
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
.
#include <fstream>
#include <iomanip>
#include <stdlib.h>
using namespace std;
typedef unsigned char BYTE;
typedef unsigned long DWORD;
void DumpMemory ( const BYTE* pMem, const size_t sz, const char* pFile) {
DWORD dw;
//
// Try to remove files that have the same name
//
_unlink ( pFile );
ofstream os;
os.open ( pFile );
os << setbase ( 16 );
//
// Write the data with a width of 40 columns
//
for ( dw = 1; dw <= sz; ++dw ) {
os << ( long) pMem [ dw ] << " ";
if ( !( dw % 40 ) ) os << endl;
}
os.close ();
}
int main () {
BYTE test [ 120 ];
for ( int i = 0; i < 120; ++i) test [ i ] = i;
DumpMemory ( test, 120, "memdump.txt" );
return 0;
}
The following code in Borland C++ Builder would access the memory by absolute address, but causes an Access Violation:
void __fastcall TForm1::Button1Click(TObje
{
int i;
register ax;
asm {
mov bx,0
mov es,bx
mov ax,[es:bx] <--- actually makes an addressing violation when attempt to read [0000:0000]
}
i=ax;
Edit1->Text=i;
}
This other also (try to) access directly the memory:
void __fastcall TForm1::Button1Click(TObje
{
int *p;
p = (int *)100;
Edit1->Text=*p;
}
Conclusion: In Windows, which is a protected operating system, you will need to write a real device driver, using the Microsoft DDK. Similar occurs to Linux.
What you can is only is get a byte inside a variable, for example:
char c = string[4];
Good times of the old DOS and Basic's PICK and POKE...
Jose
There is an API ReadProcessMemory().You can search it thru MSDN.
This function reads data from an area of memory.
aveo
We value your feedback.
Take our survey and automatically be enter to win anyone of the following:
Yeti Cooler, Amazon eGift Card, and Movie eGift Card!
#include <iostream>
#include <iomanip>
// print memory in hex and as strings
void dumpMemory(ostream& os, void* p, int nsiz)
{
os << hex << p << " " << dec << nsiz << endl;
unsigned char* pb = (unsigned char*)p;
for (int j = 0; j < nsiz; j+=16)
{
int jj;
for (jj = j; jj < j + 16 && jj < nsiz; jj++)
{
os << setw(2) << setfill('0') << hex << (unsigned int)pb[jj] << dec << ' ';
}
for (jj = j; jj < j + 16 && jj < nsiz; jj++)
{
if ((pb[jj] < ' ' || pb[jj] > '~') && pb[jj] != '|')
os << '.';
else
os << (char)pb[jj];
}
os << endl;
}
}
That can be used like that:
int main()
{
void* p = 0x06852410; // any valid memory address or pointer != NULL
dumpMemory(cout, p, 512); // use a multiple of 16 to get a proper output
return 0;
}
For output on file pass a ofstream object instead of cout. For output to Windows use a ostringstream object and put the contents of the stringstream string to a window using a monodistant font.
#include <sstream>
...
ostringstream oss;
dumpMemory(oss, p, 512); // use a multiple of 16 to get a proper output
...
LOGFONT lf = { 0 };
strcpy(lf.lfFaceName, "Courier");
lf.lfHeight = 100;
lf.lfPitchAndFamily = FIXED_PITCH;
HFONT hf = CreatePointFontIndirect(&l
SendMessage(hwnd, WM_SETFONT, (WPARAM)hf, 0)
SetWindowText(hwnd, oss.str().c_str());
Regards, Alex
Regards, Alex
very easy no need of any programming code .........ha ha
go to ur cmd prompt
1. type debug
2. then type -d 8000 80ff
3. displays ur memory
4. copy and save it in file
wowwwwwwww so easy ! curious whether this is what u need .
here i used 8000, 80ff as example u can give ur own address
A GUI debugger has some advantages over a commandline debugger that hardly can be compensated by a memory dump output.
It's 16 years ago I lastly used a commandline debugger. And I do not regret.
Regards, Alex
Random access to memory outside the addresses reserved by Windows for the program will be stoped by Windows, as an access violation.
If the objective is to watch the memory area occupied by a variable, it is trivial. I think what szcuny waits is a way of, given any valid address, say 00000010:00000100, get the values in a predifined range and show the contents of such memory space.
The only way I know is to write a low level program with freedom to access any memory address. This is why I pointed to the DDK - Device Drive Kit.
Jose
if starting the debugger from the commandline not passing an executable to debug, the addresses that could be dumped are *physical* memory addresses. If you got a pointer in your progrgram it's *virtual* memory mapped from the OS. So entering an address of your virtual memory to the debugger won't show you the contents you ainterested of. You either would need to recalculate the virtual address to a physical one - what might be difficult or impossible if the memory actually was swapped - or start the executable in question via the (commandline) debugger what is a different game either.
Note, the dump output function I posted above has an equivalent output to that of the debugger.
Regards, Alex
but when u need memory dump command line dump is suffient . i guess so :)
i also agree when u need mapped memory or paging, virtual memory etc ..... u cannot do command line
jose many thanks for support for my answer . i dunno whether i deserve it !
mmmmmmmmmmm? | https://www.experts-exchange.com/questions/21901440/memory-dump.html | CC-MAIN-2017-51 | refinedweb | 844 | 62.38 |
31 May 2011 17:26 [Source: ICIS news]
LONDON (ICIS)--Zaklady Azotowe Pulawy (ZAP) will push ahead with a plan to build a zloty (Zl) 3bn ($1.1bn, €750m) power plant having found a new joint-venture partner for the project, the Polish fertilizer, melamine and caprolactam (capro) producer said on Tuesday.
ZAP initially hoped to go ahead with a 50:50 venture to build a power or power-and-heat plant with Swedish energy producer Vattenfall in Pulawy, eastern ?xml:namespace>
“The fertilizer industry in the EU needs to undertake investment activities in energy supply,” ZAP CEO Pawel Jarczewski said.
“ZAP is aware that due to the rising costs of emissions in the EU it should look for long-term strategic solutions with a competitive advantage in the energy production field,” he added.
Under the original plan with Vattenfall, the power plant would have had a capacity of 1,400MW. ZAP said the new agreement with PGE is for a capacity of 840MW.
ZAP would consume 200MW of the generated electricity with the remainder sold through the national grid, the company said.
The project will be implemented from 2013 to 2016 via special-purpose vehicle Melamina III, while ZAP’s contribution to the project will be in the form of real estate on which the plant will be built, it added.
ZAP is located in Pulawy, with a melamine nameplate capacity of 96,000 tonnes/year.
($1 = Zl 2.79, €1 = Zl 3.98)
For more on melamine and cap | http://www.icis.com/Articles/2011/05/31/9464912/polands-zap-finds-new-partner-for-power-plant-project.html | CC-MAIN-2015-18 | refinedweb | 251 | 61.56 |
package org.springframework.scheduling.quartz does not exist
package org.springframework.scheduling.quartz does not exist Hi,
I am using Spring 4.1.1 in my web application and its giving following error:
error: package org.springframework.scheduling.quartz does not exist
What
package javax.ws.rs does not exist
package javax.ws.rs does not exist Hi,
Which jar file should I add to remove "package javax.ws.rs does not exist" error?
Thanks
package javax.validation does not exist
package javax.validation does not exist In my maven application I got following error while compiling the code:
package javax.validation does not exist
How to resolve the error?
Thanks
Hi,
You should include
Package does not exist.. - Java Beginners
Package does not exist.. Hi.. thanks for ur Answers friend..
I have completed the program quite now..
Still i have with Compilation error..
ERROR : javax.mail.*; ----> Package does not Exist..
Wat can i do now
|
Hibernate Tutorial |
Spring Framework Tutorial
| Struts Tutorial...
Tutorial | JAXB Tutorial
| Spring FrameWork
Tutorial | SOA &Web...;
|
Domain Registration
|
Business Package
|
Corporate Package
creating index for xml files - XML
record in each xml file)
{
if (new record already exist in index_output.xml(loop...creating index for xml files I would like to create an index file for xml files which exist in some directory.
Say, my xml file is like below
regarding header files - Spring
regarding header files i am working on linux platform. i a using spring framework 2.5.4.while comlinig the client program i.e from demo which given in tutorial.
error is these two package does not exist
import
Checking if a file or directory exist
Checking if a file or directory exist
In this section you will learn how to check whether a file or a directory exist
or not. The " java.io " package provide a method exist()
which return true or false. This method
Exception Spring framework - java.io.FileNotFoundException - Spring
be opened because it does not exist
java.io.FileNotFoundException: class path resource [spring-config-my-ui.xml] cannot be opened because it does not exist... Exception Spring framework - java.io.FileNotFoundException HI
Java error ArrayIndexOutofBoundsException
and trying to access the sixth array element which
does not exist... and printing the sixth element which does not exist. So, it will
throw... when accessing to an illegal array index.
The index is either greater
spring
spring package bean;
public interface AccountsDAOI{
double getBalance(int accno);
void setBalance(int accno,double amt);
}
//
package bean...){
return 1000.0;
}
}
//
package bean;
public class CheckMinBal{
public
Spring Constructor arg index
Constructor Arguments Index
In this example you will see how inject the arguments into your bean
according to the constructor argument index...://">
<bean id
import package.subpackage.* does not work
import package.subpackage.* does not work I have 3 class files.
A.java
B.java
C.java
Below is the code block
A.java:-
package com.test...()
{
System.out.println("funA");
}
}
B.java:-
package com.test;
public
index
Spring Framework Training - Spring
Spring Framework Training THinking of taking spring framework training from Intertech. Here's the class... does this give me what I need?
The package keyword
package if the Java source file does not include a package
statement...
The package keyword
The package in java programming language
is a keyword that is used to define
Index Out of Bound Exception
;
System.out.println("Execution does not reach here if there is a invalid index...
Index Out of Bound Exception
Index Out of Bound Exception are the Unchecked Exception
Determining if a File or Directory exist
does not exist : false
Download
this example...
Determining if a File or Directory Exist
...;or directory does not exist
System.out.println("
Questions on Spring - Spring
Questions on Spring 1> what is Spring Framework ? why does... is the AOP framework. While the Spring IoC container does not depend on AOP, meaning... in Spring ?
3> what is Spring - Aspect Oriented Programming,Please explain
Java file exist
;or Directory exist.");
}
else... checks whether the
file exists or not.
Output
File or Directory does
Spring
all, the application code does not depend on the Spring APIs unlike the EJB...Spring
Spring
Salient Features
Spring stresses the OO design issues rather than
Spring Security Authorized Access
Spring Security Authorized Access
In this section, you will learn about authorized access through Spring
Security.
EXAMPLE
Sometimes you need to secure... Spring Security. User needs to provide
correct login credential to view the page
Spring Security Logout
/spring-context-3.0.xsd">
<context:component-scan base-package="...Spring Security Logout
.style1 {
margin-left: 40px;
}
In this section, you will learn about adding logout in Spring Security
Application.
Before
Spring Date Property
Spring Date Property
Passing a date format in the bean property is not allowed... into the Date object.
Employee.java
package spring.date.property;
import...(String name) {
this.name = name;
}
}
Employee.java
package
What is Index?
What is Index? What is Index
Spring Framework 4.1 - First Release candidate available
2014.
Read more tutorials of Spring Framework at our Spring
Tutorials Index... Spring Framework 4.1 First Release candidate is available
It is a good news for the developers of Spring framework as the
Spring Framework 4.1
Spring Architecture
Spring Architecture
Spring is a light-weight framework that is used for the development of Enterprise-ready applications. The architecture of Spring forms... container.
Spring allows a programmer to use components/modules which
Spring Security Custom Error Message
/spring-context-3.0.xsd">
<context:component-scan base-package...Spring Security Custom Error Message
In this section, you will learn about Custom Error Message in Spring
Security.
Spring Security have predefined error. ... :
FileUploadController.java file
package example;
import
spring web
spring web Hi can you explain the flow of spring web programatically...;context:component-scan...
http
Spring - IoC
is:
------------------------
package beans;
import java.io.*;
import java.io.Serializable
Difference between Struts and Spring
tag Library while Spring does not.
5)Spring is loosely coupled while Struts... while Spring is light weight.
4)Struts supports tag Library while Spring does...)Struts supports tag Library while Spring does not.
5)Spring is loosely coupled
Spring 3 MVC Validation Example
Spring 3 MVC Validation Example
This tutorial shows you how to validate Spring 3 MVC based applications. In
Spring 3 MVC annotation based controller has... application we will be create a Validation form in Spring 3.0
What is Spring?
Spring ORM
The ORM package is related to the
database access...
applications.
Spring Core
The Core package is the most... What is Spring?
Security Customized Access Denied Page
Spring Security Customized Access Denied Page
In this section, you will learn about Customized Access Denied Page in Spring
Security.
Access denied page... related to this section is given below :
Example related to Spring Security
) Distributed Computing (Container managed RPC)
Spring does not attempt to do... is only a container. It does not
offer various special features as spring like...
SPRING Framework... AN
INTRODUCTION
Working With File,Java Input,Java Input Output,Java Inputstream,Java io
Tutorial,Java io package,Java io example
checks, the specified file "myfile.txt"
is exist or not. if it does... files using the File
class. This class is available in the java.lang
package...
to the existence of a corresponding file/directory. If the file exist, a program
can
Learn Spring Framework from where?
Learn Spring Framework from where? I want to learn the Spring... the documentation but it does not have the easy to learn examples. So, these are not good for beginners.
Could someone suggest me the best url to start learning the Spring
@Controller Annotation Example in Spring 3
the role of a
controller. Spring does not require you
to extend any controller...@Controller Annotation Example in Spring 3:
In this section we will see how we can create annoted controller class in
Spring 3. You can @Controller
Drop Index
Drop Index
Drop Index is used to remove one or more indexes from the current database.
Understand with Example
The Tutorial illustrate an example from Drop Index
java spring simple application
java spring simple application hai I have design a simple... for this I have added lib files also
StudentComponent.java:
package... StudentComponent() {
}
}
TestClient.java
package com.mazeed;
import
Spring Validation
Spring Validation
In this tutorial you will see an example of how to perform validation in
spring-core. The spring provide Validator interface....
Person.java
package com.roseindia;
public class Person {
private
Why to use Spring Framework?
not require the Spring dependency directly and does not directly
depend...: The Spring Framework
does not support the Interface Injection.
Aspect...Why to use Spring Framework in a web application?
In this article I
what is diffrence between the spring and ejb which is better for small application - Spring
support XA or distributed transactions whereas Spring does not have support...what is diffrence between the spring and ejb which is better for small application what is diffrence between the spring and ejb which is better
spring
spring sir how to access multiple jsp's in spring
Spring ResourceLoaderAware
Spring ResourceLoaderAware
We use the ResourceLoader when your application...
package com.roseindia.student.services;
import... resourceLoader.getResource(location);
}
}
AppMain.java
package
Java Spring Desktop application
Java Spring Desktop application Hi i am developing a desktop java spring application..It has many Jframes forms and classes...How to close one Jframe from another..Please tell...
First jframe
package desktopapplication2
spring
spring i am a beginner in java.. but i have to learn spring framework.. i know the core java concepts with some J2EE knowledge..can i learn spring without knowing anything about struts
net.roseindia.controller
This package contains controller class of Spring and Hibernate Jpa integration application
@Component Annotation in Spring, Spring Autoscan
@Component Annotation in Spring
In Spring normally if there is bean we need... can scan all your bean
through spring auto scan feature. The @Component... annotation tell to auto wire
the student DAO by type.
StudentDAO.java
package Security auto generated login to secure URL access
Spring Security auto generated login to secure URL access
In this section, you... using Spring Security.
The tools and technology used in this tutorial are given below :
jdk1.6.0_18
apache-tomcat-6.0.29
Eclipse 3.5.1
Spring
Spring Tutorial for Beginners
:
Spring
Tutorials: Index page of Spring Tutorials at Rose India...The Spring Framework is an open source Java platform through which...
for the Java platform.
Spring Framework was first written by Rod Johnson in his
The registerShutdownHook in spring
in spring
If you are using Spring IoC in non web application and want... in the
AbstractApplicationContext class.
AppMain.java
package com.roseindia.common;
import...://">
</beans>
Mysql Btree Index
Mysql Btree Index Mysql BTree Index
Which tree is implemented to btree index?
(Binary tree or Bplus tree or Bminus tree
ApplicationContextAware in spring
in spring
In this tutorial you will see and example of using....
StudentBean.java
package com.roseindia.common;
import...
package com.roseindia.common;
import
Spring CustomEditorConfigurer, Spring Custom Editor
Spring CustomEditorConfigurer
Passing a date format in the bean property... type is java.util.Date
Employee.java
package spring.date.property;
import... setName(String name) {
this.name = name;
}
}
AppMain.java
package
Spring Constructor Injection Example
Spring Constructor Injection Example
In Spring Framework the constructor...; An Example of Constructor Injection is
given below
StudentBean.java
package.../beans">
<
Spring Security Authorized Access Using Custom Login Form
Spring Security Authorized Access Using Custom Login Form
In this section, you will learn about authorized access using custom
login form in Spring... access by
providing customized Login form using Spring Security. User
z-index always on top
z-index always on top Hi,
How to make my div always on top using the z-index property?
Thanks
Hi,
You can use the following code:
.mydiv
{
z-index:9999;
}
Thanks
Spring Security Authorized Access with Customized Login from Database
Spring Security Authorized Access with Customized Login from Database... database using Spring Security.
Sometimes you need to secure your page from... stored in database table.
For Spring Security authorized access using auto
Spring Security customized login form to secure URL access
Spring Security customized login form to secure URL access
In this section, you will learn Spring Security custom login form to secure
URL access... URL access through auto generated Login
form using Spring Security
Advertisements
If you enjoyed this post then why not add us on Google+? Add us to your Circles | http://www.roseindia.net/tutorialhelp/comment/69476 | CC-MAIN-2015-35 | refinedweb | 2,066 | 51.65 |
We’ve seen a simple example of how to add an event handler in WPF. However, a glance at the list of events available for any object shows that WPF provides a lot of flexibility in how you handle a user action such as pressing a Button with a mouse click. We’ll have a look at some of those features here.
First, we need to mention that it is possible, and in fact easy, to add pretty well any content to a Button. By default, a Button contains some text as its Content, but that can be replaced by as complex a layout as you wish. As an example, we’ll create a Button whose content is a Grid, and the Grid in turn contains two cells, one of which contains a coloured square, and the other of which contains a TextBlock.
In Expression Blend (EB) we create a project and insert a single Button in the top-level Grid (the one named LayoutRoot by default). Centre the Button in the window. Turn off the Focusable property if you don’t want the Button to flash after it’s clicked. Now, using the Assets button (with a double chevron symbol) in the EB toolbar on the left, find a Grid and add it to the Button as its Content. In the Layout panel (under Properties, on the right) add one row and two columns to the Grid.
In column 0, add a Rectangle, and give it a size of 50 by 50, with a background colour of pure green (RGB = 0, 255, 0). In column 1, add a TextBlock, centre it horizontally and vertically, give it a margin of 5 all round, and set its text to “Press the square”. The result should look like this:
You can run the program at this point, and you should find that the button is pressable, but of course nothing will happen since we haven’t added any event handlers.
We’ve seen that you can add the standard handler for the Click event, which is triggered when the mouse’s left button is pressed and then released over the button. However, WPF actually gives you much finer control over events. Any component on a display, not just controls such as Buttons, can give rise to events. Thus in our example, the Button itself, the Grid it contains, and the Rectangle and TextBlock within the Grid can all give rise to events.
To understand how these events arise and what you can do with them, we need to remember that compound objects like the Button containing graphics are structured as a tree. In the example, the Button is the root of the tree. The Grid is the single child of the Button, and the Rectangle and TextBlock are children of the Grid. If the mouse’s left button is clicked over the Rectangle, say, then events are generated for the Rectangle, the Grid that contains it, and the Button that contains the Grid.
For some events, such as a mouse click, there are two types of events: tunneling and bubbling. Tunneling events are generated by starting at the root of the tree that contains the object over which the mouse was clicked, and then travelling down the tree until the object itself is found. Thus clicking the mouse over the Rectangle generates an event first in the Button, then in the Grid and finally in the Rectangle itself. All tunneling events have names beginning with ‘Preview’. Thus pressing the left mouse button generates tunneling events called PreviewMouseLeftButtonDown.
Once the specific object over which the mouse was clicked is located in the tree, a series of bubbling events is generated. Bubbling events are generated in the opposite order to tunneling events, so they start at the node in the tree corresponding to the object over which the mouse was clicked, and then travel up the tree, ending at the root. Typically, each tunneling event has a matching bubbling event, whose name is the same as that of the tunneling event but without the ‘Preview’ at the start. Thus the bubbling event for pressing the left mouse button is MouseLeftButtonDown.
The easiest way to see these events is to add handlers to all of them, and get each handler to print out a message when it is called. In EB, select each of the Button, Grid, square and TextBlock in turn, and add handlers for PreviewMouseLeftButtonDown and MouseLeftButtonDown.
One way to see textual output from a program is to make the application a Console application, as we mentioned earlier. A somewhat more professional way is to run the project in debug mode in Visual Studio (VS), and use the System.Diagnostics.Debug class to generate some text. To do this, add the line
using System.Diagnostics;
at the top of the C# code file. Then a typical event handler would look like this (for the tunneling event generated by pressing the left mouse button over the square:
private void Square_PreviewMouseLeftButtonDown(object sender, MouseButtonEventArgs e) { Debug.WriteLine("Square_PreviewMouseLeftButtonDown"); }
You can write similar handlers for all the other events. When the program is run in VS under Debug mode, look in the Output window at the bottom to see the output from these Debug statements.
Try clicking on various parts of the Button and look at the output. If you click over the green square, you’ll see that 3 tunneling events are generated, for the Button, then the Grid and finally the Rectangle. Following this, you will see 2 bubbling events, first for the Rectangle and then the Grid. The Button itself doesn’t get a bubbling event for mouse down, since WPF combines the mouse down with the mouse up events to generate a Click event, which is the one most commonly handled for a Button.
In practice, the tunneling events aren’t used that much, but they are useful to have in some situations. For example, you may want to change something at the root level in the tree before an event is handled by a lower-down component.
Sometimes, you may want to catch an event at a higher level and prevent any further processing of that event by lower level components. You can do this by setting the event’s Handled flag to ‘true’. In the sample of an event handler above, you’ll notice that the second argument to the handler is an object of class MouseButtonEventArgs. You can use this object to set the Handled flag by inserting this line in the handler:
e.Handled = true;
Try inserting that line in the Preview handler for the Grid and then run the program again. If you click on the square you’ll see that the Preview handlers for the Button and Grid are generated, but no further event handlers are called.
You will also notice that the first argument to the event handler method is called sender. This is the object that contains the actual component that generated the event. In our example, sender will correspond to the level in the tree at which the event is generated. For example, if we are in the handler for the Button’sPreviewMouseLeftButtonDown event and we click on the square, then sender will be the Button, not the square.
If you want to know the actual component that generated the event no matter where in the tree we are, this is contained in the MouseButtonEventArgs object, in its Source field. We can see both of these objects, sender and source, by adding a bit to the Debug statements in each handler. For example, we can write the handler for the Button’s PreviewMouseLeftButtonDown as follows.
private void Button_PreviewMouseLeftButtonDown(object sender, MouseButtonEventArgs e) { Debug.WriteLine("Button_PreviewMouseLeftButtonDown sender: " + sender.ToString() + "; Source: " + e.Source.ToString()); }
Calling the ToString() method of the objects here will return the class name of the object, so you can see which type of object it is. In the code shown, this handler will print out:
Button_PreviewMouseLeftButtonDown sender: System.Windows.Controls.Button; Source: System.Windows.Shapes.Rectangle
As an example of how these features might be used, suppose we wanted to change the colour of the square, but only if the user clicks directly on the square and not any other part of the button. We could put the code for doing this in the bubbling event handler for the square:
SolidColorBrush RosyBrownBrush = new SolidColorBrush(Colors.RosyBrown); SolidColorBrush LimeBrush = new SolidColorBrush(Colors.Lime); private void Square_MouseLeftButtonDown(object sender, MouseButtonEventArgs e) { Debug.WriteLine("Square_MouseLeftButtonDown sender: " + sender.ToString() + "; Source: " + e.Source.ToString()); if (!Square.Fill.Equals(RosyBrownBrush)) { Square.Fill = RosyBrownBrush; } else { Square.Fill = LimeBrush; } ButtonText.Text = "Press the square"; e.Handled = true; }
We define a couple of colours from the Colors class (which contains a large number of pre-defined colours with given names). The if statement on line 7 will swap the square’s colour between RosyBrown and Lime. On line 15, we reset the text of the TextBlock (we change it in another handler to be seen shortly). Finally, we set the event to Handled to prevent any further processing.
We want to catch any other mouse click that is inside the Button but not over the square, and print a helpful message for the user reminding him to click on the square. To put this message in the right place, we need to remember the order in which events are generated. Tunneling events are generated from the top down, starting with the Button. Bubbling events are generated from the bottom up, starting with either the Rectangle or the TextBlock.
We might think, therefore, that we can place the message code in the bubbling handler for the Grid, since the Grid lies behind both the Rectangle and TextBlock. So our first attempt might be something like this:
private void Grid_MouseLeftButtonDown(object sender, MouseButtonEventArgs e) { Debug.WriteLine("Grid_MouseLeftButtonDown sender: " + sender.ToString() + "; Source: " + e.Source.ToString()); Square.Fill = new SolidColorBrush(Colors.Red); ButtonText.Text = "The SQUARE, idiot!"; }
This sets the square to red as a warning, and changes the TextBlock’s text. We find that if we click directly over the current TextBlock text, this works, but if we click over the empty space within the Button above or below the text, nothing happens.
This is because the Grid cells size themselves to fit round the elements they contain, so the cell containing the TextBlock exists only behind the TextBlock itself and doesn’t extend to the top and bottom of the Button. We could try fiddling with the Grid’s settings to fix this, but in this case there’s an easier way.
Our next thought might be to put the code in the handler for the button’s MouseLeftButtonDown event, but remember that this event doesn’t get triggered for a Button, so again nothing will happen. We can solve the problem by putting the code in the Click event handler for the Button, since this doesn’t get called until the mouse button is released. Thus we get:
private void Button_Click(object sender, RoutedEventArgs e) { Debug.WriteLine("Button_Click sender: " + sender.ToString() + "; Source: " + e.Source.ToString()); Square.Fill = new SolidColorBrush(Colors.Red); ButtonText.Text = "The SQUARE, idiot!"; }
This works no matter where outside the square the mouse is clicked. Remember that we stopped the event from further processing in the square’s event handler, so if we click over the square, the Button’s Click handler is never called.
Complete project files for this example are available here.
Trackbacks
[…] the last post we saw what happens when the mouse is used to click on a Button. The mouse is, of course, often […]
[…] command connected to a user interface object. Remember that a routed command follows the same routing rules as an ordinary event: starting at the root of the interface tree (typically the Window), each event […] | https://programming-pages.com/2012/01/19/wpf-event-handling-anatomy-of-a-button-click/ | CC-MAIN-2018-26 | refinedweb | 1,974 | 70.33 |
Neural networks for regression with autograd
Posted November 18, 2017 at 02:20 PM | categories: autograd, python | tags: | View Comments
Today we are going to take a meandering path to using autograd to train a neural network for regression. First let's consider this very general looking nonlinear model that we might fit to data. There are 10 parameters in it, so we should expect we can get it to fit some data pretty well.
\(y = b1 + w10 tanh(w00 x + b00) + w11 tanh(w01 x + b01) + w12 tanh(w02 x + b02)\)
We will use it to fit data that is generated from \(y = x^\frac{1}{3}\). First, we just do a least_squares fit. This function can take a jacobian function, so we provide one using autograd.
import autograd.numpy as np from autograd import jacobian from scipy.optimize import curve_fit # Some generated data X = np.linspace(0, 1) Y = X**(1. / 3.) def model(x, *pars): b1, w10, w00, b00, w11, w01, b01, w12, w02, b02 = pars pred = b1 + w10 * np.tanh(w00 * x + b00) + w11 * np.tanh(w01 * x + b01) + w12 * np.tanh(w02 * x + b02) return pred def resid(pars): return Y - model(X, *pars)
MSE: 0.0744600049689
We will look at some timing of this regression. Here we do not provide a jacobian.
%%timeit pars = least_squares(resid, np.random.randn(10)*0.1).x
1.21 s ± 42.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
And here we do provide one. It takes a lot longer to do this. We do have a jacobian of 10 parameters, so that ends up being a lot of extra computations to do.
%%timeit pars = least_squares(resid, np.random.randn(10)*0.1, jac=jacobian(resid)).x
24.1 s ± 1.61 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
We will print these parameters for reference later.
b1, w10, w00, b00, w11, w01, b01, w12, w02, b02 = pars print([w00, w01, w02], [b00, b01, b02]) print([w10, w11, w12], b1)
[5.3312122926210703, 54.6923797622945, -0.50881373227993232] [2.9834159679095662, 2.6062295455987199, -2.3782572250527778] [42.377172168160477, 22.036104340171004, -50.075636975961089] -113.179935862
Let's just make sure the fit looks ok. I am going to plot it outside the fitted region to see how it extrapolates. The shaded area shows the region we did the fitting in.
X2 = np.linspace(0, 3) Y2 = X2**(1. / 3.) Z2 = model(X2, *pars) plt.plot(X2, Y2, 'b.', label='analytical') plt.plot(X2, Z2, label='model') plt.fill_between(X2 < 1, 0, 1.4, facecolor='gray', alpha=0.5)
You can seen it fits pretty well from 0 to 1 where we fitted it, but outside that the model is not accurate. Our model is not that related to the true function of the model, so there is no reason to expect it should extrapolate.
I didn't pull that model out of nowhere. Let's rewrite it in a few steps. If we think of tanh as a function that operates element-wise on a vector, we could write that equation more compactly at:
[w00 * x + b01] y = [w10, w11, w12] @ np.tanh([w01 * x + b01]) + b1 [w02 * x + b02]
We can rewrite this one more time in matrix notation:
y = w1 @ np.tanh(w0 @ x + b0) + b1
Another way to read these equations is that we have an input of x. We multiply the input by a vector weights (w0), add a vector of offsets (biases), b0, activate that by the nonlinear tanh function, then multiply that by a new set of weights, and add a final bias. We typically call this kind of model a neural network. There is an input layer, one hidden layer with 3 neurons that are activated by tanh, and one output layer with linear activation.
Autograd was designed in part for building neural networks. In the next part of this post, we reformulate this regression as a neural network. This code is lightly adapted from.
The first function initializes the weights and biases for each layer in our network. It is standard practice to initialize them to small random numbers to avoid any unintentional symmetries that might occur from a systematic initialization (e.g. all ones or zeros). The second function sets up the neural network and computes its output.
from autograd import grad import autograd.numpy.random as npr from autograd.misc.optimizers import adam def init_random_params(scale, layer_sizes, rs=npr.RandomState(0)): """Build a list of (weights, biases) tuples, one for each layer.""" return [(rs.randn(insize, outsize) * scale, # weight matrix rs.randn(outsize) * scale) # bias vector for insize, outsize in zip(layer_sizes[:-1], layer_sizes[1:])] def nn_predict(params, inputs, activation=np.tanh): for W, b in params[:-1]: outputs = np.dot(inputs, W) + b inputs = activation(outputs) # no activation on the last layer W, b = params[-1] return np.dot(inputs, W) + b
Here we use the first function to define the weights and biases for a neural network with one input, one hidden layer of 3 neurons, and one output layer.
init_scale = 0.1 # Here is our initial guess: params = init_random_params(init_scale, layer_sizes=[1, 3, 1]) for i, wb in enumerate(params): W, b = wb print('w{0}: {1}, b{0}: {2}'.format(i, W.shape, b.shape))
w0: (1, 3), b0: (3,) w1: (3, 1), b1: (1,)
You can see w0 is a column vector of weights, and there are three biases in b0. W1 in contrast, is a row vector of weights, with one bias. So 10 parameters in total, like we had before. We will create an objective function of the mean squared error again, and a callback function to show us the progress.
Then we run the optimization step iteratively until we get our objective function below a tolerance we define.
def objective(params, _): pred = nn_predict(params, X.reshape([-1, 1])) err = Y.reshape([-1, 1]) - pred return np.mean(err**2) def callback(params, step, g): if step % 250 == 0: print("Iteration {0:3d} objective {1:1.2e}".format(i * N + step, objective(params, step))) N = 500 NMAX = 20 for i in range(NMAX): params = adam(grad(objective), params, step_size=0.01, num_iters=N, callback=callback) if objective(params, _) < 2e-5: break
Iteration 0 objective 5.30e-01 Iteration 250 objective 4.52e-03 Iteration 500 objective 4.17e-03 Iteration 750 objective 1.86e-03 Iteration 1000 objective 1.63e-03 Iteration 1250 objective 1.02e-03 Iteration 1500 objective 6.30e-04 Iteration 1750 objective 4.54e-04 Iteration 2000 objective 3.25e-04 Iteration 2250 objective 2.34e-04 Iteration 2500 objective 1.77e-04 Iteration 2750 objective 1.35e-04 Iteration 3000 objective 1.04e-04 Iteration 3250 objective 7.86e-05 Iteration 3500 objective 5.83e-05 Iteration 3750 objective 4.46e-05 Iteration 4000 objective 3.39e-05 Iteration 4250 objective 2.66e-05 Iteration 4500 objective 2.11e-05 Iteration 4750 objective 1.71e-05
Let's compare these parameters to the previous ones we got.
for i, wb in enumerate(params): W, b = wb print('w{0}: {1}, b{0}: {2}'.format(i, W, b))
w0: [[ -0.71332351 3.23209728 -32.51135373]], b0: [ 0.45819205 0.19314303 -0.8687 ] w1: [[-0.53699549] [ 0.39522207] [-1.05457035]], b1: [-0.58005452]
These look pretty different. It is not too surprising that there could be more than one set of these parameters that give similar fits. The original data only requires two parameters to create it: \(y = a x^b\), where \(x=1\) and \(b=1/3\). We have 8 extra parameters of flexibility in this model.
Let's again examine the fit of our model to the data.
Z2 = nn_predict(params, X2.reshape([-1, 1])) plt.plot(X2, Y2, 'b.', label='analytical') plt.plot(X2, Z2, label='NN') plt.fill_between(X2 < 1, 0, 1.4, facecolor='gray', alpha=0.5)
Once again, we can see that between 0 and 1 where the model was fitted we get a good fit, but past that the model does not fit the known function well. It is coincidentally better than our previous model, but as before it is not advisable to use this model for extrapolation. Even though we say it "learned" something about the data, it clearly did not learn the function \(y=x^{1/3}\). It did "learn" some approximation to it in the region of x=0 to 1. Of course, it did not learn anything that the first nonlinear regression model didn't learn.
Now you know the secret of a neural network, it is just a nonlinear model. Without the activation, it is just a linear model. So, why use linear regression, when you can use an unactivated neural network and call it AI?
Copyright (C) 2017 by John Kitchin. See the License for information about copying.
Org-mode version = 9.1.2 | http://kitchingroup.cheme.cmu.edu/blog/2017/11/18/Neural-networks-for-regression-with-autograd/ | CC-MAIN-2020-05 | refinedweb | 1,486 | 69.28 |
MonkeyC
Sublime Text 3 syntax files for Garmin MonkeyC language for ConnectIQ platforms
Details
Installs
- Total 217
- Win 95
- OS X 95
- Linux 27
Readme
- Source
- raw.githubusercontent.com
MonkeyC
This is a Sublime Text language definition and plugin for the MonkeyC language. MonkeyC is a Garmin-developed language for the ConnectIQ platform, that runs on many of their devices, like smart watches.
When you download and set up the Connect IQ SDK this plugin will also allow you to build Connect IQ projects, Simulate and test them, and package for releasing and uploading to the Connect IQ Store.
File Extension:
.mc
Installation
- Using Package Control, install “MonkeyC”
Or.
- Open the Sublime Text Packages folder on your computer
- clone this repo
Configuration
Once installed, you should go to
Preferences > Package Settings > MonkeyC > Settings and put in the path to your Connect IQ SDK (download if you haven't already). And put in the path to your developer key. If you don't have a key and just want to generate one, you can use
Tools > MonkeyC > Generate Developer Key (or “MonkeyC: Generate Developer Key” from the Command Palette) to have this plugin make one, and update your key path for you.
You can override these settings on a per-project basis, by having a top-level key (monkeyc) in your
.sublime-project file (Project > Edit Project) that looks like this:
{ "folders": [ ... ], "monkeyc": { "sdk": "/path/to/other/SDK", "key": "~/specific/key/for/project" } }
Features
Editing
- Syntax Highlighting: including special coloring for CIQ modules in the Toybox namespace. Includes advanced syntax highlighting for
.junglefiles
- Autocomplete: for language keywords like
instanceof,
breakand full snippets for things like
modules and
classes. Autocompletes device names, qualifiers, and languages in jungle files.
- Comment-Toggle: Select some lines and hit
Ctrl-/to toggle comments on or off. Works in
.mcand
.jungle. (use
Ctrl-Shift-/for block comments)
- Go-To Symbols: Adds module, class, and function names to the Sublime symbol list, as well as
(:annotations). Hit
Ctrl-rto search symbols in current file, or
Ctrl-Shift-rto search symbols in the whole project.
Building (when connected with the SDK)
- Compile: You can compile connect iq apps (Applications, watch faces, data fields) and Barrels (modules). You can use the Sublime Build system (
ctrl-bor the Command Palette: “MonkeyC: Build …”)
- Simulate: The plugin can launch and connect to the simulator for you. (“MonkeyC: Simulate”)
- Test: Run assertions (through the simulator) and unit tests, similar to Run No Evil from the official Eclipse Plug-in. (“MonkeyC: Test” – this will re-compile your project with the
-ttest flag, and run the simulator with the
-ttest flag)
- Package: Compile a
.iqapp ready for uploading and publishing to the Connect IQ Store (“MonkeyC: Package for Release”. This strips debug and test information, includes any
:releaselabels)
- Side-load: Build for a device, to side-load it onto a device locally (“MonkeyC: Build for Device” in command palette)
- Key Generation: Don't have a developer key? Go to
Tools > MonkeyC > Generate Developer Key(or the Command Palette) and now you do! (uses
opensslto make an RSA key, formatted properly)
- App ID Generation: Each Connect IQ App needs a special ID (UUID). The plugin can generate random UUIDs for you, and update your
manifest.xmlautomatically
If you wanted to customize any of these actions, or make them key-bindings, they are available as sublime commands:
monkey_build
compiles your project. Accepts the following arguments:
- do string (optional):
"release",
"test"or
"custom".
releaseapplies the
-r -eflags to the compiler, and makes the default file extension
.iq
testapplies the
-tflag for applications. For barrels, it runs the
barreltestcommand to run unit tests
customprompts the user with the command to use right before running, allowing edits
- name string (optional): the file name of the generated app. Defaults to the project folder name
- device string (optional): adds
-d <device>as a compiler option. Use the string
"prompt"to have the plugin ask for device selection each time (based on the supported devices in your
manifest.xmlfile)
- sdk string (optional): adds
-s <sdk>as a compiler option to target an SDK. Use the string
"prompt"to have the plugin determine the supported SDK targets for the given device (a device is required).
- flags list (optional): Any additional flags or command-line arguments you wish to specify. E.g.
run_command("monkey_build",{"flags":["-r"]})to run a simple compile with the release flag (disables asserts, debug things).
monkey_simulate
runs the Connect IQ simulator. (Implicitly triggers a
monkey_build for simulation device) Accepts the following arguments:
- device string REQUIRED: the device to simulate on. Use the string “prompt” to have the plugin ask you for a device each time, based on your list in
manifest.xml.
- tests boolean (optional): If true, runs the unit tests in the project. Assertions are run regardless, unless it is a release build.
monkey_generate
Small helper creators. Like developer keys, or app IDs. Accepts the following arguments:
- gen string REQUIRED:
keyto make a developer key, and update your settings with it.
uuidto make a new App ID and update your
manifest.xmlwith it
Versions
3.1.0
Adds SDK integration. Compiles, simulates, and runs unit tests. See the Release Notes for full details.
3.0.0
Major syntax rules overhaul. Includes autocomplete, snippets, jungle file syntax, go-to symbols (module, class, function names as well as annotations), comment-toggling (Ctl-/), and much much better coloring and other-plugin support. See the Release Notes for full details.
2.1.0
Updates to include new packages in Connect IQ 3.0.0 (beta)
2.0.0
Updates to include (some? most?) language features as of SDK 2.4.4
1.0.0
Initial release, contains most language features as of SDK 1.2.5
Sublime Text 2
This package is currently not supported on ST2, as it uses
.sublime-syntax files, a new feature in ST3.
Contributing
Please use the github issues page for this repo for requests, bugs, and before starting pull requests to plan work.
This repository and code are not affiliated with or supported by Garmin in any way. MonkeyC is a product and language developed by Garmin. | https://packagecontrol.io/packages/MonkeyC | CC-MAIN-2019-35 | refinedweb | 1,018 | 56.15 |
Last month’s column introduced java.nio, one of the most significant new packages found in Java 2 Standard Edition Version 1.4. java.nio finally adds high-performance I/O features — memory-mapped files, non-blocking I/O, and managed buffers — to Java.
Last month’s column focused on Buffer, a new set of classes that holds data in linear, sequential storage. Buffer classes can be used to store and retrieve data without incurring the overhead of object allocation and garbage collection. However, a Buffer is useless if it isn’t connected to sources that add data to the Buffer and consumers that extract data. That’s where channels come in: the new java.nio .channels.* classes add data to Buffers and extract data from Buffers.
Changing to Channels
A Channel is simply a connection between a ByteBuffer and an endpoint, either a socket or file. Indeed, the four Channel classes are divided into two sets: SocketChannel, ServerSocketChannel, and DatagramChannel for sockets, and FileChannel for files.
While Channel is similar in purpose to Stream and Reader, Channel is not a replacement for those classes. Instead, Channel joins Stream and Reader as a fundamental Java capability.
In fact, in the case of files, you have to combine Stream and Channel to memory-map files and buffer I/O. Specifically (at least in 1.4), none of the classes in java.io can read from or write to a Buffer. Additionally, you cannot create a FileChannel directly. Instead, you have to combine classes from java.io and java.nio to create, open, and buffer from a file.
For example, the following code (which we’ll build on as we go) creates a FileInputStream named inData, and a FileChannel called inChannel associated with that file:
FileInputStream inData =
new FileInputStream(“input.dat”);
FileChannel inChannel =
inData.getChannel();
Note that the FileChannel is not created directly via new() (as FileInputStream is). Instead, you first create the stream, and then call inData.getChannel() to create the channel.
Once you’ve created a FileChannel, you can use that class’ size() method to find the number of bytes in the file. You can use that result with the read(ByteBuffer, long) method to fill the specified ByteBuffer with data from the channel.
For instance, the following code extends the last example by reading a file into a ByteBuffer using inChannel:
long inSize = inChannel.size();
ByteBuffer readings =
ByteBuffer.allocate((int) inSize);
inChannel.read(readings, 0);
readings.position(0);
for (int i = 0; readings.remaining() >
0; i++)
System.out.print(readings.get() + ” “);
A variant read() method, read(ByteBuffer, int, int), fills a portion of a buffer with data from a Channel, beginning at the position indicated by the second argument. The third argument specifies the number of bytes to read.
A Channel also has several write() methods to send data from a ByteBuffer. The write(ByteBuffer) method sends all of a buffer’s remaining bytes, beginning at the current position, over the Channel. The write(ByteBuffer, int, int) method sends a portion of a buffer, beginning at the offset indicated by the second argument and extending for the number of bytes indicated by the third argument.
Continuing our example code, the following code snippet sends the contents of the readings buffer over a new File Channel:
FileOutputStream opData =
new FileOutputStream(“output.dat”);
FileChannel opChannel =
opData.getChannel();
readings.flip();
opChannel.write(readings);
readings.flip();
opChannel.write(readings);
Like FileInputStream.read() and FileOutputStream .write(), reading and writing data over a channel requires that IOException be caught or passed on with throws. Listing One shows a complete working program that “copies” a file using Channels.
Listing One: “Copy” a file using stream and channels
import java.nio.channels.Channels;
import java.nio.channels.FileChannel;
import java.nio.ByteBuffer;();
}
}
No More Blocking
As mentioned above, the java.nio.channels package also includes socket channels, which are used to send and receive data over a network. Unlike FileChannel, you can create socket channels directly. The really cool thing about socket channels? They support non-blocking input and output.
Blocking, once the bane of Java client and server programmers, occurs when a statement must executive and finish before anything else can happen in a program. Until Java 1.4, all socket programming caused blocking — and lots of headaches for programmers. Because numerous things can go wrong, it can be cumbersome for networking code to stop dead in its tracks while a statement is executed. A server can go offline, a connection can break, or a read operation can hang forever while it waits for something to happen.
For example, consider the example of an RSS aggregator that reads XML data from an RSS feed over an HTTP connection, buffering the data as it arrives. It’s possible for the RSS aggregator to block waiting for a buffer to be filled even though no more data remains to be sent. The block can make it appear as if the application has halted.
Non-blocking I/O lets an application continue even though a read or write operation is in process. To use non-blocking input and output, you must work with Channel instead of Stream.
A Finger Server
Last month, we created a finger client using the java.nio classes. Recall that the finger protocol, an old-school method of telling people about yourself, serves up the text in a user’s .plan file to anyone who requests it. For examples, visit the GameFinger Web site at.
To try out non-blocking sockets, let’s create the other side of the finger protocol: a simple finger server that connects to clients with non-blocking sockets. Listing Two shows the complete source code for NioFingerServer, a server that uses a non-blocking socket channel to wait for incoming connections from finger clients.
Listing Two: A finger server using non-blocking sockets – Part 1
1 // Code requires J2SE 1.4
2 import java.io.*;
3 import java.net.*;
4 import java.nio.*;
5 import java.nio.channels.*;
6 import java.util.*;
7
8 public class NioFingerServer {
9 public NioFingerServer() {
10 try {
11 // Create a non-blocking server socket channel
12 ServerSocketChannel sockChannel = ServerSocketChannel.open();
13 sockChannel.configureBlocking(false);
14
15 InetSocketAddress server = new InetSocketAddress (“localhost”, 79);
16 ServerSocket socket = sockChannel.socket();
17
18 socket.bind(server);
19
20 // Create the selector and register it on the channel
21 Selector selector = Selector.open();
22
23 sockChannel.register (selector, SelectionKey.OP_ACCEPT);
24
25 // Loop forever, looking for client connections
26 while (true) {
27 // Wait for a connection
28 selector.select();
29
30 // Get list of selection keys with pending events
31 Set keys = selector.selectedKeys();
32 Iterator it = keys.iterator();
33
34 // Handle each key
35 while (it.hasNext()) {
36
37 // Get the key and remove it from the iteration
38 SelectionKey selKey = (SelectionKey) it.next();
39
40 it.remove();
41 if (selKey.isAcceptable()) {
42
43 // Create a socket connection with the client
44 ServerSocketChannel selChannel =
45 (ServerSocketChannel) selKey.channel();
46 ServerSocket selSocket = selChannel.socket();
47 Socket connection = selSocket.accept();
48
49 // Handle the finger request
50 handleRequest(connection);
51 connection.close();
52 }
53 }
54 }
55 } catch (IOException ioe) {
56 System.out.println(ioe.getMessage());
57 }
58 }
59
60 private void handleRequest(Socket connection) throws IOException {
61
62 // Set up input and output
63 InputStreamReader isr = new InputStreamReader (connection.getInputStream());
64 BufferedReader is = new BufferedReader(isr);
65 PrintWriter pw = new PrintWriter(new
66 BufferedOutputStream (connection.getOutputStream()),
67 false);
68
69 // Output server greeting
70 pw.println(“Nio Finger Server”);
71 pw.flush();
72
73 // Handle user input
74 String outLine = null;
75 String inLine = is.readLine();
76
77 if (inLine.length() > 0) {
78 outLine = inLine;
79 }
80 readPlan(outLine, pw);
81
82 // Clean up
83 pw.flush();
84 pw.close();
85 is.close();
86 }
87
88 private void readPlan (String userName, PrintWriter pw) {
89 try {
90 FileReader file = new FileReader (userName + “.plan”);
91 BufferedReader buff = new BufferedReader(file);
92 boolean eof = false;
93
94 pw.println(“\nUser name: ” + userName + “\n”);
95
96 while (!eof) {
97 String line = buff.readLine();
98
99 if (line == null)
100 eof = true;
101 else
102 pw.println(line);
103 }
104
105 buff.close();
106 } catch (IOException e) {
107 pw.println(“User ” + userName + ” not found.”);
108 }
109 }
110
111 public static void main(String[] arguments) {
112 NioFingerServer nio = new NioFingerServer();
113 }
114 }
On line 12, a new ServerSocketChannel is instantiated by calling the class method ServerSocketChannel.open(). The channel’s configureBlocking(boolean) method controls whether the channel blocks (if the argument is true) or not (false). Line 13 chooses non-blocking.
A ServerSocketChannel, unlike other channels, only makes connections. To send and receive any data over that channel, you must also create a server socket and bind it to an Internet address and port.
This sequence is shown in lines 15-18 (that Net code should look very famliar):
If the channel was configured to be blocking, you could call the accept() method of the server socket to wait for a client connection. However, a non-blocking socket keeps track of incoming connection requests and other networking events with the use of a special listening object called a selector.
A selector, represented by the Selector class in the java.nio.channels package, can monitor several kinds of networking socket channels: clients (SocketChannel), servers (ServerSocketChannel), datagrams (DataGramChannel), and pipes (Pipe.SourceChannel and Pipe .SinkChannel). One selector can also monitor several channels at the same time.
A selector is instantiated by calling the class method Selector.open(). The selector only monitors events it’s been configured to monitor, which is accomplished by calling a socket channel’s register(Selector, int) or register(Selector, int, Object) methods.
The first two arguments to register() are the selector and an integer value that represents the kind of events being monitored, called selection keys. If there’s a third argument, the specified object will be delivered along with the key when a monitored event occurs.
Though you can use an integer literal as the second argument, it’s easier to make use of one or more class variables in the SelectionKey class. There’s SelectionKey.OP_CONNECT to monitor connections, SelectionKey.OP_READ to monitor channel read attempts, and SelectionKey .OP_WRITE to monitor channel write attempts. These “flags” are cumulative, so you can add two or three together to monitor more than one kind of event.
For example, the following code creates a selector to monitor a socket channel called wire for inbound connections and reads:
Selector tor = Selector.open();
channel.register(tor, SelectionKey.OP_READ +
SelectionKey.OPCONNECT);
The finger server only monitors incoming connections, as shown in lines 21 and 23.
A Selector has two methods that check for monitored selection keys: select(), which blocks until a key is triggered, and select(long), which waits the specified number of milliseconds for a keys before giving up. Both select() methods return an integer, which will either be the number of events that have taken place or 0, in cases where select(long) was called and no events took place in the specified time.
After one or more keys has been triggered, the selector’s selectedKeys() method returns the keys as a set, which you can traverse by using an iterator (the Set and Iterator classes of the java.util package). Each key is retrieved from the set by calling the iterator’s next() method and casting the result as a SelectionKey object. After a key has been retrieved, it should be removed from the set by calling the iterator’s remove() method.
The following code waits for one or more keys to be triggered and iterates through the keys:
selector.select();
Set keys = selector.selectedKeys();
Iterator it = keys.iterator();
while (it.hasNext()) {
SelectionKey selKey = (SelectionKey)it.next();
it.remove();
}
Similar code appears in Listing Two between lines 28 and 40.
There are three boolean methods in the SelectionKey class that identify the key in a server: isAcceptable(), isReadable(), and isWriteable(). Each method returns true if the key is that kind of event.
The key’s own channel() method identifies the socket channel where key was triggered.
For the finger server, this channel is used to create a server socket, which is used in turn to create a socket connection:
ServerSocketChannel selChannel =
(ServerSocketChannel) selKey.channel();
ServerSocket selSocket = selSocket.socket();
Socket connection = selSocket.accept();
This call to the accept() method blocks, waiting for the connection between the client and server to negotiate a connection. This socket can be used with reader and writer classes in the java.io package to exchange data.
All of the new networking techniques in the NioFingerServer application are contained in its constructor method. The handleRequest() and readPlan() methods use traditional Java socket programming techniques, making use of the socket that represents the connection between the finger server and a client.
For simplicity, this finger server keeps user .plan files in text files with names of the form username.plan, such as linus.plan, lucy.plan, or schroeder.plan.
To run this server, create one or more of these text files in the same folder as NioFingerServer.class, then run the server as root.
# echo “Protect my blanket.” > linus.plan
# echo “Trick Charlie Brown.” > lucy.plan
# echo “Play the piano.” > schroeder.plan
# javac NioFingerServer.java
# java -cp .:$CLASSPATH NioFingerServer
You can connect to this server using last month’s NioFinger client application (available online at) or use a telnet client to connect to localhost on port 79.
% telnet localhost 79
Trying 127.0.0.1…
Connected to localhost.
Escape character is ‘^]’.
Nio Finger Server
linus
User name: linus
Protect my blanket.
Connection closed by foreign host.
User name: linus
Protect my blanket.
Connection closed by foreign host.
Clients and Sockets
Client programming using a socket channel uses many of the same techniques as server programming, with a few exceptions:
If a socket client’s channel is not blocking, any attempt to use the channel should be preceded by code that ensures that the connection has been fully established.
For instance, the following code could be used in a client before making use of a socket channel associated with a key named clientKey:
// If the connection is valid, then proceed
if (clientKey.isConnectable()) {
if (clientChannel.isConnectionPending()) {
clientChannel.finishConnect();
}
}
The call to finishConnect() blocks until a connection to the server has been completed.
Stay Tuned
The NioFingerServer application can handle something as simple as finger requests, but more robust servers would make use of threads so that each server connection does not have the potential to grind to a screeching halt in a blocking call. Server socket channels are thread-safe, preventing two threads from calling accept() at the same time.
Another kind of network programming is in the .plan for next month’s Java Matters: we’ll take a look at Velocity, the open source template creation engine that separates the presentation of a Web application from the programming required to create it. | http://www.linux-mag.com/id/1212/ | CC-MAIN-2016-44 | refinedweb | 2,478 | 58.69 |
Hi again,
I´ve one entity in which a start and a end day is stored. Now I want to store a status for each day in another entity. Following an example:
Entity A:
start date: 01.10.2012
end date: 03.10.2012
No I´d like to create for each date from the 1st to the 3rd a row in Entity B.
So the result in Entity B should be:
I hope it´s possible to catch what I mean?
Thank´s!
Felix
Hi,
the code is formally bad written. For example the condition of the while loop must be a compare and not an assignment of a variable (a = b VS a == b).
Here the full code related to your request:
#input Date startDate, Date endDate
#output Date[] resultDates
def startDateMs = startDate.getTime()
def endDateMs = endDate.getTime()
def numberOfDays = (endDateMs.minus(startDateMs))/86400000
println numberOfDays
def resultDates = [];
resultDates.add(startDate);
int count = 1;
while (count < numberOfDays){
resultDates.add(startDate + count);
count ++;
}
resultDates.add(endDate);
return ["resultDates" : resultDates]
you can find the dates between a start date and an end date by using a Script Unit, which contains the code for calculating the intermediate dates. For example, you could first calculate the number of days between the two dates received as input (e.g. start date = 10/10/12; end date = 10/14/12; number of days = 4). Secondly you could add single days to the start date, until you add all the difference days and you reach the end date (e.g. 10/10/12 + 1 = 10/11/12; 10/10/12 + 2 = 10/12/12 and so on).
To find the difference days between the start and the end date you can use the Groovy
Date ".minus" method, that subtracts a date from a another date (both dates are espressed in milliseconds). The difference has to be divided by the number of milliseconds in a day. As result, you get the number of days between two dates. For example:
#input Date startDate, Date endDate
def startDateMs = startDate.getTime()
def endDateMs = endDate.getTime()
def numberOfDays = (endDateMs.minus(startDateMs))/86400000
println numberOfDays
The intermediary dates, calculated by incrementing the start date, could be added to a list which is returned from the Script Unit and passed for example to a Create Unit (working on Entity B) that stores the dates. The Create Unit should have the "Bulk" property enabled, so it can perform multiple object creations at once.
Dear Laura,
Thank´s a lot for your reply. I tried to do the loop to add the days in a scipt unit, but it is not working at all (I´ve absolutely no plan about groovy...).
Following my try:
#input Date StartDate, int AddDays
def NewDate = StartDate
def i = 1
while(i=AddDays)
{
NewDate++;
i++;
}
return NewDate
Do you know where the mistakes are?
Thank´s a lot for your help... | https://my.webratio.com/forum/question-details/how-to-calculate-dates-between-start-and-end-point;jsessionid=077B53396149C00DA0A90036DFF58882?nav=43&link=oln15x.redirect&kcond1x.att11=437 | CC-MAIN-2021-17 | refinedweb | 482 | 74.49 |
In this tutorial I am going to show a simple Tree data structure implemented in Java.We will see how to create Tree data structure and also a mechanism of traversing the tree in a very easy way. The Tree which we will create in this tutorial will be the java representation of the image shown below.
Tree Node
Each node in the tree will be represented by the java class Node. The node class has an id attribute and you can add many other attributes to this class. It has a list of the children and a reference to the parent Node.
Node.java
package com.programtak.tree.tutorial; import java.util.ArrayList; import java.util.List; public class Node { private String id; private final List<Node> children = new ArrayList<>(); private final Node parent; public Node(Node parent) { this.parent = parent; } public String getId() { return id; } public void setId(String id) { this.id = id; } public List<Node> getChildren() { return children; } public Node getParent() { return parent; } }
Building Java Tree
Now let us start building the tree from the node objects.
1. Create the Root Element of the Tree. You can see from below code that a null is passed to the root as the root will have no parent.
Node treeRootNode = new Node(null); treeRootNode.setId("root");
2. Adding the child to parent. The below method adds a child to the parent. And also sets the parent reference to the node.
private static Node addChild(Node parent, String id) { Node node = new Node(parent); node.setId(id); parent.getChildren().add(node); return node; }
3. And once we have the tree we will also traverse of the tree. The traversal of the tree to display all the nodes is done using depth first traversal as shown by the below image. Follow the white line from the root.
And here is the function that does the traversal and prints out the tree
private static void printTree(Node node, String appender) { System.out.println(appender + node.getId()); for (Node each : node.getChildren()) { printTree(each, appender + appender); } }
Java Tree
In the below class we will create the java representation of the Tree shown in the image above.
package com.programtak.tree.tutorial; public class TreeTest { public static void main(String[] args) { Node treeRootNode = new Node(null); treeRootNode.setId("root"); // add child to root node Node childNode= addChild(treeRootNode, "child-1"); // add child to the child node created above addChild(childNode, "child-11"); addChild(childNode, "child-12"); // add child to root node Node child2 = addChild(treeRootNode, "child-2"); // add child to the child node created above addChild(child2, "child-21"); printTree(treeRootNode, " "); } private static Node addChild(Node parent, String id) { Node node = new Node(parent); node.setId(id); parent.getChildren().add(node); return node; } private static void printTree(Node node, String appender) { System.out.println(appender + node.getId()); for (Node each : node.getChildren()) { printTree(each, appender + appender); } } }
Now let’s look at the output:
root child-1 child-11 child-12 child-2 child-21
Summary
The above program shows the creation of a simple tree that can be traversed both ways from parent to child and from child to parent. In my next tutorials I will be focusing on more ways of traversing the tree and also search methods for finding objects in tree. Other functionality that you may want to add to the tree e.g; Search the root node of a tree from any node in the Java Tree and Delete nodes from a Tree in Java | http://programtalk.com/java/java-tree-implementation/ | CC-MAIN-2017-09 | refinedweb | 585 | 64.61 |
replace-attoparsec
Find, replace, and split string patterns with Attoparsec parsers (instead of regex)
See all snapshots
replace-attoparsec appears in
replace-attoparsec-1.4.4.0@sha256:4788d229537540a44cde551e1fc5ec8fee201c0c199f122824d7a63a9f44b07d,2075
Module documentation for 1.4.4.0
- Replace
- Replace.Attoparsec
replace-attoparsec
replace-attoparsec is for finding text patterns, and also replacing or splitting on.
replace-attoparsec can be used in the same sort of “string splitting”
situations in which one would use Python
re.split
or Perl
split.
See replace-megaparsec for the megaparsec version.. Parse, don’t validate.
Regular expressions are only able to pattern-match regular grammers. Attoparsec parsers are able pattern-match context-free grammers.-attoparsec/
root directory.
The examples depend on these imports and
LANGUAGE OverloadedStrings.
:set -XOverloadedStrings import Replace.Attoparsec.Text import Data.Attoparsec.Text as AT import qualified Data.Text as T import Data.Either import Data.Char = string "0x" *> hexadecimal :: Parser Integer splitCap (match hexparser) "0xA 000 0xFFFF"
[Right ("0xA",10), Left " 000 ", Right ("0xFFFF",65535)] :: Parser () parens = do char '(' manyTill (void (satisfy $ notInClass "()") <|> void parens) (char ')') pure () second fst <$> splitCap (match parens) "(()) (()())"
[Right "(())",Left " ",Right "(()())"]
Edit text with
streamEditT
Find an environment variable in curly braces and replace it with its value from the environment.
import System.Environment (getEnv) streamEditT (char '{' *> manyTill anyChar (char '}')) (fmap T.pack . getEnv) "- {HOME} -"
"- /home/jbrock -" T.Text editThree x = do i <- get if i<3 then do put $ i+1 pure $ T.singleton $ toUpper x else pure $ T.singleton x flip runState 0 $ streamEditT (satisfy isLetter)-attoparsec
1.4.4.0 – 2021-01-08
Deprecate
findAll and
findAllCap.
1.4.2.0 – 2020-09-28
Bugfix sepCap backtracking when sep fails
See replace-megaparsec/issues/33
1.4.0.0 – 2020-05-06
Running Parsers: Add
splitCap and
breakCap.
Parser Combinators: Add
anyTill.
1.2.0.0 – 2019-10-31
Benchmark improvements
Specializations of the
sepCap function, guided by
replace-benchmark.
New benchmarks
Old benchmarks
Also don’t export
getOffset anymore. It’s too complicated to explain
what it means for
Text. If users want to know positional parsing information
then they should use Megaparsec.
1.0.0.0 – 2019-09-10
- First version. | https://www.stackage.org/nightly-2021-03-01/package/replace-attoparsec-1.4.4.0 | CC-MAIN-2021-17 | refinedweb | 359 | 53.98 |
EXIT(2) BSD System Calls Manual EXIT(2)
NAME
_exit -- terminate the calling process
SYNOPSIS
#include <unistd.h> void _exit(int status);
DESCRIPTION
The _exit() function terminates a process, with the following conse- quences: o All of the descriptors that were open in the calling process are closed. This may entail delays; for example, waiting for output to drain. A process in this state may not be killed, as it is already dying. o If the parent process of the calling process has an outstanding wait call or catches the SIGCHLD signal, it is notified of the calling process's termination; the status is set as defined by wait(2). o The parent process-ID of all of the calling process's existing child processes are set to 1; the initialization process (see the DEFINI- TIONS section of intro(2)) inherits each of these processes. o. o If the process is a controlling process (see intro(2)), the SIGHUP signal is sent to the foreground process group of the controlling terminal. All current access to the controlling terminal is revoked. Most C programs call the library routine exit(3), which flushes buffers, closes streams, unlinks temporary files, etc., before calling _exit().
RETURN VALUE
_exit() can never return.
SEE ALSO
fork(2), sigaction(2), wait(2), exit(3)
STANDARDS
The _exit function is defined by IEEE Std 1003.1-1988 (``POSIX.1''). 4th Berkeley Distribution June 4, 1993 4th Berkeley Distribution
Mac OS X 10.9.1 - Generated Sun Jan 5 15:21:47 CST 2014 | http://www.manpagez.com/man/2/_exit/ | CC-MAIN-2015-06 | refinedweb | 255 | 63.09 |
Since some time addr2line, and libbfd as used by perf, fail to associate the symbol name to inlined frames. Note the "??" in the output of addr2line in the reproducer below:
$ cat test.cpp
#include <cmath>
#include <complex>
#include <iostream>
#include <random>
using namespace std;
int main()
{
uniform_real_distribution<double> uniform(-1E5, 1E5);
default_random_engine engine;
double s = 0;
for (int i = 0; i < 10000000; ++i) {
s += norm(complex<double>(uniform(engine), uniform(engine)));
}
return static_cast<int>(s);
}
$ g++ -g -O2 test.cpp
$ addr2line -e a.out 766 -if
main
/usr/include/c++/8.2.1/bits/random.tcc:123
??
/usr/include/c++/8.2.1/bits/random.h:257
main
/tmp/test.cpp:11
I'm using libbfd 2.31.1 with gcc 8.2.1 or clang 6.0.1 currently. eu-addr2line seems to work correctly, which makes me believe it's an issue with libbfd / addr2line from binutils:
$ eu-addr2line -e a.out 766 -if
_ZNSt26linear_congruential_engineImLm16807ELm0ELm2147483647EE4seedEm inlined at /usr/include/c++/8.2.1/bits/random.h:257:9 in main
/usr/include/c++/8.2.1/bits/random.tcc:123:2
_ZNSt26linear_congruential_engineImLm16807ELm0ELm2147483647EEC4Em
/usr/include/c++/8.2.1/bits/random.h:257:9
main
/tmp/test.cpp:11:27
Created attachment 11274 [details]
correctly pass through name from nested find_abstract_instance calls
The attached patch fixes the issue for me. Apparently the compilers generate debug information with nested instance, i.e. find_abstract_instance calls itself in dwarf2.c. In such a scenario, the inner call will correctly set its pname to the name it found. But the outer call will then override it with name = NULL at the end of find_abstract_instance.
Fix this by passing the pointer to the name when calling find_abstract_instance from itself. I've tested this patch with addr2line and perf on the example source code provided in the bug report. Both work again with this fix applied!
are there really no unit tests for libbfd?
The master branch has been updated by Nick Clifton <nickc@sourceware.org>:;h=c8d3f93237d77f76d14e09e44bc770ce9428b0e4
commit c8d3f93237d77f76d14e09e44bc770ce9428b0e4
Author: Millan Wolff <mail@milianw.de>
Date: Wed Oct 3 12:06:09 2018 +0100
Fix the handling of inlined frames in DWARF debug info.
PR 23715
* dwarf2.c (find_abstract_instance): Allow recursive invocations
of find_abstract_instance to override the name variable.
Hi Milian,
Thanks for the bug report and patch. I have now checked the patch
in to the mainline sources.
In answer to your question, "no - there are currently no unit tests
for the binutils". This is not because there is a policy against
them, but rather because no-one has had the time and energy to add
the necessary framework and then start writing the tests. Of course
volunteers are always welcome.
Cheers
Nick
Thanks a lot for merging the patch and providing the background information. I was asking mostly because I was wondering whether my patch was missing a unit test.
Cheers | https://sourceware.org/bugzilla/show_bug.cgi?format=multiple&id=23715 | CC-MAIN-2022-33 | refinedweb | 479 | 60.21 |
Occasionally, you need to send messages to all users on your system. Warning users of planned downtime for hardware upgrades is a good example. Sending e-mail to each user individually is extremely time consuming and wasteful; this is precisely the kind of task that e-mail aliases and mailing lists were invented for. Keeping a mailing list of all the users on your system can be problematic, however. If you are not diligent about keeping the mailing list current, it becomes increasingly inaccurate as you add and delete users. Also, if your system has many users, the mere size of the alias list can become unwieldy.
The following script, called mailfile, provides a simple method of working around these problems. It grabs the login names from the /etc/passwd file and sends e-mail to all users.
#!/bin/csh # # mailfile: This script mails the specified file to all users # of the system. It skips the first 17 accounts so # we do not send the email to system accounts like # 'root'. # # USAGE: mailfile "Subject goes here" filename.txt # # Check for a subject # if ( `echo $1 | awk '{ print $1 }'` == "" ) then echo You did not supply a subject for the message. echo Be sure to enclose it in quotes. exit 1 else # Get the subject of the message set subject=$1 endif # # Check for a filename # if ( $2 == "" ) then echo You did not supply a file name. exit 2 else # Get the name of the file to send set filename=$2 endif # # Check that the file exists # if ( -f $filename ) then echo Sending file $filename else echo File does not exist. exit 3 endif # # Loop through every login name, but skip the first 17 accounts # foreach user ( `awk -F: '{ print $1 }' /etc/passwd | tail +17` ) # Mail the file echo Mailing to $user mail -s "$subject" $user < $filename # sleep for a few seconds so we don't overload the mailer # On fast systems or systems with few accounts, you can # probably take this delay out. sleep 2 end
The script accepts two parameters. The first is the subject of the e-mail message, which is enclosed in quotes. The second is the name of the file containing the text message to send. Thus, to send an e-mail message to all users warning them about an upcoming server hardware upgrade, I may do something similar to the following:
mailfile "System upgrade at 5:00pm" upgrade.txt
The file upgrade.txt contains the text of the message to be sent to each user. The really useful thing about this approach is that I can save this text file and easily modify and resend it the next time I upgrade the system. | http://etutorials.org/Linux+systems/red+hat+linux+bible+fedora+enterprise+edition/Part+III+Administering+Red+Hat+Linux/Chapter+11+Setting+Up+and+Supporting+Users/Sending+Mail+to+All+Users/ | CC-MAIN-2018-30 | refinedweb | 447 | 69.31 |
sleeped connections return to pool after some time in jboss as 7.1Ramesh Chokkapu Jun 11, 2013 1:27 AM
Hi Good Morning,
My pool stat :
Here 12 connections are in Active. but only max 2 connection are working, remaining 10 conncetions are in sleep.
i need these sleeped connections return to pool after some time.
what i have to do for this?
[standalone@localhost:9999 /] /subsystem=datasources/data-source="MySQLDS"/statistics=pool:read-resource(include-runtime=true)
{
"outcome" => "success",
"result" => {
"ActiveCount" => "12",
"AvailableCount" => "150",
"AverageBlockingTime" => "45",
"AverageCreationTime" => "49",
"CreatedCount" => "12",
"DestroyedCount" => "0",
"MaxCreationTime" => "276",
"MaxUsedCount" => "12",
"MaxWaitTime" => "2",
"TimedOut" => "0",
"TotalBlockingTime" => "550",
"TotalCreationTime" => "596"
}
}
Thanks in advance.
1. Re: sleeped connections return to pool after some time in jboss as 7.1Wolf-Dieter Fink Jun 11, 2013 2:47 AM (in response to Ramesh Chokkapu)
2. Re: sleeped connections return to pool after some time in jboss as 7.1Ramesh Chokkapu Jun 11, 2013 5:38 AM (in response to Wolf-Dieter Fink)
Thank for Reply.
Yes, Connection Leak. these leaked connections need to be return to pool after some time.
DestroyCount should be always "DestroyedCount" => "0".
I have another Question which is :
--------------------------------------------------
i have hundreds of DAO methods like below.
some DAO methods, i forgot to session.close() at finally block.
so my connections are getting to leak (sleep).
these leaked connections are not return to pool and i need to find where is that leak.
i have two options for this: 1) i need to return these leaked connections to pool after some time. 2) Need to find leak in which DAO method.
but always DestroyCount should show as zero (its my own requirement).
i have checked with debug="true" and ccm="true" and track-statements set to true . but in my server.log is not showing these connection leak. its only shows statement.close() and resultset.close() suggestions but not about session.close() suggestions.
sample DAO method :
public Emp findById(Long id) throws DAOException {
Session session = null;
try {
session = HibernateConnector.getInstance().getSession();
Query query = session.createQuery("from Emp where id = :id");
query.setParameter("id", "" + id);
List queryList = query.list();
if(queryList.isEmpty()) {
return null;
}
return (Emp) queryList.get(0); // only one expected because of
// the unique id
} catch (HibernateException ex) {
ex.printStackTrace();
} finally {
if(session != null) {
try {
session.close(); // if not put this statement, connection get into leak.(i have forgot these statement in some DAO methods)
} catch (HibernateException ignore) {
}
}
}// try/catch/finally ..
}
please help me.
Thanks in advance.
3. Re: sleeped connections return to pool after some time in jboss as 7.1Wolf-Dieter Fink Jun 11, 2013 7:34 AM (in response to Ramesh Chokkapu)
There is no option to return connections to the pool other than closing it.
I'm not sure why setting the cache-connection-manager to debug the connection is not showing the stacktrace where the connection is opened.
If the container finish the invocation you should see a message that you should close the connection and the stacktrace.
I'm not a hibernate expert, but if you see the pool statistic hibernate should use this pool.
Do you have an extended persistence context in some cases?
4. Re: sleeped connections return to pool after some time in jboss as 7.1Ramesh Chokkapu Jun 11, 2013 8:34 AM (in response to Wolf-Dieter Fink)
Thank You for Reply.
i am not using extended persistence context. No transations are maintained and using only stateless session beans which are Bean Managed. | https://developer.jboss.org/thread/229234 | CC-MAIN-2018-17 | refinedweb | 580 | 60.61 |
Am Donnerstag, 9. März 2006 20:17 schrieb Henrique de Moraes Holschuh: > Or do you want to do this to avoid an ifeq..endif block in debian/rules > files that are currently required to detect if --host should be issued to > configure ? Personally just because I don't like the currently different naming of native-to-arch gcc and gcc-as-cross-compiler. You wouldn't have to worry about your current architecture as you only have to know the target architecture. Compiling a package for i686 on sparc would be exactly the same as compiling it on i686. I'd love that... Just as I'd love to see the different binutils package merged and binutils-multiarch to be the default. HS -- Mein GPG-Key ist auf meiner Homepage verfügbar: oder über pgp.net PingoS - Linux-User helfen Schulen: | https://lists.debian.org/debian-devel/2006/03/msg00343.html | CC-MAIN-2016-30 | refinedweb | 140 | 67.35 |
A brand new alpha of the breath-taking KDE 3.1 development branch has been announced. This release sports everything from wonderful new eye candy to tons of popular new features including new and exciting "easter eggs" (aka bugs) just waiting to be discovered. Remember, this is not a stable release -- those of you concerned with stability should use KDE 3.0.2, whereas those of you who want to help KDE 3.1 be the best KDE ever should use this alpha. Kudos to Dre for writing the announcement and to the tireless Dirk Mueller for coordinating this release. Party!
The title says it all: Could someone please fix the broken link to the compilation instructions in the announcement...
Way to go! Thanks for a marvelous desktop.
The one that points you to the "outdated" page or is there another one?
The one with the outdated page. I did not see any other one.
man, that drop shadow for menus are damn cool ! wonder what users of other competing desktop will comment :-)
Yeah, this menu-drop-shadow really rules! It would also be nice if windows could have drop shadows. What do you think?
Hmm, I believe this is more of a job for X. Let's wait for Keith.
Anyway, drop shadow menu combined with mouse cursor shadow looks really kick-ass. Pick-up good icons/window decoration/splashscreens/ and you're set to make your Windows friends totally jealous.
A BLACK X-mouse-pointer with a BLACK-drop-shadow...? *g*
BTW: Which windows-friends? :)
Forget the pointer. Those goodies will keep people busy anyway :-)
> A BLACK X-mouse-pointer with a BLACK-drop-shadow...? *g*
Oh, that reminds me of another new KDE feature: builtin white mouse cursor support :). I'm not sure if it made it in to 3.1a1, though.
-Ryan
Someone please redesign those horrible X pointers. The whole font is butt ugly.
Yes they look sweet.
Just curious, does anyone want to explain how are these being done? I thought shadows like these are impossible in X.
Better than windows; "Show shadows under menus" (Display Properties->Apperance->Effects) is a boring name. I don't know what exactly they are called in KDE, but I don't think it could be worse.
in the announcement, i believe it should be stated clearly that translucent menus are for all applications, not only for kate! (and they were already in kde3.0)
No screenshots and much "work in progress", but so far KDE-PIM package also has made great improvements compared to 3.0.x. Kudos!
Thorsten
Would it be possible for you to mention some of the kde-pim improvements/enhancements
we can look forward to? I am eagerly looking forward to the new kde-pim stuff.
I love the all the stuff now, and am excited about how good it will get in the
future.
Ok, you have a kcontrol module for selecting an addressbook storage backend.
So far you can select old multi-vcard file, single-vcard dir and an (untested) sql backend. There is some talk about a possible server approach for most of the pim datas.
kaddressbook has a configurable view style front end (tables, icons, cards...) with an instant category filter (show friends, show family). The card input looks like Outlooks contact dialog and is full featured. The addressbook has a printing backend.
What else.
There is hard work in stabilizing an common KDE sync API based on ksync and kitchen sync. If you compile the ksync backend program you get a tool to sync your bookmarks, calendars and addressbook.
KOrganizers support for publishing appointment to other PIM programs is now more compatible. A special highlight is a (free ;-) plugin for accessing an Exchange2000 server. But this is really work in progress and needs tester (*hint*).
I hope that file locking is ready for 3.1 so that you can put one central adressbook, calendar, bookmark, etc. file on a server and use this from multiple computers. I have one calender at home and another one at work. Often on both desktops runs an instance of korganizer. Caused by the missing file locking I can not use one file for both instances.
Other stuff like Outlook-like integration of the pim apps and kpilot is out of my personal interests so I don't know much about recent improvements.
If you are interested in kde-pim enter the mailing list or listen via a read-only ML2NG mapping atnews://news.uslinuxtraining.com
Bye
Thorsten
>So far you can select old multi-vcard file, single-vcard dir and an (untested) sql backend. There is some talk about a possible server approach for most of the pim datas
This would be very great. The mail problem my clients have with KMail is the inabillity to have a shared adressbook. If you could tap into an SQL-server (MySQL comes to mind!) they could all share one adressbook.
I would be more than happy to test this feature!
For the rest of the KDE team: you are unbelievable! KDE's great...
I confirm this.
The only thing i am waiting very hard for is to connect my mysql addresses to kaddressbook!
All other stuff is great for me.
I took snapshot from cvs HEAD about week ago and I'll have to say that konqi is in very good shape. It's much more stable than 3.0.2 and startup speed is very good. Overall functionality feels more stable than alpha quality. 3.1 Will Rock Your gSocks Off ;)
Screenshots......*drool*
Congrats again KDE - especially everaldo on his wonderful icon
theme.
KDE is really starting to distance itself from most other desktop
environments without creating a totally alien environment.
Can't wait to get home and install.
Hi!
Looks great!!!
I would really like to know if what we've been hearing about gcc c++ linker being not so good has been solved as we were told with gcc 3.1.
Does it finally make KDE fast loading apps? :-)
I am really looking forward to have a good distro with KDE 3 compiled with gcc 3.1. This must fly!!!
Huuuha!!!
unfortunately, it seems g++ 3.1 isn't quite that nice, at least for kde:
:O/
emmanuel
I read it
That's a shame :-(
What has happened with all what was said?
I am really surprised of that results... What is happening?
And why should we use gcc 3.1 if it's WORSE BOTH in time compiling and starting apps?
I guess KDE will be faster starting apps only in a couple of years due to faster PCs. Or should we hope on something I missed from the post? ->
The results are a bit dubious, as the -g3 parameter does very different things under GCC 2.95 and GCC 3.1. I suspect that relocating the DWARF symbols that 3.1 produces with -g3 accounts for the extra relocation time. Oh, and GCC 3.1 produces faster code, more friendly warnings and errors, and is more standards compliant. Some people care about more than speed.
Why? Because GCC 2.95 sucked as far as C++ support was concerned. Any C++ compiler suite that
(1) didn't implement the STL correctly (look at the header files)
(2) won't let you do templated friend classes (least never worked for me)
(3) doesn't understand namespaces (2.95 faked understanding)
(4) allows file descriptors to work with iostreams (bad behavior; the C++ Standard outlaws this)
(5) a lot more that I'm missing
just, well, is bleh. GCC 3.1 fixes these.
As far as GCC 3.1 goes for speed, eh, oh well. If you turn on the optimizing features of the thing, I've found that the performance is great -- both in synthetic benchmarks and in everyday use. I've used GCC 3.1 to compile everything on this system, and although C++ compile time is slower (who really cares about that?), performance is more than acceptable.
I guess you are right, but it really shocked me the benchmark results showed above.
I didn't know about the 5 nice fixes you said. I only knew that speed was going to be better because this was the only thing explained in user forums like this one.
Good to see that at least some problems have been solved.
Thanks for your work developers!!! :-)
Could anyone give a reasonable schedule to see when (if ever) we'll see loading apps speed increase with better compilers? After all, is it really a problem, or just waiting for faster PCs is the way to go? Should developers concentrate their efforts on writting a nice desktop waiting for those faster machines in future?
Developers replies with their feelings on the topic will be greatly appreciated.
> and although C++ compile time is slower (who really cares about that?)
well developpers on not so new (but no so old) cpus :(
> well developpers on not so new (but no so old) cpus :(
Eh, I don't really mind. Gives me an excuse to say "I'm working" when all I'm doing is waiting for a compile to finish :D
Not everybody in this world has the money to buy a new PC. Look at most of thecountries in the third-world. Linux (and ofcourse KDE and other open-source)has very much chances, because thos people don't have much money to spend and Linux is free. But if people have to spend a lot of money to run programs with acceteble performance they will proberly stick to a system like Windows 95, 98 or ME. Simply because these sytems run very well on low-resource machines.
This is certainly true.
But it ain't simple to make it run faster.
Another option would be to have one quite fast server and a bunch of slow (e.g. old pentiums) boxes acting as X terminals.
Bye
Alex
> But it ain't simple to make it run faster.
well.. i hope gcc 3.1 will be further improved (a lot!) during the next months.
another idea: what about using the intel compiler suite instead of gcc-3.1? anybody tried this one together with kde 3.0/3.1? i've read the intel compiler made a lot of progress regarding "gcc compatibility" recently.. and it's supposed to be faster and create about 10 to 30 percent faster binaries than gcc 2.95.3.
afaik the startup time is adressed in the dynamic linker which is a part of glibc and not of gcc. so we should see an improuvment with glibc-2.3.
any experiences with glibc CVS?
There is also a patch against glib-2.2.5 contained in the prelink sources:
Anyone made SuSE 8.0 RPMs of these yet ?
Yes!
Redirects me to download.au.kde.org, which seems to be empty (no kde-3.1 dir in unstable).
There are some on download.kde.org mirrors (in unstable/kde-3.1-alpha1/SuSE/i386/8.0/); I'd assume Adrian/SuSE has made them, but I do not know for sure.
Increased Apache MaxClients to 800:
10:51pm up 3 days, 16:33, 5 users, load average: 0.61, 2.00, 3.57
749 processes: 738 sleeping, 11 running, 0 zombie, 0 stopped
CPU states: 2.0% user, 7.7% system, 0.0% nice, 90.1% idle
Mem: 643696K av, 627828K used, 15868K free, 0K shrd, 18788K buff
Swap: 819304K av, 4536K used, 814768K free 211340K cached
Finally, we're more comfortable now. :-)
Great job guys!!!
This release seems to be more stable than 3.0.2. How could it happen??
The only issue is that this release don't have the drop shadow menus.
I don't have the alpha here but you can enable it under look --> style I think.
have fun
Felix
Are there plans to allow for closing a tab in konqueror without having to right-click the tab, or use a menu option? I've used tabbed environments in mozilla and visual studio .net, which handle this issue differently. Mozilla provides an X on each tab, while vs.net provides an X to the far right of the tabs which closes the active tab. IMO, both of these implementations are more efficient to use.
I can't wait to get my hands on this one :)
YEAH we need the X buttons to close each of the tabs like galeon tabs for example
please add this feature
btw, do u know how to enable the tabs by default, so that every time u click on a link it will open in a tab instead of a new window? because right now i have to right click on a link, then select Open In New Tab before it'll work and i want it to happen automatically.
Try Ctrl-click to open links in new tabs
I just compiled kdelibs & kdebase with gcc3.1 and is running fine. I need to enable the shadow menu and transparent panel. how do I do that? I don't see any option for that in the control center....
-Mathi
No transparent Panel in alpha
Also no shadows(its post alpha)
:(
Pull the patches for these revisions from WebCVS, apply them and recompile:
can you explain me how to pull the patches from WebCVS or point me to some doc.....
thanks a lot,
-Mathi
Are you sure, that you have the right knowledge to do all this? Read the links, search the file in WebCVS e.g. and click on "Diff to previous 1.17". | https://dot.kde.org/comment/96087 | CC-MAIN-2016-44 | refinedweb | 2,273 | 76.11 |
Diagnosing Memory Leaks
Mike Hall
Microsoft Corporation
Steve Maillet
Entelechy Consulting
October 15, 2002
Summary: Looks at the tools and functionality built into Microsoft® Windows® CE .NET 4.1 that can be used to track memory leaks in a custom operating system, specifically, debug zones, Remote Performance Monitor, and LMEMDEBUG. (15 printed pages)
Hopefully, you have been following along with the Microsoft Windows CE projects. If so, you should be comfortable building operating system images, and you've probably written some of your own code to run on top of Windows CE—either an application or perhaps drivers. This month's article focuses on memory leaks and how to track them down.
I know you are all great developers. Your code is always cleanly written with more comments than you can shake a stick at. The code is super easy to maintain, and contains no memory leaks or bugs... Okay, now back to the real world.
We can all make mistakes in our code, especially if we're on a time crunch or are simply on a roll and hammering out code deep into the night. Once we have our code complete, how do we determine whether it contains a memory leak? Better still, how do we track the leak back to source code and fix the issue? In this month's article, we will look at debug zones, Remote Performance Monitor, and LMEMDEBUG.
We will use a simple, console-based application to help illustrate some of the tools and features of Windows CE. The sample is called memLeak. This (as the name implies) leaks memory (no surprises there). The application has two threads, a main thread that spins in a sleep loop so that the application doesn't exit, and a child thread that allocates memory every 500ms. We will use this application to illustrate the use of debug zones, the Remote Performance Monitor, and LMEMDEBUG. There are a series of functions called in the memLeak application. These are (in order):
- AllocateMemory( )
- UseMemory( )
- FreeMemory( )
You can get a feel for the purpose of the functions by simply looking at the function names. AllocateMemory checks the current memory load. If we're below 60% load, we allocate 2048*TCHAR and then move on. UseMemory does something useful with the memory, and FreeMemory hopefully frees the memory we've allocated.
Here's the complete application:
// memLeak.cpp : Defines the entry point for the console application. // #include "stdafx.h" #include <celog.h> #define MAX_LOADSTRING 100 // Definitions for our debug zones #define ZONEID_INIT 0 #define ZONEID_TRACE 1 #define ZONEID_MEMORY 2 #define ZONEID_RSVD3 3 #define ZONEID_RSVD4 4 #define ZONEID_RSVD5 5 #define ZONEID_RSVD6 6 #define ZONEID_RSVD7 7 #define ZONEID_RSVD8 8 #define ZONEID_RSVD9 9 #define ZONEID_RSVD10 10 #define ZONEID_RSVD11 11 #define ZONEID_RSVD12 12 #define ZONEID_RSVD13 13 #define ZONEID_WARN 14 #define ZONEID_ERROR 15 // These masks are useful for initialization of dpCurSettings #define ZONEMASK_INIT (1<<ZONEID_INIT) #define ZONEMASK_TRACE (1<<ZONEID_TRACE) #define ZONEMASK_MEMORY (1<<ZONEID_MEMORY) #define ZONEMASK_RSVD3 (1<<ZONEID_RSVD3) #define ZONEMASK_RSVD4 (1<<ZONEID_RSVD4) #define ZONEMASK_RSVD5 (1<<ZONEID_RSVD5) #define ZONEMASK_RSVD6 (1<<ZONEID_RSVD6) #define ZONEMASK_RSVD7 (1<<ZONEID_RSVD7) #define ZONEMASK_RSVD8 (1<<ZONEID_RSVD8) #define ZONEMASK_RSVD9 (1<<ZONEID_RSVD9) #define ZONEMASK_RSVD10 (1<<ZONEID_RSVD10) #define ZONEMASK_RSVD11 (1<<ZONEID_RSVD11) #define ZONEMASK_RSVD12 (1<<ZONEID_RSVD12) #define ZONEMASK_RSVD13 (1<<ZONEID_RSVD13) #define ZONEMASK_WARN (1<<ZONEID_WARN ) #define ZONEMASK_ERROR (1<<ZONEID_ERROR) #ifdef DEBUG // These macros are used as the first arg to DEBUGMSG #define ZONE_INIT DEBUGZONE(ZONEID_INIT) #define ZONE_TRACE DEBUGZONE(ZONEID_TRACE) #define ZONE_MEMORY DEBUGZONE(ZONEID_MEMORY) #define ZONE_RSVD3 DEBUGZONE(ZONEID_RSVD3) #define ZONE_RSVD4 DEBUGZONE(ZONEID_RSVD4) #define ZONE_RSVD5 DEBUGZONE(ZONEID_RSVD5) #define ZONE_RSVD6 DEBUGZONE(ZONEID_RSVD6) #define ZONE_RSVD7 DEBUGZONE(ZONEID_RSVD7) #define ZONE_RSVD8 DEBUGZONE(ZONEID_RSVD8) #define ZONE_RSVD9 DEBUGZONE(ZONEID_RSVD9) #define ZONE_RSVD10 DEBUGZONE(ZONEID_RSVD10) #define ZONE_RSVD11 DEBUGZONE(ZONEID_RSVD11) #define ZONE_RSVD12 DEBUGZONE(ZONEID_RSVD12) #define ZONE_RSVD13 DEBUGZONE(ZONEID_RSVD13) #define ZONE_WARN DEBUGZONE(ZONEID_WARN ) #define ZONE_ERROR DEBUGZONE(ZONEID_ERROR) #endif DBGPARAM dpCurSettings = { TEXT("MemLeak"), { TEXT("Init"),TEXT("Trace Fn( );"),TEXT("Memory"),TEXT(""), TEXT(""),TEXT(""),TEXT(""),TEXT(""), TEXT(""),TEXT(""),TEXT(""),TEXT(""), TEXT(""),TEXT(""),TEXT(""),TEXT("")}, // By default, turn on the zones for init and errors. ZONEMASK_INIT }; DWORD WINAPI MemoryThread(LPVOID lpParameter); void AllocateMemory( ); void FreeMemory( ); void StartAllocation( ); void UseMemory( ); MEMORYSTATUS g_MemStatus; HLOCAL g_tcTemp,g_tc_Temp; DWORD dwThreadID; TCHAR szMessage[256]; int WINAPI main (HINSTANCE hInstance, HINSTANCE hInstPrev, LPWSTR pCmdLine, int nCmdShow) { OutputDebugString(L"leakApp Starting\n"); DEBUGREGISTER(NULL); // Register the debug zones StartAllocation( ); while(true) { Sleep(1000); } return 0; } void StartAllocation( ) { g_tcTemp=NULL; g_tc_Temp=NULL; OutputDebugString(L"Creating Thread...\n"); CreateThread(NULL,0, (LPTHREAD_START_ROUTINE)MemoryThread, (LPVOID)0,0,&dwThreadID); } DWORD WINAPI MemoryThread(LPVOID lpParameter) { while(TRUE) { Sleep(500); DEBUGMSG (ZONE_TRACE, (TEXT("-------------------------\n"))); AllocateMemory( ); UseMemory( ); FreeMemory( ); } } void AllocateMemory( ) { DEBUGMSG (ZONE_TRACE, (TEXT("Enter - AllocateMemory( ) Function\n"))); DEBUGMSG (ZONE_MEMORY, (TEXT("Check GlobalMemoryStatus( )\n")));); if (g_MemStatus.dwMemoryLoad < 60) { DEBUGMSG (ZONE_MEMORY, (TEXT("Allocate TCHAR *2048 (4096 UNICODE Characters)\n"))); g_tcTemp=LocalAlloc(LPTR,(2048*sizeof(TCHAR))); DEBUGMSG (ZONE_MEMORY, (TEXT("Pointer 0x%lx\n"),g_tcTemp)); } else { DEBUGMSG (ZONE_MEMORY, (TEXT("Memory Load too high - not allocating memory \n"), g_MemStatus.dwMemoryLoad)); } DEBUGMSG (ZONE_TRACE, (TEXT("Leave - AllocateMemory( ) Function\n"))); } void FreeMemory( ) { DEBUGMSG (ZONE_TRACE, (TEXT("Enter - FreeMemory( ) Function\n"))); DEBUGMSG (ZONE_MEMORY, (TEXT("Free Pointer 0x%lx\n"),g_tc_Temp)); LocalFree(g_tc_Temp); DEBUGMSG (ZONE_TRACE, (TEXT("Leave - FreeMemory( ) Function\n"))); } void UseMemory( ) { DEBUGMSG (ZONE_TRACE, (TEXT("Enter - UseMemory( ) Function\n"))); DEBUGMSG (ZONE_MEMORY, (TEXT("Do Something Interesting here.\n"))); DEBUGMSG (ZONE_TRACE, (TEXT("Leave - UseMemory( ) Function\n"))); }
There are a number of ways in which we can track the flow of a running program. Perhaps the simplest way is the use of OutputDebugString( ). This function can be used to output any useful information from our code. Unfortunately, we get the debug message whether we want it or not, which can perhaps lead to information overload.
It may be useful to switch on debug messages as and when we need them. For example, tracking the entry point and exit points of functions within our code would provide code flow information as our application runs. We may not need this to be running all the time, but it could be useful to determine the flow of code when we're tracking down leaks, or crashes. So how do we enable this?
The answer is debug zones. Most modules within the Windows CE operating system have debug zones enabled. Take a look at the following screen shot from Platform Builder. (The dialog box is displayed in Platform Builder using Target | CE Debug Zones.) This shows the debug zones exposed from GWES.exe. You can see that 16 zones are exposed (0-15), and that by default, zone 6, Warnings, is enabled.
Figure 1. Debug Zones dialog box from Platform Builder
Debug zones provide the ability to selectively turn debug message output from your code on and off. This allows you to trace the execution of your code without halting the operating system. Tracing is a simple and non-intrusive way of catching problems in code without causing the operating system to stop responding. Debug zones can be enabled either through Target Control (Target | CE Target Control), or through the Platform Builder IDE (Target | CE Debug Zones).
Each application or module (driver, DLL, etc.) can contain 16 debug zones. The purpose of each zone is not fixed; you can code each zone to display information appropriate to your current project. You may only need one or two zones in your application/driver. These may be used to track the entry/exit point of functions (code tracing). You may also be interested in memory allocations/free; code tracing or memory allocations could be coded as debug zones for your application or driver.
Debug zones are implemented by declaring a DBGPARAM structure, which is defined in dbgapi.h. The DBGPARAM structure contains three elements: the module name, the zone names, and a bitmask showing which zones are enabled by default. This shows how the DBGPARAM structure from the memLeak program is filled out:
We can see the name of the module 'memLeak' and then 16 strings defining the human readable names of the zones within our code. (These are the names displayed in the Platform Builder 'Debug Zones' Dialog.) In this case, we're exposing three zones: Init, Trace Fn( ), and Memory The third section of the DBGPARAM structure defines which zones are enabled by default—we have the init zone enabled.
So, how do we enable debug zones in our application? Simple. We define a DBGPARAM structure, called dpCurSettings, and on initialization of our program or module, we call DEBUGREGISTER( ). The syntax for the DEBUGREGISTER macro is DEBUGREGISTER(hMod | NULL). If you are debugging a .dll, call DEBUGREGISTER with the appropriate hModule, and pass NULL if you are building an application.
So far so good. We know how to fill out the structure and how to register the debug zones with the debugger. This will simply show the list of zones inside Platform Builder (menu item Target | CE Debug Zones). So how do we use debug zones in our code? Again, this is simple. Let's examine the Trace Fn( ) debug message and how this is enabled. Here's a sample line of code from the memLeak application:
We can see the call to DEBUGMSG( ). This function takes two parameters: a bit test and a string. The bit test can be used in a couple of different ways. If you always want the debug message to appear, you can simply use DEBUGMSG(1,L"String"). Notice the numeric one is the first parameter—or, we could test to see whether one of our debug zones is enabled using a bit test similar to the following DEBUGZONE(ZONEID_INIT,L"String"). That's as hard as it gets—either bit-test, or use numeric 1 as the first parameter to DEBUGZONE( ). We simply need a way to determine whether our specific debug zone is enabled; if so, output the debug string.
So how exactly does this help us with tracking memory leaks? We can include a MemoryAllocate, and a MemoryFree function in our applications. This can (at the basic level) track the number of memory allocations, increment a global variable, and output a debug message with the current number of allocations. Obviously, the MemoryFree function will decrement this global number and also output a debug message. Once our program run is complete, we can determine whether we have a leak by examining the value of the global variable. Hopefully, this number will be zero (in which case we have matching memory allocations and frees); we're in trouble if the number is either positive, or negative.
So, we have our application/driver with debug zones enabled, how do we use these from Platform Builder? There are two options. The first is to use the Target | CE Debug Zones... menu option. This will list all of the running processes/modules; you can then select from the list and enable/disable the appropriate zones.
Figure 2. Setting memLeak debug zones
The second way to work with debug zones is through the CE Target Control Window (Target | CE Target Control). If you've been working with Windows CE since version 2.0, this will be VERY familiar to you. The target control window provides a command-line interface to some of the common tasks when developing/debugging a Windows CE operating system image. These include getting a list of running processes, starting processes, and stopping processes, and setting debug zones on applications or modules.
Here's how I enabled memory tracing on memLeak using the Target Control window:
- gi proc displays a list of running processes. You will notice that memLeak is process #6.
- zo p 6 lists the debug zones for process #6. Only init is enabled; this is displayed with a '*' next to the zone name.
- zo p 6 on 2 turns on zone bit 2 for process #6 (memLeak).
We could also terminate the process using kp 6 (kill process #6). Here is how the above commands look in the Target Control window.
Windows CE>gi proc PROC: Name hProcess: CurAKY :dwVMBase:CurZone P00: NK.EXE 0dfff002 00000001 c2000000 00000100 P01: filesys.exe 2dff4416 00000002 04000000 00000000 P02: shell.exe 4dfd7442 00000004 06000000 00000001 P03: device.exe 8dfd750a 00000008 08000000 00000004 P04: gwes.exe adedd692 00000010 0a000000 00000040 P05: services.exe 0ded0316 00000020 0c000000 00000001 P06: memleak.exe 2de7631e 00000040 0e000000 00000001 Windows CE>zo p 6 Registered Name:MemLeak CurZone:00000001 Zone Names - Prefixed with bit number and * if currently on 0*Init : 1 Trace Fn( ); : 2 Memory : 3 4 : 5 : 6 : 7 8 : 9 :10 :11 12 :13 :14 :15 Windows CE>zo p 6 on 2 Registered Name:MemLeak CurZone:00000005 Zone Names - Prefixed with bit number and * if currently on 0*Init : 1 Trace Fn( ); : 2*Memory : 3 4 : 5 : 6 : 7 8 : 9 :10 :11 12 :13 :14 :15 Windows CE>
Here's how the debug zone output looks. We can see that function tracing is enabled, and memory allocation/free is also enabled. This shows the current memory load, and the pointer returned from the LocalAlloc( ) function.
