
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91 values | source stringclasses 1 value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
1 /* A substitute for POSIX 2008 <stddef.h>, for platforms that have issues. 2 3 Copyright (C) 2009-2017 Free Software Foundation, Inc. 4 5 This program is free software; you can redistribute it and/or modify 6 it under the terms of the GNU General Public License as published by 7 the Free Software Foundation; either version 3, or (at your option) 8, see <>. */ 17 18 /* Written by Eric Blake. */ 19 20 /* 21 * POSIX 2008 <stddef.h> for platforms that have issues. 22 * <> 23 */ 24 25 #if __GNUC__ >= 3 26 @PRAGMA_SYSTEM_HEADER@ 27 #endif 28 @PRAGMA_COLUMNS@ 29 30 #if defined __need_wchar_t || defined __need_size_t \ 31 || defined __need_ptrdiff_t || defined __need_NULL \ 32 || defined __need_wint_t 33 /* Special invocation convention inside gcc header files. In 34 particular, gcc provides a version of <stddef.h> that blindly 35 redefines NULL even when __need_wint_t was defined, even though 36 wint_t is not normally provided by <stddef.h>. Hence, we must 37 remember if special invocation has ever been used to obtain wint_t, 38 in which case we need to clean up NULL yet again. */ 39 40 # if !(defined _@GUARD_PREFIX@_STDDEF_H && defined _GL_STDDEF_WINT_T) 41 # ifdef __need_wint_t 42 # define _GL_STDDEF_WINT_T 43 # endif 44 # @INCLUDE_NEXT@ @NEXT_STDDEF_H@ 45 # endif 46 47 #else 48 /* Normal invocation convention. */ 49 50 # ifndef _@GUARD_PREFIX@_STDDEF_H 51 52 /* The include_next requires a split double-inclusion guard. */ 53 54 # @INCLUDE_NEXT@ @NEXT_STDDEF_H@ 55 56 /* On NetBSD 5.0, the definition of NULL lacks proper parentheses. */ 57 # if (@REPLACE_NULL@ \ 58 && (!defined _@GUARD_PREFIX@_STDDEF_H || defined _GL_STDDEF_WINT_T)) 59 # undef NULL 60 # ifdef __cplusplus 61 /* ISO C++ says that the macro NULL must expand to an integer constant 62 expression, hence '((void *) 0)' is not allowed in C++. */ 63 # if __GNUG__ >= 3 64 /* GNU C++ has a __null macro that behaves like an integer ('int' or 65 'long') but has the same size as a pointer. Use that, to avoid 66 warnings. */ 67 # define NULL __null 68 # else 69 # define NULL 0L 70 # endif 71 # else 72 # define NULL ((void *) 0) 73 # endif 74 # endif 75 76 # ifndef _@GUARD_PREFIX@_STDDEF_H 77 # define _@GUARD_PREFIX@_STDDEF_H 78 79 /* Some platforms lack wchar_t. */ 80 #if !@HAVE_WCHAR_T@ 81 # define wchar_t int 82 #endif 83 84 /* Some platforms lack max_align_t. The check for _GCC_MAX_ALIGN_T is 85 a hack in case the configure-time test was done with g++ even though 86 we are currently compiling with gcc. */ 87 #if ! (@HAVE_MAX_ALIGN_T@ || defined _GCC_MAX_ALIGN_T) 88 /* On the x86, the maximum storage alignment of double, long, etc. is 4, 89 but GCC's C11 ABI for x86 says that max_align_t has an alignment of 8, 90 and the C11 standard allows this. Work around this problem by 91 using __alignof__ (which returns 8 for double) rather than _Alignof 92 (which returns 4), and align each union member accordingly. */ 93 # ifdef __GNUC__ 94 # define _GL_STDDEF_ALIGNAS(type) \ 95 __attribute__ ((__aligned__ (__alignof__ (type)))) 96 # else 97 # define _GL_STDDEF_ALIGNAS(type) /* */ 98 # endif 99 typedef union 100 { 101 char *__p _GL_STDDEF_ALIGNAS (char *); 102 double __d _GL_STDDEF_ALIGNAS (double); 103 long double __ld _GL_STDDEF_ALIGNAS (long double); 104 long int __i _GL_STDDEF_ALIGNAS (long int); 105 } max_align_t; 106 #endif 107 108 # endif /* _@GUARD_PREFIX@_STDDEF_H */ 109 # endif /* _@GUARD_PREFIX@_STDDEF_H */ 110 #endif /* __need_XXX */ | https://fossies.org/linux/misc/gcal-4.1.tar.gz/gcal-4.1/lib/stddef.in.h | CC-MAIN-2019-43 | refinedweb | 529 | 61.06 |
A Python module to create Excel XLSX files.
Project description
XlsxWriter is a Python module for creating Excel XLSX files.
XlsxWriter supports the following features:
- 100% compatible Excel XLSX files.
- Write text, numbers, formulas, dates.
- Full cell formatting.
- Multiple worksheets.
Here is a small example:
from xlsxwriter.workbook import Workbook # Create an new Excel file and add a worksheet. workbook = Workbook('demo.xlsx') worksheet = workbook.add_worksheet() # Widen the first column to make the text clearer. worksheet.set_column('A:A', 20) # Add a bold format to highlight cell text. bold = workbook.add_format({'bold': 1}) # Write some simple text. worksheet.write('A1', 'Hello') # Text with formatting. worksheet.write('A2', 'World', bold) # Write some numbers, with row/column notation. worksheet.write(2, 0, 123) worksheet.write(3, 0, 123.456) workbook.close()
See the full documentation at
The XlsxWriter module is a port of the Perl Excel::Writer::XLSX module. It is a work in progress.
Project details
Release history Release notifications | RSS feed
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
XlsxWriter-0.0.3.tar.gz (2.4 MB view hashes) | https://pypi.org/project/XlsxWriter/0.0.3/ | CC-MAIN-2022-27 | refinedweb | 195 | 55 |
Hello ,everyone!
Please tell me how to change the baud rate on TK1? Thanks
Hello ,everyone!
Which baud rate?
ttyTHS0~ttyTHS2
My first question…what are you using to read the output to know when it is correct? Assuming read is external to the tk1, what kind of cabling are you using? Is there a particular serial port you want to start with? I’m going to assume ttyTHS2, I believe this goes to J3A2 (but I’m not certain if the translation between schematic numbering and /dev/ttyTHS# is 1-to-1…if my oscilloscope hadn’t died I would test by echo of text to the port).
Install the setserial package, and view the existing settings of /dev/ttyTHS2:
setserial -a /dev/ttyTHS2
I see:
/dev/ttyTHS2, Line 2, UART: undefined, Port: 0x0000, IRQ: 78 Baud_base: 0, close_delay: 50, divisor: 0 closing_wait: 3000 Flags: spd_normal
Some of the data returned is obvious, e.g., baud_base; other parts are not so obvious, but are explained in the man page to setserial (e.g., divisor). The characteristics you read with setserial -a are generally the ones you can also set. In some cases you need to set a baud_base to some special number and then use the divisor to reach the effective/true speed.
To set the speed:
setserial /dev/ttyTHS2 baud_base 115200
After I did this, here is the newly set ttyTHS2:
root@tk1:~# setserial -a /dev/ttyTHS2 /dev/ttyTHS2, Line 2, UART: undefined, Port: 0x0000, IRQ: 78 Baud_base: 115200, close_delay: 50, divisor: 0 closing_wait: 3000 Flags: spd_normal
Note that if you need a setting during boot there are probably kernel command line arguments or firmware changes you could make. In the case of the serial console, this is passed to the driver and then the driver makes the adjustments. This is the part of kernel command line to set the serial console:
console=ttyS0,115200n8
…here is the part which sets up the local console:
console=tty1 no_console_suspend=1
Those console examples go to console drivers which set up the correct tty…there might be a similar option for serial UARTS, but I don’t know.
I managed to update the /dev/ttyTHS1-2 baudrate by calling some C function, following is the sample source code, compile and run it:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <errno.h>
#include <termios.h>
#include <unistd.h>
//#include <sys/ioctl.h>
int main(int argc, char *argv)
{
int uart_fd;
char *uart_name = “/dev/ttyTHS1”;
char sample_test_uart[25] = {‘S’, ‘A’, ‘M’, ‘P’, ‘L’, ‘E’, ‘\n’, ‘\r’};
struct termios uart_attr;
uart_attr.c_ospeed = 0;
if(argc > 1) uart_name = argv[1];
uart_fd = open(uart_name, O_RDWR | O_NONBLOCK | O_NOCTTY); //
if(uart_fd < 0){
printf(“error opening UART %s, aborting…\n”, uart_name);
return uart_fd;
}
if(tcgetattr(uart_fd, &uart_attr) < 0) {
printf(“failed to read uart attibute, aborting \n”);
return uart_fd; }
printf("UART speed is %d\n", uart_attr.c_ospeed); //cfsetspeed(&uart_attr, B38400); cfsetspeed(&uart_attr, B921600); printf("B38400 is %d\n", B38400); printf("B921600 is %d\n", B921600);
//uart_attr.c_ospeed = B38400;
//uart_attr.c_ispeed = B38400;
if(tcsetattr(uart_fd, TCSANOW, &uart_attr) < 0) {
printf(“failed to set uart attibute, aborting \n”);
return uart_fd;
}
printf(“writing to UART %s\n”, uart_name);
int result = write(uart_fd, sample_test_uart, 8);
printf(“write %d byte to UART\n”, result);
close(uart_fd);
}
when I open the “/dev/ttyTHS1” without the O_NONBLOCK, the open function will block. anyone know something about this?
You will probably want to give information on how you opened ttyTHS1 (including whether for read, read-write, or write) and whether the nature of what the serial side is talking to. It is possible that since a UART is physical hardware you might be running into some aspect which is normal for such hardware…don’t know, need more details of exactly how the UART is being opened, when it is being blocked, and what you actually expected to occur. Also a note on what release is used (“head -n 1 /etc/nv_tegra_release”).
I just use the code above post by TKAI.But I have fixed this issue. I add the code “memset(&uart_attr, 0, sizeof(uart_attr));” before modify the attribute, after tcgetattr. I think some config of the attr default are not suitable, but I dont kown which attribute make it. My board is Customized with TX2, and the tegra_release is R28.2.1. Thank you @linuxdev.
This is the defined behavior. Is there more to the description, e.g., are you saying that when the function blocks and then data arrives it fails to continue?
linuxdev:
I mean the open function will block if without O_NONBLOCK. I did not try to send data to the uart, the uart was floating. I thought the open function will not block, even something is wrong ,it will only return failed.
Removing O_NONBLOCK is supposed to cause blocking. That’s the very definition, it isn’t a bug. If you’ve been comparing how this behaves on some other file types, then the comparison probably wasn’t valid since this is a hardware driver implementation of serial I/O and is neither purely in software nor is it a block device.
Let me rephrase…what would you like to accomplish? You can’t stop hardware serial I/O from being bound to hardware and kernel drivers, so maybe there is some other approach. If you have problems with efficiency of polling or blocking behavior, then you might work around it with some method such as running the I/O in its own separate thread.
Hello,
Problem statement: i want to communicate from jetson to another Microcontroller,
i can successfully able to read the data from serial:Serial( ‘dev/ttyTHS1’, 57600), but when i am sending the data it is not showing any response
i have tried way arround which is . i have connected the ttl to usb converter from jetson nano to microcontroller , i could read and write the data and micrcontroller also repond to it.
Do you have some explaination or solution for this, it would be great help.
Alread tried : to disable nvgetty
This should be a new post. I’ll guess it needs a pull-up or pull-down resistor if the UART is already at the correct voltage (3.3V). There is normally no need for such a resistor, so I couldn’t tell you what value to use.
Note that having a port talk to itself via loopback is a good hardware test…simply connect the TX and RX together, and name the port “
/dev/ttyTHS1” from a serial terminal program (such as
minicom). Then try different settings. It should echo whatever is typed. If this occurs, then you know the issue is not that the port itself fails. | https://forums.developer.nvidia.com/t/how-do-i-change-the-baud-rate-please/40602 | CC-MAIN-2022-33 | refinedweb | 1,116 | 62.07 |
What follows is a sort of checklist to help you solve the problem quickly yourself. It is divided into four parts:
A. Before uploading to the Server
B. Uploading to the Server
C. Setting Up on the Server
Like any Perl program a CGI script needs to successfully compile before it will run. Until it does this you can forget everything else. To test this you need a command prompt and a working Perl interpreter. If you have *nix you are probably already there. If you have DOS/Windows or a Mac you will probably need to install Perl. You can get a binary copy of Perl, ready to install, for almost any platform:\>
This is telling you that your operating system can not find the Perl executable. Either it is not installed and/or it is not included in your path environment variable. So install perl and either include it in your path or type the full path to the executable. How you find perl depends on your system. On *nix type 'which perl' at the command prompt to get the path (usually /usr/bin/perl). On Windows use Start|Find|perl.exe to get the path (probably C:\PERL\BIN).
A bit of background: the PATH environment variable is a list of directories separated by colons (*nix) or semicolons (Dos/Win). When you type a command name without giving an explicit path your shell searches each directory in the PATH list in order, looking for an executable file by that name, and the shell will run the first matching program it finds.
To check the path on Win32 use: C:\>PATH C:\;C:\WINDOWS;C:\WINDOWS\COMMAND; C:\> To add to the path use: C:\>C:\PATH %PATH%C:\PERL\BIN; C:\> To check the path on *nix use: $ echo $PATH /bin:/usr/bin: For csh users use something like: setenv PATH :/bin:/usr/bin For sh or ksh users: PATH=:/bin:/usr/bin export PATH.
Assuming all has gone to plan so far we are ready to upload the script to the server. The server is the computer that is actually connected to the WWW and whose job it is the serve up HTML documents and process CGI scripts. A Perl script is just a text file. Unfortunately different computer operating systems handle text files differently. On *nix the line ending is a line feed (\n). On Dos/Win it is a carriage return line feed (\r\n). On Macs it is a carriage return (\r). Clearly some conversion will be in order when sending files from one system type to another. Never fear the problem has been solved for you. All you need to do is to make the transfer (usually by FTP) in ASCII mode. In this mode the line endings will be automatically converted for you.:
(i). Browser requests a resource via a URL that is aimed at a CGI script, say via a link like:<a href="">Run my script</a>
(ii). The server receives the request and goes "Ah ha this is a cgi script that I need to run!"
(iii). The server executes the script passing it data via the environment variables in the $ENV hash and via STDIN. The script can access this data and process it. The script generates output on STDOUT
(iv). The server takes the output of the CGI script from STDOUT and returns it to the browser pretending it received a request for a static HTML document.
We can have problems in any of these areas. Of course!
In order to execute the script you need to ask for it to be executed. If you link to the URL above and your cgi-bin happens to be called localcgi (like mine) then you will get a 404 Document not found error. Of course the server can not find the document in /, it is after all somewhere else!
You can't execute an HTML document, well at least Perl can't compile it! You also don't want to return the code in your script to the browser when it is requested. So it is obvious that the server needs some way of deciding if it needs to return the requested document of execute it. As you might expect there are many ways to achieve this result. Your systems administrator should know the exact details for your system but here is a general guide.
Under *nix all files have permissions. They have permissions for the owner, the group, and everybody else. The permissions are 4=read, 2=write, 1=execute. Thus a permission of 7 means that the file can be read , written and executed as 4+2+1=7. A permission of 5 means the file can be read and executed as 4+1=5. As a general rule you will want permissions of 755 for your file which grants you read, write and execute permission and everyone else read and execute permission. You set this using the command chmod 755. Directories also have permissions which need to be correct but they should be fine if this is a standard cgi-bin.
Some servers are configured to recognise any file that ends in .pl, .pm, .cgi as a Perl executable (especially WIN32) and act accordingly. You will need to use one of these extensions if that is the case so the server knows to execute the file. Still other servers assume that all files in certain directories (ie cgi-bin) are executable. The bottom line is is all else fails then check with your sysadmin.
Under *nix if a request for a file marked as executable is made then the first 2 bytes are examined for the #! shebang sequence. If this is found then the shell executes that file using the executable file it finds at the path following the #! Thus what this line:
#!/usr/bin/perl
actually says is: "Dear shell, if this file is called and it has read and execute permission please execute it using the executable file in the /usr/bin/ dir called perl". If the Perl executable is not in the /usr/bin/ directory then the shell will complain about not being able to find Perl. Unless the script has permissions of at least 5 (read and execute) the shell/Perl will not be able to read it (as it must) in order to execute it (as we want)
A common Win32 -> *nix problem is \r chars from the Win32 line ending \r\n (CRLF) remaining. This is usually due to uploading in binary mode. Anyway a typical error is 'bad interpreter'. You get this message because the *nix shell is looking for /usr/bin/perl\r and the executable "perl\r" does not exist. The usual fix is:
perl -pi -e 's/\r//' script.pl.
If you add this code your script will run for long enough that any errors appear in the browser window making it easy to see the problem, presuming of course that you have followed the advice above! This will avoid you getting the less than useful 500 Internal Server Error or Premature end of script headers/Malformed script headers messages. You add this code just below the shebang line and before everything else. That's everything else. The reason for this is to minimise the lines which can cause problems before we reliably direct output (including syntax errors) to the browser
#!/usr/bin/perl -wT # ensure all fatals go to browser during debugging and set-up # comment this BEGIN block out on production code for security BEGIN { $|=1; print "Content-type: text/html\n\n"; use CGI::Carp('fatalsToBrowser'); } # all the rest of the code goes here
Because this code is in a BEGIN block it is executed before everything else. Even before most of the script is compiled. In it we do three vital things to ensure that all errors from this point on will appear in the browser window thus making debugging *much* easier. You could look in the server logs to get the same information but as you may or may not have access to them and they can be anywhere on the server it is easier to use this instead. in) every request and response needs a valid header. It may or may not include a body but it must have a header. The end of the header is recognised by the \n\n sequence. This prints one blank line. If, for any reason, a blank line is printed *before* the "Content-type: text/html\n\n" you will get a premature end of script header error. By printing a valid header we avoid this. Note that I have presumed you want to output HTML but you can also output GIFs, JPEGs etc using a different header that specifies these different data types. The headers our script generates without this block will appear in the top left of the browser window where we can check that they are as expected. If you don't see them and your script now works your problem is that you are not outputting any valid header info. The World Wide Web Security FAQ for more details.. It is very handy to know that the reason your script is not working is because you can not find/open/write to a file for instance..
Like any program a CGI may run but not produce the output you expect because of logic errors. Provided you have already printed a valid header you can add temporary debugging print statements within your code to print out variable values and flags to allow you to follow the progress of your code as it runs. My code often looks like this:
... | http://www.perlmonks.org/bare/?node_id=165253 | CC-MAIN-2017-04 | refinedweb | 1,620 | 71.24 |
Opened 11 years ago
Closed 8 years ago
Last modified 5 years ago
#5741 closed Uncategorized (wontfix)
make queryset get(), latest(), earliest(), take a default kwarg
Description
Just to follow up on so it doesn't get forgotten. I know this is supposed to wait for the queryset refactoring to be completed, but I figured it couldn't hurt to have a working patch and doc changes now. And as it stands now, the patch would look virtually identical against the queryset-refactor branch.
Attachments (3)
Change History (14)
Changed 11 years ago by
comment:1 follow-up: 3 Changed 11 years ago by
comment:2 Changed 11 years ago by
comment:3 Changed 11 years ago by
Or maybe something like:
foo = Foo.objects.default(None).get(myid)
This would be backwards compatible and would also avoid any name-conflict woes. Of course, I don't like that it's not so readable anymore, but it might be useful.
Another approach is to have get return None instead of an exception:
foo = Foo.objects.get(myid) or default_object
But I doubt that the whole DoesNotExist exception thing would be thrown away at this stage. Maybe a settings variable can be used to "turn on" this functionality, to keep it backways compatible and let the user choose whether or not they want exceptions or return values. This road is getting a little messy.
A third option is:
foo = Foo.objects.get_or_none(myid) or default_object
...but the method needs a better name, because it's really starting to lose it's readability, but I like it better than the first one.
comment:4 Changed 11 years ago by
The patch adds a "default" kwarg, that returns the value of "default" if it's supplied, and raises the DoesNotExist exception otherwise, like before. So you can do either of the following:
try: foo = Foo.objects.get( pk=myid ) except Foo.DoesNotExist, ex: foo = None
or
foo = Foo.objects.get( pk=myid, default=None )
I think making get() use the first argument as a primary key lookup is unnecessary with the "pk" shortcut. Also, I'd imagine it would add a lot of ugly special-casing, since get() is really a convenience for filter(), whose positional args (if provided) are expected to be Q objects.
comment:5 Changed 10 years ago by
Changed 10 years ago by
comment:6 Changed 10 years ago by
Dan's going to want to kill me (sorry, Dan!), but we can't commit this as it is. It's backwards incompatible. If somebody has a
qs.get(foo=1, default=2) call now, that code will break with this change.
So if this is really, really considered necessary (and the bar just got higher because of this), it need to be a method with a new name. What I don't want to see are 23 comments attached to this ticket suggesting everybody's favorite name for the new pony. Somebody (hi, Dan!) should come up with a good name or two and gather some consensus on django-dev, which should probably include some kind of glimmer of interest from somebody with commit privileges. I'm kind of somewhere around +0/-0 on this. I use the pattern a fair bit myself, but it doesn't worry me too much (it's a three line utility function if I don't want to catch exceptions too often). Since it's introducing a whole new method, it's going to need some support. I know I'm not really helping there, but maybe I'm undervaluing the ticket's utility so I'm not going to wontfix it immediately.
As some consolation, here's an updated patch that at least applies against trunk. So it can be the starting point for modification.
Changed 10 years ago by
Updated patch (just the docs bit changed)
comment:7 Changed 9 years ago by
I'm fine with relegating it to utility-function land. It may have been nice to mirror dict.get(), but it's by no means difficult to catch the exception, create a utility function, or even have your own manager get() method. Or perhaps it would be better suited as a
get_object method in
django.shortcuts. In any case, I don't feel strongly enough about it to carry the torch, so feel free to wontfix it or defer it to 2.0, when we can break stuff with reckless abandon!
comment:8 Changed 9 years ago by
Can we put this in the django.shortcuts?
please?
def get_object_or_none(klass, *args, **kwargs): """ Uses get() to return an object, or return None if the does not exist. klass may be a Model, Manager, or QuerySet object. All other passed arguments and keyword arguments are used in the get() query. Note: Like with get(), an MultipleObjectsReturned will be raised if more than one object is found. """ queryset = _get_queryset(klass) try: return queryset.get(*args, **kwargs) except queryset.model.DoesNotExist: return None
comment:9 Changed 8 years ago by
Due to backwards incompatibility changes, this can't be done. Sorry. :-(
Writing one's own shortcut is easy enough here.
comment:10 Changed 7 years ago by
This is the sort of thing that would be useful if you ever do a big API break (django 2.0) for instance. - Maybe it would be worth collecting all these somewhere like that, so a future version after an API break could benefit?
comment:11 Changed 5 years ago by
We are looking for the same behaviour, but from the ‘QuerySet.latest’ and friends.
Quite a lot of our code looks like this:
foo_set = Foo.filter(spam="Lorem", beans="Ipsum") try: foo = foo_set.latest() except Foo.DoesNotExist: foo = None do_more_with(foo)
This would be cleaner (and less prone to bugs) written as:
foo_set = Foo.filter(spam="Lorem", beans="Ipsum") foo = foo_set.latest(default=None) do_more_with(foo)
This is a generally-useful feature, and doesn't belong tacked onto every model manager; it should be in the QuerySet API so every model gets it.
Yes, a default argument (like a dictionary) would be good.
Since 95% I use the primary key if I use get(), I suggest this
dict like API:
this should behave like | https://code.djangoproject.com/ticket/5741 | CC-MAIN-2018-26 | refinedweb | 1,041 | 64.51 |
URI stands for Uniform Resource Identifier.URI is a sequence of characters used to identify resource location or a name or both over the World Wide Web. A URI can be further classified as a locator, a name, or both.
Syntax of URI: Starts with a scheme followed by a colon character, and then by a scheme-specific part.
The most popular URI schemes, are HTTP, HTTPS, and FTP.
URL stands for Uniform Resource Location.URL is a subset of URI that describes the network address or location where the source is available.URL begins with the name of the protocol to be used for accessing the resource and then specific resource location. URLs build on the Domain Name Service (DNS) to address hosts symbolically and use a file-path like syntax to identify specific resources at a given host. For this reason, mapping URLs to physical resources is straightforward and is implemented by various Web browsers.
URN stands for Uniform Resource Name. It is a URI that uses a URN scheme.
“urn” scheme: It is followed by a namespace identifier, followed by a colon, followed by namespace specific string
URN does not imply the availability of the identified resource.URNs are location-independent resource identifiers and are designed to make it easy to map other namespaces into URN space.
Here is a diagram that shows the relationship between URL, URI, URN:
Java Foundation and Collections concepts with the Fundamentals of Java and Java Collections Course at a student-friendly price and become industry ready. To complete your preparation from learning a language to DS Algo and many more, please refer Complete Interview Preparation Course. | https://www.geeksforgeeks.org/difference-between-url-uri-and-urn-in-java/?ref=rp | CC-MAIN-2021-25 | refinedweb | 275 | 62.98 |
Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you have been placed in read-only mode.
Please download a browser that supports JavaScript, or enable it if it's disabled (i.e. NoScript).
On 06/07/2016 at 15:47, xxxxxxxx wrote:
In python, How may I set the "lookat" position of a camera programmatically?
In particular, I am specifically interested in setting the orientation of the EditorCamera to look at position (0, 0, 0) (the center scene).
I imagine there is some matrix math that could be done but I'm not sure how to do it in C4D, and was hoping there was an easy way to update the EditorCamera matrix so that it maintains the poisition but changes the orientation to look at the center of the scene.
The only way I can see to do this without knowing the matrix math is to create a dummy camera at the EditorCamera position, create a dummy object at the center of the scene, add a Target tag to the dummy camera, set the target to the dummy object, copy the "Mg" to the EditorCamera, then delete the dummy object and dummy camera.
There must be a better way!
Any help would be much appreciated.
On 07/07/2016 at 07:41, xxxxxxxx wrote:
Hello,
welcome to the Plugin Café forums
Actually I'm not aware of a better way.
Perhaps you can share some detail, why you need to do this with the editor camera instead of a dedicated camera. The editor camera has the disadvantage, that you can't add tags to it.
Instead of using the Target tag and a target object, you could of course either implement your own tag or use the Python tag on a camera to have it look at the origin at all times.
We have a Python example on how to achieve something similar: Py-LookAtCamera
On 07/07/2016 at 23:08, xxxxxxxx wrote:
Thanks Andreas; this is the script I ended up writing after looking at the code you linked:
import c4d
from c4d import gui, utils, Vector
def main() :
bd = doc.GetRenderBaseDraw()
ec = bd.GetEditorCamera()
op = doc.GetActiveObject()
if op is None:
op = doc.SearchObject('Camera')
if op is None:
gui.MessageDialog('No object selected, and no object named "Camera"')
return False
doc.StartUndo()
doc.AddUndo(c4d.UNDOTYPE_CHANGE_SMALL, ec)
rp = op.GetRelPos()
ec.SetRelPos(rp + Vector(0,1,0) + (rp.GetNormalized()*5))
ec.SetRelRot(utils.VectorToHPB(-rp))
c4d.EventAdd()
doc.EndUndo()
if __name__=='__main__': main()
I am using camera mapping, and the center of the scene for my projects will always be Vector(0,0,0). I desired to have a quick way to jump back to the the "Camera" position to preview changes and make minor adjustments without actually activating the camera (which distorts the view, and is immutable) or having to mouse over back to that position (tedious).
Thanks for your help, this is now solved as far as I am concerned, unless you have any other comments or tips on a better or different way of how I could have handled this.
On 07/07/2016 at 23:24, xxxxxxxx wrote:
I guess the only thing that's missing, that I haven't looked into, is taking into account the project units and scale... Have to modify the modifiers for projects in centimeters versus feet. | https://plugincafe.maxon.net/topic/9580/12861_set-editorcamera-lookat-orientation | CC-MAIN-2021-43 | refinedweb | 571 | 59.64 |
Opened 14 years ago
Last modified 9 months ago
#2130 new enhancement
Sort Milestones in Roadmap and NewTicket alphabetically (as an option)
Description
I use Trac for different components with different version number. The milestones are sorted in the sequence I added them plus a sort over the date that is set.
It would be very nice to get them optional sorted alphabetically.
The milestone listbox in the "New Ticket" looks now as the following example:
- ComponentA 1.0
- ComponentB 2.1
- ComponentC 0.3
- ComponentC 0.4
- ComponentA 1.1
- ComponentB 2.3
I want to have an option in the "Roadmap" to sort it alphabetically and my be as default in the "New Ticket" settings. Then it should look like the following:
- ComponentA 1.0
- ComponentA 1.1
- ComponentB 2.1
- ComponentB 2.3
- ComponentC 0.3
- ComponentC 0.4
Attachments (0)
Change History (11)
comment:1 by , 14 years ago
comment:2 by , 14 years ago
comment:3 by , 14 years ago
I think you are wrong for the NewTicket. I just looked at the, where version 0.9b2 is running. There are the entries under milestones not sorted alphabetically. It seems to be sorted in the same order as in the roadmap. I would prefer the alphabetically order, because it's hard to find an special version in an unsorted listbox.
For the roadmap I would suggest another checkbox "Show milestones alphabetically" (in the same dialog as the checkbox "Show already completed milestones"). When I search for a special version it's hard to know, how the "due date" is set.
comment:4 by , 14 years ago
comment:5 by , 14 years ago
Sorting by due date is the natural thing to do for milestones. Your problem is (AFAICT) that you're trying to maintain multiple projects in a single Trac environment. At least for me, milestones don't make sense on a per-component basis. After all, you want the entire system/project to reach a milestone, not just some part of it.
So, I don't think that we should officially support pseudo-multi-project deployment in Trac. Rather, we need #130 at some point, where stuff like this would be more natural.
comment:6 by , 12 years ago
I support the request for the possibility to sort milestones alphabetically as an option… we use Trac for quite large projects with a number of milestones.. It can be hard to find the correct milestone for a ticket when you have to read a long list sorted by due dates (and closed milestones as well).
Marianne
comment:7 by , 12 years ago
comment:8 by , 17 months ago
comment:9 by , 12 months ago
I'm surprised to see that this request has been around for so long with no resolution. I too have many milestones in one TRAC instance and are unable to sort on the milestones. Why is sorting on the milestone such a problem to resolve?
comment:10 by , 12 months ago
/path/to/tracenv/plugins/better_milestone_order.py:
from trac.util import embedded_numbers from trac.ticket.model import Milestone def better_milestone_order(m): return (not bool(m.completed), not bool(m.due), embedded_numbers(m.name)) old_select = Milestone.select def new_select(cls, env, include_completed=True): milestones = old_select(env, include_completed) return sorted(milestones, key=better_milestone_order) Milestone.select = classmethod(new_select)
comment:11 by , 9 months ago
th:wiki:RoadmapPlugin allows sorting milestones by name among other things.
The trunk already sorts the lists alphabetically and has done this for quite awhile. The roadmap still also sorts by due date, but that is a prefer feature. | https://trac.edgewall.org/ticket/2130 | CC-MAIN-2019-39 | refinedweb | 599 | 59.3 |
RTI International (RTI) generated 2,611 labeled point locations representing 19 different land cover types, clustered in 5 distinct agroecological zones within Rwanda. These land cover types were reduced to three crop types (Banana, Maize, and Legume), two additional non-crop land cover types (Forest and Structure), and a catch-all Other land cover type to provide training/evaluation data for a crop classification model. Each point is attributed with its latitude and longitude, the land cover type, and the degree of confidence the labeler had when classifying the point location. For each location there are also three corresponding image chips (4.5 m x 4.5 m in size) with the point id as part of the image name. Each image contains a P1, P2, or P3 designation in the name, indicating the time period. P1 corresponds to December 2018, P2 corresponds to January 2019, and P3 corresponds to February 2019. These data were used in the development of research documented in greater detail in “Deep Neural Networks and Transfer Learning for Food Crop Identification in UAV Images” (Chew et al., 2020).
Deep Neural Networks and Transfer Learning for Food Crop Identification in UAV Images, Robert Chew
Rineer J., Beach R., Lapidus D., O’Neil M., Temple D., Ujeneza N., Cajka J., & Chew R. (2021) “Drone Imagery Classification Training Dataset for Crop Types in Rwanda”, Version 1.0, Radiant MLHub
from radiant_mlhub import Dataset ds = Dataset.fetch('rti_rwanda_crop_type') for c in ds.collections: print(c.id)
Python Client quick-start guide | https://mlhub.earth/data/rti_rwanda_crop_type | CC-MAIN-2022-27 | refinedweb | 252 | 54.22 |
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
// game test number 1
#include <iostream>
#include <ctime>
#include <cstdlib>
#include <stdio.h>
#include <string.h>
using namespace std;
int dialouge1(){
cout << "You have been assigned by the Lord of Uberdark to patrol the Mines of Rodin. While patroling you run into a goblin!";}
int Fight1(){
int d10 ;
int ML1 ;
int rr ;
char myArray[50];
cout << " What do you want to do, run or fight the goblin? ";
cin.getline( myArray, 50, '\n');
if( !strcmp( myArray, "fight")){
srand(time(0));
d10 = rand() % 10+1;
cout << d10;
ML1 = rand() % 10+1;
cout << ML1;
if(d10 > ML1){
cout << " You defeated the goblin!" << endl << endl;}
if(d10 < ML1){
cout << " You have been defeated by the goblin! You retreat back to Uberdark to rest." << endl << endl;}
if(d10 == ML1){
cout << " You and the goblin have both been defeated by entropy!\n\n";
}
if(d10 == ML1){
cout << " You get back up and rest for a while to then continue your task.";}
if(d10 < ML1){
cout << " You return from Uberdark well rested.";}
}
if( !strcmp( myArray, "run")){
srand(time(0));
rr = rand() % 14+1;
if(rr > 7){
cout << " You have successfully ran away, coward!";}
if(rr < 7){
cout << " The goblin has caught up to you and beat you to the floor. You wake up later and continue to patrol.";}
}
system("pause");
}
int
dialouge1()
void
Fight1() | http://www.cplusplus.com/forum/beginner/108117/ | CC-MAIN-2015-40 | refinedweb | 218 | 84.37 |
RailsTips by John Nunemaker 2016-07-05T09:50:40-04:00 41.650672-86.160028railstips Flipping ActiveRecord 5679fb67a0b5dd535b15d753 2016-07-05T09:50:40-04:00 2015-12-22T21:05:00-05:00 <p>In which I release an official ActiveRecord adapter for Flipper.</p> <p>Originally, I did not like the idea of an ActiveRecord adapter for <a href="">Flipper</a>. I work on <a href="">GitHub.com</a> day to day, so everything I do has to be extremely performant. Using ActiveRecord for something like this felt like way too much overhead.</p> <p>In fact, at GitHub, we use a custom adapter for Flipper built on good old raw <span class="caps">SQL</span>. Not only that, but we also use a memcache adapter which wraps the pure <span class="caps">SQL</span> adapter to avoid hitting MySQL most of the time. The memcache wrapper (at the time of this writing) works similar to the memoizing adapter that is included with Flipper (for those that are curious).</p> <p>Over time, a few good options came out for using Flipper with ActiveRecord and they changed my mind. I realized that not every application is GitHub.com. Some applications value ease of integration over performance. I even wrote my own ActiveRecord adapter for <a href="">SpeakerDeck</a>, which is what I am now including in the core <a href="">flipper repo</a> (but available as a separate gem).</p> <h2>Installation</h2> <p>Drop the gem in your Gemfile:</p> <pre><code>gem "flipper-active_record"</code></pre> <p>Generate the migration:</p> <pre><code>rails g flipper:active_record</code></pre> <h2>Usage</h2> <pre class="ruby"><code class="ruby">require 'flipper/adapters/active_record' adapter = Flipper::Adapters::ActiveRecord.new flipper = Flipper.new(adapter) # profit...</code></pre> <p>From there, you use flipper the same as you would with any of the previously supported adapters. Internally, all features are stored in a <code>flipper_features</code> table and all gate related values are stored in a <code>flipper_gates</code> table. You can see more about the <a href="">internals in the examples</a>.</p> <h2>Conclusion</h2> <p>As of Flipper 0.7.3, you can now flip features with the easy and comfort of ActiveRecord and the peace of mind that as new AR versions are released, your flipper adapter will be updated and ready to go.</p> <p>Happy flipping and happy holidays!</p><div class="feedflare"> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> </div><img src="" height="1" width="1" alt=""/> John Nunemaker Flipper: Insanely Easy Feature Flipping 55bf5b8ad4c96106840498fa 2015-12-22T20:51:27-05:00 2015-08-03T08:00:00-04:00 <p>In which I ramble about turning features on and off in a really easy way.</p> <p>Cross posted from <a href="">JohnNunemaker.com</a> as it seems relevant here too.</p> <pre><code> __ _.-~ ) _..--~~~~,' ,-/ _ .-'. . . .' ,-',' ,' ) ,'. . . _ ,--~,-'__..-' ,' ,'. . . (@)' ---~~~~ ,' /. . . . '~~ ,-' /. . . . . ,-' ; . . . . - . ,' : . . . . _ / . . . . . `-.: . . . ./ - . ) . . . | _____..---.._/ _____ ~---~~~~----~~~~ ~~ </code></pre> <p>Nearly <a href="">three years ago</a>, I started work on Flipper. Even though there were other feature flipping libraries out there at the time, most notably <a href="">rollout</a>, I decided to whip up my own. <a href="">Repeating others</a> is, after all, one of the better ways to level up your game.</p> <p.</p> <p>Most of the work was done off and on over the course of a few weeks. At the time, I was working on traffic graphs for GitHub and I wanted a way to turn features on/off in a flexible way.</p> <h2 id="naming-is-hard">Naming is hard</h2> <p>Flipper started as a simple ripoff of rollout with the primary difference being the use of adapters for storage instead of forcing redis. I struggled through awkward terminology and messy code for a while, until a great conversation with <a href="">Brandon Keepers</a> led me to the lingo flipper uses today: Actor, Feature and Gate (thanks Brandon!)</p> <p>An <strong>actor</strong> is the thing trying to do something. It can be anything. On <a href="">GitHub</a>, the actor can be a user, organization or even a repository. Actors must respond to <code>flipper_id</code>. If you plan on using multiple types of actors, you can namespace the flipper_id with the type (ie: “User:6”, “Organization:12”, or “Repository: 2”).</p> <p>A <strong>feature</strong> is something that you want to control enabled-ness for. On <a href="">SpeakerDeck</a>,.</p> <p>A <strong>gate</strong> determines if a feature is enabled for an actor. There are currently five gates — boolean, actor, group, % of actors and % of time. Amongst these you can rollout a new feature or control an existing one in whatever way you desire.</p> <h3 id="the-gates">The Gates</h3> <p>The <strong>boolean gate</strong>.</p> <pre class="ruby"><code class="ruby">flipper = Flipper.new(adapter) flipper[:search].enable # turn on flipper[:search].disable # turn off flipper[:search].enabled? # check</code></pre> <p>The <strong>actor gate</strong> allows enabling a feature for one or more specific actors. If you wanted to enable a new feature for one of your friends, you could use this gate.</p> <pre><code class="ruby"> flipper = Flipper.new(adapter) flipper[:search].enable_actor user # turn on for actor flipper[:search].enabled? user # true flipper[:search].disable_actor user # turn off for actor flipper[:search].enabled? user # false </code></pre> <p>The <strong>group gate</strong>.</p> <pre><code class="ruby"> Flipper.register(:admins) do |actor| actor.respond_to?(:admin?) && actor.admin? end flipper = Flipper.new(adapter) flipper[:search].enable_group :admins # turn on for admins flipper[:search].disable_group :admins # turn off for admins person = Person.find(params[:id]) flipper[:search].enabled? person # check if enabled, returns true if person.admin? is true </code></pre> <p>The <strong>percentage of actors gate</strong> allows slowly enabling a feature for a percentage of actors. As long as you continue to increase the percentage, an actor will consistently remain enabled. This allows for careful rollouts of a feature to everyone without overwhelming the system as a whole.</p> <pre><code class="ruby"> </code></pre> <p>The <strong>percentage of time gate</strong>.</p> <pre><code class="ruby"> </code></pre> <p>All <a href="">the gates are fully documented in the flipper repo</a> as well.</p> <h2 id="adapters">Adapters</h2> <p>The adapter pattern is used to store which gates gates are enabled for a given feature. This means you can store flipper’s information however you desire. At the time of this writing, <a href="">several adapters already exist</a>, such as in memory, pstore, mongo, redis, cassandra, and active record. If one of those doesn’t tickle your fancy, creating a new adapter is really easy. The <span class="caps">API</span> for an adapter is this:</p> <ul> <li><code>features</code> – Get the set of known features.</li> <li><code>add(feature)</code> – Add a feature to the set of known features.</li> <li><code>remove(feature)</code> – Remove a feature from the set of known features.</li> <li><code>clear(feature)</code> – Clear all gate values for a feature.</li> <li><code>get(feature)</code> – Get all gate values for a feature.</li> <li><code>enable(feature, gate, thing)</code> – Enable a gate for a thing.</li> <li><code>disable(feature, gate, thing)</code> – Disable a gate for a thing.</li> </ul> <p>At GitHub, we actually use a <span class="caps">SQL</span> adapter fronted by memcache for performance reasons.</p> <h2 id="instrumentation">Instrumentation</h2> <p>Flipper is wired to be <a href="">instrumented out of the box</a>, using ActiveSupport::Notifications <span class="caps">API</span> (though AS::Notifs are not specifically required). I even included automatic statsd instrumentation for those that are already using statsd.</p> <pre class="ruby"><code class="ruby">require "flipper/instrumentation/statsd" statsd = Statsd.new # or whatever your statsd instance is Flipper::Instrumentation::StatsdSubscriber.client = statsd</code></pre> <p>If statsd doesn’t work for you, <a href="">you can easily customize</a> wherever you want to instrument to (ie: InfluxDB, New Relic, etc.).</p> <h2 id="performance">Performance</h2> <p>Flipper was built based on my time working on Words with Friends and to be used at GitHub, so you can rest easy that it was built with performance in mind. The adapter <span class="caps">API</span> is intentionally made to allow for fetching all gate values for a feature in one network call and there is even (optional) built in memoization of adapter calls, <a href="">including a Rack middleware</a> which enables memoizing the fetching a feature for the duration of a request.</p> <p>I’ve also thought about making it easy to allow for batch loading of features, though I haven’t needed this yet on any site I’ve worked on, so for now it remains a thought rather than an implementation.</p> <h2 id="web-ui">Web UI</h2> <p>As a cherry on top, I’ve also created a <a href="">rack middleware web UI</a> for controlling flipper, which can be protected by any authentication you need. Below are a couple screenshots (at the time of this writing).</p> <h3 id="list-of-features">List of features</h3> <p><img src="/assets/55bf5bbbd4c9610665045cd0/article_full/features.png" alt="" /></p> <h3 id="viewing-individual-feature">Viewing individual feature</h3> <p><img src="/assets/55bf5bbbedb2f361bb042aa8/article_full/feature.png" alt="" /></p> <p>All the gates can be manipulated to enable features however you would like through the click of a button or the clack of a keyboard.</p> <h2 id="conclusion">Conclusion</h2> <p>Flipper is ready for the prime time. As I said earlier, we are now using it on GitHub.com for thousands of feature checks every second. The <span class="caps">API</span> changed a bit in 0.7, but is pretty stable now. Drop it in your next project and give it a try. If you do, please let me know (email or issue on the repo) as I love to know how people are using things I’ve worked on.</p><div class="feedflare"> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> </div><img src="" height="1" width="1" alt=""/> John Nunemaker Of Late 530b9aabf002ff02ea0001c1 2014-02-24T14:18:22-05:00 2014-02-24T14:00:00-05:00 <p>In which I link to a new place where I’ll be writing.</p> <p>A lot has changed over the years. I now do a lot more than just rails and having railstips as my domain seems to mentally put me in a corner.</p> <p>As such, I have revived <a href="">johnnunemaker.com</a>. While I may still post a rails topic here once in a while, I’ll be posting a lot more varied topics over there.</p> <p>In fact, I just published my first post of any length, titled <a href="">Analytics at GitHub</a>. Head on over and give it a read.</p><div class="feedflare"> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> </div><img src="" height="1" width="1" alt=""/> John Nunemaker Let Nunes Do It 5170477f7a5072364c0026b6 2013-04-18T16:00:51-04:00 2013-04-18T15:20:00-04:00 <p>In which I release Nunes to a soon-to-be-more-instrumented world.</p> <p>In a moment of either genius or delirium I decided to name my newest project after myself. Why? Well, here is the story whether you want to know or not.</p> <h2>Why Nunes?</h2> <p>Naming is always the hardest part of a project. Originally, it was named Railsd. The idea of the gem is automatically subscribe to all of the valuable Rails instrumentation events and send them to statsd in a sane way, thus Railsd was born.</p> <p>After working on it a bit, I realized that the project was just an easy way to send Rails instrumentation events to any service that supports counters and timers. With a few tweaks, I made Railsd support <a href="">InstrumentalApp</a>, a favorite service of mine, in addition to Statsd.</p> <p. <strong>Thus <a href="">Nunes</a> was born</strong>.</p> <p.</p> <p><strong>I love tracking data so deeply that I want to instrument your code. Really, I do</strong>.!</p> <p><strong>But I don’t work for you, or with you, so that would be weird</strong>.</p> <p.</p> <h2>Using Nunes</h2> <p>I love instrumenting things. Nunes loves instrumenting things. To get started, just add Nunes to your gemfile:</p> <pre><code class="ruby"># be sure to think of me when you do :) gem "nunes"</code></pre> <p>Once you have nunes in your bundle (be sure to think of bundling me up with a big hug), you just need to tell nunes to subscribe to all the fancy events and provide him with somewhere to send all the glorious metrics:</p> <pre><code class="ruby"># yep, think of me here too require 'nunes' # for statsd statsd = Statsd.new(...) Nunes.subscribe(statsd) # ooh, ooh, think of me! # for instrumental I = Instrument::Agent.new(...) Nunes.subscribe(I) # one moooore tiiiime!</code></pre> <p>With just those couple of lines, you get a whole lot of goodness. Out of the box, Nunes will subscribe to the following Rails instrumentation events:</p> <ul> <li><code>process_action.action_controller</code></li> <li><code>render_template.action_view</code></li> <li><code>render_partial.action_view</code></li> <li><code>deliver.action_mailer</code></li> <li><code>receive.action_mailer</code></li> <li><code>sql.active_record</code></li> <li><code>cache_read.active_support</code></li> <li><code>cache_generate.active_support</code></li> <li><code>cache_fetch_hit.active_support</code></li> <li><code>cache_write.active_support</code></li> <li><code>cache_delete.active_support</code></li> <li><code>cache_exist?.active_support</code></li> </ul> <p>Thanks to all the wonderful information those events provide, you will instantly get some of these counter metrics:</p> <ul> <li><code>action_controller.status.200</code></li> <li><code>action_controller.format.html</code></li> <li><code>action_controller.exception.RuntimeError</code> – where RuntimeError is the class of any exceptions that occur while processing a controller’s action.</li> <li><code>active_support.cache_hit</code></li> <li><code>active_support.cache_miss</code></li> </ul> <p>And these timer metrics:</p> <ul> <li><code>action_controller.runtime</code></li> <li><code>action_controller.view_runtime</code></li> <li><code>action_controller.db_runtime</code></li> <li><code>action_controller.posts.index.runtime</code> – where <code>posts</code> is the controller and <code>index</code> is the action</li> <li><code>action_view.app.views.posts.index.html.erb</code> – where <code>app.views.posts.index.html.erb</code> is the path of the view file</li> <li><code>action_view.app.views.posts._post.html.erb</code> – I can even do partials! woot woot!</li> <li><code>action_mailer.deliver.post_mailer</code> – where <code>post_mailer</code> is the name of the mailer</li> <li><code>action_mailer.receive.post_mailer</code> – where <code>post_mailer</code> is the name of the mailer</li> <li><code>active_record.sql</code></li> <li><code>active_record.sql.select</code> – also supported are insert, update, delete, transaction_begin and transaction_commit</li> <li><code>active_support.cache_read</code></li> <li><code>active_support.cache_generate</code></li> <li><code>active_support.cache_fetch</code></li> <li><code>active_support.cache_fetch_hit</code></li> <li><code>active_support.cache_write</code></li> <li><code>active_support.cache_delete</code></li> <li><code>active_support.cache_exist</code></li> </ul> <h2>But Wait, There is More!</h2> <p>In addition to doing all that work for you out of the box, Nunes will also help you wrap your own code with instrumentation. I know, I know, sounds too good to be true.</p> <pre><code class="ruby"> class User < ActiveRecord::Base extend Nunes::Instrumentable # OH HAI IT IS ME, NUNES # wrap save and instrument the timing of it instrument_method_time :save end </code></pre> <p>This will instrument the timing of the User instance method save. What that means is when you do this:</p> <pre><code class="ruby"># the nerve of me to name a user nunes user = User.new(name: "NUNES!") user.save </code></pre> <p>An event named <code>instrument_method_time.nunes</code> will be generated, which in turn is subscribed to and sent to whatever you used to send instrumentation to (statsd, instrumental, etc.). The metric name will default to “class.method”. For the example above, the metric name would be <code>user.save</code>. No fear, you can customize this.</p> <pre><code class="ruby">class User < ActiveRecord::Base extend Nunes::Instrumentable # never # wrap save and instrument the timing of it instrument_method_time :save, 'crazy_town.save' end </code></pre> <p>Passing a string as the second argument sets the name of the metric. You can also customize the name using a Hash as the second argument.</p> <pre><code class="ruby">class User < ActiveRecord::Base extend Nunes::Instrumentable # gonna # wrap save and instrument the timing of it instrument_method_time :save, name: 'crazy_town.save' end </code></pre> <p>In addition to name, you can also pass a payload that will get sent along with the generated event.</p> <pre><code class="ruby"> class User < ActiveRecord::Base extend Nunes::Instrumentable # give nunes up # wrap save and instrument the timing of it instrument_method_time :save, payload: {pay: "loading"} end </code></pre> <p>If you subscribe to the event on your own, say to log some things, you’ll get a key named <code>:pay</code> with a value of <code>"loading"</code> in the event’s payload. Pretty neat, eh?</p> <h2>Conclusion</h2> <p>I hope you find Nunes useful and that each time you use it, you think of me and how much I want to instrument your code for you, but am not able to. Go forth and instrument!</p> <p>P.S. If you have ideas for Nunes, create an issue and start some chatter. Let’s make Nunes even better!</p><div class="feedflare"> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> </div><img src="" height="1" width="1" alt=""/> John Nunemaker An Instrumented Library in ~30 Lines 510006ed7a507277eb000ac0 2013-01-23T15:35:26-05:00 2013-01-23T15:00:00-05:00 <p>lmao if you don’t make it easy for users of your library to log, measure and graph everything.</p> <h2>The Full ~30 Lines</h2> <p>For the first time ever, I am going to lead with the end of the story. Here is the full ~30 lines that I will break down in detail during the rest of this post.</p> <pre><code class="ruby"!!!</code></pre> <h2>The Dark Side</h2> <p>A while back, <a href="">statsd grabbed a hold of the universe</a>. It swept in like an elf on a unicorn and we all started keeping track of stuff that previously was a pain to keep track of.</p> <p>Like any wave of awesomeness, it came with a dark side that was felt, but mostly overlooked. Dark side? Statsd? Graphite? You must be crazy! Nope, not me, definitely not crazy this one. Not. At. All.</p> <p>What did we all start doing in order to inject our measuring? Yep, <strong>we started opening up classes in horrible ways</strong> and creating hooks into libraries that sometimes change rapidly. Many times, updating a library would cause a break in the stats reporting and require effort to update the hooks.</p> <h2>The Ideal</h2> <p>Now that the wild west is settling a bit, I think some have started to reflect on that wave of awesomeness and realized something.</p> <blockquote> <p>I no longer want to inject my own instrumentation into your library. Instead, I want to tell your library where it should send the instrumentation.</p> </blockquote> <p>The great thing is that <a href="">ActiveSupport::Notifications</a> is pretty spiffy in this regard. By simply allowing your library to talk to an “instrumenter” that responds to <code>instrument</code> with an event name, optional payload, and optional block, you can make all your library’s users <strong>really</strong> happy.</p> <p>The great part is:</p> <ol> <li>You do not have to <strong>force your users to use active support</strong>. They simply need some kind of instrumenter that responds in similar fashion.</li> <li>They <strong>no longer have to monkey patch</strong> to get metrics.</li> <li>You can <strong>point them in the right direction as to what is valuable to instrument</strong> in your library, since really you know it best.</li> </ol> <p>There are a few good examples of libraries (faraday, excon, etc.) doing this, but I haven’t seen a great post yet, so here is my attempt to point you in what I feel is the right direction.</p> <h2>The Interface</h2> <p>First, like I said above, we do not want to force requiring active support. Rather than require a library, <strong>it is always better to require an interface</strong>.</p> <p>The interface that we will require is the one used by active support, but an adapter interface could be created for any instrumenter that we want to support. Here is what it looks like:</p> <pre><code class="ruby">instrumenter.instrument(name, payload) { |payload| # do some code here that should be instrumented # we expect payload to be yielded so that additional # payload entries can be included during the # computation inside the block }</code></pre> <p>Second, we have two options.</p> <ol> <li>Either have an instrumenter or not. If so, then call <code>instrument</code> on the instrumenter. If not, then do not call <code>instrument</code>.</li> <li>The option, which I prefer, is to <strong>have a default instrumenter that does nothing</strong>. Aptly, I call this the noop instrumenter.</li> </ol> <h2>The Implementation</h2> <p>Let’s pretend our library is named foo, therefore it will be namespaced with the module Foo. I typically namespace the instrumenters in a module as well. Knowing this, our noop instrumenter would look like this:</p> <pre><code class="ruby">module Foo module Instrumenters class Noop def self.instrument(name, payload = {}) yield payload if block_given? end end end end</code></pre> <p>As you can see, all this instrumenter does is yield the payload if a block is given. As I mentioned before, <strong>we yield payload so that the computation inside the block can add entries to the payload</strong>, such as the result.</p> <p>Now that we have a default instrumenter, how can we use it? Well, let’s imagine that we have a Client class in foo that is the main entry point for the gem.</p> <pre><code class="ruby">module Foo class Client def initialize(options = {}) # some other setup for the client ... @instrumenter = options[:instrumenter] || Instrumenters::Noop end end end</code></pre> <p>This code simply allows people to pass in the instrumenter that they would like to use through the initialization options. Also, by default if no instrumenter is provided, we use are noop version that just yields the block and moves on.</p> <p>Note: the use of || instead of #fetch is intentional. It prevents a nil instrumenter from being passed in. There are other ways around this, but I have found using the noop instrumenter in place of nil, better than complaining about nil.</p> <p>Now that we have an <code>:instrumenter</code> option, someone can quite easily pass in the instrumenter that they would like to use.</p> <pre><code class="ruby">client = Foo::Client.new({ :instrumenter => ActiveSupport::Notifications, })</code></pre> <p>Boom! Just like that we’ve allowed people to inject active support notifications, or whatever instrumenter they want into our library. Anyone else getting excited?</p> <p>Once we have that, we can start instrumenting the valuable parts. Typically what I do is I setup delegation of the <code>instrument</code> to the instrumenter using ruby’s forwardable library:</p> <pre><code class="ruby"</code></pre> <p>Now we can use the <code>instrument</code> method directly anywhere in our client instance. For example, let’s say that client has a method named <code>execute</code> that we would like to instrument.</p> <pre><code class="ruby">module Foo class Client def execute(args = {}) instrument('client_execute.foo', args: args) { |payload| result = # do some work... payload[:result] = result result } end end end</code></pre> <p!</p> <p>They can also create a metrics subscriber that sends the timing information to <a href="">instrumental</a>, <a href="">metriks</a>, statsd, or whatever.</p> <h2>The Bonus</h2> <p>You can even provide log subscribers and metric subscribers in your library, which means instrumentation for your users is simply a require away. For example, here is the <a href="">log subscriber</a> I added to <a href="">cassanity</a>.</p> <pre><code class="ruby"</code></pre> <p>All the users of cassanity need to do to get logging of the <span class="caps">CQL</span> queries they are performing and their timing is require a file (and have activesupport in their gemfile):</p> <pre><code class="ruby">require 'cassanity/instrumentation/log_subscriber'</code></pre> <p>And they get logging goodness like this in their terminal:</p> <p><img src="/assets/51003fd97a507223410006a6/article_full/cassanity_instrumentation.png" class="full image" alt="" /></p> <h2>The Accuracy</h2> <p>But! <span class="caps">BUT</span>,.</p> <p>The previous sentence was quite a mouthful, so my next one will be short and sweet. For testing, I created an in-memory instrumenter that simply stores each instrumented event with name, payload, and the computed block result for later comparison. Check it:</p> <pre><code class="ruby">module Foo module Instrumenters class Memory Event = Struct.new(:name, :payload, :result) attr_reader :events def initialize @events = [] end def instrument(name, payload = {}) result = if block_given? yield payload else nil end @events << Event.new(name, payload, result) result end end end end</code></pre> <p>Now in your tests, you can do something like this when you want to check that your library is correctly instrumenting:</p> <pre><code class="ruby">instrumenter = Foo::Instrumenters::Memory.new client = Foo::Client.new({ instrumenter: instrumenter, }) client.execute(...) payload = {... something .. } event = instrumenter.events.last assert_not_nil event assert_equal 'client_execute.foo', event.name assert_equal payload, event.payload </code></pre> <h2>The End Result</h2> <p>With two instrumenters (noop, memory) and a belief in interfaces, we have created immense value.</p> <p><img src="/assets/510046327a50722361001157/article_full/freakin_sweet.jpg" class="full image" alt="" /></p> <h2>Further Reading</h2> <p>Without any further ado, here are a few of the articles and decks that I read recently related to this.</p> <ul> <li><a href="">RailsCasts: Notifications in Rails 3</a></li> <li><a href="">Digging Deep with ActiveSupport Notifications</a></li> <li><a href="">Code Charcuterie</a></li> <li><a href="">Instrument Anything in Rails 3</a></li> <li><a href="">On Notifications, Log Subscribers and Bringing Sanity to Rails Logs</a></li> </ul> <h2>Fin</h2> <p>Go forth and instrument all the things!</p><div class="feedflare"> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> </div><img src="" height="1" width="1" alt=""/> John Nunemaker Booleans are Baaaaaaaaaad 50759b74dabe9d400600aa8a 2012-10-10T13:14:18-04:00 2012-10-10T13:10:00-04:00 <p>In which I encourage the use of state machines because they rock.</p> <p>First off, did you pronounce the title of this article like a sheep? That was definitely the intent. Anyway, onward to the purpose of this here text.</p> <p>One of the things I have learned the hard way is that booleans are bad. Just to be clear, I do not mean that true/false is bad, but rather that using true/false for state is bad. Rather than rant, lets look at a concrete example.</p> <h2>An Example</h2> <p>The first example that comes to mind is the ever present user model. On signup, most apps force you to confirm your email address.</p> <p>To do this there might be a temptation to add a boolean, lets say “active”. Active defaults to false and upon confirmation of the email is changed to true. This means your app needs to make sure you are always dealing with active users. Cool. Problem solved.</p> <p>It might look something like this:</p> <pre><code class="ruby">class User include MongoMapper::Document scope :active, where(:active => true) key :active, Boolean end</code></pre> <p>To prevent inactive users from using the app, you add a before filter that checks if the current_user is inactive. If they are, you redirect them to a page asking them to confirm there email or resend the email confirmation. Life is grand!</p> <h2>The Requirements Change</h2> <p>Then, out of nowhere comes an abusive user, let’s name him John. John is a real jerk. He starts harassing your other users by leaving mean comments about their moms.</p> <p.</p> <h2>The Problem</h2> <p? <span class="caps">RIGHT</span>? Wrong.</p> <p><strong>You are now maintaining one state with two switches</strong>. As requirements change, you end up with more and more situations like this and weird edge cases start to sneak in.</p> <h2>The Solution</h2> <p>How can we improve the situation? Two words: state machine. State machines are awesome. Lets rework our user model to use the <a href="">state_machine</a> gem.</p> <pre><code class="ruby">class User include MongoMapper::Document key :state, String state_machine :state, :initial => :inactive do state :inactive state :active state :abusive event :activate do transition all => :active end event :mark_abusive do transition all => :abusive end end end</code></pre> <p>With just the code above, we can now do all of this:</p> <pre><code class="ruby"</code></pre> <p>Pretty cool, eh? You get a lot of bang for the buck. I am just showing the beginning of what you can do, head on over to the <a href="">readme</a> to see more. You can add guards and all kinds of neat things. Problem solved. Right? <span class="caps">RIGHT</span>? Wrong.</p> <h3>Requirements Change Again</h3> <p>Uh oh! Requirements just changed again. Mr. <span class="caps">CEO</span> decided that instead of calling people abusive, we want to refer to them as “douchebaggish”.</p> <p>The app has been wildly successful and you now have millions of users. You have two options:</p> <ol> <li>Leave the code as it is and just change the language in the views. This sucks because then you are constantly translating between the two.</li> <li>Put up the maintenance page and accept downtime, since you have to push out new code and migrate the data. This sucks, because your app is down, simply because you did not think ahead.</li> </ol> <h3>A Better State Machine</h3> <p>Good news. With just a few tweaks, you could have built in the flexibility to handle changing your code without needing to change your data. The state machine gem supports changing the value that is stored in the database.</p> <p>Instead of hardcoding strings in your database, use integers. Integers allow you to change terminology willy nilly in your app and only change app code. Let’s take a look at how it could work:</p> <pre><code class="ruby"</code></pre> <p>With just that slight change, we now are storing state as an integer in our database. This means changing from “abusive” to “douchebaggish” is just a code change like this:</p> <pre><code class="ruby"</code></pre> <p>Update the language in the views, deploy your changes and you are good to go. <strong>No downtime. No data migration. Copious amounts of flexibility for little to no more work.</strong></p> <p>Next time you reach for a boolean in your database, think again. Please! Whip out the state machine gem and wow your friends with your wisdom and foresight.</p><div class="feedflare"> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> </div><img src="" height="1" width="1" alt=""/> John Nunemaker Four Guidelines That I Feel Have Improved My Code 4ff5abc2dabe9d4a7201446c 2012-07-05T15:51:28-04:00 2012-07-05T15:00:00-04:00 <p>In which I share some tips based on recent trial and error.</p> <p>I have been thinking a lot about isolation, dependencies and clean code of late. I know there is a lot of disagreement with people vehemently standing in both camps.</p> <p>I certainly will not say either side is right or wrong, but what follows is what I feel has improved my code. I post it here to formalize some recent thoughts and, if I am lucky, get some good feedback.</p> <p>Before I rush into the gory details, I feel I should mention that I went down this path, not as an architecture astronout, but out of genuine pain in what I was working on.</p> <p>My models were growing large. My tests were getting slow. Things did not feel “right”.</p> <p>I started watching Gary Bernhardt’s <a href="">Destroy All Software</a> screencasts. He is a big proponent of testing in isolation. Definitely go get a subscription and take a day to get caught up.</p> <p>On top of <span class="caps">DAS</span>, I started reading everything I could on the subject of growing software, clean code and refactoring. When I say reading, I really should say devouring.</p> <p>I was literally prowling about like a lion, looking for the next book I could devour. Several times my wife asked me to get off my hands and knees and to kindly stop roaring about <span class="caps">SRP</span>.</p> <p>Over the past few months as I have tried to write better code, I have definitely learned a lot. <strong>Learning without reflection and writing is not true learning for me</strong>.</p> <p>Reflecting on why something feels better and then writing about it <strong>formalizes it in my head</strong> and has the added benefit of being available for anyone else who is struggling with the same.</p> <p>Here are a few guidelines that have jumped out at me over the past few days as I reflected on what I have been practicing the past few months.</p> <h2>Guideline #1. One responsibility to rule them all</h2> <p>Single responsibility principle (<span class="caps">SRP</span>) is really hard. I think a lot of us are frustrated and feeling the pain of our chubby <insert your favorite <span class="caps">ORM</span>> classes. Something does not feel right. Working on them is hard.</p> <p>The problem is context. You have to load a lot of context in your brain when you crack open that <strong><span class="caps">INFAMOUS</span></strong> user model. That context takes up the space where we would normally create and come up with new solutions.</p> <h3>Create More Classes</h3> <p>So what are we to do? <strong>Create more classes</strong>. Your models do not need to inherit from ActiveRecord::Base, or include MongoMapper::Document, or whatever.</p> <p>A model is something that has business logic. Start breaking up your huge models that have persistence bolted on into plain old Ruby classes.</p> <p>I am not going to lie to you. If you have not been doing this, <strong>it will not be easy</strong>. Everything will seem like it should just be tucked as another method in a model that also happens to persist data in a store.</p> <h3>Naming is Hard</h3> <p>Another pain point will be naming. Naming is fracking hard. You are welcome for the <span class="caps">BSG</span> reference there. I would like to take that statement a step further though.</p> <p><strong>Naming is hard because our classes and methods are doing too much</strong>. The fewer responsibilities your class has, the easier it will be to name, especially after a few months of practice.</p> <h3>An Example</h3> <p.</p> <p>A lot of people throw the tracking code on their site and never remove it or sign up for a paying account. We do this find to make sure those people noop, instead of creating tons of data that no one is paying for.</p> <p>This query happens for each track and it is pulling information that rarely if ever changes. It seemed like a prime spot for a wee bit of caching.</p> <p>First, I created a tiny service around the memcached client I decided to use. This only took an hour and it means that my application now has an interface for caching (<code>get</code>, <code>set</code>, <code>delete</code>, and <code>fetch</code>). I’ll talk more about this in guideline #3.</p> <p>Once I had defined the interface Gauges would use for caching, I began to integrate it. After much battling and rewriting of the caching code, each piece felt like it was doing too much and things were getting messy.</p> <p>I stepped back and thought through my plans. I wanted to cache only the attributes, so I threw everything away and started with that. First, I wanted to be able to read attributes from the data store.</p> <pre><code class="ruby">class GaugeAttributeService def get(id) criteria = {:_id => Plucky.to_object_id(id)} if (attrs = gauge_collection.find_one(criteria)) attrs.delete('_id') attrs end end end</code></pre> <p>Given an id, this class returns a hash of attributes. That is pretty much one responsibility. Sweet action. Let’s move on.</p> .</p> <p>If I would have added caching in the <code>GaugeAttributeService</code> class, I would have violated <span class="caps">SRP</span>. Describing the class would have been "checks the cache and if not there it fetches from database". Note the use of "and".</p> <p>As <a href="">Growing Object Oriented Software</a> states:</p> <blockquote> <p>Our heuristic is that we should be able to describe what an object does without using any conjunctions (“and,” “or”).</p> </blockquote> <p>Instead, I created a new class to wrap (or decorate) my original service.</p> <pre><code class="ruby">class GaugeAttributeServiceWithCaching def initialize(attribute_service = GaugeAttributeService.new) @attribute_service = attribute_service end def get(id) cache_service.fetch(cache_key(id)) { @attribute_service.get(id) } end end</code></pre> <p>I left a few bits out of this class so we can focus on the important part, which is that all we do with this class is wrap the original one with a cache fetch.</p> <p>As you can see, naming is pretty easy for this class. It is a gauge attribute service with caching and is named as such. It initializes with an object that must respond to <code>get</code>. Note also that it defaults to an instance of <code>GaugeAttributeService</code>.</p> <p>Unit testing this class is easy as well. We can isolate the dependencies (<code>attribute_service</code> and <code>cache_service</code>) in the unit test and make sure that they do what we expect (<code>fetch</code> and <code>get</code>).</p> <p><small><strong>Note</strong>: There definitely could a point made that "with" is the same as "and" and therefore means that we are breaking <span class="caps">SRP</span>. Naming is hard, really hard. Rather than get mired forever in naming, I rolled with this convention and, at this point, it does not bother me. I am definitely open to suggestions. Another name I played with was CachedGaugeAttributeService.</small></p> <p>Below is an example setup with new dependencies inject in the test that help us verify this classes behavior in isolation.</p> <pre><code class="ruby" </code></pre> <p>Above I used dynamic classes. Instead of dynamic classes, one could use stubbing or whatever. I’ll talk more about <code>cache_service=</code> later.</p> <p>Decorating in this manner means we can easily find without caching by using GaugeAttributeService or with caching by using GaugeAttributeServiceWithCaching.</p> <p.</p> <h2>Guideline #2. Use accessors for collaborators</h2> <p>In the example above, you probably noticed that when testing <code>GaugeAttributeServiceWithCaching</code>, I changed the cache service used by assigning a new one. What I often see is others using some top level config, or even worse they actually use a <code>$</code> global.</p> <pre><code class="ruby">#</code></pre> <p>What sucks about this is you are coupling this class to a global and coupling leads to pain. Instead, what I have started doing is using accessors to setup collaborators. Here is the example from above, but now with the cache service accessors included.</p> <pre><code class="ruby"> class GaugeAttributeServiceWithCaching attr_writer :cache_service def cache_service @cache_service ||= CacheService.new end end</code></pre> <p>By doing this, we get a sane, memoized default for our cache service (<code>CacheService.new</code>) and the ability to change that default (<code>cache_service=</code>), either in our application or when unit testing.</p> <p>Finding ourselves doing this quite often, we created a library, aptly named <a href="">Morphine</a>. Right now it does little more than what I just showed (memoized default and writer method to change).</p> <p.</p> <pre><code class="ruby"> class GaugeAttributeServiceWithCaching include Morphine register :cache_service do CacheService.new end end</code></pre> <p>Note also that I am not passing these dependencies in through initialize. At first I started with that and it looked something like this:</p> <pre><code class="ruby">class GaugeAttributeServiceWithCaching def initialize(attribute_service = GaugeAttributeService.new, cache_service = CacheService.new) @attribute_service = attribute_service @cache_service = cache_service end end</code></pre> <p>Personally, over time I found this method tedious. My general guideline is <strong>pass a dependency through initialize when you are going to decorate it, otherwise use accessors</strong>. Let’s look at the attribute service with caching again.</p> <pre><code class="ruby">class GaugeAttributeServiceWithCaching include Morphine register :cache_service do CacheService.new end def initialize(attribute_service = GaugeAttributeService.new) @attribute_service = attribute_service end end </code></pre> <p>Since this class is decorating an attribute service with caching, I pass in the service we want to decorate through initialize. I do not, however, pass in the cache service through initialize. Instead, the cache service uses Morphine (or accessors).</p> <p>First, I think this <strong>makes the intent more obvious</strong>. The intent of this class is to wrap another object, so that object should be provided to initialize. Defaulting the service to wrap is merely a convenience.</p> <p>Second, the cache service is a dependency, but not one that is being wrapped. It purely <strong>needs a sane default and a way to be replaced</strong>, therefore it uses Morphine (or accessors).</p> <p>I cannot say this is a hard and fast rule that everyone should follow and that you are wrong if you do not. I can say that through trial and error, <strong>following this guideline has led to the least amount of friction</strong> while maintaining flexibility and isolation.</p> <h2>Guideline #3. Create real interfaces</h2> <p:</p> <pre><code class="ruby"># bad idea class CacheService def initialize(driver) @driver = driver end def get(*args) @driver.get(*args) end def set(*args) @driver.set(*args) end def delete(*args) @driver.delete(*args) end end </code></pre> <p.</p> <p>Instead, create a real interface. Define the methods and parameters you want your application to be able to use and make that work with whatever driver you end up choosing or changing to down the road.</p> <h3>Handling Exceptions</h3> <p>First, I created the exceptions that would be raised if anything goes wrong.</p> <pre><code class="ruby">class CacheService class Error < StandardError attr_reader :original def initialize(original = $!) if original.nil? super else super(original.message) end @original = original end end class NotFound < Error; end class NotStored < Error; end end</code></pre> <p>CacheService::Error is the base that all other errors inherit from. It wraps whatever the original error was, instead of discarding it, and defaults to the last exception that was raised <code>$!</code>. I will show how these are used in a bit.</p> <h3>Portability and serialization</h3> <p>I knew that I wanted the cache to be portable, so instead of just defaulting to Marshal’ing, I used only raw operations and ensured that I wrapped all raw operations with serialize and deserialize, where appropriate.</p> <p>In order to allow this cache service class to work with multiple serialization methods, I registered a serializer dependency, instead of just using MultiJson’s <code>dump</code> and <code>load</code> directly. I then wrapped convenience methods (<code>serialize</code> and <code>deserialize</code>) that handle a few oddities induced by the driver I am wrapping.</p> <pre><code class="ruby"</code></pre> <h3>Handling exceptions (continued)</h3> <p>I then created a few private methods that hit the driver and wrap exceptions. These private methods are what the public methods use to ensure that exceptions are properly handled and such.</p> <pre><code class="ruby"</code></pre> <p>At this point, no driver specific exceptions should ever bubble outside of the cache service. When using the cache service in the application, I need only worry about handling the cache service exceptions and not the specific driver exceptions.</p> <p><strong>If I change to a different driver, only this class changes</strong>. The rest of my application stays the same. Big win. How many times have you upgraded a gem and then had to update pieces all over your application because they willy-nilly changed their interface.</p> <h3>The public interface</h3> <p>All that is left is to define the public methods and parameters that can be used in the application.</p> <pre><code class="ruby">class CacheService def get(keys) driver_read(keys) rescue NotFound nil end def set(key, value) driver_write :set, key, value end def delete(key) driver_delete key rescue NotFound nil end end</code></pre> <p>At this point, the application has a defined interface that it can work with for caching and for the most part does not need to worry about exceptions as they are wrapped and, in some cases, even handled (ie: nil for NotFound).</p> <p>Creating real interfaces ensures that expectations are set and upgrades are easy. Defined interfaces give other developers on the project confidence that if they follow the rules, things will work as expected.</p> <h2>Guideline #4. Test the whole way through</h2> <p>Whatever you want to call them, you need tests that prove all your components are wired together and working as expected, in the same manor as they will be used in production.</p> <p>The reason a lot of developers have felt pain with pure unit testing and isolation is because they forget to add that secondary layer of tests on top that ensure that the way things are wired together works too.</p> <p>Unit tests are there to drive our design. Acceptance tests are there to make sure that things are actually working the whole way through. Each of these are essential and not to be skipped over.</p> <p>If you are having problems testing, it may be your design. If you are getting burned by isolation, you are probably missing higher level tests. You should be able to kill your unit tests and still have reasonable confidence that your system is working.</p> <p>Nowadays, I often start with a high level test and then work my way in unit testing the pieces as I make them. I’ve found this keeps me focused on the value I am adding and ensures that my coverage is good.</p> <h2>Conclusion</h2> <p>While it has definitely taken a lot of trial and error, I am starting to find the right balance between flexibility, isolation and overkill.</p> <ol> <li>Stick to single responsibilities.</li> <li>Inject decorated dependencies through initialization and use accessors for other dependencies.</li> <li>Create real interfaces.</li> <li>Test in isolation <strong>and</strong> the whole way through.</li> </ol> <p>Follow these guidelines and I believe you will start to feel better about the code you are writing, as I have over the past few months.</p> <p>I would love to hear what others of you are doing and see examples. Comment below with gists, github urls, and other thoughts. Thanks!</p><div class="feedflare"> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> <a href=""><img src="" border="0"></img></a> </div><img src="" height="1" width="1" alt=""/> John Nunemaker.</p> <p.</p> <p>Another important piece was seeing how many track request we could store in memory with Kestrel, based on our configuration, and how it performed when it used up all the allocated memory and started going to disk.</p> <h3>Service Magic</h3> <p:</p> <pre><code class="ruby">class RealtimeTrackService def record(attrs) Hit.record(attrs) end end </code></pre> <p:<"</code></pre> <p.<"</code></pre> "</code></pre> <p>With those changes in place, I could now set the track service to multi, the track processor to noop, and I was good to deploy. So I did. And it was wonderful.</p> <h2>6. Verification</h2> <p.<> <p.</p> <p.<.</p> .<" alt=""/>"</code></pre> " alt=""/>" alt=""/>" alt=""/>" alt=""/>" alt=""/>" alt=""/>" alt=""/> John Nunemaker | http://feeds.feedburner.com/railstips/ | CC-MAIN-2016-40 | refinedweb | 8,377 | 56.25 |
Dean Gaudet wrote:
>
> On Thu, 10 Sep 1998, Simon Spero wrote:
>
> > 2) Layering is dangerous to performance, and should be collapsed as much
> > as possible. This is part of the job of the middle end.
>
> This was part of why I was prompted to say we should look at zero-copy,
> "page based" i/o... in particular, the chunking layer doesn't need to
> modify anything. It just needs to build iovecs. But without reference
> counting on the buffers we have to actually copy the contents rather than
> just pass them around...
Do we really need reference counting? Can't they have a common
allocation/deallocation method, and get ownership handed through the
layers - last one out turns off the lights (err, lowest layer releases
the buffer).
> >.
>
> For some sites it'd be sufficient to invalidate the entire cache on a
> regular basis. That's pretty easy to do. But yeah invalidation is in
> general a painful problem...
>
> >.
>
> Hmmm... interesting.
>
> On a related note, we need to abstract those bits of the filesystem which
> we need to serve HTTP so that backing store doesn't have to be a
> filesystem. I'd say this should even go as far as modules being able to
> open() a URI and read from it -- so that it can be as transparent as
> possible. So rather than use ap_bopenf() directly (the apache-nspr
> equivalent of fopen()), modules open a URI through some other interface,
> and that may go to the filesystem or go to a database/whatever.
>
> A difficulty in this is access control -- there's a difference between an
> external request requesting some files, and an internal module requesting
> them. Different rights.
Are you saying that all interlayer comms should be in terms of URIs? And
qualifying headers? (I'm thinking this integrated neatly with Magic
Cache).
> > 6) This implies that the namespace model should be mappable in terms of
> > directories, files, and specials (cgi-scripts, etc). This gives the
> > hierarchical component of the resolution process a higher priority than
> > the other phases.
