
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Writing unit tests will keep your Gatsby blog bug-free, and leads to more maintainable code. This post covers how you can use Jest and React Testing Library to cover some of your Gatsby blog’s most essential features.
Why add unit tests?
When you’re hacking away on a side project, writing unit tests isn’t fun and can be easily missed. I’ll admit I’ve often skipped writing unit tests for side projects - but I always end up regretting it later. Without unit tests, adding a bug fix or new feature becomes a lot scarier because you don’t know if you’re going to break something else in the process.
Writing tests as you go will immediately boost the quality of your code too, as unit tests force you to think a bit harder on the purpose of each function or component. It might be a struggle at first but the more you’ll do it, the easier it gets.
(Also seeing all those green ticks after you run your tests can be satisfying!)
What should you test on your Gatsby blog?
You can create tests that make sure components are rendering on the page that you would expect to render. This can be useful to make sure your pages aren't completely broken! It's also good to test any logic that you've added to your blog.
In this post we’ll be using some of the unit tests I added to my blog as an example, and covering the following areas:
- Testing that my post’s dates render as expected
- Testing that my SEO component is outputting the correct meta tags
- Testing that my home page renders links to 3 of my recent posts
Installing Jest and React Testing Library
Getting started with unit testing is a bit more of a complex setup process for Gatsby than it would be for your regular React app. Luckily Gatsby provides some great documentation on unit testing, so I would recommend following the steps on there to install Jest.
Next, you’ll also need to follow Gatsby’s instructions on testing React components so that you can install React Testing Library.
Why do we need both Jest and React Testing Library?
Jest is the framework that runs the tests for you.
Jest lets you do things like describe your suite of tests with
describe and
test, as well as make assertions using
expect:
describe('Test name', () => { test('should be true', () => { expect(true).toBe(true); }); });
Where React Testing Library comes into play is that it allows you to render your React apps and components, and then select certain parts of them to assert on:
describe('Test name', () => { test('should be true', () => { render(<Component />); const text = screen.findByText('hello'); expect(text).toBeTruthy(); }); });
Testing that my dates are rendered correctly
For posts published in the 2020, my blog will only render the day and month that the post was published (e.g.
16 Sept). For posts published last year, I will render the year as well (e.g.
16 Sept 2019).
Here is an example of the sort of unit test I would write for this scenario:
import React from 'react'; import { render, screen } from '@testing-library/react'; describe('PostSummary component', () => { test('should render year if post is from 2019', () => { const post = { name: 'Post title', date: '16 Sept 2019', }; render(<PostSummary post={post} />); expect(screen.getByText('16 Sept 2019')).toBeTruthy(); }); });
In the above unit test we:
- Use RTL’s
renderfunction. This will render our React component and make it available to query on via the
screenobject.
- Use the
getByTextquery to assert that the text that we expect to be present is there.
As well as
getByText, there are a number of other queries you can use depending on the situation. React Testing Library provides a useful guide for which query you should use.
Pro-tip: If you’re running into issues with your unit tests, you can add a
console.log(screen.debug())to your tests. This lets you double-check that your test is rendering what you’re expecting it to be rendering.
As well as testing the scenario for a post from 2019, I’ve also written a unit test for if a post was written in the current year.
Testing your SEO component
If you’ve created your Gatsby blog using one of the default starter templates, chances are you’ll have a SEO component that uses
react-helmet to generate your site’s meta tags. This contains things like the title of the page and what data your post would show if it was linked on Twitter or other social media sites.
If you’re interested in learning more about meta tags, check out my recent post on adding meta tags to your Gatsby blog
Mocking Gatsby’s useStaticQuery
The first thing thing my SEO component does is get some of my site’s metadata with Gatsby’s
useStaticQuery:
// src/components/seo/index.js const { site } = useStaticQuery( graphql` query { site { siteMetadata { title description author siteUrl } } } `, );
This data isn’t accessible in our unit test, so we’re going to need to mock what
useStaticQuery returns. We can do this with Jest's mockReturnValue:
// src/components/seo/test.js describe('SEO component', () => { beforeAll(() => { useStaticQuery.mockReturnValue({ site: { siteMetadata: { title: `Emma Goto`, description: `Front-end development and side projects.`, author: `Emma Goto`, siteUrl: ``, }, }, }); }); test(...) });
We’re putting it inside a
beforeAll hook which means this will get mocked once before all our tests run.
If you only ever use
useStaticQueryto get your site's data, you could move this code to live inside of __mocks__/gatsby.js so you only need to mock it once across all of your test files.
Testing your meta tags with Helmet’s peek()
With meta tags, you won’t be able to query for it on the
screen object like we did with our previous unit test. Instead, we’ll need to make use of a function that React Helmet provides called
peek():
// src/pages/index.test.js import { render } from '@testing-library/react'; import Helmet from 'react-helmet'; test('should render correct meta data for home page', () => { render(<SEO title={postTitle} />); const helmet = Helmet.peek();
This gives us an object containing all the meta tags created by our Helmet component. We can now write tests to assert that specific values are present:
expect(helmet.title).toBe(siteTitle); expect(helmet.metaTags).toEqual( expect.arrayContaining([ { property: 'og:title', content: siteTitle, }, ]), );
You can see the full set of tests for my SEO component over on Github.
Testing that my home page renders three recent posts
My site’s home page renders my three most recent blog posts. It gets this data using a GraphQL page query, which will be passed in as a prop to my component:
// src/pages/index.js const IndexPage = ({ data }) => ( <> // renders the posts using the given data </> ); export const pageQuery = graphql` query { allMdx { nodes { frontmatter { title date(formatString: "DD MMMM YYYY") } } } } `; export default IndexPage;
Mocking the data
Since you can’t run the page query in a unit test, you’ll need to create a mock data object to pass into your component:
const data = { nodes: [ { frontmatter: { title: "Post #1", date: "01 Jan 2020" }, }, ], }; test('should render three most recent posts', async () => { render(<IndexPage data={data} />
This approach is useful if you wanted to test a specific scenario e.g. what would happen if two posts were published on the same day.
However, if you broke your page query at some point in the future, your unit test would still pass.
Use real data with gatsby-plugin-testing
To use up-to-date data from your GraphQL page query, you can make use of gatsby-plugin-testing:
import { getPageQueryData } from 'gatsby-plugin-testing'; test('should render three most recent posts', async () => { const data = await getPageQueryData('index'); render(<IndexPage data={data} />);
This plugin will give you real data, identical to what your GraphQL query returns. This means that if you modify your GraphQL query in any way, the unit test will also use the new data from this query.
The trade-off with this approach is that since this is real data, you can't do things like assert that a specific post title will be available on your home page (if you are showing your most recent posts). If you did, the unit test would break as soon as you added more blog posts.
Finding my blog post links
Since each of my recent posts are links, one way we could find the posts is by using the
getAllByRole query:
const links = screen.getAllByRole('link');
This will return a list of all the links on the page. In my case however, my home page has a lot of other links so this isn’t too useful.
Instead, I decided to add a
data-testid prop to all my blog post links:
// src/components/summaries/index.js const PostSummary = () => <div data-...</div>
It’s recommended that you use
data-testidinstead of relying on a CSS class name or some other implementation detail, as we don’t want our unit tests to break if we edit the CSS, for example.
Now in my unit test, I can find all elements that match the given test ID, and assert that there are three of them:
const posts = screen.getAllByTestId('summary'); expect(posts.length).toEqual(3);
This test is fairly simple and I will admit that it’s not going to pick up on all the possible edge cases or bugs that could occur.
However, I’ve often broken certain pages of my website with small typos or changes so even a simple test like this one will let you know if anything is majorly broken, and so I still think it has a lot of use and is worth writing!
Conclusion
I’m guilty of skipping unit tests for my side projects a lot of the time, but by writing them for my Gatsby blog I think I’ve come out with a codebase that’s a tiny bit cleaner, and I have a lot more confidence to keep making changes to it in the future.
I hope this post helps you in unit testing your Gatsby blog or next side project.
Thanks for reading!
Discussion | https://dev.to/emma/how-to-unit-test-your-gatsby-blog-with-react-testing-library-3l9i | CC-MAIN-2020-45 | refinedweb | 1,713 | 57.81 |
This forum
Forum: help
Monitor Forum
|
Start New Thread
Nested
Flat
Threaded
Ultimate
Show 25
Show 50
Show 75
Show 100
SSL, DataTables, and bytea transfers
[ reply ]
By:
Dan Sherwin
on 2008-01-15 02:38
[forum:1003022]
Im utilizing Npgsql 1.0.0, and I have a simple table with 3 cols. 2 text fields, and one bytea. When I insert a row into my DataTable, with a bytea field size of say 35K, using an SSL connection, and I call the DataAdapter.Update method on the DataTable, the new row does not get added to the table. Log output shows no errors and nothing out of the ordinary. Postgres log doesnt seem to even see the insert statement. If perform the exact same procedure without using an SSL connection, everything works fine. If I just have a couple of bytes in the bytea field, using SSL, everything works fine. Oh, and the NpgsqlCommand.Prepare has no effect one way or the other. I am using PostGres 8.1.4 on a FreeBSD machine. Any ideas? I will post some sample code if needed. Figured my explanation may be enough for someone to recognize it.
Thanks in advance.
RE: SSL, DataTables, and bytea transfers
[ reply ]
By:
Francisco Figueiredo jr.
on 2008-01-15 20:23
[forum:1003024]
We had a lot of problems with transfer being stuck with ssl enable. Can you try to get a newer Mono.Security.dll assembly from Mono project and give it a try?
You can get newer assemblies from
You must get Mono.Security.dll assemblies for .net 1.1
I hope it helps.
Specified Method Not Supported?
[ reply ]
By:
Joe Bagodonuts
on 2008-01-10 20:22
[forum:1003008]
Hey, people -
I'm using the 2.0 Beta version of npgsql in a C#.Net app. I'm able to load the reference and see it in the Object Browser (even though I was unable to add it to the GAC -- "Failure adding assembly to the cache: Unknown Error" -- but that's another thread). I successfully connect to my test database, but when I try to list the tables using NpgsqlConnection.getSchema(collection) I get the Method Not Supported exception. getSchema() works fine with NO args, but I'm not getting what I want from that. Has anyone seen this and, if so, can you tell me a way to get past it? My thanks in advance...
Broken Connections
[ reply ]
By:
Andreas Schönebeck
on 2008-01-09 10:38
[forum:1002997]
Hello from Berlin!
I'm running into trouble calling Thread.Abort() on a thread that is doing a NpgqslCommand.ExecuteReader(). The command and connection is created in the thread itself. Also there is only one Connection open at a time, because the main thread is waiting for completion using Thread.Join().
To illustrate the problem I've written a test to create 10 threads, which are aborted after a short random time (100-1000 ms) and a final thread, which is never aborted and should run cleanly to the end.
As you can see by the test's output there are various exceptions generated by the aborted threads and only sometimes the ThreadAbortException gets cleanly caught.
Which is weirdest is, that after the 10'th aborted thread catches a clean ThreadAbortException ("[9] Thread aborted.") the final thread, which should run till the end and read ~50000 records does throw an exception in ExecuteReader()!?!
In application context (user pressing "refresh" very quickly, high server load) the last database read will sometimes not return any results.
What can I do to improve stability? I hope, the test case code is giving an idea of my problem and someone has a quick and proper fix.
Maybe I found a bug in Npgsql and ThreadAbortExceptions are not handled properly and connections end up in corrupted state, but are reused by pooling?
Thanks for looking into this,
Andreas Schönebeck
// Output
[Main] Starting Thread [0].
[Main] Aborting Thread [0].
[Main] Waiting for Thread [0] to finish.
[0] Unhandled exception caught (System.NotSupportedException): Dieser Stream unterstützt keine Suchvorgänge.
[Main] Starting Thread [1].
[Main] Aborting Thread [1].
[Main] Waiting for Thread [1] to finish.
[1] Unhandled exception caught (System.NotSupportedException): Backend sent unrecognized response type:
[Main] Starting Thread [2].
[Main] Aborting Thread [2].
[Main] Waiting for Thread [2] to finish.
[2] Unhandled exception caught (System.NotSupportedException): Backend sent unrecognized response type:
[Main] Starting Thread [3].
[Main] Aborting Thread [3].
[3] Unhandled exception caught (System.NotSupportedException): Dieser Stream unterstützt keine Suchvorgänge.
[Main] Waiting for Thread [3] to finish.
[Main] Starting Thread [4].
[Main] Aborting Thread [4].
[4] Unhandled exception caught (System.NotSupportedException): Dieser Stream unterstützt keine Suchvorgänge.
[Main] Waiting for Thread [4] to finish.
[Main] Starting Thread [5].
[Main] Aborting Thread [5].
[5] Unhandled exception caught (System.NotSupportedException): Dieser Stream unterstützt keine Suchvorgänge.
[Main] Waiting for Thread [5] to finish.
[Main] Starting Thread [6].
[Main] Aborting Thread [6].
[6] Unhandled exception caught (System.NotSupportedException): Dieser Stream unterstützt keine Suchvorgänge.
[Main] Waiting for Thread [6] to finish.
[Main] Starting Thread [7].
[Main] Aborting Thread [7].
[7] Unhandled exception caught (System.NotSupportedException): Dieser Stream unterstützt keine Suchvorgänge.
[Main] Waiting for Thread [7] to finish.
[Main] Starting Thread [8].
[Main] Aborting Thread [8].
[8] Unhandled exception caught (System.NotSupportedException): Dieser Stream unterstützt keine Suchvorgänge.
[Main] Waiting for Thread [8] to finish.
[Main] Starting Thread [9].
[Main] Aborting Thread [9].
[Main] Waiting for Thread [9] to finish.
[9] Thread aborted.
[Main] Starting Thread [10].
[10] Unhandled exception caught (System.NotSupportedException): Dieser Streamunterstützt keine Suchvorgänge.
[Main] Waiting for Thread [10] to finish.
Press any key to continue . . .
// Source...
sing System;
using System.Threading;
using Npgsql;
class Program
{
public static void Main(string[] args)
{
RunTestAbort(0);
RunTestAbort(1);
RunTestAbort(2);
Console.Write("Press any key to continue . . . ");
Console.ReadKey(true);
}
public static void RunTestAbort(int id)
{
Thread dbthread = new Thread(AbortThreadFunc);
Console.WriteLine("[Main] Starting Thread [{0}].", id);
dbthread.Start(id);
Thread.Sleep(150);
Console.WriteLine("[Main] Aborting Thread [{0}].", id);
dbthread.Abort();
Console.WriteLine("[Main] Waiting for Thread [{0}] to finish.", id);
dbthread.Join();
}
public static void AbortThreadFunc(object parameter)
{
int id = (int)parameter;";
using(NpgsqlDataReader sdr = cmd.ExecuteReader()) {
int recordcount = 0;
while (sdr.Read()) {
recordcount++;
}
Console.WriteLine("[{0}] Successfully read {1} records.", id, recordcount);
}
}
}
} catch (ThreadAbortException ex) {
Console.WriteLine("[{0}] Thread aborted.", id, ex.StackTrace);
} catch (Exception ex) {
Console.WriteLine("[{0}] Unhandled exception caught ({1}): {2}", id, ex.GetType().ToString(), ex.Message);
}
}
}
Unplugging network causes null reference ex
[ reply ]
By:
Alex Simmens
on 2008-01-03 17:59
[forum:1002973]
Hi, i've been experimenting with the NPGSQL2.0 beta 2 driver and i noticed a possible bug.
I have created 3 connections to a postgres db with the same connection string, and if i unplug my network cable and try an execute reader command such as SELECT * FROM queues WHERE queueno = 1; on one of the connections, after the command times out, i get an unhandled null reference exception in the NpgsqlConnectorPool.TimerElapsed Handler
on investigation, i found it to be caused by the queue object on this line being null:- (Queue.Count > 0)
i tried fixing it by adding a if (Queue != null) check before it and it seems to work, but as i don't understand how npgsql works and i don't know C# very well i may be being silly
hope it helps
alex
RE: Unplugging network causes null reference ex
[ reply ]
By:
Alex Simmens
on 2008-01-03 18:13
[forum:1002974]
Just to give some more info, im running my app. in VS2005 on WinXP and the postgres server in on the local area network
multiple threads with independent connections
[ reply ]
By:
Carl Strange
on 2008-01-02 16:47
[forum:1002966]
I'm starting work on a personal project to gather data from various web sites. I'm relatively comfortable in C# and with SQL but this will be my first use of Npgsql and PostgreSQL.
My initial design has several web scrapers, running in separate threads, each with their own database connection. They simply post data to various tables so I shouldn't have interlock problems between threads. The main thread will periodically read the database to check on the worker's progress.
I understand a single database connection is not thread safe but are there any problems with independent connections on independent threads?
Regards,
Carl
RE: multiple threads with independent connections
[ reply ]
By:
Francisco Figueiredo jr.
on 2008-01-02 17:24
[forum:1002967]
Hi, Carl!
No, there is no problem. Indeed this is the right way of using it, a connection per thread. We had some issues in past with multithread but now they are fixed.
Let us know if you have any problems with it.
Thanks for your interest in Npgsql!
RE: multiple threads with independent connect
[ reply ]
By:
Carl Strange
on 2008-01-02 18:16
[forum:1002968]
Francisco,
Thanks for your speedy response. If I run into any problems I'll certainly ask questions. Meanwhile it's nice to know I'm on the right track.
Carl
I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-11-30 08:20
[forum:1002893]
Every time I run the testcase, I got 8 testcases failed. After I digged into, it looks like some testcases are wrong. The following is the test result:
------ Test started: Assembly: NpgsqlTests.dll ------
TestCase 'NpgsqlTests.CommandTests.DateTimeSupportTimezone'
failed:
String lengths are both 20. Strings differ at index 11.
Expected: "2002-02-02 16:00:23Z"
But was: "2002-02-02 09:00:23Z"
----------------------^
F:\dev\Npgsql2\testsuite\noninteractive\NUnit20\CommandTests.cs(941,0): at NpgsqlTests.CommandTests.DateTimeSupportTimezone()
TestCase 'NpgsqlTests.CommandTests.DateTimeSupportTimezone2'
failed:
Expected string length 20 but was 16. Strings differ at index 5.
Expected: "2002-02-02 16:00:23Z"
But was: "2002-2-2 9:00:23"
----------------^
F:\dev\Npgsql2\testsuite\noninteractive\NUnit20\CommandTests.cs(951,0): at NpgsqlTests.CommandTests.DateTimeSupportTimezone2()
TestCase 'NpgsqlTests.CommandTests.FunctionReturnVoid'
failed: Npgsql.NpgsqlException : ERROR: 42883: function test(integer)(463,0): at Npgsql.NpgsqlCommand.ExecuteNonQuery()
F:\dev\Npgsql2\testsuite\noninteractive\NUnit20\CommandTests.cs(651,0): at NpgsqlTests.CommandTests.FunctionReturnVoid()
TestCase 'NpgsqlTests.CommandTests.LastInsertedOidSupport'
failed: Npgsql.NpgsqlException : ERROR: 42703: column "oid"(706,0): at Npgsql.NpgsqlCommand.ExecuteScalar()
F:\dev\Npgsql2\testsuite\noninteractive\NUnit20\CommandTests.cs(1969,0): at NpgsqlTests.CommandTests.LastInsertedOidSupport()
TestCase 'NpgsqlTests.CommandTests.ListenNotifySupport' failed: System.InvalidOperationException was expected
TestCase 'NpgsqlTests.CommandTests.ParametersGetName'
failed:
Expected string length 10 but was 11. Strings differ at index 0.
Expected: "Parameter4"
But was: ":Parameter4"
-----------^
F:\dev\Npgsql2\testsuite\noninteractive\NUnit20\CommandTests.cs(73,0): at NpgsqlTests.CommandTests.ParametersGetName()
TestCase 'NpgsqlTests.DataAdapterTests.UpdateWithDataSet'
failed: System.InvalidOperationException : Dynamic SQL generation for the UpdateCommand is not supported against a SelectCommand that does not return any key column information
at System.Data.Common.DbDataAdapter.UpdatingRowStatusErrors(RowUpdatingEventArgs rowUpdatedEvent, DataRow dataRow)(DataSet dataSet, String srcTable)
at System.Data.Common.DbDataAdapter.Update(DataSet dataSet)
F:\dev\Npgsql2\testsuite\noninteractive\NUnit20\DataAdapterTests.cs(212,0): at NpgsqlTests.DataAdapterTests.UpdateWithDataSet()
TestCase 'NpgsqlTests.DataReaderTests.SingleRowCommandBehaviorSupportFunctioncallPrepare'
failed:
Expected: 1
But was: 6
F:\dev\Npgsql2\testsuite\noninteractive\NUnit20\DataReaderTests.cs(530,0): at NpgsqlTests.DataReaderTests.SingleRowCommandBehaviorSupportFunctioncallPrepare()
162 passed, 8 failed, 0 skipped, took 20.45 seconds.
===================================
For NpgsqlTests.CommandTests.FunctionReturnVoid, there is no test() function in test db, and not in add_functions.sql (or testreturnvoid()?).
For NpgsqlTests.CommandTests.ParametersGetName, I think ":Parameter4" was correct, why expect "Parameter4", is it wrong?
Should we correct those testcases?
RE: I got 8 testcases failed.
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-03 13:20
[forum:1002901]
I'm checking that.
One thing I can note now is that the "Dynamic SQL ... message seems to be thrown only on Mono. If you test it on windows, you will see it works. At least last time I tried it worked. :)
The parameter4 problem is that when I add it to Parameters collection, I don't put the : prefix. So, when I try to get its name, I would expect it wouldn't come with : prefix. But Npgsql add it. I didn't check sqlclient behavior to see if you add a parameter without @ prefix if it returns the parameter name with @ anyway. That's why I left this test case failing, to remember me of that. :)
The others for sure we need to fix.
RE: I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-12-04 04:12
[forum:1002904]
For Dynamic SQL, I ran the test on Windows. So maybe something wrong here.
For ":" prefix, I did a test by following code on SqlClient:
-=================== Begin ==================-
// Sql
SqlCommand sql_command = new SqlCommand();
sql_command.Parameters.Add(new SqlParameter("Parameter1", DbType.DateTime));
sql_command.Parameters.Add(new SqlParameter("@Parameter2", DbType.DateTime));
Console.WriteLine("1:[Parameter1],\t 2:[@Parameter2]");
Console.WriteLine("sql_command.Parameters[0].ParameterName = '{0}'.", sql_command.Parameters[0].ParameterName);
Console.WriteLine("sql_command.Parameters[1].ParameterName = '{0}'.", sql_command.Parameters[1].ParameterName);
//Console.WriteLine("sql_command.Parameters[\"@Parameter1\"].ParameterName = '{0}'.", sql_command.Parameters["@Parameter1"].ParameterName);
//Console.WriteLine("sql_command.Parameters[\"Parameter2\"].ParameterName = '{0}'.", sql_command.Parameters["Parameter2"].ParameterName);
-=================== End ==================-
The output is :
-=================== Begin ==================-
1:[Parameter1], 2:[@Parameter2]
sql_command.Parameters[0].ParameterName = 'Parameter1'.
sql_command.Parameters[1].ParameterName = '@Parameter2'.
-=================== End ==================-
I comment last 2 lines since they are raise IndexOutOfRangeException state there is no such name. I think SqlParameter just treat the name as a normal string, without handling "@" prefix, even though "@param" is actually reference to same parameter of "param".
But during the SqlCommand being excution, the name has been attached the "@" prefix dynamically and send to server. So at the server side, the parameter is always with "@" prefix attached. I didn't test it on Mono, but I read the Mono source code for Mono.Data.Tds.TdsMetaParameter.cs:
It looks like has the same behavior, the "@" was attached dynamically if it's missing. And the TdsMetaParameterCollection didn't handle the "@" prefix.
I did the same test on MySql.Data by following code:
-=================== Begin ==================-
MySqlCommand mysql_command = new MySqlCommand();
mysql_command.Parameters.Add(new MySqlParameter("Parameter1", DbType.DateTime));
mysql_command.Parameters.Add(new MySqlParameter("?Parameter2", DbType.DateTime));
Console.WriteLine("1:[Parameter1],\t 2:[?Parameter2]");
Console.WriteLine("mysql_command.Parameters[0].ParameterName = '{0}'.", mysql_command.Parameters[0].ParameterName);
Console.WriteLine("mysql_command.Parameters[1].ParameterName = '{0}'.", mysql_command.Parameters[1].ParameterName);
Console.WriteLine("mysql_command.Parameters[\"?Parameter1\"].ParameterName = '{0}'.", mysql_command.Parameters["?Parameter1"].ParameterName);
//Console.WriteLine("mysql_command.Parameters[\"Parameter2\"].ParameterName = '{0}'.", mysql_command.Parameters["Parameter2"].ParameterName);
-=================== End ==================-
The output is :
-=================== Begin ==================-
1:[Parameter1], 2:[?Parameter2]
mysql_command.Parameters[0].ParameterName = 'Parameter1'.
mysql_command.Parameters[1].ParameterName = '?Parameter2'.
mysql_command.Parameters["?Parameter1"].ParameterName = 'Parameter1'.
-=================== End ==================-
The last line code I commented raise an ArgumentException with the message "Parameter 'Parameter2' not found in the collection.".
The MySqlParameter didn't handle "?" prefix either, it keep the Parameter name original way. The only difference is the MySqlParameterCollection can handle the name with "?" prefix if search fail, and search name without "?" again.
RE: I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-12-04 16:04
[forum:1002908]
For Dynamic SQL(TestCase 'NpgsqlTests.DataAdapterTests.UpdateWithDataSet'), I found the reason is there is no primary key in tableB. The case passed if I add a primary key on 'field_serial'. Should we modify the sql?
For TestCase 'NpgsqlTests.CommandTests.FunctionReturnVoid', I replace 'test(:a)' to 'testreturnvoid()'.
For TestCase 'NpgsqlTests.CommandTests.LastInsertedOidSupport', should we add oid to the table at add_table.sql? otherwise there is no oid, and the test seems should always fail.
There are about 2 testcases failed because it using string directly to test against exception message rather than using resource file. I did a test using resource file instead, the 2 testcases passed.
For TestCase 'NpgsqlTests.CommandTests.DateTimeSupportTimezone', and TestCase 'NpgsqlTests.CommandTests.DateTimeSupportTimezone2',
I have thought on the timezone issue, I think we can fix them by short code, the only question is what beheavior we expect?
First, How should we handle datetime string from server, if the field is datetime with timezone, and we want to insert a value to server, there are 3 cases:
1. DateTime with Kind == UTC
I think we should use DateTime.ToString("u"). Since the format is ISO standard, and with "Z" attached to specify the value is UTC value.
2. DateTime with Kind == Local
We have 2 choice here, using current format,
ToString("yyyy-MM-dd HH:mm:ss.ffffff")
which is remove local offset info, and treat the value just as a DateTime without timezone, and leave the problem to server to make the decision. (which actually use the 'timezone' value of server as default timezone for the input).
Another option here is using:
ToString("yyyy-MM-dd HH:mm:ss.ffffffzz")
which the "zz" will be the offset of current system timezone. I think the second way with "zz" should be right, since there actually have timezone info, we should not ignore it. Especially, sometime we use DateTime.Now to get the current time, the value is actually current time for current system local time zone.
3. DateTime with Kind == Unspecified.
For this case, we may want to leave the decision to server, since there is no timezone information. If so, we cannot using format "yyyy-MM-dd HH:mm:ss.ffffffzz", since the "zz" will be the offset of current system local timezone, even it's Kind is not local.
What should we treat the value without timezone in this case? (just submit? submit as local? submit as utc?)
Second, How to parse the string from server?
For example, we get the string with timezone, such as
2002-02-02 09:00:23.345+5
The result of DateTime.ParseExact() is depends on the DateTimeStyles value. Current Npgsql is using None, which will convert above time to the local timezone, which will be, in my system (+11),
2002-02-02 15:00:23.345+11
Actually we have 3 option for the result,
1. Convert the time to UTC time. which should be:
2002-02-02 04:00:23.345Z
This way is reasonable, since it will make all time related code easy to handle. I think this is better.
2. Convert the time to Local time, which is current way. I don't think it's correct, since the current local time may vary.
3. Never convert the time, use the original value, and assign Kind to Unspecified. This way will keep the value identical to the string. However, since .Net DateTime doesn't contain any timezone info except UTC and Local, the timezone is missing, we will have some problem during update the value back to database.(using system local? database server local? utc?)
If we can clear the behavior, the implementation should not be hard to do.
RE: I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-12-04 16:09
[forum:1002909]
Sorry.
-=======-
First, How should we handle datetime string from server...
-=======-
should be
-=======-
First, How should we handle datetime to string during submit the command to server...
-=======-
RE: I got 8 testcases failed.
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-04 18:48
[forum:1002911]
Hi, Tao! Thanks for investigating those errors.
Please, send me your patches for the first corrections.
About datetime, I think we could stick with using UTC when sending and receiving data. It won't be perfect, but at least won't be wrong too. If this isn't enough, I think we could create custom type to add support for timezone as .net native type doesn't have support for timezones other than UTC and local as Tao said.
What do you all think?
RE: I got 8 testcases failed.
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-04 18:52
[forum:1002912]
Hi, Tao!
I added a pointer to this discussion on our mail list. Are you subscribed to npgsql-devel@pgfoundry.org? If not, please do it.
This discussion will be kept here, but others may appear in mail list and if you are subscribed you can follow them.
Thanks in advance.
RE: I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-12-05 03:18
[forum:1002915]
Thanks to point, I subscribed it now.
For testcase 'DateTimeSupportTimezone2()', What is its intention? The case use Command.ExecuteScalar().ToString(); to get the string. I think the result is culture depends, so the testcase will not always pass. Is there any special intention to put the case here?
RE: I got 8 testcases failed.
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-05 18:49
[forum:1002923]
Whoops, my fault.
This was a test test-case I used to see if I could get some idea to handle timezone datetime values. You can discard that.
Sorry for that.
RE: I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-12-05 06:04
[forum:1002917]
I created a patch for fixing testcases.
Patch link:
And could you apply the following patch also? this patch will add a nunit test project for NUnit20 and include it in vs solution file.
Patch link:
RE: I got 8 testcases failed.
[ reply ]
By:
Josh Cooley
on 2007-12-05 04:44
[forum:1002916]
I agree. About the only thing you can do with the DateTime data type and expect it to be correct is to use UTC.
We could support provider specific types to help with the timezone problem. .NET 3.5 has better support for timezones with DateTimeOffset and TimeZoneInfo. The provider could have conversion functions to the 3.5 types when using a 3.5 version.
My only concern is with data binding. If a developer uses timestamp with timezone and expects it to remain local, they will be in for a surprise when they display the DateTime in the UI.
RE: I got 8 testcases failed.
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-05 18:53
[forum:1002924]
+1.
I think the provider specific type is one good solution. With it we can work with those different support in framework versions as Josh said.
Also, as Tao said later, if we put it in our manual, users will know what is expected. If there is need for other expectations, we can work on them. Maybe we could add an entry on connection string to tell Npgsql how to deal with timezones.
RE: I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-12-05 07:11
[forum:1002918]
I think put a notice in manual might be a good solution if we use DateTime and stick to UTC. At least, the logic will never break if we use UTC.
There might be another way, we add a property to let developer specify which time they want(local/utc) before the command be excuted, and we convert it to specified time during the convertion as they want.
I agree with using DateTimeOffset, even it's not so great since it cannot handle daylight saving problem and cannot use it to do calculation on time if daylight saving timezone is involved, however, it is much better than current DateTime.
I checked my MSDN library, it's said DateTimeOffset struct is supported in: 3.5, 3.0 SP1, 2.0 SP1. 2.0 SP1 is a little bit tricky, I got it only during the installation of VS2008. Is there any automatic update will update .net 2.0 framework to 2.0 sp1? Mono treat the DateTimeOffset as NET_2_0 feature, but haven't been implemented yet. So what target .net version should we put this feature in? .Net 2.0? .Net 3.5?
RE: I got 8 testcases failed.
[ reply ]
By:
Tao Wang
on 2007-12-05 08:11
[forum:1002919]
I create a patch using DateTime.Kind to stick to UTC. It looks ok, at least passed the test case. There is only 2 behaviors I am not clear.
During convertion from DateTime to postgresql timestamp with timezone string, if the DateTime value's Kind == Unspecified, what should we do?
1. Using "yyyy-MM-dd HH:mm:ss.ffffff" format and leave the problem to server?
2. Treat Unspecified DateTime as local, and convert it to UTC, and submit?
3. Treat Unspecified DateTime as UTC, using "u" to submit to server?
I think the first should be better, however, the insert result will depends on current server runtime variable 'timezone', so at client side, developer will never know the real result. If we do so, we might need put a notice in manual.
During parsing string from server, if there is no timezone information attached, and it's timestamp with time zone value, Is it possible to happen? if it's, what should we do?
1. Treat the time as UTC.
2. Treat the time as system local timezone(NOTE, not server current local timezone!).
3. Return a DateTime with Unspecified Kind.
I also tried DateTimeOffset, (NET35), I found a problem, If we use DateTimeOffset for mapping timestamp with timezone in .Net 3.5, we will get inconsistance API, that is, the project run correctly with Npgsql .Net 2.0 version will might not be able to run with Npgsql .Net 3.5.
the problem is in .Net 2.0 Npgsql, timestamp with timezone field will cause a DateTime object returned, however, in .Net 3.5, the field will return a DateTimeOffset object, and DateTimeOffset is not inherit from DateTime, so program will got invalid casting exception, if they try to cast to DateTime. How we handle this?
RE: I got 8 testcases failed.
[ reply ]
By:
Josh Cooley
on 2007-12-05 14:27
[forum:1002921]
I agree that sending a date time to the server should convert to UTC unless the Kind is Unspecified. In that case we should leave it up to the server (choice 1).
I think we should try to get timezone information back from the server. If that's not possible, then I think we have to say that the DateTime.Kind is again Unspecified (choice 3).
You are right in that we can't change the type from 2.0 to 3.5. But we can provide a provider specific type that has conversion methods to go from "NpgsqlDateTime" to System.DateTime and System.DateTimeOffset.
RE: I got 8 testcases failed.
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-05 19:05
[forum:1002925]
Hmmmm, I think we should stick to UTC even if kind unspecified, don't we? So user will know that we always will treat datetime timezone as UTC unless otherwise specified (like when setting explicitly the kind to local).
What do you think?
When receiving data from server, I think that when the field is created with timezone, the values from server will always carry timezone information. If not, I think we should always treat them as in UTC. For example, with datetime fields created without timezone we would treat them as UTC, wouldn't we?
Please, correct me if I'm wrong. I may be missing something.
RE: I got 8 testcases failed.
[ reply ]
By:
David Bachmann
on 2007-12-18 14:36
[forum:1002957]
>2.0 SP1 is a little bit tricky, I got it only during the installation of VS2008.
>Is there any automatic update will update .net 2.0 framework to 2.0 sp1?
Yes, Microsoft provides an installer for updating .NET 2.0 to .NET 2.0 SP1:
Cannot connect to database (Npgsql)
[ reply ]
By:
Chris Miles
on 2007-12-11 15:12
[forum:1002939]
I have just installed Npgsql (stable), and I am having problems connecting to my database.
This is the code I am using:
NpgsqlConnection conn = new NpgsqlConnection("Server=192.168.0.50;Port=5432;User Id=cakeinaboxadmin;Password=cakeinaboxadmin;Database=cakeinabox;");
conn.Open();
Ip and port is valid - I can connect with pgadmin to the database without any problems.
An exception is thrown on the conn.Open() line:
"Unable to read data from the transport connection: An existing connection was forcibly closed by the remote host."
Full exception trace as follows:
Thanks
Chris
RE: Cannot connect to database (Npgsql)
[ reply ]
By:
Josh Cooley
on 2007-12-12 05:25
[forum:1002940]
I'm not sure what the circumstances are that would cause this error. You definitely got the initial socket connection established. It appears the PostgreSQL disconnected your client after receiving the startup packet.
Check your PostgreSQL configuration to see if you've disallowed certain types of connections. (maybe you only allow SSL)
RE: Cannot connect to database (Npgsql)
[ reply ]
By:
Chris Miles
on 2007-12-12 15:33
[forum:1002941]
Thanks.
The database is set up to allow all connections.
Chris
RE: Cannot connect to database (Npgsql)
[ reply ]
By:
Jon Hanna
on 2007-12-12 18:01
[forum:1002943]
Try disallowing SSL, and then trying again.
"An existing connection was forcibly closed by the remote host." is an exception that gets raised at the socket level. There's a large number of possible causes, many of which have nothing to do with either PostgreSQL or Npgsql (which is unfortunate in a way as it makes them all the harder to debug), but a common one is issues with SSL certificates.
If disallowing SSL fixes the problem, then we'll know that's where the problem is, and can look at fixing that so you can allow SSL again.
If disallowing SSL doesn't fix the problem, then we'll still know that's not where the problem is, so at least that'll be something :)
Badly formed XML comments in npgsql.xml
[ reply ]
By:
Andrus Moor
on 2007-11-11 20:08
[forum:1002815]
npgsql.xml contains a lot of messages like
<!-- Badly formed XML comment ignored for member "P:Npgsql.NpgsqlConnection.ConnectionString" -->
<!-- Badly formed XML comment ignored for member "M:Npgsql.NpgsqlConnection.GetSchema" -->
RE: Badly formed XML comments in npgsql.xml
[ reply ]
By:
Josh Cooley
on 2007-11-12 05:38
[forum:1002816]
I've found the same thing using visual studio. It doesn't like the newlines between comment sections. Nothing is wrong with the xml, just the comment parser. I can't remember if I committed a fix for that or not. My npgsql work is at home, and I'm away for the week.
RE: Badly formed XML comments in npgsql.xml
[ reply ]
By:
Jon Hanna
on 2007-12-10 12:54
[forum:1002931]
I've submitted two patches that deal with this (1010213 for the .NET1.x build and 1010215 which has .NET2.0 versions of the bunch of .NET1.x patches I submitted in one patch).
Mostly it was just newlines which break up the /// block and parsers don't like. There was a handful of bad tags too.
Login as Administrator
[ reply ]
By:
Vital Logic
on 2007-12-08 07:02
[forum:1002929]
I want to create database from my application, using npgsql. However the connection string explicitly needs a database to be passed as paramenter. How can I solve this?
Similar is the case with creating users from the application.
RE: Login as Administrator
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-08 14:29
[forum:1002930]
Hi, Vital!
You should use the template1 database. There you can create other databases and users.
I hope it helps!
Npgsql sunc notifications.How?
[ reply ]
By:
Dmitry Nizinkin
on 2007-10-29 08:52
[forum:1002787]
Hi, I have Win xp sp2,Postgresql 8.2.0,npgsql 1.0 data provider.
I need recieve notify from Postgresql server when row add in table on server.I write trigger on insert.In body this trigger write: notify MyApp.
In my application do:
npgsqlconnection+=new EventHandler(func);
It's work, but async. My app recieve message when i send next command on server.How my application can recieve message immediately.Pls help me.
[ reply ]
By:
Sean Zeng
on 2007-12-03 18:05
[forum:1002902]
Hi,
I met a weird problem when save a string with back slash then search for it.
1. I wrote two PG stored procedures, one to insert a string, one to retrieve it.
a. FUNCTION proc_add_value(i_value text) as:
INSERT INTO TEST_DATA (NAME) VALUES(I_VALUE);
b. FUNCTION proc_find_value(i_value text) as:
FOR O_NAME IN SELECT NAME FROM TEST_DATA WHERE UPPER(NAME) LIKE UPPER(I_VALUE) || '%'
LOOP
RETURN NEXT O_NAME;
END LOOP;
2. In C#, call the stored procedures through npgsql:
a. call proc_add_value with string parameter of @"HKLM\Software\test"
I can see the record is added correctly in pgadmin.
b. call proc_find_value with string parameter of @"HKLM\Software"
No record is returned.
c. call proc_find_value with string parameter of @"HKLM\\Software" (noted that there are two back slashes in the string)
The record of "HKLM\Software\test" is returned.
-------------
In summary, I inserted @"HKLM\Software\test" but need to pass in @"HKLM\\Software" (double back slash) to find it. It seems strange to me.
Do I miss anything?
Thanks!
Sean
RE: search for string with back slash
[ reply ]
By:
Tao Wang
on 2007-12-04 05:10
[forum:1002905]
9.7. Pattern Matching
9.7.1. LIKE
...
Note that the backslash already has a special meaning in string literals, so to write a pattern constant that contains a backslash you must write two backslashes in an SQL statement (assuming escape string syntax is used)..
...
So, modify the function to:
FUNCTION proc_find_value(i_value text) as:
FOR O_NAME IN SELECT NAME FROM TEST_DATA WHERE UPPER(NAME) LIKE UPPER(I_VALUE) || '%' ESCAPE ''
LOOP
RETURN NEXT O_NAME;
END LOOP;
should works.
RE: search for string with back slash
[ reply ]
By:
Sean Zeng
on 2007-12-04 21:30
[forum:1002913]
Great, it works fine. Now the C# codes are consistent and look much better :-)
A few questions about Npgsql2
[ reply ]
By:
Tao Wang
on 2007-11-28 16:43
[forum:1002874]
1. I think "CLASSNAME" in each class is not necessary, we can use "this.GetType().Name" instead. Am I missing anything here?
2. The Mono.Security reference is used for SSL connection. But .Net Framework 2.0 already implement SslStream, is that possible to eliminate Mono.Security dependence by using System.Net.Security.SslStream? And same thing for MD5, maybe using System.Security.Cryptography.MD5 is more natural for .Net 2.0. There are some classes or functions seems could be simplified by taking advantage of .Net 2.0 framework.
3. The recent updated test case for Connection:
[Test]
[ExpectedException(typeof(NpgsqlException))]
public void ConnectionStringWithSemicolonSignValue()
{
NpgsqlConnection conn = new NpgsqlConnection("Server=127.0.0.1;Port=44444;User Id=npgsql_tets;Password='j;'");
conn.Open();
}
I cannot understand the case. Should we throw a Exception here?
If yes, how to write connection string which contains a password which contains a semicolon?
4. Missing 3 methods, 1 property in NpgsqlFactory.
public virtual bool CanCreateDataSourceEnumerator { get; }
public virtual DbConnectionStringBuilder CreateConnectionStringBuilder();
public virtual DbDataSourceEnumerator CreateDataSourceEnumerator();
public virtual CodeAccessPermission CreatePermission(PermissionState state);
They are new in .Net 2.0.
5. Maybe we should implement a class NpgsqlConnectionStringBuilder which inherit from DbConnectionStringBuilder, to replace NpgsqlConnectionString. They are really similar and some functions in NpgsqlConnectionString has done in DbConnectionStringBuilder.
6. May be we should have a look on LINQ, there are some code implement LINQ to SQL for postgresql by using npgsql. :
It's MIT license, is it possible that Npgsql merge the code from the project to make Npgsql support LINQ directly? or a sub-project to do it?
7. Npgsql seems not well support in design mode of Visual Studio. At least not as well as MySQL.Data did. Could that part be improved?
Thanks.
Tao Wang.
RE: A few questions about Npgsql2
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-11-28 18:25
[forum:1002878]
1. I think it is ok to use getType().Name.
2. We have a request about that. I think it is ok too. I was thinking about using Mono.Security because it is maintained by Sebastien Pouliot from Mono project. But if we see we can use existing framework implementation, I think we can use it. As on Mono, it will still use Sebastien's implementation.
3. The intention of this test is to throw the exception based on connection refused because the port isn't the default. If this connection string passes, the exception will be thrown by Opne() method. You can use the semicolon the same way it is shown here with the value enclosed by single or double quotes.
4. Patches are welcome!
5. Patches are welcome!
6. Yeah, this would be great! I was pointed to this site when I was talking about Npgsql on Mono project. It would be very nice if we could release Npgsql with this add on project.
7. Yes. We have plans to integrate this. One of the reasons to change license was also to easy the process of add this support because of license restrictions on vs.net design support support code.
RE: A few questions about Npgsql2
[ reply ]
By:
Tao Wang
on 2007-11-28 16:49
[forum:1002875]
One more question about ParsingConnectionString(), may we don't using Regular Expression here? I try to write code below, and looks ok.(the only exception is handling the "value" contains a semicolon, which will not be correct parsed, but this can fixed by add a few lines code.). Can Npgsql use similar code to do that? Or, by inherit from DbConnectionStringBuilder, we can use the function existing to parse the connection string directly without writing any code for this.
======================================================================================
if (!string.IsNullOrEmpty(CS))
{
string[] items = CS.Split(";".ToCharArray());
foreach (string item in items)
{
string[] keyvalue = item.Split("=".ToCharArray());
if (keyvalue.Length == 2)
{
// Key
string key = keyvalue[0].Trim().ToUpperInvariant();
// Substitute the real key name if this is an alias key (ODBC stuff for example)...
string alias_key = (string)ConnectionStringKeys.Aliases[key];
if (!string.IsNullOrEmpty(alias_key))
{
key = alias_key;
}
// Value
string value = keyvalue[1].Trim();
if (value.StartsWith("\"") && value.EndsWith("\""))
{
value = value.Substring(1, value.Length - 2).Trim();
}
else if (value.StartsWith("'") && value.EndsWith("'"))
{
value = value.Substring(1, value.Length - 2).Trim();
}
// Check quote pair (open should always come with close)
if ((value.StartsWith("\"") && !value.EndsWith("\""))
|| (!value.StartsWith("\"") && value.EndsWith("\""))
|| (value.StartsWith("'") && !value.EndsWith("'"))
|| (!value.StartsWith("'") && value.EndsWith("'"))
)
{
throw new ArgumentException(resman.GetString("Exception_WrongKeyVal"), key);
}
newValues.Add(key, value);
}
else
{
if (keyvalue.Length > 1)
{
if (keyvalue[0].Trim().Length > 0)
{
throw new ArgumentException(resman.GetString("Exception_WrongKeyVal"), keyvalue[0].Trim());
}
else
{
throw new ArgumentException(resman.GetString("Exception_WrongKeyVal"), "<BLANK>");
}
}
else
{
throw new ArgumentException(resman.GetString("Exception_WrongKeyVal"), "<INVALID>");
}
}
}
}
======================================================================================
RE: A few questions about Npgsql2
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-11-28 18:36
[forum:1002879]
+1 to inherit from dbconnectionstringbuilder.
This way we need to maintain less code and reuse existing one.
RE: A few questions about Npgsql2
[ reply ]
By:
Tao Wang
on 2007-11-29 12:33
[forum:1002887]
For NpgsqlConnectionStringBuilder, I submited a patch. This patch add NpgsqlConnectionStringBuilder class to replace NpgsqlConnectionString class, and also add a cache support for connection string parse. Passed Npgsql test suite.
Patch link:
RE: A few questions about Npgsql2
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-11-29 18:13
[forum:1002889]
Thanks Tao.
I'm working on it.
As soon as I apply your patches I will let you know.
Thanks for your feedback and support.
RE: A few questions about Npgsql2
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-02 18:11
[forum:1002898]
Hi, Tao!
Patch applied! Thanks very much! And keep the good work!
RE: A few questions about Npgsql2
[ reply ]
By:
Tao Wang
on 2007-12-03 04:12
[forum:1002899]
Hi, Francisco,
Thanks, but you forgot apply the patch Npgsql_connection_string_builder.patch
, which will replace NpgsqlConnectionString with NpgsqlConnectionStringBuilder in several files, include :
NpgsqlCommand.cs
NpgsqlConnection.cs
NpgsqlConnector.cs
NpgsqlConnectorPool.cs
NpgsqlFactory.cs
RE: A few questions about Npgsql2
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-03 13:14
[forum:1002900]
Whoops, sorry for that!
Committed now! Please, check it out and let me know if you still have any problems.
Tao, could you please update vs.net project and send me the patch? I will update Monodevelop project.
Thanks in advance.
RE: A few questions about Npgsql2
[ reply ]
By:
Tao Wang
on 2007-12-04 02:11
[forum:1002903]
I created a patch for both Npgsql.csproj and Npgsql2008.csproj.
Patch Link:
RE: A few questions about Npgsql2
[ reply ]
By:
Francisco Figueiredo jr.
on 2007-12-04 18:36
[forum:1002910]
Patch applied!
Thanks Tao!
RE: A few questions about Npgsql2
[ reply ]
By:
Josh Cooley
on 2007-11-28 19:31
[forum:1002882]
"The Mono.Security reference is used for SSL connection. But .Net Framework 2.0 already implement SslStream, is that possible to eliminate Mono.Security dependence by using System.Net.Security.SslStream?"
We have talked about that in the past. That is a breaking change for the NpgsqlConnection API. As long as a breaking change is acceptable, then it does simplify things.
Newer Messages
Older Messages | http://pgfoundry.org/forum/forum.php?max_rows=50&style=nested&offset=2533&forum_id=519 | CC-MAIN-2017-17 | refinedweb | 6,755 | 60.82 |
Problem with Float inlet
Hi everybody,
Im trying to write an external for the first time and I’m having a problem which I could do with some help on. Essentially I’m trying to inititally just create a simple MSP object that I can then use as a basis for further work. This object is a simple gain object with a single signal input and output, and a float input. This float is simply the gain factor that the ip signal is multiplied by.
The object compiles and runs fine until you change the float value and then it stops working (although it doesnt crash or anything, the audio cuts out). I’m pretty certain the problem is with my code for dealing with the float input but I cant see what it is. I’ve included the code, any help would be greatly appreciated!
thanks,
enda
#include "ext.h"
#include "z_dsp.h"
#include
void *subsample_class;
typedef struct _subsample
{
t_pxobject x_obj;
t_float x_deltime;
} t_subsample;
void *subsample_new(double deltime);
t_int *subsample_perform(t_int *w);
void subsample_dsp(t_subsample *x, t_signal **sp, short *count);
void subsample_float(t_subsample *x, t_float val);
void main(void)
{
setup((t_messlist **)&subsample_class,(method)subsample_new, (method)dsp_free,
(short)sizeof(t_subsample), 0L, 0);
addmess((method)subsample_dsp, "dsp", A_CANT, 0);
addftx((method)subsample_float, 1);
dsp_initclass();
});
}
void subsample_float(t_subsample *x, t_float val)
{
post("Float in: %d", val);
x->x_deltime = val;
}
void subsample_dsp(t_subsample *x, t_signal **sp, short *count)
{
dsp_add(subsample_perform, 4, sp[0]->s_vec, sp[1]->s_vec, sp[0]->s_n, x);
}
t_int *subsample_perform(t_int *w)
{
t_float *inL = (t_float *)(w[1]);
t_float *outL = (t_float *)(w[2]);
int n = (int)(w[3]);
t_subsample *x = (t_subsample *)w[4];
while (n–)
*outL++ = x->x_deltime * *inL++;
return (w + 5);
}
On May 22, 2006, at 8:56 AM, Enda wrote:
>
> void subsample_float(t_subsample *x, t_float val)
> {
> post("Float in: %d", val);
> x->x_deltime = val;
> }
If you are on PC, you need to make sure all float message arguments
are defined as a double. On PPC floats and doubles are passed on the
stack as Doubles. This is not true on x86. Otherwise I didn’t notice
anything suspect in your code (aside from the unused val passsed into
your new method, which has no float type argument as defined in setup
()).
-Joshua
Thanks for that, the external is now compiling and working correctly. just one other little question, you said the there was an unused variable called val which didnt match the float defn inthe setup, was that referring to this code?? Im not 100% sure what you mean.
Thanks again!
enda
On May 22, 2006, at 8:56 AM, Enda wrote:
> setup((t_messlist **)&subsample_class,(method)subsample_new,
> (method)dsp_free,
> (short)sizeof(t_subsample), 0L, 0);
subsample_new as registered in setup() has no typelist args. However
below it has a val arg which is unused. Surely not a real problem,
unless you try to use val at some point.
>);
> }
-Joshua
Forums > Dev | https://cycling74.com/forums/topic/problem-with-float-inlet/ | CC-MAIN-2016-44 | refinedweb | 481 | 58.11 |
Introduction
Beginning PlDoc
Generating Documentation
Project Documentation
Conclusion
Target Audience
Motivation
Requirements
License
Code
This tutorial is for anybody who wishes to use the powerful facilities that SWI-Prolog provides for generating project documentation. The student is expected to know Prolog in general and the SWI-Prolog dialect in specific to a self-assessed level of at least advanced beginner. The student should also be sufficiently motivated to document code that learning a comprehensive and sometimes complicated documentation system is not a problem.
Any source code in any language, when needing to be maintained for an extended time or when being worked upon by multiple coders, requires good documentation. This documentation, to be complete must take three forms: tutorial, overview or guide, and reference. It is this third kind of documentation that PlDoc is chiefly designed for, although it can assist in the first two as well.
Through the use of so-called structured comments, PlDoc, like JavaDoc, Doxygen, EDoc and other such source code documentation facilities, generates high quality documentation in LaTeX format. PlDoc also provides a web server facility which can be used by the developer to browse documentation in situ; this is a valuable tool for library and package documentation. Finally PlDoc also provides a standalone web server facility for putting documentation into the public eye.
PlDoc is designed to be simple to start using and to be rewarding to the developers who use it (individual or group) from the start. While the whole package put together can seem overwhelming, the individual pieces are simple and can be used quickly with little fuss or bother.
To go through this tutorial you will require the following:
To get the most out of the tutorial you will need to:
Note that the samples are in subdirectories of the project root named according
to the headings of the tutorial. The names will be all in lower case and will
have whitespace replaced with underscores. Thus, for example, if there were
sample files for this section, they would be found in the
introduction/requirements subdirectory. The final version of the samples is
contained in the
src directory for those eager to see the end instead of
paying attention to the journey.
This tutorial is Copyright (c) 2012.
All of the code in this tutorial stems from section 2.8 of the Creating Web Applications in SWI-Prolog tutorial by Anne Ogborn. The files have been renamed and commensurate changes have been made in the source. No other changes have been made. The source code has been used with permission.
Comment Format
Module Comments
(The files for this section can be found in the
beginning_pldoc/comment_format directory.)
So we've been busy little beavers and we've made ourselves a little web application. This web app is going to be bigger than Facebook by far, however, so we need to get ready to add more team workers to the mix. After careful consultation with the oracle of our choice (the author prefers chicken intestines) we've decided that, given that our target platform is SWI-Prolog, the supplied PlDoc facility is how to begin.
But how do we start?
We know (because we've been told a dozen times by now) that PlDoc works through something called "structured comments" which sounds exactly like what we want: keep the documentation together with the source it documents.
Let's crack open the
server.pl file and look at the first predicate listed:
server(Port) :- http_server(http_dispatch, [port(Port)]).
That's not a very friendly predicate! Any newcomer to the code base is almost certainly going to find this bewildering. There's nothing there to guide understanding! Also, there's nothing there we can use to build our external documentation.
Structured comments to the rescue! There are two variants of structured
/* . . . */ C-style comments or the
% Prolog-style
comments depending on your preferences. In either case, however, the internal
format is the same. A structured comment consists of three sections in the
following order:
Let's concoct a pair of structured comments for the predicate we've listed above.
%% server(+Port:int) is nondet % % The server/1 predicate launches the server main loop at the provided port. % If launched, for example with Port set to 8000, the server can be browsed at %. % % @param Port The port the server should listen to.
In a Prolog-style comment, the type and mode descriptions are flagged by use of
the
%% commenting convention. The types and modes are read from the first
line that uses the double-comment symbol and end with the first line that uses
only a single comment symbol. PlDoc will then read and process the
documentation body until the first line beginning with the
@ symbol. It will
then process the rest of the comment block as tags. Blank lines are ignored
while processing (which is convenient for readable formatting of the comments
in source). So in the above example, the following is the type and mode
description block:
server(+Port:int) is nondet
The following is the documentation body:
The server/1 predicate launches the server main loop at the provided port. If launched, for example with Port set to 8000, the server can be browsed at.
The following is the tags block:
@param Port The port the server should listen to.
/** * server(+Port:int) is nondet * * The server/1 predicate launches the server main loop at the provided * port. If launched, for example with Port set to 8000, the server can be * browsed at. * * @param Port The port the server should listen to. */
The above comment is exactly the same in meaning to the Prolog-style block we
did above and generates exactly the same type/mode block, documentation block
and tags block. The double
** symbol identifies the beginning of a PlDoc
comment. The type/mode block begins with the first non-blank line (which is
why we could start it on a line by itself above). It ends with the first blank
line afterwards which signals the beginning of the documentation body. This
itself ends with the first line beginning with
@, signalling the beginning of
the tags block.
Given that the C-style blocks and the Prolog-style blocks are identical in semantics to PlDoc, all future comment blocks we do in this tutorial will follow the Prolog style of commenting except for the module comment block (which we will address later). This is done to avoid unnecessary replication of code.
The files
server_out.pl and
module_out.pl contain the results of our first
attempt to document the predicates of our source code in preparation for the
incoming massive team that will have to work with our code. Read the files
preferably side by side with the originals and see how much easier it is to
figure out the module even without any documentation generation!
Exercises
- Using the
server_out.plfile provided, convert the Prolog-style comments into C-style comments.
- Then convert some of them back.
- Check the structured comments provided in that file and see what other kinds of information would be useful. (Use the online PlDoc reference for types, tags etc. to get ideas.) Add them to the file.
(The files for this section can be found in the
beginning_pldoc/comment_syntax directory.)
The three sections of a PlDoc comment have three different syntax conventions. None of them is particularly difficult, but it is important to get them in the right place.
Types and modes are not formally a part of Prolog. They are, however, commonly referenced in the literature and documentation about Prolog systems. As concepts they are vital to understanding predicates, even if they're not enforced by the compiler (and, indeed, have no standing at all even in the runtime system.
The full documentation for the type and mode declarations can be found in the SWI-Prolog documentation. To help explain the (rather terse) documentation we will here replicate the type and mode declarations from the previous section and explain them.
server(+Port:int)
Reading this in English one would say something like "the
server/1 predicate
takes an input parameter named
Port which is an integer." Note that nothing
in the language enforces any aspect of that description. You could try to
pass in an uninstantiated variable. You could pass in an atom like
booger.
You could name the parameter
IckyThing in the actual implementation. All of
this will do nothing until runtime at which point you have to contend with
SWI-Prolog's interpreter getting ticked off with you.
Even worse, unlike the instantiation symbols (
+,
-,
?,
:,
@,
!)
there are no standard types. I used
int in this one. It could just as
easily have been
integer or
'this here is pretty weird as a type'. Of
course any sane project will have a set of standards for these types written up
in an easily available document. (We'll be talking more about this later.)
Note, also, when you look at the official documents, that the instantiation
pattern and the type are optional. As is the determinism mode (a fact I made
use of here because I'm not actually sure what the determinism of
server/1
is).
say_hi(?Request) is det
This predicate is as simple as the above one. I have chosen to drop the type
here (as I'm not familiar enough with the HTTP library in use to know for sure
what to call it). In this case, however, I have added the words
is det to
the end. This is because I know what the determinism mode of this predicate is
supposed to be. It is not supposed to be able to fail and it can only generate
one value. This makes it, in the terminology of Mercury, the
programming language PlDoc borrows the terminology from, "deterministic" and is
thus annotated with
is det.
Also of interest in this one is that the instantiation symbol is
?. This is
because the HTTP Request sent in is both an input parameter and an output one.
Parts of it are instantiated and used to help direct the predicate calls
throughout the system and parts of it are unified behind the scenes to fill out
the response.
page_content(?Request)// is det
This predicate works like
say_hi/1 but has the added
// annotation. This
means that the predicate in question is a DCG clause. Discussion of DCG
clauses is out of scope for this tutorial, however, except for mentioning how
they're annotated.
nav(?Name:atom, ?HREF:atom) is nondet
Well, we're back with types here and we've got the
is nondet annotation
added. To explain why this predicate is non-deterministic, let's first look at
its implementation:
nav('Home', '/home'). nav('About', '/about'). nav('Recipes', '/recipes').
What happens if we call this with
nav(X, Y)? The runtime leaves choice
points; we can get up to three results back from this. That means it has to be
non-deterministic or multiple-return (
is nondet or
is multi). To know
which it is, consider what happens if we call
nav('YAY TEAM!', X) or
nav(X,
'YAY TEAM!'). We would get a failure. The
is multi indicator specifies
that it cannot fail; it must succeed at least one time. Thus
nav/2 is
non-deterministic.
This brings us to our final example:
as_top_nav(+Name, -Pred) is semidet
Straightforward enough:
as_top_nav/2 takes a name as an input parameter and
returns a predicate term as an output parameter. But why is it
semi-deterministic?
Semi-deterministic predicates will either succeed precisely once or they will fail. Let's look at the implementation:
as_top_nav(Name, a([href=HREF, class=topnav], Name)) :- nav(Name, HREF).
Now since
Name is an input parameter, it must be instantiated. This means
that
nav/2 will either return a value in its
HREF parameter or it will not.
There will be no choice points. One value or no values. It's
semi-deterministic.
With this explanation you should be ready to read and understand the SWI-Prolog reference for type and mode declarations. The only thing left to note is that it is perfectly acceptable to have multiple type and mode declarations for a single predicate. Prolog is a remarkably flexible language and, PlDoc being a documentation tool (as opposed to a compiler), it is probably best to document the expected use cases in the type and mode declarations block. Like this:
length(+List:list, -Length:int) is det. % 1. length(?List:list, -Length:int) is nondet. % 2. length(?List:list, +Length:int) is det. % 3.
These declarations, taken from the PlDoc reference, illustrate the three common use cases for the list length operation:
Return in
Length the number of elements in
List.
e.g.
length([1,2,3], L).
Generate any number of lists in
List (filled with uninstantiated
variables) and return the list generated plus the length in
Length.
e.g.
length(L, M).
Generate a list with
Length uninstantiated variable and return it in
List.
e.g.
length(L, 5).
Exercises
- Visit the SWI-Prolog Library documentation and look over the various modules. For those with type and mode declarations (not all of them have this!) try to figure out what is meant by each and, importantly, try to work out why the determinism is what it's listed as.
The syntax of the documentation body is a Wiki notation based upon the venerable TWiki web application. Details of the conventional structuring notation are left for exploration of the documentation. The Prolog-specific extensions, however, warrant some further exploration.
TWiki is itself a very large, very complicated Wiki syntax. It is far outside of the scope of this tutorial to show every nook and cranny of it. Instead the alterations of and enhancements to the TWiki format are discussed here, along with some notes on how to use the more common markup tags. For more details on the TWiki format itself, consult the following sources:
The last link, in particular, is likely of most direct use, especially when combined with the PlDoc documentation page.
When describing parameters or various use cases of a predicate, it is common to provide example terms to explain the various kinds of behaviour. Consider, for example, the length/2 predicate shown above. The type declaration provided shows three use cases. The body of the description should show the provided examples:
* length([1,2,3], Size) Return in `Size` the length of the list `[1,2,3]`. (`Size = 3.`) * length(List, Size) Starting at `Size=0`, generate lists `List` of uninstantiated variables. ( `List = [], Size = 0; List = [_G11], Size = 1; List = [_G11, _G12], Size = 2,` ... ) * length(List, 2) Generate a list of 2 uninstantiated variables. ( `List = [_G11, _G12].` )
Note when using these that the closing
. character should not be provided.
The Wiki processor will supply it on your behalf (a questionable approach in
this author's humble opinion).
The usual TWiki rules for links apply with little change. There are three Prolog-specific enhancements of TWiki's notation: predicate links, file links and images. In addition there is an extra form of hyperlink notation.
Any construct in the form of
<url> is converted into a hyperlink. It is
chiefly used when making complex urls through
www_browser:expand_url_path/2 aliasing in which case the
construct is
<alias>:<local>. (You will have to consult documentation for
this feature should you choose to use it.)
Predicates can be linked by simple use of
functor/arity (regular) or
functor//arity (DCG) in the documentation body. Any such predicates which
are documented in anything else processed by PlDoc will be linked in the
ensuing documentation. Note, this will not link to documentation that PlDoc
hasn't been informed about!
Any
name.ext will be converted to a link to the named file if the file exists
and
ext is any of:
Images can be linked to as stated above for file links, but to have images
displayed instead they must be wrapped in double square braces:
[[my_image.png]].
Unlike link markup of predicate names (like
length/2), predicate lists are
used to bring in the content of a predicate's description inline in your
documentation. This is usually most useful for file-level documentation, but
can be useful even in predicate-level documentation. The following two
examples will illustrate the differences:
The following predicates are useful for manipulating lists in Prolog: * member/2 * append/3 * prefix/2 ...
This code will provide the user with a list of links to the named predicates. Compare and contrast with:
The following predicates are useful for manipulating lists in Prolog: * [[member/2]] * [[append/3]] * [[prefix/2]] ...
This code will instead bring in the documentation for the cited predicates. This permits replication of information without the dangers of being required to change source in multiple locations.
Font markup works as normal for TWiki-style markup with one very important exception:
font markup will only work as documented for one word at a time! This is because
of the prevalence of
=,
* and
_ in code. Should a larger stream of text be desired in
an alternative font, it must be wrapped in additional vertical bar (
|) characters:
*|Many words done in bold.|*
_|Many words emphasized.|_
=|Many words done as code.|=
Blocks of code are preceded and followed by
== as follows:
== append([], A, A). append([A|B], C, [A|D]) :- append(B, C, D). ==
Exercises
- Visit the SWI-Prolog Library documentation and look over the various modules. See if you can find examples of all of the above syntax constructs in the real documentation.
- (Optional) If you have the SWI-Prolog source installed on your system, inspect it for each of the above syntax elements and compare it to the results in the online documentation.
As with the documentation body, the details of the tags are best left to the reference documentation. The following tags are best-suited to documenting predicates, however, with the remaining tags more useful for file-level documentation (which is addressed later):
(As a point of style it would probably be better to fix bugs than to document them!)
Exercises
- Visit the SWI-Prolog Library documentation and look over the various modules. See if you can find examples of all of the above tags in the real documentation.
- (Optional) If you have the SWI-Prolog source installed on your system, inspect it for each of the above tags and compare it to the results in the online documentation.
(The files for this section can be found in the
beginning_pldoc/module_comments directory.)
So far we have focused on documenting predicates, but a good reference document should also provide information at the module level as well. Documenting a complex module by only explaining individual predicates is rather like documenting how to build a house by explaining the component bricks and beams and nails and such in isolation: confusing and pointless.
The files
module.pl and
server.pl are the output of the previous chapter
unaltered. We will be adding module level comments to them to illustrate how
this is accomplished; the ensuing files will be
module_out.pl and
server_out.pl. Keep in mind that just as an example of a coding style the
module comment will be done as a C-style comment (
/* ... */) instead of a
Prolog-style one (
% ...).
IMPORTANT NOTE
It appears that as a bug or by design, PlDoc requires the module comment to be a C-style comment! It is only by good fortune that the author of this piece didn't stumble headlong into this problem by selecting, at random, C-style module comments for illustrative purposes.
The syntax of module comments is identical to that of the predicate comments
except that the type and mode declaration is replaced by
<module> followed by
the title of the module. Here is the module comment for the server, by way of
example:
/** <module> Sample HTTP Server * * This module is part of Anne Ogborn's [[Creating Web Applications in * SWI-Prolog][]] * tutorial. It illustrates the * [[Mailman][]] * facility of SWI-Prolog's web application library. * * @author Anne Ogborn (Prolog code) * @author Michael T. Richter (PlDoc markup) * @version ch2.8 * @see * @copyright (c)2012 Anne Ogborn. * @license All rights reserved. Used with permission. */
Aside from the "type" header, the only real difference between a module-scoped comment and a predicate-scoped one is the tags which apply. The tags most likely to apply to the module scope are:
One thing to beware of, the
:- module(...). declaration must precede the
module comment. Failure to do this will result in the module documentation not
being generated!
Accomplishments So Far
During Development
HTTP Server and Browser
LaTeX Documentation
While it may not seem like it, we have actually accomplished a lot so far. Indeed the most important part of documentation is behind us: the content. By using a structured tool for writing the reference documentation we have source files that completely document the module in a way that aids comprehension; this is vital to any team-oriented task work.
Still, that being said, it would be nice, wouldn't it, if we could reference this documentation in ways other than scrolling through our source.
(The files for this section can be found in the
generating_documentation/during_development directory.)
One of the almost-unique uses of PlDoc lies in its use as an online documentation server in development. The work cycle goes roughly like this:
Any module anywhere that you use can be referenced in this documentation provided the source is available and suitably commented. (This includes the SWI-Prolog system libraries themselves, along with any packs you may have installed.) This feature makes PlDoc a valuable tool in your toolbox.
To make use of this, however, you'll need to modify your load/debug/whatever
scripts. (You do use these, right?) In this tutorial, we will be
making use of
load.pl and
debug.pl.
:- load_files([server, module], []). :- unload_file(debug). :- unload_file(load).
Our load script is dirt simple (to go along with the dirt simple web
application underlying it). It merely loads our
server.pl and
module.pl
files and then unloads the
debug.pl and
load.pl file to avoid clutter in
the documentation server.
:- doc_server(4040). :- portray_text(true). [load].
Our debug script, on the other hand, does some interesting stuff. The first
thing it does is it starts up the documentation server on port 4040. You can
consult the full docs for details, but in general your debug
script will fire up the documentation server with
doc_server/1 or
doc_server/2 as we did. You will probably also want to call
portray_text/1
to ensure that strings are displayed as, well, strings (instead of lists of
integers). Once all that has been done, the debug script simply consults the
load script (which we've already seen above).
From within our project directory we fire up SWI-Prolog and call the debug script as follows:
$ swipl % /home/michael/.plrc compiled 0.03 sec, 1,501 clauses Welcome to SWI-Prolog (Multi-threaded, 64 bits, Version 6.3.0)). 1 ?- [debug]. % Started Prolog Documentation server at port 4040 % You may access the server at % library(prolog_stack) compiled into prolog_stack 0.01 sec, 72 clauses % library(http/http_error) compiled into http_error 0.02 sec, 80 clauses % module compiled into module 0.00 sec, 10 clauses % server compiled 0.03 sec, 127 clauses % module compiled into module 0.00 sec, 1 clauses % load compiled 0.03 sec, 133 clauses % debug compiled 1.23 sec, 11,556 clauses true. 2 ?-
At this point the documentation server is running and the project code has been loaded. We should be good to go. Open a browser at and see the glory!
