that some of the things that you would assume would work in a WPF […]
[…] of the browser, yet there is more to it… XBAP’s run in a “sandbox”, basically they run as Partial Trust by default. What this means is that some of the things that you would assume would work in a WPF […]
[…] uolhost que por ser mais sério, só permite chamadas com Partial Trust, o que isso quer dizer? Olhei aqui e entendi quase nada, mas sei que é algo que impede que o meu sistema chame outras dlls. Por sorte […]
[…] to provide a deep copy. The disadvantage is it uses Reflection, which is slower and not allowed in partial trust environments. Sample […]
|
http://www.csharp411.com/executing-code-in-partial-trust-environments/
|
CC-MAIN-2017-22
|
refinedweb
| 1,317
| 51.78
|
Hi all, this is my first post. I’m just starting to learn three.js and JS (I’ve been coding C# in Unity for 10 years). I have a project coming up that’s going to have a lot of text objects in the 3D space so I’m trying out troika-three-text to see if it’ll work for my needs.
So far so good, I can easily create text in my scene… Now I’d like to preload the font using the method provided by the maker but I can’t figure out how to reference the font after it has been loaded. Here’s what I’ve tried so far. Thanks for any help/guidance on this. -t
import { Text } from 'troika-three-text'; import { preloadFont } from 'troika-three-text'; preloadFont( { font: '', characters: 'abcdefghijklmnopqrstuvwxyz', }, () => { console.log('preload font complete'); }, ); // then later after I know the font has been loaded... function createText() { const myText = new Text(); myText.text = 'hello!!'; myText.font = // ???? how do reference the preloaded font? myText.sync(); return myText; } export { createText };
|
https://discourse.threejs.org/t/how-to-preloadfont-in-troika-three-text/22500
|
CC-MAIN-2022-33
|
refinedweb
| 177
| 75.3
|
Hello Everyone
I'm new to Xamarin and currently converting an Silverlight App to an UWP App using a SharedProject(No Xamarin.Forms!, Next step after this would then be, doing it for iOS and Android using Xamarin.Forms). But when i try to build the app in VisualStudio17 i get following error: "Object reference not set to an instance of an object", what this is means is clear to me... But it does not say where this error happened(which file, which line).
So my Question is... Why doesn't it show me where the error happened? And how do i find the file the error happened in?
Help would be greatly appreciated.
Thanks and greetings
Silas
Answers
Hi @SilasNaef
Well, this error is so annoying, I had one today and I will tell you how i fix it but, before that I recommend you to do debugging in the method that throws this error.
For me, I as passing a null object to a constructor:
`public MyClass(ClassB b)
{
Id = b.Id;
Because b is null, I was getting this error .
Hope that will help you
hello @Bagera
Thanks for the advice, but this cant really be the issue in my case, since the code was already running in a different project, in my opinion it has to be the issue with some namespace which is available in Silverlight but is not anymore in UWP.
But since u cant see my code i was hoping you could tell how to find the Error in my code without debugging.
Thanks and have a nice day
|
https://forums.xamarin.com/discussion/95877/object-reference-not-set-to-an-instance-of-an-object
|
CC-MAIN-2017-30
|
refinedweb
| 266
| 69.72
|
Guide to Porting lsof 4 to Unix OS Dialects ********************************************************************** | The latest release of lsof is always available via anonymous ftp | | from lsof.itap.purdue.edu. Look in pub/lsof.README for its | | location. | ********************************************************************** Contents How Lsof Works /proc-based Linux Lsof -- a Different Approach General Guidelines Organization Source File Naming Conventions Coding Philosophies Data Requirements Dlsof.h and #include's Definitions That Affect Compilation Options: Common and Special Defining Dialect-Specific Symbols and Global Storage Coding Dialect-specific Functions Function Prototype Definitions and the _PROTOTYPE Macro The Makefile The Mksrc Shell Script The MkKernOpts Shell Script Testing and the lsof Test Suite Where Next? How Lsof Works -------------- Before getting on with porting guidelines, just a word or two about how lsof works. Lsof obtains data about open UNIX dialect files by reading the kernel's proc structure information, following it to the related user structure, then reading the open file structures stored (usually) in the user structure. Typically lsof uses the kernel memory devices, /dev/kmem, /dev/mem, etc. to read kernel data. Lsof stores information from the proc and user structures in an internal, local proc structure table. It then processes the open file structures by reading the file system nodes that lie behind them, extracting and storing relevant data in internal local file structures that are linked to the internal local process structure. Once all data has been gathered, lsof reports it from its internal, local tables. There are a few variants on this subject. Some systems don't have just proc structures, but have task structures, too, (e.g., NeXTSTEP and OSF/1 derivatives). For some dialects lsof gets proc structures or process information (See "/proc-based Linux Lsof -- a Different Approach) from files of the /proc file system. It's not necessary for lsof to read user structures on some systems (recent versions of HP-UX), because the data lsof needs can be found in the task or proc structures. In the end lsof gathers the same data, just from slightly different sources. /proc-based Linux Lsof -- a Different Approach ============================================== For a completely different approach to lsof construction, take a look at the /proc-based Linux sources in .../dialects/linux/proc. (The sources in .../dialects/linux/kmem are for a traditional lsof that uses /dev/kmem to read information from kernel structures.) The /proc-based lsof obtains all its information from the Linux /proc file system. Consequently, it is relatively immune to changes in Linux kernel structures and doesn't need to be re-compiled each time the Linux kernel version changes. There are some down-sides to the Linux /proc-based lsof: * It must run setuid-root in order to be able to read the /proc file system branches for all processes. In contrast, the /dev/kmem-based Linux lsof usually needs only setgid permission. * It depends on the exact character format of /proc files, so it is sensitive to changes in /proc file composition. * It is limited to the information a /proc file system implementor decides to provide. For example, if a /proc/net/<protocol> file lacks an inode number, the /proc-based lsof can't connect open socket files to that protocol. Another deficiency is that the /proc-based may not be able to report file offset (position) information, when it isn't available in the /proc/<PID>/fd/ entry for a file. In contrast the /dev/kmem-based lsof has full access to kernel structures and "sees" new data as soon as it appears. Of course, that new data requires that lsof be recompiled and usually also requires changes to lsof. Overall the switch from a /dev/kmem base to a /proc one is an advantage to Linux lsof. The switch was made at lsof revision 4.23 for Linux kernel versions 2.1.72 (approximately) and higher. The reason I'm not certain at which Linux kernel version a /proc-based lsof becomes possible is that the /proc additions needed to implement it have been added gradually to Linux 2.1.x in ways that I cannot measure. /proc-based lsof functions in many ways the same as /dev/kmem-based lsof. It scans the /proc directory, looking for <PID>/ subdirectories. Inside each one it collects process-related data from the cwd, exe, maps, root, and stat information files. It collects open file information from the fd/ subdirectory of each <PID>/ subdirectory. The lstat(2), readlink(2), and stat(2) system calls gather information about the files from the kernel. Lock information comes from /proc/locks. It is matched to open files by inode number. Mount information comes from /proc/mounts. Per domain protocol information comes from the files of /proc/net; it's matched to open socket files by inode number. The Linux /proc file system implementors have done an amazing job of providing the information lsof needs. The /proc-based lsof project has so far generated only two kernel modification: * A modification to /usr/src/linux/net/ipx/af_ipx.c adds the inode number to the entries of /proc/net/ipx. Jonathan Sergent did this kernel modification. It may be found in the .../dialects/linux/proc/patches subdirectory of the lsof distribution. * An experimental modification to /usr/src/linux/fs/stat.c allows lstat(2) to return file position information for /proc/<PID>/fd/<FD> files. Contact me for this modification. One final note about the /proc-based Linux lsof: it doesn't need any functions from the lsof library in the lib/ subdirectory. General Guidelines ------------------ These are the general guidelines for porting lsof 4 to a new Unix dialect: * Understand the organization of the lsof sources and the philosophies that guide their coding. * Understand the data requirements and determine the methods of locating the necessary data in the new dialect's kernel. * Pick a name for the subdirectory in lsof4/dialects for your dialect. Generally I use a vendor operating system name abbreviation. * Locate the necessary header files and #include them in the dialect's dlsof.h file. (You may not be able to complete this step until you have coded all dialect-specific functions.) * Determine the optional library functions of lsof to be used and set their definitions in the dialect's machine.h file. * Define the dialect's specific symbols and global storage in the dialect's dlsof.h and dstore.c files. * Code the dialect-specific functions in the appropriate source files of the dialect's subdirectory. Include the necessary prototype definitions of the dialect- specific functions in the dproto.h file in the dialect's subdirectory. * Define the dialect's Makefile and source construction shell script, Mksrc. * If there are #define's that affect how kernel structures are organized, and those #define's are needed when compiling lsof, build a MkKernOpts shell script to locate the #define's and supply them to the Configure shell script. Organization ------------ The code in a dialect-specific version of lsof comes from three sources: 1) functions common to all versions, located in the top level directory, lsof4; 2) functions specific to the dialect, located in the dialect's subdirectory -- e.g., lsof4/dialects/sun; 3) functions that are common to several dialects, although not to all, organized in a library, liblsof.a. The functions in the library source can be selected and customized with definitions in the dialect machine.h header files. The tree looks like this: lsof4 ----------------------+ 3) library -- | \ lsof4/lib 1) fully common functions + \ e.g., lsof4/main.c + lsof4/dialects/ / / / / \ + + + + + 2) dialect-specific subdirectories -- e.g., lsof4/dialects/sun The code for a dialect-specific version is constructed from these three sources by the Configure shell script in the top level lsof4 directory and definitions in the dialect machine.h header files. Configure uses the Mksrc shell script in each dialect's subdirectory, and may use an optional MkKernOpts shell script in selected dialect subdirectories. Configure calls the Mksrc shell script in each dialect's subdirectory to assemble the dialect-specific sources in the main lsof directory. Configure may call MkKernOpts to determine kernel compile-time options that are needed for compiling kernel structures correctly for use by lsof. Configure puts the options in a dialect-specific Makefile it build, using a template in the dialect subdirectory. The assembly of dialect-specific sources in the main lsof directory is usually done by creating symbolic links from the top level to the dialect's subdirectory. The LSOF_MKC environment variable may be defined prior to using Configure to change the technique used to assemble the sources -- most commonly to use cp instead of ln -s. The Configure script completes the dialect's Makefile by adding string definitions, including the necessary kernel compile-time options, to a dialect skeleton Makefile while copying it from the dialect subdirectory to the top level lsof4 directory. Optionally Makefile may call the dialect's MkKernOpts script to add string definitions. When the lsof library, lsof4/lib/liblsof.a, is compiled its functions are selected and customized by #define's in the dialect machine.h header file. Source File Naming Conventions ------------------------------ With one exception, dialect-specific source files begin with a lower case `d' character -- ddev.c, dfile.c, dlsof.h. The one exception is the header file that contains dialect-specific definitions for the optional features of the common functions. It's called machine.h for historical reasons. Currently all dialects use almost the same source file names. One exception to the rule happens in dialects where there must be different source files -- e.g., dnode[123].c -- to eliminate node header file structure element name conflicts. The source modules in a few subdirectories are organized that way. Unusual situations occur for NetBSD and OpenBSD, and for NEXTSTEP and OPENSTEP. Each pair of dialects is so close in design that the same dialect sources from the n+obsd subdirectory serves NetBSD and OpenBSD; from n+os, NEXTSTEP and OPENSTEP. These are common files in lsof4/: Configure the configuration script Customize does some customization of the selected lsof dialect Inventory takes an inventory of the files in an lsof distribution version the version number dialects/ the dialects subdirectory These are the common function source files in lsof4/: arg.c common argument processing functions lsof.h common header file that #include's the dialect-specific header files main.c common main function for lsof 4 misc.c common miscellaneous functions -- e.g., special versions of stat() and readlink() node.c common node reading functions -- readinode(), readvnode() print.c common print support functions proc.c common process and file structure functions proto.h common prototype definitions, including the definition of the _PROTOTYPE() macro store.c common global storage version.h the current lsof version number, derived from the file version by the Makefile usage.c functions to display lsof usage panel These are the dialect-specific files: Makefile the Makefile skeleton Mksrc a shell script that assists the Configure script in configuring dialect sources MkKernOpts an optional shell script that identifies kernel compile-time options for selected dialects -- e.g., Pyramid DC/OSx and Reliant UNIX ddev.c device support functions -- readdev() -- may be eliminated by functions from lsof4/lib/ dfile.c file processing functions -- may be eliminated by functions from lsof4/lib/ dlsof.h dialect-specific header file -- contains #include's for system header files and dialect-specific global storage declarations dmnt.c mount support functions -- may be eliminated by functions from lsof4/lib/ dnode.c node processing functions -- e.g., for gnode or vnode dnode?.c additional node processing functions, used when node header files have duplicate and conflicting element names. dproc.c functions to access, read, examine and cache data about dialect-specific process structures -- this file contains the dialect-specific "main" function, gather_proc_info() dproto.h dialect-specific prototype declarations dsock.c dialect-specific socket processing functions dstore.c dialect-specific global storage -- e.g., the nlist() structure machine.h dialect specific definitions of common function options -- e.g., a HASINODE definition to activate the readinode() function in lsof4/node.c The machine.h header file also selects and customizes the functions of lsof4/lib/. These are the lib/ files. Definitions in the dialect machine.h header files select and customize the contained functions that are to be compiled and archived to liblsof.a. Makefile.skel is a skeleton Makefile, used by Configure to construct the Makefile for the lsof library. cvfs.c completevfs() function USE_LIB_COMPLETEVFS selects it. CVFS_DEVSAVE, CVFS_NLKSAVE, CVFS_SZSAVE, and HASFSINO customize it. dvch.c device cache functions HASDCACHE selects them. DCACHE_CLONE, DCACHE_CLR, DCACHE_PSEUDO, DVCH_CHOWN, DVCH_DEVPATH, DVCH_EXPDEV, HASBLKDEV, HASENVDC, HASSYSDC, HASPERSDC, HASPERSDCPATH, and NOWARNBLKDEV customize them. fino.c find block and character device inode functions HASBLKDEV and USE_LIB_FIND_CH_INO select them. isfn.c hashSfile() and is_file_named() functions USE_LIB_IS_FILE_NAMED selects it. lkud.c device lookup functions HASBLKDEV and USE_LIB_LKUPDEV select them. pdvn.c print device name functions HASBLKDEV and USE_LIB_PRINTDEVNAME select them. prfp.c process_file() function USE_LIB_PROCESS_FILE selects it. FILEPTR, DTYPE_PIPE, HASPIPEFN, DTYPE_GNODE, DTYPE_INODE, DTYPE_PORT, DTYPE_VNODE, HASF_VNODE, HASKQUEUE, HASPRIVFILETYPE, HASPSXSHM and HASPSXSEM customize it. ptti.c print_tcptpi() function USE_LIB_PRINT_TCPTPI selects it. HASSOOPT, HASSBSTATE, HASSOSTATE, AHSTCPOPT, HASTCPTPIQ and HASTCPTPIW customize it. rdev.c readdev() function USE_LIB_READDEV selects it. DIRTYPE, HASBLKDEV, HASDCACHE, HASDNAMLEN, RDEV_EXPDEV, RDEV_STATFN, USE_STAT, and WARNDEVACCESS customize it. rmnt.c readmnt() function USE_LIB_READMNT selects it. HASFSTYPE, MNTSKIP, RMNT_EXPDEV, RMNT_FSTYPE, and MOUNTS_FSTYPE customize it. rnam.c BSD format name cache functions HASNCACHE and USE_LIB_RNAM select them. HASFSINO, NCACHE, NCACHE_NC_CAST, NCACHE_NM, NCACHE_NMLEN, NCACHE_NODEADDR, NCACHE_NODEID, NCACHE_NO_ROOT, NCACHE_NXT, NCACHE_PARADDR, NCACHE_PARID, NCACHE_SZ_CAST, NCHNAMLEN, X_NCACHE, and X_NCSIZE, customize them. rnch.c Sun format name cache functions HASNCACHE and USE_LIB_RNCH select them. ADDR_NCACHE, HASDNLCPTR, HASFSINO, NCACHE_DP, NCACHE_NAME, NCACHE_NAMLEN, NCACHE_NEGVN, NCACHE_NODEID, NCACHE_NXT, NCACHE_PARID, NCACHE_VP, X_NCACHE, and X_NCSIZE, customize them. snpf.c Source for the snprintf() family of functions USE_LIB_SNPF selects it. The comments and the source code in these library files give more information on customization. Coding Philosophies ------------------- A few basic philosophies govern the coding of lsof 4 functions: * Use as few #if/#else/#endif constructs as possible, even at the cost of nearly-duplicate code. When #if/#else/#endif constructs are necessary: o Use the form #if defined(s<symbol>) in preference to #ifdef <symbol> to allow easier addition of tests to the #if. o Indent them to signify their level -- e.g., #if /* level one */ # if /* level two */ # endif /* level two */ #else /* level one */ #endif /* level one */ o Use ANSI standard comments on #else and #endif statements. * Document copiously. * Aim for ANSI-C compatibility: o Use function prototypes for all functions, hiding them from compilers that cannot handle them with the _PROTOTYPE() macro. o Use the compiler's ANSI conformance checking wherever possible -- e.g., gcc's -ansi option. Data Requirements ----------------- Lsof's strategy in obtaining open file information is to access the process table via its proc structures, then obtain the associated user area and open file structures. The open file structures then lead lsof to file type specific structures -- cdrnodes, fifonodes, inodes, gnodes, hsfsnodes, pipenodes, pcnodes, rnodes, snodes, sockets, tmpnodes, and vnodes. The specific node structures must yield data about the open files. The most important items and device number (raw and cooked) and node number. (Lsof uses them to identify files and file systems named as arguments.) Link counts and file sizes are important, too, as are the special characteristics of sockets, pipes, FIFOs, etc. This means that to begin an lsof port to a new Unix dialect you must understand how to obtain these structures from the dialect's kernel. Look for kernel access functions -- e.g., the AIX readx() function, Sun and Sun-like kvm_*() functions, or SGI's syssgi() function. Look for clues in header files -- e.g. external declarations and macros. If you have access to them, look at sources to programs like ps(1), or the freely available monitor and top programs. They may give you important clues on reading proc and user area structures. An appeal to readers of dialect-specific news groups may uncover correspondents who can help. Careful reading of system header files -- e.g., <sys/proc.h> -- may give hints about how kernel storage is organized. Look for global variables declared under a KERNEL or _KERNEL #if. Run nm(1) across the kernel image (/vmunix, /unix, etc.) and look for references to structures of interest. Even if there are support functions for reading structures, like the kvm_*() functions, you must still understand how to read data from kernel memory. Typically this requires an understanding of the nlist() function, and how to use /dev/kmem, /dev/mem, and /dev/swap. Don't overlook the possibility that you may have to use the process file system -- e.g., /proc. I try to avoid using /proc when I can, since it usually requires that lsof have setuid(root) permission to read the individual /proc "files". Once you can access kernel structures, you must understand how they're connected. You must answer questions like: * How big are kernel addresses? How are they type cast? * How are kernel variable names converted to addresses? Nlist()? * How are the proc structures organized? Is it a static table? Are the proc structures linked? Is there a kernel pointer to the first proc structure? Is there a proc structure count? * How does one obtain copies of the proc structures? Via /dev/kmem? Via a vendor API? * If this is a Mach derivative, is it necessary to obtain the task and thread structures? How? * How does one obtain the user area (or the utask area in Mach systems) that corresponds to a process? * Where are the file structures located for open file descriptors and how are they located? Are all file structures in the user area? Is the file structure space extensible? * Where do the private data pointers in file structures lead? To gnodes? To inodes? To sockets? To vnodes? Hint: look in <sys/file.h> for DTYPE_* instances and further pointers. * How are the nodes organized? To what other nodes do they lead and how? Where are the common bits of information in nodes -- device, node number, size -- stored? Hint: look in the header files for nodes for macros that may be used to obtain the address of one node from another -- e.g., the VTOI() macro that leads from a vnode to an inode. * Are text reference nodes identified and how? Is it necessary to examine the virtual memory map of a process or a task to locate text references? Some kernels have text node pointers in the proc structures; some, in the user area; Mach kernels may have text information in the task structure, reached in various ways from the proc, user area, or user task structure. * How is the device table -- e.g., /dev or /devices -- organized? How is it read? Using direct or dirent structures? How are major/minor device numbers represented? How are device numbers assembled and disassembled? Are there clone devices? How are they identified? * How is mount information obtained? Getmntinfo()? Getmntent()? Some special kernel call? * How are sockets identified and organized? BSD-style? As streams? Are there streams? * Are there special nodes -- CD-ROM nodes, FIFO nodes, etc.? * How is the kernel's name cache organized? Can lsof access it to get partial name components? Dlsof.h and #include's ---------------------- Once you have identified the kernel's data organization and know what structures it provides, you must add #include's to dlsof.h to access their definitions. Sometimes it is difficult to locate the header files -- you may need to introduce -I specifications in the Makefile via the DINC shell variable in the Configure script. Sometimes it is necessary to define special symbols -- e.g., KERNEL, _KERNEL, _KMEMUSER -- to induce system header files to yield kernel structure definitions. Sometimes making those symbol definitions cause other header file and definition conflicts. There's no good general rule on how to proceed when conflicts occur. Rarely it may be necessary to extract structure definitions from system header files and move them to dlsof.h, create special versions of system header files, or obtain special copies of system header files from "friendly" (e.g., vendor) sources. The dlsof.h header file in lsof4/dialects/sun shows examples of the first case; the second, no examples; the third, the irix5hdr subdirectory in lsof4/dialects/irix (a mixture of the first and third). Building up the necessary #includes in dlsof.h is an iterative process that requires attention as you build the dialect-specific functions that references kernel structures. Be prepared to revisit dlsof.h frequently. Definitions That Affect Compilation ----------------------------------- The source files at the top level and in the lib/ subdirectory contain optional functions that may be activated with definitions in a dialect's machine.h header file. Some are functions for reading node structures that may not apply to all dialects -- e.g. CD-ROM nodes (cdrnode), or `G' nodes (gnode) -- and others are common functions that may occasionally be replaced by dialect-specific ones. Once you understand your kernel's data organization, you'll be able to decide the optional common node functions to activate. Definitions in machine.h and dlsof.h also enable or disable other optional common features. The following is an attempt to list all the definitions that affect lsof code, but CAUTION, it is only attempt and may be incomplete. Always check lsof4 source code in lib/ and dialects/, and dialect machine.h header files for other possibilities AFS_VICE See 00XCONFIG. AIX_KERNBITS specifies the kernel bit size, 32 or 64, of the Power architecture AIX 5.x kernel for which lsof was built. CAN_USE_CLNT_CREATE is defined for dialects where the more modern RPC function clnt_create() can be used in place of the deprecated clnttcp_create(). CLONEMAJ defines the name of the variable that contains the clone major device number. (Also see HAS_STD_CLONE and HAVECLONEMAJ.) DEVDEV_PATH defines the path to the directory where device nodes are stored, usually /dev. Solaris 10 uses /devices. DIALECT_WARNING may be defined by a dialect to provide a warning message that will be displayed with help (-h) and version (-v) output. FSV_DEFAULT defines the default file structure values to list. It may be composed of or'd FSV_* (See lsof.h) values. The default is none (0). GET_MAJ_DEV is a macro to get major portion from device number instead of via the standard major() macro. GET_MIN_DEV is a macro to get minor portion from device number instead of via the standard minor() macro. GET_MAX_FD the name of the function that returns an int for the maximum open file descriptor plus one. If not defined, defaults to getdtablesize. HAS9660FS enables CD9660 file system support in a BSD dialect. HAS_ADVLOCK_ARGS is defined for NetBSD and OpenBSD dialects whose <sys/lockf.h> references vop_advlock_args. HAS_AFS enables AFS support code for the dialect. HAS_ATOMIC_T indicates the Linux version has an <asm/atomic.h> header file and it contains "typedef struct .* atomic_t;" HASAOPT indicates the dialect supports the AFS -A option when HAS_AFS is also defined. HAS_ASM_TERMIOBITS indicates for Linux Alpha that the <asm/termiobits.h> header file exists. HASAX25CBPTR indicates that the Linux sock struct has an ax25_db pointer. HASBLKDEV indicates the dialect has block device support. HASBUFQ_H indicates the *NSD dialect has the <sys/bufq.h> header file. HASCACHEFS enables cache file system support for the dialect. HAS_CDFS enables CDFS file system support for the dialect. HASCDRNODE enables/disables readcdrnode() in node.c. HAS_CONST indicates that the compiler supports the const keyword. HASCPUMASK_T indicates the FreeBSD 5.2 or higher dialect has cpumask_t typedef's. HAS_CRED_IMPL_H indicates the Solaris 10 dialect has the <sys/cred_impl.h> header file available. HASCWDINFO indicates the cwdinfo structure is defined in the NetBSD <sys/filedesc.h>. HASDCACHE enables device file cache file support. The device cache file contains information about the names, device numbers and inode numbers of entries in the /dev (or /device) node subtree that lsof saves from call to call. See the 00DCACHE file of the lsof distribution for more information on this feature. HASDENTRY indicates the Linux version has a dentry struct defined in <linux/dcache.h>. HASDEVKNC indicates the Linux version has a kernel name cached keyed on device number. HAS_DINODE_U indicates the OpenBSD version has a dinode_u union in its inode structure. HASDNLCPTR is defined when the name cache entry of <sys/dnlc.h> has a name character pointer rather than a name character array. HASEFFNLINK indicates the *BSD system has the i_effnlink member in the inode structure. HASENVDC enables the use of an environment-defined device cache file path and defines the name of the environment variable from which lsof may take it. (See the 00DCACHE file of the lsof distribution for information on when HASENVDC is used or ignored.) HASEXT2FS is defined for BSD dialects for which ext2fs file system support can be provided. A value of 1 indicates that the i_e2din member does not exist; 2, it exists. HASF_VNODE indicates the dialect's file structure has an f_vnode member in it. HASFDESCFS enables file descriptor file system support for the dialect. A value of 1 indicates <miscfs/fdesc.h> has a Fctty definition; 2, it does not. HASFDLINK indicates the file descriptor file system node has the fd_link member. HASFIFONODE enables/disables readfifonode() in node.c. HAS_FL_FD indicates the Linux version has an fl_fd element in the lock structure of <linux/fs.h>. HAS_FL_FILE indicates the Linux version has an fl_file element in the lock structure of <linux/fs.h>. HAS_FL_WHENCE indicates the Linux version has an fl_whence element in the lock structure of <linux/fs.h>. HAS_F_OPEN indicates the UnixWare 7.x dialect has the f_open member in its file struct. HASFSINO enables the inclusion of the fs_ino element in the lfile structure definition in lsof.h. This contains the file system's inode number and may be needed when searching the kernel name cache. See dialects/osr/dproc.c for an example. HAS_JFS2 The AIX >= 5.0 dialect has jfs2 support. HASFSTRUCT indicates the dialect has a file structure the listing of whose element values can be enabled with +f[cfn]. FSV_DEFAULT defines the default listing values. HASFSTYPE enables/disables the use of the file system's stat(2) st_fstype member. If the HASFSTYPE value is 1, st_fstype is treated as a character array; 2, it is treated as an integer. See also the RMNT_EXPDEV and RMNT_FSTYPE documentation in lib/rmnt.c HASGETBOOTFILE indicates the NetBSD or OpenBSD dialect has a getbootfile() function. HASGNODE enables/disables readgnode() in node.c. HASHASHPID is defined when the Linux version (probably above 2.1.35) has a pidhash_next member in its task structure. HASHSNODE enables/disables readhsnode() in node.c. HASI_E2FS_PTR indicates the BSD dialect has a pointer in its inode to the EXTFS dinode. HASI_FFS indicates the BSD dialect has i_ffs_size in <ufs/ufs/inode.h>. HASI_FFS1 indicates the BSD dialect supports the fast UFS1 and UFS2 file systems. HAS_INKERNEL indicates the SCO OSR 6.0.0 or higher, or UnixWare 7.1.4 or higher system uses the INKERNEL symbol in <netinet/in_pcb.h> or <netinet/tcp_var.h>. HASINODE enables/disables readinode() in node.c. HASINOKNC indicates the Linux version has a kernel name cache keyed on inode address. HASINADDRSTR is defined when the inp_[fl]addr members of the inpcb structure are structures. HASINRIAIPv6 is defined if the dialect has the INRIA IPv6 support. (HASIPv6 will also be defined.) HASINT16TYPE is defined when the dialect has a typedef for int16 that may conflict with some other header file's redefinition (e.g., <afs/std.h>). HASINT32TYPE is defined when the dialect has a typedef for int32 that may conflict with some other header file's redefinition (e.g., <afs/std.h>). HASINTSIGNAL is defined when signal() returns an int. HAS_IPCLASSIFIER_H is defined for Solaris dialects that have the <inet/ipclassifier.h> header file. HAS_IPC_S_PATCH is defined when the HP-UX 11 dialect has the ipc_s patch installed. It has a value of 1 if the ipc_s structure has an ipc_ipis member, but the ipis_s structure lacks the ipis_msgsqueued member; 2, if ipc_s has ipc_ipis, but ipis_s lacks ipis_msgsqueued. HASIPv6 indicates the dialect supports the IPv6 Internet address family. HASKERNELKEYT indicates the Linux version has a __kernel_key_t typedef in <linux/types.h>. HASKERNFS is defined for BSD dialects for which /kern file system support can be provided. HASKERNFS_KFS_KT indicates *kfs_kt is in the BSD dialect's <miscfs/kernfs/kernfs.h>. HASKOPT enables/disables the ability to read the kernel's name list from a file -- e.g., from a crash dump file. HASKQUEUE indicates the dialect supports the kqueue file type. HASKVMGETPROC2 The *BSD dialect has the kvm_gettproc2() function. HAS_KVM_VNODE indicates the FreeBSD 5.3 or higher dialect has "defined(_KVM_VNODE)" in <sys/vnode.h>. HASLFILEADD defines additional, dialect-specific elements SETLFILEADD in the lfile structure (defined in lsof.h). HASLFILEADD is a macro. The accompanying SETFILEADD macro is used in the alloc_lfile() function of proc.c to preset the additional elements. HAS_LF_LWP is defined for BSD dialects where the lockf structure has an lf_lwp member. HASLFS indicates the *BSD dialect has log-structured file system support. HAS_LOCKF_ENTRY indicates the FreeBSD version has a lockf_entry structure in its <sys/lockf.h> header file. HAS_LWP_H is defined for BSD dialects that have the <sys/lwp.h> header file. HASMOPT enables/disables the ability to read kernel memory from a file -- e.g., from a crash dump file. HASMSDOSFS enables MS-DOS file system support in a BSD dialect. HASMNTSTAT indicates the dialect has a stat(2) status element in its mounts structure. HASMNTSUP indicates the dialect supports the mount supplement option. HASNAMECACHE indicates the FreeBSD dialect has a namecache structure definition in <sys/namei.h>. HASNCACHE enables the probing of the kernel's name cache to obtain path name components. A value of 1 directs printname() to prefix the cache value with the file system directory name; 2, avoid the prefix. HASNCVPID The *BSD dialect namecache struct has an nc_vpid member. HASNETDEVICE_H indicates the Linux version has a netdevice.h header file. HAS_NFS enables NFS support for the dialect. HASNFSKNC indicates the LINUX version has a separate NFS name cache. HASNFSPROTO indicates the NetBSD or OpenBSD version has the nfsproto.h header file. HASNFSVATTRP indicates the n_vattr member of the nfsnode of the *BSD dialect is a pointer. HASNLIST enables/disables nlist() function support. (See NLIST_TYPE.) HASNOFSADDR is defined if the dialect has no file structure addresses. (HASFSTRUCT must be defined.) HASNOFSCOUNT is defined if the dialect has no file structure counts. (HASFSTRUCT must be defined.) HASNOFSFLAGS is defined if the dialect has no file structure flags. (HASFSTRUCT must be defined.) HASNOFSNADDR is defined if the dialect has no file structure node addresses. (HASFSTRUCT must be defined.) HAS_NO_ISO_DEV indicates the FreeBSD 6 and higher system has no i_dev member in its iso_node structure. HAS_NO_LONG_LONG indicates the dialect has no support for the C long long type. This definition is used by the built-in snprintf() support of lib/snpf.c. HAS_NO_SI_UDEV indicates the FreeBSD 6 and higher system has no si_udev member in its cdev structure. HASNOSOCKSECURITY enables the listing of open socket files, even when HASSECURITY restricts listing of open files to the UID of the user who is running lsof, provided socket file listing is selected with the "-i" option. This definition is only effective when HASSECURITY is also defined. HASNULLFS indicates the dialect (usually *BSD) has a null file system. HASOBJFS indicates the Pyramid version has OBJFS support. HASONLINEJFS indicates the HP-UX 11 dialect has the optional OnlineJFS package installed. HASPERSDC enables the use of a personal device cache file path and specifies a format by which it is constructed. See the 00DCACHE file of the lsof distribution for more information on the format. HASPERSDCPATH enables the use of a modified personal device cache file path and specifies the name of the environment variable from which its component may be taken. See the 00DCACHE file of the lsof distribution for more information on the modified personal device cache file path. HASPINODEN declares that the inode number of a /proc file should be stored in its procfsid structure. HASPIPEFN defines the function that processes DTYPE_PIPE file structures. It's used in the prfp.c library source file. See the FreeBSD dialect source for an example. HASPIPENODE enables/disables readpipenode() in node.c. HASPMAPENABLED enables the automatic reporting of portmapper registration information for TCP and UDP ports that have been registered. HASPPID indicates the dialect has parent PID support. HASPR_LDT indicates the Solaris dialect has a pr_ldt member in the pronodetype enum. HASPR_GWINDOWS indicates the Solaris dialect has a pr_windows member in the pronodetype enum. HASPRINTDEV this value defines a private function for printing the dialect's device number. Used by print.c/print_file(). Takes one argument: char *HASPRINTDEV(struct lfile *) HASPRINTINO this value names a private function for printing the dialect's inode number. Used by print.c/print_file(). Takes one argument: char *HASPRINTINO(struct lfile *) HASPRINTNM this value names a private function for printing the dialect's file name. Used by print.c/print_file(). Takes one argument: void HASPRINTNM(struct lfile *) HASPRINTOFF this value names a private function for printing the dialect's file offset. Used by print.c/print_file(). Takes two arguments: char *HASPRINTOFF(struct lfile *, int ty) Where ty == 0 if the offset is to be printed in 0t<decimal> format; 1, 0x<hexadecimal>. HASPRINTSZ this value names a private function for printing the dialect's file size. Used by print.c/print_file(). Takes one argument: char *HASPRINTSZ(struct lfile *) void HASPRINTNM(struct lfile *) HASPRIVFILETYPE enables processing of the private file type, whose number (from f_type of the file struct) is defined by PRIVFILETYPE. HASPRIVFILETYPE defines the function that processes the file struct's f_data member. Processing is initiated from the process_file() function of the prfp.c library source file or from the dialect's own process_file() function. HASPRIVNMCACHE enables printing of a file path from a private name cache. HASPRIVNMCACHE defines the name of the printing function. The function takes one argument, a struct lfile pointer to the file, and returns non-zero if it prints a cached name to stdout. HASPRIVPRIPP is defined for dialects that have a private function for printing the IP protocol name. When this is not defined, the function to do that defaults to printiproto(). HASPROCFS defines the name (if any) of the process file system -- e.g., /proc. HASPROCFS_PFSROOT indicates PFSroot is in the BSD dialect's <miscfs/procfs/procfs.h>. HASPSEUDOFS indicates the FreeBSD dialect has pseudofs file system support. HASPSXSEM indicates the dialect has support for the POSIX semaphore file type. HASPSXSHM indicates the dialect has support for the POSIX shared memory file type. HASPTYFS indicates the *BSD dialect has a ptyfs file system. HASRNODE enables/disables readrnode() in node.c. HASRNODE3 indicates the HPUX 10.20 or lower dialect has NFS3 support with a modified rnode structure. HASRPCV2H The FreeBSD dialect has <nfs/rpcv2.h>. HAS_SANFS indicates the AIX system has SANFS file system support. HASSBSTATE indicates the dialect has socket buffer state information (e.g., SBS_* symbols) available. HASSECURITY enables/disables restricting open file information access. (Also see HASNOSOCKSECURITY.) HASSELINUX indicates the Linux dialect has SELinux security context support available. HASSETLOCALE is defined if the dialect has <locale.h> and setlocale(). HAS_SI_PRIV indicates the FreeBSD 6.0 and higher cdev structure has an si_priv member. HASSOUXSOUA indicates that the Solaris <sys/socketvar.h> has soua_* members in its so_ux_addr structure. HASSPECDEVD indicates the dialect has a special device directory and defines the name of a function that processes the results of a successful stat(2) of a file in that directory. HASSPECNODE indicates the DEC OSF/1, or Digital UNIX, or Tru64 UNIX <sys/specdev.h> has a spec_node structure definition. HASSNODE indicates the dialect has snode support. HAS_SOCKET_SK indicates that the Linux socket structure has the ``struct sock *sk'' member. HASSOOPT indicates the dialect has socket option information (e.g., SO_* symbols) available. HASSOSTATE indicates the dialect has socket state information (e.g., SS_* symbols) available. HASSTATVFS indicates the NetBSD dialect has a statvfs struct definition. HASSTAT64 indicates the dialect's <sys/stat.h> contains stat64. HAS_STD_CLONE indicates the dialect uses a standard clone device structure that can be used in common library function clone processing. If the value is 1, the clone table will be built by readdev() and cached when HASDCACHE is defined; if the value is 2, it is assumed the clone table is built independently. (Also see CLONEMAJ and HAVECLONEMAJ.) HASSTREAMS enables/disables streams. CAUTION, requires specific support code in the dialect sources. HAS_STRFTIME indicates the dialect has the gmtime() and strftime() C library functions that support the -r marker format option. Configure tests for the functions and defines this symbol. HASSYSDC enables the use of a system-wide device cache file and defines its path. See the 00DCACHE file of the lsof distribution for more information on the system-wide device cache file path option. HAS_SYS_PIPEH indicates the dialect has a <sys/pipe.h> header file. HAS_SYS_SX_H indicates the FreeBSD 7.0 and higher system has a <sys/sx.h> header file. HASTAGTOPATH indicates the DEC OSF/1, Digital UNIX, or Tru64 UNIX dialect has a libmsfs.so, containing tag_to_path(). HASTMPNODE enables/disables readtnode() in node.c. HASTCPOPT indicates the dialect has TCP option information (i.e., from TF_* symbols) available. HASTCPTPIQ is defined when the dialect can duplicate the receive and send queue sizes reported by netstat. HASTCPTPIW is defined when the dialect can duplicate the receive and send window sizes reported by netstat. HASTCPUDPSTATE is defined when the dialect has support for TCP and UDP state, including the "-s p:s" option and associated speed ehancements. HASTFS indicates that the Pyramid dialect has TFS file system support. HAS_UFS1_2 indicates the FreeBSD 6 and higher system has UFS1 and UFS2 members in its inode structure. HAS_UM_UFS indicates the OpenBSD version has UM_UFS[12] definitions. HASUNMINSOCK indicates the Linux version has a user name element in the socket structure; a value of 0 says there is no unix_address member; 1, there is. HASUINT16TYPE is defined when the dialect has a typedef for u_int16 that may conflict with some other header file's redefinition (e.g., <afs/std.h>). HASUTMPX indicates the dialect has a <utmpx.h> header file. HAS_UVM_INCL indicates the NetBSD or OpenBSD dialect has a <uvm> include directory. HAS_UW_CFS indicates the UnixWare 7.1.1 or above dialect has CFS file system support. HAS_UW_NSC indicates the UnixWare 7.1.1 or above dialect has a NonStop Cluster (NSC) kernel. HAS_V_LOCKF indicates the FreeBSD version has a v_lockf member in the vode structure, defined in <sys/vnode.h>. HASVMLOCKH indicates the FreeBSD dialect has <vm/lock.h>. HASVNODE enables/disables readvnode() function in node.c. HAS_V_PATH indicates the dialect's vnode structure has a v_path member. HAS_VSOCK indicates that the Solaris version has a VSOCK member in the vtype enum HASVXFS enables Veritas VxFS file system support for the dialect. CAUTION, the dialect sources must have the necessary support code. HASVXFSDNLC indicates the VxFS file system has its own name cache. HASVXFS_FS_H indicates <sys/fs/vx_fs.h> exists. HASVXFS_MACHDEP_H indicates <sys/fs/vx_machdep.h> exists. HASVXFS_OFF64_T indicates <sys/fs/vx_solaris.h> exists and has an off64_t typedef. HASXVFSRNL indicates the dialect has VxFS Reverse Name Lookup (RNL) support. HASVXFS_SOL_H indicates <sys/fs/vx_sol.h> exists. HASVXFS_SOLARIS_H indicates <sys/fs/vx_solaris.h> exists. HASVXFS_U64_T if HASVXFS_SOLARIS_H is defined, this variable indicates that <sys/fs/vx_solaris.h> has a vx_u64_t typedef. HASVXFSUTIL indicates the Solaris dialect has VxFS 3.4 or higher and has the utility libraries, libvxfsutil.a (32 bit) and libvxfsutil64.a (64 bit). HASVXFS_VX_INODE indicates that <sys/fs/vx_inode.h> contains a vx_inode structure. HASWIDECHAR indicates the dialect has the wide-character support functions iswprint(), mblen() and mbtowc(). HASXNAMNODE indicates the OSR dialect has <sys/fs/xnamnode.h>. HASXOPT defines help text for dialect-specific X option and enables X option processing in usage.c and main.c. HASXOPT_ROOT when defined, restricts the dialect-specific X option to processes whose real user ID is root. HAS_ZFS indicates the dialect has support for the ZFS file system. HASXOPT_VALUE defines the default binary value for the X option in store.c. HASZONES the Solaris dialect has zones. HAVECLONEMAJ defines the name of the status variable that indicates a clone major device number is available in CLONEMAJ. (Also see CLONEMAJ and HAS_STD_CLONE.) HPUX_KERNBITS defines the number of bits in the HP-UX 10.30 and above kernel "basic" word: 32 or 64. KA_T defines the type cast required to assign space to kernel pointers. When not defined by a dialect header file, KA_T defaults to unsigned long. KA_T_FMT_X defines the printf format for printing a KA_T -- the default is "%#lx" for the default unsigned long KA_T cast. LSOF_ARCH See 00XCONFIG. LSOF_BLDCMT See 00XCONFIG. LSOF_CC See 00XCONFIG. LSOF_CCV See 00XCONFIG. LSOF_HOST See 00XCONFIG. LSOF_INCLUDE See 00XCONFIG. LSOF_LOGNAME See 00XCONFIG. LSOF_MKC See the "The Mksrc Shell Script" section of this file. LSOF_SYSINFO See 00XCONFIG. LSOF_USER See 00XCONFIG. LSOF_VERS See 00XCONFIG. LSOF_VSTR See 00XCONFIG. MACH defines a MACH system. N_UNIXV defines an alternate value for the N_UNIV symbol. NCACHELDPFX defines C code to be executed before calling ncache_load(). NCACHELDSFX defines C code to be executed after calling ncache_load(). NEVER_HASDCACHE keeps the Customize script from offering to change HASDCACHE by its presence anywhere in a dialect's machine.h header file -- e.g., in a comment. See the Customize script or machine.h in dialects/linux/proc. NEVER_WARNDEVACCESS keeps the Customize script from offering to change WARNDEVACCESS by its presence anywhere in a dialect's machine.h header file -- including in a comment. See the Customize script or machine.h in dialects/linux/proc. NLIST_TYPE is the type of the nlist table, Nl[], if it is not nlist. HASNLIST must be set for this definition to be effective. NOWARNBLKDEV specifies that no warning is to be issued when no block devices are found. This definiton is used only when HASBLKDEV is also defined. OFFDECDIG specifies how many decimal digits will be printed for the file offset in a 0t form before switching to a 0x form. The count includes the "0t". A count of zero means the size is unlimited. PRIVFILETYPE is the number of a private file type, found in the f_type member of the file struct, to be processed by the HASPRIVFILETYPE function. See the AIX dialect sources for an example. _PSTAT_STREAM_GET_XPORT indicates the HP-UX PSTAT header files require this symbol to be defined for proper handling of stream export data. TIMEVAL_LSOF defines the name of the timeval structure. The default is timeval. /dev/kmem-based Linux lsof redefines timeval with this symbol to avoid conflicts between glibc and kernel definitions. TYPELOGSECSHIFT defines the type of the cdfs_LogSecShift member of the cdfs structure for UnixWare 7 and higher. UID_ARG_T defines the cast on a User ID when passed as a function argument. USE_LIB_COMPLETEVFS selects the use of the completevfs() function in lsof4/lib/cvfs.c. USE_LIB_FIND_CH_INO selects the use of the find_ch_ino() inode function in lsof4/lib/fino.c. Note: HASBLKDEV selects the has_bl_ino() function. USE_LIB_IS_FILE_NAMED selects the use of the is_file_named() function in lsof4/lib/isfn.c. USE_LIB_LKUPDEV selects the use of the lkupdev() function in lsof4/lib/lkud.c. Note: HASBLKDEV selects the lkupbdev() function. USE_LIB_PRINTDEVNAME selects the use of the printdevname() function in lsof4/lib/pdvn.c. Note: HASBLKDEV selects the printbdevname() function. USE_LIB_PRINT_TCPTPI selects the use of the print_tcptpi() function in lsof4/lib/ptti.c. USE_LIB_PROCESS_FILE selects the use of the process_file() function in lsof4/lib/prfp.c. USE_LIB_READDEV selects the use of the readdev() and stkdir() functions in lsof4/lib/rdev.c. USE_LIB_READMNT selects the use of the readmnt() function in lsof4/lib/rmnt.c. USE_LIB_RNAM selects the use of the device cache functions in lsof4/lib/rnam.c. Note: HASNCACHE must also be defined. USE_LIB_RNCH selects the use of the device cache functions in lsof4/lib/rnch.c. Note: HASNCACHE must also be defined. USE_STAT is defined for those dialects that must use the stat(2) function instead of lstat(2) to scan /dev -- i.e., in the readdev() function. VNODE_VFLAG is an alternate name for the vnode structure's v_flag member. WARNDEVACCESS enables the issuing of a warning message when lsof is unable to access /dev (or /device) or one of its subdirectories, or stat(2) a file in them. Some dialects (e.g., HP-UX) have many inaccessible subdirectories and it is appropriate to inhibit the warning for them with WARNDEVACCESS. The -w option will also inhibit these warnings. WARNINGSTATE when defined, disables the default issuing of warning messages. WARNINGSTATE is undefined by default for all dialects in the lsof distribution. WIDECHARINCL defines the header file to be included (if any) when wide-character support is enabled with HASWIDECHAR. zeromem() defines a macro to zero memory -- e.g., using bzero() or memset(). Any dialect's machine.h file and Configure stanza can serve as a template for building your own. All machine.h files usually have all definitions, disabling some (with comment prefix and suffix) and enabling others. Options: Common and Special --------------------------- All but one lsof option is common; the specific option is ``-X''. If a dialect does not support a common option, the related #define in machine.h -- e.g., HASCOPT -- should be deselected. The specific option, ``-X'', may be used by any dialect for its own purpose. Right now (May 30, 1995) the ``-X'' option is binary (i.e., it's not allowed arguments of its own, and its value must be 0 or 1) but that could be changed should the need arise. The option is enabled with the HASXOPT definition in machine.h; its default value is defined by HASXOPT_VALUE. The value of HASXOPT should be the text displayed for ``-X'' by the usage() function in usage.c. HASXOPT_VALUE should be the default value, 0 or 1. AIX for the IBM RICS System/6000 defines the ``-X'' option to control readx() usage, since there is a bug in AIX kernels that readx() can expose for other processes. Defining Dialect-Specific Symbols and Global Storage ---------------------------------------------------- A dialect's dlsof.h and dstore.c files contain dialect-specific symbol and global storage definitions. There are symbol definitions, for example, for function and data casts, and for file paths. Dslof.h defines lookup names the nlist() table -- X_* symbols -- when nlist() is being used. Global storage definitions include such things as structures for local Virtual File System (vfs) information; mount information; search file information; and kernel memory file descriptors -- e.g., Kmem for /dev/kmem, Mem for /dev/mem, Swap for /dev/drum. Coding Dialect-specific Functions --------------------------------- Each supported dialect must have some basic functions that the common functions of the top level may call. Some of them may be obtained from the library in lsof4/lib, selected and customized by #define's in the dialect machine.h header file. Others may have to be coded specifically for the dialect. Each supported dialect usually has private functions, too. Those are wholly determined by the needs of the dialect's data organization and access. These are some of the basic functions that each dialect must supply -- they're all defined in proto.h: initialize() function to initialize the dialect is_file_named() function to check if a file was named by an optional file name argument (lsof4/lib/isfn.c) gather_proc_info() function to gather process table and related information and cache it printchdevname() function to locate and optionally print the name of a character device (lsof4/lib/pdvn.c) print_tcptpistate() function to print the TCP or TPI state for a TCP or UDP socket file, if the one in lib/ptti.c isn't suitable (define USE_LIB_PRINT_TCPTPI to activate lib/ptti.c) process_file() function to process an open file structure (lsof4/lib/prfp.c) process_node() function to process a primary node process_socket() function to process a socket readdev() and stkdir() functions to read and cache device information (lsof4/lib/rdev.c) readmnt() function to read mount table information (lsof4/lib/rmnt.c) Other common functions may be needed, and might be obtained from lsof4/lib, depending on the needs of the dialect's node and socket file processing functions. Check the functions in lsof4/lib and specific lsof4/dialects/* files for examples. As you build these functions you will probably have to add #include's to dlsof.h. Function Prototype Definitions and the _PROTOTYPE Macro ------------------------------------------------------- Once you've defined your dialect-specific definitions, you should define their prototypes in dproto.h or locally in the file where they occur and are used. Do this even if your compiler is not ANSI compliant -- the _PROTOTYPE macro knows how to cope with that and will avoid creating prototypes that will confuse your compiler. The Makefile ------------ Here are some general rules for constructing the dialect Makefile. * Use an existing dialect's Makefile as a template. * Make sure the echo actions of the install rule are appropriate. * Use the DEBUG string to set debugging options, like ``-g''. You may also need to use the -O option when forking and SIGCHLD signals defeat your debugger. * Don't put ``\"'' in a compiler flags -D<symbol>=<string> clause in your Makefile. Leave off the ``\"'' even though you want <string> to be a string literal and instead adapt the N_UNIX* macros you'll find in Makefiles for FreeBSD and Linux. That will allow the Makefile's version.h rule to put CFLAGS into version.h without having to worry about the ``\"'' sequences. * Finally, remember that strings can be passed from the top level's Configure shell script. That's an appropriate way to handle options, especially if there are multiple versions of the Unix dialect to which you are porting lsof 4. The Mksrc Shell Script ---------------------- Pattern your Mksrc shell script after an existing one from another dialect. Change the D shell variable to the name of your dialect's subdirectory in lsof4/dialects. Adjust any other shell variable to your local conditions. (Probably that won't be necessary.) Note that, if using symbolic links from the top level to your dialect subdirectory is impossible or impractical, you can set the LSOF_MKC shell variable in Configure to something other than "ln -s" -- e.g., "cp," and Configure will pass it to the Mksrc shell script in the M environment variable. The MkKernOpts Shell Script --------------------------- The MkKernOptrs shell script is used by some dialects -- e.g., Pyramid DC/OSx and Reliant UNIX -- to determine the compile-time options used to build the current kernel that affect kernel structure definitions, so those same options can be used to build lsof. Configure calls MkKernOpts for the selected dialects. If your kernel is built with options that affect structure definitions. -- most commonly affected are the proc structure from <sys/proc.h> and the user structure from <sys/user.h> -- check the MkKernOpts in lsof4/dialects/irix for a comprehensive example. Testing and the Lsof Test Suite ------------------------------- Once you have managed to create a port, here are some tips for testing it. * First look at the test suite in the tests/ sub-directory of the lsof distribution. While it will need to be customized to be usable with a new port, it should provide ideas on things to test. Look for more information about the test suite in the 00TEST file. * Pick a simple process whose open files you are likely to know and see if the lsof output agrees with what you know. (Hint: select the process with `lsof -p <process_PID>`.) Are the device numbers and device names correct? Are the file system names and mount points correct? Are inode numbers and sizes correct? Are command names, file descriptor numbers, UIDs, PIDs, PGIDs, and PPIDs correct? A simple tool that does a stat(2) of the files being examined and reports the stat struct contents can provide a reference for some values; so can `ls -l /dev/<device>`. * Let lsof list information about all open files and ask the same questions. Look also for error messages about not being able to read a node or structure. * Pick a file that you know is open -- open it and hold it that way with a C program (not vi), if you must. Ask lsof to find the file's open instance by specifying its path to lsof. * Create a C program that opens a large number of files and holds them open. Background the test process and ask lsof to list its files. * Generate some locks -- you may need to write a C program to do this, hold the locked file open, and see if lsof can identify the lock properly. You may need to write several C programs if your dialect supports different lock functions -- fnctl(), flock(), lockf(), locking(). * Identify a process with known Internet file usage -- inetd is a good one -- and ask lsof to list its open files. See if protocols and service names are listed properly. See if your lsof identifies Internet socket files properly for rlogind or telnetd processes. * Create a UNIX domain socket file, if your dialect allows it, hold it open by backgrounding the process, and see if lsof can identify the open UNIX domain socket file properly. * Create a FIFO file and see what lsof says about it. * Watch an open pipe -- `lsof -u <your_login> | less` is a good way to do this. * See if lsof can identify NFS files and their devices properly. Open and hold open an NFS file and see if lsof can find the open instance by path. * If your test system has CD-ROM and floppy disk devices, open files on them and see if lsof reports their information correctly. Such devices often have special kernel structures associated with them and need special attention from lsof for their identification. Pay particular attention to the inode numbers lsof reports for CD-ROM and floppy disk files -- often they are calculated dynamically, rather than stored in a kernel node structure. * If your implementation can probe the kernel name cache, look at some processes with open files whose paths you know to see if lsof identifies any name components. If it doesn't, make sure the name components are in the name cache by accessing the files yourself with ls or a similar tool. * If your dialect supports the /proc file system, use a C program to open files there, background a test process, and ask lsof to report its open files. * If your dialect supports fattach(), create a small test program to use it, background a test process, and ask lsof to report its open files. I can supply some quick-and-dirty tools for reporting stat buffer contents, holding files open, creating UNIX domain files, creating FIFOs, etc., if you need them. Where Next? ----------- Is this document complete? Certainly not! One might wish that it were accompanied by man pages for all lsof functions, by free beer or chocolates, by ... (You get the idea.) But those things are not likely to happen as long as lsof is a privately supported, one man operation. So, if you need more information on how lsof is constructed or works in order to do a port of your own, you'll have to read the lsof source code. You can also ask me questions via email, but keep in mind the private, one-man nature of current lsof support. Vic Abell <abe@purdue.edu> October 23, 2008
|
http://opensource.apple.com/source/lsof/lsof-42/lsof/00PORTING
|
CC-MAIN-2014-41
|
refinedweb
| 9,217
| 59.4
|
Python is the language of choice for shell scripting and task automation. It is popular in system administration because it can execute shell commands using only its default libraries. In this tutorial, you will learn how to run Linux shell commands with Python using the os and subprocess modules.
Introduction
Nowadays, automation is a buzzword as hot as a processor running at 100% in a room with no AC. Home management, data extraction, the omniscient talking boxes in the kitchen, and even self-driving cars—they are all products of automation. Well, it makes sense since we’re living in the fourth industrial revolution. Heard of it? It is where humans and machines try to work as one, and it is happening now.
Using a Raspberry Pi even opens more doors in automation. With its GPIO, you can interface the credit-card sized computer into almost anything that throws or receives digital data. And since it is a fully-fledged Linux computer, you can automate your computer tasks as well. What’s more, Python makes it unimaginably easier! There are two ways to run Linux commands with Python: using the os module and using the subprocess module.
Using the OS Module
First is the os module. According to official documentation, the os module provides a portable way of using operating system dependent functionality. Ain’t that convenient? With short python codes, you can already perform standard operating system tasks without having to interact with the Desktop interface. The system method allows you to do exactly this. To use it to run a Linux command, your code should look like below.
Sample Code using system()
import os os.system('pwd') os.system('cd ~') os.system('ls -la')
This 4-liner checks your current directory, change location to your home directory, and lists all the contents in detail. It’s a pretty straightforward implementation, but there’s a downside. With
system(), you are not allowed to store the resulting output as a variable.
Instead, you can use the
popen() method, which is still under the os module. It opens a pipe from or to the command line. A pipe connects a command’s output to another command’s input. This makes it accessible within Python. To use
popen() to store as a variable, see the example code below.
Sample code using popen()
import os stream = os.popen('ls -la') output = stream.readlines()
If you print the stream variable, you will see its return data. This consists of the actual commands executed, the mode, and the address. Furthermore, if you want to get the whole output as one string, change
readlines() to
read().
Using the Subprocess Module
The second way to run Linux commands with Python is by using the newer subprocess module. This module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes. It was created to replace both
os.system() and
os.popen() functions.
The only method that matters in the subprocess is
run(). With it, you can do everything we’ve done above and more using different arguments. Use the following codes as reference:
Writing a simple command using subprocess
import subprocess subprocess.run('ls')
Using the method like this will execute the command ls in your terminal. Unlike
os.system(), it doesn’t work when you add a switch and enter it fully like
subprocess.run('ls -la'). This feature allows the method to take care of quoting and escaping problems hence preventing errors with formatting. To execute
ls -la, you must pass the command as a list:
subprocess.run(['ls','-la'). Alternatively, you can make the shell argument True to pass the whole thing as a string. Just take note that this can pose a security risk if you’re using an untrusted input source.
Writing a command with switches
import subprocess x = subprocess.run(['ls', '-la'])
import subprocess subprocess.run(['ls -la'], shell=True)
Next, to store the command output inside a variable, simply do it just like any other data. The result won’t be what you’re expecting, however. Since the main purpose of ‘run’ is to execute the shell command within python, the result won’t be like the output you see in the terminal. It will be the return data just like in
os.open. You can check it using the code below.
Storing the command output to a variable
import subprocess x = subprocess.run(['ls', '-la']) print(x) print(x.args) print(x.returncode) print(x.stdout) print(x.stderr)
This sketch dissects the return data of your command using the method’s arguments. Here are some of the frequently used ones:
- args – returns the actual commands executed
- returncode – returns the return code of the output; 0 means no error
- stdout – captured stdout from the child process
- stderr – captured stderr stream from the child process
Since we did not capture the previous code’s output, we will get ‘none’ with both stdout and stderr arguments. To enable the capture output argument, refer to the following code:
import subprocess x = subprocess.run(['ls', '-la'], capture_output=True)
If you print x, you will get the list of items in your current directory of type bytes. Convert it to a string by writing
x.stdout.decode(). Alternatively, you can pass the argument
text=True with the main function. The output should now look exactly the same as what you have in the terminal.
Lastly, we will run Linux commands with Python and save the output you see in the terminal into a text file—a simple task with subprocess. You just need to redirect the stdout stream to your text file using the argument
stdout.
Saving the command output to a text file
import subprocess with open('list.txt', 'w') as f: subprocess.run(['ls','-la'], stdout=f)
That’s it for this tutorial! To summarize, for quick execution of a short script, consider using
os.system() and
os.popen() methods. But if you have a more comprehensive script to run, you might want to use the
subprocess module instead.
great article! keep them coming!
Great article!.
Thanks
|
https://www.circuitbasics.com/run-linux-commands-with-python/?recaptcha-opt-in=true
|
CC-MAIN-2021-39
|
refinedweb
| 1,022
| 57.87
|
FSM Generator
July 11, 2014
[ Our solution today is written by Matthew Arcus a software engineer in Cambridge, UK, mainly using C++ for networking at work, but who in the past has been paid to write Lisp and ML. Matthew wrote a comment on the previous exercise suggesting a program to generate finite state machines, and I contacted him to ask him to write that program. He graciously “volunteered,” and today’s solution is his response. Guest authors are always welcome at Programming Praxis; use the button on the menu bar above to contact me if you have an idea for an exercise. ]
Simple string processing functions, for example, removing singleton occurrences of a character, can often be implemented by a finite state machine augmented with the ability to output symbols. One such class of machine are Mealy machines, named for George H. Mealy, who defined the concept in 1954. Formally, each transition in a Mealy machine has a single associated output symbol, and the machine outputs this symbol whenever it makes that transition. For practical purposes, we can allow a machine to have N output symbols for each state, where N ≥ 0, and then, for example, we can express our singleton problem by the rules:
State 0:
X -> 1,
* -> 0,*
State 1:
X -> 1,XX
* -> 0,*
We define a machine with two states, 0 and 1. In state 0, it will accept input character X and go to state 1 with no output, or accept any other input (represented by *), output that input (another *) and stay in state 0. In state 1, it will accept a second X, stay in state 1 and output two X’s, or any other character which is output, then the machine goes back to state 0. It should be easy to see that this machine will remove singleton occurrences of X.
This exercise is to implement a program that takes a description of a Mealy machine in some suitable format, and generates a function that takes a string parameter and outputs the result of running that machine with the given string as input.
This makes a nice exercise in defining Lisp macros; modern Scheme uses “hygienic macros” that remove a lot of the problems with traditional macros, particularly to do with the avoidance of accidental variable capture, but it’s nice to do things the old-fashioned way sometimes, if only to see what we are missing, so this solution is in Common Lisp and also makes use of that language’s loop facility.
We will use a simple S-expression format for the machine rules, for example:
(mealy s
((0
(#\X 1)
(nil 0 nil))
(1
(#\X 1 #\X #\X)
(nil 0 nil)))))
This represents our singleton machine with
nil used as a wildcard.
A traditional Lisp macro is just a function that returns a piece of Lisp syntax that replaces the macro expression in the program. Conceptually, it’s just like a C macro, with the important difference that we have the full power of the Lisp language at our disposal. We need to be careful to ensure that any local variables used in the macro don’t clash with any variables used in the macro parameters — in our case, we can use variables to represent symbols or characters. This is what modern hygienic macros make straightforward, but here we will take the traditional approach of generating new, unique, symbols using the (gensym) function.
Writing macros is made much easier using the backquote feature: a backquoted expression is a literal with embedded expressions that are evaluated and inserted (with ,) or spliced (with ,@) into the literal, so
(let ((x 1)) `(+ ,x ,x)) and
(let ((x '(1 1))) `(+ ,@x)) are both just
'(+ 1 1).
We coerce the input string to a list before iterating, and coerce the result back to a string at the end, though it would be straightforward to extend the macro to work with other sequence types.
(defmacro mealy (input actions)
(let ((c (gensym)) ;; Avoid variable capture
(state (gensym))
(out (gensym))) ;; Put output here
`(loop for ,c in (coerce ,input 'list) ;; Convert input into a list
with ,state = 0
while (>= ,state 0)
append
(cond
,@(mapcar
#'(lambda (statespec)
(let ((thisstate (car statespec)))
`((= ,state ,thisstate)
(cond
,@(mapcar
#'(lambda (actionspec)
(let ((match (car actionspec))
(newstate (cadr actionspec))
(output (cddr actionspec)))
`(,(if (eq match nil) t `(eq ,c ,match))
;; Reset the state if necessary
,@(if (not (= thisstate newstate)) `((setq ,state ,newstate)))
(list
,@(mapcar
;; If output char is nil, just echo the input.
#'(lambda(outchar) (if (eq outchar nil) c outchar))
(cddr actionspec))))))
(cdr statespec))))))
actions)) into ,out
finally (return (coerce ,out 'string)))))
We can get an idea of what our macro expands to using
macro-expand-1:
(setq machine
'(mealy s
((0
(c 1)
(nil 0 nil))
(1
(c 1 c c)
(nil 0 nil)))))
(pprint (macroexpand-1 machine))
(LOOP FOR #:G3210 IN (COERCE S 'LIST)
WITH #:G3211 = 0
WHILE (>= #:G3211 0)
APPEND
(COND ((= #:G3211 0)
(COND ((EQ #:G3210 C)
(SETQ #:G3211 1) (LIST))
(T (LIST #:G3210))))
((= #:G3211 1)
(COND ((EQ #:G3210 C)
(LIST C C))
(T (SETQ #:G3211 0) (LIST #:G3210)))))
INTO #:G3212
FINALLY (RETURN (COERCE #:G3212 'STRING)))
We can use character constants in our macro:
(defun singleton1 (s)
(mealy s
((0
(#\X 1)
(nil 0 nil))
(1
(#\X 1 #\X #\X)
(nil 0 nil)))))
(print (singleton1 "XbbXXbX"))
Or pass in a variable:
(defun singleton2 (s c)
(mealy s
((0
(c 1)
(nil 0 nil))
(1
(c 1 c c)
(nil 0 nil)))))
(print (singleton2 "XbbXXbX" #\X))
Or just use the macro inline; this doubles all characters except #\a:
(print (mealy "abcacb" ((0 (#\a 0 nil) (nil 0 nil nil)))))
You can see the program in action at.
As there is already a very good FSM for Python written by Noah Spurrier, I did not try to make another one. I give here how the FSM can be used for the remove singleton problem.
In the common-lisp code above, the “output” variable is defined in the inner “let”, but left unused (courtesy of my CLISP). It can be safely commented out.
I don’t think the two-state Mealy machine in the proposed solution will correctly handle 3 or more ‘X’s in a row.
For example, an input of “XbbXXXbX” yields and output of “bbXXXXb”. I think a third state is needed:
[pre]
State 0:
X -> 1,
* -> 0,*
State 1:
X -> 2,XX
* -> 0,*
State 2:
X -> 2,X
* -> 0,*
[/pre]
Mirko: good catch, thanks, I think the program should say “output” instead of the later occurrence of “(cddr actionspec)”
Mike: also well spotted (and particularly stupid on my part as I seem to have got it right in my solution to the original problem).
This should be the right thing:
|
https://programmingpraxis.com/2014/07/11/fsm-generator/2/
|
CC-MAIN-2017-09
|
refinedweb
| 1,120
| 52.36
|
Sphinx Extension¶
We provide a Sphinx extension for including GMT/Python
figures in your documentation. The extension defines the
gmt-plot directive that
will take execute the given code and insert the generated figure into the document.
For example, the following rst code:
.. gmt-plot:: import pygmt fig = pygmt.Figure() fig.basemap(region="g", projection="W0/10i", frame="afg") fig.show()
will be rendered into the following in the compiled HTML pages:
import pygmt fig = pygmt.Figure() fig.basemap(region="g", projection="W0/10i", frame="afg") fig.show()
The last statement of the code-block should contain a call to
pygmt.Figure.show.
Anything printed to STDOUT will be captured and included between the figure and the
code. For example:
print("The variables from the previous block are preserved.") fig.coast(land="gray") fig.show()
The variables from the previous block are preserved.
The HTML rich display features that work in Jupyter notebooks also work for the extension:
quakes = pygmt.datasets.load_usgs_quakes() fig2 = pygmt.Figure() fig2.plot(x=quakes.longitude, y=quakes.latitude, region=[-180, 180, -90, 90], projection="X10id", color="yellow", style="c0.2c", pen="black") fig2.show(method="globe")
Installing¶
The extension comes with PyGMT. All you have to do is enable it in your
conf.py
file:
extensions = [ ..., "pygmt.sphinxext.gmtplot", ]
However, you will need to have IPython installed for the extension to work.
Options¶
The directive has the following options:
.. gmt-plot:: :width: size # Set the width of the image (should contain a unit, like 400px) :center: # If set, will center the output image :hide-code: # If set, then hide the code and only show the plot :namespace: # Specify a plotting namespace that is persistent within the page
|
https://www.pygmt.org/0.0.1a0/sphinxext.html
|
CC-MAIN-2020-34
|
refinedweb
| 282
| 60.31
|
CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3Vchva_349096 Jun 21, 2018 9:01 AM
Hi,
I am working with the CYBLE-224116 extended range PSoC4/BLE module. The module works great, however I am having a problem getting it to sleep the way the other PSoC4 devices do.
With my other PSoC4 devices such as the CYBLE-014008, when I put the device into deep sleep, the power consumption follows the specification of 1.3uA.
With this new CYBLE-224116 module, I am seeing a current draw of about 1.3mA @ 3.3V. The only components I have attached to this module is a red and blue LED on pins P1[0] and P0[1] and a 1uF capacitor on VREF to ground. I will attach the project to this thread as well so you can see that as well. Below is my main.c which I am using to evaluate the module's low power. Any thoughts would be greatly appreciated.
Thanks.
- Chris
#include "project.h"
#define CYREG_SRSS_TST_DDFT_CTRL 0x40030008
int main(void)
{
// Variables
uint8 intrStatus;
// Enable interrupts
CyGlobalIntEnable;
// Turn on the red LED for startup
LED_RED_Write(1);
LED_BLUE_Write(0);
// Startup code
CyDelay(500);
// Disable the PA/LNA
CY_SET_XTND_REG32((void CYFAR *)(CYREG_BLE_BLESS_RF_CONFIG), 0x0331);
CY_SET_XTND_REG32((void CYFAR *)(CYREG_SRSS_TST_DDFT_CTRL), 0x80000302);
CSD_Write(0);
CPS_Write(0);
// Turn off the LEDs
LED_RED_Write(0);
LED_BLUE_Write(0);
for(;;)
{
// Turn on the blue LED for 500 ms
LED_BLUE_Write(1);
CyDelay(500);
LED_BLUE_Write(0);
// Sleep the processor
intrStatus = CyEnterCriticalSection();
CySysPmDeepSleep();
CyExitCriticalSection(intrStatus);
}
}
- TESTING.cydsn.zip 719.5 K
1. Re: CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3VJoMe_264151 Jun 21, 2018 10:31 AM (in response to chva_349096)
You need to disable debugging for the project to reduce current consumption. In "System" view change "Debug Select" to "GPIO".
Bob
2. Re: CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3Vepr_1639216 Jun 21, 2018 11:06 AM (in response to chva_349096)1 of 1 people found this helpful
Things that draw current while in deep-sleep mode:
Pin outputs (depending on configuration)
BLE peripheral
Clocks (if running)
WDT (almost unnoticeable from what I've seen empirically)
ADC and other peripherals that may not have been put into "Sleep" mode for deep sleep.
Debug selection (as JoMe_264151 stated)
3. Re: CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3VPY_21
Jun 22, 2018 11:23 AM (in response to chva_349096)
Hello Chris,
Before entering into the deep sleep mode please follow the below steps.
1. You have to disable debugging for the project in order to reduce current consumption. In Design Wide Resources go to "system" view and change "Debug Select" to GPIO.
2. In your program before entering into deep sleep mode you need to change the pins to high impedance mode through APIs as shown.
LED_BLUE_SetDriveMode(Pin_DM_DIG_HIZ);
LED_RED_SetDriveMode(Pin_DM_DIG_HIZ);
CSD_SetDriveMode(Pin_DM_DIG_HIZ);
CPS_SetDriveMode(Pin_DM_DIG_HIZ);
3. Before entering into deep sleep mode you need to stop ECO(External Crystal Oscillator) by using API CySysClkEcoStop().
Thanks,
PSYU.
4. Re: CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3Vchva_349096 Jun 24, 2018 8:13 AM (in response to PY_21)
Thanks. I will give these suggestions a try.
5. Re: CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3Vchva_349096 Jul 3, 2018 8:34 AM (in response to PY_21)
Hi,
No luck so far. But there are some improvements. I am now seeing a current draw of about 600uA. Still a far cry from the documented sub-2uA, but certainly much better...
I have tried setting the Debug Select to "GPIO" which has not resolved the issue.
I have the build mode set to release in case that has any effect:
I am now setting the LED drive modes to:
LED_BLUE_SetDriveMode(Pin_DM_DIG_HIZ);
LED_RED_SetDriveMode(Pin_DM_DIG_HIZ);
I am setting the drive mode on the CPD and CPS pins to High-Z as well now. I am not sure if this is contrary to what is required however.
CSD_SetDriveMode(CSD_DM_DIG_HIZ);
CPS_SetDriveMode(CPS_DM_DIG_HIZ);
I am disabling the ECO clock now before sleep.
CySysClkEcoStop();
Being that the LEDs are the only components on the board, I decided to remove it. Oddly that has brought the power consumption to an acceptable 4uA. I have never had an LED cause an issue like this before and it is the same circuit and components I use with other Cypress chips:
GPIO ---- 330 Ohm resistor ---- Red LED ----- GND
Any thoughts on that one? I figured the High-Z mode would have resolved that issue.
- Chris
6. Re: CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3Vchva_349096 Jul 3, 2018 9:05 AM (in response to chva_349096)
Interestingly, it seems that when I place the LED drive pins into High-Z mode is when I see the higher current consumption. If I leave them in Strong mode, the consumption is around 4uA.
Operating them in Strong mode results in 4uA current draw when the LEDs are off. (GOOD)
Operating them in Pull up/down results in 4uA current draw when the LEDs are off. (GOOD)
Operating them in Open-Drain drives high results in > 300 uA in current draw when the LEDs are off. (BAD)
Operating them in Digital High-Z results in > 300 uA in current draw when the LEDs are off. (BAD)
Operating them in Analog High-Z results in 4uA current draw when the LEDs are off (GOOD)
Any thoughts as to why this would be the case?
Thanks.
- Chris
7. Re: CYBLE-224116 Deep Sleep consuming 1.3mA @ 3.3VPY_21
Jul 3, 2018 10:29 PM (in response to chva_349096)1 of 1 people found this helpful
Hello Chris,
In case of Digital High-Z mode the pin has buffer which will be the cause for leakage current. Configuring all unused GPIOs to Analog HI-Z unless there is a specific reason to use a different drive mode will be the good practice.