555568 PID:edee9902 TID:de7628a 0x8de766ac: ---------------------------------- 555568 PID:edee9902 TID:de7628a 0x8de766ac: Enter - AllocateMemory( ) Function 555568 PID:edee9902 TID:de7628a 0x8de766ac: Check GlobalMemoryStatus( ) 555569 PID:edee9902 TID:de7628a 0x8de766ac: Memory Load 13% 555569 PID:edee9902 TID:de7628a 0x8de766ac: Allocate TCHAR *2048 (4096 UNICODE Characters) 555570 PID:edee9902 TID:de7628a 0x8de766ac: Pointer 0x159550 555570 PID:edee9902 TID:de7628a 0x8de766ac: Leave - AllocateMemory( ) Function 555571 PID:edee9902 TID:de7628a 0x8de766ac: Enter - UseMemory( ) Function 555572 PID:edee9902 TID:de7628a 0x8de766ac: Do Something Interesting here. 555572 PID:edee9902 TID:de7628a 0x8de766ac: Leave - UseMemory( ) Function 555572 PID:edee9902 TID:de7628a 0x8de766ac: Enter - FreeMemory( ) Function 555572 PID:edee9902 TID:de7628a 0x8de766ac: Free Pointer 0x0 555572 PID:edee9902 TID:de7628a 0x8de766ac: Leave - FreeMemory( ) Function 556074 PID:edee9902 TID:de7628a 0x8de766ac: -----------------
Debug zones can be useful in tracking a variety of items within our code, including memory allocation. We can also run our application over time and examine the operating system memory load. We would expect the memory load to stay flat over the run time of our application. Obviously, if the memory load increases over time, then this is an indication of a potential memory leak.
There are a couple of ways in which we can track memory load. The first is to call the GlobalMemoryStatus( ) API within our code, and use OutputDebugMessage( ) or DEBUGMSG( ) to output a debug message showing the current load (perhaps using a debug zone to control the output of this message).
We can also make use of the Remote Performance Monitor. This tool provides the ability to track a number of items within the Windows CE operating system. (It's actually very similar to the desktop PerfMon application.) We can, for example, track Remote Access Server (RAS), Internet Control Message Protocol (ICMP), TCP IP, User Datagram Protocol (UDP), memory, battery, system, process, and thread activity within the Windows CE operating system.
In our case, we can run the Remote Performance Monitor and monitor memory load. Here's how the Performance Monitor application looks when we're running memLeak. You can see that memory load is steadily increasing over time. For some applications, this may be normal behavior. Perhaps the application is caching information into memory from a connected data source You would expect the application to flush this captured information to the file system, or to a remote server—perhaps calling an XML Web service or using MSMQ, and therefore the memory load should reduce.
Figure 3. Remote Performance Monitor
At this point, we've seen that debug zones and Remote Performance Monitor can be useful in determining whether we have a leak in our code. This doesn't necessarily help us track down the cause of the leak. This is where LMEMDEBUG can be useful. Let's take a look at LMEMDEBUG.
The goal of LMEMDEBUG is to allow developers to get a better understanding of memory allocations within their device. LMEMDEBUG can be added to a platform directly from the Platform Builder catalog. I'm currently working with a headless platform to test out the sample code for this month's article. The LMEMDEBUG component can be found here in the Platform Builder catalog: Core OS | Headless Devices | Core OS Services | Debugging Tools | LMemDebug memory debugging hooks. (Note that LMEMDEBUG is also available for display-based devices.)
LMEMDEBUG can be used for memory leak tracing as well as performance analysis. There are two logical parts to LMEMDEBUG: the hooks included in the Core operating system components and a sample installable DLL provided in source code, the location of which is C:\WINCE410\PUBLIC\COMMON\OAK\DRIVERS\LMEMDEBUG. The sample DLL exposes memory-tracking functions. When CoreDLL is loaded, it will call the LMemInit() function of heap.c. This function has been changed for Windows CE .NET 4.1 to attempt to load a DLL named LMemDebug.DLL. If this DLL can be loaded into the process space, then it will do a GetProcAddress() of the following functions:
HeapCreate
HeapDestroy
HeapAlloc
HeapAllocTrace
HeapReAlloc
HeapFree
HeapSize
You can implement all or a subset of the functions in your implementation of the LMemDebug DLL. Since all of the Local* functions (like LocalAlloc()) call into the HeapAlloc functions, all of those will be redirected. Malloc, calloc and new also go into the Local* functions and then to the Heap* functions. CoreDLL also now exports Int_ (Internal) versions of all of these functions. This allows you to call into the current implementations as a lower layer of your implementation. At a minimum, your functions could simply call into the internal implementations and keep a simple count of the total allocations or total number of bytes allocated. A simple implementation could perhaps implement HeapAlloc/HeapFree as:
The HeapAlloc and HeapFree functions could use OutputDebugString( ) to show the current number of allocations. Again, this is fine, but how do we use LMemDebug to track a leak? We already know that memLeak leaks memory; we can clearly see this from the Remote Performance Monitor output. Now let's take a look at the debug output when we close our application:
315130 PID:adee97b2 TID:aded0af2 0x8dee383c: Ptr=0x0004B410 Size=4096 Count=30 LineNum=137 File=C:\WINCE410\PUBLIC\Small\memLeak\memLeak.cpp 315130 PID:adee97b2 TID:aded0af2 0x8dee383c: Stack=0x03FBED36 315130 PID:adee97b2 TID:aded0af2 0x8dee383c: Stack=0x03FBD52A 315130 PID:adee97b2 TID:aded0af2 0x8dee383c: Stack=0x0E0111EE 315131 PID:adee97b2 TID:aded0af2 0x8dee383c: Stack=0x0E0110D6 315131 PID:adee97b2 TID:aded0af2 0x8dee383c: Stack=0x03FB6136
Now this looks interesting. LMEMDEBUG will output a stack trace, the amount of memory allocated, a file name, and line number for each allocation that wasn't tidied up by the host application, in this case memLeak. We can now quickly jump to line 137 of memLeak.cpp in the Platform Builder IDE to see where the memory was allocated. In this case, it's the following line of code:
We can now see one location within our code that may be the culprit for leaking memory—the call to LocalAlloc( ) where we allocate 2048*TCHAR. This translates to 4096 bytes. It may be useful to "break" our application when the allocation of 4096 bytes takes place, and then single step the code to determine where the LocalFree( ) is either missing or failing to free the memory (perhaps we're passing an incorrect parameter into the call). LMEMDEBUG also provides a mechanism for trapping the initial allocation and forcing a DebugBreak( ) when this occurs. To enable this feature, we need to use the Target Control window (Target | CE Target Control).
At a Target Control prompt, you can type "?" to get a list of available commands. In our case, we want to force a breakpoint when an allocation within memLeak occurs of 4096 bytes. The command-line option for this is
lmem memleak breaksize 4096. The command line simply requests a DebugBreak( ) to fire when 4096 bytes is allocated in the process memLeak. The call to DebugBreak( ) will take place in the HeapAllocTrace( ) function within LMEMDEBUG. We can use the Call Stack window within Platform Builder to step back into our application and single step from that point forward.
Here's how the Call Stack looks for the memLeak application once DebugBreak( ) has been called from LMEMDEBUG.
Figure 4. Call Stack looking for memLeak
Conclusion
In this month's article, we've looked at some of the tools and functionality built into Windows CE .NET 4.1 that can be used to track memory leaks in a custom operating system, specifically, debug zones, Remote Performance Monitor, and LMEMDEBUG.
The Windows Embedded Developers Conference is running in Las Vegas October 21–24. Hope to see you there!. | https://msdn.microsoft.com/en-us/library/aa459167.aspx | CC-MAIN-2015-27 | refinedweb | 3,400 | 53 |
a JAVA interface for a MAX patcher
Does anyone know if it’s possible to build a Java interface, interacting with a Max patcher?
I mean, I have a Max patcher, on which you can configure some values. I want to build a Java interface, so that the user can configure the patcher via the Java interface.
It involves that the Java interface can communicate with the Max patcher.
If anyone knows the solution, I’d be very thankful!
Are you instantiating the gui instance from the UI thread using
something like SwingUtilities.invokeLater()?
This is also suggested by sun. Unfortunately the apple swing
implementation seems sensitive to this sort of thing…
especially given the fact that we are hosting a cocoa UI (swing) in a
carbon application (Max).
t
On Apr 18, 2007, at 12:08 PM, guillaume wrote:
>
>
It was a workaround for a bug in 10.3 OS X done with native code.
From the javadoc….
This is a workaround for a bug in swing on OSX jaguar. Swing dialogs
cause the
app to become stuck in a modal state. If you call this function
before showing the
showing dialog the app is able to recover properly.
t
On Apr 18, 2007, at 13:37 PM, guillaume wrote:
>
>
Thank you very much. I feel what you say is what I need, but I have a problem : what is the GUI class?
OK thank you, I understood what was the GUI class : Graphic User Interface. Thank you very much!
Well, if I understand what you suggest, I have to write my UI class and to make it a Max object?
another way is, that you could build a seperated java (meaning a standalone, not initiated via mxj) application and send values etc over osc…works also quite good the other way round.
micha
bloodhy : you can declare your gui class as a private class of your maxobject.
example :
public class something extends MaxObject {
private int old = 0;
public something(){
}
public void loadbang(){
}
private class myGui extends JFrame{
// this code is generated by netbeans with matisse editor
// but you will have to add your interactions with the upper class.
}
}
G
Have you guys checked out processing.org? That’s a pretty cool package, and afaik, it can interface directly with Max (osc?). Probably worth a look for gui stuff.
J. | http://cycling74.com/forums/topic/a-java-interface-for-a-max-patcher/ | CC-MAIN-2014-42 | refinedweb | 391 | 72.87 |
Hey all,
I'm new to Jython, and I've started working on the bz2 module implementation. I've looked at the PortingPythonModulesToJython wiki, and I was following that, but I can't seem to get my bz2 module to be recognized:
Traceback (most recent call last):
File "test_bz2.py", line 11, in <module>
import bz2
ImportError: No module named bz2
It appears that there is more than one way to register a module, if the "JythonModulesInJava" is still valid:
"My new approach is borrowed slightly from CPython where it's very common to write a C library, a straight wrapper and then a Pythonic wrapper."
So, is there a way I can use the new approach? It looks like (reading the CPythonLib/csv.py) that if I create a "bz2.py" file in the CPythonLib directory, then jython might see it? Or is there a piece of ant that copies the ... oh there it is.
CPythonLib.includes. There it is. Thanks for the help!
Steve | https://sourceforge.net/p/jython/mailman/attachment/750813.84690.qm@web111308.mail.gq1.yahoo.com/1/ | CC-MAIN-2016-36 | refinedweb | 166 | 82.44 |
Getting Started with JasperReport
JasperReport is a popular reporting tool used by the Java programmer. Interestingly, what started as Teodor Danciu's (creator of JasperReport library, 2001) need for an inexpensive reporting solution, has today bloomed into a full-fledged reporting library. This facilitated the need for a simple, inexpensive yet feature rich tool to add reporting capabilities in a Java application.
Much like other Java libraries, JasperReport is an API to facilitate reporting output in a variety of formats, be it, PDF, XML, HTML, XLS, etc. Further this library is not limited to adding reporting capabilities to web-based applications only; it can also be used to generate reports from desktop and console applications as well. In this article we shall see how to go hands on rather than delving into its architectural details.
Fundamentals
Though it is a library like any other in Java, there are a few points to be noted while working with JasperReport.
1) Obviously, Jasper Library needs to be added to our project and some sort of layout has to be generated before we are able to start reporting from Java code.
2) Jasper's reporting layout design is nothing but an XML file with the extension <filename>.jrxml.
3) This JRXML file is to be compiled to create <filename>.jasper. JRXML file can be compiled on the fly, dynamically from our Java code or we can use iReport or JasperStudio to visually design the JRXML file and then compile to create a Jasper file.
4) Once compiled and <filename>.jasper are created, we are done and can feed data into the report from the Java code.
Note: In this article, we shall be using NetBeans 8.0 and iReport5.5.0 plugin. This plugin was actually meant for Netbeans 7.4 but works fine for NetBeans 8.0 as well.
So What We Need
JasperReport heavily depends on other libraries such as Apache log4j, JFreeChart, Apache Commons, etc. As a result dependencies are a little sensitive regarding versions mismatch, especially when its files are downloaded and integrated from scattered locations. The good news is that JasperReport project contains everything we need. Once you download the zip file you need not worry. The details about the library and other needs, to go hands on in accordance to this article are as follows. The versions given here are the latest, at least the time of writing this article.
Installation and Configuration
- Installing JDK and Netbeans is pretty straightforward, so I’m not going into the details.
- Once the iReport5.5.0 plugin is downloaded, unzip it in any location. Open Netbeans, select Plugins from the Tools menu. From the Download tab select Add Plugins... and open all *.nbm files.
Figure 1: Adding plugins
- To create a JasperReport user defined library, select Libraries from the Tools menu. Click on the New Library... button at the bottom left corner of the window, give a Library Name → OK. Then click on Add Jar/Folder... and navigate to the location where you have unzipped JasperReport5.6.0 library and include everything from the lib and distfolders.
Figure 2: Creating user defined library
Note: There is a huge list of jar files in the lib and dist folders of the Jasper library. Every project may not need all of the jar files, but it doesn’t hurt to create a reusable library in NetBeans with all the jars so that we can include it in our Java project without bothering about what jar to include and what not to include. This is especially helpful for beginners where identifying a particular jar may be difficult at times.
We are now ready to create a Java project with Jasper reporting.
Starting a Project
Creating a Simple Application with Jasper Reporting
1. File --> New Project...
2. Select Java from Categories and Java Application from Projects. Then Next.
3. Give the name of the application and click Finish.
4. Add JasperLibrary5.6.0 to the project by right clicking Libraries from the Project pane and Add Library and then import.
5. Open the Files pane (Window --> Files). Right click on the project root to create a folder named reports.
6. Right click on the reports folder then select New → Empty report...
7. Give the name of the report ‘report1’ and Finish.
Figure 3: Files in the project layout, what goes where
Designing a Report
Open report1.jrxml in Designer view and use Report Inspector to design the report as in figure 4.
Figure 4: Report design in NetBeans
The corresponding XML details of the report1.jrxml are shown in Listing 1.
Listing 1: report1.jrxml
<?xml version="1.0" encoding="UTF-8"?> <jasperReport xmlns="" xmlns: <property name="ireport.zoom" value="1.0"/> <property name="ireport.x" value="0"/> <property name="ireport.y" value="0"/> <field name="COLUMN_0" class="java.lang.String"/> <field name="COLUMN_1" class="java.lang.String"/> <field name="COLUMN_2" class="java.lang.String"/> <field name="COLUMN_3" class="java.lang.String"/> <pageHeader> <band height="30" splitType="Stretch"> <staticText> <reportElement x="0" y="0" width="69" height="24" uuid="012424cf-712d-4e84-9906-776e1850b85a"/> <textElement verticalAlignment="Bottom"> <font size="10" isBold="false"/> </textElement> <text><![CDATA[ID]]></text> </staticText> <staticText> <reportElement x="140" y="0" width="94" height="24" uuid="724d23ca-6ad1-4be5-bae1-77c07dd31ba0"/> <textElement textAlignment="Center"/> <text><![CDATA[Name]]></text> </staticText> <staticText> <reportElement x="280" y="0" width="69" height="24" uuid="1e85a3f6-ba9d-47a7-8f25-cf37f5b4448d"/> <text><![CDATA[Department]]></text> </staticText> <staticText> <reportElement x="420" y="0" width="108" height="24" uuid="044a8958-4960-4fa3-9cd6-c594595c521a"/> <text><![CDATA[Email]]></text> </staticText> </band> </pageHeader> <detail> <band height="30" splitType="Stretch"> <textField> <reportElement x="0" y="0" width="69" height="24" uuid="d844cada-1aa4-4208-9fc1-dcdf62a72235"/> <textFieldExpression><![CDATA[$F{COLUMN_0}]]></textFieldExpression> </textField> <textField> <reportElement x="140" y="0" width="94" height="24" uuid="14399970-e399-41e0-b6f9-1218079fd56c"/> <textFieldExpression><![CDATA[$F{COLUMN_1}]]></textFieldExpression> </textField> <textField> <reportElement x="280" y="0" width="69" height="24" uuid="b5b0fe03-9b8f-48c6-ba51-c218427028f6"/> <textFieldExpression><![CDATA[$F{COLUMN_2}]]></textFieldExpression> </textField> <textField> <reportElement x="420" y="0" width="108" height="24" uuid="c3094477-bb5e-4d5c-a440-8d7c7f2a1d3e"/> <textFieldExpression><![CDATA[$F{COLUMN_3}]]></textFieldExpression> </textField> </band> </detail> </jasperReport>
Add log4j.properties
Create a log4j.properties file inside the src folder. Without this, file compiler would complain such as:
log4j:WARN No appenders could be found for logger (net.sf.jasperreports.engine.xml.JRXmlDigesterFactory). log4j:WARN Please initialize the log4j system properly.
Listing 2: log4j.properties
Create Java Class
In the Java class we are creating a report from a model of table data. This is our basic data source in this project. We are also using JasperCompileManager to compile the jrxml file and produce .jasper file dynamically through Java code. This Jasper file is passed to the JasperPrint class along with table data from TableModel. JasperPrint object acts as a container of data from the data source. The report now is ready.
To view the report we then pass the initialized JasperPrint object to create a new JasperView object. JasperView extends Swing JFrame class and hence provides a GUI frame to display the report as in figure 5.
Listing 3: SimpleReport.java
//...import statements
public class SimpleReport { DefaultTableModel tableModel; public SimpleReport() { JasperPrint jasperPrint = null; TableModelData(); try { JasperCompileManager.compileReportToFile("reports/report1.jrxml"); jasperPrint = JasperFillManager.fillReport("reports/report1.jasper", new HashMap(), new JRTableModelDataSource(tableModel)); JasperViewer jasperViewer = new JasperViewer(jasperPrint); jasperViewer.setVisible(true); } catch (JRException ex) { ex.printStackTrace(); } }
private void TableModelData() { String[] columnNames = {"Id", "Name", "Department", "Email"}; String[][] data = { {"111", "G Conger", " Orthopaedic", "jim@wheremail.com"}, {"222", "A Date", "ENT", "adate@somemail.com"}, {"333", "R Linz", "Paedriatics", "rlinz@heremail.com"}, {"444", "V Sethi", "Nephrology", "vsethi@whomail.com"}, {"555", "K Rao", "Orthopaedics", "krao@whatmail.com"}, {"666", "V Santana", "Nephrology", "vsan@whenmail.com"}, {"777", "J Pollock", "Nephrology", "jpol@domail.com"}, {"888", "H David", "Nephrology", "hdavid@donemail.com"}, {"999", "P Patel", "Nephrology", "ppatel@gomail.com"}, {"101", "C Comer", "Nephrology", "ccomer@whymail.com"} }; tableModel = new DefaultTableModel(data, columnNames); } public static void main(String[] args) { new SimpleReport(); }
}
Figure 5: Report output in JasperView
Conclusion
The above example is very simple yet effective method of getting hands on in one’s first Jasper report projects. The tags used in JRXML though looks like a simple XML yet needs further explanation; readers will get a thorough idea if JasperReport documentation is followed. In future articles we will delve a little deeper into how we can use JasperReport further to meet our reporting needs.
| http://www.developer.com/java/getting-started-with-jasperreport.html | CC-MAIN-2014-42 | refinedweb | 1,404 | 51.14 |
25 October 2013 23:00 [Source: ICIS news]
HOUSTON (ICIS)--Here is Friday’s end of day ?xml:namespace>
CRUDE: Dec WTI: $97.85/bbl, up 74 cents; Dec Brent: $106.93/bbl, down 6 cents
NYMEX WTI crude futures finished up on pre-weekend short covering, extending the correction from a sell-off earlier in the week as a result of rising inventories.
RBOB: Nov $2.5871/gal, down 0.25 cents/gal
Reformulated blendstock for oxygen blending (RBOB) gasoline settled slightly lower on Friday, reversing Thursday’s positive settlement as concerns of supply following a Midwest refinery fire waned.
NATURAL GAS: Nov: $3.707MMBtu: up 7.8 cents
NYMEX natural gas future closed the week surging 2% to the highest daily rise in nine sessions, boosted by expectations of strong near-term demand from the power sector and residential sectors due to falling temperatures in the east and Midwest. The rise came despite US service company Baker Hughes reporting a second consecutive jump in the number of natural gas drilling rigs in use across the lower 48 states.
ETHANE: higher at 25.75-26.00 cents/gal
Ethane spot prices were higher, tracking stronger natural gas futures.
AROMATICS: styrene flat at 68.75-69.25 cents/lb
US November styrene spot activity was thin during the day, with some trade participants away from the market for an industry function. As a result, spot prices were flat form the previous session.
OLEFINS: ethylene steady at 46.5-48.0 cents/lb, PGP wider at 62.5-64.0 cents/lb
US October ethylene bid/offer levels held steady at 46.5-48.0 cents/lb as the recent rally continued to hold onto its momentum. US October polymer-grade propylene (PGP) bid/offer levels widened to 62.500-64.000 cents/lb from 62.625-63.250 | http://www.icis.com/Articles/2013/10/25/9719253/EVENING-SNAPSHOT---Americas-Markets-Summary.html | CC-MAIN-2014-52 | refinedweb | 308 | 59.5 |
<SPAN style="FONT-FAMILY: 'Verdana','sans-serif'; COLOR: black; FONT-SIZE: 10pt; mso-fareast-font-family: 'Times New Roman'; mso-bidi-font-family: 'Times New Roman'">The idea of drive through Thal desert was floated by few friends at the time of Cholistan desert Rally. The intention was to see how feasible Thal would be in case a Rally is organised here. We had some readily info available from Salman Niazi and Jeepaholic but it still needed a thorough reccee. <?xml:namespace prefix = o ns = "urn:schemas-microsoft-com
<o:p></o:p><o:p></o:p>
Five 4x4s participated in the Dxpedition....<o:p></o:p>
<o:p></o:p>
Shahid & Yousaf in Vigo<o:p></o:p>
Adnan and his Team in Vigo <o:p></o:p>
Ali Aden and his friends in Pajero 2.8 <o:p></o:p>
Rao Hamid and Kashif (Fihsak) in Pajero <o:p></o:p>
Asad & Ali Zafar in Pajero 3.0 v6<o:p></o:p>
The teams were split in three in the beginning as Ali Zafar (Charged) and myself had to go through Lakki Marwat owing to some family commitment. Rao and Fihsak had to join us directly on the morning of March 24<SUP>th</SUP>. Whereas Adnan, Ali Aden, Shahid bhai and Yousaf Niazi had to reach Thal desert outer rim on the 23<SUP>rd</SUP>. The RV for all teams was thus kept at Noorpur Thal on 24th March. <o:p></o:p>
By the time all the three teams reached the RV they had already done some bit of offroad and sand driving…hence we were all charged to take Thal on
This also included a specially arranged (by Shahid Bhai) river crossing of jeeps through local boats...scarey but very interesting... <o:p></o:p>This also included a specially arranged (by Shahid Bhai) river crossing of jeeps through local boats...scarey but very interesting... <o:p></o:p>
Left Noorpur around 11ish to see Mankera Fort. Reached around 12:45 and were disappointed to see nothing but just a left over of the walls which at first signed wasn’t convincing to be a fort however later after visiting Nawab sahibs Mazar and studying the area in detail we were convinced. <o:p></o:p>
Moved back to the main road and we had to rush to Khatwan where we would need to camp for the night. We chose to follow the GPS through the desert and not any mateled road. This part was full of fun and had the adrenalin pumping through high speed sand runs. It was a short 20-30 mins run till I weared onto a dune and go stuck in deep sand. Adnan tried to pull me out and he also got stuck (Adnan now don’t give explanations on how that happened) Then came Rao in his Jero and barely escaped the wreath of the desert. He tried again and was able to pull out both vigo and my Jero out.
<o:p></o:p>
Kept playing in sand till night fall and then reached at camp site quite late. Few of us had to leave back owing to commitment in the morning hence after having a good cup of tea and some snacks we all packed and left for our destinations. <o:p></o:p>
Our reading for the area is that it has loads of potential for hosting a good rally however that would only be possible from Nov-Jan end. Feb onwards the inhabitants cultivate channa and the entire desert turns green. That is just not the right time. <o:p></o:p>
Alhamdollilah the event though very short but went well. Since I have been told to start the thread hence I would be posting my Jeep pics first…. The rest can get jealous and start posting asap. <o:p></o:p>
Thanks to the all the members of IJC and friends for making it yet another success story. <o:p></o:p>
enjoy the pics and videos.....
- Used Cars
- New Cars
- Bikes
- Accessories
- Cool Rides
- Forums
- More
Bookmarks | https://www.pakwheels.com/forums/general-4x4-discussion/189135-ijc-drive-through-thal-dxpedition-4 | CC-MAIN-2016-50 | refinedweb | 687 | 78.48 |
# How to build a high-performance application on Tarantool from scratch

I came to Mail.ru Group in 2013, and I required a queue for one task. First of all, I decided to check what the company had already got. They told me they had this Tarantool product, and I checked how it worked and decided that adding a queue broker to it could work perfectly well.
I contacted Kostja Osipov, the senior expert in Tarantool, and the next day he gave me a 250-string script that was capable of managing almost everything I needed. Since that moment, I have been in love with Tarantool. It turned out that a small amount of code written with a quite simple script language was capable of ensuring some totally new performance for this DBMS.
Today, I’m going to tell you how to instantiate your own queue in Tarantool 2.2.
At that moment, I enjoyed a simple and fast queue broker Beanstalkd. It offered a user-friendly interface, task status tracking by connection (client’s disconnection returned the task into the queue), as well as practical opportunities for dealing with delayed tasks. I wanted to make something like that.
Here is how the service works: there is a queue broker that accepts and stores tasks; there are clients: producers sending tasks (put method); and consumers taking tasks up (take method).

This is how one task’s lifecycle looks like. The task is sent with the put method and then goes to the ready state. The take operation changes the task’s status to taken. The taken task can be acknowledged (ack) and removed or changed back to ready (release-d).

Procession of delayed tasks can be added:
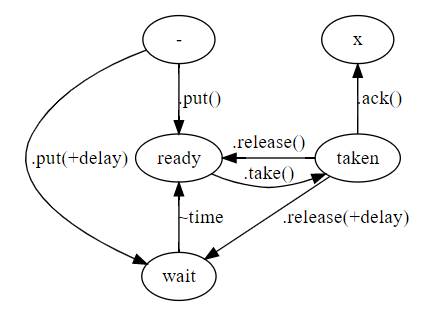
Neighborhood setup
------------------
Today, Tarantool is also a LuaJIT interpreter. To start working with it, an entry point is required – an initial file init.lua. After that a box.cfg() shall be called – it starts the DBMS internals.
For local development, you only have to connect and start the console. Then create and run a file as follows:
```
require'strict'.on()
box.cfg{}
require'console'.start()
os.exit()
```
The console is interactive and can be instantly put to use. There is no need to install and/or set up multiple tools and learn to use them. It only takes to write 10 to 15 strings of code on any local machine.
Another advice from me is to use the strict mode. Lua language is quite easy on the variable declaration, and this mode to a certain extent will help you with error management. If you build Tarantool on your own in the DEBUG mode, the strict mode will be on by default.
Let’s run our file with Tarantool:
```
tarantool init.lua
```
You’ll see something like:
```
2020-07-09 20:00:11.344 [30043] main/102/init.lua C> Tarantool 2.2.3-1-g98ecc909a
2020-07-09 20:00:11.345 [30043] main/102/init.lua C> log level 5
2020-07-09 20:00:11.346 [30043] main/102/init.lua I> mapping 268435456 bytes for memtx tuple arena...
2020-07-09 20:00:11.347 [30043] main/102/init.lua I> mapping 134217728 bytes for vinyl tuple arena...
2020-07-09 20:00:11.370 [30043] main/102/init.lua I> instance uuid 38c59892-263e-42de-875c-8f67539191a3
2020-07-09 20:00:11.371 [30043] main/102/init.lua I> initializing an empty data directory
2020-07-09 20:00:11.408 [30043] main/102/init.lua I> assigned id 1 to replica 38c59892-263e-42de-875c-8f67539191a3
2020-07-09 20:00:11.408 [30043] main/102/init.lua I> cluster uuid 7723bdf4-24e8-4957-bd6c-6ab502a1911c
2020-07-09 20:00:11.425 [30043] snapshot/101/main I> saving snapshot `./00000000000000000000.snap.inprogress'
2020-07-09 20:00:11.437 [30043] snapshot/101/main I> done
2020-07-09 20:00:11.439 [30043] main/102/init.lua I> ready to accept requests
2020-07-09 20:00:11.439 [30043] main/104/checkpoint_daemon I> scheduled next checkpoint for Thu Jul 9 21:11:59 2020
tarantool>
```
Writing a queue
---------------
Let’s create a file queue.lua to write our app. We can add all of it right to init.lua, but working with an independent file is handier.
Now, connect the queue as a module from the init.lua file:
```
require'strict'.on()
box.cfg{}
queue = require 'queue'
require'console'.start()
os.exit()
```
All the following modifications will be made in queue.lua.
As we’re making a queue, we need a place to store the task data. Let’s create a space – a data table. It can be made optionless, but we’re going to add something at once. For regular restart we have to indicate that a space shall be created only in case it doesn’t exist (if\_not\_exists). Another thing – in Tarantool, you can indicate the field format with content description (and it is a good idea to do so).
I’m going to take a very simple structure for the queue. I’ll need only task id-s, their statuses, and some random data. Data can’t be used with a primary index, so we create an index in accordance with id. Make sure the field type of the format and the index match.
```
box.schema.create_space('queue',{ if_not_exists = true; })
box.space.queue:format( {
{ name = 'id'; type = 'number' },
{ name = 'status'; type = 'string' },
{ name = 'data'; type = '*' },
} );
box.space.queue:create_index('primary', {
parts = { 1,'number' };
if_not_exists = true;
})
```
Then, we make a global queue table that will contain our functions, attributes, and methods. First of all, we bring out two functions: putting a task (put) and taking a task (take).
The queue will show states of the tasks. For status indication, we’ll make another table. Numbers or strings can be used as values, but I like one-symbol references – they can be semantically relevant, and they take little place to be stored. First of all, we create two statuses: R=READY and T=TAKEN.
```
local queue = {}
local STATUS = {}
STATUS.READY = 'R'
STATUS.TAKEN = 'T'
function queue.put(...)
end
function queue.take(...)
end
return queue
```
How do we make put? Easy as pie. We need to generate an id and insert the data to a space with the READY status. There are many ways to generate an indicator, but we’ll take clock.realtime. It can automatically determine the message queue. However, remember that the clock is likely to readjust, causing a wrong message order. Another thing is that a task with the same value can appear in the queue. You can check if there is a task with the same id, and in case of collision you just one unit. This takes microseconds, and this situation is highly unlikely, so efficiency won’t be affected.
All the arguments of the function shall be added to our task:
```
local clock = require 'clock'
function gen_id()
local new_id
repeat
new_id = clock.realtime64()
until not box.space.queue:get(new_id)
return new_id
end
function queue.put(...)
local id = gen_id()
return box.space.queue:insert{ id, STATUS.READY, { ... } }
end
```
After we’ve written the put function, we can restart Tarantool and call this function instantly. The task will be added to the queue, now looking like a tuple. We can add random data and even nested structures to it. Tuples that Tarantool uses to store data are packed into the MessagePack, which facilitates storing of these structures.
```
tarantool> queue.put("hello")
---
- [1594325382148311477, 'R', ['hello']]
...
tarantool> queue.put("my","data",1,2,3)
---
- [1594325394527830491, 'R', ['my', 'data', 1, 2, 3]]
...
tarantool> queue.put({ complex = { struct = "data" }})
---
- [1594325413166109943, 'R', [{'complex': {'struct': 'data'}}]]
...
```
Everything we put remains within the space. We can take space commands to see what we have there:
```
tarantool> box.space.queue:select()
---
- - [1594325382148311477, 'R', ['hello']]
- [1594325394527830491, 'R', ['my', 'data', 1, 2, 3]]
- [1594325413166109943, 'R', [{'complex': {'struct': 'data'}}]]
...
```
Everything we put remains within the space. We can take space commands to see what we have there:
```
tarantool> box.space.queue:select()
---
- - [1594325382148311477, 'R', ['hello']]
- [1594325394527830491, 'R', ['my', 'data', 1, 2, 3]]
- [1594325413166109943, 'R', [{'complex': {'struct': 'data'}}]]
...
```
Now, we need to learn how to take tasks. For this, we make a take function. We take the tasks that are ready for processing, i. e., the ones with the READY status. We can check the primary key and find the first ready task, but if there’re a lot of tasks to be processed this scenario won’t work. We’ll need a special index using the status field. One of the main differences between Tarantool and the key-value databases is that the former facilitates the creation of diverse indexes, almost like in relational databases: using various fields, composite ones, of different kinds.
Then, we create the second index, indicating that the first field shows status. This will be our search option. The second field is id. It will put the tasks with the same status in the ascending order.
```
box.space.queue:create_index('status', {
parts = { 2, 'string', 1, 'number' };
if_not_exists = true;
})
```
Let’s take predefined functions for our selection. There’s a special iterator that is applied to a space as pairs. We pass a part of the key to it. Here, we have to deal with a composite index, which contains two fields. We use the first one for searching and the second one for putting things in order. We command the system to find the tuples that match the READY status in the first part of their index. And the system will present them put in order in accordance with the second part of the index. If we find anything, we’ll take that task, update it and return it. An update is required to prevent anybody with the same take call taking it. If there are no tasks, we return nil.
```
function queue.take()
local found = box.space.queue.index.status
:pairs({STATUS.READY},{ iterator = 'EQ' }):nth(1)
if found then
return box.space.queue
:update( {found.id}, {{'=', 2, STATUS.TAKEN }})
end
return
end
```
Please, note that the first tuple level in Tarantool is an array. It has no names, but only numbers, and that’s why the field number used to be required at operations like update. Let’s make an auxiliary element – a table, to match the field names and numbers. To compile such a table we can use the format we’ve already written:
```
local F = {}
for no,def in pairs(box.space.queue:format()) do
F[no] = def.name
F[def.name] = no
end
```
For better visibility, we can correct descriptions of indexes like:
```
box.space.queue:format( {
{ name = 'id'; type = 'number' },
{ name = 'status'; type = 'string' },
{ name = 'data'; type = '*' },
} );
local F = {}
for no,def in pairs(box.space.queue:format()) do
F[no] = def.name
F[def.name] = no
end
box.space.queue:create_index('primary', {
parts = { F.id, 'number' };
if_not_exists = true;
})
box.space.queue:create_index('status', {
parts = { F.status, 'string', F.id, 'number' };
if_not_exists = true;
})
```
Now we can implement take in whole:
```
function queue.take(...)
for _,t in
box.space.queue.index.status
:pairs({ STATUS.READY },{ iterator='EQ' })
do
return box.space.queue:update({t.id},{
{ '=', F.status, STATUS.TAKEN }
})
end
return
end
```
Let’s check how it works. For this, we’ll put one task and call take twice. If by that moment we have any data in the space, we can clear it with the command box.space.queue:truncate():
```
tarantool> queue.put("my","data",1,2,3)
---
- [1594325927025602515, 'R', ['my', 'data', 1, 2, 3]]
...
tarantool> queue.take()
---
- [1594325927025602515, 'T', ['my', 'data', 1, 2, 3]]
...
tarantool> queue.take()
---
...
```
The first take will return us the task we’ve put. As soon as we call take for the second time, nil is returned, because there are no more ready-tasks (with R status). To make sure, we run a select command from the space:
```
tarantool> box.space.queue:select()
---
- - [1594325927025602515, 'T', ['my', 'data', 1, 2, 3]]
...
```
The consumer taking the task shall either acknowledge its procession or release it without a procession. In the latter case, somebody else will be able to take the task. For this, two functions are used: ack and release. They receive the task’s id and look for it. If the task’s status shows it’s been taken, we process it. These functions are really similar: one removes processed tasks, and the other returns them with a ready status.
```
function queue.ack(id)
local t = assert(box.space.queue:get{id},"Task not exists")
if t and t.status == STATUS.TAKEN then
return box.space.queue:delete{t.id}
else
error("Task not taken")
end
end
function queue.release(id)
local t = assert(box.space.queue:get{id},"Task not exists")
if t and t.status == STATUS.TAKEN then
return box.space.queue:update({t.id},{{'=', F.status, STATUS.READY }})
else
error("Task not taken")
end
end
```
Let’s see how it works with all four functions. We will put two tasks and take the first of them, then releasing them. It returns to the R status. The second take call takes the same task. If we process it, it will be removed. The third take call will take the second task. The order will be observed. In case the task has been taken, it won’t be available for anybody else.
```
tarantool> queue.put("task 1")
---
- [1594326185712343931, 'R', ['task 1']]
...
tarantool> queue.put("task 2")
---
- [1594326187061434882, 'R', ['task 2']]
...
tarantool> task = queue.take() return task
---
- [1594326185712343931, 'T', ['task 1']]
...
tarantool> queue.release(task.id)
---
- [1594326185712343931, 'R', ['task 1']]
...
tarantool> task = queue.take() return task
---
- [1594326185712343931, 'T', ['task 1']]
...
tarantool> queue.ack(task.id)
---
- [1594326185712343931, 'T', ['task 1']]
...
tarantool> task = queue.take() return task
---
- [1594326187061434882, 'T', ['task 2']]
...
tarantool> queue.ack(task.id)
---
- [1594326187061434882, 'T', ['task 2']]
...
tarantool> task = queue.take() return task
---
- null
...
```
This is a properly working queue. We are already capable of writing a consumer to process the tasks. However, there is a problem. When we call take, the function instantly returns either a task or an empty string. If we write a cycle for task procession and start it, it will run unproductively, doing nothing and simply wasting the CPU.
```
while true do
local task = queue.take()
if task then
-- ...
end
end
```
To fix this, we’ll need a primitive channel. It enables message communication. In fact, it’s a FIFO queue for fiber communication. We have a fiber that puts the tasks when we access the database through the network or via the console. At the fiber, our Lua-code is executed, and it needs some primitive to inform the other fiber awaiting the task that there is a new one available.
This is how a channel works: it can contain a buffer with N slots where a message can be located, even if no one is checking the channel. Another option is creating a channel without a buffer: this way, messages will be only acceptable in the slots that somebody waiting for. Let’s say, we create a channel for two buffer elements. It has two slots for put. If one consumer is waiting at the channel, it will create a third slot for put. If we are going to send messages via this channel, three put operations will be enabled without blocking, but the fourth put operation will be blocked by the fiber that sends messages via this channel. This is how an inter-fiber communication is set up. If for any chance you are familiar with channels in Go, they are literally the same there:
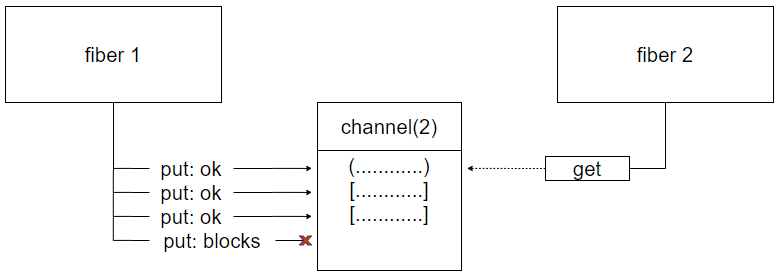
Let’s slightly modify the take function. First of all, we add a new argument – timeout, implying we’re ready to wait for the task within a set period of time. We make a cycle to search for a ready task. If it can’t be found, the cycle will compute how long it has to wait.
Now, let’s make a channel that will wait along with this timeout. While the fiber is pending at the channel (asleep), it can be woken up externally by sending a message via the channel.
```
local fiber = require 'fiber'
queue._wait = fiber.channel()
function queue.take(timeout)
if not timeout then timeout = 0 end
local now = fiber.time()
local found
while not found do
found = box.space.queue.index.status
:pairs({STATUS.READY},{ iterator = 'EQ' }):nth(1)
if not found then
local left = (now + timeout) - fiber.time()
if left <= 0 then return end
queue._wait:get(left)
end
end
return box.space.queue
:update( {found.id}, {{'=', F.status, STATUS.TAKEN }})
end
```
Altogether, take tries to take the task and if this is managed, the task is returned. However, if there is no task, it can be awaited for the rest of the timeout. Besides, the other party that creates the task will be able to wake this fiber up.
To make the performance of various tests more convenient, we can globally connect the fiber module in the init.lua file:
```
fiber = require 'fiber'
```
Let’s see how this works without waking the fiber up. In an independent fiber, we’ll put a task with a 0.1 sec. delay, i. e. at first the queue will be empty, and the task will appear in 0.1 sec. after starting. Upon that, we’ll set up a 3 sec. timeout for the take call. After the start, take will try to find the task, and then if there’s none, it goes to sleep for 3 sec. In 3 sec. it wakes up, searches again, and finds the task.
```
tarantool> do
box.space.queue:truncate()
fiber.create(function()
fiber.sleep(0.1)
queue.put("task 3")
end)
local start = fiber.time()
return queue.take(3), { wait = fiber.time() - start }
end
---
- [1594326905489650533, 'T', ['task 3']]
- wait: 3.0017817020416
...
```
Now, let’s make take wake up at the tasks’ appearance. For this, we’ll take our old put function and update it with a message sent via the channel. The message can be literally anything. Let it be true here.
Previously, I demonstrated that put can be blocked if the channel lacks place. At the same time, the task producer doesn’t care if there are consumers on the other side. It shouldn’t get blocked while waiting for a consumer. So, it’s a reasonable thing to set up a zero timeout for blocking here. If there are some consumers out there, i. e., the ones who need to be messaged about the new task, we’ll wake them up. Otherwise, we won’t be able to send the message via the channel. An alternative option is to check if the channel has any active readers.
```
function queue.put(...)
local id = gen_id()
if queue._wait:has_readers() then
queue._wait:put(true,0)
end
return box.space.queue:insert{ id, STATUS.READY, { ... } }
end
```
Now the take code is going to work in a totally different way. We create a task in 0.1 sec. and take instantly wakes up and receives it. We’ve got rid of the hot cycle that has been continuously pending, awaiting tasks. If we don’t put a task, the fiber will wait for 3 seconds.
```
tarantool> do
box.space.queue:truncate()
fiber.create(function()
fiber.sleep(0.1)
queue.put("task 4")
end)
local start = fiber.time()
return queue.take(3), { wait = fiber.time() - start }
end
---
- [1594327004302379957, 'T', ['task 4']]
- wait: 0.10164666175842
...
```
We’ve tested how things work within the instance, and now let’s try some networking. First of all, let’s create a server. For that, we add the listen option to box.cfg of our init.lua file (it will be a port used for listening). At the same time, we’ll need to give permissions. Right now we’re not going to study privilege setting up in detail, but let’s make every connection have an execution privilege. To read about the rights please check this.
```
require'strict'.on()
fiber = require 'fiber'
box.cfg{
listen = '127.0.0.1:3301'
}
box.schema.user.grant('guest', 'super', nil, nil, { if_not_exists = true })
queue = require 'queue'
require'console'.start()
os.exit()
```
Let’s create a producer client for task generation. Tarantool already has a module that facilitates connection to another Tarantool.
```
#!/usr/bin/env tarantool
if #arg < 1 then
error("Need arguments",0)
end
local netbox = require 'net.box'
local conn = netbox.connect('127.0.0.1:3301')
local yaml = require 'yaml'
local res = conn:call('queue.put',{unpack(arg)})
print(yaml.encode(res))
conn:close()
$ tarantool producer.lua "hi"
--- [1594327270675788959, 'R', ['hi']]
...
```
The consumer will connect, call take with a timeout, and process the result. If it receives the task, we’ll print or release it but won’t process it yet. Let’s say, we’ve received the task.
```
#!/usr/bin/env tarantool
local netbox = require 'net.box'
local conn = netbox.connect('127.0.0.1:3301')
local yaml = require 'yaml'
while true do
local task = conn:call('queue.take', { 1 })
if task then
print("Got task: ", yaml.encode(task))
conn:call('queue.release', { task.id })
else
print "No more tasks"
end
end
```
But when we try to release the task, something odd happens:
```
$ tarantool consumer.lua
Got task:
--- [1594327270675788959, 'T', ['hi']]
...
ER_EXACT_MATCH: Invalid key part count in an exact match (expected 1, got 0)
```
Let’s delve into this matter. When the consumer will once again attempt to execute the task we’ll see that at the previous start it has taken the task but hasn’t been able to return it. Some error’s occurred, and the tasks got stuck. Such tasks become unavailable for other consumers, and there is nobody to return them to, as the code used to take them has been completed.
```
$ tarantool consumer.lua
No more tasks
No more tasks
```
Select shows that the tasks have been taken.
```
tarantool> box.space.queue:select()
---
- - [1594327004302379957, 'T', ['task 3']]
- [1594327270675788959, 'T', ['hi']]
...
```
We have several issues at once here. Let’s start with the automatic release of the tasks in case the client disconnects.
Tarantool contains triggers for client connection and disconnection. If we add them, we’ll be able to learn about connection and disconnection events.
```
local log = require 'log'
box.session.on_connect(function()
log.info( "connected %s from %s", box.session.id(), box.session.peer() )
end)
box.session.on_disconnect(function()
log.info( "disconnected %s from %s", box.session.id(), box.session.peer() )
end)
2020-07-09 20:52:09.107 [32604] main/115/main I> connected 2 from 127.0.0.1:36652
2020-07-09 20:52:10.260 [32604] main/116/main I> disconnected 2 from nil
2020-07-09 20:52:10.823 [32604] main/116/main I> connected 3 from 127.0.0.1:36654
2020-07-09 20:52:11.541 [32604] main/115/main I> disconnected 3 from nil
```
There is this term, session id, and we can check the IP address used to connect, as well as the time of disconnection. However, calling session.peer()actually calls getpeername(2) right over the socket. That’s why at disconnection we don’t see who’s disconnected (as getpeername is called over a closed socket). Let’s do some minor hacking, then. Tarantool has a box.session.storage — a temporary table, to which anything you wish can be saved during the session lifetime. At connection, we can keep in mind the ones connected to know who’s disconnected. This will make adjustments easier.
```
box.session.on_connect(function()
box.session.storage.peer = box.session.peer()
log.info( "connected %s from %s", box.session.id(), box.session.storage.peer )
end)
box.session.on_disconnect(function()
log.info( "disconnected %s from %s", box.session.id(), box.session.storage.peer )
end)
```
So, we have a client disconnection event. And we need to somehow release the tasks it has taken. Let’s introduce the term “possession of the task.” The session that has taken the task ought to answer for it. Let’s make two tables to save these data and modify the take function:
```
queue.taken = {}; -- list of tasks taken
queue.bysid = {}; -- list of tasks for the specific session
function queue.take(timeout)
if not timeout then timeout = 0 end
local now = fiber.time()
local found
while not found do
found = box.space.queue.index.status
:pairs({STATUS.READY},{ iterator = 'EQ' }):nth(1)
if not found then
local left = (now + timeout) - fiber.time()
if left <= 0 then return end
queue._wait:get(left)
end
end
local sid = box.session.id()
log.info("Register %s by %s", found.id, sid)
queue.taken[ found.id ] = sid
queue.bysid[ sid ] = queue.bysid[ sid ] or {}
queue.bysid[ sid ][ found.id ] = true
return box.space.queue
:update( {found.id}, {{'=', F.status, STATUS.TAKEN }})
end
```
We’ll use this table to memorize that a certain task has been taken by a certain session. We’ll also need to modify the task returning code, ack, and release. Let’s make a single common function to check if the task is there and if it has been taken by a specific session. Then, it will be impossible to take the task under one connection and then return under another one requesting its deletion due to its procession completion.
```
local function get_task( id )
if not id then error("Task id required", 2) end
local t = box.space.queue:get{id}
if not t then
error(string.format( "Task {%s} was not found", id ), 2)
end
if not queue.taken[id] then
error(string.format( "Task %s not taken by anybody", id ), 2)
end
if queue.taken[id] ~= box.session.id() then
error(string.format( "Task %s taken by %d. Not you (%d)",
id, queue.taken[id], box.session.id() ), 2)
end
return t
end
```
Now ack and release functions become very simple. We use them to call get\_task, which checks if the task is possessed by us and if it is taken. Then we can work with it.
```
function queue.ack(id)
local t = get_task(id)
queue.taken[ t.id ] = nil
queue.bysid[ box.session.id() ][ t.id ] = nil
return box.space.queue:delete{t.id}
end
function queue.release(id)
local t = get_task(id)
if queue._wait:has_readers() then queue._wait:put(true,0) end
queue.taken[ t.id ] = nil
queue.bysid[ box.session.id() ][ t.id ] = nil
return box.space.queue
:update({t.id},{{'=', F.status, STATUS.READY }})
end
```
To reset statuses of all the tasks to R SQL or Lua snippet can be used:
```
box.execute[[ update "queue" set "status" = 'R' where "status" = 'T' ]]
box.space.queue.index.status:pairs({'T'}):each(function(t)
box.space.queue:update({t.id},{{'=',2,'R'}}) end)
```
When we call the consumer again, it replies: task ID required.
```
$ tarantool consumer.lua
Got task:
--- [1594327004302379957, 'T', ['task 3']]
...
ER_PROC_LUA: queue.lua:113: Task id required
```
Thus, we’ve found the first problem in our code. When we work in Tarantool, a tuple is always associated with the space. The latter has a format, and the format has field names. That’s why we can use field names in a tuple. When we take it beyond the database, a tuple becomes just an array with a number of fields. If we refine the format of return from the function, we’ll be able to return not tuples, but objects with names. For this, we’ll apply the method :tomap{ names\_only = true }:
```
function queue.put(...)
--- ...
return box.space.queue
:insert{ id, STATUS.READY, { ... } }
:tomap{ names_only = true }
end
function queue.take(timeout)
--- ...
return box.space.queue
:update( {found.id}, {{'=', F.status, STATUS.TAKEN }})
:tomap{ names_only = true }
end
function queue.ack(id)
--- ...
return box.space.queue:delete{t.id}:tomap{ names_only = true }
end
function queue.release(id)
--- ...
return box.space.queue
:update({t.id},{{'=', F.status, STATUS.READY }})
:tomap{ names_only = true }
end
return queue
```
Having replaced it, we’ll encounter another issue.
```
$ tarantool consumer.lua
Got task:
--- {'status': 'T', 'data': ['hi'], 'id': 1594327270675788959}
...
ER_PROC_LUA: queue.lua:117: Task 1594327270675788959ULL not taken by anybody
```
If we try to release the task the system will answer that we haven’t taken it. Moreover, we will see the same ID, but with a suffix – ULL.
Here we encounter a trick of the LuaJIT extention: FFI (Foreign Function Interface). Let’s delve into this matter. We add five values to the table using various alternatives of numeral 1 designation as the keys.
```
tarantool> t = {}
tarantool> t[1] = 1
tarantool> t["1"] = 2
tarantool> t[1LL] = 3
tarantool> t[1ULL] = 4
tarantool> t[1ULL] = 5
tarantool> t
---
- 1: 1
1: 5
1: 4
'1': 2
1: 3
...
```
We would expect them to be displayed as 2 (string + number) or 3 (string + number + LL). But when displayed, all the keys will appear in the table separately: we will still see all the values – 1, 2, 3, 4, 5. Moreover, at serialization, we won’t see any difference between regular, signed, or unsigned numbers.
```
tarantool> return t[1], t['1'], t[1LL], t[1ULL]
---
- 1
- 2
- null
- null
...
```
However, the most amusing thing happens when we try to extract data from the table. It goes well with regular Lua-types (number and string), but it doesn’t with LL (long long) and ULL (unsigned long long). They are a separate type of cdata, intended for working with C language types. When saving into a Lua table, cdata is hashed by address, not by value. Two numbers, no matter if they are the same in value, simply have different addresses. And when we add ULL to the table, we can’t extract them using the same value.
That’s why we’ll have to change our queue and key possession a bit. This is a forced move, but it will enable random modification of our keys in the future. Somehow, we need to transform our key into a string or a number. Let’s take the MessagePack. In Tarantool, it’s used to store tuples, and it will pack our values just like Tarantool itself does. With this pack, we’ll transform a random key into a string that will become a key to our table.
```
local msgpack = require 'msgpack'
local function keypack( key )
return msgpack.encode( key )
end
local function keyunpack( data )
return msgpack.decode( data )
end
```
Then we add the key package to take and save it into the table. In the function get\_task we need to check if the key has passed in a correct format, and if not, we change it to int64. After that, we use keypack to pack the key to the MessagePack. As this packed key will be required by all the functions that use it, we’ll return it from get\_task, so that ack and release could use it and clean it out from the sessions.
```
function queue.take(timeout)
if not timeout then timeout = 0 end
local now = fiber.time()
local found
while not found do
found = box.space.queue.index.status
:pairs({STATUS.READY},{ iterator = 'EQ' }):nth(1)
if not found then
local left = (now + timeout) - fiber.time()
if left <= 0 then return end
queue._wait:get(left)
end
end
local sid = box.session.id()
log.info("Register %s by %s", found.id, sid)
local key = keypack( found.id )
queue.taken[ key ] = sid
queue.bysid[ sid ] = queue.bysid[ sid ] or {}
queue.bysid[ sid ][ key ] = true
return box.space.queue
:update( {found.id}, {{'=', F.status, STATUS.TAKEN }})
:tomap{ names_only = true }
end
local function get_task( id )
if not id then error("Task id required", 2) end
id = tonumber64(id)
local key = keypack(id)
local t = box.space.queue:get{id}
if not t then
error(string.format( "Task {%s} was not found", id ), 2)
end
if not queue.taken[key] then
error(string.format( "Task %s not taken by anybody", id ), 2)
end
if queue.taken[key] ~= box.session.id() then
error(string.format( "Task %s taken by %d. Not you (%d)",
id, queue.taken[key], box.session.id() ), 2)
end
return t, key
end
function queue.ack(id)
local t, key = get_task(id)
queue.taken[ key ] = nil
queue.bysid[ box.session.id() ][ key ] = nil
return box.space.queue:delete{t.id}:tomap{ names_only = true }
end
function queue.release(id)
local t, key = get_task(id)
queue.taken[ key ] = nil
queue.bysid[ box.session.id() ][ key ] = nil
if queue._wait:has_readers() then queue._wait:put(true,0) end
return box.space.queue
:update({t.id},{{'=', F.status, STATUS.READY }})
:tomap{ names_only = true }
end
```
As we have a disconnection trigger, we know that a certain session has disconnected – the one possessing certain keys. We can take all the keys from that session and automatically return them to their initial state — ready. Besides, this session may contain some tasks awaiting to be take-n. Let’s mark them in the session.storage for the tasks not to be taken.
```
box.session.on_disconnect(function()
log.info( "disconnected %s from %s", box.session.id(), box.session.storage.peer )
box.session.storage.destroyed = true
local sid = box.session.id()
local bysid = queue.bysid[ sid ]
if bysid then
while next(bysid) do
for key, id in pairs(bysid) do
log.info("Autorelease %s by disconnect", id);
queue.taken[key] = nil
bysid[key] = nil
local t = box.space.queue:get(id)
if t then
if queue._wait:has_readers() then queue._wait:put(true,0) end
box.space.queue:update({t.id},{{'=', F.status, STATUS.READY }})
end
end
end
queue.bysid[ sid ] = nil
end
end)
function queue.take(timeout)
if not timeout then timeout = 0 end
local now = fiber.time()
local found
while not found do
found = box.space.queue.index.status
:pairs({STATUS.READY},{ iterator = 'EQ' }):nth(1)
if not found then
local left = (now + timeout) - fiber.time()
if left <= 0 then return end
queue._wait:get(left)
end
end
if box.session.storage.destroyed then return end
local sid = box.session.id()
log.info("Register %s by %s", found.id, sid)
local key = keypack( found.id )
queue.taken[ key ] = sid
queue.bysid[ sid ] = queue.bysid[ sid ] or {}
queue.bysid[ sid ][ key ] = found.id
return box.space.queue
:update( {found.id}, {{'=', F.status, STATUS.TAKEN }})
:tomap{ names_only = true }
end
```
For testing purposes, tasks can be taken as a group:
```
tarantoolctl connect 127.0.0.1:3301 <<< 'queue.take()'
```
At adjustment, you might see that you’ve taken the tasks, thus dropping the queue, but at restart the tasks aren’t possessed by anybody (because all connections were interrupted when you switched off), but they get the taken status. That’s why we’ll update our code with status modification at startup. Thus, the database will be started, releasing all the tasks taken.
```
while true do
local t = box.space.queue.index.status:pairs({STATUS.TAKEN}):nth(1)
if not t then break end
box.space.queue:update({ t.id }, {{'=', F.status, STATUS.READY }})
log.info("Autoreleased %s at start", t.id)
end
```
Now we have a queue ready for operation.
Adding delayed procession
-------------------------
Thereat, we only have to add delayed tasks. For that, let’s add a new field and a relevant index. We’re going to use this field to store the time when a certain task’s state should be changed. To this end, we’re modifying the put function and adding a new status: W=WAITING.
```
box.space.queue:format( {
{ name = 'id'; type = 'number' },
{ name = 'status'; type = 'string' },
{ name = 'runat'; type = 'number' },
{ name = 'data'; type = '*' },
} )
box.space.queue:create_index('runat', {
parts = { F.runat, 'number', F.id, 'number' };
if_not_exists = true;
})
STATUS.WAITING = 'W'
```
As we are flip-flopping the pattern, and as this is a development mode, let’s clear the previous pattern (via the console):
```
box.space.queue.drop()
box.snapshot()
```
Now, let’s restart our queue.
Then, we add support of delay in put and release. If delay is passed on, the task’s status shall be changed to WAITING, and we have to define when it is subject to the procession. Another thing we need is a processor. For this, we can use background fibers. At any moment we can create a fiber that isn’t associated with any connections and works in the background. Let’s make a fiber that will work infinitely and await the nearest tasks.
```
function queue.put(data, opts)
local id = gen_id()
local runat = 0
local status = STATUS.READY
if opts and opts.delay then
runat = clock.realtime() + tonumber(opts.delay)
status = STATUS.WAITING
else
if queue._wait:has_readers() then
queue._wait:put(true,0)
end
end
return box.space.queue
:insert{ id, status, runat, data }
:tomap{ names_only=true }
end
function queue.release(id, opts)
local t, key = get_task(id)
queue.taken[ key ] = nil
queue.bysid[ box.session.id() ][ key ] = nil
local runat = 0
local status = STATUS.READY
if opts and opts.delay then
runat = clock.realtime() + tonumber(opts.delay)
status = STATUS.WAITING
else
if queue._wait:has_readers() then queue._wait:put(true,0) end
end
return box.space.queue
:update({t.id},{{ '=', F.status, status },{ '=', F.runat, runat }})
:tomap{ names_only = true }
end
```
If a time comes for some of the tasks, we modify it, changing its status from waiting to ready and also notifying the clients that might be awaiting a task.
Now, we put a delayed task. Call take, make sure that there are no ready tasks. Call it again with a timeout, which fits into the task’s appearance. As soon as it appears, we see it’s been done by the fiber queue.runat.
```
queue._runat = fiber.create(function()
fiber.name('queue.runat')
while true do
local remaining
local now = clock.realtime()
for _,t in box.space.queue.index.runat
:pairs( { 0 }, { iterator = 'GT' })
do
if t.runat > now then
remaining = t.runat - now
break
else
if t.status == STATUS.WAITING then
log.info("Runat: W->R %s",t.id)
if queue._wait:has_readers() then queue._wait:put(true,0) end
box.space.queue:update({ t.id }, {
{'=', F.status, STATUS.READY },
{'=', F.runat, 0 },
})
else
log.error("Runat: bad status %s for %s", t.status, t.id)
box.space.queue:update({ t.id },{{ '=', F.runat, 0 }})
end
end
end
if not remaining or remaining > 1 then remaining = 1 end
fiber.sleep(remaining)
end
end)
```
Monitoring
----------
Never forget about monitoring the queue, because it can extend too much or even run out. We can count the number of tasks with every status in the queue and start sending the data to monitoring.
```
function queue.stats()
return {
total = box.space.queue:len(),
ready = box.space.queue.index.status:count({STATUS.READY}),
waiting = box.space.queue.index.status:count({STATUS.WAITING}),
taken = box.space.queue.index.status:count({STATUS.TAKEN}),
}
end
tarantool> queue.stats()
---
- ready: 10
taken: 2
waiting: 5
total: 17
...
tarantool> local clock = require 'clock' local s = clock.time() local r = queue.stats() return r, clock.time() - s
---
- ready: 10
taken: 2
waiting: 5
total: 17
- 0.00057339668273926
...
```
Such monitoring will work quite fast as long as there are not too many tasks. The normal state of the queue is empty. But suppose we have a million tasks. Our stats function still shows the correct value but works rather slowly. The issue is caused by the index:count call — this is always a full scan by index. Let’s cash the values of the counters.
```
queue._stats = {}
for k,v in pairs(STATUS) do
queue._stats[v] = 0LL
end
for _,t in box.space.queue:pairs() do
queue._stats[ t[F.status] ] = (queue._stats[ t[F.status] ] or 0LL)+1
end
function queue.stats()
return {
total = box.space.queue:len(),
ready = queue._stats[ STATUS.READY ],
waiting = queue._stats[ STATUS.WAITING ],
taken = queue._stats[ STATUS.TAKEN ],
}
end
```
Now, this function will work very fast regardless of the number of records. We only have to update the counters at any operations. Prior to every operation, we have to reduce one value and increase the other. We also can manually set updates of the functions, but errors and contradictions are possible. Luckily, Tarantool has triggers for spaces that are capable of tracing any changes in the space. You can even manually execute space:update or space:delete – the trigger will take that into account, too. The trigger will account for all the statuses according to the value used in the database. At the restart, we’ll once account for the values of all the counters.
```
box.space.queue:on_replace(function(old,new)
if old then
queue._stats[ old[ F.status ] ] = queue._stats[ old[ F.status ] ] - 1
end
if new then
queue._stats[ new[ F.status ] ] = queue._stats[ new[ F.status ] ] + 1
end
end)
```
There is one more operation that can’t be traced in the space directly but affects its content: space:truncate(). To monitor the clearing of the space a special space trigger can be used — \_truncate.
```
box.space._truncate:on_replace(function(old,new)
if new.id == box.space.queue.id then
for k,v in pairs(queue._stats) do
queue._stats[k] = 0LL
end
end
end)
```
After that everything will work accurately and consistently. Statistics can be sent over the network. Tarantool has convenient non-blocking sockets that can be used rather low-level, almost like in C.
To demonstrate how it works let send the metrics in a Graphite format using UDP:
```
local socket = require 'socket'
local errno = require 'errno'
local graphite_host = '127.0.0.1'
local graphite_port = 2003
local ai = socket.getaddrinfo(graphite_host, graphite_port, 1, { type = 'SOCK_DGRAM' })
local addr,port
for _,info in pairs(ai) do
addr,port = info.host,info.port
break
end
if not addr then error("Failed to resolve host") end
queue._monitor = fiber.create(function()
fiber.name('queue.monitor')
fiber.yield()
local remote = socket('AF_INET', 'SOCK_DGRAM', 'udp')
while true do
for k,v in pairs(queue.stats()) do
local msg = string.format("queue.stats.%s %s %s\n", k, tonumber(v), math.floor(fiber.time()))
local res = remote:sendto(addr, port, msg)
if not res then
log.error("Failed to send: %s", errno.strerror(errno()))
end
end
fiber.sleep(1)
end
end)
```
or using TCP:
```
local socket = require 'socket'
local errno = require 'errno'
local graphite_host = '127.0.0.1'
local graphite_port = 2003
queue._monitor = fiber.create(function()
fiber.name('queue.monitor')
fiber.yield()
while true do
local remote = require 'socket'.tcp_connect(graphite_host, graphite_port)
if not remote then
log.error("Failed to connect to graphite %s",errno.strerror())
fiber.sleep(1)
else
while true do
local data = {}
for k,v in pairs(queue.stats()) do
table.insert(data,string.format("queue.stats.%s %s %s\n",k,tonumber(v),math.floor(fiber.time())))
end
data = table.concat(data,'')
if not remote:send(data) then
log.error("%s",errno.strerror())
break
end
fiber.sleep(1)
end
end
end
end)
```
Hot code reloading
------------------
An important feature of the Tarantool platform is hot code reloading. It is rarely required in regular apps, but when you have Gigabytes of data stored in the database and every reload takes time, hot reloading is quite helpful.
When Lua loads some code on require, the content of the file is interpreted, and the returned result is cashed in the system table package.loaded under the module’s name. Subsequent require calls of the same module won’t read the file again but will return its cached value. To make Lua reinterpret and redownload the file you just have to delete the relevant record from package.loaded[…] and call require again. You need to memorize what the runtime has preloaded because there won’t be files for reloading of inbuilt modules. The simplest code snippet for reload procession looks like:
```
require'strict'.on()
fiber = require 'fiber'
box.cfg{
listen = '127.0.0.1:3301'
}
box.schema.user.grant('guest', 'super', nil, nil, { if_not_exists = true })
local not_first_run = rawget(_G,'_NOT_FIRST_RUN')
_NOT_FIRST_RUN = true
if not_first_run then
for k,v in pairs(package.loaded) do
if not preloaded[k] then
package.loaded[k] = nil
end
end
else
preloaded = {}
for k,v in pairs(package.loaded) do
preloaded[k] = true
end
end
queue = require 'queue'
require'console'.start()
os.exit()
```
As the code reload is a typical and regular task, we already have a set module package.reload, which we use in most of the apps. It memorizes the file used to download data, the modules that were preloaded, and then provides a convenient call for reload initiation: package.reload().
```
require'strict'.on()
fiber = require 'fiber'
box.cfg{
listen = '127.0.0.1:3301'
}
box.schema.user.grant('guest', 'super', nil, nil, { if_not_exists = true })
require 'package.reload'
queue = require 'queue'
require'console'.start()
os.exit()
```
To make the code reloadable, you should write it in a slightly different way. Mind that the code can be executed repeatedly. At first, it is executed at the first start, and subsequently, it is executed at reloading. We have to clearly process this situation.
```
local queue = {}
local old = rawget(_G,'queue')
if old then
queue.taken = old.taken
queue.bysid = old.bysid
queue._triggers = old._triggers
queue._stats = old._stats
queue._wait = old._wait
queue._runch = old._runch
queue._runat = old._runat
else
queue.taken = {}
queue.bysid = {}
queue._triggers = {}
queue._stats = {}
queue._wait = fiber.channel()
queue._runch = fiber.cond()
while true do
local t = box.space.queue.index.status:pairs({STATUS.TAKEN}):nth(1)
if not t then break end
box.space.queue:update({ t.id }, {{'=', F.status, STATUS.READY }})
log.info("Autoreleased %s at start", t.id)
end
for k,v in pairs(STATUS) do
queue._stats[v] = 0LL
end
for _,t in box.space.queue:pairs() do
queue._stats[ t[F.status] ] = (queue._stats[ t[F.status] ] or 0LL)+1
end
log.info("Perform initial stat counts %s", box.tuple.new{ queue._stats })
end
```
Besides, you need to remember about trigger reloading. If you leave the issue as is, every reload will cause the installation of an additional trigger. However, triggers support an indication of the old function, so the installation of the trigger returns it. That’s why we’ll just save the installation result to a variable and pass it on as an argument. At the first start, there will be no variable, and a new trigger will be installed. However, at subsequent loading, the trigger will be replaced.
```
queue._triggers.on_replace = box.space.queue:on_replace(function(old,new)
if old then
queue._stats[ old[ F.status ] ] = queue._stats[ old[ F.status ] ] - 1
end
if new then
queue._stats[ new[ F.status ] ] = queue._stats[ new[ F.status ] ] + 1
end
end, queue._triggers.on_replace)
queue._triggers.on_truncate = box.space._truncate:on_replace(function(old,new)
if new.id == box.space.queue.id then
for k,v in pairs(queue._stats) do
queue._stats[k] = 0LL
end
end
end, queue._triggers.on_truncate)
queue._triggers.on_connect = box.session.on_connect(function()
box.session.storage.peer = box.session.peer()
log.info( "connected %s from %s", box.session.id(), box.session.storage.peer )
end, queue._triggers.on_connect)
queue._triggers.on_disconnect = box.session.on_disconnect(function()
log.info( "disconnected %s from %s", box.session.id(), box.session.storage.peer )
box.session.storage.destroyed = true
local sid = box.session.id()
local bysid = queue.bysid[ sid ]
if bysid then
while next(bysid) do
for key, id in pairs(bysid) do
log.info("Autorelease %s by disconnect", id);
queue.taken[key] = nil
bysid[key] = nil
local t = box.space.queue:get(id)
if t then
if queue._wait:has_readers() then queue._wait:put(true,0) end
box.space.queue:update({t.id},{{'=', F.status, STATUS.READY }})
end
end
end
queue.bysid[ sid ] = nil
end
end, queue._triggers.on_disconnect)
```
Another essential element at reloading is fibers. A fiber is started in the background, and we don’t control it in any way. It has while … true written, and it never stops and doesn’t reload on its own. To communicate with it we’ll need a channel or rather a fiber.cond: condition variable.
There are several different approaches to fiber reload. For example, the old ones can be deleted with the fiber.kill call, but this is not a very consistent take on the issue, as we may call kill at the wrong time. This is why we usually use the fiber generation attribute: the fiber proceeds working only in the generation it has been created. At code reload, the generation changes and the fiber clearly ends. Moreover, we can prevent the simultaneous operation of several fibers, checking the status of the previous generation fiber.
```
queue._runat = fiber.create(function(queue, gen, old_fiber)
fiber.name('queue.runat.'..gen)
while package.reload.count == gen and old_fiber and old_fiber:status() ~= 'dead' do
log.info("Waiting for old to die")
queue._runch:wait(0.1)
end
log.info("Started...")
while package.reload.count == gen do
local remaining
local now = clock.realtime()
for _,t in box.space.queue.index.runat
:pairs( {0}, { iterator = 'GT' })
do
if t.runat > now then
remaining = t.runat - now
break
else
if t.status == STATUS.WAITING then
log.info("Runat: W->R %s",t.id)
if queue._wait:has_readers() then queue._wait:put(true,0) end
box.space.queue:update({ t.id }, {
{ '=', F.status, STATUS.READY },
{ '=', F.runat, 0 },
})
else
log.error("Runat: bad status %s for %s", t.status, t.id)
box.space.queue:update({ t.id },{{ '=', F.runat, 0 }})
end
end
end
if not remaining or remaining > 1 then remaining = 1 end
queue._runch:wait(remaining)
end
queue._runch:broadcast()
log.info("Finished")
end, queue, package.reload.count, queue._runat)
queue._runch:broadcast()
```
And in the end, at code reload you get an error saying the console is already on. This is how this situation can be dealt with:
```
if not fiber.self().storage.console then
require'console'.start()
os.exit()
end
```
Let’s summarize
---------------
We’ve written a working network queue with delayed processing, automatic task return by means of triggers, statistics forwarding in Graphite using TCP, and explored quite a few issues. With average state-of-the-art hardware, such a queue will easily support the transmission of 20+ thousand messages per second. It contains about 300 code strings and can be compiled in a day, document studies included.
Final files:
**queue.lua**
```
local clock = require 'clock'
local errno = require 'errno'
local fiber = require 'fiber'
local log = require 'log'
local msgpack = require 'msgpack'
local socket = require 'socket'
box.schema.create_space('queue',{ if_not_exists = true; })
box.space.queue:format( {
{ name = 'id'; type = 'number' },
{ name = 'status'; type = 'string' },
{ name = 'runat'; type = 'number' },
{ name = 'data'; type = '*' },
} );
local F = {}
for no,def in pairs(box.space.queue:format()) do
F[no] = def.name
F[def.name] = no
end
box.space.queue:create_index('primary', {
parts = { F.id, 'number' };
if_not_exists = true;
})
box.space.queue:create_index('status', {
parts = { F.status, 'string', F.id, 'number' };
if_not_exists = true;
})
box.space.queue:create_index('runat', {
parts = { F.runat, 'number', F.id, 'number' };
if_not_exists = true;
})
local STATUS = {}
STATUS.READY = 'R'
STATUS.TAKEN = 'T'
STATUS.WAITING = 'W'
local queue = {}
local old = rawget(_G,'queue')
if old then
queue.taken = old.taken
queue.bysid = old.bysid
queue._triggers = old._triggers
queue._stats = old._stats
queue._wait = old._wait
queue._runch = old._runch
queue._runat = old._runat
else
queue.taken = {}
queue.bysid = {}
queue._triggers = {}
queue._stats = {}
queue._wait = fiber.channel()
queue._runch = fiber.cond()
while true do
local t = box.space.queue.index.status:pairs({STATUS.TAKEN}):nth(1)
if not t then break end
box.space.queue:update({ t.id }, {{'=', F.status, STATUS.READY }})
log.info("Autoreleased %s at start", t.id)
end
for k,v in pairs(STATUS) do queue._stats[v] = 0LL end
for _,t in box.space.queue:pairs() do
queue._stats[ t[F.status] ] = (queue._stats[ t[F.status] ] or 0LL)+1
end
log.info("Perform initial stat counts %s", box.tuple.new{ queue._stats })
end
local function gen_id()
local new_id
repeat
new_id = clock.realtime64()
until not box.space.queue:get(new_id)
return new_id
end
local function keypack( key )
return msgpack.encode( key )
end
local function keyunpack( data )
return msgpack.decode( data )
end
queue._triggers.on_replace = box.space.queue:on_replace(function(old,new)
if old then
queue._stats[ old[ F.status ] ] = queue._stats[ old[ F.status ] ] - 1
end
if new then
queue._stats[ new[ F.status ] ] = queue._stats[ new[ F.status ] ] + 1
end
end, queue._triggers.on_replace)
queue._triggers.on_truncate = box.space._truncate:on_replace(function(old,new)
if new.id == box.space.queue.id then
for k,v in pairs(queue._stats) do
queue._stats[k] = 0LL
end
end
end, queue._triggers.on_truncate)
queue._triggers.on_connect = box.session.on_connect(function()
box.session.storage.peer = box.session.peer()
end, queue._triggers.on_connect)
queue._triggers.on_disconnect = box.session.on_disconnect(function()
box.session.storage.destroyed = true
local sid = box.session.id()
local bysid = queue.bysid[ sid ]
if bysid then
log.info( "disconnected %s from %s", box.session.id(), box.session.storage.peer )
while next(bysid) do
for key, id in pairs(bysid) do
log.info("Autorelease %s by disconnect", id);
queue.taken[key] = nil
bysid[key] = nil
local t = box.space.queue:get(id)
if t then
if queue._wait:has_readers() then queue._wait:put(true,0) end
box.space.queue:update({t.id},{{'=', F.status, STATUS.READY }})
end
end
end
queue.bysid[ sid ] = nil
end
end, queue._triggers.on_disconnect)
queue._runat = fiber.create(function(queue, gen, old_fiber)
fiber.name('queue.runat.'..gen)
while package.reload.count == gen and old_fiber and old_fiber:status() ~= 'dead' do
log.info("Waiting for old to die")
queue._runch:wait(0.1)
end
log.info("Started...")
while package.reload.count == gen do
local remaining
local now = clock.realtime()
for _,t in box.space.queue.index.runat
:pairs( {0}, { iterator = 'GT' })
do
if t.runat > now then
remaining = t.runat - now
break
else
if t.status == STATUS.WAITING then
log.info("Runat: W->R %s",t.id)
if queue._wait:has_readers() then queue._wait:put(true,0) end
box.space.queue:update({ t.id }, {
{ '=', F.status, STATUS.READY },
{ '=', F.runat, 0 },
})
else
log.error("Runat: bad status %s for %s", t.status, t.id)
box.space.queue:update({ t.id },{{ '=', F.runat, 0 }})
end
end
end
if not remaining or remaining > 1 then remaining = 1 end
queue._runch:wait(remaining)
end
queue._runch:broadcast()
log.info("Finished")
end, queue, package.reload.count, queue._runat)
queue._runch:broadcast()
local graphite_host = '127.0.0.1'
local graphite_port = 2003
queue._monitor = fiber.create(function(gen)
fiber.name('queue.mon.'..gen)
fiber.yield()
while package.reload.count == gen do
local remote = require 'socket'.tcp_connect(graphite_host, graphite_port)
if not remote then
log.error("Failed to connect to graphite %s",errno.strerror())
fiber.sleep(1)
else
while package.reload.count == gen do
local data = {}
for k,v in pairs(queue.stats()) do
table.insert(data,string.format("queue.stats.%s %s %s\n",k,tonumber(v),math.floor(fiber.time())))
end
data = table.concat(data,'')
if not remote:send(data) then
log.error("%s",errno.strerror())
break
end
fiber.sleep(1)
end
end
end
end, package.reload.count)
function queue.put(data, opts)
local id = gen_id()
local runat = 0
local status = STATUS.READY
if opts and opts.delay then
runat = clock.realtime() + tonumber(opts.delay)
status = STATUS.WAITING
else
if queue._wait:has_readers() then
queue._wait:put(true,0)
end
end
return box.space.queue
:insert{ id, status, runat, data }
:tomap{ names_only=true }
end
function queue.take(timeout)
if not timeout then timeout = 0 end
local now = fiber.time()
local found
while not found do
found = box.space.queue.index.status
:pairs({STATUS.READY},{ iterator = 'EQ' }):nth(1)
if not found then
local left = (now + timeout) - fiber.time()
if left <= 0 then return end
queue._wait:get(left)
end
end
if box.session.storage.destroyed then return end
local sid = box.session.id()
log.info("Register %s by %s", found.id, sid)
local key = keypack( found.id )
queue.taken[ key ] = sid
queue.bysid[ sid ] = queue.bysid[ sid ] or {}
queue.bysid[ sid ][ key ] = found.id
return box.space.queue
:update( {found.id}, {{'=', F.status, STATUS.TAKEN }})
:tomap{ names_only = true }
end
local function get_task( id )
if not id then error("Task id required", 2) end
id = tonumber64(id)
local key = keypack(id)
local t = box.space.queue:get{id}
if not t then
error(string.format( "Task {%s} was not found", id ), 2)
end
if not queue.taken[key] then
error(string.format( "Task %s not taken by anybody", id ), 2)
end
if queue.taken[key] ~= box.session.id() then
error(string.format( "Task %s taken by %d. Not you (%d)",
id, queue.taken[key], box.session.id() ), 2)
end
return t, key
end
function queue.ack(id)
local t, key = get_task(id)
queue.taken[ key ] = nil
queue.bysid[ box.session.id() ][ key ] = nil
return box.space.queue:delete{t.id}:tomap{ names_only = true }
end
function queue.release(id, opts)
local t, key = get_task(id)
queue.taken[ key ] = nil
queue.bysid[ box.session.id() ][ key ] = nil
local runat = 0
local status = STATUS.READY
if opts and opts.delay then
runat = clock.realtime() + tonumber(opts.delay)
status = STATUS.WAITING
else
if queue._wait:has_readers() then queue._wait:put(true,0) end
end
return box.space.queue
:update({t.id},{{'=', F.status, status },{ '=', F.runat, runat }})
:tomap{ names_only = true }
end
function queue.stats()
return {
total = box.space.queue:len(),
ready = queue._stats[ STATUS.READY ],
waiting = queue._stats[ STATUS.WAITING ],
taken = queue._stats[ STATUS.TAKEN ],
}
end
return queue
```
**init.lua**
```
require'strict'.on()
fiber = require 'fiber'
require 'package.reload'
box.cfg{
listen = '127.0.0.1:3301'
}
box.schema.user.grant('guest', 'super', nil, nil, { if_not_exists = true })
queue = require 'queue'
if not fiber.self().storage.console then
require'console'.start()
os.exit()
end
``` | https://habr.com/ru/post/530002/ | null | null | 9,626 | 62.54 |
26 August 2009 23:59 [Source: ICIS news]
LONDON (ICIS news)--Polyethylene (PE) prices have strengthened this week due to tight supply and import pressure in both northern and southern Africa, market participants said on Wednesday.
According to global chemical market intelligence service ICIS pricing, low density PE (LDPE) prices were assessed at $1,290-1,310/tonne (€903-917/tonne) CFR northern ?xml:namespace>
Linear low density PE (LLDPE) was assessed at $1,260-1,280/tonne CFR, while high density PE (HDPE) was at $1,280-1,300/tonne CFR, up by $10-30/tonne from last week, according to ICIS pricing.
“The increases are a result of continuing tight supply of PE in the region,” said a buyer and a seller.
In southern
LDPE was assessed at $1,330-1,380/tonne, LLDPE at $1,260-1,340/tonne and HDPE prices at $1,300-1,320/tonne, all on a CFR (cost and freight) southern
“This is as a result of reduced availability and pressure from Middle Eastern suppliers to push up export values,” a source said.
Domestic South African PE prices rose by Rand (R) 100-200 ($13-26/tonne) this week.
LDPE prices were assessed at R11,600-12,700/tonne, LLDPE at R11,400-12,700/tonne and HDPE at R11,900-12,500/tonne.
All prices were on a FD South Africa basis.
“This is a consequence of the ongoing ethylene shortage and higher priced imports coming in,” a trader said.
($1 = €0.70/$1=R7.80)
For more on polyethylene visit ICIS chemical | http://www.icis.com/Articles/2009/08/26/9243071/pe-firms-across-africa-due-to-tight-supply-import-pressure.html | CC-MAIN-2015-06 | refinedweb | 262 | 58.42 |
CGTalk
>
Software Specific Forums
>
Autodesk Maya
>
Maya Programming
> Maya API: QT Mouse Hover
PDA
View Full Version :
Maya API: QT Mouse Hover
migusan76
11-08-2010, 05:27 AM
Hi, I just wanted to share my code for a partial working mouse hover code using QT and maya. It was something I was working on and might not ever work on again, but would love to share it with anyone who might be on the same quest. It was originally intended for use with pre-selection highlighting type tool. So only at the moment the code grabs maya's viewport and passes it to qt to capture the mouse hover position. Hope it helps anyone looking.
nuttynut
11-08-2010, 10:22 AM
ha! Great, happy you got it to work! Thanks for sharing :beer:
NateH
11-08-2010, 04:44 PM
Neat idea! Thanks for sharing!
I went an implemented something similar using PyQt based somewhat off your example. I used the ToolTip event instead of MouseMove though, but it's easy to change it to use either:
import sip
import maya.cmds as cmds
import maya.OpenMayaUI as apiUI
from PyQt4 import QtGui, QtCore
class ToolTipFilter(QtCore.QObject):
'''A simple event filter to catch tooltip events'''
def eventFilter(self, obj, event):
if event.type() == QtCore.QEvent.ToolTip:
QtGui.QToolTip.hideText() #Hide the old tooltip, so that it can move
QtGui.QToolTip.showText(event.globalPos(), '%04f, %04f'%(event.globalX(), event.globalY()), obj)
return False
return True
#Install the event filter into all the model panels
global filter #Have to make the filter object global so it doesnt get garbage collected
filter = ToolTipFilter()
for editor in cmds.lsUI(panels=True): #For soem reason type='modelEditor' won't work...
if cmds.objectTypeUI(editor)=='modelEditor':
ptr = apiUI.MQtUtil.findControl(editor)
viewWidget = sip.wrapinstance(long(ptr), QtCore.QObject)
viewWidget.installEventFilter(filter)
ginodauri
11-08-2010, 06:53 PM
One question:
Is it possible through qt to get control under pointer or control with focus?
Maya(mel,python) don't have this functionality , but this would very interesting to have.
NateH
11-08-2010, 07:10 PM
One question:
Is it possible through qt to get control under pointer or control with focus?
Maya(mel,python) don't have this functionality , but this would very interesting to have.
Yep, easy:
def getWidgetAtMouse():
currentPos = QtGui.QCursor().pos()
widget = QtGui.qApp.widgetAt(currentPos)
return widget
def getFocusWidget():
return QtGui.qApp.focusWidget()
migusan76
11-08-2010, 08:08 PM
Hey Waldo, Yea finally got it to work. Thx's for the suggestion on it! It wasn't very hard once I learned a little on Qt. Its a good start to get the hover, but so much more to do to get some kind of pre-selection tool going. I just remeber the couple of weeks of hell I went through trying to do something so simple, that hopefully this helps out anyone on the same path. :banghead:
Awesome stuff Nate, thx's for sharing as well! :)
ginodauri
11-08-2010, 08:16 PM
Nice
But how to convert qtObjects in maya "string" representation?
NateH
11-08-2010, 08:22 PM
Nice
But how to convert qtObjects in maya "string" representation?
Unwrap the PyQt sip object to it's pointer. Then use MQtUtil fullName which takes a QObject pointer.
apiUI.MQtUtil.fullName( sip.unwrapinstance(widget) )
ginodauri
11-08-2010, 08:50 PM
For some reason this isn't working , i get error
# Error: TypeError: file <maya console> line 1: in method 'MQtUtil_fullName', argument 1 of type 'QObject const *' #
CGTalk Moderation
11-08-2010,. | http://forums.cgsociety.org/archive/index.php/t-933209.html | CC-MAIN-2014-42 | refinedweb | 596 | 57.98 |
I have worked through my first Velocity project today, and I would like to blog about the steps necessary to use caching.
First, you should read my previous post and install AppFabric on your machine.
I used Visual Studio 2010 beta 2 to create the solution. You can download the solution here. I create WPF project in order to prove that caching is not limited to web applications, although web farm would probably be an ideal application for caching. Once project is created, I added references to DLLs for Velocity. On my machine they were located in C:WindowsSystem32ApplicationServerExtensions. Two DLLs I needed were CacheBaseLibrary.dll and ClientLibrary.dll. They contain key classes that can be used to utilize caching. I could not add them directly from that folder, I was getting an error from Add Reference dialog. So, I copied them into a folder under my Solution (“Bin” folder).
Then I added a complex class that I intended to cache. I wanted to prove to myself that complex object graphs are OK since all the demos I saw just used strings. Here is the class I used:
public class CachablePerson
{
public string FirstName { get; set; }
public string LastName { get; set; }
public List<CachableAddress> Addresses { get; set; }
public CachablePerson()
{
FirstName = "Sergey";
LastName = "Barskiy";
Addresses = new List<CachableAddress>();
Addresses.Add(new CachableAddress() { Street = "Main Street", City = "Atlanta" });
Addresses.Add(new CachableAddress() { Street = "Second Street", City = "Lilburn" });
}
}
public class CachableAddress
{
public string Street { get; set; }
public string City { get; set; }
}
I put the class into its own project and referenced this project from two separate WPF application projects.
First step in using caching is to configure cache object. Here is how we can configure cache object using cache factory:
private void SetupCache()
{
DataCacheServerEndpoint[] servers = new DataCacheServerEndpoint[1];
servers[0] = new DataCacheServerEndpoint("Sergey-Laptop", 22233, "DistributedCacheService");
_cacheFactory = new DataCacheFactory(servers, false, true);
_defaultCache = _cacheFactory.GetCache("default");
}
Now we are ready to add object to cache. We will do this in steps. First we check to see if an object is already in cache, and if so, we will remove it from cache. Cache basically is using a string as the object key. In addition to that you can also version objects, thus having multiple copies of the same object with the same key existing in cache at any given time.
if (_defaultCache.Get("person") != null)
{
_defaultCache.Remove("person");
}
_defaultCache.Add("person", _person);
Now I am going to get the object from cache. Just as simple as adding it:
_person = (CachablePerson)_defaultCache.Get("person");
Simple and easy. I think Velocity is super powerful yet simple to use. Event though it would be an abuse, but one could possibly use caching to communicate between different applications.
You can download my sample solution here
Pingback: Memcached with Windows : Max Ivak Personal Site | http://www.dotnetspeak.com/net/getting-started-with-velocity-appfabric-caching-library/ | CC-MAIN-2022-21 | refinedweb | 466 | 65.01 |
Dive into the world of social Web development to explore the new features released by the Facebook platform, and the new timeline interface. Here’s a look at how adding a social aspect to your Web application can be good for how it evolves.
Most of us spend a major chunk of our day on Facebook. The platform has introduced some major changes about the way we interact with applications, and the way we interact with each other. The new timeline feature has opened up a wide variety of ways in which we can create innovative applications, and this is exactly what we are going to look at in this article.
The new open graph platform has allowed a user to do more than just like or share something. We can now read articles, listen to music and perform almost any action that the app developer has defined. This is basically achieved using a subject-predicate-object or user-action-object architecture, where you define a set of actions that a user can perform, and a set of objects that the user can interact with. These actions can be reflected in a number of ways, like the timeline view, application view, newsfeed, ticker, etc.
At the core of any new Facebook application is the open graph protocol. This protocol intersects with the various Semantic Web technologies, which enable us to represent any Web page or piece of information as an object. Of course, these objects have some properties that Facebook users interact with, and this exposes the Facebook platform to the whole Web. Basically, any application that speaks the open graph protocol can speak to the Facebook platform.
Integrating your Web app with the timeline
In case you’re wondering why and how Facebook can be integrated into your Web app, here’s the answer. Basically, the new platform allows Facebook to integrate inseparably, with the help of various plugins like the Login button, Like button, and even the open graph. These enable ease of development, and simplicity in managing the users of your Web app. They will also help you increase the use of the application, with the help of free social media publicity, which is based on referrals being made from person-to-person.
Remember, you are much more likely to use an app if your friends use it too. Some of the important technologies and tools that you’ll be using are the Facebook SDK and the Graph API. This is something that we won’t be covering in this article; you’ll have to look it up in the relevant documentation. Our motive here is to just highlight how the new platform has brought about changes that can be reflected in your application — and not to teach Facebook app development itself.
Getting started
To get started developing applications on Facebook, you need the developer app. Next, click the Create New App button, and enter the name of your application and the app namespace (Figure 1).
The app namespace is something that is used for the open graph, under which all your open graph objects and actions reside. This is why it is something that should be unique for your application. When you’ve done this, after the security check, you will be led to the basic settings page (Figure 2), where you can configure more details regarding your application.
Here you can choose your application domain, and the way in which your app integrates with Facebook. It can either be a website that adds a social layer over it, or an application that resides wholly under the Facebook interface. Either way, you will have to enter the appropriate settings related to your application here.
Apart from this, you can set up an authentication system for your application from the Auth Dialog tab (Figure 3), where you can set the headline, description and an explanation for the permissions you ask from the user.
A new feature is “authenticated referrals”, where you can set up mandatory and optional permissions for the user, and the Auth Dialog will automatically appear when a user is referred to your app. This will allow a user to be automatically logged in to your app. You can see this in the demo screenshot (Figures 4 and 5), where I have asked for the publish_actions and publish_stream permissions as mandatory and optional, respectively.
Objects, actions and aggregations
To make the user of your application interact with the open graph, you can set up objects and actions for your application that allow a user to read an article on the this website, for example. Setting this up is pretty easy. Basically, you need to go to the Open Graph tab, and in the “Getting started” section, type what a user can do — for instance, in my app, users can read an article. This will then automatically create an action and an object, and you just have to edit and save the settings (Figures 6 and 7).
The object that we defined here is basically the object type, i.e., a classification of different objects available in the application. The objects can individually be defined in your app with the help of a markup such as the following:
<head prefix="og: fb: article:"> <meta property="fb:app_id" content="25xxxxxxxxxxx11" /> <meta property="og:type" content="article" /> <meta property="og:url" content="Put Your Own URL Here" /> <meta property="og:title" content="Some Arbitrary String" /> <meta property="og:description" content="Some Arbitrary String" /> <meta property="og:image" content="" />
If you use a built-in object already present in the Facebook platform, it will automatically populate it with properties, and define aggregations that are possible for that particular object. An aggregation (Figure 8) is a new way to collectively publish the actions taken by a user in the past, like the articles read, top authors, etc.
The dashboard section allows you to add sample data, and preview some aggregations for your application. It also provides sample code for you to describe an object in the open graph on your Web page, and a sample curl command for you to retrieve, create and delete actions. Overall, aggregations are a very powerful feature that you must use in order to generate innovative time-line views for your application.
While creating new actions, you have to enter the connected objects that have been defined, the action properties, the present and past tense of the action, and the layout style of the attached data. It is important to note that you need to get the actions approved before they can be used in production.
Past actions and activity log
“Past actions” can be used in the timeline to post an action taken by a user more than three days ago. Such actions do not generate a news feed, and rather, are just tagged at that point in time, and can be visible in the activity log. These “past actions” can thus be used by setting the start time for the action as more than three days ago.
Defining roles and accessing insights
As the app administrator, you can define a role for each of the members involved in the development process of your application, whether it is the developers, testers or statistical analysts who need to retrieve data related to insights. Each of these has varied access to the application, in a differing manner. While developers can also change the settings related to the application, the tester can only access and use an application in the sand-boxed mode. You can even set up a test user account that can be used for testing purposes, from this section.
Apart from this, the new insights data tracking provides impressive visualisation tools for easy data tracking of new installs, sharing, performance, open graph activity, permission patterns, etc. This is something that is very valuable for future development and feedback, as to what the users want from your application, and what the social trends really are.
In conclusion, Facebook is a platform that has grown exponentially, and has become a hub of social Web development. There is probably no other platform that can provide such flexibility and such a wide array of tools to enable developers to build such new and innovative applications.
Connect With Us | http://opensourceforu.com/2012/05/timeline-apps-a-new-era-in-developing-facebook-apps/?shared=email&msg=fail | CC-MAIN-2018-05 | refinedweb | 1,380 | 56.39 |
I have started learning C (so, you know.. pointers).
I have this code:
#include <stdio.h>
#include <string.h>
int main (int argc, char* argv[])
{
char c = 'c';
char* cptr = &c;
printf("c = %c\n", c);
printf("*cptr = %c\n", *cptr);
printf("c address = %p\n", &c);
}
c = c
*cptr = c
c address = 0x7fff0217096f
c
Isn't [the address] too big?
This is a virtual address, meaning that its numerical value does not necessarily represent the sequential number of the byte in physical memory. Moreover, different processes may keep different data at the same virtual address, because each one has its individual address space.
How can I print the value of the pointer in an integer format?
Use
uintptr_t to represent the pointer as an integer value, then print using
PRIuPTR macro:
#include <stdio.h> #include <inttypes.h> int main(void) { char c = 'x'; char *p = &c; uintptr_t x = (uintptr_t)p; printf("Pointer as decimal: %"PRIuPTR"\n", x); return 0; } | https://codedump.io/share/79xM4vbnFguR/1/value-of-pointer-in-c | CC-MAIN-2021-25 | refinedweb | 160 | 56.76 |
I’ve tried to use the relatively new Array at method MDN in my front-end code and the app crashes in Safari and older browsers where it is not supported. Even though there is a polyfill for it (according to MDN) this doesn’t seem to be present in the ecmascript package that I’m using in my project, hence it is not working in Safari. Are there any plans to include this in the package or should I avoid using the Array at method for now?
I recently used the following and it works like a charm (
core-js
npm package):
import 'core-js/features/array/at';
1 Like
Awesome, works perfectly, thank you. | https://forums.meteor.com/t/polyfill-for-array-at-method/57168 | CC-MAIN-2022-05 | refinedweb | 116 | 61.19 |
Patent application title: OPERATING A SERVICE ON A NETWORK AS A DOMAIN NAME SYSTEM SERVER
Inventors:
Dean Drako (Los Altos, CA, US)
Zachary Levow (Mountain View, CA, US)
Assignees:
BARRACUDA NETWORKS INC.
IPC8 Class: AG06F1730FI
USPC Class:
726 5
Class name: Access control or authentication network credential
Publication date: 2010-01-14
Patent application number: 20100011420
Abstract:
Operating a service such as a remote database as a dns server, receiving
inputs such as queries as domain names and transmitting replies in the
format of IPv4 or IPv6 addresses.
Claims:
1. A method for operating a service on a network comprising: receiving a
dns query string, extracting a plurality of arguments from said query
string, operating on said arguments, and transmitting a reply formatted
in IP syntax.
2. A method for operating a database comprising the following steps:listening for a dns request class=IN from a dns client;stripping the hostname off the dns queryname "fully qualified domain name";determining at least two arguments from the remainder of the dns queryname;accessing the database according to the arguments; andtransmitting the database result as a dns query response to the dns query client.
3. The method of claim 2 further comprising listening for a dns request selected from the following: type=A, type=AAAA, type=spf, type=CNAME, and type=TXT.
4. The method of claim 2 wherein the dns query response is an IP address comprising one of two to the 32 power unique values of the IPv4 system (four octets).
5. The method of claim 2 wherein the dns query response is an IP address comprising one of two to the 128 power unique values of the IPv6 system (eight groups of 4 hexadecimal digits).
6. The method of claim 2 wherein the dns query response is cached in a distributed domain name system and served to a dns resolver.
7. The method of claim 2 wherein the dns query response represents a value to be used in a computation.
8. The method of claim 2 wherein the dns query response represents that a certain message should be displayed.
9. The method of claim 2 wherein the dns query response represents that an email should be allowed without spam scanning.
10. The method of claim 2 wherein the dns query response represents one of a subjective probability on a scale, an action suggested, and a degree of additional handling.
11. A method for operating a service comprising the following steps:listening for a dns request class=IN from a dns client;stripping the hostname off the dns queryname="fully qualified domain name";determining at least two arguments from the remainder of the dns queryname;operating on the arguments; andtransmitting the result as a dns query response to the dns query client.
12. The method of claim 11 wherein a plurality of query arguments comprises at least a first query term and a second query term separated by a dot.
13. The method of claim 11 wherein the reply comprises a plurality of groups separated by dots wherein groups are one of binary numbers, decimal numbers, hexadecimal numbers and octal numbers.
14. The method of claim 11 wherein an argument comprises an authentication code, whereby billing records may be checked or updated and users of the database may be validated or rejected.
15. The method of claim 11 wherein an argument comprises an authentication code, whereby usage is tracked.
16. The method of claim 11 wherein an argument comprises an authentication code comprising a checksum.
17. The method of claim 11 wherein the dns query response is an IP address comprising one of two to the 32 power unique values of the IPv4 system (four octets).
18. The method of claim 11 wherein the dns query response is an IP address comprising one of two to the 128 power unique values of the IPv6 system (eight groups of 4 hexadecimal digits).
19. The method of claim 11 wherein the result is one of a text string and an IP address.
20. The method of claim 11 wherein the result is a domain name.
21. The method of claim 11 wherein operating on the arguments comprises a computation or string manipulation.
22. The method of claim 1 wherein the dns query response is cached by a distributed domain name system and served to a client.
23. The method of claim 1 further comprising determining an authentication code component of the remainder of the dns queryname, validating the authentication code before accessing a stored IP address, and transmitting the stored IP address as a dns query response.
24. The method of claim 1 wherein the dns query response is cached by a distributed domain name system and served to a second client.
25. A method for operating a service on a network comprising: receiving a dns query string, extracting a plurality of arguments from said query string, operating on said arguments, and transmitting a reply formatted in IP syntax, further comprising receiving an authentication code as a query argument and checking its validity.