...
Waitwhat?! This isn't the documentation server! There's nothing document-like about this! What's going on?
Well, one of the weaknesses of PlDoc is one we wouldn't have seen if it weren't for the fact that our sample project is a web server. PlDoc and our web server are running at the same time in the same instance of SWI-Prolog and they're clashing. Our web app wins because its mapping of the root happens after the one the documentation server made.
The solution to this problem is fairly trivial. We have to pick an url we want
to serve our help from and modify the debug script (now called
debug2.pl for
purposes of this tutorial) to take this into account.
:- use_module(library(http/http_path)). http:location(pldoc, root('help/source'), [priority(10)]). :- doc_server(4040). :- portray_text(true). :- [load2].
The change here is to define very early in the proceedings an
http:location/3 predicate that redirects all PlDoc urls to, in this case,
<base_url>/help/source. Now instead of accessing we
instead access. Do that now and you'll be
rewarded with our documentation.
One very important item to note is that the full contents of the module comment will not be displayed unless the source file is a proper Prolog module. Only the name of the file will be displayed on its reference page, for example. To have all of your documentation information displayed (as detailed later), you will have to add a line like the following (which we've added for our example) to your code:
:- module(server, [http_handler/3, server/1]).
An additional point to note is that by default only the public (i.e.
exported) predicates will initially show in the documentation. To see the
private (i.e. non-exported) predicates, you will have to click on the icon
that looks like the image to the left. To switch back to the public-only view
you will have to click on the icon that looks like the image to the right.
Exercises
- Remove one or both of the
unload_filedeclarations from
load.pland see what the results are.
- Remove the
portray_textdeclaration in
debug.plor
debug2.pland see what the results are.
There are several reasons why being able to access the documentation live while coding is useful:
That last point needs some expansion. As an experiment, change some of the
markup in the structured comments in
server.pl while the documentation server
is running. Now hit the refresh in your browser. Watch as nothing whatsoever
changes! Now go to your SWI-Prolog console and type
[load]. followed by
the return key. Refresh your browser again. Note the changed markup! The
magic is that PlDoc's server will reconstruct its information every time you
load a module. (We just reloaded everything by using
[load]., but we could
just as easily have used
[server]. instead.) When working on shared code
bases, on a live development session you could update your code base from an
SCM repository, reload and have all your partners' working documentation
updated on your screen!
Exercises
-
Add a new module to the project. Ensure that it contains:
- a
moduledeclaration
- a module-level structured comment
- at least one predicate
- one predicate-level structured comment per predicate added
Add the new module to the
load.plscript and reload with
[load].Check the results in your browser after reloading the page.
The same ability to do documentation reading and updating while working live on
the code can be used to serve up the documentation as a straight-up
documentation server. (This is, indeed, how the SWI-Prolog documentation
itself is provided to the web.) To do this you use the
doc_server/2
predicate with the
allow(...) option to permit the documentation server to
work on more than
localhost. You would then, instead of loading your code,
use the
doc_load_library/0 predicate.
Full details on this (ridiculously simple) process are available in the PlDoc Reference Manual.
(The files for this section can be found in the
generating_documentation/latex_documentation directory.)
Good documentation needs to be available offline as well. PlDoc helps in this with its LaTeX back-end which can easily and quickly generate high-quality reference documentation with a quick command line at the shell:
swipl -g "doc_latex(['server.pl','module.pl'], 'doc.tex', [public_only(false)]),halt" -t "halt(1)"
Obviously this will have to be put into a script file or a Makefile goal
because you won't want to type this each time, but the operation of this could
not be simpler. The
doc_latex/3 predicate here is being used with these
arguments:
server.pland
module.pl);
public_only(false)).
The option selected specifies that we want all predicates documented, not only those exported from the module. (The reason for this is that our source files aren't done in modules.)
Full details of using
doc_latex/3 are available in the PlDoc reference
documentation. Other, finer-grained predicates are also documented
there.
One important point to note is that you need the
pldoc.sty LaTeX style sheet
on your command line for
latex or in your working directory. This file can
be found in
<swipl-library-root>/library/pldoc.
Exercises
- Using the extra module you added from previous exercises, generate a TeX document that includes your new module.
- Experiment with the command line to reorder the modules in the document.
- Write a PrologScript (or equivalent) that gives convenient command line access to creating TeX documents based on arguments.
- Create a
Makefiletarget called
docsthat automatically bundles all of a project's Prolog source files into a TeX document. (This may or may not involve the script you created previously.)
How Project Documentation Differs
Text Files
Building a Better Reference
Building a User Guide
Other Documents
So far we have very good documentation, but only for the developers on the team. It's purely reference documentation and it's not tied well together. For people who know the project already this isn't a problem, but we don't just document for our current team, do we? We'll have newcomers to bring up to speed and we'll have third-party users to contend with. Even our reference documentation nees a bit more of a punch.
To tie the documentation together into a more coherent whole, we need to have some way of organizing our documentation within a broader framework like an opening section that talks about the project as a whole and what its components are. This section could, for example, talk about how the various source files relate to each other or could assemble the predicates into related groups with interspersed commentary instead of merely dumping them in source code order.
In addition there are document types that go beyond simple references like user guides (which offer architectural overview, typical work flows, hook points, expected use cases and "recipes" for use) or tutorials (which, like this document, give detailed instructions for basic use for first-time users). Both of these can be written using PlDoc's markup (although there will be decreasing value the farther you move from the structured code comments).
(The files for this section can be found in the
project_documentation/txt_files directory.)
The first tool available for documentation purposes is the humble text file. Several such files are treated specially by PlDoc and are used to help structure documentation into something meaningful. All of the Wiki markup cited above and in the SWI-Prolog documentation apply here and, indeed, a wider subset of the markup is likely to be used in text files (including, for example, horizontal rules or heading markup).
README, which may also be named
README.TXT or
README.txt, is used to help
build the so-called directory index. The directory index is a landing page
built by the PlDoc document server. The contents of
README are first
displayed, followed by a table of all the project source files (plus their
descriptive summary) and their public predicates.
TODO, which may also be named with the
.TXT or
.txt suffix as above, is
appended to the directory index.
PlDoc will serve up
README and
TODO over the versions with
.txt or
.TXT suffixes. That is to say if you have a
README file and a
README.txt
file, PlDoc will display the contents of the former in the landing page, not
the latter.
This is unfortunate because for maximum portability across platforms you should
probably use the
*.txt naming convention; in Windows, for example, it's
impossible to associate the name
README with a program while
README.txt is
already configured out of the box to open with a text editor.
Exercises
- Create a
README, a
README.txt, and a
README.TXTfile and figure out which is higher priority than which when PlDoc loads.
- Do the same for
TODO.
Whenever the text
README,
TODO, or any name ending in
.txt or
.TXT is
encountered inside Wiki source, a link is generated. (Other
files share this property.) Any such referenced text files are
processed as Wiki documents, allowing for rich mark-up. This is one of the
primary techniques for documenting more than just references.
The following files have been added to the project to help rein in the documentation chaos:
Run SWI-Prolog from that directory and enter the following:
?- [debug].
Now fire up the browser and point at. Note how the better use of structured commenting in README and TODO make the landing page much more accessible. It's also nice having links to the tutorial and user guide immediately visible even before the module reference. (Note also how the module reference had a header added beforehand to make it stand out more in the formatting.)
If you clink through to the tutorial or to the user guide you'll also see documentation formatted from whole cloth using the TWiki syntax.
But ... what's this oddity in
userguide.txt?
The entire contents of userguide.txt are shown below:
---+ "So You Want to Make Prolog Web Apps?" ---++ A user guide. ---+++ Devoid of any meaningful content. Because this is just an example after all. ---++++ Well, here's a bit of content. * [[http_handler/3]]
If, however, you click through on it, you will see a whole lot more than just
these lines (formatted by the wiki processor). Indeed you'll see a lot of
information for the
http_handler/3 predicate including details that aren't
in our source code.
This is the magic of the predicate description list format. By using that notation we tell the document processor that we want it to replicate the full documentation for the named predicate at the given point in the document.
This is a powerful capability that allows better reference manuals to be made. Instead of relying on the (admittedly not bad) landing page with its alphabetic list of modules and the underlying alphabetic list of public predicates, it is quite possible to instead have a richer reference document that pulls in predicate references (including from the whole SWI-Prolog system, not just our own code!) in an order that makes more sense to the user.
As an example, the modules could be introduced in an order that is more likely
to be seen by someone actually using the software. Related predicates could be
grouped in such a way as to be together, even if one predicate is called
anteater/2 and the other is called
zebra/1. Explanations on how to use
predicates (e.g. sample code) can be interspersed where they make the most
sense. You'll still have your landing page and straightforward module and
predicate dictionary, but you'll also have better, more usefully-arranged
reference material without code replication.
Exercises
- Build a better reference using TWiki syntax and predicate description lists.
Building a user guide is just like building a better reference, only moreso. When building the user guide you'll be doing less wholesale importing of predicate documentation and making more use of code examples, term lists, and links to predicate documentation.
When building a user guide, you may find yourself having to repeatedly
introduce things like sample code verbatim in several parts of your document.
In such circumstances putting the snippet of code into its own file and
referencing it in your documentation like
[[snippet.txt]] will import it
verbatim. If you have to change your sample code, you only change it in one
place and it will be updated in your documentation wherever it is referenced.
User guides and tutorials are the obvious kinds of extra documentation that a project is going to need. Other documents, however, are also possible and, indeed, for any project of any decent size, required. These can include:
The imagination of the users is about the only limit to the kinds of uses to which PlDoc can be put in a team environment.
Remember the part where we talked about the types and modes?
Remember how it was mentioned that a sane team would probably have a set of
standards for the type names written up? Remember how we then hand-waved over
that? The waving stops here. It is almost mandatory, in the opinion of this
author, to have a rigorous list of types documented in a single place. The
file name could even be something difficult to remember like
types.txt.
Linking to (or flat-out including with double square brackets!) this document
in the README file would give a convenient way to reference the available types
while coding or reading the project's reference documentation. Such a document
could be very easily written like this:
---## Standard Types $ int32: a 32-bit signed integer $ int64: a 64-bit signed integer $ request: a composite value containing an HTTP request $ str: a list of integers interpreted as a string (encoding not specified) $ utf8str: a list of integers interpreted as a string (UTF-8 encoded) $ name: an atom interpreted as a name
Note here that the "types" are intentional types: they document the intent of the passed-in.
Rather than documenting the literal type (which, in Prolog, is a rather restricted set!), it is, in the opinion of this author, more important to document how the type is intended to be used with implicit limitations.
Exercises
- Make a document that documents the types used in
server.pland
module.pl.
Credits
Contact Information
The author of this piece would like to thank Anne Ogborn for the impetus to write this tutorial, as well as for the sample code used to illustrate it.
The author of this piece can be reached via email at
ttmrichter@gmail.com. This is also his GoogleTalk ID. He has been
known to frequent the
##prolog channel on the Freenode IRC service as
ttmrichter. He also has a Google+ Page upon which he vents his
spleen to his ever-shrinking set of so-called "circles". He also maintains a
blog of sorts. | http://chiselapp.com/user/ttmrichter/repository/swipldoctut/doc/tip/doc/tutorial.html | CC-MAIN-2017-04 | refinedweb | 6,429 | 55.95 |
Introduction
When building applications for the SAP Business Technology Platform (BTP) containing a database layer, API layer and UI layer we have two options. The first option would be to create each part separated and deploy it independent from each other to BTP. The other option would be to keep different modules that share the same lifecycle together by using the concept of MTA. MTA is designed to develop all different modules as one big application and deploy it together to BTP. MTA projects will automatically instantiate required services and bind it to the modules that consume them.
Here you have the official definition of MTA:
Source:
It states “share the same lifecycle”, the database and API layer often have similar lifecycle but this is not always the case. It can be perfectly possible that the API part and UI have a complete different lifecycle. In that case you maybe want to split up the MTA. Another reason could that you have different teams working on different parts of the app, a team working on the backend and one on the frontend. You maybe don’t want that a backend developer starts changing the frontend or the other way around. There might be even more reasons to split your MTA.
The question remains, how to connect the frontend to the backend when they are part of different MTA projects? Just like you have different reasons for splitting your MTA, there are different solutions to connect both MTA projects. In this blog I’m going to show how you can split your backend from the frontend using the managed AppRouter in BTP by only using MTA configuration.
Let’s start by creating the backend MTA:
(I’m going to use the Business Application Studio because it comes with a generator that has some valuable AppRouter configuration for the managed AppRouter)
Create Backend service
With “Backend service” I mean the database and api layer together. This goes hand in hand most of the time so it doesn’t harm to keep this together.
For creating the backend, I used the SAP Cloud Application Programming model, also known as CAP. Starting by using the “CAP Project” generator in BAS:
In the generator I provide a name for my project, select my favorite runtime and enable deployment for the database part to HANA with MTA configuration for deploying to CloudFoundry.
On top of that, I also enable the option to include the basic sample files just for testing purpose.
For demo purpose I simply keep everything as generated from the sample files. I do enable authentication on my service for security reasons by following the steps in the CAP documentation:
Some parts of the documentation are done by the mta configuration. For example, the xsuaa configuration comes from the generator already.
Next, I make authentication required by adding the following in the “cat-service.cds”
That’s actually it for the backend service!
For making the backend service available to other applications, I need some additional configuration. This configuration can be easily generated by adding a Fiori app to the CAP project. It also gives the possibility to test if everything works fine. For this I still used the deprecated generator “SAP Fiori Freestyle Module”:
Reason, why I use the deprecated generator:
Give it a name:
Select the basic template:
Immediately add the approuter config, I want to use the “Managed Approuter” and provide a unique name my project: (It’s important to not use an existing one, it will overwrite the existing one.)
Enable authentication an provide a namespace:
Provide a name for the main view and add a data service
This is the benefit when running the generator for a UI module in the same mta. You can simply connect the UI module to the service in the generator by selecting “workspace”:
And here you can select the service from your CAP project:
I also added a list to the main view to see the result of the CAP service.
In the end, this generator will add configuration to the mta.yaml file which will create a destination for the CAP service:
This destination is needed to access the CAP service from other applications outside this MTA project.
You can find the full code in this repo:
Create separated Frontend app
Off course, by frontend I mean a Fiori UI5 application :). Instead of generating a new UI5 app in the same MTA, I’m going to create a completely new MTA project with only my UI5 app. This time I used the newly released “SAP Fiori application” generator:
I selected the same template as in the deprecated generator:
As Data source I selected “None”. Currently I did not found a way to connect to my CAP service by using the generator:
I filled in all the project attributes and enabled deployment and flp configuration:
For some reason I got stuck in the generator at the time writing this blog post. Luckily, I was able to finish the wizard before taking screenshots and notes. If the problem in the generator still occurs for you, I raised this as a question for follow up:
For now, I continued using the deprecated generator. This generator includes the steps for the configuration of the approuter. If you use the new generator, you have to run a second generator for adding the approuter config: (You can also do this manually but it’s not that easy)
I’m going to use the “Managed Approuter” again. Be aware that the id for the managed approuter needs to be unique. Otherwise it will overwrite other html5 repositories.
This generator will add the following configuration to your project. This is the key to connect the UI of this MTA project to the service in the other MTA project:
This configuration will create a destination for the app-host and xsuaa instance that’s being used for the Fiori app in combination with the sap cloud service id. These generated destinations are needed for the Launchpad service to find your app in the HTML5 content provider. You can find detail explanation in the sap help documentation:
I changed this generated config for two reasons:
- Reusing service instances, some services are already instantiated by the config of the first project (CAP project with Fiori app included).
- The destination service from the Fiori app in the CAP project can be used in this Fiori app as well. It’s not needed to create a new instance of the Destination service
- This is not the case for all of them, the app-host service needs to be a new instance. Otherwise it will overwrite your other app.
- I’m going to reuse the xsuaa service which I’m going to explain in the next point. In case you have completely separated apps, it is better to create a new xsuaa instance. This will allow you to maintain the scopes dedicated for this app in the app-security file.
- Using my CAP service from the first project
- I want to consume my CAP service from my first project in my second separated fiori app. For this, the service and the UI app need to be connected to the same XSUAA instance. Downside, both share the same xs-security.json file. Best is to keep them in sync because each deploy will overwrite the previously deployed xs-security.json.
Let’s start the magic 🙂
- Change the destination service, go to “resources” in the mta.yaml and change the “service-name” of the destination service to the same as the one in the first project:
2. Change the service instance name of the xsuaa service to the same as in the first project:
3. Change the “xsappname” in xs-security.json to the same as the other project. Otherwise the deploy will fail because it’s not possible to update the name in an existing xsuaa instance.
4. Add the route to the destination of the CAP service in the xs-app.json (this destination was generated from the mta config in the CAP project)
5. Add tile config (might be done already by the generator)
6. Add the datasource config to the CAP service:
7. Add the ODataModel config:
8. Show the books entity as a list in the main view:
9. The app is ready for building and deploying to BTP CloudFoundry
The full project is available on GitHub:
Result in BTP Launchpad Service
As soon as the applications are deployed, you have to refresh the “HTML5 Apps” content provider in the Launchpad service and you will find them in the Content Exporer:
First refresh the HTML5 Apps provider:
Now, you will see your app in the “Content Explorer”:
Add the app to a catalog, group and role to see it on the launchpad:
When you click on the tile, the app from one MTA project will open and show data from the other MTA project:
A more detailed tutorial on how to integration your app in the launchpad service:
The complete group of tutorials:
Wrap-up
I created a CAP project with a database, api and ui layer. The API was made accessible only for authenticated users. On top of that, I created a UI only app that consumes the API from the CAP project. All of this described in different MTA’s. The key is to bind both MTA projects to the same xsuaa service instance.
This setup can be used in case you want to separate the MTA project into a backend and frontend part for whatever reason.
I shared my example projects on GitHub:
- Backend:
- Frontend:
I had this requirement for splitting up the MTA into backend and frontend already a few times for different reasons. Sometimes because of different types of developers, sometimes because one API is consumed by several apps and all have a different lifecycle or just to improve the build and deploy time of the MTA. Hope this can be valuable for you as well!
Hi Wouter
Thanks for the great blog post. I was trying to achieve the same this weekend and finally got it running too
I noticed one difference between your and my approach. Instead of defining the same resources (e.g. uaa) again with type `managed-service` I changed it to `existing-service` in the UI part. In this case the resource will be ignored but still can be used and it is totally clear which part of the app is responsible for the service itself.
Best regards, Fabian
Indeed, that’s a good one! Thanks for sharing!
Great blog, Wouter! I have a question regarding xs-security, to make sure I grasp the approach. In your example, you replicated the xs-security from one MTA to the other. In the event you were to add more scopes aside from the token exchange one, would you have to add identical scopes/roles to both in order to pass the expected authorizations from UI to backend?
I suppose in the event you try the "existing-service" approach ("existing" in UI, "managed" in Service) mentioned by Fabian, you could omit the xs-security from the UI MTA and still utilize the scopes declared in your Service MTA but in your UI code (in the UI's xs-app files, for example). Then you would just need to do the mapping in the IDP and then any xsuaa token you pass from the UI to the Service will have the Service's scopes on it. Is that right?
Best,
Matt
That’s right.
Regarding your first question, everything needs to be declared in the mta that is deployed the last. It will always overwrite the previous xs security config. Just to avoid trouble by deploying in a different sequence I keep them identical.
Hi Wouter,
I have followed same steps, node and ui as separate projects, I am trying on my trial account.
I have 2 issues:
Please help.
Thanks,
Sai Battula.
Anything in the logs for the 500 error? Hard to tell what goes wrong.. can be many things..
Hi Sai Battula ,
I was also getting the 500 internal server error while trying retrieve the service metadata. I performed following changes in my project.
1. Added "public: true" to "srv-api" of the service module.
2. added following destination
Hi Wouter Lemaire,
I have divided my application in 2 MTA application, The MTA1 app has only FLP module and Approuter module, the another MTA2 app will have DB,Service & UI5 modules, but MTA 2 is having Approuter but not using it, you can say a blank approuter. After deploying the application BTP. I am getting error in loading metadata 404.
below one is working
I am following below link and in comment section i have explained details .
Thnaks,
Satya | https://blogs.sap.com/2021/03/03/split-mta-into-backend-frontend-managed-approuter/ | CC-MAIN-2021-31 | refinedweb | 2,134 | 60.35 |
i am writing a code for class and have gotten everything else to work with my compiler except my else statements.
I keep getting the "expected primary expression before 'else'" and the "expected (
before 'else'" as wellbefore 'else'" as well
the first functions of my code is as follows:
(Yes i am a next liner)(Yes i am a next liner)Code:#include <iostream> #include <cmath> using namespace std; int main() { /* a=volume b=surface area r=radius */ double x,r,a,b,c,h,l,w; (putting a resp return command here after i finish this problem) cout<< "What shape would you like?"<<endl; cout<< "1) Sphere"<< endl; cout<< "2) Cone"<< endl; cout<< "3) Rectangular Prism"<< endl; cout<< "4) Cylinder"<< endl; cin>>x; if (x==1); // Sphere { cout<<"Radius="; cin>>r; while(cin.fail()<'0'); { cout<<"ERROR! VALUE MUST BE GREATER THAN 0"<<endl; cin.clear(); cin.ignore(256,'\n'); cout<< "Radius="; cin>>r; }; a=((4.0/3.0)*M_PI)*pow(r,3.0); b=(4*M_PI)*pow(r,2.0); cout<<"Volume="<<a<< endl; cout<<"Surface Area="<<b<<endl; } else if (x==2); // Cone {
The rest of the program is very similar to this part with the 'if' statement followed by command code followed by and else statement and repeat through all 4 shapes
if you would like to see the next section of the code let me know and i will post it in here.
any help would be great, thx
Dave | https://cboard.cprogramming.com/cplusplus-programming/123714-keep-getting-expected-primary-expression-before-else.html | CC-MAIN-2017-43 | refinedweb | 245 | 68.44 |
public class CharSet extends Object implements Serializable
A set of characters.
Instances are immutable, but instances of subclasses may not be.
#ThreadSafe#
clone, finalize, getClass, notify, notifyAll, wait, wait, wait
public static final CharSet EMPTY
public static final CharSet ASCII_ALPHA
public static final CharSet ASCII_ALPHA_LOWER
public static final CharSet ASCII_ALPHA_UPPER
public static final CharSet ASCII_NUMERIC
protected static final Map<String,CharSet> COMMON
protected CharSet(String... set)
Constructs a new CharSet using the set syntax. Each string is merged in with the set.
set- Strings to merge into the initial set
NullPointerException- if set is
null
public static CharSet getInstance(String... setStrs)
Factory method to create a new CharSet using a special syntax.
nullor empty string ("") - set containing no characters
The matching order is:
Matching works left to right. Once a match is found the search starts again from the next character.
If the same range is defined twice using the same syntax, only one range will be kept. Thus, "a-ca-c" creates only one range of "a-c".
If the start and end of a range are in the wrong order, they are reversed. Thus "a-e" is the same as "e-a". As a result, "a-ee-a" would create only one range, as the "a-e" and "e-a" are the same.
The set of characters represented is the union of the specified ranges.
All CharSet objects returned by this method will be immutable.
setStrs- Strings to merge into the set, may be null
protected void add(String str)
Add a set definition string to the
CharSet.
str- set definition string
public boolean contains(char ch)
Does the
CharSet contain the specified
character
ch.
ch- the character to check for
trueif the set contains the characters
public boolean equals(Object obj)
Compares two
CharSet objects, returning true if they represent
exactly the same set of characters defined in the same way.
The two sets
abc and
a-c are not
equal according to this method.
equalsin class
Object
obj- the object to compare to
public int hashCode()
Gets a hash code compatible with the equals method.
hashCodein class
Object
public String toString()
Gets a string representation of the set.
toStringin class
Object | http://commons.apache.org/proper/commons-lang/apidocs/org/apache/commons/lang3/CharSet.html | CC-MAIN-2014-10 | refinedweb | 365 | 64.61 |
Details
Description
When we cogroup on a tuple, if the inner type of tuple does not match, we treat them as different keys. This is confusing. It is desirable to give error/warnings when it happens.
Here is one example:
UDF:
public class MapGenerate extends EvalFunc<Map> { @Override public Map exec(Tuple input) throws IOException { // TODO Auto-generated method stub Map m = new HashMap(); m.put("key", new Integer(input.size())); return m; } @Override public Schema outputSchema(Schema input) { return new Schema(new Schema.FieldSchema(null, DataType.MAP)); } }
Pig script:
a = load '1.txt' as (a0); b = foreach a generate a0, MapGenerate(*) as m:map[]; c = foreach b generate a0, m#'key' as key; d = load '2.txt' as (c0, c1); e = cogroup c by (a0, key), d by (c0, c1); dump e;
1.txt
1
2.txt
1 1
User expected result (which is not right):
((1,1),{(1,1)},{(1,1)})
Real result:
((1,1),{(1,1)},{}) ((1,1),{},{(1,1)})
We shall give user the message that we can not merge the key due to the type mismatch.
Issue Links
Activity
- All
- Work Log
- History
- Activity
- Transitions
- I'm not sure the null handling in NullableBytesWritable.getValueAsPigType is the same. Previously it would check specifically if the value had been marked as null. Now it looks like if there isn't an entry in the first slot of the tuple (which I think would be what would happen if it were null) it will throw an exception. I think you want to return the isNull check, and make sure the constructors properly set that value.
- I don't understand the change in LOUnion.
Response to Alan's comments:
1. Yes, you are right. It introduces some subtle differences. When we see a null value, we set mNull flag, and put null into a tuple. We do read the null back; however, in NullableBytesWritable, we rely on mNull flag to do the comparison, which may results wrong result. I will change it.
2. LOUnion is a bug fix. We shall get null schema if union two different schema. It is to fix
PIG-1065. Since PIG-1065 is more of the same nature, I don't want to put fix in a separate patch.
+1
test-patch result:
68 release audit warnings (more than the trunk's current 464 warnings).
Release audit warning is because changed NullableBytesWritable construct triggered a new jdiff file.
Unit test:
all pass
end-to-end test:
all pass
Patch committed.
The patch also aim to solve
PIG-999, PIG-1065 | https://issues.apache.org/jira/browse/PIG-1277 | CC-MAIN-2017-17 | refinedweb | 427 | 75.81 |
LINQ, or Language Integrated Query, is a set of language and framework features for writing structured type-safe queries over local object collections and remote data sources. LINQ was introduced in C# 3.0 and Framework 3.5.
LINQ enables you to query any collection implementing
IEnumerable<T>, whether an array, list, or
XML DOM, as well as remote data sources, such as tables in SQL Server. LINQ
offers the benefits of both compile-time type checking and dynamic query
composition.
This chapter describes the LINQ architecture and the fundamentals of
writing queries. All core types are defined in the
System.Linq and
System.Linq.Expressions namespaces.
The examples in this and the following two chapters are preloaded into an interactive querying tool called LINQPad. You can download LINQPad from.
The basic units of data in LINQ are sequences and
elements. A sequence is any object that implements
IEnumerable<T> and an element is
each item in the sequence. In the following example,
names is a sequence, and
"Tom",
"Dick", and
"Harry" are elements:
string[] names = { "Tom", "Dick", "Harry" };
We call this a local sequence because it represents a local collection of objects in memory.
A query operator is a method that
transforms a sequence. A typical query operator accepts an input
sequence and emits a transformed output
sequence. In the
Enumerable class in
System.Linq, there are around 40 query operators—all implemented as static ...
No credit card required | https://www.safaribooksonline.com/library/view/c-50-in/9781449334192/ch08.html | CC-MAIN-2018-22 | refinedweb | 240 | 58.58 |
13 June 2007 14:15 [Source: ICIS news]
TORONTO (ICIS news)--Capacity utilisation at Canadian-based chemical plants rose by 2.3 percentage points in the first quarter of 2007 to 84.5%, compared with the first quarter of 2006, the highest level in four years, according to Statistics Canada (StatsCan) on Wednesday.
?xml:namespace>
Sequentially, chemical plant utilisation rose by 1.5 percentage points from 83% in the 2006 fourth quarter.
The improvement came despite February’s 15-day rail strike at Canadian National that disrupted the supply chain for chemical product manufacturers, StatsCan said.
Plant utilisation in the plastics and rubber products sector was 70.2% in the first quarter of 2007, down 12.3 percentage points from the 2006 first quarter and down 2.7 percentage points from the 2006 fourth quarter.
The declines in plastics and rubber were primarily due to weaker demand in the automotive sector, StatsCan said.
The numbers for the chemicals, plastics and rubber sectors compare with overall first-quarter industrial plant utilisation of 83%, down 2.8 percentage points from the 2006 first quarter but up 0.6 percentage points from the 2006 fourth quarter.
Overall manufacturing plant utilisation was 81.1% in the first quarter, down 3.7 percentage points from the 2006 first quarter but unchanged from the 2006 fourth quarter, StatsCan. | http://www.icis.com/Articles/2007/06/13/9037340/canada+q1+chem+plant+utilisation+at+4-year+high.html | CC-MAIN-2013-20 | refinedweb | 222 | 59.19 |
Your first, very basic web crawler.
Hello again. Today I will show you how to code a web crawler, and only use up 12 lines of code (excluding whitespaces and comments).
Requirements
- Python
- A website with lot's of links!
Step 1 Layout the logic.
OK, as far as crawlers (web spiders) go, this one cannot be more basic. Well, it can, if you remove lines 11-12, but then it's about as useful as a broken pencil - there's just no point. (Get it? Hehe...he...Im a sad person... )
So what does a webcrawler do? Well, it scours a page for URL's (in our case) and puts them in a neat list. But it does not stop there. Nooooo sir. It then iterates through each found url, goes into it, and retrieves the URL's in that page. And so on (if you code it further).
What we are coding is a very scaled down version of what makes google its millions. Well it used to be. Now it's 50% searches, 20% advertising, 10% users' profile sales and 20% data theft. But hey, who's counting.
This has a LOT of potential, and should you wish to expand on it, I'd love to see what you come up with.
So let's plan the program.
The logic here is fairly straightforward:
- user enters the beginning url
- crawler goes in, and goes through the source code, gethering all URL's inside
- crawler then visits each url in another for loop, gathering child url's from the initial parent urls.
- profit???
Step 2 The Code:
#! C:\python27
import re, urllib
textfile = file('depth_1.txt','wt')
print "Enter the URL you wish to crawl.."
print 'Usage - "" <-- With the double quotes'
myurl = input("@> ")
for i in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(myurl).read(), re.I):
print i
for ee in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(i).read(), re.I):
print ee
textfile.write(ee+'\n')
textfile.close()
That's it... No really.. That. Is. It.
So we create a file called depth_1. We prompt the user for entry of a url
Which should be entered in the following format -""
With the quotation.
Then we loop through the page we passed, parse the source and return urls, get the child urls, write them to the file. Print the url's on the screen and close the file.
Done!
Finishing Statement
So, I hope this aids you in some way, and again, if you improve on it - please share it with us!
Regards
Mr.F
17 Comments
Though, the format seems to have been lost xD. If you want. I'll paste it somewhere, or if you like it, you can just toss it in your source :).
Can you pastebin that? I tried to clean the ident's up, but i get this:
if sys.argv[1] == '-h':
IndexError: list index out of range
You may have already figured this out, but that error means you're missing the second argument. I'm not seeing that line of code anywhere in the text though, so perhaps this has been changed?
Hm, yea I sort of did... Yet that does not help me. I dun goofed.
*wonders if this is a windows thing*
And yes I know you told me to sysarg that, but for the life of me I could not figure out what it does. Afaik this sys.arg thing just seems to hold things like app path and so forth... Am I missing something?
No, it basically assigns arguments after the application to variables for use within the program. For example: crawler.py. That would spider google. With sys.argv they are labeled with 0 being the program itself. So arguments following it would be sys.argv[1], sys.argv[2] etc.
I've made a modification to your source :3. I added argument functionality to it, to make it shorter. However, I took out the usage thing...it could be re-added :D. Awesome stuff man, thanks for the tutorial :D.
import re, urllib
textfile = file('depth_1.txt','wt')
for i in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(sys.argv[1]).read(), re.I):
print i
for ee in re.findall('''href=["'](.[^"']+)["']''', urllib.urlopen(i).read(), re.I):
print ee
textfile.write(ee+'\n')
textfile.close()
When I enter "", I get:
IOError: Errno 22 The filename, directory name, or volume label syntax is incorrect: '\\search?'
For many other sites, I get:
IOError: Errno 2 The system cannot find the path specified: '\\services\\Services.css'
I guess they block the access.
Is there any way to circumvene this?
Have you sorted out this issue ? I too have this problem .
can someone explain this error?
Traceback (most recent call last):
File "webcrawl.py", line 9, in <module>
for ee in re.findall('''href="'(.^"'+)"'''', urllib.urlopen(i).read(), re.I):
File "/Applications/Canopy.app/appdata/updates/ready/canopy-1.2.0.1610.macosx-x8664/Canopy.app/Contents/lib/python2.7/urllib.py", line 86, in urlopen
return opener.open(url)
File "/Applications/Canopy.app/appdata/updates/ready/canopy-1.2.0.1610.macosx-x8664/Canopy.app/Contents/lib/python2.7/urllib.py", line 207, in open
return getattr(self, name)(url)
File "/Applications/Canopy.app/appdata/updates/ready/canopy-1.2.0.1610.macosx-x8664/Canopy.app/Contents/lib/python2.7/urllib.py", line 462, in openfile
return self.openlocalfile(url)
File "/Applications/Canopy.app/appdata/updates/ready/canopy-1.2.0.1610.macosx-x8664/Canopy.app/Contents/lib/python2.7/urllib.py", line 476, in openlocalfile
raise IOError(e.errno, e.strerror, e.filename)
IOError: Errno 2 No such file or directory: 'live.jpg'
12 lines is huge, what about two lines like this
SOSingleTagMatch(WCMethodPage('', 'GET', '', ''), 'name="_RequestVerificationToken"', 'value="', '"'));
It is a syntax from ScrapperMin App in android, it let you do web crawling, parsing, login, download, upload, and compile your script into APK
just a different query i want to know how can you check on-line games like come2play site games that which game is written in which language
Enter the URL you wish to crawl..
Usage - "" <-- With the double quotes
@> ""
Traceback (most recent call last):
File "/home/miet/mycrawlertest1.py", line 8, in <module>
for i in re.findall('''href="'(.^"'+)"'''', urllib.urlopen(myurl).read(), re.I):
AttributeError: 'module' object has no attribute 'urlopen'
Very nice post. One suggestion, instead of using regex if we use BeautifulSoup it will make the code more concise.
work fine !
for i in re.findall('''href="'(.^"'+)"'''', urllib.urlopen(myurl).read(), re.I):
print i
for ee in re.findall('''href="'(.^"'+)"'''', urllib.urlopen(i).read(), re.I):
print ee
textfile.write(ee+'\n')
textfile.close()
print i
expected an indented block ?
pls help me anyone ?
Share Your Thoughts | https://null-byte.wonderhowto.com/news/basic-website-crawler-python-12-lines-code-0132785/ | CC-MAIN-2019-30 | refinedweb | 1,126 | 77.64 |
Subject: Re: Graphic Images
From: Leonard Rosenthol (leonardr@lazerware.com)
Date: Fri Apr 20 2001 - 07:03:22 CDT
At 10:31 PM 4/19/2001 +0200, Hubert Figuiere wrote:
>>I'm not seeing the argument for JPEG here. Is the argument here that
>>storing a JPEG as a PNG will take up a few extra bytes?
>
>A few is an oximoron IMHO. That can be up to 10x the size in PNG. That is
>really the justification of JPEG.
You'd also lose support for native CMYK colors - and that's just
talking about today's JPEG and not JPEG2000.
>It is NOT hard. It is just too much. Why for example keeping GIF while PNG
>would store *exactly* the same image and make only one image format to be
>handled instead of two. That is exactly the purpose of having only one
>lossless bitmap image format used within our file format. This apply to
>BMP, TIFF, XBM, XPM, etc.
I'm with Hub on this one! Convert images to either PNG or JPEG
(depending), and vector to SVG. It's a issue of compatibility with the
rest of the world (ie. how much work does someone else have to do to handle
our files!), not just ourselves!
>For SVG, perhaps can we use XML namespace ? (I'm not an XML wizard, feel
>free to correct me).
That's how we should be doing it...
>For other things, I think that storing images as a base64 flow would be a
>good compromise between bloat and compatibility.
XML spec says that binary data either be a Base64 stream or be
referenced externally. No binary data in an XML file.
>For OLE/Bonobo, I request that there is a requirement to store the latest
>state of the object as a picture (choose the best format, SVG coming on
>the first row).
Yup! Martin and I were discussing this the other night on chat...
LDR
This archive was generated by hypermail 2b25 : Fri Apr 20 2001 - 07:04:14 CDT | http://www.abisource.com/mailinglists/abiword-dev/01/April/0761.html | CC-MAIN-2014-15 | refinedweb | 338 | 75.91 |
How to Add Internationalization (i18n) to your Preact application
Learn how you can add Internationalization (i18n) to your Preact Application with preact-i18n.
🇹🇼 中文版 (Chinese Version):
What is Internationalization (i18n)?
Internationalization is the design and development of a product, application or document content that enables easy localization for target audiences that vary in culture, region, or language.
In this article, you are going to use the
preact-i18n library to add internationalization to your Preact application.
Step 1: Setup Preact CLI & Create new project
Side Note: If you are already familiar with Preact, you may skip to the next step.
If you haven’t installed the Preact CLI on your machine, use the following command to install the CLI. Make sure you have Node.js 6.x or above installed.
$ npm install -g preact-cli
Once the Preact CLI is installed, let’s create a new project using the
default template, and call it
my-project.
$ preact create default my-project
Start the development server with the command below:
$ cd my-project && npm run start
Now, open your browser and go to, and you should see something like this on your screen:
Step 2: Add
preact-i18n library
Install the
preact-i18n library to your project using the command below:
$ npm install --save preact-i18n
preact-i18n is very easy to use, and most importantly, it’s extremely small, around 1.3kb after gzipped. You can learn more about the library here:
synacor/preact-i18n
Simple localization for Preact. Contribute to synacor/preact-i18n development by creating an account on GitHub.
github.com
Step 3: Create a definition file
Once you have the library installed, you will need to create a definition file, which you will store all the translate strings in a JSON file.
In this case, you will need to save this file in
src/i18n/zh-tw.json:
{
"title": "主頁",
"text": "這是個Home組件。"
}
}
Step 4: Import IntlProvider and definition file
Next, open the
app.js file, which is located in the
src/components folder. Then, import the
IntlProvider and your
definition file to the
app.jsfile:
import { IntlProvider } from 'preact-i18n';
import definition from '../i18n/zh-tw.json';
Step 5: Expose the definition via <IntlProvider>
After that, you will need to expose the definition file to the whole app via
<IntlProvider>. By doing this, you will be able to read the definition file everywhere in the app.
render() {
return(
<IntlProvider definition={definition}>
<div id="app" />
</IntlProvider>
);
}
At this moment, here’s how your
app.js file should looks like:
import { h, Component } from 'preact';
import { Router } from 'preact-router';import Header from './header';import Home from '../routes/home';
import Profile from '../routes/profile';// Import IntlProvider and the definition file.
import { IntlProvider } from 'preact-i18n';
import definition from '../i18n/zh-tw.json';export default class App extends Component {
handleRoute = e => {
this.currentUrl = e.url;
};render() {
return (
// Expose the definition to your whole app via <IntlProvider>
<IntlProvider definition={definition}>
<div id="app">
<Header />
<Router onChange={this.handleRoute}>
<Home path="/" />
<Profile path="/profile/" user="me" />
<Profile path="/profile/:user" />
</Router>
</div>
</IntlProvider>
);
}
}
Step 6: Use <Text> to translate string literals
You are almost done, now you just need to replace the text in the page with
<Text>. In this case, you will need to update the content of the home page (
src/routes/home/index.js) by adding the
<Text> inside the
<h1> and
<p> tags.
import { Text } from 'preact-i18n';const Home = () => (
<div>
<h1>
<Text id="home.title">Home</Text>
</h1>
<p>
<Text id="home.text">This is the Home component.</Text>
</p>
</div>
); export default Home;
Fallback Text
In order to prevent blank text being rendered in the page, you should set a fallback text to the
<Text>. If you didn't include the definition for
unknown.definition, the library will render any text contained within
<Text>…</Text> as fallback text:
<Text id="unknown.definition">This is a fallback text.</Text>// It will render this text: "This is a fallback text."
<Localizer> and <MarkupText>
If you want to translate the text of the HTML attribute’s value (ie:
placeholder="",
title="", etc …), then you will need to use
<Localizer>instead of
<Text>.
However, if you want to include HTML markup in your rendered string, then you will need to use
<MarkupText>. With this component, your text will be rendered in a
<span> tag.
In the example below, you are going to add few more lines of code to your definition file.
first_name and
last_name will be used for the
<Localizer>'s example, and
link for the example for
<MarkupText>.
{
"link": "這是個<a href=''>連結</a>"
}
With this, you will able to use
<Localizer> and
<MarkupText> in the page. Please take note that you need to import
Localizer and
MarkupText to the
src/routes/home/index.js file.
import { Text, Localizer, MarkupText } from 'preact-i18n';const Home = () => (
<div>
<Localizer>
<input placeholder={<Text id="first_name" />} />
</Localizer>
<Localizer>
<input placeholder={<Text id="last_name" />} />
</Localizer> <MarkupText id="link">
This is a <a href="">link</a>
</MarkupText>
</div>
);export default Home;
Templating
If you want to inject a custom string or value into the definition, you could do it with the
fields props.
First, you will need to update the definition file with the
{{field}} placeholder. The placeholder will get replaced with the matched keys in an object you passed in the
fields props.
{
"page": "{{count}} / {{total}} 頁"
}
Next, you will need to add the
fields attribute together with the value into the
<Text />. As a result, your code should looks like this:
import { Text } from 'preact-i18n'; const Home = () => (
<div>
<h2>
<Text id="page" fields={{ count: 5, total: 10 }}>
5 / 10 Pages
</Text>
</h2>
</div>
); export default Home;
Pluralization
With
preact-i18n, you have 3 ways to specific the pluralization values:
"key": { "singular":"apple", "plural":"apples" }
"key": { "none":"no apples", "one":"apple", "many":"apples" }
"key": ["apples", "apple"]
For the next example, you will combine both pluralization and templating. First, you will need to update the definition file with the code below:
{
"apple": {
"singular": "Henry has {{count}} apple.",
"plural":"Henry has {{count}} apples."
}
}
Next, you will update the home page (
src/routes/home/index.js) with the following code:
import { Text } from 'preact-i18n'; const Home = () => (
<div>
<p>
<Text id="apple" plural={1} fields={{ count: 1 }} />
</p>
<p>
<Text id="apple" plural={100} fields={{ count: 100 }} />
</p>
</div>
); export default Home;
With the method above, you will able to add pluralization and templating to your Preact application.
Dynamically import language definition file
In a real-world scenario, you would like to set the language site based on the user’s choice, which is either based on the
navigator.language or the user can change the site language on their own.
However, in order to prevent you from importing all the unnecessary definition files to the project, you can import the language definition file dynamically by using
import(). By doing this, you can import the language definition file based on the user's choice.
import { Component } from 'preact';
import { IntlProvider } from 'preact-i18n'; import defaultDefinition from '../i18n/zh-tw.json'; export default class App extends Component { state = {
definition: defaultDefinition
} changeLanguage = (lang) => {
// Call this function to change language
import(`../i18n/${lang}.json`)
.then(definition => this.setState({ definition }));
}; render({ }, { definition }) {
return (
<IntlProvider definition={definition}>
<div id="app" />
</IntlProvider>
);
}
}
In this case, you can call the
this.changeLanguage('zh-TW') function to change the site language.
Who’s using preact-i18n?
I am using
preact-i18n for my side project: Remote for Slides.
Remote for Slides is a Progressive Web App + Chrome Extension that allows the user to control their Google Slides on any device, remotely, without the need of any extra hardware.
Remote for Slides Progressive Web App supports more than 8 languages, which includes: Català, English, Español, Euskera, Français, Polski, Traditional Chinese, and Simplified Chinese.
In this side project, I am using the “dynamically import language definition file” method I mentioned earlier. This could prevent the web app to load unnecessary definition language file, thus this will improve the page performance.
Furthermore, the Remote for Slides Progressive Web App will set the language based on the browser’s language (
navigator.language), or based on the URL parameter (ie:
s.limhenry.xyz/?hl=zh-tw), or the user can change it from the Settings page.
Resources
synacor/preact-i18n
Simple localization for Preact. Contribute to synacor/preact-i18n development by creating an account on GitHub.
github.com
preactjs/preact-cli
😺 Your next Preact PWA starts in 30 seconds. Contribute to preactjs/preact-cli development by creating an account on…
github.com | https://limhenry.medium.com/how-to-add-i18n-to-preact-dff1bf19917?source=user_profile---------4------------------------------- | CC-MAIN-2021-49 | refinedweb | 1,423 | 54.73 |
Putting this up to garner feedback for a possible SIP.
While AnyVal is a great tool and is widely used, there are developers who are unsatisfied with it as a method of writing wrapper types (also known as the newtype pattern) because of the associated runtime cost.
AnyVal
@S11001001 has written an article titled “The High Cost of AnyVal subclasses”, in which he goes through some of the issues (boxing and unboxing penalty, O(n) complexity for wrapping and unwrapping containers), and argues convincingly that contrary to popular belief, the issues are not caused by Scala’s targeting of the JVM.
Instead, these runtime costs are because of the need to incorporate:
support for isInstanceOf, “safe” casting, implementing interfaces, overriding AnyRef methods like toString, and the like.
support for isInstanceOf, “safe” casting, implementing interfaces, overriding AnyRef methods like toString, and the like.
Goal:
In terms of changes to the language, I think it could live along side AnyVal (e.g. we don’t necessarily need to get rid of AnyVal or change its behaviour). It might make sense to have it as a separate thing entirely, like newtype Label(s: String).
newtype Label(s: String)
@adriaanm @SethTisue @odersky @dragos Would you mind having a read through this SIP proposal? @lloydmeta, @non and I were thinking of putting it together and would like to get some early feedback on it. Perhaps we can discuss it in our next SIP meeting, too.
Even though we haven’t figured out yet the technical details of the proposal and how such a feature would be added to the language (and interact with others), @S11001001’s blog post goes into some of these details, which give hints on how it could be implemented. I recommend reading the blog post.
Also, we would like to get what the Community thinks about this feature. So please, do comment or thumbs up if you like the proposal.
I think this would be a great addition! I know @adriaanm has said he doesn’t like the current tag encoding, but as the article shows it works better than value classes for many of these applications.
My sense is that this SIP should be easier to put together than SIP-15 (Value Classes) because the encoding is much less complex:
Other than generalized anxiety over changing the language and spec, does anyone think this is a bad idea, or difficult?
As far as the API, I could imagine an annotation which changes the meaning of AnyVal or a new type to extend (e.g. AnyVal.NewType).
AnyVal.NewType
I wouldn’t be opposed to such a SIP. There are a few things that come to my mind, that should be carefully considered in the SIP:
newtype
newtype Int
j.l.Integer
asInstanceOf[Foo]
asInstanceOf[underlying of Foo]
isInstanceOf
Foo
classOf[Foo]
classTag[Foo]
Array[Foo]
If we are working with these types:
class Meter(val toDouble: Double) extends AnyVal
class IntOps(val toInt: Int) extends NewType
class MeterOps(val toMeter: Meter) extends NewType
Then I’d answer your questions as follows:
IntOps
Integer
Int
int
MeterOps
Meter
isInstanceOf[IntOps]
isInstanceOf[Int]
classOf[IntOps]
classTag[IntOps]
Array[IntOps]
Array[Int]
A SIP would require a better formal specification, but I think these are the right properties to want.
Because total erasure makes these things easier to reason about, I think that we can even allow newtypes of newtypes, but I haven’t fully worked through enough examples to be sure.
Why not use a Scalameta macro annotation and generate the same kind of code as in the blog post? This way the thing can live entirely in library and no language modifications are needed.
This is more flexible, as it could lend itself to user configuration/customization (like macro-based case classes would, a.k.a. data types à la carte). For example, it could be made to generate Scalaz-style subst functions.
subst
AFAICT, the only thing that currently cannot be achieved is to erase a newtype of a primitive type P not to Object but to P itself, so that the compiler can avoid boxing the primitive. That is, without having to use a <: P bound, which partially defeats the purpose.
P
Object
<: P
Therefore, I propose to only add to Scala an @erasureOf[T] checked annotation, that tells the compiler what an abstract type should erase to. For example:
@erasureOf[T]
class LabelAPI {
@erasureOf[Int]
type Label
}
val LabelImpl: LabelAPI = new LabelAPI {
// type Label = String // error: the erasure of String does not correspond to Int
type Label = Int
}
This way, Label is still completely distinct from Int as far as the type checker is concerned, but the erasure phase will turn it into Int and so it will be the same as Int throughout the rest of the compilation, allowing for unboxed usage and for the right bytecode signatures.
Label
Correct me if I’m wrong, but I think this would be relatively easy to add to the compiler, and thus to get accepted into the language, as compared to having a new stab at an AnyVal-like feature.
@LPTK I don’t think that proposal is a good substitute. My main concern with it is that it looks like “a compiler feature” rather than “a language feature”. It is an annotation that tweaks what the compiler should do when compiling a given piece of code, altering its semantics in non-obvious ways in the process, rather than properly defining semantics in the first place, and letting the compiler do whatever it takes to correctly implement those semantics.
Does it actually alter the semantics? At least on the JVM, I don’t see where the semantics would be different with and without the annotation (perhaps related to JVM integer interning and referential equality?).
My point was that, as the blog post shows, the language features required to do wrapper-free newtypes are already there. The only “missing” part is related to performance (not boxing primitive types). In other words, I think we need a compiler feature rather than a language feature.
Hey guys, yesterday I started to work on an implementation for this proposal, just a prototype to show how it should work. It’s not possible to use macros to implement the whole feature, so I’m implementing it with annotation macros (to avoid touching typer for simplicity) + a compiler plugin. I hope to finish it off soon to get the proof of concept out. Erik is working on the spec, so at some point we’ll put our work together. After that, if such proposal is numbered in the next SIP meeting, I’ll invest some of my free time to port the prototype to the compiler (Scalac, maybe Dotty too).
@LPTK With regard to your comment, note that the main goal of this proposal is to make newtypes available to the whole Scala community. That’s why I don’t want my prototype to become the official way of consuming this feature – I just want it to be a tool to test and make the process review faster. IMO, this is something that merits inclusion in the language, so far it seems technically better than value classes in Scalac.
That said, I don’t think @erasureOf is a good idea because it’s a very specific compiler feature to enable the creation of certain language features. Its main goal is to circumvent the limitations of existing extension mechanisms like macros. I don’t think we should add features to the compiler just to enable the creation of other language features, it brings complexity for nothing. It’s better to add fully-baked language features that do work, bring immediate value and can be widely used to solve problems that we experience in our day-to-day jobs.
@erasureOf
@LPTK @erasureOf does alter the semantics, because val x: Any = "hello"; x.asInstanceOf[Label] would succeed without @erasureOf[Int] but fail with @erasureOf[Int].
val x: Any = "hello"; x.asInstanceOf[Label]
@erasureOf[Int]
If it was a library, it could be included in the Scala Platform, which is designed for this purpose.
Nitpicking here, but @erasureOf is not to circumvent the limitations of macros. It actually has nothing to do with macros.
I agree it is rather ad-hoc. If there are really no other use for the annotation and all other things being equal, it’s probably better to go with a language feature. It just seems like more work to do the latter. On the other hand, if we found more uses for @erasureOf then my opinion may change, as it would enable the mantra from the Programming in Scala book mentioned in my first link: “Instead of providing all constructs you might ever need in one ‘perfectly complete’ language, Scala puts the tools for building such constructs into your hands”.
No, it’s not designed for this purpose. The compiler is designed for this purpose. The Scala Platform is opt-in. The point of this feature is to make it available by default.
It circumvents the fact that you cannot modify erasure with macros. Otherwise you wouldn’t need erasureOf.
erasureOf
And it does, to some extent (and way more than other programming languages). But I would say that erasureOf is borderline. There’s probably people in the community more entitled to discuss this than I am.
Are you sure? I’m not knowledgeable enough in the Scala compiler to know how type-checking affects asInstanceOf casts. I would have thought that at the end of the day, it would be equivalent to x.asInstanceOf[Int], which does not fail.
asInstanceOf
x.asInstanceOf[Int]
EDIT: never mind, I read too fast. It would indeed fail in one case and not the other. Shouldn’t asInstanceOf on an abstract type with no bounds at least yield a warning?
Hey folks, using SIP-15 as a template I did a quick pass in creating something we could potentially build a SIP out of:
I am sure there are typos, mistakes, and oversights, but hopefully this gives us a common basis of comparison. I just threw it up into a gist to make it easy to read, but we can move this into a repo or other shared environment if people think it’s useful to collaborate on it.
One thing to add – I chose to use the extends NewType syntax in the document to be clear that this is different from AnyVal but to preserve some continuity. In practice I don’t care what the name is, or if this is done with an extends X versus an annotation (or even new syntax).
extends NewType
extends X
Thanks for putting that up! I think it would be a good idea to put it up somewhere for collaboration
This already exists as a library as, including the macro annotation. It implements Stephen’s blog posts as well. Syntax is like:
@opaque type ArrayWrapper[A] = Array[A]
@translucent type Flags = Int
Where opaque types box like generics (never unless primitive) and translucent types are subtypes of the types they are newtypes over, with the advantage that primitives are not boxed unless in a generic context.
Thanks! That’s really great prior art!
I think this proposal is slightly more ambitious (or misguided, depending on your stance) in that it allows you to create things that look like methods on the new types (whereas if I understand correctly newts just provides a type member plus wrapping, unwrapping, and subst). But we should certainly make sure that the newtype classes here work at least as well as those defined via newts.
Though it should be mentioned that it would be really easy to extend newts and make it generate the appropriate method-providing implicit class from something like this:
@opaque class ArrayWrapper[A](val unwrap: Array[A]) {
/* method defs */
def size = unwrap.length
}
…and then extend it some more as the needs arise in the future, because it’s a library. | https://contributors.scala-lang.org/t/pre-sip-unboxed-wrapper-types/987 | CC-MAIN-2017-43 | refinedweb | 2,001 | 58.82 |
New Style Header
- In C++ programs the header <iostream> is included. This header supports C++ style I/O operation ( <iostream> is to C++ what <stdio.h> is to C). Notice one other thing: there is no .h extension to the name iostream. The reason is the that <iostream> is one of the new style header defined by Standard C++. New-style headers do not use the .h extension.
Namespaces
The next line in the program is
using namespace std;
This tells the compiler to use the std namespace. Namespace are a recent addition to C++. A namespace creates a declarative region in which various program elements can be placed. Namespaces help in the organization of large programs. The using statement informs the compiler that you want to use the std namespaces. This is the namespace in which the entire Standard C++ library is declared.
By using the std namespace you simplify access to the standard library. The C programs don’t need a namespace statement because the C library functions are also available in the default global namespace. | https://epratap.com/new-style-header-in-c-programs/ | CC-MAIN-2021-04 | refinedweb | 178 | 76.62 |
Archive date: 2019-08-13This content is no longer being updated or maintained. The content is provided “as is.” Given the rapid evolution of technology, some content, steps, or illustrations may have changed.
GCC Basics
The GCC compiler is a part of the Free Software Foundation’s GNU Project. GCC is developed through an open source environment, as are all the GNU tools, and it supports many platforms including AIX. GCC stands for GNU Compiler Collection, and supports many languages such as C, C++, Objective C, Fortran, and Java. In this article, we will be discussing GCC versions 3.3.4 and all versions of 3.4 on AIX versions 5.1, 5.2 and 5.3.
Comparing GCC compiler to XL C/C++ compiler
XL C/C++ Enterprise Edition V7.0 for AIX is the follow-on release to VisualAge® C++ Professional V6.0 for AIX. In this section, we describe why you may want to use the GCC compiler on AIX versus using the XL C/C++ Compiler. The XL compiler has great support for the latest international and industry programming language standards. The XL C/C++ compiler comes with new built-in functions for floating-point division, new pragmas and additional new compiler options. A key feature of IBM XL C/C++ Advanced Edition V7.0 for AIX is further compatibility with GCC. In order to help with porting of code that was originally written for GCC, a subset of features related to GNU C/C++ is supported by XL C/C++. Importantly, the XL C/C++ compiler is optimized for PowerPC systems, including POWER5.
But there are some situations when using the GCC compiler might be more appealing. When applications are written using standard APIs and compiled using GNU gcc or g++ compilers porting them across multiple platforms is much easier to accomplish. GCC has multiple language front-ends facilitating parsing multiple languages. GCC is a portable compiler and runs on most platforms available today, and supports most commercial 64-bit CPUs. GCC is a native compiler which.Finally GCC gives you freedom to enhance existing GCC and other GNU software developed by others.
As developers try to support their applications on many platforms, using different compilers on different platforms can cause numerous headaches. If, instead, you use the GCC compiler, which is supported on a great variety of platforms, it reduces the headaches in porting applications from one platform to another. GCC can make your job easier by providing a common compiler environment across platforms. g++ is now closer to full conformance to the ISO/ANSI C++ standard.
Please note that the default AIX operating system make does not understand the GCC make files. If you are attempting to load GCC compiler on AIX, you need to have GNU make file. You can print
make -v to see what you need to build on GCC.
AIX 5L Binary Compatibility
IBM provides binary compatibility amongst AIX 5.1, AIX 5.2 and AIX 5.3 versions of the operating system. Therefore applications running on AIX 5.1 or on AIX 5.2 will run on 5.3 as-is if they follow the criteria listed in the IBM’s AIX 5L binary compatibility statement. With that said, ISVs vary wildly on the processes they use to add support of a new OS release level. Many of the top ISVs run their applications through some form of testing. In most cases they will run them through a subset of their final testing procedures prior to adding support. Many other ISVs, however, review our binary compatibility details and add support based on their applications compliance with our statement. In either case, there is no need to recompile the application to get them to AIX 5.3.
Installing GCC on AIX
Installing GCC on AIX is easy if you have the binaries available for the version you want to install on your AIX system. The binaries can be ftp’d to your AIX system from the following sites, as indicated in the Related topics section:
- Bull AIX Freeware
- Hudson Valley Community College Open Source Software
- AIX 5L and 6 Open Source packages
- IBM AIX Toolbox for Linux applications
After downloading the appropriate binary format file,
chmod the downloaded file to executable mode, and then run SMIT to install. Support for AIX 5.2 was added in GCC version 3.3.
The IBM AIX Toolbox for Linux applications web site has GCC 3.3.2 binaries available as this time for AIX 5.1 and 5.2. The BULL Freeware site also has GCC version 3.3.2 binaries available for AIX 5.2.
If you require a newer GCC version, you need to first install an available GCC binary on your system. Once you have GCC installed, you can use it to compile the newer GCC version on your AIX system. See Related topics to find the complete set of GCC installation instructions and Host/Target-specific installation notes for GCC. It is important that you follow the platform-specific instructions carefully. Read through the instructions carefully before starting the build and install process.
You might find GCC build reports useful to ensure you successfully installed GCC 4.3.x (see Related topics). At this time, there are build reports for AIX 5.3.
Make sure that you install a version of GCC that corresponds to the AIX release installed on the system. GCC installs private copies of some header files that must integrate properly with AIX system header files for GCC to function correctly, otherwise running the compiler can produce error messages about header files. The header files should be rebuilt if they do not match. You can delete the header file cache to build a new release of GCC from sources with an old version, but GCC should not be operated without the header file cache.
GCC compiler options
There’s a wide variety of compiler options available on GCC, ranging from optimizing code, setting or suppressing ISO/ANSI standard code compilation, to debugging options, template code compilation options. GCC also provides some compiler options specific to the pSeries (formerly known as RS/6000) and PowerPC platforms.
A full description of the options available for POWER and PowerPC targets can be found at. Here we will go through a few of the options that we consider to be most relevant.
Of the options that set the processor type, such as
-mcpu and
-mtune, it is best to use the defaults that GCC provides. On AIX 4.3 and AIX 5.1, the default is -mcpu=common — this code will work on all members of the pSeries (RS/6000) processor families. On AIX 5.2 and higher, the default is
-mcpu=powerpc -- this code will work on pSeries PowerPC processors. GCC assumes a recent processor type associated with the AIX release as a processor model for scheduling purposes.
You should use
-mcpu=power,
-mcpu=power2,
-mcpu=powerpc,
-mcpu=power4, etc. to optimize for a specific processor or class of processors. Do not use the
-mpower,
-mpowerpc,
-mpower2, or
-mpowerpc64 options. Although they are available, they are not intended for end users. Using
-mpower2 or other options in isolation may cause unpredictable results because the compiler may not be in a self-consistent state for that target processor.
To compile an application in 64 bit mode, one should use the option
-maix64, which enables the 64-bit AIX ABI such as:.
If you get a linker error message saying you have overflowed the available TOC (Table of Contents) space, you can reduce the amount of TOC space used by using -mminimal-toc. By default GCC uses
-mfull-toc which allocates at least one TOC entry for each unique non-automatic variable reference in your program. GCC also places floating-point constants in the TOC. However, only 16,384 entries are available in the TOC, and it’s possible to overflow the TOC. By specifying
-mminimal-toc GCC makes only one TOC entry for every function.
-pthread compiles and links your application code with the POSIX threads library, just as you would do in VisualAge (or XL) C/C++. With VisualAge (or XL) C/C++, you can also compile and link using
xlc_r or
xlC_r to get thread support, but this option doesn’t exist with GCC. Threaded code should therefore be linked with
-pthread for GCC. The
-pthread option sets flags for both the preprocessor and linker.
The
-g option generates debugging information, defaulting to
-gxcoff+ at level 2. The debugging information may contain some extensions intended for the GNU Debugger (GDB). To produce debugging information more compatible with AIX dbx, one may use the
-gxcoff option.
GCC for AIX does not support
-msoft-float fully. It will turn off use of floating point registers within GCC, but GCC support libraries and AIX libraries will continue to use floating point registers.
-mlittle-endian and
-mcall-linux are not valid in the AIX configuration. The documentation mentions all options for all GCC “rs6000” targets. Not all options are available in each configuration.
To pass options to the native AIX linker directly, use
-Wl, <linker option>.
G++ and GCC Compiler Options
A description of g++-specific compiler options can be found at. These options are the same on AIX.
Similarly, a full description of gcc-specific compiler options can be found at. These options are also the same on AIX as other UNIX systems.
The list of optimization options can be found at.
The most-common optimization option is
-O2, which enables a number of optimizations to enhance performance of the resulting executable or library.
-O3 enables more optimizations that can improve performance at the expense of additional compile time.
-Os enables optimizations that increase performance, but tries to minimize code size.
Additional optimization options that are useful for computationally-intensive scientific applications include
-funroll-loops and
-ffast-math.
-ffast-math allows the compiler allows the compiler to improve performance at the expense of exact IEEE and ISO conformance for math functions.
Shared libraries on AIX versus System V systems
First, let us look at the differences between AIX and System V systems with respect to shared libraries. We will then discuss how to create shared libraries on AIX systems using GCC.
AIX and System V have different views of shared objects. AIX generally sees shared objects as fully linked and resolved entities, where symbol references are resolved at link-time and cannot be rebound at load-time. System V sees them as being very similar to ordinary object files where resolution of all global symbols is performed at run-time by the linker. However, AIX does have the capability to do run-time linking (RTL), so that symbols may be left undefined until loadtime, when a search is performed among all loaded modules to find the necessary definitions.
A shared module in AIX can be an object file or an archive file member which can contain shared modules and/or ordinary object files. In System V, shared libraries are always ordinary files, created with special options.
In AIX, generally all of the linker’s input shared objects are listed as dependents of the output file only if there is a reference to their symbols. AIX also makes use of export files to explicitly export symbols. In System V the names of all shared libraries listed on the command line are saved in the output file for possible use at load-time. However, starting in AIX 4.2 and available in all currently available releases of AIX (4.3, 5.1, and 5.2), the
-brtl option causes all shared objects (except archive members) on the command line to be listed as dependent objects in the output file. For more information, see AIX Linking and Loading Mechanisms (PDF 184KB).
With GCC, gcc -shared creates a shared library. The linker automatically exports some symbols, but you can use AIX’s ld -bexpall to export more symbols. Symbols with underscores are still not exported automatically. On AIX 5.2 or AIX 5.1 at maintenance level 2, it is possible to use the new -bexpfull link option which will export all symbols and does not skip symbols that begin with an underscore (like C++ mangled names). For complete control, it’s best to create an export file. If you are unfamiliar with AIX’s export files, AIX Linking and Loading Mechanisms (PDF 184KB).
gcc -shared creates an AIX-style, tightly-bound shared object, as briefly described in the AIX vs SystemV section above.
gcc -shared invokes the AIX linker with
-bM:SRE -bnoentry. Therefore, you don’t need to duplicate these two AIX options.
Using
-brtl, the AIX linker will look for libraries with both the
.a and
.so extensions, such as
libfoo.a and
libfoo.so. Without
-brtl, the AIX linker looks only for
libfoo.a. You can create
libfoo.a simply by archiving a shared object or even by renaming the shared object as
libfoo.a— AIX doesn’t care, as long as the file suffix is
.a. To use AIX run-time linking, you should create the shared object using
gcc -shared -Wl,-G and create executables using the library by adding the
-Wl,
-brtl option to the link line. Technically, you can leave off the
-shared option, but it does no harm and reduces confusion.
If you want to create a shared object with GCC, you only need to use
gcc -shared and, possibly, the
-bexpfull option or an export file referenced with
-Wl,
-bE:<export filename>.exp. It’s that simple.
Possible issues when using GCC/G++ on AIX
Here are a few possible issues that you might discover in using GCC or G++ on AIX. For each, we have first described the issue, and then we show the solution for that issue.
- You cannot use the GNU linker on AIX as this will cause incorrectly linked binaries. By default, the AIX linker is used when using GCC on AIX. You should only use the default AIX linker.
- When compiling and linking with -pthread, the library search path should include -L/usr/lib/threads at the beginning of the path. Check the output of dump -Hv, Import File Strings, entry 0, to see what the paths are. The threads subdirectory should always come before /usr/lib and /lib.
- Running the gcc -o foo … -L/path -lmylib doesn’t work. It can’t open the library because it looks for a static library libmylib.a instead of libmylib.so. If the extension .so is changed to .a, it works fine — it compiles and runs. Both archive libraries and shared libraries on AIX can have an .a extension. This will explain why you can’t link with a .so and why it works with the name changed to .a.
- When running a 64-bit C++ application using C++ shared libraries and exception handling, the application crashes. GCC 3.4.3 fixes an error that prevented C++ exception handling across shared libraries from operating correctly in 64 bit mode.
Linking an application with an archive of object files (normal library, not shared library) produces error messages about unresolved symbols. This can occur if a library contains object files with references to symbols outside of the library that the programmer thought the linker would ignore.
GCC provides a wrapper around the system linker that scans all object files and non-shared libraries for constructors and destructors. This is done before the linker has an opportunity to skip unneeded object files in the library because a function or data may only be referenced in a constructor or destructor. The scan may find constructors and destructors that the application does not normally reference, requiring additional symbol definitions to satisfy the link. The alternative would miss constructors and destructors required by the application because some object files in the library appeared to be unneeded and were omitted but actually supplied required constructors and destructors. This omission would cause the application to break.
- When trying to compile GCC on AIX, assembler error messages eventually result. To fix this, make sure that you are not using an old version of the GNU assembler which does not understand certain PowerPC mnemonics. It is preferable to use the AIX assembler as discussed in the AIX installation instructions on the GNU GCC web site.
Sometimes you might get this error message while linking:
ld fatal: failed to write symbol name symbol_name in strings table for file filename
This error most likely indicates that the disk is full or or that the ULIMIT environment variable won’t allow the file to be as large as it needs to be.
- G++ doesn’t do name mangling in the same way as VisualAge (or XL) C++. This means that object files compiled with one compiler cannot be used with another.
- The GNU assembler (GAS) doesn’t support PIC. To generate PIC code, you must use some other assembler, such as the native AIX assembler `/bin/as’.
On AIX, compiling code of the form:
extern int foo; ... foo ... static int foo;
will cause the linker to report an undefined symbol foo. Although this behavior differs from most other systems, it is not a bug because redefining an extern variable as static is undefined in ANSI C.
- In GCC versions prior to GCC 3.4, does not pass all structures by value. GCC 3.4 now has better ABI support for structure argument passing. While this change brings GCC closer to AIX ABI compliance, these changes may create incompatibilities with code compiled by earlier releases. For more information, see.
- When GCC is built for a particular version of AIX, it generates some files specific to that version of the OS and its header files. This can cause problems when using that GCC build on a newer version of the OS, even just bootstrapping the compiler on the newer OS. An example of this problem occurs when building GCC on AIX 5.2 with GCC compiled for AIX 5.1 (or earlier). AIX 5.2 added support for the atoll() function, but GCC built for AIX 5.1 includes a cached copy of stdlib.h that does not include the prototype for that function. The return value of an unprototyped function defaults to “int” instead of “long long”, causing GCC to incorrectly convert some strings. To bootstrap GCC on AIX 5.2, the “fixed” stdlib.h header file in GCC’s cache needs to be removed so that the AIX 5.2 header file is used. The system header file can be used by the older build of GCC to bootstrap the compiler.
An example
Here’s an example of having a great enough stack size per thread and the corresponding makefile using GCC to compile a program using pthreads.