For more details of GPIO pins please refer PSoC® 4 and PSoC Analog Coprocessor – Using GPIO Pins.
Thanks,
PSYU.
|
https://community.cypress.com/thread/34849
|
CC-MAIN-2020-50
|
refinedweb
| 983
| 71.55
|
Java Date class "addition" FAQ: Can you show me how to add various times increments to a Java Date object?
I've been doing a lot of work with the Date class in Java lately (both java.util.Date and java.sql.Date), and before leaving this area for a while, I thought I'd put together some "Java Date add" examples that demonstrate various "date add" and "calendar add" techniques, including how to get the date and time one hour from now, tomorrow's date, next week, next month, and next year.
To help demonstrate these Date addition techniques I've put together the following
JavaDateAddExamples class. I've documented the class source code reasonably well, so hopefully it will all make sense:
import java.util.*; /** * A collection of Java "Date add" and "Calendar add" examples. * Shows how to get the next hour, next day, next week, next month, and next year. * * @author alvin alexander, devdaily.com */ public class JavaDateAddExamples { public static void main(String[] args) { // get a calendar instance at December 31, 2009, at 11:30 p.m. // this way we can test that we are rolling over to the next hour, // tomorrow, next week, and next year properly. Calendar calendar = new GregorianCalendar(2009, 11, 31, 23, 30, 0); // get a Date instance to represent "now" (the current date); // we'll need it to reset our calendar during the following date examples. Date currentDate = calendar.getTime(); System.out.format("today: %s\n", currentDate); // get the date/time one hour from now calendar.setTime(currentDate); calendar.add(Calendar.HOUR_OF_DAY, 1); Date oneHour = calendar.getTime(); System.out.format("one hour: %s\n", oneHour); // get tomorrow's date calendar.setTime(currentDate); calendar.add(Calendar.DAY_OF_YEAR, 1); Date tomorrow = calendar.getTime(); System.out.format("tomorrow: %s\n", tomorrow); // get next week's date // note: may want to use WEEK_OF_MONTH or WEEK_OF_YEAR calendar.setTime(currentDate); calendar.add(Calendar.DAY_OF_YEAR, 7); Date nextWeek = calendar.getTime(); System.out.format("next week: %s\n", nextWeek); // get next month calendar.setTime(currentDate); calendar.add(Calendar.MONTH, 1); Date nextMonth = calendar.getTime(); System.out.format("next month: %s\n", nextMonth); // get next year calendar.setTime(currentDate); calendar.add(Calendar.YEAR, 1); Date nextYear = calendar.getTime(); System.out.format("next year: %s\n", nextYear); } }
As you can see from the code, I'm intentionally setting the date and time of my
Calendar object to 11:30 p.m. on New Year's Eve, so whenever I add anything to it I will automatically cross into another day, month, and year.
Once you've seen how to perform some of these Java Date and Calendar addition examples there isn't too much to say about them, but I will say that I'm not entirely comfortable with what I've done in my "next week" example. In your real-world code that approach may need to be a little more robust than what I've shown here.
Here's the output from this Java date addition class:
today: Thu Dec 31 23:30:00 EST 2009 one hour: Fri Jan 01 00:30:00 EST 2010 tomorrow: Fri Jan 01 23:30:00 EST 2010 next week: Thu Jan 07 23:30:00 EST 2010 next month: Sun Jan 31 23:30:00 EST 2010 next year: Fri Dec 31 23:30:00 EST 2010
I haven't tried many other dates and times with this code, but for the times I have tried all the results look correct. Again, if the "next week" addition is really important to you, you might want to make that code more robust, but that's the only glaring weakness I see right away.
Here are a few links to the official Javadoc for the Date and Calendar classes used in these "Java Date add" examples:
Post new comment
|
http://alvinalexander.com/java/java-date-add-calendar-add-example
|
CC-MAIN-2015-14
|
refinedweb
| 635
| 53.31
|
For example image this was a section of your code
No errors (red squiggly lines)
To tell navigate to References
And remove the tick beside the Namespace Microsoft.VisualBasic
Now when you go back to Code Editor
You have all the following error and red squiggly lines
How to fix those error is the part of the steps of learning vb.net.
Just remember that every type as additional methods associated with it.
For example
A String -> String.Substring
Integer -> Integer.TryParse
Learning not be dependant on that namespace is part of the journey of become a vb.net code
So soon you be a Non-Legacy Coding Ninja
|
http://www.dreamincode.net/forums/topic/105373-do-i-have-vb6-legacy-code-in-my-vbnet-project/
|
CC-MAIN-2017-13
|
refinedweb
| 109
| 56.55
|
Tutorial 3: Lists and Pickers
Having laid the foundations with the previous two tutorials, now we can start to demonstrate the real power of MadComponents for mobile flash applications. In this tutorial, we’re going to investigate lists and pickers.
There have been a few version updates since the last tutorial – So always make sure that you have the latest version of the mad components library. (Currently, the latest is madComponentsLib0_5_3.swc). Download from here.
Beware Copy and Paste
Given that these tutorials are full of XML examples, it’s worth mentioning again that things can go wrong if you copy and paste XML into Flash or Flex Builder. You might get an error that says:- “TypeError: Error #2007: Parameter text must be non-null”. This is because the pasted text contains unprintable characters that screw things up. Refer to the previous tutorial for advise of how to remedy this.
Defining Data in XML
Let’s assume that we want to build an application, where the user can scroll through a list of names. We can first define the data that will populate the list like this:-
<data> <item label=”Sneezy”/> <item label=”Sleepy”/> <item label=”Dopey”/> <item label=”Doc”/> <item label=”Happy”/> <item label=”Bashful”/> <item label=”Grumpy”/> </data>
There is also an alternative shorthand way of expressing XML data in MadComponents. Given that the names have no spaces or non-alphabetic characters, we can save some typing and write:-
<data> <Sneezy/> <Sleepy/>
<Dopey/> <Doc/> <Happy/>
<Bashful/> <Grumpy/> </data>
Making a list
To put this data into a list, we simply write:-
<list> {DATA} </list>
So, the entire program looks like this:-
package { import com.danielfreeman.madcomponents.*; import flash.display.Sprite; import flash.display.StageAlign; import flash.display.StageScaleMode; public class MadLists extends Sprite { protected static const DATA:XML = <data> <Sneezy/> <Sleepy/> <Dopey/> <Doc/> <Happy/> <Bashful/> <Grumpy/> </data>; protected static const LIST:XML = <list>{DATA}</list>; public function MadLists(screen:Sprite = null) { if (screen) screen.addChild(this); stage.align = StageAlign.TOP_LEFT; stage.scaleMode = StageScaleMode.NO_SCALE; UI.create(this, LIST); } } }
If you rapidly click and drag the list up or down, you’ll see it scroll, and the scrollbar appearing at the side. You probably want a longer list of data to really see this in action. Testing an app on the desktop, using a mouse or trackpad, it can be a bit tricky to control the difference between scroll/swipe gestures and click gestures. But on the device – it all makes sense.
Listen for clicks
Listen for list clicks as follows:-
protected var _list:UIList
_list = UIList(UI.findViewById(“list”)); _list.addEventListener(UIList.CLICKED, listClickedHandler); protected function listClickedHandler(event:Event):void { var index:int = _list.index; // var group:int = _list.group; //divided and grouped lists only. }
Divided and Grouped lists have a group property, that gives the group index of the clicked row.
Tick Lists
NOTE: SINCE WRITING THIS TUTORIAL – TICK LISTS HAVE MOVED INTO EXTENDEDMADNESS. Please use ExtendedMadness.swc library, and UIe.create() for this next part.
MadComponents has two kinds of tick list. <tickList/> and <tickOneList/>. As you’d expect, <tickOneList> only allows one row to be ticked at any time. (so click on a second row, and the first one un-ticks itself).
You can read the state of the tick list using ActionScript. When listening for the state of the data to change, listen for Event.CHANGE , rather than UIList.CLICKED.
package { import com.danielfreeman.madcomponents.*; import com.danielfreeman.extendedMadness.*; //new import flash.display.Sprite; import flash.display.StageAlign; import flash.display.StageScaleMode; import flash.events.Event; public class MadTickList extends Sprite { protected static const DATA:XML = <data> <Sneezy/> <Sleepy/> <Dopey/> <Doc/> <Happy/> <Bashful/> <Grumpy/> </data>; protected static const TICKLIST:XML = <tickList id="ticks">{DATA}</tickList>; protected var _tickList:UITickList; public function MadTickList(screen:Sprite = null) { if (screen) screen.addChild(this); stage.align = StageAlign.TOP_LEFT; stage.scaleMode = StageScaleMode.NO_SCALE; UIe.create(this, TICKLIST); //new (e) _tickList = UITickList(UI.findViewById("ticks")); _tickList.addEventListener(Event.CHANGE, tickListChanged); } protected function tickListChanged(event:Event):void { trace(); for each(var item:uint in _tickList.tickIndexes) { trace(UILabel(_tickList.findViewById("label",item)).text); } } } }
Defining Grouped Data in XML
Now, we’re going to look at grouped lists in MadComponents. But first, let’s look at how to define grouped data.
<data> <group label=”dwarfs”> <Sneezy/> <Sleepy/>
<Dopey/> <Doc/> <Happy/>
<Bashful/> <Grumpy/> </group> <group label=”reindeer”> <Dasher/> <Dancer/> <Prancer/> <Vixen/> <Comet/> <Cupid/> <Donder/> <Blitzen/> </group> </data>
You can still use the alternative notation, for example: <item label=”Dasher”/> if you wish. Group label attributes above are optional. Include them if you require group headings on your grouped list.
Divided and Grouped Lists
You can create a divided list as follows:-
<dividedList> {GROUPED_DATA} </dividedList>
Or, create a grouped list like this:-
<groupedList> {GROUPED_DATA} </groupedList>
But we can improve the appearance of the grouped list, by choosing appropriate colours and spacing:-
<groupedList background=”#C6CCD6″ colour=”#CCCCCC” gapH=”32″ gapV=”4″> {GROUPED_DATA} </groupedList>
Colouring Lists
In the previous example, we used the colour, and background attributes to change the appearance of a list. This works for any list. Not just the grouped list.
The colour attributes defines the colours of the dividing lines. The background attribute can specify several colour values, separated by commas. The first parameter is the background colour, the second is the row colour. Any further parameters allow you to have rows with alternating colours. For example:-
<list colour=”#333366” background= ”#CCCCFF,#9999CC,#AAAACC”>
Creates the following result:-
Suppose you also want to make the text colour white. You can define <text> formatting as follows:-
<list colour=”#333366″ background= “#CCCCFF,#9999CC,#AAAACC”> {DATA} <font color=”#FFFFFF”/> </list>
Notice that colour attribute inside an HTML font tag has American spelling. But Colour elsewhere in the layout is spelt with a ‘u’, with British spelling.
Custom renderers
You can define a custom list item renderer in XML. Suppose, for example, each row contains a label and a switch. You can define that as follows:-
<list colour=”#333366″ background= “#CCCCFF,#9999CC,#AAAACC”> {DATA} <horizontal> <label id=”label”/> <switch id=”state” alignH=”right”/> </horizontal> </list>
Searching Lists
The <search> tag may be used to create a search bar at the top of a list. The field attribute can be used to enable searching and filtering of the list, without having to write any actionScript. In the previous “dwarfs” list example, you can modify the layout as follows to enable searching:-
<list> {DATA} <search field=”label”/> </list>
Setting data in ActionScript
You can set list data from ActionScript, rather than defining it in XML. You can assign either an array, or XML. You can assign an array of objects to the data property like this:-
list.data = [{label:”one”}, {label:”two”}, {label:”three”}];
There is also a short way to do this, using an array of strings.
list.data = [“one”,”two”,”three”];
For a custom renderer, you might have more than one value in each object, for example:-
list.data = [{label:”one”,switch:”on”}, {label:”two”,switch:”off”}, {label:”three”,switch”:on”}];
For a divided, or grouped list, use a two dimensional array:-
list.data = [[{label:”one”}, {label:”two”}], [{label:”three”}]];
You can assign XML data like this:-
list.xmlData = <data><one/><two/><three/></data>;
Or this:-
list.xmlData = <data><i label=”one”/><i label=”two”/></data>;
For a divided or grouped list, we would do something like this:-
list.xmlData = <data><group> <one/><two/></group> <group><three/> </group></data>;
Pickers
We use pickers in a similar way to a list. So we can set its data in XML, or using the data or xmlData properties, just like with a list.
The <picker> component tends to be used in conjunction with a <columns> layout. The column layout was described in the first tutorial.
Here is an example a three column picker:-
<columns gapH=”0″ widths=”40,50%,50%” pickerHeight=”200″> <picker alignH=”centre”> {NUMBERS} </picker> <picker> {DATA} </picker> <picker> {DATA} </picker> </columns>
The pickerHeight attributes enabled you to declare the height of the picker bank.
Here’s a complete code example of using a picker bank:-
package { import com.danielfreeman.madcomponents.*; import flash.display.Sprite; import flash.display.StageAlign; import flash.display.StageScaleMode; public class MadComponentsPicker extends Sprite { protected static const DATA:XML = <data> <Red/> <Orange/> <Yellow/> <Green/> <Blue/> <Indigo/> </data>; protected static const PICKER_EXAMPLE:XML = <columns gapH="0" widths="40,50%,50%" pickerHeight="180"> <picker alignH="centre"> <data> <item label="0"/> <item label="1"/> <item label="2"/> <item label="3"/> <item label="4"/> <item label="5"/> <item label="6"/> <item label="7"/> <item label="8"/> <item label="9"/> </data> </picker> <picker index="1"> {DATA} </picker> <picker index="4"> {DATA} </picker> </columns>; public function MadComponentsPicker(screen:Sprite = null) { if (screen) screen.addChild(this); stage.align = StageAlign.TOP_LEFT; stage.scaleMode = StageScaleMode.NO_SCALE; UI.create(this, PICKER_EXAMPLE); } } }
Notice the index attributes in the XML, that set the pickers to initial preset positions.
What’s next ?
In the next tutorial we’re going to learn about navigation, connecting MadComponents to server data, and we’ll build a Twitter application.
Further reading
To find out more about MadComponents, you can read the other related threads on this blog, or download the documentation at
There are also lots of code examples to view or check-out from the subversion repository at
Please subscribe to this blog if you want to catch subsequent tutorials.
Hi Daniel
I’ve played with the colour and background attributes for the picker. Is there anyway to change or remove the outside rectangular border? and possibly change the 2 background gradients? The ability to remove the border would be nice.
Regards
Rich
In MadComponentsLib0_5_4.swc,
[columns background=”#rgb0,#rgb1,#rgb2″][picker/]..etc…etc…[/columns]
#rgb0 = gradient of picker frame colour
#rgb1 = outline of picker frame colour
#rgb2 = bottom half of picker frame colour
I would like to access switch compo in list compo.
I can make the list of which row has a label and switch.
I want to know the switch state after its state has been changed.
How can I access ?
const DATA_ARRAY:Array = [
{label0:”ABC”, state0:”on”},
{label0:”CDE”, state0:”off”},
{label0:”FGH”, state0:”off”}
];
const LAYOUT:XML =
;
UI.create(this, LAYOUT);
var list:UIList = UIList(UI.findViewById(“list”));
list.data = DATA_ARRAY;
list.addEventListener(UIList.CLICKED, onTapList);
function onTapList(evt:Event):void
{
// how??
}
Make the List object global, because you’ll need to reference it in the handler.
protected var _list:UIList;
findViewById actually has three parameters. id, row, group. So,
protected function onTapList(event:Event):void {
var uiSwitch:UISwitch=UISwitch(UI.findViewById(“switch”,_list.index));
// var uiSwitch:UISwitch=UISwitch(_list.findViewById(“switch”,_list.index)); // a bit faster maybe
trace(uiSwitch.state);
}
Thank you very much for your quick res!
I could access to switch state.
Hi Daniel,
these components are really really good. Thanks for making them free.
I’d like to ask a question that I’m struggling with. Using the MadList I want to be able to click on an index and get a trace. You have provided some code to do this (protected var _list:UIList etc) but I must be putting this in the wrong place as it gives a few errors, one being that _list is undefined. Can you tell me what I’m doing wrong.
thanks
Mike
I assume protected var _list:UIList; is defined globally. (Somewhere after between class declaration, and the constructor). Make sure it isn’t defined in the code too. You should have:-
_list = UI.findViewById(… etc …
not
var _list = UI.findViewById(… etc…
Hi Daniel,
I’m looking at the dividedList Now this is what I’m after…. a scrolling list with pics that you can click on. I cant find where the mouse clicks come from, I can’t see any event listener. I can see a trace for “mouse up” when I click on the divider. How can i add mouse/touch clicks to this.
thanks (sorry for all the questions today)
mike
Hmmm, I haven’t provided an event for clicking on the divider. I’ll take a look at that for the next version.
Normally, clicking on a list will dispatch a UILIst.CLICKED event.
Hi Daniel,
I have been working using the List components (dividedList) and think its fantastic what you have done for the community. I’m putting in a lot of hours to getting it to work and have hit a major stumbling block.
I want to click on a scrolling list and get it to display another page relating to that page/index. so if I click on dog the scrolling list disappears and I get whole page of dog stuff. Then click “back” button and it goes back to the list.
I have been at it for almost a day, I’m not a beginner, but your work is worth the effort. Can you help me and post an example .as of this or tell me exactly what I need to do.
Also a separate question. I can get a “list.index” variable on click/touch and I get a trace index number. Perfect!
What I’d like to do is then goto a frame depending on the number. But it said gotoAndStop is not a function. How would we manipulate MCs/objects external to the madComponents from inside madComponents. I have tried parent and root but it can’t see the timeline or any mc on the stage
Thanks in advance
Mike
It’s a common requirement. To be able to link a list to a detail page, or detail pages within a navigation based application. I’ve written and uploaded two samples:-
The first approach is to have one detail page layout, and have an array of text and pictures indexed by “index”. In my sample, DETAIL_PAGE could be much more sophisticated if you wanted. And the DETAIL_ARRAY (Array of Objects) could have many more fields in each object. {id0:value0, id1:value1, etc…}
The second approach is to have a different detail page for each list item. In this case, we turn off automatic navigation, and explicitly goToPage() in handlers for list clicks and back button pressed.
I hope these samples help.
wow thanks Daniel
I understand how it works now.
I am trying to add pictures to the scrolling list and getting in a pickle. I’m using the code from the dividedList to embed the pics, but not having much luck. I’m adding all the constants and adding the {data} to the list.
Can you tell me how I add pics to the scrolling list. I know its in the way that the {data} is added, but once I see this working I’ll be golden!
thanks
Mike
There’s a limitation with using XML data. You can’t provide more than one bit of data per row. So if you have both a label and a image, you can’t set both using XML data. This is a limitation I guess I need to fix now someone has spotted it🙂
You can assign data in an array in ActionScript:-
uiDividedList = UIDividedList(UI.findViewById(“dividedList”));
uiDividedList.data = [“Heading A”,[{label:”zero”,pic:getQualifiedClassName(IMAGE0)}],
“Heading B”,[{label:”one”,pic:getQualifiedClassName(IMAGE1)},{label:”two”,pic:getQualifiedClassName(IMAGE2)},{label:”three”,pic:getQualifiedClassName(IMAGE3)}],
“Heading C”,[{label:”four”,pic:getQualifiedClassName(IMAGE4)}…. etc…etc…
Hi Daniel,
Your feedback is great and is very much appreciated.
I’m almost there and have been working on it for many hours. One extra thing would be great as I am really struggling.
On the link you sent me this morning “MadComponentsNavigationT0” it has a list which you tap to go to detail page.
protected static const DATA:XML =
protected static const LIST:XML =
{DATA}
;
This works but how do I make or turn this basic list in NavigationT0 to look like the image list in MadComponents or the DividedList. With the little images by the side and a bit of text.
Hope this makes sense. Basically I and trying to have an image scrolling list which when tapped goes to a detail page and back button to go back. I have got it working perfectly so far, I just can’t seem to be able to grab the code for the image scrolling list from another .as script and pop it into the NavigationTO .as without multiple errors.
thanks
Mike
Best if I take a look at your code. I’ve sent you an email.
I’ve updated the MadComponentsDividedList example. Does this help?
Hi Daniel
for the picker, when i select the picker,
how to trace the date who have been selected?
then how to choose the date manually from code?
thanks before, your picker is very nice
I’ve updated the MadComponentsPicker.as example. I hope this helps.
thank u, but i’m still stuck to trace the xml, not the index..
i’m very newbie for the as3, so please help me..
i’m stuck to trace the selected xml,.
Please help me..
thank u very much for u’re help.
ari
Ahh. Your question helped me spot a bug. You SHOULD be able to use:-
_column0.row.label
_column1.row.label
_column2.row.label
BUT. It DOESN”T WORK PROPERLY for a UIPicker, although it would work for a list. I’ll fix this bug in 0.6.1.
So, in the meantime, you can use:-
_column0.data[_column0.index+1].label
_column1.data[_column1.index+1].label
_column2.data[_column2.index+1].label
…which you give you the correct values.
wow.. thank u so much Daniel..
once more question..
for the spinner, whether it can resize automatically for the long xml label?
how to adjust the scroll speed?
thank u Daniel.. u’re very help me .. GBU
ari
Labels don’t resize. And for a picker, line wrapping isn’t a viable option.
You’ve just got to ensure that the label fits.
The scroll speed is related to how hard you flick a list. There’s no adjustment, but I can take a look for 0.6.1 if I can apply a tweak or not.
But you can adjust the sensitivity.
for example UIPicker.PICKER_DECAY = 0.99; … will make it more
fluid. (at the moment it’s set to 0.98). Don’t give it a value >1.
I am having difficulty retrieving the label for the selected row with the FlexUIPicker.
I am have tried to link the FlexUIPicker with id=”picker1″ to a variable “myPicker”
by using the approach in your example.
1 protected var myPicker:UIPicker;
2 myPicker = UIPicker(UI.findViewById(“picker1”));
and it dies every time I try line 2
any ideas?
Got it.
UIPicker(component.getChildAt(0)) gives you the UIPicker Instance
UIPicker(component.getChildAt(0)).row.label gives you the current label.
I have altered:
-UIPicker to have a get label(returns the current label)
-FlexUIPicker to have a get inst (which returns the UIPicker instance)
-FLEXUIPicker to have a get label(returns the current label)
multi column picker functions will be next.
Thanks for your work.
Note, you can also say:-
_column0 = UIPicker(UI.findViewById(“column0”));
_column1 = UIPicker(UI.findViewById(“column1”));
_column2 = UIPicker(UI.findViewById(“column2”));
etc…
(Make sure you have the recent update of the component)
See:
hai daniel.
why if i join list and switch, the switch code like
protected function toggleActivity(event:Event):void {
if (uiSwitch.state) {
trace(“on”);
UI.showActivityIndicator();
}
else {
UI.hideActivityIndicator();
trace(“off”);
}
}
this function is not run, the trace can’t run. why ?
pliss help, thanks before.
Ok, you have a switch within a list, right? A custom renderer? And the switch has an id? Assume it’s called “swch”
So you have a layout something like this?
[list]
[horizontal]
[label id=”label”]
[switch id=”swch” alignH=”right”]
[/horizontal]
[/list]
right?
But now you have many switches in the list. Which one to listen to? Suppose you want to listen to the one in the first row (index 0), you’d write…
var switch:UISwitch = UISwitch(UI.findViewById(“swch”,0)); //Notice the second parameter, the list row.
switch.addEventListener(Event.CHANGE, toggleActivity);
Is that what you’re doing?
WOW that’s work… hehhee
thanks daniel..
one more question, if i do the same in the “groupedList”, it didn’t work.? why?
pliss help
sorry daniel i find the answer…
heheheh
thanks daniel
Dear Daniel,
I was going through this tutorial and had two issues that look like layout bugs.
1. I tried the Tutorial 1 NAVIGATOR example, throwing a list into a view:
protected static const HOME_VIEW:XML =
Continue
Hello, World!
{DATA};
and running it on the desktop simulator for Android, the button is hidden by the container title (in portrait orientation), then when rotating simulated device to the right, the title hides both the button and the label.
2. I tried your custom item renderer code, mixed into the NAVIGATOR example:
protected static const HOME_VIEW:XML = ContinueHello, World!{DATA};
and in portrait mode, the layout was correct (showing the button and label), but when rotated left, both the button and label disappeared under the container title.
Thanks!
Thanks for the heads-up.
Your metatags got stripped, but I’ll try to match the pattern that’s left to the tutorial. I sent an email to your flashsim address.
Dear Dan,
Is there a way to make your TickOneList leave the highlight on instead of giving the check mark? I have used this list and set the font the 72 () and the check mark gets flattened out (about 1/4 the line height) — not a desirable look. I really just want a simple, obvious way to show that item is selected.
Thanks for a great component set!
Looks like my XML got swallowed up there around ‘the 72’ – was an XML string >list< >font size="72" /< >/list<
There is a feature of the latest MadComponents version you can use. I implemented something new to make splitView work.
If you use a normal list, and in ActionScript:-
_list.showPressed = true;
…then the selection highlight doesn’t go away. It sticks. Although it doesn’t toggle the way a tickOneList does. (so pressing a cell twice doesn’t de-select it).
Thank you so much Dan for your quick response – exactly what I needed!
one more thing here — how can I clear the selected row programmatically?
Thanks!
Ooops, I didn’t provide a method to do that. That’s something else I need to include in the next update. But there’s a messy work-around for now.
Shape(Sprite(_list.getChildAt(0)).getChildAt(0)).graphics.clear();
Hi Daniel🙂
I was wondering if there’s a way to override highlight color settings via XML.
Thanks for your attention,
Zezefreda
Yes, there IS a way in XML. You must write it in the root node. eg:
protected static const LAYOUT:XML = <vertical clickColour="#CCCC00" … etc…
The ActionScript way is:-
UIList.HIGHLIGHT = 0xCCCC00;
Hi Daniel,
I tried to get the search bar on a DividedUIList to work, but it does not seem to work. The search bar appears fine, but when trying to search/filter it has no effect on the list. Of course, it works perfectly on a regular UIList though.
I really like this library. It is excellent and by far the best out there especially for mobile development in AIR.
On another note, when successfully filtering a UIList and an item is clicked, the index of the selected item of the list refers to the index in the filtered version of the list and not the original unfiltered version of the list. Is there anyway to get the index of the item in the non-filtered list, or in some way to get data from the selected item?
Thanks!
Mark
Yup, search bar doesn’t work for a divided or grouped list – it was written just for normal lists.
But, you can make your own behaviour for it. You can treat a search bar just like you treat an input field. And repopulate the list with your own filtered data, when the user enters a search expression.
There is a work-around for the filtered index problem. You could assign something to each row’s data that uniquely identified that row.
You could define list data like this:-
<data>
<item firstname=”Fred” id=”0″/>
<item firstname=”Sarah” id=”1″/>
<item firstname=”Peter” id=”2″/>
…etc…
</data>
and then read parseInt(list.row.id) to get the unfiltered index.
But this workaround is awkward, and I think that I should provide an automatic mechanism to do this kind of thing.
I’ll think about that for the next version.
Ok! That’s great. Thanks a lot for your help and your feedback.
Hi Daniel, can I make a list (UIList) with multiple line for the label and each line with a different TextFormat?
Thanks
Eric
First – I’m a newbie🙂
I want to make short list and a button below this list.
This is code:
protected static const VERTICAL:XML =
Button
Button is only partially visible on bottom of the stage. Why? Maybe list always occupies all available stage height? How can I change this?
_____
sorry for my English
I’m afraid WordPress strips all of the XML from your question. So I don’t know what you wrote. Probably the best way to ask a question like this is to ask it on the Facebook group:-
I’m waiting for access to this group. But my problem is very basic. Code ist not necessary. I just want short list (2 – 3 entries) and a button below this list. When I try to do this button is always at the bottom of screen (partly goes beyond screen). Between list and button is white space. How can I get rid of this empty space?
I asked this question on facebook group
Beginners (like me) might use this update:
tickList, tickOneList were moved to ExtendedMadness swc. To compile, REMOVE the library ref for MadComponentsLib0_7_4.swc (or your version) and add ref to ExtendedMadnessLib0_1_6.swc (or your version). Do not reference both libraries.
I also saw error on running the adobe SDK adt after compile.
“Comparison method violates its general contract!”
It seemed to be triggered by this code… for some reason … but it’s apparently not related. Java 1.7 SDK has a bug. Uninstall 1.7, downgrade to 1.6.
If you use the original tutorial code without change, currently you likely will see:
Error #1065: Variable tickList is not defined.
Along with CHANGING the library to “Extended Madness”… it seems you need to add this line just before you do the UI.Create:
UIe.activate(this); // Gives us access to extended components
… plus…
ADD an imports.
import com.danielfreeman.extendedMadness.*;
Although you only reference the library for “ExtendedMadnessLib0_1_6.swc” and not the regular MadComponentsLib0_7_4.swc… you still import both packages
import com.danielfreeman.extendedMadness.*;
import com.danielfreeman.madcomponents.*;
Fairly new to AS3 and just started with madcomponents…very cool so far!
I do have a question though: when using custom renderers, as per your example above where each row contains a label and a switch,
If it is just repeating each row and adding a switch with an id=”state”, am I wrong in assuming that all switches in the list would end up with the same id (“state”)?
How are you able to listen for these switches change from on/off and identify which switch changed state?
Thanks in advance for any help
I think this was discussed on the Facebook group – but I couldn’t find it.
First, you might consider using a or in extended madness.
You could set the state of state of the switches with the data that populates the list:
_list.data = {{label:”hello”, onOff:”on”},… etc…
assuming
(I think that works anyway.)
To change it programmatically, for any row. var switch:UISwitch = UISwitch(UI.findViewById(“OnOff”, row));
Notice the second parameter, which is the row in the list. (A grouped or divided list has a third optional parameter for the group)
Come and join the Facebook group – there are more people there to help.
Thanks Daniel! I will check out the Facebook group
Customizing GroupedList (or DividedList) items :
I’ve spend a bit of time on your great component suites that helped me quite a lot for my app. I was wandering on how to simply customize headings and items in a groupedList whose purpose is a menu list in an application, in order to change colors/font size individually on each items, or to link a View class to open when click on each line. Was not obvious to find how to do it in Flex Wrappers approch. Finally got this solution, don’t know if it the best one, but at least it works.
you can extend the XML like this for example with new attributes
then first extend the UIGroupedList.as class like this to manage individual items font customization:
public class MyUIGroupedList extends UIGroupedList
{
public function VFUIGroupedList(screen:Sprite, xml:XML, attributes:Attributes)
{
super(screen, xml, attributes);
}
override protected function labelCell(record:*, position:Number):UILabel {
var label:UILabel = super.labelCell(record,position);
var format:TextFormat = label.getTextFormat();
if (record.color) format.color=parseInt(record.color);
if (record.fontSize) format.size=parseInt(record.fontSize);
label.setTextFormat(format);
return label;
}
}
The view holding the list will be including this to manage view classes push on each item :
protected function view_creationCompleteHandler(event:FlexEvent):void
{
myHomeList.list.removeEventListener(UIList.CLICKED, listSelect);
myHomeList.list.addEventListener(UIList.CLICKED, listSelect);
}
private function listSelect(e:Event) : void {
var item:Object = myHomeList.list.data[e.currentTarget.group*2+1][e.currentTarget.index];
if( item.hasOwnProperty(“viewClass”)) {
var aClassStr:String = item.hasOwnProperty(“viewClass”)?item.viewClass as String:””;
try {
var aClass:* =getDefinitionByName(“fr.villefluide.wedrive.views.”+aClassStr);
if (aClass!=null) {
navigator.pushView(aClass);
}
} catch (e:ReferenceError) {
trace(“undefined view class “+aClassStr);
}
}
}
}
Hope this helps…
Sorry, the XML snippet didn’t showed up, here it is :
Customizing GroupedList (or DividedList) items :
[group label=”My Group”]
[item label=”my label 1″ viewClass=”MyViewClass1″/]
[item label=”my label 2″ color=”0x000000″ fontSize=”26″ viewClass=”MyViewClass2″/]
[item label=”my label 3″ viewClass=”MyViewClass3″/]
[/group]
i am defining many items like this,
;
Each item has label,label2 and image which needs to be List image.
{DATA}
48
But this is not working.image is always blank ? How can i dynamically embedd images ? into list from XML item string ?
How can we use images in list which are defined in XML item instead of defninng them as constants ? In my case images have to be dynamic and loaded from local resource
|
https://madskool.wordpress.com/2011/06/30/tutorial-3-lists-and-pickers/
|
CC-MAIN-2016-44
|
refinedweb
| 5,089
| 66.54
|
31 August 2011 20:23 [Source: ICIS news]
SAO PAULO (ICIS)--Brazil-based Braskem plans to start up its new polyvinyl chloride (PVC) and vinyl chloride monomer (VCM) plants in the state of Alagoas in April and May, respectively, the company said on Wednesday.
The start up of the plants was initially scheduled for May and June, the company added.
The plants will cost Brazilian reais (R)1bn ($629m, €434m).
The PVC plant will have a capacity of 200,000 tonnes/year, increasing the total PVC capacity at Alagoas to 460,000 tonnes/year.
Currently, Braskem’s total PVC capacity exceeds 500,000 tonnes/year, produced mainly at its plants in Alagoas and ?xml:namespace>
($1 = R1.59)
(
|
http://www.icis.com/Articles/2011/08/31/9489259/brazils-braskem-to-start-up-pvc-vcm-plants-in-april-may.html
|
CC-MAIN-2015-14
|
refinedweb
| 118
| 70.63
|
Python module to extract CA and CRL certs from Windows' cert store (ctypes based).
Project description
wincertstore provides an interface to access Windows’ CA and CRL certificates. It uses ctypes and Windows’s sytem cert store API through crypt32.dll.
Warning
Security Fix
wincertstore 0.1 used to return all certificates although some are not suitable to verify TLS/SSL server certificates. wincertstore 0.2 only returns certificates for SERVER_AUTH enhanced key usage by default.
Example
import wincertstore for storename in ("CA", "ROOT"): with wincertstore.CertSystemStore(storename) as store: for cert in store.itercerts(usage=wincertstore.SERVER_AUTH): print(cert.get_pem().decode("ascii")) print(cert.get_name()) print(cert.enhanced_keyusage_names())
SERVER_AUTH is the default enhanced key usage. In order to get all certificates for any usage, use None. The module offers more OIDs like CLIENT_AUTH, too.
For Python versions without the with statement:
for storename in ("CA", "ROOT"): store = wincertstore.CertSystemStore(storename) try: for cert in store.itercerts(): print(cert.get_pem().decode("ascii") finally: store.close()
CertFile helper:
import wincertstore import atexit import ssl certfile = wincertstore.CertFile() certfile.addstore("CA") certfile.addstore("ROOT") atexit.register(certfile.close) # cleanup and remove files on shutdown) ssl_sock = ssl.wrap_socket(sock, ca_certs=certfile.name, cert_reqs=ssl.CERT_REQUIRED)
Requirements
- Python 2.3 to 3.3
- Windows XP, Windows Server 2003 or newer
- ctypes 1.0.2 (Python 2.3 and 2.4) from
License
Licensed to PSF under a Contributor Agreement.
See for licensing details.
Acknowledgements
References
ChangeLog
wincertstore 0.2
Release date: 26-Feb-2013
- By default CertSystemStore.itercerts() is now limited to return only certs that are suitable for SERVER_AUTH – that is to validate a TLS/SSL’s server cert from the perspective of a client.
- Add CERT_CONTEXT.get_name() to get a human readable name of a certificate.
- Add CERT_CONTEXT.enhanced_keyusage() to get enhanced key usage and trust settings from registry. The method returns either True or a frozenset of OIDs. True means that the certificate is valid for any purpose.
- CERT_CONTEXT.enhanced_keyusage_names() maps OIDs to human readable names.
- Add commin OIDs for enhanced key usages like SERVER_AUTH and CLIENT_AUTH.
- Add support for universal wheels.
- Add tox for testing Python 2.6 to 3.3. Python 2.4 and 2.5 are tested manually.
- Use pypi.python.org:443 for TLS tests.
wincertstore 0.1
Release date: 22-Mar-2013
- Initial release
Project details
Release history Release notifications
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
|
https://pypi.org/project/wincertstore/0.2/
|
CC-MAIN-2019-35
|
refinedweb
| 414
| 54.18
|
Controlling System volume objc_util
Hi
Is there a way of controlling the system volume (not the music player volume!) from objc_util ?
Cheers
- Webmaster4o
What do you mean by 'system volume', not music player volume? As far as I am aware, the system volume is the music player volume. There's the ringer volume and the music volume, but the music volume controls everything besides the ringtone.
There is no Apple-sanctioned way (public API) to do this, but this works on iOS 9.2 (things like this tend to break with system updates):
from objc_util import NSBundle, ObjCClass, on_main_thread NSBundle.bundleWithPath_('/System/Library/Frameworks/MediaPlayer.framework').load() MPVolumeView = ObjCClass('MPVolumeView') @on_main_thread def set_system_volume(value): volume_view = MPVolumeView.new().autorelease() for subview in volume_view.subviews(): if subview.isKindOfClass_(ObjCClass('UISlider')): subview.value = value break set_system_volume(0.5)
There's probably a less convoluted way that I don't know of.
@Webmaster4o notifications and ringtone on iPhone
Does this work on iOS 10?
Because I am looking for a way to mute the ringer volume, and then put it back to where it was.
Did you try the solution above? Did it work or not?
I did, it mutes the music player volume. But if i wanted to take a picture without the click noise, I want to mute the ringer. I would turn it immediately back on so I wouldn't make confusion.
|
https://forum.omz-software.com/topic/2947/controlling-system-volume-objc_util
|
CC-MAIN-2017-26
|
refinedweb
| 231
| 59.8
|
Opened 2 years ago
Last modified 2 years ago
#11306 infoneeded bug
Do not generate warning in `do` when result is of type `Void`.
Description
GHC generates warnings when
do notation statements discard their
result, without an explicit
_ <- , unless the discarded result
is of type
().
Another type which is used to indicate "no result", is
Void from
Data.Void. There are no meaningful values of this type, so we should also skip the warnings for such situations.
Here is an example:
import Data.Void f :: IO Void f = undefined main :: IO () main = do f return ()
GHC output:
test.hs:7:11: Warning: A do-notation statement discarded a result of type ‘Void’ Suppress this warning by saying ‘_ <- f’ or by using the flag -fno-warn-unused-do-bind
Change History (3)
comment:1 follow-up: 2 Changed 2 years ago by
comment:2 Changed 2 years ago by
Won't fix?
comment:3 Changed 2 years ago by
Note: See TracTickets for help on using tickets.
I'm not a fan of this warning in the first place, but if anything, I would think it is most important to warn when the discarded value is of type
Void, since that typically indicates that the following code is unreachable...
|
https://ghc.haskell.org/trac/ghc/ticket/11306
|
CC-MAIN-2018-22
|
refinedweb
| 210
| 66.47
|
Hello, I have a very big XML file, that I would like to chop a bit and then process every chunk separately, but I do not know how to handle the xsi:noNamespaceSchemaLocation attribute because now if I try to ignore it, I get an error.
First how I divide the big XML into smaller ones (query No. 1):
FROM OPENXML('<CONSOLIDATED_LIST xmlns:
<INDIVIDUALS>
<INDIVIDUAL xsi:
<FIRST_NAME>MOHAMMAD BAQER</FIRST_NAME>
<SECOND_NAME>ZOLQADR</SECOND_NAME>
<INDIVIDUAL_ALIAS>
<ALIAS_NAME>Mohammad Bakr Zolqadr</ALIAS_NAME>
</INDIVIDUAL_ALIAS>
</INDIVIDUAL>
>
</INDIVIDUALS>
</CONSOLIDATED_LIST>', '/CONSOLIDATED_LIST/INDIVIDUALS/INDIVIDUAL')
WITH(first_name varchar(200) 'FIRST_NAME',
second_name varchar(200) 'SECOND_NAME',
individual_xml long varchar '@mp:xmltext')
XML is much bigger in real life, it's just an example.
Then I try to get some stuff from one of the smaller ones (query No. 2):
FROM OPENXML('>', '/INDIVIDUAL/INDIVIDUAL_ALIAS')
WITH(alias_name varchar(200) 'ALIAS_NAME',
individual_alias_xml long varchar '@mp:xmltext')
And I get an error Undeclared namespace prefix: xsi.
I tried declaring namespace like written in documentation, no luck, my guess of course that I am doing it wrong, so if someone could show me how to do that, I would be very grateful.
Also bonus question, maybe there is a way to easily remove said attribute from XML using SA?
I am using SA12 if that matters.
asked
24 Feb '15, 09:31
Valdas
287●9●12●22
accept rate:
80%
edited
25 Feb '15, 08:30
I have a very big XML file, that I would like to chop a bit and then process every chunk separately...
I have a very big XML file, that I would like to chop a bit and then process every chunk separately...
What exactly are you trying to do? With openxml() you should be able to filter a big XML file directly (via XPath and/or a WHERE clause), so you should not need to split up the XML document beforehand by yourself. This is somewhat comparable to a SELECT statement on a big table where you can restrict the result set by using an appropriate WHERE clause instead of removing rows from the table...
How I divide the big XML into smaller ones?
How I divide the big XML into smaller ones?
So I would suggest to not modify the XML document but to use a WHERE clause to then filter the generated result set.
In case you want to shorten the XML document (primarily for testing/development) and it does contain very many "<INDIVIDUAL\>" nodes, you might be more successful if you remove most of them but preserve the underlying document structure including the root. That should prevent the namespace error, too.
As to the "xsi:noNamespaceSchemaLocation" attribute: AFAIK openxml() does not validate the schema at all, so that attribute should not matter here. To cite from the docs:
The XML parser used by the openxml system procedure is non-validating, and does not read the external DTD subset or external parameter entities.
The XML parser used by the openxml system procedure is non-validating, and does not read the external DTD subset or external parameter entities.
answered
24 Feb '15, 10:46
Volker Barth
29.9k●294●446●654
accept rate:
32%
edited
24 Feb '15, 10:51
I have a database full of individuals, I need to find a match between them and ones included in big XML and save particular individuals XML for later use. I do not think that it would be a good idea to save whole XML for every user and filter it every time I need data for specific individual.
As to the "openxml() does not validate the schema at all" I am not sure if I understand this sentence, why then I get the error?
I guess I still do not really understand your task. Do you have to check whether the particular database individuals are contained in the XML document or vice versa?
However, if you want to search the big XML for particular elements and you can use an equality test for that, that should do with a XPath expression - cf. this FAQ. Something like "openxml(..., '/CONSOLIDATED_LIST/INDIVIDUALS/INDIVIDUAL[SECOND_NAME='Valdas']) with"...
If your task is to extract just one or a few nodes from a big XML document and store the resulting XML, I'm not sure whether openxml() is the tool of choice here. That may be more appropriate for basic XML tools using XPath, XQuery or the like (note: That's not my domain...). Apparently the situation would be different if you can generate the "single-indidivual XML document" from the database contents itself.
W.r.t. validation: In my understanding the XML parser (AFAIK Apache Xerces) will check for syntax errors but will not use the specified DTD or XML schema to verify whether the elements comply with that specified schema, so it will not check if elements and attributes are named and typed and organized as specified.
I need to save XML node <individual/> for later use, and I need to do that using SA12, maybe I can use XPath, XQuery or some other tool for that, but I am pretty sure result will be the same, <individual> with xsi:noNamespaceSchemaLocation attribute.
Later the saved XML needs to be opened with openxml() again, and I can not do that because of attribute that I do not know how to handle.
So the question is, is it possible to use openxml() with XML shown in query No. 2 and if possible, then how? First query is provided just for reference, maybe there is vital information for namespace declaration?..
Well, just test this with a browser: When using Firefox, the 2nd document raises the same "undeclard namespace prefix" error while the first opens up fine.
So you'll have to add the "xmlns:xsi="" to the 2nd document, as well, just before " xsi:noNamespaceSchemaLocation". Then it should open up, too.
Thank You, this is a valid solution, but not the best because I get the XML directly from United Nations and would love to keep it unmodified, can't I use namespace-declaration for that?
If modifying the XML is the only solution, then I need a way to do that, simple REPLACE() doesn't sound like a professional move :)
Hm, it looks like your question is not really related to SQL Anywhere but to XML in general, so other forums may be more appropriate...
That being said, in case you need to refer to namespaces then you will need to have an namespace declaration within your XML document, "unmodified" or not. If you do not want to modify the single INDIVIDUAL nodes then you could simply leave the original "CONSOLIDATED_LIST" and "INDIVIDUALS" nodes as they are in the extracted document, so the latter would only consist of one single "INDIVIDUAL" node. In other words: A "single individual document" would look exactly like the big one but would not contain many but only one INDIVIDUAL node.
But as stated, I still do not really know what you are trying to achieve so my hints might not be too helpful.
And how can I achieve single "INDIVIDUAL" node with the original "CONSOLIDATED_LIST" and "INDIVIDUALS" nodes using SQL Anywhere? I tried mentioned XPatch filter but metarpoperty @mp:xmltext gives back the whole XML anyway...
Once you sign in you will be able to subscribe for any updates here
Answers
Answers and Comments
Markdown Basics
learn more about Markdown
Question tags:
sa-12 ×408
openxml ×12
question asked: 24 Feb '15, 09:31
question was seen: 1,022 times
last updated: 25 Feb '15, 09:38
How to use openxml() to list lower level nodes and filter on higher level nodes?
How can I combine several XPath queries?
BYTE ORDER MARK OFF
Are XPath "qualifiers" limited to equality tests?
Is there a way to do the database rebuild through the dbcapi?
How do I notice errors in a function used to calculate a computed column?
Running a script file with dbisql (command-line)
Java performance is awful in SQL Anywhere 12
What is the effect of DBISQL option "auto_commit"?
How does a FOREIGN KEY with MATCH UNIQUE SIMPLE treat null values?
SQL Anywhere Community Network
Forum problems?
Maintenance log
and OSQA
Disclaimer: Opinions expressed here are those of the poster and do not
necessarily reflect the views of the company.
First time here? Check out the FAQ!
|
http://sqlanywhere-forum.sap.com/questions/24121/openxml-with-xsinonamespaceschemalocation-attribute
|
CC-MAIN-2017-17
|
refinedweb
| 1,389
| 57.4
|
(>
Could you be more specific from your last response? I'm mostly following what you said, but am unclear on what you mean by "object will have to be accessible in the event map". Do you mind providing a more detailed example. Thanks.
What if I need to receive a response from the called method? For instance, the method returns a Boolean value?
Thanks and Happy New Year!
In my main I have:
<comp:DTV id="dataTable" ...>
Inside the DTV is a method:
private function export():void {}
In the eventmap I want to have my event handler call the method but it never compiles, here is what we tried:
<Script..
import mx.core.FlexGlobals;
private var dtv:DataTableView = FlexGlobals.topLevelApplication.DataTableView;
<EventHandlers ...
<InlineInvoker method {dtv.exportTableToDisk}"...
Can someone give us an answer?
First I did a typo and the function is exportTableToDisk not export and if I make it public not private, it will compile but the end result is:
TypeError: Error #1009: Cannot access a property or method of a null object reference.
on the InlineMethod.
I would recommend you to create a function in your map to make the method call you need and call that method with InlineInvoker.
|
https://mate.asfusion.com/page/documentation/tags/inlineinvoker
|
CC-MAIN-2019-13
|
refinedweb
| 201
| 66.13
|
Talk:Key:sidewalk)
- I've reverted it, as
noneis the value used in the original proposal and there hasn't been a proper proposal regarding the change to
no. --SelfishSeahorse (talk) 19:05, 31 October 2017 (UTC)
- I added it back. Maybe it is not recommended but its wide use must be documented (I have no idea whatever none or no is better and whatever there is consensus about this topic) Mateusz Konieczny (talk) 15:47, 2 November 2017 (UTC)
- OK, it makes sense that 'no' is documented as well. I've just changed your comment to make it clear that
nohasn't been approved unlike the rest of the page. (
nois only used widely because the recommendation to use
nonehas been added to this page.) --SelfishSeahorse (talk) 17:28, 2 November 2017 (UTC)
- I tweaked language a bit Mateusz Konieczny (talk) 17:55, 2 November 2017 (UTC)
- I disagree with the changes made over the last days. The reason SelfishSeahorse gave for the revert was that only "none" was part of the 2011 proposal. However, that proposal was never voted on, so I don't see how it could be considered authoritative. The "boolean values" proposal, on the other hand, was voted on, and establishes "no" as the preferred negative value for keys like this. --Tordanik 18:16, 6 November 2017 (UTC)
- Hi Tordanik. I'm sorry, I didn't see that the proposal was never voted on, I just read 'Status: approved' on the wiki page. Still, I think the boolean value proposal doesn't apply here, because a boolean variable can only be true (yes) or false (no), but the sidewalk key is used to indicate if there is a sidewalk on the
leftside of the road, on the
rightside, on
bothsides or if there isn't any (=
none) sidewalk. Besides, the value
yesisn't of much use and is only used in 0.20% of cases (and the only real occurrences of
sidewalk=yesI came across were separately mapped sidewalks that weren't correctly tagged with
footway=sidewalk). --SelfishSeahorse (talk) 19:19, 6 November 2017 (UTC)
- PS: But why does the wiki page say 'Proposed_features/Sidewalk - approved proposal for this key'?
- Because was made. I fixed it (no/none are now described as synonymous) Mateusz Konieczny (talk) 19:42, 6 November 2017 (UTC)
- "The "boolean values" proposal, on the other hand, was voted on, and establishes "no" as the preferred negative value for keys like this." - I would not protest basing description of no/none on that Mateusz Konieczny (talk) 19:43, 6 November 2017 )
- Yes, use sidewalk:bicycle=yes.--Jojo4u (talk) 00:09, 7 August 2016 (UTC)
- Okay, I'll also use sidewalk:foot=no to indicate a physical sidewalk exists but it's signposted as no pedestrians allowed + foot=no to indicate you can't walk on the road. --Aharvey (talk) 05:48, 25 July 2020 )
sidepath
This addition looks more than a bit iffy. I've commented at: --SomeoneElse (talk) 14:11, 22 January 2018 (UTC)
Sidewalk completeness
Does the presence of a left or right tag indicate that the sidewalk is fully complete on that side, or that some sidewalk exists on that side of the street. For example, if a sidewalk runs down the left side of a residential street but ends before meeting the curb of a connecting arterial, would that be considered 'left' or 'none'?
- I split the road where the sidewalk stops and starts, so the part that has sidewalk at the left has "sidewalk=left" and the part that does not "sidewalk=none". SomeoneElse (talk) 09:25, 7 February 2020 (UTC)
- "ends before meeting the curb of a connecting arterial, would that be considered 'left' or 'none'" - neither, you need to split the way and tag part as having sidewalk, and part as without it Mateusz Konieczny (talk) 09:28, 24 July 2020 (UTC)
Deprecated
I would like to mark this page as deprecated and include links to the new approved tagging so the new users don't get confused. Tag:footway=sidewalk, Tag:footway=crossing, Proposed_features/Sidewalk_as_separate_way
--Mashin (talk) 23:26, 10 July 2020 (UTC)
- According to taginfo there are 1,711,571 uses of the "sidewalk" key currently. It doesn't look very deprecated. SomeoneElse (talk) 00:13, 11 July 2020 (UTC)
- Why you think that this kind of sidewalk tagging is deprecated? Mateusz Konieczny (talk) 07:41, 11 July 2020 (UTC)
- This older sidewalk tagging scheme has been superseded, by the newer approved proposal. Therefore we should mark it as: we don't recommend tagging this way, please use the newer version. Otherwise new users get confused about what is current and what is old. The fact that the tagging is still present in the data doesn't change this, but it is a reason why to keep this page so OSM data users are warned that such-and-such tags can still be found. --Mashin (talk) 16:47, 11 July 2020 (UTC)
- "has been superseded, by the newer approved proposal" it doesn't say that.
- "we don't recommend tagging this way" We don't always recommend what level of detail should be mapped. It's up to users to decide.
- "please use the newer version" The "newer" version simply provides a higher level of detail. New is not neccessarily a replacement.
- "Otherwise new users get confused about what is current and what is old." sidewalk=separate is pretty clear to me.
- -- Kovposch (talk) 19:40, 11 July 2020 (UTC)
- The new one has been approved by OSM community vote, while the old one has never even been voted on. So yes, new supersedes old.
Yes, a person that is adding the data decides, but we certainly recommend how to tag things -- thus the whole point of this wiki portal.
Yes, new version contains the same information as old one and provides more level of detail on top of that (supersedes the old one). But that is not the point, the point is that we have a new approved version and this page should reflect that.
Yes, the text relatively clear (though it could be improved), but the point is that it is buried on the bottom and the old scheme still presented as current. Therefore I would like to do the said changes. --Mashin (talk) 20:37, 11 July 2020 (UTC)
- The proposal that you mention approved tag for marking sidewalk mapped as a separate way, without deprecating sidewalk tag.
- Without explicit deprecation approving new tagging scheme does not mean that competing tagging schemes are invalid or deprecated. In fact some approved proposals knowingly introduced duplicate tagging schemes without deprecating originals
- Primary function of Wiki is to document tagging, not act as director managing mappers
- Sidewalk tag is current and widely used
- Approved version is not new, it is from 2011
- Mateusz Konieczny (talk) 22:42, 11 July 2020 (UTC)
- Uf. First, could we please stop discussing on the meaning of my words? The approved proposal is new as: it came later than the other. I though the context was clear or am I wrong? Besides, what is that argument supposed to mean?
Again usage of the tag is not an argument. Newer proposals will always have less count at the beginning. Plus the cause is also that the approved version has not been correctly referenced so far.
There were two ways how to tag sidewalk, community chose the other so it superseded this one. No one is saying that something is wrong. Just want to bring the correct information that we have an approved way of tagging now. This one will still exist and it won't change that.
And I don't think many people are going to agree with you that approval process has no meaning and you can declare any other proposal as equal.
--Mashin (talk) 18:53, 12 July 2020 (UTC)
- "Again usage of the tag is not an argument." - yes, it is. There are many tags that were never approved but are de facto standard due to usage (sometimes of of standard ways of tagging given feature)
- "approval process has no meaning" - I am not claiming that, I am claiming that it is less important than actual use of a tag
- "you can declare any other proposal as equal" - in case of tags with similar use approved/not approved status is important, approval may also indicate that community decided to start migrating from one tagging to another. In this case it is an ancient vote so it is not indicator that community wants currently to transition to a new tagging, usage of both tagging schemes is clearly significant
- Mateusz Konieczny (talk) 07:46, 13 July 2020 (UTC)
- Again. Yes, have one way of tagging, it has some use count, we vote for different way, we start to use that one. This happened and happens all the time. This case is nothing different. As you said, community wanted to migrate.
I agree, this wiki does not command you what to use, but gives a recommendations and so I just simply want to put the one that we agreed on there.
I don't think that many are going to agree with you that after some arbitrary time we can just drop the accepted proposals and start ignoring it as we will. --Mashin (talk) 02:50, 14 July 2020 (UTC)
- "This happened and happens all the time." - and as it often happens it ended with two ways of tagging, neither deprecated (see phone=*/contact:phone=* or amenity=hospital and its intentional duplicate). Not by switching to a single scheme. 9-year old proposal is far less important that large scale use and continued acceptance/support/use of a tagging scheme. Mateusz Konieczny (talk) 08:38, 14 July 2020 (UTC)
- Accepted proposal is very important, because it directly expresses the will of the community. That the other scheme is still present in the data has no influence on this. Obviously, it will be highlighted that some regions or communities still prefer using the alternative way of tagging and mappers should discuss with locals first. Those regions can be named in some form of table. --Mashin (talk) 08:57, 15 July 2020 (UTC)
- "we vote for different way" They aren't "different" as in mutually exclusive or conflicting. They exists as two levels of details.
- It's not "community wanted to migrate". It's a scheme of addition. You can't "migrate" between them.
- "we can just drop the accepted proposals and start ignoring it" You are ignoring the content of "accepted proposals" you raised repetaedly
- -- Kovposch (talk) 09:37, 15 July 2020 (UTC)
- Community wanted and voted to have one recommended way of tagging sidewalks and in that context they are exclusive and conflicting. Only the accepted one can be recommended. So far you are the one ignoring the accepted proposal and the will of the community. --Mashin (talk) 23:40, 16 July 2020 (UTC)
- "Only the accepted one can be recommended." - this is untrue. "will of the community" - mapping activity is also important and indicates will of community Mateusz Konieczny (talk) 08:23, 17 July 2020 (UTC)
- You keep using the same argument over again. Mapping activity has nothing to do with what we recommend. The mapping activity was there also before and yet the community decided that we want to recommend the other way. If you want to keep using the old way, then keep doin so. --Mashin (talk) 16:43, 19 July 2020 (UTC)
- Why don't you first stop keep using the same misunderstanding of that proposal over and over again? The community now has one "more" method of further mapping sidewalks. What makes you think this is a mutually "exlusive and conflicting situation"? -- Kovposch (talk) 09:35, 20 July 2020 (UTC)
- I don't think there is any confusion about that on my side. What is conflicting is that both are presented as equal methods of tagging, while the community has clearly chosen to prefer tagging with separate ways.
Since there don't seem to be any new concerns, I tried to implement what I already read here. I would like to do the following: Mark separate ways proposal as recommended primary way of tagging sidewalks. Tagging on the roads would be marked as additional/extended way of tagging that provides useful information. There would be a warning that some users or areas prefer tagging that way with perhaps a table where those would be listed. --Mashin (talk) 03:48, 22 July 2020 (UTC)
- Approval De Facto is fully justified. A "principled" approach that would deprecate, the common meaning of which is, mark for future invalidation, so much carefully created data - if I may say so - borders on the insane. Besides, this scheme here has several merits over the other: My personal favourite being, to read aloud the itinerary for a walk in a city, where the "new" scheme has been adopted; that feels a lot like listening to the song "Where the Streets have no Names". Then of course, to be of any real use, when micro-mapping separate side-walks, what can be a single annotation will require at least one, most often though, several new ways. Much an effort, with not much gain, as routers can use annotations just as well, watch e.g. --Hungerburg (talk) 11:25, 17 July 2020 (UTC)
- That is great topic for conversation (Some of it took place during the approval process), but not the point of this discussion. --Mashin (talk) 16:43, 19 July 2020 (UTC)
- What makes you think this is irrelevant, please explain. --Hungerburg (talk) 21:34, 19 July 2020 (UTC)
- The discussion is about highlighting the tagging method that the community has chosen, not about advantages/disadvantages. When the vote was cast, everybody had all those information already in mind. --Mashin (talk) 03:48, 22 July 2020 (UTC)
- Of course it is about the value of the scheme. The community has chosen the annotation method "de facto" for good reasons. While in your evangelism you do not give any reasons apart from repeating on end a pseudo-legal doctrine without even quoting source and calling something new, that is just as old as the old. Deprecation requires more than missing "approval", e.g. "culvert=yes" is deprecated, because of ambiguity. --Hungerburg (talk) 09:53, 22 July 2020 (UTC)
- Again, that issue was solved when from two competing proposals, one went for vote and was approved. All of what you are saying was already discussed by others. --Mashin (talk) 00:31, 24 July 2020 (UTC)
- Why you think that approving one proposal in a vote means that all alternatives are deprecated/discouraged/wrong and should be discouraged/not used? Mateusz Konieczny (talk) 09:27, 24 July 2020 (UTC)
- I thought we discussed this. Please, just read the discussion carefully again. There can be only one recommended way of tagging of certain objects. I just simply want to move the approved proposal up so it is visible. I see you concerns, but I don't want to delete or invalidate the old way of tagging. Just put the note that community agreed on to tag sidewalks primarily as separate ways, tagging on roads is still used and is encouraged to use as supplementary way of tagging. So I don't know, let's call this state as "soft deprecated" or something like that. --Mashin (talk) 20:58, 26 July 2020 (UTC)
- "There can be only one recommended way of tagging of certain objects." is not true in OSM. OSM is not so tidy Mateusz Konieczny (talk) 22:10, 26 July 2020 (UTC)
- And that is why we vote and then recommend one way of tagging to keep it tidy. Otherwise, it would be a Babylon of hundreds of different styles and ways how the same things get entered into the database. --Mashin (talk) 01:32, 27 July 2020 (UTC)
- Actually, we have multiple styles for the same thing. See see phone=*/contact:phone=* or amenity=hospital and its intentional duplicate, see Forest Mateusz Konieczny (talk) 06:54, 27 July 2020 (UTC)
- De facto, just means that it's been used not that it is recommended. --Mashin (talk) 23:28, 29 July 2020 (UTC)
- On osm wiki "in use" status is for things that are in use but on minimal scale or there are serious issues with the tag. "de facto" is for things used so widely and with so widespread acceptance that their status is equivalent to features with proposal (or greater) Mateusz Konieczny (talk) 09:26, 30 July 2020 (UTC)
- Please note, that your proposal to deprecate this scheme here received no voice in support, but lots to the opposite. Any changes to the article in this direction therefore are to be considered unapproved by the community. --Hungerburg (talk) 08:52, 24 July 2020 (UTC)
When something is not a sidewalk
Recent changes by BudgieInWA turned this article about the sidewalk key into an advertisement for not using it. I am going to shorten that. The changelog is hard to read, but I will try to reinstate the previous version as much as possible, some deliberate exceptions included:
- If the sidewalk does not run in parallel, then it is not a sidewalk, no need to mention that twice.
- A verge is, by definition there, useful for pedestrians, to step out of traffic, so it cannot not a barrier.
- Some adverts left to please the separate way apostols
--Hungerburg (talk) 21:41, 1 August 2020 (UTC)
- I reworded the intro some more to make it read less prescriptive. After all, the separate way approach is a true alternative and the Sidewalks article already explains the options in depth. --Hungerburg (talk) 09:27, 2 August 2020 (UTC)
Same surface in sidewalk and highway
How to tag a highway that has sidewalks with the same kind of surface, for example surface=sett? --AntMadeira (talk) 02:16, 21 March 2021 (UTC)
- Exactly the same as you would when they differ: sidewalk:both:surface=sett (or left or right instead of both), unless the sidewalk is mapped separately, then both ways get surface=sett. --JeroenHoek (talk) 06:46, 21 March 2021 (UTC)
- Sorry, I don't know why my last edition doesn't show here, but I added "but different material or pattern?" to the end of my sentence. --AntMadeira (talk) 06:51, 21 March 2021 (UTC)
- I don't think you can tag the pattern of the stones, but if that is the only thing that sets off the sidewalk from the street, you could tag sidewalk:both:kerb=no to tell users they should not expect a kerb. Also if the colour of the stones differs, surface:colour=* and sidewalk:both:surface:colour=* (or left or right instead of both). You would be the first to use that compound key! (It is valid though: search for surface:colour on TagInfo for related examples). Another tag to consider is sidewalk:both:width=*.
- But I wouldn't worry about it. As long as it is clear that it is a sidewalk, just mapping its existence is fine. --JeroenHoek (talk) 07:14, 21 March 2021 (UTC)
- Thanks for your input. I know it's a stretch, but consider this: a highway=residential + surface=sett. Then, you want to use this scheme to say there is a special kind of sett on the sideways, like sidewalk:both:surface=sett + sett:style=portuguese. How would you say that the style is from the highway or the sidewalk? (this hypotetical question arose in the Portuguese community, which approved the sett:style=portuguese tag.) --AntMadeira (talk) 16:51, 21 March 2021 (UTC)
- sidewalk:both: (and sidewalk:left: and sidewalk:right:) is a namespace prefix. That means that essentially, you can use it in front of any tag that makes sense. So this would be OK: sidewalk:left:sett:style=portuguese. --JeroenHoek (talk) 17:06, 21 March 2021 (UTC)
- If the style is the same on both sides, shortened to sidewalk:surface=sett + sidewalk:sett:style=portuguese might do too - not that I am aware of any data consumer that makes use of this, but you can create one, that does. For the sake of clarity, specifying :both: might be better, but rest assured that users will find the shorthand. --Hungerburg (talk) 21:13, 21 March 2021 (UTC)
Deprecate sidewalk=separate
"This road has sidewalks but these are mapped using separate ways.". In my opinion you should still always set sidewalk=both/left/right/no because
- It makes it easier for data consumers. If they prefer to know which roads have sidewalks then it's an easy tag check. If they prefer to do accurate routing on the exact sidewalk way they can use the separately mapped way.
- It's a more OSM way of doing things. One real world feature = one object in OSM. The sidewalk is a real world feature, so it get's its own way object, which can have it's own surface, width, lit etc tags. However it's still considered an attribute or feature of the road, because they are kind of linked. "The road has a sidewalk on the right here", so you should also tag this as a tag on the road "sidewalk=right" to reflect that.
--Aharvey (talk) 01:37, 7 June 2021 (UTC)
- One use is for data consumers to be able to count the number of streets that have sidewalks in a neighbourhood (which can be a goal for improving living quality). In that case you want to count the streets tagged with separate as having a sidewalk, but renderers that want to change the casing of a street if there is a sidewalk would only want to do that if the sidewalk isn't mapped separately. So there is a need for this value.
- And of course, sidewalk=separate, sidewalk:left=separate, and sidewalk:right=separate are used over 100,000, 9,000, and 13,000 times respectively. That means they fulfil a purpose for a lot of mappers, and with those numbers deprecating them is not realistic unless you have an alternative for the data they represent. --JeroenHoek (talk) 06:39, 7 June 2021 (UTC)
- Good point, you've convinced me, and on further reflection for data consumers who just want to know about sidewalks per road segment and don't care about separate paths they can treat sidewalk=separate as being the same as sidewalk=both in their evaluation, same goes for sidewalk:left=separate being the same in this context as sidewalk=left.
I withdraw my suggestion, thanks for your feedback.--Aharvey (talk)
- You're welcome. --JeroenHoek (talk) 11:17, 7 June 2021 (UTC)
Is sidewalk=none valid?
There is some effort underway to deprecate sidewalk=none in favour of sidewalk=no:
- ID:
- JOSM:
While I am not opposed to this per se (neutral in fact). It does clash with a patch I submitted last week which treats no and none as synonyms as per the documentation here. Deprecating sidewalk=none seems like something that should be discussed and documented first (@ZeLonewolf: I may have overlooked any recent discussion on this though; if so, please link to it!). --JeroenHoek (talk) 06:55, 23 August 2021 (UTC)
- note that treating "no" and "none" as synonymous and at the same time replacing "none" by "no" is not clashing. It is fine to support existing duplicate in data display while at the same time eliminating it Mateusz Konieczny (talk) 07:45, 23 August 2021 (UTC)
- in this case usage was nearly flat before SC started using it (what can be confirmed after the next SC release when it will switch to sidewalk=no) and I support such deprecation Mateusz Konieczny (talk) 07:45, 23 August 2021 (UTC)
- So in my opinion (1) sidewalk=none is valid (2) sidewalk=none has the same meaning as sidewalk=no (3) sidewalk=none should be replaced by sidewalk=no Mateusz Konieczny (talk) 07:46, 23 August 2021 (UTC)
- Sure, but if one is to be deprecated, than that should be discussed and then documented first. The documentation provides guidance for contributors and authors of tools like ID and JOSM too. Presenting it as a fait accompli by first changing the tools and then changing the documentation seems the wrong way around.
- These two points clash though: sidewalk=none is valid and sidewalk=none should be replaced by sidewalk=no. If none is valid, replacing it is not desirable. It should be deprecated in that case, while remaining a valid value only for data consumers. I think that is what you meant though. --JeroenHoek (talk) 08:03, 23 August 2021 (UTC)
- I see no problem with value being at once "valid" and "deprecated". It is OK to use it (with "no" being preferrable), but also OK to replace it Mateusz Konieczny (talk) 09:54, 23 August 2021 (UTC)
- And in this case I see it more as "lets cleanup unpreferred tags added by SC". Note that in JOSM users see tags, in iD they can see if they really want, in SC tags are almost 100% hidden and user has no option to change tagging scheme. And I think that this talk page discussion may be sufficient Mateusz Konieczny (talk) 09:57, 23 August 2021 (UTC)
- That would make it fine for mappers to use none, but at the same time the patches proposed by ZeLonewolf will have tools constantly change these to no. That sends a mixed message. Either the value is valid and mappers and tools can use it (and tools should not automatically change it as suggested here), or it is not and its use should be discouraged. (Deprecating a value doesn't mean data consumers should treat it as invalid right away of course.).
- You can have both values valid and prefer one: that would mean presets would only offer no for example, but once you start having tools suggesting fixing none to no you are effectively deprecating none. That is probably fine, but document it first. --JeroenHoek (talk) 12:02, 23 August 2021 (UTC)
- In my mind, "valid" and "invalid" aren't concepts in OSM. The tickets I opened are simply reflecting the current state of OSM editors, which have all coalesced on sidewalk=no as the tagging for no sidewalks. Since the editors have all agreed that no is the tagging for this, adding auto-fixes is appropriate to help increase consistency across the database gradually, as objects are edited. Actual usage has spoken; none is a flat-line once you subtract StreetComplete's (fixed) bug while no was increasing continuously. There is no need to perpetuate pure synonyms. --ZeLonewolf (talk) 01:19, 24 August 2021 (UTC)
- If you are auto-fixing none, you are deprecating it. This is fine, it's not a dirty word, just document it. I was working on #21235 and from the documentation, the number of uses, and the discussion on this talk-page from 2017, you can only conclude that none and no are both equally fine. If this isn't the case — and you are both giving good reasons for it not to be! — then document it so others know why. There is no 'you should really use no' or 'none is considered non-standard for this type of value and is falling out of use' anywhere on this page, and no mention of StreetComplete inflating its use either. With hundreds of thousands of instances of sidewalk=none that documentation is really step one. --JeroenHoek (talk) 07:23, 24 August 2021 (UTC)
- To clarify two additional points. One; great work on improving the tools we use. I am not objecting to that. Two; once you start having tools offering to fix a value instead of just using the other one in presets and so-on, then you cross the boundary from 'use whichever you like' to 'this is wrong, don't use this one'. After all, if both are OK to use, then there is no reason to change one to the other. If there is reason to stop using one, then you are deprecating it. Deprecation means that the value should still be considered by data consumers (for years probably), but that data producers should no longer emit it. If you wish to avoid the word 'invalid', that is OK. Just call it deprecated.
- Also, have a look at the history of sidewalk=*. In 2017 no was documented as being an unapproved synonym of none, so the current view on this tag-value is a reversal of that. More reason to clearly document it so everyone is on the same page. --JeroenHoek (talk) 07:58, 24 August 2021 (UTC)
- sidewalk=no is shorter, seems to be more popular, and at a glance seems to have better software support. I agree with changing the wiki text to deprecate sidewalk=none. --JeroenvanderGun (talk) 16:48, 24 August 2021 (UTC)
- Bit late to this discussion, but I also support deprecating sidewalk=none in favor of sidewalk=no. --Woazboat (talk) 14:33, 31 October 2021 (UTC)
Sidewalks without curbs
I assume that by default, sidewalks are assumed to have curbs, at least in developed places. But what about sidewalks without curbs? Any way to tag this?
A common situation that may be considered as a "sidewalk without curb" is a country road with a compacted strip on each side (that isn't wide enough to be used as a shoulder). Also, such situation is often found in villages with less developed infrastructure or generally in less developed countries where e.g. at least the road is paved and there is just a compacted "area" left and right of the road where pedestrians mill about. Functionally, this is a sidewalk. But without curbs. --Westnordost (talk) 13:28, 7 January 2022 (UTC)
- The classic sidewalk in most countries used to have a kerb, but with an increased focus on accessibility this is no longer the default in many places. There has to be some boundary to separate it from the carriage way though, but in addition to kerbs there are gutters (example on Google Streetview) and various kinds of barriers (chaings, fences) as well. In some cases there is only a change of surface colour or tile pattern, despite being clear in their function as a sidewalk (often due to spaced repetition of (lamp) posts or bollards). But proper sidewalks of the kind that I think fall under this key tend to have been built as such, offering protection to the pedestrians in some way (kerbs, posts at intervals, etc.), and often fall under some kind of legal protection too (e.g., not being allowed to park on it, drive on it, or block it). A compacted surface next to a road where you would walk but which lacks any clear sings of it being a sidewalk probably falls outside of the current definition of this key.
- There is something missing though. I've come across examples in the Netherlands where a pedestrian might be allowed to walk along a road where even cyclists are forbidden to come lacking even a parallel cycling way or footpath (these are admittedly rare though). In such cases pedestrians can use the verge of the road, but must (by law or necessity) stay of the paved carriage way. Your example seems similar. I think some key that indicates the state of the verge for pedestrian use might be useful, and help indicate to other mappers that there is no sidewalk=*, only an informal (but usable) verge (which can be grass or compacted soil or gravel). The benefit of such a key would be that routers could penalize it over roads with proper sidewalks (and actual footpaths and cycleways obviously). This seems useful in cases where legally you could walk somewhere, but most people would rather not if given the choice. Such a key would by definition not be used together with sidewalk=* on the same side of the road. --JeroenHoek (talk) 09:46, 8 January 2022 (UTC)
- Such a key could take inspiration from shoulder=*, which can already (theoretically extrapolating from shoulder:bicycle=*) be used to mark pedestrian access. --JeroenHoek (talk) 09:52, 8 January 2022 (UTC)
|
https://wiki.openstreetmap.org/wiki/Talk:Key:sidewalk
|
CC-MAIN-2022-05
|
refinedweb
| 5,374
| 67.69
|
Cool, and I won't ask for C advice here, but there are no problems with writing a server in C and a client in Java are there? As long as the port is the same and all that good shtuff?