26. The method of claim 25 further comprising sending no response if the authentication code is bad.
27. The method of claim 25 further comprising transmitting an "invalid" response if the authentication code is bad.
28. The method of claim 25 further comprising counting and controlling the number of queries allowed for each authentication code.
29. The method of claim 25 further comprising storing a first use of an authentication code and associating it with the IP address of the query sender.
30. A method for operating a service on a network comprising: receiving a dns query string, extracting a plurality of arguments from said query string, operating on said arguments, and transmitting a reply formatted in IP syntax wherein operating on said arguments comprises one of the following, eliciting a response, initiating a process, measuring a value, controlling a machine, dispensing a product, transacting a sale, voting, asking a question, answering a question, requesting assistance, and stopping a process.
Description:
CO-PENDING APPLICATIONS
[0001]Three related applications with common inventors and assignee are/will be pending: querying a database as a dns client, operating a service e.g. database as a dns server, and facilitating email by checking a database with email coordinates.
[0002]Docket Number application numbers: file dates: [0003]Z-PTNTR200808 [0004]Z-PTNTR200809 [0005]Z-PTNTR200810
TECHNICAL FIELD
[0006]The field of the invention is internet based information technology operations and an application to facilitating the transmission of email.
TABLE-US-00001 Definition List 1 Term Definition Email parameter A text string which is either part of an argument of a mail protocol command or a component of a TCP packet header connecting between email servers. Not limited to but includes IP addresses and domain names. The present application defines and uses this term. IP address An internet protocol (IP) address is e.g. 151.207.245.67 defined in RFC-791 IPv4 standard of the Internet Engineering Task Force. RFC- 791 defines a replacement IPv6. Domain name Defined in RFC-1034, 1035, 1085, a e.g. domain name is a memorable host name that stands in for a numeric IP address. DNS Domain Name System defined in RFC 1035, includes resolvers and servers which respond to questions about domain names. The most basic task of DNS is to translate hostnames to IP addresses. The Domain Name System consists of a hierarchical set of DNS servers. SMTP Simple Mail Transfer Protocol documented in RFC 2821 DNSBL DNSBL is an abbreviation that usually stands for "DNS blacklist". Typically entails a domain, a nameserver for that domain, and a list of addresses to publish. Generally returns either an address, indicating that the client is listed; or an "NXDOMAIN" ("No such domain") code. DNSBL provides resources to support blocking spam. Fully qualified A fully qualified domain name has at domain name least a host and domain name, including top-level domain. A FQDN always starts with a host name and continues all the way up to the top- level domain name and includes intermediate level domains to provide an unambiguous path which specifies the exact location of a host in the Domain Name System's tree hierarchy through to a top-level domain
DOMAIN NAMES SYSTEM BACKGROUND
[0007]A domain name usually consists of two or more parts (technically labels), separated by dots. For example: example.com. [0008]The rightmost label conveys the top-level domain (for example, the address has the top-level domain com). [0009]Each label to the left specifies a subdivision, or subdomain of the domain above it. Note;"subdomain" expresses relative dependence, not absolute dependence. For example: example.com comprises a subdomain of the com domain, and comprises a subdomain of the domain example.com. In theory, this subdivision can go down to 127 levels deep. Each label can contain up to 63 characters. The whole domain name does not exceed a total length of 255 characters. In practice, some domain registries may have shorter limits. [0010]A hostname refers to a domain name that has one or more associated IP addresses; ie: the `` and `example.com` domains are both hostnames, however, the `com` domain is not.
[0011]DNS Servers
[0012).
[0013]Users generally do not communicate directly with DNS. Instead DNS-resolution takes place transparently in client-applications such as web-browsers, mail-clients, and other Internet applications. When an application makes a request which requires a DNS lookup, such programs send a resolution request to the local DNS resolver in the local operating system, which in turn handles the communications required.
[0014]The DNS resolver likely has a cache.
[0015]When a DNS client needs to look up a name used in a program, it queries DNS servers to resolve the name. Each query message the client sends contains three pieces of information, specifying a question for the server to answer: [0016]A specified DNS domain name, stated as a fully qualified domain name (FQDN) [0017]A specified query type, which can either specify a resource record by type or a specialized type of query operation. [0018]A specified class for the DNS domain name.
[0019 `hostname.example.com.`?" When the client receives an answer from the server, it reads and interprets the answered A resource record, learning the IP address for the computer it asked for by name.
[0020.
[0021]In addition, the client itself can attempt to contact additional DNS servers to resolve a name. In general, the DNS query process occurs in two parts: [0022]A name query begins at a client computer and is passed to a resolver, the DNS Client service, for resolution. [0023]When the query cannot be resolved locally, DNS servers can be queried as needed to resolve the name.
[0024.
[0025]Querying a DNS Server
[0026.
[0027]How Caching Works
[0028]As DNS servers process client queries using recursion or iteration, they discover and acquire a significant store of information about the DNS namespace. This information is then cached by the server.
[0029]Caching provides a way to speed the performance of DNS resolution for subsequent queries of popular names, while substantially reducing DNS--related query traffic on the network.
[0030.
[0031.
[0032]Other Applications
[0033.
[0034]Sender Policy Framework and DomainKeys instead of creating their own record types were designed to take advantage of another DNS record type, the TXT record. In these cases the TXT record contains a policy or a public key.
[0035]Protocol Details
[0036]DNS primarily uses UDP on port 53.
[0037]Important categories of data stored in DNS include the following: [0038]An A record or address record maps a hostname to a 32-bit IPv4 address. [0039]An AAAA record or IPv6 address record maps a hostname to a 128-bit IPv6 address. [0040]A CNAME record or canonical name record is an alias of one name to another. The A record to which the alias points can be either local or remote [0041]on a foreign name server. This is useful when running multiple services (such as an FTP and a webserver) from a single IP address. Each service can then have its own entry in DNS (like. and.) [0042]An MX record or mail exchange record maps a domain name to a list of mail exchange servers for that domain. [0043]A PTR record or pointer record maps an IPv4 address to the canonical name for that host. Setting up a PTR record for a hostname in the in-addr.arpa domain that corresponds to an IP address implements reverse DNS lookup for that address. [0044]An NS record or name server record maps a domain name to a list of DNS servers authoritative for that domain. Delegations depend on NS records. [0045]An SOA record or start of authority record specifies the DNS server providing authoritative information about an Internet domain, the email of the domain administrator, the domain serial number, and several timers relating to refreshing the zone. [0046]An SRV record is a generalized service location record. [0047]A TXT Record was originally intended to carry arbitrary human-readable text in a DNS record. Since the early 1990s, however, this record is more often used to carry machine-readable data such as specified by RFC 1464, opportunistic encryption, Sender Policy Framework and DomainKeys such as public keys or a policy. [0048]An NAPTR record ("Naming Authority Pointer") is a newer type of DNS record that support regular expression based rewriting.
SMTP Background
[0049.
[0050]Although the SMTP protocol provides for relay through a serial chain of clients and servers, in practice today, the sender client makes a direct connection to the receiver's server. Thus the IP header used to establish the handshake cannot be forged.
[0051]The envelope sender email address (sometimes also called the return-path) is used during the transport of the message from mail server to mail server, e.g. to return the message to the sender in the case of a delivery failure. It is usually not displayed to the user by mail programs.
[0052]The header sender address of an e-mail message is contained in the "From" or "Sender" header and is what is displayed to the user by mail programs. Generally, mail servers do not care about the header sender address when delivering a message. Spammers can easily forge these.
DNSBL Background
[0053.
[0054.
[0055.
[0056.
[0057.
[0058.
[0059.
[0060]The hard part of operating a DNSBL is populating it with addresses. DNSBLs intended for public use usually have specific, published policies as to what a listing means, and must be operated accordingly to attain or keep public confidence.
[0061]When a mail server receives a connection from a client, and wishes to check that client against a DNSBL (let's say, dnsbl.example.net), it does more or less the following: [0062]Take the client's IP address--say, 192.1 68.42.23--and reverse the bytes, yielding 23.42.168.192. [0063]Append the DNSBL's domain name: 23.42.168.192.dnsbl.example.net. [0064]Look up this name in the DNS as a domain name ("A" record). This will return either an address, indicating that the client is listed; or an "NXDOMAIN" ("No such domain") code, indicating that the client is not.
[0065]Optionally, if the client is listed, look up the name as a text record ("TXT" record). Most DNSBLs publish information about why a client is listed as TXT records.
[0066, or spammer-owned host.
[0067.
[0068]Other proposed solutions shift the burden of establishing credibility onto innocent senders. Examples include adding sender policy framework policies or domainkey Public Keys into the dns TXT fields.
DomainKeys
[0069]In DomainKeys, U.S. Pat. No. 6,986,049 assigned to Yahoo!, the receiving SMTP server uses the name of the domain from which. DomainKeys is primarily an authentication technology and does not itself filter spam. It also adds to the computational burden of both sender and receiver in encrypting/decrypting and computing/comparing hash values.
Sender Policy Framework
[0070.
[0071.
[0072.
[0073]SPF may offer advantages beyond potentially helping identify unwanted e-mail. In particular, if a sender provides SPF information, then receivers can use SPF PASS results in combination with a white list to identify known reliable senders.
[0074]The Sender Policy Framework (SPF) standard specifies a technical method to prevent sender address forgery. Present implementations of the SPF concept protects the envelope sender address, which is used for the delivery of messages.
[0075: [0076]TXT v=spf1 include:spf-a.hotmail.com include:spf-b.hotmail.com include:spf-c.hotmail.com include:spf-d.hotmail.com ˜all [0077]TXT spf2.0/pra ip4:152.163.225.0/24 ip4:205.188.139.0/24 ip4:205.1 88.144.0/24 ip4:205.188.156.0/23 ip4:205.188.159.0/24 ip4:64.12.136.0/23 ip4:64.12.138.0/24 ip4:64.12.143.99/32 ip4:64.12.143.100/32 ip4:64.12.143.101/32 ptr:mx.aol.com ?all
[0078.
[0079.
What is Needed is . . .
[0080.
[0081.
[0082]Therefore it is one objective of this invention to provide an improved system for looking up domains and IP addresses in an efficient manner.
[0083.
SUMMARY OF THE SOLUTION
[0084.
[0085.
[0086.
[0087".
[0088]In an embodiment, the query comprises the step of an RBL-style lookup over the domain name system (DNS). However the content of the query is at least the domain of the email sender concatenated to the IP address of the client sending the MAIL `FROM" command. The domain or the entire email address is extracted from the argument of the MAIL `FROM".
[0089.
ADVANTAGEOUS EFFECTS
[0090]The method of transmitting a query is efficient and avoids limitations in access into or out of networks. The method of replying to a query allows data to be cached close to the user.
[0091.
DESCRIPTION OF DRAWINGS
[0092]FIG. 1 is a block diagram of a dns system.
[0093]FIG. 2 is a flow chart of email entering the system.
[0094]FIG. 3 is a flow chart of a query within the dns system.
[0095]FIG. 4 is a process flow of email through the system.
DETAILED DISCLOSURE OF OPERATING A SERVICE SUCH AS A DATABASE
[0096]The present invention is a method for operating a service such as a database on a network comprising: receiving a dns query, extracting a plurality of arguments from said query, retrieving information associated with said arguments, and transmitting a reply formatted in IP syntax.
[0097]A method for operating a service (e.g.database) comprising the following steps: [0098]listening on a port in an embodiment port 53 for a dns request class=IN from a dns client; [0099]stripping the suffix off the dns queryname=fully qualified domain name which corresponds to the domain name of the website; [0100]determining at least two arguments from the remainder of the dns queryname; [0101]accessing a database according to the arguments; and [0102]transmitting the result as a dns query response to the dns query client.
[0103]In an embodiment the result is a text string or an IP address. The result may be coded as an IP address. The result may be multiple terms which are encoded by setting the octets or groups of an IP address.
[0104]In an embodiment the result may be encoded using either two to the 32 power unique values of the IPv4 system or two to the 128 power unique values of the IPv6 system.
[0105]In an embodiment, the dns query response is cached by a distributed domain name system and served to a client.
[0106.
[0107]The dns query response may be cached in a domain name system and served to a second client.
INDUSTRIAL APPLICABILITY/EMBODIMENTS
[0108.
[0109.
[0110]An email filter embodied as an apparatus or as a process preceding an SMTP server may substantially reduce the load on the server by preventing SMTP sessions with spammers to reach the point where data is transferred via the server.
[0111.
Method Embodiments in a Computer System
[0112]An embodiment of the invention is an article of manufacture comprising computer readable media encoded with instructions to adapt the operation of a processor.
[0113]An embodiment of the invention is an apparatus comprising a computing system and the above article of manufacture.
[0114.
[0115.
[0116.
CONCLUSION
[0117]The.
[0118.
[0119]The above discussion and description includes illustrations to support the understanding and appreciation of the invention but should be recognized as not limiting the scope which is defined by the claims following:
[0120]Significantly, this invention can be embodied in other specific forms without departing from the spirit or essential attributes thereof, and accordingly, reference should be had to the following claims, rather than to the foregoing specification, as indicating the scope of the invention.
Patent applications by Dean Drako, Los Altos, CA US
Patent applications by Zachary Levow, Mountain View, CA US
Patent applications by BARRACUDA NETWORKS INC.
Patent applications in class Credential
Patent applications in all subclasses Credential
User Contributions:
Comment about this patent or add new information about this topic: | http://www.faqs.org/patents/app/20100011420 | CC-MAIN-2014-23 | refinedweb | 3,541 | 51.18 |
26. Writing our own Classes¶
A class is a type. Up until this point in the book we’ve seen many classes and objects — Button, Canvas, Turtle, Random, Timer, etc. are all classes that we’ve used, but we’ve not yet designed our own classes (other than GUI windows). In this chapter we’ll learn to design our own (non-GUI) classes.
It is useful to think of a class as a factory for
creating many objects of the type.
So we’ve been able to use a class like a factory, e.g. the Button class gives rise to many Button instances, or we can create many Timer instances, or many Turtle objects:
So breaking our programs into multiple classes (instead of doing everything in one big class) has two really important advantages:
- It allows us to create many objects, all independent and disentangled from each other.
- It is an essential tool for managing bigger tasks with more complexity.
An object, as we’ve already seen, allows us to encapsulate, or chunk together,
two main things: some state of the object, and some functionality for the object.
The state can be internal to the object — private — or it can be
exposed via public properties. Think about turtles again — each one has its own
Heading, its own
BrushWidth, and so on. They also have functionality —
the things they can do. These are the public methods, like
Forward or
Stamp.
26.1. Object-oriented programming¶
In the Events chapter we animated some traffic lights. Go back to the traffic-light example there, and notice that we had three important abstractions, or “mental chunks” for the problem:
- We used a state machine to represent the Model (the internal mechanism or the “business logic”), of how traffic lights should work.
- There was a View of the traffic lights — some pictures that we changed in the GUI as the program ran.
- There was a source of events — timer tick events in this case, which was a Controller for the system. Buttons, scrollbars, menus, etc. are common parts of the controller in a GUI program.
The separation of problems so that we organize them as three different parts, a Model, a View, and a Controller, has turned out to be a really useful technique for designing software and games. The controller responds to the keyboard, mouse, gamepad, touchscreen, etc.), and it drives the changes in the model. Then the controller gets the view to show some representation of the model and its changes.
The way that we break up and organize programs into component parts is called a software architecture. Model-View-Controller (also called MVC for short) is one popular architecture.
We can get a nice overview at.
Our working problem
Here we’re going to re-implement the traffic lights, with some twists.
We now require three different sets of traffic lights. Each will have its own controller: one can be controlled by a timer, one by a keypress, and one by having the user explicitly click a button.
We’ll need three separate state machines — internal engines for the model of how the lights work. Here we’ll separate the logic for what the state machine should do into its own separate class, and we’ll create three instances of that class, one for each of the different sets of traffic lights.
And finally, we’ll have three different ways to visualize our traffic lights. One can use our pictures from the earlier chapter, one can just have some text output to say what the light is doing, and ... (we’ll make up something when we get there...).
26.2. Designing a class¶
We’ll want our own class to encapsulate (encapsulate means to enclose, as if in a capsule) the state and the functionality for a State Machine. One of the popular ways of figuring out how to break a complex system into more manageable components is to to write this information on a index card that is divided into three parts:
- What is the name of the class?
- What responsibilities will it (or the objects we instantiate from it) have,
- What other (types of) objects will it collaborate with?
See for more detail, but this is enough to get us started.
- Let’s call our class
TrafficLightFSM(FSM for finite state machine).
- Its responsibilities will be
- to keep track of what state the state machine is currently in,
- to advance (or transition) from the current state to its next state.
- Its collaborators will be
- the controller logic in the GUI part of our program,
- the viewer logic in the GUI part of our program.
One we’ve figured out what classes we want, (just the one in this case) we’ll decide what properties and methods we need to give our objects so that they can fulfil their responsibilities.
For our very simple objects, let’s start with one
property — the
CurrentState that the machine is in, and two methods:
the constructor method to initialize new objects, and a method called
AdvanceState().
To get a new class in our project in Visual Studio, right-click on our
project in the Solution Explorer pane, and choose Add | Class... You’ll
be prompted for a name (enter
TrafficLightFSM.cs). Visual Studio will
now generate a new class skeleton and add it to our project. It will open
the code, and will look something like this:
Your namespace may be different to the example above but will be the same as the namespace used
in your
MainWindow, and in any other classes we create later.
(Putting all the classes in our project into
the same namespace makes it easier for us, because they can all “see” each
other without having to add any extra
using directives at the top.)
Now we can write our methods and our property definitions or private variable definitions inside the class. Here’s what we’ll put in place of lines 6-8 now:
Lines 5-8 define the constructor for our new class — the code necessary
to initialize a new object of this type to its factory settings. The distinguishing
thing about the constructor is that it has no return type — not even the
keyword
void — and its name must be identical to the class name. If we do provide a
constructor, it will be automatically called whenever we instantiate a new object of this type.
Lines 10-24 provide the functionality we wanted — the same logic as we saw in the “More Events Handling” chapter of this book.
Line 3 is new: it shows that we’re defining a new property of
type
int. A property is like a variable, but with finer
control over how it can be used — this one says that the property is public —
it can be accessed outside the class (others can get its value),
but the
private modifier on
set restricts the property so that
it can only be set (assigned a new value) by methods within this class.
If we right-click on the class name in the Solution Explorer and choose the option “View Class Diagram”, we’ll get a diagram of the class (this feature may not be in all versions of Visual Studio):
A class diagram is a widely used notation that allows software developers to express different aspects of their design. Many people will tell us that we should draw our diagram first, and write our class according to our diagram. In Visual Studio, because we can get the diagram from a class it seems sometimes easier just to start with the class.
Well done! We’ve written our very first (non GUI) class. Now let’s make some objects of this type, and put them to good use.
26.3. Three sets of traffic lights — The Controllers and the Views¶
In the kinds of programs we write the Controllers and the Views are both intertwined in our Window class, so they’re not fantastically well separated. We’ll make a special effort to separate them in our thinking, at least.
Here’s what the finished product will look like:
Let’s begin by just getting the first set of lights to work. Most of the code is identical to what we saw previously in the More Event Handling chapter, except that the logic for the state machine is now in its own class.
In line 2 we define variables for all three models, and at lines 9-11 we instantiate all three. Otherwise the code is pretty similar to what it was before: our class constructor instantiates all the objects it needs, and starts the timer. When the timer ticks we advance our model, and then we update the view by asking the model for its current state, and using that to choose the picture that is displayed by the image control.
Our second set of traffic lights is controlled by a keyboard event,
so we create an event handler for the Window’s
KeyDown event, and respond to
a keypress like this:
So our “view” in this case is just some text that is displayed in a label. To reinforce the idea that the view is now independent from the model and controller, perhaps we can consider how easily we could change the view to display Spanish rather than English in the label.
Finally, the third set of traffic lights is controlled by clicking the button. So here is the code behind the button click event:
We’ve not used a
ProgressBar control before, but they’re
quite easy. We drag one onto our Window, and we set its orientation property
to make it grow vertically instead of horizontally. It shows progress according to
the number we assign to its
Value property. (By default, 0 represents
no progress, 100 represents “100% progress”.)
We also change the brush colour to view the different states.
26.4. The keyword
this¶
The keyword
this is available in a class, and works like the English word “me”.
So every object can use a reference to itself. So
this.CurrentState means “my CurrentState”.
Normally we don’t need to use the keyword explicitly. But it is really convenient in one
particular situation — in a class constructor.
So let us change our
TrafficLightFSM constructor. Instead of always creating an FSM which begins
in state 0, we now want the caller to be able to pass an argument to the constructor, to set the initial state:
The tricky bit is at line 7. We now have a parameter at line 5 with exactly
the same name as our property in line 3. We recall our
discussion about scope lookup rules in Chapter 24:
CurrentState
means the most closely nested definition of the name.
Which is the parameter on line 5.
Our new keyword,
this, can be used to explicitly qualify the a name
to mean “the CurrentState that belongs to me, the object”
(i.e. the one defined at line 3, in class-level scope.)
It is sometimes easier just to choose another name for the parameter, but
using the same names is popular practice in C# (and in Java). So we’ll need
to use
this to work around the scope rules to let us access the class-level
variable of the name. So we’re sure to see it often.
26.5. Summary¶
By making
TrafficLightFSM into its own class we’ve
simplified the logic, especially when we want multiple instances, each with
their own state. It would be tricky to have all the logic and variables for three
separate state machines tangled up inside our Window class.
Our first
TrafficLightFSM class was really simple: one property and one
method (apart from the constructor). But the powerful thing is the idea:
as we put more state and logic into our objects, we’ll see more
benefits from this approach of breaking programs into
separate components that interact with each other. (Consider how complicated the
behaviour of a Window or a Turtle object is, or for any of the GUI controls
that we use so easily. Having classes to organize and manage this complexity is essential!)
26.6. The bigger picture¶
C# is a fully object-oriented programming language: every method must belong to a class, and the only way to organize computation is by having classes that give rise to objects that can interact with each other. Java is like this too.
An earlier style of organizing computation is called procedural (or imperative) programming. Look it up. Fortran, C, BASIC and Pascal are popular languages that support this style.
Some procedural languages added objects and classes to their procedural core, and they now have a (sometimes messy) mixture that can be used in either style. C++, Python, Visual Basic, and some newer versions of Pascal (e.g. Delphi Pascal) work like this.
26.7. Glossary¶
- class
- A class defines a new type of object. A class can also be thought of as a template or a blueprint for the objects that are created according to its specifications.
- constructor
- Every class may have special method that is invoked automatically to initialize a new object to its factory-default state.
- instance
- An object whose type is of some class. Instance and object are used interchangeably.
- instantiate
- To create an instance of a class, and to run its constructor, if one exists.
- method
- A method is defined inside a class definition and is invoked on objects of that class. Methods give objects their behaviour.
- Model-View-Controller (MVC)
- A popular way of breaking software systems into three co-operating components.
- object
- The run-time entity that is often used to represent a real-world thing. It bundles together the state (data) and the behaviour appropriate for that kind of thing. Instance and object are used interchangeably.
- software architecture
- The overall design of a large software system.
this
- A C# keyword that refers to the current instance of the class.
- object-oriented programming
- A powerful style of programming in which data and the operations that manipulate it are organized into objects.
26.8. Exercises¶
Write a class definition for an SMSMessage that implements the class diagram here. It should contain four properties that are privately settable, but publically gettable. The constructor should initialize the sender’s number and the message from parameters, and it should also set
HasBeenReadto false, set the
TimeStampto
DateTime.Now. The
MarkAsReadmethod should change
HasBeenReadto true.
Create a new class, SMSStore, that can be used for an SMS inbox or outbox on a cellphone. It should implement the class diagram here.
This store can hold multiple
SMSMessageobjects. (Hint: use a
List<SMSMessage>!)
An SMSStore object should provide methods with these signatures:
Write the class, create a message store object, write tests for these methods, and implement the methods.
Make a GUI like the one shown. In one half of the screen you can be in the role of a friend, and “send” new SMS messages to your inbox. In the other half of the screen you can be the phone “user” — you’ll be able to refresh the status (the view) of your inbox. (In this sample I used two Canvas controls and set different background colours to provide the two halves of the screen.)
You can read any message by entering its index number.
Extend your SMS GUI so that you don’t need the “Refresh Status” button — the status automatically updates itself whenever you add a message to the Inbox, or when a message is read. Extend the interface so that the user can delete a message, or clear all messages from the Inbox.
Add another class called AddressBook to your program. Pre-program some phone numbers and names into the address book. (We won’t worry about adding new contacts or deleting contacts, or updating their information, although this could be a nice exercise too!) Now change your GUI from the previous question so that if the SMS arrives from a known contact, their name will be shown in the GUI instead of their number.
Do the following experiment on your phone. Find an SMS in your Inbox for which you have no contact details. Add a dummy contact for that number. Does your Inbox now show the dummy contact name, or does it still show the original number? What happens if you now delete the dummy contact? Do you think your phone searches your contact list when the SMS arrives, or when you want to see your Inbox, or does it update your Inbox whenever you make changes to your contact list?
Take an existing class, and add the qualifier
thisto every use of a member (variable, method, property) so that you build a good understanding that an unqualified name often resolves (using the normal scope rules) to the local scope. But the
thiskeyword explicitly forces the name to be at class-level scope. | http://7-fountains.com/7FD/ThinkSharply/ThinkSharply/classes_and_objects_I.html | CC-MAIN-2018-51 | refinedweb | 2,821 | 69.52 |
When you continuously index timestamped documents into Elasticsearch, you typically use a data stream so you can periodically roll over to a new index. This enables you to implement a hot-warm-cold architecture to meet your performance requirements for your newest data, control costs over time, enforce retention policies, and still get the most out of your data.
Data streams are best suited for append-only use cases. If you need to frequently update or delete existing documents across multiple indices, we recommend using an index alias and index template instead. You can still use ILM to manage and rollover the alias’s indices. Skip to Manage time series data without data streams.
To automate rollover and management of a data stream with ILM, you:
- Create a lifecycle policy that defines the appropriate phases and actions.
- Create an index template to create the data stream and apply the ILM policy and the indices settings and mappings configurations for the backing indices.
- Verify indices are moving through the lifecycle phases as expected.
For an introduction to rolling indices, see Rollover.
When you enable index lifecycle management for Beats or the Logstash Elasticsearch output plugin, lifecycle policies are set up automatically. You do not need to take any other actions. You can modify the default policies through Kibana Management or the ILM APIs.
Create a lifecycle policyedit
A lifecycle policy specifies the phases in the index lifecycle
and the actions to perform in each phase. A lifecycle can have up to five phases:
hot,
warm,
cold,
frozen, and
delete.
For example, you might define a
timeseries_policy that has two phases:
- A
hotphase that defines a rollover action to specify that an index rolls over when it reaches either a
max_primary_shard_sizeof 50 gigabytes or a
max_ageof 30 days.
- A
deletephase that sets
min_ageto remove the index 90 days after rollover. Note that this value is relative to the rollover time, not the index creation time.
You can create the policy through Kibana or with the create or update policy API. To create the policy from Kibana, open the menu and go to Stack Management > Index Lifecycle Policies. Click Create policy.
API example
Create an index template to create the data stream and apply the lifecycle policyedit
To set up a data stream, first create an index template to specify the lifecycle policy. Because
the template is for a data stream, it must also include a
data_stream definition.
For example, you might create a
timeseries_template to use for a future data stream
named
timeseries.
To enable the ILM to manage the data stream, the template configures one ILM setting:
index.lifecycle.namespecifies the name of the lifecycle policy to apply to the data stream.
You can use the Kibana Create template wizard to add the template. From Kibana, open the menu and go to Stack Management > Index Management. In the Index Templates tab, click Create template.
This wizard invokes the create or update index template API to create the index template with the options you specify.
API example
Create the data streamedit
To get things started, index a document into the name or wildcard pattern defined
in the
index_patterns of the index template. As long
as an existing data stream, index, or index alias does not already use the name, the index
request automatically creates a corresponding data stream with a single backing index.
Elasticsearch automatically indexes the request’s documents into this backing index, which also
acts as the stream’s write index.
For example, the following request creates the
timeseries data stream and the
first generation backing index called
.ds-timeseries-2099.03.08-000001.
POST timeseries/_doc { "message": "logged the request", "@timestamp": "1591890611" }
When a rollover condition in the lifecycle policy is met, the
rollover action:
- Creates the second generation backing index, named
.ds-timeseries-2099.03.08-000002. Because it is a backing index of the
timeseriesdata stream, the configuration from the
timeseries_templateindex template is applied to the new index.
- As it is the latest generation index of the
timeseriesdata stream, the newly created backing index
.ds-timeseries-2099.03.08-000002becomes the data stream’s write index.
This process repeats each time a rollover condition is met.
You can search across all of the data stream’s backing indices, managed by the
timeseries_policy,
with the
timeseries data stream name.
Write operations are routed to the current write index. Read operations will be handled by all
backing indices.
Check lifecycle progressedit
To get status information for managed indices, you use the ILM explain API. This lets you find out things like:
- What phase an index is in and when it entered that phase.
- The current action and what step is being performed.
- If any errors have occurred or progress is blocked.
For example, the following request gets information about the
timeseries data stream’s
backing indices:
GET .ds-timeseries-*/_ilm/explain
The following response shows the data stream’s first generation backing index is waiting for the
hot
phase’s
rollover action.
It remains in this state and ILM continues to call
check-rollover-ready until a rollover condition
is met.
{ "indices": { ".ds-timeseries-2099.03.07-000001": { "index": ".ds-timeseries-2099.03.07-000001", "managed": true, "policy": "timeseries_policy", "lifecycle_date_millis": 1538475653281, "age": "30s", "phase": "hot", "phase_time_millis": 1538475653317, "action": "rollover", "action_time_millis": 1538475653317, "step": "check-rollover-ready", "step_time_millis": 1538475653317, "phase_execution": { "policy": "timeseries_policy", "phase_definition": { "min_age": "0ms", "actions": { "rollover": { "max_primary_shard_size": "50gb", "max_age": "30d" } } }, "version": 1, "modified_date_in_millis": 1539609701576 } } } }
Manage time series data without data streamsedit
Even though data streams are a convenient way to scale and manage time series data, they are designed to be append-only. We recognise there might be use-cases where data needs to be updated or deleted in place and the data streams don’t support delete and update requests directly, so the index APIs would need to be used directly on the data stream’s backing indices.
In these cases, you can use an index alias to manage indices containing the time series data and periodically roll over to a new index.
To automate rollover and management of time series indices with ILM using an index alias, you:
- Create a lifecycle policy that defines the appropriate phases and actions. See Create a lifecycle policy above.
- Create an index template to apply the policy to each new index.
- Bootstrap an index as the initial write index.
- Verify indices are moving through the lifecycle phases as expected.
Create an index template to apply the lifecycle policyedit
To automatically apply a lifecycle policy to the new write index on rollover, specify the policy in the index template used to create new indices.
For example, you might create a
timeseries_template that is applied to new indices
whose names match the
timeseries-* index pattern.
To enable automatic rollover, the template configures two ILM settings:
index.lifecycle.namespecifies the name of the lifecycle policy to apply to new indices that match the index pattern.
index.lifecycle.rollover_aliasspecifies the index alias to be rolled over when the rollover action is triggered for an index.
You can use the Kibana Create template wizard to add the template. To access the wizard, open the menu and go to Stack Management > Index Management. In the Index Templates tab, click Create template.
The create template request for the example template looks like this:
PUT _index_template/timeseries_template { "index_patterns": ["timeseries-*"], "template": { "settings": { "number_of_shards": 1, "number_of_replicas": 1, "index.lifecycle.name": "timeseries_policy", "index.lifecycle.rollover_alias": "timeseries" } } }
Bootstrap the initial time series index with a write index aliasedit
To get things started, you need to bootstrap an initial index and designate it as the write index for the rollover alias specified in your index template. The name of this index must match the template’s index pattern and end with a number. On rollover, this value is incremented to generate a name for the new index.
For example, the following request creates an index called
timeseries-000001
and makes it the write index for the
timeseries alias.
PUT timeseries-000001 { "aliases": { "timeseries": { "is_write_index": true } } }
When the rollover conditions are met, the
rollover action:
- Creates a new index called
timeseries-000002. This matches the
timeseries-*pattern, so the settings from
timeseries_templateare applied to the new index.
- Designates the new index as the write index and makes the bootstrap index read-only.
This process repeats each time rollover conditions are met.
You can search across all of the indices managed by the
timeseries_policy with the
timeseries alias.
Write operations are routed to the current write index.
Check lifecycle progressedit
Retrieving the status information for managed indices is very similar to the data stream case. See the data stream check progress section for more information. The only difference is the indices namespace, so retrieving the progress will entail the following api call:
GET timeseries-*/_ilm/explain | https://www.elastic.co/guide/en/elasticsearch/reference/7.15/getting-started-index-lifecycle-management.html | CC-MAIN-2021-49 | refinedweb | 1,459 | 53.81 |
On Sat, May 23, 2009 at 9:20 AM, Michael Niedermayer <michaelni at gmx.at> wrote: > On Fri, May 22, 2009 at 11:13:44PM -0300, Ramiro Polla wrote: >> On Fri, May 22, 2009 at 9:24 PM, Ramiro Polla <ramiro.polla at gmail.com> wrote: >> [...] >> > Applied with the #endif comment as /* !HAVE_X86_64 */ >> >> > +#if ARCH_X86_64 >> > + >> > +#define MLPMUL(label, offset, offs, offc) ? \ >> > + ? ?MANGLE(label)": ? ? ? ? ? ? ? ? ? \n\t" \ >> > + ? ?"movslq "offset"+"offs"(%0), %%rax\n\t" \ >> > + ? ?"movslq "offset"+"offc"(%1), %%rdx\n\t" \ >> > + ? ?"imul ? ? ? ? ? ? ? ? %%rdx, %%rax\n\t" \ >> > + ? ?"add ? ? ? ? ? ? ? ? ?%%rax, %%rsi\n\t" >> >> This broke building on x86_64 with PIC. The reason is MANGLE() in that >> case appends (%%rip) to the symbol. That is not wanted for exporting a >> label from inside an asm block. The symbol must be MANGLE()d here so >> it can be picked up by the C code (or else we get undefined >> references). >> >> So I propose: >> label_mangle.diff >> use_label_mangle.diff >> restore_x86_mlpdsp.diff > > ok Applied. | http://ffmpeg.org/pipermail/ffmpeg-devel/2009-May/075850.html | CC-MAIN-2016-22 | refinedweb | 155 | 78.35 |
Component family Databases/Amazon Redshift Function This component runs a specified query in Amazon Redshift and then unloads the result of the query to one or more files on Amazon S3. Purpose This component allows you to unload data on Amazon Redshift to files on Amazon S3. database connection fields that follow are completed automatically using the data retrieved. Database settings Use an existing connection Select this check box and in the Component List click the relevant connection component to reuse the connection details you already defined. Host Type in the IP address or hostname of the database server. Port Type in the listening port number of the database server. Database Type in the name of the database. Schema Type in the name of the schema. Username and Password Type in the database user authentication data. To enter the password, click the [...] button next to the password field, and then in the pop-up dialog box enter the password between double quotes and click OK to save the settings. Table Name Type in the name of the table from which the data will be read. and Query Enter the database query paying particularly attention to the proper sequence of the fields in order to match the schema definition. Guess Query Click the button to generate the query which corresponds to the table schema in the Query field. S3 Setting Access Key Specify the Access Key ID that uniquely identifies an AWS Account. For how to get your Access Key and Access Secret, visit Getting Your AWS Access Keys. Secret Key Specify. Bucket Type in the name of the Amazon S3 bucket, namely the top level folder, to which the data is unloaded. Key prefix Type in the name prefix for the unload files on Amazon S3. By default, the unload files are written per slice of the Redshift cluster and the file names are written in the format <object_path>/<name_prefix><slice-number>_part_<file-number>. Advanced settings File type Select the type of the unload files on Amazon S3 from the list: Delimited file or CSV: a delimited/CSV file.Fixed width: a fixed-width file. Fields terminated by Enter the character used to separate fields. This field appears only when Delimited file or CSV is selected from the File type list. Enclosed by Select the character in a pair of which the fields are enclosed. This list appears only when Delimited file or CSV is selected from the File type list. Fixed width mapping Enter a string that specifies a user-defined column label and column width between double quotation marks. The format of the string is: ColumnLabel1:ColumnWidth1,ColumnLabel2:ColumnWidth2,.... Note that the column label in the string has no relation to the table column name and it can be either a text string or an integer. The order of the label/width pairs must match the order of the table columns exactly. This field appears only when Fixed width is selected from the File type list. Compressed by Select this check box and from the list displayed select the compression type of the files. Encrypt Select this check box to encrypt unload file(s) using Amazon S3 client-side encryption. For more information, see Unloading Encrypted Data Files. Encryption key Enter the encryption key used to encrypt unload file(s). This field appears only when the Encrypt check box is selected. Specify null string Select this check box and from the list displayed select a string that represents a null value in unload files. Escape Select this check box to place an escape character (\) before every occurrence of the following characters for CHAR and VARCHAR columns in the delimited unload files: linefeed (\n), carriage return (\r), the delimiter character specified for the unloaded data, the escape character (\), a quote character (" or '). Overwrite s3 object if exist Select this check box to overwrite the existing Amazon S3 object files. Parallel Select this check box to write data in parallel to multiple unload files on Amazon S3 according to the number of slices in the Redshift cluster. the Amazon Redshift. | https://help.talend.com/reader/mjoDghHoMPI0yuyZ83a13Q/uxr7cuoa1W_q0khn_1B3pw | CC-MAIN-2020-16 | refinedweb | 681 | 63.59 |
On Thu, 8 Apr 2004, Simon Peyton-Jones wrote: > You've become a very sophisticated Haskell programmer! Thank you, but I think it may only seem that way. I'll post a complete program up somewhere and they we'll see where I really stand. Among other things, I don't yet have a feel for idiom/style (e.g. when do you define classes rather than modules, when do use in default methods, in what order do you define types classes functions etc for maximum readability). > We did at one stage do something like this, by making list comprehensions= into monad comprehensions. So > =09[ x*x | x <- xs, pred x] > meant the same as > =09do { x <- xs; if pred x then mzero else return (); return (x*x)} > > But in the next iteration of the language we undid the change, a controve= rsial decision that some still regret. Because na=EFve users were getting = too many perplexing error messages about monads and functors when they thou= ght they were just manipulating lists. I guess I'm in the regret group. Nothing stops beginners from importing BeginnerUtils and using list typed functions with names like concatList (or implementors from writing better error message copy). But, ok... > Haskell is pretty good about letting you install a different Prelude, so = you could try it yourself. Hmm. That's interesting! How does this work? * Can this change propogate through the libs so that e.g. lookupFM also returns a Monad rather than Maybe without manual modification of all the libs? (Note: I am actually using lookupFM in my code, I used lookup in my example to simplify) * If I modify Monad in my prelude to have Ord, will do-notation work in my new monad class? Will the IO monad work? Can I make () an instance of Ord or EQ? * Can different modules use different Preludes? It seems like making a module dependent on a different Prelude means potential incompatibilities with third party modules. e.g. if I want to use HaXML and it hypothetically changes to define one Prelude and HaskellDB which hypothetically changes to define another Prelude, is there an easy way to import ONLY the functions defined in those modules and not all the functions defined in their respective Preludes. * Is there a formal definition of what in the Prelude is actually core to Haskell and what is really just common utilities located their? Alternatively, does an "advanced prelude" already exist that does what I probably want but don't know yet? -Alex- _________________________________________________________________ S. Alexander Jacobson mailto:me at alexjacobson.com tel:917-770-6565 > =3D foldl union emptySet $ maybe mzero return $ lookup pairs key > | goo =3D maybe emptySet toSomething $ lookup pairs key > | > | which really should look like this: > | > | foo =3D concat $ lookup pairs key > | goo =3D fmap toSomething $ lookup pairs key > | > | But, even if we don't have a Monadic/Functor Set, > | foo should at least be: > | > | foo =3D foldl union emptySet $ lookup key > | > | In other words, shouldn't Prelude define concat > | and lookup as: > | > | concat =3D foldr mplus mzero -- (Also, see PS) > | > | lookup key [] =3D mzero > | lookup key ((x,y):xyz) > | | key =3D=3D x =3D return y > | | otherwise =3D > | > | http://www.haskell.org/pipermail/haskell/2004-April/013935.html | CC-MAIN-2014-23 | refinedweb | 532 | 59.43 |
and BeOS, and runs on Mac OS X using Apple's X11 server. It was originally created for the GIMP, a popular image-manipulation program, and later became the toolkit for GNOME, the GNU Network Object Model Environment.
In Part 1 of this article, published in TPJ last month, I gave a brief overview of the event-based programming model and discussed some of the most common widgets available. This month, I'll complete the exploration of the Gtk+ widget set and also explore some of the handy time-saving features of Gtk2-Perl.
Container Widgets Continued: Panes
Panes in Gtk+ are analogous to frames in HTMLthey break the window into two separate parts, with a bar between them that can be dragged to resize the two parts.
Pane widgets come in two flavors: horizontal and vertical. They are both created in the same way:
my $hpaned = Gtk2::HPaned->new; my $vpaned = Gtk2::VPaned->new;
Panes can contain precisely two widgetsto reflect this, you add widgets to it using the add1() and add2() methods:
$hpaned->add1($left_widget); $hpaned->add2($right_widget);
or
$vpaned->add1($top_widget); $vpaned->add2($bottom_widget);
Listing 8 shows how the paned widgets can be used. The resulting widgets are shown in Figure 8.
Scrolled Windows
Scrolled windows are handy when you want to place a widget inside a scrollable area. Almost all applications have something like this because inevitably, the data the program uses will grow so that it can't all be displayed at once.
Scrolled windows are often used in conjunction with another kind of container called a viewport. Viewports are rarely used without a scrolled window, so I won't talk about them, but you do need to know about them.
Listing 9 is a simple example of scrolled window usage, which results in the window shown in Figure 9. The scrolled window allows us to view the butterfly, even though it's much larger than the window size.
Some widgets have their own scrollbars and don't need a viewport. These include the Gtk2::TextView and Gtk2::TreeView widgets. For these, you just need to use the add() method.
The add_with_viewport() method creates a new viewport, adds the image to it, and then adds it to the scrolled window. The set_policy() method tells the widget under what conditions it should display horizontal and vertical scrollbars, in that order. When set to "automatic," it will display a scrollbar when the child widget is larger than the scrolled window. Other values are "always" and "never."
Event Boxes
Event boxes allow you to add callbacks to widgets for events and signals that they don't support. For example, a Gtk2::Image cannot have any signals connected to it. However, if you place the image inside an event box, you can connect a signal to the event box, as shown in Listing 10 and the corresponding Figure 10.
Manipulating Graphics with Gtk2::Gdk::Pixbuf
The gdk-pixbuf libraries (namespaced as Gtk2::Gdk::Pixbuf in Perl) provide a flexible and convenient way to handle graphics in Gtk+. gdk-pixbuf supports a wide range of image formats, including PNG, JPG, GIF, and XPM. It also has support for animations.
The GdkPixbuf provides some methods for basic image manipulation. However, you may find that libraries such as GD and Image::Magick will be better for more complicated tasks.
Resizing an Image
To resize a pixbuf, use the scale_simple() method:
$pixbuf->scale_simple( $destination_pixbuf, $new_width, $new_height, $scaling_type );
This will resize $pixbuf and place the resulting image into $destination_pixbuf. If you don't want to create a new object, just replace $destination_pixbuf with $pixbuf. $new_width and $new_height are the dimensions desired, in pixels. $scaling_type determines the algorithm to be used: "bilinear" produces better quality images, but is slower than "nearest."
If you want to resize the pixbuf into a new pixbuf object, you must make sure that the destination pixbuf has the same properties as the source. To do this, use the various get_*() methods as arguments to the constructor:
my $destination_pixbuf = Gtk2::Gdk::Pixbuf->new( $source_pixbuf->get_colorspace, $source_pixbuf->get_has_alpha, $source_pixbuf->get_bits_per_sample, $source_pixbuf->get_width, $source_pixbuf->get_height, );
Changing the Brightness of a pixbuf
To change the brightness of an image, use the saturate_and_pixelate() method:
$pixbuf->saturate_and_pixelate( $destination_pixbuf, 2, 0 );
The second argument is the factor by which to brighten or darken the image: If it's less than 1.0, the image is darkened; if it's higher, then the image is brightened. The last argument determines whether the image is "pixelated." This draws a checkerboard over the image as though it were disabled. In this case, we don't want that, so it's set to 0.
As with the example above, the destination pixbuf must have the same properties as the source.
Copying a Region from a pixbuf
You can copy a region of the image out of a pixbuf using the copy_area() method:
$source_pixbuf->copy_area( $src_x, $src_y, $width, $height, $destination_pixbuf, $dest_x, $dest_y );
$src_x and $src_y are the horiztonal and vertical coordinates of the top left corner of the region to be copied. $width and $height define its dimensions. $dest_x and $dest_y are the coordinates in $destination_pixbuf where the copied area will be positioned.
Writing pixbuf Data to Disk
You can write a pixbuf to disk in any format that gdk-pixbuf supports. For example:
$pixbuf->save('image.png' 'png');
writes the pixbuf in PNG format.
Getting the pixbuf of a Stock Icon
Should you need the pixbuf of a stock icon, you can use the render_icon() method of any available widget:
my $stock_pixbuf = $window->render_icon($stock_id, $stock_size);
See "More Information" for references to the allowed values for $stock_id and $stock_size.
Glade
The Rapid Application Development (RAD) tool Glade is a WYSIWYG graphical interface designer. Using it, you can construct an interface in minutes that would take hours to hand craft.
The Glade program produces UI description files in XML format, and the Gtk2::GladeXML module is capable of reading these XML files and constructing your interface at runtime. The advantage in this is immediateit provides for a separation between logic and presentation that will make your job a lot easier in the future. And if you happen to work with a Human Computer Interface (HCI) expert, they can have complete control over the interface without ever having to touch a line of code, and you can get on with the job of making the program work without having to constantly revise the interface.
Here's a simplified example of how to use a Glade XML file in your program:
#!/usr/bin/perl use Gtk2 -init; use Gtk2::GladeXML; use strict; my $gladexml = Gtk2::GladeXML->new('example.glade'); $gladexml->signal_autoconnect_from_package('main'); Gtk2->main; exit; # this is called when the main window is closed: sub on_main_window_delete_event { Gtk2->main_quit; } [snip]
This program takes a Glade file called "example.glade" and creates an interface. When designing your interface, you can define the names of subroutines to handle widget signals, and the signal_autoconnect_from_package() method tells Gtk2::GladeXML which package name the handlers can be found in.
Each widget in the Glade file has a unique name, for example, my_main_window or label5. You can get the widget object for a specific object using the get_widget() method:
my $label = $gladexml->get_widget('label5'); $label->set_text('Hello World!');
You may find that just experimenting with Glade will be a good learning exercise. Glade is also an excellent prototyping utility, so that even if you don't plan to make use of Gtk2::GladeXML, you will find it invaluable for planning how your program will be organized.
Gtk2::SimpleList
As well as providing Perl bindings for the Gtk+ widget set, Gtk2-Perl comes with a couple of extra modules that provide a much more Perlish way of working with some of the more complex widgets. An example is the Model, View, Controller (MVC) system for list and tree widgets. While being extremely powerful, they're a pain to work with, especially since the average application will rarely make use of the full features available.
Gtk2::SimpleList is designed to make working with lists easy. Listing 11 is an example of its usage. You can see what this program looks like in Figure 11.
Gtk2::SimpleList acts as a wrapper around the standard Gtk2::TreeView and inherits all of the latter's methods, so that once your list is created you can manipulate it in the usual way. Data is represented as a Perl list of lists (an array of array references), and can be modified directly without having to redraw the entire list.
In the constructor, we are required to define the columns in the list we will use. We do this using a pseudohash where the column titles are the keys, and their types are the values. The allowed values are "text" for a text string, "int" for an integer, "double" for a double-precision floating-point value and "pixbuf" for a Gtk2::Gdk::Pixbuf object.
We can populate the data in the list either by writing to the $list->{data} value or using a subroutine.
In addition to the methods it inherits from Gtk2::TreeView, Gtk2::SimpleList also provides:
$list = Gtk2::SimpleList->new_from_treeview($treeview, [column_data]);
This creates a list using an already created treeview widget. This is handy for when you're using Glade and such a widget has already been created for you.
@indices = $list->get_selected_indices;
This returns an list of numbers representing the currently selected rows in the list.
$list->set_data_array($arrayref);
This method populates the list data array. $arrayref is a reference to an array of array references.
$list->select(@rows); $list->unselect(@rows);
These methods select and unselect the rows identified in the @rows array.
$list->set_column_editable($column, $editable);
Cells in the list can be edited by the userthis method can be used to enable or disable this feature. $column is the index of the column, and $editable should be a true value to enable editing, or false to disable it.
Gtk2::SimpleMenu
This module makes it easy to create hierarchical application menus (the File, Edit, View menu at the top of each window). The constructor takes as an argument a reference to an array containing a tree of menus, submenus, and items. (See Listing 12; you can see the resulting program in Figure 12.)
Each item and submenu is represented by an anonymous hash, containing data needed to set up the menu. The various item_types include Branch for a submenu, LastBranch for a right-justified menu, Item for a standard item, StockItem for an item with a stock item (which is then specified in the extra_data key), and RadioItem and CheckItem, which create items with radio buttons and checkboxes, respectively.
You can define a callback for when the item is clicked using the callback key, but you can also specify a callback_action, which is then passed as an argument to the function defined by the default_callback argument in the constructor.
Creating Your Own Widgets
It is very easy to create custom widgets with Gtk2-Perl. All you need to do is create a package that inherits from an existing Gtk+ widget, and extend the functionality. Listing 13 is an example of a simple extension to Gtk2::Button. The resulting program is shown in Figure 13.
The first thing we need to do is declare what package we want to inherit from. This is as easy as
use base 'Gtk2::SomeWidget';
Then we need to override the constructor. But we need to get hold of a Gtk2::SomeWidget object so we can play with it. The $package->SUPER::new expression does this for usthen we can re-bless() it into our own package and start playing.
The Gtk2::SimpleList and Gtk2::SimpleMenu widgets are examples of this kind of custom widget, which is derived from an existing Gtk+ widget. There's also the Gtk2::PodViewer widget, available from CPAN, which provides a Perl POD rendering widget based on Gtk2::TextView..
Gtk+ Documentation
There is no direct Gtk+, the Gtk+ stock icon.
Installing Gtk2-Perl
If you like what you see here and want to get started with Gtk2-Perl, the first thing you'll need to do is install the Gtk2-Perl modules. You can do this by downloading and compiling the source libraries from the Gtk2-Perl web site, but you can also use the CPAN bundle. With this, installaton is as simple as issuing this command:
perl -MCPAN -e 'install Bundle::Gnome2'
This will install the latest versions of all the available Gtk2-Perl libraries.
TPJ
#!/usr/bin/perl use Gtk2 -init; use strict; my $window = Gtk2::Window->new; $window->set_title('Paned Example'); $window->signal_connect('delete_event', sub { Gtk2->main_quit }); $window->set_border_width(8); my $vpaned = Gtk2::VPaned->new; $vpaned->set_border_width(8); $vpaned->add1(Gtk2::Button->new('Top Pane')); $vpaned->add2(Gtk2::Button->new('bottom Pane')); my $frame = Gtk2::Frame->new('Right Pane'); $frame->add($vpaned); my $hpaned = Gtk2::HPaned->new; $hpaned->set_border_width(8); $hpaned->add1(Gtk2::Button->new('Left Pane')); $hpaned->add2($frame); $window->add($hpaned); $window->show_all; Gtk2->main;Back to article
Listing 9
#!/usr/bin/perl use Gtk2 -init; use strict; my $window = Gtk2::Window->new; $window->set_title('Scrolled Window Example'); $window->signal_connect('delete_event', sub { Gtk2->main_quit }); $window->set_border_width(8); my $image = Gtk2::Image->new_from_file('butterfly.jpg'); my $scrwin = Gtk2::ScrolledWindow->new; $scrwin->set_policy('automatic', 'automatic'); $scrwin->add_with_viewport($image); $window->add($scrwin); $window->show_all; Gtk2->main;Back to article
Listing 10
#!/usr/bin/perl use Gtk2 -init; use strict; my $window = Gtk2::Window->new; $window->set_title('Event Box Example'); $window->signal_connect('delete_event', sub { Gtk2->main_quit }); $window->set_border_width(8); my $image = Gtk2::Image->new_from_stock('gtk-dialog-info', 'dialog'); # a Gtk2::Image widget can't have the 'clicked' signal, so this causes # an error: $image->signal_connect('clicked', \&clicked); my $box = Gtk2::EventBox->new; # but this works! $box->signal_connect('button_release_event', \&clicked); $box->add($image); $window->add($box); $window->show_all; Gtk2->main; sub clicked { print "someone clicked me!\n"; }Back to article
Listing 11
#!/usr/bin/perl use Gtk2 -init; use Gtk2::SimpleList; use strict; my $window = Gtk2::Window->new; $window->set_title('List Example'); $window->set_default_size(300, 200); $window->signal_connect('delete_event', sub { Gtk2->main_quit }); $window->set_border_width(8); my $list = Gtk2::SimpleList->new( 'Browser Name' => 'text', 'Version' => 'text', 'Uses Gecko?' => 'bool', 'Icon' => 'pixbuf' ); $list->set_column_editable(0, 1); @{$list->{data}} = ( [ 'Epiphany', '1.0.4', 1, Gtk2::Gdk::Pixbuf->new_from_file('epiphany.png') ], [ 'Galeon', '1.3.9', 1, Gtk2::Gdk::Pixbuf->new_from_file('galeon.png') ], [ 'Konqueror', '3.1.4', 0, Gtk2::Gdk::Pixbuf->new_from_file('konqueror.png') ], ); my $scrwin = Gtk2::ScrolledWindow->new; $scrwin->set_policy('automatic', 'automatic'); $scrwin->add_with_viewport($list); my $button = Gtk2::Button->new_from_stock('gtk-ok'); $button->signal_connect('clicked', \&clicked); my $vbox = Gtk2::VBox->new; $vbox->set_spacing(8); $vbox->pack_start($scrwin, 1, 1, 0); $vbox->pack_start($button, 0, 1, 0); $window->add($vbox); $window->show_all; Gtk2->main; sub clicked { my $selection = ($list->get_selected_indices)[0]; my @row = @{(@{$list->{data}})[$selection]}; printf( "You selected %s, which is at version %s and %s Gecko.\n", $row[0], $row[1], ($row[2] == 1 ? "uses" : "doesn't use") ); Gtk2->main_quit; }Back to article
Listing 12
#!/usr/bin/perl use Gtk2 -init; use Gtk2::SimpleMenu; use strict; my $window = Gtk2::Window->new; $window->set_title('Menu Example'); $window->set_default_size(300, 200); $window->signal_connect('delete_event', sub { Gtk2->main_quit }); my $vbox = Gtk2::VBox->new; my $menu_tree = [ _File => { item_type => '<Branch>', children => [ _New => { item_type => '<StockItem>', callback => \&new_document, accelerator => '<ctrl>N', extra_data => 'gtk-new', }, _Save => { item_type => '<StockItem>', callback => \&save_document, accelerator => '<ctrl>S', extra_data => 'gtk-save', }, _Quit => { item_type => '<StockItem>', callback => sub { Gtk2->main_quit }, accelerator => '<ctrl>Q', extra_data => 'gtk-quit', }, ], }, _Edit => { item_type => '<Branch>', children => [ _Cut => { item_type => '<StockItem>', callback_action => 0, accelerator => '<ctrl>X', extra_data => 'gtk-cut', }, _Copy => { item_type => '<StockItem>', callback_action => 1, accelerator => '<ctrl>C', extra_data => 'gtk-copy', }, _Paste => { item_type => '<StockItem>', callback_action => 2, accelerator => '<ctrl>V', extra_data => 'gtk-paste', }, ], }, _Help => { item_type => '<LastBranch>', children => [ _Help => { item_type => '<StockItem>', callback_action => 3, accelerator => '<ctrl>H', extra_data => 'gtk-help', } ], }, ]; my $menu = Gtk2::SimpleMenu->new ( menu_tree => $menu_tree, default_callback => \&default_callback, ); $vbox->pack_start($menu->{widget}, 0, 0, 0); $vbox->pack_start(Gtk2::Label->new('Rest of application here'), 1, 1, 0); $window->add($vbox); $window->show_all; Gtk2->main; sub new_document { print "user wants a new document.\n"; } sub save_document { print "user wants to save.\n"; } sub default_callback { my (undef, $callback_action, $menu_item) = @_; print "callback action number $callback_action\n"; }Back to article
Listing 13
#!/usr/bin/perl use Gtk2 -init; use strict; my $window = Gtk2::Window->new; $window->set_title('Custom Widget Example'); $window->set_default_size(150, 100); $window->signal_connect('delete_event', sub { Gtk2->main_quit }); $window->set_border_width(8); my $button = Gtk2::FunnyButton->new( normal => 'Click me!', over => 'Go on, click me!', clicked => 'Click me harder!', ); $window->add($button); $window->show_all; Gtk2->main; package Gtk2::FunnyButton; use base 'Gtk2::Button'; use strict; sub new { my ($package, %args) = @_; my $self = $package->SUPER::new; bless($self, $package); $self->{labels} = \%args; $self->add(Gtk2::Label->new($self->{labels}{'normal'})); $self->signal_connect('enter_notify_event', sub { $self->child->set_text($self->{labels}{'over'}) }); $self->signal_connect('leave_notify_event', sub { $self->child->set_text($self->{labels}{'normal'}) }); $self->signal_connect('clicked', sub { $self->child->set_text($self->{labels}{'clicked'}) }); return $self; }Back to article | http://www.drdobbs.com/web-development/programming-graphical-applications-with/184416069 | CC-MAIN-2016-30 | refinedweb | 2,819 | 51.68 |
"prs05@prosa.com" wrote:
> Hi!
> I'd like to know the number of currently active threads of a servlet from within that
very servlet... I don't know if I've explained well: I'd like to make a method that counts
the active threads, to know in a certain moment how many "servlet copies" are running. I'll
use this da<tum to determine if there aren't anyone, and so I can stop the service (or
do anything else) without anyone complaining and without any delay in waiting the other threads
to finish.
> Is it possible? I tried with Thread.CurrentThread().getThreadGroup().activeCount(),
but it gives me 32, that I guess is the number of the pooled threads, of all the servlet,
not only this very one...
> may you help me? Thanks!
> Germano
the following is as a refrence :-)
public class MyServlet extends HttpServlet{
private static byte[] locker=new byte[0];
private static int counter;
public void service(HttpServletRequest req, HttpServletResponse res) throws IOException,
ServletException{
synchronized(locker){
counter++;
}
}
} | http://mail-archives.apache.org/mod_mbox/tomcat-users/200110.mbox/%3C3BCC7DD6.4079CDC3@cybershop.ca%3E | CC-MAIN-2014-52 | refinedweb | 170 | 71.04 |
Created on 2016-09-16 07:17 by Sébastien de Menten, last changed 2016-09-17 18:24 by rhettinger. This issue is now closed.
It would be useful to be able to clear a single item in the cache of a lru_cache decorated function.
Currently with:
@lru_cache
def foo(i):
return i*2
foo(1) # -> add 1 as key in the cache
foo(2) # -> add 2 as key in the cache
foo.clear_cache() # -> this clears the whole cache
foo.clear_cache(1) # -> this would clear the cache entry for 1
Method with name clear() usually removes all content. It would be better to use different name: remove() or invalidate() (is there a precedence in other caches?).
I'm wary of adding too much complexity to the standard cache API, especially when it's something that isn't found in either.
I do think it could be a good idea to provide some "See Also" links to alternate caching libraries for folks that are looking for features that standard implementation doesn't provide.
I concur with Nick that the API needs to be relatively simple.
The availability of a fast ordered dictionary now makes it very easy for people to roll their own customizations.
FYI, here is a starting point for rolling your own variants. The OrderedDict makes this effortless. | https://bugs.python.org/issue28178 | CC-MAIN-2020-34 | refinedweb | 219 | 72.66 |
Greetings masters of coding!
I must begin by noting that I am fairly new to all of this, but I learn quickly and appreciate any advice. I am in my second quarter of C/C++ programming and I ran into this little doozy.
What seemed simple enough, I was tasked with writing a program that reads in state abbreviations and spits out the state names. No looping necessary, just a simple if, else if-type program.
I am sure that there are many ways to write this little guy, but this even stumped my professor and together we couldn't find fault in the code. I ran it on visual studio 6 and bloodshed dev, but was receiving the same output.
I even put it a cout to make sure that the characters (string) were reading into the declared variable and it was! However, the if statements were not working. I also took out the || (or) statement to simplify things and it still passes the entire run of if statements and simply prints the last else statement.
I am not requesting a different way to write it, I was hoping for knowledge as to why this would not work. On a side not, I was getting that weird auto-close thing, but I assume that is a setting in bloodshed and simply put a system("PAUSE") in there to alleviate it.
Here we go:
Many thanks for any help.Many thanks for any help.Code:#include <iostream> // #include <string> I tried including this, but it didn't change things using namespace std; //State Abbreviations int main() { const int SIZE = 3; //Setting the array size char abb[SIZE]; //Get State abberviation cout<<"Enter in your state abbreviation ---->"; cin>>abb; //Begin if statement checking for the upper or lower case entry if ((abb == "NC")||(abb == "nc")) cout<< "Your state is North Carolina\n"; else if ((abb == "SC" ) || (abb == "sc")) cout<< "Your state is South Carolina\n"; else if ((abb == "GA" ) || (abb == "ga")) cout<< "Your state is Georgia\n"; else if ((abb == "FL" ) || (abb == "fl")) cout<< "Your state is Florida\n"; else if ((abb == "AL" ) || (abb == "al")) cout<< "Your state is Alabama\n"; else cout << "You have entered an incorrect value"; system ("PAUSE"); return 0; } | https://cboard.cprogramming.com/cplusplus-programming/139210-program-seems-right-but-not-executing-properly-cplusplus.html | CC-MAIN-2017-30 | refinedweb | 372 | 64.44 |
I’m pleased to let you all know that Microsoft released the first beta version of the next version of Visual Studio, Visual Studio Team System and Visual Studio Team Foundation Server. This of course also includes the next version of the .NET Framework and most of the new BCL features we’ve been blogging about in the last few months.
Read Soma’s blog entry announcing Orcas Beta 1.
Visit the Visual Studio Code Name “Orcas” Download site for links to the downloads.
A note about BigInteger:
After releasing the BigInteger type in earlier CTPs we have received some good and constructive feedback from customers and partners that are interested in extended numerical types. We have learned that there are some potential improvements that we can make to this type to better serve their needs. As such, we decided to remove BigInteger from the Beta 1 release of Orcas so that we can address these issues and concerns. We would ask that you let us know if and how this affects you and what you would expect in a BigInteger class.
Thank you,
Inbar Gazit
The BCL Team
Huh, what do you want to know? I guess to tell, you would need to let us know whether BigInteger is removed for good or just for Beta 1. Plus what sort of feedback you got that lead to this decision. Just stating "for some reasons it is gone, but we don’t tell you the reasons nor whether it is gone for good" is a bit weird info.
David,
What we would like to know is:
1. Do you have a need for an Integer type that is bigger than 64 bits?
2. What is the primary purpose/scenario for usage with such a type for you?
3. What operations are important for you?
4. What are your performance expectations?
5. Anything else you can tell us about how you intended to use BigInteger
At this point we did not make a final decision about the fate of BigInteger and your input may help us do so.
Thanks,
Inbar.
I would use a BigInt for scientific calculations. However, it’s useless to me unless you add someway of knowing which types are ARITHMETIC!!! It’s nearly impossible to make generic classes without this information. Please add an IArithmetic interface.
1. Do you have a need for an Integer type that is bigger than 64 bits?
Yes.
2. What is the primary purpose/scenario for usage with such a type for you?
Scientific calculations. I often need to store arbitrarily large numbers where I do not know how many bits I will ultimately need.
3. What operations are important for you?
At a bare minimum addition, subtraction, multiplication, and division. Later (such as post-Orcas), I would like to see power, roots, logarithm, and trig functions.
4. What are your performance expectations?
None.
5. Anything else you can tell us about how you intended to use BigInteger
Generally scientific calculations. Accuracy and precision are paramount to efficiency.
I also second an IArithmetic interface. It is really difficult to design generic classes without it. (Especially since operator overloading –such as addition–is not possible with generics as they are implemented as static methods.)
It’s difficult to make any concrete comments since it was removed from Beta 1.
Yes, I do have a need for an integer type larger than 64 bits. At present, I have my own custom implementation. It has a few rough spots that I would like to fix or replace with a better alternative. I use it in a number of situations when I can not have an upper limit.
I also request an IArithmetic interface for the above reasons. I believe that I made a similar request during Whidbey, as well. There does not appear to be any work on addressing generic operator overloading, which I must say is disappointing. At least an IArithmetic interface would be a compromise.
I BigInteger(accennati da Antonio in questo post ) sono numeri a lunghezza arbitraria. Oggi volevo proprio
1. Do you have a need for an Integer type that is bigger than 64 bits?
Yes.
2. What is the primary purpose/scenario for usage with such a type for you?
Calculations on integers larger than 8 bytes, storing really large numbers, converting between Guids and 128-bit integers.
3. What operations are important for you?
At the least, I would expect it to behave just like other integer types and I would expect all mathematical methods to have an overload available for it. It should be usable in ADO.NET as well for handling massive numeric types in databases.
Like other integers, there should be an implicit cast to be available from smaller integer types.
I would actually prefer an Int128 class and a BigInteger class which expands infinitely.
I would agree adding something like IArithmetic to all numeric types would be useful for generic methods/classes.
4. What are your performance expectations?
I would like it to be as fast as possible, but I realize this will depend on the machine it’s running on and just how large the number is.
Maybe implementing an Int128 class would give a performance improvement over BigInteger for those who don’t need more than 16 bytes of storage.
Thanks.
Were there flaws (errors, bugs, whatever) in the implementation? Or just improvements to be made?
I personally have not needed an integer type that large, but can see value, especially in the scientific/research community (F# users?). I would expect it to behave just like Int64, 32, 16, etc. as far as operations go.
I haven’t had a chance to look at Orcas at all yet. Is there a BigFloat as well?
1. Do you have a need for an Integer type that is bigger than 64 bits?
yes!
2. What is the primary purpose/scenario for usage with such a type for you?
Crypto
3. What operations are important for you?
bitwise (two’s complement most of all), basic arithmetic
4. What are your performance expectations?
as good as you can get it
Thanks
I recently developed a fractal application using my own "complex" (based on two doubles) class. I found that after zooming in a few times I reach the limit of the double type resolution.
I was hoping for a quad precision type, but I think I’d do better with with a BigRational type, with which I can create classes such as BigComplex, PointBig, and RectangleBig. Then I can zoom into a fractal indefinitely.
I’d also use the Log function to use for the coloring scheme. (Maybe there’s a work-around for that one.
The Dynamic Language Runtime has a Microsoft.Scripting.Math namespace with a BigInteger and a Complex64 type.
What is the relationship, if any, between this namespace and System.Numeric? Will there be two separate implementations, or will one of the two be discarded? | https://blogs.msdn.microsoft.com/bclteam/2007/04/20/visual-studio-code-name-orcas-beta-1-has-been-released-inbar-gazit/ | CC-MAIN-2016-36 | refinedweb | 1,162 | 65.73 |
Smart Digital Magnetometer HMR2300 - Digital Magnetometer HMR2300 The Honeywell HMR2300 is a three-axis
TRANSCRIPT
Smart Digital Magnetometer HMR2300 The Honeywell HMR2300 is a three-axis smart digital magnetometer to detect the strength and direction of an incident magnetic field. The three of Honeywellsometers configuration for consistent operation. The data output is serial full-duplex RS-232 or half-duplex RS-485 with 9600 or 19,200 data rates. Applications include: Attitude Reference, Compassing & Navigation, Traffic and Vehicle Detection, Anomaly Detection, Laboratory Instrumentation and Security Systems. A RS-232 development kit version is available that includes a windows compatible demo program, interface cable, AC adapter, and carrying case. Honeywell continues to maintain product excellence and performance by introducing innovative solid-state magnetic sensor solutions. These are highly reliable, top performance products that are delivered when promised. Honeywells magnetic sensor solutions provide real solutions you can count on. FEATURES & BENEFITS 4 High Accuracy Over 1 gauss, HMR2300 2 SPECIFICATIONS Characteristics Conditions Min Typ Max Units Power Supply Supply Voltage Pin 9 referenced to Pin 5 (Ground) 6.5 15 Volts Supply Current Vsupply = 15V, with S/R = On 27 35 mA Temperature Operating Ambient -40 +85 C Storage Ambient, Unbiased -55 125 C Magnetic Field Range Full Scale (FS), Total Field Applied -2 +2 gauss Resolution Applied Field to Change Output 67 micro-gauss Accuracy RSS of All Errors @+25C 1 gauss 2 gauss 0.01 1 0.52 2 %FS Linearity Error Best Fit Straight Line @+25C 1 gauss 2 gauss 0.1 1 0.5 2 %FS Hysterisis Error 3 Sweeps Across 2 gauss @+25C 0.01 0.02 %FS Repeatability Error 3 Sweeps Across 2 gauss @+25C 0.05 0.10 %FS Gain Error Applied Field for Zero Reading 0.05 0.10 %FS Offset Error Applied Field for Zero Reading 0.01 0.03 %FS Temperature Effect Coefficient of Gain -600 114 ppm/C Power Supply Effect From +6 to +15V with 1 gauss Applied Field 150 ppm/V Mechanical Weight PCB Only PCB and Non-Flanged Enclosure PCB and Flanged Enclosure 28 94 98 grams Vibration Operating, 5 to 10Hz for 2 Hours 10Hz to 2kHz for 30 Minutes 10 2.0 mm g HMR2300 3 Characteristics Conditions Min Typ Max Units BLOCK DIAGRAM CHMC2003HMC1002HMC1001PwrCondV+EEPROMTXRXUARTADCGndCHMC2003HMC1002HMC1001PwrCondV+EEPROMTXRXUARTADCGnd RS-232 COMMUNICATIONS (Timing is Not to Scale) HMR2300 4 RS-485 COMMUNICATIONS (Timing is Not to Scale) GLOBAL ADDRESS (*99) DELAY (Timing is Not to Scale) PIN CONFIGURATION Pin Number Pin Name Description 1 NC No Connection 2 TD Transmit Data, RS-485 (B+) 3 RD Receive Data, RS-485 (A-) 4 NC No Connection 5 GND Power and Signal Ground 6 NC No User Connection (factory X offset strap +) 7 NC No User Connection (factory Y offset strap +) 8 NC No User Connection (factory Z offset strap +) 9 V+ Unregulated Power Input (+6 to +15 VDC) PCB DIMENSIONS AND PINOUT (Connector Not Shown for Clarity) HMR2300 5 CASE DIMENSIONS RS-232 UNBALANCED I/O INTERCONNECTS HMR2300HOST PCDDRRTDTDRDRDGD GDHMR2300HOST PCDDRRTDTDRDRDGD GDHMR2300 6 RS-485 BALANCED I/O INTERCONNECTS DATA COMMUNICATIONS The RS-232 signals are single-ended undirectional levels that are sent received simultaneously (full duplex). One signal is from the host personal computer (PC) transmit (TD) to the HMR2300 receive (RD) data line, and the other is from the HMR2300 TD to the PC RD data line. When a logic one is sent, either the TD or RD line will drive to about +6 Volts referenced to ground. For a logic zero, the TD or RD line will drive to about 6 Volts below ground. Since the signals are transmitted and dependent on an absolute voltage level, this limits the distance of transmission due to line noise and signal to about 60 feet. When using RS-485, the signals are balanced differential transmissions sharing the same lines (half-duplex). This means that logic one the transmitting end will drive the B line at least 1.5 Volts higher than the A line. For a logic zero, the transmitting end will drive the B line at least 1.5 Volts lower than the A line. Since the signals are transmitted as difference voltage level, these signals can withstand high noise environments or over very long distances where line loss may be a problem; up to 4000 feet. Note that long RS-485 lines should be terminated at both ends with 120-ohm resistors. Another precaution on RS-485 operation is that when the HMR2300 is in a continuous output mode of operation, the host PC may have to send repeated escape and carriage return bytes to stop the stream of output data. If the host can detect a recieved carriage return byte (0D hex), and immediately send the escape-carriage return bytes; then a systematic stop of continuous output is likely. If manually sent, beware that the half-duplex nature of the interface corrupt the HMR2300 outbound data while attempting to get the stop command interleaved between the data. As noted by the Digital I/O timing specification and Figure 3, the HMR2300 has a delayed response feature based on the programmed device ID in response to global address commands (*99.). Each HMR2300 will take its turn responding so that units do not transmit simultaneously (no contension). These delays also apply to the RS-232 interface versions of the HMR2300. HOST PC D R Z ZA - B+ HMR2300RDRD(A)TD(B)ID = 01HMR2300 R D RD(A)TD(B)ID = 02 HOST PC D R ZA - B+ HMR2300RDRD(A)TD(B)ID = 01HMR2300RDRD(A)TD(B)ID = 01HMR2300 R D RD(A)TD(B)ID = 02 HMR2300 R D RD(A)TD(B)ID = 02 Z = 120 ohms HMR2300 7 COMMAND INPUTS A simple command set is used to communicate with the HMR2300. These commands can be automated; or typed in real-time while running communication software programs, such a windows hyperterminal. Command Inputs(1) Response(2) Bytes(3) Description Format *ddWE *ddA *ddWE *ddB ASCII_ON BINARY_ON 9 10 ASCII Output Readings in BCD ASCII Format (Default) Binary Output Readings in Signed 16-bit Bianary Format Output *ddP *ddC Esc {x, y, z reading} {x, y, z stream} {stream stops} 7 or 28 ... 0 P = Polled Output a Single Sample (Default) C = Continuous Output Readings at Sample Rate Escape Key Stops Continuous Readings Sample Rate *ddWE *ddR=nnn OK 3 Set Sample Rate to nnn Where: Nnn = 10, 20, 25, 30, 40, 50, 60, 100, 123, or 154 Samples/sec (Default = 20) Set/Reset Mode *ddWE *ddTN *ddWE *ddTF *ddWE *ddT S/R_ON S/R_OFF {Toggle} 7 8 7 or 8 S/R Mode: TN ON = Auto S/R Pulses (Default) TF OFF = Manual S/R Pulses *ddT Toggles Command (Default = On) Set/Reset Pulse *dd]S *dd]R *dd] SET RST {Toggle} 4 4 4 ] Character Single S/R: ]S -> SET = Set Pulse ]R -> RST = Reset Pulse Toggle Alternates Between Set and Reset Pulse Device ID *99ID= *ddWE *ddID=nn ID=_nn OK 7 3 Read Device ID (Default = 00) Set Device ID Where nn = 00 to 98 Baud Rate *99WE *99!BR=S *99WE *99!BR=F OK BAUD_9600 OK BAUD=_19,20014 14 Set Baud Rate to 9600 bps (Default) Set Baud Rate to 19,200 bps (8 bits, no parity, 1 stop bit) Zero Reading *ddWE *ddZN *ddWE *ddZF *ddWE *ddZR ZERO_ON ZERO_OFF {Toggle} 8 9 8 or 9 Zero Reading Will Store and Use Current as a Negative Offset so That the Output Reads Zero Field *ddZR Toggles Command Average Readings *ddWE *ddVN *ddWE *ddVF *ddWE *ddV AVG_ON AVG_OFF {Toggle} 7 8 7 or 8 The Average Reading for the Current Sample X(N) is: Xavg=X(N)/2 + X(N-1)/4 + X(N-2)/8 + X(N-3)/16 + ... *ddV Toggles Command Re-Enter Response *ddWE *ddY *ddWE *ddN OK OK 3 3 Turn the Re-Enter Error Response ON (*ddY) or OFF (*ddN). OFF is Recommended for RS-485 (Default = ON) Query Setup *ddQ {See Desc.} 62-72 Read Setup Parameters. Default: ASCII, POLLED, S/R ON, ZERO OFF, AVG OFF, R ON, ID=00, 20 sps Default Settings *ddWE *ddD OK BAUD=_9600 14 Change All Command Parameter Settings to Factory Default Values Restore Settings *ddWE *ddRST OK BAUD=_9600 or BAUD=_19,200 14 16 Change All Command Parameter Settings to the Last User Stored Values in the EEPROM Serial Number *dd# SER#_nnnn 22 Output the HMR2300 Serial Number Software Version *ddF S/W_vers:_ nnnn 27 Output the HMR2300 Software Version Number Hardware Version *ddH H/W_vers:_ nnnn 19 Output the HMR2300 Hardware Version Number Write Enable *ddWE OK 3 Activate a Write Enable. This is required before commands: Set Device ID, Baud Rate, and Store Parameters. Store Parameters *ddWE *ddSP DONE OK 8 This writes all parameter settings to EEPROM. These values will be automatically restored upon power-up. Too Many Characters Wrong Entry Re-enter 9 A command was not entered properly or 10 characters were typed after an asterisk (*) and before a . Missing WE Entry Write Enable Off WE_OFF 7 This error response indicates that this instruction requires a write enable command immediately before it. (1) All inputs must be followed by a carriage return, or Enter, key. Either upper or lower case letters may be used. The device ID (dd) is a decimal number between 00 and 99. Device ID = 99 is a global address for all units. (2) The symbol is a carriage return (hex 0D). The _ sign is a space (hex 20). The output response will be delayed from the end of the carriage return of the input string by 2 msec (typ.), unless the command sent as a global device ID = 99. HMR2300 8 DATA FORMATS The HMR2300 transmits each X, Y, and Z axis as a 16-bit value. The output data format can be either 16-bit signed binary (sign plus 15 bits) or a binary coded decimal (BCD) ASCII characters. The command *ddA will select the ASCII format and *ddB will select the binary format. The order of ouput for the binary format is Xhi, Xlo, Yhi, Ylo, Zhi, Zlo. The binary format is more efficient for a computer to interpret since only 7 bytes are transmitted. The BCD ASCII format is easiest for user interpretation but requires 28 bytes per reading. There are limitations on the output sample rate (see table below) based on the format and baud rate selected. Examples of both binary and BCD ASCII outputs are shown below for field values between 2 gauss. Field (gauss) BCD ASCII Value Binary Value (Hex) High Byte Low Byte +2.0 30,000 75 30 +1.5 22,500 57 E4 +1.0 15,000 3A 98 +0.5 7,500 1D 4C 0.0 00 00 00 -0.5 -7,500 E2 B4 -1.0 -15,000 C3 74 -1.5 -22,500 A8 1C -2.0 -30,000 8A D0 Binary Format: 7 Bytes XH | XL | YH | YL | ZH | ZL | XH = Signed Byte, X axis XL = Low Byte, X axis = Carriage Return (Enter key), Hex Code = 0D ASCII Format: 28 Bytes SN | X1 | X2 | CM | X3 | X4 | X5 | SP | SP | SN | Y1 | Y2 | CM | Y3 | Y4 | Y5 | SP | SP | SN | Z1 | Z2 | CM | Z3 | Z4 | Z5 | SP | SP | The ASCII characters will be readable on a monitor as sign decimal numbers. This format is best when the user is interpreting the readings. PARAMETER SELECTION VERSUS OUTPUT SAMPLE RATE ASCII Binary Sample Rate (sps) 9600 19,200 9600 19,200 f3dB (Hz) Notch (Hz) Command Input Rate min. (msec) 10 yes yes yes yes 17 50/60 20 20 yes yes yes yes 17 50/60 20 25 yes yes yes yes 21 63/75 16 30 yes yes yes yes 26 75/90 14 40 no yes yes yes 34 100/120 10 50 no yes yes yes 42 125/150 8 60 no no yes yes 51 150/180 7 100 no no yes yes 85 250/300 4 123 no no no yes 104 308/369 3.5 154 no no no yes 131 385/462 3 HMR2300 9 DEVICE ID The Device ID command (*ddID=nn) will change the HMR2300 ID number. A Write Enable (*ddWE) command is required before the device ID can be changed. This is required for RS-485 operation when more than one HMR2300 is on a network. A Device ID = 99 is universal and will simultaneously talk to all units on a network. BAUD RATE COMMAND The Baud Rate command (*dd!BR=F or S) will change the HMR2300 baud rate to either fast (19,200 baud) or slow (9600 baud). A Write Enable (*ddWE) command is required before the baud rate can be changed. The last response after this command has been accepted will be either BAUD=9600 or BAUD=19,200. This will indicate to the user to change to the identified new baud rate before communications can resume. ZERO READING COMMAND The Zero Reading command (*ddZN) will take a magnetic reading and store it in the HMR2300s microcontroller. This value will be subtracted from subsequent readings as an offset. The zero reading will be terminated with another command input(*ddZF) or a power down condition. This feature is useful for setting a reference attitude or nulling the earths field before anomaly detection. SET/RESET AND AVERAGE COMMANDS The set-reset function generates a current/magnetic field pulse to each sensor to realign the permalloy thin film magnetization. This yields the maximum output sensitivity for magnetic sensing. This pulse is generated inside the HMR2300 and consumes less than 1mA typically. The Set/Reset Mode command (*ddTN or *ddT) activates an internal switching circuit that flips the current in a Set and Reset condition. This cancels out any temperature drift effects and ensures the sensors are operating in their most sensitive region. Fluctuations in the magnetic readings can be reduced by using the Average Readings commands (*ddVN or *ddV). These commands provide a low pass filter effect on the output readings that reduces noise due to Set/Reset switching and other environmental magnetic effects. The two figures below show the average readings effect for step and impulse responses. Switching the set-reset state is not required to sense magnetic fields. A single Set (or Reset) pulse will maximize the output sensitivity and it will stay that way for months or years. To turn off the internal switching, enter the command *ddTF or *ddT. In this state the sensors are either in a Set or Reset mode. If the HMR2300 is exposed to a large magnetic field (>10 gauss), then another set pulse is required to maximize output sensitivity. In the Set mode, the direction of the sensitive axis are shown on the enclosure label and the board dimensions figure. In the Reset mode, the sensitive field directions are opposite to those shown. By typing *dd], the user can manually activate a Set or Reset pulse. The S/R pulse commands can be used the continuous read mode to flip between a Set and Reset state. Note that the first three readings immediately after these commands will be invalid due to the uncertainty of the current pulse to the sensor sample time. DEFAULT AND RESTORE COMMANDS The Defaut Settings command (*ddD) will force the HMR2300 to all the default parameters. This will not be a permanent change unless a Store Parameter command (*ddSP) is issued after the Write Enable command. The Restore Settings command (*ddRST) will force the HMR2300 to all the stored parameters in the EEPROM. HMR2300 10 OUTPUT SAMPLE RATES The sample rate can be varied from 10 samples per second (sps) to 154 sps using the *ddR=nnn command. Each sample contains an X, Y, and Z reading and can be outputted in either 16-bit signed binary or binary coded decimal (BCD) ASCII. The ASCII format shows the standard numeric characters displayed on the host computer display. Some sample rates may have restrictions on the format and baud rate used, due to transmission time constraints. There are 7 Bytes transmitted for every reading binary format and 28 Bytes per reading in ASCII format. Transmission times for 9600 baud are about 1 msec/Byte and for 19,200 baud are about 0.5msec/Byte. The combinations of format and and baud rate selections are shown in the above Table. The default setting of ASCII format and 9600 baud will only transmit correctly up to 30 sps. Note the HMR2300 will output a higher data settings, but the readings may be incorrect and will be at alower output rate than selected. For higher sample rates (>60 sps), it is advised that host computer settings for the terminal preferences be set so a line feed is not appended to the sent commands. This slows down the reception of data, and it will not be able to keep up with the incoming data stream. INPUT SIGNAL ATTENUATION Magnetic signals being measured will be attenuated based on the sample rate selected. The bandwidth, defined by the 3dB point, is shown in the above Table for each sample rate. The default rate of 20 sps has a bandwidth of 17Hz. The digital filter inside the HMR2300 is the combination of a comb filter and a low pass filter. This provides a linear phase response with a transfer function that has zeros in it. When the 10 or 20 sps rate is used, the zeros are at the line frequencies of 50 and 60 Hz. These zeros provide better than 125 dB rejection. All multiples of the zeros extend throughout the transfer function. For example, the 10 and 20 sps rate has zeros at 50, 60, 100, 120, 150, 180, ... Hz. The multiples of the zeros apply to all the sample rates against the stated notch frequencies in the above Table. COMMAND INPUT RATE The HMR2300 limits how fast the command bytes can be recieved based on the sample rate selected. The above Table shows the minimum time between command bytes for the HMR2300 to correctly read them. This is usually not a problem when the user is typing the commands from the host computer. The problem could arise from an application program outputting command bytes too quickly. CIRCUIT DESCRIPTION The HMR2200 Smart Digital Magnetometer contains all the basic sensors and electronics to provide digital indication of magnetic field strength and direction. The HMR2300 has all three axis of magnetic sensors on the far end of the printed circuit board, away from the J1 and J2 connector interfaces. The HMR2300 uses the circuit board mounting holes or the enclosure surfaces as the reference mechanical directions. The complete HMR2300 PCB assembly consists of a mother board, daughter board, and the 9-pin D-connector (J1). The HMR2300 circuit starts with Honeywell HMC2003 3-Axis Magnetic Sensor Hybrid to provide X, Y, and Z axis magnetic sensing of the earths field. The HMC2003 contains the AMR sensing bridge elements, a constant current source bridge supply, three precision instrumentation amplifiers, and factory hand-selected trim resistors optimized for performance for magnetic field gain and offset. The HMC2003 is a daughter board that plugs into the HMC2300 motherboard, and the hybrid analog voltages from each axis is into analog multiplexors and then into three 16-bit Analog to Digital Converters (ADCs) for digitization. No calibration is necessary as the HMC2003 hybrid contains all the compensation for the sensors, and the set/reset routine handles the temperature drift corrections. A microcontroller integrated circuit receives the digitized magnetic field values (readings) by periodically querying the ADCs and performs any offset corrections. This microcontroller also performs the external serial data interface and other housekeeping functions. An onboard EEPROM integrated circuit is employed to retain necessary setup variables for best performance. The power supply for the HMR2300 circuit is regulated +5 volt design (LM2931M) with series polarity power inputs diodes in case of accidental polarity reversal. A charge pump circuit is used to boost the regulated voltage for the set/reset pulse function going to the set/reset straps onboard the HMC2003. Transient protection absorbers are placed on the TD, RD, and V+ connections to J1. HMR2300 11 APPLICATIONS PRECAUTIONS Several precautions should be observed when using magnetometers in general: The presence of ferrous materials, such as nickel, iron, steel, and cobalt near the magnetometer will create disturbances in the earths magnetic field that will distort the X, Y, and Z field measurements. The presence of the earths magnetic field must be taken into account when measuring other magnetic fields. The variance of the earths magnetic field must be accounted for in different parts of the world. Differences in the earths field are quite dramatic between North America, South America and the Equator region. Perming effects on the HMR2300 circuit board need to be taken into account. If the HMR2300 is exposed to fields greater than 10 gauss, then it is recommended that the enclosure/circuit boards be degaussed for highest sensitivity and resolution. A possible result of perming is a high zero-field output indication that exceeds specification limits. Degaussing wands are readily available from local electronics tool suppliers and are inexpensive. Severe field offset values could result if not degaussed. NON-FERROUS MATERIALS Materials that do not affect surrounding magnetic fields are: copper, brass, gold, aluminum, some stainless steels, silver, tin, silicon, and most non-metals. HANDLING PRECAUTIONS The HMR2300 Smart Digital Magnetometer measures fields within 2 gauss in magnitude with better than 0.1 milli-gauss resolution. Computer floppy disks (diskettes) store data with field strengths of approximately 10 gauss. This means that the HMR2300 is many times more sensitive than common floppy disks. Please treat the magnetometer with at least the same caution as your diskettes by avoiding motors, CRT video monitors, and magnets. Even though the loss of performance is recoverable, these magnetic sources will interfere with measurements. DEMONSTRATION PCB MODULE KIT The HMR2300 Demonstration Kit includes additional hardware and Windows software to form a development kit for with the smart digital magnetometer. This kit includes the HMR2300 PCB and enclosure, serial port cable with attached AC adapter power supply, and demo software plus documentation on a compact disk (CD). The figure below shows the schematic of the serial port cable with integral AC adapter. There will be three rotary switches on the AC adapter. These should be pointed towards the positive (+) polarity, +9 volts, and 120 or 240 VAC; depending your domestic supply of power. D9-F D9-FBLKGRY23592359datadataground+9vdcAC adapterD9-F D9-FBLKGRY23592359datadataground+9vdcAC adapterHMR2300 12 ORDERING INFORMATION Ordering Number Product HMR2300-D00-232 HMR2300-D00-485 HMR2300-D20-232 HMR2300-D20-485 HMR2300-D21-232 HMR2300-D21-485 HMR2300-D20-232-DEMO HMR2300-D20-485-DEMO HMR2300-D21-232-DEMO HMR2300-D21-485-DEMO PCB Only (No Enclosure), RS-232 I/O PCB Only (No Enclosure), RS-485 I/O Flush-Base Enclosure, RS-232 I/O Flush-Base Enclosure, RS-485 I/O Extended-Base Enclosure, RS-232 I/O Extended-Base Enclosure, RS-485 I/O Demo Kit, Flush-Base Enclosure, RS-232 I/O Demo Kit, Flush-Base Enclosure, RS-485 I/O Demo Kit, Extended-Base Enclosure, RS-232 I/O Demo Kit, Extended-Base Enclosure, RS-485 I/O FIND OUT MORE For more information on Honeywells Magnetic Sensors visit us online at or contact us at 800-323-8295 (763-954-2474 internationally). The application circuits herein constitute typical usage and interface of Honeywell product. Honeywell does not warranty or assume liability of customer-designed circuits derived from this description or depiction.. U.S. Patents 4,441,072, 4,533,872, 4,569,742, 4,681,812, 4,847,584 and 6,529,114 apply to the technology described Form #900139 Rev I September 2006 2006 Honeywell International Inc. Honeywell 12001 Highway 55 Plymouth, MN 55441 Tel: 800-323-8295
Recommended
View more >
SMART DIGITAL MAGNETOMETER HMR2300 - serial number. Also included in the HMR magnetom-eter is a digital
Smart Digital Magnetometer HMR2300 - Honeywell recieved carriage return byte (0D hex), ... If manually sent, ... or a binary coded decimal (BCD) ...
Three-axis Hall Magnetometer ? GETTING STARTED 1-Introduction The Three-axis Hall Magnetometer THM1176
3-Axis Digital Compass IC HMC5983 - Honeywell Digital Compass IC HMC5983 The Honeywell HMC5983 is a temperature compensated three-axis integrated circuit magnetometer. This surface-mount, multi-chip module is designed for low-field magnetic sensing for
3-Axis, Digital Magne Digital Magnetometer Freescales MAG3110 is a small, low-power, digital 3-axis magnetometer. The device can be used in conjunction with a 3-axis accelerometer to produce orientation independent accurate compass2 ...
PART NUMBER: Digital Tri axis Magnetometer/ Tri axis ... Specifications Rev 3.0.pdf Digital Tri-axis
MGL Avionics SP-2 Magnetometer SP-4 SP-2 magnetometer The SP-2 magnetometer is a three axis, tilt compensated electronic compass system. It outputs magnetic heading information. | https://vdocuments.site/smart-digital-magnetometer-hmr2300-digital-magnetometer-hmr2300-the-honeywell.html | CC-MAIN-2019-18 | refinedweb | 4,159 | 50.87 |
4Pcs LED Solar Powered Fence Wall Lights Step Path Decking Garden 3 Colors Lamp. AU $14.66 to AU $15.66. 12Pcs Solar Powered LED Garden Lights Outdoor Automatic Patio Yard Lawn Lamp AU. AU $12.69 to AU $37.99. LED Solar Lights Street Flood Light Motion Sensor Remote Outdoor Garden Lamp 90W. AU $60.95.Get a Quote
I used to 'try' to light my front walkway with solar powered lights, but that was a waste. These lights give my walk a professional appearance and are much brighter than the cheap box-store solar lights. I will be buying more MrBeams products , I have thought of many more practical uses for these great products!
wrap the color changing dragonfly solar string lights around bushes, trees and posts and turn passersby into spectators. this decorative solar led street light kit manufacturer, factory has a 20.8-foot string that features 20 color-changing, dragonfly-shaped lights that can cause people to stop and stare at outdoor areas of your home.Get a Quote
Overview
all in one led lamp for garden outdoor solar we offer wholesaler price, free traning and oem/odm support. power: 15w 20w 30w 40w 60w 80w 100w 120w. led chip: brand seoul led chip. light efficiency: 170-180lm/w. light distribution: 140*70. backup time: 3 nights. ambient temperature at nightGet a Quote…
make sure this fits by entering your model number. this item: member's mark solar led pathway lights, 10-pack $90.99. pathway lights solar powered 4 pack landscape led street light powered by solar ands outdoor ip65 waterproof & 10-40 lm dimmable & auto on/off warm white pathway lightsGet a Quote.
specifications solar illuminations can supply this street solar light pir motion sensor in Malaysia system which is ideal as a retro-fit solution or for a site that has an existing pole in place. solar as a complete system with a choice of led power from 35w to 135w and distribution from type i to v. prices from $2,499.99.Get a Quote
Dec 17, 2018· up of diode, resistors, LED, capacitor, and a battery of …Get a Quote
Nov 18, 2015· Solar powered automatic street light controller is one of the applications of electronics to increase the facilities of life. The use of new electronic theories has been put down by expertise to increase the facilities given by the existing appliance.
trending price is based on prices over last 90 days. {current_slide} of {total_slides} - best selling. go to previous slide - best selling. ring 88fl000ch000 security camera with floodlight 110 to 220 v 1080 pixel whi. 180w 18000lm led underground lamp led solar streetGet a Quote
The automatic solar-powered light has a solar panel that absorbs sunlight during the day to convert sunlight into electricity to recharge the aa ni-MH battery (included). Solar power lights automatically turn on at night and turn off at dawn which enables led pathway light …Get a Quote.Get a Quote
advancement in embedded systems has paved path for the design and development of microcontroller based automatic control systems. Our project presents an automatic street light controller using light dependent resistor(LDR). By using this system manual works are removed. The street lights are automatically switched ON
ip65 waterproof, heat-resistant solar lamp, suitable for most types of weather. 5. [us only] 30% off 16 led illuminate your garden, courtyard, aisle, porch, courtyard or driveway, etc. 6. it is recommended to install vertically on a wall 2-3m high from the ground.Get a Quote
4 Pack 6.5 FT Solar Lamp Post Light w/ 2 SMD LEDs Street Vintage Path Deck Dual. 4.5 out of 5 stars (2) Total Ratings 2, $199.99 New. 990000LM 250W 576LED Solar Power LED Street Light Radar PIR+ Remote Control+Pole. $10.50. 4 bids. Free shipping. Ending Dec 17 at 10:20AM PST 6d 19h.
import china 28w led street light from various high quality chinese 28w led street light suppliers & manufacturers on globalsources.com. 15w all-in-one solar street led lights solar light battery solar led solar street light. us$ 93.1 - 111.8 / piece; 1 piece (min. order) south africa (56) south korea (69) spain (100) sri lanka (50) sweden (78Get a Quote
Product Title Ktaxon Color Changing Solar Powered LED Night Light Average rating: 3 out of 5 stars, based on 1 reviews 1 ratings Current Price $6.99 $ 6 . 99 List List Price $11.99 $ 11 . 99Get.
Solar Lights Outdoor Decorative,10 Packs Solar Pathway Lights,Powered Landscape Lighting,Waterproof Solar Powered Garden Yard Lights for Walkway Sidewalk Driveway-Cool White 4.2 out of 5 stars 273 $34.99 - $35.99
guangzhou chuqi international trade co., ltd., experts in manufacturing and exporting solar battery, 20 led solar street light garden and 208 more products. a verified cn gold supplier on alibabaGet a Quote
8-Pack 1-Watt Black Low Voltage Solar LED Path Light. Model #SR03AA01H08. Compare; Find My Store. for pricing and availability. 10. WestinghouseGet a Quote
Jun 02, 2014· Types of Solar Lights. Solar path lights. These are small solar lights on stakes, which can be pushed into the ground alongside a walkway to softly illuminate the path at night.
us$41.03 us$49.24 17% off 3pcs solar powered 36 led pir motion sensor waterproof street security light wall lamp for outdoor garden 369 reviews cod us$25.34 us$30.41 17% off 213solar street light circuit 6m 30w radar pir motion sensor waterproof ip65 solar wall light
At present, the efficiency of solar fabric to capture the sun's energy is approximately 13%. However, solar fabric has been proven to be more effective in low light levels. Solar Lighting. Solar powered LED lighting is transforming streets and pathways in the US. LED solar lighting has the benefit of …Get a Quote
Use our solar powered street & roadway solar lighting solutions to illuminate your drive. Solar Parking Lot Lighting Help protect your business and pedestrians by using our outdoor solar lighting
shop all security solar all in one light at lightingdirect. we have the lowest prices, a huge selection, and great customer service. classy caps lancaster single light 8 tall led outdoor wall sconces - pack of 2. model: swl888. available in 1 finish (1) from 1 customer. Solarlusive deals, and inspiration! get 5% off your next order *Get a Quote | https://www.gierman.pl/77d8b844c1a62cc194d3329b0215d6d8 | CC-MAIN-2021-39 | refinedweb | 1,068 | 64.91 |
Python's generators sure are handy
While rewriting some older code today, I ran across a good example of the clarity inherent in Python's generator expressions. Some time ago, I had written this weirdo construct:
for regex in date_regexes: match = regex.search(line) if match: break else: return # ... do stuff with the match
The syntax highlighting makes the problem fairly obvious: there's way too much syntax!
First of all, I used the semi-obscure "for-else" construct. For those of you who don't read the Python BNF grammar for fun (as in: the for statement), the definition may be useful:
So long as the for loop isn't (prematurely) terminated by a break statement, the code in the else suite gets evaluated. To restate (in the contrapositive): the code in the else suite doesn't get evaluated if the for loop is terminated with a break statement. From this definition we can deduce that if a match was found, I did not want to return early.
That's way too much stuff to think about. Generators come to the rescue!
def first(iterable): """:return: The first item in the iterable that evaluates as True. """ for item in iterable: if item: return item return None match = first(regex.search(line) for regex in regexes) if not match: return # ... do stuff with the match
At a glance, this is much shorter and more comprehensible. We pass a generator expression to the first function, which performs a kind of short-circuit evaluation — as soon as a match is found, we stop running regexes (which can be expensive). This is a pretty rockin' solution, so far as I can tell.
Prior to generator expressions, to do something similar to this we'd have to use a list comprehension, like so:
match = first([regex.search(line) for regex in regexes]) if not match: return # ... do stuff with the match
We dislike this because the list comprehension will run all of the regexes, even if one already found a match. What we really want is the short circuit evaluation provided by generator expressions and the any builtin, as shown above. Huzzah!