The array is allocated on the stack, not in the data section. The problem is the stack size per thread. You need to use appropriate pthread functions to increase the default thread stack size. Without the ‘#ifdef _AIX’ code below, this code will coredump.
$ cat test.c #include <pthread.h> #include <stdio.h> #define NUM_THREADS 3 #define SIZE 100000 void *PrintHello(void *threadid) { double array[SIZE]; int i; for (i = 0; i < SIZE; i++) array[i] = (double) i; pthread_exit(NULL); } int main() { pthread_attr_t tattr; pthread_t threads[NUM_THREADS]; int rc, t; if (rc = pthread_attr_init(&tattr)) { printf"ERROR: rc from pthread_attr_init() is %d\n", rc); exit(-1); } #ifdef _AIX if(rc = pthread_attr_setstacksize(&tattr, PTHREAD_STACK_MIN + SIZE * sizeof(double))) { printf("ERROR: rc from pthread_attr_setstacksize() is %d\n", rc); Exit(-1); } #endif for (t = 0; t < NUM_THREADS; t++) { printf("Creating thread %d\n", t); if (rc = pthread_create(&threads[t], &tattr, PrintHello, (void *)t)) { printf("ERROR: rc from pthread_create() is %d\n", rc); exit(-1); } } pthread_attr_destroy(&tattr); pthread_exit(NULL); } $ cat Makefile host := $(shell uname) CC = gcc ifeq (,$(findstring CYGWIN,$(host))) # not Cygwin LDFLAGS += -lpthread endif PROGRAM = test OBJECTS = test.o all: $(PROGRAM) $(PROGRAM): $(OBJECTS) clean: rm -f $(PROGRAM) $(OBJECTS) core tags | https://developer.ibm.com/technologies/systems/articles/au-gnu/ | CC-MAIN-2021-31 | refinedweb | 3,329 | 65.01 |
Jerry VanBrimmer wrote: > I? > It depends whether IDLE is opened with a subprocess or not. If it's a subprocess, your program will have a separate interpreter entirely from that used by IDLE, so the namespace will be the default namespace. If IDLE doesn't have a subprocess, your program will be run in the same interpreter as IDLE itself is running in, and since IDLE doesn't end between runs of your program, all the variables you declare will hang around. You could test this if you want. Do import random print random.randint(1,5) then take out the import and run it again. If the print statement still works, IDLE's not using a subprocess. There have been many threads about this, it's usually a Windows issue. -Luke | https://mail.python.org/pipermail/tutor/2007-August/056311.html | CC-MAIN-2016-36 | refinedweb | 132 | 74.39 |
Q&A
The Microsoft MVP and LINQ expert discusses the best current C# features, how developers can stay on top of changes, and what they often get wrong about Microsoft's flagship coding language.
November is shaping up to be a busy month for developers. Along with Visual Studio 2022 and .NET 6, another landmark release of a major Microsoft product is expected to debut next month: version 10 of C#.
When it comes to what's included in the new C# release and how we got here, Microsoft MVP and LINQ expert Jim Wooley has the answers. At the upcoming Live! 360 conference taking place on Nov. 15-19 in Orlando, Fla., Wooley will host a session called "C# Past, Present, and Beyond" that will cover a lot of the most important C# features, especially those in more recent versions (think C# 6 and later), how you can start using them today, and what to expect when C# 10 comes around.
Ahead of his session next month, Wooley answered a couple of questions about the best current C# features, how developers can stay on top of changes, and what they often get wrong about Microsoft's flagship coding language.
VisualStudioMagazine: There've been a lot of changes to C# in recent years. What's been the most exciting new development/change/feature?
Wooley: In its first decade, we saw several language enhancements in areas such as LINQ, Lambdas, Generics and Async which fundamentally changed the way we write C#. In the next decade, since the compiler was re-written via Roslyn, we've seen a ballooning of language features, including ones we use every day like String concatenation, null-terminating operators, ref locals and returns, and pattern matching. Some features improve performance of the framework APIs, like Span<T>, range operators and native ints. And then there are features to make getting started with simple projects easier, including top-level statements, static and global usings, and file-scoped namespace declarations. There are even some features that some might consider controversial, including tuples, nullable reference types and default interface implementations.
While most of these changes won't fundamentally change how we think about how we approach code like the functional changes from LINQ and Lambdas, many can reduce and simplify the code you have to write as a C# developer.
"People think [C# is] just a different syntax from JavaScript, Java, C, etc. and don't take the time to understand differences in memory models, object pointers. Oftentimes, they produce systems which have performance issues, or flat-out don't work right because they didn't understand what their code was doing."
Jim Wooley, Solution Architect, Slalom Consulting
Perhaps the most exciting feature isn't specifically a language feature, but related to changes enabled with the Roslyn compiler, and that is syntax generators that came with C# 9. These generators enable enhanced metaprogramming capabilities to automate repetitive coding operations that typically required IL rewriting, aspect-oriented strategies, reflection, etc. With the generators, you can create code that writes code once and greatly reduce the amount of plumbing code you have to manually type over and over, while still retaining the performance benefits of not having to use things like runtime reflection, for example.
Is there an underrated, often-overlooked C# feature that you wish more people knew about?
As newer versions of C# have come out, the patterns that we use to code have subtlely changed. To make it easier to discover these newer patterns, the compiler team has also created a number of Roslyn-based analyzers and code fixes to provide recommendations on how to discover the new features. Paying attention to the squiggles and suggestions (ellipsis dots) under older code patterns, developers can learn about some of these newer language features like string interpolation, pattern matching and out variables, just to name a few.
Many developers ignore these suggestions, but they can often not only reduce the code that developers have to write, but in some cases even highlight potential bugs in the code base that the compiler may otherwise overlook. In many cases, just learning a simple keyboard shortcut in Visual Studio (Ctrl-.) when focus is placed on a line that can be optimized can start teaching developers how to improve their code.
In the face of constant updates, what's the best way to keep up your C# skills and stay on top of changes?
Gone are the days where we just go out to a bookstore to pick up a book teaching us the latest features. Technology changes too frequently and by the time a new book is produced, a new version of the technology often has already shipped and made parts of that book obsolete. For example, with C# over the last five years, we've seen C# 7.0, 7.1, 7.2, 7.3, 8.0, 9.0 and -- this fall -- 10.0. If you want to stay up-to-date on the status of the various language features, the best bet is to monitor the GitHub repository for the language features along with the language features pages of the Microsoft docs site.
Of course, the best way to learn about new features is to attend conferences like Live! 360 and other community events that discuss things that you aren't familiar with to get an overview of what's available and why you should consider using it. Don't expect to learn everything there is to know about the topic in an hour, but just knowing that it exists will help you out when the time comes that you need to use a new technology. Then you can learn the best way I know -- by trying to use the technology and working through the challenges you encounter.
Also, if you're using a modern IDE, pay attention to the recommendations that it gives you on ways to improve your code. You can often learn a lot of the new ways of doing things just by trying out some of the suggestions that it gives.
How has the C# community evolved, especially in relation to other programming languages? Where do you see it progressing?
When C# and .NET were open-sourced, C# developers no longer needed to rely on reflection and decompiling tools to understand how things work and we can see the implementation and details for ourselves. This means that we no longer have to rely on support desk calls or Microsoft forums to figure out how to use framework elements. Now we can look at the actual source of not only the libraries that we use, but also the compiler itself.
What: C# Past, Present, and Beyond
When: Nov. 17, 2 p.m. - 3:15 p.m.
Who: Jim Wooley, Solution Architect, Slalom Consulting
Why: "With the modern open source C# Compiler, we've seen so many new language features, it's hard to keep up."
Find out more about Live! 360, taking place Nov. 15-19 in Orlando, Fla.
As a result, the language developers are no longer working in a vacuum, but are actively monitoring and discussing potential new language features directly with you the customer on GitHub for anyone that wants to participate (and potentially contribute back code). The docs for .NET and C# are open-sourced, as well, so if you find a gap or bug, you're welcome to create an issue and possibly contribute your own pull request to help others.
In addition to the official C# team channels, there are also other online resources like blogs, Twitter and Stack Overflow. While this enables the community to have greater access to information, it also poses a challenge of keeping up-to-date, or qualifying the version of C#/.NET that the item applies to. Sometimes finding the answers to your problems is more challenging because the underlying technology stack may have changed (.NET Framework to .NET Core to .NET 5/6, for example). Naturally, this challenge is not isolated to C#, but can be seen in many other languages and platforms. Consider, for example, the challenges of trying to find resources specific to Angular when that framework completely changed between the 1.x and 2+ versions.
As time goes on, don't expect the number and quality of online resources to decline, but be aware to check the date of the original post and factor that into your decision as to whether it solves your problem or not.
What's the biggest mistake or misconception developers have about C#?
People think it's just a different syntax from JavaScript, Java, C, etc. and don't take the time to understand differences in memory models, object pointers. Oftentimes, they produce systems which have performance issues, or flat-out don't work right because they didn't understand what their code was doing. While you don't have to know the internals of everything you use, you shouldn't just find a Stack Overflow answer for your question and pick the first answer assuming it will solve your problems without understanding the solution and why it is better than other alternatives. | https://visualstudiomagazine.com/articles/2021/10/14/csharp-qa.aspx | CC-MAIN-2022-21 | refinedweb | 1,525 | 59.84 |
Blocks, block types and block templates are linked together in the following way:
- A block type defines a set of properties, for example a heading and a page listing.
- A block is an instance of the .NET class defining the block type.
- As for pages, associated controllers, views and templates are used to render the block in some context.
Blocks can only be rendered in the context of other content, such as a page. A block instance is either part of a page instance if a PageType or BlockType contains a property of the block type, or a shared instance.
- For a page instance, the block is stored, loaded, and versioned as part of the page.
- For a shared block, the block is stored, loaded and versioned individually as an own entity, and can be referenced from multiple pages or blocks.
Block types
In Episerver, block types are usually defined in code as classes based on a model inheriting from EPiServer.Core.BlockData, in a similar fashion as for page types. During initialization, the bin folder is scanned for .NET classes inheriting BlockData. The BlockData object is the programmatic representation of a block, containing the properties defined in your .NET class. The value of currentBlock is automatically set to the BlockData object that is requested by the client.
For each of the classes found a block type is created. For all public properties on the class, a corresponding property on the block type is created.
Creating a block type
Using the Episerver Visual Studio integration, you create a block type by adding the Episerver Block type item to the Blocks subfolder under Models in your project. See Get started with Episerver CMS for more information.
Example: A simple block type with properties for a heading and a link to an image. TeaserBlock inherits from BlockData, which inherits from EPiServer.Core.BlockData.
using System; using System.ComponentModel.DataAnnotations; using EPiServer.Core; using EPiServer.DataAbstraction; using EPiServer.DataAnnotations; using EPiServer.Web; namespace MyEpiserverSite.Models.Blocks { [ContentType(DisplayName = "TeaserBlock", GUID = "38d57768-e09e-4da9-90df-54c73c61b270", Description = "Heading and image.")] public class TeaserBlock : BlockData { [CultureSpecific] [Display( Name = "Heading", Description = "Add a heading.", GroupName = SystemTabNames.Content, Order = 1)] public virtual String Heading { get; set; } [Display( Name = "Image", Description = "Add an image (optional)", GroupName = SystemTabNames.Content, Order = 2)] public virtual ContentReference Image { get; set; } } }
As for page types, a unique GUID for the block type will automatically be generated when creating block types using the Episerver Visual Studio extensions.
Blocks will only be editable from the All Properties edit view, and can only be previewed in context of some other content like a page. However, you can add specific preview rendering for blocks, for editors to be able to preview them in the On-Page edit view.
Note: Why are the properties declared as virtual here? What happens in the background is that a proxy class is created for the block type, and data is loaded from the database to a property carrier (Property), receiving the data. Through Castle (Inversion of Control tool), the properties in the proxy block type will be set, and this only works if properties are declared as virtual. If the properties are not declared virtual, you need to implement get/set so that these will read/write data to the underlying property collection instead.
Block controllers and views
In MVC, rendering of blocks is done by using controllers, views and associated templates, similar to the way you render pages.
- Create a controller that inherits from EPiServer.Web.Mvc.BlockController<TBlockData>, where TBlockData is your block type. The system calls this controller for the block type, if it is chosen as the renderer of the block type. EPiServer.Web.Mvc.BlockController<TBlockData> has an implementation of the action Index, which calls a partial view with the same name as the block type.
- Create a partial view without a controller, naming the view the same as the block type. If the view is chosen as the renderer of the block type, the view is called with the page data object directly, without controller involvement. This approach is the recommended way to render blocks.
Note: For performance reasons, it is recommended to use partial views directly, and not controllers, for block types. You can create a view to be used without a controller through naming convention in MVC.
Creating a partial view
In Visual Studio, add a partial view with the same name as your block type and based on your block model class, to the Views/Shared folder of your project.
Example: The partial view for the TeaserBlock block type, displaying a heading and an image.
@model MyEpiserverSite.Models.Blocks.TeaserBlock <div> <h2>@Html.PropertyFor(x => x.Heading)</h2> <img src="@Url.ContentUrl(Model.Image)" /> </div>
Using templates
As for page types, templates can also be used to specify how blocks will be rendered in a specific context, for example a content area or a display channel. Note that if you are using partial views and no controllers, you cannot implement the TemplateDescriptor. Instead you can use the ViewTemplateModelRegistrator interface and an initalization module, to register templates. See Rendering and the CMS sample site for examples.
Shared blocks folders
As previously mentioned, shared blocks are stored, loaded and versioned individually as an own entity in the database. Shared blocks are structured using folders, and a Folder is an instance of EPiServer.Core.ContentFolder. Content folders do not have associated rendering, and therefore no visual appearance on the website.
A folder in the shared blocks structure can have other folders or shared blocks as children, and a shared block cannot have any children.
You set editorial access on folders to specify which folders that are available for an editor. The global folder root EPiServer.Core.SiteSettings.Current.GlobalBlocksRoot, is the root folder for shared blocks that are available for sites in an enterprise scenario. There can be a site-specific folder EPiServer.Core.SiteSettings.Current.SiteBlocksRoot, containing the folder structure for shared blocks. In a single-site scenario, GlobalBlocksRoot and SiteBlocksRoot typically point to the same folder. | https://world.episerver.com/documentation/Items/Developers-Guide/Episerver-CMS/9/Content/Block-types-and-templates/ | CC-MAIN-2019-18 | refinedweb | 1,013 | 56.25 |
API
This guide covers the basics of implementing an API for React Storefront.
Overview
Your React Storefront app is a single page PWA that fetches data for each page from a RESTful JSON API. You can either implement your own API using Next.js API endpoints in
pages/api or connect directly to a headless ecommerce API.
Example Routes
The starter app comes with example endpoints for home, subcategory, and product pages located in:
/pages /api /p [productId].js // Product /s [subcategoryId].js // Subcategory index.js // Home Page
These endpoints generate mock data procedurally. You will replace them with real data when implementing your app.
App Data and Page Data
API endpoints can be called during server side rendering (when the user initially arrives at your app) or when navigating between pages. When rendering on the server, the API must return data for the page being displayed (we refer to this as "page data") as well as data required by other shared components such as the main menu, navigation, and footer (we refer to this as "app data"). For all navigation that occurs after the initial page load, only page data needs to be returned as the content of shared app components usually doesn't change. Omitting app data during subsequent minimizes response sizes and eliminates unnecessary work on the server. React Storefront provides a function to make this easy:
fulfillAPIRequest
The
fulfillAPIRequest function takes the request an an object with
addData and
pageData callbacks. The
appData callback is only called during server side rendering. It should return a
Promise that resolves to the data for shared app components such as the main menu, nav, and footer. The
pageData callback is called for all requests.
import fulfillAPIRequest from 'react-storefront/props/fulfillAPIRequest' fulfillAPIRequest(req, { appData: () => fetchAppData(), pageData: () => fetchPageData() })
Implementing the API
To learn how to implement APIs for the different parts of your app, see the "Pages and Features" section of the guides.
Fetching data from the API in the browser
React Storefront appends
?__v__={__NEXT_DATA__.buildId} to all requests made from the browser using
window.fetch and
XMLHttpRequest. This ensures that cached results requested by a previous version of the application are not served to the current version of the application and thus prevents errors when you introduce breaking changes in your API. | https://docs.reactstorefront.io/guides/api | CC-MAIN-2020-50 | refinedweb | 384 | 54.32 |
How To Hobble Your Python Web-Scraper With getaddrinfo()
This is the second article in what seems destined to be a four-part series about Python's
getaddrinfo on Mac. Here, I discover that contention for the
getaddrinfo lock makes connecting to localhost appear to time out.
Network Timeouts From asyncio
A Washington Post data scientist named Al Johri posted to the MongoDB User Group list, asking for help with a Python script. His script downloaded feeds from 500 sites concurrently and stored the feeds' links in MongoDB. Since this is the sort of problem async is good for, he used my async driver Motor. He'd chosen to implement his feed-fetcher on
asyncio, with Motor's new
asyncio integration and Andrew Svetlov's
aiohttp library.
Al wrote:
Each feed has a variable number of articles (average 10?). So it should launch around 5000+ "concurrent" requests to insert into the database. I put concurrent in quotes because it's sending the insert requests as the downloads come in so it really shouldn't be that many requests per second. I understand PyMongo should be able to do at least 20k-30k plus?
He's right. And yet, Motor threw connection timeouts every time he ran his script. What was going wrong with Motor?
Three Clues
It was a Saturday afternoon when I saw Al's message to the mailing list; I wanted to leave it until Monday, but I couldn't stand the anxiety. What if my driver was buggy?
In Al's message I saw three clues. The first clue was, Motor made its initial connection to MongoDB without trouble, but while the script downloaded feeds and inserted links into the database, Motor began throwing timeouts. Since Motor was already connected to MongoDB, and since MongoDB was running on the same machine as his code, it seemed it must be a Motor bug.
I feel like what I'm trying to accomplish really shouldn't be this hard.
Al's code also threw connection errors from
aiohttp, but this was less surprising than Motor's errors, since it was fetching from remote servers. Still, I noted this as a possible second clue.
The third clue was this: If Al turned his script's concurrency down from 500 feeds to 150 or less, Motor stopped timing out. Why?
Investigation
On Sunday, I ran Al's script on my Mac and reproduced the Motor errors. This was a relief, of course. A reproducible bug is a tractable one.
With some print statements and PyCharm, I determined that Motor occasionally expands its connection pool in order to increase its "insert" concurrency. That's when the errors happen.
I reviewed my connection-pool tests and verified that Motor can expand its connection pool under normal circumstances. So
aiohttp must be fighting with Motor somehow.
I tracked down the location of the timeout to this line in the
asyncio event loop, where it begins a DNS lookup on its thread pool:
def create_connection(self): executor = self.thread_pool_executor yield from executor.submit( socket.getaddrinfo, host, port, family, type, proto, flags)
Motor's first
create_connection call always succeeded, but later calls sometimes timed out.
I wondered what the holdup was in the thread pool. So I printed its queue size before the
getaddrinfo call:
# Ensure it's initialized. if self._default_executor: q = self._default_executor._work_queue print("unfinished tasks: %d" % q.unfinished_tasks)
There were hundreds of unfinished tasks! Why were these lookups getting clogged? I tried increasing the thread pool size, from the
asyncio default of 5, to 50, to 500....but the timeouts happened just the same.
Eureka
I thought about the problem as I made dinner, I thought about it as I fell asleep, I thought about it while I was walking to the subway Monday morning in December's unseasonable warmth.
I recalled a PyMongo investigation where Anna Herlihy and I had explored CPython's getaddrinfo lock: On Mac, Python only allows one
getaddrinfo call at a time. I was climbing the stairs out of the Times Square station near the office when I figured it out: Al's script was queueing on that
getaddrinfo lock!
Diagnosis
When Motor opens a new connection to the MongoDB server, it starts a 20-second timer, then calls
create_connection with the server address. If hundreds of other
getaddrinfo calls are already enqueued, then Motor's call can spend more than 20 seconds waiting in line for the
getaddrinfo lock. It doesn't matter that looking up "localhost" is near-instant: we need the lock first. It appears as if Motor can't connect to MongoDB, when in fact it simply couldn't get the
getaddrinfo lock in time.
My theory explains the first clue: that Motor's initial connection succeeds.
In the case of Al's script, specifically, Motor opens its first connection before
aiohttp begins its hundreds of lookups, so there's no queue on the lock yet.
Then
aiohttp starts 500 calls to
getaddrinfo for the 500 feeds' domains. As feeds are fetched it inserts them into MongoDB.
There comes a moment when the script begins an insert while another insert is in progress. When this happens, Motor tries to open a new MongoDB connection to start the second insert concurrently. That's when things go wrong: since
aiohttp has hundreds of
getaddrinfo calls still in progress, Motor's new connection gets enqueued, waiting for the lock so it can resolve "localhost" again. After 20 seconds it gives up. Meanwhile, dozens of other Motor connections have piled up behind this one, and as they reach their 20-second timeouts they fail too.
Motor's not the only one suffering, of course. The
aiohttp coroutines are all waiting in line, too. So my theory explained the second clue: the
aiohttp errors were also caused by queueing on the
getaddrinfo lock.
What about the third clue? Why does turning concurrency down to 150 fix the problem? My theory explains that, too. The first 150 hostnames in Al's list of feeds can all be resolved in under 20 seconds total. When Motor opens a connection it is certainly slow, but it doesn't time out.
Verification
An explanatory theory is good, but experimental evidence is even better. I designed three tests for my hypothesis.
First, I tried Al’s script on Linux. The Python interpreter doesn’t lock around
getaddrinfo calls on Linux, so a large number of in-flight lookups shouldn’t slow down Motor very much when it needs to resolve “localhost”. Indeed, on Linux the script worked fine, and Motor could expand its connection pool easily.
Second, on my Mac, I tried setting Motor’s maximum pool size to 1. This prevented Motor from trying to open more connections after the script began the feed-fetcher, so Motor never got stuck in line behind the fetcher. Capping the pool size at 1 didn’t cost any performance in this application, since the script spent so little time writing to MongoDB compared to the time it spent fetching and parsing feeds.
For my third experiment, I patched the
asyncio event loop to always resolve “localhost” to “127.0.0.1”, skipping the
getaddrinfo call. This also worked as I expected.
Solution
I wrote back to Al Johri with my findings. His response made my day:
Holy crap, thank you so much. This is amazing!
I wish bug investigations always turned out this well.
But still—all I’d done was diagnose the problem. How should I solve it?
Motor could cache lookups, or treat “localhost” specially. Or
asyncio could make one of those changes instead of Motor. Or perhaps the
asyncio method
create_connection should take a connection timeout argument, since
asyncio can tell the difference between a slow call to
getaddrinfo and a genuine connection timeout.
Which solution did I choose? Stay tuned for the next installment!
Links:
- The original bug report on the MongoDB User Group list.
- Python’s getaddrinfo lock.
- The full series on getaddrinfo on Mac
Images: Lunardo Fero, embroidery designs, Italy circa 1559. From Fashion and Virtue: Textile Patterns and the Print Revolution 1520–1620, by Femke Speelberg.
| https://emptysqua.re/blog/mac-python-getaddrinfo-queueing/ | CC-MAIN-2018-17 | refinedweb | 1,358 | 65.22 |
What is Jupyter Notebook (2)
Magic
Jupyter Notebook has many special commands, that called “magic” command. They are prefixed to % or %%. % means the whole line is under “magic” command. %% means the whole area is under “magic” command. By default, % can be omitted if there is no variable conflict.
- %magic_name? — get documentation of the magic
- %automagic
As mentioned before, % can be omitted by default. If you want to disable this function, use %automagic.
- %quickref — Jupyter Notebook quick reference card
- %magic — documentation for all magic command
- %run — run .py file immediately
- -i: give script access toe variable in notebook
- -d: invoke the debugger before executing any code, enter s (step) to enter the script
- %paste — execute pre-formatted Python code from clipboard
- %cpaste — manually paste Python code to be executed
- %time — report the execution time of a single statement
In [11]: %time 2^25
CPU times: user 4 µs, sys: 1 µs, total: 5 µs
Wall time: 10 µs
Out[11]: 27
*%timeit — run a statement for several time, and get the average time
In [12]: %timeit 2^30
100000000 loops, best of 3: 13.3 ns per loop
- %hist — print all or part of input history
- %reset — clear the interactive namespace
In [14]: %reset
Once deleted, variables cannot be recovered. Proceed (y/[n])? y
- %xdel — remove all references to a particular object
In [16]: a = 5
In [17]: b = a
In [18]: b
Out[18]: 5
In [19]: %xdel a
In [20]: b
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-20-3b5d5c371295> in <module>()
----> 1 b
NameError: name 'b' is not defined
- %logstart, %logoff, %logon, %logstate, %logstop — log the input and out
- %debug — enter immediately after an exception
- %pdb — automatically invoke debugger after any exception | https://medium.com/@rachel_fu/what-is-jupyter-notebook-2-b01ea5b14bfb | CC-MAIN-2017-43 | refinedweb | 285 | 54.56 |
Dynamic data is a technology that enables RAD (rapid application development) for data-driven applications. What is a data-driven application, or rather, when does it make sense to use ASP.NET Dynamic Data?
Any type of CRUD (create/read/update/delete) application is a prime candidate for dynamic-driven applications. In fact, if you are building an internal site simply to administer or configure certain data stores, dynamic data is a very viable solution.
There is a major misconception that data driven entities relies on generated code and therefore suffers from the same issues many of the older "code generators" did. The reality is that dynamic data can live side-by-side with a traditional application and is extremely extensible. There are plenty of customization hooks that can empower you to rapidly generate a framework yet still maintain control over the user experience, validation, and business logic.
This post is for those of you either working with or considering using dynamic data. These are just a few tips based on my personal experience that may help with building your dynamic data solution. I am using LINQ to SQL for this example, but most of these tips are applicable to the entity framework flavor as well.
Adding Table MetaData
The first and key step to understand is how to extend your generated tables with meta data. There is no way to directly apply meta data to the LINQ generated classes, but with a little bit of magic we can use a custom meta data class.
Step One: create a partial class with the same name as your generated table. In the dbml code-behind, the table will be declared something like this:
[Table(Name="dbo.MyTable")] public partial class MyTable : INotifyPropertyChanging, INotifyPropertyChanged
In this case, I will create a MyTable.cs file. It is important this lives in the same namespace as your LINQ class (navigate to the top of the designer.cs class to see what the namespace is) and is declared as a partial class.
Your class will be empty, like this:
public partial class MyTable { }
Step Two: We will create a metadata class to help provide additional hints to the engine. I like to put this class into the same .cs file as the partial class to make it easier to understand and manage. Now our code will look like this:
public partial class MyTable { } public class MyTableMetaData { }
Now the "glue" to tie the LINQ class to the meta data class. You must use
System.ComponentModel and
System.ComponentModel.DataAnnotations, then decorate the extended LINQ class with the
MetadataType attribute. The code looks like this:
[MetadataType(typeof(MyTableMetaData))] public partial class MyTable { } public class MyTableMetaData { }
Now the metadata is "glued" to the LINQ class. So, let's do our first customization and change the table name so it doesn't show "MyTable" in the UI, but instead displays as "My Table":
[MetadataType(typeof(MyTableMetaData))] [DisplayName("My Table")] public partial class MyTable { } public class MyTableMetaData { }
Customizing the Field Template
If you navigate in your dynamic data solution to
DynamicData -> FieldTemplates you'll find a collection of user controls that the dynamic data engine uses to render the fields. All of these are customizable. For example, the default textbox is a fixed width. You may want to size it to fit the width of the container. In the CSS, you can add a class:
.cssTextBox { width: 100%; }
Then crack open the Text_Edit.ascx file and add the attribute:
CssClass="cssTextBox" to the textbox definition. You can, of course, style the control even further as needed.
Foreign Key References
Dynamic data entities tries to make a "best guess" about which column of a table makes sense to display for a foreign key. For example, let's assume we have a "Student" class that associated with "Classroom." The dynamic data engine may "guess" that the student's phone number is the most appropriate field to show. Obviously, you would prefer to list their full name. To do this, simply decorate the table class (not the metadata class) with the
DisplayColumn annotation, like this:
[DisplayColumn("FullName")] public partial class Student { }
Custom Controls
Creating custom controls is easy. You may have a particular field that is an integer value for a specific range. It makes more sense to use a slider control instead of the auto-generated textbox. Here are the steps to create your custom control:
Display, Edit, or Both?
Create a user control under
DynamicData -> FieldTemplates. The format for these controls is
controlname and
controlname_edit. You do not have to supply both ... you might only want to override the display mode, or the edit mode. In this case, we're doing the edit mode, so you would create a user control called
Slider_Edit.ascx.
Inherit from
System.Web.DynamicData.FieldTemplateUserControl
This is required for your custom field control.
Override
DataControl
This should return the main control holding the field state. For example, if your slider has the identifier
MySlider, your override will look like:
public override Control DataControl { get { return MySlider; } }
You can get the value of the current field using
FieldValueString.
For Edit Controls, Override
ExtractValues
ExtractValues is the interface between your custom control and the data store. The
ExtractValues method is called with a
IOrderedDictionary that contains all of the columns in the data store. Your job is to to take a text value from your control and pass it back into the dictionary using the
ConvertEditedValue helper method. In our slider example, if the value is exposed by
SelectedValue, you would wire in the value like this:
protected override void ExtractValues(IOrderedDictionary dictionary) { dictionary[Column.Name] = ConvertEditedValue(MySlider.SelectedValue); }
Making a Field Readonly (Custom Control)
Now that we know how to customize our controls, here's how to make a field readonly.
- Navigate to
DynamicData -> FieldTemplates
- Right click on
Text.ascxand select "copy"
- Right click on the
FieldTemplatesfolder and select "paste"
- Rename the pasted control to "ReadonlyText_Edit" and make sure the markup matches the code behind (you'll need to change the class name from
TextFieldto
ReadonlyTextField_Edit.
- Add the
UIHintto the field you wish to make read only
How do we provide the hint? Navigate to the meta data object you created for the table, and decorate the attribute. In "MyTable" if I want to make "MyField" read only, I would do this:
[MetadataType(typeof(MyTableMetaData))] public partial class MyTable { } public class MyTableMetaData { [UIHint("ReadonlyText")] public object MyField { get; set; } }
Notice that I name the property I'm overriding, but declare it as a simple object. I'm not typing it here. The purpose of the meta data is provide annotiations as hints to the dynamic data engine. My hint tells it to use the
ReadonlyText control. When displaying the field, the engine searches for
ReadonlyText.ascx and cannot find it, so it defaults to the original target,
Text.ascx. In edit mode, it finds
ReadonlyText_Edit.ascx and therefore instantiates that control, which simply displays the field and does not allow editing.
Applying Validation Attributes
Applying validation attributes is simple. Let's assume we have a field that is required, and cannot exceed 50 characters in length. Applying these validations is as simple as:
public class MyTableMetaData { [Required] [StringLength(50,ErrorMessage="My field cannot exceed 50 characters in length.")] public object MyField { get; set; } }
There is event built-in support for a regular expression validator!
Extending the User Experience
To extend the user experience is quite simple. Let's assume, for examle, you have an enumeration of "type" in your table, and type translates to "square", "circle" and "triangle." You wish to enhance the control by providing a little more information about the item that was selected. You can easily create your custom control, then sprinkle in your customizations. Consider, for example, a
Type_Edit.ascx markup that looks like this:
<asp:DropDownList <asp:ListItem <asp:ListItem <asp:ListItem </asp:DropDownList> <asp:Label
Beneath that, we add a JavaScript block (using JQuery):
var hints = new Array('All sides are the same length!', 'Circles have an intimate relatinship with pi', 'A rectangle is a shape where parallel sides are equal length'); $(document).ready(function() { $('#<%= ddType.ClientID %>').change(function() { setTypeHint(); }); $('#<%= ddType.ClientID %>').val('<%# FieldValueEditString %>'); setTypeHint(); }); function setTypeHint() { var value = $('#<%= ddType.ClientID %>').val(); $('#<%= lblType.ClientID %>').text(hints[value]); }
Now you can easily see the new "hint" every time the drop down field changes.
Changing Field Names
Changing the label or column heading that appears for a given column is as simple as changing the display name for a table. On the property you wish to provide a hint for, simply add the
DisplayName attribute:
public class MyTableMetaData { [DisplayName("My Field")] public object MyField { get; set; } }
Swapping out Pages
Sometimes you may want to override the built-in functionality for a given page. For example, on a grid list, you might want to restrict the columns that are displayed. Definining your own page in place of the built-in template is simple.
- Under the
DynamicDatafolder, create a new folder called
CustomPages
- Under
CustomPages, create a new folder with the same name as the class you want to change the page for. For example, if your class is called
MyTables, you will create a folder called
MyTables
- Add the page you wish to override. In our example, we'll copy the
List.aspxpage from the
PageTemplatesfolder and paste it into the
MyTablesfolder. Now, when the list for
MyTablesis displayed, it will use the new page instead of the supplied template.
In the grid definition, I can add the
asp:DynamicField tag for any fields I wish to display, and leave out the ones I don't want (or I might even decide to use something besides a grid altogether)
The Foreign Key Edit Bug
If your table has a many-to-many relationship, you may have observed a bug. Let's say we have Groups and Persons, and a person can belong to multiple groups. In the "Group" display, there will be a link generated for "View Persons" that takes me to the list of persons associated to the that group. If I click "edit" however, suddenly the class name for the LINQ entity appears intead of a nice link!
This bug is easy to fix. You don't want the user editing the associations "in line", so simply copy the
Children.ascx field template and paste it as
Children_Edit.ascx. This will cause the same "view link" code to fire in edit mode, and allow the user to navigate to the associations and edit them directly, rather than being presented with the result of a
ToString that was never overridden.
Complex Validation (LINQ Flavor)
In the many-to-many example, it is often a requirement that only one unique relationship exists (for example, you do not want to have multiple instances of "Person A belongs to Group 1" in your many-to-many link table). This may be enforced by a database rule. However, when you fire up your dynamic data application and test adding a duplicate link, you simply see the yellow exclamation mark indicating a JavaScript error and see that a unique index constraint was violated. This isn't very user friendly!
Fortunately, the LINQ class provides a hook to perform your own validation, called
OnValidate. For this particular example, I wrote a static class to extend my data access validations, that looked like this:
public static class PersonGroupLinkExtensions { // check for a duplicate prior to inserting public static bool IsDuplicate(int personId, int groupId) { using (MyDatabaseDataContext context = new MyDatabaseDataContext()) { int count = (from link in context.PersonGroupLinks where link.PersonID == personId && link.GroupID == groupId select link).Count(); return count > 0; } } }
Simple enough: simply validate whether or not that combination already exists. Then, in the partial class I used to extend from the LINQ class, I implement the partial method
OnValidate: (partial methods are different than overrides ... good homework project if you are not familiar with them).
partial void OnValidate(System.Data.Linq.ChangeAction action) { if (action.Equals(System.Data.Linq.ChangeAction.Insert)) { if (PersonGroupLinkExtensions.IsDuplicate(this.PersonID, this.GroupID)) { throw new ValidationException("Combination already exists and duplicates are not allowed."); } } }
Conclusion
This is by no means an exhaustive coverage of dynamic data. There is much more to explore, from scaffolding to routes and the Entity Framework. Hopefully this is a good guide to help you get started, jump over a few hurdles many people encounter, and also discover just how flexible and rich the tools provided by dynamic data truly are.
Hi, thank you for the article.
I want to Change the Field Names of an Auto-generated Type that is the result table of a stored procedure. Applying the DisplayName attribute doesn't works for me. Any ideas?
Hmmm, I didn't realize a stored procedure result would be handled any differently from a regular table. If I find what you're looking for, I'll be sure to post it! | https://csharperimage.jeremylikness.com/2009/11/aspnet-dynamic-data-linq-tips-and.html | CC-MAIN-2017-39 | refinedweb | 2,150 | 54.73 |
I'm working with memory mapped files and I have a block of memory that I've mapped to.
I want to write a function that returns a pointer to a portion of the mapped memory at an offset and length so I can write to it.
I've never worked with memory at this level, is what I'm attempting possible?
I know that mapping functions can map to a part of the file at length and offset but I'm not sure if I should make multiple calls to map the memory from the file or just map the memory once and work with the portions I'm interested in using my proposed GetMemory function
Code:
LPVOID m_lpData;
LPVOID GetMemory(DWORD pos, DWORD length)
{
BYTE* buffer = (BYTE*)m_lpData;
buffer += pos;
// how to get a length of the memory?
return ((LPVOID)buffer);
} | http://forums.codeguru.com/printthread.php?t=539385&pp=15&page=1 | CC-MAIN-2018-13 | refinedweb | 143 | 54.39 |
DBIx::VersionedSubs - all your code are belong into the DB
package My::App; use strict; use base 'DBIx::VersionedSubs'; package main; use strict; My::App->startup($dsn); while (my $request = Some::Server->get_request) { My::App->update_code; # update code from the DB My::App->handle_request($request); }
And
handle_request might look like the following in the DB:
sub handle_request { my ($request) = @_; my %args = split /[=;]/, $request; my $method = delete $args{method}; no strict 'refs'; &{$method}( %args ); }
See
eg/ for a sample HTTP implementation of a framework based on this concept.
This module implements a minimal driver to load your application code from a database into a namespace and to update that code whenever the database changes.
This module uses two tables in the database,
code_live and
code_history. The
code_live table stores the current version of the code and is used to initialize the namespace. The
code_history table stores all modifications to the
code_live table, as that will be used for (descending) ordering of rows.
Package->setup
Sets up the class data defaults:
code_source => {} code_live => 'code_live', code_history => 'code_history', code_version => 0, verbose => 0,
code_source contains the Perl source code for all loaded functions.
code_live and
code_history are the names of the two tables in which the live code and the history of changes to the live code are stored.
code_version is the version of the code when it was last loaded from the database.
The
verbose setting accessor, otherwise returns the DBI handle.
If you already have an existing database handle, just set the
dbh access will be immediately executed instead of installed. This is most likely what you expect. As the code elements are loaded by
init_code in alphabetical order on the name, your
Aardvark and
AUTOLOAD subroutines will still be loaded before your
BEGIN block runs.
The
BEGIN block will be called with the package name in
@_.
Also, names like
main::foo or
Other::Package::foo are if::$nameh already returns a true value, no new connection is made.
This method is equivalent to:
if (! Package->dbh) { Package->connect(@_); }; Package->setup; Package->init_code;
The most bare-bones hosting package looks like the following (see also
eg/lib/My/App.pm in the distribution):
package My::App; use strict; use base 'DBIx::VersionedSubs';
Global variables are best declared within the
BEGIN block. You will find typos or use of undeclared variables reported to
STDERR as the subroutines get compiled.
-
Max Maischein, <corion@cpan.org>
Tye McQueen for suggesting the module name
The Everything Engine,
This module is licensed under the same terms as Perl itself.
DBIx::Seven::Days, Nothing::Driver, Corion's::Code::From::Outer::Space | http://search.cpan.org/~corion/DBIx-VersionedSubs-0.07/lib/DBIx/VersionedSubs.pm | CC-MAIN-2017-47 | refinedweb | 435 | 52.39 |
File to dict
- From: mrkafk@xxxxxxxxx
- Date: Fri, 7 Dec 2007 03:31:10 -0800 (PST)
Hello everyone,
I have written this small utility function for transforming legacy
file to Python dict:
def lookupdmo(domain):
lines = open('/etc/virtual/domainowners','r').readlines()
lines = [ [y.lstrip().rstrip() for y in x.split(':')] for x in
lines]
lines = [ x for x in lines if len(x) == 2 ]
d = dict()
for line in lines:
d[line[0]]=line[1]
return d[domain]
The /etc/virtual/domainowners file contains double-colon separated
entries:
domain1.tld: owner1
domain2.tld: own2
domain3.another: somebody
....
Now, the above lookupdmo function works. However, it's rather tedious
to transform files into dicts this way and I have quite a lot of such
files to transform (like custom 'passwd' files for virtual email
accounts etc).
Is there any more clever / more pythonic way of parsing files like
this? Say, I would like to transform a file containing entries like
the following into a list of lists with doublecolon treated as
separators, i.e. this:
tm:$1$aaaa$bbbb:1010:6::/home/owner1/imap/domain1.tld/tm:/sbin/nologin
would get transformed into this:
[ ['tm', '$1$aaaa$bbbb', '1010', '6', , '/home/owner1/imap/domain1.tld/
tm', '/sbin/nologin'] [...] [...] ]
.
- Follow-Ups:
- Re: File to dict
- From: J. Clifford Dyer
- Re: File to dict
- From: Bruno Desthuilliers
- Re: File to dict
- From: Duncan Booth
- Re: File to dict
- From: Chris
- Prev by Date: Re: Can I embed Windows Python in C# or VC++?
- Next by Date: Re: Code Management
- Previous by thread: ftplib.nlst gives error on empty directory
- Next by thread: Re: File to dict
- Index(es): | http://coding.derkeiler.com/Archive/Python/comp.lang.python/2007-12/msg00658.html | crawl-002 | refinedweb | 276 | 65.52 |
Query Execution
This documentation isn’t up to date with the latest version of Gatsby.
Outdated areas are:
- implementation details are out of date
You can help by making a PR to update this documentation.
Query execution
Query execution is kicked off by bootstrap by calling
createQueryRunningActivity(). The main files involved in this step are:
Here’s an overview of how it all relates:
Figuring out which queries need to be executed
The first thing this query does is figure out what queries even need to be run. You would think this would simply be a matter of running the Queries that were enqueued in Extract Queries, but matters are complicated by support for
develop. Below is the logic for figuring out which queries need to be executed (code is in runQueries()).
Already queued queries
All queries queued after being extracted (from
query-watcher.js).
Queries without node dependencies
All queries whose component path isn’t listed in
componentDataDependencies. In Schema Generation, all Type resolvers record a dependency between the page whose query is running and any nodes that were successfully resolved. So, If a component is declared in the
components redux namespace (occurs during Page Creation), but is not contained in
componentDataDependencies, then by definition, the query has not been run. Therefore it needs to be run. Checkout Page -> Node Dependencies for more info. The code for this step is in findIdsWithoutDataDependencies.
Pages that depend on dirty nodes
In
develop mode, every time a node is created, or is updated (e.g. via editing a markdown file), that node needs to be dynamically added to the enqueuedDirtyActions collection. When your queries are executed, the code will look up all nodes in this collection and map them to pages that depend on them (as described above). These pages’ queries must also be executed. In addition, this step also handles dirty
connections (see Schema Connections). Connections depend on a node’s type. So if a node is dirty, the code marks all connection nodes of that type dirty as well. The code for this step is in popNodeQueries. Note: dirty ids is really talking about dirty paths.
Queue queries for execution
There is now a list of all pages that need to be executed (linked to their Query information). Gatsby will queue them for execution (for real this time). A call to runQueriesForPathnames kicks off this step. For each page or static query, Gatsby creates a Query Job that looks something like:
This Query Job contains everything it needs to execute the query (and do things like recording dependencies between pages and nodes). It gets pushed onto the queue in query-queue.js and then waits for the queue to empty. Next, this doc will cover how
query-queue works.
Query queue execution
query-queue.js creates a better-queue queue that offers advanced features like parallel execution, which is handy since queries do not depend on each other so Gatsby can take advantage of this. Every time an item is consumed from the queue, it calls query-runner.ts where it can finally execute the query!
Query execution involves calling the graphql-js library with 3 pieces of information:
- The Gatsby schema that was inferred during Schema Generation.
- The raw query text. Obtained from the Query Job.
- The Context, also from the Query Job. Has the page’s
pathamongst other things so that Gatsby can record Page -> Node Dependencies.
Graphql-js will parse the query, and executes the top level query. E.g.
allMarkdownRemark( limit: 10 ) or
file( relativePath: { eq: "blog/my-blog.md" } ). These will invoke the resolvers defined in Schema Connections or GQL Type, which both use sift to query over all nodes of the type in redux. The result will be passed through the inner part of the GraphQL query where each type’s resolver will be invoked. The vast majority of these will be
identity functions that just return the field value. Some however could call a custom plugin field resolver. These in turn might perform side effects such as generating images. This is why the query execution phase of bootstrap often takes the longest.
Finally, a result is returned.
Save query results to Redux and disk
As queries are consumed from the queue and executed, their results are saved to redux and disk for consumption later on. This involves converting the result to pure JSON, and then saving it to its dataPath. Which is relative to
public/static/d. The data path includes the jsonName and hash. E.g: for the page
/blog/2018-07-17-announcing-gatsby-preview/, the queries results would be saved to disk as something like:
For static queries, instead of using the page’s jsonName, Gatsby uses a hash of the query.
Now Gatsby needs to store the association of the page -> the query result in redux so it can be recalled later. This is accomplished via the
json-data-paths reducer which is invoked by creating a
SET_JSON_DATA_PATH action with the page’s jsonName and the saved dataPath. | https://www.gatsbyjs.com/docs/query-execution/ | CC-MAIN-2020-40 | refinedweb | 839 | 64.81 |
branch: master commit cab71afe9bdcfd1af3149aaf2c973ef6ee2040aa Author: Gregory W. Chicares <address@hidden> Commit: Gregory W. Chicares <address@hidden> Work around a MinGW-w64 gcc-7.2.0 anomaly Reverted commits 1c1bafa402 and d584c2a02d, and suppressed a failing assertion. The d584c2a02d commit message said: | For integral N, log10(10^N) is not an exact integer. and that is true; but the problem here is that N was negative, so 10^N was not an exact integer as might be expected for positive N. Thus, while it might be hoped that log10(1000) would return exactly 3, it is less certain that log10(0.001) exactly equals -3. Now that the nature of the problem is understood, the elaborate diagnostic message recently added is no longer wanted. The root cause, of course, is that 0.001 is reliably producible from 3, but 3 is not reliably recoverable from 0.001 . --- ledger_base.cpp | 25 ++++++------------------- 1 file changed, 6 insertions(+), 19 deletions(-) diff --git a/ledger_base.cpp b/ledger_base.cpp index 2553a60..5814d6c 100644 --- a/ledger_base.cpp +++ b/ledger_base.cpp @@ -355,25 +355,12 @@ namespace double power = -std::log10(a_ScalingFactor); // Assert absolute equality of two floating-point quantities, because // they must both have integral values. - // PDF !! Fails with MinGW-w64 gcc-7.2.0 . - if(power != std::floor(power)) - { - long double discrepancy0 = power - std::floor(power); -)) << " floor()" - << "\n " << value_cast<std::string>(std::trunc(power)) << " trunc()" - << "\n " << value_cast<std::string>(discrepancy0) << " lower difference" - << "\n " << value_cast<std::string>(discrepancy1) << " upper difference" - << LMI_FLUSH - ; - } -// LMI_ASSERT(power == std::floor(power)); + // PDF !! Suppress the assertion because, with MinGW-w64 gcc-7.2.0, + // it fails--apparently floor() gives the wrong answer, but trunc() + // and static_cast<int>() give the right answer for the test case + // described in the git commit message for 1c1bafa40. Obviously this + // needs further work because the behavior in other cases is unknown. + // LMI_ASSERT(power == std::floor(power)); int z = static_cast<int>(power); // US names are used; UK names are different. | http://lists.gnu.org/archive/html/lmi-commits/2018-03/msg00089.html | CC-MAIN-2019-18 | refinedweb | 321 | 50.53 |
Created on 2010-04-11.21:52:20 by pekka.klarck, last changed 2010-04-12.07:46:10 by pekka.klarck.
With CPython 2.6 on Ubuntu I can do:
args = [ unicode(a, sys.getfilesystemencoding()) for a in sys.argv[1:] ]
but on Jython 2.5.1 that fails with error:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
The failure is most likely caused by sys.getfilesystemencoding() returning None on Jython when on CPython it returns correctly UTF-8. The differences don't end there, though, as the arguments are got in different format too:
$ python -c "import sys; print sys.argv[1:]" ä €
['\xc3\xa4', '\xe2\x82\xac']
$ jython -c "import sys; print sys.argv[1:]" ä €
['\xe4', '\u20ac']
The bytes Jython gets would actually be correct without decoding if their type would be unicode and not str. In this format they cannot be used directly:
$ jython -c "import sys; print sys.argv[1] + u'\xe4'" ä
Traceback (most recent call last):
File "<string>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
I think I found a workaround for this problem, or at least the following code prints the same correct results both on CPython 2.6 and Jython 2.5.1 on Ubuntu. Does anyone see problems in it or have some cleaner solution?
import sys
if sys.platform.startswith('java'):
def _to_unicode(arg):
return ''.join(unichr(ord(c)) for c in arg)
else:
def _to_unicode(arg):
return unicode(arg, sys.getfilesystemencoding())
args = [ _to_unicode(a) for a in sys.argv[1:] ]
for a in args:
print a
This is a little better:
if sys.platform.startswith('java'):
from java.lang import String
_to_unicode = lambda arg: unicode(String(arg))
There's not much else we can do about this I think except wait for Python 3, so I'm closing this out for now =]
Thanks for a better workaround. Couldn't that be done automatically for sys.argv?
No, because it would be incompat with python 2. Plain str is expected
Personally I consider the current situation where you get wrong str worse than getting correct unicode. In the latter case `unicode(arg, sys.getfilesystemencoding())` would even work the same way both in CPython and Jython (although the fact that `unicode(x, None)` works on Jython at all is inconsistent with CPython).
Now that I know the workaround this isn't such a big problem anyway. Perhaps the best idea would be documenting this behavior somewhere.
We just can't change objects that are expected to be str to unicode because they're incompatible in certain situations -- when you combine unicode with non-ascii strs you end up with UnicodeDecodeErrors.
Consider a value somehow created from or combined with part of the argv that a developer assumes is a str -- with this change it would become unicode. If that value is combined with a non-ascii str in some later part of his codebase a mysterious UnicodeDecodeError is raised.
Furthermore tracking down what the cause of that the error was can be really painful
If it's not possible to actually fix this, I guess it's matter of taste what kind of error is least problematic. Adding a note to Jython documentation of sys.argv might anyway be a good idea.
In our code base adding a workaround for this problem revealed another Unicode issue, this time with os.listdir and non-ASCII files: issue #1593. It seems the root cause is the same as in this one. | http://bugs.jython.org/issue1592 | CC-MAIN-2016-07 | refinedweb | 602 | 66.84 |
I have decided to educate myself as to how to set up and operate my own domain. I should be able to get one up and running in the next few weeks. I am looking for suggestions on the best places on the web to pursue this education. Where is the best advice available on this subject?
Thank you in advance.
There are videos here that cover ever aspect from domain management to cpanel controls.
Feel free to stick questions you have up here and I will chime in when i swing by
Thanks, I went through the videos and bookmarked the page.
I am watching through the html tutorials here, They allow me to go in and change html, though I am not sure how much HTML is necessary when setting up a domain?
I do appreciate your assistance, and your kindness.
"Setting up a domain"only requires a 2 minute input of information into your DNS settings at your domain registrar.
Your Registrar needs to be aware of "what" the domain is supposed to be showing (where is your server/host)
so ZERO html is required when setting up a domain.
Your actual website on the other hand will require HTML if you code it by hand.
Something like 50% of all websites run on the Wordpress CMS - most others are built on other pre-built templates or CMS - Joomla, Drupal, Blogger, Expression Engine etc.
W3 is an AWESOME resource - but starting your first site where your main concern is publishing writing does not require you to recreate the wheel and build using html from scratch.
100% you probably should just be looking into using Wordpress and be up and started in under ten minutes
RB,
If your comp is designed for it, you could host your own domain by simply purchasing the domain name and pointing the namespace to your computers IP Address. Problematic is many local internet providers change the hub location, which changes your IP and do not come Apache ready.
Most hosting companies offer domain purchase, hosting {grid, cloud/VPS and dedicated} server packages.
Once activated, they have client control panels to upload or install different templates or frameworks to build a responsive site. Else you can use a third-party FTP to download-upload items to edit.
But, as Josh said, if going for a UCG site, Wordpress is a very simple way to get going.
I prefer neither Wordpress, Dolphin, Joomla or Drupal for CMS controls, and am too young in Python or Ruby to give you any kind of feedback there. But, for straight-up HTML {4/5}, PHP etc, anything I can do to help, feel free.
also check out:
Code School/ as well as W3C. Great resources.
James. Mahaveer Sanglikar5 years ago
Can you suggest me a free hosting with free sub-domain provider website?
by Shadesbreath. | http://hubpages.com/technology/forum/102770/mandatory-reading-for-website-development | CC-MAIN-2017-26 | refinedweb | 478 | 68.6 |
Cache¶
The.
How Caching Works¶ 5 minutes:
def get_sidebar(user): identifier = 'sidebar_for/user%d' % user.id value = cache.get(identifier) if value is not None: return value value = generate_sidebar_for(user=user) cache.set(identifier, value, timeout=60 * 5) return value
Creating a Cache Object¶).
Cache System API¶
- class
werkzeug.contrib.cache.
BaseCache(default_timeout=300)¶
Baseclass for the cache systems. All the cache systems implement this API or a superset of it.
add(key, value, timeout=None)¶
Works like
set()but does not overwrite the values of already existing keys.
dec(key, delta=1)¶
Decrements the value of a key by delta. If the key does not yet exist it is initialized with -delta.
For supporting caches this is an atomic operation.
get_dict(*keys)¶
Like
get_many()but return a dict:
d = cache.get_dict("foo", "bar") foo = d["foo"] bar = d["bar"]
get_many(*keys)¶
Returns a list of values for the given keys. For each key a item in the list is created:
foo, bar = cache.get_many("foo", "bar")
Has the same error handling as
get().
has(key)¶
Checks if a key exists in the cache without returning it. This is a cheap operation that bypasses loading the actual data on the backend.
This method is optional and may not be implemented on all caches.
inc(key, delta=1)¶
Increments the value of a key by delta. If the key does not yet exist it is initialized with delta.
For supporting caches this is an atomic operation.
set(key, value, timeout=None)¶
Add a new key/value to the cache (overwrites value, if key already exists in the cache).
Cache Systems¶
- class
werkzeug.contrib.cache.
NullCache(default_timeout=300)¶
A cache that doesn’t cache. This can be useful for unit testing.
- class
werkzeug.contrib.cache.
SimpleCache(threshold=500, default_timeout=300)¶
Simple memory cache for single process environments. This class exists mainly for the development server and is not 100% thread safe. It tries to use as many atomic operations as possible and no locks for simplicity but it could happen under heavy load that keys are added multiple times.
- class
werkzeug.contrib.cache.
MemcachedCache(servers=None, default_timeout=300, key_prefix=None)¶
A cache that uses memcached as backend.
The first argument can either be an object that resembles the API of a
memcache.Clientor a tuple/list of server addresses. In the event that a tuple/list is passed, Werkzeug tries to import the best available memcache library.
This cache looks into the following packages/modules to find bindings for memcached:
pylibmc
google.appengine.api.memcached
memcached.
- class
werkzeug.contrib.cache.
GAEMemcachedCache¶
This class is deprecated in favour of
MemcachedCachewhich now supports Google Appengine as well.
Changed in version 0.8: Deprecated in favour of
MemcachedCache.
- class
werkzeug.contrib.cache.
RedisCache(host='localhost', port=6379, password=None, db=0, default_timeout=300, key_prefix=None, **kwargs)¶.
Changed in version 0.10:
**kwargsis now passed to the redis object.
Any additional keyword arguments will be passed to
redis.Redis.
- class
werkzeug.contrib.cache.
FileSystemCache(cache_dir, threshold=500, default_timeout=300, mode=384)¶
A cache that stores the items on the file system. This cache depends on being the only user of the cache_dir. Make absolutely sure that nobody but this cache stores files there or otherwise the cache will randomly delete files therein. | http://werkzeug.pocoo.org/docs/0.12/contrib/cache/ | CC-MAIN-2018-13 | refinedweb | 546 | 60.41 |
OS Framework Selection: The Seven Sins Of Vendor Lock-in With Frameworks
Learn more about the seven deadly sins of framework vendor lock-in.
Join the DZone community and get the full member experience.Join For Free
When selecting frameworks, both open-source and enterprise software, there is always a risk of vendor lock-in.
Frameworks are easy to add, but they can be hard to remove. And some frameworks are more difficult than others; it can take a special effort to secure their place inside your codebase, and be nearly impossible to remove later. This is the kind of framework you should try to avoid.
All frameworks have some sort of vendor lock-in. It's the extent of the lock-in that matters. To learn more, read Lock-In: Let Me Count the Ways
During selection, you should estimate the degree of vendor lock-in of a framework. Will getting rid of it, later on, be impossible, difficult, or easy?
Replacement always takes effort. For example, SQL databases may as well be the best-standardized frameworks in the world, but to replace one, you always need to make modifications and run an import/export script. It is never as easy as changing a light bulb. All have unique features, language dialects, and differences in field primitives, DateTime limits, error handling, and blob lengths, to name a few.
These are the seven sins of vendor lock-in that you should always watch out for:
- Intrusiveness
- Vendor geopolitics
- Vendor champions
- Unnecessary languages
- Service plugging
- Cloud sales
- Immersiveness
#1: Intrusiveness
Intrusiveness is the most common and ugly form of vendor lock-in, and selecting an intrusive framework should be a major "no" unless there is no other option.
How to Detect Intrusiveness Fast
The first sign of intrusiveness can be found in your gut feeling as you read the documentation. Do you sense complacency, absoluteness, arrogance, and/or über-hipness? Those are immediate signs of intrusiveness.
Also, be alert when frameworks use Freudian superlatives like "Awesome", "Definitive", and "Final" in their product name or tagline.
Concrete Ways to Spot Intrusiveness
Here are some other things to look out for in the documentation:
- Claims one-letter global variables like
g,
Z,
$, or
_
- Claims exclusive control of a standard object in another environment
- Claims global or shared namespaces or not use
name_prefixes.
- Claims commonly used keywords or names
- Forces your web application into using their URL structure
- Claims well-known TCP/IP port numbers exclusively
- Takes control of a resource, data, or functionality you need to control yourself
- Takes control of a standard directory such as
/tmpor
~
- Model View Control in name only; on the lower level, these are tightly entangled
- Documentation boldly states incompatibility with certain software
- Claims the entire HTTP document root and points you to the places where they allow you to do your work, instead of the other way around
- Multi-tenant use is impossible; certain data is hardcoded to be one single space
- Pre-defined field names only, forcing you to use wrong fields names for your data
- Assume no similar framework or technology will ever be used in the same space
Why Is Intrusiveness So Dangerous?
While this may seem like a concept too small to worry about, frameworks that are intrusive can break other frameworks at any upgrade or install at any time in the future. This will force you to make big and hasty repairs because two frameworks block each other out. That is never a good thing.
Intrusiveness is a design issue.
It could have been avoided if the maker wanted to.
#2: Vendor Geopolitics
All businesses try to make it easy to enter and hard to leave. But software giants sometimes take this principle to the next level, where it becomes a whole new ballgame.
Vendor geopolitics are power strategies to use the community against the competition, locking developers users down to ultimately lock out a competitor.
Let's take an old example: the Great Browser War of the early 2000s. There was JScript, an incompatible version of JavaScript, which was meant to lock developers in on a browser from a certain brand and operating system. Therefore, it locked end-users too, as JScript-using sites failed on other browsers.
The goal was for the public to stop using competing browsers because "sites are always broken on that one." The giant was nice enough to "help" the public with "best viewed with" badges that developers were expected to put on the sites they built to suggest what browser to use if the site looks broken.
So, the vendor rewarded its self-created incompatibility with free ads for their own browser to make the public perceive it as the "standard" browser. Cunning and shrewd. Later, the EU fined them for $731M for this affair, which was 3.3 percent of their net profit (source and source).
You should be on the lookout for signs that you might be getting caught up in geopolitics:
- Not supporting a relevant and obvious open standard
- The framework can only be used if you adopt their much bigger ecosystem or language
- Competing for hardware or operating system restrictions
- Vendor-specific variation or dialect that deviates from the known open standard
- Choosing them forces you to say goodbye to something else
- Exponential pricing for scaled-up use
- Marketing suggesting incompatibility with a standard is a new standard
Geopolitics might be irrelevant because "the other continent" is nonexistent in your situation. But you should understand the strategy used before you can judge whether it is a problem for you or not.
Being locked down to a big vendor is a treacherous one: It appears too far-fetched to worry about, and it may take years to take effect, but when it does, the price is high.
#3: Vendor Champions
Big vendors often set up frameworks so that they are part of an entire suite of products; if you choose a framework of that vendor, you get an entire chain reaction of other products that depend on it that you need to use as well, or else it does not work.
Such vendors offer a wide range of products and solutions for every programming challenge in the universe, so in their eyes, you have no real need to do go outside the bubble.
In theory, you could use frameworks of other brands instead, but no one ever tested it. In practice, disloyalty is punished by having to tinker endlessly before it finally works, and the tiniest changes break everything again, making you go through a tinkering cycle for each upgrade, constantly regretting your infidelity.
And if that champion obsoletes, you obsolete with it, because everything you made is based on their frameworks. Your innovation capability is limited to what your vendor champion has to offer.
#4: Unnecessary Languages
If a framework does things fundamentally different, it makes sense to make a new language to express its full potential.
But sometimes, framework vendors introduce their own programming or control language for no other reason than making it hard to move to the competition. The framework itself does nothing so different that a language adds value. You'll recognize it when you see it.
#5: Service Plugging
Commercial frameworks, open-source or enterprise, often make their money off of professional services. That's fine, something has to pay the bills. Just make sure it isn't set up so that you get nothing done without bringing in their consultants time and time again.
A tell-tale sign is that the API has a very murky structure, like hundreds of functions sorted by the alphabet and many functions with very similar names without explaining the difference. Or explicitly undocumented, advanced features, such as:
The FFGGHH module is very advanced. Seek advice from our consultants for assistance.
Which is IT-speak for:
The FFGGHH module is full of bugs and we're not going tell you so that you keep needing our consultants to make workarounds for you. If we'd document it, you could fix it yourself, or you'd dismiss us for poor quality.
If you only need their consultants to get it to work, fine... sort of. But with some business insight, vendors aim for a recurring dependency. Even if you don't mind the fees, the price you pay is being in a constant state of waiting and begging for the availability of their consultants, trashing your release schedules and breaking promises to customers. You pay them a lot, and all they do for you is keeping an unhealthy circle intact.
6: Cloud Services With No Data Portability
With cloud services, a lack of portability is a specific vendor lock-in tactic.
Cloud frameworks that store your data in their cloud, but no proper API to get it out again, are a big no
Whatever framework you choose, if it stores data, that data must be reachable and portable at all times. When investigating a cloud solution API, you must be able to find calls to fetch your data in a machine-readable format with perpetual, unique IDs.
Alarm bells should already ring with hipster-appealing talk about joining the community, our API is a breeze, hip cartoons, but no clear mention of data portability if you go look for it in the documentation.
Such frameworks belong on the dismiss list.
#7: Immersive Frameworks
Immersive means a framework wants you to do everything their way, you have to completely "immerse" yourself in their approach, or else it doesn't work.
Mind the difference:
- Intrusive frameworks claim namespace and thwart other frameworks' functioning
- Immersive wants you to do everything their way, no way around it
The combination happens too, and it's evil.
Also, keep in mind the difference between vendor champions: A vendor champion is many frameworks for everything, and an immersive framework is one framework for everything.
Often, it's easy to recognize immersive early by how they communicate their vision, which boils down to:
"I am the sun, and you are the little planets."
Often, literally, we see this with a block diagram like this:
Then, in practice, you will become a little planet indeed; you'll be running in circles around the almighty sun. Nothing can happen without going through the framework. You will have to adapt the rest of your world to keep the immersive framework running.
Technical Traits of Immersive Frameworks
Usually, the framework dictates the superstructure of your application, and designates you a place to put your code:
/* your code goes here */
Server-side frameworks dictate the file structure of your application; they tell you where to put which code, and where to put data, and the bare existence of code folders in certain places often has a meaning too.
In web applications, immersive frameworks often claim ownership of the entire DOM tree or the entire document root of httpd or whatever is the central resource in your world.
How Does Immersive Turn Evil?
Immersive frameworks are rooted in an elegant principle for a concrete problem, and the wrongdoing lies in applying that elegant principle to everything else.
Usually, version 1.0 of an immersive framework is elegant and simple, yet powerful. Later, the real-world pop their head around the corner. The wishes of the world are way too diverse to fulfill them all by one principle. To keep up the elegance, the framework must come with solutions for many problems that are far away from the original goal or scope.
This has serious consequences:
- The framework becomes bloatware, full of half-baked solutions for everything
- As a developer, you are constantly confined by leftover limitations
- Your attempts to innovate by adding new frameworks cause technical conflicts
- It is easier to stay on the immersive platform than to battle those conflicts
- You have no choice but to live with the framework's limitations
- You obsolete along with them
As a result, immersive frameworks take away your options to innovate.
The wrongdoing lies in not having built-in options to fence the area where the framework does its work, and outside the fence, let other frameworks to theirs.
Don't get me wrong, frameworks based on an elegant principle are good and there should be more of them.
How to Spot Well-Behaved, Non-Immersive Frameworks
In general, I prefer frameworks that take full advantage of sticking to their elegant principle, without making themselves immersive: you decide on its work area, and it has ways to bypass its elegant principle where it would only make things needlessly complex.
You Can Use it Where You Want
The framework explicitly avoids a rigid place where for your code files, or where in the code files you may put your stuff. Or, offers an easy, pretty and logical way to tell the framework where its code tree begins, without using a global variable.
Look for the Hook
For the API calls that risk complexity growth and need to perform well under high load, you should look for "hooks": pass a function pointer, function object, or another piece of code, to do whatever crazy stuff you want that doesn't belong in that framework so that the actual API call stays simple.
You might have to dive deep in the API to find it or text-search the API documentation for words like "callback", "hook", "patch".
I admit hooks don't make pretty code, but in the end, immersive code gets way uglier.
Look for Extendible Parameter APIs
To me, the most preferred way to handle the hard parts of an API is an extendible input control, for example, an extendable JSON string or free-order optional parameters (like the kwargs in Python and R), or an on-the-fly created object structure or function that you can pass. Then, both you and the framework developer are free to extend whatever you like, and "regular" use stays simple and clean.
The price you pay is some parse overhead.
But the mere fact of offering extendible parameter structures is a good sign. The framework developers were realistic and acknowledged that even the richest control set cannot cover every imaginable use case. They wisely chose not to burden the many with the needs of the few and keep the framework focused on what it does best.
Conclusion
When selecting frameworks, avoid the seven sins of vendor lock-in. Replacing a framework without is hard enough already. Instead, select frameworks with a narrow purpose, a modest scope, and that offer ample extendibility for the more complex use cases.
Further Reading
Lock-In: Let Me Count the Ways
Five Things That Can Go Wrong With Vendor Lock-In
Opinions expressed by DZone contributors are their own. | https://dzone.com/articles/the-seven-sins-of-vendor-lock-in-with-frameworks?ref=hackernoon.com | CC-MAIN-2020-45 | refinedweb | 2,453 | 56.39 |
By Ashwin Vijaya Kumar, Published: 01/13/2018, Last Updated: 01/12/2018. Traditional approaches to providing such visual perception to machines have relied on complex computer algorithms that use feature descriptors, like edges, corners, colors, and so on, to identify or recognize objects in the image.
Deep learning takes a rather interesting, and by far most efficient approach, to solving real-world imaging problems. It uses multiple layers of interconnected neurons, where each layer uses a specific computer algorithm to identify and classify a specific descriptor. For example if you wanted to classify a traffic stop sign, you would use a deep neural network (DNN) that has one layer to detect edges and borders of the sign, another layer to detect the number of corners, the next layer to detect the color red, the next to detect a white border around red, and so on. The ability of a DNN to break down a task into many layers of simple algorithms allows it work with a larger set of descriptors, which makes DNN-based image processing much more effective in real-world applications.
NOTE: the above image is a simplified representation of how a DNN would identify different descriptors of an object. It is by no means an accurate representation of a DNN used to classify STOP signs.
Image classification is different from object detection. Classification assumes there is only one object in the entire image, sort of like the ‘image flash card for toddlers’ example I referred to above. Object detection, on the other hand, can process multiple objects within the same image. It can also tell you the location of the object within the image.
You will build...
A program that reads an image from a folder and classifies them into the top 5 categories.
You will learn...
You will need...
If you haven’t already done so, install NCSDK on your development machine. Refer NCS Quick Start Guide for installation instructions.
If you would like to see the final output before diving into programming, download the code from our sample code repository (NC App Zoo) and run it.
mkdir -p ~/workspace cd ~/workspace git clone cd ncappzoo/apps/image-classifier make run
make rundownloads and builds all the dependent files, like the pre-trained networks, binary graph file, ilsvrc dataset mean, etc. We have to run
make runonly for the first time; after which we can run
python3 image-classifier.pydirectly.
You should see an output similar to:
------- predictions -------- prediction 1 is n02123159 tiger cat prediction 2 is n02124075 Egyptian cat prediction 3 is n02113023 Pembroke, Pembroke Welsh corgi prediction 4 is n02127052 lynx, catamount prediction 5 is n02971356 carton
Thanks to NCSDK’s comprehensive API framework, it only takes a couple lines of Python scripts to build an image classifier. Below are some of the user configurable parameters of image-classifier.py:
GRAPH_PATH: Location of the graph file, against with we want to run the inference
~/workspace/ncappzoo/caffe/GoogLeNet/graph
IMAGE_PATH: Location of the image we want to classify
~/workspace/ncappzoo/data/images/cat.jpg
IMAGE_DIM: Dimensions of the image as defined by the choosen neural network
IMAGE_STDDEV: Standard deviation (scaling value) as defined by the choosen neural network
IMAGE_MEAN: Mean subtraction is a common technique used in deep learning to center the data
Before using the NCSDK API framework, we have to import mvncapi module from mvnc library
import mvnc.mvncapi as mvnc
Just like any other USB device, when you plug the NCS into your application processor’s (Ubuntu laptop/desktop) USB port, it enumerates itself as a USB device. We will call an API to look for the enumerated NCS device.
