
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91 values | source stringclasses 1 value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Holy cow, I wrote a book!
A customer was running into this problem with a shell extension:
I am writing a shell namespace extension.
I need to get data from a COM server,
which requires impersonation via
CoInitializeSecurity with
RPC_C_IMP_LEVEL_IMPERSONATE.
As I am just writing an extension into explorer.exe,
I am not able to call CoInitialize,
CoInitializeSecurity anymore from my extension.
Is there a way I can start explorer.exe
by setting RPC_C_IMP_LEVEL_IMPERSONATE
in its COM initialization?
I was browsing through web,
and explorer.exe seems to take some settings from registry,
but couldn't find anything related to this one.
CoInitializeSecurity
RPC_C_IMP_LEVEL_IMPERSONATE
explorer.exe
CoInitialize?
RPC_C_IMP_LEVEL_DELEGATE. | http://blogs.msdn.com/b/oldnewthing/archive/2009/12/02/9931183.aspx | CC-MAIN-2014-52 | refinedweb | 108 | 52.56 |
I’m sorry to post about this subject with all the other stuff I’ve been promosing to cover but I just read this and wanted to share my thoughts. I was reading Tim Bray’s post the other day about the OpenOffice conference (). He brought up a point that I’ve been asked about seperately a few times related to the lack of formula support in the OpenDocument standard:
Bad Formula Trouble.
There’s also this article on NewsForge titled OpenDocument office suites lack formula compatibility where the following was stated:
The OASIS Technical Committee in charge of this standard explicitly said last January that “while … interoperability on that level would be of great benefit to users, we do not believe that this is in the scope of the current specification. Especially since it is not specifically related to the actual XML format the specification describes.”
Even outside the Committee there is the same opinion: OpenDocument must only be about structure and how to represent content.
Someone asked me in one of my previous posts what my thoughts were on this article, and here’s a bit of what I said:…
As I’ve said before, it appears that there are a number of very similar goals between the Office XML formats and what Sun did with the StarOffice format. In Office, we have the additional responsibility of supporting everyone’s existing documents, which means there are a huge number of features we need to support (all of them). The issue here around equations happens to be just one example of one of those types of features that is really important. I’m sure the StarOffice format did have this support, it just didn’t make it into the OpenDocument spec.
This is one of those cases where it’s important to understand the nuances of someone’s design. It appears that as they moved the StarOffice format through OASIS to create the OpenDocument format one of the primarily goals was around display of content. For whatever reasons (time, effort, design goal, etc.), they made the decision that some application information (like formulas, or customer schemas) was not something they wanted to work into the standard. This is an example of where our minimum requirements have to be different.
Presentation-centered formats. You could argue that formulas affect the display, but as long as you make sure all the formulas are calculated before you save into their format you are fine.
Application interoperability
I’m curious what applications that are going to use OpenDocument as their primary format have decided to do about these missing features like formula support. I know a number of them have support for spreadsheets. Formulas are such a key part of a spreadsheet I’m assuming they have to create their own extensions to the format to support this. I’d be curious to know how the applications standardizing around OpenDocument (KOffice and OpenOffice for example) are planning to exchange spreadsheets. I would assume they will take some approach (like transformation) to ensure the interoperability they are going after. That’s one of the great benefits of an XML format; as long as it’s well documented you can take advantage of it. We’ve had people get pretty upset at us though when we’ve had to extend an existing format when there is additional functionality we want to store that the format doesn’t support (it’s referred to as “embrace and extend”). I think in this case there isn’t really a choice. You can’t have a spreadsheet without formula support.
I’m sure that the long term goals of OpenDocument do include full roundtripping of all user data and if that’s the case I’m sure they are going to work on a proposal for missing pieces of the spec like formulas at some point. Once they do decide on a way to add formula support to OpenDocument, then they’ll also need to go back to all the files that get created under the current standard and update them from the proprietary extensions to match the decided upon standard.
Full fidelity formats
I’ve talk before about how full fidelity formats are really important to us because we want to ensure that all features you want to use can be fully represented. Formulas are an extremely important part of any spreadsheet. In fact one could argue that formula support is the primary reason for using an application like Excel. The Microsoft Office Open XML formats are specifically designed as an XML representation of our full file formats. Everything you can do in our default format is represented as XML. Our formats are primarily designed around viewing, editing and integrating the files with data, formulas, and other application behavior. Collaboration is extremely important to us as well, and it would really be lame if you couldn’t collaborate on every aspect of your files (only a subset). This is another example of why we had no choice but to create our own XML file formats if we really wanted to move to XML formats as the default. Otherwise we would have been stuck with something that didn’t fully persist all of our users’ features. The key is that we fully document that XML and provide the schemas to anyone that wants to use them. This way as we continue to innovate based on customer needs and demands, we can also incorporate that functionality in the file format and expose it to anyone that would want to leverage it.
-Brian
So, what’s the problem with storing formulas as strings? That’s how they are naturally represented, and it makes perfect sense to store them that way.
ODF is the way to go at the moment, because there is no other option. There is no other equivalent that that is free to be implemented by any vendor without restrictions.
While it would be nice if were structured and could be schematized, storing as a string can still definitely work. Is there an agreed upon syntax for those strings that the different applications are using?
-Brian
I loved the Tim Bray article, the whole post. What fun. Thanks.
I agree that they should move to repair this very quickly and simply. I can’t believe it happened in the first place.
I think the whole issue of formulas is pretty much not a major problem for word-processing documents. Spreadsheets yes, but not for the average document like you’d prepare in Microsoft Word or OpenOffice Writer. It makes sense, then, to not let a spreadsheet-specific issue hold up the whole format.
I don’t think anyone should be suprised at how the formula issue is progressing. It’s how RFCs have been developed for years, after all. OASIS isn’t sure what the right thing is when it comes to formulas that lots of applications will use. They’re probably trying to find a representation that’ll allow flexibility for non-spreadsheet purposes as well as fit the existing needs of spreadsheets. That’s non-trivial. Meanwhile, rather than codify an incomplete and inadequate initial standard, they’re leaving it undefined., in fact section 2.2 on meta-data in the OpenDocument spec defines how to create application-specific metadata tags for just this kind of thing. If you maintain any kind of coherence between the XML document tree and the internal representation, I can even see how to preserve formulas in the document even if the application can’t understand or display them. Same for meta-data tags.
I’m a C++ hacker, not an XML guru. If I can figure this stuff out, I’m fairly certain the Microsoft Office developers can too. This whole hullabaloo smells like FUD to me.
MS is floated by money collected from the sales of office and OS. Now opendoc will undermine this in a relatively short time, given every countries (except USA) will adopt this standard very soon, no matter how many FUD is posted by the PR of MS. Google now join forces with Sun to provide SOA model of office. Only make it happen faster.
Given everyone will switch to linux after vista is released, MS will soon lose most of her revence. All cost centers in MS are at the mercy of Xbos team to see how many workforce bill gate will decide to lose!
Todd Knarr: …"
And then you save your spreadsheet to ODF in OOo/SO with formulae represented by OOo/SO-specific XML tags (in OOo/SO-specific namespace, I presume) and then load in KOffice or Gnumeric, who have their own app-specific tags and namespaces and thus ignore OOo/SO’s formulae. So much for a not particularly advance app-specific tags…
Still love custom tags idea? Think of upgrade scenario. What would OOo/SO and others do when the common denominator formula standard is introduced, and alas it doesn’t cover all the features of their in-house file format? Ok, OOo/SO is probably safe, thanks to Sun. KOffice? Gnumeric? Yet-unknown-but-cute underdog spreadsheet app? Sucks to be them.
I do have a question for you guys: when Office 12 schemas are published, how long till OOo/SO and others start supporting new Microsoft formats? They won’t have much of a say I figure. And why would anyone use ODF XML formats after Office 12 XML formats are integrated?
Love, SDJ
^^^ linky ^^^
SDJ: as I said, app-specific representations are a transitional matter only. As I noted, one of the reasons OASIS isn’t specifying a formula standard just yet is that they’re trying to avoid just the problem you describe. They want to be sure that the standard will cover everything and won’t leave either current or future apps out in the cold because what they need won’t fit into the standard. I consider it a feature of the standard that they can allow apps to do app-specific things without breaking the standard for other apps and without breaking future standardization. I’m still in a better position than I would be with a standard that wouldn’t ever support what my apps needed and I’ve got to go through yet another format change. By my estimation, the transition from app-specific to standardized formulas should be fairly uneventful: I’ve probably got the apps that wrote the app-specific data, so once the standard’s finalized I update them to a standards-compliant version and my files get updated to standards-compliant formulas as I open them. Meanwhile, why should I hold up a standardized word-processing format just because I’m not quite sure how to put one particular bit of spreadsheet-specific stuff (which word processors won’t care about) in?
I doubt OOo or any of the others will be supporting the Office 12 XML schemas soon. For one, the developers aren’t likely to take on the patent-infringement risk laid out in MS’s license. For another, their customers are asking for OpenDocument formats, not Office 12, and OOo are listening to customers, not their competitors. Given that the majority of the world’s going to remain on pre-12 formats for the foreseeable future, I think the pressure will actually be to avoid Office 12 formats, not adopt them. I know where I work we’ll probably be rejecting Office 12 formats since nobody will be running software that supports them. Support for the format isn’t a security issue so the next possible upgrade timeslot it could go in is summer of 2006 (assuming the virus-scanning software has had it’s upgrade to support the format by then, and that an Office 12 format plug-in for Office XP is available by no later than the end of the year). We’ve had major upgrades to Windows (to XP), Office (to OfficeXP) and several other software packages this year, another big expenditure’s going to be a hard sell (even if the plug-in’s free, staff time and disruption to work is expensive and money for it’s got to be found in the budget).
When you’re done grasping at straws trying to prove how superior your ClosedXML format is to ODF, can you please explain why you still haven’t made clear that all you said about IP problems with ODF involving Sun was a mix of FUD and lies?
OpenDocument has support by several apps. The Wikipedia article on OpenDocument has more info:
Support is not limited to OSS offerings. For example: TextMaker 2005 is a closed source application, currently in beta, with some OpenDocument support:
Adobe, Corel and IBM were behind this standards effort as well. Not just Sun.
If Microsoft has a problem with the specification, perhaps they should join the commitee. Microsoft is a member of OASIS already AFAIK.
No one is asking Microsoft to dump Office XML. Just to support OpenDocument, as RTF or Wordperfect were supported.
Thanks for the informative post. I find your comments on extending the format interesting – as surely that’s exactly what XML is for?
I personally would have no problem with an extended format, so long as features built into the format were used where they existed, instead of being replaced by custom extensions. It’s much like the support for XML blobs in PDF – sure, if you want to include your own extra metadata or other details in a PDF, why not? It doesn’t harm other readers (which can just ignore it), and adds functionality for users.
Extensions, to my mind, only become a problem when a set of tools rely on them to the exclusion of support for the standard. For example, if some hypothetical PDF viewer shipping with a product would only open PDFs that had the vendor’s own XML extensions, or if it hopelessly butchered files that lacked them, that’d be an issue. Providing extra functionality with the extended files would not – especially if those extensions were clearly documented and reasonably licensed.
Even zealots would have a hard time screaming about it if Microsoft chose to extend OpenDocument. They’d do it anyway, but they would be even less credible than usual. OpenOffice.org, after all, significantly extends the OpenDocument format. Save a .odt, unzip it, run content.xml through `tidy -xml -indent’ and have a look at it – you’ll see that it imports a number of OO.o specific schema in addition to the OpenDocument ones. That said, a fairly complex .odt I just picked up doesn’t seem to actually use any elements from the ooo namespaces.
Extensions have to be done carefully, but they’re hardly evil in and of themsevles. Where would LDAP be if we couldn’t add to the schema, for example?
I was personally rather disappointed that OpenDocument doesn’t require the undamaged preservation of unrecognised markup, let alone specify preservation options like Word supports. A few tests confirmed that current OpenOffice 2.x betas strip custom markup added to content.xml, and in fact don’t even appear to notice or complain about invalid (though well-formed) markup. Some more research indicated that this issue has been deferred for a later revision of the OpenDocument spec.
While understandable – in terms of implementation difficulty if nothing else – it’s disappointing. Support for preserving, and in fact actively working with, customer schema extensions is one area where Word has me drooling. You guys will, alas, probably never release a lightweight version for UNIX/Linux thin clients, so for the time being I’ll only be able to use it on some of the systems at work.
I must express agreement with cheesybagel on one point – it’d be very nice if Microsoft chose to ship OpenDocument import/export filters, even if only for Word at first. As he points out, much like RTF it’d only need to support what features the format could handle, plus the option of saving in that format by default. I personally see little wrong with simply warning a user that "some formatting and features may not be preserved when saving in this format". Alternately, it would seem reasonable to add schema extensions to support the round-trip of MS-specific features (though it seems other apps would clobber them). I suspect that this might, if nothing else, calm the seas of the current fuss about document formats in government.
I would be very happy to have OpenDocument filters in Word. Not "native" format use, just filters. As a business that currently uses both Word and OpenOffice, it’d actually simplify our use of Word and make it more attractive, not less. If I wanted to transition all the users across to OpenOffice, I could do it just fine based on the Word 2000 format support, so I don’t see how it’d be a threat to business.
Yuki: That’s been answered here before. As someone who was keeping an eye on the discussion, I can assure you that at the time the questions were quite legitimate. Sun had a rather ambiguous declaration that linked to the W3C policy. That policy, by the way, doesn’t guarantee perpetual availability or sublicensing, or GPL compat if that’s what you’re worred about. The declaration didn’t say if they actually had any patents on the format.
Sun has since moved, pleasantly quickly, to post an updated patent grant.
I don’t really understand why so many people are getting worked up about this. It didn’t look like a big deal then, and it doesn’t now.
Just a minor point, Brian, that in fact reflects on a larger critique I have of the FUD coming out of Redmond:
You take a small point about missing formula specs and then make a grand claim that OD is "presentation-oriented", and so somehow more limited than MS Office XML. This is just wrong. The spec has a quite clean separation of presentation logic from content/structure.
Is it as clean as, say, DocBook? No, but that’s no surprise. Does it do a better job than your format? Probably.
BTW, David Wheeler has been working on the missing formula stuff (though I know nothing about it). It’s called OpenFormula. That’s the nice thing about an open format: people can actually contribute to improving it!
Thanks for the comments everyone.
Bruce, I wasn’t trying to turn this into FUD. In reading through those articles it sounded like the OpenDocument committee had decided they wouldn’t focus as much on things like formulas and instead focus on things that affect the presentation of the files. I got that from the text in that article I pointed to. I could be completely mistaken though.
I’m actually curious about what peoples thoughts were around formulas. One could make an argument that using strings for formulas is the right way to go, but in order to have a shared document format I’m assuming they still need to have everyone agree on a single type of syntax for those strings. Otherwise the formats aren’t interoperable.
I’ll have to check out the work David is doing around the OpenFormula work. Thanks for pointing that out.
-Brian
Brian: I think strings aren’t the final format for formulas to be represented in. I suspect they’ll come up with an XML-tags-based format in the end. For the moment, though, strings let applications stuff their own specific representation in until a standard form is settled on.
And you weren’t mistaken about the committee’s focus. They know what they want from presentation, they aren’t sure yet what’s needed for formula representation, so they’re focusing on what they’ve got a firm handle on while leaving formulas simmer. proven to work best.
Brian — I was objecting to the logic of this reasoning:
<blockquote.</blockquote>
I just don’t know how you can say that. It tells me you probably haven’t looked through the details of the spec. That’s fine; it’s just I object to you making conclusions like the above based on that limited knowledge.
I’ve worked with the OD TC, and I’m just an end-user with a passion for one specific piece of the document pie: citations. When we designed the new coding for that, the focus was on really nice separation of content/structure from presentation. And when that makes it into the spec and starts to be implemented, it will mean standardized coding for this that will enable features I don’t think are possible with existing tools.
Todd Knarr: proved to work best."
Translation: "ODF standard is a work in progress, and as such is immature."
You are missing quite a few points:
1. Standardizing a big commercial office suite on such immature standard is very risky at best.
2. It’s also pointless, since most features, starting with formulas, would require creating non-standard extensions and namespaces.
3. There is no way to ensure full fidelity between old Microsoft Office file formats and ODF – they are simply too different.
4. There are more applications in Microsoft Office than ODF is designed for, meaning again completely proprietary extensions and namespaces crammed in a general ODF container.
5. ODF (or their OOo implementation, which I expect is not too shabby) are s-l-o-o-o-o-w, period. There you go again:
Need more? Ok, here is the killer:
6. Until ODF is comprehensive, there is no way to ensure interoperability of office suites. Some features and formatting would always be lost when moving documents between suites. There is simply no way successful commercial application can afford this.
Brian, you wrote in part: "We’ve had people get pretty upset at us though when we’ve had to extend an existing format when there is additional functionality we want to store that the format doesn’t support (it’s referred to as "embrace and extend")."
The extension isn’t the problem. The problem is when Microsoft tries to lock up their extensions behind onerous licensing (e.g. Kerberos) instead of working with the people charged with maintaining those standards. It’s the same deal with locking up the XML file formats with licenses and patents: totally bogus, dude.
I’m not a numbers jockey, so spreadsheet formulae aren’t that important to me: whatever OASIS settles on will be fine. What’s more important is that I be able to move into *and out of* Office as I please, taking advantage of the strengths of whatever tools I have at hand. I don’t require (or expect) that documents look exactly the same in every tool, just that I don’t lose important content (in the case of wordsmithing, that’s text and structure). Try competing on the *merits* of your software and file formats, instead of on who has the biggest set of locks, and you’ll see a lot of people change their attitude about Microsoft.
SDJ: counterpoints:
1. ODF is hardly immature. It’s been in development for quite a while, and is based off of a pre-existing format which has had several years of real-world use and modifications in response to actual problems. In addition, a large number of actual users of documents have been involved in the development specifically to insure that the resulting format met their needs. Given that, it seems to me less risky than depending on a brand-new format, designed within the last year or two, with no real-world experience or direct input from real-world users. Your assertion that ODF is immature has been, as well, thoroughly discredited by any number of others, both involved with OASIS and not.
2. Hardly pointless, since OASIS is working on those features. Applications that would need, for example, formulas already have an application-specific format that they could continue to use, and they can transparently upgrade to the standardized format when that’s finalized (as I described above).
3. Customers aren’t looking for full fidelity with Office formats, they’re looking for a standard format that can represent various document formats accurately. They’re looking for a replacement for the Office formats, not something that can reproduce them, and fidelity is irrelevant when you’re not using the Office formats.
4. Right now ODF is explicitly designed to eventually cover all the applications that exist in the Office suite. It doesn’t yet, but that’s not a major problem so far as I described above. The initial target is word processing, and frankly there’s more implementations of word processors using ODF than there are implementations of Microsoft Word.
5. Slow? Practical experience indicates that OpenOffice, KOffice and AbiWord are at least as fast as Microsoft word. In any case, whether it takes 1 second or 1.1 seconds to write out a document that took 4 hours to write and must remain accurately readable for the next 200 years seems to me not particularly critical.
6. That’s the argument "We can’t release anything until we’ve got everything perfect.". This is countered by every bit of software development methodology in the last 10 years, particularly open-source development which thrives on releasing early to get real-world feedback to guide further development. It’s also countered by the Internet protocols themselves, which follow the incremental-development model and have almost completely wiped from existence protocols developed on your "get it complete and perfect or it’s useless" model.
I don’t have to call FUD on any of these arguments, it’s already been called on all of them by many others.
I’m going to have to disagree with you a bit there Todd. First off though, I’d like to ask that you please stop using the term FUD when we have disagreements on particular issues. It really doesn’t serve a purpose. Just say you disagree and make your point. The way you use the term FUD, it could really apply to anyone that says something or asks something you don’t like, and that really kind of takes away any meaning from the term.. Of course as you move forward and add new functionality you’ll have to adjust the formats, but existing functionality has to be represented.
I really wish that cross version compatibility was as simple as you suggest, but it isn’t. Changing formats from version to version is a big pain. Let’s take the formula case here. If we were to go and use method "A" for representing formulas in version 1, we’d be ok for now. But once they come along and say that method "B" is the right way to do it, we’d have a difficult decision to make. When we move forward to version 2, do we output just method "B", or both "B" and "A"? If we don’t output method "A", then there is no way for anyone with version 1 to look at our formulas. That isn’t really acceptable because we haven’t even changed the way formulas work internally, just the way they are persisted. Maintaining cross version compatibility is extremely important. Not everyone is able to always upgrade to the latest version, so you need to take that into account. That’s the reason we’ve stuck with the same binary formats for so long. Only now are we moving to new default formats, and we’re actually doing a ton of work to provide updates to the past 3 versions of Office so they can also support this new format.
You’re third point that "customers aren’t looking for full fidelity" really blows me away! Maybe you’re only talking specifically about customers that want to move to OpenDocument (which is a really small set)? Most customers don’t care what format their files are saved in as long as everything works. We think we can do better though and that’s why we build the XML formats. We think that Office documents can play a much larger role in business processes. Most customers aren’t there yet though.
Your comments about the speed of OO are a bit surprising. I do know that we’ve had customers that would refuse to upgrade if the product slowed down, so it definitely is a big deal to a lot of people, even it if isn’t a big deal to you.
Also, as a side note, for those of you folks that claim formulas aren’t that big of a deal because they only affect spreadsheets, I unfortunately think you’re letting your bias affect you a bit. Excel is one of the key applications in the Office system, and if we told our users that a core piece of functionality in that product wasn’t supported (or at least we weren’t guaranteeing cross version compatibility), we’d be in a lot of trouble. 🙂
-Brian
Brian: ."
Not sure if I missed something but could you point me to an example of where you are being asked to move to a new primary file format? I thought everyone was just asking for a way to save in this format (as in the Save As… option)?
Thanks
Mark.
(oh and I see WorkPerfect is to support OpenDocument )
A bunch of new links about OpenDocument Format. Includes WordPerfect support, submission to ISO, adoption by Australian National Archive, and a FAQ from Massachusetts that addresses a lot of the questions that people are debating here:
Mark, we’ve definitely had a lot of requests to move to open, documented, XML formats. The average end user doesn’t care, but we’ve had a large number of big companies ask for this support. The number of people asking for XML formats compared to the number of people asking for OpenDocument format is significantly different. And aside from people specifically wanting the new format, there are also feature requests we get that we will be able to solve because of the new format.
We also have had a lot of partners request the format change to make it easier to build solutions on top of our files. And as I’ve mentioned before, even we benefit from it because it allows us to build more rich functionality into the Office System for handling Office documents in a rich and powerful way (workflow, document assembly, etc.)
I know that it’s important for people to understand why we did this work in the first place. I talked about a number of the reasons for moving to the new format in this post:
-Brian
Brian: one example of a customer asking to move to OpenDocument would be, obviously enough, Massachusetts.
As for formula formats, it’s easy and I described how to do it earlier (at least in OpenDocument, which accomodates this). You use a user-defined meta-tag to indicate the formula representation used in the document. When you need to change over to a standard format because it’s been finalized, you start writing in the standard format when you save documents. After all, everyone else will be using that format too, so there’s no reason to write in a proprietary format. When reading, you look for your meta-tags. If you find yours, it tells you what format you need to read formulas in. If you don’t find one, you attempt to read the standard format. If you can’t read the standard format, you use the numeric representation in the tags instead as a last-ditch fallback. This causes loss of backwards compatibility (old versions can’t read the formula representation of newer versions, but can still get the numeric form), but this is traditional with every MS Office version upgrade so I don’t see where it can be considered unacceptable, and reader plug-ins can be added to older versions just as they sometimes are with older versions of MS Office. In summary, this appears to only be a problem if the software authors decide to make it a major problem.
As for "full fidelity", I think what most customers are looking for isn’t what you’re saying they are. They want full fidelity of appearance and representation. That is, they want fonts, line spacing, page layout, embedded images, lists, tables and such to appear reasonably. Some details can differ (eg. the exact shape of dots in unordered lists, the exact appearance of borders on tables), but it needs to appear "close enough" to a human. I don’t think they want or need full fidelity with the way Word, for example, represents things internally. If I select 10-point Arial Bold for my text and I get 10-point Arial Bold when I look at it, I don’t care that the OpenDocument format loses some details about Windows’ and Word’s exact internal font selection. Similarly, when I’m distributing a document outside my organization I probably don’t want to make assumptions about whether the recipient can display streaming video and I likely won’t care that the format loses some information about things I’m going to avoid. And of course OpenDocument *will* be able to handle embedded multimedia content in the same way it handled embedded images, with at least as much capability as MS Office (modulo codecs and formats that aren’t available on the system being used to read the document, but that’s a problem with the Office formats as well).
I’d also note that OpenDocument was, as has been noted repeatedly, developed in consultation with a wide variety of actual users, including people like Boeing with really complex and picky document requirements. All of them appear satisfied that OpenDocument can represent everything they need (or will be able to as areas of the standard are finalized). I have to ask: what parts of Microsoft Office documents can’t be represented in OpenDocument?
And as Mark indicated earlier, to satisfy Massachusetts MS Office doesn’t need to use OpenDocument as a native format. All it needs to be able to do is save in it and be able to be set to default to saving in it. Office already can save in a large number of older formats that don’t support all the modern features. It seems to me that if it’s so hard to support OpenDocument this way, why does Office support older Office formats, ASCII text, RTF and the like which have the same problems?
Brian: there also seems to be a disconnect on the definition of "open XML format". The "XML format" part seems to be clearly understood. The "open" part, though, seems to be defined by Microsoft as "Publicly described as of the current version.". This is part of "open", but people like Massachusetts are asking for "open" in a more extensive sense:
a) Must be implementable by anyone, on any platform, for any purpose without having to get permission from any entity (beyond the minimal "You can’t call it OpenDocument unless it actually conforms to the OpenDocument spec."). This includes creating documents, not merely reading them.
b) Can’t be controlled by any one entity. No one person or company can change or add to the standard on their own, they have to get support from a wide base including users and competitors first. Equally important, no one person or company can *block* changes and additions to the standard that *do* enjoy a wide base of support.
Massachusetts has pointed out where the Office XML formats fail on both of those points.
Todd Knarr: "As for formula formats, it’s easy and I described how to do it earlier (at least in OpenDocument, which accomodates this)."
I read OpenFormula’s RFC attempt, my estimate is it’s about 3-4 years from getting to alpha quality. I’d expect that most ODF-based speadsheets would adopt OOo/SO format long before this RFC matures.
Todd Knarr: "This causes loss of backwards compatibility (old versions can’t read the formula representation of newer versions, but can still get the numeric form), but this is traditional with every MS Office version upgrade so I don’t see where it can be considered unacceptable"
And where exactly did you pull this load of [three-letter word that Brian doesn’t want in his blog] from? Most version upgrades of Excel maintained both backward AND forward compatibility on formula level. There is simply no other way if you want to keep your customers happy.
Todd Knarr: "As for "full fidelity", I think what most customers are looking for isn’t what you’re saying they are. They want full fidelity of appearance and representation."
Which application, word processor? Perhaps, although I’d rather have my text intact 😉 From your perspective PDF is the best format: even that it does not mandate persisting the actual text, it does maintain the "appearence and representation" of it.
I’d expect most customers would want full fidelity in whatever the major function of particular application is. Who cares about appearence if their models do not travel correctly between OOo and KOffice spreadsheets?
Todd Knarr: "I have to ask: what parts of Microsoft Office documents can’t be represented in OpenDocument?"
What parts of ODF cannot be represented by a bunch of XML and binary files stuffed into ZIP container? Or by a generic blob of binary data in a single .tgz gile? Same answer – none 🙂 Which does not answer or prove anything about relative values of MSO, ODF and TAR+GZIP containers.
Love, SDJ
Two posts on OFD and open standards by former Microsoft employee Stephen Walli:
OO’s Florian Reuter on various topics including ODF versus Office XML. Reuter thinks OO’s X-forms is superior to Microsoft smart forms. He also talks about some of the difficulty in reverse engineering Microsoft formats.
Regarding some of the other comments I see on here that suggest it would be easy for Microsoft to make ODF the default saving format for Office (or Word, at least), I think I can provide some clarification. I don’t work for Microsoft, and never have. I’m a developer of custom productivity applications for businesses. Some have argued that Microsoft should make Office configurable so that it can save files in ODF format by default, as MA specifies in their enterprise standard, but won’t, to protect its position in the marketplace. One suggested the reason this would be easy is that Office already saves in a multitude of other formats.
I think this represents a kind of blind naivete about how most people use office applications, and a strict allegiance to a particular brand of open standards no matter the other consequences. As a developer, I take the user experience seriously. That’s the reason I’ve bothered to follow this story at all.
Microsoft Office serves a very wide market, ranging from power users, to those who are just computer literate enough to turn on their computer, open up an application or two, and do a few simple things with it, but not much else.
If I were in Tim’s shoes, my reticence towards making it possible to make a different format the default saving format would be twofold. One, making a different format the default effectively requires the application to lock the user out of certain features. In this scenario the application has to assume that since a less feature-rich format has been selected, that the application itself must only allow access to the features that the format can handle. Also, certain documentation items in Help, would either need to be made unavailable, or notated with "Only available if native Word format is used". It would make for a terrible user experience if the application went ahead and allowed the user access to all of the features it had, but then when the user hit "Save" (ie. save to the default format), the application would warn, "FYI, you’re going to lose some of your work since the default format doesn’t support some of what you did," or alternatively, if a feature was visible, but when selected, the application said, "The default format doesn’t support this feature."
Second, given that certain features were locked out, it would create a misimpression in some customer’s minds after a while, that Office only supports the limited set of features that their selected default format supports. In other words, if asked, they would say that Office only supports features x, y, and z. They would think that, but only because the default format they selected also only supports those features. They would forget about, or not venture to explore other features that Office had that might help them do something easier. It would reduce Office’s marketability, and it would be something Microsoft would have to "fight against", I would think.
I think the focus of Office, and productivity applications from other vendors, has been to help users get something done. The emphasis is on what the application makes possible, not the file format it’s saving data in. The file format is seen primarily as supporting the features of the application, not the other way around.
The reason Office supports other formats for export is that many customers expressed a need to exchange files with other users who didn’t have Office, or had an older version of it. Sometimes the export formats are limited in capability, so the user is warned that some of their work may be lost in the conversion, but at least they have the opportunity to save the document in Word’s native format as well, to preserve their work.
Conceivably, Office could support ODF as an export/import format, IMO, but I agree that it would work against the marketability of Office in general to make it possible to change the default save format. I think the reason Microsoft has not included ODF yet is they don’t see enough of a market for it to make it worth their while.
Andrew Updegrove’s article (referred to by Eduardo’s 2nd link) is an interesting read. He reveals some facts about MA’s decision I hadn’t heard anywhere else. Everything I had read about it up to this point said "MA chooses ODF". What Updegrove says is that only the Executive Agency (I presume this means the executive branch of government) had made this decision, not the entire state government. But still, tens of thousands of computers are involved.
I listened to the audio of the Sept. 16 meeting of the committee, and I recall one of the comments made by Jonathan Zuck of ACT was that the standards document looked like "a late paper" (ie. one that was hastily written). I kind of get this feeling from reading Updegrove’s article as well, not critiquing his writing, but rather his description of the decision. The enterprise standard clearly states that the Agency must commence migrating their systems to use applications that save to ODF by default, starting in Jan., 2007. Yet, in Updegrove’s article he says the committee’s FAQ on the subject says that users can continue using Microsoft Office after that date, and can even save in native Office format, but only need to convert to ODF when documents need to be archived. He also says that outside parties (contractors, lawfirms, etc.) can continue using whatever file formats they are now, to send documents to the state. There is no requirement that they change to using ODF in order to submit documents. He also says the standard states (it may have been changed to say this) that the Agency was not going to convert existing documents to ODF, but just leave them in their existing format. He says that only new documents, created in Jan., 2007 and after need to be saved in ODF for archiving. This sounds like a more reasonable policy, given their goals, and given the difficulty in migrating technologies. I just wonder why they didn’t say all this in their enterprise standard up front. I think there’s been a lot of confusion around the issue, and perhaps the committee that came up with this standard hasn’t communicated clearly exactly what their intentions are.
Mark: I think you’re missing one point: the customer has *asked* to have the features thus restricted. I think that if, as a business, I make the decision that I don’t want certain features in my documents, I *want* my office applications to tell users they can’t use those features.
Also, regarding the apparent conflict in what formats are allowed, I don’t think it’s that confused. The Executive Agency has decided that all the documents it keeps and makes available have to be in an open format. Individual users can still use native Office formats for working copies, it’s only when the document leaves their computer headed elsewhere that it needs to be converted to a standard format. The same thing for incoming documents, it’s just the document implementation of the Internet rule "Be strict in what you generate and liberal in what yiou accept.".
Hi Todd. I understand what they wanted. I think perhaps what hamstrings Microsoft in this particular situation is that I don’t believe they’ve ever made a custom version of their software for particular clients. I could be wrong about that, but I’ve never heard of them doing it. This is just my image of Office, but I’ve always seen it as a one-size-fits-all application suite. If they implement a feature, they implement it for *everyone* that could potentially buy the product. That’s the POV I was speaking from.
To tell you the truth, MA’s decision reminds me of how government bureaucracy used to be described before President Clinton came to office. One of the initiatives the Clinton Admin. tried to put through, called "Reinventing Government", tried to do away with, as much as possible, custom designed products that were made just for the federal government. I remember Al Gore talked about an example of a floor cleaner that was made to the bureaucrats’ exact specifications. Like everyone’s been saying with this case, this was just the government saying what they wanted. It was up to manufacturers to bid and make it for them, whichever ones wanted to participate.
The thing was they couldn’t buy the floor cleaner from any well-known manufacturer, because none of them wanted to bother with making a custom product for the government. They made more money making a commodity product that was sold to more customers. It was illegal for the government to buy any formula that didn’t fit the specification. So the federal government bought it from either one or a few manufacturers at very high cost, when compared to the retail equivalent. The "Reinventing Government" program tried to change that, and as I heard, partly succeeded, thus lowering the operating cost of government a bit.
I think the Executive Agency is trying to kill two birds with one stone. They want the open archiving format, and they feel they’ll also see a significant savings by not having to pay as much in commercial licensing. The difference here is that a standards committee, OASIS, has come up with the format, so more customers than just the state of MA can potentially use it, maybe creating a greater economy of scale for products that support it.
Ultimately, I wish MA success in whatever they do. I want IT to succeed, no matter how it’s implemented. I know I can’t judge their decision entirely from afar (as I am far away from the situation, literally), but from what I’ve read, I would take issue with this decision of theirs if I was working with them, particularly about the timing. I’d say, spread the word around that this is what you want, get producers interested in the concept, wait for the products that support what you want to come out, let them find a market, let the products mature, and let the market winnow out the weaker players, and then make the choice. What’s the rush?
Mark: I think you’re wrong about the timing. Firstly, MA doesn’t intend to change over tomorrow. As I understand it the transition isn’t going to happen over the course of weeks or months, it’s going to be phased in over the course of a couple of years at least. You have to start at some point or people will just keep putting it off, and I really don’t see where anyone remotely competent will have a problem meeting timeframes of several years to comply. As for waiting for products, why wait when the products already exist and are mature? The OpenDocument standard’s had several years already to be hashed out, with document users constantly using the spec and providing feedback about what in their documents isn’t supported by the spec. Boeing and IBM both have requirements a lot more complex than most users will ever have, and I doubt they’d’ve signed off on something for their own use that they knew didn’t support their existing documents. As for products, there’s at least 3 that either already support OpenDocument or will within the next couple-three months (all of them have been preparing for this support for a long time now and have had it working in CVS releases to make sure it gets tested). Saying to wait for products to come out with support now is like saying to wait for the train to arrive when the train’s not just sitting at the platform but blowing it’s whistle and getting ready to pull out.
I think you’re right, though, about the commodity nature MA’s looking for. They explicitly said it, in fact: they’re looking for a format that can be implemented by any number of vendors so both they and anybody who has to deal with them can have a variety of choices *and* can interoperate without having to all make the same choice.
As for the expensive government purchases, I agree that some of them are silly. On the other hand, I recall a comment by an Air Force maintenance officer: "Yeah, 5 grand for a coffee-maker’s a lot more than you’ll pay for one from WalMart. But the coffee-maker in your kitchen doesn’t have to make good coffee when the boiling point of water’s 20 degrees lower because of lower cabin pressure, and it doesn’t have to keep scalding-hot water from flying around the cabin when it’s inverted and there’s 5 g’s trying to pull the pot off of the warming plate.". Or contrast document readability concerns, where Microsoft can’t even read their own formats from 15 years ago (Word95, Word 6) correctly, while governments have survey and land-title deed documents from the 1700s that’re actively used by surveyors today. We won’t even get into NASA losing data that isn’t even as old as I am because the formats aren’t known and the hardware to read the media isn’t made anymore. Silly requirements are just that, silly, but government sometimes does really have requirements that’re just that different.
As we move forward with the standardization of the Office Open XML formats, it’s interesting to look…
OK, forgive the random Sneaker Pimps reference and I promise we will move off this topic of ODF politics…
Andrew Sayers had a great suggestion that I should have a page set up that gives an overview of the blog
PingBack from
PingBack from
PingBack from
PingBack from
PingBack from | https://blogs.msdn.microsoft.com/brian_jones/2005/10/04/comments-from-tim-bray-on-opendocument/ | CC-MAIN-2016-44 | refinedweb | 8,728 | 59.13 |
Mars Exploration Hackerrank
Suppose there is a spaceship in the space which is crashed on Mars.Let’s say it was of Saifi’s spaceship. He was trying to send sequential messages to Earth for help which are of n Sequential SOS messages.But unfortunately, the message string is hindered by cosmic rays(radiation) during transmission to Earth.
Let’s say the Message in the string form is ‘S’.Now we have to find how many Saifi’s message letter get hindered by cosmic radiation while reaching to the earth.…problem-solution/
This Hackerrank question is through:
Input Format
There is one line of input: a single string, S.
Note: As the original message is just SOS repeated n times, S’s length will be a multiple of 3.
Constraints
1<=|S|<=99
S will contain only upper case English letters.
Output Format
Print the number of letters in Sami’s message that were altered by cosmic radiation.
Sample Input 0
SOSSPSSQSSOR
Sample Output 0
3
Sample Input 1
SOSSOT
Sample Output 1
1
Explanation
Sample 0
S = SOSSPSSQSSOR, and signal length |S|=12. Sami sent 4 SOS messages (i.e.: 12/3=4).
Expected signal:
SOSSOSSOSSOS
Recieved signal:
SOSSPSSQSSOR
We print the number of changed letters, which is 3.
Sample 1
S = SOSSOT, and signal length |S|=6. Sami sent SOS messages (i.e.: 6/3=2).
Expected Signal: SOSSOS
Received Signal: SOSSOT
We print the number of changed letters, which is 1.
Solution
This is an easy string problem. Construct the expected string first. It can be done by concatenating “SOS” n times where n=length(S)/3. Now use a simple loop to count how many characters mismatch. Check the problem-setters code for this approach.
#include <iostream> #include <algorithm> using namespace std; int main(){ int res = 0;//Counter variable string S, m = "SOS";//Input String cin >> S;//Custom Input according to test case for(int i=0; i<S.size(); i=i+3){ string s= S.substr(i,3); cout<<s<<endl; if(s!=m) res+=1; } cout<<res; return 0; }
import java.io.*; import java.util.*; import java.text.*; import java.math.*; import java.util.regex.*; public class Solution { public static void main(String[] args) { Scanner in = new Scanner(System.in); String S = in.next(); String sos = "SOS"; int count = 0; for (int i = 0; i < S.length(); i++) { if (S.charAt(i) != sos.charAt(i % 3)) count++; } System.out.println(count); } }
#include <cstring> #include <cstdlib> #include <fstream> #include <numeric> #include <sstream> #include <iostream> #include <algorithm> #include <unordered_map> using namespace std; int main(){ int res = 0;//Counter variable string S, m = "SOS";//Input String cin >> S;//Custom Input according to test case for(int i = 0;i < int(S.size());i++) res += (S[i] != m[i%3]); printf("%d\n", res); return 0; }
S=raw_input() assert len(S)%3==0 and len(S)<=99 n=len(S)/3 exp="SOS"*n #Expected string ans=0 for i in range(len(S)): if exp[i]!=S[i]: ans=ans+1 print ans | https://coderinme.com/mars-exploration-hackerrank-problem-solution/ | CC-MAIN-2020-45 | refinedweb | 506 | 67.65 |
. You can also write your own custom backend, see Custom template backend.
About this section
This is an overview of the Django template language’s syntax. For details see the language syntax reference.
A Django template is, and you can implement your own additional context processors, too. should look for template source files, in search order.
APP_DIRS tells() is just like
get_template(), except it takes a
list of template names. It tries each name in order and returns the first
template that exists.
If loading a template fails, the following two exceptions, defined in
django.template, may be raised: is an origin-like object and
status is a string with the reason the template wasn’t found.
chain
A list of intermediate
TemplateDoesNotExist
exceptions raised when trying to load a template. This is used by
functions, such as
get_template(), that
try to load a given template from multiple engines.
This exception is raised when a template was found but contains errors.
Template objects returned by
get_template() and
select_template()
must provide a
render() method with the following signature:() to be used as the template’s context for rendering.
request
An optional
HttpRequest that will be available
during the template’s rendering process.
using
An optional template engine
NAME. The:
Template engines are available in
django.template.engines:
from django.template import engines django_engine = engines['django'] template = django_engine.from_string("Hello {{ name }}!")
The lookup key —
'django' in this example — is the engine’s
NAME.
'utf-8'.
.
Requires Jinja2 to be installed:
$ python -m:
Making an expensive computation that depends on the request.
Needing the result in every template.
Using the result multiple times in each template.
Unless all of these conditions are met, passing a function to the template by calling a function in Jinja2 templates, as shown in the example above. Jinja2’s global namespace removes the need for template context processors. The Django template language doesn’t have an equivalent of Jinja2 tests.
A
{% comment %}tag provides multi-line comments. | https://django.readthedocs.io/en/3.2.x/topics/templates.html | CC-MAIN-2022-40 | refinedweb | 329 | 59.3 |
Introduction: Light Reactive Curtain
For the last project of the semester in my Craft and Computing class, we had to make a family of items that fulfilled some need that people have. My team partner and I are all about self expression and so we decided we wanted to make something artistic to help people express themselves in some way. Since we live in dorms, we are not allowed to do very many things to our rooms as far as decorating and painting and things, so we decided to make some cool things people could use in their dorms.
One of those things was a light reactive curtain for a window. When the curtain senses that there is light outside, the servo pulls the curtain up to let more light into the room and it closes when it is dark outside.
Materials:
-Fabric
-Arduino Uno
-Curtatin rod
-Wire (and spool)
-Foam core
-Zipties
-Hot glue
Step 1: Sew the Curtain
First, we sewed the curtain. You can really make your curtain any kind you want. We found some pretty, sheer, sparkly, green fabric, which was awesome, but we also wanted the curtain to not be see through so we added a layer of black fabric to the back.
I sewed the short edges of both fabrics together and hemmed the other sides so there would be no loose threads. I then sewed a channel at the top for a curtain rod to go through. Finally, I sewed two seams down the center of the curtain about half an inch apart for a cord to go through and pull the curtain open.
Step 2: Mechanism
To open and close the curtain, we ran a wire through the channel in the center of the curtain and attached a Popsicle stick to the bottom so that the wire wouldn't be pulled out. We opted for a a wire instead of a string or cord because the wire is smooth and therefore able to gather the curtain up with minimal friction.
We hacked a servo so that it was able to rotate completely, made a box out of foam core to house our electronics, and made a hole in one side so that most of the servo was inside the box with just the part that rotates sticking out. We attached a spool to wind the wire onto the servo, then attached the whole box to the hanger that we used to demonstrate our curtain.
Step 3: Circuit
We used an Arduino Uno to control our sensor and servo. The circuit and circuit are shown below. You will have to adjust the delay in the code based on your servo and the length of your curtain, and the light threshold based on your location.
#include <Servo.h>
Servo myservo; // create servo object to control a servo
int lightPin = 0; // analog pin used to connect the photoresistor
int ledPin = 11; //analog pin to connect to LED
void setup()
{
myservo.attach(9); // attaches the servo on pin 9 to the servo object
pinMode(ledPin, OUTPUT); //sets the led pin to output
Serial.begin(9600);
}
void loop()
{
int threshold = 400; //400 for classroom, 100 for bedroom/dorm
int lightLevel = analogRead(lightPin);
Serial.println(lightLevel);
if (lightLevel>threshold){ //if it sees light (light=high resistance, dark = low resistance)
myservo.write(180);//forward
//digitalWrite(ledPin, HIGH);
delay (5000); //spin servo for 5 sec
while (analogRead(lightPin)>threshold){ //while light is still above threshold
// digitalWrite(ledPin, LOW);
myservo.write(87); //do nothing (no movement)
delay(10);
}
}else{ //if it sees no light
myservo.write(0); //reverse
// digitalWrite(ledPin, HIGH);
delay (5000);//spin servo for 5 sec
while (analogRead(lightPin)<threshold){ //while light is still below threshold
//digitalWrite(ledPin, LOW);
myservo.write(87); //do nothing (no movement)
delay(10);
}
}
}
Step 4: Awesome Curtain
Our curtain ended up working remarkably well! One problem is that the code has to be re calibrated if you move the curtain into different lighting conditions, but if this were to just be hanging in a window as an actual curtain, that would not be a problem.
Video coming soon!
20 Discussions
cool idea. thx for sharing
Danger is your middle name? Your making curtains, dude. I love the instructable though, very intuitive.
i think this might be a girl =D
My sincerest apologies my dear Madam. I do believe I was confused earlier but now believe to be in proper state. A good day to you as well as your colleagues, I do wish you the brightest (and according to the curtain, dimmest) of days.
Heheh, "dear Madam". I think that's the most formal Ms Danger's ever been addressed!
I have been called Madam before, actually, and by strangers (!). But that's another story...
I would love to hear it if you so please.
No chance of that on this website :P
Danger, as admin, don't make me have to flag you :)
Like I said, not saying anything here <.< >.>
Well, thanks?! But men can make curtains too, ya know! Feminism and all that stuff!
I noticed you where a girl not because you where making curtains but because of your beautiful feminine hands in some of the pictures
Yes, I am a lady, haha. If it were a man making curtains that would be awesome, too. Guys who have crafting skills are hot! haha :)
wow, um i know nothing about what you just said :S what kind of classes would i need to take to understand if not make this?
will simple electronics work?
and what was the cost of the equipment?
ps.. this is an awsome!!!!!!!!!! idea.. i would like to use it to keep a ceiling window closed during day and open at night.
can same principal be applyed accordingly?
I'm an engineering student, which probably helps, but I know of plenty of non-engineering students who have figured out basic circuitry and stuff. There are some instructables about it!
This basic principle could definitely be applied to a ceiling window, although your rig might be a bit more complicated. Let us know how it goes!
Probably the most expensive thing would be the arduino, and you can find most of the information about using that and the circuits online.
This is awesome! I'm definitely going to implement a version of this to keep those pesky floodlights from the apartment complex next door from keeping me awake. Thanks for the idea!
Awesome as always! Arduino is always really fun.
Cool! | http://www.instructables.com/id/Light-Reactive-Curtain/ | CC-MAIN-2018-30 | refinedweb | 1,082 | 71.34 |
AOP – Encrypting with AspectJ
Lets say you want to encrypt a field of a class. You might think that this is not a crosscutting concern, but it is. What if throughout and entire solution you need to encrypt random fields in many of your classes. Adding encryption to each of the classes can be a significant burden and breaks the “single responsibility principle” by having many classes implementing encryption. Of course, a static method or a single might be used to help, but even with that, code is must be added to each class. With Aspect Oriented Programming, this encryption could happen in one Aspect file, and be nice and modular.
Prereqs
This example assumes you have a development environment installed with at least the following:
- JDK
- AspectJ
- Eclipse (Netbeans would work too)
Step 1 – Create an AspectJ project
- In Eclipse, choose File | New | Project.
- Select AspectJ | AspectJ Project.
- Click Next.
- Name your project.
Note: I named my project AOPEncryptionExample
- Click Finish.
Step 2 – Create a class containing main()
- Right-click on the project in Package Explorer and choose New | Class.
- Provide a package name.
Note: I named my package the same as the project name.
- Give the class a name.
Note: I often name my class Main.
- Check the box to include a public static void main(String[] args) method.
- Click Finish.
package AOPEncryptionExample; public class Main { public static void main(String[] args) { // TODO Auto-generated method stub } }
Step 3 – Create an object with an encrypted value
For this example, I am going to use a Person object, and we are going to encrypt the SSN on that object.
- Right-click on the package in Package Explorer and choose New | Class.
Note: The package should already be filled out for you.
- Give the class a name.
Note: I named mine Person.
- Click Finish.
- Add String fields for FirstName, LastName, and SSN.
- Add getters and setters for each.
package AOPEncryptionExample; public class Person { // First Name private String FirstName = ""; public String getFirstName() { return FirstName; } public void setFirstName(String inFirstName) { FirstName = inFirstName; } // Last Name private String LastName = ""; public String getLastName() { return LastName; } public void setLastName(String inLastName) { LastName = inLastName; } // Social Security Number private String SSN = ""; public String getSSN() { return SSN; } public void setSSN(String inSSN) { SSN = inSSN; } }
Right now, SSN has no encryption. We don’t want to clutter our Person class with encryption code. So we are going to put that in an aspect.
Step 4 – Add sample code to main()
- Create in instance of Person.
- Set a FirstName, LastName, and SSN.
- Ouput each value.
public static void main(String[] args) { Person p = new Person(); p.setFirstName("Billy"); p.setLastName("Bob"); p.setSSN("123456789"); System.out.println("FirstName: " + p.getFirstName()); System.out.println(" LastName: " + p.getLastName()); System.out.println(" SSN: " + p.getSSN()); }
If you run your project, you will now have the following output.
FirstName: Billy LastName: Bob SSN: 123456789
Step 5 – Create and object to Simulate Encryption
You don’t have to do full encryption, or any encryption at all for that matter, to test this. The important thing to realize is that you can configure how the value is stored in an object without cluttering the object with the encryption code.
I created a FakeEncrypt static object and will use this object as an example.
package AOPEncryptionExample; public class FakeEncrypt { public static String Encrypt(String inString) { return "#encrypted#" + inString + "#encrypted#"; } }
The goal is to passing in an SSN, 123-456-789, and have it return an encrypted value (or in this case a fake encrypted value), #encrypted#123-456-789#encrypted#.
Step 6 – Create an Aspect object
- Right-click on the package in Package Explorer and choose New | Other.
- Choose AspectJ | Aspect.
- Click Next.
Note: The package should already be filled out for you.
- Give the Aspect a name.
Note: I named mine EncryptFieldAspect.
- Click Finish.
package AOPEncryptionExample; public aspect EncryptFieldAspect { }
Step 7 – Add the pointcut
- Add a pointcut called SetSSN.
- Include two parameters, the Person object and the SSN string.
- Implement it with a call to void Person.setSSN(String).
- Add a target for the Person p.
- Add an args for the SSN string.
- Add a !within this class (to prevent an infinite loop).
package AOPEncryptionExample; public aspect EncryptFieldAspect { pointcut setSSN(Person p, String inSSN): call(void Person.set*(String)) && target(p) && args(inSSN) && !within(EncryptFieldAspect); }
You now have your pointcut.
Step 8 – Implement around advice to replace the setter
- Add void around advice that takes a Person and a String as arguments.
- Implement it to be for the setSSN pointcut.
- Add code to encrypt the SSN.
- Add a return statement.
package AOPEncryptionExample; public aspect EncryptFieldAspect { pointcut setSSN(Person p, String inSSN): call(void Person.set*(String)) && target(p) && args(inSSN) && !within(EncryptFieldAspect); void around(Person p, String inSSN) : setSSN(p, inSSN) { p.setSSN(FakeEncrypt.Encrypt(inSSN)); return; }
You are done with this one method. Here is the output of running this program.
FirstName: Billy LastName: Bob SSN: #encrypted#123456789#encrypted#
So we aren’t exactly done because we have two issues that would be nice to resolve. First, the Aspect is not reusable and second, their is no way for a developer to know by looking at the Person object that the SSN should be encrypted. Both of these issue are resolved by using annotations and will be explained in the next article.
Continue reading at AOP – Encrypting with AspectJ using an Annotation
Return to Aspected Oriented Programming – Examples | https://www.rhyous.com/2012/05/26/aop-encrypting-with-aspectj/ | CC-MAIN-2021-43 | refinedweb | 902 | 58.08 |
Know what changes are in store for PHP V6 and how your scripts will change
Document options requiring JavaScript are not displayed
Help us improve this content
Level: Intermediate
Nathan A. Good (mail@nathanagood.com), Senior Information Engineer, Consultant
06 May 2008.
New PHP V6 features
PHP V6 is currently available as a developer snapshot, so you can download and try out
many of the features and changes listed in this article. For features that
have been implemented in the current snapshot, see Resources.
Improved Unicode support
Much improved for PHP V6 is support for Unicode strings in many of the core functions.
This new feature has a big impact because it will allow PHP to support a broader set of
characters for international support. So, if you're a developer or architect using a
different language, such as the Java™ programming language, because it has
better internationalization (i18n) support than PHP, it'll be time to take another look at PHP when the support improves.
Because you can download and use a developer's version of PHP V6 today, you will see
some functions already supporting Unicode strings. For a list of functions that have
been tested and verified to handle Unicode, see Resources.
Namespaces
Namespaces are a way of avoiding name collisions between functions and classes
without using prefixes in naming conventions that make the names of your methods and
classes unreadable. So by using namespaces, you can have class names that someone else
might use, but now you don't have to worry about running into any problems. Listing 1
provides an example of a namespace in PHP.
You won't have to update or change anything in your code because any PHP code you write
that doesn't include namespaces will run just fine. Because the namespaces feature
appears to be back-ported to V5.3 of PHP, when it becomes available, you can start to
introduce namespaces into your own PHP applications.
<
Depending on how you use PHP and what your scripts look like now, the language and
syntax differences in PHP V6 may or may not affect you as much as the next features,
which are those that directly allow you to introduce Web 2.0 features into your PHP application.
SOAP
SOAP is one of the protocols that Web services "speak" and is supported in quite a few
other languages, such as the Java programming language and Microsoft® .NET. Although there
are other ways to consume and expose Web services, such as Representational State
Transfer (REST), SOAP remains a common way of allowing different platforms to have
interoperability. In addition to SOAP modules in the PHP Extension and Application
Repository (PEAR) library, a SOAP extension to PHP was introduced in V5. This extension
wasn't enabled by default, so you have to enable the extension or hope your ISP did. In
addition, PEAR packages are available that allow you to build SOAP clients and servers, such as the SOAP package.
Unless you change the default, the SOAP extension will be enabled for you in V6. These
extensions provide an easy way to implement SOAP clients and SOAP servers, allowing you
to build PHP applications that consume and provide Web services.
If SOAP extensions are on by default, that means you won't have to configure them in
PHP. If you develop PHP applications and publish them to an ISP, you may need to check
with your ISP to verify that SOAP extensions will be enabled for you when they upgrade.
XML
As of PHP V5.1, XMLReader and XMLWriter have been part of the core of PHP, which makes
it easier for you to work with XML in your PHP applications. Like the SOAP extensions,
this can be good news if you use SOAP or XML because PHP V6 will be a better fit for
you than V4 out of the box.
The XMLWriter and XMLReader are stream-based object-oriented classes that allow you to
read and write XML without having to worry about the XML details.
Things removed
In addition to having new features, PHP V6 will not have some other functions and
features that have been in previous versions. Most of these things, such as register_globals and safe_mode, are
widely considered "broken" in current PHP, as they may expose security risks. In an
effort to clean up PHP, the functions and features listed in the next section will be
removed, or deprecated, from PHP. Opponents of this removal will most likely cite
issues with existing scripts breaking after ISPs or enterprises upgrade to PHP V6, but
proponents of this cleanup effort will be happy that the PHP team is sewing up some
holes and providing a cleaner, safer implementation.
register_globals
safe_mode
Features that will be removed from the PHP version include:
magic_quotes
register_long_arrays
magic_quotes
Citing portability, performance, and inconvenience, the PHP documentation discourages
the use of magic_quotes. It's so discouraged that it's being
removed from PHP V6 altogether, so before upgrading to PHP V6, make sure that all your
code avoids using magic_quotes. If you're using
magic_quotes to escape strings for database calls, use your
database implementation's parameterized queries, if they're supported. If not, use your
database implementation's escape function, such as mysql_escape_string for MySQL or pg_escape_string for PostgreSQL. Listing 2 shows an example of magic_quotes use.
The register_globals configuration key was already defaulted
to off in PHP V4.2, which was controversial at the time. When register_globals is turned on, it was easy to use variables that
could be injected with values from HTML forms. These variables don't really require
initialization in your scripts, so it's easy to write scripts with gaping security
holes. The register_globals documentation (see Resources) provides much more information about register_globals. See Listing 4 for an example of using();
?>
The register_long_arrays setting, when turned on, registers
the $HTTP_*_VARS predefined variables. If you're using the
longer variables, update now to use the shorter variables. This setting was introduced
in PHP V5 — presumably for backward-compatibility — and the PHP folks
recommend turning it off for performance reasons. Listing 6 shows an example of register_long-arrays use.
The safe_mode configuration key, when turned on, ensures
that the owner of a file being operated on matches the owner of the script that is
executing. It was originally a way to attempt to handle security when operating in a
shared server environment, like many ISPs would have. (For a link to a list of the
functions affected by this safe_mode change, see Resources.) Your PHP code will be unaffected by this change, but
it's good to be aware of it in case you're setting up PHP in the future or counting on
safe_mode in your scripts. 1
The PHP team is removing support for both FreeType 1 and GD 1, citing the age and lack
of ongoing developments of both libraries as the reason. Newer versions of both of
these libraries are available that provide better functionality. For more information
about FreeType and GD, see Resources.
ereg
ereg
The ereg extension, which supports Portable Operating System
Interface (POSIX) regular expressions, is being removed from core PHP support. If you
are using any of the POSIX regex functions, this change will affect you unless you
include the ereg functionality. If you're using POSIX regex
today, consider taking the time to update your regex functions to use the
Perl-Compatible Regular Expression (PCRE) functions because they give you more features
and perform better. Table 1 provides a list of the POSIX regex functions that will not be available after
ereg is removed. Their PCRE replacements are also shown.
ereg()
eregi()
preg_match()
ereg_replace()
ereg_replacei()
preg_replace()
PHP V5.3
Some of the features mentioned here. The following list of features have been
back-ported to? | http://www.ibm.com/developerworks/opensource/library/os-php-future/ | crawl-001 | refinedweb | 1,304 | 59.84 |
ONTAP Discussions
I'd want to know , how to work load balancing multipul storage with Kubernetes
I have 2 FAS8200 Storage without cluster, and 1 FAS8300 Storage
1 kubernetes master node and 100~ worker nodes
We are going to build a service using a total of 3 storage units.
I am planning to use iscsi, and I am curious how loadbalancing is performed when generating pv in k8s at this time.
I want to use the capacity of the three storage units as evenly as possible.
Your best bet is to cluster all of your nodes so you have one big namespace for all of your loads. Then, use Trident and perhaps rebalance the loads as they develop by moving the volumes between aggregates. Loads will probably vary too much to be able to guess at where they should be placed at creation time. Moving the volumes used by Trident is mostly unproblematic as Trident only communicates with the SVM using volumes (and qtrees with the correct backend driver), so it doesn't matter which aggregate they are. | https://community.netapp.com/t5/ONTAP-Discussions/K8S-Multi-storage-works-load-balancing/m-p/170111/highlight/true | CC-MAIN-2022-27 | refinedweb | 178 | 54.46 |
Import.
Before I dive into describing the import statements, let me make the distinction between an import and an include. An import statement brings in other namespaces. An include statement brings other declarations into the current namespace.
Let's look at a basic XSD import, such as the one highlighted in red in Listing 1. All that this statement does is import a namespace from one schema to another. The schema, which defines the namespace of
urn:listing2, is importing
the schema of urn:listing3. That's it. No file is being imported. Both schemas are in this same file in Listing 1.
Listing 1. Address book WSDL using two namespaces
Hopefully, it's clear from the example in Listing 1 that the primary purpose of an import is to import a namespace. A more common use of the XSD import statement is to import a namespace which appears in another file. You might be gathering the namespace information from the file, but don't forget that it's the namespace that you're importing, not the file (don't confuse an import statement with an include statement).
When you're importing a namespace from a file, you will see a
schemaLocation attribute on the XSD import statement, but it is an optional attribute. As you can see in Listing 1,
schemaLocation is not necessary because the namespace of the import statement is at the same location (in the same file) as the import statement itself. In fact, even if you had provided a file location (as Listing 2 does), an XML parser is free to ignore the location if it wishes. The
schemaLocation attribute is merely a hint. If the parser already knows about the schema types in that namespace, or has some other means of finding them, it does not have to go to the location you gave it. This behavior should be another hint to you that the primary purpose of the XSD import statement is to import the namespace, not tell you where you can find the declarations in that namespace. Of course, most of the time you will be importing namespaces that the XML parser knows nothing about, so the
schemaLocation attribute becomes necessary, and it's easy to forget that it's only a hint.
Now, take a look at the import statements I highlighted in blue in Listing 1. Since I use the XSD namespace, I should really import it. But this is a very common namespace. Virtually every XML parser inherently knows about it. Most parsers are rather forgiving about including the import statement for it. In fact, many tools even forgive you if you neglect to include the red import statement -- the imported namespace is in the same file, after all -- but you should really make a habit of importing all namespaces that you use. You never know when you, or someone who uses your WSDL file, might use a stricter tool.
Be very sure that the namespace you use in the import statement is the same as the
targetNamespace of the schema you are importing. In the example in Listing 1, it's fairly obvious that you have to do this. But if you move the
urn:listing3 schema into a file called listing3.xml, and import that file (as Listing 2 does), then it might not be so obvious. In fact, it might look like you can change the namespace of the schema in the file by using a different namespace attribute on the import statement than in the targetNamespace. This is a mistake. You cannot change namespaces. The namespace attribute of the import statement must match the targetNamespace of the schema.
Listings 2 and 3 are derived from Listing 1. Listing 2 is Listing 1 with the Phone schema removed to a different file -- the file in Listing 3. The import statement in Listing 2 now includes the
schemaLocation attribute (highlighted in blue). This is the recommended way to import schema from a file.
Listing 2. Address Book WSDL importing XSD file for Phone schema
Listing 3. XSD file for Phone schema
Take a look at Listings 4 and 5. They are essentially the same as Listings 2 and 3. Listing 4 imports Listing 5 as Listing 2 imports Listing 3. But this time, I used a WSDL import rather than an XSD import. The differences between Listing 2 and Listing 4 are highlighted in blue in Listing 4. Likewise, the differences between Listing 3 and Listing 5 are highlighted in blue in Listing 5.
Listing 4. Address Book WSDL importing WSDL file for Phone schema
Listing 5. WSDL file for Phone schema
Is this a good thing to do? If you run your favorite WSDL-to-Java tool on listing4.wsdl, you should get an error. In Listing 4, I've highlighted two references to the
Phone type, one in green and one in red. The green reference is in a WSDL message statement. This statement finds
Phone because it is a WSDL statement, and the WSDL file imports
Phone via a WSDL import statement. The red reference is in the schema. This reference does not find
Phone because it wasn't imported via an XSD import. You cannot step outside of a schema to find other schemas. You must import schemas from inside schemas.
If the
Address type did not have a phone element and, therefore, did not reference the
urn:listing5 namespace, then this pair, Listings 4 and 5, would be legal. However, it is not a good practice to import schema information with a WSDL import. Listings 2 and 3 are preferred over Listings 4 and 5. Use XSD import to import schema. Use WSDL import to import WSDL.
For an example of proper WSDL imports, you'll notice that Listing 4 doesn't have a binding nor a service statement. Presumably some other file, which contains a binding and a service, will import listing4.wsdl via a WSDL import statement.
A couple of last comments about WSDL imports. Like an XSD import, the
namespace attribute of the WSDL import must be the same as the targetNamespace of the imported WSDL. The
location attribute of the WSDL import, like the
schemaLocation attribute of the XSD import, is just a hint. However, unlike the
schemaLocation of the XSD import, the
location attribute of the WSDL import is required to be present. (This is not clear in the WSDL 1.1 specification, but the Basic Profile on the WS-I Web site clarifies this. (See Resources.)
In short, what this tip is trying to say is:
- It is a good practice to use XSD imports to import schema, and to use WSDL imports to import WSDL.
- It is a good practice to import all of the namespaces that you use.
- An attribute value of the import namespace must match the imported targetNamespace value.
- The primary purpose of an import statement is to import namespaces. The
schemaLocationand
locationattributes, though sometimes necessary, are really only hints.
- Read the Web Services Description Language (WSDL) 1.1, the specification of WSDL.
- Read the XML Schema Primer.
- Browse the Web Services Interoperability (WS-I) organization's web pages.
- Get the IBM® WebSphere® Application Server Technology for Developers, Version 6.0, an early release of the next WebSphere Application Server.
- Find additional SOA and Web services technology resources on the developerWorks SOA and Web services technology zone.
- Find a number of Web services programming tips from developerWorks.
- Browse for books on these and other technical topics.
- Interested in test driving IBM products without the typical high-cost entry point or short-term evaluation license? The developerWorks Subscription provides a low-cost, 12-month, single-user license for WebSphere, DB2®, Lotus®, Rational®, and Tivoli® products -- including the Eclipse-based WebSphere Studio IDE -- to develop, test, evaluate, and demonstrate your applications.
Russell Butek is an IBM Web services consultant. He has been. Contact Russell at butek@us.ibm.com. | http://www.ibm.com/developerworks/xml/library/ws-tip-imports.html | crawl-002 | refinedweb | 1,325 | 65.12 |
> From: Byron DeLaBarre [mailto:byron@...]
> Subject: [PyMOL] color association with state?
> Do any pymolers out there know how to associate the color of=20
> a single object
> with its state?
Sorry, this can't be done with the current versions -- colors are either =
atomic or whole-object properties (with a couple of minor exceptions). =
The only way around this right now is to distribute the states you want =
to show over a set of objects with different colors:
isomesh m1,map1,1.0,state=3D1
isomesh m2,map2,1.0,state=3D2
isomesh m3,map3,1.0,state=3D3
color red,m1
color blue,m2
color green,m3
> I have a multi-state map that I want to color as it moves through the
> different states in a movie. I want the colors to be associated with
> specific states. I only know how to color the entire=20
> collection of states a
> single color. (something like: color =3D red, object)
> Alternatively, how could I associate a number of text objects=20
> (you can do
> those in pymol, right?) with individual states within the=20
> collection of
> states.
Text objects are brand new, and can only be built right now using =
compiled graphics objects (CGOs).
CGOs are always associated with specific states, so adding a label which =
changes during the course of a movie would be straightforward, except =
that text objects are completely undocumented. Here is a start:
# REQUIRES PyMOL 0.80
# save as cgo_3Dtext01.py
from pymol import cmd
from pymol.cgo import *
from pymol.vfont import plain
cgo =3D []
axes =3D [[2.0,0.0,0.0],[0.0,2.0,0.0],[0.0,0.0,2.0]]
pos =3D [0.0,0.0,0.0]
wire_text(cgo,plain,pos,'Hello World',axes)
pos =3D [0.0,-3.0,0.0]
cyl_text(cgo,plain,pos,'Hello Universe',0.10,axes=3Daxes)
cmd.set("cgo_line_radius",0.03)
cmd.load_cgo(cgo,'txt')
cmd.zoom("all",2.0)
- Warren
mailto:warren@...
Warren L. DeLano, Ph.D.
Do any pymolers out there know how to associate the color of a single object
with its state?
I have a multi-state map that I want to color as it moves through the
different states in a movie. I want the colors to be associated with
specific states. I only know how to color the entire collection of states a
single color. (something like: color = red, object)
Alternatively, how could I associate a number of text objects (you can do
those in pymol, right?) with individual states within the collection of
states.
Thanks -
Byron
Byron DeLaBarre, Ph. D.
P250 MSLS Building
Stanford University
(650)736-1714 | https://sourceforge.net/p/pymol/mailman/pymol-users/?viewmonth=200204&viewday=15 | CC-MAIN-2018-17 | refinedweb | 442 | 59.8 |
Hi there,
as a powershell newby i'm facing following challenge:
I want to list ALL the mails in a mailbox(Inbox,Sent,Deleted,Outbox,Personal Folders,........)