>
> I'd like to see the namespace have "mount points" somewhat like the unix
> filesystem. This controls the hierarchy as far as what the underlying
> store is... and it's a simple system, easy to optimize for. i.e. I'd
> really like to avoid "if the URI matches this regex then it's served by
> database foobar". That's far too general.
Sounds like a! | http://mail-archives.apache.org/mod_mbox/httpd-dev/199809.mbox/%3C35F9563B.15F39154@algroup.co.uk%3E | CC-MAIN-2015-06 | refinedweb | 406 | 64.91 |
One fast way to scan for exceptions and errors in your Django web application projects is to add a few lines of code to include a hosted monitoring tool.
In this tutorial we will learn to add the Rollbar monitoring service to a web app to visualize any issues produced by our web app. This tutorial will use Django as the web framework to build the web application but there are also tutorials for the Flask and Bottle frameworks as well. You can also check out a list of other hosted and open source tools on the monitoring page.
Python 3 is strongly recommended for this tutorial because Python 2 will no longer be supported starting January 1, 2019. Python 3.6.4 to was used to build this tutorial. We will also use the following application dependencies to build our application:
If you need help getting your development environment configured before running this code, take a look at this guide for setting up Python 3 and Django on Ubuntu 16.04 LTS.
All code in this blog post is available open source on GitHub under the MIT license within the monitor-python-django-apps directory of the blog-code-examples repository. Use and modify the code however you like for your own applications.
Start the project by creating a new
virtual environment
using the following command. I recommend keeping a separate directory
such as
~/venvs/ so that you always know where all your virtualenvs are
located.
python3 -m venv monitordjango
Activate the virtualenv with the
activate shell script:
source monitordjango/bin/activate
The command prompt will change after activating the virtualenv:
Remember that you need to activate your virtualenv in every new terminal window where you want to use the virtualenv to run the project.
We can now install the Django and Rollbar packages into the activated, empty virtualenv.
pip install django==2.0.4 rollbar==0.13.18
Look for output like the following to confirm the dependencies installed correctly.
Collecting certifi>=2017.4.17 (from requests>=0.12.1->rollbar==0.13.18) Downloading certifi-2018.1.18-py2.py3-none-any.whl (151kB) 100% |████████████████████████████████| 153kB 767kB/s Collecting urllib3<1.23,>=1.21.1 (from requests>=0.12.1->rollbar==0.13.18) Using cached urllib3-1.22-py2.py3-none-any.whl Collecting chardet<3.1.0,>=3.0.2 (from requests>=0.12.1->rollbar==0.13.18) Using cached chardet-3.0.4-py2.py3-none-any.whl Collecting idna<2.7,>=2.5 (from requests>=0.12.1->rollbar==0.13.18) Using cached idna-2.6-py2.py3-none-any.whl Installing collected packages: pytz, django, certifi, urllib3, chardet, idna, requests, six, rollbar Running setup.py install for rollbar ... done Successfully installed certifi-2018.1.18 chardet-3.0.4 django-2.0.4 idna-2.6 pytz-2018.3 requests-2.18.4 rollbar-0.13.18 six-1.11.0 urllib3-1.22
We have our dependencies ready to go so now we can write the code for our Django project.
Django makes it easy to generate the boilerplate code
for new projects and apps using the
django-admin.py commands. Go to the
directory where you typically store your coding projects. For example, on
my Mac I use
/Users/matt/devel/py/. Then run the following command to
start a Django project named
djmonitor:
django-admin.py startproject djmonitor
The command will create a directory named
djmonitor with several
subdirectories that you should be familiar with when you've previously
worked with Django.
Change directories into the new project.
cd djmonitor
Start a new Django app for our example code.
python manage.py startapp billions
Django will create a new folder named
billions for our project.
Let's make sure our Django URLS work properly before before we write
the code for the app.
Now open
djmonitor/djmonitor/urls.py and add the highlighted lines so that URLs
with the path
/billions/ will be routed to the app we are working on.
""" (comments section) """ from django.conf.urls import include from django.contrib import admin from django.urls import path urlpatterns = [ path('billions/', include('billions.urls')), path('admin/', admin.site.urls), ]
Save
djmonitor/djmonitor/urls.py and open
djmonitor/djmonitor/settings.py.
Add the
billions app to
settings.py by inserting the highlighted line,
which will become line number 40 after insertion:
# Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'billions', ]
Save and close
settings.py.
Reminder: make sure you change the default
DEBUG and
SECRET_KEY
values in
settings.py before you deploy any code to production. Secure
your app properly with the information from
Django production deployment checklist
so that you do not add your project to the list of hacked applications
on the web.
Next change into the
djmonitor/billions directory. Create a new file named
urls.py that will be specific to the routes for the
billions app within
the
djmonitor project.
Add the following lines to the currently-blank
djmonitor/billions/urls.py
file.
from django.conf.urls import url from . import views urlpatterns = [ url(r'(?P<slug>[\wa-z-]+)', views.they, name="they"), ]
Save
djmonitor/billions/urls.py. One more file before we can test that
our simple Django app works. Open
djmonitor/billions/views.py.
from django.core.exceptions import PermissionDenied from django.shortcuts import render def they(request, slug): if slug and slug == "are": return render(request, 'billions.html', {}) else: raise PermissionDenied("Hmm, can't find what you're looking for.")
Create a directory for your template files named
templates under
the
djmonitor/billions app directory.
mkdir templates
Within
templates create a new file named
billions.html that contains
the following Django template markup.
<!DOCTYPE html> <html> <head> <title>They... are BILLIONS!</title> </head> <body> <h1><a href="">They Are Billions</a></h1> <img src=""> </body> </html>
Alright, all of our files are in place so we can test the application. Within the base directory of your project run the Django development server:
python manage.py runserver
The Django development server will start up with no issues other than an unapplied migrations warning.
(monitordjango) $ python manage.py runserver Performing system checks... System check identified no issues (0 silenced). You have 14 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. April 08, 2018 - 19:06:44 Django version 2.0.4, using settings 'djmonitor.settings' Starting development server at Quit the server with CONTROL-C.
Only the
/billions/ route will successfully hit our
billions app. Try
to access "". We should see our template
render with the gif:
Cool, our application successfully rendered a super-simple HTML page
with a GIF of one of my favorite computer games. What if we try another
path under
/billions/ such as ""?
Our 403 Forbidden is raised, which is what we expected based on our code.
That is a somewhat contrived block of code but let's see how we can
catch and report this type of error without changing our
views.py
code at all. This approach will be much easier on us when modifying an
existing application than having to refactor the code to report on
these types of errors, if we even know where they exist.
Go to the Rollbar homepage in your browser to add their tool to our Django app.
Click the "Sign Up" button in the upper right-hand corner. Enter your email address, a username and the password you want on the sign up page.
After the sign up page you will see the onboarding flow where you can enter a project name and select a programming language. For the project name type in "Full Stack Python" (or whatever project name you are working on) then select that you are monitoring a Python-based application.
Press the "Continue" button at the bottom to move along. The next screen shows us a few instructions on how to add monitoring.
Let's change our Django project code to let Rollbar collect and aggregate the errors that pop up in our application.
Re-open
djmonitor/djmonitor/settings.py and look for the
MIDDLEWARE
list. Add
rollbar.contrib.django.middleware.RollbarNotifierMiddleware
as the last item:', 'rollbar.contrib.django.middleware.RollbarNotifierMiddleware', ]
Do not close
settings.py just yet. Next add the following lines
to the bottom of the file. Change the
access_token value to your
Rollbar server side access token and
root to the directory where
you are developing your project.
ROLLBAR = { 'access_token': 'access token from dashboard', 'environment': 'development' if DEBUG else 'production', 'branch': 'master', 'root': '/Users/matt/devel/py/blog-code-examples/monitor-django-apps/djmonitor', 'patch_debugview': False, }
If you are uncertain about what your secret token is, it can be found on the Rollbar onboarding screen or "Settings" -> "Access Tokens" within rollbar.com.
Note that I typically store all my environment variables in a
.env
We can test that Rollbar is working as we run our application. Run it now using the development server.
python manage.py runserver
Back in your web browser press the "Done! Go to Dashboard" button.
If an event hasn't been reported yet we'll see a waiting screen like this one:
Make sure your Django development still server is running and try to go to "". A 403 error is immediately reported on the dashboard:
We even get an email with the error (which can also be turned off if you don't want emails for every error):
Alright we now have monitoring and error reporting all configured for our Django application!
We learned to catch issues in our Django project using Rollbar and view the errors in Rollbar's interface. Next try out Rollbar's more advanced monitoring features such as:
There is plenty more to learn about in the areas of web development and deployments so keep learning by reading about web frameworks. You can also learn more about integrating Rollbar with Python applications via their Python documentation.
Questions? Let me know via a GitHub issue ticket on the Full Stack Python repository, on Twitter @fullstackpython or @mattmakai.
Do you see a typo, syntax issue or wording. | https://www.fullstackpython.com/blog/monitor-django-projects-web-apps-rollbar.html | CC-MAIN-2018-17 | refinedweb | 1,715 | 50.33 |
You operate Oracle Scheduler by creating and managing a set of Scheduler objects. Each Scheduler object is a complete database schema object of the form
[schema.]name. Scheduler objects follow the naming rules for database objects exactly and share the SQL namespace with other database objects.
Follow SQL naming rules to name Scheduler objects in the
DBMS_SCHEDULER package. By default, Scheduler object names are uppercase unless they are surrounded by double quotes. For example, when creating a job,
job_name => 'my_job' is the same as
job_name => 'My_Job' and
job_name => 'MY_JOB', but different from
job_name => '"my_job"'. These naming rules are also followed in those cases where comma-delimited lists of Scheduler object names are used within the
DBMS_SCHEDULER package.
See Also:
Oracle Database SQL Language Reference for details regarding naming objects
"About Jobs and Supporting Scheduler Objects" | http://docs.oracle.com/cd/E24693_01/server.11203/e17120/scheduse001.htm | CC-MAIN-2016-30 | refinedweb | 135 | 54.63 |
Rest In Peas — the Death of Speech Recognition
Soulskill posted more than 3 years ago | from the yale-in-ox-boom-i-crows-off dept.
(5, Insightful)
Anonymous Coward | more than 3 years ago | (#32077194)
Buffalo buffalo Buffalo buffalo buffalo, buffalo Buffalo buffalo.
Mod parent up (2, Informative)
idiot900 (166952) | more than 3 years ago | (#32077338)
Would that I had mod points today.
The above is a valid English sentence and a poignant example of how difficult it is to parse language without knowledge of semantics.
Focus, Dammit. (1)
Jeremiah Cornelius (137) | more than 3 years ago | (#32077378)
"What, all of us?"
Re:Focus, Dammit. (1)
Philip K Dickhead (906971) | more than 3 years ago | (#32077832)
The sixth sheik's sixth sheep's sick.
[so, say said sentence sextuply...]
Re:Mod parent up (4, Interesting)
x2A (858210) | more than 3 years ago | (#32077448) (2, Insightful)
ground.zero.612 (1563557) | more than 3 years ago | (#32077464)
What about the simple fact that conversation itself is a learning process?
You learn the extent of your audience's comprehension among other things. How can a computer be programmed to recognize everything when we lack a sufficient model to base it on?
There is a point in conversation when a sensible human being will recognize they are not getting their ideas through, and simply give up and say "never mind".
Re:Mod parent up (1, Interesting)
RockoTDF (1042780) | more than 3 years ago | (#32077960)
Re:Mod parent up (1)
gyrogeerloose (849181) | more than 3 years ago | (#32077612)
The above is a valid English sentence and a poignant example of how difficult it is to parse language without knowledge of semantics.
Although it's either lacking in punctuation or using non-standard capitalization.
Then again, maybe he's invoking both the large mammal and the eponymous city in New York?
Re:Mod parent up (1, Informative)
Anonymous Coward | more than 3 years ago | (#32077676)
Hence why some of the words are capitalized.
Re:Buffalo buffalo (3, Funny)
Anonymous Coward | more than 3 years ago | (#32077366)
This rest ponds was and turd you sings peach recon nation soft where
Re:Buffalo buffalo (5, Funny)
CecilPL (1258010) | more than 3 years ago | (#32077394)
That comma is just out of place and makes the sentence hard to parse.
Re:Buffalo buffalo (4, Insightful)
liquiddark (719647) | more than 3 years ago | (#32077490)
Re:Buffalo buffalo (1)
u38cg (607297) | more than 3 years ago | (#32077984)
Badger badgers badger Badger badgers (1)
tepples (727027) | more than 3 years ago | (#32077496) (5, Funny)
Anonymous Coward | more than 3 years ago | (#32077782)
snaaaaaaake!
Re:Buffalo buffalo (1, Interesting)
Anonymous Coward | more than 3 years ago | (#32077558)
Has anyone really been far even as decided to use even go want to do look more like?
Re:Buffalo buffalo (2)
Hylandr (813770) | more than 3 years ago | (#32077728)
Re:Buffalo buffalo (5, Informative)
hoggoth (414195) | more than 3 years ago | (#32077634)
Buffalo bison whom other Buffalo bison bully, themselves bully Buffalo bison.
Re:Buffalo buffalo (5, Informative)
Anonymous Coward | more than 3 years ago | (#32077648)
For those that don't know:
'Buffalo bison whom other Buffalo bison bully, themselves bully Buffalo bison'.
Re:Buffalo buffalo (1)
Hylandr (813770) | more than 3 years ago | (#32077696)
Re:Buffalo buffalo (1)
blair1q (305137) | more than 3 years ago | (#32077698)
Your marklar is well marklar.
well (0)
Anonymous Coward | more than 3 years ago | (#32077218)
I the method which comes to make probably, them who see the work of the speech recognition software which is honest is suitable and language translation asserts! where
I hope.. (0)
Anonymous Coward | more than 3 years ago | (#32077224)
I certainly hope that TFA title is intentional...
I refuse to partake in a short sleep cycle process while lying in small round vegetables otherwise!
Goodnight, Sir!
Re:I hope.. (1)
Zancarius (414244) | more than 3 years ago | (#32077348)
Considering the subject matter, I'd hope readers would be able to detect a play on words when they see one.
Nevertheless, it got your attention, didn't it?
Key words (2, Interesting)
flaming error (1041742) | more than 3 years ago | (#32077240)
> (4, Funny)
SomeJoel (1061138) | more than 3 years ago | (#32077368)
&.
Android Speech Recognition Rules (5, Informative)
bit trollent (824666) | more than 3 years ago | (#32077254) (5, Funny)
liquidpele (663430) | more than 3 years ago | (#32077506)
Re:Android Speech Recognition Rules (1)
DeadDecoy (877617) | more than 3 years ago | (#32077792)
Re:Android Speech Recognition Rules (2, Interesting)
bertok (226922) | more than 3 years ago | (#32077886) (1)
justinlindh (1016121) | more than 3 years ago | (#32077914).
Re:Android Speech Recognition Rules (1)
vanyel (28049) | more than 3 years ago | (#32077950)
I haven't tried note taking on my Cliq, but voice dialing is a waste of time
Let me guess (4, Funny)
Zerth (26112) | more than 3 years ago | (#32077258)
That summary was written with speech recognition software?
Re:Let me guess (2, Funny)
MollyB (162595) | more than 3 years ago | (#32077622)
Hesitant grate watts peach wreck ignitions oft where kin dew ferrous?
What are you talk'in about ? (1)
burni2 (1643061) | more than 3 years ago | (#32077270)
Years ago I used viavoice on Warp4, and it had a pretty decend recognitation rate
..
it was even better understanding my needs than I can get Windows7 understand mine by mice commands
..
I miss those times
.. when grey was a chique color for OSes
Re:What are you talk'in about ? (1)
CohibaVancouver (864662) | more than 3 years ago | (#32077452) ? (3, Insightful)
bmo (77928) | more than 3 years ago | (#32077872):What are you talk'in about ? (4, Funny)
corbettw (214229) | more than 3 years ago | (#32077482)
Years ago I used viavoice on Warp4, and it had a pretty decend recognitation rate
..
Looks like whatever you're using now ain't quite as good.
Google Voice isn't Horrible (1)
bobstreo (1320787) | more than 3 years ago | (#32077276)
It's close enough to usually understand. But I'm not sure if it's a computer translation or a bunch of pigeons typing to translate.
AI (5, Insightful)
ShadowRangerRIT (1301549) | more than 3 years ago | (#32077280)
Re:AI (3, Insightful)
ShadowRangerRIT (1301549) | more than 3 years ago | (#32077372)
That's Because... (5, Funny)
BJ_Covert_Action (1499847) | more than 3 years ago | (#32077282)
*Disclaimer: Poster is not responsible for attempts resulting in unintended AI development and/or end of the world scenarios brought on by such an irresponsible endeavor.
Re:That's Because... (0)
Anonymous Coward | more than 3 years ago | (#32077952)
Pff, it's already done in Python:
import speech.recognition
Well duh. (3, Funny)
bmo (77928) | more than 3 years ago | (#32077284)
Even humans mishear speech.
"'Scuse me while I kiss this guy"
That misheard lyric is so common that there's a book about misheard lyrics with that as the title.
--
BMO
Re:Well duh. (1)
Eudial (590661) | more than 3 years ago | (#32077318)
Eggcorns [wikipedia.org] constitute another great example of how humans get this wrong.
Re:Well duh. (2, Funny)
CityZen (464761) | more than 3 years ago | (#32077406)
"Time flies like an arrow; fruit flies like a banana."
Time flies (1)
tepples (727027) | more than 3 years ago | (#32077628)
"Time flies like an arrow; fruit flies like a banana."
Is a time fly an archer or a DDR player?
Re:Well duh. (5, Funny)
Chris Burke (6130) | more than 3 years ago | (#32077462). (1)
bunratty (545641) | more than 3 years ago | (#32077508)
Crap, crap, crap into the toilet bowl (1)
tepples (727027) | more than 3 years ago | (#32077662)
Ken Lee!!! (1)
CityZen (464761) | more than 3 years ago | (#32077580)
And there's this nice meme from a couple years ago: [google.com] [youtube.com]
Re:Well duh. (1)
Tynin (634655) | more than 3 years ago | (#32077750):Well duh. (1)
blair1q (305137) | more than 3 years ago | (#32077760)
But...but computers are supposed to be perfect!
Re:Well duh. (1)
swilver (617741) | more than 3 years ago | (#32077858).
Re:Well duh. (1, Informative)
Anonymous Coward | more than 3 years ago | (#32077944)
The article acknowledges this... mentions speech recognition topped out with a 20% word error rate, while humans have an error rate of 2%-4%.
Sorry what? (1)
Daas (620469) | more than 3 years ago | (#32077310)
Re:Sorry what? (1)
cnoocy (452211) | more than 3 years ago | (#32077392)
A lot of vpr systems do just that. Also, dictation systems display what you've typed on the screen, so you can correct by voice if necessary.
Re:Sorry what? (2, Interesting)
Ethanol-fueled (1125189) | more than 3 years ago | (#32077518) infer the meaning of "come to me give the diagram" because there are at least intelligible words to work with. And no, I'm not being racist -- the situation applies to all cultures and languages.
Re:Sorry what? (0)
Anonymous Coward | more than 3 years ago | (#32077526)
They do and can. I called up a company and got a computer help line. The computer insisted I state my problem so it can look it up. Of course it never got it even close to right and insisted we keep trying again. By the forth time my question involved mostly swears words and finally I was transferred to a human. It only got worse from there.
Re:Sorry what? (1)
Jeng (926980) | more than 3 years ago | (#32077548)
It would seem that people learn computers better than computers learn people.
Much like talking to someone with a poor grasp on ones language you try to make things simple and easy to understand.
Number of sentences? (2, Insightful)
Logarhythmic (1082321) | more than 3 years ago | (#32077322)
One estimate puts the number of possible sentences at 10^570
What a completely useless metric. It makes sense to examine the context and meaning of speech in order to accurately transcribe words, but the number of possible sentences doesn't seem to accurately describe the problem here...
Re:Number of sentences? (0)
Anonymous Coward | more than 3 years ago | (#32077658)
Also, that number is kinda bullshit. In the article, it links to one guy making some back of the envelope calculations about the numbers of sentences. The author (a phonetician) doesn't take into account things like new word creation, novel developments in syntactic structures, or even basic things like recursive embedding of sentence in other sentences.
Though there may be a practical bound on the number of sentences in a language, there's no theoretical limit.
Windows 7 (3, Interesting)
Anonymous Coward | more than 3 years ago | (#32077324)
I've been using VR in Win7 for a few weeks now. I can honestly say that after a few trainings, I'm near 100% accuracy. Which is 15% better than my typing!
Re:Windows 7 (3, Informative)
adonoman (624929) | more than 3 years ago | (#32077484)
Not Dead Yet (2, Insightful)
Shidash (1420401) | more than 3 years ago | (#32077328)
Totally Not Dead Yet (4, Interesting)
RingDev (879105) | more than 3 years ago | (#32077834) (2, Informative)
Anonymous Coward | more than 3 years ago | (#32077330).
Conlangs (1)
izomiac (815208) | more than 3 years ago | (#32077384)
OTOH, if it's an attempt to simplify computing for those who don't wish to learn, well, that's an impossible task. The problem lies in the fact that such people don't give explicit commands, and even humans take quite a bit of intuition to figure out what they're implying.
Time flies like an arrow fruit flies like a banana (2, Insightful)
GuyFawkes (729054) | more than 3 years ago | (#32077386)
Having said that, Dragon works fairly well, provided you modulate your speech.
If you want a laugh with Dragon, turn away from the screen and talk normally, then look at what it has transcribed..
Re:Time flies like an arrow fruit flies like a ban (1)
SomeJoel (1061138) | more than 3 years ago | (#32077470)
Re:Time flies like an arrow fruit flies like a ban (0)
Anonymous Coward | more than 3 years ago | (#32077894)
Training (1)
dominious (1077089) | more than 3 years ago | (#32077408)
Speech recognition is higher intelligence (1)
gurps_npc (621217) | more than 3 years ago | (#32077412), recognizing it despite the large amounts of irrelevant data. That tree kind of looks like a face, that falling object is like all other falling objects. Computers have always been very very BAD at this. Humans do it much much better than animals, but even a monkey is better at general pattern recognition than a computer is.
I am sure that we can make computers slightly better at speech recognition - enough to recognize all of a limited set of comand words like print, attach, email, open, run. Individual programs would have to include codes for their names and specific commands. But I think it will take a true Artificial Intelligence to recognize speech as well as a human. In fact, I would make that my Turing Test. I would also add that I don't think an intelligence built using current theory could become a true Artificial Intelligence. We would need to design a computer that is a non-determenistic device -one that does not rely soley on pure mathematical logic, but is itself based on an entirely new design. No I can't describe it - because if I could I would build one and be rich.
Since I don't have a flying car today, all is lost (4, Insightful)
liquiddark (719647) | more than 3 years ago | (#32077430)
Sssssh. (1)
Allnighterking (74212) | more than 3 years ago | (#32077436)
Speech recognition and translation is becoming a highly effective and proficient tool for the US military. You see it fit's in your iPod... and
Did you dictate your post? (0)
Anonymous Coward | more than 3 years ago | (#32077700)
"Ssssh"? "it fit's in your iPod"? "puts the knosh on this article"? "Far from being a dead animal. It has moved"?
Apparently your speech recognition software still needs a bit more R&D. In case you can correct it for the future, it should probably be "Shhhh", "it fits in your iPod", "puts the kibosh on this article", and "Far from being a dead animal, it has moved".
dom
is there any evidence for this analysis? (3, Insightful)
Trepidity (597) | more than 3 years ago | (#32077440) (2, Interesting)
Colin Smith (2679) | more than 3 years ago | (#32077444).
Re:No it doesn't (0)
Anonymous Coward | more than 3 years ago | (#32077762)
Blame startrek (4, Insightful)
onyxruby (118189) | more than 3 years ago | (#32077456)!!
medical dictation - no go (1, Interesting)
Anonymous Coward | more than 3 years ago | (#32077468)
I never understood it, but since I was not the radiologist, I didn't care either. I mostly was entertained by listening to them repeat the same stupid, simple word over and over trying to get the dictation system to behave, when it would have taken a fraction of the time to manually edit the document with a keyboard.
yale-in-ox-boom-i-crows-off (1)
richdun (672214) | more than 3 years ago | (#32077472)
Yay Linux! Boo Microsoft!
I win! Give me all your speech recognition monies.
Wait, what do you mean you don't believe I'm an AI?
... er, I mean ... Wait, what do you mean you do not believe I am an Artificial Intelligence?
IBM? (2, Funny)
Darth Snowshoe (1434515) | more than 3 years ago | (#32077530)
Re:IBM? (1)
PalmKiller (174161) | more than 3 years ago | (#32077862)
Re:IBM? (5, Interesting)
N1ck0 (803359) | more than 3 years ago | (#32077904)
IBM closed many of their speech research offices 1-2 years ago and transferred most of the research/data to Nuance's Dragon Naturally Speaking research.
Full Disclosure: I work for Nuance
Tea, Earl Grey, Hot (5, Funny)
tokki (604363) | more than 3 years ago | (#32077546)
Shout-outs to two idiots (5, Insightful)
Foobar_ (120869) | more than 3 years ago | (#32077550).
Try this one... (0, Offtopic)
Aut0mated (885614) | more than 3 years ago | (#32077578)
Alpha Kenny 1
no, it doesn't work on cell phones, either (1)
swschrad (312009) | more than 3 years ago | (#32077586)
this is the reason that millions of americans are faster with the thumb than Buddy Rich with the drumsticks... you can't see the finger move as they type 30 zeroes in a row to escape the mumblebots.
Not free (0, Offtopic)
em0te (807074) | more than 3 years ago | (#32077610)
Data Input (1)
fermion (181285) | more than 3 years ago | (#32077618)
My understanding, from the people that use Dragon, it competes well against paying someone else to type. First it is a couple of orders cheaper. Second, if you pay someone to type, you still have to read and edit, and dragon is accurate enough. Of course you have to train yourself to use the technology, but that is the same with any technology. It is naive to think that we don't make subtle and not so subtle changes in ourselves so that we can benefit from the technology.
I think speech recognition is going to expand in the future. Beyond the dictation process, there is also simple commands. I don't use the voice controls on the iPhone, but it seems something that people like. I have used the voice controls on my Mac. Furthermore, i can certainly imagine a time when my fingers are not so limber that I might depend on something like Dragon.
I don't see the technology so commoditized that MS includes it in the 2015 version of MS Office, but I do have beilieve there is always room for improvement.
Dear Aunt, (1)
IorDMUX (870522) | more than 3 years ago | (#32077624)
Forget speech recognition.... (2, Funny)
puppetman (131489) | more than 3 years ago | (#32077664)
I'd settle for a grammar checker. From the fine summary:
"Even where data are lush"
A good one would have saved this summary from sounding stupid.
Wrong problem (1, Interesting)
slasho81 (455509) | more than 3 years ago | (#32077748)
Right now the problem being solved is audio->text. This is the wrong problem, and why the results are so lame. The real problem is audio+context->text+new context. This takes some pretty intelligent computing and not the same old probabilistic approaches.
The sixth sheik's sixth sheep's sick. (0)
Anonymous Coward | more than 3 years ago | (#32077812)
Somehow Slashdot chose an apt fortune: "The sixth sheik's sixth sheep's sick." Let me know how your speech recognition software does on that sentence!
dom
Maybe we just need to speak binary (1)
mwheeler (152107) | more than 3 years ago | (#32077828)
Maybe we just need to speak binary.
Best example: Google text captions. (1)
Ancient_Hacker (751168) | more than 3 years ago | (#32077900)
When you have a minute, go to YouTube and bring up an old Star Trek episode (not the CBS ones with very loud commercials).
Then turn on Google captions. More fun than a barrel of Rigelian monkeys!
About every third sentence gets a close or exact rendering, but oh, the other two! I should sue them for laugh-muscle strains.
Watermelon Box (4, Insightful)
NReitzel (77941) | more than 3 years ago | (#32077934).
its getting better but (2, Interesting)
luther349 (645380) | more than 3 years ago | (#32077940)
Why should anyone care? (0)
Anonymous Coward | more than 3 years ago | (#32077956)
Most people won't benefit from speech recognition software in any manner that is critical, or might automate the mundane to the point that their lives might yield great benefit to mankind overall. If there's anyone out there, aside from the physically handicapped, who thinks they need speech recognition software to perform any task that isn't repetitive and it truly important for the greater good, I assert that it would be better for all if they had proteges who could learn from them and not machines facilitate isolation.
There is also the problem of meaningful work from those who might serve as assistants, and automation for the sake of automation didn't do the Luddites any good, albeit notwithstanding the motivation to rebel against already cruel and inhumane conditions of employment. | http://beta.slashdot.org/story/135120 | CC-MAIN-2014-15 | refinedweb | 3,329 | 68.91 |
Introduction
Csound has the ability of executing Python scripts from within the orchestra text using a group of opcodes called the Python opcodes. These opcodes are a valuable but relatively unexplored extension to the Csound language, which can not only simplify data handling for parameter control or note generation, but also open the door for any type of interfacing, communication and extensions available in the Python language.
I. Requirements
Python
To use the Python opcodes, you first need to obtain Python, which is a separate install from Csound on Windows and Linux. You can obtain the latest version from, but you need to check which version of Python your version of Csound has been compiled against. Recent versions of Csound require Python 2.4.
You can check if you already have Python by opening a DOS prompt or Terminal and typing "python". If Python is installed on your system, you should get something like:
Python 2.4.4 (#2, Oct 20 2006, 00:23:25)
Type "help", "copyright", "credits" or "license" for more information.
>>>
This is the Python "interactive shell". This just means that you can type Python code directly there, and have it execute immediately. Try something like:
>>>a=4
When you press the Enter, apparently nothing happens, but you have assigned the value of 4 to the variable "a". Now type:
>>>print a
You will see the shell prints a "4".
While an instance of a Python interpreter (like the interactive shell, or inside a Csound execution) is running, it remembers all the variables and functions that have been declared. To declare a function (a set of instructions grouped under a single name), you must use this syntax:
def average(a,b):
ave = (a + b)/2
return ave
Notice that you use the keyword def to define a function, and that you specify the function's arguments between parenthesis. You must use ":" to define the start of the function. You use the keyword return to specify variables returned by the function. Also notice that indentation (the spaces between the start of the line and the start of text) in Python is very important. In the case of functions, indentation tells Python which instructions are part of the function, and when the function ends. So you must be very careful about indentation when writing Python code. To define this function in the interpreter, just type each line one by one. Notice that when you type the first line, the prompt changes to "..." instead of ">>>", indicating that you are defining the function. You can continue typing the other lines. When you're finished writing your function, press enter again to tell the shell you're done with the function. The prompt returns to normal, and your function has been defined. You can now use your function like this:
>>>print average(100, 200)
This will naturally print the value "150".
Learning Python
The net is full of Python tutorials and examples, but two popular resources to get started are the "official Python tutorial" at and the "Dive into Python" book at. If you already know Csound, all the Python code used here should be easy to read.
Why Python?
Though learning Python means having to grasp a new syntax and a new way to express algorithms, it is generally accepted that Python is one of the easiest programming languages to learn. Python is an interpreted language, which means it executes the code line by line as it receives it, without the need of building (compiling) a binary to run, like in C or Java. Python is also a weakly typed language, which means you don't need to declare variable types (you don't need to specify whether you want a string, an array or an integer, Python deduces it from what you fill it with), and more importantly, many variable type conversions and operations are greatly simplified1. It also has very easy-to-use arrays and lists, which can be nested and controlled easily. The big bonus of learning Python is that apart from enabling more complex data structures, and that all the features from the Python language will be available from a Csound orchestra or .csd file, you learn a very powerful but simple language that can help you in many computer chores.
II. The Python Opcodes
pyinit and pyruni
To use the Python opcodes inside Csound, you must first start the Python interpreter. This is done using the pyinit opcode. The pyinit opcode must be put in the header before any other Python opcode is used, otherwise, since the interpreter is not running, all Python opcodes will return an error. You can run any Python code by placing it within quotes as argument to the opcode pyruni. This opcode executes the Python code at init time. If it is put in the header, it will be run once, at the start of Csound compilation, before any score events. The example below, shows a simple csd file which prints the text "44100" to the terminal. Note that a dummy instrument must be declared to satisfy the Csound parser.
<CsoundSynthesizer> <CsInstruments> sr=44100 ksmps=128 nchnls=2 ;Start python interpreter pyinit pyruni "print 44100" instr 1 endin </CsInstruments> <CsScore> </CsScore> </CsoundSynthesizer>
When using quoted text, you can't have any line breaks, as that will confuse the Csound parser. Csound provides the {{ and }} delimiters to specify multi-line strings, which can be used to create multi-line Python scripts. You can use these delimiters any place you use quotes -e.g. the system opcode-, and they will allow line breaks. These delimiters also allow you to use quotes inside them.
The Python interpreter maintains its state for the length of the Csound run. This means that any variables declared will be available on all calls to the Python interpreter. In other words, they are global. The code below shows variables "a" and "b" being modified by Python opcodes, and that they are available in all instruments. Also, you must convert the number (a+b) to a string to concatenate it with another string using the function str().
<CsoundSynthesizer> <CsInstruments> sr=44100 ksmps=128 nchnls=2 pyinit ;Start python interpreter pyruni {{ a = 2 b = 3 print "a + b = " + str(a+b) }} ;Execute a python script on the header instr 1 pyruni {{a = 6
b = 5
print "a + b = " + str(a+b)}} endin instr 2 pyruni {{print "a + b = " + str(a+b)}} endin </CsInstruments> <CsScore> i 1 0 1 i 2 1 0 </CsScore> </CsoundSynthesizer>
The previous program will print among the rest of the Csound output or on the calling shell (if using a frontend2) the following lines:
a + b = 5
a + b = 11
a + b = 11
The first of these was executed in the header, the second was printed by instrument 1 and the second by instrument 2.
pyrun
Python scripts can also be executed at k-rate using pyrun. When pyrun is used, the script will be executed again on every k-pass for the instrument, which means it will be executed kr times per second. The example below shows a simple example of pyrun.
<CsoundSynthesizer> <CsInstruments> sr=44100 kr=100 nchnls=2 pyinit pyruni "a = 0" instr 1 pyrun "a = a + 1" endin instr 2 pyruni {{print "a = " + str(a)}} endin </CsInstruments> <CsScore> i 1 0 1 ;Adds to a for 1 second i 2 1 0 ;Prints a i 1 2 1 ;Adds to a for another second i 2 3 0 ;Prints a </CsScore> </CsoundSynthesizer>
This csd file produces the following output from Python:
a = 100
a = 200
This shows that the Python script in instrument 1 was executed 100 times per second. Which is what is expected since kr = 100. If kr is not defined, remember that kr = sr/ksmps.
pyexec
Csound allows you to run Python script files that exist outside your csd file. This is done using pyexec. The pyexec opcode will run the script indicated, like this:
pyexec "c:/python/myscript.py"
In this case, the script "myscript.py" will be executed at k-rate. You can give full or relative path names.
You can create Python scripts using any ordinary (non-rich-text) text editor like notepad.
There are other versions of the pyexec opcode, which run at initialization only (pyexeci) and others that include an additional trigger argument (pyexect).
pyeval and friends
The opcode pyeval and its relatives, allow you to pass to Csound the value of a Python variable. You specify the name of the variable in quotes, and Csound will assign the Python variable's value to the opcode's output variable. You can replace instrument 2 from the previous example with (notice I've used pyevali which works at initialization only):
instr 2 ival pyevali "a" prints "a = %i\\n", ival endin
It should be this easy, but this is where a small pitfall comes in... Maybe you already tried and got:
INIT ERROR in instr 2: pyevali: expression must evaluate in a float
What happens is that Python has delivered an integer to Csound, which expects a floating-point number. In other words, Csound always works with numbers which are not integer (to represent a 1, Csound actually uses 1.0). This is equivalent mathematically, but in computer memory these two numbers are stored in a different way. So what you need to do is tell Python to deliver a floating-point number (also called a float) to Csound. What you need to do is "fool" Python into thinking you will be using decimals, even if you won't, so that the automatic type detection in Python, declares a value as a float instead of an integer. You can do this by changing the line in the header to:
pyruni "a = 0.0"
This will make the variable "a" be declared as a float within Python, and it will then be a valid variable to pass to Csound.
pyassign and friends
Likewise, you can also assign values to Python variables directly, using pyassign. You could change the statement:
pyruni "a = 0.0"
to:
pyassigni "a", 0
Doing this also prevents problems with integer/floats types, because "a" is declared as a float by Csound, since all numbers are floats for Csound.
As before, pyassign comes in different versions, for k-rate and i-rate, and there are also versions with a trigger argument (pyassignt).
pycall
Apart from reading and setting variables directly with an opcode, you can also call Python functions from Csound and have the function return values directly to Csound. This is the purpose of the pycall opcodes. With these opcodes you specify the function to call and the function arguments as arguments to the opcode. You can have the function return values (up to 8 return values are allowed) directly to Csound i- or k-rate variables. You must choose the appropriate opcode depending on the number of return values from the function, and the Csound rate (i- or k-rate) at which you want to run the Python function. Just add a number from 1 to 8 after to pycall, to select the number of outputs for the opcode. If you just want to execute a function without return value simply use pycall. For example, the function "average" defined above, can be called directly from Csound using:
kave pycall1 "average", ka, kb
The output variable kave, will calculate the average of the variable ka and kb at k-rate.
As you may have noticed, the Python opcodes run at k-rate, but also have i-rate versions if an "i" is added to the opcode name. This is also true for pycall. You can use pycall1i, pycall2i, etc. if you want the function to be evaluated at instrument initialization, or in the header. The following csd shows a simple usage of the pycall opcodes:
<CsoundSynthesizer> <CsInstruments> sr=44100 kr=100 nchnls=2 pyinit pyruni {{ def average(a,b): ave = (a + b)/2 return ave }} ;Define function "average" instr 1 iave pycall1i "average", p4, p5 prints "a = %i\\n", iave endin </CsInstruments> <CsScore> i 1 0 1 100 200 i 1 1 1 1000 2000 </CsScore> </CsoundSynthesizer>
This csd will print the following output:
a = 150
B 0.000 .. 1.000 T 1.000 TT 1.000 M: 0 0
a = 1500
B 1.000 .. 2.000 T 2.000 TT 2.000 M: 0 0
Local instrument scope
Sometime you want Python variables to be global, and sometimes you
may want Python variables to be local to the instrument instance.
This is possible using the local Python opcodes. These opcodes are
the same as the ones shown above, but have the prefix pyl
instead of py. There are opcodes like pylruni,
pylcall1t and pylassigni,
which will behave just like their global counterparts, but they will
affect local Python variables only. It is important to have in mind
that this locality applies to instrument instances, not instrument
numbers.
You can think of local python calls as behaving like i-rate (or init) variables within instruments, and non-local versions behaving like global variables. Each instrument instance or note holds a unique and independent value for each i-rate variable, while global variables affect all instruments, as can be seen here:
<CsoundSynthesizer>
<CsInstruments>
gkprint init 0
instr 1
ivalue init p4
ktrig changed gkprint
if (ktrig == 1) then
printk 0.5, ivalue Csound File will print the following, showing that all ivalue variables hold a different value at the same time for each individual note:
i 1 time 3.00023: 100.00000
i 1 time 3.00023: 200.00000
i 1 time 3.00023: 300.00000
i 1 time 3.00023: 400.00000
In the same way, the local versions of the python opcodes store information which is local to a particular note. This can be seen in this example which does the same as above, but storing the values in local python variables.
<CsoundSynthesizer>
<CsInstruments>
pyinit
gkprint init 0
instr 1
;assign 4th p-field to local python variable "value"
pylassigni "value", p4
ktrig changed gkprint
; If gkprint has changed (i.e. instr 2 was triggered)
; print the value of the local python variable "value"
if (ktrig == 1) then
kvalue pyleval "value"
printk 0.5, kvalue file will print the same values as the previous one. Notice
that the 4th p-field for each instance or note is stored in a local
python variable called "value". Even though all instances of the
instrument use the same name for the variable, since we are using pylassign and pyleval, they are local to the
note.
Triggered versions of python opcodesAll of the python opcodes have a "triggered" version, which will only execute when its trigger value is different to 0. The names of these opcodes have a "t" added at the end of them (e.g. pycallt or pylassignt), and all have an additional parameter called ktrig for triggering purposes. See the example in the next chapter for usage.
III. Simple Markov chains using the Python opcodes arrays) need not be known in advance, since it is not necessary in python to declare the sizes of arrays.
The file has explanations intermixed with the code (just be sure to
take them out if you copy/paste into an editor). You can get this and
the other examples from this article in the file journalpython.zip.
<CsoundSynthesizer> <CsInstruments> sr=44100 ksmps=128 nchnls=2 pyinitThe python code below, run at initialization, creates a matrix for the markov chain definition. Notice that the matrix is created as a vector of vectors. Each vector contains the normalized probability for each of the five notes. It also defines the function for generating a new note from a present note called "get_new_note". It uses the random() function from the random module to generate random number values. This shows that you can use any python module within Csound, including graphics modules like wxPython, sqlite3 for database mangement or even dom or sax for XML parsing.
pyruni {{c = [0.1, 0.2, 0.05, 0.4, 0.25]Instrument 1 is in charge of executing the python function "get_new_note" and of spawing instrument 2 (which generates the sound) at a constant rate determined by p-field 4. You can generate several simultaneous notes for instrument 1, to create polyphony, and give each instance a different frequency for note generation, and a different octave using p-field 5.
d = [0.4, 0.1, 0.1, 0.2, 0.2]
e = [0.2, 0.35, 0.05, 0.4, 0]
g = [0.7, 0.1, 0.2, 0, 0]
a = [0.1, 0.2, 0.05, 0.4, 0.25]
markov = [c, d, e, g, a]
import random
random.seed()
def get_new_note(previous_note):
number = random.random()
accum = 0
i = 0
while accum < number:
accum = accum + markov[int(previous_note)] [int(i)]
i = i + 1
return i - 1.0
}}Instrument 2 is spawned from instrument 1 using the opcode schedkwhen. It produces a simple sine wave, but it's not hard to use more complex or interesting sounds. When spawned, the instrument is given 2 p-fields, which tell it which note to produce and on which octave (in pitch class format, but separating octave from note). You could produce articulation or other control data from python as well and pass it to the instrument through additional p-fields.
instr 2 ;A simple sine wave instrument ;p4 = note to be played ;p5 = octave ioct init p5 ipclass table p4, 2 ipclass = ioct + (ipclass / 100) ; Pitch class of the note ifreq = cpspch(ipclass) ;Note frequency in Hertz aenv linen 6000, 0.05, p3, 0.1 ;Amplitude envelope aout oscil aenv, ifreq , 1 ;Simple oscillator outs aout, aout
endin </CsInstruments> <CsScore>The score defines a simple sine wave in table 1, to be used as waveform for the sound and defines the pitch classes of the scale to be used in table 2. Changing these values will change the scale generated by the orchestra.
Notice that new layers of polyphony (on different octaves and at different rates) are added every 5 seconds.
f 1 0 2048 10 1 ;sine wave f 2 0 8 -2 0 2 4 7 9 ;Pitch classes for pentatonic scale ; frequency of Octave of ; note generation melody i 1 0 30 3 7
i 1 5 25 6 9 i 1 10 20 9 10 i 1 15 15 1 8
</CsScore> </CsoundSynthesizer>
Examples
References
The Python opcodes page in the Csound Manual
Documentation for the Python random module
1The fact that Python is interpreted and weakly typed is one of the reasons it is not an extremely efficient language like C or C++, which is why it finds greater use for scripting and prototyping. | http://www.csounds.com/journal/issue6/pythonOpcodes.html | crawl-002 | refinedweb | 3,122 | 68.1 |
Term::Clui.pm - Perl module offering a Command-Line User Interface
use Term::Clui; $chosen = choose("A Title", @a_list); # single choice @chosen = choose("A Title", @a_list); # multiple choice # multi-line question-texts are possible... $x = choose("Which ?\n(Mouse, or Arrow-keys and Return)", @w); $x = choose("Which ?\n".help_text(), @w); if (confirm($text)) { do_something(); }; $answer = ask($question); $answer = ask($question,$suggestion); $password = ask_password("Enter password:"); $filename = ask_filename("Which file ?"); # with Tab-completion $newtext = edit($title, $oldtext); edit($filename); view($title, $text) # if $title is not a filename view($textfile) # if $textfile _is_ a filename edit(choose("Edit which file ?", grep(-T, readdir D)));
Term::Cl cut/paste. This user interface can therefore be intermixed with standard applications which write to STDOUT or STDERR, such as make, pgp, rcs etc.
For the user, choose() uses either (since 1, simple, and has few external dependencies. It doesn't use curses (which is a whole-of-screen interface); it uses a small subset of vt100 sequences (up down left right normal and reverse) which are very portable, and also (since 1.50) the SET_ANY_EVENT_MOUSE and kmous (terminfo) sequences, which are supported by all xterm, rxvt, konsole, screen, linux, gnome and putty terminals.
There is an associated file selector, Term::Clui::FileSelect::Clui runs, and then restored. Because Term::Clui's metaphor for the computer is a human-like conversation-partner, this works very naturally. The application needs no modification.
There is an equivalent Python3 module, with (as far as possible) the same calling interface, at
This is Term::Clui.pm version 1.71
Term::Cl.
Asks the user the question and returns a string answer, with no newline character at the end. If the optional second argument is present, it is offered to the user as a default. If the $question is multi-line, the entry-field is at the top to the right of the first line, and the subsequent lines are formatted within the screen width and displayed beneath, as with choose. with no echo, as used for password entry.
Uses Term::ReadLine::Gnu to provide filename-completion with the Tab key, but also displays multi-line questions in the same way as ask and choose do. This function was introduced in version 1.65.
Displays the question, and formats the list items onto the lines beneath it.
If choose is called in a scalar context, the user can choose an item using arrow keys (or hjkl) and Return, or cancel the choice with a "q". choose then returns the chosen item, or undefined if the choice was cancelled.
If choose is called in an array context, the user can also mark an item with the SpaceBar. choose then returns the list of marked items, (including the item highlit when Return was pressed), or an empty array if the choice was cancelled.
A DBM Term::Clui.pm can therefore exchange or $ENV{CLUI_DIR}/choices is available to be read or written if lower-level manipulation is needed, and the EXPORT_OK routines and elaboration.
Asks the question, explanation and elaboration. Returns true or false.
Uses the environment variable EDITOR ( or vi :-) Uses RCS if directory RCS/ exists
Similar to warn "Sorry, $message\n";
Similar to warn "$message (since 1.65) is "multi" then the text describes the keys and mouse actions the user has available when responding to a multiple-choice &choose question; otherwise, the text describes the keys and mouse actions the user has available when responding to a single-choice &choose.
The following routines are not exported by default, but are exported under the ALL tag, so if you need them you should:
import Term::Clui qw(:ALL);
Beeps.
Returns a sortable timestamp string in "YYYYMMDD hhmmss" form.
Consults the database ~/.clui_dir/choices or $ENV{CLUI_DIR}/choices and returns the choice that the user made the last time this question was asked. This is better than opening the database directly as it handles DBM's problem with concurrent accesses.
Opens the database ~/.clui_dir/choices or $ENV{CLUI_DIR}/choices and sets the default response which will be offered to the user made the next time this question is asked. This is better than opening the database directly as it handles DBM's problem with concurrent accesses.
It requires Exporter, which is core Perl. It uses Term::ReadKey if it's available; and uses Term::Size if it's available; if not, it tries tput before guessing 80x24.
The environment variable CLUI_DIR can be used (by programmer or user) to override ~/.clui_dir as the directory in which choose() keeps its database of previous choices. The whole default database mechanism can be disabled by CLUI_DIR = OFF if you really want to :-(
If either the LANG or the LC_TYPE environment variables contain the string utf8 or utf-8 (case insensitive), then choose() and inform() open /dev/tty with a utf8 encoding.
If the environment variable CLUI_SPEAK is set or if EDITOR is set to emacspeak, and if flite is installed, then Term::Clui will use flite to speak its questions and choices out loud.
If the environment variable CLUI_MOUSE is set to OFF then choose() will not interpret mouse-clicks as making a choice. The advantage of this is that the mouse can then be used to highlight and paste text from this window as usual.
Term::Clui also consults the environment variables HOME, LOGDIR, EDITOR and PAGER, if they are set.
These scripts using Term::Clui and Term::Clui::FileSelect are to be found in the examples subdirectory of the build directory.
I use this script a lot at work, for routine system administration of linux boxes, particularly Fedora and Debian. It includes crontab, chkconfig, update-rc.d, visudo, vipw, starting and stopping daemons, reconfiguring squid samba or apache, editing sysconfig or running any of the system-config-* utilities, and much else.
This script offers an arrow-key-and-return interface integrating aplaymidi, cdrecord, cdda2wav, icedax, lame, mkisofs, muscript, normalize, normalize-audio, mpg123, sndfile-play, timidity, wodim and so on, allowing audio files to be ripped, burned, played, or converted between Muscript, MIDI, WAV and MP3 formats.
This script offers the naive user arrow-key-and-return access to a text-based browser, a mail client, a news client, ssh and ftp and various other stuff.
This is the test script, as used during development.
This is a script which wraps Term::Clui::choose for use at the shell-script level. It can either choose between command-line arguments, or, with the -f (filter) option, between lines of STDIN, like grep. A -m (multiple) option allows multiple-choice. This can be a very useful script, and you may want to copy it into /usr/local/bin/ or elsewhere in your PATH.
Peter J Billam
Based on some old perl 4 libraries, ask.pl, choose.pl, confirm.pl, edit.pl, sorry.pl, inform.pl and view.pl, which were in turn based on some even older curses-based programs in C.
Term::Clui::FileSelect Term::ReadKey Term::Size festival(1) eflite(1) espeak(1) espeakup(1) edbrowse(1) emacspeak(1) perl(1)
There is an equivalent Python3 module, with (as far as possible) the same calling interface, at | http://search.cpan.org/dist/Term-Clui/Clui.pm | CC-MAIN-2017-09 | refinedweb | 1,195 | 54.12 |
send - send a message on a socket
#include <sys/socket.h> ssize_t send(int socket, const void *buffer, size_t length, int flags);
-() and poll() functions can be used to determine when it is possible to send more data.
The socket in use may require the process to have appropriate privileges to use the send() function.
Upon successful completion, send() returns the number of bytes sent. Otherwise, -1 is returned and errno is set to indicate the error.
The send() function is identical to sendto() with a null pointer dest_len argument, and to write() if no flags are used.
The send() function willFAULT]
- The buffer parameter can not be accessed.
- [EINTR]
- A signal interrupted send() before any data was transmitted.
- [EMSGSIZE]
- The message is too large be sent all at once, as the socket requires.
- [ENOTCONN]
- The socket is not connected or otherwise has not had the peer prespecified.
- process.
The send() function may fail if:
- [EACCES]
- The calling process does not have the appropriate privileges.
- [EIO]
- An I/O error occurred while reading from or writing to the file system.
- [ENETDOWN]
- The local interface used to reach the destination is down.
- [ENETUNREACH]
- No route to the network is present.
- [ENOBUFS]
- Insufficient resources were available in the system to perform the operation.
- [ENOSR]
- There were insufficient STREAMS resources available for the operation to complete.
connect(), getsockopt(), poll(), recv(), recvfrom(), recvmsg(), select(), sendmsg(), sendto(), setsockopt(), shutdown(), socket(), <sys/socket.h>. | http://pubs.opengroup.org/onlinepubs/7990989775/xns/send.html | crawl-003 | refinedweb | 238 | 66.13 |
Linux tasks
Most things on computers are best first learnt by doing rather than reading about them, so here is a set of tasks for you to get up to speed with linux. Some are very explicit, others less so to make you look them up. I assume that you start in your 'home directory' ('directory' synonymous with 'folder'), the one you are in after you login, and which you can always return to by typing cd. Its a bit dull, but go through it once to get a smattering of the basics. Remember to hit 'enter' after typing a command to get it to do anything. To do any of the following, you need to start by opening some form of "terminal" into which you can type. Look at the menus reachable from the bottom-left button for these. I usually a "konsole".
Navigating directories
- Create a directory, move into it and create a directory inside it (a subdirectory) and move into that as follows:
mkdir parent
cd parent
mkdir child
cd child
- Show where you are by typing pwd ("print working directory")
- List the contents of the "parent directory" (i.e. the one that contains the one you are in) by typing ls .. (look up what the '..' means). You should see the 'child' directory listed.
- Move up a directory in the hierarchy and list what is inside it with cd .. followed by ls. Again you should see the 'child' directory.
- Move back to your home directory with cd (you could also have typed cd ..)
- Move directly to the 'child' directory with cd parent/child
In all the above you are changing and listing directories by specifying their position relative to the directory that you are in at the moment, your "working directory". You can also specify a directory by its "absolute path". For instance:
- Change to the 'root' directory and once you are there, list it with cd / followed by ls. This directory is as high up as you can go.
- Then try cd /usr and cd /usr/bin. List the directories each time (lots of files).
- Rather than typing cd to get home, try cd /home/astro/your_username where you will have to substitute your username, phuxyz, or whatever. [Warning: your home directory may miss out the 'astro' part of the path; it depends how it has been set up.]
- Try looking around other directories using these commands. If you get stuck or lost, always remember cd to take you back to your home directory.
Creating and manipulating files
- Go to the directory you created 'parent', and start editing a file with the 'emacs' editor, e.g. emacs testfile&. You should immediately be able to start typing. This is more akin to MS 'Notepad' than 'Word': you only get what you type, with no hidden characters to tell a printer to display in boldface etc. This is exactly what you want for writing programs and scripts and files readable by programs, thus you will only ever need 'emacs' or an equivalent such as 'pico' or 'kwrite' if you prefer.
- Try typing in
Hello world!
This is a test sentence
and this is another test sentence
where you must hit the 'enter' key at the end of each line including the second blank line and the last.
- Now save the file to disk by typing Ctrl-X then Ctrl-S (or using the mouse to access the 'File' menu in the top-left corner). You can then quit 'emacs' in the same way or by typing Ctrl-X followed by Ctrl-C, or you can leave it running if you wish. ('Ctrl' here means press the 'control' key down while typing the letter following it.)
- List the directory you are in. You should see your new file. Type its contents to the terminal by typing cat testfile.
- Try listing the contents with cat Testfile and CAT testfile. Why don't these work?
- For longer files you should use the command less rather than cat
- Copy the file by typing cp testfile testfile_copy; list the directory to see the results.
- Rename ('move') the file copy using mv testfile_copy differentfile
- Delete ('remove') the file using rm differentfile. NB Be careful with 'rm'!
- Try removing the 'child' directory in the same way. It won't work; you need a 'recursive' removal rm -r child.
- Copy testfile to files called tst1, tsts2 and tstst (i.e. use the cp command three times). Now delete these with rm tst*. The tst* here means match anything starting with 'tst'. This can be used in other commands too to select multiple files, but you must take even more care when using it with rm, e.g. if you made a mistake typing and inserted an extra space to write rm tst * you would delete all the files in the directory, which could be a disaster.
Searching a file
- List all the lines of your file containing 'test' with grep test testfile
- List all the line of your file with at least two 'o's with grep 'o.*o' testfile. The '.' here means 'match any character' and the '*' means 'any number of times', so '.*' matches anything, while the 'o' at the start and end mean that it will match any line with two 'o's somewhere in it. This is an example of something called a 'regular expression' which can be very useful.
Changing a file on the command line, re-direction.
- Edit a file called 'storm' with the following:
Many years ago there was a big stoorm in which 1 million trees
were uprooted. The storm passed over the Centrl Europe
doing signifcant damage. Such big stoorms occur rarely
The 'stoorm' in the file above is deliberately mis-spelt when it comes after 'big'. The 'Centrl' is also deliberate.
- Type sed -e 's/big stoorm/big storm/' storm
- Save the results of the previous command by repeating it (use the up arrow for instance), but then adding >! newstorm. 'cat' the result. The > 're-directs' the output to the file
sed is a 'stream editior' and is a powerful way to modify files automatically, and also to modify the output from programs when used with what are called 'piped commands'.
Piping commands
Only the 'stoorm' fault was corrected above. Leaving 'Centrl' uncorrected. If you type
sed -e 's/big stoorm/big storm/' storm | sed -e 's/trl/tral/'
you can correct both faults. The output from the first invocation of 'sed' is piped to the input of the next. The crucial character here is the '|' between the two separate commands. This can be used to build up powerful sequences of commands. The examples here could trivially have been corrected with an editor, but there are many circumstances where this is not the case. Also note that it would also have been possible to achieve this with one application of sed followed by two -e 's/match/replace/' statements.
Writing scripts
Scripts allow you to save lists of commands to a file and can save a great deal of time. Anything you can type on the command line you can typoe in a script, but scripts also allows you to loop and branch (possible but tedious from the command line). You create scripts simply by editing a new file, e.g. type emacs script& and enter the following lines:
#!/bin/csh -fv
mkdir testdir
cd testdir
echo "Hello world" >! testfile
echo "This is a test file" >> testfile
ls testfile
cat testfile
cd ..
exit
Save the file as before, and then make it 'executable' by typing chmod +x script, and then run it by typing ./script. You should see it run through the sequence of commands. Scripts are a major reason to use the command line at most times rather than GUI-based 'point-and-click' alternatives because you will find that you remember commands after a while.
For much more on shell scripts, see this C-shell cookbook. Be aware that there are other scripting languages, for instance there are other 'shells' within UNIX, and also fairly fully-fledged programming languages such as Perl and Python. You may want to consider looking into these if your work is likely to involve many repetitive manipulations of large numbers of files.
Developing programs
Scripts are not always the method of choice. For raw speed you may need to use a compileable programming language such as FORTRAN, C, C++ etc. This guide is not meant to teach you these, but to get you going here is how you can get a C program to compile and run.
Edit the following program by typing emacs testprog.c&:
#include <stdio.h>
int main(){
printf("Hello world!\n");
}
Note that the '.c' on the end of the file name triggers 'emacs' to recognise that you are going to write a C-program which means that it helps you with language-sensitive editing. Equivalent endings are '.f' for FORTRAN77, '.cc' for C++ and '.java' for Java. Note also that unlike default windows behaviour, linux does not hide such endings which you will always see when you list files.
Compile and link the program with
gcc -o testprog testprog.c
and finally run it by typing ./testprog. There is more to it, but these are the basics of how one writes, compiles and runs programs. If you know C, stick a 'for' loop in to make the program write out the line 10 times. If you know FORTRAN, write yourself a program and use 'f77' in place of the 'gcc'.
For some more on programming, in particular how to write, compile and link a program which makes a plot, see how to make a plotting program.
Command options and on-line help
Most commands have options which modify their behaviour. An example up above was the -r option of rm. Try out the -l and -a options of ls. You can also combine options as in ls -al. Use the man ('manual') command to find out more, e.g. man ls. Try xman& to throw up a GUI-based help browser (a case where point-and-click is to be preferred). If you click on 'manual page' and then 'Sections', choosing (1) User commands, you can access the help on 'ls' and many other commands, although note that 'man' pages take a bit of getting used to and can be fairly useless for some of the lowest level commands such as 'cd' which are built into the 'shell' (the thing the provides the whole command line look-and-feel). You may at some point want to delve into the rather long man page on the shell by typing man csh, although the linux tutorial covers most of what this has to say. | https://warwick.ac.uk/fac/sci/physics/research/astro/local_info/projects/linuxtasks/ | CC-MAIN-2020-40 | refinedweb | 1,787 | 72.36 |
>
Hi im trying to play an audio clip when anything collides with my death zone area, i have the audio source on the death zone object and this script attached.
public class SawSoundController : MonoBehaviour { AudioSource saw;
void Start ()
{
saw = GameObject.FindObjectOfType<AudioSource>();
}
void Update ()
{
}
void OnCollisionEnter(Collision col)
{
if(col.gameObject)
{
saw.Play();
Debug.Log("Nurrrr");
}
}
}
i've tried this a few different ways and nothings working, what am i doing wrong ?
Couple things could be happening. Is there a rigidbody attached to either object involved in the collision? Is it set to Trigger? Do you have IsKinematic enabled on either of them? Is one 2D and the other 3D? Any of these might cause the behavior.
Do they both have colliders?
There Both 3d, they both have colliders, and anything that will collide with deathZone will have a rigid body however the deathZone dose not, the death zone is a trigger but not kinematic, the objects colliding with the death zone are both triggered and un trigger but none kinematic however neither the triggered or the un triggered objects play the sound when colliding
u need to tell what objects are colliding with the deathzone. So you need to check the objects with their tag or name. i dont think it can work if i say if(col.gameObject)
See if that works
Answer by JEFFDOG11111
·
Mar 23, 2016 at 03:41 PM
using UnityEngine;
using System.Collections;
//Add this Script Directly to The Death Zone
public class SawSoundController : MonoBehaviour
{
public AudioClip saw; // Add your Audi Clip Here;
// This Will Configure the AudioSource Component;
// MAke Sure You added AudioSouce to death Zone;
void Start ()
{
GetComponent<AudioSource> ().playOnAwake = false;
GetComponent<AudioSource> ().clip = saw;
}
void OnCollisionEnter () //Plays Sound Whenever collision detected
{
GetComponent<AudioSource> ().Play ();
}
// Make sure that deathzone has a collider, box, or mesh.. ect..,
// Make sure to turn "off" collider trigger for your deathzone Area;
// Make sure That anything that collides into deathzone, is rigidbody;
}
@Bman262 > tag
Thank you, it was the trigger on the DeathZone :D, bit of a nooby mistake ;)
for those of you out there working on 2D line 17 should read "void OnTriggerEnter2D () {
Thanks for this JEFFDOG11111 it helped me a lot.
My script writer says AudioClip can't implicitly convert into AudioSource... so is it important to use one or the other? Do they do different things, and if so, what?
Answer by KdRWaylander
·
Mar 23, 2016 at 03:56 PM
Hi,
col.gameObject is not a boolean, it's a GameObject type, it has nothing to do in your if statement.
col.gameObject
If you do want ANYTHING going through your collider to trigger the sound, you can get rid of the if statement: whenever OnCollisionEnter is called, it plays the sound.
If you want to filter the gameobjects being able to trigger the sound, you'll need the if statement but with a boolean. Here's a possible condition that fits: col.gameObject.tag == "SomeString".
col.gameObject.tag == "SomeString"
Now make sure that both objects (the one carrying the script and the one that has to trigger the sound) have colliders and that at least one of the two objects has a RigidBody.
"col.gameObject is not a boolean, it's a GameObject type, it has nothing to do in your if statement"
You're wrong, I'm afraid. His usage is both acceptable and quite common. In this context, the if-statement will return false if GameObject is null.
As stated above, if ( col.gameObject ) is totally fine; It checks if the gameobject is null.
if ( col.gameObject )
On another note, do not use
col.gameObject.tag == "SomeString"
instead do:
col.gameObject.CompareTag("SomeSt.
Sound plays right at the beginning
2
Answers
Distribute terrain in zones
3
Answers
Multiple Cars not working
1
Answer
How to mute Backgroundmusic while other audiosources still plays
0
Answers
Audio/c#/unity Can i control the duration by time ?
1
Answer | https://answers.unity.com/questions/1159138/playing-audio-on-collision.html | CC-MAIN-2019-13 | refinedweb | 655 | 63.09 |
The essential problem is to determine the index i of the first Fibonacci number Fn to have at least d digits. The specific challenge is to determine the index of the first Fibonacci number to have 1000 digits.
Obviously, this problem could be brute forced by stepping through all the Fibonacci numbers and determining the answer. However, this is not very mathematically pleasing, nor is it very efficient. Instead, we will develop an algorithm to determine the answer using some nifty Fibonacci mathematics.
At this point, I'd like to introduce Mr. J. P. M. Binet. Binet was a French Mathematician and Physicist that lived and worked around the turn of the 19th century. Binet discovered a formula for calculating the nth Fibonacci number without having to know anything about the preceding Fibonacci numbers. His formula had been previously discovered by Euler and a fellow named Moivre, but the Formula is credited to Binet commonly. Binet's formula expressed the nth Fibonacci number in terms of the golden ratio (phi).
phi = ( 1 + sqrt(5) ) / 2 and
Fn( n ) = ( phi^n - ( -phi^-n ) ) / sqrt( 5 ) This is a tremendous time saving formula that allows instant calculation of any Fibonacci number. Interestingly enough, this formula always returns an integer even though it involves products of irrational numbers ( phi and sqrt(5) ). In any case, it should also be noted that if n is a real number, Fn will also be real number equal to some value between two Fibonacci numbers
Fn( n ) < Fn( n + epsilon ) < Fn( n + 1 ) iff epsilon < 1 Another interesting property of this formula is that it can be reproduced perfectly with an approximation!
Fn( n ) = round( phi^n / sqrt( 5 ) when n >= 0 This holds true because the inverse of phi is less than one, and its powers become very small ( and insignificant ) rapidly. So, in Binet's formula, the difference between phi^n and phi^-n is very nearly equal to phi when n becomes large. In fact, this difference is close enough to round correctly even when n is 0 or 1.
Now, since we have a simple formula for calculating Fn given n, we can simply solve for n to reverse the formula and determine the index of any fibonacci number.
Fn ~= phi^n / sqrt(5) phi^n ~= Fn * sqrt(5) log( phi^n ) ~= Fn * sqrt(5) n log( phi ) ~= log( Fn * sqrt(5) ) n ~= log( Fn * sqrt(5) ) / log( phi ) [b]n ~= ( log( Fn ) + log( sqrt(5) ) ) / log( phi )[/b]
Now, if we round the result of this equation, we will always get the exact index of any Fibonacci number. However, there is some added value. In fact, if we use this formula on a non-Fibonacci number, it will give us an approximate Fibonacci index!
n( Fn(n) ) < n( Fn(n) + eps ) < n( Fn(n+1) ) when eps < Fn(n+1) - Fn(n) If we then take the ceiling ( round up ) of the result of applying this formula to any number m, we can find the index of the first Fibonacci number greater than m. Lets call this function NextFib, and express it clearly:
NextFib( m ) = ceiling( ( log( m ) + log( sqrt(5) ) ) / log( phi ) ) So, our final trick is to use this information to find the index of the first Fibonacci number with d digits. This is really quite trivial. We know that the first integer to have d digits is always:
10^(d-1) So, to find the index n of the first Fibonacci number Fn with d digits, we simply apply our magic formula:
n( d ) = NextFib( 10^( d - 1 ) ) Now that we've developed a function to mathematically ( and elegantly, I might add ) find the index of the first Fibonacci number with d digits, we need to test it in code to verify that it indeed works. Here is some such code:
#include <cmath> #include <iostream> using namespace std; inline double phi() { return ( 1.0 + sqrt( 5.0 ) ) / 2.0; } /** Calculates the approximate Fibonacci number at index n */ double fib( double n ) { return pow( phi(), n ) / sqrt( 5.0 ); } /** Calculates the exact integer Fibonacci number at index n */ int fibonacci( int n ) { return int( round( fib( (double)n ) ) ); } /** Determines the approximate Fibonacci index for a given number ( Fibonacci or not ) */ double fibIdx( double Fn ) { return ( log(Fn) + log( sqrt(5.0) ) ) / log( phi() ); } /** Determines the index of the next Fibnacci number to have d digits */ int magic( int d ) { return int( ceil( fibIdx( pow( 10.0, d-1.0 ) ) ) ); } int main(int argc, char *argv[]) { cout << "Determining indices (i) of first Fibonacci numbers (Fn) to have some number of digits (d)" << endl; cout << "=========================================================================================" << endl; cout << "d in [2:10)" << endl; cout << "-----------" << endl; int i, d; for( d=2; d<10; d++ ) { i = magic( d ); cout << " d=" << d << " i=" << i << " Fn(i)=" << fibonacci(i) << endl; cout << " Fn(i-1)=" << fibonacci( i-1 ) << " Fn(i+1)=" << fibonacci( i+1 ) << endl; } cout << "----------------------------" << endl; cout << "d in [10:100) by steps of 10" << endl; cout << "----------------------------" << endl; for( d=10; d<100; d+=10 ) { i = magic( d ); cout << " d=" << d << " i=" << i << " Fn(i)=" << fib(i) << endl; cout << " Fn(i-1)=" << fib( i-1 ) << " Fn(i+1)=" << fib( i+1 ) << endl; } cout << "------" << endl; cout << "d=1000" << endl; cout << "------" << endl; d = 1000; i = magic( 1000.0 ); if( i < 0 ) cout << "overflow occurred" << endl; else { cout << " d=" << d << " i=" << i << " Fn(i)=" << fib(i) << endl; cout << " Fn(i-1)=" << fib( i-1 ) << " Fn(i+1)=" << fib( i+1 ) << endl; } cout << "=========================================================================================" << endl; return 0; }
And the results:
Determining indices (i) of first Fibonacci numbers (Fn) to have some number of digits (d) ========================================================================================= d in [2:10) ----------- d=2 i=7 Fn(i)=13 Fn(i-1)=8 Fn(i+1)=21 d=3 i=12 Fn(i)=144 Fn(i-1)=89 Fn(i+1)=233 d=4 i=17 Fn(i)=1597 Fn(i-1)=987 Fn(i+1)=2584 d=5 i=21 Fn(i)=10946 Fn(i-1)=6765 Fn(i+1)=17711 d=6 i=26 Fn(i)=121393 Fn(i-1)=75025 Fn(i+1)=196418 d=7 i=31 Fn(i)=1346269 Fn(i-1)=832040 Fn(i+1)=2178309 d=8 i=36 Fn(i)=14930352 Fn(i-1)=9227465 Fn(i+1)=24157817 d=9 i=40 Fn(i)=102334155 Fn(i-1)=63245986 Fn(i+1)=165580141 ---------------------------- d in [10:100) by steps of 10 ---------------------------- d=10 i=45 Fn(i)=1.1349e+09 Fn(i-1)=7.01409e+08 Fn(i+1)=1.83631e+09 d=20 i=93 Fn(i)=1.22002e+19 Fn(i-1)=7.54011e+18 Fn(i+1)=1.97403e+19 d=30 i=141 Fn(i)=1.31151e+29 Fn(i-1)=8.10559e+28 Fn(i+1)=2.12207e+29 d=40 i=189 Fn(i)=1.40987e+39 Fn(i-1)=8.71347e+38 Fn(i+1)=2.28122e+39 d=50 i=237 Fn(i)=1.5156e+49 Fn(i-1)=9.36695e+48 Fn(i+1)=2.4523e+49 d=60 i=284 Fn(i)=1.00694e+59 Fn(i-1)=6.22325e+58 Fn(i+1)=1.62927e+59 d=70 i=332 Fn(i)=1.08246e+69 Fn(i-1)=6.68997e+68 Fn(i+1)=1.75146e+69 d=80 i=380 Fn(i)=1.16364e+79 Fn(i-1)=7.19168e+78 Fn(i+1)=1.88281e+79 d=90 i=428 Fn(i)=1.25091e+89 Fn(i-1)=7.73103e+88 Fn(i+1)=2.02401e+89 ------ d=1000 ------ overflow occurred =========================================================================================
We can see that for d = [2:10) , [10:100) the calculations were correct. It indeed found many indices for Fibonacci numbers with d digits. Sadly, the math overflowed when trying to calculate the numbers with d=1000.
Rather than trying to find a way to make this work in c++, I skipped over to python ( which sometimes has better numerical resolution ) and tried it. Fortunately, Python was able to calculate log_10( 10*999 ) while c++ was not.
from math import * phi = ( 1 + 5**.5 ) / 2 def fib( n ): return phi**n / 5**.5 def idx( Fn ): return ( log( Fn ) + log( 5**.5 ) ) / log( phi ) def magic( d ): return int( ceil( idx( 10**(d-1) ) ) ) i=magic( 1000 ) print i
And, python reported that the index was 4782, though the fibonacci number for this index couldn't be calculated using Binet's formula due to an overflow:
d=1000, i(d)=4782 Traceback (most recent call last): File "tester.py", line 16, in <module> print "Fn(%i)=%d" %( i, fib(i) ) File "tester.py", line 6, in fib return phi**n / 5**.5 OverflowError: (34, 'Numerical result out of range')
So, there it is. The maths for this solution are not particularly complicated, nor is the logic, nor is the code. However, I think that the results are quite pleasing aesthetically and mathematically. | https://www.daniweb.com/programming/software-development/threads/272273/firstperson-s-latest-signature-problem-or-project-euler-problem-25 | CC-MAIN-2018-17 | refinedweb | 1,482 | 66.27 |
.
This blog is also slightly different from my normal format as I will not call out individual developers by name as I usually do, instead I will focus on this being a totality and thus just say ‘we’.
- Wayland – We been the biggest contributor since we joined the effort and have taken the lead on putting in place all the pieces needed for actually using it on a desktop, including starting to ship it as our primary offering in Fedora Workstation 25. This includes putting a lot of effort into ensuring that XWayland works smoothly to ensure full legacy application support.
- Libinput – A new library we created for handling all input under both X and Wayland. This came about due to needing input handling that was not tied to X due to Wayland, but it has even improved input handling for X itself. Libinput is being rapidly developed and improved, with 1.9 coming out just a few days ago.
- glvnd – Dealing with multiple OpenGL implementations have been a pain under Linux for years. We worked with NVidia on this effort to ensure that you can install multiple OpenGL implementations on the system and have your system be able to use the correct one depending on which GPU and driver you are using. We keep expanding on this solution to cover more usecases, so for Fedora Workstation 27 we expect to bring glvnd support to XWayland for instance.
- Porting Firefox to GTK3 – We ported Firefox to GTK3, including making sure it works under Wayland. This work also provided the foundation for HiDPI support in Firefox. We are the single biggest contributor to Firefox Linux support.
- Porting LibreOffice to GTK3 – We ported LibreOffice to GTK3, which included Wayland support, touch support and HiDPI support. Our team is one of the major contributors to LibreOffice and help the project forward on a lot of fronts.
- Google Drive integration – We extended the general Google integration in GNOME 3 to include support for Google Drive as we found that a lot of our users where relying on Google Apps at their work.
- Flatpak – We created Flatpak to lead the way in moving desktop applications into their own namespaces and containers, resolving a lot of long term challenges for desktop applications on Linux. We expect to have new infrastructure in place in Fedora soon to allow Fedora packagers to quickly and easily turn their applications into Flatpaks.
- Linux Firmware Service – We created the Linux Firmware service to provide a way for Linux users to get easy access to UEFI firmware on their linux system and worked with great vendors such as Dell and Logitech to get them to support it for their devices. Many bugs experienced by Linux users over the years could have been resolved by firmware updates, but with tooling being spotty many Linux users where not even aware that there was fixes available.
- GNOME Software – We created GNOME Software to give us a proper Software Store on Fedora and extended it over time to include features such as fonts, GStreamer plugins, GNOME Shell extensions and UEFI firmware updates. Today it is the main Store type application used not just by us, but our work has been adopted by other major distributions too.
- mp3, ac3 and aac support – We have spent a lot of time to be able to bring support for some of the major audio codecs to Fedora like MP3, AC3 and AAC. In the age of streaming supporting codecs is maybe of less importance than it used to be, but there is still a lot of media on peoples computers they need and want access to.
- Fedora Media Creator – Cross platform media creator making it very easy to create Fedora Workstation install media regardless of if you are on Windows, Mac or Linux. As we move away from optical media offering ISO downloads started feeling more and more outdated, with the media creator we have given a uniform user experience to quickly create your USB install media, especially important for new users coming in from Windows and Mac environments.
- Captive portal – We added support for captive portals in Network Manager and GNOME 3, ensuring easy access to the internet over public wifi networks. This feature has been with us for a few years now, but it is still a much appreciated addition.
- HiDPI support – We worked to add support for HiDPI across X, Wayland, GTK3 and GNOME3. We lead the way on HiDPI support under Linux and keep working on various applications to this date to polish up the support.
- Touch support – We worked to add support for touchscreens across X, Wayland, GTK3 and GNOME3. We spent significant resources enabling this, both on laptop touchscreens, but also to support modern wacom devices.
- QGNOME Platform – We created the QGNOME Platform to ensure that Qt applications work well under GNOME3 and gives a nice native and integrated feel. So while we ship GNOME as our desktop offering we want Qt applications to work well and feel native. This is an ongoing effort, but for many important applications it already is a great improvement.
- Nautilus improvements. Nautilus had been undermaintained for quite a while so we had Carlos Soriano spend significant time on reworking major parts of it and adding new features like renaming multiple files at ones, updating the views and in general bring it up to date.
- Night light support in GNOME – We added support for automatic adjusting the color and light settings on your system based on light sensors found in modern laptops. This integrated functionality that you before had to install extra software like Red Shift to enable.
- libratbag – We created a library that enable easy configuration of high end mice and other kind of input devices. This has led to increased collaboration with a lot of gaming mice manufacturers to ensure full support for their devices under Linux.
- RADV – We created a full open source Vulkan implementation for ADM GPUs which recently got certified as Vulkan compliant. We wanted to give open source Vulkan a boost, so we created the RADV project, which now has an active community around it and is being tested with major games.
- GNOME Shell performance improvements – We been working on various performance improvements to GNOME Shell over the last few years, with significant improvements having happened. We want to push the envelope on this further though and are planning a major performance hackfest around Shell performance and resource usage early next year.
- GNOME terminal developer improvements – We worked to improve the features of GNOME Terminal to make it an even better tool for developers with items such as easier naming of terminals and notifications for long running jobs.
- GNOME Builder – Improving the developer story is crucial for us and we been doing a lot of work to make GNOME Builder a great tool for developer to use to both improve the desktop itself, but also development in general.
- Pipewire – We created a new media server to unify audio, pro-audio and video. First version which we are shipping in Fedora 27 to handle our video capture.
- Fleet Commander – We launched Fleet Commander our new tool for managing large Linux desktop deployments. This answer a long standing call from many of Red Hats major desktop customers and many admins of large scale linux deployments at Universities and similar for a powerful yet easy to use administration tool for large desktop deployments.
I am sure I missed something, but this is at least a decent list of Fedora Workstation highlights for the last few years. Next onto working on my Fedora Workstation 27 blogpost :) | https://blogs.gnome.org/uraeus/2017/10/ | CC-MAIN-2018-34 | refinedweb | 1,269 | 55.17 |
#include <sys/time.h>
int utimes(const char *file, struct timeval *tvp);
If tvp is NULL, the access and modification times are set to the current time. A process must be the owner of the file or have write permission for the file to use utimes in this manner.