Edit
Originally I thought that the any built-in returned the first object which evaluated to a boolean True, but it actually returns the boolean True if any of the objects evaluate to True. I've edited to reflect my mistake. | http://blog.cdleary.com/2008/01/pythons-generators-sure-are-handy/ | CC-MAIN-2017-30 | refinedweb | 399 | 71.04 |
public class Solution { public ListNode deleteDuplicates(ListNode head) { ListNode newHd = new ListNode(0);//0 or whatever number you like, does not matter ListNode res = newHd;//Copy of newHd, because newHd is gonna change during the iteration. We are going to return res.next. ListNode next = head;//Assign head to next as the start point ListNode following = null;//Assign null or whatever nodes. while(next != null) { following = next.next; // In each loop, only when following node val is not equal to next val, next is valid. if(following == null||following.val != next.val){ newHd.next = next; newHd = newHd.next; newHd.next = null; }else{ //Else we find the first node which the value is not equal to next, and start the next loop from there. while(following != null && following.val == next.val) following = following.next; } next = following; } return res.next; } }
AUG!!! Short and Clean and Click Here! JAVA
Looks like your connection to LeetCode Discuss was lost, please wait while we try to reconnect. | https://discuss.leetcode.com/topic/51480/aug-short-and-clean-and-click-here-java | CC-MAIN-2018-05 | refinedweb | 162 | 66.94 |
Google, no matter which coding contest you’re participating in or practising for, there’s a high chance that the IDE will tell you that your program encountered a runtime error.
The error message simply says “Sample Failed: RE“. And even when you click on the eye button, it says “RE“, which means Runtime Error. It does not provide any further info regarding why the error occurred. And the most surprising thing is, in most cases, your code will run fine in any other IDE other than Google’s Coding Competition IDE.
I too came across this problem some time ago and even after visiting many forums, I didn’t find the answer. But then, the idea struck my mind and I finally solved the Runtime Error in my Google Kickstart Code. This solution to fix the runtime error will work in all Google Coding Competitions, e.g. Code Jam, Kickstart and Hash Code.
How To Fix The Runtime Error In Google Code Jam/Kickstart/Hash Code
Well, this problem is caused by nothing but your program’s class name.
Google follows a convention where you must always define the Main class of your program (the class that contains the main method) as “public class Solution“.
Thus, to fix the runtime error issue, all you gotta do is, rename your class declaration to “public class Solution”
This is a weird convention set by Google. The more annoying part is that it is nowhere mentioned about this convention and thus programmers like I and you spend hours looking for the reason why the compiler is throwing us a Runtime Error even though the other compilers are running it perfectly.
I hope this article helped you solve the Runtime Error issue. Do let me know in the comments section below if there’s any other problem that you’re facing with the Google Coding Contests IDE. I will try my best to help you out!
Do check out some other posts on my site for more cool stuff! Have a great day ahead!
18 thoughts on “Solved: Google Coding Competitions Runtime Error (RE) Issue (JAVA)”
Thank you so much, this works. And it’s pretty weird why would Google set such conventions. But that’s how it is… Anyways thanks for discussing it in detail.
How to handle the same error in case of Pyhton?
This kind of false error doesn’t happen in the case of Python. If you’re facing a runtime error in Python, that’s most probably due to a real mistake in your code.
I have tested the same code on codechef, repl, and geeksforgeeks and it ran fine on every site except for google competition website. That’s why I am saying it.
Please share the code here, Nitin.
The input I am taking here is the same as the sample input given in the question in kickstart round D today. Here the code is working fine. But there it is showing “Sample Failed: RE”.
Yeah, I see it now. This seems to be another undiscovered bug of Google Coding Platform that is generating false Runtime Errors. This article is dedicated to Java. However, thanks for informing me that this problem is occurring with Python as well. I will do some more research on this and publish a new article on that topic separately. You will be notified via an e-mail in case the solution is found. However, if you find the solution to that problem before, you can mail it to [email protected] and your solution will be posted on this website, with full credits going to you. Thanks.
hey any fix for this python RE issue
i already named my class as “Solution” but still i am facing this issue. my java code runs on any other online compiler but it shows RE on kickstart. can you help me with this?
my code is attached below.
Hi Mustansir,
There’s a REAL ERROR in your code. You are trying to store an int value in an array without specifying the index, which is causing the error.
Please take a look at the picture given below for your reference.
I renamed the class name as Solution still i’m getting RE, while same code is producing correct answer on gfg and codechef for sample test cases
Please provide your code so that I can have a look at it and point out the error.
hello.. I have my program running perfectly and also my class name is “Solution”. What is the issue with the code now?
import java.util.*;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class Solution
{
{
{
{
}
public static void main(String []args)
Scanner sc=new Scanner(new BufferedReader(new InputStreamReader(System.in)));
int test=sc.nextInt();
if(test>=1 && test<=100){
for(int t=1;t<=test;t++)
int n=sc.nextInt();
int b=sc.nextInt();
int arr[]=new int[n];
for(int i=0;i=0)
b=b-arr[i];
count++;
i++;
return count-1;
}
}
Hi Tripti,
Your code has the following two errors:
1. On line 17, the for loop is invalid. The syntax for a for loop in Java is for(initialization;condition;changes). Although you can skip one or more parameters, but the two semicolons are mandatory, however, your code misses a semicolon after the second parameter.
2. On line 23, I believe you forgot to end the outer for loop. The compiler cannot parse your code properly due to the missing closing bracket.
Take a look at the picture below for reference:
Thank you so much you literally made my day…
Glad it was helpful! 🙂
also you cannot put your class into a package
you cannot write like this:
package task;
public class Solution {
}
As far as I know, in most of the problems you don’t need to create packages. You can just write other classes alongside the Solution class and use their objects normally. Google doesn’t allow you to host packages, so how can you expect it to not throw an error when you try to declare a package name, which neither exists, nor can be created. | https://www.techrbun.com/google-coding-competitions-runtime-error-solved/ | CC-MAIN-2022-21 | refinedweb | 1,025 | 72.56 |
Wiki
SCons / GregNoel / OptionsAndConfigure
This is not in any way ready for review and comment, but Steven is working on dealing with command-line flags that haven't been specified in advance, and that part is mostly done, so I'm publishing this so he can look at it for ideas. Please don't edit this; I'll update it when it's ready for true public scrutiny. Tks. -JGN [[!toc ]]
Unifying Options and Configuration
This page presents a position that command-line options (both flags and assignments) and configuration should be unified into a single framework (or, worst case, that they should be derived from a common base class). The idea behind the position is that these are ways that SCons gets "outside" information; that is, information that is not embedded in the SConscripts.
Options and configuration results either affect program flow or are converted into into values for construction variables (or both). Those values are then incorporated into a SCons Environment which is used to build objects. The message in this wiki page is how those construction variables are calculated and then incorporated.
The command line consists of four types of tokens:
- Single-character flags. These flags are preceded by a single hyphen. They may or may not take a value (an auxilliary token on the command line). More than one flag may be grouped after the hyphen.
- Word-based flags. These are preceded by two hyphens. They may or may not take a value; if they do take a value, an equal sign <ins>always</ins> separates the name and the value.
- Variable assignments. These are
name=valuepairings.
- Arguments. Anything that is not a flag option or a variable assignment option. Arguments are outside the scope of this discussion; the only thing we will say about them is that they are gathered into a list and made available to the SCons scripts. Another source of options are control files. These are text files containing
name=valuepairs similar to command-line variable assignments. (They are actually Python scripts, so any legal Python value is acceptable.)
The last source of options are configure tests. These values are programmatically determined by probing the platform on which the build is run.
<a name="SingleCharacterFlags"></a>
Single-character flags
Synopsis: Single-character flags are converted to their equivalent word-based flags.
Single-character flags are reserved to SCons and may not be specified for user flags. When the command line is cracked, single-character flags are converted to their equivalent word-based flags; the translation is hard-wired, so single-character flags cannot be extended.
Here is what single-character flags become. Any flag not recognized causes an error. [[!table header="no" class="mointable" data=""" -a | --always-build () | | -A | ERROR -b | ignored for compatibility | | -B | ERROR -c | --clean | | -C directory | --directory=directory -d flag(s) | --debug=flag(s) | | -D | --up=defaults () -e | --environment-overrides () | | -E | ERROR -f file | --file=file | | -F | ERROR -g | ERROR | | -G | ERROR -h | --help | | -H | --help-options -i | --ignore-errors | | -I directory | --include-dir=directory -j N | --jobs=N | | -J | ERROR -k | --keep-going | | -K | ERROR -l N | --load-average=N () | | -L | ERROR -m | ignored for compatibility | | -M | ERROR -n | --dry-run | | -N | ERROR -o file | --old-file=file | | -O | ERROR -p | --print-data-base () | | -P | ERROR -q | --question | | -Q | --no-status-messages () -r | --no-builtin-rules () | | -R | --no-builtin-variables () -s | --silent | | -S | --no-keep-going -t | --touch | | -T | ERROR -u | --up=dot () | | -U | --up=here () -v | --version | | -V | ERROR -w | --print-directory | | -W file | --what-if=file (*) -x | ERROR | | -X | ERROR -y | ERROR | | -Y repository | --repository=repository -z | ERROR | | -Z | ERROR """]]
The (*) marks entries that are future or otherwise assume something at variance with the current flags. Also, the
-W usage conforms to
GNU make, not the
--warnings usage of
automake. TODO: insert a list here with the differences.
<a name="WordBasedFlags"></a>
Word-based flags
Synopsis: When the command line is cracked, flag options are placed in a private list. A flag may occur more than once on the command line; the multiple occurrences are accumulated. A defining instance of a flag causes all of its occurences to be removed from the list and a value calculated. This value is available immediately, so it may be saved or used for further calculations. Values calculated from the flag value may be accumulated in a pool and passed to an Environment when it is instantiated. At the end of the parse phase, any flags still on the list cause an error message.
- (Note that how the error message is presented is crucial to acceptance; rather than "Unrecognized flag" with the implication that it should have been noticed immediately, it should say something like "Flag never defined during processing; check the spelling.") (Open question: Command-line flags can have internal dashes. A
configurescript will convert (most of) these internal dashes into underscores before matching on the name (it's inconsistent). Thus, when comparing flags
enable_foois used for
--enable-fooand
exec_prefixis used for
--exec-prefix. Should SCons convert dashes to underscores prior to matching so that SCons scripts will be more compatible with
configure?)
The defining instance can save the calculated value in a Python dict (called FLAGS? OPTIONS? neither is good) where it can be retrieved later by any interested party. Convenience functions will be provided to implement common paradigms used in specifying flags. Previously-defined flags are immediately available, so, for example, the value of
prefix can be determined and used as the default for
exec-prefix.
Flag values may be processed into a pool that accumulates construction variables. The values may be used as-is or they may be calculated.
One or more pools may then be used to initialize the construction variables of an Environment. These values may then be used in the construction of command lines in the normal way.
Fundamental operation
- The fundamental operation on flags removes any flags matching a set of names from the private list, runs the extracted flags through an auditor to determine the value:
- value = Query.Flag(names, audit, args)
- The names are a list of one or more strings of flag names to match.
The audit function takes the matched values and calculates the value to use.
The args are in a dict and are passed as keyword parameters to the audit function.
- The audit function takes two positional parameters, plus any keyword arguments from the args parameter:
- value = audit(flags, values, **args)
- The flags are a list of matching flag names from the command line, in the order they appear on the command line.
The values are a list of the corresponding values for the flags;
Noneis used to indicate that the flag was not given a value.
The args are the keywords given to the
Query.Flagfunction.
Here's a sample implementation of EnableFlag (see below) with little error checking:
def EnableFlag(key, state = 'no', default = 'yes', help=None): # could use bound variables for audit function if desired def audit(flags, values, state = 'no', default = 'yes'): if not values: # not on command line state = yesno(state) if state == 'no': return 'no' return yesno(default) f = flags[-1] # last flag wins v = values[-1] if f[0:7] == 'disable': if v is not None: print "value ignored for'--%s'" % f return 'no' if v is None: # no value for --enable, use default v = default return yesno(v) # Scan the command line for this set of flags v = Query.Flag(['enable-'+key, 'disable-'+key], audit, { 'state':state, 'default':default }) FLAGS['enable-'+key] = v HelpText(help) return v
Additional pre-defined flag values
These command-line flags should be pre-defined; they are the flags supported by
configure (plus
--install to support RPM and Debian build notions). Even if they aren't used today, someday we will be glad to have them.
[[!table header="no" class="mointable" data="""
Deployment directories||
--prefix=PREFIX | install architecture-independent files in PREFIX [/usr/local]
--exec-prefix=EPREFIX | install architecture-dependent files in EPREFIX [PREFIX]
-]
Packaging||
--install=DIR | install tree is relative to DIR [empty]
(called DESTDIR by configure and BUILDROOT by RPM) Configuration selection|| --enable-FEATURE[=ARG] | include FEATURE (ARG=yes) --disable-FEATURE | do not include FEATURE (same as --enable-FEATURE=no) --with-PACKAGE[=ARG] | use PACKAGE (ARG=yes) --without-PACKAGE | do not use PACKAGE (same as --with-PACKAGE=no) Cross-compilation|| --build=BUILD | configure for building on BUILD [guessed] (unneeded?) --host=HOST | cross-compile to build programs to run on HOST [BUILD] --target=TARGET | programs should produce output for TARGET [HOST] --program-prefix=PREFIX | prepend PREFIX to installed program names --program-suffix=SUFFIX | append SUFFIX to installed program names --program-transform-name=PROGRAM | run '
sed PROGRAM' on installed program names
"""]]
Only the last one is problematical. It's a rarely-used feature, and maybe some other mechanism could be used.
Enable/Disable flags
Command-line flags that begin
'--disable-' are treated as if they were an
--enable- with the value
'no'. That is,
--disable-foo is turned into
--enable-foo=no; any value that the flag had is ignored.
- A possible prototype:
- Query.EnableFlag(key, state, default, help=None)
- Evaluate flags with the names
--enable-key or
--disable-key. If no such flag is present, the default state is state. The state parameter must be either yes or no; if it is not present, no is assumed. If no value is present for an
--enable.
With/Without flags
The processing of the with/without flags is very similar to that of the enable/disable flags, except that
--without-foo is converted to
--with-foo=no.
- A possible prototype:
- Query.WithFlag(key, state, default, help=None)
- Evaluate flags with the names
--with-key or
--without-key. If no such flag is present, the default state is state. The state parameter must be either yes or no; if it is not present, no is assumed. If no value is present for an
--with.
print 'with foo?', Query.WithFlag('foo', state = 'no', default = '/with/foo') print 'with bar?', Query.WithFlag('bar', state = 'yes', default = '/with/bar') % scons with foo? no with bar? /with/bar % scons --with-foo --with-bar with foo? /with/foo with bar? /with/bar % scons --without-foo --without-bar with foo? no with bar? no % scons --with-foo=/opt/foo --with-bar=/opt/bar with foo? /opt/foo with bar? /opt/bar
Other user-defined flags
- Here's a sample of possible pre-defined flag types (i.e., wrappers with audit functions that are maintained as part of SCons). These are chosen to indicate the range of functionality possible and may not be realistic as described.
- Query.BoolFlag(key, default, help=None)
- Evaluate a flag whose initial value is default (False if not present) and the value is reversed each time the flag is specified on the command line. The flag cannot have a value. The flag will have the specified key and display the specified help text. For example:
tf = pool.BoolFlag('exclusive', False)
- Each occurrence of the
--exclusiveflag will flip whether or not it should be exclusive.
- ``
- Query.CountFlag(key, help=None)
- Evaluate a flag whose initial value is zero and the value is incremented each time the flag is specified on the command line. The flag cannot have a value. The flag will have the specified key and display the specified help text. For example:
number = pool.CountFlag('clean')
- Query.LastFlag(key, default, help=None)
- Evaluate the flag(s) specified; return is
Noneif the flag is not present, the default if the flag is present without a value, and the value if there is one. The specified help text will be passed to the help subsystem. If there are multiple occurences of the flag, the last one wins. For example:
opt = pool.LastFlag(['opt', 'optimize'], '-O')
- Query.EnumFlag((key, default, allowed_values[, map[, ignorecase]], help=None)
- Like
Options.EnumOption.
- Query.ListFlag(key, default, names[, map], help=None)
- Like
Options.ListOption.
- Query.PackageFlag(key, help, default)
- Like
Options.PackageOption.
- Query.PathFlag(key, default[, validator], help=None)
- Like
Options.PathOption; the last one on the command line wins.
- Query.PathFlags(key, default[, validator], help=None)
- Like
PathFlagexcept that multiple occurrences are accumulated.
Cross-compilation flags
If the
--host command-line flag is present, SCons cross-compiles files for use on another system. If the
--target command-line flag is present (or defaulted from the
--host flag), the appropriate flags are made available to the compile stages so that their generated output will be for the selected system. (For compatibility, the
--build option is processed but must match the current system, as SCons always builds on the system where it is running.)
TODO: what the flags cause to happen internally; replace config.guess and config.sub?; other stuff (I've edited a number of configure scripts that did cross-compiling, but I've never written one from scratch, so my knowledge of what autoconf does here is small. Can anyone help?)
Thoughts
User-defined validation function:
def validate(flags, values, arg = value, ...)
The flags are a list of flag names that matched the selection.
The values are a list of the corresponding values.
The arg parameters are passed through from the Define call.
Prototype to define flag:
value = DefineFlag(key, names, validate, args, help options)
The key is the name under which to keep the calculated value.
The names are a list of one or more strings of flag names to match.
The validate function takes the matched values and calculates the value to use.
The args are in a dict and are passed as named parameters to the validate function.
The help options will be defined elsewhere.
Prototype to retrieve flag:
Fetch(key)
The key specifies the flag value to return
def audit(flags, values, none = None, default = None): if not values: # not on command line return none v = values[-1] # last flag present wins if v is None: # no value specified return default return v opt = DefineFlag('opt', ['opt', 'optimize'], audit,{'none':'', 'default':'-O'}) print """optimization level is <%s>""" % opt % scons optimization level is <> % scons --opt optimization level is <-O> % scons --optimize optimization level is <-O> % scons --opt=-O1 optimization level is <-O1> % scons --opt=-O1 --opt=-O2 optimization level is <-O2> % scons --optimize=-O1 --opt=O2 optimization level is <-O2> % scons --opt=-O1 --optimize=-O2 optimization level is <-O2>
<a name="Variables"></a>
Variable Assignments
When the command line is cracked, variable assignments are placed in a global pool using their canonical name (the primary name for the variable). Variables are marked valid by encountering a defining instance of the variable (see DefiningHelpText for details). Variable assignments may also be read from an option file; the option file will be rewritten if a value changes. At the end of the parse phase, any variables not marked valid cause an error message to be generated.
- (Note that how the error message is presented is crucial to acceptance; rather than "Unrecognized variable" with the implication that it should have been noticed immediately, it should say something like "Variable never defined during processing; check the spelling.") The defining instance of a variable may specify semantics to modify the variable's value as it is placed in its pool, or a variable can have a value calculated and placed in a pool. In this way, the value of a variable may be preserved across runs.
These values may then be processed into a context that accumulates construction variables. The values may be used as-is or they may be calculated.
One or more contexts may then be used to initialize the construction variables of an Environment. These values may then be used in the construction of command lines in the normal way.
<a name="ControlFiles"></a>
Control Files
<a name="ConfigTests"></a>
Configure Tests
Synopsis: Configure operates in an infinite sea of tests. Each test is uniquely named by some convention (probably a tuple that captures all of the salient facts). When a configuration function is executed, it composes these tests into a DAG; obviously, if the test has already been run, there's no need to repeat it and the result can be used immediately. Some tests exist only for a side-effect (in which case the "test" is really "Has this side-effect been done?"). Each test produces a result, which can be true/false, values from some enumerated set, or whatever. These results can in turn be used for calculations. In some cases, those calculations can be saved in a context that can set the initial values of an Environment's construction variables.
Access to the sea of tests is via a Config context:
conf = Config(autoconf = None,
custom_tests = None,
conf_dir = '#/.sconf_temp',
log_file = '#/config.log')
All tools used in a Config context must be initialized, either by using the autoconf parameter (e.g.,
autoconf = ['cc', 'c++', 'python']) or by calling the appropriate configuration function (e.g.,
conf.Prog.CC(cross='yes')). In some cases, the initialization is implicit; a test can require that the C compiler be configured and include that test result in its own DAG.
Header files can be created to pass configure results to program logic:
conf_h = ConfigHeader(file = 'config.h', lang = 'C')
conf_h.Define(name, value = 1, comment=None)
The conf_h object is a wrapper for a built file with the given name and a builder that builds the given type of file from the dependencies; the Define() method encapsulates its parameters into some specialty Node type and creates a dependency on the conf_h node. The file itself is <ins>not</ins> built until it is needed during the build phase; standard dependency checking will prevent it from being regenerated if it hasn't changed.
If the value in a
conf_h.Define() is None, the name is specifically undefined (i.e.,
#undef name is generated) in languages that allow it.
API
- Still not even half-baked.
- Commonality
- Need a 'pool' object for each type (FlagPool, VariablePool, ConfigPool) where values are filled in from external sources. One global FlagPool, one global VariablePool plus one for each options file, zero or more ConfigPools.
- Need a 'value' object for each type (FlagValue, VariableValue, ConfigValue).
- At the defining instance (which also assigns the help text), the external value may be examined and modified before being stored in the pool.
- Need an 'accumulating' object (Accumulate) to select from other pools, to be able to mix-n-match values from other pools. Can transform selected value when accumulating.
- After the defining instance, the a pool value can be retrieved and placed in an Accumulator.
- Can assign a calculated value to an Accumulator.
# pool objects, all really the same class cf = CommandFlags( xxx ) co = CommandOptions( xxx ) fo = FileOptions( xxx ) cc = Config( xxx ) # defining instance cf.CountFlag('clean', 'Clean') co.ListOption('status', 'Marital status', 'single,married,divorced,widowed') fo.ValueOption('CCFLAGS', 'Common C/C++ flags', '-Wall') cc.Prog.CC() cc.Prog.CXX() # accumulate, another of the pool object class a = Accumulate( xxx ) a.Fetch(cf, 'prefix') a.Fetch(fo, 'CCFLAGS') # use env = Environment( config = [cc, a] )
Stuff below this line is retained from an earlier draft. The basic ideas are OK, but I no longer believe in a lot of the details. Eventually, this will be re-written into something usable..
Thoughts
There's a global object called
HelpText.
HelpText.Wrap('Text printed first', 'Text printed last')
section = HelpText.Section('section_name')
section.Wrap('Text at beginning of section', 'Text at end of section')
HelpText.__call__('section_name', key, short_help, long_help)
section.__call__(key, short_help, long_help)
So '
scons -h' prints a short blurb and the list of sections.
And '
scons -h target ...' prints detailed information:
- If target is a section name, all the keys and their short help is printed, wrapped in the beginning and ending text. The reserved target '
ALL' prints all the sections.
- If target is a key, the long help for the key is printed.
Updated | https://bitbucket.org/scons/scons/wiki/GregNoel/OptionsAndConfigure?highlight=SubstitutionEnvironment | CC-MAIN-2015-35 | refinedweb | 3,303 | 54.52 |
Alan Kay Receives ACM Turing Award 120
TheAncientHacker writes "Alan Kay, the creator of the Smalltalk computer language (and a good deal of what we call Object Oriented Programming) is the winner of this year's Turing Award from the ACM. Kay is also the co-winner of this year's Charles Stark Draper Prize. For more, check out the website of Kay's latest project, Squeak - an open, highly-portable Smalltalk-80 implementation go to the Squeak homepage or the page of the SqueakLand community which uses Squeak in schools. For more on Kay's Turing Award, see this article on the SqueakLand site." Couple of other awards to announce: bth writes "The." And finally, squidfrog writes "Nick Holonyak Jr., inventor of the LED, is being awarded the $500,000 Lemelson-MIT Prize at a ceremony in Washington. Edith Flanigen, 75, was also recognized, with the $100,000 Lemelson-MIT Lifetime Achievement Award for her work on a new generation of 'molecular sieves,' porous crystals that can separate molecules by size."
MVC too? (Score:5, Interesting)
Re:MVC too? (Score:5, Informative)
Re:MVC too? (Score:4, Informative)
Re:MVC too? (Score:3, Insightful)
Sort of. It uses a secondary layer on top, "VisualWorks", the manages the interations between the models and the controllers and views. Then the UIBuilder builds to this structure. It makes it a lot easier to use. Technicaly it's down there but you don't have to worry about it much
MVP is a pretty good improvement over MVC
It's been awhile since I used VisualAge and they use something else, with a Bridge pattern thrown
Re:MVC too? (Score:4, Informative)
Re:MVC too? (Score:2, Informative)
That's PARC, for Palo Alto Research Center
Re:MVC too? (Score:2)
I invented the term 'object-oriented' and I can tell you I did not have C++ in mind.
-- Alan Kay
I invented the term! (Score:5, Funny)
A lot of the developers and managers at Apple were gathered around watching a presentation from someone about some "wonderful" new product that would save the world. All through the presentation, he had been stating that the product was "object-oriented" while he blathered on.
Finally, someone at the back of the room piped up:
"So, this product doesn't support inheritance, right?"
"that's right".
"And it doesn't support polymorphism, right?"
"that's right"
"And it doesn't support encapsulation, right?"
"that's correct".
"So, it doesn't seem to me like it's object-oriented".
To which the presenter huffily responded,
"Well, who's to say what's object-oriented and what's not?"
At this point the person replied,
"I am. I'm AlanKay and I invented the term."
Re:I invented the term! (Score:4, Informative)
Re:I invented the term! (Score:5, Informative)
Re:I invented the term! (Score:1)
Re:I invented the term! (Score:2)
Re:I invented the term! (Score:3, Informative)
Re:I invented the term! (Score:2)
the oberon system is pretty fun to play with, for those of you out there who like to play with new and funky languages, OSes and window systems. Like Squeak Smalltalk, it's a self-contained OS, with it's own widget set and windowing system that exists parallel to win32/x11/quartz, being blitted to one big window. A lot of fun to play with, although the stodgy Pascal-like language of Oberon itself is a bit too formal for me, and I prefer Squeak. But
Re:I invented the term! (Score:5, Funny)
...and my CS professor StephenKeckler was just awarded the GraceHopper award.
Are you an overworked sysadmin? Do you manually assign so many logins that you normalize all full names?
Re:I invented the term! (Score:1)
Re:I invented the term! (Score:2)
Re:I invented the (language)! (Score:4, Funny)
"Maybe they're ashamed of it!" quipped my friend, in reply.
Another (better informed) friend quickly pulled him aside and explained that Grace had been one of the prime movers in the design of Cobol.
Re:I invented the (language)! (Score:1, Insightful)
It was a great regret of hers that COBOL remained the state of the art for as long as it did. She never intended for it to become an entrenched obstacle to CS progress for 30 years.
Re:I invented the term! (Score:2)
Magical Microsoft Moments..
Re:Magical Microsoft Moments. (Score:1)
He also said.. (Score:5, Funny)
No he did not (Score:3, Informative)
Re:No he did not (Score:2)
Re:No he did not (Score:2)
No, that word is also Norwegian!
:-)
Original -- vindöga. Literally, Wind Eye.
(Since that time we Scandinavians have imported the French (?) word for windows. At least here in Sweden.)
Re:I invented the term! (Score:1)
ST does support single inheritance.
ST does support polymorphism.
ST mandates encapsulation.
Sounds pretty OO to me.
Re:I invented the term! (Score:1)
Re:I invented the term! (Score:1)
Nick Holonyak Jr., inventor of the LED (Score:2, Funny)
New generation? (Score:4, Interesting)
Surprising (Score:3, Informative)
Re:Surprising (Score:1, Informative)
What NYU is really like [seventeen.com]
Fuck CS. No one goes to NYU for academics.
Wasn't MOOcode based on Smalltalk? (Score:4, Interesting)
-P.M.
Re:Wasn't MOOcode based on Smalltalk? (Score:4, Interesting)
LambdaMoo and similar systems are very cool, indeed. Something we bring up on the Squeak Smalltalk mailing list sometimes. In addition to the kind of stuff vanilla Smalltalk supports, in a MOO you've also (usually) got a multi-user system spread over multiple servers with full objectspersistance for free. badass.
Re:Wasn't MOOcode based on Smalltalk? (Score:5, Interesting)
It's a nice language. A bit baroque in places, but it has lots of nice features if you're programming this kind of thing; persistance (never need to worry about storing your data on disk!); incremental updates (connect to the server and fiddle with the code while it's up and running and serving requests!); a nice threading model (cooperative multitasking with teeth --- your thread has complete control until it suspends, but if you wait too long the thread's killed)... The VM is sophisticated enough that the game server runs its own web server.
The language itself is sort-of garbage collected (parts are, parts aren't), object oriented with pure dynamic dispatch, has some very nice security measures which I didn't use in Stellation because I wasn't letting users program it, and generally behaves like a slightly gothic Smalltalk with C syntax. Very easy to get used to.
If you're interested, check it out. I was really rather pleased with that game, and at its peak I got a reasonable number of players. It needs redesigning from the ground up, but I've yet to find a VM that's quite as nice as LambdaMOO for doing it in.
(Anyone want to adopt it?)
There's no justice I tell you! (Score:3, Informative)
Cobbling together the mass of awkward syntax, unextendability, and tabs that is make ranks alongside actual advancement of human knowledge? I'd rather they'd awarded the prize on the basis of something other than sheer number of victims
Thank goodness for Ant -- teaching the world that we don't need to use make any more was the best thing Java ever did for us.
Hrm, well, that was my curmudgeonly rant for the day.
Re:There's no justice I tell you! (Score:5, Interesting)
Re:There's no justice I tell you! (Score:5, Informative)
Re:There's no justice I tell you! (Score:1)
*weeps*
Re:There's no justice I tell you! (Score:5, Funny)
Thank goodness for Ant.
<reply tone="sarcastic" style="parody" effectiveness="probably low">
<conjunction value="Because"></conjunction>
<gerund value="programming"></gerund>
<preposition value="in"></preposition>
<acronym value="XML"></acronym>
<verb value="is"></verb>
<adverb value="much"></adverb>
<adverb value="less"></adverb>
<adjective value="awkward"></adjective>
</reply>
Re:There's no justice I tell you! (Score:1)
Wait! You didn't specify the various namespaces that your attributes come from, or provide a DTD or XSD so that I can read your document with a validating reader! You're just NOT LONG-WINDED ENOUGH to use XML!
Anyway, XML is merely the data format. I'm sure you could bolt a nicer data format onto Ant if you wanted, but the limitations of make are best addressed by using something modern.
What Ant's creator has to say about that (Score:1)
Re:There's no justice I tell you! (Score:2, Interesting) [apache.org] [scons.org]
Seriously, I'm just curious. I've heard a lot more about SCONS than Ant. For instance Blender [blender.org] is switching over to a SCONS build system.
ObQuote (Score:5, Insightful)
Re:ObQuote (Score:5, Funny)
Re:ObQuote (Score:5, Funny)
Re:ObQuote (Score:5, Funny)
C makes it easy to shoot (Score:1)
"C makes it easy to shoot yourself in the foot; C++ makes it harder, but when you do, it blows away your whole leg."
Re:ObQuote (Score:5, Funny)
- attributed to Edsger Dijkstra [wikipedia.org]
Re:ObQuote (Score:2, Interesting)
Only half right. It originated in Norway by the designers of Simula-67. However, the term perhaps may have been coined in California.
Re:ObQuote (Score:1)
Re:ObQuote (Score:1)
-Tom Cargill, C++ Journal, Fall 1990
Make! (Score:3, Funny)
Make! Just about time. We would be ants without it.
Dr. Stuart I. Feldman deserves the award but... (Score:3, Funny)
yes, it was a joke
Squeak? I guess I could use a new hobby. (Score:5, Informative)
Now with Squeak [squeak.org] and this quick tutorial [mucow.com], it might be about time to explore SmallTalk.
Besides, I've always wanted a real OO language where I could send the message "to:do:" to the object "1".
Re:Squeak? I guess I could use a new hobby. (Score:1)
Re:Squeak? I guess I could use a new hobby. (Score:2)
Squeak - old news (Score:2, Interesting)
Not to say it's good for nothing - Squeak is particularly good at web crawling apps, IIRC.
As an added bit of trivia, I believe Squeak was so named because one of its biggest proponents is the Mouse himself [disney.com].
Squeak - not so old after all (Score:5, Informative)
Check out this web-app technology [beta4.com] built (first) in squeak, now also available in the descendant to ParcPlace smalltalk (now Cincom Smalltalk [cincomsmalltalk.com])
Also of interest is croquet [slashdot.org], a virtual 3d environment. I saw a live demo [cincomsmalltalk.com] of this where the presenter (David Smith, one of the engineers) showed his avatar moving between worlds existing one each on two separate machines. It was not fast, but not as slow as you might expect.
Also, smalltalk solutions [smalltalksolutions.com] is next week (in Seattle) so come by if you're interested and available.
P.S. what is now known as Squeak was started at Apple. The Squeak group left Apple during Amelio's reign when the company was gutting it's research depts.
Re:Squeak - old news (Score:3, Interesting)
I can't say whether or not Squeak was named for Disney, although Squeak was developed under Disney for some years, with the team on Disney's payroll. However, Squeak was born at Apple in 95-96, before any Disney involvement.
Squeak is useful in education (Score:2, Interesting)
Re:Wow (Score:1, Informative)
A similarly good choice for teaching maths would be lisp or forth.
My All Time Favorite Quote (Score:3, Insightful)
Misquoted. (Score:4, Informative)
"It is the difference of point of view that leads to problems: point of view is worth 80 IQ points."
It is from an essay of Alan Kay's, printed in Winston and Prendergast's (eds.) AI Business, 1984.
Alan Kay is awesome (Score:4, Interesting)
He is an amazing guy and Squeak is a pretty cool language/environment to program in.
Its nice to see his work with Squeak finally being recognized. Word has it that he and some other people (including the guy who is leaving our company) are going to be working on some educational software in Squeak that will come with HP PCs.
In case you didn't know (Score:3, Informative)
Simula is still used and there is a research facility [simula.no] named after it.
Re:In case you didn't know (Score:1)
The Simula people already won the award years earlier IIRC.
A Great Squeak Demo (Score:1)
Re:A Great Squeak Demo (Score:2, Informative)
*sigh*
Alan Kay Etech 2003 presentation (Score:5, Informative)
Someone to tell (Score:2)
He should be higly pleased (Score:5, Funny)
Isn't this news item 17 years late? (Score:1)
Re:Isn't this news item 17 years late? (Score:1)
Congratulations! (Score:1)
Dr. Kay's deep interest in children and education (Score:1)
Re:I HATE Dr. Stuart I. Feldman !!! (Score:3, Funny)
Is Squeak your problem? (Score:3, Interesting)
There are two factors here, that I can see: Squeak, and Windows 2000. Which is the more reliable of the two? I think I know... | http://developers.slashdot.org/story/04/04/22/1243254/alan-kay-receives-acm-turing-award | CC-MAIN-2014-52 | refinedweb | 2,225 | 67.45 |
Writing to a file using a MemoryMappedFile in C# .NET
November 13, 2015 Leave a comment
You can use memory-mapped files to map a file to a place in memory that multiple processes can access. The necessary objects reside in the System.IO.MemoryMappedFiles namespace.
The following example will create a MemoryMappedFile object using the following ingredients:
- The file path
- The file mode which in this example is CreateNew, i.e. a new file will be created if it doesn’t exist
- A map name that other processes can refer to
- An initial size of the file. This is mandatory for files that don’t exist otherwise you’ll get an exception. The file will be given this initial size with a lot of string-termination characters. If you try to open the file in a text editor then you may get a warning that the file is full of NULL characters. This depends on the type of editor you’re using
We use the MemoryMappedViewAccessor object extracted from MemoryMappedFile to read and write to the mapped file. You’ll see that writing a string to the file looks somewhat awkward. The reason is that only value types and byte arrays are allowed to be written to a memory mapped file. This conversion is just a trick to save a string.
The first argument to the WriteArray method specifies the location where the string – the byte array – should be inserted.
static void Main(string[] args) { using (MemoryMappedFile memoryMappedFile = MemoryMappedFile.CreateFromFile(@"c:\temp\log.txt", FileMode.CreateNew, "log-map", 10000)) { using (MemoryMappedViewAccessor viewAccessor = memoryMappedFile.CreateViewAccessor()) { byte[] textBytes = Encoding.UTF8.GetBytes("Here comes some log message."); viewAccessor.WriteArray(0, textBytes, 0, textBytes.Length); } } }
Here’s the file itself after running the method:
The file is of size 10KB as specified in the CreateFromFile method.
If you run the above code twice after another then you’ll get an exception saying the source file already exists. Use the “OpenOrCreate” enumeration value of FileMode if it’s OK to work with an existing file. The Append enumeration value is not allowed in conjunction with memory-mapped files. Instead, you’ll need to specify the position of the byte(s) you’d like to write in the file.
Read all posts dedicated to file I/O here. | https://dotnetcodr.com/2015/11/13/writing-to-a-file-using-a-memorymappedfile-in-c-net/ | CC-MAIN-2022-40 | refinedweb | 383 | 56.66 |
In today’s exercise, our goal is to write an algorithm that, given an alphabet and a length, generates all possible sequences that do not have two adjacent indentical subsequences. Let’s get started, shall we?
Some imports:
import Control.Monad import Data.List
We build up the list of possible sequences from the end. Whenever we add a character we check that we do not generate a repeated subsequence. This bit could be optimised a little since checking past the first half of the list is pointless, but performance wasn’t a problem so I didn’t bother. Although not explicitly stated in the problem description, two sequences are considered identical if one can be obtained by permuting the other’s alphabet, e.g. 123 is considered the same thing as 321. Therefor we add the criterium that in the final list of permutations all unique characters must occur in ascending order.
nonAdjacent :: Ord a => [a] -> Int -> [[a]] nonAdjacent xs = sort . filter (and . zipWith (==) xs . nub) . f where f 0 = [[]] f n = filter (\x -> not . or . tail $ zipWith isPrefixOf (inits x) (tails x)) $ liftM2 (:) xs (f $ n - 1)
Some tests to see if everything is working properly:
main :: IO () main = do mapM_ putStrLn $ nonAdjacent "123" 5 mapM_ putStrLn $ nonAdjacent "123" 12 mapM_ putStrLn $ nonAdjacent "123" 20
Tags: bonsai, code, Haskell, kata, praxis, programming, repeated, subsequences, wirth | https://bonsaicode.wordpress.com/2012/12/11/programming-praxis-stepwise-program-development-a-heuristic-algorithm/ | CC-MAIN-2016-50 | refinedweb | 227 | 54.42 |
This thread has now been closed to direct all further updates about this release onto the latest announcement:
This preview release of Xamarin Studio introduces a new type system based on Roslyn and other important changes such as a revamped project model, a new visual style, and better support for F#. We want to show those features in an early preview since they significantly change the way Xamarin Studio works.
Xamarin Studio 6.0.0.3668 - Preview 4
This post will be updated when a new preview release is made. There is a release notes page with more detailed information about Xamarin Studio 6.0.
NOTE: Items marked with the tag [UPDATE] are changes done since the last preview release.
Xamarin Studio's type system is now based on Roslyn, Microsoft's open source .NET compiler platform. Even though this is an internal change, it has several practical benefits:
The new model has a deeper integration with MSBuild, and can can handle projects that take advantage of advanced MSBuild features. Here are some features that are now supported:
In this release we are presenting the new look of Xamarin Studio. It has a more modern style, a dark variant and many visual tweaks to make Xamarin Studio more pleasant to use. Here are the highlights:
We have been busy improving our F# support, and we are happy to report that we are addressing many limitations in our F# support, in this release:
This release of Xamarin Studio for Mac is a 64bit application, so you’ll be able to take advantage of all the memory of your system when working with large solutions.
This release introduces support for watchOS 2 and tvOS when combined with a preview of Xamarin.iOS that supports it. We have added new project types, templates and file templates to support those frameworks as well as a wizard to guide you through the setup.
Available for previews of Xamarin.Mac with binding support. This feature has been available on iOS projects for a long time, and we have finally brought it to the Mac.
ASP.NET support has been greatly improved. There is a new project wizard for creating Web Forms and MVC projects and all templates have been reviewed and updated.
Please check the release notes page to know more about what's new in Xamarin Studio 6.0.
File a bug against Xamarin Studio
Please file a bug for any new issue you find in this preview that you would like the Xamarin team to investigate. If you have any comment or suggestion you can also post to this thread. This preview is a chance to help ensure that the final release of Xamarin Studio with Roslyn will work smoothly with your specific projects and environment.
After installing the preview, you'll get an update notification for the stable channel (or whatever channel you are following). You can at any time install that update to go back to the stable release.
Fake integration \o/
Now would be the perfect time to fix this issue :
In case you are having issues with shared projects and the editor analysis engine (namespaces and classes underlined as not found), removing and adding a reference to the shared project fixed it for me.
How does this influence the add-ins you can build for Xamarin Studio? Will there be a new model in XS6?
@Stefan_CaveBirdLabs There are some changes in the add-in model. I'll push documentation about the changes soon.
Thanks. I tried to find the Addin Maker in 6.0 but the repositories are showing no entries at all.
I was following
But when I navigate to gallery all repositories are empty.
@Stefan_CaveBirdLabs the build server doesn't yet support 6.0 but you can build addin maker from source:
Is it possible to have this release and the stable one installed at the same time?
@Nuninz very good question. I also have the same question.
Anybody has any idea or workaround?
thanks in advance
@Nuninz you can on Mac, but not on Windows. On Mac, open the dmg and just copy the app to any folder other than Applications, and run it from there.
Guys, the "Quick Fix" feature gone missing, I can't live without it.
thank you @LluisSanchez , will do!
Hi!
The preview 3 of Xamarin Studio 6.0 with Roslyn Support has been published, with many bug fixes. Links to new builds are available in the first post of this thread. Please update!
@LluisSanchez, How does Xamarin Studio 6.0.0.1752 play with the Cycle 6 RC1 stuff currently on the Alpha Channel? Can we use this one instead of Xamarin Studio 5.10?
P.S. Thanks for the great job with the Roslyn integration, XS is much more usable now.
@FabioG Xamarin Studio 6.0 contains all features in 5.10, so yes, you can use it instead of 5.10.
Does this install alongside or on top of an existing Xamarin Studio installation?
I just found out that we need Mono 4.2.1 to run Roslyn. Does this mean we should switch to the Alpha channel to install that suite before installing this? If so, how do we maintain a stable release (XS 5.x + Mono 4.0.5) whilst playing with the new stuff?
@DavidDancy you can on Mac, but not on Windows. On Mac, open the dmg and just copy the app to any folder other than Applications, and run it from there
@joehanna I added a link to Mono 4.2.1 in the post, which is what is available in the alpha channel. You can install that instead of switching to the alpha channel. XS 5.x should work just fine with Mono 4.2.1.
Thanks @LluisSanchez. Mono 4.2.1 has recently moved into the beta channel.
Hi, issues I have with the new build:
I am reinstalling xamarin from the installer. Choose not to install Xamarin.Android, but it still downloading android SDK (!?)
I just installed this preview version, and mono 4.2.1, and opened one of my simple projects. Upon compiling it complains about EVERY one of my C# 6.0 statements, such as
\InventoryHelpers.cs(20,20): Error CS1056: Unexpected character '$' (CS1056) (InventoryUpdaterLibrary)
InventoryHelpers.cs(7,7): Error CS1041: Identifier expected; 'static' is a keyword (CS1041) (InventoryUpdaterLibrary)
Those are the only errors I get. According to the mono docs the c# 6.0 stuff is supposed to work in version 4, what am I missing?
@JoshuaAustill Are you running on Windows or Mac?
@NamDuong.0933 In this preview you have to enable Source Analysis in the preferences (Text Editor -> Source Analysis panel). This will be fixed in the next preview. After enabling that option, the refactoring menu will be available.
I'm running windows 7 and 10 on different machines. Same behavior on both. Also, I installed this release, and it auto updated itself back to 5.10 lol. Not the end of the world, I know now to pay better attention to what it's saying it will update
Also, I'm running Visual Studio 2015 with LinqPad and ReSharper installed. Don't know if either of those would cause issues or not.
I reinstalled everything, and started digging through the options. If I set the target framework to mono .NET 4.5 under each project, it compiles fine. If I leave it set to .NET 4.5.2, it does not. I'm a complete mono noob, so this may be the expected behavior for all I know? Either way, I'm having fun figuring it out, thanks!
@Lluis Sanchez Thanks Lluis, it works for me now.
I found another bug where the syntax to search by class name "type:MyClass" has been changed to "class:MyClass", but its short cut key "Go to type" still pre filling with "type:"
Hi, I found some other bugs:
I really like the new IDE, it's faster and the auto complete somehow smarter, and now I can use nameof. Great work. Waiting for the new build.
@NamDuong.0933
I fixed the creating new classes & toggle definition bug - the short cut bug is known and tracked - I suppose it'll be fixed soon.
It would be nice if new bugs could be reported via the bug tracking tool - then the internal QA team can track the fixes more easily
.
ty for testing & reporting
Still not working:
Object?.SomeProperty;
@Thomas.8817 C#6 is not supported on Windows in preview 3. It will be supported in the next preview.
@LluisSanchez can you remove that part in the first post?
Going back to stable After installing the preview, you'll get an update notification for the stable channel (or whatever channel you are following). You can at any time install that update to go back to the stable release.
Because it's not true. Want to go back to 5.10, but everytime i do the "update" xamarin crashes and says
'Error
Xamarin Update must be launched from Xam'
Filed this bug about warnings I'm seeing in the latest preview (preview 3): The type Xyz conflicts with the imported type Xyz - Shared Projects and iOS Today Extension
@LluisSanchez Is there a timeline for when the Roslyn compiler and typesystem will be moved into the Alpha channel? Planning on developing tooling that uses the AST soon and would prefer not to write code against NRefactory if it is being retired.
How are you doing guys?
Other than Xamarin sketches, this is the most exciting product I am looking forward for.
Wondering if there was a rough ETA on the next preview release is coming, or when it might move to the Alpha channel? Thanks!
What about vi modes?
@Matthew-Robbins No timeline yet. Maybe in 1 month or so.
@woot I'd like to do another preview release early next week
@FokkeVermeulen this will be fixed in the next preview
Great, thanks for the reply - looking forward to it! | https://forums.xamarin.com/discussion/comment/159795/ | CC-MAIN-2019-47 | refinedweb | 1,668 | 74.39 |
Microsoft.
Office. Tools. Ribbon Namespace
The Microsoft.Office.Tools.Ribbon namespace contains components, controls, and supporting collections, classes, and enumerations that enable you to customize the Ribbon in the user interface (UI) of several Microsoft Office applications.
Classes
Interfaces
Enums
Delegates
Remarks
All of the controls in the Microsoft.Office.Tools.Ribbon namespace can be added to your Office customization by dragging them from the Office Ribbon Controls tab of the ToolBox onto the Ribbon Designer. In addition, the RibbonMenu control enables you to add the following controls at run time:
To add these controls to a RibbonMenu at run time, you must set the Dynamic property of the menu to
true at design time.
When you create a control at run time to add to a menu, you can change any properties of the newly created control before you add it to the menu. After you add a control to a menu, some of its properties become read-only. For more information, see Ribbon Object Model Overview.
You can use other properties to control the appearance and behavior of your controls at run time. For example, you can implement run-time changes to the user interface by using the Enabled and Visible properties to enable, disable, show, and hide controls that were added at design time. | https://docs.microsoft.com/en-us/dotnet/api/microsoft.office.tools.ribbon?view=vsto-2017 | CC-MAIN-2020-45 | refinedweb | 217 | 50.26 |
Member Since 2 Years Ago Livewire Get The Auth::user()->id
Sorry it was my bad i have forget to add user_id to the fillabel array in the model
Replied to Livewire Get The Auth::user()->id
yes 100% sure that user logged in and i haveing the following errror: "SQLSTATE[HY000]: General error: 1364 Field 'user_id' doesn't have a default value" So it seamlike 'user_id' => Auth::user()->id,not working
Replied to Livewire Get The Auth::user()->id
Then there must be somethog wrong with mycode:
<?php namespace App\Http\Livewire; use App\Models\User; use App\Models\menhely; use Livewire\Component; use Livewire\WithFileUploads; use Auth; class MenhelyProfile extends Component { use WithFileUploads; public $name; public $tel; public $email; public $webcim; public $irsz; public function register() { $menhely = menhely::create([ 'user_id' => Auth::user()->id, 'name' => $this->name, 'tel' => $this->tel, 'email' => $this->email, 'webcim' => $this->webcim, 'irsz' => $this->irsz, ]); } public function render() { return view('livewire.menhely-profile'); } }
Started a new Conversation Livewire Get The Auth::user()->id
When I create a post in livewire how can i get the authenticated user id like Auth::user()->id so I can save it into the post model user_id field?
Replied to How To Use Livewire With Laravel Fortify For Registration?
Hi @sshateri ! What I was ended up is the conclusion that fortiy is handeling the authentication so there is nothiong special how fortify register users so I created a Livewire register component: "php artisan make:livewire Register" and then I save the user inside my app/Http/Livewire/Register.php with the following code:
<?php namespace App\Http\Livewire\Auth; use App\Models\User; use Livewire\Component; use Illuminate\Support\Facades\Hash; class Register extends Component { public $email = ''; public $password = ''; public $passwordConfirmation = ''; protected $rules = [ 'email' => 'required|email|unique:users', 'password' => 'required|min:6|same:passwordConfirmation', ]; public function updatedEmail() { $this->validate(['email' => 'unique:users']); } public function register() { $this->validate(); $user = User::create([ 'email' => $this->email, 'password' => Hash::make($this->password), ]); auth()->login($user); return redirect('dashboard'); } public function render() { return view('livewire.register') ->layout('layouts'); } }
And it willcreate exatly the same users that fortify would save. So there is no difference between the two users saved with livewire an fortify. for user update and for user authentication i use fortify "out of the box" code.
I hope it helped to you.
Replied to How To Submit The Registration Form Using Livewire To Fortify?
Ohh yes I have checked. And the problem is with livewire you submit the form to a method but for fortify I have to submit the form to the register route
Started a new Conversation How To Submit The Registration Form Using Livewire To Fortify?
Is there any way to submit a livewire registration form to Laravel Fortify?
Replied to How To Use Livewire With Laravel Fortify For Registration?
Probably I will do that.
Replied to How To Use Livewire With Laravel Fortify For Registration?
I wanted to do it with livewire because i have a select option ( using alpine.js ) on the registration page and based on the user selection i show different registration form for the users, but if the user submit the form and there is any validation error then the page reloads and user is dropped back to the select option and of course they cant see the validation error as the paged reloded and the selected option has ben reseted so the registration form is hidden again. With livewire i could prevent the page reload so the user would see the validation errors.
But as i digging deeper into this topic it is clearly it is out of my knowlade i wont be able to merge livewire and "the out of the box fortify registration view and controller" so probably i just register the user without fortify using livewire component.
Replied to Vue Js - Add Selection Dynamically To Form.
so you can push a new row into dropdown but you cant delete it?
Replied to How To Use Livewire With Laravel Fortify For Registration?
Thanks for that, to creating a new post or contact form using livewire is no problem. My problem comes when i would like to use the livewire real time validationon the laravael jetstream "out of the box " registration form because in this case there is no app/http/livewire/Register.php where i could write my validation there is only app/actions/fortify/CreateNewUser.php but the wire:model="email" wire:model="password" wire:model="password_confirmation" wont "communicate" with this file
Replied to How To Use Livewire With Laravel Fortify For Registration?
OK so let's say I would like to add livewire validation to the register form. I use on the form tag and i add the wire:model="email" wire:model="password" wire:model="password_confirmation"
so if i hit the register button and get the validation errors without refresh the registration page.
Replied to How To Use Livewire With Laravel Fortify For Registration?
Ok it will be probobly the a stupid question, but I still ask it becase the picture is not clear for me at the moment.
Lets say I install a new laravle project with Jetstream and livewire. In ths case I will have a working user registration out of the box with user dashboard. And let's say i create my ownuser registration form as well by using the following command: "php artisan make:livewire Wireuserreg" it will creat form me 2 files 1 inside the views/livewire/Wireuserreg.blade.php and the other one is inside App/http/livewire/Wireuserreg.php If I save the user with my App/http/livewire/Wireuserreg.php withthe following:
public function register() { $this->validate(); $user = User::create([ 'email' => $this->email, 'password' => Hash::make($this->password), ]); auth()->login($user); return redirect('/'); }
will be there any difference between users saved with livewire and users saved with the out of the box fortify ?
Replied to How To Use Livewire With Laravel Fortify For Registration?
I know that is how i installed but the registration is using simple blade without livewire and the data is passed to the fortify controller not to livewire "controller"
Started a new Conversation How To Use Livewire With Laravel Fortify For Registration?
I have fresh Laravel installation with Jetstream using Livewire. My question is how can i implement livewire into the registration? The out of the boxlaravel using fortify for registration and iwould like to keep the fortify par I just would like to implement livewire for better validation during the registration.
Replied to Vimeo Api Using Laravel Best Package
Hi Have you been able to achieve it?
Replied to Any Tutorial Recommendation About This X-jet Markup?
Started a new Conversation Any Tutorial Recommendation About This X-jet Markup?
Is there any tutorial about this new jetstream markups? for example x-jet-application-logo, x-jet-welcome and so on.
Replied to Try To Use Laravel 8 And Livewire
Aha ok! An in-depth laracast series about laravel 8 and jetstream would priceless for me :)
Replied to Try To Use Laravel 8 And Livewire
Replied to Try To Use Laravel 8 And Livewire
Thnaks for your answers guys. I think I going back to fortify and vue.js instead of Jetstream. I dont want to and I dont have time to learn this livewire think. I have published the livewire files and it published 25 blade files form me and i dont even started my project :) ... no thanks.
Started a new Conversation Try To Use Laravel 8 And Livewire
This code is in laravel 8 layouts/app.blade.php where is the content coming from? what is {{ $header}} and what is {{ $slot}} ? I want my own contetn there
<!-- Page Heading --> <header class="bg-white shadow"> <div class="max-w-7xl mx-auto py-6 px-4 sm:px-6 lg:px-8"> {{ $header }} </div> </header> <!-- Page Content --> <main> {{ $slot }} </main> </div>
Replied to Laravel Got Stuck After Login. Laravel 5.8
@jlrdw yeah I saw that github issue page you just linked in. So as you can see I am not the only person who has this issue.. I understand that you dont experienced this problem before, but I havent changed my setup for a while and I disabled all my chrome extensions to track the issue. still now solution. Only think i can think of is that probably you are using a Mac and I am using a Win machine and maybe there are some differences, probably i will reinstall my whole system and see if it is solve this issue.
Replied to Laravel Got Stuck After Login. Laravel 5.8
Replied to Laravel Got Stuck After Login. Laravel 5.8
i did not modify anything. this is happening with out of the box authentication..
Replied to Laravel Got Stuck After Login. Laravel 5.8
I have just created a fresh Laravel app.. Ihave experience this issue every time when i open chrome in this video you will see the issue:
Replied to Laravel Got Stuck After Login. Laravel 5.8
I have the same issue with a freshly installed Laravel app.. However i think it is somehow Chrome related because I dont experience this problem in Firefox.
Replied to Store Users Selected Language Option
@aurawindsurfing I know it is a feature and not a bug. I dont complain about it my question is is there any way to keep only that variable in the session ? If i save it in cookie would be the same result? Or is there a way to modify the logout function that just before it do the return redirect to the welcome page i set the language variable in the session?
Started a new Conversation Store Users Selected Language Option
Hi, I am creating an app.and currently I store the user selected language option in session and it works perfectly for example if user selects English language then I store the 'en' in session with the following controller:
public function index($locale){ App::setlocale($locale); session()->put('locale', $locale); return redirect()->back(); }
and I do the following in a middleware:
public function handle($request, Closure $next) { if (session()->has('locale')) { App::setlocale(session()->get('locale')); }else{ App::setlocale('hu'); session()->put('locale', 'hu'); } return $next($request); }
It works fine user can navigate trough the app back and forward and the selected language is stay as users selected. I can log in into app and the selected language option is stay as selected and stored in session. However when the user logout from the app and redirected to the welcome page then the session is reset and the selected language cleared and the default language is set. Is there any way to prevent the logout function to clear the selected language optino?
Replied to Vue SPA With Laravel Authentication
Thanks @jeffreyvanrossum and @doncho85 for your replies. So basically it is adviced to install vue and laravel separately, but if i want i can develop them in the same project folder too. The main point here i need to use laravel api route as a connection between vue and laravel.
Replied to How To Get Products Where Category Id
@michaloravec like this? it is not woking
$products = Product::whereHas('categories', function ($query) use ($id){ $query->where('categories.id', $id); }) ->with(['productimages' => function($q){ $q->where('productimages.featured', '=', '1')->select(['id', 'image']); }, 'categories'])->orderBy('id', 'DESC') ->paginate(9);
Replied to How To Get Products Where Category Id
Thanks @michaloravec Yeah that was my bad a wrote it incorrectly in my question but of course i used belongsToMany on both models in my projects. However now as you can see i load productimges as well but i would like to load only the image with featured field is 1. and select only the image column. It works
$products = Product::whereHas('categories', function ($query) use ($id){ $query->where('categories.id', $id); }) ->with(['productimages' => function($q){ $q->where('productimages.featured', '=', '1'); }, 'categories'])->orderBy('id', 'DESC') ->paginate(9);
but when i try to select only the image column then it is not working
$products = Product::whereHas('categories', function ($query) use ($id){ $query->where('categories.id', $id); }) ->with(['productimages' => function($q){ $q->where('productimages.featured', '=', '1')->select('image); }, 'categories'])->orderBy('id', 'DESC') ->paginate(9);
Replied to How To Get Products Where Category Id
i have found the solution:
public function fetchproducts($catid){ $products = Product::whereHas('categories', function ($query) use ($catid){ $query->where('categories.id', $catid); }) ->with(['productimages', 'categories'])->orderBy('id', 'DESC') ->paginate(9); return $products; }
Started a new Conversation How To Get Products Where Category Id
Hi, I have a products and categories and category_product tables. So i have hasMany and belongsToMany relationship between the Products and Categories. When the user clicks on the category then i send an axios request to the controller and I would like to return the products related to that category. I have something like this in my controller but I cant make it work:
public function fetchproducts($catid){ $products = Product::where('categories', function ($query) use ($catid){ $query->where('id', $catid); }) ->with('productimages')->orderBy('id', 'DESC') ->paginate(9); return $products; }
Started a new Conversation Vue SPA With Laravel Authentication
Hi, I am in a learning phase in learning Vue js SPA with Laravel. I watching tutorials on YouTube and all the tutorials shows that they create a new Laravel project then the create a new Vue js project with Vue CLI. But I am a bit confused why they so that? Laravel comes with vue js if I run "composer require laravel/ui" and then "php artisan ui vue" so why the they do it separately? Is it not working if I install vue with laravel?
Commented on Refactoring Views: Part 2
Will you publish a video about the animated rating circle as well?
Started a new Conversation Video About How Laracast Handling Videos
Hi, I saw your video about video.js but as I can see now you are using vimeo for hosting videos on Laracast. A tutorial about how you upload and then display videos on Laracast website would be useful. Are you using the Vimeo API to upload videos or you are uploading the videos straight on Vimeo website?
Replied to Can't Save Boolean Into Mysql With Laravel
Thnaks @frankielee now I just convert it in my vue js compontent to 1 or 0 and i send it that way to the controller and it works. I thought I can update the $request->completed in the controller and then use update($request->all()); You were right it not working that way. Now in my vue js componetn my code looks like this and it works.
toggleTodo(e){ e.completed = !e.completed let data = new FormData(); data.append('_method', 'PATCH'); if(e.completed == true){ data.append('completed', 1); } if(e.completed == false){ data.append('completed', 0); } axios.post('/api/todo/'+e.id, data).then((res) =>{ }).catch((error) => { this.form.errors.record(error.response.data.errors) }) },
Replied to Can't Save Boolean Into Mysql With Laravel
No i have button with v-on:click there is no input field as I only need to toggle the completed to true or false
v-on:click="toggleTodo(todo)"
Replied to Can't Save Boolean Into Mysql With Laravel
Actually i have my form in a vue js component, basically i have a button to trigger this method.
toggleTodo(e){ e.completed = !e.completed let data = new FormData(); data.append('_method', 'PATCH'); data.append('completed', e.completed); axios.post('/api/todo/'+e.id, data).then((res) =>{ }).catch((error) => { this.form.errors.record(error.response.data.errors) }) },
Replied to Can't Save Boolean Into Mysql With Laravel
when i dd( $request->completed ); i get 1 but when i delete the dd and i try to update the database i receive the error above
Replied to Can't Save Boolean Into Mysql With Laravel
I know, as you can see i tried it with int $request->completed = 1;
Started a new Conversation Can't Save Boolean Into Mysql With Laravel
Hi, I am not able to save boolean into mysql database I have a the following message: "SQLSTATE[22007]: Invalid datetime format: 1366 Incorrect integer value: 'true' for column
I have set the request-> completed value to 1 but i still have the error above
public function update(Request $request, $id) { $todo = Vuejstodo::findOrFail($id); $request->completed = 1; $todo->update($request->all()); $todo->save(); return $todo; }
Started a new Conversation PDF As Image
Hi, Is there any option to display PDF files as image in laravel ? Basically i upload a PDF document and i would like to display the PDF content on my page as an image.
I wanted to use this package: But exec() disabled on the server i use so this package is not an option for me.
Started a new Conversation How To Convert Associative Arrays To Indexed?
Basically i want to get from the users table only the email addresses. When i use the following code i get an associative array
the output is :
$emails = array:6 [ 0 => array:1 [ "email" => "[email protected]" ] 1 => array:1 [ "email" => "[email protected]" ] 2 => array:1 [ "email" => "[email protected]" ] 3 => array:1 [ "email" => "[email protected]" ] 4 => array:1 [ "email" => "[email protected]" ] 5 => array:1 [ "email" => "[email protected]" ] ]
how to convert it to :
$emails = array("[email protected]", "[email protected]", "[email protected]", "[email protected]", "[email protected]", "[email protected]")
Replied to How To Use Mailgun API To Send Emails To Multiple Users With Attachment
OMG!!! It was so easy! I literally spent more then a day installing mailgun/mailgun and different packages and testing them. Shame on me that i haven't read the documentation on the first place :/
Thanks!
Started a new Conversation How To Use Mailgun API To Send Emails To Multiple Users With Attachment
Hi, I am able to send emai with Mailgun API to 1 email adress but I am not sure how to sendsame email to multiple email addresses with attachment. And also i would like to send html message (view).
Has anyone have any experience on this field?
I have tried to use Bogardo/Mailgun package it would be great and easy to use, but i was not able to install this package. I think laravel 7 is not supported by this package.
Replied to How To Send Multiple Attachment In Laravel
Hi I am not sure if your problem sorted, but the following code is working perfectly for me, and I can send multiple attachment with the email. So here is the code:
Form:
<form action="" method="post" enctype="multipart/form-data">@csrf <div class="row justify-content-center"> <div class="col-md-8"> <div class="card"> <div class="card-header">General Information</div> <div class="card-body"> <div class="form-group"> <div id="person"> <select name="person" class="form-control"> <option value="">select</option> @foreach(App\User::all() as $user) <option value="{{$user->id}}">{{$user->name}}</option> @endforeach </select> </div> </div> <input type="file" name="file[]"> <div class="form-group"> <textarea name="body" class="form-control"></textarea> </div> <br> <div class="form-group"> <button class="btn btn-primary " type="submit">Submit</button> </div> </div> </div> </form>
My controller where i receive the post request: (I am sending the whole request to my sendmail.php
public function mailsend(Request $request) { $people = User::get(); foreach($people as $p){ Mail::to($p->email) ->send(new SendMail($request)); } } return redirect()->back(); }
sendmail.php
<() ]); } } }
So basically you only store the files temporary and send them.
Hope it helped to you.
Started a new Conversation Video Uploading
Hi guys, I would like to create website where i can upload videos and then display them on my website with video.js. Videos are usually big in file size. Is there any good practice how to upload videos with laravel on the website and save them on the server? should I use AWS or similar service to store my videos? Should be videos uploading async?
Awarded Best Reply on Get Comment Where Users Are Active
Found the solution | https://laracasts.com/@Norbertho | CC-MAIN-2020-50 | refinedweb | 3,331 | 51.18 |
July 2017
Volume 32 Number 7
[Machine Learning]
Introduction to the Microsoft CNTK v2.0 Library
Disclaimer: CNTK version 2.0 is in Release Candidate mode. All information is subject to change.
The Microsoft Cognitive Toolkit (CNTK) is a powerful, open source library that can be used to create machine learning prediction models. In particular, CNTK can create deep neural networks, which are at the forefront of artificial intelligence efforts such as Cortana and self-driving automobiles.
CNTK version 2.0 is much, much different from version 1. At the time I’m writing this article, version 2.0 is in Release Candidate mode. By the time you read this, there will likely be some minor changes to the code base, but I’m confident they won’t affect the demo code presented here very much.
In this article, I’ll explain how to install CNTK v2.0, and how to create, train and make predictions with a simple neural network. A good way to see where this article is headed is to take a look at the screenshot in Figure 1.
Figure 1 CNTK v2.0 in Action
.png)
The CNTK library is written in C++ for performance reasons, but v2.0 has a new Python language API, which is now the preferred way to use the library. I invoke the iris_demo.py program by typing the following in an ordinary Windows 10 command shell:
> python iris_demo.py 2>nul
The second argument suppresses error messages. I do this only to avoid displaying the approximately 12 lines of CNTK build information that would otherwise be shown.
The goal of the demo program is to create a neural network that can predict the species of an iris flower, using the well-known Iris Data Set. The raw data items look like this:
5.0 3.5 1.3 0.3 setosa 5.5 2.6 4.4 1.2 versicolor 6.7 3.1 5.6 2.4 virginica
There are 150 data items, 50 of each of three species: setosa, versicolor and virginica. The first four values on each line are the predictor values, often called attributes or features. The item-to-predict is often called the class or the label. The first two feature values are a flower’s sepal length and width (a sepal is a leaf-like structure). The next two values are the petal length and width.
Neural networks work only with numeric values, so the data files used by the demo encode species as setosa = (1,0,0), versicolor = (0,1,0) and virginica = (0,0,1).
The demo program creates a 4-2-3 neural network; that is, a network with four input nodes for the feature values, two hidden processing nodes and three output nodes for the label values. The number of input and output nodes for a neural network classifier are determined by the structure of your data, but the number of hidden processing nodes is a free parameter and must be determined by trial and error.
You can think of a neural network as a complex mathematical prediction equation. Neural network training is the process of determining the constants that define the equation. Training is an iterative process and the demo performs 5,000 training iterations, using 120 of the 150 iris data items.
After training, the prediction model is applied to the 30 iris data items that were held out of the training process. The model had a classification error of 0.0667, which means that the model incorrectly predicted the species of 0.0667 * 30 = 2 flower items and, therefore, correctly predicted 28 items. The classification error on a holdout test set is a very rough estimate of how well you’d expect the model to do when presented with a set of new, previously unseen data items.
Next, the demo program uses the trained neural network to predict the species of a flower with features (6.9, 3.1, 4.6, 1.3). The prediction is computed and displayed in terms of probabilities: (0.263, 0.682, 0.055). Notice that the three values sum to 1.0. Because the middle value, 0.682, is the largest, the prediction maps to (0,1,0), which in turn maps to versicolor.
The remainder of the output shown in Figure 1 displays the values of the constants that define the neural network prediction model. I’ll explain where those values come from, and what they can be used for, shortly.
This article makes no particular assumptions about your knowledge of neural networks, or CNTK or Python. Regardless of your background, you should be able to follow along without too much trouble. The complete source code for the iris_demo.py program is presented in this article, and is also available in the accompanying download.
Installing CNTK v2.0
There are several ways to install CNTK, but I’ll describe the simplest approach. The first step is to install a CNTK-compatible version of Anaconda onto your Windows machine.
At the time I wrote this article, CNTK v2.0 RC1 required Anaconda (with Python 3), version 4.1.1, 64-bit, which contains Python version 3.5.2 and NumPy 1.11.1. So I went to the Anaconda Download site (which you can easily find with an Internet search), then to the archives page and found a self-extracting executable installer file named Anaconda3-4.1.1-Windows-x86_64.exe and double-clicked on it.
The CNTK library and documentation is hosted on GitHub at github.com/Microsoft/CNTK. I strongly advise you to review the current CNTK system requirements, especially the version of Anaconda, before trying to install CNTK.
The Anaconda install process is very slick and I accepted all the default installation options. You might want to take note of the Anaconda installation location because CNTK will go there, too.
By far the easiest way to install CNTK is indirectly, by using the Python pip utility program. In other words, you don’t need to go to the CNTK site to install it, though you do need to go to the CNTK installation directions to determine the correct installation URL. In my case that URL was:
The URL you’ll want to use will definitely be different by the time you read this article. If you’re new to Python, you can think of a .WHL file (pronounced “wheel”) as somewhat similar to a Windows .MSI installer file. Notice the CPU-Only part of the URL. If you have a machine with a supported GPU, you can use it with a dual CPU-GPU version of CNTK.
Once you determine the correct URL, all you have to do is launch an ordinary Windows command shell and type:
> pip install <url>
Installation is very quick, and files are placed in the Anaconda directory tree. Any install errors will be immediately and painfully obvious, but you can check a successful installation by typing the following at a command prompt and you should see the CNTK version displayed:
> python -c "import cntk; print(cntk.__version__)"
Understanding Neural Networks
CNTK operates at a relatively low level. To understand how to use CNTK to create a neural network prediction model, you have to understand the basic mechanics of neural networks. The diagram in Figure 2 corresponds to the demo program.
Figure 2 Neural Network Input-Output Mechanism
The network input layer has four nodes and holds the sepal length and width (6.9, 3.1) and the petal length and width (4.6, 1.3) of a flower of an unknown species. The eight arrows connecting each of the four input nodes to the two hidden processing nodes represent numeric constants called weights. If nodes are 0-base indexed with [0] at the top, then the input-to-hidden weight from input[0] to hidden[0] is 0.6100 and so on.
Similarly, the six arrows connecting the two hidden nodes to the three output nodes are hidden-to-output weights. The two small arrows pointing into the two hidden nodes are special weights called biases. Similarly, the three output nodes each have a bias value.
The first step in the neural network input-output mechanism is to compute the values of the hidden nodes. The value in each hidden node is the hyperbolic tangent of the sum of products of input values and associated weights, plus the bias. For example:
hidden[0] = tanh( (6.9)(0.6100) + (3.1)(0.7152) + (4.6)(-1.0855) + (1.3)(-1.0687) + 0.1468 ) = tanh(0.1903) = 0.1882
The value of the hidden[1] node is calculated in the same way. The hyperbolic tangent function, abbreviated tanh, is called the hidden layer activation function. The tanh function accepts any value, from negative infinity to positive infinity, and returns a value between -1.0 and +1.0. There are several choices of activation functions supported by CNTK. The three most common are tanh, logistic sigmoid and rectified linear unit (ReLU).
Computing the output node values is similar to the process used to compute hidden nodes, but a different activation function, called softmax, is used. The first step is to compute the sum of products plus bias for all three output nodes:
pre-output[0] = (0.1882)(3.2200) + (0.9999)(-0.8545) + 0.1859 = -0.0625 pre-output[1] = (0.1882)(-0.7311) + (0.9999)(0.3553) + 0.6735 = 0.8912 pre-output[2] = (0.1882)(-4.1944) + (0.9999)(0.0244) + (-0.8595) = -1.6246
The softmax value of one of a set of three values is the exp function applied to the value, divided by the sum of the exp function applied to all three values. So the final output node values are computed as:
output[0] = exp(-0.0625) / exp(-0.0625) + exp(0.8912) + exp(-1.6246) = 0.263 output[1] = exp(0.8912) / exp(-0.0625) + exp(0.8912) + exp(-1.6246) = 0.682 output[2] = exp(-1.6246) / exp(-0.0625) + exp(0.8912) + exp(-1.6246) = 0.055
The purpose of softmax is to coerce the preliminary output values so they sum to 1.0 and can be interpreted as probabilities.
OK, but where do the values of the weights and biases come from? To get the values of the weights and biases, you must train the network using a set of data that has known input values and known, correct, output values. The idea is to use an optimization algorithm that finds the values for the weights and biases that minimizes the difference between the computed output values and the correct output values.
Demo Program Structure
The overall structure of the demo program is shown in Figure 3.
Figure 3 Demo Program Structure
# iris_demo.py import cntk as C ... def my_print(arr, dec): def create_reader(path, is_training, input_dim, output_dim): def save_weights(fn, ihWeights, hBiases, hoWeights, oBiases): def do_demo(): def main(): print("\nBegin Iris demo (CNTK 2.0) \n") np.random.seed(0) do_demo() # all the work is done in do_demo() if __name__ == "__main__": main()
The demo program has a function named main that acts as an entry point. The main function sets the seed of the global random number generator to 0 so that results will be reproducible, and then calls function do_demo that does all the work.
Helper function my_print displays a numeric vector using a specified number of decimals. The point here is that CNTK is just a library, and you must mix program-defined Python code with calls to the various CNTK functions. Helper function create_reader returns a special CNTK object that can be used to read data from a data file that uses the special CTF (CNTK text format) formatting protocol.
Helper function save_weights accepts a filename, a matrix of input-to-hidden weights, an array of hidden node biases, a matrix of hidden-to-output weights, and an array of output node biases, and writes those values to a text file so they can be used by other systems.
The complete listing for the demo program, with a few minor edits, is presented in Figure 4. I use an indent of two-space characters instead of the more common four, to save space. Also, all normal error-checking code has been removed.
Figure 4 Complete Demo Program
# iris_demo.py # Anaconda 4.1.1 (Python 3.5, NumPy 1.11.1) # CNTK 2.0 RC1 # Use a one-hidden layer simple NN with 2 hidden nodes # to classify the Iris Dataset. # This version uses the built-in Reader functions and # data files that use the CTF format. # trainData_cntk.txt - 120 items (40 each class) # testData_cntk.txt - remaining 30 items import numpy as np import cntk as C from cntk import Trainer # to train the NN from cntk.learners import sgd, learning_rate_schedule, \ UnitType from cntk.ops import * # input_variable() def from cntk.logging import ProgressPrinter from cntk.initializer import glorot_uniform from cntk.layers import default_options, Dense from cntk.io import CTFDeserializer, MinibatchSource, \ StreamDef, StreamDefs, INFINITELY_REPEAT # ===== def my_print(arr, dec): # print an array of float/double with dec decimals fmt = "%." + str(dec) + "f" # like %.4f for i in range(0, len(arr)): print(fmt % arr[i] + ' ', end='') print(") def save_weights(fn, ihWeights, hBiases, hoWeights, oBiases): f = open(fn, 'w') for vals in ihWeights: for v in vals: f.write("%s\n" % v) for v in hBiases: f.write("%s\n" % v) for vals in hoWeights: for v in vals: f.write("%s\n" % v) for v in oBiases: f.write("%s\n" % v) f.close() def do_demo(): # create NN, train, test, predict input_dim = 4 hidden_dim = 2 output_dim = 3 train_file = "trainData_cntk.txt" test_file = "testData_cntk.txt" input_Var = C.ops.input(input_dim, np.float32) label_Var = C.ops.input(output_dim, np.float32)]) max_iter = 5000 # 5000 maximum training iterations batch_size = 5 # mini-batch size 5 progress_freq = 1000 # print error every n minibatches reader_train = create_reader(train_file, True, input_dim, output_dim) my_input_map = { input_Var : reader_train.streams.features, label_Var : reader_train.streams.labels } pp = ProgressPrinter(progress_freq) print("Starting training \n") for i in range(0, max_iter): currBatch = reader_train.next_minibatch(batch_size, input_map = my_input_map) trainer.train_minibatch(currBatch) pp.update_with_trainer(trainer) print("\nTraining complete") # ----------------------------------) # ---------------------------------- # make a prediction for an unknown flower # first train versicolor = 7.0,3.2,4.7,1.4,0,1,0 unknown = np.array([[6.9, 3.1, 4.6, 1.3]], dtype=np.float32) print("\nPredicting Iris species for input features: ") my_print(unknown[0], 1) # 1 decimal predicted = nnet.eval( {input_Var: unknown} ) print("Prediction is: ") my_print(predicted[0], 3) # 3 decimals # --------------------------------- print("\nTrained model input-to-hidden weights: \n") print(hLayer.hidLayer.W.value) print("\nTrained model hidden node biases: \n") print(hLayer.hidLayer.b.value) print("\nTrained model hidden-to-output weights: \n") print(oLayer.outLayer.W.value) print("\nTrained model output node biases: \n") print(oLayer.outLayer.b.value) save_weights("weights.txt", hLayer.hidLayer.W.value, hLayer.hidLayer.b.value, oLayer.outLayer.W.value, oLayer.outLayer.b.value) return 0 # success def main(): print("\nBegin Iris demo (CNTK 2.0) \n") np.random.seed(0) do_demo() # all the work is done in do_demo() if __name__ == "__main__": main() # end script -------------------------------------------------------------------
The demo program begins by importing the required Python packages and modules. I’ll describe the modules as they’re used in the demo code.
Setting Up the Data
There are two basic ways to read data for use by CNTK functions. You can format your files using the special CTF format and then use built-in CNTK reader functions, or you can use data in non-CTF format and write a custom reader function. The demo program uses the CTF data format approach. File trainData_cntk.txt looks like:
|attribs 5.1 3.5 1.4 0.2 |species 1 0 0 ... |attribs 7.0 3.2 4.7 1.4 |species 0 1 0 ... |attribs 6.9 3.1 5.4 2.1 |species 0 0 1
You specify the feature (predictor) values by using the “|” character followed by a string identifier, and the label values in the same way. You can use whatever you like for identifiers.
To create the training data, I go to the Wikipedia entry for Fisher’s Iris Data, copy and paste all 150 items into Notepad, select the first 40 of each species, and then do a bit of edit-replace. I use the leftover 10 of each species in the same way to create the testData_cntk.txt file. The create_reader function that uses the data files is defined)
You can think of this function as boilerplate for CTF files. The only thing you’ll need to edit is the string identifiers (“attribs” and “species” here) used to identify features and labels.
Creating a Neural Network
The definition of function do_demo begins with:
def do_demo(): input_dim = 4 hidden_dim = 2 output_dim = 3 train_file = "trainData_cntk.txt" test_file = "testData_cntk.txt" input_Var = C.ops.input(input_dim, np.float32) label_Var = C.ops.input(output_dim, np.float32) ...
The meanings and values of the first five variables should be clear to you. Variables input_Var and label_Var are created using the built-in function named input, located in the cntk.ops package. You can think of these variables as numeric matrices, plus some special properties needed by CNTK.
The neural network is created with these statements:
The Dense function creates a fully connected layer of nodes. You pass in the number of nodes and an activation function. The name parameter is optional in general, but is needed if you want to extract the weights and biases associated with a layer. Notice that instead of passing an array of input values for a layer into the Dense function, you append an object holding those values to the function call.
When creating a neural network layer, you should specify how the values for the associated weights and biases are initialized, using the init parameter to the Dense function. The demo initializes weights and biases using the Glorot (also called Xavier initialization) mini-algorithm implemented in function glorot_uniform. There are several alternative initialization functions in the cntk.initializer module.
The statement nnet = oLayer creates an alias for the output layer named oLayer. The idea is that the output layer represents a single layer, but also the output of the entire neural network.
Training the Neural Network
After training and test data have been set up, and a neural network has been created, the next step is to train the network. The demo program creates a trainer with these statements:])
The most common approach for measuring training error is to use what’s called cross-entropy error, also known as log loss. The main alternative to cross-entropy error for numeric problems similar to the Iris demo is the squared_error function.
After training has completed, you’re more interested in classification accuracy than in cross-entropy error—you want to know how many correct predictions the model makes. The demo uses the built-in classification_error function.
There are several optimization algorithms that can be used to minimize error during training. The most basic is called stochastic gradient descent (SGD), which is often called back-propagation. Alternative algorithms supported by CNTK include SGD with momentum, Nesterov and Adam (adaptive moment estimation).
The mini-batch form of SGD reads in one subset of the training items at a time, calculates the calculus gradients, and then updates all weights and bias values by a small increment called the learning rate. Training is often highly sensitive to the values used for the learning rate. After a CNTK trainer object has been created, the demo prepares training with these statements:
max_iter = 5000 batch_size = 5 progress_freq = 1000 reader_train = create_reader(train_file, True, input_dim, output_dim) my_input_map = { input_Var : reader_train.streams.features, label_Var : reader_train.streams.labels } pp = ProgressPrinter(progress_freq)
The SGD algorithm is iterative, so you must specify a maximum number of iterations. Note that the value for the mini-batch size should be between 1 and the number of items in the training data.
The reader object for the trainer object is created by a call to create_reader. The True argument that’s passed to create_reader tells the function that the reader is going to be used for training data rather than test data and, therefore, that the data items should be processed in random order, which is important to avoid training stagnation.
The my_input_map object is a Python two-item collection. It’s used to tell the reader object where the feature data resides (input_Var) and where the label data resides (label_Var). Although you can print whatever information you wish inside the main training loop, the built-in ProgressPrinter object is a very convenient way to monitor training. Training is performed with these statements:
print("Starting training \n") for i in range(0, max_iter): currBatch = reader_train.next_minibatch(batch_size, input_map = my_input_map) trainer.train_minibatch(currBatch) pp.update_with_trainer(trainer) print("\nTraining complete")
In each training iteration, the next_minibatch function pulls a batch (5 in the demo) of training items, and uses SGD to update the current values of weights and biases.
Testing the Network
After a neural network has been trained, you should use the trained model on the holdout test data. The idea is that given enough training time and combinations of learning rate and batch size, you can eventually get close to 100 percent accuracy on your training data. However, excessive training can over-fit and lead to a model that predicts very poorly on new data.)
The next_minibatch function examines all 30 test items at once. Notice that you can reuse the my_input_map object for the test data because the mapping to input_Var and label_Var is the same as to the training data.
Making Predictions
Ultimately, the purpose of a neural network model is to make predictions for new, previously unseen data.
unknown = np.array([[6.9, 3.1, 4.6, 1.3]], dtype=np.float32) print("\nPredicting Iris species for features: ") my_print(unknown[0], 1) # 1 decimal predicted = nnet.eval( {input_Var: unknown} ) print("Prediction is: ") my_print(predicted[0], 3) # 3 decimals
The variable named unknown is an array-of-array-style numpy matrix, which is required by a CNTK neural network. The eval function accepts input values, runs them through the trained model using the neural network input-output process and the resulting three probabilities (0.263, 0.682, 0.055) are displayed.
In some situations it’s useful to iterate through all test items and use the eval function to see exactly which items were incorrectly predicted. You can also write code that uses the numpy.argmax function to determine the largest value in the output probabilities and explicitly print “correct” or “wrong.”
Exporting Weights and Biases
The demo program concludes by fetching the trained model’s weights and biases, and then displays them to the shell, as well as saves them to a text file. The idea is that you can train a neural network using CNTK, then use the trained model weights and biases in another system, such as a C# program, to make predictions.
The weights and bias values for the hidden layer are displayed like this:
print("\nTrained model input-to-hidden weights: \n") print(hLayer.hidLayer.W.value) print("\nTrained model hidden node biases: \n") print(hLayer.hidLayer.b.value)
Recall that a CNTK network layer is a named object (hLayer), but that an optional name property was passed in when the layer was created (hidLayer). The tersely named W property of a named layer returns an array-of-arrays-style matrix holding the input-to-hidden weights. Similarly, the b property gives you the biases. The weights and biases for the output layer are obtained in the same way:
print("\nTrained model hidden-to-output weights: \n") print(oLayer.outLayer.W.value) print("\nTrained model output node biases: \n") print(oLayer.outLayer.b.value)
The values of the (4 * 2) + (2 * 3) = 14 weights, and the (2 + 3) = 5 biases, are saved to text file, and function do_demo concludes, like so:
... save_weights("weights.txt", hLayer.hidLayer.W.value, hLayer.hidLayer.b.value, oLayer.outLayer.W.value, oLayer.outLayer.b.value) return 0 # success
The program-defined save_weights function writes one value per line. The order in which the values are written (input-to-hidden weights, then hidden biases, then hidden-to-output weights, then output biases) is arbitrary, so any system that uses the values from the weights file must use the same order.
Wrapping Up
If you’re new to neural networks, the number of decisions you have to make when using CNTK might seem a bit overwhelming. You need to decide how many hidden nodes to use, pick a hidden layer activation function, a learning optimization algorithm, a training error function, a training weight-initialization algorithm, a batch size, a learning rate and a maximum number of iterations.
However, in most cases, you can use the demo program presented in this article as a template, and experiment mostly with the number of hidden nodes, the maximum number of iterations, and the learning rate. In other words, you can safely use tanh hidden layer activation, cross-entropy for training error, Glorot initialization for weights and biases, and a training mini-batch size that is roughly 5 percent to 10 percent of the number of training items. The one exception to this is that instead of using the SGD training optimization algorithm, even though it’s the most commonly used, I suggest using the Adam algorithm.
Once you become familiar with CNTK basics, you can use the library to build very powerful, advanced, deep neural network architectures such as convolutional neural networks (CNNs) for image recognition and long short-term memory recurrent neural networks (LSTM RNNs) for the analysis of natural language data. and Sayan Pathak
Discuss this article in the MSDN Magazine forum | https://docs.microsoft.com/en-us/archive/msdn-magazine/2017/july/machine-learning-introduction-to-the-microsoft-cntk-v2-0-library | CC-MAIN-2020-05 | refinedweb | 4,285 | 55.74 |
Often I find myself having a expression where a division by int is a part of a large formula. I will give you a simple example that illustrate this problem:
int a = 2;
int b = 4;
int c = 5;
int d = a * (b / c);
In this case, d equals 0 as expected, but I would like this to be 1 since 4/5 multiplied by 2 is 1 3/5 and when converted to int get's "rounded" to 1. So I find myself having to cast c to double, and then since that makes the expression a double also, casting the entire expression to int. This code looks like this:
int a = 2;
int b = 4;
int c = 5;
int d = (int)(a * (b / (double)c));
In this small example it's not that bad, but in a big formula this get's quite messy.
Also, I guess that casting will take a (small) hit on performance.
So my question is basically if there is any better approach to this than casting both divisor and result.
I know that in this example, changing a*(b/c) to (a*b)/c would solve the problem, but in larger real-life scenarios, making this change will not be possible.
EDIT (added a case from an existing program):
In this case I'm caclulating the position of a scrollbar according to the size of the scrollbar, and the size of it's container. So if there is double the elements to fit on the page, the scrollbar will be half the height of the container, and if we have scrolled through half of the elements possible, that means that the scroller position should be moved 1/4 down so it will reside in the middle of the container. The calculations work as they should, and it displays fine. I just don't like how the expression looks in my code.
The important parts of the code is put and appended here:
int scrollerheight = (menusize.Height * menusize.Height) / originalheight;
int maxofset = originalheight - menusize.Height;
int scrollerposition = (int)((menusize.Height - scrollerheight) * (_overlayofset / (double)maxofset));
originalheight here is the height of all elements, so in the case described above, this will be the double of menusize.Height.
First of all, C# truncates the result of int division, and when casting to int. There's no rounding.
There's no way to do
b / c first without any conversions.
Disclaimer: I typed all this out, and then I thought, Should I even post this? I mean, it's a pretty bad idea and therefore doesn't really help the OP... In the end I figured, hey, I already typed it all out; I might as well go ahead and click "Post Your Answer." Even though it's a "bad" idea, it's kind of interesting (to me, anyway). So maybe you'll benefit in some strange way by reading it.
For some reason I have a suspicion the above disclaimer's not going to protect me from downvotes, though...
I would actually not recommend putting this into any sort of production environment, at all, because I literally thought of it just now, which means I haven't really thought it through completely, and I'm sure there are about a billion problems with it. It's just an idea.
But the basic concept is to create a type that can be used for arithmetic expressions, internally using a
double for every term in the expression, only to be evaluated as the desired type (in this case:
int) at the end.
You'd start with a type like this:
// Probably you'd make this implement IEquatable<Term>, IEquatable<double>, etc. // Probably you'd also give it a more descriptive, less ambiguous name. // Probably you also just flat-out wouldn't use it at all. struct Term { readonly double _value; internal Term(double value) { _value = value; } public override bool Equals(object obj) { // You would want to override this, of course... } public override int GetHashCode() { // ...as well as this... return _value.GetHashCode(); } public override string ToString() { // ...as well as this. return _value.ToString(); } }
Then you'd define
implicit conversions to/from
double and the type(s) you want to support (again:
int). Like this:
public static implicit operator Term(int x) { return new Term((double)x); } public static implicit operator int(Term x) { return (int)x._value; } // ...and so on.
Next, define the operations themselves:
Plus,
Minus, etc. In the case of your example code, we'd need
Times (for
*) and
DividedBy (for
/):
public Term Times(Term multiplier) { // This would work because you would've defined an implicit conversion // from double to Term. return _value * multiplier._value; } public Term DividedBy(Term divisor) { // Same as above. return _value / divisor._value; }
Lastly, write a
static helper class to enable you to perform
Term-based operations on whatever types you want to work with (probably just
int for starters):
public static class TermHelper { public static Term Times(this int number, Term multiplier) { return ((Term)number).Times(multiplier); } public static Term DividedBy(this int number, Term divisor) { return ((Term)number).DividedBy(divisor); } }
What would all of this buy you? Practically nothing! But it would clean up your expressions, hiding away all those unsightly explicit casts, making your code significantly more attractive and considerably more impossible to debug. (Once again, this is not an endorsement, just a crazy-ass idea.)
So instead of this:
int d = (int)(a * (b / (double)c)); // Output: 2
You'd have this:
int d = a.Times(b.DividedBy(c)); // Output: 2
Well, if having to write casting operations were the worst thing in the world, like, even worse than relying on code that's too clever for its own good, then maybe a solution like this would be worth pursuing.
Since the above is clearly not true... the answer is a pretty emphatic NO. But I just thought I'd share this idea anyway, to show that such a thing is (maybe) possible.
Multiply b times 100. Then divide by 100 at the end.
In this case, I would suggest Using
double instead, because you don't need 'exact' precision.
However, if you really feel you want to do it all without floating-point operation, I would suggest creating some kind of fraction class, which is far more complex and less efficient but you can keep track of all dividend and divisor and then calculate it all at once. | http://www.dlxedu.com/askdetail/3/302820d3a2c1a4bde0fa2fa486ff913c.html | CC-MAIN-2018-47 | refinedweb | 1,070 | 62.27 |
5D III Cinema DNG not importing correctlyloopyumpa Oct 31, 2013 7:05 PM
When I import 5D III cinemadng's into Premiere 7.1, the footage comes in with a weird pink overlay. It's not just a tint shift, but some sort of color distortion. After Effects and Photoshop both read the file just fine via Camera Raw. Is anyone else having this issue or know any solution?
1. Re: 5D III Cinema DNG not importing correctlyJim_Simon Oct 31, 2013 7:11 PM (in response to loopyumpa)
Are you sure it's CinemaDNG? I don't think DNG used for stills is the same just because you have 24 of them every second.
2. Re: 5D III Cinema DNG not importing correctlyloopyumpa Oct 31, 2013 7:20 PM (in response to Jim_Simon)
Yes they are. I've used other conversion programs (Raw2DNG and Son of Batch) that create only normal DNGs. Those cannot be imported into Premiere. The CinemaDNGs I have are created from RareVision's RAWMagic, and they are importing and playing smoothly in Premiere, just with the pink overlay. I've imported Black Magic DNGs and they work fine.
3. Re: 5D III Cinema DNG not importing correctlyJim_Simon Oct 31, 2013 7:33 PM (in response to loopyumpa)
That would suggest the conversion software is doing something wrong. You're the second user to report an issue using it.
4. Re: 5D III Cinema DNG not importing correctlyloopyumpa Oct 31, 2013 7:48 PM (in response to Jim_Simon)
DaVinci Resolve reads them fine, so they can be read by a NLE, and Camera RAW reads them correctly. I just wish that instead of changing the conversion software, Adobe had created their importer correctly since it seems it can be done. It's unfortunate that Adobe has been so behind DaVinci Resolve in this area.
5. Re: 5D III Cinema DNG not importing correctlyJim_Simon Oct 31, 2013 8:22 PM (in response to loopyumpa)
Definitely. Premiere Pro and After Effects should have been two of the very first programs to fully support CinemaDNG. I mean, it's an Adobe-led initiative for gooness sake.
6. Re: 5D III Cinema DNG not importing correctlySpaceCherryFilms Oct 31, 2013 9:31 PM (in response to loopyumpa)
I have the exact same problem. Resolve/After Effects/Photoshop have no problems reading the Cinema DNG file but for some reason Premiere Pro CC gives the Cinema DNG a pink overlay.
7. Re: 5D III Cinema DNG not importing correctlyBob Ramage Oct 31, 2013 9:40 PM (in response to loopyumpa)
Yes, same issue for me using raw footage from the Canon 5d Mk III converted to Cinema DNG using RAWMagic: heavy pink tinting. I'm pretty impressed that I can play the Cinema DNG files smoothly and easily perform normal edits, but the pink overlay makes it unusable. Might be okay for an offline editing workflow using Resolve, although the pink overlay makes it difficult to see what you're working with. I'd be curious to know why Premiere isn't interpreting the colour information in the RAWMagic Cinema DNG files correctly, and whether or not the same issue occurs with CinemaDNG files from other cameras. Early days yet and the smooth playback is a good start.
8. Re: 5D III Cinema DNG not importing correctlyloopyumpa Oct 31, 2013 9:58 PM (in response to Bob Ramage)
I would hate to have to go through another program though. I was really excited about keeping everything contained within Adobe and giving Speedgrade a shot (now that the workflow is finally usable), but you're right, the pink is totally unusable. I just tried correcting it in Speedgrade. Impossible. It's just not reading it right. Sad that I'm considering switching altogether if Resolve can improve their editing features. I'm shooting mostly 5D III RAW at this point and Adobe can't find a way to support it when other companies can. Really hope this gets fixed soon, but seeing how long we've already waited for CinemaDNG support.......
9. Re: 5D III Cinema DNG not importing correctlySpaceCherryFilms Oct 31, 2013 10:00 PM (in response to loopyumpa)
What makes this even worst is Adobe CREATED CinemaDNG and it doesn't work correctly. Sad. Just sad.
10. Re: 5D III Cinema DNG not importing correctlynpfilms Oct 31, 2013 10:09 PM (in response to loopyumpa)
Cinema DNG is also not working correctly for me. Similiar to what others have described, I'm seeing a strong pink cast on all clips. They work fine when used with davinci resolve. What is the most effective way to report this to Adobe in the hopes of a possible patch?
11. Re: 5D III Cinema DNG not importing correctlyloopyumpa Oct 31, 2013 10:12 PM (in response to npfilms)
Hoping this thread gets enough attention for a staff member to get involved. I'm not sure how much good that will do, but other than that there is a feature request form.
12. Re: 5D III Cinema DNG not importing correctlynpfilms Oct 31, 2013 10:33 PM (in response to loopyumpa)
I would recommend as many people as possible reporting this as a bug using this link:
Select 'report bug' and submit.
13. Re: 5D III Cinema DNG not importing correctlyloopyumpa Oct 31, 2013 10:52 PM (in response to npfilms)
Agreed. Also, it's being discussed here and here
I guess open source will just have to do what large companies won't again.
14. Re: 5D III Cinema DNG not importing correctlyrejdmast1 Oct 31, 2013 11:16 PM (in response to loopyumpa)
I imported some .dng files from a Blackmagic camera and they are fine.
15. Re: 5D III Cinema DNG not importing correctlynpfilms Oct 31, 2013 11:29 PM (in response to rejdmast1)
As the thread implies the problem is with the 5D Mark III and not with the BMC. The problem is with Cinema DNG files that were converted from Magic Lantern RAW. Resolve suffered from a similar problem early on that was described as 'pink fringing' in the highlights. This problem was addressed with the release of resolve 10.
There has to be a way to help adobe specify the color space or determine white balance similar to what is done with the AE workflow.
16. Re: 5D III Cinema DNG not importing correctlyloopyumpa Oct 31, 2013 11:46 PM (in response to npfilms)
I talked with tech support on the phone and he had me Dropbox him a frame so he could take a look at it. I don't know when I'll hear back or if I will, but it's a start.
17. Re: 5D III Cinema DNG not importing correctlySteveHoeg
Nov 1, 2013 6:54 AM (in response to loopyumpa)
The Canon 5D MKIII doesn't make CinemaDNG files, these are specifically from MagicLantern. CinemaDNG is a huge spec, we targeted getting the colours correct from the BlackMagic camera first.
18. Re: 5D III Cinema DNG not importing correctlynpfilms Nov 1, 2013 8:01 AM (in response to SteveHoeg)
The problem seems to be with how the DNG is interpreted in Premiere, may not be isolated to the RAW files that are converted to Cinema DNG as you explained. Take a look at this article under the bad news. It may be really helpful in making this DNG support usable. Because as stated in the article, we are not beta testers, we are paying customers and as such we reasonably expect a lot more. -support-tried-tested
19. Re: 5D III Cinema DNG not importing correctlyAndy T2
Nov 1, 2013 9:30 AM (in response to loopyumpa)1 person found this helpful
To be very clear, for this 7.1 release, we are only supporting CinemaDNG media from the Blackmagic Camera. No other format is being supported at this time. The pink overlay problem with DNG derived from Canon RAW media is a known issue.
We are currently in discussions of how to expand our CinemaDNG support going forward, and user input is a vital factor. Nonetheless, Premiere support for the CinemaDNG format is different from the support in other Adobe applications. For more on this, see the section "Enhanced BlackMagic Cinema Camera support" at this link:
-- Andy
-- Premiere Pro Team
20. Re: 5D III Cinema DNG not importing correctlySpaceCherryFilms Nov 1, 2013 9:32 AM (in response to Andy T2)
thanks for clarification and acknowledging the problem.
21. Re: 5D III Cinema DNG not importing correctlyloopyumpa Nov 1, 2013 10:01 AM (in response to Andy T2)
Thank you for the updated information, although I do wish that Adobe had made it clear at the time of the update announcement that CinemaDNG support would only be for the BMCC. I've heard other cameras, such as the KineRAW which shoots CinemaDNG, are not handled correctly either. Still, thank you for pushing this initiative forward, and I'm hoping that Adobe can keep up with the chaning industry and provide full support for all forms of Cinema DNG like Davinci Resolve has found a way to do.
22. Re: 5D III Cinema DNG not importing correctlySupermalex Nov 2, 2013 6:04 AM (in response to loopyumpa)
Hi, I'm another magic lantern user making DNG from my 5D3, and I got myself premiere and speedgrade because of DNG support... and I'm kind of disapointed now that this support is only for 1 camera... it's weird, but we'll be patient hoping that you support 5D3 DNG files one day...
Meanwhile, I'll have to switch to Davinci resolve 10 which can do editing now.
Magic lantern users are a huge community, so it wouldn't be a smart move not to support us, For many of us working with premiere and switching to speedgrade was gonna be a perfect raw workflow.