Instead of accessing the different folders (which i got working via mapi namespace,folders,items),
i created a search folder "All Documents" without criteria and want to scan this new search folder only.
But as i understand search folders are not part of MAPI and i can't find a way to access my new search folder.
Any tipps to access search folders in powershell or on accessing all mails from all folders ?
Regards,
Gaston
I'm using Windows 10 Enterprise and PowerShell v5.1
2 Replies
Hi Gaston,
A little confused, what is it that you are trying to achieve? As far as I am aware what you are trying isn't possible as the Search folder isn't a real folder, see MS' definition:
'A. '
The only thing that I can suggest is to use the advanced searching tools in Outlook to narrow down your search.
Thanks
Osman
Hello Osman,
thanks for your reply.
I know that search folder are just views.
My goal is to get a list of ALL emails of a mailbox, with the smallest possible effort.
In fact i need to compare all mails (sender,date,subject, NOT the body content) between two mailboxes and
report missing mails on either side.
That's why i want to do that in a powershell script.
Regards,
Gaston | https://community.spiceworks.com/topic/2113276-scanning-outlook-search-folders | CC-MAIN-2019-04 | refinedweb | 248 | 70.33 |
Project MySQL service
SourceForge.net provides MySQL database services on a opt-in basis.
These database services may be used for a variety of things, including:
- Data storage for dynamic project websites.
- Data storage for demos of the project's software residing in project web space.
- In support of project software testing and development needs.
- Data storage for applications deployed by the project to Project web.
We encourage developers new to MySQL to familiarize themselves with the MySQL manual. Since the database servers are shared among many projects, appropriate application performance tuning should be performed by the project to avoid impacting other projects.
Projects developing applications on MySQL are additionally encouraged to check out the book, "High Performance MySQL".
Features
- Service is based on MySQL 5.0.x on the x86_64 architecture and supports standard features, with the following caveats:
- We discourage use of pconnect due to the way we distribute load among our server pool. Please use standard connects.
- We discourage use of INSERT DELAYED due server load risks.
- Query runtime is capped at 120 seconds. Queries that exceed the cap will be killed.
- Project databases are accessible from the project web servers.
- Project databases are accessible from the interactive shell servers. The command-line MySQL client is installed on the shell servers.
- A centralized install of phpMyAdmin is provided to ease database management.
- Direct access is provided over the Internet, enabled on a time-limited basis using a self-service interface.
- Three database users are provided for each database, one for each access level: admin, read/write, and read-only.
- Projects may create multiple databases (under the namespace provided to the project) using their admin database account.
Access
phpMyAdmin is provided as an easy-to-use web-based interface to your MySQL database.
Project MySQL databases may be accessed from Project web, from the Shell service or over the Internet using the following details:
MySQL host
MySQL service is split to database servers based on the first letter of the project's UNIX name. This will be denoted as LETTER in the following documentation.
The hostname for our MySQL server is mysql-LETTER.sourceforge.net
For example, if the project's UNIX name is "leaf", the LETTER value for this project would be "l". The MySQL database server for the leaf project is mysql-l.sourceforge.net
Database naming
To ensure database namespace is unique for each project, databases created by a project all use a project-specific prefix. This prefix uses a combination of the LETTER and the group ID for the project, in the form {LETTER}{GROUP ID}_* Multiple databases may be created by a project.
Continuing our example: Since the "leaf" project's group ID is 13751, their database names would be prefixed by: l13751_ The leaf project can create multiple databases as needed, such as l13751_cmsdata and l13751_apptest.
The admin user is used to create new databases for your project.
Authentication
Each project is provided three database users, each with a specific level of permissions.
Continuing our example, the "leaf" project's three users are: l13751ro, l13751rw, and l13751admin.
Passwords are set individually for these accounts from the project database administration page. Before an account can be used, an initial password must be set by the project administrator.
Management
FIXME.
Backups
SourceForge.net performs routine backups for all of our servers and will restore from these backups in the event of catastrophic server failure. We encourage projects to make their own backups of their MySQL data as that data restore can be performed by the project in the event of accidental data destruction by a member of the project team or exploit of their database via project web.
Backups may be performed using phpMyAdmin or using mysqldump as follows:
mysqldump --host=mysql-{LETTER}.sourceforge.net \ --user={LETTER}{GROUP ID}admin -p --opt \ {LETTER}{GROUP ID}_{DATABASENAME} | gzip --fast > dumpfile.mysql.gz
Getting Help
- Support is provided for MySQL databases housed at SourceForge.net.
- Request an enhancement | http://sourceforge.net/apps/trac/sourceforge/wiki/Project%20database?version=19 | CC-MAIN-2014-15 | refinedweb | 664 | 56.35 |
Quant Basics 1: Data Sources
Introduction
Welcome to the Quant Basics series. This mini series came from the observation that most people starting in quantitative trading focus almost entirely on the generation of trading signals. While this is important, several other areas in quantitative trading strategy development are even more cruicial such as:
- Data
- Vectorised Backtesting
- Performance analysis and strategy optimisation
- Position management
- Execution
In this series we will mostly focus on the first for those areas. We start with an introduction on how to download and condition market data from free sources. This is important as vectorised backtests are usually fast and it is possible to run through a wide range of possible configurations to find tradable sweet spots. In subsequent articles we cover:
- Parameter optimisation with Monte Carlo, grid sweep and (possibly) simulated annealing/genetic algos
- Out-of-sample shortfall estimation with bootstrapping, BRAC, train-test correlation
- Ways to avoid overfitting and find regions of tradable parameter sets using unsupervised machine learning
- Manually train a machine learning classifier to produce a compound metric from PnL, drawdown, Sharpe and other rather than using ranking
- Build a machine learning model of our strategy that helps us to speed up walk-forward optimisation
Preparing Market Data
Lets look at some simple code we can use to download data for free. In the example below we have three sources: Google Finance, Quantopian and a random number generator. We also show how to save the data in a cPickle file for repeated use without having to download them every time. You might ask why we would use a random number generator. The short answer is that this gives us a more controllable time series which will produce results that are easier to understand and useful for code testing.
import pandas as pd import numpy as np import pandas_datareader.data as web from dateutil.parser import parse import cPickle # BACKEND = 'google' BACKEND = 'file' tickers = ['AAPL','MSFT','CSCO','XOM'] start = '2003-01-01' end = '2017-06-01' def prices(tickers,start,end,backend='google'): if backend == 'quantopian': p = get_pricing(tickers,start,end) field = 'price' elif backend == 'google': p = web.DataReader(tickers, 'google', parse(start), parse(end)).ffill() field = 'Close' cPickle.dump(p,open('prices.pick','w')) elif backend == 'random': field = 'Close' p = web.DataReader(tickers, 'google', parse(start), parse(end)).ffill() for ticker in tickers: p[field][ticker] = np.cumsum(np.random.randn(len(p[field][ticker]))-0.0)+500 elif backend == 'file': p = cPickle.load(open('prices.pick')) field = 'Close' pp=pd.DataFrame(p[field],index=p[field].index,columns = tickers) return pp p = prices(tickers,start,end,backend=BACKEND)
What is happening here? In the first lines we import a few Python modules, you should be reasonably familiar with this already. The dateutil.parser.parse function is incredibly handy as it can turn almost any time string into a datetime object which can then be used for datetime arithmetic. The only drawback of this function is its speed. Every time it is called it has to infer a suitable format from the string, which takes time. The fastest way to parse time strings is to write your own function that is specifically tailored to a pre-defined format. You can try to do this as an exercise and compare the speed of your function with the dateutil parser.
Next, we define a global variable BACKEND. Global variables should be used sparingly and never change during the running of the code. This variable defines where the data are coming from. In our case we have a choice between the Quantopian backend (which can only be used within the Quantopian research environment), Google Finance, which we call with another incredibly useful module called Pandas, furthermore, a random data generator and finally we can retrieve data from a cPickle file. cPickle is a ‘serializer’, which means that it can turn almost any Python object into a file that can be stored on disk. In our case we can store the data we’ve downloaded from Google Finance, in order to avoid calling their API every time. This often can help to save processing time, particularly when the amount of data we try to download is large.
When we request data from one of the backends we usually have to specify a start and an end time, which we define as a string. Note, that for the Google web data reader we have to parse the dates into a datetime object while for Quantopian accepts a basic string format. Take note of the function ffill() at the end of the data reader line. This is also called a forward fill. Sometimes we end up with missing data points for some reason due to a difference in exchange opening times, public holidays or emergencies where a particular exchange has to close. In this case we carry forward the last price and assume that nothing has changed on that date. This is important since many functions cannot handle NaN’s, Inf’s or other non-numerical values.
Preparing Synthetic Price Data
Let’s now focus on the random number generator which is contained in the following line:
np.cumsum(np.random.randn(len(p[field][ticker]))-0.0)+500
This nifty piece of code singlehandedly produces something that looks like a real price series. How does it do that? Let’s run through the statement bit by bit. First we see random.randn(N) which produces N normally distributed random numbers. These numbers are price differences from one period to the next. Here, we look at absolute price differences as opposed to percentage returns. The length of that vector is the same as for the length of the number of trading days for google finance, so we can compare the series more easily if we wish to do so.
Next we can see that we subract (or add) a constant value from the random number. In our case this is zero but it could be some arbitrary value. This causes the mean of our normally distributed returns to shift such that the expected value is nonzero. This bias creates an artificial trend which can be helpful sometimes when we test our strategy. In most cases a trending series will be simulated using autocorrelation but in our case we are mainly looking for a series which we understand very well and which gives us consistent results when we test our strategy.
Once we have our biased or unbiased price differences we apply the cumsum() function in order turn them into “actual” price data. This process of cumulative summation is also called stochastic integration.
The image above shows a series without bias on the left and with bias on the right. Note the the curves are NOT the actual prices of the stocks in the legend. In contrast, lets look at the price differences before we apply the cumulative sum:
We can see that our price differences generally hover around the zero point and it would be impossible to guess from the image where the cumulative sum of these changes would move to.
Finally, we notice that we add a value of 500 to the cumulative series. This is done to shift the whole data set deeply into the positive region to avoid negative values. Arguably, a better way to do this is to use geometric brownian motion (GBM). With GBM we generate percentage returns, add 1 to them and calculate the cumulative product. This would look similar to the following example:
gbm = np.cumprod(1+np.random.randn(1000)*0.01)*500
Note, that we need to multiply the random normal distribution with a volatility value of 0.01. If we make the values larger our price ends up drifting towards zero very quickly and not moving back up again as shown in the next figure:
The above figure shows one of the great properties of GBM: the price movement is a function of the absolute price level since we are working with relative differences. The underlying price distribution is now log-normal.
Both of these data sets have their pros and cons and we have to decide which one of them fits our purpose. Personally, I often tend to use cumulative sums for testing as they are simpler and easier to handle.
This concludes the first part of the quantitative mini course. If this was too basic for you, please stay with us. In the next part we look at how to set up a vectorised backtest.
The code base for this section can be found on Github. | http://aaaquants.com/2017/08/17/hello-world/ | CC-MAIN-2019-39 | refinedweb | 1,429 | 53.31 |
Yasmin Akbar-Husain and Eoin Lane show how to construct an optimistic locking solution that produces transactionally safe EJB code, portable across all application servers. The authors implement the solution in a versioned entity bean for fail-safe concurrent updates. The Optimistic Locking pattern encourages short commit cycles, thus increasing throughput and improving performance.
The pattern is at:.
What do you guys think of this pattern?
Optimistic Locking pattern for EJBs (14 messages)
- Posted by: Dion Almaer
- Posted on: July 26 2001 17:28 EDT
Threaded Messages (14)
- Optimistic Locking pattern for EJBs by Floyd Marinescu on July 27 2001 14:10 EDT
- Optimistic Locking pattern for EJBs by Hai Hoang on July 27 2001 15:36 EDT
- Optimistic Locking pattern for EJBs by null on July 27 2001 16:31 EDT
- Optimistic Locking pattern for EJBs by Hai Hoang on July 27 2001 04:48 EDT
- Optimistic Locking pattern for EJBs by Milos Dunjic on March 05 2003 05:02 EST
- Optimistic Locking pattern for EJBs by null on July 27 2001 16:28 EDT
- Optimistic Locking pattern for EJBs by Indranil Banerjee on July 27 2001 17:40 EDT
- Optimistic Locking pattern for EJBs by Gal Binyamini on July 27 2001 19:55 EDT
- Optimistic Locking pattern for EJBs by William Louth on July 28 2001 16:42 EDT
- Optimistic Locking pattern for EJBs by Eddie Fung on July 28 2001 07:02 EDT
- Optimistic Locking pattern for EJBs by Hai Hoang on July 30 2001 11:51 EDT
- Optimistic Locking pattern for EJBs by Marko Milicevic on July 30 2001 03:35 EDT
- Optimistic Locking pattern for EJBs by Hai Hoang on July 30 2001 04:14 EDT
- Optimistic Locking pattern for EJBs by fmarchioni fmarchioni on August 01 2001 10:23 EDT
Optimistic Locking pattern for EJBs[ Go to top ]
I think it looks suspiciously like a pattern that was posted by Doug Bateman here on TheServerSide, way back in October 27, 2000:
- Posted by: Floyd Marinescu
- Posted on: July 27 2001 14:10 EDT
- in response to Dion Almaer
Long-Lived Optimistic PseudoTransactions (Version Numbering).
Optimistic Locking pattern for EJBs[ Go to top ]
Timestamps, Version count, and State comparison describe in the article is inadequate in in a cluster environment. To adequately handle optimistic locking you need a database solution combine with Version count. Specifically, you need a version field in the database table and basically follow the instruction in the article. ATG's Repository implement this pattern perfectly with their version property.
- Posted by: Hai Hoang
- Posted on: July 27 2001 15:36 EDT
- in response to Dion Almaer
Optimistic Locking pattern for EJBs[ Go to top ]
[Quote]
- Posted by: null
- Posted on: July 27 2001 16:31 EDT
- in response to Hai Hoang
Timestamps, Version count, and State comparison describe in the article is inadequate in in a cluster environment.
[end quote]
Hi
Would you be willing to touch on this a bit more. I'm not quite clear why you feel it's inadequete in a cluster environment. Do you feel it's just not a reliable enoguh solutions or that it 'plain doesn't work'?
Thanks.
Optimistic Locking pattern for EJBs[ Go to top ]
Basically, If you attempt to update the item from a transaction whose version does not match the current version number in the bean, an Exception is thrown to abort that update. In the clustered environment, you have multiple servers and each server will have it own bean and version number. Therefore, how do you know that you've the latest data? With the version field in the database table, you should be able to tell this if you've the same version number.
- Posted by: Hai Hoang
- Posted on: July 27 2001 16:48 EDT
- in response to null
Optimistic Locking pattern for EJBs[ Go to top ]
I am not sure that this is true. Every instance of application server in the cluster is supposed to sync its bean's state at transaction boundaries. Therefore if transactions are handled correctly then the solution shall work in cluster just fine.
- Posted by: Milos Dunjic
- Posted on: March 05 2003 17:02 EST
- in response to Hai Hoang
Optimistic Locking pattern for EJBs[ Go to top ]
Hi
- Posted by: null
- Posted on: July 27 2001 16:28 EDT
- in response to Dion Almaer
To me this is always a great topic to dicsuss as technologies change while trying to solve this in the present day "web environment".
[I've left out comments on state comparison as I feel that as much as it's a 'solution', the memory overhead of comparing 'original' objects to 'new' objects doesn't usually make it past the 'brainstorming' phase of our projects.]
My problem with it (the solution of versioning and timestamping) are as follows. It seems you really only need to implement a locking pattern when using BMP. I"ve noticed that some/most people pick BMP over CMP because of the performance drawbacks to CMP and the tough time involved in mapping complex relationships.
How much performace gain are you getting if you forgo CMP for BMP and a custom Optimistic locking pattern? Add this to the situation where you have a complex heavy weight object that has multiple levels of object isolation. (ObjectA has ObjectB which has ObjectC etc etc). If each Object maps nicely to a row in a database you've pretty much almost home free, but if it doesn't, the additional checks and balances to take into consideration all the timestamping, versioning etc can be hell in a a handbasket.
After all that work you've just put in to handle all this locking, aren't you pretty much just recreating what the application server was meant to do anyway?
My other problem is that being relatively new to EJB's and the inherited problems with state data and it's staleness is that I haven't found a clear cut solution to yet.
I am still searching, and continue to await comments to topics such as this.
Optimistic Locking pattern for EJBs[ Go to top ]
Hi,
- Posted by: Indranil Banerjee
- Posted on: July 27 2001 17:40 EDT
- in response to null
Another writer has pointed out that this solution wouldn't work in a clustered environment where each app server is handing out its own version numbers. (Unless you create a networked RMI Singleton to issue version numbers, but that might have worse performance than pessimistic locking)
But this problem wont go away with CMP. This isn't a BMP/CMP issue.
It's a problem with the Value Object pattern.
Sending a copy of data out to a client which can become stale if another client makes an update first. Version checking would have to be made in the setValueObject() method regardless of the persistence mechanism.
Optimistic Locking pattern for EJBs[ Go to top ]
This article shows a technique very similar to one showed on the patterns section a long while ago. I have commented there that this pattern won't work even in a single server environment unless the container uses commit option A exclusively. Otherwise multiple instances representing the same entity would lead to corruption.
- Posted by: Gal Binyamini
- Posted on: July 27 2001 19:55 EDT
- in response to Dion Almaer
If for any reason this has become incorrect in EJB2.0 (which I doubt), could you please post here?
Gal
Optimistic Locking pattern for EJBs[ Go to top ]
I have not read the article on the JavaWorld website but based on the summary provided above this is not a new pattern and has been used in other distributed and client/server architectures/solutions.
- Posted by: William Louth
- Posted on: July 28 2001 16:42 EDT
- in response to Gal Binyamini
In fact I used state and versioning solutions in an EJB 1.1 project at AT&T in 1999, yes 1999, with CMP entity beans. This project was probably one of the first to use CMP entity beans on a major J2EE project. The project is documented in the J2EE in Pratice book which can be read online at:
It should be noted that this pattern works across transactions but still requires similar support within a transaction if optimistic concurrency at the database is in use. So yes in a clustered environment or where another process updates the database between the read and update in the final transaction this pattern DOES NOT WORK.
The AT&T project did not suffer from this failing since support for optimistic concurrency was built into the Borland cmp engine. I believe the only other appserver supporting this is Sybase EAServer, which has just come out with it.
William Louth
Optimistic Locking pattern for EJBs[ Go to top ]
There are a number of points worth making here:
- Posted by: Eddie Fung
- Posted on: July 28 2001 19:02 EDT
- in response to William Louth
a) William is correct in that the pattern will not work for CMP unless the CMP engine supports optimistic locking and yes, Sybase EA Server does support this.
b) The check for version changes has to be at the point that the row is about to be updated on the database. This is because it is possible that an update could occur between the reading of the row and the update of the row. Clustered environments are an obvious case here. The simplest way to avoid this problem is to perform an ""Update EntityBeanTable e .... Where e.id ="myPrimaryKey" and e.version=4" (to quote Doug Bateman's article of Sept 2000). The update will fail if the version has changed. The only downside to this is if the row is not found we don't know if it is because the row has been deleted by another process or whether the version is different. The other alternative which would fix this last problem is to perform a 'SELECT..FOR UPDATE' which would allow you to check the version prior to performing the update without losing the (intent to be update/exclusive)lock but this is another SQL statement across the wire. Furthermore we could just send back a message 'instance/row state has changed' message back to the caller in the first case and let them sort out the reason it failed.
Oh yeah, the version number must be updated to 1 more than what it is currently..none of this keeping a version count per server (which is obviously flawed).
So in the case of CMP, the CMP engine has to support optimistic locking. For BMP, you have have do the check and lock the row AT THE SAME TIME.
Optimistic Locking pattern for EJBs[ Go to top ]
I'm curious, with the introduction of local interfaces, co-located clients and EJB can accessed by using pass-by-reference, then why do we still need value-object?
- Posted by: Hai Hoang
- Posted on: July 30 2001 11:51 EDT
- in response to Eddie Fung
Optimistic Locking pattern for EJBs[ Go to top ]
Why the need for value-objects? Two reasons pop to mind.
- Posted by: Marko Milicevic
- Posted on: July 30 2001 15:35 EDT
- in response to Hai Hoang
1. From a design perspective, it is good practice for clients to access the system through a Session Bean layer that abstracts the business logic/rules/workflow and Data Layer (Entity Beans, or some other persistence mechanism). In this case, the Session Bean would return value objects rather than handles to the persistence layer (Entity Beans).
2. Because Entity Beans have been architected for poor performance. To me, this is the show stopper that leads me to avoid using Entity Beans.
eg. For each of 100 customers you wish to update 10 attributes.
What is the rough cost of doing this?
** Case #1: Entity Bean impl.
- 100 remote calls for home lookup.
- 100 database queries for home lookup (primary key).
- for each Customer Entity Bean.
- for each of 10 attributes,
- 1 remote call to set the attribute.
- 1 or more database queries to load the Entity Bean.
- 1 or more database updates to store the Entity Bean.
Lets total that up,
total remote calls == 100 + (100*10) == 1100
total database transactions ~= 100 + (100*10*2) >= 2100
** Case #2: Value Object through a Session Bean Facade. To simplify the case I will omit the Entity Bean.
- one remote call to send the Session Bean an array of 100 Customer value objects.
- for each Customer value object,
- 1 database transaction to update the Customer data.
total remote calls == 1
total database transactions ~= 100
Case #2 could be further optimized by doing the updates in batch, or using a stored procedure.
Case #1 could also be partially optimized by using local interfaces, smart containers, etc. It would be interesting to try and speculate what the theoretical minimum cost of case #1 is, but I suspect it could never approach the performance, and simplicity, of case #2.
Optimistic Locking pattern for EJBs[ Go to top ]
I've a One-to-many bidirectional relationships between the PERSON and PHONE tables could be manifested in a relational database in a variety of ways. For this example, we chose to have the PHONE table include a foreign key to the PERSON table. My question is should I included the Person field, which is cmr field, in my value object (keep in mind that these are local interface entity bean)
- Posted by: Hai Hoang
- Posted on: July 30 2001 16:14 EDT
- in response to Marko Milicevic
CREATE TABLE PHONE
(
PHONE_ID INT PRIMARY KEY,
NUMBER CHAR(20),
TYPE INT,
PERSON_ID INT
}
// The local interface for the Phone EJB
public interface PhoneLocal extends javax.ejb.EJBLocalObject {
public void setPhoneId(Long phoneId);
public Long getPhoneId();
public String getNumber();
public void setNumber(String number);
public byte getType();
public void setType(byte type);
public PersonLocal getPerson();
public void setPerson(PersonLocal person);
}
// The bean class for the Phone EJB
public class PhoneBean implements javax.ejb.EntityBean {
public Integer ejbCreate(LongId, String number, byte type, PersonLocal
person){
setPhoneId(id);
setNumber(number);
setType(type);
}
public void ejbPostCreate(LongId, String number,byte type, PersonLocal
person) {
setPerson(person);
}
// persistent fields
public abstract void setPhoneId(Long phoneId);
public abstract Long getPhoneId();
public abstract String getNumber();
public abstract void setNumber(String number);
public abstract byte getType();
public abstract void setType(byte type);
public abstract PersonLocal getPerson();
public abstract void setPerson(PersonLocal person);
// standard callback methods
.
}
Should I include a person, which is cmr field the value object for the Phone
EJB?
public class PhoneValue implements java.io.Serializable {
private Long _phoneId;
private String _number;
private String _type;
public PhoneValue() {
}
public void setPhoneId(Long phoneId){
_phoneId = phoneId;
}
public Long getPhoneId(){
return _phoneId;
}
public void setNumber(String number){
_number = number;
}
public String getNumber(){
return _number;
}
public void setType(String type){
_type = type;
}
public String getType(){
return _type;
}
}
Optimistic Locking pattern for EJBs[ Go to top ]
Hello,
- Posted by: fmarchioni fmarchioni
- Posted on: August 01 2001 10:23 EDT
- in response to Hai Hoang
I'd like to make a summary of many message posted about this pattern to make clear things for myself and for others.
1) If you choose to implement your beans as BMP then you can achieve data-consistency with some patterns like timestamp or versioning pattern, checking the timestamp after reading and just before updating (as an alternative using an UPDATE ... set field A = ... WHERE timestamp = ..)
2) If you choose to implement your beans as CMP then the Container will care for proper locking of data
3) I don't understand well the question with the cluster environment: if I read a timestamp that is persistent on the DB -and check it to see if the data has been altered- what is the difference if the environment is clustered or not?
Hope to receive some answers
Thanks
Francesco | http://www.theserverside.com/discussions/thread.tss?thread_id=8122 | CC-MAIN-2016-50 | refinedweb | 2,643 | 55.27 |
This article shall describe the construction of three custom controls; each is used to format its text content to be either all upper case, all lower case, title case, or normal (as typed) case regardless of the format of the input.
Introduction
This article shall describe the construction of three custom controls; each is used to format its text content to be either all upper case, all lower case, title case, or normal (as typed) case regardless of the format of the input. Such controls may be useful if it is necessary to load the control's text from a source in which the values are in the wrong case; for example, if one were to load a ListBox from a column in a database where all of the values were stored as all upper case strings but the desire was to display the text using title case, the Case List control contained in the sample project will make the conversion once the values are loaded into its list.
Figure 1: The Case Controls in Use.
Getting Started
The Case Controls solution contains two projects. The first project is called "CaseControls" and it contains three extended controls (the RichTextBox, the ListBox, and the ComboBox). Each of the controls was extended such that the modified version offered the option of formatting the text contained is the control into one of four options (Upper Case, Lower Case, Normal Case, and Title Case). The second project is called "TestCaseControl" and it is provided to demonstrate use of the controls in a Win Forms application.
Figure 2: Solution Explorer with Both Projects Visible.
The Case Controls Project
Code: Case Text
The CaseText control is an extended version of the RichTextBox control; this control was extended such that text sent to the control or keyed directly into it is immediately formatted into one of the four available options (Upper Case, Lower Case, Normal Case, or Title Case). In use, the developer may drop the control onto a form and set a single property "TextCase" that is used by the control to determine how to format the text.
The control is built in a single class entitled "CaseText". The class begins with the following imports, namespace, and class declarations:
using System;
using System.Collections;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Text;
using System.Windows.Forms;
using System.Globalization;
using System.Threading;
namespace CaseControls
{
/// <summary>
/// Extend the RichTextBox control
/// </summary>
public class CaseText : RichTextBox
{
The class is declared to inherit from the RichTextBox control. By inheriting from the RichTextBox control, all of the functionality of that control is included. After declaring the class, the next section of code is used to declare an enumeration defining the case mode options, a private member variable used to hold the currently selected text case mode, and a public property used to set or retrieve the selected case mode:
/// <summary>
/// Enumeration of case type options
/// </summary>
public enum CaseType
Normal,
Title,
Upper,
Lower
}
/// Set the current case type for the control;
/// default to normal case
private CaseType mCaseType = CaseType.Normal;
/// property used to maintain current case type
public CaseType TextCase
get
{
return mCaseType;
}
set
mCaseType = value;
UpdateTextCase();
}
The next block of code contains the default constructor and the component initialization code; since this control is intended to serve as either a textbox or a richtextbox, the control's constructor contains a bit of code to make the control look more like a standard textbox control when it is created (the multi-line property is set to false and the height is set to 20). The initialize component method also includes the addition of a text changed event handler:
/// Default Constructor
public CaseText()
InitializeComponent();
this.Text = string.Empty;
this.Multiline = false;
this.Height = 20;
/// Initialization/Event Handlers
private void InitializeComponent()
this.SuspendLayout();
//
// CaseText
this.TextChanged += new System.EventHandler(this.CaseText_TextChanged);
this.ResumeLayout(false);
The last bit of code required by the control is the text changed event handler which is used merely to call a method used to update the case of the text based upon the selected case mode property. Since this method is called whenever text changed event fires, the textbox will update the case as the user types. When the UpdateTextCase method is called, the method stores the text currently contained in the control and it stores the position of the insert cursor. The copy of the text placed in the string varible is operated on within the method and then is used to replace the text contained in the control. The position of the insert is stored so that the cursor may be restored to its original position after the text has been replaced. This supports edits made to sections of the string other than the end or beginning of the string.
/// Call the Update Text Case function each time
/// the text changes
/// <param name="sender"></param>
/// <param name="e"></param>
private void CaseText_TextChanged(object sender, EventArgs e)
UpdateTextCase();
/// Depending upon the Case Type selected,
/// process the textbox accordingly
private void UpdateTextCase()
string sControlText = this.Text;
int cursorPosition = this.SelectionStart;
switch (this.TextCase)
case CaseType.Lower:
// convert to all lower case
this.Text = this.Text.ToLower();
break;
case CaseType.Normal:
// do nothing, leave as entered
break;
case CaseType.Title:
// convert to title case
string sTemp = this.Text.ToLower();
CultureInfo ci = Thread.CurrentThread.CurrentCulture;
TextInfo ti = ci.TextInfo;
this.Text = ti.ToTitleCase(sTemp);
case CaseType.Upper:
// convert to all upper case
this.Text = this.Text.ToUpper();
default:
// move to the corrent position in the string
this.SelectionStart = cursorPosition;
}
The code used in the CaseList and CaseCombo controls is very similar and is all included in the download; for that reason I won't describe it here in this document. The only major difference between the code used in those controls is that the Update Text methods are made public in the list controls so that the user may evoke the method whenever the list is created or changed. Whenever the user evokes the method, the update method will loop through the text in the collection and update the case of each list item.
Code: Test Case Control
This project is used to test the custom controls. The project contains a single Windows form. The form contains four of each type of custom control, each of which is intended to demonstrate one of the case mode options.
The form class begins with the default imports and class declaration:
using System.Collections.Generic;
namespace TestCaseControl
public partial class Form1 : Form
In the form constructor, the list type controls are all populated manually using strings formatting contrary to what is desired for display. For example, the if the custom listbox control is set to display upper case text, the text submitted to the control's list is passed in using lower case or mixed case strings. After each list is loaded, the controls update text case method is evoked to reformat the case used in the list items:
public Form1()
InitializeComponent();
// C O M B O B O X E X A M P L E
//
// load an Upper Case list with these items
caseCombo1.Items.Add("popeye");
caseCombo1.Items.Add("olive oil");
caseCombo1.Items.Add("brutus");
caseCombo1.Items.Add("whimpy");
caseCombo1.Items.Add("sweet pea"); // update the case of these list items
caseCombo1.UpdateListTextCase();
// load a Lower Case list with these items
caseCombo2.Items.Add("CHOCOLATE CREAM");
caseCombo2.Items.Add("Rasberry Truffle");
caseCombo2.Items.Add("PINEAPPLE Sling");
caseCombo2.Items.Add("COCONUT HEaRt");
caseCombo2.Items.Add("VANILLA ICE Cream");
// update the case of these list items
caseCombo2.UpdateListTextCase();
// load a Normal Case list with these items
caseCombo3.Items.Add("George S. Patton");
caseCombo3.Items.Add("Mikhail Miloradovich");
caseCombo3.Items.Add("Bernard Montgomery");
caseCombo3.Items.Add("Carl von Clausewitz");
caseCombo3.Items.Add("Sun Tzu");
caseCombo3.UpdateListTextCase();
// load a Title Case list with these items
caseCombo4.Items.Add("john lennon");
caseCombo4.Items.Add("paul mc cartney");
caseCombo4.Items.Add("ringo starr");
caseCombo4.Items.Add("george harrison");
caseCombo4.Items.Add("peter best");
caseCombo4.UpdateListTextCase();
// L I S T B O X E X A M P L E
//
// load an Upper Case list with these items
caseList1.Items.Add("popeye");
caseList1.Items.Add("olive oil");
caseList1.Items.Add("brutus");
caseList1.Items.Add("whimpy");
caseList1.Items.Add("sweet pea");
caseList1.UpdateListTextCase();
// load a Lower Case list with these items
caseList2.Items.Add("CHOCOLATE CREAM");
caseList2.Items.Add("Rasberry Truffle");
caseList2.Items.Add("PINEAPPLE Sling");
caseList2.Items.Add("COCONUT HEaRt");
caseList2.Items.Add("VANILLA ICE Cream");
// update the case of these list items
caseList2.UpdateListTextCase();
// load a Normal Case list with these items
caseList3.Items.Add("George Patton");
caseList3.Items.Add("Mikhail Miloradovich");
caseList3.Items.Add("Bernard Montgomery");
caseList3.Items.Add("Carl von Clausewitz");
caseList3.Items.Add("Sun Tzu");
caseList3.UpdateListTextCase();
caseList4.Items.Add("john lennon");
caseList4.Items.Add("paul mc cartney");
caseList4.Items.Add("ringo starr");
caseList4.Items.Add("george harrison");
caseList4.Items.Add("peter best");
caseList4.UpdateListTextCase();
The only other code in the form class are a set button event handlers that will pass an improperly formatted string to each of the four custom case text controls:
/// Button event handlers used to send
/// formatted strings to each of the
/// CaseText controls on the page. Each
/// example is set to a different type
/// of case (Upper, Lower, Normal, and Title)
private void btnToUpper_Click(object sender, EventArgs e)
caseText1.Text = lblToUpperCase.Text;
private void btnToLower_Click(object sender, EventArgs e)
caseText2.Text = lblToLowerCase.Text;
private void btnToNormal_Click(object sender, EventArgs e)
caseText3.Text = lblToNormalCase.Text;
private void btnToTitle_Click(object sender, EventArgs e)
caseText4.Text = lblToTitleCase.Text;
Summary.
This article was intended to demonstrate an approach to building a set of custom controls that could be used to reformat the case of the text or list item text; the purpose of such a control would be to allow improperly formatted text obtained from an external source to be properly displayed in the context of a Windows application without the need to modify the source of text. Such a control may be useful if one is, for example, attempting to display data obtained from a database that is not stored in the proper format (e.g., the column contains all upper case strings but the desire is to display it as title case strings or all lower case string).
View All | https://www.c-sharpcorner.com/article/enforce-text-case-with-custom-controls/ | CC-MAIN-2020-50 | refinedweb | 1,716 | 56.76 |
Modern-day JavaScript developers love npm. GitHub and the npm registry are a developer’s first choice place for finding a particular package. Open-source modules add to the productivity and efficiency by providing developers with a host of functionalities that you can reuse in your project. It is fair to say that if it were not for these open-source packages, most of the frameworks today would not exist in their current form.
A full-fledged enterprise-level application, for instance, might rely on hundreds if not thousands of packages. The usual dependencies include direct dependencies, development dependencies, bundled dependencies, production dependencies, and optional dependencies. That’s great because everyone’s getting the best out of the open-source ecosystem.
However, one of the factors that get overlooked is the amount of risk involved. Although these third-party modules are particularly useful in their domain, they also introduce some security risks into your application.
Are Open-Source Libraries Vulnerable?
OSS dependencies are indeed vulnerable to exploits and compromises. Let's have a look at a few examples:
A vulnerability was discovered recently in a package called eslint-scope which is a dependency of several popular JavaScript packages such as babel-eslint and webpack. The account of the package maintainer was compromised, and the hackers added some malicious code into it. Fortunately, someone found out the exploit soon enough that the damage was reportedly limited to a few users.
Moment.js, which is one of the most-used libraries for parsing and displaying dates in JavaScript, was recently found to have a vulnerability with a severity score of 7.5. The exploit made it vulnerable to ReDoS attacks. Patches were quickly released, and they were able to fix the issue rather quickly.
But that's not all. A lot of new exploits get unearthed every week. Some of them get disclosed to the public, but others make headlines only after a serious breach.
So how do we mitigate these risks? In this article, I'll explain some of the industry-standard best practices that you can use to secure your open-source dependencies.
1. Keep Track of Your Application’s Dependencies
Logically speaking, as the number of dependencies increase, the risk of ending up with a vulnerable package can also increase. This holds true equally for direct and indirect dependencies. Although there’s no reason that you should stop using open-source packages, it’s always a good idea to keep track of them.
These dependencies are easily discoverable and can be as simple as running
npm ls in the root directory of your application. You can use the
–prod argument which displays all production dependencies and the
–long argument for a summary of each package description.
Furthermore, you can use a service to automate the dependency management process that offers real-time monitoring and automatic update testing for your dependencies. Some of the familiar tools include GreenKeeper, Libraries.io, etc. These tools collate a list of the dependencies that you are currently using and track relevant information regarding them.
2. Get Rid of Packages That You Do Not Need
With the passage of time and changes in your code, it is likely that you'll stop using some packages altogether and instead add in new ones. However, developers tend not to remove old packages as they go along.
Over time, your project might accumulate a lot of unused dependencies. Although this is not a direct security risk, these dependencies almost certainly add to your project’s attack surface and lead to unnecessary clutter in the code. An attacker may be able to find a loophole by loading an old but installed package that has a higher vulnerability quotient, thereby increasing the potential damage it can cause.
How do you check for such unused dependencies? You can do this with the help of the depcheck tool. Depcheck scans your entire code for
requires and
import commands. It then correlates these commands with either installed packages or those mentioned in your package.json and provides you with a report. The command can also be modified using different command flags, thereby making it simpler to automate the checking of unused dependencies.
Install depcheck with:
npm install -g depcheck
3. Find and Fix Crucial Security Vulnerabilities
Almost all of the points discussed above are primarily concerned with the potential problems that you might encounter. But what about the dependencies that you’re using right now?
Based on a recent study, almost 15% of current packages include a known vulnerability, either in the components or dependencies. However, the good news is that there are many tools that you can use to analyze your code and find open-source security risks within your project.
The most convenient tool is npm’s
npm audit. Audit is a script that was released with npm’s version 6. Node Security Platform initially developed npm audit, and npm registry later acquired it. If you’re curious to know what npm audit is all about, here’s a quote from the official blog:
A security audit is an assessment of package dependencies for security vulnerabilities. Security audits help you protect your package's users by enabling you to find and fix known vulnerabilities in dependencies. The npm audit command submits a description of the dependencies configured in your package to your default registry and asks for a report of known vulnerabilities.
The report generated usually comprises of the following details: the affected package name, vulnerability severity and description, path, and other information, and, if available, commands to apply patches to resolve vulnerabilities. You can even get the audit report in JSON by running
npm audit --json.
Apart from that, npm also offers assistance on how to act based on the report. You can use
npm audit fix to fix issues that have already been found. These fixes are commonly accomplished using guided upgrades or via open-source patches.
Feel free to refer npm’s documentation for more information.
4. Replace Expired Libraries With In-House Alternatives
The concept of open-source security is heavily reliant on the number of eyes that are watching over that particular library. Packages that are actively used are more closely watched. Therefore, there is a higher chance that the developer might have addressed all the known security issues in that particular package.
Let’s take an example. On GitHub, there are many JSON web token implementations that you can use with your Node.js library. However, the ones that are not in active development could have critical vulnerabilities. One such vulnerability, which was reported by Auth0, lets anyone create their own "signed" tokens with whatever payload they want.
If a reasonably popular or well-used package had this flaw, the odds of a developer finding and patching the fault would be higher. But what about an inactive/abandoned project? We’ll talk about that in the next point.
5. Always Choose a Library That’s in Active Development
Perhaps the quickest and most efficient way to determine the activity of a specific package is to check its download rate on npm. You can find this in the Stats section of npm’s package page. It is also possible to extract these figures automatically using the npm stats API or by browsing historic stats on npm-stat.com. For packages with GitHub repositories, you should check out the commit history, the issue tracker, and any relevant pull requests for the library.
6. Update the Dependencies Frequently
There are many bugs, including a large number of security bugs that are continually unearthed and, in most cases, immediately patched. It is not uncommon to see recently reported vulnerabilities being fixed solely on the most recent branch/version of a given project.
For example, let's take the Regular Expression Denial of Service (ReDoS) vulnerability reported on the HMAC package ‘hawk’ in early 2016. This bug in hawk was quickly resolved, but only in the latest major version, 4.x. Older versions like 3.x were patched a lot later even though they were equally at risk.
Therefore, as a general rule, your dependencies are less likely to have any security bugs if they use the latest available version.
The easiest way to confirm if you’re using the latest version is by using the
npm outdated command. This command supports the
-prod flag to ignore any dev dependencies and
--json to make automation simpler.
Regularly inspect the packages you use to verify their modification date. You can do this in two ways: via the npm UI, or by running
npm view <package> time.modified.
Conclusion
The key to securing your application is to have a security-first culture from the start. In this post, we’ve covered some of the standard practices for improving the security of your JavaScript components.
- Use open-source dependencies that are in active development.
- Update and monitor your components.
- Review your code and write tests.
- Remove unwanted dependencies or use alternatives.
- Use security tools like
npm auditto analyze your dependencies.
If you have any thoughts about JavaScript security, feel free to share<< | https://code.tutsplus.com/articles/how-secure-are-your-javascript-open-source-dependencies--cms-31685 | CC-MAIN-2021-17 | refinedweb | 1,519 | 55.24 |
Hi Everybody! I'm very new to Java. I started learning Java about 5 months ago in my high school computer science class, so I'm just a beginner. Earlier in class we were learning about inheritance and the keyword "extends". For example: public class subClass extends superClass. I'm very new to programming, especially object oriented programming, so I have no idea what's wrong with my code.
I have a superclass called Animal and two subclasses, Dog and Ant, that both extend Animal. Here's my code and then I'll explain my problem:
Animal superclass:
Code Java:
public class Animal { public Animal(){} public void isAnAnimal(){ System.out.println("This is an animal.");} public void has4Legs(){ if(getNumberOfLegs() == 4) System.out.println("The animal has 4 legs."); else System.out.println("The animal does not have 4 legs.");} public int getNumberOfLegs(){ return Animal.numberOfLegs;} public static int numberOfLegs; }
Dog subclass:
Ant subclass:
Code Java:
public class Ant extends Animal { public Ant(){ Ant.numberOfLegs = 6;} public int getNumberOfLegs(){ return Ant.numberOfLegs;} public static int numberOfLegs; }
Main:
Code Java:
public static void main(String args[]) { Dog Onyx = new Dog("Poodle","Onyx"); Dog Fido = new Dog("Dalmation","Fido"); System.out.println("Onyx:"); System.out.println("Onyx.numberOfLegs: " + Onyx.numberOfLegs); Onyx.has4Legs(); System.out.println("Fido:"); System.out.println("Fido.numberOfLegs: " + Fido.numberOfLegs); Fido.has4Legs(); Fido.numberOfLegs = 3; System.out.println("Fido.numberOfLegs: " + Fido.numberOfLegs); Fido.has4Legs(); Ant Jeff = new Ant(); System.out.println("Jeff:"); Jeff.isAnAnimal(); System.out.println("Jeff.numberOfLegs: " + Jeff.numberOfLegs); Jeff.has4Legs(); System.out.println("Fido.numberOfLegs: " + Fido.numberOfLegs); Fido.has4Legs(); System.out.println("Onyx.getNumberOfLegs(): " + Onyx.getNumberOfLegs()); // 3?????? }
Here's my output when I compile and run the program:
Onyx:
Onyx.numberOfLegs: 4 // These lines are red to show how the logic of the program doesn't make sense.
The animal has 4 legs.
Fido:
Fido.numberOfLegs: 4
The animal has 4 legs.
Fido.numberOfLegs: 3
The animal does not have 4 legs.
Jeff:
This is an animal
Jess.numberOfLegs: 6
The animal does not have 4 legs.
Fido.numberOfLegs: 3
The animal does not have 4 legs.
Onyx.getNumberOfLegs(): 3 // These lines are red to show how the logic of the program doesn't make sense.
Press any key to continue...
Here's my problem:
I noticed that this line of code in my main class ------> Fido.numberOfLegs =3; also changes the value of Onyx.numberOfLegs to 3. Is this because they're both a Dog object? How do I make it so that Onyx and Fido can have a different value of numberOfLegs? I'm pretty sure that if I made another Ant object called Billy and I used Jeff.numberOfLegs = 100; than the value of Billy.numberOfLegs would also be 100. I'm completely lost and have no idea what to do. This isn't for a school project or anything. I decided to do this on my own so I could better understand inheritance.
Thanks for all the help! I really appreciate it!
--- Update ---
If you have any questions, please ask me. I'll try to explain my best! | http://www.javaprogrammingforums.com/%20whats-wrong-my-code/35526-i-have-problem-class-inheritance-printingthethread.html | CC-MAIN-2014-35 | refinedweb | 516 | 52.66 |
This project plugs Google Gears in Ruby on Rails.
Gears on Rails helps developers to write fully offline functionnal web applications based on Gears without learning a bit of Gears.
Here we provide an demo to show what we have got and illustrate our ideas.
In this page, I am going to show how to make an offline read-only application using GoR Plugin.
In order to use this Plugin, Json should be installed on the system.
gem install json_pure
We need Goolge Gears also installed on your system. You would be prompted to install Google Gears when you first time vist this web application if you havn't install it.
Now I am playing as a Rails programmer, who wants to make an offline version web app but without how to do this in javascript and havn't heard of Google Gears.
1. Setup a Rails project and Install Plugin
rails demo ruby script/plugin install
1.1 Config the database.yml properly
2. Generate Controller and Edit View
script/generate controller say hello
In hello.html.erb in the View folder.
<html> <head> <%= javascript_include_tag 'prototype' %> </head> <body> <h1>Online Status: <%= online_status_tag %> <BR> </h1> <b>Gears Status: <%= gears_status_tag %></b> <table> <tr> <td><%= link_to_local "SaySomething", :update=>'result', :action=>'saysomething'%></td> </tr> <tr> <td>Rui says:</td> <td id="result"></td> </tr> </table> </body> </html>
Notes: In order to use 'online_status_tag' and 'link_to_local' helpers, you must add <%= javascript_include_tag 'prototype' %> in <head>.
You can add online_status_tag multiple times to the places you need. gears_status_tag is used to indicate the current offline app status.
3. Edit Controller and add local controller
In app/controller/say_controller.rb add
acts_as_local
then add action 'saysomething'
def saysomething render :text=>Time.now end
In app/controller, make subfolder 'local' and add file 'say_controller.json'
Note that all offline actions in 'say' controller are stored in this file in valid json format as "action_name":"code"
Add saysomething offline version in say_controller.json
{ "saysomething": "return ('blabla...');" }
4. Done! Start Server
visit:
The default offline view is the static page of each view. However, once you define the corresponding local action in json file, the offline response would be the return value of that local action. If you either don't want stale pages of your views or write javascript actions, you could simply write like this:
acts_as_local :except=>['hello']
Visitors can't vist these excluded pages when they are offline.
You can exclude more actions like
acts_as_local :except=>['hello','aaa','bbb']
Not working?
Change TARGET in vendor/plugins/acts_as_local/lib/gor/javascripts/data_switch.js to your host
The following will show how to create an offline view of a message board application.
Quick Start for Message Board
Use the 4 easy steps to convert your web-application to an offline working web-application.
Step 0 - Installation of GoR Plugin.
Install GoR from Googlecode. Inorder to install GoR from google code run the following command :
ruby script /plugin install
Step1 - Create offline actions by editing the controller
After installing GoR edit the controller to create the offline actions. Make the following changes to the controller.
1.1)
add acts_as_local at the start of the controller.
1.2)
Define a new Local action in the controller. It is important to include the single inverted comma '. Add the following code to the controller.
def new_local ' posts = Post.find_local("all"); ' end
1.3)
Define create_local action. It is important to include the single inverted comma '. Add the following code to the controller.
def create_local ' post = Post.build(params("post")); Post.create_local(post); window.location.reload( false ); ' end
Step 2 - Debug Information
Edit view to create offline view.
Add debug info to online view
<p><b> Debug info: Online: <%= online_status_tag %> Gears: <%= gears_status_tag%> </b></p>
Create a new html.erb file and copy the contents from the online view as it is to make the offline template.
Step 3.Edit View to create offline view.
After offline view is created replace following Ruby functional part
<% for post in @posts %> <tr> <td><%=h post.title %></td> <td><%=h post.body %></td> </tr> <% end %>
by
<%= local ' var posts; posts.each(function(post) { puts "<tr>" puts "<td>"+post.title+"</td>" puts "<td>"+post.body+"</td>" puts "</tr>" }); ' %>
At the end replace
<form action="/posts/new" onSubmit="alert(Form.serialize(this));" class="new_post" id="new_post" >
by
<% form_local_for('post',:action=>'create') do |f| %> | http://code.google.com/p/gearsonrails/ | crawl-002 | refinedweb | 723 | 59.19 |
chmod(2) chmod(2)
NAME [Toc] [Back]
chmod(), fchmod() - change file mode access permissions
SYNOPSIS [Toc] [Back]
#include <sys/stat.h>
int chmod(const char *path, mode_t mode);
int fchmod(int fildes, mode_t mode);
DESCRIPTION [Toc] [Back]
The chmod() and fchmod()wise.
S_IRUSR 00400 Read by owner.
S_IWUSR 00200 Write by owner.
S_IXUSR 00100 Execute (search) by owner.
S_IRGRP 00040 Read by group.
S_IWGRP 00020 Write by group.
S_IXGRP 00010 Execute (search) by group.
S_IROTH 00004 Read by others , mode bit S_ISVTX is cleared.
If the effective user ID of the process is not that of a user with
appropriate privileges, and the effective group ID of the process does
not match the group ID of the file and none of the group IDs in the
supplementary groups list match the group ID of the file, mode bit
S_ISGID is cleared.
The mode bit S_ENFMT (same as S_ISGID) is used to enforce file-locking
mode (see lockf(2) and fcntl(2)) on files that are not group
executable. This might affect future calls to open(), creat(),
Hewlett-Packard Company - 1 - HP-UX 11i Version 2: August 2003
chmod(2) chmod(2)
read(), and write() on such files (see open(2), creat(2), read(2), and
write).
If the path given to chmod() contains a symbolic link as the last
element, this link is traversed and path name resolution continues.
chmod() changes the access mode of the symbolic link's target, rather
than the access mode of the link.
Access Control Lists - HFS File Systems Only [Toc] [Back]ac
).
To set the permission bits of access control list entries, use
setacl() instead of chmod().
Access Control Lists - JFS File Systems Only [Toc] [Back]
The effective permissions granted by optional entries in a file's
access control list may be changed when chmod() is executed. In
particular, using chmod() to remove read, write and execute
permissions from a file's owner, owning group, and all others works as
expected, because chmod() affects the class entry in the ACL, limiting
any access that can be granted to additional users or groups via
optional ACL entries. The effect can be verified by doing a getacl(1)
on the file after the chmod(), and noting that all optional (nondefault)
ACL entries with nonzero permissions also have the comment #
effective:---.
To set the permission bits of access control list entries, use
setacl() instead of chmod().
For more information on access control list entries, see acl(5) and
aclv(5).
RETURN VALUE [Toc] [Back]
chmod() returns the following values:
Hewlett-Packard Company - 2 - HP-UX 11i Version 2: August 2003
chmod(2) chmod(2)
0 Successful completion.
-1 Failure. errno is set to indicate the error.
ERRORS [Toc] [Back]
If chmod() fails, the file mode is unchanged. errno is set to one of
the following values:
[EACCES] Search permission is denied on a component of
the path prefix.
[EFAULT] path points outside the allocated address
space of the process. The reliable detection
of this error is implementation dependent.
[EINVAL] path or fildes descriptor does not refer to
an appropriate file.
[ELOOP] Too many symbolic links were encountered in
translating path.
[ENAMETOOLONG] A component of path exceeds NAME_MAX bytes
while _POSIX_NO_TRUNC is in effect or path
exceeds PATH_MAX bytes.
[ENOENT] A component of path.
If fchmod() fails, the file mode is unchanged. errno is set to one of
the following values:
[EBADF] fildes is not a valid file descriptor.
[EPERM] The effective user ID does not match that of
the owner of the file, and the effective user
ID is not that of a user with appropriate
privileges.
[EINVAL] path or fildes descriptor does not refer to
an appropriate file.
Hewlett-Packard Company - 3 - HP-UX 11i Version 2: August 2003
chmod(2) chmod(2)
[EROFS] The named file resides on a read-only file
system.
AUTHOR [Toc] [Back]
chmod() was developed by AT&T, the University of California, Berkeley,
and HP.
fchmod() was developed by the University of California, Berkeley.
SEE ALSO [Toc] [Back]
chmod(1), getacl(1), chown(2), creat(2), fcntl(2), getacl(2), read(2),
lockf(2), mknod(2), open(2), setacl(2), write(2), acl(5), aclv(5).
STANDARDS CONFORMANCE [Toc] [Back]
chmod(): AES, SVID2, SVID3, XPG2, XPG3, XPG4, FIPS 151-2, POSIX.1
fchmod(): AES, SVID3
Hewlett-Packard Company - 4 - HP-UX 11i Version 2: August 2003 | http://nixdoc.net/man-pages/HP-UX/man2/chmod.2.html | CC-MAIN-2015-22 | refinedweb | 725 | 63.29 |
Review Questions for Exam 2
Solutions
This review sheet is intended to give you some practice questions to use in preparing for our first midterm. It is not necessarily complete. The first exam covers the reading assignments, programming projects and class/discussion material through Friday 4/2/10.
1. Re-work all questions on the exam 1 review sheet and exam 1. I will assume that you can work all these questions quickly and accurately.
2. Work the discussion assignment questions again.
3. Write Python code that reads an integer from the user. If the integer is 1, it prints the word "one", if it's 2, it prints the word 2, ..., if it's 5 it prints the word "five". If the integer is less than 1, print "non-positive" and if it's greater than 5, print "more than 5". Use an if-elif structure.
n = input("enter an integer")
if n == 1:
print "one"
elif n == 2:
print "two"
elif n == 3:
print "three"
elif n == 4:
print "four"
elif n == 5:
print "five"
elif n < 1:
print "non-positive"
elif n > 5:
print "more than 5"
4. Print the value stored in x in a field of minimum width 15 and with 3 digits after the decimal point.
x = input("Enter a floating point number: ")
See string formatting notes
5. Fill in the blanks below:
x = input("Enter an integer: ")
y = input("Enter another integer: ")
print "%__d__ + %___d____ is a big %__s___!" % (x, y, "number")
6. Explain what it means to say that + is overloaded.
See class notes.
7. What is the value of the Python expression? If the expression is not valid, write "error". The way in which you write the value should indicate its type.
a. 25%2
b. "call " + 911
c. 3 - 8 + 6 * 4 % 2
d. round(3.55)
e. str(411)
f. (20 + 20 + 20) / 3
g. not (true or false)
h. (3 > 1) or ("help" > "fire")
This are easy to check with the interpreter.
8. Write a couple of lines of code that indicate whether or not the string referenced by variable s contains the substring "hi".
if string.find("hi") >= 0:
print "contains hi"
else:
print "does not contain hi"
9. Write a function reverseIt() that takes a string s and returns the reverse of s.
We did this one in class.
10. Write a function evenPos() that takes a string s and returns the string that contains the characters of s at even indices. That is, if s is "helloworld" then the string returned by evenPos() should be "hlool".
def evenPos(s):
str = ""
for i in range(0, len(s), 2):
str += str[i]
return str
11. What is a variable's scope? See online class notes.
12. Write a function numTimes(n) that returns a tuple containing: n, 2n, 3n, and 4n.
def numTimes(n):
return n, 2*n, 3*n, 4*n
13. Write a program that computes the sum of a list of integers entered by the user. The user hits the enter key when they have no more numbers to enter.
We did this sentinel loop example in class.
14. Explain how eval() works.
See class notes.
15. what is the output?
s = "hello world"
print s[-2]
print s[-3]
print s[0]
print s[2:]
16. Describe how the functions count(), upper() and capitalize() in the string library work.
17..
This problem was worked in discussion.
18. Write a program that prints the following output. You may only print one character at a time.
1
12
123
1234
12345
123456
1234567
12345678
...
12345678910111213... 20
for i in range(1, 21):
for j in range(1, i+1):
sys.stdout.write(str(j))
print # go to new line
19. Write a function printBox(m, n). If m and n aren't both positive, do nothing. If they are both positive, print a box like this, where m is the number of rows and n is the number of asterisks in the top (and bottom) rows.
****
* *
* *
* *
****
def printBox(m, n):
if m > 0 and n > 0:
print "*" * n
s = " "* (n-2)
s = "*" + s + "*"
s = s + "\n"
print s*m
print "*" * n
20. Write a function getPowers(x) that returns a tuple containing x, x^2, x^3, and x^4. Then write a main() function that reads 10 integers from the user, and for each integer read, prints that value raised to the powers 3 and 4.
21. Write a function that takes the name of an input file as its argument, and returns the number of lines in the file that contain the word "hello". Then write a main() function that calls this function for a text file you've created.
I've left it to you to write the main function.
def countHello(myFile):
# myFile is a string
f = open(myFile, "r")
count = 0
for line in f:
if line.find("hello") >= 0:
count = count + 1
f.close()
return count
22. Write a Python program that creates a new file named outFile.txt and prints the following to it:
1 2 3
4 5
6
Done in discussion sections.
23: Write a python program that reads all the lines from a file inFile.txt and prints the last character in each line to the screen.
If inFile.txt contains:
hello world
Elvis lives!
Then your program should print:
d!
to the screen.
str = ""
f = open("inFile.txt", "r")
for line in f:
s = line
if s[-1] = '\n':
s = s[:-1]
str += s[-1]
print str
f.close() | http://www.cs.utexas.edu/~eberlein/cs303e/mid2ReviewSols.html | CC-MAIN-2015-27 | refinedweb | 926 | 84.78 |
ARDUINO
Shields And Hardware
Infrared Sensors
Supplier: DealExtreme
Supplier Link: (unknown)
Price: (unknown)
A simple three PIN device that is good for binary (on/off) short-range detection between 0-30mm. Uses a POT to adjust the threshold. This came with the Arduino 4WD Robot platform.
Freetronics LCD And Keypad Shield
Part Number: SH-16X2LCD
Supplier: Freetronics, Jaycar
Price: US$29.95 (as of 2013)
The Freetronics LCD And Keypad shield is a very popular display/UI shield for the Arduino.
The Arduino comes with a LCDCrystal library, making it almost too easy to use the LCD display (see the minimal code example below).
#include <LiquidCrystal.h> // Code example taken from the Freetronics website LiquidCrystal lcd( 8, 9, 4, 5, 6, 7 ); void setup() { lcd.begin(16, 2); lcd.print("hello, world!"); } void loop() { // your main loop code here... }
Motor Controller
Sensor Shield
Ultrasonic Ranging Module HCSR-04
Part Number: HCSR-04
Supplier: DealExtreme
Supplier Link: (click here)
Price: US$4.00 (as of 2012)
Very easy to interface to, due there being a native Arduino API function called pulseIn(), which returns the length of a digital pulse measured on one of it’s pins. Example firmware code for this module can be found on the xAppSoftware Blog. Included in the Arduino 4WD Robot Platform.
The DealExtreme Robotic Platform
Supplier: DealExtreme
Product Link: (, as of Dec 2017, URL is unavailable)
Price: US$71.70 (as of 2012)
A cheap, versatile, easy-to-use (well, kind of, but read the next paragraph) robotics platform.
No instructions come with this! You are left on your own to figure out how to assemble and then use it. That said, you can find instructions written by users for most of the individual components on online blogs. | https://blog.mbedded.ninja/programming/microcontrollers/arduino/shields-and-hardware/ | CC-MAIN-2020-40 | refinedweb | 292 | 64.61 |
I'm trying to fetch a list of timestamps in MySQL by Python. Once I have the list, I check the time now and check which ones are longer than 15min ago. Onces I have those, I would really like a final total number. This seems more challenging to pull off than I had originally thought.
So, I'm using this to fetch the list from MySQL:
db = MySQLdb.connect(host=server, user=mysql_user, passwd=mysql_pwd, db=mysql_db, connect_timeout=10)
cur = db.cursor()
cur.execute("SELECT heartbeat_time FROM machines")
row = cur.fetchone()
print row
while row is not None:
print ", ".join([str(c) for c in row])
row = cur.fetchone()
cur.close()
db.close()
>> 2016-06-04 23:41:17
>> 2016-06-05 03:36:02
>> 2016-06-04 19:08:56
fmt = '%Y-%m-%d %H:%M:%S'
d2 = datetime.strptime('2016-06-05 07:51:48', fmt)
d1 = datetime.strptime('2016-06-04 23:41:17', fmt)
d1_ts = time.mktime(d1.timetuple())
d2_ts = time.mktime(d2.timetuple())
result = int(d2_ts-d1_ts) / 60
if str(result) >= 15:
print "more than 15m ago"
I assume
heartbeat_time field is a datetime field.
import datetime import MySQLdb import MySQLdb.cursors db = MySQLdb.connect(host=server, user=mysql_user, passwd=mysql_pwd, db=mysql_db, connect_timeout=10, cursorclass=MySQLdb.cursors.DictCursor) cur = db.cursor() ago = datetime.datetime.utcnow() - datetime.timedelta(minutes=15) try: cur.execute("SELECT heartbeat_time FROM machines") for row in cur: if row['heartbeat_time'] <= ago: print row['heartbeat_time'], 'more than 15 minutes ago' finally: cur.close() db.close()
If data size is not that huge, loading all of them to memory is a good practice, which will release the memory buffer on the MySQL server. And for DictCursor, there is not such a difference between,
rows = cur.fetchall() for r in rows:
and
for r in cur:
They both load data to the client. MySQLdb.SSCursor and SSDictCursor will try to transfer data as needed, while it requires MySQL server to support it. | https://codedump.io/share/jscTs8VRARls/1/python-foreach-from-a-mysqldb | CC-MAIN-2018-09 | refinedweb | 329 | 61.33 |
If you have already read the article and only want to know what's new, click here. The second update is here.
I already wrote the article Yield Return Could Be Better and I must say that
async/await could be better if a stack-saving mechanism was implemented to do real cooperative threading. I am not saying that the async/await is a bad thing, but it could be added without compiler changes (enabling any .NET compiler to use it)
and maybe adding keywords to make its usage explicit. Different from the other time, I will not only talk about the advantages, I will provide a sample implementation of a stacksaver and show its benefits.
async/await
The async/await was planned for .NET 5 but it is already available in the 4.5 CTP. Its promise is to make asynchronous code easier to write, which it indeed does.
But my problem with it is: Why do people want to use the asynchronous pattern to begin with?
The main reason is: To keep the UI responsive.
We can already maintain the UI responsive using secondary threads. So, what's the real difference?
Well, let's see this pseudo-code:
using(var reader = ExecuteReader())
while(reader.ReadRecord())
listbox.Items.Add(reader.Current)
Very simple, a reader is created and while there are records, they are added to a listbox. But imagine that it has 60 records, and that each
ReadRecord takes one second to complete. If you put that code in the Click of a Button, your UI will freeze for an entire minute.
ReadRecord
If you put that code in a secondary thread, you will have problems when adding the items to the listbox, so you will need to use something
like listbox.Dispatcher.Invoke to really update the listbox.
listbox.Dispatcher.Invoke
With the new await keyword, your method will need to be marked as async and you will need to change the
while line, like this:
await
async
while
while(await reader.ReadRecordAsync())
And your UI will be responsible.
Your UI became responsible by a simple call to await?
And what's that ReadRecordAsync?
ReadRecordAsync
Well, here is where the complexity really lives. The await is, in fact, registering a continuation and then allowing the actual method
to finish immediately (in the case of a Button Click, the thread is free to further process UI messages). Everything that comes
after await
will be stored in another method, and any data used before and after the await keyword will live in another class created by the compiler and passed
as a parameter to that continuation.
Then there is the implementation of ReadRecordAsync. This one may be considered the hardest part, as it may use some kind of real asynchronous
completion (like IO completion ports of the Operating System) or it will still use a secondary thread, like a ThreadPool thread.
ThreadPool
If it still uses secondary threads, you may wonder how it is going to be faster than a normal secondary thread.
Well... it is not going to be faster, it may be a little slower as it by default needs to send a message back to the UI thread when the process is completed.
But if you are going to update the UI, you will already need to do that.
Some speed advantage may reside on the fact that the actual thread may already start something else (instead of waiting doing nothing) and also on the
ThreadPool usually used by the Tasks, which forbids too many concurrent work items. That is, some work items need to end so new work
items (including Tasks) can start. With normal threads, we may risk having too many threads trying to run at once (much more than the real processor count),
when it will be faster to let some threads simply wait to start (and also too many threads occupy too many OS resources).
Task
Independent of the benefits of the ThreadPool and the ease of use of the async keyword, did you notice that when you put an await
in a method the actual thread is free to do another job (like processing further UI messages)?
And that at some point such await will receive a result and continue? With that you can very easily start
five different jobs. Each one, at the end,
will continue running on the same thread (probably the UI).
It is not hard to see those jobs as "slim" threads. As a Job, they start, they "block" awaiting, and they continue. The real
thread can do other things in the "blocking" part, but the same already happens with the CPU when a real thread enters a blocking state (the CPU continues
doing other things while the thread is blocked).
Job
Such Jobs don't necessarily have priorities, they run as a simple queue in their manager thread but every time they finish or enter in a "wait state",
they allow the next job to run.
So, they will all run in the same real thread, and one Job must await or finish to allow others to run. That's cooperative threading.
I said at the beginning that it could be better so, how?
Well, real cooperative threads will do the same as the await keyword, but without the
await keyword, without returning a Task, and consequently
making the code more prepared to future changes.
You may think that code using await is prepared for future changes, but do you remember my pseudo-code?
Imagine that you update it to use the await keyword. At this moment, only the
ReadRecord method is asynchronous, so the code ends-up like this:
using(var reader = ExecuteReader())
while(await reader.ReadRecordAsync())
listbox.Items.Add(reader.Current)
But in the future, the ExecuteReader method (which is almost instantaneous today) may take 5 seconds to respond. What do I do then?
ExecuteReader
I should create an ExecuteReaderAsync that will return a Task and should replace all the calls to ExecuteReader()
by an await ExecuteReaderAsync(). That will be a giant breaking change.
ExecuteReaderAsync
ExecuteReader()
await ExecuteReaderAsync()
Wouldn't it be better if the ExecuteReader itself was able to tell "I am going to sit and wait, so let another job run in my place"?
Here is where all the problems are concentrated and here is the reason await keyword exists. Well, I think people at Microsoft got so fascinated
that they could change the compiler to manage secondary callstacks using objects and delegates (effectively creating the continuation) that they forgot they can
create a full new callstack and replace it.
If you don't know what the callstack is, you may have already seen it in the debugger window. It keeps track of all methods that are actually executing and all
variables. If method A calls method B, which then calls method C, it will have the exact position in method C, the position it will be when C returns, and also the
position to return to A when B returns.
A continuation is the hard version of this. In fact, simply continuing with another method is easy, the problem is creating a try/catch block in method
A and putting a continuation to B that is still in the same try/catch. In fact the compiler will create an entire try/catch in method A and
in method B, both executing the same code in the catch (probably with an additional method to be reutilized by the catch code).
try/catch
catch
If instead of managing a "secondary callstack" in a continuation they created a completely new callstack and replaced the thread callstack by the new and,
at wait points, restored the original callstack, it will be much simpler as all the code that uses the callstack will continue to use it. No additional methods or different
control flows to deal with try/catches.
Such an alternative callstack is what I call a StackSaver in the other article but my original idea was misleading. It does not need to save and restore
part of the callstack. It is a completely separate callstack that can be be used in place of the normal callstack (and will restore the original callstack in waits or
as its last action). It will be a "single pointer" change to do all the job (or even a single CPU register change).
StackSaver
The .NET team did a lot of changes to support the "compiler magic" to make the async work, and I tell that if we can simply create new callstacks,
we can have the same benefits with an even easier to use and more main tenable code, and that all we need is to be able to switch from one callstack to another.
That looks too simple and maybe you think that I am missing something, even if you don't know what, and so you believe it will not work.
Well, that's why I created my simulation of a StackSaver to prove that it works.
My simulation uses full threads to store the callstack, after all there is no way to switch from one callstack to another at the moment. But this is a simulation,
and it will prove my point.
Even being full threads, I am not simply letting them run in parallel as that will have all the problems related to concurrency (and will be normal threading).
The StackSaver class is fully synchronized to its main thread, so only one runs at a time.
This will give the sensation of:
StackSaver.Execute
StackSaver.YieldReturn
The only big difference of my StackSaver is that anything that uses the Thread identify (like WPF) will notice that it is another thread.
So it is not a real replacement but works for my simulation purposes and already allows to create a yield return replacement without any compiler tricks.