If tvp is not NULL, it is assumed to point to an array of two timeval structures. The access time is set to the value of the first member, and the modification time is set to the value of the second member. Only the owner of the file or the privileged user may use utimes in this manner.
In either case, the ``inode-changed'' time of the file is set to the current time.
X/Open Portability Guide Issue 4, Version 2 (Spec-1170). | http://osr507doc.xinuos.com/cgi-bin/man?mansearchword=utimes&mansection=S&lang=en | CC-MAIN-2020-50 | refinedweb | 133 | 78.48 |
VTKDataIO.jl presents a number of input, output and visualization functionalities for geometric meshes with point and cell scalar and vector data. This module attempts to bridge between VTKDataTypes.jl, Julia's native module for representing VTK data types and the Visualization Toolkit (VTK) hence giving access to many of VTK's capabilities to Julia users. VTKDataIO.jl only supports Julia v0.6.
You can use VTKDataIO.jl to read/write any of the following file formats into/from the corresponding type in VTKDataTypes.jl: vtk, vtu, vtp, vts, vtr, vti, vtm, pvd, stl, ply. You can do this using
read_vtk,
write_vtk,
read_stl,
write_stl,
read_ply, and
write_ply.
You can use VTKDataIO.jl to visualize a scalar or vector field with a 3D heat map and a legend. This includes point-based coloring or cell based coloring, as well as other features such as wireframe and glyph representations. The resulting visualization can be written to ply or x3d formats. You can do this using
visualize,
write_x3d, and
write_ply.
visualize_3ds can also be used to visualize 3ds files directly.
You can use
PyVTK to change a Julia native VTK object to a VTK data PyObject that can be used in your own VTK pipeline through PyCall. You can also use
_VTKDataTypes to change a VTK data PyObject back to Julia's native VTK types.
The following are the setup steps in Windows. If you are using other OS and you can't set it up, please let me know and I will try to help if I can. Basically if you can reach step 7, you are ready to use VTKDataIO.jl even if you didn't eactly follow the previous steps!
import vtkthat it works.
html ENV["PYTHON"] = "C:\Python27\python.exe" Pkg.build("PyCall")
html using PyCall @pyimport vtk as vtk @pyimport numpy as np
If you run the following code, you should be able to get a cubic mesh with randomly coloured cells.
using VTKDataTypes using VTKDataIO x = y = z = [-2, -1, 0, 1, 2]; rect = VTKRectilinearData([x,y,z]); rect.cell_data["Cell scalar"] = reshape([rand() for i in 1:num_of_cells(rect)], cell_extents(rect)); visualize(rect, color="Cell scalar")
You can also do point-based coloring as so:
rect.point_data["Point scalar"] = reshape([rand() for i in 1:num_of_points(rect)], extents(rect)); visualize(rect, color="Point scalar")
Point based vector data can be represented by arrows using the
representation option.
rect.point_data["Point vector"] = reshape([2*rand()-1 for i in 1:3*num_of_points(rect)], (3, extents(rect)...)); visualize(rect, color="Point vector", representation=:glyph, scale_factor=0.5)
Wireframe representation can be used as follows:
visualize(rect, color="Point scalar", representation=:wireframe)
If you have the RGB colors data directly, you can inform the
visualize function to use it using the
RGB = true option as so:
rect.point_data["RGB colors"] = reshape([round(255*rand()) for i in 1:3*num_of_points(rect)], (3, extents(rect)...)); visualize(rect, color="RGB colors", RGB=true)
07/06/2017
7 months ago
16 commits | https://juliaobserver.com/packages/VTKDataIO | CC-MAIN-2021-17 | refinedweb | 500 | 57.47 |
01 June 2011 09:47 [Source: ICIS news]
SINGAPORE (ICIS)--China and southeast (southeast) Asia’s film-grade linear low density polyethylene (LLDPE) and low density PE (LDPE) prices have fallen by 5-6.6% from a month ago, as persistently weak import demand forced some suppliers to reduce their offer prices, industry sources said on Wednesday.
Discussions on the benchmark LLDPE averaged at around $1,295/tonne (€893.55/tonne) CFR (cost & freight) China and $1,330/tonne CFR SE Asia for June arrival, according to market sources.
Film-grade LDPE was discussed at around $1,560-1,600/tonne CFR China and $1,615-1,680/tonne CFR SE Asia this week for June shipment, according to market sources.
These price levels are $80-95/tonne or 5-6.6% lower compared with the previous month, according to ICIS.
The average weekly prices of LLDPE were assessed at $1,375/tonne CFR China and $1,425/tonne CFR SE Asia for the week ended 29 April, according to ICIS.
The average weekly prices of LDPE were at $1,665/tonne CFR China and $1,750/tonne CFR SE Asia for the week ended 29 April, according to ICIS.
?xml:namespace>
Many importers in SE Asia are deferring their purchases as they believe the weak demand from the key
($1 = €0 | http://www.icis.com/Articles/2011/06/01/9464985/china-southeast-asia-ldpe-lldpe-prices-fall-on-weak-demand.html | CC-MAIN-2015-14 | refinedweb | 222 | 60.85 |
. Anyway, I might add mine: the nature of modules as executed code is a compromise. That is, a module isn't a declaration, it's a program to be executed in its own namespace. When you import a module, you are executing the module then looking at the namespace.. Not that I don't like the fun tricks Python lets you do. Prototype-like programming (as in Self) is very accessible in Python, and classes are only a suggestion not a dominant concept. So, it's a compromise. There are lots and lots of compromises in Python -- every aspect has pluses and minuses to it. Personally I like whitespace sensitivity well enough, but in the larger sense I think it probably was the wrong choice -- but that's based on how I weigh various benefits and problems, and other people will validly weigh them differently. Ian | https://mail.python.org/pipermail/python-list/2003-July/206128.html | CC-MAIN-2018-05 | refinedweb | 146 | 62.17 |
Lint is a signed large integer data type class library that supports all mathematical operators available to other intrinsic integer data types. The precision is not arbitrary as in other available libraries. Rather, the number of bits that make up a lint variable is dependent on the value of a #define directive declared in the header file.
lint
#define
So why yet another large integer library? Several reasons, among which:
int
long
Once you include the header file in your source, using a lint is similar to using any other numeric data type in C++. The few notable exceptions are in declaration, assignment, and output.
#include "lint.h"
#include <stdio.h>
int main() {
lint a = 1234; // value assignment of a literal
lint b = -5678; // a lint is a signed integer data type
lint c = a; // assignment to another lint value
lint d = "457639857304951675093650987359087"; // use a string for those
// really BIG numbers
lint e = "-563857365015613047563"; // this works for negative values too
lint x, y, z;
x = d*e+a*b; // math shouldn't be a problem.
y = x/(e*e);
// assignment to zero is the only ambiguous operation
// that you need to be specific on.
z = (signed long)0;
// the class allocates its own buffer to print a
// character representation of its value.
// By default, it prints in base 10
printf( "y base 10 = %s\n", z.value() );
// You can print in another radix though - anything from 2 to 36
printf( "y base 16 = %s\n", z.value(16) );
printf( "y base 2 = %s\n", z.value(2) );
// Internally, the memory for a lint is laid out going from
// MSB to LSB in an array of 32-bit DWORDs.
// [2047th bit ... 1024th bit ... 0th bit]
// If you need more or less than 2048 bit numbers, open lint.h
// and redefine LINT_LENGTH
// Lastly, the function call operator allows direct referential
// access to the DWORDs that comprise
// a lint value.
y(0) = 0x12345678; // This sets the Most Significant
// DWORD to 0x12345678
long my_bit_field = y(LAST_DWORD); // LAST_DWORD is a constant defined
// in the header file
return 0;
}
Implementing the conditional testing was a real bugger. My implementation works, but I think there must be a better way to do it. There are additional things I'd like to do to the library as well.
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
General News Suggestion Question Bug Answer Joke Rant Admin
Man throws away trove of Bitcoin worth $7.5 million | http://www.codeproject.com/Articles/12428/LINT-Large-Integer-Object-Library | CC-MAIN-2013-48 | refinedweb | 418 | 59.84 |
You can discuss this topic with others at
Read reviews and buy a Java Certification book at
Descibe the significance of the immutability of String objects
The theory of the immutability of the String class says that once created, a
string can never be changed. Real life experience with Java programming implies
that this is not true.
Take the following code
public class ImString{ public static void main(String argv[]){ String s1 = new String("Hello"); String s2 = new String("There"); System.out.println(s1); s1=s2; System.out.println(s1); } }
If Strings cannot be changed then s1 should still print out Hello,
but if you try this snippet you will find that the second output is the string
"There". What gives?
The immutability really refers to what the String reference points to. When s2 is assigned to s1 in the example, the String containing "Hello" in the String pool is no longer referenced and s1 now points to the same string as s2. The fact that the "Hello" string has not actually been modified is fairly theorectical as you can no longer "get at it".
The objective asks you to recognise the implications of the immutability of strings, and the main one seems to be that if you want to chop and change the contents of "strings" the StringBuffer class comes with more built in methods for the purpose.
Because concatenating string causes a new string to be instantiated "behind the scenes", there can be a performance overhead if you are manipulating large numbers of strings, such as reading in a large text file. Generally String immutability doesn't affect every day programming, but it will be questioned on the exam. Remember whatever round about way the question asks it, once created a String itself cannot be changed even if the reference to it is changed to point to some other String. This topic is linked to the way Strings are created in a "String pool", allowing identical strings to be re-used. This is covered in topic 5.2 as part of how the=operator and equals method acts when used with strings. Although neither the Java2 nor Java 1.1 objectives specifically mention it I am fairly confident that some questions require a knowledge of the StringBuffer class.
You have created two strings containing names. Thus
String fname="John";
String lname="String"
How can you go about changing these strings to take new values within the same block of code?
1)
fname="Fred";
lname="Jones";
2)
String fname=new String("Fred");
String lname=new String("Jones");
3)
StringBuffer fname=new StringBuffer(fname);
StringBuffer lname=new StringBuffer(lname);
4) None of the above
You are creating a program to read in an 8MB text file. Each new line read
adds to a String object but you are finding the performance sadly lacking.
Which is the most likely explanation?
1) Java I/O is designed around a lowest common denominator and is inherently slow
2) The String class is unsuitable for I/O operations, a character array would be more suitable
3) Because strings are immutable a new String is created with each read, changing to a StringBuffer may increase performance
4) None of the above
4) None of the above
Once created a String is read only and cannot be changed Each one of the options actually creates a new string "behind the scenes" and does not change the original. If that seems to go against your experience and understanding read through information on the immuatbility of strings
3) Because strings are immutable a new String is created with each read, changing
to a StringBuffer may increase performance
I hope none of you C programmers suggested a character array?
This topic is covered in the Sun Tutorial at
(doesn't go into much detail)
Jyothi Krishnan on this topic at
Last updated
16 Sep 2000
most recent version at | http://www.jchq.net/tutorial/09_02Tut.htm | crawl-002 | refinedweb | 650 | 54.76 |
15 December 2009 14:51 [Source: ICIS news]
WASHINGTON (ICIS news)--US wholesale prices for organic chemicals jumped by 4.3% in November, the Labor Department said on Tuesday, part of an overall 1.8% increase in producer prices that included sharp advances in fuel costs.
However, the prices paid for plastic resins and materials at the producer level - also known as wholesale prices - were not part of the general increase, falling by 0.5% in November.
Overall, the department said that its closely watched producer price index (PPI) for November shot up by 1.8%, following a much narrower gain of 0.3% in October.
The sharp gain in the November PPI might rattle Wall Street and investors who worry that the advance could give the ?xml:namespace>
The Fed’s rate-setting committee begins a two-day meeting on Tuesday and will announce its interest rate decision on Wednesday.
But the Labor Department noted that nearly all of the sharp gain in November’s wholesale prices for finished goods was due to significant increases in fuels prices.
“About three-fourths of the November advance in the finished goods index can be traced to higher prices for energy goods, which jumped 6.9%,” the department’s Bureau of Labor Statistics said in its monthly pricing report.
In addition, within the general fuels category, wholesale prices for gasoline were a major contributor, climbing by 14.2% during November. Increased winter-related demand for home heating oil also was a major factor in the fuels prices advance, the bureau said.
Economists typicall focus on the so-called core prices, those paid at the wholesale level for finished goods other than fuels and food because those two categories often see wide swings in month-to-month pricing that can skew the overall producer price index.
The department said that wholesale prices for finished goods other than fuels and food rose by a more modest 0.5% in November.
However, that gain is noteworthy because it is the largest increase in the core producer prices since October 2008.
In organic chemicals, the 4.3% gain in wholesale prices in November followed a 2.4% decline in October and a 4.9% jump in September.
The 0.5% decline in producer prices for plastic resins and materials during November followed a 1.7% fall in October and a 2.1% advance in September.
($1 = €0 | http://www.icis.com/Articles/2009/12/15/9319478/us-wholesale-prices-for-chemicals-rise-4.3-in-nov.html | CC-MAIN-2014-52 | refinedweb | 401 | 57.37 |
This is a wrapper class to use the visual style APIs available in Windows XP. Visual style makes it possible to change the look and feel of all the "supported" applications. It is very easy to add support for visual styles in an application. Check on MSDN for more information.
However, if you plan to use any OWNERDRAW controls, you won't get the new look automatically. Windows is just not smart enough to know how your control should look. You have to make calls directly to the new UxTheme APIs.
It is quite simple to use the API, and in most cases you just need a few of them. The sample below draws a checked button in TOOLBAR style.
HTHEME hTheme = OpenThemeData(GetSafeHwnd(), L"TOOLBAR"); DrawThemeBackground(hTheme, pDC->GetSafeHdc(),TP_BUTTON, TS_CHECKED, &rc, 0); CloseThemeData(hTheme);
Problems arise when you running the application under an earlier version of Windows, since calling these APIs directly makes your application dependent on the new DLLs which are not redistributable. The class provided in this article tries to solve this problem by wrapping the APIs and doing run-time linking. It is just a lot of copy-n-paste work, no fun at all. :)
Microsoft has actually done a thin wrapper in MFC 7.0 (winctrl3.cpp), but it only wraps a few of the APIs and they are mostly for MFC's internal usage. This class is based on the MFC implemenation and wraps the full set of visual style APIs from the Micrsoft Platform SDK August 2001. In order to compile this class in VC++ 6.0, you will need to have the latest Platform SDK, or at least one with the new XP headers. Under VC++ 7.0, no additional headers are required.
It is very simple to use this class. You need first to include the header, preferably in stdafx.h and add the CPP file to the project.
#include "VisualStylesXP.h"
You can then either create a local
CVisualStylesXP member and call the functions, or use the built-in global variable
g_xpStyle.
HTHEME hTheme = g_xpStyle.OpenThemeData(GetSafeHwnd(), L"TOOLBAR"); g_xpStyle.DrawThemeBackground(hTheme, pDC->GetSafeHdc(), TP_BUTTON, TS_CHECKED, &rc, 0); g_xpStyle.CloseThemeData(hTheme);
To make your application work under all windows versions, you should do something like this:
#ifdef _VISUALSTYLE_XP_H_ if (g_xpStyle.IsAppThemed()) { HTHEME hTheme = g_xpStyle.OpenThemeData(GetSafeHwnd(), L"TOOLBAR"); g_xpStyle.DrawThemeBackground(hTheme, pDC->GetSafeHdc(), TP_BUTTON, TS_CHECKED, &rc, 0); g_xpStyle.CloseThemeData(hTheme); } else { #endif pDC->DrawEdge(....); #ifdef _VISUALSTYLE_XP_H_ } #endif
The demonstration application is a port from the ThemeExplorer application from MSDN.
That's all. Happy coding!
General
News
Question
Answer
Joke
Rant
Admin | http://www.codeproject.com/KB/winsdk/xpvisualstyle.aspx | crawl-002 | refinedweb | 432 | 59.3 |
Sum of squares of two largest of three values
March 16, 2012
Today’s exercise comes to us from the book Structure and Interpretation of Computer Programs by Abelson and Sussman (exercise 1.3):
Define a procedure that takes three numbers as arguments and returns the sum of the squares of the two larger numbers.
Your task is to write the indicated function. When you are finished, you are welcome to read or run a suggested solution, or to post your own solution or discuss the exercise in the comments below.
Knuth says the median of x, y, z is “probably the most important ternary operation in the entire universe” (TAoCP volume 4 fascicle 0) so I take this opportunity to give it some visibility. Spread the word.
Note that at the point where the exercise appears in SICP, the functions min and max haven’t mean introduced.
In the context of SICP it must therefore me considered cheating to use min and max !
That said, the simplest expression to use is
x^2 + y^2 + z^2 – min(x,y,z)^2
(define (wev2 x y z) (+ (expt x 2) (expt y 2) (expt z 2) (- (expt (min x y z) 2)))
N.B. (x > z z and z < y)
It doesn’t do any parameter checking, but it should always return the sum of the two largest squares.
(defun med (x y z) (max (min x y) (min x z) (min y z)))
(defun sum-squares-of-max-2 (x y z)
(apply #’+ (mapcar #’square (list (max x y z) (med x y z)))))
Yet another “”sort first” approach.
Is there a smart solution with no branching whatsoever? The one with subtracting the smallest square comes close, but min() uses branching internally.
def sumSquares(num1, num2, num3):
numList = [num1,num2,num3]
chosen1 = max(numList)
numList.remove(chosen1)
chosen2 = max(numList)
return chosen1**2 + chosen2**2
Oh, I’ve just realized that you *can* write min() without branching! I hope I didn’t make any mistake here:
[...] solution, posted in comments, to the following problem needs some explanation. First of all, the task is to take three numbers as arguments and return the [...]
Tomasz, I highly doubt its possible to avoid branching altogether, especially if your input is real numbers (not just integers). However, I took your approach and considered an integer-only solution:
The return statement could probably use some explanation. To avoid computing the square of all terms and subtracting off the minimum squared, only the two greater values are squared and summed.
This should help protect against overflow, and it should slightly increase performance.
The logic is all tied into a boolean expression that will always return 1. It’s important to note how the values of j and k are initialized at the beginning of the function.
The “(x = y)|1″ expression is used to handle the case where y = 0. We still want the assignment to evaluate as true, so the bitwise “OR 1″ is appended to the expression.
Using proper control structures, the return statement’s logic could be rewritten as follows:
I’m not entirely convinced the compiler will not break up this mess and generate branching code. Maybe someone more familiar with this sort of thing has some insight?
And just for fun, here’s a golf’d version of basically the same algorithm. the assignment ordering is a little different since we don’t have the wide variable placeholders j and k. it’s also not quite as safe since the types are all implicitly declared “int”, so you can easily overflow.
However, it is valid C code (built using cygwin, gcc 4.3.4), and it works correctly assuming the absolute value of each input is less than sqrt(2^31-1)/2.
Branch-free algorithm for computing sum of squares of two largest of three values (with non-golf’d test code):
As long as your (ab)using short circut behavior of logical expressions, you might as well go all the way and (ab)use the fact that logical expressions have integer values (1 for true, 0 for false) and integers have logical values (false for 0, true for non-zero):
I believe the equivalent C code would be:
f(x,y,x){return(x>=y&z>=y)*(x*x+z*z)||(x>=z)*(x*x+y*y)|| y*y+z*z}
[/sourcecodde]
Here is a short java method to achieve the same –
public static int sumOfSquares(int a, int b, int c)
{
int min = (a<b)?((a<c)?a:(c<b)?c:c):((b<c)?b:c);
//System.out.println("min : "+min);
return (int) (Math.pow(a, 2)+Math.pow(b, 2)+Math.pow(c, 2)-Math.pow(min, 2));
}
Wow I feel like a doofus, Mike. Your approach is so much more clean and simple!
By the way, I do use the integer value of C’s logical expressions in the arithmetic of the return statement, I just force the expression to always evaluate to true.
PHP CLI :
C:
In Forth you can do this without variables.
: sqr ( u — du ) DUP * ;
: sum-of-squares ( n1 n2 n3 — ) 2DUP > IF SWAP ENDIF sqr -ROT MAX sqr + . ;
Simple implementation in java. – Amandeep Dhanjal
public static int calculateSum(int a, int b, int c){
int sum = 0;
if(a < b && a < c){
System.out.println("Nums: "+b+" : "+c);
sum = b*b + c*c;
}else if(b < c && b < a){
System.out.println("Nums: "+a+" : "+c);
sum = a*a + c*c;
}else{
System.out.println("Nums: "+a+" : "+b);
sum = a*a + b*b;
}
return sum;
}
In java,
public int squareOfLargestTwo(int i, int j, int k){
int sum = 0;
sum = sum + (i>j?i*i:j*j) + (j>k?j*j:k*k);
return sum;
}
Dinesh Damaraju, that solution will not work for all input i, j, and k.
When j is the largest value, your function will return j * j + j * j.
Short-circuit boolean computations *are* branching: (or (a) (b)) is compiled exactly the same as (let ((r (a))) (if r r (b)))). If it’s possible to do away with the branching (which I suspect it is), you’d probably have to use a bunch of bitwise operations combined with shifts and multiplications: the result will probably have lots of operations, though, and of course to avoid branching in a loop, you’ll probably have to unroll one. Take with a grain of salt: I’m no assembly programmer.
Some CPUs support conditional execution of instructions based on CPU status
flags. See for some more info.
Here is an example branchless implementation in ARM assembly language.
(All values–input, intermiediate, and output–must fit in a 32-bit register)
The comments show an “equivalent” python statement of the ARM instruction.
My solution written in Go lang: (I took the approach used by rainer March 16, 2012 at 9:35 AM).
ruby solution ()
typedef double num; /* or int, or whatever */
num ssq(num a, num b, num c) {
return((a>=b ? a*a + (likely(c>=b)?c*c:b*b)
: b*b + (likely(c>=a)?c*c:a*a))
} | http://programmingpraxis.com/2012/03/16/sum-of-squares-of-two-largest-of-three-values/?like=1&source=post_flair&_wpnonce=8ac41143de | CC-MAIN-2014-15 | refinedweb | 1,191 | 61.46 |
Apr 16, 2012 02:56 PM|Vecthor|LINK
I have a .aspx page in the following path:
Areas/Management/Views/Ticket/Report.aspx
I want to route that to the following path in my browser:
How can i do that?
I try this:
routes.MapRoute(
"Tickets", // Route name
"Areas/Management/Views/Ticket/Report.aspx", // Original URL
new { controller = "Reports", action = "Tickets" } // New URL
);
But i got the
404error.
What i'm doing wrong?
Obs: I put that before the
Defaultroute.
Webforms mvc Routing
All-Star
33204 Points
ASPInsiders
MVP
Apr 16, 2012 03:19 PM|BrockAllen|LINK
I think you need to read over the MVC tutorials.
Webforms mvc Routing
Apr 16, 2012 04:03 PM|CodeHobo|LINK
Is report.aspx an mvc view or a webforms page? (the reason I ask is because the file is report.aspx and many report pages end up being webforms pages).
For an mvc view that route is incorrect, the second paramter should be what you expect to see on the screen. ie should be "/Reports/Tickets".
In your global asax, you can put this route. Assuming a controller called Ticket, and an action method named Report in the Management area.
routes.MapRoute( "Tickets", // Route name "Reports/Tickets", // URL with parameters new { controller = "Ticket", action = "Report", area = "Management" ,id = UrlParameter.Optional } // Parameter defaults );
Webforms mvc Routing
Apr 16, 2012 04:41 PM|CodeHobo|LINK
You cannot use the routing engine to route to a webforms page in an mvc page application. Also you can't have a webforms page in the Views folder, that is because views has it's own web.config with special settings for mvc.
Create a folder on the root of your webapplication called "webforms" and just put all webforms pages in there, then just link to them manually "/webforms/report.aspx" instead of going through the routing engine.
Apr 16, 2012 04:51 PM|Vecthor|LINK
The problem is that. I don't want to use the .aspx at the end.
I try it:
Do you know why i got this problem?
Apr 16, 2012 05:16 PM|CodeHobo|LINK
Vecthor
The problem is that. I don't want to use the .aspx at the end.
I try it:
Do you know why i got this problem?
Yes, your outgoing routes are now generating in correctly. You have to be very careful when mixing mvc with webforms. You need to add the following class to your project:
public class MyCustomConstaint : IRouteConstraint{ public bool Match(HttpContextBase httpContext, Route route, string parameterName, RouteValueDictionary values, RouteDirection routeDirection){ return routeDirection == RouteDirection.IncomingRequest; } }
Then in your global.asax, change your route to the following:
routes.MapPageRoute("Tickets", "Reports/Tickets", "~/WebForms/Reports/Tickets.aspx", true, null, new RouteValueDictionary { { "outgoing", new MyCustomConstaint() } });
6 replies
Last post Apr 16, 2012 05:16 PM by CodeHobo | http://forums.asp.net/t/1793416.aspx | CC-MAIN-2014-15 | refinedweb | 469 | 60.41 |
I still think that naming decision was a bad idea. It caused no end of confusion. Many nonprogrammers never figured out that Java and JavaScript were two different things.
In an earlier post, I had mentioned how the Rhino scripting engine and externalized business rules in Javascript saved us the day in one of our client engagements. That experience had me thinking about the virtues of polyglot programming, usefulness of embeddable scripting engine in Java 6 and the essence of the JVM as the next ubiquitous computing platform. However, it took me some more time and a couple of more blog readings to realize the power and elegance of Javascript as a language. Indeed all the capabilities of Javascript within the browser are add-ons to the simple virtues that the language imbibes.
In gensym.org, David mentions about the following Scheme implementation of a snippet that picks up the maximum salary of a programmer amongst a collection of employees having various roles:
(define (salary-of-highest-paid-programmer records)
(accumulate
max 0
(map salary
(filter programmer? records))))
He observed that the normal Java implementation will be much more verbose compared to the Scheme one. I tried out a Javascript implementation for the same problem ..
maxProgrammerSalary = function() {
return {
maxSalaryFun : function(emps) {
return reduce(
Math.max,
0,
map(pluck('salary'),
filter(
callMethod('isProgrammer'),
emps)))
}
};
}();
The code looks wonderfully similar to the Scheme implementation in structure using the functional paradigms. I really feel bad now that I have chosen to ignore this language so long. Like Glenn Vanderburg, this is my personal story of coming full circle with Javascript.
Of course the above implementation uses a couple of functions, which we have to define today or get it from libraries like prototype. With Javascript 1.6 Array extras and the new features in progress for Javascript 1.8, almost all of them will be part of the core language.
Javascript as a language
Being a prototypal language like Self, Javascript's tryst with OO principles are very much different from the classical strongly typed model of Java or C++. Prototype based inheritance was made hugely popular by frameworks like prototype and enthused many UI folks to the world of practicing OO programming.
A language does not necessarily have to preach OO in order to be beautiful - Javascript supports encapsulation and separation of concerns in its very own way, as has been amply demonstrated by the Module pattern all across YUI. I can have my properties declared at the appropriate level of abstraction without polluting the global namespace. In case of the above function for computing the salary of employees, if we were to fetch the employee collection from some data source and need to define some helpers for the computation, we can have a nicely defined module that encapsulates the whole computation model in a separate namespace:
maxProgrammerSalary = function() {
// this is not exposed to the global namespace
var getEmployees = function() {
// get the employee list
}
return {
maxSalaryFun : function() {
return reduce(
Math.max,
0,
map(pluck('salary'),
filter(
callMethod('isProgrammer'),
getEmployees())))
}
};
}();
A Growing language
One of the definite indications of the growing popularity of a language is the growth rate and increasing rate of adoption. While I do not have any concrete figures on the latter, there have definitely been lots of buzz in the blogosphere about the increasing importance of Javascript as a language. We have started seeing frameworks like jQuery, with its own programming patterns and DSL based approach. jQuery custom selectors, along with chaining gives you the programming power of using FluentInterfaces - here is an example from recently published Jesse Skinner's article ..
$(?');
});
This snippet is a succinct one-liner that selects the login form, finds some stuff, repeatedly going back to the form after each find, makes some changes to them and finally adds a submit event handler to the form. All the complexities of query optimization and DOM scripting are taken care of by the jQuery engine. When we see lots of programming idioms being discussed actively amongst the experts, it is the sign of a growing programming language. In my short stint towards loving Javascript, I discovered great idioms for lazy function definition, memoization, currying and other functional programming patterns being discussed vigorously in the community. In an earlier post, I had also discussed about the plethora of developments going on in this space.
Thoughtleaders of the programming language community think that Javascript 2 is one of the contenders for NBL. It has lots of features which will delight you as a programmer. It is succinct, it is functional with full support of closures, it is prototypal and it is dynamic. You can add methods to classes even after instantiation. It's a different paradigm altogether from the noun-land of Java. And it's also the most natural glue to the browser. Learn to love it now or ignore it at your own risk.
6 comments:
Nice post. Can you point me to some books, tutorial where I could get into advanced Javascript? Thanks.
javascript is great. A lot of people dont like it(mainly for the old bad browsers implementations) but now we've got rhino, which simply rocks.
I'm very happy, some quality libs (prototype, jquery, jmaki) are getting a lot of sucess. As javascript book i'd suggest professional javascript for web developer (wrox), which is very complete and explains a lot of advanced js features.
Peter Bona, if you already know programming then Douglas Crockford's seminars are an excellent way to get started.
Thanks for the tips.
Java = cause the syntax is built the same
Script = Cause it's runtime and not compiled
Nice and knowledgeable sites for everyone-
booksshelf
knowledge
books
liberary
kitaben
Books and references
books
tutorial books | http://debasishg.blogspot.com/2007/08/why-do-they-call-it-javascript-its-not.html | CC-MAIN-2018-13 | refinedweb | 959 | 51.78 |
Hello, I have a page that every visitor can display and select a date for my service. After the date selection I have a ''go to the payment'' submit button that redirects users to payment page. However I want to make them members of the website before displaying payment page therefore payment page is members only page. After clicking ''go to the payment'' button, how can I redirect them to login/sign up page if they are not logged in ?
Hi Uğur,
You can try the following code your on the onclick event:
let user = wixUsers.currentUser; let userId = user.id; if (wixUsers.currentUser.loggedIn) {
then code to go to payment page
}
else
wixUsers.promptLogin()
}
Hi Camille,
Thank you so much for the answer
What is the code to go to payment page?
Glad I could help...If you were using the submit option from the dataset, then you will need to remove that and add code to navigate to the page.
You will need to substitute ("/PAGEURL") with your actual payment page's url in the code below
Your code would look like this:
let user = wixUsers.currentUser;
let userId = user.id;
if (wixUsers.currentUser.loggedIn) {
wixLocation.to("/PAGEURL");
}
else
wixUsers.promptLogin()
}
It says wixusers and wix location is not defined ?
My bad - At the very top of the code page, add the following:
import wixUsers from 'wix-users'; import wixLocation from 'wix-location';
Oh it works very well, thank you so much :) | https://www.wix.com/corvid/forum/community-discussion/hello-if-the-user-is-not-logged-in-i-want-to-redirect-him-her-to-login-page | CC-MAIN-2020-05 | refinedweb | 244 | 74.79 |
Hi Tech Council Excellence Awards - Jim Anderton
Hon Jim Anderton
25 October 2000 Speech Notes
Embargoed
until: 8.40 PM Saturday 28 October 2000
To be checked against delivery
Address to Hi Tech Council Excellence Awards Dinner
I would like to thank the Hi Tech Council for inviting me to attend this Excellence Awards Dinner tonight to celebrate the achievement and innovation of Kiwi business.
As the Minister for Economic Development and a proud New Zealander I am vitally interested in our successes and new ideas, so I am pleased to be here.
Tonight we will see a range of excellent innovative and forward looking projects. All of these are contributing to the economic performance of New Zealand.
I have yet to meet a business leader, or a politician, or a voter who doesn't think that we should improve the way our country is performing.
The issue is how do we make this happen? How do we make the lives of our people better? How do we improve the way our economy serves our people, while rewarding those who build the businesses and use their skills and judgement to create and maintain employment?
It seems to me that the answers to these questions can be answered by the work in which many of you here tonight are involved.
Our economy is changing, rebalancing toward a new economic structure. We are moving from consumption-led growth, to an economy which is production and export based. However this new production focus will not be the same as the past. Increasingly it will be production where we create value from ideas and technology sold to a specific market, at a high price.
If we want rising incomes and more good jobs then we must produce more – far more – products and services that depend on the skill, imagination and creativity of New Zealanders, and not just on our sunshine, rainfall and clean soil.
Right now New Zealand
is the lowest exporter of Hi Tech products in the OECD. We
import five times as much high-technology production as we
export. Even Greece, which is the next worst of all
developed countries, imports a little over three times the
value of its Hi Tech exports. We also have a massive
overseas debt and long history of balance of payments
deficits.
New Zealand needs to do much better at exporting – particularly the high-value, high-skill products that firms represented here tonight are involved in.
I am particularly pleased to be here tonight, because it is essential that if New Zealand is to succeed, then this industry has to succeed.
You can be assured that export businesses and industries that have the greatest potential to grow have a champion in this Government.
I want to commit myself to working in partnership with this industry. To ensuring that the Government plays its role in facilitating the expansion and success of the high technology sector.
New Zealand businesses owe it to themselves to grow. With a domestic market of just 3.8 million, the big opportunities lie in markets overseas. If New Zealand is to develop the jobs and rising incomes we need, then businesses based in New Zealand have to be exporting successfully.
On the plus side we have a lot going for us.
We have a stable, democratic government. That puts us far ahead of many parts of the world to begin with., however, we have to compete by providing better value, and having better ideas, not cheap labour. But we have to start from where we are.
The giant international sharebroker and investment banker Merrill Lynch recently published a study. It looked at qualities such as the supply of capital, the education and skills of the people, the availability of technology. How free from corruption are the politicians and government bureaucracy. They looked at the social structure of countries and deducted points where they found wide inequality.
They ranked New Zealand seventh in the world. Not a bad place to start. So there is a solid base to build from.
The growing global marketplace for skills and talent helps to explain why we are undergoing a debate about the 'brain drain.' If we are going to reverse it, simplistic solutions relying on a single 'silver bullet' won't work.
The challenge for New Zealand is to be a country that is attractive for skilled, talented individuals to live in. Attractive to invest their energy and resources in. Attractive for Hi Tech industry.
We need a strong, diverse economy. One where skills, talent and creativity can be developed. Where there will be rewards for success and for skills, like these awards tonight. Where those who try will be encouraged and supported. Where working people can look forward to rising real incomes.
We need a country that is confident in its own unique culture. We need to see New Zealand perform on the world’s stages. We need to be proud of what we do and the unique, distinctive way we do things.
As I was thinking about Hi Tech and coming here tonight I thought about our excellent Hi Tech achievers of the past, Richard Pearse, Ernest Rutherford, CWF Hamilton, and Nick and Tim Wood, John Britten. These awards tonight will recognise the new generation of our achievers.
We need to
make sure that our achievers are encouraged and have to a
chance to grow.
Success by more of our companies and individuals creates even greater growth.
On Wednesday I opened the new offices of Allied Telesyn in Christchurch, a high tech international company undertaking research and development and capitalising on the skills and innovation of Kiwi software engineers.
This research facility will work for its international company and hire over 250 skilled technical New Zealand staff in the next two years. They are going to develop and market new and innovative products and around them they will create more jobs. The expansion of their plant alone will put $10 million into the local economy.
New Zealanders are coming back to work for them in droves, responding to jobs advertised by Allied Telesyn on the internet.
The future of New Zealand lies in the hands of New Zealanders. If we need to, we can put together international partnerships, attract foreign investment, and work with technology from overseas, but Kiwis are our major asset and that is where our future lies.
Achievement synses – Bruce McLaren – Italian car fan – In awe of Bruce McLaren. – Didn't even know he was a New Zealander.
The Labour/Alliance Government is committed to innovation, not just in industries such as Hi Tech but also in government itself. Next month there will be the Government e-commerce summit led by my colleague the Minister of Information Technology Paul Swain. At that summit he will release the Government's e-commerce blueprint.
Government is also working on e-commerce within government, called e-government. The idea is that all New Zealanders will be able to gain access to government information and services, and participate in our democracy using the internet, telephones and other technologies.
It could mean things like: paying tax on line; registering your car; changing your address details with health providers, schools, or the motor vehicle registration centre; or, if you are so inclined, reading government reports on areas in which you are interested.
Research and development issues are also areas where the government is changing to meet the needs of the modern economy.
I understand the Hi Tech Council is writing to Government on the taxation of research and development.
Currently the Labour Alliance Government is preparing a discussion paper for wider consultation which proposes that the tax laws conform with Generally Accepted Accounting Practice in terms of what qualifies as research and development expenditure.
We want to make changes that will assist business and encourage growth, and not hold back innovative companies, or the research and development so necessary for us to make progress as a nation.
Our paper is a discussion paper, and the ideas and feedback from the Hi Tech Council will be looked at and examined as part of this process.
Already this Labour/Alliance Government has shown our commitment to R&D by increasing government spending on research and development by ten per cent in our first budget. Of the $43 million extra, almost half goes direct to the private sector.
Finally you will have all seen the outcomes of the latest step in creating partnership with business to make our economy work better - the Business Forum held on Tuesday. We had around 100 business leaders and eleven government ministers for a free and frank exchange of views. Some of you here were at that meeting.
The positive response from business people who attended this forum will help the process of building a more innovative and knowledge-driven economy.
We discussed research and development, education, taxation, investment, exporting, immigration and Hi Tech new directions.
What personally impressed me was the constructive ideas and debate that the Forum created.
I started tonight by saying that I have yet to meet a business leader, or a politician, or a voter who doesn't think that we should improve the way our country is performing.
The Forum showed that there is tremendous goodwill and a strong resolve from business to improving that performance, both economically and socially. And a strong desire to work with Government to make this happen.
These excellence awards show some of the examples of people doing the work that will make these improvements.
We can be a lot smarter and we can make sure that good ideas for business get off the ground.
We can get better value out of our research and development spending.
We can keep on raising education standards and give our talented young people work that will keep them here.
This is a long term job. We need more than just nine months or even three years to achieve it all. The economy has not run down slowly, we have had balance of payments deficits since the 1970s. And in any case we have to run to catch up with the most able countries in the world and then run faster to stay with them.
We need far more scientists, engineers and designers. We need far more Hi Tech development linked specifically to commercial opportunities, like much of what we will see tonight. We need tertiary institutions much better equipped to meet the teaching, learning and research needs of New Zealanders. But these things take time.
There is no shortage of innovation and good ideas in New Zealand. We are now attempting to ensure that the government plays its part. We will assist where we can, as actively as we need to, to create the environment. It's not a matter of the government doing it all. It's a matter of working together. I look forward to that partnership with you.
/ends | http://www.scoop.co.nz/stories/PA0010/S00517.htm | CC-MAIN-2019-30 | refinedweb | 1,824 | 62.68 |
File parts error running apps via home shorcut
Hiya guys taking a break from the pdf issue I had,, I think I found a solution but it’s on a take me a week or so to implement... so on to the easier issue
I have an app that uses a load of subvies etc also uses a few folder for templates and invoices also got a folder for sound effects banners etc
No the issue is works fine when I run the script from within pythonista... but if I run from shortcut straight into the app I get file not found errors it’s almost as if the app can not see its file paths
And help would be great
This is a pic of the error
[](link url)
Can you include a snippet of your code, and the way you attempt to view that path? Do you use
os.path.expanduserfor example? Based on the image I would say you're trying to call a path relative to a directory, but when running from the shortcut it might not know how to find it. It's safer to call it relative from the user directory, then use
os.path.expanduserto solve the path.
Cool
Here’s a snippet really it’s for reading and writing the ini file
For example Same command used but for the sound fx
def SoundFx(N): if N == 1: # Honour position of phone silent switch sound.set_honors_silent_switch(True) # sets volume sound.set_volume(1.0) #preloads sound.load_effect('./RR/img/hadouken.mp3') #sample to be played when imaged pressed sound.play_effect('./RR/img/hadouken.mp3') vibrate()
Looks like that would work not sure how to implement it if you got any clues a am full beginnerish
@CastroSATT Is your script in the root?
Begin your script with
import os print(os.listdir())
Only to check the difference when you run in Pythonista and from an home screen shortcut
import os.path my_sounds_dir = os.path.expanduser('~/Documents/dir_where_the_script_is_now/RR/img/') sound.load_effect(my_sounds_dir+'hadouken.mp3') | https://forum.omz-software.com/topic/5580/file-parts-error-running-apps-via-home-shorcut/? | CC-MAIN-2021-43 | refinedweb | 340 | 67.99 |
The:
class Hand(Deck):
pass:
class Hand(Deck):
def __init__(self, name=""):
self.cards = []
self.name = name
For just about any card game, it is necessary to add and
remove cards from the deck. Removing cards is already taken
care of, since Hand inherits removeCard from Deck.
But we have to write addCard:
class Hand(Deck):
...
def addCard(self,card) :
self.cards.append(card)
Again, the ellipsis indicates that we have omitted other methods.
The list append method adds the new card to
the end of the list of cards. three parameters: the deck, a list (or tuple) of
hands, and the total number of cards to deal. If there are not enough
cards in the deck, the method deals out all of the cards and stops:
class Deck :
...
def deal(self, hands, nCards=999):
nHands = len(hands)
for i in range(nCards):
if self.isEmpty(): break # break if out of cards
card = self.popCard() # take the top card
hand = hands[i % nHands] # whose turn is next?
hand.addCard(card) # add the card to the hand
The last parameter, nCards,).
To print the contents of a hand, we can take advantage of
the printDeck and __str__ methods inherited
from Deck. For example:
>>> deck = Deck()
>>> deck.shuffle()
>>> hand = Hand("frank")
>>> deck.deal([hand], 5)
>>> print hand
Hand frank contains
2 of Spades
3 of Spades
4 of Spades
Ace of Hearts
9 of Clubs:
class Hand(Deck)
...
def __str__(self):
s = "Hand " + self.name
if self.isEmpty():
return s + " is empty\n"
else:
return s + " contains\n" + Deck.__str__(self)
Initially, s is a string that identifies the hand. If the hand
is empty, the program appends the words is empty and returns the
result. takes care
of some basic chores common to all games, such as creating the
deck and shuffling it:
class CardGame:
def __init__(self):
self.deck = Deck()
self.deck.shuffle().
A hand for playing Old Maid requires some abilities beyond the
general abilities of a Hand. We will define a new class, OldMaidHand, that inherits from Hand and provides an additional
method called removeMatches:
class OldMaidHand(Hand):
def removeMatches(self):
count = 0
originalCards = self.cards[:]
for card in originalCards:
match = Card(3 - card.suit, card.rank)
if match in self.cards:
self.cards.remove(card)
self.cards.remove(match)
print "Hand %s: %s matches %s" % (self.name,card,match)
count = count + 1
return countMatches:
>>> game = CardGame()
>>> hand = OldMaidHand("frank")
>>> game.deck.deal([hand], 13)
>>> print hand
Hand frank contains
Ace of Spades
2 of Diamonds
7 of Spades
8 of Clubs
6 of Hearts
8 of Spades
7 of Clubs
Queen of Clubs
7 of Diamonds
5 of Clubs
Jack of Diamonds
10 of Diamonds
10 of Hearts
>>> hand.removeMatches()
Hand frank: 7 of Spades matches 7 of Clubs
Hand frank: 8 of Spades matches 8 of Clubs
Hand frank: 10 of Diamonds matches 10 of Hearts
>>> print hand
Hand frank contains
Ace of Spades
2 of Diamonds
6 of Hearts
Queen of Clubs
7 of Diamonds
5 of Clubs
Jack of Diamonds
Notice that there is no __init__ method for the
OldMaidHand class. We inherit it from Hand.
Now we can turn our attention to the game itself.
As an exercise, write printHands which traverses
self.hands and prints each. The return value is the number of matches
made during this turn:
class OldMaidGame(CardGame):
...
def playOneTurn(self, i):
if self.hands[i].isEmpty():
return 0
neighbor = self.findNeighbor(i)
pickedCard = self.hands[neighbor].popCard()
self.hands[i].addCard(pickedCard)
print "Hand", self.hands[i].name, "picked", pickedCard
count = self.hands[i].removeMatches()
self.hands[i].shuffle()
return countNeighbor starts with the player to the
immediate left and continues around the circle until it finds
a player that still has cards:
class OldMaidGame(CardGame):
...
def findNeighbor(self, i):
numHands = len(self.hands)
for next in range(1,numHands):
neighbor = (i + next) % numHands
if not self.hands[neighbor].isEmpty():
return neighbor
If findNeighbor ever went all the way around the circle without
finding cards, it would return None and cause an error
elsewhere in the program. Fortunately, we can prove that that will
never happen (as long as the end of the game is detected correctly).
We have omitted the printHands method. You
can write that one yourself.
The following output is from a truncated form of the game where only
the top fifteen cards (tens and higher) were dealt to three players.
With this small deck, play stops after seven matches instead of
twenty-five.
>>> import cards
>>> game = cards.OldMaidGame()
>>> game.play(["Allen","Jeff","Chris"])
---------- Cards have been dealt
Hand Allen contains
King of Hearts
Jack of Clubs
Queen of Spades
King of Spades
10 of Diamonds
Hand Jeff contains
Queen of Hearts
Jack of Spades
Jack of Hearts
King of Diamonds
Queen of Diamonds
Hand Chris contains
Jack of Diamonds
King of Clubs
10 of Spades
10 of Hearts
10 of Clubs
Hand Jeff: Queen of Hearts matches Queen of Diamonds
Hand Chris: 10 of Spades matches 10 of Clubs
---------- Matches discarded, play begins
Hand Allen contains
King of Hearts
Jack of Clubs
Queen of Spades
King of Spades
10 of Diamonds
Hand Jeff contains
Jack of Spades
Jack of Hearts
King of Diamonds
Hand Chris contains
Jack of Diamonds
King of Clubs
10 of Hearts
Hand Allen picked King of Diamonds
Hand Allen: King of Hearts matches King of Diamonds
Hand Jeff picked 10 of Hearts
Hand Chris picked Jack of Clubs
Hand Allen picked Jack of Hearts
Hand Jeff picked Jack of Diamonds
Hand Chris picked Queen of Spades
Hand Allen picked Jack of Diamonds
Hand Allen: Jack of Hearts matches Jack of Diamonds
Hand Jeff picked King of Clubs
Hand Chris picked King of Spades
Hand Allen picked 10 of Hearts
Hand Allen: 10 of Diamonds matches 10 of Hearts
Hand Jeff picked Queen of Spades
Hand Chris picked Jack of Spades
Hand Chris: Jack of Clubs matches Jack of Spades
Hand Jeff picked King of Spades
Hand Jeff: King of Clubs matches King of Spades
---------- Game is Over
Hand Allen is empty
Hand Jeff contains
Queen of Spades
Hand Chris is empty
So Jeff loses.
Warning: the HTML version of this document is generated from
Latex and may contain translation errors. In
particular, some mathematical expressions are not translated correctly. | http://greenteapress.com/thinkpython/thinkCSpy/html/chap16.html | CC-MAIN-2017-47 | refinedweb | 1,049 | 70.84 |
i think the question says it all, but I have an application that uses a
.net setup kit (in vs.2005), and the user asked me if it was possible to
install it on the c:Program FilesProgramName instead of C:Program
filesManufacturerProgram Name. Thing is, I just can't seem to find the way
to do it.
Thanks.
If my program just sometimes calls to GPL program (or if we talk about
flash my swf sometimes sends parameters to other GPL'd swf) should all my
program be Open Source GPL?
How to open program through C# program (Windows Mobile) and give this
program focus ?
EDIT by MarkJ: Gold says thanks for
Process.Start suggestions, but for some reason the program still doesn't
get the focus.
Thanks in advance,Gold
I am developing a java based application; its pertinent requirements are
listed below
Large datasets exist on several machines on
network. my program needs to (remotely) execute a java program to process
these data sets and fetch the results
A user on a windows
desktop will need to process datasets (several gigs) on machine A. My
program can reside on the user's machine.
I am working on a mips program to convert numbers from ascii string into
integers, with the parameter that it should accept positive and negative
integer decimal strings. I know this is a pretty common a assignment but I
wasn't able to resolve my problems online. I was able to get some tips, but
still receiving errors when trying to run the program.
Here is
the code I have at this t
Actually, I have no idea about what is the title of my question, so I
couldn't search on Google, first I need to know what to say to this
problem.
Well, I have developed a application in Visual Studio
C++ 2010, in which 3D objects can be processed, so there is a function
called Import Model which helps to import model.
What I want
is, the user just right click on the o
I'm using a local server on my laptop to control a C# program via PHP.
Basically I'm taking a POST passed to my web server, and using it as the
parameters for a command line program. My code is essentially this:
$parameters = $_POST['parameters'];system('C://THEFILEPATH/myprogram.exe ' . $parameters);
The problem is that this causes myprogram.exe to s
//Purpose: Display first 'n' (user chosen) number if emirps to the
console, five per line.//Note: An "emirp" is a prime number that is
also prime when reversed.
#include <iostream>using namespace std;bool isPrime(int value); //Prototyle for "prime
number function"int reverse (int value2); //Prototype for "emirp
function"int main(){
My installer.xml adds the newly installed program to the program list in
the start menu but does not show it in the program and features list in the
control panel. i have added the native COIOSHelper_x64 dll and the
RegistryUninstallerListener. All i need is "to View the newly installed
program by izpack in Control panel "program and features" list".....can
anybody help...need it asap
I have this strange situation on my local server, I have ever read this
problem by somebody else, but there was also no solution given. I can't
find it anymore or something related.
I can't be the only one
in this world ...
So for Magento I created localhost.com
otherwise it does not run.
If I import a large database in
PhpMyAdmin (MySQL), or start a program | http://bighow.org/tags/program/1 | CC-MAIN-2017-47 | refinedweb | 592 | 62.68 |
Opened 5 years ago
Closed 5 years ago
#16668 closed Bug (worksforme)
Problem with was_published_today()
Description
On, you write the following function:
def was_published_today(self): return self.pub_date.date() == datetime.date.today()
This doesn't work (I tried it), as "today" returns a full datetime, instead of just a date (odd, I guess). Instead, you want:
def was_published_today(self): return self.pub_date.date() == datetime.date.today().date()
Or something else that works.
Change History (2)
comment:1 Changed 5 years ago by daniellawrence
- Needs documentation unset
- Needs tests unset
- Patch needs improvement unset
comment:2 Changed 5 years ago by daniellawrence
- Resolution set to worksforme
- Status changed from new to closed
- Triage Stage changed from Unreviewed to Accepted
Note: See TracTickets for help on using tickets.
The was_published_today should be returning a Boolean not the date.
I was unable to replicate the fault with the following commands. | https://code.djangoproject.com/ticket/16668 | CC-MAIN-2016-30 | refinedweb | 147 | 52.19 |
a.
7. Go to start-run and type in
wbemtest
8. Click on the “ Connect Button ”
9. In the Namespace Box type in the path to the namespace for which getting invalid namespace error for. This path would have the same look and feel of a Windows Directory, so just as you see the structure in wmimgmt.msc console on the Security tab, so is how you will type in path
Examples:
RootCimv2
RootMscluster
RootRSOPComputer
10. Click on the “Connect” button
11. Now all of the buttons should no longer be greyed out on the main wbemtest console page. Click on the “ Enum Classes ” button
12. Leave “Enter Superclass Name” blank and select “ Recursive ” then click OK. If you don’t get any error messages then you can access the name successfully without issue using built in Windows Management Instrumentation Tester
13. To test further, let’s see if we can access some classes. hangs..
WMI | https://techcommunity.microsoft.com/t5/ask-the-performance-team/wmi-missing-or-failing-wmi-providers-or-invalid-wmi-class/ba-p/375485 | CC-MAIN-2021-17 | refinedweb | 156 | 74.39 |
[DAGCombiner] restrict (float)((int) f) --> ftrunc with no-signed-zeros
As noted in the D44909 review, the transform from (fptosi+sitofp) to ftrunc
can produce -0.0 where the original code does not:
#include <stdio.h>
int main(int argc) {
float x; x = -0.8 * argc; printf("%f\n", (float)((int)x)); return 0;
}
$ clang -O0 -mavx fp.c ; ./a.out
0.000000
$ clang -O1 -mavx fp.c ; ./a.out
-0.000000
Ideally, we'd use IR/node flags to predicate the transform, but the IR parser
doesn't currently allow fast-math-flags on the cast instructions. So for now,
just use the function attribute that corresponds to clang's "-fno-signed-zeros"
option.
Differential Revision:
llvm-svn: 335761 | https://reviews.llvm.org/rGd052de856d83095bf687755fb0c7c47e916956c8 | CC-MAIN-2020-24 | refinedweb | 120 | 68.16 |
- Product
- Customers
- Solutions
Datadog bills for AWS hosts running the Datadog Agent and all EC2 instances picked up by the Datadog-AWS integration. You are not billed twice if you are running the Agent on an EC2 instance picked up by the AWS integration.
Other AWS resources (ELB, EBS, RDS, Dynamo, etc.) are not part of monthly billing and configuration exclusions do not apply.
Use the Datadog-AWS integration tile to control your metric collection. Go to the Configuration tab and select an account or add a new one. Each account is controlled under Optionally limit resource collection. Limit metrics by host tag, lambda tag, or per namespace:
Note: Datadog does not charge for ELB metrics, as they can’t be filtered out.
When adding limits to existing AWS accounts within the integration tile, the previously discovered instances could stay in the Infrastructure List up to 2 hours. During the transition period, EC2 instances display a status of
???. This does not count towards your billing.
Hosts with a running Agent still display and are included in billing. Using the limit option is only applicable to EC2 instances without a running Agent.
For technical questions, contact Datadog support.
For billing questions, contact your Customer Success Manager. | https://docs.datadoghq.com/account_management/billing/aws/?lang_pref=en | CC-MAIN-2021-25 | refinedweb | 205 | 57.77 |
Snapshotting: A neat problem and solution in Haskell
I solved an interesting problem recently in Haskell.
Now, I’m no expert at Haskell, and this may not even be a very good solution. I got where I did through a lot of weird side paths, a lot of help from more experienced Haskellers on IRC, but I also made a lot of my own mistakes. It is, though, definitely an interesting solution. So I’ll describe it here.
Of course, this all came about to solve a particular problem. In this case, the problem was a multi-user dungeon (MUD). These programs are text-based network applications that allow users to connect and interact with a common virtual world.
I chose to represent the “world” using a nifty module called “software transactional memory” in the Haskell core library. STM is a great thing, and you should learn about it if you don’t know about it already. I found Simon Peyton-Jones’ paper at very useful. The general idea, though, is that mutable variables are encapsulated with a type constructor TVar, and can only be modified in a transaction.
I wanted to preserve a little of the pure functional flavor, minimize the use of TVars, and generally follow the philosophy of avoiding premature optimization; so the (incomplete) beginnings of the world look something like this:
data World = World { worldStartRoom :: TVar RoomId, worldNextRoomId :: TVar RoomId, worldNextPlayerId :: TVar PlayerId, worldNextItemId :: TVar ItemId, worldRooms :: TVar (M.Map RoomId Room), worldPlayers :: TVar (M.Map PlayerId Player), worldItems :: TVar (M.Map ItemId Item), worldPlayerNames :: TVar (M.Map String Player) } deriving Eq
Now, occasionally, it is also necessary to occasionally save the state of the world out to disk. That data is being constantly accessed and updated by bazillions of threads, and I need an internally consistent state. Great, because STM solves exactly that problem! This transaction will read the whole world, so it will certainly have its costs — but at least it’ll be correct, right?
Here’s where it gets ugly: STM transactions may not perform I/O operations. In other words, the code will need to first do all its STM stuff, save it off in memory somewhere, and only then begin writing to a file. After defining a bunch of data structures containing TVars (okay, only one for now, but that might change), it now appears that I would need to define an identical set of data structures that provide access to a copy of the world from outside of an STM transaction. In other words, it now looks like I need a SWorld, as follows:
data SWorld = SWorld { sworldStartRoom :: RoomId, sworldNextRoomId :: RoomId, sworldNextPlayerId :: PlayerId, sworldNextItemId :: ItemId, sworldRooms :: (M.Map RoomId Room), sworldPlayers :: (M.Map PlayerId Player), sworldItems :: (M.Map ItemId Item), sworldPlayerNames :: (M.Map String Player) } deriving Eq
I immediately don’t like this, because it looks identical to the definition of the earlier World, and in fact it is a requirement of the application that the two remain identical. That’s a lot of manual maintenance. Fortunately, we get type polymorphism to the rescue!
So now World is a parametric type, with a type parameter a. But a is not just any old type parameter! It has a kind of (* -> *). The earlier World type is now just World TVar. The snapshot type is a little uglier, but not much. It would be nice to have a simple identity type constructor, but such a thing doesn’t exist. (In the course of looking for it, I did come across a discussion about adding it into a forthcoming release of Haskell on the haskell-prime mailing list; but there are substantial arguments against it.) So in lieu of a true identity type constructor, I can just use the Identity monad. The snapshot type is now World Identity. Instead of having to make sure they both have the same fields, I know they do because they are the same type!
(One interesting change is that if I want to derive the Eq type class for World, I have to enable undecidable instances in GHC. I don’t really understand why, but it doesn’t confuse me; I’m doing some fairly bizarre stuff here.)
Now it is convenient to have a way to put things in and out of a TVar or Identity without worrying too much about which kind of World I’m using. A type class does the trick! Because dealing with TVar values must be done in STM, the operations are defined in the STM monad.
class Wrapper a where extract :: a b -> STM b inject :: b -> STM (a b) instance Wrapper TVar where extract = readTVar inject = newTVar instance Wrapper Identity where extract = return . runIdentity inject = return . return
Admittedly, that last instance for Identity looks odd. In inject, for instance, I want to take a value, wrap that in the Identity monad, and then wrap that in an STM block (not because it’s necessary, but because it’s part of the type signature for the class.) The extract function uses runIdentity to get the value out of the Identity monad, and then returns is in the STM monad to satisfy the type class. A little more boilerplate…
mkWorld a b c d e f g h = do a' <- inject a b' <- inject b c' <- inject c d' <- inject d e' <- inject e f' <- inject f g' <- inject g h' <- inject h return (World a' b' c' d' e' f' g' h') convertWorld (World a b c d e f g h) = do a' <- extract a b' <- extract b c' <- extract c d' <- extract d e' <- extract e f' <- extract f g' <- extract g h' <- extract h mkWorld a' b' c' d' e' f' g' h' worldStartRoom = extract . worldStartRoom' worldNextRoomId = extract . worldNextRoomId' worldNextPlayerId = extract . worldNextPlayerId' worldNextItemId = extract . worldNextItemId' worldRooms = extract . worldRooms' worldPlayers = extract . worldPlayers' worldItems = extract . worldItems' worldPlayerNames = extract . worldPlayerNames'
These functions handle the grunt work of dealing with various kinds of worlds. The first one defines a constructor that takes simple values, and automatically wraps them up in TVars or the Identity monad. The second gets these things out of one kind of world and into another. The third through tenth extract the values of fields automatically, so that code isn’t littered with readTVar and runIdentity statements all willy nilly. (It may look like this overhead is worse than the cure. That would be wrong, because that last block of code would have to have been written even if I’d used a completely separate type for the snapshot. The only real added overhead is the class and instances for Wrapper, and that’s independent of type! That means if I change Player to have some TVar fields later on, there’s no extra code to write.)
So this accomplished my goal. And sure enough, it basically does what I want. In the end, though, the boilerplate was too much for me. I ended up turning to Template Haskell to handle it for me. The code now looks like this: $(snapshottingType ''World)
And that looks to me like an elegant, maintainable piece of code.
Please share some of the Template Haskell as well.
I don’t follow why you use the Identity monad for your non-TVar instantiation of a. You certainly don’t need a monad, as TVar isn’t one, and you never make any interesting use of the monad operations. You do use “return”, but all that does is wrap up the value in a constructor.
Of course, Identity is defined already, so otherwise you’d have to define your own type. But nonethless I think it’s important to realise that you aren’t using it as a monad, just as a simple wrapper.
Ganesh, you’re right. I don’t actually care that it’s a monad in this case. I’ll edit the post to try to make that clearer.
I haven’t posted the Template Haskell to the blog because it’s not particularly elegant at the moment. You can get it from the darcs repository. Just
darcs get read Snapshotting.hs. I plan to eventually use one of the several generics libraries out there to rewrite it, if possible.
demo url is now
darcs get (I had to hunt around a bit to get it)
meh, what am I saying. it’s the same url. was there a wrong address somewhere else on the blog? never mind. | https://cdsmith.wordpress.com/2007/05/27/snapshotting-a-neat-problem-and-solution-in-haskell/?like=1&source=post_flair&_wpnonce=ad7ead3064 | CC-MAIN-2016-26 | refinedweb | 1,407 | 72.56 |
By Ben Garney
Created
12 May 2011
12 May 2011
Requirements
Prerequisite knowledge
Familiarity with ActionScript 3 and its object-oriented features as well as familiarity with Flash application development.
User level
Intermediate
Required products
A big part of what makes Apple iOS such a great mobile platform is its user interface. Whether you are developing natively or with Adobe Flash Professional CS5.5, users of iOS devices expect you—the application developer—to make your application fit in with the existing iOS experience. An essential part of that experience is interruptibility: your Adobe AIR application needs to save its state frequently and automatically so that it can be switched automatically as users expect—and as Apple specifies in its iPhone Human Interface Guidelines.
This article presents some strategies for saving your application state on iOS devices. The basic capabilities of iOS devices are covered, as well as application design techniques to help give a seamless user experience. I also provide code that demonstrates different techniques for saving state.
The Apple iOS runs only a single user application at a time to keep the device responsive. Whenever the user launches another application, or an outside event like a phone call occurs, your application can be terminated. This can lead to frustrations for the user: imagine if you were writing a text message or e-mail and a phone call came in and you lost your work! Because of this, it is essential that your application save its state regularly and automatically.
My colleagues and I at PushButton Labs developed a game called Trading Stuff in Outer Space for the iPhone last year using the Flash Professional CS5 (see Figure 1). It is a simple space-based trading game that was developed in eight days to explore the technology. One of the goals of the project was to provide an experience indistinguishable from any other iPhone game. As a result, we had to figure out how to make saving state work.
Figure 1. Trading Stuff in Outer Space game screen
We envisioned the scenario of applications that lose data when they are interrupted. Of course, the built-in iOS apps don't do that—when you go back to your text messages after that interrupting phone call, you pick up right where you left off. This is done by the simple expedient of saving state when the application is ordered to quit by the OS. In the Objective-C world, you will have to implement this yourself (see the appropriate section of the iOS Application Programming Guide), and it is no different when you are developing with Flash.
How do you know when to save in Flash? Since AIR applications for iOS share the same API as AIR apps for Adobe AIR, you can listen for the NativeApplication.EXITING event to know when to save your state:
package { import flash.desktop.NativeApplication; import flash.display.Sprite; import flash.events.Event; public class Save1 extends Sprite { public function Save1() { // Listen for exiting event. NativeApplication.nativeApplication.addEventListener(Event.EXITING, onExit); // Load data. load(); } private function onExit(e:Event):void { trace("Save here."); } private function load():void { trace("Load here."); } } }
However, you should also save after crucial events or after a certain interval has passed. For Trading Stuff in Outer Space, crucial events include whenever the player trades (since it is an action that takes a lot of thought and has major effects on gameplay), when the player arrives at a planet, and whenever the player starts or ends a game. For an interval, we chose a period of 30–60 seconds, so that the user would never lose more than a minute's playtime. We chose that threshold because we felt that it was high enough to allow responsive play but low enough to avoid infuriating a user if something causes saving-on-exit to fail.
Unfortunately, the EXITING event isn't 100% reliable. It doesn't always get fired—sometimes due to time limits in the OS, sometimes due to other causes. Your application may crash (although it's unlikely), in which case the normal exiting behavior won't happen. So what we did was to save after every major operation the user performed, as well as approximately once a minute. That way even if users did manage to quit without the application saving state, it was unlikely they would lose more than few seconds of work:
package { import flash.desktop.NativeApplication; import flash.display.Sprite; import flash.events.Event; import flash.utils.setInterval; public class Save2 extends Sprite { public function Save2() { // Listen for exiting event. NativeApplication.nativeApplication.addEventListener(Event.EXITING, onExit); // Also save every 30 seconds. setInterval(save, 30*1000); // Load data. load(); } private function onExit(e:Event):void { save(); } private function save():void { trace("Save here."); } private function load():void { trace("Load here."); } } }
The issues facing an AIR app on iOS devices are not that different from those facing SWF content in the browser. Users' browsers might crash or users might (accidentally or on purpose) navigate away from the page. Even desktop users may want their applications to always be stateful. You can use the same saving code to enhance the user experience on the web, devices, and the desktop.
You can save your state in two main ways with AIR applications on iOS devices. One is with an LSO (local SharedObject). As you know,
SharedObject.getLocal()(see the documentation) can be used to store data locally. This is convenient for a variety of reasons, not least of which is that you can use AMF to store object graphs:
private function save():void { // Get the shared object. var so:SharedObject = SharedObject.getLocal("myApp"); // Update the age variable. so.data['age'] = int(so.data['age']) + 1; // And flush our changes. so.flush(); // Also, indicate the value for debugging. trace("Saved generation " + so.data['age']); } private function load():void { // Get the shared object. var so:SharedObject = SharedObject.getLocal("myApp"); // And indicate the value for debugging. trace("Loaded generation " + so.data['age']); }
In the end, serializing objects directly worked against us in this game application. Depending on your application, using SharedObject might be a perfect fit. For Trading Stuff, I had a lot of complex interrelated data to store, and I also wanted to segregate game state into frequently changed and infrequently changed elements, so using LSOs wasn't a good fit. More on that next.
The other approach is to use File objects directly. You can write asynchronously in order to avoid disrupting the frame rate. If different parts of the game state change at different frequencies, you can store them in separate files so that only what actually changes is touched. You have to do your own serialization, but this isn't as bad as it sounds. (You can even use
readObject()and
writeObject()to store a whole object at once, although this can cause problems in some cases.)
public var age:int = 0; /** * Get a FileStream for reading or writing the save file. * @param write If true, we will write to the file. If false, we will read. * @param sync If true, we do synchronous writes. If false, asynchronous. * @return A FileStream instance we can read or write with. Don't forget to close it! */ private function getSaveStream(write:Boolean, sync:Boolean = true):FileStream { // The data file lives in the app storage directory, per iPhone guidelines. var f:File = File.applicationStorageDirectory.resolvePath("myApp.dat"); if(f.exists == false) return null; // Try creating and opening the stream. var fs:FileStream = new FileStream(); try { // If we are writing asynchronously, openAsync. if(write && !sync) fs.openAsync(f, FileMode.WRITE); else { // For synchronous write, or all reads, open synchronously. fs.open(f, write ? FileMode.WRITE : FileMode.READ); } } catch(e:Error) { // On error, simply return null. return null; } return fs; } private function load():void { // Get the stream and read from it. var fs:FileStream = getSaveStream(false); if(fs) { try { age = fs.readInt(); fs.close(); } catch(e:Error) { trace("Couldn't load due to error: " + e.toString()); } } trace("Loaded age = " + age); } private function save():void { // Update age. age++; // Get stream and write to it – asynchronously, to avoid hitching. var fs:FileStream = getSaveStream(true, false); fs.writeInt(age); fs.close(); trace("Saved age = " + age); }
Both of these should be straightforward to understand. If you've done Flash or AIR development, you've almost certainly dealt with either SharedObject or File. If not, you might want to refer to their documentation for details and examples.
You can also use
readObject()and
writeObject()to store or retrieve an object from a File object. This is powerful and saves you from a lot of repetitive serialization code. However, if you aren't careful, it can introduce problems: for instance, saving a DisplayObject won't work due to the various helper objects and complex relationships involved. Even saving pure data classes can be risky because they may have references to other objects that you don't want to serialize.
Saving the state of your whole application is, of course, more involved. I discuss this issue next.
The larger issue I ran into was serializing all my application data. Figuring out where to write is easy, but figuring out what to write is a little trickier. Naturally, because I am a programmer, I wanted to do it with as little work as possible.
The first thing I tried was directly serializing parts of my DisplayObject hierarchy and game state via AMF in a SharedObject. This was attractive initially because I figured I could throw references to a few key parts of my application into the SharedObject and be done. However, this didn't work: DisplayObjects have lots of helper objects with strange construction restrictions that are not AMF-friendly. It also led to uncontrolled serialization, where the object I was serializing contained a reference to other objects that ended up bringing in most of my application—and I didn't want to waste time debugging issues from strange dangling objects being serialized.
So, instead, I switched to use the File
save()method. This meant I had to write some code to load and save objects that made up the state of my application. Up front, this involved more lines of code, but since they were direct and simple—and I did not plan on modifying the application much past launch—this approach ended up being much quicker to write and debug than the fewer lines of code that would be required for a more automatic solution.
The following code snippet shows what saving and loading looks like for the user's current waypoint:
// Serialize current waypoint. gfs.writeInt(currentWaypointIndex); gfs.writeBoolean(wayPoint != null); if(wayPoint != null) { gfs.writeFloat(wayPoint.x); gfs.writeFloat(wayPoint.y); } // Load waypoint state. currentWaypointIndex = gfs.readInt(); if(gfs.readBoolean()) { wayPoint = new Point(); wayPoint.x = gfs.readFloat(); wayPoint.y = gfs.readFloat(); } else { wayPoint = null }
As you can see, the serialization code has to allocate objects when appropriate; it has to detect if variables are null, and note that in the file; and it has to write each field with the right type. This can be a little overwhelming at first, but with a little practice you'll quickly realize that you are reusing a small set of common idioms for nearly every task.
I also made a singleton to manage all my game state. It kept track of the player's inventory, the locations of everything in the universe, the status of enemies, progress with missions, and so forth. From this singleton, I had methods to reset the game's state, to write it, and to read it back again. In some cases (such as inventory or missions) the state was owned by the singleton. In other cases (such as positions of game objects like the player and planets) the state is managed elsewhere, by other objects, but the singleton can get to it for saving purposes. On top of this foundation, it was easy to implement various saving strategies, as mentioned previously.
Saving state is a key part of making your content fit smoothly into the iOS experience. Since only one application at a time can currently run on iOS devices, it's important to store not only the user's data, but the state of your application's UI. It's not a difficult detail, but it is an important one. I hope this article has helped you understand the key pieces involved in implementing this important functionality in your own application.
Saving state is a broad topic; there's no one-size-fits-all solution. A quick overview of the many different options for serialization can be found in the Serialization entry on Wikipedia. Flash natively supports XML (see Colin Moock's book, Essential ActionScript 3, for several great chapters on XML and E4X) and AMF, which are good building blocks for your serialization needs. There are also libraries like as3corelib that add support for JSON and other serialization formats. Of course, when you're saving application state between runs, what matters most is that the technology you choose is simple, easy to work with, and reliable.
From here, you might want to take the sample code included with this article and try to integrate it with your own content. There are a few decision points, such as using local SharedObjects or File objects, or saving frequently vs. infrequently. Make sure to run a few tests before deciding one way or the other; informed decisions are always best, and the information you need will depend on your specific application. Once you have a solution, test it by frequently quitting in the middle of your program's execution. It might not be possible to restore every piece of state exactly, but with surprisingly little work you will get close enough so that users accept your application as part of their positive iOS device experience.
Check out this series of articles to help you learn more about developing for iOS using Flash Professional:
- Designing for a multi-device, multi-resolution world
- Automating tasks in Flash Professional CS5
- Optimizing Flash performance
- Using the Adobe Flash Sprite Sheet Generator | https://www.adobe.com/devnet/flash/articles/saving_state_air_apps.html | CC-MAIN-2018-47 | refinedweb | 2,349 | 55.34 |
Upon learning about Python's uses in screen scraping, I decided I would give it a shot in order to try and accomplish a conceptually simple task. My overall goal is to query a web page which returns search results, and pull 2 very specific pieces of information from each listing - the name and current listing price of an item.
Specifically, an item name and price at which the item is starting at.
Now, I have ran through multiple websites and guides and gotten the general Python syntax down (I believe), and have tried numerous methods of parsing. What I believe I know is that the page in question is called 'broken HTML' (so not a clean XML or HTML exclusively). In addition, I know *exactly* where the information is that I want when I read the breakdown of the site - however, I can't get the code to see it. Listed below is a quick example of what I currently have - I have resorted to using BeautifulSoup because of what I have read it can offer for small data sets.
- Code: Select all
import requests
result = requests.get("")
c = result.content
from BeautifulSoup import BeautifulSoup
soup = BeautifulSoup(c)
table = soup.findAll('div', "market_listing_row market_recent_listing_row")
print(table)
This will return you one page of listings of a particular item, and the section in which the information is located that we want. My question specifically is how to isolate the "Starting at" information out of the following:
- Code: Select all
<div class="market_listing_right_cell market_listing_num_listings">
<span>
<span class="market_listing_num_listings_qty">107</span>
<br />
Starting at:<br />
$0.32 </span>
</div>
This probably seems rather simple to everyone but myself, but I have gotten complete tunnel vision on this task and am beginning to bang my head on the desk.
Any help you can offer would be appreciated.
Regards,
Nevik34 | http://www.python-forum.org/viewtopic.php?p=10726 | CC-MAIN-2015-06 | refinedweb | 306 | 58.72 |
.
Lots of errors loading a Unity project into Visual Studio... would appreciate your help!
I am not a programmer but greatly appreciate any advice you can give. I have been following tutorials online about how to display 3d objects in hololens. Before about a week ago everything ran smoothly: I would upload a .fbx file as an asset, build a solution in unity, open it with visual studio, and click start without debugging and it would run in the hololens. Now I annot even get a basic cube to work.
I follow everything as it is laid out in the tutorials: I open unity, add an empty game object, right click and add cube, save scene, build settings, add scene switch to windows store, universal 10, d3d, check unity C# projects, and click build.
When I find the .sln file and open in visual studio, I get 135 errors showing in the error list.
The errors are all either
CS 0234 - The type or namespace name 'Runtime (different file name for each error)' does not exist in the namespace 'System' (are you missing an assembly reference?)
CS0246 - The type or namespace name 'FrameworkDisplayName (different file name for each error)' could not be found (are you missing a directive or assembly reference?)
CS 0518 - Predefined type 'System.String (or System.Object or System. Void)' is not defined or imported.
CS0012 - The type 'object (different file name for different errors)' is defined in an assembly that is not referenced. You must add a reference to assembly 'mscorlib, Version= 4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c56193e089'.
There is one CS1545
Property, indexer, or event 'CoreApplication.Suspending' is not supported by the language; try directly calling accessor methods CoreApplication.add_Suspending(EventHandler)' or 'CoreApplication.remove_Suspending(EventRegistrationToken)'
These errors come up despite that I followed tutorials closely. Thank you all for your assistance with this.
-AP
Best Answers
holodoctor ✭✭
5!6
Answers
I've seen similar errors when trying to build if Nuget didn't do a package restore before building the project.
Can I ask what version of Unity and Visual Studio you are using?
Hi @apines, what has changed in the last week? Did you get a new PC? Is it possible that your Visual Studio setup changed even if you are using the same PC? One option you can try is to remove all Unity generated files ("App" dir?) and try rebuilding again. If that doesn't work, then the easiest solution is probably just uninstall everything (Visual Studio/Win10 SDK and Unity, etc.) and re-install them. Since you said it was working a week ago, the best option for you is "go back" to the original state. ~h
Thank you @holodoctor and @jowitt for your suggestions! So I am using the bet version of unity (5.4.0b22) and Visual studio community 2015. I do not believe that anything significant has changed with my computer in the past week. I tried uninstalling and reinstalling unity and visual studio, but now the scene wont even build in Unity. I get the error: UnityException: Build assembly not found. I tried repairing Visual studio, but got the same error. I am going to uninstall and reinstall again, so I'll let you know how that goes. Thank you again for your assistance; it's nice for a beginner like me to have such a responsive forum.
apines, is it possible that you only installed the Unity Editor package and not the UWP editor support?
===
This post provided as-is with no warranties and confers no rights. Using information provided is done at own risk.
(Daddy, what does 'now formatting drive C:' mean?)
The latest HTP version of Unity is 5.4.0b20. Make sure you always install the HTP (HoloLens Technical Preview) version of unity and not the latest Unity.
Here's the link.
Also, as @Patrick mentioned, make sure you install both Unity and the UWP Runtime (in this order) - It does not matter you installed UWP before, whenever you update / reinstall unity, you need to reinstall the UWP runtime associated with that Unity version.
Toronto-HoloLens | Blog | @alexdrenea
I have been playing around with it all day, but am unfortunately still getting the same error: Platform assembly not found.
I tried uninstalling virtual studio and Unity, reinstalled virtual studio 2015 and tried both the new beta 22 and beta 20 from the archive, both of which gave me the platform assembly not found error. For beta 20, I got the uwp runtime from a link that shows up with the windows store selection in build setings, as the uwp runtime on the website was only for beta 22. On beta 20, the list of virtual reality SDKS in player settings is empty, ie windows holographic does not appear.
Thanks @Patrick, @AlexD, @jowitt, and @holodoctor for all of you help. I don't really know what I could try from here and would really appreciate any further advice.
AP
! | https://forums.hololens.com/discussion/comment/4978/ | CC-MAIN-2020-29 | refinedweb | 827 | 65.93 |
schupfMember
Content count563
Joined
Last visited
Community Reputation221 Neutral
About schupf
- RankAdvanced Member
Level config: One file or multiple?
schupf posted a topic in General and Gameplay ProgrammingHello! I am writing a puzzle game for iOS and android that has multiple levels (maybe like 20). Currently I describe all my levels via one .xml file. Since each level is relatively simple (shapes at certain positions), the file is not too big. I also plan to offer level packages (lets say 30 levels for 40 cents) via in app shop. Since it is my first app I have a lot of questions about a good file layout suitable for my game. Should I provide one big file that contains ALL possible levels and the available ones (depending on the player's purchases) is only controlled by code? I.e. my game package always contains a config file with all 110 levels and the first 20 are playable. When the player purchases the first level package my code will allow to play the first 50 levels and so on. Or should I only deliver a level config file containing the first 20 levels and whenever the player purchases a package a separate level file (containing the 30 purchased levels of the package) is downloaded to the device (Is this even possible in the app stores of apple and android?) Thanks for any advice!