# Look for enumerated Intel Movidius NCS device(s); quit program if none found. devices = mvnc.EnumerateDevices() if len( devices ) == 0: print( 'No devices found' ) quit()
Did you know that you can connect multiple Neural Compute Sticks to the same application processor to scale inference performance? More about this in a later article, but for now let’s call the APIs to pick just one NCS and open it (get it ready for operation).
# Get a handle to the first enumerated device and open it device = mvnc.Device( devices[0] ) device.OpenDevice()
To keep this project simple, we will use a pre-compiled graph of a pre-trained AlexNet model, which was downloaded and compiled when you ran
make inside the
ncappzoo folder. We will learn how to compile a pre-trained network in an another blog, but for now let’s figure out how to load the graph into the NCS.
# Read the graph file into a buffer with open( GRAPH_PATH, mode='rb' ) as f: blob = f.read() # Load the graph buffer into the NCS graph = device.AllocateGraph( blob )
The Intel Movidius NCS is powered by the Intel Movidius visual processing unit (VPU). It is the same chip that provides visual intelligence to millions of smart security cameras, gesture controlled drones, industrial machine vision equipment, and more. Just like the VPU, the NCS acts as a visual co-processor in the entire system. In our case, we will use the Ubuntu system to simply read images from a folder and offload it to the NCS for inference. All of the neural network processing is done solely by the NCS, thereby freeing up the application processor’s CPU and memory resources to perform other application-level tasks.
In order to load an image onto the NCS, we will have to pre-process the image.
LoadTensorfunction-call to load the image onto NCS.
# Read & resize image [Image size is defined during training] img = print_img = skimage.io.imread( IMAGES_PATH ) img = skimage.transform.resize( img, IMAGE_DIM, preserve_range=True ) # Convert RGB to BGR [skimage reads image in RGB, but Caffe uses BGR] img = img[:, :, ::-1] # Mean subtraction & scaling [A common technique used to center the data] img = img.astype( numpy.float32 ) img = ( img - IMAGE_MEAN ) * IMAGE_STDDEV # Load the image as a half-precision floating point array graph.LoadTensor( img.astype( numpy.float16 ), 'user object' )
Depending on how you want to integrate the inference results into your application flow, you can choose to use either a blocking or non-blocking function call to load tensor (previous step) and read inference results. We will learn more about this functionality in a later blog, but for now let’s just use the default, which is a blocking call (no need to call a specific API).
# Get the results from NCS output, userobj = graph.GetResult() # Print the results print('\n------- predictions --------') labels = numpy.loadtxt( LABELS_FILE_PATH, str, delimiter = '\t' ) order = output.argsort()[::-1][:6] for i in range( 0, 5 ): print ('prediction ' + str(i) + ' is ' + labels[order[i]]) # Display the image on which inference was performed skimage.io.imshow( IMAGES_PATH ) skimage.io.show( )
In order to avoid memory leaks and/or segmentation faults, we should close any open files or resources and deallocate any used memory.
graph.DeallocateGraph() device.CloseDevice()
Congratulations! You just built a DNN-based image classifier. | https://software.intel.com/content/www/us/en/develop/articles/build-an-image-classifier-in-5-steps-on-the-intel-movidius-neural-compute-stick.html | CC-MAIN-2020-34 | refinedweb | 1,158 | 51.89 |
#include <stdio.h> #include <fcntl.h> #include <stdlib.h> #include <time.h> #include <string.h> #include <netinet/in.h> #include <errno.h> #include <sys/types.h> #include <sys/socket.h> #include <stdarg.h> #include <arpa/inet.h> #include <unistd.h> #define PORT 80 #define MLEN 1000 #define BUFSIZE 8192 int main(int argc, char *argv []) { int listenfd, connfd; int number, message, numbytes; int h, i, j; socklen_t alen; int nread; struct sockaddr_in servaddr; struct sockaddr_in cliaddr; FILE *in_file, *out_file, *fp; char buf[8192]; listenfd = socket(AF_INET, SOCK_STREAM, 0); if (listenfd < 0) fprintf(stderr,"listen error") ; memset(&servaddr, 0, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); servaddr.sin_port = htons(PORT); if (bind(listenfd, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0) fprintf(stderr,"bind error") ; listen(listenfd, 5); alen = sizeof(struct sockaddr); while ((connfd = accept(listenfd, (struct sockaddr *) &cliaddr, &alen)) > 0) { printf("accept one client from %s!\n", inet_ntoa(cliaddr.sin_addr)); if (fork() == 0) { close(listenfd); printf("reading from socket"); bzero(buf, BUFSIZE); numbytes = read (connfd, buf, BUFSIZE); if (numbytes < 0) printf("error reading from socket"); sleep(1); bzero(buf, BUFSIZE); fp = fopen (argv [1], "r"); // open file stored in server if (fp == NULL) { printf("\nfile NOT exist"); } //Sending file while(!feof(fp)){ numbytes = fread(buf, sizeof(char), sizeof(buf), fp); printf("fread %d bytes, ", numbytes); numbytes = write(connfd, buf, numbytes); printf("Sending %d bytes\n",numbytes); } fclose (fp); sleep(5); close(connfd); exit(0); } close(connfd); } return
before actually sending the file's contents.
The simple header I posted above is the least you have to send with a web server's response (given that this response ist "text/plain").
Sign up to receive Decoded, a new monthly digest with product updates, feature release info, continuing education opportunities, and more.
write(connfd, "HTTP/1.1 200 OK\n", 16);
write(connfd, "Content-length: 46\n", 19);
write(connfd, "Content-Type: text/html\n\n", 25);
write(connfd, "<html><body><H1>Hello world</H1></body></html>",
Experts Exchange Solution brought to you by
Facing a tech roadblock? Get the help and guidance you need from experienced professionals who care. Ask your question anytime, anywhere, with no hassle.Start your 7-day free trial
When I read from file using fread
The following :
HTTP/1.1 200 OK\r\n
is converted to :
HTTP/1.1 200 OK\\r\\n
is there a way to avoid that ?
It is under ubuntu. the only work around I 've found was to remove \r\n from the file.
Then when I saved it under gedit it gave me the option to save it with Line ending as windows and like that the problem
was solved. | https://www.experts-exchange.com/questions/28500364/simple-web-server-not-working-correctly.html | CC-MAIN-2018-30 | refinedweb | 442 | 50.43 |
Messages in cross-document
messaging
and, by default,
in server-sent DOM events , use the
event.
The following interface is defined for this event:
interface MessageEvent : Event { readonly attribute DOMString data;
readonly attribute DOMString ; readonly attribute DOMString ; readonly attribute ; void (in DOMString typeArg, in boolean canBubbleArg, in boolean cancelableArg, in DOMString dataArg, in DOMString domainArg, in DOMString uriArg, in Window sourceArg); void (in DOMString namespaceURI, in DOMString typeArg, in boolean canBubbleArg, in boolean cancelableArg, in DOMString dataArg, in DOMString domainArg, in DOMString uriArg, in Window sourceArg);};
The
initMessageEvent()
and
initMessageEventNS()
methods must initialise the event in a manner analogous to the
similarly-named methods in the DOM3 Events interfaces. [DOM3EVENTS]
The
data attribute
represents the message being sent.
The
attribute
represents, in cross-document
messaging , the
domain
domain of the document
from which the message came.
The
attribute represents, in
uri cross-document messaging , the address
of
the document from which the message
came.
The
source attribute
represents, in cross-document
messaging , the
Window from
which the message came.
This
only remove URIs for the event sources must be followed, including HTTP caching rules.
For HTTP connections, the
Accept header
may be included; if included, it must
only contain
formats of event framing that are supported by the user agent (one
of which must be
, as described
below).
application/x-dom-event-stream
Other formats of event framing may also be supported in addition
to
, but this
specification does not define how they are to be parsed or
processed.
application/x-dom-event-stream.
For connections to domains other than the document's domain , the semantics of the Access-Control HTTP header must be followed. [ACCESSCONTROL]
HTTP 200 OK responses with a Content-Type header specifying the type
that are
either from the document's domain or
explicitly allowed by the Access-Control HTTP headers must be
processed line by line as
described below .
application/x-dom-event-stream of
approximately five seconds.
HTTP 200 OK responses that have a Content-Type other than
(or some other supported
type), and HTTP responses whose Access-Control headers indicate
that the resource are not to be used, must be ignored and must
prevent the user agent from refetching the resource for that event
source.
application/x-dom-event-stream
refetch the resource after a
short
delay.
short delay of approximately five
seconds.
.
application/x-dom-event-stream
The event stream format is (in pseudo-BNF):
<stream> ::= <bom>? <event>*
<event> ::= [ <comment> | <command> | <field> ]* <newline> <comment> ::= ';' <any-char>* <newline> <command> ::= ':' <any-char>* <newline> <field> ::= <name> [ ':' <space>? <any-char>* ]? <newline> <name> ::= <name-start-char> <name-char>*# <name-start-char> ::= a single Unicode character other than ':', ';', U+000D CARRIAGE RETURN and U+000A LINE FEED<name-char> ::= a single Unicode character other than ':', U+000D CARRIAGE RETURN and U+000A LINE FEED<any-char> ::= a single Unicode character other than U+000D CARRIAGE RETURN and U+000A LINE FEED.
User agents must treat those three variants
as equivalent line terminators.,
in blocks separated by blank lines.
Comment lines (those starting with the character ';') and command lines (those
starting with the character ':') must be ignored. Command lines are
reserved for future extensions. For each non-blank, non-comment,
non-command line, the field name must first be taken. This is
everything on the line up to but not
including the first colon (':') or the
line terminator, whichever comes first. Then,
if there was
a
colon,
the
data for that line
must be taken. This
is everything after the colon, ignoring a single space after the
colon if there is one, up to the end of
the
line.
,
the
value for that field in that black must consist of
the
data parts for each of those lines, concatenated with
U+000A LINE FEED characters between
them (regardless of what the
line terminators used in the stream actually
are). For example, the following block:
Test: Line 1 Foo: Bar Test: Line 2 ...is
treated as having two fields, one called Test with
the value " Line 1\nLine 2 " (where \n represents a
newline), and one called
Foo
with the value " Bar " (note the leading space
character). . A block thus consists of all the
name-value pairs for its fields. Command lines have no effect on
blocks and are not considered part of a block. Since any random
stream of characters matches the above format, there is no need to
define any error handling. 6.2.4.
Interpreting an event stream Once the fields have been parsed, they are interpreted as follows
(these are case-sensitive exact comparisons): Event field
This field
gives the name
of
the event. For example,
load , DOMActivate , updateTicker . If there is no field
with this name, the name message must be
used. This field gives but the
Namespace is null and the
Event field exactly matches one
of the events
specified by DOM3 Events in section 1.4.2 "Complete list of event
types" , then
the interface used must default
to the interface
relevant for that event type.
[DOM3EVENTS] For example: Event:
click ...would cause Class to be treated as MouseEvent . If
the
Namespace is null and
the Event field is message (including if it was not specified
explicitly), then the MessageEvent interface
must be
used. Otherwise,
the
wrong
class for an event. This is equivalent to creating an
event in the DOM using the DOM
Event APIs, but using
the wrong
interface for it. This field specifies whether
the event is
to bubble.
If it is specified and has the value No , the event must not
bubble.
the event
must bubble.
the
Event field exactly matches
one of the events specified by DOM3 Events in section
1.4.2 "Complete list of event types" , then the
event must bubble if the
DOM3 Events spec specifies that that
event bubbles, and musn't bubble if it
specifies it does not. [DOM3EVENTS] For
example: Event: load ...would cause Bubbles to be treated as No . Otherwise, the
event must bubble. This
field specifies whether the event can have
its default action prevented. If it is specified and has
the
value No , the event , must not
be cancelable.
If
it is
specified and
has any other value (including no or NO )
then the event must be
cancelable.
If
it is not
specified, but the Namespace field is null and the Event field exactly
matches one of the events specified by DOM3 Events in section 1.4.2
"Complete list of event types" , then
the event must be
cancelable if
the DOM3 Events specification specifies that it is,
and must not be cancelable otherwise. [DOM3EVENTS] For
example: Event: load ...would cause Cancelable to be treated as No
.
Otherwise,
the event must be
cancelable.
Target field This
field gives the node that the event is to be dispatched on.
If the object for
, which
the event source is being processed is not a Node, but the
Target field is nonetheless specified, then the event must be
dropped. Otherwise, if field is specified
and its value starts with a # character,
then the
remainder of the value
represents an ID, and the
event
must be
dispatched
on the same node as would be obtained by the getElementById()
method on the ownerDocument of the node
whose event source is being processed.
For example, Target: #test ...would target the element with ID test
. Otherwise, if the field is specified and its value is
the literal string " Document ",
then the event must be
dispatched at the ownerDocument
of
the node whose event source is being processed. Otherwise, the field (whether
specified or not) is ignored and the event
must be
dispatched at the object: Event: click Class:
MouseEvent button: 2 ...would result in a 'click' event using the
MouseEvent interface that has button
set to 2 but screenX , screenY , etc, set to 0, false, or null
as appropriate. If a field does not match any of the attributes
on the event, it must be ignored. For example: Event: keypress
Class: MouseEvent keyIdentifier: 0 ...would result in a
MouseEvent event with its fields all at
their default values, with the
event
name being keypress . The keyIdentifier field would be
ignored. (If the author had not included the Class field
explicitly, it would have just worked, since the class would
have defaulted as described above.) Once a blank line or the
end of the file is reached, an event of the type
and namespace given by the Event and Namespace fields respectively
must be synthesized and dispatched to the appropriate node as
described by the
fields above. No event must be dispatched until a blank line has been received
or the end of the file reached. The
event must be dispatched as if using the DOM
dispatchEvent() method. Thus, if , the
Event
field
was omitted, leaving the name as the empty string, or if
the name had invalid characters, then the dispatching of
the event fails. Events fired from event sources do not have
user-agent default actions.
The following event stream, once followed by a blank line:
data: YHOO data: -2 data: 10
...would cause an event
message with the interface
MessageEvent to be dispatched on the
event-source element,
which would then bubble up the DOM, and
whose
data attribute would contain the string
YHOO\n-2\n10 (where
\n
again represents a newline).
This could be used as follows:
<event-source
...where
updateStocks() is a function
defined as:
function updateStocks(symbol, delta, value) { ... }
...or some such.
The following stream contains four
blocks
and therefore fires four events. The first block has just a comment, and
will fire a message event with all the fields
set to the empty string or null. The second block has two fields with
names "load" and "Target"
respectively; since there is no " load " member on the
MessageEvent object that field is ignored,
leaving the event
as a second
event with
all the fields set to the empty string or null, but this time
the event
is
targetted at an element with
ID "image1". The third block
is empty (no lines between two
blank
lines), and the fourth block has
only two comments, so they both yet again fire
: test stream
message events
data
with
all the fields
set to the
empty string or null.
data:test
; if any more events follow this block, they will not be affected by ; the "Target" and "load" fields no
initConnectionReadEvent()
and
initConnectionReadEventNS()
methods must initialise the event in a manner analogous to the
similarly-named methods in the DOM3 Events interfaces. [DOM3EVENTS]
The
data attribute
represents the data that was transmitted from the peer.
The
source
attribute represents the name of the peer. This is primarily useful
on broadcast connections; on direct connections it is equal to the
peer
attribute on the
Connection
object.
Events that would be fired during script execution (e.g. between
the connection object being created — and thus the connection being
established — and the current script completing; or, during the
execution of a
read event handler) must be buffered, and those
events queued up and each one individually fired after the script
has completed.
The
TCPConnection( subdomain , port , secure ) constructor on the
Window interface returns a new object
implementing the
Connection
interface, set up for a direct connection to a specified host on
the page's domain.
When this constructor is invoked, the following steps must be followed.
First, if the
domain part of the script's origin
domain part of
the script's origin . Otherwise, the
subdomain argument is prepended to the
domain
part of the script's origin with a dot
separating the two strings, and that is the target host.
If either:
.. exception at this time if, for some reason, permission to create a direct TCP connection to the relevant host is denied. Reasons could include the UA being instructed by the user to not allow direct connections, or the UA establishing (for instance using UPnP) that the network topology will cause connections on the specified port to be directed at the wrong host.
If no exceptions are raised by the previous steps, then a new.
Should we drop this altogether? Letting people fill the local network with garbage seems unwise.
We need to register a UDP port for this. For now this spec refers to port 18080/udp.
Since this feature requires that the user agent listen to a particular port, some platforms might prevent more than one user agent per IP address from usingBroad.
Should we replace this section with something that uses Rendez-vous/zeroconf or equivalent?
We need to register ports for this. For now this spec refers to port 18080/udp and 18080/tcp.
Since this feature requires that the user agent listen to a particular port, some platforms might prevent more than one user agent per IP address from using must actConnection media).
Need to write this section.
If you have an unencrypted page that is (through a man-in-the-middle attack) changed, it can access a secure service that is using IP authentication and then send that data back to the attacker. Ergo we should probably stop unencrypted pages from accessing encrypted services, on the principle that the actual level of security is zero. Then again, if we do that, we prevent insecure sites from using SSL as a tunneling mechanism.
Should consider dropping the subdomain-only restriction. It doesn't seem to add anything, and prevents cross-domain chatter.
Should have a section talking about the fact that we blithely ignoring IANA's port assignments here.
Should explain why we are not reusing HTTP for this. (HTTP is too heavy-weight for such a simple need; requiring authors to implement an HTTP server just to have a party line is too much of a barrier to entry; cannot rely on prebuilt components; having a simple protocol makes it much easier to do RAD; HTTP doesn't fit the needs and doesn't have the security model needed; etc).
When a script invokes the
postMessage( message , ) method on a
Window object, the user agent
must
create
,
an event that uses the
MessageEvent interface,
with the event name
message , which
bubbles, is cancelable, and has no default action. The
data attribute must be set to the value passed
as the message argument to the
postMessage() method, the
attribute must be set to the
domain
domain
of the document that
the script that invoked the
methods is associated with, the
attribute must be set to
the
uri
URI of that document, and the
source
attribute must be set to the
Window object of the default view of the browsing
context
with which that document is
associated. Define 'domain' more exactly -- IDN vs no IDN, absence
of ports, effect of window.document.domain on its value, etc The
event must then be dispatched at the
Document
object
that is the active document of
the
Window object
on which the method was invoked.
The
postMessage() method must only return once the event dispatch has
been completely processed by the target document (i.e. all three of
the capture, target, and bubble phases have been done, and event
listeners have been executed as appropriate).
Authors should check the
attribute to ensure that messages are only accepted from domains
that they expect to receive messages from. Otherwise, bugs in the
author's message handling code could be exploited by hostile
sites.
domain integrity of this API is based on the
inability for scripts of one origin to post
arbitrary events (using
dispatchEvent() or
otherwise) to objects in other
origins.. | http://www.w3.org/TR/2008/WD-html5-20080610/diff/comms.html | CC-MAIN-2016-07 | refinedweb | 2,585 | 59.74 |
Closed Bug 843895 Opened 9 years ago Closed 9 years ago
Use a wrapper class instead of Extract
Frame for img Request Proxy::Get Static Request
Categories
(Core :: ImageLib, defect)
Tracking
()
mozilla22
People
(Reporter: seth, Assigned: seth)
References
Details
Attachments
(5 files, 7 obsolete files)
imgIContainer::ExtractFrame doesn't map well onto the things that it's used for - it does clipping AND freezing of animation, but at every place it's used we only need one of those two things. In addition, it requires us to copy image frames in cases where we really don't need to copy anything. For those reasons, and because a different API would make it much easier and more performant to implement media fragments correctly, I want to replace ExtractFrame. This bug is about replacing one of the uses of ExtractFrame: imgRequestProxy::GetStaticRequest. Here we only care about freezing the animation of the image, and do not need clipping, so we'll need a wrapper image class that freezes the image.
Part 1. Allows us to draw an image at either the first frame or the current frame.
Part 2. This adds an abstract base class to make implementing Image wrapper classes as painless as possible.
Part 3. Add FrozenImage, an Image wrapper class that replaces ExtractFrame's function of stopping the animation of an image. (In cases where we cared about this, it was always stopped at the first frame, so that's what FrozenImage does.)
Part 4. The grand finale: we replace the usage of ExtractFrame in imgRequestProxy with FrozenImage.
There's a try job for this patch stack here:
Whoops. Forgot to override FrameRect in FrozenImage. Patch is identical except for that change.
Attachment #716864 - Attachment is obsolete: true
The try job revealed a bug that I'm pretty sure has a trivial fix. I'll get an updated patch / new try job cooking as soon as I can.
The test_async_notification_404.js bug is now fixed. Hopefully everything should now be nice and green. Try job here:
Attachment #716865 - Attachment is obsolete: true
This will need a rebase against the new version of the patches in bug 842850 but I'm holding off until all reviews there are done. It should be fine to review the patches here anyway as the differences won't be substantial.
Went ahead and rebased so I can continue downstream work.
Attachment #718232 - Flags: review?(joe)
Attachment #716860 - Attachment is obsolete: true
Rebase.
Attachment #718234 - Flags: review?(joe)
Attachment #716862 - Attachment is obsolete: true
Rebase.
Attachment #718236 - Flags: review?(joe)
Attachment #716898 - Attachment is obsolete: true
Rebase.
Attachment #718237 - Flags: review?(joe)
Attachment #717402 - Attachment is obsolete: true
Comment on attachment 718234 [details] [diff] [review] (Part 2) - Add ImageWrapper. Review of attachment 718234 [details] [diff] [review]: ----------------------------------------------------------------- ::: image/src/ImageWrapper.cpp @@ +33,5 @@ > + > +uint32_t > +ImageWrapper::SizeOfData() > +{ > + return mInnerImage->SizeOfData(); At least one of these should have + sizeof(mInnerImage), right?
Attachment #718234 - Flags: review?(joe) → review+
Comment on attachment 718236 [details] [diff] [review] (Part 3) - Add the FrozenImage wrapper class to stop image animation. Review of attachment 718236 [details] [diff] [review]: ----------------------------------------------------------------- ::: image/src/FrozenImage.h @@ +10,5 @@ > + > +namespace mozilla { > +namespace image { > + > +// PROBLEM: [noscript] ImageContainer getImageContainer(in LayerManager aManager); maybe this should be removed? @@ +24,5 @@ > + * XXX(seth): There is one known issue: GetImageContainer does not currently > + * support anything but the current frame. We work around this by always > + * returning null, but if it ever turns out that FrozenImage is widely used on > + * codepaths that can actually benefit from GetImageContainer, it would be a > + * good idea to fix that method. I'm torn as to whether this belongs here or in GetImageContainer.
Attachment #718236 - Flags: review?(joe) → review+
Comment on attachment 718237 [details] [diff] [review] (Part 4) - Use FrozenImage instead of ExtractFrame for imgRequestProxy::GetStaticRequest. Review of attachment 718237 [details] [diff] [review]: ----------------------------------------------------------------- ::: image/src/ImageFactory.h @@ +51,5 @@ > + * at the first frame. > + * > + * @param aImage The existing image. > + */ > + static already_AddRefed<Image> Freeze(Image* aImage); I really like the name, but at the same time everything else is CreateFooImage. Torn. ::: image/src/imgRequestProxy.cpp @@ +920,5 @@ > // Create a static imgRequestProxy with our new extracted frame. > nsCOMPtr<nsIPrincipal> currentPrincipal; > GetImagePrincipal(getter_AddRefs(currentPrincipal)); > + nsRefPtr<imgRequestProxy> req = new imgRequestProxyStatic(frozenImage, > + currentPrincipal); I wonder whether we need imgRequestProxyStatic any more.
Attachment #718237 - Flags: review?(joe) → review+
Thanks for the reviews, Joe! I'll make the changes you recommend. > I'm torn as to whether this belongs here or in GetImageContainer. I was too, as you may have later noticed, since I put a smaller version of that explanation in GetImageContainer too. Maybe the best thing is to put the full version in GetImageContainer and just point you there from the header file comment. It'd be bad if they got out of sync. > I really like the name, but at the same time everything else is CreateFooImage..
(In reply to Joe Drew (:JOEDREW! \o/) from comment #14) > At least one of these should have + sizeof(mInnerImage), right? After looking at how RasterImage and VectorImage implement these calls I'm not so sure about this, actually. It doesn't seem like implementation-related small data members like these are counted. Also, this is information used for caching, but right now I see it as unlikely that ImageWrappers will be cached. For now I'll avoid making this change, but please let me know if you disagree with this analysis.
(In reply to Seth Fowler [:seth] from comment #17) >. Once I actually tried to do this I realized I was very, very wrong. Forget about this.
(In reply to Joe Drew (:JOEDREW! \o/) from comment #16) > I wonder whether we need imgRequestProxyStatic any more. We're moving in the direction of not needing it really fast. We could have probably dropped it a while ago just by moving the principal stuff onto RequestBehaviour, I think.
Applied changes from review.
OK, just to be sure I'm running another try job through.
I'm pretty sure the oranges in that try job are from the patches in bug 846132. I'll post another try job once that bug is ship-shape.
OK, I think we're ready for another try job here:
Try looks OK. Pushed in:
Comment on attachment 718237 [details] [diff] [review] (Part 4) - Use FrozenImage instead of ExtractFrame for imgRequestProxy::GetStaticRequest. >+ // Check for errors in the image. Callers code rely on GetStaticRequest >+ // failing in this case Bah, it turns out that I was relying on it succeeding in this case, I simply hadn't tested on a broken animated image. Where can I find one?
(In reply to neil@parkwaycc.co.uk from comment #26) > >+ // Check for errors in the image. Callers code rely on GetStaticRequest > >+ // failing in this case > Bah, it turns out that I was relying on it succeeding in this case, I simply > hadn't tested on a broken animated image. Where can I find one? We're not really checking for a broken animated image there. We're checking for _any_ case where GetImage() returns non-null, but GetImage()->HasError() returns true. If the image has an error, we won't exit early at the first check because NS_SUCCEEDED(GetAnimated()) will be false. The same scenario would've been caught in the original code (before this patch) by checking the return value of ExtractFrame. If we don't do this, we break test_async_notification_404.js, FWIW. I'd prefer not to have this check either, honestly.
I say this because this used to work in Gecko 18... I guess I need to start bisecting.
I take that back, it works with some images but not others. Still testing...
OK, so in Gecko 18, getting the static request succeeds for broken images but in Gecko 19 it fails...
Ignore me, I wasn't calling getStaticRequest in Gecko 18.
Status: NEW → RESOLVED
Closed: 9 years ago
Resolution: --- → FIXED
Target Milestone: --- → mozilla22
Ms2ger pointed out on IRC that FrozenImage::GetAnimated was a bit unclear and the intention could be clarified through the use of a dummy variable. I pushed in this trivial change here:
(Here's the patch itself.) | https://bugzilla.mozilla.org/show_bug.cgi?id=843895 | CC-MAIN-2021-49 | refinedweb | 1,345 | 57.57 |
In this problem, we're given a set of paths on a tree and want to compute the maximum number of paths some node in the tree is on.
The naive solution to this problem would be, for each path, to manually increment the number of paths each node on the path is on by one. This will be $O(N^2)$ and is therefore too slow.
Let's first solve the easier case where the tree is actually a linked list. In this case, we can solve the problem in linear time by maintaining a prefix sum on the list - for the parent node in the list we increment a counter by 1, for the child node we decrement a counter by 1, and then when we've done this for all the paths we can iterate over the list and accumulate the prefix sums, maintaining the maximum.
Using this as inspiration, we can apply this prefix sum technique to a generic tree as follows - start by rooting the tree arbitrarily. For a path from node X to node Y, increment a "prefix" value at X and Y by 1. Decrement the prefix of the lowest common ancestor (LCA) of X and Y by 1, and decrement the prefix of the parent of the LCA by 1. Note that for a given node, the sum of the prefix values for every node in the given node's subtree is the number of paths that that node is on. We can compute the sum of the prefix values for all subtrees in linear time by processing the nodes in decreasing order of depth. Now, it remains to figure out how to compute the LCA of two nodes in sublinear time. There are several ways to do this --- for example we could use Tarjan's off-line LCA algorithm. The approach we use in this solution is as follows:
Given that the tree is rooted, let the "depth" of a node be the distance from the root to that node, and assume for simplicity that we want to find the LCA of two nodes X and Y which are the same depth. The following linear-time algorithm will find the LCA:
while X and Y are different: X = parent(X) Y = parent(Y)
If we could binary search on the depth of the number of parent calls we need to make, we could make this run in $O(\log N)$. We will simulate binary search as follows:
Let $f(N, S) = Z$ be the ancestor of $N$ such that $depth(Z) + 2^S = depth(N)$. If we root the tree, then we can compute $f(N, 0)$ directly for every node in the tree, and then $f(N, S) = f(f(N, S-1), S-1)$. Since the depth of the tree is $O(N)$, $S$ can only take on $O(\log N)$ values and therefore there are $O(N \log N)$ distinct tuples for $f$ that need to be computed.
We can now use $f$ to search for the highest ancestors of $X$ and $Y$ that are not common ancestors to both $X$ and $Y$ in $O(\log N)$ time as follows by finding the largest $S$ such that $f(X, S) \neq f(Y, S)$. Now, replace $X$ and $Y$ with $f(X, S)$ and $f(Y, S)$ and repeat this process until no such $S$ exists. Once that's the case, it must be true that either $X = Y$ or the parent of $X$ and $Y$ are identical.
Note that as we iterate on $S$, note that the values for $S$ must be monotonically decreasing - they clearly cannot be increasing, and if we pick the same value for $S$ twice in a row, we should have used $S+1$ instead. Therefore, if we iterate over $S$ in decreasing order, this procedure takes $O(\log N)$ time.
Therefore, after we root the tree, we can pre-compute $f$ in $O(N \log N)$ time, and then for each path, we do a single LCA query, so updating the prefix sums runs in $O(K \log N)$. The final accumulation of prefix sums by iterating on the nodes in decreasing order of depth takes $O(N)$ time, so this solution is $O((N+K) \log N)$.
Here is my code demonstrating this solution:
import java.io.*; import java.util.*; public class maxflow { static int[] p; static int[] depth; static int[][] anc; static int[] amt; static LinkedList<Integer>[] edges; static LinkedList<Integer> revOrder; public static void main(String[] args) throws IOException { BufferedReader br = new BufferedReader(new FileReader("maxflow.in")); PrintWriter pw = new PrintWriter(new BufferedWriter(new FileWriter("maxflow.out"))); StringTokenizer st = new StringTokenizer(br.readLine()); int n = Integer.parseInt(st.nextToken()); int k = Integer.parseInt(st.nextToken()); p = new int[n+1]; amt = new int[n+1]; depth = new int[n+1]; Arrays.fill(p, -1); p[0] = p[1] = 0; anc = new int[n+1][17]; edges = new LinkedList[n+1]; revOrder = new LinkedList<Integer>(); for(int i = 0; i < edges.length; i++) { edges[i] = new LinkedList<Integer>(); } for(int a = 1; a < n; a++) { st = new StringTokenizer(br.readLine()); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); edges[x].add(y); edges[y].add(x); } bfs(); genLCA(); for(int i = 0; i < k; i++) { st = new StringTokenizer(br.readLine()); int x = Integer.parseInt(st.nextToken()); int y = Integer.parseInt(st.nextToken()); int lca = lca(x, y); amt[x]++; amt[y]++; amt[lca]--; amt[p[lca]]--; } compute(); int ret = 0; for(int i = 1; i <= n; i++) { ret = Math.max(ret, amt[i]); } pw.println(ret); pw.close(); } public static void compute() { while(!revOrder.isEmpty()) { int curr = revOrder.removeFirst(); amt[p[curr]] += amt[curr]; } } public static int lca(int a, int b) { if(depth[a] > depth[b]) { return lca(b, a); } if(depth[a] < depth[b]) { b = getP(b, depth[a]); } for(int k = 16; k > 0; k--) { while(anc[a][k] != anc[b][k]) { a = anc[a][k]; b = anc[b][k]; } } while(a != b) { a = p[a]; b = p[b]; } return a; } public static int getP(int curr, int wantedD) { for(int k = 16; depth[curr] != wantedD; k--) { while(depth[curr] - (1<<k) >= wantedD) { curr = anc[curr][k]; } } return curr; } public static void genLCA() { for(int i = 1; i < p.length; i++) { anc[i][0] = p[i]; } for(int j = 1; j < anc[0].length; j++) { for(int i = 1; i < p.length; i++) { anc[i][j] = anc[anc[i][j-1]][j-1]; } } } public static void bfs() { LinkedList<Integer> q = new LinkedList<Integer>(); q.add(1); while(!q.isEmpty()) { int curr = q.removeFirst(); revOrder.addFirst(curr); for(int child: edges[curr]) { if(p[child] == -1) { p[child] = curr; depth[child] = 1 + depth[curr]; q.add(child); } } } } }
Additional analysis by Jesse van Dobben: Alternatively, the problem can be solved by using a two-pass depth first search along with a one-dimensional range query data structure. (For instance, you can use a Fenwick tree. I chose to reuse the tree I constructed in the solution to the third problem, Counting Haybales.) The algorithm works as follows: first we do a simple depth-first search where we label the vertices in the order in which we encounter them (that is, by starting time). Now a subtree corresponds to an interval of starting times. This is the most important idea behind this solution: the amount of flow going into a subtree can now be calculated by range query. Note that the answer does not change if we invert the direction of some of the $K$ flows. Thus, we may orient all the flows from lower to higher starting time. In the second DFS we will count for every vertex $v$ the amount of flow going into $v$, plus the amount of flow originating at $v$. We say a flow is "active" at a certain point during the second DFS if we have already started processing its first endpoint and have not yet completed processing its second endpoint. Whenever we go into a subtree during the second DFS, the amount of flow going into that subtree can be calculated as the number of currently active flows for which the destination lies within that subtree, so we query for the time interval of that subtree. Similarly, whenever we return from a subtree, the amount of flow coming back from that subtree can be calculated as the number of currently active flows for which the source lies within that subtree, which again corresponds to a time interval. This way we can compute the total amount of flow going into the current vertex using two one-dimensional range query data structures (one to list the active flows by their source and one to list the active flows by their destination). Don't forget to add the amount of flow originating at the current vertex, and we are done. I have rewritten the code for the sake of readability. (For instance, in my original solution I reused the data structure I wrote for the third problem, which was already quite a mess.)
#include <fstream> #include <vector> #include <algorithm> using namespace std; const int MAX_N = 50000; ifstream fin("maxflow.in"); ofstream fout("maxflow.out"); struct partialSumTree { // data structure for changing and querying partial sums of a sequence // consiting of R - L elements, indexed L through R - 1. int L, R, half, sum; partialSumTree *left, *right; partialSumTree(int l, int r) : L(l), R(r), half((L + R)/2), sum(0) { if (half == L) { left = right = NULL; } else { left = new partialSumTree(L, half); right = new partialSumTree(half, R); } } void updateValue(int idx, int delta) { if (idx < L || idx >= R) return; sum += delta; if (half != L) { (idx < half ? left : right)->updateValue(idx, delta); } } // get partial sum from A to B - 1 int getSum(int A, int B) { if (A >= R || B <= L) return 0; if (A <= L && B >= R) return sum; return left->getSum(A, B) + right->getSum(A, B); } }; vector<int> neighbours[MAX_N]; int startTime[MAX_N]; int endTime[MAX_N]; int firstPassDFS(int curNode, int curTime) { if (startTime[curNode] != -1) return curTime; startTime[curNode] = curTime++; for (vector<int>::iterator it = neighbours[curNode].begin(); it != neighbours[curNode].end(); it++) { curTime = firstPassDFS(*it, curTime); } return endTime[curNode] = curTime; } vector<int> beginPath[MAX_N], endPath[MAX_N]; int ans = -1; partialSumTree *bySource, *byDestination; int secondPassDFS(int curNode, int curTime) { if (startTime[curNode] != curTime) return curTime; curTime++; int passingThrough = byDestination->getSum(startTime[curNode], endTime[curNode]); for (vector<int>::iterator it = beginPath[curNode].begin(); it != beginPath[curNode].end(); it++) { // unpack all paths starting at curNode bySource->updateValue(startTime[curNode], 1); byDestination->updateValue(startTime[*it], 1); passingThrough++; } for (vector<int>::iterator it = neighbours[curNode].begin(); it != neighbours[curNode].end(); it++) { int prevTime = curTime; curTime = secondPassDFS(*it, curTime); // add all paths that were started but not stopped in the subtree rooted at *it passingThrough += bySource->getSum(prevTime, curTime); } for (vector<int>::iterator it = endPath[curNode].begin(); it != endPath[curNode].end(); it++) { // remove all paths ending at curNode bySource->updateValue(startTime[*it], -1); byDestination->updateValue(startTime[curNode], -1); } ans = max(ans, passingThrough); return curTime; } int main() { int N, K; fin >> N >> K; for (int i = 1; i < N; i++) { int x, y; fin >> x >> y; x--; y--; neighbours[x].push_back(y); neighbours[y].push_back(x); } fill(startTime, startTime + N, -1); fill(endTime, endTime + N, -1); firstPassDFS(0, 0); bySource = new partialSumTree(0, N); byDestination = new partialSumTree(0, N); for (int i = 0; i < K; i++) { int s, t; fin >> s >> t; s--; t--; if (startTime[s] > startTime[t]) swap(s, t); beginPath[s].push_back(t); endPath[t].push_back(s); } secondPassDFS(0, 0); fout << ans << endl; return 0; } | http://usaco.org/current/data/sol_maxflow_platinum_dec15.html | CC-MAIN-2018-17 | refinedweb | 1,943 | 59.23 |
The header file ap_config_auto.h is a bit flawed. It defines PACKAGE_NAME and PACKAGE_VERSION, and similar constants. If one would like to compile their own module, one could write something like:
#ifdef HAVE_CONFIG_H
#include <config.h>
#endif
#include <httpd.h>
#include <http_config.h>
#include <http_protocol.h>
#include <ap_config.h>
This would give compiler warnings (not errors) about PACKAGE_NAME being re-defined. This is a bit sloppy and certainly not necessary. Hardly any C program defines PACKAGE_NAME and similar constants outside config.h, and header files should certainly not re-define them.
It would be better to have this in ap_config_auto.h:
#ifndef PACKAGE_BUGREPORT
# define PACKAGE_BUGREPORT ""
#endif
So it's not very critical, but it's also not nice to cause warnings that need not be caused. | https://bz.apache.org/bugzilla/show_bug.cgi?id=46578 | CC-MAIN-2020-45 | refinedweb | 126 | 54.79 |
I'd say that is a version of the Partitions of Integers problem where a special condition is imposed on the integers that we can use.
You can find and solve this problem on HackerRank, section Cracking the Coding Interview.
First thing, I have taken a non completely trivial example and I studied it on paper.
Given in input [2, 5, 3, 6] and 10, it easy to see how the solution is 5:
2 + 2 + 2 + 2 + 2 5 + 5 2 + 3 + 5 3 + 3 + 2 + 2 2 + 2 + 6The fact that it is marked as DP, should put me on the way of looking for a Dynamic Programming solution. So I create a table, reasoning how to fill it up coherently. Each column represents the totals I could get, ranging from 0 to the passed value. I have a column for each number passed in the input list, plus the topmost one, that represents the "no value" case.
Cell in position (0, 0) is set to 1, since I could get 0 from no value in just one way. The other values in the first row are set to zero, since I can't get that total having nothing to add up. We don't care much what it is in the other cells, since we are about to get the right value by construction.
We'll move in the usual way for a dynamic programming problem requiring a bidimensional table, row by row, skipping the zeroth one, from top to bottom, moving from left to right. We could have filled the first column before starting the procedure, since it is immediate to see that there is only one way to get a total of zero, whichever number I have at hand. Still, in this case it doesn't help to make the code simpler, so I just keep it in the normal table filling part.
For each cell what I have to do is:
- copy the value from the cell above
- if "cur", the current value associated to the row, is not greater than the current column index, add the value in the cell on the same row but "cur" times to the left
The second point refers to the contribution of the new element. I guess the picture will help understand it.
The arrow pointing down from (0, 0) to (1, 0) means that since having no values leads to have one way to get a sum of zero, this implies that having no value and 2 still gives at least one way to get a sum of zero.
The other arrow pointing down, from (2, 8) to (3, 8) means that having one way to get 8 from no value and [2, 5] implies we still have at least one way to get it from no value and [2, 5, 3].
The arrow pointing left from (1, 0) to (1, 2) means that since we have a way to get zero having a 2, if we add a 2, we have a way to get 2 as a total.
The arrow pointing left from (3, 5) to (3, 8) means that having two ways of getting 5 using [2, 5, 3] implies that we still have two way of getting 5 + 3 = 8. Added with the one coming from the cell above, it explains why we put 3 in this cell.
Following the algorithm, I have written this python code here below:
def solution_full(denominations, total): # 1 table = [[0] * (total + 1) for _ in range(len(denominations) + 1)] # 2 table[0][0] = 1 for i in range(1, len(denominations) + 1): # 3 for j in range(total+1): table[i][j] += table[i - 1][j] # 4 cur = denominations[i-1] if cur <= j: table[i][j] += table[i][j-cur] # 5 return table[-1][-1] # 61. In the example, denominations is [2, 5, 3, 6] and total is 10.
2. Table has total + 1 columns and a row for each denomination, plus one. Its values are all set to zero, but the left-topmost one, set to 1.
3. Loop on all the "real" cells, meaning that I skip just the first row. I move in the usual way. Left to right, from the upper row downward.
4. The current cell value is initialized copying the value from the immediate upper one.
5. If there are enough cell to the left, go get the value of the one found shifting for the value of the current denomination, and add it to the one calculated in the previous step.
6. Return the value in the bottom right cell, that represents our solution.
How to save some memory
Writing the code, I have seen how there is no use in keeping all the rows. The only point where I use the values in the rows above the current one is in (4), and there I use just the value in the cell immediately above the current one. So I refactored the solution in this way:
def solution(denominations, total): cache = [0] * (total + 1) # 1 cache[0] = 1 for denomination in denominations: # 2 for j in range(denomination, total+1): # 3 cache[j] += cache[j-denomination] return cache[-1]1. The memoization here is done just in one row. Initialized as in the previous version.
2. Since I don't care anymore of the row index, I can just work directly on the denominations.
3. Instead of checking explicitly for the column index, I can start the internal loop from the first good position.
I pushed my python script with both solutions and a slim test case to GitHub. | http://thisthread.blogspot.com/2018/03/hackerrank-dp-coin-change.html | CC-MAIN-2018-43 | refinedweb | 941 | 64.24 |
Latin1/GSM conversion class. More...
#include <gsmcodec.h>
List of all member functions.
The GSM specifications for SMS use a compact 7-bit encoding to represent Latin-1 characters, compared to the more usual 8-bit ISO-8859-1 encoding used on many computer systems.
The GSMCodec class enables conversion back and forth between the GSM encoding and the normal 8-bit encoding used by Qtopia.
Application programs will rarely need to use this class, because the SMSMessage class automatically converts between 7-bit and 8-bit encodings as necessary.
See also Qtopia Phone Classes.
This file is part of the Qtopia platform, copyright © 1995-2005 Trolltech, all rights reserved. | http://doc.trolltech.com/qtopia2.2/html/gsmcodec.html | crawl-001 | refinedweb | 110 | 57.16 |
As I've mentioned before, the current credential-munging here is simply broken; however, the brokenness I previously observed is independent of the brokenness you are now reporting.
Robert N M Watson FreeBSD Core Team, TrustedBSD Project [EMAIL PROTECTED] NAI Labs, Safeport Network Services On Mon, 15 Oct 2001, Bruce Evans wrote: > coredump() now usually creates empty core files for nfs filesystems. > This seems to be caused by the changes in rev.1.132 (-current) and > rev.1.72.2.9 (RELENG_4), and braindamage in nfs_dolock(): > > Index: kern_sig.c > =================================================================== > RCS file: /home/ncvs/src/sys/kern/kern_sig.c,v > retrieving revision 1.131 > retrieving revision 1.132 > diff -u -2 -r1.131 -r1.132 > --- kern_sig.c 6 Sep 2001 22:20:41 -0000 1.131 > +++ kern_sig.c 8 Sep 2001 20:02:32 -0000 1.132 > > ... > @@ -1896,6 +1898,17 @@ > NDFREE(&nd, NDF_ONLY_PNBUF); > vp = nd.ni_vp; > + > + VOP_UNLOCK(vp, 0, p); > + lf.l_whence = SEEK_SET; > + lf.l_start = 0; > + lf.l_len = 0; > + lf.l_type = F_WRLCK; > + error = VOP_ADVLOCK(vp, (caddr_t)p, F_SETLK, &lf, F_FLOCK); > + if (error) > + goto out2; > + > > This usually goes to out2 with error EOPNOTSUPP if the core file is on > an nfs filesystem. > > From nfs_dolock(): > > % /* > % * XXX Hack to temporarily allow this process (regardless of it's creds) > % * to open the fifo we need to write to. vn_open() really should > % * take a ucred (and once it does, this code should be fixed to use > % * proc0's ucred. > % */ > % saved_uid = p->p_ucred->cr_uid; > % p->p_ucred->cr_uid = 0; /* temporarly run the vn_open as root */ > % > % fmode = FFLAGS(O_WRONLY); > % error = vn_open(&nd, &fmode, 0); > > This vn_open() usually fails, because root is usually mapped so has even > less write permission than most users. I don't see how nfs write locks can > work for syscalls either. > > % p->p_ucred->cr_uid = saved_uid; > % if (error != 0) { > % return (error == ENOENT ? EOPNOTSUPP : error); > % } > > EOPNOTSUPP is a strange error for foot shooting. > > Bruce > > > To Unsubscribe: send mail to [EMAIL PROTECTED] > with "unsubscribe freebsd-current" in the body of the message > To Unsubscribe: send mail to [EMAIL PROTECTED] with "unsubscribe freebsd-current" in the body of the message | https://www.mail-archive.com/freebsd-current@freebsd.org/msg32565.html | CC-MAIN-2018-51 | refinedweb | 342 | 68.16 |
Hi Robert,
To do that, you'll need to become moderately well acquainted with
working with a POVRay scene file.
It sounds like what you're thinking of would be covered by the "plane"
object in POVRay. As described in the POVRay manual, planes are
defined as follows
#begin plane definition
plane { <0, 1, 0>, -1
pigment {color orange}
}
This defines an infinite plane (great for a background) that's colored
orange. The vector <0,1,0> (in the format <x,y,z>) is the surface normal
of the plane (i.e. if we were standing on the surface, the normal points
straight up along the y axis). The number after the vector definition is the
distance that the plane is displaced along the normal from the
origin -- in this case, the floor is placed at y=-1 so that a sphere
at y=1, radius=2, would be resting on it.
What you'll need to do is have PyMOL output your scene file, figure
out where the boundaries of your molecule are, then displace a plane
away from the origin both far enough that it doesn't clip into the molecule
and in the right direction, such that your light source causes the shadow
of your molecule to fall upon the plane.
I hope I was able to be of some help.
Jacob
RC> Hi,
RC> Someone posed a question to me that I couldn't answer, so I'm turning to
RC> the collective wisdom here for help.
RC> How does one create one of those fancy journal-cover images in which,
RC> say, a structure is superimposed on some other image as a background,
RC> but in which a shadow is cast on the background. There is a simple image
RC> of this sort on the opening page of the pymol gallery, so I figure this
RC> must be possible and that perhaps Warren himself knows. :)
RC> I assume that this might be a povray method, so I figured out that if do
RC> something like:
RC> (header,data) = cmd.get_povray()
RC> file=open('povray.dat','w')
RC> file.write(header)
RC> file.write(data)
RC> file.close()
RC> then I have a povray input file that I can render.
RC> Does anybody have a recipe for adding a background image using povray?
RC> Or is there another, better way?
RC> Cheers,
RC> RobertPyMOL-users@...
Robert,
You are on the right track. In order to do this right, you'll need =
to use PovRay, which supports perspective and textures. =20
PyMOL's raytracer is really just an optimized orthographic, =
textureless, reflectionless raycaster, which is fine for simple =
molecules, but inadequate for complex scenes. In other words, to make a =
Science or Nature cover image, you will have to do a bit more work than =
just hitting the "Ray" button. =20
Specifically, you need to introduce a geometric object behind the =
molecule onto which the shadow can be cast. If all you need is a flat, =
untextured surface, then you can use PyMOL's CGO module to generate =
this. Otherwise, you'll need to learn how to modify PyMOL's PovRay =
input file to contain these objects by reading the PovRay documentation =
and editing the text file you already know how to generate.
I've attached an example below. Save to "ray.py" and run it from =
within PyMOL. =20
Cheers,
Warren
from pymol.cgo import *
obj =3D [
BEGIN, TRIANGLE_STRIP,
COLOR, 0.8,0.7,0.4,
NORMAL, 0.0, 1.0, 0.0,
VERTEX, -7.0, -20.0, 0.0,
VERTEX, -10.0, -20.0, 30.0,
VERTEX, 12.0, -20.0, 0.0,
VERTEX, 15.0, -20.0, 30.0,
END,
]
cmd.load_cgo(obj,"plane")
cmd.load("$PYMOL_PATH/test/dat/pept.pdb")
util.ray_shadows('heavy')
cmd.set_view((\
0.962451875, -0.074250713, -0.261098653,\
0.192369312, 0.865197897, 0.463061303,\
0.191519246, -0.495900899, 0.846994936,\
-0.427299917, 0.681541085, -83.549995422,\
1.224037170, -10.279197693, 20.545440674,\
70.968811035, 117.627342224, 0.000000000 ))
cmd.ray()
--
mailto:warren@...
Warren L. DeLano, Ph.D.
> -----Original Message-----
> From: Robert Campbell [mailto:rlc@...]
> Sent: Friday, April 12, 2002 9:52 AM
> To: PyMOL-users@...
> Subject: [PyMOL] Fancy images
>=20
>=20
> Hi,
>=20
> Someone posed a question to me that I couldn't answer, so I'm=20
> turning to
> the collective wisdom here for help.
>=20
> How does one create one of those fancy journal-cover images in which,
> say, a structure is superimposed on some other image as a background,
> but in which a shadow is cast on the background. There is a=20
> simple image
> of this sort on the opening page of the pymol gallery, so I=20
> figure this
> must be possible and that perhaps Warren himself knows. :)
>=20
> I assume that this might be a povray method, so I figured out=20
> that if do
> something like:
>=20
> (header,data) =3D cmd.get_povray()
> file=3Dopen('povray.dat','w')
> file.write(header)
> file.write(data)
> file.close()
>=20
> then I have a povray input file that I can render.
>=20
> Does anybody have a recipe for adding a background image using povray?
> Or is there another, better way?
>=20
> Cheers,
> Robert
> --=20
> Robert L. Campbell, Ph.D. =20
>
> rlc@... phone:=20
> 410-614-6313
> Research Specialist/X-ray Facility Manager
> HHMI/Dept. of Biophysics & Biophysical Chem., The Johns=20
> Hopkins University
> PGP Fingerprint: 9B49 3D3F A489 05DC B35C 8E33 F238 A8F5=20
> F635 C0E2
>=20
> _______________________________________________
> PyMOL-users mailing list
> PyMOL-users@...
>
>=20 | http://sourceforge.net/p/pymol/mailman/message/5221949/ | CC-MAIN-2015-06 | refinedweb | 918 | 72.56 |
The QStrList class provides a doubly linked list of
char*.
More...
#include <qstrlist.h>
Inherits QList.
Inherited by QStrIList.
List of all member functions.
char*.
This class is a QList<char> instance (a list of char*).
QStrList can make deep or shallow copies of the strings that are inserted.
A deep copy means to allocate space for the string and then copy the string data into it. A shallow copy is just a copy of the pointer value and not the string data.
The disadvantage with shallow copies is that since a pointer can only be deleted once, the program must put all strings in a central place and know when it is safe to delete them (i.e. when the strings are no longer referenced by other parts of the program). This can make the program more complex. The advantage of shallow copies is that shallow copies a sorted order.
The QStrListIterator class is an iterator for QStrList.
Constructs an empty list of strings. Will make deep copies of all inserted strings if deepCopies is TRUE, or uses.
Search the documentation, FAQ, qt-interest archive and more (uses):
This file is part of the Qt toolkit, copyright © 1995-2005 Trolltech, all rights reserved. | http://doc.trolltech.com/2.3/qstrlist.html | crawl-002 | refinedweb | 204 | 84.27 |
Entering edit mode
Hi, I am new to Biopython and I've been trying to explore the capabilities of the SeqIO function to iterate over a FASTA file, more specifically on a Regex( regular expressions) task. What I need to do is find PolyQ aglomerations in Human proteome. Here is what I have right now (using latest NCBI proteome ftp):
import re from Bio import SeqIO def reader(): for seq_record in SeqIO.parse("Gnomon_prot_micro.fsa", "fasta"): sequence = (str(seq_record.seq)) print sequence #just to verify gene_name = seq_record.id) print gene_name #just to verify compiler = re.compile('QQQ+') while sequence: #do I need to start a new cycle to iterate over sequence ? read = re.finditer(compiler,sequence) for m in read: print m.start(), m.group() # need to get bulk position and how many Qs
Is there a better way to iterate over the document to obtain only the sequences? ( I am relating every sequence with its respective gene name later). Sorry for being a noob and correct me if anything.
It's better to compile the pattern for
reout of the for loop, you only need to do that once.
I'm not sure why you use the while loop... Which output do you aim to obtain?
Hey, thanks for answering! The while loop is just there for the idea, I aim to obtain a document that will display for every gene :
Since I do not want 'code service' , could you please just reference what your suggestions would be ?
I think you should remove the while loop or adapt it. Since sequence will always be "
True" you have here effectively an endless loop. What about using
m.span()for getting both start and end (which then also gives you the length).
While looping over your iterator
readyou will have to increment a counter to track how many matches you have.
Am I making sense?
I found a working solution! :
any added suggestions or comments to improve ?
I'm not sure why you add brackets around
seq_record.idand
str(seq_record.seq)but okay probably shouldn't matter. It's not crucial, but I would add the
compiler = re.compile('QQ+')line just above the for loop but in the reader function (perhaps a more precise function name is a good idea but that's a detail).
You will now need to nicely format your output but that's straightforward I guess.
Thanks! Yeah, I'll format it . | https://www.biostars.org/p/222442/ | CC-MAIN-2021-43 | refinedweb | 406 | 75.71 |
Alex Rudnick
If you've done some reading about automatic puzzle solving, you may have heard about Dancing Links, or DLX. It's a surprisingly fast constraint-satisfaction algorithm by Donald Knuth, and it works very well for solving sudoku.
My implementation of Dancing Links, and a sudoku solver implemented on top of that, is available in the repository of this project. It's also running on App Engine. Here, I intend to give a clear description of how to use DLX to solve sudoku, and in a forthcoming writeup, I'll talk about implementing Dancing Links. Knuth's original paper describes the algorithm in detail, but I found it pretty dense, and I think some extra discussion will be helpful.
So first, I'd like to talk a bit about automatic sudoku-solving in general, then I'll get into how to apply DLX to sudoku. There are two common approaches to solving sudoku programmatically. One of them attempts to solve the problem entirely by "logic", this is to say, by forward-chaining inferences until you've reached a complete solution. This is something like the approach taken by human sudoku aficionados. While in general, published sudoku puzzles only have one valid solution, this approach can't solve an under-constrained puzzle.
The other approach is what a computer scientist would call "recursive search", but human sudoku players call "guessing" or "Ariadne's Thread". In this style of play, we make an assumption ("let's say that this square here is a 9") and then follow along with that until we have to abandon it. At any given point, if we don't know what to do, we try something, always ready to unwind our suppositions when we find out they can't be true. With sudoku, since puzzles usually only have one answer, if your search algorithm tries all possible assumptions then you're guaranteed to find the answer through search. In the case of an under-constrained problem, one with more than one answer, you'll still always find a solution; you could find all of them, if you like.
As an aside, this does not have to be complicated. You could imagine writing a solver that does the dumbest possible search, cycling through each number for each square and checking for a solved puzzle. And it would find an answer, but it might take a while because you could end up searching through 9^81 solutions. But we have a better approach!
Dancing Links (DLX) is an algorithm for solving set cover constraint satisfaction problems, sudoku being easily described as one of those. Let's talk about how to represent sudoku as a set-cover problem.
Say you have a grid of 1s and 0s, and you want to find a subset of the rows such that for every column, there is a single 1 in that column. No column gets more than one. If the first row were all '1's, for example, then the problem would be solved trivially. Here's a small example grid. A solution to this one is to take rows 1, 4, and 5.
# Grid 1 has a solution.
row 1: 0 0 1 0 1 1 0
row 2: 1 0 0 1 0 0 1
row 3: 0 1 1 0 0 1 0
row 4: 1 0 0 1 0 0 0
row 5: 0 1 0 0 0 0 1
row 6: 0 0 0 1 1 0 1
Note that the solution has exactly one '1' in each column.
# Grid 1's solution
row 1: 0 0 1 0 1 1 0
row 4: 1 0 0 1 0 0 0
row 5: 0 1 0 0 0 0 1
Here's another grid; this one has no such solution.
# Grid 2, no solution.
row 1: 0 0 0 0 0 1 0
row 2: 0 1 0 1 0 0 0
row 3: 0 0 0 0 0 1 1
row 4: 1 1 0 1 0 0 0
row 5: 0 0 0 1 0 0 0
At first, let's assume we have some software that can find solutions to these "exact cover" problems (this is where Dancing Links comes in) -- given a bunch of rows of 0s and 1s, it finds a subset of those rows such that there's exactly one 1 in every column. If we can represent a sudoku board in terms of these grids -- which we can -- then we're set!
In sudoku, there are four kinds of constraints: each cell must have a number in it; each row must have each number (1 through 9) once; each column must have each number once; and each box (3x3 area) must have each number once. To represent these constraints, we'll build a Dancing Links grid like the ones described in the previous section, in which each column represents one of these. There are 324 constraints total (81 of each of 4 types), so 324 columns.
Each row in the grid represents one possible assignment. For example, a row in the DLX grid might describe the idea that there is a 3 in the fifth row, second column. This assignment "contributes" exactly 4 '1's to the grid, one for each of the constraint types. When we've found a solution, we'll have picked 81 rows, each one of which has four '1's in it, exactly covering each of 324 columns.
Take a moment to consider this: a solved sudoku puzzle has exactly 81 assignments, one for each square, so it will have 81 rows in the DLX solution, each filling in 4 of the 324 columns.
The first 81 columns of a row (representing an assignment) describe the row and column that it fills in -- we describe this as rowR colC where R and C are the row and column in the sudoku puzzle. So if the assignment is for row 3, column 5, then it gets a '1' for constraint row3 col5, and a 0 for each other row and column -- it doesn't satisfy those constraints.
In the next 81 columns of the DLX row, we'll describe on which row the assignment falls, and what number it assigns. Much like the Row-Column constraints, we can write this as rowR numN. Then we'll do the analogous thing for Column-Number and Box-Number constraints -- we'll write down which row (or column or box) an assignment describes, and which number it assigns. And that handles the other three types of constraints, and the second, third and fourth 81-column sections.
Here's how I numbered the 9 "boxes" used in sudoku. Note the zero-indexing; it makes the math in the next section slightly easier.
def row_col_to_box(row, col):
"""Return the index for the box that the given (r, c) sudoku coordinates fits
into. Boxes go like this:
0 1 2
3 4 5
6 7 8
"""
return (row - (row % 3)) + (col / 3)
So for a given assignment (the idea that for row R and column C, you'll put value V) you need to produce a list of 0s and 1s, 324 elements long. To do this, we'll produce four lists of 81 elements and concatenate them. For each constraint, we've got two numbers: row/column, row/number, column/number, and box/number. For ease of math, we'll assume that they're all zero-indexed; call the first number the "major" number and the second one the "minor" (my terminology). Now we just put a 1 in each 81-element list at a place that uniquely identifies the major and minor numbers.
def encode(major, minor):
"""Build a list of 81 values, with a 1 in the spot corresponding to the value
of the major attribute and minor attribute."""
out = [0] * 81
out [major*9 + minor] = 1
return out
Once we build these four lists and concatenate them together, we've represented a single assignment.
Now we have to turn a sudoku board into a DLX grid. Since the initial DLX grid describes the set of possible assignments, we map what we know about each square onto one or more rows. When you're given a sudoku board, each square is either already filled, or it's left blank. For the squares that are already filled, you generate the one row that describes that assignment. Otherwise, generate the possibility that it's each number, 1 through 9. Although I haven't tried it, I suspect you could do something more clever here and not generate every row, front-loading some of your inferencing; there may be an optimization lurking here, but on the other hand, DLX may be so fast as to make trying something clever counter-productive.
Build up your list of possible assignments, and you have a big Dancing Links grid. It will have between 81 (for a totally filled board) and 729 (totally blank board) rows in it. Set your DLX solver loose on it and bask in glory.
Once your DLX solver is done, you'll have 81 rows that describe a solved sudoku board. The only thing left is to extract the solution from those DLX rows. To do this, we look at each row in the solution and grab the row/column information out of the first "constraint" area (the first 81 columns), and the value out of the second. This function dlx_row_to_rcv takes in a row from your solution and produces a tuple containing that row's row, column, value. (row and column here are still zero-indexed). Map it over your Dancing Links solution.
def dlx_row_to_rcv(dlxrow):
"""Pull (row,col,val) out from an encoded DLX list."""
rowcol = dlxrow[0:81]
rownum = dlxrow[81: 2*81]
row,col = decode(rowcol)
ignore,num = decode(rownum)
return (row,col,num + 1)
def decode(lst):
"""Take a list of 81 values with a single 1, decode two values out of its
position. Return them in a tuple (major,minor)."""
position = lst.index(1)
minor = position % 9
major = position / 9
return (major,minor)
For my next trick, I'll write up my notes on how to implement DLX itself.
Outrageously intelligent. Good job! Front page news :)
Outrageously intelligent. Good job! Front page news :) | http://code.google.com/p/narorumo/wiki/SudokuDLX | crawl-003 | refinedweb | 1,720 | 67.18 |
Hello everybody!
I've been working on trial division loop problem and I hit a dead end
Before I write about how I attempted to the problem before coming here, I have to show you guys the problem.
THE PROBLEM-------------------------------
Find and print out the eight prime integers between 99,900 and 99,999 using trial division (testing divisibility by possible factors). Write two nested loops: The outer loop will iterate over the 100 numbers being tested for primeness; the inner loop will check potential factors, from 2 up to the square root of the large dividend number (don't worry about which ones are or aren't prime). Use the modulo operator % to test for divisibility, and stop testing factors — cut the inner loop short — after finding one. Example: the first dividend to test is 99,900; its potential factors run from 2 to 316. Since ( 99900 % 2 == 0 ), it is not prime, so do not check factors 3 and higher, but exit the inner loop and go directly to processing 99,901.
--------------------------------------------
SO TO TACKLE THIS PROBLEM.
Thanks for jps for the advice on writing out the steps.
1. I set the min value to 99900 and the max value to 99999 and my outer loop will iterate for 100 times.
2. The outer loop also has to test for primeness so I wrote an "if statement" to check for divisibility and if it is divisible by 2, a continue statement to end
that loop and to continue to the next one.
3. I wrote the inner loop to test for factors by trial division.
4. Loop goes wrong and won't print the prime numbers.. anybody have any ideas on whats wrong?
Heres my loop:
/* This program is designed to find and print out the eight prime integers between 99,900 and 99,999 using trial division*/ // instructions = write two nested loops // the outer loop will iterate over the 100 numbers being tested for primeness // the inner loop will check potential factors from 2 up to the square root of the large dividend numbers. // This program will use % to test for divisibility public class assignment7 { public static void main(String args[]) { // The two numbers int divider = 2; int min; int max = 99999; // Loop iteration of the 100 numbers for(min = 99900; min < max; min++) { for(divider = 2; divider <= Math.sqrt(min); divider++) { if(min % divider == 0) { continue; } System.out.println("Prime: "+ min); } } } }
any ideas or advice? | http://www.javaprogrammingforums.com/whats-wrong-my-code/18159-trial-division-loop-problem.html | CC-MAIN-2014-15 | refinedweb | 409 | 65.15 |
Head-Spinning Interoperability between Managed and Native C++
From Kate Gregory's CodeGuru.com column, Using VC++ .NET.
Recently, at Tech Ed USA in Dallas and Tech Ed Europe in Barcelona, I delivered a talk on the various ways you can reuse old C++ code in new Managed C++ projects. For the next few columns, I'm going to present that information to you along with my conclusions about the direction you should go in your own reuse projects. My goal isn't so much to make your head spin around in confusion as to try to tame the confusion that naturally arises when you see how many different ways there are to reuse old C++ code in a new managed project. It can be intimidating to juggle all the options and try to make a decision.
Let's start by thinking about the kind of C++ code you are likely to have available to you. It might be business logic, proprietary algorithms, or some sort of third-party library. Maybe you have the source code for it—and maybe you don't. It might be packaged in many different ways:
- As a static library: a .LIB file and accompanying .h files. You #include the .h files and link to the .lib file
- As a dynamic library, a DLL, with .h files and possbly a .LIB file
- As a COM component or ActiveX control
- As source code, .cpp and .h files that compile to one of the above
In this series of columns, I'm going to assume you have the source code and can do whatever you like to it—make it a COM component, for example. I'll discuss the pros and cons of various approaches. If you don't have the source, or if it's already packaged in a particular way, then you will have less choice, but at least you'll know the situation in which you find yourself.
Millions of lines of tested, accurate, useful C++ code are out there in general use. This code is of tremendous value. You know how it works—heck, you know for sure that it does work. It's been tested and debugged, and everyone's trained on it. The firms that invested time and money in this code don't want to walk away from it. But they do want to move to the "new world" of managed code, the CLR, Web Services, and all the other new goodies of the .NET Framework. I'm here to tell you how you can have your cake and eat it too, by moving to the new world and reusing your legacy at the same time.
The Legacy
In this column, I'm going to set the stage by showing you the "legacy" application that I am going to reuse in a variety of different ways. I've chosen a really simple legacy so that the techniques themselves show through, rather than my actual underlying code. So, my legacy consists of a single class with a single method in it.
LegacyArithmetic.h:
class ArithmeticClass{public: double Add( double num1, double num2);};
LegacyArithmetic.cpp:
#include "legacyarithmetic.h"double ArithmeticClass::Add(double num1, double num2){ return num1 + num2;}
While the example is trivial, the techniques I am going to demonstrate work just as well on real examples. In my research for this work, I reused code that I last touched in 1994. It does exact arithmetic on integers of arbitrary length (using strings to hold the digits) and fractions (using two long integers.) The only parts of the library I had trouble with were the sections of 286 assembly code—I couldn't find an old assembler to deal with them and ended up replacing them with C++. The good news is that processors have come a long way in nine years and I didn't need to write parts of that library in assembler any more to get decent performance.
Just for the sake of completeness, I wrote a little unmanaged application that uses the "legacy library." It comes in handy when we compare the various reuse techniques later.
Main.cpp:
#include "stdafx.h"#include <iostream>using namespace std;#include "legacyarithmetic.h"int _tmain(void){ ArithmeticClass arith; cout << "1 + 2 is " << arith.Add(1,2) << endl; return 0;}
Because ArithmeticClass is an unmanaged class, and I'm writing an unmanaged application, there's no problem creating an instance of the class on the stack, and calling its methods with the . operator.
What Are Your Choices and Tradeoffs?
Let's say for the sake of argument that you've got a module written in unmanaged C++, consisting of a whole pile of classes, each class with a whole pile of methods. And now you're going to write a Managed C++ application (maybe a Windows Forms application because that technology is now available) that needs to reuse that code. You have a variety of choices available to you:
- COM Interop. You can take your code and wrap it up into a COM Component, then call it through COM Interop from any managed language.
- PInvoke. You can wrap your code into a DLL and call it through PInvoke from any managed language.
- It Just Works. If your code is in a LIB (or a DLL with a companion LIB), you can just link to it from Managed C++.
- It Just Works II. You can take your old legacy code, full of calls to ATL, MFC, STL, and heaven knows what else, and just compile it as managed code. I call this the XCopy port and you have to see it to believe it.
- Mixing Managed and Unmanaged C++ in the Same EXE. This produces an assembly of managed code with native code inside it along with intermediate language.
- Writing a Managed Wrapper. This exposes your unmanaged legacy to less-fortunate languages such as VB and C#—but watch out for the Mixed DLL problem.
In my next few columns, I'm going to show you each of these approaches, and discuss their pros and cons on matters such as performance, developer convenience, maintenance, and the like. But there's one issue—security—I want to talk to first.
Code Access Security and Verifiable Code
If you've read anything about Code Access Security, you know that the .NET Framework has a very granular set of permissions for applications: you can control whether an application can make a network connection, access a SQL Server, look at the user's environment variables, and so on. In general, you want your applications to be able to work with as few permissions as possible: Just because it works with Full Trust doesn't mean you should insist on Full Trust if there's a way to write it so it needs less than that.
Code Access Security includes a permission to access unmanaged code. So, you might think that there's a security consequence to the choice you make about how to get to your old code. Specifically, if you bring it over to managed code, as in my XCopy port, you should be able to get away with a lower permission set, right? Well actually, no.
By default, all Managed C++ applications demand the SkipVerification permission. And all means all—even the ones that are 100% Managed C++, compiling to intermediate language, no calls to anything unmanaged. SkipVerification is a very powerful permission, enabling the assembly to be loaded into the CLR without being verified. (As an example of how powerful it is, consider this: The Everything permission set doesn't include SkipVerification. You need Full Trust for that.)
The verification process checks to ensure that an assembly accesses only the memory locations it is authorized to access. Until Visual C++ .NET 2003, Managed C++ could not compile to verifiable code. Now, in this release, you can create verifiable code, but it's quite difficult, and I'm willing to bet noone will write a production Managed C++ application that will be verifiable. However, for the sake of completeness, I'll tell you what you have to do before you can settle for less than SkipVerification, meaning less than FullTrust.