Cool, and I won't ask for C advice here, but there are no problems with writing a server in C and a client in Java are there? As long as the port is the same and all that good shtuff?
What is the best method to accomplish getting data from my computer to a server so that I can then view it in a applet in a browser?
I have a sensor attached to my computer, I already have that...
I believe the problem is that switching the sign of denom makes it so when you ADD two each time, you are not always adding to the absolute value of the number, as adding to a negative gets it closer...
Check out the charAt() or indexOf() methods of the String class
this link : Java 2 Platform SE 5.0 Will tell you about the next() methods, nextInt() is to get a number, you want next() or nextLine()
With yours, if you don't pop the queue, and keep using front() it'll be the same thing repeatedly. Also if you use Size() in the for loop and pop, you will be counting up and lowering the count so...
will print the front item in the queue repeatedly without changing it.
as the last part of the for loop means it WILL be in the from but the if empty works fine just pointless
There is one problem, the for loops that use MyQueue.Size() and pop() together are cut short as pop reduces size, make a variable to remember the original size before you start the loop...as such:
...
In that example what happens between "After Iteration 1" when the from queue is empty and "Iteration 2" where it has data...you must transfer it...
There appears to be a problem with your MyQueue or DoublyLinkedList classes...the to queue is not growing properly. my mistake not true..same poping reducing size problem
Hmm...well, you need to empty from as you go through it or it will build up, but I see that doing so changes Size() and makes me run out faster than I should.
Problem though, the final sequence from the generator-koch.txt file has spaces for some reason...so an error in the code somewheres
make it str = console.nextLine().trim(); in the penguin loop
...
// this class takes in productions and generates turtle commands.
import java.util.ArrayList;
import java.io.*;
import java.util.*;
public class program6_part_3
{ // beginning of class...
I misspoke, it ends in the "from" queue, so print from the "from" queue
No offense but your teacher's outline is a bit weird, steps 1&2 are on a different scope than 3,4,5&6, 4,5&6 should have been under 3 and it should have been worded different....but anway, okay, the...
for (int iter =0; iter < numberOfIterations; iter++)
{ // beginning of for
for (int iter2 = 0; iter2 < from.Size(); iter2++)
{ // beginning of for
if(leftSide.contains(from.front()))
{ //...
Still use two circles, since the repeated part has two circles.
for(int i = 200;i>=20;i-=40) {
Circle c = new Circle(250, 250, i);
Circle c2 = new Circle(250, 250, i-20);...
Make a for loop that goes to.length iterations and pop them from the 'to' queue into the 'from' queue
for(int asdf = 0;asdf<to.length();asdf++) {
from.push(to.front());
to.pop();
}
For the generator-koch.txt file, I get
F-F++F-F++F-F++F-F++F-F++F-FF-F++F-F++F-F++F-F++F-F++F-FF-F++F-F++F-F++F-F++F-F++F-FF-F++F-F++F-F++F-F++F-F++F-FF-F++F-F++F-F++F-F++F-F++F-F
as the...
It appears it would yes.
But what you need to do is in the for loop, once you read in a production, stick it in two queues, one for the lhs(from) and one for the rhs(to)
static Scanner in;
public static void main(String[] args) throws IOException {
in = new Scanner(new File("generator-koch.txt"));
for(int i = 0;i<6;i++) {
...
He means make a queue of all the chars in the starting sequence, then for each char, check if it is a lhs(left hand side) symbol, if so, take the corresponding rhs and substitute the symbol
With scanner.next() it gives you what is inbetween spaces, so if you use
for (int penguin = 0; penguin < numberOfProductions; penguin++)
{
// should read in single character that is on left...
Alright, try this, post a(1) specific-ish question, and the part of the code that goes with it
|
http://www.javaprogrammingforums.com/search.php?s=8d82897b843a1b87c9246fdb2faa5712&searchid=204066
|
CC-MAIN-2016-30
|
refinedweb
| 824
| 80.31
|
Created on 2007-10-16 11:59 by ygale, last changed 2012-11-28 07:00 by eric.snow. This issue is now closed.
The.
Do you have a use-case for this? In Py3k, I don't think adding support
for the 'with' statement to StringIO makes any sense, since the close()
method does nothing.
These objects are supposed to be drop-in replacements
for file handles. Except in legacy code, the way you
use a file handle is:
with function_to_create_fh as fh:
<do stuff>
If these objects do not support the with protocol,
the only way to use them is to refactor this code.
That may not even be possible, e.g., if it is in
a library, or it may not be desirable to refactor.
Even if you can refactor it, I don't think you
can call these objects file-like objects if
you can't use them like a file.
Note that in legacy code, you used to write:
fh = function_to_get_fh
try:
<do stuff>
finally:
fh.close()
If function_to_get_fh happens to return some other
file-like object and not an actual file,
this still works fine without any refactoring.
You wrote:
> In Py3k, I don't think adding support
> for the 'with' statement to StringIO makes
> any sense, since the close()
> method does nothing.
So do you propse removing the close() method
altogether? Of course the answer is "no",
because then you could not use the object like
a file. The same is true for the with protocol.
(I now retract the words "that needs to be closed"
from my original comment. All file-like objects
should support the with protocol, regardles of
whether their close() method actually does anything.)
Makes sense to me.
Let's not get overexcited. I agree that it makes sense for fileinput,
but I disagree about *StringIO; its close() isn't needed to free
resources (since it doesn't use up a scarce resource like a file
descriptor).
Can you whip up a patch for fileinput? Please include unit tests and
documentation.!
Why is this getting over-excited? It's a very
lightweight change. You can't beat the cost/benefit ratio.
2007/10/25, Yitz Gale <report@bugs.python.org>:
>!
I don't understand. What did your code look like after the refactoring?
I find that typically a useful idiom is to have one piece of code
handle opening/closing of streams and let the rest of the code just
deal with streams without ever closing them. E.g.
f = open(filename)
try:
process(f)
finally:
f.close()
or, if you want:
with open(filename) as f:
process(f)
As I don't understand how you are working the StringIO() call into
this I'm still not sure what the issue is.
> Why is this getting over-excited? It's a very
> lightweight change. You can't beat the cost/benefit ratio.
Until you submit a patch it's more work for me. :-)
FYI, StringIO and BytesIO, in Python 3K, already support the context
management protocol.
Attached patch implements context management protocol for StringIO.
Attached is a patch against trunk r76325 which implements context
manager support for fileinput/FileInput, with tests and doc change.
I reviewed the patches attached.
- The patch to add Context Manager support for fileinput.py seems good.
It has docs too.
This discussion did not conclude on the need for Context Manager for
StringIO. With py3k having it, it should be good for py2.7 to provide
the support too. The attached patch seems good enough, Docs can be added
further.
FWIW, for the sake of consistency I'm +1 on supporting the context
manager protocol on all file-like objects in the stdlib.
For 3.x, the builtin io.StringIO and io.BytesIO already have context manager capability. Added fileinput in r83359.
Any chance this patch could be applied to version 2.7? It's still an issue in 2.7.3, even though a suitable patch was supplied 3 years ago.
I understand that it's fixed in python3, but for us poor maintainers of ancient code, it would be convenient to be able to do things like
with StringIO() as test:
test.write("hi!")
return test.getvalue()
It would be a new feature, and as such forbidden to add in maintenance releases.
Keep in mind that it's pretty easy to roll your own CM wrapper:
@contextlib.contextmanager
def closes(file):
yield file
file.close()
Then you can do this:
with closes(StringIO()) as test:
test.write("hi!")
return test.getvalue()
This works for 2.5 and up.
borrowed the time machine did we? ;)
|
http://bugs.python.org/issue1286
|
CC-MAIN-2017-09
|
refinedweb
| 772
| 76.93
|
Those of us who have to tiptoe around non-standard or ancient compilers will know that template template parameters are off limits.
- Hubert Matthews [Matthews03]
Dvbcodec fail
Long ago, way back in 2004, I wrote an article for Overload [Guest04] describing how to use the Boost Spirit [Spirit] parser framework to generate C++ code which could convert structured binary data to text. I went on to republish this article on my website, where I also included a source distribution.
Much has changed since then. The C++ language hasn't, but compiler and platform support for it has improved considerably. Boost survives - indeed, many of its libraries will feed into the next version of C++. Overload thrives, adapting to an age when print programming magazines are all but extinct. My old website can no longer be found. I've changed hosting company and domain name, I've shuffled things around more than once. But you can still find the article online if you look hard enough, and recently someone did indeed find it. He, let's call him Rick, downloaded the source code archive, dvbcodec-1.0.zip [DVBcodec], extracted it, scanned the README, typed:
$ make
... and discovered the code didn't even build.
At this point many of us would assume (correctly) the code had not been maintained. We'd delete it and write off the few minutes it took to evaluate it. Rick decided instead to contact me and let me know my code was broken. He even offered a fix for one problem.
Code rot
Sad to say, I wasn't entirely surprised. I no longer use this code. Unused code stops working. It decays.
I'm not talking about a compiled executable, which the compiler has tied to a particular platform, and which therefore progressively degrades as the platform advances. (I've heard stories about device drivers for which the source code has long gone, and which require ever more elaborate emulation layers to keep them alive.) I'm talking about source code. And the decay isn't usually literal, though I suppose you might have a source listing on a mouldy printout, or on an unreadable floppy disk.
No, the code itself is usually a pristine copy of the original. Publishers often attach checksums to source distributions so readers can verify their download is correct. I hadn't taken this precaution with my dvbcodec-1.0.zip but I'm certain the version Rick downloaded was exactly the same as the one I created 5 years ago. Yet in that time it had stopped working. Why?
Standard C++
As already mentioned, this was C++ code. C++ is backed by an ISO standard, ratified in 1998, with corrigenda published in 2003. You might expect C++ code to improve with age, compiling and running more quickly, less likely to run out of resources.
Not so. My favourite counter-example comes from a nice paper 'CheckedInt: A policy-based range-checked integer' published by Hubert Matthews towards the end of 2003 [Matthews03], which discusses how to use C++ templates to implement a range-checked integer. The paper includes a code listing together with some notes to help readers forced to 'tiptoe around non-standard or ancient compilers' (think: MSVC6). Yet when I experimented with this code in 2005 I found myself tripped up by a strict and up-to-date compiler (see Figure 1).
I emailed Hubert Matthews using the address included at the top of his paper. He swiftly and kindly put me straight on how to fix the problem.
What's interesting here is that this code is pure C++, just over a page of it. It has no dependencies on third party libraries. Hubert Matthews is a C++ expert and he acknowledges the help of two more experts, Andrei Alexandrescu and Kevlin Henney, in his paper. Yet the code fails to build using both ancient and modern compilers. In its published form it has a brief shelf-life.
Support rot
Code alone is of limited use. What really matters for its ongoing health is that someone cares about it - someone exercises, maintains and supports it. Hubert Matthews included an email address in his paper and I was able to contact him using that address.
How well would my code shape up on this front? Putting myself in Rick's position, I unzipped the source distribution I'd archived 5 years ago. I was pleased to find a README which, at the very top, shows the URL for updates,. I was less pleased to find this URL gave me a 404 Not Found error. Similarly, when I tried emailing the project maintainer mentioned in the README, I got a 550 Invalid recipient error: the attempted delivery to thomas.guest@ntlworld.com had failed permanently.
Cool URIs don't change [W3C] but my old NTL home was anything but cool; it came for free with a dial-up connection I've happily since abandoned. Looking back, maybe I should have found the code a more stable location. If I'd created (e.g.) a Sourceforge project then my dvbcodec project might still be alive and supported, possibly even by a new maintainer.
How did this ever compile?
These wise hindsights wouldn't fix my code. If I wanted to continue I'd have to go it alone. Figure 2 is what the README had to say about platform requirements.
A 'good C++ compiler', eh? As we've already seen, GCC 3.3.1 may be good but my platform has GCC 4.0.1 installed, which is better. If my records can be believed, this upperCase() function (see Listing 1) compiled cleanly using GCC 3.3.1 and MSVC 7.1.
Huh? Std::string is a typedef for std::basic_string<char> and, as GCC 4.0.1 says, there's no such thing as a std::basic_string<char><char>::iterator:
stringutils.cpp:58: error: 'std::string' is not a template
The simple fix is to write std::string::iterator instead of std::string<char>::iterator. A better fix, suggested by Rick, is to use std::transform(). I wonder why I missed this first time round? (See Listing 2.)
Boost advances
GCC has become stricter about what it accepts even though the formal specification of what it should do (the C++ standard) has stayed put. The Boost C++ libraries have more freedom to evolve, and the next round of build problems I encountered relate to Boost.Spirit's evolution. Whilst it would be possible to require dvbcodec users to build against Boost 1.31 (which can still be downloaded from the Boost website) it wouldn't be reasonable. So I updated my machine (using Macports) to make sure I had an up to date version of Boost, 1.38 at the time of writing.
$ sudo port upgrade boost
Boost's various dependencies triggered an upgrade of boost-jam, gperf, libiconv, ncursesw, ncurses, gettext, zlib, bzip2, and this single command took over an hour to complete.
I discovered that Boost.Spirit, the C++ parser framework on which dvbcodec is based, has gone through an overhaul. According to the change log the flavour of Spirit used by dvbcodec is now known as Spirit Classic. A clever use of namespaces and include path forwarding meant my 'classic' client code would at least compile, at the expense of some deprecation warnings (Figure 3).
To suppress these warnings I included the preferred header. I also had to change namespace directives from boost::spirit to boost::spirit::classic. I fleetingly considered porting my code to Spirit V2, but decided against it: even after this first round of changes, I still had a build problem.
Changing behaviour
Actually, this was a second level build problem. The dvbcodec build has multiple phases (Figure 4):
- it builds a program to generate code. This generator can parse binary format syntax descriptions and emit C++ code which will convert data formatted according to these descriptions
- it runs this generator with the available syntax descriptions as inputs
- it compiles the emitted C++ code into a final dvbcodec executable
I ran into a problem during the second phase of this process. The dvbcodec generator no longer parsed all of the supplied syntax descriptions. Specifically, I was seeing this conditional test raise an exception when trying to parse section format syntax descriptions.
if (!parse(section_format, section_grammar, space_p).full) { throw SectionFormatParseException( section_format); }
Here, parse is boost::spirit::classic::parse, which parses something - the section format syntax description, passed as a string in this case - according to the supplied grammar. The third parameter, boost::spirit::classic::space_p, is a skip parser which tells parse to skip whitespace between tokens. Parse returns a parse_info struct whose full field is a boolean which will be set to true if the input section format has been fully consumed.
I soon figured out that the parse call was failing to fully consume binary syntax descriptions with trailing spaces, such as the the one shown below.
" program_association_section() {" " table_id 8" " section_syntax_indicator 1" " '0' 1" .... " CRC_32 32" " } "
If I stripped the trailing whitespace after the closing brace before calling parse() all would be fine. I wasn't fine about this fix though. The Spirit documentation is very good but it had been a while since I'd read it and, as already mentioned, my code used the 'classic' version of Spirit, in danger of becoming the 'legacy' then 'deprecated' and eventually the 'dead' version. Re-reading the documentation it wasn't clear to me exactly what the correct behaviour of parse() should be in this case. Should it fully consume trailing space? Had my program ever worked?
I went back in time, downloading and building against Boost 1.31, and satisfied myself that my code used to work, though maybe it worked due to a bug in the old version of Spirit. Stripping trailing spaces before parsing allowed my code to work with Spirit past and present, so I curtailed my investigation and made the fix.
(Interestingly, Boost 1.31 found a way to warn me I was using a compiler it didn't know about.
boost_1_31_0/boost/config/compiler/gcc.hpp:92:7: warning: #warning "Unknown compiler version - please run the configure tests and report the results"
I ignored this warning.)
Code inaction
Apologies for the lengthy explanation in the previous section. The point is that few software projects stand alone, and that changes in any dependencies, including bug fixes, can have knock on effects. In this instance, I consider myself lucky; dvbcodec's unusual three phase build enabled me to catch a runtime error. Of course, to actually catch that error, I needed to at least try building my code.
Put more simply: if you don't use your code, it rots.
Rotten artefacts
It wasn't just the code which had gone off. My source distribution included documentation - the plain text version of the article I'd written for Overload - and the Makefile had a build target to generate an HTML version of this documentation. This target depended on Quickbook, another Boost tool. Quickbook generates Docbook XML from plain text source, and Docbook is a good starting point for HTML, PDF and other standard output formats.
This is quite a sophisticated toolchain. It's also one I no longer use. Most of what I write goes straight to the web and I don't need such a fiddly process just to produce HTML. So I decided to freshen up dead links, leave the original documentation as a record, and simply cut the documentation target from the Makefile.
Stopping the rot
As we've seen, software, like other soft organic things, breaks down over time. How can we stop the rot?
Freezing software to a particular executable built against a fixed set of dependencies to run on a single platform is one way - and maybe some of us still have an aging Windows 95 machine, kept alive purely to run some such frozen program.
A better solution is to actively tend the software and ensure it stays in shape. Exercise it daily on a build server. Record test results. Fix faults as and when they appear. Review the architecture. Upgrade the platform and dependencies. Prune unused features, splice in new ones. This is the path taken by the Boost project, though certainly the growth far outpaces any pruning (the Boost 1.39 download is 5 times bigger than its 1.31 ancestor). Boost takes forwards and backwards compatibility seriously, hence the ongoing support for Spirit classic and the compiler version certification headers. Maintaining compatibility can be at odds with simplicity.
There is another way too. Although the dvbcodec project has collapsed into disrepair the idea behind it certainly hasn't. I've taken this same idea - of parsing formal syntax descriptions to generate code which handles binary formatted data - and enhanced it to work more flexibly and with a wider range of inputs. Whenever I come across a new binary data structure, I paste its syntax into a text file, regenerate the code, and I can work with this structure. Unfortunately I can't show you any code (it's proprietary) but I hope I've shown you the idea. Effectively, the old C++ code has been left to rot but the idea within it remains green, recoded in Python. Maybe I should find a way to humanely destroy the C++ and all links to it, but for now I'll let it degrade, an illustration of its time.
Is it possible that software is not like anything else, that it is meant to be discarded: that the whole point is to see it as a soap bubble?
Alan J. Perlis
Thanks
I would like to thank to Rick Engelbrecht for reporting and helping to fix the bugs discussed in this article. My thanks also to the team at Overload for their expert help.
References
[DVBcodec] Download of the DVBcodec is available from:
[Guest04] Thomas Guest, 'A Mini-project to Decode a Mini-language - Part One', Overload #63, October 2004. Available from:
[Matthews03] Hubert Matthews, 'CheckedInt: A Policy-Based Range-Checked Integer', Overload #58, December 2003. Available from:
[Spirit] 'Spirit User's Guide' Available from:
[W3C] 'Cool URIs don't change' Available from:
|
https://accu.org/index.php/journals/1573
|
CC-MAIN-2019-09
|
refinedweb
| 2,373
| 64.51
|
Question:
In Python, how do you get the last element of a list?
Solution:1
some]
Solution:2.
Solution:3
You can also do:
alist.pop()
It depends on what you want to do with your list because the
pop() method will delete the last element.
Solution:4
The simplest way to display last element in python is
>>> list[-1:] # returns indexed value [3] >>> list[-1] # returns value 3
there are many other method to achieve such a goal but these are short and sweet to use.
Solution:5
In Python, how do you get the last element of a list?
To just get the last element,
- without modifying the list, and
- assuming you know the list has a last element (i.e. it is nonempty)
pass
-1 to the subscript notation:
>>> a_list = ['zero', 'one', 'two', 'three'] >>> a_list[-1] 'three'
Explanation
Indexes and slices can take negative integers as arguments.
I have modified an example from the documentation to indicate which item in a sequence each index references, in this case, in the string
"Python",
-1 references the last element, the character,
'n':
+---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5 -6 -5 -4 -3 -2 -1 >>>>> p[-1] 'n'
Assignment via iterable unpacking
This method may unnecessarily materialize a second list for the purposes of just getting the last element, but for the sake of completeness (and since it supports any iterable - not just lists):
>>> *head, last = a_list >>> last 'three'
The variable name, head is bound to the unnecessary newly created list:
>>> head ['zero', 'one', 'two']
If you intend to do nothing with that list, this would be more apropos:
*_, last = a_list
Or, really, if you know it's a list (or at least accepts subscript notation):
last = a_list[-1]
In a function
A commenter said:
I wish Python had a function for first() and last() like Lisp does... it would get rid of a lot of unnecessary lambda functions.
These would be quite simple to define:
def last(a_list): return a_list[-1] def first(a_list): return a_list[0]
Or use
operator.itemgetter:
>>> import operator >>> last = operator.itemgetter(-1) >>> first = operator.itemgetter(0)
In either case:
>>> last(a_list) 'three' >>> first(a_list) 'zero'
Special cases
If you're doing something more complicated, you may find it more performant to get the last element in slightly different ways.
If you're new to programming, you should avoid this section, because it couples otherwise semantically different parts of algorithms together. If you change your algorithm in one place, it may have an unintended impact on another line of code.
I try to provide caveats and conditions as completely as I can, but I may have missed something. Please comment if you think I'm leaving a caveat out.
Slicing
A slice of a list returns a new list - so we can slice from -1 to the end if we are going to want the element in a new list:
>>> a_slice = a_list[-1:] >>> a_slice ['three']
This has the upside of not failing if the list is empty:
>>> empty_list = [] >>> tail = empty_list[-1:] >>> if tail: ... do_something(tail)
Whereas attempting to access by index raises an
IndexError which would need to be handled:
>>> empty_list[-1] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
But again, slicing for this purpose should only be done if you need:
- a new list created
- and the new list to be empty if the prior list was empty.
for loops
As a feature of Python, there is no inner scoping in a
for loop.
If you're performing a complete iteration over the list already, the last element will still be referenced by the variable name assigned in the loop:
>>> def do_something(arg): pass >>> for item in a_list: ... do_something(item) ... >>> item 'three'
This is not semantically the last thing in the list. This is semantically the last thing that the name,
item, was bound to.
>>> def do_something(arg): raise Exception >>> for item in a_list: ... do_something(item) ... Traceback (most recent call last): File "<stdin>", line 2, in <module> File "<stdin>", line 1, in do_something Exception >>> item 'zero'
Thus this should only be used to get the last element if you
- are already looping, and
- you know the loop will finish (not break or exit due to errors), otherwise it will point to the last element referenced by the loop.
Getting and removing it
We can also mutate our original list by removing and returning the last element:
>>> a_list.pop(-1) 'three' >>> a_list ['zero', 'one', 'two']
But now the original list is modified.
(
-1 is actually the default argument, so
list.pop can be used without an index argument):
>>> a_list.pop() 'two'
Only do this if
- you know the list has elements in it, or are prepared to handle the exception if it is empty, and
- you do intend to remove the last element from the list, treating it like a stack.
These are valid use-cases, but not very common.
Saving the rest of the reverse for later:
I don't know why you'd do it, but for completeness, since
reversed returns an iterator (which supports the iterator protocol) you can pass its result to
>>> next(reversed([1,2,3])) 3
So it's like doing the reverse of this:
>>> next(iter([1,2,3])) 1
But I can't think of a good reason to do this, unless you'll need the rest of the reverse iterator later, which would probably look more like this:
reverse_iterator = reversed([1,2,3]) last_element = next(reverse_iterator) use_later = list(reverse_iterator)
and now:
>>> use_later [2, 1] >>> last_element 3
Solution:6
mylist = [ 1 , 2 , 3 , 4 , 5] #------------------------------------ # Method-1 : Last index #------------------------------------ print(mylist[-1]) #------------------------------------ # Method-2 : Using len #------------------------------------ print(mylist[len(mylist) - 1]) #------------------------------------ # Method-3 : Using pop, pop will remove the last # element from the list. #------------------------------------ print(mylist.pop())
Solution:7
Ok, but what about common in almost every language way
items[len(items) - 1]? This is IMO the easiest way to get last element, because it does not require anything pythonic knowledge.
Solution:8
some_list = [1, 2, 3]
Method 1:
some_list[-1]
Method 2:
**some_list.reverse()** **some_list[0]**
Method 3:
some_list.pop()
Solution:9
if you want to just get the last value of list, you should use :
your_list[-1]
BUT if you want to get value and also remove it from list, you can use :
your_list.pop()
OR: you can pop with index too...
your_list.pop(-1)
Solution:10
Date: 2017-12-06
alist.pop()
I make an exhaustive cheatsheet of all list's 11 methods for your reference.
{'list_methods': {'Add': {'extend', 'append', 'insert'}, 'Entire': {'clear', 'copy'}, 'Search': {'count', 'index'}, 'Sort': {'reverse', 'sort'}, 'Subtract': {'remove', 'pop'}}}
Solution:11
list[-1] will retrieve the last element of the list without changing the list.
list.pop() will retrieve the last element of the list, but it will mutate/change the original list. Usually, mutating the original list is not recommended.
Alternatively, if, for some reason, you're looking for something less pythonic, you could use
list[len(list)-1], assuming the list is not empty.
Solution:12
You can also use the code below, if you do not want to get IndexError when the list is empty.
next(reversed(some_list), None)
Solution:13
popes = ['john paul II', 'benedict XIV', 'francis I'] current_pope = [] for pope in popes: current_pope = pope
after the for loop you'll get last item in current_pope variable.
Note:If u also have question or solution just comment us below or mail us on toontricks1994@gmail.com
EmoticonEmoticon
|
http://www.toontricks.com/2018/06/tutorial-getting-last-element-of-list.html
|
CC-MAIN-2018-34
|
refinedweb
| 1,258
| 55.58
|
In this tutorial we will learn how to combine the cpplinq skip and take operators to be able to obtain a given section of an integer array. The tests shown on this tutorial were performed using an ESP32 board from DFRobot.
Introduction
In this tutorial we will learn how to combine the cpplinq skip and take operators to be able to obtain a given section of an integer array. We will be using the ESP32 and the Arduino core.
The technique we will use here is the same we can apply for pagination, using these two operators.
This might seem a feature that we don’t need on a microcontroller, but with the increase of the processing capabilities of these devices and the fact that we can setup a HTTP web server in a device such as the ESP32, being able to implement pagination might be useful when developing an API.
When we are doing pagination, we need to specify the offset from which we want to obtain our page, as we are going through the pages. Common approaches consist on allowing to specify either the index of the first element of the page or the page number.
The skip operator allows to specify the starting index of the range from which we want to start obtaining elements, thus serving this purpose.
Besides that, for pagination, we need to specify the number of elements we want per page, starting from the previously mentioned offset.
The take operator allows to obtain a given number of elements from a range and ignoring the remaining ones.
Thus, by using the skip operator followed by the take operator, we can specify the starting index and the number of elements we want to obtain from a sequence.
In this tutorial we are operating the pagination over a simple integer array, for illustration purposes. Naturally, for a real application scenario, we would most likely be applying the operators over an array of objects.
The tests shown on this tutorial were performed using an ESP32 board from DFRobot.
The code
As usual, the first thing we will do is including the cpplinq library. After that, we will declare the use of the cpplinq namespace.
#include "cpplinq.hpp" using namespace cpplinq;
Moving on to the setup function, we will first open a serial connection, so we are able to output the results of our program. Then, we will declare an array of integers, over which we will apply the operators.
Serial.begin(115200); int ints[] = {1,2,3,4,5,6,7,8,9};
Then, before we can apply the cpplinq operators, we need to convert our array to a range object. We do this by calling the from_array operator, passing as input our integer array.
from_array(ints)
Then we will apply the skip operator, which allows us to skip a given number of elements from our range. For illustration purposes, we will pass the value 4 to the operator, thus indicating that we want to skip the 4 first elements of the array.
skip(4)
Naturally, just by applying the skip operator, we would get all the remaining elements of the array. If we stopped here, the final range we would get would have the following elements:
[5,6,7,8,9]
Since, in our case, we want to get a fixed amount of elements (our page size), we need to keep processing the resulting range.
So, we then need to call the take operator. This operator allows to specify how many elements we want to take from the sequence, ignoring the remaining ones.
For this tutorial, we will assume a page size of 4 elements, meaning that we will get the first 4 elements of the already skipped sequence.
take(4)
After this, we expect to obtain the following sequence:
[5,6,7,8]
Then we need to convert the range back to a format we can iterate. Thus, we will use the to_vector function to convert it to a C++ vector. The full expression tree can be seen below.
auto result = from_array(ints) >> skip(4) >> take(4) >> to_vector();
To finalize, we will iterate through all the elements of the vector and print them to the serial port.
for(int i=0; i<result.size(); ++i){ Serial.print(result[i]); Serial.print("|"); }
The complete code can be seen below.
#include "cpplinq.hpp" using namespace cpplinq; void setup() { Serial.begin(115200); int ints[] = {1,2,3,4,5,6,7,8,9}; auto result = from_array(ints) >> skip(4) >> take(4) >> to_vector(); for(int i=0; i<result.size(); ++i){ Serial.print(result[i]); Serial.print("|"); } } void loop() {}
Testing the code
To test the code, simply compile it and upload it to your device using the Arduino IDE. After the procedure finishes, open the IDE serial monitor.
You should get an output similar to figure 1. As can be seen, the resulting sequence contains the expected elements.
|
https://techtutorialsx.com/2019/06/23/esp32-cpplinq-combining-the-skip-and-take-operators/
|
CC-MAIN-2020-40
|
refinedweb
| 819
| 53
|
pagecache 0.1.1
Page caching WSGI middleware
WSGI caching middleware.
PageCache is a WSGI middleware that can be used to cache complete responses from WSGI applications. PageCache works well with memcached but can be used with other caching backends as well.
PageCache has not been widely tested, use with caution.
Usage
Here's a simple example to get you started:
from pagecache import PageCacheMiddleware app = ... cache = memcache.Client(...) cached_urls = (('/foo', 30, 120), # url prefix, TTL, grace period ('/bar', 3600, 60)) app = PageCacheMiddleware(app, cached_urls, cache)
Cached urls
The list of urls to cache is given in the cached_urls list (or tuple). Each entry of this list is a tuple in the following format: (<url prefix>, <TTL in seconds>, <grace period in seconds>)
Pages are served from the cache in the TTL period. When the TTL period has expired the grace period begins. The first request coming in in the grace period will recalculate the page and store the new result in the cache. While the new result is being calculated stale results are served from the cache (until the grace period expires). This is to protect against the dog-pile effect
The cache object
PageCache was only tested with memcached, but it may work with other cache backends as well. The only requirement is that the cache object should have the following methods with reasonably similar semantics as in memcached: get, set, delete, add
Install
You can install the latest version from the github repository:
git clone git://github.com/abiczo/pagecache.git cd pagecache python setup.py install
TODO
- more unit testing
- better syntax for the cached urls configuration
- regexp based url matching
- configurable cache keys (so that multiple applications can use the same memcached instance without having to worry about having the same cached urls)
- configurable request charset
Patches / pull-requests are welcome.
- Author: Andras Biczo
- Keywords: cache wsgi
- License: MIT
- Categories
- Package Index Owner: abiczo
- DOAP record: pagecache-0.1.1.xml
|
http://pypi.python.org/pypi/pagecache/0.1.1
|
crawl-003
|
refinedweb
| 326
| 59.03
|
Prototyping with qmlscene
Qt includes
qmlscene, a utility that loads and displays QML documents even before the application is complete. This utility also provides the following additional features that are useful while developing QML applications:
- View the QML document in a maximized window.
- View the QML document in full-screen mode.
- Make the window transparent.
- Disable multi-sampling (anti-aliasing).
- Do not detect the version of the .qml file.
- Run all animations in slow motion.
- Resize the window to the size of the root item.
- Add the list of import paths.
- Add a named bundle.
- Use a translation file to set the language.
The
qmlscene utility is meant to be used for testing your QML applications, and not as a launcher in a production environment. To launch a QML application in a production environment, develop a custom C++ application or bundle the QML file in a module. See Deploying QML applications for more information. When given a bare Item as root element,
qmlscene will automatically create a window to show the scene. Notably, QQmlComponent::create() will not do such a thing. Therefore, when moving from a prototype developed with
qmlscene to a C++ application, you need to either make sure the root element is a Window or manually create a window using QtQuick's C++ API. On the flip side, the ability to automatically create a window gives you the option to load parts of your prototype separately with
qmlscene.
To load a .qml file, run the tool and select the file to be opened, or provide the file path on the command prompt:
qmlscene myqmlfile.qml
To see the configuration options, run
qmlscene with the
-help argument.
Adding Module Import Paths
Additional module import paths can be provided using the
-I flag. For example, the QML plugin example creates a C++ plugin identified with the namespace,
TimeExample. To load the plugin, you must run
qmlscene with the
-I flag from the example's base directory:
qmlscene -I imports plugins.qml
This adds the current directory to the import path so that
qmlscene will find the plugin in the
imports directory.
Note: By default, the current directory is included in the import search path, but modules in a namespace such as
TimeExample are not found unless the path is explicitly added.
Often, QML applications are prototyped with test data that is later replaced by real data sources from C++ plugins. The
qmlscene utility assists in this aspect by loading test data into the application context. It looks for a directory named
dummydata in the same directory as the target QML file, and loads the .qml files in that directory as QML objects and bind them to the root context as properties named after the files.
For example, the following QML document refers to a
lottoNumbers property which does not exist within the document:
import QtQuick ListView { width: 200; height: 300 model: lottoNumbers delegate: Text { text: number } }
If, within the document's directory, there is a
dummydata directory which contains a
lottoNumbers.qml file like this:
import QtQuick ListModel { ListElement { number: 23 } ListElement { number: 44 } ListElement { number: 78 } }
Then this model would be automatically loaded into the ListView in the previous document.
Child properties are included when loaded from
dummydata. The following document refers to a
clock.time property:
The text value could be filled by a
dummydata/clock.qml file with a
time property in the root context:
To replace this with real data, bind the real data object to the root context in C++ using QQmlContext::setContextProperty(). This is detailed in Integrating QML and.
|
https://doc.qt.io/qt-6/qtquick-qmlscene.html
|
CC-MAIN-2021-31
|
refinedweb
| 595
| 55.54
|
It has come up in the discussion forum that people find the API hard to read. I don’t, I find it rather easy, but maybe that’s just through practice.
I though I’d create this thread to show how to use the API.
All access to the API can be summarized as looking for a method or property of, well, something. You may want to know whether it’s obj.localPosition or obj.localLocation. Or you may want to know what said method or property returns. Either way, you have to find that thing in the API.
There are two ways to find the methods and properties relating to something.
First, here is the API
***Chaining:
This is just remembering how you got said object in the script. Let’s say we have the script:
import bge cont = bge.logic.getCurrentController() own = cont.owner
How can we find the methods/properties of “own”?. Well, to get there we used bge.logic, then getCurrentController, then owner.
So we can do:
And there we have a list of all the properties/methods of “own”
***Types
Each object has a type, and this allows us to find objects via a more direct route, as chaining doesn’t work in long scripts.
Let’s use the same code, but this time, we’ll add something:
own = cont.owner print(type(own))
Now when we run the script, in the terminal, we get printed the text:
<KX_GameObject>
Now we know exactly what it’s called in the API. We’ve used the function type, so it makes sense to look in bge.types:
***Subclassing:
Now you may notice that it seems some are missing. The documentation for a controller gotten via bge.logic.getCurrentController (SCA_PythonController) doesn’t have sensors or actuators as properties, yet people definitely use them!
This is because the SCA_PythonController is a subclass of something. Notice how at the top it says:
“class bge.types.SCA_PythonController(SCA_IController)”
The last part in brackets contains more information. So if we find the SCA_IController, we will find the sensors and actuators. The reason for this heirachy is because the python controller shares a lot in common with other controllers, so it makes sense to put them together. So to find all the attributes of an object, we can:
Anything listed under all these pages is accessible through the thing you have.
Now, I’ve haven’t clicked on CValue. That’s because there’s generally nothing of interest below it, just the name and whether the thing you have is valid or not.
***You can get some help straight from python itself, by typing:
help(own)
It will hang the game engine, but in the console you can scroll through everything the object contains, without using the API. I’m not a big fan of this though.
***Some things are functions, some things are properties. As a rule of thumb, if the item in the API has brackets after it, then so should your code!
And that’s all there is to the API. No mystery in how things are laid out, no magic involved.
Have fun.
|
https://blenderartists.org/t/reading-the-blender-api/620386
|
CC-MAIN-2019-30
|
refinedweb
| 524
| 74.59
|
Details
- Type:
Bug
- Status:
Closed
- Priority:
Major
- Resolution: Fixed
- Affects Version/s: JRuby 1.3
-
- Component/s: Intro, Java Integration
- Labels:None
- Environment:OS X 10.5.8
- Number of attachments :
Description
When using threadify to create a multi-threaded script where a class uses the Java/Ruby integration layer and where imports are package imports such as:
import org.apache.http
And that class only gets instantiated inside the thread block, the following warning is displayed at start up for a number of classes that are loaded:
/usr/local/lib/jruby-1.3.0/lib/ruby/site_ruby/1.8/builtin/javasupport/core_ext/module.rb:27 warning: already initialized constant HttpHost
Where HttpHost may be a variety of class names.
I showed this to Charles tonight at RubyConf 2009, and he said he thought it could be fixed inside the JRuby code.
Activity
Just notice that module.rb changed a little bit in version 1.4 and the code that actually shows the messaage is the next one, in line 37:
JavaUtilities.create_proxy_class(constant, java_class, self)
Anthony, could you attach a test case or a script to check this problem?
We've fixed other cases like this in the past, but this should be fixed in 1.5. The problem here is that the lazy lookup and constantification of classes from a package import is not thread-safe and does not quietly ignore when the constant has already been assigne the same class in another thread.
Here's a dumb example that causes it:
require 'java' threads = [] 100.times do threads << Thread.new(Object.new) do |o| class << self import java.util ArrayList; Vector; HashMap; Collection; List; Map end end end threads.map(&:join)
I'm marking this intro, since the logic for package imports isn't terribly complicated, and it could be an easy one for someone to fix.
I fixed this by making the actual const set be quiet on overwrites (for this specific case) but to add a warning (for this specific path) if a constant is going to be overwritten with a different value. So this quiets your warnings, and should never warn unless there's something actually being overwritten in a destructive way. Pushed in 68f4623...and I have no idea how we'd test this, so I didn't.
Sorry, the version should be Affects Version: JRuby 1.3, not Fix Version: JRuby 1.3.
|
http://jira.codehaus.org/browse/JRUBY-4251
|
CC-MAIN-2013-48
|
refinedweb
| 401
| 56.05
|
Best Practices¶
It is easy to get started with Dask delayed, but using it well does require some experience. This page contains suggestions for best practices, and includes solutions to common problems.
Call delayed on the function, not the result¶
Dask delayed operates on functions like
dask.delayed(f)(x, y), not on their results like
dask.delayed(f(x, y)). When you do the latter, Python first calculates
f(x, y) before Dask has a chance to step in.
Don’t
dask.delayed(f(x, y))
Do
dask.delayed(f)(x, y)
Compute on lots of computation at once¶
To improve parallelism, you want to include lots of computation in each compute call.
Ideally, you want to make many
dask.delayed calls to define your computation and
then call
dask.compute only at the end. It is ok to call
dask.compute
in the middle of your computation as well, but everything will stop there as
Dask computes those results before moving forward with your code.
Don’t
for x in L: y = dask.delayed(f)(x) y.compute() # calling compute after every delayed call stops parallelism
Do
results = [] for x in L: y = dask.delayed(f)(x) results.append(y) results = dask.compute(*results) # call compute after you have collected many delayed calls
Don’t mutate inputs¶
Your functions should not change the inputs directly.
Don’t
@dask.delayed def f(x): x += 1 return x
Do
@dask.delayed def f(x): return x + 1
If you need to use a mutable operation, then make a copy within your function first:
@dask.delayed def f(x): x = copy(x) x += 1 return x
Avoid global state¶
Ideally, your operations shouldn’t rely on global state. Using global state might work if you only use threads, but when you move to multiprocessing or distributed computing then you will likely encounter confusing errors.
Don’t
L = [] @dask.delayed def f(x): L.append(x)
Don’t rely on side effects¶
Delayed functions only do something if they are computed. You will always need to pass the output to something that eventually calls compute.
Don’t
dask.delayed(f)(1, 2, 3) # this has no effect
Do
x = dask.delayed(f)(1, 2, 3) ... dask.compute(x, ...) # need to call compute for something to happen
Break up computations into many pieces¶
Every
dask.delayed function call is a single operation from Dask’s perspective.
You achieve parallelism by having many delayed calls, not by using only a
single one: Dask will not look inside a function decorated with
@dask.delayed
and parallelize that code internally. To accomplish that, it needs your help to
find good places to break up a computation.
Don’t
def load(filename): ... def process(data): ... def save(data): ... @dask.delayed def f(filenames): results = [] for filename in filenames: data = load(filename) data = process(data) results.append(save(data)) return results dask.compute(f(filenames)) # this is only a single task
Do
@dask.delayed def load(filename): ... @dask.delayed def process(data): ... @dask.delayed def save(data): ... def f(filenames): results = [] for filename in filenames: data = load(filename) data = process(data) results.append(save(data)) return results dask.compute(f(filenames)) # this has many tasks and so will parallelize
Avoid too many tasks¶
Every delayed task has an overhead of a few hundred microseconds. Usually this
is ok, but it can become a problem if you apply
dask.delayed too finely. In
this case, it’s often best to break up your many tasks into batches or use one
of the Dask collections to help you.
Don’t
results = [] for x in range(1000000000): # Too many dask.delayed calls y = dask.delayed(f)(x) results.append(y)
Do
# Use collections import dask.bag as db b = db.from_sequence(1000000000, npartitions=1000) b = b.map(f)
# Or batch manually def batch(seq): sub_results = [] for x in seq: sub_results.append(f(x)) return sub_results batches = [] for i in range(0, 1000000000, 1000000): # in steps of 1000000 result_batch = dask.delayed(batch, range(i, i + 1000000)) batches.append(result_batch)
Avoid calling delayed within delayed functions¶
Often, if you are new to using Dask delayed, you place
dask.delayed calls
everywhere and hope for the best. While this may actually work, it’s usually
slow and results in hard-to-understand solutions.
Usually you never call
dask.delayed within
dask.delayed functions.
Don’t
@dask.delayed def process_all(L): result = [] for x in L: y = dask.delayed(f)(x) result.append(y) return result
Do
Instead, because this function only does delayed work, it is very fast and so there is no reason to delay it.
def process_all(L): result = [] for x in L: y = dask.delayed(f)(x) result.append(y) return result
Don’t call dask.delayed on other Dask collections¶
When you place a Dask array or Dask DataFrame into a delayed call, that function will receive the NumPy or Pandas equivalent. Beware that if your array is large, then this might crash your workers.
Instead, it’s more common to use methods like
da.map_blocks or
df.map_partitions, or to turn your arrays or DataFrames into many delayed
objects.
Don’t
import dask.dataframe as dd df = dd.read_csv('/path/to/*.csv') dask.delayed(train)(df) # might as well have used Pandas instead
Do
import dask.dataframe as dd df = dd.read_csv('/path/to/*.csv') df.map_partitions(train) # or partitions = df.to_delayed() delayed_values = [dask.delayed(train)(part) for part in partitions]
However, if you don’t mind turning your Dask array/DataFrame into a single chunk, then this is ok.
dask.delayed(train)(..., y=df.sum())
Avoid repeatedly putting large inputs into delayed calls¶
Every time you pass a concrete result (anything that isn’t delayed) Dask will hash it by default to give it a name. This is fairly fast (around 500 MB/s) but can be slow if you do it over and over again. Instead, it is better to delay your data as well.
This is especially important when using a distributed cluster to avoid sending your data separately for each function call.
Don’t
x = np.array(...) # some large array results = [dask.delayed(train)(x, i) for i in range(1000)]
Every call to
dask.delayed(train)(x, ...) has to hash the NumPy array
x, which slows things down.
Do
x = np.array(...) # some large array x = dask.delayed(x) # delay the data, hashing once results = [dask.delayed(train)(x, i) for i in range(1000)]
|
https://docs.dask.org/en/latest/delayed-best-practices.html
|
CC-MAIN-2019-13
|
refinedweb
| 1,081
| 60.72
|
Looks like interesting work. How does this differ from the already existing Time library?
Was looking at your code, alvarojusten, saw the function to represent the day of week as a string. Don't know if you noticed, but all the clock does in increment the day of the week by one (rolling from 7 to 1) every time it hits midnight. It does *not* seem to have any fixed association between the date/month/year and what day of the week it is. Convenient in some ways as you are perfectly able to define 1=Sunday, 1=Monday... or 1=Thursday for that matter (if you can get the hang of Thursdays...).Similarly, it is perfectly happy to let you set the date to Feb 30... and then it continues to the 31st. Seems to know if the current m/d/y is the last day of the month -- and if so, it will roll to the next month at midnight. But it won't force the date to be valid for the month/year.
Had a chance to learn Git and put what I've done up at goal in creating yet another DS1307 library was to provide easy access to some of the other functions I needed from the chip, specifically its square wave output (for an interrupt) and its battery-backed RAM (to allow configuration info to persist across restarts of the Arduino. (It's annoying, but I suppose necessary, that the Arduino restarts every time you open the Serial Monitor.)I've included an example sketch which allows you to set most everything interactively from the Serial Monitor. Also a Fritzing board based on the Sparkfun module.
(the Time library has) a lot of features that I don't need (NTP, time deltas etc.)
The Time library also "polutes" the namespace since it add a lot of functions (hour(), minute() etc.) instead of creating a class, instantiate it etc.
Please enter a valid email to subscribe
We need to confirm your email address.
To complete the subscription, please click the link in the
Thank you for subscribing!
Arduino
via Egeo 16
Torino, 10131
Italy
|
http://forum.arduino.cc/index.php?topic=59256.msg496464
|
CC-MAIN-2016-30
|
refinedweb
| 359
| 71.85
|
15 October 2012 06:08 [Source: ICIS news]
By Felicia Loo
?xml:namespace>
SINGAPORE
At noon, open-spec naphtha was at $975.50-978.50/tonne (€751.14-753.45/tonne) CFR (cost and freight)
But in the week ended 12 October, prices increased by $22.50/tonne from the previous week, according to ICIS data.
“The market will be tighter because of less [naphtha] availability from
The arbitrage economics in moving European naphtha supply to
The intermonth spread between the naphtha contracts for the second half of November and the second half of December was assessed at a backwardation of $14.00/tonne in the week ended 12 October, compared with a backwardation of $13.00/tonne from the previous week.
The naphtha crack spread versus November Brent crude futures widened to $123.45/tonne in the week ended 12 October, from $121.88/tonne in the previous week.
European naphtha prices are firm because of ongoing refinery turnarounds and some naphtha supply is being diverted for blending, so that European gasoline could meet the rising motor fuel demand from
In response to tight European supply, the premiums that were fetched in the South Korean spot naphtha purchases rose in the week ended 12 October, they added.
Honam previously bought 50,000 tonnes of spot naphtha supply for first-half November delivery to Daesan at a premium of $10.50/tonne to
Another South Korean chemical producer LG Chem bought three spot cargoes of naphtha totalling 75,000 tonnes for delivery in November.
Two of the cargoes were purchased at a premium of $11.00-12.00/tonne to
India’s Mangalore Refinery and Petrochemicals Ltd (MRPL) has sold by tender a 35,000-tonne cargo of naphtha for loading in mid-November at a higher premium, reflecting tight supply and firm demand, traders said.
The deal for the cargo, which was awarded to Chinese trader Unipec, was done at a premium of $39.00/tonne to Middle East quotes FOB (free on board) for loading from New Mangalore on the West Coast of India on 13-15 November, they said.
In its previous tender, MRPL sold a similar-sized cargo of naphtha for loading from New Mangalore on 7-9 November to Singapore-based company Petro-Diamond at a premium of $35.00/tonne to
Term naphtha premiums also increased given a strong market outlook, traders said.
Bahrain Petroleum Co (Bapco) agreed to sell term naphtha supply for January to December 2013. The term deal for the naphtha supply of the B210 grade was done at a premium of $28/tonne to
Kuwait Petroleum Corp (KPC), on the other hand, agreed to sell term full-range naphtha supplies at a premium of $27.00/tonne to.
|
http://www.icis.com/Articles/2012/10/15/9603764/asia-naphtha-to-draw-support-from-tight-supply-firm-demand.html
|
CC-MAIN-2013-20
|
refinedweb
| 458
| 51.58
|
In this article, we are going to learn how to perform CRUD operations with Razor Pages in ASP.NET CORE 2.0
In this article, we are going to learn how to perform CRUD operations with Razor Pages in ASP.NET CORE 2.0. Before getting started let’s get a basic idea of what Razor pages are.
What are Razor pages?
Razor Pages is a new feature of ASP.NET Core MVC that makes coding page-focused scenarios easier and more productive.
Definition taken from here.
Where do we use Razor pages?
There are some pages in the application which are not too big where you are still required to create a controller and add action Method, along with that we need to add View.
In this part we can use Razor Pages which has code behind it . We just need to add a Razor Page and on view “Customer.cshtml” you can design your view and on the same page you can write code for handling requests such as get and Post, but if you think you want to separate it then you can use code behind “Customer.cshtml.cs”
Pre prerequisite for Razor Pages Application
Visual Studio Community 2017
Free, fully-featured IDE for students, open-source and individual developers
Let’s start with the Create Razor Pages application. Creating Razor page project
For creating a project just choose File Menu from Visual studio IDE then New, inside that, choose Project.
After choosing a project, a new dialog will pop up with the name “New Project”. In that, we are going to choose Visual C# Project Templates - Web - ASP.NET Core Web Application. Then, we are going to name the project as “RazorPagesDemo”.
After naming the project we are going click on OK button to create a project.
A new dialog will pop up for choosing templates for Creating “ASP.NET Core Web Application” in that template we are going to Create ASP.Net Core Razor Pages application. That's why we are going to choose “Web Application” and next we will have the option to choose framework 1.Net core or 2.Net Framework, and also ASP.NET Core Version. In that, we are going to choose “.Net Core” and “ASP.NET Core 2.0” as ASP.NET Core Version as click on OK button to create a project.
After clicking on OK button it will start to create a project. Project Structure
You'll see some new project structure you in this project. There are no Model, View, Controller folders in this project.
You will only able to see Pages folder in this folder all Razor pages are stored.
One thing which is back again is a little code behind to make thinks little easier.
Yes Razor pages has Code behind.
In the first steps we are going to add a model folder and inside that folder we are going to add Customer Model.
Creating Model folder and Adding Customer Model in it
In this part, we are going to add a Model folder in “RazorPagesDemo” Project after adding folder next we are going to add Customer class (Model) in Models folder.
For details see below snapshot,
After adding Customer Model now next we are going to add a property to this class.
Adding Properties and DataAnnotations to Customer Model
In Razor pages, you can use the same DataAnnotations which are there in MVC.
After completing with adding model and DataAnnotations next we are going to add Razor page.
Adding Razor Page to project
For adding Razor page just right click on Pages folder then select Add - inside that select New Item.
After selecting New Item a new dialog will pop up with name “New item” in that we are going to select Razor Page Item and name it as “Customer.cshtml” and click on add button.
After clicking on add button below is Pages folder structure in this part you can see “Customer.cshtml” View with “Customer.cshtml.cs” code behind which will have all handlers’ part to handle the request. Understanding “Customer.cshtml” View
This “Customer.cshtml” file looks more like a Razor View.
In Customer.cshtml view the first thing you are going to see is @page directive which tells Razor view engine that this page is Razor page, not MVC View and it makes a page to handle request directly without going to the controller.
Next, you can see @model is a CustomerModel is a code-behind class name.
The CustomModel file name is the same name as Razor page file “Customer.cshtml.cs” just “.cs” appended at last.
This CustomModel class inherits from PageModel which make this class to handle the request.
Next thing you can see in CustomModel is OnGet Method (handler) which handles get request.
Let’s start will simple example then we are going to start with CRUD operation.
Displaying Message
In this part, we have simply added a string with name WelcomeMessage and assigned value to it.
Next, on view, we are going to display a message in the following format.
Now Save Application and run.
And to access page just enter Page Name “Customer”.
URL -
E.g. ####### (port number)
Wow, we have created our first razor page. CRUD Operation with Razor Pages
The first thing we are going to do is Create Customer; for doing that we have added Customer Model in the Models folder.
Next, we are going to declare that model in CustomerModel class as below.
Code snippet of CustomerModel
After declaring this Customer model in CustomerModel class now Customer Model is accessible on Razor page file (Customer.cshtml)
Now let’s Design View.
Adding input Controls on Customer.cshtml View
In this part, we have used New MVC tag helper to create input fields and we have added all model properties on View.
Noteif you want to learn about details of New Tag Helpers visit this link.
Now save Application and run project.
Eg. ####### (port number)
Snapshot of Customer page After entering URL the first request goes to OnGet handler.
While Debugging
Note - Handlers
There are 2 default handlers in Razor pages
If you want you can create your own handlers you can create I will show in the upcoming example.
After completing with Designing Razor Page file (“Customer.cshtml”) now let’s add another handler to handle post request.
Adding OnPost Handler
In this part, we are going to add Post Handler to get all data which is filled by the user.
We have added OnPost handler but it is not filling data of model what we have posted.
While Debugging For binding data, we need to add [BindProperty] attribute on the (Customer) property we declare in CustomerModel class.
If we try to Post model again then we are going to get model populated with values. Let’s save these values in the database.
Database Part
I have created a database with the name “CustomerDB” and in that, it has “CustomerTB” table.
First thing for saving data in Database we need an ORM we are going to use “Entity framework core”
Installing package for Entity framework core from NuGet
To install the package, just right click on the project (RazorPagesDemo)].
Code snippet of DatabaseContext class
Next, we are going to add a new Service in Startup.cs class for injecting dependency.
Now, whenever you use DatabaseContext class, DbContext instance will be injected there. DbSet in DatabaseContext class next we are going to add a constructor in CustomerModel class.
Setting up Dependency injection at CustomerModel class
In this part wherever we use DatabaseContext class, DbContext instance will be injected there.
Now using (“_Context”) object we can save data in the database, let’s make a change in OnPost handler to save data in the database.
Below snapshot, you can see we have made changes in OnPost handler
Code snippet of CustomerModel class
URL - Eg. ####### (port number)
Now on save button data will be saved in the database. Database Output Now we have completed adding part let’s add another Razor Page to display all customers (AllCustomer).
Adding All Customer Razor page
In this part, we are going to add another razor page to display All Customer which is saved in the database.
Adding new razor page in same way as we added customer Razor page
After adding AllCustomer.cshtml Razor page next we are going to adding Constructor and OnGet Handler
Adding Constructor and OnGet Handler
In this part onGet Handler we are going to get all customer details from the database and assign those values to CustomerList and this CustomerList on razor page we are going to iterate and display customer details.
Adding AllCustomer.cshtml
On AllCustomer razor page view we are going to declare @page directive after that namespace and at last
@model which is “AllCustomerModel”
Now we are going to Iterate data (CustomerList).
Code snippet of AllCustomerModel.cshtml
While iterating CustomerList you might have seen a new tag helper which we have used for Creating link for Edit and Delete button.
Edit link
In edit link, we have just assign EditCustomer razor page name to “asp-page” property and “asp-route-id” we have assigned CustomerID to it, We haven't added EditCustomer razor page yet but we will soon.
Delete link
In Delete link we have just assigned AllCustomer razor page names to “asp-page” property and we have assigned CustomerID to “asp-route-id; " next we are going to assign “asp-page-handler” property which is a new one especially for Razor pages. Here we are going to add Handler name “Delete” which we are going to create in AllCustomer Razor page.
Adding Delete Handler
In Razor pages, we have 2 default handlers, OnGet and OnPost but we can add custom handlers also to handle OnGet and OnPost request
Below is a snapshot of it.
Code snippet of Delete Handler
In this part, we are going add Delete handler “OnGetDelete” which take CustomerID as input.
After receiving CustomerID (id) next we are going get Customer details from the database by passing CustomerID (id) and pass it to remove method to delete it and finally we redirect after deleting to the All Customer page.
Now save the application and run it.
Access AllCustomer page.
Now if you see delete link by hovering it you can see we are passing id (CustomerId) and along with that we are also passing handler name (“Delete”)
e.g.
While debugging
Finally, we have created delete handler the last thing that remains in CRUD operation is Edit Customer (Update) let’s start adding EditCustomer Razor page.
Adding EditCustomer page
In this part, we are going to add another Razor page to Edit Customer Details which is saved in the database.
Adding new Razor page in the same way as we add customer razor page
After adding EditCustomer.cshtml Razor page next we are going to adding Constructor and OnGet Handler
In this part onGet Handler, we are going to get CustomerID (id) from query string from that we are going to get Customer Details from the database and assign those values to Customer Model this model we are going to send to Edit Customer View.
Code snippet of Edit Customer Model
Next, we are going to design Edit View for displaying records for editing.
Code snippet of Edit Customer Page
In this page we are creating edit page means we are going to show record and allow the user to edit details and update it.
The first thing you are going to see is @page"{id: int}" directive, which tells that page need "{id: int}"int id (CustomerID) then only it will accept requests else it will returns an HTTP 404 (not found) error.
It id (CustomerID) we are going to send from All Customer View Edit link.
Note@page"{id: int}" it is kind of routing in Razor pages.
Link example: -
Now save the application and run.
Access All Customer page
Now hover edit link you can see URL which is generated () now click on Edit link it will display EditCustomer Page.
Now we have completed Edit page OnGet Handler implementation which helps to display customer data in edit mode, next we need to update data; for doing that we need to Add Onpost Handler which will handle post request.
Code snippet of OnPost Request
In this part we are posting data which will update Customer model which we are going to check it is valid or not if it is not valid then we are going to return Page() which will show Error Message.
If it is valid then we are going to update data in the database and redirect page to AllCustomer Page.
Code snippet of Complete EditCustomerModel
Snapshot of Edit Customer Page
We have updated Name of Customer. Now let’s view All customer view -- that value is updated.
Wow, we have successfully Updated Customer Name in the database.
Validation of Form
In Razor page validation is similar to MVC validation and there is no change in it. Just add DataAnnotations attribute on Model properties and on view starts its validation control.
Finally, we have learned, about Razor Pages and along with that how to do CRUD operations with Razor Pages in a step by step way. I hope you liked my article.
View All
|
https://www.c-sharpcorner.com/article/crud-operation-with-razor-pages-in-asp-net-core-2-0/
|
CC-MAIN-2020-50
|
refinedweb
| 2,216
| 71.34
|
Ask for latest version for hibernate
Ask for latest version for hibernate any new version for hibernate after 3.0, if yes can u give some exmp for latest version of hibernate
Ask about looping in database
Ask about looping in database Good afternoon,
I want to ask...=True,A2=True
: code is the same data Rule and Heritage.
I want to ask... like this.
i need help ,
Thank's,
Hendra
ask java - Date Calendar
ask java sory i'am wrong language. i want to ask to this forum how... but in java i found too but i can't to join in another frame. And i want to ask how... day right, how to get 1 month 10 day?.need help please give me a way and tutorial
Ask java count
Ask java count Good morning,
I have a case where there are tables sumborrowbook fieldnya: codebook, bookname, and sumborrowbook . I want to make... sum is displayed in the message.
Can you give a code from my case,
please help me
Ask date difference
Ask date difference Hello,
I have a problem about how to calculate date, the result from this code is not complete , this is my code . please help me. thank you
public void a(){
String date1 = jTextField33.getText();
String
Ask Questions
Ask Questions
..., professions, students and learners, we have initiated a new service ‘Ask Question’. Using this new service, our visitors can ask any sort of question
Ask iBatis Questions Online
Ask iBatis Questions Online
... model.
iBatis is also a popular framework like Hibernate... relating to programming, coding, implementing and using. Ask any iBatis
Help! thanks for ur code, I'd like to ask a question:
after press "c" or "C", timer starts and after every delay ms, it'll print "This line is printed only once." or just print once. I'm writting a timer but it seems to perform
Ask Hibernate Questions Online
Ask Hibernate Questions Online
....
Feel free to ask questions on Hibernate related problems. In the move... is open for all.
Ask Hibernate related
Ask PHP Questions
Ask PHP Questions
PHP Questions and Answers
Ask PHP Questions and get answers from....
In your questions and answers section you can ask PHP questions and
get
Hibernate - Hibernate
Hibernate application development help Hi, Can anyone help me in developing my first Java and Hibernate application
Hibernate - Hibernate
a doubt in that area plz help me.That is
In Hibernate mapping file I used tag... plz help me. Hi friend,
Read for more information..
Ask Programming Questions and Discuss your Problems
Ask Programming Questions and Discuss your Problems
... read this. This will help you enormously and can save your lots of time.
Before You Ask, read it carefully.
Try to find the solutions in archive, use our
What is hibernate
This tutorial will help you in understanding the concept of Hibernate
Software Questions and Answers
any software development related questions
ask it now. You can
also help... Questions - Ask
Hibernate Interview questions and browser the answers... and Answer page.
Ask the Questions and provide your help to solve the questions
help me in inserting data into db using hibernate
help me in inserting data into db using hibernate How to insert data into dependent tables through hybernate
Hi Friend, Tools Update Site
the confirmation
message and then ask for restart. After restart Hibernate tools...
Hibernate Tools Update Site
Hibernate Tools Update Site
In this section
I want to build sessionfactory in hibernate 4. Need help.
I want to build sessionfactory in hibernate 4. Need help. Hello,
I want to build sessionfactory in hibernate 4. Need help
Hibernate-Criteria - Hibernate
Hibernate-Criteria Hi friends,
I am new to hibernate. Im... help me plzzzzzzzzzzz.
Cheers,
Srikanth. Hi friend,
Read for more... relations in Hibernate(with examples).But not showing the link available... a link . This link will help you.
visit for more information.
http
about hibernate - Hibernate
about hibernate tell me the uses and advantages of hibernate Hi friend,
I am sending a link. This link will help you.
Please visit for more information.
Thanks
Hibernate Insert
This tutorial will help you to learn how to insert data into table by using
Ask about java
Ask about java Create a java program for add and remove the details of a person, which is not using by database, a simply java program.
If possible, please wil it in switch
Ask EJB Questions online
Ask EJB Questions online
... have started a new service ‘ask question on EJB online’.
We assure you that our new service will help you better in developing
Ask JavaFX Questions Online
Ask JavaFX Questions Online
Ask programming questions related to the JavaFX development. Ask if
you have query about JavaFX. With the
hibernate code problem - Hibernate
hibernate code problem String SQL_QUERY =" from Insurance...: "
+ insurance. getInsuranceName());
}
in the above code,the hibernate... that is dynamically assigned like this
lngInsuranceId="'+name+'"
plz help me out
Ask Wimax Questions Online
Ask Wimax Questions Online
....
Ask questions regarding Wimax technology if you face any problem... us, our eminent visitors will also help you in finding the solution of your
Ask Ajax Questions Online
Ask Ajax Questions Online
.... Ask Ajax Questions online and get the correct answers immediately or within... our visitors can also help us by posting the correct answers
ask - Java Beginners
ask dear
how to "print out" into a file ?
regard
suhadi Hi friend,
Please explain properly requirement. I am sending simple code according to your requirement.
import java.io.*;
public class
Reg Hibernate - Hibernate
Reg Hibernate Hi,
iam using hibernate in myeclipse ide. I got an error.
After doing reverse-engineering my table user, i opened HQL editor....
org.hibernate.hql.ast.QuerySyntaxException:user not mapped[from user]
plz help me. I tried
Reg Hibernate in Myeclipse - Hibernate
Reg Hibernate in Myeclipse Hi,
My table name is user and database name is search in mysql.
I created the connection successfully and did... plz help me.
regards
usha
Ask XML Questions
Ask XML Questions
.... If our visitors face any sorts of problem in XML scripting, share with us. Ask... need to login and post your questions on our site under our service ‘Ask
java help?
java help? Write a program, where you first ask values to an array with 6 integer values and then count the sum and average of the values in methods (send in the array & return the counted value to the main program). Print
Help With an Array
Help With an Array // ********************
// Sales.java
//
// Reads... need help from this part on. I need that part corrected and add a portion that would ask the user to input a number, return the "salesperson" id tag's
Hibernate application
Hibernate application Hi,
I am using Netbeans IDE.I need to execute a **Hibernate application** in Netbeans IDE.can any one help me to do
Ask Programming Questions Online
Ask Programming Questions Online
With the rapid development of technology..., SOA questions, Hibernate questions, Struts questions, JavaFX
Ask DBMS Questions online
Ask DBMS Questions online
..., Structure Query Language (SQL), Sybase, Ingres,
Ask any questions... regarding to DBMS query. Our proficient visitors will also help you in finding
Ask GPS Questions Online
Ask GPS Questions Online
... and provide accurate position of any GPS equipped system.
Ask any question... valuable visitors can also post the correct answers and help you in finding
request to help
or not.
If invalid date is entered, then display an appropriate error message and ask the user
HIBERNATE
Ask Struts Questions Online
Ask Struts Questions Online
Apache Struts is a standard open source... will also help you in finding the right solutions.
Struts...
ask a user to enter 5 integer
ask a user to enter 5 integer make a program that enter 5 numbers then identify the largest and the smallest number
sample program
2
4
3
5
6
the smallest number: 2
the largest number: is 6
66
Persist a List Object in Hibernate - Hibernate
on hibernate.
How to persist a List object in Hibernate ?
Can you give me a working Code /Example for the same ?
Help provided will be highly appreciated.... Video Tutorial
. Hibernate video tutorials at Roseindia are created with an objective to help...Roseindia.net provides you the best Hibernate video tutorials embedded... the basics of hibernate as well as advance hibernate.
Hibernate, which
Hibernate Mapping
Hibernate Mapping
In this Hibernate Mapping tutorials series you will
learn Hibernate in depth. We will show everything on Hibernate Mappings with
running code example. We have used easy to learn examples that will help you
understand
Dirty Checking In Hibernate Example
Dirty Checking In Hibernate Example Hi,
What is Dirty Checking In Hibernate?
Explain me with the help of Example.
Thanks
The Dirty Checking In Hibernate is an mechanism for automatically detects the changes
Explain Hibernate Relationships with example.
Explain Hibernate Relationships with example. Hello,
Please explain various hibernate relationships. And if you can provide some examples that would be a great help..
Thank you....
Hi,
Hibernate relational
Hibernate Tutorial: Learn Hibernate with examples
of Hibernate Framework. Learn latest topics of Hibernate framework with the help
of articles and example programs given here.
Hibernate is popular open source ORM... Hibernate Tutorial: Concise tutorial of Hibernate
framework
Hibernate
J2ee - Hibernate
that cannot insert exampleVO into database.. please help to me to solve this problem
Hibernate Tools Download
Hibernate Tools Download
In this we will show you how to download the Hibernate
Tools for the development. Hibernate Tools is really a good tool that help
Java - Hibernate Interview Questions
Java how to write a sql join in hibernate query language? Hi Friend,
Please visit the following link for more help on the HQL join and many more examples:
http
|
http://www.roseindia.net/tutorialhelp/comment/80623
|
CC-MAIN-2015-11
|
refinedweb
| 1,613
| 57.57
|
Up to [cvs.NetBSD.org] / src / lib / libc / gen
Request diff between arbitrary revisions
Default branch: MAIN
Revision 1.14.44.1 / (download) - annotate - [select for diffs], Thu May 22 11:36:52 2014 UTC (3 years, 8 months ago) by yamt
Branch: yamt-pagecache
Changes since 1.14: +4 -3 lines
Diff to previous 1.14 (colored) next main 1.15 (colored)
sync with head. for a reference, the tree before this commit was tagged as yamt-pagecache-tag8. this commit was splitted into small chunks to avoid a limitation of cvs. ("Protocol error: too many arguments")
Revision 1.14.50.1 / (download) - annotate - [select for diffs], Sun Jun 23 06:21:05 2013 UTC (4 years, 7 months ago) by tls
Branch: tls-maxphys
Changes since 1.14: +4 -3 lines
Diff to previous 1.14 (colored) next main 1.15 (colored)
resync from head
Revision 1.15 / (download) - annotate - [select for diffs], Wed Mar 6 11:27:46 2013 UTC (4 years, 11 months ago) by yam.14: +4 -3 lines
Diff to previous 1.14 (colored)
wrap a long line
Revision 1.14 / (download) - annotate - [select for diffs], Wed May 17 20:36:50 2006 UTC (11 years,, tls-maxphys
Changes since 1.13: +5 -5 lines
Diff to previous 1.13 (colored)
PR/24324: Arne H Juul: Re-implement seekdir/telldir using a pointer of locations per directory instead of a global hash table to avoid memory leak issues, and incorrect results.
Revision 1.13 / (download) - annotate - [select for diffs], Tue Jan 24 19:33:10 2006 UTC (12 years ago) by christos
Branch: MAIN
Changes since 1.12: +6 -5 lines
Diff to previous 1.12 (colored)
rename __func to _func_unlocked, and add their prototypes in extern.h instead of exposing them in dirent.h. More locking consistency fixes.
Revision 1.12 / (download) - annotate - [select for diffs], Tue Jan 24 14:00:57 2006 UTC (12 years ago) by christos
Branch: MAIN
Changes since 1.11: +6 -9 lines
Diff to previous 1.11 (colored)
PR/32609: Tanaka Akira: seekdir blocks if pthread is linked Do locking consistently to avoid recursive locks (like the bug reported in this pr), and to avoid leaking locks on errors.
Revision 1.11 / (download) - annotate - [select for diffs], Thu Aug 7 16:42:56 2003 UTC (14 years,: +3 -7 lines
Diff to previous 1.10 (colored)
Move UCB-licensed code from 4-clause to 3-clause licence. Patches provided by Joel Baker in PR 22280, verified by myself.
Revision 1.10 / (download) - annotate - [select for diffs], Wed May 28 20:03:37 2003 UTC (14 years, 8 months ago) by christos
Branch: MAIN
Changes since 1.9: +12 -2 lines
Diff to previous 1.9 (colored)
add mutex locking for directories and readdir_r(3). Influenced by FreeBSD.
Revision 1.9 / (download) - annotate - [select for diffs], Sat Jan 22 22:19:12 2000 UTC (18], Mon Sep 20 04:39:05:04 1999 UTC (18 years, 5 months ago) by lukem
Branch: MAIN
Changes since 1.6: +8 Jul 21 14:07:28 1997 UTC (20 years, 7: +7 -2.5 / (download) - annotate - [select for diffs], Sun Jul 13 19:46:13 1997 UTC (20 years, 7 months ago) by christos
Branch: MAIN
Changes since 1.4: +3 -2 lines
Diff to previous 1.4 (colored)
Fix RCSID's
Revision 1.4.4.1 / (download) - annotate - [select for diffs], Mon Sep 16 18:40:35:06:17 1995 UTC (22 years, 9 months ago) by jtc
Branch: ivory_soap
Changes since 1.3: +3 -2 lines
Diff to previous 1.3 (colored)
#include "namespace.h" Added __weak_reference defns.
Revision 1.4 / (download) - annotate - [select for diffs], Sat Feb 25 08:51:44 1995 UTC (22: +7 -2 lines
Diff to previous 1.3 (colored)
clean up Id's on files previously imported...
Revision 1.3.2.2 / (download) - annotate - [select for diffs], Wed Jul 27 14:39:52 1994 UTC (23 years, 6 months ago) by jtc
Branch: netbsd-1-0
Changes since 1.3.2.1: +53 -0 lines
Diff to previous 1.3.2.1 (colored) to branchpoint 1.3 (colored) next main 1.4 (colored)
Add RCS Id's
Revision 1.3.2.1, Wed Jul 27 14:39:51 1994 UTC (23 years, 6 months ago) by jtc
Branch: netbsd-1-0
Changes since 1.3: +0 -53 lines
FILE REMOVED
file seekdir.c was added on branch netbsd-1-0 on 1994-07-27 14:39:52 +0000
Revision 1.3 / (download) - annotate - [select for diffs], Wed Jul 27 14:39:51 1994 UTC (23 years, 6 months
Branch point for: netbsd-1-0, ivory_soap
Changes since 1.2: +2 -1 lines
Diff to previous 1.2 (colored)
Add RCS Id's
Revision 1.2 / (download) - annotate - [select for diffs], Wed Jul 27 14:37:43 1994 UTC (23 years, 6 months ago) by jtc
Branch: MAIN
Changes since 1.1: +5 :43 1994 UTC (23 years, 6 months ago) by jtc
Branch: WFJ-920714, CSRG
CVS Tags: lite-2, lite-1
Changes since 1.1.1.1: +3 -3 lines
Diff to previous 1.1.1.1 (colored)
opendir() & friends from 4.4lite.
Revision 1.1.1.1 / (download) - annotate - [select for diffs] (vendor branch), Sun Mar 21 09:45:37 1993 UTC (24 years, 11.
|
http://cvsweb.netbsd.org/bsdweb.cgi/src/lib/libc/gen/seekdir.c
|
CC-MAIN-2018-09
|
refinedweb
| 893
| 76.01
|
Note: This code has now been migrated to a codeplex project. For the latest source and dos go to.
Recently I was working on an internal project that required me to invoke a set of POX (Plain Old XML) services from a windows client application. For those that don’t know what POX is, it’s basically a web page that receives and returns XML content. How does this differ from an ASMX? Web services transfer SOAP messages, while POX services carry any kind of XML you can think of. SOAP uses well defined contracts for passing data back and forth. Also SOAP supports advanced protocols such as WS-*. POX services on the other hand are kind of the outlaws of the services world in that there are very few constraints imposed. That does not mean that constraints cannot be enforced, for example by creating an XSD, but it means that the message format itself is completely open.