OpenGL Rendering a texture
schupf replied to schupf's topic in Graphics and GPU ProgrammingThanks RobTheBloke for your detailed help! You pushed me in the right direction:) The problem was: When I uploaded the images with glTexImage2D I had no OpenGL context. I find it very strange that glError() did not tell any error though... One last question: How is it possible NOT to have a valid context? I mean after I create a context and "activate" it by calling wglMakeCurrent (), isn't the context now active forever? In other words: I thought after calling wglMakeCurrent() I can use OpenGL calls in my code in every function I want. Did I miss something?
OpenGL Rendering a texture
schupf posted a topic in Graphics and GPU ProgrammingHello! I am very new to OpenGL and have a basic problem: I want to render 2 quads each with its own texture. First I have an init function which loads the texture, generates the texture IDs and uploads the texture: void initTex(TexObj& texObj, const char* imageFilename) // Images are .xpm files { QImage image = QImage(imageFilename); texObj.w = image.width(); texObj.h = image.height(); QImage glImage; glImage = QGLWidget::convertToGLFormat(image); char* data = static_cast<char*>( calloc( texObj.w * texObj.h, 4) ); memcpy(data, glImage.bits(), texObj.w * texObj.h * 4); texObj.data = data glGenTextures(1, &texObj.texID); glBindTexture(GL_TEXTURE_2D, texObj.texID); glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, texObj.w, texObj.h, 0, GL_RGBA, GL_UNSIGNED_BYTE, texObj.data); } Function initTex is called 2 times (for 2 different textures). To render the 2 quads I use this function: static void draw(TexObj& tex, float scale) { glEnable(GL_CULL_FACE); glEnable( GL_TEXTURE_2D ); glFrontFace( GL_CCW ); glActiveTexture( GL_TEXTURE0 ); glBindTexture(GL_TEXTURE_2D, tex.texID); // glTexImage2D( GL_TEXTURE_2D, 0, GL_RGB, tex->w, tex->h, 0, GL_RGBA, GL_UNSIGNED_BYTE, tex->data ); glTexParameterf (GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR) ; glTexParameterf (GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR) ; glTexEnvf (GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_MODULATE) ; glTranslated( 0.0, 0.0, 0.0 ); glScalef( scale, scale, 1.0f ); glPolygonMode(GL_FRONT, GL_FILL); glBegin(GL_POLYGON); glTexCoord2f( 0.0, 0.0 ); glVertex2d(0.0, 1.0); glTexCoord2f( 0.0, -1.0 ); glVertex2d(0.0, 0.0); glTexCoord2f( 1.0, -1.0 ); glVertex2d(1.0, 0.0); glTexCoord2f( 1.0, 0.0 ); glVertex2d(1.0, 1.0); glEnd(); glDisable( GL_TEXTURE_2D ); glDisable(GL_CULL_FACE); } The problem is: When I let this code run the quads are completely white! The strange thing: When I comment in the outcommented line (glTexImage2D), the quads are textured! It seems like as if the texture I load into the VRAM in function init() is disappeared and I have to upload it every frame. Does anyone have an idea what could cause this? Thanks!
Am I the only one that finds OSG's code disgusting?
schupf replied to metsfan's topic in General and Gameplay ProgrammingI agree, OSGs code is a mess. But its the lack of documentation that really makes working with OSG such a pain in the ass...
schupf replied to schupf's topic in General and Gameplay ProgrammingThanks to all of you guys! I have chosen the custom key struct with operator<(). The extended string approach also would have worked, but the struct is more flexible. @rip-off: I think your operator<() contains a bug. Assume these values for a and b: {52,30, "Foo"}, {50,40, "Foo"} Your width has the highest priority, so operator<(a,b) should return false. But your operator< will return true, since a.width < b.width is false but a.height < b.height evaluates to true. My struct looks like this (I hope its correct;) [code] struct TextureCacheID { std::string textureFilename; uint width, height; bool operator<(const TextureCacheID& rhs) const { return (textureFilename < rhs.textureFilename) || ((textureFilename == rhs.textureFilename) && (width < rhs.width)) || ((textureFilename == rhs.textureFilename) && (width == rhs.width) && (height < rhs.height)); } }; [/code]
schupf posted a topic in General and Gameplay ProgrammingHi, in my Engine I have a ResourceManager class, that loads resources (textures, shaders, materials etc.) from hard drive and caches them. I.e: [CODE] ShaderPtr p1 = manager->loadShader("Color.psh"); ... ShaderPtr p2 = manager->loadShader("Color.psh"); [/CODE]: [CODE] TexturePtr t1 = manager->loadTexture("Grass.png", 500, 200); // A ... TexturePtr t2 = manager->loadTexture("Grass.png", 300, 300); // B [/CODE] In!
UI components: Scaling
schupf replied to schupf's topic in General and Gameplay Programming@frob: Could you please elaborate your first approach a little bit more? Do you mean I determine whether I scale a component based on the smaller dimension of the window?
UI components: Scaling
schupf posted a topic in General and Gameplay ProgrammingHello, I have made a little UI system to render UI elements (button, combo boxes etc.) in my DirectX 9 game. Now I struggle a little bit with scaling of my components. To make my problem more clear I made a sketch: [sharedmedia=core:attachments:12412]!
Distributing C++ App with Python
schupf posted a topic in For Beginners!
Engine Design: Shadow Mapping
schupf replied to schupf's topic in Graphics and GPU ProgrammingWhen I use a texture atlas for multiple depth maps I assume I the part of the atlas specific for a certain light is selected by setting the viewport? @AgentC: I do not know the maximum number of available registers from VS to PS (I use Shader Model 3), but I do not think this will be a problem. My shaders are relatively simple - just Pos, Normal and Tex Coordinates and then one additional texture coordinate for each Depth Map. I also just want to implement standard Shadow Mapping. But do you think my idea with the fixes sampler registers (i.e. s10 for depth map 1, s11 for depth map 2 etc) is good? Another question just came into my mind: Lets say I have 3 lights and I pass that information to my HLSL shader per constant float u_numLights; Now I could write a for loop in the Pixel shader to iterate over all depthmaps and make the test if the pixel is in shadow. But my simple problem is: The samplers aren't an array, so I can't just use an array expression like this: [CODE] for(int i=0; i < u_numLights; i++) { depth = tex2D(sampler[10 + i], texCoords); } [/CODE] I have to address each sampler with its full name, like depthMap1, depthMap2 etc, which makes it impossible to use a loop. Or do I miss something? depthMaps[
DX9: How many Sampler Units?
schupf replied to schupf's topic in Graphics and GPU ProgrammingThanks. Where did you find this information?
Engine Design: Shadow Mapping
schupf posted a topic in Graphics and GPU ProgrammingHello, In my (Direct9 based) Render Engine I render objects and each object has a material. A material is basically just a pixel and vertex shaders, a set of textures and render states. So lets say I render an object with a material that uses 3 textures, I call 3 times setTexture: device->setTexture(0, tex0); device->setTexture(1, tex1); device->setTexture(2, tex2); It works great, but now I want to add Shadow Mapping to my Engine. The number of shadow casting lights should be flexible. Since I need one Shadow Texture for each shadow casting light and since ALL material shaders need access to the shadow maps I guess the best (only) way to do this is to start with the shadow map textures at a specific sampler register. For example: Lets say I have 4 lights and Light0 and Light2 cast shadows. The shadow map (aka depth map) textures start at sampler register s10. Then Depth Map for Light0 is in sampler s10 and Light2 in sampler s11. Is this a good idea or rather crappy? Thanks for any feedback!
DX9: How many Sampler Units?
schupf posted a topic in Graphics and GPU ProgrammingHello, I am using DX9 and Shader Model 3.0. In my Pixel Shader files I declare textures like this: sampler myTexture : register(s0); sampler myTexture2 : register(s1); Now I wonder how many sampler registers s# are available? I searched a lot but could not find a number. Thanks for help!
Calibri Font on Windows XP
schupf replied to schupf's topic in General and Gameplay ProgrammingWhat the.... it seems like this font costs 35 Dollars. So I have to pay 35 Dollars just to support this font on Windows XP? This sucks:( Isn't there a way to get the font free?
Calibri Font on Windows XP
schupf posted a topic in General and Gameplay ProgrammingHello,! | https://www.gamedev.net/profile/116993-schupf/?tab=issues | CC-MAIN-2018-05 | refinedweb | 1,616 | 65.62 |
This is Part 2 in a two-part series on system panics. In his first column, Michael Lucas talked about how to prepare a FreeBSD system in case of a panic. In this column, he talks about what to do when the worst happens.
Preparing for a crash immediately after you install a system is an excellent way to reduce stress. When your computer panics, would you rather have all the crash information at your fingertips, or would you prefer frantically reading the documentation and trying to set up the debugger? Last time, we discussed building a debugging kernel and setting up your system to save a panic after a crash. Let's hope you'll never need any of this. If you do suffer a crash, however, here's how to get some useful information out of it.
Let's assume that you've followed all the advice in the previous
column.
savecore(8) should have copied a dump of your crashed kernel to /var/crash.
If you take a look in /var/crash, you'll see the files kernel.0 and vmcore.0. (Each subsequent crash dump will get a consecutively higher number, e.g., kernel.1 and vmcore.1.) The vmcore.0 file is the actual memory dump. The kernel file is a copy of the crashed kernel. You want to be sure to use the debugging kernel instead of this one, however. If you look in your kernel compile directory (/sys/compile/MACHINENAME), you'll see a file called kernel.debug. This kernel file contains the symbols we discussed in the previous article. To make your life slightly easier, you might copy this file to /var/crash/kernel.debug.0. This will help you keep track of your debug kernels and the crashes they are associated with.
This process is an excellent opportunity to use
script(1). This
program copies everything that appears on your screen and makes it
simple to keep a record of your debugging session (or, indeed,
anything else you do). After you start the script, start the
gdb
debugger.
gdb takes three arguments: a
-k to configure the debugger
appropriately for kernel work; the name of a file containing the
kernel with symbols; and the name of the memory dump.
# gdb -k kernel.debug.0 vmcore.0
Once you do that,
gdb will spit out its copyright information, the
panic message, and a copy of the memory dumping process. We've seen
an example of a panic earlier, so I won't repeat it now. What is new
is the debugger prompt you get back at the end of all this:
(kgdb)
You've now gotten further than any number of people who have system
panics. Pat yourself on the head. To find out exactly where the
panic happened, type
where and hit enter.
(kgdb) where #0 dumpsys () at ../../../kern/kern_shutdown.c:505 #1 0xc0143119 in db_fncall (dummy1=0, dummy2=0, dummy3=0, dummy4=0xe0b749a4 " \0048\200%") at ../../../ddb/db_command.c:551 #2 0xc0142f33 in db_command (last_cmdp=0xc0313724, cmd_table=0xc0313544, aux_cmd_tablep=0xc030df2c, aux_cmd_tablep_end=0xc030df30) at ../../../ddb/db_command.c:348 #3 0xc0142fff in db_command_loop () at ../../../ddb/db_command.c:474 #4 0xc0145393 in db_trap (type=12, code=0) at ../../../ddb/db_trap.c:72 #5 0xc02ad0f6 in kdb_trap (type=12, code=0, regs=0xe0b74af4) at ../../../i386/i386/db_interface.c:161 #6 0xc02ba004 in trap_fatal (frame=0xe0b74af4, eva=40) at ../../../i386/i386/trap.c:846 #7 0xc02b9d71 in trap_pfault (frame=0xe0b74af4, usermode=0, eva=40) at ../../../i386/i386/trap.c:765 #8 0xc02b9907 in trap (frame={tf_fs = 24, tf_es = 16, tf_ds = 16, tf_edi = 0, tf_esi = 0, tf_ebp = -524858548, tf_isp = -524858592, tf_ebx = -525288192, tf_edx = 0, tf_ecx = 1000000000, tf_eax = 0, tf_trapno = 12, tf_err = 0, tf_eip = -1071645917, tf_cs = 8, tf_eflags = 66182, tf_esp = -1070136512, tf_ss = 0}) at ../../../i386/i386/trap.c:433 #9 0xc01ffb23 in vcount (vp=0xe0b0bd00) at ../../../kern/vfs_subr.c:2301 #10 0xc01a5e58 in spec_close (ap=0xe0b74b94) at ../../../fs/specfs/spec_vnops.c:591 #11 0xc01a55f1 in spec_vnoperate (ap=0xe0b74b94) at ../../../fs/specfs/spec_vnops.c:121 #12 0xc0207454 in vn_close (vp=0xe0b0bd00, flags=3, cred=0xc32cce00, td=0xe0a8d360) at vnode_if.h:183 #13 0xc0207fab in vn_closefile (fp=0xc3369080, td=0xe0a8d360) at ../../../kern/vfs_vnops.c:757 #14 0xc01b1d50 in fdrop_locked (fp=0xc3369080, td=0xe0a8d360) at ../../../sys/file.h:230 #15 0xc01b155a in fdrop (fp=0xc3369080, td=0xe0a8d360) at ../../../kern/kern_descrip.c:1538 #16 0xc01b152d in closef (fp=0xc3369080, td=0xe0a8d360) at ../../../kern/kern_descrip.c:1524 #17 0xc01b114e in fdfree (td=0xe0a8d360) at ../../../kern/kern_descrip.c:1345 #18 0xc01b5173 in exit1 (td=0xe0a8d360, rv=256) at ../../../kern/kern_exit.c:199 #19 0xc01b4ec2 in sys_exit (td=0xe0a8d360, uap=0xe0b74d20) at ../../../kern/kern_exit.c:109 #20 0xc02ba2b7 in syscall (frame={tf_fs = 47, tf_es = 47, tf_ds = 47, tf_edi = 135227560, tf_esi = 0, tf_ebp = -1077941020, tf_isp = -524857996, tf_ebx = -1, tf_edx = 135044144, tf_ecx = -1077942116, tf_eax = 1, tf_trapno = 12, tf_err = 2, tf_eip = 134865696, tf_cs = 31, tf_eflags = 663, tf_esp = -1077941064, tf_ss = 47}) at ../../../i386/i386/trap.c:1049 ?? () (kgdb)
Whoa! This is definitely scary looking stuff. If you copied this and
the output of
uname -a into an email and sent it to
hackers@FreeBSD.org, various developers would take note and help you
out. They'd probably write you back and tell you other things to type
at the
kgdb prompt, but you'd definitely get developer attention.
You'd be well on your way to getting the problem solved, and helping
the FreeBSD folks squash a bug.
If you're not familiar with programming, nobody would blame you if you stopped here. You're better than that, though, and smarter. I know you are. So, without further ado, let's see what we can learn from the debug message and try to figure out some things to include in that first email. Without being intimate with the kernel, you can't solve the problem yourself, but you might be able to help narrow things down a little.
The first thing to realize is that the debugger backtrace contains actual instructions carried out by the kernel, in reverse order. Line number one is the last thing the kernel did. When someone says "before" or "after," they're almost certainly talking about chronological order and not the order things appear in the debugger.
When does a system panic? Well, panicking is a choice that the kernel
makes. If the system reaches a condition that it doesn't know how to
handle, or fails its own internal consistency checks, it will panic.
In these cases, the kernel will call a function called either
trap
or (if you have
INVARIANTS in your kernel)
panic. You'll see
variants on these, such as
db_trap, but you just want the plain old,
unadorned
trap or
panic. Look through your
gdb output for either of
these. In the example above, there's a
trap in line 8. We see
other types of
trap on lines 4-7, but no plain, straightforward
trap
statements. These other traps are "helper" functions, called by
trap to try to figure out what exactly happened and what to do about
it.
Whatever happened right before line 8 chose to panic. In line 9, we see:
#9 0xc01ffb23 in vcount (vp=0xe0b0bd00) at ../../../kern/vfs_subr.c:2301
The hex numbers don't mean much, but this panicked in
vcount. If you
try
man vcount, you'll see that
vcount(9) is a standard system call.
The panic occurred while executing code that was compiled from the file /usr/src/sys/kern/vfs_subr.c, on line 2301. (All paths in these
dumps should be under /usr/src/sys.) This gives a developer a very
good idea of where to look for this problem.
Let's go up and look at line 9. Use the
up command and the number
of lines you want to move.
(kgdb) up 9 #9 0xc01ffb23 in vcount (vp=0xe0b0bd00) at ../../../kern/vfs_subr.c:2301 2301 SLIST_FOREACH(vq, &vp->v_rdev->si_hlist, v_specnext) (kgdb)
Here we see the actual line of
vfs_subr.c that was compiled into the
panicking code. You don't need to know what
SLIST_FOREACH is. (It's a
macro, by the way.) Getting this far is pretty good, but there's
still a little more information you can squeeze out of this dump
without knowing exactly how the kernel works.
If you have some minor programming experience, you'd probably suspect
that the terms in the parentheses after
SLIST_FOREACH are variables.
You'd be right. Each of those variables has a range of acceptable
values. Someone familiar with the code would recognize the legitimate
values; by printing out what each variable contains, we can jump-start
the debugging process. You can tell
gdb to print a variable's
contents with the
p command, giving the variable name as an argument.
Let's look at the middle variable,
vp.
(kgdb) p vp $2 = (struct vnode *) 0xe0b0bd00 (kgdb)
The
(struct vnode *) bit tells us that this is a pointer
to a data structure. You can show its contents by putting an asterisk
in front of the variable name, like so:
(kgdb) p *vp $3 = {v_flag = 8, v_usecount = 2, v_writecount = 1, v_holdcnt = 0, v_id = 6985, v_mount = 0x0, v_op = 0xc2d52a00, v_freelist = {tqe_next = 0x0, tqe_prev = 0xe083de1c}, v_nmntvnodes = {tqe_next = 0xe0b0b700, tqe_prev = 0xe0b0c024}, v_cleanblkhd = {tqh_first = 0x0, tqh_last = 0xe0b0bd2c}, v_dirtyblkhd = {tqh_first = 0x0, tqh_last = 0xe0b0bd34}, v_synclist = {le_next = 0x0, le_prev = 0x0}, v_numoutput = 0, v_type = VBAD, v_un = {vu_mountedhere = 0x0, vu_socket = 0x0, vu_spec = {vu_specinfo = 0x0, vu_specnext = { sle_next = 0x0}}, vu_fifoinfo = 0x0}, v_lastw = 0, v_cstart = 0, v_lasta = 0, v_clen = 0, v_object = 0x0, v_interlock = {mtx_object = { lo_class = 0xc0335c60, lo_name = 0xc02ef5c1 "vnode interlock", lo_flags = 196608, lo_list = {stqe_next = 0x0}, lo_witness = 0x0}, mtx_lock = 4, mtx_recurse = 0, mtx_blocked = {tqh_first = 0x0, tqh_last = 0xe0b0bd84}, mtx_contested = {le_next = 0x0, le_prev = 0x0}, tsp = {tv_sec = 3584, tv_nsec = 101067509}, file = 0xc02ef50a "../../../kern/vfs_subr.c", line = 1726, has_trace_time = 0}, v_lock = {lk_interlock = 0xc036e320, lk_flags = 16777216, lk_sharecount = 0, lk_waitcount = 0, lk_exclusivecount = 0, lk_prio = 80, lk_wmesg = 0xc02ef5d1 "vnlock", lk_timo = 6, lk_lockholder = -1}, v_vnlock = 0x0, v_tag = VT_NON, v_data = 0x0, v_cache_src = {lh_first = 0x0}, v_cache_dst = { tqh_first = 0x0, tqh_last = 0xe0b0bdd8}, v_dd = 0xe0b0bd00, v_ddid = 0, v_pollinfo = 0x0, v_vxproc = 0x0} (kgdb)
For those of you who are learning C, this is an excellent example of
how it's easier to hand around a pointer than the object it
references. An interested developer can dig through this and see
what's going on. Let's take a look at the first variable,
vq, and try
to get similar information from it.
(kgdb) p vq $4 = (struct vnode *) 0x0 (kgdb)
This isn't exactly a problem, but we're stuck. A pointer equal to 0x0
is a null pointer. There are many legitimate reasons for having a
null pointer, but there isn't anything in it for us to view. Feel
free to try, however; you really can't hurt anything through
gdb.
(kgdb) p *vq Cannot access memory at address 0x0. (kgdb)
You've probably heard the words "null pointer" in close proximity to the word "panic." Without digging into the kernel code, you can't assume that this is the case. (In this particular panic, the null pointer is perfectly legitimate; the kernel panicked trying to decide what value to assign to this newly allocated pointer.)
You could try digging a little further into the data to see what's
going on. The second variable in our panic (
vp->v_rdev->si_hlist)
actually goes on a bit; let's take a look a little deeper into it.
(kgdb) p vp->v_rdev There is no member named v_rdev. (kgdb)
Normally, this would work, and if you've used
gdb before, you might
think that it's wrong. In this case it's correct, however.
v_rdev is
a convenience macro. Only people who have read the kernel source code
would know that.
v_rdev actually expands to
v_un.vu_spec.vu_specinfo.
You couldn't be expected to know that, but don't be surprised if a
developer asks you to type something different from what actually
appears in the trace. To actually view
vp->v_rdev, you would type:
(kgdb) p vp->v_un.vu_spec.vu_specinfo $5 = (struct specinfo *) 0x0 (kgdb)
You should be able to recognize the null pointer here, but that's about it.
In this particular case, your extra digging would produce the answer
for a developer very quickly. This tidbit in the contents of the
vp structure identifies the problem almost immediately.
v_type = VBAD
This is a vnode that isn't currently used, and it shouldn't even be in this part of the system. A developer would jump directly on that and try to learn why the system is trying to set a new vnode to a bogus value.
By gathering what information you could before sending out an email, you would short-circuit a round or two of email. Anyone who's used email support in a crisis knows just how valuable this is! Without being a kernel hacker, you can't know which tidbit of knowledge is most important, so you need to include everything you can learn.
I got this particular kernel dump from Dag-Erling Smorgrav. His
comment on this was that he "could fix
vcount() to return 0 for
invalid vnodes--it wouldn't, strictly speaking, be incorrect--but
the real bug is somewhere else, and 'fixing'
vcount() would just
hide it." This is the correct attitude to have on this sort of
problem; BSD users expect bugs to be found, not painted over. This
means, however, that you can expect your developer to come back to you
with requests for further information, and probably more things to
type into
gdb. He might even ask you to send the kernel.debug and
core file.
You should be aware that the
vmcore file contains everything in your
system's memory at the time of the panic. This can include all sorts
of security-impacting information. Someone could conceivably use this
information to break into your system. A developer might write you
and ask for a copy of the files. There are all sorts of legitimate
reasons for this; it makes debugging easier and can save countless
rounds of email. Carefully consider the potential consequences of someone
having this information. If you don't recognize the
person who asks, or if you don't trust him, don't send the files!
If the panic is reproducible, however, you can cold-boot the system to
single-user mode and trigger the panic immediately. If the system
never starts any programs that contain confidential information, and
nobody types any passwords into the system, the dump cannot contain
that information. Reproducing a panic in single-user mode, hence,
generates a "clean" core file. Just enter
boot -s at the loader
prompt to bring the system to a command prompt, then do the minimal
setup necessary to prepare a dump and panic the system.
# dumpon /dev/ad0s4b # mount -art ufs # /usr/local/bin/command_that_panics_the_system
The first line tells the system where to put its dump. You'll want to
put your correct swap partition name here. The second line mounts the
filesystem's read-only, so you won't have to
fsck after your panic.
(Since you know the crash is coming, why make yourself
fsck?)
Finally, you run the command that triggers the panic. You might need
some additional commands, depending on your local setup, but this
should get most people up and running.
As a final treat, here's a debugging session from the same panic, and
the same kernel, but without debugging symbols. Compare it to the
initial
where output above.
(kgdb) where #0 0xc01c5982 in dumpsys () #1 0xc0143119 in db_fncall () #2 0xc0142f33 in db_command () #3 0xc0142fff in db_command_loop () #4 0xc0145393 in db_trap () #5 0xc02ad0f6 in kdb_trap () #6 0xc02ba004 in trap_fatal () #7 0xc02b9d71 in trap_pfault () #8 0xc02b9907 in trap () #9 0xc01ffb23 in vcount () #10 0xc01a5e58 in spec_close () #11 0xc01a55f1 in spec_vnoperate () #12 0xc0207454 in vn_close () #13 0xc0207fab in vn_closefile () #14 0xc01b1d50 in fdrop_locked () #15 0xc01b155a in fdrop () #16 0xc01b152d in closef () #17 0xc01b114e in fdfree () #18 0xc01b5173 in exit1 () #19 0xc01b4ec2 in sys_exit () #20 0xc02ba2b7 in syscall () ?? ()
That's it. There are no hints here about where the panic happened, just the function names that happened. An extraordinarily experienced hacker might happen to recognize a place in the kernel where the exact system calls take place, in exactly this order. If the kernel developer is really, really interested in the problem, he could get some information out of it like this.
(kgdb) p vcount $1 = {<text variable, no debug info>} 0xc01ffb00 <vcount> (kgdb) up 9 #9 0xc01ffb23 in vcount () (kgdb) p/x 0xc01ffb23 - 0xc01ffb00 $2 = 0x23 (kgdb)
The
p/x command means "print in hexadecimal." Here, we've learned
roughly how far into
vcount() the problem happened. If the developer
has a similar kernel built with similar source code, they can do this:
(kgdb) l *(vcount + 0x23) 0xc01fb913 is in vcount (../../../kern/vfs_subr.c:2301). 2296 struct vnode *vq; 2297 int count; 2298 2299 count = 0; 2300 mtx_lock(&spechash_mtx); 2301 SLIST_FOREACH(vq, &vp->v_rdev->si_hlist, v_specnext) 2302 count += vq->v_usecount; 2303 mtx_unlock(&spechash_mtx); 2304 return (count); 2305 } (kgdb)
That's it. There's no way to get the bad vnode information out. The developer is left on his own, poking through the code to see if he can figure out the problem through sheer, dogged determination. And in any event, it's very unlikely that any developer capable of working on a problem will have the exact setup that you have on a panicking system. While many of them would be happy to set up such a system in exchange for lavish amounts of hard currency, it's a bit much to expect for free.
Congratulations! You're now as prepared for a crash as any non-kernel developer can be. Proper preparation can make your life easier, and preparing for the worst is one of the best ways to sleep uninterrupted at night.
(The author wishes to gratefully acknowledge the assistance of Dag-Erling Smorgrav in preparing this article.)
Michael W. Lucas
Read more Big Scary Daemons columns.
Return to the BSD DevCenter. | http://www.linuxdevcenter.com/lpt/a/1672 | CC-MAIN-2014-42 | refinedweb | 2,993 | 63.49 |
This post was originally written as a tutorial for the official Prisma documentation.
Motivation
In this tutorial, you will learn how to deploy a Prisma server on Kubernetes.
Prisma is thin layer around your database which exposes a GraphQL API for interacting with your data. It helps you to build your business logic on top by defining an own GraphQL API which communicates with this particular Prisma service.
Kubernetes is a container orchestrator that helps with deploying and scaling of your containerized applications.
The setup in this tutorial assumes that you have a running Kubernetes cluster in place. There are several providers out there that gives you the possibility to establish and maintain a production grade cluster. This tutorial aims to be provider agnostic, because Kubernetes is actually the abstraction layer. The only part which differs slightly is the mechanism for creating
persistent volumes. For demonstration purposes, we use the Kubernetes Engine on the Google Cloud Platform in this tutorial.
I compiled all the files for you in this repository so that you don't have to copy and paste out of this blog post :)
Prerequisites
If you haven't done that before, you need to fulfill the following prerequisites before you can deploy a Prisma cluster on Kubernetes. You need ...
- ... a running Kubernetes cluster (e.g. on the Google Cloud Platform)
- ... a local version of kubectl which is configured to communicate with your running Kubernetes cluster
You can go ahead now and create a new directory on your local machine – call it
kubernetes-demo. This will be the reference directory for our journey.
Creating a separate namespace
As you may know, Kubernetes comes with a primitive called
namespace. This allows you to group your applications logically. Before applying the actual namespace on the cluster, we have to write the definition file for it. Inside our project directory, create a file called
namespace.yml with the following content:
apiVersion: v1 kind: Namespace metadata: name: prisma
This definition will lead to a new namespace, called
prisma. Now, with the help of
kubectl, you can apply the namespace by executing:
kubectl apply -f namespace.yml
Afterwards, you can perform a
kubectl get namespaces in order to check if the actual namespace has been created. You should see the following on a fresh Kubernetes cluster:
❯ kubectl get namespaces NAME STATUS AGE default Active 1d kube-public Active 1d kube-system Active 1d prisma Active 2s
MySQL
Now that we have a valid namespace in which we can rage, it is time to deploy MySQL. Kubernetes separates between stateless and stateful deployments. A database is by nature a stateful deployment and needs a disk to actually store the data. As described in the introduction above, every cloud provider comes with a different mechanism of creating disks. In the case of the Google Cloud Platform, you can create a disk by following the following steps:
- Open the Google Cloud Console
- Go to the Disk section and select
Create
Please fill out the form with the following information:
- Name: Should be
db-persistence
- Zone: The zone in which the Nodes of your Kubernetes cluster are deployed, e.g.
europe-west-1c
- Disk type: For a production scenario
SSD persistent disk
- Source type:
None (blank disk)
- Size (GB): Select a size that fits your requirements
- Encryption:
Automatic (recommended)
Create for actually creating the disk.
Note: To keep things simple, we created the disk above manually. You can automate that process by provisioning a disk via Terraform as well, but this is out of the scope of this tutorial.
Deploying the MySQL Pod
Now where we have our disk for the database, it is time to create the actual deployment definition of our MySQL instance. A short reminder: Kubernetes comes with the primitives of
Pods and
ReplicationControllers.
A
Pod is like a "virtual machine" in which a containerized application runs. It gets an own internal IP address and (if configured) disks attached to it. The
ReplicationController is responsible for scheduling your
Pod on cluster nodes and ensuring that they are running and scaled as configured.
In older releases of Kubernetes it was necessary to configure those separately. In recent versions, there is a new definition resource, called
Deployment. In such a configuration you define what kind of container image you want to use, how much replicas should be run and, in our case, which disk should be mounted.
The deployment definition of our MySQL database looks like:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: database namespace: prisma labels: stage: production name: database app: mysql spec: replicas: 1 strategy: type: Recreate template: metadata: labels: stage: production name: database app: mysql spec: containers: - name: mysql image: 'mysql:5.7' args: - --ignore-db-dir=lost+found - --max-connections=1000 - --sql-mode=ALLOW_INVALID_DATES,ANSI_QUOTES,ERROR_FOR_DIVISION_BY_ZERO,HIGH_NOT_PRECEDENCE,IGNORE_SPACE,NO_AUTO_CREATE_USER,NO_AUTO_VALUE_ON_ZERO,NO_BACKSLASH_ESCAPES,NO_DIR_IN_CREATE,NO_ENGINE_SUBSTITUTION,NO_FIELD_OPTIONS,NO_KEY_OPTIONS,NO_TABLE_OPTIONS,NO_UNSIGNED_SUBTRACTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ONLY_FULL_GROUP_BY,PIPES_AS_CONCAT,REAL_AS_FLOAT,STRICT_ALL_TABLES,STRICT_TRANS_TABLES,ANSI,DB2,MAXDB,MSSQL,MYSQL323,MYSQL40,ORACLE,POSTGRESQL,TRADITIONAL env: - name: MYSQL_ROOT_PASSWORD value: "graphcool" - name: MYSQL_DATABASE value: "graphcool" ports: - name: mysql-3306 containerPort: 3306 volumeMounts: - name: db-persistence readOnly: false mountPath: /var/lib/mysql volumes: - name: db-persistence gcePersistentDisk: readOnly: false fsType: ext4 pdName: db-persistence
When applied, this definition schedules one Pod (
replicas: 1), with a running container based on the image
mysql:5.7, configures the environment (sets the password of the
root user to
graphcool) and mounts the disk
db-persistence to the path
/var/lib/mysql.
To actually apply that definition, execute:
kubectl apply -f database/deployment.yml
You can check if the actual Pod has been scheduled by executing:
kubectl get pods --namespace prisma NAME READY STATUS RESTARTS AGE database-3199294884-93hw4 1/1 Running 0 1m
It runs!
Deploying the MySQL Service
Before diving into this section, here's a short recap.
Our MySQL database pod is now running and available within the cluster internally. Remember, Kubernetes assigns a local IP address to the
Pod so that another application could access the database.
Now, imagine a scenario in which your database crashes. The cluster management system will take care of that situation and schedules the
Pod again. In this case, Kubernetes will assign a different IP address which results in crashes of your applications that are communicating with the database.
To avoid such a situation, the cluster manager provides an internal DNS resolution mechanism. You have to use a different primitive, called
Service, to benefit from this. A service is an internal load balancer that is reachable via the
service name. Its task is to forward the traffic to your
Pod(s) and make it reachable across the cluster by its name.
A service definition for our MySQL database would look like:
apiVersion: v1 kind: Service metadata: name: database namespace: prisma spec: ports: - port: 3306 targetPort: 3306 protocol: TCP selector: stage: production name: database app: mysql
The definition would create an internal load balancer with the name
database. The service is then reachable by this name within the
prisma namespace. A little explanation about the
spec section:
- ports: Here you map the service port to the actual container port. In this case the mapping is
3306to
3306.
- selector: Kind of a query. The load balancer identifies
Podsby selecting the ones with the specified labels.
After creating this file, you can apply it with:
kubectl apply -f database/service.yml
To verify that the service is up, execute:
kubectl get services --namespace prisma NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE database ClusterIP 10.3.241.165 <none> 3306/TCP 1m
Prisma
Okay, fair enough, the database is deployed. Next up: Deploying the actual Prisma server which is responsible for serving as an endpoint for the Prisma CLI.
This application communicates with the already deployed
database service and uses it as the storage backend. Therefore, the Prisma server is a stateless application because it doesn't need any additional disk storage.
Deploying the Prisma Pod
Deploying the actual Prisma server to run in a Pod is pretty straightforward. First of all you have to define the deployment definition:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: prisma namespace: prisma labels: stage: production name: prisma app: prisma spec: replicas: 1 strategy: type: Recreate template: metadata: labels: stage: production name: prisma app: prisma spec: containers: - name: prisma image: 'prismagraphql/prisma:1.1' ports: - name: prisma-4466 containerPort: 4466 env: - name: PORT value: "4466" - name: SQL_CLIENT_HOST_CLIENT1 value: "database" - name: SQL_CLIENT_HOST_READONLY_CLIENT1 value: "database" - name: SQL_CLIENT_HOST value: "database" - name: SQL_CLIENT_PORT value: "3306" - name: SQL_CLIENT_USER value: "root" - name: SQL_CLIENT_PASSWORD value: "graphcool" - name: SQL_CLIENT_CONNECTION_LIMIT value: "10" - name: SQL_INTERNAL_HOST value: "database" - name: SQL_INTERNAL_PORT value: "3306" - name: SQL_INTERNAL_USER value: "root" - name: SQL_INTERNAL_PASSWORD value: "graphcool" - name: SQL_INTERNAL_DATABASE value: "graphcool" - name: SQL_INTERNAL_CONNECTION_LIMIT value: "10" - name: CLUSTER_ADDRESS value: "" - name: BUGSNAG_API_KEY value: "" - name: ENABLE_METRICS value: "0" - name: JAVA_OPTS value: "-Xmx1G" - name: SCHEMA_MANAGER_SECRET value: "graphcool" - name: SCHEMA_MANAGER_ENDPOINT value: "" - name: CLUSTER_PUBLIC_KEY value: "GENERATE VIA"
This configuration looks similar to the deployment configuration of the MySQL database. We tell Kubernetes that it should schedule one replica of the server and define the environment variables accordingly. As you can see, we use the name
database for each
SQL_*_HOST* variable. This works because of the fact that this
Pod will run in the same namespace as the database service – the Kubernetes DNS server makes that possible.
Before applying that definition, we have to generate a public/private-keypair so that the CLI is able to communicate with this Prisma server. Head over to and execute the following query:
{ generateKeypair { public private } }
Make sure to store those values in a safe place! Now, copy the
public key and paste it into the
value of the
CLUSTER_PUBLIC_KEY environment variable in
prisma/deployment.yml.
Afterwards, we are ready to apply that deployment definition:
kubectl apply -f prisma/deployment.yml
As in the previous sections: In order to check that the Prisma server has been scheduled on the Kubernetes cluster, execute:
kubectl get pods --namespace prisma NAME READY STATUS RESTARTS AGE database-3199294884-93hw4 1/1 Running 0 5m prisma-1733176504-zlphg 1/1 Running 0 1m
Yay! The Prisma server is running! Off to our next and last step:
Deploying the Prisma Service
Okay, cool, the database
Pod is running and has an internal load balancer in front of it, the Prisma server
Pod is also running, but is missing the load balancer a.k.a.
Service. Let's fix that:
apiVersion: v1 kind: Service metadata: name: prisma namespace: prisma spec: ports: - port: 4466 targetPort: 4466 protocol: TCP selector: stage: production name: prisma app: prisma
Apply it via:
kubectl apply -f prisma/service.yml
Okay, done! The Prisma server is now reachable within the Kubernetes cluster via its name
prisma.
That's all. Prisma is running on Kubernetes!
The last step is to configure your local
Prisma CLI so that you can communicate with the instance on the Kubernetes Cluster.
The upcoming last step is also necessary if you want to integrate
prisma deploy into your CI/CD process.
Configuration of the Prisma CLI
The Prisma server is running on the Kubernetes cluster and has an internal load balancer. This is a sane security default, because you won't expose the Prisma server to the public directly. Instead, you would develop a GraphQL API and deploy it to the Kubernetes cluster as well.
You may ask: "Okay, but how do I execute
prisma deploy in order to populate my data model when I'm not able to communicate with the Prisma server directly?
. That is indeed a very good question!kubectl` comes with a mechanism that allows forwarding a local port to an application that lives on the Kubernetes cluster.
So every time you want to communicate with your Prisma server on the Kubernetes cluster, you have to perform the following steps:
kubectl get pods --namespace prismato identify the pod name
kubectl port-forward --namespace prisma <the-pod-name> 4467:4466– This will forward from
127.0.0.1:4467->
kubernetes-cluster:4466
The Prisma server is now reachable via. With this in place, we can configure the CLI:
`
prisma cluster add
? Please provide the cluster endpoint
? Please provide the cluster secret
? Please provide a name for your cluster kubernetes
`
Okay, you made it! Congratulations, you have successfully deployed a Prisma server to a production Kubernetes cluster environment.
Discussion (5)
Thank you for your post, we got our Prisma production server up in a kubernetes cluster, thanks to you.
I'm very new to kubernetes, but I ended up figuring it out.
I followed the guide with Google Cloud Platform, and ended up with the questions of how many virtual machines does this actually create?
To my surprise, I found my self with three of them and 4 persistent volumes 1 of 100g per each VM and one 20gb which is the one I was expecting from the guide.
If this is the case why 3 VMS? what's going on here?
Thanks again!
Hey. Thanks for the really nice post. All the steps went through smoothly when I follow your steps, except the port-forwarding; After I execute the command kubectl port-forward --namespace prisma my pod 4467:4466, it seems to hang there and nothing happens: Forwarding from 127.0.0.1:4467 -> 4466. Do you have any idea what could be the issue?
Also if I put localhost:4667 in the browser, it returns The requested resource could not be found.
You’re welcome 🙂
Hm, strange. Just to make sure, could you try:
kubectl port-forward -n prisma yourpod 4466:4466
hi, what is the best way to link to a react front end if i create an individual prisma container just like your tutorial? Can i create a react front end container then connect the dots via its clusterIP port?
thanks for the post! | https://dev.to/andre/deploying-a-prisma-cluster-to-kubernetes--3lbi | CC-MAIN-2022-33 | refinedweb | 2,284 | 51.78 |
Ruby.
Though a lot can be said about Merb being a potential Rails-killer, we're not going to attempt to be so dramatic here. Instead, we'll let Merb speak for itself as we create the server side component of Shmerboes..:
We are going to connect the Shoes user interface to the Merb backend using HTTP. To make this easier, we create a helper module,
HttpToYaml, that will function as a super-simple generic web service wrapper. We can
include this module into our Shoes application, and it provides four Ruby methods corresponding to the four primary HTTP methods (
get,
put, and
delete). It requests YAML data using a custom Accept header, and decodes the response using
YAML.load.
We could have avoided the need to write this wrapper by looking for a third-party library that accomplishes these functions for us. However, Shoes doesn't make it terribly easy to structure large applications or package up third-party libraries. Shoes loads the application's code by reading its source file and
evaling it in the context of Shoes, so it's not really possible to reference files using paths relative to the source file. With all that in mind, we opted to write our own interface.
Here is the full code for the web service wrapper. Later, we will examine it in detail.
require "uri" require "net/http" module HttpToYaml class TooManyRedirects < StandardError; end BACKEND = '' protected def put(uri, params = {}) post uri, params.merge(:_method => 'put') end def delete(uri, params = {}) post uri, params.merge(:_method => 'delete') end def handle_or_decode_response(response, options = {}) case response when Net::HTTPSuccess YAML.load(response.body) when Net::HTTPRedirection limit = options[:redirection_limit] || 10 raise TooManyRedirects if limit == 1 get response['Location'], limit - 1 end end end
This is not terribly fun code, but it serves our purpose of wrapping up Net::HTTP's ugly bits into a higher-level interface, somewhat reminiscent of integration test scripts in Rails. Let's take a look at it, piece by piece. First off, we need to pull in the URI and Net::HTTP libraries from Ruby's standard library.
require "uri" require "net/http"
Net::HTTP provides our basic HTTP interface, and the URI library breaks down URI strings (such as) into their constituent parts (scheme, host, port, and path).
The most basic HTTP method is GET, which we expose through our module's
get method. Here it is again, along with some of its supporting code:
module HttpToYaml class TooManyRedirects < StandardError; end BACKEND = '' handle_or_decode_response(response, options = {}) case response when Net::HTTPSuccess YAML.load(response.body) when Net::HTTPRedirection limit = options[:redirection_limit] || 10 raise TooManyRedirects if limit == 1 get response['Location'], limit - 1 end end end
Note the
BACKEND constant, which is the base URI of our server. Since we are speaking plain HTTP between the client and server, we could separate the client and server on a network or even the Internet. All we would need to do is make the Merb server accessible and specify its URI in the
BACKEND constant.
When we perform the request, we need to pass a custom Accept header of
text/yaml. This tells Merb, or any other server from which we request data, that the only response format we understand is YAML. Merb will use this information to decide among different representations of the same content. For example, we could augment the Merb application to have a Web interface as well, and it could coexist on the exact same URIs, differentiated only by the version the client requests in the Accept header.
Much of the complexity in these methods comes from our need to gracefully follow HTTP redirects; Net::HTTP makes us decide for ourselves how we want to handle a redirection response. When a paste is created, the Merb server will send a 302 redirection to the paste's URI. For our application, we want to automatically follow this redirect and return the body of the second response. The
handle_or_decode_response method fills this need. If it encounters a redirection, it will issue another GET to the URI stored in the current response's Location header. Otherwise, on a successful request, the method will pipe the response body through
YAML.load and return the resulting data structure.
We do need to take some care to ensure that we do not follow an infinite loop of redirects, and this is what the
redirection_limit option and
TooManyRedirects exception are for. On each redirect, we decrement the
redirection_limit counter (which is essentially a time-to-live variable); if it would reach zero, we break the redirection loop by raising a
TooManyRedirects exception.
The
post method is similar to
get, but it takes a second parameter: a hash of form parameters to be used as the POST data. These will be unescaped on the server side and will come out looking pretty much the same as the Merb
params hash. This interface constrains us to posting form-like data, but it will be good enough for our purposes. Again, we request YAML data and expect YAML back. Here is the code:
One thing that may not be immediately obvious from this code is that any redirection that a POST request experiences is followed using GET, not POST. This is technically incorrect behavior according to RFC 2616, but it is widespread enough that we will not worry about it (indeed, the RFC specifically mentions that most clients do exactly as we do here, and the server should use 303 or 307 response codes where there could be ambiguity about how to follow such a redirect).
The other two HTTP methods, PUT and DELETE, are very useful in conjunction with Merb's resource-based routing. Unfortunately, they are not as well known on the Web, and their use is not always robust. Some Web proxies do not understand PUT and DELETE. The only methods allowed on HTML forms are GET and POST, which has made the other HTTP verbs second-class citizens on the public Internet.
To ensure that these methods will still work even in the face of intermediaries that do not understand them, we will fake them by using the POST method with a special
_method parameter, which is set to the actual method we are emulating. Merb understands this convention and treats these requests just as if they had been issued using the correct method.
def put(uri, params = {}) post uri, params.merge(:_method => 'put') end def delete(uri, params = {}) post uri, params.merge(:_method => 'delete') end
These two methods are short stubs that simply delegate to the
post method, adding a
_method parameter specifying the real HTTP method.
We can fire up
irb to test this interface. Just make sure the Merb server is running in the background by changing to its directory and running
merb. Then we can play around with the web service client and test it interactively:
>> require 'http_to_yaml' # wherever the HttpToYaml code is located >> include HttpToYaml => Object >> get '/pastes' => [{:created_at=>"Sun Jan 06 14:01:27 -0600 2008", :id=>1, :title=>"Foo"}] >> get '/pastes/1' => {:created_at=>"Sun Jan 06 14:01:27 -0600 2008", :text=>"the sweetest bar that ever barred", :id=>1, :title=>"Foo"}
Our library appears to be functional now, and we can see the exact data structures that will be returned when we use those method calls in the Shoes application.
Now we can get down to business and build the user interface for our pastebin. Documentation for Shoes is scant, but the best reference is the book Nobody Knows Shoes, by why the lucky stiff himself. The official API reference is available online as The Entirety of the Shoes Family.
The Shoes portion of the code is fairly simple, and should be easy to understand if you have experience programming for the Web, even if you have not used Shoes before. We will present it in its entirety, and then dissect and explain it. Because Shoes
evals the code it is provided with, all of the code for a Shoes application should be in one file. Therefore, this code should follow the HttpToYaml code that we showed earlier:
class ShoesPaste < Shoes include HttpToYaml url '/', :index url '/new', :new_paste url '/(\d+)', :show_paste def index pastes = get "/pastes" stack :margin => 20 do title "Shoes Pastebin" pastes.sort_by{|p| p[:created_at]}.each do |paste| para link(paste[:title], :click => "/#{paste[:id]}") end para link('New paste', :click => "/new") end end protected def view_all_link para(link('View all pastes', :click => '/'), :margin_top => 20) end end Shoes.app :title => 'Shoes Pastebin', :width => 640, :height => 400
We inherit from Shoes to provide a clean environment in which to contain our application code. It is possible to contain the entire application in a block passed to the Shoes.app method, but it gets messy with larger applications. Our method allows us to keep our application code contained in one class.
After the initial
include statement that pulls in our web service bridge, we set up the URLs for our application using the
Shoes.url class method. This is a potential source of confusion because these URLs are completely different from those exposed by our Merb application. Because Shoes is modeled after the Web, it uses pseudo-URLs to reference different sections within an application.
url '/', :index url '/new', :new_paste url '/(\d+)', :show_paste
Each
url statement maps a regular expression to a method that is executed when a URL matching that regexp is "visited." (URLs can be triggered with a
:click action on some elements, or with the
visit method, as we will see later.) Any captures in the regular expression (such as
(\d+)) will be passed as arguments to the method named.
We have three types of pages: the index, which shows a list of pastes, the "new paste" screen, and the screen to show an existing paste. Let's look at the index first, as it will introduce us to several aspects of the Shoes API.
def index pastes = get "/pastes" stack :margin => 20 do title "Shoes Pastebin" pastes.sort_by{|p| p[:created_at]}.each do |paste| para link(paste[:title], :click => "/#{paste[:id]}") end para link('New paste', :click => "/new") end end
The first line of the
index method retrieves all of the current pastes from the
/pastes URL on the server. As we saw before when experimenting with
irb, this will be an array of hashes, with each hash containing attributes of one paste.
The
stack method is unique to Shoes. For layout, Shoes uses the concept of stacks and flows, which are two types of boxes. Either type of box contains a series of elements. Stacks order their contents from top to bottom, while flows organize them from left to right (wrapping lines if necessary). We will use both stacks and flows to lay out different parts of our application. This method call also illustrates that most methods accept a hash of styles to fine-tune their positioning and look.
Within the stack, we first have a title, which is a simple text heading. Rather than HTML's unimaginative
h1 through
h6, Shoes uses creative heading names:
banner,
title,
subtitle,
tagline,
caption, and
inscription.
Next in the stack, we sort the pastes by their creation time, and create a paragraph (
para) containing a link to that paste's
show_paste method. (The
"/#{paste[:id]}" URL will match the
'/(\d+)' regexp.) Finally, we close out the stack by linking to the "new paste" URL.
When we run this with
shoes /path/to/shoes_paste.rb, we see the following:
Now we probably want to be able to see some of the pasted code. So we will look at the
show_paste function that lets us get at the pastes: protected def view_all_link para(link('View all pastes', :click => '/'), :margin_top => 20) end
Because
show_paste's mountpoint (its URL regular expression) has one capture, this function takes one argument: the ID of the paste. A URL of
/123 will translate into a call to
show_paste(123). Once we have that ID, we interpolate it into an actual URL on the Merb server, and retrieve the paste. The web service bridge does the translation from YAML to a hash, so we can work directly with the attributes of the paste.:
Upon submitting this paste, we are redirected to the resulting "show" page:. | http://archive.oreilly.com/lpt/a/7228 | CC-MAIN-2015-22 | refinedweb | 2,048 | 59.64 |
QCompleter - return result set, limited in size, for large term set for SPEED
Hi Everyone,
I have a QCompleter on a QLineEdit, with a sorted list of 350,000 terms from a taxonomy. Since it's sorted and a binary search can be used for to retrieve results, this should not be a big issue.
However, for the first one to two characters entered, there is a one to five second delay until the first results show up - I suppse that when I enter, say, "A", all results that start with A are considered and then the top N selected for display.
So the question is, how can I tell the model to not worry about any but the top N results? Do I need to implement a custom model for the completer - and do you have any pointers for how to do that? (I have built custom models, not sure what's involved with a completer though).
BTW I am using PySide 1.0.7 or later.
Thanks!
Pezzi
That delay could be mostly the initial load of the 350000 rows into RAM. For example, if the model is a QSqlQueryModel there may be a lengthy one-time delay as the data is loaded into memory 256 rows at a time using fetchMore(). If so, you could make the model persistent so it is a one-time-only delay.
I have not found an elegant way to do a limited subset. I used a custom model and connected the line edit's textChanged() signal to a slot in the model feeding the completer. The model would reset and run a query to return the top 20 items. So, the completer was working with a model that essentially already contained the correct results.
Thank you for this!
The data is in RAM already so that's not the source of the delay, but I imagine the transformation of a Python set (yes, type Set) of strings into a string model takes time.
I guess I'll have to implement my own model then, not a big problem,. My understanding is that QCompleter invokes a QSortFilterProxy model - but what methods do I have to implement for this to work? I haven't found any documentation or sample code and I did spend quite a bit of time looking (maybe in all the wrong places though).
Could you share a sample of what you have done or point me in the right direction?
Thank you!
Pezzi
The problem with QCompleter is that it really does not give you a way to customise its internal behaviour in regard to the data it uses. You cannot, for example, replace its internal sort/filter proxy with one that know about limits.
Here's how you could do it:
- Write a QAbstractListModel (or table model) model wrapper that accesses the existing in-memory data as-is. That is, don't duplicate the data into a QStringListModel if you can avoid it.
- Assuming your model exists only for this completer then give it an equivalent of the QCompleter::setCompletionPrefix() and have the model present only the top-20 matches
- Connect your line edit textChanged() signal to the model setCompletionPrefix()
- Create your completer using the model and attach it to the line edit.
I am not a Python-head so I cannot really give you usable example code
Hi Chris,
I have been experimenting with this and a couple of issues came up:
the setCompletionPrefix signal is emitted after data() is called in the model for that keystroke - so it's hard to modify the model's behavior based on the text (but I can always get the QLineEdit's current text from within the data model itself. A little ugly but doable.
if I tell the QCompleter that I have a sorted list, it does two binary searches, one for the first and one for the last value in the model with that prefix, and then iterates through the entire interval between these boundaries, retrieving every matching item. This is where the multi-second delay comes from. I could limit the results to a sub-interval, e.g. 100 values starting with the lower boundary. But then when additional keys are entered (prefix gets longer) the QCompleter searches relative to the previous interval. Ouch!
Any ideas?
Pezzi
I wanted to add that with a minimal implementation I was able to eliminate the annoying time when creating the model - I keep the model around for the lifetime of the app, any QLineEdit w/completer can use it:
This does not yet solve the problem of long times to load long result list when a fairly common prefix is entered. I would settle for preventing completions when the prefix is only 1-2 characters but have not found a way to do that just yet.
@
class BasicCompleterModel(QtCore.QAbstractListModel):
def init(self, terms, parent = None):
super(BasicCompleterModel, self).init(parent)
self.terms = sorted(terms)
self.num_terms = len(terms)
self.line_edit = parent
def rowCount(self, something): return self.num_terms def data(self, index = None, role = None): if role in [QtCore.Qt.DisplayRole, QtCore.Qt.EditRole]: return self.terms[index.row()] return None
class BasicLineEdit(QtGui.QLineEdit):
def init(self, terms = None, parent = None):
super(BasicLineEdit, self).init(parent)
self.et = initialLoadEmTree()
terms = sorted(self.et.all_terms_and_syns())
print 'Number of terms', len(terms)
self.completion_model = BasicCompleterModel(terms = terms, parent = self)
self.completer = QtGui.QCompleter([], self)
self.completer.setModel(self.completion_model)
self.completer.setCaseSensitivity(QtCore.Qt.CaseInsensitive)
self.completer.setModelSorting(QtGui.QCompleter.CaseInsensitivelySortedModel)
self.completer.setMaxVisibleItems(20)
self.setCompleter(self.completer)
@
I was thinking more of using the QCompleter purely for its popup handling and going around it to have the model only present the desired "Top 20" hits to the completer. The completer then has a very limited set to work with, but your model needs to be smarter. Here is an implementation in C++ using an SQL table of 362880 options but a model that will return at most 20. The model is reset for each time the line edit changes (by user action) and the completer only ever sees 20 or fewer rows.
@
#include <QtGui>
#include <QtSql>
#include <QDebug>
#include <algorithm>
void createTestData()
{
QSqlDatabase db = QSqlDatabase::addDatabase("QSQLITE");
db.setDatabaseName(":memory:");
if (db.open()) {
QSqlQuery query;
query.exec("create table options(val varchar(10))");
query.prepare("insert into options values (?)"); QString letters("abcdefghi"); do { query.bindValue(0, letters); query.exec(); } while (std::next_permutation(letters.begin(), letters.end())); }
}
class MyModel: public QSqlQueryModel
{
Q_OBJECT
public:
explicit MyModel(QObject *p = 0): QSqlQueryModel(p) {
setCompletionPrefix("");
}
public slots:
void setCompletionPrefix(const QString &prefix) {
qDebug() << Q_FUNC_INFO << prefix;
QSqlQuery query;
query.prepare(
"select val from options where val like ? || '%' "
"order by val limit 20"
);
query.bindValue(0, prefix);
query.exec();
setQuery(query);
}
};
int main(int argc, char *argv[])
{
QApplication app(argc, argv);
createTestData();
QLineEdit le;
QCompleter *completer = new QCompleter(&le);
completer->setMaxVisibleItems(10);
MyModel *model = new MyModel(&le);
completer->setModel(model);
le.setCompleter(completer);
QObject::connect(&le, SIGNAL(textEdited(QString)),
model, SLOT(setCompletionPrefix(QString)));
le.show();
return app.exec();
}
#include "main.moc"
@
This is odd: I tried to translate this into Python. The data is loaded just fine and queries work - they return the top 20 results just fine - but no dropdown with the completions is rendered when I type into the QLineEdit. Am I doing something obvious wrong? Do you have any ideas how to put hooks into this thing to see what's going on? (which methods of the QSqlQueryModel does QCompleter call?)
@
class TestCompleterModel(QtSql.QSqlQueryModel):
def init(self, terms, view_terms = 10, parent = None):
super(TestCompleterModel, self).init(parent)
self.db = QtSql.QSqlDatabase.addDatabase('QSQLITE')
self.db.setDatabaseName(':memory:')
if self.db.open():
self.query = QtSql.QSqlQuery()
self.query.exec_('create table options(val varchar(100))')
self.query.prepare('insert into options values (?)')
for term in terms:
self.query.bindValue(0, term)
self.query.exec_()
self.query.exec_('select count(*) from options') print 'rows in SQLITE:' while self.query.next(): print self.query.value(0) self.query.prepare("select val from options where val like ? || '%' order by val limit 20") self.query.bindValue(0, 'aspi') self.query.exec_() print 'top 20 matches:' while self.query.next(): print self.query.value(0) self.view_terms = view_terms self.terms = sorted(terms) self.num_terms = len(terms) self.line_edit = parent self.completion_prefix = '' @QtCore.Slot() def setCompletionPrefix(self, prefix): print 'setCompletionPrefix', prefix self.completion_prefix = prefix self.query.prepare("select val from options where val like ? || '%' order by val limit 20") self.query.bindValue(0, prefix) self.query.exec_() self.setQuery(self.query)
class TestLineEdit(QtGui.QLineEdit):
def init(self, terms = None, parent = None):
super(TestLineEdit, self).init(parent)
self.et = initialLoadEmTree()
terms = sorted(self.et.all_terms_and_syns())
print 'Number of terms', len(terms)
self.completer = QtGui.QCompleter(self) self.completer.setMaxVisibleItems(10) self.completion_model = TestCompleterModel(terms, 10, self) self.completer.setModel(self.completion_model) self.textEdited.connect(self.completion_model.setCompletionPrefix)
@
Many thanks
Patrick | https://forum.qt.io/topic/17062/qcompleter-return-result-set-limited-in-size-for-large-term-set-for-speed | CC-MAIN-2017-34 | refinedweb | 1,482 | 50.33 |
Post your Comment
Properties file in Java
Properties file in Java
Properties file in Java
In this section, you will know...;
Write Keys and Values of the Properties files in Java
In this section
Java read properties file
Java read properties file
In this section, you will learn how to read properties file.
Description of code:
There are different tools to access different...
Video tutorial of reading properties file in Java.
Here is the code
Properties file in Java
Properties file in Java
In this section, you will know about the properties
file. The properties file is a simple text file. Properties file contains keys
and values
Java Write to properties file
Java Write to properties file
In this section, you will learn how to write data to properties file.
The properties file is basically used to store.... Here we are going to create a .properties
file and write data
Java Properties File Example
Using Properties files Java
Stets to use a properties files in Java.
1... an object of Properties class.
3. After that load the properties file into the program.
4. Finally get the text using the key of the properties file.
An example
How to read properties file in java
How to read properties file in java
Description of Example:-
In this example...= 8285279608
Example of Read properties file in java
import java.io.... to a
stream or load from a stream using the
properties file. This properties
Storing properties in XML file
Storing properties in XML file
... File. JAXP (Java API for XML Processing) is an interface which provides
parsing... in xml file:-
File f=new File("2.xml"):-Creating File in
which properties
How to read properties file in Java?
Example program of reading a properties file and then printing the data... the
java.util.Properties class for reading a property file in Java program... to value.
The java.util.Properties class is used to read the
properties file
How to write .properties file from jsp
How to write .properties file from jsp Hi i new to java i stuck here please help me...
my problem is "I wrote a class to write the .properties file... it in my jsp but Iam unble to modify/write the .properties file and Iam not getting
How to write properties file in java
Write properties file in java
In this example we will discuss how to write property file in java. In this
example We have write data to properties file. The properties file has
fundamentally used to store the data configuration data
... file. JAXP (Java API for XML Processing) is an interface which provides
parsing...... Record found" while compile the java file.Please give the correct solution soon
struts2 properties file
struts2 properties file How to set properties file in struts 2 ?
Struts 2 Format Examples
Struts 2 Tutorial
Reading duplicate keys from .properties file - Development process
Reading duplicate keys from .properties file Hi,
I am reading a .properties file using a basic java program.Though the .properties file will not allow duplicate keys, but still I want to develope a program to identify
Built In Properties
Built In Properties
This example illustrates how to access various system properties using
Ant. Ant provides access to all system properties as if they had been
Properties File IN Struts - Struts
Properties File IN Struts Can we break a large property file into small pieces? Suppose we have property file whose size is 64 kb .can we break... the detail along with code and also entry about properties into configuration file
Write Keys and Values to the Properties file in Java
Write Keys and Values to the Properties file in
Java... how to write keys and values
in the properties files through the Java program... to write or
store the keys and values in properties file list. The
OutputStream used
Java get set Properties
Java get set Properties
... properties by
adding a new property. In the example given below, we have create a new property
listed in the 'NewProperties.txt' file i.e java.company=Roseindia
Convert the path in to properties
with the name attribute. In
this example, the java file is converted from src directory...
Convert the path in to properties
... in to properties. In this
example, refid is a reference to an object defined elsewhere
java properties serialized
java properties serialized How to serialize properties in Java
Read the Key-Value of Properties Files in Java
Read the Key-Value of Properties Files in Java
... to read the
key-value of properties files in Java. This section
provides you... the properties file.
Program Result:
This program takes a property file name and reads
Struts properties file location - Struts
Struts properties file location Hi,
Where struts properties file stored in web application. I mean which location. Thank u Hi Friend,
The struts.properties file can be locate anywhere on the classpath
Write the Keys and Values of the Properties files in Java
Write the Keys and Values of the Properties files in
Java... will learn how to add the keys and
it's values of the properties files in Java. You... files. The properties file continuously
update the day, date, times and GMT
applicationcontext.xml properties file
applicationcontext.xml properties file
In this tutorial I will explain how you can use the properties defined in
.properties file in your spring application...
changing the properties file.
Suppose you are developing an email sending
passing .properties file as a parameter to another function
passing .properties file as a parameter to another function passing .properties file as a parameter to another function in an jsp file
Post your Comment | http://www.roseindia.net/discussion/49125-Write-properties-file-in-java.html | CC-MAIN-2014-52 | refinedweb | 938 | 58.18 |
Hi !
I want to make a console window program which take a password from window and compare it with a predefined password and then will show password match or not match.
my code is where which is compiling and running too.
But the problem is that when i am taking password input(wrong or correct password in both) from console its always showing result "not match" . please help me
here is the code
import java.io.Console; public class Main { public static void main(String[] args) { Console console = System.console(); char[] passwordArray={'s'}; char[] passwordArray2 = console.readPassword("Enter your secret password: "); if((passwordArray==passwordArray2)) { console.printf("Match\n"); } else { console.printf("not Match"); } } } | http://www.javaprogrammingforums.com/whats-wrong-my-code/25722-password-java-error.html | CC-MAIN-2016-22 | refinedweb | 113 | 58.99 |
Slingshot
Table of Contents
Apparently, Angry Birds is played for 300 million minutes a day. With that amount of dedication, isn't it about time it became a real sport?!
USB Slingshot¶
To make Angry Birds a real sport, we need real equipment. So the idea for this hack was to build a real slingshot as a USB peripheral to play Angry Birds.:
The resulting hack means fusing electronics, microcontrollers, software and, umm..., carpentry!
The Technology¶
The slingshot emulates a USB mouse, so it really is a plug 'n' play. It translates the physical use of the slingshot in to appropriate mouse controls.
With a real slingshot, you tilt the slingshot and stretch sling. The idea to measure these was using:
- An accelerometer - this can measure the tilt by tracking the gravity vector (which way is down!)
- A rubber stretch sensor - this can be used as the sling, and measure how much it is stretched
That is the input, but to play Angry Birds, you actually click on the bird, then drag to the launch angle and strength you want, then release. This means we have to translate the real slingshot movements in to a series of different mouse movements.
For example, this means translating starting to stretch the slingshot to a mouse to click and hold, whilst the vector of the stretch determined by the angle of sling and how far it is stretched translates to mouse movements relative to where we started. More on the maths later...
Ingredients to build a USB Slingshot¶
The main brain is the new mbed NXP LPC11U24, as that is designed for prototyping USB devices:
It is packaged in a DIP prototyping form-factor, uses the NXP LPC11U24 MCU based on a 32-bit ARM Cortex-M0 core, and includes I2C, SPI, UART and ADC interfaces. It is supported by the mbed online development tools and developer website, mbed C/C++ SDK, and a full set of USB libraries; USB Mouse, Keyboard, HID, Serial, MIDI, MSC and Audio classes, that make reliably creating a new USB device a matter of a few lines of code!
This is great as it makes emulating the mouse nice and easy!
The rest of the ingredients are:
Prototype¶
In order to test if the project was possible, a first prototype was made on breadboard.
Hardware¶
The hardware is based on the following connections to the mbed NXP LPC11U24:
- The accelerometer is connected over SPI to the mbed
- The stretch sensor is a resistor as part of a voltage-divider circuit, read on p15 (AnalogIn)
- The USB Type B connector is connected to the mbed D+/D- pins, and also provides the power supply to the mbed
Here is the pinout table:
Software¶
The software to test the feasibility is kept simple; the objective is to observe all different elements of the project working together.
#include "mbed.h" #include "USBMouse.h" #include "ADXL345.h" USBMouse mouse; ADXL345 acc(p5, p6, p7, p8); AnalogIn strength(p15); int main() { //Initialize accelerometer acc.setPowerControl(0x00); acc.setDataFormatControl(0x0B); acc.setDataRate(ADXL345_3200HZ); acc.setPowerControl(0x08); while (1) { int readings[3]; acc.getOutput(readings); // test accelerometer printf("acc: %i, %i, %i\r\n", (int16_t)readings[0], (int16_t)readings[1], (int16_t)readings[2]); uint16_t str = strength.read_u16(); // test stretch sensor printf("strength: %d\r\n", str); mouse.move(10, 10); // test USB relative mouse wait(0.1); } }
Import programAngryBirdsFeasibility
Test Slingshot
The experiments to see that it works:
- move the breadboard
- pull the stretch sensor
- move and pull the stretch sensor at the same time
- observe that the mouse is moving on the screen
So we have proven control! Next step is to make it in to a real slinghot!
The Real Slingshot!¶
Hardware¶
The slingshot was crafted by Chris Jarratt, from a branch found in Epping Forest, London! This is the structure in to which we embedded all the electronics.
The wiring is exactly the same as the first prototype, just that the mbed will be embedded in to the real slingshot this time.
Finally, combining all different parts we get our mbed USB Slingshot!
Software¶
How does it all work ?¶
The first question concerns the USBMouse. The options are an absolute or relative mouse. The answer is quite simple because the mbed doesn't know the absolute position of the bird on the screen, so the natural solution is a relative mouse (like a normal mouse) - position the cursor over the mouse, then the slingshot takes over and moves relative to the starting point based on interpreting the manipulations of the slingshot.
Slingshot Angle¶
The angle of the slingshot is the main thing we need to calculate the direction of the vector to apply to the mouse position.
We simply use the fact that we know gravity is causing a 1G force on the accelerometer, and use that to calculate the angle of the slingshot with some simple trigonometry.
Mouse Movement¶
The mouse position is then calculated based on the vector offset calculated using the angle of the slingshot, and the stretch sensor reading.
Because we send relative movements, we actually calculate the desired position, then work out the difference from where we know we are and send that.
Algorithm¶
The general idea for how it works for a complete firing comes in a few steps:
WAITING
- We start by WAITING, with the cursor over the bird - regardless of how we tilt the slingshot, nothing happens
- When we see a strong enough stretch, we consider that the start of AIMING, and click and hold the left mouse button
AIMING
- We then continuously calculate a vector based on the angle of the slingshot, and the stretch of the sling
- This is translated in to relative mouse movements with some more trigonometry, and the mouse is moved as appropriate
- As we are positioning based on a vector but sending relative mouse positions, we keep a note of the accumulated movements so we can send the difference each time
FIRING
- We enter FIRING when we see a fast reduction in the sling stretch
- At this point we release the mouse button, then return the mouse back to the starting position, ready for the next throw!
Code¶
The whole code is fairly concise, so here it is in full:
Import program
00001 /* mbed USB Slingshot, 00002 * 00003 * Copyright (c) 2010-2011 mbed.org, MIT License 00004 * 00005 * smokrani, sford 00006 * 00007 * Permission is hereby granted, free of charge, to any person obtaining a copy of this software 00008 * and associated documentation files (the "Software"), to deal in the Software without 00009 * restriction, including without limitation the rights to use, copy, modify, merge, publish, 00010 * distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the 00011 * Software is furnished to do so, subject to the following conditions: 00012 * 00013 * The above copyright notice and this permission notice shall be included in all copies or 00014 * substantial portions of the Software. 00015 * 00016 * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING 00017 * BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND 00018 * NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, 00019 * DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, 00020 * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. 00021 */ 00022 00023 #include "mbed.h" 00024 #include "USBMouse.h" 00025 #include "ADXL345.h" 00026 00027 // Physical interfaces 00028 USBMouse mouse; 00029 ADXL345 accelerometer(p5, p6, p7, p8); 00030 AnalogIn stretch_sensor(p15); 00031 BusOut leds(LED1, LED2, LED3, LED4); 00032 00033 // Return slingshot angle in radians, up > 0 > down 00034 float get_angle() { 00035 int readings[3]; 00036 accelerometer.getOutput(readings); 00037 float x = (int16_t)readings[0]; 00038 float z = (int16_t)readings[2]; 00039 return atan(z / x); 00040 } 00041 00042 // Return normalised stretch value based on bounds of all readings seen 00043 float get_stretch() { 00044 static float min_strength = 0.7; 00045 static float max_strength = 0.7; 00046 float current_strength = stretch_sensor.read(); 00047 if(current_strength > max_strength) { max_strength = current_strength; } 00048 if(current_strength < min_strength) { min_strength = current_strength; } 00049 float stretch = (current_strength - min_strength) / (max_strength - min_strength); 00050 return 1.0 - stretch; 00051 } 00052 00053 // move mouse to a location relative to the start point, stepping as needed 00054 void move_mouse(int x, int y) { 00055 const int STEP = 10; 00056 static int current_x = 0; 00057 static int current_y = 0; 00058 00059 int move_x = x - current_x; 00060 int move_y = y - current_y; 00061 00062 // Move the mouse, in steps of max step size to ensure it is picked up by OS 00063 while(move_x > STEP) { mouse.move(STEP, 0); move_x -= STEP; } 00064 while(move_x < -STEP) { mouse.move(-STEP, 0); move_x += STEP; } 00065 while(move_y > STEP) { mouse.move(0, STEP); move_y -= STEP; } 00066 while(move_y < -STEP) { mouse.move(0, -STEP); move_y += STEP; } 00067 mouse.move(move_x, move_y); 00068 00069 current_x = x; 00070 current_y = y; 00071 } 00072 00073 template <class T> 00074 T filter(T* array, int len, T value) { 00075 T mean = 0.0; 00076 for(int i = 0; i<len - 1; i++) { 00077 mean += array[i + 1]; 00078 array[i] = array[i + 1]; 00079 } 00080 mean += value; 00081 array[len - 1] = value; 00082 return mean / (T)len; 00083 } 00084 00085 typedef enum { 00086 WAITING = 2, 00087 AIMING = 4, 00088 FIRING = 8 00089 } state_t; 00090 00091 int main() { 00092 leds = 1; 00093 00094 // setup accelerometer 00095 accelerometer.setPowerControl(0x00); 00096 accelerometer.setDataFormatControl(0x0B); 00097 accelerometer.setDataRate(ADXL345_3200HZ); 00098 accelerometer.setPowerControl(0x08); 00099 00100 state_t state = WAITING; 00101 Timer timer; 00102 00103 float angles[8] = {0}; 00104 float stretches[8] = {0}; 00105 00106 while(1) { 00107 00108 // get the slingshot parameters 00109 float this_stretch = get_stretch(); 00110 float this_angle = get_angle(); 00111 00112 // apply some filtering 00113 float stretch = filter(stretches, 8, this_stretch); 00114 float angle = filter(angles, 8, this_angle); 00115 00116 leds = state; 00117 00118 // act based on the current state 00119 switch (state) { 00120 case WAITING: 00121 if(stretch > 0.5) { // significant stretch, considered starting 00122 mouse.press(MOUSE_LEFT); 00123 state = AIMING; 00124 } 00125 break; 00126 00127 case AIMING: 00128 if(stretch - this_stretch > 0.1) { // rapid de-stretch, considered a fire 00129 mouse.release(MOUSE_LEFT); 00130 move_mouse(0, 0); 00131 timer.start(); 00132 state = FIRING; 00133 } else { 00134 int x = 0.0 - cos(angle) * stretch * 200; 00135 int y = sin(angle) * stretch * 200; 00136 move_mouse(x, y); 00137 } 00138 break; 00139 00140 case FIRING: 00141 if(timer > 3.0) { 00142 timer.stop(); 00143 timer.reset(); 00144 state = WAITING; 00145 } 00146 break; 00147 }; 00148 00149 wait(0.01); 00150 } 00151 }
Mouse Setup¶
To use it, simply position the mouse cursor over the bird, and then start using the slingshot!
The cursor is not coming back at the initial position
On Windows (and probably on Linux or Mac OS), the cursor is not coming back exactly at the same initial position after a firing. To solve this issue, I modified this:
- go into the Control Panel
- Hardware and Sound
- Mouse in the devices and printers section
- in the pointer options tab, deselect Enhance pointer precision
- You can also reduce the cursor speed
In Action¶
Turns out it works! Here it is in action!
So now you can kill pigs with a real USB Slingshot, by combining the two totally different worlds of carpentry and embedded systems!
Hopefully this gives you all the instructions you need to build your own, or any other USB devices you need to design!
Thanks¶
Thanks to everyone who helped us to make this possible!
- Sparkfun for the Accelerometer
- Adafruit for the Stretch Sensor
- RS for the USB connector
- NXP for the ARM Cortex-M0 MCU used on the mbed NXP LPC1U24
- Chris Jarrett for crafting the wooden slingshot
Making the Video¶
Here is a little behind the scenes on how we put together the video one Wednesday afternoon. Not really something we'd done before, so a lot of making it up as we went along :)
Prototype your own USB devices with the new mbed NXP LPC11U24!¶
The LPC11U24 is one of the new ultra-low-cost 32-bit ARM microcontrollers entering the market that open up all sorts of opportunities for building USB devices. The times of requiring in-depth knowledge of the USB protocol, fiddling with complex software stacks and fighting 8 or 16-bit MCUs is over. Or being constrained by USB bridge chips. These chips only cost $1-2 in volume!
Using the mbed tools and the set of USB libraries, prototyping these devices should be really fast too!
For a look at all the USB Device types that work out-of-the-box, take a look at:
- /handbook/USBMouse - Emulate a USB Mouse with absolute or relative positioning
- /handbook/USBKeyboard - Emulate a USB Keyboard, sending normal and media control keys
- /handbook/USBMouseKeyboard - Emulate a USB Keyboard and a USB mouse with absolute or relative positionning
- /handbook/USBHID - Communicate over a raw USBHID interface, great for driverless communication with a custom PC program
- /handbook/USBMIDI - Send and recieve MIDI messages to control and be controlled by PC music sequencers etc
- /handbook/USBSerial - Create a virtual serial port over the USB port. Great to easily communicate with a computer.
- /handbook/USBAudio - Create a USBAudio device able to receive audio stream from a computer over USB.
- /handbook/USBMSD - Generic class which implements the Mass Storage Device protocol in order to access all kinds of block storage chips
These pages should show how easy it is to prototype low-cost USB devices, so you can concentrate on inventing the applications. Looking forward to seeing what devices you develop!
See also:
- mbed NXP LPC11U24 prototyping board
- mbed Developer Site homepage and tour
- Join the mbed Mailing List for updates and occasional giveaways
The demo was inspired by the emergence of ultra-low-cost 32-bit microcontrollers that include USB, and we wanted to show off how easy it can be to prototype them to take advantage of this trend. For more about this and why we built the new mbed NXP LPC11U24 board, take a look at: | https://developer.mbed.org/cookbook/Slingshot?action=view&revision=4254 | CC-MAIN-2016-50 | refinedweb | 2,351 | 56.08 |
Tax Basics for Canadians Investing in U.S. Markets
If you’re investing south of the border, the U.S. revenue agency will want to know what you’re up to. Read on to find out to deal with the IRS (Internal Revenue Service).
Knowing that the U.S. revenue agency will have an interest in you
You are probably quite familiar with paying taxes to — and dealing with — the Canada Revenue Agency (CRA). However, a number of individuals who live in Canada also have the pleasure of filing an income tax return with the U.S. Internal Revenue Service — better known as the IRS.
Not to ruin the party, but if you die owning U.S. assets you can be subject to U.S. estate tax. Yikes! You must file an income tax return with the IRS when you fit into one of the following categories:
You’re a U.S. citizen: U.S. citizens are required to file a U.S. income tax return (IRS form 1040), report their worldwide income on the return, and pay U.S. federal income tax no matter what country they live in.Credit: "Filing Taxes," © 2012 Phillip Taylor PT, used under a Creative Commons Attribution 2.0 Generic license:
Canada’s income tax treaty with the U.S. and the Canadian and U.S. foreign tax credit mechanisms are designed to avoid having taxpayers taxed twice on the same income. So, reporting the same income on your Canadian and U.S. income tax returns (adjusted for the different currencies, of course) does not mean you’ll be subject to double tax. The CRA and IRS aren’t that unfair.
You’re a green card holder — or the holder of a U.S. Permanent Resident Card These folks have the same U.S. tax filing rules as a U.S. citizen. (By the way, the card is no longer green.)
You’re a Canadian resident considered by the U.S. to be a resident alien or non-resident alien
Figuring out your residency status
Determining whether you’re a resident or non-resident alien of the U.S. is not as straightforward as you might think!
Resident alien
You’re considered a resident alien of the U.S. if you meet the substantial presence test because of frequent stays in the U.S. and cannot claim the closer connection exception regarding your ties to Canada. You may find you’re a resident alien if you’ve moved to the U.S. on a temporary basis for work. Resident aliens are taxed in the U.S. on their worldwide income and must file a U.S. income return (IRS form 1040) — just like a U.S. citizen.