Thread
yield return
You didn't see wrong, I am not committing an error, by default the StackSaver allows for a yield return replacement, not for an async/await replacement.
To use the StackSaver as an async/await replacement, we must have a thread that deals with one or more StackSavers.
I am calling the class that creates such a thread as CooperativeJobManager.
CooperativeJobManager
It runs like an eternal loop. If there are no jobs, it waits (real thread waiting, no job waiting). If there are one or more Jobs, it dequeues a Job
and makes it run. As soon as it returns (by a yield return or by finishing) and the original caller regains execution, it checks if it should put the
Job again in
the queue (as the last one) or not.
The only problem then is to wait for something. When the Job request a "blocking" operation, it must create a CooperativeWaitEvent, will set-up how the
async part of the job really works (maybe using the ThreadPool, maybe using IO completion ports), will mark itself as waiting, and will yield return.
CooperativeWaitEvent
The main callstack, after seeing the Job is waiting, will not put it in the execution queue again. But when the real operation ends and "Sets" the wait event,
it will requeue the job.
It is simple as that and here is the entire code of the CooperativeJobManager:
using System;
using System.Collections.Generic;
using System.Threading;
namespace Pfz.Threading.Cooperative
{
public sealed class CooperativeJobManager:
IDisposable
{
private readonly HashSet<CooperativeJob> _allTasks = new HashSet<CooperativeJob>();
internal readonly Queue<CooperativeJob> _queuedTasks = new Queue<CooperativeJob>();
internal bool _waiting;
private bool _wasDisposed;
public CooperativeJobManager()
{
// The real implementation uses my UnlimitedThreadPool class.
// I removed such class in this version to give a smaller download
// and make the right classes easier to find.
var thread = new Thread(_RunAll);
thread.Start();
}
public void Dispose()
{
lock(_queuedTasks)
{
_wasDisposed = true;
if (_waiting)
Monitor.Pulse(_queuedTasks);
}
}
public bool WasDisposed
{
get
{
return _wasDisposed;
}
}
private void _RunAll()
{
CooperativeJob task = null;
//try
//{
while(true)
{
lock(_queuedTasks)
{
if (_queuedTasks.Count == 0)
{
if (task == null)
{
do
{
if (_wasDisposed && _allTasks.Count == 0)
return;
_waiting = true;
Monitor.Wait(_queuedTasks);
}
while (_queuedTasks.Count == 0);
}
}
else
{
if (task != null)
_queuedTasks.Enqueue(task);
}
if (_queuedTasks.Count != 0)
{
_waiting = false;
task = _queuedTasks.Dequeue();
}
}
CooperativeJob._current = task;
if (!task._Continue() || task._waiting)
task = null;
}
//} will only work with real stacksavers.
//finally
//{
// CooperativeTask._current = null;
//}
}
public CooperativeJob Run(Action action)
{
if (action == null)
throw new ArgumentNullException("action");
var result = new CooperativeJob(this);
var stackSaver = new StackSaver(() => _Run(result, action));
result._stackSaver = stackSaver;
lock(_queuedTasks)
{
_allTasks.Add(result);
_queuedTasks.Enqueue(result);
if (_waiting)
Monitor.Pulse(_queuedTasks);
}
return result;
}
private void _Run(CooperativeJob task, Action action)
{
try
{
CooperativeJob._current = task;
action();
}
finally
{
CooperativeJob._current = null;
lock(_allTasks)
_allTasks.Remove(task);
}
}
}
}
With it, you can call Run passing an Action and that action will start as a CooperativeJob.
Run
CooperativeJob
If the action never calls a CooperativeJob.YieldReturn or some cooperative blocking call, it will effectively execute the action directly.
If the action does some kind of yield or cooperative wait, then another job can run in its thread.
CooperativeJob.YieldReturn
Now imagine this in your old Windows Forms application. At each UI event, you
call CooperativeJobManager.Run to execute the real code.
In those codes, any operation that may block (like accessing databases, files, or even Sleeps) allows another job to run. And that's all, you have full
asynchronous code that does not have the complication of multi-threading and really looks like synchronous code.
CooperativeJobManager.Run
The source for download is done in .NET 3.5 and I am sure it may work even under .NET 1.0 (may require some changes).
The real missing thing is the StackSaver class which, as I already told
you, uses real threads in this implementation, so it is more useful for demonstration purposes only.
I can only see one. It is explicit, so users can't say they faced an asynchronous problem when they did synchronous code.
But that can be easily solved in cooperative threading by flags that will effectively tell the CooperativeJob that it cannot
"block", raising an exception if a "blocking" call is done. It is certainly easier to make an area as "must not run other jobs here"
than to have to await 10 times to do 10 different reads or writes.
From my writing, you may notice that a "blocking" call is not the same as a blocking call.
A "blocking" call blocks the actual job but lets the thread run freely. A real blocking call blocks the thread and, when it returns, it continues running the same job.
Surely it may be problematic if we have a framework full of blocking and "blocking" calls. But Microsoft is already reinventing everything
with Metro (and even Silverlight has a network API that is asynchronous only).
So, why not replace all thread-blocking calls with job-blocking calls and make programming async software as easy as normal blocking software?
Then ask Microsoft to add real cooperative threading through a stack-saver by clicking
on this
link and then voting for it.
I only did a very simple sample to show the difference of a real thread-blocking call versus a job-blocking call.
I am surely missing better samples and maybe I will add them later. Do not let the simplicity of the sample kill the real potential of the callstack "switching" mechanism,
which can make better versions of asynchronous code, yield return, and also open a lot of new scenarios for cooperative programming, making it easier to write
more isolated code that can both scale and be prepared for future improvement without breaking changes.
I am finally presenting the first version of a StackSaver for .NET itself (even if it is a simulation) but this is not the first time
I show a working version of the concept. I already presented it working in my POLAR language.
The language is still an hybrid between compilation and interpretation, but it uses the stacksaver as a real callstack replacement
and it will be relatively easy to implement asynchronous calls to it using the Job concept instead of the await keyword.
I don't have a date for it as I am doing too many things at the time (like still adapting to a new country), but I can guarantee that it could be capable
of working with such Jobs without even knowing how to deal with secondary threads.
stacksaver
When I started writing this article, I didn't really know what coroutines where and I had no idea what a fiber was.
Well, at this moment I am really considering renaming my StackSaver class to Coroutine, as that is what it is really providing.
And Fibers are OS resources that allow to save the callstack and jump to another one and is the resource needed to create coroutines.
I did try to implement the StackSaver class using Fibers through P/Invoke but unfortunately unmanaged Fibers don't really work in .NET.
I really think that it is related to garbage collection, after all when searching for root objects, .NET will not see the "alternative callstacks"
created by unmanaged fibers and will collect objects that are still alive, but unseen.
Either way, at this moment I will keep the name StackSaver and "Jobs", as this is similar to task but does not cause trouble with
the Task class.
From the comments I understand that I did not give the best explanation and people
are getting confused by my claims.
If you see the source code of the StackSaver, you will see threads that block. So don't see the code of the StackSaver. See its idea:
You create a StackSaver with a delegate. When you call stacksaver.Execute, it will execute that delegate until it ends or until it finds
a stacksaver.YieldReturn/StackSaver.StaticYieldReturn.
stacksaver.Execute
stacksaver.YieldReturn/StackSaver.StaticYieldReturn
When yielding, the original caller returns to its execution, and when it calls Execute again, the statement of the delegate just after
the YieldReturn will continue. This will generate the exact same effect of the yield return used by enumerators.
Execute
YieldReturn
Then the async/await replacement is based on a kind of "scheduler" that I call CooperativeJobManager. That scheduler is able to wait
if it has 0 jobs scheduled or runs one job after the other when there are jobs scheduled.
The only thing missing by default is the the capacity to "unschedule" a job while it is waiting and to reschedule it again when the asynchronous part gets a result.
That is done by marking the job as waiting and "yield returning". The scheduler then does not reschedule that job immediately, but when the "wait event" is
signaled,
the job is scheduled again.
If the scheduler was using the ThreadPool, it will have the same
capacity of async/await in the sense that after awaiting, the job may be continued
by another thread.
If that is still not enough to understand, I am already considering creating
a C++ version of the code that does not use Threads in the StackSaver class.
But the rest of the code (that uses the StackSaver) will be the same... and I am not sure if C++ code will really help get the idea.
I said that my approach is more prepared for future changes but the examples where too abstract. That may be one of the reasons for confusion. So, let's focus on something more real.
Let's imagine a very simple interface for getting ImageSources. The interface has a Get method that receives a filename. Very simple, but let's see two completely different implementations. One loads all the images on startup, so when asking for an image, it is always there and returns immediately.
ImageSource
Get
The other always loads images when asked to. It does not try to do any caching.
Now, let's imagine that when I click a button, I get all the images (let's say there are 100s of them), generate the thumbnails for all of them in a single image, and then save them. Here comes the problem with asynchronous code: How can the interface return an ImageSource if the image loading is asynchronous?
The answer is: The interface can't return an ImageSource. It should return a Task<ImageSource>.
Task<ImageSource>
In the end, with the Task based asynchronous code, we will:
Write
As you can see, there are a lot of tasks created here, even when the implementation has all things in memory.
It is possible to store the tasks themselves in the cache (and that will avoid some of the async magic) but we will still have a higher overhead when reading
the results from the cache that has everything in memory.
With my proposed "job synchronous/thread asynchronous code":
Total jobs? 1. If we use the implementation that has all images in memory, we will have faster code because we will receive
the ImageSources as results, not Tasks to then get their results.
If you believe that Task based asynchrony will be better because
it may use secondary threads if needed, then think again, as Job
based asynchrony can too. The secondary threads, if any, are used by the real asynchronous code (when loading or reading a file, IO completion ports can be used).
After the asynchronous action ends, it should ask the continuation Task to be scheduled (with a Job, it will be rescheduled).
If the image loading itself may use hardware acceleration to convert bytes into image representation and so is returning a Task too, well,
the Job can also start that hardware asynchronous code and be put to sleep, returning its execution when the generated image is ready.
All the advantages of the Task based approach that I can resume as can be continued later, be it on the same thread or on another thread
are there. Most part of the disadvantages (like you getting lost when a [ThreadStatic] value is not there anymore) are present too. But all your methods can continue to return
the right value types (not Tasks).
[ThreadStatic]
With my proposed solution, if some code may end-up calling synchronous or asynchronous code (like the interface that may return images directly or load them)
you don't need to generate extra Tasks only to be sure that it will work when the code is asynchronous. Simply let the Job block and be rescheduled later.
I hope it makes more sense now.
After a lot of talk with Eugene Sadovoi, I am sure I am not clear enough. So, for those who are still lost, I am sorry. I really tried to omit some things trying to make the article shorter and easier to read, but apparently I did the opposite.
And, for those who simply want more info, I will try to give it now. So, some new "viewpoints" on the matter:
Not only the words Job and Task may have the same meaning, they are effectively the same. In all my article, I tried to use the word Job to represent a cooperative Job,
while a Task represents .NET classes (Task and Task<T>).
Task<T>
But the only thing that is really needed for a Task to become a Job is the possibility to "pause" at any moment. With the await
keyword, we can only pause the actual method if it returns a Task. We can't pause the caller of the actual method.
If the await was capable of pausing the actual Task, be it the Task returned by this method, the Task
that called this method directly, or the Task that called an unknown number of methods before reaching the actual method, the Task
will be a Job and await will really represent a "make the actual Task/Job wait and let the actual thread do something else".
So, all my article is in fact "Under the Hood". How we can make the actual Task be paused at any moment?
Returning a Task is an implementation detail. What users want is to use the
await keyword... and, when using it,
they really want to say: While waiting for this result, allow the actual thread to do something else.
With the actual compiler implementation, it is impossible for a method to return
void and make the caller Task await. They make the actual
task "return a continuation to continue later". I think that is too much implementation details, users don't want that.
void
With cooperative threading, which is in fact based on some kind of stack saving/switching mechanism, we can really make a Task wait at any moment.
It is not required to register a continuation and return all methods on the call stack (and those, to register continuations if needed). It can simple say: "await now,
independent of how many things I have on the callstack" and then have the continuation code as the next instruction. That affects a lot
of the other methods (the callers) not the actual method.
The Tasks are not created for any method that may await. They are created at "keypoints" only.
For a WPF or Windows Forms application, that means that every "UI event" must create a Task",
so it can await at any moment.
As long as you don't need parallel execution, you simply write synchronous code that will work with asynchronous sub-methods. But when you really want parallel
execution, you create Tasks over the calling methods (that will become delegates) and use things like Task.WaitAny or Task.WaitAll.
Task.WaitAny
Task.WaitAll
Maintenance - My solution works as any blocking code and does not require changes if in the future an inner method starts to block.
Learning curve - As you don't really change the code, it is easy to learn.
Speed - Considering a Job can be a "pausable Task", all optimizations done to tasks can be done to jobs.
Speed 2 - Considering the state machine (used by the actual Task implementation), you always have a little "cost" to return to the exact
same position in the method, which is a fixed time with the stack-saving mechanism (and I am not even sure if there aren't optimizations or specific CPU commands to save the stack/registers).
Memory - My approach may use more memory for the callstack, but it may end-up allocating much less Task objects, so it may even end-up using less memory. I will consider here
the actual implementation and mine are equivalent, no one is really better.
Context switches - As happens with any await use, will only happen when the
Operating System re-schedules the actual thread with another real thread (that is unavoidable)
or when the actual "Task/Job" yields or enters some await state.
To compiler developers - It will not require other compilers to change as the Tasks will be a "pausable" and "awaitable" class. As there
are no compiler tricks,
there is no chance of one compiler generating a better state machine than other. There is no chance of one compiler supporting it and other compilers not.
Also, with the exact same implementation, all errors that users may face will be the same independent of the used compiler. With the compiler based trick,
it is possible that some compilers have one kind of issue, while other compilers have others.
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
Paulo Zemek wrote:Instead of doing the job in the compiler, it could be done in the CLR.
[Yes,] if you believe that it can be done, if you understand the [system] inside and out, and if you're willing to think past the obvious solution to unconventional but potentially more fruitful approaches. --Graphics Programming Black Book
Paulo Zemek wrote:it wouldn't require copying the full callstack, only the area needed by the continuation.
Paulo Zemek wrote:About walking the full callstack...
async void ArchiveDocuments(List<Url> urls)
{
Task archive = null;
for(int i = 0; i < urls.Count; ++i)
{
var document = await FetchAsync(urls[i]);
if (archive != null)
await archive;
archive = ArchiveAsync(document);
}
}
DoEvents()
Job.Start(delegate{})
Task.WhenAll(someList.Select(x => x.DoAsync()))
Job.Start
DoEvents
Paulo Zemek wrote:Can I put those in the article directly? I really think they should be visible.
In the end, with the Task based asynchronous code, we will:
• Create 100 Tasks, even when using the implementation that has all images in memory.
• 1 extra task will be created for the method that generates the thumbnails.
• Finally, when saving, an extra task is generated for the file save (even if we don't use it, but the asynchronous Write will create it).
• In fact, there are some more tasks, as the opening and reading are two different asynchronous things, like creating and writing to the files.
With my proposed "job synchronous/thread asynchronous code":
• 1 job is created to execute all the code.
• The 100 image gets will not "block" with the cache that has all images already loaded, or they will block 100 times the Job, not the Thread, when loading the images with the other implementation.
• After getting or loading all images with "synchronous" semantics it will execute the thumbnail generation normally, and then saves the image, "blocking" the Job again.
• Then by ending the method the job ends.
Total jobs? 1. If we use the implementation that has all images in memory, we will have a faster code because we will receive the ImageSources as resuls, not Tasks to then get their results.
I really tried to show many points of advantage and gave a simulation to show the benefits to the user.
... on the ThreadPool usually used by the Tasks, which forbid too many concurrent tasks.
General News Suggestion Question Bug Answer Joke Praise Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages. | http://www.codeproject.com/Articles/357724/Async-Await-Could-Be-Better?msg=4216661 | CC-MAIN-2015-48 | refinedweb | 4,983 | 60.95 |
I presume I'm just missing something obvious, but maybe its something more serious. The namespace is reasonably new (as is the entire project). Powered by Blogger. Error: unsupported MXML namespace found (‘'). have a peek at this web-site
It so happens that the ToolTip class isn't included in the native Flex component manifest, and consequently the compiler won't be able to find it if you just write "
well, actually Flex autotyped it. The problem comes when you try to use a component that is expected to be found, by the framework or parent component, in the default namespace. solution: rename myform.as to be myformscript.as or something different with the mxml file.
How much effort (and why) should consumers put into protecting their credit card numbers? Thanks for asking a question that pointed me in the right direction! –reidLinden Jul 1 '10 at 12:21 What I'm not understanding, however, is, why is the compiler picking Click "Flex Library Build Path" Click the "Classes" tab Try to find the name of your new component in there. The error goes away again.
thus the error was thrown because a mx namespace property tag cannot go inside another namespace component. As far as I can tell, there are no other components with that name. Related Could not resolve to a componentimplementation Post navigation ←Installed Flash Player Not ADebuggerConfirm Overwrite→ 8 thoughts on “Could not resolve to a componentimplementation” JabbyPanda says: I do not understand you🙂 First, I added a new component, of the exact same variety, and then copied the contents of the erroring component into it.
People Assignee: Unassigned Reporter: Alexander Farber Votes: 0 Vote for this issue Watchers: 3 Start watching this issue Dates Created: 10/Aug/13 10:23 Updated: 11/Aug/13 18:14 Resolved: 11/Aug/13 18:14 DevelopmentAgile View on I did a small mistake, which I identified and fixed. What am I missing? In your situation you may need to include a xmlns:ns1="*" or xmlns:myNamespace="pathtoclasses" in application tag.
in my project i included it and used namespace "ns1" to reference my components. Browse other questions tagged flex or ask your own question. share|improve this answer answered Nov 4 '12 at 15:40 carbon fiber 414 I have done that before as well and had it help other situations. Is the effect of dollar sign the same as textit?
does that make sense? [xml] [/xml] LikeLike January 16, 2007 at 5:04 pm Reply JabbyPanda says: Thanks for the clarification, now I got the idea better, although still not 100%, because Check This Out Aloseous Nov 18, 2009 6:03 AM (in response to Gregory Lafrance) Thanks for the reply.I replace the
Posted by: Thijs | October 9, 2008 9:16 AM Thanks very much! Now here is the catch; This is technically valid and will often work. I was getting a "Could not resolve mx:Application to a component implementation" message. Source That should solve the problem right there, but you may have to clean and (sometimes) quit FB4 and relaunch.
Sparrow | May 17, 2009 4:06 PM Thank you very much for posting this. I'd really like to understand what I've done wrong here. Designed by ST Software for PTF.
You can not post a blank message. thanksReplyDeleteAdd commentLoad more... Does having a finite number of generators with finite order imply that the group is finite? McClane is a NYPD cop.
Until then, it won't appear on the entry. Fixing HP Mopier, Collation, and Storage problems (WIN 7) Java 8 on OS X Yosemite Archives Archives Select Month March 2016 (2) December 2015 (1) October 2015 (1) November 2014 (1) I may have been able to just set it to "4.6.0" without having to first set it to "3.6" but wanted to report exactly what I had done. have a peek here I renamed the actionscript file, relinked, and Voile!
Please reply in the comments below if this helped you or not Share this:TwitterFacebookGoogleLike this:Like Loading... Does having a finite number of generators with finite order imply that the group is finite? Fill in your details below or click an icon to log in: Email (required) (Address never made public) Name (required) Website You are commenting using your WordPress.com account. (LogOut/Change) You are I first got this error after removing all the script from OrderEntryView_2_Cart.mxml and placing it into a file OrderEntryView_2_Cart.as which is then sourced into the mxml file.
I then tried changing the Flex SDK in Project->Properties->Flex Compiler from the "Use default SDK (currently "4.6.0") back to "Use a specific SDK: Flex 3.6" (which was the only other one Like Show 0 Likes(0) Actions 5. | http://gsbook.org/error-could/error-could-not-resolve-to-a-component-implementation.php | CC-MAIN-2018-17 | refinedweb | 801 | 64.61 |
After doing a lot of python GTK+ work on Exaile, I’ve found that it uses glib.idle_add() extensively — and usually with good reason. idle_add is great if you want to ensure that whatever you’re calling is being called on the GUI thread, so that way you don’t have to worry too much about thread interactions as long as you keep things separate.
Another mentor and I are developing a GUI video game along with a ‘fake wpilib’ for our FIRST Robotics programming students to help them learn how to program, and as such we’ve decided to use TKinter for the GUI toolkit (since it supports Python 3, and usually doesn’t require the kids to install anything special to make it work). However, as I started making things I couldn’t find the equivalent of idle_add() for TKinter, and I guess there isn’t one — after_idle() apparently blocks until the event loop is idle, and so that isn’t what I wanted.
A number of posts I found online advocated to poll a queue for input… but I *really* dislike polling, and try to avoid it when I can. So I wrote up this set of routines that is roughly equivalent to idle_add() in tkinter, and uses a queue while avoiding polling.
import Tkinter as tk from queue import Queue, Empty def idle_add(callable, *args): '''Call this with a function and optional arguments, and that function will be called on the GUI thread via an event. This function returns immediately. ''' queue.put((callable, args)) root.event_generate('<<Idle>>', when='tail') def _on_idle(event): '''This should never be called directly, it is called via an event, and should always be on the GUI thread ''' while True: try: callable, args = queue.get(block=False) except queue.Empty: break callable(*args) queue = Queue() root = tk.Tk() root.bind('<<Idle>>', _on_idle) | http://www.virtualroadside.com/blog/index.php/2012/11/ | CC-MAIN-2018-05 | refinedweb | 310 | 66.07 |
Type: Posts; User: hamee67
Write a java program named ConvertDate that converts a date entered by the user into another form. the users inout will have the form
month day, year
the month will be one of the word january ,...
import java.util.*;
import java.io.*;
public class convertdate{
public static void main(String[] args){
System.out.print("Enter date to be converted: "); // Inputs the...
need a program that works
--- Update ---
every on e is crashing
write a class namesd fibonacci which when called by the class CalcFib will calcul;ate the fibonacci sequence of numbers. the first two numbers in the Fibonacci sequence are 1 and should be accounted... | http://www.javaprogrammingforums.com/search.php?s=2a718d573c7c30b3f4b0f26a291052ea&searchid=1075359 | CC-MAIN-2014-41 | refinedweb | 110 | 62.48 |
vers
Notes
This section describes the available solvers that can be selected by the ‘method’ parameter. The default method is Brent.
Method Brent uses Brent’s algorithm to find a local minimum. The algorithm uses inverse parabolic interpolation when possible to speed up convergence of the golden section method.
Method Golden uses the golden section search technique. It uses analog of the bisection method to decrease the bracketed interval. It is usually preferable to use the Brent method.
Method Bounded can perform bounded minimization. It uses the Brent method to find a local minimum in the interval x1 < xopt < x2.
Custom minimizers
It may be useful to pass a custom minimization method, for example when using some library frontend to minimize_scalar. You can simply pass a callable as the method parameter.
The callable is called as method(fun, args, **kwargs, **options) where kwargs corresponds to any other parameters passed to minimize (such as bracket, tol, etc.), except the options dict, which has its contents also passed as method parameters pair by pair..
Examples
Consider the problem of minimizing the following function.
>>> def f(x): ... return (x - 2) * x * (x + 2)**2
Using the Brent method, we find the local minimum as:
>>> from scipy.optimize import minimize_scalar >>> res = minimize_scalar(f) >>> res.x 1.28077640403
Using the Bounded method, we find a local minimum with specified bounds as:
>>> res = minimize_scalar(f, bounds=(-3, -1), method='bounded') >>> res.x -2.0000002026 | http://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize_scalar.html | CC-MAIN-2016-18 | refinedweb | 238 | 58.08 |
Ideally, the hash function will assign each key to a unique bucket, but most hash table designs use an imperfect hash function, which might cause hash collisions where the hash function generates the same index for more than one key. In computing, a hash table (hash map) is a data structure that implements an associative array abstract data type, a structure that can map keys to values. In January 1953, Hans Peter Luhn write an internal IBM memorandum that used hashing with chaining. gene Amdahl, Elaine M. McGraw, Nathaniel Rochester, and Arthur Samuel implemented a plan use hashing at about the same time. open addressing with linear probing (relatively prime stepping) is credited to Amdahl, but Ershov (in Russia) had the same idea.
#!/usr/bin/env python3 from hash_table import HashTable from number_theory.prime_numbers import next_prime, check_prime class DoubleHash(HashTable): """ Hash Table example with open addressing and Double Hash """ def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) def __hash_function_2(self, value, data): next_prime_gt = ( next_prime(value % self.size_table) if not check_prime(value % self.size_table) else value % self.size_table ) # gt = bigger than return next_prime_gt - (data % next_prime_gt) def __hash_double_function(self, key, data, increment): return (increment * self.__hash_function_2(key, data)) % self.size_table def _collision_resolution(self, key, data=None): i = 1 new_key = self.hash_function(data) while self.values[new_key] is not None and self.values[new_key] != key: new_key = ( self.__hash_double_function(key, data, i) if self.balanced_factor() >= self.lim_charge else None ) if new_key is None: break else: i += 1 return new_key | http://python.algorithmexamples.com/web/data_structures/hashing/double_hash.html | CC-MAIN-2020-29 | refinedweb | 246 | 51.44 |
Search Criteria
Package Details: python2-exiv2 0.3.2-22
Required by (8)
- jbrout-git
- movietitle
- nautilus-image-tools
- nautilus-pdf-tools
- ojo (requires pyexiv2)
- ojo-bzr (requires pyexiv2)
- phatch (requires pyexiv2) (optional)
- smartshine (requires pyexiv2)
Latest Comments
codebling commented on 2020-02-02 00:10
@dmitmel thanks! I'll definitely use that if I have another go at packaging picty! Explanation is the comments is super useful. Thanks again!
dmitmel commented on 2020-01-27 22:13
@codebling Take a look at my partial reimplementation of
python2-exiv2I wrote while packaging the latest version of mirage: You might be able to adapt this to your needs. Also, take a look at the comment at the top, I describe the alternative libraries there (and why they didn't work in my specific case).
codebling commented on 2020-01-27 21:38
Didn't notice that the package has been orphaned. Looks like it's end of life.
codebling commented on 2020-01-27 21:37
@dmitmel thanks for the quick response. Trying to package picty. Picty itself seems rather dated, so maybe this isn't even worth the effort.
dmitmel commented on 2020-01-27 21:21
@codebling I've tried patching this package to work on modern systems a while ago. It is most likely "beyond repair". Do you use it in your application or did you install it as a dependency for another one?
codebling commented on 2020-01-27 21:18
I get an error when building
haawda commented on 2019-06-20 19:24
Confirmed, but upstream did no commit since 2012, so this was about to happen. Orphaning.
tavla commented on 2019-06-20 12:55
compile-time errors: src/exiv2wrapper.cpp: In function 'void exiv2wrapper::unregisterXmpNs(const string&)': src/exiv2wrapper.cpp:1387:23: error: 'Error' in namespace 'Exiv2' does not name a type src/exiv2wrapper.cpp:1393:22: error: 'Error' is not a member of 'Exiv2' src/exiv2wrapper.cpp:1397:22: error: 'Error' is not a member of 'Exiv2' scons: *** [build/exiv2wrapper.os] Error 1 | https://aur.tuna.tsinghua.edu.cn/packages/python2-exiv2/ | CC-MAIN-2020-16 | refinedweb | 341 | 57.87 |
Project Euler 15: Find the number of routes from the top left corner to the bottom right corner in a rectangular grid.
Problem Description.
Determining the number of routes for a square grid (n × n) is the central binomial coefficient or the center number in the 2nth row of Pascal's triangle.
The formula in general for any rectangular grid (n × m) using the notation for the binomial coefficient is:
Any combination using nDowns(D) and mRights(R) would be a valid move.
In the example provided in the problem description there would be (2 + 2)! or 24 possible moves, but many would be indistinguishable, and we would have to divide by (2! × 2!) to eliminate them. So, (2 + 2)! / (2! × 2!) = 24 / 4 = 6. Namely, RRDD, RDRD, RDDR, DRRD, DRDR and DDRR. By indistinguishable we mean DDR1R2 is the same move as DDR2R1.
Project Euler 15 SolutionRuns < 0.001 seconds in Python 2.7.
from Euler import factorial as fact, binomial n, m = 20, 20 # method 1, n == m, square grid, central number in row 2*n of Pascal's triangle if n == m: print "Project Euler 15 Solution (square grid) =", binomial(2*n, n) # method 2, n != m or n == m, rectangular grid print "Project Euler 15 Solution (rectangular grid) =", fact(n+m) / (fact(n)*fact(m))
>.
- Reference: The On-Line Encyclopedia of Integer Sequences (OEIS) A000984: Central binomial coefficients: C(2*n,n) = (2*n)!/(n!)^2.
- If we added the condition "which do not pass below the diagonal" to our problem statement, we would use a Catalan number. It is calculated as 2n! / n! / (n+1)!
Discussion | http://blog.dreamshire.com/project-euler-15-solution/ | CC-MAIN-2014-35 | refinedweb | 271 | 56.66 |
This documentation is archived and is not being maintained.
Advanced Save Options Dialog Box
Visual Studio 2005
Use this dialog box to select a language encoding scheme and to specify the characters to be inserted at the end of each line. To access this dialog box, open a code file for editing in Visual Studio and choose Advanced Save Options on the File menu.
- Encoding
Use this list box to apply a new language encoding scheme to the target file.
- Line Endings
To ensure that the target file will run on a specific operating system, select whether a carriage return (for Macintosh systems), a line feed (for Unix systems), or both characters (for Windows systems) will mark the end of each line.
See Also
Show: | https://msdn.microsoft.com/en-US/library/66d2abf2(v=vs.80).aspx | CC-MAIN-2016-36 | refinedweb | 125 | 58.82 |
Search: Search took 0.02 seconds.
- 30 Jan 2011 11:48 PM
- Replies
- 6
- Views
- 5,277
Anyone have implement the way how to swap the css files which look like switchTheme from BLUE to GRAY?
- 9 Apr 2010 1:09 AM
- Replies
- 7
- Views
- 1,653
Hi~
Would like to ask how to check the target of the click is the ICON?
- 15 Dec 2009 10:15 PM
Jump to post Thread: "Mask and Unmask" window bug? by Roby
- Replies
- 0
- Views
- 1,146
I find the masked Window unmask inside the loaderload event have some bugs.
The window bar (the bar with "X" button) is still masked!!
public class Testing implements EntryPoint {
...
- 18 Aug 2009 6:28 PM
Thanks so much Colin,
I have solved the case with construct a Json format string myself and call by:
JSONObject json = (JSONObject) JSONParser.parse(jsonStr);
jsonParams = json.toString();...
- 18 Aug 2009 5:27 PM
here is the error when I use set:
java.lang.ClassCastException
at java.lang.Class.cast(Unknown Source)
at com.google.gwt.dev.shell.JsValueGlue.get(JsValueGlue.java:122)
at...
- 18 Aug 2009 1:43 AM
Thanks again Colin,
Your suggestion come near the result I want, just one thing can't be resolve.
Params postParams = new Params();
postParams.set("key", "value");
JSONObject json = new...
- 18 Aug 2009 12:44 AM
Dear Colin,
I have writa new WCFJsonReader for breaking up the Json respone and pass back to the JsonReader. It work fine now!!:)) Thanks so much!!
And now come to the problem similar to what...
- 17 Aug 2009 10:00 PM
Thanks Colin with your kindly help;)
My code is simply like this:
ModelType Jsontype = new ModelType();
Jsontype.setRoot("GetStatusListResult");
- 17 Aug 2009 5:08 PM
Thanks Colin,
I am now successfully connect to my .net webservice.
But another problem from reading the Json response.
My json result string is something like this:
{"customers":
- 17 Aug 2009 1:10 AM
- Replies
- 1
- Views
- 1,608
I am trying to get the JSON return from ASP.NET 3.5 WCF webservice in GXT2.0 with the below code:
ModelType Jsontype = new ModelType();
Jsontype.setRoot("GetStatusListResult"); ...
- 14 Aug 2009 12:12 AM
Thanks Colin,
Actually I am using ExtJs 2.0 now, I am wonder any easiest way to change to Ext GWT.
What I concern most is that, how to adopt Ext GWT without any changes to my WCF webservice and...
- 13 Aug 2009 5:01 PM
Is Ext GWT can connect to .NET WCF web service? Any code sample if possible?:D
Results 1 to 12 of 12 | http://www.sencha.com/forum/search.php?s=83cc8cab332d1307e2174fba95bf1fc6&searchid=3106434 | CC-MAIN-2013-20 | refinedweb | 433 | 76.11 |
Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you have been placed in read-only mode.
Please download a browser that supports JavaScript, or enable it if it's disabled (i.e. NoScript).
Hi,
I understand there is GetWidth for GeUserArea.
Is there also a GetWidth equivalent for GeDialog?
GetWidth
GeUserArea
GeDialog
I have a bunch of images in a grid with 5 colums.
I want the number of columns to change based on the Width of the GeDialog
Is there a way around this?
Hi @bentraje you can retrieve the size of the current window with BFM_ADJUSTSIZE
def Message(self, msg, result) :
if msg.GetId() == c4d.BFM_ADJUSTSIZE:
print 'x => ' + str(msg[c4d.BFM_ADJUSTSIZE_WIDTH])
print 'y => ' + str(msg[c4d.BFM_ADJUSTSIZE_HEIGHT])
return c4d.gui.GeDialog.Message(self, msg, result)
Then it's up to you to store the value in a member variable of your class.
Cheers,
Maxime.
@m_adam
Thank you. Works as expected.
Hi @m_adam .
Apologies for bringing up the thread again. I just have a follow up question.
The def Message works well for the consecutive duration of the dialog.
But for the initial life (i.e on startup), the def Message will not be executed .
def Message
Is there a way to determine the width and height of the dialog upon its startup? | https://plugincafe.maxon.net/topic/12561/getwidth-for-gedialog/1 | CC-MAIN-2022-27 | refinedweb | 225 | 77.84 |
RTX51 Tiny User's Guide
Technical Support
On-Line Manuals
#include <rtx51tny.h>
char os_wait (
unsigned char event_sel, /* events to wait for */
unsigned char ticks, /* timer ticks to wait */
unsigned int dummy); /* unused argument */
The os_wait function halts the current task and waits for one or several events such as a time interval, a time-out, or a signal from another task or interrupt. The event_sel argument specifies the event or events to wait for and can be any combination of the following manifest constants:
Events may be logically ORed using the vertical bar character ('|'). For example, K_TMO | K_SIG, specifies that the task wait for a time-out or for a signal.
The ticks argument specifies the number of timer ticks to wait for an interval event (K_IVL) or a time-out event (K_TMO).
The dummy argument is provided for compatibility with RTX51 Full and is not used in RTX51 Tiny.
Note
When one of the specified events occurs, the task is put in the READY state. When the task resumes execution, the manifest constant that identifies the event that restarted the task is returned by os_wait. Possible return values are:
#include <rtx51tny.h>
#include <stdio.h> /* for printf */
void tst_os_wait (void) _task_ 9
{
while (1)
{
char event;
event = os_wait (K_SIG + K_TMO, 50, 0);
switch (event)
{
default: /* this never happens */
break;
case TMO_EVENT: /* time-out */
/* 50 tick time-out */
break;
case SIG_EVENT: /* signal received */
break;
}
}
}
Related Knowledgebase Articles | http://www.keil.com/support/man/docs/tr51/tr51_os_wait.htm | crawl-002 | refinedweb | 238 | 58.92 |
Hi, after I upgraded to 1.5.1 and getting material design in place, my app is working and looking great in Android. HOWEVER the view when focussing or unfoccusing the keyboard does not work as expected.
I have a Grid with icons at the bottom of my ContentPage. So when the keyboard expands the Grid should be sitting on top of the keyboard and the Editor shrinking in height to accomodate. As mentioned this worked before the Material Design update.
I am using the IosKeyboardFixPageRenderer from for iOS and it works great.
How do I fix this on Android with Material Design?
Thank you
After calling base.OnCreate in your FormsAppCompatActivity subclass, call this:
Window.SetSoftInputMode (SoftInput.AdjustResize);
It will restore the old behavior if you depended on it.
Thanks, but it only work on 4.x Android, not 5+
oh right I forgot this is disabled by the fullscreen flag... hmmmmmmmmmmmmm we might need to add a config option to FormsAppCompatActivity.
If you can that will be great. My app is quite unusable in 5+ with material design as key buttons are hidden. There's also some full screen quirks, modal not going up the full way, etc. I can give you access to a private GitHub repo so you can download and run the code if you want, you'll see exactly what the issues are. Send me a private message with your GitHub username
An update on this, since my app was unusable in Android 5+ I did some more digging and finally found a solution that seems to be working in the meantime. I blogged about it here: link
Below is the code in MainActivity.cs
// Fix the keyboard so it doesn't overlap the grid icons above keyboard etc if ((int)Build.VERSION.SdkInt >= Build.VERSION_CODES.L) { // Bug in Android 5+, this is an adequate workaround AndroidBug5497WorkaroundForXamarinAndroid.assistActivity (this, WindowManager); } else { // Only works in Android 4.x Window.SetSoftInputMode (SoftInput.AdjustResize); }
And the AndroidBug5497WorkaroundForXamarinAndroid class implementation with thanks from these StackOverflow posts link and link
`using System;
using Android.App;
using Android.Widget;
using Android.Views;
using Android.Graphics;
using Android.OS;
using Android.Util;
namespace MyNamespace.Droid
{
public class AndroidBug5497WorkaroundForXamarinAndroid
{
private readonly View mChildOfContent;
private int usableHeightPrevious;
private FrameLayout.LayoutParams frameLayoutParams;
}`
This very nearly works - only issue I have is that sometimes Xamarin.Forms does not seem to redraw the bottom part of the screen when you press the back button. The part under the keyboard shows up as blank.
Did you see the same behavior? Any ideas?
@RezaMousavi, I have the same issue here. Strange part here for me is that if you add a breakpoint at the first line in possiblyResizeChildOfContent method the issue is fixed, layout is fully redrawn. It's really looks like a bug
After Xamarin Forms version 2.3.3.168 update, and with the new ones versions, the AndroidBug5497WorkaroundForXamarinAndroid solution no longer works, even it is causing an extra scroll out of screen bounderies, leaving a white space between the bottom of the view and the soft-keyboard without any scrolling option to get the view right.
Could you please help us with any solution for this?
Hi @DiegoVarela my app heavily relies on AndroidBug5497WorkaroundForXamarinAndroid, I haven't released an update to my app with Xamarin Forms 2.3.3, but I just quickly updated it to Xamarin Forms 2.3.3.180 and in the VS Android emulator, everything with the soft keyboard kept working as expected. I did make some minor tweaks to AndroidBug5497WorkaroundForXamarinAndroid though, not sure if that's what kept it working... can share my tweaks if you still have issues.
Hi @MichaelDimoudis, maybe your tweaks prevent the wrong behavior that I am getting. Could you please share it?
Thanks
Sorry for delay @DiegoVarela, here is my file.
`using System;
using Android.App;
using Android.Widget;
using Android.Views;
using Android.Graphics;
using Android.OS;
using Android.Util;
namespace ContinuousFeedback.Droid
{
///
/// Android bug5497 workaround for xamarin android.
/// Answer from
///
/// For more information, see
/// To use this class, simply invoke assistActivity() on an Activity that already has its content view set.
///
/// CREDIT TO Joseph Johnson () for publishing the original Android solution on stackoverflow.com
///
public class AndroidBug5497WorkaroundForXamarinAndroid
{
private readonly View mChildOfContent;
private int usableHeightPrevious;
private FrameLayout.LayoutParams frameLayoutParams;
}`
Also this is what I have in my MainActivity.cs inside OnCreate()
Window.SetSoftInputMode (SoftInput.AdjustResize); if (Build.VERSION.SdkInt >= BuildVersionCodes.Lollipop) { AndroidBug5497WorkaroundForXamarinAndroid.assistActivity (this, WindowManager); }
I have had this same issue and through exploring other posts, I discovered this thread:
As someone mentioned earlier, the problem originates from Xamarin's switch to FormsAppCompatActivity from FormsApplicationActivity in MainActivity.cs. A solution was posted in that thread that simplifies the workaround posted by MichaelDimoudis. However, the solution is still broken when using the back arrow. Just kidding. When I implemented the solution from the other thread, I guess the effects of the solution in this thread still stuck around. Therefore, while the other thread has good information, it didn't really solve this problem - as far as I can tell.
As a functional alternative, you could manually downgrade your app to use FormsApplicationActivity instead of FormsAppCompatActivity. Doing so would make the keyboard interact with the pages correctly. To do that (which I haven't) you would have to adjust some files such as MainActivity.cs, App.cs, and styles.xml.
At the same time that I asked in this thread, I also file a bug to Xamarin in: when today this marked solved using Platform Specifics features in this way in PCL project:
using Xamarin.Forms.PlatformConfiguration.AndroidSpecific;
Application.Current.On<Xamarin.Forms.PlatformConfiguration.Android>().UseWindowSoftInputModeAdjust(WindowSoftInputModeAdjust.Resize);
All the documentation and sample code is in:.
I would try this in my project to fix it.
Thanks a lot @MichaelDimoudis and @ConnorSchmidt for your feedback and help.
Hi,
I have tried this solution it works fine with nuget android.support.v4 version 23.3.0 but as i have updated packages to 27 it is not working as expected. Can you tell me why? Any information will be helpful. | https://forums.xamarin.com/discussion/comment/244852/ | CC-MAIN-2019-18 | refinedweb | 1,013 | 51.14 |
My requirement is to pass dataframe as input parameter to a scala class which saves the data in json format to hdfs.
The input parameter looks like this:
case class ReportA(
parm1: String,
parm2: String,
parm3: Double,
parm4: Double,
parm5: DataFrame
)
def write(xx: ReportA) = JsObject(
"field1" -> JsString(xx.parm1),
"field2" -> JsString(xx.parm2),
"field3" -> JsNumber(xx.parm3),
"field4" -> JsNumber(xx.parm4),
"field5" -> JsArray(xx.parm5)
)
A DataFrame can be seen to be the equivalent of a plain-old table in a database, with rows and columns. You can't just get a simple array from it, the closest you woud come to an array would be with the following structure :
[ "col1": [val1, val2, ..], "col2": [val3, val4, ..], "col3": [val5, val6, ..] ]
To achieve a similar structure, you could use the
toJSON method of the DataFrame API to get an
RDD<String> and then do
collect on it (be careful of any
OutOfMemory exceptions).
You now have an
Array[String], which you can simply transform in a
JsonArray depending on the JSON library you are using.
Beware though, this seems like a really bizarre way to use Spark, you generally don't output and transform an RDD or a DataFrame directly into one of your objects, you usually spill it out onto a storage solution. | https://codedump.io/share/0CFqepskeBrH/1/sparksql-convert-dataframe-to-json | CC-MAIN-2017-43 | refinedweb | 213 | 72.97 |
Openstack Mitaka: can not access dashboard(internal server 500)
Bug Description
Openstack Mitaka on Ubuntu 14.04.
It is a two-node environment installed following the guide:
http://
When I tried to access http://
Apache2 hangs when loading '/usr/share/
It looks like something related to dependency? Please take a look what else information I need to attach here.
Many thanks
#######
[/var/log/
[Fri Apr 22 16:51:38.033769 2016] [authz_core:debug] [pid 30211:tid 140178471515904] mod_authz_
[Fri Apr 22 16:51:38.033870 2016] [authz_core:debug] [pid 30211:tid 140178471515904] mod_authz_
[Fri Apr 22 16:51:38.085433 2016] [:info] [pid 30208:tid 140178545293056] mod_wsgi (pid=30208): Create interpreter 'controller|
[Fri Apr 22 16:51:38.089348 2016] [core:trace1] [pid 30211:tid 140178471515904] util_script.c(601): [client 10.0.0.11:32905] Status line from script 'django.wsgi': 200 Continue
[Fri Apr 22 16:51:38.089471 2016] [:info] [pid 30208:tid 140178545293056] [remote 10.0.0.11:33762] mod_wsgi (pid=30208, process='horizon', application=
[Fri Apr 22 08:56:41.512825 2016] [:info] [pid 30208:tid 140178562078464] mod_wsgi (pid=30208): Daemon process deadlock timer expired, stopping process 'horizon'.
[Fri Apr 22 08:56:41.513111 2016] [:info] [pid 30208:tid 140178648561536] mod_wsgi (pid=30208): Shutdown requested 'horizon'.
[Fri Apr 22 08:56:46.514631 2016] [:info] [pid 30208:tid 140178291226368] mod_wsgi (pid=30208): Aborting process 'horizon'.
[Fri Apr 22 16:56:46.526999 2016] [core:error] [pid 30211:tid 140178471515904] [client 10.0.0.11:32905] End of script output before headers: django.wsgi
[Fri Apr 22 16:56:46.764577 2016] [:info] [pid 30205:tid 140178648561536] mod_wsgi (pid=30208): Process 'horizon' has died, restarting.
[Fri Apr 22 16:56:46.765623 2016] [:info] [pid 30380:tid 140178648561536] mod_wsgi (pid=30380): Starting process 'horizon' with uid=125, gid=133 and threads=10.
[Fri Apr 22 16:56:46.766640 2016] [:info] [pid 30380:tid 140178648561536] mod_wsgi (pid=30380): Initializing Python.
[Fri Apr 22 16:56:46.810913 2016] [:info] [pid 30380:tid 140178648561536] mod_wsgi (pid=30380): Attach interpreter ''.
#######
root@controller:~# cat /usr/share/
import logging
import os
import sys
from django.core.wsgi import get_wsgi_
from django.conf import settings
# Add this file path to sys.path in order to import settings
sys.path.insert(0, os.path.
os.environ[
sys.stdout = sys.stderr
sys.path.
DEBUG = True
application = get_wsgi_
HI did you resolve this problem !!!!! can you help i have a similar situation
Hi Itxaka,
Thanks for your reply.
I don't have specific apache config for horizon in /etc/apache2/
But here is the default setting:
root@controller:~# cat /etc/apache2/
_
CustomLog ${APACHE_
#/
</VirtualHost>
# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
root@controller:~# cat /etc/apache2/
# This is the main Apache server configuration file. It contains the
# configuration directives that give the server its instructions.
# See http://
# the directives and /usr/share/
# hints.
#
#
# Summary of how the Apache 2 configuration works in Debian:
# The Apache 2 web server configuration in Debian is quite different to
# upstream's suggested way to configure the web server. This is because Debian's
# default Apache2 installation attempts to make adding and removing modules,
# virtual hosts, and extra configuration directives as flexible as possible, in
# order to make automating the changes and administering the server as easy as
# possible.
# It is split into several files forming the configuration hierarchy outlined
# below, all located in the /etc/apache2/ directory:
#
# /etc/apache2/
# |-- apache2.conf
# | `-- ports.conf
# |-- mods-enabled
# | |-- *.load
# | `-- *.conf
# |-- conf-enabled
# | `-- *.conf
# `-- sites-enabled
# `-- *.conf
#
#
# * apache2.conf is the main configuration file (this file). It puts the pieces
# together by including all remaining configuration files when starting up the
# web server.
#
# * ports.conf is always included from the main configuration file. It is
# supposed to determine listening ports for incoming connections which can be
# customized anytime.
#
# * Configuration files in the mods-enabled/, conf-enabled/ and sites-enabled/
# directories contain particular configuration sn...
Hi Dico,
I haven't solved the problem yet. I decided to back to Liberty release. It works fine.
This seems to be a legitimate bug, if you try and follow the ubuntu mitaka install. Is this being looked at? Are there any pointers? I've run into the EXACT same issue. ubuntu 14.04.4 LTS.
Hmm. Fixed. (at least in my environment).
root@mitakamast
WSGIScriptAlias /horizon /usr/share/
WSGIDaemonProcess horizon user=horizon group=horizon processes=3 threads=10
WSGIProcessGroup horizon
WSGIApplication
Alias /static /usr/share/
Alias /horizon/static /usr/share/
<Directory /usr/share/
Order allow,deny
Allow from all
</Directory>
Restarted apache, and bingo. Dashboard access on ubuntu 14.04 / mitaka.
Hi,
I'm facing the same issue after following mitaka openstack installation guide on Ubuntu 14.04.4 LTS,
Please find the apache2 logs below,
[Fri May 13 11:31:04.573431 2016] [:info] [pid 1066:tid 139768017549184] mod_wsgi (pid=1066): Attach interpreter ''.
[Fri May 13 11:31:12.477906 2016] [authz_core:debug] [pid 1083:tid 139767832377088] mod_authz_
[Fri May 13 11:31:12.477967 2016] [authz_core:debug] [pid 1083:tid 139767832377088] mod_authz_
[Fri May 13 11:31:12.478073 2016] [authz_core:debug] [pid 1083:tid 139767832377088] mod_authz_
[Fri May 13 11:31:12.478083 2016] [authz_core:debug] [pid 1083:tid 139767832377088] mod_authz_
[Fri May 13 11:31:12.492575 2016] [:info] [pid 1067:tid 139767914018560] mod_wsgi (pid=1067): Create interpreter 'controller|
[Fri May 13 11:31:12.494695 2016] [:info] [pid 1067:tid 139767914018560] [remote 192.168.1.140:1863] mod_wsgi (pid=1067, process='horizon', application=
[Fri May 13 06:06:14.575389 2016] [:info] [pid 1067:tid 139767930803968] mod_wsgi (pid=1067): Daemon process deadlock timer expired, stopping process 'horizon'.
[Fri May 13 06:06:14.575539 2016] [:info] [pid 1067:tid 139768017549184] mod_wsgi (pid=1067): Shutdown requested 'horizon'.
[Fri May 13 06:06:19.576133 2016] [:info] [pid 1067:tid 139767662200576] mod_wsgi (pid=1067): Aborting process 'horizon'.
[Fri May 13 11:36:19.584275 2016] [core:error] [pid 1083:tid 139767832377088] [client 192.168.
[Fri May 13 11:36:19.813866 2016] [:info] [pid 1063:tid 139768017549184] mod_wsgi (pid=1067): Process 'horizon' has died, restarting.
I tried solution suggested by Freerider (seanjohnmcgrath), it did not resolve the issue in my environment, I got a new exception with that change in /etc/apache2/
[Fri May 13 06:20:47.166292 2016] [:error] [pid 1777:tid 139671292704512] File "/usr/lib/
[Fri May 13 06:20:47.166393 2016] [:error] [pid 1777:tid 139671292704512] 'You may need to run "python manage.py compress".' % key)
[Fri May 13 06:20:47.166488 2016] [:error] [pid 1777:tid 139671292704512] OfflineGenerati
i have the same problem,and my error.log only have "End of script output before headers: django.wsgi"
my apache2 have no broblem,http://
I tried solution suggested by #6 ,but it did not resolve the issue.
comandline service apache2 restart with follews:
root@controller
* Restarting web server apache2 [fail]
* The apache2 configtest failed.
Output of config test was:
AH00526: Syntax error on line 4 of /etc/apache2/
Invalid command 'WSGIApplicatio
Action 'configtest' failed.
The Apache error log may have more information.
error.log
[Sun May 15 07:49:37.296060 2016] [mpm_event:notice] [pid 10704:tid 139920269113216] AH00489: Apache/2.4.7 (Ubuntu) mod_wsgi/3.4 Python/2.7.6 configured -- resuming normal operations
[Sun May 15 07:49:37.296102 2016] [core:notice] [pid 10704:tid 139920269113216] AH00094: Command line: '/usr/sbin/apache2'
[Sun May 15 10:30:51.322057 2016] [mpm_event:notice] [pid 10704:tid 139920269113216] AH00491: caught SIGTERM, shutting down
aaishish, Are you seeing this error? Trying running it?
[Fri May 13 06:20:47.166488 2016] [:error] [pid 1777:tid 139671292704512] OfflineGenerati
xiaoqiyixin, post your entire openstack-
Freerider, Yes I see the below mentioned error when I tried the solution mentioned in #6,
[Thu May 19 04:26:58.202768 2016] [:error] [pid 19301:tid 140428522313472] OfflineGenerati
When I try to access the dashboard from the browser, I'm getting below error,
OfflineGenerati
You have offline compression enabled but key "337c10dadc650d
Request Method: GET
Request URL: http://
Django Version: 1.8.7
Exception Type: OfflineGenerati
Exception Value:
You have offline compression enabled but key "337c10dadc650d
Exception Location: /usr/lib/
Python Executable: /usr/bin/python
Python Version: 2.7.6
Python Path:
['/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
'/usr/
Server time: Thu, 19 May 2016 04:26:58 +0000
Solution in #6 does not address the problem you are having. Trying running the compression?
You have offline compression enabled but key "337c10dadc650d
python manage.py compress
Freerider, I'm not executing compression. After adding "WSGIApplicatio
When I reverted the changes, I'm getting End of script error as mentioned in #7
Freerider, I'm able to access the dashboard now. Thanks for your suggestion.
After solution suggested in #6 I executed "python manage.py compress", the issue was resolved
/usr/share/
[sudo] password for controller:
Found 'compress' tags in:
Compressing... done
Compressed 4 block(s) from 3 template(s) for 1 context(s).
But is this an additional step for installation in mitaka release, please confirm the same?
[Expired for OpenStack Dashboard (Horizon) because there has been no activity for 60 days.]
Still the issue persists, and after following #6 and #14 resolved for me.
I got same situation, even with that 2 resolution, no luck.
Any more suggestions? thanks
For anyone with similar issue.
Fix with
WSGIApplicatio
in
openstack-
should work.
Please remember to restart httpd (CentOS/
systemctl restart httpd
In Ubuntu/Debian
systemctl start apache2.service
For anyone using Kolla and Kolla-ansible for an allinone or multinode deployment :
- Edit the file /etc/kolla/
After -------> WSGIProcessGroup horizon-http
ADDED THIS -------> WSGIApplication
- docker stop/start ALL_HORIZON_
This should fix the issue (Kolla 5.0.0 / CentOS 7.4)
Queens still has such issue.
Env:
CentOS 7.2
kernel: 3.10.0-
rpm -qa|grep dashboard
openstack-
Install doc:
https:/
And yes, add the fix to /etc/httpd/
WSGIApplication
then restart the httpd service:
systemctl restart httpd.service
Apart from the documention bug, this is a packaging bug in CentOS package. The horizon upstream development team does not maintain individual package, so a packaging bug needs to be filed to CentOS package.
Note that documentation bug is handled as bug 1741354 and a backport to queens documentation has been proposed.
What is your apache config for horizon? Can you paste it to be sure that its ok? | https://bugs.launchpad.net/horizon/+bug/1573488 | CC-MAIN-2019-09 | refinedweb | 1,735 | 59.8 |
WCSSPN(3) Linux Programmer's Manual WCSSPN(3)
wcsspn - advance in a wide-character string, skipping any of a set of wide characters
#include <wchar.h> size_t wcsspn(const wchar_t *wcs, const wchar_t *accept);
The wcsspn() function is the wide-character equivalent of the strspn(3) function. It determines the length of the longest initial segment of wcs which consists entirely of wide-characters listed in accept. In other words, it searches for the first occurrence in the wide-character string wcs of a wide-character not contained in the wide-character string accept.
The wcsspn() function returns the number of wide characters in the longest initial segment of wcs which consists entirely of wide- characters listed in accept. In other words, it returns the position of the first occurrence in the wide-character string wcs of a wide- character not contained in the wide-character string accept, or wcslen(wcs) if there is none.csspn() │ Thread safety │ MT-Safe │ └──────────┴───────────────┴─────────┘
POSIX.1-2001, POSIX.1-2008, C99.
strspn(3), wcscspn(3)
This page is part of release 5.07 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at. GNU 2015-08-08 WCSSPN(3)
Pages that refer to this page: strcspn(3), strspn(3), wcscspn(3), signal-safety(7) | https://www.man7.org/linux/man-pages/man3/wcsspn.3.html | CC-MAIN-2020-29 | refinedweb | 226 | 53.71 |
Musings on Windows, Graphics, and Technology).
If you would like to receive an email when updates are made to this post, please register here
RSS
Questions from a reader:
How does it relate to the managed code APIs?
Direct2D is an unmanaged (native) code API. No part of it is managed.
Will we see a Managed Direct2D, and another transition period during which the unmanaged and managed APIs are not in synch?
This is an interesting idea, and we are discussing the possibility of a managed wrapper. Stay tuned for that.
Or should we regard Direct2D as WPF re-surfacing in the unmanaged world?
Direct2D and WPF are targeted at different customers. Direct2D is a lightweight native code API which uses an immediate-mode calling pattern (like Direct3D), and will be used primarily by native C/C++ developers. WPF is a managed code framework which uses a retained-mode calling pattern, and will be used primarily by .NET developers.
"Server-side rendering"
Does this mean support for RDP?
Also, are there any accessibility issues at this point?
And, what will it take for broad adoption? Unfortunately, there seems to be a dearth of WPF apps.. Is there any way existing apps can leverage D2D (without being rewritten), or is this just wishful thinking on my part? Could GDI/GDI+ commands somehow be mapped onto a D2D renderer, gaining of its benefits (or at least some)?
"Server-side rendering" Does this mean support for RDP?
This is a two-part answer. Direct2D is built on top of Direct3D 10.1 and, since D3D10.1 provides both bitmap- and primitive-level remoting via RDP, it does mean support for RDP.
But there's another point to made here, too. Server-side rendering also means that you can render high quality anti-aliased content using Direct2D in server environments where, for example, you would not be able to use Direct3D. We will automatically fall back to software in those scenarios. And we are considerably faster than GDI+.
Can you be more specific? We are a 2D rendering API. Other than text, we have no policy regarding layout.
Developers should use whatever tool is appropriate for their needs. If you're writing native C/C++ code, and you need to do high-quality 2D rendering with hardware acceleration on Win7, you should use Direct2D. If you're using managed .NET code, you should use WPF. The technologies are not in competition..
Direct2D uses DirectWrite typography APIs to do font management, layout, and glyph coverage. Font smoothing is applied consistently using DWrite; in fact, DWrite goes further than previous ClearType implementations by doing y-axis smoothing, which yields unparalleled text quality.
Is there any way existing apps can leverage D2D (without being rewritten), or is this just wishful thinking on my part? Could GDI/GDI+ commands somehow be mapped onto a D2D renderer, gaining of its benefits (or at least some)?
Yes, I'm glad you asked. Direct2D supports interoperability with both GDI/GDI+ and Direct3D. So, for example, you could do one of a couple things:
1. You could create a Direct2D render target; then, whenever you need to render GDI content, you QI the render target for IGdiInteropRenderTarget, call GetDC on that interface, BeginDraw, render the GDI stuff to the resulting HDC, and EndDraw.
2. You create a DC render target, call BindDC to your GDI HDC, BeginDraw, draw the D2D content, and then EndDraw.
I'll discuss GDI/GDI+ interop in more depth in an upcoming post. But, to answer your question, it's built-in. You don't need to rewrite your app to use Direct2D.
Very cool - A lot of familiar names on the "making it possible" list :)
A few questions:
- :)
- Any plans on the Windows 7 team introducing a retained mode API?
- Also curious what "Server side rendering" means?
- Does the API remote automagically through RDP? If so, what is the compatability story: ie. Will it remote from Windows 7 -> Vista client?
- Related to the previous question: What version(s) of D3D does this run on? Will it be backwards compatible? ie. Can I run it on Vista?
Thanks!
Rajat ... Rajat ... the name sounds very familiar... ;-) :)
WIC did a fair bit of prototyping of decoding in hardware, but the metadata, TIFF, and progressive decode work was higher priority. Interesting perf note: We compared doing Map/decode/Unmap on a D3D surface to decoding into a system memory buffer and calling UpdateResource on a D3D surface -- and found that the latter was actually faster.
- Any plans on the Windows 7 team introducing a retained mode API?
Not in Windows 7.
It means we can run in server environments using software fallback.
There are 2 types of remoting a Direct2D app via RDP: bitmap remoting and Direct3D primitive-level remoting. Look at the D2D factory and render target properties for details on how to specify one versus the other.
- Related to the previous question: What version(s) of D3D does this run on? Will it be backwards compatible?
It runs on Direct3D 10.1, which includes so-called 10Level9 functionality -- which allows you to run D3D10.1 apps on a D3D9 driver.
ie. Can I run it on Vista?
We are discussing downlevel support now. Keep posted.
You're welcome. :)
Hi Tom,
I looking forward to managed wrapper, make sure it is a good one. And I have a couple of questions, too:
1. Will there be support for video playback.
2. Will it run on Windows XP? I assume not...
Yes, with certain caveats. Since we interop with Direct3D, you will be able to take frames (D3D surfaces) from a DirectShow filter graph, and render them using D2D. Keep in mind that DirectShow currently uses Direct3D9, while D2D uses Direct3D10.1, so you will need to use a Direct3D9 shared surface. We are currently working up a sample that shows how to do this. Stay tuned.
Not currently. We've had a number of customers asking for XP, and we're still evaluating downlevel support. As above, stay tuned. ;)
1. If you create a sample that really really works and even better, a managed wrapper - that'd be awesome.
2. XP is important in gaming industry. Not the one for the PCs but rather the one that delivers games on cabinets (i.e. casino machines).
Samples will be posted relatively soon. Not sure about the availability of a managed wrapper. We're still discussing that.
I will pass your feedback on to my management. Thank you for letting us know what you need/want. :)
Questions posed in email from a reader:
Hi, I just read your blog post introducing Direct2D, and it looks really interesting.
I have a few questions though:
1. When can we expect to see it? The Nov 2008 DXSDK is probably too soon to hope for.
The bits will be available in prerelease form to MSDN subscribers and PDC attendees. We tried to hit the November DX SDK date, but there wasn't enough time to get all of our dependencies ready. I'm trying to get clarity on the actual public release date. Will let you know.
2. How much control do we have over how it renders the 2-d content?
It's a fairly comprehensive 2D graphics API. You have a ton of control.
3. Can we use programmable vertex/pixel shaders with it? In our current graphics engine, we have a number of shaders specifically for 2-d sprite quads that render in various special ways.
Yes, you can, but you need to do it via Direct3D interop. The API does not directly expose pixel/vertex shaders. I'm making a note to create a sample which shows how to do it.
4. What is this Direct3D10Level9 that you are talking about?
D3D10Level9 is a special adapter for D3D10 which allows it to use D3D9 drivers. So, for example, if you only have a D3D9 driver, D3D10 could still run -- which greatly broadens the reach of D3D10. It will be available on Windows 7.
5. When Direct2D is released to the public, could the dx sdk include a sample showing how to use Direct2D for rendering a simple gui over a Direct3D app?
We will have a sample which shows you how to do this. But not in the Nov DX SDK.
Hey thanks for posting the answers to my questions. Those samples would be great to have.
I'm curious still about this Direct3D10Level9 adapter. What exactly is the point of an adapter to let D3D10 use a D3D9 driver?
It’s all about reach. There are a fairly broad number of D3D9 drivers available on the market right now. Xbox360 runs on D3D9, as do most current PC games. D3D10 is gaining adoption, but it will take time. The advantage of providing a way to use D3D9 drivers from D3D10 is that it allows developers to code to a single API – D3D10 – so that they don’t have to write two sets of code.
Since, you certainly wouldn't be able to use any of the new D3D10 features, as the D3D9 driver certainly wouldn't have a clue about how to implement them.
That’s not entirely accurate. There is a reasonably broad subset of the D3D10 features which will run on D3D9; albeit with differing performance and quality characteristics. No, D3D9 doesn’t do everything, but it does a lot. The D3D team has done an excellent job in trying to match feature sets of the two APIs via D3D10Level9.
Any D3D10 level hardware is certainly going to have a D3D10 level driver for it, or its D3D10 features are useless. Particularly, in regards to Windows 7, as I imagine it needs new/modified drivers to be written for it anyways. Unless you are planning to use Direct2D in the Windows 7 gui. But, you still wouldn't be able to use any D3D10 specific features, so, why not write a D3D9 version of Direct2D instead? (which would also enable Xp support and support for old (but still commonly in use) hardware)
Like you, we, too, are customers of D3D10 and D3D10Level9. It allows us to code to a single API, while still getting all the perf benefits of D3D10.
Or unless you are planning on releasing D3D10 for Xp, but, that seems extremely unlikely due to the massive differences between Vista and Xp, and is contrary to everything I've heard from Microsoft with regards to that.
There are no plans at present to port D3D10 to XP. The driver models are very different.
A few more general questions for you (feel free to answer on your blog):
1. You mentioned support for D3D10.1, but, what about regular D3D10? Since there's no support from Nvidia for D3D10.1, what happens there?
D3D10.1 drivers are a logo requirement for Win7.
2. Will there be D3D11 support as well? Or will that require Direct2D2?
D3D11 will provide compatibility with prior versions.
3. Will there be support for using Direct2D with Direct3D9?
Yes, to a point, but the support is essentially provided through D3D9 shared surfaces. We had a earlier question about how to render video decoded into D3D surfaces. We’ll have a sample which demonstrates how that works.
4. Compared to rendering screen-aligned quads, how does Direct2D perform?
There’s no quick answer to your question. It depends on a lot of variable factors: what kind of hardware are you using, what is the driver overhead for state changes, how many drawing primitives are you trying to perform, etc. Similarly, since we continue to make perf advancements in the D2D rendering code, what you see today will not be what you see in the final RTM release.
5. Interally, does Direct2D work by generating and rendering screen-aligned quads, or is it more of a true bitblt DirectDraw style rendering?
I can’t discuss internal implementation issues.
6. Is this the end of ID3DXSprite and ID3DXFont?
Not yet. D3DX will continue to live on. But, like everything else, there were undoubtedly be changes to D3DX. Time and technology march onward.
For those who are wondering how to create a Direct3D10 or Direct3D10Level9 device.
HRESULT CreateD3DDevice( __in IDXGIAdapter *pAdapter, D3D10_DRIVER_TYPE DriverType, UINT Flags, __deref_out ID3D10Device1 **ppDevice ){ HRESULT hr = E_FAIL; < ARRAY_SIZE(levelAttempts); level++) { hr = D3D10CreateDevice1( pAdapter, DriverType, NULL, Flags, levelAttempts[level], D3D10_1_SDK_VERSION, ppDevice );
if (SUCCEEDED(hr)) { break; } } return(hr);}
hello.
Great post.I expect also future post.
I have an unclear thing, does D3D10 GPU run as D3D10Level9 device for D3D10.1?
does D3D10 GPU run as D3D10Level9 device for D3D10.1?
No, D3D10Level9 is only used in conjunction with a D3D9 driver.
What about interop with WPF? With .NET 3.5 SP1, it can work with IDirect3D9[Ex] via the D3DImage WPF class.
Is the software rasterizer optimized for multicore?+?
Also, I bet if a server wants to do a LOT of rendering, then they will want a GPU sitting in there to help out. So, any support for GPU accelerated rendering in session 0? Especially for these:
Regarding GDI/GDI+ - has GDI/GDI+ been ported so that it sits ontop of Direct2D? specifically, under Vista it was unaccelerated - given the number of applications dependent on GDI (and I assume the widget kits in Windows), will this happen?
Having come back from PDC2008 with one of the giveaway sensorboards I'm really keen on trying to put together an example that allows me to manipulate the windows on screen using the accelerometers/tilt sensors. For example, by attaching the sensor to the lid of my laptop I could infer the relative orientation of the screen to the keyboard and therefore apply a transformation to the window layout so that shapes appear correctly from the viewers perspective.
How does the Direct2D API play with the changes to the DWM? Do you have any examples of using this to control the windows at the DWM level? Another scenario I'd like to try is to use the multi-touch resize gestures to enable the windows to be scaled by the GPU, rather than just resized.
Hey Tom, thanks for answering ym blog post on Channel 9 MSDN here:
It looks like you're really going to deliver. Great job! You're working on the right project!
I added a few questions at the end.
Will it be compatible with GDI device contexts? Could I blit from a D2D context to a GDI context interchangeably?
Can I use D2D to draw directly to a window?
Will the result be available immediately (could I read back the pixels right after a command)?
I didn't see this in the post, but are there going to be stroke styles, join and end caps, miter types, spline curves, and blur effects?
Will this be a Windows 7 only feature or to which OS will it be back ported?.
Is the software rasterizer optimized for multicore?
Not yet. We originally had tasks on our schedule to optimize the rasterizer for multicore, but we ended up prioritizing hardware support.+?
It is relatively easy to do banded/tiled rendering.