Here’s an example of a simple POX request message for illustrative purposes.
<?xml version="1.0" encoding="utf-8" ?>
<order orderNumber="12345" account="acme" accountNo="999" >
<items>
<item productNumber="12345678" qty="5" price="29.99"/>
<item productNumber="87654321" qty="10" price="35.99"/>
</items>
</order>
The response from the POX service might look like this.
<orderResponse orderNumber="12345" account="acme" accountNo="999" >
<status>confirmed</status>
<confirmationNo>1000</confirmationNo>
</orderResponse>
In the early days when XML first appeared on the scene, POX services were quite common. Often POX was (and is still used) for doing AJAX style application development. Additionally it is not uncommon for POX style services to be used on the corporate intranet (as in my example). Now for making POX calls Microsoft provides the XMLHTTP object along with the MSXML parser. The XMLHTTP object provides the ability to post an XML string off to a URL and to receive a response either synchronously or asynchronously. As IE supports instantiating COM objects, this makes XMLHTTP the perfect answer for invoking POX from both windows and web clients.
Now flash forward to .NET. So what kind of support do we have natively in .NET for doing POX? It turns out very little. Basically you can do it, but you have to manage the streams and the transport yourself. POX is supported in WCF, but my application was not using .NET 3.0 and I really wanted to find a way to support it in 2.0. Another option was to use XMLHTTP via interop, but that seemed less than optimal.
The Dilemma
So after several hours of trial and error, here’s how you do it in .NET.
Post to the request:
1. Create a stream that contains the xml that you want to post. (If you are starting from an XmlDocument then you need to write the document to a stream using an XmlWriter)
2. Create a byte array and read your stream into the byte array
3. Create a web request.
4. Write the byte array to the request stream
Get the response
1. Grab the response stream from the web request
2. Create a byte array for storing the resulting stream
3. Read the response stream into the byte array buffer. The data is delivered over the stream in chunks so you need to continually read until the buffer is emptied.
4. Read the buffer back into a stream (To convert this back to a document then you can pass the stream to an XmlDocument constructor.
Here’s the code….
public XmlDocument Post(string url, XmlDocument document)
{
//convert the document to stream
MemoryStream Stream = new MemoryStream();
XmlWriter Writer = XmlWriter.Create(Stream);
document.WriteContentTo(Writer);
//reset the stream position
Stream.Position = 0;
//create the request and set the content type and length
WebRequest Request = WebRequest.Create(url);
Request.Method = "POST";
Request.ContentType = "text/xml";
Request.ContentLength = Stream.Length;
//get the request stream and post the xml
Stream RequestStream = Request.GetRequestStream();
RequestStream.Write(Stream.GetBuffer(), 0, (int) Stream.Length);
return GetResponseXml(Request);
}
private XmlDocument GetResponseXml(WebRequest request)
//grab the respons stream
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream ResponseStream = response.GetResponseStream();
//create the response buffer
byte[] ResponseBuffer = new byte[response.ContentLength];
int BytesLeft = ResponseBuffer.Length;
int TotalBytesRead = 0;
bool EOF = false;
//loop while not EOF
while (!EOF)
{
//get the next chunk and calc the remaining bytes
int BytesRead = ResponseStream.Read(ResponseBuffer, TotalBytesRead, BytesLeft);
TotalBytesRead += BytesRead;
BytesLeft -= BytesRead;
//has EOF been reached
EOF = (BytesLeft == 0);
}
ResponseStream.Close();
//create a memory stream and pass in the respones buffer
ResponseStream = new MemoryStream(ResponseBuffer);
//load the stream into an xml document
XmlDocument ResponseDocument = new XmlDocument();
ResponseDocument.Load(ResponseStream);
return ResponseDocument;
I was elated once I saw the code actually working. However a few things kept nagging at me about my implementation.
For one thing it was the fact that I was passing an XmlDocument to the Post method. I vowed years ago when I first laid eyes on the classes of the XmlSerialization namespace, that I would never write ‘ConvertMyObjectToXml’ and ‘ConvertXmlToObject’ methods again unless it was an absolute necessity. Although I could make my objects serializable and then manually serialize them to an XmlDocument , and deserialize the response, I felt like I shouldn’t need to. What I really wanted was a Post(object objectToPost) method that would handle all the XML serialization and transport for me. In the same way I wanted to have a GetResponseObject() method that returns to me a deserialized object based on the XML stream it received.
Second, I felt that the methods above were handling too much. I might want to change certain properties on the WebRequest object such as which credentials to use. Or I might need to use a CookieContainer for passing cookies in the post. In my implementation, the underlying request is locally scoped and shielded from the caller. I could have expanded the signature of the methods to accept additional parameters such as the request itself, but this then would require for me to always explicitly manage creating and destroying request instances, which I was trying to avoid.
Lastly the other problem was that the methods were too tightly coupled. I might want in one instance to send an XmlDocument and return an object, or vice versa. In another scenario, I might want to just pass a stream directly and then return a document or an object.
Bearing all of this in mind I decided what I really wanted was a helper class that would handle instantiating a WebRequest object and configuring it with default values, while still allowing access to the underlying request for further configuration. Also I wanted the helper class to contain various Post and GetRequest methods allowing posting and retrieving in different formats including an XML serializable object. And so I wrote the POXClient class.
POXClient
Here’s the highlights of the functionality the class provides (I added a few extras)
1. Encapsulates a WebRequest. This underlying request is managed by the helper object, but you can access it directly via a WebRequest.Request property.
2. Provides overloaded Post methods for passing an XmlDocument, Stream, or an XML serializable object.
3. Provides several methods for retrieving the response as either an XmlDocument, an object or a Stream. Although you can get to the response stream directly off of the response object, this method returns a MemoryStream created off of the original response Stream. The advantage of this is that you can reread the MemoryStream several times whereas the actual response stream is forward only allowing it to be read once.
4. Provides tracing of the xml payloads sent and received
5. Allows configuring the underlying xml reading and writing.
Here’s an example of how you use the new class…
public OrderResponse SubmitOrder(Order order)
POXClient Client = new POXClient("");
Client.Post(order);
return Client.GetResponse<OrderResponse>();
Now let’s say you want to submit an object, but you want to receive an XmlDocument rather than a reconstituted object. No problem, you can use the following syntax.
return Client.GetResponseDocument();
Also you can still access the underlying request and response if you need them. So let’s say you need to examine the cookies that were returned as part of the response.
HttpWebResponse Response = (HttpWebResponse) Client.Request.GetResponse();
Cookie SomeCookie = Response.Cookies["SomeCookie"];
Or you want to configure the request to use default credentials.
Client.Request.Credentials = CredentialCache.DefaultCredentials;
Finally you can also override the default XmlWriter and XmlReader settings through setting the ReaderSettings and WriterSettings properties, i.e.
XmlWriterSettings Settings = new XmlWriterSettings();
Settings.Indent = false;
Settings.OmitXmlDeclaration = true;
Settings.CheckCharacters = false;
WriterSettings = Settings;
POXPage / POXCommon
I thought my work was done having completed POXClient. However, as I was throwing together a sample application to show how to use the new POXClient class, I realized I needed to have some kind of POX server. Often a POX Server is simply a web page that receives an XML Post and returns XML content. As I started to write a sample page, I realized that the dilemmas were the same on the server as on the client, i.e. you need to maange the streams, serialization and deserialization in the same manner. So, I fired up my IDE along with Resharper and began refactoring out my POXClient into a separate POXCommon class. POXCommon contains the basic logic for serialization / deserialization as well reading and writing from a stream into a memory stream. The nice thing is that POXCommon knows nothing about the source of the stream, so it is completely decoupled from the source and destination thus allowing it to be reused in many scenarios. POXClient now just grabs the underlying streams from the request / response object and passes them to the appropriate methods on POXCommon.
Thus having POXCommon in place, I was now able to tackle a new POXPage class. Simply put, POXPage is a base page class that exposes a set of GetRequest and WriteResponse methods that will either accept or return objects, streams or documents. Just to show you how easy it is to write a page that will accept a POX message. Check out the code below for the SubmitOrder.aspx page that is included in the sample.
protected void Page_Load(object sender, EventArgs e)
Order CurrentOrder = GetRequest<Order>();
if (CurrentOrder != null)
OrderResponse OrderResponse = new OrderResponse(CurrentOrder, "confirmed", "1000");
WriteResponse(OrderResponse);
The base page sets the content type and such for you. GetRequest automatically intercepts the request stream, reads in the XML and deserializes to the requested object type. WriteResponse does the reverse with the response object.
What’s in the BOX?
If you check out the attachment you’ll find a solution that has 4 projects. The solution is built around the order scenario I described the beginning of this post. Just to reiterate, this is just for illustration. The schema I have used is very simplistic, the service is unsecure, and the code is mostly demo code. But it does illustrate all the different parts and how they function.
Here’s a summary of each of the projects.
POXUtils – Contains POXCommon, POXClient and POXPage classes.
POXData – Contains Order, OrderResponse serializable classes.
POXWeb – Contains a web project with a simple SubmitOrder.aspx page that inherits from POXPage. The port is hard wired to be 4000 for the website because I didn’t want to require people to have IIS running. Also the logic within the page is totally ridiculous as all it does is take the request and repackage it into an approved order (if only life were so simple).
POXClient – Contains a console app that creates an order, instantiates a POXClient and submits the order. The received OrderResponse is then outputted to the console window so that you can see that data is roundtripping.
Final Thoughts.
After spending much too much time on this library that evolved out of a simple internal tool I was building that relied on POX, what are my thoughts on how usable this library will be? Well, I think it will be incredibly useful to some, and totally useless to many :). But even if it helps one than I really believe it’s worth it!
Also if you have any ideas on how to improve the code please let me know. You'll find almost no exception handling within as all the code is delegating to objects that inherently provide handling. For example if you pass an unserializable object then the serializer will throw a nice meaningful exception for you.
Have fun and happy POXing.
|
http://blogs.msdn.com/b/gblock/archive/2007/01/22/pox-xmlhttp-in-net-2-0.aspx
|
CC-MAIN-2015-40
|
refinedweb
| 2,073
| 56.76
|
- You can find details about seeing a live version of this project, both web and Facebook interfaces, here. The live version now has the nifty ajax voting we will implement in this segment as well.
Now we have most of the fb app put together, we just need to add a little ajax functionality to the fb app and we're ready to go. If you haven't followed along, you can download [a snapshot of the code we've developed][polling6].
In general this is where we'd begin to spin up the urls -> views -> tempates development engine, but we actually already implemented the urls and views for this in the web app. Its a little bit unseemly to make our apps dependent on each other, and a cleaner way would be to have a third app that would hold all universal or shared components (I like to call that third app api).
Refreshing our memory
Lets take a quick gander at the urls and views that we are reusing. First lets look at the url we are reusing from the web app.
urlpatterns = patterns('', (r'^vote/$', 'polling.web.views.vote') )
And remember what the polling.web.views.vote view looks like:')
So, basically we want to send a GET request to "", and have it contain the arguments pk and vote. The argument vote should contain either the value up or the value down.
But there is a slight problem. FaceBook Javascript (described more below) doesn't support sending GET requests. So we have to send POST requests instead, and our vote() function doesn't know how to deal with POST requests. So, we need to make a few minor changes to polling/web/views.py.
emacs polling/web/views.py
And change vote() to look like this:
def vote(request): results = {'success':False} if request.method == u'GET': data = request.GET elif request.method == u'POST': data = request.POST if data.has_key(u'pk') and data.has_key(u'vote'): pk = int(data[u'pk']) vote = data[u'vote'] poll = Poll.objects.get(pk=pk) if vote == u"up": poll.up() elif vote == u"down": poll.down() results = {'success':True} json = simplejson.dumps(results) return HttpResponse(json, mimetype='application/json')
This code is a bit awkward, and you may prefer to rewrite it as:
def vote(request): results = {'success':False} if request.REQUEST.has_key(u'pk') and request.REQUEST.has_key(u'vote'): pk = int(request.REQUEST[u'pk']) vote = request.REQUEST[u'vote'] poll = Poll.objects.get(pk=pk) if vote == u"up": poll.up() elif vote == u"down": poll.down() results = {'success':True} json = simplejson.dumps(results) return HttpResponse(json, mimetype='application/json')
The REQUEST attribute of request first looks in the POST attribute, and then looks in the GET attribute. As such, it is exactly what we want in this situation. However, using REQUEST is a bit discouraged (it is less explicit). At some point choosing between the two becomes a philosophical question that each individual must answer for themselves.
Either way, lets save views.py and proceed.
FaceBook JavaScript
First, you may want to take a glance at the Facebook Javascript documentation, and specifically the documentation about the FBJS Ajax object.
FBJS is essentially javascript being run in a security sandbox. For the most part things will work the same as standard javascript, but some things simply won't work. Another difference is that FBJS exposes some functionality via object instances that exist within its namespace. We are going to be using two of those exposed objects.
The first is the Dialog object. This a Facebook stylized way to require simple interactions from users. We're going to use this in the same way we used alert() in the JQuery example (to notify the user of success).
The FBJS to create our dialog is going to look like this:
var successful = "True"; var d = new Dialog(Dialog.DIALOG_POP); d.showMessage("Ajax", "The operation was " + successful);
Other than the Dialog object, we're also going to use one other FBJS object, the Ajax object. The developers' wiki describes it as "a very powerful AJAX object," so lets see what all that power is good for.
It turns out that the Ajax object is very similar to the simplified ajax functionality you get from JQuery, Prototype, or MochiKit.
Sending a simple POST request looks like this:
var a = new Ajax(); // Can also be Ajax.RAW or Ajax.FBML a.responseType = Ajax.JSON; // If you want to require login a.requireLogin = true; var p = { "one":10, "name":"Jack" }; a.post('', p);
About as simple as we could hope for. Now lets put FBJS into action.
Editing the detail.fbml template
We're going to be editing the polling/templates/fb/detail.fbml template. So lets open it up quickly:
emacs polling/templates/fb/detail.fbml
Starting out, this is what it looks like (before we add any Ajax functionality):
{% load facebook %} <fb:dashboard> <fb:create-buttonCreate a new poll</fb:create-button> </fb:dashboard> <fb:tabs> <fb:tab-item </fb:tabs> <div class="poll"> <p> Score for "{{ poll.question }}" is {{ poll.score }}!</p> <p>Do you <span id="up">agree</span> or <span id="down">disagree</span>?</p> </div>
Now lets first make a javascript function that votes and object either up or down depending on the parameter passed to it:
function vote(pk, voteUp) { if (voteUp == true) typ = "up"; else typ = "down"; var ajax = new Ajax(); ajax.responseType = Ajax.JSON; ajax.requireLogin = true; var params = { "pk":pk, "vote":typ }; ajax.post('', params); }
Okay, and now we just need to modify our template to make use of the vote() function we just wrote. In our detail.fbml template we're going to rewrite the html div with id poll. After our modifications its going to look like:
<div class="poll"> <p> Score for "{{ poll.question }}" is {{ poll.score }}!</p> <p> Do you <a href="#" onclick="vote({{ poll.pk }}, true)">agree</a> or <a href="#" onclick="vote({{ poll.pk }}, false)">disagree</a>? </p> </div>
Notice that we can still use our handy "customize javascript using Django templates" trick.
Okay. What we have works, but we have one little problem: its a pain to check that it works (you have to reload the page you are on manually). So, as a slight improvement, lets use the Dialog object to notify us if the vote was successful or not.
Lets modify the vote() function a bit. Now its going to look like:
function vote(pk, voteUp) { if (voteUp == true) typ = "up"; else typ = "down"; var ajax = new Ajax(); ajax.ondone = function(data) { var d = new Dialog(Dialog.DIALOG_POP); if (data.success == true) msg = "Your vote was successful!"; else msg = "Your vote failed. :("; d.showMessage("Voting Result", msg); } ajax.responseType = Ajax.JSON; var params = { "pk":pk, "vote":typ }; ajax.post('', params); }
We are assigning an anonymous function to the ondone field of ajax. Any methods assigned to that field is called with one parameter: the content returned by Ajax request. That content is in the format specified when you created your Ajax object (either raw, json, or fbml).
And, with these changes, our Ajax functionality for the fb app is done as well.
Whats next?
After these seven tutorial segments you've learned about a lot of pieces: the Django testing framework, PyFacebook, FBJS, and others. This is a good time to take a step back and to start modifying the pieces we've been playing with, and seeing if you can impose your own will onto the code by taking it to newer (and more interesting) places. If anything goes wrong, you can always download the [code snapshot we just finished][polling7].
At this point this series is finished, but a second series that picks up here and continues is in the works. That series will be a bit different, because it will look at improving the quality of what we have built, as opposed to simply adding rough functionality.
Well done Will!
trackback to Building two-faced Facebook-Web applications on Django
Your tutorials are very useful. Thanks.
It's very useful, Thanks for your distribution!
Reply to this entry
|
http://lethain.com/entry/2007/dec/17/two-faced-django-part-7-pyfacebook-and-fbjs-ajax/
|
crawl-002
|
refinedweb
| 1,359
| 67.55
|
import os
import time
source = ['/home/stan/Desktop']
target_dir= '"/media/TOSHIBA EXT/backup"'
today = target_dir + os.sep + time.strftime('%Y%m%d')
now = time.strftime('%H%M%S')
if not os.path.exists(today):
os.mkdir(today)
print("directory successfully created.")
target = today + os.sep + now + '.zip'
zip_command = "zip -qr {0} {1}".format(target, ' '.join(source))
if os.system(zip_command) == 0:
print("Successful backup to: ",target)
else:
print("backup failed!!")
+++++++++++++++++++++++++++++++++++++
I know my problem is the " not being in the right place, how do I fix that?
OSError: [Errno 2] No such file or directory: '"/media/TOSHIBA EXT/backup"/20140108'
It looks like you're new here. If you want to get involved, click one of these buttons!
|
http://programmersheaven.com/discussion/434196/oserror-errno-2-no-such-file-or-directory-media-toshiba-ext-backup-20140108
|
CC-MAIN-2018-17
|
refinedweb
| 118
| 55
|
All about the container registry product!
@drazzib
Concerning the pricing, following the quasi unanimous answer we got from the beta survey, we chose to embrace a fully transparent and all-inclusive (therefore predictable) pricing. The exact price point and storage space is currently being adjusted but basically :
- You will have a serie of a few plans
- Each plan will include a given storage space (the smallest should be around 200GB) and unlimited traffic, with a limit on the concurrent connections (the larger your team/projects, the bigger the plan we invite you to take). You can create as many namespaces and users as you wish for a given plan and managed also as many users as you want.
- The smallest plan should be around 15/20 € per month (but billed as a hourly ressource on your public cloud bill, so you can test the service with very low risk).
and yes, the traffic both to OVH and the internet will be free :)
|
https://gitter.im/ovh/container-registry
|
CC-MAIN-2019-51
|
refinedweb
| 162
| 61.5
|
This lesson will be a very simple Hello World demonstrating the Nasa World Wind Java SDK. I will explain how to get the WWJ SDK going in NetBeans 5.5.1 in this article. Before we get started you need to make sure that you download and unzip the World Wind SDK - Java World Wind SDK.
Choose Tools->Palette Manager->Swing/AWT Components. Click the Add from JAR button. Browse to the unzipped worldwind sdk directory and choose worldwind.jar, click Next. This will list all the JavaBeans inside the JAR, choose the WorldWindowGLCanvas, click Next. Choose Swing as the Palette Category, click Finish. Click Close on the Palette Manager.
Choose File -> New Project. Choose General - Java Application and Click next. Choose a project name, for the example I chose “HelloWorldWind”, uncheck the “Create Main Class” check box, click Finish.Create new Java Project
File:Create the Java Project
Right click on your newly created project from the project explorer frame and choose Properties. Choose libraries from the categories list. With the Compile tab selected, click Add JAR/Folder button. Browse to your unzipped worldwind directory and choose worldwind.jar. Now select the Run tab and add jogl.jar and gluegen-rt.jar. Click OK to close the Project Properties.Add the Libraries
File:Add the Libraries
Right click you project and choose New->JFrame Form. Enter a class name, I chose “HelloWorldWindMain”, click finish.Add JFrame
File:Add a JFrame
Simply drag and drop the WorldWindowGLCanvas from the palette onto the JFrame. Here you can resize the WorldWindowGLCanvas, so that it takes up the full JFrame.Add WorldWindGLCanvas
File:Add WorldWindowGLCanvas
Click on the source tab. Add import gov.nasa.worldwind.*; to the source just below the first set of comments. Inside your HelloWorldWindMain() method, just after initComponents(); add the following:
Model m = (Model) WorldWind.createConfigurationComponent(AVKey.MODEL_CLASS_NAME);
worldWindowGLCanvas1.setModel(m);
Update:If you are using release 20070817 0 - you will also need to import:
import gov.nasa.worldwind.avlist.AVKey;
The last step is telling our project where to find everything. Right click you project and choose Properties. With the Run category selected enter -Djava.library.path=/path/to/directory in the VM Options text box, click OK. Example: -Djava.library.path=C:\Users\george\Desktop\worldwindAdd VM command line options
File:VM command options
Choose Run->Run Main Project, or, hit F6. The first time you run it will ask you to select the main class, choose the HelloWorldWindMain, click OK.Run the project
File:World Wind Example
For this and more examples and tutorials, visit my blog -.
|
http://wiki.netbeans.org/wiki/index.php?title=HelloWorldWindJavaSDK&oldid=27542
|
CC-MAIN-2019-43
|
refinedweb
| 431
| 69.38
|
I search the board using "Regular Expression" and regex_search as keywords. I get "Sorry - no matches. Please try some different terms."
Anyway, I'm trying to get the output below using regex_search only. I'm playing it by ear because all I read seems to take me out the regex_search function. For instance out of all the great things I learned here, he cut it off right here:
These leaves us with:
Replace any * characters with .*
Replace any ? characters with .
Leave square brackets as they are.
Replace any characters which are metacharacters with a backslashified version.
Code:#include <iostream> #include <string> #include <boost/regex.hpp> using namespace std; int main() { boost::regex expression( ""x*\.o"" ); string string1 = "How to re"; boost::smatch match; while ( boost::regex_search( string1, match, expression, boost::match_not_dot_newline ) ) { cout << match << endl; string1 = match.suffix(); } }
Code:// Output needed: oH to tore
After over 30 hours of trying I found nothing that show me how to move back to the beginning to grab the {T} or how to store it for farther use. All of this and hundreds more ... after 30 hours, I still stuck. All I ask is how to move backwards or what do I have to do to get the first word in my result list in that order. I got enough below and more to take care of the rest I think.
Thanks in advance.
... but I still read nothing about:... but I still read nothing about:Code:// boost::regex expression( "(\w)\o" ); // back reference DON'T WORK // boost::regex expression( "[A-Z][a-zA-Z]*" ); // match first word, no symbols. // boost::regex expression( "[A-Z][A-Za-z]*" ); // same as above // boost::regex expression( "[a-zA-Z]+" ); // match all words and char only. // boost::regex expression( "[^a-zA-Z0-9]+" ); // match symbols only. // boost::regex expression( "[*.jpg]" ); // match word // boost::regex expression( "[*.jpg]+" ); // with + inc any matching char // boost::regex expression( "*.[ch]pp" ); // DON'T WORK FOR BOOST // boost::regex expression( "[^B]" ); // don't find this char or sequence // boost::regex expression( "[*B]" ); // Find all // boost::regex expression( "B+" ); // find one or more // boost::regex expression( "[a-z]+://" ); // get the header https:// // boost::regex expression( "yM?" ); // must find more than one char of one // boost::regex expression( "{1}y" ); // match one DON'T WORK // boost::regex expression( "( "( ?B)+" ); // will only get 4 char // boost::regex expression( "( "( ?B)+" )"; // will only get 4 char // boost::regex expression( "[ ?Bith]+" ); // find any of these // boost::regex expression( "( ?ho)+" ); // whole word per line sequence // boost::regex expression( "cow(ard|age|boy|l)?" ); // connect parts // boost::regex expression( "^(\\D{2})" ); // get 5 char - (d) digit // [^\5] // [^(\k<1>)] // [^${1}] // boost::regex expression( "(\\D+)(\\s*)(cow|M(M)?)" ); // back up and M to M //boost::regex expression( "[^M]+(y+ig)?[big(igbay|age|boy|l)?]?+(ho|M(y)?)" ); // works great // boost::regex expression( "^(\\D{2})+(\\D{2}) " ); // don't find this char or sequence // boost::regex expression( ".*\.o" ); // copy all o // boost::regex expression( "x*\.o" ); // copy only first o
Regular Expressions TutorialRegular Expressions TutorialThese leaves us with:
Replace any * characters with .*
Replace any ? characters with .
Leave square brackets as they are.
Replace any characters which are metacharacters with a backslashified version.
... boost::regex_search for what I'm trying to do.
flat assembler - View topic - Feature Request: Regular Expressions
Regular Expression Matching Can Be Simple And Fast
Benchmark of Regex Libraries
Qt 4.7: QRegExp Class Reference
Regular expression - Wikipedia, the free encyclopedia
Perl Regular Expression Syntax - Boost 1.43.0 ... now things are getting easier. It's a new way to do your abc's ... That took me until Junior High ... heehee
PS: After posting this thread now I see 4 links to Regular Expression below but 9 out of 10 they are not related. Going to read them now.
The new forum look is very nice and it feels smooth
|
http://cboard.cprogramming.com/cplusplus-programming/136901-regular-expression-using-regex_search.html
|
CC-MAIN-2015-40
|
refinedweb
| 641
| 67.55
|
This post was originally published on this blog
Nowadays, more than 60 percent of trading activities with different assets (such as stocks, index futures, commodities) are not made by “human being” traders anymore, instead relying on automated trading. There are specialized programs based on particular algorithms that automatically buy and sell assets over different markets, meant to achieve a positive return in the long run.
In this article, I’m going to show you how to predict, with good accuracy, how the next trade should be placed to get a positive gain. For this example, as the underlying asset to trade, I selected the S&P 500 index, the weighted average of 500 US companies with bigger capitalization. A very simple strategy to implement is to buy the S&P 500 index when Wall Street Exchange starts trading, at 9:30 AM, and selling it at the closing session at 4:00 PM Eastern Time. If the closing price of the index is higher than the opening price, there is a positive gain, whereas a negative gain would be achieved if the closing price is lower than the opening price. So the question is: how do we know if the trading session will end up with a closing price higher than opening price? Machine Learning is a powerful tool to achieve such a complex task, and it can be a useful tool to support us with the trading decision.
Machine Learning is the new frontier of many useful real life applications. Financial trading is one of these, and it’s used very often in this sector. An important concept about Machine Learning is that we do not need to write code for every kind of possible rules, such as pattern recognition. This is because every model associated with Machine Learning learns from the data itself, and then can be later used to predict unseen new data.
Machine Learning is the new frontier of many useful real life applications
Disclaimer: The purpose of this article is to show how to train Machine Learning methods, and in the provided code examples not every function is explained. This article is not intended to let one copy and paste all the code and run the same provided tests, as some details are missing that were out of the scope the article. Also, base knowledge of Python is required. The main intention of the article is to show an example of how machine learning may be effective to predict buys and sells in the financial sector. However, trade with real money means to have many other skills, such as money management and risk management. This article is just a small piece of the “big picture”.
Building Your First Financial Data Automated Trading Program
So, you want to create your first program to analyze financial data and predict the right trade? Let me show you how. I will be using Python for Machine Learning code, and we will be using historical data from Yahoo Finance service . As mentioned before, historical data is necessary to train the model before making our predictions.
To begin, we need to install:
Note that only a part of GraphLab is open source, the SFrame , so to use the entire library we need a license. There is a 30 day free license and a non-commercial license for students or those one participating in Kaggle competitions. From my point of view, GraphLab Create is a very intuitive and easy to use library to analyze data and train Machine Learning models.
Digging in the Python Code
Let’s dig in with some Python code to see how to download financial data from the Internet. I suggest using IPython notebook to test the following code, because IPython has many advantages compared to a traditional IDE, especially when we need to combine source code, execution code, table data and charts together on the same document. For a brief explanation to use IPython notebook, please look at the Introduction to IPython Notebook article.
So, let’s create a new IPython notebook and write some code to download historical prices of S&P 500 index. Note, if you prefer to use other tools, you can start with a new Python project in your preferred IDE.
import graphlab as gl from __future__ import division from datetime import datetime from yahoo_finance import Share # download historical prices of S&P 500 index today = datetime.strftime(datetime.today(), "%Y-%m-%d") stock = Share('^GSPC') # ^GSPC is the Yahoo finance symbol to refer S&P 500 index # we gather historical quotes from 2001-01-01 up to today hist_quotes = stock.get_historical('2001-01-01', today) # here is how a row looks like hist_quotes[0] {'Adj_Close': '2091.580078', 'Close': '2091.580078', 'Date': '2016-04-22', 'High': '2094.320068', 'Low': '2081.199951', 'Open': '2091.48999', 'Symbol': '%5eGSPC', 'Volume': '3790580000'}
Here,
hist_quotes is a list of dictionaries, and each dictionary object is a trading day with
Open ,
High ,
Low ,
Adj_close ,
Volume ,
Symbol and
Date values. During each trading day, the price usually changes starting from the opening price
Close , and hitting a maximum and a minimum value
High and
Low . We need to read through it and create lists of each of the most relevant data. Also, data must be ordered by the most recent values at first, so we need to reverse it:
l_date = [] l_open = [] l_high = [] l_low = [] l_close = [] l_volume = [] # reverse the list hist_quotes.reverse() for quotes in hist_quotes: l_date.append(quotes['Date']) l_open.append(float(quotes['Open'])) l_high.append(float(quotes['High'])) l_low.append(float(quotes['Low'])) l_close.append(float(quotes['Close'])) l_volume.append(int(quotes['Volume']))
We can pack all downloaded quotes into an
SFrame object, which is a highly scalable column based data frame, and it is compressed. One of the advantages is that it can also be larger than the amount of RAM because it is disk-backed. You can check the documentation to learn more about SFrame.
So, let’s store and then check the historical data:
qq = gl.SFrame({'datetime' : l_date, 'open' : l_open, 'high' : l_high, 'low' : l_low, 'close' : l_close, 'volume' : l_volume}) # datetime is a string, so convert into datetime object qq['datetime'] = qq['datetime'].apply(lambda x:datetime.strptime(x, '%Y-%m-%d')) # just to check if data is sorted in ascending mode qq.head(3)
Now we can save data to disk with the
SFrame method
save , as follows:
qq.save(“SP500_daily.bin”) # once data is saved, we can use the following instruction to retrieve it qq = gl.SFrame(“SP500_daily.bin/”)
Let’s See What the S&P 500 Looks Like
To see how the loaded S&P 500 data will look like, we can use the following code:
import matplotlib.pyplot as plt %matplotlib inline # only for those who are using IPython notebook plt.plot(qq['close'])
The output of the code is the following graph:
Training Some Machine Learning Models
Adding Outcome
As I stated in the introductory part of this article, the goal of each model is to predict if the closing price will be higher than the opening price. Hence, in that case, we can achieve a positive return when buying the underlying asset. So, we need to add an
outcome column on our data which will be the
target or
predicted variable. Every row of this new column will be:
+1for an Up day with a
Closingprice higher than
Openingprice.
-1for a Down day with a
Closingprice lower than
Openingprice.
# add the outcome variable, 1 if the trading session was positive (close>open), 0 otherwise qq['outcome'] = qq.apply(lambda x: 1 if x['close'] > x['open'] else -1) # we also need to add three new columns ‘ho’ ‘lo’ and ‘gain’ # they will be useful to backtest the model, later qq['ho'] = qq['high'] - qq['open'] # distance between Highest and Opening price qq['lo'] = qq['low'] - qq['open'] # distance between Lowest and Opening price qq['gain'] = qq['close'] - qq['open']
Since we need to assess some days before the last trading day, we need to lag data by one or more days. For that kind of lagging operation, we need another object from GraphLab package called
TimeSeries .
TimeSeries has a method
shift that lags data by a certain number of rows.
ts = gl.TimeSeries(qq, index='datetime') # add the outcome variable, 1 if the bar was positive (close>open), 0 otherwise ts['outcome'] = ts.apply(lambda x: 1 if x['close'] > x['open'] else -1) # GENERATE SOME LAGGED TIMESERIES ts_1 = ts.shift(1) # by 1 day ts_2 = ts.shift(2) # by 2 days # ...etc.... # it's an arbitrary decision how many days of lag are needed to create a good forecaster, so # everyone can experiment by his own decision
Adding Predictors
Predictors are a set of feature variables that must be chosen to train the model and predict our outcome . So, forecasting factor choice is crucial, if not the most important, component of the forecaster.
Just to name a few examples, a factor to consider may be if today’s close is higher than yesterday’s close, and that might be extended with two previous days’ close, etc. A similar choice can be translated with the following code:
ts['feat1'] = ts['close'] > ts_1['close'] ts['feat2'] = ts['close'] > ts_2['close']
As shown above, I’ve added two new features columns,
feat1 and
feat2 on our data set (
ts ) containing
1 if the comparison is true and
0 otherwise.
This article is intended to give an example of Machine Learning applied to the Financial sector. I prefer to focus on how Machine Learning models may be used with financial data, and we will not go into detail regarding how to choose the right factors to train the models. It is too exhaustive to explain why certain factors are used in respect to others, due to a considerable increase in complexity. My job research is to study many hypotheses of choosing factors to create a good predictor. So for a start, I suggest you experiment with lots of different combinations of factors, to see if they may increase the accuracy of the model.
# add_features is a helper function, which is out of the scope of this article, # and it returns a tuple with: # ts: a timeseries object with, in addition to the already included columns, also lagged columns # as well as some features added to train the model, as shown above with feat1 and feat2 examples # l_features: a list with all features used to train Classifier models # l_lr_features: a list all features used to train Linear Regression models ts, l_features, l_lr_features = add_features(ts) # add the gain column, for trading operations with LONG only positions. # The gain is the difference between Closing price - Opening price ts['gain'] = ts['close'] - ts['open'] ratio = 0.8 # 80% of training set and 20% of testing set training = ts.to_sframe()[0:round(len(ts)*ratio)] testing = ts.to_sframe()[round(len(ts)*ratio):]
Training a Decision Tree Model
GraphLab Create has a very clean interface to implement Machine Learning models. Each model has a method
create used to fit the model with a training data set. Typical parameters columns names of features used for training the model.
verbose– if
true, print progress information during training.
Whereas other parameters are typical of the model itself, such as:
max_depth– it is the maximum depth of a tree.
With the following code we build our decision tree:
max_tree_depth = 6 decision_tree = gl.decision_tree_classifier.create(training, validation_set=None, target='outcome', features=l_features, max_depth=max_tree_depth, verbose=False)
Measuring Performance of Fitted Model
Accuracyis an important metric to evaluate the goodness of the forecaster. It is the number of correct predictions divided by the number of total data points. Since the model is fitted with training data, the accuracy evaluated with the training set is better than the one obtained with a test set.
Precisionis the fraction of positive predictions that are positive. We need precision to be a number closer to
1 , to achieve a “perfect” win-rate. Our
decision_tree , as another classifier from GraphLab Create package, has its method
evaluate to get many important metrics of the fitted model.
Recallquantifies the ability of a classifier to predict positive examples. Recall can be interpreted as the probability that a randomly selected positive example is correctly identified by the classifier. We need that precision would be a number closer to
1 , to achieve a “perfect” win-rate.
The following code will show the accuracy of the fitted model both with training set and testing set:
decision_tree.evaluate(training)['accuracy'], decision_tree.evaluate(testing)['accuracy'] (0.6077348066298343, 0.577373211963589)
As shown above, the accuracy of the model with the test set is about 57 percent, which is somehow better than tossing a coin (50 percent). ### Predicting Data
GraphLab Create has the same interface to predict data from different fitted models. We will use the
predict method, which needs a test set to predict the target variable, in our case
outcome . Now, we can predict data from the testing set:
predictions = decision_tree.predict(testing) # and we add the predictions column in testing set testing['predictions'] = predictions # let's see the first 10 predictions, compared to real values (outcome column) testing[['datetime', 'outcome', 'predictions']].head(10)
False positivesare cases where the model predicts a positive outcome whereas the real outcome from the testing set is negative. Vice versa, False negatives are cases where the model predicts a negative outcome where the real outcome from the test set is positive.
Our trading strategy waits for a positively predicted outcome to buy S&P 500 at the
Opening price, and sell it at the
Closing price, so our hope is to have the lowest False positives rate to avoid losses. In other words, we expect our model would have the highest precision rate.
As we can see, there are two false negatives (at 2013-04-10 and 2013-04-11) and two false positives (at 2013-04-15 and 2013-04-18) within the first ten predicted values of the testing set.
With a simple calculation, considering this small set of ten predictions:
- accuracy = 6/10 = 0.6 or 60%
- precision =3/5 = 0.6 or 60%
- recall = 3/5 = 0.6 or 60%
Note that usually the numbers above are different from each other, but in this case they are the same. ### Backtesting the Model
We now simulate how the model would trade using its predicted values. If the predicted outcome is equal to
+1 , it means that we expect an Up day . With an Up day we buy the index at the beginning of the session, and sell the index at the end of the session during the same day. Conversely, if the predicted outcome is equal to
-1 we expect a Down day , so we will not trade during that day.
The Profit and Loss (
pnl ) for a complete daily trade, also called round turn , in this example is given by:
pnl = Close - Open(for each trading day)
With the code shown below, I call the helper function
plot_equity_chart to create a chart with the curve of cumulative gains (equity curve). Without going too deep, it simply gets a series of profit and loss values and calculates the series of cumulative sums to plot.
pnl = testing[testing['predictions'] == 1]['gain'] # the gain column contains (Close - Open) values # I have written a simple helper function to plot the result of all the trades applied to the # testing set and represent the total return expressed by the index basis points # (not expressed in dollars $) plot_equity_chart(pnl,'Decision tree model')
Mean of PnL is 1.843504 Sharpe is 1.972835 Round turns 511
Here, Sharpe is the Annual Sharpe ratio, an important indicator of the goodness of the trading model. Considering trades expressed day by day
whereas
mean is the mean of the list of profit and loss, and
sd is the standard deviation. For simplicity in the formula depicted above, I have considered a risk-free return equal to 0.
Some Basics About Trading
Trading the index requires buying an asset, which is directly derived from the index. Many brokers replicate the S&P 500 index with a derivative product called CFD (Contract for difference), which is an agreement between two parties to exchange the difference between the opening price and closing price of a contract.
Example: Buy 1 CFD S&P 500 at
Open (value is 2000), sell it at
Close of the day (value is 2020). The difference, hence the gain, is 20 points. If each point has a value of $25:
- Gross Gain is
20 points x $25 = $500with 1 CFD contract.
Let’s say that the broker keeps a slippage of 0.6 points for its own revenue:
- Net gain is
(20 - 0.6) points x $25 = $485.
Another important aspect to consider is to avoid significant losses within a trade. They may happen whenever the predicted outcome is
+1 but the real outcome value is
-1 , so it is a false positive . In that case, the ending session turns out to be a Down day with a closing price lower than the opening, and we get a loss.
A stop loss order must be placed to protect against a maximum loss we would tolerate within a trade, and such an order is triggered whenever the price of the asset goes below a fixed value we have set before.
If we look at the time series downloaded from Yahoo Finance at the beginning of this article, every day has a
Low price which is the lowest price reached during that day. If we set a stop level of
-3 points far from the
Opening price, and
Low - Open = -5 the stop order will be triggered, and the opened position will be closed with a loss of
-3 points instead of
-5 . This is a simple method to reduce the risk. The following code represents my helper function to simulate a trade with a stop level:
# This is a helper function to trade 1 bar (for example 1 day) with a Buy order at opening session # and a Sell order at closing session. To protect against adverse movements of the price, a STOP order # will limit the loss to the stop level (stop parameter must be a negative number) # each bar must contains the following attributes: # Open, High, Low, Close prices as well as gain = Close - Open and lo = Low - Open def trade_with_stop(bar, slippage = 0, stop=None): """ Given a bar, with a gain obtained by the closing price - opening price it applies a stop limit order to limit a negative loss If stop is equal to None, then it returns bar['gain'] """ bar['gain'] = bar['gain'] - slippage if stop<>None: real_stop = stop - slippage if bar['lo']<=stop: return real_stop # stop == None return bar['gain']
Trading Costs
Transaction costs are expenses incurred when buying or selling securities. Transaction costs include brokers’ commissions and spreads (the difference between the price the dealer paid for a security and the price the buyer pays), and they need to be considered if we want to backtest our strategy, similarly to a real scenario. Slippage in the trading of stocks often occurs when there is a change in spread. In this example and for the next ongoing simulations, trading costs are fixed as:
- Slippage = 0.6 points
- Commission = 1$ for each trade (one round turn will cost 2$)
Just to write some numbers, if our gross gain were 10 points, 1 point = $25, so $250 including trading costs, our net gain would be
(10 - 0.6)*$25 - 2 = $233 .
The following code shows a simulation of the previous trading strategy with a stop loss of -3 points. The blue curve is the curve of cumulative returns. The only costs accounted for are slippage (0.6 points), and the result is expressed in basis points (the same base unit of S&P 500 values downloaded from Yahoo Finance).
SLIPPAGE = 0.6 STOP = -3 trades = testing[testing['predictions'] == 1][('datetime', 'gain', 'ho', 'lo', 'open', 'close')] trades['pnl'] = trades.apply(lambda x: trade_with_stop(x, slippage=SLIPPAGE, stop=STOP)) plot_equity_chart(trades['pnl'],'Decision tree model') print("Slippage is %s, STOP level at %s" % (SLIPPAGE, STOP))
Mean of PnL is 2.162171 Sharpe is 3.502897 Round turns 511 Slippage is 0.6 STOP level at -3
The following code is used to make predictions in a slightly different way. Please pay attention to the
predict method which is called with an additional parameter
output_type = “probability” . This parameter is used to return probabilities of predicted values instead of their class prediction (
+1 for a positively predicted outcome,
-1 for a negatively predicted outcome). A probability greater than or equal to
0.5 is associated with a predicted value
+1 and a probability value less than
0.5 is related to a predicted value of
-1 . The higher that probability is, the more chance we have to predict a real Up Day .
predictions_prob = decision_tree.predict(testing, output_type = 'probability') # predictions_prob will contain probabilities instead of the predicted class (-1 or +1)
Now we backtest the model with a helper function called
backtest_ml_model which calculates the series of cumulative returns including slippage and commissions, and plots their values. For brevity, without explaining thoroughly
backtest_ml_model function, the important detail to highlight is that instead of filtering those days with a predicted
outcome = 1 as we did in the previous example, now we filter those
predictions_prob equal to or greater than a
threshold = 0.5 , as following:
trades = testing[predictions_prob>=0.5][('datetime', 'gain', 'ho', 'lo', 'open', 'close')]
Remember that Net gain of each trading day is:
Net gain = (Gross gain - SLIPPAGE) * MULT - 2 * COMMISSION .
Another important metric used to evaluate the goodness of a trading strategy is the Maximum Drawdown . In general, it measures the largest single drop from peak to the bottom, in the value of an invested portfolio. In our case, it is the most significant drop from peak to bottom of the equity curve (we have just one asset in our portfolio, S&P 500). So given an
SArray of profit and loss
pnl , we calculate the drawdown as:
drawdown = pnl - pnl.cumulative_max() max_drawdown = min(drawdown)
Inside the helper function
backtest_summary is calculated:
- Maximum drawdown (in dollars) as shown above.
- Accuracy, with
Graphlab.evaluationmethod.
- Precision, with
Graphlab.evaluationmethod.
- Recall, with
Graphlab.evaluationmethod.
Putting it all together, the following example shows the equity curve representing cumulative returns of the model strategy, with all values expressed in dollars.
model = decision_tree predictions_prob = model.predict(testing, output_type="probability") THRESHOLD = 0.5 bt_1_1 = backtest_ml_model(testing, predictions_prob, target='outcome', threshold=THRESHOLD, STOP=-3, MULT=25, SLIPPAGE=0.6, COMMISSION=1, plot_title='DecisionTree') backtest_summary(bt_1_1)
Mean of PnL is 54.054286 Sharpe is 3.502897 Round turns 511 Name: DecisionTree Accuracy: 0.577373211964 Precision: 0.587084148728 Recall: 0.724637681159 Max Drawdown: -1769.00025
To increase the precision of forecasted values, instead of a standard probability of
0.5 (50 percent) we choose a higher threshold value, to be more confident that the model predicts an Up day .
THRESHOLD = 0.55 # it’s the minimum threshold to predict an Up day so hopefully a good day to trade bt_1_2 = backtest_ml_model(testing, predictions_prob, target='outcome', threshold=THRESHOLD, STOP=-3, MULT=25, SLIPPAGE=0.6, COMMISSION=1, plot_title='DecisionTree') backtest_summary(bt_1_2)
Mean of PnL is 118.244689 Sharpe is 6.523478 Round turns 234 Name: DecisionTree Accuracy: 0.560468140442 Precision: 0.662393162393 Recall: 0.374396135266 Max Drawdown: -1769.00025
As we can see by the chart above, the equity curve is much better than before (Sharpe is 6.5 instead of 3.5), even with fewer round turns.
From this point on, we will consider all next models with a threshold higher than a standard value.
Training a Logistic Classifier
We can apply our research, as we did previously with the decision tree, into a Logistic Classifier model. GraphLab Create has the same interface with Logistic Classifier object, and we will call the
create method to build our model with the same list of parameters. Moreover, we prefer to predict the probability vector instead of the predicted class vector (composed of
+1 for a positive outcome, and
-1 for a negative outcome), so we would have a threshold greater than
0.5 to achieve a better precision in our forecasting.
model = gl.logistic_classifier.create(training, target='outcome', features=l_features, validation_set=None, verbose=False) predictions_prob = model.predict(testing, 'probability') THRESHOLD = 0.6 bt_2_2 = backtest_ml_model(testing, predictions_prob, target='outcome', threshold=THRESHOLD, STOP=-3, plot_title=model.name()) backtest_summary(bt_2_2)
Mean of PnL is 112.704215 Sharpe is 6.447859 Round turns 426 Name: LogisticClassifier Accuracy: 0.638491547464 Precision: 0.659624413146 Recall: 0.678743961353 Max Drawdown: -1769.00025
In this case, there is a summary very similar to Decision Tree. After all, both models are classifiers, they only predict a class of binary outcomes (
+1 ,
-1 ).
Training a Linear Regression Model
The main difference of this model is that it deals with continuous values instead of binary classes, as mentioned before. We don’t have to train the model with a target variable equal to
+1 for Up days and
-1 for Down days , our target must be a continuous variable. Since we want to predict a positive gain, or in other words a Closing price higher than the Opening price, now target must be the gain column of our training set. Also, the list of features must be composed of continuous values, such as the previous
Open ,
Close , etc.
For brevity, I won’t go into the details of how to select the right features, as this is beyond the scope of this article, which is more inclined to show how we should apply different Machine Learning models over a data set. The list of parameters passed to the create method column names of features used for training the model, for this model we will use another set respect to the Classifier models.
verbose– if
true, it will print progress information during training.
max_iterations– it is the maximum number of allowed passes through the data. More passes over the data can result in a more accurately trained model.
model = gl.linear_regression.create(training, target='gain', features = l_lr_features, validation_set=None, verbose=False, max_iterations=100) predictions = model.predict(testing) # a linear regression model, predict continuous values, so we need to make an estimation of their # probabilities of success and normalize all values in order to have a vector of probabilities predictions_max, predictions_min = max(predictions), min(predictions) predictions_prob = (predictions - predictions_min)/(predictions_max - predictions_min)
So far, we have predictions which is
SArray of predicted gains, whereas
predictions_prob is
SArray with
predictions values normalized. To have a good accuracy and a certain number of round turns, comparable with previous models, I’ve chosen a threshold value of
0.4 . For a
predictions_prob less than
0.4 , the
backtest_linear_model helper function will not open a trade because a Down day is expected. Otherwise, a trade will be opened.
THRESHOLD = 0.4 bt_3_2 = backtest_linear_model(testing, predictions_prob, target='gain', threshold=THRESHOLD, STOP = -3, plot_title=model.name()) backtest_summary(bt_3_2)
Mean of PnL is 138.868280 Sharpe is 7.650187 Round turns 319 Name: LinearRegression Accuracy: 0.631989596879 Precision: 0.705329153605 Recall: 0.54347826087 Max Drawdown: -1769.00025
Training a Boosted Tree
As we previously did training a decision tree, now we are going to train a boosted tree classifier with the same parameters used for other classifier models. In addition, we set the number of
max_iterations = 12 in order to increase the maximum number of iterations for boosting. Each iteration results in the creation of an extra tree. We also set a higher value of threshold than
0.5 to increase precision.
model = gl.boosted_trees_classifier.create(training, target='outcome', features=l_features, validation_set=None, max_iterations=12, verbose=False) predictions_prob = model.predict(testing, 'probability') THRESHOLD = 0.7 bt_4_2 = backtest_ml_model(testing, predictions_prob, target='outcome', threshold=THRESHOLD, STOP=-3, plot_title=model.name()) backtest_summary(bt_4_2)
Mean of PnL is 112.002338 Sharpe is 6.341981 Round turns 214 Name: BoostedTreesClassifier Accuracy: 0.563068920676 Precision: 0.682242990654 Recall: 0.352657004831 Max Drawdown: -1769.00025
Training a Random Forest
This is our last trained model, a Random Forest Classifier, composed by an ensemble of decision trees. The maximum number of trees to use in the model is set to
num_trees = 10 , to avoid too much complexity and overfitting.
model = gl.random_forest_classifier.create(training, target='outcome', features=l_features, validation_set=None, verbose=False, num_trees = 10) predictions_prob = model.predict(testing, 'probability') THRESHOLD = 0.6 bt_5_2 = backtest_ml_model(testing, predictions_prob, target='outcome', threshold=THRESHOLD, STOP=-3, plot_title=model.name()) backtest_summary(bt_5_2)
Mean of PnL is 114.786962 sharpe is 6.384243 Round turns 311 Name: RandomForestClassifier Accuracy: 0.598179453836 Precision: 0.668810289389 Recall: 0.502415458937 Max Drawdown: -1769.00025
Collecting All the Models Together
Now we can join all the strategies together and see the overall result. It’s interesting to see the summary of all Machine Learning models, sorted by their precision.
If we collect all the profit and loss for each one of the previous models in the array
pnl , the following chart depicts the equity curve obtained by the sum of each profit and loss, day by day.
Mean of PnL is 119.446463 Sharpe is 6.685744 Round turns 1504 First trading day 2013-04-09 Last trading day 2016-04-22 Total return 179647
Just to give some numbers, with about 3 years of trading, all models have a total gain of about 180,000 dollars. The maximum exposition is 5 CFD contracts in the market, but to reduce the risk they all are closed at the end of each day, so overnight positions are not allowed.
Statistics of the Aggregation of All Models Together
Since each model can open a trade, but we added 5 concurrent models together, during the same day there could be from 1 contract up to 5 CFD contracts. If all models agree to open trades during the same day, there is a high chance to have an Up day predicted. Moreover, we can group by the number of models that open a trade at the same time during the opening session of the day. Then we evaluate precision as a function of the number of concurrent models.
As we can see by the chart depicted above, the precision gets better as the number of models do agree to open a trade. The more models agree, the more precision we get. For instance, with 5 models triggered the same day, the chance to predict an Up day is greater than 85%.
Conclusion
Even in the financial world, Machine Learning is welcomed as a powerful instrument to learn from data and give us great forecasting tools. Each model shows different values of accuracy and precision, but in general, all models can be aggregated to achieve a better result than each one of them taken singularly. GraphLab Create is a great library, easy to use, scalable and able to manage Big Data very quickly. It implements different scientific and forecasting models, and there is a free license for students and Kaggle competitions.
Additional disclosure:This article has been prepared solely for information purposes, and is not an offer to buy or sell or a solicitation of an offer to buy or sell any security or instrument or to participate in any particular trading strategy. Examples presented on these sites are for educational purposes only. Past results are not necessarily indicative of future results.
About the author
member since January 19, 2016
Andrea is a data scientist with a long experience in programming with R, Python, VBA, Excel, SQL, and about 4 years as quantitative analyst/trader. In addition to a Master’s degree in Engineering, he has several certifications in quantitative analysis, machine learning as well as computational finance. His strong points are data analysis in order to find out predictive patterns with mathematical and statistical analysis. [click to » Rise Of Automated Trading: Machines Trading S&P 500
评论 抢沙发
|
http://www.shellsec.com/news/23590.html
|
CC-MAIN-2016-44
|
refinedweb
| 5,312
| 53.51
|
The ResourceLoader class does exactly that. It overrides the __getitem__ and __delitem__ hooks to behave like a dictionary, and you can adapt it for a particular resource type by subclassing it, and overriding the load and locate methods. This is all very nice. However, there is a design issue in the class: It uses the dictionary through containment.
What I mean by that, is that the class has an attribute, self.resources, that is a dictionary of all the resources I have currently loaded. If the __getitem__ method is called, the class first tries to retrieve the requested item from the dictionary, and if it is not available, attempts to load it:
class ResourceLoader:So why is this wrong? Remember that this class essentially is a dictionary, with some altered access mechanics. Therefore, it makes much more sense if the class is also derived from a dictionary, instead of containing one. This is the difference between an is-a and a has-a relationship. It makes no sense for this object to have a dictionary attribute if all access of the object is passed onto that dictionary anyway.
def __init__(self, paths):
self.paths = paths
self.resources = {}
def __getitem__(self, key):
if key not in self.resources:
self.resources[key] = self.locate(key)
return self.resources[key]
There are also concrete benefits to using inheritance in this case. Most importantly, we get all the nice things a dictionary can do, like iterating over it, retrieving it's length, etc. Another bonus is that it is a bit faster, since we don't have to look up self.resources each time. Another benefit we get in this case is that we can forget about the __getitem__ hook, and simply implement the __missing__ method, which is called if a key is missing.
It is not always so clear when to use inheritance, and when to use containment. Think about how your class should behave. If it's behavior is mostly like a dictionary or other type, and the class would benefit from having the methods that type has, inherit it. If the class uses the dictionary more as an implementation detail, and it makes no sense to call something like has_key on your object, it is better to use containment.
I have rewritten the ResourceLoader class as described here, and I'm going to push a new version of it out sometime in the future.
|
http://goingamerica.blogspot.com/2008/03/containment-versus-inheritance.html
|
CC-MAIN-2017-39
|
refinedweb
| 403
| 64.41
|
In our previous tutorials, we learned some Python file operations like reading, writing and deleting. Let’s learn to copy a file in Python in this tutorial.
We can copy a file in Python using different methods under the below-mentioned modules,
shutilmodule
osmodule
subprocessmodule
In this tutorial, we are going to learn using the different methods provided by the above modules to copy a file in Python.
1. shutil Module to Copy a File in Python
The
shutil module provides some easy to use methods using which we can remove as well as copy a file in Python. Let’s look at the different methods defined under this module specifically used for copying.
1. copyfileobj()
The
copyfileobj() method copies the content of the source file to the target file using their respective file objects. Let’s take a look at the code below,
import shutil src_file_obj=open('src.txt', 'rb') targ_file_obj= open('targ.txt' , 'wb') shutil.copyfileobj( src_file_obj , targ_file_obj )
Note: that the file objects should be pointing to the 0 positions (start position) for both the respective source and target files, to copy the entire content.
2. copyfile()
The
copyfile() method copies the content from the source to the target file using the file paths. It returns the target file path. The target file path must be writeable or else an OSerror exception would occur.
import shutil shutil.copyfile( 'src.txt' , 'targ.txt' )
It is to be kept in mind, that the method only allows the use of file paths and not directories.
3. copy()
This method copies the source file to the target file or the target directory. Unlike
copyfile(), the method
copy() allows the use of the target directory as an argument and also copies the file permissions.
copy() returns the path to the target file after copying the contents.
import shutil shutil.copy('/Users/test/file.txt', '/Users/target/')
A file named ‘file.txt’ is created in the target destination with all the content and permissions copied from ‘/Users/test/file.txt’.
4. copy2()
The
copy2() method is used exactly the same way as of the
copy() method. They also function in the same way, except for the fact that
copy2() also copies the meta-data from the source file.
import shutil shutil.copy2('/Users/test/file.txt', '/Users/target/')
2. os Module to Copy a File in Python
1. popen()
The
popen() method creates a pipe to the command, cmd. The method returns a file object connected to the cmd pipe. Take a look at the code below,
#for Windows import os os.popen('copy src.txt targ.txt' )
#for Linux import os os.popen('cp src.txt targ.txt' )
With this method, not only can we copy files but also execute other regular commands.
2. system()
The
system() method directly calls and executes a command argument in a subshell. Its return value depends on the OS that runs the program. For Linux, it is the exit status, whereas for Windows it is the return value by the system shell.
#for Linux import os os.system(' cp src.txt targ.txt' )
#for Windows import os os.system(' copy src.txt targ.txt' )
3. subprocess Module to Copy a File in Python
1. call()
The
call() method similar to
os.system() directly calls or runs the command passed as an argument to the function.
# In Linux import subprocess subprocess.call('cp source.txt target.txt', shell=True)
# In Windows import subprocess subprocess.call('copy source.txt target.txt', shell=True)
|
https://www.askpython.com/python/copy-a-file-in-python
|
CC-MAIN-2020-16
|
refinedweb
| 584
| 67.45
|
Andy manages programmers for Follett Library Resources in McHenry, IL. In his spare time, he works on his CPAN modules and does technical writing and editing. Andy is also the maintainer of Test::Harness and can be contacted at andy@petdance.com.
Andy brings us the news from the 2004 O'Reilly Open Source Convention in Portland, Oregon. If you're going to an upcoming conference and would like to write a conference report for TPJ, drop me a line at kcarlson@tpj.com Ed.
Walking in to the Portland Marriott this year, I felt like I was home again. It's like nothing had changed, starting with the dozen geeks in the lobby, mostly on Mac laptops, sucking up the free OSCON wireless goodness.
Monday morning started with a bang, with Damian Conway's tutorial "Perl Best Practice." For three hours, he lectured on how to write good, maintainable code in a language that makes it so easy to write bad code. It was the most pragmatic talk I'd seen from someone whose talks are more often aimed at the "proof of crazed concept" angle. Most interesting, or at least most Perl-specific, was a discussion on writing maintainable regular expressions, including the importance of building up regular expressions from components using the qr// operators, and always using the /s, /m, and /x flags.
Damian also mentioned lesser known modules like IO::Prompt, which makes the drudgery of getting user input slick and handy, and Readonly, which makes variables nonmodifiable. (Actually, IO::Prompt is so little-known that Damian hasn't published it yet.) It was interesting to see a few items on which we disagree, like the use of mutator methods instead of setter/getter pairs and inline POD. I firmly believe that POD belongs interspersed throughout the code (see WWW::Mechanize for an example) so that changes can be made to the docs easily when the code changes; Damian says it all begins after the __END__ token. TMTOWTDI, indeed.
This session effectively paid for the entire trip, since I've been working on getting departmental coding standards, and this session covered 90 percent of what I wanted to have in them. If you can see Damian give this talk, do so. If not, don't worry. He'll be turning it into a book for O'Reilly. (And by the way, O'Reilly & Associates is now O'Reilly Media.)
After the lunch break, it was back to Damian talking about how to give a quality presentation. Although there was no Perl content, I'd have been a fool to miss a master of presentation give away his secrets. He discussed every aspect of giving a talk, from what to call it and what to talk about, to what to wear. Key concepts included the importance of telling a story, rather than presenting a hierarchical tree of ideas; that the presentation is meant to inspire and give a taste of the topic, since the talk will probably not be the primary source of information; and the importance of "stair-stepping" your talk, leaving "landings" of less content to let the audience catch its breath.
Larry Wall's yearly State Of The Onion address was a love letter to the Perl community. No big announcements, just a recap of the last year of Larry's life based on the theme of screensavers, and a heartfelt thanks to the people that keep Perl going. After Larry's talk, David Adler and Ann Barcomb presented the Perl Foundation's yearly White Camel awards. Awards went to Dave Cross, the current leader of the Perl Mongers user groups (http://), and to two Perl magazine publishers: Jon Orwant is the original publisher of the magazine you're currently reading, and brian d foy is the publisher of The Perl Review, as well as the founder or the Perl Mongers. brian also had copies of TPR's first print issue. It's great to see another magazine about Perl. It makes me feel like we're increasing our collective strength and mindshare.
Speaking of mindshare, Tim O'Reilly's talk on "What Book Sales Tell Us" gave some interesting computer trends reflected in publishing sales trends. Most notable is that PHP books are 50-100 percent better sellers than Perl books, which reinforces what I've been seeing: PHP's lower barrier to entry means more bodies, but more beginner programmers. Perhaps Perl will be seen as more of an "adult" programming language.
The session calendar also backed up the popularity of PHP. PHP was all over the place, especially with the recent release of PHP 5. PHP still doesn't have namespaces, but darned if people aren't doing a lot of cool stuff with it. Ruby was all but nonexistent this year. I hope Ruby hasn't had its day in the sun, fading away into obscurity.
Finally, this year's Lightning Talks were a little different. Normally, Mark-Jason Dominus presents 16 talks in 90 minutes. This year, the reins were in the capable hands of Geoff Avery, who gave us 45 minutes of Lightning Talks, and 45 minutes of Current Projects talks. He referred to these project talks as "lightning talks without the time limit," where project leaders were able to get up and give a call for help on their current projects. Autrijus Tang discussed svk, a Perl-Subversion integration project he's involved with, and Jouke Visser's pVoice generated a lot of interest. Jouke's daughter Krista is unable to speak, and pVoice allows her to speak using the computer. See for details. (And of course, I plugged the Phalanx project:.)
As always, OSCON was a blast, and well worth the time away from the family and the mountain of e-mail awaiting my return. It's amazing to watch the interaction of these people who make Perl happen. As immediate as e-mail and IRC and blogs may be, there's no comparison to having people meet in person. I ask everyone interested in Perl development to get somewhere that they can meet other Perl folks, whether it's OSCON, YAPC, or just a local Perl Mongers meeting. I'll see you next year!
TPJ
|
http://www.drdobbs.com/web-development/2004-oscon-round-up/184416138
|
CC-MAIN-2015-48
|
refinedweb
| 1,040
| 69.11
|
At Artsy we <3 TypeScript. We use it with React Native via Emission and on the web via Reaction. Until recently, however, projects that required the use of Babel had to implement convoluted tooling pipelines in order to work with the TypeScript compiler, increasing friction in an already complex landscape. (An example of this is Emission's use of Relay, which requires babel-plugin-relay to convert
graphql literals into require calls.) Thankfully, those days are over. Read on for an example project, as well as some advice on how to avoid common pitfalls when working with the new beta version of Babel 7.
Babel configurations can be complicated. They take time to set up and maintain and can often contain some pretty far-out features that make interop with other environments difficult. That's why we were elated when this PR appeared in the wild from @andy-ms, a developer on the TypeScript team, announcing a new parser for Babylon. @babel/preset-typescript arrived soon after and we felt it was finally time to give it a try. There was a catch, however: TypeScript support only works with Babel 7+!
TLDR; Check out the project on GitHub >
Here's list of setup issues we faced in no specific order:
1) New @babel Namespace
One of the first things Babel 7 users will notice is the package ecosystem now exists as a monorepo and all NPM modules are namespaced behind the
@babel org address. Packages that used to be installed via
are now installed via
which immediately creates upgrade conflicts between libraries that use Babel 6 and Babel 7. For example,
babel-jest internally points to
babel-core which supports a version range between 6 and 7 -- but! --
babel-core is now
@babel/core so this breaks.
This wasn't immediately apparent at the time, and so we would often find errors like
These errors appeared ambiguous because the folder structure was correct and commands like
yarn list @babel/preset-env yielded expected results:
Why was the package not found? Digging deeper, it seemed like Babel 6 was still being used somewhere. Running
yarn list babel-core revealed the culprit:
Thankfully, babel-bridge exists to "bridge" the gap, but one can see how complications can and will arise. Further, not all packages have implemented this fix and so we had to rely on
yarn's new selective dependency resolution feature which overrides child dependency versions with a fixed number set directly in
package.json:
With this in place many of our errors disappeared and packages like
jest now worked like a charm.
2) Missing ES2015 Features
Another error we faced early on surrounded language features that worked with Babel or TypeScript, but not with Babel and TypeScript. For example, take an existing Babel project that points to
index.js as an entrypoint, configure it to support TypeScript via Babel 7, and then run it:
Running
Everything seems to be working; our
.js entrypoint is configured to support
.ts extensions and we kick off the boot process.
Let's now try to import a file from within
app/server.ts:
Maybe my
tsconfig.json file is misconfigured?
Nope, all good. How about my
.babelrc?
We're using
@babel/preset-env which handles selecting the JS features we need, so thats not it. And anyways, doesn't TypeScript support
ES2015 modules right out of the box?
Continuing, how about specifying the extension list directly in
package.json:
Still no go 🙁
Last try: Create a new entrypoint file that uses a
.ts extension and then use that to boot the rest of the app:
Once this change was in place, we could ditch
@babel/register and instead rely on the
--extensions configuration from
package.json, just like the README suggests (doh! 🤦).
NOTE: If you're using
babel-plugin-module-resolver to support absolute path imports make sure to update the
extensions option with
.ts and
.tsx.
3) Type-Checking
Lastly, since Babel 7 is now responsible for compiling our TypeScript files we no longer need to rely on TypeScript's own
tsc compiler to output JavaScript and instead just use it to type-check our code. Again, in
package.json:
This reads in settings located in
tsconfig.json:
Notice the
noEmit flag? That tells
tsc not to output any JS and instead only check for correctness. The "pretty" flag gives us nicer type-checker output.
While this seemed to be all that was needed, running
yarn type-check would throw an error:
Why is it TypeChecking my
node_modules folder when
rootDirs is set to
src? It looks like we missed a TypeScript setting:
With that last missing piece everything now works:
Proper type-checking, but compilation handled by Babel 😎.
4) TypeScript and Flow
Unfortunately, the TypeScript and Flow plugins for Babel cannot be loaded at the same time, as there could be ambiguity about how to parse some code.
This is usually ok, because the general advice is to compile your library code to vanilla JS before publishing (and thus strip type annotations), but there are packages that could still enable the Flow plugin.
For example, the React Babel preset in the past would enable the Flow plugin without really needing it for its own source, but just as a default for consumers of React.
This issue cannot really be worked around without patching the code that loads the plugin. Ideally this patch would be sent upstream so that the issue goes away for everybody.
This issue can be worked around by either eliminating the dependency on the preset that loads the plugin, for instance by depending on the individual plugins directly, or if that’s not possible by patching the code. Ideally that patch should go upstream, of course, but if you need something immediate then we highly recommend patch-package, as can be seen used in this example.
There’s even projects that publish their Flow annotated code without compiling/stripping type annotations, the one we know of and use is React Native. There’s no way around this other than patching the code. You may think that you could use a plugin like babel-plugin-transform-flow-strip-types, but in reality that transform needs the Flow plugin to be able to do its work and thus is a no-go.
The way we’ve worked around that is by stripping Flow type annotations from all dependencies at dependency install time using the
flow-remove-types tool. It can get a little slow on many files which is why we do a bunch of filtering to only process files that have
@flow directives, the downside is that some files don’t have directives like they should and so we patch those to add them using the aforementioned patch-package.
5) Limitations in TypeScript support
It is important to note that you may run into a few cases that TypeScript’s Babel plugin does/can not support. From the plugin’s README:
Does not support
namespaces or
const enums because those require type information to transpile. Also does not support
export =and
import =, because those cannot be transpiled to ES.next.
The lack of namespace support hasn’t been a problem for us, we’re only using it in one place which could easily be changed to use regular ES6 modules as namespace. This is also why for instance the ‘recommended’ list of TSLint checks includes the
no-namespace rule.
The
const enum feature is a runtime optimization that will cause the compiler to inline code. We don’t have a need for this at the moment, but some discussion is happening to possibly still being able to make use of this feature when compiling production builds with the TypeScript compiler instead.
The
export = and
import = syntax is meant to work with CommonJS and AMD modules; however, we strictly use ES6 modules.
References:
|
https://artsy.github.io/blog/2017/11/27/Babel-7-and-TypeScript/
|
CC-MAIN-2021-49
|
refinedweb
| 1,312
| 60.55
|
shutil.which for those not using Python 3.3 yet.
Project description
A copy & paste backport of Python 3.3’s shutil.which function.
Usage
First, install the package: pip install shutilwhich
Importing the package:
import shutilwhich
will monkey-patch the shutil package, so from that point on you can simply import the which function:
from shutil import which
To keep things a little more concise, you can also import which directly from shutilwhich:
from shutilwhich import which
This will still monkeypatch the shutil module. On Python 3.3 and above, the module never do anything but return the stdlib shutil.which function.
Project details
Release history Release notifications | RSS feed
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
shutilwhich-1.1.0.tar.gz (2.3 kB view hashes)
|
https://pypi.org/project/shutilwhich/
|
CC-MAIN-2022-40
|
refinedweb
| 145
| 65.32
|
Simulating a (simplified) Ring Oscillator
Okay, simulating the analog parts of the actual physical ring oscillator last night made me ask some questions, so I thought it might be useful to try a very simple discrete simulation. If you looked at the schematic I posted yesterday, you’ll note that the ring is really just made up of single transistor inverters. The capacitors in combination with the resistors implement a delay line. So, that’s what I decided to code up: a ring of simple inverters, each with a “gate delay” of values which are very close to 1 second. Whenever the input to the inverter is scheduled, the output is swapped to its negation at the time in the future plus its gate delay, which resets the clock of the next gate, and so on. I normally would use a priority queue and the like to keep track of which gate should fire next, but for as few stages as I’m likely to implement, I frankly just search for the gate with the lowest time by linear search, and then proceed. To make the “simulation” a tiny bit more interesting, I print the values of the gates in “pseudo-real” time (I spend it up by a factor of 10). Here’s the code.
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #define N 79 unsigned char val[N] ; double delay[N] ; double clock[N] ; #define BIG 1e6 main() { int i, idx ; double t = 0., soonest ; for (i=0; i<N; i++) { val[i] = 0 ; delay[i] = clock[i] = 1.0 + drand48() * 0.01 - 0.005 ; } for (;;) { /* find the inverter that will trip soonest */ idx = 0 ; soonest = clock[idx] ; for (i=1; i<N; i++) if (clock[i] < soonest) { soonest = clock[i] ; idx = i ; } /* subtract the clock from all the inputs */ for (i=0; i<N; i++) clock[i] -= soonest ; t += soonest ; val[(idx+1)%N] = 1-val[idx] ; clock[(idx+1)%N] = delay[(idx+1)%N] ; clock[idx] = BIG ; usleep(soonest * 1000000. / 10.) ; for (i=0; i<N; i++) putchar("_X"[val[i]]) ; printf("\r") ; fflush(stdout) ; } }
It’s pretty interesting to watch (at least to me). I’ll have more to comment tonight.
Comment from Alan Yates
Time 1/9/2011 at 5:59 am
Mark,
This simulation is very interesting, in particular how a small region of alternating values seems to propagate backwards against the rest of the flow of the pattern.
I have some old java code for simulating arbitrary automata that I had planned to rewrite to support more continuous time simulations, but alas other ideas consumed the weekend. Hopefully I’ll get around to it this coming week.
Like yourself I want to do more software study, especially of cross-connected loops and bifurcated chains of simple stages like this, and eventually build them in hardware. I dug through the old capacitor box today and found a large cache of 470 uF and 10 uF capacitors, combined with other devices I have in bulk just itching for some use I think this will be a great way to give them some life beyond drying out in my junkbox.