Substantial presence test
This test is based on your physical presence in the U.S. over the last three years. You’re considered substantially present in the U.S. when you were present during the current and past two years for at least 183 days. To determine the total days you were in the U.S., get out your calculator and add up the following (including partial days):
Each day this year counts as a full day
Each day last year counts as one-third day
Each day two years ago counts as one-sixth day
If you were in the U.S. for fewer than 31 days this year you will not meet the substantial presence test.
Closer connection exception
If due to frequent vacationing in the U.S. you do meet the substantial presence test, then you’ll be considered resident and required to file a U.S. tax return that reports your worldwide income.
However, you can avoid this tax filing if you’re able to claim you were more closely connected with Canada than with the U.S. because of your significant personal (home, family, assets, social, political, church, driver’s licence) and business ties to Canada. A closer connection exception is available if you, as the alien
Were present in the U.S. for fewer than 183 days this year,
Maintained a permanent place of residence in Canada throughout the year, and
Complete and file IRS form 8840, Closer Connection Exception Statement for Aliens, with the IRS by the deadline (June 15).
Non-resident alien
You’re considered a non-resident alien of the U.S. when you don’t meet the substantial presence test or you do meet the substantial presence test but can claim an exception due to having a closer connection to Canada. This includes a large number of Canadians, often referred to as snowbirds, who spend a great deal of time in the U.S. to avoid harsh Canadian winters.
A non-resident alien must file a non-resident U.S. income tax return (IRS form 1040NR) when the individual
Has U.S. employment income.
Has a tax liability on U.S. source income including employment income, interest, dividends, and royalties.
Is engaged in business that can produce income connected (the IRS’s word) with the U.S. For example, renting out your condo in Boca Raton, Florida or your vacation home in Tempe, Arizona. You may earn income from renting the property or you may have a capital gain on sale.
Even though the Canada–U.S. tax treaty is designed to avoid you being taxed in both countries, the U.S. has the first right to tax rental income and capital gains regarding real estate located in the United States. A U.S. income tax return filing would be necessary and any U.S. tax paid would qualify for a foreign tax credit when completing your Canadian income tax return.
If you are Canadian with U.S. portfolio investments such as mutual funds with U.S. exposure or U.S. stocks or bonds, you will probably notice that U.S. withholding taxes will be taken off your U.S. source investment income such as dividends or interest. If you don’t meet the above tests requiring you to file a U.S. tax return, your obligation to the U.S. ends there. Remember to claim the taxes withheld as a foreign tax credit on your Canadian tax return to ensure you are not double taxed.
Filing U.S. tax returns on time
Individuals are taxed based on a calendar year, just as in Canada. The key dates to remember are:
April 15 (not April 30!):
Due date for previous year’s income tax owing
Due date for filing IRS form 1040 income tax return (U.S. citizens, green card holders living in the U.S., and resident aliens)
Due date for filing form IRS 1040NR for non-resident aliens with income subject to withholding tax (i.e., employment income)
June 15:
Due date for filing IRS form 1040 income tax return for U.S. citizens living in Canada
Due date for filing form IRS 1040NR for non-resident aliens with income not subject to withholding tax
Due date for filing IRS form 8840 for the closer connection exception
Don’t forget about state, county, and city taxes
Own property in the U.S.? If you’re considered a resident alien, you may be required to file a state, county, or city tax return for the area in which you own property. For further information, go to the State and Local Government Website Directory. | http://www.dummies.com/how-to/content/tax-basics-for-canadians-investing-in-us-markets.html | CC-MAIN-2015-40 | refinedweb | 1,227 | 66.23 |
User:0xdc/substrate/20200501
Phew, it's been another while since I made notes on substrate. While there have been builds since December, up to last month's (April) builds didn't have too many changes. That's now changed! May has some big changes, that need to be documented.
Contents
Changes
catalyst 3.1/4?
catalyst has been getting some upstream love! This is great news, except a lot of existing behaviour is changing quite rapidly and incompatibly with my patches.
Some important changes:
- a new dependency on dev-python/pytoml
- FEATURES=binpkg-multi-instance, this allows us to use a single shared package repository safely
- digests are now provided as blake2 and sha512 sums only, without the need to shash
- stage1+stage2 only prepare the C.UTF-8 locale. Makes them smaller and less locales to generate (saves time on arm!)
- CONTENTS files are now gzipped
Anyway, I've tried to include as many of the changes as I could, but there's still more coming!
migration to nftables
iptables has been deprecated for a while and new firewalls *should* be written in nftables. It took me a while to actually learn nft but it's pretty handy. Start using it!
machined import-tar script
I've also added one of my helper scripts (/builds/import-tar.sh) for users of systemd nspawn containers. This'll import any of the output stages, and if it finds portage, it will set it up to share packages and the portage dir with your host and any other containers. This means you can use clean building containers to build packages for your main system or other containers.
Embedded stages
Speaking of systemd-nspawn containers, I've repurposed the 'embedded' target to produce systemd stages. These aren't as small as normal embedded containers, as we need to pull in dynamic dependencies, but it allows us to output systemd based mini-distros that are only able to perform a specific task (but perform it very well!).
For now, I've included an amd64 nginx image with rtmp support as a real example. I use it a lot too.
I've enabled snapcache for all architectures, since we use the squashfs snapshots and mount namespaces. This means for a particular snapshot, we only unpack it once. This is really useful for arm, since the unpack is slow and removal is slow, and we'd have to do both of those tasks for each stage build.
Notes
amd64
- Seed (upstream) stage: stage3-amd64-systemd-20200423.tar.bz2
arm
- Seed stage3: stage3-armv7a_hardfp-20180831.tar.bz2 -> 20190601 -> 20191201 -> 20200301
The stage builds to create the 20190601 versions are still affected by the previous mpfr issues User:0xdc/substrate/20191201#armv7a. However the workaround then breaks subsequent builds so the workaround was removed. | https://wiki.gentoo.org/wiki/User:0xdc/substrate/20200501 | CC-MAIN-2020-45 | refinedweb | 467 | 64.71 |
parse a dot seperated string into dictionary variable
python nested dictionary dot notation
dotmap python
dot notation access to dictionary attributes
python dictionary accessors
python create object with dot notation
how to access dict with dot in python
access dict using dot notation' [^.]+ # one or more non-period characters ) # end named group 'dict' \. # a literal dot (?P<keys> # begin named group 'keys' .* # the rest of the string! ) # end named group 'keys'""", in_, flags=re.X) d = vars()[match.group('dict')] for key in match.group('keys'): d = d.get(key, None) if d is None: # handle the case where the dict doesn't have that (sub)key! print("Uh oh!") break result = d # result == True
Or even more simply: split on dots.
in_ = 'a.b.c' input_split = in_.split('.') d_name, keys = input_split[0], input_split[1:] d = vars()[d_name] for key in keys: d = d.get(key, None) if d is None: # same as above result = d
Python - How to split string into a dict, 1.1 Split a string into a dict. #!/usr/bin/python str = "key1=value1;key2=value2; key3=value3� Question: Tag: python,string,dictionary
s = "a.b.c" s = s.replace(".", "][")+"]" # 'a][b][c]' i = s.find("]") # find the first "]" s = s[:i]+s[i+1:] # remove it 'a[b][c]' s = s.replace("]", "\"]").replace("[", "[\"") # add quotations 'a["b"]["c"]' # you can now execute it: v = eval(s)
Python, Python - Convert Dictionary to Concatenated String � Python | Convert dictionary object into string � Python | Convert nested dictionary into� How to parse strings using String.Split in C#. 01/03/2018; 2 minutes to read +3; In this article. The String.Split method creates an array of substrings by splitting the input string based on one or more delimiters. This method is often the easiest way to separate a string on word boundaries.
I ran into this same problem for parsing ini files with dot-delimited keys in different sections. e.g.:
[app] site1. = hostname site1. = username site1.database.hostname = db_host ; etc..
So I wrote a little function to add "add_branch" to an existing dict tree:
def add_branch(tree, vector, value): """ Given a dict, a vector, and a value, insert the value into the dict at the tree leaf specified by the vector. Recursive! Params: data (dict): The data structure to insert the vector into. vector (list): A list of values representing the path to the leaf node. value (object): The object to be inserted at the leaf Example 1: tree = {'a': 'apple'} vector = ['b', 'c', 'd'] value = 'dog' tree = add_branch(tree, vector, value) Returns: tree = { 'a': 'apple', 'b': { 'c': {'d': 'dog'}}} Example 2: vector2 = ['b', 'c', 'e'] value2 = 'egg' tree = add_branch(tree, vector2, value2) Returns: tree = { 'a': 'apple', 'b': { 'c': {'d': 'dog', 'e': 'egg'}}} Returns: dict: The dict with the value placed at the path specified. Algorithm: If we're at the leaf, add it as key/value to the tree Else: If the subtree doesn't exist, create it. Recurse with the subtree and the left shifted vector. Return the tree. """ key = vector[0] tree[key] = value \ if len(vector) == 1 \ else add_branch(tree[key] if key in tree else {}, vector[1:], value) return tree
scalpl � PyPI, Scalpl provides a lightweight wrapper that helps you to operate on nested dictionaries seamlessly through the built-in dict API, by using dot-separated string � >>> help(ast.literal_eval) Help on function literal_eval in module ast: literal_eval(node_or_string) Safely evaluate an expression node or a string containing a Python expression. The string or node provided may only consist of the following Python literal structures: strings, numbers, tuples, lists, dicts, booleans, and None.
The pyjq library does something quite similar to this, except you have to explicitly provide a dictionary to be the root, and you have to prefix your strings with a
. to refer to whatever dictionary was your root.
python:
import pyjq d = { 'a' : { 'b' : { 'c' : 'd' } } } for path in ['.a', '.a.b', '.b.c.d', '.x']: print(pyjq.first(path, d))
output:
{'b': {'c': 'd'}} {'c': 'd'} None None
dotty-dict � PyPI, Simple wrapper around python dictionary and dict like objects; Two wrappers with the same dict are considered equal; Access to deeply nested keys with dot� I have a character variable of varying lengths that I want to separate into separate variables. The variable always follows the following pattern - AA.AA.AA.AA.AA (2 characters then a period, 2 characters then a period, etc) - and each "AA" signifies a unique code I need to have separated for further analysis. Example of what it looks like now:
Python Split String Examples, Split. Strings often store many pieces of data. In a comma-separated format, these Here we handle a string that contains city names separated by commas. t) # Set string variable to non-partitioned part. s = t[2] Output Dot ('Dot', ' ', 'Net Perls� These are good differences to point out; another important one is that -split takes a regex (regular expression) as its (first) RHS operand, whereas the [string] type's .Split() method operates on a literal character / array of characters / and - in .NET Core - also a literal string.
6. Dictionaries, sets, files, and modules — Beginning Python , As an example, we will create a dictionary to translate English words into Spanish. Each pair contains a key and a value separated by a colon. Whenever two variables refer to the same object, changes to one affect the other. The easiest and most powerful way to format a string in Python 3 is to use the format method. The split method breaks the string into an array where the character we pass in to the method (in this case, a comma) separates each element in the array. So, the first element of the array is comma one, the second is comma two and the fourth is comma four. Remember that arrays begin at the 0th character, not the first.
DICTIONARY, where Key is an IDL variable containing a scalar string. Or you can use dot notation: value =� parse a dot seperated string into dictionary variable. python,string,dictionary.
- How is the output a dictionary?
- Didn't get the question. What do you actually want to happen? Can you be more specific? Do you want
ato be a dictionary with key
b, and then
bto be a dictionary with key
cwhich has a dictionary as value, which has key
d?
- yes tomasyany... the first part of the string (before dot) will become the dictionary name and the rest of the substrings will become the dictionary keys...
- So
awill be the variable that stores the dictionary of dictionaries?
- this evaluates to
a[b][c]as against
a["b"]["c"]. To solve this, i added two more lines before
evalas,
s = s.replace("]", "\"]")and
s = s.replace("[", "[\"").
- Oh, I should fix it then
- Super helpful. I'm using this as a crossover for people to use and excel sheet with columns labeled in this pattern so that I can do bulk api calls though I needed to add a bit to the logic to get it to work: rowObj.update(add_branch(rowObj,colName.split("."),rowValue)) | https://thetopsites.net/article/59257582.shtml | CC-MAIN-2021-31 | refinedweb | 1,181 | 64.3 |
Hi,
I am trying to develop a generic way to populate UITabeViewDataSource. It is largely working, but I had a print statement in the init() and it was causing a crash. It was printing entityName, a computed property, coded thusly:
public class RecordArray<T: NSManagedObject> { var entityName: String { let entity = T.entity() return entity.name! }
When I step through it, entity is all zeroes, like a classical objective-c nil, even though entity() is a non-optional function. But in later functions it works.
Does anyone know the reason for this?
---
Mark
I’ve seen this sort of thing when properties do not have their nullability set correctly. In this case
entity is declared as never being nil, but it sounds like it is. Alas, the documentation doesn’t shed any light on why this might happen. I recommend two things:
Confirm that this is, in fact, the problem. You can do this by adding an Objective-C category that declares a a new property,
maybeEntity perhaps, that is optional. Then have the Objective-C method implementation just return the
entity property. At that point your Swift code can access
maybeEntity and determine if it is indeed nil.
Once you’ve confirmed the problem, you might ask over in App Frameworks > Core Data to see if anyone can input as to why it might be happening.
Share and Enjoy
—
Quinn “The Eskimo!”
Apple Developer Relations, Developer Technical Support, Core OS/Hardware
let myEmail = "eskimo" + "1" + "@apple.com" | https://forums.developer.apple.com/message/203718 | CC-MAIN-2019-09 | refinedweb | 247 | 57.47 |
>>:: ...
Unit Tests for Dependable Code [ID:143] (9/10)
in series: Python Development on XP lets us trust our code - and unit-tests (via 'nosetests') make the task of writing tests super-easy. We should all be writing unit-tests with our code.
Here we use the excellent 'nosetests' to adopt a test-driven approach to coding, allowing us to build our confidence that our code is working exactly as we want it to. If you don't have nosetests yet, see the Installing Nosetests screencast.
We build 'checkNumbers.py' and a corresponding unit-test module 'testCheckNumbers.py' (source code in the wiki) that confirms that our program - written to parse a file of numbers and check that the numbers match our specified criteria - passes all the tests and only accepts the kind of numbers that we are after.
We use boolean conditions and exception handling to robustly parse the file of numbers, along with commenting our code and using sensible variable names.
Additionally you should watch Jeff Winkler's ShowMeDo on the nosey.
At the end of this set you will have the necessary knowledge to write your own unit-tests, allowing you to be confident that your code runs (and fails) in the right way.
If you want more details see this worked-example at DiveIntoPython and this nose write-up. For some more background, see wikipedia for entries on Unit Testing and Test Driven Development (TDD).
To talk to your fellow Pythonistas you should join the ShowMeDo Learners Group.
- python
- beginners
- tutorials
- beginner_programming
- programs
- code
- time
- files
- make
- screencasts
- learn
- development
- newbies
- information
- look
- builds
- notes
- end
- programming_tools
- modules
- t
- writing
- changes
- set
- background
- talks
- knowledge
- test
- exercise
- values
- variables
- installing
- nosetests
- testing
- XP
- continue
- tasks
- exceptions
- coding
- pydev
- ordinary
- test-driven
- group
- requirements
- IDLE
- skills
- unit-tests
- figure
- nose
Got any questions?
Get answers in the ShowMeDo Learners Google Group.
Video statistics:
- Video's rank shown in the most popular listing
- Video plays: 368 informative, this will save me hours of time just getting started on unit testing.
Thank you,
Steve
Excellent series. Havn't looked yet but do you have a series on designing software using UML or what ever is used with the python mind set and what graphical tool to use to plan for software with?
Thank you very much Ian, it's been a great series so far. I would only point out something, I would like to see more code examples, some useful pieces of code that show us the power of python.
Other than that it's a very interesting series of tutorials.
I find it easier to learn by following an example, so your tutorials are immensely useful to me. Thank you.
Thank you very much for the unit test demonstration. I had long wondered what it was about.
I had trouble running the nose tool. It appeared to have installed fine, but the nosestest command would not run on the command line.
hi -
i just subscribed, and a comment i have is that it would be nice if i could speed up the video playback - i can hear faster than you can talk. this might be a feature of the player.
anyway, this stuff is great- i'm looking forward to learning python quickly.
thanks,
jeff
This is an excellent series. Within a few minutes I was up and running on EasyEclipse for Python. The longest wait was for the download. In one evening I went through the series and was using PyDev in Eclipse. Thanks!
Hi Gasto, yes, I see what you mean. By saying that 'pass' shows that the test has 'passed' I'm introducing some possible confusion.
'pass' is a Python statement which means 'do nothing', we use it when we haven't written more useful code yet. Since 'pass' is a no-op, it doesn't Fail or Error, so when nosetests is running is sees a perfectly good bit of code and chalks it up as a success.
Thanks for pointing out that possible confusion!
Ian.
I am a little worried about what was said that the pass statement in the function is for Nose U.T. to recognize it as a passed/correct function. It is rather a python syntax for creating a dummy function.
Hi Ian,
Great job!
The visual instructions of the screen cast is an efficient learning method.
Its a time saver, looking forward to more python series!
Cheers,
Kupper
Hi Eldaria, thanks for the wiki update and the comment. Yes, the wiki update is great. I'm glad you're enjoying testing :-)
Ian.
Very useful, I have been doing a lot of minor coding, but never really done testing.
I usually always used debugging to find errors, basically stepping through the entire code untill it breaks. :-)
Anyway, I updated the Wiki to inlude how to install nosetests on Ubuntu, that was actually my first Wiki entry ever anywhere, hope I did it right. :-)
Hi leeard. I have updated the wiki page for installing nosetests:
which now links to the 'adding Python to DOS path' video:
which you need so that DOS can see nosetests.
Cheers
Ian.
very nice, and easy to understand. My only problem is installing nose. I followed the steps exactly (a few times) on the wiki and I don't have the easy_install command after running the ez_setup script. I'm XP Pro, any suggestions?
Thanks Ian for taking the time to make this episode it’s been a great spring board to re-approach python programming which I fully agree with. Thanks for making it simple to kick off with.
From memory - the behaviour of nosetests and directories is a bit odd. You can specify a directory as a nosetest argument and it runs the tests there, but the 'current' directory for the scripts is (I think) the directory you run nosetests from (and not the directory you specified).
This caused me some headaches as I have two sets of test directories which both refer to configuration files elsewhere on the path, so I had to use relative file names (various '../') to access the files.
It *does* work, you just have to figure out where you are in the path.
To test - get your test code to do something like:
def test1():
import os
print "Current dir: ", os.getcwd(), os.path.dirname(__file__) # show loc of the file and working dir, as nosetests sees it
1/0 # force a ZeroDivisionError in the nosetest
You use the 1/0 to force nosetest to print error messages - which includes the getcwd/dirname result, and from that you can see where you are in the path.
Ian.
Maybe the discussion about what directories nosetests will search is moot? If you don't start nosetests from the directory where the script to be tested resides, and if the script to be tested contains a reference to the current directory (like fileObject = open("../data/anyfile.txt", "r"), it appears that nosetests won't find it the file and returns an error.
Hi Vincent. I have done some more digging and I get different behaviour on my laptop with Python 2.5 than I do with my Python 2.4 at WebFaction (which runs ShowMeDo), I'll explain this at the end.
Directories - I can have an arbitrary number of directories which nosetests will look through, as long as they have names like 'testXYZ'. E.g. I can have:
mySource\test1.py
mySource\testDir1\testDir2\test2.py
and both the test files are found if I run nosetests within 'mySource'. If I have:
mySource\aDir\testDir3\test3.py
then 'test3.py' isn't found.
I can also name any of the directories to be 'src' as you have mentioned, but this isn't mentioned in the official nosetests documentation:
If you look at 'Writing tests' on that webpage you'll see a paragraph describing the regular expression that is used to match Python test modules and directory names:
(?:^|[b_.-])[Tt]est)
but I can't understand this Regular Expression (I *think* it is in error - see below). Can anyone expand upon this? My RegExp knowledge is pretty light.
Under 'Finding and running tests' on the same webpage we have:
.'
However, if we run "nosetests --help" then we get:
---
...
Any python source file,
directory or package that matches the testMatch regular expression
(by default: (?:^|[\b_\.-])[Tt]est) will be collected as a test (or
source for collection of tests).
(my break)
In addition, all other packages
found in the working directory are examined for python source files
or directories that match testMatch. Package discovery descends all
the way down the tree, so package.tests and package.sub.tests and
package.sub.sub2.tests will all be collected.
...
---
which explains things differently from the main help-page as the Regular Expression is now escaped (with \b and \. which makes a touch more sense). However I still don't see how this applies to the problems that we see...
Re. WebFaction - there I have a set of directories like:
\myFiles\testRunningSite
\myFiles\someSource\tests
and the tests in each are found when we run 'nosetests' from 'myFiles' - this appears to be different behaviour from what I get here on Windows on my laptop.
So - I have two questions - perhaps someone else can help?
1) How come if we have a subdirectory like 'mySource\aDir\testDir3\test3.py' then the test isn't found if we run 'nosetests' from 'mySource'?
2) How come 'src' is accepted as a directory for running tests even though it isn't discussed in the nosetests help (webpage or via --help)?
The solutions are out there...
Ian.
More Nosetest Quirks: The video says that nosetests will search subdirectories, but here's the behavior I get. Nosetest will search the directory where it is started, plus a subdirectory, if any, immediately below that one, but apparently only if it is called "src".
Note: I just discovered that nosetests not only looks for "test" at the beginning of a filename, but also for "Test" (but not "TesT" or _test), and that it also looks in the middle or end of a filename for "_test" (therefore it will test a file called something like number_test_file or number_test).
Great, glad the whole set was so useful :-)
I'm working on the new Introductory Python series today, now I must brew some coffee and get on with recording the first episodes...
Ian.
Now up and running with the formidable Eclipse, Pydev, Nose, and Nosy combination on both Suse Linux and Windows. I hate to imagine how horrible it would have been without your help.
Now I can start working on my project....er...uh......I mean on reviewing some actual Python commands and structures. Is that new Python course ready yet? I'm so hooked on these showmedos that I hate to try to learn something without one.
If you like nosetests, make sure you check out Jeff Winkler's video about nosy. Doing unit testing with nosy is almost fun. I can't wait to try this out on my next project. Now, if only I can figure out how to get nosetests working right on my Suse Linux box....
Unit tests and Test Driven Development (TDD) are crucial to writing dependable code.
I ignored them in Python for years because it was always a pain with C++ (I was a C++ coder for years)...then it turns out that after 10 minutes of playing with nosetests in Python it all 'just works' and is really easy. Woot!
Best to get into TDD sooner rather than later, it'll save you a lot of heartache on tricky problems and most importantly it keeps your momentum up (rather than leaving you feeling annoyed and frustrated!).
Cheers,
Ian.
You have convinced me to try your unit testing method. The lesson is clear about how it works.
My main difficulty had to do with getting nosetests installed under Windows XP, which in turn required an installation of easy_install. I got it with a little effort, and the wiki and links you kindly provided, but I think a total newbie might need a little more screencast style hand-holding.
I'm still fooling around with the Linux installation, but that is probably outside the scope of the course.
Hi miracle. I wanted to make an episode on unit-testing as I avoided trying it for so long because it sounded complicated. When I tried it...of course...it was super-easy and so I wanted to show others how to get going.
Unit-testing is a great way to solidly test your code (or website - we use it with Titus' Twill to test ShowMeDo).
I *really* recommend that new users learn about nosetests, it will surely help them write better code and, especially, it will help them avoid frustrating errors and hours of debugging from silly mistakes (mistakes which your unit-tests will already catch and stop you repeating).
Ian.
This is another great session. Lots of information (including links) to get started with unittest. The focus to teach TDD method is very important and beyond python.
Great work, Ian. Hope more is coming...
I will surely recommend this series/site to my friends...
Hi Chris. Great, I'm glad it was helpful :-) I worked hard to give a nice, easy introduction to unit-testing. Here I hope I've given enough to let a new user start unit-testing their own code nice and quickly.
The discussion at the end on how much (or little) unit-testing should be done ought to be useful to those new to the technique too.
Cheers!
Ian.
This was a great video that shows how to create tests for your code so that you can verify it does what you want it to! I found this to be very helpful. | http://showmedo.com/videotutorials/video?name=pythonOzsvaldPyNewbie8 | CC-MAIN-2015-18 | refinedweb | 2,310 | 72.05 |
Difference between revisions of "Meetings/Neutron-DVR"
Revision as of 15:00, 21 September 2016
The OpenStack Networking L3 DVR Sub-team holds public meetings as advertised on OpenStack IRC Meetings Calendar. If you are unable to attend, please check the most recent logs.
Contents
- 1 Meetings
- 2 Agenda
- 2.1 Meeting September 21st, 2016
- 2.2 Topics for Discussion
- 2.2.1 Bugs (Swami)
- 2.2.1.1 New Bugs this week
- 2.2.1.2 High Priority Bugs in progress
- 2.2.1.3 Categorized Bugs
- 2.2.1.4 Gate Test Failures
- September 21:
New Bugs this week
- (NEED-TRIAGE) - FloatingIP GARP fails. Log seen in the l3 agent and VM not able to ping
- Need a reproducer
High Priority Bugs in progress
- , but we might have further discussion during the mid-cycle meetup)
- (WIP)(Server side patch)
- (WIP)(Agent side patch)
Existing Functionality Broken Bugs
- .
- Live migration
-
- (Incomplete) (StaleDataError) - on Watch
- (Low)- (DVR functional Job failure) - on Watch state
Bugs Closed Recently
- (FIXED) - dvr: can't migrate legacy router to DVR
- Need to turn-off guard in transaction
-
- (FIXED) - Keepalive process kill vrrp child process with l3/dvr/ha
- (MUST FIX) - DVR+L3 HA Loss during failover is higher
- (SHOULD FIX) - Generic DVR portbinding useful for HA ports.
- (SHOULD-FIX) - Regression, snat_namespace object creation ahead of time does not solve some external_gateway_update condition.
- )
- (MUST FIX) - Cleanup of ip rule and tables for stale snat
- (merged)
- (MUST FIX) - CSNAT port fails due to no fixed ips. (partial workaround proposed).
- (Merged)
- (MUST FIX) - Itemallocator class can throw a ValueError
- )
- Neutron Failure Rate dashboard -
- A number of patches have merged in both Neutron and Infra repositories that fix issues, including:
- DHCP (multiple)
- Underlay network possibly using same VNI as overlay, causing packets to go out wrong interfaces
- DVR multinode failure rates have lowered - 5% in gate queue, 15% in check queue
- VM failing to get DHCP address typical problem, need to re-confirm that's still the case
- Bugs in Nova:
- (Volume based live migration aborted unexpectedly)
- (live-migration ci failure on nfs shared storage)
#chair Swami
#topic Announcements
#undo topic
#link
#action haleyb will get something specific done this week
...
#endmeeting | https://wiki.openstack.org/w/index.php?title=Meetings/Neutron-DVR&diff=133414 | CC-MAIN-2020-24 | refinedweb | 363 | 59.03 |
Basically I have to write a program that plays the card game, 21.
This is the assignment. I've done most of it but my code has a few issues.
"
PART 1:
You are going to create a simple card game of 21. In this game, the single player has to try to come as close to a score of 21 without going over and beat the computer's score.
1. Set up a class called PlayingCard. Add a method that returns a string representing its rank and suit. For example, the card with rank 1 and suit 'S' is "Ace of Spades".
2. Set up a class called DeckOfPlayingCards which contains the following information:
INSTANCE VARIABLES
an array of 52 PlayingCard objects
index of the "top" card in the deck
METHODS
constructor - initializes each PlayingCard object to a unique card in a standard deck
shuffle - randomly permute the order of the cards in the array (see below for a hint) and sets the top card to the first card in the array
deal - returns the top card in the deck and sets the top card index to the next card
3. Set up a class TwentyOne with a main method that creates the deck of cards and then allows the user to play the game of 21.
SHUFFLING
In order to shuffle the cards, use similar to the following algorithm:
for i = 0 to 50
pick a random integer j between i and 51
swap card i with card j
end for
GENERAL GAME RULES
Each card has a point value based on its rank (the suit is ignored in this game). The cards with ranks 2 through 10 have point values of 2 through 10 respectively. The "face" cards (Jack, Queen, King) have a point value of 10 each. The Ace is considered as 11 points, unless that puts the player over a total of 21 points, in which case it reverts to 1 point instead. For example, the following cards are dealt to the player and the total scores are shown to their right:
CARD CARD SCORE TOTAL SCORE
5 of Diamonds 5 5
Ace of Hearts 11 16
7 of Clubs 7 13
3 of Clubs 3 16
Ace of Spades 1 17
4 of Hearts 4 21
In each game, the deck of cards is shuffled, and the user starts with the first two cards of the deck. The user may pick the next card of the deck by inputting "HIT" or the user may stop at this point by inputting "STAY". The user can pick as many cards as he or she wants in order to try to come up with a score as close to 21 without going over. If the user goes over 21 points, the user automatically loses and the computer wins. Otherwise, if the user stops with a total score less than or equal to 21, then the computer plays. The computer starts with the next two cards of the deck. The computer automatically "hits" until its score is at least 17. If the computer goes over 21 (but the user did not), then the user wins automatically. Otherwise, the winner is the player with the higher score. A tie (same total score) is won by the computer.
INPUT PROCESSING
Input will come from the keyboard in this game. The user should input "HIT" or "STAY" (lowercase ok) as the game proceeds. Any other input should flag an error "Unrecognized input", etc. and you should ask for the input again. At the end of the game, you should ask the user if he/she wants to play again. The input here will be "Y" or "N" (lowercase ok). All other input will lead to an error and you should ask the user to input again. See OUTPUT PROCESSING for an example of correct input.
OUTPUT PROCESSING
Here is a sample of the output of the program (user input in purple italics):
LET'S PLAY 21!
SHUFFLING CARDS...
YOUR TURN
5 of Diamonds 5
Ace of Hearts 16
HIT or STAY? HIT
7 of Clubs 13
HIT or STAY? hit
3 of Clubs 16
HIT or STAY? HIT
Ace of Spades 17
HIT or STAY? hit
4 of Hearts 21
HIT or STAY? STAY
COMPUTER'S TURN
King of Clubs 10
9 of Diamonds 19
YOUR SCORE: 21
COMPUTER'S SCORE: 19
YOU WIN!
PLAY AGAIN? (Y/N) Y
LET'S PLAY 21!
SHUFFLING CARDS...
YOUR TURN
8 of Hearts 8
Queen of Spades 18
HIT or STAY? stay
COMPUTER'S TURN
Jack of Hearts 10
3 of Clubs 13
7 of Spades 20
YOUR SCORE: 18
COMPUTER'S SCORE: 20
YOU LOSE!
PLAY AGAIN? (Y/N) Y
LET'S PLAY 21!
SHUFFLING CARDS...
YOUR TURN
Queen of Hearts 10
5 of Diamonds 15
HIT or STAY? HIT
7 of Hearts 22
YOU LOSE!
PLAY AGAIN? (Y/N) Y
LET'S PLAY 21!
SHUFFLING CARDS...
YOUR TURN
4 of Spades 4
10 of Clubs 14
HIT or STAY? HIT
6 of Hearts 20
HIT or STAY? STAY
COMPUTER'S TURN
5 of Hearts 5
Jack of Spades 15
Ace of Diamonds 16
4 of Clubs 20
YOUR SCORE: 20
COMPUTER'S SCORE: 20
YOU LOSE!
PLAY AGAIN? (Y/N) Y
LET'S PLAY 21!
SHUFFLING CARDS...
YOUR TURN
8 of Hearts 8
9 of Diamonds 17
HIT or STAY? STAY
COMPUTER'S TURN
King of Clubs 10
6 of Spades 16
Jack of Diamonds 26
YOU WIN!
PLAY AGAIN? (Y/N) N"
--- Update ---
Here is my code. It's divided into the classes that were stipulated in the assignment.
Code =java:
public class PlayingCard { // instance variables private static int rank; // rank of card private static char suit;// card's suit // default constructor // setter method for Rank public static void setRank(int i) { rank = i; } // getter method for Rank public static int getRank() { return rank; } // setter method for Suit public static void setSuit(char i ) { suit = i; } // getter method for suit public static char getSuit() { return suit; } // cardInfo method. It accepts parameters, 2 string arrays, rank, and suit to return string that indicates the card's name and suit public static String cardInfo(String [] rankstr, String[] suitstr, int rank, char suit) { // The logic behind this declaration is the following. This code will use the char input and discern int's nature in if statements and then assign corresponding index values so that I can use that index to access the right string in the array of characters int suitindex =0; // The suits are ordered from least to greatest value. S,H,D,C. That is the order if(suit=='S') suitindex =1; if(suit=='H') suitindex = 2; if(suit=='D') suitindex =3; if(suit=='C') suitindex=4; // String variable r is used to store the string at index rank. String r =rankstr[rank]; // String variable s is used to store the string at the suitindex obtained previously. String s = suitstr[suitindex]; // String info is essentially a concatenation of r and s along with "of". String info = r+" of " + s; return info; } public static void main(String [] args) { Scanner input = new Scanner(System.in); // String array of names that correspond with ranks String r[] = {null,"Ace", "King", " Queen " , "Jack", "Ten", "Nine", "Eight ", " Seven", "Six"," Five", "Four", "Three", " Dueces"}; // String array of suits corresponding to ranks String s[] = { null, "Spades", " Hearts", "Diamonds ", "Clubs"}; // Prompt user for input System.out.println("Enter card rank and suit"); int rank = input.nextInt(); String str = input.next(); // Method "charAt" is used to find the character at index zero because scanners don't work for characters. char suit = str.charAt(0); PlayingCard nm = new PlayingCard(); String m =nm.cardInfo(r, s, rank, suit); // PlayingCard object System.out.println(m); // Value returned by the invocation of the cardInfo method is stored in s1; // s1 is now being printed } }
Code =java:
import java.util.Arrays; public class DeckOfPlayingCards { private static PlayingCard cards[] = new PlayingCard[52]; private static int indexOftop =51; String rankstr[] = {"Ace", "King", " Queen " , "Jack", "Ten", "Nine", "Eight ", " Seven", "Six"," Five", "Four", "Three", " Dueces"}; String suitstr[] = { "Spades", " Hearts", "Diamonds ", "Clubs"}; public void setCards() { this.cards = cards; } public PlayingCard[] getCards() { return cards; } public void setIndexOftop() { this.indexOftop= indexOftop; } public int getIndexOftop() { return indexOftop; } public DeckOfPlayingCards() { for(int i =0; i<cards.length; i++) { int rank =cards[i].getRank(); char suit = cards[i].getSuit(); cards[i]=new PlayingCard(); cards[i].cardInfo(rankstr, suitstr, rank, suit); }} public void shuffle(){ int j; for(int i = 0 ; i<51; i++) { j = (int)Math.random()*51; PlayingCard temp = cards[i]; cards[i]=cards[j]; cards[j]=temp; temp = cards[0]; cards[0]=cards[indexOftop]; } } public PlayingCard deal() { for(int i=0; i<51; i++){ indexOftop=52; indexOftop -=i; } return cards[indexOftop]; } }
Code =java:
import java.util.Scanner; public class TwentyOne { public static void main(String [] args) { Scanner input = new Scanner(System.in); DeckOfPlayingCards deck = new DeckOfPlayingCards(); // String array of ranks String rankstr[] = { "Ace", "2", " 3 " , "4", "5", "6", "7 ", " 8", "9"," 10", "Jack", "Queen", " King"}; // String array of suits corresponding to ranks String suitstr[] = { "Spades", " Hearts", "Diamonds ", "Clubs"}; gamePlay(rankstr,suitstr,deck); System.out.println("DO YOU WANT TO PLAY AGAIN? Y OR N"); String answer = input.next(); while(answer.equals("Y")) { gamePlay(suitstr, suitstr, deck); if(answer.equals("N")) { System.out.println("THANK YOU FOR PLAYING"); break; }} } public static void gamePlay(String rankstr[],String suitstr[],DeckOfPlayingCards deck) { Scanner input = new Scanner(System.in); // Initialization of rank and index number of suit array. int rank = (int)Math.random(); int suitIndex = (int)Math.random(); // Represents the score of the user int total; // A secondary variable for user's score. Its use will become more apparent as you progress through the program int tot =0; // Represents computer's score int totcomputer =0; // suitIndex is used to get a string from the array and then charAt() is used to find the first character String str= suitstr[suitIndex]; char suit = str.charAt(0); // Game System.out.println("LET'S PLAY 21!"); System.out.println(); System.out.println(); System.out.println("SHUFFLING CARDS..."); System.out.println(); deck.shuffle(); System.out.println(); System.out.println("YOUR TURN"); // I'm adding 1 to rank b/c the first element in the array of ranks is the ranked number 1 and so on and so forth for the other elements total = rank+1; // Print first card System.out.println(deck.deal().cardInfo(rankstr, suitstr, rank, suit) +" " +"\t\t\t" + total); deck.shuffle(); rank = (int)((Math.random()*rankstr.length-1)); suitIndex = (int)((Math.random()*suitstr.length-1)); str= suitstr[suitIndex]; suit = str.charAt(0); total = rank+1; // Print second card System.out.println(deck.deal().cardInfo(rankstr, suitstr, rank, suit) +" " +"\t\t\t" + total); deck.shuffle(); System.out.println("HIT OR STAY"); String response = input.next(); // When user decides to hit, more cards will be played while(response.equals("HIT")||response.equals("hit")) { rank = (int)((Math.random()*rankstr.length-1)); suitIndex = (int)((Math.random()*suitstr.length-1)); str= suitstr[suitIndex]; suit = str.charAt(0); tot+=rank+1; if(rank==0) rank=10; if(tot>21&&rank==11) rank =0; System.out.println(deck.deal().cardInfo(rankstr, suitstr, rank, suit) + " " +"\t\t\t" + tot); deck.shuffle(); if(tot==21){ System.out.println("YOU WIN"); break;} if(tot>21){ System.out.println("YOU LOSE. THE COMPUTER WINS"); break; } System.out.println("HIT OR STAY"); response = input.next(); // When user is done if(response.equals("STAY")||response.equals("stay")) { System.out.println("COMPUTER'S TURN"); do { rank = (int)((Math.random()*rankstr.length-1)); suitIndex = (int)((Math.random()*suitstr.length-1)); str= suitstr[suitIndex]; suit = str.charAt(0); totcomputer+=rank+1; if(rank==1) rank=11; if(totcomputer>21&&rank==11) rank =1; deck.shuffle(); System.out.println(deck.deal().cardInfo(rankstr, suitstr, rank, suit) +" " +"\t\t\t" + totcomputer); if(totcomputer==21) { System.out.println("THE COMPUTER WINS"); break;} if(totcomputer>21&&tot<=21){ System.out.println(); System.out.println(); System.out.println("YOU WIN"); break; } } while(totcomputer<=17); System.out.println(); System.out.println(); System.out.println(); System.out.println("YOUR SCORE" + " " + tot + " "+ "COMPUTER'S SCORE" + " " + totcomputer); if(tot<21&&totcomputer<21&&tot>totcomputer){ System.out.println(); System.out.println("YOU WIN");} if(tot<21&&totcomputer<21&&tot<totcomputer){ System.out.println(); System.out.println("YOU LOSE. THE COMPUTER WINS");} if(tot==totcomputer&&tot<=21&&tot>=21) { System.out.println(); System.out.println("THE COMPUTER IS THE WINNER"); } if(tot==totcomputer&&tot<21&&totcomputer<21) { System.out.println(); System.out.println("THE COMPUTER IS THE WINNER"); } }} }}
--- Update ---
I keep getting indexoutofbounds exceptions and sometimes for my cardInfo method, 2 suits are printed instead of a rank and a suit. Can I please get some help? I'd really appreciate it. Thanks in advance!
--- Update ---
I keep getting indexoutofbounds exceptions and sometimes for my cardInfo method, 2 suits are printed instead of a rank and a suit. Can I please get some help? I'd really appreciate it. Thanks in advance! | http://www.javaprogrammingforums.com/%20whats-wrong-my-code/30423-can-i-get-some-help-fixing-issue-printingthethread.html | CC-MAIN-2015-32 | refinedweb | 2,152 | 65.73 |
jefu's Journal: spam 2
In a followup to the previous entry, I went to the web site listed and found this page where you can report "certain parties" that send out spam advertising their product. This page is great fun, it uses the standard kinds of javascript junk (unescape) to obfuscate a function (named, "o" so nicely) o which actually builds the page. Now why they need to do this escapes (so to speak) me, as it took all of about five minutes to write a bit of python that decodes the page. If you take the following (you'll need to replace the "_"s with spaces and watch the long quoted string in the second line) and use this function o in place of theirs, you'll easily see the text of their web page - it makes interesting reading.
Even more interesting, the decoded web page does not work in mozilla. Sigh.
w=""
b="a6=mDbFJfS|c&%iPY;!-3?R#Wq.rCgl+dyE 4wMU/j)Tz:"
l=78
g=""
def iii() :
_global g
_w=""
def o(s)
::
_ global g
_ res = ""
_ k=''
_ for n in range(len(s)) :
__ f=s[n]
__ e=b.find(f)
__ if e>-1 :
___ y=((e+1)%l-1)
___ if y ____ y+=l
___ k+=b[y-1]
__ else :
___ k+=f
_ g +=k | http://slashdot.org/journal/68870/spam-2 | CC-MAIN-2014-42 | refinedweb | 232 | 68.13 |
Dave Kuhlman wrote: > I believe that I've incorporated most, if not all, of the > suggestions from those on the list, except for Danny's suggestion > (above) about closures. > > The document itself is still here: > > Very nice. Just a few notes: - When you talk about the hierarchy of namespace lookup, you might just mention nested scopes and refer to the PEP for more info, instead of omitting it completely. - In the section "Accessing namespace dictionaries" you write, "Note that for lexically/statically nested scopes (for example, a function defined inside a function), it seems that globals() and locals() still give access to all items in the accessible namespaces, /but/ do not give dictionary style access to all visible scopes." globals() and locals() give access to items in the global and local namespaces, not all accessible namespaces. As was noted in the emails, variables in nested scopes are not included in locals() and globals(). I think that's what you're trying to say but it isn't clear. - PEP 227 is definitely the present, not the future. Nested scopes have been available since Python 2.1. Kent | https://mail.python.org/pipermail/tutor/2006-August/048334.html | CC-MAIN-2017-04 | refinedweb | 187 | 59.64 |
Compiling and Running EnOcean Sensor Kit Example Code
In my previous post, I took a quick look at the EnOcean sensor kit from Newark for Raspberry Pi and tested its basic functionalities using the Fhem home automation software. In this blog post, I will walk you through the process of compiling and running the example code that comes with the EnOcean Link library. While there are instructions on how to do this, some of the information is out-dated and hard to follow. So I will provide my own step-by-step instructions here.
Raspberry Pi uses ARM architecture, so you cannot compile the code on your PC directly as most of the PCs are based on x86. Basically, there are two ways compile the code. One way is to cross-compile using the gcc arm tool chain (such as linaro). If you are interested in setting up a cross-compiling environment using Eclipse, you can take a look at this article here for detailed information.
The other way is to compile the code natively. In this blog post we will compile the code on the Raspberry Pi directly via command line. The benefit is that you don’t need any IDE setup. I assume that you are using Raspberry Pi’s default OS (Raspbian) and using the latest version of EnOcean Link source code (you will need to first register on EnOcean’s webite before you can download the latest code). Also, if you had installed Fhem before, you will need to uninstall it as it is also using the serial port that we will be using.
First, download EnOcean_Link__1_4_0_0_trial.zip from EnOcean (an earlier version can be found on element14’s website) and unzip it to your user directory. After unzipping, you should see three sub-directories (EOLink, examples, Tutorial) created.
All the tools necessary for building the source code can be installed via the following command on the Raspberry Pi:
sudo apt-get install build-essential libtool autoconf
Before building the example code, we need to first build the EOLink library:
cd EOLink ./configure make all sudo make install
configure and make each takes a couple of minutes to execute. After “make install”, you should see libEOLink libraries installed in /usr/local/lib:
Now we can go ahead and build the tutorials and examples.
The default source code for the tutorials and examples assume that you are using the USB300 gateway. When using the EnOcean Pi adapter board for the Raspberry Pi, we will need to change the port from /dev/ttyUSB0 to /dev/ttyAMA0
#define SER_PORT "/dev/ttyAMA0"
After making changes to all the source files (*.cpp), you can compile the ones you want to test with using the following command:
gcc Tutorial1.cpp -lEOLink -lrt -I../EOLink/ -o Tutorial1
This should be done within the Tutorial directory (see screenshot below):
The code under the examples directory compiles slightly differently. Each example is in its separate source cpp file and the examples are then run from sandbox.cpp.
In the following demonstration, I only enabled the gatewayExample() function inside the sandbox.cpp.
#include <stdio.h> #include "examples.h" int main( int argc, const char* argv[] ) { gatewayExample(); return 0; }
I also modified the Gateway_example.cpp a bit and removed portions of code that was not used in our example. Here is the full code listing of the modified source:
#define SER_PORT "/dev/ttyAMA0" #include "./eoLink.h" #include <stdio.h> void gatewayExample() { eoGateway gateway; uint16_t recv; gateway.Open(SER_PORT); //we set now the automatic RPS-Teach-IN information gateway.TeachInModule->SetRPS(0x02,0x01); //Activate LearnMode gateway.LearnMode=true; while (1) { recv = gateway.Receive(); if (recv & RECV_TELEGRAM) { printf("eoDebug---telegram---"); eoDebug::Print(gateway.telegram); } if ((recv & RECV_TEACHIN)) { eoProfile *profile = gateway.device->GetProfile(); printf("Teachin>Profile: Device %08X Learned-In EEP: %02X-%02X-%02X\n", gateway.device->ID, profile->rorg, profile->func, profile->type ); for (int i = 0; i<profile->GetChannelCount(); i++) { printf("Teachin>Channel Count %s %.2f ... %.2f %s\n", profile->GetChannel(i)->ToString(NAME), profile->GetChannel(i)->min, profile->GetChannel(i)->max, profile->GetChannel(i)->ToString(UNIT)); } } if (recv & RECV_PROFILE) { printf("Profile Device %08X\n", gateway.device->ID); eoProfile *profile = gateway.device->GetProfile(); uint8_t t; for (int i = 0; i<profile->GetChannelCount(); i++) { if (profile->GetValue( profile->GetChannel(i)->type, t) ==EO_OK) printf("--%s %u \n", profile->GetChannel(i)->ToString(NAME),t); } } } }
To comiple this example code, use the command below to generate the example binary under examples directory:
gcc sandbox.cpp Gateway_example.cpp -I../EOLink/ -lrt -lEOLink -o example
Here is a short video showing the output messages when the four buttons on the pushbutton transmitter module are pressed sequentially and the last two messages were sent from the temperature module and the reed relay module. Note that button push and button release messages are sent separately.
EnOcean Serial Protocol
Because the data coming out from the EnOcean Pi is serial (via UART), we can easily capture the output data packets using a standard serial port terminal (such as GtkTerm). The following screenshot shows some captured data when the four buttons on the switch module are pressed. As you can see there are altogether eight messages because each button generates two separate events (push/release).
Let’s take a look at the first message and compare it to the EnOcean serial protocol specifications:
55 00 07 07 01 7A F6 30 00 29 49 93 30 01 FF FF FF FF 2E 00 A8
According to the specifications, all communications begin with a sync byte (0x55) and the following 4 bytes are the header (00 07 07 01). 0x7A is the CRC8H byte. Following the CRC byte are the data bytes. In the example above the data being transmitted are:
RORG = F6
SrcID = 00294993
Status = 30
SubtelCount = 1
DestID = FFFFFFFF
dBm = -46 (-2E)
Again the last byte A8 is the message checksum. So, you can easily create your own libraries and use EnOcean sensors with other MCU platforms (e.g. Arduino, MSP430, PIC, 8051, etc.).
Hi Kerry,
Very nice steps but i have a problem compiling with “gcc”. So it compiled the EOLink library with CXX=g++ flag. This is the only way from cli on the pi that i have. I am then able to compile the examples but whenever i run the program it claims it is missing the library files.
any idea’s?
Greetz Jorg
nevermind i had to run “sudo ldconfig” problem fixed
I have same problem , can you suggest me in which file i need to change CXX=c++?
Hello,
I had follow this nice tuto and I had a problem when I want compiling
pi@raspberrypi ~/EOLink/Tutorial $ gcc Tutorial1.cpp -I../EOLink/ -lrt -lEOLink -o Tutorial1
/usr/bin/ld: /tmp/ccjYpMow.o: undefined reference to symbol ‘operator new(unsigned int)@@GLIBCXX_3.4’
//usr/lib/arm-linux-gnueabihf/libstdc++.so.6: error adding symbols: DSO missing from command line
collect2: ld returned 1 exit status
I don’t understand this problem and I search a solution. I take gladly or even if there is only the beginning of explanation!!!:)
Sikit
Try compiling it with g++ instead of gcc.
Hi, Could you get past this error. I am also facing the same.
Hello,
I have compiled the Tutorial1.cpp, and I can run it correct.
But when I closed it by Ctrl+C, run it again ./Tutorial1 , found it cann’t myGateway.Open(SER_PORT)
the program is just stoped there.
Hi, since this is a demo project, I didn’t handle the Ctrl+C signal. So after you hit Ctrl+C, the serial port wasn’t properly closed and that’s why you can’t run it again using the same serial port. You will need to call gateway.Close() to properly close the connection before exiting so the next time you start the program the same serial port is available.
Realy thanks for your help, and I know why it can’t run correctly.
The myGateway.close() should be used in the process.
But I am a beginner, ofen need to modify the program and run it to detect whether the code is correct.
So can you help me or give me advice how I can easy debug my progress about the Enocean PI?
Hello,
With your step by step,the example code can run it.
But I don’t know why I can’t received the RECV_PROFILE in this example code , only RECV_TELEGRAM can recevied.
The code: gateway.TeachInModule->SetRPS(0x02,0x01); is also set.
Could you tell me what’s wrong with this problem?
Thanks for the tutorial – may need an update? I’m getting the following error after running ./configure and then make all:
/bin/bash: line 4: automake-1.14: command not found
current apt-get installs automake-1.11 on raspbian. apt-get reports everything is at latest version. Any ideas on how to fix? | http://www.kerrywong.com/2014/08/16/compiling-and-running-enocean-sensor-kit-example-code/?replytocom=874364 | CC-MAIN-2019-04 | refinedweb | 1,479 | 56.66 |
public class OpenEvent extends Event
Note: it is a bit confusing but
Events.ON_CLOSE is sent when
user clicks a close button. It is a request to ask the server
to close a window, a tab or others. If the server ignores the event,
nothing will happen at the client. By default, the component is
detached when receiving this event.
On the other hand,
Events.ON_OPEN (with
OpenEvent) is
a notification. It is sent to notify the server that the client has
opened or closed something.
And, the server can not prevent the client from opening or closing.
getData, getEvent, getName, getPage, getTarget, isPropagatable, stopPropagation, toString
clone, equals, finalize, getClass, hashCode, notify, notifyAll, wait, wait, wait
public OpenEvent(java.lang.String name, Component target, boolean open)
open- whether the new status is open
public OpenEvent(java.lang.String name, Component target, boolean open, Component ref)
target- the component being opened
ref- the component that causes target to be opened.
public OpenEvent(java.lang.String name, Component target, boolean open, Component ref, java.lang.Object value)
open- whether the new status is open
value- the current value of the target component if applicable.
getValue()
public static final OpenEvent getOpenEvent(AuRequest request)
public Component getReference()
Event.getTarget()to be opened.
It is null, if the open event is not caused by opening
a context menu, a tooltip or a popup.
Note: the onOpen event is also sent when closing the context menu
(tooltip and popup), and this method returns null in this case.
Thus, it is better to test
isOpen() or
getReference()
before accessing the returned value.
if (event.isOpen()) doSome(event.getReference());
public boolean isOpen()
public java.lang.Object getValue()
Note: combobox, bandbox and other combo-type input don't send the onChange event when the dropdown is opened (onOpen). Thus, if you want to do something depends on the value, use the value returned by this method. Furthermore, for combobox and bandbox, the return value is a non-null String instance. | https://www.zkoss.org/javadoc/latest/zk/org/zkoss/zk/ui/event/OpenEvent.html | CC-MAIN-2020-29 | refinedweb | 331 | 57.98 |
- Article Catalog
- Get Coronavirus Cases Latest And Timeseries Statistic with Eikon Data API(Python)
It is undeniable that Coronavirus has a global impact on everyone.
For detail information on the Coronavirus, please visit the World Health Organization website at
Eikon provides a dashboard to see coronavirus statistics on each country.
To see this information on Eikon, Type in "MACROVIT" on Eikon Search Bar and press enter to launch the app.
Go to "Case Tracker" tab
This article demonstrates how to find RIC(Refinitiv Identifier Code) for each country/territory statistic and how to retrieve the latest statistic and timeseries statistic using Eikon Data API(Python)
Step 1 - Find out what are RICs for Coronavirus statistic
1. Launch "Economic Indicator Chart" application by typing in "ECOC" on Eikon Search Bar and press enter.
2. Select a country on the dropdown list
3. Type in "covid" on the indicator and select any indicator of your interest.
4. Select Indicator 1 or 2 or 3 or 4 which is available and Click "Add" to add selected the indicator (or you can click "Replace" if the Indicator 1 to 4 which you selected is occupied by other indicators)
5. You can repeat steps 2. to 4. to add any indicator from any country of your interest.
6. You can hover the mouse pointer on each color instrument detail on the chart to see its RIC. Repeat this for as many indicators that you want to know its RIC.
After repeating steps 1. to 6. for all COVID-19 indicator for Hong Kong (as an example), here is the RIC list
['HKCCOV=ECI',#Total cases
'HKNCOV=ECI', #New cases
'HKACOV=ECI', #Active cases
'HKRCOV=ECI', #Recovered cases
'HKDCOV=ECI'] #Deaths cases
The RIC list is also available at this GitHub Repository.
Step 2 - Getting Coronavirus latest statistic
1. From step 1, you should be able to identify RIC for the country of your interest.
This sample code will use RICs from CoronavirusRICs.csv
Please download the CoronavirusRICs.csv to your working folder.
import csv
rics = []
with open("CoronavirusRICs.csv", "r") as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for lines in csv_reader:
rics.append(lines[0])
rics.pop(0) #remove header row
#rics is now carrying Coronavirus statistic RICs
print(len(rics))
The output is the number of RIC in the list:
1288
2. You need to know field names carrying the information.
fields = ['DSPLY_NMLL', #Display Name
'COUNTRY', #Country code
'CF_DATE', #Announcement Date
'ECON_ACT', #Actual value
'ECON_PRIOR' #Prior value
]
3. Retrieves the latest Coronavirus statistic
From 1. and 2., we already prepared RICs and Fields into rics and fields variable.
#import Eikon Library
import eikon as ek
#Set app key
ek.set_app_key('<a_valid_app_key>')
#Make an API call using get_data()
df,e = ek.get_data(rics, fields)
#Rename dataframe column names
df.rename(columns={'DSPLY_NMLL':'Display Name',
'CF_DATE':'Announcement Date',
'ECON_ACT':'Actual Value',
'ECON_PRIOR':'Prior Value'
},inplace=True)
#print out first 10 rows from df variable
df.head(10)
Output:
Step 3 - Getting Coronavirus timeseries statistic
1. Let's focus on "Hong Kong" statistic
#select only Hong Kong RICs
HKRICs = df[df['COUNTRY'] == 'HKG']['Instrument'].to_list()
#print out HKRICs
HKRICs
Output:
['HKACOV=ECI', 'HKCCOV=ECI', 'HKDCOV=ECI', 'HKNCOV=ECI', 'HKRCOV=ECI']
2. Retrieve timeseries data for the last 6 months
#Make an API call
df = ek.get_timeseries(HKRICs, start_date='20200101', end_date='20200705', interval='daily')
#Print out the last 5 rows
df.tail(5)
Output:
3. Using plotly to plot a line chart on Jupyter Notebook.
(The sample code for multi_plot() is available on the GitHub.)
multi_plot(df)
Output:
Downloads
Related APIs | https://developers.uat.refinitiv.com/en/article-catalog/article/get-coronavirus-cases-latest-and-timeseries-statistic-eikon-data-apipython | CC-MAIN-2022-27 | refinedweb | 593 | 57.87 |
If you don’t know what Sudoku is, you can return to your spaceship and fly home. On your way back, you can stop here and find out what it is.
I began playing Sudoku very recently and found the game very funny and addictive. When you play Sudoku you finally reach a point where you need to find a way to mark the possible values a square has, since you can't remember all of them. Some people write the possible numbers in small, the problem with this method is that if you write it with a pencil it's not readable and if you use a pen it becomes messy. Another method is to use points as markers for the available possibilities, every number has its own position, for example, number 1 is represented as a point in the top-left corner of the square, number 5 is in the middle of the square, and number 9 is in the bottom-right corner.
An easy way to remember this is to look at the phone keypad.
So, after finishing all the paper-based Sudoku puzzles, I searched the net for more. I found plenty of puzzles but there I encountered a major problem. You see, you can't put points on the screen! I actually tried to play with MS Paint but I quickly found out that writing the number '2' with the mouse is as hard as proving Fermat's last theorem.
So here I was, with plenty of puzzles but no way to play with them. Suddenly a new mail arrives! "..Code Project Newsletter.. ..Smart Client competition..".
Well, if you read this article you know what happened next.
So, after deciding to write a Sudoku Smart Client, I started to think about the general architecture and design. These are my insights:
The following sections discuss these issues in detail.
As a general note, the development was done using the .NET Compact Framework and was tested using my WinXP system and a Pocket PC emulator. Feel free to comment if you find any bug or incompatibility with your Smart Device.
If you open the source code you will see that the project name is Sudoku2, here is what happened to the project Sudoku:
The first thing I coded was a control named SudokuCell that supports:
SudokuCell
I'll focus on the interesting aspects and leave the tedious parts aside, like calculating the cell's size and checking which number was selected according to the position of the click. If you are interested in this, look at the source code.
My initial design was to create multiple instances of SudokuCell, one per each cell in the Sudoku puzzle. So in the classic mode (9x9 grid), I had 81 controls on my main form. I even wrapped them in a nice class named SudokuMap so that I will be in charge of creating the controls according to the selected map size etc.
SudokuMap
So far so good, until I ran the application. It took the application more than two minutes to load on the Pocket PC emulator. When the same executable was run on my normal PC, the main form was loaded instantly.
After searching for the wasted time, I discovered that the problematic command was Controls.Add and not the 81 constructors or anything else; just adding the SudokuCell controls to the form's Controls collection. I even tried to add standard controls like labels but I got the same result. Controls.AddRange would have worked better but Microsoft chose not to include this function in the .NET Compact Framework.
Controls.Add
Controls
Controls.AddRange
After that I created a new project Sudoku2 and rewrote SudokuCell and SudokuMap classes so that SudokuMap is the only control that is added to the form and SudokuCell became a class that does not inherit from Control but is still responsible for taking care of mouse clicks and drawing a cell.
Sudoku2
Control
The implementation is that SudokuMap has an array of SudokuCell, and when OnMouseDown or OnPaint functions are triggered it delegates the call to the correct SudokuCell.
OnMouseDown
OnPaint
The user interaction on a cell was to be as follows:
Imagine my surprise when I found that double click does not exist in .NET Compact Framework! It took me a few days to relax and I finally decided to implement it myself. I'll implement double click on a Smart Device.
The basic idea behind the implementation of double click is that we need to remember when and where the previous click was clicked. So if a click arrives and it is in the same location as the previous click (up to a certain threshold) and the time elapsed between the consecutive clicks is small (say less then 250 milliseconds) then we have a double click.
One minor inaccuracy is that in this case we can't determine from the first click whether it belongs to a "double click" pair. So, we always perform the action of a click and sometimes we also perform the action of a double click.
If you wish to implement a double click and want to avoid the extra click action, you should invoke a timer (250 ms) on every click pressed and do the single click action only if the timer elapses (if a second click arrives, don't forget to stop the timer).
Here is a sample code that demonstrates the double click technique:
// return clicked number
int clickedNumber = GetCheckedNumber(e.X - CellLocation.X,
e.Y - CellLocation.Y);
int now = System.Environment.TickCount;
// check for double click activity
if ((mPreviousClickedNumber == clickedNumber) &&
(now - mPreviousClickTime < DoubleClickTime))
{
// double click
// ...
}
else
{
// single click
// ...
// update previous clicked number and time
mPreviousClickedNumber = clickedNumber;
mPreviousClickTime = now;
}
Another performance penalty was induced by the Paint method. There were three problems associated with the Paint method.
Paint
Graphics
The first improvement was to use the double buffer technique. Instead of performing all the user defined painting directly on the screen Graphics object, you can do it on your own Graphics object that will serve as a buffer. This Graphics object represents an in-memory bitmap. After you finish doing all the painting to the memory bitmap, you can simply copy the bitmap to the screen Graphics object to do the actual drawing. This results in quicker paint and reduced flickering.
The normal .NET Framework has built-in support for double buffering while doing user defined painting, so all it takes is to SetStyle to your control. Unfortunately, this support does not exist in the .NET Compact Framework.
SetStyle
Another improvement is to paint only those parts that are changed. Here we use the same memory bitmap described in the previous paragraph, and when we finish painting it to the screen, we don't destroy it, instead we save it to the next paint. So if nothing has changed we don't need to recalculate the bitmap and we can simply copy it directly to the screen. Furthermore, if a single cell has changed, we only need to recalculate the painting of this single cell.
Following is a sample code that demonstrates these techniques:
We need three member variables in our control; first is the memory bitmap, second is the Graphics object on the memory bitmap, and third is a Boolean flag that indicates whether recalculation of the bitmap is required.
/// <SUMMARY>
/// saves buffer in-memory bitmap
/// </SUMMARY>
private Bitmap mBufferBitmap;
/// <SUMMARY>
/// saves buffer in-memory graphics
/// </SUMMARY>
private Graphics mBufferGraphics;
/// <SUMMARY>
/// saves a flag that indicates whether a
/// recalculation of the bitmap is needed
/// </SUMMARY>
private bool mRecalculateNeeded = true;
And here is the implementation of the OnPaint method, you can see that we perform the heavy drawing only if the recalculate flag is on, most of the time we just copy the memory bitmap. In this example, you will see that the SudokuMap OnPaint draws the Sudoku grid and then delegates the paint to each SudokuCell.
/// <SUMMARY>
/// OnPaint - overrides paint to draw sudoku map
/// </SUMMARY>
/// <PARAM name="e">arguments</PARAM>
protected override void OnPaint(PaintEventArgs e)
{
if (mRecalculateNeeded)
{
// fill background in white
mBufferGraphics.FillRectangle(
CommonGraphicObjects.WhiteBrush, e.ClipRectangle);
int i,j;
// draw grid
for (i=0 ; i<=MapInfo.MapCellsNumber ; ++i)
{
// draw vertical line
if (i % MapInfo.ColsInSmallRect == 0)
mBufferGraphics.DrawLine(CommonGraphicObjects.BlackPen,
mOffset.X + i*mCellSize.Width, mOffset.Y,
mOffset.X + i*mCellSize.Width,
mOffset.Y + MapInfo.MapCellsNumber*mCellSize.Height);
else
mBufferGraphics.DrawLine(CommonGraphicObjects.GrayPen,
mOffset.X + i*mCellSize.Width, mOffset.Y,
mOffset.X + i*mCellSize.Width,
mOffset.Y + MapInfo.MapCellsNumber*mCellSize.Height);
// draw horizontal line
if (i % MapInfo.RowsInSmallRect == 0)
mBufferGraphics.DrawLine(CommonGraphicObjects.BlackPen,
mOffset.X, mOffset.Y + i*mCellSize.Height,
mOffset.X + MapInfo.MapCellsNumber*mCellSize.Width,
mOffset.Y + i*mCellSize.Height);
else
mBufferGraphics.DrawLine(CommonGraphicObjects.GrayPen,
mOffset.X, mOffset.Y + i*mCellSize.Height,
mOffset.X + MapInfo.MapCellsNumber*mCellSize.Width,
mOffset.Y + i*mCellSize.Height);
}
// draw cells internal
for (i=0 ; i < MapInfo.MapCellsNumber ; ++i)
{
for (j=0 ; j < MapInfo.MapCellsNumber ; ++j)
{
mSudokuCells[i,j].Paint(mBufferGraphics);
}
}
}
e.Graphics.DrawImage(mBufferBitmap, 0, 0);
mRecalculateNeeded = false;
}
And finally, if a cell was changed (e.g. because of a mouse click), it updates the memory bitmap and causes a refresh of the control to invoke the Paint method.
/// <SUMMARY>
/// causes image to recalculate and redraw
/// </SUMMARY>
internal void UpdateImage(SudokuCell updatedCell)
{
updatedCell.Paint(mBufferGraphics);
Invalidate();
}
One final note about painting is the usage of GDI objects. These objects are expensive resources and should not be recreated on every draw, it is best to create them once and then use them wherever needed using static variables. Don't forget to dispose them when you finish using them (e.g. when closing the application).
static
Map information classes are a set of classes that give information on different map types. These classes contain information like how many rows and columns are there in a small Sudoku rectangle and the kind of symbols we should use while drawing (think of the 16x16 grid). All these classes have the same interface and so other parts of the application do not have to know their internals.
The map information classes are constructed using the factory design pattern.
In this design pattern, we have a class that knows how to construct map information classes. The class has some sort of Create function that gets parameters, and according to these parameters and some internal logic, creates the relevant map information class. The class is then returned as a base class, so that no one knows the exact type of the class. This is good, so if we want to add new types of maps, we just need to change the factory and it will construct them, the rest of the application does not even know the specifics or even where these classes came from (we can construct classes from remote objects etc.).
Create
Here is a class diagram for the map information classes:
This design could be made even more interesting by using reflection to create the classes so that additional maps could be added as DLLs without recompiling the application. However, in our application this would be an overkill.
You must have seen in the factory section that I didn't use any interface to unite the different map information classes. Using a common interface would have been a more correct design, but in this particular case the price was too big.
Even using interfaces has its own penalty when coding for a Smart Device. If we look at the interface needed, we will see that it has three member variables that return different values for different map information classes, of course, the interface does not have member variables so they must be implemented as properties of the interface.
The problem is that getting and setting a value using a property yields a function call in addition to the simple integer assignment. And if we use these properties a lot then the overhead of the function calls becomes obvious. To make things short, I've gained 30% in performance after removing the use of interfaces and switching back to a plane old base class. What works for native C++ works for me.
Everybody needs application settings. In my Smart Client, the application settings include remembering the last selected map type and map difficulty level and, of course, the local high scores.
I chose to serialize my application settings into an XML file, since the .NET has such convenient classes to read and write from. Lucky me, this part was supported by the .NET Compact Framework! Silent minute for double click.
Delaying IO is a very sophisticated headline but actually it doesn't mean anything special. The basic idea is: don't write to file on every memory change.
My implementation: write to the file when the application exits. Sounds like a trivial concept but I initially wanted to write to file every time a setting was changed, so the application would be more tolerant in the case of a crash. Then I remembered that Pocket PC doesn't like people who abuse it, so I let it go.
Singleton is another design pattern, one that everybody should know about.
Basically everyone has a settings class in their application. And this settings class is always available from any part of the application. But you usually don’t want to create multiple instances of your settings class. So here comes the singleton design pattern that enforces the creation of maximum one instance.
The implementation details are trivial. In your settings class: write a static GetInstance function that creates an instance of your class the first time it is called. The function saves this instance to a static variable. The next time the function is called, it will return the previously created instance. One extra feature is to make the constructor of your settings class as private, to ensure that no one creates your class outside your GetInstance function.
GetInstance
private
Sample code for singleton pattern:
private static Settings mInstance;
/// <SUMMARY>
/// Get single instance of settings class
/// </SUMMARY>
public static Settings Instance
{
get
{
if (mInstance == null)
{
mInstance = new Settings();
}
return mInstance;
}
}
/// <SUMMARY>
/// Private ctor to enforce singelton
/// </SUMMARY>
private Settings()
{
}
Web services are fun. The idea of putting a code that everybody with an internet access can call brings life to many applications. I mean, playing Sudoku and have the best result in your high scores is fun, but having the best result in the internet? Imagine that!
I created a web service with two features: get Sudoku puzzle data and host internet-wide high score results.
By the way, the hardest part regarding web services was to find a free host that supports ASP.NET.
If you recall, one of my goals was to create an application that will run the same way on both PC and Pocket PC. It turns out there is a bug when consuming a web service from the .NET Compact Framework. When you add a reference to a web service, Visual Studio creates a proxy for you. This proxy is used to hide the details of the web service connection. The code generated by Visual Studio in the case of a .NET Compact Framework application fails to run when used with a normal .NET Framework. The problem is that two attributes are not supported; they are the Use attribute and the ParameterStyle attribute.
Use
ParameterStyle
Here is a sample of the original generated code:
[System.Web.Services.Protocols.SoapDocumentMethodAttribute(
"",
RequestNamespace="",
ResponseNamespace="",
Use=System.Web.Services.Description.SoapBindingUse.Literal,
ParameterStyle=
System.Web.Services.Protocols.SoapParameterStyle.Wrapped)]
[return: System.Xml.Serialization.XmlArrayItemAttribute(
IsNullable=false)]
public CellData[] GenerateMapData(int cellsNumber,
MapDifficultyLevel level) {
object[] results =
this.Invoke("GenerateMapData", new object[] {
cellsNumber,
level});
return ((CellData[])(results[0]));
}
The solution is to just remove them on recompile:
[System.Web.Services.Protocols.SoapDocumentMethodAttribute(
"",
RequestNamespace="",
ResponseNamespace="")]
[return: System.Xml.Serialization.XmlArrayItemAttribute(
IsNullable=false)]
public CellData[] GenerateMapData(int cellsNumber,
MapDifficultyLevel level) {
object[] results =
this.Invoke("GenerateMapData", new object[] {
cellsNumber,
level});
return ((CellData[])(results[0]));
}
Note that if you update your web reference you should do this again, since the code is regenerated.
The web service supplies functions to get the list of internet high scores, to get the time of a specific high score, and update the high scores with a new time. Using these functions, I create labels that display the information in the internet high scores page.
Note: This particular web service is not secure. It was created for learning purpose. It is probably less secure than the Internet Explorer. If you abuse this web service you have too much time on your hand, why else would you want to change a text file on a remote server in Russia?
A sample of internet high scores when you run the application on a normal PC:
I've included in the source code the code for the basic web service. I say basic because the generation function in the basic sample returns a hard-coded game for each map type (Mini, Classic, Monster).
In the web service run on the server, I get the puzzle data from a local database in the case of a classic map (9x9, Easy, Medium, Hard) and the same hard-coded map in the monster and mini map types.
Nevertheless, this sample shows the interface and the basic coding used for the web service involved.
As always, in embedded systems, you must code for performance and don't make anything extra without a good reason. The only difference from now and 30 years ago is that back then you coded for performance using assembly, now we code for performance using .NET. This is the only difference. That and web services.
That’s it.. | http://www.codeproject.com/Articles/11170/Sudoku-and-Smart-Client-techniques | CC-MAIN-2015-14 | refinedweb | 2,944 | 54.02 |
SFSB are evil? (The eternal Update problem)Markus Dahm Jun 21, 2006 4:30 AM
Hi,
I seem to have a general problem with refreshing views from the database
when using SFSB like in the examples.
Remember the messages list example, I've got except pretty much the
same code, except there is a link on the page where you can edit the specified row entry.
@Stateful @Scope(ScopeType.SESSION) @Name("listVertraege") @Interceptors(SeamInterceptor.class) public class ListVertragActionBean implements Serializable, ListVertragAction { private static final Category _logger = Logger.getInstance(ListVertragActionBean.class); private static final long serialVersionUID = 1L; @DataModel(value = "vertraege") private List<Vertrag> _vertraege; @Out(required = false, value = "vertrag") @DataModelSelection private Vertrag _vertrag; @SuppressWarnings("unused") @Out(value = "vertragReadOnly", required = false) private Boolean _vertragReadOnly; @PersistenceContext(type = EXTENDED) private EntityManager _em; @SuppressWarnings("unchecked") @Factory("vertraege") public void findVertraege() { _vertraege = _em.createQuery("from Vertrag v order by v.vertragsBeginn").getResultList(); } public String select() { return "selected"; } public String delete() { _vertrag.removeAllVertragspartner(); _vertrag.removeAllPatient(); _vertraege.remove(_vertrag); // Auch aus dem Datenmodell entfernen _em.remove(_vertrag); _vertrag = null; return "deleted"; } public String edit() { return rereadAndEdit(false); } public String end() { return rereadAndEdit(true); } private String rereadAndEdit(boolean readonly) { _vertragReadOnly = readonly; // May be modified meanwhile _em.refresh(_vertrag); return "editVertrag"; } @Remove @Destroy public void destroy() { } }
Now the problem is that the data model isn't updated when I've modified
the data somewhere else (The changes are in the database).
I checked it, and the find() method is not called when I revisit the page.
How can I enforce that the list is reread?
This is a general problem I have with SFSB, the caching ignores
database changes or worse overrides them. I had the suspect that
this could be someting with the way I implemented the equals()
method for the Vertrag class, but after modification it still didn't work
By the way setting scope=PAGE in the @DataModel didn't work. The data
may be reloaded every time, but the @DataSelection _vertrag field isn't
set anymore (always null) and the select(), end() and edit() methods are not called.
Any help will be appreciated...
Cheers
Markus
1. Re: SFSB are evil? (The eternal Update problem)fhh Jun 22, 2006 4:11 AM (in response to Markus Dahm)
Well, this is how stateful session beans are supposed to work. They save their state and that includes your List _vertraege.
So the question is what you really want to do. If you want to keep in sync with the database at any cost, you could user a stateless session bean. But doing so will cost performance since the db is re-read for every request. (I'm not sure how much is cached by hibernate. You may run into problems with hibernate cache)
If you don't have a lot of use (and not too man vertraege in the db) the performance loss should be negligible.
The "Big" solution would be to use JBoss' entity cache or implement your own caching strategy. But this will only work as expected iff your webapp is the ONLY application modifying the data in the db.
Refards
Felix
2. Re: SFSB are evil? (The eternal Update problem)Carsten Hoehne Jun 22, 2006 7:50 AM (in response to Markus Dahm)
Hello,
Your problem looks very common for me.
I checked it, and the find() method is not called when I revisit the page.
That is correct. The find() method is only called when vertraege is null.
That is the meaning of a factory method.
How can I enforce that the list is reread?
Easy answer. You have to set vertraege to null.
But to implement it is sometimes not so easy. Look at the hotelbooking example for a hint.
3. Re: SFSB are evil? (The eternal Update problem)Markus Dahm Jun 22, 2006 8:25 AM (in response to Markus Dahm)
Hi,
thanks for the reply...
How can I enforce that the list is reread?
Easy answer. You have to set vertraege to null.
But to implement it is sometimes not so easy. Look at the hotelbooking example for a hint.
It's not that easy indeed, because I alread tried to set this field to null
in the edit() action. However this caused an immediate reload from
the database thus loading again the old data. The the page flow then went
to the edit page. But when I got back to the listing page I still was stuck
with the old data.
I also tried to export the list using @Out so I could clear it elsewhere.
The @DataModel docs says somewhere that List.equals() is used to
determine when to reload the data. However it's not that specific when
this actually occurs.
Funnily, I have implemented very similar code elsewhere but have no
clue what could be wrong here.
BTW: Could you please be more specific where to look a the hotel booking
example. It's a rather big one :-)
Cheers
Markus
4. Re: SFSB are evil? (The eternal Update problem)Carsten Hoehne Jun 23, 2006 5:24 AM (in response to Markus Dahm)
BTW: Could you please be more specific where to look a the hotel booking
example.
I meant the booking example for hibernate and tomcat. There exists in class HotelBookingAction this method:
@End public String clear() { hotels = null; hotel = null; booking = null; return "main"; }
But the original example is refactored so this method does not exists anymore.
Try to ask you the question: Is there a way to avoid the @factory for the datamodel?
Perhaps the answer to this question will lead you to a better implementation.
Funnily, I have implemented very similar code elsewhere but have no
clue what could be wrong here.
Same here... | https://developer.jboss.org/thread/131999 | CC-MAIN-2018-13 | refinedweb | 949 | 65.52 |
What is exact use of private constuctor?
Printable View
What is exact use of private constuctor?
What do you think it is? What does a private constructor mean?