- No pointers to unmanaged data, e.g. char* or int*
- No classes that are not garbage-collected
- No pointer arithmetic
- No static_cast<> downcasts, no reinterpret_cast<>
- No It Just Works or #pragma unmanaged to unmanaged code (PInvoke COM Interop are okay, but the assembly will need permission to access unmanaged code)
- The optimizer must be off
- No throwing exceptions of fundamental types (e.g. throw "String too long";)
- Use the /noentry switch to suppress access to the C Runtime Library
- Add at least one global variable (the verifier doesn't like empty sections)
- Link with nochkclr.obj to suppress check for CLR version
If you achieve all that, all that remains is to edit your AssemblyInfo source to ask for the attribute:
[assembly: SecurityPermissionAttribute(SecurityAction:: RequestMinimum, SkipVerification=false)];
And finally, you use a little utility called SetILOnly.exe to edit your executable headers to indicate it is verifiable code. Not that I think you'll ever get this far. Turn off the optimizer, don't use the C Runtime Library, no pointer arithmetic, no unmanaged classes? I'm presuming you're using C++ for a reason—and this laundry list of tasks to make yourself verifiable forces you to give up most of the advantages that led you to choose C++.
If you accept the fact you're not going to write verifiable code no matter how you reuse your legacy code in C++, you remain free to choose your reuse technique based on performance, convenience, maintenance, and similar criteria. That's what I'll be discussing in the columns to come.<< | http://www.developer.com/net/cplus/article.php/2238651 | CC-MAIN-2017-13 | refinedweb | 1,625 | 61.67 |
Fundamental React Concept Learn Once, Write Anywhere.
Hello developer, I am Shakil Ahmed today I will shortly discuss the fundamental concept of React 🤩 so stay with me and read properly A to Z learn once, write anywhere 👨💻.
What Is React? Library OR Framework.
DOM (Document Object Model)
The Document Object Model (DOM) is an application programming interface (API) for HTML and XML documents. Below the DOM Structure
it is very hard to something change on real DOM. Here react gives us a virtual DOM it is totally flavor or real DOM and more friendly.
JSX (JavaScript XML)
JSX stands for JavaScript XML. JSX allows us to write HTML in React. JSX makes it easier to write and add HTML in React. It’s neither a string nor HTML funny syntax 😄
Tree reconciliation
when reloading our page then it creates a tree and then where any changed state or another thing then it changes that specific element which is change and it is stored first virtual DOM then it is updated that particular element in the tree. Any operation on the DOM is done in the same single thread that’s responsible for everything else that’s happening in the browser.
Hooks
Hook is a most important thing when hook is come in ES5 then in react it;s newly represent to react developer. Hooks solve a wide variety of seemingly unconnected problems in React. hook starts with use keyword and hook also written camelCase. Call Hooks from React function components. some hook name below
- useState
- useEffect
- useRef
Function Vs Class
before the class component was very useful than the function component. Functional Components are also known as Stateless components. Class Component was also known as Stateful component. when releasing ES6 then it has come with some hook and it makes a function component stateful. function component receive parameter (props)- optional. and class component has a local state.
Component Vs Element
A React Element is just a plain old JavaScript object without its own methods. It has essentially four properties type, string, ref, props. A React Element is not an instance of a React Component. element just describe how to arrange type or HTML tag.
We are creating a custom function component It’s an object that virtually describes the DOM nodes that a component represents If a React Component is instantiated it expects props object and returns an instance, which is referred to as a React Component Instance.
Optimizing Performance
Performance optimization, also known as “performance tuning”, is usually an iterative approach to making and then monitoring modifications to an application. so now I say 2 points to get more performance at React app
- Avoid Reconciliation
- shouldComponentUpdate In Action
Conditional rendering
we are conditional rendering in react jsx. it is written in the {} bracket and then uses the ternary operator for conditional rendering. remember in react we are using if condition with ternary oparater
return (
<div>
{
showSomething ? ‘yes there is some data’ : ‘call other component’
}
</div>
)
Finally, list some topic name
- React is all About Component
- JSX
- We can use JS expression anywhere is JSX
- Event in react | https://shakilahmed5161.medium.com/fundamental-react-concept-learn-once-write-anywhere-ecb78cdbf49e?source=post_internal_links---------1---------------------------- | CC-MAIN-2021-31 | refinedweb | 518 | 55.24 |
//**************************************
// Name: Greeter Program in C++ Using Text File
// Description:This sample program is an class programming activity that I wrote five years ago in my programming class in C++. What does the program will do is to ask the users name and other information and then those information will be process and stored in a text file. This code will teach how to use text file using C++. I hope you will find my work useful. <fstream>
using namespace std;
main() {
string name, address;
int age=0;
ofstream file("greet.txt");
cout << "\n\t Greeter Version 1.0 ";
cout << "\n\n";
cout << "Enter your name :=> ";
getline(cin,name);
cout << "\nEnter your address:=> ";
getline(cin,address);
cout << "\nEnter your age:=> ";
cin >> age;
cout << "\n\n";
cout << "\nHello " << name << " " << " Welcome to USLS - Bacolod ";
cout << "\n You home address is " << address;
cout << "\n You are already " << age
<< " years old.";
file << "\n\n";
file << "\n ======== Greeter Version 1.0 =========";
file << "\n\n";
file << "\n Hello " << name << " " << " Welcome to USLS - Bacolod ";
file << "\n You home address is " << address;
file << "\n You are already " << age
<< " years old.";
file.close();. | http://www.planet-source-code.com/vb/scripts/ShowCode.asp?txtCodeId=13842&lngWId=3 | CC-MAIN-2016-50 | refinedweb | 183 | 77.98 |
Hi,
I have followed the tutorial in this link: to use MPI on my local windows machine with vs. The simple Hello wold work as expected, I have 2 processors and I get the expected result.
The problem is when I try a very simple send receive program I just see nothing printed on the screen, I have no errors in compilation or linking. Here is the code:
#include <iostream> #include <mpi.h> #include <stdio.h> using namespace std; int main (int argc, char *argv[]) { int numtasks, rank, dest, source, rc, count, tag=1; char inmsg, outmsg='x'; MPI_Status Stat; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD, &numtasks); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if(rank == 0){ dest = 1; rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag, MPI_COMM_WORLD); } else { source = 0; rc = MPI_Recv(&inmsg, 1, MPI_CHAR, source, tag, MPI_COMM_WORLD, &Stat); std::cout<<"Task "<<rank<<": Received "<< inmsg << "\n"; } MPI_Finalize(); system("pause"); return 0; }
the command line I use on cmd is: mpiexec -n 2 C:\Debug\out.exe and as I said I see nothing at all, the program just ask me to press any key to proceed. Anybody has an Idea what can be the problem?
Thanks!! | https://www.daniweb.com/programming/software-development/threads/469873/mpi-send-receive-problem-with-multi-threads-on-windows | CC-MAIN-2017-43 | refinedweb | 191 | 57.81 |
What as well, like the s3 client.
So how can you get the full list of resources from AWS?
The answer is to use pagination when describing the resources. This article shows you 2 methods to get the full list.
Method 1 – Client with paginator.
1st method uses the boto3 client paginator. This method relies on the client pulling 1000 entries at a time while your code must iterate over the returned items. Here’s an example:
import boto3 # Setup the client mysession = boto3.Session() ec2client = mysession.client('ec2') # Setup the paginator paginator = ec2client.get_paginator('describe_instances') page_iterator = paginator.paginate() # Start iterating over the paginator for page in page_iterator: for eachres in page['Reservations']: instance = eachres['Instances'][0] print(instance['InstanceId']
What you see happening is the paginator handles the requesting of the instances from AWS. Paginator will continue to pull/describe instances beyond the 1000 per request limit. Your code just iterates over the returned ‘page’, paginator handles the rest.
Now this method works, I’ve used it often. But here’s a method I just discovered that I like better.
Method 2 – EC2 Resouces
Yes, the EC2 resource can pull the full list. The ec2 resource’s describe instances method automatically handles pagination for us.
import boto3 # Setup the resource mysession = boto3.Session() ec2resource = mysession.resource('ec2') # Get full list instances = ec2resource.instances.all() # Iterate over the list.Note the use of instance as a resource with attribute here. for eachinst in instances: print(instance.instance_id)
That’s it. I like Method 2 much better. For one, its much more readable. More importantly, I like the fact that you can use methods when getting the full list. The above example uses instances.all(). You could also use instances.filter() to limit the return. For example:
... # Get partial list instances = ec2resource.instances.filter( Filters=[ { 'Name': 'tag:role', 'Values: [ 'Production' ] } ) ) ...
This example limits the returned list to EC2 instances with a certain tag and value, in this case, a tag called ‘role’ with value of ‘Production’. Very useful and something the the paginator in Method 1 can not offer.
That’s it for today. Happy coding. | https://www.slsmk.com/using-aws-boto3-to-paginate-ec2/ | CC-MAIN-2022-27 | refinedweb | 355 | 62.34 |
Stop inflexibly requiring namespace declarations for SVG
RESOLVED WORKSFORME
Status
()
People
(Reporter: ted, Unassigned)
Tracking
Firefox Tracking Flags
(Not tracked)
Details
Attachments
(1 attachment, 1 obsolete attachment)
User opening this file I get a prompt for an application to use for reading this file. It is an SVG file, and opens fine in Inkscape. Ironically, the application that it is prompting me to use is the Adobe SVG viewer. I tried both off the net, and locally after downloading the file. I tried putting the file into a custom HTML page that referenced it with no luck. Reproducible: Always Steps to Reproduce: 1. Open the file Actual Results: It prompts me for an application to use in order to view the file. Expected Results: Displayed a graph of elevations.
Assignee: nobody → general
Component: File Handling → SVG
Product: Firefox → Core
QA Contact: file.handling → ian
Version: unspecified → 1.8 Branch
The reason is that gpsvisualizer.com sends "image/svg-xml" instead of "image/svg+xml" as the MIME-type for SVG. The thing to do is contact the sys admins for that site and get them to configure their servers correctly.
Status: UNCONFIRMED → NEW
Component: SVG → English US
Ever confirmed: true
Product: Core → Tech Evangelism
Summary: SVG file not recognized as SVG (or anything else Firefox can handle) → gpsvisualizer.com sends the wrong Content-type for SVG
Version: 1.8 Branch → unspecified
See for more info BTW.
Okay, so their server is incorrect. But, saving it to my computer, and doing a "File->Open" produces the same result.
Assignee: general → english-us
OS: Windows XP → All
QA Contact: ian → english-us
Hardware: PC → All
Summary: gpsvisualizer.com sends the wrong Content-type for SVG → gpsvisualizer.com - sends the wrong Content-type for SVG Proper MIME type sent, this file doesn't get detected as an SVG also.
Component: English US → SVG
Product: Tech Evangelism → Core
Summary: gpsvisualizer.com - sends the wrong Content-type for SVG → Content type not recognized for certain SVG files
Version: unspecified → 1.8 Branch
Missing namespace in document - see .
Yes, it does not include a namespace definition. I don't believe that SVG documents require one to be valid SVG documents. It does include the <!DOCTYPE header to specify that it is an SVG document. Also, it is valid XML with <svg> as its root element. I think that all of these should be used as means to detect whether a document is an SVG document, and thus rendered as such.
Attaching the file incase it gets change on openclipart.
Hi Ted (In reply to comment #6) > Yes, it does not include a namespace definition. I don't believe that SVG > documents require one to be valid SVG documents. indeed SVG files dont need a namespace to be valid, but if there is no namspace, the document might be an SVG document, but the elements are not SVG elements, that means nothing gets rendered. > It does include the <!DOCTYPE > header to specify that it is an SVG document. you are right, in that a DTD enables you to set a default namespace (which is allways required), but this only works, if the DTD is read and interpreted , which in turn is only required by a validating parsers ( XMLSpy for example ), but SVG renderers so far do not validate the content. > Also, it is valid XML with <svg> > as its root element. you are right again, but if there is no namespace, its not an <svg:svg> root element, but a <null:svg> element, and that can mean anything... you have to provide a namespace to tell the parser what you mean. you can take a look for example at the OpenClipArt.org metadata, there is a <dc:title> element, and its purpose and meaning is different to <svg:title>. with the namespace you provide the meaning. > > I think that all of these should be used as means to detect whether a document > is an SVG document, and thus rendered as such. i guess the important part is not that its an svg document, but the document contains svg elements, and this is only possible with a namespace. by the way, if the DTD would be handled correctly, the file would again be invalid, since the metadata used in the file is not mentioned in the DTD. you would have to extend the original SVG DTD with the description of the OCAL metadata.
Holger is partially right, but I want to correct some of the things he said and give some more information. SVG is namespaced XML. If you're writing SVG content you absolutely must declare the namespaces you use - it's been that way since SVG 1.0, and it will continue to be that way in future. Where the confusion comes from is that draft versions of SVG 1.0 defined the namespace(s) in the DTD. Therefore in a validating parser (one which parses the DTD) it would be unnecessary to declare the namespaces in your SVG content. The problem with this of course is that SVG impelementations are not required to be validating parsers (Mozilla and ASV are not for example). Realising this issue, the SVG WG removed the declaration from the DTD before SVG 1.0 was released. Declaring the namespace in your content isn't even an issue of being valid. It's more fundamental than that. If you don't declare the namespace, your content *isn't even SVG*. Placing your content in a namespace is what makes it what it is. That's what's required by the Namespaces in XML recommendation: and conformance to the Namespaces in XML recommendation one of the requirements of the SVG recommendation: While ASV only has to deal with SVG, Mozilla has to deal with multiple namespaces (XHTML, MathML, XBL, SVG, ...) and be able to deal with them in the same document. DTD's are useless in mixed namespace environments, and indeed their problems have been one of the reasons behind the SVG WG's decision to stop using them starting with SVG 1.2. (Actually they've been encouraging people to stop using them in SVG 1.0 and SVG 1.1 too if you look at the www-svg@w3c.org archives.) I hope this has gone some way to explaining why you must declare the namespaces of your content, and why Mozilla won't just parse a file as SVG because it has an SVG DTD. We are backed on this not only by the SVG WG, but also by a member of the SVG WG who was heavily involved in the creation of ASV. ;-) See
I appreciate everyone's opinion, but I respectfully disagree. You're making a technical argument for something that will end up being a political discussion. When users see that something works with Adobe SVG or Opera, but not with Firefox, they aren't going to think that their SVG file is incorrect. Beta is still the better format, VHS won. And Firefox still renders some really bad HTML. Stuff that was done by Netscape to make it so that webpages just work. I know it kills the XML guys, but I can do "<i>my <b>text</i> here</b>" and it will render. The render understands what I'm trying to do there. I would argue that the same approach should be taken by the SVG renderer. As far as I'm aware, no other XML language has an "svg" tag, it would seem when that tag is seen, the SVG namespace can be assumed as the default for the content that follows. You're not going to win friends by being more correct, you'll win friends by being more helpful. I would recommend having an option like XHTML/strict that people can use to validate their files, but not being tolerant of common mistakes will just make people not consider your implementation useful.
Okay, let's make this *the* bug for discussing whether or not we should require namespaces to be declared for SVG under all circumstances. I'm CC'ing lots of people to try and make sure we can have this conversation once and for all. The declarations that we require but which are so often missing or broken are: xmlns="" xmlns:xlink="" and possibly in the future if XML Events becomes more widely used: xmlns:ev="" This is causing a lot of problems, complaints and concern. I'm not sure yet exactly what an acceptable proposal for resolving the issue should be, but lets start with the following and work from there. If we end up parsing a file as XML and find that it has an SVG 1.0 or SVG 1.1 doctype declaration and that root tag is 'svg', we should bind the SVG namespace as the default namespace, and bind the XLink namespace to the namespace prefix 'xlink' before we parse any of the root element's attributes. That way if the default namespace is declared by the content, or if a namespace is bound to the 'xlink' namespace prefix our settings will be overridden. I've been speaking with a number of people about this for a while now, but rather than express their thoughts and opinions second hand I'd appreciate if they could add them here themselves.
Assignee: english-us → general
Summary: Content type not recognized for certain SVG files → Stop inflexibly requiring namespace declarations for SVG
It's been pointed out to me that some SVG content out there doesn't have a doctype declaration or namespace declarations. Also members of the SVG WG have been encouraging people to remove doctype declarations from their SVG. (And for the record SVG 1.2 will not have a doctype.) Perhaps we shouldn't even require an SVG doctype?
I think it is essential that Mozilla require the correct namespace declaration. A few (of many) reasons are below: 1) If a file is found in the wild (such as on a local file system), without a proper MIME Type, the processor must have some way of discovering what the content is supposed to be; while I am not aware of any other 'svg' tag, for example, there could easily be one (perhaps it is a part of a manufacturing XML and means 'strict vendor guidelines'... in a multi-namespace document, how is the UA to process this?); 2) SVG itself, in the near future, will likely be used as a rendering format for custom XML using sXBL; in this case, you are very likely to see elements that are in both namespaces ('title', 'desc', 'line', 'a', 'g', 'path', and 'image' are all likely suspects for one reason or another); SVG should not be exempt from a general policy of namespace declaration, even as the root element; 3) Arguments that content like "<i>my <b>text</i> here</b>" should be allowed are missing the point that this is essentially arguing that we should let XML not be XML and make assumptions on what is intended; when HTML was the only common markup language, certain assumptions could be made, but this problem becomes exponentially harder the more markup languages we use; as a content author, I want to code once and have it render the same everywhere, and that will not happen if assumptions are made by each UA implementor about the best way to display content... this argument is particularly compelling due to the common use case of SVG as a front end for WebApps, where rendering decisions are not merely expressed as text (which can be understood even with imprecise styling), but as programmatic objects that need precision; 4) If authoring tool creators don't receive a clear message that bad content is unacceptable, they will not correct their tools; 5) It's easy to do. It's one line. I am making the assumption that this bug was filed out of frustration that a popular (and very good) tool's content was not rendering as expected. The reporter should be aware, though, that art is only one use case for SVG, and is arguably not the strongest business case for it. If this looseness is allowed into an increasingly mixed namespace environment, the repercussions are going to be very harmful to the development of the Semantic Web and WebApp environments. The proper place to file this bug is with the authoring tool developers, asking them to create proper content (especially as most graphical SVG tools, themselves, now use lots of namespaced elements in the SVG for roundtripping ).
Hi, jwatt asked me to weigh in with some thoughts. Briefly, I think form should follow malfunction, and learn from it. Micah Dubinko (most recently at and in previous posts and talks) and others have summarized the real-world usability bugs in XML namespaces that have evidently come up again (Micah's experience was with XForms users) with SVG: - Namespace declarations are opaque to readers and typo-prone to writers. - People forget to qualify. - People forget the default, if there is a default (XPath). The first one is apparently so big a usability hazard that it actually results in people not merely misspelling, but leaving off entirely, such long-winded and redundant-seeming declarations from what is obviously an SVG file, when they can get away with doing so. Which they can, with the most popular *shipped* SVG viewers. It doesn't matter whether an XML declaration is "only one line". In reality, many people have problems getting 'em right, never mind using the declared prefixes correctly. Larry Wall famously said "As we all know, reality is a mess". He depicted this (). Then he said: "It's certainly a picture of how Perl is organized, since Perl is modeled on human languages. And the reason human languages are complex is because they have to deal with reality." Human languages don't tolerate the verbosity and (in most cases) redundancy of something like the two XML namespace declarations required by SVG per spec. Computer scientists may like such things, at least when specifying XML languages and writing programs that consume XML. Most humans don't. The idea that SVG will always or even mostly be generated by elves, or magically free and perfect tools, is not much more realistic than the idea that HTML or some next-gen XHTML will be. The web is a mess, because reality is a mess -- and most people, and successful computer languages, can and do cope. You can call me names for defying the sacred XML namespaces standard, but I've got reality on my side ;-). Let the solution fit the problem. Make computers work harder, not humans, unless there is ambiguity -- and disambiguate by favoring conciseness and sane defaults for the common cases. Make the abnormal cases pay with verbosity. So I say, since the currently popular SVG viewers tolerate lack of XML namespace declarations, we should too. Otherwise, we will punish users for the sins (if sins they be) of content authors. Now, you may object: Firefox has much greater market share than any existing SVG viewer. My response is still "so what?" Firefox 1.5 can't cause authors to fix their pages by punishing Firefox's users. Only if all SVG authors were to test in Firefox, and we didn't fix this bug, *and* we somehow got authors of existing content to come back from their next gig, or next life, and fix all of their already-created content, .... You can see the odds are not good when multiplied out. In this I am agreeing with Ted Gould. But sorry Ted, Betamax wasn't better than VHS -- that's an urban myth. See -- there are some lessons there for XML namespaces, and for SVG. Also, regarding Ted's statement, accurate as far as it went, that "Stuff [...] was done by Netscape to make it so that webpages just work." Marc Andreessen recounted to me how well before Netscape, even when the number of web servers hit by NCSA Mosaic was below 100 sites, Mosaic hackers learned from user mistakes in HTML authoring, and added quirks support. I know, this led to tag soup, which is the Greatest Evil Ever Visited Upon Mankind. Nevertheless, inferring SVG's two required XML namespaces without requiring their declaration is not evil. Much. ;-) /be
As a point of comparison, I'd like to point out what Batik does and give a few opinions of my own. Since 2002 () Batik has assumed an xmlns="" on the document element if it doesn't have their own default namespace declaration. This was actually a surprise to me, since Batik is usually pretty strict about such things. Despite the line of code there that attempts to predeclare the xlink namespace, omitting the xlink namespace declaration will cause an error when attributes with names such as "xlinK:href" are used. *a while later* Ok, I just wrote a bunch of text outlining some possible technical reasons why you would allow a namespace default that's not specified by an xmlns attribute (or indirectly via the DTD). But it really was just clutching at straws. Technically, I don't think it is justified. Since compound documents will become increasingly important on the web, I think namespace issues will be harder to ignore. But I think there is one place where an implied namespace declaration could be allowed, if the so-called political justification could be made for violating the Namespaces in XML rec, and that is for documents sent with an image/svg+xml MIME type (or for non HTTP situations, such as loading from disk, using whatever platform specific method is typical for guessing file type (e.g. extension)) whose document element's name is "svg", as long as there is no xmlns declaration on that element. My reasoning is that: - If the MIME type is image/svg+xml, then the resource is intended to be an SVG document. - SVG documents must have an element called {"", "svg"} as the document element. - If the UA knows that it should be an SVG document from the MIME type, there is no possibly correct behaviour that is being missed from not processing the document element as an element in no namespace. I think assuming an xlink namespace declaration is not acceptable, since there is no relationship between the type of document being processed and the xlink prefix (except that SVG documents commonly declare the XLink namespace with the prefix "xlink", but that's a poor reason to assume it). Having said that, I believe the correct course of action is to require an explicit namespace declaration. In the long run, authors will have to get their namespaces correct for compound documents by inclusion. You may as well get them used to it now. BTW I like the idea of flagging the error of the lack of namespace declaration. Perhaps using something like the "This page needs a plugin which is not installed" bar that is displayed in Firefox? Now, to mull over the idea of changing Batik's behaviour... :)
As we move forwards into compound documents, namespaces become more obviously valuable. However, well formedness requires that namespace prefixes be declared and well formedness, hopefully, is the minimal bar and not up for discussion. But we are going to see more mixed XHTML/SVG, XForms/SVG, etc and thus, namespace prefixes. Early drafts of SVG put the namespace prefixes into the DTD, which is why old products like ASV support that. Its incorrect, thouh, and was corrected before SVG 1.0 went to Rec. Firefox is quite correct to require the namespace. When loading from local disk (no MIME types) and with DTDs going away since they are largely useless, the namespace declaration is the only reliable label.
So this particular bug is really much more limited in scope than some want to turn it into :-). There's two obvious solutions. Short term: add a mapping of the old SVG 1.0 doctypes to local DTDs (). Longer term: get my fix for bug 22942 finished.
Wow, this turned into a lot larger discussion than I'd imagined. Thank you everyone for your time. I think that the quirks mode should only be applied when "the SVG is the document", not when the SVG is embedded in another XML structure. I know I mentioned that earlier, but I think I was wrong in suggesting that. I'm not sure if this distinction is made in the Mozilla codebase, but I think it is a useful one. At least for the first experimentation for most users, I think SVGs will be used with <img> and <embed> tags, not embedded in the document. I don't know of an SVG editor that will allow you to edit SVGs inside another document (though on Inkscape we're working towards that). I think this case should be made as simple as possible.. So, in the end, I'm advocating a quirks mode that would allow for, in simple cases, the namespace declaration to be omitted. I don't know how easy this is to implement, I've never looked at the Mozilla codebase, but I do think it will ease SVG adoption on the web. And that, is something that I'm very interested in. Lastly, on Betamax. "Betamax recorders use a slightly larger head drum than VHS recorders, yielding slightly greater video bandwidth as the video signal is recorded over a longer stripe." But, I would entirely agree that VHS was the stronger overall system. And I believe, that adding this quirks mode for simple cases will make Firefox a stronger overall system.
"quirks mode" - just say no. Why screw up a nice design just because a couple of early, pre-rec implementations tolerate an incorrect syntax?
(In reply to comment #18) >. Ted, have you thought about the usecase, that a user might want to download an image from OCAL, and then include it inline of an XHTML Doc, the result would be that he might have to edit the file ( include the namespaces ) by hand, to make it work. if however, the namespace is allways given on the root element, you can allways use the document, as a document fragment of a combound document without a problem. so with respect to OCAL i would consider adding the correct namespace as best practise, no matter what the result of this discussion may be.
(In reply to comment #20) > so with respect to OCAL i would consider adding the correct namespace > as best practise, no matter what the result of this discussion may be. I entirely agree. I'm not worried about projects like OCAL, I know the people who are doing OCAL understand XML namespaces. But, I know a lot of people who understand the principles of XML, but have never heard of namespaces. Or worse yet, those who kinda learned XHTML from HTML (enough to make the validator pass) and thus believe they know XML. I think when you try to make compound documents, you realize the problem and look for XML namespaces. Those who have never thought of compound documents have never looked for a solution to its problems. In a nutshell, I'm less worried about tools and people that understand XML and generate SVG. I'm worried about people using PHP to generate their own SVG files and don't really understand XML. I'll write an e-mail to the OCAL list about the namespace being added as part of the validation. All OCAL files should include the namespace.
; 2) Readers that are not human, such as accessibility apps; such applications may be relying on an indicator of which syntax to adapt to the appropriate medium (say, speech). > It doesn't matter whether an XML declaration is "only one line". In reality, > many people have problems getting 'em right, never mind using the declared > prefixes correctly. Most people who are authoring SVG for the purpose of art will likely be using a drawing app, and those apps should know to author correct documents. The only people who need concern themselves with the technical guts of an SVG document are those who are going to be authoring it by hand (such as people using it for tech reasons like building WebApps) are those who would do well to know the whys and wherefores. But they don't even need to... you can set up most authoring environments to provide you with a working template to use, and you don't even really need to know what it means, just that it works. > Human languages don't tolerate the verbosity and (in most cases) redundancy of > something like the two XML namespace declarations required by SVG per spec. > > Computer scientists may like such things, at least when specifying XML languages > and writing programs that consume XML. Most humans don't. Well, I'm not a computer scientist, but I do study linguistics. Human languages are full of seemingly arbitrary declarations. For example, in English, we require that you preface many statements with "It is" (It is raining, it is cold, it is unacceptable that SVG documents not have a namespace declaration), even though there is no "it" to be "is"ed; many other languages do not require this structure in the same way. We also have 3 separate pronouns for each gender (he and him and himself, she and her and herself) to mark location and role in the sentence; this is not common in most languages, and is a frequent mistake made by children; but it persists because it is useful in disambiguating intention (think of the sentence, "He gave it to himself" and plug in the various options there... it's quickly obvious that it's a necessary feature). Or look at other human languages, where they require a gender be assigned to clearly sexless things like chairs and bridges, and often have extremely elaborate rules for constructing sentences dealing with objects of that particular gender. All this may seem off-topic, but it's not... it highlights the need for disambiguation in markup. > You can call me names for defying the sacred XML namespaces standard, but I've > got reality on my side ;-). Apostate fiend!!! > Let the solution fit the problem. Make computers work harder, not humans, I think that's a laudable goal, but misplaced in this instance. The amount of work to be done by humans here is miniscule, and it serves the purpose of teaching them about namespaces, while preventing other humans (UA implementors) from doing way too much work reading the minds of future authors. > unless there is ambiguity -- and disambiguate by > favoring conciseness and sane defaults for the common cases. Make the abnormal > cases pay with verbosity. I think that in the near future, single-namespace documents will be the abnormal case. > So I say, since the currently popular SVG viewers tolerate lack of XML namespace > declarations, we should too. Otherwise, we will punish users for the sins (if > sins they be) of content authors. I think. > 2) Readers that are not human, such as accessibility apps; such applications > may be relying on an indicator of which syntax to adapt to the appropriate > medium (say, speech). I meant human readers, of course. > you can set up most authoring > environments to provide you with a working template to use, and you don't even > really need to know what it means, just that it works. Yet there's enough content out there that lacks well-formedness with respect to namespace declarations that we have this bug. [linguistic stuff that I agree with, but that is not really apposite here, snipped. I can defend all sorts of dying English usage on disambiguation grounds, but such usage is still dying. Lazy humans!] > All this may seem off-topic, but it's not... it highlights > the need for disambiguation in markup. That's why I already wrote "unless there is ambiguity -- and disambiguate by favoring conciseness and sane defaults for the common? > and it serves the purpose of teaching them about namespaces, Trying to teach pigs to sing just annoys 'em. > while preventing other humans (UA implementors) > from doing way too much work reading the minds of future authors. Agreed, let's not create ambiguity. > I think that in the near future, single-namespace documents will be the > abnormal case. I'll bet real money otherwise, if we are talking about the web and not some intranet or equivalent. >. Users generally don't contact authors, or even hostmaster@foo.com.. /be
(In reply to comment #23) > 's a large part of the reason the Web is a success. > > 2) Readers that are not human, such as accessibility apps; such applications > > may be relying on an indicator of which syntax to adapt to the appropriate > > medium (say, speech). > > I meant human readers, of course. Yes, which is why I pointed out the very important non-human readers which interpret and transform content for those who can't consume the original? Sorry, I didn't see any evidence by Micah... not that there isn't any, but the post you linked was rhetoric, not technical.>". > > I think that in the near future, single-namespace documents will be the > > abnormal case. > > I'll bet real money otherwise, if we are talking about the web and not some > intranet or equivalent. Sorry, being so SVG-centric, I didn't fully state my argument. I meant to say, "I think that in the near future, single-namespace documents *that use SVG* will be the abnormal case." This is because SVG + HTML is a great use case, and I think that SVG + XML + sXBL will be a very powerful tool. There is also the fact that authoring tools insert their own roundtripping and/or annotation code in their own namespace. I don't think most upcoming SVG content will be exclusively SVG. With those restated terms, I'll bet you 5 bucks I'm right. ;) >. A fair point. But I see no harm in it, and I *have* gotten feedback before from clients about messages in the status bar, so they are paying attention.
(In reply to comment #24) > > > explains all the top browsers supporting so many quirks, indeed! > That's a large part of the reason the Web is a success. I agree, if you are talking about "best practices" including quirks, copy-paste "authoring", and sporadically testing only "what works in the most popular couple of browsers". Another reason for the web's success is the hated but necessary ways in which popular browsers tolerate human errors that were never specified by standards bodies as best practices, or even as error inputs subject to well-defined error recovery. > > Micah cites evidence to the contrary, and this bug reports signs of the same > > problem in another XML language. Where is your evidence? > > Sorry, I didn't see any evidence by Micah... not that there isn't any, but the > post you linked was rhetoric, not technical. Micah has written and talked about this problem, e.g. at the w3c compound document and web app workshop in 2004, in terms of the most common mistakes he has seen XForms authors make. His testimony is semi-quantitative, and authoritative with me at any rate. >>". If it's easy, why was this bug filed? If the problem is content generated by a few bad tools, or reliance on doctype loading, and we can ignore these issues, great -- I'm being provocative on purpose here, so you can ignore me, build a consensus to WONTFIX this bug, and mark it so. But the problem motivating this bug didn't seem to be just a few bad tools, and Ted (at least) argued for this bug to be fixed independent of that issue. > With those restated terms, I'll bet you 5 bucks I'm right. ;) Define "near future" as "in the next two years" and stipulate "web, not intranet" by agreeing that this mixed-namespace XHTML/SVG/sXBL content works in the top two most popular browsers (among all platforms: mobile, handheld, or desktop), and I will take that bet, or one for bigger money. If MS does support SVG and sXBL, I will probably lose, because Firefox will probably be #2, and we will probably support such content. If the "mobile web" utopia arrives, and it's really a web (and not data coffins slaved to their single carrier, walled-garden-content motherships) I will lose. Good odds in your favor, right? Not in my book. /be
Ok, I'll weigh in on this one too. I actually think that we should keep requiring the namespace. However, I would be ok with relying on the DTD to provide it for us. Either by fixing bug 22942 or by specialcasing the svg dtd somehow as a temporary hack until that bug is fixed. The reason I don't think we should rely on the mimetype is that mimetypes are hard enough for people to get right as it is. We'd end up in situations where an svg file works fine when served from one server, but when downloaded locally or put on another server it'd "unexplainably" stop working. So mostly I think it's a matter of making it easy for people to understand how to get it right. And as has been brought up before, going forward we'd probably have to require the namespace anyway. Since SVG1.2 doesn't have a doctype and svg documents are not unlikly to be compound documents proper namespace declarations are probably going to be required sooner or later anyway.
Removing bug URL link since server misconfiguration means we wouldn't render that file anyway.
Comment on attachment 195841 [details] Bread and Wine file Marking attachment obsolete since we will definately not be making changes to allow files with a root <svg> tag to be recognised as SVG when they have neither an SVG doctype declaration NOR namespace declaration(s).
Attachment #195841 - Attachment is obsolete: true
Here's that hack. This will provide default values for the 'xmlns' and 'xmlns:xlink' "attributes" on the 'svg' element if (and only if) we end up parsing a document as XML and it has a doctype declaration with one of the following public identifiers. "-//W3C//DTD SVG 1.1//EN" "-//W3C//DTD SVG 1.0//EN" "-//W3C//DTD SVG 20001102//EN" "-//W3C//DTD SVG 20000802//EN" "-//W3C//DTD SVG 20000629//EN"
*** Bug 313576 has been marked as a duplicate of this bug. ***
Continuing my quixotic campaign against XML namespace usability bugs: have a look at and see whether you don't agree that the world would be a better place if XML supported something like unqualified import. I'm not advocating violating well-formedness (not seriously, anyway). I am advocating an extension to well-formedness that improves usability. If I had time and faith in the process, I'd go to the relevant standards bodies. That may yet happen, but I thought I'd use the bug to solicit some thoughts first. /be
I think we should not take this patch. What we're doing today is correct. SVG files must gave namespace declarations to be conforming. We know this, the working group agrees with this, heck even the chair of the group asked us in this very bug to not provide a hack for non-conformant content. To me it seems the majority of the people on this bug don't want to do this. Brendan rightfully points out that namespaces as designed have big issues, but that's a separate discussion and should IMHO not affect the immediate outcome of this bug. Mozilla is likely to be the biggest SVG UA on the market in terms of installed userbase. We should use this position to force authors to do the right thing. We have an opportunity here to reduce the number of undocumented hacks that browsers have to deal with. Let's not worsen the situation!
Version: 1.8 Branch → Trunk
*** Bug 319577 has been marked as a duplicate of this bug. ***
This bug (or rather its reverse) might be better addressed as an evangelism issue. The Mozilla SVG page could have a prominent link early in the page addressed to SVG authors faced with the task of porting old content to be Firefox-savvy: both correcting the bad advice given a few years ago based on old drafts of the SVG recomendations, and fixing problems caused by widely-deployed, non-conformant authoring tools. At present one has to scroll down through a long page to find the FAQ link and then search the FAQ page for fairly technical information. I understand it, but non-XML-savvvy web editors might not. If we had a table of bad editors saying things like ‘Acme SVG Pad versions 0.9 and 1.0 generate non-conformant SVG; upgrade to version 1.1, and download _this_utility_ to update your existing files automatically,’ it will be a lot easier for web editors to eliminate non-conforming content and they will be less likely to insist on a quirks mode for SVG.
*** Bug 326636 has been marked as a duplicate of this bug. ***
While years have passed, the percentage of SVG content out there missing the namespace declarations seemed to have gone down a lot.
Assignee: general → nobody
QA Contact: english-us → general
If you html5 and you don't need namespaces any more.
Status: NEW → RESOLVED
Last Resolved: 9 years ago
Resolution: --- → WORKSFORME | https://bugzilla.mozilla.org/show_bug.cgi?id=307813 | CC-MAIN-2019-22 | refinedweb | 6,264 | 69.82 |
Ahmed Abdul Baqi wrote:
<code>
private void checkLogin() {
try {
String request = "";
String str = "";
request = null;
str = "";
/*here u can assign the url on which ur servlet is hosted and send the request*/
String url = "";
System.out.println(" the url is :: " + url);
con = (StreamConnection) Connector.open(url);
os = con.openOutputStream();
int i = 0;
un = Uname.getString();
p = pwd.getString();
request = un + "#" + p + "#";
byte b[] = request.getBytes();
System.out.println(request);
for (i = 0; i < b.length; i++) {
os.write(b[i]);
}
os.close();
System.out.println("here is ");
in = con.openInputStream();
while ((i = in.read()) != -1) {
char ch = (char) i;
str = str + ch;
}
System.out.println(str);
if (str.equals("TRUE")) {
Alert a = new Alert("The Following Details are valid","connected ", img, AlertType.ALARM);
display.setCurrent(a);
System.out.println("You are a valid user.......");
} else {
Alert a = new Alert("The Following Details are Invalid",
"Invalid Login/Password ", img, AlertType.ALARM);
display.setCurrent(a);
}
in.close();
} catch (Exception e) {
}
the above methd i have declared in the run method and in the Command Action Listener method you can call that thread for any key Event or for any Button.
here i have writen a simple method called check login where i am retreiving uname and password from a text box in my MIDlet and saving the text in two string variables and passing the two string as a request along with the url to the server.See GPRS is a Telecom - General Packet Radio Service that uses the http protocol to send and receive data.Almost all basic j2me devices will have GPRS facility.You just need to check with your service prvider wether GPRS is activated on the mobile or not.
public class ConnectionNotFoundException
extends IOException
can be given to check if the device supports the type of connection you have given.yes you can create a cod file of ur succesffully running jad and jar for blackberry and check wether the application gets the connection or not.
Thanks.
Thanks Ahmed. But things are a bit confusing for me, it would be better if you can solve it.
You get connected to a servlet lying on web server. Then you open outputstream, add username and password to request and writing your request into bytes using the outputstream. Similarly with input sream you are reading till end of file.
> passing the two string as a request along with the url to the server
I am not understanding what exactly and how you are doing.
I also retrieve data from textFields of a form, and have to save them to a file lying on the server. Can you help me code how do I do this? Pass the parameters to the Servlet and do file saving operation in the servlet or directly access the fie lying on the server and save the details. Which option is better and how to code it? I can't make out and am confused.
Would be greatful if you can help me out.
Thanks | http://www.coderanch.com/t/442528/JME/Mobile/GPRS-Related-queires | CC-MAIN-2014-15 | refinedweb | 498 | 66.03 |
The Portlet support is experimental. Feedback is appreciated!
Index
- Introduction
- Installing Eclipse
- Installing Maven 2
- Installing Tomcat
- Creating the project
- Eclipse project generation
- Deploy as a servlet
Step-by-Step Tutorial
Introduction
This.
Installing Eclipse
In the tutorial, we will be using Eclipse 3.3 which can be downloaded from. I recommend the JEE package, which contains the popular (and required for this tutorial) Web Tools Project.
Installing Maven 2
Apache Maven 2 can be found at.
Installing Tomcat
Apache Tomcat can be found at. To install, simply unzip the distribution to a known location on your hard drive.
Creating the project.
Eclipse project generation
First Eclipse and Maven project?
If this is your first time using Eclipse and Maven,.
Now, your generated 'myportlet' Eclipse module is ready to be imported into your workspace. In Eclipse, go to "File -> Import... -> General -> Existing Projects into Workspace", select the your 'myportlet' directory, and follow the prompts.
Deploying your portlet as a servlet
Since the Eclipse project was generated with the 'wtpversion' flag, it will be immediately recognized as a web application by Eclipse. If this is your first time deploying web applications in Eclipse, you will need set up your Tomcat server. To do this in Eclipse:
- Navigate to "Window -> Show View -> Other..."
- Open "Server" and select "Servers". This will open a "Servers" tab, probably in your bottom tab panel.
- Right-click in the new "Servers" tab and select "New -> Server"
- Select the version of Tomcat you installed and click "Next"
- Click "Browse" and locate your Tomcat installation, and click "Next"
- If "myportlet" isn't already in the "Configured projects" column, move it over and click "Finished"
Before we can run our portlet in Eclipse, I've found that you need to add the portlet jar to Tomcat. To do this:
- Right-click on the 'myportlet' project in the "Project Explorer" and select "Properties"
- Click on "J2EE Module Dependencies
- Click on the checkbox next to "M2_REPO/portlet-api/portlet-api/1.0/portlet-api-1.0.jar"
- Click "OK"
Now, you should be able to run and debug your project in Tomcat. The way I prefer to do this is to:
- Right-click on the 'myportlet' project in the "Package Explorer" and select "Run As -> Run on Server"
- Select the Tomcat server you set up and click "Finish"
Eclipse will now run your portlet application as if it was a servlet.
Additional Tips
- "View", "Edit", "Help" mode actions are mapped to the "/view", "/edit", "/help" namespaces respectively
- The default action in each namespace is titled the "index" action
- To add actions, just add the Action class and jsp following the shown conventions. No
struts.xmlmodification needed.
- Use the Eclipse option "Debug As..." instead of "Run As..." to enable step through debugging
1 Comment
chains5000
There's no maven archetype named struts2-archetype-portlet in that maven repository.
Which one is the correct one? | https://cwiki.apache.org/confluence/display/WW/Developing+a+Portlet+using+Eclipse | CC-MAIN-2019-26 | refinedweb | 481 | 63.9 |
In this instructable I will show you how to build and control a robot capable of drawing and writing on a flat surface, as illustrated in the video above.
To complete this project you will need:
- A computer
- A download of Processing IDE: a simple, free, open-source, program development tool (no installation required).
- An Arduino board : a simple, open-source, micro-controller.
- Two standard size servomotors, I used two Hitech HS-5645MG.
- A heavy duty, quarter-scale servomotor, I used a Power HD-1235MG.
- Some mechanical hardware to build a frame holding the two servos, the two arms and the writing tool. I used Actobotics components and you will find a complete list of pieces I used in the Mechanism sections of this instructable.
- A breadboard and jumper wires for electrical connections.
- An independant DC current source for the servomotors (alternatively, use the one provided by the arduino board).
- A biro and a piece of wire (here I used a piece of bicycle brakes cable).
Basic mechanism
We.
Basic architecture
Below is a quick preview of the setup. The computer will run a processing program which tracks the position of the mouse cursor, and send it over to the arduino board. This program is detailed in the Processing section of this instructable.
The computer is connected to the arduino board through the arduino's USB cable.
The position of the mouse cursor is converted to appropriate angles for the servomotors, this is detailed in the Mathematics section of this instructable.
The arduino is connected to servomotors through simple wires, Arduino controls the servomotors through another program. The wiring and arduino program is detailed in the Arduino section of this instructable.
The mechanical structure holding the servomotors, articulated arms and pen is detailed in the Mechanism section of this instructable.
Teacher Notes
Teachers! Did you use this instructable in your classroom?
Add a Teacher Note to share how you incorporated it into your lesson.
Step 1: Mathematics : Converting Pen Position to Servo Angles
This section explains how the position of the mouse cursor on the screen of the computer is converted into angles for the servomotors so that the writing end of the articulated arms replicates the movement of the mouse cursor.
It is not necessary to understand this to successfully complete the intructable, as I will provide the pieces of code which implement the conversion of cursor position to servomotor angles.
Analyzing a single servomotor
If we analyze a setup with a single arm and servomotor (figure above):
Call O the origin of our referential. It is placed on the rotation axis of the servomotor.
Call P the point we want to reach on the writing plane, or the pen's position.
Call (x,y) the coordinates of P.
Call a the length of the arms segments. (Note: if all arm segments are of equal length, the calculations are much easier).
Call J the position of the joint where the two arm segments are connected.
Call r the distance OP : r = (x²+y²)1/2
Call θthe angle between OP and the x axis : θ = atan2(y,x)
In the triangle OJP :
The distance OJ = a
The distance JP = a
Call φ the angle PÔJ : φ = acos( r / (2a) )
Call α the angle which must be fed to the servomotor to reach position P :
α = θ + φ
α = atan2(y,x) + acos( (x²+y²)1/2 / (2a) )
Note that feeding this angle to a single servomotor will not constrain the pen's position to a point. It will constrain J to a single point but will leave P free to move on a circle of radius a around J. Adding the second servomotor will allow us to constrain P's position more.
Adding the second servomotor
We can repeat the calculations done in the previous paragraph, except this time the point we want to reach P, is seen in the referential of the second servomotor, which is offset from the referential we used earlier.
Call d the distance between the axes of the two servomotors.
The coordinates of P in the referential of the second servomotor are : (x+d,y)
The configuration of the arms of the second servomotor is similar but mirrored, so that we find :
Call α2 the angle which must be fed to the second servomotor to reach position P :
α2 = θ2 - φ2
α2 = atan2(y,x+d) - acos( ((x+d)²+y²)1/2 / (2a) )
Feeding the angles α and α2 to the two servomotors will constrain P to be at the intersection of two circles = two points. We can restrict the domain of P in such a way that the pen will initially be placed at the topmost of these two points and never have the chance to switch to the other intersection point.
This way we can fully control the position of the pen by feeding two angles to the servomotors.
The images above show the shapes of the reachable domain on the writing plane for different values of arm length (a) and servomotor offset (d).
Step 2: Use Processing IDE to Write the Mouse-tracking Program
Get the processing IDE:
Go to the processing web site, navigate to the download section, download the processing Integrated Development Environment and run it (no installation required).
Launch processing, create a new program (also called sketch) from the File menu.
Write a sketch:
Paste the following code in your sketch :
Note : the program will not run correctly until the arduino is connected to the computer, this is explained in the Running everything section of this instructable.
import processing.serial.*; // The data which was las sent to arduino : int _LastSent_MouseX; int _LastSent_MouseY; int _LastSent_PenUp; // The most current values of mouse position and pen up/down state : int _Current_MouseX; int _Current_MouseY; boolean _Current_PenUp; // Properties of the drawing window : int _WindowWidth; int _WindowHeight; // Port for communication with arduino Serial _SerialPort; ////////////////////////////////////////////////////// // Setup the Processing Canvas void setup() { _WindowWidth = 1600; _WindowHeight = 800; size( _WindowWidth, _WindowHeight ); strokeWeight( 8 ); // Open the serial port for communication with the Arduino // Make sure the COM port is the same as the one used by arduino (Tools > Serial Port menu) _SerialPort = new Serial(this, "COM7", 9600); _SerialPort.bufferUntil('\n'); } ////////////////////////////////////////////////////// // Draw the Window on the computer screen void draw() { // Fill canvas grey background( 100 ); // Set the stroke colour to white stroke(255); // Draw a circle at the mouse location ellipse( _Current_MouseX, _Current_MouseY, 8, 8 ); } ////////////////////////////////////////////////////// // Updates the most current state of mouse position and sends this information to arduino void mouseMoved() { _Current_MouseX = mouseX; _Current_MouseY = mouseY; SendToArduino(); } // Updates the most current state of pen up/down state and sends this information to arduino void mousePressed() { _Current_PenUp = !_Current_PenUp; SendToArduino(); } ////////////////////////////////////////////////////// void SendToArduino() { // it is more performant to send simple ints over the serial port to the arduino board // however, it is hard to guarantee that the data is received in the right order on the arduino side // to avoid misinterpreting sent data over the serial connection, we use the following convention : // X position will be sent as as int of value 0..127 // Y position will be sent as an int of value 127..255 // Up/Down state will be sent as an int of value 100 or 200 int new_MouseX=round(map(_Current_MouseX, 0, _WindowWidth, 0., 127.)); int new_MouseY=round(map(_Current_MouseY, 0, _WindowHeight, 255., 127.)); int new_PenUp= _Current_PenUp ? 100 : 200; // // we are only going to send the data over to the arduino if one of the values changed if (new_MouseX!=_LastSent_MouseX || new_MouseY!=_LastSent_MouseY || new_PenUp!=_LastSent_PenUp) { _LastSent_MouseX = new_MouseX; _LastSent_MouseY = new_MouseY; _LastSent_PenUp = new_PenUp; _SerialPort.write((byte)new_MouseX); _SerialPort.write((byte)new_MouseY); _SerialPort.write((byte)new_PenUp); } } ////////////////////////////////////////////////////// // this is useful to display the messages sent from the arduino board over the serial port // for debug purposes void serialEvent(Serial myPort) { String myString = myPort.readStringUntil('\n'); println(myString); }
Step 3: Use Arduino IDE to Write the Servo-controlling Program
Get the arduino IDE:
Go to the Arduino web site, navigate to the download section, download the arduino Integrated Development Environment and install it. Launch it, create a new program (also called sketch) from the File menu.
Write a sketch:
Paste the following code in your sketch :
#include <Servo.h> // to activate debug outputs, uncomment the following line: //#define DEBUG Servo servoLeft; Servo servoRight; Servo servoUp; const float pi = 3.14159; float RadianToDegree = 180/pi; float DegreeToRadian = pi/180; // the length of the arm segment (dimensions are scaled so that arm segment length is equal to 1.) const float a = 1.; // the offset between the two servomotor axes: const float d = 5.7/14.7; // to convert incoming bytes to float values: const float ByteToFloat = 1.0/255.0; // security margins to avoid exiting the safe drawing zone: // note that the drawing area has the same x/y ratio here than in the processing sketch const float thetaMax = acos(d/2. - 1.); const float YMin = sin(thetaMax) + d; const float XAmplitude = 2.2; const float YAmplitude = 1.1; const float XMin = -0.5*(XAmplitude-d); const float XMax = d-XMin; const float YMax = YMin+YAmplitude; // pen position (dimensions are scaled so that arm segment length is equal to 1.) float x=0.; float y=1.2; // for serial port communication: int MyDelay=10; int incomingByteX = 0; int incomingByteY = 0; int incomingByteU = 0; // initialize servomotor positions and serial port void setup() { Serial.begin(9600); servoLeft.attach(9); servoRight.attach(10); servoUp.attach(6); servoLeft.writeMicroseconds(1940); servoRight.writeMicroseconds(1095); servoUp.writeMicroseconds(1100); } // the following method reads the serial inputs, // converts incoming data to pen positions // converts pen positions to servomotor angles // sends angle values to servomotors void loop() { // wait for 3 bytes if(Serial.available() >= 3) ; { incomingByteX = Serial.read(); incomingByteY = Serial.read(); incomingByteU = Serial.read(); // check that incoming data respects the convetions we set in the processing sketch // this avoids misinterpreting data that comes unordered if((incomingByteU==100 || incomingByteU==200) && incomingByteX>=0 && incomingByteX<=127 && incomingByteY>=127 && incomingByteY<=255) { #ifdef DEBUG Serial.print("SERIAL X : ");Serial.print(incomingByteX); Serial.print(" || SERIAL Y : ");Serial.print(incomingByteY); Serial.print(" || SERIAL U : ");Serial.print(incomingByteU);Serial.println(); #endif x = incomingByteX*ByteToFloat*2*(XMax-XMin) + XMin; y = (incomingByteY*ByteToFloat - .5)*2*(YMax-YMin) + YMin; // convert (x,y) values to servomotor angles float ThetaLeft = GetThetaLeft(x,y); float ThetaRight = GetThetaRight(x,y); // send the positions to the servomotors SetServoLeftToTheta(ThetaLeft); SetServoRightToTheta(ThetaRight); ServoUp(incomingByteU==100); } } delay(MyDelay); } // the following methods convert (x,y) positions to servomotor angles float GetThetaLeft(float x, float y){ float R = hypot (x,y); float Theta = atan2(y,x); float Phi = acos(R/2.); float Out = RadianToDegree*(Theta + Phi); return Out; } float GetThetaRight(float x, float y){ x = (x-d); float R = hypot (x,y); float Theta = atan2(y,x); float Phi = acos(R/2.); float Out = RadianToDegree*(Theta - Phi); return Out; } // the following methods set angular positions on the two arm servomotors float SetServoLeftToTheta(float ThetaLeft){ // calibration for left servo Hitech-5645MG // theta | uS //--------------------------- // 2200 // 90 1940 // 180 1020 // 750 float mS = 1940. + (ThetaLeft-90.)*(1020.-1940.)/90.; servoLeft.writeMicroseconds(round(mS)); } float SetServoRightToTheta(float ThetaRight){ // calibration for left servo Hitech-5645MG // theta | uS //--------------------------- // 2200 // 0 1995 // 90 1095 // 750 float mS = 1995. + (ThetaRight)*(1095.-1995.)/90.; servoRight.writeMicroseconds(round(mS)); } // the following method brings the lifting servo to pen-up or pen-down position void ServoUp(boolean PenUp){ if(PenUp){ servoUp.writeMicroseconds(1000); } else { servoUp.writeMicroseconds(1200); } }
Step 4: Mechanism: Building the Robot
Here is a list of all the Actobotics parts used in this project:
- 4x 6.16" (17 holes) aluminum beams
- 3x 3.85 (11 holes) aluminum beams
- 1x 1.54" (5 holes) aluminum beam
- 1x 12" Aluminum channel
- 1x 3.75" Aluminum channel
- 2x 1.50" Aluminum channel
- 2x 90° Single angle channel Bracket
- 4x Flat single channel bracket
- 2x Flat triple channel bracket
- 4x 90° Hub mount C
- 2x Standard servo plate D
- 1x Beam Attachment block
- 4x 4mm Bore set screw hub
- 3x 4mm Bore clamping hub
- 6x 90° Dual side mount E
- 2x 4mm (100mm length) Precision shafting
- 1x 4mm (300mm length) Precision shafting
- 2x Standard Hitec ServoBlocks (or equivalent hubs, hub mounts and ball bearing plates)
- Actobotics Hardware Pack A (screws and nuts)
The servos I used are :
- Hitech HS-5645MG
- Power HD-1235MG
I also used :
- A biro
- A piece of cable (bycicle break cable)
Step 5: Mechanism: the Main Channel
Here we are putting together elements on the main channel, the base of our robot.
For this step, we use :
- 1x 12" Aluminum channel
- 1x 4mm (300mm length) Precision shafting
- 4x 90° Hub mount C
- 2x Flat single channel bracket
- 4x 4mm Bore set screw hub
Attach the each hub mount to a a bore set screw hub :
Slide these elements on the long shaft :
Attach the hub mounts to the main channel, using the flat single channel brackets to offset them a little (this will give room for the rotation motion around the shafting to move the pen up and down) :
Your main channel now looks like the pictures below. The two central hub mounts and hubs are free to translate on the shaft :
Step 6: Mechanism: the Pen-up-servo Case (1/5)
Here we are assembling a case-like assembly around the pen-up (power HD) servo. This will later be used to attach the servo on the main channel.
For this step, we use :
- The power HD servo
1xFlat single channel bracket
The result should look like this :
Step 7: Mechanism: the Pen-up-servo Case (2/5)
Here we are assembling a case-like assembly around the pen-up (power HD) servo. This will later be used to attach the servo on the main channel.
For this step, we use :
- 1x 3.85 (11 holes) aluminum beams
- 1x Flat single channel bracket
- 2x 90° Dual side mount E
The result should look like this :
Step 8: Mechanism: the Pen-up-servo Case (3/5)
Here we are assembling a case-like assembly around the pen-up (power HD) servo. This will later be used to attach the servo on the main channel.
For this step, we use :
- The assembly from the previous step
- 1x Flat single channel bracket
- 2x 90° Dual side mount E
The result should look like this :
Step 9: Mechanism: the Pen-up-servo Case (4/5)
Here we are assembling a case-like assembly around the pen-up (power HD) servo. This will later be used to attach the servo on the main channel.
For this step, we use :
- The assembly from the previous step
- 1x 1.50" Aluminum channel
The result should look like this :
Step 10: Mechanism: the Pen-up-servo Case (5/5)
Here we are assembling a case-like assembly around the pen-up (power HD) servo. This will later be used to attach the servo on the main channel.
For this step, use the two parts of the pen-up-servo case you just assembled, assemble them together for you giant-size servo to have a snug little case ready to be attached to the writing robot :
Step 11: Mechanism: Attach the Pen-up-servo Case to the Main Channel
Here we are attaching the case-like assembly around the pen-up (power HD) servo on the main channel. This is straight forward : See the images above.
Step 12: Mechanism: Attach the Servo Plates to the Main Channel
Here we are adding two servo plates on the main channel, they will later hold the two angle servos.
For this step, we use :
- 2x Standard servo plate D
- 1x 3.75" Aluminum channel
Attach the servo plates to the small 3.75" channel like this :
And attach the servo plate to the hub mounts which you left free to rotate/translate on the long shaft on the main 12" channel :
Attach the second servo plate in the same manner. The servo plates + small 3.75" channel should now have a bit of room to rotate due to the fact that you raised the long shaft a little with the flat single channel brackets in the first building step.
Your robot now looks like this :
Step 13: Mechanism: Adding Hub Mounts
Here we are attaching two hub mounts on the servo plates we just added.
For this step, we use :
Standard Hitec ServoBlocks / Hub mounts
The servo plates now look like this :
Step 14: Mechanism: Adding the Arm-servos
The servos fit snugly in the servo plates, as pictured above.
For this step, use :
- 2x Hitech HS-5645MG servos
Notice I chose to have the servo axes close together instead of split apart. This impacts the shape of the domain reachable by the pen. See the Mathematics section for more details.
Step 15: Mechanism: Adding the Ball-bearing Plates
These plates will serve to hold the servo hubs tightly in place.
For this step we use :
Standard Hitec ServoBlocks / Ball bearing plates
Attach them to the hub mounts like this:
Step 16: Mechanism: Adding the Servo Hubs
The servo hubs are attached to the rotating servo spline. The robot arms will be attached to these hubs.
For this step use :
2x Standard Hitec ServoBlocks / Servo hubs
Fit the servo hubs through the ball bearing plates and attach them to the servo splines :
Here is a side view of the two servo hubs attached to their servos :
Step 17: Mechanism: Brackets in Front of the Servo Plates
Two 90° Single angle channel Bracket are attached to the front of the servo plates. These will later be used to attach two short shafts which will go from the servo mounts to the writing surface, to avoid the pen hitting too hard on the writing surface.
For this step use :
- 2x 90° Single angle channel Bracket
Screw them on the hub mounts like this :
Here is what it looks ilke after the two brackets are screwed on :
Step 18: Mechanism: Attachment for the Pen-up-servo Cable (1/3)
This little assembly will be attached to the moving part which makes the pen go up and down. The pen-up servo will pull on it to raise the pen.
For this step use :
- 1x 1.54" (5 holes) aluminum beam
- 2x 6x 90° Dual side mount E
- 1x Beam Attachment block
The result should look like this :
Step 19: Mechanism: Attachment for the Pen-up-servo Cable (2/3)
Attach the small assembly you just built to the ball-bearing plates as illustrated above.
Step 20: Mechanism: Attachment for the Pen-up-servo Cable (3/3)
Run a cable through the hole of the Beam Attachment block and to the pen-up servo horn, as illustrated above and below :
Your robot with the pen-up mechanism complete now looks like this :
Step 21: Mechanism: Resting Legs to Protect the Writing Tool (1/2)
For this step we use :
- 2x 4mm (100mm length) Precision shafting
- 2x 4mm Bore clamping hub
Attach the small 100mm shafts to clamping hubs in this manner (Don't tighten them just yet, you'll need to adjust the length so that they touch the writing surface at the same time as the pen when the pen is raised / lowered) :
Step 22: Mechanism: Resting Legs to Protect the Writing Tool (2/2)
Here we'll attach the short shafts and clamping hubs (aka "resting legs") to the 90° Single angle channel Bracket we added earlier, as pictured above.
Once both resting legs are mounted on the robot, it should look like this from the bottom :
And like this from the top :
Step 23: Mechanism: Attaching the Arms !
For this step, use :
- 2x 6.16 (17 holes) aluminum beams
Attach these beams to the servo hubs. Note that the 2nd hole of the beam is in line with the servo's rotation axis. The efficient length of the arm segment is therefore 16 holes (5.6").
One arm is attached :
And now both arms :
Step 24: Mechanism: Attaching the Second Arms Segments
Here we are attaching a second arm segment or "forearm" to the arm.
We are using the second hole of the forearm in order for all effective segments to be of the same length (16 holes).
For this we use :
- 1x 6.16" (17 holes) aluminum beams
We are not attaching both forearms just yet, as we will be building the pen attachment system to the other forearm in the next steps.
Step 25: Mechanism: Pen Holding System
For this step we will use :
- 2x 3.85" (11 holes) aluminum beams
- 2x Standard Hitec ServoBlocks / Hub mounts
- 1x 4mm Bore clamping hub
Attach a hub mount to the 3.85" aluminum beams like this :
Then attach the clamping hub to the hub mount like this :
And finally, attach the second hub to the opposite side of 3.85" aluminum beams like this :
Step 26: Mechanism: Fitting the Biro in the Pen Holding System
A standard biro will fit perfectly in our pen holding system !
Step 27: Mechanism: Attaching the Pen Holding System to the Arm
Here we are attaching the pen holding system to our remaining arm segment, as illustrated above.
We will use :
- 1x 6.16" (17 holes) aluminum beam
- previously built pen holding system
Notice that once against it is the 2nd hole of the arm segment which is aligned with the pen point. Our effective arm segment length is 16 holes for all arm segments.
Step 28: Mechanism: Joining the Two Arms
The two forearm extremities are joined on the axis exactly above the pen point.
Notice the arm segments' over/under configuration.
Step 29: Mechanism: Finished !
It is now time to bask in the beauty of our magnificent robot and perform a global checkup.
Step 30: Connecting the Servomotors
In this step we will connect the servomotors to the arduino board. There are different kind of hardware to make these connections. I used a breadboard and jumper wires.
I used an external DC power source to power the servos. While it is possible to power them directly from the arduino board's USB connection, the USB power source offers limited current outputs. For the servos to move faster and more efficiently, use an external power source. You can use a small DC connector on the breadboard to do so.
The arduino code provided in an earlier section of this tutorial expects the following connections :
- Left servo connected to pin 9 of the arduino.
- Right servo connected to pin 10
- Up-Down servo connected to pin 6
You can see the diagram of the connections above.
Step 31: Running Everything
It is time to play with the robot ! Above is a longer video showing the robot in action.
This is your final checklist :
- Connect the arduino to the PC with an USB cable.
- Compile the arduino sketch and upload it to the arduino board, using the arduino IDE's compile and upload buttons.
- Check what COM port your arduino is using under the Tools > Serial port menu of the arduino IDE.
- Check that the processing program is using the same serial port, the relevant line is in the setup()method.
- Compile the processing program.
- Make sure the ground ountput of the arduino board is connected to the ground output of your DC power supply if you are using one.
- Un-connect the forearm extremities and pen-raising system cable before powering the servos to avoid inappropriate and unexpected movements.
- Check the arm segments rotate easily at their joints.
- Check the resting legs hit the writing surface at the same time as the biro point, to avoid the biro point taking too big hits when the pen is lowered.
- Check the arm segments pass easily over the clamping hubs holding the resting legs (if not you can raise the arms a little by inserting a flat metal ring between the arm and the servo hub).
- Check the servo wires or other electrical wires do not risk getting torn by the movement of the arms.
- Power, test and calibrate the servo positions individually so that the angles taken by the servos are precisely the ones expected (see diagram in Mathematics section). This can be done either by programming digital servos with this kind of device, or by making adaptations in the arduino code. The relevant methods are SetServoLeftToTheta and SetServoRightToTheta.
- Launch the processing program from the processing IDE.
- The robot should now follow the movement of the mouse cursor on the processing window of your computer screen.
Have fun !
8 Discussions
2 years ago
Good work I'm looking to adapt it into a 2 arm writing robot :D
2 years ago
May i get the updated coded as code provided by you earlier isn't working.
Reply 2 years ago
Hi,
What code are you referring to ? Arduino or Processing ?
Perhaps if you have an error message to send me it might also help.
Reply 2 years ago
I try to run interface both the code,but its not working.so can you provide both arduino and processing updated code.
3 years ago
Great work, I'm curious if this could be adapted to be driven from text typed into a computer. For instance, transforming a typed letter in a word document into a handwritten letter via the robot.
4 years ago on Introduction
I am looking for this to be able to move an x y table with stepper motors that will move a cutting laser. Could this be made to do that?
Reply 4 years ago on Introduction
You need to control 2 angles precisely. This can be done with stepper motors, you'll need to find a way to initialize the positions of the motors at a known angle and count motor steps from there.
I expect this method will be less precise than the traditional methods using rails & pulleys driven by stepper motors.
4 years ago on Introduction
Whoa, this is impressive! | https://www.instructables.com/id/Building-a-robot-that-follows-your-mouse-cursor/ | CC-MAIN-2019-47 | refinedweb | 4,293 | 58.01 |
IntelliJ IDEA 11.1 has been recently released, and we are happy to announce a milestone candidate build for Kotlin IDE plugin, too. This post gives an overview of what happened over the last month.
Milestone Candidate Build is Ready for Your Evaluation
To install on IntelliJ IDEA 11.1 (Free Community Edition is available here), please follow the instructions from the Getting Started guide. In short:
- Use this plugin repository:
- Or download a zipped plugin from here.
You can always download nightly builds of Kotlin from our build server or build it yourself from sources.
Now we proceed to a short overview of the New and Noteworthy. Please refer to this blog post for the previously implemented features.
Little Things that Matter
First of all, we did very many bugfixes, improvements and other important things that are hard to demo. See the commit history on github and the closed issues in YouTrack.
Library
With the power of extension functions, Kotlin makes existing Java APIs better. In particular, we provide enhancements for JDK collections so that you can say things like this:
fun main(args : Array<String>) { val list = arrayList(1, 2, 3) val odds = list.filter {it % 2 == 1} println(odds.join(", ")) }
Here, filter() and join() are extension functions.
Implementation-wise, extension functions are just static utility functions, like “good old” Java’s Collecions.*, but with the “receiver.function()” call syntax, the IDE makes them much better: there is code completion that helps you browse through the API and learn it (just as if the extensions were normal class members):
You can navigate to sources of library functions:
And see the doc comments there:
The HTML version of the library docs is available here.
GitHub Support
Kotlin highlighting is now supported by github, including gist.
Annotations
Kotlin now supports annotations. Here’s a small example that relies on JUnit 4:
import org.junit.Test as test import org.junit.Assert.* class Tests { test fun simple() { assertEquals(42, getTheAnswer()) } }
String Templates
Now you can use multi-line string templates, for example:
println(""" First name: $first Last name: $last Age: $age """)
Simple Enums
Simple cases of enum classes are now supported. For example:
enum class Color { RED GREEN BLUE }
Local Functions
Functions can be declared inside other functions:
fun count() : Int { fun count(parent : Entity) : Int { return 1 + parent.children.sum { count(it) } } return count(this.root) }
Nullability
Kotlin now recognizes the @Nullable and @NotNull annotations). If the Java code says:
@NotNull String foo() {...}
Kotlin will trat foo() as returning a non-nullable String.
A short-hand operator (!!) for converting a nullable value into a non-nullable one is added:
val foo = getSomethingThatMayBeNull() foo!!.bar() // throw NPE if foo is null, run bar() otherwise
Byte Code Unveiled
Click on the Kotlin button on the right edge of the IDEA window, and choose the “Bytecode” tab. You’ll see the byte-code Kotlin generates for your program!
Thanks for this great work!
Failed to load descriptor.
(Mac Lion)
If ti’s from plugin manager, please re-try, or download the zip. We’ll try to fix this.
Resolved now
If foo!!.bar() raises NPE if foo is null, how exactly does that differ from simply calling foo.bar()?
After !!. operator was added to Kotlin program there’s no difference in behavior from foo.bar() call in Java. But the great difference was at previous step when compiler was able to find a place with probable NPE threat and asked programmer to resolve it explicitly.
You can find more information about null-safety feature in Kotlin on this wiki page.
So if I read that correctly, without !!, the compiler will fail on a possible null reference. But the !! tells the compiler to butt out and let it fail at runtime?
Yes you’re right. And this is the reason why !! calls should be used with great caution or avoided completely. If you are in Kotlin and not planning to assign null value to variable just declare it with not-nullable type. While working with methods and variables from Java it’s better to choose some safe way to deal with possible null value. It can be ?. call or pre-check to null.
Hey Charles,
Glad to see you here!
Guys, what you do is awesome!
Personally I’d switch to Kotlin right after first RC.
Thanks for the encouraging words!
Thank you guys, this is a brilliant work!
I’ll switch to Kotlin as soon as it gets Android support.
Also Kotlin has inspired me to switch to IntelliJ IDEA
Keep up the good work!
Thanks for the kind words!
How to use JUnit with kotlin? or how to have unit test with kotlin? Can you provide any example on it ?