Regards,
Alan
|
http://brainwagon.org/2011/01/05/simulating-a-simplified-ring-oscillator/
|
CC-MAIN-2015-18
|
refinedweb
| 529
| 65.46
|
----------------------------------------------------------------------------- -- | -- Module : XMonad.Actions.CycleRecentWS -- Copyright : (c) Michal Janeczek <janeczek@gmail.com> -- License : BSD3-style (see LICENSE) -- -- Maintainer : Michal Janeczek <janeczek@gmail.com> -- Stability : unstable -- Portability : unportable -- -- Provides bindings to cycle through most recently used workspaces -- with repeated presses of a single key (as long as modifier key is -- held down). This is similar to how many window managers handle -- window switching. -- ----------------------------------------------------------------------------- module XMonad.Actions.CycleRecentWS ( -- * Usage -- $usage cycleRecentWS, cycleWindowSets ) where import XMonad hiding (workspaces) import XMonad.StackSet -- $usage -- You can use this module with the following in your @~\/.xmonad\/xmonad.hs@ file: -- -- > import XMonad.Actions.CycleRecentWS -- > -- > , ((modm, xK_Tab), cycleRecentWS [xK_Alt_L] xK_Tab xK_grave) -- -- For detailed instructions on editing your key bindings, see -- "XMonad.Doc.Extending#Editing_key_bindings". -- | Cycle through most recent workspaces with repeated presses of a key, while -- a modifier key is held down. The recency of workspaces previewed while browsing -- to the target workspace is not affected. That way a stack of most recently used -- workspaces is maintained, similarly to how many window managers handle window -- switching. For best effects use the same modkey+key combination as the one used -- to invoke this action. cycleRecentWS :: [KeySym] -- ^ A list of modifier keys used when invoking this action. -- As soon as one of them is released, the final switch is made. -> KeySym -- ^ Key used to switch to next (less recent) workspace. -> KeySym -- ^ Key used to switch to previous (more recent) workspace. -- If it's the same as the nextWorkspace key, it is effectively ignored. -> X () cycleRecentWS = cycleWindowSets options where options w = map (view `flip` w) (recentTags w) recentTags w = map tag $ tail (workspaces w) ++ [head (workspaces w)] cycref :: [a] -> Int -> a cycref l i = l !! (i `mod` length l) -- | Cycle through a finite list of WindowSets with repeated presses of a key, while -- a modifier key is held down. For best effects use the same modkey+key combination -- as the one used to invoke this action. cycleWindowSets :: (WindowSet -> [WindowSet]) -- ^ A function used to create a list of WindowSets to choose from -> [KeySym] -- ^ A list of modifier keys used when invoking this action. -- As soon as one of them is released, the final WindowSet is chosen and the action exits. -> KeySym -- ^ Key used to preview next WindowSet from the list of generated options -> KeySym -- ^ Key used to preview previous WindowSet from the list of generated options. -- If it's the same as nextOption key, it is effectively ignored. -> X () cycleWindowSets genOptions mods keyNext keyPrev = do options <- gets $ genOptions . windowset XConf {theRoot = root, display = d} <- ask let event = allocaXEvent $ \p -> do maskEvent d (keyPressMask .|. keyReleaseMask) p KeyEvent {ev_event_type = t, ev_keycode = c} <- getEvent p s <- keycodeToKeysym d c 0 return (t, s) let setOption n = do windows $ const $ options `cycref` n (t, s) <- io event case () of () | t == keyPress && s == keyNext -> setOption (n+1) | t == keyPress && s == keyPrev -> setOption (n-1) | t == keyRelease && s `elem` mods -> return () | otherwise -> setOption n io $ grabKeyboard d root False grabModeAsync grabModeAsync currentTime setOption 0 io $ ungrabKeyboard d currentTime
|
http://hackage.haskell.org/package/xmonad-contrib-0.10/docs/src/XMonad-Actions-CycleRecentWS.html
|
CC-MAIN-2014-23
|
refinedweb
| 489
| 53.92
|
You can write browser plug-ins with the native WebKit plug-in API. Written in Objective-C, WebKit-based plug-ins are supported only by WebKit-based applications and cannot be ported to other platforms. The API is extremely simple, so many fewer lines of code are required to deploy a WebKit plug-in versus a Netscape one and you can use Xcode and Interface Builder to design and implement a plug-in’s functionality.
Introduction To WebKit Plug-ins
Becoming A Plug-in
Using Plug-in Scripting
Implementing a Plug-in
WebKit plug-ins are based on core Cocoa API. The plug-in itself is simply an instance of an NSView, a common class in many other Objective-C applications. It provides a cornucopia of features, including the management of events such as mouse and keyboard inputs. Your plug-in inherits these “for free.” URL loading is also inherited, via NSURLConnection. You can access WebKit classes through the plug-in’s WebFrame and the browser scripting environment through the WebKit WebScriptMethods protocol.
For the plug-in to act like a standard web browser plug-in, it needs to conform to the
WebPlugIn informal protocol. This protocol has just one required constructor method,
plugInViewWithArguments:, which your NSView subclass should implement.
Optional methods you can implement include:
webPlugInInitialize, which is called just after the plug-in is created and allows you to perform any prestartup actions in the plug-in.
webPlugInStart, which is called when the plug-in should begin doing whatever it has been designed to do.
webPlugInStop, which is called to tell the plug-in to cease its usual actions.
webPlugInDestroy, which is called to give the plug-in a chance to deallocate any objects or resources it may have created or retained.
webPlugInSetIsSelected:, which is called when the selection state of the plug-in has changed, allowing you to do any custom drawing or actions based off that event.
These methods are implemented by the container of the plug-in; that is, they affect the web view that surrounds the plug-in:
webPlugInContainerLoadRequest:inFrame: allows you to tell the browser to load a URL request into a given frame (or the container’s frame itself).
webPlugInContainerShowStatus: allows you to tell the container to print a status message to the browser’s status bar.
webPlugInContainerSelectionColor returns the color that the container should use to draw plug-in’s selection state when it is selected.
webFrame allows you to access the other WebKit elements of the container, such as its
WebView.
The WebKit API allows your plug-ins to easily access a scripting environment (such as JavaScript) from the plug-in, and vice versa. Your plug-in can call JavaScript methods and read JavaScript properties, while your containing page can call methods from your plug-in from its JavaScript environment.
When the browser encounters your plug-in, it will use JavaScript to request the object representing your plug-in using
objectForWebScript. The object that you return from that method represents the interface to your plug-in. This can be, but is not required to be, the same object as your plug-in. In that case, your implementation of
objectForWebScript would simply look like:
The object you return needs to have control over which of its methods should be visible to the scripting environment. In all likelihood, you don’t want all of your methods exposed to the environment, which they will be, by default. To counteract this, implement these methods:
webScriptNameForSelector: returns the name that a given selector should inherit so that it can be called from the JavaScript environment. The default renaming scheme (to prevent against namespace conflicts) can lead to confusing method names in the scripting environment, so you should make a habit of rewriting the names of all your exposed methods. For example, if you had an Objective-C method called
startMovieAtBeginning, you might want it to reflect its own name in the scripting environment instead of going through a rewrite. An implementation example would look like:
isSelectorExcludedFromWebScript: lets the scripting environment know whether or not a given Objective-C method in your plug-in can be called from the scripting environment. A common mistake first-time plug-in developers make is forgetting to implement this method, causing the plug-in to expose no methods and making the plug-in unscriptable. As a security precation this method returns
YES by default exposing no methods. You want to expose only methods that you know are secure, to do this the function should return
NO. You may only want to export a couple of your Objective-C methods to JavaScript. In this example, the plug-in’s
play method can be called from JavaScript, but any other method cannot::
Similarly, you want to give the scripting environment access to all of your properties. The syntax is very similar for restricting those:
webScriptNameForKey: should be implemented to return a more human-readable name for a method to the scripting environment.
isKeyExcludedFromWebScript: allows you to selectively expose properties to the scripting environment.
In this example, you create a QuickTime movie plug-in. This is a powerful example, because it requires very few lines of code and yet provides a useful extension to a web browser or WebKit application.
First, you need to create the view class. In this case, you use Cocoa’s built-in NSMovieView and subclass it to create your
PlugInMovieView (see Listing 1).
Listing 1 PlugInMovieView header (PlugInMovieView.h)
Now you can write the implementation. You first need to conform to the
WebPlugIn protocol, by implementing
plugInViewWithArguments: (see Listing 2). Create an instance of your movie view, assign it the arguments passed into your method, and return it. Notice that an accessor method is being used to set the arguments—this is good Cocoa coding style.
Listing 2 Returning your plug-in’s view
Now that you’ve returned the view, you need to make a decision. Do you have any operations to perform on initialization? In the case of NSMovieView, you can set a movie’s controller to be visible (or not) and also specify whether or not you’d like the user to be able to adjust its size. In this case, you should show the controller but prevent the user from resizing the movie in the frame—the most common layout for embedded movies (see Listing 3).
Listing 3 Initializing the movie plug-in
From the enclosing container, nestled in an embed tag, you’ll receive a URL pointing to a movie. This will arrive in one of the keys specified by the arguments dictionary that you set in Listing 2. Use that URL to load and play the movie (see Listing 4).
Listing 4 Loading and playing a movie from a URL
Eventually, all good things must come to an end, and so shall your plug-in. This will be announced by a call to
webPlugInStop. You should take the opportunity to stop the movie from playing (see Listing 5).
Listing 5 Stopping the movie
You’ve just implemented a fully functional WebKit movie-playing plug-in. You could build this code, install the plug-in, and have your own working QuickTime player embedded in Safari or a WebKit-based application. However, you might want to add a little more flair and use a form—with HTML buttons—to play and pause the movie. It just takes a few more lines of code (see Listing 6).
Listing 6 Opening the plug-in to JavaScript
You only had to add two extra methods,
play and
pause, so that the buttons in the interface could be tied to public methods. Then you exposed those methods to the JavaScript scripting environment.
If you want to explore further, this example is available at:
Last updated: 2008-10-15
|
http://developer.apple.com/documentation/InternetWeb/Conceptual/WebKit_PluginProgTopic/Tasks/WebKitPlugins.html
|
crawl-002
|
refinedweb
| 1,300
| 52.09
|
Modular Arithmetic
Before going straight to cryptography, it is necessary to have clear a few mathematical concepts, as cryptography in based on them.
First, I am going to talk about modular arithmetic, also known as clock arithmetic, which is defined as:
\[a \equiv b\pmod n,\]
if \(b - a\) is multiple of \(n\), in other words, \(a\) and \(b\) have the same remainder when divided by \(n\).
For example, \(3\equiv 8\pmod 5\), because \(8 - 3 = 5\), which is a 5 multiple. Another way would be knowing that both remainders of 3 divided by 5 and 8 divided by 5 are 3. From now on, I'll write the remainder of a number like this:
\[a\bmod n = r,\]
where \(r\) is the remainder of \(a\) divided by \(n\).
Computing modular inverses
Given \(a \in \mathbb Z_n\), \(a\) has inverse (also called unit) if \(\exists b \in \mathbb Z_n\ :\ ba = 1\), and its written \(a^{-1}\).
The set of all \(\mathbb Z_n\) units is called \(\mathcal{U}(\mathbb Z_n)\) and is defined as:
\[\mathcal{U}(\mathbb Z_n) = \{ a \in \mathbb Z_n : \exists a^{-1}\} = \{ a \in \mathbb Z_n : gcd(a, n) = 1\},\]
where gcd is Greatest Common Divisor.
If \(p\) is prime, every element in \(\mathbb Z_p\) but zero has inverse, therefore, \(\mathbb Z_p\) is a field. Cryptography works with fields \(\mathbb Z_p\) where \(p\) is prime.
The number of units in \(\mathbb Z_n\) can be computed with Euler's function \(\phi(n)\):
- If \(p\) is prime \(\phi(p) = p - 1\), because all its elements but zero are units.
- Given two integers a,b: \( \phi(ab) = \phi(a)\phi(b)\ \text{iff}\ gcd(a, b) = 1\).
- Given \(p\) prime: \(\phi(p^n) = p^n - p^{n-1}\).
Help me keep writing
Practical example
Lets see an example. \(\#\mathcal{U}(\mathbb Z_5) = 4\), because all its elements have inverse (1,2,3,4), and \(\phi(5) = 4\), therefore \(\mathbb Z_5\) is a field. However, \(\#\mathcal{U}(\mathbb Z_{15}) = 8\), because \(\phi(15) = \phi(3)\phi(5) = 2\cdot 4 = 8\). The units of \(\mathbb Z_{15}\) are 1,2,4,7,8,11,13,14.
The code below uses the Euclidean algorithm to compute the inverse of a number in \(\mathbb Z_n\). This python code is on my github:
def extGcd(a,b): """ Compute the Greatest Common Divisor d of a and b, and integers x and y satisfying ax + by = d. :returns: a tuple (d,x,y) """ if b == 0: return a,1,0 x2 = 1 x1 = 0 y2 = 0 y1 = 1 while b != 0: q = a//b r = a - q * b x = x2 - q * x1 y = y2 - q * y1 a = b b = r x2 = x1 x1 = x y2 = y1 y1 = y if a < 0: return map(int, (-a, -x2, -y2)) return map(int, (a, x2, y2))
This algorithm returns a tuple
(d, x, y), where
d is
gcd(a,b) and
x is
a mod b inverse. For example,
gcd(2, 5), will return
[1, -2, 1], where 1 is
gcd(2, 5), and \(-2\) its inverse, if you want a positive number, just sum 5 to \(-2\), which is 3, therefore 2 mod 5 inverse is 3, because \(2 \cdot 3 = 6\), and 6 mod 5 = 1.
In order to make the task of computing a number's inverse, I've created the method bellow, the code is also available at my github:
def moduloInverse(a,n): """:returns: the inverse of a modulo b, if it exists""" d,x,y = extGcd(a,n) if d > 1: return u' a inverse does not exist' else: return x % n
Execute it with the same numbers as before, 2 and 5, and it'll return \(2^{-1},\) that is, 3.
Aknowledgements
I'd like to thank josealberto4444 for helping me with some corrections.
References
The code shown along this series is hosted on my github
Cryptography course notes by Professor Jesús García Miranda, Higher Technical School of Information Technology and Telecommunications Engineering of the University of Granada.
More resources
Spot a typo?: Help me fix it by contacting me or commenting below!
|
https://elbauldelprogramador.com/en/cryptography-101-math-basis-i/
|
CC-MAIN-2018-43
|
refinedweb
| 683
| 64.54
|
I'm trying to update a project using ArcObjects 10.0 to 10.4.1. I'm having trouble at this line in the code:
ESRI.ArcGIS.DataManagementTools.CreateRandomPoints CreateRandomPointsTool = new CreateRandomPoints();
This namespace doesn't appear to exist anymore. Have geoprocessing tools moved somewhere else? Also, I'm confused because this page: GitHub - Esri/arcobjects-sdk-community-samples: This repository contains ArcObjects SDK Samples for the ArcObjects SDK 1… shows a lot of sample code that uses that namespace, despite the page being labelled as 10.4.1 examples (and 10.5 elsewhere on the same page).
Hi Shane,
Maybe from VS project go to Add ArcGIS reference > Reference > Choose Engine (core) > you can find Esri .AcGIS.DsataManagementsTools.
Hope this help you,
Fred
|
https://community.esri.com/thread/202631-cant-find-esriarcgisdatamanagementtools
|
CC-MAIN-2018-22
|
refinedweb
| 124
| 52.26
|
Code to generate and manipulate dubins curves
Project description
Overview
This software finds the shortest paths between configurations for the Dubins’ car [Dubins57],
Discrete Sampling of a Dubin’s path at finite step sizes
import dubins q0 = (x0, y0, theta0) q1 = (x1, y1, theta1) turning_radius = 1.0 step_size = 0.5 path = dubins.shortest_path(q0, q1, turning_radius) configurations, _ = path.sample_many(step_size)
Acknowledgements
This work was completed as part of [Walker11].
References
Dubins, L. E. (July 1957). “On Curves of Minimal Length with a Constraint on Average Curvature, and with Prescribed Initial and Terminal Positions and Tangents”. American Journal of Mathematics 79 (3): 497–516
Shkel, A. M. and Lumelsky, V. (2001). “Classification of the Dubins set”. Robotics and Autonomous Systems 34 (2001) 179–202
Walker, A. (2011). “Hard Real-Time Motion Planning for Autonomous Vehicles”, PhD thesis, Swinburne University.
Project details
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
|
https://pypi.org/project/dubins/
|
CC-MAIN-2022-40
|
refinedweb
| 162
| 52.05
|
You.
In Part I, I will cover the three types of character encodings. It is crucial that you understand how the encoding schemes work. Even if you already know that a string is an array of characters, read this part. Once you've learned this, it will be clearer how the various string classes are related.
In Part II I will describe the string classes themselves, when to use which ones, and how to convert among them.
All string classes eventually boil down to a C-style string, and C-style strings are arrays of characters, so I'll first cover the character types. There are three encoding schemes and three character types. The first scheme is the single-byte character set, or SBCS. In this encoding scheme, all characters are exactly one byte long. ASCII is an example of an SBCS. A single zero byte marks the end of a SBCS string.
The second scheme is the multi-byte character set, or MBCS. An MBCS encoding contains some characters that are one byte long, and others that are more than one byte long. The MBCS schemes used in Windows contain two character types, single-byte characters and double-byte characters. Since the largest multi-byte character used in Windows is two bytes long, the term double-byte character set, or DBCS, is commonly used in place of MBCS.
In a DBCS encoding, certain values are reserved to indicate that they are part of a double-byte character. For example, in the Shift-JIS encoding (a commonly-used Japanese scheme), values 0x81-0x9F and 0xE0-0xFC mean "this is a double-byte character, and the next byte is part of this character." Such values are called "lead bytes," and are always greater than 0x7F. The byte following a lead byte is called the "trail byte." In DBCS, the trail byte can be any non-zero value. Just as in SBCS, the end of a DBCS string is marked by a single zero byte.
The third scheme is Unicode. Unicode is an encoding standard in which all characters are two bytes long. Unicode characters are sometimes called wide characters because they are wider (use more storage) than single-byte characters. Note that Unicode is not considered an MBCS - the distinguishing feature of an MBCS encoding is that characters are of different lengths. A Unicode string is terminated by two zero bytes (the encoding of the value 0 in a wide character).
Single-byte characters are the Latin alphabet, accented characters, and graphics defined in the ASCII standard and DOS operating system. Double-byte characters are used in East Asian and Middle Eastern languages. Unicode is used in COM and internally in Windows NT.
You're certainly already familiar with single-byte characters. When you use the
char data type,
you are dealing with single-byte characters. Double-byte characters are also manipulated using the
char
data type (which is the first of many oddities that we'll encounter with double-byte characters). Unicode characters
are represented by the
wchar_t type. Unicode character and string literals are written by prefixing
the literal with
L, for example:
wchar_t wch = L'1'; // 2 bytes, 0x0031 wchar_t* wsz = L"Hello"; // 12 bytes, 6 wide characters
Single-byte strings are stored one character after the next, with a single zero byte marking the end of the
string. So for example,
"Bob" is stored as:
The Unicode version,
L"Bob", is stored as:
with the character 0x0000 (the Unicode encoding of zero) marking the end.
DBCS strings look like SBCS strings at first glance, but we will see later that there are subtleties that make
a difference when using string manipulating functions and traversing through the string with a pointer. The string
"
" ("nihongo")
is stored as follows (with lead bytes and trail bytes indicated by LB and TB respectively):
Keep in mind that the value of "ni" is not interpreted as the
WORD value 0xFA93. The
two values
93 and
FA, in that order, together encode the character "ni".
(So on a big-endian CPU, the bytes would still be in the order shown above.)
We've all seen the C string functions like
strcpy(),
sprintf(),
atol(),
etc. These functions must be used only with single-byte strings. The standard library also has versions
for use with only Unicode strings, such as
wcscpy(),
swprintf(),
_wtol().
Microsoft also added versions to their CRT (C runtime library) that operate on DBCS strings. The
strxxx()
functions have corresponding DBCS versions named
_mbsxxx(). If you ever expect to encounter DBCS strings
(and you will if your software is ever installed on Japanese, Chinese, or other language that uses DBCS), you should
always use the
_mbsxxx() functions, since they also accept SBCS strings. (A DBCS string might
contain only one-byte characters, so that's why
_mbsxxx() functions work with SBCS strings too.)
Let's look at a typical string to illustrate the need for the different versions of the string handling functions.
Going back to our Unicode string
L"Bob":
Because x86 CPUs are little-endian, the value 0x0042 is stored in memory as
42 00. Can you see
the problem here if this string were passed to
strlen()? It would see the first byte
42,
then
00, which to it means "end of the string," and it would return 1. The converse situation,
passing
"Bob" to
wcslen(), is even worse.
wcslen() would first
see 0x6F42, then 0x0062, and then keep on reading past the end of your buffer until it happened to hit a
00
00 sequence or cause a GPF.
So we've covered the usage of
strxxx() versus
wcsxxx(). What about
strxxx()
versus
_mbsxxx()? The difference there is extremely important, and has to do with the proper
way of traversing through DBCS strings. I will cover traversing strings next, then return to the subject of
strxxx()
versus
_mbsxxx().
Since most of us grew up using SBCS strings, we're used to using the
++ and
-- operators
on a pointer to traverse through a string. We've also used array notation to access any character in the string.
Both these methods work perfectly well with SBCS and Unicode strings, because all characters are the same length
and the compiler can properly return the character we're asking for.
However, you must break those habits for your code to work properly when it encounters DBCS strings. There are two rules for traversing through a DBCS string using a pointer. Breaking these rules will cause almost all of your DBCS-related bugs.
1. Don't traverse forwards with
++unless you check for lead bytes along the way.
2. Never traverse backwards using
--.
I'll illustrate rule 2 first, since it's easy to find a non-contrived example of code that breaks it. Say you
have a program that stores a config file in its own directory, and you keep the install directory in the registry.
At runtime, you read the install directory, tack on the config filename, and try to read it. So if you install
to
C:\Program Files\MyCoolApp, the filename that gets constructed is
C:\Program Files\MyCoolApp\config.bin,
and it works perfectly when you test it.
Now, imagine this is your code that constructs the filename:
bool Get = strchr ( szConfigFilename, '\0' ); // Now move it back one character. pLastChar--; if ( *pLastChar != '\\' ) strcat ( szConfigFilename, "\\" ); // Add on the name of the config file. strcat ( szConfigFilename, "config.bin" ); // If the caller's buffer is big enough, return the filename. if ( strlen ( szConfigFilename ) >= nBuffSize ) return false; else { strcpy ( pszName, szConfigFilename ); return true; } }
This is very defensive code, yet it will break with particular DBCS characters. To see why, suppose a Japanese
user gets hold of your program and changes the install directory to
C:\
. Here is that directory name as stored in memory:
When
GetConfigFileName() checks for the trailing backslash, it looks at the last non-zero byte
of the install directory, sees that it equals
'\\', and doesn't append another slash. The result is
that the code returns the wrong filename.
So what went wrong? Look at the two bytes above highlighted in blue. The value of the backslash character is
0x5C. The value of
'
'
is
83
5C. (The light bulb should be going on just about now...) The above code mistakenly
read a trail byte and treated it as a character of its own.
The correct way to traverse backwards is to use functions that are aware of DBCS characters and move the pointer the correct number of bytes. Here is the correct code, with the pointer movement shown in red:
bool FixedGet = _mbschr ( szConfigFilename, '\0' ); // Now move it back one double-byte character. pLastChar = CharPrev ( szConfigFilename, pLastChar ); if ( *pLastChar != '\\' ) _mbscat ( szConfigFilename, "\\" ); // Add on the name of the config file. _mbscat ( szConfigFilename, "config.bin" ); // If the caller's buffer is big enough, return the filename. if ( _mbslen ( szInstallDir ) >= nBuffSize ) return false; else { _mbscpy ( pszName, szConfigFilename ); return true; } }
This fixed function uses the
CharPrev() API to move
pLastChar back one character,
which might be two bytes long if the string ends in a double-byte character. In this version, the if condition
works properly, since a lead byte will never equal 0x5C.
You can probably imagine a way to break rule 1 now. For example, you might validate a filename entered by the
user by looking for multiple occurrences of the character
':'. If you use
++ to traverse
the string instead of
CharNext(), you may incorrectly generate errors if there happen to be trail
bytes whose values equal that of
':'.
Related to rule 2 is this one about using array indexes:
2a. Never calculate an index into a string using subtraction.
Code that breaks this rule is very similar to code that breaks rule 2. For example, if
pLastChar
were set this way:
char* pLastChar = &szConfigFilename [strlen(szConfigFilename) - 1];
it would break in exactly the same situations, because subtracting 1 in the index expression is equivalent to moving backwards 1 byte, which breaks rule 2.
It should be clear now why the
_mbsxxx() functions are necessary. The
strxxx() functions
know nothing of DBCS characters, while
_mbsxxx() do. If you called
strrchr("C:\\
", '\\') the
return value would be wrong, whereas
_mbsrchr() will recognize the double-byte characters at the end,
and return a pointer to the last actual backslash.
One final point about string functions: the
strxxx() and
_mbsxxx() functions that
take or return a length return the length in
chars. So if a string contains three double-byte characters,
_mbslen() will return 6. The Unicode functions return lengths in
wchar_ts, so for example,
wcslen(L"Bob") returns 3.
Although you might never have noticed, every API and message in Win32 that deals with strings has two versions.
One version accepts MCBS strings, and the other Unicode strings. For example, there is no API called
SetWindowText();
instead, there are
SetWindowTextA() and
SetWindowTextW(). The A suffix (for ANSI) indicates
the MBCS function, while the W suffix (for wide) indicates the Unicode version.
When you build a Windows program, you can elect to use either the MBCS or Unicode APIs. If you've used the VC
AppWizards and never touched the preprocessor settings, you've been using the MBCS versions all along. So how is
it that we can write "SetWindowText" when there isn't an API by that name? The winuser.h header file
contains some
#defines, like this:
BOOL WINAPI SetWindowTextA ( HWND hWnd, LPCSTR lpString ); BOOL WINAPI SetWindowTextW ( HWND hWnd, LPCWSTR lpString ); #ifdef UNICODE #define SetWindowText SetWindowTextW #else #define SetWindowText SetWindowTextA #endif
When building for the MBCS APIs,
UNICODE is not defined, so the preprocessor sees:
#define SetWindowText SetWindowTextA
and replaces calls to
SetWindowText() with calls to the real API,
SetWindowTextA().
(Note that you can, if you wanted to, call
SetWindowTextA() or
SetWindowTextW() directly,
although you'd rarely need to do that.)
So, if you want to switch to using the Unicode APIs by default, you can go to the preprocessor settings and
remove the
_MBCS symbol from the list of predefined symbols, and add
UNICODE and
_UNICODE.
(You should define both, as different headers use different symbols.) However, you will run into a snag if you've
been using plain
char for your strings. Consider this code:
HWND hwnd = GetSomeWindowHandle(); char szNewText[] = "we love Bob!"; SetWindowText ( hwnd, szNewText );
After the compiler replaces "SetWindowText" with "SetWindowTextW", the code becomes:
HWND hwnd = GetSomeWindowHandle(); char szNewText[] = "we love Bob!"; SetWindowTextW ( hwnd, szNewText );
See the problem here? We're passing a single-byte string to a function that takes a Unicode string. The first
solution to this problem is to use
#ifdefs around the definition of the string variable:
HWND hwnd = GetSomeWindowHandle(); #ifdef UNICODE wchar_t szNewText[] = L"we love Bob!"; #else char szNewText[] = "we love Bob!"; #endif SetWindowText ( hwnd, szNewText );
You can probably imagine the headache you'd get having to do that around every string in your code. The solution
to this is the
TCHAR.
TCHAR is a character type that lets you use the same codebase for both MBCS and Unicode builds,
without putting messy
#defines all over your code. A definition of the
TCHAR looks like
this:
#ifdef UNICODE typedef wchar_t TCHAR; #else typedef char TCHAR; #endif
So a
TCHAR is a
char in MBCS builds, and a
wchar_t in Unicode builds.
There is also a macro
_T() to deal with the
L prefix needed for Unicode string literals:
#ifdef UNICODE #define _T(x) L##x #else #define _T(x) x #endif
The
## is a preprocessor operator that pastes the two arguments together. Whenever you have a string
literal in your code, use the
_T macro on it, and it will have the
L prefix added on
when you do a Unicode build.
TCHAR szNewText[] = _T("we love Bob!");
Just as there are macros to hide the
SetWindowTextA/
W details, there are also macros
that you can use in place of the
strxxx() and
_mbsxxx() string functions. For example,
you can use the
_tcsrchr macro in place of
strrchr() or
_mbsrchr() or
wcsrchr().
_tcsrchr expands to the right function based on whether you have the
_MBCS or
UNICODE
symbol defined, just like
SetWindowText does.
It's not just the
strxxx() functions that have
TCHAR macros. There are also, for example,
_stprintf (replaces
sprintf() and
swprintf()) and
_tfopen (replaces
fopen() and
_wfopen()). The full list of macros is in MSDN under the title "Generic-Text
Routine Mappings."
Since the Win32 API documentation lists functions by their common names (for example, "SetWindowText"),
all strings are given in terms of
TCHARs. (The exception to this is Unicode-only APIs introduced in
XP.) Here are the commonly-used typedefs that you will see in MSDN:
So, after all this, you're probably wondering, "So why would I use Unicode? I've gotten by with plain
chars
for years." There are three cases where a Unicode build is beneficial:
MAX_PATHcharacters.
The vast majority of Unicode APIs are not implemented on Windows 9x, so if you intend your program to be run on 9x, you'll have to stick with the MBCS APIs. (There is a relatively new library from Microsoft called the Microsoft Layer for Unicode that lets you use Unicode on 9x, however I have not tried it myself yet, so I can't comment on how well it works.) However, since NT uses Unicode for everything internally, you will speed up your program by using the Unicode APIs. Every time you pass a string to an MBCS API, the operating system converts the string to Unicode and calls the corresponding Unicode API. If a string is returned, the OS has to convert the string back. While this conversion process is (hopefully) highly optimized to make as little impact as possible, it is still a speed penalty that is avoidable.
NT allows very long filenames (longer than the normal limit of
MAX_PATH characters, which is 260)
but only if you use the Unicode APIs. Once nice side benefit of using the Unicode APIs is that your program will
automatically handle any language that the user enters. So a user could enter a filename using English, Chinese,
and Japanese all together, and you wouldn't need any special code to deal with it; they all appear as Unicode characters
to you.
Finally, with the end of the Windows 9x line, MS seems to be doing away with the MBCS APIs. For example, the
SetWindowTheme() API, which takes two string parameters, only has a Unicode version. Using a Unicode
build will simplify string handling as you won't have to convert from MBCS to Unicode and back.
And even if you don't go with Unicode builds now, you should definitely always use
TCHAR
and the associated macros. Not only will that go a long way to making your code DBCS-safe, but if you decide to
make a Unicode build in the future, you'll just need to change a preprocessor setting to do it!
General
News
Question
Answer
Joke
Rant
Admin
|
http://www.codeproject.com/KB/string/cppstringguide1.aspx
|
crawl-002
|
refinedweb
| 2,825
| 70.63
|
To use Resnet-50 to run CIFAR100 dataset, I wrote a program by using Tensorflow. But when running it, the loss seems keeping in about 4.5~4.6 forever:
step: 199, loss: 4.61291, accuracy: 0 step: 200, loss: 4.60952, accuracy: 0 step: 201, loss: 4.60763, accuracy: 0 step: 202, loss: 4.62495, accuracy: 0 step: 203, loss: 4.62312, accuracy: 0 step: 204, loss: 4.60703, accuracy: 0 step: 205, loss: 4.60947, accuracy: 0 step: 206, loss: 4.59816, accuracy: 0 step: 207, loss: 4.62643, accuracy: 0 step: 208, loss: 4.59422, accuracy: 0 ...
After changed models (from Resnet to fully-connect-net), optimizers (from AdamOptimizer to AdagradOptimizer), and even learning rate (from 1e-3 to even 1e-7), the phenomena didn’t change at all.
Finally, I checked the loss and the output vector step by step, and found that the problem is not in model but dataset code:
def next_batch(self, batch_size = 64): images = [] labels = [] for i in range(self.pos, self.pos + batch_size): image = self.data['data'][self.pos] image = image.reshape(3, 32, 32) image = image.transpose(1, 2, 0) image = image.astype(np.float32) / 255.0 images.append(image) label = self.data['fine_labels'][self.pos] labels.append(label) if (self.pos + batch_size) >= CIFAR100_TRAIN_SAMPLES: self.pos = 0 else: self.pos = self.pos + batch_size return [images, labels]
Every batch of data have the same pictures and same labels! Than’t why the model didn’t converge. I should have used ‘i’ instead of ‘self.pos’ as index to fetch data and labels.
So in DeepLearning area, problems comes not only from models and hyper-parameters, but also dataset, or faulty codes…
|
https://donghao.org/2018/05/11/764/
|
CC-MAIN-2021-39
|
refinedweb
| 280
| 63.15
|
Results 1 to 3 of 3
- Join Date
- May 2003
- Location
- Pittsburgh, Pennsylvania, USA
- 629
- Thanks
- 0
- Thanked 0 Times in 0 Posts
import one SS into another (2003)
Is there a rational method to open open an Excel spreadsheet sheet into another file? I mean like a "File.. Import.. Into current sheet" command?
I'm having to open each file I want to use, and copy and paste them. Making a new sheet first, and then moving it because Excel puts it in a dumb order, and then rename it, and then copy it, and then paste it, and then maybe do that more than once if you weren't perfect, and then deal with the clipboard error message which you have to read every single time since it has about 5x too many words, and the dialog box is upside down from the "standard" way of doing things, etc. etc. etc. etc. etc.
I looked at "Merge workbooks" but that's an even madder rabbithole to go down. I quit after the 4th consecutive "You haven't set up so-and-so correctly yet." message.
Thanks for any ideas.
Jim Helfer
- Join Date
- Mar 2002
- 84,353
- Thanks
- 0
- Thanked 30 Times in 30 Posts
Re: import one SS into another (2003)
If you open both the source and the target workbook, you can move or copy an entire worksheet in several ways:
1. Activate the source worksheet, then select Edit | Move or Copy Sheet... (also available when right-clicking the sheet tab.) You can specify the workbook to move/copy the sheet to, and where to place the worksheet.
or
2. Select Window | Arrange... to tile the workbooks. You can drag (to move) or Ctrl-drag (to copy) the source worksheet to the target workbook; drop it in the position where you want it.
- Join Date
- Feb 2001
- Location
- Dublin, Ireland, Republic of
- 2,697
- Thanks
- 1
- Thanked 0 Times in 0 Posts
Re: import one SS into another (2003)
In addition to Hans' suggestions, you could look at the following Menu items :
Data,
Import External Data
Import Data
and in the Select Data Source dialog, browse to and select the file with the data you wish to import. You should then be able to select which sheet to import and which starting cell to import the data to.
Andrew C.
|
http://windowssecrets.com/forums/showthread.php/58216-import-one-SS-into-another-%282003%29
|
CC-MAIN-2017-22
|
refinedweb
| 394
| 74.02
|
I've just have started to work with Blender and have a problem with importing data in it...
I have a point cloud data and importing it to Blender via Python script
import cPickle
import Blender
import numpy as np
from deflectometry.geometry.mesh import Mesh
def visualize(fn):
pts = cPickle.load(open(fn,"rb"))
# Bring the points to blender
m = Mesh()
pts = np.asarray(pts)
# pts /= 1000.maybe when converting from mm to blender units
m.verts = pts
return m.to_blender(fn[:-4])
visualize("result.pck")
With the first variant of pts representation it gives an error. With the second one there is no error, but data is not displayed at all... What could be wrong here?
|
https://www.blender.org/forum/viewtopic.php?t=24912
|
CC-MAIN-2018-17
|
refinedweb
| 118
| 69.68
|
Every thread is a member of a thread group. A thread group provides a mechanism for collecting multiple threads into a single object and manipulating those threads all at once rather than individually. For example, you can interrupt all the threads within a group with a single method call. Thread groups are implemented by the ThreadGroup [1] class in the java.lang package.
[1]
The runtime system puts a thread into a thread group during thread construction. When you create a thread, you can either allow the runtime system to figure out the appropriate thread group, or you can explicitly set the new thread's group. The thread is a permanent member of whatever thread group it joins on its creation. You cannot move a thread to a new group after the thread has been created.
The Thread Group
If you create a new thread without specifying its group in the constructor, the runtime system automatically places the new thread in the same group as the thread that created it (called the current thread group and the current thread, respectively). When an application first starts up, the Java runtime environment creates a ThreadGroup named main. Thus, all new threads that a program creates become members of the main thread group unless the program explicitly creates other groups and puts threads in them.
Note
If you create a thread within an applet, the new thread's group may be something other than main, depending on the browser or the viewer in which the applet is running. Refer to the sections Threads in AWT Applets (page 449) and Threads in Swing Applets (page 459) in Chapter 11 for information.
Many programmers ignore thread groups altogether and allow the runtime system to handle
To put a new thread in a thread group other than the default, you must specify the thread group explicitly when you create it. The Thread class has three constructors that set a new thread's group:
public Thread(ThreadGroup group, Runnable target) public Thread(ThreadGroup group, String name) public Thread(ThreadGroup group, Runnable target, String name)
Each constructor creates a new thread, initializes it based on the Runnable and String parameters, and makes the new thread a member of the specified group. For example, the following code sample creates a thread group (myThreadGroup) and then creates a thread (myThread) in that group:
ThreadGroup myThreadGroup = new ThreadGroup("My Group of Threads"); Thread myThread = new Thread(myThreadGroup, "a thread for my group");
The ThreadGroup passed into a Thread constructor can be any group: one created by your program, by the Java runtime environment, or by the browser in which an applet is running.
Getting a Thread's Group
To find out what group a thread is in, call its getThreadGroup method:
theGroup = myThread.getThreadGroup();
Once you've obtained a thread's ThreadGroup, you can query the group for information, such as what other threads are in the group. You also can modify the threads in that group by using a single method invocation.
Using the ThreadGroup Class
The ThreadGroup class manages groups of threads for programs. A ThreadGroup can contain any number of threads and can contain other ThreadGroups. The threads in a group are generally related, such as by who created them, what function they perform, or when they should be started and stopped.
The topmost thread group in an application is the thread group named main. A program can create threads and groups in the main group or in its subgroups. The result is a hierarchy of threads and groups, as shown in Figure 85.
Figure 85. Thread groups can be nested, thereby creating a hierarchy of groups and threads.
The ThreadGroup class has several categories of methods, discussed in the following sections.
Collection Management Methods
The ThreadGroup provides a set of methods that manage the threads and subgroups within the group and that allow other objects to query the ThreadGroup for information about its contents. For example, you can call ThreadGroup's activeCount method to learn the number of active threads currently in the group. This method can be used with the enumerate method to get an array filled with references to all the active threads in a ThreadGroup. For example, the listCurrentThreads method in the following example fills an array with all the active threads in the current thread group and prints their names:
public class EnumerateDemo { public void listCurrentThreads() { ThreadGroup currentGroup = Thread.currentThread().getThreadGroup(); int numThreads = currentGroup.activeCount(); Thread[] listOfThreads = new Thread[numThreads]; currentGroup.enumerate(listOfThreads); for (int i = 0; i < numThreads; i++) { System.out.println("Thread #" + i + " = " + listOfThreads[i].getName()); } } }
Other collection management methods provided by the ThreadGroup class include activeGroupCount, which returns an estimate of the number of active threads in the group, and list, which prints information about this thread group to the standard output.
Methods That Operate on the Group Object
The ThreadGroup class they do not affect any of the threads within the group. Following are the ThreadGroup methods that operate at the group level:
When you use setMaxPriority to change a group's maximum priority, you are changing only the attribute on the group object; you are not changing the priority of any of the threads within it. Consider the following program that creates a group and a thread within that group:
public class MaxPriorityDemo {()); } }
When the ThreadGroup groupNORM is created, the thread inherits its maximum priority attribute from its parent thread group. In this case, the parent group priority is the maximum (MAX_PRIORITY) allowed by the Java runtime environment. Next, the program sets the priority of the priorityMAX thread to the maximum allowed by the Java runtime environment. Then the program lowers the group's maximum to the normal priority (NORM_PRIORITY). The setMaxPriority method does not affect the priority of the priorityMAX thread, so at this point, the priorityMAX thread has a priority of MAX_PRIORITY, which is greater than the maximum priority of its group. Here is the output from the program:
Group's maximum priority = 5 Thread's priority = 10
As you can see, a thread can have a priority higher setPriority to change the thread's priority. Note that the setMaxPriority method does change the maximum priority of all its descendant-thread groups.
Similarly, a group's daemon status applies only to the group object. Changing a group's daemon status does not affect the daemon status of any thread in the group. Furthermore, a group's daemon status does not in any way determine the daemon status of its threadsyou can put any thread within a daemon thread group. The daemon status of a thread group simply indicates that the group will be destroyed when all its threads have been terminated.
Methods That Operate on All Threads within a Group
The ThreadGroup class has a method for interrupting all the threads within it: interrupt. The ThreadGroup's interrupt method calls the interrupt method on every thread in the group and its subgroups.
The resume, stop, and suspend methods operate on all threads in the group. However, these methods have been deprecated. Refer to Deprecated Thread Methods (page 527).
Access Restriction Methods
The ThreadGroup class itself does not impose any access restrictions, such as allowing threads from one group to inspect or to modify threads in a different group. Rather, the Thread and the ThreadGroup classes cooperate with security managers (subclasses of the java.lang.SecurityManager class), which can impose access restrictions based on thread group membership.
The Thread and the ThreadGroup classes both have a method, checkAccess, that calls the current security manager's checkAccess method. The security manager decides whether to allow the access based on the group membership of the threads involved. If access is not allowed, the checkAccess method throws a SecurityException. Otherwise, checkAccess simply returns.
Following is a list of ThreadGroup methods that call ThreadGroup's checkAccess method before performing the action of the method. These are called regulated accesses. A regulated access must be approved by the security manager before it can be completed.
Here are the Thread class constructors and methods that call checkAccess before proceeding:
By default, a standalone application does not have a security manager. No restrictions are imposed, and any thread can inspect or modify any other thread, regardless of the group in which they are located. You can define and implement your own access restrictions for thread groups by subclassing SecurityManager, overriding the appropriate methods, and installing the SecurityManager as the current security manager in your application.
The HotJava™ Web browser is an example of an application that implements its own security manager. HotJava needs to ensure that applets are well behaved and don't attempt any negative interactions with other applets, such as lowering the priority of another applet's threads, that are running at the same time. HotJava's security manager does not allow threads in different groups to modify one another. Note that access restrictions based on thread groups may vary among browsers, and thus applets may behave differently in different browsers.
|
https://flylib.com/books/en/2.33.1/grouping_threads.html
|
CC-MAIN-2020-10
|
refinedweb
| 1,499
| 50.67
|
Hugin Coding Style Guide
Consistent application of a style makes life easier for everybody. You'll find other people's code more readable, and they will find your code more readable. While nobody will tap on your fingers for not following these conventions to the letter, it is highly recommended that you familiarize with them and follow them.
History and Status of this Document
This document started from a discussion on coding style and consistency. It is currently just a collection of the wisdom and opinion of Hugin contributors and we won't do hard enforcement / policing, but it would be nice if we could all stick to the same convention and make the code more readable and manageable for everyobdy.
Naming Conventions
- Names should be clear and descriptive. No contractions, with a few listed below.
- In general, we prefer CamelCase over underscore_insertions.
- LeadingCaps (capitalized first letter of a name) should be used only for classes, structs, and typedefs.
- Variables and functions should not have an initial capital. (although Ryan was suggesting that public function be LeadingCaps and private ones not).
- Private variables should be prefixed with m_. Many (but not all) private variables are currently prefixed.
- Constants are ALL_CAPS with underscore insertions.
- Where there are contractions, they should be used consistently across the code base. Make yourself familiar with the list. There are some hisotrical exceptions, e.g. Pano instead of Panorama. Any more exceptions?
Contraction Lists
- Pano: for panorama
- FOV: for Field of View
- ROI: for Region of Interest
The list is incomplete.
Metadata
Documentation
Document your code (or the code you are reading and understanding) with doxygen. Doxygen is a useful tool and can also be used to create other documentation that just class interface descriptions. It works by prefixing the function prototypes with a special comment. Pablo usually puts); }
Identify Work in Progress
- Maintain the @todo and @bug sections of doxygen. They are summarized and listed in the automatically generated documentation's todo and bugs lists.
- For small things inside the code, put // FIXME or // TODO comments - they will be automatically highlighted by gedit and other editors, and will be easily searchable with grep.
Comments and inline-documentation are always welcome, please give them lines of their own and don't append them to existing code:
exit(); do_stuff(); //Don't do this
File Names
Try to keep one class per file, and give the file a meaningful name in CamelCase.
Code Layout
Spacing and indentation contirbute a lot to the readability of the code. Use them liberally.
Bracing
There are many different indentation styles. 1TBS (like the Linux Kernel) is the preferred one. However it is more important to keep consistency within a file, so if you are editing a file with a different convention, adopt it (or read the clean up section of this style guide).
if (1 == 0) { printf("never"); } else { printf("ever"); }
Tabulation
Use spaces instead of tabulators (to maintain consistency across editors). The preferred indentation is four spaces for one tab, but most important is to keep consistency within a single file.
Spacing
I would not go into that much detail. or maybe we should adopt/adapt a strict coding guide like Blender?
Line Ends
Set your editor to Unix-style line ending (LF) - not Windows' LF+CR. Or if you are on Windows, use the Mercurial EOL extension.
To prevent accidentally committing a file with Windows line endings, you can add the following snippet to your global .hgrc or mercurial.ini file:
[hooks] pretxncommit.crlf = python:hgext.win32text.forbidcrlf
Character Set
Ideally we are striving to use UTF-8, but because Windows has issue dealing with it, the wxWidgets XRC ressources are ISO-8859-1.
Multiple Statements on one Line
Avoid multiple statements on one line, it makes the code harder to read.
Line Width
Try to keep line width below 80 characters.
Repository
Commits
It is tempting to clean up old code while fixing bugs or adding new code. Please don't - it makes the committ (diff!) much more difficult to read / understand. Keep style clean up committs separated and mention them as such in the log message.
It is important that nobody goes around changing existing code to suit without thinking about it first - We have several branches waiting to be merged, changing the amount of whitespace makes that difficult, and splitting or joining lines of code makes it enormously more so.
Work in Progress
If something needs work, mark it with a // FIXME or // TODO comment so that a grep will reveal places that needs attention. Gedit automatically highlights TODO and FIXME.
For minor changes, feel free to commit directly into the default codeline. For everything else, branch out. Branches are cheap.
Strings for Translation
Release branches are string-frozen. Strings for translation are updated prior to branching and in principle no new string shall be added to a release branch. An exception may be requested if the underlying motive is important enough. The request must receive the support of a significant majority of developers (coders, builders, translators) to be granted. Silence is interpreted as supportive of the request.
API stability
Release branches are frozen regarding classes/function/namespace names and functions parameters. An exception may be requested if the underlying motive is important enough. The request must receive the support of a significant majority of developers (coders and scripters) to be granted. Silence is interpreted as supportive of the request.
License
- Make sure all new files added to the repository come with a license.
- Hugin is historically licensed GPL 2 or later.
- Best is to choose the same license, or a compatible one.
- If you want to license under the GPL 2 or later, just copy and the text below into a comment at the beginning of each of your new files.
/* ** <>. */
Goto / Case Labels
Try to write code that is linear to read and does not jump all over the place too much.
Compilation Warnings and Diagnostic Output
Try to prevent compiler warnings.
Encapsulate diagnostic output in a condition and commit it so that by default there is no diagnostic output. Consider that some CMake output must be clicked away on Windows while it is just an extra line of display in Linux.
- First drafted February 14, 2011 by Yuval Levy
- Last changed: February 14, 2011 by Yuval Levy
|
http://hugin.sourceforge.net/community/coding_style/
|
CC-MAIN-2015-18
|
refinedweb
| 1,053
| 56.96
|
Opened 5 years ago
Closed 4 years ago
#21466 closed Bug (invalid)
override_settings(LOGIN_URL=…) does not work when not first test
Description
Overriding
LOGIN_URL in the tests does not work when another test is run beforehand.
from django.test import TestCase from django.test.utils import override_settings from django.core.urlresolvers import reverse from django.conf import settings class OverrideSettingsTest(TestCase): def test_a(self): """ Toggle this test by commenting it out and see whether test_b() passes. """ response = self.client.get(reverse("harmless-view")) self.assertEqual(response.status_code, 301) @override_settings(LOGIN_URL="/THIS_IS_FINE/") def test_b(self): # settings appear to be overridden as expected self.assertEqual(settings.LOGIN_URL, "/THIS_IS_FINE/") response = self.client.get(reverse("redirect-to-login")) # The following assertion fails only when test_a() is run. self.assertRedirects(response, "/THIS_IS_FINE/", status_code=301, target_status_code=404 ) def test_c(self): response = self.client.get(reverse("harmless-view")) self.assertEqual(response.status_code, 301)
.F. ====================================================================== FAIL: test_b (override_bug.tests.OverrideSettingsTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "django/test/utils.py", line 224, in inner return test_func(*args, **kwargs) File "override_bug/override_bug/tests.py", line 24, in test_b target_status_code=404 File "django/test/testcases.py", line 617, in assertRedirects (url, expected_url)) AssertionError: Response redirected to '', expected '' ---------------------------------------------------------------------- Ran 3 tests in 0.031s
Attachments (1)
Change History (6)
Changed 5 years ago by
comment:1 Changed 5 years ago by
I'm almost sure the problem is related to the way you are using
settings.LOGIN_URL. In your sample project, it is used as a parameter of the
as_view call in your URLConf, that means that it will be defined once and for all requests at import time.
You can workaround this issue by subclassing
RedirectView and overriding
get_redirect_url() so that when
settings.LOGIN_URL changes your view can take that change into account. I don't think we can do anything on Django's side.
comment:2 Changed 5 years ago by
Sorry for opening this ticket. You're right that this has nothing to do with Django.
I used django-braces'
LoginRequiredMixin which sets
settings.LOGIN_URL at import time and replicated this bug in my example project without further reflecting upon this issue.
comment:3 Changed 4 years ago by
I think I'm hitting the same issue as well. In my project, I have set a variable called
REGISTRATION_ENABLED. However, when I try to override this setting in my tests, it's never read. Changing the setting beforehand in my settings.py makes the test pass, however. This is how it's used in my tests:
def test_auth(self): """ Test that a user can register using the API, login and logout """ # test registration workflow submit = { 'username': 'Otto', 'password': 'password', 'first_name': 'first_name', 'last_name': 'last_name', 'email': 'email@email.com', 'is_superuser': False, 'is_staff': False, } url = '/api/auth/register' response = self.client.post(url, json.dumps(submit), content_type='application/json') self.assertEqual(response.status_code, 201) # test disabled registration with self.settings(REGISTRATION_ENABLED=False): submit['username'] = 'anothernewuser' response = self.client.post(url, json.dumps(submit), content_type='application/json') self.assertEqual(response.status_code, 403)
And the code block in my views:
class HasRegistrationAuth(permissions.BasePermission): """ Checks to see if registration is enabled """ def has_permission(self, request, view): return settings.REGISTRATION_ENABLED
Note that I'm using in my application.
comment:4 Changed 4 years ago by
apologies, I forgot to add the output of my tests!
$ ./manage.py test api Creating test database for alias 'default'... .......F.................................................... ====================================================================== FAIL: test_auth (api.tests.test_auth.AuthTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "/api/tests/test_auth.py", line 64, in test_auth self.assertEqual(response.status_code, 403) AssertionError: 201 != 403 ---------------------------------------------------------------------- Ran 60 tests in 29.056s FAILED (failures=1) Destroying test database for alias 'default'...
When i modify the setting to
False in settings.py, the test passes without failure.
comment:5 Changed 4 years ago by
I think it's more likely that your use of
override_settings() is invalid. Please be sure you've read the caveats in the documentation and ask questions using our support channels. If after doing those setps you still believe you've found a bug, please open a new ticket, thanks.
An example project which exhibits the bug (filetype: tar)
|
https://code.djangoproject.com/ticket/21466
|
CC-MAIN-2018-26
|
refinedweb
| 686
| 51.85
|
# Crime, Race and Lethal Force in the USA — Part 2

In the [previous part](https://habr.com/ru/post/519154/) of this article, I talked about the research background, goals, assumptions, source data, and used tools. Today, without further ado, let's say together…
Chocks Away!
------------
We start by importing the required packages and defining the root folder where the source data sit:
```
import pandas as pd, numpy as np
# root folder path (change for your own!)
ROOT_FOLDER = r'c:\_PROG_\Projects\us_crimes'
```
Lethal Force Fatalities
-----------------------
First let's look into the use of lethal force data. Load the CSV into a new DataFrame:
```
# FENC source CSV
FENC_FILE = ROOT_FOLDER + '\\fatal_enc_db.csv'
# read to DataFrame
df_fenc = pd.read_csv(FENC_FILE, sep=';', header=0, usecols=["Date (Year)", "Subject's race with imputations", "Cause of death", "Intentional Use of Force (Developing)", "Location of death (state)"])
```
You will note that not all the fields are loaded, but only those we'll need in the research: year, victim race (with imputations), cause of death (not used now but may come in useful later on), intentional use of force flag, and the state where the death took place.
It's worth understanding what «subject's race with imputations» means. The fact is, the official / media sources that FENC uses to glean data don't always report the victim's race, resulting in data gaps. To compensate these gaps, the FENC community involves third-party experts who estimate the race by the other available data (with some degree of error). You can read more on this on the [FENC website](https://fatalencounters.org/) or see notes in the original [Excel spreadsheet](https://docs.google.com/spreadsheets/d/1dKmaV_JiWcG8XBoRgP8b4e9Eopkpgt7FL7nyspvzAsE/edit#gid=0) (sheet 2).
We'll then give the columns handier titles and drop the rows with missing data:
```
df_fenc.columns = ['Race', 'State', 'Cause', 'UOF', 'Year']
df_fenc.dropna(inplace=True)
```
Now we hava to unify the race categories with those used in the crime and population datasets we are going to match with, since these datasets use somewhat different racial classifications. The FENC database, for one, singles out the Hispanic/Latino ethnicity, as well as Asian/Pacific Islanders and Middle Easterns. But in this research, we're focusing on Blacks and Whites only. So we must make some aggregation / renaming:
```
df_fenc = df_fenc.replace({'Race': {'European-American/White': 'White',
'African-American/Black': 'Black',
'Hispanic/Latino': 'White', 'Native American/Alaskan': 'American Indian',
'Asian/Pacific Islander': 'Asian', 'Middle Eastern': 'Asian',
'NA': 'Unknown', 'Race unspecified': 'Unknown'}}, value=None)
```
We are leaving only White (now including Hispanic/Latino) and Black victims:
```
df_fenc = df_fenc.loc[df_fenc['Race'].isin(['White', 'Black'])]
```
What's the purpose of the UOF (Use Of Force) field? For this research, we want to analyze only those cases when the police (or other law enforcement agencies) *intentionally* used lethal force. We leave out cases when the death was the result of suicide (for example, when sieged by the police) or pursuit and crash in a vehicle. This constraint follows from two criteria:
1) the circumstances of deaths not directly resulting from use of force don't normally allow of a transparent cause-and-effect link between the acts of the law enforcement officers and the ensuing death (one example could be when a man dies from a heart attack when held at gun-point by a police officer; another common example is when a suspect being arrested shoots him/herself in the head);
2) it is only intentional use of force that counts in official statistics; thus, for instance, the future FBI database I mentioned in the previous part of the article will collect only such cases.
So to leave only intentional use of force cases:
```
df_fenc = df_fenc.loc[df_fenc['UOF'].isin(['Deadly force', 'Intentional use of force'])]
```
For convenience we'll add the full state names. I made a separate [CSV file](https://yadi.sk/d/Fb5NOSiLiVXwDA) for that purpose, which we're now merging with our data:
```
df_state_names = pd.read_csv(ROOT_FOLDER + '\\us_states.csv', sep=';', header=0)
df_fenc = df_fenc.merge(df_state_names, how='inner', left_on='State', right_on='state_abbr')
```
Type `df_fenc.head()` to peek at the resulting dataset:
| | Race | State | Cause | UOF | Year | state\_name | state\_abbr |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 1 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 2 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 3 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
| 4 | Black | GA | Gunshot | Deadly force | 2000 | Georgia | GA |
Since we're not going to investigate the individual cases, let's aggregate the data by years and victim races:
```
# group by year and race
ds_fenc_agg = df_fenc.groupby(['Year', 'Race']).count()['Cause']
df_fenc_agg = ds_fenc_agg.unstack(level=1)
# cast numericals to UINT16 to save memory
df_fenc_agg = df_fenc_agg.astype('uint16')
```
The resulting table is indexed by years (2000 — 2020) and contains two columns: 'White' (number of white victims) and 'Black' (number of black victims). Let's take a look at the corresponding plot:
```
plt = df_fenc_agg.plot(xticks=df_fenc_agg.index, color=['olive', 'g'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Number of police victims')
plt
```
[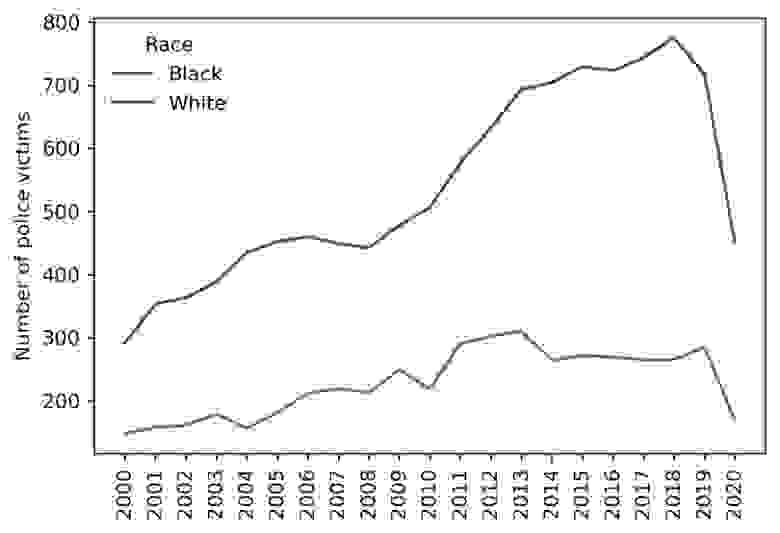](https://habrastorage.org/webt/ck/uv/7o/ckuv7orp_udcp6ieq19v614ca00.jpeg)
**Intermediate conclusion:**
> White police victims outnumber black victims in absolute figures.
>
>
The average difference factor between the two is about 2.4. It's not a far guess that this is due to the difference between the population of the two races in the US. Well, let's look at per capita values then.
Load the population data:
```
# population CSV file (1991 - 2018 data points)
POP_FILE = ROOT_FOLDER + '\\us_pop_1991-2018.csv'
df_pop = pd.read_csv(POP_FILE, index_col=0, dtype='int64')
```
Then merge the data with our dataset:
```
# take only Black and White population for 2000 - 2018
df_pop = df_pop.loc[2000:2018, ['White_pop', 'Black_pop']]
# join dataframes and drop rows with missing values
df_fenc_agg = df_fenc_agg.join(df_pop)
df_fenc_agg.dropna(inplace=True)
# cast population numbers to integer type
df_fenc_agg = df_fenc_agg.astype({'White_pop': 'uint32', 'Black_pop': 'uint32'})
```
OK. Finally, create two new columns with per capita (per million) values dividing the abosulte victim counts by the respective race population and multiplying by one million:
```
df_fenc_agg['White_promln'] = df_fenc_agg['White'] * 1e6 / df_fenc_agg['White_pop']
df_fenc_agg['Black_promln'] = df_fenc_agg['Black'] * 1e6 / df_fenc_agg['Black_pop']
```
Let's see what we get:
| | Black | White | White\_pop | Black\_pop | White\_promln | Black\_promln |
| --- | --- | --- | --- | --- | --- | --- |
| Year | | | | | | |
| 2000 | 148 | 291 | 218756353 | 35410436 | 1.330247 | 4.179559 |
| 2001 | 158 | 353 | 219843871 | 35758783 | 1.605685 | 4.418495 |
| 2002 | 161 | 363 | 220931389 | 36107130 | 1.643044 | 4.458953 |
| 2003 | 179 | 388 | 222018906 | 36455476 | 1.747599 | 4.910099 |
| 2004 | 157 | 435 | 223106424 | 36803823 | 1.949742 | 4.265861 |
| 2005 | 181 | 452 | 224193942 | 37152170 | 2.016112 | 4.871855 |
| 2006 | 212 | 460 | 225281460 | 37500517 | 2.041890 | 5.653255 |
| 2007 | 219 | 449 | 226368978 | 37848864 | 1.983487 | 5.786171 |
| 2008 | 213 | 442 | 227456495 | 38197211 | 1.943229 | 5.576323 |
| 2009 | 249 | 478 | 228544013 | 38545558 | 2.091501 | 6.459888 |
| 2010 | 219 | 506 | 229397472 | 38874625 | 2.205778 | 5.633495 |
| 2011 | 290 | 577 | 230838975 | 39189528 | 2.499578 | 7.399936 |
| 2012 | 302 | 632 | 231992377 | 39623138 | 2.724227 | 7.621809 |
| 2013 | 310 | 693 | 232969901 | 39919371 | 2.974633 | 7.765653 |
| 2014 | 264 | 704 | 233963128 | 40379066 | 3.009021 | 6.538041 |
| 2015 | 272 | 729 | 234940100 | 40695277 | 3.102919 | 6.683822 |
| 2016 | 269 | 723 | 234644039 | 40893369 | 3.081263 | 6.578084 |
| 2017 | 265 | 743 | 235507457 | 41393491 | 3.154889 | 6.401973 |
| 2018 | 265 | 775 | 236173020 | 41617764 | 3.281493 | 6.367473 |
The two rightmost columns now contain per million victim counts for both races. Time to visualize that:
```
plt = df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].plot(xticks=df_fenc_agg.index, color=['g', 'olive'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Number of police victims\nper 1 mln. within race')
plt
```
[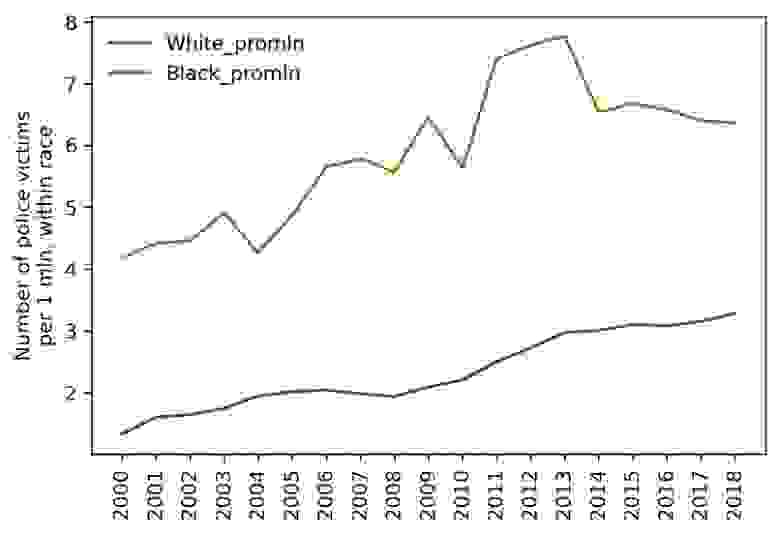](https://habrastorage.org/webt/uq/ku/vd/uqkuvdrtqjwwntliqrl3uc014ca.jpeg)
We'll also display the basic stats for this data by running:
```
df_fenc_agg.loc[:, ['White_promln', 'Black_promln']].describe()
```
| | White\_promln | Black\_promln |
| --- | --- | --- |
| count | 19.000000 | 19.000000 |
| **mean** | **2.336123** | **5.872145** |
| **std** | **0.615133** | **1.133677** |
| min | 1.330247 | 4.179559 |
| 25% | 1.946485 | 4.890977 |
| 50% | 2.091501 | 5.786171 |
| 75% | 2.991827 | 6.558062 |
| max | 3.281493 | 7.765653 |
**Intermediate conclusions:**
> 1. Lethal force results on average in 5.9 per one million Black deaths and 2.3 per one million White deaths (Black victim count is 2.6 greater in unit values).
> 2. Data deviation (scatter) for Blacks is 1.8 higher than for Whites — you can see that the green curve representing White victims is considerably smoother.
> 3. Black victims peaked in 2013 at 7.7 per million; White victims peaked in 2018 at 3.3 per million.
> 4. White victims grow continuously from year to year (by 0.1 — 0.2 per million on average), while Black victims rolled back to their 2009 level after a climax in 2011 — 2013.
>
>
>
>
Thus, we can answer our **first question**:
— ***Can one say the police kill Blacks more frequently than Whites?***
— **Yes, it is a correct inference. Blacks are 2.6 times more likely to meet death by the hands of law enforcement agencies than Whites.**
Bearing in mind this inference, let's go ahead and look at the crime data to see if (and how) they are related to lethal force fatalities and races.
Crime Data
----------
Let's load our crime CSV:
```
CRIMES_FILE = ROOT_FOLDER + '\\culprits_victims.csv'
df_crimes = pd.read_csv(CRIMES_FILE, sep=';', header=0,
index_col=0, usecols=['Year', 'Offense', 'Offender/Victim', 'White',
'White pro capita', 'Black', 'Black pro capita'])
```
Again, as before, we're using only the relevant fields: year, offense type, offender / victim classifier and offense counts for each race (absolute — 'White', 'Black' and per capita — 'White pro capita', 'Black pro capita').
Let's look what we have here (with `df_crimes.head()`):
| | Offense | Offender/Victim | Black | White | Black pro capita | White pro capita |
| --- | --- | --- | --- | --- | --- | --- |
| Year | | | | | | |
| 1991 | All Offenses | Offender | 490 | 598 | 1.518188e-05 | 2.861673e-06 |
| 1991 | All Offenses | Offender | 4 | 4 | 1.239337e-07 | 1.914160e-08 |
| 1991 | All Offenses | Offender | 508 | 122 | 1.573958e-05 | 5.838195e-07 |
| 1991 | All Offenses | Offender | 155 | 176 | 4.802432e-06 | 8.422314e-07 |
| 1991 | All Offenses | Offender | 13 | 19 | 4.027846e-07 | 9.092270e-08 |
We won't need data on offense victims so far, so get rid of them:
```
# leave only offenders
df_crimes1 = df_crimes.loc[df_crimes['Offender/Victim'] == 'Offender']
# leave only 2000 - 2018 data years and remove redundant columns
df_crimes1 = df_crimes1.loc[2000:2018, ['Offense', 'White', 'White pro capita', 'Black', 'Black pro capita']]
```
Here's the resulting dataset (1295 rows \* 5 columns):
| | Offense | White | White pro capita | Black | Black pro capita |
| --- | --- | --- | --- | --- | --- |
| Year | | | | | |
| 2000 | All Offenses | 679 | 0.000003 | 651 | 0.000018 |
| 2000 | All Offenses | 11458 | 0.000052 | 30199 | 0.000853 |
| 2000 | All Offenses | 4439 | 0.000020 | 3188 | 0.000090 |
| 2000 | All Offenses | 10481 | 0.000048 | 5153 | 0.000146 |
| 2000 | All Offenses | 746 | 0.000003 | 63 | 0.000002 |
| ... | ... | ... | ... | ... | ... |
| 2018 | Larceny Theft Offenses | 1961 | 0.000008 | 1669 | 0.000040 |
| 2018 | Larceny Theft Offenses | 48616 | 0.000206 | 30048 | 0.000722 |
| 2018 | Drugs Narcotic Offenses | 555974 | 0.002354 | 223398 | 0.005368 |
| 2018 | Drugs Narcotic Offenses | 305052 | 0.001292 | 63785 | 0.001533 |
| 2018 | Weapon Law Violation | 70034 | 0.000297 | 58353 | 0.001402 |
Now we need to convert the per capita (per 1 person) values to per million values (in keeping with the unit data we use throughout the research). Just multiply the per capita columns by one million:
```
df_crimes1['White_promln'] = df_crimes1['White pro capita'] * 1e6
df_crimes1['Black_promln'] = df_crimes1['Black pro capita'] * 1e6
```
To see the whole picture — how crimes committed by Whites and Blacks are distributed across the offense types, let's aggregate the absolute crime counts by years:
```
df_crimes_agg = df_crimes1.groupby(['Offense']).sum().loc[:, ['White', 'Black']]
```
| | White | Black |
| --- | --- | --- |
| Offense | | |
| All Offenses | 44594795 | 22323144 |
| Assault Offenses | 12475830 | 7462272 |
| Drugs Narcotic Offenses | 9624596 | 3453140 |
| Larceny Theft Offenses | 9563917 | 4202235 |
| Murder And Nonnegligent Manslaughter | 28913 | 39617 |
| Sex Offenses | 833088 | 319366 |
| Weapon Law Violation | 829485 | 678861 |
Or in a graph:
```
plt = df_crimes_agg.plot.barh(color=['g', 'olive'])
plt.set_ylabel('')
plt.set_xlabel('Number of offenses (sum for 2000-2018)')
```
[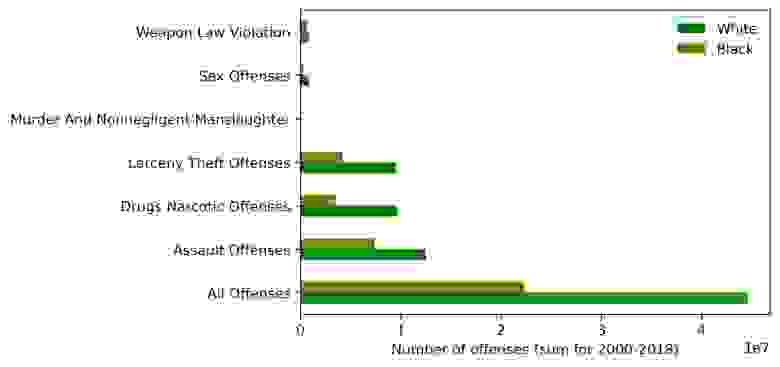](https://habrastorage.org/webt/a3/lw/wz/a3lwwz2zux5w9azxhbyguwsm7we.jpeg)
We can observe here that:
* drug offenses, assaults and 'All Offenses' dominate over the other offense types (murder, weapon law violations and sex offenses)
* in absolute figures, Whites commit more crimes than Blacks (exactly twice as much for the 'All Offenses' category)
Again we realize that no robust conclusions can be made about 'race criminality' without population data. So we're looking at per capita (per million) values:
```
df_crimes_agg1 = df_crimes1.groupby(['Offense']).sum().loc[:, ['White_promln', 'Black_promln']]
```
| | White\_promln | Black\_promln |
| --- | --- | --- |
| Offense | | |
| All Offenses | 194522.307758 | 574905.952459 |
| Assault Offenses | 54513.398833 | 192454.602875 |
| Drugs Narcotic Offenses | 41845.758869 | 88575.523095 |
| Larceny Theft Offenses | 41697.303725 | 108189.184125 |
| Murder And Nonnegligent Manslaughter | 125.943007 | 1016.403706 |
| Sex Offenses | 3633.777035 | 8225.144985 |
| Weapon Law Violation | 3612.671402 | 17389.163849 |
Or as a graph:
```
plt = df_crimes_agg1.plot.barh(color=['g', 'olive'])
plt.set_ylabel('')
plt.set_xlabel('Number of offenses (sum for 2000-2018) per 1 mln. within race')
```
[](https://habrastorage.org/webt/w1/xo/js/w1xojs5kjf-urlypjndmcobis5c.jpeg)
We've got quite a different picture this time. Blacks commit more crimes for each analyzed category than Whites, approaching a triple difference for 'All Offenses'.
We will now leave only the 'All Offenses' category as the most representative of the 7 and sum up the rows by years (since the source data may feature several entries per year, matching the number of reporting agencies).
```
# leave only 'All Offenses' category
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'] == 'All Offenses']
# could also have left assault and murder (try as experiment!)
#df_crimes1 = df_crimes1.loc[df_crimes1['Offense'].str.contains('Assault|Murder')]
# drop absolute columns and aggregate data by years
df_crimes1 = df_crimes1.groupby(level=0).sum().loc[:, ['White_promln', 'Black_promln']]
```
The resulting dataset:
| | White\_promln | Black\_promln |
| --- | --- | --- |
| Year | | |
| 2000 | 6115.058976 | 17697.409882 |
| 2001 | 6829.701429 | 20431.707645 |
| 2002 | 7282.333249 | 20972.838329 |
| 2003 | 7857.691182 | 22218.966500 |
| 2004 | 8826.576863 | 26308.815799 |
| 2005 | 9713.826255 | 30616.569637 |
| 2006 | 10252.894313 | 33189.382429 |
| 2007 | 10566.527362 | 34100.495064 |
| 2008 | 10580.520024 | 34052.276749 |
| 2009 | 10889.263592 | 33954.651792 |
| 2010 | 10977.017218 | 33884.236826 |
| 2011 | 11035.346176 | 32946.454471 |
| 2012 | 11562.836825 | 33150.706035 |
| 2013 | 11211.113491 | 32207.571607 |
| 2014 | 11227.354594 | 31517.346141 |
| 2015 | 11564.786088 | 31764.865490 |
| 2016 | 12193.026562 | 33186.064958 |
| 2017 | 12656.261666 | 34900.390499 |
| 2018 | 13180.171893 | 37805.202605 |
Let's see how it looks on a plot:
```
plt = df_crimes1.plot(xticks=df_crimes1.index, color=['g', 'olive'])
plt.set_xticklabels(df_fenc_agg.index, rotation='vertical')
plt.set_xlabel('')
plt.set_ylabel('Number of offenses\nper 1 mln. within race')
```
[](https://habrastorage.org/webt/c8/6n/xu/c86nxuwdqvodtjkpugnnknvkjpa.jpeg)
**Intermediate conclusions**:
> 1. Whites commit twice as many offenses as Blacks in absolute numbers, but three times as fewer in per capita numbers (per 1 million population within that race).
> 2. Criminality among Whites grows more or less steadily over the entire period of investigation (doubled over 19 years). Criminality among Blacks also grows, but by leaps and starts, showing steep growth from 2001 to 2006, then abating slightly over 2007 — 2016 and plummeting again after 2017. Over the entire period, however, the growth factor is also 2, like with Whites.
> 3. But for the period of decrease in 2007 — 2016, criminality among Blacks grows at a higher rate than that among Whites.
>
>
>
>
We can therefore answer our **second question**:
— ***Which race is statistically more prone to crime?***
— **Crimes committed by Blacks are three times more frequent than crimes committed by Whites.**
Criminality and Lethal Force Fatalities
---------------------------------------
We've now come to the most important part. Let's see if we can answer the third question: *Can one say the police kills in proportion to the number of crimes?*
The question boils down to looking at the correlation between our two datasets — use of force data (from the FENC database) and crime data (from the FBI database).