1. Allocate some system memory for a pixel buffer, and implement your own IWICBitmap wrapper to reference that memory. Your implementation of IWICBitmap should do nothing in response to calls to Lock/Unlock (D2D will attempt to lock and unlock the memory -- but since you're managing the bands, you don't need to lock or unlock the memory).
2. Create a multi-threaded D2D factory.
3. Call ID2D1Factory::CreateWicBitmapRenderTarget for each band that you need, and pass in your implemented IWICBitmap. Keep in mind that resources created by a given render target are bound to that render target, which would require that you create separate resources for each render target (i.e. you can't share them). The only exception is a shared bitmap. Shared bitmaps can be used across software render targets -- or across hardware render targets on the same physical adapter.
Direct3D cannot currently run in session 0.
How does the Direct2D API play with the changes to the DWM? Do you have any examples of using this to control the windows at the DWM level?
Both Direct2D and DWM in Windows 7 are built on top of D3D10. D2D doesn't handle anything relative to window orientation/sizing/etc.
Another scenario I'd like to try is to use the multi-touch resize gestures to enable the windows to be scaled by the GPU, rather than just resized.
No, we really wanted to port GDI+ to use D2D, but the scope was way beyond possible for this release. But we're definitely interested in the idea.
Will D2D be compatible with GDI device contexts? Could I blit from a D2D context to a GDI context interchangeably?
Yes. You can render from a D2D render target to a HDC -- or draw from a HDC into a D2D render target.
You need to create a HwndRenderTarget which maps to the window; then, you draw to that render target.
The results of drawing operations are committed immediately upon calling ID2D1RenderTarget::EndDraw. We don't provide readback for hwnd render targets. If you need readback, either create a WicBitmapRenderTarget or a DXGISurfaceRenderTarget and access the underlying bits after rendering.
didn't see this in the post, but are there going to be stroke styles, join and end caps, miter types, spline curves, and blur effects?
Yes to stroke styles, join and end caps, miter types, and spline curves. No to blur effects. You can implement your own blur but it requires using a shader via D3D interop.
Initially, Windows 7. We are still looking at which platforms we want to backport the functionality to.
Thomas,
Thanks for the info. Your a real professional and this blog/announcement really has me psyched.
One thing I thought of though, and I really hope you read this:
Could you please ask your team about SERIOUSLY considering implementing polygon clipping AND hit testing?
For an example of polygon clipping see:
That would be a HUGE step forward in programmability, especially if your could design a clipping algorithm which could output complex shapes with splines.
I know polygon clipping is not directly a graphic draw function, but it's so closely tied to it. And think about it, if you guys could figure out a way to implement and advanced clipper using a feedback buffer from the GPU ... well I would be totally blow away!
By the way, for your entertainment/inspiration, you might want check this out this vector simulation program:
And here is my contribution to that project:
One modification one my request above. When I asked about polygon clipping, I meant clipping where the path data is captured and can be read back as a path.
This would be essential for providing the ability to clip paths, and then allowing the path to be edited and/or saved between sessions.
Editing involves showing nodes and curves handles on the screen, and allowing those nodes to be modified through dragging, joining, or deleting. Of course editing would be implemented by the programmer by modifying a path structure, but reading that path back after clipping is essential.
Final note, most/all clipping algorithms don't handle curves (including circle/ellipse/spline) and yours obviously should.
Direct2D supports both polygon clipping and hit-testing. Here's a quick example of how you'd clip two geometries. The geometries can be any type of supported geometry (lines, beziers, etc), and it should be noted that ID2D1Geometry::CombineWithGeometry will preserve polygons; that is, beziers will remain beziers, etc. One additional note. Geometries do not provide a direct way to extract their line or curve data. If you need to access that data, you should implement your own ID2D1SimplifiedGeometrySink object and pass it in to ID2D1Geometry::CombineWithGeometry. Direct2D will then call the ID2D1SimplifiedGeometrySink object that you supply (SetFillMode, SetSegmentFlags, BeginFigure, AddLines, AddBeziers, EndFigure) during the CombineWithGeometry. This will permit you to access the line and curve data for the resulting figure(s), so you can persist them or whatever.
__in ID2D1Geometry *pGeometry1,
__in ID2D1Geometry *pGeometry2,
__in D2D1_COMBINE_MODE combineMode,
__in_opt CONST D2D1_MATRIX_3X2_F *inputGeometryTransform,
__out ID2D1PathGeometry **ppOutGeometry)
{
CComPtr<ID2D1GeometrySink> spGeometrySink;
CComPtr<ID2D1PathGeometry> spOutGeometry;
IFR(m_spFactory->CreatePathGeometry(&spOutGeometry));
IFR(spOutGeometry->Open(&spGeometrySink));
IFR(pGeometry1->CombineWithGeometry( pGeometry2, combineMode, //D2D1_COMBINE_MODE_UNION, ..._INTERSECT, ..._XOR, ..._EXCLUDE inputGeometryTransform, //can be NULL spGeometrySink ));
IFR(spGeometrySink->Close());
*ppOutGeometry = spOutGeometry;
return S_OK;
}
Here's how you hit test. This method tells you whether the selected point is on a widened stroke.
HRESULT ID2D1Geometry::StrokeContainsPoint(
D2D1_POINT_2F point,
FLOAT strokeWidth,
__in_opt ID2D1StrokeStyle *strokeStyle,
CONST D2D1_MATRIX_3X2_F &worldTransform,
__out BOOL *contains
);
This method tells you whether a given point is contained within a given geometry.
HRESULT ID2D1Geometry::FillContainsPoint(
FLOAT flatteningTolerance,
);
Wow, that is seriously sweet. I can't wait to start playing with this stuff. I know having access to this stuff is going to radically benefit all my programming.
TTYL
Glad to hear that, sysrpl. Always happy to answer any more questions that you have. :-)
Okay, another question then. Since Direct2D is going to be C/C++ compatible and based on COM interfaces, I was wondering if you guys would be kind enough to ship it with a type library?
I know type libraries are usually thought of as benefiting COM automation (IDispatch), but a complete type library assists developers not using C/C++. An ITypeLib can be used to machine generate alternate language source code files (interface declarations, enumerations, constants, structs, ect).
Example of my app importing nvidia information:
Since Direct2D is going to be C/C++ compatible and based on COM interfaces, I was wondering if you guys would be kind enough to ship it with a type library?
I'll share that feedback with the team. Thanks.
Regarding GDI+/GDI - with the widgets individual applications use; are the native widgets for Windows drawn using Direct2D/DirectWrite or are they still reliant on GDI+/GDI?
I hope you don't mind all these question. I feel like I'm abusing some privilege.
I was thinking more about Direct2D and wanted to know if you guys were building in some of these optimizations or if developers would need to handle them ourselves:
Would you handle, to some extend, view frustum culling?
If rendering a complex scene with many 2D shapes, would your API discard and return immediately attempts to draw objects which are completely outside the bounds of the bitmap or window?
That optimization would speed up things a lot and simplify development for us if we had complex drawings (think a CAD blueprint). We wouldn't need to write boilerplate code to to transform bounding boxes and perform test ourselves.
It would probably make Direct2D much more elastic/faster for the average user.
Also, would you apply the optimizations for LOD (level of detail) as well? This is where 2D objects are reduced in size in to such an extent that they might to render to only a single or few pixels. An optimization on your end to reduce drawing a bunch of geometry at that point would could save many unnecessary calculations.
Thanks again
Great stuff, especially new text renderer. Currently it's almost impossible to measure text width properly with GDI+. GDI rendering seem to be much slower than GDI+ if I use it from managed application (at least on Vista) and UniScribe is way too undocumented.
I have been looking for something like this for a long time (basically since I realized that WPF is not fast enough for our purposes).
_Please_ make this available for Windows XP. I work in space operations, and people here are _very_ conservative. I imagine this is similar to other sectors such as banking.
It took us a long time to convince one customer to drop NT 4.0 support for our application. So if Direct2D is only available for windows 7, we won't be able to use it for at least 5 years even though it does exactly what we need.
The XP support would not necessarily have to be accelerated. Just make the software pipeline available for XP if that is easier.
We have looking for something like this, too.
But, as MS didn't have a 2d drawing API using hw acceleration, we felt free to create our own implementation for our cad program, almost with the same functionality that Direct2D provides. Altough it sits on top of D3D9/D3D9Ex because of the "mandatory" XP support.
Will Direct2D be ported back to Vista? If it will, we could use it as a new implementation.
Win7 is so far yet...
@sysrpl:
Hi, I’m Anthony, another dev on the D2D team (I work on the geometry and tessellation engines). I thought I’d take a crack at a couple of your questions.
Regarding off-screen culling: D2D is optimized to take into account off-screen (and partially off-screen) content. That said, there is still some per-primitive overhead, and we expect that some app writers will find it useful to implement culling on top of us. Indeed, in many ways, app writers have a much better opportunity to perform these sorts of operations than we do, as they can group primitives together into a single unit and do one cull test for the entire unit. Think of a vectorized button, for instance: this might be composed of several individual D2D primitives, and rather than performing a cull test on each individual primitive, it probably makes more sense to cull test the button as a whole.
Regarding LOD: Like most 2D rasterizers, D2D does have some concept of level-of-detail in that our Beziers will dynamically flatten to a level appropriate to the resolution of the display and the scale of the world transform. The concept of a more general geometric LOD (allowing the user to generate entirely new geometries based on the scale of the world transform) is an interesting idea.
The native controls are still reliant on GDI/GDI+.
I understand. Thank you very much for your feedback on this issue. I'll share it with the team.
Can Direct2D 'help out' in WPF? I mean, my experience with WPF is its quite slow in terms of rendering compared to GDI/GDI+. Maybe you guys can build an additional layer that can make WPF render using Direct2D
Will Direct2D be ported back to Vista?
Microsoft announced at PDC that Direct2D will be ported to Vista. But there is no specific timetable yet. Stay tuned for that.
WPF can interop with Direct3D9. Read these articles for more details.
Okay, another question. Previously I asked about the ability to capture data back from polygon clipping operations. This is a related request.
Will you have a function to return the bounding box (transform or untransformed) for paths?
This would be needed where paths contain bezier curves and determining their bounds would be difficult for programmers.
@sysrpl:
ID2D1Geometry::GetBounds() is your friend :-). It supports Beziers and also accepts a transform.
Alright. I'm totally sold. This API is going to be awesome. I've been waiting for it for a long time.
I believe the only thing more we are going need is BLISTERING SPEED through hardware acceleration.
How do you believe this API would perform for complex realtime 2D animation? How would it perform as animation directly to a HWND vs a DX surface? Is there a faster blit function, or is AlphaBlend still going to the fastest way to transfer 32bpp pixel data to HDCs?
Looks like a great rendering layer for VG.net. We've been waiting for something like this from Microsoft for years. We would also love XP support.
Looks like a great rendering layer for VG.net.
Agree. Looks like a nice fit. VG.net looks very cool, btw.
We've been waiting for something like this from Microsoft for years.
So have we. ;-)
We would also love XP support.
I'll pass that on to my management. Thanks for the feedback.?
@Tihiy:?
The benchmarks at PDC are illustrative of performance characteristics on Win7. It would be difficult to draw a direct comparison with GDI on XP because D3D10 only runs on Vista and Win7.
How do you believe this API would perform for complex realtime 2D animation?
The performance for complex 2D animations is excellent. Check out the animation demo toward the end of the PDC session ().
How would it perform as animation directly to a HWND vs a DX surface? Is there a faster blit function, or is AlphaBlend still going to the fastest way to transfer 32bpp pixel data to HDCs?
The short answer is ... it depends. :) It's difficult to give you an unequivocal answer without assessing the hardware and drivers. My advice is measure, measure, measure. :)
Hey, Tom,
From later comments, I think you get this, but it scared me to see you write "Direct2D and WPF are targeted at different customers". I think Microsoft needs to assume that *many* applications will use both. Why? Because WPF is a great UI platform, but the overhead of the retained mode graphics is too high for many applications, IMHO. I think the application model of choice going forward is going to be a WPF "skin" with any serious graphical content rendered with D2D/DWrite and displayed in WPF via Interop. That's not to say that for many scenarios (database front ends), WPF retained-mode graphics are fine, but for others (scientific visualization), WPF graphics don't cut it. WPF + D2D is a great solution for those scenarios. So please make the interop clean (looking forward to the sample app)!
Eric
@Eric:
Thanks for your comments. My point earlier was that customers will typically tend to choose one technology or the other; however, I do agree with you that there are customers who will want to use both WPF and D2D, and we intend to make the technologies work well with one another. We're working on samples. Hang in there. :)
Great stuff, Tom! I was wondering if this technology does anything to address two problems that have been driving me crazy:
1. Many programs fail badly if the system DPI is set to anything other than the default 96 DPI (I need to use 120). Text is cut off, dialog buttons are invisible because they fall off the bottom of the dialog... it's a serious problem.
2. The Text Size setting in IE6 is ignored by many websites - I assume because it messes up their page structure/formatting. This makes it hard for me to read the text, expecially on modern high-resolution monitors. I know that IE7 has a zoom level control as well, but it doesn't work in all cases...
Any comments?
D2D was designed from the ground up to make it as easy as possible to write a DPI aware application.
D2D:
• Automatically honors the system DPI when creating a windowed render target, so long as the application manifest indicates that the application handles DPI correctly.
• Expresses all of its coordinates in DIPs (Device Independent Pixels), which allows the application to scale automatically when the DPI changes.
• Allows bitmaps to have a DPI and correctly scales them taking this into account. This can also be used to maintain icons at different resolutions.
• Expresses most resources in DIPs, which are then also automatically resolution independent, especially compatible render targets and layers
• Expresses a floating point coordinate space and can render anti-aliased, so, any content can be scaled to any arbitrary DPI.
• We have a pipeline authored over D2D shipping in Windows 7 that scales from 96 to 1200 DPI using these techniques.
Direct2D looks excellent. I'm new to graphics programming (currently working on a charting application written in MFC) so this is likely to be a silly question but.. will I\can I already program using Direct2D using MFC or will I need to use Win32?
Best regards
Direct2D looks excellent.
Thanks.
I'm new to graphics programming (currently working on a charting application written in MFC) so this is likely to be a silly question but.. will I\can I already program using Direct2D using MFC or will I need to use Win32?
Not a silly question. Currently, you would need to use Win32; however, we are definitely interested in having frameworks such as MFC, WinForms, and others (which currently use GDI or GDI+) use D2D.
This is very exciting news to me. I develop multimedia applications as a hobby, making great use of 2-D graphics. I've been thoroughly impressed by the flexibility and performance demonstrated in the sample videos. I can't wait to have that power at my fingertips.
I would like to throw in some chips for XP support. I don't consider it mandatory, but it would definitely be convenient. The XP market in Middle America remains fantastically huge. I'm a technician and software engineer for a citywide school system. Our entire district (26 buildings, plus administration) uses XP and will continue to do so for at least another three years. Personally, I design software with XP (32-bit) as the baseline and troubleshoot on Vista (32- and 64-bit) to make sure it works every which way. My philosophy is: it has to run under XP. Vista support is a convenience.
As yet I've been unable to test D2D/DW first-hand. I've installed the Windows 7 beta and SDK (both at work and home) under VPC, but I haven't have time to compile anything. It may interest you to know that the SlimDX team — responsible for picking up Managed DX where Microsoft left off — has already begun implementing Windows 7 features into the next release. When Direct2D, et al, do hit the market, SlimDX will be my weapon of choice for utilizing them. To that extent, an "official" managed wrapper would be strictly unnecessary, but it might yet be a good idea for folks who haven't heard of SlimDX.
I have only one question at the moment. When you say "device independent pixels," how does that translate to screen pixels? May we assume all transformations are given/retrieved in DIP's that match the display device's own pixels, and that all conversion is done under the hood? I'm always a bit confused when it comes to graphical units and how they interact.
On XP support. We will chain that up to management. To answer your question on Device Independent Pixels (DIPs).
A device independent pixel is a logical pixel that maps to the physical device pixels through a scalar called the “DPI”. DPI stands for Dots Per Inch. And to further unravel this, a dot means a physical device pixel. (The nomenclature comes from printing where dots are the smallest ink dot that a printer can produce). Since a standard monitor used to have 96 dots per inch, a DPI of 96 means that a device independent pixel (or DIP) maps 1:1 with a physical pixel. So, if, for example, the DPI were 96*2 = 192, then a DIP would in fact encompass two physical pixels. When the user adjusts the “size” of what’s on the screen, what they are actually modifying is this internal scalar, which is known as the system DPI. There are many reasons why applications don’t necessarily handle this correctly, but, one of the simplest is that they have to do all of the heavy lifting of working out how to use this scalar value to do their rendering. In D2D, this is applied by default. You might realize that by doing this mapping, physical device pixels might end up at fractional DIP coordinates this is (one of) the reasons why it is also important that D2D have a floating point coordinate space.
DIPS -> Pixels: pixel = (dip * DPI) / 96.
Pixels-> DIPS: dip = (pixel * 96) / DPI.
I am so glad that the C++ Lighweight COM approach was used. I was worried that Direct2D was going to managed route and this would be terrible.
The lighweight COM approach works very well.
@dave:
"I am so glad that the C++ Lighweight COM approach was used. I was worried that Direct2D was going to managed route and this would be terrible. The lighweight COM approach works very well."
Thanks for the feedback.
I'd be interested to see what reaction you have to Jonathan Blow's (the creator of "Braid" for XBox) comments on the API examples/design. Is this just a misunderstanding of how the API is meant to be used?
@Keith
Well, Jonathan's sample isn't really a 1:1 comparison:
* It doesn't do anti-aliasing. D2D does an 8x8 mutli-sample AA by default.
* On a related note - it isn't resolution independent.
* It doesn't handle device lost, or any other errors at all.
* It has a completely different coding style.
* It has no comments.
* It has a whole bunch of global variables.
* It won't do primitive remoting over RDP.
Which, is a somewhat doubtful comparison if you are looking at LoC against a sample that is intended to be a well-structure base for someone writing something of a workable application.
In addition, D2D doesn't only draw rectangles, a not much more complicated sample from the D2D side would be a lot more interesting as a comparison. e.g.
@Keith again...
Also, we have evaluated the sample. The brushes can be created and released at any time and don't have to be held over the lifetime of the render target. This was just an artifact of how the sample was written.
· I want to remind everyone that DemoApp is not "the Direct2D API." DemoApp is sample code. Most of it is boilerplate Win32 programming that registers a window class, creates a window, processes and routes messages, and handles window messages. It isn't intended to be a tutorial on Win32 programming, nor is it intended to represent the smallest or the best or the only possible D2D application. It merely reflects best practices. I can understand if someone doesn't like DemoApp's C++ class -- it's a personal preference, after all -- but the benefits of object-oriented languages are well-known and, given the state of optimizing compilers, characterizing a single wrapper class as "bloat" is a gross mischaracterization. I don't have much to say about comment style. Comments are for documentation, and they vary widely.
· Direct2D is a general-purpose 2D rendering API. It wasn't designed solely for the purpose of drawing a single rectangle. If you really want an honest comparison of code size, try a counter-example which draws antialiased ClearType text, buttons, lists, and most other common UI elements solely with Direct3D -- and then tell me whether you think it requires less code than Direct2D. I don't think so. For extra credit, try drawing complex paths, radial-gradient- or bitmap-filled ClearType text with Direct3D, and then get back to me about the ease of Direct3D programming. Furthermore, if anyone is going to use lines of code as the sole metric for evaluating code, then let's be honest and include fundamental things such as error-handling (eg. device loss, allocation failures, etc), resource cleanup (completely absent), useful comments, etc before casting stones. I wouldn't ship code with such low quality, so it really isn't worthy of comparison.
· All of our brushes (solid color brush, radial gradient brush, linear gradient brush, bitmap brush) derive from a common base interface. Polymorphism allows us to use each brush interchangeably for stroking and filling of geometries, masks, and text, without having to resort to parametric structs or other weirdness. Brushes can be created, modified, used to draw, and torn down in a similar manner to GDI brushes. Whether you create, use, and destroy a brush during a single rendering pass, or create and hold a brush for the duration of an app is dependent on your particular needs.
· COM (particularly lightweight COM) provides a lot of positive benefits (clean separation of interface and implementation, versioning, language independence, extensibility, etc). In the interest of brevity, I'll simply refer everyone to a paper on the subject ().
Hi Thomas,
Thanks for the responses. Please understand that my comment was not meant to be critical; I was legitimately curious as to what you thought of Jonathan's post. I think many of your points are quite reasonable, but at the same time I think that they point out several issues with the demo code. Although of course the demo code is not synonymous with the Direct2D API, I think that the fact that the sample does something (drawing a rectangle) which apparently doesn't highlight many of the wins that you see the API providing is a real flaw.
I hope I don't come off as argumentative; I'm definitely not trying to claim that the API is bad. But I do think that it's important to have sample code that clearly demonstrates how the API is meant to be used. Do you feel that the DemoApp meets these goals? Is the DemoApp being taken out of context? Is there a better set of example code somewhere, and could Microsoft be doing a better job of drawing attention to it?
I feel like things like unnecessarily creating and releasing brushes make the demo actively harmful. Like it or not, people take a cargo cult approach to coding and will build off of sample code that Microsoft releases. If the demo code does unnecessary work, then 1) people will overestimate the difficulty of working with the API, leading to reduced uptake and 2) lots of other people's code will be littered with unnecessary code, making it a maintenance burden and further reinforcing views about the difficulty of working with the API. I have no doubt that the people writing the demo code had the best of intentions, and that things like evolving APIs can make it hard to keep samples up-to-date, but based on your responses it sounds like Microsoft could do a better job of writing sample code that concisely demonstrates using the API to achieve functionality that would be hard to do with the current set of APIs.
Well, interestingly though - If we rewrote the sample to have the same general style, error handling, and resource handling philosophy of Jonathan's blog post, it would most definitely be shorter than his, and do more (antialiasing, primitive remoting, resolution independence).
We are very aware of the tendency that people have to copy samples -- which is why we sometimes do things in the samples which are "best practice" or "safe" rather than "optimally simple". For example, D2D does have device dependent resources that can go away (if you use the HW rasterizer), and further, can be expensive to create because they are doing so on an external GPU. So, we structure the code to assume that resources should be created and held on to, because, this is generally best practice. However, brushes, as it turns out, are really cheap and can be created and thrown away at will. Was the demo wrong? That is actually a more complex question than you might think. For example, you could just maintain a single brush for your entire app, and just change the color whenever you draw; this would be very optimal, but, it might have decreased the readability of the sample.
Also, since resources can be held on the GPU, they can go away. You can choose to care, or you can choose not to care about this. (Jonathan's sample chooses not to care). There is a debate as to whether this is appropriate for a 2D rendering API. Here are some observations:
* Some resources, such as bitmaps, are really big. Maintaining a system memory copy simply to update the one on the GPU is really expensive.
* GPU video memory doesn't count against system memory on a discrete part. So, there is a huge working set win in keeping it only on the GPU.
* Existing APIs which maintain system memory copies do not (based on our performance measurement and experience) achieve the same performance or working set usage as D2D for the same scenario.
* D2D is transparent and policy-free in the way that it handles resources. When you create a resource, you pay the cost of associating that resource's data with the GPU immediately. Some rendering systems attempt to hide and delay this association -- thus, imposing their own policy -- but this simultaneously makes it difficult or impossible for the application programmer to predict what the cost is, when they're going to have to pay it, and how to work around it. We would argue that it's better to let the programmer decide if/when they want to pay that cost.
* Some resources are inescapably on the GPU and cannot be recovered. Your render target is on the GPU, it contains a back-buffer. If the GPU device is lost, the back-buffer contents are lost. Same for an offscreen surface you are using for rendering.
* Some of these resource might not even be on the same machine in the remoting cases.
As to why the brushes are bound to the devices. It turns out that SOME brushes either have, create or point to device dependent resources. In fact, all of the brushes outside of the solid color brush (eg. bitmap brush, linear/radial gradient brush) do one of these things. Given this, it is conceptually simpler to put the brushes into the same "domain" as the render target. Otherwise, someone could get a bitmap brush, point it to an incompatible bitmap and then fail when drawing it, this is a much harder to understand developer experience than keeping the objects together.
And, bear in mind, this is the very first version of this API. We generally felt that it was safer when designing it to assume a cautious contract that could be expanded based on customer feedback than to create a way open contract that we would have a hard time restricting in the future without breaking existing applications.
And finally, yes there are many more samples:
This one, interestingly, was chosen precisely because it closely matches the WPF introductory sample. So, it serves a good purpose if someone who knows WPF is evaluating D2D in comparison.
I would like to see a version of Jonathan's Direct3D code which does more advanced things such as use different stroke widths, stroke styles, etc. The Direct2D code would be quite a bit cleaner.
Also, custom text handling in any 3D API (OpenGL, Direct3D, I don't care) is a pain. The text rendering feature alone of D2D/DWrite make the APIs quite nice in my eyes. Not everyone is able to use C# for their applications.
Mark: thanks for the description. Does this mean we tell D2D/DW what DPI to use, or does it automatically detect what the current device is using?
My only fear with Blow's hideously malformed (and curiously vehement) opinions is that people will read his blog without bothering to do the research themselves. That is precisely the sort of dangerous misinformation that sets back any advance. Nevertheless, one must have faith that sensible minds will make things right, and that Blow will spit out his own feet.
@ Tom
On the DPI aspect:
For bitmaps - You have to tell D2D what DPI to use, we default them to 96 DPI since this will tend to work acceptably if the App was authored at 96 DPI and later is scaled. Otherwise, you can set the bitmap DPI to be the same as the render target DPI and you will always get linear scaling of the pixels. Or, you could have a library of icons of different sizes and select amongst them depending on the system's DPI to keep them sharp when rendered. In keeping with our other decisions, we have tried to keep this as policy-free and flexible as possible while adhering to a goal of helping applications be resolution independent. Also, note that the bitmap DPI isn't relevant to the DrawBitmap API since in this case you specify the destination rectangle and we will always scale to fill it, it is relevant to the default scaling of bitmap brushes.
You *can* ask WIC what the DPI is and apply it to the bitmap yourself, however, this value can sometimes be of limited utility. For example:
* What is the DPI of a random camera shot?
* Some formats specify the equivalent of DPI in metric units, so, the DPI can end up fractional in inches when converted.
* Some applications don't set the DPI to a good value when saving the bitmap.
For the render target DPI, it depends on the type of render target.
* For windowed render targets. The system DPI is used by default. However, you can override it. You also need to indicate in your manifest that you want to handle arbitrary DPIs.
* For "surface" render targets, we default them to 96 DPI. This includes WIC bitmap render targets and DXGI surface render targets.
* For compatible render targets, the DPI will be inherited from the parent target if you specify its size exclusively in either DIPs or pixels. Howver, if you specify both sizes, then you have also implicitly specified the DPI.
As to negative feedback about the API, we listen, we learn, we evaluate our designs and their underlying philosophies and the samples that illustrate them. But, we also look at both positive and negative feedback, you can't please everyone all the time, neither do you necessarily succeed if you try. :)
@Tom
To add to Mark's comments, we really DO want to see both positive and negative feedback about the API. Even if we don't necessarily agree with the conclusions of a particular piece of feedback, it doesn't mean that we don't want to understand that person's point of view. We do. This is a learning process for all of us, and everything that you tell us informs our architectural decisions. Sometimes, it isn't exactly obvious why we've made certain choices, but we really do try to be exhaustive in going over scenarios -- evaluating, questioning, probing, debating; nonetheless, we're only human, so it helps to have more eyes looking over our shoulders. Our primary consideration, whenever there's been a tough decision, has been to yield more control to the developer. We understand that this won't please all people but, then again, this API isn't for all people. Our challenge has been to build something flexible enough to allow other developers to build GDI/GDI+, control frameworks, plug-ins, applications, etc, with our solution. Time will tell whether we've made the correct choices. So, by all means, we'd like to hear about what you're building with D2D, problems you encounter, challenges, suggested improvements, etc. Keep 'em coming -- we read and appreciate everything.
Thanks for the clarifications. I have one more question, related only through the PC18 video presentation. Toward the end (right before Q&A), Kam shows off the UIAnimation API in action (not to be confused, I assume, with the iPhone API), demonstrating D2D as the renderer. I understand they're completely different modules and D2D is only superficially connected as a render path, but this is actually the first (and last) reference I've seen to UIAnimation in Win7. Is there any chance you could point us to a site with more information?
1. Is there metafile?
2. Is there some brush such as WPF DrawingBrush?
3. Can I output to XPS?
Ah, good question: can we natively load metafiles? Also, what sort of geometry manipulation tools are we looking at? Obviously we can apply transformation matrices; how are we able to manipulate raw vertex data? A better question might be, is this done in any of the samples, or will there be samples demonstrating any/all of this?
@ Yamada Hiro
* There is no metafile support.
* WPF Drawing Brush is a retained mode rendering construct, it requires re-rasterizing its contents to an intermediate surface for each scale it is used at, so, directly supporting it would have violated a tenate of the API that you should control your resources (the intermediate surface in this case). It also requires a scene graph. However, it is fairly trivially implemented by creating a compatible render target, rendering the scene into it and then using the resulting bitmap in a bitmap brush. This also has the advantage that you can intentionally use the bitmap at different scales and don't need to re-render into the compatible render target if you don't want to.
* We don't output to XPS. However, D2D constructs have been intentionally chosen to correspond to the XPS XAML subset, and there is an API in windows 7 that allows you to output XPS directly using the XPS Object Model and to print it using the XPS Print Path (even to a GDI driver).
D2D has a superset of the WPF geometric functionality, including:
* Geometry Groups
* Geometric transforms (i.e. pre-stroke transform)
* Combine operators
* Lenght/Area/Position
* Tesselation
* Outlines
* etc.
You can directly manipulate 2D triangular vertices by creating a Mesh object. You can either populate the mesh yourself, or, you can ask D2D to tesselate a geometry into the Mesh. The Mesh is stored as a vertex buffer on the GPU. It can render aliased geometries through the DrawMesh API. For an anti-aliased optimization that can be stored on the card, you can create an A8 compatible render target and either render to provide a mask, or update it yourself. This can be combined with a brush with the FillOpacityMask API.
The extruded text sample already uses some of these operations, and the path animation sample uses others. Our geometric support is very large, I wouldn't assume that every possible operation would end up in a sample. There is after-all an SDK.
@ Tom again
If you really want to get creative with meshes and HW based rendering, we also have extensive DXGI interop support. See the "SciFiText" sample.
Thanks for your reply.
WPF has DrawingBrush.
GDI+ has TextureBrush. This TextureBrush.Image property is Bitmap or 'Metafile'.
I hope that D2D supports some geometry pattern brush.
@ Yamada
Yeah, I am not saying that the debate is closed on MetaFiles, Drawings, or other retained structures in D2D, I would say that we do need to understand the primary application usage for them based on further customer interaction. The space is really crowded with XAML, XPS and EMF(+) already out there and we want to make sure we do the right thing (TM).
However, here is a thought I would like to leave you with:
* Texture creation is REALLY expensive in HW. Except under extremely narrow conditions, geomtric brushes have to be rendered through intermediate surfaces, and these intermediate surfaces need to be of different sizes each time they are drawn. It has been our experience that HW renderers that try to hide this have issues with predictability, performance and/or cost.
* Absent a metafile implementation internally, and a set of optimizations around this, there just isn't a huge difference between the application issuing the drawing calls and us doing it for them.
@Yamada:
You can create a geometry pattern brush with D2D, but you need to do it explicitly, and there are certain caveats.
1. Call ID2D1RenderTarget::CreateCompatibleRenderTarget() with a specified size, which produces an intermediate surface (ID2D1BitmapRenderTarget) that you can draw into.
2. Draw your geometry into the intermediate surface render target (ID2D1BitmapRenderTarget::BeginDraw|Draw*Fill*|EndDraw).
3. Retrieve the intermediate surface texture via ID2D1BitmapRenderTarget::GetBitmap().
4. Create a bitmap brush via ID2D1RenderTarget::CreateBitmapBrush using the surface that you obtained in Step 2.
5. Use the bitmap brush to stroke or fill a geometry.
As Mark said in a previous post, creating intermediate textures in GPU memory is an expensive operation, so you're going to want to do it sparingly and then cache the result, not repeat frame-over-frame.
Thank you for your reply. I try this method.
There is an another question.
I want to maximize speed of draw line, by off anti-alias.
Our CAD application draws 100,000 lines. In 'Edit Mode', We don't need anti-alias. In 'Preview Mode', We need high quality rendering.
Can D2D off anti-alias ?
@Yamada: "Can D2D off anti-alias ?"
ID2D1RenderTarget::SetAntialiasMode(D2D1_ANTIALIAS_MODE_ALIASED);
If you pair Direct2D aliased rendering with Direct3D MSAA (Multisample Antialiasing -- ie. full scene antialiasing), you should get better performance with high primitive count scenarios.
Can DirectWrite off anti-alias?
In WPF, I can use only anti-aliased fonts, I am troubled.
This is delayed followup to Tom's question above about UIAnimation (a.k.a. The Scenic Animation platform). There's lots more information on MSDN:
Scenic Animation provides a simple way to add time-based interpolation, variable management and event based animated change to apps that already have rendering. It's used in several Windows 7 components and can be used with D2D, GDI or your own rendering. Remember that this only does the mathematics of animation - it's still up to you to find a way to draw the pixels - of which D2D is the best way in my view.
Do feel free to contact me if you'd like to know more.
Martyn
First of all, i was waiting for a API like this for long time: i am using now GDI+ for 2D stuff and Direct3D for 3D stuff but sure Direct2D seem to be more suitable for mixing 2D and 3D in the same application. Great work !
You say that DIP should be 1/96 inch: why not use 72 DPI instead ? It is because 1 pt = 1/72 inch and so with DIP of 1/72 inch we have exactly 1 pixel = 1 point and point seem to be a more suitable standard for device independant pixel than arbitrary 1/96.
Thanks!
A DIP is 1/96 inch by default because that's the default system DPI. But a DIP is really an arbitrary unit that isn't tied to any particular DPI. In fact, it's trivial to override the default to your own preferred unit. For example, just call ID2D1RenderTarget->SetDPI(72.0f, 72.0f).
I noticed a some bugs (?) when rendering a bitmap to a hwnd render target that has a scrollbar.
First issue: when you call ScrollWindow on the window, the window flickers to white before direct2d updates the view.
Second issue (this one might be my bug, but if it is, I can't find it): when you render a clipped bitmap to a window that has a scrollbar, the bitmap is rendered with a extra space before the scrollbar (the space is incidentally equivalent to the width of the scrollbar). If you resize the window just a little (if even by a pixel) te bitmap gets snapped to the correct place.
And there is also an issue when the render target is a window that is using a ribbon: the titlebar of the window gets rendered to, overwriting the custom titlebar the the ribbon creates.
I have tried d2d sample in windows 7 7057.It seems does't work.D2D1CreateFactory return E_NOINTERFACE.
But it works on build 7022 and 7000.
@Te-jé Rodgers:
1, We will take a look at the ScrollWindow issues. Thanks for letting me know.
2. Can you provide a snippet of code that illustrates how you're creating the window and rendering the bitmap? The position of the bitmap should be relative to the top left corner of the window and the transform that you use.
@jq: "I have tried d2d sample in windows 7 7057.It seems does't work.D2D1CreateFactory return E_NOINTERFACE. But it works on build 7022 and 7000."
You can't just mix and match the Beta Direct2D headers/libs with any random Windows build. We have made some changes to the Direct2D interfaces with subsequent builds and, every time we do that, we automatically regenerate new interface GUIDs. What that means is that you can't use older headers/libs with newer builds. This avoids the problem where you're calling interfaces with a different v-table than the actual binaries you're using, which could cause a crash. Returning E_NOINTERFACE tells us immediately that you're using mismatched headers/libs.
My advice would be to wait until the Windows RC build, and use the Windows RC SDK with it. Obviously, I can't promise that we won't change any interfaces beyond that point, but the probability is very, very low.
Thanks for the responses.
I guess I should install the 7000 build to experience d2d and dwrite, and wait for the RC build.
I guess I should read these last few comments. I just installed W7 7057 specifically to start testing Direct2D. So am I dead in the water with this version?
BTW, I too have been waiting for something like Direct2D for a LONG time, I excited to get started code with it and really hope MS backs this new API all the way!
Your new framework sounds great! We work a lot with 2D graphics in the field of GIS (geo information systems) and are dependent on a high performance on the one side and on rich graphical possibilities on the other side. Your
framework seems to combine both which makes it extremely interesting for us. We are using the existing 2d-frameworks (GDI, GDI+) in a very intensive manner, so there were always some things we ever wished to get better.
Here are some things we would enjoy:
* Support for Win XP because most of our customers use this system
* Large Hatch Brushes, that means Brushes with a HatchStyle, a set of colors and a set of hatch-sizes which define the width of every bar in the hatch.
Today we have a workaround for this by creating a tile and drawing it with a TextureBrush, but if printing this, the results are disappointing.
* Support for relativly extreme transformation. If we draw in meter-based map-projections like mercator etc., we have transformation-matrices with scales about 0.001 (which means in this context: 100000 reality-metres are
mapped to 100 pixels). We often had various problems with GDI+ and these transforms: text output and some pen-operations didn't work correctly. We had always switch to 1:1-output whick previous rescaling fonts and pens.
* Some more sophisticates pen-styles as they are used in map-signatures: double-lines, combined and complex lines (see for examples), or at least a possibility to define such line-styles
* exact matrix-calculations also with nearly-0 values (I reported this GDI+-Bug in microsoft-connect:)
Here's how to get an updated Direct2D build:
@Markus:
Thanks for the feedback. Good stuff.
After a rough time installing Windows7 multiple times I finally got Direct2D sample compiling. I notice a March DX SDK so I install and put their include/lib paths first. This stops the samples from compiling. To my suprise DirectX now includes some beta includes/libs for D2D which has some updated function calls.
Can we assume this API will now work with Vista, or is it still only Win7 Man I wish the SDK came out a couple days earlier! haha I was pulling my hair out re-installing for days trying to get Direct2D setup for testing in Win7!
Would it be possible to get specific data from Direct2D: E.g. I prepare Direct2D to draw an ellipse and instead of drawing it I want the vertices (as I may read it some posts before) to draw it with Direct3D. Any chance, and if so which interface? Mesh interface?
Thx,
Vertex
Hi, Vertex. You can do this by implementing ID2D1TessellationSink and passing an instance to ID2D1Geometry::Tessellate. This will generate TRIANGLELIST data that you can then pass to D3D.
I'm not terribly familiar with the whole DirectX paradigm, which may be why I'm wondering what the difference is between D2D and the (now apparently deprecated) DirectDraw. Wasn't that also hardware-accelerated? At first glance it looks like it was dropped then resurrected and rebranded, but something tells me that's not the case.
DirectDraw is a deprecated technology that was all about providing hardware frame buffer access to applications, so that they could do very fast display blits and frame flipping. DirectDraw, itself, didn't provide drawing commands for rendering high-quality 2D text, geometries, bitmaps, etc. Direct2D does. Plus, Direct2D interoperates with the latest versions of Direct3D.
thx for your last comment!
My 1st question: How is the D2D anti-aliasing level/quality comparable to D3D? Or if this is easier: What quality does D2D anti-aliasing has? (e.g. sample count, sample mask,...) This is very interesting if someone uses D2D and D3D stuff together.
My 2nd question: D2D can use different hardware level or software to render. Can this be set and if not can someone get this info from D2D interface,factory or whatever?
My 3rd question: Does D2D need D3D10.1 level hardware to fully work with without software emulation/computation?
My 4th and last question: Am I right (as far what I have read) that software rendering (all that can be done on hardware) can be component wise? In other words: Is software and hardware rendering mixed?
1. D2D does 8x8 per-primitive anti-aliasing (Note: For performance reasons, in HW in some cases we use alpha ramps to simulate 8x8). The “8x8” part means that the quality is much higher, but the “per-primitive” part means that if you have abutting edges you will see artifacts. If you prefer MSAA you can do so using a ID2D1DxgiSurfaceRenderTarget.
2. Sort of. When you create a render target you can specify a minimum feature level via the D2D1_RENDER_TARGET_PROPERTIES::minLevel parameter. We don’t allow you to get this information from the render target directly for versioning reasons. Instead, you can call ID2D1RenderTarget::IsSupported to determine if the render target has at least the minLevel of HW.
3. No, Direct2D does not require D3D10.1 hardware. We require D3D10.1 interfaces, but these can be used on D3D9 hardware via Direct3D 10Level9. Using D3D9 hardware does impose some restrictions (e.g. bitmap and render target sizes). All rendering involves computation on the CPU since we need to send instructions to the GPU (also things like geometry tessellation are always done on the CPU). Using D3D9 level hardware may result in higher CPU usage because of the overhead associated with interacting with the D3D9 runtime, but we don’t emulate anything in software.
4. No, Direct2D does not do mixed rendering. Each Direct2D render target is either SW or HW. If apps really want mixed rendering, they can explicitly compose results from different render target types. E.g. render to an IWICBitmap render target, then use the results in a ID2D1HwndRenderTarget that is doing HW rendering. Of course you will pay a performance penalty when copying across the bus, so apps should only do this if they have measured it to be more efficient.
Thx Tom!
To 3.: If Direct3D10.0 hardware is available: Does Direct2D fall back to Direct3D 10Level9 or does it use Direct3D 10.0?
Two more questions: Let's say someone wants to use Direct2D instead of existing GDI/GDI+ implementations. Is there anything missing in Direct2D, when replacing GDI/GDI+? (I know that you can use them together, but what I am talking about is only using D2D)
Second question: Does the software rendering of Direct2D use WARP10?).
+ ...as far as I tested, you did great job with D2D!
Hello..
Regards
Viktor Skarlatov
@Vertex:
To 3.: If Direct3D10.0 hardware is available: Does Direct2D fall back to Direct3D 10Level9 or does it use Direct3D 10.0?
Direct2D will use Direct3D 10 if a Direct3D 10.1 driver is installed; otherwise, we will fallback to Direct3D 10Level9.
Direct2D provides much of the functionality contained in GDI/GDI+. We have a smaller subset of ROPs.
No. Although you can use WARP in conjunction with Direct2D via DXGI interop.).
Thank you for the feedback. We are interested in moving more CPU funtionality to the GPU.
@Viktor.
Hi, Viktor. Are you using the Windows 7 Beta? Or the DX SDK on Vista? We have made a lot of performance improvements to Direct2D in the Windows 7 RC build.
I tried with the SDK on Vista. Later today I will try it on Win 7 RC. Thank you for the reply.
I still do not understand though. Is using a DCRenderTarget supposed to consume more CPU than a HwndRenderTarget? My questions was is this normal?
Regards
Hi, it's me again ;) (with feedback)
I played a bit with porting GDI+ stuff to D2D. Doing this I mixed GDI+ and D2D drawings and found out (also in msdn docs) that clipping compatibility or interoperability is not given. (correct me if I am wrong plz!)
GetDC of ID2D1GdiInteropRenderTarget should not be called between Push- and PopAxisAlignedClip functions. (as far as I tested, it doesn't work anyway, the function returns no hdc)
Any chance to see full clipping interoperability (clipping settings in e.g. D2D results in correct clipping regions in DC)in RTM?
Using DX SDK March 09, since 7 RC is not yet available, I think. Will there be an updated SDK, and can you say if it comes out sometimes around 7 RC or some weeks later? Can we expect D2D changes (beside performance) in 7 RC?
@Viktor Skarlatov: I had similar problems (I am working with GDI+ AND D2D, don't know if you do). I switched over to ID2D1GdiInteropRenderTarget. As a result I changed architecture and reduced the following: Try to reduce BeginDraw/EndDraw to one if you have multiple calls (improves performance) and create factories/rendertargets only once at start (if possible).
Would it be possible to support the GDI/GDI+ antialiasing modes to get fully compatible pixel output. My testings (simple Fillrectangle and a DrawRectangle for the border) showed me blurry results compared to GDI+. Nevertheless, it could also be my fault (maybe I am doing something wrong).
Can you confirm this behaviour?
Switching an application from GDI/GDI+ to D2D would mean that pixel output could not be guaranteed to be the same.
What's the recommended way to PRINT geometries created with D2D? Creating bitmaps would be very resource intensive, especially on large-scale-printers (HP DesignJet e.g.).
Do we have to use two different code paths for screen (D2D) and print (GDI) or can we use DC render targets?
Thanks,
Thomas
The way that DC render target works is by copying the DC contents to an offscreen bitmap (which is in HW or SW depending on how you created the render target), rendering the D2D content to this bitmap and then copying the result back to the DC.
When you run Windows 7 with WDDM 1.1 drivers, window DCs are mostly backed with video memory, and therefore the copying mentioned above is done in HW in this case. This copying is very efficient - there is still some overhead but it is not too bad.
If you do not have these newer drivers, or you have a DC that has a system memory bitmap selected into it (such as a DIB section), then you will be either doing system memory copies (for software rendering) or copies to / from video memory (for hardware rendering). Copying to and from video memory is an expensive operation. You might be able to do it quickly, but it will use CPU cycles. It is best to profile your application to figure out if the gain from rendering in HW is worth the expense to get the results to / from video memory. For example - if drawing a relatively small amount of content it might be the case that rendering in SW is the best option.
Remember that each time you bind to a DC with a DC render target, memory is being allocated, potentially on the GPU, and this can be expensive, so try not to do it each frame. Also try to reduce how many times you do Begin / End draw per frame, because this reduces the number of copies. And remember that DC render target does not do any syncing with the presentation interval of the window manager, and this means that it does not naturally throttle like a hardware rendered HWND render target would. Using D2D1_PRESENT_OPTIONS_IMMEDIATELY will let the HWND target to unthrottled rendering if you want to compare - this creates a more apples to apples comparison for CPU usage.
Ben Constable, D2D team
I have resolved my blur problem (which wasn't an AA problem anyway) more or less. It was the missing 0.5 Offset (which also comes with D3D10).
Can we expect Direct2D on the next Windows Embedded Compact (not Standard) platform? (previously known as Windows Embedded CE or Windows CE)
[B]"Hi, Vertex. You can do this by implementing ID2D1TessellationSink and passing an instance to ID2D1Geometry::Tessellate. This will generate TRIANGLELIST data that you can then pass to D3D."[/B]
Can someone explain me how this is meant exactly? The tessellationsink does not give me any triangle data. It can be used for the mesh interface. But as far as I can see mesh can only be used for drawing, not for getting the trianglelist.
...or was the initial intention to implement the triangle stuff myself in an inherited tessellate interface?
Anyone who can explain this to me?
Vertex: I just tried that.
If you only need the data you implement an tesselationsink that copies the data.
If you want to create a mesh at the same time you implement a tesselation sink that takes the tesseletion sink from D2D1Mesh.Open(), copy the data and pipe them to the other sink.
Here's a sample (2nd case, but without coyping the data):
(MySink.h)
#pragma once
class MySink : public ID2D1TessellationSink
public:
MySink(ID2D1TessellationSink *pSink);
~MySink(void);
STDMETHOD_(void, AddTriangles)(
__in_ecount(trianglesCount) CONST D2D1_TRIANGLE *triangles,
UINT trianglesCount
);
STDMETHOD(Close)();
unsigned long STDMETHODCALLTYPE AddRef();
unsigned long STDMETHODCALLTYPE Release();
HRESULT STDMETHODCALLTYPE QueryInterface(IID const& riid, void** ppvObject);
private:
LONG volatile m_cRefCount;
ID2D1TessellationSinkPtr m_spSink;
};
(MySink.cpp)
#include "StdAfx.h"
#include "MySink.h"
MySink::MySink(ID2D1TessellationSink *pSink) : m_cRefCount(0)
m_spSink = pSink;
m_spSink->AddRef();
MySink::~MySink(void)
m_spSink->Release();
STDMETHODIMP_(void) MySink::AddTriangles(__in_ecount(trianglesCount) CONST D2D1_TRIANGLE *triangles,
UINT trianglesCount)
m_spSink->AddTriangles(triangles, trianglesCount);
STDMETHODIMP MySink::Close()
return m_spSink->Close();
STDMETHODIMP_(unsigned long) MySink::AddRef()
return InterlockedIncrement(&m_cRefCount);
STDMETHODIMP_(unsigned long) MySink::Release()
if (InterlockedDecrement(&m_cRefCount) == 0)
{
delete this;
return 0;
}
return m_cRefCount;
STDMETHODIMP MySink::QueryInterface(IID const& riid, void** ppvObject)
if (__uuidof(ID2D1TessellationSink) == riid)
*ppvObject = dynamic_cast<ID2D1TessellationSink*>(this);
else if (__uuidof(IUnknown) == riid)
*ppvObject = dynamic_cast<IUnknown*>(this);
else
*ppvObject = NULL;
return E_FAIL;
return S_OK;
In the AddTriangles implementation you can copy the data to your own array.
To use it you create a mesh, open it, save the tesselation sink ptr you get, create a MySink and put this ptr into the ctor:
ID2D1TessellationSinkPtr sp_tessSink;
hr = m_spRT->CreateMesh(&sp_mesh[i]);
hr = sp_mesh[i]->Open(&sp_tessSink);
MySink *pSink = new MySink(sp_tessSink);
pSink->AddRef();
hr = sp_path[i]->Tessellate(matResult, 3.0f, pSink);
hr = pSink->Close();
// insert a call here to get the data from your copy...
pSink->Release();
Hope that helps
Thx Thomas!
That helped a lot. My tests are working now!
Are the device independent Interfaces like ID2D1Geometry implemented in hardware or software? What performance do I have to expect?
@John: Can we expect Direct2D on the next Windows Embedded Compact (not Standard) platform? (previously known as Windows Embedded CE or Windows CE)
I can't comment on future product plans for Direct2D at this time.
@Thomas: Are the device independent Interfaces like ID2D1Geometry implemented in hardware or software? What performance do I have to expect?
ID2D1Geometry is implemented in software. If you want the hardware equivalent, you can use ID21RenderTarget::CreateMesh to create a ID2D1Mesh.
A ID2D1Mesh does not help because I can only draw it and I have no geometric operations available.
The performance of the ID2D1Geometry operations is comparable to our own routines, some are faster, some are slower. So a hardware assisted implementation would be desirable for performance reasons.
Btw. I just created a blog on my current experiences with D2D:
I'm getting an E_NOINTERFACE on the D2D1CreateFactory call and I have the last version of Windows 7 (RC 7100) and the RC version of the SDK. I also installed Visual Studio 10 (Beta 1). Need help!!!!
Is Direct2D suitable for drawing UI components?
I am currently playing around (in Windows Forms) with the SlimDX managed Direct2D wrapper and I was wondering if there is a point to this. I am concerned about resource creation and disposal, since these operations are expensive. My idea is to make an implementation of the IGraphics interface which uses Direct2D underneath.
@Jack Harris: "I'm getting an E_NOINTERFACE on the D2D1CreateFactory call and I have the last version of Windows 7 (RC 7100) and the RC version of the SDK. I also installed Visual Studio 10 (Beta 1). Need help!!!! "
Jack, you have some kind of header/lib mismatch with the D2D binaries. Check to make sure that you're not picking up D2D headers from either VS10 Beta 1 or from the DXSDK. If you pick up the wrong headers, you will be passing the wrong RIID as the second parameter to D2D1CreateFactory, we won't recognize it, and we'll return E_NOINTERFACE. The prescribed place to get the RC headers/libs is the RC WinSDK. Hope that helps. Let me know if you continue to have problems.
@ViktorSkarlatov: "Is Direct2D suitable for drawing UI components?
Yes, it is suitable. There are some things to keep in mind. For example, remember that Direct2D uses a float coordinate space and does per-primitive antialiasing; in other words, it supports sub-pixel positioning. GDI uses an INT coordinate space and can only do aliased primitives. What this means is that you have more flexibility with Direct2D about positioning but, at the same time, getting precise pixel alignment (as envisioned by UI designers) needs to take into account the differences between sub-pixel and pixel alignment. Just something to keep in mind. Of course, you can turn on aliased rendering in Direct2D if you prefer the GDI style.
Resource creation and disposal can be expensive, but there are ways that you can mitigate the cost. For example, you can reuse textures rather than constantly thrash thru creation and disposal. It's one of the reasons that many games preload most or all of their textures up front. Consider using a single atlas texture and updating tiles, as needed. Certain types of resources are mutable (eg. ID2D1SolidColorBrush) so, if you need to use a bunch of them, you could call ID2D1SolidColorBrush::SetColor rather than create separate resources. There are other things that you can do. Check out this article.
I'm always happy to brainstorm on your scenarios, too.
I figures things out. The problem is that the Visual Studio Beta uses older bindings then the bindings for Windows 7. VS sets WindowsSdkDir macro to the 7.0A directory while the Window7 RC SDK using the 7.0 directory. The problem is that even when you try to set up an environment variable VS doesn't pick it up. It only uses the value set in the registry. I had to change the registry so that VS could alter the WindowsSdkDir variable.
If you ask me this is a bug in Visual Studio because it should allow you to override the macro setting via the environment rather than the registry.
."
I am really interested in the interop demo. Have you already made a sample application? How about performance? Is there a large overhead?
Is texture swizzling needed? | http://blogs.technet.com/thomasolsen/archive/2008/10/29/introducing-the-microsoft-direct2d-api.aspx | crawl-002 | refinedweb | 13,372 | 64.51 |
perlman gods <HR> <P> <H1><A NAME="NAME">NAME</A></H1> <P> perlref - Perl references and nested data structures <P> <HR> <H1><A NAME="DESCRIPTION">DESCRIPTION</A></H1> <P>. [perlman:perlobj] for a detailed explanation.) If that thing happens to be an object, the object is destructed. See [perlman:perlobj|the perlobj manpage] for more about objects. (In a sense, everything in Perl is an object, but we usually reserve the word for references to objects that have been officially ``blessed'' into a class package.) <P> Symbolic references are names of variables or other objects, just as a symbolic link in a Unix filesystem contains merely the name of a file. The [perlfunc:glob] notation is a kind of symbolic reference. (Symbolic references are sometimes called ``soft references'', but please don't call them that; references are confusing enough without useless synonyms.) <P>. <P>. <P> <HR> <H2><A NAME="Making_References">Making References</A></H2> <P> References can be created in several ways. <OL> <LI><STRONG><A NAME="item__">.</A></STRONG> <P> By using the backslash operator on a variable, subroutine, or value. (This works much like the & (address-of) operator in <FONT SIZE=-1>C.)</FONT> Note that this typically creates <EM>ANOTHER</EM> reference to a variable, because there's already a reference to the variable in the symbol table. But the symbol table reference might go away, and you'll still have the reference that the backslash returned. Here are some examples: <P> <PRE> $scalarref = \$foo; $arrayref = \@ARGV; $hashref = \%ENV; $coderef = \&handler; $globref = \*foo; </PRE> <P> It isn't possible to create a true reference to an <FONT SIZE=-1>IO</FONT> handle (filehandle or dirhandle) using the backslash operator. The most you can get is a reference to a typeglob, which is actually a complete symbol table entry. But see the explanation of the <CODE>*foo{THING}</CODE> syntax below. However, you can still use type globs and globrefs as though they were <FONT SIZE=-1>IO</FONT> handles. <P><LI><STRONG>.</STRONG> <FONT SIZE=-1>A</FONT> reference to an anonymous array can be created using square brackets: <P> <PRE> $arrayref = [1, 2, ['a', 'b', 'c']]; </PRE> <P> Here we've created a reference to an anonymous array of three elements whose final element is itself a reference to another anonymous array of three elements. (The multidimensional syntax described later can be used to access this. For example, after the above, <CODE>$arrayref->[2][1]</CODE> would have the value ``b''.) <P> Note that taking a reference to an enumerated list is not the same as using square brackets--instead it's the same as creating a list of references! <P> <PRE> @list = (\$a, \@b, \%c); @list = \($a, @b, %c); # same thing! </PRE> <P> As a special case, <CODE>\(@foo)</CODE> returns a list of references to the contents of <CODE>@foo</CODE>, not a reference to <CODE>@foo</CODE> itself. Likewise for <CODE>%foo</CODE>. <P><LI><STRONG>.</STRONG> <FONT SIZE=-1>A</FONT> reference to an anonymous hash can be created using curly brackets: <P> <PRE> $hashref = { 'Adam' => 'Eve', 'Clyde' => 'Bonnie', }; </PRE> <P> <CODE>local()</CODE> or <CODE>my())</CODE> are executable statements, not compile-time declarations. <P> Because curly brackets (braces) are used for several other things including BLOCKs, you may occasionally have to disambiguate braces at the beginning of a statement by putting a <CODE>+</CODE> or a [perlfunc:return|return] in front so that Perl realizes the opening brace isn't starting a <FONT SIZE=-1>BLOCK.</FONT> The economy and mnemonic value of using curlies is deemed worth this occasional extra hassle. <P> For example, if you wanted a function to make a new hash and return a reference to it, you have these options: <P> <PRE> sub hashem { { @_ } } # silently wrong sub hashem { +{ @_ } } # ok sub hashem { return { @_ } } # ok </PRE> <P> On the other hand, if you want the other meaning, you can do this: <P> <PRE> sub showem { { @_ } } # ambiguous (currently ok, but may change) sub showem { {; @_ } } # ok sub showem { { return @_ } } # ok </PRE> <P> Note how the leading <CODE>+{</CODE> and <CODE>{;</CODE> always serve to disambiguate the expression to mean either the <FONT SIZE=-1>HASH</FONT> reference, or the <FONT SIZE=-1>BLOCK.</FONT> <P><LI><STRONG>.</STRONG> <FONT SIZE=-1>A</FONT> reference to an anonymous subroutine can be created by using [perlfunc:sub|sub] without a subname: <P> <PRE> $coderef = sub { print "Boink!\n" }; </PRE> <P> Note the presence of the semicolon. Except for the fact that the code inside isn't executed immediately, a [perlfunc:sub] is not so much a declaration as it is an operator, like [perlfunc:do] or [perlfunc:eval]. (However, no matter how many times you execute that particular line (unless you're in an [perlfunc:eval|eval("...")]), <CODE>$coderef</CODE> will still have a reference to the <EM>SAME</EM> anonymous subroutine.) <P> Anonymous subroutines act as closures with respect to <CODE>my()</CODE>. <P>man:perlobj|the perlobj manpage]. <P> You can also think of closure as a way to write a subroutine template without using eval. (In fact, in version 5.000, eval was the <EM>only</EM> way to get closures. You may wish to use ``require 5.001'' if you use closures.) <P> Here's a small example of how closures works: <P> <PRE> sub newprint { my $x = shift; return sub { my $y = shift; print "$x, $y!\n"; }; } $h = newprint("Howdy"); $g = newprint("Greetings"); </PRE> <P> <PRE> # Time passes... </PRE> <P> <PRE> &$h("world"); &$g("earthlings"); </PRE> <P> This prints <P> <PRE> Howdy, world! Greetings, earthlings! </PRE> <P> Note particularly that <CODE>$x</CODE> continues to refer to the value passed into <CODE>newprint()</CODE> <EM>despite</EM> the fact that the ``my $x'' has seemingly gone out of scope by the time the anonymous subroutine runs. That's what closure is all about. <P> This applies only to lexical variables, by the way. Dynamic variables continue to work as they have always worked. Closure is not something that most Perl programmers need trouble themselves about to begin with. <P><LI><STRONG>.</STRONG> <CODE>new()</CODE> and called indirectly: <P> <PRE> $objref = new Doggie (Tail => 'short', Ears => 'long'); </PRE> <P> But don't have to be: <P> <PRE> $objref = Doggie->new(Tail => 'short', Ears => 'long'); </PRE> <P> <PRE> use Term::Cap; $terminal = Term::Cap->Tgetent( { OSPEED => 9600 }); </PRE> <P> <PRE> use Tk; $main = MainWindow->new(); $menubar = $main->Frame(-relief => "raised", -borderwidth => 2) </PRE> <LI><STRONG>.</STRONG> <P> References of the appropriate type can spring into existence if you dereference them in a context that assumes they exist. Because we haven't talked about dereferencing yet, we can't show you any examples yet. <P><LI><STRONG>.</STRONG> <FONT SIZE=-1>A</FONT> reference can be created by using a special syntax, lovingly known as the *foo{THING} syntax. *foo{THING} returns a reference to the <FONT SIZE=-1>THING</FONT> slot in <CODE>*foo</CODE> (which is the symbol table entry which holds everything known as foo). <P> <PRE> $scalarref = *foo{SCALAR}; $arrayref = *ARGV{ARRAY}; $hashref = *ENV{HASH}; $coderef = *handler{CODE}; $ioref = *STDIN{IO}; $globref = *foo{GLOB}; </PRE> <P> All of these are self-explanatory except for *foo{IO}. It returns the <FONT SIZE=-1>IO</FONT> handle, used for file handles ([perlfunc:open|open]), sockets ([perlfunc:socket|socket] and [perlfunc:socketpair|socketpair]), and directory handles ([perlfunc:opendir|opendir]). For compatibility with previous versions of Perl, *foo{FILEHANDLE} is a synonym for *foo{IO}. <P> *foo{THING} returns undef if that particular <FONT SIZE=-1>THING</FONT> hasn't been used yet, except in the case of scalars. *foo{SCALAR} returns a reference to an anonymous scalar if <CODE>$foo</CODE> hasn't been used yet. This might change in a future release. <P> *foo{IO} is an alternative to the <FONT SIZE=-1>\*HANDLE</FONT> mechanism given in [perlman. <P> <PRE> splutter(*STDOUT); splutter(*STDOUT{IO}); </PRE> <P> <PRE> sub splutter { my $fh = shift; print $fh "her um well a hmmm\n"; } </PRE> <P> <PRE> $rec = get_rec(*STDIN); $rec = get_rec(*STDIN{IO}); </PRE> <P> <PRE> sub get_rec { my $fh = shift; return scalar <$fh>; } </PRE> </OL> <P> <HR> <H2><A NAME="Using_References">Using References</A></H2> <P> That's it for creating references. By now you're probably dying to know how to use references to get back to your long-lost data. There are several basic methods. <OL> <LI><STRONG>.</STRONG> <P> Anywhere you'd put an identifier (or chain of identifiers) as part of a variable or subroutine name, you can replace the identifier with a simple scalar variable containing a reference of the correct type: <P> <PRE> $bar = $$scalarref; push(@$arrayref, $filename); $$arrayref[0] = "January"; $$hashref{"KEY"} = "VALUE"; &$coderef(1,2,3); print $globref "output\n"; </PRE> <P> It's important to understand that we are specifically <EM>NOT</EM> dereferencing <CODE>$arrayref[0]</CODE> or <CODE>$hashref{"KEY"}</CODE> there. The dereference of the scalar variable happens <EM>BEFORE</EM> it does any key lookups. Anything more complicated than a simple scalar variable must use methods 2 or 3 below. However, a ``simple scalar'' includes an identifier that itself uses method 1 recursively. Therefore, the following prints ``howdy''. <P> <PRE> $refrefref = \\\"howdy"; print $$$$refrefref; </PRE> <LI><STRONG>.</STRONG> <P> Anywhere you'd put an identifier (or chain of identifiers) as part of a variable or subroutine name, you can replace the identifier with a <FONT SIZE=-1>BLOCK</FONT> returning a reference of the correct type. In other words, the previous examples could be written like this: <P> <PRE> $bar = ${$scalarref}; push(@{$arrayref}, $filename); ${$arrayref}[0] = "January"; ${$hashref}{"KEY"} = "VALUE"; &{$coderef}(1,2,3); $globref->print("output\n"); # iff IO::Handle is loaded </PRE> <P> Admittedly, it's a little silly to use the curlies in this case, but the <FONT SIZE=-1>BLOCK</FONT> can contain any arbitrary expression, in particular, subscripted expressions: <P> <PRE> &{ $dispatch{$index} }(1,2,3); # call correct routine </PRE> <P> Because of being able to omit the curlies for the simple case of <CODE>$$x</CODE>,, <EM>NOT</EM> case 2: <P> <PRE> $$hashref{"KEY"} = "VALUE"; # CASE 0 ${$hashref}{"KEY"} = "VALUE"; # CASE 1 ${$hashref{"KEY"}} = "VALUE"; # CASE 2 ${$hashref->{"KEY"}} = "VALUE"; # CASE 3 </PRE> <P> Case 2 is also deceptive in that you're accessing a variable called %hashref, not dereferencing through <CODE>$hashref</CODE> to the hash it's presumably referencing. That would be case 3. <P><LI><STRONG>.</STRONG> Subroutine calls and lookups of individual array elements arise often enough that it gets cumbersome to use method 2. As a form of syntactic sugar, the examples for method 2 may be written: <P> <PRE> $arrayref->[0] = "January"; # Array element $hashref->{"KEY"} = "VALUE"; # Hash element $coderef->(1,2,3); # Subroutine call </PRE> <P> The left side of the arrow can be any expression returning a reference, including a previous dereference. Note that <CODE>$array[$x]</CODE> is <EM>NOT</EM> the same thing as <CODE>$array->[$x]</CODE> here: <P> <PRE> $array[$x]->{"foo"}->[0] = "January"; </PRE> <P> This is one of the cases we mentioned earlier in which references could spring into existence when in an lvalue context. Before this statement, <CODE>$array[$x]</CODE> may have been undefined. If so, it's automatically defined with a hash reference so that we can look up <CODE>{"foo"}</CODE> in it. Likewise <CODE>$array[$x]->{"foo"}</CODE> will automatically get defined with an array reference so that we can look up <CODE>[0]</CODE> in it. This process is called <EM>autovivification</EM>. <P> One more thing here. The arrow is optional <EM>BETWEEN</EM> brackets subscripts, so you can shrink the above down to <P> <PRE> $array[$x]{"foo"}[0] = "January"; </PRE> <P> Which, in the degenerate case of using only ordinary arrays, gives you multidimensional arrays just like C's: <P> <PRE> $score[$x][$y][$z] += 42; </PRE> <P> Well, okay, not entirely like C's arrays, actually. <FONT SIZE=-1>C</FONT> doesn't know how to grow its arrays on demand. Perl does. <P><LI><STRONG>.</STRONG>. </OL> <P> The <CODE>ref()</CODE> operator may be used to determine what type of thing the reference is pointing to. See [perlman:perlfunc|the perlfunc manpage]. <P> The <CODE>bless()</CODE> operator may be used to associate the object a reference points to with a package functioning as an object class. See [perlman:perlobj|the perlobj manpage]. <P> <FONT SIZE=-1>A</FONT> typeglob may be dereferenced the same way a reference can, because the dereference syntax always indicates the kind of reference desired. So <CODE>${*foo}</CODE> and <CODE>${\$foo}</CODE> both indicate the same scalar variable. <P> Here's a trick for interpolating a subroutine call into a string: <P> <PRE> print "My sub returned @{[mysub(1,2,3)]} that time.\n"; </PRE> <P> The way it works is that when the <CODE>@{...}</CODE> is seen in the double-quoted string, it's evaluated as a block. The block creates a reference to an anonymous array containing the results of the call to <CODE>mysub(1,2,3)</CODE>. So the whole block returns a reference to an array, which is then dereferenced by <CODE>@{...}</CODE> and stuck into the double-quoted string. This chicanery is also useful for arbitrary expressions: <P> <PRE> print "That yields @{[$n + 5]} widgets\n"; </PRE> <P> <HR> <H2><A NAME="Symbolic_references">Symbolic references</A></H2> <P> We said that references spring into existence as necessary if they are undefined, but we didn't say what happens if a value used as a reference is already defined, but <EM>ISN'T</EM> a hard reference. If you use it as a reference in this case, it'll be treated as a symbolic reference. That is, the value of the scalar is taken to be the <EM>NAME</EM> of a variable, rather than a direct link to a (possibly) anonymous value. <P> People frequently expect it to work like this. So it does. <P> <PRE> $Not-so-symbolic references</A></H2> <P> <FONT SIZE=-1>A</FONT> new feature contributing to readability in perl version 5.001 is that the brackets around a symbolic reference behave more like quotes, just as they always have within a string. That is, <P> <PRE> $Pseudo-hashes: Using an array as a hash</A></H2> <P> <FONT SIZE=-1>WARNING:</FONT> This section describes an experimental feature. Details may change without notice in future versions. <P>: <P> <PRE> $struct = [{foo => 1, bar => 2}, "FOO", "BAR"]; </PRE> <P> <PRE> $struct->{foo}; # same as $struct->[1], i.e. "FOO" $struct->{bar}; # same as $struct->[2], i.e. "BAR" </PRE> <P> <PRE> keys %$struct; # will return ("foo", "bar") in some order values %$struct; # will return ("FOO", "BAR") in same some order </PRE> <P> <PRE> while (my($k,$v) = each %$struct) { print "$k => $v\n"; } </PRE> <P> Perl will raise an exception if you try to delete keys from a pseudo-hash or try to access nonexistent fields. For better performance, Perl can also do the translation from field names to array indices at compile time for typed object references. See <U>the fields manpage</U><!--../lib/fields.html-->. <P> <HR> <H2><A NAME="Function_Templates">Function Templates</A></H2> <P> As explained above, a closure is an anonymous function with access to the lexical variables visible when that function was compiled. It retains access to those variables even though it doesn't get run until later, such as in a signal handler or a Tk callback. <P> Using a closure as a function template allows us to generate many functions that act similarly. Suppopose you wanted functions named after the colors that generated <FONT SIZE=-1>HTML</FONT> font changes for the various colors: <P> <PRE> print "Be ", red("careful"), "with that ", green("light"); </PRE> <P> The <CODE>red()</CODE> and <CODE>green()</CODE> functions would be very similar. To create these, we'll assign a closure to a typeglob of the name of the function we're trying to build. <P> <PRE> @colors = qw(red blue green yellow orange purple violet); for my $name (@colors) { no strict 'refs'; # allow symbol table manipulation *$name = *{uc $name} = sub { "<FONT COLOR='$name'>@_</FONT>" }; } </PRE> <P> Now all those different functions appear to exist independently. You can call <CODE>red(),</CODE> <CODE>RED(),</CODE> <CODE>blue(),</CODE> <CODE>BLUE(),</CODE> <CODE>green(),</CODE> [perlfunc:my|my] on the loop iteration variable. <P> This is one of the only places where giving a prototype to a closure makes much sense. If you wanted to impose scalar context on the arguments of these functions (probably not a wise idea for this particular example), you could have written it this way instead: <P> <PRE> *$name = sub ($) { "<FONT COLOR='$name'>$_[0]</FONT>" }; </PRE> <P> However, since prototype checking happens at compile time, the assignment above happens too late to be of much use. You could address this by putting the whole loop of assignments within a <FONT SIZE=-1>BEGIN</FONT> block, forcing it to occur during compilation. <P> Access to lexicals that change over type--like those in the <CODE>for</CODE>: <P> <PRE> sub outer { my $x = $_[0] + 35; sub inner { return $x * 19 } # WRONG return $x + inner(); } </PRE> <P> <FONT SIZE=-1>A</FONT> work-around is the following: <P> <PRE> sub outer { my $x = $_[0] + 35; local *inner = sub { return $x * 19 }; return $x + inner(); } </PRE> <P> Now <CODE>inner()</CODE> can only be called from within <CODE>outer(),</CODE> because of the temporary assignments of the closure (anonymous subroutine). But when it does, it has normal access to the lexical variable <CODE>$x</CODE> from the scope of <CODE>outer().</CODE> <P> This has the interesting effect of creating a function local to another function, something not normally supported in Perl. <P> <HR> <H1><A NAME="WARNING">WARNING</A></H1> <P> You may not (usefully) use a reference as the key to a hash. It will be converted into a string: <P> <PRE> $x{ \$a } = $a; </PRE> <P> If you try to dereference the key, it won't do a hard dereference, and you won't accomplish what you're attempting. You might want to do something more like <P> <PRE> $r = \@a; $x{ $r } = $r; </PRE> <P> And then at least you can use the <CODE>values(),</CODE> which will be real refs, instead of the <CODE>keys(),</CODE> which won't. <P> The standard Tie::RefHash module provides a convenient workaround to this. <P> <HR> <H1><A NAME="SEE_ALSO">SEE ALSO</A></H1> <P> Besides the obvious documents, source code can be instructive. Some rather pathological examples of the use of references can be found in the <EM>t/op/ref.t</EM> regression test in the Perl source directory. <P> See also [perlman:perldsc|the perldsc manpage] and [perlman:perllol|the perllol manpage] for how to use references to create complex data structures, and [perlman:perltoot|the perltoot manpage], [perlman:perlobj|the perlobj manpage], and [perlman:perlbot|the perlbot manpage] for how to use them to create objects. <HR> <BR>Return to the [Library]<BR> | http://www.perlmonks.org/index.pl/jacques?displaytype=xml;node_id=396 | CC-MAIN-2016-07 | refinedweb | 3,201 | 50.46 |
I read that the following format comes under parametric polymorphism, but can we classify it in one, either runtime or compile time polymorphism?
public class Stack<T>
{ // items are of type T, which is known when we create the object
T[] items;
int count;
public void Push(T item) {...}
//type of method pop will be decided when we create the object
public T Pop()
{...}
}
It's a little of both. In order to use a generic class, you have to give it a type parameter at compile time, but the type parameter could be of an interface or base class, so the actual, concrete type of the objects used at runtime can vary.