23. Re: 5D III Cinema DNG not importing correctlychmee Dec 5, 2013 2:43 PM (in response to Supermalex)
just to push this Thread and make it more vital.. It's really a pitty, that Adobe as Inventor of a "universal" picture-format can't cope with its own idea.
Suggestions:
(A) Use the (cinema)DNG-Attributes as they're written into the tif(dng) header.
(B) Give a Interface/Translator for color-matrices.
As its working fairly good in Speedgrade (but sadly not to link it from there to premiere), i state the dng-Importer in Premiere as Beta-Codeproof working merely with BMCC-Files. I dont want to squeeze/recalculate the magiclantern-raws to bmcc-like data - cdng-import cant deliver, what was promised with the idea of dng - by now
regards chmee
24. Re: 5D III Cinema DNG not importing correctlyironmountainfilms Jan 13, 2014 5:57 PM (in response to SteveHoeg)
Are you folks aware that the Rawmagic CDNG files work flawlessly in AE and photoshop ACR and look completely correct? They do not however open correctly in PPro or SG. Is this because of RGB to YUV conversion? AE being 100% RGB.
25. Re: 5D III Cinema DNG not importing correctlychmee Jan 15, 2014 6:04 AM (in response to ironmountainfilms)
Every Import via ACR is read correctly because of translation to rgb-data. Premiere only works accordingly with Blackmagic-data-structure (12bit log with delinearizationcurve), Speedgrade is able to convert to xyz with according color/translation-matrix.
Delinearization Curve -
Speedgrade Handling (look-file) -
regards chmee
26. Re: 5D III Cinema DNG not importing correctlywat d hell editor Jan 22, 2014 12:52 AM (in response to loopyumpa)
Hey Guys, i think i found a work Around to the Pink Cast!
I imported CDNG's in to AE used the ACR plugin then Saved project as
a CS6 AE project then, Start a new project in Premiere Pro CC
import the AE CS6 project , its links to the original cdng's
And import with the ACR adjustments with no pink cast.
But if you try and send your AE project to premiere the cdng's will
have the pink cast.
So when you save as a "CS6" project in AE you can continue on to edit etc..
I did this test on my PC, i have not tried it on the MAC.
Can someone confirm this workaround please
27. Re: 5D III Cinema DNG not importing correctlychmee Feb 9, 2014 12:55 PM (in response to loopyumpa)
i think, i found a "recalculated way". 12bit linear with debiased blacklevel works quite good - i just coded the audio-convertion from mlv today. so take a look at raw2cdng 1.4.9 (raw&mlv)
regards chmee
28. Re: 5D III Cinema DNG not importing correctlyAtonMusic Apr 15, 2014 1:40 PM (in response to loopyumpa)
Try sending to Speedgrade via DirectLink. Then save the SG Project and re-open in PPRO - that should take care of the problem...
To Adobe... It is a real embarrassment that you cannot read a format developed by yourself !!!
SG and PPRO both... This is simply put - a total embarrassment
You develop a so-called UNIFIED RAW format so that this RAW world is less complicated. But then you write RED and ARRI specific RAW decoders with access to Metadata (NEEDED for RAW) ---
The CinemaDNG Implementation in PPRO doesn't spark ONE access to ANY metadata... Even with Black Magic cDNGs... No Exposure, No WB no NOTHING !!!
As I mentioned - this is totally embarrassing - for the INVENTOR of the format - PERIOD !
29. Re: 5D III Cinema DNG not importing correctlySupermalex Apr 15, 2014 2:47 PM (in response to AtonMusic)
I'm sure it would be easy for them to sumon ACR stuff in premiere just like with after effects. They must have some reasons not to do it... Maybe it's Canon who is paying them to hold on full CDNG support so that life isn't too easy for us magic lantern users! :O
30. Re: 5D III Cinema DNG not importing correctlyrejdmast1 Apr 15, 2014 2:55 PM (in response to Supermalex)
Adobe is suppose to have a fix for Convergent Design's Odyssey 7's version of Cinema DNG in the next release. Hopefully, Adobe will process DNG's files the same in all applications with the next upgrade.
31. Re: 5D III Cinema DNG not importing correctlychmee Apr 15, 2014 3:22 PM (in response to rejdmast1)
be patient, it will be better but, acr is NOT the way to go. its much too slow. how do you want to edit, if you have to wait for godot? a quite good idea would be a video-effect with some basic highlight- and shadow recovery.
32. Re: 5D III Cinema DNG not importing correctlyBjoernHolmer May 18, 2014 2:23 PM (in response to SteveHoeg)
Another half a year has gone by, and the problem is still unresolved. Given the ratio of 5D users versus BM users out there, and the ever ongoing migration to Raw, it is starting to get silly that this issue is still unresolved by Adobe. Do I really have to switch to Da Vinci Resolve? I don't want to, but Adobe seem hell bent on forcing me to. Surely this cannot be such a huge problem to fix when, again, it's been working just fine in Resolve since like forever.
Kind regards,
Paying customer
33. Re: 5D III Cinema DNG not importing correctlyThomas Worth May 18, 2014 11:06 PM (in response to BjoernHolmer)
RAWMagic 1.1 writes 12 bit CinemaDNG files that both look correct and play properly in Premiere CC. If your MLV file contains audio, the audio will work as well.
34. Re: 5D III Cinema DNG not importing correctlyAtonMusic May 19, 2014 1:49 AM (in response to Thomas Worth)
Why truncate a perfectly good 14bit signal to 12bit ?
35. Re: 5D III Cinema DNG not importing correctlyThomas Worth May 19, 2014 7:03 PM (in response to AtonMusic)
Because CinemaDNG only supports 12 and 16 bit files, and Premiere currently only works properly with 12 bit CinemaDNG files. RAWMagic can write 16 bit DNGs as well, but they don't work with Premiere.
36. Re: 5D III Cinema DNG not importing correctlyThomas Worth May 22, 2014 11:09 AM (in response to Thomas Worth)
Just for clarification: what I should have said was Premiere supports 12 and 16 bit CinemaDNG files, but only 12 bit ones render properly.
37. Re: 5D III Cinema DNG not importing correctlynpfilms Jun 19, 2014 1:30 PM (in response to loopyumpa)
Premiere Pro CC 2014 now plays these Cinema DNG folders without the pink shift - looks great and no hiccups in playback using my iMac late 2013. (some magenta colors in overexposed areas only)
38. Re: 5D III Cinema DNG not importing correctlyBasem87 Oct 5, 2014 1:24 PM (in response to loopyumpa)
Hi all
I know this is too old now, but wanted to post what solved the same problem for me (the pink overlay)
In the RAWMAGIC app I set everything to 'AutoDetect' and it worked, I guess the problem was with the 'black level', it should be 'autodetect' unless you know what u r doing
39. Re: 5D III Cinema DNG not importing correctlyxaviermmmac Feb 4, 2015 10:34 AM (in response to Basem87)
Never too old! You just made my day! | https://forums.adobe.com/thread/1326153 | CC-MAIN-2017-22 | refinedweb | 2,890 | 59.03 |
This recipe provides an easy-to-use, decorator-based solution to the problem of using functions from other languages, especially C, in Python. It takes advantage of Python's new annotations to provide simple type checking and automatic conversion. If you like it, you may also want to check out my C structure decorator
How To Use It
Let's say I want to wrap a C function with the following signature
int process_foo(int bar);
from libfoo.so. Using this decorator, I could simply write the following Python:
>>> @C_function("libfoo.so") ... def process_foo(bar: "int") -> "int" : ... return process_foo.c_function(bar) ...
I could then call that just as I would any other Python function:
>>> process_foo(5) 7
It also works with pointers- simply prefix the type with a *- and allows you to add types via C_function.register_type.
That's a really nice snippet!
@david: thanks! I'm working on a similar one for structs/classes using the new class decorators- stay tuned!
To avoid namespace vagaries in looking up "process_foo", a variant might be to make the first argument the C function, or else simply throw the original function away entirely (i.e return "function" from the decorator rather than "f". Nice example of using function annotations effectively, though. | https://code.activestate.com/recipes/576731-c-function-decorator/ | CC-MAIN-2022-05 | refinedweb | 209 | 53.81 |
only just found out that i could and how to execute python code on my server, and only just found out i can execute python code in the terminal app in os x; all you've got to do is type python, and you're away.
anyway, just dipping my toes into python... what is python good and bad for? (i know the syntax is nice and clean). would you use it instead of php for example to do webpages with a bit of functionality? or not? also i have to put the python code file into the cgi-bin folder with a file extension of cgi then call it from browser to run it. if i wanted to use python like php, for webpages etc., how would the python file be called? i don't want urls xyz.com/cgi-bin/whatever.cgi. how's that usually handled? or do you not usually use python as a replacement for php, only use it in particular situations? if so, what kind of situations?
thanks.
Well, first of all, you should never have urls with .cgi no matter what your backend language.
If you're running Apache you might want to check out mod_python which is basically a replacement for cgi (which is slow).
The reason you would switch from PHP to Python might be if you liked Python more. Python is not a language that tries to be the fastest (pythonistas do not seek excessive optimisation), so you'll want other reasons like coding style, the extensive Python libraries (one of Python's strong points, like Perl's CPAN), or maybe because something else you're using is coded in Python (Gimp for example allows users to write their own Gimp scripts in Python).
So far as I know, you can choose to run an entire site on Python just as with any other popular backend language, so it can replace PHP if you want.
> Well, first of all, you should never have urls with .cgi no matter what your backend language.
right, i'm just messing round at the moment though. just running a hello world script to see it work.
> If you're running Apache you might want to check out mod_python which is basically a replacement for cgi (which is slow).
would that appear in the phpinfo() output if it were installed/avaliable? i guess so. i'm using a shared hosting set up.
i see right, thanks.
anyway, just dipping my toes into python... what is python good and bad for?
python is a general purpose programming language, which can be used to do anything. Because of it's clean syntax, great libraries, and the numerous python books (many recently published), I highly recommend python. Famously, google hired the top python gurus to work for them because google uses python extensively in house.
would you use it instead of php for example to do webpages with a bit of functionality?
Yes. In addition, there are also python 'frameworks' available for more complex websites.
if i wanted to use python like php, for webpages etc., how would the python file be called?
I think it depends on the server. For instance, with Apache set up for local development on my pc (which is something everyone should have set up), the url I use to run a python script that uses cgi (cgi is used to communicate with the server) is:
Here is the script:
#!/usr/bin/env python
import cgitb; cgitb.enable()
print "Content-type: text/html"
print
print "<h1>Hello World</h1>"
1) You need a 'shebang' line at the top of myprog.py.
2) You need to change the permissions for the file myprog.py to give everyone execute privileges, e.g.
$ chmod a+x myprog.py
3) Put the file in the cgi-bin directory on the server, e.g. /Library/Apache2/cgi-bin
i don't want urls xyz.com/cgi-bin/whatever.cgi. how's that usually handled?
Servers, like Apache, allow you to map fake urls like:
to real urls like:
In addition, python frameworks provide additional ways to map urls, an example is here:
Setting up mod_python and figuring out how to call scripts is a bit of a pain, but if your host already has it setup, it is well worth learning. If you are going to use mod_python on your host, then you should bite the bullet and set it up for local development on your pc, too.
Python is not a language that tries to be the fastest (pythonistas do not seek excessive optimisation)
That isn't true. python is a language that has been developed with an eye on the speedometer. All the 'p' languages along with ruby, compete for users--and speed is a major selling point. Furthermore, python allows you to identify bottlenecks in your code, so that you can opt to rewrite those portions in an even speedier language like C\C++, and then call those functions from your python program. In addition, on discussion forums the efficiency of various solutions is always discussed.
ruby is the language that plays down optimizations/speed--presumably because it can't compete with python's speed, so the rubyist's fall back motto is: if you need speed, you probably don't, but if you really do, then write the code in C--not ruby. There are plenty of speed tests posted around the internet, so you can decide for yourself where python stands.
Because sitepoint puts no effort into any language except php, the best python discussion forum resides here:
Maybe my impressions of Python not trying to be the fastest was based on old speed tests between Python and PHP in the cgi area (I read them years ago), and some once-popular retorts from the Python camp ("python should be good enough, otherwise look for bottlenecks in code"). I've heard of the "freezing" you can do with code but I don't know how it differs from something like mod_perl where all your modules get pre-compiled anyway.
Ruby is of course known for being slow, even when it isn't. The Fail Whale is burnt into our minds too.
So, maybe my impressions of Python are old. Initially the community was not trying to be the fastest. They wanted their code to be the cleanest, the easiest to work with, and focussed on the extensive libraries to make a ready-made Python solution to whatever problem you came across.
If I hadn't already had Perl on the table as the planned First Backend Language, I might have chosen Python. It's a nice language. It's unfortunate that PHP dominates everything, but that's my opinion too.
> Maybe my impressions of Python not trying to be the fastest was based on old speed tests between Python and PHP in the cgi area (I read them years ago)
cgi, regardless of which language is being run, is slow though itsn't it? it creates a new process for each run (possibly, could be wrong there). fast cgi which is what php makes use of i think avoids creating a new process each time, i think. could easily be talking total rubbish there.
anyway, thanks both for all the info there. very useful.
i found this which i haven't read yet about using python on a webserver:
thanks
The python docs you linked don't recommend mod_python, so I would pay attention to that and disregard what I said above. The docs recommend something called WSGI if you are writing new programs.
cgi, regardless of which language is being run, is slow though itsn't it? it creates a new process for each run (possibly, could be wrong there)
Yes, this is actually where Perl first got its reputation for being slow, since In The Beginning...Perl was CGI in many people's minds. And it had that very problem, everything being started up again every single time.
fastCGI was one solution to that, but that got superceded by mod_perl, which is what PHP ended up doing too (mod_php) where your modules and stuff are pre-compiled... mod_perl was made specifically to work excellently with Apache so you could have just everything get going on startup and that was it... everything just kept running.
The python docs you linked don't recommend mod_python, so I would pay attention to that and disregard what I said above. The docs recommend something called WSGI if you are writing new programs.
Yeah the pages I found mentioning mod_python mentioned it being a bit hard to get going with Apache and also people who use 3rd-party hosters may have problems too. I did see something about "mod_wsgi" but hadn't read further into it. I don't know how it compares to the Python Server Pages that mod_python uses.
Obviously if the OP has 3rd-party hosting then the hoster gets to determine a lot. Or if the server isn't Apache.
my server is apache.
right so basically i'd have to ask the people/company who run my server if WSGI is possible. if not i'm stuck with putting things in cgi-bin and possibly url rewriting. or go to another hosting company who do offer WSGI.
ok, thanks.
url writing is pretty much a separate thing, and it's recommended you do it anyway... supposedly, not letting people see what language you use behind your site is safer, or just a Smart Thing To Do. So even if you ran PHP, Perl, whatever... you're going to want to use mod_rewrite and there's a module for dealing with rewriting to a script who builds a page (scriptAlias), and those are just Apache, regardless of chosen back-end language.
Anyway, hope you enjoy Python! Hook up with the Python community while you're at it. A language with a good community is nice.
> url writing is pretty much a separate thing
right, but it takes on bit more of a prominant/necessary role if/while having to put pythonsourcecodefile.cgi in the cgi-bin folder.
yup, i've always been a big fan of url rewriting to make urls as human as possible. not for any security reason but ease of use for the user. and more aesthetically pleasing (for me anyway)
> Anyway, hope you enjoy Python!
yup, thanks, i quite fancy it. know next to nothing about it at the moment apart from: it has a clean/simple syntax, it's object oriented, and can be used like php given a bit of preliminary set up. am in the process of starting a new project, kind of cms, so am thinking of python for that.
looks like my hosting company can and will set up WSGI for me. not done and dusted yet but looks like it.
great, thanks. | https://www.sitepoint.com/community/t/python-just-getting-toes-wet-pros-cons/96229 | CC-MAIN-2017-09 | refinedweb | 1,820 | 72.05 |
Search...
FAQs
Subscribe
Pie
FAQs
Recent topics
Flagged topics
Hot topics
Best topics
Search...
Search within Swing / AWT / SWT:
Swing / AWT / SWT
painting a custom JComponent on a JLayeredPane
alex schulze
Greenhorn
Posts: 7
posted 12 years ago
Number of slices to send:
Optional 'thank-you' note:
Send
EDIT: this is an edited version of the original post since that was probably a bit too much at once... i'll try to keep it a bit simpler now to hopefully get an answer...
dear javaranch community,
i have found this place a valueable source of information then and when and finally signed up to discuss an issue i'm not really sure about.
i have the OpenJDK Runtime Environment (build 1.6.0_0-b11) installed, my OS is Ubuntu-Linux.
the scenario is as follows:
i want to display a number of lines and some filled rectangles on a panel. all of these objects can possibly overlap and the z-order (or stacking order) is important.
i found that when i draw onto a normal JPanel, its not entirely reliable that the last painted object is also displayed on top so i found JLayeredPane might be useful for what i am trying to achieve. since i wan't full control over where my lines and rectangles appear, i use a null-layout (no layout-manager).
it took some time until i found out, that my custom JComponents won't get painted unless i call setSize() with values > 0 before.
further, when i set my custom JComponent to lets say a size of 50x50, it seems i can only use draw commands within the area of (0,0) and (50,50), everything outside this area won't get displayed.
so unless line 29 on SimpleLine is commented in, no lines are visible and since there is no output on the console, paintComponent() is probably never called.
:?: can anybody please tell me whats happening here or confirm this behaviour?
here is a code example, the controlling class:
package custJComponentDrawingSimple; import javax.swing.JFrame; import javax.swing.JLayeredPane; import java.awt.Color; public class CJCD { private static JFrame frm; private static JLayeredPane lpnl; protected static int pnlw, pnlh; // the inner dimensions of the panel (without windowborders) public static void main(String[] args) { // main window settings CJCD.frm = new JFrame( "custJComponentDrawingTest" ); CJCD.frm.setDefaultCloseOperation( JFrame.EXIT_ON_CLOSE ); CJCD.frm.setSize( 400, 400 ); CJCD.frm.setResizable(false); CJCD.frm.setLayout(null); CJCD.frm.setVisible( true ); // determine inner size of window CJCD.pnlw = CJCD.frm.getContentPane().getWidth(); CJCD.pnlh = CJCD.frm.getContentPane().getHeight(); // SimpleLines will be stacked in a layered pane CJCD.lpnl = new JLayeredPane(); // set panes size to main windows inner size CJCD.lpnl.setSize( CJCD.pnlw, CJCD.pnlh ); CJCD.lpnl.setOpaque(true); CJCD.lpnl.setBackground(new Color(31, 31, 31)); CJCD.lpnl.setVisible(true); CJCD.frm.add(CJCD.lpnl); // add lpnl to frame // add some test-lines SimpleLine cSL1, cSL2; cSL1 = new SimpleLine(1, 10, 10, 360, 360); CJCD.lpnl.add(cSL1, 1); // this doesn't help cSL1.setVisible(true); cSL1.repaint(); // explicitly request repaint of the component cSL2 = new SimpleLine(2, 80, 300, 380 , 10); CJCD.lpnl.add(cSL2, 2); CJCD.lpnl.repaint(); // explicitly request repaint of the container } }
and my JComponent:
package custJComponentDrawingSimple; import java.awt.Color; import java.awt.Graphics; import java.awt.Graphics2D; import java.awt.BasicStroke; import javax.swing.JComponent; public class SimpleLine extends JComponent { private int id, xstart, ystart, xend, yend; private static Color basecolor = new Color(159, 31, 31, 255); private static BasicStroke str = new BasicStroke(2 , BasicStroke.CAP_ROUND, BasicStroke.JOIN_MITER); // constructor public SimpleLine( int id, int xstart, int ystart, int xend, int yend ) { this.id = id; this.setNewCoords(xstart, ystart, xend, yend); } // the line should get changed through this method public void setNewCoords(int xstart, int ystart, int xend, int yend) { this.xstart = xstart; this.ystart = ystart; this.xend = xend; this.yend = yend; // comment in the line below to make the lines appear // this.setSize(Math.max(this.xstart, this.xend), Math.max(this.ystart, this.yend)); } @Override public void paintComponent(Graphics g) { super.paintComponent(g); Graphics2D g2d = (Graphics2D) g; g2d.setColor(SimpleLine.basecolor); g2d.setStroke(SimpleLine.str); g2d.drawLine( this.xstart, this.ystart, this.xend, this.yend ); System.out.println("SimpleLine #"+this.id+" values are (" +this.xstart+","+this.ystart+") to (" +this.xend+","+this.yend+") ."); } }
note that both classes are in a package called 'custJComponentDrawingSimple', so to run the code, you'd need to put the two files into a folder named like the package and call 'javac custJComponentDrawingSimple/*.java' to compile and '
java
custJComponentDrawingSimple.CJCD' to run the compiled code.
thanks a lot,
alex
alex schulze
Greenhorn
Posts: 7
posted 12 years ago
Number of slices to send:
Optional 'thank-you' note:
Send
oh right, i could of course set the size of the component to the visible area of the parent container, but i noticed that this seriously impacts the drawing performance of my application. i guess that is because the whole area is considered as dirty region and redrawn on the next update no matter if necessary or not. and i guess its not quite the way this was meant to be used...
alex schulze
Greenhorn
Posts: 7
posted 12 years ago
Number of slices to send:
Optional 'thank-you' note:
Send
well, i finally found the reason why these issues were happening the way i described scattered over some threads on
sun-forums
:
it has to do with the null-layout manager. with a layout manager, one would use setPreferredSize and set the components size. the layout manager then would determine the display-size according to its rules and call setSize as well as the location and call setLocation on that component.
when java2d finally renders the component it relies on the values set through these methods.
if there is no layout-manager (and this is what null-layout means), the size and location is not set, so the default values of (0,0) for components and (10,10) for JPanels are used!
in this case, calling setPreferredSize() would of course have no effect because there is nobody who takes care of the preferred values.
oh right, note that setBounds( ... ) does the same as calling setSize and setLocation, just within one single call.
alex schulze
Greenhorn
Posts: 7
posted 12 years ago
Number of slices to send:
Optional 'thank-you' note:
Send
one more think if ever someone may stumble over this
thread
trying to do the same:
this was the entirely wrong approach for what i wanted to do and its rendering is far too slow!
i luckily came across a wonderful book that covers plenty java-graphics issues in-depth,
the title sounds not like it would be very helpful but in fact it turned out as a great resource.
the book is called 'filthy rich clients', was written by Chet Haase and Romain Guy
and can be obtained through
.
my solution in short: don't misuse custom jcomponents as graphical objects put into a jlayeredpanel,
use bufferedImages and draw them to a bufferedimage instead, but make sure to get ito java2d and the like.
(one more time: this book helped me a lot with this!)
greez - alex
I'm THIS CLOSE to ruling the world! Right after reading this tiny ad:
the value of filler advertising in 2021
reply
reply
Bookmark Topic
Watch Topic
New Topic
Boost this thread!
Similar Threads
Converting a two dimensional int array into a byte array
Problem checking condition in a loop
JDesktopPane Graphics
How to draw straight line instead of curved line??
Array Testing Output Confusion
More... | https://coderanch.com/t/425740/java/painting-custom-JComponent-JLayeredPane | CC-MAIN-2021-10 | refinedweb | 1,263 | 54.83 |
AudioPlayerSwift alternatives and similar libraries
Based on the "Audio" category
AudioKit9.8 8.9 L2 AudioPlayerSwift VS AudioKitPowerful audio synthesis, processing and analysis, without the steep learning curve.
SwiftySound7.0 3.0 L5 AudioPlayerSwift VS SwiftySoundSwifty Sound is a simple library that lets you play sounds with a single line of code.
AudioPlayer6.5 0.8 L3 AudioPlayerSwift VS AudioPlayerA wrapper around AVPlayer with some cool features.
Beethoven6.2 0.0 L4 AudioPlayerSwift VS BeethovenAn audio processing Swift library for pitch detection of musical signals.
MusicKit5.8 0.0 L4 AudioPlayerSwift VS MusicKitA framework for composing and transforming music in Swift.
voice-overlay-iosAn overlay that gets your user’s voice permission and input as text in a customizable UI.
TuningFork5.0 0.0 L5 AudioPlayerSwift VS TuningForkA Simple Tuner for iOS.
ModernAVPlayerPersistence AVPlayer to resume playback after bad network connection even in background mode.
SwiftAudioPlayerSimple audio player for iOS that streams and performs realtime audio manipulations with AVAudioEngine.
Soundable2.0 0.0 AudioPlayerSwift VS SoundableSoundable allows you to play sounds, single and in sequence, in a very easy way.
* Code Quality Rankings and insights are calculated and provided by Lumnify.
They vary from L1 to L5 with "L5" being the highest. Visit our partner's website for more details.
Do you think we are missing an alternative of AudioPlayerSwift or a related project?
README
AudioPlayer
AudioPlayer is a simple class for playing audio in iOS, macOS and tvOS apps.
Usage
// Initialize let audioPlayer = AudioPlayer("sound.mp3") // Start playing audioPlayer.play() // Stop playing with a fade out audioPlayer.fadeOut()
See the samples project to see advanced usage
Installation
CocoaPods
Add the following to your Podfile:
pod 'AudioPlayerSwift'
Carthage
Add the following to your Cartfile:
github 'tbaranes/AudioPlayerSwift'
Swift Package Manager
AudioPlayer is available on SPM. Just add the following to your Package file:
import PackageDescription let package = Package( dependencies: [ .Package(url: "", majorVersion: 1) ] )
Manual Installation
Just drag the
Source/*.swift files into your project.
AudioPlayer properties
name
The name of the sound. This is either the name that was passed to the
init, or the last path component of the audio file.
url
The absolute URL of the audio file.
completionHandler
A callback closure that will be called when the audio finishes playing, or is stopped.
isPlaying
Is it playing or not?
duration
The duration of the sound.
currentTime
The current time offset into the sound of the current playback position.
volume
The volume for the sound. The nominal range is from 0.0 to 1.0.
numberOfLoops
Number of times that the sound will return to the beginning upon reaching the end.
- A value of zero means to play the sound just once.
- A value of one will result in playing the sound twice, and so on..
- Any negative number will loop indefinitely until stopped.
pan
The left/right stereo pan of the file. -1.0 is left, 0.0 is center, 1.0 is right.
AudioPlayer methods
init(fileName: String) throws init(contentsOfPath path: String) throws init(contentsOf url: URL) throws
These methods create a new AudioPlayer instance from a file name or file path.
func play()
Plays the sound. Has no effect if the sound is already playing.
func stop()
Stops the sound. Has no effect if the sound is not already playing.
func fadeTo(volume: Float, duration: TimeInterval = 1.0)
This method fades a sound from it's current volume to the specified volume over the specified time period.
func fadeIn(duration: TimeInterval = 1.0)
Fades the sound volume from 0.0 to 1.0 over the specified duration.
func fadeOut(duration: TimeInterval = 1.0)
Fades the sound from it's current volume to 0.0 over the specified duration.
Notifications
SoundDidFinishPlayingNotification
This notification is fired (via NSNotificationCenter) whenever a sound finishes playing, either due to it ending naturally, or because the stop method was called. The notification object is an instance of the AudioPlayer class. You can access the AudioPlayer class's
name property to find out which sound has finished.
What's next
- AudioPlayerManager
- Your features!
Contribution
- If you found a bug, open an issue
- If you have a feature request, open an issue
- If you want to contribute, submit a pull request
Licence
AudioPlayerSwift is available under the MIT license. See the LICENSE file for more info.
*Note that all licence references and agreements mentioned in the AudioPlayerSwift README section above are relevant to that project's source code only. | https://swift.libhunt.com/audioplayerswift-alternatives | CC-MAIN-2020-24 | refinedweb | 737 | 51.75 |
Go's object-oriented model revolves around interfaces. I personally believe that interfaces are the most important language construct and all design decisions should be focused on interfaces first.
In this tutorial, you'll learn what an interface is, Go's take on interfaces, how to implement an interface in Go, and finally the limitations of interfaces vs. contracts.
What Is a Go Interface?
A Go interface is a type that consists of a collection of method signatures. Here is an example of a Go interface:
type Serializable interface { Serialize() (string, error) Deserialize(s string) error }
The
Serializable interface has two methods. The
Serialize() method takes no arguments and returns a string and an error, and the
Deserialize() method takes a string and returns an error. If you've been around the block, the
Serializable interface is probably familiar to you from other languages, and you can guess that the
Serialize() method returns a serialized version of the target object that can be reconstructed by calling
Deserialize() and passing the result of the original call to
Serialize().
Note that you don't need to provide the "func" keyword at the beginning of each method declaration. Go already knows that an interface can only contains methods and doesn't need any help from you telling it it's a "func".
Go Interfaces Best Practices
Go interfaces are the best way to construct the backbone of your program. Objects should interact with each other through interfaces and not through concrete objects. This means that you should construct an object model for your program that consists only of interfaces and basic types or data objects (structs whose members are basic types or other data objects). Here are some of the best practices you should pursue with interfaces.
Clear Intentions
It's important that the intention behind every method and the sequence of calls is clear and well defined both to callers and to implementers. There is no language-level support in Go for that. I'll discuss it more in the "Interface vs. Contract" section later.
Dependency Injection
Dependency injection means that an object that interacts with another object through an interface will get the interface from the outside as a function or method argument and will not create the object (or call a function that returns the concrete object). Note that this principle applies to standalone functions too and not just objects. A function should receive all its dependencies as interfaces. For example:
type SomeInterface { DoSomethingAesome() } func foo(s SomeInterface) { s.DoSomethingAwesome() }
Now, you call function
foo() with different implementations of
SomeInterface, and it will work with all of them.
Factories
Obviously, someone has to create the concrete objects. This is the job of dedicated factory objects. Factories are used in two situations:
- At the beginning of the program, factories are used to create all the long-running objects whose lifetime typically matches the lifetime of the program.
- During the program runtime, various objects often need to instantiate objects dynamically. Factories should be used for this purpose too.
It is often useful to provide dynamic factory interfaces to objects to sustain the interface-only interaction pattern. In the following example, I define a
Widget interface and a
WidgetFactory interface that returns a
Widget interface from its
CreateWidget() method.
The
PerformMainLogic() function receives a
WidgetFactory interface from its caller. It is now able to dynamically create a new widget based on its widget spec and invokes its
Widgetize() method without knowing anything about its concrete type (what struct implements the interface).
type Widget interface { Widgetize() } type WidgetFactory interface { CreateWidget(widgetSpec string) (Widget, error) } func PerformMainLogic(factory WidgetFactory) { ... widgetSpec := GetWidgetSpec() widget := factroy.CreateWidget(widgetSpec) widget.Widgetize() }
Testability
Testability is one of the most important practices for proper software development. Go interfaces are the best mechanism to support testability in Go programs. To thoroughly test a function or a method, you need to control and/or measure all inputs, outputs and side-effects to the function under test.
For non-trivial code that communicates directly with the file system, the system clock, databases, remote services and user interface, it is very difficult to achieve. But, if all interaction goes through interfaces, it is very easy to mock and manage the external dependencies.
Consider a function that runs only at the end of the month and runs some code to clean up bad transactions. Without interfaces, you would have to go to extreme measures such as changing the actual computer clock to simulate the end of the month. With an interface that provides the current time, you just pass a struct that you set the desired time to.
Instead of importing
time and directly calling
time.Now(), you can pass an interface with a
Now() method that in production will be implemented by forwarding to
time.Now(), but during testing will be implemented by an object that returns a fixed time to freeze the test environment.
Using a Go Interface
Using a Go interface is completely straightforward. You just call its methods like you call any other function. The big difference is that you can't be sure what will happen because there may be different implementations.
Implementing a Go Interface
Go interfaces can be implemented as methods on structs. Consider the following interface:
type Shape interface { GetPerimeter() int GetArea() int }
Here are two concrete implementations of the Shape interface:
type Square struct { side uint } func (s *Square) GetPerimeter() uint { return s.side * 4 } func (s *Square) GetArea() uint { return s.side * s.side } type Rectangle struct { width uint height uint } func (r *Rectangle) GetPerimeter() uint { return (r.width + r.height) * 2 } func (r *Rectangle) GetArea() uint { return r.width * r.height }
The square and rectangle implement the calculations differently based on their fields and geometrical properties. The next code sample demonstrates how to populate a slice of the Shape interface with concrete objects that implement the interface, and then iterate over the slice and invoke the
GetArea() method of each shape to calculate the total area of all the shapes.
func main() { shapes := []Shape{&Square{side: 2}, &Rectangle{width: 3, height: 5}} var totalArea uint for _, shape := range shapes { totalArea += shape.GetArea() } fmt.Println("Total area: ", totalArea) }
Base Implementation
In many programming languages, there is a concept of a base class that can be used to implement shared functionality used by all sub-classes. Go (rightfully) prefers composition to inheritance.
You can get a similar effect by embedding a struct. Let's define a
Cache struct that can store the value of previous computations. When a value is retrieved from the case, it also prints to the screen "cache hit", and when the value is not in the case, it prints "cache miss" and returns -1 (valid values are unsigned integers).
type Cache struct { cache map[string]uint } func (c *Cache) GetValue(name string) int { value, ok := c.cache[name] if ok { fmt.Println("cache hit") return int(value) } else { fmt.Println("cache miss") return -1 } } func (c *Cache) SetValue(name string, value uint) { c.cache[name] = value }
Now, I'll embed this cache in the Square and Rectangle shapes. Note that the implementation of
GetPerimeter() and
GetArea() now checks the cache first and computes the value only if it is not in the cache.
type Square struct { Cache side uint } func (s *Square) GetPerimeter() uint { value := s.GetValue("perimeter") if value == -1 { value = int(s.side * 4) s.SetValue("perimeter", uint(value)) } return uint(value) } func (s *Square) GetArea() uint { value := s.GetValue("area") if value == -1 { value = int(s.side * s.side) s.SetValue("area", uint(value)) } return uint(value) } type Rectangle struct { Cache width uint height uint } func (r *Rectangle) GetPerimeter() uint { value := r.GetValue("perimeter") if value == -1 { value = int(r.width + r.height) * 2 r.SetValue("perimeter", uint(value)) } return uint(value) } func (r *Rectangle) GetArea() uint { value := r.GetValue("area") if value == -1 { value = int(r.width * r.height) r.SetValue("area", uint(value)) } return uint(value) }
Finally, the
main() function computes the total area twice to see the cache effect.
func main() { shapes := []Shape{ &Square{Cache{cache: make(map[string]uint)}, 2}, &Rectangle{Cache{cache: make(map[string]uint)}, 3, 5} } var totalArea uint for _, shape := range shapes { totalArea += shape.GetArea() } fmt.Println("Total area: ", totalArea) totalArea = 0 for _, shape := range shapes { totalArea += shape.GetArea() } fmt.Println("Total area: ", totalArea)
Here is the output:
cache miss cache miss Total area: 19 cache hit cache hit Total area: 19
Interface vs. Contract
Interfaces are great, but they don't ensure that structs implementing the interface actually fulfill the intention behind the interface. There is no way in Go to express this intention. All you get to specify is the signature of the methods.
In order to go beyond that basic level, you need a contract. A contract for an object specifies exactly what each method does, what side effects are performed, and what the state of the object is at each point in time. The contract always exists. The only question is if it's explicit or implicit. Where external APIs are concerned, contracts are critical.
Conclusion
The Go programming model was designed around interfaces. You can program in Go without interfaces, but you would miss their many benefits. I highly recommend that you take full advantage of interfaces in your Go programming adventures.
><< | https://code.tutsplus.com/tutorials/how-to-define-and-implement-a-go-interface--cms-28962 | CC-MAIN-2021-21 | refinedweb | 1,558 | 55.44 |
Sergey Nivens - Fotolia
Spring MVC tutorial: How Spring Boot web MVC makes Java app development easy
Spring Boot has provided an opinionated approach to developing microservices. In this Spring MVC tutorial, we show how Spring Boot has changed Java web development as well.
There's a great deal of talk about how Spring Boot has simplified microservices development, but there's been relatively little talk about how it also makes the development of a Spring MVC application a decidedly simple endeavor.
In this Spring MVC tutorial, we will use the SpringSource Tool Suite to create a Spring Boot project with only three built-in Spring Boot facilities -- Thymeleaf, DevTools and Web support -- to build a simple Rock-Paper-Scissors application.
Flow of the Spring MVC example
The flow of the Spring MVC application is as follows:
- The landing page, index.html, will ask the user to click on one of three anchor links -- namely rock, paper or scissors.
- The anchor link will trigger a Spring MVC web controller. The Spring MVC controller will process the input and evaluate if the user won, lost or tied. The server will always choose rock just to keep the logic simple.
- After the Spring MVC controller has processed the input, the outcome of the game is stored as a String in a Spring MVC model object. The Spring MVC model is then passed to the results.html page for view generation.
- The results.html page uses the Thymeleaf framework to read the outcome from the Spring MVC model and subsequently generate HTML for the user's request.
Spring MVC web development in Eclipse
The toughest part of putting together a Spring MVC application with Spring Boot is simply setting up the project. Eclipse provides a special Spring Boot Starter project, which we'll use to create a Spring MVC application from scratch:
File → New → Project → Spring Boot → Spring Starter Project
Spring Boot has provided an opinionated approach to developing microservices. In this Spring MVC tutorial, we'll show how Spring Boot has changed Java web development as well.
The Spring MVC Maven dependencies
Once we start the Spring Boot project wizard and provide the attributes for the project's Maven POM file, the wizard will let the user choose from a number of optional project dependencies. The only three dependencies needed for this Spring MVC example are Web, DevTools and Thymeleaf. Spring will add in a fourth Maven dependency, starter-testing, to encourage developers to perform Spring MVC testing as development proceeds.
When you select the three Spring MVC Maven dependencies, click Finish on the Spring Boot wizard screen to create the project.
The Spring MVC Maven POM file
The auto-generated dependencies section of the Spring MVC Maven POM file looks as follows:
>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
When the new Spring MVC project opens in Eclipse, look for a Java file under the src/main/java folder that is named after the project and is suffixed with the word Application. In the accompanied Spring MVC video tutorial, I've named the file SpringMvcRpsApplication.java.
Spring Boot MVC configurations
This file, decorated with the @SpringBootApplication annotation, is the heart of any Spring Boot project. Any subsequent configurations -- beans subject to Inversion of Control or components that you wish to make available for dependency injection in other parts of the program -- will be configured here. Fortunately though, Spring Boot MVC applications require very little configuration, so we won't have to add any new code to this file in this Spring MVC tutorial.
This Spring MVC tutorial only creates three new files:
- index.html
- WebController.java
- results.html
The index.html file simply provides three anchor links that point to a URI (Uniform Resource Identifier) on the server named playagame. Each link identifies itself to the server through a parameter named choice that takes on a value of rock, paper or scissors.
<html>
<body>
<p>What will it be?</p>
<a href="/playagame?choice=rock">rock</a>
<a href="/playagame?choice=paper">paper</a>
<a href="/playagame?choice=scissors">scissors</a>
</body>
</html>
Pay special attention to the href property of the anchor tag. It indicates that once it is clicked, a link named playagame will be invoked on the server, and a name-value pair associated with the parameter choice will be passed from the browser to the server.
Spring MVC controller example
The full code for the Spring MVC controller example is as follows. Take note of the @Controller decoration before the WebController class declaration. This Spring MVC annotation tells Spring Boot to use this component to handle web-based requests:
Remember how the anchor link in the index.html page linked to a resource named playagame? The @GetMapping annotation is what connects that anchor link to the playGame method of the WebController.
<a href="/playagame?choice=rock">rock</a>
Spring MVC annotations
Furthermore, the anchor link contains a parameter named choice. The value associated with this parameter is automatically assigned to the method argument named theChoice through the @RequestParam annotation.
@RequestParam(name="choice", required=false) String theChoice
The Spring MVC model
The objective of the playGame method is to figure out if the user has generated a win, loss or draw. A String variable named theOutcome is assigned a value of win, loss or tie by the program as it runs, and theOutcome is subsequently attached to the Spring MVC model class through the addAttribute method.
model.addAttribute("outcome", theOutcome);
At the conclusion of the Spring MVC controller example, a String named result is returned by the controller to the Spring MVC framework, which triggers the invocation of the results.html file for view generation.
The Spring MVC view component
For legacy Java developers, it may feel peculiar to forward to an HTML page rather than a Java Server Page (JSP), but it's all part of Spring Boot's opinionated approach to modern Java development. Spring Boot asserts that JavaServer has far too many shortcomings in web development, and Java developers should prefer HTML-based templating technology, like Thymeleaf, Groovy templates, FreeMarker or Mustache. In this example, we use Thymeleaf. The content of the results.jsp is as follows:
<html xmlns:
<body>
<p th:
<p>Thanks for playing. Play again?</p>
<a href="/playagame?choice=rock">rock</a>
<a href="/playagame?choice=paper">paper</a>
<a href="/playagame?choice=scissors">scissors</a>
</body>
</html>
The only minor imposition Thymeleaf makes on the HTML file is the addition of the XML namespace attribute and the use of Thymeleaf tag attributes. Fortunately, the Thymeleaf tag attributes are relatively easy to use, and the syntax for pulling the outcome variable out of the Spring MVC model class is just standard Spring Expression Language and makes the learning curve small. After developers work with Thymeleaf, they will quickly lose their longing for JSPs.
The complete Spring Boot MVC example
And that's it. We have a multipage application all within the confines of a Spring Boot project. When the user runs a Java web program as a Spring Boot application in Eclipse, a landing page will provide the links, and when the user clicks, they'll land on a results page that will indicate whether the user won, lost or tied the game.
Microservices and Docker deployments tend to get all the attention when it comes to Spring Boot and cloud-native computing, but as this Spring MVC example demonstrates, Spring Boot has plenty to offer the Java web developer as well.
The full source code for this example can be found on GitHub.
Start the conversation | https://www.theserverside.com/tutorial/Spring-MVC-tutorial-How-Spring-Boot-aids-Java-web-development | CC-MAIN-2019-30 | refinedweb | 1,275 | 52.7 |
Perhaps I misunderstand the 'scala script' option (it doesn't seem to be documented in the product help), but I tried creating a new file with just a function definition like:
def foo(msg: String) {}
or even just a single line file like:
println("Hello world")
...but when trying to compile I get an compilation error:
scala: expected class or object definition
def hello(msg: String) {
^
I'd assumed that a 'scala <scriptfile>' would let me create scripts that could be run from the command line, or via 'scala' (as opposed to the 'salac' compiler). Such command line scripts do not require me to define any classes or objects and execute fine with the scala command line.
Is there documentation or can someone guide me on what a 'scala script' actually is and how to use that feature of the scala plugin?
By default, the 'Scala Script' run configuration includes a 'make' step.. perhaps I just need to remove that step or perhaps there's a make setting that understands 'script' mode where I shouldn't have to create objects or classes?
hmm, can't seem to edit posts?
Anyway, I'm running IntelliJ 12.0.2 and scala 2.10.0
You have few possible workarounds for this problem:
1. Use Scala Worksheet. It have .sc extention, so it won't be compiled.
2. Move your script outside of source root. Then compiler won't compile it, but probably you will get problems with dependencies.
3. Don't use external compiler (not external compiler is deprecated and probably will be removed, but before this you still can you it)
In external compilation there is no way to analyze file and to understand that it's script file. Additionally it's not really simple to compile such project with script files using any other build system, because it doesn't contain scripting feature.
Best regards,
Alexander Podkhalyuzin. | https://intellij-support.jetbrains.com/hc/en-us/community/posts/205999589-How-to-use-scala-script- | CC-MAIN-2020-16 | refinedweb | 317 | 62.17 |
Simulating Rails like Environments in Django
I was always a fan of Rail environments and as part of some work upgrading this site to the latest version of Django I decided to clean up my whole deployment process. Part of that involved replacing everything in settings.py with the following snippet of code:
ENV = "development" try: exec "from environments." + ENV + " import *" except ImportError: print "You must specify a valid environment" exit()
I now have two settings files stored in an environments module containing all the usual django settings; one for my development environment and one suitable for live. The settings.py above is for my local development environment, with only one small change for live (this file doesn’t get deployed along with the source code for the site, so doesn’t get overwritten).
ENV = 'live'
This isn’t quite the same as the Rails implementation obviously. I run completely different server setups so I’m not too bothered about a flag on the runserver command like the -e flag for mongel. I could also probably do something to autodetect the environment but this works fine for me.
I do something using regular settings files:
... all my crap here…
from settings_development import *
... override things…
from settings_development import *
The stuff in settings.py assumes that the majority of the time you’ll be invoking it via runserver, so it’ll Just Work™ in development. Obviously in production you need to pass the—settings flag, but that’s all in Capistrano (or WSGI configs), right? ;)
The naming convention is so all the files are next to each other when a directory listing is shown.
Bradley Wright - 2nd November 2008
wel I also miss the environments (symfony background)
the exec is a pitty though, you could also use a import
Thierry - 4th December 2008
Leave a comments | http://morethanseven.net/2008/11/01/simulating-rails-environments-django/ | crawl-002 | refinedweb | 304 | 51.68 |
Dr. GUI .NET 1.1 #3
June 17, 2003
Summary: Dr. GUI shows the canonical polymorphism example, an application that derives drawable objects from a common abstract base class. He also demonstrates using an interface, and a few design patterns to factor out common code when implementing an interface or abstract base class. Finally, he demonstrates a simple Windows Forms application and an ASP.NET version of the drawing application that manipulates a bitmap on the server side, without assistance from client-side script or other client code. (42 printed pages)
Links
Dr. GUI .NET home page.
Source code for this article.
Run the sample GraphicalASPX application.
Contents
Introduction
Where We've Been; Where We're Going
Putting It All Together: The Drawing Classes
Using Our Drawable Objects in a Windows Forms Application
Using Our Drawable Objects in an ASP.NET Application
Passing State Between Pages and Requests
Drawing in a Separate Page
Give It a Shot!
Yo! Let's talk!
What We've Done; What's Next
Speak Out!
Tell the world and us what you think about this article on the Dr. GUI .NET message board. Or read what Dr. GUI's thinking—and comment on it—on his blog.
Be sure to check out the sample running as a Microsoft® ASP.NET application. Or just take a look at the source code in a new window.
Introduction
Welcome back to Dr. GUI's fourth Microsoft® .NET Framework programming article. The first three are called—in honor of .NET Framework array element numbering, which starts at zero rather than one—Dr. GUI .NET 1.1 #0 through Dr. GUI .NET 1.1 #2. If you're looking for the earlier articles, check out the Dr. GUI .NET home page.
Again, Dr. GUI hopes to see you participate in the message board. There are already some good discussions there, but they'll be better once you join in! Anyone can read the messages, but you'll need a Microsoft .NET Passport to authenticate you if you want to post. But don't worry—it is easy to set up a Passport and you can associate it with any of your e-mail accounts.
Where We've Been; Where We're Going
Last time, we reviewed inheritance and polymorphism and showed how the .NET Framework implements them.
This time, we're going to see a more complete example of inheritance, abstract (MustInherit) base classes, and interfaces in a cute drawing application. This won't be a console application; because it's graphical, it will be a Microsoft® Windows® Forms application instead. (That'll give us the chance to explore Windows Forms a little.)
The ASP.NET version will demonstrate using custom-drawn bitmaps on Web pages—something that's very hard to do in most Web programming systems, but easy with ASP.NET. Dr. GUI thinks you'll like it. Run the application to try it out.
Putting It All Together: The Drawing Classes
Last time we discussed using some pretty abstract examples, inheritance, interfaces, and polymorphism. The good doctor thought that this time we'd do something different and take a look at a small but somewhat realistic sample that demonstrates all that we've learned. And, since the application really needs graphics, that'll give us a chance to explore some new things: Windows Forms, as well as a very cool technique for creating bitmaps on the fly for display in Web pages—all without any client-side script!
The Canonical Polymorphism Example
In teaching programming, there is a set of pretty standard example programs that are commonly used. When Dr. GUI started out, he swore he'd never use any of them: that he'd never use a string class as an example, nor complex numbers, nor a drawing application. After all, doing so just wouldn't be original.
Well, as it turns out, there's a good reason (besides sloth) that these examples are used: they're very rich, very easy to explain and understand, and about as simple as possible while clearly demonstrating the crucial concepts.
So long ago, the good doctor capitulated and started using the "canonical" samples. Thus, for this column we have the granddaddy of polymorphism examples: the polymorphic drawing program.
Here's a screen shot of what the Windows Forms version of this program looks like:
Figure 1. Windows Form version of canonical polymorphism example
And here's what the ASP.NET version looks like in the browser:
Figure 2. ASP.NET version of canonical polymorphism example
You can run the ASP.NET version shown above.
What We're Doing Here
The basic idea of this program is this: we have an abstract base class (MustInherit in Microsoft® Visual Basic®) that contains the common data, such as bounding rectangle, and a set of virtual methods, mostly abstract (MustOverride in Visual Basic), such as Draw. Note that it's important that Draw be polymorphic since each type of drawable object, such as point, line, rectangle, circle, etc., is drawn with entirely different code.
While methods can be polymorphic, data cannot. Therefore, we put only the data in the program that truly applies to all possible drawable objects—in this case, a bounding rectangle and the color in which to draw the line(s) of the object.
Data specific to a particular type of drawable object, such as the center and radius of a circle, the coordinates of the opposite points of a rectangle, or the endpoints of a line, should be declared in the particular class (derived from the abstract base class) that corresponds with that type of drawable object. Note that it is possible to use a second level of derivation (or even several deeper levels) to consolidate similarities. For instance, circle could be derived from ellipse, since all circles are ellipses. Similarly, squares could be derived from rectangles, since all squares are also rectangles (and also quadrilaterals, and also polygons). The derivation tree you pick will ideally reflect not only the relationships between the classes but also the common expected usage patterns, so that operations you'll perform frequently are fast and easy.
Below is a diagram with our class derivation:
Figure 3. Class derivation diagram
Since the main reason for constructors (New in Visual Basic) exist is to initialize the data, constructors aren't (in fact, can't be) polymorphic, either. That means that the original creation operation can't be polymorphic, which makes sense since the data requirements vary from type to type. However, with good design, once the object is created, it can be treated for the rest of its life as a polymorph, as we do here.
Let's take a look at what's in this set of classes, starting with the root abstract base class:
The Abstract (MustInherit) Base Class
Here's the code for the abstract base class in C#. Dr. GUI calls it DShape for "drawable shape." Click to see the entire source file.
C#
And here's the equivalent code in Visual Basic .NET. Click to see the entire source file.
Visual Basic .NET
The syntax is different, but it's clear that it's exactly the same class.
Note that the Draw method is implicitly virtual (Overridable) because it's declared abstract (MustOverride). Note also that we do not provide an implementation in this class. Since we don't know what object we're implementing in this class, how could we possibly write drawing code?
What's the data?
Note also that there isn't much data—but we've declared all the data that we can for such an abstract class.
Every drawable object, no matter what its shape, has a bounding rectangle—that is, the smallest possible rectangle which can completely enclose the object. The bounding rectangle is used for drawing points (as very small rectangles), rectangles, and circles—and it's useful for other shapes as a first very quick approximation for hit or collision testing.
There's not much else that all objects have in common; while the center makes sense for some objects, such as circles and rectangles, it doesn't make sense for others, such as triangles. And you'd want to represent a rectangle by its corners, not its center. But you can't specify a circle by its corners, since it has no corners. (For this application, we'll actually represent the circle with its bounding rectangle, since we have no need for the center or radius once the circle is created, and since the method we'll use to draw the circle, DrawEllipse, requires a bounding rectangle to know where to draw the circle.) Dr. GUI trusts that you see the difficulty in specifying other data for a generic drawable object. Also notice that since the data is private, we can use exactly the data that makes sense for our object without worrying about showing weird data to the users.
Every drawable object also has a color associated with the lines used to draw it, so we declare that here, as well. Note that we didn't declare the color for fillable objects, since not all objects are fillable. (We'll still make it possible for us to share implementation as well as interface, as you'll see later.)
Some Derived Classes
As noted, we can't actually create an object of the abstract base class's type, although we can treat any object derived from the abstract base class (or any base class) as though it was a base class object.
So in order to create an object to draw, we'll have to derive a new class from the abstract base class—and be sure to override all of the abstract/MustOverride methods.
The example we'll see here is for the DHollowCircle class. The DHollowRectangle class and the DPoint class are very similar.
Here's DHollowCircle in C#. Click to see the other classes.
C#
public class DHollowCircle : DShape { public DHollowCircle(Point p, int radius, Color penColor) { p.Offset(-radius, -radius); // need to convert to upper left int diameter = radius * 2; bounding = new Rectangle(p, new Size(diameter, diameter)); this.penColor = penColor; } public override void Draw(Graphics g) { using (Pen p = new Pen(penColor)) { g.DrawEllipse(p, bounding); } } }
And here's the same class in Visual Basic .NET. Click to see the other classes.
Visual Basic .NET
Public Class DHollowCircle Inherits DShape Public Sub New(ByVal p As Point, ByVal radius As Integer, _ ByVal penColor As Color) p.Offset(-radius, -radius) ' need to convert to upper left Dim diameter As Integer = radius * 2 bounding = New Rectangle(p, New Size(diameter, diameter)) Me.penColor = penColor End Sub Public Overrides Sub Draw(ByVal g As Graphics) Dim p = New Pen(penColor) Try g.DrawEllipse(p, bounding) Finally p.Dispose() End Try End Sub End Class
Note that we didn't declare any additional data for this class—as it turns out, the bounding rectangle and the pen are enough. (That happens to be true for points and rectangles, too; it wouldn't be true for triangles and other polygons, however.) Our application doesn't need to know the center or radius of the circle after it is set, so we ignore them. (If we really needed them, we could either store them or calculate them from the bounding rectangle.)
But we absolutely need the bounding rectangle, since it is a parameter to the Graphics.DrawEllipse method we're using to draw the circle. So we calculate the bounding rectangle from the center point and radius we were passed in the constructor. This is an example of how encapsulating the data helps allow you to make the best choices in data representation for your situation. The user of this class knows nothing of bounding rectangles, yet since we store only the bounding rectangle, our drawing code is more efficient and we store only one representation of the circle.
Let's look at each of the methods in depth.
The constructor
The constructor takes three parameters: a point that contains the coordinates for the center of the circle, the radius of the circle, and a System.Drawing.Color structure that contains the color in which to draw the circle's outline.
We then calculate the bounding rectangle from the center and radius, and set our pen color member to the color object we were passed.
The Draw-ing code
The Draw method overload is actually quite simple: it creates a pen object from the color object we saved in the constructor, then uses that pen to draw the circle using the Graphics.DrawEllipse method, passing also the bounding rectangle we created earlier.
Graphics and Pens and Brushes, oh MY!
The Graphics, Pen, and Brush objects deserve a little explanation. (We'll see the Brush objects shortly when we start filling our fillable objects.)
The Graphics object represents a virtualized drawing space associated with some real drawing surface. By virtualized, we mean that you use the same Graphics methods to draw on whatever type of surface you actually have associated with the Graphics object on which you're drawing. For those of you who are used to programming in MFC or the Microsoft Windows® SDK, the Graphics object is the .NET version of what's called a "Device Context" (or "DC") in Windows.
In this Windows Form application, the Graphics object that's passed into Draw will be associated with a window on the screen—specifically, our PictureBox. When we use this exact same code with our Microsoft ASP.NET application, the Graphics object Draw is passed will be associated with a bitmap image. It could also be associated with a printer or other devices. In essence, Graphics behaves like an abstract base class—it defines the interface, but doesn't constrain the implementations. The different ways of getting a Graphics object give you different types of objects with different behavior, but all implement the same core interface.
The advantage of this scheme is that we can use the exact same drawing code to draw on different types of surfaces. And in our drawing code, we don't need to know anything about the differences between screens, bitmaps, printers, and so on—the .NET Framework (and the underlying operating system, device drivers, and so on) take care of all the details for us.
By the same token, pens and brushes are virtualized drawing tools. A pen represents the attributes of a line—color, width, pattern, and perhaps even a bitmap that can be used to draw the line. A brush represents the attributes of a filled area—color, pattern, and perhaps even a bitmap used to fill an area.
Cleaning up after yourself using using (or at least Dispose)
Graphics, Pen, and Brush objects are all associated with Windows objects of a similar type. These Windows objects are allocated in the operating system's memory—memory that's not managed by the .NET runtime. Leaving these objects allocated for long periods of time can cause performance problems, and can even cause painting problems under Microsoft Windows 98 as the graphics heap fills up. As a result, you should release the Windows objects as quickly as possible.
You may be wondering why, if the .NET runtime provides memory management, you have to manage these objects yourself. Won't the runtime eventually free the objects?
The .NET runtime will indeed free the Windows objects automatically when the corresponding .NET Framework object is finalized and garbage collected. However, it might take a long time for the garbage collection to happen—and all sorts of bad things that won't trigger a garbage collection, including filling up Windows heaps and using up all the database connections, can occur if we don't free these objects promptly. This would be especially bad in the ASP.NET version of this application since many users could be accessing the application on the same server box.
Because these objects are associated with unmanaged resources, they implement the IDisposable interface. This interface has one method, Dispose, that detaches the .NET Framework object from the Windows object and frees the Windows object, thus keeping your computer happy.
You have but one obligation: to be sure to call Dispose when you're done with the object.
The canonical form for this is shown in the Visual Basic .NET code: you create the object, then use it in a Try block, then dispose of the object in the Finally block. The Try/Finally assures that the object will be disposed even if an exception is thrown. (In this case, the drawing method we call probably can't throw an exception, so the Try/Finally block probably isn't necessary. But it's good practice to get into, and the good doctor wanted to show you the correct form.)
This pattern is so common that C# has a special statement for it: using. The using statement in the C# code is exactly equivalent to the declaration and Try/Finally in the Visual Basic .NET code—but much neater, more convenient, and less error-prone. (Why Visual Basic .NET didn't include something like the using statement is totally beyond Dr. GUI.)
The Interface
Some, but not all, drawable objects can be filled. Objects such as points and lines can't be filled since they're not enclosed regions, while objects such as rectangles and circles can be either hollow or filled.
On the other hand, it would be handy, just as we can treat all drawable objects as polymorphs, to be able to treat all fillable objects as polymorphs. For instance, just as we put all of the drawable objects in a collection and draw them by iterating through the collection and calling Draw on each object, it would also be handy to be able to fill all the fillable objects in a collection, regardless of the actual type of the fillable object. So somehow, we'd like to use some mechanism like inheritance to achieve true polymorphism (in one lifetime, nonetheless!).
Since not all drawable objects can be filled, we can't put the Fill method declaration in the abstract base class. The .NET Framework doesn't allow multiple inheritances of classes, so we can't put it in another abstract base class, either. And if we derive the fillable objects from a different base class than the non-fillable ones, then we'd lose the ability to treat all drawable objects as polymorphs.
But the .NET Framework does support interfaces—and a class can implement any number of interfaces. The interfaces can't have any implementation—no code, nor any data. The class that implements the interface has to provide everything.
All the interface can have is declarations. And here's what our interface, IFillable, looks like in C#. Click to see the entire source file.
C#
The equivalent Visual Basic .NET code is shown below. Click to see the entire source file.
Visual Basic .NET
We don't need to declare the method nor the property virtual/Overridable or abstract/MustOverride or anything, since all methods and properties in interfaces are automatically public and abstract/MustOverride.
Use a property: Can't have data in an interface
Note that while we can't declare a field in an interface, we can declare a property, since properties are actually implemented as methods.
But doing so puts a burden on the implementer of the interface, as we'll see shortly. The implementer has to implement the get and set methods, as well as whatever data is necessary to implement the property. If the implementation is very complex, you might be able to write a helper class to encapsulate some of it. We'll show how you might use a helper class later in the article in a slightly different context.
Implementing the Interface
Now that we have the interface defined, we can implement it in our classes. Note that we have to provide complete implementations of the interfaces we implement: we can't pick and choose the parts we want to implement.
So let's look at the code for the DFilledRectangle class in C#. Click to see the code for all the classes (including DfilledCircle).
C#
public class DFilledCircle : DHollowCircle, IFillable { public DFilledCircle(Point center, int radius, Color penColor, Color brushColor) : base(center, radius, penColor) { this.brushColor = brushColor; } public void Fill(Graphics g) { using (Brush b = new SolidBrush(brushColor)) { g.FillEllipse(b, bounding); } } protected Color brushColor; public Color FillBrushColor { get { return brushColor; } set { brushColor = value; } } public override void Draw(Graphics g) { Fill(g); base.Draw(g); } }
And here's the code for the DFilledRectangle class in Visual Basic .NET. (Click to see the code for all the classes (including DFilledCircle).
Visual Basic .NET
Public Class DFilledRectangle Inherits DHollowRectangle Implements IFillable Public Sub New(ByVal rect As Rectangle, _ ByVal penColor As Color, ByVal brushColor As Color) MyBase.New(rect, penColor) Me.brushColor = brushColor End Sub Public Sub Fill(ByVal g As Graphics) Implements IFillable.Fill Dim b = New SolidBrush(FillBrushColor) Try g.FillRectangle(b, bounding) Finally b.dispose() End Try End Sub Protected brushColor As Color Public Property FillBrushColor() As Color _ Implements IFillable.FillBrushColor Get Return brushColor End Get Set(ByVal Value As Color) brushColor = Value End Set End Property Public Overrides Sub Draw(ByVal g As Graphics) Dim p = New Pen(penColor) Try Fill(g) MyBase.Draw(g) Finally p.Dispose() End Try End Sub End Class
Following are some things to note about these classes.
Derived from HollowRectangle
We derived the filled class from the hollow version of the class. Most everything changes in this class: the Draw method and constructor are new (but both call the base class's versions) and we've added implementation for the Fill method of the IFillable interface and an implementation for the FillBrushColor property.
The reason that we need a new constructor is that we've got additional data in this class that needs to be initialized, namely the fill brush. (You'll recall our discussion of brushes above.) Note how this constructor calls the base class constructor: in C#, the "call" is built into the declaration (
: base(center, radius, penColor)); in Visual Basic .NET, you make the call explicitly as the first line (
MyBase.New(rect, penColor)) of the New method (aka "the constructor").
Since we've passed two of the three parameters to the base class constructor, all we have to do is initial the final field.
How Draw changes
You'll note that the Draw method is pretty much the same as the base class—the main exception being that it calls the Fill method, since doing a complete job of drawing a filled object involves filling it. Rather than rewriting the code for drawing the outline, we again call the base class's method:
MyBase.Draw(g) in Visual Basic .NET, and
base.Draw(g); in C#.
Since we're allocating a pen with which to draw the outline, we have to use using or Try/Finally and Dispose to make sure the Windows pen object is released promptly. (Again, if we were absolutely positive that the methods we're calling would never throw an exception, we could skip the exception handling and simply call Dispose when we're done with the pen. But we must call Dispose, whether directly or via the using statement.)
Implementing the Fill method
The Fill method is simple: allocate a brush, then fill the object on the screen—and make sure that we Dispose the brush.
Note that in Visual Basic .NET, you have to explicitly specify that you're implementing a method of an interface ("
... Implements IFillable.Fill") while in C#, the fact that you're implementing a method or property in an interface is determined by the signature of the method or property (since you wrote a method called "
Fill" that returns nothing and takes a Graphics, that MUST be the implementation of IFillable.Fill). Oddly enough, Dr. GUI, who generally prefers concise programming structures (if not concise writing), actually prefers Visual Basic's syntax because it's both clearer and more flexible (the name of the method in the implementing class in Visual Basic doesn't have to match the name in the interface, and a given method could conceivably implement more than one interface method).
Implementing the property
The IFillable interface also includes a property that allows us to set and get the brush color. (We use this in the Change fills to hot pink button handler.)
In order to implement the public property, we need to have a private or protected field. We made it protected here to ease access from derived classes without allowing any class to access it.
Once we have the field, it's easy to write a very simple pair of set and get methods to implement the property. Note once again that in Visual Basic .NET, you have to explicitly specify what property you're implementing.
You'll also notice that the implementation of this property is identical for every class. Later on, we'll see how to use a helper class to provide this implementation. In this case, the benefit is minimal (common code for the implementation can make changes easier). But in cases where the implementation of the property is more complex, the benefits of using a helper class can be great.
Interface or Abstract (MustInherit) Base Class?
One of the most common arguments in object-oriented programming is whether to use abstract base classes or interfaces.
Interfaces give you some additional flexibility, but at a cost: you have to implement everything in every class that implements that interface. We can use a helper class to assist with this (we'll have a related example later), but you still have to implement everything everywhere. And interfaces can't contain data (although, unlike in Brand J's system, they can contain properties, so they can look as though they contain data).
In this case, the good doctor chose to use an abstract base class rather than an interface for DShape because he didn't want to re-implement the data as properties in each class. Also, he chose a class rather than an interface because everything derived from DShape "is a" shape, where as the fillable objects are still shapes that also "can do" filling.
Your mileage may vary, of course, but Dr. GUI thinks he chose pretty well for this situation.
A Container for Our Drawing Objects
Since we're going to be drawing our objects repeatedly (each time the image paints in the Windows Forms version; each time the Web page is reloaded in the ASP.NET version), we need to keep them in a container so we can access them again and again.
Dr. GUI went a step further and made the containers smart containers that know how to draw the objects contained inside. Here's the C# code for this container class:
C# (click to see the entire file)
public class DShapeList { ArrayList wholeList = new ArrayList(); ArrayList filledList = new ArrayList(); public void Add(DShape d) { wholeList.Add(d); if (d is IFillable) filledList.Add(d); } public void DrawList(Graphics g) { if (wholeList.Count == 0) { Font f = new Font("Arial", 10); g.DrawString("Nothing to draw; list is empty...", f, Brushes.Gray, 50, 50); } else { foreach (DShape d in wholeList) d.Draw(g); } } public IFillable[] GetFilledList() { return (IFillable[])filledList.ToArray(typeof(IFillable)); } }
And here's the Visual Basic .NET code for the same class:
Visual Basic .NET (click to see the entire file)
Public Class DShapeList Dim wholeList As New ArrayList() Dim filledList As New ArrayList() Public Sub Add(ByVal d As DShape) wholeList.Add(d) If TypeOf d Is IFillable Then filledList.Add(d) End Sub Public Sub DrawList(ByVal g As Graphics) If wholeList.Count = 0 Then Dim f As New Font("Arial", 10) g.DrawString("Nothing to draw; list is empty...", _ f, Brushes.Gray, 50, 50) Else Dim d As DShape For Each d In wholeList d.Draw(g) Next End If End Sub Public Function GetFilledList() As IFillable() Return filledList.ToArray(GetType(IFillable)) End Function End Class
Maintaining two lists
Since we're going to want to change the fill color of our objects to implement that stylish Change fill to hot pink button, we maintain two lists of drawable objects: one list of *ALL* the objects, and one list of just the fillable objects. We use the ArrayList class for both of these. ArrayList objects hold a set of Object references—so an ArrayList can hold a mixed bag of any type in the system.
That's actually not helpful—we'd prefer that the ArrayLists contain only drawable/fillable objects. In order to do this, we make the ArrayList objects private; then we make the way to add objects to the lists a method that we write to take only a DShape.
When we add objects to the list using the Add method, we add every object into the wholeList and then check to see if the object should also be added to the filledList collection as well.
Remember that the Add method (and therefore the list) is typesafe: it only takes a DShape (or some type derived from DShape, such as all the types we created above). You can't add an integer or a string into this list; so we always know that this list only contains drawable objects. Being able to make that assumption is very handy! Strong typing is a good thing—a very good thing.
Drawing the items
We also have a method called DrawList that draws the objects in the list on the Graphics object it is passed as a parameter. This method has two cases: if the list is empty, it draws a string saying that the list is empty. But if the list isn't empty, it uses a for each construct to iterate through the list, calling Draw on each object. The code for the actual iteration and drawing almost couldn't be simpler, as shown in Visual Basic below.
Visual Basic .NET
The C# code is almost identical (but, of course, it takes fewer lines!).
C#
Since we know that the list is type-safe because it's encapsulated, we know it's safe to just call the Draw method without checking the object's type.
Returning the fillable list
Finally, our Change fills to hot pink button needs an array of references to all the fillable objects so it can change their FillBrushColor property. Although it would be possible to write a method that iterated the list and changed the color to the value passed in, for this time the good doctor chose to return an array of object references instead. Luckily, the ArrayList class has a ToArray method that allows us to create an array that we pass back. This method takes the type that we want the array elements to be—thus allowing us to pass back the type we want—an array of IFillable.
C#
Visual Basic .NET
In both languages, we use a built-in operator to get the Type object for a given type—in C#, we say "
typeof(IFillable)", in Visual Basic, "
GetType(IFillable)".
The calling program uses this array to iterate over the array of references to fillable objects. For instance, the Visual Basic code to change the fill colors to hot pink looks like this:
This method is for demonstration purposes. The good doctor would hesitate before using this method in code he shipped. Why? Well, this design is questionable because it returns references to the list's internal data. (The array returned, however, is a copy of filledList, so at least the caller can't mess with that. But the references are still to the actual drawable objects.) It's usually better to provide a method to make the changes in a way you can check, rather than handing out references so the caller can do anything they want.
So why didn't Dr. GUI design this differently? First off, the idea is to demonstrate the polymorphism of using an object through a reference typed to its interface.The only thing the caller knows about the objects is that they implement IFillable. Second, it's hard to predict all the ways someone might want to manipulate the objects, so it's sometimes desirable to provide a method that returns references to internal data so that the caller has more flexibility. Like all engineering problems, there are trade-offs involved here—in this case, flexibility versus breaking encapsulation.
Helper Methods and Classes for Factoring Common Code
You might have noticed that the Draw and Fill methods have a lot of code in common Specifically, the code to create a pen or brush, set up a Try/Finally block, and dispose of the pen or brush is the same in every class—the only difference is the actual method called to do the drawing or filling. (Because of the very clean using syntax in C#, the amount of extra code isn't as obvious.) In Visual Basic .NET, there's one unique line of code to five lines of code that's identical in all implementations
You might also have noticed that the implementation of the property in IFillable is always identical.
In general, when you have a lot of repeated code, you want to look for ways to factor out the common code into common subroutines that are shared by all classes. Dr. GUI is pleased to show you three (of many) possible methods for doing this. The first method is an option for classes only; the second will work with either classes or interfaces, although we use it only with an interface in this example.
A note: We only did this code in Visual Basic, and only for the ASP.NET version of the application. But we could use the modified code in the Windows Forms applications with no problem. Dr. GUI did only one version so you could see the differences as you looked at the code.
Using calls to a helper class to replace identical code
The first problem we'll deal with is that the property implementation for IFillable is the same in all the classes that implement it. What we'll do is factor out the common code into a helper class, then create and call the helper in our code. In this case, creating and calling the helper takes as much code (actually a bit more) as just doing the work directly. It's also a little slower. But for a more complicated implementation of the property, this technique might make sense. In addition, it's easier to maintain code that's been factored into helpers; if you need to make a change to the helper, you change it in one place, not every place the code occurs. In some cases, that advantage might make using a helper class a good choice.
Systems such as C++ that support multiple inheritance of implementation (not just interfaces) can allow you to write helper classes with mix-ins that are inherited. But this is harder in a single-inheritance-only system like the .NET Framework—we'll have to directly instantiate the helper class and explicitly access it.
First, let's look at our helper class (click to see all the code):
We'll talk about the <Serializable()> attribute later on...please ignore it for now.
It's easy to look at this class and see it as the implementation of a property. Again, this isn't very interesting as factored code, but if it was more complicated, or if you thought you'd be likely to want to modify the helper and have the changes used by all the classes that use the helper, you might want to use this technique even for a helper class that's this simple. But doing so will make your code somewhat bigger and slower.
In our client class (DFilledCircle), we have to declare and instantiate the helper object:
We still have to implement the property in our class, since it's part of the IFillable interface we're implementing. This implementation just accesses the property in the helper class.
Again, note that in this particular simple case, we didn't save any code in the client class that uses the helper—and we created an extra object, and made method calls rather than accessing a field directly in our class. (Compare with DFilledRectangle.) Because this particular implementation doesn't save any code and is slower, Dr. GUI probably wouldn't use it even though it is a bit more flexible if you need to modify the code that deals with the property. But in more complex cases, this technique can be very valuable.
Using common code when the code isn't identical
Approach 1: Common entry point calls virtual method
The next problem we'll attack is that the Draw and Fill methods are almost, but not quite, identical. This means we have to have a way to do different behavior. Virtual methods provide one way to do that, delegates provide another. We'll use one technique for Draw and a different method for Fill.
In this first approach, we'll also take advantage of the fact that abstract/MustInherit classes, unlike interfaces, can contain code. So we provide an implementation of the Draw method that creates a pen along with the exception handler and Dispose and then calls an abstract/MustOverride method that actually does the drawing. Specifically, the DShapes class changes to accommodate this new Draw method and to declare the new JustDraw method (click to see all the code):
Public MustInherit Class DShape ' The fact that Draw is NOT virtual is somewhat unusual...usually ' Draw would be abstract (MustOverride). ' But this method is the framework for drawing, not the ' drawing code itself, which is done in JustDraw. ' Note also that this means that these classes has a different ' interface than the original version, although they ' do the same thing. Public Sub Draw(ByVal g As Graphics) Dim p = New Pen(penColor) Try JustDraw(g, p) Finally p.Dispose() End Try End Sub ' Here's the part that needs to be polymorphic--so it's abstract Protected MustOverride Sub JustDraw(ByVal g As Graphics, _ ByVal p As Pen) Protected bounding As Rectangle Protected penColor As Color ' should have property, too ' should also have methods to move, resize, etc. End Class
An interesting note: the Draw method is not virtual/Overridable. Since all derived classes will do this part of the drawing in the exact same way (if you're drawing on a Graphics, which by definition we are, you'll absolutely have to allocate and dispose of a pen), there's no need for it to be virtual/Overridable.
In fact, Dr. GUI would argue that in this case, Draw should not be virtual/Overridable. If it were conceivable that you'd want to override Draw's behavior (and not just the behavior of JustDraw), you'd want to make it virtual/Overridable. But in this case, there's no good reason to ever override Draw's behavior, and there's a danger in encouraging programmers to override it—they might not deal with the pen correctly, or they might do something other than call JustDraw to draw the object, thus breaking assumptions we've built into our class. So making Draw non-virtual (an option we don't even have in Brand J, by the way) makes our code perhaps less flexible but also more robust—Dr. GUI thinks that in this case, this is the right trade-off.
A typical implementation of JustDraw looks like this (this one is from the DHollowCircle class; click to see all the code):
As you can see, we've achieved the simplicity in the derived class implementations we were looking for. (The implementations in the fillable classes are only slightly more complicated—we'll see that later.)
Note that we've added an additional public method to our interface called JustDraw that takes, in addition to the Graphics object on which to draw, a reference to the Pen object we created in Draw. Since this method needs to be abstract/MustOverride, it must be public.
This isn't a huge problem, but it is a change to the public interface of the class. So even though this approach of factoring out common code is simple and convenient, you might choose the other approach to avoid having to change the public interface.
Approach 2: Virtual method calls common helper method, using callback
When it comes time to implement the Fill method of the interface, the complication of the code is similar: there's one unique line out of six lines of implementation. But we can't put the common implementation into the interface, since interfaces are purely declarations; they contain no code nor data. In addition, the approach outlined above isn't acceptable because it would change the interface—we might not want to do that, or we might even not be able to do that because someone else created the interface!
So what we need to do is to write a helper method that does the setup and then calls back into our class to allow it to actually do the fill. For this example, Dr. GUI put the code in a separate class so that any class could use it. (If you were taking the approach for implementing Draw, you might want to implement the helper method as a private method in the abstract base class.)
Without further ado, here's the class we created (click to see all the code):
' Note how the delegate helps us still have polymorphic behavior. Class FillHelper Public Delegate Sub Filler(ByVal g As Graphics, ByVal b As Brush) Shared Sub SafeFill(ByVal i As IFillable, ByVal g As Graphics, _ ByVal f As Filler) Dim b = New SolidBrush(i.FillBrushColor) Try f(g, b) Finally b.dispose() End Try End Sub End Class
Our helper method called SafeFill takes a fillable object (note we're using the IFillable interface type here, not DShape, so that only fillable objects can be passed!), a Graphics to draw on, and a special variable called a delegate. You can think of a delegate as a reference not to an object, but to a method—if you've programmed much in C or C++, you can think of it as a type-safe function pointer. The delegate can be set to point to any method, whether an instance method or a static/Shared method, that has the same types of parameters and return value. Once the delegate is set to point to an appropriate method (as it will be when SafeFill is called), we can call that method indirectly through the delegate. (By the way, since delegates aren't available in Brand J, this approach would be considerably more difficult and less flexible if you were using it.)
The declaration for the delegate type Filler is just above the class declaration—it's declared as a method that returns nothing (a Sub in Visual Basic .NET) and takes a Graphics and a Brush as parameters. We'll be discussing delegates more in-depth in a future column.
The SafeFill operation is simple: it allocates the brush and sets up the Try/Finally and Dispose as common code. It does the variable behavior by calling the method referred to by the delegate we received as a parameter: "
f(g, b)".
To use this class, we'll need to add a method to our fillable object classes that can be called through the delegate, and be sure to pass a reference (the address) of that method to SafeFill, which we'll call in the Fill implementation of the interface. Here's the code for DFilledCircle (click to see all the code):
So when the object needs to be filled, IFillable.Fill is called on the object. That calls our Fill method, which calls FillHelper.SafeFill, passing a reference to our self, the Graphics object we were passed to draw on, and a reference to the method that will actually do the filling—in this case, our private JustFill method.
SafeFill then sets up the brush and calls, via the delegate, our JustFill method, which does the fill by calling Graphics.FillEllipse and returns. SafeFill disposes of the brush and returns to Fill, which returns to the caller.
Finally, JustDraw is very similar to Draw in the original version in that we both call Fill and call the base class's Draw method (this is what we did before). Here's the code for that (click to see all the code):
Remember that the complication of allocating the brushes and pens is dealt with in the helper functions—in the case of Draw, in the base class; in the case of Fill, in the helper class.
If you think that this is a bit more complex than before, you're right. If you think it's a little slower than before because of the extra calls and the need for dealing with a delegate, you're right again. Life is about trade-offs.
So, is it worth it? Maybe. It depends on how complicated the common code is and how many times it would be duplicated; in other words, it's a trade-off. If we'd decided to eliminate the Try/Finally and simply dispose of the pen and brush after we were done drawing with them, that code would have been simple enough that neither of these approaches would have been warranted (unless the maintenance advantage was important). And in C#, the using statement is simple enough that we probably wouldn't want to bother with these approaches, either. Dr. GUI thinks that the Visual Basic case using Try/Finally is on the borderline as to whether it's worthwhile to use one of these approaches or not, but he wanted to show these approaches to you in case you have situations with more complicated code.
Making Our Objects Serializable
We need to make one more change to our drawable objects classes in order to use them with ASP.NET: they need to be serializable so that the data can be passed between the main Web page and the Web page that generates the image (more on this later). Serialization is the process of writing the data for a class to a storage medium in a way that it can be stored and/or passed around and deserialized later. Deserialization is the process of re-creating the object from the serialized data. We'll discuss this more in-depth in a later column.
When Dr. GUI originally wrote this application as a Windows Forms application, he used only the stock brushes and pens available in the Brushes and Pens classes that are pre-allocated by the .NET Framework and the operating system. Since these are already allocated, keeping references to them doesn't hurt anything, and they don't need to be Disposed.
But pens and brushes, because they can be pretty complicated objects, are not serializable, so the good doctor had to change his strategy. He decided to store the color of the pens and brushes instead, and to create pens and brushes on the fly as the objects need to be drawn and filled.
How do you make things serializable?
Serialization is a big part of the .NET Framework, so the Framework makes it easy to serialize objects.
All we have to do to make a class serializable is to mark it with the Serializable attribute. (This is the same kind of attribute we used before on our enumeration to mark it as a set of flags.) The syntax in C# and Visual Basic .NET is as follows:
C#
Visual Basic .NET
A note: in addition to marking your class serializable, all of the data your class contains has to be serializable as well or the serialization framework will throw an exception when you attempt to serialize the data.
Making the container serializable, too
One of the cool things about the .NET Framework is that the container classes are serializable. That means that if you store objects in them that are serializable, the container will automatically be able to serialize them, too.
So in our case, the DShapeList class contains two ArrayList objects. Since ArrayList is serializable, all we have to do to make DShapeList serializable is to mark it with the Serializable attribute as follows:
Visual Basic .NET
C#
Provided that the objects we place in the DShapeList are all serializable, we will be able to serialize and de-serialize the whole list with a single statement!
By the way, this would be a good change for the Windows Forms versions of the applications because it would allow us to write our drawings out to a disk file and load them back in.
Three versions of drawable objects; any can be used in any context
You've probably noted by now that we have three versions of our drawable objects code: one each in C# and Visual Basic .NET that do not use the helper methods we wrote just above, and one in Visual Basic .NET that does use the helpers.
There is one other minor difference: the data classes in the file with the helpers are marked as Serializable; the data classes in the other files are not.
But note this very important point: if we went back and marked the data classes in all the files Serializable, we'd be able to use any of the classes with any of the applications. We'd be able to mix C# and Visual Basic .NET. And we'd be able to use code originally written for a Windows Form application with an ASP.NET application.
This kind of easy code re-use means that the code you write is more valuable, since it can be reused in so many different places.
Using Our Drawable Objects in a Windows Forms Application
Now that we've discussed the drawable objects classes, let's talk about how we make use of them in a Windows Forms application. First, let's talk a little about how Windows Forms applications work.
Main Parts of a Windows Forms Application
Simple Windows Forms applications consist of a main window, or form, that contains children that are controls. If you're a Visual Basic programmer, you'll find this model very familiar.
The Main Window
The key object in any Windows Forms application is the main window. This form will be created in the static/Shared Main method of your application, as shown below.
In a simple Windows Forms application like we're writing, all of the other controls will be children of this main form.
Buttons and Text Boxes
Our form has a set of buttons and a few text boxes. Each button has a handler that causes a shape to be added to the list and the list to be drawn. The text boxes are included to show you how to get input from a form. And there's a group box to provide a visual indication about the text boxes and associated buttons.
PictureBox
On the left is the most important control of all: the PictureBox. This is where the image is drawn and displayed. In a Windows application, you need to be able to redraw the image at any time—for instance, if the window is minimized or covered by another window, you'll need to redraw when the window is again exposed.
This on-demand drawing is done in response to the Paint message, which is handled by an event handler in the parent form window class.
Main Routines in a Windows Forms Application
Let's take a quick look at the important routines in our Windows Forms application. Note that the code for the UI is quite short compared with the code for the drawable objects. That's the power of having the .NET Framework doing a lot of the work for you. (And it shows we did a pretty good job with the drawable objects classes.)
Form methods
The form, or main window, is derived from System.Windows.Forms.Form, so it inherits all of its behavior. All of the controls are declared as members of this class, so they'll be disposed when the class is disposed (which is actually done explicitly in the Dispose method).
It also contains declarations for the data we need (the DShapeList and a random number generator object), Main, and event handlers for button clicks and the paint event of the PictureBox.
Main
Main's job is simply to create and run the main window object. The code for this in C# is below.
C# (click to see all the code)
The STAThread attribute is important for Main of Windows Forms applications—you should always use it so that functionality that relies on OLE Automation (such as drag-and-drop and the Clipboard) will work correctly.
You won't find this method in the Visual Basic .NET source code generated for you by Microsoft Visual Studio®; but if you look in the generated .exe using ILDASM, you'll find a Main that does the same thing as the one above—probably generated by the Visual Basic .NET compiler.
InitializeComponent
Under Windows Form Designer generated code (click on the little plus sign if you can't see the code in this region), you'll see the code for creating and initializing all of the buttons and other controls on the form. You can click to see all the code for C# and for Visual Basic .NET, including this region.
Data declarations/random number generation
In addition to all of the controls declared in the hidden region of your code, we also need to declare two variables: the data structure to hold our drawing list, and an object of type Random. We use the Random object to generate random numbers for the positions of objects we create. You can check the Random class reference documentation.
The data declarations are inside the MainWindow class but outside of any method. In C# and Visual Basic .NET, it looks like the following:
C#
Visual Basic .NET
We also wrote a helper method to get a random point:
C#
Visual Basic .NET
It generates two random numbers between 30 and 320 to use as the coordinates for our random point.
Button click event handlers
The next thing we have is a button click handler for each button. Most of them just add a new drawable object to the drawing list and call Invalidate on the PictureBox, causing it to repaint using the updated drawing list. Code for a typical button handler is as follows:
C#
Visual Basic .NET
The Change fills to hot pink button is a little different—it gets an array of all the fillable objects in the list, then changes their brush color to hot pink. The code for that is shown above at the end of the Returning the fillable list section. (You also have to invalidate the PictureBox.)
Lastly, the Erase All button simply creates a new drawing list and makes our drawingList field point to it. By doing this, it releases the old drawing list for eventual garbage collection. It then invalidates the PictureBox so it's erased, too.
PictureBox paint event handler
The last item we have to take care of is painting the image in the PictureBox. To do this, we handle the Paint event that the PictureBox generates, and use the Graphics object we're passed by this event to draw on. To do the drawing, we just call the drawing list's DrawList method—a for each loop and polymorphism take care of the rest!
C# (Click to see all the code).
Visual Basic .NET (Click to see all the code).
This concludes our tour of the Windows Forms applications—play with the code and modify it some to learn more!
Using Our Drawable Objects in an ASP.NET Application
Although there are some differences between ASP.NET Web applications and Windows Forms applications, the amazing thing to Dr. GUI is how similar the two types of applications are! So if you're used to Visual Basic forms or Windows applications, this section should help you make the transition to ASP.NET Web applications.
By the way, once again, you can run the ASP.NET application.
Main Parts of a Web Forms Application
The main parts of the ASP.NET Web Forms application correspond closely to the parts of the Windows Forms application.
The Page
This corresponds to the main window in the Windows Forms application. The page is the container for all of the buttons and other controls.
Buttons
Again, there is a set of buttons that cause actions to be performed on the form. Note that, unlike in our previous applications, we set the pageLayout property of the page's document to GridLayout rather than FlowLayout. That means that we'll be able to position each button (and other control) exactly by pixel position.
Note that there are a few text boxes, too.
Note also that you can't copy and paste Windows Forms controls into a Web Form—you'll have to create the page all over again.
Image Control
The image control corresponds to the PictureBox in the Windows Forms application. However, there are some important differences: instead of generating Paint messages, the image control contains the URL from which we'll load our image.
We set this URL to be a second Web page, ImageGen.aspx. In other words, we have a Web page whose whole job is to generate the bits in the image from our drawing list, and to send that image to the client's Web browser.
We'll discuss the code for this below.
Main Routines of a Web Forms Application
There are some important differences between the code for Windows Forms applications and Web Forms applications—but there are some interesting similarities, too. And note that all the code in the drawable objects file can be used for any of the three applications.
Our page is derived from
System.Web.UI.Page and has a bunch of declarations for all of the controls, in addition to:
All the same: Data declarations and GetRandomPoint
This code is almost the same as in the Visual Basic .NET Windows Forms application. If you like, take another look at it above. The one difference is that the fields are declared but not initialized. They'll be initialized in the Page_Load method (see below).
The GetRandomPoint method is exactly the same as in the other applications. Being able to reuse code is cool, isn't it?
Very similar: Button click handlers
The button click handlers are the same as in the Windows Forms applications with one exception: since the image will be redrawn each time a button is clicked on the Web form, there's no need (and no way) to "invalidate" the image control. Rather, it will be redrawn automatically—so the only call is to the drawing list's Add method.
Here's a typical button handler—this one for a point (click to see all the code):
The other button handlers are similar to the Windows Forms case, with the exception, of course, of not calling any sort of method to invalidate the image.
Very different: Page load and unload handlers
What's totally new is that page load and unload handler methods.
Remember that our page object is created anew with each HTTP request. Since it's created anew with each request, we cannot store data as member variables as in the Windows Forms case, where the main window exists as long as the application exists.
So we'll have to store the information we need between requests and across pages in some sort of state variable. There are several options here—we'll discuss this next.
Passing State Between Pages and Requests
In order for our application to work, it needs to be able to maintain state between requests and to pass that state to the drawing page (see below).
There are several ways of maintaining and passing state. If our application was strictly a single-page application (as previous applications were), you could use view state, where the data is encoded in a hidden input field in the Web page.
But our image control does its drawing in a separate page, so we need something more flexible. Our best choices are cookies and session state. Session state is very flexible, but requires server resources to use. The browser maintains cookies, but they're very limited in size.
Page_Load
Page_Load is called after the page object is created but before any event handlers are run. So our Page_Load method is a perfect place to attempt to load our persistent data. If we don't find it, we create new data. Here's the code:
Private Sub Page_Load(ByVal sender As System.Object, _ ByVal e As System.EventArgs) _ Handles MyBase.Load randomGen = ViewState("randomGen") If randomGen Is Nothing Then randomGen = New Random ' Option 1: use Session state to get drawing list ' (saved in Page_Unload) ' (Note: requires state storage on server) drawingList = Session("drawingList") If drawingList Is Nothing Then drawingList = New DShapeList ' Option 2: Session state using SOAP (or base 64) serialization ' Note: helpers convert to string; might be better to stop at ' stream or byte array.... : retrieve drawing state from cookie ' on the user's browser ' (Note: no server storage, but some users disable cookies) ' (2nd note: deserialization is not automatic with cookies! :( ) ' (3rd note: Using a cookie will severely limit the number ' of(shapes you can draw) End Sub
First, we attempt to load the random number generator state from the view state. If it's there, we use the stored value. If it's not, we create a new Random object.
Next, we attempt to load the drawing list from the session state. Again, if there's no drawing list present, we create an empty one.
Both the view state and the session state automatically serialize our objects if need be. The view state is always serialized so it can be represented as an encoded string in a hidden input field in the browser. The session state is serialized if it's to be stored in a database or passed between servers, but it's not serialized if your application is running on a single server, as in when testing on your development machine.
The "Option 2" commented-out code would load the drawing list from the session state, but by using either SOAP serialization or Base64 encoding of binary serialization. In either case, this code converts the serialized stream into a string. This isn't necessary for saving your data in session state, since session state automatically serializes. However, it can be interesting to read the SOAP representation of your data—you might try this in the debugger sometime.
The "Option 3" commented-out code tries to load the drawing list from a cookie. Note that dealing with a cookie is considerably more complicated than dealing with view or session state. For one thing, you don't get automatic serialization. In order to serialize to a string, we wrote the helper function in a new class, as shown below (click to see all the code):
Public Shared Function DeserializeFromBase64String( _ ByVal base64String As String) As Object Dim formatter As New BinaryFormatter() Dim bytes() As Byte = Convert.FromBase64String(base64String) Dim serialMemoryStream As New MemoryStream(bytes) Return formatter.Deserialize(serialMemoryStream) End Function
Dr. GUI used a binary formatter and converted to a printable base 64 string because neither the SOAP nor XML formatters worked well for this serializing to cookies. We had to convert to a base 64 string from a pure binary representation to avoid potential problems with control characters in the string if we simply copied the bytes. The base 64 string uses one character A-Z, a-z, 0-9, + or / (that's 64, or 2^6, characters) to represent each six bits in the binary string, so four characters represent three bytes—the first character represents six bits in the first byte, the second character represents the last two bits of the first byte and the first four bits of the second byte, and so on. Again, the point is that by restricting our string to printable characters, we avoid any potential problems with control characters.
The XML formatter won't serialize private data—and Dr. GUI wasn't about to add public access to the private data in the drawing list. The SOAP formatter doesn't have that limitation, but produces such large strings that even a drawing object or two would overflow the capacity of a cookie. (Version 1.0 of the .NET Framework had a nasty bug where the SOAP formatter wouldn't serialize an empty list such that it could be deserialized. Instead, it wrote nothing to the stream for the empty list, causing an exception to occur when we attempted to deserialize, but that bug was fixed in Version 1.1.)
For readability, the good doctor would have preferred to serialize in a readable XML format, but since neither of the XML serialization formatters would do the job for cookies, he settled for the binary formatter and a conversion to a base 64 string.
Note, however, that the size restriction on cookies makes it impossible to save much data using them. Using session state usually works much better unless the data is very small.
Page_Unload
Page_Unload is called before the page object, including any contained data, is destroyed. So it's a great place to persist our important data so we can pick it up later in Page_Load (or in the image's Page_Load).
So we save the data in Page_Unload, and retrieve it in Page_Load. Seems a little strange, but it's the right thing to do.
Here's our code for Page_Unload (click to see all the code):
Private Sub Page_Unload(ByVal sender As Object, _ ByVal e As System.EventArgs) _ Handles MyBase.PreRender ViewState("randomGen") = randomGen ' Option 1: write session state using automatic serialization Session("drawingList") = drawingList ' Option 2: session state using SOAP (or base 64) serialization ' Since session state can serialize anything, didn't have to ' convert to string--but needed string for Option 3 ' Session("drawingList") = _' (or use SerializeToBase64String) ' SerialHelper.SerializeToSoapString(drawingList) ' Option 3: write a cookie. Must write code to serialize. ' NOTE: Using a cookie will severely limit the number of shapes ' you can draw--not even usuable with SOAP serialization because ' cookie size is limited and SOAP serialization takes a lot of ' space. 'Dim drawingListString As String = _ ' SerialHelper.SerializeToBase64String(drawingList) '' another option: SerializeToSoapString, but don't--see article 'Response.Cookies.Add(New HttpCookie("drawingList", _ ' drawingListString)) End Sub
This code is somewhat simpler since we don't have to check to see if the state is already in the view or session state object; we just unconditionally write it out.
Again, while view state and session state serialize themselves automatically, cookies do not, so we need to do it ourselves. Dr. GUI wrote the following helper function (in a separate class), with the code shown here:
Public Shared Function SerializeToBase64String(ByVal o As Object) _ As String Dim formatter As New BinaryFormatter() Dim serialMemoryStream As New MemoryStream() formatter.Serialize(serialMemoryStream, o) Dim bytes() As Byte = serialMemoryStream.ToArray() Return Convert.ToBase64String(bytes) End Function
(There are also helper functions for SOAP serialization in the complete code).
Drawing in a Separate Page
As we mentioned before, the drawing is done in a separate page. Here's the code for that page (click to see all the code):
Private Sub Page_Load(ByVal sender As System.Object, _ ByVal e As System.EventArgs) Handles MyBase.Load Dim drawingList As DShapeList ' Get the drawing list: ' Option 1: use session state w/ automatic serialization drawingList = Session("drawingList") If drawingList Is Nothing Then drawingList = New DShapeList ' Option 2: session state with SOAP/base 64 serialization ' (See main page code for more comments) : use a cookie... ' (See main page code for more comments)
First, we get the drawing list from session state or a cookie. (The code for this is similar to the Page_Load method above. See the section above for an explanation.)
Next, we set the ContentType of the response stream we're writing to be a GIF image.
After that, we do something really funky: we create a bitmap of the exact size we want (in this case, the same size as in the Windows Forms application).
Then we get a Graphics object associated with that bitmap, clear it, and draw our list onto it.
Here's the important part: we next write the image contents in GIF format out to the response stream (i.e. to the browser). We set the response type to make sure the browser interprets the image properly, and then sends the bits of the image. (The .NET Framework makes it amazingly easy to do this. Just drawing on a bitmap was a royal pain in the old Windows GDI days!)
The other important part is to remember to dispose of the Graphics and Bitmap objects—and use a Try/Finally so the objects will get disposed even if an exception is thrown.
Phew! That was a lot, but it was worth it to get this application running as an ASP.NET application—and better yet, one that relies on no client-side script. Check it out! You can run the application.
Give It a Shot!
If you've got .NET, the way to learn it is to try it out. If not, please consider getting it. If you spend an hour or so a week with Dr. GUI .NET, you'll be an expert in the .NET Framework before you know. Some of it is excerpted from larger programs; it's good practice to build up the program around those snippets. (Or use the code the good doctor provides, if you must.) Play with the code some.
Add a few different shapes, filled and unfilled, to the drawing program. A note: although we've not covered it yet, the classes you add could be in a different assembly (and therefore a different executable file) from the other files. That means that the classes you add could even be in a different language than the rest. You get extra credit for doing the reading and work necessary to make this work.
In the Windows Forms version of this program, use serialization to write your data out to a file so you can save and load drawings. For a real challenge, figure out how to print.
Add some methods to the classes here, and fiddle with the user interface. Make yourself a cute little CAD program.
Use inheritance, abstract/MustInherit classes, interfaces, and polymorphism in a project of your own choosing. Inheritance works best when the family of classes has a great deal in common. Interfaces work best when the classes don't have much in common but the functionality is similar.
Try doing your own drawing apps in ASP.NET. Note that if you can run the .NET Framework, all you need is Microsoft Internet Information Server (IIS) in order to run ASP.NET on your very own machine—no server required! Dr. GUI thinks it's indescribably cool to be able to build and test web applications on his three-pound laptop using just the standard OS and the free .NET Framework. (But the good doctor prefers to use Visual Studio or at least Visual Basic or Microsoft Visual C#® Standard Edition as well.) Look Ma! No server! You don't even need an Internet connection! (Try that with Brand J's extended edition….)
Yo! Let's talk!
Do you have some questions or comments about this column? Come visit the Dr. GUI .NET message board on GotDotNet.
What We've Done; What's Next
This time, we saw a more complete example of inheritance, abstract (MustInherit) base classes, and interfaces in a simple drawing application—and we did it using both Windows Forms and ASP.NET Web Forms.
Now that we understand how inheritance, interfaces, and polymorphism all work, next time we'll delve into the mother of all .NET Framework classes: System.Object. If we have time, we'll also discuss memory management, including garbage collection and Dispose. | https://msdn.microsoft.com/en-us/library/aa302310.aspx | CC-MAIN-2018-51 | refinedweb | 12,113 | 61.97 |
ES6 Features That Can't Be Ignored (part 1)
Now that we have some great starter projects for Angular 2 and React, it's easy to hit the ground running with ES6. I summed up the features that will change the way JavaScript Developers code. You can get a full Angular 2 environment here or you can go to es6fiddle or babeljs to test it online.
Let's get started!
Constants that are inconstant
Since JavaScript is Object Oriented, when you see 'constant', you can think that your object is going to stay the same forever.
Well not really.
This only concern the primitive, if you want to make an object immutable, you need to use Object.freeze, example:
const A = { name: 1 }; Object.freeze(A); A.name = 2; // fail
You can't be half a gangster
Do you like CoffeeScript? Well they tried to get some inspiration there. What most likely went through their mind: "Guys, we might as well put some CoffeeScript like syntax in it since it's very compact and readable. We will not use curly brackets anymore".
let array1 = [1, 2, 3]; let sum = array1.map(value => value + 1); // 2,3,4
"Ahhh nevermind I already miss those lovely brackets, let's put them back.":
let array2 = [1, 2, 3]; array2.forEach(num => { if (num == 2) console.log("number 2 found"); });
All this fumble because of implicit return. If you only have one line of code, you can skip the brackets since the returned value can only be the result of this line, if not, you need to add them.
So. Quick test.
1. Almost CoffeeScript (ES6):
let doSomething = x => { const a = x + 1; const b = a + 2; return b; }; doSomething(1);
2. CoffeeScript:
doSomething = (x) -> a = x + 1 b = a + 2 return b doSomething 1
Which one do you want to bring to prom night? (Hint: Number 2).