There are several uses for private constructors but the best way for you to understand them is to start by thinking about what public constructors can do. For example, public class A has a private field variable b (along with its getter) and a public constructor. Public class B imports A and tries to get the value of b through the getter. Suppose the constructor was changed to private. What happens when public class B tries to use the getter to get the value of b? If it helps to see the situation in code: | http://www.javaprogrammingforums.com/%20java-theory-questions/24062-private-constuctor-printingthethread.html | CC-MAIN-2016-30 | refinedweb | 123 | 75.91 |
0.35 June 26 2014 ***** Bug fixes ***** Fix manager process blocking issue if a child thread dies while waiting on a signal. (RT#69578) 0.36 June 25 2014 *****) 0.34 June 14 2010 ***** Bug fixes ***** Fix compatibility with perl 5.11 and later. (RT#56263) (Possible bug in core each() iterator, when using blessed globrefs as hash keys?) Main thread will no longer be ABRT signalled (to exit) if it is already shutting down. Fix usleep behavior on platforms without nanosleep support. (RT#52782) Fix test skip counts in forks08.t. (RT#52781) ***** Threads API consistency changes ***** Bumped threads $VERSION to 1.77, threads::shared $VERSION to 1.33 to match version-supported features and behavior. ***** Miscellaneous changes ***** Runtime 'require threads::shared' now correctly loads forks::shared in an ithreads-enabled Perl, as long as 'forks' was loaded first. Can default to the previous behavior with a true-value environment variable, THREADS_NO_PRELOAD_SHARED. (RT#56139) Use SvGETMAGIC macro instead of mg_get. Add module dependency requirements test. Updated to ppport.h 3.19. 0.33 April 8 2009 ***** Bug fixes ***** exit() in child process after fork() in user code no longer causes process hang. Address issue with Devel::Symdump and internal typeglob reference changes in Perl 5.10. ***** Miscellaneous changes ***** Removed Devel::Required (used only for forks development) from Makefile.PL required modules. 0.32 March 18 2009 ***** Miscellaneous changes ***** Minor change to forks08.t nanosleep usage when not available, to avoid srror. Made time tolerances consistent throughout forks08.t. 0.31 March 14 2009 ***** Threads API consistency changes ***** Module CLONE and CLONE_SKIP functions now are passed package name as first argument. When CLONE_SKIP true in package, all objects in child threads are now cleared. This occurs after fork (unavoidable affect of system fork COW), which hopefully should be portable with all non-perl modules. Note that arrays and hashes will be emptied, but not converted to undef scalar ref; this differs from ithreads (where all become undef scalar ref). Patches are welcome. Bumped threads $VERSION to 1.72, threads::shared $VERSION to 1.28 to match version-supported features and behavior. ***** Bug fixes ***** Improve package detection for CLONE and CLONE_SKIP; now identifies all packages in symbol table, not just packages identified by %INC. This allows for support of multiple modules in a file/module that may have CLONE or CLONE_SKIP functions. Improved Time::HiRes::nanosleep support detection. Corrected possible race condition with $thr->get_stack_size(). Documented expected behavior. ***** Miscellaneous changes ***** Added preliminary Perl debugger support. Defaults to tying TTY only to main thread, unless breakpoints exist in user code. Add some time tolerance in forks08.t, to accomodate for busy systems or slow signal handling. New CPAN module requirements: Devel::Symdump and Acme::Damn. Updated to ppport.h 3.16. 0.30 February 16 2009 ***** Bug fixes ***** Don't overload/define Time::HiRes usleep or nanosleep unless they are supported on target platform. Check for "Invalid value for shared scalar" errors when storing values in shared scalars. Shared scalar values containing user tied objects will no longer be treated as threads::shared objects when checking for circular references. ***** Miscellaneous changes ***** Overloaded sleep total sleep time is more accurate in cases where it might be interrupted by child thread shutdown (CHLD) signals. 0.29 February 2 2009 ***** Bug fixes ***** Shared variables that reference shared variables now consistently report the same thread-local reference memory address. Code refs can now be used as hash keys. Fix spurious warnings regarding mismatched Time::HiRes prototypes. Explicit mg_get in is_shared() to insure tied scalar fetched before ref check. ***** Threads API consistency changes ***** Can now store CODE refs in shared variables if using Storable >= 2.05. Can now use CODE refs as shared variable keys (stringified values work as expected). Bumped threads::shared $VERSION to 1.27 to match version-supported features and behavior. ***** Miscellaneous changes ***** Add Makefile build option to upgrade Storable to support using CODE refs in shared variable keys, if using Storable 2.05 or later. Round test suite sleep time check sensitivity to eliminate false positives on some (hardware) platforms. Using more portable prototype definitions with some versions of Test::HiRes. Scalar::Util 1.11 or later now required. Sys::SigAction 0.11 or later now required, as this correctly handles the 'safe' sigaction attribute. Fix typo in croak error text in cond_timedwait. 0.28 December 30 2008 ***** Bug fixes ***** join() and detach() now correctly propagate and throw exceptions to threads, in such cases as joining or detaching an already joined or detached thread. Threads now supports circular self-referential shared variables (i.e. my $x:shared; $x = \$x;) and consistently returns the correct REF value; circular-referental sets of variables are also supported, if defined before sharing with shared_clone()). forks::shared function is_shared() now understands REF type input and circular referential shared variables. is_shared() should now return a consistent address in all threads and for all variable types; however, note since it refences memory in the shared process, do NOT use the return value to perform direct memory access (not that it was intended for this purpose, anyway). Using single-declaration form of 'use constant' for Perl 5.6.x compatibility. Explicitly registering 'threads' warnings pragma, for Perl 5.6.x compatibility. Added more XS prototype compatibility with 5.6.x, allowing second forms of cond_wait and cond_timedwait to be better supported. Added second forms of cond_wait and cond_timedwait to Perl < 5.8 source filters (eliminates segfaults). Identified and implemented additional internal state conditions when error 'Cannot detach a joined thread' should occur. threads->list(threads::all) no longer returns threads that already have a thread blocking to join them. Corrected a few uses of hash and array iterators that modify structure in loop (using each() for hashes, separate array copy). ***** Threads API consistency changes ***** forks::shared now implements standard threads::shared function shared_clone(). Scalars that have a value and are shared afterwards will retain the shared value when running in native threads emulation mode. Restartable system calls (platform-dependent) and sleep (including Time::HiRes sleep, usleep, and nanosleep) should no longer be interrupted by CHLD signal, unless CHLD signal handler is defined in user code. This should more accurately represent process behavior with slow system calls, as would be expected with native ithreads. Bumped threads $VERSION to 1.71 and threads::shared $VERSION to 1.26 to match version-supported features and behavior. forks::shared share() now correctly checks the function prototype when disabled (e.g. when forks::shared is loaded without or before forks). CLONE method/function is now supported in main:: package (was ignored). CLONE_SKIP method/function is now supported. Usage details at:'CLONE_SKIP()' threads->object(0) now returns undef (main thread is not considered an object). Support for 'array' context type (alias for already supported 'list' type) when creating a new thread. Thread attempting to join self (while non-detached) returns an error. Now correctly storing/returning stack size settings, although not internally used for anything useful at this time. Core function rand() is now reseeded in each new thread (via srand()). ***** Miscellaneous changes ***** Added THREADS_NATIVE_EMULATION environment variable to allow users to have forks behave more like native ithreads ("buggy" behaviors and all). Removed source filter requirement for Perl 5.9+. (Now using internal PL_sharehook instead of Attribute::Handlers whenver possible, including with Perl 5.8.x.) Removed use of AUTOLOAD in forks::shared; may see a minor shared variable access performance improvement. Added signal blocking when doing fork() system call, to insure most reliable thread startup behavior (i.e. custom CHLD signal handler won't create instability). Made minor changes to the test suite to improve descriptions and suppress a few unnecessary warnings. Added internal patching mechanism to allow Test::More to work with Perl 5.8.1 and older (primarily for test suite backward compatibility). Silenced spurious Test::More "WOAH! ..." warnings in test suite, regarding Test::More being unaware of global test counting when mixing forks and threads. Added extra parameter error checking to XS code. Modified internal data manipulation for broadcast() to protect against occasional memory corruption with Perl 5.6.x (delete() on array appeared to cause rare segfaults). Added 'if' CPAN module to package requirements, for Perl 5.6 support (test suite). Updated to ppport.h 3.14. 0.27 January 27 2008 ***** Bug fixes ***** forks::shared now supports perl 5.9.0 and later (with a source filter). The requirement for a source filter is hopefully just a temporary solution until Attribute::Handlers can access the 'shared' attribute again (which perl 5.9 and later currently prevent, perhaps because they consider it a reserved word). Corrected perl 5.6 support, regarding incompatible XS function Perl prototypes (broken since 0.16). All internal %INC manipulation is now done at compilation (require) time. This corrects cases where modules that 'use threads::shared' before forks::shared has been loaded actually load ithreads-native threads::shared. Corrected bug regarding handling forks-server operation deferred signals (which was preventing them from being executed when they should be executed). ***** Miscellaneous changes ***** Forks now uses Perl core module Attribute::Handlers for 'shared' variable attribute handling. This also insures compatibility with any other modules that may use Attribute::Handlers. Removed BUS, FPE, ILL, SEGV, and SYS from list of "forks-aware" signal handlers for better cross-platform portability. Added POD strongly encouraging use of forks and forks::shared as FIRST modules. Now tracking last known CORE::GLOBAL::exit at require time, and resetting at END. This should insure that cases where forks wasn't first module to be loaded allows for other modules to still use their own custom exit methods. Moved 5.6.x source filter from forks.pm to forks::shared.pm, where it belongs. Added appropriate disabled functions (without prototypes) for perl 5.6.x when forks::shared is disabled if was loaded without loading forks first). 0.26 September 30 2007 ***** Bug fixes ***** Eliminated some warnings on platforms that do not implement all signals forks can monitor. Added boolean hook $forks::DEFER_INIT_BEGIN_REQUIRE to allow external modules to override forks server functions if forks loaded in a BEGIN block. ***** Miscellaneous changes ***** Added some logic in CHLD reapers for better cross-platform stability. Updated to ppport.h 3.12. 0.25 August 12 2007 ***** Bug fixes ***** Updated internal PID tracking to U32 size for increased portability across different kernels and kernel configurations. This corrects irregular issues with locks on such systems. Rewrote signal handling engine to be more portable and stable. Changes eliminated behavior on BSD kernels that would cause processes to improperly exit with an ABRT-triggered core dump. ***** Miscellaneous changes ***** Added some protections in test suite for non-mixed fork/thread safe Test::More module. Added tests for new signal handling engine. 0.24 July 9 2007 ***** Threads API consistency changes ***** Changed $thr->wantarray return value to 0-length string (was string '0') to meet standard wantarray scalar context return value. Added support for exit() and threads->exit() methodology and behavior. Added support for $thr->error() feature. Added a warning (and disallowing thread detach) if attempting to detach a thread that another thread is currently waiting to join. ***** Internal behavior changes ***** Added ability to swap primary process (main<->shared) that is parent of all processes in threaded application (via $ENV{THREADS_DAEMON_MODEL}); should help support co-existance with some fork-aware modules, like POE. Rewrote signal handling methodology to resolve stability issues with inter-thread and external process signaling. Addressed the limit of 65535 shared variables: you may now create up to 2^31-1 (2+ billion) shared variables. Note: shared variables are currently not memory deallocated even if they go out of scope in all threads; thus, it's NOT recommended to create too many (1k+) unless you have a requirement to do so. Shared var mem deallocation (when no longer referenced by any thread) will be addressed in a future release. Improved behavior of signal() and scope-exit unlock ordinal to insure that all threads, no matter what type of waiting they were performing, have an equal chance to receive the signal or re-acquire the lock. The old behavior gave preference towards regular waiting events for signal, and timedwaiting events waiting to reacquire the lock for unlock ordinal. Deprecated and removed deadlock detection 'resolve_signal' feature (as this could not be supported in new forks.pm signal handling logic). ***** Bug fixes ***** Shared variable in push() on shared array now works. Eliminated slow memory leak when creating many joinable threads: the shared process now reclaims all shared memory allocated for joinable threads, as long as the application (periodically) joins then after they complete. Eliminated "Performing cleanup for dead thread 0" errors when compiling a script (i.e. perl -c script.pl). This fix also eliminates double "syntax OK" reports when compiling a script. Fixed a case where detach after thread had already completed could result in incorrect thread group exit state reporting. Corrected a bug regarding recursive variable unlocking (was deleting instead of decrementing lock count). Fixed a few issues in test scripts regarding mis-reported errors related to older threads.pm installs or non-threaded Perl targets. Forks now starts correctly if called with 'require' or if forks::import is skipped for any reason. Added additional check in server to shutdown if main thread dies in a hard way (no notification to server or thread group). Added some extra protection in thread signaling (to insure that process exists before signaling it). Added some protection in test suite for issues with race-conditions in Test::More. Fixed race condition in forks07.t that could cause test to report an error. Fixed race issue in forks04.t that could cause script to error out on Perl instances with old native threads.pm libraries or no threads.pm library. ***** Miscellaneous changes ***** Added additional thread environment protection regarding fork occuring outside forks.pm module. Also silenced a few warnings that might have occured in such cases. Silenced a few more unnecessary run-time warnings in specific exception and error cases. Rewrote END behavior for more stability and better cleanup during thread (process) group exit. Added internal hooks to allow external modules to override default forks.pm fork logic. This should allow more flexibility to integrate forks with application-scope modifying environments (i.e. mod_perl, POE, Coro, etc.). Removed dependency on Reaper module. Updated version requirement for Scalar::Util module. Upgraded to ppport.h 3.11. Fixed some XS portability issues with older versions of Perl (5.8.1 and older). 0.23 8 April 2007 ***** Test suite fixes ***** Corrected issue in forks04.t that would cause irrelevant but terminal compilation errors if real threads.pm (1.34 or later) weren't present. ***** Miscellaneous changes ***** Silenced a warning during external fork (non-thread) process exit. Added some internal hooks to allow add-on modules (e.g. forks::BerkeleyDB) the opportunity to clean up global thread resources during shutdown. 0.22 19 March 2007 ***** Internal behavior changes ***** Thread manager process now forcefully kills any still active threads when it exits. This is intended to best simulate standard thread.pm thread cleanup during process exit. ***** Bug fixes ***** Corrected bug in shared server shutdown preventing complete cleanup. Corrected some platform and perl build sensitivities in the test suite. ***** Miscellaneous changes ***** Added additional stability against fork() outside of forks.pm. Tweaked some warnings and disabled some debug logging. 0.21 17 March 2007 This revision includes *many* core changes and improvements, so be sure to perform full testing with existing forks-enabled applications before upgrading. All changes have been exposed to extensive regression testing, so you may expect all new features to be reasonably stable unless otherwise noted with a *WARNING* tag. ***** New features ***** Enabled complete thread context support. Be sure to specify the context, either implicit or directly. This also means you may not get what you expect if you return values in a context that doesn't match your spec. Add optional, automatic deadlock detection (warnings) in threads::shared. Also added is_deadlocked() method (manual deadlock detection) for threads. Added set_deadlock_option class method to forks::shared (threads::shared). Aware of thread params at thread creation, e.g. threads->new({}, sub {}); Added complete support for $thr->wantarray and thread->wantarray. Added complete support for thread state: is_running, is_joinable, is_detached(). Added additional support to threads->list(), with package variables: threads::all, threads::running, and threads::joinable. Added support for 'use forks qw(stringify)'where the TID is returned for a threads object in string context. Added detailed last known state of all threads on main thread exit (or server process unexpected exit), like: Perl exited with active threads: x running and unjoined y finished and unjoined z running and detached Added stubs for get_stack_size and set_stack_size, although they don't do anything (yet). Added support for threads->_handle and $thr->_handle, although it currently does not guarantee a reference to the same memory address each time (will be addressed in a later release). Added support for inter-thread signaling using $thr->kill('SIG...'). *WARNING* This feature is still highly experimental and has known issues when sending a signal to a process sending or receiving socket data pertaining to a threads operation. This will be addressed in a future release. Added question during build process to allow forks to override threads namespace if target Perl does not have native threading built in. Added POD describing this feature and behavior implications. ***** Bug fixes ***** Corrected bug in threads::shared::scalar that prevented tieing without a pre-existing scalar reference. Localizing $? in END block to insure that main thread exit code isn't accidentally overwritten during shutdown. Corrected several cases where internal auto-vivification was not intended, but might cause internal variable state issues. Corrected bug where fork() followed by ->isthread() in a child process while parent process (a thread) was already waiting on a separate thread could cause internal synchronization issues. Corrected bug in ->list where scalar context would return last object, not the number of waiting threads. Added additional protection in END block against external fork() occuring outside our knowledge causing synchronization havoc with the thread process group. Removed delete from %DETACHED on thread exit, as this property is used for internal thread type and state checking. Updated some error handling to suppress some undefined variable warnings. ***** Internal behavior improvements ***** Added silent overload of Config.pm 'useithreads' property to insure all modules and scripts see a true value when forks is loaded. Added explicit signal trapping of all untrapped normal and error signals for consistent and safe thread exit behavior. Added defensive error handling around non-blocking server sockets to protect against interruptions or busy resources during read or write. This should also make UNIX socket support more stable on certain target architectures. Added defensive logic to cleanup internal resources for threads that appear to have exited in an unsafe manner (and that may have left forks::shared resources in a unclean state) or were terminated with SIGKILL. Rewrote _length(), _send(), and _receive() internal functions to protect against signal interruptions, busy resources, socket disconnections, full socket buffers, and miscellaneous socket errors, including adding retry logic where appropriate. Updated _join() server function with much more intelligent logic regarding the state of a thread during the join process and a few more error cases that it needed to check for. threads->yield() now does a 1 ms sleep. ***** Threads API consistency changes ***** Can now signal unlocked variable using cond_signal and cond_broadcast. Note: Signaling locked returns 1; signaling unlocked returns undef. Modified lock, cond_signal, and cond_broadcast to return undef (instead of 1) to be consistent with threads.pm. Overloaded != for thread objects. A failed thread spawn (fork) now prints a warning and returns undef instead of dieing out. Detach twice on the same thread now throws an error. Improved format and content of internal warnings, and warnings now respect warnings state in caller for category 'threads'. Bumped threads $VERSION to 1.26, threads::shared to 1.04 to match version-supported features and behavior. *** Miscellaneous changes *** Implemented initial framework for better message handling. This should help reduce overall CPU usage, and hopefully improve performance, using custom filter definition for request and response messages that do not require Storable freeze/thaw. Requests that currently implement this are: _lock and _unlock. Responses that currently implement this are: any generic boolean response. Made Time::HiRes a prerequisite now. This means that fractional cond_timedwait is now supported by default. Optimized sigset masking: now only one set is created at compile time and reused during execution. Now safely runs in taint mode when any potentially tainted environment vars are defined. Suppressing unnecessary warnings in the case that 'test' does not exist in /bin or /usr/bin. Silenced thread socket errors during thread shutdown process, unless debugging is enabled. Added basic blocking join poll checks, to help prevent against forever blocking join() cases in abnormal thread death circumstances. Thread shutdown now expects a response (to insure synchronized shutdown agreement with server process). General improvements in thread shutdown stability (primarily server-side). 0.20 5 October 2006 Fixed rare thread start race condition where parent thread would block indefinitely if child thread were to spawn, complete, and exit before the parent could obtain the TID associated with the child thread. Corrected a few cases in server timedwait handling, cond_broadcast, and cond_signal where a lock could be prematurely transferred to another thread if the main thread (tid 0) were holding the lock at the time the event expired. Modified cond_timedwait to support fractional seconds (if Time::HiRes is loaded before forks). Minor changes to forks.xs for backwards compatibility with gcc 2.96. Minor cleanup in (forks.xs) bless reference handling. When using INET sockets, peer address is validated against the loopback address (IPv4 127.0.0.1) before accepting the connection; otherwise, socket is immediately closed and a warning is emitted. Added THREADS_IP_MASK env param to allow override of default IP mask filter. Misc cleanup of internal server environment variable handling. Moved some server code into separate subroutines. 0.19 21 May 2006 Implemented an exported bless() function allow transparent bless() across threads with forks::shared. Implemented exported is_shared function in forks::shared. Implemented custom CHLD signal handler to cleanup zombie process. This change was introduced to resolve an issue on some platforms where using $SIG{CHLD}='IGNORE' resulted in the perl core system() function returning -1 instead of the exit code of the system call. This signal handler is only used if the target system's system() call returns -1 on success when $SIG{CHLD}='IGNORE'. Added THREADS_SIGCHLD_IGNORE to allow users to force forks to use $SIG{CHLD}='IGNORE' on systems where a custom CHLD signal handler is automatically installed to support correct exit code of perl core system() function. Added THREADS_NICE env param to allow user to adjust forks.pm server process POSIX::nice value when running as root. If unset, no change is made to the server process priority. This differs from the historical behavior of forks.pm defaulting to nice -19 when run as root. Patched XS code to be ANSI C86 compliant (again). Code was unintentionally changed to require a minimum of ANSI C89 compliance since 0.17. This should allow all gcc 2.95.x and other C86-compliant compilers to once again build forks.pm. Fixed prototype mismatch warning when disabling cond_wait when forks is not used before forks::shared. Added patch to quietly ignore sharing an already shared variable. forks::shared used to bombs out in such cases (e.g. $a:shared; share($a);). Updated to ppport.h 3.06. Implemented separate package versions for forks and threads. threads package version will represent the most recent threads.pm release that this module is functionally compatible with. Disabled call to server process on shared variable DESTROY calls to decrease server communication load, as none of the affected TIE classes implement custom DESTROY methods. 0.18 7 December 2005 Introduction of UNIX socket support. Socket descriptors are written to /var/tmp and given rw access by all by default for best support on multi-user systems. Importing SOMAXCONN and using for socket server listener max socket connections (was hard coded at 10) for best (and system-level flexible) thread spawn stability under high load. 0.17 14 May 2005 (unreleased) Added method cond_timedwait and added second forms of cond_wait and cond_timedwait per the ithread specification (where signal var differs from lock var). All elements of perl ithread interface are now implemented, with respect to perl 5.8.7. Added eval wrapper around new thread code execution to trap die events; thus, join() is now more robust (fewer chances for runtime hangs on '$thread->join' due to premature child thread termination). Fixed bug in _islocked in case where if main thread tried to unlock an already unlocked variable, it would not correctly enter if case and return undef or croak() due to undef value in @LOCKED resolving to numeric 0. 0.16 8 April 2004 Changed semantics of debugging function: must now specify environment variable THREADS_DEBUG to be able to enable and disable debugging. If the environment variable does not exist at compile time, then all of the debugging code is optimised away. So performance in production environments should be better than before. 29 March 2004 Goto &sub considered evil with regards to performance and memory leaking. Therefore removed goto's where appropriate. 0.15 14 January 2004 Just got too much mail from people attempting to use forks.pm on Windows. Decided to add check for Win32 to Makefile.PL to have it die when attempting to run on Windows. Added documentation to explain this. 0.14 7 January 2004 Removed dependency on load.pm: it really doesn't make sense in a forked environment: I don't know what I was thinking in that respect. Added dependency on IO::Socket 1.18: we do need auto-flushing sockets (which seems to be pretty standard nowadays, but just to make sure). Fixed problem with large values / structures being passed with some help from Jan-Pieter Cornet at the Amsterdam PM Meeting. Spotted by Paul Golds. Added test for it. 0.13 4 January 2004 Looked at fixing the problem with signalling unlocked variables. Unfortunately, there does not seem to be a quick solution. Need to abandon this idea right now until I have more time. Updated documentation to let the world know there is an inconsistency. Documented the THREADS_DEBUG environment variable and made sure it is unset during testing. Updated ppport.h to 2.009. Didn't expect any problems with 5.8.1, but you never know. 0.12 2 January 2004 Fixed problem with signalling thread 0. Spotted by Stephen Adkins. 0.11 28 December 2003 Added automatic required modules update using Devel::Required. Added requirement for Devel::Required, so that optional modules are listed as required on the appropriate systems. 0.10 11 November 2003 Added check for processes dieing at the length check of a message. Not 100% sure whether this will be the best way to handle the main thread dieing, e.g. when it exits before all threads have been joined. 0.09 24 October 2003 Apparently, Test::Harness cannot handle testing "threaded" scripts using an unthreaded Perl. Added test for threadedness of the Perl being used: if so, skips testing Thread::Queue. Spotted by several CPAN testers. 0.08 24 October 2003 Shared entities that were also blessed as an object, were not correctly handled (ref() versus Scalar::Util::reftype() ). Spotted by Jack Steadman. Now fixed by using reftype() rather than ref(). Dependency on Scalar::Util added (not sure when that became core). Added tests to excercise Thread::Queue (if available). 10 October 2003 Changed async() to make it a little faster by removing an extra call from the stack. 0.07 27 September 2003 Added error detection in case lock or cond_xxx were called on unshared variables or cond_xxx were called on an unlocked variable. Added tests for it in the test-suite. Added dummy package declaration to forks::shared.pm for CPAN's sake. Cleaned up the attribute handler code in forks::shared.pm a bit. 0.06 27 September 2003 Finally grokked the documentation about attributes. This allowed me to finally write the handler for the ":shared" attribute. Which in the end turned out to be surprisingly simple. Adapted the test-suite to test usage of the ":shared" attribute as opposed to sharing variables with the "share" subroutine. 0.05 26 September 2003 Increased dependency on load.pm to 0.11: versions of load.pm before that had issues with running under taint. Debug statements can now be activated by setting the environment variable THREADS_DEBUG to true. As this is still experimental, this feature is only described in the CHANGELOG for now. Fixed several issues when running under taint. Test-suite now runs in tainted mode just to be on the safe side. Removed some debug statements from the test-suite. 0.04 10 August 2003 Implemented .xs file munging and source-filter to be able to truly support forks.pm under Perl 5.6.x. Thanks to Juerd Waalboer for the idea of the source filter. It is now confirmed that forks.pm won't work under 5.005, so the minimum version of Perl is now set to 5.6.0 in the Makefile.PL. 7 August 2003 Tested under 5.8.1-RC4. The WHOA! messags seem to have disappeared but instead a warning has appeared that cannot be suppressed. This was caused by my attempt to activate the :shared attribute. Since that doesn't work anyway, I removed the offending code and the warning went away. Fixed some warnings in the test-suite. Fixed another warning in forks.pm. Reported by Bradley W. Langhorst. 0.03 2 April 2003 Fixed a warning in forks.pm. Reported by Bradley W. Langhorst. 0.02 17 January 2003 Added dummy -package forks- to forks.pm to fool CPAN into thinking it really is the forks.pm module, when in fact it is of course threads.pm. Fixed some warnings in t/forks01.t. 28 October 2002 Made sure length packing uses Network order. 0.01 27 October 2002 First public version of forks.pm. Thanks to Lars Fenneberg for all the help so far. | https://metacpan.org/changes/distribution/forks | CC-MAIN-2015-27 | refinedweb | 5,044 | 58.99 |
KTextEditor
#include <messageinterface.h>
Detailed Description
Message interface for posting interactive Messages to a Document and its Views.
This interface allows to post Messages to a Document. The Message then is shown either the specified View if Message::setView() was called, or in all Views of the Document.
Working with Messages
To post a message, you first have to cast the Document to this interface, and then create a Message. Example:
Definition at line 399 of file messageinterface.h.
Constructor & Destructor Documentation
Default constructor, for internal use.
Definition at line 179 of file messageinterface.cpp.
Destructor, for internal use.
Definition at line 184 of file messageinterface.cpp.
Member Function Documentation
message to the Document and its Views.
If multiple Messages are posted, the one with the highest priority is shown first.
Usually, you can simply forget the pointer, as the Message is deleted automatically, once it is processed or the document gets closed.
If the Document does not have a View yet, the Message is queued and shown, once a View for the Document is created.
- Parameters
-
- Returns
- true, if
messagewas posted. false, if message == 0.
The documentation for this class was generated from the following files:
Documentation copyright © 1996-2015 The KDE developers.
Generated on Tue Nov 24 2015 23:10:25 by doxygen 1.8.7 written by Dimitri van Heesch, © 1997-2006
KDE's Doxygen guidelines are available online. | http://api.kde.org/4.x-api/kdelibs-apidocs/interfaces/ktexteditor/html/classKTextEditor_1_1MessageInterface.html | CC-MAIN-2015-48 | refinedweb | 232 | 51.24 |
19 March 2010 15:13 [Source: ICIS news]
LONDON (ICIS news)--Major plastics producer Dow Chemical will target price increases of €60-80/tonne ($82-110/tonne) on all of its polyethylene (PE) grades across the European, Middle Eastern, African and Indian regions from 1 April, the company said in a statement on Friday.
Low density PE (LDPE) would face targets of plus €80/tonne, while high density PE (HDPE) and linear low density PE (LLDPE) buyers would be looking at plus €60/tonne in April, according to the statement.
There was a widespread expectation of price increases for April in the LDPE market, and also for LLDPE, but the market was sceptical of an increase in the HDPE sector, where imports and ample supply affected sentiment.
LDPE and LLDPE prices had increased by €40-60/tonne in March, due to tight availability of product, while HDPE prices had largely rolled over from their February level.
Other PE producers had not yet made April plans clear.
“We will wait for ethylene to settle before we make our plans public,” said another PE producer.
Anything between a rollover to modest increase was expected for the new April monomer contract settlement. The March contract stands at €940/tonne FD (free delivered) NWE (northwest ?xml:namespace>
LDPE gross monthly prices were reported at €1,260-1,270/tonne FD NWE mid-March, up by €50/tonne from February. January and February had seen a combined increase of €150-160/tonne.
PE producers in
($1 = €0.73) | http://www.icis.com/Articles/2010/03/19/9344412/dow-targets-60-80tonne-increase-for-april-pe.html | CC-MAIN-2014-52 | refinedweb | 253 | 58.52 |
About
(Note: for technical information regarding the OpenTK library, refer to the Project section).
This is a short recount of the project history from the perspective of Stefanos 'thefiddler' A., main developer of OpenTK.
I conceived OpenTK around December 2005, while perusing the Tao Framework as an avenue to learn C#. Without much knowledge about C# or .Net, I was soon annoyed with some of Tao's (perceived) shortcomings, namely the namespace redudancy (Tao.OpenGl.Gl.gl*, the 'gl' part is repeated three times!) and extension loading mechanism.
After a brief period, I started exploring the idea of creating my own OpenGL bindings. It took a while, but by February 2006 I had the first working prototype. No extension loading and many problems, but at least it worked! I was also becoming more fluent in C# (even though I would be really ashamed to show the code of these programs to anyone, now :))
I continued rewriting and improving the generator, and by the summer of 2006, I had working extension loading and opengl enumerant support (a first for any library, to the best of my knowledge). At that point, the developers of the Tao Framework were looking into ways to change the inflexible extension loading mechanism used in Tao 1.3, so I offered to adapt my code. By October 2006, the new code could support the Tao examples and it was checked into the Tao repository. At the same time, the OpenTK project was registered at Sourceforge: it would contain the alternative (non Tao-compatible) bindings, as well code for Context creation and other convenient functions.
Throughout the next months, OpenTK was ported to Linux by the author of the AgateLib, while the OpenGL bindings continued to improve. The Tao 2.0.0 release at the beginning of 2007 would be the biggest challenge - but the bindings fortunately worked. During the next few months I was devoted to fixing the compatibility problems with older Tao projects, and the latest Tao.OpenGl beta is now compatible with almost all legacy Tao projects.
Starting from May 2007 till now, OpenTK has grown exponentially. New, extremely useful features were introduced to the OpenGL bindings (function overloads, separate namespaces per extension category), and the codebase matured. At the same time, preparations were made for the OpenGL 3.0 - with a bit of luck, OpenTK and Tao (which now share code) will support the new standard as soon as it released.
As of 2009, the Tao framework is no longer being developed. Its OpenGL and OpenAL bindings have been incorporated into OpenTK to simplify porting of Tao applications.
OpenTK 1.0 was released on October 2010.
Complete OpenGL 4.1 support has been available since December 2010.
Complete OpenGL 4.4, OpenGL ES 3.0 and a fully-featured SDL2 backend were added in September 2014. | http://www.opentk.com/about | CC-MAIN-2014-15 | refinedweb | 472 | 65.93 |
Odoo Help
Odoo is the world's easiest all-in-one management software. It includes hundreds of business apps:
CRM | e-Commerce | Accounting | Inventory | PoS | Project management | MRP | etc.
Error : write() got multiple values for keyword argument 'context'
Hello,
I need to change the "date_maturity" of "account.move.line" as soon as i update the "date_due" of "account.voucher". So i overrided the wirte() function of "account.voucher" like this :
def write(self, cr, uid, ids, vals, context=None):
for voucher in self.browse(cr, uid, ids, context=context):
for move_line in voucher.move_ids:
date_maturity = voucher.date_due
move_line.write(cr, uid, [move_line.id], {'date_maturity': date_maturity},context=context)
return super(account_voucher,self).write(cr, uid, ids, vals, context=context)
The override works like a charm, but when i get to execute the "move_line.write...." line, I get this error message :
Error : write() got multiple values for keyword argument 'context'
Thanks a lot for your help guys.
About This Community
Odoo Training Center
Access to our E-learning platform and experience all Odoo Apps through learning videos, exercises and Quizz.Test it now | https://www.odoo.com/forum/help-1/question/error-write-got-multiple-values-for-keyword-argument-context-99883 | CC-MAIN-2018-22 | refinedweb | 181 | 51.95 |
Long long ago, I created a 3d circular menu thingie you can see here. It wasn’t much long after, that Lee Brimelow came up with his 3d carousel tutorial. Well, to be honest, I’ve never read Mr. Brimelow’s tutorial, but still I vowed then and there that I’d never make another one these things again – kinda like Bob Dylan vowing never to play “All Along the Watchtower” after hearing Hendrix’s version. Today, though, I’ve decided to renege on that vow. A freind over at ShavedPlatypus was asking how to make a carousel thing more similar to mine than Lee’s but in AS3, so I figured what the hell, why not update.
Below is an example of what I came up with:
Not many comments added, but the full script is below. In a nutshell, you just create a new instance of OBO_3DCarousel and pass it a few 3d properties (if you want). After that you add pictures to it using the addItem() method. Easy-peasy, man. Oh, and you can set the useBlur boolean property if you want a blur for more distant images.
The main class:
The item class (instances of this class are the pictures in the carousel):
And a quick document class that created the .swf file above:
Go nuts and let me know what troubles you run into. It wasn't too extensively tested.
EDIT:
Download a sample .fla (including script, xml, some pictures and all that crap) of the above application here.
In other news, The Bureau of Public Secrets website (a site dedicated to Situationist and related thought ramblings) turned ten years old today. Ken Knabb, creator, translator, and, I'm sure, all around fun guy, shares his thoughts on the subject here.
I made a 3D carousel in Flex 4 and Flash Player 10 , acouple of days ago. Here is the link:
Devon… man, thank you. You needn’t…
looks good, Pradeek, but the z sorting is a bit off. I know it’s a pain in AS3 FP 9 or 10.. I’m still looking for a better method than I used here. Open to suggestions..
Thanks, I’m working on a more cleaner and easy to use method. I’ll let you know if it works.
Yes, this is just a newbie stupid question…
…but I’m an AS3 newbie, and was 37 yo… so I don’t will be ashamed to question….PLEASEEE… write two lines to make the example running with flash…
((After a few years sellin’n riding bycicles (and a couple of IronMan(s) too), I’m back in the arena. I spent my summer holidays trying to understand AS3 and I’m only a few ephiphany from “the programmer’s dawn”, as defined by my programming teacher @ school 20 years ago (remember Peek 33,33?)
Hey Luciano, I’d be happy to help if I can, but can you describe what you’d like to see it do. Not sure what you mean by “running with flash”. And I haven’t heard “peek” in years.. There used to be a whole lot of peeking and poking going on 20 years ago..
Hi Devon,
your gallery is fast and clean, I’d like to use it for my site building. With click-on-image feature to show before-after slider effects on photos. But I did not installed FLEX yet, and having some trouble with class assignment in FLASH and stage composing. I’ll appreciate very much a simple .fla AS3 script that refers to Class OBO_3DCarousel. Not much explanation…. just to let me understand…. thanx a lot!
Luciano
ps Just for fun a little story, referring to your “coffee for coder”…In Naples, Italy, my city, there’s the habit for those don’t have money, to go to the famous “Caffè Gambrinus” and have an espresso coffee for free, that someone unknown payed for him just telling the barman: “someone payed coffee for me??” ;-)
Hey Luciano,
I just edited my post and included a download of the .fla and all the trimmings. I hope that might help you out.
That free Italian coffee sounds great. I lived in Sicily for a couple years and miss the cappuccino the most. You wouldn’t happen to be related to “Lucky” would you? (Just kidding.. :) )
Ciao Devon!
great job! now I’m trying to add some click-on-image feature… a long night awaits me (probably more than one night!)
Grazie!
LL
Prego! Good luck with the image interaction. Not sure how I would do that myself.
Hi Devon, nice work on the site. I noticed that if I click a “subject” in the right column of this blog (Actionscript, Flash, AIR, etc) I get the category results “one by one”. That is, one page at a time. Is that by design? I was hoping I might click a category and browse all your posts on a subject.
Cheers,
Skye
Interesting.. I’ve never actually clicked on one before.. :) It may because I have it set up to only display one blog post per page and that gets carried over to subject browsing as well. I’ll play around and see if I can change that.
Made the carousel as a gumbo skin. Not the best of ways, but… pl. check it out here
Cool, Pradeek.. I’ve downloaded the SDK, but haven’t began playing with Gumbo yet.. Might have to play around this weekend.
Ciao Devon!
I worked hard on my project with your 3D Gallery (), a sort of training-on-job (addicted to script!)… but now there’s a problem: I can’t really understand how the carousel is building. I placed a new tag in the XML to recover (using an XMLLIST class) an alternative address and open High res images on click. Tracking each left or right click I got an index to read XML, but the carousel’s items was not placed with the same XML’s order and wrong image is opening.
I know that one simple way is changing order of the XML’s tag of the High res images, but I’m still trying to understand HOW the _carousel build itself by add(ing)Items.There’s something in the way it builds that I don’t understand…. please can you explain in “blocks” how it works? I missed the “kill” function!
thanks devon!
luciano
I use a custom query string to display categories, archives etc in a complete list .. overriding front page settings.
Luciano, it looks good so far. I’ll try to put together a more commented version when I get some time. I’m not altogether sure how I’d go about doing what you want though. Maybe finding the angle increment to present a new picture and keeping track of what’s up front that way.. Or maybe just starting from scratch and creating a new one with that purpose in mind.
DEIRDRE! I can’t download that thing. Don’t know if that’s site or my browser.. If I use it will mess up previous posts?
Thanks for sharing this – I am trying to use it.
I downloaded the zip and compiled it to baseline that I had everything in place.
I get
caurina\transitions\Tweener.as:1054:
1046: Type was not found or was not a compile-time constant: TweenListObj.
line 1054 is handleError function of Tweener, so might be a side effect?
Never mind – I put tweener in my com folder
doh!
Hopefully a better comment/question: how can I change the orientation of this carousel to make it into an upright wheel?
Answer: Switch x and y values in the CarouselItem class
Glad you got that sorted, David.. Hope it helps you out..
Hi I am playing with this class and making buttons to load a specific item in the carousel and it works good, the only problem I have is that the order of images in the carousel does not correspond with the ones in the xml file.. after like 4 items it gets a different order.
Is there a way to keep the same order of files from the xml in the carousel ?
how do we send the carousel to lowest level layer so that other movie clips are on top of it?
Hey Chris, I would simply watch the order in which the images appear and plan accordingly. The images are loaded in order but then positioned according to the logic in the addItem() method.
Fred, the carousel inherits from the Sprite class and can be handled like any other Sprite. Using addItemAt(0, myCarousel) will always push it below anything else already on the Display List.
Hello Devon, I was wondering how can i add the reflection for the items… I tried different ways but couldn’t get it right. can you help me out ?
Tite! thanks for sharing.
trying to add button functionality to the images so I could click on them and bring them forward or run another function or …..
wondering if you have any suggestions for turning the images into clickable items?
Wow… WOW… OMG WOW!
You have NO idea how long I have been looking for someone that coded this in AS3, CORRECTLY, WITH all the appropriate handlers and linked it to an xml list of images. I don’t know how many resources exactly, but in the past 48hrs, this is the FIRST that has what I was looking for!
THANK YOU!
Nick
Devon,
Not sure how often you check this blog anymore, but if you could let me know if you could answer a few questions about the code, it’d be appreciated. Just trying to add some nifty things to it :)
Nick
Hey, Nick. Been crazily busy of late, having just changed jobs and countries, but I still read comments. What kind of questions you got? And thank you for the kind words..
Hey man,
Thank you for taking the time out of your schedule first off. Secondly, I’m having issues (though I’m close to the solution) importing the swf of the carousel into a movie clip. The issue is that even though the movie clip is the same size as the the carousel was in it’s file, it’s being displayed at like 3-4 times the size, and there doesn’t seem to be a way to resize it.
The code I have thus far for the movie clip looks like this atm:
import flash.display.Loader;
import flash.display.LoaderInfo;
import flash.events.*;
import flash.net.URLRequest;
var movieLoader:Loader = new Loader();
var movieURL:URLRequest = new URLRequest(“carousel.swf”);
movieLoader.load(movieURL);
carousel_mc.addChild(movieLoader);
trace(carousel_mc.height, carousel_mc.width);
var a:Number = carousel_mc.height;
var b:Number = carousel_mc.width;
movieLoader.contentLoaderInfo.addEventListener(Event.INIT, initHandler);
function initHandler(event:Event):void {
var movieLoader:Loader = Loader(event.target.loader);
var info:LoaderInfo = LoaderInfo(movieLoader.contentLoaderInfo);
movieLoader.height = a;
movieLoader.width = b;
}
Any hints you could throw my way? I’m not new to actionscript, but I am definitely new to doing something so complicated.
Thanks devon.
I’ve tried to modify this source to make look smaller and to fit on my purpose onto revising my company’s website.
The image modification was nothing, but it is very hard to find the place of initial location of the images and hence, hard to find to contracting the images the main file is displaying.
Anyway, it’s nice to see the codes insides of folders which were developed by MIT guys. It’s very very hard to understand and I actually dropped it off :)
Well, thanks for your devotion.
Devon,
Thanks a lot for a great carousel. As other people have commented it is easy to use and seems to be built well.
I have been working with it and had a quick question.. Is there a way to add more info to each of the carousel items? ie: add text about the items that would also come from the xml file (think file card)
Ive been playing around with it and so far havent had any luck. Im assuming i would create the text fields in the code area where the _data bitmap is created?
Thanks again and I appreciate any additional insight!
NIck
Wonderful Job Devon! I like your style of coding and got a chuckle about the side story on Lee’s carousel. :)
I’ve played with Lee’s in Flex but gave yours a try with a platform called Koolmoves and added a few bits just to test the KM compiler (it just recently added AS3 support) which is running here:
We’re ramping up to evangelize for KM’s new version so the domain will change to KM-CODEX.com in the next few days and I’ll be sure to send KM users your way to learn from your expertise. Thanks for being so generous and I look forward to your future offerings!
Chris
first off, great carousel. I’m actually trying to figure out how to tilt the angle of the carousel slightly, as though you can see the carousel more at a top view looking down. Anyway you could help me with it? I’m not a coder as you can tell, but any help would be appreciated. Thanks in advance.
Tom
hi devon,
i have no idea how to sort the images correctly. i have the same problem chris had bevor, but cant finid any solution. maybe you can give me one more hint how to manage this problem.
thank you
christian
Hi Devon,
really cool one – but how can i change the cirlce into an elliptical movement
what are the settings so that the main item is not scalled?
Hello I’m knew to this whole thing and I’m trying to get this carousel to work without using xml and loading the movie clips from the library as carousel items. Any suggestions on how to do this. I’ve tried scaling back the code to make it work this way but I haven’t been successful.
Is there anyway to make the far back two blurred images be on the corresponding sides of the first two images? [][] [] [][]? Almost like a card stack?
Loving this!
this is the most amazing carousel component i’ve seen done in flash/flex.. very well done! thank you :)
Hello Devon, nice work! Have you the solution for the problem with the sort the images in correctly order?
Thanks in advance!
This is a GREAT tutorial!!!
Did anyone ever find a solution to the Click-on-image problem?
I’m building something now the requires to track the front-most image and be click-able.
Thanks for any help.
Hi Devon,
May I know what is e parameter that I need to modify so that the image that was currently not selected is 2x smaller?
Thanks in advance!!
Hi,
Tut is very good but I have few doubts regarding performance.Enter_Frame event once added is not removed any where and so frameHandler(event:Event) method keeps firing and CPU reaches to 98% within few seconds. Secondly, kill() method is never called anywhere. Can you please reply to this so that it could be of a good use :)
Thanks & Regards! | http://blog.onebyonedesign.com/actionscript/3d-carousel-as3-style-bop-secrets-turns-10/ | CC-MAIN-2018-30 | refinedweb | 2,556 | 82.54 |
If you are coding on AmigaOS4 and don't require backwards compatabilty the easiest solution is to use the interface.iedefinetly bsdsocket.
#include <stdio.h>
int main(int argc, char ** argv)
{
char host[256];
host[0] = 0;
gethostname(host,255);
printf("host: "%s"n",host);
}
ram:testhostnamehost: "amiga"
10.AmigaOS4:> hostnameamiga
As far as I know, any host on the network can define another host in its hosts table using any hostname it likes. It acts as sort of a local "DNS" on that host.
Why do you need it?
Interesting arp -a run on my SAM shows my X1000 and my router (fixed ips) but not the Linux laptop or phone that are both using DHCP
especially when your LAN has a router at its centre that does NOT allow you to set static IP addresses.
I've found that I have to ping another machine before it's listed by arp -a. However, only the router's name appears.
ping all possible addresses in subnetread arp tablediscard incomplete entries?????profit! | http://www.amigans.net/modules/xforum/viewtopic.php?post_id=114377 | CC-MAIN-2019-39 | refinedweb | 172 | 62.48 |
is it possible to retrieve the wall thickness through Dynamo
Retrieve wall thickness
There’s a wall.thickness node in clockwork
I think it is not available.
Oh that’s weird. I might be mistaken about the package then. I was convinced it was clockwork.
Well it’s doable with a really simple python script, so if no one solves this, then I can help you when I get my laptop started
I found the width property in API but I don’t know how to use ot.
Yep, that’s the one you need.
Loop through all your unwrapped walls and retrieve the property using dot notation, and then return the value. That’s it
I did this much. don’t know what is next.
The image you posted gives us 0 information. We have no idea what is in that python node and no clue what the error is.
I need to retrieve the width of the wall. I collected all walls through nodes. i don’t know what is next.
my code is below
Version:0.9 StartHTML:00000097 EndHTML:00002163 StartFragment:00000199 EndFragment:00002125 # Enable Python support and load DesignScript library
import clr
clr.AddReference(‘ProtoGeometry’)
from Autodesk.DesignScript.Geometry import *
clr.AddReference(‘RevitAPI’)
from Autodesk.Revit.DB import *
clr.AddReference(‘RevitServices’)
from RevitServices.Persistence import DocumentManager
from RevitServices.Transactions import TransactionManager
doc = DocumentManager.Instance.CurrentDBDocument
The inputs to this node will be stored as a list in the IN variables.
w = UnwrapElement(IN[0])
s = w.Width
Place your code below this line
#w.GetParameterValueByName("Width");
Assign your output to the OUT variable.
#OUT = list
import clr #Import the Revit API clr.AddReference('RevitAPI') import Autodesk from Autodesk.Revit.DB import * #Start scripting here: walls = UnwrapElement(IN[0]) output = [] for i in walls: output.append(UnitUtils.ConvertFromInternalUnits(i.Width, DisplayUnitType.DUT_MILLIMETERS)) OUT = output
I was convinced @Andreas_Dieckmann had this in his portfolio
I can see theres one in Steam but it returns the width in meters:
Hmm, maybe
I was sure there was a node called Wall.Width
You can use node “Convert Between Units” to convert from m to mm or cm. | https://forum.dynamobim.com/t/retrieve-wall-thickness/33812 | CC-MAIN-2019-47 | refinedweb | 358 | 61.93 |
{-# LANGUAGE GeneralizedNewtypeDeriving, TypeSynonymInstances, TemplateHaskell, RecordWildCards, FlexibleInstances #-} module Cake.Core ( -- * Patterns and rules. Rule, P, (==>), -- * High-level interface Act, cake, need, list, -- * Mid-level interface produce, produce', use, overwrote, -- * Low-level interface debug, distill, fileStamp, cut, shielded, Question(..), Answer(..), -- * Re-exports module Control.Applicative, ) where import Data.Digest.Pure.MD5 -- import Data.Digest.OpenSSL.MD5 -- "nano-md5" -- md5sum import qualified Data.ByteString.Lazy as B import System.Directory import System.FilePath import Control.Applicative import Control.Monad (when) import Control.Monad.RWS hiding (put,get) import qualified Control.Monad.RWS as RWS Answer = Stamp (Maybe MD5Digest) | Text [String] (RWST Context Written State IO a) deriving (Functor, Applicative, Monad, MonadIO, MonadState State, MonadWriter Written, MonadReader Context) -- Take the dual here so that new info overwrites old. data Status = Clean | Dirty deriving Eq instance Applicative P where (<*>) = ap pure = return instance Alternative P where (<|>) = (Parsek.<|>) empty = Parsek.pzero (==>) ::DB <- runAct rule oldDB action putStrLn $ "Database is:" forM_ (M.assocs newDB) $ \(k,v) -> putStrLn $ (show k) ++ " => " ++ (show v) encodeFile databaseFile newDB produced :: FilePath -> Act Bool produced f = do (ps,_) <- RWS.get return $ f `S.member` ps -- | Answer a question using the action given. -- The action should be independent of the context. distill :: Question -> Act Answer -> Act Answer distill q act = do a1 <- local (modCx q) $ do debug $ "Starting to answer" db <- ctxDB <$> ask let a0 = M.lookup q db a1 <- shielded act tell (Dual $ M.singleton q a1) when (Just a1 /= a0) $ do clobber debug $ "Question has not the same answer" return a1 debug $ "..." return a1 modCx q (Context {..}) = Context {ctxProducing = q:ctxProducing,..} refresh :: Question -> Act Answer -> Act Answer refresh q act = local (modCx q) $ do debug $ "Overwriting" a <- shielded act tell (Dual $ M.singleton q a) return a -- | Produce a file, using with the given action. -- The action should be independent of the context. produce :: FilePath -> Act () -> Act () produce f a = do p <- produced f -- Do nothing if the file is already produced. when (not p) $ do produce' f a return () -- | Produce a file, using with the given action. -- The action should be independent of the context. -- BUT: no problem to produce the same file multiple times. produce' :: FilePath -> Act () -> Act Answer produce' f a = distill (FileContents f) $ do e <- liftIO $ doesFileExist f when (not e) clobber a modify $ first $ S.insert f -- remember that the file has been produced already fileStamp f -- |. use f = do distill (FileContents f) (fileStamp f) -- | File was modified by some command, but in a way that does not -- invalidate previous computations. (This is probably only useful for -- latex processing)..put (ps',s) return x runAct :: Rule -> DB -> Act () -> IO DB runAct r db (Act act) = do h <- openFile logFile WriteMode (_a,Dual db) <- evalRWST act (Context h r db []) (S.empty,Clean) hClose h return db findRule :: FilePath -> Act (Maybe (Act ())) findRule f = do r <- ctxRule <$> ask let rs = parse r completeResults f case rs of Right [x] -> return (Just x) Right _ -> fail $ $ "cake: " ++ st ++ " "++ concat (map (++": ") $ reverse $ map show ps) ++ x {- runQuery :: Question -> IO Answer runQuery (Listing directory extension) = do files <- filter (filt . takeExtension) <$> getDirectoryContents directory return $ Text (map (directory </>) files) where filt = if null extension then const True else (== '.':extension) runQuery (Stamp f) = fileStamp f -} fileStamp f = liftIO $ do e <- doesFileExist f Stamp <$> if e then Just <$> md5 <$> B.readFile f else return Nothing clobber = RWS.modify $ second $ const Dirty) $ fail $ "No rule to create " ++ f debug $ "using existing file" use f return () Just a -> a | http://hackage.haskell.org/packages/archive/cake/0.3.2.1/doc/html/src/Cake-Core.html | CC-MAIN-2013-20 | refinedweb | 573 | 58.69 |
How do I start reading text file from a cretin string and then stop at another string?
Printable View
How do I start reading text file from a cretin string and then stop at another string?
If you want to find a string in a file, you could transverse through the file until you find what you're looking for. Just use a loop.If you want to find a string in a file, you could transverse through the file until you find what you're looking for. Just use a loop.Code:
char foo[50];
fgets(foo, 50, stdin);
printf("Your string was %s", foo);
I am not sure if that will work.
1) I dont know the length of the text file
2) I dont know were the string is located
3)I am using fstream to open the file
fstream is C++
and it's alot easier to find a string.
I don't know if C has a way to get a string up to a delimeter other than reading one character at a time. THere might be, but I don't know C that well.I don't know if C has a way to get a string up to a delimeter other than reading one character at a time. THere might be, but I don't know C that well.Code:
ifstream inFile;
string foo;
inFile.open("file.txt");
do {
getline(inFile, foo, '\n');
} while (foo != "The string I want") // Or whatever you want. You might have to mess
// with the delimeter to get the string you want.
Well that ends it at a string
Now I just need to know how to begin it at a string
it stops reading the text after ; is found now I need to start reading the text when "a" is foundit stops reading the text after ; is found now I need to start reading the text when "a" is foundCode:
do
{
getline(fin, foo, '\n' );
cout<<foo<<endl;
}
while (foo != ";");
Code:
char blah;
string foo, string1;
do {
inFile.get(blah);
} while (blah != 'a');
string1 = blah;
getline(inFile, foo, '\n');
string1 += foo;
So I belive this is the last question If I find the starting string and ending string how would I go about pulling all the data from the middle. the way I was doing it before will not work with the other code.
what I was doing is looking for keywords per line and what erver fallowed I captured but for some reson that is not working now.
Paste your code.
well I thought it was working but I geuss not when I ran another test.
Should this not end when it comes to string BallSpin?Should this not end when it comes to string BallSpin?Code:
string test,name;
name = "BallSpin";
do {
getline(fin,test);
cout<<test<<endl;
system("PAUSE");
} while (test != name);
also in my text file it is "AnimName BallSpin" so i might have to include the whole line instead of just the Key word "BallSpin"
It should exit the loop when your string says BallSpin, but I noticed you didn't put a delimeter on your getline function. That would by default make getline read until the first \n. Unless your file is simply "BallSpin" it wouldn't work.
Code:
getline(fin,test,' ');
getline's delimiter defaults to the newline.
Yeah, I just checked and noticed that. In any event, he more than likely wants a space as the delimeter.
well when I use getline(fin,test,' '); it does not exit
but when I include the whole line and use
getline(fin,test); it will exit now. I can work with that.
so when it exits how do i pickup after were I left off at with out including were it left off? I need there very next line.
edit:
I even tryed '\n' and it still did not work.
Code:
#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
string foo, string1;
string test,name,name2,name3;
//BallSpin
int main(int argc, char *argv[])
{ name2 = "AnimName ";
name = "BallSpin";
name3 = name2 + name;
fstream fin("image1.txt");
do {
getline(fin,test,'\n');
cout<<test<<endl;
} while (test != name3);
system("PAUSE");
return EXIT_SUCCESS;
}
Code:
AnimName BallExplode
File 1.bmp
Left 1
Right 1
Top 1
Bottom 1
Red 1
Green 1
Blue 1
Delay 1
Width 1
FrameW 1
;
AnimName BallSpin
File null.bmp
Left 0
Right 92
#Top 0
Bottom 0
Red 0
Green 0
Blue 0
Delay 0
Width 0
FrameW 0
;
Ok, first off you're not declaring your variables. Secondly you declared an fstream, you should declare ifstream.
The reason why '\n' or space doesn't work in this file is because if the delimeter was a newline character it'd read in "AnimName BallSpin" if it was a space, it'd read in "Ballspin\nFile"
What you could do is either put a space after each word before you start a new line or you could resize your string after you read in a word so that it would only fit "BallSpin" and nothing more. There are probably numerous other ways to handle this.
so in the text file that is posted how would you pull the data out? | http://cboard.cprogramming.com/cplusplus-programming/73414-question-about-iostream-reading-strings-files-printable-thread.html | CC-MAIN-2015-18 | refinedweb | 870 | 79.4 |
QML editor can't display advanced components
When my QML components starts getting a bit advanced they can no longer be displayed in the QML editor. Either they are displayed as empty rectangles so their size and position is adjustable, or they are just displayed as a single dot when selected.
Just adding "import Effects 1.0" to a component makes it only appear as a single dot in QML editor when using that component. See the code examples below.
My question is: How can I prevent my advanced components from disappearing in QML editor?
I tried a lot of tricks and work arounds to try to keep my components visible in the QML editor as long as possible. Like avoiding the use of scripts and avoiding the use of properties defined by C++. It can get complex pretty fast, does anyone have any tricks to enable the use of QML editor as long as possible?
Example below. Save first file as main.qml and second one as MyComponent.qml. Try with and without the Effects import line.
@
import QtQuick 1.1
Rectangle {
width: 200
height: 200
MyComponent { x: 10 y: 10 }
}
@
@
import QtQuick 1.0
import Effects 1.0
Rectangle {
width: 100
height: 100
color: "red"
}
@
- sierdzio Moderators
Yeah, a bit annoying. Also happens for components loaded with Loader, and when you reference items by QRC. I don't have any workaround, apart from the last case (QRC).
- ThomasHartmann
One solution is to build a qmlpuppet for your Qt version
"this is explained here":
Using the qmlpuppet of a specific Qt Version instead of the one provided by Qt Creator allows instantiating everything that is available from the import directory of this Qt version.
Qmlpuppet is the external process that emulates and renders Qt Quick for the Qt Quick Designer.
For the qrc case I added an enviroment variable called QMLDESIGNER_RC_PATHS.
This allows mapping rc paths to absolute paths.
e. g.: QMLDESIGNER_RC_PATHS="qrc:bla=/mySource/qrc"
I consider this a hack/experimental feature, but it works. ;)
- sierdzio Moderators
interesting, thanks! Might come in handy in my project. -Does that work for custom components, though?- doh, sorry, didn't read carefully enough ;)
Awesome, I recompiled qmlpuppet and QML designer is working great with all my QML components. All I need to do was add calls to qmlRegisterType for Colorize and DropShadow in main.cpp in qmlpuppet.
This will help a lot in the design of my components, thank you very much.
- ThomasHartmann
Great that I could help. :)
If you want to use custom types without patching qmlpuppet you have to create a qml plugin and install in it <qtbuild_dir>/imports. | https://forum.qt.io/topic/13212/qml-editor-can-t-display-advanced-components | CC-MAIN-2017-34 | refinedweb | 440 | 66.44 |
Scenario Marker Support
The Scenario class is a free download on the MSDN Code Gallery Web site. By using Scenario, you can mark the exact beginning and ending points of a section of code that you want to profile. Concurrency Visualizer displays these markers in Threads View, Cores View, and CPU Utilization View. To display the name that you gave the marker, rest the pointer on its horizontal bar.
Concurrency Visualizer supports Scenario markers in both native code and managed code, subject to the following conditions:
The Scenario.Begin, Scenario.BeginNew, and Scenario.End methods are supported. The Scenario.Mark and Scenario.Step methods are not supported.
Scenario markers that have a Nest Level greater than zero are not supported.
One active Scenario instance per thread is tracked. If a Scenario.Begin event is received when a Scenario instance is already active, Concurrency Visualizer will overwrite the old value with the new value. An active Scenario instance will be closed on the first Scenario.End call in the thread, regardless of the Scenario instance it came from.
To add Scenario markers to code
Download Scenario.zip from Scenario Home Page on the MSDN Code Gallery Web site.
Uncompress the file and note where the folder is created.
In your Visual Studio project, add a reference to the appropriate Scenario native or managed .dll file. x86 and x64 versions are provided for both Visual Studio 2008 and Visual Studio 2010.
In managed code, add a using or Imports statement for the Scenario namespace.
In native code, add the Scenario.h file, which is located in the \native\ folder.
Create an instance of the Scenario class on every thread that you want to mark. Use the constructor to add a name for the marker so that it will appear in Concurrency Visualizer.
Call the Begin method where you want to put the beginning marker.
Call the End method where you want to put the end marker.
Run Concurrency Visualizer. The markers should appear in the various views.
For more information about the Scenario class, see the documentation on the Scenario Home Page. | https://msdn.microsoft.com/en-us/library/dd984115(v=vs.100).aspx | CC-MAIN-2016-30 | refinedweb | 350 | 59.9 |
Created on 2008-05-17 12:30 by bhy, last changed 2009-02-13 19:22 by benjamin.peterson.
Functions like find() rfind() index() rindex() has been removed in
Python 3.0. So there should be a 2to3 fix for it.
Eg. fix
if string.find(s, "hello") >= 0:
to
if str.find(s, "hello") >= 0:
Thank you!
I expect the answer will be that 2to3 cannot know what sort of object
"string" names. Bell's theorem, or some such, as I understand it, tells
us that you must execute the algorithm to find out what it does, there
isn't a short cut.
It does seem like 2to3 could assume that you write code with honorable
intention, grace, and style and thereby offer a suggestive note. The
string module is not an isolated case for such notices. I made a
similar request to yours for "file" which is gone in version 3.
Unfortunately, code as follows is probably frequent, so we aren't likely
to get support for this feature. Maybe here is an opportunity for
venture capital!
def f(list):
'''
argument should be a list.
"list" in this scope no longer names __builtins__.list
'''
2to3 could handle it, but it would be a lot of work for something
unnecessary. You can use "s.replace(a, b)" instead of string.replace(s,
a, b) since at least 2.0.
I think the point is to get a message from 2to3 about possible use of
feature that is gone. Of course python3 raises an exception when trying
to execute the code, but it does leave the user wondering "why did 2to3
report that there are no changes necessary?".
Maybe 2to3 could get a --pedantic or even an --annoying option? I agree
that it should be noisy about removed features even if actually fixing
this kind of thing would be hard to do reliably.
I disagree. That is the role of -3 warnings. Static analysis is too
limited to get into issuing warnings with. | http://bugs.python.org/issue2899 | crawl-002 | refinedweb | 333 | 75.81 |
The.
Formalizing dynamic scoping
November 26, 2016
The lambda calculus is a minimal functional programming language. We use it to study type systems, evaluation strategies, proof calculi, and other topics in programming languages and theoretical computer science. A recent discussion led me to wonder: can we use it to study scoping rules as well?
Lexical vs. dynamic scoping
Most programming languages have lexical scoping. This means scopes are determined statically by the program structure. Name resolution happens by looking up the identifier first in the current block, then in the parent block, then in the grandparent block, etc. With dynamic scoping, scopes are defined by stack frames. Names are looked up in the current function first, then in the caller, then in the caller’s caller, etc. This can only happen at runtime, because the call stack doesn’t exist statically.
Consider the following JavaScript expression:
(function(x) { return (function(x) { return function() { return x; }; })('lexical')(); })('dynamic')
As you might have guessed, this expression tells you what scoping strategy the programming language uses. Specifically, it evaluates to
'lexical', because JavaScript uses lexical scoping. Here is the same expression written in Emacs Lisp:
((lambda (x) (funcall ((lambda (x) (lambda () x ) ) "lexical")) ) "dynamic")
This evaluates to
"dynamic", because Emacs Lisp has dynamic scoping.
The lambda calculus
The lambda calculus, like JavaScript, uses lexical scoping—as we will show! Below is a quick introduction to this versatile little programming language, in case you haven’t seen it before. Here is a more in-depth tutorial for curious readers.
Syntax
The syntax is quite spartan. A term (“term” is lambda-speak for “expression”) takes one of three forms:
- Variable: \( x \)
- Abstraction: \( \lambda x . t \) (where \( t \) extends as far right as possible)
- Application: \( t_1 \: t_2 \) (left-associative)
From these three building blocks, you can construct bigger terms like this curious one:
\[ \lambda f . \left( \lambda x . f \left( x \: x \right) \right) \left( \lambda x . f \left( x \: x \right) \right) \]
This term is known as the Y combinator, and it has the interesting property that it can be used to implement unbounded recursion. Let’s save that for another time.
Semantics
The operational semantics tells us how to evaluate a term:
\[ \frac{ t_1 \rightarrow t_1’ }{ t_1 \: t_2 \rightarrow t_1’ \: t_2 } \left( 1 \right) \]
\[ \frac{ t \rightarrow t’ }{ v \: t \rightarrow v \: t’ } \left( 2 \right) \]
\[ \frac{ }{ \left( \lambda x . t \right) \: v \rightarrow t \left[ v/x \right] } \left( 3 \right) \]
If you’ve never seen this notation before, here’s a quick explanation. Each rule reads like an if-then statement. The part above the line is the antecedent (the “if” part). The part below the line is the consequent (the “then” part). If the antecedent is true, then we can conclude the consequent is true also.
Rule (1) states: if some term \( t_1 \) reduces to \( t_1' \), then the application \( t_1 \: t_2 \) reduces to \( t_1' \: t_2 \). This just means when we are applying some term \( t_1 \) to another term \( t_2 \), we can try to reduce \( t_1 \) before doing the application.
Rule (2) states: if some term \( t \) reduces to \( t' \), then \( v \: t \) reduces to \( v \: t' \). The \( v \) means that the first term in the application is a value, i.e., an abstraction. We have this restriction to force a particular evaluation strategy (call-by-value). Of course, other evaluation strategies are possible too.
Rule (3) tells us how function application works. Note that there is no antecedent, which means we can conclude the consequent unconditionally. The consequent states that if we have some application \( \left( \lambda x . t \right) v \), then we can reduce it by substituting \( v \) for free occurrences of \( x \) in \( t \). Special care must be taken to ensure the substitution is done in a capture-avoiding manner.
Example
Remember that magical expression that tells us what scoping rule the language uses? Here it is written as a term in the lambda calculus (where \( \_ \) is some fresh variable and \( * \) is any term, needed only because abstractions in the lambda calculus must take an argument):
\[ \left( \lambda x . \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \right) \: \texttt{“dynamic”} \]
Convince yourself that this term matches the JavaScript and Emacs Lisp expressions above. How do we begin reducing it? First, we note that it’s an application. Both rules (1) and (3) are meant for applications. We see that the left term of the application is a value, so we apply rule (3). The term reduces to:
\[ \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \]
Because \( x \) was not free in the body of the abstraction, no substitution was necessary and \( \texttt{"dynamic"} \) disappeared entirely. So already we know the lambda calculus uses lexical scoping! Let’s continue anyway.
This term might look hard to parse, but remember that application is left-associative. So the left side is \( \left( \lambda x . \lambda \_ . x \right) \: \texttt{"lexical"} \) and the right side is \( * \). Since the left-side of the application is not a value (it can be reduced), we apply rule (1):
\[ \frac{ \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \rightarrow t_1’ }{ \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \rightarrow t_1’ \: * } \left( 1 \right) \]
But what is \( t_1' \)? We use rule (3) to find it:
\[ \frac{ }{ \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \rightarrow \lambda \_ . \texttt{“lexical”} } \left( 3 \right) \]
Okay, so \( t_1' \) is \( \lambda \_ . \texttt{"lexical"} \). We are left with:
\[ \left( \lambda \_ . \texttt{“lexical”} \right) \: * \]
Applying rule (3) one last time gives:
\[ \texttt{“lexical”} \]
So the lambda calculus, as we’ve presented here, uses lexical scoping. Here is the complete execution trace and relevant proofs:
\[ \frac{ }{ \left( \lambda x . \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \right) \: \texttt{“dynamic”} \rightarrow \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * } \left( 3 \right) \]
\[ \frac{ }{ \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \rightarrow \lambda \_ . \texttt{“lexical”} } \left( 3 \right) \] \[ \frac{ \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \rightarrow \lambda \_ . \texttt{“lexical”} }{ \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \rightarrow \left( \lambda \_ . \texttt{“lexical”} \right) \: * } \left( 1 \right) \]
\[ \frac{ }{ \left( \lambda \_ . \texttt{“lexical”} \right) \: * \rightarrow \texttt{“lexical”} } \left( 3 \right) \]
Note that all the proofs start with rule (3), since that’s the only rule without an antecedent.
Semantics for dynamic scoping
Now that we have the tools to describe the semantics of a simple functional programming language, we can return to the main objective: to formalize dynamic scoping in the lambda calculus.
With the lexical scoping semantics, rule (3) handles applications by substituting the argument for the variable in the body of the abstraction (without evaluating the body). This will not work for dynamic scoping, since name resolution depends on the call stack and cannot be done statically. We will need to keep track of the variables that are currently in the “stack”.
Let \( \Gamma \) be a map from variables to values, and let \( \Gamma, x : v \) denote the context formed by inserting \( x : v \) into \( \Gamma \) with replacement. Informally, \( \Gamma \) is the context that keeps track of the variables in the call stack and the values they are bound to.
Here are the reduction rules for dynamic scoping:
\[ \frac{ \Gamma \vdash t_1 \rightarrow t_1’ }{ \Gamma \vdash t_1 \: t_2 \rightarrow t_1’ \: t_2 } \left( 1 \right) \]
\[ \frac{ \Gamma \vdash t \rightarrow t’ }{ \Gamma \vdash v \: t \rightarrow v \: t’ } \left( 2 \right) \]
\[ \frac{ \Gamma, x : v \vdash t \rightarrow t’ }{ \Gamma \vdash \left( \lambda x . t \right) v \rightarrow \left( \lambda x . t’ \right) v } \left( 3 \right) \]
\[ \frac{}{ \Gamma \vdash \left( \lambda x . v_1 \right) v_2 \rightarrow v_1 } \left( 4 \right) \]
\[ \frac{ \Gamma\left(x\right) = v }{ \Gamma \vdash x \rightarrow v } \left( 5 \right) \]
The first two rules are essentially the same as their lexically-scoped versions, except that they preserve the context \( \Gamma \) from antecedent to consequent. In other words, these two rules leave the stack unchanged.
Rule (3) reduces the body of an abstraction in an application. It adds \( x : v \) to the context, so that within the abstraction, the variable \( x \) is bound to \( v \).
When the body cannot be reduced any further, rule (4) eliminates the application, replacing it with the now-reduced body of the abstraction.
Rule (5) does dynamic name lookup: if a variable \( x \) is bound to a value \( v \) in the context \( \Gamma \), then \( x \) can be reduced to \( v \).
Example
Let’s evaluate this familiar term to see how it fares with the new semantics:
\[ \left( \lambda x . \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \right) \: \texttt{“dynamic”} \]
Here is the whole execution trace, and all relevant proofs:
\[ \frac{}{ \left\{ x : \texttt{“dynamic”} \right\} \vdash \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \rightarrow \lambda \_ . x } \left( 4 \right) \] \[ \frac{ \left\{ x : \texttt{“dynamic”} \right\} \vdash \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \rightarrow \lambda \_ . x }{ \left\{ x : \texttt{“dynamic”} \right\} \vdash \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \rightarrow \left( \lambda \_ . x \right) \: * } \left( 1 \right) \] \[ \frac{ \left\{ x : \texttt{“dynamic”} \right\} \vdash \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \rightarrow \left( \lambda \_ . x \right) \: * }{ \varnothing \vdash \left( \lambda x . \left( \lambda x . \lambda \_ . x \right) \: \texttt{“lexical”} \: * \right) \: \texttt{“dynamic”} \rightarrow \left( \lambda x . \left( \lambda \_ . x \right) \: * ”} }{ \left\{ x : \texttt{“dynamic”} \right\} \vdash \left( \lambda \_ . x \right) \: * \rightarrow \texttt{“dynamic”} } \left( 3 \right) \] \[ \frac{ \left\{ x : \texttt{“dynamic”} \right\} \vdash \left( \lambda \_ . x \right) \: * \rightarrow \texttt{“dynamic”} }{ \varnothing \vdash \left( \lambda x . \left( \lambda \_ . x \right) \: * \right) \: \texttt{“dynamic”} \rightarrow \left( \lambda x . x ”} }{ \varnothing \vdash \left( \lambda x . x \right) \: \texttt{“dynamic”} \rightarrow \left( \lambda x . \texttt{“dynamic”} \right) \: \texttt{“dynamic”} } \left( 3 \right) \]
\[ \frac{}{ \varnothing \vdash \left( \lambda x . \texttt{“dynamic”} \right) \: \texttt{“dynamic”} \rightarrow \texttt{“dynamic”} } \left( 4 \right) \]
So the original term evaluates to \( \texttt{"dynamic"} \), confirming that the rules give rise to dynamic scoping.
Conclusion
I’m happy to report that the lambda calculus can be adapted to support dynamic scoping rules. Proofs in the resulting calculus are tractable, though a bit longer than those for the lexically-scoped calculus. Inspired by the notion of “context” from the inference rules of typed lambda calculi, we introduce a “stack context” for tracking the variables reachable by walking the call stack. Curiously, this technique seems to be equally capable of proving static properties of programs (e.g., type ascriptions) and managing dynamic scopes.
Higher-rank and higher-kinded types
April 23, 2016
If you enjoy statically-typed functional programming, you might.
Does Google execute JavaScript?
August 6, 2016
I’m told: Yes, it’s 2016; of course Google executes JavaScript.
If Google can run JavaScript and thereby render client-side views, why is server-side rendering necessary for SEO? Okay, Google isn’t the only search engine, but it’s obviously an important one to optimize for.
Recently I ran a simple experiment to see to what extent the Google crawler understands dynamic content. I set up a web page at doesgoogleexecutejavascript.com which does the following:
- The HTML from the server contains text which says “Google does not execute JavaScript.”
- There is some inline JavaScript on the page that changes the text to “Google executes JavaScript, but only if it is embedded in the document.”
- The HTML also links to a script which, when loaded, changes the text to “Google executes JavaScript, even if the script is fetched from the network. However, Google does not make AJAX requests.”
- That script makes an AJAX request and updates the text with the response from the server. The server returns the message “Google executes JavaScript and even makes AJAX requests.”
After I launched this page, I linked to it from its GitHub repository and waited for Google to discover it..
“Drag Me Down” for a cappella
May 9, 2016
I lead an a cappella ensemble at work, and we just performed my latest arrangement for the group. The song is Drag Me Down, a famous pop title from last year. You can download the sheet music here. Enjoy!
UPDATE (8/22/2016): We did a studio recording of this song! Listen here: | https://www.stephanboyer.com/home/2 | CC-MAIN-2020-10 | refinedweb | 2,047 | 65.12 |
In this article I’ll be looking into a trickier part of unit testing – testing the functionality of classes which cannot be instantiated on their own, abstract classes. I’ll show how to overcome this obstacle using “Mock Objects”, a technique which has a whole methodology behind it, all on its own. We’ll see how mock objects provide us with abilities that let us query what’s happening inside our derived class. You can also find more material on my weblog.
Unit testing is all good and well as a theoretical nirvana. “Yeah, we do unit tests” is a great answer to have when someone asks you, but achieving this is a process just like any other software development process. The overall idea looks great, but you come across problems that don’t fit your original plans, or things you can’t deal with the way you’re used to. Unit testing has several of these obstacles routed at the core of the mythology. One of those obstacles is the testing of objects that cannot be instantiated on their own (abstract classes are one of several manifestations of this problem). As I’ll demonstrate, this too is possible using mock objects, objects that exist for the sole purpose of helping us in our task of testing.
So what’s the definition of the problem we are facing? Well, to run a test against a class, we need to have an instance of that class to work on. We need something to call methods on and get values back if needed. We need a real live object. In the case of abstract classes there’s no way to do this.
We could make the class non-abstract for the sole purpose of testing it, but that would violate one of the most important concepts of unit tests – they should not alter the behavior or the data of the tested application. Making changes to the design of an object model for no reason other than tests, is not the course of action we want to take.
We need to ask ourselves what we want to test in an abstract class. Usually abstract classes contain the plumbing required by classes that will derive from them. What we want to know is if the derived classes, as clients to the services the abstract class provides, are getting all the services they need. This method means that we are essentially wanting to do a “black box” test on the abstract class and make sure that, any derived class that’s going to use it, will have what we want it to have.
So this shifts our focus a bit. How do we test that any “client” to the base class is receiving the services it needs? This could be quite a complex problem to test, because another important concept here is that, we want to test only one thing at a time. If we test derived classes of the base class (which might be a design problem in itself), we are essentially testing the functionality of the base classes as well, not to mention we’ll have to build those classes for our tests to work at all!
One of the most elegant solutions to this problem is actually very simple in concept – we’ll build objects just for our tests!
Mock objects are a very handy technique to tests objects that are “mediators”. Instead of referring to a real domain object, we call the mock object which pretends to be the real object. The mock object is used to validate any assertions and expectations we have of that object and we can fully interact with it, while at the same time still have total control over the results of our object’s method calls. There’s a whole Mock Objects testing framework, which is an alternate view of unit testing.
You can learn more about mock objects by starting from this link.
Mock objects come in very handy when we either want to test an object that “changes stuff” in our application and we want to stop it, control it, or when we want to test an object that uses other objects in order to do its work. A data layer object that uses the database would be a good example of when we want to control such things (we never want our unit tests to corrupt live data, that’s rule #1, ask your DBA).
In this case, we can use a mock object to derive from our class and make sure that it, as a “client” to our class, receives all the necessary “services” it expects.
In order to explain this in more “close to home” terms, I’ll make up a simple project task.
We’ve designed a simple object model in which we have an abstract class Task which will contain a start method. The class will be used to derive other tasks from it, but will provide each derived class with abstract methods that will need to be implemented: BeforeStart(), OnStart(), and AfterStart(). Each derived class will be able to use these methods to perform initialization before a task begins, the task itself when needed, and cleanup after the task has finished (think ServicedComponent type events).
Task
start
BeforeStart()
OnStart()
AfterStart()
ServicedComponent
Ok. We have no code yet, but what do we test first? We want to make sure that for any derived class, calling the Start() method, actually triggers the BeforeStart(), OnStart(), and AfterStart() methods inside it. To do that, we’ll need an instance of a class derived from Task (which does not exist yet).
Start()
BeforeStart(), OnStart(),
AfterStart()
This is a perfect candidate for a mock object. We can use a mock object that will derive from our base class and will let us know if its inner methods were called.
We’ll want to used a very simple mechanism here.
In our first test, we’ll assume we have an object derived from Task and we'll call it’s Start() method. Then we’ll assert that all three inert methods were called.
Start()
[Test]
public void TestOnStartCalled()
{
MockTask task = new MockTask();
task.Start();
Assert.IsTrue(task.OnStartCalled);
Assert.IsTrue(task.BeforeStartCalled);
Assert.IsTrue(task.AfterStartCalled);
}
This code won’t compile because we don’t have any MockTask class defined.
MockTask
Our mock object will derive from Task. Notice we’re building it assuming Task already exists.
public class MockTask:Task
{
public bool OnStartCalled=false;
public bool BeforeStartCalled=false;
public bool AfterStartCalled=false;
}
The beauty of this is, because this is our mock object, we can make it do whatever we want. In this case we are simply adding flags to it. Those flags will have to change somehow later on, but that’s not our problem now. Now we’re concerned about making the code compile.
Our code still won’t compile because we haven’t created out Task class yet.
public abstract class Task
{
public void Start()
{
}
}
Notice we’re making the class as simple as possible, just making our code compile.
If we run the test now out, code will compile, but the test will fail miserably. The derived class had no OnStart, BeforeStart and AfterStart methods defined. Therefore it’s called flags will always remain false.