For example, here I have a snippet of code with a
Stack<T> field. I've chosen to use an interface as the type parameter. This utilizes parametric polymorphism at compile time. You must choose which type parameter your
_stack field will use at compile time:
public interface IFoo { void Foo(); } public Stack<IFoo> _stack = new Stack<IFoo>();
Now, when this snippet of code is actually run, I can use any object whose class implements
IFoo, and that decision doesn't have to be made until run time:
public class Foo1 : IFoo { public void Foo() { Console.WriteLine("Foo1"); } } public class Foo2 : IFoo { public void Foo() { Console.WriteLine("Foo2"); } } public class Foo3 : IFoo { public void Foo() { Console.WriteLine("Foo2"); } } _stack.Push(new Foo1()); _stack.Push(new Foo2()); _stack.Push(new Foo3());
This is an example of subtype polymorphism, which is utilized at run time. | http://www.dlxedu.com/askdetail/3/d0477f4c4fd76e75194c86e504e0fa22.html | CC-MAIN-2018-30 | refinedweb | 256 | 62.78 |
On 05/26/2016 09:40 AM, Michal Privoznik wrote: > I've encountered the following problem (introduced by 6326865e): > > ../../tests/testutils.c: In function 'virtTestRun': > ../../tests/testutils.c:289:5: error: implicit declaration of function 'unsetenv' [-Werror=implicit-function-declaration] > unsetenv("VIR_TEST_MOCK_TESTNAME"); > > Apparently, mingw does not have unsetenv(). Therefore we should > call it iff we are sure platform we are building for has it. > > Signed-off-by: Michal Privoznik <mprivozn redhat com> > --- > > This is a tentative patch. Ideally, we would use gnulib's > implementation (like we do for setenv()), but there are some > licensing problems right now [1]. If they are resolved before our > release, we can just pick new gnulib. If, however, they are not, > we can just push this patch. Conditional ACK; this is a nice fallback if the gnulib stuff doesn't happen fast enough for us, but is indeed something we'd revert once gnulib is ready. > > 1: > > tests/testutils.c | 2 ++ > 1 file changed, 2 insertions(+) > > diff --git a/tests/testutils.c b/tests/testutils.c > index f4fbad2..8b7bf70 100644 > --- a/tests/testutils.c > +++ b/tests/testutils.c > @@ -286,7 +286,9 @@ virtTestRun(const char *title, > } > #endif /* TEST_OOM */ > > +#ifdef HAVE_UNSETENV > unsetenv("VIR_TEST_MOCK_TESTNAME"); > +#endif > return ret; > } > > -- Eric Blake eblake redhat com +1-919-301-3266 Libvirt virtualization library
Attachment:
signature.asc
Description: OpenPGP digital signature | https://www.redhat.com/archives/libvir-list/2016-May/msg01976.html | CC-MAIN-2020-50 | refinedweb | 219 | 50.23 |
Red Hat Bugzilla – Bug 998937
[abrt] ypbind-1.37.1-3.fc19: __netlink_free_handle: Process /usr/sbin/ypbind was killed by signal 6 (SIGABRT)
Last modified: 2015-02-17 11:50:43 EST
Description of problem:
The system was booting.
[New LWP 829]
[New LWP 872]
[New LWP 849]
[New LWP 850]
Traceback (most recent call last):
File "/usr/share/gdb/auto-load/usr/lib64/libgobject-2.0.so.0.3600.3-gdb.py", line 9, in <module>
from gobject import register
File "/usr/share/glib-2.0/gdb/gobject.py", line 3, in <module>
import gdb.backtrace
ImportError: No module named backtrace
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
Core was generated by `/usr/sbin/ypbind -n'.
Program terminated with signal 6, Aborted.
#0 0x00007fcf38853a19 in __GI_raise (sig=sig@entry=6) at ../nptl/sysdeps/unix/sysv/linux/raise.c:56
56 ../nptl/sysdeps/unix/sysv/linux/raise.c: No such file or directory.
Thread 4 (Thread 0x7fcf306cf700 (LWP 850)):
#0 __lll_lock_wait () at ../nptl/sysdeps/unix/sysv/linux/x86_64/lowlevellock.S:135
No locals.
#1 0x00007fcf38e00ba1 in _L_lock_790 () from /lib64/libpthread.so.0
No symbol table info available.
#2 0x00007fcf38e00aa7 in __GI___pthread_mutex_lock (mutex=mutex@entry=0x7fcf3a02e140 <search_lock>) at pthread_mutex_lock.c:64
type = 0
id = 850
#3 0x00007fcf39e29ec6 in do_binding () at serv_list.c:1105
i = <optimized out>
active = <optimized out>
#4 0x00007fcf39e2adc2 in go_online () at ypbind_dbus_nm.c:105
No locals.
#5 dbus_filter (connection=0x7fcf28001460, message=0x7fcf280042a0, user_data=<optimized out>) at ypbind_dbus_nm.c:176
state = NM_STATE_CONNECTED_GLOBAL
handled = <optimized out>
connection = 0x7fcf28001460
user_data = <optimized out>
message = 0x7fcf280042a0
handled = DBUS_HANDLER_RESULT_NOT_YET_HANDLED
#6 0x00007fcf397a19e6 in dbus_connection_dispatch (connection=connection@entry=0x7fcf28001460) at dbus-connection.c:4631
filter = <optimized out>
next = 0x0
message = 0x7fcf280042a0
link = <optimized out>
filter_list_copy = 0x7fcf28000a20
message_link = 0x7fcf28000a08
result = DBUS_HANDLER_RESULT_NOT_YET_HANDLED
pending = <optimized out>
reply_serial = <optimized out>
status = <optimized out>
found_object = 32719
__FUNCTION__ = "dbus_connection_dispatch"
#7 0x00007fcf399e2cc5 in message_queue_dispatch (source=source@entry=0x7fcf28005500, callback=<optimized out>, user_data=<optimized out>) at dbus-gmain.c:90
connection = 0x7fcf28001460
#8 0x00007fcf3925ee06 in g_main_dispatch (context=0x7fcf280018a0) at gmain.c:3054
dispatch = 0x7fcf399e2cb0 <message_queue_dispatch>
was_in_call = 0
user_data = 0x0
callback = 0x0
cb_funcs = 0x0
cb_data = 0x0
need_destroy = <optimized out>
current_source_link = {data = 0x7fcf28005500, next = 0x0}
source = 0x7fcf28005500
current = 0x7fcf28005160
i = 0
#9 g_main_context_dispatch (context=context@entry=0x7fcf280018a0) at gmain.c:3630
No locals.
#10 0x00007fcf3925f158 in g_main_context_iterate (context=0x7fcf280018a0, block=block@entry=1, dispatch=dispatch@entry=1, self=<optimized out>) at gmain.c:3701
max_priority = 0
timeout = 0
some_ready = 1
nfds = <optimized out>
allocated_nfds = 2
fds = 0x7fcf280055a0
#11 0x00007fcf3925f55a in g_main_loop_run (loop=0x7fcf28000990) at gmain.c:3895
__PRETTY_FUNCTION__ = "g_main_loop_run"
#12 0x00007fcf39e2afe1 in watch_dbus_nm (param=<optimized out>) at ypbind_dbus_nm.c:416
status = 1
loop = <optimized out>
dbus_init_ret = 1
#13 0x00007fcf38dfec53 in start_thread (arg=0x7fcf306cf700) at pthread_create.c:308
__res = <optimized out>
pd = 0x7fcf306cf700
now = <optimized out>
unwind_buf = {cancel_jmp_buf = {{jmp_buf = {140527847405312, 8619424248616730436, 0, 140527847406016, 140527847405312, 140733883108152, -8646849203350257852, >
#14 0x00007fcf3891313d in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:113
No locals.
Thread 3 (Thread 0x7fcf30ed0700 (LWP 849)):
#0 0x00007fcf38e05d41 in do_sigwait (sig=0x7fcf30ecfd6c, set=<optimized out>) at ../sysdeps/unix/sysv/linux/sigwait.c:61
__arg4 = 8
__arg2 = 0
_a3 = 0
_a1 = 140527855795600
resultvar = <optimized out>
__arg3 = 0
__arg1 = 140527855795600
_a4 = 8
_a2 = 0
ret = <optimized out>
tmpset = {__val = {829, 140527855798016, 0, 0, 0, 0, 0, 140528005702488, 140527034957840, 140527855795552, 140527855795488, 140527989137211, 4294967295, 0, 140527855795600, 140528005704080}}
#1 __sigwait (set=set@entry=0x7fcf30ecfd90, sig=sig@entry=0x7fcf30ecfd6c) at ../sysdeps/unix/sysv/linux/sigwait.c:99
oldtype = 0
result = 128
#2 0x00007fcf39e26ee3 in sig_handler (v_param=<optimized out>) at ypbind-mt.c:443
ret = <optimized out>
lock = {l_type = 0, l_whence = 0, l_start = 0, l_len = 0, l_pid = 0}
sigs_to_catch = {__val = {87047, 0 <repeats 15 times>}}
caught = 0
#3 0x00007fcf38dfec53 in start_thread (arg=0x7fcf30ed0700) at pthread_create.c:308
__res = <optimized out>
pd = 0x7fcf30ed0700
now = <optimized out>
unwind_buf = {cancel_jmp_buf = {{jmp_buf = {140527855798016, 8619424248616730436, 0, 140527855798720, 140527855798016, 140733883108152, -8646848104375500988, 2 (Thread 0x7fcf2fece700 (LWP 872)):
#0 0x00007fcf388da71d in nanosleep () at ../sysdeps/unix/syscall-template.S:81
No locals.
#1 0x00007fcf388da5b4 in __sleep (seconds=0) at ../sysdeps/unix/sysv/linux/sleep.c:137
ts = {tv_sec = 11, tv_nsec = 636465800}
set = {__val = {65536, 0 <repeats 15 times>}}
oset = {__val = {87047, 140527839010192, 140528008225044, 140528006107096, 1, 0, 140528041050592, 1376985848, 140527571830976, 0, 18446744069414584320, 0, 0, 0, 34359738369, 140528041050592}}
result = <optimized out>
#2 0x00007fcf39e2a50e in test_bindings (param=<optimized out>) at serv_list.c:1141
success = 0
lastcheck = 0
#3 0x00007fcf38dfec53 in start_thread (arg=0x7fcf2fece700) at pthread_create.c:308
__res = <optimized out>
pd = 0x7fcf2fece700
now = <optimized out>
unwind_buf = {cancel_jmp_buf = {{jmp_buf = {140527839012608, 8619424248616730436, 0, 140527839013312, 140527839012608, 4294967295, -8646903081030631612, 1 (Thread 0x7fcf39dbf800 (LWP 829)):
#0 0x00007fcf38853a19 in __GI_raise (sig=sig@entry=6) at ../nptl/sysdeps/unix/sysv/linux/raise.c:56
resultvar = 0
pid = 829
selftid = 829
#1 0x00007fcf38855128 in __GI_abort () at abort.c:90
save_stage = 2
act = {__sigaction_handler = {sa_handler = 0x7fcf3899944d, sa_sigaction = 0x7fcf3899944d}, sa_mask = {__val = {3, 140733883101820, 4, 140527984543264, 1, 140527984551929, 3, 140733883101796, 12, 140527984551933, 2, 140527984551933, 2, 140733883102608, 140733883102608, 140733883104368}}, sa_flags = 16, sa_restorer = 0x7fff291c3790}
sigs = {__val = {32, 0 <repeats 15 times>}}
#2 0x00007fcf38893d47 in __libc_message (do_abort=do_abort@entry=2, fmt=fmt@entry=0x7fcf3899bb88 "*** Error in `%s': %s: 0x%s ***\n") at ../sysdeps/unix/sysv/linux/libc_fatal.c:196
ap = {{gp_offset = 40, fp_offset = 48, overflow_arg_area = 0x7fff291c3c80, reg_save_area = 0x7fff291c3b90}}
ap_copy = {{gp_offset = 16, fp_offset = 48, overflow_arg_area = 0x7fff291c3c80, reg_save_area = 0x7fff291c3b90}}
fd = 2
on_2 = <optimized out>
list = <optimized out>
nlist = <optimized out>
cp = <optimized out>
written = <optimized out>
#3 0x00007fcf3889b0e8 in malloc_printerr (ptr=<optimized out>, str=0x7fcf3899bc40 "double free or corruption (out)", action=3) at malloc.c:4916
buf = "00007fcf3bf80980"
cp = <optimized out>
#4 _int_free (av=0x7fcf38bd7780 <main_arena>, p=<optimized out>, have_lock=0) at malloc.c:3768
size = <optimized out>
fb = <optimized out>
nextchunk = <optimized out>
nextsize = <optimized out>
nextinuse = <optimized out>
prevsize = <optimized out>
bck = <optimized out>
fwd = <optimized out>
errstr = 0x7fcf3899bc40 "double free or corruption (out)"
locked = <optimized out>
#5 0x00007fcf3893460b in __netlink_free_handle (h=h@entry=0x7fff291c3dc0) at ../sysdeps/unix/sysv/linux/ifaddrs.c:86
tmpptr = 0x7fcf3bf81650
ptr = <optimized out>
saved_errno = 9
#6 0x00007fcf38934b08 in getifaddrs_internal (ifap=ifap@entry=0x7fff291c3f40) at ../sysdeps/unix/sysv/linux/ifaddrs.c:815
nh = {fd = 9, pid = 829, seq = 1376985551, nlm_list = 0x7fcf3bf80980, end_ptr = 0x7fcf3bf81850}
nlp = <optimized out>
ifas = <optimized out>
i = <optimized out>
newlink = <optimized out>
newaddr = <optimized out>
newaddr_idx = <optimized out>
map_newlink_data = <optimized out>
ifa_data_size = <optimized out>
ifa_data_ptr = <optimized out>
result = 0
#7 0x00007fcf38935700 in __GI_getifaddrs (ifap=ifap@entry=0x7fff291c3f40) at ../sysdeps/unix/sysv/linux/ifaddrs.c:831
res = 0
#8 0x00007fcf3894096e in is_network_up (sock=<optimized out>) at clnt_udp.c:277
ifa = 0x7fcf3bf81890
run = <optimized out>
#9 clntudp_call (cl=<optimized out>, proc=2, xargs=0x0, argsp=0x0, xresults=0x7fcf38945d50 <__GI_xdr_bool>, resultsp=0x7fff291c4090 "", utimeout=...) at clnt_udp.c:386
cu = 0x7fcf3bf7c1e0
xdrs = 0x7fcf3bf7c238
outlen = 0
inlen = <optimized out>
fromlen = 689717424
fd = {fd = 8, events = 1, revents = 0}
milliseconds = 5000
from = {sin_family = 25954, sin_port = 26482, sin_addr = {s_addr = 1936287085}, sin_zero = "e.ims.un"}
reply_msg = {rm_xid = 562608583, rm_direction = CALL, ru = {RM_cmb = {cb_rpcvers = 2, cb_prog = 0, cb_vers = 0, cb_proc = 0, cb_cred = {oa_flavor = 0, oa_base = 0x7fff291c4090 "", oa_length = 949247312}, cb_verf = {oa_flavor = 24, oa_base = 0x2 <Address 0x2 out of bounds>, oa_length = 1006113264}}, RM_rmb = {rp_stat = (unknown: 2), ru = {RP_ar = {ar_verf = {oa_flavor = 0, oa_base = 0x0, oa_length = 0}, ar_stat = SUCCESS, ru = {AR_versions = {low = 140733883105424, high = 140527984205136}, AR_results = {where = 0x7fff291c4090 "", proc = 0x7fcf38945d50 <__GI_xdr_bool>}}}, RP_dr = {rj_stat = RPC_MISMATCH, ru = {RJ_versions = {low = 0, high = 0}, RJ_why = AUTH_OK}}}}}}
reply_xdrs = {x_op = (unknown: 17760), x_ops = 0x7fcf38937624 <__GI_authnone_create+276>, x_public = 0x0, x_private = 0x7fcf3893e327 <_create_xid+119> "\203=\306\354)", x_base = 0x7fff291c3f80 "\307\271\210!", x_handy = 949246123}
time_waited = {tv_sec = 0, tv_usec = 0}
ok = <optimized out>
nrefreshes = <optimized out>
timeout = {tv_sec = 0, tv_usec = 0}
anyup = 0
#10 0x00007fcf39e28d7e in ping_all (list=0x7fcf3bf7c1e0) at serv_list.c:915
TIMEOUT00 = {tv_sec = 0, tv_usec = 0}
clnt = 0x7fcf3bf7c1c0
pings = <optimized out>
s_in = {sin_family = 2, sin_port = 37378, sin_addr = {s_addr = 2608806541}, sin_zero = "\000\000\000\000\000\000\000"}
any = 0x7fcf3bf7c1a8
found = 0
xid_seed = 689717392
xid_lookup = <optimized out>
sock = 8
dontblock = 1
clnt_res = 0
i = 3
pings_count = 3
cu = 0x7fcf3bf7c1e0
domain = 0x7fcf3bf7c1e0 "\b"
old_active = -1
#11 0x00007fcf39e2a1e7 in test_bindings_once (lastcheck=lastcheck@entry=1, req_domain=req_domain@entry=0x7fcf3bf7c120 "mydomain") at serv_list.c:1274
domain = 0x7fcf3bf7c1e0 "\b"
out = 1
status = RPC_SUCCESS
i = 0
active = -1
#12 0x00007fcf39e2790d in ypbindproc_domain (domain_name=0x7fcf3bf7c120 "mydomain", result=0x7fff291c41d0, rqstp=<optimized out>) at ypbind_server.c:88
No locals.
#13 0x00007fcf39e27785 in ypbindprog_2 (rqstp=0x7fff291c4240, transp=0x7fcf3bf7c820) at ypbind_svc.c:176
argument = {ypbindproc_domain_2_arg = 0x7fcf3bf7c120 "mydomain", ypbindproc_setdom_2_arg = {ypsetdom_domain = 0x7fcf3bf7c120 "mydomain", ypsetdom_binding = {ypbind_binding_addr = "\000\000\000", ypbind_binding_port = "\000"}, ypsetdom_vers = 0}}
result = {ypbindproc_domain_2_res = {ypbind_status = YPBIND_FAIL_VAL, ypbind_resp_u = {ypbind_error = 2, ypbind_bindinfo = {ypbind_binding_addr = "\002\000\000", ypbind_binding_port = "\000"}}}}
retval = <optimized out>
xdr_argument = 0x7fcf39e27280 <ypbind_xdr_domainname>
xdr_result = 0x7fcf39e27300 <ypbind_xdr_resp>
local = 0x7fcf39e27be0 <ypbindproc_domain_2_svc>
#14 0x00007fcf38943991 in __GI_svc_getreq_common (fd=fd@entry=6) at svc.c:534
s = <optimized out>
high_vers = <optimized out>
r = {rq_prog = 100007, rq_vers = 2, rq_proc = 1, rq_cred = {oa_flavor = 0, oa_base = 0x7fff291c4340 "\020F\034)\377\177", oa_length = 0}, rq_clntcred = 0x7fff291c4660 "`\034\370;\317\177", rq_xprt = 0x7fcf3bf7c820}
why = <optimized out>
low_vers = <optimized out>
prog_found = <optimized out>
stat = <optimized out>
msg = {rm_xid = 1174538895, rm_direction = CALL, ru = {RM_cmb = {cb_rpcvers = 2, cb_prog = 100007, cb_vers = 2, cb_proc = 1, cb_cred = {oa_flavor = 0, oa_base = 0x7fff291c4340 "\020F\034)\377\177", oa_length = 0}, cb_verf = {oa_flavor = 0, oa_base = 0x7fff291c44d0 "\001\200\255\373", oa_length = 0}}, RM_rmb = {rp_stat = (unknown: 2), ru = {RP_ar = {ar_verf = {oa_flavor = 100007, oa_base = 0x2 <Address 0x2 out of bounds>, oa_length = 1}, ar_stat = SUCCESS, ru = {AR_versions = {low = 140733883106112, high = 0}, AR_results = {where = 0x7fff291c4340 "\020F\034)\377\177", proc = 0x0}}}, RP_dr = {rj_stat = (AUTH_ERROR | unknown: 100006), ru = {RJ_versions = {low = 2, high = 1}, RJ_why = AUTH_REJECTEDCRED}}}}}}
xprt = 0x7fcf3bf7c820
cred_area = "\020F\034)\377\177\000\000\322\301\300\071\317\177\000\000P_\340\070\317\177\000\000\320D\034)\377\177\000\000\000\000\000\000\377\177\000\000\000\000\000\000\000\000\000\000\320\\!9\317\177\000\000\322\301\300\071\317\177\000\000\230\t\342\071\317\177", '\000' <repeats 26 times>, "\240\272\300\071\317\177\000\000\310H\034)\377\177\000\000\b\020\342\071\317\177\000\000\000\000\000\000\000\000\000\000\270H\034)\377\177\000\000\000\000\000\000\000\000\000\000\240\272\300\071\317\177\000\000h\rT9\317\177\000\000\000\000@\222\070R\376\377\001\000\000\000\000\000\000\000\300\000\000\000\000\000\000\000\221\273\343\326\000\200\377\377\r\000\000\000\317\177\000\000"...
#15 0x00007fcf38943ade in __GI_svc_getreq_poll (pfdp=pfdp@entry=0x7fcf3bf80f90, pollretval=1) at svc.c:460
p = 0x7fcf3bf80f90
i = 0
fds_found = 0
#16 0x00007fcf389472cf in __GI_svc_run () at svc_run.c:96
max_pollfd = <optimized out>
i = <optimized out>
my_pollfd = 0x7fcf3bf80f90
last_max_pollfd = 3
#17 0x00007fcf39e25b7d in main (argc=<optimized out>, argv=<optimized out>) at ypbind-mt.c:1000
i = <optimized out>
sigs_to_block = {__val = {87047, 0 <repeats 15 times>}}
sig_thread = 140527855798016
ping_thread = 140527839012608
dbus_thread = 140527847405312
disable_dbus = <optimized out>
st = {st_dev = 64770, st_ino = 2490371, st_nlink = 2, st_mode = 16877, st_uid = 0, st_gid = 0, __pad0 = 0, st_rdev = 0, st_size = 4096, st_blksize = 4096, st_blocks = 8, st_atim = {tv_sec = 1376985393, tv_nsec = 431664848}, st_mtim = {tv_sec = 1376985393, tv_nsec = 431664848}, st_ctim = {tv_sec = 1376985393, tv_nsec = 431664848}, __unused = {0, 0, 0}}
configcheck_only = <optimized out>
From To Syms Read Shared Object Library
0x00007fcf399e2570 0x00007fcf399f3bb4 Yes /lib64/libdbus-glib-1.so.2
0x00007fcf39799840 0x00007fcf397c1c94 Yes /lib64/libdbus-1.so.3
0x00007fcf3954dad0 0x00007fcf3957ab60 Yes /lib64/libgobject-2.0.so.0
0x00007fcf39231260 0x00007fcf392ca12c Yes /lib64/libglib-2.0.so.0
0x00007fcf39013da0 0x00007fcf39014b3a Yes /lib64/libsystemd-daemon.so.0
0x00007fcf38dfc790 0x00007fcf38e073c4 Yes /lib64/libpthread.so.0
0x00007fcf38be2110 0x00007fcf38beed94 Yes /lib64/libnsl.so.1
0x00007fcf3883d410 0x00007fcf3897fd30 Yes /lib64/libc.so.6
0x00007fcf384f5970 0x00007fcf385adc7c Yes /lib64/libgio-2.0.so.0
0x00007fcf382bf2c0 0x00007fcf382c20bc Yes /lib64/librt.so.1
0x00007fcf380b6870 0x00007fcf380baf58 Yes /lib64/libffi.so.6
0x00007fcf37eb1ed0 0x00007fcf37eb29d0 Yes /lib64/libdl.so.2
0x00007fcf39bffae0 0x00007fcf39c19c3a Yes /lib64/ld-linux-x86-64.so.2
0x00007fcf37cae120 0x00007fcf37caefd8 Yes /lib64/libgmodule-2.0.so.0
0x00007fcf37a99170 0x00007fcf37aa55f0 Yes /lib64/libz.so.1
0x00007fcf3787a260 0x00007fcf3788be9c Yes /lib64/libselinux.so.1
0x00007fcf3765da40 0x00007fcf3766c71c Yes /lib64/libresolv.so.2
0x00007fcf373f75f0 0x00007fcf3743fcc8 Yes /lib64/libpcre.so.1
0x00007fcf2f4c31e0 0x00007fcf2f4ca3cc Yes /lib64/libnss_files.so.2
0x00007fcf2f2adaf0 0x00007fcf2f2bd198 Yes /lib64/libgcc_s.so.1
$1 = 0x7fcf39e1d000 ""
$2 = 0x0
rax 0x0 0
rbx 0x0 0
rcx 0xffffffffffffffff -1
rdx 0x6 6
rsi 0x33d 829
rdi 0x33d 829
rbp 0x7fff291c3c70 0x7fff291c3c70
rsp 0x7fff291c3238 0x7fff291c3238
r8 0x0 0
r9 0xe 14
r10 0x8 8
r11 0x202 514
r12 0xa 10
r13 0x7fff291c3790 140733883103120
r14 0x59 89
r15 0x2 2
rip 0x7fcf38853a19 0x7fcf38853a19 <__GI_raise+57>
eflags 0x202 [ IF ]
cs 0x33 51
ss 0x2b 43
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
Dump of assembler code for function __GI_raise:
0x00007fcf388539e0 <+0>: mov %fs:0x2d4,%eax
0x00007fcf388539e8 <+8>: mov %eax,%ecx
0x00007fcf388539ea <+10>: mov %fs:0x2d0,%esi
0x00007fcf388539f2 <+18>: test %esi,%esi
0x00007fcf388539f4 <+20>: jne 0x7fcf38853a28 <__GI_raise+72>
0x00007fcf388539f6 <+22>: mov $0xba,%eax
0x00007fcf388539fb <+27>: syscall
0x00007fcf388539fd <+29>: mov %eax,%ecx
0x00007fcf388539ff <+31>: mov %eax,%fs:0x2d0
0x00007fcf38853a07 <+39>: mov %eax,%esi
0x00007fcf38853a09 <+41>: movslq %edi,%rdx
0x00007fcf38853a0c <+44>: movslq %esi,%rsi
0x00007fcf38853a0f <+47>: movslq %ecx,%rdi
0x00007fcf38853a12 <+50>: mov $0xea,%eax
0x00007fcf38853a17 <+55>: syscall
=> 0x00007fcf38853a19 <+57>: cmp $0xfffffffffffff000,%rax
0x00007fcf38853a1f <+63>: ja 0x7fcf38853a3a <__GI_raise+90>
0x00007fcf38853a21 <+65>: repz retq
0x00007fcf38853a23 <+67>: nopl 0x0(%rax,%rax,1)
0x00007fcf38853a28 <+72>: test %eax,%eax
0x00007fcf38853a2a <+74>: jg 0x7fcf38853a09 <__GI_raise+41>
0x00007fcf38853a2c <+76>: mov %eax,%ecx
0x00007fcf38853a2e <+78>: neg %ecx
0x00007fcf38853a30 <+80>: test $0x7fffffff,%eax
0x00007fcf38853a35 <+85>: cmove %esi,%ecx
0x00007fcf38853a38 <+88>: jmp 0x7fcf38853a09 <__GI_raise+41>
0x00007fcf38853a3a <+90>: mov 0x38341f(%rip),%rdx # 0x7fcf38bd6e60
0x00007fcf38853a41 <+97>: neg %eax
0x00007fcf38853a43 <+99>: mov %eax,%fs:(%rdx)
0x00007fcf38853a46 <+102>: or $0xffffffffffffffff,%rax
0x00007fcf38853a4a <+106>: retq
End of assembler dump.
Version-Release number of selected component:
ypbind-1.37.1-3.fc19
Additional info:
reporter: libreport-2.1.6
backtrace_rating: 4
cmdline: /usr/sbin/ypbind -n
crash_function: __netlink_free_handle
executable: /usr/sbin/ypbind
kernel: 3.10.7-200.fc19.x86_64
runlevel: unknown
uid: 0
Truncated backtrace:
Thread no. 1 (10 frames)
#5 __netlink_free_handle at ../sysdeps/unix/sysv/linux/ifaddrs.c:86
#6 getifaddrs_internal at ../sysdeps/unix/sysv/linux/ifaddrs.c:815
#7 getifaddrs at ../sysdeps/unix/sysv/linux/ifaddrs.c:831
#8 is_network_up at clnt_udp.c:277
#9 clntudp_call at clnt_udp.c:386
#10 ping_all at serv_list.c:915
#11 test_bindings_once at serv_list.c:1274
#12 ypbindproc_domain at ypbind_server.c:88
#13 ypbindprog_2 at ypbind_svc.c:176
#14 svc_getreq_common at svc.c:534
Created attachment 788442 [details]
File: backtrace
Created attachment 788443 [details]
File: cgroup
Created attachment 788444 [details]
File: core_backtrace
Created attachment 788445 [details]
File: dso_list
Created attachment 788446 [details]
File: environ
Created attachment 788447 [details]
File: limits
Created attachment 788448 [details]
File: maps
Created attachment 788449 [details]
File: open_fds
Created attachment 788450 [details]
File: proc_pid_status
Created attachment 788451 [details]
File: var_log_messages
Thank you for the report, but I don't see ypbind doing anything wrong. Is that failure reproducible? If it happened only once, I'd say it could be caused by some unspecified memory problem. ***
When I have started ypbind by hand (systemctl restart ypbind), then it works as expected, no crash.
In the meentime I found that firewalld.service was disabled. I had a line "firewall --disable" in my kickstart file, but this line was ignored in the last weeks by kickstart / anaconda. It seems that something has changed - it is fine that the kickstart option is honored now.
Now I have enabled firewalld.service manually and rebooted the host again - two times. Now - with firewalld.service enabled - ypbind starts and don't crash and works fine.
So this is ok for me, you may close the bug.
But I am wondering about the message about the corrupted double-linked list. ypbind got a timeout, it founds no nis servers, if firewalld was disabled. ***
...
If I enable firewalld again then ypbind does not crash.
So it is reproducible.
(In reply to Edgar Hoch from comment #12)
> ***
Memory corruption again, but a bit different message this time, so I'd wonder if the backtrace looks the same or not.
> When I have started ypbind by hand (systemctl restart ypbind), then it works
> as expected, no crash.
But this time the firewall was fixed and ypbind was able to connect to YP servers, right?
>?
> If I enable firewalld again then ypbind does not crash.
> So it is reproducible.
I see some changes in relevant part of code in glibc, especially the following chunk seems suspicious to me, since enabling strict-aliasing could make problem in some memory operations. But it's just a guess:
diff -rup glibc-2.16-75f0d304/sunrpc/Makefile glibc-2.18/sunrpc/Makefile
--- glibc-2.16-75f0d304/sunrpc/Makefile 2013-08-20 15:21:08.131164559 +0200
+++ glibc-2.18/sunrpc/Makefile 2013-08-11 00:52:55.000000000 +0200
@@ -150,10 +150,6 @@ sunrpc-CPPFLAGS = -D_RPC_THREAD_SAFE_
CPPFLAGS += $(sunrpc-CPPFLAGS)
BUILD_CPPFLAGS += $(sunrpc-CPPFLAGS)
-CFLAGS-clnt_tcp.c += -fno-strict-aliasing
-CFLAGS-clnt_udp.c += -fno-strict-aliasing
-CFLAGS-clnt_unix.c += -fno-strict-aliasing
-
$(objpfx)tst-getmyaddr: $(common-objpfx)linkobj/libc.so
$(objpfx)tst-xdrmem: $(common-objpfx)linkobj/libc.so
$(objpfx)tst-xdrmem2: $(common-objpfx)linkobj/libc.so
Created attachment 788605 [details]
Lines with ypbind from /var/log/messages
I attached an extract of /var/log/messages with the lines containing ypbind. I hope this helps.
(In reply to Honza Horak from comment #13)
> But this time the firewall was fixed and ypbind was able to connect to YP
> servers, right?
I only have enabled the firewall (systemctl enable firewalld) and have rebooted. The network interface is configured to zone "work".
> >?
I have disableed the firewall this time.
For testing, I have enabled the firewall and rebooted, disabled the firewall and rebooted, enabled again...
Thank you for your feedback and also bug #999121 reported. It is weird that the daemon crashes in different places and with different signals. What seems clear that something is terribly wrong with memory. But it's not clear to me if it is in ypbind/glibc/kernel or it can be some more general problem (memory physically damaged).
I understand that the bug could have been there for some time already and just didn't show up because the firewalld was enabled. But still, it could give some clue if you would be able to downgrade ypbind, glibc and eventually kernel to some of the older builds and see if it helps. Otherwise I don't have any concrete idea where to start.. | https://bugzilla.redhat.com/show_bug.cgi?id=998937 | CC-MAIN-2017-43 | refinedweb | 3,008 | 55.34 |
addu_sis 1.0.0
addu_sis: ^1.0.0 copied to clipboard
A Dart library for accessing AdDU Student Information System (SIS) data. Originally built for AdDU Hub Flutter app.
AdDU Student Information System Node.js Library #
A Dart library for accessing AdDU Student Information System (SIS) data. This library scrapes data using dio and the http HTML parser. No data is saved when using this library by itself.
Getting Started #
These instructions will get you the library up and running on your local machine for development and testing purposes
Installing #
Add this to your package's pubspec.yaml file:
dependencies: addu_sis: ^1.0.0
Usage #
Here is an example that:
- initializes the SIS library
- gets and prints user information
import 'package:addu_sis/addu_sis.dart'; Future<void> main() async { var sis = new SIS('username', 'password'); var user = await sis.getUser(); // user.card, user.id, user.name, user.course, user.section, user.division, user.year, user.status }
Getting and printing the grades of the account
var grades = await sis.getGrades(); print(grades.all());
Getting and printing the balance of the account
var balance = await sis.getBalance(); print(balance.all());
Getting and printing the registration of the account
var registration = await sis.getRegistration(); print(registration.all());
Getting and printing all of the subjects in the curriculum of the account
var curriculum = await sis.getCurriculum(); print(curriculum.all());
Searching for currently available classes with class code 4-%
var search = await sis.searchClasses('4-%'); print(search);
Testing #
This package does not come with examples for testing yet.
Versioning #
We use SemVer for versioning. For the versions available, see the tags on this repository.
Authors #
- Son Roy Almerol - Initial work - sonroyaalmerol
See also the list of contributors who participated in this project.
License #
This project is licensed under the MIT License - see the LICENSE.md file for details
Acknowledgments #
- AdDU SIS ;)
- Hat tip to anyone whose code was used
- Inspiration
- etc | https://pub.dev/packages/addu_sis/versions/1.0.0 | CC-MAIN-2021-17 | refinedweb | 315 | 50.33 |
Settings Managing on Rails Applications
Is it a nightmare to manage global settings in your Rails Apps? I used to have this problem, and I was just tired of it, so I contributed to write a gem! check this out:
MC-Settings
As its README says:
This gem provides an easy and Capistrano-friendly way to manage application configuration across multiple environments, such as development, QA, staging, production, etc.
The Problem to solve
Let’s say that you need specific configurations per environment, or even, per server!
Example: I want my stage environment to use a single memcached server, storefront production to use two memcacheds, admin production to have caching disabled and my dev machine to use local memcached.
How would you solve this? The answer is easy: use mc-settings, go to its github page and read the details about it. I’ll describe how we were able to manage different configurations without ugly conditionals.
Settings per environment
I’m assuming a normal rails app folder structure.
config/settings/default.yml:
caching: enabled: false memcached: host: localhost port: 11211
config/settings/environments/development.yml
caching: enabled: true memcached: host: 127.0.0.1 port: 11211
config/settings/environments/staging.yml
caching: enabled: true memcached: host: 192.168.10.5 port: 11211
config/settings/environments/production.yml
caching: enabled: false memcached: host: localhost port: 11211
config/settings/stages/admin.yml
caching: enabled: false memcached: host: port:
config/settings/systems/cluster1.yml
caching: enabled: true memcached: host: 192.168.5.5 port: 11211
config/settings/systems/cluster2.yml
caching: enabled: true memcached: host: 192.168.5.6 port: 11211
Capistrano integration
When writing your capistrano recipes, add this task:
namespace :settings do desc "Symlinks correct configuration file" task :symlink_local_file do system_file_name = "#{current_release}/config/settings/" + "systems/#{full_stage_name}.yml" run "cd #{current_release}/config && if [ -f #{system_file_name} ]; " + "then echo 'symlinking systems/#{full_stage_name}.yml into locals' " + "&& ln -sf #{system_file_name} #{current_release}/config/settings/local ; fi" end end
Then, just call it:
namespace :deploy do task :default do ... settings.symlink_local ... end end
This will create a symbolic link between your staging config file into config/settings/local folder, mc-settings will load this settings and override any previous value.
In Action
I’ll just show the input in every single environment, and you will get the idea:
Local machine:
rails c test ree > Setting.cache(:enabled) => false
It returned false because test didn’t have specific configuration and mc-settings loaded this value from default.yml
Local machine:
rails c ree > Setting.cache(:enabled) => true ree > Setting.cache(:host) => "127.0.0.1" ree > Setting.cache(:port) => 11211
When running in development mode, since we specified that the cache should be enabled, it returns the local configuration.
Local machine:
rails c production ree > Setting.cache(:enabled) => false
Notice that in production.yml I set cache(:enabled) as false, how cool, isn’t it?
Staging app server
rails c staging ree > Setting.cache(:enabled) => true ree > Setting.cache(:host) => "192.168.10.5" ree > Setting.cache(:port) => 11211
Look at staging.yml, mc-settings return the correct value for this environment, without any manual configuration!
admin app server
rails c production ree > Setting.cache(:enabled) => false
When I saw this I said: yes! now I can disable caching in admin servers very easily without ugly configurations or extra deployment efforts.
cluster1 app server
rails c production ree > Setting.cache(:enabled) => true ree > Setting.cache(:host) => "192.168.5.5" ree > Setting.cache(:port) => 11211
This is where the magic begins, mc-settings + capistrano you can really do fine grain tuning with your configurations and still keep your precious hair!!
cluster2 app server
rails c production ree > Setting.cache(:enabled) => true ree > Setting.cache(:host) => "192.168.5.6" ree > Setting.cache(:port) => 11211
Again, you get a very powerful combination using mc-settings + capistrano, this is how we were able to manage rails configuration across 3 clusters with more than 30 app servers plus the staging servers
Promise to write a new post later on describing how could you get the same mc-settings + capistrano power with services like Heroku and Engine Yard. | http://blog.magmalabs.io/2012/02/27/settings-managing-rails-aplications.html | CC-MAIN-2019-09 | refinedweb | 685 | 50.94 |
- 12 Feb, 2010 2 commits
Fixed Geni XML parse bugs. Added additional checks for absent tags. Fixed bug where the ticket was created using the original string rather than the updated rspec.
- 11 Feb, 2010 6 commits
- 10 Feb, 2010 1 commit
Added component_manager information to links in both versions 0.1 and 2 of the rspec. The request-tunnel.xml example uses component_manager tags on links.
- 09 Feb, 2010 6 commits
- Mike Hibler authored
is looking more and more like a urn, and so have to be careful when using it to lookup a local node.
Added initial versions for CreateDocument and AddElement utility functions which handle boilerplate and namespace issues automatically. Fixed a problem with how SetText handles namespaces.
- 08 Feb, 2010 2 commits
- 05 Feb, 2010 1 commit
- 04 Feb, 2010 4 commits
Fixed several XML bugs. Fixed two bugs where raw URNs were being passed to Emulab lookup functions. I have no idea how those were working before..
- 03 Feb, 2010 2 commits
Checkpoint. All the conversion is done, but I need to refactor the xpaths to account for brittleness in the xpath specification.
* When resolving a component, return the gif (certificate) of the authority it belongs to. * Quick fix for skiping links that are for another CM. This will change later when the schema defines it.
- 29 Jan, 2010 1 commit
- 27 Jan, 2010 2 commits
- 26 Jan, 2010 1 commit
-) | https://gitlab.flux.utah.edu/emulab/emulab-devel/-/commits/50d9cc568327e432ef303e2d5fb34cdab2482685/protogeni | CC-MAIN-2021-43 | refinedweb | 236 | 66.84 |
To do some Basic Works of Excel with EPPlus Library, See this.
To do some Basic Works of Excel with EPPlus Library, See this.
Following 4 New Contents are added in this Release:
Following 4 New Contents are added in this Release:
Recently I was looking for an Advance tool through which I can generate complex
Excel Reports. And after going through many tools I found EP Plus. For further details
see this link. Through this tool we can
easily create reports with charts, graphs and other drawing objects. I have planned
to shared few samples with the community, so if any one is interested in using this
library he will get a good kick start.
Or you can download the library DLL from the above link. Then
do the following:
/* To work eith EPPlus library */
using OfficeOpenXml;
using OfficeOpenXml.Drawing;
/* For I/O purpose */
using System.IO;
/* For Diagnostics */
using System.Diagnostics;
Reading a simple excel sheet containing text and number into DataTable.
private DataTable WorksheetToDataTable(ExcelWorksheet oSheet)
{
int totalRows = oSheet.Dimension.End.Row;
int totalCols = oSheet.Dimension.End.Column;
DataTable dt = new DataTable(oSheet.Name);
DataRow dr = null;
for (int i = 1; i <= totalRows; i++)
{
if (i > 1) dr = dt.Rows.Add();
for (int j = 1; j <= totalCols; j++)
{
if (i == 1)
dt.Columns.Add(oSheet.Cells[i, j].Value.ToString());
else
dr[j - 1] = oSheet.Cells[i, j].Value.ToString();
}
}
return dt;
}
How you do this in this project?
The Sample Excel file is the following:
The Final Resule is below:
The Useful properties which you can set are:
In the following way you can set the properties:
using (ExcelPackage excelPkg = new ExcelPackage())
{
excelPkg.Workbook.Properties.Author = "Debopam Pal";
excelPkg.Workbook.Properties.Title = "EPPlus Sample";
}
Merge Excell Cells by providing the Row Index and Column Index of the Start Cell
and the End Cell. The syntax is: Cell[fromRow, fromCol, toRow, toCol]. In the following
way you can merge excel cells:
//Merge Excel Columns: Merging cells and create a center heading for our table
oSheet.Cells[1, 1].Value = "Sample DataTable Export";
oSheet.Cells[1, 1, 1, dt.Columns.Count].Merge = true;
The following Fill Styles are available under OfficeOpenXml.Style.ExcelFillStyle:
OfficeOpenXml.Style.ExcelFillStyle
You can use any color from System.Drawing.Color as your Background
Color. In the following way you can set the Background Color along with Fill Style:
System.Drawing.Color
var cell = oSheet.Cells[rowIndex, colIndex];
//Setting the background color of header cells to Gray
var fill = cell.Style.Fill;
fill.PatternType = OfficeOpenXml.Style.ExcelFillStyle.Solid;
fill.BackgroundColor.SetColor(Color.Gray);
The following Border styles are available under OfficeOpenXml.Style.ExcelBorderStyle:
OfficeOpenXml.Style.ExcelBorderStyle
In the following way you can set the border style of a cell:
var cell = oSheet.Cells[rowIndex, colIndex];
//Setting top,left,right,bottom border of header cells
var border = cell.Style.Border;
border.Top.Style = border.Left.Style = border.Bottom.Style = border.Right.Style = OfficeOpenXml.Style.ExcelBorderStyle.Thin;
var cell = oSheet.Cells[rowIndex, colIndex];
//Setting Sum Formula for each cell
// Usage: Sum(From_Addres:To_Address)
// e.g. - Sum(A3:A6) -> Sums the value of Column 'A' From Row 3 to Row 6
cell.Formula = "Sum(" + oSheet.Cells[3, colIndex].Address + ":" + oSheet.Cells[rowIndex - 1, colIndex].Address + ")";
///
<summary>
/// Adding custom comment in specified cell of specified excel sheet
/// </summary>
///
<param name="oSheet" />The ExcelWorksheet object
/// <param name="rowIndex" />The row number of the cell where comment will put
/// <param name="colIndex" />The column number of the cell where comment will put
/// <param name="comment" />The comment text
/// <param name="author" />The author name
private void AddComment(ExcelWorksheet oSheet, int rowIndex, int colIndex, string comment, string author)
{
// Adding a comment to a Cell
oSheet.Cells[rowIndex, colIndex].AddComment(comment, author);
}
///
<summary>
/// Adding custom image in spcified cell of specified excel sheet
/// </summary>
///
<param name="oSheet" />The ExcelWorksheet object
/// <param name="rowIndex" />The row number of the cell where the image will put
/// <param name="colIndex" />The column number of the cell where the image will put
/// <param name="imagePath" />The path of the image file
private void AddImage(ExcelWorksheet oSheet, int rowIndex, int colIndex, string imagePath)
{
Bitmap image = new Bitmap(imagePath);
ExcelPicture excelImage = null;
if (image != null)
{
excelImage = oSheet.Drawings.AddPicture("Debopam Pal", image);
excelImage.From.Column = colIndex;
excelImage.From.Row = rowIndex;
excelImage.SetSize(100, 100);
// 2x2 px space for better alignment
excelImage.From.ColumnOff = Pixel2MTU(2);
excelImage.From.RowOff = Pixel2MTU(2);
}
}
public int Pixel2MTU(int pixels)
{
int mtus = pixels * 9525;
return mtus;
}
The all shapes are available under enum eShapeStyle. In the following
way we can create object of the specified shape and inserting text inside it.
enum eShapeStyle
///
<summary>
/// Adding custom shape or object in specifed cell of specified excel sheet
/// </summary>
///
<param name="oSheet" />The ExcelWorksheet object
/// <param name="rowIndex" />The row number of the cell where the object will put
/// <param name="colIndex" />The column number of the cell where the object will put
/// <param name="shapeStyle" />The style of the shape of the object
/// <param name="text" />Text inside the object
private void AddCustomObject(ExcelWorksheet oSheet, int rowIndex, int colIndex, eShapeStyle shapeStyle, string text)
{
ExcelShape excelShape = oSheet.Drawings.AddShape("Custom Object", shapeStyle);
excelShape.From.Column = colIndex;
excelShape.From.Row = rowIndex;
excelShape.SetSize(100, 100);
// 5x5 px space for better alignment
excelShape.From.RowOff = Pixel2MTU(5);
excelShape.From.ColumnOff = Pixel2MTU(5);
// Adding text into the shape
excelShape.RichText.Add(text);
}
public int Pixel2MTU(int pixels)
{
int mtus = pixels * 9525;
return mtus;
}
Now, we're going to take the Existing Excel Sheet what we've got from the extension of this article. The name of the existing excel sheet was 'Sample1.xlsx'. Now we are going to create 'Sample2.xlsx' by taking values from 'Sample1.xlsx' and adding some new values.
Here is 'Sample1.xlsx':
Now, see how you can do it:
// Taking existing file: 'Sample1.xlsx'. Here 'Sample1.xlsx' is treated as template file
FileInfo templateFile = new FileInfo(@"Sample1.xlsx");
// Making a new file 'Sample2.xlsx'
FileInfo newFile = new FileInfo(@"Sample2.xlsx");
// If there is any file having same name as 'Sample2.xlsx', then delete it first
if (newFile.Exists)
{
newFile.Delete();
newFile = new FileInfo(@"Sample2.xlsx");
}
using (ExcelPackage package = new ExcelPackage(newFile, templateFile))
{
// Openning first Worksheet of the template file i.e. 'Sample1.xlsx'
ExcelWorksheet worksheet = package.Workbook.Worksheets[1];
// I'm adding 5th & 6th rows as 1st to 4th rows are already filled up with values in 'Sample1.xlsx'
worksheet.InsertRow(5, 2);
// Inserting values in the 5th row
worksheet.Cells["A5"].Value = "12010";
worksheet.Cells["B5"].Value = "Drill";
worksheet.Cells["C5"].Value = 20;
worksheet.Cells["D5"].Value = 8;
// Inserting values in the 6th row
worksheet.Cells["A6"].Value = "12011";
worksheet.Cells["B6"].Value = "Crowbar";
worksheet.Cells["C6"].Value = 7;
worksheet.Cells["D6"].Value = 23.48;
}
Now, we're going to add formula for 'Value' column i.e. 'E' as the values in column 'E' come from the product of 'Quantity' and 'Price' column, as you can see in the above picture of Sample1.xlsx. In the Extension of this Article, I've told how to add basic formula in this respect. So, I hope, you're now able to add basic formula Now, we're going to see how we add 'R1C1' formula. If you don't know what it is, just click here...I'm waiting for you here Lets see:
worksheet.Cells["E2:E6"].FormulaR1C1 = "RC[-2]*RC[-1]";
Just one line of code, its so simple
You don't know 'Excel Named Range'? No problem, just read a few lines here. Like the following way we can add Named Range:
var name = worksheet.Names.Add("SubTotalName", worksheet.Cells["C7:E7"]);
By the following way we can add any formula to the Named Range:
name.Formula = "SUBTOTAL(9, C2:C6)";
Read about Excel Chart here.
Read about Pie Chart here.
EPPlus Library suport following type of chart below:
OfficeOpenXml.Drawing.Chart
// Adding namespace to work with Chart
using OfficeOpenXml.Drawing.Chart;
// Adding Pie Chart to the Worksheet and assigning it in a variable 'chart'
var chart = (worksheet.Drawings.AddChart("PieChart", OfficeOpenXml.Drawing.Chart.eChartType.Pie3D) as ExcelPieChart);
Setting title text of the chart:
chart.Title.Text = "Total";
Setting Chart Position: 5 pixel offset from 5th column of the 1st row:
chart.SetPosition(0, 0, 5, 5);
Setting width & height of the chart area:
chart.SetSize(600, 300);
In the Pie Chart value will come from 'Value' column and category name come from the 'Product' column, see how to do it:
ExcelAddress valueAddress = new ExcelAddress(2, 5, 6, 5);
var ser = (chart.Series.Add(valueAddress.Address, "B2:B6") as ExcelPieChartSerie);
Setting Chart Properties:
// To show the Product name within the Pie Chart along with value
chart.DataLabel.ShowCategory = true;
// To show the value in form of percentage
chart.DataLabel.ShowPercent = true;
Formmatting the style of the Chart:
chart.Legend.Border.LineStyle = eLineStyle.Solid;
chart.Legend.Border.Fill.Style = eFillStyle.SolidFill;
chart.Legend.Border.Fill.Color = Color.DarkBlue;
Please Download the source code for detail. I hope you'll understand as the source
code is documented. If any doubt, just post your comment below. Thank You.
Please Download the source code for detail. I hope you'll understand as the source
code is documented. If any doubt, just post your comment below.. | http://www.codeproject.com/Articles/680421/Create-Read-Edit-Advance-Excel-Report-in?msg=4700683 | CC-MAIN-2014-35 | refinedweb | 1,539 | 51.24 |
gnutls_pubkey_get_key_id — API function
#include <gnutls/abstract.h>
Holds the public key
should be 0 for now
will contain the key ID
holds the size of output_data (and will be replaced by the actual size of parameters)
This function will return a unique ID that depends on the public key parameters. This ID can be used in checking whether a certificate corresponds to the given public key.
If the buffer provided is not long enough to hold the output, then *output_data_size is updated and GNUTLS_E_SHORT_MEMORY_BUFFER will be returned. The output will normally be a SHA−1 hash output, which is 20 bytes.: | http://man.linuxexplore.com/htmlman3/gnutls_pubkey_get_key_id.3.html | CC-MAIN-2019-22 | refinedweb | 101 | 60.04 |
XTAN allows XML software to be written expecting input in one language and then successfully handle inputs written in other (similar) languages. The other languages can be "competitors", other languages written by other people for a similar purpose, or they can be later versions or variant versions of the original language.
XTAN may be the silver bullet to the forward compatibility problem. In decentralized systems like the Web, where we can't upgrade all the software at once, deploying any new version of a language requires some level of forward compatibility. In many case, the available level of forward compatibility (such as provided by HTML's ignore-unknowns rule) is really not enough. XTAN gives us a lot more.
XTAN is a fairly simple idea. You get an XML document. If it doesn't match the schema you have in mind, use the XML namespaces as web addresses to retrieve annotated schemas. Annotations in those schemas provide transform information which allows you to rewrite the document to match the language you're looking for. While you're re-writing, notice that some transforms are "lossy". Keep track of the losses, and see how bad they are when you're done.
For more details, follow the links below
XTAN was proposed to the Rule Interchange Format (RIF) Working Group in February, 2008, and was well received as a potential solution to addressing its extensibility requirement. In May, however, RIF decided on an XML syntax where all dialects can be mechanically translated to RDF. This may allow RIF to use an RDF-based approach to extensibility, instead of XTAN. That approach needs to be explored in more detail, then RIF will have to decide which approach to take.
In April, 2009, RIF-WG decided not to standardize in this space. It was, in a sense, out of scope for the WG. It wanted something like XTAN, but was not quite the right group to develop such a technology. If you're interested in taking up or supporting this kind of work, please contact Sandro.
Feel free to send e-mail to sandro@w3.org. Let him know if you want to be on a mailing list. (If enough people do, he'll make one.)
Namespace documents. How do we get to the XML schema from the namespace URI? | http://www.w3.org/2008/02/xtan/ | CC-MAIN-2013-20 | refinedweb | 386 | 64.2 |
12.6. Object Detection Data Set (Pikachu)¶
There are no small data sets, like MNIST or Fashion-MNIST, in the object detection field. In order to quickly test models, we are going to assemble a small data set. data set on the disk and improve the reading efficiency. If you want to learn more about how to read images, refer to the documentation for the GluonCV Toolkit[2].
12.6.1. Download the Data Set¶
The Pikachu data set in RecordIO format can be downloaded directly from
the Internet. The operation for downloading the data set is defined in
the function
_download_pikachu.
In [1]:
import sys sys.path.insert(0, '..') %matplotlib inline import d2l from mxnet import gluon, image from mxnet.gluon import utils as gutils import os(): gutils.download(root_url + k, os.path.join(data_dir, k), sha1_hash=v)
12. data set. We also do not
need to read the test data set in random order.
In [2]:
# This function has been saved in the d2l package for future use # Edge_size: the width and height of the output image def load_data_pikachu(batch_size, edge_size=256): data set mini-batch data set. Although computation for the mini-batch mini-batch))
12 = d2l.show_images(imgs, 2, 5).flatten() for ax, label in zip(axes, batch.label[0][0:10]): d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
12.
12.6.5. Exercises¶
- Referring to the MXNet documentation, what are the parameters for the constructors of the
image.ImageDetIterand
image.CreateDetAugmenterclasses? What is their significance?
12.6.6. References¶
[1] im2rec Tool.
[2] GluonCV Toolkit. | http://d2l.ai/chapter_computer-vision/object-detection-dataset.html | CC-MAIN-2019-18 | refinedweb | 263 | 52.26 |
later iterations of Windows, the .NET Framework began shipping with the operating system; and, life became even easier as a .NET developer. What could possibly improve?
This setup served us well, but Microsoft's burly .NET ecosystem had grown stale. There was one glaring issue in particular — the ecosystem's reliance upon the Windows platform. To maintain relevancy in a rapidly-evolving application development landscape, Microsoft needed to meet developers outside of the Windows community.
But enticing that elusive audience of developers was no small feat. It would entail supporting Mac OS X and the most widely-used Linux distributions. Doing so would lower the barrier to entry into the .NET ecosystem and attract developers who otherwise wouldn't have considered Microsoft technologies.
June 27, 2016 marked the day on which Microsoft addressed the aforementioned platform limitation with the release of .NET Core 1.0, ASP.NET Core 1.0, and Entity Framework Core 1.0. This day also marked the beginning of much bewilderment for millions of .NET developers worldwide. Questions were aplenty, but they mostly centered around migration to this reincarnation of the ASP.NET proper framework. Is my ASP.NET proper investment now obsolete? How does ASP.NET Core differ from ASP.NET proper? What tools are available to assist in my migration?
This article attempts to demystify and to provide guidance on this migration, although it isn't intended to serve as an exhaustive upgrade manual. Let's take a look at some architectural and tooling considerations, as well as upgrade paths.
Ed. note: This post is the first part of a full week dedicated to ASP.NET Core content. Check back every day this week for a new article.
If your day job involves writing ASP.NET applications, it's important to understand the major differences between ASP.NET Core and ASP.NET proper. Many of us can describe our current ASP.NET investment as follows:
Where does one go from here? The graphic below paints the upgrade path landscape quite well.
Whoa! Why the influx of choices?!? With this graphic in mind, let's dive deeper into the specifics of each category.
It's a common misconception that selecting ASP.NET Core alone provides cross-platform capabilities. When coupled with .NET Core as a target framework, the nirvana of true cross-platform support is achieved. Targeting the .NET Framework, the battle-tested monolith many of us have used for years, shackles the application to Windows.
It's also important to recognize that while .NET Core is the new kid on the block, .NET Framework is still thriving and will continue to receive investment. Don't think of .NET Framework as a poor choice because of its age — think of it as a more mature, feature-complete .NET flavor for Windows users. .NET Core aims to serve the previously ignored audiences of developers on Mac and Linux.
One of the lesser-known options is a dual target scenario, whereby the ASP.NET Core application targets both .NET Core and .NET Framework. This results in a dual compilation of the application bits, since APIs available in .NET Framework may not be available in .NET Core.
As a rule of thumb, ties to Windows APIs are barred from .NET Core. The same has generally been true for any API regarded internally as legacy, which explains the difference in API surface area. Refer to the .NET Core API Reference to determine whether your desired APIs are present. .NET Standard aims to close this API gap by consolidating the various base class libraries into one governing library to rule them all.
The term distribution channel refers to the install location of the desired .NET platform and the application deployment model. The .NET Framework APIs are installed on the developer's machine and on the web server hosting the ASP.NET application. Think of this conceptually as a Framework-Dependent Deployment (FDD).
With .NET Core applications, it's also possible to support FDD, whereby the application targets a .NET Core version installed on the machine. However, .NET Core introduces a second option: Self-Contained Deployment (SCD). In the latter deployment model, the necessary runtime bits are packaged and deployed alongside the application.
If Docker containerization is a goal, SCD with .NET Core boasts great curb appeal. This deployment model provides a degree of isolation from any machine-level patches that may be installed down the road. Furthermore, it better supports the running of multiple .NET Core versions side-by-side on the same machine. See Scott Hanselman's "Self-contained .NET Core Applications" blog post or the ".NET Core Application Deployment" article for more detail.
Only upon identification of the operating system requirements should an editor and/or IDE be selected. If your IT department has mandated development on Windows, Visual Studio 2015/2017 is the best choice when targeting .NET Framework. Since debugging against .NET Framework isn't currently supported in Visual Studio Code, it's best to avoid in this scenario.
If your development team is divided in terms of preferred operating system, Visual Studio Code provides a consistent, first-class development and debugging experience across Windows, Mac, and Linux. Open the same project on virtually any platform, and expect the same type of development experience. With the assistance of OmniSharp, Visual Studio Code offers rich features such as syntax highlighting, CodeLens, and IntelliSense.
Visual Studio proper is largely tied to Windows, so it's not a contender in this particular scenario. Although, with the announcement of Visual Studio for Mac Preview at Microsoft's recent Connect(); event, there is renewed optimism for Mac users. As touted by John Montgomery, Director of Program Management for Visual Studio, in a recent blog post:
Visual Studio for the Mac is built from the ground up for the Mac and focused on full-stack, client-to-cloud native mobile development, using Xamarin for Visual Studio, ASP.NET Core, and Azure.
Visual Studio for the Mac is built from the ground up for the Mac and focused on full-stack, client-to-cloud native mobile development, using Xamarin for Visual Studio, ASP.NET Core, and Azure.
Time will tell whether Visual Studio for Mac is a viable solution for ASP.NET Core development. And unfortunately, Linux users are still left behind when it comes to Visual Studio proper support.
As was true with editors and IDEs, web server selection hinges on the operating system requirement. For the large enterprise planning to double down on their Windows Server platform investment, IIS continues to play a major role. There is one small change, however — IIS reverse proxies HTTP to a lightweight, cross-platform web server called Kestrel. Kestrel lacks multi-port bindings at the time of writing, thus it's incapable of port 80 and 443 forwarding. Consequently, it's inadequately equipped to serve as a public-facing edge server.
When IIS isn't an option on Windows, WebListener is a practicable alternative that can be used with either .NET Framework or .NET Core. WebListener eradicates the need for Kestrel as well and doesn't require a reverse proxy server. For those hosting ASP.NET Core applications on Linux, both Nginx and Apache are viable options. As was true with IIS, either Nginx or Apache will pose as a reverse proxy to Kestrel.
There are certain frameworks under the ASP.NET umbrella for which no clear migration path exists at this time. Web Forms is constrained by its technical underpinnings, which necessitates a target of .NET Framework. SignalR support on the Core stack is in the works for a future release, again binding us to .NET Framework for now. In the realm of languages, there is no support for VB.NET in ASP.NET Core.
MVC and Web API with C#, on the other hand, are ideal candidates for a migration. My findings have proven that the heavier the reliance upon System.Web APIs, the more impractical and arduous the migration. Moreover, migrating a legacy application to ASP.NET Core targeting .NET Framework is an easier feat than targeting .NET Core.
With a particular upgrade path in mind, there are some tools and techniques which can ease the pain of migration from ASP.NET to ASP.NET Core (and even from .NET Framework to .NET Core). If targeting both .NET Core and .NET Framework in the same ASP.NET Core application, conditional preprocessor directives aid in executing code intended for only one of the two platforms. It's a solution to the following problem while porting an application:
The tooltip which appears when hovering over DataSet clearly states that the API is unavailable in .NET Core. The following code snippet demonstrates how a target framework moniker, such as net462, can be used in a preprocessor directive to control execution of this code:
DataSet
#if NET462
// This only executes when targeting .NET Framework 4.6.2
DataSet set = new DataSet();
#endif
Aside from techniques such as that described above, a few popular migration utilities include I Can Has .NET Core and the .NET Portability Analyzer. For the sake of brevity, the remainder of this article focuses on the latter of the two named tools.
As depicted in the chart below, .NET Portability Analyzer is offered in the following three variations:
1. Console Application
2. Visual Studio Extension
3. .NET Core Application
The Console Application is a CLI-based tool for power users on Windows who prefer using the command shell over the IDE. Like the Console Application, the Visual Studio Extension is tied to Windows, as it also targets .NET Framework 4.6. The obvious benefit of the extension is that intricacies of the CLI are abstracted away from the developer.
What if you're not a Windows user? The .NET Core Application fills this particular void. It targets .NET Core instead of .NET Framework, which inherently means it runs on Windows, Mac OS X, and Linux. This is the best option for development teams who are unable to settle their differences in terms of preferred operating system.
How does the tool work? It scans a target folder and analyzes the assemblies within for portability to the desired platform(s) by sending the appropriate level of detail to a web service called the .NET Portability Service.
Microsoft respects your intellectual property by only sending details of Microsoft-owned assemblies to the service — specifically, assemblies prefixed with "Microsoft.", "System.", or "Mono.". Another assembly type destined for the service is one which is signed using Microsoft's public key tokens. If you're still skeptical about what's sent, here's the relevant snippet from the GitHub repository:
public class DotNetFrameworkFilter : IDependencyFilter
{
/// <summary>
/// These keys are a collection of public key tokens derived from all the reference assemblies in
/// "%ProgramFiles%\Reference Assemblies\Microsoft" on a Windows 10 machine with VS 2015 installed
/// </summary>
private static readonly ICollection<string> s_microsoftKeys = new HashSet<string>(new[]
{
"b77a5c561934e089", // ECMA
"b03f5f7f11d50a3a", // DEVDIV
"7cec85d7bea7798e", // SLPLAT
"31bf3856ad364e35", // Windows
"24eec0d8c86cda1e", // Phone
"0738eb9f132ed756", // Mono
"ddd0da4d3e678217", // Component model
"84e04ff9cfb79065", // Mono Android
"842cf8be1de50553" // Xamarin.iOS
}, StringComparer.OrdinalIgnoreCase);
private static readonly IEnumerable<string> s_frameworkAssemblyNamePrefixes = new[]
{
"System.",
"Microsoft.",
"Mono."