The very useful ones
The spread operator
This feature might be very useful if you are working with Angular 2 and the change detection doesn't kick in when you update an array.
This operator is a quick way to realise a concatenation or splitting a string:
const array1 = [1, 2, 3]; const array2 = [...array1, 4, 5]; // [1, 2, 3, 4, 5] const name = "Matthieu"; const chars = [...name]; // M,a,t,t,h,i,e,u.
let variableHere = "just a variable"; let a = `some text ${variableHere} other text`;
Export/Import
It's something that you must have encountered if you have read other articles about Angular 2. Here is an example:
export var a = 1; export cb = function(x,y) { console.log(x,y); }
import { a, cb } from "somewhere/over/the/rainbow"; cb(a, a); //Or import * as importedModule from "somewhere/over/the/rainbow"; importedModule.cb(importedModule.a, importedModule.a);
Property Shorthand
This one is by far my favourite.
Before:
const obj = { variableWithAnnoyingLongName: variableWithAnnoyingLongName, anotherVariableWithAnnoyingLongName: anotherVariableWithAnnoyingLongName };
Now with ES6:
const obj = { variableWithAnnoyingLongName, anotherVariableWithAnnoyingLongName };
Combined with the new Function Signature feature it gets more powerful ! [optin-cat id=1473]
Function Signature
We can now assign the parameters of a function:
- By default ex: doSomething(a=1, b=2)
- By destructuring:
const arr1 = [1, 2, 3]; function destructure([a, b]) { console.log(a, b); //1 2 } destructure(arr1);
- By changing the arguments names ex: f({a: name, b: age})
- Or by selecting them with a shorthand ex: f({name, age}) So now we can do cool things like:
function doSomething({ age, name, id }) { console.log(age, id, name); //26 2 } const age = 26; const id = 2; doSomething({ age, id });
The controversial one
Do you like JAVA? Well ES6 is now JAVA. Period. Next.
Joke aside.
There are many features that have been
stolen implemented from JAVA. The most obvious ones:
Classes:
class Animal { constructor(id, name) { this.id = id; this.name = name; } }
Inheritance:
class Bird extends Animal { constructor(id, name, featherType) { super(id, name); this.featherType = featherType; } }
Eric Elliott said about classes that they are "the marauding invasive species" you can (must) have a look at his well-described article here.
If you are ready to fight for your own style, prepare to receive friendly-fire from many of your Angular 2 colleagues.
Conclusion
ES6 comes with new features that make JavaScript looks like a different language.
Some features are really easy to use like the multi line strings. Others will however require a little bit of time to master like the use of constants.
The next post will be about generators, promises, symbols, destructuring assignment and many other features. | https://javascripttuts.com/es6-features-can-make-life-easy/ | CC-MAIN-2019-26 | refinedweb | 752 | 55.24 |
CLR via C#, Second Edition
Programming Microsoft Visual C# 2005: The Language
Programming Microsoft ASP.NET 2.0 Applications: Advanced Topics
Programming Microsoft ADO.NET 2.0 Applications: Advanced Topics
Programming Microsoft ASP.NET 2.0 Core Reference
Format: Paperback
Author: Francesco Balena
ReleaseDate: 10 May, 2006
Publisher: Microsoft Press
Rating:
Programming Microsoft Visual C# 2005: The Base Class Library (Pro-Developer)
. I found the book on time in good condition.
Francesco Balena never disappoints
Francesco Balena is one of them (yes, Jeffrey Richter is another one). There are only a few authors who writes about Microsoft technologies whose book you can buy without reading reviews. Both of these authors write for a particular segment of developers - those who have some programming experience and have tried some things on their own or have read some beginner's book and is ready for the serious stuff. The style is lucid, but no stone is left unturned on the topic being discussed. Both of them (Balena and Richter) also give practical coding advices which we wont find in the usual programming books. The approach is very pragmatic without losing the spirit of good programming idioms. Well, I am diverging. The point is - you dont need to read any reviews to buy a Balena book - rush to the store and get it. They are all gems.
Well, if you are still reading this and have not ordered it yet, it means you are interested in knowing a bit more about the book. This book is almost a C# port of his book Visual Basic 2005 book. The chapters go like this :
1. . NET Framework basic types - Balena speaks about the System. Object type, String types, Numeric types,DateTime type etc.
2. Object Lifetime - Memory management, Garbage collection etc.
3. Interfaces - Usage of common interfaces in . NET like IComparable, IDisposable etc.
4. Generics - Why we need Generics, how to write generic code and some advanced topics like support for Math operators.
5. Arrays and Collections - The different types of arrays, overview of System. Collections namespace as well as Generic collections.
6. Regular Expressions - This is an excellent tutorial of using regular expressions in . NET
7. Files, Directories and Streams - IO in . NET is a bit confusing, this chapter might help to clear things up.
8. Assemblies and Resources - Everything u need to know about assmeblies.
9. Reflection - Working with assemblies, modules, types - retrieving information about assembly at runtime and how to use that information.
10. Custom Attributes - how to create custom attributes, shows some scenarios for using custom attributes.
11. Threads - Thread fundamentals, synchronization, Thread pool etc. This is a very nice tutorial for using Threads in . NET
12. Object serialization - Serialization techniques - both built-in and custom.
13. PInvoke and COM Interop - Nice introduction, shows how to call plain C DLLs, and COM DLLs from . NET and also calling . NET components from COM. For more details get Adam Nathan's book.
Well, that is it. . . Not fit as your first C# book, but if you know some C#, this is a very good book for anybody. | http://www.linux-directory.com/programming/Programming-Microsoft-Visual-C-2005-The-Base-Class-Library-Pro-Developer.shtml | crawl-001 | refinedweb | 513 | 67.15 |
Create a HTML Mashup in SAP Cloud for Customer to Consume a Google Map API and combines it with Cloud Application Studio: Add Facet (Embedded Component) based on BO Extensions by @stefankrauth.
This will be the final screen of this tutorial:
The outline for this document will be:
1. Create a Business Object Extension for Customer
2. Create an Embedded Component to display the map
3. Extend Individual Customer TI Screen with Embedded Component
4. Create HTML Mashup to consume Google Maps API
5. Create Port Type Package (PTP)
6. Add the Mashup to the Embedded Component
We have lots of things to do, so let’s start 🙂
1. Create a Business Object Extensin for Customer
First create a folder for this BO extension. It is a good practice to organize your objects in folder in Cloud Applications Studio. Without folders, it will be very difficult for you to organize your objects when the solution gets crowded.
So let’s create a folder and name it as GoogleMaps. (Right click on your Solution and Add->New Folder)
In this new folder we will create our objects. Right click on GoogleMaps folder and add Business Object Extension for Customer. Name it as XBO_Customer.
It will ask you to select the Business Object to extend.
Customer is in namespace, so select it. And then select Customer from the dropdown list.
We will extend Common node of standard Customer BO. In common node add the code below:
We created FE_address field to keep the complete formatted address of the Customer. To do this we should implement Before Save event of Root node.
Right click on the XBO_Customer and click on Create Script Files option. Create Script Files dialog will popup. Select Event:BeforeSave of Root node. Make sure you uncheck Mass Enable column.
In the code editor of BeforeSave Event write the ABSL code below:
We have finished Business Object and Event Extension part. Save and Activate your work.
2. Create an Embedded Component to display the map.
We will create an Embedded Component to extend standard Customer TI screen. In this EC we will first catch the current Customer Instance and read the FE_address data to use it as a map parameter.
To create EC, right click on the GoogleMaps folder and Add->New Item ->Embedded Component. Name it as EC_Map_Address.
Double click on the newly created EC to edit it in UI Designer.
In the UI Designer, open the DataModel tab. Right click on the Root element and select Add Data Structure. Name it as Inport.
On the Inport structure, right click and select Add Data Field. Name the data field as AccountID. Your structure shoul look like this:
Now, we will bind this data model to Customer business object. To do this we have to select the namespace first. Namespace is and the business object is Customer.
Drag and drop InternalID field from Customer BO on to the Root of our Data Model. InternalID field will be added to our model and our model will be bound to Customer. (You may need to Drag it twice.)
Next, switch to Controller tab of the UI Designer. Right click on the Inports folder and click Add Inport. For the added InPort add a parameter and name it as AccountID. Bind this parameter to AccountID of the Inport Structure (which you created in data model).
Next, open the Properties of our InPort. InPort has RequestFireOnInitialization attribute. Set its value to true.
RequestFireOnInitialization will enable InPort to fire the declared event handler, when it is filled (initialized).
We will declare this event handler now. Under the Events section of InPort properties, there is an event as OnFire. To create an event handler for this event select …New Event Handler… .
New Event Handler screen will popup. Name the event handler as ReadCustomer. This event handler will read the current instance of the Customer. Configure it as follows:
In the event handler, create a BO Operation of type Read to read the current Customer. The parameter type should be alternativeKey, bind it to /Root/Inport/AccountID and the path should be /Root/InternalID.
Now the Inport configuration is set. To see the result we will add two fields on the Designer. Switch to Designer tab page. On the right side of the UI Designer, open BO Browser/Data Model view. Open Data Model pane of this view.
Drag and drop InternalID and InPort/AccountID from the Data Model onto the screen. Rename the texts as InternalID->Current Customer ID and AccountID->Inport AccountID.
Save and Activate your changes. You can close UI Designer and come back to the Studio.
3. Extend Individual Customer TI Screen with Embedded Component
Since we have our Embedded Component ready, we can now bind it to Individual Customer TI screen. In our GoogleMaps folder, we already created XBO_Customer business object extension. Now we will select the screen to embed our EC_Map_Address.
Right click on XBO_Customer and select Enhance Screen. We will enhance COD_SEOD_IND_ACCOUNT_TI (Thing Inspector) screen which is the big object screen for Individual Customer. Select it and click on OK button.
Double click on the COD_SEOD_IND_ACCOUNT_TI object to open it in UI Designer. We will add our embedded component on this standard screen. The only way to interact with the standard C4C screens is by Extensibility Explorer. Open Extensibility Explorer view on the right.
Our embedded component (EC_Map_Address) will be added as a facet on the main TI screen. The facet menu is under Undefined entity.
Click on Add View with embedded Component button in the Operations section. Add Embedded Component popup screen will open.
Write down tne name of your facet as MAP LOCATION. Make sure it is all in capital letters. For Embedded Component select your EC_Map_Address.
Now we selected our EC and it is time to bind the Individual Customer outport to our EC inport. Click on Bind button. The bind configuration dialog will popup.
Select PublicOutportECIndCustomerRoot as Outport and AccountID as Outport Parameter. On the right side, select InPort as Inport and AccountID as parameter. After selecting both sides click on Bind button in the middle. If bind is successfull click on OK and then Apply.
Now, you shall se your MAP LOCATION facet on Individual Customer TI screen.
Let’s check if our embedded component works or not.
Login to your C4C system as a business user and open any Individual Customer to see the screen. If you navigate to MAP LOCATION facet you should see both fields are filled automatically. This means our EC and binding works.
Since we got the current customer via our binding, we can use this to get the formatted address.
We have already created a field to keep the formatted address in Section 1. The field name was FE_address and now we will use it in our EC screen.
Open EC_Map_Address in UI Designer and navigate to DataModel tab screen. (Switch to Edit mode if it is in Display.)
Right click on the Root node and Add Data Structure. Name the newly created structure as Address. Right click on it and Add Data Field. Rename the field as FE_address.
On the right side, navigate to Common node of Customer. We created our FE_address in Common node while extending the BO, so the field should reside there. Drag and drop FE_address field from Common node on to the FE_address under Address structure on the left. Now the binding is done and we can use this field on the screen.
Switch to Designer tab. On the right side of the screen, open BO Browser/Data Model view and switch to Data Model pane. Drag and drop the FE_address field on to the EC screen.
Double click on the label of FE_address and override the label text as Main Address.
Save and Activate the EC and test again on C4C screen.
You may see the Main Address as empty in MAP LOCATION facet. Don’t panic 🙂 This is expected, because our FE_address fied is empty. We set it to be copied in BeforeSave event. And since we didn’t save this customer, it is still empty. Now let’s add address to our Individual Customer and save it.
After save, you will see Main Address in MAP LOCATION facet is filled automatically. Our binding works fine and we are ready to move on.
Before leaving this section, let’s hide the ID fields and Pane Header of our facet. In UI Designer, switch to Design tab. First select Pane Header and open Properties on the right. Set Show Header to false.
Next select Current Customer ID field and set Visible attribute to false. Repeat for Inport AccountID field.
Save and Activate EC and test it one more time.
So far everything seems fine. Let’s move on to HTML mashup configuration.
4. Create HTML Mashup to consume Google Maps API
To create the Mashup, right click on the solution folder and Add New Item. From the Mashups and Web Services list select HTML Mashup. Name it as GoogleMapsAddressMashup. (Make sure you enabled Admin mode in the Studio.)
After clicking on Add button, New HTML Mashup screen will appear. Configure the Mashup as follows:
- Mashup Category: Productivity & Tools
- Port Binding: URL Navigation
- Mashup Name: GoogleMapsAddressMashup
- Mashup Description: Custom Mashup to display Google Maps on Individual Customer TI.
- Status: Active
- Type: URL
- URL:
Click on Add button to add parameters. We will add two parameters for this mashup.
- Parameter 1:
- Name: output
- Constant: embed
- Mandatory: yes
- Parameter 2:
- Name: q
- Parameter Binding: URL
- Mandatory: yes
Click on Preview button, if it shows Google Maps then you can Save and Close your mashup.
MashupConfiguration folders will be added to your solution automatically.
5. Create Port Type Package (PTP)
PTP Definition from SDK: A PTP hosts one or more port types. A port type is a blueprint for an inport or an outport. You can create a PTP to facilitate navigation between components that have inports and outports within the same PTP without any mapping.
So we will create a PTP for our HTML Mashup. To create the PTP, right click on GoogleMaps folder and select Add->New Item. From the object list select PTP and name it PTP_GoogleMapsAddress.
After clicking Add button, the Studio will ask for the business object. Select Customer and click OK.
Double click on the created PTP to configure it in UI Designer. Configure the PTP as follows:
- Right click on the Root node and select Add PortType.
- Rename the created Port Type as Google_Maps_URL.
- Right click on the Port Type and click Add Parameter.
- Rename the parameter as URL.
- Right click on the parameter again and select Set as Key.
Save and Activate the Port Type Package. The PTP should look like this:
6. Add the Mashup to the Embedded Component
As the final step, we will add the HTML Mashup (GoogleMapsAddressMashup) to the Embedded Component (EC_Map_Address).
Open the EC_Map_Address in UI Designer and switch to Edit mode.
On the top bar, click on the Add FlexLayoutRow button. The Designer will add a new row.
We will add the Google Maps Address Mashup in to this new row. In the Configuration Explorer on the left, navigate to <Your Solution>_MAIN -> SRC -> Mashups -> Pipes. Drag and drop the HTML Mashup on to the EC.
Switch to Controller tab of EC. We will configure the Outport to . Right click on Outports and select Add Outport.
For the Outport Configuration, select the previously created PTP (PTP_GoogleMapsAddress). Select Google_Maps_URL for PortType Reference. URL parameter will appear.
Add a new parameter and name it as Address. Select the Key checkbox and for Parameter Binding select FE_address in path /Root/Address/FE_address.
Now it is time for Mashup Configuration. Select the mashup listed below Mashup Configuration. On the right side switch to Simple Navigation. You will see Navigations folder. Right click on this folder and select Add Navigation.
For Source details: Select OutPort for OutPort.
For Target details: Selet URL_Navigation_Info_In for InPort.
Finally bind the Address and URL. Your Mashup Configuration should be like this:
Save and Activate your Embedded Component. We are ready to see the final result.
Login to C4C as a business user and open Individual Customer TI screen and navigate to MAP LOCATION facet.
And here is our pretty map showing the exact location of our Customer 🙂
It works in HTML5, Silverligt Client and Fiori Client.
HTML5 Client.
Silverlight Client:
Here is the screenshot of IPhone C4C Extended App. (Fiori Client)
Hi,
Do we need to buy Google APIs in the above scenario for Location Positioning and tracking?
Regards,
Hemant
Hi Hemant,
You can check the pricing here:
Regards
Hi,
Do I need to buy an Google API to do the steps?
Best regards,
Iulia
Hello Iulia,
No you don’t need to buy Google API. At least in my case, I didn’t buy one.
Cheers
Hello Arda,
Thank you very much.
Have a nice day,
Iulia | https://blogs.sap.com/2017/08/28/html-mashup-for-google-maps-api-in-sap-cloud-for-customer-c4c-a-step-by-step-tutorial/ | CC-MAIN-2018-43 | refinedweb | 2,156 | 68.67 |
this code GLCD.DrawLine(31,31,31,0); creates a vertical line not a horizontal
This may be a really silly question. Is there a document that shows all the commands for these glcd screens? Or do you just have to pick apart the examples. IV got my screen working but im having trouble getting complex functions to materialize.Thanks, swiffty
Is there some way to change pin assignments without editing the .h files? I tried doing a #define in my sketch but it doesn't seem to make any different. Also tried #undef and #define.Thanks...
What is the driving need?
Hi Bill,Thank you for your time on this great update.I just installed v3 RC2 on my Teensy++ v2 and it works great. It shows 16.4 FPS.A request -- Please consider including the ks0108_Teensy++.h config file, attached.Thanks again for your time on this project.Regards,Larry
void glcd::BarGraph(uint8_t x, uint8_t y, uint8_t width, uint8_t height, uint8_t fullval, uint8_t currentval){ float range = (float)width / (float)fullval; int currentwidth = currentval * range; GLCD.DrawRect(x, y, width, height); for (int i = 1; i < height; i++) { GLCD.DrawHLine(x, y+i, currentwidth);} GLCD.FillRect(x+currentwidth+1, y+1, width-currentwidth-2, height-2, WHITE);}
void BarGraph(uint8_t x, uint8_t y, uint8_t width, uint8_t height, uint8_t max, uint8_t current);
#include <glcd.h>#include "fonts/fixednums15x31.h"long sec = 0;int min = 0;long starttime; void setup() { GLCD.Init(NON_INVERTED); GLCD.ClearScreen(); }void loop() { gText ClockArea; ClockArea.DefineArea(20, 0, 6, 1, fixednums15x31); ClockArea.CursorToXY(2,0); sec = (millis() - starttime) / 1000; if (sec > 59) { min++; sec = 0; starttime = millis(); } if (min < 10) { ClockArea.print(0);} ClockArea.print(min); ClockArea.print(":"); if (sec < 10) { ClockArea.print(0);} ClockArea.print(sec); GLCD.BarGraph(10, 40, 108, 8, 59, sec);}
What happened to the "Pinout D panels" that were described on have the same display as described on and was trying to hook it up to de V3 GLCD library.Any ideas???
I made a function that creates a bar graph, for anyone interested. To use it, simply add this to your glcd.cpp file:
Quote from: thehobojoe on Jun 15, 2011, 07:29 pmI made a function that creates a bar graph, for anyone interested. To use it, simply add this to your glcd.cpp file:While this works well, it will be expensive in terms of code space because of the use of floating point.It should be possible to re-arrange the calculations to use simple integer math.--- bill
Please enter a valid email to subscribe
We need to confirm your email address.
To complete the subscription, please click the link in the
Thank you for subscribing!
Arduino
via Egeo 16
Torino, 10131
Italy | http://forum.arduino.cc/index.php?topic=56705.msg464175 | CC-MAIN-2015-11 | refinedweb | 457 | 68.26 |
In the next few posts, we will be working with Isolated Storage on the phone. In this post, we are going
to cover the basics of saving to, and reading from storage. As we move forward we will modify this application with more complexity and best practices.
If you have every used the System.IO namespace in your .Net projects, you will find working with the storage on the phone very simple. It is just an extension of that namespace called System.IO.IsolatedStorage.
The first thing we want to do is to create a simple application that allows us to save some data. We create a PhoneApplicatiton and add some TextBoxes and TextBlocks as shown on the left.
As you can see, we want to capture three simple points of data, First Name, Last Name, and Age.
If we go to the code behind file, we first need to add the using statements for IsolatedStorage.
using System.IO.IsolatedStorage;
Next, lets look at the code that lies under the Set button. As you can see, we first create the storage for the application and then define a streamwriter that we will use to write our data to storage
{
//get the storage for your app
IsolatedStorageFile store = IsolatedStorageFile.GetUserStoreForApplication();
//define a StreamWriter
StreamWriter writeFile;
Since we will be writing to this file many times, we need to determine if this is the first time that someone has used the application. If it is, we create a folder and a file, if it is not, we just open the file and append it.
{
//Create a directory folder
store.CreateDirectory("SaveFolder");
//Create a new file and use a StreamWriter to the store a new file in the directory we just created
writeFile = new StreamWriter(new IsolatedStorageFileStream("SaveFolder\\SavedFile.txt", FileMode.CreateNew, store));
}
else
{
//Create a new file and use a StreamWriter to the store a new file in the directory we just created
writeFile = new StreamWriter(new IsolatedStorageFileStream("SaveFolder\\SavedFile.txt", FileMode.Append, store));
}
Now we gather the data needed, add a comma to seperate the data, and save the data to the file we created in the last step.
str.Write(txtFirstName.Text);
str.Write(",");
str.Write(txtLastName.Text);
str.Write(",");
str.Write(txtAge.Text);
writeFile.WriteLine(str.ToString());
writeFile.Close();
txtFirstName.Text = string.Empty;
txtLastName.Text = string.Empty;
txtAge.Text = string.Empty;
}
Now that we have the data saved to file. We can retrieve the data using a StreamReader. This is the code under the GET button.
IsolatedStorageFile store = IsolatedStorageFile.GetUserStoreForApplication();
//use a StreamReader to open and read the file
StreamReader readFile = null;
try
{
readFile = new StreamReader(new IsolatedStorageFileStream("SaveFolder\\SavedFile.txt", FileMode.Open, store));
string fileText = readFile.ReadToEnd();
//The control txtRead will display the text entered in the file
txtReturn.Text = fileText;
readFile.Close();
}
catch
{
//For now, a simple catch to make sure they created it first
//we will modify this later
txtReturn.Text = "Need to create directory and the file first.";
}
This will read the file and place it in the TextBlock as shown below.
Download the files for this post
In our next post on IsolatedStorage, we will modify this section to read, search, and delete specific records.
Happy Coding
Daniel Egan – The Sociable Geek | https://thesociablegeek.com/uncategorized/wp7-saving-to-isolated-storage/ | CC-MAIN-2022-40 | refinedweb | 538 | 55.95 |
.net; 27 28 import java.io.*; 29 30 /** 31 * This class provides input and output streams for telnet clients. 32 * This class overrides write to do CRLF processing as specified in 33 * RFC 854. The class assumes it is running on a system where lines 34 * are terminated with a single newline <LF> character. 35 * 36 * This is the relevant section of RFC 824 regarding CRLF processing: 37 * 38 * <pre> 39 * The sequence "CR LF", as defined, will cause the NVT to be 40 * positioned at the left margin of the next print line (as would, 41 * for example, the sequence "LF CR"). However, many systems and 42 * terminals do not treat CR and LF independently, and will have to 43 * go to some effort to simulate their effect. (For example, some 44 * terminals do not have a CR independent of the LF, but on such 45 * terminals it may be possible to simulate a CR by backspacing.) 46 * Therefore, the sequence "CR LF" must be treated as a single "new 47 * line" character and used whenever their combined action is 48 * intended; the sequence "CR NUL" must be used where a carriage 49 * return alone is actually desired; and the CR character must be 50 * avoided in other contexts. This rule gives assurance to systems 51 * which must decide whether to perform a "new line" function or a 52 * multiple-backspace that the TELNET stream contains a character 53 * following a CR that will allow a rational decision. 54 * 55 * Note that "CR LF" or "CR NUL" is required in both directions 56 * (in the default ASCII mode), to preserve the symmetry of the 57 * NVT model. Even though it may be known in some situations 58 * (e.g., with remote echo and suppress go ahead options in 59 * effect) that characters are not being sent to an actual 60 * printer, nonetheless, for the sake of consistency, the protocol 61 * requires that a NUL be inserted following a CR not followed by 62 * a LF in the data stream. The converse of this is that a NUL 63 * received in the data stream after a CR (in the absence of 64 * options negotiations which explicitly specify otherwise) should 65 * be stripped out prior to applying the NVT to local character 66 * set mapping. 67 * </pre> 68 * 69 * @author Jonathan Payne 70 */ 71 72 public class TelnetOutputStream extends BufferedOutputStream { 73 boolean stickyCRLF = false; 74 boolean seenCR = false; 75 76 public boolean binaryMode = false; 77 78 public TelnetOutputStream(OutputStream fd, boolean binary) { 79 super(fd); 80 binaryMode = binary; 81 } 82 83 /** 84 * set the stickyCRLF flag. Tells whether the terminal considers CRLF as a single 85 * char. 86 * 87 * @param on the <code>boolean</code> to set the flag to. 88 */ 89 public void setStickyCRLF(boolean on) { 90 stickyCRLF = on; 91 } 92 93 /** 94 * Writes the int to the stream and does CR LF processing if necessary. 95 */ 96 public void write(int c) throws IOException { 97 if (binaryMode) { 98 super.write(c); 99 return; 100 } 101 102 if (seenCR) { 103 if (c != '\n') 104 super.write(0); 105 super.write(c); 106 if (c != '\r') 107 seenCR = false; 108 } else { // !seenCR 109 if (c == '\n') { 110 super.write('\r'); 111 super.write('\n'); 112 return; 113 } 114 if (c == '\r') { 115 if (stickyCRLF) 116 seenCR = true; 117 else { 118 super.write('\r'); 119 c = 0; 120 } 121 } 122 super.write(c); 123 } 124 } 125 126 /** 127 * Write the bytes at offset <i>off</i> in buffer <i>bytes</i> for 128 * <i>length</i> bytes. 129 */ 130 public void write(byte bytes[], int off, int length) throws IOException { 131 if (binaryMode) { 132 super.write(bytes, off, length); 133 return; 134 } 135 136 while (--length >= 0) { 137 write(bytes[off++]); 138 } 139 } 140 } | http://checkstyle.sourceforge.net/reports/javadoc/openjdk8/xref/openjdk/jdk/src/share/classes/sun/net/TelnetOutputStream.html | CC-MAIN-2017-51 | refinedweb | 632 | 68.2 |
AWT List | Adding and Deleting list
AWT in java
The Standard for of AWT is Abstract Window Toolkit. It is Java‘s original platform-dependent windowing, graphics, and user-interface widget toolkit preceding Swing. The java.awt package provides classes for AWT API such as TextField, Label, TextArea, RadioButton, CheckBox, Choice, AWT List etc.
The AWT is part of the Java Foundation Classes (JFC) , the standard API for providing a graphical user interface (GUI) for a Java program. Java AWT components are platform-dependent i.e. components are displayed according to the view of operating system. AWT is heavyweight i.e. its components uses the resources of system.
AWT List
AWT List is a class for AWT API (Application Program Interface) which is available in java.awt package.
Adding items in AWT list
import java.applet.Applet; //create an applet import java.awt.List; //create a list import java.awt.Color; //fill the background color public class Demo extends Applet{ public void init(){ List l = new List(8, true); // create a list // add item to a list l.add("Gadgets"); //adds item "Gadgets" in the list at [0] position l.add("Electronics"); //adds item "Electronics" in the list at [1] position l.add("Ecommerce"); //adds item "Ecommerce" in the list at [2] position l.add("Programs"); // and so on.. l.add("Technology"); l.add("Brands"); l.add("Resources"); l.add("Organisations"); add(l); // add the list setBackground(Color.GRAY); //set the setBackground color 'gray' } }
Output:
We can observe in the above applet image that all the items has been added in the AWT list with a gray background color.
Deleting items from AWT list
By adding a line of code to remove or delete the items in the above code example.
First Way
We can delete items defining item’s position.
l.remove(3); //remove item at [3] position from the list i.e ‘Programs’
Output:
We can see that the 3rd positioned item (according to the AWT list) “Programs” has been removed or deleted from the AWT list.
We can also remove or delete multiple items at a time.
l.remove(5); //remove item at [5] position from the list i.e ‘Brands’ l.remove(1); //remove item at [1] position from the list i.e ‘Electronics’
Output:
Another way
Items can also be removed or deleted by defining item’s name as given below.
l.remove("Technology"); l.remove("Brands"); l.remove("Resources"); l.remove("Organisations");
Output:
We can see that the last 4 items has been removed at once.
Note: All the items can be removed at once by using following syntax.
l.removeAll();
Output:
And finally all items are vanished now. 😉
Keep visiting here for more stuffs like this 🙂
Thank you for your patience 🙂
Cool web post and website.
Way cool! Some very valid points! I appreciate you penning this post and the rest of the website is also really good.
Some nice points there. Spot on with this. | http://www.letustweak.com/basic-stuffs/awt-list-adding-deleting-list/ | CC-MAIN-2019-30 | refinedweb | 493 | 67.55 |
Introduction
In this article we would be talking about implementing TDD (Test-Driven Development) in a WebAPI for a blog, Excited? But before we dive into all the coding, we would talk a little about TDD.
So what is Test-Driven Development?
I actually like the definition from Wikipedia, appears to give the whole picture in few words. According to whomever wrote that part, TDD is a software development process that relies on the repetition of a very short development cycle; requirements are turned into very specific test cases; then the software is improved to pass the new test only.
But honestly that definition up there is what TDD is about. Yeah, there is a lot of software jargon involved, which we will get to soon, but understanding this in plain English sets us on the write path.
What are the steps involved in TDD?
Red Green Refactor Cycle is the software jargon that sugarcoats the entire steps involved in TDD.
- RED: This is the first step, where you write the code to test your use case. Remember, you are starting a blank code file, so this test must fail. Do not be tempted to write anything to make the test pass, not even defining classes. This failure is what makes it know as RED.
- GREEN: This is the next step where you write the code to make your test pass. The rule at this point is to write enough code to pass only that test. Continue writing code until the test is passed, never leave a test red and write another one.
- REFACTOR: This is the step you make your code beautiful by refactoring. You make it cleaner by doing several things not limited to but include obeying the rules of your language, your design, your architecture etc.
Here is the summary, Write test for your use case which must fail the first time, then write enough production code to make it pass.
So let's code
Create a WebAPI project
I would be using Visual Studio Community 2017 in this tutorial, but feel free to use any IDE of choice that support dotnet core. Follow this steps, if you are like me:
- File > New Project > Select ASP.NET Core Web Application
- Rename to a name of your choosing, mine is "TddBlogDevto", then click Ok
- It should take you to the page where you select the template, just select API and click OK
- You should be up and running, run it to ensure everything is fine.
Setup for Testing
The kind of testing we would be doing in this tutorial is called unit testing, lamely; when you test units which could be described as functions/methods.
The testing is mostly done using some sort of framework to make the work easier. And in this case, we would be using the xunit framework. Here are the things to get it setup:
- Right click your solution > Add > New Project
- On the project panel Select xUnit Test Project(.NET Core) template
- Rename to something really meaningful and related to your projects which in my case is TddBlogDevto.Tests
- You should have a new project and a default class which we should change the name to something also meaningful. Meaningful naming is essential in all type of coding.
Writing our first test
As the title so depicts, we are writing an WebAPI for a blog. So it is quite obvious that the first thing we want anyone using our API to get is the list of posts, right?
There you have it, your first test case, writing a test for displaying the list of posts. Okay?
A bit jargon at this point. You know we said we are to display a list but how do we trick the class into believing we have a list without actually having one. The way to do this is called creating mock, sort of a fake value for a real class.
In this case, we are going to try to mock a list of post and we are going to do it using a nuget package called Moq. I know right, lots of frameworks and libraries just to write tests, but you know all programmers are lazy so we look for the way that makes us write the less code in clean ways.
Right Click your solution > Manage NuGet Packages > Browse > Search for "moq" > Install it
We now have a way to mock the classes. Yay!
Something before we move far,
Right Click your test project (BlogDevto.Tests) > Add > Reference > Select your production project (BlogDevto).
This helps to add reference to the production project.
Write this code inside the class inside the test project,
public class BlogService { private readonly BlogController _blogController; private Mock<List<Post>> _mockPostsList; public BlogService() { _mockPostsList = new Mock<List<Post>>(); _blogController = new BlogController(_mockPostsList.Object); } [Fact] public void GetTest_ReturnsListofPosts() { //arrange var mockPosts = new List<Post> { new Post{Title = "Tdd One"}, new Post{Title = "Tdd and Bdd"} }; _mockPostsList.Object.AddRange(mockPosts); //act var result = _blogController.Get(); //assert var model = Assert.IsAssignableFrom<ActionResult<List<Post>>>(result); //Assert.Equal(2, model.Value.Count); }
Let's explain the test code
private readonly BlogController _blogController; private Mock<List<Post>> _mockPostsList;
The BlogController is from our production code. The controller is the entry point for our WebAPI, it is a class we wish to implement in our production code to expose our webAPI. The Mock is a mock class of a list of Post. We have List of Posts that we want to Mock so we use this code (we discussed mocking earlier).
public BlogService() { _mockPostsList = new Mock<List<Post>>(); _blogController = new BlogController(_mockPostsList.Object); }
Here is the constructor (a method that has the same name with the class) where we assign the variables we declared previously. We are basically saying when this class is created assign these values to an instance of Mock>() and an instance of BlogController while passing in _mockPostsList.Object
The first seven lines of code we just discussed is just a way of Object oriented design thinking by injecting an object into the constructor. Please bear with me and do not stray away from the goal of this tutorial, TDD.
[Fact] public void GetTest_ReturnsListofPosts() { //.. }
This is the method that test if a list of post is return which should be obvious from the name. Name is very crucial in coding especially in testing; your method name should explain what the test does.
The [Fact] attribute that designs this class is from the library we are using for testing, xunit. It is a way of telling the compiler that this class method is test method.
The way we approach testing in dotnet and I think most language is the 3As; Arrange, Act Assert. I would explain as we go.
//arrange var mockPosts = new List<Post> { new Post{Title = "Tdd One"}, new Post{Title = "Tdd and Bdd"} }; _mockPostsList.Object.AddRange(mockPosts);
This is the arrange part. We are arranging the data or the output that we need, in this case a list of post. The var mockPosts is just plain old csharp variable representing a list of Post. After the creation of mockPosts we added it to the List we created before the mockPostsList.
This is the essence of a mock. We have a class of Post and trying to create some fake/mock posts which we later add to a mock/fake list to stand as our reference.
//act var result = _blogController.Get();
The Act part. Here we get the supposed implementation of the use case (i.e. a method that list all the post). We are proposing that the Blog Controller class would have a Get class.
//assert var model = Assert.IsAssignableFrom<ActionResult<List<Post>>>(result);
The Assert part is the part were we check if the proposed result from act correlates with the reference.
In our case we are asserting that the result from act is in fact a List of Posts.
To run:
Open up the test Explorer: Test > Windows > Test Explorer
This would show all the methods inside the class.
Run the GetTest_ReturnsListofPosts test. Remember it must fail. If it doesn't you have failed.
Also remember that compiler error is also a failure
If the test has failed then we begin to think of how to pass it.
- We need a class of Post since we are to return of list of Post. Thus go into the production project (TddBlogDevto) and add a class file and name it Post. Put the following code inside.
public class Post { public Guid Id { get; set; } public string Title { get; set; } public string Content { get; set; } }
This model just contains the definition of the Post; a post must contain an Id, a Title and a Content. Plain Old Clr Object.
- Create a Controller title BlogController. Right Click your production Project > Add > Controller > Select API Controller Empty .
Write the following code inside it:
private readonly List<Post> _posts; public BlogController(List<Post> posts) { _posts = posts; } public ActionResult<List<Post>> Get() { return _posts.ToList(); }
This code is the actual implementation that gives the list of Post. The Get Method returns the previous defined list _posts.
This method was the one we were calling in act part of the test we previously wrote, Got it?
At this point we should be set, but if there are any red underlines in your code, check to see if the reference is missing; mostly due to the file being inside a folder.
If no red underlines. Run the test again. This time, if all is done right, we should pass.
Conclusion
If all things work well, we have successfully implemented a WebAPI using dotnet core following the TDD principle. And always remember these rules of TDD; write implementation of the use cases (test), make sure it fails, then write enough production code to pass only that test, nothing more. You should go on to implement the other test for the remaining use cases that a blog might need.
I hope I have being help to you. Here is the link to the github repo where I actually implemented a lot of test.
Happy coding!
Discussion | https://dev.to/mrsimi/build-a-tdd-restful-webapi-for-a-blog-using-dotnet-core-5fo8 | CC-MAIN-2020-50 | refinedweb | 1,684 | 72.05 |
Using Crawlera with Splash is possible, but you have to keep some things in mind before integrating them.
Unlike a standard proxy, Crawlera is designed for crawling and it throttles requests speed to avoid users getting banned or imposing too much load on websites. This throttling translates to Splash being slow when also using Crawlera.
When you access a web page in a browser (like Splash), you typically have to download many resources to render it (images, CSS styles, JavaScript code, etc.) and each resource is fetched by a different request against the site. Crawlera will throttle each request separately, which means that the load time of the page will increase dramatically.
To avoid the page loading being too slow, you should avoid unnecessary requests. You can do so by:
- Disabling images in Splash
- Blocking requests to advertisement and tracking domains
- Not using Crawlera for subresource requests when not necessary (for example, you probably don't need Crawlera to fetch jQuery from a static CDN)
How to integrate them
To make Splash and Crawlera work together, you'll need to pass a Lua script similar to this example to Splash's /execute endpoint. This script will configure Splash to use Crawlera as a proxy and will also perform some optimizations, such as disabling images and avoiding some sorts of requests. It will also make sure that the Splash requests go through the same IP address, by creating a Crawlera session.
In order to make it work, you have to provide your Crawlera API key via the crawlera_user argument for your Splash requests (example). Or, if you prefer, you could hardcode your API key in the script.
Using Splash + Crawlera with Scrapy via scrapy-splash
Let's dive into an example to see how to use Crawlera and Splash in a Scrapy spider via scrapy-splash (for the full working example, check this repo).
This is the project structure:
├── scrapy.cfg ├── setup.py └── splash_crawlera_example ├── __init__.py ├── settings.py ├── scripts │ └── crawlera.lua └── spiders ├── __init__.py └── quotes-js.py
A few details about the files listed above:
- settings.py: contains the configurations for both Crawlera and Splash, including the API keys required for authorization (note that Crawlera should be disabled in the settings, since routing requests to Crawlera is handled by the Lua script mentioned below).
- scripts/crawlera.lua: the Lua script that integrates Splash and Crawlera.
- spiders/quote-js.py: the spider that needs Splash and Crawlera for its requests. This spider loads the Lua script into a string and sends it along with its requests.
In our spider, we load the Lua script into a string in the __init__ method:
self.LUA_SOURCE = pkgutil.get_data( 'splash_crawlera_example', 'scripts/crawlera.lua' ).decode('utf-8')
Note: to load the script from a file both locally and on Scrapy Cloud, you have to include the Lua script in your package's setup.py file, as shown below:
from setuptools import setup, find_packages setup( name = 'project', version = '1.0', packages = find_packages(), package_data = {'splash_crawlera_example': ['scripts/*.lua',]}, entry_points = {'scrapy': ['settings = splash_crawlera_example.settings']}, )
Once we have the Lua script loaded in our spider, we pass it as an argument to the SplashRequest objects, along with Crawlera's and Splash's credentials (authorization with Splash can be also be done via http_user setting):
yield SplashRequest( url='', endpoint='execute', splash_headers={ 'Authorization': basic_auth_header(self.settings['SPLASH_APIKEY'], ''), }, args={ 'lua_source': self.LUA_SOURCE, 'crawlera_user': self.settings['CRAWLERA_APIKEY'], }, # tell Splash to cache the lua script, to avoid sending it for every request cache_args=['lua_source'], )
And that's it. Now, this request will go through your Splash instance, and Splash will use Crawlera as its proxy to download the pages and resources you need.
Customizing the Lua Script
You can go further and customize the Lua script to fit your exact requirements. In the example provided here, we commented out some lines that filter requests to useless resources or undesired domains. You can uncomment those and customize them to your own needs. Check out Splash's official docs to lean more about scripting.
A working example for Scrapy Cloud
You can find a working example of a Scrapy project using Splash and Crawlera in this repository. The example is ready to be executed on Scrapy Cloud. | https://support.scrapinghub.com/support/solutions/articles/22000188428-using-crawlera-with-splash-scrapy | CC-MAIN-2018-51 | refinedweb | 698 | 62.88 |
This article shows how to run a system command from Python and how to execute another program.
Use
subprocess.run()to run commands
Use the subprocess module in the standard library:
import subprocess subprocess.run(["ls", "-l"])
It runs the command described by args. Note that args must be a List of Strings, and not one single String with the whole command. The
run function can take various optional arguments. More information can be found here.
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, capture_output=False, shell=False, cwd=None, timeout=None, check=False, encoding=None, errors=None, text=None, env=None, universal_newlines=None, **other_popen_kwargs)
Note: In Python 3.4 and earlier, use
subprocess.call() instead of
.run():
subprocess.call(["ls", "-l"])
Another option is to use
os.system():
import os os.system("ls -l")
This takes one single String as argument. However,
subprocess.run() is more powerful and more flexibel and even the official documentation recommends to use it over
os.system().
Use
subprocess.Popen()to execute programs
To execute a child program in a new process, use
subprocess.Popen():
import subprocess subprocess.Popen(["/usr/bin/git", "commit", "-m", "Fixes a bug."])
Similar to
.run()it can take a lot of optional arguments which can be found here.
Warning: Using
shell=True is discouraged
Both
runand
Popen can take the keyword argument shell. If shell is True, the specified command will be executed through the shell. However, using this is strongly discouraged for security reasons! More information can be found here. | https://www.python-engineer.com/posts/python-execute-system-command/ | CC-MAIN-2022-21 | refinedweb | 255 | 52.56 |
After I explained in previous posts seperately how to use RSA in C# and RSA in PHP, I today want to show how to use this combining both languages.
I am doing this, since the implementation is somewhat tricky, especially concerning the different used public / private key formats and the coding of the data when transmitting. Further I only found pieces of explanations about this on the internet, thus I wanted to post here a complete working example, in which PHP server and C# client both create keys, exchange them and send each other encrypted messages.
The .Net RSA implementation manages keys in an XML format, the in the previous post described PHP implementation phpseclib uses the PEM format. Although a conversation would of course be possible manually, I used for both directions external classes. To be able to read the XML format in PHP, I used this extension of the RSA class from phpseclib.
To read the PEM format with C#, I slightly changed the class OpenSSLKeys.cs and used that.
Read XML format in PHP: On the Codeblog linked above the idea was described and an extension of the RSA class posted. First one has to download the script (since the download link does not work on the site, here a reupload), which then has to be uploaded into the same directory as the file RSA.php from phpseclib. Then we include the script RSA_XML.php in the code via include and use the class Crypt_RSA_XML instead of Crypt_RSA. This is an extension of the class Crypt_RSA and provides next the standard function loadKey() also the function loadKeyfromXML(), with which a key can be read in which has been created in C# via the function ToXmlString() of the class RSACryptoServiceProvider.
Read PEM format in C#: For this I used the above linked class OpenSSLKeys.cs, which has been developed by JavaScience. This has to be added to the project, then we can access the needed function with JavaScience.opensslkey.DecodePEMKey(). I slightly changed the file, since in its original form it was thought of as a standalone program, with which one can communicate via the console. In principle I just removed the main function and added a return value to the function (only tested for converting public and private keys, the class can do more). The changed file can be downloaded here.
As already mentioned, one also has to be a bit careful when transmitting the data. I use the HTTP Post method for sending data to the server. First one has to get the used coding of the server, in my case it is UTF8. Thus I convert data into this format. When now sending a public key in the XML format, this contains amongst others symbols like <, >. These are viewed as control characters by the server, thus we have to escape them, which we do via Uri.EscapeDataString(). When encryting a string with RSA the output is pretty cryptic, a lot of special characters result. These cannot be represented in UTF8, therefor we convert the result via Convert.ToBase64String() into a Base64 string. The server then has to convert it back. We also escape this string to correctly send possible control characters. When outputting the public key on the server via echo, we also use the function nl2br(), which ensures the correct displaying of linebreaks.
Now let us come to the code, I want to present a little sample program. The C# program and the PHP script both create public / prviate key pairs and communicate the public key to the other. Then they encrypt a message with it, send it and the receiver decrypts it using its private key.
The PHP script looks as follows ():
<?php
include('Crypt/RSA_XML.php');
session_start();
if (!isset($_SESSION["username"])) {
$_SESSION["username"] = $_POST["username"];
$_SESSION["ClientPubKey"] = $_POST["ClientPubKey"];
$rsa = new Crypt_RSA_XML();
extract($rsa->createKey());
$_SESSION["ServerPrivateKey"] = $privatekey;
echo nl2br($publickey);
}
else {
$rsaclient = new Crypt_RSA_XML();
$rsaclient->loadKeyfromXML($_SESSION["ClientPubKey"]);
echo base64_encode($rsaclient->encrypt("Hello client"))."<br />";
$rsaserver = new Crypt_RSA_XML();
$rsaserver->loadKey($_SESSION["ServerPrivateKey"]);
echo "Client sent: ".$rsaserver->decrypt(base64_decode($_POST["SecretMessage"]));
}
?>
We work with sessions (see the post about sessions in C#). The script is called twice from the C# program. If no session has been created yet, the server first creates a keypair and saves its private key. Also it saves the sent public key of the client and outputs its own public one. On the next call via loadKeyFromXML() the saved public key of the client is imported and the text "Hello client" encrypted. For transmitting this is converted into a Base64 string and outputted. Further the server loads its private key and with that decrypts the message sent by the client, which also was transmitted as a Base64 string.
The C# code looks as follows:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.Net;
using System.IO;
using System.Security.Cryptography;
namespace ClientServerRSA
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
}
CookieContainer Cookie = null;
private void Form1_Load(object sender, EventArgs e)
{
Cookie = new CookieContainer();
RSACryptoServiceProvider ClientRSA = new RSACryptoServiceProvider();
string ServerPubKeyOutput = HTTPPost("", "username=MyName&ClientPubKey=" + Uri.EscapeDataString(ClientRSA.ToXmlString(false)));
File.WriteAllText("serverpubkey.txt", ServerPubKeyOutput.Replace("<br />", ""));
StreamReader sr = System.IO.File.OpenText("serverpubkey.txt");
string pemkey = sr.ReadToEnd();
string ServerPubKey = JavaScience.opensslkey.DecodePEMKey(pemkey);
RSACryptoServiceProvider ServerRSA = new RSACryptoServiceProvider();
ServerRSA.FromXmlString(ServerPubKey);
string SecretMessage = Uri.EscapeDataString(Convert.ToBase64String(RSAEncrypt(Encoding.UTF8.GetBytes("Hello server"), ServerRSA.ExportParameters(false))));
string ServerAnswer = HTTPPost("", "username=MyName&SecretMessage=" + SecretMessage);
string[] SplitAnswer = ServerAnswer.Split(new string[] { "<br />" }, StringSplitOptions.None);
string ServerMessage = Encoding.UTF8.GetString(RSADecrypt(Convert.FromBase64String(SplitAnswer[0]), ClientRSA.ExportParameters(true)));
MessageBox.Show("Server sent: " + ServerMessage + Environment.NewLine + SplitAnswer[1]);
}
private string HTTPPost(string url, string postparams)
{
string responseString = "";; charset=utf-8";
request.ContentLength = data.Length;
using (var stream = request.GetRequestStream())
{
stream.Write(data, 0, data.Length);
}
var response = (HttpWebResponse)request.GetResponse();
responseString = new StreamReader(response.GetResponseStream()).ReadToEnd();
return responseString;
}
static public byte[] RSAEncrypt(byte[] DataToEncrypt, RSAParameters RSAKeyInfo)
{
byte[] encryptedData;
RSACryptoServiceProvider RSA = new RSACryptoServiceProvider();
RSA.ImportParameters(RSAKeyInfo);
encryptedData = RSA.Encrypt(DataToEncrypt, true);
return encryptedData;
}
static public byte[] RSADecrypt(byte[] DataToDecrypt, RSAParameters RSAKeyInfo)
{
byte[] decryptedData;
RSACryptoServiceProvider RSA = new RSACryptoServiceProvider();
RSA.ImportParameters(RSAKeyInfo);
decryptedData = RSA.Decrypt(DataToDecrypt, true);
return decryptedData;
}
}
}
In the functions RSADecrypt() and RSAEncrypt() passing true as the second parameter is important, this enables the usage of OAEP padding (the default setting for phpseclib, but it can also be changed there).
Otherwise I explained the functions HTTPPost(), RSADecrypt() and RSAEncrypt() in previous posts, thus I will not mention them again here.
In the 3rd line of Form_Load() we wescape the created public key and send this to the server. Then we read its answer, its public key, and write it to a file. This PEM file we then convert via JavaScience.opensslkey.DecodePEMKey() into an XML key and import it. With this we encrypt the message "Hello server" and send this string encoded as a Base64 string and escaped to the server. Eventually we decrypt the message from the server. | http://csharp-tricks-en.blogspot.com/2015/04/rsa-with-c-and-php.html | CC-MAIN-2017-51 | refinedweb | 1,178 | 50.43 |
I would like to start a series of posts devoted to best practices when designing mobile applications. So in this first post I will describe the MVC pattern that I have been using when creating CF applications for the customers.
I realize that a lot has been written on the subject, explaning what the MVC pattern is. If you don't know what it is, you can start from the Wikipedia. The main purpose of the MVC pattern is to decouple data access and business logic from data presentation and user interaction. While Mobile Client Software Factory developed by the P&P group implements it (actually it's a combination of MVP and MVC patterns), I think that their implementation is too heavy and slow for mobile devices. That's why I came up with my own implementation which I think is much more lightweight and simpler than the P&P one. So let's start, shell we?
For simplicity, I am going to create a very straightforward application that contains just a Login form.
1. Interfaces
First we need a few simple interfaces: IView and IController:
public interface IView
{
void Show();
void Hide();
void Close();
string Text { get;set;}
}
public interface IController
IView View
{
get;
set;
}
As you can see, IView interface essentially declares methods that exist in any Form, it means that we wouldn't even need to implement them.
2. Add a new form: LoginForm
Let's add a new form, drop a few textboxes and labels (txtUser and txtPassword), add menu items (Exit and OK). It should look like this:
Since it's a login form, the requirements should be obvious : when the OK menu is selected take the values from the text boxes and either compare them to some existing values from the local database or via a web service etc... and return the result to the same form and show it in the status label. If we would not use the MVC pattern, we'd just end up with the code that makes appropriate calls to let's say a web service directly in the OK menu event handler, making future modifications for the business logic or UI more difficult.
3. Add ILoginView interface
public interface ILoginView : IView
void UpdateStatus(string status);
event EventHandler Exit;
event EventHandler Login;
string User { get;}
string Password { get; }
This new interface inherits from our base IView interface.
4. Implement LoginController class
This class is going to hold the logic that will be using the ILoginView interface to communicate with the LoginForm. We add the LoginController class and make sure that it implements the IController interface we've declared earlier:
public class LoginController: IController
private ILoginView view;
public LoginController(ILoginView view)
{
this.view = view;
this.AttachView(this.view);
}
private void AttachView(ILoginView view)
// Hook up into the view's events
view.Login += new EventHandler(view_Login);
view.Exit += new EventHandler(view_Exit);
void view_Exit(object sender, EventArgs e)
Application.Exit();
void view_Login(object sender, EventArgs e)
// The login event is been raised from the form.
// Ideally we should pass the user and password to a Business layer to validate against database or a web service
// For now we'll just compare to some hardcoded values
if (view.User == "Alex" && view.Password == "test")
{
// Update the status on the LoginForm
view.UpdateStatus("Login successfull.");
}
else
view.UpdateStatus("Login failed.");
#region IController Members
public IView View
get
return view;
set
view = (ILoginView)value;
AttachView(view);
#endregion
5. Implement the ILoginView interface in the LoginForm:
public partial class LoginForm : Form, ILoginView
private string user;
private string password;
public LoginForm()
InitializeComponent();
#region ILoginView Members
public void UpdateStatus(string status)
lblStatusValue.Text = status;
public event EventHandler Exit;
public event EventHandler Login;
public string User
return user;
public string Password
return password;
private void menuOK_Click(object sender, EventArgs e)
this.user = txtUser.Text;
this.password = txtPassword.Text;
// Notify the controller
if (this.Login != null)
this.Login(this, null);
}
private void menuExit_Click(object sender, EventArgs e)
// Notify the controller
if (this.Exit != null)
this.Exit(this, null);
As you should notice from this code, we don't directly talk to the controller. All what the LoginForm knows about is the ILoginView interface, which it faithfully implements and it just raises the appropriate events for whoever is listening to them. That's all for now. You can be wondering how would you connect the LoginController and ILoginView together without destroying the decoupling that we are trying to achieve. And where do we create an instance of the controller for the view? I will explain it to you in my next post. Meanwhile I welcome your comments or suggestions on how you think we should proceed.
I've just got back from a long and big project with one of our customers for whom we have created an
In order to show you the Mobile MVC framework I came up with, let me walk you through the same excersise
When My Form Inherited From ViewForm,the Form Desginer Came Error.
I Take This Way To Enable Form Designer(Can`t Compile):
#if !DESIGN
public partial class LoginForm : Form
#else
public partial class LoginForm : ViewForm
#endif
Have Another Way?
Thanks!
Trademarks |
Privacy Statement | http://blogs.msdn.com/priozersk/archive/2007/08/06/implementing-mvc-pattern-in-net-cf-applications-part-1.aspx | crawl-002 | refinedweb | 861 | 60.04 |
.
.
XSL: I like your style
People who work in SGML and need to format it generally use DSSSL (Document Style Semantics and Specification Language) to do the job. DSSSL is a dialect of Scheme, itself a venerable and popular form of LISP (which stands either for "List Processing" or lots of irritating, superfluous parentheses," depending on who you ask). Of course, if you're using DSSSL, you're already an SGML god and veteran LISP hacker, and therefore should not be reading in this article.
Fortunately, the W3C committees discussing style, HTML, and XML have included in their design the Extensible Style Language, or XSL. XSL is based on DSSSL (and DSSSL-O, the online version of DSSSL), and also uses some of the style elements of CSS. It's simpler than DSSSL, while retaining much of its power (much like the relationship between XML and SGML). XSL's notation, however, may be surprising: it's XML. The simplest way to say it is: XSL is an XML document that specifies how to transform another XML document. Say, what?
Why XSL is so useful
XSL is immensely powerful. It can be used to add structure to a document (as in CSS), and it can also completely rearrange the input elements for a particular purpose. For example, XSL can transform XML of one structure into HTML of a different structure. (We'll see an example of this below.) XSL can also restructure XML into other document formats: TeX, RTF, and PostScript.
XSL can even transform XML into a different dialect of XML! This may sound crazy, but it's actually a pretty cool idea. For example, multiple presentations of the same information could be produced by several different XSL files applied to the same XML input. Or, let's say two systems speak different "dialects" of XML but have similar information requirements. XSL could be used to translate the output of the first system into something compatible with the input of the second system.
These last few reasons are of special interest to Java programmers, since XSL can be used to translate between different languages in a distributed network of subsystems, as well as to format documents. Understanding how to use XSL in simple applications, like transforming XML to HTML, will help a Java developer understand XSL in general. Let's look at an example of how to transform XML to HTML with an XSL style sheet.
Formatting XML as HTML: An example
An XSL file is a series of rules, called templates, that are applied to an input XML file. Each time a template matches something in the input, the template produces a new structure in the output (often HTML, as in the example we're about to see). The new structure is the XML's content, with the appropriate style applied and arranged as the XSL specifies. The templates in the XSL file are written in XML, using specific tags with defined meanings.
The example below refers again to the XML recipe example in Listing 3. We're going to look at an XSL file that transforms the XML in Listing 3 into the HTML in Listing 1.
<?xml version="1.0"?> <xsl:stylesheet xmlns: <xsl:template <HTML> <HEAD> <TITLE> <xsl:value-of </TITLE> </HEAD> <BODY> <H3> <xsl:value-of </H3> <STRONG> <xsl:value-of </STRONG> <xsl:apply-templates/> </BODY> </HTML> </xsl:template> <!-- Format ingredients --> <xsl:template <H4>Ingredients</H4> <TABLE BORDER="1"> <TR BGCOLOR="#308030"><TH>Qty</TH><TH>Units</TH><TH>Item</TH></TR> <xsl:for-each <TR> <!-- handle empty Qty elements separately --> <xsl:if <TD><xsl:value-of</TD> </xsl:if> <xsl:if <TD BGCOLOR="#404040"> </TD> </xsl:if> <TD><xsl:value-of</TD> <TD><xsl:value-of <xsl:if <SPAN> -- <em><STRONG>optional</STRONG></em></SPAN> </xsl:if> </TD> </TR> </xsl:for-each> </TABLE> </xsl:template> <!-- Format instructions --> <xsl:template <H4>Instructions</H4> <OL> <xsl:apply-templates </OL> </xsl:template> <xsl:template <LI><xsl:value-of</LI> </xsl:template> <!-- ignore all not matched --> <xsl:template </xsl:stylesheet>
Listing 7. XSL used as an XML language that transforms XML into something else
(A printable version of this file is in example.xsl).
Looking at this code you'll notice, first of all, that the file starts with the
<?xml...?> tag, indicating that this file is XML (even though it's also XSL). Each template is bounded by the tags
<xsl:template ...> and
</xsl:template ...>. Every tag that begins with
<xsl: is an XSL command.
While we won't go over all the templates in the XSL file (since this isn't an XSL tutorial), Listing 8 provides a quick look at the first template in the file, just to get the general idea.
<xsl:template <HTML> <HEAD> <TITLE> <xsl:value-of </TITLE> </HEAD> <BODY> <H3> <xsl:value-of </H3> <U> <xsl:value-of </U> <xsl:apply-templates/> </BODY> </HTML> </xsl:template>
Listing 8. The first template from the XSL style sheet in Listing 7
Notice the
<xsl:template> tag: It has an attribute
match="/Recipe". This indicates that this template is to be applied when a
<Recipe> element is encountered at the input. Everything enclosed within this
<xsl:template> element will be placed in the output.
The XSL processor sees a
<Recipe> element, so it begins building its output by using the contents of the
<xsl:template> element in the XSL file. It adds an
<HTML> element, then a
<HEAD> element inside of that, and then a
<TITLE> element. It's actually building a new HTML document by creating HTML from the template, based on what it sees. The
<xsl:value-of> tag instructs the XSL processor to go get the text contained in some other element -- in this case, the sub element
<Name>. Moving a few lines down, you can see the same thing happening, as the XSL processor again fetches and uses the same string within the
<H3> tag, and the
<Description> tag after it. (Note that we're using the same text in more than one place in a document, something CSS simply can't do.) Finally, we come to the
<xsl:apply-templates> command, which tells the XSL processor to apply all the other templates in the file to the input.
The resulting HTML is very similar to the HTML we saw in Listing 1. If you want to study the XML, XSL, and resulting HTML, and want to learn how to use XSL to format XML yourself, see the links on XSL in the Resources section of this article.
Additional XSL capabilities
XSL isn't limited to just producing HTML. XSL also has complete support for "native" formatting, which doesn't rely on translation to some other format. Nobody has yet implemented this part of XSL, though, primarily because page formatting and layout is a very tough to wrangle. (There is, however, a contest to implement all of XSL. See Resources.)
XSL's design also includes embedded scripting. Currently, IBM's LotusXSL package (written in Java) provides the functionality of almost all of the current draft specification of XSL, including the ability to call embedded ECMAScript (the European standard JavaScript) from XSL templates.
Of course, as always, with power comes complexity. Learning to write XSL isn't a piece of cake. But the power's there if you want it.
XML is more than just content management
XSL, like CSS, can be used on either the client or the server in a client/server system. This fact provides immense flexibility and organization to Web site designers and managers. So much so, in fact, that many people think of XML, CSS, and XSL as another set of technologies for "content management" for their Web sites. It makes styling Web documents easier and more consistent, facilitates version control of the site, simplifies multibrowser management (think of using a style sheet to overcome the many differences between browsers), and so forth. CSS is also useful for Dynamic HTML (which we'll discuss a bit below), where much of the user interaction occurs on the client side, where it belongs. From the point of view of people managing Web sites, XML, CSS, and XSL are indeed big wins. And yet, there's a whole world of applications that have nothing to do with browsers and Web pages. The map of that world is called the Document Object Model.
Modeling information structure in XML
So far, we've looked at XML as a way of representing data as human-readable documents, and we've spent some time discussing formatting. But XML's real power is in its ability to represent information structure -- how various pieces of information relate to one another -- in much the same way a database might.
Structured documents of the type we've been looking at have the property that all of their elements nest inside one another, as in Listing 5 above. Instead of looking at a document as a file, though, consider what happens if we look at the structure of the tags as a tree:
The figure above shows the recipe as a tree of document tags. The child nodes of a document nest within the parent node. What if there were a way to automagically convert an XML document into a tree of objects in a programming language -- like, oh, say, Java maybe? And what if these objects all had properties that could be set and retrieved -- such as the list of each element's children, the text each object contained, and so on. Wouldn't that be interesting?
The Document Object Model (DOM) Level 1 Recommendation (see Resources), created by a W3C committee, describes a set of language-neutral interfaces capable of representing any well-formed XML or HTML document.
With the DOM, HTML and XML documents can be manipulated as objects, instead of just as streams of text. In fact, from the DOM point of view, the document is the object tree, and the XML, HTML, or what have you is simply a persistent representation of that tree.
The availability of the DOM makes it much simpler to read and write structured document files, since standard HTML and XML parsers are written to produce DOM trees. If these objects have GUI representations, it's easy to see how to create an application that reads structured document files (XML or HTML), lets the user edit the structure visually, and then save it in its original format. Programs that interface with existing Web sites become much easier to write, because once the document is parsed, you're working with objects native to your programming language.
One of the earliest popular uses for the Document Object Model is Dynamic HTML, where client-side scripts manipulate and display (and redisplay) an HTML document in response to user actions. Dynamic HTML manipulates the client-side document in terms of the scripting language's binding to the DOM structure of the document being displayed. For instance, a
<BUTTON> object might, when clicked, reorder a table on the same page by sorting the
<TR> (table row) nodes on a particular column.
But aside from all this browers-document-Web technology, the DOM provides a common way of accessing general data structures from structured documents. Any language that has a binding (that is, a specific set of interfaces that implement the DOM in that language) can use XML as an interface for storing, retrieving, and processing generic hierarchical (and even nonhierarchical) object structures.
How DOM and XML work together
The DOM opens the door to using XML as the lingua franca of data interchange on the Internet, and even within applications. Tim Berners-Lee, discussed earlier and commonly known as the "inventor of the World Wide Web," says that, these days, it's important to understand that if a system you're designing survives, it will someday be used as a module in another system. So it's best to design it that way from the start. The DOM is completely described in IDL, the Interface Definition Language used in CORBA, so it's connected to existing software interoperation standards.
Let's think a moment about how DOM with XML would be useful in programming a database system. First, represent your database schema as a set of DOM objects. Want a document that describes that schema? No problem: write it out as XML. Use XSL to format the XML as HTML and you've got a complete, browseable schema reference that's always up to date. Want to automatically construct SQL for updating your relational database from a record set coming into your system? Just traverse your database's (DOM) schema tree, matching up the names of the columns from the record set with those of the schema, and build an SQL UPDATE statement as you go. What's that you say? The schema has changed, and the record set you've received doesn't match up with the new schema? You can write code to handle that, or present the user with error messages that state exactly what's wrong. You even might be able to use XSL to refactor the DOM tree of your record set into something matching the new schema.
Finally, it's time to start programming in Java! In the next section, we're going to examine the Java bindings of the DOM and see how to use the DOM in a Java program.
XML and Java
Up to this point I've been laying out general information about XML, without a lot of reference to Java. Now that you understand XML, it's time to look at how to process XML in Java. Java's a great language for XML, as you'll see. It provides a portable data format that nicely complements Java's portable code.
SAX appeal
The easiest way to process an XML file in Java is by using the Simple API for XML, or SAX. SAX is a simple Java interface that many Java parsers can use. A SAX parser is a class that implements the interface
org.xml.sax.Parser. This parser "walks" the tree of document nodes in an XML file, calling the methods of user-defined handler classes. methods of the
DocumentHandler interface are as shown in Listing 9.
public interface DocumentHandler {
public abstract void setDocumentLocator (Locator locator);
public abstract void startDocument () throws SAXException;
public abstract void endDocument () throws SAXException;
public abstract void startElement (String name, AttributeList atts) throws SAXException;
public abstract void endElement (String name) throws SAXException;
public abstract void characters (char ch[], int start, int length) throws SAXException;
public abstract void ignorableWhitespace (char ch[], int start, int length) throws SAXException;
public abstract void processingInstruction (String target, String data) throws SAXException; }
Listing 9. interface org.xml.sax.DocumentHandler
Package
org.xml.sax includes a utility class called
HandlerBase, which implements the interface in Listing 9 (as well as some other interfaces in the SAX package) with methods that do nothing. Programmers can create a subclass of
HandlerBase that overrides only the methods they want to use.
For example, say we want a class that counts the elements in an XML document. We could write a class as follows:
import org.xml.sax.*; public class ElementCounter extends HandlerBase { protected int _iElements = 0; public ElementCounter() { } // Each time the SAX parser encounters an element, it // will call this method public void startElement (String name, AttributeList atts) throws SAXException { _iElements++; } public void endDocument() { System.out.println("Document contains " + _iElements + " elements."); } };
Listing 10. A class that counts the elements in an XML document
To create a Java program that counts elements in an XML file, you'd simply create a SAX parser (how you do that depends on your particular parser package), then create an instance of your
ElementCounter class. You then call the parser's
setDocumentHandler method with the new
ElementCounter as an argument. The parser keeps a reference to the
DocumentHandler you passed to it. When you call the parser's
parse() method, the parser reads its input source. Each time it encounters an element (that is, a tag) in the XML file, it calls the
startElement() method of your
ElementCounter object, passing the name of the tag and a list of attributes the tag may have had.
Experimenting with SAX
An example package,
com.javaworld.JavaBeans.XMLApr99, can be downloaded for free (see Resources). The sample
main() program lets you specify (in this order):
- An XML file to parse
- The fully specified class name of the parser (optional)
- The fully specified class name of a document handler
The package includes two document handlers: the
ElementCounter from Listing 10, and a handler called
SimplePrinter, which (naturally) simply prints the XML with an easy-to-read indentation. You can try writing your own document handler and passing it to the main method (called
com.javaworld.JavaBeans.XMLApr99.ParseDemo.main()).
You'll need the JAR file called "XMLApr99.jar," and you'll need to download the JAR file for IBM's excellent "XML for Java" package (version 2). Place both JAR files in your CLASSPATH, and type
java com.javaworld.JavaBeans.XMLApr99.ParseDemo
for instructions. The XML for Java package includes excellent documentation, a programmer's guide, and several example programs to get you started.
The source code is also available in zip and tar.gz formats. As an exercise, try downloading one of the other vendors' XML parsers from the Resources section, and then overriding the method
ParseDemo.createParser() in the sample code to create a parser from the new package.
Become a tree surgeon!
One final, somewhat more advanced topic, before we close. The SAX interface allows you to parse an XML file and execute particular actions whenever certain structures (like tags) appear in the input. That's great for a lot of applications. There are times, though, when you want to be able to cut and paste whole sections of XML documents, restructure them, or maybe even build from scratch an object structure like the one in Figure 3, and then save the whole structure as an XML file. For that, you need access to the DOM API.
The DOM API allows you to represent your XML document as a tree of nodes in your Java (or other language) program. While a SAX parser reads an XML file, doing callbacks to a user-defined class, a DOM parser reads an XML file and returns a representation of the file as a tree of objects, most of which are of type
org.w3c.dom.Node This gives you immense power in manipulating structured documents. Figure 4 is an example of what I'm talking about.
The Document Object Model, in the package
org.w3c.dom, defines interfaces for document elements (that is, tags), DTD elements, text nodes (where the actual text inside the tags is kept), and quite a few other things we haven't even discussed. Figure 4 is a schematic of a general system that can transform one XML document to some other form programmatically. Your program uses a DOM parser to parse an XML file, and the parser returns a tree that is an exact representation of the XML in the file. Note that, at this point, you've read an input file, checked it for formatting and semantic validity, and built a complex hierarchical object structure, all in just a few lines of code. You can then traverse the document tree in software, doing whatever you like to the tree structure. Add nodes, delete them, update their values, read or set their attributes -- basically anything you like. When your tree has the new structure you desire, tell the top node to print itself to another XML file, and the new document is created.
XML-Java synergy
One of the reasons Java and XML are so well-suited for one another is that Java and XML are both extensible: Java through its class loaders, XML through its DTD. Imagine a server, reading and writing XML, where the DTD for the system input can change. When a new element is added to the input language, a running server (written in Java) could automatically load new Java classes to handle the new tags. You would not only have an extensible application server -- you wouldn't even have to take the server down to add the extensions!
One small idea points to the possible implementations of XML and Java together. The next section is about a company whose combination of XML and Java is its core technology.
XML with Java in the real world
You now have a handle on XML technology, including how it's implemented in Java. You understand that a document can be viewed as a tree of objects and manipulated using SAX or DOM. Let's have a look at a real company that is using all of these technologies to provide solutions for its clients.
DOM interfaces exist not only for XML, but for HTML, as well. This means that the leftmost document in Figure 4 could be a Web page from which you wish to extract information for manipulation in Java.
In fact, Epicentric, an Internet startup in San Francisco, does just that. Epicentric uses Java and XML in its turnkey systems to allow creation of custom portal sites. Portal sites, like the front pages of Netscape Netcenter and Excite!, are integrated aggregations of information from various Internet sources. In a corporate Internet environment, a portal may contain information gleaned from external Web pages (for example, weather reports), alongside internal enterprise data. Portals are also often customizable by each user.
Epicentric's systems read HTML from the Internet as DOM documents, extract information from those documents, and store that information in a standard XML format. Other information sources are also converted into this same XML format and stored on Epicentric's server. The company then uses the XML with XSL and Java Server Pages to create custom portals for its clients.
"A lot of good work has been done on the basics ... like parsers and XSL processors," says Ed Anuff, CEO of Epicentric. One benefit of using XML is that it makes designers think through the system structure in a very structured way, Anuff says.
When asked about concerns with XML, Anuff states that many of the problems he runs into are architectural, such as which DTD to use, and designating the appropriate places in the system to use XML. Systems designers are still working out how to use this new technology most effectively in an enterprise environment.
Also, since the technology is so new, it's often hard to know what pieces of the system to build in-house. For example, quite a few companies built their own XML parsers but now have little return on investment because larger companies are developing superior XML technology and giving it away for free. "The biggest challenge today is figuring out when you're reinventing the wheel, and when you're adding value," says Anuff.
Despite these challenges, the future looks bright for Epicentric, which has several "pretty decent-sized customers" using the company's software in beta. With clients and advertisers that include the likes of Eastman Kodak Company, Sun Microsystems, Chase Bank, and LIFE Magazine, Epicentric is using XML to aggregate and redistribute information in novel ways.
Conclusion
XML is a powerful data representation technology for which Java is uniquely well-suited. You're going to be hearing a lot about XML in the coming months and years. Anyone working with information systems that communicate with other systems (and what systems don't, these days?) has a lot to gain by understanding XML technology and using it to its full advantage.
Using XML with XSL or CSS, you can manage your Web site's content and style, and change style in one place (the style sheet) instead of editing piles of HTML files or, worse, editing the scripts that produce HTML dynamically. Using SAX or DOM, you can treat Web documents as object structures and process them in a general and clean way. Or, you can leave browsers behind entirely and write pure-Java clients and servers that talk to each other -- and other systems -- in XML, the new lingua franca of the Internet. Sun Microsystems, the creator of Java, has perhaps best described the power of XML and Java together in its slogan: Portable Code -- Portable Data. Start experimenting with XML in Java, and you'll soon wonder how you ever lived without it.
Thanks to Dave Orchard for his comments on drafts of this article, and to the many helpful people I met in San Jose, CA.
Learn more about this topic
- There are so many XML resources on the Web, I've had to categorize. The first section here is the most useful, since the documents are either high-level summaries or excellent link sites. Apologies to anyone who was omitted.
- XML and JavaGeneral XML resources
- "XML, Java and the Future of the Web," Jon Bosak. The paper that started it all, at least from a Java programmer's point of view. Definitely worth a read, even if it's a bit dated. Jon is commonly considered to be the father of XML. Funny how all of these technologies seem to have paternity
- "Media-Independent PublishingFour Myths about XML" Jon Bosak
- Robin Cover's XML-SGML site is, according to my SGML buddies, the bible of XML resources
- The W3C's XML resource page lets you cheer from the sidelines as XML technology proposals develop into recommendations, or join in the fray on their active mailing lists
- OASIS, the Web site of the Organization for the Advancement of Structured Information Standards, offers general news and information about XML
- The Graphics Communications Association, host of the XTech '99 conference (March 11 to 13, 1999, San Jose, CA) and the upcoming XML Europe '99 conference in Granada, Spain, (April 26 to 30, 1999) has a Web site packed with XML information
- XML.com is great for watching trends and digging up XML news
- Textuality hosts Tim Bray's site. Check it out for a look at the "big picture" of how XML fits into the structured document universe -- and for a look at Lark, Tim's nonvalidating XML processor
- The XML FAQ
- IBM's XML Website is an outstanding supplement to alphaWorks
- XML and Java
- "XML and JavaThe Perfect Pair" by Ken Sall (Internet.com, November 1998) provides information about XML, Java, and why these two are a match made in heaven
- Tutorials and training
- Generally Markup, Richard Lander's Web site may be of interest to you if you haven't yet read enough about markup languages
- The Mulberry Technologies Web site is a good resource for commercial training in XML, as well as general XML and SGML consulting by seasoned SGML experts
- The Web Developer's Virtual Library Series on XML offers good summaries of various XML technologies, as well as annotated indices of XML software
- Microsoft's Site Builder Network provides a series of articles called "Extreme XML," one of which appears in the following link. While some of it focuses on Microsoft-only, Windows-only technology, there's still some great stuff here
- Webmonkey has a good series of articles introducing readers to XML. The index is at
- "What the ?xml!" by L.C. Rees offers an interesting take on XML and why it's necessary -- nicely written and entertaining to boot
- "The XML Revolution" by Dan Connolly is a quick backgrounder on XML (Nature)
- Cascading Style Sheets
- W3C's CSS page will get your started learning about CSS
- "Cascading Style Sheets Designing for the Web" by Hakom Wium Lie and Bert Bos (Addison-Wesley, 1997) Sample chapters from the book appear at
- Extensible Style Language (XSL)
- The W3C's XSL page
- Read (and comment on) the W3C's XSL Working Draft (currently dated December 16, 1998)
- "The Extensible Style LanguageStyling XML Documents" (WebTechniques Magazine) XSL tutorial information and examples
- Microsoft's XML and XSL tutorial site is especially interesting because of the recent release of client-side XSL in Internet Explorer 5.0. Extensive and excellent
- If you're still using IE 4.0, you can still experiment with XML, using Microsoft's internal DOM
- If you want to experiment with XSL, try downloading IBM's LotusXSL. It's all Java, and for the time being, it's free
- Or, you can try James Clark's XT XSL engine, downloadable from
- Upcoming XSL contest
- Though the details aren't yet worked out, Sun Microsystems will soon announce a call for proposals for a 0,000 grant to develop a client-side processor for full XSL implementation in Mozilla. It will also announce, in conjunction with Adobe, a contest (first prize 0,000, second prize 0,000) to develop a pure-Java, server-side processor of the entire XSL language, to format XML to PDF (Adobe's document format). Keep watching the Java Developer Connection (requires free registration), and Mozilla sites for the eventual announcements.
- "XTech '99Java and the XML wave" by Mark Johnson (JavaWorld, April 1999) offers the most current information on the contest
- Simple API for XML (SAX)
- The definitive description of SAX is available online. You can also download free SAX software here
- Document Object Model (DOM)
- The W3C information page for the Document Object Model appears on the W3C site
- Among other things, you'll find the W3C Recommendation for DOM Level 1
- The Java bindings for DOM, for both XML and HTML, are in this Recommendation appendix
- A great DOM tutorial by William Robert Stanek appears on PC Magazine Online in "Object-Based Web Design." This tutorial includes a discussion of using DOM with IDL, CORBA's Interface Definition Language
- Dynamic HTML
- The Dynamic HTML Resource page contains several links to DHTML articles
- Software
- Epicentric, Inc.
- More XML (and other Java) technology than you can shake a stick at is available at IBM's alphaWorks
- Version 2 of IBM's excellent XML parser package, xml4j, is available for download. This package includes several parsers, both validating and nonvalidating
- See also IBM's exciting Bean Markup Language project, which uses XML to represent and manipulate JavaBeans
- Another free Java XML parser was written by the indefatiguable James Clark, download at
- XEENA is IBM alphaWorks's DTD-guided XML editor. You want it, you need it, you gotta have it
- Mozilla.org is the open source community's effort to extend the Netscape source code. Find out about it at
- Information about XML and CSS in Mozilla appears at
- You can read about Sun's XML and Java initiatives at
- In addition, Java Project X includes source code downloadable from
- ArborText has a suite of sophisticated tools for editing SGML, XML, and XSL
- Oracle8i from Oracle corporation uses XML inside the Oracle core
- Download Oracle's free XML for Java parser
- Microsoft's Internet Explorer 5.0, released this month, implements part of the XSL spec. You can find it on Microsoft's Web site -- and also just about anywhere else
- You can also download a beta release of Microsoft's XML Notepad editor (limited to running only on Microsoft Windows)
- Vervet Logic of Bloomington, IN, has announced XML <PRO>, a commercial XML editor
- Majix, to transform XML to HTML via XSL, is available at
- If your French is rusty, you might want to try the English-language site at
- History
- Read about the history of HTML here. It's part of an online book, so there's no telling for how long it will be available
- The two chapters listed below (of the book "HTML Unleashed" by Rick Darnell, et al., also cover some of the technical background of these languages.
- SGML history
- XML history (such as it is)
- Nothing to do on Friday night? Why not read up on the history of SGML? Charles Goldfarb, considered by many to be the "father of SGML," reminisces publicly at
- Useful XML and SGML information appears at Goldfarb's Web site, including a comprehensive XML book list
- Miscellaneous links
- Uche Ogbuji has written an interesting article in LinuxWorld about using XML on Linux in the Enterprise. It's at
- Bluestone Software has recently made a splash with pure-Java XML application servers, and a freely downloadable Swing package called XwingML
- Everyone (except Microsoft) is pretty freaked out about the US Patent Office awarding Microsoft a patent for certain kinds of functionality in style sheets. What happens with this patent, and its impact on developing technology, remains to be seen. Judge for yourself by reading the patent at
- The title of the sample recipe is actually the title of a very funny song by William Bolcom. Similar recipes may be found at
- The song appears on a compact disc (with other odd songs) available from the Public Radio Music Source at | https://www.javaworld.com/article/2076396/java-xml/xml-for-the-absolute-beginner.amp.html | CC-MAIN-2018-22 | refinedweb | 5,469 | 57.5 |
[
]
Jakob Homan updated HADOOP-6080:
--------------------------------
Attachment: HADOOP-6080-v20.patch
HADOOP-6080.patch
Attaching two new files:
* Updated patch. Previous patch missed updating the help text for rmr to include -skipTrash
option. No change to actual code.
* Patch for Hadoop 20 off of the Hadoop-20 branch from svn. Nothing had to be changed for
patch, just file locations were different. Code is still the same. Passes unit tests.
> Handling of Trash with quota
> -----------------------------
>
> Key: HADOOP-6080
> URL:
> Project: Hadoop Common
> Issue Type: New Feature
> Components: fs
> Reporter: Koji Noguchi
> Assignee: Jakob Homan
> Attachments: HADOOP-6080-v20.patch, HADOOP-6080.patch, HADOOP-6080.patch, javac_warnings_diff.txt
>
>
> Currently with quota turned on, user cannot call '-rmr' on large directory that causes
over quota.
> {noformat}
> [knoguchi src]$ hadoop dfs -rmr /tmp/net2
> rmr: Failed to move to trash: hdfs://abc.def.com/tmp/net2
> [knoguchi src]$ hadoop dfs -mv /tmp/net2 /user/knoguchi/.Trash/Current
> mv: org.apache.hadoop.hdfs.protocol.QuotaExceededException: The quota of /user/knoguchi
is exceeded: namespace
> quota=37500 file count=37757, diskspace quota=-1 diskspace=1991250043353
> {noformat}
> Besides from error message being unfriendly, how should this be handled?
--
This message is automatically generated by JIRA.
-
You can reply to this email to add a comment to the issue online. | http://mail-archives.apache.org/mod_mbox/hadoop-common-dev/200906.mbox/%3C208199559.1246332347273.JavaMail.jira@brutus%3E | CC-MAIN-2017-47 | refinedweb | 211 | 60.41 |
On Mon, 2006-23-10 at 08:46 -0400, Tres Seaver wrote: > -----BEGIN PGP SIGNED MESSAGE----- > Hash: SHA1 > > Benji York wrote: > > Jim Fulton wrote: > >> Perhaps we should change the package option so that it uses the > >> pkg_resources > >> API to load ZCML files from packages. > > > > +1 I'd prefer not having to specify if the source was an egg or just a > > "normal" package. > > +1 here as well, because it avoids breaking user-edited ZCML for the > "simple" case (a package which used to be installed traditionally is now > installed as an egg). The rarer cases (namespace packages, or those > whose egg names don't match their package names) may still require the > extra syntax.
Advertising
+1 here too. After looking at the pkg_resources api ... it seems the ZCML loader could just use ``ResourceManager.resource_stream`` to parse the ZCML. - Rocky -- Rocky Burt ServerZen Software -- News About The Server (blog) --
signature.asc
Description: This is a digitally signed message part
_______________________________________________ Zope3-dev mailing list Zope3-dev@zope.org Unsub: | https://www.mail-archive.com/zope3-dev@zope.org/msg06764.html | CC-MAIN-2016-44 | refinedweb | 168 | 72.56 |
So I’ve got this project where I would like Radiant to render the
initial page, but do subsequent updates to various divs via AJAX. I
decided this because I don’t want a separate but identical layout files
within Radiant and the app/views/layout of my extension. I won’t be the
one to use this CMS once it is installed and if the user has to come
back to me for minor layout changes once things are in place, that won’t
be nice.
I created an extension with the idea that I would create a tag for each
div and define them to render the same partials that my the AJAX calls
return, just with some default parameters. I imagined I would use
render_component or maybe render_partial but quickly found there is no
controller to make these accessible from the tag definition context.
Without partials and without helpers like form_remote_tag and
link_to_remote, I found myself putting lots of raw html and javascript
(Prototype Ajax.request methods) in each tag block. Pretty nasty, so I
scrapped that.
Another solution would be the ability to render snippets from my
controller instead of the usual views. I’ve looked at Radiant on Rails
but support for processing Radiant tags while doing such output is still
a work in progress. Even if tag processing is finished soon, there is
still the issue of getting to Prototype/AJAX helper methods into those
snippets. I really like the idea of using snippets via my controller
though, if it were combined with an extension that exposes rails
Form/Prototype/Javascript helpers via Radiant Tags, that could maybe
work, without introducing that complexity into the core Radiant code.
For example, instead of my controller/view outputting an entire AJAX
sortable table, if I could define it as a snippet w/ the appropriate
AJAX helpers in place as Radiant tags, the end user could then tweak
considerably more, adding/dropping columns or changing class/id/css
information. I’ve already created radiant tags to access and iterate
over rows in my model so I think this would be a nice fit.
Which brings me back to my original approach, accessing rails
view/controller helpers from an extension tag block. I’ve read a few
posts where people were trying to do this, but they all have their
problems. Below are my experiences with various ways I’ve tried to get
around this.
Mental Tags - FormTagHelper?
This could allow tags to use rails helpers, thought it may be buggy. But
without the ability to render snippets from my controller, it is only a
half solution as my the AJAX responses from my controller will need to
output snippets, which RadiantOnRails does, but without processing
Radiant tags, so it would only work for the initial request served up by
Radiant. I could use a separate partial for the AJAX responses but I
don’t want my user making changes in the CMS and finding the AJAX
responses look different.
ActionView helpers in a behavior - I think I got it!
Same issues as above, possible bugs, no controller access to output
snippets after tag expansion.
RJS/Tracking Controller through Radiant Extension?
Requires modifying a page’s process method to look for AJAX requests,
but I thought my extension’s controller can already receive requests
directed to it, so I don’t see the point.
[Radiant] Can you use controllers/views within a tag
Ahh, bring a controller instance into my Tag module/mixin. This may be
my best solution at this point. This would allow me to render entire
divs using single tags that output partials using my controller - the
same partials that my AJAX responses will continue to return. No need to
import rails view helpers into my tag module, and no need to render
snippets from the controller with tag processing. Not as as flexible as
I would like, but this approach doesn’t require me to duplicate the site
layout in app/views/layouts. The sample code in the above post doesn’t
work as is, it needed a few changes, which the the guys in #ruby-lang
help me come up with. Posted below, with asterisks by the added/changed
lines -
def activate
require ‘application’
end
Page.class_eval do
attr_accessor :controller
def process_controller(controller)
@controller = controller
process(controller.request, controller.response)
end
end
Page.send :include, MemberDirectoryTags
end
So after that, from your tag definition, you just call -
tag.globals.page.controller.render_component_as_string :controller =>
“member_directory”, :action => “sortable_table”
Right? Nope. render_component_as_string is protected.
So I tried something different -
From my controller (MemberDirectoryController) -
def sortable_table_as_string
render_component_as_string :controller => “member_directory”,
:action => “sortable_table”, :params => { :person => “david” }
end
From my tag definition -
tag ‘member_test_tag’ do |tag|
@controller = MemberDirectoryController.new
puts @controller
@controller.sortable_table_as_string
end
well when I use <r:member_test_tag /> this displays in my browser -
can’t dup NilClass
Through using some output statements I found this happens during
render_component_as_string in my controller. I’m guessing the controller
needs more initialization than just calling new on it.
And finally I tried…
(asterisks on lines added over prior example)
def activate
require 'application'
def unprotected_render_component_as_string(options)
render_component_as_string options
end
end
Page.class_eval do
attr_accessor :controller
def process_controller(controller)
puts ‘!!!in process_controller’
@controller = controller
process(controller.request, controller.response)
end
end
Page.send :include, MemberDirectoryTags
end
Like my past attempts but I attempted to get around the protected
render_component_as_string and half-initialized controller by adding a
public instance method to SiteController called
unprotected_render_component_as_string(options) to expose the protected
method.
And in my tag definition file I put:
tag.globals.page.controller.unprotected_render_component_as_string
:controller => “member_directory”, :action => “sortable_table”
The <r:member_test_tag /> produced the error “interning empty string”
Below is the framework trace -
/usr/lib/ruby/gems/1.8/gems/radiant-0.6.1/lib/login_system.rb:16:in
intern' /usr/lib/ruby/gems/1.8/gems/radiant-0.6.1/lib/login_system.rb:16:inauthenticate’
Looks like an authentication issue? I don’t really know.
Well, that is it. I’ve outlined this quest to get things working with
AJAX so it will be available as a use case, and maybe help the devs
decide how to go forward with official changes to accommodate such apps.
I very much like Radiant for non-ajax use, I’ll be keeping an eye on it
for future projects as well.
If someone could point out how to access render_component_as_string from
my tag definition I’d be grateful. I’ve got to move on with this project
so I will be doubling up on my layouts for now, but if there is a way,
I’d like to know. | https://www.ruby-forum.com/t/ajax-controller-view-methods-helpers-in-extension-tag-block/106895 | CC-MAIN-2022-33 | refinedweb | 1,102 | 53.31 |
With so much JavaScript development on the client side, it only makes sense that developers and organizations would want to develop server side applications using JavaScript as well. Node.js has become a popular choice for building server side applications using JavaScript because of its asynchronous event-driven model and many libraries and extensions that are available.
But sometimes JavaScript is not the best choice for what you need to do, even in a Node.js application.
There is package for Node.js that allows you to invoke .NET code in-process from a Node.js application – Edge.js.
Edge.js is supported on Windows, Linux and OS X with .NET Framework 4.5 or Mono 3.4.0. Edge.js works with a variety of .NET languages including C#, F#, IronPython and LISP. It also works with T-SQL and Windows PowerShell. It was created by Tomasz Janczuk.
Here are some reasons for using .NET with Node.js:
- Integrating/reusing existing .NET components
- Accessing a SQL Server database using ADO.NET
- Using CLR threading for CPU intensive processing
- Writing native extensions to Node.js using a .NET language instead of C/C++.
- Use your imagination…You’ll come up with something
Installation is easy, just use the node package manager to run the command:
npm install edge
This installs the core Edge.js module with support for C#. Additional Edge.js modules are required for other languages:
- T-SQL: edge-sql
- F#: edge-fs
- LISP: edge-lsharp
- Windows Powershell: edge-ps
- IronPython: edge-py
Functions
The first thing you will probably want to do is create a JavaScript proxy to some C# code. In Edge.js, functions in C# are defined as Func <object, task<object>> where the first parameter is the input and the second parameter is the callback function. The edge.func() function will create the JavaScript proxy to the your C# code that can be executed synchronously or asynchronously from your Node.js code.
I’ll show how to do this with C# code inline with JavaScript, using a multi-line lamdba expression and a Startup class with an Invoke method. The downside of these methods are that you are writing code inside the comment block, so you don’t get the benefits of intellisense and syntax checking. You can also reference a pre-compiled assembly or C# in a separate file. Both examples below show a reference to the Linq assembly but you can reference any external assemblies you need.
Multi-line Lambda
var edge = require('edge'); var add = edge.func( { source: function() {/* async (dynamic input) => { return (int)input.a + (int)input.b; } */}, references: ["System.Linq.dll"] }); add({ a: 5, b: 10}, function (error, result) { console.log(result); });
Startup Class With Invoke Method
var edge = require('edge'); var add = edge.func( { source: function() {/* using System.Threading.Tasks; public class Startup { public async Task<object> Invoke(dynamic input)</object> { int a = (int)input.a; int b = (int)input.b; return MathHelper.Add(a, b); } } static class MathHelper { public static int Add(int a, int b) { return a + b; } } */}, references: ["System.Linq.dll"] }); add({ a: 5, b: 10}, function (error, result) { console.log(result); });
Asynchronous vs. Synchronous Execution
// asynchronous execution with a callback add({a: 10, b:20 }, function(error, result) { }); // synchronous execution with a return value var result = add({a: 10, b:20 }, true)
Data Marshalling
Edge.js can marshal any JSON data between Node.js and .NET. JavaScript objects are represented as dynamics in .NET that can be cast to an IDictionary<string, object>. Arrays in JavaScript become object arrays in .NET. For binary data, a Node Buffer will get translated into a .NET byte array. When marshalling data from .NET back to Node.js, classes and anonymous types that are JSON serializable will both get converted to JavaScript objects. Be careful to avoid circular references in your object graphs as these will most likely result in a stack overflow.
This example shows how you might pass data to a legacy component that would save an order. The Invoke method also returns an asynchronous function so the .NET code will run on a separate thread and not block Node.js.
var edge = require('edge'); var submitOrder = edge.func({ source: function() {/* using System.Threading.Tasks; using System.Collections.Generic; public class Order { public string orderNumber { get; set; } public int customerId { get; set; } public double total { get; set; } public List<OrderItem> items { get; set; } } public class OrderItem { public string name { get; set; } public double price { get; set; } public int quantity { get; set; } } public class Startup { public async Task<object> Invoke(dynamic input) { // returning the async function here // allows the .NET code to run on a // separate thread that doesn't block Node.js return await Task.Run<object>(async () => { var order = new Order { orderNumber = System.DateTime.Now.Ticks.ToString(), customerId = (int)input.customerId, items = new List<OrderItem>() }; dynamic [] items = input.items; foreach (var item in items) { var orderItem = new OrderItem { name = (string)item.name, price = (double)item.price, quantity = (int)item.quantity }; order.items.Add(orderItem); order.total += orderItem.price; } // ... invoke legacy code to save order here return order; }); } } */}, references: ["System.Collections.dll"] }); var order = { customerId: 1001, items: [ { name: 'XBox One Console', price: 329.95, quantity: 1 }, { name: 'Madden NFL 15', price: 49.95, quantity: 1} ] }; submitOrder(order, function (error, result) { if (error) console.log(error); else console.log(result); });
On Windows, you can debug .NET code in your Node.js applications. To debug C# code from a Node.js application, you first need to set the environment variable EDGE_CS_DEBUG=1. After starting node.exe, you simply attach your .NET managed code debugger to the node.exe process.
Should you have a need to script Node.js code from a .NET app, there is also an Edge.js NuGet package that enables this.
Final Thoughts
As you can see, there is a lot of flexibility with using Edge.js as a interop layer between Node.js and .NET. If you are building Node.js apps and have existing .NET code you want to reuse (or find something you think would just be a lot easier/quicker to code in .NET than JavaScript), you probably want to give Edge.js a try.
For more information and examples, see and
— Brian Wetzel, asktheteam@keyholesoftware.com | https://keyholesoftware.com/2014/11/29/node-js-meets-net-edge-js/ | CC-MAIN-2018-43 | refinedweb | 1,046 | 61.43 |
Organize Code with Modules
After completing this unit, you’ll be able to:
- Describe how support for modules has evolved over the years.
- Recognize the basic syntax used to define modules.
- Distinguish between different importing styles.
- Demonstrate how named exports results in read-only properties.
If you are a developer coming from another language, then you likely understand the importance of modular programming. Modular programming involves breaking your code up into logical chunks so that it’s easier to access. Using modules generally results in code that is easier to read and maintain.
That’s great, but up until ES6, creating modules in JavaScript wasn’t easy. You either had to create an enclosed function and closure, or you could rely on one of the competing module specs like Asynchronous Module Definition (AMD) and Universal Module Definition (UMD), or CommonJS if you were doing Node.js development..
To see how this works for yourself, create a CodePen project that uses the HTML5 script tag to load modules and import a function and two variables.
- In your Google Chrome browser, navigate to.
- Click Create and New Project.
- CodePen projects are just for logged in users. If you already have a CodePen account, you can click Log In to enter your credentials. Otherwise, you need to click Sign Up and follow the instructions to get set up with a free account before continuing.
- When asked whether you want to use a template, click Basic HTML5 Structure.
- From the Project Root pane, expand the scripts folder and select index.js to load it into the project editor.
- Replace all the code with the following:
import { printMsg } from './module1.js'; import { msg2, msg1 } from './module2.js'; printMsg(msg1 + msg2);
- From the Project Root folder, right-click the scripts folder and select New File to add a new JavaScript file in the scripts folder.
- When prompted for the name, enter module1.js.
- Enter the following code:
export function printMsg(message) { const div = document.createElement('div'); div.textContent = message; document.body.appendChild(div); }
- From the Project Root folder, right-click the scripts folder and select New File to add a new JavaScript file in the scripts folder.
- When prompted for the name, enter module2.js.
- Enter the following code:
let msg1 = 'Hello World! '; let msg2 = 'This message was loaded from a module.'; export { msg1, msg2 };
- From the Project Root folder, select the index.html file to load into the code editor.
- Scroll down in the file and look for the script tag that loads the index.js file. Replace that line of code with the following. Notice that all that was really done was to add the type="module" attribute to the script tag.
<script type="module" src="./scripts/index.js"> </script>
- Click Save All + Run.
- The preview window should display the text, “Hello World! This message was loaded from a module” in the preview window.
In the code we’ve looked at so far, the function and variables exported were imported using the same names. That’s fine. But what if you wanted to rename the functions and variables and use different names? You can do this using an alias. In the last example we used the following code to import the variables from the module2 file.
import { msg2, msg1 } from './module2.js'; printMsg(msg1 + msg2);
The concatenated value of those two variables was then passed as a parameter to the printMsg function using the same variable names (msg1 + msg2). But let’s say that you want to use a different variable name for one of those variables. Something like msg3. You can just change the code like this:
import { msg2, msg1 as msg3 } from './module2.js'; printMsg(msg3 + msg2);
At this point if you try to use the msg1 variable name you get a reference error telling you that msg1 is not defined. So just remember that once you set an alias, always use that same name.
Let’s consider another scenario. Assume now that you just want to import everything from a module and not worry about naming any of the exports. You can do that too. If you use an asterisk, everything is imported as a single object. You can see how this works if you change the code in index.js to be the following:
import { printMsg } from './module1.js'; import * as message from './module2.js'; printMsg(message.msg1 + message.msg2);
Notice how the newly created object was assigned an alias using the
as keyword. Also notice how the object name message is now referenced when accessing the values of the variables. So even though you did not have to worry about specifying
the names when exporting, you still need to know what the names are before referencing them as a property of the exported object.
When referring to module exports, we call them named exports. But what do you think is actually being exported? Is it just a reference to the exported variable, function, or class? Or is it the actual variable, function, or class?
Just the name gets exported, and you can see this for yourself. If you export a variable and then try to change the value in the imported module, you get an error. Essentially, it’s read-only. For example, if you change the code in index.js to the following and then save all the changes in CodePen, you just get a blank preview window.
import { printMsg } from './module1.js'; import { msg1, msg2 } from './module2.js'; msg1 = 'Did this variable change?'; printMsg(msg1 + msg2);
The preview window is blank because the last line of code was never executed and an error was thrown, which you can see for yourself if you go to the console in developer tools. Access Chrome’s developer tools by right-clicking inside the browser window and selecting Inspect.
The thing to remember here is that you are not allowed to reassign the exported value. It can only be changed from inside the module it was exported from.
- Modules always execute in strict mode, which means that variables need to be declared.
- They only get executed once, which is right when they are loaded.
- Import statements get hoisted, which means that all dependencies will execute right when the module is loaded.
Understanding ES6 Modules via Their History
ECMAScript 6 modules: the final syntax
<script:> The Script Element | https://trailhead.salesforce.com/en/content/learn/modules/modern-javascript-development/organize-code-with-modules | CC-MAIN-2019-22 | refinedweb | 1,056 | 66.84 |
after yesterday's webinar
after yesterday's webinar
I'm really temped to start using the Designer. I really like how the export file generated seperate the UI component from the business and tie them together.
However, from what I could understand from the presentation, you can only export to a specific folder ? In a big project where namespaces are used and files / directory structure this wouldn't really work if you have to move your files around each time you export a new file.
There should be a way to include namespace and some export logic into folders based on namespace ?
Also, (since there is no roadmap) are there plans to support ux and other plugins /extension ?