We start by routinely merging the two datasets into one:
```
# glue together the FENC and CRIMES dataframes
df_uof_crimes = df_fenc_agg.join(df_crimes1, lsuffix='_uof', rsuffix='_cr')
# we won't need the first 2 columns (absolute FENC values), so get rid of them
df_uof_crimes = df_uof_crimes.loc[:, 'White_pop':'Black_promln_cr']
```
The resulting combined data:
| | White\_pop | Black\_pop | White\_promln\_uof | Black\_promln\_uof | White\_promln\_cr | Black\_promln\_cr |
| --- | --- | --- | --- | --- | --- | --- |
| Year | | | | | | |
| 2000 | 218756353 | 35410436 | 1.330247 | 4.179559 | 6115.058976 | 17697.409882 |
| 2001 | 219843871 | 35758783 | 1.605685 | 4.418495 | 6829.701429 | 20431.707645 |
| 2002 | 220931389 | 36107130 | 1.643044 | 4.458953 | 7282.333249 | 20972.838329 |
| 2003 | 222018906 | 36455476 | 1.747599 | 4.910099 | 7857.691182 | 22218.966500 |
| 2004 | 223106424 | 36803823 | 1.949742 | 4.265861 | 8826.576863 | 26308.815799 |
| 2005 | 224193942 | 37152170 | 2.016112 | 4.871855 | 9713.826255 | 30616.569637 |
| 2006 | 225281460 | 37500517 | 2.041890 | 5.653255 | 10252.894313 | 33189.382429 |
| 2007 | 226368978 | 37848864 | 1.983487 | 5.786171 | 10566.527362 | 34100.495064 |
| 2008 | 227456495 | 38197211 | 1.943229 | 5.576323 | 10580.520024 | 34052.276749 |
| 2009 | 228544013 | 38545558 | 2.091501 | 6.459888 | 10889.263592 | 33954.651792 |
| 2010 | 229397472 | 38874625 | 2.205778 | 5.633495 | 10977.017218 | 33884.236826 |
| 2011 | 230838975 | 39189528 | 2.499578 | 7.399936 | 11035.346176 | 32946.454471 |
| 2012 | 231992377 | 39623138 | 2.724227 | 7.621809 | 11562.836825 | 33150.706035 |
| 2013 | 232969901 | 39919371 | 2.974633 | 7.765653 | 11211.113491 | 32207.571607 |
| 2014 | 233963128 | 40379066 | 3.009021 | 6.538041 | 11227.354594 | 31517.346141 |
| 2015 | 234940100 | 40695277 | 3.102919 | 6.683822 | 11564.786088 | 31764.865490 |
| 2016 | 234644039 | 40893369 | 3.081263 | 6.578084 | 12193.026562 | 33186.064958 |
| 2017 | 235507457 | 41393491 | 3.154889 | 6.401973 | 12656.261666 | 34900.390499 |
| 2018 | 236173020 | 41617764 | 3.281493 | 6.367473 | 13180.171893 | 37805.202605 |
Let me refresh you memory on the individual columns here:
1. **White\_pop** — White population
2. **Black\_pop** — Black population
3. **White\_promln\_uof** — White lethal force victims per 1 million Whites
4. **Black\_promln\_uof** — Black lethal force victims per 1 million Blacks
5. **White\_promln\_cr** — Number of crimes committed by Whites per 1 million Whites
6. **Black\_promln\_cr** — Number of crimes committed by Blacks per 1 million Blacks
We next want to see how the police victim and crime curves compare on one plot. For Whites:
```
plt = df_uof_crimes['White_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
plt.set_ylabel('Number of White offenses per 1 mln. within race')
plt2 = df_uof_crimes['White_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt2.set_ylabel('Number of White UOF victims per 1 mln. within race', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
```
[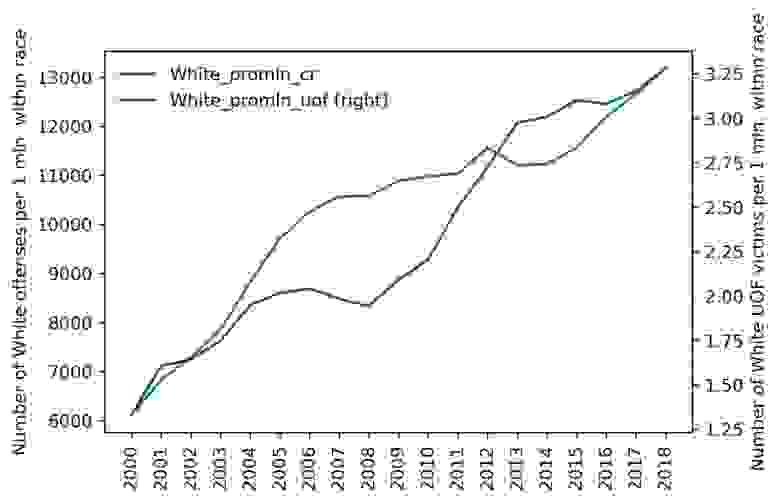](https://habrastorage.org/webt/cg/qy/bi/cgqybi1swb60nc9l20nyws-7au0.jpeg)
The same on a scatter plot:
```
plt = df_uof_crimes.plot.scatter(x='White_promln_cr', y='White_promln_uof')
plt.set_xlabel('Number of White offenses per 1 mln. within race')
plt.set_ylabel('Number of White UOF victims per 1 mln. within race')
```
[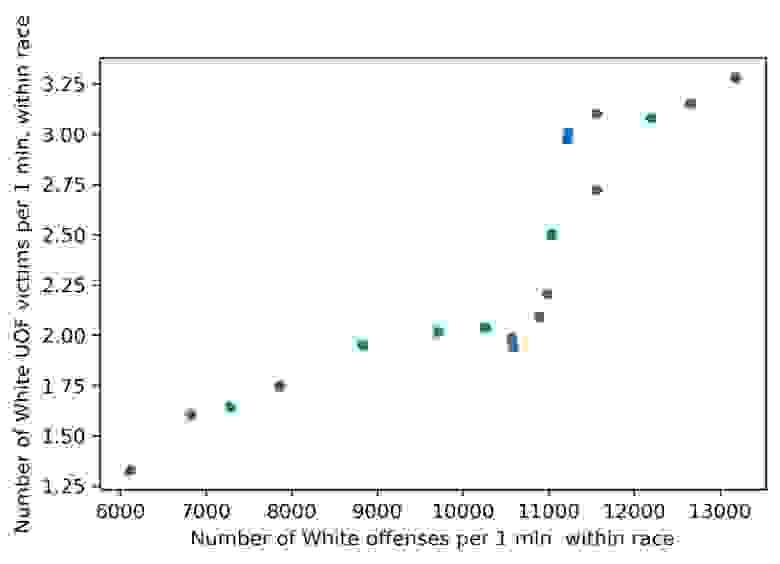](https://habrastorage.org/webt/mo/me/oi/momeoiwaxj_fqy4mzostuzvnons.jpeg)
A quick look at the graphs shows that some correlation is present. OK, now for Blacks:
```
plt = df_uof_crimes['Black_promln_cr'].plot(xticks=df_uof_crimes.index, legend=True)
plt.set_ylabel('Number of Black offenses per 1 mln. within race')
plt2 = df_uof_crimes['Black_promln_uof'].plot(xticks=df_uof_crimes.index, legend=True, secondary_y=True, style='g')
plt2.set_ylabel('Number of Black UOF victims per 1 mln. within race', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_uof_crimes.index, rotation='vertical')
```
[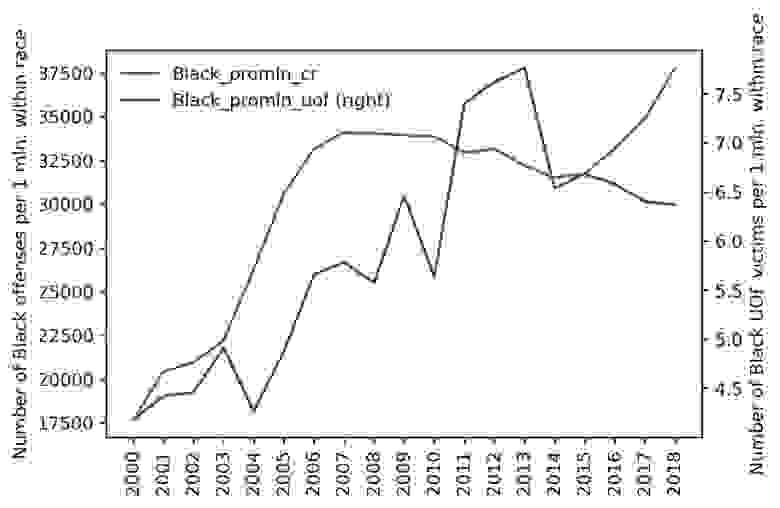](https://habrastorage.org/webt/8n/lo/pw/8nlopwra5t46nofeennonmaht1e.jpeg)
And on a scatter plot:
```
plt = df_uof_crimes.plot.scatter(x='Black_promln_cr', y='Black_promln_uof')
plt.set_xlabel('Number of Black offenses per 1 mln. within race')
plt.set_ylabel('Number of Black UOF victims per 1 mln. within race')
```
[](https://habrastorage.org/webt/p1/ux/wd/p1uxwdjmgslydeoxtsy5htak9zm.jpeg)
Things are much worse here: the two trends duck and bob a lot, though the principle correlation is still visible, the proportion is positive, if non-linear.
We will make use of statistical methods to quantify these correlations, making correlation matrices estimated with the [Pearson correlation coefficient](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient):
```
df_corr = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof',
'Black_promln_cr', 'Black_promln_uof']].corr(method='pearson')
df_corr.style.background_gradient(cmap='PuBu')
```
We get this table:
| | White\_promln\_cr | White\_promln\_uof | Black\_promln\_cr | Black\_promln\_uof |
| --- | --- | --- | --- | --- |
| White\_promln\_cr | 1.000000 | 0.885470 | 0.949909 | 0.802529 |
| White\_promln\_uof | **0.885470** | 1.000000 | 0.710052 | 0.795486 |
| Black\_promln\_cr | 0.949909 | 0.710052 | 1.000000 | **0.722170** |
| Black\_promln\_uof | 0.802529 | 0.795486 | 0.722170 | 1.000000 |
The correlation coefficients for both races are in bold: it is **0.885** for Whites and **0.722** for Blacks. Thus a positive correlation between lethal force victims and criminality is observed for both races, but it is more prominent for Whites (probably significant) and nears non-significant for Blacks. The latter result is, of course, due to the higher data heterogeneity (scatter) for Black crimes and police victims.
As a final step, let's try to estimate the probability of Black and White offenders to get shot by the police. We have no direct ways to do that, since we don't have information on the criminality of the lethal force victims (who of them was found to be an offender and who was judicially clear). So we can only take the easy path and divide the per capita victim counts by the per capita crime counts for each race and multiply by 100 to show percentage values.
```
# let's look at the aggregate data (with individual year observations collapsed)
df_uof_crimes_agg = df_uof_crimes.loc[:, ['White_promln_cr', 'White_promln_uof',
'Black_promln_cr', 'Black_promln_uof']].agg(['mean', 'sum', 'min', 'max'])
# now calculate the percentage of fatal encounters from the total crime count in each race
df_uof_crimes_agg['White_uof_cr'] = df_uof_crimes_agg['White_promln_uof'] * 100. /
df_uof_crimes_agg['White_promln_cr']
df_uof_crimes_agg['Black_uof_cr'] = df_uof_crimes_agg['Black_promln_uof'] * 100. /
df_uof_crimes_agg['Black_promln_cr']
```
We get this table:
| | White\_promln\_cr | White\_promln\_uof | Black\_promln\_cr | Black\_promln\_uof | White\_uof\_cr | Black\_uof\_cr |
| --- | --- | --- | --- | --- | --- | --- |
| mean | 10238.016198 | 2.336123 | 30258.208024 | 5.872145 | **0.022818** | **0.019407** |
| sum | 194522.307758 | 44.386338 | 574905.952459 | 111.570747 | 0.022818 | 0.019407 |
| min | 6115.058976 | 1.330247 | 17697.409882 | 4.179559 | 0.021754 | 0.023617 |
| max | 13180.171893 | 3.281493 | 37805.202605 | 7.765653 | 0.024897 | 0.020541 |
Let's show the means (in bold above) as a bar chart:
```
plt = df_uof_crimes_agg.loc['mean', ['White_uof_cr', 'Black_uof_cr']].plot.bar(color=['g', 'olive'])
plt.set_ylabel('Ratio of UOF victims to offense count')
plt.set_xticklabels(['White', 'Black'], rotation=0)
```
[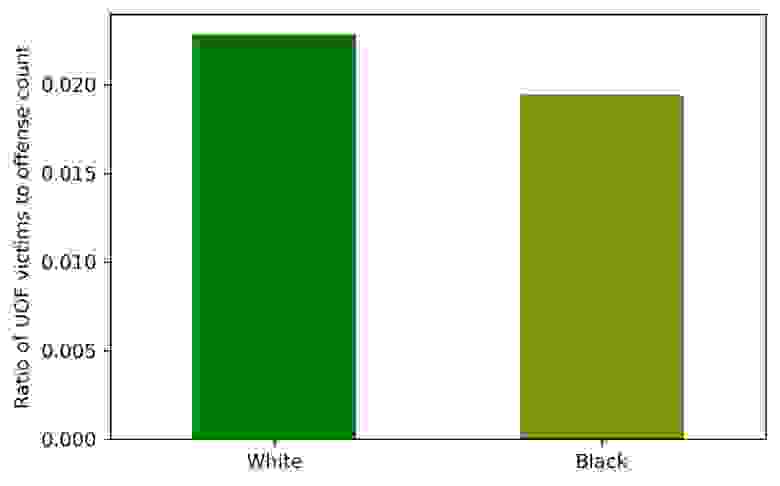](https://habrastorage.org/webt/hd/5-/zv/hd5-zv09i0hrarnffxhubplhmtm.jpeg)
Looking at this chart, you can see that the probability of a White offender to be shot dead by the police is somewhat higher than that of a Black offender. This estimate is certainly quite tentative, but it can give at least some idea.
**Intermediate conclusions**:
> 1. Fatal encounters with law enforcement *are connected* with criminality (number of offenses committed). The correlation though differs between the two races: for Whites, it is almost perfect, for Blacks — far from perfect.
> 2. Looking at the combined police victim / crime charts, it becomes obvious that lethal force victims grow 'in reply to' criminality growth, generally with a few years' lag (this is more conspicuous in the Black data). This phenomenon chimes in with the reasonable notion that the authorities 'react' on criminality (more crimes > more impunity > more closeups with law enforcement > more lethal outcomes).
> 3. White offenders tend to meet death from the police more frequently than Black offenders, although the difference is almost negligible.
>
>
>
>
Finally, the answer to our **third question**:
— ***Can one say the police kills in proportion to the number of crimes?***
— **Yes, this proportion can be observed, though different between the two races: for Whites, it is almost perfect, for Blacks — far from perfect.**
**In the [next (and final) part of the narrative](https://habr.com/ru/post/519640/), we will look into the geographical distribution of the analyzed data across the states.**
|
https://habr.com/ru/post/519484/
| null | null | 4,046
| 60.31
|
Occasionally, usually when setting up a new C++ project, I see this error from IntelliSense and the C++ compiler: cannot open source file "_config-eccp.h" (dependency of "Mstn/MdlApi/MdlApi.h"). It's sole mention is in include file _config.h...
cannot open source file "_config-eccp.h" (dependency of "Mstn/MdlApi/MdlApi.h")
_config.h
#if defined (__EDG__) \
&& !defined (__DECCXX) \
&& !defined (__HP_aCC) \
&& !defined (__INTEL_COMPILER) \
&& !defined (_SGI_COMPILER_VERSION)
// FIXME: make this more robust by detecting the EDG eccp demo
// during library configuration (and avoid relying on compiler
// specific macros)
# include "_config-eccp.h"
#endif // __EDG__
IntelliSense is correct: file _config-eccp.h is not part of the SDK: it doesn't exist.
_config-eccp.h
Presumably something (the VC++ compiler?) is defining macro __EDG__, but those other macros are all undefined. Judging by the comment, someone in Bentley Systems development planned to do something about this, but hasn't yet got around to it.
__EDG__
What can I do to suppress that message? Is it safe simply to #undefine __EDG__?
#undefine __EDG__
Hi Jon Summers,
Though not ideal, if you have an application/common library header, then you can include this there or directly in your .cpp file having issue. As Jan mentions, I am looking into improving the MicroStation SDK by eventually removing the 8DOT3 name requirements that are known to cause issues with IntelliSense. If this issue is not resolved by those changes, then a separate defect will be filed to address this issue as well.
// Need to undefine __EDG__ to work-around intellisense error
// Prevents config-eccp.h error
#ifdef __EDG__
#undef __EDG__
#endif
HTH,Bob
Robert Hook said: if you have an application/common library header, then you can include this
#ifdef __EDG__
#undef __EDG__
#endif
Yes, that's the conclusion I reached.
Robert Hook said:If this issue is not resolved by those changes, then a separate defect will be filed to address this issue as well
I don't see a connection with 8DOT3 file naming. The file _config-eccp.h simply doesn't exist in the delivered include folders...
Directory of C:\PROGRA~1\Bentley\MICROS~1\SDK\include\Bentley\stdcxx\rw
27/11/2020 06:59 9,921 _config-gcc.h
27/11/2020 06:59 5,678 _config-msvc.h
27/11/2020 06:59 6,360 _config-msvcrt.h
27/11/2020 06:59 19,322 _config.h
With a certain combination of preprocessor macros, the include logic attempts to read that non-existent file.
Robert Hook said: in your .cpp file having issue
It occurs with #include <Mstn/MdlApi/MdlApi.h>. That file is commonly used as the first header in any C++ project.
#include <Mstn/MdlApi/MdlApi.h>
Regards, Jon Summers LA Solutions
so in order to get rid of the pesky _config-eccp.h error, what I do is undefine the __EDG__ macro?
I have one project that runs fine with nmake set with bmake project_name.
When I try to do it with a Bentley example, it just pop up with the error. But if I just bmake the two, both compile without problem.
Hi amender,
please respect the rules and do not steal existing (and nearly a year old) discussion with own new question. Ask in a new post and specify you environment (SDK version, VS version...).
amender carapace said:so in order to get rid of the pesky _config-eccp.h error, what I do is undefine the __EDG__ macro?
I do not understand what your question is: Did you try solution provided by Bob Hook and verified by Jon, and it does not work?
amender carapace said:When I try to do it with a Bentley example
What is "Bentley example"?
amender carapace said:But if I just bmake the two, both compile without problem.
What is "the two" and "both"?
Regards,
Jan
Bentley Accredited Developer: iTwin Platform - AssociateLabyrinth Technology | dev.notes() | cad.point
|
https://communities.bentley.com/products/programming/microstation_programming/f/microstation-programming---forum/211476/connect-c-_config-eccp-h/692951
|
CC-MAIN-2022-27
|
refinedweb
| 650
| 58.69
|
Hi all,
I have encountered a weird behaviour of Xerces 1.3.1 validating with one of
my schemas.
Basically, I have the definition of my attributes and attributeGroups in
another namespace which I import in the main schema.
It seems that having one globally declared attribute and an attribute
inside a group with the same name creates the problem, after which the
validator doesn't handle anything.
I have attached a test case I made to illustrate this.
Is there something I'm doing wrong ?
Thanx
--
Etienne
infos: using Xerces 1.3.1
java version 1.3.0
sax.SAXCount -v
(See attached file: attrbs.xsd)(See attached file: test.xml)(See attached
file: test.xsd)
|
http://mail-archives.apache.org/mod_mbox/xml-general/200105.mbox/%3COFD457655F.69DFAECF-ON85256A4F.006EDFD2@pok.ibm.com%3E
|
CC-MAIN-2015-22
|
refinedweb
| 117
| 70.39
|
25 June 2009 10:06 [Source: ICIS news]
LONDON (ICIS news)--BASF plans to close an 80,000 tonne/year polystyrene plant at its site in Ludwigshafen, Germany, due to poor market conditions for the product, the chemicals major said on Thursday.
BASF said it had been hit by decreased demand for PS and the affected plant had been out of operation since mid-April.
Effective 30 June, the closure would reduce BASF’s total European PS capacity by about 15% to 540,000 tonnes/year.
“We are working intensively to restructure our styrenics business and increase its profitability,” said head of the styrenics unit Joachim Streu.
“In doing so, we are investigating all options in order to strengthen the business on a sustainable basis. This also includes reducing production capacities. We nevertheless still intend to sell this business,” he added.
The plant was set to be dismantled, with personnel working at the plant transferred to other positions within the company.
Customers previously buying PS from ?xml:namespace>
Remaining PS production at the German site would be used internally to produce branded
|
http://www.icis.com/Articles/2009/06/25/9227352/basf-to-close-ludwigshafen-ps-plant-due-to-weak-demand.html
|
CC-MAIN-2015-18
|
refinedweb
| 182
| 53.92
|
I find it interesting that even after working on .NET code for years, I still keep evolving my usage of the platform and style. Today's post is an example of such a thing.
Hopefully you already know about the Debug.Assert API. This allows you to make assertions about how your code behaves, and works only on debug builds (technically, on any build that defines DEBUG). On release builds, this call (and the calls used to build up its arguments) are compiled out of the binary.
This means, for example, that it's appropriate to use it to check locally what has already been checked elsewhere, but it shouldn't be used to check parameters on public method - you'd want a real check with an exception thrown for the latter case.
One of the overloads for the Assert method takes the condition to be asserted and a message to output. A good message is very useful, as it helps you to track down exactly what went wrong.
Typically I start my assertion messages with the condition, especially for something simple. Here's an example.
public void Foo(string text) {
if (text == null) throw new ArgumentNullException("text"); // remember this is public!
InternalFoo(text);
}
private void InternalFoo(string text) {
Debug.Assert(text != null, "text != null");
Console.WriteLine("Value: " + text);
}
This example shows that for simple parameter checks, the assertion text is probably enough. If the assertion fires, you'll get a stack trace leading to the method with the assertion, and the message identifying which parameter failed.
For non-trivial cases (pretty much anything that isn't a direct fault of the caller with a bad argument), I like to include a short explanation that gives an idea of (a) why I think the check should be an assertion rather than a runtime check, and (b) who is to blame.
A classis non-trivial example is when a value is captured in one method but used in another. For example, let's say we have a Foo class that can write its argument to the console, but takes the argument in the constructor. Here's how we might code it.
public class Foo {
private readonly string textField;
public Foo(string text) {
if (text == null) throw new ArgumentNullException("text");
this.textField = text;
}
public void WriteItOut() {
Debug.Assert(this.fieldText != null, "this.fieldText != null -- otherwise .ctor should have thrown an exception");
Console.WriteLine("Value: " + this.fieldText);
}
}
This is the typical format I'll use - first the assertion code, then a little separator and an "otherwise" explanation, pointing to who I think should have checked this before. Of course this isn't infallible - for example, if textField later changes to not being readonly and a different method changes the field to null after the constructor has run, then the assertion might be misleading. But in general (more so the more consistent you are in validation designs), the assertion message is a very good hint, one that may often save you from even having to fire a debugger to figure out where your bug is.
Enjoy!
Good post. Now I always ponder if the comment on the assertion should be for the true or false sides of the assertion. For example in your sample you could also write it as:
Debug.Assert(this.fieldText != null, "this.fieldText is null and we need it to print it to the console — someone may have changed it after the ctor");
I guess the thinking on this is that when you (or someone else that uses the code) sees the assertion poping, the message tells him what actually failed.
Thoughts?
Jaime
Jaime, I always pondered the same thing, until I came up with these rules:
(1) The text of the assertion is the actual code of the assertion, followed by ‘ — ‘ and an explanation of who/what is to blame otherwise.
(2) OR, the text of the assertion is completely free-form English and then it better be non-ambiguous about what failed.
Your snippet is a great example of (2), although I typically reserve it for complicated/obscure expressions.
Great post. Actually, the Debug.Assert implementation covers the case of Marcelo and the point brought up by Jaime. Just use the following overload:
Debug.Assert(Boolean, String, String)
The last string parameter is your detail message, so for instance you might have:
// reactive assert
Debug.Assert(segment != null, "segment == null", "Calling public method is expected to fail.");
// proactive assert
Debug.Assert(member != null, "member == null", "GetCustomAttribute will fail with ArgumentNullException.");
You’ve been kicked (a good thing) – Trackback from DotNetKicks.com
|
https://blogs.msdn.microsoft.com/marcelolr/2008/10/24/writing-a-good-debug-assert/
|
CC-MAIN-2018-30
|
refinedweb
| 763
| 61.36
|
.
React Native is a framework to build native apps using only Javascript.
For the Javascript fan I am, it’s a great opportunity.
React Native builds native apps, and not hybrid apps or «HTML5» apps.
This is possible because the Javascript written is transformed into native UI blocks for Android or iOS.
I suggest you check React Native’s official website for more information.
Let’s jump into building our first mobile app.
The first step is installing React Native :)
I won’t pretend explaining this better than what has already been done in the last few months.
However, I have a few suggestions and links to share.
To install the CLI tools for React Native, you’ll need Node.js (Node.js 6 works fine, I haven’t tested other versions but React Native should work with Node.js 4 or newer).
Then you can just run
npm install -g react-native-cli to install React Native.
In order to develop an iOS app, you’ll need a Mac with xCode (you can find it on the AppStore).
If you are using Linux, a great article has been published to help you develop iOS app on Linux.
XCode comes up with a simulator, which we will use for development.
Testing you application on an Android device is a bit tougher.
The best practices are described on React Native’s website.
Here are the main points:
Set up paths
export ANDROID_HOME=~/Android/Sdk export PATH=${PATH}:${ANDROID_HOME}/tools
Set up Android Virtual Device (if not set up by Android Studio)
android avd
Everything in this article is summed up in this Github repository.
To create a React Native App run:
react-native init <YourAppNameHere>
Then launch it on the simulator you want with :
react-native run-ios react-native run-android
You should see the following screen on your emulator:
Let’s enter the fun part!
Creating our first cross platform mobile app!
Open you favorite editor and let’s take a look at what React Native generated for us.
The whole code for this article is available here.
We have two files that represent our two entry points: one for iOS (
index.ios.js) and one for Android (
index.android.js).
Let’s play with the
index.ios.js and change the text and style.
<Text style={styles.welcome}> Our first React Native App </Text>
You can see the changes in your emulator by pressing Ctrl+R or Cmd+R thanks to some live reloading.
This makes React Native development so much easier.
The sample app gives us an example of how the styling works in React Native.
const styles = StyleSheet.create({ container: { flex: 1, justifyContent: 'center', alignItems: 'center', backgroundColor: '#F5FCFF', }, });
There are two key points to have in mind when developing in React Native.
background-color=>
backgroundColor
border-width=>
borderWidth
You can find a list of components to use in React Native on their official website.
For our demo app, we’ll use the navigation component given to us by RN :
Navigator
Let’s create a src folder where the components inside will be used by both our Android and iOS app.
Inside our src folder, let’s create a components folder and inside it two JS files :
firstPage.js and
secondPage.js
firstPage.js
import React, {Component} from 'react'; import { StyleSheet, Text, TouchableHighlight, View } from 'react-native'; import SecondPage from './secondPage'; class FirstPage extends Component { static route(props) { return { id: 'FirstPage', component: FirstPage }; } render() { return ( <View style={styles.container}> <Text>This is the first view</Text> <TouchableHighlight onPress={() => this.props.navigator.push(SecondPage.route())}</TouchableHighlight> </View> ); } } const styles = StyleSheet.create({ container: { flex: 1, justifyContent: 'center', alignItems: 'center', backgroundColor: '#FF00FF', }, }); export default FirstPage;
secondPage.js
import React, {Component} from 'react'; import { StyleSheet, Text, View } from 'react-native'; class SecondPage extends Component { static route(props) { return { id: 'FirstPage', component: SecondPage }; } render() { return ( <View style={styles.container}> <Text>This is the second view</Text> </View> ); } } const styles = StyleSheet.create({ container: { flex: 1, justifyContent: 'center', alignItems: 'center', backgroundColor: '#FFFF00', }, }); export default SecondPage;
In the FirstPage component, our button is a
TouchableHighlight and it has a
onPress method that pushes the second view.
Our second page component just has a text.
We then need to set up our Navigator to go back and forth from one page to the other.
First, in our
index.ios.js, let’s remove what’s in the container View and add a Navigator:
index.ios.js
render() { return ( <View style={styles.container}> <Navigator initialRoute={FirstPage.route()} renderScene={this.renderScene} style={styles.navigator} /> </View> ); }
Let’s analyze these lines.
What should our
renderScene do?
Well, it should render our component.
Let’s see how to write this:
index.ios.js
renderScene = (route, navigator) => { return React.createElement(route.component, {navigator: navigator}); }
Our
renderScene method takes two arguments.
The first one is the component we want to mount and the second one is the navigator itself.
We’ll need to pass the navigator to our components as a prop to be able to navigate back and forth.
FirstComponent
static route(props) { return { id: 'FirstPage', component: FirstPage }; }
Let’s run our app… Here is how it should look.
First Screen
Second Screen
Now, there’s something missing here.
Indeed, when navigating in an app, we’re expecting a Navbar on the top to navigate!
Navigator has a way of doing this.
You can pass a component written by your hands to it and it will display it as a Navbar.
However, react native being an open source project, the community has developed a lot of packages for us to use.
In this repository, you’ll find a non-exhaustive list of great packages.
Here, we’ll be using the package React Native Navbar.
Let’s install it.
npm i --save react-native-navbar
Then, let’s import it in our two views.
import NavBar from 'react-native-navbar';
FirstComponent
render() { const titleConfig = { title: 'First Component', }; return ( <View style={styles.container}> <NavBar title={titleConfig} /> <View style={styles.content}> <Text>This is the first view</Text> <TouchableHighlight onPress={() => this.props.navigator.push(SecondPage.route())} style={styles.button}> <Text>Go to second view</Text> </TouchableHighlight> </View> </View> ); }
SecondComponent
render() { const titleConfig = { title: 'Second Component', }; const leftButtonConfig = { title: 'Previous', handler: () => this.props.navigator.pop(), } return ( <View style={styles.container}> <NavBar title={titleConfig} leftButton={leftButtonConfig} /> <View style={styles.content}> <Text>This is the second view</Text> </View> </View> ); }
In order for our components to render as we expect them to, we need to change a bit our components’ styles.
container: { flex: 1 }, content: { flex: 1, backgroundColor: '#FFFF00', justifyContent: 'center', alignItems: 'center' }
Here is what we have now!
We now have a fully functional React Native app.
Of course, it doesn’t do much yet but I’m sure you’ll be able to build on this.
To go further in building apps, the next good thing to take a look at is redux.
Web Developer at Theodo
|
https://blog.theodo.com/2016/12/bootstrap-a-cross-platform-app-in-10-minutes-with-react-native/
|
CC-MAIN-2020-29
|
refinedweb
| 1,152
| 58.38
|
tweaking with HTML tags. Were these editors developed by incompetent beginners? No, they were designed by very skillful people, but the HTML language is not up to the task. And that is not all. The data exchange between the server and the client is ultimately primitive. There are no common objects. Even with ASP.NET, the situation has not improved much. Unfortunately, the model can not be changed instantly. We have to live with it for a few more years, and this article is about how some internet data exchange problems can be solved.
Would it be nice to program the client the same way
The first logical step is to create the data structures that will serve our needs.
public class EmployeeAddress
{
public string City;
public string Country;
public string Street;
public string Phone;
public ArrayList PhotoAlbum = new ArrayList();
}
public class Employee
{
public long somelong = 8598065;
public double Salary = 787878.344;
public float Scale = 8.66F;
public string Name;
public string SName;
public string Title;
public string Position;
public int Age;
public DateTime Date;
public string PictureUrl;
public EmployeeAddress Address;
public bool Married = true;
public ArrayList SomeDataCollection;
public Employee
{
Address = new EmployeeAddress();
}
}
Note that the instance of the EmployeeAddress class is the member of the Employee class. Actually, the depth of the nested classes is not limited. We create the instances of Employee(s) and initialize them.
EmployeeAddress
Employee
ArrayList MyEmployees = new ArrayList();
Employee emp = new Employee()
emp1.Name = "Bob";
emp1.SName = "Smith";
emp1.Title = "Mr";
emp1.Position = "waiter";
emp1.Date = new DateTime(2003, 2, 6);
emp1.Address.City = "London";
emp1.Address.Phone = "(043)8984 63535";
emp1.Age = 33;
emp1.PictureUrl = "BobSmith.jpg";
//add employee to ArrayList
MyEmployees.Add(emp);
//....then create more employees and also add them to ArrayList
MyEmployees.Add(emp1);
After that, we a JavaScript class ArrayList.
var EmployeesArrList = _Get("MyObjectKey");
Get the first employee:
var emp = EmployeesArrList.GetAt(0);
alert(emp.SName + ", " + emp.Name + "," + emp.Title + "," +
emp.Position + "," + emp.Address.Street);
Same with other employees.
The employees in the collection can be modified and sent back to the server via the traditional Postback or [and] AJAX. You can invoke the method on the server with EmployeesArrList (or another class) as the parameter as well.
EmployeesArrList
var Params = new Array();
Params.push(EmployeesArrList );
var Ret = r.Invoke("ReadEmployeesMethod", Params);
You can create the instance of the Employee(s) and initialize it:
var Emp1 = new Employee ();
Emp1.Name = "Peter";
Emp1.Age = 20;
And so on ... Add this employee to the collection.
The business objects on the server are initialized and then serialized to XML format. Then, this code is injected into the HTML page body and sent to the client for rendering. The data is kept in the hidden field. The serialized data is deserilized on the client into the collection of JavaScript objects when the page is loaded.
Now that we have the data from the server in the form of JavaScript objects, like the Employee object, we can change the fields of these classes.
emp.Position = "waiter";
The next logical step is sending the objects back to the server. This can be done in two ways: Postback and AJAX. The updating of the server objects only requires calling the method.
_Put("MyEmployeesArr", EmpArrList);
before the Postback takes place. of Employee(s) and initialize it:
var Emp1 = new Employee ();
Emp1.Name = "Peter";
Emp1.Age = 20; //..... And so on ...
Add this employee to the collection:
var EmpCollection = new ArrayList();
EmpCollection.Add(Emp1);
Add other employees and send this collection to the server [Postback/AJAX].
private void l_PostBackDataReceivedEvent(object obj)
{
Hashtable ht = (Hashtable)obj;
// all objects on the client are packed to hashtable when PostBack is used
ArrayList emps = (ArrayList)ht["MyEmployeesArr"];
Convertor.RegisterObject("MyEmployeesArr", emps);
}.
|
https://www.codeproject.com/articles/13810/generic-data-exchange-framework-with-ajax?fid=293422&df=90&mpp=10&sort=position&spc=none&select=2469312&tid=2468872
|
CC-MAIN-2017-09
|
refinedweb
| 618
| 52.15
|
Posted 07 Jul 2016
Link to this post
Hi,
I have a problem with kendo. Yesterday I've installed Kendo.MVC library from NuGet pagckages, do all the configurations established in the web regarding Kendo and Razor, and it just don seem to work.
Web.Config configuration:
" />
<add namespace="Kendo.Mvc.UI" />
<add namespace="FNASystem" />
</namespaces>
</pages>
</system.web.webPages.razor>
In the index.cshtml file:
@(Html.Kendo().Menu()
.SecurityTrimming(false)
)
All the documentation that I found said that this should work, but the Kendo() function appears underline in red and with an error message that said "HtmlHelper<dynamic> does not contains a definition for 'Kendo' are you missing a using directive or a reference?", so, I do this In the index.cshtml file:
@using Kendo.Mvc.UI
But the @using Kendo.Mvc.UI part said "the using directive is not necesary, it previously appears in this namespace."
So, can yo help me with this issue?
Best regards
|
http://www.telerik.com/forums/kendo-is-not-working
|
CC-MAIN-2017-13
|
refinedweb
| 158
| 60.72
|
import "go/doc"
Package doc extracts source code documentation from a Go AST.
var IllegalPrefixes = []string{ "copyright", "all rights", "author", }
func IsPredeclared(s string) bool
IsPredeclared reports whether s is a predeclared identifier.
func Synopsis(s string) string.
func ToHTML(w io.Writer, text string, words map[string). source files.
func Examples(files ...*ast.File) []*Example
Examples returns the examples found in the files, sorted by Name field. The Order fields record the order in which the examples were encountered.. )
type Note struct { Pos, End token.Pos // position range of the comment containing the marker UID string // uid found with the marker Body string // note body text }
A.
type Package struct { Doc string Name string ImportPath string Imports []string Filenames []string Notes map[string][]*Note // Deprecated: For backward compatibility Bugs is still populated, // but all new code should use Notes instead. Bugs []string // declarations Consts []*Value Types []*Type Vars []*Value Funcs []*Func } }
Type is the documentation for a type declaration.
type Value struct { Doc string Names []string // var or const names in declaration order Decl *ast.GenDecl // contains filtered or unexported fields }
Value is the documentation for a (possibly grouped) var or const declaration.
|
https://static-hotlinks.digitalstatic.net/go/doc/
|
CC-MAIN-2018-51
|
refinedweb
| 194
| 57.27
|
utime, utimes - change access and/or modification times of an inode
#include <sys/types.h>
#include <utime.h>
int utime(const char *filename, const struct utimbuf *buf);
#include <sys/time.h>
int utimes(const char *filename, const struct timeval times[2]);
int utime(const char *filename, const struct utimbuf *buf);
#include <sys/time.h>
int utimes(const char *filename, const struct timeval times[2]); must is NULL and the process has write permission to the file.
The utimbuf structure */
};
On success, zero is returned. On error, -1 is returned, and
errno is set appropriately.().
Linux is not careful to distinguish between the EACCES and EPERM error returns.
On the other hand, POSIX.1-2001 is buggy in its error description for
utimes().
utime(): SVr4, POSIX.1-2001.
utimes(): 4.3BSD
chattr (1)
futimesat (2)
stat (2)
Advertisements
|
http://www.tutorialspoint.com/unix_system_calls/utimes.htm
|
CC-MAIN-2014-15
|
refinedweb
| 137
| 69.99
|
6.1. Functions¶
In Python, a function is a named sequence of statements that belong together. Their primary purpose is to help us organize programs into chunks that match how we think about the solution to the problem.
The syntax for a function definition is:
def name( parameters ): statements
You can make up any names you want for the functions you create, except that you can’t use a name that is a Python keyword, and the names must follow the rules for legal identifiers that were given previously. The parameters specify what information, if any, you have to provide in order to use the new function. Another way to say this is that the parameters specify what the function needs to do its work.:
- A header line which begins with a keyword and ends with a colon.
- A body consisting of one or more Python statements, each indented the same amount – 4 spaces is the Python standard – from the header line.
We’ve already seen the
for loop which follows this pattern.
In.
We need to say a bit more about the parameters. In the definition, the parameter list is more specifically known as the formal parameters. This list of names describes those things that the function will need to receive from the user of the function. When you use a function, you provide values to the formal parameters.
The figure below shows this relationship. A function needs certain information to do its work. These values, often called arguments or actual parameters, are passed to the function by the user.
This type of diagram is often called a black-box diagram because it only states the requirements from the perspective of the user. The user must know the name of the function and what arguments need to be passed. The details of how the function works are hidden inside the “black-box”.
Suppose we’re working with turtles and a common operation we need is to draw squares. It would make sense if we did not have to duplicate all the steps each time we want to make a square. “Draw a square” can be thought of as an abstraction of a number of smaller steps. We will need to provide two pieces of information for the function to do its work: a turtle to do the drawing and a size for the side of the square. We could represent this using the following black-box diagram.
Here is a program containing a function to capture this idea. Give it a try.
This function is named
drawSquare. It has two parameters — one to tell
the function which turtle to move around and the other to tell it the size
of the square we want drawn. In the function definition they are called
t and
sz respectively. Make sure you know where the body of the function
ends — it depends on the indentation and the blank lines don’t count for
this purpose!
docstrings
If the first thing after the function header is a string (some tools insist that it must be a triple-quoted string), it is called a docstring and gets special treatment in Python and in some of the programming tools.
Another way to retrieve this information is to use the interactive
interpreter, and enter the expression
<function_name>.__doc__, which will retrieve the
docstring for the function. So the string you write as documentation at the start of a function is
retrievable by python tools at runtime. This is different from comments in your code,
which are completely eliminated when the program is parsed.
By convention, Python programmers use docstrings for the key documentation of their functions.
Defining a new function does not make the function run. To do that we need a
function call. This is also known as a function invocation. We’ve already seen how to call some built-in functions like
range and
int. Function calls contain the name of the function to be
executed followed by a list of values, called arguments, which are assigned
to the parameters in the function definition. So in the second to the last line of
the program, we call the function, and pass
alex as the turtle to be manipulated,
and 50 as the size of the square we want.
Once we’ve defined a function, we can call it as often as we like and its
statements will be executed each time we call it. In this case, we could use it to get
one of our turtles to draw a square and then we can move the turtle and have it draw a different square in a
different location. Note that we lift the tail so that when
alex moves there is no trace. We put the tail
back down before drawing the next square. Make sure you can identify both invocations of the
drawSquare function.
In the next example, we’ve changed the
drawSquare
function a little and we get
tess to draw 15 squares with some variations. Once the function has
been defined, we can call it as many times as we like with whatever actual parameters we like.
Note
This workspace is provided for your convenience. You can use this activecode window to try out anything you like.
Check your understanding
func-1-1: What is a function in Python?
- (A) A named sequence of statements.
- Yes, a function is a named sequence of statements.
- (B) Any sequence of statements.
- While functions contain sequences of statements, not all sequences of statements are considered functions.
- (C) A mathematical expression that calculates a value.
- While some functions do calculate values, the python idea of a function is slightly different from the mathematical idea of a function in that not all functions calculate values. Consider, for example, the turtle functions in this section. They made the turtle draw a specific shape, rather than calculating a value.
- (D) A statement of the form x = 5 + 4.
- This statement is called an assignment statement. It assigns the value on the right (9), to the name on the left (x).
func-1-2: What is one main purpose of a function?
- (A) To improve the speed of execution
- Functions have little effect on how fast the program runs.
- (B) To help the programmer organize programs into chunks that match how they think about the solution to the problem.
- While functions are not required, they help the programmer better think about the solution by organizing pieces of the solution into logical chunks that can be reused.
- (C) All Python programs must be written using functions
- In the first several chapters, you have seen many examples of Python programs written without the use of functions. While writing and using functions is desirable and essential for good programming style as your programs get longer, it is not required.
- (D) To calculate values.
- Not all functions calculate values.
func-1-3: Which of the following is a valid function header (first line of a function definition)?
- (A) def drawCircle(t):
- A function may take zero or more parameters. It does not have to have two. In this case the size of the circle might be specified in the body of the function.
- (B) def drawCircle:
- A function needs to specify its parameters in its header.
- (C) drawCircle(t, sz):
- A function definition needs to include the keyword def.
- (D) def drawCircle(t, sz)
- A function definition header must end in a colon (:).
- (A) def drawSquare(t, sz)
- This line is the complete function header (except for the semi-colon) which includes the name as well as several other components.
- (B) drawSquare
- Yes, the name of the function is given after the keyword def and before the list of parameters.
- (C) drawSquare(t, sz)
- This includes the function name and its parameters
- (D) Make turtle t draw a square with side sz.
- This is a comment stating what the function does.
func-1-4: What is the name of the following function?
def drawSquare(t, sz): """Make turtle t draw a square of with side sz.""" for i in range(4): t.forward(sz) t.left(90)
- (A) i
- i is a variable used inside of the function, but not a parameter, which is passed in to the function.
- (B) t
- t is only one of the parameters to this function.
- (C) t, sz
- Yes, the function specifies two parameters: t and sz.
- (D) t, sz, i
- the parameters include only those variables whose values that the function expects to receive as input. They are specified in the header of the function.
func-1-5: What are the parameters of the following function?
def drawSquare(t, sz): """Make turtle t draw a square of with side sz.""" for i in range(4): t.forward(sz) t.left(90)
- (A) def drawSquare(t, sz)
- No, t and sz are the names of the formal parameters to this function. When the function is called, it requires actual values to be passed in.
- (B) drawSquare
- A function call always requires parentheses after the name of the function.
- (C) drawSquare(10)
- This function takes two parameters (arguments)
- (D) drawSquare(alex, 10):
- A colon is only required in a function definition. It will cause an error with a function call.
- (E) drawSquare(alex, 10)
- Since alex was already previously defined and 10 is a value, we have passed in two correct values for this function.
func-1-6: Considering the function below, which of the following statements correctly invokes, or calls, this function (i.e., causes it to run)? Assume we already have a turtle named alex.
def drawSquare(t, sz): """Make turtle t draw a square of with side sz.""" for i in range(4): t.forward(sz) t.left(90)
func-1-7: True or false: A function can be called several times by placing a function call in the body of a loop.
- (A) True
- Yes, you can call a function multiple times by putting the call in a loop.
- (B) False
- One of the purposes of a function is to allow you to call it more than once. Placing it in a loop allows it to executed multiple times as the body of the loop runs multiple times.
|
http://interactivepython.org/runestone/static/thinkcspy/Functions/functions.html
|
CC-MAIN-2017-22
|
refinedweb
| 1,705
| 72.76
|
HTML is, so let me just touch upon that as well.
also read:
JavaFX is the RIA platform envisaged by Sun Microsystems as the next UI toolkit for Java, as Swing has been around for a long time and has started to age. The initiative was good, but was not rightly implemented. The JavaFX 1, 1.2, 1.3 or in general anything before 2.0 is no longer supported. Pre JavaFX 2.0 one had to use JavaFX Script to create the applications and these could invoke the Java API. But learning a new language altogether was not appealing for a Java developer as one couldn’t easily use with existing Java code base. In 2.0 the JavaFX Script was totally removed to make way for the Java based api for creating JavaFX components. Once you have setup the JavaFX SDK, you get to use the JavaFX specific API in the javafx.* packages. There are lot of cool things underneath the JavaFX platform, but that’s out of the scope of this article.
Coming back to our main focus, JavaFX provides a component called WebView which with the help of WebEngine can be used to load web pages along with constructing the DOM and running the required JavaScript. But that’s a JavaFX component. How is it going to help us in our Swing application? Exactly, JavaFX provides another component called JFXPanel which can be used to embed JavaFX components into Swing applications and in turn the JFXPanel is added to our JFrame or other Swing containers.
JFrame myFrame = new JFrame(); JFXPanel myFXPanel = new JFXPanel(): myFrame.add(myFXPanel);
Now the required JavaFX components would be added to the JFXPanel. The JavaFX components are to be created only in the JavaFX Application thread and not in the main thread or the thread created using SwingUtilities.invokeLater. Before that lets just get familiar with a few JavaFX components which we would be using in this example:
- javafx.scene.Scene: All components in the JavaFX application are represented as a scene graph – a collection of parent and child components. The Scene component is the container for the scene graph or the components, and we define the root for all these containers when we instantiate the Scene component.
- javafx.scene.layout.BorderPane: Its the JavaFX’s version of all familiar Swing BorderLayout.
So lets try to add a WebView component to the JFXPanel.
Platform.runLater(new Runnable() { @Override public void run() { BorderPane borderPane = new BorderPane(); WebView webComponent = new WebView(); webComponent.getEngine().load(""); borderPane.setCenter(webComponent); Scene scene = new Scene(borderPane,450,450); myFXPanel.setScene(scene); } });
The Platform.runLater creates a JavaFX application thread, and this thread has to be used for all the JavaFX based operations (we can create multiple such threads, but yes, for any of the JavaFX related operation is carried out as part of this thread).
In the above snippet, we create an instance of BorderPane, set it as the root of scene when we create a Scene object and then add the WebView to the BorderPane. We also ask the WebEngine of the WebView to load the URL:. The scene object is then added to the JFXPanel. Remember, that JFXPanel is alread added to the JFrame or some Swing components. So you have a Swing application loading your web pages.
Below is the complete code for loading web pages in Swing applications.
import javafx.application.Platform; import javafx.embed.swing.JFXPanel; import javafx.scene.Scene; import javafx.scene.layout.BorderPane; import javafx.scene.web.WebView; import javax.swing.*; import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; public class SwingHtmlDemo { public static void main(String [] args){ SwingUtilities.invokeLater(new Runnable() { @Override public void run() { ApplicationFrame mainFrame = new ApplicationFrame(); mainFrame.setVisible(true); } }); } } /** * Main window used to display some HTML content. */ class ApplicationFrame extends JFrame{ JFXPanel javafxPanel; WebView webComponent; JPanel mainPanel; JTextField urlField; JButton goButton; public ApplicationFrame(){ javafxPanel = new JFXPanel(); initSwingComponents(); loadJavaFXScene(); } /** * Instantiate the Swing compoents to be used */ private void initSwingComponents(){ mainPanel = new JPanel(); mainPanel.setLayout(new BorderLayout()); mainPanel.add(javafxPanel, BorderLayout.CENTER); JPanel urlPanel = new JPanel(new FlowLayout()); urlField = new JTextField(); urlField.setColumns(50); urlPanel.add(urlField); goButton = new JButton("Go"); /** * Handling the loading of new URL, when the user * enters the URL and clicks on Go button. */ goButton.addActionListener(new ActionListener() { @Override public void actionPerformed(ActionEvent e) { Platform.runLater(new Runnable() { @Override public void run() { String url = urlField.getText(); if ( url != null && url.length() > 0){ webComponent.getEngine().load(url); } } }); } }); urlPanel.add(goButton); mainPanel.add(urlPanel, BorderLayout.NORTH); this.add(mainPanel); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); this.setSize(700,600); } /** * Instantiate the JavaFX Components in * the JavaFX Application Thread. */ private void loadJavaFXScene(){ Platform.runLater(new Runnable() { @Override public void run() { BorderPane borderPane = new BorderPane(); webComponent = new WebView(); webComponent.getEngine().load(""); borderPane.setCenter(webComponent); Scene scene = new Scene(borderPane,450,450); javafxPanel.setScene(scene); } }); } }
I used JavaFX SDK for Linux on Ubuntu and IntelliJ to develop this sample application. One can download the JavaFX SDK from here.
Very Interesting Code
Thanks! I was more looking towards embedding Google maps! I would try to do that and share it on the blog.
“Embedding HTML into Java Swing Applications” – Not JavaFX applications.
There is no point in using Swing if you have JFX handy. Also, JavaFX has its immediate drawback being not integral part of JDK.
“Swing doesn’t provide components to embed HTML” – This is wrong as several components like JLabel support HTML. Their implementation is nearly useless however (CSS problems, failing to parse if doctype declaration present, even snippets must be enclosed in tags, etc.)
Quick-and-dirty smaple snippet:
// NOTE: excluded pkg and imports
class Whatever {
public static void main(String[] args) {
JFrame f = new JFrame(“HTML Sample”);
f.getContentPane().add(new JLabel(“ThisisHTML”));
f.pack();
f.setVisible(true);
}
}
Again, this feature is, in most cases, insufficient for presenting nice-looking UI’s.
“must be enclosed in tags” – WTH it swallowed all the HTML and /HTML tags
|
http://www.javabeat.net/embedding-html-into-java-swing-applications/
|
CC-MAIN-2014-52
|
refinedweb
| 992
| 50.12
|
I have a script named
1st.py
print "Something to print"
while True:
r = raw_input()
if r == 'n':
print "exiting"
break
else:
print "continuing"
1st.py
p = subprocess.Popen(["python","1st.py"], stdin=PIPE, stdout=PIPE)
print p.communicate()[0]
Traceback (most recent call last):
File "1st.py", line 3, in <module>
r = raw_input()
EOFError: EOF when reading a line
p.stdout.read()
.communicate() writes input (there is no input in this case so it just closes subprocess' stdin to indicate to the subprocess that there is no more input), reads all output, and waits for the subprocess to exit.
The exception EOFError is raised in the child process by
raw_input() (it expected data but got EOF (no data)).
p.stdout.read() hangs forever because it tries to read all output from the child at the same time as the child waits for input (
raw_input()) that causes a deadlock.
To avoid the deadlock you need to read/write asynchronously (e.g., by using threads or select) or to know exactly when and how much to read/write, for example:
from subprocess import PIPE, Popen p = Popen(["python", "-u", "1st.py"], stdin=PIPE, stdout=PIPE, bufsize=1) print p.stdout.readline(), # read the first line for i in range(10): # repeat several times to show that it works print >>p.stdin, i # write input p.stdin.flush() # not necessary in this case print p.stdout.readline(), # read output print p.communicate("n\n")[0], # signal the child to exit, # read the rest of the output, # wait for the child to exit
Note: it is a very fragile code if read/write are not in sync; it deadlocks.
Beware of block-buffering issue (here it is solved by using "-u" flag that turns off buffering for stdin, stdout in the child).
bufsize=1 makes the pipes line-buffered on the parent side.
|
https://codedump.io/share/GBzh4nF6hwEF/1/understanding-popencommunicate
|
CC-MAIN-2017-34
|
refinedweb
| 310
| 73.88
|
.
What is a decorator
Decorators are most commonly used with the
@decorator syntax. You may have seen Python that looks something like these examples.
@app.route("/home") def home(): return render_template("index.html") @performance_analysis def foo(): pass @property def total_requests(self): return self._total_requests
To understand what a decorator does, we first have to take a step back and look at some of the things we can do with functions in Python.
def get_hello_function(punctuation): """Returns a hello world function, with or without punctuation.""" def hello_world(): print("hello world") def hello_world_punctuated(): print("Hello, world!") if punctuation: return hello_world_punctuated else: return hello_world if __name__ == '__main__': ready_to_call = get_hello_function(punctuation=True) ready_to_call() # "Hello, world!" is printed
In the above snippet,
get_hello_function returns a function. The returned function gets assigned and then called. This flexibility in the way functions can be used and manipulated is key to the operation of decorators.
As well as returning functions, we can also pass functions as arguments. In the example below, we wrap a function, adding a delay before it’s called.
from time import sleep def delayed_func(func): """Return a wrapper which delays `func` by 10 seconds.""" def wrapper(): print("Waiting for ten seconds...") sleep(10) # Call the function that was passed in func() return wrapper def print_phrase(): print("Fresh Hacks Every Day") if __name__ == '__main__': delayed_print_function = delayed_func(print_phrase) delayed_print_function()
This can feel a bit confusing at first, but we’re just defining a new function
wrapper, which sleeps before calling
func. It’s important to note that we haven’t changed the behaviour of
func itself, we’ve only returned a different function which calls
func after a delay.
When the code above is run, the following output is produced:
$ python decorator_test.py Waiting for ten seconds... Fresh Hacks Every Day
Let’s make it pretty
If you rummage around the internet for information on decorators, the phrase you’ll see again and again is “syntactic sugar”. This does a good job of explaining what decorators are: simply a shortcut to save typing and improve readability.
The
@decorator syntax makes it very easy to apply our wrapper to any function. We could re-write our delaying code above like this:
from time import sleep def delayed_func(func): """Return `func`, delayed by 10 seconds.""" def wrapper(): print("Waiting for ten seconds...") sleep(10) # Call the function that was passed in func() return wrapper @delayed_func def print_phrase(): print("Fresh Hacks Every Day") if __name__ == '__main__': print_phrase()
Decorating
print_phrase with
@delayed_func automatically does the wrapping, meaning that whenever
print_phrase is called we get the delayed wrapper instead of the original function;
print_phrase has been replaced by
wrapper.
Why is this useful?
Decorators can’t change a function, but they can extend its behaviour, modify and validate inputs and outputs, and implement any other external logic. The benefit of writing decorators comes from their ease of use once written. In the example above we could easily add
@delayed_func to any function of our choice.
This ease of application is useful for debug code as well as program code. One of the most common applications for decorators is to provide debug information on the performance of a function. Let’s write a simple decorator which logs the datetime the function was called at, and the time taken to run.
import datetime import time from app_config import log def log_performance(func): def wrapper(): datetime_now = datetime.datetime.now() log.debug(f"Function {func.__name__} being called at {datetime_now}") start_time = time.time() func() log.debug(f"Took {time.time() - start_time} seconds") return wrapper @log_performance def calculate_squares(): for i in range(10_000_000): i_squared = i**2 if __name__ == '__main__': calculate_squares()
In the code above we use our
log_performance decorator on a function which calculates the squares of the numbers 0 to 10,000,000. This is the output when run:
$ python decorator_test.py Function calculate_squares being called at 2018-08-23 12:39:02.112904 Took 2.5019338130950928 seconds
Dealing with parameters
In the example above, the
calculate_squares function didn’t need any parameters, but what if we wanted to make our
log_performance decorator work with any function that takes any parameters?
The solution is simple: allow
wrapper to accept arguments, and pass those arguments directly into
func. To allow for any number of arguments and keyword arguments, we’ve used
*args, **kwargs, passing all of the arguments to the wrapped function.
import datetime import time from app_config import log def log_performance(func): def wrapper(*args, **kwargs): datetime_now = datetime.datetime.now() log.debug(f"Function {func.__name__} being called at {datetime_now}") start_time = time.time() result = func(*args, **kwargs) log.debug(f"Took {time.time() - start_time} seconds") return result return wrapper @log_performance def calculate_squares(n): """Calculate the squares of the numbers 0 to n.""" for i in range(n): i_squared = i**2 if __name__ == '__main__': calculate_squares(10_000_000) # Python 3!
Note that we also capture the result of the
func call and use it as the return value of the wrapper.
Validation
Another common use case of decorators is to validate function arguments and return values.
Here’s an example where we’re dealing with multiple functions which return an IP address and port in the same format.
def get_server_addr(): """Return IP address and port of server.""" ... return ('192.168.1.0', 8080) def get_proxy_addr(): """Return IP address and port of proxy.""" ... return ('127.0.0.1', 12253)
If we wanted to do some basic validation on the returned port, we could write a decorator like so:
PORTS_IN_USE = [1500, 1834, 7777] def validate_port
Now it’s easy to ensure our ports are validated, we simply decorate any appropriate function with
@validate_port.
@validate_port def get_server_addr(): """Return IP address and port of server.""" ... return ('192.168.1.0', 8080) @validate_port def get_proxy_addr(): """Return IP address and port of proxy.""" ... return ('127.0.0.1', 12253)
The advantage of this approach is that validation is done externally to the function – there’s no risk that changes to the internal function logic or order will affect validation.
Dealing with function attributes
Let’s say we now want to access some of the metadata of the
get_server_addr function above, like the name and docstring.
>>> get_server_addr.__name__ 'wrapper' >>> get_server_addr.__doc__ >>>
Disaster! Since our
validate_port decorator essentially replaces the functions it decorates with our wrapper, all of the function attributes are those of
wrapper, not the original function.
Fortunately, this problem is common, and the
functools module in the standard library has a solution:
wraps. Let’s use it in our
validate_port decorator, which now looks like this:
from functools import wraps def validate_port(func): @wraps
Line 4 indicates that
wrapper should preserve the metadata of
func, which is exactly what we want. Now when we try and access metadata, we get what we expect.
>>> get_server_addr.__name__ 'get_server_addr' >>> get_server_addr.__doc__ 'Return IP address and port of server.' >>>
Summary
Decorators are a great way to make your codebase more flexible and easy to maintain. They provide a simple way to do runtime validation on functions and are handy for debugging as well. Even if writing custom decorators isn’t your thing, an understanding of what makes them tick will be a significant asset when understanding third-party code and for utilising decorators which are already written.
22 thoughts on “Make Your Python Prettier With Decorators”
Thanks. I’ve been coding with python for a couple years now (small projects, nothing major) and had used decorators but never thought to dig into the details. Useful article!
Ditto. I gather this is like inheritance for non-classes.
Oh…this is how you add code profiling in a non intrusive manner.
Out of curiosity, how many find the non-decorated, unsugared version easier to read and understand. I know I do, and I find myself mentally converting the decorated version back in to the non-decoreated one if I get to any real complications in the code. Actually I was frustrated when I first came across them, as I had to wade through pages of unhelpful expalnations before I finally understood what I was doing when I called one. Maybe life would be easier if I was the sort of person who just unthinkingly copied great chunks of code from the web without worrying what it was actually doing.
peopleAgreeing += 1
Lol
Confused here, in your first decorator example print_phrase() is called which is decorated. Can you also call print_phrase() without decoration? Or once decorated always decorated. Thanks.
Once a function is decorated at definition (using the @ syntax), the function is replaced by the decorated version, so yes, calling print_phrase() after it was defined with @decorated_func will always result in the decorated version. If you need to call a function without decoration, just use the slightly more verbose syntax in the example above it, (ie not using the @ syntax).
OK, I get it. I’ll re-read this post from my now less-confused state and work on the other decorators. I’ll also dig into this decorator, @app.route(“/home”) which I know flask maps the ‘/home’ url to the function home(). You don’t cover this decorator style and that’s fine. Thanks.
very simple explanation, thanks. I’ve seen these things in code before, but always thought it was a lot more complicated so never really used them.
“Decorators” and “syntactic sugar” are absolutely awful ways to describe these, and I blame them entirely for the confusion.
They’re wrappers. Call them wrappers and be done with it. Who thought “decorators! That’s a descriptive and unambiguous term!”
the same ****** who thought whitespace was good for defining blocks
Because the syntax is decorators, but the examples are only of wrappers. There are other uses as well, that do not wrap the function. As you can also set attributes on functions, or store the reference to a function somewhere (flask and python-dbus use this for example)
“Out of curiosity, how many find the non-decorated, unsugared version easier to read and understand. I know I do” ….
I do too. I never found a ‘need’ to use decorators (wrappers). Going to keep it that way!
I agree
For small projects may be, but for large projects that need to apply common behaviour, they can be a great time saver. For example, a `permission_required` decorator can apply a common, well-tested behaviour to a function without having to introduce additional complexity into the function (and the associated test cases).
I don’t see the value added.
+1
OK, I found a little different decorator example that helped me understand decorators a little more
ps. I agree, “syntactic sugar” has no meaning.
I disagree with “syntactic sugar” having no meaning. It is something that does not make the code behave better but does make writing/reading it easier. That is sugar. Can do without but its nice to have. Python has quite alot of sugar in its design compared to other languages.
Some here seem to think that decorators and sugar are the same thing. Decorators are a design pattern and they are extremely useful constructs that come from functional languages. As most tend to learn object orjented in these parts working with ideas from functional languages seems foreign and it sorta is. Functional languages have a bit steeper learning curve but they also produce value in places where OO fails.
This is how you could regularly call a decorator without the sugar:
calculate_squares_log_performance = log_performance(calculate_squares)
calculate_squares_log_performance(n)
In javascript you could do:
log_performance(calculate_squares)(n)
not sure it is the same in python.
With the @ notation you can just add the decorator to the definiton of the function and it allows you to keep the name of the function the same and what not. No more nesting functions which imho are worse to work with. Each line is concise in what it does. Each function does exactly one thing.
You can make python have static typing by creating type decorators that check inputs and outputs and throw errors when they arent valid:
@ accepts(int,int)
@ returns(float)
def bar(low,high):
…
TL:DR
Decorators are a software programming pattern. Syntactic sugar is some shorthand to express some functionality in a easier to understand fashion.
“use case of decorators”. What is a case of decorators? Like a container or array?
As decorators in python which are really a great function to implement it.
It made easy syntax for calling higher order function.
|
https://hackaday.com/2018/08/31/an-introduction-to-decorators-in-python/?hmsr=pycourses.com&utm_source=pycourses.com&utm_medium=pycourses.com&replytocom=4959959
|
CC-MAIN-2019-43
|
refinedweb
| 2,063
| 55.64
|
Zend PHP 5 Certification Zend 200-500
Zend PHP Certification is globally recognized as the industry standard for benchmarking and validating PHP expertise. Developed specifically by Zend Certified Engineers (ZCE). Zend 200-500 Dumps
200-500 Question Answers
Exam Topics • •
PHP Basics Functions • Arrays • Object-oriented Programming • Security • Databases • Data Format & Types • Arrays • Strings & Patterns • Web Features • I/O • Error Handling
Why should take a Zend Certification exam?.
Zend 200-500 Dumps 200-500 Question Answers
Download Latest July Zend 200-500 Exam Questions - Zend 200-500 Exam Dumps PDF
Download ZEND 200-500 Braindumps – 200-500 Real Exam Questions – Realexamdumps.com
Practice: A,C,D
Zend 200-500 Dumps 200-500 Question Answers
Practice Question : 2
What DOMElement method should be used to check for availability of a nonnamespaced attribute? A. getAttributeNS() B. getAttribute() C. hasAttribute() D. hasAttributeNS()
Answer: C 200-500 Braindumps 200-500 Practice Question
Practice Question : 3
Which of the following data types is implicitly passed by reference in PHP 5 while it is passed by value in PHP 4? A. Class B. String C. Object D. Array
Answer: C 200-500 Braindumps 200-500 Practice Question
Practice Question : 4
REST is a(n) ... A. Web service protocol similar to SOAP with a strict XML schema. B. Principle to exchange information using XML and HTTP. C. API to get information from social networking sites.
Answer: B 200-500 PDF 200-500 Study Material
Practice Question : 5
What is the output of the following code?
echo 0x33, ' monkeys sit on ', 011, ' trees.'; A. 33 monkeys sit on 11 trees. B. 51 monkeys sit on 9 trees. C. monkeys sit on trees. D. 0x33 monkeys sit on 011 trees.
Answer: B 200-500 PDF 200-500 Study Material
Pass Your Zend 200-500 Actual Test In Just One Day With Realexamdump s.com Braindumps
Now you can ace your IT exam with the help of 200-105 Braindumps which is the most valid and reliable study material. It has been designed o...
|
https://issuu.com/abriabby/docs/zend_php_certification.pptx
|
CC-MAIN-2018-30
|
refinedweb
| 334
| 63.59
|
Today I have attempted CKAD certification test.
It was TOUGH, but not impossible, actually I was expecting worse in term of complexity. And pass threshold is 66%, which is mild.
Good thing is that each of the 19 questions is self-contained, so you can easily skip it and try later.
This fellow says already everything on the topic:
I would say:
"Kubernetes in Action" book is surely very complete (I have ready it 3 times) but not really preparing you for the test. Too verbose IMHO.
MUST 1: Take the Udemy course "", definitely excellent and very hands on.
MUST 2: and do at least 3 times all the exercises here
then go for the test. You might fail at the first attempt (time pressure is very high!) but it will make you stronger. You have a free retake, so no worries, lick your wounds and try again a couple of weeks later.
CAVEAT CANEM: many exercises entail usage of namespaces - remember to practice usage of namespaces.
IMPORTANT: if you google around for CKAD VOUCHER or CKAD DISCOUNT you should find some magic words to get a 20% rebate on the exam (normally 300 USD.... I got it for 250 or so).
Monday, November 4, 2019
|
http://www.javamonamour.org/2019/11/ckad-cncf-kubernetes-certification.html
|
CC-MAIN-2020-40
|
refinedweb
| 206
| 74.49
|
18 March 2005 05:22 [Source: ICIS news]
SINGAPORE (CNI)--Indonesia’s Petrokimia Nusantara Interindo (Peni) plans to restart at least one production line at its 450,000 tonne/year linear low-density PE (lldPE)/high-density PE (hdPE) swing plant at Merak, West Java by early-April after securing a second shipment of cheap ethylene feedstock, CNI was told on Friday.
The non-integrated polyethylene (PE) producer restarted its 125,000 tonne/year No 1 line in February after securing 3,000 tonne of ethylene from a Southeast Asian producer at a low price, an industry source said.
The No 1 line was in operation for only 10 days while the company’s 125,000 tonne/year No 2 line remained shut due to the limited feedstock supply. Peni’s 200,000 tonne/year No 3 line has been shut since June 2004.
?xml:namespace>
Asian ethylene price rose to $1,300/tonne FOB ?xml:namespace>
The source declined to say how long the plant will be in operation in April.
Another source told CNI earlier that the negative price spread between ethylene and PE in October was pegged at $70/tonne.
He added that although margins climbed up to $30/tonne in February, a minimum spread of $100/tonne is necessary for PE producers to break even.
The price of ethylene is currently pegged at $1,150/tonne CFR Southeast Asia, while PE price is $1,120-1,130/tonne CFR Southeast.
|
http://www.icis.com/Articles/2005/03/18/661588/indons+peni+plans+to+restart+at+least+one+pe+line+in.html
|
CC-MAIN-2013-20
|
refinedweb
| 244
| 55.98
|
This interface is used to display a confirmation dialog before launching a "helper app" to handle content not handled by Mozilla. More...
import "nsIHelperAppLauncherDialog.idl";.
Invoke a save-to-file dialog instead of the full fledged helper app dialog.
Returns the a nsILocalFile for the file name/location selected.
Show confirmation dialog for launching application (or "save to disk") for content specified by aLauncher.
This request is passed to the helper app dialog because Gecko can not handle content of this type.
The server requested external handling.
Gecko detected that the type sent by the server (e.g.
text/plain) does not match the actual type.
|
http://doxygen.db48x.net/comm-central/html/interfacensIHelperAppLauncherDialog.html
|
CC-MAIN-2019-09
|
refinedweb
| 106
| 58.79
|
[I'm on vacation so I'll just give this a quick glance for now.]On Wed, Sep 30, 2020 at 01:07:38PM +0200, Michael Kerrisk (man-pages)?> > =====> > NAME> seccomp_user_notif - Seccomp user-space notification mechanism> > SYNOPSIS> #include <linux/seccomp.h>> #include <linux/filter.h>> #include <linux/audit.h>> > int seccomp(unsigned int operation, unsigned int flags, void *args);> >."In contrast, the user notification mechanism allows to delegate thehandling of the system call of one process (target) to anotheruser-space process (supervisor)."?>.This section reads a bit difficult imho:"A suitably privileged supervisor can use the user notificationmechanism to perform actions in lieu of the target. The supervisor willusually be able to retrieve information about the target and theperformed system call that the seccomp filter itself cannot."> > In the discussion that follows, the process that has installed> the seccomp filter is referred to as the target, and the.I think it would be good to mention that seccomp notify fds areO_CLOEXEC by default somewhere.> >).I think a few people have already pointed out other ways of retrievingan fd. :)> >Maybe mention that the task is killable when so blocked?>> event is available..(Technically TID.)> >This has already been answered, I believe.> >).Nit: It is not _yet_ executed it may very well be if the response is"continue". This should either mention that when the fd becomes_RECVable the system call is guaranteed to not have executed yet orspecify that it is not yet executed, I.I think here or above you should mention that the id or "cookie" _must_be used when a file descriptor to /proc/<pid>/mem or any /proc/<pid>/*is opened:fd = open(/proc/pid/*);verify_via_cookie_that_pid_still_alive(cookie);operate_on(fd)Otherwise this is a potential security issue.> >Yes.> >This has been discussed later in the thread too, I believe. My patchsetfixed a different but related bug in ->poll() when a filter becomesunused. I hadn't noticed this behavior since I'm always polling. (Pureioctls() feel a bit fishy to me. :) But obviously a valid use.)> > SECCOMP_IOCTL_NOTIF_ID_VALID> This operation can be used to check that a notification ID> returned by an earlier SECCOMP_IOCTL_NOTIF_RECV operation> is still valid (i.e., that the target process still> exists).> > The third ioctl(2) argument is a pointer to the cookie> (id) returned by the SECCOMP_IOCTL_NOTIF_RECV operation.> > This operation is necessary to avoid race conditions that> can occur when the pid returned by the SEC‐> COMP_IOCTL_NOTIF_RECV operation terminates, and that> process ID is reused by another process. An example of> this kind of race is the following> > 1. A notification is generated on the listening file> descriptor. The returned seccomp_notif contains the> PID of the target process.> > 2. The target process terminates.> > 3. Another process is created on the system that by chance> reuses the PID that was freed when the target process> terminates.> > 4. The supervisor open(2)s the /proc/[pid]/mem file for> the PID obtained in step 1, with the intention of (say)> inspecting the memory locations that contains the argu‐> ments of the system call that triggered the notifica‐> tion in step 1.> >Missing a ".", I think.> tion asso‐> ciate this response with the system call that trig‐> gered the user-space notification.> > val This is the value that will be used for a spoofed> success return for the target process's system> call; see below.> > error This is the value that will be used as the error> number (errno) for a spoofed error return for the> target process's system call; see below.Nit: "val" is only used when "error" is not set.> > flags This is a bit mask that includes zero or more of> the following flags> > SECCOMP_USER_NOTIF_FLAG_CONTINUE (since Linux 5.5)> Tell the kernel to execute the target> process's system call.> >.I think Jann has pointed this out. This needs to come with a big warningand I would explicitly put a:"The user notification mechanism cannot be used to implement a syscallsecurity policy in user space!"You might want to take a look at the seccomp.h header file where Iplaced a giant warning about how to use this too.> > · A spoofed return value for the target process's system> call. In this case, the kernel does not execute the> target process's system call, instead causing the system> call to return a spoofed value as specified by fields of> the seccomp_notif_resp structure. The supervisor should> set the fields of this structure as follows:> > + flags does not contain SECCOMP_USER_NOTIF_FLAG_CON‐> TINUE.> > + error is set either to 0 for a spoofed "success"> return or to a negative error number for a spoofed> "failure" return. In the former case, the kernel> causes the target process's system call to return the> value specified in the val field. In the later case,> the kernel causes the target process's system call to> return -1, and errno is assigned the negated error> value.> > + val is set to a value that will be used as the return> value for a spoofed "success" return for the target> process's system call. The value in this field is> ignored if the error field contains a nonzero value.> >.This should also note that when a filter becomes unused, i.e. the lasttask using that filter in its filter hierarchy is dead (beenreaped/autoreaped) ->poll() will notify with (E)POLLHUP.> > SEC‐> COMP_RET_USER_NOTIF action value if a call is made to mkdir(2).> The child process then calls mkdir(2) once for each of the sup‐> plied command-line arguments, and reports the result returned by> the call. After processing all arguments, the child process ter‐> minates.> > The parent process acts as the supervisor, listening for the> notifications that are generated when the target process calls> mkdir(2). When such a notification occurs, the supervisor exam‐> ines the memory of the target process (using /proc/[pid]/mem) to> discover the pathname argument that was supplied to the mkdir(2)> call, and performs one of the following actions:> > · If the pathname begins with the prefix "/tmp/", then the super‐> visor‐> name), the supervisor sends a SECCOMP_USER_NOTIF_FLAG_CONTINUE> response to the kernel to say that kernel should execute the> target process's mkdir(2) call.Potentially problematic if the two processes have the same privilegelevel and the supervisor intends _CONTINUE to mean "is safe to execute".An attacker could try to re-write arguments afaict.A good an easy example is usually mknod() in a user namespace. A_CONTINUE is always safe since you can't create device nodes anyway.Sorry, I can't review the rest in sufficient detail since I'm onvacation still so I'm just going to shut up now. :)Christian
|
https://lkml.org/lkml/2020/10/1/429
|
CC-MAIN-2021-17
|
refinedweb
| 1,103
| 54.93
|
Writing the basis of an HTML Server with Elixir
Building a basic http server in Elixir.