};
public bool IsFrameworkAssembly(AssemblyReferenceInformation assembly)
{
if (assembly == null)
{
// If we don't have the assembly, default to including the API
return true;
}
if (s_microsoftKeys.Contains(assembly.PublicKeyToken))
{
return true;
}
if (s_frameworkAssemblyNamePrefixes.Any(p => assembly.Name.StartsWith(p, StringComparison.OrdinalIgnoreCase)))
{
return true;
}
if (string.Equals(assembly.Name, "mscorlib", StringComparison.OrdinalIgnoreCase))
{
return true;
}
return false;
}
}
To demonstrate the Visual Studio Extension, let's look at migrating an ASP.NET proper MVC application targeting .NET Framework 4.6 to ASP.NET Core 1.0 targeting .NET Core 1.0.
Install the extension via Visual Studio's Tools --> Extensions and Updates... dialog:
Select the desired target platform(s) via the .NET Portability Analyzer section of Visual Studio's Tools --> Options... dialog:
Create a new ASP.NET proper MVC project targeting .NET Framework 4.6 via Visual Studio's File --> New --> Project... dialog.
Right-click the project name in Solution Explorer, and click Analyze Assembly Portability in the context menu.
Upon completion of the four steps listed above, it's time to make sense of the results and to take action. Open the generated Excel spreadsheet via the Open Report link found in the Portability Analysis Results window. Note that the document contains the following three sheets:
1. Portability Summary
2. Details
3. Missing assemblies
The Portability Summary sheet displays an executive summary / report card of how portable the project is to the desired target platform(s) — ASP.NET Core 1.0 and .NET Core 1.0 in this case. In the following example, the project is nearly 74% portable to .NET Core 1.0 and just over 12% portable to ASP.NET Core 1.0:
The Details tab provides a high degree of detail to help better understand the incompatibilities. If we were using the Console Application instead of the Visual Studio Extension, this tab would prove invaluable. In particular, this sheet's Recommended changes column sometimes provides useful hints for achieving compatibility. Since we are using the extension, focus your attention to Visual Studio's Error List window and view the Messages:
Double-clicking an entry in this window sets the editor's focus to the offending line of code. In the case of the first entry, System.Web.Optimization (and all of System.Web for that matter) isn't supported in ASP.NET Core 1.0. The offending line of code is attempting to make use of that API.
Lastly, the Missing assemblies sheet provides an inventory of those assemblies which were excluded from analysis. These assemblies are referenced in the project; however, the tool doesn't handle dependency resolution during the scan. A common cause for this is the presence of a referenced assembly from the GAC. It's outside of the folder for the project, so the tool is unable to analyze the assembly.
In this article, we identified upgrade paths for an existing ASP.NET proper investment. We also walked through options for migrating the application to ASP.NET Core once an upgrade path has been identified. Take this information and head down the migration path so that you can begin to reap the benefits of Microsoft's hard labor.
Want a tour of changes introduced in ASP.NET Core before you migrate? Download the whitepaper "ASP.NET Core MVC Changes Every Developer Should Know" to better understand what you're missing out on.
Related resources:
Subscribe to be the first to get our expert-written articles and tutorials for developers! | https://www.telerik.com/blogs/migration-asp-net-core-considerations-strategies | CC-MAIN-2019-51 | refinedweb | 2,421 | 60.11 |
Investors in The Materials Select Sector SPDR Fund (Symbol: XLU) saw new options begin trading today, for the May 22nd expiration. At Stock Options Channel, our YieldBoost formula has looked up and down the XLU options chain for the new May 22nd contracts and identified one put and one call contract of particular interest.
The put contract at the $52.00 strike price has a current bid of $2.58. If an investor was to sell-to-open that put contract, they are committing to purchase the stock at $52.00, but will also collect the premium, putting the cost basis of the shares at $49.42 (before broker commissions). To an investor already interested in purchasing shares of XLU, that could represent an attractive alternative to paying $53.35/share today.
Because the $52.96% return on the cash commitment, or 36.22%.00 strike price has a current bid of $2.65. If an investor was to purchase shares of XLU stock at the current price level of $53.35/share, and then sell-to-open that call contract as a "covered call," they are committing to sell the stock at $54.00. Considering the call seller will also collect the premium, that would drive a total return (excluding dividends, if any) of 6.19% if the stock gets called away at the May 22nd expiration (before broker commissions). Of course, a lot of upside could potentially be left on the table if XLU shares really soar, which is why looking at the trailing twelve month trading history for The Materials Select Sector SPDR Fund, as well as studying the business fundamentals becomes important. Below is a chart showing XLU's trailing twelve month trading history, with the $54.00 strike highlighted in red:
Considering the fact that the $54.97% boost of extra return to the investor, or 36.26% annualized, which we refer to as the YieldBoost.
The implied volatility in the put contract example is 50%, while the implied volatility in the call contract example is 45%.
Meanwhile, we calculate the actual trailing twelve month volatility (considering the last 252 trading day closing values as well as today's price of $53.35) to be 34%.. | https://www.nasdaq.com/articles/interesting-xlu-put-and-call-options-for-may-22nd-2020-04-02 | CC-MAIN-2021-39 | refinedweb | 371 | 64.61 |
I have been using Ruby for a while now and I find, for bigger projects, it can take up a fair amount of memory. What are some best practices for reducing memory usage in Ruby?
Don't do this:
def method(x) x.split( doesn't matter what the args are ) end
or this:
def method(x) x.gsub( doesn't matter what the args are ) end
Both will permanently leak memory in ruby 1.8.5 and 1.8.6. (not sure about 1.8.7 as I haven't tried it, but I really hope it's fixed.) The workaround is stupid and involves creating a local variable. You don't have to use the local, just create one...
Things like this are why I have lots of love for the ruby language, but no respect for MRI | https://codedump.io/share/1XXuGPAxZPzq/1/ruby-memory-management | CC-MAIN-2017-17 | refinedweb | 140 | 85.39 |
The inconsistencies of AWS EKS IAM permissions
AWS EKS is a remarkable product: it manages Kubernetes for you, letting you focussing on creating and deploying applications. However, if you want to manage permissions accordingly to the shared responsibility model, you are in for some wild rides.
Image courtesy of unDraw.
Image courtesy of unDraw.
The shared responsibility model
First, what’s the shared responsibility model? Well, to design a well-architected application, AWS suggests following six pillars. Among these six pillars, one is security. Security includes sharing responsibility between AWS and the customer. In particular, and I quote,
Customers are responsible for managing their data (including encryption options), classifying their assets, and using IAM tools to apply the appropriate permissions.
Beautiful, isn’t it? AWS gives us a powerful tool, IAM, to manage permissions; we have to configure things in the best way, and AWS gives us the way to do so. Or does it? Let’s take a look together.
Our goal
I would say the goal is simple, but since we are talking about Kubernetes, things cannot be just simple.
Our goal is quite straightforward: setting up a Kubernetes cluster for our developers. Given that AWS offers AWS EKS, a managed Kubernetes service, we only need to configure it properly, and we are done. Of course, we will follow best practices to do so.
A proper setup
Infrastructure as code is out of scope for this post, but if you have never heard about it before, I strongly suggest taking a look into it.
Of course, we don’t use the AWS console to manually configure stuff, but Infrastructure as Code: basically, we will write some code that will call the AWS APIs on our behalf to set up AWS EKS and everything correlated. In this way, we can have a reproducible setup that we could deploy in multiple environments, and countless other advantages.
Moreover, we want to avoid launching scripts that interact with our infrastructure from our PC: we prefer not to have permissions to destroy important stuff! Separation of concerns is a fundamental, and we want to write code without worrying about having consequences on the real world. All our code should be vetted from somebody else through a merge request, and after being approved and merged to our main branch, a runner will pick it up and apply the changes.
A runner is any CI/CD that will execute the code on your behalf. In my case, it is a GitLab runner, but it could be any continuous integration system.
We are at the core of the problem: our runner should follow the principle of least privilege: it should be able to do only what it needs to do, and nothing more. This is why we will create a IAM role only for it, with only the permissions to manage our EKS cluster and everything in it, but nothing more.
I would have a massive rant about how bad is the AWS documentation for IAM in general, not only for EKS, but I will leave it to some other day.
The first part of creating a role with minimum privileges is, well, understanding what minimum means in our case. A starting point is the AWS documentation: unfortunately, it is always a bad starting point concerning IAM permissions, ‘cause it is always too generous in allowing permissions.
The “minimum” permission accordingly to AWS
According to the guide, the minimum permissions necessary for managing a cluster is being able to do any action on any EKS resource. A bit farfetched, isn’t it?
Okay, hardening this will be fun, but hey, do not let bad documentations get in the way of a proper security posture.
You know what will get in the way? Bugs! A ton of bugs, with absolutely useless error messages.
I started limiting access to only the namespace of the EKS cluster I wanted to create. I ingenuously thought that we could simply limit access to the resources belonging to the cluster. But, oh boy, I was mistaken!
Looking at the documentation for IAM resources and actions, I created this policy:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "eks:ListClusters", "eks:DescribeAddonVersions", "eks:CreateCluster" ], "Resource": "*" }, { "Effect": "Allow", "Action": "eks:*", "Resource": [ "arn:aws:eks:eu-central-1:123412341234:addon/my-cluster/*/*", "arn:aws:eks:eu-central-1:123412341234:fargateprofile/my-cluster/*/*", "arn:aws:eks:eu-central-1:123412341234:identityproviderconfig/my-cluster/*/*/*", "arn:aws:eks:eu-central-1:123412341234:nodegroup/my-cluster/*/*", "arn:aws:eks:eu-central-1:123412341234:cluster/my-cluster" ] } ] }
Unfortunately, if a role with these permissions try to create a cluster, this error message appears:
Error: error creating EKS Add-On (my-cluster:kube-proxy): AccessDeniedException: User: arn:aws:sts::123412341234:assumed-role/<role>/<iam-user> is not authorized to perform: eks:TagResource on resource: arn:aws:eks:eu-central-1:123412341234:/createaddon
I have to say that at least the error message gives you a hint: the
/createddon action is not scoped to the cluster.
After fighting with different polices for a while, I asked DuckDuckGo for a help, and indeed somebody reported this problem to AWS before, in this GitHub issue.
What the issue basically says is that if we want to give an IAM role permission to manage an add-on inside a cluster, we must give it permissions over all the EKS add-ons in our AWS account.
This of course breaks the AWS shared responsibility principle, ‘cause they don’t give us the tools to upheld our part of the deal. This is why it is a real and urgent issue, as they also mention in the ticket:
Can’t share a timeline in this forum, but it’s a high priority item.
And indeed it is so high priority, that it has been reported the 3rd December 2020, and today, more than one year later, the issue is still there.
To add insult to the injury, you have to write the right policy manually because if you use the IAM interface to select “Any resource” for the add-ons as in the screenshot below, it will generate the wrong policy! If you check carefully, the generated resource name is
arn:aws:eks:eu-central-1:123412341234:addon/*/*/*, which of course doesn’t match the ARN expected by AWS EKS. Basically, also if you are far too permissive, and you use the tools that AWS provides you, you still will have some broken policy.
Do you have some horror story about IAM yourself? I have a lot of them, and I am thinking about a more general post. What do you think? Share your thoughts in the comments below, reach me on Twitter (@rpadovani93) or drop me an email at [email protected].
Ciao,
R. | https://rpadovani.com/eks-iam-permissions | CC-MAIN-2022-33 | refinedweb | 1,127 | 50.87 |
Java Language Integrity & Security: Uncovering Bytecodes
Obviously, there is a Java language specification. Although the Microsoft version of java.exe will run only on a Windows platform, the java compiler on UNIX and other platforms must abide by the same Java language specification. Despite the fact that each individual platform has its own non-portable java compiler, they all, theoretically at least, behave in consistent ways. Thus, a Java program on a Windows platform should run unchanged on a UNIX platform—even though the tools themselves were written on different platforms by different developers.
As already stated, the Microsoft javac.exe file contains Microsoft Windows-specific machine code. It is interesting to try and open an executable file with a text editor. This is actually a meaningless operation in this context, except that you will be able to compare it to a file of bytecodes and it provides a baseline for this discussion. When you open the javac.exe file in Notepad, you get the results seen in Figure 3.
Figure 3: javac.exe opened in Notepad.
Obviously, this exercise provides us no useful information. However, I always find it interesting to take a look at this type of output. It also provides students a way to differentiate between character and binary files. Because Notepad is a text editor, the characters displayed are the ACSII representation of the file. Perhaps the most interesting thing about the display of this file is that there are no recognizable words—at least none that I can determine. That is not the case when you look at a file of bytecodes in the same way.
Dynamically Linked Executables
The bytecode model uses a different approach. In this case, if you don't want the kitchen sink, you won't get it. The corresponding definition of dynamically linked is:
Figure 4 shows the life-cycle of source code in the bytecode model. In this model, instead of creating machine dependent object modules, bytecode is produced. Although there are drawbacks to this model, which you will explore shortly, a primary advantage is that the bytecodes are, again theoretically, platform independent.
Figure 4: Bytecode model
Under The Hood
Perhaps the best way to explain the bytecode model is to look at it directly. You'll design a small Java application for this illustration. In this case, you will create a simple application called Performance presented in Listing 1 and use a class called Employee presented in Listing 2.
Listing 1: The Employee Class
public class Performance { public static void main(String[] args) { System.out.println("Performance Example"); Employee joe = new Employee(); } }
Listing 2: The Employee Class
public class Employee { private int employeeNumber; }
As I normally do with these examples, I compile them from a batch file as seen in Listing 3.
Listing 3: Compiling the Application
cls "C:Program FilesJavajdk1.5.0_07binjavac" -Xlint -classpath .Performance.java
Although I do most of my development with an Integrated Development Environment (IDE), I normally will use batch files like these so that I know my CLASSPATH information is correct. This helps in the instruction phase of programming, and it also assists in the testing of the various versions of the development kits. For example, as was mentioned earlier, a web developer must allow for various platforms while developing and testing. In the same manner, a developer must allow for various versions of a development kit. If Java is the development platform, what version of the SDK should be used? The answer is that all reasonable versions must be tested. This means that multiple versions of the development kit may be installed on a machine at the same time. Therefore,, keeping track of the CLASSPATH is problematic.
To deal with this, I like to use batch files to insure that I am using the version of the development kit that I intend to use. Granted, there are much more sophisticated methods of doing this and there are many development tools available to the professional developer; however, in an academic environment, using a more simple, and inexpensive solution is often desirable.
When this application is compiled, there are two separate class files produced, Performance.class and Employee.class, as seen in Figure 5.
Figure 5: Application Class Files.
Take another look at Figure 3, when you opened the statically linked javac.exe file with Notepad. Open the employee.class file and see what you get. The results, using Notepad, can be seen in Figure 6.
Figure 6: Employee.class.
Again, this exercise provides no real benefit from a technical perspective; however, it does provide a window into the structure of the bytecodes. Primarily, you can see that there are some textual components of the file that are recognizable. The word Employee is clearly identifiable in at least a couple of locations. The reason why this is important is because it hints at the possibility of decoding this file and providing much more information about it. Could you potentially even re-create the original source code?
Page 2 of 4
| https://www.developer.com/design/article.php/10925_3663526_2/Java-Language-Integrity-amp-Security-Uncovering-Bytecodes.htm | CC-MAIN-2017-47 | refinedweb | 837 | 57.06 |
I wanted to test if a key exists in a dictionary before updating the value for the key.
I wrote the following code:
if 'key1' in dict.keys():
print "blah"
else:
print "boo"
in is the intended way to test for the existence of a key in a
dict.
d = dict() for i in xrange(100): key = i % 10 if key in d: d[key] += 1 else: d[key] = 1
If you wanted a default, you can always use
dict.get():
d = dict() for i in xrange(100): key = i % 10 d[key] = d.get(key, 0) + 1
... and if you wanted to always ensure a default value for any key you can use
defaultdict from the
collections module, like so:
from collections import defaultdict d = defaultdict(lambda: 0) for i in xrange(100): d[i % 10] += 1
... but in general, the
in keyword is the best way to do it. | https://codedump.io/share/MNhL8aUY0qEv/1/check-if-a-given-key-already-exists-in-a-dictionary | CC-MAIN-2016-50 | refinedweb | 151 | 79.19 |
API (extension) instance enumerationJon Tara Apr 22, 2015 4:38 PM
I am struggling to understand the intended use and implementation of enumeration of API instances. In particular, I am interested in understanding it in the context of Rhodes native extensions. However, the same code structure is used in (many of) the internal APIs.
With the exception of Camera, all of the enumeration implementations seem to be dummied-up. Some will enumerate only one instance, regardless of how many there actually are. some will arbitrarily enumerate two instances. And it is only implemented for iOS, where the enumerated values can be "back" or "front".
I'm also confused that all this really is enumerating is some strings that might symbolically identify instances.
I don't understand how/where to generate instance IDs for additional instances. Is there some assumption that you have a number at the tail of the string, and there is some base class code that will increment the number?
This seems like unfinished code, perhaps an idea that was never implemented?
FWIW, the extension I am creating is a Factory-style extension with a default instance. It's a Bonjour Browser extension. It's handy to have a default instance, but it might also be useful to have multiple instances. (For example, you might do multiple simultaneous searches for different services. Or you might not use them simultaneously, but it might be convenient to leave multiple browser objects laying around for use.)
A side-effect of enumeration might be useful to me, but is not essential. I make use of the ID value, because the extension has callbacks, and it's handy to include the ID value in each callback. That way, application code can choose to either send callbacks from each instance to a different controller URL (or lambda function) or all to the same. So, the callback code has a way of distinguishing instances in the callbacks.
I haven't actually tried creating a non-default instance yet. But, if I read the code correctly, as I have it currently written, the ID value will be nil for all but the default instance:
#import "BonjourBrowserSingleton.h" @implementation BonjourBrowserSingleton -(NSString*)getInitialDefaultID { return @"BonjourBrowser1"; } -(void) enumerate:(id<IMethodResult>)methodResult { NSMutableArray* ar = [NSMutableArray arrayWithCapacity:1]; [ar addObject:@"BonjourBrowser1"]; [methodResult setResult:ar]; } @end
Most of the Rhodes APIs arbitrary return an array with "SCN1" and "SCN2". That's clearly not correct.
So, I get the idea that enumerate ought to return an array with the ID strings of the instances that exist? Is application code supposed to be able to change the IDs? The ID is an API property (that we don't have to declare in our XML) so, in instance initialization, set the value of the ID property? (So that is where you would implement generation of IDs...) Then I would have to keep track of instances in some data structure (probably a hash/dictionary/etc.) in a class variable?
I checked the current master, and there doesn't seem to be any significant difference. I only find this dead-end half-implemented code.
Maybe I am misunderstanding intent, and this doesn't really apply to my scenario, as it seems oriented toward enumerating multiple hardware feature instances. (Such as cameras).
I don't really have a use for the enumeration in my code, but I do have a use for the IDs. And, perhaps that is the answer. I should generate a unique ID when an instance is created, but enumerate will "enumerate" only the default instance.
Re: API (extension) instance enumerationJon Tara Apr 22, 2015 9:05 PM (in response to Jon Tara)
Now even more confused...
Common API usage for Ruby is described here:
Rhomobile | Using RhoMobile Ruby API’s
Of course, the example shown is bogus, because (as of 5.0.30) the Camera API is still a 2.2 API... (I believe it is a Common API in 5.1, right?)
The implication from this is that enumerate should return an object. But, clearly, the code currently implemented for all of the common APIs enumerates the string IDs, not any kind of object. Maybe there is some magic I am missing. How do we get from those ID strings to actual Ruby/Javascript objects? The example proceeds to attempt to call a method. take_picture on the returned object. That clearly can't work if what enumerate returns is the string, "front"...
Does enumeration actually work? I mean, as documented?
I do see, at least from the Camera example, that the purpose of enumeration seems to be to enumerate hardware assets of some particular class handled by an API. And, so, probably has no role in my Bonjour Browser code. It would be strange (though perhaps of some utility) to be able to enumerate API object instances created by application code...
It seems like unfinished code/loose ends.
Re: Re: API (extension) instance enumerationJon Tara Apr 22, 2015 9:40 PM (in response to Jon Tara)
OK, I have this figured-out! At least mostly...
I deduced to go ahead and actually try instantiating a second browser object, and see what happens. I'm guessing that there IS some "magic" going on here with the IDs. I ran two of my Bonjour Browsers simultaneously, and since I log the instance IDs, that told me what is going on here.
This is a controller method I used for test. It's run when you push a button on the Settings page.
def bonjour_browser_search # Note: default service type is '_http._tcp_.', default domain is '.local' # This will find all local web servers that are advertising Rho::BonjourBrowser.search({}, lambda do |callback_data| {{#logInfo}} "got callback from Rho::BonjourBrowser.search callback_data = #{callback_data.inspect}" {{/logInfo}} end # lambda ) # Get two browsers going at once as a test meta_browser = Rho::BonjourBrowser.new meta_browser.search({serviceType: Rho::BonjourBrowser::SERVICE_TYPE_META_QUERY}, lambda do |callback_data| {{#logInfo}} "got callback from meta_browser.search callback_data = #{callback_data.inspect}" {{/logInfo}} end # lambda ) end
The initial default ID and enumerate do indeed seem to be about the default instance(s). That (s) points-out an omission in the documentation. Depending on the API, there might be one OR MORE default instances! Makes sense for hardware devices.
So, the (non-existant, at least in 5.0.30...) new, (common API) Camera API might allow you to enumerate the camera assets on the device. In this case, there isn't a "default instance", but "default instances".
That code doesn't seem to come into play at all for instances that you create. In that case, the ID is set to a hex string that looks suspiciously like a memory address.
It's a bit ironic, since my API deals with some objects (service instances) it creates internally (in Objective-C) and I give those IDs as well, and include those IDs in the callbacks. (They can be used as "handles" in method calls to do something with a service instance.) I thought it a bad idea to return string-encoded addresses, and so I took the extra step to assign sequential IDs instead...
A callback example from the default instance:
2015-04-22 21:21:32.679 rhorunner[20191:994029] I 04/22/2015 21:21:32:679 5d6d7000 HttpServer| Process URI: '/system/call_ruby_proc_callback'
2015-04-22 21:21:32.679 rhorunner[20191:994029] I 04/22/2015 21:21:32:679 5d6d7000 APP| Params: {"__rho_object"=>{"body"=>"2"}, "rho_callback"=>"1"}
2015-04-22 21:21:32.680 rhorunner[20191:994029] I 04/22/2015 21:21:32:679 5d6d7000 SettingsController| [block in bonjour_browser_search](39) got callback from Rho::BonjourBrowser.search callback_data = {"searching"=>true, "port"=>80, "hostName"=>"colossus.local.", "API"=>"BonjourBrowser", "addresses"=>[{"address"=>"10.0.1.102", "port"=>80, "family"=>"ipv4"}, {"address"=>"fe80::215:f2ff:fed3:1e35", "port"=>80, "scopeID"=>4, "flowInfo"=>0, "family"=>"ipv6"}], "event"=>"didResolve", "resolved"=>true, "serviceID"=>"BonjourBrowser1-4", "serviceName"=>"Apache Web Server on colossus", "ID"=>"BonjourBrowser1", "resolving"=>false}
And one from the instance I created:
2015-04-22 21:21:53.376 rhorunner[20191:994029] I 04/22/2015 21:21:53:376 5d6d7000 HttpServer| Process URI: '/system/call_ruby_proc_callback'
2015-04-22 21:21:53.377 rhorunner[20191:994029] I 04/22/2015 21:21:53:377 5d6d7000 APP| Params: {"__rho_object"=>{"body"=>"2"}, "rho_callback"=>"1"}
2015-04-22 21:21:53.377 rhorunner[20191:994029] I 04/22/2015 21:21:53:377 5d6d7000 SettingsController| [block in bonjour_browser_search](47) got callback from meta_browser.search callback_data = {"searching"=>true, "moreComing"=>false, "API"=>"BonjourBrowser", "event"=>"didFindService", "resolved"=>false, "serviceID"=>"EF0159A8-21", "serviceName"=>"_apple-mobdev2", "ID"=>"EF0159A8", "resolving"=>false}
I think it make sense for this API to set the default instance ID to "default". Then, enumerating will return the single instance with ID "default".
I dunno what's going on with many of the APIs returning two instances SCN1 and SCN2. That seems bogus to me. Most of these APIs clearly have only a single default instance.
I'll test if Rhodes magically returns an actual object if I enumerate them (it).
Re: API (extension) instance enumerationJon Tara Apr 22, 2015 9:56 PM (in response to Jon Tara)
Part of the confusion: "singletons" aren't (necessarily) singletons! They're "builtin"s, and there (can be) more than one. | https://developer.zebra.com/thread/30249 | CC-MAIN-2017-34 | refinedweb | 1,537 | 57.57 |
On the basis of the part of URL that the router will use to track the content that the user is trying to view, React Router provides three different kinds of routers:
Pre-requisite: Before start this article you need to have basic knowledge of React Router.
Memory Router: Memory router keeps the URL changes in memory not in the user browsers. It keeps the history of the URL in memory (does not read or write to the address bar so the user can not use the bowser’s back button as well as the forward button. It doesn’t change the URL in your browser. It is very useful for testing and non-browser environments like React Native.
- Syntax:
import { MemoryRouter as Router } from 'react-router-dom';
- Program:chevron_rightfilter_none
- Output:
Browser Router: It uses HTML 5 history API (i.e. pushState, replaceState and popState API) to keep your UI in sync with the URL. It routes as a normal URL in the browser and assumes that the server is handling all the request URL (eg., /, /about) and points to root
index.html. It accepts forceRefresh props to support legacy browsers which doesn’t support HTML 5 pushState API
- Syntax:
import { BrowserRouter as Router } from 'react-router-dom';
- Program:chevron_rightfilter_none
- Output:
Hash Router: Hash router uses client-side hash routing. It uses the hash portion of the URL (i.e. window.location.hash) to keep your UI in sync with the URL. Hash portion of the URL won’t be handled by the server, the server will always send the index.html for every request and ignore the hash value. It doesn’t need any configuration in the server to handle routes. It is used to support legacy browsers which usually don’t support HTML pushState API. It is very useful for the legacy browsers or you don’t have a server logic to handle the client-side. This route isn’t recommended to be used by the react-router-dom team.
- Syntax:
import { HashRouter as Router } from 'react-router-dom';
- Program:chevron_rightfilter_none
- Syntax:. | https://www.geeksforgeeks.org/reactjs-types-of-routers/ | CC-MAIN-2020-50 | refinedweb | 344 | 63.09 |
Hello everyone, I am so close to achieving my goal with this program. I just can't seam to figure out where the for loop goes wrong and "mis-counts" the amount of consonants and vowels. Also, in the else...if statement if anyone has advise to make it so it excludes all characters (like !, -, ...etc) besides vowels that would help so much! Part of the consonant problem I believe is it is counting spaces and other characters maybe?
Thanks so much in advance for any help!
import java.lang.String; public class StringProcessor { String string; int vowels; int consonants; public void Count() { vowels = 0; consonants = 0; for(int i = 0; i < string.length(); i++) { char c = string.charAt(i); if(c == 'a' || c == 'e' || c == 'i' || c == 'o' || c == 'u') vowels++; else if(c != 'a' || c != 'e' || c != 'i' || c != 'o' || c != 'u' || c != ' ') consonants++; } } public void display() { System.out.println(string + " has " + vowels + " vowels and " + consonants + " consonants."); } public StringProcessor(String aString) { string = aString; } public void setString(String stString) { string = stString; } } public class TestProcessor { public static void main(String[] args) { StringProcessor processor = new StringProcessor("Java Rules"); processor.Count(); processor.display(); processor.setString("I like on-line classes"); processor.Count(); processor.display(); processor.setString("Spring break was AWESOME!"); processor.Count(); processor.display(); } }
The output is supposed to look like this:
"Java Rules" has 4 vowels and 5 consonants
"I like on-line classes" has 8 vowels and 10 consonants
"Spring break was AWESOME!" has 8 vowels and 13 consonants
And I get this:
Java Rules has 4 vowels and 6 consonants.
I like on-line classes has 7 vowels and 15 consonants.
Spring break was AWESOME! has 4 vowels and 21 consonants.
Thanks again! | http://www.javaprogrammingforums.com/whats-wrong-my-code/7653-counting-vowels-consonants-string.html | CC-MAIN-2016-30 | refinedweb | 284 | 58.58 |
Creation of a matching game with Flash and AS3
Filed Under Actionscript 3, Flash, Game design • 15 Comments
This tutorial was inspired by the one written at chapter 3 in ActionScript 3.0 Game Programming University, but I changed some mechanics because I did not like some choices made by the author.
Anyway, this is not a "mine is better", just a tutorial that I did not write completely on my own.
Do you know what is a matching game?
In this version, you have 16 grey tiles. You can flip two tiles at a time by clicking on them. If colors of the flipped tiles match, they will be removed from the table. If colors don't match, they turn grey again.
Having 16 matchable tiles means having 8 different colors, and a "void" color to represent the unclicked tile.
The only object used in this movie is this movieclip:
The movieclip is linked as
colors and has 9 frames: the ones from 1 to 8 represent the eight colors, while frame number 9 represents the grey tile.
The
.fla file is called
color_match.as and in its properties window the document class is
color_match
Then, in the
color_match.as file, the actionscript is:
- package {
- import flash.display.Sprite;
- import flash.events.MouseEvent;
- import flash.events.TimerEvent;
- import flash.utils.Timer;
- public class color_match extends Sprite {
- private var first_tile:colors;
- private var second_tile:colors;
- private var pause_timer:Timer;
- var colordeck:Array = new Array(1,1,2,2,3,3,4,4,5,5,6,6,7,7,8,8);
- public function color_match() {
- for (x=1; x<=4; x++) {
- for (y=1; y<=4; y++) {
- var random_card = Math.floor(Math.random()*colordeck.length);
- var tile:colors = new colors();
- tile.col = colordeck[random_card];
- colordeck.splice(random_card,1);
- tile.gotoAndStop(9);
- tile.x = (x-1)*82;
- tile.y = (y-1)*82;
- tile.addEventListener(MouseEvent.CLICK,tile_clicked);
- addChild(tile);
- }
- }
- }
- public function tile_clicked(event:MouseEvent) {
- var clicked:colors = (event.currentTarget as colors);
- if (first_tile == null) {
- first_tile = clicked;
- first_tile.gotoAndStop(clicked.col);
- }
- else if (second_tile == null && first_tile != clicked) {
- second_tile = clicked;
- second_tile.gotoAndStop(clicked.col);
- if (first_tile.col == second_tile.col) {
- pause_timer = new Timer(1000,1);
- pause_timer.addEventListener(TimerEvent.TIMER_COMPLETE,remove_tiles);
- pause_timer.start();
- }
- else {
- pause_timer = new Timer(1000,1);
- pause_timer.addEventListener(TimerEvent.TIMER_COMPLETE,reset_tiles);
- pause_timer.start();
- }
- }
- }
- public function reset_tiles(event:TimerEvent) {
- first_tile.gotoAndStop(9);
- second_tile.gotoAndStop(9);
- first_tile = null;
- second_tile = null;
- pause_timer.removeEventListener(TimerEvent.TIMER_COMPLETE,reset_tiles);
- }
- public function remove_tiles(event:TimerEvent) {
- removeChild(first_tile);
- removeChild(second_tile);
- first_tile = null;
- second_tile = null;
- pause_timer.removeEventListener(TimerEvent.TIMER_COMPLETE,remove_tiles);
- }
- }
- }
Lines 2-5: importing the required libraries
Line 6: declaration of the main class
Line 7: declaration of the variable that will save the value of the first tile clicked. Its type is
colors because
colors is the linkage name of the movieclip with all tiles
Line 8: Same thing for the second tile clicked
Line 9: Declaring a
Timer variable that will be useful when I'll need to pause the game. I am going to pause the game when the player clicked two cards. If I don't pause the game, the player won't be able to see the second card clicked
Line 10: Initializing the
colordeck array: it's an array containing all possible tiles value. Every value represent a color, and a frame where to stop the
color movieclip
Line 11: Main function
Lines 12-13 : Loops to place 4 rows of 4 tiles each. Let's say four rows and four columns
Line 14: Choosing a random number between zero and the length of
colordeck array
-1. This means "choose a random tile"
Line 15: Creation of the tile. The type of the tile is
colors, of course.
Line 16: Assigning an attribute to the tile called
col that represent the color f the tile
Line 17: Removing the element at the position found at line 14 from the
colordeck array. It feels just like we drawn a tile
Line 18: Showing the 9th frame in the tile timeline. The 9th frame is the grey tile
Lines 19-20: Defining the x and y position of the tile on the stage
Line 21: Adding an even listener to the tile: when the player will click on it, the function tile_clicked will be called
Line 22: Physically placing the tile on the stage
Line 26: Beginning of the
tile_clicked function, the function to call every time the player clicks on a tile
Line 27: Assigning to a variable called
clicked the value of the tile just clicked, the one that called the function
Line 28: If this is the first of two tiles clicked...
Line 29: Define this tile as the first of two tiles clicked
Line 30: Show the tile color by stopping at the proper frame in the timeline
Line 32: If we already clicked on a tile and we are clicking on another tile, the second one...
Line 33: Define this tile as the second of two tiles clicked
Line 34: Show the tile color by stopping at the proper frame in the timeline
Line 35: If the colors of the two clicked tiles match...
Line 36: Defining a variable containing a one second timer
Line 37: Adding a listener that will call the function
remove_tiles once the amount of time defined at the previous line has passed. It means: "wait a second, then remove the cards from the table"
Line 38: Start the timer
Line 40: If the colors of the two clicked tiles don't match...
Lines 41-43: Same thing as lines 36-38, just calling a function to reset the tiles
Line 47: Beginning of the function that will reset the tiles
Lines 48-49: Turning both tiles grey
Lines 50-51: Turning the variables that store the first and second clicked tiles to
null (empty)
Line 52: Remove the time listener
Line 54: Beginning of the function that will remove the tiles
Lines 55-56: Removing both tiles
Lines 57-58: Same thing as lines 50-51
Line 59: Remove the time listener
And this is the result:
Download the source and turn it into a complete game, if you want.
They can be easily customized to meet the unique requirements of your project.
15 Responses to “Creation of a matching game with Flash and AS work.
I believe there are some people who wish to see the conclusion of some “already-running” tutorials.
Anyway, I aprecciate how frequently the blog’s being updated, it gives me a reason to come back and check things out almost daily. Keep it up.
Thanks, great tutorial Emanuele.
Keep up the good work!
How do you make a movieclip on Flex Development cause I made all the actionscript stuff but I can’t make the moveiclip so when I ry to run it, it says Error Please do…… cause I don’t have a movieclip and there’s no place where it says make new movieclip or anything like that.
I’m on here so often, mainly because your tutorials are great ! I also enjoy the people on the forum !
Edward, you could alter the code to dynamically draw the squares, the fill colour could be held in the array and you just redraw the squares with the appropriate fill after the click.
Like Edward I’m confused by the fla or movieclip part. I haven’t bought the Adobe tools so I’m kind of in the dark as to how this part is created.
For the ones who don’t have Flash CS3, the code for a Flex version can also be found (developed independently).
See under Memory Game @ Flex labs. No explanation or tutorial though, only the source
I have tweaked your game design slightly so that each matching pair is a picture and the word for that picture. (I used Math.floor / 2)
Also, I made it a 5X5 board with a wild card.
I have been trying and failing to make the wild card work. Any suggestions?
Basically, I need a function that will find the other match when the wild card is picked then remove all three cards.
Thanks
I was wondering how it would be possible to create a seperate AS file for different amount of colors.
F.E. I want to create 3 different difficulties, I’d create 3 actionscript files that link to the corresponding movieclip. And then in the main AS file that is linked to the document class I’d be able to click on the difficulty.
How would I go about doing this?
how to match 2 different objects,like color box and its name.how i can use ths to create matching game in flash8.
Thanks
Does anyone know how I could insert video into the game… I was hoping to assign a video to each of the 8 cards and for each time the cards were matched the corresponding video would appear and afterwards return to the game.
Thanks
Great tutorial, I downloaded the source files and I started working from scratch. I am trying to make the tiles bigger. When I make them all the same size & then play the movie they are all different sizes. How do I make sure they are all 150×150 regardless?
Awesome Scripting for the Card Game…nice and simple Emanuelle!
~Any feedback on how I can remove all the cards?…I created a function with this code but it only removes the one card?
tried:
removeChild(tile);
~any ideas much appreciated!
sincerely Stephen!
Wow this is amazing Emanuele!
(Not sure if you will read this :-(
I’ve been trying desperately to make a matching interaction that only matches cards across a row. I’ve got text underneath the tiles which I have set an alpha to so that I can stress to my students that reading across the row is very important.
That is, I would like to change this var
var random_card = Math.floor(Math.random()*colordeck.length);
and it’s functions to state tiles in row 1 only, tiles in row 2 only, etc. Can I somehow do this using your code by specifying the row?
Can you or anyone else help with this?
Thank you dearly,
Lehoa
I downloaded the Fla file, but when i open it in Flash CS4 I am upable to edit it and often it will crash flash. How to I edit the fla file? | http://www.emanueleferonato.com/2008/05/02/creation-of-a-matching-game-with-flash-and-as3/ | crawl-002 | refinedweb | 1,731 | 70.73 |
Clojure: expectations unit testing wrap-up
Join the DZone community and get the full member experience.Join For Free
The previous blog posts on expectations
unit testing syntax cover all of the various ways that expectations can
be used to write tests and what you can expect when your tests fail.
However, there are a few other things worth knowing about expectations.
Stacktraces
expectations aggressively removes lines from the stacktraces. Just like many other aspects of expectations, the focus is on more signal and less noise. Any line in the stacktrace from clojure.core, clojure.lang, clojure.main, and java.lang will be removed. As a result any line appearing in your stacktrace should be relevant to your application or a third-party lib you're using. expectations also removes any duplicates that can occasionally appear when anonymous functions are part of the stacktrace. Again, it's all about improving signal by removing noise. Speaking of noise...
Test Names
You might have noticed that expectations does not require you to create a test name. This is a reflection of my personal opinion that test names are nothing more than comments and shouldn't be required. If you desire test names, feel free to drop a comment above each test. Truthfully, this is probably a better solution anyway, since you can use spaces (instead of dashes) to separate words in a comment. Comments are good when used properly, but they can become noise when they are required. The decision to simply use comments for test names is another example of improving signal by removing noise.
Running Focused Expectations
Sometimes you'll have a file full of expectations, but you only want to run a specific expectation - expectations solves this problem by giving you 'expect-focused'. If you use expect-focused only expectations that are defined using expect-focused will be run.
For example, if you have the following expectations in a file you should see the following results from 'lein expectations'.
(ns sample.test.core (:use [expectations])) (expect zero? 0) (expect zero? 1) (expect-focused nil? nil) jfields$ lein expectations Ran 1 tests containing 1 assertions in 2 msecs IGNORED 2 EXPECTATIONS 0 failures, 0 errors.As you can see, expectations only ran one test - the expect-focused on line 6. If the other tests had been run the test on line 5 would have created a failure. It can be easy to accidentally leave a few expect-focused calls in, so expectations prints the number of ignored expectations in capital letters as a reminder. Focused expectation running is yet another way to remove noise while working through a problem.
Tests Running
If you always use 'lein expectations' to run your tests you'll never even care; however, if you ever want to run individual test files it's important to know that your tests run by default on JVM shutdown. When I'm working with Clojure and Java I usually end up using IntelliJ, and therefore have the ability to easily run individual files. When I switched from clojure.test to expectations I wanted to make test running as simple as possible - so I removed the need to specify (run-all-tests). Of course, if you don't want expectations to run for some reason you can disable this feature by calling (expectations/disable-run-on-shutdown).
JUnit Integration
Lack of JUnit integration was a deal breaker for my team in the early days, so expectations comes with an easy way to run all tests as part of JUnit. If you want all of your tests to run in JUnit all you need to do is implement ExpectationsTestRunner.TestSource. The following example is what I use to run all the tests in expectations with JUnit.
import expectations.junit.ExpectationsTestRunner; import org.junit.runner.RunWith; @RunWith(expectations.junit.ExpectationsTestRunner.class) public class SuccessTest implements ExpectationsTestRunner.TestSource{ public String testPath() { return "test/clojure/success"; } }As you can see from the example above, all you need to do is tell the test runner where to find your Clojure files.
That should be everything you need to know about expectations for unit testing use. If anything is unclear, please drop me a line in the comments.
From
Opinions expressed by DZone contributors are their own. | https://dzone.com/articles/clojure-expectations-unit | CC-MAIN-2020-45 | refinedweb | 711 | 55.74 |
A Github repo but that I didn’t find interesting or important enough to reproduce here.
Last week we looked at some tweaking and barely any functional changes. This week I looked at my giant list of features I was considering and implemented the most complicated one. It all started with an idea for a monster: the wraith. The overall “spec” is:
- It doesn’t attack normally; it attempts to “haunt” the player, destroying itself if it succeeds.
- It is incorporeal and needs to move through walls.
- It can follow the player even if the player breaks line of sight.
- It should deal a lot of damage (to be a threat despite attacking only once), but it should also not suddenly blow a player up with little warning. So the damage will be dealt over time.
- Being an intangible ghost, it probably shouldn’t have a visible corpse.
A New Monster
First things first, I needed to create a new monster. This is when I ran into a disagreement with the way the tutorial does some things. In the tutorial, the code that creates and defines a monster is all stuffed into the
place_entities function. Personally I prefer to have the monster definitions together, ideally separate from the level generation, so it’s easy to call on them whenever needed (imagine a scroll or monster ability that summons other monsters, for instance). So I ended up putting this together:
import tcod as libtcod import components.ai as ai from components.fighter import Fighter from entity import Entity from render_functions import RenderOrder class Monster(Entity): def __init__(self, x, y, char, color, name, blocks=True, render_order=RenderOrder.ACTOR): super().__init__(x, y, char, color, name, blocks, render_order) class Orc(Monster): def __init__(self, x, y): super().__init__(x, y, 'o', libtcod.desaturated_green, 'Orc', blocks=True, render_order=RenderOrder.ACTOR) Fighter(hp=20, defense=0, power=4, xp=35).add_to_entity(self) ai.BasicMonster().add_to_entity(self) class Troll(Monster): def __init__(self, x, y): super().__init__(x, y, 'T', libtcod.darker_green, 'Troll', blocks=True, render_order=RenderOrder.ACTOR) Fighter(hp=30, defense=2, power=8, xp=100).add_to_entity(self) ai.BasicMonster().add_to_entity(self)
(I think it’s possible I’m going a bit overboard with the OOP stuff, which is why I’m careful to state this as a preference rather than The Right Way)
With this in mind, our monster generation code now looks like this:
# imports now include "import map_objects.monsters as monsters" if not any([entity for entity in entities if entity.x == x and entity.y == y]): monster_choice = random_choice_from_dict(monster_chances) if monster_choice == 'orc': monster = monsters.Orc(x, y) else: monster = monsters.Troll(x, y) entities.append(monster)
Now let’s add the most trivial possible monster type: the same thing but with beefier stats:
class Balrog(Monster): def __init__(self, x, y): super().__init__(x, y, 'B', libtcod.dark_flame, 'Balrog', blocks=True, render_order=RenderOrder.ACTOR) Fighter(hp=45, defense=4, power=12, xp=250).add_to_entity(self) ai.BasicMonster().add_to_entity(self)
From there it’s a simple matter of updating the
monster_chances and above
if statement to add a third option in
game_map.py, which is easy enough.
A New Component
Given the “damages over time” aspect of the wraith, I wanted a way to represent a temporary status effect on the player. The existing inventory gives a decent template for it. Once I opened that door, I realized that I already had a second status effect I wanted to add. The tutorial game as presented is super easy, and a big part of that is that there’s too much healing. A strategy of “drink potions at 10 or lower HP, always pick Agility as the level bonus, and only fight monsters one at a time in hallways” will generally result in the player becoming invincible without ever seriously being in danger.
A gradual heal stops at least part of this problem by making it so the player can’t jump from 10 health to 50 in one turn. So I created a
HealOverTime status effect to add it to a potion:
from components.component import Component from game_messages import Message class StatusEffect(Component): def __init__(self, status_name, effect, duration): super().__init__('status_effect') self.status_name = status_name self.effect = effect self.duration = duration class StatusEffects(Component): def __init__(self): super().__init__('status_effects') self.active_statuses = {} def add_status(self, status): self.active_statuses[status.status_name] = status def process_statuses(self): results = [] to_delete = set() for name, status in self.active_statuses.items(): if status.duration == 0: to_delete.add(name) else: status.duration -= 1 results.extend(status.effect(self.owner)) for name in to_delete: del self.active_statuses[name] results.append({'message': Message("{0} wore off.".format(name))}) return results class HealOverTime(StatusEffect): def __init__(self, status_name, amount, duration): def effect(target): target.fighter.heal(amount) return [] super().__init__(status_name, effect, duration)
I decided I wouldn’t allow multiple effects by the same name; if there’s more than one at a time, the newest one “wins” and ends the older one early. This means you can’t drink 4 potions to heal four times as fast, and also prevents getting wrecked out of nowhere by multiple simultaneous wraiths.
Putting these effects in the game was surprisingly hard. Currently, the main turn loop works by repeatedly requesting the player’s input and then changing the game state based on what it is (where the game state can include things like looking at the character sheet or taking other actions that don’t eat a turn).
I can’t run the status effects in that loop or we end up with an exploit where the player can just open their character sheet over and over until the healing potion wears off. I also can’t just shove it in the enemy turn logic because that includes a loop over every game entity; it would mean that if there are four monsters, the potion would heal four times as each monster took its turn. I also didn’t want to wire something up where the monsters go before potion effects as it feels janky to have the player drink a potion, get hit by a monster, then start healing. So instead I ended up putting status effects in their own
for loop at the beginning of the enemy turn. (There was a bug here but I didn’t notice until implementing the wraith. I’ll come back to this.)
Now to try applying one of those status effects. First we’ll create a use function similar to the potion function already in the game:
def regenerate(*args, **kwargs): entity = args[0] name = kwargs.get('name') amount = kwargs.get('amount') duration = kwargs.get('duration') results = [] results.append({'consumed': True, 'message': Message('You feel a warmth pass over you.', libtcod.green)}) entity.status_effects.add_status(status_effects.HealOverTime(name, amount, duration)) return results
From there we just change the code that generates the healing potions in
game_map.py:
if item_choice == 'rejuvenation_potion': item = Entity(x, y, '!', libtcod.desaturated_blue, "Potion of Rejuvenation", render_order=RenderOrder.ITEM) Item(use_function=regenerate, amount=10, duration=4).add_to_entity(item)
Everything works exactly as intended, except the game crashes if you try to save.
Wait, What?
AttributeError: Can't pickle local object 'HealOverTime.__init__.<locals>.effect'
Oh, I get it. I’m glad I knew quite a bit of python before starting this tutorial. For those who didn’t:
pickle is the module that
shelve uses to save data. It’s complaining that it can’t save
effect, a function I defined in
HealOverTime‘s
__init__ method.
pickle isn’t up to the task of saving an arbitrary function that was only created at runtime (
effect is defined in
__init__ and doesn’t exist until
__init__ actually runs).
There’s another library called
dill that may be up to the task, but instead I found an even easier option. You can define custom
__setstate__ and
__getstate__ methods for
pickle‘s benefit. So, how could we represent the state of a partially-completed heal-over-time effect as a Python dictionary? That’s actually pretty easy. Say a player drinks a potion, heals the first 10 hp of it, then exits. Then we want to save and quit the game. When the player reloads, we can just give them a new 3-turn heal over time effect at 10 points/turn. This is almost as easy to write in Python as it is in English:
def __getstate__(self): return {'status_name': self.status_name, 'amount': self.amount, 'duration': self.duration} def __setstate__(self, state): self.__init__(state['status_name'], state['amount'], state['duration'])
It turns out we also have to add
self.amount = amount to the initializer to make that work, but otherwise everything goes without a hitch.
This also gave me the opportunity to fix something else that was bugging me. The tutorial’s saving code didn’t actually work on my machine. I suspect, though do not know for sure, that the difference is OS-specific. While poking around the
shelve documentation to fix my crashing bug, I also tweaked the saving/loading code slightly so that it no longer cares about the exact filename used for saved games. I hope this version (in the github repo) is more portable.
Damage Over Time
Given what we’ve already done at this point, this is barely any effort.
class DamageOverTime(StatusEffect): def __init__(self, status_name, amount, duration): self.amount = amount def effect(target): # unlike healing, take_damage returns results return target.fighter.take_damage(amount) super().__init__(status_name, effect, duration) def __getstate__(self): return {'status_name': self.status_name, 'amount': self.amount, 'duration': self.duration} def __setstate__(self, state): self.__init__(state['status_name'], state['amount'], state['duration'])
Finally, the Wraith
The Wraith class itself isn’t much:
class Wraith(Monster): def __init__(self, x, y): super().__init__(x, y, 'w', libtcod.han, 'Wraith', blocks=False, render_order=RenderOrder.ACTOR) Fighter(hp=1, defense=0, power=0, xp=50).add_to_entity(self) ai.WraithMonster().add_to_entity(self)
The real work is in the AI:
class WraithMonster(Component): def __init__(self): super().__init__('ai') self.player_spotted = False def take_turn(self, target, fov_map, game_map, entities): results = [] monster = self.owner # Return without doing anything until it spots the player for the first time if not self.player_spotted and not libtcod.map_is_in_fov(fov_map, monster.x, monster.y): return results self.player_spotted = True self.owner.move_towards(target.x, target.y, game_map, entities, ignore_blocking=True) if monster.distance_to(target) == 0: results.append({'message': Message("The wraith has haunted you!")}) target.status_effects.add_status(status_effects.DamageOverTime('Haunted by Wraith', 5, 10)) results.extend(monster.fighter.take_damage(1)) return results
I’ll mostly skip the silly bugs on this one, though it was pretty funny when I didn’t think to have the wraiths wait before following the player. You’d sometimes start a floor and have three or four previously-unseen wraiths pop into the room all at the same time.
There is one bug worth discussing because it was in the original tutorial code. It turns out that if
move_towards tries to check the distance between two objects in the same location, it throws a
ZeroDivisionError. It turns out this same function was the easiest way to implement creatures that can walk through walls by adding a new parameter:
def move_towards(self, target_x, target_y, game_map, entities, ignore_blocking=False): dx = target_x - self.x dy = target_y - self.y distance = math.sqrt(dx ** 2 + dy ** 2) dx = int(round(dx / distance)) if distance != 0 else 0 dy = int(round(dy / distance)) if distance != 0 else 0 if ignore_blocking or not (game_map.is_blocked(self.x + dx, self.y + dy) or get_blocking_entities_at_location(entities, self.x + dx, self.y + dy)): self.move(dx, dy)
Now would be a good time to go back to that bug I talked about in the main game loop. It turns out that the tutorial version of the game only checks for a dead player when a monster attacks. This meant that going to zero HP from wraith damage let the player run around with a zero or negative HP total and continue playing the game.
I dislike the code I wrote to handle this. Enough that I’m not going to post it here (it’s in the Github repo if you really want to see it). I’m still deciding on what less-kludgy way I would prefer to do this.
Ghosts Don’t Leave Corpses
So, now we have wraiths that mostly work except they’re leaving dead ghost bodies. It turns out that the function that kills monsters also has all the corpse logic built in. Even worse, it doesn’t actually delete the monster, but replace its attributes with the corpse attributes. I decided that for now I’d settle for making dead wraiths “invisible” so they don’t render.
So first step, factor that stuff out and put it in the
Monster class:
class Monster(Entity): def __init__(self, x, y, char, color, name, blocks=True, render_order=RenderOrder.ACTOR): super().__init__(x, y, char, color, name, blocks, render_order) def set_corpse(self): self.char = '%' self.color = libtcod.dark_red self.blocks = False self.fighter = None self.ai = None self.name = 'remains of ' + self.name self.render_order = RenderOrder.CORPSE
Next step, immediately go back to
Wraith and override it:
def set_corpse(self): self.blocks = False self.fighter = None self.ai = None self.name = '' self.render_order = RenderOrder.INVISIBLE
And making
RenderOrder.INVISIBLE a thing just requires a couple small tweaks to the renderer:
class RenderOrder(Enum): INVISIBLE = auto() STAIRS = auto() CORPSE = auto() ITEM = auto() ACTOR = auto() # intervening code omitted # Draw all entities in the list visible_entities = [e for e in entities if e.render_order != RenderOrder.INVISIBLE] entities_in_render_order = sorted(visible_entities, key=lambda x: x.render_order.value)
Whew!
That was a lot of work for (mostly) one monster, but I’m really happy at the groundwork it laid for later things. I may want other creatures that can ignore walls, or leave different/no corpses, or other temporary statuses I can throw around, or spawn monsters outside of the level generation function.
In case you somehow missed it, I’ve put the whole thing on GitHub.
2 thoughts on “Roguelike Tutorial Week 3: The Wraith” | https://projectwirehead.home.blog/2019/07/07/roguelike-tutorial-week-3-the-wraith/ | CC-MAIN-2021-04 | refinedweb | 2,352 | 50.63 |
Translation Guidelines¶
Zulip’s has full support for Unicode (and partial support for RTL languages), so you can use your preferred language everywhere in Zulip. We also translate the Zulip UI into more than a dozen major languages, including Spanish, German, Hindi, French, Chinese, Russian, and Japanese, and we’re always excited to add more. If you speak a language other than English, your help with translating Zulip is be greatly appreciated!
If you are interested in knowing about the technical end-to-end tooling and processes for tagging strings for translation and syncing translations in Zulip, read about Internationalization for Developers.
Translators’ workflow¶
These are the steps you should follow if you want to help translate Zulip:
Sign up for Transifex and ask to join the Zulip project on Transifex, requesting access to any languages you’d like to contribute to (or add new ones).
Join #translation in the Zulip development community server, and say hello. That stream is also the right place for any questions, updates on your progress, reporting problematic strings, etc.
Wait for a maintainer to approve your Transifex access; this usually takes less than a day. You should then be able to access Zulip’s dashboard in Transifex.
Translate the strings for your language in Transifex.
If possible, test your translations (details below).
Ask in Zulip for a maintainer to sync the strings from Transifex, merge them to master, and deploy the update to chat.zulip.org so you can verify them in action there.
<...>); just keep them verbatim.; if setting one up is a problem for you, ask in chat.zulip.org and we can usually just deploy the latest translations there.
First, download the updated resource files from Transifex using the
tools/i18n/sync-translationscommand (it will require some initial setup). This command will download the resource files from Transifex and replace your local resource files with them, and then compile them. You can now test your translation work in the Zulip UI.
There are a few ways to see your translations in the Zulip UI:
You can insert the language code as a URL prefix. For example, you can view the login page in German using. This works for any part of the Zulip UI, including portico (logged-out) pages.
For Zulip’s logged-in UI (i.e. the actual webapp), you can pick the language in the Zulip UI.
If your system has languages configured in your OS/browser, Zulip’s portico (logged-out) pages will automatically use your configured language. Note that we only tag for translation strings in pages that individual users need to use (e.g.
/register/, etc.), not marketing pages like
/features/.
In case you need to understand how the above interact, Zulip figures out the language the user requests in a browser using the following prioritization (mostly copied from the Django docs):
It looks for the language code as a url prefix (e.g.
/de/login/).
It looks for the
LANGUAGE_SESSION_KEYkey in the current user’s session (the Zulip language UI option ends up setting this).
It looks for the cookie named ‘django_language’. You can set a different name through the
LANGUAGE_COOKIE_NAMEsetting.
It looks for the
Accept-LanguageHTTP header in the HTTP request (this is how browsers tell Zulip about the OS/browser language).
Using an HTTP client library like
requests,
cURLor
urllib, you can pass the
Accept-Languageheader; here is some sample code to test
Accept-Languageheader using Python and
requests:
import requests headers = {"Accept-Language": "de"} response = requests.get("", headers=headers) print(response.content)
This can occassionally be useful for debugging.
Translation style guides¶
We maintain translation style guides for Zulip, giving guidance on how Zulip should be translated into specific languages (e.g. what word to translate words like “stream” to), with reasoning, so that future translators can understand and preserve those decisions:
Some translated languages don’t have these, but we highly encourage translators for new languages (or those updating a language) write a style guide as they work (see our docs on this documentation for how to submit your changes), since it’s easy to take notes as you translate, and doing so greatly increases the ability of future translators to update the translations in a consistent way.”
The Zulip test suite enforces these capitalization guidelines in the
webapp codebase in our test
suite
(
./tools/check-capitalization;
tools/lib/capitalization.py has
some exclude lists, e.g.
IGNORED_PHRASES). | https://zulip.readthedocs.io/en/latest/translating/translating.html | CC-MAIN-2019-47 | refinedweb | 737 | 61.87 |
django-pagetimerdjango-pagetimer
Simple but effective endpoint for tracking users' time spent on pages.
backgroundbackground
Often, we have clients ask to see metrics on how long users spent on each page of the application. Tracking that properly in the wild is actually really difficult and comes with a lot of caveats (eg, we can tell if they have the browser open to the page, but not that someone is actually looking at it; they may have wandered off with the tab open).
This library provides a django app that implements a simple, but surprisingly effective approach to solving that problem in the general case.
At its core, there's a templatetag that inserts a bit of JS (with no dependencies) that just does a heartbeat back to an endpoint once every 60s (configurable). The backend endpoint stores an entry with username, session id, ipaddress, path, and a timestamp. From there, reports can be generated and timelines reconstructed with a reasonable accuracy (commensurate with the amount of effort required to implement).
Much more accurate and complex approaches can be taken, but in my experience, this is good enough to drop in quickly and get started. It creates one DB entry per user per minute by default, which is unlikely to blow up your database usage too quickly. The approach encourages you to just pull down CSVs for offline processing. Once you've been using something like this for a while, you may have a better idea of where you need more precision in your tracking, but this will help you get there.
installationinstallation
$ pip install django-pagetimer
Then add
pagetimer to your
INSTALLED_APPS and include
('pagetimer/', include('pagetimer.urls')), in you
urls.py.
Next, in your
base.html, include
{% load pagetimertags %} and,
preferably near the end of the
<head>, insert a
{% pagetimer %}.
Now, anytime a user is on any page of your site, their browser will ping the pagetimer endpoint once every 60s and it will log it.
You can set
PAGETIMER_INTERVAL to the number of seconds between
heartbeats. Default is 60 seconds.
By default, all visits are kept until they are manually purged. This is probably a bad idea if you get much traffic and aren't actively monitoring DB size. So pagetimer includes two different retention policies that you can enable:
PAGETIMER_MAX_RETENTION_INTERVAL can be set to a
datetime.timedelta. Any entries further back than that will
automatically be dropped. Eg:
from datetime import timedelta PAGETIMER_MAX_RETENTION_INTERVAL = timedelta(days=7)
Will drop entries after a week.
PAGETIMER_MAX_RETENTION_COUNT can be set to a maximum count of
entries to keep. This is good as a last-ditch limit. You can set both
of them.
featuresfeatures
- simple admin dashboard to see recent visits
- admin view for downloading CSV dumps
- admin function for clearing out older entries (to free up disk space in the DB)
- js will only heartbeat to the endpoint if the tab is visible (via Page Visibility API)
- admin view for downloading anonymized CSV dumps (with username, ipaddress anonymized)
- pluggable backend architecture. The existing DB model will be one (and probably the default) model. A simple textfile appending backend will be added and there will be a nice interface for implementing, eg, an ElasticSearch backend. | https://libraries.io/pypi/django-pagetimer | CC-MAIN-2018-47 | refinedweb | 533 | 61.77 |
ioctl_tty(2) [bsd man page]
IOCTL_TTY(2) Linux Programmer's Manual IOCTL_TTY(2) NAME
ioctl_tty - ioctls for terminals and serial lines SYNOPSIS
#include <termios.h> int ioctl(int fd, int cmd, ...); DESCRIPTION
The ioctl(2) call for terminals and serial ports accepts many possible command arguments. Most require a third argument, of varying type, here called argp or arg. Use of ioctl makes for nonportable programs. Use the POSIX interface described in termios(3) whenever possible. Get and set terminal attributes TCGETS struct termios *argp Equivalent to tcgetattr(fd, argp). Get the current serial port settings. TCSETS const struct termios *argp Equivalent to tcsetattr(fd, TCSANOW, argp). Set the current serial port settings. TCSETSW const struct termios *argp Equivalent to tcsetattr(fd, TCSADRAIN, argp). Allow the output buffer to drain, and set the current serial port settings. TCSETSF const struct termios *argp Equivalent to tcsetattr(fd, TCSAFLUSH, argp). Allow the output buffer to drain, discard pending input, and set the current serial port settings. The following four ioctls are just like TCGETS, TCSETS, TCSETSW, TCSETSF, except that they take a struct termio * instead of a struct termios *. TCGETA struct termio *argp TCSETA const struct termio *argp TCSETAW const struct termio *argp TCSETAF const struct termio *argp Locking the termios structure The termios structure of a terminal can be locked. The lock is itself a termios structure, with nonzero bits or fields indicating a locked value. TIOCGLCKTRMIOS struct termios *argp Gets the locking status of the termios structure of the terminal. TIOCSLCKTRMIOS const struct termios *argp Sets the locking status of the termios structure of the terminal. Only.h>. TIOCGWINSZ struct winsize *argp Get window size. TIOCSWINSZ const struct winsize *argp Set window size. The struct used by these ioctls is defined as struct winsize { unsigned short ws_row; unsigned short ws_col; unsigned short ws_xpixel; /* unused */ unsigned short ws_ypixel; /* unused */ }; When the window size changes, a SIGWINCH signal is sent to the foreground process group. Sending a break TCSBRK int arg Equivalent to tcsendbreak(fd, arg). If the terminal is using asynchronous serial data transmission, and arg is zero, then send a break (a stream of zero bits) for between 0.25 and 0.5 seconds. If the terminal is not using asynchronous serial data transmission, then either a break is sent, or the function returns without doing anything. When arg is nonzero, nobody knows what will happen. (SVr4, UnixWare, Solaris, Linux treat tcsendbreak(fd,arg) with nonzero arg like tcdrain(fd). SunOS treats arg as a multiplier, and sends a stream of bits arg times as long as done for zero arg. DG/UX and AIX treat arg (when nonzero) as a time interval measured in milliseconds. HP-UX ignores arg.) TCSBRKP int arg So-called "POSIX version" of TCSBRK. It treats nonzero arg as a timeinterval measured in deciseconds, and does nothing when the driver does not support breaks. TIOCSBRK void Turn break on, that is, start sending zero bits. TIOCCBRK void Turn break off, that is, stop sending zero bits. Software flow control TCXONC int arg Equivalent to tcflow(fd, arg). See tcflow(3) for the argument values TCOOFF, TCOON, TCIOFF, TCION. Buffer count and flushing FIONREAD int *argp Get the number of bytes in the input buffer. TIOCINQ int *argp Same as FIONREAD. TIOCOUTQ int *argp Get the number of bytes in the output buffer. TCFLSH int arg Equivalent to tcflush(fd, arg). See tcflush(3) for the argument values TCIFLUSH, TCOFLUSH, TCIOFLUSH. Faking input TIOCSTI const char *argp Insert the given byte in the input queue. Redirecting console output TIOCCONS void Redirect output that would have gone to /dev/console or /dev/tty0 to the given terminal. If that was a pseudoterminal master, send it to the slave. In Linux before version 2.6.10, anybody can do this as long as the output was not redirected yet; since version 2.6.10, only a process with the CAP_SYS_ADMIN capability may do this. If output was redirected already EBUSY is returned, but redi- rection can be stopped by using this ioctl with fd pointing at /dev/console or /dev/tty0. Controlling terminal TIOCSCTTY call- er has the CAP_SYS_ADMIN capability and arg equals 1, in which case the terminal is stolen, and all processes that had it as con- trolling terminal lose it. TIOCNOTTY void If the given terminal was the controlling terminal of the calling process, give up this controlling terminal. If the process was session leader, then send SIGHUP and SIGCONT to the foreground process group and all processes in the current session lose their controlling terminal. Process group and session ID TIOCGPGRP pid_t *argp When successful, equivalent to *argp = tcgetpgrp(fd). Get the process group ID of the foreground process group on this terminal. TIOCSPGRP const pid_t *argp Equivalent to tcsetpgrp(fd, *argp). Set the foreground process group ID of this terminal. TIOCGSID pid_t *argp Get the session ID of the given terminal. This; other- wise, place zero in *argp. TIOCNXCL void Disable exclusive mode. Line discipline TIOCGETD int *argp Get the line discipline of the terminal. TIOCSETD const int *argp Set the line discipline of the terminal. Pseudoterminal ioctls TIOCPKT const int *argp Enable (when *argp is nonzero) or disable packet mode. Can be applied to the master side of a pseudoterminal only (and will return ENOTTY otherwise). In packet mode, each subsequent read(2) will return a packet that either contains a single nonzero control byte, or has a single byte containing zero (' ') followed by data written on the slave side of the pseudoterminal. If the first byte is not TIOCPKT_DATA (0), it is an OR of one or more of the following bits: TIOCPKT_FLUSHREAD The read queue for the terminal is flushed. TIOCPKT_FLUSHWRITE The write queue for the terminal is flushed. TIOCPKT_STOP Output to the terminal is stopped. TIOCPKT_START Output to the terminal is restarted. TIOCPKT_DOSTOP The start and stop characters are ^S/^Q. TIOCPKT_NOSTOP The start and stop characters are not ^S/^Q. While this int *argp Get the status of modem bits. TIOCMSET const int *argp Set the status of modem bits. TIOCMBIC const int *argp Clear the indicated modem bits. TIOCMBIS const int *argp Set the indicated modem bits. The following bits are used by the above ioctls: TIOCM_LE DSR (data set ready/line enable) TIOCM_DTR DTR (data terminal ready) TIOCM_RTS RTS (request to send) TIOCM_ST Secondary TXD (transmit) TIOCM_SR Secondary RXD (receive) TIOCM_CTS CTS (clear to send) TIOCM_CAR DCD (data carrier detect) TIOCM_CD see TIOCM_CAR TIOCM_RNG RNG (ring) TIOCM_RI see TIOCM_RNG TIOCM_DSR DSR (data set ready) int *argp ("Get software carrier flag") Get the status of the CLOCAL flag in the c_cflag field of the termios structure. TIOCSSOFTCAR const int *argp ("Set software carrier flag") Set the CLOCAL flag in the termios structure when *argp is nonzero, and clear it otherwise. If the CLOCAL flag for a line is off, the hardware carrier detect (DCD) signal is significant, and an open(2) of the corresponding terminal will block until DCD is asserted, unless the O_NONBLOCK flag is given. If CLOCAL is set, the line behaves as if DCD is always asserted. The software carrier flag is usually turned on for local devices, and is off for lines with modems. Linux-specific For the TIOCLINUX ioctl, see
Check the condition of DTR on the serial port. #include <termios.h> #include <fcntl.h> #include <sys/ioctl.h> int main(void) { int fd, serial; fd = open("/dev/ttyS0", O_RDONLY); ioctl(fd, TIOCMGET, &serial); if (serial & TIOCM_DTR) puts("TIOCM_DTR is set"); else puts("TIOCM_DTR is not set"); close(fd); } SEE ALSO
ldattach(1), ioctl(2), ioctl_console(2), termios(3), pty(7) COLOPHON
This page is part of release 4.15 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at. Linux 2017-09-15 IOCTL_TTY(2) | https://www.unix.com/man-page/bsd/2/ioctl_tty | CC-MAIN-2022-40 | refinedweb | 1,310 | 65.22 |
Hey guys,
the following code snippet is from my textbook (section about file I/O):
I typed it exactly like it is given in my textbook, but the program wouldn't even let me type in the target's file name.I typed it exactly like it is given in my textbook, but the program wouldn't even let me type in the target's file name.Code:
// datacopy.cpp
#include <cstdlib>
#include <fstream>
#include <iostream>
#include <string>
using namespace std;
int main() {
ifstream source;
string sFilename;
cout << "Source file: ";
cin >> sFilename;
source.open(sFilename.c_str(), ios::binary|ios::in);
if (!source) {
cerr << sFilename << " cannot be opened.\n";
exit(-1);
}
cout << "Target file: ";
string tFilename;
ofstream target(tFilename.c_str(), ios::binary|ios::out);
if (!target) {
cerr << tFilename << " cannot be opened.\n";
exit(-1);
}
char ch;
while (source.get(ch)) {
target.put(ch);
}
source.close();
target.close();
}
I tried it with several different source file names, like test_file.txt, test_file, testfile, etc. Seems after typing in the source file name there is something remaining in the input buffer (the '\n'?), right?