- Join Date
- Mar 2007
- Location
- Frederick, MD
- 1,747
- | http://www.sencha.com/forum/showthread.php?111822-after-yesterday-s-webinar | CC-MAIN-2014-49 | refinedweb | 127 | 62.27 |
Gerry Reno wrote: > Gerry Reno wrote: >> Andrew Straw wrote: >>> Gerry Reno wrote: >>>>. >>> >>> I figured out what the reason for >>> --single-version-externally-managed is >>> -- it is required for namespace packages to function properly. Thus, I >>> can't remove it, as doing so would be a regression. >>> >>> However, if you create a patch I can apply against the old-stable >>> branch >>> that makes this optional, (e.g. set in a similar way as the >>> --ignore-install-requires option), I can add that and make release >>> 0.3.1. >> Ok, I'll look at getting you a patch that removes the option. > > > Patch to utils.py in old-stable branch attached. I saw your patch, but that wasn't what I meant. Disabling --single-version-externally-managed has to be optional, and the argument must continue to be used by default. Simply removing the call will create a regression for namespace packages. Thus, the --single-version-externally-managed should only be removed when someone explicitly asks for it to be removed (because they presumably know what they're doing or are at least aware it may have negative consequences). Hence my suggestion to look at how the --ignore-install-requires works as an example of how to pass an option via the distuils infrastructure. >>> Note also that I'm very close to releasing 0.4, as the 0.3 line >>> has major problems with Jaunty and later. >>> >>> Are you planning to submit a patch for the bdist_deb command? I could >>> include that, too. >> Yes, I have something ready but I think the 'bdist_deb' command >> belongs as a distutils patch. I created the command by subclassing >> the distutils Command class. Maybe Tarek could comment on what might >> be best here. >> Here is my working 'bdist_deb' code verbatim from inside my setup.py: OK, based on your code I added a "bdist_deb" distutils command to stdeb. I've checked this into the old-stable branch and I'd appreciate it if you can check whether this works for you and send me any comments. Invoke it like this: python -c "import stdeb; excecfile('setup.py')" bdist_deb The implementation is in the old-stable branch I will merge this into the master branch soon. -Andrew | https://mail.python.org/pipermail/distutils-sig/2009-September/013394.html | CC-MAIN-2016-40 | refinedweb | 370 | 66.74 |
Microsoft is tipping the scales in its favor with ASP.NET Web Matrix, a free download that lets you create ASP.NET Web applications, services, etc. This IDE runs on Windows 2000 and Windows XP machines. Here's an overview of Web Matrix, as well as the steps you need to take to create a .NET Web solution using Web Matrix.
Web Matrix looks similar to Visual Studio .NET, and some of the functionality is the same as VS.NET. One thing that you'll miss right away (if you use Microsoft development tools) is IntelliSense; however, there is a class browser that lets you peruse the different classes available from the .NET Framework. Using the class browser, you can devise a plan of attack for creating the code necessary to complete the functionality you're trying to implement.
Other highlights include the SELECT, INSERT, UPDATE, DELETE, and Send Email code wizards that generate the code you need in order to run queries against a SQL or Microsoft Access database and send e-mail. This is a great training tool for anyone who wants to take the fabricated code and personalize it to create new functionality. Another highlight is the Custom Controls tab in the Toolbox. By right-mouse clicking, you can add controls from the online components library to your IDE. This is useful if you want to bypass all the headaches involved with creating your own custom components—well, it's a headache if you don't have any desire to develop these components.
Without going into too much detail, let's create a Web service that selects data from a SQL table and returns the results as a dataset. Fortunately, there's an online tutorial that will walk you through the process of creating such a solution. I'll follow the online tutorial somewhat, though I'll address some of the items that are left out. Also, I'll mix-and-match a couple of tutorials so you get a grasp of how to create a more realistic solution.
Follow the steps in the tutorial for creating the Web service. But instead of using the Filename, Class, Language, and Namespace that the tutorial uses, I suggest you use "mydata.asmx", "MyDataClass", "C#", "MyData", respectively. You'll end up with code in the code window that looks like this:
<%@ WebService language="C#" class="MyDataClass"
%>
using System;
using System.Web.Services;
using System.Xml.Serialization;
public class MyDataClass {
[WebMethod]
public int Add(int a, int b) {
return a + b;
}
}
I'll change this a bit by adding debugging to my solution—changing the first line to include Debug="true". I'll also declare a namespace for my class by adding the following line right before the class constructor line:
[WebService(Namespace="")]
If you don't add this, Web Matrix will set the namespace to "". This is fine for development, but you'll need to change it for release.
The wizard adds the method "Add" to your class; you can delete this code. We'll add a method that selects the data and returns a dataset. You can do this by clicking the Code Wizard tab on the Toolbox. Then, click and drag the SELECT button to a blank space in your class block. When you release the mouse button, the wizard appears.
The first screen of the wizard asks you to choose a database connection. Set the Select A Database field to <New Database Connection>. Set the Select A Database Type to SQL Server/MSDE Database. At this point, in order to use this, you'll have to have an available SQL Server or the MSDE installed. I happen to have the MSDE installed, so I'll use that connection. If you don't have either of these, you might want to consider installing MSDE 2000.
Next, click the Create button. Enter the server name in the Server field (or keep the default (local) if you're using a local instance of SQL or MSDE). Keep the Windows Authentication selection. (This will be important down the line.) Select the Database that you wish to connect to and click OK. (I'm connecting to a local database called MAIN_DB.) Follow the next few wizard windows to create the SELECT query. When you get to the last screen, where you'll see the Finish button, change the method name to GetMyData and make sure the return value is set to DataSet. Click Finish.
Now you'll see the generated code in the code window. Here's the code:
[WebMethod]
public System.Data.DataSet GetMyData() {
string connectionString = "server=\'(local)\'; trusted_connection=true;
database=\'MAIN_DB\'";
System.Data.IDbConnection dbConnection = new
System.Data.SqlClient.SqlConnection(connectionString);
string queryString = "SELECT [zips].* FROM [zips]";;
}
Notice that I added the [WebMethod] declaration to the resulting code. This identifies the method as a Web method. I also added the public scope qualifier to the method.
Note: Once you download and install Web Matrix, you can look through the class browser, which includes links to all of the online documentation for the .NET classes and associated methods/properties.
Running the Web service
First, save your file to a project directory of your choice. This directory will become a virtual root directory, so make sure you're comfortable with the location. Either go to View | Start and hit [F5], or click the Play button on the toolbar. You'll receive a prompt to start the application in either the included Web Matrix Server or IIS. The Web Matrix Server makes things easy to test out and comes with Web Matrix. However, I decided to test the code on my IIS installation. To do so, choose Use Or Create An IIS Virtual Root. Then, type the name of the alias you wish to give the new virtual root. (I chose MatrixTest.) Note: You should save your file in the Application Directory field. You may have to adjust the security settings on this directory later.
If all goes well, you'll see a page with a link to your method name. If not, you'll probably have one of two problems: 1) IIS doesn't have an association for .asmx files; or 2) IIS cannot access the folder where the file is located. To cure the first problem, you can either add the extension mappings yourself, or you can reinstall the current .NET Framework. To map the extensions yourself, you'll need the Internet Information Systems Manager, which is usually located under Administrative Tools in the Control Panel. Using the IIS Manager, you'll navigate to your virtual directory where your ASP.NET Web service resides (which, in my case, is the MatrixTest directory). To do so, right-click on the directory and choose Properties. Click on the Configuration. . . button under the Virtual Directory tab. Under the Mappings tab in the next window, click the Add button to add a new mapping. If you don't already have the .asmx extension mapped, map it to %windir%\Microsoft.NET\Framework\<version>\aspnet_isapi.dll, where <version> is the version of your .NET Framework installation.
If you get an access violation error when trying to run your Web service, you may have to allow access to the directory where your ASP.NET files are located. (This is the virtual root location from earlier.) Using Windows Explorer, navigate to the virtual root folder. Right-click on the folder and choose Properties. Under the Security tab in the next window, check to make sure the ASP.NET Machine Account has permissions to access this directory. If not, click the Add button and enter <computer name>\ASPNET as the new account username where <computer name> is the name of the computer where IIS is located. The minimum access requirements are List Folder Contents and Read.
Now you should be able to access your Web service. Try running the Web service from Web Matrix again. If you get the method name link, click on the method name. You'll get a screen with information on using your Web service but, most importantly, you're provided with an Invoke button to test your Web service. Click Invoke to invoke your Web service. A separate window should open displaying the XML data from your query.
If, like me, you get an HTTP 404 Page not found error, the best thing to do is to uninstall your .NET Framework installation and reinstall the latest .NET Framework.
The class browser that comes with Web Matrix allows you to research the .NET model. On the left-hand side of the browser, you'll find the available interfaces and classes that you need. Double-clicking on these interfaces or classes displays the methods and properties available on the right-hand side. It will also provide you with a link to online documentation for the associated class, method, or property.
You can follow the tutorials on Microsoft's ASP.NET home page to create a Web service client to test your Web service. You'll also find ASP.NET tutorials, forums, and newsgroups, as well as downloads for the .NET Framework v1.1 and MSDE 2000.
Keep your developer skills sharp by automatically signing up for TechRepublic's free Web Development Zone newsletter, delivered each Tuesday. | http://www.techrepublic.com/article/dive-into-net-with-web-matrix/5805075/ | CC-MAIN-2016-36 | refinedweb | 1,539 | 66.54 |
Hello,
probably it’s stupid question, but I’ve spent last 2 hours to find the solution, with no result.
Everybody tell to use getTextFromValue(); or getValueFromText(); But nobody tells how exactly use it?
Those methods just return value, but I don’t want to return anything. I want to set text value other than Slider value. What I mean: my Slider range is from 0.0 to 1.0. But I want text box to display from 20 Hz to 20000 Hz.
Please could anyone help me?
Slider text value other than Slider value
Hello,
If you want the slider to format the text it displays you can set the lambdas
juce::Slider::textFromValueFunction and
juce::Slider::valueFromTextFunction for your slider.
Using your range for a basic example:
mySlider.textFromValueFunction = [](double value) { double freq = (value * (20000.0 - 20.0)) + 20.0; return juce::String(freq) + "Hz"; }; mySlider.valueFromTextFunction = [](const String &text) { double freq = text.removeCharacters("Hz").getDoubleValue(); return (freq - 20.0) / (20000.0 - 20.0); };
The
valueFromTextFunction can allow the user to use your units & formatted range when they enter in values. In this case typing
10010Hz into the text box would display that frequency while setting the slider’s actual value to
0.5
Hello,
great thanks for reply and for help. Probably first I should try your code and then ask additional question. But my first impression is: When I do that code I have lambda functions stored in
mySlider.textFromValueFunction and in
mySlider.valueFromTextFunction, but both of those lambda functions return some value. So anytime I call
mySlider.textFromValueFunction(someValue); and
mySlider.valueFromTextFunction("some text"); they return values. But how to put those values in the text box. That is what I am asking for.
textFromValueFunction returns a
juce::String, which the slider will put into its text box
But you should mention that after I create that lambda function I should use it by calling
mySlider.textFromValue(someValue);
Because at first I tried to call
mySlider.textFromValueFunction(someValue); and nothing happened, just error
Just wanted to point you to a more readable approach using jmap
auto freq = jmap (value, 20.f, 20000.f); auto v = jmap (freq, 20.f, 20000.f, 0.f, 1.f);
If you’re having trouble to compile, make sure that all arguments have the same type, since these templated functions are picky and don’t do implicit casts.
Another option is, let the range of the slider take care of it, but that would mean, that you set the Range to
Range<float> (20.f, 20000.f) and all is sorted…
Hey everybody,
It’s old subject, but now I’ve found one more issue.
When I set:
mySlider.textFromValueFunction = [](double value) { double freq = (value * (20000.0 - 20.0)) + 20.0; return juce::String(freq) + “Hz”; };
Slider works great but unfortunately if I have editable textBox, and I edit text I get crazy values. It looks like that lambda calculates my edited value also. How to prevent that?
Look at @TonyAtHarrison’s answer, he gave you both needed functions. | https://forum.juce.com/t/slider-text-value-other-than-slider-value/27298 | CC-MAIN-2018-34 | refinedweb | 509 | 59.7 |
tag: DigitalOcean Community Questions 2017-10-16T20:25:35Z tag: 2017-10-16T20:25:34Z 2017-10-16T20:25:35Z How do I create a signed public 'share' URL similar to the 'Quick Share' option in Spaces? <p>How do I create a signed public 'share' URL similar to the 'Quick Share' option in Spaces?</p> <p. </p> <p>The DigitalOcean UI already has this "Quick Share" feature, but there doesn't seem to be any documentation about what its doing to create that URL and I cant figure out how to sign the request correctly to generate one myself.</p> <p>The URL parameters in question are, AWSAccessKeyId, Expires and Signature. The AWSAccessKeyId and Expires seem simple enough, but how do I go about calculating the signature?</p> repkam09 tag: 2017-10-16T19:44:58Z 2017-10-16T19:44:59Z Digital Ocean Firewall Prevents PPTPD Connections <p>After implementing a cloud firewall using Digital Ocean Firewall (DOF) console, my pptpd server will no longer connect to clients. As soon as the DOF is unassigned from the droplet the pptpd service connects perfectly. </p> <p>I am connecting from a Win 10 machine over pptpd with a user name and password. </p> <p>There seems to be an error thrown when I call <code>service pptpd status</code></p> <pre class="code-pre "><code langs="") </code></pre> <p>I've also tried opening port 1723 on both TCP / UDP incoming and outgoing to no avail<br> Custom TCP 1723 All IPv4 All IPv6</p> <p>What I assume is happening is that the cloud firewall is taking over the IPTABLE rules which allows pptpd to allow the connection through. </p> R Lutken tag: 2017-10-16T14:49:22Z 2017-10-16T14:49:23Z Please provide the community updates on the following requests <p>As a new customer checking out Digital Ocean and also viewing the competition as well, I'm still deciding what platform to focus our efforts into utilizing. Digital Ocean's pricing model is definitely something I'm a fan of. The services so far have performed exactly as expected, and I'm very happy with the overall system.</p> <p>But.. there are several things on my mind, and apparently they are on the minds of 5000+ other people as well. Things that we would love to see on Digital Ocean, so despite us being new here, I believe I speak for the crowd on this.</p> <p>So that the community can further understand what to expect on these things that has been patiently waited on. Please provide at least some cursory updates and/or a roadmap plan for:</p> <p><a href="" rel="nofollow"></a><br> <a href="" rel="nofollow"></a><br> <a href="" rel="nofollow"></a><br> <a href="" rel="nofollow"></a><br> <a href="" rel="nofollow"></a><br> <a href="" rel="nofollow"></a><br> <a href="" rel="nofollow"></a></p> <p>I'm including things here that are 5000 votes and up, and also things that are important to me as an individual user. While I have no personal needs in Australia, it does fit in the 5000+ votes category... I do see there was a response on uservoice.com to the AU question, but there's no date on it. So it's unclear as to if this is a recent improvement in the status or not. </p> <p>There is of course an endless list of TODO items for any business. But this is a start of things I (and the Users do as well, according to the votes) consider major missing pieces of functionality.</p> <p>So, in conclusion, If the DO Staff were to initially respond with just a few words about each item, with things like "Planned for 2018", or "Won't do Ever". that would be incredibly helpful.</p> <p>Thanks!</p> Mark Murawski tag: 2017-10-16T12:51:39Z 2017-10-16T13:04:00Z Does DigitalOcean have a plan to offer shared storage volumes for Docker Swarm Mode in near future? <p>We have been using DO for all development/testing activities..</p> <p>Without an officially supported solution for shared storage from DO, we have to regretfully leave DO and join the AWS band wagon.</p> pteli tag: 2017-10-16T12:45:24Z 2017-10-16T12:45:24Z Error 403 Forbidden <p>I am running this website: <a href="" rel="nofollow"></a> and unexpectedly it just prints "Error 403 Forbidden". Therefore I looked into my log file and this is what's written:<br> 2017/10/16 07:09:48 [error] 25750#25750: *159 directory index of "/home/fede/apps/spalaxys/public/" is forbidden, client: 165.227.67.242, server: , request: "HEAD / HTTP/1.0"</p> <p>Does anyone know how to solve this? Any help would be greatly appreciated!</p> Federico Cucinotta tag: 2017-10-16T11:50:32Z 2017-10-16T11:50:33Z start a service only after mysql has entered Active (running) state <p>I have a service that requires mysql to be fully up and running before it starts otherwise it fails. I have very alrge mysql databases and mysqld takes up to 40 minutes before entering an active (running) state.</p> <p>I have tried adding After=mysqld.service in the secondary services .service file {unit] section without success. It starts my secondary service ass soon as mysqld is enabled. I have tried using Wants=mysqld.service and Requires=mysqld.service without success. </p> <p>Any help or suggesstions would be appreciated.</p> <p>Thank you</p> Ken Lassey tag: 2017-10-15T20:30:39Z 2017-10-15T20:30:39Z SSH Connection drops offline after a few minutes of no activity <p>Whenever this?</p> Andrew Fox tag: 2017-10-15T19:13:03Z 2017-10-15T19:15:53Z Getting any kind of first boot config working on FreeBSD Droplets... <p>I've seen a number of ways to configure my initial system:</p> <ul> <li><a href="" rel="nofollow">bsdconfig</a></li> <li><a href="" rel="nofollow">configinit</a></li> <li><a href="" rel="nofollow">bsd-cloudinit</a></li> </ul> <p>I can't figure out how to get any of them to bootstrap my salt config, has anyone had any luck getting a droplet configured without the need to ssh there and run commands?</p> alastairc tag: 2017-10-15T17:35:34Z 2017-10-15T17:35:35Z How do I update my node version from 6.11.2 to v8+? <p>How do I update my node version from 6.11.2 to v8+? Any tutorial of it? I need help if not my thing won't work...</p> echoitia tag: 2017-10-15T16:11:15Z 2017-10-15T16:46:40Z This site can’t be reached refused to connect. <p>I'm trying to get nginx to work on my server. I was trying to get it to work with a more complex config, but I gave up and reinstalled it. I'm working with a really simple config here:</p> <p>*<em>File: /etc/nginx/nginx.conf *</em></p> <pre class="code-pre "><code langs="">user www-data; worker_processes auto; pid /run/nginx.pid; events { worker_connections 768; # multi_accept on; } http { ## # Basic Settings ## on; gzip_disable "msie6"; include /etc/nginx/conf.d/*.conf; include /etc/nginx/sites-enabled/*; } </code></pre> <p>*<em>File: /etc/nginx/sites-enabled/default *</em></p> <p>server {<br> listen 80 default<em>server;<br> listen [::]:80 default</em>server;</p> <pre class="code-pre "><code langs=""> root /var/www/html; index index.html index.nginx-debian.html; server_name [mydomain] []; location / { # First attempt to serve request as file, then # as directory, then fall back to displaying a 404. try_files $uri $uri/ =404; } </code></pre> <p>}</p> <p>I followed the instructions on: <a href="" rel="nofollow"></a></p> <p>I still get a This site can’t be reached [my IP] refused to connect. </p> Stéphane LaFlèche tag: 2017-10-15T15:16:17Z 2017-10-15T15:16:18Z cant access to squirrel mail <p>hi guys</p> <p>i installed squirrel mail from <a href="" rel="nofollow">this tutorial</a></p> <p>but i cant login to squirrel mail ( <a href="" rel="nofollow"></a>) <br> my password is true but i dont know why cant login to SquirrelMail ?</p> <pre class="code-pre "><code langs="">tail /var/log/mail.log Oct 15 15:10:01 debian-2gb-nyc3-01 dovecot: imap-login: Disconnected (no auth attempts in 0 secs): user=<>, rip=127.0.0.1, lip=127.0.0.1, secured, session=<aPGzSJdbAQB/AAAB> Oct 15 15:10:01 debian-2gb-nyc3-01 dovecot: pop3-login: Disconnected (no auth attempts in 0 secs): user=<>, rip=127.0.0.1, lip=127.0.0.1, secured, session=<ETK0SJdbXAB/AAAB> Oct 15 15:10:01 debian-2gb-nyc3-01 postfix/smtpd[11300]: connect from localhost[127.0.0.1] Oct 15 15:10:01 debian-2gb-nyc3-01 postfix/smtpd[11300]: lost connection after CONNECT from localhost[127.0.0.1] Oct 15 15:10:01 debian-2gb-nyc3-01 postfix/smtpd[11300]: disconnect from localhost[127.0.0.1] Oct 15 15:15:01 debian-2gb-nyc3-01 dovecot: imap-login: Disconnected (disconnected before auth was ready, waited 0 secs): user=<>, rip=127.0.0.1, lip=127.0.0.1, secured, session=<wPSXWpdbCAB/AAAB> Oct 15 15:15:01 debian-2gb-nyc3-01 dovecot: pop3-login: Disconnected (no auth attempts in 0 secs): user=<>, rip=127.0.0.1, lip=127.0.0.1, secured, session=<cESYWpdbYwB/AAAB> Oct 15 15:15:01 debian-2gb-nyc3-01 postfix/smtpd[11483]: connect from localhost[127.0.0.1] Oct 15 15:15:01 debian-2gb-nyc3-01 postfix/smtpd[11483]: lost connection after CONNECT from localhost[127.0.0.1] Oct 15 15:15:01 debian-2gb-nyc3-01 postfix/smtpd[11483]: disconnect from localhost[127.0.0.1] </code></pre> mm580486 tag: 2017-10-15T14:44:02Z 2017-10-15T14:44:03Z My word-press (one click droplet) woocommerce email is being sent to spam folder.Please help me with SMTP plugin setup ,What is SMTP Host ? <p>Am currently trying with Easy WP SMTP ,which requires lot of values which i dont really know the meaning of .Can anybody please guide me to some beginner tuts </p> Kiran Johny tag: 2017-10-15T12:27:08Z 2017-10-15T12:27:09Z Cectos 7 No TCP/IP 4 gateway <p>Hello,</p> <p>After doing yum update my Centos 7 machine lost the eth0 gateway.<br> I need to access in from other server in the same zone, via the local IP and set back the gateway using the command like:</p> <p>ip route replace default via X.Y.Z.1 dev eth0</p> <p>How can I fix the setting so that the gate way it be all way define.<br> My IP is dynamic because I delete the server and restore a snapshot from time to time.</p> rad6 tag: 2017-10-15T09:06:34Z 2017-10-15T09:06:34Z Your account is under review and you will shortly receive an email from us with any next steps. <p>How long should I wait to accept my account?<br> They took me 5e after paypal.</p> bciprian57 tag: 2017-10-15T07:55:24Z 2017-10-15T07:55:25Z Network throughput on new datacenters (FRA1) <p>Do droplets on new data centers like FRA1 get more network throughput?</p> <p>According to this answer, users are expected to limit the transfer speed to 300Mbps:<br> <a href="" rel="nofollow"></a></p> <p>Is this also true for FRA1? Each hypervisor on FRA1 has 40GbE connection so I would expect the limit to be much higher.</p> <p>Is there higher limit for high-cpu droplets?</p> pablop tag: 2017-10-15T02:57:50Z 2017-10-15T02:57:52Z Does Certbot offer self-signed SSL certificates only? <p>Just wondering if they offer anything other than self signed SSL certificates. </p> stradaentracasa tag: 2017-10-15T02:55:40Z 2017-10-15T02:58:26Z How do I require a private key for SSH connection? <p?</p> <p>Thanks and best wishes</p> stradaentracasa tag: 2017-10-14T21:59:41Z 2017-10-14T21:59:42Z I have hosted my django website project on digital ocean but my media folder not working . <p>I have hosted my django website project on digital ocean but my media folder not working actully i am uploading image from admin bit image is not displaying on website rest of my static file are working fine .pls any one can solve my prblem.<br> at the place of image display on mu web it showing path of image problem related to media imagefiled. but it working fine in my localhost. but not working on digital ocean when i deployed i have already chmod 777 permission to that folder.</p> aayushsanjeet tag: 2017-10-14T20:44:14Z 2017-10-14T20:44:15Z Add www to my url <p>How can I add www to my URL?</p> <p>I followed the instructions for setting a host name <a href="" rel="nofollow">here</a>, but whenever I browse for <a href="" rel="nofollow"></a>, I get redirected to <a href="" rel="nofollow"></a>.</p> <p>How do constantly keep <a href="" rel="nofollow"></a>?</p> <p>I have the following DNS records:</p> <table><thead> <tr> <th>Type</th> <th>Hostname</th> <th>Value</th> <th>TTL (seconds)</th> </tr> </thead><tbody> <tr> <td>CNAME</td> <td>*.foo.com</td> <td>is an alias of <a href="" rel="nofollow"></a>.</td> <td>43200</td> </tr> <tr> <td>A</td> <td>foo.com</td> <td>directs to 201.227.660.894</td> <td>3600</td> </tr> <tr> <td>A</td> <td><a href="" rel="nofollow"></a></td> <td>directs to 201.227.660.894</td> <td>3600</td> </tr> <tr> <td>NS</td> <td>foo.com</td> <td>directs to ns1.digitalocean.com.</td> <td>1800</td> </tr> <tr> <td>NS</td> <td>foo.com</td> <td>directs to ns2.digitalocean.com.</td> <td>1800</td> </tr> <tr> <td>NS</td> <td>foo.com</td> <td>directs to ns3.digitalocean.com.</td> <td>1800</td> </tr> </tbody></table> warrio tag: 2017-10-14T14:26:43Z 2017-10-14T14:26:44Z Why my old account has been Blocked ? but I've created a new account and got Blocked. Please tell me why ? <p>Please un-block my account for me, or I need chatting with DO supporter</p> Kim Young tag: 2017-10-14T14:16:12Z 2017-10-14T14:16:12Z Problem getting packages with APT-GET with mirrors.digitalocean.com (on LON1) <p>Hi!<br> It seems mirrors.digitalocean.com is not working. I've tried to install a package with apt-get (php7.0-dev) but it doesn't even start to transfer the package:</p> <p>0% [Connecting to mirrors.digitalocean.com (95.85.0.50)]<br> Err:1 <a href="" rel="nofollow"></a> xenial/main amd64 libpcrecpp0v5 amd64 2:8.38-3.1<br> Could not connect to lon1.mirrors.digitalocean.com:80 (95.85.0.50), connection timed out [IP: 95.85.0.50 80]</p> Emeve tag: 2017-10-14T13:35:24Z 2017-10-14T13:35:25Z how to upgrade php 5.6 to php 7 in centos 6.6 <p>i have a Centos 6.6 with php 5.6, i need upgrade to php 7</p> comerciallevante tag: 2017-10-14T12:23:52Z 2017-10-14T12:23:52Z Site Can't be Reached, DNS Error <p>Hello</p> <p>Suddenly I can't access my domain <a href="" rel="nofollow">pcare.id</a>. I'm using your DNS service. My droplet IP : 128.99.87.57 Everything was fine before. Is there something wrong, because I'm using your DNS management service for another domain and it works fine, no problem at all. Please help me to solve my problem. Thanks.</p> Agasi Gilang Persada tag: 2017-10-14T05:44:45Z 2017-10-14T05:44:46Z How to runserver django in ubuntu 17.04 i have created django app but when i try to run server the terminal says invalid syntax <p>i run this code i terminal </p> <p>$ python3 manage.py runserver 'my ip address:8000'</p> <p>and the result is </p> <p>Traceback (most recent call last):<br> File "manage.py", line 22, in <module><br> execute<em>from</em>command<em>line(sys.argv)<br> File "/usr/local/lib/python3.5/dist-packages/django/core/management/</em><em>init</em><em>.py", line 364, in execute</em>from<em>command</em>line<br> utility.execute()<br> File "/usr/local/lib/python3.5/dist-packages/django/core/management/<strong>init</strong>.py", line 308, in execute<br> settings.INSTALLED<em>APPS<br> File "/usr/local/lib/python3.5/dist-packages/django/conf/</em><em>init</em><em>.py", line 56, in _</em>getattr__<br> self.<em>setup(name)<br> File "/usr/local/lib/python3.5/dist-packages/django/conf/</em><em>init</em><em>.py", line 41, in _setup<br> self.</em>wrapped = Settings(settings<em>module)<br> File "/usr/local/lib/python3.5/dist-packages/django/conf/</em><em>init</em><em>.py", line 110, in _</em>init__<br> mod = importlib.import<em>module(self.SETTINGS</em>MODULE)<br> File "/usr/lib/python3.5/importlib/<strong>init</strong>.py", line 126, in import<em>module<br> return _bootstrap.</em>gcd<em>import(name[level:], package, level)<br> File "<frozen importlib.</em>bootstrap>", line 986, in <em>gcd</em>import<br> File "<frozen importlib._bootstrap>", line 969, in <em>find</em>and<em>load<br> File "<frozen importlib.</em>bootstrap>", line 958, in <em>find</em>and<em>load</em>unlocked<br> File "<frozen importlib._bootstrap>", line 673, in <em>load</em>unlocked<br> File "<frozen importlib._bootstrap_external>", line 669, in exec<em>module<br> File "<frozen importlib.</em>bootstrap<em>external>", line 775, in get</em>code<br> File "<frozen importlib._bootstrap_external>", line 735, in source<em>to</em>code<br> File "<frozen importlib._bootstrap>", line 222, in <em>call</em>with<em>frames</em>removed<br> File "/home/aditya/test<em>django</em>app/testsite/testsite/settings.py", line 28<br> ALLOWED_HOSTS = [my ip address]<br> ^<br> SyntaxError: invalid syntax</p> Aditya Kumar tag: 2017-10-13T22:47:52Z 2017-10-13T23:26:17Z SendMail Installed but PHPMailer not sending mails and not giving error <p>i've already installed sendmail and i edited my /etc/hosts file and then restarted apache<br> the content of the hosts file looks like this:</p> <p>127.0.0.1 localhost localhost.localdomain myhostname<br> 127.0.0.1 localhost</p> <p>however, when i try to send a simple email using PHPMailer it doesn't send the mail.</p> <p>have i misconfigurared something? any help please!</p> edwinmunguia tag: 2017-10-13T16:36:14Z 2017-10-13T16:36:15Z What is the best way to set up a SFTP with multiple users? Which products work best to set this up and about what price would it be? <ul> <li>20-50 GBs for storage</li> <li>Fast connection</li> <li>And work for giving different access to each user</li> </ul> chrisgage tag: 2017-10-13T15:06:10Z 2017-10-13T15:06:10Z Is it possible to create custom routing for private addresses? <p. <br> For example I add custom route on second droplet<br> ip ro add 1.1.1.0/24 via <private_ip_of_first_droplet><br> The rule is added, but packets for network 1.1.1.0/24 still does not go through first droplet. Tcpdump sees nothing. Is it possible to configure such scheme? </p> kulago tag: 2017-10-13T13:51:23Z 2017-10-13T13:51:24Z My webserver wont send mail <p>Hi, My webserver wont send mail.<br> Its a webserver with ubuntu 16.04 an apache2 and php 7.0.<br> And is has multiple site's running on it but it wont send mail if a contact form is filled in.</p> jensmarrink tag: 2017-10-13T12:12:06Z 2017-10-13T12:12:07Z How to execute script pyhon with php? <p>I have a project PHP in my droplet LEMP 16.04 with script python, when I run in terminal is ok, but when I run in the browser don't execute the script.</p> <p>My PHP</p> <pre class="code-pre "><code langs="">$vehicleJSON = shell_exec('python vehiclepy.py ' . $plate); </code></pre> <p>I've already tried:</p> <ol> <li>change to $vehicleJSON = shell_exec('python vehiclepy.py ' . $plate . ' 2>&1');</li> <li>change to $vehicleJSON = shell_exec('usr/bin/python /var/www/myapp/vehiclepy.py ' . $plate);</li> <li>add in sudoers www-data NOPASSWD: /var/www/myapp but don't execute.</li> </ol> <p>Please help me kkkkk, thanks!</p> artudp tag: 2017-10-13T06:40:38Z 2017-10-13T06:40:39Z I have attached a volume, mounted it to specific path. How can I use droplet's and volume's space as one docker volume? <p.</p> ademkerenci tag: 2017-10-13T05:33:57Z 2017-10-13T05:33:58Z Why is my domain purchased from Google pointing to mediatemple servers when i have digitalocean servers named? <p>I have purchased a domain from Google Domains and pointed it to my digitalocean servers. When i whois on PuTTY the registar is GoDaddy. the name servers are under ns#.mediatemple.net. I would understand if this was the old dns servers before i purchased the domain, but after a week to allow propagation, the problem persists</p> joeyhob tag: 2017-10-13T03:42:08Z 2017-10-13T03:42:08Z Automatic redirection to another website in the same droplet <p>When I try to access my site via <a href="" rel="nofollow"></a>, it redirects to <a href="" rel="nofollow"></a> which are hosted in the same droplet. Both sites are currently using the same SSL certificate. And the certificate is valid. Could this be a configuration issue or an SSL issue?</p> <p>OS: Ubuntu 14.04</p> Krishna Prasad K tag: 2017-10-12T19:03:57Z 2017-10-12T19:03:58Z High CPU Droplet availability via the DigtialOcean API <p>Are High CPU Droplet available via the DigtialOcean API? Are there any special considerations when creating them via the API?</p> Andrew SB tag: 2017-10-12T18:17:51Z 2017-10-12T18:17:52Z After adding my domain to ALLOWED_HOSTS in django settings I am still getting a 502 error. Not sure why my settings are not recognized. <p>So, I created an Ubuntu droplet with nginx, gunicorn and django. I added my domain and when trying to access my django site I got a 502 error. I read in several places that adding my domain to ALLOWED<em>HOSTS</em>HOSTS but I already added it. After digging a little further I notice that there are three files that contain an ALLOWED<em>HOSTS variable. There is ./var/lib/digitalocean/settings.py, ./var/lib/digitalocean/allow</em>hosts.py and /home/django/django<em>project/django</em>project/settings.py. So far I have attempted adding my domain into each of thes files and still recieve the same error. This is a stupid, really really frustrating error. Anyone have any suggestions or have the same issue?</p> bschreiber tag: 2017-10-12T17:43:38Z 2017-10-12T17:43:39Z Does DO Spaces provide a CDN in front of the storage for fast global access? <p :(</p> surgevelocityon tag: 2017-10-12T16:23:05Z 2017-10-12T16:23:06Z Cloud Panel like ServerPilot for NodeJS and Python <p>I see there's many cloud hosting panels like SeverPilot, Moss, Runcloud, Laravel Forge. But they're all focused on PHP environments. Are there any cloud hosting panels that focus on NodeJS and Python?</p> J Tan tag: 2017-10-12T15:01:43Z 2017-10-12T15:01:43Z SMTP blockedTicket <p>Hello I have opened a ticket #673364 to get unblocked on SMTP ports, </p> <p>I have double checked firewall and modified settings on gai.conf file. (precedence ::ffff:0:0/96 100)<br> Yet, I am not being able to send mails.</p> <p>I am starting my business and stuck with this.<br> Thank you very much for your prompt help.<br> Kind Regards!</p> dcassisi tag: 2017-10-12T07:11:45Z 2017-10-12T07:11:46Z Can I deploy Dradis Pro OVA files on Digital Ocean? <p>Can I deploy Dradis Pro OVA files on Digital Ocean?</p> redteam tag: 2017-10-12T04:50:19Z 2017-10-12T04:50:19Z Should I Afraid? (Someone trying to connect my ssl) <p>hi,5 minutes ago, I login to my VPS with username and password.<br> And there was a message that: "There were 142453 failed login attempts since the last successful login." (i login last night)</p> <p>what should I do? someone is trying to find my password.<br> how can I solve this problem?</p> cagkana9f5cd873f5b8188e469 tag: 2017-10-12T03:40:02Z 2017-10-12T03:40:02Z pls help i cannot login my old acc digitalocean <p>i can't receive email from digital ocean. it mean cannot login because digitalocean need code to verify login <br> becuase i close this email but can send </p> <p>can you switch this email </p> <p>suppost don't help me just tell me </p> <p>"Hello!</p> <p>Changing your email address is no problem!</p> <p>Please click on the cog wheel button in the upper-right of your account page, then click Settings. This will take you to your Settings page. On the left, please click Profile.</p> <p>From there, simply click Edit Profile, update your email address in the field there, and click Update Profile.</p> <p>A confirmation will be sent to your old email address to confirm the change. If you cannot receive email at the old address, then please let us know.</p> <p>Best regards,</p> <p>Mike G.<br> Platform Support Advocate<br> Check out our community for helpful articles and tutorials!<br> <a href="" rel="nofollow"></a><br> ref:<em>00Do0IjOV.</em>5001NU6XkB:ref "</p> <p>like this if i cannot login how i can change mother of god !!!!!</p> <p>THank you </p> caramell607 tag: 2017-10-12T00:05:16Z 2017-10-12T00:05:17Z I have an old backup made with Duplicator, I can't figure how to install it... maybe I could get some help? <p>I have a couple of backups made like 2 years ago. I have tried to put it back online, but I couldn't manage to make even thought I watched several tutorials... </p> <p>Maybe I can get some help?</p> AntonioMadrid tag: 2017-10-11T20:01:58Z 2017-10-11T20:03:48Z upstream prematurely closed while reading response header from upstream, reques: "GET / HTTP/1.1", upstream: "uwsgi://unix:///tmp/web.sock:" <p>upstream prematurely closed connection while reading response header from upstream, client: xxx.xx.xx.xx, server: website.com, request: "GET / HTTP/1.1", upstream: "uwsgi://unix:///tmp/web.sock:", host: "website.com"</p> <p>How to solve this ?</p> Devi Saranya Dadi tag: 2017-10-11T18:27:04Z 2017-10-11T18:27:05Z Can't login to the droplet and support doesn't answer already one day <p.</p> <p>I emailed support yesterday but no answer. Then posted ticket 4+ hours ago and now Google'd that it's suggested to post here for faster answers.</p> kaspar tag: 2017-10-11T17:06:06Z 2017-10-11T17:11:00Z Can not send mail with postfix <p>Hi everyone, I'm trying to config sending email from application thought this <a href="" rel="nofollow">tutorial</a>.</p> <p>But when I try to send an test email to my emails, its not work, I also try to sen one or another.</p> <p>looking for log file its show</p> <pre class="code-pre "><code langs="">Oct 11 16:41:32 mail postfix/pickup[4727]: 81676819B8: uid=1000 from=<myuser@mydomain.com> Oct 11 16:41:32 mail postfix/cleanup[5349]: 81676819B8: message-id=<20171011164132.81676819B8@mydomain.com > Oct 11 16:41:32 mail postfix/qmgr[4728]: 81676819B8: from=<myuser@mydomain.com >, size=396, nrcpt=1 (queue active) Oct 11 16:41:41 mail postfix/qmgr[4728]: 8CF22819B5: from=<myuser@mydomain.com >, size=396, nrcpt=1 (queue active) Oct 11 16:42:02 mail postfix/smtp[5351]: connect to gmail-smtp-in.l.google.com[173.194.68.27]:25: Connection timed out Oct 11 16:42:02 mail postfix/smtp[5351]: connect to gmail-smtp-in.l.google.com[2607:f8b0:400d:c0c::1b]:25: Network is unreachable Oct 11 16:42:02 mail postfix/smtp[5351]: connect to alt1.gmail-smtp-in.l.google.com[2800:3f0:4003:c01::1a]:25: Network is unreachable Oct 11 16:42:11 mail postfix/smtp[5354]: connect to gmail-smtp-in.l.google.com[209.85.201.26]:25: Connection timed out Oct 11 16:42:11 mail postfix/smtp[5354]: connect to gmail-smtp-in.l.google.com[2607:f8b0:400d:c03::1b]:25: Network is unreachable Oct 11 16:42:11 mail postfix/smtp[5354]: connect to alt1.gmail-smtp-in.l.google.com[2800:3f0:4003:c01::1a]:25: Network is unreachable Oct 11 16:42:32 mail postfix/smtp[5351]: connect to alt1.gmail-smtp-in.l.google.com[64.233.190.26]:25: Connection timed out Oct 11 16:42:32 mail postfix/smtp[5351]: connect to alt2.gmail-smtp-in.l.google.com[2a00:1450:400b:c03::1a]:25: Network is unreachable Oct 11 16:42:32 mail postfix/smtp[5351]: 81676819B8: to=<myemail@gmail.com>, relay=none, delay=60, delays=0.01/0.01/60/0, dsn=4.4.1, status=deferred (connect to alt2.gmail-smtp-in.l.google.com[2a00:1450:400b:c03::1a]:25: Network is unreachable) Oct 11 16:42:41 mail postfix/smtp[5354]: connect to alt1.gmail-smtp-in.l.google.com[64.233.190.26]:25: Connection timed out Oct 11 16:42:41 mail postfix/smtp[5354]: connect to alt2.gmail-smtp-in.l.google.com[2a00:1450:400b:c03::1a]:25: Network is unreachable Oct 11 16:42:41 mail postfix/smtp[5354]: 8CF22819B5: to=<myemail@gmail.com>, relay=none, delay=1535, delays=1475/0.01/60/0, dsn=4.4.1, status=deferred (connect to alt2.gmail-smtp-in.l.google.com[2a00:1450:400b:c03::1a]:25: Network is unreachable) </code></pre> <p>I already using zoho mail service, could it be the reason. </p> <p>Every thing I work on ubuntu 17.04</p> <p>Thanks for any help.</p> thanhtunguyen0608 tag: 2017-10-11T17:01:19Z 2017-10-11T17:01:20Z How to make SFTP work above 40kbps? <p>I got SFTP set up on my server, a standard setup following D.O. tutorials. It works properly with FileZilla, WinSCP etc, but won't move above 40kbps, where both the server and the client have a ton of bandwidth. How do I fix this? We need at least 5mbps.</p> Viktor274 tag: 2017-10-11T16:37:27Z 2017-10-11T16:37:28Z I’m currently using Godaddy as the hosting company for my music streaming service. Can I switch to your service as my hosting company? <p>Site is only a few weeks old. Looking to increase my max upload size for a music streaming service. </p> Romel tag: 2017-10-11T16:04:09Z 2017-10-11T16:04:10Z Rails binding to 'ip':3000 is giving me connection timeout <p>Hi im following this tutorial </p> <p><a href="" rel="nofollow"></a></p> <p>except that im using Ubuntu 16<br> The problem is after i bundle install my app, and following the </p> <pre class="code-pre "><code langs="">RAILS_ENV=production rails server --binding=server_public_IP </code></pre> <p>and try to access it via web app, all i get is err<em>conn</em>timeout</p> <p>my app is indeed running, and this is what it shows</p> <pre class="code-pre "><code langs="">=> </code></pre> <p>i only followed the instructions on the tutorial and im not yet installing nginx.<br> Im also quite new on this stuff, i had to rebuild my droplet cause i thought i broke something on my first run as i really can't see my app and now im quite loss</p> <p>this was also my netstat </p> <pre class="code-pre "><code langs="" -``` </code></pre> genevievejoshua tag: 2017-10-11T14:17:08Z 2017-10-11T14:17:08Z ssh_exchange_identification: read: Connection reset by peer Ask Question <p>I have a droplet on Digital Ocean. Its credentials are shared with one of my friend. We used to connect to it via ssh as:<br><br> <code>ssh root@IP_Address</code> <br> Now due to lack of concentration we did a mistake by running the following command while on the server: <code>sudo chmod -R 777 /</code> <br> due to which server is not connecting anymore via anything (SSH/SCP/FTP/...) and is giving the following error: ssh<em>exchange</em>identification: read: Connection reset by peer<br><br> Following is the output of <code>ssh root@IP_Address -vv</code> </p> <pre class="code-pre "><code langs="">OpenSSH_7.2p2 Ubuntu-4ubuntu2.2, OpenSSL 1.0.2g 1 Mar 2016 debug1: Reading configuration data /etc/ssh/ssh_config debug1: /etc/ssh/ssh_config line 19: Applying options for * debug2: resolving "IP_Address" port 22 debug2: ssh_connect_direct: needpriv 0 debug1: Connecting to IP_Address [IP_Address] port 22. debug1: Connection established. debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_rsa type -1 debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_rsa-cert type -1 debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_dsa type -1 debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_dsa-cert type -1 debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_ecdsa type -1 debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_ecdsa-cert type -1 debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_ed25519 type -1 debug1: key_load_public: No such file or directory debug1: identity file /home/talha/.ssh/id_ed25519-cert type -1 debug1: Enabling compatibility mode for protocol 2.0 debug1: Local version string SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.2 ssh_exchange_identification: read: Connection reset by peer </code></pre> <p>Kindly help me ASAP as I don't have latest backup of hosted projects and databases.<br><br> Thank you in advance!</p> Talha Siddiqi tag: 2017-10-11T13:13:50Z 2017-10-11T13:34:26Z How to launch a droplet via API? <p>I am interested in a reliable way of launching droplets over API. I want to know how to check for all possible errors and how to detect if a new droplet is finally running.</p> <p>Just doing POST to /v2/droplets sometimes might not be enough. I had following problems:</p> <ul> <li>An error response but a simple repeat works fine. I had following errors "There was an error while trying to create your tags. Please try again", "Server was unable to give you a response." Repeating the exact same request helped in those cases.</li> <li.</li> <li.</li> </ul> <p>It looks quite complex to me.</p> <p>What would be a reliable yet simple approach to launch droplets that works around all possible cases and keeps working even if you have hundreds of droplets?</p> rapoport tag: 2017-10-11T12:31:56Z 2017-10-11T12:31:57Z Is it possible to mount DO Spaces as external storage in Nextcloud as I mount AWS S3 storage? <p>I'm using $5 Droplet for my Nextcloud instance. It is possible to mount AWS S3 buckets in Nextcloud as an external storage. So is it possible to mount Spaces as S3?</p> Waad tag: 2017-10-11T08:44:24Z 2017-10-11T08:44:25Z Can't access Ticket I made <p."</p> <p>Do I now need to create a new ticket?</p> daredevil28 tag: 2017-10-11T04:48:32Z 2017-10-11T04:48:33Z $JAVA_HOME path not sourced correctly in ~/bash_profile at login? <p>Hi,</p> <p>Upon logging into my CentOS 7 VM, my $JAVA<em>HOME is always set to : /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86</em>64/jre, which is incorrect.</p> <p>My ~/.bash_profile reads:</p> <h1 id="bash_profile">.bash_profile</h1> <h1 id="get-the-aliases-and-functions">Get the aliases and functions</h1> <p>if [ -f ~/.bashrc ]; then<br> . ~/.bashrc<br> fi</p> <h1 id="user-specific-environment-and-startup-programs">User specific environment and startup programs</h1> <p>JAVA<em>HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.144-0.b01.el7</em>4.x86<em>64/jre<br> export JAVA</em>HOME</p> <p>PYCHARM<em>HOME=/opt/pycharm-community-2017.2.3/<br> export PYCHARM</em>HOME</p> <p>ECLIPSE<em>HOME=/opt/eclipse<br> export ECLIPSE</em>HOME</p> <p>export SPARK_HOME=/opt/spark</p> <p>PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA<em>HOME/bin:$SPARK</em>HOME/bin:$PYCHARM<em>HOME/bin:$ECLIPSE</em>HOME</p> <p>export PATH<br> Sourcing .bash<em>profile each time I open a new terminal appears to correct the issue, but why is my $JAVA</em>HOME path defaulting to an old version on startup and not being set to the directory specified in .bash_profile?</p> <p>help me!</p> Kristine Conderman tag: 2017-10-10T22:26:42Z 2017-10-10T22:32:27Z Ghost droplet prevents PHP from executing files? <p>In a fresh Ghost droplet installation of Ubuntu 14.04 LTS, I put a php script into a /var/www/static folder, but the file always wants to download instead of run. Is this because of Ghost? How can I get PHP to execute the script instead of trying to download it?</p> <p>Edit: I can execute the file from the terminal, but running it in a browser always tries to download or just show the plaintext.</p> sirrico tag: 2017-10-10T20:30:02Z 2017-10-10T20:30:05Z Max_input_vars not applying changes <p>Hi!<br>.</p> <p>Any solution?<br> Thanks!</p> s3sergio tag: 2017-10-10T19:23:58Z 2017-10-10T19:23:58Z QFontDatabase addApplicationFont works in Embedded Linux, but not in Linux Ubuntu? <p>Hi,</p> <p..</p> <p..</p> <p>Any help will be appreciated.</p> <p>Here is the code I'm using:</p> <p>QFontDatabase::removeAllApplicationFonts();</p> <p>QDir fontDir(DEFAULT<em>FONTS</em>PATH);<br> QStringList fontFileList = fontDir.entryList(QStringList("*.ttf"), QDir::Files | QDir::NoDotDot | QDir::NoDot);</p> <p>mDebugS(QString("Found %1 fonts on folder theme/fonts").arg(fontFileList.size()));</p> <p>//<br> qint32 fontId;</p> <p>foreach (const QString& filename, fontFileList)<br> {<br> fontId = QFontDatabase::addApplicationFont(DEFAULT<em>FONTS</em>PATH "/" + filename);</p> <pre class="code-pre "><code langs="">if (Q_UNLIKELY(fontId == -1)) { const QString strTemp = QString("Unable to install font %1").arg(filename); mLog(strTemp); mDebugS(strTemp); } else applicationFontsIdList.append(fontId); </code></pre> <p>}</p> <p>mDebugS(QString::number(applicationFontsIdList.size()) + " fonts are installed");</p> <p>Help me.</p> LON MA MAY tag: 2017-10-10T18:09:32Z 2017-10-10T18:12:22Z Which would be the best distro & desktop for remote VNC? <p>I'm don't know much of Linux & all these different distributions, so could you please help me a bit. I would like to create a droplet that allows me to use some simple & light desktop thru VNC every now and then, but I have no idea which kind of a droplet I should create? I will also need Node.js and MongoDB. </p> <p>And since I'm not so familiar with Linux over all (yet), I will also need exact step-by-step instructions for installing the desktop & configuring the VNC for it etc.</p> <p>So, what's your opinion; what would be the best & easiest platform for me? ;=)</p> jasurakk tag: 2017-10-10T14:50:27Z 2017-10-10T14:50:28Z SubDomains on CentOS 7.4 Apache2(httpd). <p>Hi,</p> <p>I want to setup a new subdomain on my centos server. <br> I cannot figure out how to do it properly,<br> I've done a subdomain like this:<br> sub.domain.it ----> <a href="" rel="nofollow"></a><br> but I want that i remain on sub.domain.it how can i do it? without a redirect?<br> I've already searched a lot on the web but no solution D:.</p> Mattia tag: 2017-10-10T11:49:35Z 2017-10-10T11:52:56Z Yahoo customer care number australia <p>We provide Yahoo Customer care Number Australia clients as well as around the globe. Call Yahoo Customer Care Number for any email issues. If you forgot your password or lost your password, deleted mails, Attachment issues, compose mailing, send and receive mail dial free phone number -1800 763 395 or visit our website- email-support-australia.com/yahoo-helpline-support.html</p> Aaron Hank tag: 2017-10-10T10:53:08Z 2017-10-10T10:53:09Z "spaces" and restic 0.7.3 <p>im trying to backup data to a spaces bucket, <br> since spaces should be s3 compliant i assume this should work, see: <a href="" rel="nofollow"></a> </p> <pre class="code-pre "><code langs="">$ restic -r s3:nyc3.digitaloceanspaces.com/mysupernicebucket init create backend at s3:nyc3.digitaloceanspaces.com/mysupernicebucket failed: client.BucketExists: Get: dial tcp 169.254.169.254:80: i/o timeout </code></pre> <p>i hate to say so but "yesterday it was working okay". </p> <p>weird thing is i see the same ip as the aws user data endpoint appearing in the error message.<br> whats going on here? what am i missing? </p> Herrmann Hinz tag: 2017-10-10T09:08:18Z 2017-10-10T09:12:24Z Errors Occurrs Each Time "GIT pushing" to remote. <p>Hello everyone,</p> <p>I encounter two issues with my laravel web app each time I "git push" to the server. Everything works fine on the local machine (Mac). I am running nginz server on DigitalOcean.</p> <p>1- Each time I "git push" to remote, all the pictures only the website get broken. The only way I solve this is, cd to public/storage, delete the storage folder and then run <code>php artisan storage:link</code>. This is tedious because I have to do it every time I "git push" to remote.</p> <p>2- Each time I "git push" to remote and when I try to updating/populating any of my tables, I receive this error after the table has been updated/populated: <br> <code>(1/1) PDOException SQLSTATE[HY000]: General error: 8 attempts to write a readonly database</code></p> <p>Sinc,e I am using TNTSearch package, I notice it tries to write to the index file. I figured out that I need to give permission to the database, so I solve this issue using: <code>chmod -R 0777 /path/to/index</code> . This solves the problem but it recurs when I "git push" to the remote.</p> <p>How can I give a permanent write permission to public/storage (in the first case) so that I do not have to run the command each time I push to remote?<br> Also, How do I give a permanent write permission to the database, so that I do not have to do that each time I push to remote?</p> <p>Thank you in advance.</p> Shola tag: 2017-10-10T08:30:56Z 2017-10-10T08:30:57Z i don't understand what is my URL problem <p>Sometime I find that there is some problem in my URL. I can't figure out what it is.<br> my URL address: <a href="" rel="nofollow"></a></p> seoinfotechbd tag: 2017-10-10T07:41:48Z 2017-10-10T07:41:49Z command not getting executed in console (control panel console) <p>I am able to login to console . but when i type any command , i m not getting any response </p> sukumarmanpravah tag: 2017-10-10T06:14:49Z 2017-10-10T06:18:25Z Has anyone managed to get a beanstalk admin console to work? <p>I have been trying to get an admin interface working for beanstalk on my Ubuntu 16.04 server. The one I chose was <a href="" rel="nofollow"></a> which is the most frequently recommended web interface for the beanstalk queues on a Laravel application.</p> <p>I installed the console code at "/home/<user-name>/public<em>html/beanstalk</em>console" and then navigated to that folder and started the php server with this command, as per the instructions:</p> <pre class="code-pre "><code langs="">php -S xxx.xxx.xxx.xx:7654 -t public </code></pre> <p>where xxx etc. is the IP address of the droplet.</p> <p>I got a response that seemed to indicate the console was working as expected:</p> <pre class="code-pre "><code langs="">PHP 7.0.22-0ubuntu0.16.04.1 Development Server started at Tue Oct 10 02:02:10 2017 Listening on Document root is /home/<user-name>/public_html/beanstalk_console/public Press Ctrl-C to quit. </code></pre> <p>However, when I try to bring up the web console by visiting <a href="" rel="nofollow"></a>, I get a blank page in the browser. No matter what I try, the beanstalk web console page doesn't launch.</p> <p>In /etc/default/beanstalkd, the settings are the default:</p> <pre class="code-pre "><code langs="">BEANSTALKD_LISTEN_ADDR=127.0.0.1 BEANSTALKD_LISTEN_PORT=11300 </code></pre> <p>I have a feeling I am missing something but am not sure what that is. I hope someone here could share some insights into what is wrong with my setup.</p> <p>Thanks in advance.</p> cloudnine tag: 2017-10-10T05:41:57Z 2017-10-10T05:41:58Z Server login problems from terminal (NGINX, UBUNTU 16.04) <p>Hi there,</p> <p>I'm create ssh key following <a href="" rel="nofollow">this </a>tutorial. <br> But when i'm set PermitRootLogin 'yes' to 'without-password' then i'm running 'reload ssh' command and i'm" and also try to login from my pc terminal, But showing me "Permission denied, please try again"</p> <p>How i will fix these problem? Please help to solve this problem.</p> <p>Thanks so much,<br> Arafat</p> MD Arafat tag: 2017-10-10T03:55:56Z 2017-10-10T03:55:56Z <p>New Movie Blade Runner 2049New Movie Blade Runner 2049New Movie Blade Runner 2049New Movie Blade Runner 2049</p> carl blairre tag: 2017-10-10T03:42:08Z 2017-10-10T03:42:09Z Cookies work great on localhost but does not work on VPS <p>I have a Nodejs and Angularjs web app. Everything works perfectly on localhost but when I push my code to my droplet, cookie does not work. Everything that I saved in cookie does not appear on Cookies. I have just created an Amazon VPS and the same problem. I know that cookie is client side but why does it happen ? This is my piece of angular code:<br> $scope.login = function () {</p> <pre class="code-pre "><code langs="">var isEmpty = AuthService.checkEmptyLogin($scope.user); if (!isEmpty.isErr) { UserService.login($scope.user).then(function (result) { if (result.data.success) { $rootScope.userLogin = result.data.data.name; //------------------ var day = new Date(); day.setDate(day.getDay() + 30); var options = { domain: "localhost", httpOnly: true, expires: day }; // nothing in cookies $cookies.put('token', result.data.data.token, options); $cookies.put('name', result.data.data.name, options); // session storage works fine $sessionStorage.user = 'heheeheh'; flash.success = result.data.message; $state.go('home'); } else { flash.error = result.data.message; } }); } else { $scope.loginMessage = isEmpty.message; } </code></pre> hbathach tag: 2017-10-10T01:55:58Z 2017-10-10T01:55:59Z can a session be conducted and run through a browser without installing anything on the client? <p.</p> <p>Any ideas? Putting the chrome books in developer mode & booting from a usb stick is out of bounds I'm afraid.</p> <p>I'm hoping for a browser based login or portal that the kids can use. </p> jbc tag: 2017-10-10T01:40:54Z 2017-10-10T01:40:55Z Run express and ghost on same droplet <p</p> Deskrive Diego tag: 2017-10-09T21:01:02Z 2017-10-09T21:01:02Z I'm not receiving the 6-digit verification email! <p>The email account I need to login is:</p> <p><a href="mailto:contato@studiobluemind.com.br" rel="nofollow">contato@studiobluemind.com.br</a></p> <p>I created this account with my personal email just to ask this question.</p> <p>Kind of a crisis here, need to access the panel asap!</p> <p>Thanks,</p> thiagonucci tag: 2017-10-09T17:39:07Z 2017-10-09T17:39:08Z Running two WordPress sites using Apache, first one is redirecting to the other? SSL w/ LetsEncrypt, 16.04 <p>Hey there,</p> <p>I'm having a problem where my domain davidparrella.com is being redirected to another wordpress site on my server, 512filmfestival.com.<br> Some older (2013) tutorials seem to say that for multiple WordPress sites I would need Docker, but newer posts on the community seem to have people running multiple WordPress sites just fine using Apache normally to redirect domains.<br> I also have two other static HTML sites on this droplet which are not affected by this glitch, and they get directed to their appropriate folders normally.</p> <p>Here's what I did:<br> I started a WordPress site with the domain davidparrella.com, DNS server is pointed to my droplet IP with an A record. This is in the directory /var/www/dp</p> <p</p> <p>Here are my Apache config files for:<br> <a href="" rel="nofollow">512filmfestival.com.conf</a><br> <a href="" rel="nofollow">512filmfestival.com-le-ssl.conf</a></p> <p>and <br> <a href="" rel="nofollow">davidparrella.com.conf</a><br> <a href="" rel="nofollow">davidparrella.com-le-ssl.conf</a></p> <p>My hostname for the machine is:<br> davidparrella</p> <p>My hosts file has 127.0.1.1 as davidparrella.com</p> <p>Any help would be greatly appreciated as I can't seem to track this one down...<br> Thanks!</p> parrella20 tag: 2017-10-09T17:24:59Z 2017-10-09T17:24:59Z my site not working (error_connection refused). sudo reboot not working <p>my website <a href="" rel="nofollow"></a> and <a href="" rel="nofollow"></a> not working . <br> I am getting error as error<em>connection</em>refused .<br> in console i am getting message as system restart required . So i tried with sudo reboot command in control panel but website has not yet started </p> sukumarmanpravah tag: 2017-10-09T17:10:01Z 2017-10-09T17:10:01Z I can not connect to sgp server by using putty,but sf server is OK <p>I use a sgp server. ping is ok before putty connection. But after trying to use putty to connect to my server, it goes wrong. And, a few min later, I ping requests can be replyed by server again.</p> <p>re-power or rebuild os dose not work, but newyork server is OK.</p> 512398975 tag: 2017-10-09T16:07:03Z 2017-10-09T16:07:04Z Is there a Wagtail droplet? <p>I've tried your Django droplet but it would be awesome to have a droplet with Wagtail CMS…</p> Helder Luis tag: 2017-10-09T15:16:53Z 2017-10-09T15:16:54Z Result is not as described in the published guide. <p>Following this tutorial, <a href="" rel="nofollow"></a>, I have done everything exactly, including the server setup guide at <a href="" rel="nofollow"></a>, and at the first launch of the application: <code>manage.py runserver</code>,...</p> konghai tag: 2017-10-09T14:15:05Z 2017-10-09T14:39:57Z How to add ssh key after creating droplets & Login Problems <p>Hi there,</p> <p>I'm create ssh key following <a href="" rel="nofollow">this</a> tutorial. <br> But when i'm set PermitRootLogin 'yes' to 'without-password' then i". <br> How i will fix these problem? Please help to solve this problem.</p> <p>Thanks so much,<br> Arafat</p> MD Arafat tag: 2017-10-09T13:11:13Z 2017-10-09T13:11:56Z My hosting failed to send email from gmail <p>I had contacted Digital Ocean about my gmail server. They said I must add the record on the domain side.</p> <p>I had add SPF google and the domain IP is my server IP.</p> <p>But I failed to send the gmail from my hosting server.</p> <pre class="code-pre "><code langs="">"v=spf1 ip4:128.199.69.30 include:_spf.google.com -all" </code></pre> <p>I'm using nodeJS to test email function:</p> <pre class="code-pre "><code langs="">var transporter = nodemailer.createTransport({ host: 'smtp.gmail.com', port: 587, secure: false, // secure:true for port 465, secure:false for port 587 auth: { user: mConfig.sender_email, // Your email id pass: mConfig.sender_password // Your password } }); </code></pre> longsookeat tag: 2017-10-09T12:20:10Z 2017-10-09T12:20:10Z High CPU droplet CPUs (Xeon Platinum 8168 vs Xeon E5-2697A v4) <p>"Access some of Intel's® most powerful CPUs including Xeon Platinum 8168 (Skylake) with a 2.7 Ghz Clock Speed and Xeon E5-2697A v4 (Broadwell) with a 2.6 Ghz Clock Speed. "</p> <p?</p> Firze tag: 2017-10-09T09:30:56Z 2017-10-09T09:31:34Z Problem with add expire days for bucket from s3cmd <p>Hello!<br> I try add expire days from file and bucket but have this problem:</p> <pre class="code-pre "><code langs="">sudo s3cmd expire s3://<my-bucket>/ --expiry-days=3 expiry-prefix=backup </code></pre> <p>ERROR: Error parsing xml: syntax error: line 1, column 0<br> ERROR: not found<br> ERROR: S3 error: 404 (Not Found)</p> <p>and this</p> <pre class="code-pre "><code langs="">sudo s3cmd expire s3://<my-bucket>/<folder>/<file> --expiry-day=3 </code></pre> <p>ERROR: Parameter problem: Expecting S3 URI with just the bucket name set instead of 's3://<my-bucket>/<folder>/<file>'</p> <p>How add expire days in DO Spaces for folder or file from s3cmd?</p> dorlenko tag: 2017-10-09T07:36:39Z 2017-10-09T12:58:25Z 403 Forbidden error <p>403 Forbidden error when visiting subdomain.example.com.</p> <p>For the last few days I have been trying to setup a subdomain on my Nginx server for my website, the main website in the /var/www/html dictionary is working fine but can't figure out the subdomain and example.com/forum ( with vanilla forum files are in the /var/www/html with my main domain name and have not made any changes to the config for forum when trying to install vanilla it goes to <a href="" rel="nofollow"></a> page rather than <a href="" rel="nofollow"></a> and setup link) if there is anything I need to change in the default config file for the forum please advise. </p> <p>Regarding the subdomain.example.com I have setup a server with below config and have copied it to sites-enabled as well as sites-available but it still returns 403 error as mention above however when I place an a index.html file in the dictionary it loads fine but doesn't work with WordPress files. Thanks in advance for any answers/help</p> <pre class="code-pre "><code langs=""> server { listen 80; listen [::]:80; root /var/www/uk.watchallchannels.com/html; index index.html index.htm index.nginx-debian.html; server_name uk.watchallchannels.com;; } } </code></pre> mishfaq tag: 2017-10-09T03:47:08Z 2017-10-09T03:47:08Z SSH through IPv6 times out --</p> <pre class="code-pre "><code langs="">debug1: Connecting to example.com [****:****:***:**::****:8001] port 22. debug1: connect to address ****:****:***:**::****:**** port 22: Connection timed out debug1: Connecting to example.com [***.***.**.240] port 22. debug1: Connection established. </code></pre> <p>(I generalized the message. It's not exactly a secret site, though.)</p> <p>And when I try to connect using only the IPv6 address instead of the domain, it fails. (Works fine with IPv4 address.)</p> <p>I went through the DO SSH troubleshooting article, but it didn't make any difference. Where can I go to try to troubleshoot this?</p> <p>(If it's relevant, I'm using nginx on this server. I have another server that uses nginx, but it doesn't have this problem.)</p> anorman728 tag: 2017-10-09T00:24:02Z 2017-10-09T00:24:04Z FlaskApp running and can be accessed via IP. Already went through the steps for configuring a domain name and not working? What should I do <p>I purchased a domain name from namespace and followed the instructions <a href="" rel="nofollow"></a> and changed the DNS servers. I then followed these instructions <a href="" rel="nofollow"></a>?</p> abmamo tag: 2017-10-08T23:50:48Z 2017-10-08T23:50:49Z How do i create a new droplet from a saved snapshot using doctl cmdline tool? <p>I was trying to create a droplet using a snapshot that I created from an existing droplet. While I can do it from the Web UI, I seem to be struggling with it using the "droplet create" command, since the snapshot does not come with an "image slug".</p> <p>Bottom line, can I create a new droplet using a saved snapshot using doctl?</p> Anand Sharma tag: 2017-10-08T23:39:19Z 2017-10-08T23:39:20Z How do I change the Roundcube webmail URL to mail.example.com instead of mail.example.com/mail with iRedMail installation? <p>The apache installation for iRedMail is not the same as a normal apache installation so I'm struggling to get the site working. I tried editing roundcubemail.conf in /etc/apache2/conf-enabled to <VirtualHost> instead of <Directory> but that broke the server. Not sure where I have to edit or what to put.</p> forestman11 tag: 2017-10-08T17:02:57Z 2017-10-08T17:02:58Z What else is required to access node app outside of the DigitalOcean droplet? <p><a href="" rel="nofollow">Originally posted on SO</a></p> <p>We have set up a node server which runs on PORT 5000.</p> <p>In a <a href="" rel="nofollow">newly created droplet</a>, we have <a href="" rel="nofollow">installed and started nginx</a>. To access the node app, we have changed the default port from 80 to 5000 in <code>/etc/nginx/sites-enabled/default</code></p> <pre class="code-pre "><code langs="">server { listen 5000 default_server; listen [::]:5000 default_server; </code></pre> <p><a href="" rel="nofollow"><code>ufw</code> is enabled</a></p> <pre class="code-pre "><code langs="">sudo ufw enable </code></pre> <p>Also <a href="" rel="nofollow">the port is enabled</a></p> <pre class="code-pre "><code langs="">sudo ufw allow 5000/tcp </code></pre> <p>Also, tried this way too:</p> <pre class="code-pre "><code langs="">sudo ufw allow 5000 </code></pre> <p>As confirmed with <code>sudo ufw status</code></p> <p><a href="" rel="nofollow"><img src="" alt="sudo ufw status"></a></p> <p>Also <a href="" rel="nofollow">the app is configured to listen on the public interface</a></p> <pre class="code-pre "><code langs="">const server = app.listen(process.env.PORT || 5000, '0.0.0.0', () => { console.log('Express server listening on port %d in %s mode', server.address().port, app.settings.env); }); </code></pre> <p>However, not even the default PORT was responding. HENCE, reverted to 80 as the default PORT.</p> <p>What else is required to access node app outside of the droplet?</p> xameeramir tag: 2017-10-08T14:39:43Z 2017-10-08T14:39:44Z forced ssh-add? <p>When you first setup a droplet if you added a ssh public key to the server in order to log in to the server you must use ssh-add <path-to-key> in order to log in as root. However if I create a new user, and dump that same key (or even a different one) into it's authorized_keys file then I am able to ssh in directly to that new user without using ssh-add. Can someone explain to me why I can log into one but not the other without using ssh-add?</p> James tag: 2017-10-08T05:33:56Z 2017-10-08T05:33:57Z How do I get the LAMP Stack one-click app to use my domain? <p>I added a LAMP stack one-click app droplet on Digital Ocean, directed my A record on Gandi to point "@" and "www" to the IP and ran Let's Encrypt to get SSL certificated for <a href="" rel="nofollow"></a> and pellux.net (my domain). <a href="" rel="nofollow"></a> takes me to the default LAMP stack page (although it doesn't auto-redirect as I specificed in the LE setup, for some reason) but "pellux.net" gives the error "pellux.net’s server DNS address could not be found." What can I do to fix both the auto-redirect to https not working and the pellux.net URL not working?</p> forestman11 tag: 2017-10-07T21:27:10Z 2017-10-07T21:27:11Z Console access automatically logs in into username? <p>I tried to access my droplet using the "console access" in the droplet settings under "Access", and it was already logged in to my "username" which is protected by a password.<br> Is that normal? is seems pretty odd, and never happened before.</p> Samuelgozi tag: 2017-10-07T17:29:10Z 2017-10-07T17:29:11Z someone is pointing my ip to his domain name <p>Hi I am running my website in Linux VPS with dedicated IP few weeks ago I found someone else domain is pointing to my website</p> <p>Ex :: mydomain.com === server my site content<br> otherdomain.com === also server my site content<br> If I update or modify its getting updated on other domain too..</p> <p>please need help any settings to prevent this</p> abderbij tag: 2017-10-07T14:46:32Z 2017-10-07T14:46:33Z Set up servers now then take offline to use later <p>I want to set up everything (MERN stack) and then take it all offline and upload or call back the configs later on when I am ready to deploy. Ideally I could download them then reupload when needed to save on the minimal cost</p> Josh tag: 2017-10-07T12:35:02Z 2017-10-07T12:40:37Z http2 with nginx not working with Safari <p>Hello guys,</p> <p>My https http2 from server block, it displays fine in Safari.</p> <p>Thanks for any useful info.</p> <p>Config:</p> <pre class="code-pre "><code class="code-highlight language-nginx">server { listen 443 ssl http2 default_server; listen [::]:443 ssl http2; http2_max_field_size 16k; http2_max_header_size 32k; http2_recv_buffer_size 32k; #includeSubDomains" always; location ~ \.php$ { include snippets/fastcgi-php.conf; fastcgi_pass unix:/run/php/php7.0-fpm.sock; } location ~ /\.ht { deny all; } server { listen 80; listen [::]:80; server_name domain.com; return 301; } </code></pre> Michael Novak tag: 2017-10-07T11:48:48Z 2017-10-07T11:48:48Z why wont this verify its been 3 hours <p>make a online chat why wont this verify its been 3 hours</p> cody wilson tag: 2017-10-07T10:46:58Z 2017-10-07T10:55:03Z We're reviewing your account <p>Hello, i just added 5$ in my account and i received this message Your account is under review and you will shortly receive an email from us with any next steps. How long it takes? Thanks.</p> mihaildragos18o tag: 2017-10-07T01:59:05Z 2017-10-07T01:59:06Z Spaces bandwidth pricing <p>Does the Spaces transfer pricing of $0.02 per GB apply to transfers between the object storage and a Droplet instance within the same region? </p> Matt Doza tag: 2017-10-06T20:08:32Z 2017-10-06T20:08:32Z Nginx http basic not working <p>Hi </p> <p>I've a droplet with Nginx installed, but I can get the http basic working - I followed this tutorial</p> <p>[<a href="" rel="nofollow"></a><br> ](http://)</p> <p>And here is the Nginx config</p> <pre class="code-pre "><code langs=""> location /test { auth_basic "Restricted"; auth_basic_user_file /etc/nginx/htpasswd/.test.com; } </code></pre> <p>I went to the /test and it return 404</p> <p>I suspect the official nginx doesn't come with http basic module, here is the output of</p> <pre class="code-pre "><code langs="">test@v1 /etc/nginx $ nginx -V nginx version: nginx/1.10.3 (Ubuntu) built with OpenSSL 1.0.2g 1 Mar 2016 TLS SNI support enabled configure test@v1 /etc/nginx $ </code></pre> <p>The nginx doesn't have <strong>ngx<em>http</em>auth<em>basic</em>module</strong> compiled as indicated by</p> <p>[<a href="" rel="nofollow"></a><br> ](http://)</p> <p>However this is the official nginx, can you help me to get http basic auth working?</p> vitohuang tag: 2017-10-06T19:28:23Z 2017-10-06T19:28:23Z PhpMyAdmin - Access denied for user 'phpmyadmin'@'localhost' <pre class="code-pre "><code langs=""> ┌─────────────────────────────────────────────────────────────────────────────────────────────────┤ Configuring phpmyadmin ├──────────────────────────────────────────────────────────────────────────────────────────────────┐ │ An error occurred while installing the database: │ │ │ │ mysql said: mysql: [Warning] mysql: Empty value for 'port' specified. Will throw an error in future versions ERROR 1045 (28000): Access denied for user 'phpmyadmin'@'localhost' (using password: YES) . Your options are: │ </code></pre> Lewis Holt tag: 2017-10-06T18:41:44Z 2017-10-06T18:41:45Z Account email verification not working for me.... help? <p>I'm trying to sign up for an account (my first account here) and I'm not receiving the verification email. I've requested that it be resent, but still haven't received it.</p> <p>I've checked my spam folder as well.</p> <p>Is anyone out there that can do anything to help me?</p> <p>Thanks</p> SwordSmith tag: 2017-10-06T17:06:56Z 2017-10-06T17:06:57Z how I send smtp mail server <p>I got time out when I try to send mail server</p> <pre class="code-pre "><code langs="">Oct 6 16:55:27 mst postfix/qmgr[26733]: BC956BB893: from=<xxx@domain.com>, size=388, nrcpt=1 (queue active) Oct 6 16:55:54 mst postfix/smtp[26735]: connect to gmail-smtp-in.l.google.com[74.125.68.27]:25: Connection timed out Oct 6 16:55:54 mst postfix/smtp[26736]: connect to gmail-smtp-in.l.google.com[74.125.68.27]:25: Connection timed out Oct 6 16:55:54 mst postfix/smtp[26737]: connect to gmail-smtp-in.l.google.com[74.125.68.27]:25: Connection timed out Oct 6 16:55:54 mst postfix/smtp[26738]: connect to gmail-smtp-in.l.google.com[74.125.68.26]:25: Connection timed out Oct 6 16:55:57 mst postfix/smtp[26744]: connect to gmail-smtp-in.l.google.com[74.125.68.26]:25: Connection timed out Oct 6 16:56:24 mst postfix/smtp[26736]: connect to alt1.gmail-smtp-in.l.google.com[74.125.28.26]:25: Connection timed out Oct 6 16:56:24 mst postfix/smtp[26737]: connect to alt1.gmail-smtp-in.l.google.com[74.125.28.27]:25: Connection timed out Oct 6 16:56:24 mst postfix/smtp[26738]: connect to alt1.gmail-smtp-in.l.google.com[74.125.28.26]:25: Connection timed out Oct 6 16:56:24 mst postfix/smtp[26735]: connect to alt1.gmail-smtp-in.l.google.com[74.125.28.26]:25: Connection timed out Oct 6 16:56:27 mst postfix/smtp[26744]: connect to alt1.gmail-smtp-in.l.google.com[74.125.28.27]:25: Connection timed out Oct 6 16:56:54 mst postfix/smtp[26737]: connect to alt2.gmail-smtp-in.l.google.com[64.233.178.26]:25: Connection timed out Oct 6 16:56:54 mst postfix/smtp[26738]: connect to alt2.gmail-smtp-in.l.google.com[64.233.178.27]:25: Connection timed out Oct 6 16:56:54 mst postfix/smtp[26735]: connect to alt2.gmail-smtp-in.l.google.com[64.233.178.26]:25: Connection timed out Oct 6 16:56:54 mst postfix/smtp[26736]: connect to alt2.gmail-smtp-in.l.google.com[64.233.178.26]:25: Connection timed out Oct 6 16:56:57 mst postfix/smtp[26744]: connect to alt2.gmail-smtp-in.l.google.com[64.233.178.26]:25: Connection timed out Oct 6 16:57:25 mst postfix/smtp[26736]: connect to alt3.gmail-smtp-in.l.google.com[74.125.124.26]:25: Connection timed out Oct 6 16:57:25 mst postfix/smtp[26738]: connect to alt3.gmail-smtp-in.l.google.com[74.125.124.27]:25: Connection timed out Oct 6 16:57:25 mst postfix/smtp[26735]: connect to alt3.gmail-smtp-in.l.google.com[74.125.124.27]:25: Connection timed out Oct 6 16:57:25 mst postfix/smtp[26737]: connect to alt3.gmail-smtp-in.l.google.com[74.125.124.26]:25: Connection timed out Oct 6 16:57:27 mst postfix/smtp[26744]: connect to alt3.gmail-smtp-in.l.google.com[74.125.124.26]:25: Connection timed out Oct 6 16:57:55 mst postfix/smtp[26738]: connect to alt4.gmail-smtp-in.l.google.com[173.194.219.26]:25: Connection timed out Oct 6 16:57:55 mst postfix/smtp[26735]: connect to alt4.gmail-smtp-in.l.google.com[173.194.219.27]:25: Connection timed out Oct 6 16:57:55 mst postfix/smtp[26736]: connect to alt4.gmail-smtp-in.l.google.com[173.194.219.27]:25: Connection timed out Oct 6 16:57:55 mst postfix/smtp[26737]: connect to alt4.gmail-smtp-in.l.google.com[173.194.219.26]:25: Connection timed out Oct 6 16:57:55 mst postfix/smtp[26738]: DE7DEBB8D3: to=<test@gmail.com>, relay=none, delay=2307, delays=2157/0.03/150/0, dsn=4.4.1, status=deferred (connect to alt4.gmail-smtp-in.l.google.com[173.194.219.26]:25: Connection timed out) Oct 6 16:57:55 mst postfix/smtp[26738]: using backwards-compatible default setting relay_domains=$mydestination to update fast-flush logfile for domain "gmail.com" Oct 6 16:57:55 mst postfix/smtp[26735]: 6EFBFBB8CF: to=<test@gmail.com>, relay=none, delay=2564, delays=2413/0.01/150/0, dsn=4.4.1, status=deferred (connect to alt4.gmail-smtp-in.l.google.com[173.194.219.27]:25: Connection timed out) Oct 6 16:57:55 mst postfix/smtp[26735]: using backwards-compatible default setting relay_domains=$mydestination to update fast-flush logfile for domain "gmail.com" Oct 6 16:57:55 mst postfix/smtp[26736]: 1ACCABB8B8: to=<test@gmail.com>, relay=none, delay=4799, delays=4649/0.02/150/0, dsn=4.4.1, status=deferred (connect to alt4.gmail-smtp-in.l.google.com[173.194.219.27]:25: Connection timed out) Oct 6 16:57:55 mst postfix/smtp[26736]: using backwards-compatible default setting relay_domains=$mydestination to update fast-flush logfile for domain "gmail.com" Oct 6 16:57:55 mst postfix/smtp[26737]: 7DA7BBB8B4: to=<test@gmail.com>, relay=none, delay=4852, delays=4701/0.02/150/0, dsn=4.4.1, status=deferred (connect to alt4.gmail-smtp-in.l.google.com[173.194.219.26]:25: Connection timed out) Oct 6 16:57:55 mst postfix/smtp[26737]: using backwards-compatible default setting relay_domains=$mydestination to update fast-flush logfile for domain "gmail.com" Oct 6 16:57:57 mst postfix/smtp[26744]: connect to alt4.gmail-smtp-in.l.google.com[173.194.219.26]:25: Connection timed out Oct 6 16:57:57 mst postfix/smtp[26744]: BC956BB893: to=<test@gmail.com>, relay=none, delay=150, delays=0.03/0.01/150/0, dsn=4.4.1, status=deferred (connect to alt4.gmail-smtp-in.l.google.com[173.194.219.26]:25: Connection timed out) Oct 6 16:57:57 mst postfix/smtp[26744]: using backwards-compatible default setting relay_domains=$mydestination to update fast-flush logfile for domain "gmail.com" Oct 6 16:58:05 mst kernel: [1296062.103471] [UFW BLOCK] IN=eth0 OUT= MAC=##:##:##:##:##:##:##:c##:##:##:##:##:##:## SRC=##.##.##.## DST=##.##.#.#¯ LEN=122 TOS=0x00 PREC=0x00 TTL=48 ID=0 DF PROTO=UDP SPT=31135 DPT=1900 LEN=102 </code></pre> <p>how I fix them</p> loveten tag: 2017-10-06T15:19:05Z 2017-10-06T15:19:06Z How to add a card? Looks like you are having an issue adding a credit card. We recommend opening a support ticket to help us resolve this... <p>I cannot add my card. Looks like you are having an issue adding a credit card. We recommend opening a support ticket to help us resolve this issue with you.</p> Effective Investment tag: 2017-10-06T14:40:44Z 2017-10-06T14:40:45Z Installing PhpMyAdmin on Ubuntu 16.04 LEMP <p>Hi,<br> I'm trying to install phpMyAdmin by SSH on Ubuntu 16.04 with LEMP..<br> I'm stopped on this string:</p> <pre class="code-pre "><code langs="">sudo ln -s /usr/share/phpmyadmin /usr/share/nginx/html </code></pre> <p>They take to me this error:</p> <pre class="code-pre "><code langs="">ln: failed to create symbolic link '/usr/share/ngix/html': No such file or directory </code></pre> <p>I've watched by FTP and the folders exist..!<br> Why take to me this error?</p> LuigiMdg tag: 2017-10-06T13:25:08Z 2017-10-06T13:25:08Z ERR_CONNECTION_TIMED_OUT in node.js Using Centos 7 <h3 id="node-version">node version</h3> <p>v8.6.0</p> <h2 id="app-js">App.js</h2> <p>var express = require('express');</p> <p>var app = express();</p> <p>app.get('/' , function(req,res){<br> res.send('Works');<br> });</p> <p>var logger = function(req,res,next) {<br> console.log('Logging......');<br> next();<br> }</p> <p>app.use(logger);</p> <p>app.listen(3000 , function() {<br> console.log('hello');</p> <p>});</p> <p>when i try to access it in the browser i get ERR<em>CONNECTION</em>TIMED_OUT and I tried it in localhost it worked</p> Jamal Abo Mokh | https://www.digitalocean.com/community/questions/feed.atom | CC-MAIN-2017-43 | refinedweb | 12,556 | 57.37 |
Apply a force to the rigidbody..
If you don’t specify a ForceMode2D the default will be used. The default in this case is ForceMode2D.Force which adds force over time, using mass.
To use the example scripts below, drag and drop your chosen script onto a Sprite in the Hierarchy. Make sure that the Sprite has a Rigidbody2D component.
See Also: AddForceAtPosition, AddTorque, mass, velocity, AddForce, ForceMode2D.
// The sprite will fall under its weight. After a short time the // sprite will start its upwards travel due to the thrust force that is added // in the opposite direction
using UnityEngine; using System.Collections;
public class ExampleTwo : MonoBehaviour { private Rigidbody2D rb2D; private float thrust = 10.0f;
void Start() { rb2D = gameObject.AddComponent<Rigidbody2D>(); transform.position = new Vector3(0.0f, -2.0f, 0.0f); }
void FixedUpdate() { rb2D.AddForce(transform.up * thrust); } }
// For short bursts of force (such as an explosion) use ForceMode2D.Impulse // This adds an instant force impulse to the Rigidbody2D, using mass
using System.Collections; using UnityEngine;
public class ExampleOne : MonoBehaviour { private Rigidbody2D rb2D; private float thrust = 10.0f;
private void Start() { rb2D = gameObject.AddComponent<Rigidbody2D>(); transform.position = new Vector3(0.0f, -2.0f, 0.0f); }
private void Update() { if (Input.GetKeyDown(KeyCode.Space)) { rb2D.AddForce(transform.up * thrust, ForceMode2D.Impulse); } } }
Did you find this page useful? Please give it a rating: | https://docs.unity3d.com/ScriptReference/Rigidbody2D.AddForce.html | CC-MAIN-2020-16 | refinedweb | 221 | 54.29 |
(This page was started based on a thread in a mailing list. Please add your own experience here for the benefit of you collegue developers over the world. Please also add negative experiences. Also, please edit the proposed format for entries if you have a better idea; it's just a first setup now.)
Entries here should discuss how well tools that aid in web app development do in different environments. Please add relevant platform and version information to each entry.
An entry should look like:
==<product name>== { * Version: <product version> * OSS | FreeWare | Price * OS: <os name> * OS version: <os version> [If it is a plugin: * Platform: eclipse | netbeans | … * Platform version: <platform version>] * <Several appreciation entries> * ... }*
eclipse
- Version: 3.1
- OSS
- OS: Mac OS X
- OS version: 10.3.9
- Very good overal development tool. Nothing JSF, JSP or webapp specific in itself, but can be extended with relevant plugins.
- Version: 3.2
- OSS
- OS: Windows Server 2003
- OS version: 5.2
- This version called "Callisto" have several improvments, the Eclipse Webtools Project offers very good tooling support for JSP, JSF and EJB3.
netbeans
- Version: 5.0 beta 2
- OSS
- OS: Linux, Windows, others
- OS version: Linux Mandriva 2006.0; Windows XP
- Very good overall development.
- Ant-based project and build process - can build projects without IDE.
- Code completion for faces-config.xml and web.xml as well as JSF component tags and other taglibs within JSPs.
- Handles deployment to, and debugging in, Tomcat, JBoss and some other servers.
Sysdeo Tomcat Plugin
- Version: 3.1.0 beta
- OSS
- OS: Mac OS X
- OS version: 10.3.9
Little awsome plugin that lets you start and stop Tomcat from within eclipse. Output comes in the eclipse console, debugging of webapps is possible. With DevLoader (advised!), you can also debug different projects in your webapp.
Exadel Studio Pro
- Version: 3.6
- 199$ and 59$/year maintenance
- OS: Runs on Java plattform indeopendent
- OS version: Java 1.4 and 1.5 supported
- Platform: eclipse plugin
- Platform version: eclipse 3.1
- Very good overal development tool.
- ORM Explorer
Code assist, JavaServerFaces support together with facelets support
- Very good support via exadel forum
- We also use the free version of this tool
<oXygen/>
- Version: 6.1
- $180 - $238, with "continuous discounts"
- OS: Mac OS X
- OS version: 10.3.9
Platform: standalone & as eclipse plugin
- Platform version: eclipse 3.1
- Pure XML/XSLT editor, no real support for web apps, JSP, JSF
- Mixed feelings about quality
- louzy UI
- annecdotal: on save, window looses focus as eclipse plugin
- other annoyances
- Better XML editor than what we get in eclipse, which we can really use, since we always create JSPX pages, and most tools don't support that (how come?)
If xml:<namespace> filled out correctly, with reference to schema, does autocompletion well
- Syntax coloring is nice
JSFToolbox for Dreamweaver
- Version: 1.5.0
- Price: $149 US
- OS: Windows 2000/XP
- Platform: Dreamweaver MX 2004 / Dreamweaver 8
- First-class Web design environment for JSF
- Full round-trip engineering with Java IDEs
- Visual JSF Core and JSF HTML tags
- Drag-and-drop tag toolbars
- Managed bean introspection
- Comprehensive documentation
- Supports Facelets and Seam
Mailing List Reports
(This page starts with a quick'n'dirty copy paste from the mailing list, unedited. Please edit and expand. This section should evolve away over time.)
Combination of Exadel_IDE and MyEclipse_IDE, while I tend to use Exadel for the User Interface and core JSF stuff I use MyEclipse for the rest. Probably I will add JSR220 to the mix as soon as I move to EJB3.
- Eclipse + FacesIDE + EclipseHTMLEditor.
IntelliJ IDEA - without Faces support whatsoever
- trying Exadel v3 pro: good JSF-editor, good JSP-editor (Macromedia-style)
- mostly NitroX from M7: good JSF-editor, good JSP-editor (Macromedia-style), good recognization for distributed applications (apps relying on other apps...)
tried MyEclipse_IDE v4: a bit disappointing support for JSF-components | https://wiki.apache.org/myfaces/What_Tools_Do_You_Use_to_Develop_Web_Applications_Using_JSF?action=recall&rev=2 | CC-MAIN-2017-47 | refinedweb | 647 | 57.87 |
This.
Status: very very sketchy, disorganised collection of URLs, excerpts and commentary. This is a pile of stuff for some (possibly non-existent) future version to flesh out. Suggestions for other related materials welcomed (W3 folk, feel free to edit directly).
Author: dan brickley.
@@in-progress. This is a dump of some resources / references to collect and summarise.
RDF Syntax proposals are tracked in the discussion documents section of the RDF Interest Group home page.
XML-Data submission. Subsequent publications in same tradition: QL'98 position paper from Layman, "XML Syntax Recommendation for Serializing Graphs of Data (Dec 2nd 1998).
BizTalk white papers: Serializing Graphs of Data in XML, Adam Bosworth, Andrew Layman, Michael Rys:. Biztalk.org Resources: Canonical Reference Thu, 01 Jan 1970 00:00:00 GMT
The elements and attributes in an XML document often are a representation of objects from a specific data model such as Directed-Labelled-Graph or Database Relations. We can annotate a schema so that a reader can determine the mapping from an XML document instance to an instance of the other data model. Mapping information for a specific data model is expressed using attributes from a namespace specific to the mapping. Each mapping system will have its own rules. For example, mapping from XML instances to Directed-Labelled-Graph instances has the rule that all attributes and all elements whose names differ from their type represent edges. However, elements without a name distinct from the type may represent either nodes or edges, and we must indicate which by using a role attribute in the type declaration in the schema. XML Schemas NG Guide Mon, 14 Jun 1999 05:54:24 GMT
xml-dev threads: object-oriented serialization, dec 1999.
I honestly feel that XML provides all the tools to do what RDF is trying to do, without an additional syntactic layer. What is missing from the picture is a mechanism for modelling object structures according to object-oriented principles, and this is why an OO schema language is necessary. The only other thing the RDF brings to the game is that it turns relationships into first-class objects that can be referenced as well xml-dev-Dec-1999: Object-oriented serialization (Was Re: Some q Sat, 11 Dec 1999 00:14:28 GMT
If you're interested in a collection of objects in the first place, why should you have to see or know about XML elements and attributes at all? Or to put it a different way, why should people constantly have to redo the work of extracting objects from XML, when they're all trying to do the same thing? I think that reasonable people can argue that RDF is not the best solution to the problem of object exchange in XML, but I am somewhat surprised to hear people deny that the problem even exists: there is an enormous demand for exchanging objects in XML (businesses exchange a lot of structured data), and it's hard work to have to figure out over and over how to construct objects from a SAX stream or a DOM tree especially when programmers with XML knowledge are scarce and expensive. I have no doubt that we need an abstract object layer on top of XML. Right now, RDF is the best solution currently available (XMI also has its advocates), but I'm ready to listen about anything better. xml-dev-Dec-1999: Re: Object-oriented serialization (Was Re: So Fri, 03 Dec 1999 14:25:07 GMT
As a recap: There are, broadly, two approaches to serializing a graph in XML. One is to invent a meta-grammar, a set of canonicalization rules. That is what RDF syntax did, and what the attribute-centric and element-centric canonical format papers do, what SOAP section eight does. I think of this as "tunnelling the graph through XML." The other is to allow XML documents to follow any pattern described in a schema, and augmenting the schema with a set of mapping rules. There appears to be significant value to each approach. (In particular, however, I disagree with the sometimes-asserted claim that graphs capture the semantics of a communication while grammars do not. Graphs are just another grammar. This makes me reluctant to deprecate grammars.) xml-dev-Dec-1999: RE: Object-oriented serialization (Was Re: So Fri, 10 Dec 1999 23:07:19 GMT
In this vein, schematron-rdf at generates RDF documents (currently with bogus XLinks, but you can customize it easily) based on Schematron schemas. In this case, the schema is not converted to RDF, rather the RDF shows which assertions in the schema apply to each element in the instance. This is a rather different use for schemas: as programs for automated annotation. The thing that became immediately clear from working on it was that RDF is good for arcs (relationships) but grammar-based schemas largely hide these relationships (between elements, attributes, data) behind a few generic but superficial types: containment, sequence, repetition. Schematron assertions now allow a "role" attribute, for labelling classes of arcs. I think developers of other schema languages might also consider this kind of thing too: that the connectors between particles of patterns (e.g., compositors in the content models in a grammar-based schema language) should have some role attribute (and documentation?) for labelling their significance. For example, if element A must be follwed by element B, to say why. The nodes that conventional schemas define (e.g. elements and attributes) are interesting, but the arcs between them can also be very interesting for automatic annotation using RDF. xml-dev-Dec-1999: Re: Object-oriented serialization (Was Re: So Sun, 05 Dec 1999 17:58:02 GMT
Presentations by Michael Rys WWW8 (@@URL?)
Topic-maps syntax effort -- @@TODO: egroups URL, charter, example RDF mappingetc., emiller's msg...
Henrik Neilsen, WWW9 presentation on on RDF/SOAP. SOAP as an RDF serialization syntax:.
There are also a set of more specific examples.
As is stated in the slides, take this as input rather than anything else.
Henrik Frystyk Nielsen mailto:frystyk@microsoft.com www-rdf-interest@w3.org from August 2000: Slides from WWW9 pres Tue, 22 Aug 2000 07:32:46 GMT
Papers from Lore(l) group at stanford. Also Pensylvania work and some of the XML query proposals. Point to discussion point in XMLQ data model work.
Other XML specs: XML Schema 'edge-labelled graph' mention. XML Infoset RDF appendix (current status?). XML-Linking RDF model (Ron Daniel's Note draft). Context: XArc proposal, (X)HTML typed links. Web architecture stuff.
RDF Syntax proposals: Sergey's strawman (and Java parser). TimBL's strawman. EricP's syntax (and Perl parser).
RDF dump syntax proposal(s) on www-rdf-interest. Issues (raise one in rdf issue list on the dependencies between model + syntax.
Dan Connolly notes on Jigsaw's Java serialization system:
ntuition: RDF, SOAP, WebDAV, and Java Beans share a data model, and should be able to share many implementation details A review of Jigsaw Tue, 29 Aug 2000 07:44:36 GMT
XSLT-based screenscraping approach. Cambridge communique, online demos, DanC stuff.
Annotated DTDs / schemata. Do we have any implementation experience of this? Henry Thompson had a good presentation on this topic (@@url??). Point into extensibility mechanism in XML Schema. Also issue (who owns this problem?) that XML Schema constructs need URIs.
$Log: Overview.html,v $ Revision 1.5 2000/09/06 19:38:22 danbri minor tidyup, added H3s, XHTML valid. linked from /RDF/Interest/ Revision 1.4 2000/09/06 14:14:15 danbri added danc notes on jigsaw / rdf serialisation Revision 1.3 2000/09/06 11:18:19 danbri Added a bunch of excerpts from XML-DEV thread and related discussion, papers etc. Revision 1.2 2000/09/05 18:53:45 danbri added few linksmaintained: dan brickley | http://www.w3.org/2000/09/XGraph/ | CC-MAIN-2015-06 | refinedweb | 1,307 | 55.24 |
Hi,
Recently I bought a 2s9v1 motordriver and connected to two motors to M0 and M1 channels.
It seems to work nicely (both reverse and forward) when timeout configuration is not set (timeout = 0x00).
However, if I set the timeout to 0x01 (for the shortest timeout), the reverse mode doesn’t work while the forward mode still works with timeout. I tried 0x0F for the timeout, same result…
I didn’t fix its baudrate using a jumper and I am sending commands at 38400.
a weird part is that it works for the first time I send commands after turning the driver on, but after the timeout occurs to make the motors stop, it doesn’t respond to rotate motors reverse (while it responds to rotate forward properly)
I am using python3 and code looks like:
import serial
s = serial.Serial(port, baudrate=38400)
s.write(bytes([0xAA, 0x09, 0x08, 0x1F])
s.write(bytes([0xAA, 0x09, 0x0C, 0x1F])
then for the reverse mode:
import serial
s = serial.Serial(port, baudrate=38400)
s.write(bytes([0xAA, 0x09, 0x0A, 0x1F])
s.write(bytes([0xAA, 0x09, 0x0E , 0x1F])
I don’t want to use it without timeout, so if you have any idea, please help me…
Thank you | https://forum.pololu.com/t/2s9v1-motor-reverse-not-working-when-timeout-is-set/13087 | CC-MAIN-2018-51 | refinedweb | 205 | 71.55 |
Sharing the goodness…
Beth Massi is a Senior Program Manager on the Visual Studio team at Microsoft and a community champion for business application developers. Learn more about Beth.
More videos »
Very often in business applications we need to validate data through another service. I’m not talking about validating the format of data entered – this is very simple to do in LightSwitch -- I’m talking about validating the meaning of the data. For instance, you may need to validate not just the format of an email address (which LightSwitch handles automatically for you) but you also want to verify that the email address is real. Another common example is physical Address validation in order to make sure that a postal address is real before you send packages to it.
In this post I’m going to show you how you can call web services when validating LightSwitch data. I’m going to use the Address Book sample and implement an Address validator that calls a service to verify the data.
In Visual Studio LightSwitch there are a few places where you can place code to validate entities. There are Property_Validate methods and there are Entity_Validate methods. Property_Validate methods run first on the client and then on the server and are good for checking the format of data entered, doing any comparisons to other properties, or manipulating the data based on conditions stored in the entity itself or its related entities. Usually you want to put your validation code here so that users get immediate feedback of any errors before the data is submitted to the server. These methods are contained on the entity classes themselves. (For more detailed information on the LightSwitch Validation Framework see: Overview of Data Validation in LightSwitch Applications)
The Entity_Validate methods only run on the server and are contained in the ApplicationDataService class. This is the perfect place to call an external validation service because it avoids having clients calling external services directly -- instead the LightSwitch middle-tier makes the call. This gives you finer control over your network traffic. Client applications may only be allowed to connect to your intranet internally but you can allow external traffic to the server managing the external connection in one place.
There are a lot of services out there for validating all sorts of data and each service has a different set of requirements. Typically I prefer REST-ful services so that you can make a simple http request (GET) and get some data back. However, you can also add service references like ASMX and WCF services as well. It’s all going to depend on the service you use so you’ll need to refer to their specific documentation.
To add a service reference to a LightSwitch application, first flip to File View in the Solution Explorer, right-click on the Server project and then select Add Service Reference…
Enter the service URL and the service proxy classes will be generated for you. You can then call these from server code you write on the ApplicationDataService just like you would in any other application that has a service reference. In the case of calling REST-ful services that return XML feeds, you can simply construct the URL to call and examine the results. Let’s see how to do that.
In this sample we have an Address table where we want to validate the physical address when the data is saved. There are a few address validator services out there to choose from that I could find, but for this example I chose to sign up for a free trial of an address validation service from ServiceObjects. They’ve got some nice, simple APIs and support REST web requests. Once you sign up they give you a License Key that you need to pass into the service.