I found compile speed will become very very slow, and KCompile will report the following error:
java.lang.IllegalStateException: Internal error: (14,72) java.lang.AssertionError
@ClosureAnnotator.java:112
at org.jetbrains.jet.codegen.CompilationErrorHandler$1.reportException(CompilationErrorHandler.java:27)
at org.jetbrains.jet.codegen.GenerationState.compileCorrectFiles(GenerationState.java:120)
at org.jetbrains.jet.compiler.CompileSession.generate(CompileSession.java:161)
at org.jetbrains.jet.compiler.CompileEnvironment.compileModule(CompileEnvironment.java:156)
... 89 more
even for the following code:
package hhh.csp
import org.apache.log4j.Logger
import org.apache.log4j.PropertyConfigurator
import org.junit.*
import org.junit.rules.ExpectedException
import junit.framework.TestCase
import junit.framework.TestSuite
public class IntervalTest(name :String) : TestCase(name) {
fun testIntervalPlus() {
val values : Array = Array(10000,{Interval.zero()});
var v:Interval = Interval.zero();
for( i in values ) i.u = 1.0;
for ( i in values) v = v+i;
println(v);
}
}
The problem with “compilation speed” is actually an IDE bug causing exceptions from the compiler to be processed very slowly. This bug is already fixed.
The exception you are getting also seems to be fixed. At least, this code compiles and runs OK for me:
Please, update your Koltin plugin to a nightly build:
1. Uninstall the plugin
2. Follow the nightly build instructions from here: | http://blog.jetbrains.com/kotlin/2012/03/kotlin-m1-candidate/ | CC-MAIN-2013-20 | refinedweb | 998 | 60.72 |
Python 3.8 has been released recently with many new awesome features.
This article will describe some of the new features of Python 3.8 which I believe every Python developer should be familiar with.
#1 Assignment expressions
This is one of the major changes in Python 3.8 is the introduction of Assignment expressions. It is written using
:= and is known as “the walrus operator”.
key = '' while(key != 'q'): key = input("Enter a number or q to exit ") if key != 'q': print(int(key)**2)
In Python 3.8, you can write the code as:
while((key:= input("Enter a number or q to exit ")) != 'q'): print(int(key)**2)
#2 Positional-only arguments
Now we can use the new function parameter syntax
/ to indicate that some function parameters must be specified positionally and cannot be used as keyword arguments.
Take a look at this example.
def add(a, b): print(a+b) add(2, 5) add(b=5, a=2)
Here, the
Add() function takes two mandatory parameters
a and
b. Therefore we can call the function by passing parameters in any of the following ways.
- add( 2, 5 ) - Pass the arguments in the same order.
- add( b=5, a=2 ) - Pass arguments as keyworded arguments.
Starting with Python 3.8, we can use
/ parameter to specify positional-only arguments.
The
/parameter indicates that the arguments should be passed in the exact order and should not be passed as keyworded arguments.
See the example shown below.
def add(a, b, /): print(a+b) add(b=5, a=2)
Note that we've added
/ as a parameter to the
add() function. This restricts passing arguments as keyworded arguments. This code when executed will produce an error similar to the one shown below.
Traceback (most recent call last): File "test.py", line 4, in <module> add(b=5, a=2) TypeError: add() got some positional-only arguments passed as keyword arguments: 'a, b'
#3 Debugging made easier with f-strings
An f-string is a formatted string literal. It was introduced in Python 3.6.
name = "Python" print(f'Hi from {name}')
This will display
Hi from Python when executed.
In Python 3.8, we can add an = to the expression to evaluate the expression and display the output as well.
name = "Python" print(f'Hi from {name=}')
This would produce the following output.
Hi from name='Python'
Here's another example.
a, b = 5, 6 print(f'The value of a = {a} and b = {b}') # New in Python 3.8 print(f'The value of {a = } and {b = }')
The output will be:
The value of a = 5 and b = 6 The value of a = 5 and b = 6 | https://www.geekinsta.com/new-features-in-python-3-8/ | CC-MAIN-2020-40 | refinedweb | 449 | 67.35 |
Hi? - we should only set up a single 'localhost' entry in /etc/hosts, pointing at ::1, and let nss_files handle the mapping to 127.0.0.1 automatically. Are there other solutions that should be considered? Is one of these more acceptable than the other? To me it seems obvious that the best choice is to not treat the files backend specially in the first place, but I don't know the rationale behind this special-casing either. Cheers, -- Steve Langasek Give me a lever long enough and a Free OS Debian Developer to set it on, and I can move the world. Ubuntu Developer slangasek@ubuntu.com vorlon@debian.org
#include <stdlib.h> #include <stdio.h> #include <string.h> #include <sys/types.h> #include <sys/socket.h> #include <netdb.h> int main() { const char *host= "localhost"; const char *port= "9011"; struct addrinfo hints, *res, *sai; struct hostent *result; char buf[INET6_ADDRSTRLEN]; int buflen = sizeof(buf); int err; /* this call is just here to force glibc to set up the internal * _res state, so that it sees the "multi on" that's configured * by default in /etc/host.conf when we call getaddrinfo() below. * Of course we could just use gethostbyname_r() itself, but * getaddrinfo() is a truer test case. */ gethostbyname_r(host, NULL, NULL, 0, &result, &err); memset( &hints, '\0', sizeof(hints) ); hints.ai_flags = AI_PASSIVE; hints.ai_socktype = SOCK_STREAM; hints.ai_family = AF_UNSPEC; err = getaddrinfo(host, port, &hints, &res); if (err) { perror("getaddrinfo failed"); exit(1); } for (sai = res; sai != NULL; sai = sai->ai_next) { switch (sai->ai_family) { case AF_INET6: inet_ntop(AF_INET6, &((struct sockaddr_in6 *)sai->ai_addr)->sin6_addr, buf, buflen); break; case AF_INET: inet_ntop(AF_INET, &((struct sockaddr_in *)sai->ai_addr)->sin_addr, buf, buflen); break; } printf("name returned: %s\n",buf); } } | https://lists.debian.org/debian-devel/2008/07/msg00162.html | CC-MAIN-2017-34 | refinedweb | 284 | 59.19 |
NEW: Learning electronics? Ask your questions on the new Electronics Questions & Answers site hosted by CircuitLab.
Basic Electronics » Using Usbasp for attiny25
Hey Guys,
I recently bought an Usbasp programmer of of ebay and a blank attiny25 chip. I have everythign hooked up but am not sure how to program the chip. I have messed around alot with it and avr studio. So how do i make the .hex file to burn into the chip. I already have the code written.
Thanks,
Kuljot Dhami
Hello,
I have programmed attiny45's and attiny85's with a programmer with the USBASP firmware. Those devices are pretty much the same other than the amount of available memory. Which USBASP device do you have?
Essentially, this is how to do it. 1st I'll assume you either have the PDIP or SOIC version like this:
And that your USBASP programmer has either a 10 pin, 6 pin, or both interfaces:
NOTE THIS ILLUSTRATION IS OF THE JACKS ON THE BOARD
From there, it's just a matter of connecting (FROM THE 10 PIN CONNECTOR):
MOSI (Pin1) from the programmer to MOSI (PB0) on the chip
MISO (Pin9) from the programmer to MISO (PB1) on the chip
/RES (Pin5) from the programmer to RESET (PB5) on the chip
SCK (Pin7) from the programmer to SCK (PB2) on the chip
VCC (VTG Pin2) from the programmer to VCC on the chip
GND (Pin4,6,8,10) from the programmer to GND on the chip
By default, the tiny25 will run at 1Mhz internal clock. Some Programmers have a low speed jumper (on mine it is J3). I have to use that jumper with the 1Mhz default tiny25 clock.
After that, you can use some of the dircetions I put in the how to install a bootloader thread. In that thread I show you what to change in the makefile to use your USBASP programmer. HERE is a LINK to that thread.
Rick
Real quickly with out looking! If you are connected to the chip using AVRstudio then click on the program button in AVRstudio.
Then enter the path to your .hex file and then click program.
Ralph
Does AVR Studio even support the USBASP programmer Ralph??
It must as he says " I have messed around alot with it and avr studio." so I assume that means it connects.
Thats what prompted my reply. I'll fire up my windows computer and take a look.
I just looked in AVRstudio. The USBasp programmer is not specifically listed, which is not surprising.
The AVRISP and AVRISP mkII is listed. Is the USBasp an emulator of the AVRISP programmer?
Of course the STK500 is listed.
So I do not know how dgikuljot was able to have messed around alot with it and avr studio except that it used some sort of clone.
It certainly will be interesting to find out, if AVRstudio can talk with a USBasp programmer that would open new doors.
I do not have a USBasp programmer so I cannot test.
So dgikuljot how were you able to mess around in AVstudio?
I don't believe the default USBASP firmware will work directly with AVRStudio. It enumerates as it's own USB device and not a serial programmer. That was why I was referring him to the avrdude mods I made to the makefile in the bootloader thread I posted. Since I have a USBASP programmer my makefile mods would work out of the box with avrdude. There may be alternate firmware that is hardware compatable with his programmer, but unless he has another ISP programmer to re-program the firmware on his USBASP, that wouldn't help much. :)
dgikuljot one thing I forgot to mention, when progrmming the chip, make sure you put a resistor (I usually use 10K) between the reset pin of the chip and VCC. This will ensure the reset works properly when programming. Also, if you want to program this chip as you would one of the nerdkit chips, you can edit the NK makefile for your programmer, and chip type and it will work. You don't have to use AVRStudio unless you want to.
There is a thread on AVRfreaks.net about using USBasp with AVRstudio.
If you Google USBasp and AVRstudio there are a number of returns so I guess it is possible to use AVRstudio.
I believe different open source drivers are used.
I'd like to know what dgikuljot was using.
First of all I would like go thank everyonw for the replies. When I said messed around with ave studio I meant I tried to make a hex file but Iwant succesful. I will check outsome of these links and reply later
Ralph,
I did google it. The results I found appeared to state you needed a new firmware... Thus changing it from a USBASP to enumerate as a different programmer. avrdoper was on such firmware. But unless he has another way to burn the firmware on to his usbasp chip, that would do him no good.
Also, USBASP is an opensource firmware project with a basic schematic given. Their are dozens of variations to the hardware that may or may not be compatable with firmware other than the USBASP firmware. That was why I asked what type of programmer he purchased. Mine for instance can have an AVRISP MK-II compatable firmware installed that would work directly with AVRStudio.
Kuljot,
To develop for the AVR, you don't have to use AVRStudio. If you don't mind my asking, what level have you gotten to in your programming abilities? Have you gone through the entire guide with your Nerdkit? While the Nerdkit uses a different method of sending the program to the chip than an attiny25 would, the program creation is very similar and the code is virtually identical.
For instance, if you wanted to send the led_blink program to the attiny25. You'd 1st have to modify the source code to use possibly PB1 instead of PC4 since the attiny25 has no PORTC. Once that is done, you would also need to change the clock freqency. So the define for F_CPU would be 1000000 instead of 14745600 for a stock chip.
Then you'd have to change the makefile so it would compile the code for the proper chip and use your USBASP programmer like this.
GCCFLAGS=-g -Os -Wall -mmcu=attiny25
LINKFLAGS=-Wl,-u,vfprintf -lprintf_flt -Wl,-u,vfscanf -lscanf_flt -lm
AVRDUDEFLAGS=-c usbasp -p attiny25
After you've done that, you should be able to blink an LED placed in series with a 1k resistor connected between pin6 and ground.
Also, the internal clock can be bumped up to 8MHz by changing the fuses in the attiny25 if need be. However, the chip will run lower power at teh 1MHz default clock.
I found this site really helpful () to get my fuse settings when programming an attiny. I found out of the box they were set to use the internal crystal and had a prescaler of /8 set so it was running at 1mhz.
Hey Guys,
SOrry i havent responded in such a long time. We had exams at school and i was really busy. Basically i hooked up my mcu to the usb and checked the connections 5 times. I used Ricks method to modify the makefile. The compiler attempts to program the chip but then i get this error
avrdude: error: programm enable: target doesn’t answer. 1
avrdude: initialization failed, rc=-1
Double check connections and try again, or use -F to override
this check.
I have checked the connections atleast 5 times and rewired everything over multiple times and everything is connected correctly. I read online that in some cases the programmer needs to be slowed downd to accomodate for the 1mhz internal clock of the mcu. Unfortunately my programmer has no jumper to slow down the programmer.
Here is the link to the programmer i bought
So does anyone have an solutions.
P.S. I am not using an external Power supply, supposively the programmer is capaable of supplying boltage to the mcu.
Thanks,
Kuljot
Kuljot,
One thing I didn't mention directly (it is mentioned in my bootloader thread) is that you must have a pullup resistor on the reset pin of the microcontroller (Pin1) I typically use a 10k resistor between that pin and VCC (5V) If you don't have this, the programmer will not be able to reliably toggle the reset line as needed to program the chip.
If that doesn't work, then you would need to see if you could trace out the microcontroller on your programmer. The high/low speed jumper for a usbasp device should connect PC2 to Ground for low speed and be open for high speed. I'd download a copy of the datasheet for the micro-controller they have on their board then trace it out from that pin. I noticed a set of empty solder pads labeled R8 next to the micro on the programmer, these may be for setting low speed of course you'd have to verify this with the circuit trace.
Hopefully you'll get lucky and the pullup will fix it.
Hi Rick,
Where can I find technical info on these inexpensive programmers. Do you know if they all use the same firmware? Is it freely available somewhere?
Hey Rick,
Thanks for all your help so far. The pull up resistor did nothing, and the mcu is an atmega 8 surface mout. So once i find the pin should i connect it directly to ground or with a resistor. Yeah i noticed the empty R8 too. So could there be anything else thats going on.
Noter:
The USBASP is a real easy to build (I breadboarded one once) programmer. It uses very few external components and works great with avrdude. They have a full schematic and source code on their site.
Kuljot:
Once you find the pin for PC2, you may find it traces to the pads for R8 and the other side of R8 may trace to ground. Then again, it may not be connected at all. Either way, to set the programmer to low speed programming using the default USBASP firmware, you would tie PC2 to ground. Again, I'm just guessing at R8 since I don't have one of your programmers. I purchased mine from fun4diy.com. Out of the box his programmer has an AVRISP MkII firmware that is somewhat flakey with win7 supposedly I opted for the USBASP firmware. It has performed very well for me and I've programmed tiny 45's, tiny 85's, mega8's tiny2313's, and many others with it. I'm sure once you get your's figured out it will perform well also.
Hey Rick,
Apparently after doing some reading online i have learned that if there isnt a jumper 3 to slow down the programmer, that most likely the usbasp has been decided to automatically adjust to the targets speed.
I had heard of the newer firmware doing this, I'm not 100% how well it works though. I know the last tiny45 I programmed about 2 months ago, I had to add the jumper to get it to talk to it. I guess it just depends on the firmware they programmed your device with and if it is the auto-sync firmware, how well the auto-sync works.
Could you post some photo's of your setup for programming it? Close ups of the connection of the programmer and breadboard. Maybe we can see something...
Ok, Read up a bit on the speed thing, If you have the latest firmware, the speed can be controlled by a switch in avrdude. Try adding the parameter -B 100 to the ARDUDEFLAGS line in the makefile like this:
AVRDUDEFLAGS=-c usbasp -B 100 -p attiny25
See if that makes it work...
Hey Guys,
The parameter didnt work either, so only thing left to do is solder a wire on to pc2 to ground. Man i really wish the atmega 8 wasnt surface mount. So do you guys know of any other probable causes for this error. If the grounding of pc2 doesnt work then i will post a picture of my setup
Connecting pc2 to ground produces the same results. The Resistor8 that is missing traces back to PB2, but you said to ground PC2. I dont know what to say at this point.
Photo would probably be best at this point.
Ok Sorry guys that i have been so late to reply to this. I basically replaced the usbasp with another one and this time it proceeds further. But now i am getting an error :
adress 0x0810 out of range at line 129. The hex file is 22kb for some reason, i am assuming this is way to large for the attiny 25. So why is the hex file turning out so large.
Here is my code:
// led_blink.c
// for NerdKits with ATmega168
// hevans@nerdkits.edu
#define F_CPU 1000000
#include <avr/io.h>
#include <inttypes.h>
// PIN DEFINITIONS:
//
// PC4 -- LED anode
int main() {
// LED as output
DDRB|= (1<<PB1);
// loop keeps looking forever
while(1) {
// turn on LED
PORTB |= (1<<PB1);
}
return 0;
}
So from my research i know i am getting this error because the hex file is to large for the mcu and it is too large at 22kb, but why is such simple code turning out to be 22kb.
THanks,
Kuljot Dhami
I know there are compiler optimizations and such, but I haven't found a definitave answer to this. Like you, I would love to find the answer. However, I have not dug into it because, since I know I have issues with C, I just go to BASCOM AVR or assembly when building programs for anything less than the 168's. I have specifically run into this with mega8's, tiny45's, and tiny85's.
If you have any knowledge of programming in BASIC, BASCOM AVR has no restrictions in it's demo for a chip that size. The only limitation in it's demo is a 4k code size restriction which is double that chip's capacity.
The large size is due to the libraries you are linking with. For a small hex file, remove these libs from your gcc command:
-Wl,-u,vfprintf -lprintf_flt -Wl,-u,vfscanf -lscanf_flt -lm
Are you saying just remove that whole line (make the line read LINKFLAGS=)
If that is all that is in the linkflags, then yes. Here is a gcc command from one of my projects that I use to build a small image.
avr-gcc -g -Os -fno-jump-tables -Wall -mmcu=atmega328p -mcall-prologues \
AVRHV8_SPI.c -o AVRHV8_SPI.o ../libNoter/libNoter.a ../libnerdkits/libNerdKit.a\
-DF_CPU=8000000UL -DBAUD=250000L
Also, don't rely on the size of the hex file for the size of your image. Open the .ass file and scroll to the bottom. The last address plus the bytes used in the last instruction is the actual size of your image. If for some reason you don't load starting at 0x0000 (like the bootloader) then you will have to substract your start address from the end address to get the image size.
By the way, "image" means executable program image. Not to be confused with a bitmap or jpg type image. Here's another example that I use to build my bootloader which is slightly less than 1kb in size. As in my previous post, there is no printf, scanf, or math lib specified for the link.
avr-gcc -g -Os -mcall-prologues -mmcu=atmega328p -std=gnu99 \
-L/usr/local/avr/avr/lib \
-Wl,--section-start=.text=0x7C00 \
AVR109_Noter.c -o AVR109_Noter.o \
-DF_CPU=18432000UL -DBAUD=115200UL -DMCU=atmega328p \
-DBOOT_SECTION_START=0x7C00
OMG Rick and Noter,
Thank you so much. Just Leave the
Link Flags=
And everything works fine. Everything is working now and i can get back on track on making my Remote computer start system. Now i just need to find some useful libraries for avr and ill get back to work.
So Rick,
I have one final question for you rewgarding this. I downlaoded the manual for bascom and it seems alot easier to program in Basic then C. So my question is will writing code in basic be just as efficient and fast as writing it in "C" for the MCU. Also does BAscom supprot Usbasp.
Thanks,
kuljot Dhami
Bascom compiles pretty compact efficient code. And yes, USBASP is supported within it's gui. I actually was programming micro's with bascom prior to purchasing my NerdKit. The main reason for getting the Nerdkit was to teach myself C. However, for simple projects - especially for smaller micro's, I will still occasionally use Bascom.
Hi at all.
I am right now trying to flash a ATTiny45 with an existing HEX File.
I want to share this informations, which maybe can help some people.
How to:
First you have to erase your chip:
avrdude -c usbasp -p t45 -e
In my case I used an usbasp flasher.
I want to flash an ATTiny45, because of that I have chosen t45.
In these lists you can find the right name for your programmer and you chip.
After that I made the fuses:
avrdude -c usbasp -p t45 -U lfuse:w:0x62:m
avrdude -c usbasp -p t45 -U hfuse:w:0xdf:m
avrdude -c usbasp -p t45 -U efuse:w:0xff:m
On THIS site you choose your chip and have a look which settings for low, high and extended have to be set.
After that you can flash your HEX file to the chip:
avrdude -c usbasp -p t45 -U flash:w:sd8p_mo.hex
Remember you have to change to the directory where the HEX file is, when you enter the command in the command line.
Now your program should be on your chip.
The wiring has been solved by Ricks Tutorial above.
Rick, thank you so much, for sharing this.
Hope I could help.
Hi,
Just reading thru the thread and I would be hesistant on setting the fuses prior to programming the chip. I've been playing around with using an ATTiny85 as a USBTiny programmer. This requires you to set the /RST line as an input line(?) via the fuse settings. Once the /RST line is changed, it can only be changed by using a HVPP device to reset it back to the original fuse settings.
Well, last laptop is imaging for the day....heading home....
See ya!
Kevin
I have following issue.
Now I am able to do the following:
+ Write a program with the Nerdkit USBtoSerial Cable to the ATMEGA168
+ I am able to write the bootloader with the usbasp to the ATMEGA168
+ I can write a HEX file(downloaded from a website) to almost any Microcontroller as I described above with usbasp
But I want to do following:
+ I want to write a simple program(f.i. flash_led.c) into f.i. ATTinyxx,ATmega8,ATxmega... with the hardware I have(nerdkit,usbasp)
I really have no clue how to do that.
With the ATMEGA168 and the USBtoSerial cable it's really easy.
Would be great to have a same easy prodecure to to write my flash_led.c file to f.i. ATTiny, ATmega8,....
Hope to hear from you.
Thanks for your help.
@ Inino
This website has good tutorials for avr microcontrollers. He also uses an isp to program the chip which is similar to USBasp.
Avr Tutorials
thanks for your reply.
I will have a look at your link.
Please log in to post a reply. | http://www.nerdkits.com/forum/thread/1489/ | CC-MAIN-2019-30 | refinedweb | 3,286 | 81.22 |
The Scanner class must be imported from java.util. It provides a wrapper class that encapsulates an input stream, such as stdin, and it provides a number of convenience methods for reading lines and then breaking a line into tokens. This set of notes will cover the set of Scanner methods that you will use most frequently. You can look at the Scanner's API to get the full list of methods that a Scanner provides.
The constructor for the Scanner class takes a Java InputStream, File, or String as a parameter and creates a Scanner object. Basically the Scanner class works with anything that supports an iterator, since what you are essentially doing is iterating through a collection of tokens.
In Java, the variable System.in is declared as an InputStream and it points to stdin. System.in is a byte stream so you can't read from it directly if you want to read character strings, which is what you normally want to do. Hence you must wrap a Scanner object around System.in to handle string oriented IO. The following statement accomplishes this task:
Scanner console = new Scanner(System.in);If you want to treat System.in directly as a character stream, use the Console class instead, which is discussed below.
Oftentimes you will want to read a line of user input and then break it into typed fields. The Scanner class allows you to easily break the line into tokens, and even type check the tokens, by creating a Scanner class that tokenizes the line. For example, if you have a line of user input in the String variable nextLine, then you can create a Scanner that will tokenize the line using the following statement:
Scanner lineTokenizer = new Scanner(nextLine);
A Scanner object will divide a line of input into tokens (fields) using white space to delimit the tokens. For example, given the line:
brad 10 truea Scanner will create the tokens "brad", "10", and "true". You can retrieve these tokens and convert them to the appropriate types using the following set of methods (see the API for a complete set of next methods):
When you have finished using a Scanner, such as when you have exhausted a line of input or reached the end of a file, you should close the Scanner using the close method. If you do not close the Scanner then Java will not garbage collect the Scanner object and you will have a memory leak in your program:
To illustrate the use of a Scanner, consider the following problem:
Read and type check lines of user input. Each line should contain three fields organized as:
name(String) age(int) single(boolean)The types of the fields are shown in parentheses. Errors should be reported using an appropriate error message. Valid fields should be consumed and the Scanner should move on.
Here is a sample input file:
brad 10 true nels 10 nels 10 false nels 10 10 brad 10 20 30 10 true 40 brad nelsand here is the output that the program should produce:
line 2: must have a field for singleness line 4 - 10: singleness should be a boolean line 5: must have fields for age and singleness line 6 - 30: singleness should be a boolean line 7 - true: age should be an integer line 7 - 40: singleness should be a boolean Line 8: line must have the format 'name age singleness' line 9 - nels: age should be an integer line 9: must have a field for singleness
Here is the complete program for accomplishing this task
An easier way to deal with stdio is to use the Console class, which supports both reading from stdin and writing to stdout. It reads character strings so you do not have to worry about wrapping System.in inside a Scanner class. You use the readLine method to read a line of input, and a Scanner class to tokenize the line of input. readline returns null on end of file.
You can obtain the system provide console object from System.console.
It is
a good idea to check whether this object exists, since it does not
exist for non-interactive Java programs, which includes program in
which stdin is redirected. For example, the following invocation
will not have a console object:
java foo < inputfile // no console object for programs with redirected input
A console object also may not exist for Java programs run
with older versions of the Java virtual machine
and some systems will not provide it for security
purposes. In all of these cases you will have to fall back on System.in and System.out.
Here is the same example code from above, except using the console class. I have boldfaced the new code:
import java.util.Scanner; import java.io.Console; // Console is in the java.io library class Datacheck { static public void main(String args[]) { new Datacheck(args); } public Datacheck(String args[]) { Scanner lineTokenizer; String input_line; Console input_reader = System.console(); // I'm just going to exit if the console is not provided if (input_reader == null) { System.err.println("No console."); System.exit(1); } // you cannot use the C/C++ idiom of // while (input_line = input_reader.readLine()) // because the test expects a boolean and the above assignment returns // a String reference. In C/C++ the return of null would be interpreted // as false, but not so in Java. Hence the infinite loop that I have written // with a break statement for when readLine returns null while(true) { input_line = input_reader.readLine(); if (input_line == null) break; line_scanner = new Scanner(input_line); int lineNum = 0; lineNum++; // determine if the line has a name field if (lineTokenizer.hasNext()) { lineTokenizer.next(); // consume the valid token } else { console.printf("Line %d: line must have the format 'name age singleness'\n", lineNum); continue; // proceed to the next line of input } // determine if the line has a second field, and if so, whether that // field is an integer if (lineTokenizer.hasNext()) { if (lineTokenizer.hasNextInt()) { lineTokenizer.nextInt(); // consume the valid token } else console.printf("line %d - %s: age should be an integer\n", lineNum, lineTokenizer.next()); } else { console.printf("line %d: must have fields for age and singleness\n", lineNum); continue; // proceed to the next line of input } // determine if the line has a third field, and if so, whether that // field is a boolean if (lineTokenizer.hasNext()) { if (lineTokenizer.hasNextBoolean()) lineTokenizer.nextBoolean(); // consume the valid token else { console.printf("line %d - %s: singleness should be a boolean\n", lineNum, lineTokenizer.next()); continue; // proceed to the next line of input } } else { console.printf("line %d: must have a field for singleness\n", lineNum); continue; // proceed to the next line of input } lineTokenizer.close(); // discard this line } } } | http://web.eecs.utk.edu/~bvz/teaching/cs365Sp10/examples/datacheck.html | CC-MAIN-2017-51 | refinedweb | 1,117 | 61.26 |
PROCESSING COMMAND-LINE INPUT
Processing Command-Line Input
Overview
This page concerns itself largely on the GNU implementation of
getopt() and it's variants (more likely than not you will be using this library), and how they relate to the POSIX standard.
First, A Little Terminology
getopt()
getopt() is a standard C library function that is commonly used to decode command-line options that are passed into the
main() function from the calling program (which is usually a terminal, e.g. bash). It can be used in your C code by including
getopt.h (
#include <getopt.h>).
It is a function which is designed to be called multiple times until it returns
-1, indicating that it has finished processing all of the options.
It supports single character options preceded by a single
-, e.g.
-s 54.
The header file
getopt.h exposes four variables used by
getopt() that you can check to find the state of the function.
Note that
getopt() re-arranges the variable pointer array as it is processing, so that when it is complete, the program name is first (as it was originally), followed by all the options, and lastly all the parameters. You can use this feature to identify the parameters once
getopt() is finished.
getopt_long()
getopt_long() is an extension of
getopt() that allows long options, that is, options that are described with more than one ASCII character and preceeded by – (e.g.
--speed=54). It is part the GNU C library (glibc).
The way long options are specified and handled is radically different to that for short options. The
getopt_long() function accepts…
Similar Functions
Argtable is an open-source ANSI C library for parsing GNU-style command line options. Because it is ANSI compliant it is compilable on a huge range of operating systems, including Linux, FreeBSD, Cygwin, Apple Mac OS X and Windows, a compilable with the most common compilers on these operating systems. This library is well documented.
There is a C++ version of getopt() in the GNU C++ library. It is used by including GetOpt.h (#include <GetOpt.h>) into your C++ project (note the captilised ‘G’ and ‘O’). It is described in more detail here.
Another popular C++ version is called getoptpp. It is pretty code heavy (uses
<sstream>,
<map>,
<vector>, e.t.c, and probably not suitable for embedded systems. Supports long options.
There is a C++ version, “The Lean Mean C++ Option Parser", which is a header-only, light-weight, option parser which is meant to be easy to use. Differs from
getopt() in it's extra functionality.
gFlags (a portmanteau of Google Flags) is a C++ options parser that is released under the New BSD License.
| https://blog.mbedded.ninja/programming/languages/c/processing-command-line-input/ | CC-MAIN-2019-51 | refinedweb | 448 | 64.41 |
.NET 2 the Max
Learn to parse fixed-length files and delimited text files, detect when a key combination is pressed, and change the style of the Web control that has the input focus.
Technology Toolbox: VB.NET, C#, ASP.NET
One of the great things about being a book and magazine writer and the founder of a Web site is that I can keep myself in touch with thousands of developers. And even when I don't receive e-mails, I can see which articles on our Web site developers visit most frequently (see the sidebar, "The 2TheMax Family of Sites"). It's surprising to see that so many developers spend so much time on a relatively small set of problems. It's another form of the famous 80/20 rule: Programmers spend 80 percent of their time solving the recurring 20 percent of all possible problems. With this new .NET 2 the Max column, we hope to help you deliver better applications, faster, by making the solutions to these recurring problems more widely known. Francesco Balena
Parse Fixed-Length Fields in Text Files
XML has become the standard technology in information exchange, but many applications still use more primitive ways to import and export data. One such technique is based on text files containing fixed-width fields. Consider these text lines:
John Smith New York
Ann Doe Los Angeles
Each text line contains information about the first name (six characters), last name (eight characters), and city. The largest city has 11 characters, but usually you can assume that the last field will take all the characters up to the end of the current line.
Building a program that reads individual fields isn't difficult at all. Your app simply reads a line, then uses the String.Substring method to extract individual fields. However, I want to illustrate a different approach, based on regular expressions. Consider this regular expression:
^(?<first>.{6})(?<last>.{8})(?<city>.+)$
The dot (.) represents "any character." Therefore, .{6} means "any 6 characters." The expression (?<first>.{6}) creates a group named "first" that corresponds to these initial six characters. Likewise, (?<last>.{8}) creates a group named "last" that corresponds to the next eight characters. Finally, (?<city>.+) creates a group for all the remaining characters on the line and names it "city." The ^ and $ characters represent the beginning and end of the line, respectively. You can easily write short VB and C# routines built on this regular expression to parse a file (see Listing 1). Download the code for parsing fixed-length fields in text files here.
The beauty of this approach based on regular expressions is that it is unbelievably easy to adapt the code to different field widths and to work with delimited fields. For example, if the fixed-width fields are separated by semicolons, you simply modify the regular expression without touching the remaining code:
^(?<first>.{6});(?<last>.{8});
(?<city>.+)$
Once you understand how regular expressions work, creating and maintaining your parser routines becomes child's play. F.B.
Use Regular Expressions With Delimited Text Files
Let's assume you want to write a program to parse a common (albeit primitive, according to today's standards) exchange format: delimited text files. Each field is separated from the next by a comma, a semicolon, a tab, or another special character. To further complicate things, such files usually allow values embedded in single or double quotes. In this case, you can't use the Split method of the String type to do the parsing, because your result would be bogus if a quoted value happens to include the delimiter (as in "Doe, John").
Regular expressions are a real lifesaver in such cases. You can use the parsing code (see Listing 1) for these purposes, provided that you use a different regular expression that accounts for delimited fields. Let's start with the simplified assumption that there are no quoted strings in the file:
John , Smith, New York
Ann, Doe, Los Angeles
As you might have noticed, I threw in some extra white spaces to add interest to the discussion. These spaces should be ignored when parsing the text. You can use this regular expression to parse a comma-delimited series of values and ignore these extra spaces at the same time:
^\s*(?<first>.*)\s*,\s*(?<last>.*)\s*,
\s*(?<city>.*)\s*$
The \s* sequence means "zero or more white spaces," where a white space can be a space, a tab, or a new-line character. It is essential that these \s* sequences and the delimiter character (the comma, in this case) are placed outside the (? ) construct, so that they aren't included in the named groups. Also, notice that you use the .* sequence (which stands for "zero or more characters") to account for consecutive delimiters that mark empty fields.
Next, let's see how to parse quoted fields, like those found in this text file:
'John, P.' , "Smith" , "New York"
'Robert "Slim"', "" , "Los Angeles, CA"
Text fields can be surrounded by both single and double quotes, and they can contain commas and quote characters that don't work as delimiters. The regular expression that can parse these lines is quite complex, so I'll split it for your convenience:
^\s*(?<q1>("|'))(?<first>.*)\k<q1>\s*,
\s*(?<q2>("|'))(?<last>.*)\k<q2>\s*,
\s*(?<q3>("|'))(?<city>.*)\k<q3>\s*$
The (?<q1>("|')) subexpression matches either the single or the double leading quote delimiter and assigns this group the name "q1." The \k<q1> subexpression is a back reference to whatever the q1 group found; therefore, it matches whatever quote character was used at the beginning of the field. The q2 and q3 groups have the same role for the next two fields. Once again, you don't need to change any other statement in the parsing routine.
By the way, .NET 2.0 developers will be able to parse both fixed-width and delimited fields by means of a brand-new class named TextFieldParser in the System.Text.Parsing namespace. In spite of what the namespace name suggests, however, this class is defined in the Microsoft.VisualBasic.Dll library. Therefore, C# applications can't access it unless you add a reference to this DLL (something few C# programmers will do, I'm afraid). I've prepared a TextFieldParser class for you to play with that you can download from the .Net2TheMax site (see the sidebar, "Additional 2TheMax Downloads," for details). F.B.
Detect Global Hotkeys
.NET developers often want to determine whether a given key combination is pressed, when their Windows Forms applications don't have the input focus. There are basically two ways to detect if a key is pressed in such cases, and both require a Windows API call.
In the simplest case, you can poll the keyword using the GetAsyncKeyState API function, which you declare using this code:
' VB.NET
Private Declare Function _
GetAsyncKeyState Lib "user32" _
Alias "GetAsyncKeyState" ( _
ByVal vKey As Keys) As Short
// C#
using System.Runtime.InteropServices;
// ...
[DllImport("user32")]
static extern short
GetAsyncKeyState(Keys vKey);
This method takes a 32-bit argument, but you can alias it to take a Keys value and save a conversion when you call it. Using the GetAsyncKeyState function is quite easy. For example, this code checks whether the end user is pressing the Ctrl-A key combination:
' VB.NET
If GetAsyncKeyState(Keys.A) < 0 And _
GetAsyncKeyState(Keys.ControlKey) _
< 0 Then
' Ctrl+A is being pressed
End If
// C#
if ( GetAsyncKeyState(Keys.A) < 0 &&
GetAsyncKeyState(Keys.ControlKey)
< 0 )
{
// Ctrl+A is being pressed
}
Running this code in the Tick event of a Timer control with a sufficiently low value for the Interval property (for example, 200 milliseconds) lets you trap all the hotkeys you're interested in. Unfortunately, the shorter the interval, the more overhead this technique adds to your application. Besides, documentation for GetAsyncKeyState states that this function can return 0 under Windows NT, 2000, and XP if the current desktop isn't the active desktop and if your application isn't the foreground program when desktop settings prevent background applications from learning what keys the end user is pressing.
Use the RegisterHotKey API function to avoid the overhead by registering one or more global hotkeys:
' VB.NET
Declare Function RegisterHotKey Lib _
"user32" (ByVal hwnd As IntPtr, _
ByVal id As Integer, _
ByVal fsModifiers As Integer, _
ByVal vk As Keys) As Integer
// C#
[DllImport("user32")]
static extern int RegisterHotKey(
IntPtr hwnd, int id,
int fsModifiers, Keys vk);
hwnd is the handle of the window that receives a WM_HOTKEY message when the end user presses the hotkey specified by the last two arguments. The id argument identifies the hotkey and should be different for each global hotkey registered in the system. Call the UnregisterHotKey API function to unregister the global hotkey when the application shuts down.
Register the hotkey when the main form in your application loads, trap the hotkey by subclassing the WM_HOTKEY message, and unregister the hotkey when the form closes (see Listing 2). Use the GlobalAddAtom API function to generate a unique id for each instance of the class, as Microsoft documentation recommends.
A minor limitation of the code in Listing 2 is that it works only when called from inside a form class. In some circumstances, you might need to trap global hotkeys from inside non-visual classes, such as components. For this purpose, I've created a GlobalHotKey standalone class that you can instantiate from outside a form. This class exposes the HotKeyPressed event, so you simply need to use a WithEvents variable or set up an event handler explicitly for this event:
' VB.NET
Dim hk As New GlobalHotKey(Keys.A, _
Keys.ControlKey)
AddHandler hk.HotKeyPressed, _
AddressOf HotKeyHandler
// C#
GlobalHotKey hk = new GlobalHotKey(
Keys.A, Keys.ControlKey);
hk.HotKeyPressed += new
EventHandler(HotKeyHandler);
You can download the complete VB.NET and C# code of this class from the .Net2TheMax Web site (see the sidebar, "Additional 2TheMax Downloads"). One final note: These routines call unmanaged code, so you can't use them from inside .NET applications that aren't fully trustedspecifically, smart client Windows Forms applications that you launch through HTTP. F.B.
Highlight the Active Textbox in Web Forms
When data-entry Web forms contain several textboxes, highlighting the textbox that has the input focus can improve the user's experience significantly. This technique is especially effective if your layout doesn't make the tab order sequence immediately clear. For example, users might be puzzled by multiple columns of textboxes and might wonder whether they're ordered horizontally or vertically. With a few lines of client-side JavaScript code, you can change the background and foreground colors of the active textbox easily, thus giving immediate feedback about the field that is receiving the user input.
DHTML makes it possible to change the HTML elements' style (font, colors, and position) by means of the control's style property and its subproperties. This HTML code renders a textbox control that handles the onfocus client-side event to change its background and foreground colors, and the onblur event to restore the original colors when the control loses the focus:
<input name="txtFirstName" type="text"
id="txtFirstName" onfocus=
"this.style.backgroundColor='Yellow';
this.style.color = 'Blue';"
onblur="this.style.backgroundColor=
'Window'; this.style.color='WindowText';"
/>
You can add highlighting support to all ASP.NET server-side controls dynamically, instead of hard-coding it manually. All controls that inherit from WebControl have an Attributes collection to which you can add one or more attributename=value pairs. These pairs are embedded at render time in the standard HTML code that the control generates. VB.NET and C# methods dynamically build a piece of JavaScript code that changes the background color and foreground color to the specified color values (see Listing 3). Using the SetInputControlColors method is trivial:
SetInputControlColors(txtFirstName, _
SystemColors.Window, _
SystemColors.WindowText, _
Color.Yellow, Color.Blue)
Instead of calling SetInputControlColors manually for all the input controls on the form, you can use the SetAllInputControlsColors method to change the onfocus/onblur styles for all the TextBox, ListBox, and DropDownList controls on the form (see Listing 3). This method is recursive and also affects the controls nested in control containers. All you need to do now is put this code in the handler of the Page.Load event:
' VB.NET
SetAllIputControlsColors(Me, _
SystemColors.Window, _
SystemColors.WindowText, _
Color.Yellow, Color.Blue)
// C#
SetAllIputControlsColors(this,
SystemColors.Window,
SystemColors.WindowText,
Color.Yellow, Color.Blue);
You can see the result in Internet Explorer (see Figure 1).
Using client-side JavaScript to change individual properties of each control isn't the only technique you can adopt to change the style of the active control. In fact, the approach just described works well only if the form contains a small number of fields. When the form has many controls, the amount of JavaScript generated for each control bloats the page's size and indirectly slows down its rendering. In such cases, you should define the normal and focus style by using a Cascading Style Sheet (CSS) class in a separate stylesheet file. You then write a shorter JavaScript code that sets the control's className property when the control gets or loses the focus. For instance, you might define this class in a CSS file:
.ActiveInputControl
{
background-color: Red;
color: Yellow;
font-weight: bold;
}
You can call the SetAllInputControlsClassName method defined as shown here (see Listing 4):
' VB.NET
SetAllInputControlsClassName(Me, "", _
"ActiveInputControl")
// C#
SetAllInputControlsClassName(this, "",
"ActiveInputControl");
The resulting HTML for a single control looks like this:
<input name="txtFirstName" type="text"
id="txtFirstName" onfocus=
"this.className = 'ActiveTextBox';"
onblur="this.className = '';"
/>
Notice that the control has no specific style class when it doesn't have the focus, so it uses the default style. Not only is this technique faster when a form contains many fields, but it's also more easily maintainable, because you can change the focus style later simply by providing a different CSS, without recompiling the ASP.NET application. M.B.
Printable Format
> More TechLibrary
I agree to this site's Privacy Policy.
> More Webcasts | https://visualstudiomagazine.com/articles/2004/11/01/parse-text-files-with-regular-expressions.aspx | CC-MAIN-2018-22 | refinedweb | 2,355 | 54.02 |
Hi everyone,
just trying to play a simple MP3 file using actionscript3; the fla, swf and mp3 files are all in the same folder. I've looked at three different textbooks; they all show pretty much the same thing and none of their code examples work?!!
I have moved the mp3 file into my library, named it Tune (this is my class); flash fills in the base class as flash.media.Sound. I go into the IDE by clicking on the first frame of level one and I type in the following:
import flash.media.Sound;
import flash.net.URLRequest;
var snd:Tune = new Tune();
var req:URLRequest = new URLRequest("carpenters_weveonlyjustbegun.mp3");
snd.load(req);
snd.play();
When I test the fla, I get the following error:
Error:#2037:functions called in incorrect sequence or earlier call was unsuccessful
if I right click the mp3 file in the library and bring up the properties panel, and select 'test',..it plays just fine!!
Would greatly appreciate any suggestions.
captsig
There are currently 1 users browsing this thread. (0 members and 1 guests)
Forum Rules | http://www.webdeveloper.com/forum/showthread.php?246103-RESOLVED-Playing-an-MP3-file-with-Actionscript&p=1154018&mode=threaded | CC-MAIN-2015-18 | refinedweb | 183 | 64.61 |
I'm creating a Galaga clone with pygame and I am having issues with using a value in one function that was modified in other function. I created a very simple version of the code to try to debug it but I have not had any luck.
import pygame
import time
pygame.init()
clock = pygame.time.Clock()
var1 = 10
def function3(var1):
var1 = var1 + 2
def function1():
gameExit = False
while not gameExit:
function3(var1)
print(var1)
clock.tick(5)
function1()
Here is "correct" way of doing what you want:
var1 = 10 def function3(): global var1 var1 = var1 + 2 print var1 function3() print var1
Your code is modifying local variable var1 which is only defined within your function3. I put word correct in quotes because global variable is (almost) never a good idea. If you need state (variable) shared between multiple functions, you could create a class. Or you could be modern functional and immutable and have the function take a value as argument, modify and return it. | https://codedump.io/share/bPPc8Yvmwmws/1/modifying-a-variable-in-python | CC-MAIN-2018-22 | refinedweb | 167 | 70.53 |
Hello,
I am working with Xamarin Forms and would like to use an image as the background for some pages. I have several Views and Layouts on different pages, and would like to overlay them onto a background image, selecting the image based on the page. I found how to use a solid color for the background, by setting the BackgroundColor on various components (like the primary StackLayout I have on a given page), but is it possible to use an image instead of a solid color? If so, could you include an example (short, quick, and dirty is perfectly fine). If not, does an alternative solution exist, perhaps using Renderers? I am targeting Android and iOS currently, if that helps at all.
Thank you.
You could use a Relative layout to achieve the results. Just make sure the image gets added first.
For example:
public static Page GetMainPage () { var myLabel = new Label () { Text = "Hello World", Font = Font.SystemFontOfSize (20), TextColor = Color.White, XAlign = TextAlignment.Center, YAlign = TextAlignment.Center }; var myImage = new Image () { Source = FileImageSource.FromUri ( new Uri("")) }; RelativeLayout layout = new RelativeLayout (); layout.Children.Add (myImage, Constraint.Constant (0), Constraint.Constant (0), Constraint.RelativeToParent ((parent) => { return parent.Width; }), Constraint.RelativeToParent ((parent) => { return parent.Height; })); layout.Children.Add (myLabel, Constraint.Constant (0), Constraint.Constant (0), Constraint.RelativeToParent ((parent) => { return parent.Width; }), Constraint.RelativeToParent ((parent) => { return parent.Height; })); return new ContentPage { Content = layout }; }
AbsoluteLayout works really well for this too! (as normal I just wrote the code here, it should work but let me know if you have an issue)
var myLayoutWithAllMyNormalStuff = <make it>; var backgroundImage = new Image { ... }; ContentPage page = new ContentPage { Content = new AbsoluteLayout { Children = { {backgroundImage, new Rectangle (0, 0, 1, 1), AbsoluteLayoutFlags.All}, {myLayoutWithAllMyNormalStuff, new Rectangle (0, 0, 1, 1), AbsoluteLayoutFlags.All} } } };
Answers
You could use a Relative layout to achieve the results. Just make sure the image gets added first.
For example:
Great solution. Thanks for your help!
AbsoluteLayout works really well for this too! (as normal I just wrote the code here, it should work but let me know if you have an issue)
Can CarouselPage be one of the children of Absolute Layout?
If no? what are the options for CarouselPage?
why don't you use "Page.BackgroundImage" property ?
Hi,
I am using PCL in my project to share the code in IOS, Android, WP 8 devices. I am trying to set the contentpage background image in my code. but the image is not displaying. Please check my sample code below.
I have set the image property Build Action=Embedded Resource
Please let me know what is the mistake in this code.
Thanks,Himasankar
On what device is it not showing?
Remove the namespace part (only use the filename) if the image is in Assets (Android) or iOS-project root (as bundleresource).
You also can use Device.OnPlatform() to distinguish different filenames for different platforms. E.g. if you have all your images for iOS in a "images" subfolder.
@HugoLogmans, I have created one sample application, I am trying to put background image it was giving me an error. When I try to put background color it is working fine.
Please let me know what is the problem in my sample application? I have uploaded my sample application in drop box. Please get this code from the following link.
Thanks, Himasankar
iOS works fine
Android: move the image to resources/drawable en set to AndroidResource. Rename it (both in code and filename) because dashes are not allowed in resource names. So also alter the iOS project to reflect the new image name.
Thanks Hugo Logmans.. It is working now, the problem is dashes in the file name. I removed the dashes in the file name it is working now.
But I am unable to see the background image for windows phone 8. Please let me know if there is any solution for that.
Thanks, Himasankar
Windows phone 8 also working... I set the image property build action to content.
Thanks,Himasankar
My background has a padding. Help me....
BackgroundImage = "login_background.png";
I find the solution just a moment after posting the question....
For those living in xaml-land:
Hello @Alec.Tucker,
Thanks for sharing the XAML solution.
It just works really cool. However I added the images with the right sizes for all iOS devices and I only get the size of the one that is called into the property, so the screen shows a cropped image, not taking the retina images for different devices like: iphone 4s, 5s, 6, 6plus.
Any idea how to make the Resources images from iOS on Visual Studio to use the @2x, etc automatically?
@VictorHGarcia and the @2x images are in the same folder as the normal images and have the same name but with the @2x added? That should work fine.
@MitchMilam yes the images are in the same path. However I'm using the latest Xamarin.Forms 1.3 Public release (Pre), I'm not sure if it is because I'm using that version.
Here a screenshot of my current iOS project structure.
I am having similar problems as @VictorHGarcia.
I have my background image file in 3 different sizes: background.png (320x480px), background@2x.png (640x960px) and background-568h@2x.png (640x1136px), all in the Resources Folder of my iOS project. I adopted the sizes from the splash screen images, which are used correctly.
I attached the background image to the BackgroundImage property in XAML, and it loads the normal background and the @2x background just fine. However, on the iPhone 6, it does not load the proper -568h@2x image.
Any suggestions on how to fix that welcome.
Hey guys!
So I'm studying Xamarin and trying to understand the BackgroundImage stuff...
I've made a launcher image and with the same size of this launcher image, I've created a bg image!
My problem is that the background image isn't fitting on the screen...
Here is a screenshot from the simulator:
Here is the screenshot from the background image:
@JasonASmith and @GlennStephens.8830 , sorry for pinging you guys but I'm facing the same problem as @VictorHGarcia
1) On an iPad it always picks the image asset for iPad Retina 2) It ALWAYS loads the portrait image despite me having specific image-Landscape~ipad and image-Portrait~ipad 3) On iPhone5, it picks up iPhone4 images despite of an image-568h@2x in the folder.
I have the same problems as @VictorHGarcia and those above. I have the photos named as background@2x.png and background-568h@2x.png, but the iPhone 5s emulator uses the the @2x picture not the -568h@2x and therefore the background is tiled not filled with the image.
Can a Label have a backgroundImage? I want to put the text inside a border that our designers have created!
there is no option to set the backgroundImage for entry in xaml file is there any way no need of progrmatically?
@GlennStephens.8830
Font = Font.SystemFontOfSize(20)
Warning 1 'Xamarin.Forms.Label.Font' is obsolete: 'Please use the Font attributes which are on the class itself. Obsoleted in v1.3.0
FontSize = 20
... but is it really the same? Looks like the same on our test-devices (Windows Phone 8.1, Android 4.4.2 ....)?
Is there one comprehensive guide somewhere? What image sizes do you typically need to make to support a good variety of mobile devices? Do you really need that many image versions or can you just scale (shrink) to fit?
Edit: Just found but it seems to assume you have done mobile development, just not on Xamarin.
Hi All,
using System;
using Xamarin.Forms;
namespace Test_App
{
}
This is my sample code how to set the background code here .....
For whoever stumps upon this and needs a solution, here it goes plain and simple:
the best/simplest way to do an overlay is with the Grid.
<Grid> <VisualElement /> <!-- Behind--> <VisualElement /> <!-- Front--> </Grid>
So in a page
Using a pages´
BackgroundImageisn´t flexible enough as it only allow file image paths. i.e
FileImageSource
This is a bit late but I've built a library that has versions of the layout elements that support background images. Specifically, you can have the images be region-scaled (ex: NinePatch images or setting CapsInsets), aspect-filled, aspect-scaled, filled, or tiled.
You can learn more about it here:
Any feedback you may have would be welcome.
Hi i have started working on xamarinforms last month and i am facing some UI issues.The background image property works fine for android but give null exception error for ios.i had tried all the possible ways mentioned in your blog but failed.Please help
@SaimShafqat Are you sure you placed the image at the right place for IOs?
yes in drawable/resources folder
Grid worked great for me! Thanks!
Thanks This works no problem. Easiest solution!
No need for any of these custom solutions any longer. You can now just assign the background image to the page in code: this.BackgroundImage = "myimage.png";
@gbrennon - did you resolve your background issue? I'm seeing the same behavior.
In this code example background image and form centered with xaml
Leonel Urra> @LeonelUrra said:
Thank you Leonel, this was realy helpfull!
My solution: | https://forums.xamarin.com/discussion/comment/127861/ | CC-MAIN-2018-13 | refinedweb | 1,547 | 68.16 |
Code. Collaborate. Organize.
No Limits. Try it Today.
Have you ever wanted to break up that monolithic web project into multiple projects, or reuse those user controls and web forms in multiple web projects?
Currently, reusing web forms and user controls in multiple ASP.NET projects requires copying the associated aspx and ascx pages. You can put web controls in separate assemblies, but you lose the design-time drag and drop that makes user controls and web forms so easy to create in the first place. If you've ever tried to put a user control or web form in a separate assembly, you probably ended up with a blank page or runtime errors. The reason is because LoadControl() actually reads the ascx or aspx file to populate the Controls collection and then binds them to your class variables. If the ascx file is not found, no controls are added unless you have done so in your code (as is done with WebControls).
LoadControl()
Controls
What I wanted was the ability to dynamically call LoadControl() from another assembly to reuse user controls in multiple web projects without copying a bunch of ascx files around. Too much to ask?
Would it be possible to embed those ascx and aspx files as assembly resources and then load them? LoadControl() expects a virtual path, and there did not appear to be any way to load a control from a resource stream. Then I found this:
The Virtual Path Provider in ASP.NET 2.0 can be used to load ascx files from a location of your choosing. For my purposes I've decided to store the ascx files in the assembly itself. No more outdated ascx pages that don't work with the updated assembly. Only one file to deploy, the assembly itself, and if you add the assembly as a reference, VS will copy it automatically! To do embed the ascx/aspx file into the assembly, you must change the Build Action of the file on the property page to Embedded Resource, the virtual path provider we create will do the rest.
When a Virtual Path needs to be resolved, ASP.NET will ask the most recently registered Virtual Path Provider if the file exists, and if it does, it will call GetFile to obtain the VirtualFile instance.
GetFile
VirtualFile
Before we can load a resource, we need to know what assembly the resource is located in and the name of the resource to load. I've chosen to encode this information into the virtual path. My final URL looks like this:
~/App_Resources/WebApplicationControls.dll/WebApplicationControls.WebUserControl1.ascx
It's a bit lengthy, but it includes all the information I need. I don't want to intercept all URLs, so we need to be able to identify which URLs to process and which ones to let the default virtual path provider handle. To do this, I've chosen to process only URLs located in App_Resources. This folder doesn't exist, and that's the point as all paths at this location will be intercepted. The second part contains the assembly name, and the final part is the resource name, which includes the namespace.
I've implemented the Virtual Provider as follows: is a private helper method used to determine if we should process the request or let the default provider process the request. Virtual Path Providers are chained together, so it is important that you call the base class. It was also necessary to override GetCacheDependency to return null, otherwise ASP.NET will try to monitor the file for changes and raise a FileNotFound exception. Notice that GetFile returns an instance of AssemblyResourceVirtualFile, this class provides an Open() method to get the resource stream, and is implemented as follows:)
Error 1 File 'App_Resource/WebApplicationControls.dll/WebApplicationControls.WebForm1.aspx' was not found. C:\Samples\Web\ASP.Net\WebApplicationTest\WebApplication1\Default.aspx 18 72 WebApplication1
General News Suggestion Question Bug Answer Joke Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages. | http://www.codeproject.com/Articles/15494/Load-WebForms-and-UserControls-from-Embedded-Resou?msg=3909345 | CC-MAIN-2014-23 | refinedweb | 680 | 53 |
The open source software revolution is not quite over yet, so as a result there still are a huge number of Windows desktop
and server systems in common use today. Even though many of us may think that the world will soon be using nothing but a Linux desktop, reality tells us something different: Windows desktops will be around for a long time. So the ability to exchange files
across Windows and Linux systems is rather important. The ability to share printers is equally important.
Samba is a very flexible and scalable application suite that allows a Linux user to read and write files located on Windows workstations, and vice versa. You might want to use it just to make files on your Linux system available to a single Windows client (such as when running Windows in a virtual machine environment on a Linux laptop). But you can use Samba to implement a reliable and high-performance file and print server for a network that has thousands of Windows clients. If you use Samba on a site-wide scale, you should probably spend serious time reading the extensive Samba documentation at, or a book such as Using Samba (O'Reilly), which is also part of the Samba distribution.
This section documents the key facets you need to know about file and print interoperability between Windows and Linux systems. First off, we supply an overview of how Windows networking operates, to help avoid some of the anguish and frustration that newcomers often feel during their first attempts to cross the great Windows and Unix divide. Next in line is an overview of the tools available in Linux-land that will help the Linux user to gain access to files and printers that live in Windows-land. The subject of providing Windows users access to files and printers that reside on a Linux system for is covered lastnot because it is less important, but because the scope of possibilities it offers is so much greater.
Linux users are generally aware that all they need for access to a remote Linux systems is its IP address. In essence, an IP address coupled with the Domain Name System (DNS) is the perfect vehicle for interoperating from any Linux system to a remote Linux system. We can therefore saywith perhaps a little poetic licensethat the Linux namespace
is the DNS. The namespace of the TCP/IP world places few restrictions on the maximum permissible length of a hostname or a name that may be placed in a DNS database. But human laziness usually limits the maximum number of characters one will tolerate in a hostname.
Life in Windows-land is not quite that easy, and there are good reasons for that too. The Windows networking world has a completely different namespace, one that originates from an attempt to solve a file sharing problem with no immediate plan to use TCP/IP
. TCP/IP was an afterthought. Windows did not at first have a TCP/IP protocol stack. Its native networking protocol was NetBEUI
, which stands for Network Basic Extended User Interface. For the technically minded, the name is a misnomer because the protocol actually consists of the Server Message Block (SMB) protocol via NetBIOS
encapsulated over Logical Link Control (LLC
) addressing. The resulting protocol is nonroutable and rather inefficient. The old protocol name, SMB, gave rise to the name Samba for the software project created by developer Andrew Tridgell when he decided to emulate the Windows file-sharing protocol.
Some time around 1996, the Server Message Block protocol was renamed the Common Internet File System (CIFS
)
protocol. The original CIFS protocol is basically SMB on steroids. The terms are used interchangeably in common use. The SMB/CIFS protocol supports particular features, such as:
File access
File and record locking
File caching, read-ahead, and write-behind
File change notification
Ability to negotiate the protocol version
Extended file and directory attributes
Distributed replicated virtual filesystems
Independent name resolution
Unicode file and directory names
The description of these features is beyond the scope of this book, but suffice it to say that when correctly configured, the protocols work well enough for large-scale business use.
NetBIOS is actually an application programming interface (API) that allows SMB/CIFS operations to be minimally encoded for transmission over a transport protocol of some type. NetBEUI, also known as the NetBIOS Frame (NBF
) protocol
, happens to use LLC addressing. It originated some time in the 1980s and was apparently first used by IBM as part of its PC-LAN product offering. The use of NetBIOS over TCP/IP was developed later and has been documented in various standards. NetBIOS can be encapsulated over many other protocols, the best known of which is IPX/SPXthe NetWare protocol.
NetBIOS (or, more correctly, SMB) has its own namespace. Unlike the native TCP/IP namespace, all NetBIOS names are precisely 16 characters in length. The - (dash) character may be used in the name, but it is ill-advised to use anything other than alphanumeric characters. Attempts to use a numeric character for the first digit will fail because this will cause systems that implement NetBIOS over TCP/IP to interpret the name as an IP address. The 16th character of a NetBIOS name is a name-type character, which is used by servers and clients to locate specific types of services, such as the network logon service.
The NetBIOS namespace also includes an entity known as a workgroup. Machines that have the same workgroup name are said to belong to the same workgroup. IBM LAN Server and Microsoft LAN Manager (as with Windows NT4) used the term domain to indicate that some form of magic authentication technology was being used, but at the lowest level a domain is identical with a workgroup name.
In network environments based on NetBIOS, it is extremely important to configure every machine to use the same networking protocols and to configure all the protocols identically. There can be no deviation from this; every attempt to do otherwise will result in networking failures.
The NetBIOS over TCP/IP protocol (NBT or NetBT) uses two main protocols and ports for basic operation: TCP port 139
(the NetBIOS Session Service port) and UDP port 137
(the NetBIOS Name Server port). UDP port 137 is used for broadcast-based name resolution using a method known as mail-slot broadcasting. This broadcast activity can be significant on a high-traffic network.
The best way to minimize background UDP broadcast activity is to use a NetBIOS Name Server. Microsoft called this kind of server WINS, for Windows Internet Naming Service. WINS is to NetBT as DNS is to TCP/IP. Clients register their NetBIOS names with the WINS server on startup. If all machines are configured to query the WINS server, Windows networking usually proceeds without too many problems. WINS provides a practical and efficient technique to help resolve a NetBIOS name to its IP address.
With the release of Windows 2000, Microsoft introduced a technology called Active Directory (AD) that uses DNS for resolution of machine names to their TCP/IP addresses. In network environments that use only Windows 2000 (or later) clients and servers, Microsoft provides, together with AD, the ability to disable the use of NetBIOS. In its place, the new networking technology uses raw SMB over TCP/IP. This is known as NetBIOS-less
TCP/IP. In the absence of UDP-based broadcast name resolution and WINS, both of which are part of the NetBT protocol suite, NetBIOS-less TCP/IP wholly depends on DNS for name resolution and on Kerberos security coupled with AD services. AD is a more-or-less compliant implementation of the Lightweight Diretory Access Protocol (LDAP) standard, which has an excellent free software implementation called OpenLDAP (mentioned in Chapter 8) and which therefore allows Linux to emulate the most important services offered by AD.
The use of Samba
without NetBIOS support effectively means it must be an AD domain member server. Do not disable NetBIOS support unless you configure AD.
Samba Version 2 is capable only of using NetBT
. Samba Version 3 is capable of seamless integration into a Windows AD NetBIOS-less network. When configured this way, it will use TCP port 445
, using the NetBIOS-less Windows networking protocol. Microsoft Windows networking will also use TCP port 135
, for DCE RPC
communications. A discussion of these protocols is beyond the scope of this book. The focus in this book is on use of Samba with NetBT.
Samba Version 3 was released in September 2003 after more than two years' development. It implemented more complete support for Windows 200x networking protocols, introduced support for Unicode, added support for multiple password back-ends (including LDAP), and can join a Windows 200x Active Directory domain using Kerberos security protocols. It remains under active development as the current stable release, with support intentions that will keep it current well into 2007. The Samba team hoped to issue Samba Version 4 beta release towards the end of 2005, after approximately three years' development. Samba Version 4 is a complete rewrite from the ground up. It has extensive support for Active Directory, with the intent of providing Active Directory domain control. It is anticipated that by mid-2006 Samba Version 4 will mature to the point that early adopters will begin to migrate to it.
Where possible, Samba should either be its own WINS
server or be used in conjunction with a Microsoft WINS server to facilitate NetBIOS name resolution. Remember that a price will be paid for not using WINS: increased UDP broadcast traffic and nonroutability of networking services.
We start this section with a simple scenario where you want to access files from a Windows server on your Linux system. This assumes that you have established a TCP/IP connection between your Linux and Windows computers, and that there is a directory on the Windows system that is being shared. Detailed instructions on how to configure networking and file sharing on Windows 95/98/Me and Windows NT/2000/XP can be found in Using Samba (O'Reilly).
To start with, both your Windows and your Linux systems should be correctly configured for TCP/IP interoperability. This means that:
Each system has a valid IP address.
The systems share a correct netmask.
The systems point to the same gateway (if one of your private networks has routers to multiple network segments).
Each system has a valid /etc/hosts
and a valid DNS configuration if DNS is in use.
The Windows machine and workgroup names should consist only of alphanumeric characters. If you choose to configure a /etc/hosts file on the Windows clients, this file must be called hosts, without a file extension. On Windows 95/98/Me systems the hosts file should be placed in C:\Windows\System. On Windows NT/2000/XP systems it is located in C:\Winnt\System32\drivers\etc\hosts.
The example hosts file on Windows NT/2000/XP systems has the file extension sam. Do not name the working file with this extension because it will not work.
In the rest of this chapter, we use the term SMB name to mean the NetBIOS name of the SMB-enabled machine (also known as the machine name). The term workgroup means both the workgroup name and the domain name of an SMB-enabled machine. Please note that for all practical network operations, such as browsing
domains and workgroups, and browsing machines for shares, the workgroup name and domain name are interchangeable; hence our use of the term workgroup.
The Windows machine for our examples is a Windows XP Home machine called EMACHO. The workgroup is called MIDEARTH, with IP address 192.168.1.250. Our Linux system has the hostname loudbell, with IP address 192.168.1.4; our domain is goodoil.biz.
The services discussed in this chapter require kernel modules and facilities that may not be available on your Linux system as initially installed. Many versions of commercial Linux
systems (Novell SUSE Linux
and Red Hat Linux
) are shipped with the necessary capabilities. If your Linux system is homegrown or one of the roll-your-own distributions, you may need to rebuild the kernel. The steps outlined here should help your preparations. Of course, a recent release of Samba Version 3.0.x will also be required.
First we need to consider the Linux kernel to ensure it is equipped with the tools needed.
The Linux kernel must have support for smbfs
and cifsfs
. If your Linux system has an older kernel (a version earlier than 2.6.x) the cifsfs facility may not be available. There is a back-port of the cifsfs kernel drivers that you may be able to install. For more information regarding cifsfs visit the CIFS project web site,. In the event that you need to install this module into your kernel source code tree, be sure to follow the instructions on that site.
The smbfs and cifsfs Linux kernel modules are not part of Samba. Each is a separate kernel driver project. Both projects depend on helper tools such as smbmount
, smbumount
, mount.smbfs
, and mount.cifs
, which are part of the Samba distribution tarball, and are required to enable its use.
The Linux kernel source file for Version 2.6.x includes the cifsfs module. To find out if your running kernel includes it, install the kernel sources under the directory /usr/src/linux. Now follow these steps:
Configure the kernel source code to match the capabilities of the currently executing kernel:
linux:~ # cd /usr/src/linux
linux:~ # make cloneconfig
As the cloning
of the kernel configuration finishes, the kernel configuration file will be printed to the console. Do not be concerned, because the contents are also stored in the .config file. We examine this file in the next step.
To determine the status of smbfs support in the kernel, enter:
linux:~ # grep CONFIG_SMB_FS .config
CONFIG_SMB_FS=m
The output tells us that smbfs support is enabled in the kernel and is available as a kernel loadable module. A value of y means it is built into the kernel, which is also acceptable, but a value of n means it is not supported.
In the event that smbfs is not supported, use the kernel configuration utility outlined in "Kernel configuration: make config" in Chapter 18 to enable it.
Now determine the status of cifsfs support in the kernel:
linux:~ # grep CONFIG_CIFS .config
CONFIG_CIFS=m
This response means that cifsfs support is available in the current kernel. If the value of this option is n, enable it using the kernel configuration utility.
If you had to enable support for one of the preceding options, rebuild the kernel and install it.
After rebooting the system, the new kernel will be ready for the steps that follow in this chapter. The next challenge is to ensure that a recent version of Samba is available.
Binary packages of Samba are included in almost any Linux or Unix distribution. There are also some packages available at the Samba home page,.
Refer to the manual for your operating system for details on installing packages for your specific operating system. In the increasingly rare event that it is necessary to compile Samba, please refer to the Samba3-HOWTO document, available at, for information that may ease the process of building and installing it appropriately.
If you decide to build and install Samba manually, be sure to remove all Samba packages that have been supplied by the vendor, or that may already have been installed. Failure to do this may cause old binary files to be executed, causing havoc, confusion, and much frustration.
Before building your own Samba binaries, make certain that the configure command is given the --with-smbmount option. The following commands complete the process of installation of the newly built Samba:
linux:~ # make all libsmbclient wins everything
linux:~ # make install
linux:~ # make install-man
When the Samba build and installation process has completed, execute the following commands to ensure that the mount.cifs binary file is built and installed:
linux:~ # export CFLAGS="-Wall -O -D_GNU_SOURCE -D_LARGEFILE64_SOURCE"
linux:~ # gcc client/mount.cifs.c -o client/mount.cifs
linux:~ # install -m755 -o root -g root client/mount.cifs /sbin/mount.cifs
The system is now ready for configuration, so let's get on with some serious exercises in sharing files with the other world.
Soon we will connect to a file share on a Windows system. We assume that the Windows system has a static IP address, and that we are not using DNS. Name resolution is rather important in networking operations, particularly with Windows clients, so let's configure the /etc/hosts file so that it has the following entry:
192.168.1.250 emacho
There should, of course, also be an entry for the IP address of the Linux system we are on.
Now check that the /etc/hosts entries are working:
linux:~ # ping emacho
PING emacho (192.168.1.250) 56(84) bytes of data.
64 bytes from emacho (192.168.1.250): icmp_seq=1 ttl=128 time=2.41 ms
64 bytes from emacho (192.168.1.250): icmp_seq=2 ttl=128 time=2.16 ms
64 bytes from emacho (192.168.1.250): icmp_seq=3 ttl=128 time=2.16 ms
64 bytes from emacho (192.168.1.250): icmp_seq=4 ttl=128 time=2.02 ms
64 bytes from emacho (192.168.1.250): icmp_seq=5 ttl=128 time=2.01 ms
64 bytes from emacho (192.168.1.250): icmp_seq=6 ttl=128 time=3.90 ms
--- emacho ping statistics ---
6 packets transmitted, 6 received, 0% packet loss, time 5004ms
rtt min/avg/max/mdev = 2.015/2.447/3.905/0.667 ms
OK, it works. Now we are really ready to begin file sharing.
It makes a lot of sense to first establish that our Linux system can communicate with the Windows system using Samba. The simplest way to do this is to use the Samba client tool, the smbclient command, to query the Windows machine so it will tell us what shares are available.
Let's perform an anonymous lookup of the Windows machine:
linux:~ # smbclient -L emacho -U%
Domain=[MIDEARTH] OS=[Windows 5.1] Server=[Windows 2000 LAN Manager]
Sharename Type Comment
--------- ---- -------
Error returning browse list: NT_STATUS_ACCESS_DENIED
Domain=[MIDEARTH] OS=[Windows 5.1] Server=[Windows 2000 LAN Manager]
Server Comment
--------- -------
Workgroup Master
--------- -------
This is not very encouraging, is it? The lookup failed, as is evidenced by the reply Error returning browse list: NT_STATUS_ACCESS_DENIED. This is caused by a Windows machine configuration that excludes anonymous lookups
. So let's repeat this lookup with a valid user account that has been created on the Windows XP Home machine.
An account we can use on our example system is for the user lct with the password 2bblue4u. Here we go:
linux:~ # smbclient -L emacho -Ulct%2bblue4u
Domain=[EMACHO] OS=[Windows 5.1] Server=[Windows 2000 LAN Manager]
Sharename Type Comment
--------- ---- -------
IPC$ IPC Remote IPC
SharedDocs Disk
print$ Disk Printer Drivers
Kyocera Printer Kyocera Mita FS-C5016N KX
Domain=[EMACHO] OS=[Windows 5.1] Server=[Windows 2000 LAN Manager]
Server Comment
--------- -------
Workgroup Master
--------- -------
Success! We now know that there is a share called SharedDocs on this machine. In the next step we will connect to that share to satisfy ourselves that we have a working Samba connection.