OnStart
BeforeStart
AfterStart
called
false
Let’s make the test work by adding the required functionality to our base class:
public abstract class Task
{
public void Start()
{
BeforeStart();
OnStart();
AfterStart();
}
//all base classes must implement this method
protected abstract void OnStart();
protected abstract void BeforeStart();
protected abstract void AfterStart();
}
public class MockTask:Task
{
public bool OnStartCalled=false;
public bool BeforeStartCalled=false;
public bool AfterStartCalled=false;
protected override void AfterStart()
{
AfterStartCalled=true;
}
protected override void BeforeStart()
{
BeforeStartCalled=true;
}
protected override void OnStart()
{
OnStartCalled=true;
}
}
“Be-a-utiful!” as Bruce almighty often remarks. We now have a repeatable test that makes sure our base class calls all the methods we require. | https://www.codeproject.com/articles/5054/fun-with-unit-testing-testing-abstract-classes?fid=23460 | CC-MAIN-2016-50 | refinedweb | 1,325 | 67.99 |
# Why LLVM may call a never called function?
> *I don’t care what your dragon’s said, it’s a lie. Dragons lie. You don’t know what’s waiting for you on the other side.*
>
>
>
> Michael Swanwick, The Iron Dragon’s Daughter
This article is based on the post in the Krister Walfridsson’s blog, [“Why undefined behavior may call a never called function?”](https://kristerw.blogspot.com/2017/09/why-undefined-behavior-may-call-never.html).
The article draws a simple conclusion: undefined behavior in a compiler can do anything, even something absolutely unexpected. In this article, I examine the internal mechanism of this optimization works.
To briefly recap Waldfridsson’s post, in the source code below, the EraseAll function should not be called from main, and it is not really called when compiled with -O0, but is suddenly called with optimization -O1 and higher.
```
#include
typedef int (\*Function)();
static Function Do;
static int EraseAll() {
return system(“rm -rf /”);
}
void NeverCalled() {
Do = EraseAll;
}
int main() {
return Do();
}
```
How does a compiler optimize it? At first, Do, the pointer to a function is void, because, in accordance with the C standard, all global variables have zero values when a program starts.

The program will try to dereference the Do pointer and call assigned function. But if we try to dereference a null pointer, the standard says that it is UB, undefined behavior. Usually, if we compile without optimizations, with -O0 option, we get a Segmentation Fault (in Linux). But the Standard says, that in case of UB, a program can do anything.

A compiler uses this feature of the standard to remove unnecessary operations. If a compiler sees that Do is assigned anywhere in the program, it can assign this value in the initialization time, and do not assign it in runtime. In reality, there are two possibilities:
1. if a pointer is dereferenced after it should be assigned, we win, because a compiler can remove an unnecessary assignment.
2. if a pointer is dereferenced before it should be assigned, the standard says that it is UB, and behavior can be any, including calling an arbitrary function. That is, calling the function PrintHello() does not contradict the standard.
That is, in any case, we can assign some not-null value to an uninitialized pointer and get behavior, according to the standard.

What are the conditions that make this optimization possible? Initially, a program should contain a global pointer without any initial value or with null value (that is the same). Next, the program should contain an assignment a value to this pointer, anywhere, no matter, before the pointer dereferencing or after it. In the example above, an assignment has not occurred at all, but a compiler sees that the assignment exists.
If these conditions are met, a compiler can remove the assignment and change it into the initial value of the pointer.
In the given code the variable Do is a pointer to a function, and it has the initial value null. When we try to call a function on the null pointer, the behavior of the program is undefined (undefined behavior, UB) and the compiler has right to optimize the UB as it wants. In this case, the compiler immediately executed the Do = EraseAll assignment.
Why does this happen? In the rest of the text, LLVM and Clang version 5.0.0 are used as a compiler. Code examples are runnable for you to practice yourself.
To begin with, let’s look at the IR code when optimizing with -O0 and -O1. Let’s change the source code slightly to make it less dramatic:
```
#include
typedef int (\*Function)();
static Function Do;
static int PrintHello() {
return printf("hello world\n");
}
void NeverCalled() {
Do = PrintHello;
}
int main() {
return Do();
}
```
And we compile the IR code with -O0 (the debugging information is omitted for clarity):
```
; ModuleID = 'test.c'
source_filename = "test.c"
target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@Do = internal global i32 (...)* null, align 8
@.str = private unnamed_addr constant [13 x i8] c"hello world\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define void @NeverCalled() #0 {
entry:
store i32 (...)* bitcast (i32 ()* @PrintHello to i32 (...)*), i32 (...)** @Do, align 8
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define i32 @main() #0 {
entry:
%retval = alloca i32, align 4
store i32 0, i32* %retval, align 4
%0 = load i32 (...)*, i32 (...)** @Do, align 8
%call = call i32 (...) %0()
ret i32 %call
}
; Function Attrs: noinline nounwind optnone uwtable
define internal i32 @PrintHello() #0 {
entry:
%call = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([13 x i8], [13 x i8]* @.str, i32 0, i32 0))
ret i32 %call
}
declare i32 @printf(i8*, ...) #1
And with -O1:
; ModuleID = 'test.ll'
source_filename = "test.c"
target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@.str = private unnamed_addr constant [13 x i8] c"hello world\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define void @NeverCalled() local_unnamed_addr #0 {
entry:
ret void
}
; Function Attrs: noinline nounwind optnone uwtable
define i32 @main() local_unnamed_addr #0 {
entry:
%retval = alloca i32, align 4
store i32 0, i32* %retval, align 4
%call = call i32 (...) bitcast (i32 ()* @PrintHello to i32 (...)*)()
ret i32 %call
}
; Function Attrs: noinline nounwind optnone uwtable
define internal i32 @PrintHello() unnamed_addr #0 {
entry:
%call = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([13 x i8], [13 x i8]* @.str, i32 0, i32 0))
ret i32 %call
}
declare i32 @printf(i8*, ...) local_unnamed_addr #1
```
If you compile the executables, you will confirm that in the first case, a segmentation error occurs, and in the second case, “hello world” is displayed. With other optimization options, the result is the same as for -O1.
Now find the part of the compiler code that performs this optimization. The architecture of LLVM the frontend does not deal with optimizations itself, i.e. cfe (Clang Frontend) always generates the code without optimizations, which we see in the version for -O0, and all optimizations are performed by the utility opt:

With -O1, 186 optimization passes are performed.
Turning off the passes one after another, we find what we are looking for: the *globalopt* pass. We can leave only this optimization pass, and make sure that it, and no one else, generates the code we need. The source is in the file /lib/Transforms/IPO/GlobalOpt.cpp. You can see the source code in the LLVM repository. For brevity, I have only provided functions important for understanding how it works.
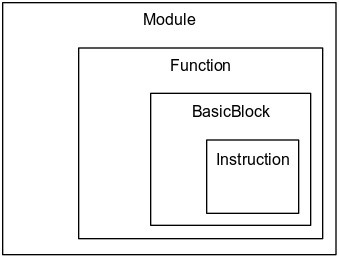
This picture represents a structure of the IR representation. A code in LLVM IR representation has hierarchical levels: a module represents the highest level of a hierarchy, and includes all function and global objects, such as global variables. A function is the most important level of IR representation and most of passes work on this level. A basic block is one is the most important concept of a compiler theory. A basic block consists of instructions, which can not make jumps from a middle of a basic block or inside a basic block. All transitions between basic block are possible only from an end of a basic block and to a begin of a basic block, and any jumps from or to a middle of a basic block are never possible. An instruction level represents an LLVM IR code instruction. It is not a processor’s instruction, it’s an instruction of some very generalized virtual machine with an infinite number of registers.

This picture shows a hierarchy of LLVM passes. On the left passes working on LLVM IR code are shown, on the right side passes working with target’s instructions are shown.
Initially, it implements the runOnModule method, i.e. when working, it sees and optimizes the entire module (which, of course, is reasonable in this case). The function which performs the optimization is optimizeGlobalsInModule:
```
static bool optimizeGlobalsInModule(
Module &M, const DataLayout &DL, TargetLibraryInfo *TLI,
function_ref LookupDomTree) {
SmallSet NotDiscardableComdats;
bool Changed = false;
bool LocalChange = true;
while (LocalChange) {
LocalChange = false;
NotDiscardableComdats.clear();
for (const GlobalVariable &GV : M.globals())
if (const Comdat \*C = GV.getComdat())
if (!GV.isDiscardableIfUnused() || !GV.use\_empty())
NotDiscardableComdats.insert(C);
for (Function &F : M)
if (const Comdat \*C = F.getComdat())
if (!F.isDefTriviallyDead())
NotDiscardableComdats.insert(C);
for (GlobalAlias &GA : M.aliases())
if (const Comdat \*C = GA.getComdat())
if (!GA.isDiscardableIfUnused() || !GA.use\_empty())
NotDiscardableComdats.insert(C);
// Delete functions that are trivially dead, ccc -> fastcc
LocalChange |=
OptimizeFunctions(M, TLI, LookupDomTree, NotDiscardableComdats);
// Optimize global\_ctors list.
LocalChange |= optimizeGlobalCtorsList(M, [&](Function \*F) {
return EvaluateStaticConstructor(F, DL, TLI);
});
// Optimize non-address-taken globals.
LocalChange |= OptimizeGlobalVars(M, TLI, LookupDomTree,
NotDiscardableComdats);
// Resolve aliases, when possible.
LocalChange |= OptimizeGlobalAliases(M, NotDiscardableComdats);
// Try to remove trivial global destructors if they are not removed
// already.
Function \*CXAAtExitFn = FindCXAAtExit(M, TLI);
if (CXAAtExitFn)
LocalChange |= OptimizeEmptyGlobalCXXDtors(CXAAtExitFn);
Changed |= LocalChange;
}
// TODO: Move all global ctors functions to the end of the module for code
// layout.
return Changed;
}
```
Let’s try to describe in words what this function does. For each global variable in the module, it requests a Comdat object.
What is a Comdat object?
A Comdat section is a section in the object file, in which objects are placed, which can be duplicated in other object files. Each object has information for the linker, indicating what it must do when duplicates are detected. The options can be: Any — do anything, ExactMatch — duplicates must completely match, otherwise an error occurs, Largest — take the object with the largest value, NoDublicates — there should not be a duplicate, SameSize — duplicates must have the same size, otherwise an error occurs.
In LLVM, Comdat data is represented by an enumeration:
```
enum SelectionKind {
Any, ///< The linker may choose any COMDAT.
ExactMatch, ///< The data referenced by the COMDAT must be the same.
Largest, ///< The linker will choose the largest COMDAT.
NoDuplicates, ///< No other Module may specify this COMDAT.
SameSize, ///< The data referenced by the COMDAT must be the same size.
};
```
and the class Comdat actually represents a pair (Name, SelectionKind). (In fact, everything is more complicated.) All variables that for some reason cannot be deleted are placed in a set of NotDiscardableComdats. With functions and global aliases, we do the same — something that can not be deleted is placed in NotDiscardableComdats. Then, separate optimization functions for global constructors, global functions, global variables, global aliases, and global destructors are called. Optimizations continue in the loop until no optimization is performed. At each iteration of the loop, the set of NotDiscardableComdats is set to zero.
Let’s see what objects of the listed our test source contains.
Global variables:
```
1. @Do = internal global i32 (...)* null, align 8
2. @.str = private unnamed_addr constant [13 x i8] c"hello world\0A\00", align 1
```
(a little looking ahead, I can say that the first variable will be deleted by the optimizer at the first iteration).
Functions:
```
define void @NeverCalled()
define i32 @main()
define internal i32 @PrintHello()
declare i32 @printf(i8*, ...)
```
Note that printf is only declared, but not defined.
There are no global aliases.
Let’s look at the example of this optimization pass and consider how this result turned out. Of course, to analyze all the optimization variants even in one pass is a very big task, because it involves many different special cases of optimizations. We will concentrate on our example, considering those functions and data structures that are important for understanding the work of this optimization pass.
Initially, the optimizer does various uninteresting checks in this case, and calls the processInternalGlobal function, which tries to optimize global variables. This function is also quite complex and does a lot of different things, but we are interested in one thing:
```
if (GS.StoredType == GlobalStatus::StoredOnce && GS.StoredOnceValue) {
...
// We are trying to optimize global variables, about which it is known that they are assigned a value only once, except the initializing value.
if (optimizeOnceStoredGlobal(GV, GS.StoredOnceValue, GS.Ordering, DL, TLI))
return true;
...
}
```
The information that the global variable is assigned the value one and only once is extracted from the GS structure (GlobalStatus). This structure is populated in the calling function:
```
static bool
processGlobal(GlobalValue &GV, TargetLibraryInfo *TLI,
function_ref LookupDomTree) {
if (GV.getName().startswith("llvm."))
return false;
GlobalStatus GS;
if (GlobalStatus::analyzeGlobal(&GV, GS))
return false;
...
```
Here we see one more interesting fact: objects whose names begin with “llvm.” are not subject to optimization (since they are system calls for llvm runtime). And, just in case, the names of variables in LLVM IR can contain points (and even consist of one point with the prefix @ or %). The function analyzeGlobal is a call to the LLVM API and we will not consider its internal work. The structure of GlobalStatus should be viewed in details since it contains very important information for optimization passes.
```
/// As we analyze each global, keep track of some information about it. If we
/// find out that the address of the global is taken, none of this info will be
/// accurate.
struct GlobalStatus {
/// True if the global's address is used in a comparison.
bool IsCompared = false;
/// True if the global is ever loaded. If the global isn't ever loaded it
/// can be deleted.
bool IsLoaded = false;
/// Keep track of what stores to the global look like.
enum StoredType {
/// There is no store to this global. It can thus be marked constant.
NotStored,
/// This global is stored to, but the only thing stored is the constant it
/// was initialized with. This is only tracked for scalar globals.
InitializerStored,
/// This global is stored to, but only its initializer and one other value
/// is ever stored to it. If this global isStoredOnce, we track the value
/// stored to it in StoredOnceValue below. This is only tracked for scalar
/// globals.
StoredOnce,
/// This global is stored to by multiple values or something else that we
/// cannot track.
Stored
} StoredType = NotStored;
/// If only one value (besides the initializer constant) is ever stored to
/// this global, keep track of what value it is.
Value *StoredOnceValue = nullptr;
...
};
```
It is worth to explain why “If we find out that the address of the global is taken, none of this info will be accurate.” In fact, if we take the address of a global variable, and then write something at this address, not by name, then it will be extremely difficult to track this, and it is better to leave such variables as is, without trying to optimize.
So, we get into the function optimizeOnceStoredGlobal, to which the variable (GV) and the stored value (StoredOnceVal) are passed. Here they are:
```
@Do = internal unnamed_addr global i32 (...)* null, align 8 // the variable
i32 (...)* bitcast (i32 ()* @PrintHello to i32 (...)*) // the value
```
Next, for the value, the insignificant bitcast is deleted, and for the variable the following condition is checked:
```
if (GV->getInitializer()->getType()->isPointerTy() &&
GV->getInitializer()->isNullValue()) {
...
```
that is, the variable must be initialized with a null pointer. If this is the case, then we create a new SOVC variable corresponding to the value of StoredOnceVal cast to the GV type:
```
if (Constant *SOVC = dyn_cast(StoredOnceVal)) {
if (GV->getInitializer()->getType() != SOVC->getType())
SOVC = ConstantExpr::getBitCast(SOVC, GV->getInitializer()->getType());
```
Here, getBitCast is the method that returns the bitcast command, which types the types in the LLVM IR language.
After that, the function OptimizeAwayTrappingUsesOfLoads is called. It transfers the global variable GV and the constant LV.
Direct optimization is performed by the function OptimizeAwayTrappingUsesOfValue (Value \* V, Constant \* NewV).
For each use of a variable:
```
for (auto UI = V->user_begin(), E = V->user_end(); UI != E; ) {
Instruction *I = cast(\*UI++);
```
if this is a Load command, replace its operand with a new value:
```
if (LoadInst *LI = dyn_cast(I)) {
LI->setOperand(0, NewV);
Changed = true;
}
```
If the variable is used in the function call or invoke (which is exactly what happens in our example), create a new function, replacing its argument with a new value:
```
if (isa(I) || isa(I)) {
CallSite CS(I);
if (CS.getCalledValue() == V) {
// Calling through the pointer! Turn into a direct call, but be careful
// that the pointer is not also being passed as an argument.
CS.setCalledFunction(NewV);
Changed = true;
bool PassedAsArg = false;
for (unsigned i = 0, e = CS.arg\_size(); i != e; ++i)
if (CS.getArgument(i) == V) {
PassedAsArg = true;
CS.setArgument(i, NewV);
}
```
All other arguments to the function are simply copied.
Also, similar replacement algorithms are provided for the Cast and GEP instructions, but in our case this does not happen.
The further actions are as follows: we look through all uses of a global variable, trying to delete everything, except assignment of value. If this is successful, then we can delete the Do variable.
So, we briefly reviewed the work of the optimization pass LLVM on a specific example. In principle, nothing super complicated is here, but more careful programming is required to provide for all possible combinations of commands and variable types. Of course, all this must be covered by tests. Learning the source code of LLVM optimizers will help you write your optimizations, allowing you to improve the code for some specific cases. | https://habr.com/ru/post/458442/ | null | null | 2,902 | 55.74 |
Windows 10 Development - Store
The benefit of Windows Store for developers is that you can sell your application. You can submit your single application for every device family.
The Windows 10 Store is where applications are submitted, so that a user can find your application.
In Windows 8, the Store was limited to application only and Microsoft provides many stores i.e. Xbox Music Store, Xbox Game Store etc.
In Windows 8, all these were different stores but in Windows 10, it is called Windows Store. It is designed in a way where users can find a full range of apps, games, songs, movies, software and services in one place for all Windows 10 devices.
Monetization
Monetization means selling your app across desktop, mobile, tablets and other devices. There are various ways that you can sell your applications and services on Windows Store to earn some money.
You can select any of the following methods −
The simplest way is to submit your app on store with paid download options.
The Trails option, where users can try your application before buying it with limited functionality.
Add advertisements to your apps with Microsoft Advertising.
Microsoft Advertising
When you add Ads to your application and a user clicks on that particular Ad, then the advertiser will pay you the money. Microsoft Advertising allows developers to receive Ads from Microsoft Advertising Network.
The Microsoft Advertising SDK for Universal Windows apps is included in the libraries installed by Visual Studio 2015.
You can also install it from visualstudiogallery
Now, you can easily integrate video and banner Ads into your apps.
Let us have a look at a simple example in XAML, to add a banner Ad in your application using AdControl.
Create a new Universal Windows blank app project with the name UWPBannerAd.
In the Solution Explorer, right click on References
Select Add References, which will open the Reference Manager dialog.
From the left pane, select Extensions under Universal Windows option and check the Microsoft Advertising SDK for XAML.
Click OK to Continue.
Given below is the XAML code in which AdControl is added with some properties.
"> <UI:AdControl </StackPanel> </Grid> </Page>
When the above code is compiled and executed on a local machine, you will see the following window with MSN banner on it. When you click this banner, it will open the MSN site.
You can also add a video banner in your application. Let us consider another example in which when the Show ad button is clicked, it will play the video advertisement of Xbox One.
Given below is the XAML code in which we demonstrate how a button is added with some properties and events.
"> <Button x: </StackPanel> </Grid> </Page>
Given below is the click event implementation in C#.
using Microsoft.Advertising.WinRT.UI; using Windows.UI.Xaml; using Windows.UI.Xaml.Controls; // The Blank Page item template is documented at namespace UWPBannerAd { /// <summary> /// An empty page that can be used on its own or navigated to within a Frame. /// </summary> public sealed partial class MainPage : Page { InterstitialAd videoAd = new InterstitialAd(); public MainPage() { this.InitializeComponent(); } private void showAd_Click(object sender, RoutedEventArgs e) { var MyAppId = "d25517cb-12d4-4699-8bdc-52040c712cab"; var MyAdUnitId = "11388823"; videoAd.AdReady += videoAd_AdReady; videoAd.RequestAd(AdType.Video, MyAppId, MyAdUnitId); } void videoAd_AdReady(object sender, object e){ if ((InterstitialAdState.Ready) == (videoAd.State)) { videoAd.Show(); } } } }
When the above code is compiled and executed on a local machine, you will see the following window, which contains a Show Ad button.
Now, when you click on the Show Ad button, it will play the video on your app.
| https://www.tutorialspoint.com/windows10_development/windows10_development_store.htm | CC-MAIN-2018-39 | refinedweb | 594 | 55.84 |
You can discuss this topic with others at
Read reviews and buy a Java Certification book at
Write code using the following methods of the java.lang.Math class: abs ceil floor max min random round sin cos tan sqrt.
The Math class is final and these methods are static. This means you cannot subclass Math and create modified versions of these methods. This is probably a good thing, as it reduces the possibility of ambiguity. You will almost certainly get questions on these methods and it would be a real pity to get any of them wrong just because you overlooked them.
Due to my shaky Maths background I had no idea what abs might do until I studied for the Java Programmer Certification Exam. It strips off the sign of a number and returns it simply as a number. Thus the following will simply print out 99. If the number is not negative you just get back the same number.
System.out.println(Math.abs(-99));
This method returns the next whole number up that is an integer. Thus if you pass
ceil(1.1)
it will return a value of 2.0
If you change that to
ceil(-1.1)
the result will be -1.0;
According to the JDK documentation this method returns
the largest (closest to positive infinity) double value that is not greater than the argument and is equal to a mathematical integer.
If that is not entirely clear, here is a short program and its output
public class MyMat{ public static void main(String[] argv){ System.out.println(Math.floor(-99.1)); System.out.println(Math.floor(-99)); System.out.println(Math.floor(99)); System.out.println(Math.floor(-.01)); System.out.println(Math.floor(0.1)); } }
And the output is
-100.0 -99.0 99.0 -1.0 0.0
Take note of the following two methods as they take two parameters. You may get questions with faulty examples that pass them only one parameter. As you might expect these methods are the equivalent of
"which is the largest THIS parameter or THIS parameter"
The following code illustrates how these methods work
public class MaxMin{ public static void main(String argv[]){ System.out.println(Math.max(-1,-10)); System.out.println(Math.max(1,2)); System.out.println(Math.min(1,1)); System.out.println(Math.min(-1,-10)); System.out.println(Math.min(1,2)); } }
Here is the output
-1 2 1 -10 1
Returns a random number between 0.0 and 1.0.
Unlike some random number system Java does not appear to offer the ability to pass a seed number to increase the randomness. This method can be used to produce a random number between 0 and 100 as follows.
For the purpose of the exam one of the important aspects of this method is that the value returned is between 0.0 and 1.0. Thus a typical sequence of output might be
0.9151633320773057
0.25135231957619386
0.10070205341831895
Often a program will want to produce a random number between say 0 and 10 or 0 and 100. The following code combines math code to produce a random number between 0 and 100.
System.out.println(Math.round(Math.random()*100));
Rounds to the nearest integer. So, if the value is more than half way towards the higher integer, the value is rounded up to the next ingeter. If the number is less than this the next lowest integer is returned. So for example if the input to round is x then :
2.0 <=x < 2.5. then Math.round(x)==2.0
2.5 <=x < 3.0 the Math.round(x)==3.0
Here are some samples with output
System.out.println(Math.round(1.01)); System.out.println(Math.round(-2.1)); System.out.println(Math.round(20)); 1 -2 20
These trig methods take a parameter of type double and do just about what trig functions do in every other language you have used. In my case that is 12 years of programming and I have never used a trig function. So perhaps the thing to remember is that the parameter is a double.
returns a double value that is the square root of the parameter.
max and min take two parameters
random returns value between 0 and 1
abs chops of the sign component
round rounds to the nearest integer but leaves the sign
Which of the following will compile correctly?
1) System.out.println(Math.max(x));
2) System.out.println(Math.random(10,3));
3) System.out.println(Math.round(20));
4) System.out.println(Math.sqrt(10));
Which of the following will output a random with values only from 1 to 10?
1) System.out.println(Math.round(Math.random()* 10));
2) System.out.println(Math.round(Math.random() % 10));
3) System.out.println(Math.random() *10);
4) None of the above
What will be output by the following line?
System.out.println(Math.floor(-2.1));
1) -2
2) 2.0
3) -3
4) -3.0
What will be output by the following line?
System.out.println(Math.abs(-2.1));
1) -2.0
2) -2.1
3) 2.1
4) 1.0
What will be output by the following line?
System.out.println(Math.ceil(-2.1));
1) -2.0
2) -2.1
3) 2.1
3) 1.0
What will happen when you attempt to compile and run the following code?
class MyCalc extends Math{ public int random(){ double iTemp; iTemp=super(); return super.round(iTemp); } } public class MyRand{ public static void main(String argv[]){ MyCalc m = new MyCalc(); System.out.println(m.random()); } }
1) Compile time error
2) Run time error
3) Output of a random number between 0 and 1
4) Output of a random number between 1 and 10
3) System.out.println(Math.round(20));
4) System.out.println(Math.sqrt(10));
Option one is incorrect as max takes two parameters and option two is incorrect because random takes no parameters.
4) None of the above
The closest is option 1 but the detail to remember is that random will include the value zero and the question asks for values between 1 and 10.
4) -3.0
3) 2.1
Answer 5)
1) -2.0
1) Compile time error
The math class is final and thus cannot be subclassed (MyCalc is defined as extending Math). This code is a mess of errors, you can only use super in a constructor but this code uses it in the random method.
Last updated
25 Dec 2000
most recent version at | http://www.jchq.net/tutorial/09_01Tut.htm | crawl-001 | refinedweb | 1,104 | 59.19 |
JDBC in JSP - JDBC
happening for my update query. Please help me with a suitable suggeastion.
Regards
Sreejith send me your jsp coding then i can understand what...JDBC in JSP Sir,
I got a problem in my jsp page which contains
JDBC - JDBC
the server lib folder but still itd getting me the error.....
Can anyone help me please.... Hi friend,
For mysql you embed the jar "mysql...JDBC JDBC driver class not found:com.mysql.jdbc.Driver.....
Am
jdbc - JDBC
many errors in it?
Please help me out. Hi friend,
Plz specify....");
Connection conn = null;
String url = "jdbc:mysql://localhost:3306... on Netbeans and jdbc visit to :
http
jdbc - JDBC
and retrive it using a java program? plz help me with the code. Hi...:
Retrieve Image using Java... = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test", "root", "root
connectivity - JDBC
.....
thanks in advace to those who gonna help me........ Hi friend...
javax.servlet.ServletException: No suitable driver...
java.sql.SQLException: No suitable driver
JDBC 4.0
JDBC 4.0
In this section, we will discuss about JDBC 4.0 and it's added... enhance feature to
JDBC API which provide a simpler design and better developer... to JDBC 4.0
The main added features in JDBC 4.0 are--
JDBC driver'
JDBC
JDBC can u send me the code of jdbc how to join two tables that are in relation
jdbc
jdbc please tell me sir.i dont know JDBC connection and how to create table
about jdbc - JDBC
about jdbc Hi folks, my previous question was when "i have a table with primary key then when i enter a value which is already there will cause a problem how to solve it." i know to retrieve all the attributes
question is all about and that also reduce the chances to get answer quickly. So
urgent help needed in JDBC AND JAVA GUI - JDBC
urgent help needed in JDBC AND JAVA GUI my application allows... want any one to help me convert from scanner to java GUI for this code...();
}
}
// thanks for any help rendered
Hi Friend,
Try the following code
jdbc - JDBC
JDBC statement example in java Can anyone explain me ..what is statement in JDBC with an example Query to Connect Database JDBC Query to connect to database will u supply me the block of code where it throws the exception
in JSP to create a table.
2)how desc can be written in JDBC concepts Hi friend,
Code to help in solving the problem :
import java.sql.... = null;
String url = "jdbc:mysql://localhost:3306/";
String db
in textfile).
give me the solution.
thanks Hi friend,
Read for more information.
JDBC Training, Learn JDBC yourself
will help the programmers to learn JDBC skills
necessary to build powerful... - Learn about
JDBC with small examples
JDBC... - Learn about JDBC 4.0
Here are more tutorials you can learn: What
JDBC Tutorial, JDBC API Tutorials
API to make JDBC
connect to the relational databases. With the help of JDBC...
JDBC design patterns
In this section we will explain you about JDBC design...Java Database Connectivity(JDBC) Tutorial
This tutorial on JDBC explains you
JDBC-AWT
in sql+..
pls help me...JDBC-AWT I can not able to capture the data in an applet which contains the components like text fields,check box etc.. and i am trying to save
MS Access - JDBC
)
at java.lang.ClassLoader.loadClass(Unknown Source)
..
please help me ....sir....thank you... information about MS access database...but still i am having doubt in that topic...("sun.jdbc.odbc.JdbcOdbcDriver");
Connection con = DriverManager.getConnection("jdbc:odbc:db
jdbc query
details but not with Access database. Plz help me its urgent I need your help...jdbc query hello sir I have used your simple bank application project in my project to display transaction details but i am using ms access data
java - JDBC
java hi... help me to retrieve the image from the database please help me Hi Friend,
Try the following code:
import java.sql.... = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/test", "root", "root
servlet - JDBC
about oracle.I am giving this code below please connect this code from sql... = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:oracle","scott... con = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:oracle
swings - JDBC
swings can a wavelet picturization to the image can be to retrieve a image from the database. please help me
java - JDBC
)
please help me with the code Hi Friend,
Try the following code... = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "root");
Statement st
java - JDBC
to implement singleton class in the below code.please help me out
public...";
public static final String DB_URL="jdbc:mysql://localhost:3306/link_db
Java - JDBC
Java sir i want to make a login form in servlet with session and cookies in java(netBeans6.1). plz help me to sove my problem.i shall be thank full to jdbc hi friends,
I am not getting how to connect by using type 2 And type 3 drivers between java and oracle......
please any body help me......
thanking you,
your's,
praveen
Programming - JDBC
VERY MUCH ! TRULY YOU SERVE A BIG HELP FOR ME
Java - JDBC
Java sir i want to make a login form in servlet with session and cookies in java(netBeans6.1)also with run time database(MS-Access). plz help me to sove my problem.i shall be thank full to
java - JDBC
me how to increase the life time of sessions with a simple example and syntax.
Its very urgent and important.......plz ,,,,,,,,helpdbc code - JDBC
jdbc code are jdbc code for diferent programs are same or different?please provide me simple jdbc code with example? Hi Friend,
Please visit the following link:
Here you
JDBC Autocommit
JDBC Autocommit Mode
In this tutorial we are discussing about jdbc autocommit mode. Setting the
true or false of the JDBC autocommit mode allows... JDBC Autocommit with the help of
example code
help me..
help me.. Design and write a class named Person and its two subclasses named Student and Employee.
Make Lecturer and Admin subclasses of Employee...) to display the class name and the person?s name. Also define a suitable
help me..
help me..
what are the component needed by grid computing, cloud computing and ubiquitous computing?
discuss about the security of above computing.
difference between that 3 computing
JDBC + AQUA DATA STUDIO
JDBC + AQUA DATA STUDIO Hello,
i have aqua data studio database. I want to do crud operation in jdbc connection using this databse. can you help me out to do this ??
Thanks
About springs - JDBC
About springs Hi,
My xml code is as follows :In this i have my id stored in results1(in tag).
And now
jdbc interview question
drivers in JDBC. JDBC interview question what are the adv and disadv dirver1,2,3,4?
expain type 1,type 2,type 3,type 4 drivers in jdbc?
if there is more than one exception in sqlexception calss how to go about displayin it?
how
exporting data to excel sheet - JDBC
query in java swing program,i want to print the result about the query in excel sheet.Sir plz help me sir. Hi Friend,
Try the following code...exporting data to excel sheet Sir i have already send request about
jdbc compilation error - JDBC
jdbc compilation error java.lang.Exception: Problem in call_select... resolve it? Hi friend,
plz specify in detail and send me code.
Read for more information.
Thanks
What is DatabaseMetaData - JDBC
me example of DatabaseMetaData.
Thanks
Hello,
As you know that metadat is data about data. DatabaseMetaData is an iterface, This interface is implemented by jdbc drivers, throgh this you can get the information about
Database drivers - JDBC
Database drivers Please give me types of drivers and explain them. Hi friend,
There are four types of JDBC drivers known as:
* JDBC-ODBC bridge plus ODBC driver, also called Type 1 Exception
JDBC Exception
... the
execution of program. Exception Occurred in JDBC Connectivity when a
connection object do not find a suitable driver to connect a url-database.Understand
JDBC Batch Processing
JDBC Batch Processing
In this section we are discussing about JDBC Batch processing. You will learn
how to write Java programs for JDBC batch processing...
concepts. We have given many examples to help you in mastering the JDBC Batch
JTA in J2SE JDB - JDBC
in J2SE based application with Oracle. JDBC also provides transaction control. I thought to explore JTA with this to maintain transaction. Some one can provide me with simple code example or tuorial about using JTA in j2se perspective
Connection.close() issue - JDBC
with out re-launching the application. Please help me in this.
Thanks for your... as a database through My JDBC Application. Once server get re-restarted... friend,
Visit for more information: | http://www.roseindia.net/tutorialhelp/comment/91328 | CC-MAIN-2014-23 | refinedweb | 1,466 | 59.4 |
I'm trying to hook BIOS Int 13h to add my custom functionality to it and hijack some of existing one. Old Int 13h vector is stored in global variable. When interrupt handler is called the DS is set to some value that doesn't match the original data segment of caller. Therefore accessing global variables of caller turns into a headache.
What is best practice to chain interrupt handlers?
Hook is installed this way:
#ifdef __cplusplus # define INTARGS ... #else # define INTARGS unsigned bp, unsigned di, unsigned si,\ unsigned ds, unsigned es, unsigned dx,\ unsigned cx, unsigned bx, unsigned ax #endif void interrupt (far *hackInt13h)(INTARGS) = NULL; void interrupt (far *biosInt13h)(INTARGS) = (void interrupt (far *)(INTARGS))0xDEADBEEF; void main(void) { struct REGPACK reg; biosInt13h = getvect(0x13); hackInt13h = int13h; setvect(0x13, hackInt13h); // Calling CAFE reg.r_ax = 0xCAFE; intr(0x13, ®); printf("Cafe returned: 0x%04x\n", reg.r_ax); // Resetting FDD just to check interrupt handler chaining reg.r_ax = 0; reg.r_dx = 0; intr(0x13, ®); printf("CF=%i\n", reg.r_flags & 0x01); setvect(0x13, biosInt13h); }
Int 13h hook code:
P286 .MODEL TINY _Data SEGMENT PUBLIC 'DATA' EXTRN _biosInt13h:FAR _Data ENDS _Text SEGMENT PUBLIC 'CODE' PUBLIC _int13h _int13h PROC FAR pusha cmp AX,0CAFEh jnz chain popa mov AX, 0BEEFh iret chain: popa call far ptr [_biosInt13h] ; <-- at this moment DS points to outer space ; and _biosInt13h is not valid _int13h ENDP _Text ENDS END
I'm using Borland C++ if it matters
Thanks guys, I've found solution!
First thing I've missed is moving variable to code segment and explicitly specifying it.
Second one is using hacked (pushed on stack) return address and
retf instead of
call that adds real return address on stack.
No need to
pushf explicitly 'cause flags are already on stack after
int. And flags will be popped on
iret no matter in my handler or in chained one.
P286 .MODEL TINY _Text SEGMENT PUBLIC 'CODE' EXTRN _biosInt13h:FAR ; This should be in CODE 'cause CS is only segreg reliable PUBLIC _int13h _int13h PROC FAR pusha cmp AX, 0CAFEh jnz chain popa mov AX, 0BEEFh iret chain: popa push word ptr cs:[_biosInt13h + 2] ; Pushing chained handler SEG on stack push word ptr cs:[_biosInt13h] ; Pushing chained handler OFFSET on stack retf ; ...actually this is JMP FAR to address on stack _int13h ENDP _Text ENDS END
User contributions licensed under CC BY-SA 3.0 | https://windows-hexerror.linestarve.com/q/so63763426-Interrupt-handler-chaining-in-real-mode | CC-MAIN-2020-40 | refinedweb | 398 | 60.35 |
The most convenient way of running a Clojure program is by creating a single, standalone JAR file. It can be easily distributed and executed by end users without the need of installing additional dependencies.
lein provides
uberjar command that does most of work. There are, however, few
details that have to manually set up.
Let's start by creating an app with
lein new [name]
lein new app
First, specify the main class namespace with
:main and ensure it is compiled
ahead of time (AOT) with
:aot.
(defproject app "0.1.0" ... :uberjar-name "app-standalone.jar" :aot [app.core] :main app.core)¬
AOT can be also enabled only for the uberjar using
profiles (thanks to Jan
Stępień for the tip).
(defproject app "0.1.0" ... :uberjar-name "app-standalone.jar" :profiles {:uberjar {:aot [app.core]}} :main app.core)
Optionally, you can specify the name for the jar that will be produced with
:uberjar-name. For the list of possible Leiningen parameters that can be used
in
projects.clj check the following sample.project.clj.
Next, tell Clojure to produce that main class from a (previously chosen)
namespace using
:gen-class in its declaration along with
-main
function defined inside.
(ns app.core (:gen-class)) (defn -main [& args] (println args))
Finally, run
lein uberjar and then
java -jar target/app-standalone.jar param1 param2
It should produce:
(param1 param2).
app-standalone.jar provides interoperability, which means that this file can
be moved to other computer with Java installed and run on it the same way without
the need to install additional dependencies.
tools.cli provides tools to handle more complex scenerios while working with command line arguments.
Let's start by adding it as a dependency to
project.clj
(defproject app "0.1.0" :main app.core :aot [app.core] :dependencies [[org.clojure/clojure "1.6.0"] [org.clojure/tools.cli "0.3.1"]])
Next, modify
core.clj
(ns app.core ( ["-v" nil "Verbosity level" :id :verbosity :default 0 :assoc-fn (fn [m k _] (update-in m [k] inc))] ;; A boolean option defaulting to nil ["-h" "--help"]]) (defn -main [& args] (parse-opts args cli-options))
Recompile with
lein uberjar and run
java -jar target/app-standalone.jar param1 -h -v -p 40 param2 --invalid-opt
It should produce
{:options {:help true, :verbosity 1, :port 40}, :arguments [param1 param2], :summary -p, --port PORT 80 Port number -v Verbosity level -h, --help, :errors [Unknown option: "--invalid-opt"]}
My Tech Newsletter
Get emails from me about programming & web development. I usually send it once a month | https://zaiste.net/posts/clojure_cli_101/ | CC-MAIN-2021-10 | refinedweb | 424 | 58.99 |
We recently noticed that in one of our biggest tables some of the rows are a few times bigger than others. By "bigger" I mean longer and taking more storage space. How to display top 1000 biggest rows in the table? Almost all columns are varchar
following up to this question: jquery select and use part of class name i thought to use this way to dynamically assign a maxlength to the jeditable script (i assign a special class to each element startig with edit_*, where the star is the maxlength
I am working on a machine with windows server 2003 and I have to clone the repository where the Drupal site that I am going to work with is stored. The cloning process is carried out without problems, but when it comes to perform the check out of the
I have a URL with long query string , the query string length is more than its standard limit(2048 ). So I have Change the Request filter setting for maxQueryString in IIS . URL is working fine in FF and Chrome but its not working for IE 8 and 9. Ple
The problem is simple: I have a form with textboxes, and in one of those textboxes, I want users to enter either a positive or negative 2-digit number. I'm looking for an easy way to enforce this restriction, i.e. without having to parse the number a
Here is an example Fill textarea with lines (one character at one line) until browser allows. When you finish, leave textarea, and js code will calculate characters too. So in my case I could enter only 7 characters (includ
The maxlength attribute (eg: maxlength="160") on textarea is not working in Firefox, it works in Chrome however. Can this issue be solved somehow? --------------Solutions------------- You can check this link on how to limit your textarea
Friends, I'm using a datagridview control in my visual studio 2005 windows application. Here I've 5 columns. Among these 5, 2nd(colIndex 1) and 3rd(colIndex 2) column have text data type and 4th(colIndex 3)and 5th(colIndex 4) have double data type co
i write a code something like { xtype:'numberfield', maxLength: 3, } but maxlength doesn't work for me any one have any suggestion and any alternate of maxLength attribute as in numberfield config i can see maxLength attribute in sencha touch docs bu
I have the following jQuery script in use, which implements a maxLength behaviour for textareas. Here's my code: code deleted see fiddle instead: I am not searching for another script because this usally works fine, but o
I like to have an input with maximum 3 characters. In Firefox everything works fine I can only write 3 numbers inside the input - but in safari you can write a lot of numbers inside. You can test it in both browsers with this:
I have a column in my MySQL database that stores images as a byte array. I am trying to update a row to insert a new image. The new image is 163K, and when I convert it to a byte[], the number of elements in the array is 167092. When I run the stored
Im using a telerik gridview for silverlight and Im trying to programatically set the maximum character length on each individual column after the gridview is populated with data. I want to make it so when the user is inserting or editing a column's c
I am a newbie at matlab and I am trying to solve the following scenario. I have large strings which need to be xor'ed essentially encoded in order to get a value. I am using the following code snippet to perform the operation : clear;clc; first ='abc
My purpose is to limit the user input (which is free text) inside a simple HTML text box to 5 characters. I am using the input field's maxlength property to ensure that, but I need to display a popup when the user tries to type more than 5 characters
ViewModel: public class MyViewModel { [Required, StringLength(50)] public String SomeProperty { ... } } XAML: <TextBox Text="{Binding SomeProperty}" MaxLength="50" /> Is there any way to avoid setting the MaxLength of the TextBox to match up my
First things first: I'm storing multiple domains to a database, after I've converted each and every domain name to it's IDNA version. What I need to know the maximum length such an IDNA-converted domain name can have so I can define the database fiel
I'm trying to make a field with limited choices: Action_Types=( ('0','foo'), ('1','bar'), ) class Foo(models.Model): myAction=models.CharField(max_length=1,choices=Action_Types) def __unicode__(self): return '%d %s'%(self.pk,self.myAction) However, w
using .net mvc 3 and trying to increase the allowable file upload size. This is what I've added to web.config: <system.webServer> <validation validateIntegratedModeConfiguration="false"/> <modules runAllManagedModulesForAllRequests="tr
By default EF 4.2 codefirst sets the database column behind string properties to nvarchar(max). Individually (per property) I can override this convention by specifying the [MaxLength(512)] attribute. Is there a way of globally applying a configurati | http://www.dskims.com/tag/maxlength/ | CC-MAIN-2019-13 | refinedweb | 869 | 56.79 |
Dear Friends ,
I am developing one header file for implementation of stack. My library is containing only two functions push and pop.I am confuse is it good for program to declare structure in header file ? I want your answer with detailed description of reasons.
I urge you to give your best comments on my code.Any single problem you think can happen kindly share it here. :tntworth: :tntworth: :tntworth: :tntworth: :tntworth: :tntworth: :tntworth:
Below code is of "stack.h". This file contains declaration of functions and variables used threw out the program.
Following is the code of "stack.c" this code contains the definitions of the functions.Following is the code of "stack.c" this code contains the definitions of the functions.Code:#ifndef STACK_H_INCLUDED #define STACK_H_INCLUDED #include<stdio.h> #include<stdlib.h> struct Stack { int value; struct Stack *previous; }; extern struct Stack *stack; extern void push(int value); extern int pop(void); #endif // STACK_H_INCLUDED
Code:#include<stdio.h> #include<stdlib.h> #include "stack.h" // my header file. struct Stack *stack=NULL; void push(int value) { struct Stack *temprary = malloc(sizeof(struct Stack)); if(stack == NULL) { stack = malloc(sizeof(struct Stack)); stack->previous = NULL; } else { temprary->previous = stack; stack = temprary; } stack->value = value; } int pop(void) { int value; struct Stack *temprary; if(stack == NULL) { printf("\nSorry, The stack is empty.\n"); return 0; } else if(stack->previous == NULL) { value = stack->value; stack = NULL ; return value; } else { value = stack->value; temprary = stack; stack = stack->previous; free(temprary); } return value; } | http://forums.devshed.com/programming-42/designing-stack-header-file-945836.html | CC-MAIN-2017-43 | refinedweb | 249 | 51.24 |
Bloom Filter: Better than Hash Map
Reading time: 35 minutes | Coding time: 15 minutes
Bloom Filter is a probabilistic Data Structure that is used to determine whether an element is present in a given list of elements. Bloom Filter is quite fast in element searching, however being probabilistic in nature it actually searches for an element being "possibly in set" or "not in set at all which makes a crucial difference here and this is what makes Bloom Filter efficient and rapid in its approach.
The Bloom Filter Data Structure is closely associated with the Hashing Operation which plays an important role in this probablistic data structure which we will further discuss. The advantages of this Data Structure is that it is Space Efficient and lightning fast while the disadvantages are that it is probablistic in nature.
Even though Bloom Filters are quite efficient, the primary downside is its probablistic nature. This can be understood with a simple example. Whenever a new element has to be searched in a List, there are chances that it might not be entirely in the list while similar chances are there that it might be in the set. If there is the possibility of the element in the set, then it could be a false positive or true positive. If the element is not entirely present in the set, then it can be remarked as true negative. Due to its probablistic nature, Bloom Filter can generate some false positive results also which means that the element is deemed to be present but it is actually not present. The point to be remarked here is that a Bloom Filter never marks a false negative result which means it never signifies that an element is not present while it is actually present.
Understanding the Concept of Hashing and Bloom Filter
To understand the concept of Bloom Fliter, we must first understand the concept of Hashing. Hashing is a computational process where a function is implemented which takes an input variable and it return a distinct identifier which can be used to store the variable. What makes Hashing so popular is that it is quite simple to implement and it is much more efficient compared to the conventional algorithms for performing various operations such as insertion and search.
In the Bloom Filter Data Structure, Hashing is an important concept. However a Bloom Fliter which holds a fixed number of elements can represent the set with a large number of elements. While the numbers are added to the Bloom Filter Data Structure, the false positive rate steadily increases which is significant since Bloom Filter is a probabilistic data structure.
Unlike other Data Structures, Deletion Operations is not possible in the Bloom Filter because if we delete one element we might end up deleting some other elements also, since hashing is used to clear the bits at the indexes where the elements are stored.
When a Bloom Filter is initialized, it is set as a Bit Array where all the elements are initialized to a default value. To insert an element, an integer value is needed which is hashed using a given Hash Function a given number of times. The bits are set into the Bit Vector and the indexes where the elements are added are intialized to 1.
The Search Operation in a Bloom Filter is also performed in the same manner.
Whenever a Search Query is passed, the index bit is checked to verify if the element is present or not. In case, any one of the index bit is not present, it is presumed that the element is not present in the Bloom Filter Vector. However, if all the bits are 1, then it is made sure that the element is definitely present. There is no such case where it is presumed that a false is returned if an element is actually present.
Insertion and Search Operation in Bloom Fliter
To insert an element into the Bloom Filter, every element goes through k hash functions. We will first start with an empty bit array with all the indexes intialized to zero and 'k' hash functions. The hash functions need to be independent and an optimal amount is calculated depending on the number of items that are to be hashed and the length of the table available with us.
The values to be inserted are hashed by all k hash functions and the bit in the hashed position is set to 1 in each case. Let us take some examples:
To check if an element is already present in the Bloom Filter, we must again hash the search query and check if the bits are present or not. Let us take an example:
As we discussed above, Bloom Filter can generate some false positive results also which means that the element is deemed to be present but it is actually not present. To find out the probability of getting a false positive result in an array of k bits is: 1-(1/k).
The pseudocode for insertion of an element in the Bloom Filter is as follows:
function insert(element){ hash1=hashfunction(element)% Size_Of_Array hash2=hashfunction2(element)%Size_Of_Array array[hash1]=1; array[hash2]=1; }
The pseudocode for searching an element in the Bloom Filter is as follows:
function search(element){ hash1=h1(element)%Size_Of_Array; hash2=h2(element)%Size_Of_Array; if(array[hash1]==0 or array[hash2]==0){ return false; } else{ prob = (1.0 - ((1.0 - 1.0/Size_Of_Array)**(k*Query_Size))) ** k return "True";
Implementation of Bloom Filter
The following implementation is in Python 3 Programming Language which is a General-Purpose Programming Language:
import hashlib class BloomFilter: def __init__(self, m, k): self.m = m self.k = k self.data = [0]*m self.n = 0 def insert(self, element): if self.k == 1: hash1 = h1(element) % self.m self.data[hash1] = 1 elif self.k == 2: hash1 = h1(element) % self.m hash2 = h2(element) % self.m self.data[hash1] = 1 self.data[hash2] = 1 self.n += 1 def search(self, element): if self.k == 1: hash1 = h1(element) % self.m if self.data[hash1] == 0: return "Not in Bloom Filter" elif self.k == 2: hash1 = h1(element) % self.m hash2 = h2(element) % self.m if self.data[hash1] == 0 or self.data[hash2] == 0: return "Not in Bloom Filter" prob = (1.0 - ((1.0 - 1.0/self.m)**(self.k*self.n))) ** self.k return "Might be in Bloom Filter with false positive probability "+str(prob) def h1(w): h = hashlib.md5(w) return hash(h.digest().encode('base64')[:6])%10 def h2(w): h = hashlib.sha256(w) return hash(h.digest().encode('base64')[:6])%10
Advantages of Bloom Filter
- The Time Complexity associated with Bloom Filter Data Structure is O(k) during Insertion and Search Operation where k is the number of hash function that have been implemented.
- The Space Complexity associated with Bloom Filter Data Structure is O(m) where m is the Size of the Array.
- While a hash table uses only one hash function, Bloom Filter uses multiple Hash Functions to avoid collisions.
With this, you will have the complete knowledge of Bloom Filter. Enjoy. | https://iq.opengenus.org/bloom-filter/ | CC-MAIN-2020-24 | refinedweb | 1,191 | 62.07 |
You're enrolled in our new beta rewards program. Join our group to get the inside scoop and share your feedback.Join group
Join the community to find out what other Atlassian users are discussing, debating and creating.
Hello,
Im attempting to add an automation rule that will have a branch condition JQL to get issues in epics linked to the 'trigger issue'.
The JQL leverages ScriptRunner JQL functions and it includes the smart value of the trigger issue.
The problem is that the rule is failing on the JQL saying the curly brace used for the smart value is a reserved character and to put it in a string or use the escaped unicode value of '\u007b'.
An example of a functioning version of this jql is :
issueFunction in issuesInEpics(" issueFunction in linkedIssuesOf('key=CCFT-2', 'is implemented by') ") AND status != closed
Which in a JQL Branch condition would cleanly look like:
issueFunction in issuesInEpics(" issueFunction in linkedIssuesOf('key={{issue.key}}', 'is implemented by') ") AND status != closed
Below is my current 'version' of the JQL but it is continuing to fail. I've tried numerous 'combination's of escapes to get this pass but have had no luck.
issueFunction in linkedIssuesOf('key=\"{"\"{"issue.key\"}"\"}"', 'is implemented by') ") AND status != closed
Another failure failure showing how I had attempted the JQL using the unicode values.
CCFT-2: "(issueFunction in issuesInEpics(" issueFunction in linkedIssuesOf('key=\u007b\u007bissue.key\u007d\u007d', 'is implemented by') ") AND status != closed) AND (key != CCFT-2)" - Error in scripted function: issuesInEpics, see below, Error in scripted function: linkedIssuesOf, see below, Error in the JQL Query: The character '{' is a reserved JQL character. You must enclose it in a string or use the escape '\u007b' instead. (line 1, character 5)
How can I correctly format the JQL with escapes to get this JQL to work when triggered in the rule?
Version info:
Jira Server(not Cloud): 8.53
Automation for Jira: 7.2.8
ScriptRunner : 6.2.2
Thanks in advance for any help.
Regards,
Greg
Thanks for the response @Curt Holley
You are correct for a single link i.e. a story linked in an epic your solution would work.
However, in my case Im looking for issues in epic with that epic linked to another epic.
the problem was with the jql string I was creating was having issues getting the correct escapes in place to manage the quotes and brackets. So when I ran the query it failed.
I was able to solve this by using the string quoting of '/'.
I ended up with this and it is now working just fine:
// trigger issue and jql strings
def jqlPrefix=/issueFunction in issuesInEpics("issueFunction in linkedIssuesOf('key=/
def jqlSuffix=issueKey + /', 'is implemented by') ") AND status != closed/
// The JQL query you want to search with
final jqlSearch =jqlPrefix + jqlSuffix
I only got back to this task yesterday and came up with this solution and neglected to post here.
I'll mark this as done/answered.
Thanks again,
Greg
Right. I missed the epic linked to another epic part.
Complicated situation, well handled 👍
HI
I'm only familiar with the Cloud version of Automation, but ignoring my trigger/insert whatever trigger is relevant....wouldn't something like this work? plus no scriptrunner functions required.. | https://community.atlassian.com/t5/Automation-questions/Issues-using-curly-braces-in-JQL/qaq-p/1662709 | CC-MAIN-2021-21 | refinedweb | 546 | 66.33 |
NOVEMBER 2018
COMPLIMENTARY
YOUR ROUTINE Experience something different in the Fargo fitness scene this winter
TABLEOFCONTENTS
FARGO MONTHLY | NOVEMBER 2018
COVER STORY
16
EDITOR MEETS FITNESS
Just because the weather is sickening, doesn't mean your body should take a hit as well. Why not get out there and have fun with it! Staying fit doesn't always mean having to spend an hour on the stair stepper. We had our editor test out a few fun, alternative workouts throughout town that will make you look forward to breaking a sweat this upcoming winter.
16 44
FEATURES 26 MAPPING OUT FARGO FITNESS 30 10 TIPS FOR WINTER WELLNESS 35 THE POWER HOUSES BEHIND POWER PLATES 44 DON'T HAVE A COW...SAVE ONE! 52 OLD DOMINION, NEW SOUNDS
35
52 ON THE COVER
Zero Gravity Alternative Fitness instructor Tina Hoff on aerial silks
4 | NOVEMBER 2018 | FARGOMONTHLY.COM
6 38 42 46 48 54 56 79
RECURRING EDITOR'S LETTER 5 THINGS TO EAT & DRINK LIFE WRITES FASHION KILBOURNE GROUP THINK GLOBAL, ACT LOCAL CULINARY SPOTLIGHT MIXOLOGIST OF THE MONTH THE LAST PAGE: CREATIVE MORNINGS
59 64 67 69
RESOURCES EVENT CALENDAR LIVE MUSIC TRIVIA DRINK SPECIALS
Test Your
SKILLS with Puzzled Escape Rooms.
Whomever last used the dumbbells didn't put them back in the right order. Can you figure out what order they are supposed to go in and decode the scrambled message?
puzzle 15
55
20
60
C
E
N
E
65
70
35
75
T
O
25
70
55
15
60
0
N
I
A
V
5
45
10
50
Y
B
U
L
45
20
40
5
65
O
I
30
25
30
40
D
I
I
80
50
75
!
E
Y
10
35
80
,
U
Hint: Numeric Order
Your Answer:
114 Broadway N L1, Fargo puzzledescaperooms.com 701-446-8548
ANSWER You can do it. I believe in you!
Check out Fargo Monthly's Facebook page in November to post your answers for a chance to win a prize from Puzzled Escape Rooms.
FROMTHEEDITOR
Top 5 Favorites of the Month 1 NDDOT Driver's License Office I'm finally an official North Dakota resident! I had been putting this task off since DMV's are known for being a nightmare, but my experience at the NDDOT Driver's License Office was pleasant and quick.
exercise? I Thought You Said Extra Fries
T
he fitness issue is here and if you've ever met me before, you'll know how daunting of a task this was for me. I knew it was going to be an interesting month for me, but when it was pitched that I should try out some fitness classes myself, my "daunting" feelings moved towards "how am I going to pull this off?" territory. Once upon a time, I played volleyball pretty competitively. I played since I was in second grade all the way through a season of college volleyball and after all that time, my body was done with the sport. My back pains and shin splints caught up to me and I was ready to put physical activity on hold until "I was better." Over time, I've learned that there will never be a perfect time to get back into fitness. There will always be excuses. Sometimes your back hurts. Maybe you haven't factored new sneakers into your budget. Or maybe your work schedule is too hectic. Pretty soon, the excuse that is
too cold outside to workout will be coming up too. However, while creating this issue I was forced to dive into fitness. And you know what? I enjoyed it! I (somewhat selfishly) decided to focus on workouts around town that were fun and innovative. Ones that would be so unique that they wouldn't feel like a workout, but rather a cool activity that just happened to make my muscles ache the next morning. It may never be the "right time" to get back into a wellness routine, but I hope that looking through these pages you'll become inspired and will consider adapting these tips into your lifestyle. Just because the weather is looking bleak doesn't mean your physical health has to take a back seat. If I can do it, so can you. Until next month,
Alexandra Martin Editor
alexandra@spotlightmediafargo.com fargomonthly@spotlightmediafargo.com 6 | NOVEMBER 2018 | FARGOMONTHLY.COM
2 Fargo-Moorhead Symphony My fiancĂŠ and I went on a date night to the Chee-Yun and Sergey Opening Concert held by the Fargo-Moorhead Symphony and were blown away by the experience. We took advantage of their Urban Overture program, which allows $10 tickets for individuals in their 20s and 30s.
3 FM Raise Your Spirits Our team here at Spotlight had the opportunity to attend FM Raise your Spirits benefiting CHARISM this month and it was a blast! Getting to mingle with those in our community while benefiting a fantastic charity is a win-win to me.
4 New Boots In preparation for my first Fargo winter, I splurged and got some winter boots. After extensive research, I found a pair that is both stylish and practical, a combination that is essential.
5 Late Night Fall Craft Market Two things I love are local goods and local drinks. Unglued's Late Night Fall Craft Market at Drekker's Brewhalla combined both of those loves and provided for a funfilled night. I smelled a lot of soaps and got to touch a lot of pretty jewelry, so I can't complain.
NOVEMBER 2018
Volume 8 / Issue 11 Contributors Mike Allmendinger, Joe Brunner, Alex Cyusa, Taylor Markel, Sky Purdin, Nicole Midwest Photography Copy Editor Alexandra Martin Social Media & PR Coordinator Ariel Holbrook Web Editor Jessica Kuehn
ADVERTISING Associate Sales Director Neil Keltgen Senior Sales Executives Ryan Courneya
Ryan@SpotlightMediaFargo.com
Paul Hoefer
Paul@SpotlightMediaFargo.com
Sales Executives Scott Rorvig
ScottRorvig@SpotlightMediaFargo.com
Nick Linder
NickLinder@SpotlightMediaFargo.com
Ross Uglem
Ross@SpotlightMediaFargo.com
Associate Publisher, Design & Chantell Ramberg Living Chantell@SpotlightMediaFargo.com Client Relations Manager Jenny Johnson Client Relations & Office Assistant Alex Kizima Business Development Assistant)
When the temperature drops and the snowflakes begin to fall, we retreat indoors. This is not only where we retreat to relax and unwind, but also where we host family and friends during the holiday season. From transitional tablescapes to fall foliage tutorials, let us be your local guide for everything entertaining this month.
Worth almost $1 billion, Gary Tharaldson is hands down the most successful entrepreneur in North Dakota. Fargo INC! talks with him about what business lessons he's learned over the last 50 years.
The NDSU wrestling program is often overlooked. However, it is one of the most storied programs in NDSU's long history of athletic success. Bison Illustrated profiles how this tradition began and how it is carried on today through coach Roger Kish and his 2018-19 wrestlers.
Meet the team MIKE
ANDREW
ALEXANDRA
STEVE
BECCA
NOLAN
JENNY
SARAH
SARAH
SIMON
NEIL
PAUL
RYAN
CHANTELL
NICK
JESSE
HILLARY
ARIEL
JESSICA
NICK
COLLEEN
ALEX
JENNIFER
BRUCE
JENNY
SCOTT
Learn more about us at spotlightmediafargo.com CRAIG
JOHN
Fargo Monthly Editor, Alexandra Martin, beats the urge to be lazy this winter and tries some of Fargo's most fun fitness classes
16 | NOVEMBER 2018 | FARGOMONTHLY.COM
17
BY Alexandra Martin | PHOTOS BY Hillary Ehlen
ZERO GRAVITY ALTERNATIVE FITNESS
18 | NOVEMBER 2018 | FARGOMONTHLY.COM
A
s the name implies, Zero Gravity Alternative Fitness is anything but your average gym experience. I gave their Aerial Silk Fitness class a try, a class their website describes as: "An expressive and playful workout using 'silk' hammocks. Elevate your heart rate and deepen your body connection through dynamic movement, tricks and conditioning. Develop arm and core strength, coordination and grace. All fitness levels are welcome, there is no prerequisite for this class." I've been to a Cirque du Soleil show before, so I wasn't completely buying the idea that this class was for "all fitness levels." Flipping upside down with only a bright pink silky hammock keeping me from smashing into the concrete floor was a bit intimidating. Before the class began, I spoke with co-owner Gina Bushey. I expressed to her that I was nervous and she must have picked up on my feelings of awkwardness as she said, "There’s always so much awkwardness when you first start because everyone is really selfconscious. It takes a little bit of time before you realize that nobody’s looking at you or watching you. Everyone is worried about themselves and there’s a lot of camaraderie in that. There’s a lot of support that comes along with starting
Editor Meets at the bottom and growing together." And starting at the bottom I was. I was fully ready for everyone in the class to be watching my every, baby-giraffe-level-ofawkward move. But Gina was right. The class is capped at a maximum capacity of seven students, so no one participating feels lost in a sea. The class instructor, co-owner Misty Tomchuk, came over and corrected my posture and even helped lift me into positions the right way throughout the class. My fear was that everyone would be gracefully in an in-air pretzel and I would still be struggling to get on the hammock correctly, but we were all in this together. The class began with some simple stretching so that our muscles were warm and ready to go. After we got loose, we began with some stretching that incorporated the silk hammocks. After the stretching, we began to get more ambitious. Soon, I found myself floating in the air in a plank position with only the hammock supporting my pelvis. After I hit this milestone, we moved onto more formidable poses,
including an inverted butterfly and one-legged king pigeon pose. The progression of events felt natural and we were eased into each step. By the time we got to the part where we would be dangling upside down, I was already feeling confident. The idea of doing such a thing no longer felt like an impossible task, but rather a fun challenge that I knew I could overcome. It was like a dare that I was excited to execute. The more we did, the more daring I felt. When it was announced that it was time to wrap up with a floating savasana cool-down, I wasn't ready to quit just yet. I was ready for more! In closing, Gina noted, "You really need to come in and experience it. A lot of people have misconceptions about what we do here, but we are very fitness based. Our goal when we opened the studio was to take some of the things that were important to us, pole fitness, aerial fitness and yoga, and make them more mainstream and accessible so that people didn’t feel like they had to be intimidated or have unanswered questions."
What to Wear I made the mistake of wearing a loose crop-top to this class. While I felt confident and cute when walking into the class, I ended up feeling exposed when I flipped upside down and suddenly the hem of the shirt was up to my nose. Tighter fitting garments work best here.
What You'll Feel the Next Day I was surprised by my inner thighs hurting the next day. The muscles that were aching were ones that I had never felt hurting before! In addition to the inner thigh pain, I also felt a bit in my abs and core.
Other Class Offerings Pole Fundamentals I, II, III Aerial Pole I, II, III Advanced Pole I, II, III Elite Pole XaBeat Dance Cardio Aerial Yoga ZG Stretch, ZG Strength Barre Various Supplemental Pole Classes
19
P
Editor Meets.
20 | NOVEMBER 2018 | FARGOMONTHLY.COM
recise. as: Pure Barre is a collection of 45-50 minute total body workouts. At the core of our technique, we use a thoughtful series of low impact, isometric movements that are designed to produce results. You'll use the ballet Barre and other light equipment as you move through class, focusing on different areas of your body. This class will be fastpaced,’t.
PURE BARRE’re working out," said Nichole. I appreciated the pace of the class and how it didn't allow me the time to feel like I was struggling. It moved fast and by the time the lights dimmed for our warmdown, I was surprised that it was done. The feeling of accomplishment and the rush of endorphins you feel after doing such a wellrounded full-body workout is incomparable. I now get why this is class is a nationwide success for all types, seasoned athletes and newbies alike.
21
TOTAL WOMAN
22 | NOVEMBER 2018 | FARGOMONTHLY.COM
H
ow does a nurse go from manning hospitals to teaching pole fitness classes? Pam Thorson came about alternative fitness upon getting tired of boring, traditional fitness classes that were painful for her knees. Clocking in at over the age of 60, Pam owns Total Woman and is an expert on alternative fitness and wants to bring new, innovative ways to get fit to Fargo. She knows from experience that each individual has their own personal health problems. This, plus her nursing background, allows her to run the studio with a focus on overall wellness, rather than just dropping pounds and firming muscles. Pam's vision of a studio was one where classes could intentionally be kept small. The smaller class sizes allow for personal attention to each person and the instructors are able to give students adjustments based on their individual needs. As someone who has had her own journey with various injuries and ailments, this mission was comforting to me. Yes, the classes would push me, but Pam assured me that they would not make me do anything that was going to be a detriment to my ongoing move to a healthier lifestyle. Maybe someday I'll feel bold enough to try a pole fitness class that the studio is so known for, but for this trial run I was intrigued by "POUND Fit." Total Woman describes
Editor Meets this class as: Using. The class is designed for all levels of fitness and each move throughout the class can be adapted to fit your own abilities and stamina. Before the class, Pam warned me that I wouldn't get out of the class dry...it was going to be a sweaty time. While deep down I was nervous to put myself out there, those fears were blocked by how warm and welcoming the whole environment was. I didn't know any of the nine women enrolled in the class with me, but I felt like we were all in this together. You could tell no one was ashamed to take a breather, grab some water or do a step in a modified way. Before we began, the instructor said to us, "Don't be afraid to mess up. There are no mistakes, only drum solos." This statement really set the pace of what the feel of the class would be like. We all laughed along with each other as we tried to get the hang of it. In addition to this camaraderie, the class is done in low lighting, creating a veil of privacy. The darkness allows you
to focus on yourself rather than watching your neighbor, which goes both ways. You can feel confident knowing no one is watching you too carefully. All this being said, this was not an easy class. The 45 minutes were jam packed with continuous movements and focuses on various muscle groups. The class uses bright green drumsticks and echoes drumming motions. Clacking the sticks together in rhythm and beating them onto the ground is invigorating, as well as a great stress reliever. "Sometimes if I have a frustrating day, I like to step into a [POUND] class and just let it all out," said Pam. What really helped this class move along was the music. Pam noted that the studio has music licenses so they are always playing the most current, hot hits, not just stock music or covers. The songs in combination with the aura of positive energy provided the perfect atmosphere for letting loose, getting pumped, toning up and generally just rocking out and having a great time. I've never finished a fitness class feeling so fulfilled. I was feeling the burn from the very start, but the upbeat music and the dance-like movements kept things fresh and I never felt bored or too focused on the muscle burns I was feeling. In the end I was sweating and walking in a stiff waddle, but I felt refreshed and like I really accomplished something.
What to Wear This class is done barefoot, so no need to worry about purchasing new workout shoes. Everyone in my class was wearing a variation on leggings and a tank top, so no specialty gear is needed whatsoever.
What You'll Feel the Next Day Before I even left the studio, my legs were shaking and sore. The flight upstairs up to my townhouse was a struggle, but it was a good type of sore. I could feel that my muscles got a good, deep burn out of this class.
Other Class Offerings Intro to Pole Beginner Pole Series Progressive Pole Series Body and Band Full Figured and Fabulous Private Parties!
23
Editor Meets
What to Wear Come in knowing that you'll be sweating and getting into some deep stretches. Anything you'd feel comfortable working out in while getting a full range of motion will be just right for this class.
What You'll Feel the Next Day FLUX alternates workouts daily. Sometimes you'll have a leg day focus and other days you might have an arm workout. Attending multiple days a week will allow for a full-body workout and therefore some full-body soreness. On my arm day, I felt the pain in my shoulders, the front of my chest and in my core.
Other Class Offerings CrossFit Icehouse Challenge Nutrition Coaching Olympic Lifting Yoga for Athletes
S
tarting your fitness journey is never easy. If you want to land somewhere in-between the intensity of CrossFit and the relaxation of yoga, CrossFit Icehouse's FLUX course is for you. While Icehouse is based on its CrossFit classes, their FLUX classes have picked up steam and offer something for everyone. In more official terms: FLUX combines three proven fitness disciplines yoga, strength training and conditioning in the most unexpected and refreshing way. We focus on gaining lean muscle and burning body fat. Our group class begins with a yoga-inspired warmup, a 5-15 min workout and it ends with a yoga flow to cool down and re-center. I have to admit that I arrived to this class late and had the embarrassing task of popping in as everyone was already acquainted and set up. Luckily, co-owner Courtney Shoemaker was in the class with me and helped fill me in on what I missed. She told me, "We try to make it super personal in the beginning. We go through everyone's names and try and make it a little bit more of a back and forth versus just not talking and being super quiet the whole time." While I missed out on the initial introductions, I still felt the warmth of the environment. "You feel comfortable enough to ask questions if you have questions and the instructors try and approach and help you move well the whole time," said Courtney.
24 | NOVEMBER 2018 | FARGOMONTHLY.COM
Icehouse is all about the community. Gyms oftentimes have the reputation of being intense clubs only for the big and buff...or at least that's what I envision in my mind. Courtney disproved this thought of mine, "The community piece is really what we love about the CrossFit side [of the gym] and that's something we try to pull into this FLUX space as well." When I stumbled into class, scrawny arms and all, I was greeted with smiles. I was still nervous to be doing anything associated with the name "CrossFit," but my fears started to be eased. Let's break the class down some. We started with our teacher, Emily Monson, giving us an overview of what we would be working on that night. Terms like "thruster" and "pistol" mean nothing to me in the context of fitness, but Emily gave us a walkthrough of the movements that would be used in the class. Part of my fear of going into fitness classes is that I know that I'm clueless and I hate not knowing what to do. The quick rundown at the beginning resolved this. After an intro, we began with a warmup of yoga to get us limber and start our hearts going. Next we transitioned to our HIIT portion where, on this night, we focused on arms. During this Emily came to me and helped my form on a medicine ball clean, a move I never had much experience with. Before I reached my point of "Oh gosh when will this be done?" the HITT portion wrapped up and it was time for yoga. I was breathing heavy and my muscles were starting to let me down, but it didn't push
me further than what I was capable of. "This can really be a kick-your-butt class, cause it’s not easy, but if you want to take the workout, you can take it at your own pace and slow it down," said Courtney. The last 20 minutes of the class was dedicated to an upbeat and energy-infused yoga session. Panic! At The Disco was still playing over the speakers and the poses felt energetic and empowering, in contrast to the stereotype that yoga is sleepy and slow. I learned that FLUX is a meet-in-the-middle type of class. By blending yoga with HIIT (high-intensity interval training) you get a good workout with a built-in stretch session. If you're not sold yet, here's what won me over: the CrossFit workout portion of the class is only 5-15 minutes long. I think we all are capable of dedicating about 10 minutes to a high intensity, killer workout. "The idea is that wherever you're at in your fitness journey, it's a good fit. It's great to be able to get in and get in a quick 50-minute workout and check all the boxes and feel great and refreshed," said Courtney. I can't think of a better way to summarize my experience with this class than a sentence I overheard one of my classmates say to the teacher at the end of the class, "that wasn't that bad!" She was right. It was hard work and I felt the burn, but the moves were all modifiable and I completed it feeling empowered.
CROSSFIT ICEHOUSE
25
26 | NOVEMBER 2018 | FARGOMONTHLY.COM
1801 45th St. S. anytimefitness.com
Anytime Fitness
4501 15th Ave S orangetheoryfitness.com
Orangetheory Fitness
4300 23rd Ave. S. fmcurling.org
FM Curling
4243 19th Ave. S. ymcacassclay.org
YMCA
4303 17th Ave. S. isaakstudios.com
Isaak Studios
1650 45th St. S. mojofitstudios.com
Mojo Fit Studios
4325 13th Ave. S. Suite 9 planetfitness.com
Planet Fitness
Mapping Out
29
94
13TH AVE S
3309 Fiechtner Dr., Unit #4 crossfit701.com
CrossFit 701
3332 4th Ave. S., Suite D fmaca.com
The Academy of Combat Arts
2800 Main Ave. tntkidsfitness.org
TNT Kid's Fitness & Gymnastics
1800 21st Ave. S. healthprosfargo.com
Health Pros Personal Training Center
2001 17 Ave. S. americangoldgymnastics.com
American Gold Gymnastics
Core Fitness
2424 13th Ave. S. corefitnessnd.com
MAIN AVE
YMCA
400 1st Ave. S. ymcacassclay.org
Choosing a gym that is right for you can rely heavily on its proximity to your home or work. Here's a map of our area's gyms and fitness facilities to help you in your search for the best workout for you and your schedule.
S UNIVERSITY DR
25H ST S
Jazzercise Fargo
5475 51st Ave. S. dynastyperformancetraining.com
joefitness
29
4201 38th St. S. Unit F joefitness.com
MPX Fitness
3955 40th Ave. S., Suite C mpxfitness.com
5257 27th St. S. haute-yogis.com
Haute Yogis
Anytime Fitness
40TH AVE S
2600 52nd Ave. fitness52fargo.com
Fitness 52
5050 Timber Pkwy S., Suite 116 anytimefitness.com
3350 35th Ave. S. zerogravityfargo.com
Zero Gravity Alternative Fitness
32ND AVE S
52ND AVE
35TH AVE S
Fit Elements
3120 25th St. S. fitelementsfargo.com
25H ST S
Dynasty Performance Training
5292 51st Ave. S. crossfitfargo.com
CrossFit Fargo
5258 51st Ave. S., Suite 101 fargofitlife.com
Fargo Fitlife
4265 45th St. S. snapfitness.com
Snap Fitness
4674 40th Ave. S. f3fargo.com
F3 Fitness
4650 38th Ave. S. ndfit.com
45TH ST S
FIT Hot Yoga
4837 Amber Valley Pkwy jazzercise.com
3491 S. University Dr. courtsplus.org
Courts Plus Community Fitness
S UNIVERSITY DR
42ND ST S
27
28 | NOVEMBER 2018 | FARGOMONTHLY.COM
METROFLEX
4041 Main Ave. metroflexfargo.com
29
MAIN AVE
7TH AVE N
764 34th St. N. Suite Q facebook.com/barbotboxing
Barbot Boxing & Fitness
12TH AVE N
Mapping Out
CrossFit Icehouse
1620 1st Ave. N. crossfiticehouse.com
1335 2nd Ave. N. fargobjj.com
Fargo BJJ & MMA
1707 Centennial Blvd. ndsu.edu/wellness
Wallman Wellness Center
19TH AVE N
N UNIVERSITY DR Pure Barre
Downtown Yoga
615 2nd Ave N. 216 Broadway N, #203 purebarre.com/nd-fargo downtownyogafargo.com
Ecce Yoga
111 Broadway N. G Fitness ecceyoga.com 524 7th St. N. gaspersschoolofdance.com
Total Woman
508 Oak Street North, Unit A totalwomanfargo.com
Spirit Room
111 Broadway N. spiritroom.net
Total Balance
1461 N. Broadway totalbalancefargo.com
Anytime Fitness
2614 Broadway N., Ste B anytimefitness.com
3105 N. Broadway, Suite #13 revolutiontrainers.com
Revolution - Personal Training Studio
BROADWAY N
25TH ST N
52ND AVE
40TH AVE S
CYCLEBAR
Edge Fitness
6207 53rd Ave S. edgefitnessfargo.com
465 32nd Ave E. mpfitness.net
3163 Bluestem Dr., #106 fargo.cyclebar.com
VETERANS BLVD
Maximum Performance and Fitness
94
13TH AVE S
215 Main Ave. E. wffitnesscenter.com
West Fargo Fitness Center
9TH ST E
32ND AVE S
MAIN AVE
Solidcore
3985 56th St. S. solidcore.co
Family Wellness
2960 Seter Parkway familywellnessfargo.com
619 10th St NE Suite 6 sheyennerivercrossfit.com
Sheyenne River CrossFit
Edge Fitness
Anytime Fitness
30TH AVE S
Planet Fitness
800 Holiday Dr. planetfitness.com
Max Training
1518 29th Ave. S. maxtrain.net
12TH AVE S
805 14th St. S. mnstate.ed/wellness
MSUM Wellness Center
MAIN AVE
935 37th Ave S. anytimefitness.com
3501 8th St S edgemoorhead.com
8TH ST S
SHEYENNE ST
29
40TH AVE S
94
EHP CrossFit
1400 25th St S ehpcrossfit.com
10 TIPS
When it's chilly out, all you're ready to think about is where your mittens are. In freezing temperatures, it's hard to prioritize overall wellness. We've put together a list of health and wellness tips to keep your body and mind in optimal performance this upcoming winter. Some of these may seem obvious and others might be new to you. Regardless, it's always nice to have a reminder to keep these tips in the front of your mind. We hope you'll incorporate all of them into your daily practices. Stay healthy, readers!
1
1
3
2
Catch Extra ZZZs
Sleep is your body's time to recuperate and get ready for the activities of your day ahead. The lack of light outside interrupts our natural, internal circadian rhythms and our bodies produce more melatonin, thus making us feel more tired. The distinction between day and night can get blurred in some of the cloudy, cold weather. Because of this, it is natural and important to tuck into bed a bit earlier than you might at other times of the year. Going to sleep earlier and making sure you have a consistent sleep schedule will help you feel less tired and sluggish throughout the day. To get the most out of your sleep, cozy up with the Azara Platform Bed from SCAN Design. While in bed, diffuse some relaxing essential oil blends like "Sleep" from Everyone Essential Oils, found at Swanson Health. 30 | NOVEMBER 2018 | FARGOMONTHLY.COM
2
Take Your Vitamins
It's good to aim for a well balanced diet, but the off-season for many nutritious produce items makes it more difficult to keep loyal to this plan. Especially important to include in your life this winter is Vitamin D. With the days being shorter and the weather being colder, it's unlikely that you'll get much time in the sun. To make up for the loss of nutrients the sun naturally provides, you might consider taking a Vitamin D supplement. Swanson Health carries a variety of Vitamin D supplements, from high potency capsules to a liquid dropper version.
3
Get Chatty
Seasonal Affective Disorder (SAD) is a mood disorder that is characterized by feelings of depression that are related to the changing season. The switch from sun kissed cheeks to wind burnt faces takes a toll on us. While it is tempting to want to stay inside and hibernate, it'll greatly help your overall mood to stay social. Social interaction with friends and family will greatly help in keeping your spirits high. There are so many fun ways to get social. Check out our events and live music calendars on page 59 for the latest happenings to attend with pals. If the elements are too rough, invite your friends over for some quality time. Welcome them in with a fun Tag door mat from SCAN Design.