A sample request looks like this:
Which gives you back the result:
<?xml version="1.0" encoding="UTF-8"?>
<Address xmlns=""
xmlns:xsi=""
xmlns:
<Address>1 Microsoft Way</Address>
<City>Redmond</City>
<State>WA</State>
<Zip>98052-8300</Zip>
<Address2/>
<BarcodeDigits>980528300997</BarcodeDigits>
<CarrierRoute>C012</CarrierRoute>
<CongressCode>08</CongressCode>
<CountyCode>033</CountyCode>
<CountyName>King</CountyName>
<Fragment/>
</Address>
If you enter a bogus address or forget to specify the City+State or PostalCode then you will get an error result:
<?xml version="1.0" encoding="UTF-8"?>
<Address xmlns=""
xmlns:xsi=""
xmlns:
<Error>
<Desc>Please input either zip code or both city and state.</Desc>
<Number>2</Number>
<Location/>
</Error>
</Address>
So in order to interact with this service we’ll first need to add some assembly references to the Server project. Right-click on the Server project (like shown above) and select “Add Reference” and import System.Web and System.Xml.Linq.
Next, flip back to Logical View and open the Address entity in the Data Designer. Drop down the Write Code button to access the Addresses_Validate method. (You could also just open the Server\UserCode\ApplicationDataService code file if you are in File View).
First we need to import some namespaces as well as the default XML namespace that is returned in the response. (For more information on XML in Visual Basic please see: Overview of LINQ to XML in Visual Basic and articles here on my blog.) Then we can construct the URL based on the entity’s Address properties and query the result XML for either errors or the corrected address. If we find an error, we tell LightSwitch to display the validation result to the user on the screen.
Imports System.Xml.Linq
Imports System.Web.HttpUtility
Imports <
Namespace LightSwitchApplication
Public Class ApplicationDataService
Private Sub Addresses_Validate(entity As Address, results As EntitySetValidationResultsBuilder)
Dim isValid = False
Dim errorDesc = ""
'Construct the URL to call the web service
Dim url = String.Format("?" &
"Address={0}&Address2={1}&City={2}&State={3}&PostalCode={4}&LicenseKey={5}",
UrlEncode(entity.Address1),
UrlEncode(entity.Address2),
UrlEncode(entity.City),
UrlEncode(entity.State),
UrlEncode(entity.ZIP),
"12345")
Try
'Call the service and load the XML result Dim addressData = XElement.Load(url)
'Check for errors first
Dim err = addressData...<Error>
If err.Any Then
errorDesc = err.<Desc>.Value
Else
'Fill in corrected address values returned from service
entity.Address1 = addressData.<Address>.Value
entity.Address2 = addressData.<Address2>.Value
entity.City = addressData.<City>.Value
entity.State = addressData.<State>.Value
entity.ZIP = addressData.<Zip>.Value
isValid = True
End If
Catch ex As Exception
Trace.TraceError(ex)
End Try
If Not (isValid) Then
results.AddEntityError("This is not a valid US address. " & errorDesc)
End If
End Sub
End Class
End Namespace
Now that I’ve got this code implemented let’s enter some addresses on our contact screen. Here I’ve entered three addresses, the first two are legal and the last one is not. Also notice that I’ve only specified partial addresses.
If I try to save this screen, an error will be returned from the service on the last row. LightSwitch won’t let us save until the address is fixed.
If I delete the bogus address and save again, you will see that the other addresses were verified and all the fields are updated with complete address information.
I hope this gives you a good idea on how to implement web service calls into the LightSwitch validation pipeline. Even though each service you use will have different requirements on how to call them and what they return, the LightSwitch validation pipeline gives you the necessary hooks to implement complex entity validation easily.
Enjoy!
Thanks for the article. I would be extremely grateful for an article demonstrating the calling of a web service viaa button click here. The button click code is understood. Getting a WSDL service (which can only be implemented in the server) to be called by a button is a mystery though. I have been down the WCF RIA path...you can read about that plight here: social.msdn.microsoft.com/.../3a547ac4-5ed2-49f0-82bf-873925335a81
Perhaps a look at a walkthough I uploaded:
code.msdn.microsoft.com/LightSwitch-Consuming-Web-c54979e0
may be of interest.
Thank You
The given information is very effective
i will keep updated with the same
<a href ="">web services</a>
This is good information, thanks. I'm very new and I'm having trouble making an ebay API call in lightswitch. In visual studio I add a web reference then type "using application1.com.ebay.developer;" and it works. In lightswitch I cant add a web reference to the client. Instead, I added a service reference to the client and typed "using lightswitchapplication.servicereference1;" into the new c# client class. What happens is that all the API code becomes recognised except for one piece of code: "eBayAPIInterfaceService".
Is there a way i can call a web reference in lightswitch? the button just isnt there in the advanced settings.
Or is there another way I can get the API working with the service reference?
Thanks :)
Danny
LightSwith 2012 can not be
Imports System.Xml.Linq
Imports System.Web.HttpUtility
I have added a reference System.xml.linq
System.Web
Please help! | http://blogs.msdn.com/b/bethmassi/archive/2012/01/30/calling-web-services-to-validate-data-in-visual-studio-lightswitch.aspx | CC-MAIN-2014-35 | refinedweb | 1,511 | 54.73 |
We were using Pandas to get the number of rows for a parquet file:
import pandas as pd df = pd.read_parquet("my.parquet") print(df.shape[0])
This is easy but will cost a lot of time and memory when the parquet file is very large. For example, it may cost more than 100GB of memory to just read a 10GB parquet file.
If we only need to get the number of rows, not the whole data, Pyarrow will be a better solution:
import pyarrow.parquet as pq table = pq.read_table("my.parquet", columns=[]) print(table.num_rows)
This method only spend a couple seconds and cost about 2GB of memory for the same parquet file. | http://donghao.org/category/bigdata/ | CC-MAIN-2022-21 | refinedweb | 115 | 73.47 |
The Python assert statement is one of the tools that as a Python developer is available to you to make your programs more robust.
What is the Python assert statement?
The assert statement allows to verify that the state of a Python program is the one expected by a developer. Expressions verified by assert should always be true unless there is an unexpected bug in a program.
In this article we will learn how to use the assert statement in your Python applications.
Let’s get started!
1. Practice a Very Basic Example of Assert Statement
To show you how assert works we will start with a basic expression that uses assert (also called assertion).
Open a terminal and type Python to open a Python Interactive Shell:
$ python Python 3.7.4 (default, Aug 13 2019, 15:17:50) [Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin Type "help", "copyright", "credits" or "license" for more information. >>>
Execute the following expression that is logically true:
>>> assert 5>0
As you can see nothing happens…
Now execute a different expression that is logically false:
>>> assert 5<0 Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError
This time we see an exception raised by the Python interpreter and the exception is of type AssertionError.
From this example we can define the behaviour of the assert statement.
The assert statement verifies a logical condition. If the condition is true the execution of the program continues. If the condition is false assert raises an AssertionError.
In this case the error that we are returning is not very clear…
…what if we want the AssertError to also provide a message that explains the type of error?
To do that we can pass an optional message to the assert statement.
assert <condition>, <optional message>
Try to update the previous expression with the following message:
>>> assert 5<0, "The number 5 is not negative" Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError: The number 5 is not negative
This time we get back an exception that clearly explains what’s causing the error.
2. Compare Assert vs Raise in Python
To give you a full understanding of how the assert statement behaves we will look at alternative code using raise that behaves like assert does.
if __debug__ if not <condition>: raise AssertionError(<message>)
Let’s apply it to our example:
if __debug__: if not 5<0: raise AssertionError("The number 5 is not negative")
As you can see below, the behaviour is identical to the one of the assertion we have seen in the previous section:
>>> if __debug__: ... if not 5<0: ... raise AssertionError("The number 5 is not negative") ... Traceback (most recent call last): File "<stdin>", line 3, in <module> AssertionError: The number 5 is not negative
The second and third line of our code are pretty self-explanatory.
But what about the first line? What is __debug__?
Let’s see if the Python shell can answer this question:
>>> __debug__ True
Interesting, so __debug__ is True. This explains why the second and third lines of our code are executed.
But this still doesn’t tell us what __debug__ is…
It’s not something we have defined. This means it’s something that is provided out-of-the-box by Python as a language.
According to the Python documentation __debug__ is a built-in constant that is true if you don’t execute Python with the -O flag.
Let’s find out if this is really the case…
Open a new Python interactive shell using the -O option:
$ python -O Python 3.7.4 (default, Aug 13 2019, 15:17:50) [Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin Type "help", "copyright", "credits" or "license" for more information. >>> __debug__ False
This time the __debug__ constant is False. And if we run the previous code…
>>> if __debug__: ... if not 5<0: ... raise AssertionError("The number 5 is not negative") ... >>>
Nothing happens. Obviously because the first if condition is false.
3. How to Disable Assertions in Python
In the previous section I have given you a hint on how you can disable assertions in Python.
Let’s use a different example to explain this…
Create a new Python program called assert_example.py that contains the following code:
month = "January" assert type(month) == str print("The month is {}".format(month))
We use an assert to make sure the variable month is of type String and then we print a message.
What happens if the value of the variable month is not a String?
month = 2021
We get the following output:
$ python assert_example.py Traceback (most recent call last): File "assert_example.py", line 2, in <module> assert type(month) == str AssertionError
As expected we get an AssertionError back.
And now…
…we add the -O flag when we run the program:
$ python -O assert_example.py The month is 2021
Interesting and scary at the same time!
The assert statement has not been called or to be more precise has been disabled.
The Python -O flag disables the execution of assert statements in your Python program. This is usually done for performance reasons when generating a release build to be deployed to Production systems.
In this case you can see that the missing assert logic has introduced a bug in our program that just assumes that the month is in the correct format.
In the next section we will see why this is not necessarily the correct way of using assert.
4. Do Not Validate Input Data Using Assert
In the previous example we have seen how disabling assertions made our program behave incorrectly.
This is exactly what shouldn’t happen if you disable assertions. The assert statement is designed to be used to test conditions that should never occur, not to change the logic of your program.
The behaviour of your program should not depend on assertions and you should be able to remove them without changing the way your program works.
Here’s a very important rule to follow…
Do not use the assert statement to validate user input.
Let’s see why…
Create a program that reads a number using the input function:
number = int(input("Insert a number: ")) assert number>0, "The number must be greater than zero" output = 100/number print(output)
We use the assert statement to make sure the number is positive and then we calculate the output as 100 divided by our number.
$ python assert_example.py Insert a number: 4 25.0
Now, let’s try to pass zero as input:
$ python assert_example.py Insert a number: 0 Traceback (most recent call last): File "assert_example.py", line 2, in <module> assert number>0, "The number must be greater than zero" AssertionError: The number must be greater than zero
As expected the assert statement raises an AssertionError exception because its condition is false.
Now let’s execute Python with the -O flag to disable assertions:
$ python -O assert_example.py Insert a number: 0 Traceback (most recent call last): File "assert_example.py", line 3, in <module> output = 100/number ZeroDivisionError: division by zero
This time the assertions is not executed and our program tries to divide 100 by zero resulting in the ZeroDivisionError exception.
You can see why you should not validate user inputs using assertions. Because assertions can be disabled and at that point any validation using assertions would be bypassed.
Very dangerous, it could cause any sort of security issues in your program.
Imagine what would happen if you used the assert statement to verify if a user has the rights to update data in your application. And then those assertions are disabled in Production.
5. Verify Conditions That Should Never Occur
In this section we will see how assert statements can help us find the cause of bugs faster.
We will use assert to make sure a specific condition doesn’t occur. If it does then there is a bug somewhere in our code.
Let’s have a look at one example with a Python function that calculates the area of a rectangle:
def calculate_area(length, width): area = length*width return area length = int(input("Insert the length: ")) width = int(input("Insert the width: ")) print("The area of the rectangle is {}".format(calculate_area(length, width)))
When I run this program I get the following output:
$ python assert_example.py Insert the length: 4 Insert the width: 5 The area of the rectangle is 20
Now, let’s see what happen if I pass a negative length:
$ python assert_example.py Insert the length: -4 Insert the width: 5 The area of the rectangle is -20
This doesn’t really make sense…
…the area cannot be negative!
So, what can we do about it? This is a condition that should never occur.
Let’s see how assert can help:
def calculate_area(length, width): area = length*width assert area>0, "The area of a rectangle cannot be negative" return area
I have added an assert statement that verifies that the area is positive.
$ python assert_example.py Insert the length: -4 Insert the width: 5 Traceback (most recent call last): File "assert_example.py", line 8, in <module> print("The area of the rectangle is {}".format(calculate_area(length, width))) File "assert_example.py", line 3, in calculate_area assert area>0, "The area of a rectangle cannot be negative" AssertionError: The area of a rectangle cannot be negative
As expected we get an AssertionError exception because the value of area is negative.
This stops the execution of our program preventing this value from being potentially used in other operations.
6. Parentheses and Assert in Python
If you are using Python 3 you might be wondering why in the previous assert examples we have never used parentheses after assert.
For example, as you know in Python 3 you write a print statement in the following way:
print("Message you want to print")
So, why the same doesn’t apply to assertions?
Let’s see what happens if we take the previous assert expression and we surround it with parentheses:
>>> number = 0 >>> assert(number>0, "The number must be greater than zero")
Try to run this assert statement in the Python shell. You will get back the following error:
<stdin>:1: SyntaxWarning: assertion is always true, perhaps remove parentheses?
But, why the error says that the assertion is always true?
That’s because the assert condition, after adding the parentheses, has become a tuple.
The format of a tuple is (value1, value2, …, valueN) and a tuple in a boolean context is always True unless it doesn’t contain any values.
Here is what happens if we pass an empty tuple so an assert statement:
>>> assert() Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError
Python raises an AssertionError exception because an empty tuple is always false.
Here is how you can verify the way a tuple gets evaluated as a boolean:
>>> number = 0 >>> print(bool((number>0, "The number must be greater than zero"))) True >>> print(bool(())) False
An empty tuple translates into False in a boolean context. A non empty tuple translates to True.
Below you can see the correct way of using parentheses with assert:
>>> number = 0 >>> assert(number>0), "The number must be greater than zero" Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError: The number must be greater than zero
So, remember to be careful when using parentheses with assert to avoid bugs caused by the fact that you might be thinking your assert is correct when in fact it doesn’t perform the check you expect.
7. The Assert Statement in Unit Tests
Assert statements are also used in unit tests to verify that the result returned by a specific function is the one we expect.
I want to write unit tests for our function that calculates the area of a rectangle (without including the assert statement in the function).
This time we will pass the arguments via the command line instead of asking for length and width interactively:
import sys def calculate_area(length, width): area = length*width return area def main(length, width): print("The area of the rectangle is {}".format(calculate_area(length, width))) if __name__ == '__main__': length = int(sys.argv[1]) width = int(sys.argv[2]) main(length, width)
The output is:
$ python assert_example.py 4 5 The area of the rectangle is 20
First of all, let’s create the test class…
Don’t worry about every single details of this class if you have never written unit tests in Python before. The main concept here is that we can use assert statements to perform automated tests.
Let’s write a simple success test case.
import unittest from assert_example import calculate_area class TestAssertExample(unittest.TestCase): def test_calculate_area_success(self): length = 4 width = 5 area = calculate_area(length, width) self.assertEqual(area, 20) if __name__ == '__main__': unittest.main()
As you can see we import unittest and also the calculate_area function from assert_example.py.
Then we define a class called TestAssertExample that inherits another class, unittest.TestCase.
Finally, we create the method test_calculate_area_success that calculates the area and verifies that its value is what we expect using the assertEqual statement.
This is a slightly different type of assert compared to what we have seen until now. The are multiple types of assert methods you can use in your Python unit tests depending on what you need.
Let’s execute the unit test:
$ python test_assert_example.py . ---------------------------------------------------------------------- Ran 1 test in 0.000s OK
The test is successful.
What if I want to test a negative scenario?
I want to make sure an exception is raised by my function if at least one between length and width is negative. I can add the following test method to our test class and to test for exceptions we can use the assertRaises method:
def test_calculate_area_failure(self): length = -4 width = 5 self.assertRaises(ValueError, calculate_area, length, width)
Let’s find out if both tests are successful…
$ python test_assert_example.py F. ====================================================================== FAIL: test_calculate_area_failure (__main__.TestAssertExample) ---------------------------------------------------------------------- Traceback (most recent call last): File "test_assert_example.py", line 15, in test_calculate_area_failure self.assertRaises(TypeError, calculate_area, length, width) AssertionError: ValueError not raised by calculate_area ---------------------------------------------------------------------- Ran 2 tests in 0.001s FAILED (failures=1)
Hmmm, they are not!
There is one failure caused by the fact the the calculate_area method doesn’t raise a ValueError exception if either length or width are negative.
It’s time to enhance our function to handle this scenario:
def calculate_area(length, width): if length < 0 or width < 0: raise ValueError("Length and width cannot be negative") area = length*width return area
And now let’s run both unit tests again:
$ python test_assert_example.py .. ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK
All good this time 🙂
Below you can find the complete test suite:
import unittest from assert_example import calculate_area class TestAssertExample(unittest.TestCase): def test_calculate_area_success(self): length = 4 width = 5 area = calculate_area(length, width) self.assertEqual(area, 20) def test_calculate_area_failure(self): length = -4 width = 5 self.assertRaises(ValueError, calculate_area, length, width) if __name__ == '__main__': unittest.main()
Conclusion
In this tutorial I have introduced the Python assert statement and showed you what is the difference between assert and a combination of if and raise statements.
We have seen that in Python it’s possible to disable assertions and this can be useful to improve the performance of Production builds.
This is also the reason why the assert statements should never be used to implement application logic like input validation or security checks. If disabled those assertions could introduce critical bugs in our program.
The main purpose of assert is to make sure certain conditions that go against the way our program should behave never occur (e.g. a variable that should always be positive somehow ends up being negative or a variable doesn’t fall within its expected range).
Finally we have learned why using parentheses in assert statements can lead to bugs and how the concept of assertion is extremely important when we want to develop unit tests to guarantee a robust code.
Which part of this article has been the most useful to you?
Let me know in the comment below 🙂
I’m a Tech Lead, Software Engineer and Programming Coach. I want to help you in your journey to become a Super Developer! | https://codefather.tech/blog/python-assert-statement/ | CC-MAIN-2021-31 | refinedweb | 2,718 | 62.07 |
DB2. Table 1. SQLSTATE Class Codes Class Code 00 01 02 07 08 09 0A 0F 0K 0N Meaning For subcodes, refer to...
Unqualified Successful Completion Warning No Data Dynamic SQL Error Connection Exception Triggered Action Exception Feature Not Supported Invalid Token Resignal When Handler Not Active SQL/XML Mapping Error
Table 2 Table 3 Table 4 Table 5 Table 6 Table 7 Table 8 Table 9 Table 10 Table 11
Table 1. SQLSTATE Class Codes Class Code 10 20 21 22 23 24 25 26 2D 34 35 36 37 38 39 3B 3C 40 42 44 XQuery Error Case Not Found for Case Statement Cardinality Violation Data Exception Constraint Violation Invalid Cursor State Invalid Transaction State Invalid SQL Statement Identifier Invalid Transaction Termination Invalid Cursor Name Invalid Condition Number Cursor Sensitivity Exception Syntax Error (OBSOLETE) External Function Exception External Function Call Exception Savepoint Exception Ambiguous Cursor Name Transaction Rollback Syntax Error or Access Rule Violation WITH CHECK OPTION Violation Meaning For subcodes, refer to...
Table 12 Table 13 Table 14 Table 15 Table 16 Table 17 Table 18 Table 19 Table 20 Table 21 Table 22 Table 23 Table 24 Table 25 Table 26 Table 27 Table 28 Table 29 Table 30 Table 312 Lodh Biswajitt | DB WWDC, ST MICROELECTRONICS
Table 1. SQLSTATE Class Codes Class Code 46 51 53 54 55 56 57 58 5U Java Errors Invalid Application State Invalid Operand or Inconsistent Specification SQL or Product Limit Exceeded Object Not in Prerequisite State Miscellaneous SQL or Product Error Resource Not Available or Operator Intervention System Error Common Utilities and Tools Meaning For subcodes, refer to...
Table 2. Class Code 00: Unqualified Successful Completion SQLSTATE Value 00000 Meaning
Execution of the operation was successful and did not result in any type of warning or exception condition.
Table 3. Class Code 01: Warning SQLSTATE Value 01xxx 01003 01004 01005 0100C Meaning
Valid warning SQLSTATEs returned by an SQL routine. Also used for RAISE_ERROR and SIGNAL. Null values were eliminated from the argument of an aggregate function. The value of a string was truncated when assigned to another string data type with a shorter length. Insufficient number of entries in an SQLDA. One or more ad hoc result sets were returned from the procedure.
Table 3. Class Code 01: Warning SQLSTATE Value 0100E 01011 01503 01504 01505 01506 The procedure returned too many result sets. The PATH value has been truncated. Array data, right truncation. The number of result columns is larger than the number of variables provided. The UPDATE or DELETE statement does not include a WHERE clause. The statement was not executed because it is unacceptable in this environment. An adjustment was made to a DATE or TIMESTAMP value to correct an invalid date resulting from an arithmetic operation. One or more non-zero digits were eliminated from the fractional part of a number used as the operand of a multiply or divide operation. The tablespace has been placed in the check-pending state. The null value has been assigned to a variable, because the non-null value of the column is not within the range of the variable. An inapplicable WITH GRANT OPTION has been ignored. A character that could not be converted was replaced with a substitute character. The null value has been assigned to a variable, because a numeric value is out of range. The null value has been assigned to a variable, because the characters cannot be converted. A specified server-name is undefined but is not needed until the statement is executed or the alias is used. The local table or view name used in the CREATE ALIAS statement is undefined. ALL was interpreted to exclude ALTER, INDEX, REFERENCES, and TRIGGER, because these privileges cannot be granted to a remote user. The result of an aggregate function does not include the null values that were caused by evaluating the arithmetic expression implied by the column of the view. The number of INSERT values is not the same as the number of columns.4 Lodh Biswajitt | DB WWDC, ST MICROELECTRONICS
Meaning
01507
01514 01515
01522 01523
01524
01525
A SET statement references a special register that does not exist at the AS. WHERE NOT NULL is ignored, because the index key cannot contain null values. Definition change may require a corresponding change on the read-only systems. An undefined object name was detected. An undefined column name was detected. An SQL statement cannot be EXPLAINed, because it references a remote object. The table cannot be subsequently defined as a dependent, because it has the maximum number of columns. Connection is successful but only SBCS characters should be used. A limit key has been truncated to 40 bytes. Authorization ID does not have the privilege to perform the operation as specified. A duplicate constraint has been ignored. An unqualified column name has been interpreted as a correlated reference. A column of the explanation table is improperly defined. The authorization ID does not have the privilege to perform the specified operation on the identified object. A table in a partitioned tablespace is not available, because its partitioned index has not been created. An ambiguous qualified column name was resolved to the first of the duplicate names in the FROM clause. Isolation level RR conflicts with a tablespace locksize of page.
01551
01552
01553
Table 3. Class Code 01: Warning SQLSTATE Value 01554 01558 01560 01561 01565 Decimal multiplication may cause overflow. A distribution protocol has been violated. A redundant GRANT has been ignored. An update to a data capture table was not signaled to the originating subsystem. The null value has been assigned to a variable, because a miscellaneous data exception occurred; for example, the character value for the CAST, DECIMAL, FLOAT, or INTEGER scalar function is invalid; a floating-point NAN (not a number) or invalid data in a packed decimal field was detected. The index has been placed in a pending state. The dynamic SQL statement ends with a semicolon. Type 2 indexes do not have subpages. The result of the positioned UPDATE or DELETE may depend on the order of the rows. Insufficient number of entries in an SQLDA for ALL information (i.e. not enough descriptors to return the distinct name). Comparison functions were not created for a distinct type based on a long string data type. Specific and non-specific volume IDs are not allowed in a storage group. SUBPAGES ignored on alter of catalog index. Optimization processing encountered a restriction that might have caused it to produce a sub-optimal result. A recursive common table expression may contain an infinite loop. An unsupported value has been replaced. There are fewer locators than the number of result sets. The estimated CPU cost exceeds the resource limit. Meaning
Table 3. Class Code 01: Warning SQLSTATE Value 01624 01625 01628 01629 01640 Meaning
The GBPCACHE specification is ignored because the buffer pool does not allow caching. The schema name appears more than once in the CURRENT PATH. The user-specified access path hints are invalid. The access path hints are ignored. User-specified access path hints were used during access path selection. ROLLBACK TO SAVEPOINT occurred when there were uncommitted INSERTs or DELETEs that cannot be rolled back. Assignment to SQLCODE or SQLSTATE variable does not signal a warning or error. DEFINE NO is not applicable for a lob space or data sets using the VCAT option. ROLLBACK TO savepoint caused a NOT LOGGED table space to be placed in the LPL. Binary data is invalid for DECRYPT_CHAR and DECYRYPT_DB. A non-atomic statement successfully processed all requested rows with one or more warning conditions. NOT PADDED clause is ignored for indexes created on auxiliary tables. Option not specified following the ALTER PARTITION CLAUSE. The last partition's limit key value is set to the highest or lowest possible value. A rowset FETCH statement returned one or more rows of data, with one or more bind out processing error conditions. Use GET DIAGNOSTICS for more information. A trusted connection cannot be established for the specified system authorization ID. The option is not supported in the context in which it was specified. The trusted context is no longer defined to be used by specific attribute value. The ability to use the trusted context was removed from some but not all authorization IDs specified in statement.
A SELECT containing a non-ATOMIC data change statement successfully returned some rows, but one or more warnings or errors occurred. An operation was partially successful and partially unsuccessful. Use GET DIAGNOSTICS for more information. A decimal float operation produced an inexact result. A decimal floating point operation was invalid. A decimal float operation produced an overflow or underflow. A decimal float operation produced division by zero. A decimal float operation produced a subnormal number. No routine was found with the specified name and compatible arguments. WITH ROW CHANGE COLUMNS ALWAYS DISTINCT was specified, but the database manager is unable to return distinct row change columns. The combination of target namespace and schema location hint is not unique in the XML schema repository. The statement was successfully prepared, but cannot be executed. A deprecated feature has been ignored. Adjustment made to a value for a period as a result of a data change operation. Valid warning SQLSTATEs returned by a user-defined function, external procedure CALL, or command invocation.
0168B
0168X
Table 4. Class Code 02: No Data SQLSTATE Value 02000 One of the following exceptions occurred: Meaning
The result of the SELECT INTO statement or the subselect of the INSERT statement was an empty table.
02502 02504
The number of rows identified in the searched UPDATE or DELETE statement was zero. The position of the cursor referenced in the FETCH statement was after the last row of the result table. The fetch orientation is invalid.
Delete or update hole detected. FETCH PRIOR ROWSET returned a partial rowset.
Table 5. Class Code 07: Dynamic SQL Error SQLSTATE Value 07001 07002 07003 Meaning
The number of variables is not correct for the number of parameter markers. The call parameter list or control block is invalid. The statement identified in the EXECUTE statement is a select-statement, or is not in a prepared state. The statement name of the cursor identifies a prepared statement that cannot be associated with a cursor. The option specified on PREPARE is not valid.
07005
07501
Table 6. Class Code 08: Connection Exception SQLSTATE Value 08001 08002 08003 08004 Meaning
The connection was unable to be established to the application server or other server. The connection already exists. The connection does not exist. The application server rejected establishment of the connection.
Table 7. Class Code 09: Triggered Action Exception SQLSTATE Value 09000 A triggered SQL statement failed. Meaning
Table 8. Class Code 0A: Feature Not Supported SQLSTATE Value 0A001 Meaning
The CONNECT statement is invalid, because the process is not in the connectable state.
Table 9. Class Code 0F: Invalid Token SQLSTATE Value 0F001 Meaning
Table 10. Class Code 0K: Resignal When Handler Not Active SQLSTATE Value 0K000 Meaning
Table 11. Class Code 0N: SQL/XML Mapping Error SQLSTATE Value 0N002 Meaning
Table 12. Class Code 10: XQuery Error SQLSTATE Value 10501 10502 10503 Meaning
An XQuery expression is missing the assignment of a static or dynamic context component. An error was encountered in the prolog of an XQuery expression. A duplicate name was defined in an XQuery or XPath expression.
Table 12. Class Code 10: XQuery Error SQLSTATE Value 10504 10505 10506 10507 10509 10601 10602 10606 10608 Meaning
An XQuery namespace declaration specified an invalid URI. A character, token or clause is missing or invalid in an XQuery expression. An XQuery expression references a name that is not defined. A type error was encountered processing an XPath or XQuery expression. An unsupported XQuery language feature is specified. An arithmetic error was encountered processing an XQuery function or operator. A casting error was encountered processing an XQuery function or operator. There is no context item for processing an XQuery function or operator. An error was encountered in the argument of an XQuery function or operator.
Table 13. Class Code 20: Case Not Found for Case Statement SQLSTATE Value 20000 Meaning
Table 14. Class Code 21: Cardinality Violation SQLSTATE Value 21000 Meaning
The result of a SELECT INTO, scalar fullselect, or subquery of a basic predicate is more than one value. A multiple-row INSERT into a self-referencing table is invalid. A multiple-row UPDATE of a primary key is invalid.
21501 21502
Table 15. Class Code 22: Data Exception SQLSTATE Value 22001 Meaning
Character data, right truncation occurred; for example, an update or insert value is a string that is too long for the column, or a datetime value cannot be assigned to a variable, because it is too small. A null value, or the absence of an indicator parameter was detected; for example, the null value cannot be assigned to a variable, because no indicator variable is specified. A numeric value is out of range. A null value is not allowed. An invalid datetime format was detected; that is, an invalid string representation or value was specified. Datetime field overflow occurred; for example, an arithmetic operation on a date or timestamp has a result that is not within the valid range of dates. The XML value is not a well-formed document with a single root element. The XML document is not valid. The XML comment is not valid. The XML processing instruction is not valid. A context item is an XML sequence of more than one item. An XML value contained data that could not be serialized. A substring error occurred; for example, an argument of SUBSTR or SUBSTRING is out of range. Division by zero is invalid. The character value for a CAST specification or cast scalar function is invalid. The LIKE predicate has an invalid escape character. The XML document is not valid. A character is not in the coded character set or the conversion is not supported.
22002
22008
2200L 2200M 2200S 2200T 2200V 2200W 22011 22012 22018 22019 2201R 22021
Table 15. Class Code 22: Data Exception SQLSTATE Value 22023 22024 22025 22501 22502 22503 22504 22505 22506 A parameter or variable value is invalid. A NUL-terminated input host variable or parameter did not contain a NUL. The LIKE predicate string pattern contains an invalid occurrence of an escape character. The length control field of a variable length string is negative or greater than the maximum. Signalling NaN was encountered. The string representation of a name is invalid. A mixed data value is invalid. The local date or time length has been increased, but the executing program relies on the old length. A reference to a datetime special register is invalid, because the clock is malfunctioning or the operating system time zone parameter is out of range. CURRENT PACKAGESET is blank. ADT length exceeds maximum column length. The value for a ROWID or reference column is not valid. A variable in a predicate is invalid, because its indicator variable is negative. A CCSID value is not valid at all, not valid for the data type or subtype, or not valid for the encoding scheme. Partitioning key value is not valid. Invalid input data detected for a multiple-row insert. Binary data is invalid for DECRYPT_CHAR and DECYRYPT_DB. A non-atomic statement successfully completed for at least one row, but one or more errors occurred. A non-atomic statement attempted to process multiple rows of data, but no row was inserted and one or more errors occurred. Meaning
22508 22511
22512 22522
22530
Table 15. Class Code 22: Data Exception SQLSTATE Value 22531 22532 22533 22534 Meaning
The argument of a built-in or system provided routine resulted in an error. An XSROBJECT is not found in the XML schema repository. A unique XSROBJECT could not be found in the XML schema repository. An XML schema document is not connected to the other XML schema documents using an include or redefine. A rowset FETCH statement returned one or more rows of data, with one or more non-terminating error conditions. Use GET DIAGNOSTICS for more information. The binary XML value contains unrecognized data. The INSERT or UPDATE in not allowed because a resulting row does not satisfy row permissions. The binary XML value contains a version that is not supported. An XML schema cannot be enabled for decomposition.
22537
Table 16. Class Code 23: Constraint Violation SQLSTATE Value 23502 23503 23504 23505 23506 23507 23508 23509 Meaning
An insert or update value is null, but the column cannot contain null values. The insert or update value of a foreign key is invalid. The update or delete of a parent key is prevented by a NO ACTION update or delete rule. A violation of the constraint imposed by a unique index or a unique constraint occurred. A violation of a constraint imposed by an edit or validation procedure occurred. A violation of a constraint imposed by a field procedure occurred. A violation of a constraint imposed by the DDL Registration Facility occurred. The owner of the package has constrained its use to environments which do not include that of the14 Lodh Biswajitt | DB WWDC, ST MICROELECTRONICS
Table 16. Class Code 23: Constraint Violation SQLSTATE Value application process. 23510 23511 23512 A violation of a constraint on the use of the command imposed by the RLST table occurred. A parent row cannot be deleted, because the check constraint restricts the deletion. The check constraint cannot be added, because the table contains rows that do not satisfy the constraint definition. The resulting row of the INSERT or UPDATE does not conform to the check constraint definition. The unique index could not be created or unique constraint added, because the table contains duplicate values of the specified key. The range of values for the identity column or sequence is exhausted. An invalid value has been provided for the SECURITY LABEL column. A violation of a constraint imposed by an XML values index occurred. An XML values index could not be created because the table data contains values that violate a constraint imposed by the index. Meaning
23513 23515
Table 17. Class Code 24: Invalid Cursor State SQLSTATE Value 24501 24502 24504 24506 24510 24512 The identified cursor is not open. The cursor identified in an OPEN statement is already open. The cursor identified in the UPDATE, DELETE, SET, or GET statement is not positioned on a row. The statement identified in the PREPARE is the statement of an open cursor. An UPDATE or DELETE operation was attempted against a delete or update hole The result table does not agree with the base table. Meaning
Table 17. Class Code 24: Invalid Cursor State SQLSTATE Value 24513 Meaning
FETCH NEXT, PRIOR, CURRENT, or RELATIVE is not allowed, because the cursor position is not known. A cursor has already been assigned to a result set. A cursor was left open by an external function or method. A cursor is not defined to handle row sets, but a rowset was requested. A hole was detected on a multiple-row FETCH statement, but indicator variables were not provided. The cursor identified in the UPDATE or DELETE statement is not positioned on a rowset. A positioned DELETE or UPDATE statement specified a row of a rowset, but the row is not contained within the current rowset. The fetch orientation is inconsistent with the definition of the cursor and whether rowsets are supported for the cursor. A FETCH CURRENT CONTINUE was requested, but there is no truncated LOB or XML data to return.
24522
24524
Table 18. Class Code 25: Invalid Transaction State SQLSTATE Value 25000 Meaning
An insert, update, or delete operation or procedure call is invalid in the context where it is specified.
Table 19. Class Code 26: Invalid SQL Statement Identifier SQLSTATE Value 26501 The statement identified does not exist. Meaning
Table 20. Class Code 2D: Invalid Transaction Termination SQLSTATE Value 2D521 2D528 Meaning
SQL COMMIT or ROLLBACK are invalid in the current operating environment. Dynamic COMMIT or COMMIT ON RETURN procedure is invalid for the application execution environment Dynamic ROLLBACK is invalid for the application execution environment.
2D529
Table 21. Class Code 34: Invalid Cursor Name SQLSTATE Value 34000 Cursor name is invalid. Meaning
Table 22. Class Code 35: Invalid Condition Number SQLSTATE Value 35000 Condition number is invalid. Meaning
Table 23. Class Code 36: Cursor Sensitivity Exception SQLSTATE Value 36001 Meaning
Table 24. Class Code 37: Syntax Error (OBSOLETE) SQLSTATE Value 37520 Meaning
Table 25. Class Code 38: External Function Exception SQLSTATE Value 38xxx Meaning
Table 25. Class Code 38: External Function Exception SQLSTATE Value 38000 38001 38002 A Java routine has exited with an exception. The external routine is not allowed to execute SQL statements. The external routine attempted to modify data, but the routine was not defined as MODIFIES SQL DATA. The statement is not allowed in a routine. The external routine attempted to read data, but the routine was not defined as READS SQL DATA. A user-defined function or procedure has abnormally terminated (abend). A routine has been interrupted by the user. An SQL statement is not allowed in a routine on a FINAL CALL. An MQSeries function failed to initialize. MQSeries Application Messaging Interface failed to terminate the session. MQSeries Application Messaging Interface failed to properly process a message. MQSeries Application Messaging Interface failed in sending a message. MQSeries Application Messaging Interface failed to read/receive a message. An MQSeries Application Messaging Interface message was truncated. Error occurred during text search processing. Text search support is not available. Text search is not allowed on a column because a text search index does not exist on the column. A conflicting search administration procedure or command is running on the same text search index. Text search administration procedure error. Meaning
38003 38004 38503 38504 38505 38H01 38H02 38H03 38H04 38H05 38H06 38H10 38H11 38H12 38H13 38H14
Table 26. Class Code 39: External Function Call Exception SQLSTATE Value 39004 Meaning
A null value is not allowed for an IN or INOUT argument when using PARAMETER STYLE GENERAL or an argument that is a Java primitive type. An output argument value returned from a function or a procedure was too long.
39501
Table 27. Class Code 3B: Savepoint Exception SQLSTATE Value 3B001 3B501 3B502 3B503 The savepoint is not valid. A duplicate savepoint name was detected. A RELEASE or ROLLBACK TO SAVEPOINT was specified, but a savepoint does not exist. A SAVEPOINT, RELEASE SAVEPOINT, or ROLLBACK TO SAVEPOINT is not allowed in a trigger, function, or global transaction. Meaning
Table 28. Class Code 3C: Ambiguous Cursor Name SQLSTATE Value 3C000 The cursor name is ambiguous. Meaning
Table 29. Class Code 40: Transaction Rollback SQLSTATE Value 40001 Meaning
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 42501 Meaning
The authorization ID does not have the privilege to perform the specified operation on the identified object. The authorization ID does not have the privilege to perform the operation as specified.19 Lodh Biswajitt | DB WWDC, ST MICROELECTRONICS
42502
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value Meaning
42503
The specified authorization ID or one of the authorization IDs of the application process is not allowed. A specified privilege, security label, or exemption cannot be revoked from a specified authorizationname. Connection authorization failure occurred. Owner authorization failure occurred. SQL statement is not authorized, because of the DYNAMICRULES option. The authorization ID does not have the privilege to create functions or procedures in the WLM environment. The authorization ID does not have security to the protected column. The authorization ID does not have the MLS WRITE-DOWN privilege. The specified authorization ID is not allowed to use the trusted context. A character, token, or clause is invalid or missing. A character that is invalid in a name has been detected. An unterminated string constant has been detected. An invalid numeric or string constant has been detected. The number of arguments specified for a scalar function is invalid. An invalid hexadecimal constant has been detected. An operand of an aggregate function or CONCAT operator is invalid. The use of NULL or DEFAULT in VALUES or an assignment statement is invalid. All operands of an operator or predicate are parameter markers.20 Lodh Biswajitt | DB WWDC, ST MICROELECTRONICS
42504
42512 42513 42517 42601 42602 42603 42604 42605 42606 42607 42608 42609
A parameter marker or the null value is not allowed. The column, argument, parameter, or global variable definition is invalid. The statement string is an SQL statement that is not acceptable in the context in which it is presented. Clauses are mutually exclusive. A duplicate keyword or clause is invalid. An invalid alternative was detected. The statement string is blank or empty. A host variable is not allowed. Read-only SCROLL was specified with the UPDATE clause. The check constraint or generated column expression is invalid. A name or label is too long. A DEFAULT clause cannot be specified. A CASE expression is invalid. A column specification is not allowed for a CREATE INDEX that is built on an auxiliary table. Parameter names must be specified for SQL routines. An SQLSTATE or SQLCODE variable is not valid in this context. An AS clause is required for an argument of XMLATTRIBUTES or XMLFOREST. The XML name is not valid.
42613 42614 42615 42617 42618 42620 42621 42622 42623 42625 42626 42629 42630 42633 42634
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 42701 42702 42703 42704 42705 42707 42708 42709 42710 42711 42712 Meaning
The same target is specified more than once for assignment in the same SQL statement. A column reference is ambiguous, because of duplicate names. An undefined column or parameter name was detected. An undefined object or constraint name was detected. An undefined server-name was detected. A column name in ORDER BY does not identify a column of the result table. The locale specified in a SET LOCALE or locale sensitive function was not found. A duplicate column name was specified in a key column list. A duplicate object or constraint name was detected. A duplicate column name was detected in the object definition or ALTER TABLE statement. A duplicate table designator was detected in the FROM clause or REFERENCING clause of a CREATE TRIGGER statement. A duplicate object was detected in a list or is the same as an existing object. A host variable can be defined only once. The local server name is not defined. The special register name is unknown at the server. A routine with the same signature already exists. Unable to access an external program used for a user-defined function or a procedure. A routine was referenced directly (not by either signature or by specific instance name), but there is more than one specific instance of that routine. Duplicate names for common table expressions were detected.
42726
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 42732 42734 42736 42737 42749 Meaning
A duplicate schema name in a special register was detected. A duplicate parameter-name, SQL variable name, label, or condition-name was detected. The label specified on the GOTO, ITERATE, or LEAVE statement is not found or not valid. The condition specified is not defined. An XML schema document with the same target namespace and schema location already exists for the XML schema. An XSROBJECT is not found in the XML schema repository. A unique XSROBJECT could not be found in the XML schema repository. The specified attribute was not found in the trusted context. The specified attribute already exists in the trusted context. The specified attribute is not supported in the trusted context. An undefined period name was detectedy. Isolation level UR is invalid, because the result table is not read-only. The number of insert or update values is not the same as the number of columns or variables. A column reference in the SELECT or HAVING clause is invalid, because it is not a grouping column; or a column reference in the GROUP BY clause is invalid. The result expressions in a CASE expression are not compatible. An integer in the ORDER BY clause does not identify a column of the result table. A value cannot be assigned to a variable, because the data types are not compatible. The data-change statement is not permitted on this object. A column identified in the INSERT or UPDATE operation is not updatable.
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 42809 42810 42811 42813 42815 42816 42818 42819 42820 42821 42822 42823 42824 42825 42826 42827 42828 Meaning
The identified object is not the type of object to which the statement applies. A base table is not identified in a FOREIGN KEY clause. The number of columns specified is not the same as the number of columns in the SELECT clause. WITH CHECK OPTION cannot be used for the specified view. The data type, length, scale, value, or CCSID is invalid. A datetime value or duration in an expression is invalid. The operands of an operator or function are not compatible or comparable. An operand of an arithmetic operation or an operand of a function that requires a number is invalid. A numeric constant is too long, or it has a value that is not within the range of its data type. A data type for an assignment to a column or variable is not compatible with the data type. An expression in the ORDER BY clause or GROUP BY clause is not valid. Multiple columns are returned from a subquery that only allows one column. An operand of LIKE is not a string, or the first operand is not a column. The rows of UNION, INTERSECT, EXCEPT, or VALUES do not have compatible columns. The rows of UNION, INTERSECT, EXCEPT, or VALUES do not have the same number of columns. The table identified in the UPDATE or DELETE is not the same table designated by the cursor. The table designated by the cursor of the UPDATE or DELETE statement cannot be modified, or the cursor is read-only. FOR UPDATE OF is invalid, because the result table designated by the cursor cannot be modified. The foreign key does not conform to the description of the parent key.
42829 42830
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 42831 Meaning
A column of a primary key, unique key, ROWID, ROW CHANGE TIMESTAMP does not allow null values. The operation is not allowed on system objects. SET NULL cannot be specified, because no column of the foreign key can be assigned the null value. Cyclic references cannot be specified between named derived tables. The specification of a recursive, named derived table is invalid. The column cannot be altered, because its attributes are not compatible with the current column attributes. A column or parameter definition is invalid, because a specified option is inconsistent with the column description. An invalid use of a NOT DETERMINISTIC or EXTERNAL ACTION function was detected. Cast from source type to target type is not supported. The specified option is not supported for routines. The privileges specified in GRANT or REVOKE are invalid or inconsistent. (For example, GRANT ALTER on a view.) The assignment of the LOB or XML to this variable is not allowed. The target variable for all fetches of a LOB or XML value for this cursor must be the same for all FETCHes. The alter of a CCSID to the specified CCSID is not valid. The data type in either the RETURNS clause or the CAST FROM clause in the CREATE FUNCTION statement is not appropriate for the data type returned from the sourced function or RETURN statement in the function body. FETCH statement clauses are incompatible with the cursor definition. An invalid number of rows was specified in a multiple-row FETCH or multiple-row INSERT. The column name cannot be qualified.
42832 42834
42842
42855
42856 42866
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 42878 42879 Meaning
An invalid function or procedure name was used with the EXTERNAL keyword. The data type of one or more input parameters in the CREATE FUNCTION statement is not appropriate for the corresponding data type in the source function. The CAST TO and CAST FROM data types are incompatible, or would always result in truncation of a fixed string. The specific instance name qualifier is not equal to the function name qualifier. No routine was found with a matching signature. No routine was found with the specified name and compatible arguments. The number of input parameters specified on a CREATE FUNCTION statement does not match the number provided by the function named in the SOURCE clause. The IN, OUT, or INOUT parameter attributes do not match. The function is not valid in the context where it occurs. The table does not have a primary key. The table already has a primary key. A column list was specified in the references clause, but the identified parent table does not have a unique constraint with the specified column names. The object or constraint cannot be dropped, altered, or transferred or authorities cannot be revoked from the object, because other objects are dependent on it. The value of a column or sequence attribute is invalid. For static SQL, an input variable cannot be used, because its data type is not compatible with the parameter of a procedure or user-defined function. An invalid correlated reference or transition table was detected in a trigger. Correlated references and column names are not allowed for triggered actions with the FOR EACH STATEMENT clause.
42880
42893
42894 42895
42898 42899
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 428A1 428B3 428B4 428B7 428C1 428C2 Meaning
Unable to access a file referenced by a file reference variable. An invalid SQLSTATE was specified. The part clause of a LOCK TABLE statement is not valid. A number specified in an SQL statement is out of the valid range. The data type or attribute of a column can only be specified once for a table. Examination of the function body indicates that the given clause should have been specified on the CREATE FUNCTION statement. The number of elements on each side of the predicate operator is not the same. A ROWID or reference column specification is not valid or used in an invalid context. A column defined as GENERATED ALWAYS cannot be specified as the target column of an insert or update operation. AS LOCATOR cannot be specified for a non-LOB parameter. GENERATED is not allowed for the specified data type or attribute of a column. A cursor specified in a FOR statement cannot be referenced in an OPEN, CLOSE, or FETCH statement. The ending label does not match the beginning label. UNDO is not allowed for NOT ATOMIC compound statements. The condition value is not allowed. The sqlcode or sqlstate variable declaration is not valid. The fullselect specified for the materialized query table is not valid. The schema qualifier is not valid. The table cannot be converted to or from a materialized query table.27 Lodh Biswajitt | DB WWDC, ST MICROELECTRONICS
An integer expression must be specified on a RETURN statement in an SQL procedure. The SENSITIVITY specified on FETCH is not allowed for the cursor. The invocation of a routine is ambiguous. A sequence expression cannot be specified in this context. The scale of the decimal number must be zero. Sequence-name must not be a sequence generated by the system. The length of the encryption password is not valid. The data is not a result of the ENCRYPT function. ORDER BY or FETCH FIRST is not allowed in the outer fullselect of a view or materialized query table. A data change statement is not allowed in the context in which it was specified. An SQL data change statement within a SELECT specified a view which is not a symmetric view. Only one INSTEAD OF trigger is allowed for each kind of operation on a view. An INSTEAD OF trigger cannot be created because of how the view is defined. A column cannot be altered as specified. A column cannot be added to an index. The partitioning clause specified on CREATE or ALTER is not valid. A column cannot be added, dropped, or altered in a materialized query table. FINAL TABLE is not valid when the target view of the SQL data change statement in a fullselect has an INSTEAD OF trigger defined.
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 428G4 428G5 Invalid use of INPUT SEQUENCE ordering. The assignment clause of the UPDATE statement must specify at least one column that is not an INCLUDE column. A character could not be converted and substitution characters are not allowed. An invalid string unit was specified for a function. The data type of one or more parameters specified in the ADD VERSION clause does not match the corresponding data type in the routine being altered. An XML schema is not complete because an XML schema document is missing. The table cannot be truncated because DELETE triggers exist for the table or the table is a parent table of a referential constraint that would be affected by the statement. The system authorization ID specified for a trusted context is already specified in another trusted context. The trusted context is already defined to be used by this authorization ID or PUBLIC. The specified authorization ID or PUBLIC is not defined in the specified trusted context. A table must include at least one column that is not implicitly hidden. The object must be defined as secure because another object depends on it for row-level or columnlevel access control. PERMISSION or MASK cannot be altered. An argument of a user-defined table function must not reference a column for which a column mask is defined. A permission or mask cannot be created on the specified object. A column mask is already defined for the specified column. The statement cannot be processed because a column mask cannot be applied or the definition of the mask conflicts with the statement. Meaning
428GI 428GJ
428GL
428H9 428HA
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 428HJ 428HK 428HM 428HN 428HO 428I1 42902 Meaning
The organization clause specified on CREATE or ALTER is not valid. The specified hash space is not valid for the implicitly created table space. The system versioning clause specified on CREATE or ALTER is not valid. The period specification is not valid. The system versions clause was specified, but the table is not defined with system versioning. The columns updated by the XMLMODIFY function were not specified in the UPDATE SET clause. The object of the INSERT, UPDATE, or DELETE is also identified (possibly implicitly through a view) in a FROM clause. Invalid use of an aggregate function or OLAP function. DISTINCT is specified more than once in a subselect. An aggregate function in a subquery of a HAVING clause includes an expression that applies an operator to a correlated reference. The string is too long in the context it was specified. The statement does not include a required column list. CREATE VIEW includes an operator or operand that is not valid for views. A decimal divide operation is invalid, because the result would have a negative scale. A column cannot be updated, because it is not identified in the UPDATE clause of the selectstatement of the cursor. The DELETE is invalid, because a table referenced in a subquery can be affected by the operation. An invalid referential constraint has been detected. The object cannot be explicitly dropped or altered. A user-defined data type cannot be created with a system-defined data type name (for example,30 Lodh Biswajitt | DB WWDC, ST MICROELECTRONICS
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value INTEGER). 42924 42925 42927 An alias resolved to another alias rather than a table or view at the remote location. Recursive named derived tables cannot specify SELECT DISTINCT and must specify UNION ALL. The function cannot be altered to NOT DETERMINISTIC or EXTERNAL ACTION because it is referenced by one or more existing views. The program preparation assumptions are incorrect. The name cannot be used, because the specified identifier is reserved for system use. ALTER CCSID is not allowed on a table space or database that contains a view. The server name specified does not match the current server. A long column, LOB column, structured type column or datalink column cannot be used in an index, a key, generated column, or a constraint. Invalid specification of a security label column. The package was not created. An expression in a join-condition or ON clause of a MERGE statement references columns in more than one of the operand tables. The source table of a rename operation is referenced in a context where is it not supported. The statement or routine is not allowed in a trigger. The operation is not allowed with mixed ASCII data. The column, as defined, is too large to be logged. The requested function does not apply to global temporary tables. Capability is not supported by this version of the DB2 application requester, DB2 application server, or the combination of the two. Meaning
Table 30. Class Code 42: Syntax Error or Access Rule Violation SQLSTATE Value 429B1 429BI 429BN Meaning
A procedure specifying COMMIT ON RETURN cannot be the target of a nested CALL statement. The condition area is full and cannot handle more errors for a NOT ATOMIC statement. A CREATE statement cannot be processed when the value of CURRENT SCHEMA differs from CURRENT SQLID. The specified alter of the data type or attribute is not allowed. Invalid index definition involving an XMLPATTERN clause or a column defined with a data type of XML. Invalid specification of a ROW CHANGE TIMESTAMP column. The statement cannot be processed due to related implicitly created objects. The expression for an index key is not valid. The statement is not allowed when using a trusted connection. A data type cannot be determined for an untyped parameter marker.
429BQ 429BS
Table 31. Class Code 44: WITH CHECK OPTION Violation SQLSTATE Value 44000 Meaning
The INSERT or UPDATE is not allowed, because a resulting row does not satisfy the view definition.
Table 32. Class Code 46: Java Errors SQLSTATE Value 46001 46002 46003 Meaning
The URL specified on an install or replace of a jar procedure did not identify a valid jar file. The jar name specified on the install, replace, or remove of a Java procedure is not valid. The jar file cannot be removed, a class is in use by a procedure.
Table 32. Class Code 46: Java Errors SQLSTATE Value 46007 46008 4600C 4600D 4600E 46103 46501 46502 Meaning
A Java function has a Java method with an invalid signature. A Java function could not map to a single Java method. The jar cannot be removed. It is in use. The value provided for the new Java path is invalid. The alter of the jar failed because the specified path references itself. A Java routine encountered a ClassNotFound exception. The install or remove jar procedure specified the use of a deployment descriptor. A user-defined procedure has returned a DYNAMIC RESULT SET of an invalid class. The parameter is not a DB2 result set.
Table 33. Class Code 51: Invalid Application State SQLSTATE Value 51002 51003 51004 51005 51006 51008 51015 51021 51024 Meaning
The package corresponding to an SQL statement execution request was not found. Consistency tokens do not match. An address in the SQLDA is invalid. The previous system error has disabled this function. A valid connection has not been established. The release number of the program or package is not valid. An attempt was made to execute a section that was found to be in error at bind time. SQL statements cannot be executed until the application process executes a rollback operation. An object cannot be used, because it has been marked inoperative.
Table 33. Class Code 51: Invalid Application State SQLSTATE Value 51030 Meaning
The procedure referenced in a DESCRIBE PROCEDURE or ASSOCIATE LOCATOR statement has not yet been called within the application process. A valid CCSID has not yet been specified for this DB2 for z/OS subsystem. The operation is not allowed because it operates on a result set that was not created by the current server. The routine defined with MODIFIES SQL DATA is not valid in the context in which it is invoked. A PREVIOUS VALUE expression cannot be used because a value has not been generated for the sequence yet in this session. An implicit connect to a remote server is not allowed because a savepoint is outstanding. The ENCRYPTION PASSWORD value is not set.
51032 51033
51034 51035
51036 51039
Table 34. Class Code 53: Invalid Operand or Inconsistent Specification SQLSTATE Value 53001 53004 53014 53022 53035 53036 53037 53038 53039 Meaning
A clause is invalid, because the table space is a workfile. DSNDB07 is the implicit workfile database. The specified OBID is invalid. Variable or parameter is not allowed. Key limits must be specified in the CREATE or ALTER INDEX statement. The number of PARTITION specifications is not the same as the number of partitions. A partitioned index cannot be created on a table in a non-partitioned table space. The number of key limit values is zero or greater than the number of columns in the key. The PARTITION clause of the ALTER statement is omitted or invalid.
Table 34. Class Code 53: Invalid Operand or Inconsistent Specification SQLSTATE Value 53040 53041 53043 53044 53045 53088 53089 Meaning
The buffer pool cannot be changed as specified. The page size of the buffer pool is invalid. Columns with different field procedures cannot be compared. The columns have a field procedure, but the field types are not compatible. The data type of the key limit constant is not the same as the data type of the column. LOCKMAX is inconsistent with the specified LOCKSIZE. The number of variable parameters for a stored procedure is not equal to the number of expected variable parameters. Only data from one encoding scheme, either ASCII, EBCDIC or Unicode, can be referenced in the same SQL statement. The encoding scheme specified is not the same as the encoding scheme currently in use for the containing table space. Type 1 index cannot be created for a table using the ASCII encoding scheme. The CCSID ASCII or UNICODE clause is not supported for this database or table space. The PLAN_TABLE cannot be created with the FOR ASCII clause. CREATE or ALTER statement cannot define an object with the specified encoding scheme. The PARTITION clause was specified on CREATE AUXILIARY TABLE, but the base table is not partitioned. The auxiliary table cannot be created because a column was specified that is not a LOB column. A WLM ENVIRONMENT name must be specified on the CREATE FUNCTION statement. An ALTER TABLE statement specified FLOAT as the new data type for a column, but there is an existing index or constraint that restricts the use of FLOAT. The PARTITIONING clause is not allowed on the specified index.
53090
53091
530A2
Table 34. Class Code 53: Invalid Operand or Inconsistent Specification SQLSTATE Value 530A3 530A4 Meaning
The specified option is not allowed for the internal representation of the routine specified The options specified on ALTER statement are not the same as those specified when the object was created. The REGENERATE option is only valid for an index with key expressions. EXCHANGE DATA is not allowed because the tables do not have a defined clone relationship. A system parameter is incompatible with the specified SQL statement.
Table 35. Class Code 54: SQL or Product Limit Exceeded SQLSTATE Value 54001 54002 54004 54005 54006 54008 54010 54011 54024 54025 54027 54035 The statement is too long or too complex. A string constant is too long. The statement has too many table names or too many items in a SELECT or INSERT list. The sort key is too long, or has too many columns. The result string is too long. The key is too long, a column of the key is too long, or the key many columns. The record length of the table is too long. Too many columns were specified for a table, view, or table function. The check constraint, generated column, or key expression is too long. The table description exceeds the maximum size of the object descriptor. The catalog has the maximum number of user-defined indexes. An internal object limit exceeded. Meaning
Table 35. Class Code 54: SQL or Product Limit Exceeded SQLSTATE Value 54038 54041 54042 54051 54054 Meaning
Maximum depth of nested routines or triggers was exceeded. The maximum number of internal identifiers has been reached. Only one index is allowed on an auxiliary table. Value specified on FETCH ABSOLUTE or RELATIVE is invalid. The number of data partitions, or the combination of the number of table space partitions and the corresponding length of the partitioning limit key is exceeded The maximum number of versions has been reached for a table or index. The internal representation of an XML path is too long. The maximum of 99999 implicitly generated object names has been exceeded.
Table 36. Class Code 55: Object Not in Prerequisite State SQLSTATE Value 55002 55003 55004 55006 55007 55011 55012 55014 55015 The explanation table is not defined properly. The DDL registration table is not defined properly. The database cannot be accessed, because it is no longer a shared database. The object cannot be dropped, because it is currently in use by the same application process. The object cannot be altered, because it is currently in use by the same application process. The operation is disallowed, because the workfile database is not in the stopped state. A clustering index is not valid on the table. The table does not have an index to enforce the uniqueness of the primary key. The ALTER statement cannot be executed, because the pageset is not in the stopped state. Meaning
Table 36. Class Code 55: Object Not in Prerequisite State SQLSTATE Value 55016 55017 55019 55020 55023 55030 55035 55048 55058 55059 55063 55078 Meaning
The ALTER statement is invalid, because the pageset has user-managed data sets. The table cannot be created in the table space, because it already contains a table. The object is in an invalid state for the operation. A work file database is already defined for the member. An error occurred calling a procedure. A package specified in a remote BIND REPLACE operation must not have a system list. The table cannot be dropped, because it is protected. Encrypted data cannot be encrypted. The DEBUG MODE cannot be changed for a routine that was created with DISABLE DEBUG MODE. The currently active version for a routine cannot be dropped. The XML schema is not in the correct state for the operation. The table is already in the specified state.
Table 37. Class Code 56: Miscellaneous SQL or Product Error SQLSTATE Value 56010 Meaning
The subtype of a string variable is not the same as the subtype at bind time, and the difference cannot be resolved by character conversion. The ranges specified for data partitions are not valid. A column cannot be added to the table, because it has an edit procedure. An invalid reference to a remote object has been detected. An invalid use of AT ALL LOCATIONS in GRANT or REVOKE has been detected.
Table 37. Class Code 56: Miscellaneous SQL or Product Error SQLSTATE Value 56027 Meaning
A nullable column of a foreign key with a delete rule of SET NULL cannot be part of the key of a partitioned index. The clause or scalar function is invalid, because mixed and DBCS data are not supported on this system. Specific and non-specific volume IDs are not allowed in a storage group. The requested feature is not supported in this environment. CURRENT SQLID cannot be used in a statement that references remote objects. The application must issue a rollback operation to back out the change that was made at the readonly application server. The remote requester tried to bind, rebind, or free a trigger package. The parent of a table in a read-only shared database must also be a table in a read-only shared database. User-defined datasets for objects in a shared database must be defined with SHAREOPTIONS(1,3). The database is defined as SHARE READ, but the table space or indexspace has not been defined on the owning system. The description of an object in a SHARE READ database must be consistent with its description in the OWNER system. A database cannot be altered from SHARE READ to SHARE OWNER. An error occurred when binding a triggered SQL statement. An LE function failed. A distributed operation is invalid, because the unit of work was started before DDF. The bind operation is disallowed, because the program depends on functions of a release from which fallback has occurred. The bind operation is disallowed, because the DBRM has been modified or was created for a different release.
56031
56052 56053
56054 56055
56056
56065
Table 37. Class Code 56: Miscellaneous SQL or Product Error SQLSTATE Value 56066 Meaning
The rebind operation is disallowed, because the plan or package depends on functions of a release from which fallback has occurred. The rebind operation is disallowed, because the value of SYSPACKAGE.IBMREQD is invalid. Execution failed due to the function not supported by a downlevel server that will not affect the execution of subsequent SQL statements. Execution failed due to the function not supported by a downlevel server that will affect the execution of subsequent SQL statements. The data type is not allowed in DB2 private protocol processing. An unsupported SQLTYPE was encountered in a select list or input list. ALTER FUNCTION failed because functions cannot modify data when they are processed in parallel. Specified option requires type 2 indexes. The alter of an index or table is not allowed. A bind option is invalid. Bind options are incompatible. The table space name is not valid. A LOB table and its associated base table space must be in the same database. The table is not compatible with the database. The operation is not allowed on an auxiliary table. An auxiliary table already exists for the specified column or partition. A table cannot have a LOB column unless it also has a ROWID column or cannot have an XML column unless it also has a DOCID. GBPCACHE NONE cannot be specified for a table space or index in GRECP.
56067 56072
56073
56080 56084 56088 56089 56090 56095 56096 560A1 560A2 560A3 560A4 560A5 560A6
560A7
Table 37. Class Code 56: Miscellaneous SQL or Product Error SQLSTATE Value 560A8 560A9 560AB 560AD Meaning
An 8K or 16K buffer pool pagesize is invalid for a WORKFILE object. A discontinued parameter, option, or clause was specified. The data type is not supported in an SQL routine. A view name was specified after LIKE in addition to the INCLUDING IDENTITY COLUMN ATTRIBUTES clause. The specified table or view is not allowed in a LIKE clause. Procedure failed because a result set was scrollable but the cursor was not positioned before the first row. Open failed because the cursor is scrollable but the client does not support scrollable cursors. Procedure failed because one or more result sets returned by the procedure are scrollable but the client does not support scrollable cursors. Local special register is not valid as used. The SQL statement cannot be executed because it was precompiled at a level that is incompatible with the current value of the ENCODING bind option or special register. Hexadecimal constant GX is not allowed. The encryption and decryption facility has not been installed. An AFTER trigger cannot modify a row being inserted for an INSERT statement. The package must be bound or rebound to be successfully executed. ALTER VIEW failed. ALTER INDEX failed. An XML value contains a combination of XML nodes that causes an internal identifier limit to be exceeded. The maximum number of children nodes for an XML node in an XML value is exceeded.to be
560AE 560B1
560B2 560B3
560B5 560B8
560CH
Table 37. Class Code 56: Miscellaneous SQL or Product Error SQLSTATE Value exceeded. 560CK 560CM 560CU 560CV 560CY Explain monitored statements failed. An error occurred in a key expression evaluation. The VARCHAR option is not consistent with the option specified when the procedure was created. Invalid table reference for table locator. A period specification or period clause is not valid as specified. Meaning
Table 38. Class Code 57: Resource Not Available or Operator Intervention SQLSTATE Value 57001 57002 57003 57004 57005 57006 57007 57008 57010 57011 57012 Meaning
The table is unavailable, because it does not have a primary index. GRANT and REVOKE are invalid, because authorization has been disabled. The specified buffer pool has not been activated. The table is unavailable, because it lacks a partitioned index. The statement cannot be executed, because a utility or a governor time limit was exceeded. The object cannot be created, because a DROP or CREATE is pending. The object cannot be used, because an operation is pending. The date or time local format exit has not been installed. A field procedure could not be loaded. Virtual storage or database resource is not available. A non-database resource is not available. This will not affect the successful execution of subsequent statements.
Table 38. Class Code 57: Resource Not Available or Operator Intervention SQLSTATE Value 57013 Meaning
A non-database resource is not available. This will affect the successful execution of subsequent statements. Processing was canceled as requested. Connection to the local DB2 not established. Character conversion is not defined. A DDL registration table or its unique index does not exist. The DDL statement cannot be executed, because a DROP is pending of a DDL registration table. Deadlock or timeout occurred without automatic rollback. The estimated CPU cost exceeds the resource limit. A table is not available in a routine or trigger because of violated nested SQL statement rules. A table is not available until the auxiliary tables and indexes for its externally stored columns have been created. The SQL statement cannot be executed due to a prior condition in a DRDA chain of SQL statements. Adjustment not allowed for a period as a result of a data change operation.
57057 57062
Table 39. Class Code 58: System Error SQLSTATE Value 58001 58002 58003 58004 Meaning
The database cannot be created, because the assigned DBID is a duplicate. An exit has returned an error or invalid data. An invalid section number was detected. A system error (that does not necessarily preclude the successful execution of subsequent SQL statements) occurred.
Table 39. Class Code 58: System Error SQLSTATE Value 58006 58008 A system error occurred during connection. Execution failed due to a distribution protocol error that will not affect the successful execution of subsequent DDM commands or SQL statements. Execution failed due to a distribution protocol error that caused deallocation of the conversation. Execution failed due to a distribution protocol error that will affect the successful execution of subsequent DDM commands or SQL statements. The DDM command is invalid while the bind process in progress. The bind process with the specified package name and consistency token is not active. The SQLCODE is inconsistent with the reply message. The DDM command is not supported. The DDM object is not supported. The DDM parameter is not supported. The DDM parameter value is not supported. The DDM reply message is not supported. The number of variables in the statement is not equal to the number of variables in SQLSTTVRB. Meaning
58009 58010
Table 40. Class Code 5UA: Common Utilities and Tools SQLSTATE Value 5UA01 Meaning | https://ru.scribd.com/document/109565004/DB2-SQLSTATE-Values-and-Common-Error-Codes | CC-MAIN-2019-43 | refinedweb | 10,043 | 57.67 |
Prev
Java Enum Code Index
Headers
Your browser does not support iframes.
Re: Collection interfaces (Was: Creating a byte[] of long size)
From:
ClassCastException <zjkg3d9gj56@gmail.invalid>
Newsgroups:
comp.lang.java.programmer
Date:
Sat, 10 Jul 2010 05:32:00 +0000 (UTC)
Message-ID:
<i190kf$3fp$2@news.eternal-september.org>
On Fri, 09 Jul 2010 16:54:53 -0400, Eric Sosman wrote:
On 7/9/2010 4:06 PM, Daniel Pitts wrote:
interface Hasher<T> {
long hash(T value);
}
A 64-bit hashCode() would be of little use until you got to
more than 2^32 hash buckets. Just saying.
Gets us back to the original topic. :-)
interface Equivalence<T> {
boolean equal(T left, T right);
}
I don't get it: Why not just use equals()? I guess a class
could choose not to implement Equivalence at all (and thus make itself
unusable in whatever framework relies on Equivalence), but is that an
advantage? Also, you could get a compile-time error instead of a
run-time `false' for trying to call equal() on references of dissimilar
classes; again, where's the benefit?
Then, all the appropriate Collection code could use those interfaces.
There should also be the obvious default implementations.
It might be helpful to give some examples of the "appropriate"
uses, and of the "obvious" defaults. For example, how does a HashMap
make use of a key that implements Hasher? Does it reflect on each key
its given and make a run-time choice between using hash() and
hashCode()? I don't get it ...
Note that those interfaces specify methods with an "extra" parameter
each. They're like Comparator versus compareTo/Comparable.
The purpose is clear: so a HashMap could be given, optionally, a
Hasher<K> to use in place of the keys' own hashCode methods and an
Equivalence<K> to use in place of the keys' own equals methods.
One obvious benefit is that you get rid of IdentityHashMap by folding
that functionality into plain HashMap. Instead of a separate class, you'd
get an identity hash map with
new HashMap<K,V>(new Hasher<K>() {
public long hash (K x) {
return System.identityHashCode(x);
}
}, new Equivalence<K>() {
public boolean equal (K x, K y) {
return x == y;
}
};
or with canned instances of IdentityHasher and IdentityEquivalence
provided by the library.
With this, you would also be able to get identity WeakHashMaps and the
like; by separating the "how strong is the reference" aspect into one
class and the "how is identity decided" aspect into another, you avoid a
combinatorial explosion and possible lacunae of capability (right now we
have no WeakIdentityHashMap, in particular).
You'd also be able to reduce some of the clumsier uses of HashMap to
HashSet. Picture a
class Record {
public final int id;
public final String name;
public final String address;
}
with the obvious equality semantics (all fields equal) and constructor
added.
Now throw in an Equivalence and a Hasher that use only the record's id
field.
So maybe you keep a change log for an individual person as a
List<Record>, chronological:
id 0001
name Jane Herman
address 1600 Pennsylvania Avenue
id 0001
name Jane Herman
address 18 Wisteria Lane
id 0001
name Jane Thurston
address 18 Wisteria Lane
OK, so she got voted out of office, then got married, or something like
that.
Of course you might want to throw a jumble of records in a Set and have
different ones of the above count as different.
But you might also want a record of the current state of affairs. Given a
HashSet implementation that can use a supplied Hasher and Equivalence the
way TreeSet can use an externally-supplied Comparator, and that also has
the semantics that adding an element that equals an already-present
element replaces that element with the new one, you can update the 0001
record simply by putting a more recent one into this set -- if it already
has a 0001 record, the provided Hasher and Equivalence will lead to the
new one replacing that one.
So in some contexts you can treat records identically only if they're
actually identical; in others if they have the same id; all without
monkeying with an explicit id-to-record HashMap or suchlike.
Another way to achieve this last, though, is to have a KeyExtractor<T>
interface that you implement in this case to return the id field of a
Record and a HashSet implementation that uses the object itself as the
key in its internal HashMap if no KeyExtractor is specified during
construction, and uses the supplied KeyExtractor otherwise. This is
actually closer to the conceptual truth of what you're doing in a case
like this: keying on the id field in a particular HashSet. The
implementation would be something like
public class HashSet<T> {
private HashMap<Object,T> data = new HashMap<Object,T>();
private KeyExtractor<T> ke = new KeyExtractor<T>() {
public Object getKey (T val) {
return val;
}
}
...
public T put (T newElem) {
Object key = ke.getKey(newElem);
T oldElem = data.get(key);
data.put(key, newElem);
return oldElem;
}
}
whereas the Hasher/Equivalence version would just pass the Hasher and
Equivalence to the HashMap constructor when initializing Data and not
have the key local in put, just newElem.
The really interesting thing is that we don't really need to wait for any
hypothetical future Sun (Oracle?) update to do some of this; KeyExtractor
and the above variation of HashSet can be implemented now, perhaps
calling the latter RecordMap instead as it acts as a map from key fields
of records of some sort to whole records, in the typical case, and in
fact you probably do also want to do lookups of whole records by just the
keys. And you might sometimes want to hold the records via weak or soft
references, e.g. to make it a cache. In that case you want to allow
specifying two more things, a type of reference to use (enum
ReferenceType {STRONG; SOFT; WEAK;} with default STRONG) and an optional
ExpensiveGetter that defaults to return null but can be replaced with one
whose expensiveGet() does something like, say, retrieve disk records.
Then get() calls expensiveGet() on not-found and if expensiveGet()
doesn't throw or return null, does a put() before returning the result.
You can throw in another type parameter, too:
public class RecordMap <K,V,E> {
private ExpensiveGetter<K,V,E> eg = new ExpensiveGetter<K,V,E>() {
public V expensiveGet (K key) throws E {
return null;
}
}
private HashMap<K,Object> data = new HashMap<K,Object>();
public enum ReferenceType {
STRONG {
public Object wrap (Object o) {
return o;
}
};
SOFT {
public Object wrap (Object o) {
return new SoftReference(o);
}
};
WEAK {
public Object wrap (Object o) {
return new WeakReference(o);
}
};
public abstract Object wrap (Object o);
}
private ReferenceType referenceType = ReferenceType.STRONG;
...
@SuppressWarnings("unchecked")
public V get (K key) throws E {
Object result = data.get(key);
if (result instanceof Reference) result = result.get();
if (result != null) return (V)result;
result = eg.expensiveGet(key);
if (result == null) return null;
put(key, result);
return (V)result;
}
public void put (K key, V val) {
data.put(key, referenceType.wrap(val);
}
}
This is a bit messy but it's just a quick draft. It doesn't actually
implement Map because it doesn't quite fit the Map contract in a few
places (and making it do so would be difficult, particularly since get
seems to have to be able to throw exceptions). You might want to change
ExpensiveGet to a more general BackingSource that provides both get and
put methods; puts write through to the real backing store whenever
performed as well as writing to the RecordMap in memory, making a
RecordMap with a non-default BackingSource a cache backed by something in
a two-way fashion.
I may be a bit rusty on the syntax of giving enum constants behavior,
too. Clearly in this case that's the right thing to do, from an OO
perspective, rather than having a switch clause in the put method that
could get out of synch if someone decided to add PHANTOM to the thing for
whatever reason or a future JDK added more Reference types that
influenced GC policy in as-yet-unforeseen ways.
Generated by PreciseInfo ™
"He who would give up essential liberty in order to have a little security
deserves neither liberty, nor security." -- Benjamin Franklin | http://preciseinfo.org/Convert/Articles_Java/Enum_Code/Java-Enum-Code-100710083200.html | CC-MAIN-2021-49 | refinedweb | 1,393 | 55.78 |
Home › Forums › WPF controls › Xceed DataGrid for WPF › Disappointing performance with 10 columns, 36 rows?
- AuthorPosts
- User (Old forums)MemberMarch 7, 2008 at 2:08 pmPost count: 23064
I’ve just started working with this product, so maybe I’m doing something wrong, but I notice that if I bind a DataGridControl to a DataGridCollectionViewSource (which holds a DataView with 10 columns and 36 rows), performance is pretty disappointing. Specifically, as I move the cursor up and down without clicking, the “hover” selection bar is always several rows behind the cursor. Then, if I actually click, it takes maybe half a second for the row to fully select. Is this normal for such a small grid?
(Note: I’m running this on a machine with a 2.16-Mhz DuoCore, 1 Gb RAM, and Windows XP SP2)
While I’m posting, I thought I’d mention a couple other things:
1. There doesn’t seem to be a straightforward way to turn on cell selection (rather than row selection). If I were creating, say, a color palette, how would the user select a particular color chip? How could I detect this event? It seems to me the regular ol’ Windows Forms DataGrid used to support cell selection. Adobe Flex certainly does.
2. I see a method to AutoFit the width of a column to its contents but no property to do this automatically. I could be missing something, but having to write code to manually AutoFit the columns whenever the underlying data changes sort of defeats the purpose of binding. I also don’t think I came across a way to prevent users from resizing columns.
3. Just my opinion, but I don’t think the “drag to group” header region should be on by default, and a simple property should be available to turn this on/off.
Some of my issues may be just weaknesses with WPF in general, and some is me not having a very deep understanding the product yet. But I wanted to throw my issues out there now so I don’t pull my hair out trying to do things that aren’t practical to do with this product.
Thanks for any feedback you may have,
-Dan
Imported from legacy forums. Posted by Daniel (had 4683 views)Xceed SupportMemberMarch 7, 2008 at 2:41 pmPost count: 5658
Hi Dan,
The performance issue you are reporting is quite abnormal compared to our own tests on the product. If you can provide more information on the exact setup of the application and of the DataGridControl, we can try to work things through to determine the nature of the issue.
1. Excel-like Cell selection is not part of the current feature set of the DataGrid for WPF, but is on our todo list of features yet to be implemented. We have no timeframe on this feature at the moment.
2. This one was a bugger for us from the start as well. Due to UI virtualization, it was not possible for us to determine a data source wide auto fit size. Therefore we decided not to include automatic AutoFit as this would result in columns constantly changing sizes as scrolling goes. We did not gave up on the topic, but we want to take our time to design a solid solution.
3. Determining the default configuration of the DataGridControl is an exercise where we have to try to please the largest proportion of our users. Unfortunately, by its nature, this process is bound to be unfit for some of our clients. At the same time, when building our control’s design, we have to leave some doors opened for extensibility. For this reason, we chose a design where one have to modify the content Headers and Footers collection ( + their Fixed counterparts ) to modify their content, and stick as close as possible to WPF’s Content Model and Templating features.
If you are interested, I already built a sample class, based on TableView that possess properties to turn On/Off the default Headers/Footers component. This class is far from perfect, but maybe it would fit in your intended usage (main limitation is that it limits the possibility to use custom Headers/Footers, but can be extended to better fit your needs ).
Imported from legacy forums. Posted by Marcus [Xceed] (had 415 views)Odi [Xceed]SpectatorMarch 7, 2008 at 4:34 pmPost count: 426
Dan,
I’ll add something here. When you try our XBAP Live Explorer demo (<a href=””>here</a>), are the speeds excellent? Say, in the first demo, the “Solid Foundation” tab in “Look and feel”.
Just wondering if at least the reference samples work well on your system.
Thanks,
Odi
Imported from legacy forums. Posted by Odi [Xceed] (had 525 views)User (Old forums)MemberMarch 7, 2008 at 5:45 pmPost count: 23064User (Old forums)MemberMarch 8, 2008 at 1:38 amPost count: 23064
Well, I tried out your demo. It flies! No lag at all. So, I tried out another test with my data, this time on a completely blank window. Perfect! Again, no lag. Then I went back to my original example and started commenting features out, one by one. I finally landed on the cause: a BitmapEffect applied to a DockPanel.
Here’s the XAML (sorry for the–lack of–formatting):
<Window
x:Class=”MyNamespace.TestWindow”
xmlns=””
xmlns:x=””
xmlns:local=”clr-namespace:MyNamespace”
xmlns:xcdg=””
Title=”Test Window” Height=”600″ Width=”800″>
<Window.Resources>
<xcdg:DataGridCollectionViewSource
x:Key=”_myDataView”
Source=”{Binding Source={x:Static local:ModelAccessor.Model}, Path=ViewSource[MyDataSource]}”/>
</Window.Resources>
<DockPanel Margin=”10″>
<DockPanel.BitmapEffect>
<DropShadowBitmapEffect Color=”Black” Direction=”315″ ShadowDepth=”3″ />
</DockPanel.BitmapEffect>
<Label DockPanel.Dock=”Top”>My Test Grid</Label>
<xcdg:DataGridControl
x:Name=”OrdersGrid”
ItemsSource=”{Binding Source={StaticResource _myDataView}}”
View=”TableView.Aero.NormalColor”
Margin=”10″ />
</DockPanel>
</Window>
If you comment out the bitmap effect, everything is great. If you leave it uncommented, the DataGrid is completely lagged. This seems like a bug. I would expect an initial hit of a bitmap effect when the screen first renders, but not continuously. Note that I’m using .NET FW 3.0. Perhaps this doesn’t happen with 3.5.
Hope this helps. Thanks for your detailed answers to my questions.
-Dan
Imported from legacy forums. Posted by Daniel (had 558 views)User (Old forums)MemberMarch 8, 2008 at 3:05 pmPost count: 23064
Okay, a little further investigating and I figured out the problem: applying a bitmap effect to a container (like a DockPanel), causes that effect to propogate down the tree to all child elements. This understandably has huge performance implications.
If I do the following, the problem goes away:
1. Create a Grid
2. Place a Border in the Grid.
3. Place the DockPanel in the Grid.
4. Note that there is only one cell and the Border and DockPanel share the same cell (but there is no nesting between the Border and DockPanel–neither is inside the other).
5. Remove the bitmap effect form the DockPanel (which has several child elements) and put it on the Border (which has no child elements) instead.
The result? Performance is back up to full speed.
-Dan
Imported from legacy forums. Posted by Daniel (had 457 views)Odi [Xceed]SpectatorMarch 8, 2008 at 7:30 pmPost count: 426
Good job figuring that out!
Side notes:
– Microsoft demoed .NET 3.5 SP1 at Mix08 and one of the new things was hardware accelerated effects, I’m not sure this replaces BitmapEffects but it seems promissing.
– Currently, .NET 3.0/3.5 BitmapEffects can’t be used in XBAPs, word of warning
– I expect as part of the roadmap we’ll be publishing soon, you’ll see Xceed will continue to dedicate a lot of work on improving performance again. I say again, because last year around this time we were doing the same thing, and got some great results. Though this time around, we’ll also add “perceived performance” and “data virtualization” to the items to work on.
– .NET 3.5 SP1 itself might provide certain new APIs/objects that will help Xceed improve the DataGrid’s performance. We’ll be looking into that too.
Thanks for posting your results.
Imported from legacy forums. Posted by Odi [Xceed] (had 5629 views)
- AuthorPosts
- You must be logged in to reply to this topic. | https://forums.xceed.com/forums/topic/Disappointing-performance-with-10-columns-36-rows/ | CC-MAIN-2021-25 | refinedweb | 1,393 | 64.41 |
JavaScript and functional programming go hand in hand. There are times when our functions will be expensive in terms of performance. Performing the same functions with the same input over and over again could degrade the experience of the application and it is unnecessary.
Memoization is an optimization technique in which we cache the function results. If we provide the same input again, we fetch the result from the cache instead of executing code that can cause a performance hit.
In case the result is not cached, we would execute the function and cache the result. Let's take an example of finding the square of a number.
const square = () => { let cache = {}; // set cache return (value) => { // if exists in cache return from cache if (value a limited range of input but highly recurring.
Discussion (6)
Hi Parwinder and thanks for your article.
If you use a constant for your cache, you would still be able to add some keys to it. Plus, it makes reassignment by mistake throw an error which is an added security.
You can even use an immediately invoked function expression to handle to prevent having to call the function to get the closure first.
Plus, your
elsebranch is not necessary since you are returning (and thus stopping the execution of the function) in your conditional statement.
In the end, this proposal could serve as an alternative for implementing the memoized square function.
And if you need to create multiple memoized functions, you can even extract the memoization in its own helper function.
You could also use a
Mapfor that.
👏🏼 I like this
Why not just
cache.get(parameters) !== undefined?
Thanks for the feedback @aminnairi . Excellent writeup and valid points. Instead of updating my original post with your recommendation, I am going to add a note to it. Readers can see how I approached it and how you made it better (and the reasoning behind it)
In the case of multiple memorization functions I do however prefer @shadowtime2000 implementation (but that is just a preference based on readability)
I recently had a need to cache the results of decryption of an encrypted string so that decryption only runs once, and ended up using a cache where the 'key' of the cache is the hash of the string. Here's the hashing functions I have:
Although the above isn't perfectly good in terms of avoiding hash collisions. I guess I should boost it up to a SHA-256 to be more 'solid' code. | https://dev.to/bhagatparwinder/memoization-in-javascript-2ncl | CC-MAIN-2021-49 | refinedweb | 416 | 61.87 |
D (The Programming Language)/d2/Strings and Dynamic Arrays
Lesson 8: Strings and Dynamic Arrays[edit]
In this chapter, you will learn about strings in depth. In the meantime, you will also learn about another type: the dynamic array.
Introductory Code[edit]
Dynamic Arrays[edit]
import std.stdio; void main() { int[] a = [1,2,3,4]; int[] b = [5,6]; auto c = a ~ b; writeln(c); // [1,2,3,4,5,6] writeln(c.length); // 6 int* ptr_c = c.ptr; ptr_c[0] = 3; writeln(c); // [3,2,3,4,5,6] }
Immutable and Strings[edit]
import std.stdio; void main() { // Concept: Immutable immutable(int) a = 10; // a = 11; Error: cannot modify immutable immutable a = 10; // Concept: Strings as Arrays immutable(char)[] str = "Hello"; auto str1 = str ~ "1"; writeln(str1); // Hello1 writeln(str1.length); // 6 // str1[] = 'z'; error! str1's elements are not mutable char[] mutablestr1 = str1.dup; // Concept: Char Literals mutablestr1[] = 'z'; // 'z' is not a string, but a char str1 = mutablestr1.idup; // The str1 itself is mutable // only its elements are not mutable writeln(str1); // zzzzzz }
Concepts[edit]
Dynamic Arrays[edit]
Dynamic Arrays versus Static Arrays[edit]
In the previous lesson, you learned about static arrays. Dynamic arrays are different from those in that they do not have a fixed length. Essentially, a dynamic array is a structure with this info:
- A pointer to the first element
- The length of the entire array
You create a dynamic array like this:
int[] a;
You can create a dynamic array initiated with a specific length:
int[] a = new int[](5);
You will learn more about the
new keyword later.
The syntax for filling an array with a single value is the same for both static and dynamic arrays:
int[] a = [1,2,3]; a[] = 3; writeln(a); // [3, 3, 3]
Dynamic arrays are indexed in the same fashion as static arrays. The syntax for accessing an element at a certain index is the same:
a[2];
However, since dynamic arrays don't have a length known at compile-time, the compiler can't check if the index that you are accessing is really within that length. Code like this would compile but would also cause a runtime Range Violation error:
int[] a = [1,2,3]; writeln(a[100]); //Runtime error, Range violation
Manipulation of Dynamic Arrays[edit]
Dynamic arrays can be combined with other dynamic arrays or even with static arrays using the
~ operator. Appending a new element to the array uses the same operator.
int[] a = [1,2]; auto b = a ~ [3,4]; writeln(b); //[1, 2, 3, 4] b ~= 5; // same as b = b ~ 5; writeln(b); //[1, 2, 3, 4, 5]
You shouldn't assign a dynamic array to a static array (
my_static_arr = my_dynamic_arr;) unless if you are certain that
my_dynamic_arr.length is the equal to
my_static_arr.length. Otherwise, a runtime error will occur. You can always assign a static array to a dynamic array variable, though, since the dynamic array will automatically resize if the static array's length is too big.
int[] a = [9,9,9,9,9,9]; int[3] b = [1,2,3]; int[200] c; a = b; writeln(a); // [1, 2, 3] a = c; writeln(a.length); // 200 int[] d = [5,4,3]; b = d; // OK: lengths are both 3 // c = d; runtime error! lengths don't match.
Passing Dynamic Arrays to Functions[edit]
Dynamic Arrays are passed by value to functions. That means, when you pass a dynamic array to a function, the structure that contains the pointer to the first element and the length is copied and passed.
void tryToChangeLength(int[] arr) { arr.length = 100; } void main() { int[] a = [1,2]; tryToChangeLength(a); writeln(a.length); // still 2 }
You learned in the last chapter that you can cause things to be passed by reference instead of by value by adding the
ref modifier.
Array and Other Properties[edit]
These properties apply to both static and dynamic arrays:
There are also other properties which are common to every object or expression. Two of such properties are the
.init and
.sizeof properties.
Immutable[edit]
In D,
immutable is a storage-class just like
auto. It converts a type to a non-modifiable type.
immutable(int) fixed_value = 37; immutable int another_value = 46;
Note that
immutable(type) means the same as
immutable type to the compiler.
Storage-Classes and
auto[edit]
When you have a storage class like
immutable, you can omit
auto for type inference.
immutable fixed_value = 55;
The type of whatever is immutable is inferred from the compiler. This next code example is not valid because there is no way the compiler could infer the type:
immutable fixed_value; //Error!
Using
immutable Variables[edit]
This is allowed and perfectly fine code:
immutable(int) a = 300; int b = a;
It only sets
b equal to the value of
a.
b does not have to be
immutable. That changes if you are taking a reference:
immutable(int) a = 13; immutable(int)* b = &a; // int* c = &a; Error.
You are allowed to cast the
immutable away, but if you were to modify an immutable value using that hack, the result is undefined.
immutable(int) a = 7; int* b = cast(int*)&a; // Just make sure you do not modify a // through b, or else!
Strings as Arrays[edit]
You've seen strings since Lesson 1. A
string is the exact same thing as
immutable(char)[], a dynamic array of immutable char elements. Likewise, a
wstring is the same as
immutable(wchar)[], and a
dstring is the same as
immutable(dchar)[].
String Properties[edit]
Strings have the same built-in properties as dynamic arrays. One useful property is the
.dup property, for creating a mutable
char[] copy of a string if you want to modify the individual characters of the string.
string a = "phobos"; char[] b = a.dup; b[1] = 'r'; b[4] = 'e'; writeln(b); // probes
The
.idup property is useful for creating a copy of an existing string, or for creating a string copy of a
char[].
string a = "phobos"; string copy_a = a.idup; char[] mutable_a = copy_a.dup; mutable_a[3] = 't'; copy_a = mutable_a.idup; writeln(mutable_a); // photos writeln(a); // phobos
Char Literals[edit]
A
char literal is enclosed by single-quotes. There are also
wchar and
dchar literals.
auto a = "a"; // string auto b = 'b'; // char auto c = 'c'c; // char auto d = 'd'w; // wchar auto e = 'e'd; // dchar | http://en.wikibooks.org/wiki/D_(The_Programming_Language)/d2/Strings_and_Dynamic_Arrays | CC-MAIN-2014-41 | refinedweb | 1,064 | 63.09 |
OpenGL-ES
[edit] OpenGL ES
OpenGL ES is an API that allows programmers to draw 3D graphics on mobile and embedded devices. Hardware accelerated OpenGL ES 1.1 and 2.0 are available on Maemo devices beginning with the N900.
[edit] OpenGL variants
OpenGL ES is a subset of the full OpenGL standard, and therefore the two APIs are not directly compatible. The following diagram shows the relationship of the major OpenGL versions and variants.
OpenGL 1.0 has fixed shaders and fixed function API for using them. OpenGL 2.0 adds programmable shaders, but fixed function pipeline API is still supported for backward compatibility.
In contrast, OpenGL ES 1.1 is based on OpenGL 1.x with some APIs removed and fixed point integer support added. OpenGL ES 2.0 is based on OpenGL 2.0 with the fixed function API removed.
[edit] Porting between OpenGL variants
All versions and variants of OpenGL are not directly compatible, so a certain amount of changes are needed when moving applications from one variant to another. The following diagram summarizes these changes for major OpenGL versions.
OpenGL 1.0 applications work with OpenGL 2.0 but not vice versa. OpenGL 1.0 applications can be ported to OpenGL ES 1.1, but need changes if they are using some of the removed APIs. OpenGL 2.0 application that only uses programmable shaders is possible to port OpenGL ES 2.0, but may still need some work due to , e.g., differences in the shading language versions. Finally, porting OpenGL 1.0 or OpenGL ES 1.1 applications to OpenGL ES 2.0 requires a rewrite to replace fixed function API usage with programmable shaders.
Most desktop Linux OpenGL applications are written using the legacy OpenGL 1.x fixed function pipeline (e.g. usage of glBegin/glEnd and the matrix stack). OpenGL 2.0 introduced programmable shaders, but it still supports the legacy fixed function pipeline. Since in OpenGL ES 2.0 the fixed function pipeline has been completely removed, porting applications from OpenGL 2.0 to OpenGL ES is likely to require a major rewrite of the application's graphics code.
[edit] Getting started
An excellent way to familiarize yourself with OpenGL ES 2.0 is to try the tutorials that can be found in the PowerVR SGX SDK under the TrainingCourse directory.
The SDK libs and headers can be dropped into your Scratchbox X86 environment and run inside the Xephyr X11 window - but you'll need to kill the window manager first!
The examples have their own Makefiles for Linux hosts but you can copy the files to your own directory and try the Makefile below. Reason to use this own Makefile is that the makefiles coming with the SDK compiles examples with x86 libraries part of the SDK and not armel/x86 maemo libraries in scratchbox.
This Makefile at the moment supports the basic and PvrShell examples (01..05) but does not yet support PvrTools examples (06 and above).
To compile some of PowerVR tutorial examples, you can use the following Makefile
CC=g++ CPPFLAGS = -DBUILD_OGLES2 LDLIBS=-lEGL -lX11 -lGLESv2 all:OGLES2Texturing OGLES2BasicTnL OGLES2IntroducingPVRTools OGLES2HelloTriangle_LinuxX11 OGLES2HelloTriangle_LinuxX11:OGLES2HelloTriangle_LinuxX11.o OGLES2Texturing: PVRShellOS.o OGLES2Texturing.o PVRShell.o PVRShellAPI.o OGLES2BasicTnL: PVRShellOS.o OGLES2BasicTnL.o PVRShell.o PVRShellAPI.o OGLES2IntroducingPVRTools: PVRShellOS.o OGLES2IntroducingPVRTools.o PVRShell.o PVRShellAPI.o
[edit] Installation
You can compile OpenGL ES applications with Scratchbox. The ESBox IDE makes it much easier to execute the application on the device. It automates copying the binary onto the device and execution.
Firstly you want to install the following packages in Scratchbox.
[sbox-FREMANTLE_ARMEL: ~] > fakeroot apt-get install libgles2-sgx-img-dev
This installs the OpenGL ES 2.0 development files required for compiling.
[sbox-FREMANTLE_ARMEL: ~] > fakeroot apt-get install opengles-sgx-img-common-dev
This installs the EGL library (used for portable context creation, see the documentation) and PowerVR development files. It also includes some simple demos.
If you want OpenGL ES 1.x compatibility then install the following package in Scratchbox:
[sbox-FREMANTLE_ARMEL: ~] > fakeroot apt-get install libgles1-sgx-img-dev
Now install the required libraries on the N900:
Nokia-N900-42-11:~# apt-get install libgles1-sgx-img libgles2-sgx-img opengles-sgx-img-common
[edit] Library support
This section includes a partial list of library options for using OpenGL ES.
[edit] SDL 1.2 + SDL-GLES
The N900 ships with SDL 1.2. You can use that and a external library, SDL-GLES (available in extras), to create simple OpenGL ES 1.1 and 2.0 applications.
NeHeGLES is a port of several of the famous NeHe OpenGL lessons to Maemo5/SDL-GLES.
[edit] SDL 1.3
SDL 1.3 supports OpenGL ES 1.x. This does not seem to work in the N900 as of now.
[edit] OpenGL ES 1.x utilies
Information:
Git repositories:
Sami Kyöstilä has developed a number of utilities. This includes SDL with OpenGL ES 1.x support, libglutes, python-opengles and several translators to convert OpenGL ES and OpenGL. Note that these utilities are designed for the Nokia N810 and OpenGL ES 1.x.
[edit] Qt
You can use Qt with OpenGL ES 2.x on the N900.
[edit] Clutter
libclutter supports OpenGL ES 2.x and OpenGL ES 1.1. It is oriented towards toolkits and applications with user interface elements.
[edit] Xlib (X11)
You can use Xlib (X11) and utilize the EGL library for context creation along with OpenGL ES. This is what the Bounce Evolution game uses.
You can use OpenGL ES version 1 or 2 directly without worrying about the version that is supported by the library.
See below for an example Xlib application.
[edit] PVRShell
The Khronos OpenGL ES 2.0 SDK includes a simple API for window creation called PVRShell. They also include additional tools for more advanced computer graphics applications. It is much simpler to create an OpenGL ES 2.0 application using PVRShell. It doesn't seem to have much support for handling events.
[edit] Examples
[edit] Qt Example
You need to install libqt4-opengl-dev:
[sbox-FREMANTLE_ARMEL: ~] > fakeroot apt-get install libqt4-opengl-dev
There is an example application called hellogl_es2. There is also equivalent examples for desktop opengl and opengl_es2. Get it here:
This example shows how to use OpenGL ES embedded in a QtWidget. The example is also good showing what is different between OpenGL versions. hellogl uses plain desktop "glBegin / glEnd" functions with display lists. hellogl_es2 uses vertex attribute pointers and shaders instead of glBegin/glEnd. helloes_gl2 is even more complicated because it uses programmable shaders instead of fixed pipeline in both of the previous examples.
If you try to compile the unmodified version of hellogl_es2 for Maemo, you need to add in
void GLWidget::initializeGL (). Modify glwidget.h and change
#include <QGLWidget> to
#include <QtOpenGL/QGLWidget>.
setlocale(LC_NUMERIC, "C"); // Reset locale for compilationand after shaders has been compiled line
setlocale(LC_ALL, ""); // restore locale
because locale affects in shader compilation even it should not do.
Edit
hellogl_es2.pro and add:
QT += openglThen run:
qmake -project qmake make
Which will (hopefully) compile hellogl_es2. Then you can copy the binary to the device and run it.
[edit] Xlib Examples
You can usually compile any Xlib example with a simple Makefile like:
CC=g++ LDLIBS=-lEGL -lX11 -lGLESv2 all: main main: main.o
In the PowerVR SDK TrainingCourse directory there are a number of examples. The first two use only Xlib. The rest make use of PowerVR libraries which have to be linked in with the program.
There is a simple Xlib example in a separate article.
[edit] SDL-GLES Example
The NeHeGLES examples are available from extras-devel. Within armel-scratchbox, a simple
fakeroot apt-get build-dep nehegles
will install all the necessary libraries. An additional
fakeroot apt-get source nehegles
will then install the sourcecode of the nehegles lessons. A "make" in the nehegles root directory builds all the included lessons as well as the gui. Individual lessons can be recompiled by a simple "make" in their respective directories.
[edit] Python example
On [1] you can find xlib_wrapper.py and opengltest.py (port of SimpleGL example).
[edit] Notes
- WARNING: If you try to run an OpenGL application with scratchbox then it will most likely work. This is because it uses the native operating system OpenGL libraries to execute. However, if you try and run it on the device it will not work as it only has OpenGL ES libraries.
- OpenGL ES does not run natively on a desktop computer. It is possible to get some kind of emulation library from the PowerVR Insider SDK [2] so that you can test on a desktop computer. The OpenGL ES 2.0 emulation library was packaged for use inside the FREMANTLE_X86 scratchbox target (package libgles2-dev, extras-devel non-free repository).
- If you require any kind of performance in Maemo 5, you need to make your window full screen.
[edit] Further reading
Here are some useful resources.
- - Maemo Experiments
- - hellogl_es2 example for Qt 4.5
- - Khronos OpenGL ES 2.0 SDK has useful examples
- - Thread discussing performance of OpenGL ES
- Game_development - Page describing game development on Maemo. More oriented towards 2D games but has some useful information
- - If you don't know how to start with Maemo development in general then look here
- - Information about repositories
- - OpenGL ES 2.0 Reference Page
- - OpenGL ES 1.1 Reference Page. It also has information about EGL
- - Thread discussing ideas about OpenGL and Maemo
- Kate Alhola's presentation in Bossa 2009 conference about Fremantle and section about OpenGL ES 2.0
[edit] Books
- Mobile 3D graphics with OpenGL ES and M3G – Excellent introductory section covering OpenGL basics. Covers OpenGL ES 1.1, not 2.0.
- OpenGL ES 2.0 programming guide – This 'Gold Book' is hardly in the same league as the above book, or the original 'Red Book' - being aimed at folk who already know their OpenGL lingo. It dives into laborious detail as if trying to spew as much of the ES 2.0 spec onto the page as possible. It assumes a Windows audience and the AMD simulator. You may be better off looking at the PowerVR SDK tutorial code than reading this book, then coming back to it for reference and further code examples.
- This page was last modified on 10 October 2010, at 14:04.
- This page has been accessed 82,591 times. | http://wiki.maemo.org/OpenGL-ES | CC-MAIN-2018-51 | refinedweb | 1,731 | 59.6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.