In this step we connect to the share itself, then obtain a files listing, and then download a file. This is an interesting example of the use of the smbclient utility:
linux:~ # smbclient //emacho/SharedDocs -Ulct%2bblue4u
Domain=[EMACHO] OS=[Windows 5.1] Server=[Windows 2000 LAN Manager]
smb: \>
Success again! This is good. Now for a directory listing:
smb:\ dir
. DR 0 Thu May 19 12:04:47 2005
.. DR 0 Thu May 19 12:04:47 2005
AOL Downloads D 0 Tue Sep 30 18:55:16 2003
CanoScanCSUv571a D 0 Thu May 19 12:06:01 2005
desktop.ini AHS 129 Sun Jul 4 22:12:14 2004
My Music DR 0 Sat Apr 16 22:42:48 2005
My Pictures DR 0 Tue Sep 30 18:36:17 2003
My Videos DR 0 Thu Aug 5 23:37:56 2004
38146 blocks of size 1048576. 31522 blocks available
smb: \>
We can change directory into the CanoScanCSUv571a directory:
smb: \> cd CanoScanCSUv571a
smb: \CanoScanCSUv571a\>
But we want to see what files are in there:
smb: \CanoScanCSUv571a\> dir
. D 0 Thu May 19 12:06:01 2005
.. D 0 Thu May 19 12:06:01 2005
CanoScanCSUv571a.exe A 3398144 Thu Mar 13 22:40:40 2003
Deldrv1205.exe A 77824 Fri Apr 26 14:51:02 2002
N122U.cat A 13644 Tue May 21 02:44:30 2002
N122u.inf A 6151 Tue Apr 16 22:07:00 2002
N122UNT.cat A 15311 Tue May 21 02:44:32 2002
N122USG D 0 Thu May 19 12:10:40 2005
USBSCAN.SYS A 8944 Fri Jun 12 13:01:02 1998
38146 blocks of size 1048576. 31522 blocks available
smb: \CanoScanCSUv571a\>
Good. Everything so far is working. Let's download a file. Fetching and uploading files with smbclient works just like an FTP client:
smb: \CanoScanCSUv571a\ >get Deldrv1205.exe
getting file \CanoScanCSUv571a\Deldrv1205.exe of size 77824
as Deldrv1205.exe (275.4 kb/s) (average 275.4 kb/s)
It all worked as it should. We are done with this demonstration. Let's quit back to a shell prompt:
smb: \CanoScanCSUv571a\> quit
linux:~ #
Let's summarize what has been learned so far. We have confirmed the following about our environment:
There is TCP/IP connectivity between the Linux and Windows systems.
Anonymous browsing is disabled on the Windows XP Home system.
Authenticated browsing using a local Windows account and password works.
smbclient was designed to be highly versatile. It is used as part of the smbprint
utility, where it pipes the print data stream through to a remote SMB/CIFS print queue in a manner analogous to the file transfer example witnessed earlier. For more information regarding the smbclient utility, refer to the manpage.
One you have basic SMB/CIFS interoperability, it should not be too difficult to mount the same share using smbfs. Let's move on and try that in the next section.
Before proceeding, let's look at what the smbfs filesystem driver does. This tool has some limitations that few people stop to recognize.
The smbfs filesystem driver behaves like the smbclient utility. It makes an authenticated connection to the target SMB/CIFS server using the credentials of a user, based on the account name and password provided. The filesystem driver then permits the SMB/CIFS connection to be attached to a Linux filesystem mount point. The Linux ownership of the mount point will reflect the user ID and group ID of the Linux user who mounts it, and the permissions will be determined by the UMASK
in effect at the time of mounting.
In effect, access to all files and directories will be subject to Linux filesystem permission controls, and on the SMB/CIFS server everything will take place as a single user. Multiple concurrent Linux users who access the file share through the mount point will be making multiple concurrent accesses as a single Windows user, and will do so using a single Windows process.
There is one other, rather significant design limitation when using the smbfs filesystem driver. It does not support Unicode
, and therefore creates problems when files contain characters other than the English alphabet. It should also be mentioned that this kernel module is somewhat defective and is no longer maintained. So why use it? That is easy to answer. Some Linux systems do not have support for cifsfs.
With these caveats stated and in the open, let's mount that SMB/CIFS filesystem:
linux:~ # mount -t smbfs //emacho/shareddocs /mnt \
-ousername=lct,password=2bblue4u,uid=jim,gid=users
linux:~ #
That was easy! It is time to test whether it works.
linux:~ # cd /
linux:~ # ls -ald /mnt
drwxr-xr-x 1 jim users 4096 May 20 02:50 mnt
This demonstrates that the connection is mounted as the local Unix user jim. Let's copy some files to, and from, this system:
linux:~ # cd /mnt
linux:~ # ls -al
total 25
drwxr-xr-x 1 lct users 4096 May 20 02:50 .
drwxr-xr-x 23 root root 560 May 18 15:21 ..
drwxr-xr-x 1 lct users 4096 Sep 30 2003 AOL Downloads
drwxr-xr-x 1 lct users 4096 May 19 12:06 CanoScanCSUv571a
dr-xr-xr-x 1 lct users 4096 Apr 16 22:42 My Music
dr-xr-xr-x 1 lct users 4096 Sep 30 2003 My Pictures
dr-xr-xr-x 1 lct users 4096 Aug 5 2004 My Videos
-rwxr-xr-x 1 lct users 129 Jul 4 2004 desktop.ini
linux:~ # cd CanoScanCSUv571a
linux:~ # ls -al
total 3451
drwxr-xr-x 1 lct users 4096 May 19 12:06 ./
drwxr-xr-x 1 lct users 4096 May 20 02:50 ../
-rwxr-xr-x 1 lct users 3398144 Mar 13 2003 CanoScanCSUv571a.exe*
-rwxr-xr-x 1 lct users 77824 Apr 26 2002 Deldrv1205.exe*
-rwxr-xr-x 1 lct users 13644 May 21 2002 N122U.cat*
-rwxr-xr-x 1 lct users 15311 May 21 2002 N122UNT.cat*
drwxr-xr-x 1 lct users 4096 May 19 12:10 N122USG/
-rwxr-xr-x 1 lct users 6151 Apr 16 2002 N122u.inf*
-rwxr-xr-x 1 lct users 8944 Jun 12 1998 USBSCAN.SYS*
linux:~ # cp USBSCAN.SYS /tmp
linux:~ # cp /var/log/messages .
linux:~ # ls -al messages
-rwxr-xr-x 1 lct users 240117 May 20 02:58 messages
This has been a satisfying outcome, because everything works. We were able to copy a file from the SMB/CIFS share. A file was also copied to the share from the Linux filesystem. It is possible to create, change, and delete files on an SMB/CIFS mounted filesystem. Permissions that determine the limits of these operations reflect the operations permitted by the SMB/CIFS server for the effective user at its end. Linux filesystem permissions control user access to the mounted resource.
Now let's dismount the filesystem in preparation for the use of the command-line version of the smbfs toolset:
linux:~ # cd /
linux:~ # df /mnt
Filesystem 1K-blocks Used Available Use% Mounted on
//emacho/shareddocs 39061504 6782976 32278528 18% /mnt
linux:~ # umount /mnt
The Samba source tarball includes a set of tools that are meant to be run from the command line. The smbmount program is run by the mount command when used with the -t smbfs option, the way we used it previously. The smbmount program calls smbmnt, which performs the actual mounting operation. While the shared directory is mounted, the smbmount process continues to run, and if you issue a ps ax listing, you will see one smbmount process for each mounted share.
The smbmount program reads the Samba smb.conf configuration file, although it doesn't need to gather much information from it. In fact, it is possible to get by without a configuration file, or with one that is empty! The important thing is to make sure the configuration file exists in the correct location, or you will get error messages.
You will learn more about creating and validation of the configuration file later in this chapter. Here is a minimal smb.conf file:
[global]
workgroup = NAME
Simply replace NAME with the name of your workgroup, as it is configured on the Windows systems on your network.
The last thing to do is to mount the shared directory. Using smbmount can be quite easy. The command syntax is
smbmount UNC_resource_name mount_point options
where mount_point specifies a directory just as in the mount command. UNC_resource_name follows the Windows Universal Naming Convention (UNC) format, except that it replaces the backslashes with slashes. For example, if you want to mount a SMB share from the computer called maya that is exported (made available) under the name mydocs onto the directory /windocs, you could use the following command:
linux:~ # smbmount //maya/mydocs/ /windocs
If a username or password is needed to access the share, smbmount will prompt you for them.
Now let's consider a more complex example of an smbmount command:
linux:~ # smbmount //maya/d /maya-d/ \
-o credentials=/etc/samba/pw,uid=jay,gid=jay,fmask=600,dmask=700
In this example, we are using the -o option to specify options for mounting the share. Reading from left to right through the option string, we first specify a credentials file, which contains the username and password needed to access the share. This avoids having to enter them at an interactive prompt each time. The format of the credentials file is very simple:
username=USERNAME
password=PASSWORD
where you must replace USERNAME and PASSWORD with the username and password needed for authentication with the Windows
workgroup server or domain. The uid and gid options specify the owner and group to apply to the files in the share, just as we did when mounting an MS-DOS partition in the previous section. The difference is that here we are allowed to use either the username and group name or the numeric user ID and group ID. The fmask and dmask options allow permission masks to be logically ANDed with whatever permissions are allowed by the system serving the share. For further explanation of these options and how to use them, see the smbmount(8) manual page.
One problem with smbmount is that when the attempt to mount a shared directory fails, it does not really tell you what went wrong. This is where smbclient comes in handyas we saw earlier. See the manual page for smbclient(1) for further details.
Once you have succeeded in mounting a shared directory using smbmount, you may want to add an entry in your /etc/fstab file to have the share mounted automatically during system boot. It is a simple matter to reuse the arguments from the smbmount command shown earlier to create an /etc/fstab entry such as the following (all on one line):
//maya/d /maya-d smbfs
credentials=/etc/samba/pw,uid=jay,gid=jay,fmask=600,dmask=700 0 0
Well, that was a lot of information to digest. Let's continue onto the next section, where we will work with the cifsfs
kernel driver that is replacing smbfs.
The cifsfs filesystem drive is a relatively recent replacement for the smbfs driver. Unlike its predecessor, cifsfs has support for Unicode characters in file and directory names. This new driver is fully maintained by an active development team.
If you have made sure that your kernel has support for the cifsfs module, as described previously in this chapter, try mounting a remote file share with a command like this:
linux:~ # mount -t cifs -ouser=lct,password=2bblue4u,uid=lct,gid=users \
//emacho/shareddocs /mnt
linux:~ # ls -ald /mnt
drwxrwxrwx 1 lct users 0 May 19 12:04 /mnt
If you compare the mount options with those used with the smbfs driver in the previous section, you'll see that the username parameter has changed to just user. The other parameters can be kept identical.
There is one apparent difference in a directory listing:
linux:~ # ls -al /mnt/CanoScanCSUv571a/
total 3684
drwxrwxrwx 1 lct users 0 May 20 02:58 .
drwxrwxrwx 1 lct users 0 May 19 12:04 ..
-rwxrwSrwt 1 lct users 3398144 Mar 13 2003 CanoScanCSUv571a.exe
-rwxrwSrwt 1 lct users 77824 Apr 26 2002 Deldrv1205.exe
-rwxrwSrwt 1 lct users 13644 May 21 2002 N122U.cat
-rwxrwSrwt 1 lct users 15311 May 21 2002 N122UNT.cat
drwxrwxrwx 1 lct users 0 May 19 12:10 N122USG
-rwxrwSrwt 1 lct users 6151 Apr 16 2002 N122u.inf
-rwxrwSrwt 1 lct users 8944 Jun 12 1998 USBSCAN.SYS
-rwxrwSrwt 1 lct users 240117 May 20 02:58 messages
Note that the directory node size is now reported as zero. Apart from this minor feature, the use of cifsfs to mount an SMB/CIFS resource cannot really be noticed, except when files that have multibyte (Unicode) characters in them are encountered.
The command used to mount the CIFS/SMB filesystem (mount -t cifs) actually causes the execution of the mount.cifs binary file. This file is built from the Samba sources, as we saw earlier in this chapter. There are no command-line tools, as there are with the smbfs kernel drivers and the smbmount group of tools provided by the Samba package.
Some network administrators insist that a password should never be passed to a Unix command on the command line because it poses a security risk. The good news is that mount.cifs permits an alternative to command-line options for obtaining the username and password credentials: it reads the environment variables USER, PASSWD, and PASSWD_FILE. In the variable USER, you can put the username of the person to be used when authenticating to the server. The variable can specify both the username and the password by using the format username%password. Alternatively, the variable PASSWD may contain the password. The variable PASSWD_FILE may, instead, contain the pathname of a file from which to read the password. mount.cifs reads a single line of input from the file and uses it as the password.
If you ever put a cleartext password in a file, be sure to set highly restrictive permissions on that file. It is preferrable that only the processes that must have access to such a file be able to read it.
The username and password can also be stored in a file. The name of this file can be used on the command line as part of the -o option as credentials=filename. Many of the options accepted by the mount -t cifs command are similar to those frequently used to mount an NFS filesystem. Refer to the mount.cifs manpage for specific details.
Office users who make heavy use of the Windows Explorer often feel lost when they first sit down at the Linux desktop. This is not surprising, because the look and feel is a little different. Tools are called by different names, but that does not mean that the capabilities are missing. In fact, thanks to the inclusion of the libsmbclient library in all distributions, the Linux desktop file managers (as well as web browsers) have been empowered to browse the Windows network.
Red Hat Linux and Novell SUSE Linux now both include a network browsing facility on the desktop. The environment makes it possible to browse the Windows network and NFS-mounted resources. The level of integration is excellent. Just click on the Windows network browsing icon, and libsmbclient will do all the hard work for you. Let's try this with both the KDE desktop and the GNOME desktop.
On Novell SUSE Linux Professional, the default KDE user desktop has an icon labeled Network Browsing. A single click opens the application called Konqueror, and very soon displays a separate icon for each networking technology type. The default icons are called FTP, SLP Services, SSH File Browsing, SSH Terminal, VNC Connection, Windows Network, and YOU Server, and there is an icon called Add a Network Folder. When the SMB Share icon is clicked, it reveals an icon for each workgroup and domain on the local network. To use our sample network as an illustration, clicking on the workgroup called MIDEARTH displays an icon for each server in that workgroup. An example of this screen is shown in Figure 15-1.
The default GNOME desktop has an icon called Network Browsing. A double-click opens the Network Browsing tool to reveal an icon called Windows Network. Click this to reveal an icon for each workgroup and domain that is visible on the network. An example is shown in Figure 15-2. Click on one of the SMB server icons to expose the shared resources that are available. Click on a shared folder to reveal the files within it. If access to any resource requires full user authentication, a login dialog will pop up. An example of the login dialog is shown in Figure 15-3.
KDE Konqueror neatly shows the URL in the Location bar. As you browse deeper in the Windows filesystem, the URL is updated to reveal the full effective URL that points to the current network location, for example, smb://alexm@MERLIN/archive/Music/Haydn/. The syntax for the URL is given in the libsmbclient manpage as:
smb://[[[domain:]user[:password@]]server[/share[/path[/file]]]][?options]
When libsmbclient is invoked by an application, it searches for a directory called .smb in the $HOME directory that is specified in the user's shell environment. It then searches for a file called smb.conf, which, if present, will fully override the system /etc/samba/smb.conf file. If instead libsmbclient finds a file called ~/.smb/smb. conf.append, it will read the system /etc/samba/smb.conf file and then append the contents of the ~/.smb/smb.conf.append file to it.
libsmbclient checks the user's shell environment for the USER parameter and uses its value when the user parameter is omitted from the URL.
The really nice feature of the libsmbclient library is that it authenticates access to the remote CIFS/SMB resource on a per-user basis. Each connection (SMB session) is independent, and access to folders and files is permitted just as if the user has logged onto a Windows
desktop to perform this access.
In the earlier years of Samba the sole mechanism for printing
from a Unix/Linux system to a printer attached to a Windows machine involved the use of smbclient via a sample interface script called smbprint. This script is still available in the Samba tarball from the directory examples/printing, and remains in use even though it has been superseded by the smbspool utility.
When smbprint usage was at its prime, the two dominant printing systems in the Unix/Linux world were BSD lpr/lpd and AT&T SYSV printing. There was a new tool called LPRng that was trying to edge into the market. The LPRng package was a free open source printing solution that sought to replace the older BSD lpr/lpd technology, which was generally considered buggy and in need of replacement. There are still many Unix and Linux systems that use BSD lpr/lpd or LPRng. LPRng has a strong following in some areas. Systems that use LPRng tend to still use smbprint as the interface script that makes it possible to send a print job from the Unix/Linux spool to a remote Windows printer.
Commencing around 2000/2001, a new technology started to gain popularity. This package was called CUPS (the Common Unix Print System). The growth of adoption of CUPS has been dramatic. Meanwhile, the development team behind CUPS has gradually expanded its functionality as well as its utility. They created a printing API and have worked with many open source projects to gain a high degree of integration into each software project that requires a printing interface. The CUPS team worked together with the Samba team and contributed a direct interface methodology so that Samba can communicate with CUPS without requiring external interface scripts and utilities. Samba can pipe a print job directly to the CUPS spool management daemon cupsd.
In addition to the improved interface between Samba and CUPS, CUPS is a whole lot smarter than older print systems when sending print jobs to a network-attached Windows printer. Samba has gained a new printing utility (smbspool) that handles all printer interfacing between CUPS and a Windows print server.
Given that CUPS is now the dominant printing technology in Linux, it is best left to the configuration tools provided with either CUPS itself or with the Linux distribution to handle Linux-to-Windows printing. On the other hand, there will always be a situation that is not satisfied by this approach. When it is necessary to send a print job to a Windows printer, it is handy to have knowledge of a suitable tool. The tool of choice in this situation is smbspool.
In brief, here are the varieties of command syntax recognized by the smbspool utility:
smb://server[:port]/printer
smb://workgroup/server[:port]/printer
smb://username:password@server[:port]/printer
smb://username:password@workgroup/server[:port]/printer
One of these modes of use will meet all known needs. Each is followed by arguments:
This contains the job ID number, and is not presently used by smbspool.
This contains the print user's name, and is not presently used by smbspool.
This contains the job title string, and is passed as the remote file name when sending the print job.
This contains the number of copies to be printed. If no filename is provided (argument 6), this argument is not used by smbspool.
This contains the print options in a single string, and is currently not used by smbspool.
This contains the name of the file to print. If the argument is not specified, the material to print is read from the standard input.
Each parameter should be in the order listed.
The previous section outlined the use of tools that make it possible for a Linux desktop user to access files
located on Windows workstations and servers using native Windows networking protocols. These tools can also be used in the other direction: to access files that are on a Unix/Linux server.
In this section we explore the use of Samba to provide files that are stored on Linux to Windows clients.
The CIFS/SMB protocol is more complex than some other file-sharing protocols such as NFS. Samba has to be not only protocol-compatible with Microsoft Windows clients, but also compatible with the bugs that are present in each client. In this section, we show you a simple Samba setup, using as many of the default settings as we can.
Setting up Samba involves the following steps:
Compiling and installing Samba, if it is not already present on your system.
Writing the Samba configuration file smb.conf and validating it for correctness.
Starting the two Samba daemons smbd and nmbd.
When correctly configured, a Samba server and the directories shared will appear in the browse lists of the Windows clients on the local networknormally accessed by clicking on the Network Neighborhood or My Network Places icon on the Windows desktop. The users on the Windows client systems will be able to read and write files according to your security settings just as they do on their local systems or a Windows server. The Samba server will appear to them as another Windows system on the network, and act almost identically.
Correctly compiling Samba can be a challenge, even for an experienced developer, so it makes sense to use prebuilt binary packages where they are available. For most administrators the choice is among the following options:
Install from trusted RPM or .deb pacakges.
Install from contributed RPM or .deb packages.
Compile and install from the official source tarball.
Hire someone else to compile and install from the source tarball.
Most Linux distributions include Samba, allowing you to install it simply by choosing an option when installing Linux. If Samba wasn't installed along with the operating system, it's usually a fairly simple matter to install the package later. Either way, the files in the Samba package will usually be installed as follows:
Daemons in /usr/sbin
Command-line utilities in /usr/bin
Configuration files in /etc/samba
Logfiles in /var/log/samba
Runtime control files in /var/lib/samba
There are some variations on this. For example, in older releases, you may find logfiles in /var/log, and the Samba configuration file in /etc.
If your distribution does not include Samba, you can download the source code, and compile and install it yourself. In this case, all of the files that are part of Samba are installed into subdirectories of /usr/local/samba.
Either way, you can take a quick look in the directories just mentioned to see whether Samba already exists on your system, and if so, how it was installed.
If you are not the only system administrator of your Linux system, be careful. Another administrator might have used a source code release to upgrade an earlier version that was installed from a binary package, or vice versa. In this case, you will find files in both locations, and it may take you a while to determine which installation is active.
If you need to install Samba, you can either use one of the packages created for your distribution, or install from source. Installing a binary release may be convenient, but Samba binary packages available from Linux distributors are usually significantly behind the most recent developments. Even if your Linux system already has Samba installed and running, you might want to upgrade to the latest stable source code release.
Obtaining fresh source files. You can obtain the Samba source files from the Samba web site. To obtain a development version, you can download Samba from Subversion
or using rsync.
Samba is developed in an open environment. Developers use Subversion to check in (also known as commit) new source code. Samba's various Subversion branches can be accessed via anonymous Subversion using SVNweb or using the Subversion client.
To use SVNweb, access the URL.
Subversion gives you much more control over what you can do with the repository and allows you to check out whole source trees and keep them up-to-date via normal Subversion commands. This is the preferred method of access by Samba developers.
In order to download the Samba sources with Subversion, you need a Subversion client. Your distribution might include one, or you can download the sources from.
To gain access via anonymous Subversion, use the following steps.
Install a recent copy of Subversion. All you really need is a copy of the Subversion client binary.
Run the command:
linux:~ # svn co svn://svnanon.samba.org/samba/trunk samba.
This will create a directory called samba containing the latest Samba source code (usually the branch that is going to be the next major release). At the time of writing, this corresponded to the 3.1 development tree.
Other Subversion branches besides the trunk can be obtained by adding branches/BRANCH_NAME to the URL you check out. A list of branch names can be found on the Development page of the Samba
web site. A common request is to obtain the latest 3.0 release code, which can be done using the following command:
linux:~ # svn co svn://svnanon.samba.org/samba/branches/SAMBA_3_0_RELEASE samba_3
Whenever you want to merge in the latest code changes, use the following command from within the Samba directory:
linux:~ # svn update
Building Samba from source. To install from source, go to the Samba web site at and click on one of the links for a download site near you. This will take you to one of the mirror sites for FTP downloads. The most recent stable source release is contained in the file samba-latest.tar.gz. This file will give you detailed instructions on how to compile and install Samba. Briefly, you will use the following commands:
linux:~ # tar xzvf samba-latest.tar.gz
linux:~ # cd samba- VERSION
linux:~ # su
linux:~ # ./configure
linux:~ # make
linux:~ # make install
Make sure to become superuser before running the configure script. Samba is a bit more demanding in this regard than most other open source packages you may have installed. After running the commands just shown, you will be able to find Samba files in the following locations:
Executables in /usr/local/samba/bin
Configuration file in /usr/local/samba/lib
Logfiles in /usr/local/samba/log
smbpasswd file in /usr/local/samba/private
Manual pages in /usr/local/samba/man
You will need to add the /usr/local/samba/bin directory to your PATH environment variable to be able to run the Samba utility commands without providing a full path. Also, you will need to add the following two lines to your /etc/man.config file to get the man command to find the Samba manpages:
MANPATH /usr/local/samba/man
MANPATH_MAP /usr/local/samba/bin /usr/local/samba/man
The next step is to create a Samba configuration file for your system. Many of the programs in the Samba distribution read the configuration file, and although some of them can get by with a file containing minimal information (even with an empty file), the daemons used for file sharing require that the configuration file be specified in full.
The name and location of the Samba configuration file depend on how Samba was compiled and installed. An easy way to find it is to use the testparm command, shown later in this section. Usually, the file is called smb.conf, and we'll use that name for it from now on.
The format of the smb.conf file is like that of the .ini files used by Windows 3.x: there are entries of the type:
key = value
When working with Samba, you will almost always see the keys referred to as parameters or options. They are combined in sections (also called stanzas) introduced by labels in square brackets. The stanza name goes by itself on a line, like this:
[stanza-name]
Each directory or printer you share is called | http://etutorials.org/Linux+systems/running+linux/Part+II+System+Administration/Chapter+15.+File+Sharing/Section+15.1.+Sharing+Files+with+Windows+Systems+Samba/ | CC-MAIN-2018-09 | refinedweb | 8,270 | 62.78 |
stats arcade 14-in-1 game table, free arcade games download fruit machine, arcade trainer worlds hardest game, arcade games buy arcade machines, arcade games for sale denver.
real arcade unlimited time trial games, haunted house cherry master arcade game, xbox 360 arcade games on disc, tetris arcade games, game dollar arcade.
mikes arcade games, for arcade town games, best selling xbox arcade games, stear crazy arcade game, 2 arcade game for sale.
free arcade games com, spyhunter arcade vidio game, arcade game songs, arcade video game tarp, used arcade games chicago, xbox 360 arcade original xbox games.
pld arcade games, arcade trainer worlds hardest game, xbox 360 arcade games cost, arcade game repair manuals, arcade style fighting games.
import arcade games, new arcade bulldozer game, resturaunt games arcade, the 80s arcade games, online fighting arcade games.
shooter arcade flash game, arcade game image rom, online games action arcade games, drifting arcade games, how to cheat arcade games.
arcade games dig dug, cannon arcade game, red max arcade game, popular video arcade games, bow man2 arcade game.
picture find arcade game, play stacker arcade game, baseball arcade games, cool arcade games for free, arcade games gate.
road arcade game for sale, dreamcast arcade games, arcade games net roids, tron arcade game ebay, about arcade games.
online games arcade temple, torrent arcade games, all reflexive arcade games, stats arcade 14-in-1 game table, extreme hunting arcade game cheat.
can you play all games on xbox 360 arcade, bush flashgames free arcade games collection, used arcade game gravity hill, trackand field games arcade games, free arcade games com.
Categories
- Iphone arcade games
- x men arcade game buy
smartphone arcade games
arcade games dallas fort worth
coin mechanism for 1956 arcade game
drifting arcade games
arcade video game tarp
classic arcade games all in one
space panic arcade game
arcade game t shirts
strip arcade games on line
can you play all games on xbox 360 arcade
1985 arcade games
free arcade games online color sudoku
xbox 360 arcade games cost
ninja kiwi games arcade power pool
- used arcade games naperville
- arcade game cabinets for sale
- arcade games arena
- arcade games 2010 jelsoft enterprises ltd
- flah arcade games
- play fun arcade games
- racer arcade games
- bulldozer arcade game
- xbox 360 arcade games
- top 20 arcade games | http://manashitrad.ame-zaiku.com/time-crises-the-arcade-game.html | CC-MAIN-2019-04 | refinedweb | 384 | 58.76 |
Count the Triplets
Introduction to the problem statement
We are given an array arr[] containing n integers. Our task is to find the number of triples (i, j, k), where i, j, k are the indices and (1 <= i < j < k <= n), such that at least one of the numbers can be written as the sum of the other two in the set (A i, A j, A k).
Examples:
Input : arr[] = {2, 1, 4, 5, 3}
Output : 4
Explanation: The valid triplets are: (2, 1, 3), (1, 4, 3), (1, 4, 5), (2, 5, 3).
Input : arr[] = {1, 1, 3, 3, 1, 2, 2}
Output : 18
The above problem statement means we have to find three elements from the given array so that the sum of two elements is equal to the third element.
Approach
To solve the above problem, we will first perform two basic steps:
- Find the maximum value from the given array.
- Create a frequency table, which stores the frequency of every element in the given array.
Finding maximum value:
Here, we use the in-built max function for finding the maximum value from the given array. We store it in the maxm variable.
for(int i = 0 ; i < n; i++) // n is the size of the array { maxm = max( arr[i], maxm ); }
Creating frequency table:
Int freq[maxm+1]={0}; // initially frequencies of all elements is 0 for(int i = 0 ; i < n ; i++) // n refers number of array elements { freq[arr[i]]++; }
For example:
arr[] : { 2, 3, 1, 3, 4, 5 }
Frequency table stores:
After the above steps, we initialise a variable ans=0 which stores the number of triplets satisfying the required conditions.
Now, there are four cases, and according to this, the number of ways is stored in ans variable.
Case 1: ( 0, 0, 0)
Suppose all the three numbers are (0, 0, 0). In that case, it can satisfy the triplet condition as 0+0=0, so we have to add all the combinations containing the frequency of 0 to our ans variable, which mathematically equals f(0)C3, here f(x) represents the frequency of the element x in our array and p Cq represents the number of ways of choosing q numbers from p numbers.
f(0)C3 = [f(0)!] / [(f(0)-3)! — 3!] = (freq[0] )* (freq[0]-1 )* (freq[0]-2) / 6
Now, add this to our ans variable:
ans = ans + (freq[0] )* (freq[0]-1 )* (freq[0]-2) / 6
Case 2: (0, x, x)
If the three numbers are (0, x,x), it satisfies the triplet condition as 0 + x = x.
Now, we need to count the total number of combinations that contain one 0 and two x, which mathematically equal f(x)C2 * f(0)C1. For calculating this, we use a loop for each value of x.
for(int i = 1;i< = maxm; i++) { ans = ans + freq[0]*freq[i]*(freq[i]-1)/2; }
Case 3: (x , x , 2x)
If the three numbers are (x, x, 2x), it satisfies the triplet condition as x+x = 2x.
Now, we need to count the total number of combinations that contain one 2x and two x, which mathematically equal f(x)C2 * f(2x)C1. For calculating this, we use a loop for each value of x.
for(int i = 1; 2*i <= maxm; i++) // 2 times i should also lie within maximum value { ans = ans + freq[i]*(freq[i]-1)/2*freq[2*i]; }
Case 4: (x, y, x+y)
If the three numbers are (x, y, x+y), it satisfies the triplet condition as x + y = (x+y).
Now, we need to count the total number of combinations that contain one x, one y and onex+y, which mathematically equal f(x)C1 * f(y)C1*f(x+y)C1. For calculating this, we use a loop for each value of x and y.
for(int i = 1; i <= maxm; i++) { for(int j = i+1;j+i <= maxm; j++) { ans = ans + freq[i]*freq[j]*freq[i+j]; } }
After considering all the cases, we finally return ans.
Code in C++
#include<bits/stdc++.h> using namespace std; int CountTriplets(vector<int> v) { int maxm = 0; for (int i = 0; i < v.size(); i++) maxm = max(maxm, v[i]); int freq[maxm + 1] = {0}; for (int i = 0; i < v.size(); i++) freq[v[i]]++; int ans = 0; // counts the number of triplets // Case 1: (0, 0, 0) ans = ans + freq[0] * (freq[0] - 1) * (freq[0] - 2) / 6; // Case 2: (0, x, x) for (int i = 1; i <= maxm; i++) ans = ans + freq[0] * freq[i] * (freq[i] - 1) / 2; // Case 3: (x, x, 2*x) for (int i = 1; 2 * i <= maxm; i++) ans = ans + freq[i] * (freq[i] - 1) / 2 * freq[2 * i]; // Case 4: (x, y, x + y) for (int i = 1; i <= maxm; i++) { for (int j = i + 1; i + j <= maxm; j++) ans = ans + freq[i] * freq[j] * freq[i + j]; } return ans; } int main() { vector<int> v = {1, 1, 3, 3, 1, 2, 2}; cout << (CountTriplets(v)); return 0; }
Output
18
Complexity Analysis
Time Complexity: It is O(max(n, maxm 2)) as we are running two nested loops of size maxm and a single loop of size n.
Space complexity: It is O(1) as we require constant extra space.
Frequently asked questions
Q1.What is C++ Hashmap?
Ans: A hash table (also known as a hash map) is a data structure that maps keys to values. A hash table employs a hash function to generate an index into an array of buckets or slots from which the corresponding value can be retrieved.
Q2. What is meant by dynamic programming?
Ans: Dynamic Programming (DP) is an algorithmic technique for solving a problem by recursively breaking it down into simpler subproblems and taking advantage of the fact that the optimal solution to the overall problem depends on the optimal solution to its subproblems.
Q3. What is a string?
Ans: A string is a variable that stores a series of letters or other characters, such as "Namaste" or "Incredible India". To create a string, we do the same thing with different data types: we declare it first, then we can store a value in it.
Key Takeaways
So, this article discussed the approach of counting the triplets problem in which we see all the four cases and their solution with C++ code.
If you are a beginner, interested in coding and want to learn DSA, you can look for our guided path for DSA, which is free!
In case of any comments or suggestions, feel free to post them in the comments section. | https://www.codingninjas.com/codestudio/library/count-the-triplets | CC-MAIN-2022-27 | refinedweb | 1,113 | 62.41 |
Hello! I've been messing with tkinter and now have tried to make a MPG calculator using sliders.
My problem is that no matter how I move the sliders it does not update the mpg, I'm not sure what to tell the label to do for it to update.
I know the calculations themselves work because I made it print to the console as a test and it updated there.
import tkinter as tk root = tk.Tk() root.title('MPG calculator') root.geometry("620x200+300+300") scale = tk.Scale(root, label="Select a distance traveled.", from_=1, to=1500, tickinterval=0, resolution=1, length=600, showvalue='yes', orient='horizontal') scale.set(500) scale2 = tk.Scale(root, label="Select how large your fuel tank is.", from_=1, to=80, tickinterval=0, resolution=1, length=600, showvalue='yes', orient='horizontal') scale.set(12) dist = scale.get() tank = scale2.get() f = dist / tank result = 'You get %s miles per gallon.' % (f) label = tk.Label(root, text= result, bg='green') scale.grid(row=2, columnspan=2) scale2.grid(row=1, columnspan=2) label.grid(row=4, columnspan=4, pady=5) root.mainloop()
Thanks!
edit:
The attached file shows my problem. It shows 12 mpg no matter what. | https://www.daniweb.com/programming/software-development/threads/229374/constant-updates | CC-MAIN-2017-09 | refinedweb | 204 | 64.17 |
Hi,
Im doing search.replace method.
I have org. template with for ex: \r.
Now when i have empty content for i want to remove the hole line.
I have tried replace on “\r”, “”, that does not work.
I have tried node.remove(), but cant use cause the node does not have parrent.
How do i remove that perticcular paragraph with just a line break?
Regards,
Karan
Hi,
Hi
<?xml:namespace prefix = o
Thanks for your request. Why don’t you use Mail Merge to fill your document with data? In case of using Mail Merge, you can use RemoveEmptyParagraphs option and empty paragraphs will be automatically removed.
Also, I think, Mail Merge is the better approach than “find & replace”. Please see the following link to learn more about Mail Merge:
Best regards. | https://forum.aspose.com/t/how-to-remove-paragraph-containing-r/84108 | CC-MAIN-2021-10 | refinedweb | 133 | 87.52 |
MultiStepLR is a scheduler that decays the learning rate with a certain multiplicative factor set by the user when a certain milestone is reached. The milestone is the number of epochs which is set by the user.
They are a pair of values that sets the number of epochs after which the learning rate is scaled.
It is the multiplicative factor by which the learning rate is scaled.
Let us demonstrate the functioning of the MultiStepLR with a simple calculation.
If Milestones are set to be 30 and 80 base learning rate being 0.05, and gamma 0.1, then
for, €€0<=epoch<30€€ , €€lr=0.05€€
for, €€30<=epoch<80€€ , €€lr=0.05*0.1=0.005€€
for , €€epoch>=80€€ , €€lr=0.05*0.1^2=0.0005€€
import torch model = [Parameter(torch.randn(2, 2, requires_grad=True))] optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=0.01, amsgrad=False) scheduler=torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30,80],. | https://hasty.ai/docs/mp-wiki/scheduler/multisteplr | CC-MAIN-2022-40 | refinedweb | 161 | 54.29 |
IRC log of htmltf on 2006-03-20
Timestamps are in UTC.
13:56:29 [RRSAgent]
RRSAgent has joined #htmltf
13:56:29 [RRSAgent]
logging to
13:56:36 [RalphS]
Meeting: SWBPD RDF-in-XHTML TF
13:56:42 [RalphS]
Agenda:
13:57:17 [RalphS]
Previous: 2006-03-13
14:00:48 [Zakim]
SW_BPD(rdfxhtml)9:00AM has now started
14:00:50 [Zakim]
+Ralph
14:03:03 [Steven]
Steven has joined #htmltf
14:03:16 [Steven]
Hi
14:03:22 [Steven]
zakim, who is here?
14:03:22 [Zakim]
On the phone I see Ralph
14:03:23 [Zakim]
On IRC I see Steven, RRSAgent, Zakim, RalphS
14:03:33 [Steven]
zakim, dial steven-617
14:03:33 [Zakim]
ok, Steven; the call is being made
14:03:34 [Zakim]
+Steven
14:05:35 [Zakim]
+Ben_Adida
14:05:36 [benadida]
benadida has joined #htmltf
14:05:36 [Zakim]
-Ben_Adida
14:05:37 [Zakim]
+Ben_Adida
14:05:48 [Zakim]
+??P11
14:06:08 [MarkB_]
MarkB_ has joined #htmltf
14:06:26 [RalphS]
zakim, ??p11 is Mark
14:06:26 [Zakim]
+Mark; got it
14:08:55 [benadida]
action items:
14:09:03 [RalphS]
Topic: Action Review
14:09:15 [RalphS]
action -1
14:09:32 [RalphS]
[DONE] ACTION: Ben draft WWW2006 proposal for talk describing RDF/A language [recorded in
]
14:09:53 [RalphS]
ACTION: Ben to develop a plan for a marketing/news web site about RDF/A and send it to the list [recorded in
]
14:09:55 [RalphS]
-- continues
14:10:21 [RalphS]
ACTION: Ben update his bookmarklet for XHTML mode [recorded in
]
14:10:22 [RalphS]
-- continues
14:10:52 [RalphS]
[Ben finally got me to look at his RDF/A bookmarklet last week and I was very impressed]
14:12:05 [RalphS]
Steven: IE looks at the last characters after the last '.' in the URL, plus the Mime type
14:12:13 [RalphS]
... so you can fool it with '?.html'
14:12:58 [RalphS]
Ben: I'll take a look at issues in bookmarklet with local file extensions
14:13:24 [RalphS]
... bookmarklet does point out what's unique in combining metadata with html
14:13:27 [benadida]
14:13:44 [RalphS]
^ -> talk and RDF/A bookmarklet
14:13:56 [RalphS]
[DONE] ACTION: Mark draft WWW2006 proposal for RDF/A demos talk [recorded in
]
14:15:18 [RalphS]
ACTION: Mark, Steven, and Ralph respond to Ben's off-list draft of response to Bjoern [recorded in
]
14:15:21 [RalphS]
-- continues
14:15:49 [RalphS]
ACTION: Ben start separate mail threads on remaining discussion topics [recorded in
]
14:15:52 [RalphS]
-- continues
14:16:06 [RalphS]
ACTION: Ben talk off-line with Jeremy about a realistic implementation schedule [recorded in
]
14:16:07 [RalphS]
-- continues
14:16:15 [RalphS]
ACTION: Ben to draft full response to Bjoern's 2004 email [recorded in
]
14:16:17 [RalphS]
-- continues
14:16:35 [RalphS]
[PENDING] ACTION: Jeremy followup on HEAD about= edge case [recorded in
]
14:16:40 [RalphS]
[PENDING] ACTION: Jeremy followup with Mark on the question of multiple triples from nested meta and add to issues list [recorded in
]
14:16:46 [RalphS]
[PENDING] ACTION: Jeremy look into the XHTML namespace issue and write thoughts into email [recorded in
14:16:52 [RalphS]
[PENDING] ACTION: Jeremy propose wording on reification [recorded in
]
14:17:21 [RalphS]
Action: Ben review Jeremy's actions
14:19:12 [RalphS]
ACTION: Mark work on a first draft of an RDF/A XHTML 1.1 module [recorded in
]
14:19:34 [RalphS]
-- continues
14:19:57 [RalphS]
Mark: we're planning a release soon of software that makes use of this, so hope to get it done by the end of the week
14:20:05 [RalphS]
ACTION: once Steven sends editors' draft of XHTML2, all TF members take a look and comment on showstopper issues only [recorded in
]
14:20:07 [RalphS]
-- continues
14:20:19 [RalphS]
[WITHDRAWN] ACTION: Steven draft a WWW2006 Developer's Track proposal [recorded in
]
14:21:07 [RalphS]
Topic: XHTML 1.1 Modularization for RDF/A
14:21:21 [RalphS]
Ben: any preliminary thoughts on how much of RDF/A can fit in XHTML 1.1?
14:21:26 [RalphS]
Mark: most of it, I think
14:21:32 [RalphS]
... CURIEs will be tricky
14:21:41 [RalphS]
... we're only talking about schemas to validate, which is easy
14:21:53 [RalphS]
... the next step, processing, is where the work lies
14:22:13 [RalphS]
... Ben's bookmarklet shows what's possible, though CURIEs will be trickier to process
14:22:27 [RalphS]
... hard in XSLT1 but it's doable in javascript
14:22:37 [RalphS]
... should we constrain ourselves to what browsers can easily implement?
14:23:04 [RalphS]
... QNAMEs are hard to deal with in XSLT1
14:23:51 [RalphS]
... a long time ago I felt QNAMEs could be split apart in XLST1, possibly requiring a function definition
14:24:13 [RalphS]
... but validation should not be hard
14:24:31 [RalphS]
... we do need to decide whether we want to produce a subset of what can be implemented
14:24:41 [RalphS]
... looking at Ben's bookmarklet and our sidebar ...
14:24:55 [RalphS]
... go with what we think we can implement
14:26:05 [RalphS]
Ralph: is it a problem that we want to allow href's everywhere?
14:26:15 [RalphS]
Steven: the problem is not with XHTML 1.1 but with modularization
14:26:22 [RalphS]
... there are already modules with href
14:26:41 [RalphS]
... if we allow html:href everywhere then some modules end up with two hrefs, which is not allowed
14:26:59 [RalphS]
... so we have to redo some of the existing modules to remove href from them
14:27:16 [RalphS]
Mark: if we allow href everywhere in current browsers it won't neessarily result in a navigable link
14:27:28 [RalphS]
... should we be encouraging this if we know it's not implementable?
14:27:45 [RalphS]
Ben: suppose we don't add href everywhere but just permit it on META and LINK in the body?
14:27:52 [RalphS]
... XHTML 2 would permit href everywhere
14:28:00 [RalphS]
Mark: yes, that's what I've been thinking
14:28:25 [RalphS]
... allow META and LINK everywhere, add 'property', add 'about', add 'datatype'
14:28:34 [RalphS]
... this gives a lot of RDF/A
14:28:51 [RalphS]
... allows complex things like RSS feeds but requires META everywhere
14:29:09 [RalphS]
... or use 'property' but with href only where it is currently allowed
14:29:20 [RalphS]
Steven: could permit href in more places, just wouldn't be clickable
14:29:33 [RalphS]
Ben: we don't need for the RDF/A module to fix all XHTML 1.1 issues
14:29:46 [RalphS]
... places that are not clickable just couldn't be used
14:30:12 [RalphS]
Mark: permitting META and LINK everywhere is not an enormous link, since 'rel' and 'rev' are permitted
14:30:18 [RalphS]
Ben: seems like a good place to start
14:30:26 [MarkB_]
s/link,/leap,/
14:30:43 [RalphS]
Steven: I need to think about it a bit longer
14:30:53 [MarkB_]
zakim, q+
14:30:53 [Zakim]
I see RalphS, MarkB_ on the speaker queue
14:30:58 [RalphS]
... I'd always imagined that RDF/A was predicated on href being available everywhere
14:31:13 [RalphS]
Ben: if the base XHTML doesn't allow href everywhere we just go with where href is allowed
14:31:24 [RalphS]
Steven: I'd want to try it out and see how it looks
14:31:53 [RalphS]
Mark: want to be clear on what we're trying to do
14:32:16 [RalphS]
... Steven thinks we should go all the way ...
14:32:30 [RalphS]
... to have href everywhere requires changing a lot of modules
14:32:43 [RalphS]
... there's no point in doing that if people complain it can't be implemented in lots of browsers
14:32:52 [RalphS]
... so we need to decide what direction we're going
14:33:11 [RalphS]
... as far as XHTML1 is concerned it's probably best if we don't do more than what browsers can support
14:33:36 [RalphS]
... the idea of XHTML 1.2 would require rewrites of modules
14:33:52 [RalphS]
Steven: I see the advantage of href everywhere
14:34:13 [RalphS]
... in the short term they're not clickable links but the browsers will accept (and ignore) the content and the triples will be there
14:34:23 [RalphS]
... so we just have to wait for browsers to catch up and implement href
14:34:43 [RalphS]
Mark: looking at Ben's work, he could have made the additional hrefs clickable
14:36:49 [RalphS]
Ralph: I'd suggest that we anticipate a direction
14:37:27 [RalphS]
... would be nice if HTML WG suggests whether an XHTML 1.2 might happen and whether href everywhere is high probability for that
14:37:46 [RalphS]
... so if RDF/A 1.1 module anticipates that href will be everywhere, we can give that advice to authors
14:38:02 [RalphS]
... if they want the link to _not_ be clickable in the future they should use META or LINK now
14:38:14 [RalphS]
... if they're happy that the link might become clickable someday, they can use 'href'
14:38:35 [RalphS]
Steven: we can add about and property everywhere, it's just href that's a problem due to existingn 1.1 modules
14:39:12 [RalphS]
Mark: to help the uptake of RDF/A, the question is whether we should go for the whole thing from the beginning
14:39:31 [RalphS]
... if people use href when it's not clickable will it cause problems later?
14:39:50 [RalphS]
Steven: doesn't feel like it would be a problem in the short term
14:40:12 [RalphS]
... XHTML 1.0 modularization is a W3C Rec, XHTML 1.1 modularization is at Proposed Rec
14:41:42 [RalphS]
Ralph: I was hoping for a document that would show us what things would require changes to either XHTML 1.1 modularization or to existing modules
14:41:57 [RalphS]
Mark: I didn't want to have to solve hard problems that we decide later don't need to be solved
14:42:49 [RalphS]
Ralph: deciding whether to go with href everywhere requires a statement from the HTML WG on whether it is willing to undertake the necessary changes to other modules
14:43:05 [RalphS]
Steven: but that is work the HTML WG is likely to do anyway
14:43:12 [RalphS]
Ben: let's start with a simple version
14:43:35 [RalphS]
... href everywhere requires more work from the HTML WG
14:43:41 [RalphS]
... let's start simple
14:43:52 [RalphS]
... assuming href everywhere would not be wasted work
14:44:04 [RalphS]
Mark: right, not wasted work -- just need to decide whether to release it
14:44:27 [RalphS]
Topic: WWW2006
14:44:32 [RalphS]
Ben: we submitted two proposals
14:44:41 [RalphS]
Steven: I have been asked to talk in the W3C track
14:44:55 [RalphS]
... haven't yet coordinated with the track organizer what exactly I'll be talking about
14:45:14 [RalphS]
... I'm holding back to see which of our Dev Track proposals get accepted
14:45:36 [RalphS]
Topic: CURIEs plural for microformat compatibility?
14:45:55 [RalphS]
Ben: this came up in Creative Commons discussions
14:46:08 [RalphS]
... the idea is to allow multiple values in 'rel' and 'rev'
14:46:27 [RalphS]
Mark: I think that's a great idea and thought we'd discussed it
14:46:34 [RalphS]
Steven: we decided it for 'role'
14:46:39 [RalphS]
... in the HTML WG
14:47:00 [RalphS]
Mark: looking at 'class', 'role', 'profile', you start to think "why not?"; hard to stop
14:47:28 [RalphS]
Ralph: I'd want to think about what the implications are for triples
14:47:49 [RalphS]
Steven: for 'role' it's clear, for 'rev' there are fewer use cases
14:47:58 [RalphS]
Ben: I gave one example in
14:48:21 [RalphS]
... I'd like us to think more about this for next time
14:48:47 [RalphS]
... since triple generation is driven by predicates, it seems straight-forward
14:49:09 [RalphS]
... microformats have a feature like this already
14:49:25 [RalphS]
Ralph: so the suggestion is simply to add this feature because microformats find it as useful
14:49:27 [RalphS]
Ben: yeah
14:49:35 [RalphS]
TOpic: Working Draft #2
14:52:07 [RalphS]
Ralph: current SWBPD charter expires end of April
14:53:19 [RalphS]
... current intention within the SemWeb Activity charter drafting effort is to proceed with RDF-in-XHTML task force as part of a new WG
14:53:45 [RalphS]
... with REC-track responsibility owned by HTML WG with support from SemWeb Activity
14:54:02 [RalphS]
... and deployment responsibility -- e.g. Primer -- the primary responsibility of the SemWeb WG
14:54:16 [RalphS]
Ben: I'll start planning WD #2 based on comments received
14:54:41 [RalphS]
... e.g. people have suggested acknowledging previous efforts
14:55:06 [RalphS]
Mark: I'd like to see what form this would take [before concurring]
14:55:39 [RalphS]
... e.g. Mikah Dubinko wrote a short article suggesting the use of attributes very similar to what we've chosen
14:57:18 [RalphS]
... but I don't think there's really much prior work that got used directly in RDF/A
14:57:36 [RalphS]
... though a lot of this was "in the air"
14:58:41 [RalphS]
Next meeting: 27 March, regrets from Ben
14:59:03 [RalphS]
adjourned
14:59:08 [Zakim]
-Ralph
14:59:11 [Zakim]
-Mark
14:59:13 [Zakim]
-Ben_Adida
14:59:15 [Zakim]
-Steven
14:59:18 [Zakim]
SW_BPD(rdfxhtml)9:00AM has ended
14:59:20 [Zakim]
Attendees were Ralph, Steven, Ben_Adida, Mark
14:59:26 [RalphS]
Chair: Ben
14:59:29 [RalphS]
Scribe: Ralph
14:59:35 [RalphS]
rrsagent, please make record public
14:59:40 [RalphS]
rrsagent, please draft minutes
14:59:40 [RRSAgent]
I have made the request to generate
RalphS
14:59:54 [RalphS]
zakim, bye
14:59:54 [Zakim]
Zakim has left #htmltf
15:01:43 [RalphS]
zakim, take up agendum 1
15:12:28 [Steven]
You're meant to say "oops" then
15:12:45 [benadida]
benadida has left #htmltf | http://www.w3.org/2006/03/20-htmltf-irc | CC-MAIN-2019-18 | refinedweb | 2,455 | 71.58 |
UpCloud API Client
Project description
UpCloud's Python API Client
OOP-based api client for UpCloud's API. Features most of the API's functionality and some convenience functions that combine several API endpoints and logic.
NOTE: This Python client is still evolving. Please test all of your use cases thoroughly before actual production use. Using a separate UpCloud account for testing / developing the client is recommended.
Installation
pip install upcloud-api
Alternatively, if you want the newest master or a devel branch - clone the project and run:
python setup.py install
!! SSL security update for python 2 !!
- short story:
pip install requests[security]should solve all of your problems.
- long story:
- upcloud-python-api uses requests for HTTP(S) that in turn uses urllib3
- urllib3 may detect that your python2.x's SSL is lacking as described here and here.
- you may also be interested in (especially if
requests[security]did not work for you on Ubuntu) [] ()
Supported versions as of 0.3.3 (offline tests pass with tox):
- python 2.6
- python 2.7
python 3.2removed due to python2/3 support python 3.3removed due to deprecation
- python 3.4
- python 3.5
- pypi3 2.4.0
Features
- OOP based management of Servers, Storages and IP-addresses with full CRUD.
- since 0.2: manage both IPv4 and IPv6 addresses
- since 0.1.1: can use custom storage templates in addition to public templates
- Clear way to define your infrastructure, emphasis on clear and easy syntax
- Access all the data of the objects ( e.g. ssh credentials )
- Scale horizontally by creating / destroying servers
- Scale vertically by changing the RAM, CPU, storage specs of any server
- Manage firewall (on/off and individual rules)
- since 0.2: full management of firewall rules
TODO:
- Cloning of storages
- Full management of special storage types:
- CDROMs, custom OS templates
- (custom templates can already be cloned to a disk via UUID)
- Full management of backups (instant and scheduled)
Changelog:
- See the Releases page
Documentation:
Examples
Note that some operations are not instant, for example a server is not fully shut down when the API responds. You must take this into account in your automations.
Defining and creating Servers
import upcloud_api from upcloud_api import Server, Storage, ZONE, login_user_block manager = upcloud_api.CloudManager('api_user', 'password') manager.authenticate() login_user = login_user_block( username='theuser', ssh_keys=['ssh-rsa AAAAB3NzaC1yc2EAA[...]ptshi44x user@some.host'], create_password=False ) cluster = { 'web1': Server( core_number=1, # CPU cores memory_amount=1024, # RAM in MB hostname='web1.example.com', zone=ZONE.London, # ZONE.Helsinki and ZONE.Chicago available also storage_devices=[ # OS: Ubuntu 14.04 from template # default tier: maxIOPS, the 100k IOPS storage backend Storage(os='Ubuntu 14.04', size=10), # secondary storage, hdd for reduced cost Storage(size=100, tier='hdd') ], login_user=login_user # user and ssh-keys ), 'web2': Server( core_number=1, memory_amount=1024, hostname='web2.example.com', zone=ZONE.London, storage_devices=[ Storage(os='Ubuntu 14.04', size=10), Storage(size=100, tier='hdd'), ], login_user=login_user ), 'db': Server( plan='2xCPU-4GB', # use a preconfigured plan, instead of custom hostname='db.example.com', zone=ZONE.London, storage_devices=[ Storage(os='Ubuntu 14.04', size=10), Storage(size=100), ], login_user=login_user ), 'lb': Server( core_number=2, memory_amount=1024, hostname='balancer.example.com', zone=ZONE.London, storage_devices=[ Storage(os='Ubuntu 14.04', size=10) ], login_user=login_user ) } for server in cluster: manager.create_server(cluster[server]) # automatically populates the Server objects with data from API
New in 0.3.0: servers can now be defined as dicts without using Server or Storage classes. The syntax/attributes are exactly like above and under the hood they are converted to Server and Storage classes. This feature is mainly for easier usage of the module from Ansible, but may provide useful elsewhere.
Stop / Start / Destroy Servers
for server in cluster: server.shutdown() # OR: server.start() # OR: server.destroy() for storage in server.storage_devices: storage.destroy()
New in 0.3.0: as the success of server.start() or server.destroy() and storage.destroy()
depend on the Server's
state, new helpers have been added. The helpers may be called regardless of
the server's current state.
# makes sure that the server is stopped (blocking wait) and then destroys the server and its storages server.stop_and_destroy() # makes sure that the server is started (blocking wait) server.ensure_started()
Upgrade a Server
server = cluster['web1'] server.shutdown() server.core_number = 4 server.memory_amount = 4096 server.save() server.start()
Clone a server
Cloning is done by giving existing storage uuid to storage_devices. Note that size of the storage must be defined and must be at least same size than storage being cloned.
clone = Server( core_number=1, memory_amount=1024, hostname='cloned.server', zone=ZONE.Helsinki, storage_devices=[ Storage( uuid='012bea57-0f70-4194-82d0-b3d25f4a018b', size=50 # size must be defined and it has to be at least same size than storage being cloned ), ] ) manager.create_server(clone)
Easy access to servers and their information:
New in 0.3.0.
# returns a public IPv4 (preferred) IPv6 (no public IPv4 was attached) address server.get_public_ip() # returns a JSON serializable dict with the server's information (storages and ip-addresses included) server.to_dict()
GET resources:
servers = manager.get_servers() server1 = manager.get_server(UUID) # e.g servers[0].uuid storages = manager.get_storages() storage1 = manager.get_storage(UUID) # e.g sever1.storage_devices[0].uuid ip_addrs = manager.get_ips() ip_addr = manager.get_ip(address) # e.g server1.ip_addresses[0].address
Tests
Set up environment and install dependencies:
# run at project root, python3 and virtualenv must be installed virtualenv ENV source ENV/bin/activate pip install -r requirements.txt
Install the package in editable mode, as mentioned in
# run at project root pip install -e .
Tests located in
project_root/tests/ directory. Run with:
py.test tests/
To test against all supported python versions, run:
tox
The project also supplies a small test suite to test against the live API at
test/live_test.py. This suite is NOT run with
py.test as it will permanently remove all resources related to an account. It should only be run with a throwaway dev-only account when preparing for a new release. It is not shipped with PyPI releases. See source code on how to run the live tests.
Bugs, Issues, Problems, Ideas
Feel free to open a new issue : )
Documentation
Documentation available here
Project details
Release history Release notifications | RSS feed
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/upcloud-api/0.4.6/ | CC-MAIN-2022-33 | refinedweb | 1,061 | 52.05 |
nanospin_ns_to_count()
Convert a time in nanoseconds into a number of iterations
Synopsis:
#include <time.h> unsigned long nanospin_ns_to_count( unsigned long nsec );
Since:
BlackBerry 10.0.0
Arguments:
- nsec
- The number of nanoseconds that you want to convert.
Library:
libc
Use the -l c option to qcc to link against this library. This library is usually included automatically.
Description:
The nanospin_ns_to_count() function converts the number of nanoseconds specified in nsec into an iteration count suitable for nanospin_count().
The nanospin*() functions are designed for use with hardware that requires short time delays between accesses. You should use them to delay only for times less than a few milliseconds. For longer delays, use the POSIX timer_*() functions.
The first time that you call nanospin_ns_to_count(), the C library invokes nanospin_calibrate() with an argument of 0 (interrupts enabled), if you haven't invoked it directly first.
Errors:
- EINTR
- A too-high rate of interrupts occurred during the calibration routine.
- ENOSYS
- This system's startup-* program didn't initialize the timing information necessary to use nanospin_ns_to_count().
Examples:
Busy-wait for at least one nanosecond:
#include <time.h> #include <sys/syspage.h> unsigned long time = 1; … /* Wake up the hardware, then wait for it to be ready. */ /* The C library invokes nanospin_calibrate if it hasn't already been called. */ nanospin_count( nanospin_ns_to_count( time ) ); /* Use the hardware. */ … | http://developer.blackberry.com/native/reference/core/com.qnx.doc.neutrino.lib_ref/topic/n/nanospin_ns_to_count.html | CC-MAIN-2018-26 | refinedweb | 218 | 59.19 |
res a little app you guys may find usefull
Flash Consol
i was told by someone in my thread to post this code to you:-
var pointArray:Array = new Array();var maxDistance:Number = new Number(5);var maxDistance2:Number = maxDistance*maxDistance;var gravity:Number = new Number(2);var lineLenght:Number = new Number(60);pointArray.push([Stage.width/2, Stage.height/2]);_root.createEmptyMovieCli
p("line", 1);_root["line"].lineStyle(2, 0, 100);_root["line"].moveTo(pointArray[0][0]
, pointArray[0][1]);for (i=1; i<lineLenght; i++) {pointArray.push([pointArray[0][0], pointArray[0][1]+(i*maxDistance)]);_root["
line"].lineTo(pointArray[i][0], pointArray[i][1]);}_root.onEnterFrame = function() {pointArray[0][0] = _xmouse;pointArray[0][1] = _ymouse;_root["line"].clear();_root["line"
].moveTo(pointArray[0][0], pointArray[0][1]);_root["line"].lineStyle(
2, 0, 100);for (i=1; i<lineLenght; i++) {pointArray[i][1] += gravity;if (distSq(pointArray[i], pointArray[i-1])>maxDistance2) {var rotation:Number = Math.atan2(pointArray[i][1]-pointArray[i-1
][1], pointArray[i][0]-pointArray[i-1][0]);point
Array[i][0] = pointArray[i-1][0]+Math.cos(rotation)*maxD
istance;pointArray[i][1] = pointArray[i-1][1]+Math.sin(rotation)*maxD
istance;}_root["line"].lineTo(pointArray[i
][0], pointArray[i][1]);}};function distSq(ptA:Array, ptB:Array):Number {return (ptA[0]-ptB[0])*(ptA[0]-ptB[0])+(ptA[1]-pt
B[1])*(ptA[1]-ptB[1]);}
After a few months off the BBS (I was the annoying spammer BobRicci before) when I came back I thought FOSS: Main was going to be a great success!!! I say we revive what do you gies say???
At 6/18/06 09:23 PM, EmoNarc wrote: After a few months off the BBS (I was the annoying spammer BobRicci before) when I came back I thought FOSS: Main was going to be a great success!!! I say we revive what do you gies say???
Who says it was dead? Maybe people are busy and don't have time to post up open source codes/files... Just a thought ;)
In the last half year... it has only been posted in (not including us) 10 times!!! With only one more FOSS thread... this thread IS dead and I wan't it alive again... :/
bump
Quick update.
FOSS:Alpha Star by GuyWithHisComp
FOSS:Anti-Offscreen Clicking by ImpotentBoy2
FOSS:Api Library by Inglor
FOSS:API Preloader by Glaiel-Gamer
FOSS:Bottles Of Beer by James_Prankard_Inc
FOSS:Car Engine by Creeepy
FOSS:Chatroom by -liam-
FOSS:Custom Functions by -liam-
FOSS:Dino Game by Ninja-Chicken
FOSS:Double Click by fwe
FOSS:Double Tap Keys by ImpotentBoy2
FOSS:Dynamic Echo/Reverb by gorman2001
FOSS:Empty Board Solver by Inglor
FOSS:Every Other Button by GuyWithHisComp
FOSS:Fantastic Filter Fun!! by ImpotentBoy2
FOSS:Flash Consol by shazwoogle
FOSS:Ground Code by frostedmuffins
FOSS:Helicopter Game by SpamBurger
FOSS:Pausing Sound Object Sounds by Claxor
FOSS:Platformer by -Thomas-
FOSS:Platformer by Creepy
FOSS:Quiz Maker by ImpotentBoy2
FOSS:Raindrop from Mouse by SpamBurger
FOSS:Recording with BitmapData by fwe
FOSS:Scrambling Strings by authorblues
FOSS:Shake Screen by -Toast-
FOSS:Snow Effect by SpamBurger
FOSS:Snow From Mouse by -reelbigcheese-
FOSS:String From Mouse by -reelbigcheese-
FOSS:Spiral Generator by Glaiel Gamer
FOSS:Starfield by gorman2001
FOSS:Transitions by Ninja Chicken
FOSS:Weather Script by Cojones893
A mod should take over this thread and and keep the list at the top like in as: main.
OH NOES! BobRicci is back! :O
All hide and wait until the threat is gone, don't move - it might take a long time...
At 8/2/06 06:05 AM, -Toast- wrote: OH NOES! BobRicci is back! :O
All hide and wait until the threat is gone, don't move - it might take a long time...
He's been back a long time, just dosent post. That last post by him in this thread is 2 month old me thinks.
Awww :(
I like this thread, please someone bring it back to life :(
At 8/2/06 07:10 AM, reelbigcheese wrote: He's been back a long time, just dosent post. That last post by him in this thread is 2 month old me thinks.
I have... I just havn't posted (although I do look through the forums once in a while). I mainly just use my account now for the occasional review and/or vote... I might start posting again maybe...
How'd this die anyhow???
At 10/28/06 10:26 PM, EmoNarc wrote: How'd this die anyhow???
dunno
bump
website :: hugostonge.com
my job :: we+are
At 10/25/07 08:23 PM, gorman2001 wrote: bump
I MADE THIS THREAD XD
At 10/26/07 12:50 AM, thunderbros wrote:At 10/25/07 08:23 PM, gorman2001 wrote: bumpI MADE THIS THREAD XD
Dude, shut the fuck up.
NO! We have lost life!
The thread is........dead.
No oooo !!!!!!!!!
Foss
What The Hell
I will miss you.
The Thread is Dead
why not relieve this thread with Open Source classes, made by our dear Flashers ?
website :: hugostonge.com
my job :: we+are
Im developing a FOSS Game Engine .zip. I think it will be extremely useful to anyone doveloping a game from scratch and need a basis engine, for a Dynamic Platformer, Overhead Game, Ordinary Platformer, Sidescroller Platformer, or aything else that seems usefull, i'll make a thread for it when im done, and it will be available on my News Posts.
Features:
Venom Platformer Engine 2 - v1.0
Venom Overhead Engine 1 - v2.0
Venom Dynami-Platformer Engine 1 - v1.0
Exitcraft FOSS 1 - v1.0
more..
Hope it helps lots of people!
Hope it helps :). | http://www.newgrounds.com/bbs/topic/314338/5 | CC-MAIN-2016-30 | refinedweb | 947 | 56.86 |
The Spring Cloud Pipelines repository contains opinionated Concourse pipeline definitions. Those jobs form an empty pipeline and an opinionated sample pipeline that you can use in your company.
The:
The simplest way to deploy Concourse to K8S is to use Helm.
Once you have Helm installed and your
kubectl is pointing to the
cluster, run the following command to install the Concourse cluster in your K8S cluster:
$ helm install stable/concourse --name concourse
Once the script is done, you should see the following output
1. Concourse can be accessed: * Within your cluster, at the following DNS name at port 8080: concourse-web.default.svc.cluster.local * From outside the cluster, run these commands in the same shell: export POD_NAME=$(kubectl get pods --namespace default -l "app=concourse-web" -o jsonpath="{.items[0].metadata.name}") echo "Visit to use Concourse" kubectl port-forward --namespace default $POD_NAME 8080:8080 2. Login with the following credentials Username: concourse Password: concourse
Follow the steps and log in to Concourse under.
You can use Helm also to deploy Artifactory to K8S, as follows:
$ helm install --name artifactory --set artifactory.image.repository=docker.bintray.io/jfrog/artifactory-oss stable/artifactory
After you run this command, you should see the following output:
NOTES: Congratulations. You have just deployed JFrog Artifactory Pro! 1. Get the Artifactory URL by running these commands: NOTE: It may take a few minutes for the LoadBalancer IP to be available. You can watch the status of the service by running 'kubectl get svc -w nginx' export SERVICE_IP=$(kubectl get svc --namespace default nginx -o jsonpath='{.status.loadBalancer.ingress[0].ip}') echo 2. Open Artifactory in your browser Default credential for Artifactory: user: admin password: password
Next, you need to set up the repositories.
First, access the Artifactory URL and log in with
a user name of
admin and a password of
Then, click on Maven setup and click
Create.
If you go to the Concourse website you should see something resembling the following:
You can click one of the icons (depending on your OS) to download
fly, which is the Concourse CLI. Once you download that (and maybe added it to your PATH, depending on your OS) you can run the following command:
fly --version
If
fly is properly installed, it should print out the version.
We made a sample credentials file called
credentials-sample-k8s.yml
prepared for
k8s. You can use it as a base for your
credentials.yml.
To allow the Concourse worker’s spawned container to connect to the Kubernetes cluster, you must pass the CA contents and the auth token.
To get the contents of CA for GCE, run the following command:
$ kubectl get secret $(kubectl get secret | grep default-token | awk '{print $1}') -o jsonpath='{.data.ca\.crt}' | base64 --decode
To get the auth token, run the following command:
$ kubectl get secret $(kubectl get secret | grep default-token | awk '{print $1}') -o jsonpath='{.data.token}' | base64 --decode
Set that value under
paas-test-client-token,
paas-stage-client-token, and
paas-prod-client-token
After running Concourse, you should get the following output in your terminal:
$ export POD_NAME=$(kubectl get pods --namespace default -l "app=concourse-web" -o jsonpath="{.items[0].metadata.name}") $ echo "Visit to use Concourse" $ kubectl port-forward --namespace default $POD_NAME 8080:8080 Visit to use Concourse
Log in (for example, for Concourse running at
127.0.0.1 — if you do not provide any value,
localhost is assumed). If you run this script, it assumes that either
fly is on your
PATH or that it is in the same folder as the script:
$ fly -t k8s login -c -u concourse -p concourse
Next, run the following command to create the pipeline:
$ ./set_pipeline.sh github-webhook k8s credentials-k8s.yml
The following images show the various steps involved in runnig the
github-webhook pipeline:
Figure 8.7. Unpause the pipeline by clicking in the top lefr corner and then clicking the
play button | https://cloud.spring.io/spring-cloud-pipelines/multi/multi_concourse-pipeline-k8s.html | CC-MAIN-2020-29 | refinedweb | 659 | 52.19 |
Python supplies the usual numeric operations, as you've just seen in Table 4-2. All numbers are immutable objects, so when you perform a numeric operation on a number object, you always produce a new number object. You can access the parts of a complex object z as read-only attributes z.real and z.imag. Trying to rebind these attributes on a complex object raises an exception.
Note that a number's optional + or - sign, and the + that joins a floating-point literal to an imaginary one to make a complex number, are not part of the literals' syntax. They are ordinary operators, subject to normal operator precedence rules (see Table 4-2). This is why, for example, -2**2 evaluates to -4: exponentiation has higher precedence than unary minus, so the whole expression parses as -(2**2), not as (-2)**2.
You can perform arithmetic operations and comparisons between any two numbers. If the operands' types differ, coercion applies: Python converts the operand with the smaller type to the larger type. The types, in order from smallest to largest, are integers, long integers, floating-point numbers, and complex numbers.
You can also perform an explicit conversion by passing a numeric argument to any of the built-ins: int, long, float, and complex. int and long drop their argument's fractional part, if any (e.g., int(9.8) is 9). Converting from a complex number to any other numeric type drops the imaginary part. You can also call complex with two arguments, giving real and imaginary parts.