I've been writing an http server in Erlang, which is still far from finished but coming together slowly, as a way of learning more in depth the http protocol and how to deal with it from scratch.
To write down my findings and share them I decided I should write a post on how to do that and in the process show some very neat more lowlevel aspects of erlang. There's a good range of http server libs available in Erlang, if you use Phoenix you'll be using Cowboy underneath, each one with its own design decisions, all of them pretty fine.
We won't be tackling in this post websockets nor any proper http connection upgrades, http2 and such, that will be hopefully for future posts, but instead we'll see how to create a simple socket acceptor pool, use gen_statems to create a way to run a "pipeline", design a basic router, parse the incoming requests, etc.
You can find the final source code for this at satellitex repo up to the end of the tutorial.
We'll have at least 4 components:
- the socket acceptor pool - creates a number of ready to work socket listeners waiting for requests on a given port
- the gen_statem that will use a modular and exchangeable pipeline definition to parse the request and route it appropriately
- the router module that allows a custom DSL that generates a proper router for our gen_statem to call with the appropriate routes and data
- a response creator, to send the responses to our clients when they visit our website
We'll also need several parsing functions.
To follow along you need to have installed erlang 22 and elixir 1.9 (compiled with erlang 22). After having those installed, lets start by creating an umbrella app, from the command line:
mix new satellitex --umbrella
Lets go into our newly created directory and further into the
apps folder and create our socket acceptor app (it will be a simple lib and not an application with a supervision tree):
cd satellitex/apps mix new launchpad
Now we'll be using gen_statem and so we should add some key properties to our logger configuration so that we can get system reports if the gen_statem crashes, otherwise we won't see the actual errors caused by it since
Logger by default doesn't output system logs unless told to do so and gen_statem outputs its errors as system reports. Lets open our
config.exs file for the umbrella (
satellitex/config/config.exs) and make it look like the following:
use Mix.Config import_config "../apps/*/config/config.exs" config :logger, handle_otp_reports: true, handle_sasl_reports: true
Now save the file. This is not to say that our code will have errors, that's quite outrageous to even think, but just in case we mistyped something.
Let's start writing our acceptor. This will be our "server" per se. It won't deal with requests by itself, instead, what it will do is open a socket in a given
port and then create any number of ready to fire acceptors, listening on the socket. Each acceptor will be itself an independent process, to which we give "control" of the request as soon as a tcp connection is open, so that they can read from the socket and parse the request into something structured and usable for our application. We'll dive into that shortly after, but the idea is that it will be able to accept a "pipeline" definition and process the request according to that pipeline so that it's easily extendable.
First, if you never used the
gen_statem OTP behaviour it's a fairly useful abstraction. It's similar to
gen_servers, but it's newer and requires a bit more ceremony.
gen_servers, due to having been there for so long and having a very simple layout are used much more often but lately I've been finding that gen_statems are really nice to use in a lot of different situations, even if you're not writing anything that is a complex state machine, whenever you may have state transitions it fits very well (I already used continue handles a lot in
gen_servers and now I think they're the poor man's version of a gen_statem).
They're a behaviour, so we need to declare that, and they can operate in two different modes of callback,
state_functions or
handle_event_functions. We'll use handle_events mode, but to just cover the differences, in handle event mode you write every callback as
def handle_event(........) end and the state can be as complex as you want. In
state_function mode you write functions where the name of the function is the
state to which it refers and the state must always be an atom. So if you had a
state of
starting, you would have a
def starting(.....) end function(s) to handle all events when the state machine is in that state and other similarly named functions for each state you have. I personally like better the handle mode.
Our ideal server will accept a bunch of settings to decide how to start itself, it will have a start_link function that receives these options, then call a init function with these options that opens up the socket and starts the acceptors.
So let's go to our launchpad application, and open
/apps/launchpad/lib/launchpad.ex and replace it with the following:
defmodule Launchpad do @behaviour :gen_statem defstruct [:socket, :config, max_pool: 5, pool_count: 0, acceptors: %{}] def start_link(opts) do name = Map.get(opts, :name, {:local, __MODULE__}) :gen_statem.start_link(name, __MODULE__, opts, []) end @impl true def callback_mode(), do: :handle_event_function @impl true def init(opts) do Process.flag(:trap_exit, true) port = Map.get(opts, :port, 4000) {:ok, socket} = :gen_tcp.listen(port, [:binary, {:packet, :raw}, {:active, false}, {:reuseaddr, true}]) data = %__MODULE__{socket: socket, config: opts} {:ok, :starting, data, [{:next_event, :internal, :create_listener}]} end @impl true def handle_event(:internal, :create_listener, _state, %__MODULE__{ socket: socket, config: config, max_pool: max, pool_count: pc, acceptors: acceptors } = data ) when pc < max do {:ok, pid} = Satellite.start_link(socket, Map.put(config, :number, pc)) n_acceptors = Map.put(acceptors, pid, true) {:keep_state, %{data | pool_count: pc + 1, acceptors: n_acceptors}, [{:next_event, :internal, :create_listener}]} end def handle_event(:internal, :create_listener, :starting, data), do: {:next_state, :running, data, []} def handle_event(:internal, :create_listener, _state, _data), do: {:keep_state_and_data, []} def handle_event(:info, {:EXIT, pid, _reason}, _, %{pool_count: pc, acceptors: acceptors} = data) when :erlang.is_map_key(pid, acceptors) do {_, n_acceptors} = Map.pop(acceptors, pid) {:keep_state, %{data | pool_count: pc - 1, acceptors: n_acceptors}, [{:next_event, :internal, :create_listener}]} end def handle_event(:info, {:EXIT, pid, reason}, _, _data) do IO.puts("Received exit from unknown process #{inspect pid} with reason #{reason}") {:keep_state_and_data, []} end end
There's quite a lot going on there so let's break it up:
@behaviour :gen_statem- we're simply stating that this module will implement the
:gen_statemOTP behaviour
defstruct ....- a structure we created to hold the relevant information about our server, it has a few keys,
:socket, which will hold the socket ref once we open it,
:config, which will store the configuration passed to it,
:max_pool, which is the maximum number of acceptors we want to have running at each time,
:pool_count, just a counter that holds how many acceptors we have running to decide if we need to start more or not, and
:acceptorswere we keep a map of our acceptors pids
def callback_mode()- it's a required function for this behaviour and it informs what type of callbacks our
:gen_statemwill be running, in this case we set it to return
:handle_event_function
The others are regular things, a
start_link/1 function that takes an argument (which will be a map/struct with configuration) a
init/1 function that the behaviour requires to start, in our case the argument will be the same as passed down to start_link, and then two
handle_event functions, these are functions defining the behaviour of our :gen_statem and how it should act when there's either a state change or an event trigger.
In the
start_link/1, for now, we will just try to get a key
:name from it in order to register our process. In case no
name is provided we default to
{:local, __MODULE__}, which will register our process locally, on start, as
Launchpad (that's what
__MODULE__ gets translated to).
So for
:gen_statem.start_link(name, __MODULE__, opts, []), the first argument is the name to register, the second is the module implementing the statem (in this case it's this module itself), the 3rd is the arguments passed to
init/1 and the 4th is a list of keyword options for the :gen_statem initialization itself, that we're leaving empty. We could also make
gen_statem anonymous by excluding the 1st argument.
On the
init/1 function we're setting the process to trap exits by using
Process.flag(:trap_exit, true), the reason for this is because we'll be starting each acceptor as a link, so that if our "launchpad" process dies they are killed as well, but in turn, because links are bi-directional, this makes it so that if any of the acceptors dies our "launchpad" would too. Since we set it to trap exits, instead, if an acceptor dies, what will happen is we will receive a message telling us about it, this will allow us to "know" when one of them goes down in case we want to start another one to replace it, instead of it simply exiting automatically.
Then we read the port from the config or default to
4000 and next we start the actual socket process listening on that port, with a bunch of options through
:gen_tcp.listen.
The options we pass are
:binary, telling we want to read the socket as binary segments, we set
{:active, false}, this means that we don't want to read data immediately whenever it arrives, we want to control how and when the reading is going to happen. :reuseaddr is for the socket to allow reusing the same address and
{:packet, :raw}, tells to pass the data as read. If the
:gen_tcp.listen succeeds it means we were able to bind to that socket port, otherwise this will raise an error, crash, and if the user of our server started it from a supervisor hopefully crash their app, so that they notice something is wrong.
Then we just create a struct for our data, with the previously opened socket and the config map passed to it.
The
init/1 callback has to return when successful an
{:ok, ...statem_definitions} tuple, in our case:
{:ok, :starting, data, [{:next_event, :internal, :create_listener}]}
Means, set the internal initial state to
:starting and the statem data as the contents of
data. The last element is a list of actions specific to the :gen_statem behaviour that dictate any event it should trigger upon finishing this callback. In this case we say, we want to trigger a new event, a specific internal one that we can be sure is only triggered from our gen_statem, with the name
:create_listener.
Hence the next
handle_event functions we wrote. Each handle_event function receives as its arguments:
type_of_event,
event,
currrent_state,
current_data
The type of event can be
:internal,
:info,
:call,
:cast,
:timeout, etc… You can find all the documentation for gen_statem in erlang documentation The event is the contents of that event, and the others are self explanatory. An
:internal event type can only be issued by your own code inside the gen_statem where they happen, you can be sure these were generated by you.
On the first
handle_event we pattern match on our struct specifically so we can access the value of
:max_pool and
:pool_count. This way we can know if the maximum number of acceptors are already running or not, and we do that by setting a guard clause,
when pc < max.
So if the pool_count is lower than the max we have set, then open a new one, otherwise the next function head that matches will be the one called - we have two, one if we're in the
:starting state, which will just switch to the state
:running while keeping everything else, and another one that matches whenever the state is not starting and the max acceptors have already been created, it does nothing by returning
{:keep_state_and_data, []}, which is a shorthand for
{:next_state, :same_state, same_data, []}.
When we create a new listener, we increment the pool count, we add that pid as a key to our
acceptors map and we trigger the same event again.
So it repeats the listener creation until we have the max number of acceptors created and then sits waiting, doing a siesta.
Lastly we have a function to receive the
EXIT message in case any of our linked processes dies, because we're trapping exits. When we receive one we decrease the pool count by one and trigger a new event to create another listener. We know this exit is from an "acceptor" process because we use the guard
:erlang.is_map_key(acceptors, pid), basically saying only match this function when the pid on the
EXIT message is a key on the map
acceptors, meaning one of the pids from an acceptor we started (that we know because we placed them in the acceptors map as keys). If it's not we do a naive log of it because we should theoretically not have received that exit signal.
So our app is actually a library, this is because we don't want to control how it's started from itself, instead we expose the
start_link/1 function that then someone can start on their own supervisor trees. We'll see that later but, for now, lets see if it does something already. Go to the root of the umbrella and start an iex shell, with:
iex -S mix run
You should see some warnings, and:
Erlang/OTP 22 [erts-10.4.3] [source] [64-bit] [smp:8:8] [ds:8:8:10] [async-threads:1] [hipe] ==> launchpad Compiling 1 file (.ex) warning: function Satellite.start_link/2 is undefined (module Satellite is not available) lib/launchpad.ex:39 19:02:57.776 [info] Application logger started at :nonode@nohost 19:02:57.776 [info] Application launchpad started at :nonode@nohost
We can see already a problem, we don't have a
Satellite.start_link/2 function neither a
Satellite module, and if we try to start our
Launchpad we see that error actually happening:
iex(1)> Launchpad.start_link(%{}) {:ok, #PID<0.151.0>} iex(2)> 19:05:14.065 [error] Process Launchpad (#PID<0.151.0>) terminating ** (UndefinedFunctionError) function Satellite.start_link/2 is undefined (module Satellite is not available) Satellite.start_link(#Port<0.8>, %{number: 0}) .....
But the
Launchpad did start and effectively tried to start one acceptor. Lets write the first completely barebones version of the acceptor.
Lets navigate again to
apps/ dir, and do:
mix new satellite
Now let's open
apps/satellite/lib/satellite.ex
defmodule Satellite do @behaviour :gen_statem defstruct [:socket, :config, :conn, pipeline: [], request: %{}] def start_link(socket, opts) do :gen_statem.start_link(__MODULE__, {socket, opts}, []) end @impl true def callback_mode(), do: :handle_event_function @impl true def init({socket, config}) do {:ok, :waiting, %__MODULE__{socket: socket, config: config}, [{:next_event, :internal, :wait}]} end @impl true def handle_event(:internal, :wait, :waiting, %{socket: socket} = data) do {:ok, conn} = :gen_tcp.accept(socket) :gen_tcp.controlling_process(conn, self()) {:next_state, :parsing, %{data | conn: conn}, [{:next_event, :internal, :read}]} end def handle_event(:internal, :send_response, :response, %{conn: conn, request: request} = data) do b = :erlang.iolist_to_binary(request) response = :io_lib.fwrite( "HTTP/1.0 200 OK\nContent-Type: text/html\nContent-Length: ~p\n\n~s", [:erlang.size(b), b] ) :gen_tcp.send(conn, response) {:keep_state, data, [{:next_event, :internal, :close}]} end def handle_event(:internal, :close, _, %{conn: conn} = data) do :gen_tcp.close(conn) {:next_state, :waiting, %{data | conn: nil, request: %{}}, [{:next_event, :internal, :wait}]} end end
This is nowhere close to what we want, but it will allow us to already receive http requests. Lets see that and then go through the code. Go to the root of your umbrella on the terminal and again run
iex -S mix run
Inside the shell now do:
Launchpad.start_link(%{})
You should see
{:ok, #PID....}
Now open a browser and visit.
Voilá, we have a "server" listening on port 4000. It doesn't do really anything, it just echoes whatever was the request as a
text/html response.
To confirm that indeed we have 5 acceptors currently running, let's change this line:
To:
def handle_event(:internal, :read, :parsing, %{conn: conn, config: %{number: number}} = data) do case :gen_tcp.recv(conn, 0, 1000) do {:ok, packet} -> IO.inspect(packet, label: "received") n_data = %{data | request: packet <> "\n\nAcceptor number: #{number}"} {:next_state, :response, n_data, [{:next_event, :internal, :send_response}]} {:error, reason} -> IO.inspect(reason, label: "error on recv") {:keep_state, data, [{:next_event, :internal, :close}]} end end
Save the file and on the iex shell run
recompile().
Now visit the browser and refresh the page some times. You should see the acceptor changing as you do. Which means that each request you're sending from the browser is being answered by a different process altogether.
If you look in the shell you should also be seeing the output from the
IO.inspect functions we placed.
So this string you're seeing will vary depending on the browser, but it will have a structure that is the same. Using Safari I see this:
GET / HTTP/1.1\r\nHost: localhost:4000\r\nConnection: keep-alive\r\nCache-Control: max-age=0\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36\r\nSec-Fetch-Mode: navigate\r\nSec-Fetch-User: ?1\r\nDNT: 1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\nSec-Fetch-Site: none\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: pt-PT,pt;q=0.9,en-US;q=0.8,en;q=0.7\r\n\r\n" received: "GET /favicon.ico HTTP/1.1\r\nHost: localhost:4000\r\nConnection: keep-alive\r\nPragma: no-cache\r\nCache-Control: no-cache\r\nSec-Fetch-Mode: no-cors\r\nDNT: 1\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36\r\nAccept: image/webp,image/apng,image/*,*/*;q=0.8\r\nSec-Fetch-Site: same-origin\r\nReferer:\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: pt-PT,pt;q=0.9,en-US;q=0.8,en;q=0.7\r\n\r\n
There's a whole bunch of documents detailing exactly how an HTTP request (on the various versions of the protocol) must be constructed, what it can contain, how those things are encoded and the same for the HTTP responses. We'll not read the RFC for the HTTP Protocol but basically implement the logic for parsing these requests and deliver a response on a more lightway approach.
We can see that the request is basically:
VERB
whitespace PATH
whitespace PROTOCOL/VERSION\r\nHEADERS\r\n\r\n
where
\r\n is the carriage return escape sequence.
After the headers there would be a body but in this case since it's a get request there's none. In case of having a body the request should include a Content-Length header stating the size of the body although it's not totally required that it has.
So if we approach this from the point of view of creating a pipeline, basically we would need to:
- Parse the Verb
- Parse the Path
- Parse the Protocol
- Parse the headers
- Maybe Parse the Body if it has one
- Dispatch to the appropriate route
On each step we can then store the information we parsed so that we can later decide how to respond to it, which we'll do by dispatching that request into an appropriate handler.
We should read the RFC to make sure our server is completely correct, but like we said before, this is a lightweight version so we'll just read the basics from that request to decide what we need.
Verb, Path and Protocol are each one separated by a white space. Headers are separated from the previous section and between them by
\r\n, meaning carriage return, a set of two characters,
\r return and
\n newline, each header key ends with
: followed by a white space, after which comes the respective value.
The end of the headers is separated by double carriage return,
\r\n\r\n. After this is the body and this can be formatted in different ways depending on the type of request.
There's many ways we can implement the parsing part, but we want it to be modular, so that anybody can hook their own things into a pipeline if they want, or change it completely, the idea is the basic pipeline will parse everything needed and then dispatch the request. We will want to implement some control on maximum length of the requests (or allow that even if by default it accepts anything). We want the pipeline to be halt-able, meaning that we can trigger an halt between any actions. We don't want to have explicit hardcoded behaviour, we want each step to be a call to a function that can be customised.
We will also want to have different kinds of actions, we'll want to have parsing/reading actions, that get part of the data from the socket and do something with it (parse it and if needed store it in the context of that specific request), we want to have actions that simply change the form of the data according to something in a certain place when they occur in the pipeline and we want actions that check the current state of what we have parsed/stored to decide if to continue parsing, halt, error, or dispatch.
One problem we will always run into is that the HTTP protocol doesn't require a request to say how many bytes it is in total, so we can't know how many bytes to read from the socket until we figure the end of the request. To add to that, we have the fact that we might read incomplete requests due to the buffering on the socket at the os level (and subsequent transmission to the Erlang VM). Most of the times the socket when read will contain all the data, but on big length requests we might need to read more than once from it.
When we set the socket to
{:active, false} we explicitly told that we will somehow read the socket by ourselves. The reason to do this is because if we say
{:active, true} we forego any possibility of applying backpressure to the data being sent and read from the socket, and someone could potentially flood our server with gigantic requests, possibly crashing it down in the process.
By saying
{:active, false} the BEAM will not automatically send that data, it will be in the socket buffer, waiting to be read at which point we need to manually request a reading on it. One normal way of doing it is after we set the acceptor and pass the controlling process to the one that will receive the request, to set the socket to
{:active, :once}, which means it will process once the data currently in the buffer (emptying it so at the os level the client tcp connection can push more data into it), send it as a message to the controlling process, and then switch automatically to
{:active, false} again.
This has the benefit of allowing us to apply backpressure, it's like opening a faucet once for a little while and immediately closing it again. If we need to read more we repeat the same.
Other option is by using
:gen_tcp.recv. In this way you can control how many bytes to read along with a timeout for it and instead of receiving that data as a message, you get the result of the read as the return of the function with
{:ok, data}, or an
{:error, reason} if there was some error (the socket was closed on the client for instance), or
:timeout if the amount of bytes specified couldn't be read in that given time frame.
:gen_tcp.recv/3 takes the accepted socket from where to read as its first argument, the number of bytes to read as its second argument and the timeout as its third argument.
One thing to notice is that, if we specify a number that is not zero, then this function will only return after having read EXACTLY that number of bytes. In this case, this is not very useful, because we don't know beforehand how many bytes there will be in total, so unless we read a single byte at a time we would always end up timing out. Reading one byte at a time is not efficient in any way either. But if we specify the number as zero (0) then
recv will act like
{:active, :once}, in that it reads the whole available buffer in one go, and then returns that data. If we need to read more we call again
recv and again we get whatever is in the buffer up to that point and so on. This again allows us to manually control the backpressure and the flow of data (we can even when creating the socket say what's the size we want for our buffer and other things but we'll not cover that).
(sidenote: you might ask then why is there an option to specify the number of bytes and not only 0, and the reason is, if you control the client (it's an application you wrote) or you have a defined protocol where you can specify the length, then you can optimise the readout to your specific system, network and even the client application flow. Of course when dealing with HTTP requests, that's not the case)
We can then implement a way of limiting the maximum number of bytes a request might have before we close the connection. We'll see that in more detail when we get to it. Now lets start implementing our basic request parser.
First we'll need to define a structure that will hold the parsed information in an organised way, so that we can check it. We also need to define a structure to hold the
configuration information.
For the request lets create another module in the satellite app,
apps/satellite/lib/satellite_request.ex . Open the file and add to it:
defmodule Satellite.Request do defstruct [ :verb, :protocol, :version, :accept, :body, path: [], host: [], query: %{}, headers: %{}, finished_headers: false, halt: false, params: %{}, ] end
The
:query,
:headers and
:params field are maps, because they're key-value elements.
:path and
:host are defined as lists although the url requested and the host will be strings if we want to dispatch on certain paths, match parts of the path, etc, and the same for the host/domain/port, we will need to decompose it into individual elements in order to do so. The remaining keys will either be booleans or strings/atoms that we will fill as we move through the pipeline.
Save that file.
Now let's create one for the configuration. The previous request structure is only used by the acceptors gen_statem and possibly any lib that depends on our whole application. On the other hand the config is used by the
launchpad and
satellite. So we will create a new app/lib to store these shared elements. We haven't added any dependencies to our apps until now but we will afterwards.
Go to the
apps folder on the terminal again, and execute
mix new satellite_shared.
Now create and open a file at
apps/satellite_shared/lib/satellite_configuration.ex
Place inside it the following:
defmodule Satellite.Configuration do defstruct [ :pipeline, :name, :router, port: 4000, acceptors: 5, max_size: 50_000, keep_full_request: false, ] end
Now open
apps/launchpad/mix.exs and replace the
deps function by:
defp deps do [ {:satellite, in_umbrella: true}, {:satellite_shared, in_umbrella: true} ] end
Open the
apps/satellite/mix.exs and replace the
deps function by:
defp deps do [ {:satellite_shared, in_umbrella: true} ] end
The reason we were able to run previously without specifying these dependencies is because
mix will compile and load all applications and modules in the umbrella, but if we were to assemble a release, then the compilation would fail, because the dependencies weren't specified.
Basically we're now saying
launchpad depends on both the app
satellite and
satellite_shared and the app
satellite depends on
satellite_shared.
Ok, so now let's think about how we want to actually have this working. (I've done the thinking for you but I'll pretend it's fresh).
I'll throw in that one neat way of having it defined is as a list of things, so that we can move through it as we go. Each element of this list should have the type of action it is, the name for that particular step, which function to call for doing the step and also, because we might get things in several receives, an accumulator specific for that step. So say we want to encode the step for parsing the verb out of the request, given the 4 elements we mentioned previously, it could look like this:
{:read, :verb, &Satellite.Verb.parse/3, <<>>}
So the action would be of the type
:read, the name of the step would be
:verb, the function that would execute this step would be
Satellite.Verb.parse/3 and the accumulator would be an empty binary.
Let's start writing it, first create another file in the satellite lib,
apps/satellite/lib/satellite_defaults.ex and write in it:
defmodule Satellite.Defaults do def default_pipeline() do [ {:read, :verb, &Satellite.Verb.parse/3, <<>>} ] end end
Save it. We'll add the others as we go. Now we need to create a module
Satellite.Verb. So lets create another file
apps/satellite/lib/satellite_verb.ex and put in it:
defmodule Satellite.Verb do def parse(ctx, rem, <<"GET">>), do: {:done, %{ctx | verb: :get}, rem} def parse(ctx, rem, <<"POST">>), do: {:done, %{ctx | verb: :post}, rem} def parse(ctx, <<>>, acc), do: {:cont, ctx, acc} def parse(ctx, <<?\s, rem::bits>>, acc), do: parse(ctx, rem, acc) def parse(ctx, <<h, rem::bits>>, acc), do: parse(ctx, rem, <<acc::bits, h>>) def parse(ctx, _, _), do: {:error, "Parsing Verb"} end
Here the idea is very simple, we create a recursive function. First this function will be called the first time with
(ctx, the_request_binary_from_the_socket, <<>>) because the initial accumulator is
<<>> as set in our pipeline definition. So it won't match the first 4 functions, but will match the 5th, were we pluck 1 single character from it, add call again parse with the remaining of the packet, while adding that single character we removed to the accumulator.
It repeats this until the accumulator is
<<"GET">> or
<<"POST">>, at which point we consider it done because we have a matching verb (right now it will fail for any other verb). If there was a white-space somewhere, it would ignore it and move on to the next character, but because it will assemble GET or POST before that it's never called, anyway, I'm leaving it there just because.
Most parsing will be similar to this, but it will have its own peculiarities. This should work even if for instance we were reading 1byte at a time from the socket, because in that case, we would read the first, rendering an accumulator of
<<"G">>, and an remaining of
<<>>, which would match the 3rd function and in that case return
{:cont, ctx, acc}, which would trigger a new read from the socket and consequent parsing.
Now how do we make our satellite actually work with this? So one thing we can do is treat our state of the gen_statem as the current step in the pipeline. With pattern matching we can describe this very elegantly, because if the pipeline is a list, we can simply pluck the first element from it and store it as the current state, and every time it moves we pluck another one, until we have no more steps to do, at which point we know we've finished the pipeline and parsed the full request. The complete story is a bit different because of the specifics of http requests, but that's the overall idea, we'll adjust as we need while going through it. So now we need to change how the
launchpad is started, so that it uses our recent
Satellite.Configuration struct.
Add this to
apps/launchpad/lib/launchpad.ex
alias Satellite.Configuration, as: Config defp set_defaults(config) do maybe_set_name(config) |> maybe_set_port() |> maybe_set_pipeline() end defp maybe_set_name(%Config{name: name} = config), do: maybe_set(:name, name, {:local, __MODULE__}, config) defp maybe_set_port(%Config{port: port} = config), do: maybe_set(:port, port, 4000, config) defp maybe_set_pipeline(%Config{pipeline: pipeline} = config) do maybe_set(:pipeline, pipeline, Satellite.Defaults.default_pipeline(), config) end defp maybe_set(key, nil, default, config), do: Map.put(config, key, default) defp maybe_set(_, _, _, config), do: config
And change
start_link and
init to the following:
def start_link(%Config{} = config) do %{name: name} = ok_config = set_defaults(config) :gen_statem.start_link(name, __MODULE__, ok_config, []) end def init(%{port: port} = config) do Process.flag(:trap_exit, true) {:ok, socket} = :gen_tcp.listen(port, [:binary, {:packet, :raw}, {:active, false}, {:reuseaddr, true}]) data = %__MODULE__{socket: socket, config: config} {:ok, :starting, data, [{:next_event, :internal, :create_listener}]} end
We created some helper functions to set defaults in case it isn't passed into and also changed the
start_link and
init to use that. If there's no
:name,
:port or
:pipeline set in the config it will set them to some default. Because we're now matching explicitly on the
%Config{} struct in
start_link/1, if you pass anything else it will fail with an unmatched function call.
Now we need to change the
satellite.ex file, to use the pipeline and create the
handle_event functions that will coordinate that.
I'm going to past the full file as it should look and we go through the changes:
defmodule Satellite do @behaviour :gen_statem alias Satellite.Request defstruct [:socket, :config, :conn,: %{pipeline: pipeline}} = data) do {:ok, conn} = :gen_tcp.accept(socket) :gen_tcp.controlling_process(conn, self()) n_data = %{data | conn: conn, pipeline: pipeline, request: %Request{}} set_next_step(n_data, <<>>) end def handle_event(:internal, :read, _, %{conn: conn} = data) do case :gen_tcp.recv(conn, 0, 1000) do {:ok, packet} -> {:keep_state_and_data, [{:next_event, :internal, {:parse, packet}}]} {:error, reason} -> {:next_state, :response, %{data | request: "Error: #{inspect reason}"}, [{:next_event, :internal, :send_response}]} end end def handle_event(:internal, {:parse, packet}, {type, name, fun, acc}, %{request: request} = data) do case fun.(request, packet, acc) do {:cont, n_request, n_acc} -> {:next_state, {type, name, fun, n_acc}, %{data | request: n_request}, [{:next_event, :internal, :read}]} {:done, n_request, remaining} -> set_next_step(%{data | request: n_request}, remaining) {:error, reason} -> {:next_state, :response, %{data | request: "#{inspect reason}"}, [{:next_event, :internal, :send_response}]} end end def handle_event(:internal, :send_response, :response, %{conn: conn, request: request} = data) do :gen_tcp.send(conn, make_response(request)) {:keep_state, data, [{:next_event, :internal, :close}]} end def handle_event(:internal, :close, _, %{conn: conn} = data) do :gen_tcp.close(conn) {:next_state, :waiting, %{data | conn: nil}, [{:next_event, :internal, :wait}]} end defp set_next_step(%{pipeline: [h | t]} = data, remaining) do event = case remaining do <<>> -> :read _ -> {:parse, remaining} end {:next_state, h, %{data | pipeline: t}, [{:next_event, :internal, event}]} end defp set_next_step(%{pipeline: [], request: request} = data, _remaining) do n_request = "#{inspect request}" {:next_state, :response, %{data | request: n_request}, [{:next_event, :internal, :send_response}]} end defp make_response(request) do b = :erlang.iolist_to_binary(request) :io_lib.fwrite( "HTTP/1.0 200 OK\nContent-Type: text/html\nContent-Length: ~p\n\n~s", [:erlang.size(b), b] ) end end
So first, we changed the
defstruct to hold a
%Satellite.Request{} (we aliased the module so we can write
%Request{} instead) by default instead of an empty map.
Then the
init is the same as before, but the
:wait event while
:waiting is different. Now, because we know we have the pipeline in the
%Config{} structure, we take out that through pattern matching and then after having made a connection we create a new structure with the
:conn, the
:pipeline value and an empty
%Satellite.Request{} as the
:request, we then, instead of returning the statem tuple, call the
set_next_step function, which takes a
Satellite struct, and the bytes read from the socket as the 2nd argument. In this case, since we're just starting the pipeline we don't have any bytes, so we pass an empty binary
<<>>.
This function then pattern matches on the
:pipeline key and sees if we have at least one element there, and in case we do, it means we haven't finished the pipeline yet. In that matching function we also check the already read data we have available to parse and depending wether it's empty (
<<>>) or not, we set the next event for the state machine. This event will either be
{:parse, data} or
:read in case we don't have any data to parse. First time this is called it will obviously be
:read because we passed
<<>>.
In case we have no other elements in the pipeline, instead, we know we have reached the end of the pipeline and as such should send a response back. This function will change of course, for now it just does an inspect on the current
request struct so that it becomes a stringified version, and then sets the next event to
:send_response.
On the first iteration though we have a pipeline element, we will have a single one, so the function match will look like this:
set_next_step(%{pipeline: [h | t]} = data, remaining)
Where
h will be
{:read, :verb, &Satellite.Verb.parse/3, <<>>} and
t will be
[].
Because remaining is
<<>>, event will be
:read.
So the final return from the
set_next_step will be:
{:next_state, {:read, :verb, &Satellite.Verb.parse/3, <<>>}, %{data | pipeline: []}, [{:next_event, :internal, :read}]}
This shows how cool is the
:handle_event_function type of callbacks, due to that we can have complex states as this one, which allows us to describe in very clean steps what should happen when such states have to process new events.
This means that now, it will trigger the event
:read that doesn't care about what state it's in, and just does what we were doing before by reading from the socket. When it reads then it sets the next event to be
{:parse, data_that_was_read}, and now this will trigger the next event were we parse and - in this case - we do care about what state we're in because it contains the function we need to call to handle this step.
We had set the state to be
{:read, :verb, &Satellite.Verb.parse/3, <<>>}, which means the accumulator starts empty. We also used the
& notation to capture that function, because what we want is a reference to a given function so that we can then apply it. We do that by calling
fun.(request, packet, acc). The first argument is the current
%Request struct as it is, the second is what was read from the socket up till now, and the third is the accumulator, which starts empty.
This function should return one of 3 possible outcomes (we would write a proper behaviour for this but now we'll skip it):
{:cont, new_request_struct, new_acc}
this return means that that given function was unable to finish with the current data retrieved from the socket, so we should ask to read more from the socket, it replaces the state of the
gen_statem by almost the same as it is currently, with exception of the
acc, which gets replaced by the
new_acc returned from the function. It also replaces the
:request key in the gen_statem's data, in case the
new_request_struct has changed. When we get this event, the next event will be
:read and afterwards it will trigger this event again, with new data read from the socket. The
new_request_struct might or may not have changed, but to simplify logic we just replace it.
{:done, new_request_struct, remaining}
this return means, the function was able to according to its logic finish all it had to do, so this step can be considered complete, lets move to the next one. It includes the
new_request_struct and any bytes that weren't parsed. This calls
set_next_step which will follow the logic we already discussed, placing the next step in the pipeline as the current. In this case we might or may not have any remaining bytes available, and
set_next_step will decide accordingly what is the next event to trigger
{:error, reason}this is self explanatory - right now it just translated whatever is the error reason into a string and jumps right to the
:send_responseevent. We will further down change this and the
:send_responsesteps as well
We will also need to add proper error catching but everything at its time.
If we look at what we have right now, we should be able to see some response already containing our
%Satellite.Request{} struct and the proper verb parsed and included in it. Lets recompile / restart the iex shell, and do now:
` Launchpad.start_link(%Satellite.Configuration{})`
You should see again the familiar
{:ok, pid...}
Now lets open up a browser and visit again - you should be greeted by:
%Satellite.Request{accept: nil, finished_headers: false, halt: false, headers: %{}, host: nil, params: %{}, path: [], protocol: nil, query: %{}, verb: :get, version: nil}
And as you can see, the
:verb key is set to
:get. Very nice very good, great success!
Let's go adding one by one the remaining parsing steps, open
apps/satellite/lib/satellite_defaults.ex and replace it by:
defmodule Satellite.Defaults do def default_pipeline() do [ {:read, :verb, &Satellite.Verb.parse/3, <<>>}, {:read, :path, &Satellite.Path.parse/3, {false, [], <<>>}} ] end end
Now let's create the
Satellite.Path module, in
apps/satellite/lib/satellite_path.ex. This one is going to be more complex because we want to separate the path into it's individual constituents, so if someone would visit our final path list would look like
["basic", "path"] and because a path might include also query strings, in the form of
?key=value&key2=value2 we need to do more work, and in case there is query string we need to place it on the
:query key of the
%Request{} struct.
The reason we want to do this will become clearer when we design the dispatching mechanism, but it will allow us to do some cool stuff with it.
defmodule Satellite.Path do def parse(ctx, <<>>, acc), do: {:cont, ctx, acc} def parse(ctx, <<?\s, rem::bits>>, {false, _, _} = acc), do: parse(ctx, rem, acc) def parse(ctx, <<?\s, rem::bits>>, {true, acc, prior}) do n_acc = maybe_add_prior(acc, prior) n_ctx = %{ ctx | path: Enum.reverse( List.flatten(n_acc) ) } {:done, n_ctx, rem} end def parse(%{query: q} = ctx, <<?\s, rem::bits>>, {:query, :value, key, value}) do {:done, %{ctx | query: Map.put(q, key, value)}, rem} end def parse(ctx, <<?\s, rem::bits>>, _), do: {:done, ctx, rem} def parse(ctx, <<?=, rem::bits>>, {:query, :key, key}) do parse(ctx, rem, {:query, :value, key, <<>>}) end def parse(ctx, <<h, rem::bits>>, {:query, :key, key}) do parse(ctx, rem, {:query, :key, <<key::binary, h>>}) end def parse(%{query: q} = ctx, <<?&, rem::bits>>, {:query, :value, key, value}) do parse(%{ctx | query: Map.put(q, key, value)}, rem, {:query, :key, <<>>}) end def parse(ctx, <<h, rem::bits>>, {:query, :value, key, value}) do parse(ctx, rem, {:query, :value, key, <<value::binary, h>>}) end def parse(ctx, <<?/, rem::bits>>, {_, acc, prior}) do n_acc = maybe_add_prior(acc, prior) parse(ctx, rem, {true, n_acc, <<>>}) end def parse(ctx, <<??, rem::bits>>, {:true, acc, prior}) do n_acc = maybe_add_prior(acc, prior) n_ctx = %{ ctx | path: Enum.reverse( List.flatten(n_acc) ) } parse(n_ctx, rem, {:query, :key, <<>>}) end def parse(ctx, <<h, rem::bits>>, {_, acc, prior}) do parse(ctx, rem, {true, acc, <<prior::binary, h>>}) end def parse(_ctx, _, _), do: {:error, "Parsing path"} defp maybe_add_prior(acc, <<>>), do: acc defp maybe_add_prior(acc, prior), do: [prior | acc] end
We won't go through all the logic in this one, but suffice to say that, it will parse bytes until it reads a
"/", at that point it will look to see if it has accumulated anything, in case it has it puts that as one element of the paths list. It does that until it either finds a whitespace or a
? character. If it finds a
? character it means it's expecting query parameters, so it changes its own internal acc state to now match on first extracting the value of the key for that query parameter, and once finding an
= sign, switching to finding the value for that. Once it does it places those under the
:query key on the context map (that is the
%Satellite.Request{} struct), and it does this until again, it finds a white space.
When it finds a white space it considers this step complete. Now you know why URI's can't contain white-spaces and instead use either
+ or
%20, imagine having to deal with that …
Now our implementation doesn't deal with everything, it's definitively not RFC compliant, anyway, it will work mostly fine for what we want, and you can extend it by yourself, how the remaining works is left as an exercise.
Let's quit the shell and restart it, then run again:
Launchpad.start_link(%Satellite.Configuration{})
And this time visit
You should see now:
%Satellite.Request{accept: nil, finished_headers: false, halt: false, headers: %{}, host: nil, params: %{}, path: ["some", "path"], protocol: nil, query: %{"query1" => "val1"}, verb: :get, version: nil}
So even more success! It correctly parsed the path and separated it into each individual segment and also the query string!
Next is the
Satellite.Conn, create the file at
apps/satellite/lib/satellite_conn.ex and place inside it:
defmodule Satellite.Conn do def parse(ctx, rem, <<"HTTP/1.1", ?\r, ?\n>>), do: {:done, %{ctx | version: {1, 1}}, rem} def parse(ctx, rem, <<"HTTP/1.0", ?\r, ?\n>>), do: {:done, %{ctx | version: {1, 0}}, rem} def parse(ctx, <<>>, acc), do: {:cont, ctx, acc} def parse(ctx, <<?\s, rem::bits>>, acc), do: parse(ctx, rem, acc) def parse(ctx, <<h, rem::bits>>, acc), do: parse(ctx, rem, <<acc::binary, h>>) def parse(ctx, _, _), do: {:error, "Parsing Conn"} end
Again we're not dealing with everything possible here, but for now it will work.
Set the
satellite_defaults.ex to:
defmodule Satellite.Defaults do def default_pipeline() do [ {:read, :verb, &Satellite.Verb.parse/3, <<>>}, {:read, :path, &Satellite.Path.parse/3, {false, [], <<>>}}, {:read, :conn, &Satellite.Conn.parse/3, <<>>} ] end end
You can restart the shell, start again the
launchpad and visiting localhost should now show you the version as well in the struct.
Now we'll move to the headers part, add the following line to the
default_pipeline() (don't forget to add a comma on the previous last line)
{:read, :headers, &Satellite.Headers.parse/3, {:header, <<>>}}
And let's create the
apps/satellite/lib/satellite_headers.ex file, and place this on it:
defmodule Satellite.Headers do import Satellite.Shared, only: [downcase: 1] def parse(ctx, <<>>, acc), do: {:cont, ctx, acc} def parse(ctx, <<?:, rem::bits>>, {:header, key}), do: parse(ctx, rem, {:value, key, <<>>}) def parse(ctx, <<?\s, rem::bits>>, {:header, key}), do: parse(ctx, rem, {:header, key}) def parse(ctx, <<?\s, rem::bits>>, {:value, key, acc}), do: parse(ctx, rem, {:value, key, acc}) def parse(ctx, <<h, rem::bits>>, {:header, key}) do n_h = downcase(h) parse(ctx, rem, {:header, <<key::binary, n_h>>}) end def parse(ctx, <<?\r, rem::bits>>, {:header, _}) do parse(ctx, rem, {:in_termination, <<?\r>>}) end def parse(ctx, <<?\n, rem::bits>>, {:in_termination, <<?\r>>}) do parse(ctx, rem, {:in_termination, <<?\r,?\n>>}) end def parse(ctx, <<?\r, rem::bits>>, {:in_termination, <<?\r, ?\n>>}) do parse(ctx, rem, {:in_termination, <<?\r,?\n,?\r>>}) end def parse(ctx, <<?\n, rem::bits>>, {:in_termination, <<?\r, ?\n, ?\r>>}) do {:done, %{ctx | finished_headers: true}, rem} end def parse(ctx, <<h, rem::bits>>, {:in_termination, <<?\r, ?\n>>}) do n_h = downcase(h) parse(ctx, rem, {:header, <<n_h>>}) end def parse(%{headers: headers} = ctx, <<?\r, rem::bits>>, {:value, key, acc}) do value = translate_header_content(key, acc) n_ctx = %{ctx | headers: Map.put(headers, key, value)} parse(n_ctx, rem, {:in_termination, <<?\r>>}) end def parse(ctx, <<h, rem::bits>>, {:value, key, acc}) do n_h = case downcased_header?(key) do true -> downcase(h) _ -> h end parse(ctx, rem, {:value, key, <<acc::binary, n_h>>}) end def parse(_ctx, _, _), do: {:error, "Parsing headers"} def translate_header_content(<<"content-length">>, val) when is_binary(val) do :erlang.binary_to_integer(val) catch _ -> 0 end def translate_header_content(_, val), do: val def downcased_header?(<<"content-type">>), do: true def downcased_header?(<<"accept">>), do: true def downcased_header?(_), do: false end
Before doing some explanations, lets create/rewrite the
apps/satellite_shared/lib/satellite_shared.ex (it should be there unless you deleted it), and place this inside of it:
defmodule Satellite.Shared do use Bitwise, only_operators: true Enum.each(?A..?Z, fn(value) -> downcased = value ^^^ 32 def downcase(unquote(value)), do: unquote(downcased) end) def downcase(val), do: val end
So this module uses the
Bitwise macros, we specify we only want the
operators type, which are in the form of
^^^ (which is the same as using the
Bitwise.bxor(a, b)).
We use some simple macro magic to basically, at compile time, create a list of functions for all letters that can be uppercase that just return their downcased counterpart. We have then a catch all that just returns the arg passed into it as it is, because if it's being called the reason is the arg isn't an uppercased letter.
In erlang strings are lists of integers that are represented by their ascii code, so for instance
'A' is actually a list with one element, the integer
65, as in
[65]. When erlang sees a list that is composed only of printable ascii characters it actually prints them in the shell as characters! So if you write on the shell
[65, 66, 67], you'll see
'ABC'.
The elixir operator prefix
? before a character actually gives us the numeric code for that character. If you do
?A you'll see
65. So if you use a range such as
?A..?Z what will happen is that the range will be
65..90, which encompasses all the regular uppercase letters in the alphabet.
The ascii table design also has a very neat property when it comes to the alphabet letters, they're placed in such a way, that if you flip one single bit in them they become the other case, and that's what
value ^^^ 32 does, so if
?A is 65, when you do that bitwise operation of
bxor 32 on it it becomes 97, which is the ascii code for
a so effectively you downcased the character.
Knowing this we can see that basically we define all these functions with those 5 lines of code.
def downcase(65), do: 97 def downcase(66), do: 98 ... all other integers in the range def downcase(90), do: 122 def downcase(something_else), do: something_else
And there's it! A downcase function very succintly written that doesn't do any string work, assembled at compile time. Now, this only works with ascii letters, but that's fine, because that's what we need when parsing a request at this level. We would need to add other properties for when possibly parsing url encoded characters that aren't ascii, but that is left as an exercise.
You can now also see why we used
<<?some_character, ....>> in the pattern matching, basically it gives us the numeric code of the character and because binaries are at their inner structure integer sequences it works.
The headers
parse function on the other hand is again following the same logic as the previous ones, it starts with an accumulator of
{:header, <<>>}, and adds characters to the
<<>> until it runs into a
:, which signifies that the key for the header is finished, and then switches the accumulator to
{:value, previously_parsed_header, <<>>} which now accumulates characters until it runs into
\r which will be the ending sequence, so we change the acc to be
:in_termination mode, when followed by
\n indicates the header and its value has finished, if it's followed by another
\r\n sequence then it means all headers have been parsed, if it's not we know we're in another header key and we change to start accumulating the new header key and then value and then entering again the termination sequence until we hit
\r\n\r\n, and we're now done with the request unless it has a body too, which it won't in a
get request.
The headers keys should be case insensitive, so we always downcase them. We also add some logic for certain headers that we want their values to also be always downcased, namely
content-type and
accept. We could add additional ones or remove these if we wanted to. We also add a special case for the
content-length header in case it's present, before we set it in the request struct, we try to translate it into an integer value because that will be more useful if we wanted then to use the value to count how many bytes we need to parse or whatever.
If you restart the iex console and the launchpad, and then visit localhost you should see that now we also have the
headers key filled with all headers neatly mapped.
The same way we downcase the value for certain headers, we could also create, if wanted, a special white-list of header keys to be placed as :atoms in our headers map, but that would be confusing by mixing both atom and string keys so we won't worry with that now.
Let's add this new pipeline element to
apps/satellite/lib/satellite_defaults.ex
{:noread, :host, &Satellite.Host.set/2, nil}
And create the respective module in
apps/satellite/lib/satellite_host.ex with the following content:
defmodule Satellite.Host do import Satellite.Shared, only: [downcase: 1] def set(%{headers: headers} = ctx, _) do host = Map.get(headers, "host", "") {:ok, %{ctx | host: split_host(host)}} end def split_host(val), do: split_host(val, <<>>, []) def split_host(<<>>, segment, acc), do: Enum.reverse([segment | acc]) def split_host(<<?., rem::bits>>, segment, acc), do: split_host(rem, <<>>, [segment | acc]) def split_host(<<?:, _::bits>>, segment, acc), do: Enum.reverse([segment | acc]) def split_host(<<h, rem::bits>>, segment, acc) do n_h = downcase(h) split_host(rem, <<segment::binary, n_h>>, acc) end def split_host(_, _, _), do: [] end
This step in the pipeline is new, so we also have to implement our handle_event for this particular case.
Place this
handle_event function between the existing
...:internal, :wait and
...:internal, :read, the order in which these appear is important, because otherwise, if this was after the
:internal, :read that would be the one being matched and it would hang and timeout waiting for new data on the socket, since it doesn't care about which state we're in. By placing this one before, we actually make it so that when the state is of type
{:noread, ....} it will be called instead of anything else.
def handle_event(:internal, event, {:noread, _name, fun, acc}, %{request: request} = data) do case fun.(request, acc) do {:ok, n_request} -> set_next_step(%{data | request: n_request}, {:event, event}) {:error, reason} -> {:next_state, :response, %{data | request: "Error: #{inspect reason}"}, [{:next_event, :internal, :send_response}]} end end
Now, the
event that is matched as the second argument already contains either
{:parse, data} or
:read as its event, so we will pass the remaining to
set_next_step as a new type of tuple,
{:event, event} and change our
set_next_step function to account for this new type by changing it to:
defp set_next_step(%{pipeline: [h | t]} = data, remaining) do event = case remaining do <<>> -> :read {:event, event} -> event _ -> {:parse, remaining} end {:next_state, h, %{data | pipeline: t}, [{:next_event, :internal, event}]} end
This way, it sets the already existing defined event as the next one.
Let's restart iex and launchpad and make sure its still working, we should now see the host key populated as well. Again, we're setting it as a list, instead of a plain string, because, imagine we would want to distinguish between requests in our router that went to a certain subdomain, by having it as a list split by the periods, we will be able to easily encode that logic in our dispatcher/router, which is not evident when you only see a list with a single element
["localhost"], but if it was
["mysubdomain", "domain", "com"] things change, the same if we wanted to have localised logic pertaining to the top domain, then it becomes more evident why it's a good idea.
Next on the pipeline will be this:
{:noread, :accept, &Satellite.Accept.set/2, nil}
Since we already wrote the handle for the
:noread case we just need to write a module at
apps/satellite/lib/satellite_accept.ex with:
defmodule Satellite.Accept do def extract(%{headers: headers} = ctx, _) do {:ok, %{ctx | accept: extract_accept(headers)}} end def extract_accept(%{"accept" => <<"application/json", _::bits>>}), do: :json def extract_accept(%{"accept" => <<"text/html", _::bits>>}), do: :html def extract_accept(_), do: :any end
Now this is very basic, perhaps we would like to do as we did with paths and hosts to split all accepted content-types and create a list of that that we could further match down the road but for now this will do, if the first characters of the header are
application/json or
text/html we set it to
:json or
:html respectively, anything else we set to
:any (which is obviously incorrect, but we would also need to set up mimes and… we'll leave it for a future occasion).
Restart iex and the launchpad, you should now see the
accept key also populated.
We're getting closer to finishing our first version of our server. Add this new step to the pipeline:
{:check, :check_request_type, &Satellite.Check.check/2, nil}
And create
apps/satellite/lib/satellite_check.ex with:
defmodule Satellite.Check do def check(%{verb: :get} = ctx, _), do: {:dispatch, ctx} def check(%{verb: :post} = ctx, _), do: {:next, ctx} def check(ctx, _), do: {:dispatch, ctx} end
This of course is not enough to cover everything an http request might have, but is enough for our sample, if it's a
get request we'll immediately run the not yet written
dispatch event and if it's a
post we will actually want to continue parsing. Now we need to write the corresponding handling for this event with those possible return values on our
satellite.ex gen_statem:
def handle_event(:internal, event, {:check, _name, fun, acc}, %{request: request} = data) do case fun.(request, acc) do {:next, n_request} -> set_next_step(%{data | request: n_request}, {:event, event}) {:dispatch, n_request} -> {:next_state, :dispatching, %{data | request: n_request}, [{:next_event, :internal, :dispatch}]} {:response, resp} -> {:next_state, :response, %{data | request: resp}, [{:next_event, :internal, :send_response}]} {:error, reason} -> {:next_state, :response, %{data | request: "Error, #{inspect reason}"}, [{:next_event, :internal, :send_response}]} end end
Again this needs to be placed before the
handle_event(:internal, :read.....) function. There's some things we haven't implemented yet, like the
:dispatch event and in the
{:error, ...} or
{:response, ...} we're just doing a very silly thing, so to correct that we will now work on the router and afterwards implement the request dispatcher and lastly the body parsing step. If we restart the shell and
launchpad we'll now hit an error when visiting the page because the next event
:dispatch isn't implemented yet.
For the router we'll use some of elixir's macro magic. Macros have some complexity but also allow us to write some really useful code. We'll try to not abuse their usage and basically write code that is still readable, with the main difference being it's written to be run at compile time. I'm no expert in elixir macros, so I won't explain everything (there's much I don't understand also), but basically they allow you to define AST code to be used in code generation at compile time.
What we want to achieve is the ability to create a module and then be able to write:
route "get", "/some/:path", AnotherModule, :a_function
(just like Phoenix does for us, but our version will be very plain and lacking many other features)
And with this create a route that accepts a
get request, on a path composed by
/some/*anything* and calls a
:a_function on
AnotherModule passing it the parsed request, and in the process setting a variable in the params with key
:path set to the whatever was the second segment of that path.
So we want to accept literal paths, path segments to be bound to a named key (prefixed by
:), or any segment (
*). We also want for each route to be able to accept optionally a host/domain to be matched, defaulting to
* (any), and again offering the possibility of binding those parts of the domain to named keys in the params map that will be populated in the request. Create the file
apps/satellite/lib/satellite_routing.ex and place in it:
defmodule Satellite.Routing do defmacro __using__(_opts) do quote do import Satellite.Routing @before_compile Satellite.Routing end end defmacro route(verb, path, module, function, domain \\ "*") do verb_atom = String.to_atom(String.downcase(verb)) {path_splitted, vars} = split_path(path) {domain_splitted, domain_vars} = split_domain(domain) all_vars = vars ++ domain_vars quote do def route(unquote(verb_atom), unquote(path_splitted), unquote(domain_splitted), %{params: params} = request) do ctx = %{ request | params: Enum.reduce(unquote(all_vars), params, fn({key, var}, acc) -> Map.put(acc, key, Macro.escape(var)) end) } apply(unquote(module), unquote(function), [ctx]) end end end defp split_path(path) do case String.split(path, "/", trim: true) do ["*"] -> {(quote do: _), []} split -> Enum.reduce(split, {[], []}, fn ("*", {acc1, acc2}) -> {[(quote do: _) | acc1], acc2} (<<?:, rem::binary>>, {acc1, acc2}) -> {[Macro.var(String.to_atom(rem), nil) | acc1], [{String.to_atom(rem), Macro.var(String.to_atom(rem), nil)} | acc2]} (other, {acc1, acc2}) -> {[other | acc1], acc2} end) |> case do {paths, vars} -> {Enum.reverse(paths), Enum.reverse(vars)} end end end defp split_domain(domain) do case String.split(domain, ".", trim: true) do ["*"] -> {(quote do: _), []} [<<?:, rem::binary>>] -> host_var = String.to_atom("host_#{rem}") {Macro.var(host_var, nil), [{host_var, Macro.var(host_var, nil)}]} split -> Enum.reduce(split, {[], []}, fn ("*", {acc1, acc2}) -> {[(quote do: _) | acc1], acc2} (<<?\\, rem::binary>>, {acc1, acc2}) -> {[rem | acc1], acc2} (<<?:, rem::binary>>, {acc1, acc2}) -> host_var = String.to_atom("host_#{rem}") {[Macro.var(host_var, nil) | acc1], [{host_var, Macro.var(host_var, nil)} | acc2]} (other, {acc1, acc2}) -> {[other | acc1], acc2} end) |> case do {paths, vars} -> {Enum.reverse(paths), Enum.reverse(vars)} end end end defmacro __before_compile__(_env) do quote do def route(_, _, _, _ctx) do Satellite.Response.not_found() end end end end
We start by defining a
__using__ macro. This is a special macro definition that then allows us to write
use Name_of_the_module_where_the_using_is_defined and it automatically makes the contents of block available in that module.
This
__using__ does only two things, it imports the module to where it is invoked and sets a hook to be run before that module that calls
use is compiled.
Then we define our actual
route macro. This macro accepts 4 or 5 arguments, defaulting the last one to
"*" (the domain). It takes the verb to match, the path, the module to call, and the function in that module to call and, optionally a domain string to match.
With this info it makes some transformations, the verb to an atom (to match what our parser creates), splits the
path into its own individual segments - it does this by a regular function, and with help of
Macro.var creates representations for
variables -
this is what allows us to actually transform a segment such as
:something, into a variable in the function definition, and then use that and the parsed named to set a key in the params map with the value that that variable will be bound to when ran at runtime. Since this is creating a AST representation of code it doesn't have any values right now, it just has a "representation" of what that code will be when run -
and does the same for the domain. On the splitting functions, you can see that we treat the
"*" match in the domain and path in a special way when it's the only segment. Because if we treated it as other segments, the generated code would look like
[ _ ]. If then someone did a request and our host was
host.domain.com, this would be split into
["host", "domain", "com"], and that wouldn't match a list with a single value like
[ _ ], so we need to treat it specially so that the whole thing is simply
_, this way it matches anything like the wildcard actually means, either
["localhost"], or
["some", "domain", "com"].
Then, because we do
quote do and inside it define a function, when the macro is called from some other module, what will actually happen is that this function definition we're creating is written in that module with the arguments we prepared.
So let's say again we have this module:
defmodule Test.Router do use Satellite.Routing route "get", "/some/:path", AnotherModule, :a_function end
(the route macro could be written as
route("get", "/some/:path", AnotherModule, :a_function), but we can omit parenthesis and in this case it makes it look more declarative, like the Phoenix Router).
When elixir compiles this particular module with that sample code, what actually ends up being defined is
defmodule Test.Router do def route(:get, ["some", path], _, %{params: params} = request) do ctx = %{ request | params: Enum.reduce([{:path, ast_representation_of_the_var_variable}], params, fn({key, var}, acc) -> Map.put(acc, key, var) end) } apply(AnotherModule, :a_function, [ctx]) end def route(_, _, _, _ctx), do: Satellite.Response.not_found() end
The last
route definition comes from the
@before_compile Satellite.Routing declaration in the
__using__ macro, which basically allows us to run that macro function that defines that route, after the other macros have been run, but before compilation, so they end up having the correct order.
We can see how we can use this in our
satellite gen_statem to dispatch the requests since we have the verb, the path and domain neatly decomposed into segments from the parsing we do in the pipeline.
So now we need to change our
satellite.ex file. The changes are mostly self-evident but to prevent errors I'm just going to past the full contents of the file as it should be:
defmodule Satellite do @behaviour :gen_statem alias Satellite.{Request, Response} defstruct [:socket, :config, :conn, :response, :router,: %{router: router, pipeline: pipeline}} = data) do {:ok, conn} = :gen_tcp.accept(socket) :gen_tcp.controlling_process(conn, self()) n_data = %{data | conn: conn, router: router, pipeline: pipeline, request: %Request{}} set_next_step(n_data, <<>>) end def handle_event(:internal, event, {:noread, _name, fun, acc}, %{request: request} = data) do case fun.(request, acc) do {:ok, n_request} -> set_next_step(%{data | request: n_request}, {:event, event}) {:error, reason} -> response = Response.error_resp("#{inspect reason}") {:next_state, :response, %{data | response: response}, [{:next_event, :internal, :send_response}]} end end def handle_event(:internal, event, {:check, _name, fun, acc}, %{request: request} = data) do case fun.(request, acc) do {:next, n_request} -> set_next_step(%{data | request: n_request}, {:event, event}) {:dispatch, n_request} -> {:next_state, :dispatching, %{data | request: n_request}, [{:next_event, :internal, :dispatch}]} {:response, response} -> {:next_state, :response, %{data | response: response}, [{:next_event, :internal, :send_response}]} {:error, reason} -> response = Response.error_resp("#{inspect reason}") {:next_state, :response, %{data | response: response}, [{:next_event, :internal, :send_response}]} end end def handle_event(:internal, :read, _, %{conn: conn} = data) do case :gen_tcp.recv(conn, 0, 1000) do {:ok, packet} -> IO.inspect(packet, label: "packet") {:keep_state_and_data, [{:next_event, :internal, {:parse, packet}}]} {:error, reason} -> response = Response.error_resp("#{inspect reason}") {:next_state, :response, %{data | response: response}, [{:next_event, :internal, :send_response}]} end end def handle_event(:internal, {:parse, packet}, {type, name, fun, acc}, %{request: request} = data) do case fun.(request, packet, acc) do {:cont, n_request, n_acc} -> IO.inspect({:cont, n_request, n_acc}) {:next_state, {type, name, fun, n_acc}, %{data | request: n_request}, [{:next_event, :internal, :read}]} {:done, n_request, remaining} -> IO.inspect({:done, n_request, remaining}) set_next_step(%{data | request: n_request}, remaining) {:error, reason} -> response = Response.error_resp("#{inspect reason}") {:next_state, :response, %{data | response: response}, [{:next_event, :internal, :send_response}]} end end def handle_event(:internal, :dispatch, :dispatching, %{request: request, conn: conn, router: router} = data) do try_dispatch(conn, router, request) {:next_state, :waiting, %{data | conn: nil}, [{:next_event, :internal, :wait}]} end def handle_event(:internal, :send_response, :response, %{conn: conn, response: response} = data) do try_send_response(conn, response) {:next_state, :waiting, %{data | conn: nil}, [{:next_event, :internal, :wait}]} end def handle_event(:internal, :close, _, %{conn: conn} = data) do :gen_tcp.close(conn) {:next_state, :waiting, %{data | conn: nil}, [{:next_event, :internal, :wait}]} end defp set_next_step(%{pipeline: [h | t]} = data, remaining) do event = case remaining do <<>> -> :read {:event, event} -> event _ -> {:parse, remaining} end {:next_state, h, %{data | pipeline: t}, [{:next_event, :internal, event}]} end defp set_next_step(%{pipeline: []} = data, _remaining) do {:next_state, :dispatching, data, [{:next_event, :internal, :dispatch}]} end defp try_dispatch(conn, router, %{verb: verb, path: path, host: host} = request) do case apply(router, :route, [verb, path, host, request]) do response -> try_send_response(conn, response) end rescue e -> try_send_response(conn, Response.error_resp()) end defp try_send_response(conn, %Response{} = response) do n_response = Response.make_resp(response) send_response(conn, n_response) after :gen_tcp.close(conn) end defp try_send_response(conn, response) when is_binary(response) do send_response(conn, response) after :gen_tcp.close(conn) end defp send_response(conn, response) do :gen_tcp.send(conn, response) end end
And we need to define also, a module to handle responses, create a file
apps/satellite/lib/satellite_response.ex with:
defmodule Satellite.Response do defstruct [code: 200, headers: [{<<"content-type">>, <<"text/html">>}], body: <<>>] @codes [{200, "OK"}, {404, "Not Found"}, {500, "Internal Server Error"}] def make_resp( %__MODULE__{ code: code, headers: headers, body: body } ) do code_prep = make_code(code) headers_prep = map_headers(headers) {n_body, content_length_prep} = create_length(body) <<"HTTP/1.0 ", code_prep::binary, "\n", headers_prep::binary, content_length_prep::binary, "\n", n_body::binary>> end defp map_headers(headers), do: map_headers(headers, <<>>) defp map_headers([{header, value} | t], acc), do: map_headers(t, <<acc::binary, header::binary, ": ", value::binary, "\n">>) defp map_headers([], acc), do: acc defp create_length(nil), do: {<<>>, <<"content-length: 0">>} defp create_length(<<>>), do: {<<>>, <<"content-length: 0">>} defp create_length(body) do size = :erlang.integer_to_binary(:erlang.size(body)) {body, <<"content-length: ", size::binary, "\n">>} end Enum.each(@codes, fn({code, val}) -> string_v = Integer.to_string(code) atom_v = String.to_atom(string_v) defp make_code(unquote(code)), do: <<unquote(string_v)::binary, " ", unquote(val)::binary>> defp make_code(unquote(string_v)), do: <<unquote(string_v)::binary, " ", unquote(val)::binary>> defp make_code(unquote(atom_v)), do: <<unquote(string_v)::binary, " ", unquote(val)::binary>> end) def error_resp(body \\ "Internal Server Error") do %__MODULE__{code: 500, headers: [{<<"content-type">>, <<"text/html">>}], body: body} end def not_found(body \\ "Not Found") do %__MODULE__{code: 404, headers: [{<<"content-type">>, <<"text/html">>}], body: body} end end
And lastly, just to test that everything goes according to plan, lets create a test router and a controller for it.
apps/satellite/lib/test_router.ex:
defmodule Test.Router do use Satellite.Routing route "get", "/", Test.Controller, :test route "get", "/:any/oi/:some", Test.Controller, :test2, "*" route "get", "*", Test.Controller, :test3 route "post", "/data", Test.Controller, :test4 end defmodule Test.Controller do def test(request) do %Satellite.Response{body: "this is the root path, nothing to see here"} |>} = request) do>, <<"application/json">>}]} |> Satellite.Response.make_resp() end end
Since we'll also want to test
post requests and we'll use
Jason to encode JSON, we might as well go ahead and add the last bit to our pipeline, the body parser. Right now we'll only do it for JSON.
On
apps/satellite/lib/satellite_defaults.ex add the following
{:read, :body, &Satellite.Body.parse/3, {0, <<>>}}
The full pipeline should now look like:
defmodule Satellite.Defaults do def default_pipeline() do [ {:read, :verb, &Satellite.Verb.parse/3, <<>>}, {:read, :path, &Satellite.Path.parse/3, {false, [], <<>>}}, {:read, :conn, &Satellite.Conn.parse/3, <<>>}, {:read, :headers, &Satellite.Headers.parse/3, {:header, <<>>}}, {:noread, :host, &Satellite.Host.set/2, nil}, {:noread, :accept, &Satellite.Accept.set/2, nil}, {:check, :check_request_type, &Satellite.Check.check/2, nil}, {:read, :body, &Satellite.Body.parse/3, {0, <<>>}} ] end end
(note: we kept it as tuples, because tuples are the fastest way to access something, if in erlang we would use
Records which are still tuples underneath and in Elixir we would use proper structs to encode this, something like
%Satellite.Step{mode: :read, name: :verb, fun: &Satellite.Verb.parse/3, acc: <<>>}, this would be much more structured, specially with
@enforce_keys we could give some guarantees on when placing a step in the pipeline but that's all out of scope for this tutorial)
And create the file
apps/satellite/lib/satellite_body.ex:
defmodule Satellite.Body do def parse(%{verb: :post, headers: headers} = request, rem, {count, acc}) do n_size = count + :erlang.size(rem) case headers do %{<<"content-length">> => 0} -> {:done, request, <<>>} %{<<"content-length">> => ^n_size} -> case parse_content(headers, <<acc::binary, rem::binary>>) do {:ok, decoded} -> {:done, %{request | body: decoded}, <<>>} {:error, error} -> {:error, error} end _ -> {:cont, request, {n_size, <<acc::bits, rem::bits>>}} end end def parse(request, _, _), do: {:done, request, <<>>} def parse_content(%{<<"content-type">> => <<"application/json">>}, rem) do Jason.decode(rem) catch e -> {:error, e} end end
Lastly, we need to add Jason as a dependency so we can use it, on
apps/satellite/mix.exs change your
deps function to this:
defp deps do [ {:satellite_shared, in_umbrella: true}, {:jason, "~> 1.0"} ] end
After that, save the file, quit the shell and do:
mix deps.get
This will install the dependencies.
With this in place, let's exit the shell, restart it with
iex -S mix run and then do
Launchpad.start_link(%Satellite.Configuration{router: Test.Router})
Now visit, and
You should see the correct ouput in the browser.
Now to test
posts we'll use
curl with the
-v flag (verbose) option to see if it works. Open a new terminal window (but don't close the one running the server ofc), and execute:
curl -v -d '{"key1":"value1", "key2":"value2"}' -H "Content-Type: application/json" -X POST
You should see an output of the request details, finished by:
* upload completely sent off: 34 out of 34 bytes * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < content-type: application/json < content-length: 42 < Parsed: {"key1":"value1","key2":"value2"} Closing connection 0
If you try:
curl -v -d 'oiioi' -H "Content-Type: application/json" -X POST
You should see instead:
%Jason.DecodeError{data: "oiioi", position: 0, token: nil} as the response, which is the error from trying to parse invalid json
"oiioi". Of course this is also not how it should in reality be implemented, it should not leak the details of what is wrong internally, but we wrote it in such a way to illustrate that although the request raised an error, it was still answered.
Now one last thing is to see if we can use this on another app. So let's remove the file
apps/satellite/lib/test_router.ex, go outside the folder of the umbrella and create a new app, with
mix new test_satellitex --sup
Then add to
test_satellitex/lib two files,
router.ex and
controller.ex, on
router.ex add:
defmodule Router do use Satellite.Routing route "get", "/", Controller, :test route "get", "/:any/oi/:some", Controller, :test2, "*" route "get", "*", Controller, :test3 route "post", "/data", Controller, :test4 end
And on
controller.ex add:
defmodule Controller do def test(request) do %Satellite.Response{body: "#{inspect request}"} |>}) do>, <<"application/json">>}]} |> Satellite.Response.make_resp() end end
On
test_satellitex/mix.exs change the deps to:
defp deps do [ {:satellitex, path: "../satellitex"} ] end
(assuming you created the
test_satellitex app on the same folder level as
satellitex, if not change the relative path accordingly).
We're using a local path just to test, in a real situation this would be either in git or hex and you would use either a git path or a normal dep definition.
Save the file, and edit
test_satellitex/lib/test_satellitex/application.ex to:
defmodule TestSatellitex.Application do @moduledoc false use Application def start(_type, _args) do children = [ Supervisor.child_spec(%{id: Server1, start: {Launchpad, :start_link, [%Satellite.Configuration{router: Router}]}}, type: :worker) ] opts = [strategy: :one_for_one, name: TestSatellitex.Supervisor] Supervisor.start_link(children, opts) end end
Then from the root dir of this app do
mix deps.get to install the dependencies.
And then start it with:
iex -S mix run
And you should have a running server on another application.
And that's it! This post is already gigantic, so we'll stop here. It's very, very far from being a compliant http server, there's many things missing but the general structure is laid out, about what is missing:
- parsing cookies!
- serving static assets
- appropriate response handlers for different formats other than html/json
- mime support
- html full range of response codes
- http protocol version negotiation
- ssl/tls
- websockets
- another type of callback in our gen_statem besides
:read,
:noreadand
:check, probably named
:connectionwhere the called function receives the request and the socket itself, so if wanted it could retrieve information from the socket such as the peer_address (ip address of whoever is making the request, amongst other things) - this would allow to easily create a rate-limiter as the first step of the pipeline, if wanted without actually reading anything from the socket
- preparing templates & "views" to send as responses
- defining the pipeline elements as behaviours so that it would be easier to understand what you need to do to have a "compliant" pipeline step created
And many of those are really grunt work, extensive research (reading the RFC's and making the implementation be spec compliant) and/or tricky to implement correctly, so hopefully, besides having learned some things about gen_statems, erlang and elixir it also increased your appreciation for the existing libraries that do all of this, correctly and efficiently and available for free!
|
https://micaelnussbaumer.com/programming/elixir/2019/09/14/a-basic-http-server-in-elixir.html
|
CC-MAIN-2021-25
|
refinedweb
| 12,968
| 58.92
|
A recent Stack Overflow survey found that many developers loved using or wanted to develop with the Rust language. That’s an incredible number! So, what’s so good about Rust? This article explores the high points of this
C-like language and illustrates why it should be next on your list of languages to learn.
Rust and its genealogy
First, let’s start with a quick history lesson. Rust is a new language relative to its predecessors (most importantly
C, which preceded it by 38 years), but its genealogy creates its multiparadigm approach. Rust is considered a
C-like language, but the other features it includes create advantages over its predecessors (see Figure 1).
First, Rust is heavily influenced by Cyclone (a safe dialect of
C and an imperative language), with some aspects of object-oriented features from
C++. But, it also includes functional features from languages like Haskell and OCaml. The result is a
C-like language that supports multiparadigm programming (imperative, functional, and object oriented).
Figure 1. Rust and its family tree
Key concepts in Rust
Rust has many features that make it useful, but developers and their needs differ. I cover five of the key concepts that make Rust worth learning and show these ideas in Rust source.
First, to get a feel for the code, let’s look at the canonical “Hello World” program that simply emits that message to the user (see Listing 1).
Listing 1. “Hello World” in Rust
fn main() { println!( "Hello World."); }
This simple program, similar to
C, defines a main function that is the designated entry point for the program (and every program has one). The function is defined with the
fn keyword followed by an optional set of parameters within parentheses (
()). The curly braces (
{}) delineate the function; this function consists of a call to the
println! macro, which emits formatted text to the console (
stdout), as defined by the string parameter.
Rust includes a variety of features that make it interesting and worth the investment to learn. You’ll find concepts like modules for reusability, memory safety and guarantees (safe vs. unsafe operations), unrecoverable and recoverable error handling features, support for concurrency, and complex data types (called collections).
Reusable code via modules
Rust allows you to organize code in a way that fosters its reuse. You achieve this organization by using modules, which contain functions, structures, and even other modules that you can make public (that is, expose to users of the module) or private (that is, use only within the module and not by the module users — at least not directly). The module organizes code as a package that others can use.
You use three keywords to create modules, use modules, and modify the visibility of elements in modules.
- The
modkeyword creates a new module
- The
usekeyword lets you use the module (expose the definitions into scope to use them)
- The
pubkeyword makes elements of the module public (otherwise, they’re private).
Listing 2 provides a simple example. It starts by creating a new module called
bits that contains three functions. The first function, called
pos, is a private function that takes a
u32 argument and returns a
u32 (as indicated by the
-> arrow), which is a 1 value shifted left
bit times. Note that a
return keyword isn’t needed here. This value is called by two public functions (note the
pub keyword):
decimal and
hex. These functions call the private
pos function and print the value of the bit position in decimal or hexadecimal format (note the use of
:x to indicate hexadecimal format). Finally, it declares a
main function that calls the
bits module’s two public functions, with the output shown at the end of Listing 2 as comments.
Listing 2. Simple module example in Rust
mod bits { fn pos(bit: u32) ‑> u32 { 1 << bit } pub fn decimal(bit: u32) { println!("Bits decimal {}", pos(bit)); } pub fn hex(bit: u32) { println!("Bits decimal 0x{:x}", pos(bit)); } } fn main( ) { bits::decimal(8); bits::hex(8); } // Bits decimal 256 // Bits decimal 0x100
Modules enable you to collect functionality in public or private ways, but you can also associate methods to objects by using the
impl keyword.