Is this an error in the code snippet I should e-mail the author? Or am I wrong somewhere and don't see it myself?
EDIT: Here's an example output, just for clarification:
Quote:
[dennis@marx k2]$ ./datacopy
Source file: datacopytest
Target file: cannot be opened.
[dennis@marx k2]$ | http://cboard.cprogramming.com/cplusplus-programming/144806-file-i-o-example-book-wont-work-printable-thread.html | CC-MAIN-2015-18 | refinedweb | 230 | 67.55 |
Build a simple python web crawler
pranay749254
Aug 20 '17
What is a Web Crawler?
Web crawler is an internet bot that is used for web indexing in World Wide Web.All types of search engines use web crawler to provide efficient results.Actually it collects all or some specific hyperlinks and HTML content from other websites and preview them in a suitable manner.When there are huge number of links to crawl , even the largest crawler fails.For this reason search engines early 2000 were bad at providing relevant results,but now this process has improved much and proper results are given in an instant
Python Web Crawler
The web crawler here is created in python3.Python is a high level programming language including object-oriented, imperative, functional programming and a large standard library.
For the web crawler two standard library are used -
requests and
BeautfulSoup4.
requests provides a easy way to connect to world wide web and
BeautifulSoup4 is used for some particular string operations.
Example Code
import requests from bs4 import BeautifulSoup def web(page,WebUrl): if(page>0): url = WebUrl code = requests.get(url) plain = code.text s = BeautifulSoup(plain, "html.parser") for link in s.findAll('a', {'class':'s-access-detail-page'}): tet = link.get('title') print(tet) tet_2 = link.get('href') print(tet_2) web(1,'')
Output:
C:\Python34\python.exe C:/Users/Babuya/PycharmProjects/Youtube/web_cr.py Apple iPhone 6 (Gold, 32GB) OnePlus 5 (Slate Gray 6GB RAM + 64GB memory) OnePlus 5 (Midnight Black 8GB RAM + 128GB memory) Apple iPhone 6 (Space Grey, 32GB) OnePlus 5 (Soft Gold, 6GB RAM + 64GB memory) Mi Max 2 (Black, 64 GB) Moto G5 Plus (32GB, Fine Gold) Apple iPhone SE (Space Grey, 32GB) Honor 8 Pro (Blue, 6GB RAM + 128GB Memory) Apple iPhone 7 (Black, 32GB) BlackBerry KEYone (LIMITED EDITION BLACK) Apple iPhone SE (Gold, 32GB) Apple iPhone SE (Rose Gold, 32GB) Apple iPhone 6s (Space Grey, 32GB) Samsung Galaxy J7 Max (Gold, 32GB) Honor 8 Pro (Black, 6GB RAM + 128GB Memory) Samsung Galaxy J7 Max (Black, 32GB) OnePlus 3T (Soft Gold, 6GB RAM + 64GB memory) Apple iPhone 6s (Gold, 32GB) Apple iPhone 6s (Rose Gold, 32GB) Samsung Galaxy C7 Pro (Navy Blue, 64GB) Samsung J7 Prime 32GB ( Gold ) 4G VoLTE Vivo V5s (Matte Black) with Offers Vivo V5s (Crown Gold) with Offers
Here this crawler collects all the product headings and respective links of the products pages from a page of amazon.in . User just need to specify what kind of data or links to be crawled.Though the main use of web crawler is in search engines,this way it can also be used to collect some useful information.
Here all the HTML of the page is fetched using
requests in plain text form.Then it is converted into a
BeautifulSoup object.From that object all title and href with class
s-access-detail-page is accessed.That's all how this basic web crawler works.
How have you fund an open-source project ?
Open-source project are now at the heart of the industry, but how do you eat at the end of the day ?
Great, scraping is so great with python. Have you ever been wondering about using something like scrapy from here | https://practicaldev-herokuapp-com.global.ssl.fastly.net/pranay749254/build-a-simple-python-web-crawler | CC-MAIN-2018-39 | refinedweb | 540 | 61.56 |
New TopicSylvain Leroux Feb 19, 2008 12:25 PM
Hi there,
First a word of warning: I'm new to Seam, EJB3, JSF, Hibernate, and so on... So please forgive me for this
newbie question.
Conversation, as I understand it
I have some trouble with the @End annotation in my stateful session bean (conversation scope). As I have said, I'm new to Seam. But by reading the Seam Reference manual and previous posts on the old forum (most notably this one), it appears to be clear that calling a @Begin method will start (or join) a conversation, and calling a @End method will end the current conversation.
I have (mis?)understood that the SFSB will then be destroyed by the application server after the @End method is completed. So the next time a @Begin method on that bean will be used in my JSF page, a new instance of the STSB will be created.
Conversation in my sample application
So, I've made a sample application to check that. Very simple, not much more that the
Hello Seam world program on Michael Yuan's book.A conversation scoped entity bean (Book), and a conversation scoped stateful session bean (BookManagerAction).
Here is the code:
@Entity @Name("book") @Scope(ScopeType.CONVERSATION) public class Book implements Serializable { private static final long serialVersionUID = 1L; @SuppressWarnings("unused") @Id @Length(min=10,max=10) private String ISBN; private String title; public Book() {}; public Book(String ISBN, String title) { this.ISBN = ISBN; this.title = title; } public String getISBN() { return ISBN; } public void setISBN(String isbn) { ISBN = isbn; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } @Override public String toString() { return title + "/" + ISBN; } }
@Stateful @Scope(ScopeType.CONVERSATION) @Name("bookManager") public class BookManagerAction implements BookManager { @PersistenceContext(type=EXTENDED) private EntityManager em; @In private Book book; @In private FacesContext facesContext; public BookManagerAction() { System.err.println("xxxxxxxxx PrintManagerAction()"); } @SuppressWarnings("unchecked") @Override public List<Book> allBooks() { return em.createQuery("select b from Book b") .getResultList(); } @Override public String save() { try { em.persist(book); em.flush(); book = new Book(); } catch(javax.persistence.EntityExistsException e) { FacesMessage message = new FacesMessage("Error: already exists. " + e.getMessage()); facesContext.addMessage(null, message); return null; } return "done"; } @Remove @Destroy public void destroy() { // nothing to do } }
And the view:
<>This page allow to add a new book to the database</p> <h2>Create</h2> <h:messages /> <form jsfc="h:form" id="Book"> <s:validateAll> <p><label for="title">Title:</label><input id="title" type="text" jsfc="h:inputText" value="#{book.title}" /><h:message</p> <p><label for="isbn">ISBN-10:</label><input id="isbn" type="text" jsfc="h:inputText" value="#{book.ISBN}" /><h:message</p> <p><input type="submit" jsfc="h:commandButton" value="Submit" action="#{bookManager.save()}" /></p> </s:validateAll> </form> <h2>Books in the database</h2> <h:form> <h:dataTable <h:column>#{book.title}</h:column> <h:column>#{book.ISBN}</h:column> </h:dataTable> </h:form> </body> </html>
Notice that the application is deployed as an EAR, and that I do not use any page.xml.
At this point, it works fine. When running the application, I could see that a new STSB instance is created after each user action.
So, I've decided to use @Begin and @End annotation:
allBooks will start the conversation, and
save will end it:
@Begin(join=true) @SuppressWarnings("unchecked") @Override public List<Book> allBooks() { ... }
@End @Override public String save() { ... }
To my mind:
- a new conversation will begin when the user will load the page.
- The bean will join that conversation when allBooks will be called.
- In case of input error (wrong format for the ISBN), the page will be redisplayed, using the same conversation and the same STSB.
- And finally, the conversation will end at
savetime, and a new one will begin when the result page will be rendered, so the process will continue.
But, it doesn't work like that! It appears to me that the same bean will be used even after a save, just like if there wasn't any @End annotation ???
I cannot figure exactly what's wrong here. Maybe it is due to the fact that I use the same page to end and start a new conversation using the same STSB?
Or maybe it is due to something I read in a previous post (an that I don't really understand)
When an @End method is encountered, any long-running conversation context is demoted to a temporary conversation
So, if you have any idea...
Thanks in advance,
Sylvain.
1. Re: New TopicSylvain Leroux Feb 19, 2008 12:26 PM (in response to Sylvain Leroux)
Sorry for the title of this topic: It should have been something like
@End does not close a conversation- but I've jumped too quickly on the
Savebutton... If anyone knows how to change that...
Sylvain
2. Re: New TopicCarsten Hoehne Feb 19, 2008 12:39 PM (in response to Sylvain Leroux)
What happens when you press the save button? Your action returns
done. Are you having a navigation rule for this outcome?
IMHO, if you render the same page again, after clicking the save-button, the conversations is not ended because you have annotated the method allBooks with @Begin.
Try to render a different page after clicking save and see what happens.
Ciao,
Carsten
3. Re: New TopicSylvain Leroux Feb 19, 2008 1:54 PM (in response to Sylvain Leroux)
First of all, thanks Carsten for your answer.
You're right: I render the same page after a click on the save button. My idea was to have some kind of
quick addfeature on the list page.
Nevertheless, I've tried as you suggested to add a
confirmpage:
<>Change confirmed</p> <p><a href="new-book.seam">go back to list</a></p> </body> </html>
And the corresponding navigation rule:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE faces-config PUBLIC "-//Sun Microsystems, Inc.//DTD JavaServer Faces Config 1.0//EN" ""> <faces-config> <navigation-rule> <from-view-id>*</from-view-id> <navigation-case> <from-outcome>done</from-outcome> <to-view-id>/confirm.xhtml</to-view-id> <redirect /> </navigation-case> </navigation-rule> </faces-config>
That time it works just fine.
But, I have some trouble to understand why it is not working with the
one page does allversion?
As far as I understand, in the
one pageversion, when the user click on the save button:
- The entity bean is updated with the values entered by the user
- The save method is called on the bookManager STSB. This terminates the conversation, and removes the STSB.
- Then the response in rendered. So, when the #{bookManager.allBooks} EL is reached, since there is no longer any bookManager in the conversation context, a new one is created.
Obviously, this is not the way it's done! So the right questions here are:
- When a STSB is removed from the context when a @End method is called? After the request is handled or after the response is rendered? (my guess now is the second case;)
- What appends if I call a method from a JSF page on a bean after an @End method on that bean has already be called (especially if I call a @Begin after a @End method)? Does this cancel the end of the conversation?
Sylvain
4. Re: New TopicCarsten Hoehne Feb 27, 2008 10:56 AM (in response to Sylvain Leroux)
Hello,
Sorry for the delay. There is this Jira Issue.
IMDO, a conversation is never terminated. It is created when a request begins and it is destroyed when the response is rendered.
Please read the conversation chapter of the seam documentation. Espesially chapter 6.1 and you will understand the behaviour.
There is the attribute beforeRedirect which changes the described behaviour. It ends the converstaion before rendering the page.
@End(beforeRedirect="true")
Try it out after reading the above mentioned documentation:-)
5. Re: New TopicSylvain Leroux Feb 28, 2008 10:43 AM (in response to Sylvain Leroux)
Hi Carsten,
Thanx for the answer!
For some reason, I understood quite literally from the doc that the context will be destroyed just after the request is handled. Here is the relevant extract from Seam Tutorial - 1.6.3: Understanding Seam conversations
The @End annotation specifies that the annotated method ends the current long-running conversation, so the current conversation context will be destroyed at the end of the request.
But, in fact, as I could have read it from Michael Yuan's book (p100) the conversation is
destroyed after the response page is fully rendered.
By the way, I've missed the beforeRedirect attribute too... that does exactly what I wanted:
beforeRedirect — by default, the conversation will not actually be destroyed until after any redirect has occurred. Setting beforeRedirect=true specifies that the conversation should be destroyed at the end of the current request, and that the redirect will be processed in a new temporary conversation context.
Seems I have to read the doc more carefully!-)
Nevertheless, things are getting much more clear now!
Sylvain
6. Re: New TopicDamian Harvey Feb 28, 2008 11:46 AM (in response to Sylvain Leroux)
You can always manually remove your Bean from the context eg: Contexts.removeFromAllContexts("myBean");
I find that this is often useful if you want to remain on the same page.
Cheers,
Damian.
7. Re: New TopicGavin King Feb 28, 2008 10:57 PM (in response to Sylvain Leroux)
Please don't forget to rate Carsten's posts, thanks :-)
8. Re: New TopicKeith Naas Feb 29, 2008 2:51 AM (in response to Sylvain Leroux)
Great, I explained the promotion/demotion of conversations yesterday and no one gave me a rating..heh heh
Of course, it looks like I was typing the response after shooting a gallon of coffee.
9. Re: New TopicSylvain Leroux Mar 1, 2008 4:11 PM (in response to Sylvain Leroux)
Sorry Keith, I missed that from an other post:
[...] Ending the conversation doesn't immediately end it. Instead it demotes it to a temporary conversation. In the case of JSF, this temporary conversation is then over when the render response phase is completed.
It is an important aspect of conversation life cycle that explain the behavior I described in my original post.
Well, now that I know that, it's quite logical: @Begin promote a temporary conversation to a long-running conversation and @End does the exact opposite: demote from a long-running conversation to a temporary conversation.
Moreover, this is the answer to my question about calling a @Begin method on a component after a call to an @End method: the conversation is just demoted to a temporary conversation, then (re)promoted to a long-running conversation. And that conversation just continue using the same component.
Things are getting much more clear now, thanks
Sylvain | https://developer.jboss.org/message/661318 | CC-MAIN-2019-30 | refinedweb | 1,792 | 55.64 |
Hey all. I'm trying to get dynamic memory working (im making a quick file-system based database system, and I need the dynamic alloc in there) but it doesnt seem to be working...
Right now im using this code to test (with NetBeans g++):
and this leads to the cmd to instantly crash (no error flag of a bad allocation has been sent)...and this leads to the cmd to instantly crash (no error flag of a bad allocation has been sent)...Code:#include <cstdlib> #include <iostream> #include <sstream> #include <fstream> #include <string> using namespace std; int main() { int aSize = 5; string* dmt = new string[aSize]; string* temp = NULL; int i = 0; int ii = 0; ostringstream oss; while(i<=100) { oss << i; dmt[i] = oss.str(); oss.str(""); if(i>=aSize) { aSize = aSize * 2; temp = new string[aSize]; while(ii<=i) { temp[ii] = dmt[ii]; ii++; } delete dmt; dmt = temp; temp = NULL; } } for(int iii=0; iii<=100; iii++) cout << dmt[iii] << endl; return 0; }
can anyone say what I have done wrong and how to fix it? | https://cboard.cprogramming.com/cplusplus-programming/139581-cplusplus-dynamic-arrays.html | CC-MAIN-2017-26 | refinedweb | 179 | 64.98 |
Kotlin does indeed use default arguments and named parameters. This was something I really enjoy in Python but isn’t supported in Java.
For those people who aren’t familiar with the term, named arguments is a feature in a programming language where a developer can specify the name of a parameter and assign it a value when calling a function. It helps improve code readability. Here is a little Python to show off named arguments.
def func(arg1, arg2, arg3): pass # Which is more clear? # Named arguments? func(arg1=1, arg2=2, arg3=3) # Non-named arguments? func(1, 2, 3)
In the above code snippet, the developer calls each argument in the function by it’s name and assigns a value to the parameter. It’s a lot nicer because you can instantly see what each value in the function is doing.
Many people have probably heard of default arugments. This is a feature in many programming languages where a developer can specify a default value for a parameter. When calling the function, the client code can choose to specify a value or just use the default. Here is another little Python teaser.
def func(arg1='Hello World'): pass # Using default func() # Using custom value func('Thunderbiscuit') Java does not support either of these concepts. It does support function overloading. In this portion of Kotlin Kroans, we have to translate this Java code into Kotlin. package i_introduction._3_Default_Arguments; import util.JavaCode; public class JavaCode3 extends JavaCode { private int defaultNumber = 42; public String foo(String name, int number, boolean toUpperCase) { return (toUpperCase ? name.toUpperCase() : name) + number; } public String foo(String name, int number) { return foo(name, number, false); } public String foo(String name, boolean toUpperCase) { return foo(name, defaultNumber, toUpperCase); } public String foo(String name) { return foo(name, defaultNumber); } }
Readers will notice that the function foo is overloaded three times with different versions specify default arguments. It works, but it's also super verbose. Kotlin cuts through all of that noise. Here is the same code in Kotlin.
fun foo(name: String, number: Int = 42, toUpperCase: Boolean=false): String { if (toUpperCase) { return name.toUpperCase() + number } else { return name + number } }
Readers will see that Kotlin is much more consice. One Kotlin function can do the same job as four functions in Java. We can call this function using this code.
fun task3(): String { return (foo("a") + foo("b", number = 1) + foo("c", toUpperCase = true) + foo(name = "d", number = 2, toUpperCase = true)) }
In this code snippet, we make four distinct calls to foo. Each time, we only specify the arguments that we need. I am also a huge fan of using the named arguments also. It makes it much easier to read the code.
You can click here to see Part 3 or Part 5
2 thoughts on “Kotlin Koans—Part 4” | https://stonesoupprogramming.com/2017/06/03/kotlin-koans-part-4/ | CC-MAIN-2018-05 | refinedweb | 471 | 65.62 |
# Recovering Data of a Windows To Go Workspace
Read more about this portable version of Windows: how to create and boot it. How to recover data with a Windows To Go drive, or from a drive containing the portable version of the operating system. Windows To Go is a new tool inside Windows 10 that can be used to create a portable version of the operating system on an external hard drive or a USB pen drive. Such operating system can be booted and used on any computer.

This feature is in no way a replacement for the operating system installed on the computer’s hard disk, but rather one more alternative to use workspaces.
Windows To Go feature
---------------------
A Windows To Go workspace operates just as any installation of Windows, but with the following exceptions:
* **Internal disks are offline.** To ensure that data of the host computer isn’t used in an unauthorized way, its internal hard disks are offline by default when booted into a Windows To Go workspace. And vice versa, any information from a Windows To Go drive is inaccessible from the Windows installed on the host computer. It means, that Windows Explorer on the host computer won’t be able to access a Windows To Go drive, because it won’t be listed in This PC folder. In the same way, if you boot a Windows To Go workspace, its folder This PC will not show the disks of the host computer – they become sort of invisible.
* **Trusted Platform Module (TPM) is not used.** To ensure security when using BitLocker Drive Encryption, a pre-operating system boot password will be used rather than the TPM since the TPM is tied to a specific computer while Windows To Go drives are supposed to move between computers.
* **Hibernate is disabled by default.** To ensure that the Windows To Go workspace is able to move between computers easily, hibernation is disabled by default. Hibernation can be re-enabled by using Group Policy settings.
* **Windows Recovery Environment is not available.** In the rare case when you need to recover your Windows To Go drive, you should re-image it with a fresh image of Windows.
* **Refreshing or resetting a Windows To Go workspace is not supported.** Resetting to the manufacturer’s defaults for the computer doesn’t apply when running a Windows To Go workspace, so the feature was disabled.
* **Microsoft Store is disabled by default.** For licensing purposes, applications licensed with the Microsoft Store are linked to licensed hardware. As Windows To Go has been developed as an environment for moving between computers, access to the Microsoft store is disabled. You can allow using the store if your Windows To Go workspaces won’t be moving from one computer to another.
How to create a Windows To Go drive
-----------------------------------
To create a Windows To Go drive, open Control Panel and select the corresponding menu, Windows To Go.
You can see that the operating system warns you at once: Windows To Go is best used with USB 3.0 drives. If you use USB 2.0, the performance of this environment may be reduced.
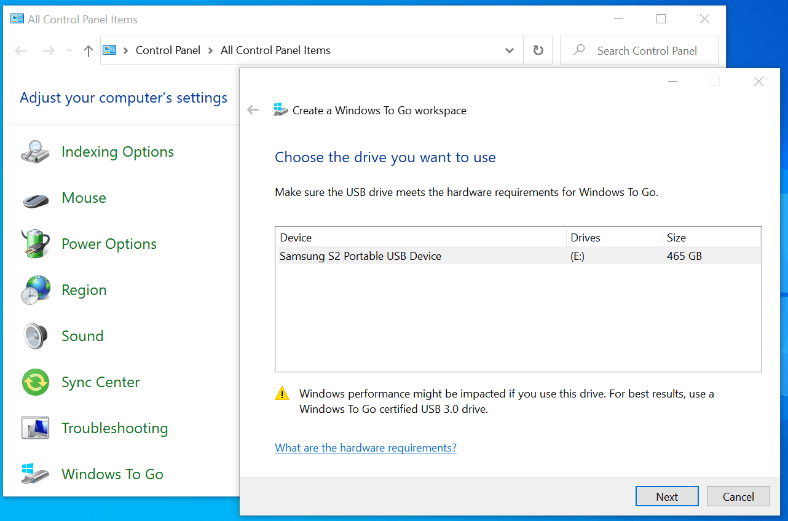
Plug into a USB port an external drive or pen drive of sufficient capacity (the optimal disk space is 32 GB) where you’d like to create a Windows To Go environment, select it and click Next.
After that, you’ll be asked to choose a system image to use in creating the Windows To Go drive. Do it by clicking on the Add search location button and specify the folder containing he system image.
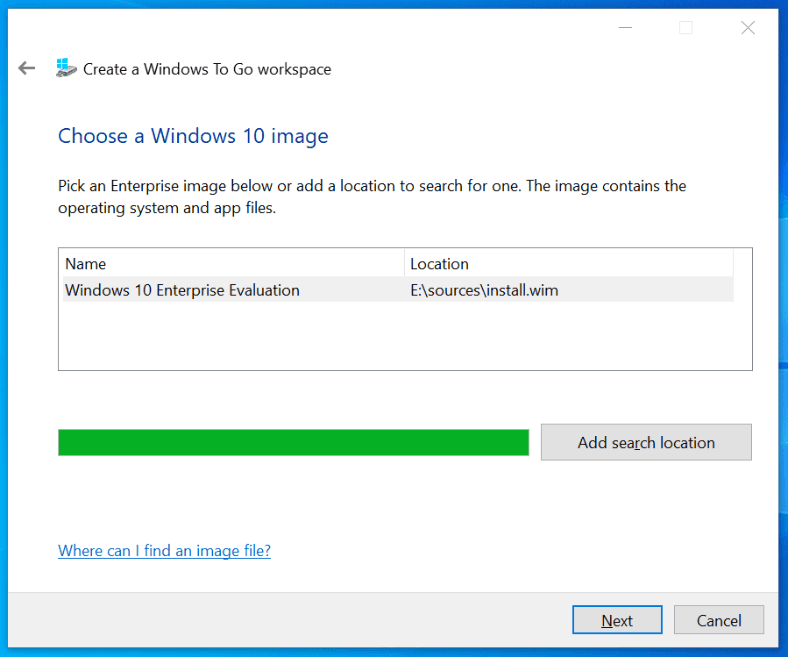
If you wish, your Windows To Go drive can be encrypted with BitLocker immediately.
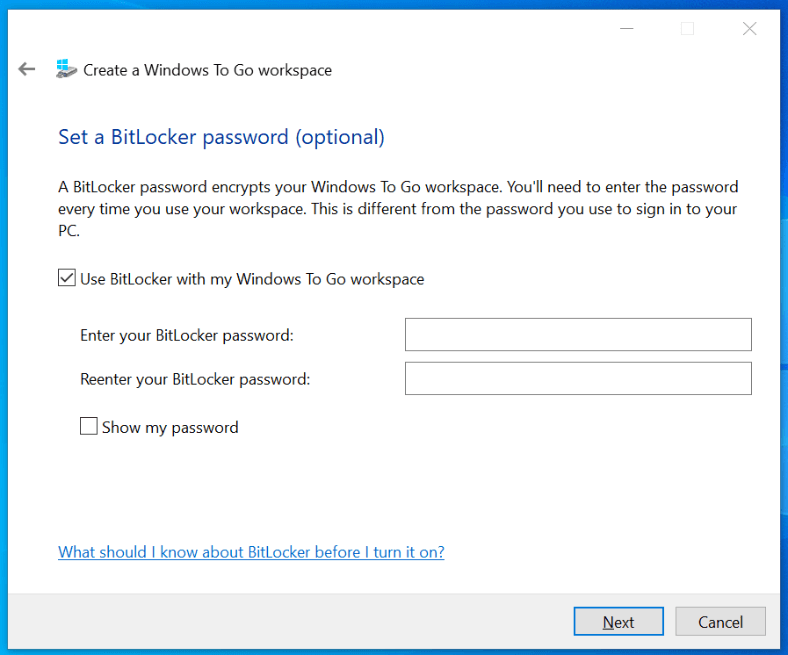
Configure drive encryption or protect access to it with a password and click Next, then confirm your intention to create a Windows To Go workspace. It can take some time.
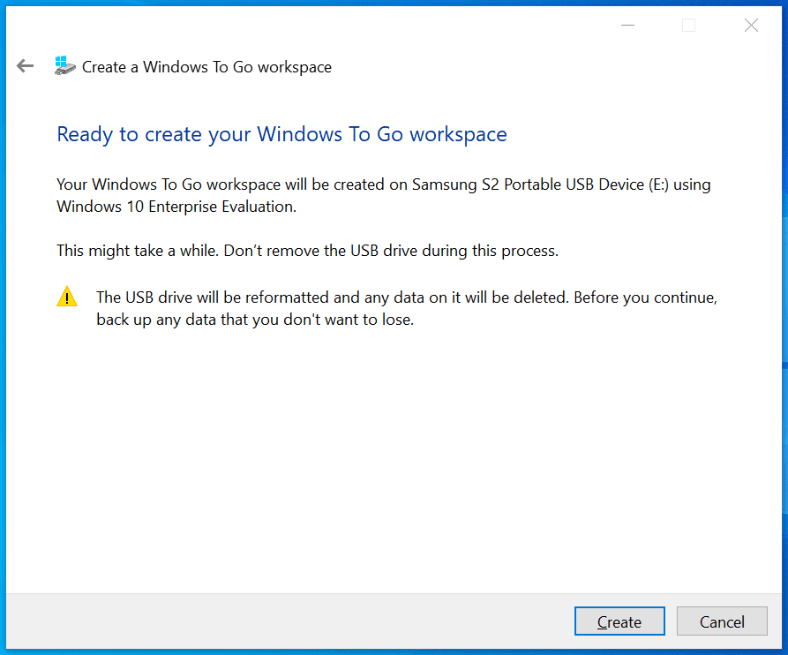
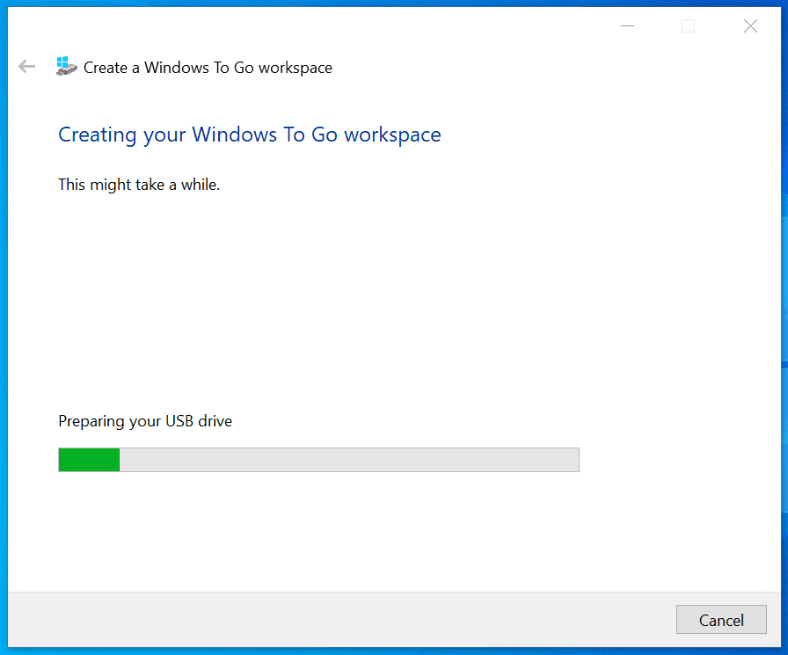
After the Windows To Go drive is ready, the operating system will suggest you to choose how it boots: automatically after you restart the computer, or manually.
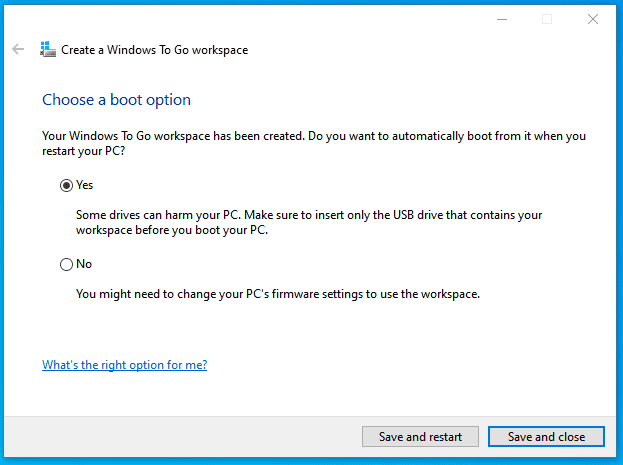
Your Windows To Go drive is ready and you can start using it as a portable workspace for Windows 10.
How to boot a Windows To Go workspace
-------------------------------------
A Windows To Go workspace can be run on any computer. This is a portable version of Windows that you can use anywhere.
To start working with Windows To Go, connect this drive to the computer and boot from it. Starting the workspace will take a bit longer than booting the operating system from the internal hard drive, but in all other aspects it feels just the same.
When you boot Windows To Go for the first time on a certain computer, you will need to configure some things like date and time, time zone, language etc.
Recovering data with a Windows To Go drive
Let us explore a situation when the operating system of the host computer is inoperable for some reason, or it cannot be accessed. As we mentioned before, host computer drives are inaccessible for the user if the computer is booted with a Windows To Go drive. However, the host drives can be accessed with a specialized tool for recovering HDD data – [Hetman Partition Recovery](https://hetmanrecovery.com/hard-drive-data-recovery-software).
Start your Windows To Go workspace and install Hetman Partition Recovery. Start the program, and here is what you see.
Compare the list of available drives displayed in This PC folder of your Windows To Go workspace and the drives accessible for Hetman Partition Recovery.
Windows To Go can only access the external hard drive that the workspace is booted from. It is used as the system drive and the drive to save user data and install programs to. Other disks of this computer are not available. This is not a bug – on the contrary, it’s the way that things are supposed to be.
Now look at Hetman Partition Recovery. The program is able to detect and display all physical and local disks connected to a computer, without any exceptions. If you need to recover data from the main drive of the host computer (in our case, this is a SanDisk 111 GB drive, double-click on it and run a Fast scan.
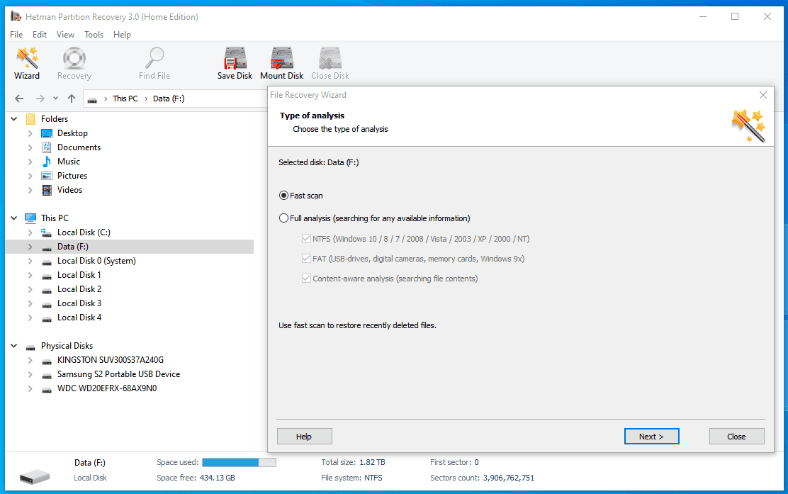
Wait for the process to be over, and the program will show you all files and folders found in the disk, with the directory tree preserved. Select the files you need to restore and drag them to the Recovery List.
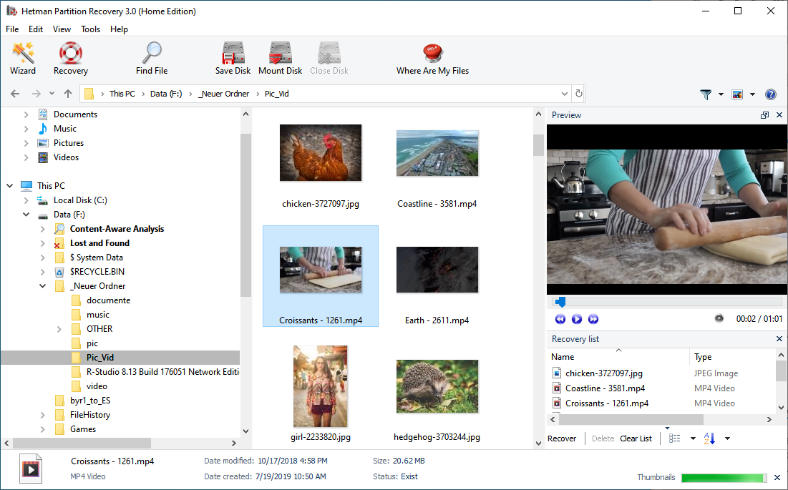
Remember that files located in the desktop of the host computer can be found following this path:
`Disk\Users\Username\Desktop`
The Documents folder of the host computer can be accessed by following the path:
`Disk\Users\Username\Documents`
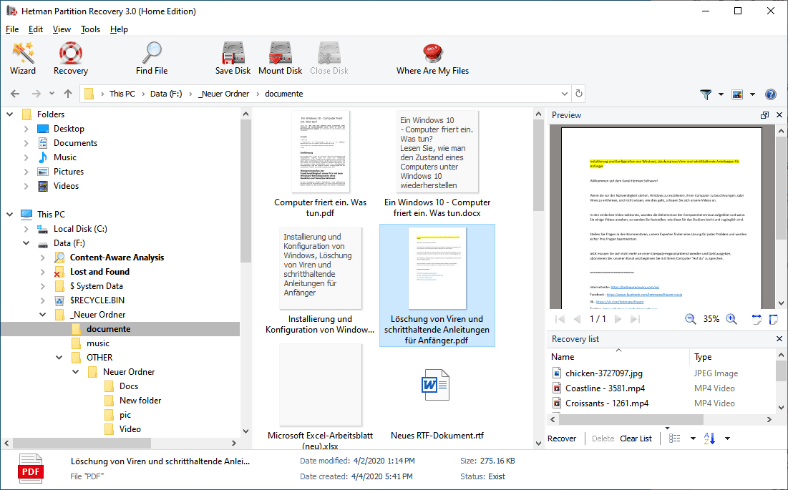
Keep in mind: it’s better to save the recovered files immediately and do it to another external storage device. If you choose to save them to the Windows To Go drive, they will be accessible only when you start the workspace again. If you don’t have another removable disk at hand, save the files to your Windows To Go drive temporarily, and then send them elsewhere at the convenient time.
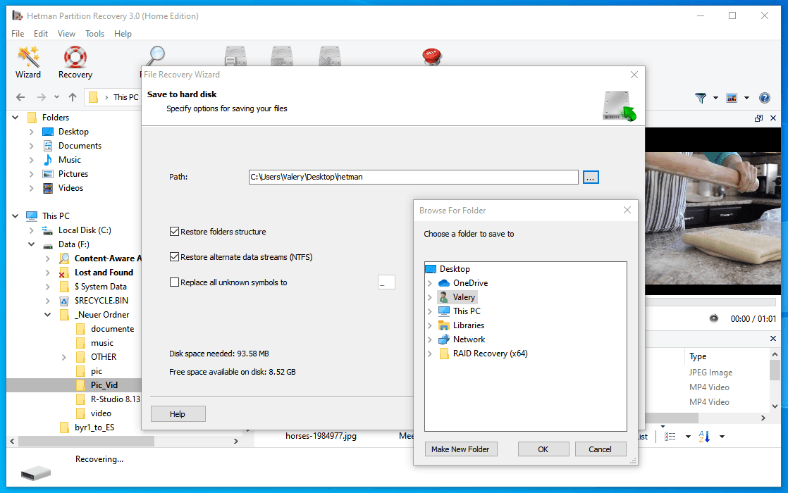
Summary.
Anyone can create a portable Windows To Go drive for personal use; if the computer’s operating system fails, such drive will help you to recover valuable data from your PC. This could be one more option for cases when you may need to recover data from the computer.
See the [full article](https://hetmanrecovery.com/recovery_news/data-recovery-workspace-windows-to-go.htm) with all additional video tutorials. If you still have any questions, please ask in a comments. Also visit our [Youtube channel](https://www.youtube.com/channel/UCu-D9QnPsAPn7AtxL4HXLUg), there are over 400 video tutorials. | https://habr.com/ru/post/553410/ | null | null | 1,444 | 52.19 |
LiveView makes it easy to solve for some of the most common UI challenges with little to no front-end code. It allows us to save JavaScript for the hard stuff––for complex and sophisticated UI changes. In building out a recent admin-facing view that included a table of student cohorts at the Flatiron School, I found myself reaching for LiveView. In just a few lines of backend code, my sortable table was up and running. Keep reading to see how you can leverage LiveView’s
live_link/2 and
handle_params/3 to build out such a feature.
The Feature
Our view presents a table of student cohorts that looks like this:
Users need to be able to sort this table by cohort name, campus, start date or status. We’d also like to ensure that the “sort by” attribute is included in the URL’s query params, so that users can share links to sorted views.
Here’s a look at the behavior we’re going for. Note how the URL changes when we click on a given column heading to sort the table.
Using
live_link/2
LiveView’s
live_link/2 function allows page navigation using the browser’s pushState API. This will ensure that that URL will change to include whatever parameters we include in a given
live_link/2 call.
One important thing to note before we proceed, however. In order to use the live navigation features, our live view needs to be mounted directly in the router, not rendered from a controller action.
Our router mounts the live view like this:
# lib/course_conductor_web/router.ex scope "/", CourseConductorWeb do pipe_through([:browser, :auth]) live "/cohorts", CohortsLive end
And we’re ready to get started!
We’ll start by turning the
"Name" table header into a live link.
# lib/course_conductor_web/templates/cohorts/index.html.leex <table> <th><%= live_link "Name", to: Routes.live_path(@socket, CourseConductorWeb.CohortsLive, %{sort_by: "name"}) %></th> ... </table>
The
live_link/2 function generates a live link for HTML5 pushState based navigation without page reloads.
With the help of the the
Routes.live_path helper, we’re generating the following live link:
"/cohorts?sort_by=name". Since this route belongs to the
CohortsLive live view that we’ve already mounted, and since that live view is defined in our router (as opposed to rendered from a controller action), this means we will invoke our existing live view’s
handle_params/3 function without mounting a new LiveView. Pretty cool!
Let’s take a look at how we can implement a
handle_params/3 function now.
Implementing
handle_params/3
The
handle_params/3 callback is invoked under two circumstances.
- After
mount/2is called (i.e. when the live view first renders)
- When a live navigation event, like a live link click, occurs. This second circumstance only triggers this callback when, as described above, the live view we are linking to is the same live view we are currently on and the LiveView is defined in the router.
handle_params/3 receives three arguments:
- The query parameters
- The requested url
- The socket
We can use
handle_params/3 to update socket state and therefore trigger a server re-render of the template.
Given that
handle_params/3 will be invoked by our live view whenever our
"Name" live link is clicked, we need to implement this function in our live view to match and act on the
sort_by params our live link will send.
Assuming we have the following live view that mounts and renders a list of cohorts:
# lib/course_conductor_web/live/cohorts_live.ex defmodule CourseConductorWeb.CohortsLive do use Phoenix.LiveView def render(assigns) do Phoenix.View.render(CourseConductorWeb.CohortView, "index.html", assigns) end def mount(_, socket) do cohorts = Cohort.all_cohorts() {:ok, assign(socket, cohorts: cohorts)} end end
We’ll implement our
handle_params/3 function like this:
# lib/course_conductor_web/live/cohorts_live.ex def handle_params(%{"sort_by" => sort_by}, _uri, socket) do case sort_by do sort_by when sort_by in ~w(name) -> {:noreply, assign(socket, cohorts: sort_cohorts(socket.assigns.cohorts, sort_by))} _ -> {:noreply, socket} end end def handle_params(_params, _uri, socket) do {:noreply, socket} end def sort_cohorts(cohort, "name") do Enum.sort_by(cohorts, fn cohort -> cohort.name end) end
Note that we’ve included a “catch-all” version of the
handle_params/3 function that will be invoked if someone navigates to
/cohorts and includes query params that do not match the
"sort_by" param that we care about. If our live view receives such a request, it will not update state.
Now, when a user clicks the
"Name" live link, two things will happen:
- The browser’s pushState API will be leveraged to change the URL to
/cohorts?sort_by=name
- Our already-mounted live view’s
handle_params/3function will be invoked with the params
%{"sort_by" => "name"}
Our
handle_params/3 function will then sort the cohorts stored
socket.assigns by cohort name and update the socket state with the sorted list. The template will therefore re-render with the sorted list.
Since
handle_params/3 is also called after
mount/2, we have therefore allowed a user to navigate directly to
/cohorts?sort_by=name via their browser and see the live view render with a table of cohorts already sorted by name. And just like that we’ve enabled users to share links to sorted table views with zero additional lines of code!
More Sorting!
Now that our “sort by name” feature is up and running, let’s add the remaining live links to allow users to sort by the other attributes we listed earlier: campus, start date and status.
First, we’ll make each of these table headers into a live link:
<table> <th><%= live_link "Name", to: Routes.live_path(@socket, CourseConductorWeb.CohortsLive, %{sort_by: "name"}) %></th> <th><%= live_link "Campus", to: Routes.live_path(@socket, CourseConductorWeb.CohortsLive, %{sort_by: "campus"}) %></th> <th><%= live_link "Start Date", to: Routes.live_path(@socket, CourseConductorWeb.CohortsLive, %{sort_by: "start_date"}) %></th> <th><%= live_link "Status", to: Routes.live_path(@socket, CourseConductorWeb.CohortsLive, %{sort_by: "status"}) %></th> </table>
And we’ll build out our
handle_params/3 function to operate on params describing a sort by any of these attributes:
def handle_params(%{"sort_by" => sort_by}, _uri, socket) do case sort_by do sort_by when sort_by in ~w(name course_offering campus start_date end_date lms_cohort_status) -> {:noreply, assign(socket, cohorts: sort_cohorts(socket.assigns.cohorts, sort_by))} _ -> {:noreply, socket} end end
Here, we’ve added a check to see if the
sort_by attribute is included in our list of sortable attributes.
when sort_by in ~w(name course_offering campus start_date end_date lms_cohort_status)
If so, we will proceed to sort cohorts. If not, i.e. if a user pointed their browser to
/cohorts?sort_by=not_a_thing_we_support, then we will ignore the
sort_by value and refrain from updating socket state.
Next up, we’ll add the necessary version for the
sort_cohorts/2 function that will pattern match against our new “sort by” options:
def sort_cohorts(cohorts, "campus") do Enum.sort_by(cohorts, fn cohort -> cohort.campus.name end) end def sort_cohorts(cohorts, "start_date") do Enum.sort_by( cohorts, fn cohort -> {cohort.start_date.year, cohort.start_date.month, cohort.start_date.day} end, &>=/2 ) end def sort_cohorts(cohorts, "status") do Enum.sort_by(cohorts, fn cohort -> cohort.status end) end
And that’s it!
Conclusion
Once again LiveView has made it easy to build seamless real-time UIs. So, while LiveView doesn’t mean you’ll never have to write JavaScript again, it does mean that we don’t need to leverage JavaScript for common, everyday challenges like sorting data in a UI. Instead of writing complex vanilla JS, or reaching for a powerful front-end framework, we were able to create a sophisticated real-time UI with mostly back-end code, and back it all with the power of fault-tolerant Elixir processes.
Caught a mistake or want to contribute to the article? Edit this page on GitHub! | https://elixirschool.com/blog/sorting-a-table-with-live-view-live-links/ | CC-MAIN-2021-25 | refinedweb | 1,282 | 55.13 |
Experts Exchange connects you with the people and services you need so you can get back to work. your file is fixed length line file, then it is
Using fseek ( fp, 0, END) go to the end of file,
Then as you know the no of bytes in each line [being a fixed length line file],
again use fseek with a negative value of the size of the line.
HTH
Amit
Most of the time you won't know the length of the last line. In that case you'll have to find it "the hard way" and then delete it by moving EOF with the truncate() function.
There are several ways to do this. For short files, it's probably easiest to just read through the file, keeping track of the number of bytes read. But this is not very efficient and will cause quite a delay on large files. Here's (untested) code to do what you want.
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#define BUFFERL 512 /* Disk I/O is usually in 512 word blocks, so reading 512 words at a time is pretty efficient */
int FileHandle;
main (int argc, char **argv)
{
int Buffer[BUFFERL];
struct stat StatBuff;
long FileLength;
long DropCount; /* Not really used, but you might want to print it to stderr for debuggin */
long FilePosition;
int BlockLength;
int idx;
FileHandle = open (argv[1], O_RDWR); /* Sanity check needed that argv[1] actually exists and could be opened in this mode */
stat (argv[1], &StatBuff); /* If open() is successful, this should be, too */
FileLength = StatBuff.st_size;
BlockLength = (StatBuff & 0x7F); /* byte count in last 512 word block */
if (BlockLength == 0)
BlockLength = BUFFREL
DropCount = 0;
while (FilePosition > 0)
{
FilePosition = FileLength - BlockLength;
Read (FileHandle, Buffer, BlockLength);
for (idx = BlockLength-1; idx >= 0; idx--)
if (Buffer[idx] == '\n' || Buffer[idx] == '\r') /* found a carriage return or a line feed */
{
truncate (FileHandle, FilePosition + idx);
exit ();
}
DropCount += BlockLength;
BlockLength = BUFFERL;
}
/* no end of line found */
}
Kent
If managing Active Directory using Windows Powershell® is making you feel like you stepped back in time, you are not alone. For nearly 20 years, AD admins around the world have used one tool for day-to-day AD management: Hyena. Discover why.
I tried this and it does not work
#include <stdio.h>
#include <string.h>
typedef struct CMD_INFO{
char cmd[51];
double startTime;
double endTime;
int pid;
} CMD_INFO;
void read_stat();
void delete_last_stat();
int main() {
delete_last_stat();
read_stat();
return 1;
}
// read statistics from file
void read_stat() {
CMD_INFO cmdInfo;
FILE *fp;
int i=0;
fp = fopen(".stats.log", "r+");
fseek(fp, 0, SEEK_SET);
fread(&cmdInfo, sizeof(cmdInfo), 1, fp);
while ( !feof(fp) ) {
printf("Record %d\n", ++i);
printf("cmd = %s\n", cmdInfo.cmd);
printf("startTime = %f\n", cmdInfo.startTime);
printf("endTime = %f\n", cmdInfo.endTime);
printf("pid = %d\n\n", cmdInfo.pid);
fread(&cmdInfo, sizeof(cmdInfo), 1, fp);
}
fclose(fp);
}
// Write statistics to file
void delete_last_stat() {
CMD_INFO cmdInfo;
FILE *fp;
fp = fopen(".stats.log", "a+");
fseek(fp, 0, SEEK_END);
fseek(fp, (sizeof(cmdInfo))*-1, SEEK_CUR);
fclose(fp);
}
.stats.log exists and has got contents. Content does not change after I use fseek. My understanding of fseek is to move the file pointer right?
I mis-read your question. I thought u wanted to read the last line efficiently.
Sorry for that
Yes, fseek is only for moving the file pointer
But Yes, we can continue our apporach
Just use fteel to get the size of File - Last line
and then use truncate
Here's the code for that
fseek ( fp, (sizeof(cmdInfo))*-1, SEEK_END ) ;
newsize = ftell ( fp ) ;
truncate ( fp, newsize ) ;
Just have a look at help for truncate
HTH
Amit
newsize =
at this time i have already solved my problem using google :)
I am using ftruncate(); | https://www.experts-exchange.com/questions/20790045/File-Manipulation.html | CC-MAIN-2018-13 | refinedweb | 630 | 69.82 |
All functions and data in Houdini is represented as nodes. In Houdini Engine, nodes are identified via the HAPI_NodeId. Most things that you can do in Houdini with nodes, you can also do with HAPI. For example, setting parameters on a node. See Parameters.
Given a HAPI_NodeId you can fill a HAPI_NodeInfo struct with a call to HAPI_GetNodeInfo(). You can also get specialized node infos for specific types:
You can promote a node network (any node in Houdini that can have nodes inside it) as an editable node network by adding its relative path to the Editable Nodes field of your asset's Operator Type Properties, under the Node tab.
You can then query the list of editable node networks using HAPI_ComposeChildNodeList(), using HAPI_NODEFLAGS_EDITABLE and HAPI_NODEFLAGS_NETWORK.
Once you have the HAPI_NodeId of a node you know is a node network, like one returned from HAPI_ComposeChildNodeList(), you can start creating, deleting, and connecting nodes inside it.
First, you will probably want to see what is already inside a node network with HAPI_ComposeChildNodeList() with the
recursive argument set to
false. The number of children in a node network is returned in the
child_count argument. You can then get the HAPI_NodeId array with HAPI_GetComposedChildNodeList().
You can create nodes with HAPI_CreateNode(). The
operator_name parameter should include only the namespace, name, and version. For example, if you have an Object type asset, in the "hapi" namespace, of version 2.0, named "foo", the operator_name here will be: "hapi::foo::2.0". Normally, if you don't have a namespace or version, just pass "foo".
Here's an example of creating a Box SOP node in an exposed OBJ node network:
You can delete nodes with HAPI_DeleteNode(). Note that you can only delete nodes that you created with HAPI_CreateNode() or that were created via an internal script in the asset (like Python). More specifically, you can only delete nodes that have their HAPI_NodeInfo::createdPostAssetLoad set to true.
Here's an example of deleting nodes:
You can also connect nodes with HAPI_ConnectNodeInput(), disconnect them with HAPI_DisconnectNodeInput(), and query existing connections with HAPI_QueryNodeInput(). HAPI_QueryNodeInput() will return -1 as the node id of the connected node if nothing is connected.
If any of these node changes have an affect on an HAPI-exposed part of the asset, like the Material or Geo, you need to call HAPI_CookNode() for the changes to be incorporated.
Here's an example of connecting two nodes and then disconnecting them - querying the connection at each step: | http://www.sidefx.com/docs/hengine3.0/_h_a_p_i__nodes.html | CC-MAIN-2018-51 | refinedweb | 412 | 62.27 |
The Trident Stream class provides a number of methods that modify the content of a
stream. The
Stream.each() method is overloaded to allow the application
of two types of operations: filters and functions.
For a complete list of methods in the Stream class, see the Trident JavaDoc.; } }
Trident functions are similar to Storm bolts, in that they consume individual
tuples and optionally emit new tuples. An important difference is that tuples
emitted by Trident functions are additive. Fields emitted by Trident functions
are added to the tuple and existing fields are retained. The
Split
function in the word count example illustrates a function that emits additional
tuples:
public class Split extends BaseFunction { public void execute(TridentTuple tuple, TridentCollector collector) { String sentence = tuple.getString(0); for (String word : sentence.split(" ")) { collector.emit(new Values(word)); } } }
Note that the
Split function always processes the first (index 0)
field in the tuple. It guarantees this because of the way that the function was
applied using the
Stream.each() method:
stream.each(new Fields("sentence"), new Split(), new Fields("word"))
The first argument to the
each() method can be thought of as a
field selector. Specifying “sentence” tells Trident to select only that field
for processing, thus guaranteeing that the “sentence” field will be at index 0
in the tuple.
Similarly, the third argument names the fields emitted by the function. This behavior allows both filters and functions to be implemented in a more generic way, without depending on specific field naming conventions. | https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.1/bk_storm-component-guide/content/storm-trident-operations.html | CC-MAIN-2017-47 | refinedweb | 250 | 55.44 |
Execute a file
#include <unistd.h> int execve( const char * path, char * const argv[], char * const envp[] );
This function is declared in <process.h>, which <unistd.h> includes.
libc
Use the -l c option to qcc to link against this library. This library is usually included automatically.
The execve() function replaces the current process image with a new process image specified by path. also inherits at least the following attributes from the calling process image:* failed but was able to locate the process image file, whether the st_atime field is marked for update is undefined. On success, the process image file is considered to be opened with open(). The corresponding close() is considered to occur at a time after this open, but before process termination or successful completion of a subsequent call to one of the exec* functions.
When execve() is successful, it doesn't return; otherwise, it returns -1 and sets errno.
POSIX 1003.1
abort(), atexit(), errno, execl(), execle(), execlp(), execlpe(), execv(), execvp(), execvpe(), _exit(), exit(), getenv(), main(), putenv(), spawn(), spawnl(), spawnle(), spawnlp(), spawnlpe(), spawnp(), spawnv(), spawnve(), spawnvp(), spawnvpe(), system()
Processes and Threads chapter of Getting Started with QNX Neutrino | http://www.qnx.com/developers/docs/6.5.0SP1.update/com.qnx.doc.neutrino_lib_ref/e/execve.html | CC-MAIN-2022-27 | refinedweb | 192 | 54.22 |
[
]
Navis commented on HIVE-4737:
-----------------------------
If it would be exposed to client, how about make a interface?
> Allow access to MapredContext
> -----------------------------
>
> Key: HIVE-4737
> URL:
> Project: Hive
> Issue Type: Improvement
> Affects Versions: 0.11.0
> Reporter: Nicolas Lalevée
>
> In order to tackle HIVE-1016, I have been pointed to HIVE-3628. But MapredContext.get()
is package protected.
> Here is my current work around, a hack which I put in my code:
> {code:java}
> package org.apache.hadoop.hive.ql.exec;
> public class MapredContextAccessor {
> public static MapredContext get() {
> return MapredContext.get();
> }
> }
> {code}
--
This message is automatically generated by JIRA.
If you think it was sent incorrectly, please contact your JIRA administrators
For more information on JIRA, see: | http://mail-archives.apache.org/mod_mbox/hive-dev/201306.mbox/%3CJIRA.12652909.1371226267542.121311.1371354081165@arcas%3E | CC-MAIN-2018-05 | refinedweb | 116 | 50.02 |
We've been using Magento at work lately, for clients. Its hard sometimes because the clients complain about stuff like "not being able to print shipping labels". Has anyone used magento and if so do you like it?Read more
Hi all I have a script need to snip in to the custom.phtml How do I snip it in correctly? such as I have to remove html and body tags. How about the include jquery thing? <script src="//ajax.googleapis.com/ajax/libs/jquery/2.1.0/jquery.min.js"></script> I need to remove it as well right or have some other replacement? <html> <body> <script src="//ajax.googleapis.com/ajax/libs/jquery/2.1.0/jquery.min.js"></script>Read more
Hello i want to do if there is simple product is added in cart then when customer is try to add configurable product then they should get message "you can’t add configurable product with simple product please remove simple product from cart and then add the configurable product" i want this functionality how can iRead more
I’m learning Magento 2 and can see that Magento has two index.php files. One is in the root folder and another one is in Pub folder. While reading many of the posts regarding webroot of Magento, I can see that we have to set the webroot to Pub folder for security. Currently, I have installedRead more
I’m kinda stuck with a Magento project. My client has products with each product having multiple images. I want to show a random product image from each product in the shop on the homepage. I already got random products showing on the homepage but I need to know how to fetch a different product imageRead more
I’m trying to set up cross device tracking in Google Analytics and was wondering what the best user ID to use to track the most users? Here’s what I have: Email subscribers IDs Customer IDs I don’t see any ID for just those who purchase without starting an account. It seems the one thing thatRead more
I have created crontab.xml in vendor/module/etc directory <config xmlns:xsi=”” xsi:noNamespaceSchemaLocation=”urn:magento:module:Magento_Cron:etc/crontab.xsd”> <group id=”default”> <job name=”get_carriers” instance=”Vendor\Module\Cron\GetCarriers” method=”execute”> <schedule>* * * * *</schedule> </job> </group> And create GetCarriers.php in Vendor/Module/Cron/GetCarriers.php namespace Vendor\Module\Cron; class GetCarriers { protected $ _logger; public function __construct(\Psr\Log\LoggerInterface $ logger) { $ this->_logger = $ logger; } public function execute() { $ writer =Read more
In Magento Message Collection /vendor/magento/framework/Message/Collection.php. There are two method to get and delete message by Identifier, getMessageByIdentifier and deleteMessageByIdentifier. But I didn’t get any way to set message with identifier, Does anyone knows how to set identifier?Read more | https://extraproxies.com/tag/magento/ | CC-MAIN-2021-43 | refinedweb | 473 | 54.63 |
#include "nsIUrlListener.idl" 00040 00041 interface nsIURI; 00042 interface nsIStreamListener; 00043 interface nsIMsgWindow; 00044 00045 [ref] native nsFileSpec(nsFileSpec); 00046 00047 %{C++ 00048 #include "nsFileSpec.h" 00049 %} 00050 00051 [scriptable, uuid(EEF82460-CB69-11d2-8065-006008128C4E)] 00052 interface nsIMailboxService : nsISupports { 00053 00054 /* 00055 * All of these functions build mailbox urls and run them. If you want a 00056 * handle on the running task, pass in a valid nsIURI ptr. You can later 00057 * interrupt this action by asking the netlib service manager to interrupt 00058 * the url you are given back. Remember to release aURL when you are done 00059 * with it. Pass nsnull in for aURL if you don't care about the returned URL. 00060 */ 00061 00062 /* 00063 * Pass in a file path for the mailbox you wish to parse. You also need to 00064 * pass in a mailbox parser (the consumer). The url listener can be null 00065 * if you have no interest in tracking the url. 00066 */ 00067 [noscript] nsIURI ParseMailbox(in nsIMsgWindow aMsgWindow, in nsFileSpec aMailboxPath, 00068 in nsIStreamListener aMailboxParser, 00069 in nsIUrlListener aUrlListener); 00070 00071 }; | https://sourcecodebrowser.com/lightning-sunbird/0.9plus-pnobinonly/ns_i_mailbox_service_8idl_source.html | CC-MAIN-2017-51 | refinedweb | 181 | 54.12 |
Scripting electronic components with Raspberry Pi Pico and MicroPython
Raspberry Pi Pico is a board from the Raspberry Pi foundation. It's based on RP2040 microcontroller that provides 26 GPIO allowing us to control various electronic components at low cost and very low power consumption. Lets go over some of such components.
Raspberry Pi Pico
Getting started
In this tutorial I will be scripting electronics connected to the Pi Pico with MicroPython. Visit official getting started guide for instructions on how to use MicroPython with this board.
Note that Pi Pico does not come with goldpins soldered so you will have to get and solder them yourself or look for other board with RP2040 chip that is ready to use.
MicroPython shell - REPL
Quick and easy way to interact with MicroPython is to use REPL (Read Evaluate Print Loop) - a shell where you can write MicroPython code and watch it being executed. It's not best for writing larger or permanent chunks of code but it's handy to get started.
Establishing serial connection with REPL on Linux, macOS, Windows and Android
To use REPL we have to connect to the device via a serial connection. This can be done by hand from a shell/terminal or via Thonny editor. Windows, macOS and Linux users should just use Thonny as it's the easiest way.
Connect the board to a PC and then establish the connection. For Linux we can use:
By default the board should appear as /dev/ttyACM0 device but if you have other serial devices connected it may be a different number. You can check dmesg logs after connecting the board to see what label it got from the
dmesg command logs:
Dmesg log after connecting Pi Pico running MicroPython
On macOS it will have a different label but you should be able to find the label like so:
And then connect
To close screen connection (detach) press CTRL + A and then CTRL + D.
On Windows you can list connected serial devices by executing in cmd.exe (windows terminal):
Then you can try using third party app PuTTy to connect to Pi Pico.
Android options are limited - some devices will ship with Android build that has serial drivers and gives you enough permissions to use a serial connections. On top of that you need USB-OTG or Host USB port (common but not guaranteed on every device). You can try applications like Serial USB Terminal to see if you device supports this feature.
ChromeOS does allow installing Debian packages as well as using Python (Thonny can be installed as Python package) but at the time of writing this article Pi Pico isn't yet whitelisted for USB pass-through.
Using Thonny
Thonny is a Python IDE (code editor) that supports MicroPython and REPL. It's available for Linux, macOS and Windows and takes all of the serial connection hassle unnecessary. If you can use Thonny for all of your MicroPython programming.
Run the app, then from top menu select Tools -> Options -> Interpreter. Select MicroPython for Pi Pico, then serial port the board uses and we should be good to go:
Selecting Pi Pico in Thonny
Thonny offers REPL access while main area can be used to write scripts that either can be executed or saved and sent to the board. When you power the board MicroPython will boot and will start looking for a file called main.py and if it finds it it will execute it - this is a way to keep the board programmed after disconnecting it from PC and using it stand-alone.
REPL in Thonny
Working with REPL
If you established the connection try writing help() in the shell window. You should see a response like this:: CTRL-C -- interrupt a running program CTRL-D -- on a blank line, do a soft reset of the board CTRL-E -- on a blank line, enter paste mode For further help on a specific object, type help(obj) For a list of available modules, type help('modules')
To blink an on-board LED you can write such simple code:
from machine import Pin led = Pin(25,Pin.OUT) led.high()
This is an example of MicroPython code. It has it own custom modules like
machine. We import Pin class that handles simple GPIO pin actions. We set it to output and then put it on
high state - send current through it which causes a LED to light up. Similarly using .low() would turn it off.
You can script connected electronics from REPL which is a quick and easy solution. For more complicated or permanent code write scripts saved as files that then MicroPython can execute when the boards boot.
Scripting Pi Pico
If you want to execute a MicroPython script as you write it you can use Thonny. If you want to save your script on the board and make it run when the board is powered (while not connected to a PC) you can save it as a
main.py file.
Digital input/output
Simple digital input/output allows us to turn LEDs on, trigger switches or check if a button is pressed. We can start with the on-board LED that is assigned to pin 25:
import time from machine import Pin led = Pin(25,Pin.OUT) for _ in range(10): led.high() time.sleep(1) led.low() time.sleep(1)
This script will blink the green LED on the board 10 times - we have a loop that:
- Sets the pin high (lights up a LED)
- Waits one second
- Sets the pin low (turns off the LED)
- Waits one second
- And repeat
While working with Pi Pico you will check which pins offer features you need and what's their in-code labels and then you will use a matching MicroPython class that handles simple input/output or something more complex like SPI, I2C or UART. The bord layout is as follows:
Pi Pico board layout
So for example GP0 can be a output pin. We can recreat the LED setup with this pin connecting an LED to it and one of ground pins (GND):
Blink a LED circuit
Here I also used a small resistor to limit the current as it's bit to high for LEDs (although if you don't have one you can still do this, just for a short moment).
As we used Pin GP0 we use that label in our code:
from machine import Pin led = Pin(0,Pin.OUT) led.high()
We can use output pins to control stepper motors that are used in high precision machines like 3D printers or focusers - they can move to specific positions repeatably and with high accuracy. Each position is a step thus the name.
For this example I used a low power 28BYJ-48 motor with ULN2003 control board - such kits are sold by various electronics shops. It's rated for 5V power and I/O but 3.3V Raspberry Pi Pico can handle it just fine. Note that more common motors found in devices will use much more power, often requiring 12V and those would require external power source to work when controlled by Pi Pico.
ULN2003 requires four output pins for controlling the motor. Power is provided by a pair of separate pins (USB 5V while for a short example even Pi Pico 3.3V will do):
Stepper motor connected to Pi Pico
In the ULN2003 documentation we can find that to move the motor forward we have to put specific pins high for a moment: pin 1, then 1 and 2, then 2, then 2 and 3 and so on. In MicroPython it can be done like so:
First let start by configuring GP0, GP1, GP2 and GP3 pins for output:
import time from machine import Pin pin1 = Pin(0,Pin.OUT) pin2 = Pin(1,Pin.OUT) pin3 = Pin(2,Pin.OUT) pin4 = Pin(3,Pin.OUT) pins = [ pin1, pin2, pin3, pin4, ]
Now let write those steps as lists of pins that must be high to move:
steps = [ [pin1], [pin1, pin2], [pin2], [pin2, pin3], [pin3], [pin3, pin4], [pin4], [pin4, pin1], ] current_step = 0
Based on which step we are in we can select which pins must be set high. After reaching the last element the sequence starts from the beginning:
while True: high_pins = steps[current_step] set_pins_low(pins) set_pins_high(high_pins) current_step += 1 if current_step == len(steps): current_step = 0 time.sleep(0.001)
Here we have an infinite loop that for current step sets all pins to low, then sets selected pins to high, increments step number and waits 0,001 of a second. The full code looks like so:
import time from machine import Pin pin1 = Pin(0,Pin.OUT) pin2 = Pin(1,Pin.OUT) pin3 = Pin(2,Pin.OUT) pin4 = Pin(3,Pin.OUT) pins = [ pin1, pin2, pin3, pin4, ] steps = [ [pin1], [pin1, pin2], [pin2], [pin2, pin3], [pin3], [pin3, pin4], [pin4], [pin4, pin1], ] current_step = 0 def set_pins_low(pins): [pin.low() for pin in pins] def set_pins_high(pins): [pin.high() for pin in pins] while True: high_pins = steps[current_step] set_pins_low(pins) set_pins_high(high_pins) current_step += 1 if current_step == len(steps): current_step = 0 time.sleep(0.001)
If you reverse the sequence order the motor will move in the opposite direction.
Stepper motor control
Digital input can be used to check for yes/no states - like if button is pressed or not:
import time from machine import Pin state = Pin(0,Pin.IN) led = Pin(25,Pin.OUT) while True: if state.value(): led.high() else: led.low() time.sleep(0.1)
Digital input returns 1 if current is flowing through it and 0 if not. We can connect 3.3V pin with GP0 via a button or other similar component. If the button is pressed and the circuit is closed the on-board LED should light up.
Button and digital input
Digital input proximity sensor
The E18-D50NK proximity sensor is quite simple - it has an infrared LED and a photodiode. The LED is constantly on and when you get close enough to an obstacle enough light will be bounced back onto the photodiode to close the circuit and return 1 on the pin. This isn't that precise (depends on surface and ambient light) but it's a good example of GPIO input usage.
XD-YK04 remote toggle
XD-YK04 remote toggle is one of cheap Chinese remote control switches. After pressing a button on the remote a digital pin on the receiver board will be set to low for few seconds - which Pi Pico GPIO Input can read. This can be used by Pi Pico to trigger some actions. Just note that such simple components may not offer the security and reliability needed when operating actual devices.
MicroPython also supports interrupts allowing you to wait for state change on the input pin without a need for a loop and constant value reading.
Pulse width modulation - PWM
PWM is a way to get an artificial analog output on a digital pin - getting a range of values from one pin and digital 0/1 operations. This can be used to control some electronics like servo motors, H-bridges for DC motors, LED dimming and alike.
MicroPython depending on microcontroller has some helper classes for servo handling but for Pi Pico there is none and using servo is bit tricky:
import machine pin = machine.Pin(0) pwm = machine.PWM(pin) pwm.freq(50) min = 0 max = 9000 for _ in range(10): for duty in range(min, max): pwm.duty_u16(duty) for duty in range(max, min, -1): pwm.duty_u16(duty)
GP0 pin is one of PWM capable so we configure it as such. Servos use 50Hz frequency while duty values will differ between servos (and what angle each value represents). And there are continuous servos as well, which are bit harder to code with this approach (hopefully someone will provide a smart helper library for servos).
Servo motor controlled by Pi Pico
Note that you need external power for the servo as well as you have to connect Pi Pico ground to the power supply ground. Servos use 3-pin connection (PWM, VCC, GND) - PWM goes to the microcontroller while the other two to the servo power supply.