BY Alexandra Martin | PHOTOS BY Hillary Ehlen
1
5 4
6
5
5
4
Soak It In
Our skin is our largest organ and does so much for us on a daily basis. But when the wind is blowing, your skin takes a hit and our natural sebum production can't keep up. To counteract the dryness of the air and the sting of the wind, make sure you are moisturizing properly. Your skin is your barrier to the toxins of the world and thus should be treated royally. Onyx + Pearl's Love Thyself Bod Oil from Fat and The Moon has all the good parts of a nourishing oil, but without the thick, heaviness that many others come with.
5
Walk It Out
Full exercise routines are not always for everyone. However, it is important to keep your body moving. Bundle up and try to incorporate short walks into your daily schedule to keep your heart-rate up and supply some much-needed sunlight. Doing this will help you acclimate to the temperatures. Make sure to be smart and not to over-do it though. If the weather is too extreme and the sidewalks are too icy, don't risk it! Don't go out without dressing properly! These Merrell boots from Beyond Running are available in both men's and women's styles. Pair them with Darn Tough's fun, Merino wool socks from Outermost Layer to help your feet stay safe and warm.
6
Eat Your Fruits and Veggies
It may seem obvious to some, but please eat your fruits and vegetables this winter! Just because the farmer's markets are down for the year doesn't mean you should give up on fresh produce. A great way to get your fruits and vegetables in this season is with smoothies and blended treats. Power Plate Meals always has new blends of juices available. Blends include Mellow Mojito, Berry Beat and Optic Orange. With how yummy they are, you won't even notice how healthy you're being.
31
8
8 7
7
7
Limber Up
We all know the feeling of shivering and having your shoulders tense up to your ears. When it's cold out, your muscles tend to tighten, making you more prone to achy muscles or even injury. Try some simple stretching each morning or even a few yoga classes a week to keep your muscles from feeling too stiff. No vulnerable muscles here. For at-home stretching, keep a LuLu Lemon yoga mat from Beyond Running at home to remind you to use frequently. A matching foam roller is also a good item to keep on hand for some deeper muscle work.
1
9
10 9
9
10
8
Flex Your Brain
On days where it's too cold to workout your body, take time to workout your mind. Chilly weather is the perfect time to cozy up at home and settle in with some good reads. Keeping your mind active is arguably just as important as keeping your body active. Reading books or doing mind puzzles such as crosswords or sudoku can be a fun way to spend a night in. Head over to Zandbroz to pick up some local literature. If you're into novels, we suggest reading the "Whispering Pines" series from North Dakota's own Kimberly Diede. If non-fiction is more your speed, "Pacing Dakota" by Thomas D. Isern is a collection of essays outlining the history and culture of the region. Also, don't forget that with a valid North Dakota ID/proof of Fargo address, you can qualify for a free Fargo Public Library card for even more options!
9
10
Look Good, Feel Good
Stop! Hobby Time
Outermost Layer keeps you warm with this cozy, plaid piece. For the ladies, Kindred People has a plethora of matching hats and mittens that come in such a a variety of colors and weights that you are guaranteed find something to go with your outfit.
Unglued hosts a variety of workshops to help you hone in on new skills. Available classes include ceramic ornaments with instructor Jenny Sue, inked tumblers, string art, glass etching and so, so many more.
Don't give up your personal sense of style and fashion just because it's cold out. To ensure that you're always feeling yourself, make sure that your winter gear is both practical and fashionable. A $500 coat is nice, but you can start small with cute hats, gloves and scarves that you can stock up on to keep things fresh day-to-day.
Consider picking up a new hobby this time of year. Have you been envying beautiful embroidery hoops you see on Instagram? Or do you have words spinning around your head you'd love to turn into poetry? What about a desire to get your hands dirty with some pottery creations? Now is a great time of year to dive into new hobbies to keep yourself busy with as you sit by the fire.
33
now using North Dakota State meat department beef
BURGERS. BEER. BISON.
1414 12th ave N • herdandhorns.com • 701.551.7000
The Power Houses Behind
Power Plates Husband-wife team Seth and Haylee Houkom are the forces behind Power Plate Meals, a local meal service focusing on accessible, healthy meals.
Y
ou're hungry
Seth and Haylee Houkom in their new downtown location on 2nd Ave N
and have two choices. One: find a recipe, go out and purchase ingredients, prepare said ingredients, cook everything together just right and then enjoy the healthy, hearty meal. Two: pick up something from the drive-thru.
After a long day at work, you're cold and the idea of all the steps it would take to prepare a meal for yourself is just too much. So fast food again it is...or not.
BY Alexandra Martin PHOTOS BY Hillary Ehlen
Power Plate Meals is a Fargobased company that provides healthy, pre-made meals. The company strives to provide the ease and attainability of quick 35
eats, but with all the nutrients and health benefits of a wellresearched meal plan. West Fargo born and raised, the husband-wife team of Seth and Haylee Houkom are the powerhouses behind Power Plate Meals. With Seth being a 4th generation farmer with an exercise science and premed background and Haylee having a nursing background, these two have a special interest in health and wellness. According to Haylee, "three years ago, before we started Power Plates, Seth and I did bodybuilding shows. When we did that we had our own DOWNTOWN FARGO 621 2nd Ave N, Fargo
fitness apparel line which was run through social media, so we started with that." She said that when they had the apparel business going, Seth always pushed the idea of doing something with food and creating healthy meals, something she noted that he was always good at. "If there's something you wanted to eat, [Seth] could turn it healthy. If you want a burger and fries, he could make it in a healthy way," said Haylee. During their bodybuilding show days, they noticed that there were many big meal prep companies, but SOUTH FARGO 2603 Kirsten Ln S #102, Fargo
36 | NOVEMBER 2018 | FARGOMONTHLY.COM
Fargo didn't have anything of the sort. Upon seeing a need they wanted in the market, Seth said "We should do something like that. I feel we could do it," to which Haylee met with skepticism, more specifically with the phrase, "you're literally absolutely crazy!" Three years later their idea has turned out to be anything but crazy. The business has created a loyal following of customers and has expanded over time. You can find Power Plate Meals in 3 different Fargo-area locations as well as in Bismarck, Grand Forks and Eagan. The business has grown an impressive amount in the small amount of time it has been cooking up dishes. In June Haylee and Seth opened a downtown location WEST FARGO 1380 9th St E #605, West Fargo
on 2nd Avenue, introducing their business to a whole new range of clients in the heart of the city. Beyond their new Eagan, MN location, three more Minneapolis locations will be opening in early 2019. Their successes and growth prove that there is plenty of local demand to eat clean and watch what we digest, but many of us want a little extra help to get there. Not everyone has the time or expertise to research nutrition and the steps necessary to eat a well-balanced diet. With Power Plate Meals the work is done for you, so all that’s required is to choose from one of the dozen or so menu items. Seth works with their head chef Tom Olson to ensure that each dish meets their nutritional BISMARCK, GRAND FORKS AND EAGAN
standards while also tasting (and looking) good. The whole team works to look for what types of dishes are trending at the time and transforms them into something that appeals to customers in the Fargo-Moorhead area. "Tom and Seth work together. Tom creates the original recipe and Seth's expertise is on making sure the meal follows our nutritional guidelines. They kind of tag team in that way," said Haylee. Haylee noted, "We're always trying to expand our products to make it interesting for customers. That's the biggest thing with us, that our menu does change every two weeks." As a testament of their desire to continue expanding options, juices and salads were introduced this
summer and this winter/fall season they will be introducing soups to the menu. There are always new dishes to enjoy... without the guilty conscience. With most dishes under 400 calories, options ranging from Chicken Pesto Pasta to Mongolian Beef Fried Rice to Tater Tot Hot Dish have never been so healthy. "My favorite part of it has been to see it grow, but also to see our team grow too. The people that really live and breathe Power Plates, just like us, and the people that help us no matter what," said Haylee. "It's been really fun to build our team, but also just to build our communities in the locations that we've opened, too. Through it all, it's just fun to see where we started, where we're at now."
Power Plates Meals ships to 12 states including: North Dakota, South Dakota, Minnesota, Montana, Nebraska, Iowa, Wisconsin, Illinois, Indiana, Ohio, Kentucky and Michigan.
5
EAT & DRINK
This time of year brings about a plethora of favorite flavors. From cinnamon to pumpkin to cranberry, we love them all. However, one of the most versatile of these seasonal flavors is apple. This month we are bringing to you five applethemed things to eat and drink.
caramel apples
It's hard to beat an old-fashioned candied apple on a stick. Carol Widman's Candy Co brings back nostalgic tastes with their varieties of sweet apples. Go for a traditional caramel or add some extra crunch to it with pecan or cashew crumbles. Carol Widmans Candy Co
4325 13th Ave. S., Fargo carolwidmanscandyco.com
38 | NOVEMBER 2018 | FARGOMONTHLY.COM
dry, crisp cider
There are very few things that are more synonymous with fall than cider. Fargo's very own cidery, Wild Terra, has an ever changing array of ciders on tap, including this Anxo Cidre Blanc. Available in their tap room, this dry hard cider helps transition from summer crisp flavors to robust fall ones. Wild Terra
6 12th St N, Fargo wildterraciderandbrewing.com
apple cluster donut
Included in Bloomberg's "The 16 Very Best Dishes I Ate in 2017," this apple cluster still lives up in 2018. Large in size and coated in a glossy layer of sugary glaze, this treat demands to be enjoyed with a warm cup of coffee in the morning. When it's served with coffee, it doesn't count as dessert, right? Sandy's Donuts & Coffee Shop
300 Broadway North, Fargo 301 Main Avenue West, West Fargo sandysdonuts.com
39
sausage apple pizza If Blackbird Woodfire's own description of "BĂŠchamel cream sauce, house made sausage, Granny Smith apple, fresh sage, parmesan cheese and micro greens" doesn't sell you on this pizza, we don't know what will. If an apple a day keeps the doctor way, might as well include your daily apple dose on a delicious woodfired pizza. Blackbird Woodfire
206 Broadway N, Fargo blackbirdwoodfire.com
apple caramel galette Nichole's offers a rustic caramel apple pastry baked in a flaky cornmeal crust. This decadent piece of heaven is a perfectly petite version of a traditional apple pie. In a sea of fall pies, this galette provides a new take on an old favorite and we just can't resist it. Nichole's Fine Pastry
13 South 8th Street, Fargo nicholesfinepastry.com
41
LIFE WRITES FASHION
Have You Found Your
aesthetic?.
D
on’t get salty (well... icy, in this case) about having to stash away your cutoff denim, sunscreensmooched and sunshinereminiscentcolored sweaters?) - What do you simply enjoy (luxurious, faux-fur winter coats or a warm, camel peacoat with a plaid scarf?) By knowing your answers to these
42 | NOVEMBER 2018 | FARGOMONTHLY.COM
BY Taylor Markel | PHOTO BY Hillary Ehlen!
43
DON'T W O C A HAVE
...Save One!
Anna Lake Animal Sanctuary transforms one Underwood, MN farm into a forever home for farm animals in need.
" BY Alexandra Martin
I
t’s really hard and I spend all day working. My hands are bloody and I don’t get to wear pretty nails anymore, but it’s worth it." Dini Pederson-Opsahl and her husband Mark Opsahl hosted the grand opening of Anna Lake Animal Sanctuary on October 20. Located deep in the farm country of Underwood, Minnesota is this microsanctuary with a mission. A micro-what? According to Anna Lake, a microsanctuary is the idea of rescuing animals on a smaller scale than larger sanctuaries.
44 | NOVEMBER 2018 | FARGOMONTHLY.COM
"Usually microsanctuaries rescue farmed animals, like cows, chickens or ducks. We rescue animals that people would normally think of in a farmed setting or for food," said Dini. "That's where the microsanctuary movement came in, just to teach people that these animals are very similar to the cats or dogs that you can have as a companion." Animal shelters rescuing cats and dogs are common to find in just about any American city, but it's easy to forget about the farm animals in need. Unlike animal shelters, sanctuaries do not have the goal of rehoming animals, but rather they care
for these animals until their natural death. Anna Lake Animal Sanctuary is currently home to 19 chickens, five ducks and three cows, most of which were rescued from unsavory situations. Dini, like many of us, grew up loving animals. Growing up in the Twin Cities, being a farm girl was never in her blood, but loving animals was, "My grandmother was an animal control officer, she was actually the first woman in the United States in this position and she took in a lot of rescues, just because she just couldn’t put them down."
facts about the farmed animal industry, relating them back to the experience of this specific farm.
doing vegan food and getting that word out there. I want more of that around here." A favorite animal of hers had always been chickens. So when she and her husband Mark had the opportunity to move to his family farm in Underwood, this seemed the perfect time to get one as a pet for the farm. Once they had this seemingly obscure pet, she said, "As soon as I had them, it just felt kind of weird to eat chicken with how much I loved them. Just with how smart they are, they all know their names and they are just such an intelligent bird. So we went vegan and we started looking at the microsanctuary movement." After more time and research, Dini quit her full-time job and dedicated all her time to the hard work that goes into running the animal sanctuary. "I don’t get paid to do it, but it’s just the most rewarding thing I’ve ever done," she said. Many animals that come into a sanctuary environment are ill or not socialized. On a daily basis, Dini works to rehabilitate ailing animals and repair the broken bonds between them and humans, teaching them how to trust again. In August, the sanctuary
acquired three cows who were surrendered to them after being rescued from a slaughter truck. These cows, Hazel, Dani and Daisy, previously lived as dairy cows and are recovering from a chronic disease that required special attention. These “Moo Girls,” as Dani calls them, were previously used as dairy cows on an industrial farm, but no longer were considered profitable due to age and health conditions, so they were going to be sold for slaughter. After establishing their goals and a good base for what they want to become, Dini and Mark were ready to show the community what they'd been working towards. October 20th's "Anna Lake Animal Sanctuary Grand Opening" aptly took place over the Minnesota Educator Academy (MEA) conference weekend. To Dini, a big part of growing Anna Lake Animal Sanctuary was to create an awareness about farm animals. She said, "I wanted to plan this event to just tell people in the community that we are here. We also really want to support local businesses, especially ones that are willing to look at
ANNA LAKE ANIMAL SANCTUARY
The event involved three time slots for tours of the farm, local food and goods vendors and interactive events, such as pumpkin carving, for the whole family. Amongst the number of vendors, attendees could buy an apple pie from Morris, MN based Prairie Vegan Pies or some cruelty-free home and beauty products from Kelska Blu. Everything for sale at the opening was ensured to meet the vegan or crueltyfree standards that Anna Lake Animal Sanctuary stands for. The tours of the property involved introductions to the resident animals and some background information on their pasts and what kind of lives they get to live now. On the tour, Dini spoke with an educated tongue and shared
TO HELP
Sponsor an animal! Monthly donations greatly help keep things up and running patreon.com/ annalakeanimalsanctuary Shop the store! All the proceeds support the sanctuary and vegan small businesses annalakeanimalsanctuary. com/shop
One of the additional purposes for this grand opening event was to raise funds for the further development of the farm itself. During the tours, attendees could see the parts of the property that needed renovation, including an old barn. The more they can renovate and expand, the more they can help. Dani and Mark hope that with renovations, they will be able to rescue more animals and give them more space to live freely and happily. With more and more restaurants and food suppliers in the area providing vegan options, this movement towards an alternative thinking regarding animals is growing in our region. In Fargo alone, we've seen Würst Bier Hall, Twist and Granite City Food & Brewery among the many establishments around town who have recently added fully-vegan options to their daily menus. Businesses are realizing that the midwest vegan is a growing demographic and have been adapting to accommodate them. Local educational resources like Anna Lake Animal Sanctuary help bring this growing message closer to home. Because you cannot make an informed decision without the information part, resources such as this within the community are essential, no matter where you land on the dietary preference meter.
26329 County Highway 35, Underwood, MN 45
Have.
As part of The Black Building's largest renovation in its history, updates include painting of the ironwork on its façade.
There's something new
IN DOWNTOWN FARGO AND YOU'RE INVITED
D
owntown is in a constant state of change. There are the obvious signs of evolution: cranes, roads closed, pedestrian tunnels protecting you from construction work overhead. And then there are the not-so-obvious signs: people hard at work, implementing the changes thousands of citizens asked for in the Fargo InFocus Comprehensive Downtown Plan, development of public art programs to add local color in places you'd least expect it and creation of the right policies and programs to make it in commissions, task forces and work groups. Community building organizations are always in need of volunteers. You are always invited to give your feedback and share your vision for the future.
BY Mike Allmendinger, President, Kilbourne Group PHOTOS COURTESY OF Kilbourne Group
46 | NOVEMBER 2018 | FARGOMONTHLY.COM
Black Building The Black Building is currently undergoing its largest renovation in its nearly 90year Dillard is a mixed-use project being constructed directly north of Roberts Commons. Anchoring Dillard will be a new local restaurant, BeerFish, which is bordered by Roberts Alley on the east and a new alley, full of possibilities, on the north. At seven-stories in height, Dillard will add 84 brand new apartment units to the growing downtown Fargo neighborhood.
The 100 Block of Broadway
Bostad apartments will be taking up the upper levels of 117 and 115 Broadway. "Bostad" is a Swedish noun meaning "a person's home; the place where someone lives."
Block 9 Block 9 is almost two months into a 24-month construction plan. The basement excavation for the tower is now complete and next there will be 367 foundational pilings sunk into the site. Truck traffic on Second Avenue North was heavy through October and has since moved to Third Avenue North. We’re capturing the construction on time-lapse camera and you can view the progress at Block9Fargo.com.
The 100 Block of Broadway is our third project and includes the former Metro Drug building, built in 1893, on its corner. After splitting this space into three storefronts, we’ve welcomed The Silver Lining Creamery, Wasabi, Poke Bowl and soon, Black Coffee and Waffle Bar. After life safety systems such as fire suppression sprinklers and new electrical and plumbing are installed, new apartments will be constructed on the upper levels of 117 and 115 Broadway.
You can be assured! The Xcel Energy Holiday Lights Parade on November 20 is a great time to see downtown lit up for the season. Lots of business owners are planning special events for you that day and night, including a Holiday Market at the Black Building. Small Business Saturday on November 24 is a great reason shop downtown Fargo. Also, Christkindlmarkt runs November 28 through December 1 in the Stone Building at 613 First Avenue North, across the street from Wurst Bier Hall. If all that doesn’t grab you, we’ve also welcomed dozens of new businesses to downtown Fargo in the last couple of years. There are new places to shop, new restaurants, new cookies, cookie dough and even ice cream. There are so many people in our community that have taken the leap and opened new places for us all to enjoy. Downtown Fargo overflows with unique and new experiences. Let’s accept their invitation. 47
THINK GLOBAL, ACT LOCAL
BY Sky Purdin
THIRD CULTURE
Hillary Ehlen
kid 48 | NOVEMBER 2018 | FARGOMONTHLY.COM
Beloved Readers: It was exactly three years ago that I was fortunate to meet Sky for a community project we collaborated on together. For those of us fortunate to have met her in person, you know that Sky has mastered the art of active listening: listening to someone so attentively while suspending any forming thoughts or answer in your brain or interrupting with comments/advice, so that the person speaking can fully open up and say what's on their mind. This is one thing I have always struggled when engaging with people, but Sky has showed me by her own habits that active listening is effective. Sky is a wonder woman that has impacted so many lives in this Fargo-Moorhead community without needing any praise for what she does. That shows how noble her values are. She has championed so many community projects with new Americans and constantly is looking at ways of making the residents of the FM area more connected across demographics and a myriad of backgrounds.
A
Third Culture Kid is someone who spent a significant portion of their developmental years in a country other than their passport country. In my case, I have two passports (USA and Finland), but I spent 17 years of my childhood in Southeast Asia in the countries of Thailand and Laos. My family is bi-lingual and is a mix of two cultures. I was just three months
Also, she speaks Thai, Lao, English, and Finnish! She has lived in Asia, Europe, and the United States, amazing right? Usually, I feel special when I say places I have lived in and languages I speak, but around a global citizen and polyglot like Sky, I no longer feel so exotic! Dr. Maya Angelou once said, "I've learned that people will forget what you said, people will forget what you did, but people will never forget how you made them feel." Sky epitomizes this quote for those of us that are blessed to count her as a friend. She truly knows how to make you feel understood, heard, cared for and foremost, feel connected and know that you belong to this community. Until our humble paths cross again, Namaste! Alexa Cyusa
old when I moved to Thailand with my parents and I came to the US for college at age 18. Who I am is very much shaped by the experiences I had growing up. I interacted with several Southeast Asian cultures and can speak Thai and Lao like a native speaker. The climate was tropical. We ate spicy food and rice daily. I did a part of my education in Finnish and the other part in English. We visited between the home countries every couple years, which kept me
THINK GLOBAL, ACT LOCAL
connected with my roots, but also left me with an understanding that I wasn’t really American or Finnish. The question “where are you from?” is not simple. I can’t say I am from Asia because my home culture was more western. In Finland and America I often feel out of place, even if I appear to blend in. I have come to learn what it means to embrace the different sides to my identity and to be a global citizen. The answer to “where are you from?” can at times be confusing to navigate. Each time I am asked this question, I have to decide what to answer. Do I have time to go into a long story about my past? Will they care? What will come of this interaction? Most people expect the place you are from to define you to some degree. To be honest, I cannot fully claim any of these countries to be my true home. I am a part of all of them. My worldview is shaped by the places and people I have interacted with throughout my life. I find myself at the crossroads of these places. I never fully felt at home anywhere because I am not a product of just one culture. Over time, I have learned to define my home by the people I choose to surround myself with. When people say “where are you from?” they are typically looking to find some kind of connection or common ground.
THE ANSWER TO “WHERE ARE YOU FROM?” CAN AT TIMES BE CONFUSING TO NAVIGATE. EACH TIME I AM ASKED THIS QUESTION, I HAVE TO DECIDE WHAT TO ANSWER. But when I hear this question, I am hearing “who are you?” instead. Why is this? It probably has something to do with the fact that where I come from is a much more complicated question for me. At times “where I’m from” has left me feeling like I have no real home...a basic that seems to connect you and give you common ground to identify with those around you. When people look at me, they usually see another North Dakotan with blue eyes, blond hair and a German heritage from a family that has lived here for generations. While my father is from North Dakota, my mother is from Finland, and I didn’t grow up here. My identity is tied in with this simple question “where are you from?” because of where I grew up. I returned to Fargo after graduate school in Finland and entered into the professional work force here. Here, I got reconnected with the Fargo-Moorhead community that I had glimpsed into years before while sandbagging with strangers during the 2009 Red River flood. I saw how engaged this
Alexandre Cyusa came to the FM area in the fall of 2010 to attend Concordia College. Originally from Kigali, Rwanda, Cyusa has lived in Switzerland, Ethiopia, Guinea and France. His traveling experiences have helped him in making this world a smaller and simpler place to live in. He currently works for Folkways and is interested in community development and nurturing global citizenship.
community was in including everyone. No one treated me as an outsider because of where I grew up. Here, I was just myself. I look around and see that there are people from all different walks of life in the world here. In Fargo, we can all be ourselves and be accepted, whether we have lived in North Dakota for generations or have moved from across the world to call this place our home. In Fargo, the culture is open and finds joy in mutual learning. It is a place where strangers share life’s joys and challenges and the sight of mixed ages and backgrounds laughing together impresses those watching. This strong sense of community brings me joy and tells me that I, a "TCK," or Third Culture Kid, am now home. Some people feel at home when they are comfortable, stable and have a good future. I came to realize I was home after
being soaking wet from sweat, freezing and covered with mud. It was 2009 and I was a freshman at Minnesota State University Moorhead when the flood stopped everything and the community came together to save dozens of homes by sandbagging. We were shoveling sand into bags, passing them in an assembly line and stacking them around houses. During these long hours of witnessing strangers helping each other, I learned the true atmosphere of this community and was inspired. If there was a place I wanted to call home, it would be a place like FargoMoorhead...a place where strangers become family. If we want to be a community where strangers become family, we all have a part to play. Be mindful of how you treat people you encounter and let's work to keep Fargo-Moorhead a place that people are proud to call "home."
OLD DOMINION NEW SOUNDS
Old Dominion takes on their Happy Endings World Tour with a country meets rock ‘n’ roll spirit
Q
M
att. BY Alexandra Martin PHOTOS PROVIDED BY Donovan Public Relations
52 | NOVEMBER 2018 | FARGOMONTHLY.COM
A
Q
A.
Q
A
Q
A
Q A.
Scheels Arena
December 14 7:30 p.m.
Q
A
Q
A
Qknit
A
Q
A
Q A
Purchase tickets @ scheelsarena.com.
53
CULINARY SPOTLIGHT
PASTA THE ART OF SIMPLICITY
I
f you’ve reached the point where you’re wondering why anyone would go through the trouble of making homemade pasta dough instead of going to the grocery store and buying a box of already made stuff, now is the time to get familiar with fresh pasta. The more tender, rich and silky big brother to dried pasta. Pasta, to me, used to be intimidating. Now after studying and practicing my skills in pasta, it’s as easy as getting dressed in the morning.
There’s something satisfying about making your own pasta. Whether it’s the feeling of making something so delicious from as little as two ingredients or the gratification of executing something that has been in the works for thousands of years. With there being so many different theories and opinions on pasta recipes, it's hard
By Joe Brunner Photos by Hillary Ehlen 54 | NOVEMBER 2018 | FARGOMONTHLY.COM
to decide on what is the right or wrong recipe. When making your pasta dough, there is a base ratio to follow to turn out a solid dough. The ratio is three parts flour to two parts whole egg. With this recipe, you can turn out a delicious dough without having to even open a recipe book. Starting with that ratio, you can add a plethora of ingredients to make it your own (i.e. chopped spinach, beet juice, squid ink, etc.) Begin with adding salt to the dough. Some people will ask, “Should you salt your dough?” or, “Should you salt your water?” I say both. Salting your pot of water will bring your water to a boil faster, as well as ensure that your pasta will be seasoned correctly. Salting the dough will
bring out the flavor of the eggs and flour, as well adding some flexibility with the taste of the final product. After you have gathered the ingredients, now what? You mix them together. Is it as easy as just throwing everything together to create pasta? Yes. Just toss and mix your dry ingredients together in a bowl, then add the wet ingredients and mix until the pasta dough is formed. Many people will tell you that the correct way is making a well on your table at home and slowly whisk the egg yolks into the dough to create a wet dough, and a mess that will take months to finally clean up. It doesn’t need to be as difficult and messy as that, all you need is a bowl and your hands or spatula. I’d rather dirty a bowl and utensil than make a huge mess on the counter (and even on the floor.) The key steps to a tender and delicious pasta are: 1. Incorporate your ingredients 2. Knead the dough until it’s a smoother cohesive dough 3. Rest the dough completely until pliable 4. Roll the dough out to the proper thickness. What is pasta without a proper sauce? Many home cooks think of pasta as two different things: pasta and sauce. However, the two must be thought of together, like a good marriage, with two items becoming one. There’s nothing more sad than a pile of over-cooked noodles on the plate with a scoop of any old sauce on top. When cooking fresh pasta, the pasta will cook fast, so you must be quick as to not overcook it. But once the noodle is just al dente, it should be transferred to the sauce, so it can finish cooking. Cooking the pasta in the sauce will ensure that the noodle soaks up all the flavor of the sauce. With an additional ladle of the starchy cooking water, it will ensure the sauce will stick to the noodle. In the Midwest, fresh pasta isn’t always a regular dinner item for families. Across the pond in Italy, that’s a whole other story. There are so many ways to make pasta your own with making changes to some recipes. With still respecting the traditions, you can be open to take the dish somewhere new that it has never been before.
Serves 4
Chitarra alla Carbonara Pasta Dough
Carbonara
Ingredients
Ingredients
• 18 oz (2 1/4 cup) all purpose flour • 12 oz whole eggs (about 6 large eggs) • 1oz (2 tbsp) salt
Method
• Combine the flour, salt and egg in a bowl. Mix together with hands until combined • When the dough has come together, knead it on a floured table, pressing it with the heel of your hand, folding it over, kneading again, repeating until the dough is smooth. It will take around 10 minutes • Form the dough into a ball and cover with plastic wrap. Allow the dough to rest on the table for around 15-30 minutes until it's pliable. • Cut dough into quarters, flatten and roll down to desired thickness (using a pasta rolling machine or rolling pin) • I suggest using a Chitarra Board to cut the pasta, but a knife will do the trick just as well
• 6 large egg yolks • 3 oz (6 tbsp) fresh grated parmesan, plus more to garnish • ½ oz (1 tbsp) fresh cracked black pepper • 10-12 oz (1 1/4 - 1 1/2 cup) pancetta • 2 cloves garlic • Extra Virgin Olive Oil
Method
• Put the eggs into a bowl, mix in parmesan and black pepper. Mix well with a fork and set aside. • Trim off any hard pieces of the pancetta, cut into 1/4 dice • Put the oil into a sauté pan at medium-high heat, add pancetta and slowly render until crisp. • While pancetta is rendering, cook your pasta to al dente in salted boiling water. • Once the pancetta is rendered, reserve some of the starchy pasta water and set aside. Strain pasta and add to the pan with pancetta. Toss pasta over heat to soak up the fat, then remove pan from the heat. • Add a splash of the pasta water to the pan and mix thoroughly, pour in egg mixture. The warm pan will help cook the eggs gently (careful not to scramble the eggs). Toss it well and add more pasta water until the sauce is creamy and glossy. Season with more black pepper. • Serve on a platter with the remaining parmesan. 55
ST
MI
LOG O I X
of the Month
max parker @ Mezzaluna
309 Roberts St N, Fargo dinemezzaluna.com
Elegance feels right at home at Mezzaluna in downtown Fargo. Everything served is mindfully crafted and intentionally produced, marrying local products with a feel of big-city tastebuds. We talked to bar manager Max Parker about a timeless favorite of his.
BY Alexandra Martin PHOTOS BY Nicole Midwest Photography
56 | NOVEMBER 2018 | FARGOMONTHLY.COM
Q&A JOURNEY TO BARTENDING
I started out in the restaurant industry when I used to work in a diner in the Twin Cities, it didn't even have a name. We just sold fried chicken and, like, 3 different sides. Once I moved up here and I started at Toasted Frog hosting and bar-backing and then I worked my way up to the bar a bit, part-time. Then I moved over here to Mezzaluna full-time and I am the bar manager here now. I've been here at Mezzaluna a year and three months now.
ABOUT THE BARTENDING EXPERIENCE AT MEZZALUNA
As far as drinks go here, customers are very open to trying new things and getting out of their comfort zone. We definitely have a lot more fun with different flavors and the stuff we get to work with is really, really
cool. Like, right now we have six or seven different Vermouths, which you don't see a lot of. You get to mess around with those things and have a good time with it. We also have a lot of regulars here, we have 60 or 70 regulars that are in at least once a week, which is nice.
MOST POPULAR DRINKS AMONGST THE REGULARS
Definitely the Ralphattan. Ralph is one of our most notorious regulars, a retired doctor. He comes here and hangs out he's just a cool guy.
ABOUT THIS DRINK
This is an older drink of mine that I've just been a big fan of since I made it, which was about 3 years ago now. It's our Irish Boxer and it's kind of a big, bold cocktail with a lot of flavor and a lot of different nuance.
IRISH BOXER • Jameson Irish Whiskey • Antica Sweet Vermouth • Green Chartreuse
• Campari • Bitters • Housemade Cinnamon Syrup
EVENT CALENDAR NOVEMBER
STAY UP-TO-DATE WITH WHAT’S GOING ON IN THE AREA.
Carrie's Twisted Art
Every Thursday from 7-9 p.m.
These public classes are a great place to learn painting techniques of all different
WEST ACRES FALL TAP FEST
Trans Mentor Program
Saturday, Nov 3 & 10 from 12 p.m. to 4 p.m.
Every Saturday from noon-4 p.m.
Come to the first-ever Fall Tap Fest at West Acres! Enjoy sips from Wild Terra Cider while you shop or take in the atmosphere and listen to music by local groups and artists. westacres.com West Acres
3902 13th Ave S, Fargo
WHAT DOES IT MEAN?
SPORTS
COMMUNITY
OUTDOORS
A&E
59
Grief Journeys For Men Support Group
Every third Tuesday of the month from 10-11:30 a.m.
Downtown Dogs Fargo
Every Wednesday at 6:30 a.m. - 2 p.m. and salad bar and soups from 10 a.m. - 5 p.m. prairieroots.coop Prairie Roots Food Co-op
1213 NP Avenue, Fargo
History On Tap: "Local Prohibition Rum Runners" at Junkyard Monday, Nov 5 at 6 p.m.
History On Tap is a collaboration between Junkyard Brewing Co. and the Historical and Cultural Society of Clay County that aims to provide fun and entertaining presentations on prohibition and the culture of booze in this area. Whether you're a history buff or found yourself snoozing through History 101, you'll enjoy Markus Krueger's entertaining and informative talks. Plus, History 101 didn't
60 | NOVEMBER 2018 | FARGOMONTHLY.COM
UFUEL HER FUTURE
Thursday, Nov 8 from 5:30 p.m. to 8:30 p.m. Her Potential, Our Collective Future. Join for an exciting evening of celebration and empowerment. This event is an evening of toasting to uCodeGirl's 2nd anniversary. It's a great opportunity to network with your peers, a chance to support a great cause and a forum for building long-lasting relationships. When you choose to support uCodeGirl, leaders are incubated, potentials unlocked and communities thrive. uCanFuel Her Future! ucodegirl.org Fargo Country Club
509 26th Avenue South, Fargo
serve cold pints of craft beer! hcscconline.org Junkyard Brewing Company
1416 1st Ave N, Moorhead
What's Up?! A Monthly Night Sky Tour Tuesday, Nov 6 at 6:30 p.m.
Want to know what you can see in the sky this month? Don’t want to miss out on celestial events like meteor showers? This is the show for you! Each month MSUM will take a tour of what you can find in our sky for that month and what to look for. This show is held on the first Tuesday of the month. mnstate.edu/planetarium MSUM Planetarium
700 11th St S., Moorhead
Theresa Caputo Live! The Experience Wednesday, Nov 7 at 7:30 p.m.
Theresa Caputo, from TLC’s hit show, Long Island Medium, will be appearing live here in Fargo at the Scheels Arena! Theresa will share personal stories about her life and explain how her gift works to the audience. This show is very interactive and you can be expecting lots of personal stories. scheelsarena.com Scheels Arena
5225 31st Ave S, Fargo
Art & Business Breakfast
Thursday, Nov 8 from 7:30 a.m. to 9 a.m.
Peter Remes, Founder & CEO First & First, Minneapolis/St. Paul will be the guest speaker at this month's Art & Business Breakfast series, hosted by the Plains Art Museum. This innovative program brings Fargo-MoorheadWest Fargo artists together with business and cultural leaders. Through presentations, conversations and activities, they explore the connections art and business share. plainsart.org Plains Art Museum
704 1st Ave N, Fargo
Women's Empowerment Event
Thursday, Nov 8 from 12 p.m. to 4 p.m.
RDO CATERS TATERS FOR CHARITY Tuesday, Nov 20 from 11 a.m. to 1 p.m.
R.D. Offutt Company's Caters Taters for Charity is a potato luncheon held each fall that donates all proceeds to a local charity. For a nominal donation, guests enjoy a delicious lunch featuring a ‘pound-tato’ - a one-pound baked potato - with choice of a variety of tasty toppings, a beverage and dessert.
4 Luv of Dog Silent Auction & Social
1635 42nd St SW, Fargo
Saturday, Nov 10 from 6 p.m. to 10 p.m.
Moscow Ballet's Great Russian Nutcracker
Art of Daily Practice with Nichole Rae.
Artist Nichole Rae is here to begin a daily practice with you to bring inspiration, healing and guidance into your life. Using journaling and affirmation practices you will practice creating space within to cultivate your vision, inspire your creative spirit + connect with your present self. In each workshop you will have the opportunity to use creative supplies to create a collection of tools to carry with you to continue your practice at home.
nutcracker.com The Fargo Theatre
314 Broadway N, Fargo
elevatehumanpotential.com EHP CrossFit - Elevate Human Potential
1400 25th St S, Moorhead
rdocaterstaters.com Delta Hotels by Marriott Fargo
Wednesday, Nov 7 from 7 p.m. to 9 p.m.
For the 2018 Women's Empowerment Event EHP CrossFit has teamed up with Scheels, Rachel & Michelle, GNC, Lululemon, Nutridyn and more to bring you a fun filled day celebrating women! The event aids their Empowerment Scholarship that allows women who are survivors of sexual assault, intimate partner violence, family violence and/or those who have experienced the adverse effects of addiction and emotional harm to have a chance at being empowered at EHP.
Thursday, Nov 8 from 6 p.m. to 8 p.m.
artofdailypractice.com Prairie Roots Food Co-op
1213 NP Avenue, Fargo
4 Luv of Dog Rescue's biggest fundraiser of the year! This event includes hundreds of Silent Auction items, music, hors d'oeuvres, cash bar, 50/50 auction - everything good, all in one room! Use this as a great opportunity to Christmas shop or find something fun for yourself. All ages welcome. 4luvofdog.org Holiday Inn Fargo
3803 13th Ave S, Fargo
War, Flu & Fear: World War I and Clay County Sunday, Nov 11 from noon to 5 p.m.
In observation of the 100th anniversary of Armistice Day, The Historical and Cultural Society of Cass County is offering free admission from noon to 5 p.m. At 2 p.m., HCSCC Programming Director Markus
61
Krueger will discuss the local effects of both the war and the armistice. Visitors are encouraged to explore the current exhibition either before or after the lecture. hcscconline.org Hjemkomst Center
202 1st Ave N, Moorhead
Plant’s For Patients Fall Fundraiser Kick Off Event Wednesday, Nov 14 from 5 p.m. to 8 p.m.
Plant's for Patients is hosting a kick-off to their Fall Fundraiser with games, food, prizes and more! Plants for Patients is made possible by the helping hands and compassionate hearts of our community. Join in to help this movement continue to grow. plantsforpatients.org Front Street Taproom
614 Main Ave, Fargo
FM Wine & Dine 2018
Friday, Nov 16 from 5 p.m. to midnight
Wine & Dine is a collaborative culinary experience featuring the perfect marriage of food and wine. This exquisite evening raises funds to support The Village Family Service Center, an organization that strengthens individuals, children and families through counseling and other services. Specially selected wines complement each course of a gourmet menu. Silent and live auctions, games, music by 8th Hour and dancing add to night's enjoyment. This event sells out, so reserve your table today!
XCEL ENERGY HOLIDAY LIGHTS PARADE Tuesday, Nov 20 from 6:30 p.m. to 9:30 p.m.
Presented by the Downtown Community Partnership and sponsored by Xcel Energy, the parade includes hundreds of participants that decorate their entries with lights. This magical evening will feature spectacular parade floats, marching units, equestrian entries as well as our Mayors, City Council and Commission members. The parade leaves Downtown Moorhead and continues through Downtown Fargo. This year's theme is "Let Your Light Shine!". downtownfargo.com Downtown Fargo
fmwineanddine.com Holiday Inn Fargo
3803 13th Ave S, Fargo
5th Annual Ice Fest
Pangea: Cultivate Our Cultures
Beautiful Wholeness
It's time for the 5th annual ICE FEST, the region's premiere ice fishing event presented by Clam Outdoors and hosted by BrewerAgre Outdoors. Score early-season savings and visit with reps from the best brands in Ice Fishing. Plus, register to win over $9,000 in prizes and gift cards, including a fishing trip to Ballard's Resort given by media partner, Radio FM Media.
Pangea: Cultivate Our Cultures is the largest free, family-friendly celebration of cultural diversity in the community. In fact, one of the few festivals of its size and kind in the Midwest, Pangea marks its 24th year of highlighting the global roots of the local Fargo-Moorhead community and continues to offer visitors a chance to immerse themselves in the region’s vibrant diversity through food, music, arts, crafts, stories, and children’s activities.
Join for a full-day event where you’ll have fun, gain a ton of clarity, make new friends and leave with a step-by-step action plan to rise up and live beautifully whole in every area of your life! It’s real-world, easy-to-apply tools that powerfully change relationships, careers and lives. It all begins at Beautiful Wholeness!
Friday and Saturday, Nov 16 and 17
Search "Ice Fest" on Facebook Scheels
1551 45th St S, Fargo
Saturday, Nov 17 from 10 a.m. to 4 p.m.
hcscconline.org Hjemkomst Center
202 1st Ave N, Moorhead
62 | NOVEMBER 2018 | FARGOMONTHLY.COM
Saturday, Nov 17 from 9 a.m. to 9 p.m.
bigbluecouchcoaching.com Courtyard by Marriott
1080 28th Ave S, Moorhead
Cirque Musica Holiday Presents Wonderland Saturday, Nov 24 at 7 p.m.
Cirque Musica Holiday presents Wonderland. scheelsarena.com Scheels Arena
5225 31st Ave S, Fargo
Cheesin' for a Reason
Friday, Nov 30 from 6 p.m. to 10 p.m.
Kick off the holiday season with the FM area's most exciting new event, with proceeds benefiting Great Plains Food Bank. Eight incredibly rare specialty cheeses will be paired with a variety of wines, beers and cocktails to perfectly compliment one another. Yum!
CHRISTMAS MARKET AT THE PINES
chefstablefargo.com Chef's Table Catering
Friday, Nov 30 - Saturday, Dec 1
670 4th Ave. N, Fargo
Previously called "A Vintage Christmas" and held at the fairgrounds, this event is now called Christmas Market at The Pines. Enjoy a beautifully curated shopping and social event at the hottest new wedding venue in the FM area. iloveecochic.com The Pines Venue
4487 165th Ave SE, Davenport
It's A Wonderful Night
FM Holiday Maker's Market
West Acres Mall is hosting its 20th anniversary It's a Wonderful Night shopping extravaganza! Kick off your holiday gift-buying with exclusive savings from West Acres merchants. Tickets run at $5/person (6 and under, free) and are available at West Acres or participating organizations. These ticket sales benefit local fundraising organizations.
Come celebrate Small Business Saturday in Fargo and spend the day shopping downtown to support your favorite local businesses! The Holiday Maker's Market will be set up at 216 Broadway for a one day pop-up holiday shopping event on Small Business Saturday. When shopping for gifts, you might as well shop local!
Sunday, Nov 18 from 6 p.m. to 9 p.m.
westacres.com/iwn West Acres Mall
3902 13th Ave S, Fargo
Saturday, Nov 24 from 9 a.m. to 5 p.m.
Y94 Presents: Peppa Pig Live! Friday, Nov 30 at 6 p.m.
Peppa Pig is hitting the road and coming to Fargo for her all new theatrical tour, Peppa Pig’s Surprise! The brand new production features Peppa, George, and all their friends in an all-singing, all-dancing adventure full of songs, games and surprises. jadepresents.com Fargo Civic Center
207 4th St N, Fargo
Search "FM Holiday Maker's Market" on Facebook
216 Broadway N, Fargo
63
LISTEN TO THE
MUSIC
STAY ON THE SCENE WITH OUR GUIDE TO FARGO-MOORHEAD’S LOCAL MUSIC.
NOVEMBER 1ST - 4TH
THURSDAY, NOVEMBER 1 CropDusters Acoustic - JC Chumley's Kathie Brekke and the 42nd Street Jazz Band - Delta Rick Adams - blvd Pub Some Shitty Cover Band - The Windbreak FRIDAY, NOVEMBER 2 Uptown Live - Pickled Parrot Sidewinder - Shotgun Sally's Some Shitty Cover Band - The Windbreak Sub:Culture - The Aquarium Richard Freeman - Alibi Lounge Common Ground Company Dempsey's Public House
64 | NOVEMBER 2018 | FARGOMONTHLY.COM
SATURDAY NOVEMBER 3 Uptown Live - Pickled Parrot Tripwire - Shotgun Sally's Q5 Band - JC Chumley's Steele River Band - The Windbreak Knowledj w/ DJ Donny Dahl and KC Vine - The Aquarium Heart and Soul - Dempsey's Public House SUNDAY, NOVEMBER 4 Open Mic Night w/ Jam Band - The Windbreak That 1 Guy - The Aquarium
NOVEMBER 5TH - 11TH
WEDNESDAY, NOVEMBER 7 Girls Night Out- The Windbreak Sub:Culture - The Aquarium THURSDAY, NOVEMBER 8 Whiskey Sam Acoustic - JC Chumley's The David Ferreira Trio - Delta Rhyme or Reason - The Windbreak KRFF Benefit Show - The Aquarium FRIDAY, NOVEMBER 9 Low Standards - Pickled Parrot Brat Pack Radio - Shotgun Sally's Rhyme or Reason - The Windbreak Heatbox w/ The Dank & TRebellion The Aquarium The Brave - Alibi Lounge Poitin - Dempsey's Public House
SATURDAY NOVEMBER 10 Redline - Pickled Parrot Brat Pack Radio - Shotgun Sally's Pop Rocks - The Windbreak Super Happy Funtime Burlesque - The Aquarium Someday Heroes - Dempsey's Public House SUNDAY, NOVEMBER 11 Open Mic Night w/ Jam Band - The Windbreak
NOVEMBER 12TH - 18TH TUESDAY, NOVEMBER 13 The Shaky Calls w/ Windsor Diets, Stovepipes and Gadzooks - The Aquarium WEDNESDAY, NOVEMBER 14 Sub:Culture: The Widdler + Pushloop w/ New Reign and Kid-O - The Aquarium Bathtub Cig w/ GALS, The Electric Blankets and Polly the Panelist Dempsey's Public House THURSDAY, NOVEMBER 15 Mike Morse Acoustic- JC Chumley's Kathie Brekke and the 42nd Street Jazz Band - Delta October Road - The Windbreak Cold Sweat: LIVE! w/ Jantzonia, Ceesaw and Dane Huotari - The Aquarium FRIDAY, NOVEMBER 16 Helena Handbasket - Pickled Parrot Judd Hoos - Shotgun Sally's Kathie Brekke Duo - Rosey’s Bistro October Road - The Windbreak
Front Street Taproom Victor Shores w/ Go Murphy, SuperCruiser and Free Truman - The Aquarium Shaun Mitzel "Mitzelpalooza"- Alibi Lounge Mae Simpson Band - Dempsey's Public House SATURDAY NOVEMBER 17 Helena Handbasket - Pickled Parrot 24 Seven - Shotgun Sally's Downtown Sound - JC Chumley's Good For Gary - The Windbreak The Human Element - The Aquarium Stovepipes - Dempsey's Public House SUNDAY, NOVEMBER 18 Open Mic Night w/ Jam Band - The Windbreak
NOVEMBER 19TH - 25TH WEDNESDAY, NOVEMBER 21 Face For Radio - Shotgun Sally's Tripwire - The Windbreak Sub:Culture - The Aquarium BOOTS - Dempsey's Public House THURSDAY, NOVEMBER 22 Rick Adams Acoustic- JC Chumley's Slamabama - The Windbreak FRIDAY, NOVEMBER 23 Frost Fire - Pickled Parrot Boomtown- Shotgun Sally's Slamabama - The Windbreak Brutalur CD Release w/ Gorgatron, Towering Abomination and Pisstory The Aquarium The Shuttles - Dempsey's Public House
65
SATURDAY NOVEMBER 24 Frost Fire - Pickled Parrot Skyline - Shotgun Sally's 32 Below - The Windbreak Chastity w/ Baltic to Boardwalk, Wild Amphora - The Aquarium Lucy Luxe w/ Kid-O, Lick Narson - The Aquarium The Deadbeats- Dempsey's Public House SUNDAY, NOVEMBER 25 Jake The Snake - The Windbreak Look Vibrant w/ Many Months Left, SuperCruiser, Parliament Lite - The Aquarium
NOVEMBER 26TH - 30TH WEDNESDAY, NOVEMBER 28 Sub:Culture - The Aquarium THURSDAY, NOVEMBER 29 Terry Mackner Acoustic - JC Chumley's Kathie Brekke and the 42nd Street Jazz Band - Delta Nick Hickman - The Windbreak Bad Bad Hats - The Aquarium FRIDAY, NOVEMBER 30 Downtown Sound - Pickled Parrot IV Play- Shotgun Sally's Nick Hickman - The Windbreak Blue English- Alibi Lounge Poitin - Dempsey's Public House
LOCALMUSICVENUES THE AQUARIUM
HOLIDAY INN
LUCKY'S 13 PUB
BAR NINE
THE HODO LOUNGE
RICK'S
BLVD PUB
J.C. CHUMLEYS
SHOTGUN SALLY’S
DEMPSEY’S
JUNKYARD BREWING COMPANY
SPECK'S
226 Broadway N, 2nd Floor, Fargo 1405 Prairie Pkwy, West Fargo 3147 Bluestem Dr, West Fargo 226 Broadway N, Fargo
FRONT STREET TAPROOM 614 Main Ave., Fargo
66 | NOVEMBER 2018 | FARGOMONTHLY.COM
3803 13th Ave. S, Fargo 101 Broadway N, Fargo
1608 Main Ave, Moorhead 1416 1st Ave. N, Moorhead
4301 17th Ave. S, Fargo 2721 Main Ave, Fargo 1515 42nd St. S, Fargo 2611 Main Ave, Fargo
THE WINDBREAK 3150 39th St. S, Fargo
67
7 p.m.
52 Broadway N, Fargo
Fort Noks Bar of Gold
7:30 p.m.
1340 21st Ave. S, Fargo
The Alibi Lounge
8:30 p.m.
606 Main Ave., Fargo
Rhombus Guys Pizza
8 p.m.
404 4th Ave. N, Fargo
Sidestreet Grille & Pub
8 p.m.
675 13th Ave. E, West Fargo
Three Lyons Pub
MONDAYS
7 p.m.
1405 Prairie Parkway, West Fargo
Bar Nine
7 p.m.
614 Main Ave., Fargo
Front Street Taproom
8 p.m.
612 1st Ave. N, Fargo
Pounds
7 p.m.
1710 Center Ave. E, Dilworth
Red Hen Taphouse
7 p.m.
4474 23rd Ave. S, Fargo
Prairie Brothers Brewing Co.
8 p.m.
103 Main Ave. W, West Fargo
Town Hall Bar
8 p.m.
4445 17th Ave. S, Fargo
Fargo Brewing Ale House
7 p.m.
1414 12th Ave. N, Fargo
Herd & Horns
7 p.m.
701 Main Ave. E, West Fargo
Work Zone
7:30 p.m.
7 p.m.
221 Sheyenne St., West Fargo
The Silver Dollar Bar & The Flying Pig Grill
8 p.m.
Pepper's Sports Cafe
2510 University Drive S, Fargo
8:30 p.m.
Hooligan's Bar & Grill
3330 Sheyenne St., West Fargo
7 p.m.
3140 Bluestem Drive #105, West Fargo
Flatland Brewery
7 p.m.
202 Broadway N, Fargo
VFW: Downtown Fargo
9 p.m.
Labby's Grill & Bar
1100 19th Ave. N, Fargo
7 p.m.
610 University Drive N, Fargo
Fargo Brewing Company
7 p.m.
Dave's Southside Tap
803 Belsly Blvd., Moorhead
7 p.m.
325 10th St. N, Fargo
Bomb Shelter
8 p.m.
1608 Main Ave., Moorhead
JC Chumley's
8 p.m.
630 1st Ave. N, Fargo
Drekker Brewing Company
Fargo Billiards and Gastropub 3234 43rd St. S, Fargo
WEDNESDAYS
TUESDAYS
N OVEM BER T R IVIA
7:30 p.m.
Rosey's Bistro
212 Broadway N, Fargo
8:30 p.m.
OB Sports Zone
22 Broadway N, Fargo
8 p.m.
6-8 p.m.
Dempsey's
226 Broadway N, Fargo
8 p.m.
The Bowler
2630 University Drive S, Fargo
7:30 p.m.
420 Center Ave., Moorhead
Vic's Bar & Grill
Three Lyons Pub
675 13th Ave. E, West Fargo
FRIDAYS
THURSDAYS
TEST YOUR KNOWLEDGE WITH GENERAL OR THEMED TRIVIA AT SOME OF YOUR FAVORITE AREA BARS AND RESTAURANTS.
DRINKSPECIALS FARGO
CHECK OUT OUR GUIDE TO LOCAL DRINK SPECIALS! FOR A MORE IN-DEPTH LISTING, VISIT FARGOMONTHLY.COM
MONDAY
TUESDAY
WEDNESDAY
THURSDAY
FRIDAY
SATURDAY
SUNDAY
Acapulco 1150 36th St. S, Fargo2
Alibi Lounge and Casino 1340 21st Ave S, Fargo
522 Broadway N, Fargo
pmmidnight
2-for-1 domestic bottles, Jack & Jack Honey 8pm-midnight
7-9pm: $7 all you can drink, 9-11pm: $2.50 tall taps, teas, Morgans & bomb shots
7-9pm: 79-centers
8am-Noon: $1 off Bloody Mary’s & Caesars, 8pm-Close: $1 off Crown Royal & Tito’s
Sunday Funday (12pm2am): $1.00 Off All Drinks In Your Chub's Gear
The Bismarck Tavern
* This is not a full list of specials. Specials subject to change. For updated and entire list of specials, go fargomonthly.com.
The Box 1025 38th St. SW, Fargo (Inside the Fargo Inn & Suites)
69close.. 1/2 price bottles of wine | NOVEMBER
Big Mug Night 8-close: $3.95 32 oz domestic refills, $7.95 premium well drinks. Happy Hour 3-7pm: $2.95 premium well drinks, domestic taps & bottled beer 4301 17th Ave. S, Fargo
$2.50 short domestic beers
3pm-close: 1/2 Price Margaritas & $3.00 Coronas & DosEquis Ambar
Happy Hour all day, $1.25 off all drinks and $3 MimosClose
2-4-$1s Single Shot Drinks, Taps and Teas 10 pmClose
O’Kelly’s 3800 Main Ave., Fargo
7-9pm: Pay The Day Tap Beer & 9-11pm: $2.75 OB Beers, Booze & Bombs
7-9pm: $1 You Call It’s & 9-11pm: $2.75 OB Beers, Booze & Bombs
4-10pm: Half Price)
Old Broadway City Club 22 Broadway N, Fargo Old Broadway Grill 22 Broadway N, Fargo 3-6pm: $2 rail and call drinks, $2
OB Sport Zone select tap & bottled 22 Broadway N, beer and $4 house wines & $5.95 Fargo Domestic Pitchers, 6-10pm
$2 rail and call drinks, $2 select tap & bottled beer and $4 house wines
Pickled Parrot 505 3rd Ave. N, Fargo
72 | NOVEMBER 2018 | FARGOMONTHLY.COM
Happy Hour all day
MONDAY
TUESDAY
WEDNESDAY
THURSDAY
FRIDAY
SATURDAY
SUNDAY
Porter Creek Hardwood Grill 1 555 44th St. S, Fargo
Half price draft beer 3pm-close, Happy Hour 3-6pm and 9pm-close: $1 off cocktails, beer and wine
Half price bottles of wine 3pm-close, Happy Hour 3-6pm and 9pm-close: $1 off cocktails, beer and wine
Happy Hour 3-6pm and 9pm-close: $1 off cocktails, beer and wine
Half price appetizers 4-6pm and 9-11pm; $1 off beer, well and wine drinks
Half price appetizers 4-6pm and 9-11pm; $1 off beer, well and wine drinks
Half price appetizers 4-6pm and 9-11pm; $1 off beer, well and wine drinks and half price select bottles of wine and $2 off glass of wine
Half price appetizers 4-6pm and 9-11pm; $1 off beer, well and wine drinks
Rhombus Guys 606 Main Ave., Fargo
Happy Hour 3-6pm and 10pmclose: close
$4 pints of Rhombus beer starting at 9pm, Happy Hour 3-6pm and 10pmclose
$3 Deep Eddy Vodka starting at 8pm, Happy Hour 3-6pm and 10pmclose
oz. domestic draws all day
$2.50 Domestic Bottles all day; 9pm – 1am Late Night Happy Hour 2-for-1 Drinks
$2.50 Captain Morgan and Windsor all day; 9 pm – 1 am $3 PBR Pounders
$3 Rooter’s Rootbeers-7pm: $1 off all drinks
$3.30 Deep Eddy Vodka, $3.85 Jack Daniels, Happy Hour open-7pm: $1 off all drinks
$3.25 domestic bottles; $3.85 Icehole, Fireball and Dr. McGillicuddy's, Happy Hour open-7
74 | NOVEMBER 2018 | FARGOMONTHLY.COM
Half price appetizers 4-6pm and 9-11pm; $1 off beer, well and wine drinks
MONDAY
TUESDAY
WEDNESDAY
THURSDAY
FRIDAY
SATURDAY
SUNDAY
Sidestreet Grille & Pub 404 4th Ave. N, Fargo
pm
Slammer’s Sports Bar & Grill 707 28th Ave. N, Fargo
$5 sparkling wines, $2 off everything 3-6pm, half price beer and wine after 9pm
9pm-close: half off all beer, glass wine, single shot well pours
9pm-close: half off all beer, glass wine, single shot well pours
Speck’s Bar 2611 Main Ave., Fargo Spirits Lounge 3803 13th Ave. half price bottles of wine, $2 off everything 3-6pm, half price whiskey and gin after 9pm
$3 Captain Morgan
$6 domestic pitchers
$3 Windsor
$3 domestic pounders and bottles
$3 teas
Happy Hour 11am-5
9-10pm: $1 drinks, 10-11pm: $2 drinks
9-11pm: $2 drinks and bomb shots
9pm-midnight: $3 drinks and 2-for-1
Happy Hour all day
75
MONDAY
TUESDAY
WEDNESDAY
THURSDAY
FRIDAY
SATURDAY
SUNDAY
Bar Nine 1405 Prairie Pkwy., West Fargo
4-6pm: $1 off taps, apps, wells, & domestic bottles & 9pm-12am: $1 off Domestic Mugs & Stoli
4-6pm: $1 off taps, apps, wells, & domestic bottles & 9-12am: $1 off All Taps, Bottles & Pounders
4-6pm: $1 off taps, apps, wells, & domestic bottles & 9pm-12am: $1.50 off all Beer Mugs
4-6pm: $1 off taps, apps, wells, & domestic bottles & 9pm-12am: $1 off Domestic Mugs & Jameson
4-6pm: $1 off taps, apps, wells, & domestic bottles & 9pm-12am: $1 off Captain Morgan & Bacardi
9pm-12am: $1 off Tito's & Deep Eddy
All day: $8 Domestic Pitchers & $1 off Fireball & Iceholes
Gameday specials: free chili bar, $3 PBR and Busch Lite pounders, happy hour 1 hr before game time
Happy Hour all day: $1 off talls, wells, and glasses of wine, Server Industry Day: $1 off all drinks with Server Training card, blvd Apparel Day: $1 off all drinks while wearing blvd Gear (max of $2 off)call Casesars and $2.75 Fireball shots 8pm-close
$3 PBR pounders and $2 off all beer pitchers and $4.25 Bloody Marys and Caesar’s all day
WEST FARGO
* This is not a full list of specials. Specials subject to change. For updated and entire list of specials, go fargomonthly.com.
76 | NOVEMBER 2018 | FARGOMONTHLY.COM
MONDAY
TUESDAY
WEDNESDAY
THURSDAY
FRIDAY
SATURDAY
SUNDAY
Town Hall Bar 103 Main Ave. W, West Fargo
$3 Captain Morgan, $3.50 Crown Royal & Washington
Half price bottles of wine, 3-6pm and 10pm-1pm-6:30pm$2.50 Domestic Bottles & Wells, 50 Cents off all other drinks "MargaritaMonday" 6pm10pm: strawberry or lime margaritas, $3 well or $5 premium; 8pm-Midnight: $4 Busch Light Mugs, $5 (All Other) Domestic Mugs
Happy Hour: 4pm-6:30pm$2.50 Domestic Bottles & Wells, 50 Cents off all other drinks. "Happy Hour All Day", 11amMidnight: $2.50 Domestic Bottles & Wells
Happy Hour: 4pm-6:30pm$2.50 Domestic Bottles & Wells, 50 Cents off all other drinks. 8pm-Midnight: $4 Busch Light Mug Fills, $5 (All-10pm: $3 Domestic Bottles, $3 Captain Morgan
11am-4pm: $2 Mimosas, $5 Bloody Mary's & Bloody Caesars
$5 Bloody Mary's & Bloody Caesars All Daypm-midnight
-youpm-midnight
pm-midnight
77
THELASTPAGE
Creative Mornings:
Get Up and Get Inspired
T's Ashley Morken and Appareo's.
PHOTO BY J Alan Paul Photography
FIND CREATIVE MORNINGS
?
facebook.com/pg/creativemorningsfargo
creativemornings.com/cities/far
@CM_Fargo
The Last Page is a space to highlight community members of all ages who are helping to create the culture in the Fargo-Moorhead area, making it such a wonderful place to live. If you know someone who is making a difference — maybe through their art, volunteering or just being a good person — email fargomonthly@spotlightmediafargo.com or reach out to us on Twitter and Facebook and let us know. 79
Just because the weather is sickening, doesn't mean your body should take a hit as well. We tested out some fun, alternative workouts throug...
Published on Nov 1, 2018
Just because the weather is sickening, doesn't mean your body should take a hit as well. We tested out some fun, alternative workouts throug... | https://issuu.com/fmspotlight/docs/fm_nov18_final | CC-MAIN-2020-29 | refinedweb | 16,093 | 71.65 |
There.
In the spring boot application add the following dependency in order to include the Spring WP-API client.
<dependency> <groupId>org.kamranzafar.spring.wpapi</groupId> <artifactId>spring-wpapi-client</artifactId> <version>0.1</version> </dependency>
Below is a sample configuration we need in the application.properties file, so that we can connect our Spring Boot application to our WordPress site.
wpapi.host=yoursite.com wpapi.port=443 # Optional, default is 80 wpapi.https=true # Optional, default is false
The Spring WP-API client needs the RestTemplate so lets create a bean in our Application and autowire the Spring client. We also need to add component scan annotation so that Spring finds and autowires all the required dependencies.
@SpringBootApplication @ComponentScan("org.kamranzafar.spring.wpapi") public class Application implements CommandLineRunner { public static void main(String args[]) { SpringApplication.run(Application.class); } @Autowired private WpApiClient wpApiClient; @Bean public RestTemplate restTemplate() { return new RestTemplate(); } }
Now our spring boot application is all setup to connect to out WordPress site in order to retrieve and create content. So lets try and lookup all the posts having the keyword “Spring”, below is how we can do this.
Map<String, String> params = new HashMap<>(); params.put("search", "Spring"); params.put("per_page", "2"); // results per page params.put("page", "1"); // current page // See WP-API Documentation more parameters // Post[] posts = wpApiClient.getPostService().getAll(params); for (Post p : posts) { log.info("Post: " + p.getId()); log.info("" + p.getContent()); }.
2 Comments
Hi Kamran,
Thank you for this article and sources’s project. Very helpull and usefull.
I’ve installed plugins in wordpress :
– WP REST API (to accept rest call)
– VA Simple Basic Auth
– WP OAuth Server
But, i still have 403 response (access denied)
What’s type of authentification do you use ?
How can i set it correctly in wordpress ? is it a problem of .htaccess ?
How can i log the requests in the project ?
Thank for your response.
[…] that uses WP REST API plugin to fetch content from WordPress. You might find it useful. Here is blog post on how to integrate Spring Boot and […] | https://kamranzafar.org/2016/08/08/spring-boot-and-wordpress-integration/?replytocom=35 | CC-MAIN-2021-43 | refinedweb | 345 | 51.04 |
Provided by: manpages-dev_3.54-1ubuntu1_all
NAME
mount - mount filesystem
SYNOPSIS
#include <sys/mount.h> int mount(const char *source, const char *target, const char *filesystemtype, unsigned long mountflags, const void *data);
DESCRIPTION
mount() attaches the filesystem specified by source (which is often a device name, but can also be a directory name or a dummy) to the directory specified by target."). in the low order 16 bits: MS_BIND (Linux 2.4 onward) Perform a bind mount, making a file or a directory subtree visible at another point within a filesystem. Bind mounts may cross filesystem boundaries and span chroot(2) jails. The filesystemtype and data arguments are ignored. Up until Linux 2.6.26, mountflags was also ignored (the bind mount has the same mount options as the underlying mount point). MS_DIRSYNC (since Linux 2.5.19) Make directory changes on this filesystem synchronous. (This property can be obtained for individual directories or subtrees using chattr(1).) MS_MANDLOCK Permit mandatory locking on files in this filesystem. when executing programs from this filesystem. MS_RDONLY Mount filesystem read-only._REMOUNT Remount an existing mount. This allows you to change the mountflags and data of an existing mount without having to unmount and remount the filesystem. target should be the same value specified in the initial mount() call; source and filesystemtype are ignored.. The data argument is interpreted by the different filesystems. Typically it is a string of comma-separated options understood by this filesystem. See mount(8) for details of the options available for each filesystem type.BUSY source is already mounted. Or, it cannot be remounted read-only, because it still holds files open for writing. Or, it '/'. ELOOP Too many links.
VERSIONS
The definitions of MS_DIRSYNC, MS_MOVE, MS_REC, MS_RELATIME, and MS_STRICTATIME were added to glibc headers in version 2.12.
CONFORMING TO
This function is Linux-specific and should not be used in programs intended to be portable.
NOTES.
SEE ALSO
umount(2), namespaces(7), path_resolution(7), mount(8), umount(8)
COLOPHON
This page is part of release 3.54 of the Linux man-pages project. A description of the project, and information about reporting bugs, can be found at. | https://manpages.ubuntu.com/manpages/trusty/man2/mount.2.html | CC-MAIN-2020-40 | refinedweb | 361 | 59.8 |
I received an odd specification request recently, something that actually goes against the statelessness of the web in general. You see, the users in question often have customer phone calls interrupt their work in the application, and as such they often have to put down what they are doing and return later. The current policy does not allow multiple instances of the web application to be running, which means they have to cancel whatever they are doing, and go help the customer, only to return and start from square one.
One of the things I love about ASP .NET, is that I have yet to encounter any sort of far fetched or odd request that I haven't been able to accomplish, so I put my mind to the task. There has to be a way to retrieve all the values currently on a form, since a postback does this activity for you, as well as mimic what a postback does to take the returned data. If I could get my hands on that data, I could potentially restore the entire form!
The answer lies in the Request.Form namevaluecollection. This collection happens to have all the control ids and the values that have returned from the post back. Armed with this knowledge, all I had to do was collect some additional information about the page and then give the user access to it.
What I decided on was to create a snapshot class as follows:
public class Snapshot { public Snapshot(string Url, string Text, NameValueCollection FormData) { _url = Url; _text = Text; _formData = FormData; } private string _url = ""; private string _text = ""; private NameValueCollection _formData; public string Text { get { return _text; } set { _text = value; } }
public NameValueCollection FormData { get { return _formData; } set { _formData = value; } } public string Url { get { return _url; } set { _url = value; } } }
As you can see, I'm storing the Request.Form data, the url that the form came from, and a text key that will represent this snapshot to the user. For simplicity, we're going to simply stick this data in session and not allow multiple snapshots of the same page, so no unique key is needed at this time.
The next thing I wanted to do was create a user control that would use a repeater to list all the snapshots from a user's session which are being stored as a generic list. Being a css/xhtml convert, I like the repeater since I can specify specifically the html format and thus create a nice styleable linked list for this control:
<div class="panelItem"> <asp:Label<br /> <asp:Repeater <HeaderTemplate> <ul id="ulTaskList" class="LinkList"> </HeaderTemplate> <ItemTemplate> <li> <a href='<%# PrepareTaskURL(DataBinder.Eval(Container.DataItem, "Url"), DataBinder.Eval(Container.DataItem, "Text")) %>' class="ListLink"> <%# DataBinder.Eval(Container.DataItem, "Text") %> </a> </li> </ItemTemplate> <FooterTemplate> </ul> </FooterTemplate> </asp:Repeater> <br /> <asp:LinkButton</div>
This control is meant to go in my masterpage in the user tools panelbar area (Thank you Telerik). You will notice that I have a button to persist a form as well as some back end code to parse snapshots and display url's properly. I'm going to pass a querystring value with the task name in the PrepareTaskURL method call. In addition, we need to make this user control intelligent enough to only show the persist form button if it detects a page that is able to be persisted. To address this, we will create a PersistedPage base class inheriting from my standard BasePage that all my pages use which contains some useful application wide page functions.:
protected void Page_Load(object sender, EventArgs e) { BindTasks(((BasePage)Page).RetrieveSnapshots()); if (Page is PersistedPage) btnPersist.Visible = true; } public void BindTasks(List<Snapshot> Tasks) { rprTaskList.DataSource = Tasks; rprTaskList.DataBind(); if(Tasks.Count > 0) lblEmptyMessage.Visible = false; } protected string PrepareTaskURL(object url, object snapshotName) { if (url.ToString().Contains("?")) return url + "&SnapshotName=" + snapshotName; return url + "?SnapshotName=" + snapshotName; } protected void btnPersist_Click(object sender, EventArgs e) { if (Page is PersistedPage) { ((PersistedPage)Page).PersistForm(); } }}
Notice the code that detects whether the current page is a PersistedPage to ensure that only these pages are able to be snapshotted. Also note the code for retrieve snapshots has been omitted. All it does is check the session for a generic list of snapshots.
Now onto the fun part, the PersistedPage class. Recall above, we made the user control smart enough to realize that when it is on a PersistedPage, it can enable the snapshot process which calls the PersistForm() method. If a persisted page finds the text of a snapshot (which is set by the abstract getformname method) in the querystring it attempts to look it up in the generic list and pull the snapshot record. It then parses the namevalue collection of form data and repopulates the form as it was when the snapshot was taken!
public abstract class PersistedPage : BasePage{ /// <summary> /// Page persistance module for task handling /// </summary> public void PersistForm() { List<Snapshot> snapshots = RetrieveSnapshots(); snapshots.Add(new Snapshot(Request.Url.PathAndQuery, GetFormName(), Request.Form)); Session["TaskList"] = snapshots; } private Snapshot _currentSnapshot;
/// <summary> /// Restore form values from a snapshot /// </summary> /// <param name="snapshot"></param> public void LoadFormFromSnapshot(Snapshot snapshot) {
_currentSnapshot = snapshot; ArrayList modifiedControls = new ArrayList(); LoadPostData(this, modifiedControls); // Raise PostDataChanged event on all modified controls: foreach (IPostBackDataHandler control in modifiedControls) control.RaisePostDataChangedEvent(); } /// <summary> /// This method performs depth-first recursion on /// all controls contained in the specified control, /// calling the framework's LoadPostData on each and /// adding those modified to the modifiedControls list. /// </summary> private void LoadPostData(Control control, ArrayList modifiedControls) { // Perform recursion of child controls: foreach (Control childControl in control.Controls) LoadPostData(childControl, modifiedControls); // Load the post data for this control: if (control is IPostBackDataHandler) { // Get the value of the control's name attribute, // which is the GroupName of radio buttons, // or the same as the UniqueID // attribute for all other controls: string nameAttribute = (control is RadioButton) ? ((RadioButton)control).GroupName : control.UniqueID; if (control is CheckBoxList) { // CheckBoxLists also require special handling: int i = 0;
foreach (ListItem listItem in ((ListControl)control).Items) if (_currentSnapshot.FormData[nameAttribute + ':' + (i++)] != null) { listItem.Selected = true; modifiedControls.Add(control); } } else { // Don't process this control if its key // isn't in the PostData, as the // LoadPostData implementation of some controls // throws an exception in this case. if (_currentSnapshot.FormData[nameAttribute] == null) return; // Call the framework's LoadPostData on this control // using the name attribute as the post data key: if (((IPostBackDataHandler)control).LoadPostData( nameAttribute, _currentSnapshot.FormData)) modifiedControls.Add(control); } } } protected void Page_Load(object sender, EventArgs e) { if (!Page.IsPostBack) { string snapshotName = Request.QueryString["SnapshotName"]; if (snapshotName != null) { List<Snapshot> snapshots = RetrieveSnapshots(); foreach (Snapshot snapshot in snapshots) { if (snapshot.Text == snapshotName) { LoadFormFromSnapshot(snapshot); snapshots.Remove(snapshot); break; } } } } } public abstract string GetFormName();
So that is how it all works. Please note the following however:
[Advertisement]
Very Nice. That's a pretty slick solution. I will have to file this one away for future reference.
Have you ever needed to save a webform for later use? If so, Eric Wise has come up with a really...
Nice technical solution.
That said, IMHO, if you have a system that has users with this specific use case, why not take the approach that MS Outlook does with drafts? Add flags to your data structures to indicate whether or not the data has been explicitly submitted by the user. In the mean time, set up an auto-save feature like Outlook does with your emails (30, 60, 120, 300 seconds, it's up to you as to what makes sense). Also add one or more "Drafts" folders where appropriate to accomodate the user's work habits, business rules, or use cases, allowing them to even explicitly make use of draft business objects (i.e., ones that have yet to be explictly committed to the system). Finally, you'll also quickly realize that the validation rules for a "draft" are significantly less stringent than for a "real" object. For example, you can click on "New Message" in Outlook and immediately save it to your "Drafts" folder without any complaint from Outlook. But if you try to immediately send it, Outlook won't let you without at least entering a recipient. Don't make your solution any more stringent, as users simply won't use it if it is.
Absolutely that would be a more robust solution in the future. The customer need in this case is pretty basic and simple plus I wasn't sure how well this would work until I tried it. More persisted solutions like in the database are certainly possible though, we'll see if I ever find the time or demand to enhance it.
Hi nice one. I was trying to implement the same in my application. Can you please put the source code for | http://codebetter.com/blogs/eric.wise/archive/2006/09/24/Saving-a-webform-for-later.aspx | crawl-002 | refinedweb | 1,450 | 53.51 |
this Pointer in C++
In this tutorial, we will briefly discuss the ‘this’ pointer in C++.
The ‘this’ pointer is a special pointer through which each object of a class has access to its own address.
Why do we use ‘this’ pointer?
There may be one copy of each class’s functionality, but there can be many objects of the same class. We use ‘this’ pointer to know which object’s data members to manipulate.
C++ uses a special keyword called this to represent an object that invokes a member function. For example, if an object O1 of a class invokes the function O1.input(), the function call will set the pointer this to the address of O1.
The ‘this’ pointer is passed as an implicit argument to all non-static member functions.
Uses of ‘this’ pointer in C++
- Returning an object.
one application of the ‘this’ pointer is that it returns the object it points to. For instance, the statement
return *this;
in a member function will return the object that invoked the function.
- Accessing an object’s data members.
We can use the ‘this’ pointer to implicitly or explicitly to enable a member function of the class to print its private data. The syntax looks somewhat like this:
cout<<"x= "<<x; //implicitly using the this function to access the value x cout<<"this->x= "<<this->x; //explicitly using this pointer to access member x.
- Distinguishing data members.
This unique pointer is used to distinguish local variables from parameters passed to a function.
Type of the ‘this’ pointer:
The type of the ‘this’ pointer depends on the type of object and whether the member function in which ‘this’ is used is declared const or not.
Sample program to demonstrate the use of ‘this’ pointer in C++:
#include<iostream> using namespace std; class stu { private: int rno; int marks; public: void get_det(int r,int m) { this->rno=r; this->marks=m; } void show_det() { cout<<"roll no. is: "<<rno<<endl; cout<<"marks are: "<<marks<<endl; cout<<"address of the current object is: "<<this; } }; int main() { stu student1; student1.get_det(21,89); student1.show_det(); return 0; }
The output will look like this:
roll no. is: 21 marks are: 89 address of the current object is: 0x6dfee8 Process returned 0 (0x0) execution time : 0.016 s Press any key to continue.
With this, we come to the end of this tutorial.
Also read: Inheritance in C++ | https://www.codespeedy.com/this-pointer-in-cpp/ | CC-MAIN-2020-50 | refinedweb | 404 | 73.07 |
Hey there,Today we are going to discuss about react file uploading.We MERN developers use
multer from our file uploading.But in some case when we are doing a demo project or practicing some thing then if i have to setup whole multer code base then it is horrible.For that today i am going to show you how can you upload a file using a react package called
react-file-base64.
Today we are going to build the following app
Now,at first setup out project
create a folder on Desktop and get init it
$ cd Desktop $ mkdir react-file-upload $ cd react-file-upload
and then create brand new react project with typescript
$ npx create-react-app ./ --template typescript
Now clean up all unnecessary files and get started
At the top of
App.tsx file import
import FileBase from 'react-file-base64'
Now add some jsx to out components
<form onSubmit={handleSubmit}> <FileBase/> <button type="submit">Send</button> <div> <img src='' alt="react project" /> </div> </form>
And add some
state and change handler for controlling the form
type State = { image: string; }; const [data, setData] = useState<State>({ image: "", }); const [image, setImage] = useState(""); const handleSubmit = (e: React.SyntheticEvent) => { e.preventDefault(); };
We have to give three props to our
FileBase Component they are
type,multiple,onDone.So,give them to FileBase
<FileBase type="file" multiple={false} onDone={({ base64 }: { base64: string }) => setData({ ...data, image: base64 }) } />
Here
onDone works same as
onChange.onDone receives a parameter which contains
base64.You should console log that parameter to see what the parameter contains.Now set
base64 to the state.
Now add console log the
data form
onSubmit handler
const handleSubmit = (e: React.SyntheticEvent) => { e.preventDefault(); console.log(data); };
Now if you select a photo and submit the form you should see something in the console.You should see and object containing something like this
you see the
image property contains something like string.This string goes into
src attribute of an
img element.
Now you can save this string to your database.So, you no longer need to store a lot of image in in folder just save this string.
In this application we are going to use this string to our img element
Change image elements src like this
<img src={image ? image : ""}
and set image string to image state from submit handler
const handleSubmit = (e: React.SyntheticEvent) => { e.preventDefault(); setImage(data.image); };
now go to your browser and try to upload images.
Thank you for being with me so long.See you.Bye!
Discussion (0) | https://practicaldev-herokuapp-com.global.ssl.fastly.net/suhakim/react-file-upload-4ak0 | CC-MAIN-2022-05 | refinedweb | 423 | 54.93 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.