Safety checks for cleaner code
The Rust compiler enforces memory safety guarantees and other checking that make the programming language safe (unlike
C, which can be unsafe). So, in Rust, you’ll never have to worry about dangling pointers or using an object after it has been freed. These things are part of the core Rust language. But, in fields such as embedded development, it’s important to do things like place a structure at an address that represents a set of hardware registers.
Rust includes an
unsafe keyword with which you can disable checks that would typically result in a compilation error. As shown in Listing 3, the
unsafe keyword enables you to declare an unsafe block. In this example, I declare an unmutable variable
x, and then a pointer to that variable called
raw. Then, to de-reference
raw (which in this case would print 1 to the console), I use the
unsafe keyword to permit this operation, which would otherwise be flagged at compilation.
Listing 3. Unsafe operations in Rust
fn main() { let a = 1; let rawp = &a as const i32; unsafe { println!("rawp is {}", rawp); } }
You can apply the
unsafe keyword to functions as well as blocks of code within a Rust function. The keyword is most common in writing bindings to non-Rust functions. This feature makes Rust useful for things like operating system development or embedded (bare-metal) programming.
Better error handling
Errors happen, regardless of the programming language you use. In Rust, errors fall into two camps: unrecoverable errors (the bad kind) and recoverable errors (the not-so-bad kind).
Unrecoverable errors
The Rust
panic! function is similar to
C‘s
assert macro. It generates output to help the user debug a problem (as well as stopping execution before more catastrophic events occur). The
panic! function is shown in Listing 4, with its executable output in comments.
Listing 04. Handling unrecoverable errors in Rust with panic!
fn main() { panic!("Bad things happening."); } // thread 'main' panicked at 'Bad things happening.', panic.rs:2:4 // note: Run with RUST_BACKTRACE=1 for a backtrace.
From the output, you can see that the Rust runtime indicates exactly where the issue occurred (line 2) and emitted the provided message (which could emit more descriptive information). As indicated in the output message, you could generate a stack backtrace by running with a special environment variable called
RUST_BACKTRACE. You can also invoke
panic! internally based on detectable errors (such as accessing an invalid index of a vector).
Recoverable errors
Handling recoverable errors is a standard part of programming, and Rust includes a nice feature for error checking (see Listing 5). Take a look at this feature in the context of a file operation. The
File::open function returns a type of
Result<T, E>, where T and E represent generic type parameters (in this context, they represent
std::fs::File and
std::io::Error). So, when you call
File::open and no error has occurred (
E is
Ok),
T would represent the return type (
std::fs::File). If an error occurred,
E would represent the type of error that occurred (using the type
std::io::Error). (Note that my file variable
_f uses an underscore [
_] to omit the unused variable warning that the compiler generated.)
I then use a special feature in Rust called
match, which is similar to the
switch statement in
C but more powerful. In this context, I match
_f against the possible error values (
Ok and
Err). For
Ok, I return the file for assignment; for
Err, I use
panic!.
Listing 5. Handling recoverable errors in Rust with Result<t, e>
use std::fs::File; fn main() { let _f = File::open("file.txt"); let _f = match _f { Ok(file) => file, Err(why) => panic!("Error opening the file {:?}", why), }; } // thread 'main' panicked at 'Error opening the file Error { repr: Os // { code: 2, message: "No such file or directory" } }', recover.rs:8:23 // note: Run with RUST_BACKTRACE=1 for a backtrace.
Recoverable errors are simplified within Rust when you use the
Result enum; they’re further simplified through the use of
match. Note also in this example the lack of a
File::close operation: The file is automatically closed when the scope of
_f ends.
Support for concurrency and threads
Concurrency commonly comes with issues (data races and deadlocks, to name two). Rust provides the means to spawn threads by using the native operating system but also attempts to mitigate the negative effects of threading. Rust includes message passing to allow threads to communicate with one another (via
send and
recv as well as locking through mutexes). Rust also provides the ability to permit a thread to borrow a value, which gives it ownership and effectively transitions the scope of the value (and its ownership) to a new thread. Thus, Rust provides memory safety along with concurrency without data races.
Consider a simple example of threading within Rust that introduces some new elements (vector operations) and brings back some previously discussed concepts (pattern matching). In Listing 6, I begin by importing the
thread and
Duration namespaces into my program. I then declare a new function called
my_thread, which represents the thread that I’ll create later. In this thread, I simply emit the thread’s identifier, and then sleep for a short time to permit the scheduler to allow another thread to run.
My
main function is the heart of this example. I begin by creating an empty mutable vector that I can use to store values of the same type. I then create 10 threads by using the
spawn function and push the resulting join handle into the vector (more on this later). This
spawn example is detached from the current thread, which allows the thread to live after the parent thread has exited. After emitting a short message from the parent thread, I finally iterate the vector of
JoinHandle types and wait for each child thread to exit. For each
JoinHandle in the vector, I call the
join function, which waits for that thread to exit before continuing. If the
join function returns an error, I’ll expose that error through the
match call.
Listing 6. Threads in Rust
use std::thread; use std::time::Duration; fn mythread() { println!("Thread {:?} is running", std::thread::current().id()); thread::sleep(Duration::from_millis(1)); } fn main() { let mut v = vec![]; for _i in 1..10 { v.push( thread::spawn(|| { my_thread(); } ) ); } println!("main() waiting."); for child in v { match child.join() { Ok() => (), Err(why) => println!("Join failure {:?}", why), }; } }
On execution, I see the output provided in Listing 7. Note here that the main thread continued to execute until the join process had begun. The threads then executed and exited at different times, identifying the asynchronous nature of threads.
Listing 7. Thread output from the example code in Listing 6
main() waiting. Thread ThreadId(7) is running Thread ThreadId(9) is running Thread ThreadId(8) is running Thread ThreadId(6) is running Thread ThreadId(5) is running Thread ThreadId(4) is running Thread ThreadId(3) is running Thread ThreadId(2) is running Thread ThreadId(1) is running
Support for complex data types (collections)
The Rust standard library includes several popular and useful data structures that you can use in your development, including four types of data structures: sequences, maps, sets, and a miscellaneous type.
For sequences, you can use the vector type (
Vec), which I used in the threading example. This type provides a dynamically resizeable array and is useful for collecting data for later processing. The
VecDeque structure is similar to
Vec, but you can insert it at both ends of the sequence. The
LinkedList structure is similar to
Vec, as well, but with it, you can split and append lists.
For maps, you have the
HashMap and
BTreeMap structures. You use the
HashMap structure to create key-value pairs, and you can reference elements by their key (to retrieve the value). The
BTreeMap is similar to the
HashMap, but it can sort the keys, and you can easily iterate all the entries.
For sets, you have the
HashSet and
BTreeSet structures (which you’ll note follow the maps structures). These structures are useful when you don’t have values (just keys) and you easily recall the keys that have been inserted.
Finally, the miscellaneous structure is currently the
BinaryHeap. This structure implements a priority queue with a binary heap.
Installing Rust and its tools
One of the simplest ways to install Rust is by using
curl through the installation script. Simply execute the following string from the Linux® command line:
curl -sSf | sh
This string transfers the
rustup shell script from rust-lang.org, and then passes the script to the shell for execution. When complete, you can execute
rustc -v to show the version of Rust you installed. With Rust installed, you can maintain it by using the
rustup utility, which you can also use to update your Rust installation.
The Rust compiler is called
rustc. In the examples shown here, the build process is simply defined as:
rustc threads.rs
…where the rust compiler produces a native executable file called
threads. You can symbolically debug Rust programs by using either
rust-lldb or
rust-gdb.
You’ve probably noticed that the Rust programs I’ve demonstrated here have a unique style. You can learn this style through the automatic Rust source formatting by using the
rustfmt utility. This utility, executed with a source file name, will automatically format your source in a consistent, standardized style.
Finally, although Rust is quite strict in what it accepts for source, you can use the
rust-clippy program to dive further in to your source to identify elements of bad practice. Think of
rust-clippy as the
C lint utility.
Windows considerations
On Windows, Rust additionally requires the
C++ build tools for Visual Studio 2013 or later. The easiest way to acquire the build tools is by installing Microsoft Visual C++ Build Tools 2017 which provides just the Visual C++ build tools. Alternately, you can install Visual Studio 2017, Visual Studio 2015, or Visual Studio 2013 and during the install, select C++ tools.
For further information about configuring Rust on Windows, see the Windows-specific rustup documentation.
Going further
In mid-February 2018, the Rust team released version 1.24. This version includes incremental compilation, automatic source formatting with
rustfmt, new optimizations, and library stabilizations. You can learn more about Rust and its evolution at the Rust blog and download Rust from the Rust Language website. There, you can read about the many other features Rust offers, including pattern matching, iterators, closures, and smart pointers.
|
https://developer.ibm.com/articles/os-developers-know-rust/
|
CC-MAIN-2021-25
|
refinedweb
| 2,476
| 62.78
|
I'm having a bit of trouble with this one, the goal of this program is to enter in 1 to 5 numbers, with a maximum of 5, into a vector and then popping as many numbers as the user wants until the vector contains nothing. My problem is that I can't figure out how to print out the numbers contained in the vector. I also am thinking about putting something in to detect whether or not there is anything in the vector so that the user doesn't crash the program. Any ideas on how I can solve these two problems?
#include <iostream> #include <vector> using namespace std; int main() { int addnums; int index; char selection; int counter = 0; vector<int> values; values.push_back(1); values.push_back(2); values.push_back(3); values.push_back(4); values.push_back(5); do { cout << "How many entries would you like to add (up to 5): "; cin >> addnums; if (addnums <= 5) { for (index = 0; index < addnums; index++) { int tempnums; cout << "Enter integer " << (index + 1) << ": "; cin >> tempnums; values.push_back(tempnums); counter++; } } if (addnums >= 6) { cout << "Please choose a number in the range of 1 and 5\n\n"; } else break; }while (counter != addnums); do { cout << "Press E to End or Press P to pop a value: "; cin >> selection; if(selection == 'p' || selection == 'P') { cout << "The integer you popped was: " ; << values.begin(); values.erase (values.begin()); } else break; }while(selection == 'p' || selection == 'P'); return 0; }
|
https://www.daniweb.com/programming/software-development/threads/195673/trouble-printing-ints-from-a-vector
|
CC-MAIN-2018-51
|
refinedweb
| 239
| 55.58
|
A central function that takes a key as an arg would be able to tell what config options changed.
Although that may be to much. Even a general notification that a config change has occured
in a modules "namespace" would do the trick.
...dale
------Original Message------
From: Ben Laurie <ben@algroup.co.uk>
Much as I like the idea of notifying config changes, I think it is
likely to lead to trouble. Here's the problem in a nutshell: either you
notify in detail what the changes are, in which case we are looking at
horrendous complexity and likely lots of interesting failure modes, or
you just say "it's changed" in which case you only need a single module
that requires a restart (canonical example: Apache listeners - these
cannot change without a restart) and every change gives you a restart
anyway.
I suppose its possible that there's some middle ground, but I'm afraid
my imagination has failed me...
-----------------------------------------------
FREE! The World's Best Email Address @email.com
Reserve your name now at
|
http://mail-archives.apache.org/mod_mbox/tomcat-dev/199907.mbox/%3C385087954.932507727576.JavaMail.root@web08.pub01%3E
|
CC-MAIN-2013-48
|
refinedweb
| 175
| 69.72
|
don't thinks so, at least not in IE. There are strict security regarding these things, otherwise viruses would be able to go everywhere. The only thing I can see if for the user to download it, or create something like the exe in ASP, for instance.
Regards,
Zyloch
If it's a single form program, it might be easy to convert as a control.
Matti
This course teaches how to install and configure Windows Server 2012 R2. It is the first step on your path to becoming a Microsoft Certified Solutions Expert (MCSE).
Internet
1) Normally you would change the type of you project from a Standard EXE to an ActiveX DLL. You make a public class that activaes your application. You create a little ASP paqe that creates an instance of your object. You can then pass to your application the IIS objects that make life easy: Application, Session, Request & Response objects which are easy to use, that tell you what the client has ask for. You then send the clinet information via the response object. It sounds hard but it is as easy as this:
response.write "<HTML><BODY>Hello World</BODY></HTML>
2) You can create a CGI EXE which is a standard exe program which when run by IIS uses the STDIN and STDOUT channels to decode the request data and send a response back to the client. This type of EXE is quite envolved but not impossible.
Intrarnets (where all pc's running windows)
3) This option only works on intranets but is quite cool and very affective. If you want to run the exe on the client system but have it load from a web page there is a cute trick you can do. You register an extension on the client system, say for exmple .SAR. You can create a text file and rename it, say DoSomething.SAR. In your text file you place instructions and data like FUNCTION X "\\serverx\data\myfile.xyz
4) Create a an ActiveX DLL which is registered on your server. Create a TLB for the DLL which is registered on each client. The client can link to a script that creates an object on the server.
Set MyObject = CreateObject("MyObject.MyC
You can now run methods and get results from the DLL/ or ActiveX EXE running on the server.
Results = MuObject.Run("Passing some data")
Which way do you want to go?
Does the user have to interact with the forms?
1. How will I call this DLL from my ASP page and pass the parameters to it. lets say that instead of creating a form in VB, i create a form in ASP with all required textboxes in it.
2. Is some special settings at IIS required to use this DLL?
When this link is activated IIS is bypassed and your exe will get a connection request. You accept the connection in an array of winsock controls. You then do the numbercrunching and create an http response string. Actually this way works about 2000 times faster than IIS.
IIS allows you to run activex exe. You need to enable the AspAllowOutOfProcComponent
"HKLM\SYSTEM\CurrentContro
To enable the flag
ie
Dim IISComp
On Error Resume Next
Set IISComp = GetObject("IIS://localhost
IISComp.Put "AspAllowOutOfProcComponen
IISComp.SetInfo
Set IISComp = Nothing
>>2. How can the user interact with the exe through a browser. possibly the browser will ask the user to download the exe at his/her machine.
You can start your exe from asp and use XML data island to pass the result back to client
I think that converting a whole app from exe to a DLL that generates HTML is going to take a long time.
My only questions that remained unanswered are:
1. How will I call this DLL from my ASP page and pass the parameters to it. Lets say that instead of creating forms in VB, I create a form in ASP with all required textboxes in it and by pressing Submit, the Dll is called and all the values accepeted from the user arepassedto the DLL.
2. Is some special settings at IIS required to use this DLL?
Appart from the look of each form, your main conversion problem will be that your exe will want to process all events interactivly. Example say if you have a text box that has some code in a keypress event you have to find a way of doing that using (horrid) client-site scripting. But a web-server app gets all of the data in one hit so needs to validate the whole screen and then accept thet data or redisplay. So when you validate your fields you need to store which fields are wrong so that wen you display the results you can display error fields in say red.
|
https://www.experts-exchange.com/questions/21090195/Call-a-VB-Exe-from-a-web-page.html
|
CC-MAIN-2018-22
|
refinedweb
| 805
| 71.85
|
Accounts.Provider
Representation of an account provider. More...
#include <Accounts/Provider>
Detailed Description
Representation of an account provider.
The Provider object represents an account provider. It can be used to retrieve some basic properties of the provider (such as the name) and to get access to the contents of the XML file which defines it.
Definition at line 48 of file provider.h.
Constructor & Destructor Documentation
Copy constructor.
Copying a Provider object is very cheap, because the data is shared among copies.
Definition at line 65 of file provider.cpp.
Member Function Documentation
Get the description of the provider, untranslated.
- Returns
- The description of the provider.
Definition at line 124 of file provider.cpp.
Get the display name of the provider, untranslated.
- Returns
- The display name of the provider.
Definition at line 115 of file provider.cpp.
- Returns
- A regular expression pattern which matches all the internet domains in which this type of account can be used.
Definition at line 161 of file provider.cpp.
- Returns
- The DOM of the whole XML provider file.
Definition at line 177 of file provider.cpp.
- Returns
- The provider icon name.
Definition at line 152 of file provider.cpp.
- Returns
- Whether the provider supports creating one account at most.
Definition at line 169 of file provider.cpp.
Check whether this object represents a Provider.
Definition at line 95 of file provider.cpp.
Referenced by Provider::name().
Get the name of the provider.
This can be used as a unique identifier for this provider.
- Returns
- The unique name of the provider.
Definition at line 105 of file provider.cpp.
References Provider::isValid().
Get the name of the account plugin associated with the provider.
Some platforms might find it useful to store plugin names in the provider XML files, especially when the same plugin can work for different providers.
- Returns
- The plugin name.
Definition at line 135 of file provider.cpp.
- Returns
- The name of the translation catalog, which can be used to translate the displayName().
Definition at line 144 of file provider.cpp.
|
https://phone.docs.ubuntu.com/en/scopes/api-cpp-current/Accounts.Provider
|
CC-MAIN-2020-45
|
refinedweb
| 338
| 70.6
|
SignalR is a library that brought push notifications to ASP .NET web applications. It abstracted away the complexity of dealing with websockets and other front-end technologies necessary for a web application to spontaneously push out updates to client applications, and provided an easy programming model.
Essentially, SignalR allows us to implement publish/subscribe on the server. Clients, which are typically (but not necessarily) webpages, subscribe to a hub, which can then push updates to them. These updates can be sent spontaneously by the server (e.g. stock ticker) or triggered by a message from a client (e.g. chat).
The old SignalR, however, is not compatible with ASP .NET Core. So if you wanted to have push notifications in your web application, you had to look elsewhere… until recently. Microsoft shipped their first alpha release of SignalR Core (SignalR for ASP .NET Core 2.0) a few weeks ago, and the second alpha was released just yesterday. They also have some really nice samples we can learn from.
This article explains how to quickly get started with SignalR Core, by means of a simple Hello World application that combines a simple server-side hub with a trivial JavaScript client. It is essentially the first example from my “Getting Started with SignalR“, ported to SignalR Core.
The source code for this article is in the SignalRCoreHello folder at the Gigi Labs BitBucket Repository.
Hello SignalR Core: Server Side
This example is based on SignalR Core alpha 2, and uses ASP .NET Core 2 targeting .NET Core 2. As this is pre-release software, APIs may change.
Let’s start off by creating a new ASP .NET Core Web Application in Visual Studio 2017. We can start off simple by using the Empty project template:
This project template should come with a reference to the Microsoft.AspNet.All NuGet package, giving you most of what you need to create our web application.
In addition to that, we’ll need to install the NuGet package for SignalR. Note that we need the
-Pre switch for now because it is still prerelease.
Install-Package Microsoft.AspNetCore.SignalR -Pre
Next, let’s add a Hub. Just add a new class:
public class HelloHub : Hub { public Task BroadcastHello() { return Clients.All.InvokeAsync("hello"); } }
In SignalR Core, a class that inherits from Hub is able to communicate with any clients that are subscribed to it. This can be done in several ways: broadcast to all clients or all except one; send to a single client; or send to a specific group. In this case, we’re simply broadcasting a “hello” message to all clients.
In the Startup class, we need to remove the default “Hello world” code and register our Hub instead. It should look something like this:
public class Startup { // This method gets called by the runtime. Use this method to add services to the container. // For more information on how to configure your application, visit public void ConfigureServices(IServiceCollection services) { services.AddSignalR(); } // This method gets called by the runtime. Use this method to configure the HTTP request pipeline. public void Configure(IApplicationBuilder app, IHostingEnvironment env) { if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); } app.UseFileServer(); app.UseSignalR(routes => { routes.MapHub<HelloHub>("hello"); }); } }
UseSignalR() is where we register the route by which our Hub will be accessed from the client side.
UseFileServer() is there just to serve the upcoming HTML and JavaScript.
Hello SignalR Core: Client Side
In order to have a webpage that talks to our Hub, we first need a couple of scripts. We’ll get these using npm, which you can obtain by installing Node.js if you don’t have it already.
npm install @aspnet/signalr-client npm install jquery
The first package is the client JavaScript for SignalR Core. At the time of writing this article, the file you need is called signalr-client-1.0.0-alpha2-final.js. The second package is jQuery, which is no longer required by SignalR Core, but will make life easier for our front-end code. Copy both signalr-client-1.0.0-alpha2-final.js and jquery.js into the wwwroot folder.
Next, add an index.html file in the wwwroot folder. Add references to the aforementioned scripts, a placeholder for messages (with ID “log” in this example), and a little script to wire things up:
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>Hello SignalR Core!</title> <script src="jquery.js"></script> <script src="signalr-client-1.0.0-alpha2-final.js"></script> <script type="text/javascript"> $(document).ready(function () { var connection = new signalR.HubConnection('/hello'); connection.on('hello', data => { $("#log").append("Hello <br />"); }); connection.start() .then(() => connection.invoke('BroadcastHello')); }); </script> </head> <body> <div id="log"></div> </body> </html>
This JavaScript establishes a connection to the hub, registers a callback for when a “hello” message is received, and calls the
BroadcastHello() method on the hub:
The way we implemented our Hub earlier, it will send a “hello” message to all connected clients.
Let’s give that a try now:
Good! The connection is established, and we’re getting something back from the server (i.e. the Hub). Let’s open a couple more browser windows at the same endpoint:
Here, we can see that each time a new window was opened, a new “hello” message was broadcasted to all connected clients. Since we are not holding any state, messages are sent incrementally, so newer clients that missed earlier messages will be showing fewer messages.
The Chat Sample
If you want to see a more elaborate example, check out the Chat sample from the official SignalR Core samples:
The principle is the same, but the Chat sample is a little more interesting.
|
https://gigi.nullneuron.net/gigilabs/tag/signalr/
|
CC-MAIN-2021-31
|
refinedweb
| 948
| 58.08
|
this pointer in C++ Programming
In C++, this pointer is used to represent the address of an object inside a member function. For example, consider an object obj calling one of its member function say method() as obj.method(). Then, this pointer will hold the address of object obj inside the member function method(). The this pointer acts as an implicit argument to all the member functions.
class ClassName { private: int dataMember; public: method(int a) { // this pointer stores the address of object obj and access dataMember this->dataMember = a; ... .. ... } } int main() { ClassName obj; obj.method(5); ... .. ... }
Applications of this pointer
1. Return Object
One of the important applications of using this pointer is to return the object it points. For example, the statement
return *this;
inside a member function will return the object that calls the function.
2. Method Chaining
After returning the object from a function, a very useful application would be to chain the methods for ease and a cleaner code.
For example,
positionObj->setX(15)->setY(15)->setZ(15);
Here, the methods setX, setY, setZ are chained to the object, positionObj. This is possible because each method return *this pointer.
This is equivalent to
positionObj->setX(15); positionObj->setY(15); positionObj->setZ(15);
3. Distinguish Data Members
Another application of this pointer is distinguishing data members from local variables of member functions if they have same name. For example,
Example 1: C++ program using this pointer to distinguish local members from parameters.
#include <iostream> #include <conio.h> using namespace std; class sample { int a,b; public: void input(int a,int b) { this->a=a+b; this->b=a-b; } void output() { cout<<"a = "<<a<<endl<<"b = "<<b; } }; int main() { sample x; x.input(5,8); x.output(); getch(); return 0; }
A class sample is created in the program with data members a and b and member functions input() and output(). input() function receives two integer parameters a and b which are of same name as data member of class sample. To distinguish the local variable of input() data member of class, this pointer is used. When input() is called, the data of object inside it is represented as this->a and this->b while the local variable of function is represented simply as a and b.
Output
a = 13 b = -3
Example of this pointer
Example 2: C++ program to display the record of student with highest percentage.
#include<iostream> #include<conio.h> using namespace std; class student { char name[100]; int age,roll; float percent; public: void getdata() { cout<<"Enter data"<<endl; cout<<"Name:"; cin>>name; cout<<"Age:"; cin>>age; cout<<"Roll:"; cin>>roll; cout<<"Percent:"; cin>>percent; cout<<endl; } student & max(student &s1,student &s2) { if(percent>s1.percent && percent>s2.percent) return *this; else if(s1.percent>percent && s1.percent>s2.percent) return s1; else if(s2.percent>percent && s2.percent>s1.percent) return s2; } void display() { cout<<"Name:"<<name<<endl; cout<<"Age:"<<age<<endl; cout<<"Roll:"<<roll<<endl; cout<<"Percent:"<<percent; } }; int main() { student s,s1,s2,s3; s1.getdata(); s2.getdata(); s3.getdata(); s=s3.max(s1,s2); cout<<"Student with highest percentage"<<endl; s.display(); getch(); return 0; }
This program is used to compare the percentage of three students and display the highest among them. The concept of this pointer is used in this program. A class student is created with data members name, roll, age and percent and member functons getdata(), max() and display(). Data for each student is entered by calling getdata() function. Then, max() function is called by object s3 and s2 and s1 are passed as parameter in the function. The value of percent is compared and the object with highest percent is returned. If the object calling the method has the highest percentage then, it is returned by using this pointer as,
return *this;
Output
Enter data Name:Paul Age:24 Roll:11 Percent:79 Enter data Name:Reem Age:21 Roll:9 Percent:87 Enter data Name:Philip Age:23 Roll:5 Percent:81 Student with highest percentage Name:Reem Age:21 Roll:9 Percent:87
It should be noted that, friend function and static function cannot have this pointer. It's because friend function is not a member function of the class. And static function can be invoked without initialization of an object, i.e, static functions are not associated with any object.
|
https://www.programtopia.net/cplusplus/docs/this-pointer
|
CC-MAIN-2019-30
|
refinedweb
| 731
| 54.52
|
The buttons in a toolbar get rendered incorrectly in FireFox after programmatically collapsing the ContentPanel that contains the ToolBar. The icons and the text overlap. (shown in attachment)
...
Type: Posts; User: villemustonen
The buttons in a toolbar get rendered incorrectly in FireFox after programmatically collapsing the ContentPanel that contains the ToolBar. The icons and the text overlap. (shown in attachment)
...
I am also trying to implement this sort of TextField looking ComboBox. If the user types "met" and a match for "metallica" is found, and the user presses Enter, the value "met" should be in the...
Can you change the icons dynamically, e.g. when user hovers the mouse over the icon?
Maybe this will help
treeBinder.setMask(true);
Hello,
My problem is that I want to embed a small swf-component into a GXT ContentPanel. I can do this in html with this:
<object id="fplayer" width="400"
height="250"...
Got working by extending store:
public class ResultStore<M extends ModelData> extends ListStore {
@Override
public void sort(String field, SortDir sortDir) {
SortInfo prev = new...
Hello,
I need to implement my on version of sorting for my application's grid. I still want the results to be sorted when I click the column headers, but I will do this manually -- I sort the...
Hello,
I need to implement my on version of sorting for my application's grid. I sort the result when I send the a search query (Hibernate) to our DB. Therefore, I want to disable the local...
Hello,
Also note that the scrollbars do not appear until the grid has data.
If you post some runnable code, I will gladly look into it.
--Ville
Hello,
I have a listener hooked to a TextField that I want to use to format the user inputted character to something else. Basically, I want it so that I can cancel the event from continuing (the...
Hello,
Try calling layout() on the Container
--ville
I will post my current code again, because this is sort of a major issue for me.
If anyone can figure out (if it is even possible) how to keep the TextFields auto-sized, and add a vertical...
Hello,
First of all, thank you for taking the time to reply to my posts and helping me solve this problem.
I think I didn't mention it clearly enough. Of course, the horizontal scrollbars...
Except for just one thing. The scrollbars are not visible when the content doesn't fit the east panel.
Thank you, this solved it for me.
--Ville
Hello,
Here is how I understand this.
Events.Select is the event that is fired when the component is selected (ie. button clicked). Components also fire other events, check the API for those.
...
Hello,
The Explorer had an example where a fields FormData could be set to "100%" and it would auto-size itself with the container, if the container has FitLayout.
My problem is that in my...
I don't know how I had missed this
binder.setAutoLoad(true);This loads the entire tree at once. It would still be nice to select the amount of levels to load, if the tree levels are very deep.
I would suggest that you have all the possible icons in the CSS, and change the CSS at runtime. Isn't this basically the same as changing the icon at runtime?
Hello,
I also need this kind of functionality in my program. I want the entire tree would be loaded on the same call, or that I could specify the number of levels to load.
I have experimented...
Hello,
I have a small media player in my application that runs inside a GXT-Window. It uses the Windows Media Player 11 -plugin, and I add it the window with .addText(String html).
My problem...
Solved. Adding custom styles does work.
box1.setStyleName("combobox");and
.combobox {
padding-right: 20px !important;
}
Has anyone found a solution to this? For me it is rather important that I could programmatically collapse the panel when needed.
Hello,
I am trying to add a SimpleComboBox and a TextField into a HorizontalPanel, and several of these HorizontalPanels into a Window. What happens is that the SimpleComboBox's button gets hidden...
Hello,
How do I listen for browser window resize events? I want to move a certain GXT window inside my application whenever the user resizes the browser window. To be precise, I want to pin this...
|
https://www.sencha.com/forum/search.php?s=e40d7eba369bd4d83540d52637e27398&searchid=19530653
|
CC-MAIN-2017-34
|
refinedweb
| 738
| 66.84
|
On Sat, Apr 08, 2017 at 08:19:59PM +0100, Alan Third wrote: > On Sat, Apr 08, 2017 at 08:47:25AM -0700, Aaron Jensen wrote: > > On Sat, Apr 8, 2017 at 12:37 AM, YAMAMOTO Mitsuharu > > <address@hidden> wrote: > > > > > > Probably "fork" copies some GUI resources. That would also explain > > > why the performance is worse on the Mac port, where each frame > > > allocates an extra NSWindow for overlaying. > > > > > > It becomes much faster and seemingly unaffected by the frame size if > > > you comment out "#undef HAVE_WORKING_VFORK" and "#define vfork fork" > > > in src/conf_post.h. But I'm not sure if it is safe. > > > > Wow, that does make a big difference. The comment says that Emacs > > hangs when evaluating: > > > > (make-comint "test0" "/nodir/nofile" nil "") > > > > But I can not reproduce that currently with vfork. I can’t reproduce a hang with that command either. > > I do not understand the second comment: "Also, setsid is not > > allowed in the vfork child's context as of Darwin 9/Mac OS X > > 10.5." > > It looks to me like we could replace the call to setsid with > > setpgid (0, 0); > > for Darwin builds. No, forget that. It doesn’t do the same thing at all. If you run Emacs, then M‐x ansi-term RET RET You should get a shell prompt. Using fork/setsid, your shell will be able to do job control, but using vfork it can’t. You can test this by typing the `bg` command. Zsh (and I assume bash, etc.) responds by telling you either there are no jobs, or that the shell has no job control. We could work around this in a rather ugly manner by doing something like: #ifdef DARWIN_OS if (pty_flag) pid = fork (); else pid = vfork (); #else pid = vfork (); #endif which would use fork where we’re expecting to run setsid, and vfork otherwise. -- Alan Third
|
https://lists.gnu.org/archive/html/bug-gnu-emacs/2017-04/msg00259.html
|
CC-MAIN-2020-05
|
refinedweb
| 310
| 79.6
|
How to Read ATtiny85 VCC Voltage Without Connecting to ADC pin
How to Read ATtiny85 VCC Voltage Without Connecting to ADC pin
How to Read ATtiny85 VCC Voltage Without Connecting to ADC - Today I am trying to implement an ADC to read the VCC voltage of an ATtiny85. This does not require a cable or wire connected between the ADC pin and the VCC pin, but rather reads using the internal registers on the chip.
The VCC voltage read by ATtiny85 will be sent to the computer via serial communication and displayed on the Arduino Serial monitor.
ATtiny85 by default has no Tx Rx pins. To be able to outsmart this we use the SoftwareSerial.h library.
A. Schematic
In this experiment, I used 2 circuits. The first circuit is Arduino as an ISP which is connected to ATtiny85. It is used to program the ATtiny85. Read here.
The second circuit is, the ATtiny85 circuit is connected to the FT232. This is used to receive ATtiny data and will be forwarded to the computer. Read here.
B. Program
To program the VCC voltage reading using the internal ADC, please use the following program:
#include "SoftwareSerial.h" int Rx = 3; int Tx = 4; SoftwareSerial mySerial(Rx, Tx); void setup() { pinMode(Rx, INPUT); pinMode(Tx, OUTPUT); mySerial.begin(9600); } void loop() { float supply = readVcc() / 1000.0; mySerial.print ("VCC: "); mySerial.println (supply); delay(100); } long readVcc() { long result; // Read 1.1V reference against AVcc ); // Convert while (bit_is_set(ADCSRA, ADSC)); result = ADCL; result |= ADCH << 8; result = 1126400L / result; // Calculate Vcc (in mV); 1126400 = 1.1*1024*1000 return result; }
Once uploaded, open the serial monitor. Make sure:
- You select port FT232 FTDI
- Set the baud rate of the serial monitor at 9600.
You will see a response from ATTiny85 in the form of a voltage that is read in the Arduino IDE Monitor serial. If you don't receive the response, check the circuit again. Thank you for visiting the website Chip Piko.
May be useful.
Post a Comment for "How to Read ATtiny85 VCC Voltage Without Connecting to ADC pin"
|
https://www.chippiko.com/2020/09/cara-membaca-tegangan-vcc-attiny85.html
|
CC-MAIN-2021-39
|
refinedweb
| 348
| 65.32
|
Jan Beulich wrote:
>>>> Gerd Hoffmann <kraxel@xxxxxxx> 09.02.07 15:00 >>>
>> Jan Beulich wrote:
>>> But wouldn't that change behavior for domU-s then in an undesirable way?
>> Why? dom0 and domU should have the same behavior ...
>
> I didn't check how the old domU-related tools code behaved here, I just
> assumed the new code was based more on the old tools code than the
> hypervisor one, and hence old behavior might have been the one I had
> just seen.
Old domU builder was cut&pasted from old dom0 builder three years ago ;)
> Regardless of that, the function shouldn't return here, but rather
> continue the loop.
No, the function parses just one note, the loop is one level up.
>>> Even better, I would think, would be to split the note namespace to
>>> distinguish
>>> - general required notes
>>> - general optional notes
>>> - dom0 required notes
>> Point being? I'm not aware of any dom0-required note. And I don't
>> think splitting into required and optional is useful, especially as this
>> is arch-dependent ...
>
> To e.g. catch notes the presence of which is necessary (i.e. a newer
> hypervisor will misbehave in its absence), but ignore such that only
> provide hints in certain directions.
I don't think there are such notes. domU's are supposed to be
compatible in both directions.
> At present I also don't know of any dom0 required note, yet if any
> splitting is done, then all possible (i.e. foreseeable) groups should be
> allowed for. As you say, the list should also include an arch-specific
> range.
Shouldn't happen. Starting with 3.0.3 dom0 kernel has no hypervisor
dependencies any more, only xen kernel and tools must match version-wise.
cheers,.
|
https://lists.xenproject.org/archives/html/xen-devel/2007-02/msg00349.html
|
CC-MAIN-2021-39
|
refinedweb
| 290
| 73.47
|
Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you have been placed in read-only mode.
Please download a browser that supports JavaScript, or enable it if it's disabled (i.e. NoScript).
On 12/12/2017 at 02:22, xxxxxxxx wrote:
User Information:
Cinema 4D Version:
Platform:
Language(s) : PYTHON ;
---------
data = c4d.gui.GeDialog().GetColorRGB(c4d.COLOR_TEXT)
print data
data = c4d.gui.GeDialog().GetColorRGB(c4d.COLOR_TEXTFOCUS)
print data
The first one work, the second one return None
On 13/12/2017 at 04:35, xxxxxxxx wrote:
Hello,
can you explain what exactly you are doing? GeDialog is the base class for defining a custom dialog class. GetColorRGB() is a member function that is supposed to be used from within that dialog class. So creating a "GeDialog" instance is not really a thing.
best wishes,
Sebastian
On 13/12/2017 at 05:01, xxxxxxxx wrote:
I just want to retrieve the color of the COLOR_TEXTFOCUS, in order to store it in some Constant class I made and there is no other way for doing it as I know.
Note that code produce the same things. (Pretty obvious since it's the the same code, since self is nothing more than the object)
So first one works, second return None.
import c4d
class test(c4d.gui.GeDialog) :
def __init__(self) :
print self.GetColorRGB(c4d.COLOR_TEXT) #Return rgb data
print self.GetColorRGB(c4d.COLOR_TEXTFOCUS) # Return None
test()
On 13/12/2017 at 09:28, xxxxxxxx wrote:
the problem is that at __ini__() the dialog is not yet a real dialog; it hasn't allocated all resources. You actually have to display the dialog with .Open() to do that. If you call GetColorRGB() in the context of e.g. GeDialog.CreateLayout() you can obtain COLOR_TEXTFOCUS without problem.
On 13/12/2017 at 10:13, xxxxxxxx wrote:
But I guess it's a bug, since it's not written, that the dialog has to be open to retrieve some values.
Color are not really related to GeDialog, imagine I would like to have this color into a bitmap?
The only way to retrieve that is to open an empty dialog, get the color and close the dialog.
It's a weird workflow...
And again same enum, but fails on some, succes on others while this is just a color, it just read some values, and return them, nothing fanzy.
Anyway thanks you !
On 13/12/2017 at 23:57, xxxxxxxx wrote:
I filed a bug report.
|
https://plugincafe.maxon.net/topic/10508/13959_getcolorrgb-fail-on-some-values
|
CC-MAIN-2021-31
|
refinedweb
| 422
| 65.93
|
table of contents
NAME¶
wcstok - split wide-character string into tokens
SYNOPSIS¶
#include <wchar.h>
wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim, wchar_t **ptr);
DESCRIPTION¶ null wide character (L'\0'), and it updates *ptr so that subsequent calls will continue searching after the end of recognized token.
RETURN VALUE¶
The wcstok() function returns a pointer to the next token, or NULL if no further token was found.
ATTRIBUTES¶
For an explanation of the terms used in this section, see attributes(7).
CONFORMING TO¶
POSIX.1-2001, POSIX.1-2008, C99.
NOTES¶
The original wcs wide-character string is destructively modified during the operation.
EXAMPLES¶
The following code loops over the tokens contained in a wide-character string.
wchar_t *wcs = ...; wchar_t *token; wchar_t *state; for (token = wcstok(wcs, " \t\n", &state);
token != NULL;
token = wcstok(NULL, " \t\n", &state)) {
... }
SEE ALSO¶
COLOPHON¶
This page is part of release 5.10 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at.
|
https://manpages.debian.org/unstable/manpages-dev/wcstok.3.en.html
|
CC-MAIN-2022-05
|
refinedweb
| 175
| 66.54
|
26622/handling-imbalanced-dataset
When you refresh the page in the ...READ MORE
You can initially use kmeans, to calculate ...READ MORE
Outlier values can be identified by using ...READ MORE
No, the time to train the random ...READ MORE
Try this,
lapply(airquality, function(x) { sum(is.na(x)) }) READ MORE
Supervised Learning is applied when we have ...READ MORE
def dense_layers(sizes):
return tfk.Sequential([tfkl.Dense(size, ...READ MORE
Check the python version installed. Tensorflow is ...READ MORE
You may want to check out the ...READ MORE
Hi@Usman,
It seems you are using an older ...READ MORE
OR
Already have an account? Sign in.
|
https://www.edureka.co/community/26622/handling-imbalanced-dataset
|
CC-MAIN-2021-17
|
refinedweb
| 108
| 71.31
|
Sean Lynch <seanl at literati.org> writes: > I have the beginnings of an automatic C and ctypes wrapper generator for > C++ code. I've been successful generating the C wrapper with namespaces > and non-class functions with the user telling the generator how to > rename overloaded functions, and my gccxml parser supports pretty much > all features of C++ except for templates now, but I still need to work > on the output for class-using code and ctypes code output. The idea is > to generate C wrappers for every exported function/constructor/class and > to recreate the same class structure in Python with the methods calling > with ctypes the appropriate C function in the wrapper. I've gotten this > far with about eight hours of programming, including writing my gccxml > parser, switching to pygccxml, then switching back to my own parser and > finishing it when I realized that pygccxml is messy and doesn't properly > support function pointers. Have you seen Armin's autoctypes? Scary code, and a rather different approach :-) > As for boost::python, you knew you were stuck with CPython when you > started, since it doesn't support IronPython or Jython either. However, > given a wrapper generator like the one I've started on, you should be > able to throw out all the Python-related code and just wrap the pure C++ > code. I wish we could just support the gcc 3.4+ (i.e. Itanium) ABI > directly, but that would be kind of pointless since VC++ doesn't support > it and uses a completely undocumented and unstable ABI. > >. Cheers, mwh -- Richard Gabriel was wrong: worse is not better, lying is better. Languages and systems succeed in the marketplace to the extent that their proponents lie about what they can do. -- Tim Bradshaw, comp.lang.lisp
|
https://mail.python.org/pipermail/pypy-dev/2007-January/003515.html
|
CC-MAIN-2014-15
|
refinedweb
| 297
| 58.11
|
Introduction
This article describes my version of digital input/output functions for Arduino, which work faster than the 'built-in' functions while remaining as easy to use and portable as the original ones. If you just want to try the new functions, feel free to go directly to "Using the code" section, otherwise, read on for some introduction to the problem.
It is rather well known that the functions for digital I/O in Arduino are quite slow. It takes about 4 microseconds to change the logical level of an output pin (for example, to turn on an LED) using the Arduino digitalWrite function, while it takes less than 0.1 microsecond if you write the code 'natively', using the I/O registers of the Atmel AVR microcontroller (which is the brain of the Arduino board). Sure, for most users it does not matter whether it takes 0.1 or 4 microseconds, it is still fast enough, but there are situations where the speed or power consumption are critical.
digitalWrite
Some time ago I wrote an article about this topic - 'Why is the digital I/O in Arduino slow and what can be done about it?'. This article was mostly about why the functions are slow; it did not offer any easy-to-use solution. In this new article I finally present my solution.
Certainly, there is the ultimate solution - use the I/O registers directly. In other words, get closer to the hardware. But by this you lose the portability of your program. While digitalWrite will work with any Arduino board, this approach will only work with one board and you will have to modify the code to use it with different board (e.g. if you move from Arduino Uno to Arduino Mega). Moreover, you need to understand the I/O registers to be able to use them.
I wondered if the digital I/O could be made faster, but also portable and easy to use. I tried various options (described at the end of this article) and came up with the solution presented here.
digitalWrite2(13, HIGH);
digitalWrite2f(DP1, HIGH);
I know it sounds like an advertisement, so here are the numbers. The following tables compare the speed of the standard I/O in Arduino and the new version, which I call I/O 2 for short (and for lack of imagination).
Note: 'us' is used as a symbol for microsecond.
Arduino Standard (Uno)
Arduino Mega
The results were obtained using Arduino software version 1.0.5-r2; test programs were build in the Arduino IDE with default settings.
The numbers in parentheses for I/O 2 functions are times obtained with user option set to prefer small size of the program rather than speed (which in fact means the I/O functions are not 'inlined 'into the code but called).
Note 1: In the Arduino implementation of digitalWrite and digitalRead there is a check whether the affected pin is used by a timer. It seems 'silly' to do this each time a pin is written or read - as the Arduino developer(s) themselves write in a source comment - so I did not include this check in my digital I/O functions. To provide fair comparison I measured the speed of the standard Arduino functions with this check disabled besides the standard 'out-of-the-box' version. Notice that for Arduino Mega this 'silly' timer check accounts for about half of the time it takes to execute digitalWrite!
Note 2: For the digital I/O functions I created, the 'native' identification of a pin is a 'pin code', rather than plain pin number used in Arduino. However, I realize that for many people it is easier to use plain numbers in their programs, so I created wrapper functions which take the pin number as an integer, convert it to the pin code and then call the native function. To my surprise (and satisfaction) even those wrapper functions are still quite a bit faster than the original Arduino I/O.
digitalRead
In March 2015 I measured the speed again using the new Arduino 1.6.0 IDE and different, more exact method: switching output pin HIGH and LOW at full speed and measuring the output with oscilloscope. Here are the results for Arduino Uno:
There are two big differences compared to the older results:
There are two ways how to use the I/O 2 functions in your program:
1) Install as Arduino library (named DIO2)
OR
2) Copy 3 files into your Arduino installation
Option 2 was used from the beginning and is still supported. I added the library option (1) in March 2015 as this seems to be the right way to extend the Arduino environment. Unfortunately, you still need to copy one file into the right folder in your Arduino location, because it is not possible to determine which board is selected from within the library code and there needs to be board-specific definition of the pins. The advantage of the library option is that you have syntax coloring in the editor for the new functions, easy access to example programs and if you need to build your program for a different board than the Uno or Mega supported in DIO2 now, you will not get errors.
Step 1: Install the DIO2 library as any other Arduino library, that is extract the downloaded files into you Arduino libraries folder or use the automatic library install from the Arduino drop-down menu Sketch > Import Library.
Note that the automatic library install will install the library into your user profile only; into the Documents\Arduino\libraries folder (at least this is where I found it on my Win7 computer).
Step 2: Copy the pin2_arduino.h file for the board(s) you plan to use into the appropriate folder in your Arduino location.
You will find this file in the attached zip file (or in the extracted library folder) in [zip file]\board\[board], where [board] is standard for Arduino Uno and mega for Arduino Mega.
This destination folder is:
For Arduino 1.6.0 IDE:
[your_arduino_location]\hardware\arduino\avr\variants\[board]
Examples: c:\arduino-1.6.0\hardware\arduino\avr\variants\standard or
c:\arduino-1.6.0\hardware\arduino\avr\variants\mega
For the older Arduino 1.0.x IDE:
[your_arduino_location]\hardware\arduino\variants\[board]
Examples: c:\arduino-1.0.5-r2\hardware\arduino\variants\standard or
c:\arduino-1.0.5-r2\hardware\arduino\variants\mega.
Please note that the pin2_arduino.h file is different for Arduino standard and Arduino Mega. Use the appropriate file for your Arduino variant.
Also note that you are not overwriting anything in your Arduino installation and you can still use the original digital I/O functions.
If you decide to use this option rather than library, you need to copy 3 files into appropriate folders in your Arduino location. You will find these files in the attached zip file; the source and destination locations are as follows:
Arduino 1.6.0 IDE
Copy arduino2.h and digital2.c from [zip file]\src\ to [your_arduino_location]\hardware\arduino\avr\cores\arduino\.
Copy pins2_arduino.h from [zip file]\board\standard or mega to [your_arduino_location]\hardware\arduino\avr\variants\standard or mega.
Arduino 1.0.x IDE
Copy arduino2.h and digital2.c from [zip file]\src\ to [your_arduino_location]\hardware\arduino\cores\arduino\
Copy pins2_arduino.h from [zip file]\board\standard or mega to [your_arduino_location]\hardware\arduino\variants\standard or mega.
Note that using this option 2 has one disadvantage: if you need to build a program for other Arduino variant than Uno or Mega, you will encounter build error because of missing pins2_arduino.h file for this variant. To solve this, you can copy the "dummy" pins2_arduino.h file provided in [zip file]\board\dummy to the appropriate folder in the Arduino variants folder.
Once the above is done, start Arduino IDE and create a new program (sketch) as you normally do. You can now use the I/O 2 functions described below instead of the standard Arduino functions.
Here is an example program which blinks the LED at pin 13. It should work without change both for Arduino Uno and Mega.
/*
Blink2 - Blink example modified for using digital I/O 2 instead of standard Arduino digital I/O.
*/
//include the fast I/O 2 functions
#include "arduino2.h"
// Pin 13 has an LED connected on most Arduino boards.
// give it a name:
const int led = 13;
// the setup routine runs once when you press reset:
void setup() {
// initialize the digital pin as an output.
pinMode2(led, OUTPUT);
}
// the loop routine runs over and over again forever:
void loop() {
digitalWrite2(led, HIGH); // turn the LED on (HIGH is the voltage level)
delay(1000); // wait for a second
digitalWrite2(led, LOW); // turn the LED off by making the voltage LOW
delay(1000); // wait for a second
}
There are only two small changes compared to the normal Arduino Blink example:
#include "arduino2.h"
pinMode2()
pinMode()
There is also optional third change you could make - adding one #define above the #include "arduino2.h" line, which decides, whether you prefer fast program execution or smaller size:
#define GPIO2_PREFER_SPEED 1
#include "arduino2.h"
If the GPIO2_PREFER_SPEED is set to 1, the I/O 2 functions will be declared inline which results in faster execution, but the program may grow big if you use the functions many times, because each time you call the function in your program, this call is replaced with the complete code of the function.
GPIO2_PREFER_SPEED
inline
If GPIO2_PREFER_SPEED is 0, then the functions will be normally called, which means only one copy of each function exists in the program. This may save some program memory but the program runs slower (the function call takes some CPU time).
If you do not define this constant, default value 1 will be used. In most cases I recommend using value 1, that is, prefer the speed. Only if you would be running our of program memory, try to change the value to 0. However, it seems unlikely that some program would use up all the program memory just by digital I/O, so you should not really need to use the value 0.
If you want your digital I/O to run faster and can live with referring to a pin as DP1 instead of 1, you can use functions with '2f' in the name. As mentioned above, these are the native functions of the I/O 2 library, which do not have the overhead of converting the integer pin number to special pin code. Here is the code for the Blink example using these native functions:
DP1
#include "arduino2.h" // include the fast I/O 2 functions
// The I/O 2 functions use special data type for pin
// Pin codes, such as DP13 are defined in pins2_arduino.h
const GPIO_pin_t led_pin = DP13;
void setup() {
pinMode2f(led_pin, OUTPUT);
}
void loop() {
digitalWrite2f(led_pin, HIGH);
delay(1000);
digitalWrite2f(led_pin, LOW);
delay(1000);
}
Note that instead of int we define the pin as GPIO_pin_t. This data type is described in the Reference section below.
int
GPIO_pin_t
In the attached file there are also example programs (sketches) for Arduino standard (Uno) and Mega. Three programs are provided for each board besides the simple blink examples metioned above:
You will find instructions on use of these examples directly in the source code in comments.
GPIO_pin_t - data type used for digital pins. The name of a pin is DP + pin number. For example, the digital pin 13, where LED is connected, is referred to as DP13. Using this special data type instead of just simple number (int) allows the functions to work faster. See the 'How it works' section if you wonder how.
DP13
These functions are fully compatible with the original Arduino I/O functions. Just add '2' to the name of the original function and you are using the new faster version.
void pinMode2(uint8_t pin, uint8_t mode);
Set the direction of the pin. Possible options are INPUT, INPUT_PULLUP and OUTPUT.
uint8_t digitalRead2(uint8_t pin);
Read the value at given pin. The pin should be previously configured as input with pinMode2. Return value is either HIGH or LOW.
void digitalWrite2(uint8_t pin, uint8_t value);
Set given pin to HIGH or LOW level. The pin should be configured as output with pinMode2.
These functions are faster than the previous ones. They differ from the original Arduino functions by the type of pin parameter - they use GPIO_pin_t instead of uint8_t (or int). So in your program, you define the pin as
GPIO_pin_t pin = DP1;
instead of
int pin = 1;.
The other parameters are the same as for standard Arduino functions.
uint8_t
int
GPIO_pin_t pin = DP1;
int pin = 1;
void pinMode2f(GPIO_pin_t pin, uint8_t mode);
uint8_t digitalRead2f(GPIO_pin_t pin);
void digitalWrite2f(GPIO_pin_t pin, uint8_t value);
In this section I will describe how the new I/O functions work internally. This version of the functions is the result of many experiments with different approaches. For those interested, I describe those various approaches at the end of this article.
First, it is necessary to understand a little bit about how the digital I/O works in a microcontroller.
Simple explanation
This explanation is (hopefully) easier to understand, but also simplified and inaccurate. Imagine that for the microcontroller used in Arduino, the pin named 13 on the Arduino board would be known as a pin number 8229. It would be impractical for us to write 8229 in the program to refer to this pin. We want to be able to write simply 13. On the other hand, if we force the microcontroller to 'translate' the number 13 into 8229 each time we perform a read or write on the pin, this will cost some CPU time. If we do this translation 'off line' in our code by defining symbolic names for the pins, something like:
#define PIN_13 8229it will work faster.
This way, in our program, we can use the symbol PIN_13, which is still meaningful to a human, and in fact give the microcontroller the number it needs. The compiler will do the translation of PIN_13 into 8229.
#define PIN_13 8229
PIN_13
More exact explanation
The brain of the Arduino, a microcontroller (MCU for short) organizes I/O pins into ports. Ports are named A, B, C, etc. Each port has 8 pins. So there are, for example, pins 0 to 7 on port A (referred to as PA0 to PA7), pins 0 to 7 on port B (PB0 to PB7), etc.
Each port is controlled by a set of registers. For example, there is a register for setting the direction (input or output) and a register for setting the voltage level at the pin (high or low). For now, let's just think about the register which sets the voltage level on an output pin. We call this register the data register. You can imagine this register as a normal variable in your program, which is 8 bits long. Each bit in this variable controls one pin of a given port. For example, to set pin number 0 in port D to logical 1 (high voltage) you need to set bit 0 in data register of port D (PORTD). The code in C can look like this:
PORTD = PORTD | 1;
or for short:
PORTD |= 1;
You could also write it like this:
PORTD = 1;
But this way you would not only set the bit 0 to logical 1, but also set all the other pins to logical 0. You would set the value for the whole byte (all 8 bits/pins), and since you are writing value 1 (0000 0001 in binary), you would be actually saying 'set the first bit to logical 1 and all other bits to logical 0'. Usually, you want to change just one bit and leave the others untouched, that is why there is the OR operation.
In Arduino programs, we do not want to deal with the registers and ORs and ANDs, we just want to write digitalWrite(pin, value); and have the software library translate this into the appropriate PORTx |= bit_mask; The problem is how to do this translation as fast and possible and/or with as little code as possible.
digitalWrite(pin, value);
PORTx |= bit_mask;
After trying other options I came to the conclusion that the fastest operation of the I/O functions can be obtained if they get the information they need as their input parameter. This information is the address of the register, which controls the port and the bit mask of the pin within this port. These two pieces of information are encoded into a single 16-bit number, which I call pin code. The lower byte of this 16-bit number contains the address of the data register and the upper byte is the bit mask of the pin. Let's look at an example to make it clear:
For Arduino Uno an LED is connected to digital pin 13. Physically, in the MCU, this is pin 5 on port B (PB5). The address of the data register for port B is 0x25 (this information is obtained from the datasheet of the MCU). The bit mask for pin 5 is a byte, in which bit 5 has value 1, all other bits are 0. So it will be 00100000 in binary; 0x20 in hexadecimal. You can also create this number by writing (1 << 5) in a C program - shift 1 five times to the left. Note that bit 5 means actually the 6th bit from the right-hand side, because the bit numbers start from 0.
Put together, the pin code for Arduino pin 13 will look like this: 0x2025.
It would be possible to work with the pin codes in this way, but the C language offers some tools to make the use more comfortable and safe. First, we will not define the pin code as a simple integer, but will create a new data type for it. This type is called GPIO_pin_t and means 'this is a pin', not just 'any integer'. If we do this, the compiler can help us detect incorrect use of our I/O functions. If someone by mistake calls our function which expects pin code with plain pin number, for example, digitalWrite2f(13, HIGH); (ERROR!) instead of digitalWrite2f(DP13, HIGH);, the compiler will complain "invalid conversion from 'int' to 'GPIO_pin_t'". Cool, isn't it? To achieve this, the pin codes are defined in an enum rather than using #define.
digitalWrite2f(13, HIGH);
digitalWrite2f(DP13, HIGH);
enum
#define
The 2nd trick is invisible for the 'end user' but helps a lot when defining the pins for a new board. It is a macro GPIO_MAKE_PINCODE(port, pin). Thanks to this macro, the definition of the pin for given arduino board can look like this:
GPIO_MAKE_PINCODE(port, pin)
enum GPIO_pin_enum
{
DP_INVALID = 0x0025,
DP0 = GPIO_MAKE_PINCODE(MYPORTD,0),
DP1 = GPIO_MAKE_PINCODE(MYPORTD,1),
DP2 = GPIO_MAKE_PINCODE(MYPORTD,2),
...
which is much more readable than this:
enum GPIO_pin_enum
{
DP_INVALID = 0x0025,
DP0 = 0x012B,
DP1 = 0x022B,
DP2 = 0x042B,
DP3 = 0x082B,
...
You can see the actual pin definitions for Arduino Uno and Mega in pins2_arduino.h files in the attached source code.
Personally, I think using a symbolic name for something like a pin comes as a natural thing when you deal with programming for some time. It is a pity that it is not used in Arduino, because now those millions of Arduino users would be used to writing something like digitalWrite(PIN_13, HIGH); instead of digitalWrite(13, HIGH); and once you have the actual pin 'hidden' behind some symbolic name, you can do some things with it - such as encoding useful information into it.
digitalWrite(PIN_13, HIGH);
digitalWrite(13, HIGH);
But since people got used to plain numbers for pins in Arduino, the I/O 2 library provides functions which take such numbers. If you use these functions, you do not have to change anything in your programs, just call digitalWrite2 instead of digitalWrite.
digitalWrite2
How it works? There is an array defined in pins2_arduino.h file which contains the pin codes for pins available in given board. When you call e.g. digitalWrite2, it will convert the pin number into its pin code using this array and then call the native digitalWrite2f with this pin code. Of course, this conversion takes some time, but the functions are still faster than the original Arduino ones.
digitalWrite2
digitalWrite2f
I decided to organize the files for the new I/O in the same way they are organized in original Arduino. So there is pins2_arduino.h file in this folder:
[your_arduino_location]\hardware\arduino\variants\[variant_name]\, which contains the definitions specific for given Arduino variant (e.g. Uno or Mega).
And there is common code, placed in arduino2.h and digital2.c files located in:
[your_arduino_location]\hardware\arduino\cores\arduino\.
If you decide to use the I/O 2 functions on other Arduino board than the Uno or Mega, you will have to create your on version of the pin2_arduino.h file with the pin codes. This is relatively easy task. I would say easier than creating the various arrays needed for standard Arduino digital I/O. You just define the enum GPIO_pin_enum with pin codes appropriate for your board and the gpio_pins_progmem array, which maps these pin codes to the pin number. There should be no changes needed in the other parts of the code. For detailed instructions, please see the comments in the provided pins2_arduino.h files.
GPIO_pin_enum
gpio_pins_progmem
Registers with address larger than one byte
For the MCU used in Arduino Mega, some I/O registers have address higher than 0xFF, which means their address will not fit into the single byte reserved for this purpose in the pin code. Luckily, their addresses are just between 0x0100 and 0x01F0, so we only need one extra bit to store such address. And luckily again, the registers with addresses which fit into one byte do not have addresses larger than about 0x40. So the top bit (bit 7) in the address byte is free to be used for this purpose. It requires some extra bit manipulation when working with the addresses, but it does not slow down the functions too much.
The pin is not an int
Please note that the use of GPIO_pin_t instead of int in this library does not limit your ability to store pins in a variable. You just have to write
instead of
What it does affect, however, is your ability to easily manipulate pins in a loop. Say, you would need to switch on LEDs connected to pins 1 to 4 in a sequence. With standard Arduino digitalWrite you can write:
digitalWrite
int pin;
for ( pin = 1; pin <= 4; pin++) {
digitalWrite(pin, HIGH);
}
You cannot do this with the GPIO_pin_t because the numerical values of the pin codes are not related. If you do need/want to use loop for this and do want to use the faster native functions of I/O 2, you can use this trick:
GPIO_pin_t pins[] = {
DP10,
DP11,
DP12,
DP13,
DP_INVALID,
};
...
int i;
for ( i = 0; pins[i] != DP_INVALID; i++) {
digitalWrite2f(pins[i], HIGH);
}
Or, the easy way: use the Arduino-compatible functions which take integer pin number (e.g. digitalWrite2).
Turning off the timer
As mentioned earlier, in my implementation of the digital I/O, I omitted the check, whether given pin is on a timer and eventually disabling the timer, as it is done in the standard Arduino implementation. I assume that this check is intended for forgetful users who want to read or write a pin which they used previously in the same program as a PWM output (analogWrite). But I did not actually follow the code into all details, so it is possible that it will be needed to add the check and/or turning off the timer somewhere, probably into pinMode. If you encounter a problem related to this, please let me know.
pinMode
Possible mistakes in use of the I/O 2 functions
It is not possible to mistakenly call digitalWrite2f with an integer instead of pin code; the compiler will report an error: "invalid conversion from 'int' to 'GPIO_pin_t'". It is, however, possible to mistakenly call digitalWrite2 with a pin code instead of integer pin number. This will only result in a compiler warning and, unfortunately, the Arduino IDE does not show build warnings in default configuration. You may enable verbose output for compilation in the File > Preferences and check the output window in Arduino IDE for warnings, which are printed in red letters instead of while for the normal output. Note that there are some warnings in the Arduino library itself; this is not related to I/O 2.
In this section I will briefly describe the other methods I tried for making the Arduino I/O faster and of which the method described above came as a winner.
The basic presumption for all the methods is, that there must be simple interface for the user, such as digitalWrite(pin, value). This leads to task of somehow converting the 'pin' parameter into appropriate port register and bit mask for the given pin and then reading/writing to the register using the bit mask.
digitalWrite(pin, value)
If you want to do similar experiments, I can recommend using Atmel Studio for this. It contains simulator where you can measure the time it takes for your code to execute and step through it in the debugger, which makes the experiments much easier and faster. Later, for experiments with the hardware, you will probably want to use some real IDE. I used Eclipse with AVR plug-in, and only in the last phase, for final verification, returned to the Arduino IDE.
This method is used in the digital I/O in Arduino. For detailed description of how it works please see my older article. I did not experiment with this approach on my own, but from measuring the speed of standard Arduino digitalWrite we can say it takes about 3.4 us for writing a pin (without checking the timer).
This is the second method I described in the older article. It is used in Wiring, which is the ancestor of Arduino. In principle you compare the pin number with the ranges of values belonging to each port. For example, in Arduino Uno the pins 0 to 7 belong to port D, the pins 8 to 13 to port B, etc. The code could look like this:
if ( pin < 8)
return &PORTD;
else if (pin < 14)
return &PORTB;
else if ( pin < 20 )
return &PORTC;
else
return NOT_A_REG;
And the bit mask can be obtained from the pin number as follows:
/* the lower 3 bits are always the pin number if each port has 8 pins (0-7; 8-15;...)
But Arduino standard has only 6 pins (0-5) for port B and C, so we have to compensate for the 2 missing pins. */
#define GPIO_PIN_MASK(pin) ( (pin < 14) ? (1 << (pin & 0x07)) : (1 << ((pin+2) & 0x07) ) )
In the real implementation the code would be put info macro using the C Ternary conditional operator (a ? b : c) rather than if-else, but that it not important for our explanation here.
a ? b : c
This method has one advantage compared to the option 1: if the pin number is a constant, the compiler can evaluate the conditions during compilation and the result is as efficient as if you used the registers directly and wrote something like PORTB |= 0x20; in your program. But if the pin is stored in a variable, the speed and size are similar to the option 1. To make things worse, the size and speed depend on how many pins there are on your board and how 'chaotic' is the mapping of these pins to the actual MCU ports. So while in case of Arduino Uno this method would be better than the option 1, thanks to the speed improvement for constant pins, for Arduino Mega it would probably perform much worse than the array version (with non-constant pins; with const pins it would still be very fast).
I tried this method in various combinations, such as obtaining both port and bit mask this way, or obtaining port and/or mask using a switch statement or an array, but the results were not satisfactory, over 2 us for writing a digital pin for Arduino Uno. Given the expected (and considerable) decrease of speed with more pins (Arduino Mega), this is not a good option.
This method was the biggest surprise for me. We can write a switch which will directly contain the operation on the appropriate register with the appropriate mask for each possible pin number:
#define PORT_WRITE(port, pin, value) ((value == 0)?(port &= ~(1<<pin)):(port |= (1<<pin)) )
void switch_digitalWrite(uint8_t pin, uint8_t val)
{
switch(pin)
{
case 0:
PORT_WRITE(PORTD, 0, val);
break;
case 1:
PORT_WRITE(PORTD, 1, val);
break;
..
You will probably think that this is not a good approach. Maybe OK for Arduino Uno with 20 pins, but what about Arduino Mega with 70 pins? It will take forever to evaluate all the possible values if you, for example, want to use pin 60... Not so. The compiler is smart and 'optimizes' the switch statement into sort of table with jumps directly to the code for each case. Or, if you just assign some values to a variable in each case, it can even create an array in memory with the possible values for each case and simply read and store the value. As a result, the switch produces pretty fast code and the speed does not depend on the pin number. In my tests I could get about 2.2 us for pin write with switch and even below 2.0 us if I wrote the code with if statements in a sort of binary search.
Why I discarded this method was that you would need such a big switch for each register, or we can say for each operation - one for writing a pin, one for reading, one for setting the direction. Such code would be hard to port to other boards and to maintain - if you fix some bug in one of the switches, you have to remember to fix it also in all the others.
This method means that we somehow compute the register address and pin mask from the pin number. Pin number is still simple integer, as it is in Arduino. I will explain by one example, which I tried: Suppose we have Arduino Uno board with the Atmega328 MCU, but reorder the pins a little so that Arduino's digital pin 0 is port B, bit 0; digital pin 1 is port B, bit 1; and so on up to pin 7 which is port B, bit 7. Pin 8 is port C, bit 0; pin 9 is port C, bit 1;.... pin 16 is port D, bit 0, etc. So there is relationship between the pin number and port and bit. Then we can calculate the port number:
port_number = pin / 8;
and bit number:
bit_number = pin % 8;
If the MCU registers are designed in a favorable way (as is the case with Atmega328), we just need to add some offset to the port_number to obtain the address of the register for this port. The offset would be 0x25 in our case, because port_number 0 means port B, which has the address 0x25. The bit mask is computed from bit number in a straightforward way by bit shift: (1 << bit_number).
port_number
This method looks promising, but there are drawbacks.
First, it would require renumbering the pins on the Arduino board - surely not feasible.
Or creating a conversion function, which would convert Arduino's pin number to our pin number - easy, but will cost CPU time.
Or including some conditions into the computation - also costs CPU time.
Secondly, the computations itself are not as fast as one would expect. For example, I was surprised how much time a simple bit shift (1 << N) takes if N is a variable and the compiler will actually have to generate a loop which shifts the bit N-times. My results for this methods were about 2.0 us in the ideal case, with reordered pins. Add the need to map the Arduino pin numbers to these reordered pin numbers and it is not as fast as you would want.
This is the option which won in my tests; it provided the best trade-off between speed and maintainability (and portability) of the code. The particular implementation I used is described in detail above. In general, we can say that the principle is to include the port address and bit mask in the definition of the pin. So the functions for digital I/O do not receive directly the number of the pin, but some kind of a code (or data structure) which includes all the information needed to manipulate the pin. The advantage compared to the other methods is, that it does not need 'expensive' computations, like shifting bits by variable number, or comparisons and branches.
2014-02-25 First version.
2014-05-30 Minor updates in the text; fixed version of the code uploaded which works also on Linux.
2015-02-27 Code updated to build in Arduino IDE 1.6.0, locations for files updated in text
2015-03-09 Changes to allow use as Arduino library (directories reorganized) and zip file renamed to dio2.zip. Also new speed tests added using oscilloscope (without error from loop control code).
This article, along with any associated source code and files, is licensed under The GNU Lesser General Public License (LGPLv3)
// #define MYPORTA (0x22)
#define MYPORTB (0x25)
// #define MYPORTC (0x28)
...
// DP9 = GPIO_MAKE_PINCODE(MYPORTH,6),
DP10 = GPIO_MAKE_PINCODE(MYPORTB,4),
DP11 = GPIO_MAKE_PINCODE(MYPORTB,5),
DP9 = GPIO_MAKE_PINCODE(MYPORTB,3),
DP12 = GPIO_MAKE_PINCODE(MYPORTB,6),
DP13 = GPIO_MAKE_PINCODE(MYPORTB,7),
// DP14 = GPIO_MAKE_PINCODE(MYPORTJ,1),
...
// Number of GPIO pins.
// Used in Arduino_to_GPIO_pin
#define GPIO_PINS_NUMBER (6)
* Step 3) if the addresses of all the GPIO registers are lower than 0xFF, you
* can use the simple macros as defined here.
* If there are some registers with higher address (such as the case in
* Atmega 2560 used in Arduino Mega), we need to encode the address into
* single byte or use a different approach. Use the macros defined in
* pins2_arduino.h for Arduino mega.
*
#define GPIO_MAKE_PINCODE(port, pin) (((uint16_t)port & 0x00FF) | ((1<<pin) << 8))
#define GPIO_MAKE_PINCODE(port, pin) ((uint16_t)port > 0xFF ) ? \
(((uint16_t)port & 0x00FF) | ((1<<pin) << 8) | 0x0080 ) : \
(((uint16_t)port & 0x00FF) | ((1<<pin) << 8))
const int Background = 4; // Background Drain
const int Pulse = 8;
//turn off backgRound current
pinMode2(Background, INPUT); //rev 1.4 //rev 1.71
digitalWrite2(Background, LOW); //HiZ disable internal pullup //rev 1.4
//turn on pulse current on Pulse
pinMode(Pulse, OUTPUT); //Pulse on Pulse //rev 1.4 //rev 1.71
digitalWrite(Pulse, HIGH); //rev 1.4
time = millis();
//Read batteries again during the applied Pulse
//because we have several Pulse options like rx/tx and such, we may
// want to put this into a separate function
while(millis() < (time + P_WIDTH - 15)); //wait for Pulse -15
readAD();
while(millis() < (time + P_WIDTH)); //wait for Pulse end of Pulse output
pinMode(Pulse, INPUT); //rev 1.4 //rev 1.71
digitalWrite(Pulse, LOW); //HiZ disable internal pullup //rev 1.4
pinMode2(Background, OUTPUT); //Pre //rev 1.4 //rev 1.71
digitalWrite2(Background, HIGH); //rev 1.4
digitalWrite(LED, mBlink); //rev 1.72 Blink
mBlink = 1 - mBlink; // rev 1.72 invert for ne
//Unfortunately we cannot use the PORTA etc. definitions from avr/io.h in the<br />
// GPIO_MAKE_PINCODE macro, so I define the port register addresses here to make<br />
// it more comfortable to define the pins<br />
// This is the address of the port register, e.g. PORTA or PORTB, from the datasheet.<br />
#define MYPORTB (0x25)<br />
#define MYPORTC (0x28)<br />
#define MYPORTD (0x2B)<br />
#define MYPORTE (0x2E)<br />
#define MYPORTF (0x31)<br />
<br />
/*<br />
* GPIO_pin_t<br />
* Define the type for digital I/O pin.<br />
* We will not use simple integer (int) to identify a pin.<br />
* Instead we use special code, which contains the address of the I/O register<br />
* for given pin (lower byte) together with its bit mask (upper byte).<br />
* For this code we create our special data type (GPIO_pin_t) which will prevent<br />
* the user from calling our digitalRead/Write with invalid pin numbers.<br />
*<br />
*/<br />
enum GPIO_pin_enum<br />
{<br />
// Note: The invalid value can be 0 which means digitalWrite will write to<br />
// reserved address on Atmega 328 used in Arduino Uno,<br />
// or it can be any valid port register - as long as the bit mask in upper <br />
// byte is 0, the operation on this register will have no effect.<br />
DP_INVALID = 0x0025,<br />
DP0 = GPIO_MAKE_PINCODE(MYPORTD,2),<br />
DP1 = GPIO_MAKE_PINCODE(MYPORTD,3),<br />
DP2 = GPIO_MAKE_PINCODE(MYPORTD,1),<br />
DP3 = GPIO_MAKE_PINCODE(MYPORTD,0),<br />
DP4 = GPIO_MAKE_PINCODE(MYPORTD,4),<br />
DP5 = GPIO_MAKE_PINCODE(MYPORTC,6),<br />
DP6 = GPIO_MAKE_PINCODE(MYPORTD,7),<br />
DP7 = GPIO_MAKE_PINCODE(MYPORTE,6),<br />
DP8 = GPIO_MAKE_PINCODE(MYPORTB,4),<br />
DP9 = GPIO_MAKE_PINCODE(MYPORTB,5),<br />
DP10 = GPIO_MAKE_PINCODE(MYPORTB,6),<br />
DP11 = GPIO_MAKE_PINCODE(MYPORTB,7),<br />
DP12 = GPIO_MAKE_PINCODE(MYPORTD,6),<br />
DP13 = GPIO_MAKE_PINCODE(MYPORTC,7),<br />
DP14 = GPIO_MAKE_PINCODE(MYPORTF,7),<br />
DP15 = GPIO_MAKE_PINCODE(MYPORTF,6),<br />
DP16 = GPIO_MAKE_PINCODE(MYPORTF,5),<br />
DP17 = GPIO_MAKE_PINCODE(MYPORTF,4),<br />
DP18 = GPIO_MAKE_PINCODE(MYPORTF,1),<br />
DP19 = GPIO_MAKE_PINCODE(MYPORTF,0),<br />
};
DP8 = GPIO_MAKE_PINCODE(MYPORTB,0),
with:
DP8 = GPIO_MAKE_PINCODE(MYPORTB,4),
const int Pulse = 8;
pinMode2(Background, INPUT);
digitalWrite2(Background, LOW);
pinMode(Pulse, OUTPUT);
digitalWrite(Pulse, HIGH);
PORTB |= (1 << pulse);
PORTB &= ~(1 << pulse);
General News Suggestion Question Bug Answer Joke Praise Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages.
|
https://www.codeproject.com/Articles/732646/Fast-digital-I-O-for-Arduino
|
CC-MAIN-2020-50
|
refinedweb
| 6,306
| 60.55
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.