Servo motor control
DC motors often found in various robots and toy vehicles can be controlled by H bridges - chips that take DC motor power and limit how much it gets based on PWM signal from the microcontroller - thus controlling the speed at which a DC motor rotates. You can buy a raw H bridge chip and design a circuit on your own or you can get ready to use boards with such chip - DC motor driver boards. I used Pololu DRV8833 but any such board operates on the same principle:
If you want to control one motor in both directions then you will need 2 PWM pins but for a one-direction example we can use just one:
import time import machine pin = machine.Pin(0) pwm = machine.PWM(pin) pwm.freq(50) duties = [0, 32512, 48768, 65025] for duty in duties: pwm.duty_u16(duty) time.sleep(4) duties.reverse() for duty in duties: pwm.duty_u16(duty) time.sleep(4)
Here we set high duty cycles up to max value to get max speed from the DC motor. This may differ a bit between board and motor.
DC motor controlled by H bridge board and PWM
DC motor control
UART - serial communication
Pi Pico has two UART interfaces. Serial (text) communication is often use to communicate with a more complex circuitry. Some multimeters and other measurement devices offer a serial connection where they send current measurement value. Even bigger devices like a PC (Raspberry Pi board) can use UART for debugging or simple communication.
MicroPython supports UART communication with an simple API:
uart = machine.UART(0, baudrate=9600) # uart.write() # uart.read()
Where
0 is the UART interface number you want to use (Pi Pico has 0 and 1). Baudrate can differ depending on which device you connect to.
I've tried to used Hobbytronics LCD to Serial adapter and a LCD screen but sadly on Pi Pico it didn't worked even when working for USB-UART and PySerial code on PC (this could be related to how data is formatted?):
Serial LCD adapter sadly didn't worked with Pi Pico
SPI communication
SPI is a simpler communication protocol yet it supports multiple devices which gets quite pin efficient. MAX7219 8x8 LED driver uses SPI communication and has MicroPython third party libraries, yet with Pi Pico something is not quite right as it doesn't work. I'll try to research SPI and UART problems and update this section when things get resolved.
MAX7219 8x8 LED board
Resources
For MicroPython you can check Pi Pico SDK documentation. Aside of that there likely will be libraries popping up on Github and support on the Pi forums.
CircuitPython
CircuitPython is Adafruit fork of MicroPython. It promises a more consistent API across boards, easier introduction process and much better high level support for scripting various components.
For Pi Pico version of CircuitPython check learn.adafruit.com. | https://rk.edu.pl/en/scripting-electronic-components-raspberry-pi-pico/ | CC-MAIN-2021-21 | refinedweb | 2,523 | 68.6 |
Custom Root Element
I have a page class (PageRadioWide) in which I want to inherit from UiPageFeature but I'm getting the following error:
PageRadioWide.xaml(2,5): error MC3074: The tag 'UiPageFeature' does not exist in XML namespace 'clr-namespace:ACPUi'. Line 2 Position 5.
Can anyone provide some assistance? Thanks in advance.
Here's some additional information:
XAML File:
<MyACPUiNS:UiPageFeature
x:Class="ACPUiTempTestApp.PageRadioWide"
xmlns=""
xmlns:x=""
xmlns:MyACPUiNS="clr-namespace:ACPUi"
xmlns:ACPUiNS="clr-namespace:ACPUi;assembly=ACPUi"
xmlns:
Code-Behind File:
public partial class PageRadioWide : ACPUi.UiPageFeature
Generated g.cs File:
public partial class PageRadioWide : ACPUi.UiPageFeature
ACPUi Namespace:
namespace ACPUi
{
/// <summary>/// Interaction logic for UiPageFeature.xaml /// </summary> public partial class UiPageFeature : System.Windows.Controls.Page
{
Answers
mmm interesting I just ran across this post: "Inheriting from inherited user control"
"..."?"
..so I changed my Custom Page from a WinFx Page file (XAML) to a Class file (no XAML) and it seems to compile now but I guess I can't do any XAML coding in my Custom Page.
All Replies
Add assembly also to this
xmlns:MyACPUiNS="clr-namespace:ACPUi"
- Tuesday, August 15, 2006 3:22 PM
Brownie PointsMVP, Moderator
Replace this
<MyACPUiNS:UiPageFeature
with this
<MyACPUiNS:PageRadioWide
I tried that originally by using: xmlns:ACPUiNS="clr-namespace:ACPUi;assembly=ACPUi"
But I got the following error: PageRadioWide.xaml(2,5): error MC6017: 'ACPUi.UiPageFeature' cannot be the root of a XAML file because it was defined using XAML. Line 2 Position 5.
In another posting I noticed someone said to remove the assembly so I added: xmlns:MyACPUiNS="clr-namespace:ACPUi" for the root element (UiPageFeature) and kept the other namespace for my other user controls (b/c that one requires the assembly). Removing the assembly got rid of the above error but introduced the this one:
PageRadioWide.xaml(2,5): error MC3074: The tag 'UiPageFeature' does not exist in XML namespace 'clr-namespace:ACPUi'. Line 2 Position 5.Is there a way to resolve the first error then, if I add back the assembly?
Thanks!
something like this should work
namespaceLee.Controls {
public partial class CustomPage : System.Windows.Controls.Page
{
...
}}
<qa:CustomPage x:
<Canvas Width="200" Height="200" Background="Yellow"></Canvas>
</qa:CustomPage> public partial class Page3 : Lee.Controls.CustomPage
{public Page3()
{
InitializeComponent();
}
}
Thanks for your reply.
I've double-checked my implementation and it matches your sample above. I also tried a test app with the above code and got the same results:
Page3.xaml(1,16): error MC6017: 'Lee.Controls.CustomPage' cannot be the root of a XAML file because it was defined using XAML. Line 1 Position 16.
I'm using the June CTP. Is anyone aware of any known issues?
Thanks!
- that is strange, I am using june CTP also
- Yep, strange (and frustrating =P). I appreciate your time, though. Thanks.
- do you have any XAML for the customcontrol
- can you post the complete definition of UiPageFeature class
I added controls to my custompage, they seem to work fine
- mmm That's strange. Well I got what I needed for now. I appreciate your time and assistance. | http://social.msdn.microsoft.com/forums/en/wpf/thread/863877a3-8041-48dc-ab7e-eec7c6bcecb1/ | crawl-002 | refinedweb | 518 | 59.8 |
Lambda Expressions in Kotlin
Last modified: November 5, 2018
1. Overview
In this article, we’re going to explore Lambdas in the Kotlin language. Keep in mind that lambdas aren’t unique to Kotlin and have been around for many years in many other languages.
Lambdas Expressions are essentially anonymous functions that we can treat as values – we can, for example, pass them as arguments to methods, return them, or do any other thing we could do with a normal object.
2. Defining a Lambda
As we’ll see, Kotlin Lambdas are very similar to Java Lambdas. You can find out more about how to work with Java Lambdas and some best practices here.
To define a lambda, we need to stick to the syntax:
val lambdaName : Type = { argumentList -> codeBody }
The only part of a lambda which isn’t optional is the codeBody.
The argument list can be skipped when defining at most one argument and the Type can often be inferred by the Kotlin compiler. We don’t always need a variable as well, the lambda can be passed directly as a method argument.
The type of the last command within a lambda block is the returned type.
2.1. Type Inference
Kotlin’s type inference allows the type of a lambda to be evaluated by the compiler.
Writing a lambda that produces the square of a number would be as written as:
val square = { number: Int -> number * number } val nine = square(3)
Kotlin will evaluate the above example to be a function that takes one Int and returns an Int: (Int) -> Int
If we wanted to create a lambda that multiplies its single argument numbers by 100 then returns that value as a String:
val magnitude100String = { input : Int -> val magnitude = input * 100 magnitude.toString() }
Kotlin will understand that this lambda is of type (Int) -> String.
2.2. Type Declaration
Occasionally Kotlin can’t infer our types and we must explicitly declare the type for our lambda; just as we can with any other type.
The pattern is input -> output, however, if the code returns no value we use the type Unit:
val that : Int -> Int = { three -> three }
val more : (String, Int) -> String = { str, int -> str + int }
val noReturn : Int -> Unit = { num -> println(num) }
We can use lambdas as class extensions:
val another : String.(Int) -> String = { this + it }
The pattern we use here is slightly different to the other lambdas we have defined. Our brackets still contain our arguments but before our brackets, we have the type that we’re going to attach this lambda to.
To use this pattern from a String we call the Type.lambdaName(arguments)so to call our ‘another’ example:
fun extendString(arg: String, num: Int) : String { val another : String.(Int) -> String = { this + it } return arg.another(num) }
2.3. Returning from a Lambda
The final expression is the value that will be returned after a lambda is executed:
val calculateGrade = { grade : Int -> when(grade) { in 0..40 -> "Fail" in 41..70 -> "Pass" in 71..100 -> "Distinction" else -> false } }
The final way is to leverage the anonymous function definition – we must define the arguments and return type explicitly and may use the return statement the same as any method:
val calculateGrade = fun(grade: Int): String { if (grade < 0 || grade > 100) { return "Error" } else if (grade < 40) { return "Fail" } else if (grade < 70) { return "Pass" } return "Distinction" }
3. it
A shorthand of a single argument lambda is to use the keyword ‘it’. This value represents any lone that argument we pass to the lambda function.
We’ll perform the same forEach method on the following array of Ints:
val array = arrayOf(1, 2, 3, 4, 5, 6)
We’ll first look at the longhand form of the lambda function, followed by the shorthand form of the same code, where ‘it’ will represent each element in the following array.
Longhand:
array.forEach { item -> println(item * 4) }
Shorthand:
array.forEach { println(it * 4) }
4. Implementing Lambdas
We’ll very briefly cover how to call a lambda that is in scope as well as how to pass a lambda as an argument.
Once a lambda object is in scope, call it as any other in-scope method, using its name followed by brackets and any arguments:
fun invokeLambda(lambda: (Double) -> Boolean) : Boolean { return lambda(4.329) }
If we need to pass a lambda as an argument into a higher-order method, we have five options.
4.1. Lambda Object Variable
Using an existing lambda object as declared in section 2, we pass the object into the method as we’d with any other argument:
@Test fun whenPassingALambdaObject_thenCallTriggerLambda() { val lambda = { arg: Double -> arg == 4.329 } val result = invokeLambda(lambda) assertTrue(result) }
4.2. Lambda Literal
Instead of assigning the lambda to a variable, we can pass the literal directly into the method call:
Test fun whenPassingALambdaLiteral_thenCallTriggerLambda() { val result = invokeLambda({ true }) assertTrue(result) }
4.3. Lambda Literal Outside the Brackets
Another pattern for lambda literals encouraged by JetBrains – is to pass the lambda in as the last argument to a method and place the lambda outside the method call:
@Test fun whenPassingALambdaLiteralOutsideBrackets_thenCallTriggerLambda() { val result = invokeLambda { arg -> arg.isNaN() } assertFalse(result) }
4.4. Method References
Finally, we have the option of using method references. These are references to existing methods.
In our example below, we take Double::isFinite. That function then takes on the same structure as a lambda, however, it’s of type KFunction1<Double, Boolean> as it has one argument, takes in a Double and returns a Boolean:
@Test fun whenPassingAFunctionReference_thenCallTriggerLambda() { val reference = Double::isFinite val result = invokeLambda(reference) assertTrue(result) }
5. Kotlin Lambda in Java
Kotlin uses generated function interfaces to interop with Java. They exist in the Kotlin source code here.
We have a limit on the number of arguments that can be passed in with these generated classes. The current limit is 22; represented by the interface Function22.
The structure of a Function interface’s generics is that the number and represents the number of arguments to the lambda, then that number of classes will be the argument Types in order.
The final generic argument is the return type:
import kotlin.jvm.functions.* public interface Function1<in P1, out R> : Function<R> { public operator fun invoke(p1: P1): R }
When there is no return type defined within the Kotlin code, then the lambda returns a Kotlin Unit. The Java code must import the class from the kotlin package and return with null.
Below is an example of calling a Kotlin Lambda from a project that is part Kotlin and part Java:
import kotlin.Unit; import kotlin.jvm.functions.Function1; ... new Function1<Customer, Unit>() { @Override public Unit invoke(Customer c) { AnalyticsManager.trackFacebookLogin(c.getCreated()); return null; } }
When using Java8, we use a Java lambda instead of a Function anonymous class:
@Test void givenJava8_whenUsingLambda_thenReturnLambdaResult() { assertTrue(LambdaKt.takeLambda(c -> c >= 0)); }
6. Anonymous Inner Classes
Kotlin has two interesting ways of working with Anonymous Inner Classes.
6.1. Object Expression
When calling a Kotlin Inner Anonymous Class or a Java Anonymous Class comprised of multiple methods we must implement an Object Expression.
To demonstrate this, we’ll take a simple interface and a class that takes an implementation of that interface and calls the methods dependent on a Boolean argument:
class Processor { interface ActionCallback { fun success() : String fun failure() : String } fun performEvent(decision: Boolean, callback : ActionCallback) : String { return if(decision) { callback.success() } else { callback.failure() } } }
Now to provide an anonymous inner class, we need to use the “object” syntax:
@Test fun givenMultipleMethods_whenCallingAnonymousFunction_thenTriggerSuccess() { val result = Processor().performEvent(true, object : Processor.ActionCallback { override fun success() = "Success" override fun failure() = "Failure" }) assertEquals("Success", result) }
6.2. Lambda Expression
On the other hand, we may also have the option of using a lambda instead. Using lambdas in lieu of an Anonymous Inner Class has certain conditions:
- The class is an implementation of a Java interface (not a Kotlin one)
- the interface must have max
If both of these conditions are met, we may use a lambda expression instead.
The lambda itself will take as many arguments as the interface’s single method does.
A common example would be using a lambda instead of a standard Java Consumer:
val list = ArrayList<Int>(2) list.stream() .forEach({ i -> println(i) })
7. Conclusion
While syntactically similar, Kotlin and Java lambdas are completely different features. When targeting Java 6, Kotlin must transform its lambdas into a structure that can be utilized within JVM 1.6.
Despite this, the best practices of Java 8 lambdas still apply.
More about lambda best practices here.
Code snippets, as always, can be found over on GitHub. | https://www.baeldung.com/kotlin-lambda-expressions | CC-MAIN-2019-04 | refinedweb | 1,435 | 52.29 |
The Alpha AXP, part 16: What are the dire consequences of having 32-bit values in non-canonical form?
Raymond
On the Alpha AXP, 32-bit values are typically represented in so-called canonical form. But what happens if you use a non-canonical representation?
Well, it depends on what instruction consumes the non-canonical representation.
If the consuming instruction is an explicit 32-bit instruction, such as
ADDL or
STL, then the upper 32 bits are ignored, and the operation proceeds with the lower 32 bits. In that case, the non-canonical representation causes no harm. For example, consider this calculation:
; Calculate Rc = Ra + Rb + 0x1234 (32-bit result) LDA Rc, 0x1234(zero) ; Rc = 0x00000000`00001234 ADDL Rc, Rb, Rc ; Rc = Rb + 0x1234 ADDL Rc, Ra, Rc ; Rc = Ra + Rb + 0x1234
If we are willing to use a non-canonical form temporarily, we could simplify this to
; Calculate Rc = Ra + Rb + 0x1234 (32-bit result) LDA Rc, 0x1234(Rb) ; Rc = Rb + 0x1234 (64-bit intermediate) ADDL Rc, Ra, Rc ; Rc = Ra + Rb + 0x1234 (32-bit result)
The
LDA will put Rc into non-canonical 32-bit form if Rb is in the range
0x7FFFEDCC to
0x7FFFFFFF because the
LDA instruction is 64-bit only, and the result would be in the range
0x00000000`80000000 through
0x00000000`80001233, which are non-canonical. But all is forgiven at the
ADDL instruction, since it considers only the 32-bit portion of the addends (ignoring the non-canonical part) and generates a 32-bit result in canonical form.
On the other hand, if the instruction that consumes the non-canonical 32-bit value is a 64-bit instruction, then the non-canonical value will cause trouble.
Consider this simple function:
void f(int x) { if (x == 0) DoSomething(); }
The Windows ABI for Alpha AXP requires that all 32-bit values be passed and returned in canonical form. You are welcome to use non-canonical values inside your function, but all communication with the outside world must use canonical form for 32-bit values.
This function might assemble to something like this:
BEQ a0, DoSomething ; tail call optimization RET zero, (ra), 1 ; return without doing anything
The first instruction checks whether x is zero. If so, then it jumps directly to the
DoSomething function, leaving the return address unchanged, so that when
DoSomething returns, it returns to the caller of
f. (This is a tail call optimization.)
If the value is not zero, then it returns to the caller.
There is no 32-bit version of the
BEQ instruction; it always tests the full 64 bits.
If the value of x were not canonical, then the branch instruction could suffer false negatives: Even though the lower 32 bits are zero, there may be nonzero bits set in the upper half. That cause the
BEQ to report “sorry, not zero” even though the 32-bit part of a0 was zero.
There are a number of instructions which do not have a 32-bit version and which always operate on the full 64-bit register value. Another example:
void f(int x, int y) { if (x < y) DoSomething(); }
This function might assemble to something like this:
CMPLT a0, a1, t0 ; t0 = 1 if a0 < a1 BNE t0, DoSomething ; tail call optimization RET zero, (ra), 1 ; return without doing anything
In this version, the compiler performs a signed less-than operation and branches based on the result. The
CMPLT instruction always operates on the full 64-bit register value; there is no 32-bit version. Consequently, passing a non-canonical value can result in the debugger reporting strange things like “Well, even though you passed x = 1 and y = 2, the less-than comparison returned false because x was passed in the non-canonical form of
0xFFFFFFFF`00000001.
Using sign-extended values for canonical form for 32-bit values has the nice property that signed and unsigned comparisons of 32-bit values have the same results as signed and unsigned comparisons of their corresponding canonical forms.
If zero-extension had been used for canonical form, then unsigned comparisons would be preserved, but signed comparisons would not agree: The 32-bit signed comparison of
0x00000000 with
0xFFFFFFFF would report that the first value is larger (0 > −1) but the 64-bit signed comparison
0x00000000`00000000 with
0x00000000`FFFFFFFF of the corresponding zero-extended values would report that the second value is larger (0 < 4,294,967,295).
I’m pretty sure this was not a coincidence.
Bonus chatter: Non-canonical values introduce another case where uninitialized variables can result in strange behavior. Consider:
int f() { int v; ... a bunch of code that somehow forgot to set v ... ... but in a complicated way that eluded code flow analysis ... return (v < 0) ? -1 : 0; }
This might get compiled to the following:
; compiler chooses t0 to represent v ... SRA t0, #32, v0 ; v0 = 0xFFFFFFFF`FFFFFFFF if t0 was negative ; v0 = 0x00000000`00000000 if t0 was nonnegative RET zero, (ra), 1 ; return the result
If the code forgets to assign a value to v, then it will have the value left over from whatever code ran earlier. Suppose that leftover value happened to be the non-canonical value
0x12345678`12345678. In that case, the result of the
SRA would be
0x00000000`12345678, and the function
f ends up returning some value that seems to be impossible from reading the code: According to the code, the function always returns either
-1 or
0, yet sometimes we crash because it returned the crazy value
0x12345678! | https://devblogs.microsoft.com/oldnewthing/20170829-00/?p=96897 | CC-MAIN-2019-43 | refinedweb | 921 | 54.36 |
Steps to Deploy your Trading Robot to the Cloud
7 min read
I recently helped a newbie Python Developer host his trading robot on the cloud, which made me realize how daunting this process can be for people just starting with the world of programming. It gets even more confusing because of the wide variety of industry terms floating around, like an AWS EC2 Instance, a DigitalOcean Droplet, AWS Lambda, Azure Server, Alibaba Cloud.
Oh my god, can't they keep things simple? But I guess they probably do this to differentiate their products from each other from a marketing standpoint. Still, every major cloud provider provides more or less similar services. Anyway, getting back to the point, How do you host a Trading Robot to the Cloud?
I will be using a Virtual Server by DigitalOcean to demonstrate this, which they call a Droplet. If you find this reading worthwhile and would like to follow the steps I have mentioned, do signup for DigitalOcean using our affiliate badge below, which will give you $100 worth free credits, and you can launch your own Virtual Machine for free.
We will divide this into a few steps, but before I lay out the steps, I want to tell you that this article is more about how to deploy rather than discussing the specifics of the Trading Bot. I will be using a very simple snippet of code below, which will send me the average price of
RELIANCE for the last 5 minutes on Telegram. This is to show you the overall process; you are, of course, free to upload your complex strategies. To achieve this, here are the steps:
- Building the Trading Robot.
- Building a Telegram Bot.
- Creating a DigitalOcean Droplet.
- Deploying Our Code.
If you prefer watching rather than reading, we have prepared the below Youtube video for you.
Building The Trading Robot.
Installing the Libraries
pip install jugaad_data
pip install telegram_send
We will be using jugaad_data to fetch live prices from NSE Website and use telegram_send to send messages to our Telegram.
from jugaad_data.nse import NSELive import telegram_send as ts import time def get_prices(stockSymbol): '''A function to get live prices using jugaad_data library''' n = NSELive() q = n.stock_quote(stockSymbol) return q['priceInfo']['lastPrice'] def send_telegram_message(message): ts.send(messages = [str(message)]) live_prices = [] count = 0 while True: current_price = get_prices('HDFC') live_prices.append(current_price) count = count + 1 print(f'{count} Minutes Done') if len(live_prices) == 5: avg_price = round((sum(live_prices[-5:])/len(live_prices[-5:])),2) if count == 5: send_telegram_message(f'The Average Price of HDFC For Last 5 Minutes is {avg_price}') #print(f'The Average Price of HDFC For Last 5 Minutes is {avg_price}') count = 0 live_prices.clear() time.sleep(60)
What's Happening in the Above Code?
- We create function
get_pricesto get live prices from NSE and function
send_telegram_messageto send a message. Note:
jugaad_datascrapes the actual NSE website for data and may be illegal; please use it at your own risk. This is just for demonstration purposes only. The
whileloop runs continuously, fetches a price, and sleeps for 60 seconds. - The
current_priceis added to a list
live_prices, as soon as there are additional 5 entries in that list, we calculate the
avg_priceand send it to Telegram.
Building A Telegram Bot.
To send messages via Python to our Telegram App, we need to create a Bot; if you are a Telegram user, you might have already seen such bots. Follow these steps to create a Bot.
- Open Anaconda Prompt and change the directory to where your
.pyfile is; for me, it's in a folder called
cloud_bot. If the below is not visible properly, please zoom in.
- I have redacted by Unique Bot ID for obvious reasons. Enter this Unique ID back into the anaconda terminal.
Great, our Telegram Bot is now ready to use, wasn't that really easy?
Creating a DigitalOcean Droplet
A DigitalOcean Droplet is nothing but a Virtual Machine in the Cloud. There are various advantages to deploy your strategy to Cloud primary one being stability. For example, you have a very risky strategy running on your laptop, and you have many positions open, and suddenly your home Wi-Fi stops working, and your algo stops running. Imagine that nightmare! Better to deploy on the cloud and let DigitalOcean take care of the infrastructure. If you follow me in this article, I would really appreciate it if you could sign up using my affiliate badge below.
- Once you are logged in, create a new Droplet.
- Select Your Machine Configuration and other Resources. If you plan to deploy your trading robot in India, I recommend selecting the Bangalore Data Centre. DigitalOcean does not offer Windows VMs, and just so you know, Windows VM is generally costlier than Linux VMs due to Windows License Fee. (Talk about Bill Gates being a philanthropist LOL)
Create an Authentication Method, to keep things simple, select Password and enter a complex password.
Give Your Droplet a HostName and Create It. Great, now you have your own Virtual Machine at zero cost.
- Let's login into our Virtual Machine to see if we can access it. a. Open
cmdon your Windows Machine or the Terminal on Linux.
b. Type in
ssh root@your.ipv4.addresshighlighted in the above image and input the password you entered while creating the droplet.
Awesome, if you see a screen like above, that means you are now logged into your Ubuntu Virtual Machine. How cool, right? Moreover, this droplet comes pre-installed with
Python3. If you got an error in the above step, please let me know in the comments.
Deploying Our Trading Robot
To deploy the robot you created on your personal laptop, you will first have to transfer it to the Droplet and then try and run it. You can do it in various ways, but here is the preferred way.
Transferring the Code to our Droplet
Download FileZilla from this link. This will be used to transfer the file. Once downloaded, please install it.
Go to File --> Site Manager --> New Site --> Select SFTP Protocol --> Enter Host (this is your Droplet ipv4 address) --> Logon Type (Interactive) --> User (root) --> Connect
- You will get a popup saying Unknown host key if you connect this for the first time, ignore that and click OK.
- Enter the Droplet Password and click OK. If everything goes well, you should be connected to the
rootfolder on your Virtual Machine.
- Now, it's just as simple as finding the relevant folder in your local site on the left-hand side of the screen and then dragging it to the remote site.
Awesome, you now have your files on the Virtual Machine. Now it's just a matter of running them from your Terminal.
Running the Code on Droplet
- Go back to your Command Prompt
cmd, log in again into your Droplet if you haven't already and type in
lsinto the terminal; you will see your folder
cloud_botpresent there. Change your directory using
cd cloud_botand then try and run the code
python3 cloud_botv2.py(Substitute it with your file name, please)
- Woah! We got an error; if you look closely, that was pretty much expected. Our code uses external libraries like
jugaad_dataand
telegram_send, which are not present on this machine, so first, we have to install them again. But, to do that, first, we need to install
pip3into this machine as well.
apt install python3-pip
Followed by:
pip3 install jugaad_data telegram_send
- Configure the Telegram Bot on this Droplet Again and finally run the code.
Awesome 🎆, so now you have a code running on your Virtual Machine (Droplet) where there is no dependency on your local system at all. This was a very basic example but you can upload complex options trading strategies or just bots where you want to get notified if certain conditions meet. There are tons of possibilities if you imagine.
Conclusion
I hope this is a very detailed step-by-step guide for you to set up your own Droplet and host your trading robot on it. If you are confused at any time, please feel free to comment below or email me. I am happy to help each one of my readers with their doubts, but my only request is to research your doubts on Google/StackOverflow before reaching out 😃
In the next article, I will cover how to set up a
cron job on your Virtual machine so that a program starts automatically at a given certain time without you having to maintain it. So Stay Tuned.
You can also find the code I uploaded to the Droplet here on Github.! | https://tradewithpython.com/steps-to-deploy-your-trading-robot-to-the-cloud | CC-MAIN-2022-21 | refinedweb | 1,435 | 71.65 |
django-formfield 0.2
django-formfield
Change Log
- 0.1.3
- Fixed bug when a form’s initial value evaludated to False
- pep8 related fixes
Getting Started
django-formfield is a form field that accepts a django form as its first argument, and validates as well as render’s each form field as expected. Yes a form within a form, within a dream? There are two types of fields available, FormField and ModelFormField. For ModelFormField the data is stored in json. For FormField data is simply returned as a python dictionary (form.cleaned_data)
Installation
Installation is easy using pip or easy_install.
pip install django-formfield
or
easy_install django-formfield
Add to installed apps
INSTALLED_APPS = ( ... 'formfield', ... )
Example
from django.db import models from django import forms from formfield import ModelFormField class PersonMetaForm(forms.Form): age = forms.IntegerField() sex = forms.ChoiceField(choices=((1, 'male'), (2, 'female')), required=False) class Person(models.Model): name = CharField(max_length=200) meta_info = ModelFormField(PersonMetaForm)
Which will result in something like this (using the admin)
The ModelFormField is automatically set to null=True, blank=True, this is because validation is done on the inner form. As a result you will see something like the following if we hit save on the change form:
If we supply the change for valid data you should get a python dictionary when retrieving the data:
>>> person = Person.objects.get(pk=1) >>> person.meta_info {u'age': 12, u'sex': u'1'}
The form is the only thing forcing valid input, behind the scenes the data is being serialized into json. Therefore on the python level we can supply meta_info any valid json::
>>> from sample_app.models import Person >>> data = {'some': 'thing', 'is': 'wrong', 'here': 'help!'} >>> p = Person.objects.create(name="Joan", meta_info=data) >>> p.meta_info {'is': 'wrong', 'some': 'thing', 'here': 'help!'}
Note
If the form field is being made available via a change form, such as the admin, any unexpected value will be overridden by what the form returns . For example, the PersonMetaForm above only expects age and sex, so none of the values above (‘is’, ‘some’ and ‘here’) match and will be overridden when the form submitted.
We can however, make the field hidden or readonly and use it to supply any valid json, but its not really the intension of this app.
Form within a form within a form within a form within a form…..
Sure its possible..
- Downloads (All Versions):
- 6 downloads in the last day
- 90 downloads in the last week
- 369 downloads in the last month
- Author: Jose Soares
- Categories
- Package Index Owner: jsoa, coordt
- DOAP record: django-formfield-0.2.xml | https://pypi.python.org/pypi/django-formfield/ | CC-MAIN-2015-27 | refinedweb | 433 | 56.35 |
brewer2mpl 1.4.1
Connect colorbrewer2.org color maps to Python and matplotlib
NOTICE
brewer2mpl is now Palettable! brewer2mpl will no longer be updated, but will stay available here for the foreseeable future.
To launch your browser and see a color map at colorbrewer2.org use the colorbrewer2 method:
bmap.colorbrewer2())
Direct Access
If you know the color map you want there is a shortcut for direct access. You can import the sequential, diverging, or qualitative modules from brewer2mpl. On the module namespace are dictionaries containing BrewerMap objects keyed by number of defined colors.
Say you want the Dark2 qualitative color map with 7 colors. To get it directly you can do:
from brewer2mpl import qualitative bmap = qualitative.Dark2[7]
There is also a special key ‘max’ for each name that points to the color map with the most defined colors:
from brewer2mpl import sequential bmap = sequential.YlGnBu['max']
- Author: Matt Davis
- Categories
- Package Index Owner: jiffyclub
- DOAP record: brewer2mpl-1.4.1.xml | https://pypi.python.org/pypi/brewer2mpl | CC-MAIN-2017-47 | refinedweb | 164 | 50.23 |
Represent a travel containning Point(s) More...
#include <Travel.hpp>
Represent a travel containning Point(s)
Travel class is not only an array containing Point(s) but also a sequence listing of the Point(s).
Definition at line 27 of file Travel.hpp.
Default Constructor.
Definition at line 49 of file Travel.hpp.
Copy Constructor.
Travel is an array of Point(s) as gene(s). The copy constructor of Travel doesn't copy member variables which are related to G.A. because the sequence of gene(Point)s can be shuffled by process of evolution of genetic algorithm.
Definition at line 63 of file Travel.hpp.
Move Constructor.
Definition at line 72 of file Travel.hpp.
Calculate distance to move.
Definition at line 103 of file Travel.hpp.
Compare which object is less.
Compares distances to move. The result is used to optimize and evolve genes by G.A.
Definition at line 124 of file Travel.hpp.
A tag name of children.
< TAG>
<CHILD_TAG />
<CHILD_TAG />
</TAG>
Implements samchon::protocol::EntityGroupBase.
Definition at line 136 of file Travel 141 of file Travel.hpp.
Convert the Travel to String.
Have of form of tab and enter delimeters for Excel.
{$uid1} {$x} {$y}
{$uid2} {$x} {$y}
{$uid3} {$x} {$y}
...
Definition at line 162 of file Travel.hpp.
References samchon::library::StringUtil::numberFormat().
Estimated hours to move.
A variable for avoiding duplicated calculation
Definition at line 40 of file Travel.hpp. | http://samchon.github.io/framework/api/cpp/d4/d7b/classsamchon_1_1examples_1_1tsp_1_1Travel.html | CC-MAIN-2022-27 | refinedweb | 237 | 54.08 |
10 hours ago,Frank Hileman wrote
@kettch: Thanks, but in the mydigitallife forum thread, I could not see any namespace that was definitely for immediate mode rendering.
Indeed, there isn't. The only graphics namespace that's available is Windows.Graphics.Imaging which is a simple wrapper for WIC. Well, there's Windows.UI.DirectUI.Shapes but I suppose you aren't looking for that.
11 minutes ago,evildictaitor wrote
Direct2D apis just call Direct3D using textures on top of XYZ_RHW (post-translation) vertexes, so if you want a fast .NET way to do this your best bet is XNA - in particular the SpriteBatch class which draws 2D textures to the screen.
Umm, there's way more than that going on inside 2D. If you're not familiar with the subject maybe you should not make baseless affirmations such as this one. | https://channel9.msdn.com/Forums/Coffeehouse/New-Direct2D-wrapper-for-next-version-of-net/f3cfc65291c74695a8cf9f110086669a | CC-MAIN-2015-48 | refinedweb | 142 | 66.94 |
Is addeventlistener at DOM level 2 ? what else is in DOM level 2 and what is the different between DOM level 1 and 2 ?
That's a broad question. Maybe a Google search will provide quicker and more detailed answered.
Web Development, Mobile Apps - Hands-on Training Online - Online Marketing
Give me some elements in DOM level 2
DOM means a model of referring and interacting with the HTML (and XML) Elements. Therefor, the DOM levels are versions of an interacting model. not versions of the HTML language. You will not find new elements in DOM 2, but you will find new ways to find, represent and interact with the same HTML elements.
And yes, addEventListener is a method added in DOM 2, along with a specific event model . DOM 2 standardized also the getElementById, getElementsByTagName, getElementsByName. And the keyboard event handling. And many others...
Why do you asked that?
KOR
Windows Forum
Register as or Find a freelancer
Offshore programming
getelementbyid from what i read is in DOM level 1 ?
Originally Posted by stevengoh
getelementbyid from what i read is in DOM level 1 ?
Could be. Who cares, after all? Are you writing the history of DOM, or what?
I am trying to understand fully on javascript so all details I wish I could know.
2 should really be 1 since "0" was 1, but version numbers on web techs are always a mess.
the dom as of 4 years ago is dom2:
most print media refers to this dom, and most of the features are still used today.
dom2 basically solidified the existing Netscape and MS doms. I'd say adding namespace support was the biggest over-all change. i can see it trying to use the same interface for html and xml, and being released ion 2000 hot on the heels of xhtml, you can guess that xmlishness was indeed the main focus. i think normalize(), textContent, replaceChild(), and isSupported() were first codified in 2, if memory serves me correct.
I still people using Node.data to this day; just because something's formalized, doesn't mean it's popular.
dom3 added children, draggable, dataset, classList, querySelectorAll, and a few other nice methods.
we are now on 4 if anyone is still counting.
the recent changes basically tone down Node(), so that attrib nodes and the like are not still referred to by iterating just dumb nodes. also form validation, nextElementSibling, and a few other lazy methods were added. | http://www.webdeveloper.com/forum/showthread.php?260421-DOM-level-2 | CC-MAIN-2014-10 | refinedweb | 412 | 66.23 |
the following sample code is crashing with this error when I close the application:
QBasicTimer::start: QBasicTimer can only be used with threads started with QThread
import sys
from PyQt4 import QtGui ,QtCore
app = QtGui.QApplication(sys.argv)
data=[]
data.append("one")
model=QtGui.QStringListModel(data)
combobox=QtGui.QComboBox()
combobox.show()
combobox.setModel(model)
sys.exit(app.exec_())
The program is not "crashing": it is merely printing an error message during the normal shutdown process.
The reason the message is being shown is a side-effect of garbage-collection. When python shuts down, the order in which objects get deleted can be unpredictable. This may result in objects on the C++ side being deleted in the "wrong" order, and so Qt will sometimes complain when this happens.
One way to "fix" the sample code would be to simply rename some of the PyQt objects. If I change the name
combobox to
combo, for instance, the error message goes away. There's nothing mysterious about this - it just changes the order in which the objects are deleted.
But another, much more robust, way to fix the problem would be to make sure the
QStringListModel has a parent, since it's possible that Qt doesn't take ownership of it when it's passed to the combo-box. Qt should always handle the deletion of child objects correctly when they're linked together in this way. So the code example would become:
import sys from PyQt4 import QtGui, QtCore app = QtGui.QApplication(sys.argv) combobox = QtGui.QComboBox() data = [] data.append("one") model = QtGui.QStringListModel(data, combobox) combobox.setModel(model) combobox.show() sys.exit(app.exec_()) | https://codedump.io/share/cA9Wj5wzzowR/1/error-in-model-view-implemention-of-gui-in-pyqt | CC-MAIN-2018-22 | refinedweb | 273 | 56.66 |
Up, working on my java skills.
The isDelimiter function is suppose to return true if there is a delimiter in the string and false otherwise. The main is suppose to call this function and count the number of words in the string:
Here is what I came up with:
import java.util.*; public class NumberOfWordsInString { public static void main (String[] args){ Scanner in= new Scanner (System.in); String s; int count =0; char ch [] = new char [s.length]; System.out.printf("Enter string\n"); s= in.nextLine(); for (int i = 0; i <s.length(); i++) { ch[i] = s.charAt(i); if (isDelimiter (ch)) { count ++; } } System.out.printf("%d\n", count); } public static boolean isDelimiter (char c){ if (ch!= delimiter) { return false; } else return true; } }
Somehow my method isn't being successfully called by my main and the following error msg was received:
Exception in thread "main" java.lang.Error: Unresolved compilation problems:
length cannot be resolved or is not a field
The method isDelimiter(char) in the type NumberOfWordsInString is not applicable for the arguments (char[])
at javaimprovements.NumberOfWordsInString.main(Number OfWordsInString.java:10)
line 10:
char ch [] = new char [s.length];
and the main doesn't call the isDelimiter function | http://www.javaprogrammingforums.com/whats-wrong-my-code/37162-delimiter-function-number-words-string.html | CC-MAIN-2014-35 | refinedweb | 201 | 58.89 |
Freelance need help wsdl fileJobs
You will
create java soap client for 2 services: 1st. one use client certificate for security 2nd. use IP whitelisting (you need to provide a static ip and I'll whitelist it) and username/password for security WSDL and test environment are already deployed. I can also provide working soapUI projects. project delivery can be: 1. (most preferred) - a grails..
The ( more likely would it be to use Android Studio).
Need to create PHP SOAP server/client with implementented WS-Security.
Hie we need to complete soap response using wsdl xml response. here is documentation link. [log ind for at se URL]
Hi, I noticed your profile and would like to offer yo...
Create C# web service from Java Code implementation Code with WSDL. Create a method as example that gets a port for the web service and calls a specific function on the server. I need it to be done today.
I need to call a webservice (VB.NET ) sending a file base64binary in mtom. THe service provider is in java.
using given wsdl file develop web service in asp.net. user authentication within asp.net code. need single asp.net code which will pass data as mention in [log ind for at se URL] and receive out in MI_HPHInvoice_OutService_test If you have done this work then
I want to send bill...from my project to approved payment (SOAP API) C# desktop application string WSDL_TARGET_NAMESPACE = "[log ind for at se URL]"; string SOAP_ADDRESS = "[log ind for at se [log ind for at se [log ind for at se URL]; - tried to create WSDL file separately. I always have the same error: "The type or namespace name 'WS' does not exist in the namespace 'xxx' (are you missing an assembly reference?)" I a...
.. '[log ind for at se URL]' : failed to load external entity "[log ind for at se[log ind for at se URL] 提供的wsdl地址:地址:[log ind for at se [log ind for at se URL] [log ind for at se :- [log ind for at se URL]@[log ind for at se.
...[log ind for at se URL] I am trying to redirect the url and replace or remove the string “wsdl&” in the url using iis rewrite module: <rule name="replaceWSDL" enabled="true" patternSyntax="ECMAScript" stopProcessing="true"> <match url="^(.*)(wsdl&)(.*)$" /> &...
when i transfer the website i am getting a issue with salesforce API on new server SOAP-ERROR: Parsing WSDL: Couldn't load from '/xxxx/xxxx/public_html/xxxx/xxxx/[log ind for at se URL]' : failed to load external entity "/home/xxxx/xxxx/xxxx/xxxx/[log ind for at se [log ind for at se. | https://www.dk.freelancer.com/job-search/freelance-need-help-wsdl-file/ | CC-MAIN-2018-47 | refinedweb | 443 | 72.26 |
16 May 2008 08:55 [Source: ICIS news]
?xml:namespace>
“So far, we have not been hearing any shipping schedules being affected. As long as the ports are not affected, it will be business as usual,” a broker said.
Demand for chemical tonnage remained lacklustre but is slowly picking up for June nominations.
Another broker said business was so slow that there were not many schedules to cancel even if they were affected.
Freight rates for 3,000 tonne chemical cargoes remained unchanged at $49-51/tonne from
The 7.9-magnitude earthquake hit the country’s southwest
Have you personally or your business been impacted by the earthquake | http://www.icis.com/Articles/2008/05/16/9124313/china-chem-shipping-activity-unaffected-by-quake.html | CC-MAIN-2014-41 | refinedweb | 109 | 65.32 |
30 November 2010 17:35 [Source: ICIS news]
TORONTO (ICIS)--?xml:namespace>
The rate for
Sequentially, Canadian third-quarter economic growth was up 0.3% from the second, following a 0.6% gain in the second quarter from the first, the agency said.
On a monthly basis, however, Canadian GDP growth fell 0.1% in September from August, it said.
The statistics agency attributed the slower third-quarter growth rate to declining exports and slow housing markets.
Analysts said the Canadian growth data was disappointing, especially when compared with the
“Just one percent growth in the third quarter is certainly disappointing,” said Benjamin Reitzes, an economist at Toronto-based BMO Bank.
“
Also, the decline in September in Canada was "certainly not good news for Q4, either", he added.
Statistics
The increase in manufacturing was concentrated in the production of durable goods, while the strength in mining was attributable largely to higher activity at copper, nickel, lead and zinc mines, it said.
Business investment in plant and equipment rose 6.5% in the third quarter from the second. An increase in consumer spending also contributed to the growth in final domestic demand, the agency said.
In the Canadian chemical industry, sales fell 0.1% in September from August, according to the latest data.
Meanwhile, Canadian chemical railcar shipments are up 23.1% year to date to 20 November. | http://www.icis.com/Articles/2010/11/30/9415348/canadas-economic-growth-slows-to-1.0-in-third-quarter.html | CC-MAIN-2014-52 | refinedweb | 227 | 58.69 |
A hyperclick provider that lets you jump to where variables are defined.
This project was created primarily to assist navigating projects that use many small modules. This project solves some of my problems and I share it in the hope that it solves some of yours.
js-hyperclick is a scanner that integrates with hyperclick. It does not have any keyboard shortcuts or commands. It does not have any user interface. All of that is managed by hyperclick.
js-hyperclick uses Babylon (Babel) to parse JavaScript. It scans for all
imports, exports, requires, identifiers (variables), and scopes. Using this
information it can locate the origin of any identifier. It does not and will not
track properties (ex.
identifier.property), see below for more info.
If you have configured your project to avoid
../ in your imports, you can
configure js-hyperclick using
moduleRoots in your
package.json. The
configuration belongs there and not in Atom because it is specific to your
project.
For most use cases, you just need to specify the folders to search.
If you want
import 'foo' to resolve to
src/lib/foo, just drop this in your
package.json.
"moduleRoots": [ "src/lib" ],
If you're using something more advanced like module aliases you can implement
your own custom resolver. Instead of pointing
moduleRoots to a folder, just
point it to a JavaScript file and
js-hyperclick will
require() and use it *.
While
js-hyperclick doesn't use these kinds of features in practice, I have
configured them as an example and to validate functionality.
Custom resolvers run inside Atom and extend the functionality of
js-hyperclick. This means there is some risk that you could checkout a project
that contains a malicious custom resolver. In order to mitigate this risk, when
js-hyperclick encounters a new resolver it will open it and ask if you want to
trust it. Whether you trust or distrust the resolver,
js-hyperclick stores
that hash so you don't get prompted when switching between branches of a
project, or if you have use the exact same resolver code across multiple
projects.
require('./otherfile')open
otherfile.jsinstead of
otherfile.jsx?
There is a setting in
js-hyperclick to add additional extensions. My
configuration is
.js, .jsx, .coffee. This does not cause js-hyperclick to scan
CoffeeScript. This will just locate them if you require the file without the
extension.
this.doSomething()?
No, There is no way to know for sure what
this is or what properties it might
have. Instead of trying to pick some set of patterns to support and get partly
right, I'm just not going to support that at all.
If you want this you might look into, or if you'll switch to writing Flow instead of standard JavaScript Nuclide has jump to definition support
I just don't see a future in AMD, so I won't invest time in supporting it. I used RequireJS for years
Good catch. Let us know what about this package looks wrong to you, and we'll investigate right away. | https://github-atom-io-herokuapp-com.global.ssl.fastly.net/packages/js-hyperclick | CC-MAIN-2021-21 | refinedweb | 510 | 65.62 |
:Simple Helloworld.
In this (archived) article we will learn how to start Qt programing using Qt in Carbide.c++. We will create a simple Hello World program which can be written in Qt.
Note: This article is based on Carbide C++ and Qt SDK for Symbian (which may be deprecated later), if you would like to use Qt Creator with new Nokia Qt SDK then please don't follow this article. It is better to use Nokia Qt SDK instead.
Prerequisites
Note :If you already have Carbide C++ setup and you are the Symbian developer then move on and just install Qt SDK only, Or else follow this steps
- Install Active Perl
- Install JRE
- Install S60 SDK
- Install Carbide C++
- Guide to install Carbide C++ (Optional)
- Install Qt If you don't find it please try here
Creating Hello World Project
- Launch Carbide C++
- Click on File->New->Qt Project->Select Qt GUI Main Window (Under Qt GUI) -> Put project name ->Select SDK->Check Qt Modules
- Your project will be created and ready to build.
- Open main.cpp from the project explorer
- Paste the below code in your main.cpp file. Build and run the project.
#include <QApplication>
#include <QPushButton>
int main(int argc, char *argv[])
{
QApplication app(argc, argv);
QPushButton helloButton("Hello World");
helloButton.resize(80, 20);
helloButton.show();
return app.exec();
}
First we include the definitions of the QApplication and QPushButton classes. For every Qt class, there is a header file with the same name (and capitalization) as the class that contains the class's definition.Inside {{Icode|main()} the QApplication object to manage application-wide resources. The QApplication constructor requires argc and argv because Qt supports a few command-line arguments of its own. The QPushButton which is a button widget class in Qt and we set the button name as Hello World. resize() helps us to make the size of the button. show() display the button on the screen.
Screenshot
This screenshot was taken from Qt running on an old Symbian emulator (S60 3rd Edition FP2).
18 Sep
2009
22 Sep
2009 | http://developer.nokia.com/community/wiki/Archived%3ASimple_Helloworld_in_Qt | CC-MAIN-2014-52 | refinedweb | 346 | 62.58 |
Streams FAQ¶
Attention
We are looking for feedback on APIs, operators, documentation, and really anything that will make the end user experience better. Feel free to provide your feedback via email to
users@kafka.apache.org.
General¶
Is Kafka Streams a project separate from Kafka?¶
No, it is not. The Kafka Streams API – aka Kafka Streams – is a component of the Apache Kafka® open source project, and thus included in Kafka 0.10+ releases. The source code is available at
Is Kafka Streams a proprietary library of Confluent?¶
No, it is not. The Kafka Streams API – aka Kafka Streams – is a component of the Kafka open source project, and thus included in. tha Kafka.
How do I migrate my older Kafka Streams applications to the latest Confluent Platform version?¶+. Additionally, Kafka Streams ships with a Scala wrapper on top of Java. You can also write applications in other JVM-based languages such as Kotlin or Clojure, but there is no native support for those languages..
The configuration setting
offsets.retention.minutes controls how long Kafka will remember offsets in the special topic.
The default value is 10,080 minutes (7 days).
Note that the default value in older versions is only 1,440 minutes (24 hours).
If your application is stopped (hasn’t connected to the Kafka cluster) for a while, you could end up in a situation where you start reprocessing data on application restart because the broker(s) have deleted the offsets in the meantime.
The actual startup behavior depends on your
auto.offest.reset configuration that can be set to “earliest”, “latest”, or “none”.
To avoid this problem, it is recommended to increase
offsets
How should I retain my Streams application’s processing results from being cleaned up?¶
Same as any Kafka topics, you can set the
log.retention.ms,
log.retention.minutes and
log.retention.hours configs
on broker side for the sink topics to indicate how long processing results written to those topics will be retained, and brokers
will then determine whether to cleanup old data by comparing the record’s associated timestamp with the current system time.
As for the window or session states, their retention policy can also be set in your code via
Materialized#withRetention(), which will then
be honored by Streams library similarly by comparing stored record’s timestamps with the current system time (key-value state stores do
not have retention policy as their updates will be retained forever).
Note that Kafka Streams applications by default do not modify the resulted record’s timestamp from its original source topics. In other words, if processing an event record as of some time in the past (e.g., during a bootstrapping phase that is processing accumulated old data) resulted in one or more records as well as state updates, the resulted records or state updates would also be reflected as of the same time in the past as indicated by their associated timestamps. And if the timestamp is older than the retention threshold compared with the current system time, they will be soon cleaned up after they’ve been written to Kafka topics or state stores.
You can optionally let the Streams application code to modify the resulted record’s timestamp in version 5.1.x and beyond (see 5.1 Upgrade Guide for details), but pay attention to its semantic implications: processing an event as of some time would actually result in a result for a different time. scheduled
punctuate() function,.
Often, users want to get read-only access to the key while modifying the value.
For this case, you can call
mapValues() with a
ValueMapperWithKey instead of using the
map() operator.
The
XxxWithKey extension is available for multiple operators. config properties,), the Kafka, null, } }.
Sending corrupt records to a quarantine topic or dead letter queue?¶
See Option 3: Quarantine corrupted records (dead letter queue) as described in Handling corrupted records and deserialization errors (“poison pill records”)?.¶(topology,() method.
For a
KTable you can inspect changes to it by getting a
KTable’s changelog stream via
KTable#toStream().
You can use
print() to print the elements to
STDOUT as shown below
or you can write into a file via
Printed.toFile("fileName").
Here is an example that uses
KStream#print(Printed.toSysOut()):
import java.util.concurrent.TimeUnit; KStream<String, Long> left = ...; KStream<String, Long> right = ...; // Java 8+ example, using lambda expressions KStream<String, String> joined = left .join(right, (leftValue, rightValue) -> leftValue + " --> " + rightValue, /* ValueJoiner */ JoinWindows.of(Duration.ofMinutes(5)), Joined.with( Serdes.String(), /* key */ Serdes.Long(), /* left value */ Serdes.Long())) /* right value */ .print(Printed.toSysOut()); Kafka Streams?¶
-PartitionTime without the Scala wrapper,.
It is recommended to use the Scala wrapper to avoid this issue. If this is not possible, you must three options.
Option 1 (recommended if on 5.5.x or newer): Use
KStream.toTable()¶
This new toTable() API was introduced in CP 5.5 to simplify the steps. It will completely transform an event stream
into a changelog stream, which means null-values shall still be serialized as a delete and every record
will be applied to the KTable instance. The resulted KTable may only be materialized if the overloaded function
toTable(Materialized)
is used when the topology optimization feature is turned on.
Option.
StreamsBuilder builder = new Streams( 3: Perform a dummy aggregation¶
As an alternative to option 2 but has the advantage that (a) no manual topic management is required and (b) re-reading the data from Kafka is not necessary.
In option 3, 3 versus manual topic management in option); | https://docs.confluent.io/platform/current/streams/faq.html | CC-MAIN-2022-21 | refinedweb | 922 | 56.96 |
Accord.Net makes it easy to add Image Stitching/Panoramas to your application
- Posted: Nov 23, 2011 at 6:00AM
![if gt IE 8]> <![endif]>
I know I'm on a little bit of an "image" kick, but when I saw today's project, though originally published a year ago, I liked how it shows off something that you might think is hard (it is) and something you might have thought you could never include in your application. Yet this project, which shows off a cool framework, makes it look easy. (And I promise, no more "image" stuff for a bit now. I've got it out of my system... well unless I come across something really cool... lol)
Automatic Image Stitching with Accord.NET
Introduction
The Accord.NET Framework is a relatively new.
What I liked was the depth that this article went into. It doesn't simply cover the sample, but the science and math behind the magic that the sample makes look easy.
Feature Extraction.
...
Feature Matching.
...
Homography Estimation.
...
Once you have a firm foundation, the article does cover the code;
Source Code):
The source code accompanying this article contains the sample application plus only a small subset of the Accord.NET Framework to avoid cluttering namespaces. If you wish to use Accord.NET, please be sure to download the latest version from the project page at Origo..
...
Here's a snap of the Solution (which compiled and ran the first time for me, which given the number of projects I look at, I really appreciate
);
Here's the app running;
Remember I said the blend/merge/stitching looked "easy"? Here's pretty much all the code behind...); } private void btnBlend_Click(object sender, EventArgs e) { // Step 4: Project and blend the second image using the homography Blend blend = new Blend(homography, img1); pictureBox.Image = blend.Apply(img2); } private void btnDoItAll_Click(object sender, EventArgs e) { // Do it all btnHarris_Click(sender, e); btnCorrelation_Click(sender, e); btnRansac_Click(sender, e); btnBlend_Click(sender, e); }
If you're looking to add image processing to your application, then this sample may be that first step down the Accord.Net/AForge.Net road you. | https://channel9.msdn.com/coding4fun/blog/AccordNet-makes-it-easy-to-add-Image-StitchingPanoramas-to-your-application | CC-MAIN-2016-40 | refinedweb | 359 | 64 |
span8
span4
span8
span4
World_Contours.zip
ffs2postgis.fmw
contour-rasterizationpostgis.fmw
rasterizerrunnerpostgis.fmw
Latest (post-release) FME 2009 or FME 2010 is needed to run the attached workspaces!
This scenario shows how to prepare raster tiles from vector data for web mapping platforms. The scenario uses Microsoft Bing Maps tile system, however, results can be used with Google Maps and other mapping platforms.
Bing Maps (aka Virtual Earth) is a powerful and flexible tool to serve data over the Internet. FME can play an essential role in preparing data for Bing Maps. I have already published a scenario that explains how to convert raster data into Bing Maps layers of raster tiles.
What I find very convenient about Bing Maps tiles is that we always know tile and pixel sizes in ground units, which are constant throughout whole Earth at each zoom level. This is defined by the Spherical Mercator projection. It allows to set some parameters in an easy way.
Now imagine, we would like to take some vector data and display it in Bing Maps or Google Maps (note that both links point to the same tile set). There are several ways of doing this; in this article I will speak about just one way – rasterization and making Bing Maps tiles.
This article implies that you know some basics about how Bing Maps works, what are tiles, quadkeys, and zoom levels.
As a source map I used contour data from VMap level 0.This dataset has worldwide coverage and detail level of 1:1,000,000 map.
The contours give us an interesting challenge – if we display all the lines at every zoom level, at lower zoom levels contours will simply cover the background map in the mountain areas entirely, so we have to invent an algorithm that would take care about selecting contours of certain elevations for each zoom level. For example, 1000 m contour should be seen at any zoom level, whereas 100 m contour only when we zoom in closer than level 7.
On the other hand, it can be quite useful to see all the contours to get the feeling of the Earth relief. Besides, keeping all the contours is a wonderful stress test for FME Desktop and FME Server, so I publish both variants.
We also would like to achieve the highest quality of the raster tiles at each zoom level. This means that we cannot resample tiles created for one zoom level when we go to the next one – rasterization should happen separately for each level.
Have a look at the illustration below. We can see how the the raster tiles fade out when WebMapTiler makes tiles from a source raster (the row above). When we make vector tiles and rasterize them separately, we have consistent quality across all zoom levels, plus, we have control over the contents at each level (the row below):
There are 19 zoom levels in Virtual Earth. Each new layer has four times more tiles than the previous one. If we would like to go down to zoom levels 14-15, we should get dozens of millions of tiles, and this is why I am also going to talk about performance challenges that we had to overcome. The process shows how to use the full power of FME with spatially enabled database and FME Server.
The source data in VPF format can be downloaded from the National Geospatial-Intelligence Agency (NGA) web site. For your convenience, I downloaded and converted data into FFS format. The full archive can be downloaded from the attached World_Contours.zip. Uncompressed, the full dataset occupies over 600 megabytes. The data contains contours with 1000 feet interval (in some places 500 feet and a few other contour lines with different intervals).
The best way to store and retrieve such amounts of data for our purpose is in a spatially enabled database. In my example, I used PostGIS database (the workspace converting FFS to PostGIS is attachment ffs2postgis.fmw).
For those, who are scared of databases, I can tell that it took me just above an hour to download, install, and be able to run PostgreSQL and PostGIS on top of it, despite the fact that I am not a database specialist at all.
While preparing data for rasterization, I added a filter, that selects data depending on contour interval, so that say zoom level 14 has all contours, zoom level 13 – only divisible by 10, level 12 will have contours divisible by 20, etc.We can use testers for that, but sometimes a simple expression in ExpressionEvaluator does a perfect job:
@Value(_elevation)%1000==0?8:(@Value(_elevation)%500==0?9: (@Value(_elevation)%200==0?10:(@Value(_elevation)%100==0?11: (@Value(_elevation)%20==0?12:(@Value(_elevation)%10?13:14)))))
This way we calculate the highest (smallest number) zoom level at which a contour should be seen.
After that, a little loop will allow us to make several set of contours for each zoom level.
So the first set would contain only a thousandth contour, the second - 1000th and 500th, third, 1000th, 500th and 200th, and so on.
Gradient ramp is a good choice for a wide range of values such as contour elevations. Setting colors with a PythonCaller is a fast and easy way to assign fme_color attribute. Here is an example of the python code used in the attached workspaces:
import pyfme logger = pyfme.FMELogfile() class ColorSetter(object): def input(self, feature): self.elev = feature.getIntAttribute('elevation_ft') if self.elev < 2000: if self.elev < 1000: self.color = '0,' + str(0.24 + 0.0004*self.elev) + ',0' else: self.color = '0.5,' + str(0.24 + 0.0004*self.elev) + ',0.5' elif self.elev <= 6000: if self.elev <= 3500: self.color = str(0.0002*(7000 - self.elev)) + ',' + str(0.0002*(7000 - self.elev)) + ',0' else: self.color = '0.7,' + str(0.0002*(7000 - self.elev)) + ',0' elif self.elev <= 15000: if self.elev < 10000: self.color = '1,' + str(0.0001*(self.elev/2)) + ',0' else: self.color = '1,' + str(0.0001*(15000-self.elev)) + ',0.5' elif self.elev < 25000: self.color = str(0.0001*(25000 - self.elev)) + ',0,' + str(0.0001*(self.elev/3)) else: self.color = '0.5,0.5,1' feature.setAttribute('fme_color', self.color) feature.setAttribute('fme_fill_color', self.color) self.pyoutput(feature)
Usually, FME makes Bing Maps tiles from an incoming raster with the WebMapTiler transformer. This approach may work not so well with vector datasets. Rasterizing a map down to zoom level 10 would produce an image with 262,144 pixels along each side, and those rasters are a bit hard to handle. We could rasterize smaller portions of the dataset and then use WebMapTileron those smaller rasters, but this will involve two raster operations (rasterization itself and raster tiling). Besides, if we pick an arbitrary grid, we may end up with incomplete tiles, and will have to take care about mosaicking them together. After some tests I gave up this route and decided to try a direct clipping and rasterization to Bing Maps tiles. That is, the ImageRasterizertransformer should get exact portions of data that are needed to make separate tiles. So now we have only one raster transformer. Another positive side effect of this change is that now we won't produce tiles that don't have any data.
How can we make such portions? The answer is easy – the Clipper transformer. We can make vector tile polygons that serve as Clippers, and the dataset supplies Clippees. That was the theory. If we tile our world from zoom level 1 down to level 10, we have to create almost 1,500,000 Clippers. That’s a lot. Despite all the improvements, we still have some performance problems when the number of Clippers exceeds 20,000-60,000 (depending on the amount of clipped data).
I tried replacing Clipper with Intersector, which allowed me to go two zoom levels further than Clipper, however, it required some extra work on computing quadkeys, and still, it could not be used for even deeper tiling.
The next logical step in my approximations to the final workflow was making a procedure consisting of two (or more) steps. With step one, I would tile the original dataset into smaller datasets with the extents matching the tile extents of some zoom level (say, 7 or 8 as in my tests), and then make the same tiling and final rasterization for each of those smaller datasets down to zoom levels 14-15.
In fact, there shouldn’t be too much need in a process that would take some data and tile it across the whole zoom level range from level 1 (world) to level 19 (mole-hill). The map of the world and street map have quite different contents, and even if some elements are the same (coast line, for example), they are usually represented by geometries that are quite different - generalized or detailed.
For managing such a workflow, I had to set up the following procedure. At the first stage, the original dataset is cut into smaller portions and stored in some convenient format (preferably with spatial index - an FFS or some spatial database). There are two workspaces at the second stage, one executes another with WorkspaceRunner or ServerJobSubmitter transformer.
The first workspace decides what portion (what file or database table) of the data should be taken, the second workspace knows how to tile and rasterize whatever is entering it.
Still, the necessity to generate and keep multiple smaller datasets instead of one large dataset is not an ideal solution – it is harder to manage data storage and distribution, easier to loose some parts, etc. This is why a spatial database comes out to play a more significant role in the whole process.
Spatial databases such as Oracle, SQL Server, MySQL or PostGIS are very effective at quick reading subsets of spatial data. If we need to extract some data from a traditional vector format such as MapInfo or DGN, we would have to read the whole dataset, add a polygon that would define the boundaries of the area of interest, and then, with either Clipper or one of the Overlayers (e.g. AreaOnAreaOverlayer)get the data. With database readers getting the same result is just a matter of setting reader parameters, which can be published, and hence, set from an external workspace.
The final workflow published here looks as follows.
We take a feature that represents our area – it can be a country area or simple bounding box. We ask for the parameters – minimum and maximum zoom levels (from which to which zoom level data should be seen), and we also have to specify so called 'tiling level' (I used to call it reading, but it is not very good word for the purpose it is used for).
Using Rasterizer we make a small raster (1*1 or maybe 10*10 pixels to avoid any rounding problems), and pass the this raster through WebMapTiler. We get VE tiles, which know their quadkey names.
Then with BoundsExtractor, we get minimum and maximum X and Y, and they together with the quadkey serve as the parameters to the second workspace.
In the example below, we got 28 VE tiles, what means that we will execute 28 workspaces from zoom level 5 to zoom level 7 (which is that tiling level). BTW, we have someone on Madagascar transforming TIFF to BMP with FME, and maybe at the next conference I’ll tell you how we know it, how we collect and how we use statistics about our users.
Now what do we do in those 28 workspaces? We apply parameters (tile extents) sent from the external workspace to the database reader. With option 'Clip' we get only data that is inside of quadkey we submitted.
After that we do our regular job – coloring and scale selection if needed.
Then, we either simply rasterize with group by what we read into a tile and save it as a PNG file, or we perform additional tiling.
Why some of the tiles are written immediately, and some are tiled again? This depends on tiling level. Again, talking about the image above – data read with the tiles of the zoom levels 5 and 6 is rasterized and written right away.
Data read with tiles of zoom level 7 is also rasterized directly, but also before that, is tiled, to make tiles of zoom levels 8 and 9.
This all gives us great flexibility. Now we can control how many workspaces will be executed, and how many tiles each workspace will make. When we increase the number of tiles (by increasing tiling level number) in the first workspace, we increase the number of workspace that will be executed, which means that each workspace will have less to do. Or, if we submit less tiles, that means less workspaces, and more job (more tiles) per workspace.
The diagram below shows tiling up to (or down to) zoom level 8. When I tried to tile everything with one workspace, I had to give up after 36 hours – I didn't see any work going. Either my FME stalled, or I wasn't patient enough – the rest of the numbers tells us that further waiting had no sense.
When the workspaces don't have to make that many clippings, the situation starts to improve. 4000 tiles per workspace seem to be doing much better than 16,000, and the interval between 64 and a thousand tiles per workspace seems to be the optimum. When we have too many workspaces, the necessity to pass data through all other transformers outweighs any advantages of the faster clipping.
Tiling Level # of Workspaces Tiles per wksp
1 1 16384
2 16 4096
3 64 1024
4 320 256
5 1344 64
6 5440 16
7 21824 4
If we need really lots of tiles, the process can go quite slow. Depending on different conditions, my machine was able to produce between 6 and 10 tiles per second, and that means very roughly ~500,000 - 850,000 tiles a day. However, big project, say Canada-wide, with detailness down to zoom level 14-15 would require millions and millions of tiles.
The workflow explained above fits really well into FME Server technology.
In fact, all what has to be done (assuming that FME Server is up and running) is to replace WorkbenchRunner with ServerJobSubmitter. This transformer will take the same parameters, and once changes are made, we are ready to make tiles with FME Server.
Initially, we tried a single FME Server quad core machine with a single engine and the results were pretty close to those we got on a machine with FME Desktop, and that was expected. Then we thought, if we put four engines on that quad core machine we would see real improvements in performance. However, we got worse performance with many engines than with just one (columns 1 and 5):
Our next couple of tests compared performance on four machines with single and then with two engines on each. As you can see, results are really close – both around 2.5 hours (columns 2 and 4).
The fastest result was reached with 8 single engine machines. Perhaps, we would have the same for two engine machines, but when you pay for an engine there is probably not much sense to have twice as more to get about the same result.
Why is it so? We checked Task Manager for CPU consumption, and for the most part of the process it was quite low. After some consultations with more technically experienced Safers, we agreed that the bottleneck is I/O – we simply can't write more files in a given time period, so multiple engines will just wait when they will get their chance to write something, but the outcome will be the same or worse – just because we make such a crowd.
Then we made some simple performance tests to get the idea how fast we can generate our tiles. We tiled the VMap contours down to zoom level 8. For this we ran our tiling process with 1, 2, 4, and 8 machines, and as you can see, we decreased out time from two hours to less that 20 minutes.
Then we tried how fast we can be if we go to level 10 and 11, and the table shows the numbers. 250,000 tiles can be done in about 2 hours, and one million tiles was completed in 6.4 hours. On a single machine, it would take almost two days.
Level Tiles Minutes (hours)
8 24,500 18 (0.3)
10 245,000 105 (1.75)
11 1,000,000 384 (6.4)
Now it is easy to imagine that tiling a big area with multiple layers down to zoom level 14 or 15 can take either very long time or a lot of computing resources.
So, if we had unlimited number of computers how fast we could reach our goal?
This graph does not deal with total time; it shows the average and the maximum time per workspace.
The process illustrated with this graph generates about 3500 tiles, taking about half an hour for a single workspace. When the number of workspaces grows, an average and maximum times are going down. With 82 workspaces, that is, with 82 engines, this process can finish in half a minute (if there is no other bottle necks).
FME Server now can work in the cloud, and the tests described above were also performed by our colleagues at WeoGeo.
It is really easy to start making tiles with FME. Only FME Desktop is needed to start making them as long as the number of tiles does not exceed hundreds of thousands or a few millions of tiles.
The results of the tiling process are not limited to a single mapping platform Bing Maps. It can be used with Google Earth and other web mapping platforms.
The general idea how to split data processing into multiple workspaces is not limited to the described process and as such, is even more valuable.
FME Server allows much quicker data production, so if your volumes are big or you need frequent updates, this is the way to go.
Even if FME Server not enough, FME now lives in a cloud, which can scale out really wide.
World_Contours.zip - Source data in FFS format
ffs2postgis.fmw - Workspace to translate FFS to PostGIS
RasterizerRunnerPostGIS.fmw - Parent Workspace to execute helper workspaces
contour_rasterizationPostGIS.fmw - Helper workspace producing tiles
Results in Bing Maps
Results in Google Maps
The process described above is quite complex, feel free to contact Technical Support with any related questions or if you notice anything not working properly. | https://knowledge.safe.com/articles/606/rasterization-for-web-mapping-platforms.html?smartspace=web-cloud_2 | CC-MAIN-2019-04 | refinedweb | 3,133 | 70.02 |
I'm learning with a book and one of the excercises is to have the computer guess a number of which you think. My problem is that I need to keep altering the range which works for a couple tries then it seemingly forgets the range and goes on its own.
//Computer guesses your number #include <iostream> #include <cstdlib> #include <ctime> using namespace std; int main () { char yourNumber; int randRangeY = 100; int randRangeX = 1; int secretNumber = 1; srand (time(NULL)); while(yourNumber != 'y') { if (yourNumber == 'h') { randRangeX = (secretNumber+1); } else if (yourNumber == 'l') { randRangeY = (secretNumber-1); } secretNumber = (rand()%randRangeY)+randRangeX; cout << randRangeX << "," << randRangeY << endl; cout << "Is it " << secretNumber << "? (h/l/y)" << endl; cin >> yourNumber; } cout << "Awesome"; return 0; }
Thank you for your help :) | https://www.daniweb.com/programming/software-development/threads/498641/computer-guesses-your-number | CC-MAIN-2017-39 | refinedweb | 123 | 56.79 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.