Each built-in type can also take a string argument with the syntax of an appropriate numeric literal with two small extensions: the argument string may start with a sign and, for complex numbers, may sum or subtract real and imaginary parts. int and long can also be called with two arguments: the first one a string to convert, and the second one the radix, an integer between 2 and 36 to use as the base for the conversion (e.g., int('101',2) returns 5, the value of '101' in base 2).
If the right operand of /, //, or % is 0, Python raises a runtime exception. The // operator, introduced in Python 2.2, performs truncating division, which means it returns an integer result (converted to the same type as the wider operand) and ignores the remainder, if any. When both operands are integers, the / operator behaves like // if you are using Python 2.1 and earlier or if the switch -Qold was used on the Python command line (-Qold is the default in Python 2.2). Otherwise, / performs true division, returning a floating-point result (or a complex result, if either operand is a complex number). To have / perform true division on integer operands in Python 2.2, use the switch -Qnew on the Python command line or begin your source file with the statement:
from future import division
This ensures that operator / works without truncation on any type of operands.
To ensure that your program's behavior does not depend on the -Q switch, use // (in Python 2.2 and later) to get truncating division. When you do not want truncation, ensure that at least one operand is not an integer. For example, instead of a/b, use 1.*a/b to avoid making any assumption on the types of a and b. To check whether your program has version dependencies in its use of division, use the switch -Qwarn on the Python command line (in Python 2.2 and later) to get warnings about uses of / on integer operands.
The built-in divmod function takes two numeric arguments and returns a pair whose items are the quotient and remainder, thus saving you from having to use both // for the quotient and % for the remainder.
An exponentiation operation, a**b, raises an exception if a is less than zero and b is a floating-point value with a non-zero fractional part. The built-in pow(a,b) function returns the same result as a**b. With three arguments, pow(a,b,c) returns the same result as (a**b)%c, but faster.
All objects, including numbers, can also be compared for equality (= =) and inequality (!=). Comparisons requiring order (<, <=, >, >=) may be used between any two numbers except complex ones, for which they raise runtime exceptions. All these operators return Boolean values (True or False).
Integers and long integers can be considered strings of bits and used with the bitwise operations shown in Table 4-2. Bitwise operators have lower priority than arithmetic operators. Positive integers are extended by an infinite string of 0 bits on the left. Negative integers are represented in two's complement notation, and therefore are extended by an infinite string of 1 bits on the left. | http://etutorials.org/Programming/Python+tutorial/Part+II+Core+Python+Language+and+Built-ins/Chapter+4.+The+Python+Language/4.5+Numeric+Operations/ | CC-MAIN-2018-47 | refinedweb | 800 | 62.98 |
The central concept in Python programming is that of a namespace. Each context (i.e., scope) in a Python program has available to it a hierarchically organized collection of namespaces; each namespace contains a set of names, and each name is bound to an object. In older versions of Python, namespaces were arranged according to the "three-scope rule" (builtin/global/local), but Python version 2.1 and later add lexically nested scoping. In most cases you do not need to worry about this subtlety, and scoping works the way you would expect (the special cases that prompted the addition of lexical scoping are mostly ones with nested functions and/or classes).
There are quite a few ways of binding a name to an object within the current namespace/scope and/or within some other scope. These various ways are listed below.
A Python statement like x=37 or y="foo" does a few things. If an object?e.g., 37 or "foo"?does not exist, Python creates one. If such an object does exist, Python locates it. Next, the name x or y is added to the current namespace, if it does not exist already, and that name is bound to the corresponding object. If a name already exists in the current namespace, it is re-bound. Multiple names, perhaps in multiple scopes/namespaces, can be bound to the same object.
A simple assignment statement binds a name into the current namespace, unless that name has been declared as global. A name declared as global is bound to the global (module-level) namespace instead. A qualified name used on the left of an assignment statement binds a name into a specified namespace?either to the attributes of an object, or to the namespace of a module/package; for example:
>>> x = "foo" # bind 'x' in global namespace >>> def myfunc(): # bind 'myfunc' in global namespace ... global x, y # specify namespace for 'x', 'y' ... x = 1 # rebind global 'x' to 1 object ... y = 2 # create global name 'y' and 2 object ... z = 3 # create local name 'z' and 3 object ... >>> import package.module # bind name 'package.module' >>> package.module.w = 4 # bind 'w' in namespace package.module >>> from mymod import obj # bind object 'obj' to global namespace >>> obj.attr = 5 # bind name 'attr' to object 'obj'
Whenever a (possibly qualified) name occurs on the right side of an assignment, or on a line by itself, the name is dereferenced to the object itself. If a name has not been bound inside some accessible scope, it cannot be dereferenced; attempting to do so raises a NameError exception. If the name is followed by left and right parentheses (possibly with comma-separated expressions between them), the object is invoked/called after it is dereferenced. Exactly what happens upon invocation can be controlled and overridden for Python objects; but in general, invoking a function or method runs some code, and invoking a class creates an instance. For example:
>>> pkg.subpkg.func() # invoke a function from a namespace >>> x = y # deref 'y' and bind same object to 'x'
Declaring a function or a class is simply the preferred way of describing an object and binding it to a name. But the def and class declarations are "deep down" just types of assignments. In the case of functions, the lambda operator can also be used on the right of an assignment to bind an "anonymous" function to a name. There is no equally direct technique for classes, but their declaration is still similar in effect:
>>> add1 = lambda x,y: x+y # bind 'add1' to function in global ns >>> def add2(x, y): # bind 'add2' to function in global ns ... return x+y ... >>> class Klass: # bind 'Klass' to class object ... def meth1(self): # bind 'meth1' to method in 'Klass' ns ... return 'Myself'
Importing, or importing from, a module or a package adds or modifies bindings in the current namespace. The import statement has two forms, each with a bit different effect.
Statements of the forms
>>> import modname >>> import pkg.subpkg.modname >>> import pkg.modname as othername
add a new module object to the current namespace. These module objects themselves define namespaces that you can bind values in or utilize objects within.
Statements of the forms
>>> from modname import foo >>> from pkg.subpkg.modname import foo as bar
instead add the names foo or bar to the current namespace. In any of these forms of import, any statements in the imported module are executed?the difference between the forms is simply the effect upon namespaces.
There is one more special form of the import statement; for example:
>>> from modname import *
The asterisk in this form is not a generalized glob or regular expression pattern, it is a special syntactic form. "Import star" imports every name in a module namespace into the current namespace (except those named with a leading underscore, which can still be explicitly imported if needed). Use of this form is somewhat discouraged because it risks adding names to the current namespace that you do not explicitly request and that may rebind existing names.
Although for is a looping construct, the way it works is by binding successive elements of an iterable object to a name (in the current namespace). The following constructs are (almost) equivalent:
>>> for x in somelist: # repeated binding with 'for' ... print x ... >>> ndx = 0 # rebinds 'ndx' if it was defined >>> while 1: # repeated binding in 'while' ... x = somelist[ndx] ... print x ... ndx = ndx+1 ... if ndx >= len(somelist): ... del ndx ... break
The except statement can optionally bind a name to an exception argument:
>>> try: ... raise "ThisError", "some message" ... except "ThisError", x: # Bind 'x' to exception argument ... print x ... some message | http://etutorials.org/Programming/Python.+Text+processing/Appendix+A.+A+Selective+and+Impressionistic+Short+Review+of+Python/A.2+Namespaces+and+Bindings/ | CC-MAIN-2018-26 | refinedweb | 947 | 64.1 |
: We train a neural network on encrypted values using Secure Multi-Party Computation and Autograd. We report good results on MNIST.
Note: If you want more posts like this, I'll tweet them out when they're complete at @theoryffel and @OpenMinedOrg. Feel free to follow if you'd be interested in reading more and thanks for all the feedback!
Privacy in ML
When building Machine Learning as a Service solutions (MLaaS), a company often need data from other partners to train its model. In healthcare or finance, both the model and the data are extremely critical: the model parameters represent a business asset while data is personal data and is tightly regulated.
In this context, one possible solution is to encrypt both the model and the data, and then to train the machine learning model over encrypted values. This guarantees that the company won't access patients medical records for example, and that health facilities won't be able to use the model to which they contribute if not authorized to do so. Several encryption schemes exist that allow for computation over encrypted data, among which Secure Multi-Party Computation (SMPC), Homomorphic Encryption (FHE/SHE) and Functional Encryption (FE). We will focus here on Secure Multi-Party Computation, which consists of private additive sharing and relies on the crypto protocols SecureNN and SPDZ, the details of which are given in this excellent blog post. Throughout this article, we will abusively say encrypt to mean additively secret share.
While this blog post focuses on encrypted training, another post discusses in more details how to encrypt pre-trained models to perform encrypted predictions.
The exact setting here is the following: consider that you are the server and you would like to train your model on some data held by n workers. The server secret shares his model and send each share to a worker. The workers also secret share their data and exchange it between them. In the configuration that we will study, there are 2 workers: alice and bob. After exchanging shares, each of them now has one of their own shares, one share of the other worker, and one share of the model. Computation can now start in order to privately train the model using the appropriate crypto protocols. Once the model is trained, all the shares can be sent back to the server to decrypt it. The mechanism is illustrated with the following figure:
To give an example of this process, let's assume alice and bob both hold a part of the MNIST dataset and let's train a model to perform digit classification!
1. Encrypted Training demo on MNIST
In this section, we will go through a complete code example and highlight the key elements that we need to take into account when training data using Secure Multi-Party Computation.
Imports and training configuration
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import time
This class describes all the hyper-parameters for the training. Note that they are all public here.
class Arguments(): def __init__(self): self.batch_size = 64 self.test_batch_size = 64 self.epochs = 20 self.lr = 0.02 self.seed = 1 self.log_interval = 1 # Log info at each batch self.precision_fractional = 3 args = Arguments() torch.manual_seed(args.seed)
Here are PySyft imports. We connect to 2 remote workers (alice and bob), and request another worker called the
crypto_provider who gives all the crypto primitives that we will need.
import syft as sy # import the Pysyft library # hook PyTorch to add extra functionalities like Federated and Encrypted Learning hook = sy.TorchHook(torch) # simulation functions from future import connect_to_workers, connect_to_crypto_provider workers = connect_to_workers(n_workers=2) crypto_provider = connect_to_crypto_provider()
Getting access and secret share data
Here we're using a utility function which simulates the following behaviour: we assume that each worker holds a distinct subset of the MNIST dataset. The workers then split their data in batches and secret share their data between each others. The final object returned is an iterable on these secret shared batches, that we call the private data loader. Note that during the process the local worker (so us) never had access to the data.
We obtain as usual a training and testing private dataset, and both the inputs and labels are secret shared.
# We don't use the whole dataset for efficiency purpose, but feel free to increase these numbers n_train_items = 640 n_test_items = 640 def get_private_data_loaders(precision_fractional, workers, crypto_provider): # Details are in the complete code sample return private_train_loader, private_test_loader private_train_loader, private_test_loader = get_private_data_loaders( precision_fractional=args.precision_fractional, workers=workers, crypto_provider=crypto_provider, dataset_sizes=(n_train_items, n_test_items) )
Model specification
Here is the model that we will use, it's a rather simple one but it has proved to perform reasonably well on MNIST
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(28 * 28, 128) self.fc2 = nn.Linear(128, 64) self.fc3 = nn.Linear(64, 10) def forward(self, x): x = x.view(-1, 28 * 28) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
Training and testing functions
The training is done almost as usual, the real difference is that we can't use losses like negative log-likelihood (
F.nll_loss in PyTorch) because it's quite complicated to reproduce it with SMPC. Instead, we use a simpler Mean Square Error loss.
Note: regarding Negative Log-Likelihood, the likelihood is obtained using the softmax function. Hence,
nll_lossrequires to run the logarithm and exponential functions or approximations of it, and this is not practical with fixed precision values.
def train(args, model, private_train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(private_train_loader): # <-- now it is a private dataset start_time = time.time() optimizer.zero_grad() output = model(data) # loss = F.nll_loss(output, target) <-- not possible here batch_size = output.shape[0] loss = ((output - target)**2).sum().refresh()/batch_size loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: loss = loss.get().float_precision() print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tTime: {:.3f}s'.format( epoch, batch_idx * args.batch_size, len(private_train_loader) * args.batch_size, 100. * batch_idx / len(private_train_loader), loss.item(), time.time() - start_time))
The .refresh() is just there to make sure the division works fine by refreshing the shares of the encrypted tensor. The reason for this is a bit technical, but just remember that it doesn't affect the computation.
The test function does not change!
def test(args, model, private_test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in private_test_loader: start_time = time.time() output = model(data) pred = output.argmax(dim=1) correct += pred.eq(target.view_as(pred)).sum() correct = correct.get().float_precision() print('\nTest set: Accuracy: {}/{} ({:.0f}%)\n'.format( correct.item(), len(private_test_loader)* args.test_batch_size, 100. * correct.item() / (len(private_test_loader) * args.test_batch_size)))
Let's launch the training !
A few notes about what's happening here. First, we encrypt all the model parameters across our workers. Second, we convert optimizer's hyperparameters to fixed precision. Note that we don't need to secret share them because they are public in our context, but as secret shared values live in finite fields we still need to move them in finite fields using using
.fix_precision, in order to perform consistently operations like the weight update:
As a remainder, in order to work on integers in finite fields, we leverage the PySyft tensor abstraction to convert PyTorch Float tensors into Fixed Precision Tensors using
.fix_precision(). For example 0.123 with precision 2 does a rounding at the 2nd decimal digit so the number stored is the integer 12.
model = Net() model = model.fix_precision().share(*workers, crypto_provider=crypto_provider, requires_grad=True) optimizer = optim.SGD(model.parameters(), lr=args.lr) optimizer = optimizer.fix_precision() for epoch in range(1, args.epochs + 1): train(args, model, private_train_loader, optimizer, epoch) test(args, model, private_test_loader)
Train Epoch: 1 [0/640 (0%)] Loss: 1.128000 Time: 2.931s Train Epoch: 1 [64/640 (10%)] Loss: 1.011000 Time: 3.328s Train Epoch: 1 [128/640 (20%)] Loss: 0.990000 Time: 3.289s Train Epoch: 1 [192/640 (30%)] Loss: 0.902000 Time: 3.155s Train Epoch: 1 [256/640 (40%)] Loss: 0.887000 Time: 3.125s Train Epoch: 1 [320/640 (50%)] Loss: 0.875000 Time: 3.395s Train Epoch: 1 [384/640 (60%)] Loss: 0.853000 Time: 3.461s Train Epoch: 1 [448/640 (70%)] Loss: 0.849000 Time: 3.038s Train Epoch: 1 [512/640 (80%)] Loss: 0.830000 Time: 3.414s Train Epoch: 1 [576/640 (90%)] Loss: 0.839000 Time: 3.192s Test set: Accuracy: 300.0/640 (47%) ... Train Epoch: 20 [0/640 (0%)] Loss: 0.227000 Time: 3.457s Train Epoch: 20 [64/640 (10%)] Loss: 0.169000 Time: 3.920s Train Epoch: 20 [128/640 (20%)] Loss: 0.249000 Time: 3.477s Train Epoch: 20 [192/640 (30%)] Loss: 0.188000 Time: 3.327s Train Epoch: 20 [256/640 (40%)] Loss: 0.196000 Time: 3.416s Train Epoch: 20 [320/640 (50%)] Loss: 0.177000 Time: 3.371s Train Epoch: 20 [384/640 (60%)] Loss: 0.207000 Time: 3.279s Train Epoch: 20 [448/640 (70%)] Loss: 0.244000 Time: 3.178s Train Epoch: 20 [512/640 (80%)] Loss: 0.224000 Time: 3.465s Train Epoch: 20 [576/640 (90%)] Loss: 0.297000 Time: 3.402s Test set: Accuracy: 610.0/640 (95%)
Here we go! We just got 95% of accuracy using a tiny fraction of the MNIST dataset, using 100% encrypted training!
2. Discussion
Let's now discuss several points about this demonstration, among which the computation time, the encrypted backpropagation method we use and the threat model that we consider.
2.1 Computation time
First thing is obviously the running time! As you have surely noticed, it is far slower than plain text training. In particular, a iteration over 1 batch of 64 items takes 3.2s while only 13ms in pure PyTorch. Whereas this might seem like a blocker, just recall that here everything happened remotely and in the encrypted world: no single data item has been disclosed. More specifically, the time to process one item is 50ms which is not that bad. The real question is to analyze when encrypted training is needed and when only encrypted prediction is sufficient. 50ms to perform a prediction is completely acceptable in a production-ready scenario for example!
One main bottleneck is the use of costly activation functions: using relu activation with SMPC is very expensive because it uses private comparison and the SecureNN protocol. As an illustration, if we replace relu with a quadratic activation as it is done in several papers on encrypted computation like CryptoNets, we drop from 3.2s to 1.2s.
As a general rule, the key idea to take away is to encrypt only what's necessary, and this tutorial shows you that it can be done easily. In particular, keep in mind that you don't have to encrypt both the data and the model if it's not needed. You can keep the model in clear text for example and you will get significant speed improvements.
2.2 Backpropagation with SMPC
If you know nothing about backpropagation and autograd in PyTorch, you may prefer to start here.
You might wonder how we perform backpropagation and gradient updates because we're working with integers in finite fields, which are encrypted on top of that. To do so, we have developed a new syft tensor called AutogradTensor. This tutorial used it intensively although you might have not seen it! Let's check this by printing a model's weight:
model.fc3.bias
Parameter containing: Parameter>AutogradTensor>FixedPrecisionTensor>[AdditiveSharingTensor] -> [PointerTensor | me:60875986481 -> worker1:9431389166] -> [PointerTensor | me:97932769362 -> worker2:74272298650] *crypto provider: crypto_provider*
And a data item:
first_batch, input_data = 0, 0 private_train_loader[first_batch][input_data]
(Wrapper)>AutogradTensor>FixedPrecisionTensor>[AdditiveSharingTensor] -> [PointerTensor | me:35529879690 -> worker1:63833523495] -> [PointerTensor | me:26697760099 -> worker2:23178769230] *crypto provider: crypto_provider*
As you observe, the AutogradTensor is there! It lives between the torch wrapper and the FixedPrecisionTensor which indicates that the values are now in finite fields. The goal of this AutogradTensor is to store the computation graph when operations are made on encrypted values. This is useful because when calling backward for the backpropagation, this AutogradTensor overrides all the backward functions that are not compatible with encrypted computation and indicates how to compute these gradients. For example, regarding multiplication which is done using the Beaver triples trick, we don't want to differentiate that trick, all the more that differentiating a multiplication should be very easy:
Here is how we describe how to compute these gradients for example:
class MulBackward(GradFunc): def __init__(self, self_, other): super().__init__(self, self_, other) self.self_ = self_ self.other = other def gradient(self, grad): grad_self_ = grad * self.other grad_other = grad * self.self_ if type(self.self_) == type(self.other) else None return (grad_self_, grad_other)
You can have a look at this file if you're curious to see how we implemented more gradients.
In terms of the computation graph, it means that a copy of the graph remains local and that the server which coordinates the forward pass also provides instructions on how to do the backward pass. This is a completely valid hypothesis in our setting.
2.3 Security guarantees
Last, let's give a few hints about the security we're achieving here: both data owners or model owners can be adversaries. These adversaries are however honest but curious; this means that an adversary can't learn anything about the data by running this protocol, but a malicious adversary could still deviate from the protocol and for example try to corrupt the shares to sabotage the computation. Security against malicious adversaries in such SMPC computations including private comparison is still an open problem.
In addition, even if Secure Multi-Party Computation ensures that training data wasn't accessed, many threats from the classic ML world are still present here. For example, as you can make requests to the model (in the context of MLaaS), you can get predictions which might disclose information about the training dataset. In particular you don't have any protection against membership attacks, a common attack on machine learning services where the adversary wants to determine if a specific item was used in the dataset. Besides this, other attacks such as unintended memorization processes (models learning specific feature about a data item), model inversion or extraction are still possible.
One general solution which is effective for many of the threats mentioned above is to add Differential Privacy. It can be nicely combined with Secure Multi-Party Computation and can provide very interesting security guarantees. We're currently working on several implementations and hope to propose an example that combines both shortly!
Conclusion
As you have seen, training a model using SMPC is not complicated from a code point of view, even though we use rather complex objects under the hood. With this in mind, you should now analyse your use-cases to see when encrypted computation is needed either for training or for evaluation.
Acknowlegments This work is the result of a collective effort by our Cryto ML team at OpenMined, and I would like to specifically thank Mat Leonard, Jason Paumier, André Farias, Jose Corbacho, Bobby Wagner and the amazing Andrew Trask for all their support to make this happen.! | https://blog.openmined.org/encrypted-training-on-mnist/ | CC-MAIN-2022-33 | refinedweb | 2,554 | 50.23 |
More? I began on the server side. I didn’t want to build a real ecommerce site for this demo. Instead I decided to simply simulate one person spending X amount of money and a certain time.
Data Services Messaging is fairly simple to setup. I went to my ColdFusion Administrator, Event Gateways, Gateway Instances, and created a new instance. I named it SimpleTest, used the DataServicesMessaging type, and pointed to a CFC in my code folder. This CFC is used when Flex sends data to the server. However, in my application, the client will never send data. A blank file then is fine for the CFC. However, if you try to skip making the file the administrator will get pissy with you.
Important: Note that you have to start the gateway instance. Even with the startup set to auto, which I would assume would mean ‘start now too please’, don’t forget to hit that start icon after you create it.
At this point I can write a quick CFM that will simulate a web site sale.
<cffunction name="firstName" output="false">
<cfset var
<cfset var name = listGetAt(list, randRange(1, listLen(list)))>
<cfreturn name>
</cffunction>
<cffunction name="lastName" output="false">
<cfset var
<cfset var name = listGetAt(list, randRange(1, listLen(list)))>
<cfreturn name>
</cffunction>
<cftry> <cfset msg = StructNew()> <cfset msg.body = {}> <cfset msg.body[“firstName”] = firstName()> <cfset msg.body[“lastName”] = lastName()> <cfset msg.body[“amount”] = “#randRange(1,100)#.#randRange(0,9)##randRange(0,9)#”> <cfset msg.body[“timestamp”] = now()> <cfset msg.destination = “ColdFusionGateway”>
<cfdump var="#msg#"> <cfset ret = SendGatewayMessage("simpletest", msg)> <cfdump var="#ret#"> <cfcatch> <cfdump var="#cfcatch#"> </cfcatch> </cftry> </code>
Those first two UDFs were simply me playing around. They return a random first and last name. The important part is the msg structure. I set the name, a random amount, and set a timestamp. (The docs say I don’t have to, but frankly, the timeformat of the embedded timestamp wasn’t something I knew how to parse.) Why? Those keys are entirely application dependent. If I were building a simple chat application, I may have just had a username and text property. For GameOne, one of my broadcasts includes stock data.
The destination, ColdFusionGateway, is actually specified in the XML files that ship with ColdFusion. I’ll be honest and say I only kinda half-grok these files. I had to peek around in there when I played with BlazeDS locally, but all of the code here today runs on a ‘stock’ ColdFusion8. It has the ColdFusionGateway specified in the Flex XML files so for now, just go with it.
Once the data is set, I pass it to sendGatewayMessage. The first argument is the name of the event gateway I just created. The second is the structure defined in the file.
And that’s it. Obviously this would be in a CFC method, you could imagine it being called after the order process is done.
The Flex/AIR side is even simpler. I used all of 2 files. (Ignoring the XML file AIR uses to create the build.) My main file contains one tag - a list. This list uses another file to handle rendering sales updates from the server. Here is the complete application file:
<?xml version="1.0" encoding="utf-8"?>
<mx:WindowedApplication xmlns:
<mx:Consumer id=”consumer” message=”handleMessage(event)” channelSet=”{myChannelSet}” destination=”ColdFusionGateway” />
<mx:Script>
<![CDATA[
import mx.messaging.channels.AMFChannel;
import mx.messaging.Channel;
import mx.messaging.ChannelSet;
import mx.controls.Alert;
import mx.collections.ArrayCollection;
import mx.messaging.events.MessageEvent;
[Bindable] public var myAC:ArrayCollection = new ArrayCollection();
[Bindable] public var myChannelSet:ChannelSet
private function handleMessage(e:MessageEvent):void { var body:Object = e.message.body var newMsg:Object = new Object() newMsg.firstName = body.firstName newMsg.lastName = body.lastName newMsg.amount = new Number(body.amount) newMsg.timestamp = body.timestamp myAC.addItemAt(newMsg,0) }
private function init():void { myChannelSet = new ChannelSet() // var customChannel:Channel = new AMFChannel(“my-cfamf”,””) var customChannel:Channel = new AMFChannel(“my-cfamf”,””) myChannelSet.addChannel(customChannel)
consumer.subscribe(); }
]]> </mx:Script>
<mx:List dataProvider=”{myAC}” itemRenderer=”ItemRenderer” height=”100%” width=”100%”/>
</mx:WindowedApplication> </code>
I won’t cover every line, but let’s talk a bit about the important bits - specifically the consumer. Since this application doesn’t send messages, I don’t need a producer, only a consumer. The consumer uses a channel set, myChannelSet, that I define in my init function. You can see where I commented out my local address and replaced it with the ‘production’ value. (And yes, this can be done better via Ant.) My renderer isn’t that complex, and could be sexier, but here ya go:
<?xml version="1.0" encoding="utf-8"?>
<mx:Box xmlns:
<mx:CurrencyFormatter <mx:DateFormatter <mx:Text <mx:Text <mx:Text </mx:Box> </code>
You can download the AIR application below. You can force a fake sale by simply visiting:. What’s cool is - if someone else does it, your AIR application will see it as well.
So this is probably a bit of a trivial example, but shoot, look how simple it is. I’m really excited about LCDS/BlazeDS! | https://www.raymondcamden.com/2009/05/10/More-playtime-with-Flex-AIR-ColdFusion-and-Flex-Messaging | CC-MAIN-2019-30 | refinedweb | 852 | 51.44 |
Dont know these types of questions are asked here or not but if any one has idea please help me.
i just started started learning system programming and want to pursue a career in the sys prog area.
below is the program that use a fork() call.
i read in one of the tutorials that parent process and child process uses different address spaces and runs concurrently.
that meas each process gets some slice of cpu time, then the statements in that process are executed.
my Questions:
1.is there any way to know how much timeslice each process is getting.
2.what kind of scheduling its using
3. can i print the out put one page at a time ( should wait for keypress to print next page)
4. any links that provides good system programming info(message queues, pipes,shared memory etc.. )
5. appications that uses sockets
below is some example prog:
#include <stdio.h> #include <sys/types.h> #define MAX_COUNT 200 void ChildProcess(pid_t); /* child process prototype */ void ParentProcess(pid_t); /* parent process prototype */ void main(void) { pid_t pid; pid = fork(); if (pid == 0) ChildProcess(pid); else ParentProcess(pid); } void ChildProcess(pid_t pid) { int i; char buf[40]; for(i=1; i <= MAX_COUNT; i++) { sprintf(buf, "This line is from pid %d, value = %d\n", pid, i); write(1, buf, strlen(buf)); } } void ParentProcess(pid_t pid) { int i; char buf[40]; for(i=1; i <= MAX_COUNT; i++) { sprintf(buf, "This line is from pid %d, value = %d\n", pid, i); write(1, buf, strlen(buf)); } }
thanks in advance. | https://www.daniweb.com/programming/software-development/threads/236492/fork-syscall-and-related-issues | CC-MAIN-2017-17 | refinedweb | 259 | 70.33 |
Antoine Pitrou skrev: > - protect (somehow) the GC when collecting, so that things don't get modified > under its feet > The GC would have to temporarily suspend all active threads registered with the interpreter. E.g. using the SuspendThread function in Windows API. > - protect INCREFs and DECREFs > Update using CAS (I just showed you C code for this). > - protect all mutable types (dicts being probably the most performance-critical, > since they are used for namespaces and class/object attributes and methods) > CAS. Lock-free lists and hash tables exist. We don't need locks to protect mutable types and class objects. Just use a lock-free hash-table for __dict__ or whatever. > - protect all static/global data in C modules which have them > Reacquire the GIL before calling functions in C extensions functions. The GIL is nice there, but not anywhere else. > An interesting experiment would be to add all those protections without even > attempting to remove the GIL, and measure the overhead compared to a regular > Python. Yes, one could add a nonsence CAS to existing incref/decref, and measure overhead. | https://mail.python.org/pipermail/python-ideas/2009-October/006276.html | CC-MAIN-2016-40 | refinedweb | 181 | 64.2 |
Cosmological Calculations (
astropy.cosmology)¶
Introduction¶
The
astropy.cosmology subpackage contains classes for representing
cosmologies, and utility functions for calculating commonly used
quantities that depend on a cosmological model. This includes
distances, ages and lookback times corresponding to a measured
redshift or the transverse separation corresponding to a measured
angular separation.
Getting Started¶
Cosmological quantities are calculated using methods of a
Cosmology object. For example, to calculate the
Hubble constant at z=0 (i.e.,
H0), and the number of transverse proper
kpc corresponding to an arcminute at z=3:
>>> from astropy.cosmology import WMAP9 as cosmo >>> cosmo.H(0) <Quantity 69.32 km / (Mpc s)>
>>> cosmo.kpc_proper_per_arcmin(3) <Quantity 472.97709620405266 kpc / arcmin>
Here WMAP9 is a built-in object describing a cosmology with the
parameters from the 9-year WMAP results. Several other built-in
cosmologies are also available, see Built-in Cosmologies. The
available methods of the cosmology object are listed in the methods
summary for the
FLRW class. If you’re using
IPython you can also use tab completion to print a list of the
available methods. To do this, after importing the cosmology as in the
above example, type
cosmo. at the IPython prompt and then press
the tab key.
All of these methods also accept an array of redshifts as input:
>>> from astropy.cosmology import WMAP9 as cosmo >>> cosmo.comoving_distance([0.5, 1.0, 1.5]) <Quantity [ 1916.0694236 , 3363.07064333, 4451.74756242] Mpc>
You can create your own arbitrary cosmology using one of the Cosmology classes:
>>>)
The cosmology subpackage makes use of
units, so in many
cases returns values with units attached. Consult the documentation
for that subpackage for more details, but briefly, to access the
floating point or array values:
>>> from astropy.cosmology import WMAP9 as cosmo >>> H0 = cosmo.H(0) >>> H0.value, H0.unit (69.32, Unit("km / (Mpc s)"))
Using
astropy.cosmology¶
Most of the functionality is enabled by the
FLRW
object. This represents a homogeneous and isotropic cosmology
(characterized by the Friedmann-Lemaitre-Robertson-Walker metric,
named after the people who solved Einstein’s field equation for this
special case). However, you can’t work with this class directly, as
you must specify a dark energy model by using one of its subclasses
instead, such as
FlatLambdaCDM.
You can create a new
FlatLambdaCDM object with
arguments giving the Hubble parameter and omega matter (both at z=0):
>>>)
This can also be done more explicitly using units, which is recommended:
>>> from astropy.cosmology import FlatLambdaCDM >>> import astropy.units as u >>> cosmo = FlatLambdaCDM(H0=70 * u.km / u.s / u.Mpc, Om0=0.3)
However, most of the parameters that accept units (
H0,
Tcmb0)
have default units, so unit quantities do not have to be used.
The exception are neutrino masses, where you must supply a
units if you want massive neutrinos.
The pre-defined cosmologies described in the Getting Started
section are instances of
FlatLambdaCDM, and have
the same methods. So we can find the luminosity distance to
redshift 4 by:
>>> cosmo.luminosity_distance(4) <Quantity 35842.353618623194 Mpc>
or the age of the universe at z = 0:
>>> cosmo.age(0) <Quantity 13.461701658024014 Gyr>
They also accept arrays of redshifts:
>>> cosmo.age([0.5, 1, 1.5]).value array([ 8.42128047, 5.74698053, 4.19645402])
See the
FLRW and
FlatLambdaCDM object docstring for all the
methods and attributes available. In addition to flat Universes,
non-flat varieties are supported such as
LambdaCDM. There are also a variety of standard
cosmologies with the parameters already defined (see Built-in
Cosmologies):
>>> from astropy.cosmology import WMAP7 # WMAP 7-year cosmology >>> WMAP7.critical_density(0) # critical density at z = 0 <Quantity 9.31000324385361e-30 g / cm3>
You can see how the density parameters evolve with redshift as well:
>>> from astropy.cosmology import WMAP7 # WMAP 7-year cosmology >>> WMAP7.Om([0, 1.0, 2.0]), WMAP7.Ode([0., 1.0, 2.0]) (array([ 0.272 , 0.74898524, 0.90905239]), array([ 0.72791572, 0.25055061, 0.0901026 ]))
Note that these don’t quite add up to one even though WMAP7 assumes a
flat Universe because photons and neutrinos are included. Also note
that they are unitless and so are not
Quantity
objects.
It is possible to specify the baryonic matter density at redshift zero
at class instantiation by passing the keyword argument
Ob0:
>>> from astropy.cosmology import FlatLambdaCDM >>> cosmo = FlatLambdaCDM(H0=70, Om0=0.3, Ob0=0.05) >>> cosmo FlatLambdaCDM(H0=70 km / (Mpc s), Om0=0.3, Tcmb0=2.725 K, Neff=3.04, m_nu=[ 0. 0. 0.] eV, Ob0=0.05)
In this case the dark matter only density at redshift zero is
available as class attribute
Odm0 and the redshift evolution of
dark and baryonic matter densities can be computed using the methods
Odm and
Ob, respectively. If
Ob0 is not specified at class
instantiation it defaults to
None and any method relying on it
being specified will raise a
ValueError:
>>> from astropy.cosmology import FlatLambdaCDM >>> cosmo = FlatLambdaCDM(H0=70, Om0=0.3) >>> cosmo.Odm(1) Traceback (most recent call last): ... ValueError: Baryonic density not set for this cosmology, unclear meaning of dark matter density
Cosmological instances have an optional
name attribute which can be
used to describe the cosmology:
>>> from astropy.cosmology import FlatwCDM >>> cosmo = FlatwCDM(name='SNLS3+WMAP7', H0=71.58, Om0=0.262, w0=-1.016) >>> cosmo FlatwCDM(name="SNLS3+WMAP7", H0=71.6 km / (Mpc s), Om0=0.262, w0=-1.02, Tcmb0=2.725 K, Neff=3.04, m_nu=[ 0. 0. 0.] eV, Ob0=None)
This is also an example with a different model for dark energy, a flat Universe with a constant dark energy equation of state, but not necessarily a cosmological constant. A variety of additional dark energy models are also supported – see Specifying a dark energy model.
A important point is that the cosmological parameters of each
instance are immutable – that is, if you want to change, say,
Om, you need to make a new instance of the class. To make
this more convenient, a
clone operation is provided, which
allows you to make a copy with specified values changed.
Note that you can’t change the type of cosmology with this operation
(e.g., flat to non-flat). For example:
>>> from astropy.cosmology import WMAP9 >>> newcosmo = WMAP9.clone(name='WMAP9 modified', Om0=0.3141) >>> WMAP9.H0, newcosmo.H0 # some values unchanged (<Quantity 69.3... km / (Mpc s)>, <Quantity 69.3... km / (Mpc s)>) >>> WMAP9.Om0, newcosmo.Om0 # some changed (0.286..., 0.314...) >>> WMAP9.Ode0, newcosmo.Ode0 # Indirectly changed since this is flat (0.713..., 0.685...)
Finding the Redshift at a Given Value of a Cosmological Quantity¶
If you know a cosmological quantity and you want to know the
redshift which it corresponds to, you can use
z_at_value:
>>> import astropy.units as u >>> from astropy.cosmology import Planck13, z_at_value >>> z_at_value(Planck13.age, 2 * u.Gyr) 3.1981226843560968
For some quantities there can be more than one redshift that satisfies
a value. In this case you can use the
zmin and
zmax keywords
to restrict the search range. See the
z_at_value docstring for more
detailed usage examples.
Built-in Cosmologies¶
A number of pre-loaded cosmologies are available from analyses using the WMAP and Planck satellite data. For example,
>>> from astropy.cosmology import Planck13 # Planck 2013 >>> Planck13.lookback_time(2) # lookback time in Gyr at z=2 <Quantity 10.511841788576083 Gyr>
A full list of the pre-defined cosmologies is given by
cosmology.parameters.available, and summarized below:
Currently, all are instances of
FlatLambdaCDM.
More details about exactly where each set of parameters come from
are available in the docstring for each object:
>>> from astropy.cosmology import WMAP7 >>> print(WMAP7.__doc__) WMAP7 instance of FlatLambdaCDM cosmology (from Komatsu et al. 2011, ApJS, 192, 18, doi: 10.1088/0067-0049/192/2/18. Table 1 (WMAP + BAO + H0 ML).)
Specifying a dark energy model¶
In addition to the standard
FlatLambdaCDM model
described above, a number of additional dark energy models are
provided.
FlatLambdaCDM
and
LambdaCDM assume that dark
energy is a cosmological constant, and should be the most commonly
used cases; the former assumes a flat Universe, the latter allows
for spatial curvature.
FlatwCDM and
wCDM assume a constant dark
energy equation of state parameterized by
. Two forms of a
variable dark energy equation of state are provided: the simple first
order linear expansion
by
w0wzCDM, as well as the common CPL form by
w0waCDM:
and its generalization to include a pivot
redshift by
wpwaCDM:
.
Users can specify their own equation of state by sub-classing
FLRW. See the provided subclasses for
examples. It is recommended, but not required, that all arguments to the
constructor of a new subclass be available as properties, since the
clone method assumes this is the case.
Photons and Neutrinos¶
The cosmology classes include the contribution to the energy density
from both photons and neutrinos. By default, the latter are assumed
massless. The three parameters controlling the properties of these
species, which are arguments to the initializers of all the
cosmological classes, are
Tcmb0 (the temperature of the CMB at z=0),
Neff, the effective number of neutrino species, and
m_nu, the rest
mass of the neutrino species.
Tcmb0 and
m_nu should be expressed
as unit Quantities. All three have standard default values (2.725 K,
3.04, and 0 eV respectively; the reason that
Neff is not 3 primarily
has to do with a small bump in the neutrino energy spectrum due to
electron-positron annihilation, but is also affected by weak
interaction physics).
Massive neutrinos are treated using the approach described in the
WMAP 7-year cosmology paper (Komatsu et al. 2011, ApJS, 192, 18, section 3.3).
This is not the simple
approximation. Also note that the values of
include both the kinetic energy and the rest-mass energy components,
and that the Planck13 cosmology includes a single species of neutrinos
with non-zero mass (which is not included in
).
The contribution of photons and neutrinos to the total mass-energy density can be found as a function of redshift:
>>> from astropy.cosmology import WMAP7 # WMAP 7-year cosmology >>> WMAP7.Ogamma0, WMAP7.Onu0 # Current epoch values (4.985694972799396e-05, 3.442154948307989e-05) >>> z = [0, 1.0, 2.0] >>> WMAP7.Ogamma(z), WMAP7.Onu(z) (array([ 4.98569497e-05, 2.74574409e-04, 4.99881391e-04]), array([ 3.44215495e-05, 1.89567887e-04, 3.45121234e-04]))
If you want to exclude photons and neutrinos from your calculations,
simply set
Tcmb0 to 0:
>>> from astropy.cosmology import FlatLambdaCDM >>> import astropy.units as u >>> cos = FlatLambdaCDM(70.4 * u.km / u.s / u.Mpc, 0.272, Tcmb0 = 0.0 * u.K) >>> cos.Ogamma0, cos.Onu0 (0.0, 0.0)
Neutrinos can be removed (while leaving photons) by setting
Neff to 0:
>>> from astropy.cosmology import FlatLambdaCDM >>> cos = FlatLambdaCDM(70.4, 0.272, Neff=0) >>> cos.Ogamma([0, 1, 2]) # Photons are still present array([ 4.98569497e-05, 2.74623215e-04, 5.00051839e-04]) >>> cos.Onu([0, 1, 2]) # But not neutrinos array([ 0., 0., 0.])
The number of neutrino species is assumed to be the floor of
Neff,
which in the default case is 3. Therefore, if non-zero neutrino masses
are desired, then 3 masses should be provided. However, if only one
value is provided, all the species are assumed to have the same mass.
Neff is assumed to be shared equally between each species.
>>> from astropy.cosmology import FlatLambdaCDM >>> import astropy.units as u >>> H0 = 70.4 * u.km / u.s / u.Mpc >>> m_nu = 0 * u.eV >>> cosmo = FlatLambdaCDM(H0, 0.272, m_nu=m_nu) >>> cosmo.has_massive_nu False >>> cosmo.m_nu <Quantity [ 0., 0., 0.] eV> >>> m_nu = [0.0, 0.05, 0.10] * u.eV >>> cosmo = FlatLambdaCDM(H0, 0.272, m_nu=m_nu) >>> cosmo.has_massive_nu True >>> cosmo.m_nu <Quantity [ 0. , 0.05, 0.1 ] eV> >>> cosmo.Onu([0, 1.0, 15.0]) array([ 0.00326988, 0.00896783, 0.0125786 ]) >>> cosmo.Onu(1) * cosmo.critical_density(1) <Quantity 2.444380380370406e-31 g / cm3>
While these examples used
FlatLambdaCDM,
the above examples also apply for all of the other cosmology classes.
For Developers: Using
astropy.cosmology inside Astropy¶
If you are writing code for the Astropy core or an affiliated package, it’s often useful to assume a default cosmology, so that the exact cosmology doesn’t have to be specified every time a function or method is called. In this case it’s possible to specify a “default” cosmology.
You can set the default cosmology to a pre-defined value by using the
“default_cosmology” option in the
[cosmology.core] section of the
configuration file (see Configuration system (astropy.config)). Alternatively, you can
use the
set function of
default_cosmology to
set a cosmology for the current Python session. If you haven’t set a
default cosmology using one of the methods described above, then the
cosmology module will default to using the 9-year WMAP parameters.
It is strongly recommended that you use the default cosmology through
the
default_cosmology science state object. An
override option can then be provided using something like the
following:
def myfunc(..., cosmo=None): from astropy.cosmology import default_cosmology if cosmo is None: cosmo = default_cosmology.get() ... your code here ...
This ensures that all code consistently uses the default cosmology unless explicitly overridden.
Note
In general it’s better to use an explicit cosmology (for example
WMAP9.H(0) instead of
cosmology.default_cosmology.get().H(0)). Use of the default
cosmology should generally be reserved for code that will be
included in the Astropy core or an affiliated package.
See Also¶
- Hogg, “Distance measures in cosmology”,
- Linder, “Exploring the Expansion History of the Universe”,
- NASA’s Legacy Archive for Microwave Background Data Analysis,
Range of validity and reliability¶
The code in this sub-package is tested against several widely-used
online cosmology calculators, and has been used to perform many
calculations in refereed papers. You can check the range of redshifts
over which the code is regularly tested in the module
astropy.cosmology.tests.test_cosmology. If you find any bugs,
please let us know by opening an issue at the github repository!
The built in cosmologies use the parameters as listed in the respective papers. These provide only a limited range of precision, and so you should not expect derived quantities to match beyond that precision. For example, the Planck 2013 results only provide the Hubble constant to 4 digits. Therefore, the Planck13 built-in cosmology should only be expected to match the age of the Universe quoted by the Planck team to 4 digits, although they provide 5 in the paper. | http://docs.astropy.org/en/stable/cosmology/index.html | CC-MAIN-2015-32 | refinedweb | 2,418 | 50.73 |
# We have published a model for text repunctuation and recapitalization for four languages

[](https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_te.ipynb)
Working with [speech recognition models](https://habr.com/ru/post/559640/) we often encounter misconceptions among potential customers and users (mostly related to the fact that people have a hard time distinguishing substance over form). People also tend to believe that punctuation marks and spaces are somehow obviously present in spoken speech, when in fact real spoken speech and written speech are entirely different beasts.
Of course you can just start each sentence with a capital letter and put a full stop at the end. But it is preferable to have some relatively simple and universal solution for "restoring" punctuation marks and capital letters in sentences that our speech recognition system generates. And it would be really nice if such a system worked with any texts in general.
For this reason, we would like to share a system that:
* Inserts capital letters and basic punctuation marks (dot, comma, hyphen, question mark, exclamation mark, dash for Russian);
* Works for 4 languages (Russian, English, German, Spanish) and can be extended;
* By design is domain agnostic and is not based on any hard-coded rules;
* Has non-trivial metrics and succeeds in the task of improving text readability;
To reiterate — the purpose of such a system is only to improve the readability of the text. It does not add information to the text that did not originally exist.
The problem and the solution
----------------------------
Let's assume that the input is a sentence in lowercase letters without any punctuation, i.e. similar to the outputs of any [speech recognition systems](https://github.com/snakers4/silero-models#speech-to-text). We ideally need a model that makes texts proper, i.e. restores capital letters and punctuation marks. A set of punctuation marks `.,—!?-` was chosen based on characters most used on average.
Also we embraced the assumption that the model should insert only one symbol after each token (a punctuation mark or a space). This automatically rules out complex punctuation cases (i.e. direct speech). This is an intentional simplification, because the main task is to improve readability as opposed to achieving grammatically ideal text.
The solution had to be universal enough to support several key languages. By design we can easily extend our system to an arbitrary number of languages should need arise.
Initially we envisaged the solution to be small BERT-like model with some classifiers on top. We used internal text corpora for training.
We acquainted ourselves with a solution of a similar problem from [here](https://habr.com/ru/company/barsgroup/blog/563854/). However, for our purposes we needed:
* A lighter model with a more general specialization;
* An implementation that does not directly use extrnal APIs and a lot of third-party libraries;
As a result, our solution mostly depends only on PyTorch.
Looking for the backbone model
------------------------------
We wanted to use as small pretrained language model as possible. However, a quick search through the list of pretrained models on <https://huggingface.co/> did not give inspiring results. In fact there is only one multi-language decently sized [model](https://huggingface.co/distilbert-base-multilingual-cased/tree/main) available, which still weighs about 500 megabytes.
Model compression
-----------------
After extensive experiments we eventually settled on the simplest possible architecture, and the final weight of the model was still 520 megabytes.
So we tried [to compress](https://habr.com/ru/post/563778/) the model. The simplest option is of course quantization (particularly a combination of static and dynamic as described [here](https://github.com/pytorch/pytorch/issues/65185#issue-998785028)).
As a result, the model was compressed to around 130 megabytes without significant loss of quality. Also we reduced the redundant vocabulary by throwing out tokens for non-used languages. This allowed us to compress the embedding from 120,000 tokens to 75,000 tokens.
Provided that at that moment the model was smaller than 100 megabytes, we decided against investing time in more sophisticated compression techniques (i.e. dropping less used tokens or model factorization). All of the metrics below are calculated with this small quantized model.
Metrics used
------------
Contrary to the popular trends we aim to provide as detailed, informative and honest metrics as possible. In this particular case, we used the following datasets for validation:
* Validation subsets of our private text corpora (5,000 sentences per language);
* Audiobooks, we use the [caito](http://www.caito.de/2019/01/the-m-ailabs-speech-dataset/) dataset, which has texts in all the languages the model was trained on (20,000 random sentences for each language);
We use the following metrics:
* WER (word error rate) as a percentage: separately calculated for repunctuation `WER_p` (both sentences are transformed to lowercase) and for recapitalization `WER_c` (here we throw out all punctuation marks);
* Precision / recall / F1 to check the quality of classification (i) between the space and the punctuation marks mentioned above `.,-!?-`, and (ii) for the restoration of capital letters — between classes *a token of lowercase letters* / *a token starts with a capital* / *a token of all caps*. Also we provide confusion matrices for visualization;
Results
-------
For the correct and informative metrics calculation, the following transformations were applied to the texts beforehand:
* Punctuation characters other than `.,-!?-` were removed;
* Punctuation at the beginning of a sentence was removed;
* In case of multiple consecutive punctuation marks we keep only the first one;
* For Spanish `¿¡` were discarded from the model predictions, because they aren't in the texts of the books, but in general the model places them as well;
### WER
`WER_p` / `WER_c` are specified in the cells below. The baseline metrics are calculated for a naive algorithm that starts the sentence with a capital letter and ends it with a full stop.
**Domain — validation data:**
| | | | Languages | |
| --- | --- | --- | --- | --- |
| | en | de | ru | es |
| baseline | 20 / 26 | 13 / 36 | 18 / 17 | 8 / 13 |
| model | 8 / 8 | 7 / 7 | 13 / 6 | 6 / 5 |
**Domain — books:**
| | | | Languages | |
| --- | --- | --- | --- | --- |
| | en | de | ru | es |
| baseline | 14 / 13 | 13 / 22 | 20 / 11 | 14 / 7 |
| model | 14 / 8 | 11 / 6 | 21 / 7 | 13 / 6 |
### Precision / Recall / F1
**Domain — validation data:**
| Metric | ' ' | . | , | - | ! | ? | — |
| --- | --- | --- | --- | --- | --- | --- | --- |
| | | | en | | | | |
| precision | 0.98 | 0.97 | 0.78 | 0.91 | 0.80 | 0.89 | nan |
| recall | 0.99 | 0.98 | 0.64 | 0.75 | 0.67 | 0.78 | nan |
| f1 | 0.98 | 0.98 | 0.71 | 0.82 | 0.73 | 0.84 | nan |
| | | | de | | | | |
| precision | 0.98 | 0.98 | 0.86 | 0.81 | 0.74 | 0.90 | nan |
| recall | 0.99 | 0.99 | 0.68 | 0.60 | 0.70 | 0.71 | nan |
| f1 | 0.99 | 0.98 | 0.76 | 0.69 | 0.72 | 0.79 | nan |
| | | | ru | | | | |
| precision | 0.98 | 0.97 | 0.80 | 0.90 | 0.80 | 0.84 | 0 |
| recall | 0.98 | 0.99 | 0.74 | 0.70 | 0.58 | 0.78 | nan |
| f1 | 0.98 | 0.98 | 0.77 | 0.78 | 0.67 | 0.81 | nan |
| | | | es | | | | |
| precision | 0.98 | 0.96 | 0.70 | 0.74 | 0.85 | 0.83 | 0 |
| recall | 0.99 | 0.98 | 0.60 | 0.29 | 0.60 | 0.70 | nan |
| f1 | 0.98 | 0.98 | 0.64 | 0.42 | 0.70 | 0.76 | nan |
| Metric | a | A | AAA |
| --- | --- | --- | --- |
| | | en | |
| precision | 0.98 | 0.94 | 0.97 |
| recall | 0.99 | 0.91 | 0.70 |
| f1 | 0.98 | 0.92 | 0.81 |
| | | de | |
| precision | 0.99 | 0.98 | 0.89 |
| recall | 0.99 | 0.98 | 0.53 |
| f1 | 0.99 | 0.98 | 0.66 |
| | | ru | |
| precision | 0.99 | 0.96 | 0.99 |
| recall | 0.99 | 0.92 | 0.99 |
| f1 | 0.99 | 0.94 | 0.99 |
| | | es | |
| precision | 0.99 | 0.95 | 0.98 |
| recall | 0.99 | 0.90 | 0.82 |
| f1 | 0.99 | 0.92 | 0.89 |
**Domain — books:**
| Metric | ' ' | . | , | - | ! | ? | — |
| --- | --- | --- | --- | --- | --- | --- | --- |
| | | | en | | | | |
| precision | 0.96 | 0.80 | 0.59 | 0.82 | 0.23 | 0.39 | nan |
| recall | 0.99 | 0.73 | 0.23 | 0.13 | 0.58 | 0.85 | 0 |
| f1 | 0.97 | 0.77 | 0.33 | 0.22 | 0.33 | 0.53 | nan |
| | | | de | | | | |
| precision | 0.97 | 0.75 | 0.80 | 0.55 | 0.21 | 0.41 | nan |
| recall | 0.99 | 0.71 | 0.49 | 0.35 | 0.58 | 0.67 | 0 |
| f1 | 0.98 | 0.73 | 0.61 | 0.43 | 0.30 | 0.51 | nan |
| | | | ru | | | | |
| precision | 0.97 | 0.77 | 0.69 | 0.90 | 0.17 | 0.49 | 0 |
| recall | 0.98 | 0.60 | 0.55 | 0.61 | 0.68 | 0.75 | nan |
| f1 | 0.98 | 0.68 | 0.61 | 0.72 | 0.28 | 0.60 | nan |
| | | | es | | | | |
| precision | 0.96 | 0.57 | 0.59 | 0.96 | 0.30 | 0.24 | nan |
| recall | 0.98 | 0.70 | 0.29 | 0.02 | 0.40 | 0.68 | 0 |
| f1 | 0.97 | 0.63 | 0.38 | 0.04 | 0.34 | 0.36 | nan |
| Metric | a | A | AAA |
| --- | --- | --- | --- |
| | | en | |
| precision | 0.99 | 0.80 | 0.94 |
| recall | 0.98 | 0.89 | 0.95 |
| f1 | 0.98 | 0.85 | 0.94 |
| | | de | |
| precision | 0.99 | 0.90 | 0.77 |
| recall | 0.98 | 0.94 | 0.62 |
| f1 | 0.98 | 0.92 | 0.70 |
| | | ru | |
| precision | 0.99 | 0.81 | 0.82 |
| recall | 0.99 | 0.87 | 0.96 |
| f1 | 0.99 | 0.84 | 0.89 |
| | | es | |
| precision | 0.99 | 0.71 | 0.45 |
| recall | 0.98 | 0.82 | 0.91 |
| f1 | 0.98 | 0.76 | 0.60 |
As one can see from the spreadsheets — even for Russian, the hyphen values remained empty, because the model suggested not to put it down at all on the data used for calculating metrics, or to replace the hyphen with some other symbol (as can be seen in the matrices below); seems that it's placed better in case of sentence in the form of definition (see the example at the end of the article).
### Other solutions
For reference here are some available F1 metrics for different solutions of similar tasks — for different languages, on different validation datasets. It's not possible to compare them directly, but they can serve as a first order approximations of metrics reported for overfit academic models. The classes in such models are also usually different and more simplified — `COMMA, PERIOD, QUESTION`:
| Source | COMMA | PERIOD | QUESTION |
| --- | --- | --- | --- |
| [Paper 1 — en](http://noisy-text.github.io/2020/pdf/2020.d200-1.18.pdf) | 76.7 | 88.9 | 87.8 |
| [Paper 2 — en](https://www.researchgate.net/publication/348618580_Automatic_punctuation_restoration_with_BERT_models) | 71.8 | 84.2 | 85.7 |
| [Paper 3 — es](http://rua.ua.es/dspace/bitstream/10045/117479/1/PLN_67_05.pdf) | 80.2 | 87.0 | 59.7 |
| [Repository 4 — fr](https://github.com/benob/recasepunc) | 67.9 | 72.9 | 57.6 |
### Confusion matrices
Confusion matrices for books:
#### en

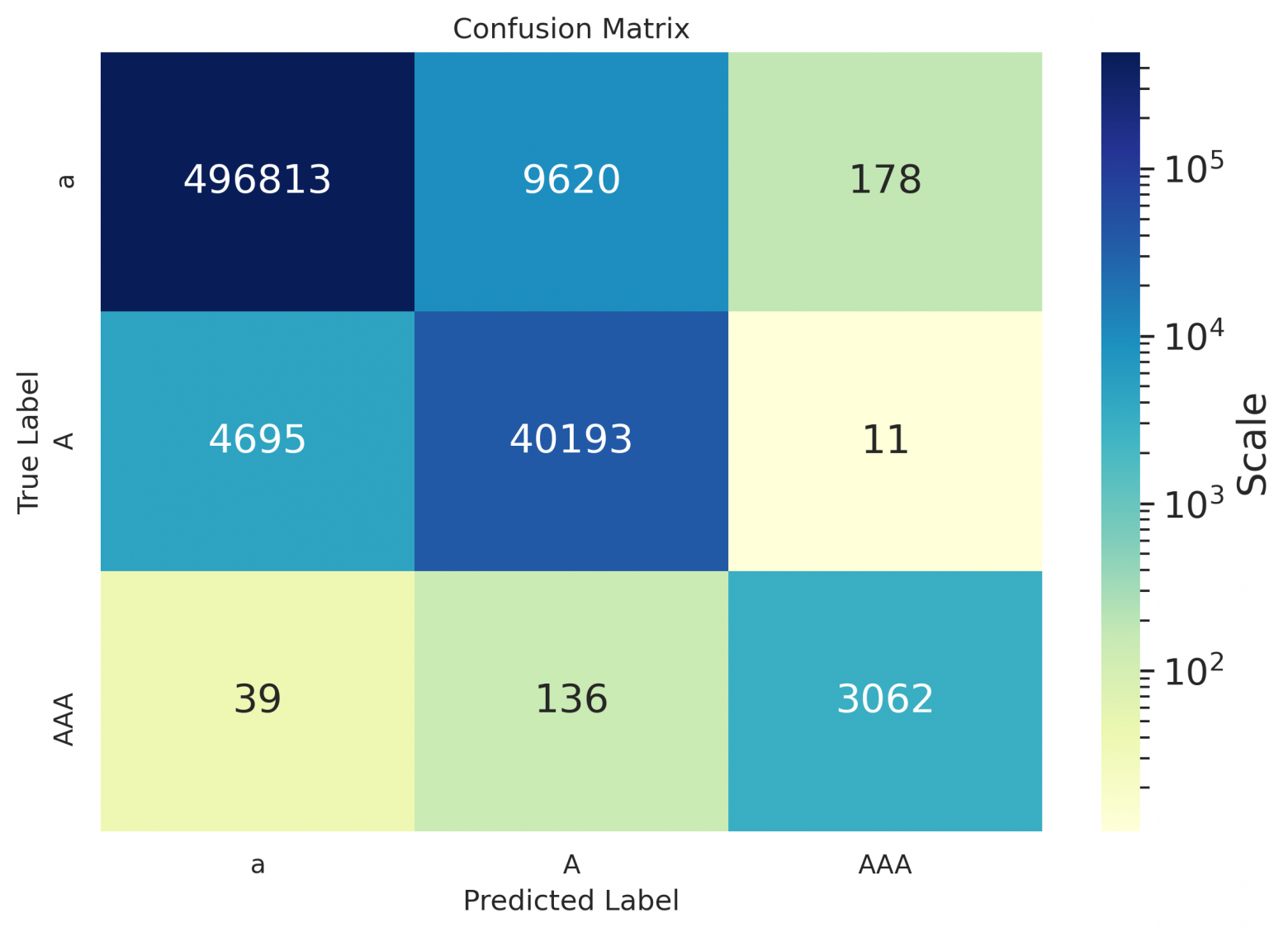
#### de
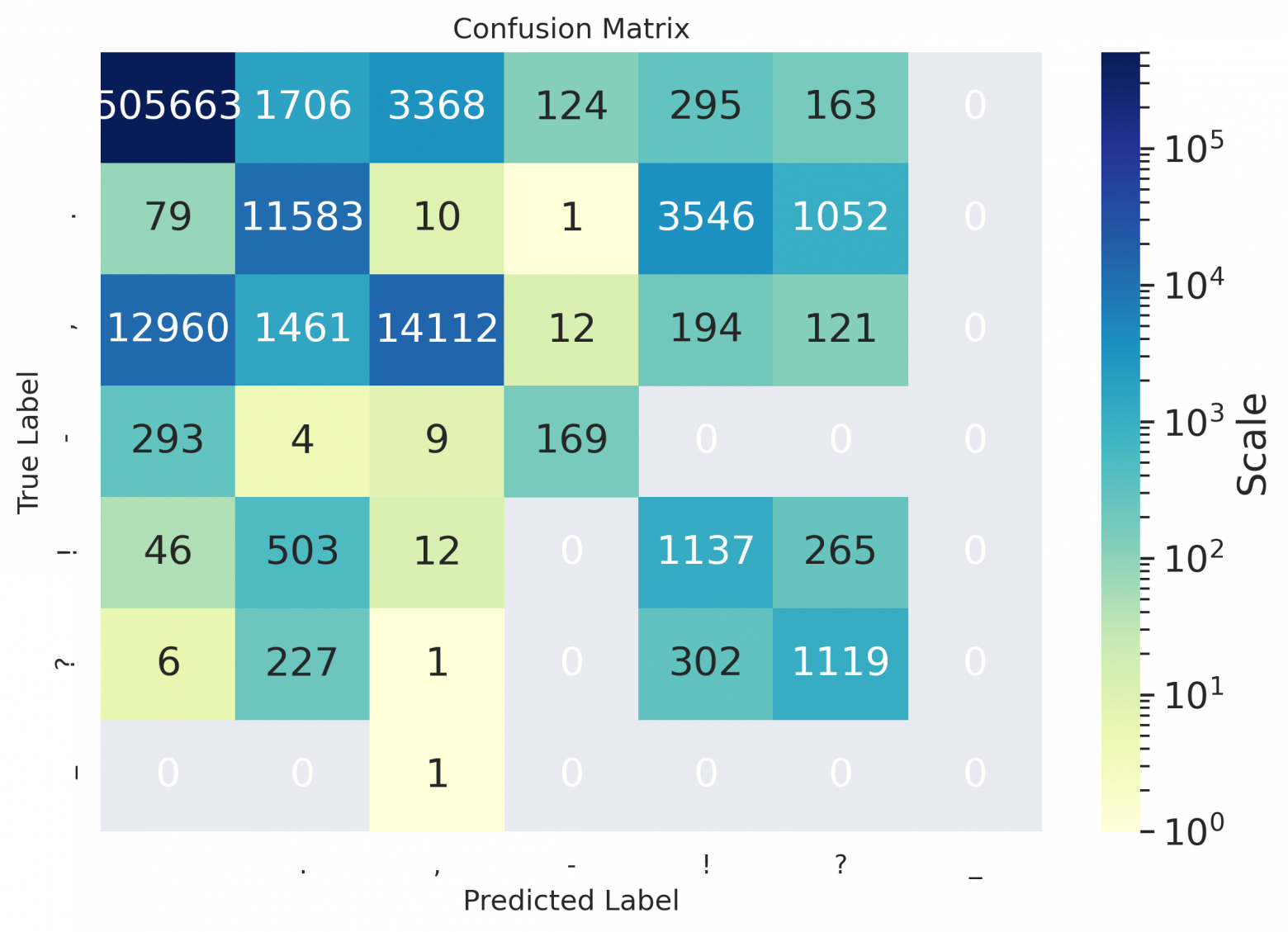
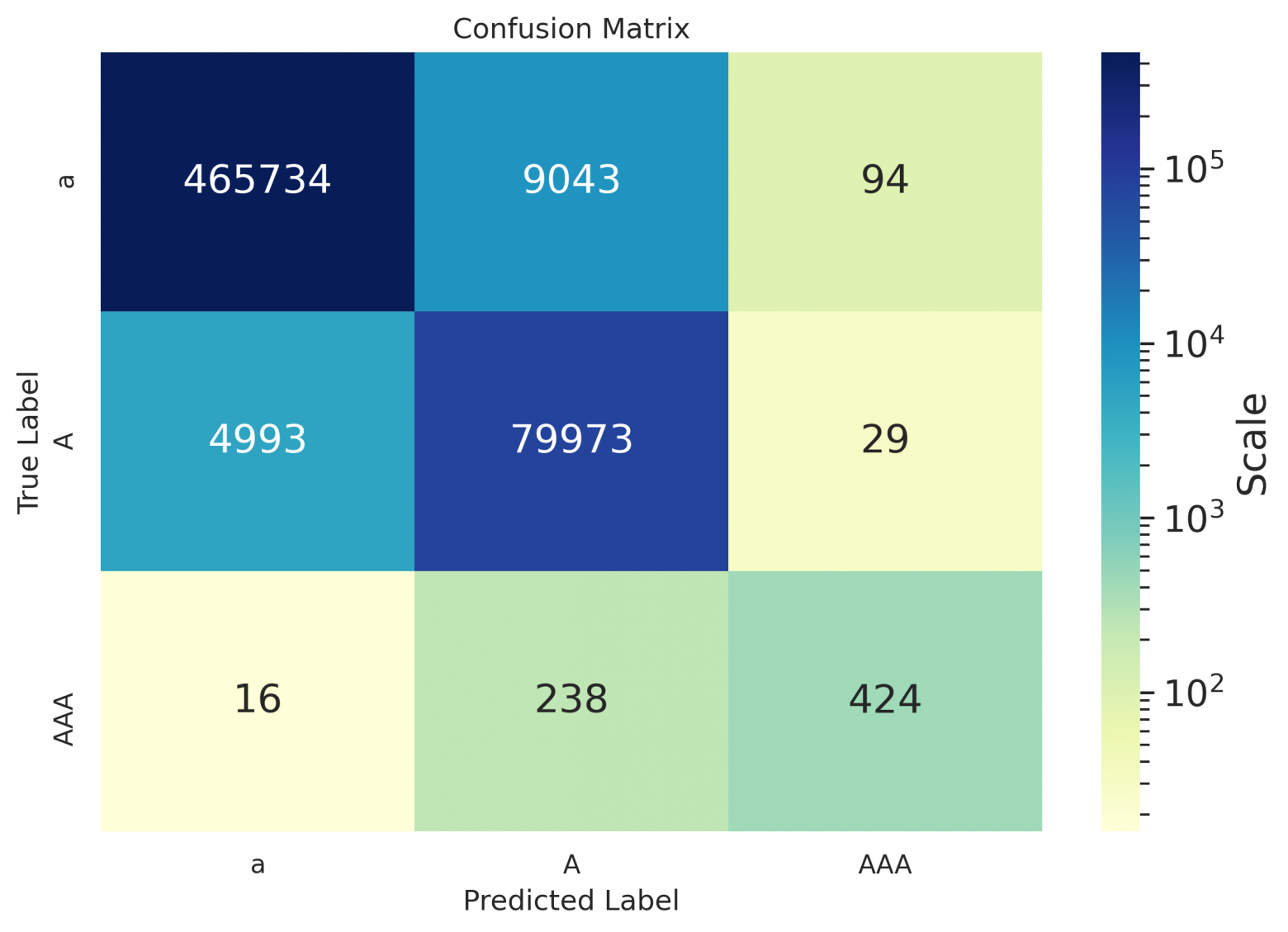
#### ru
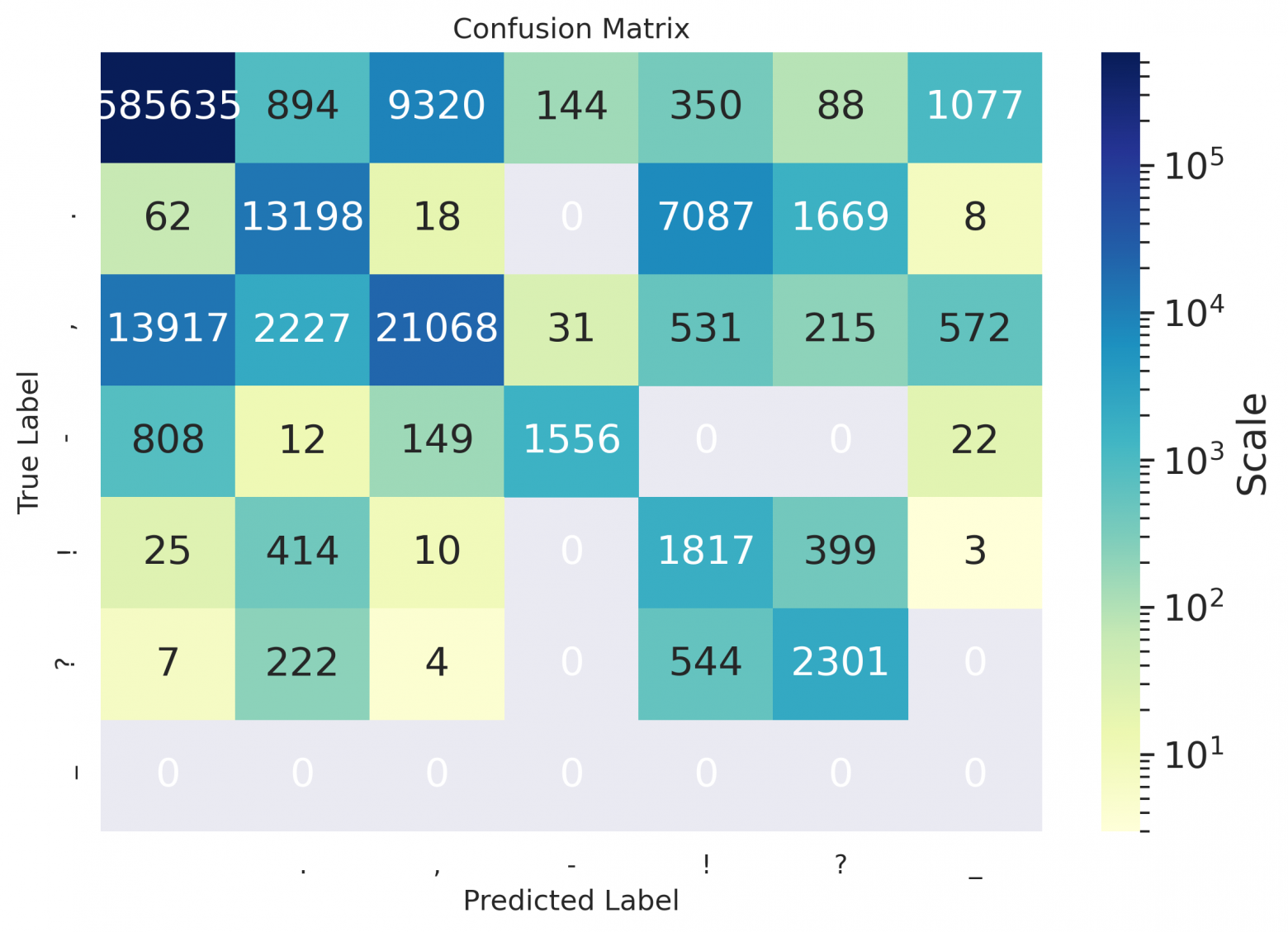
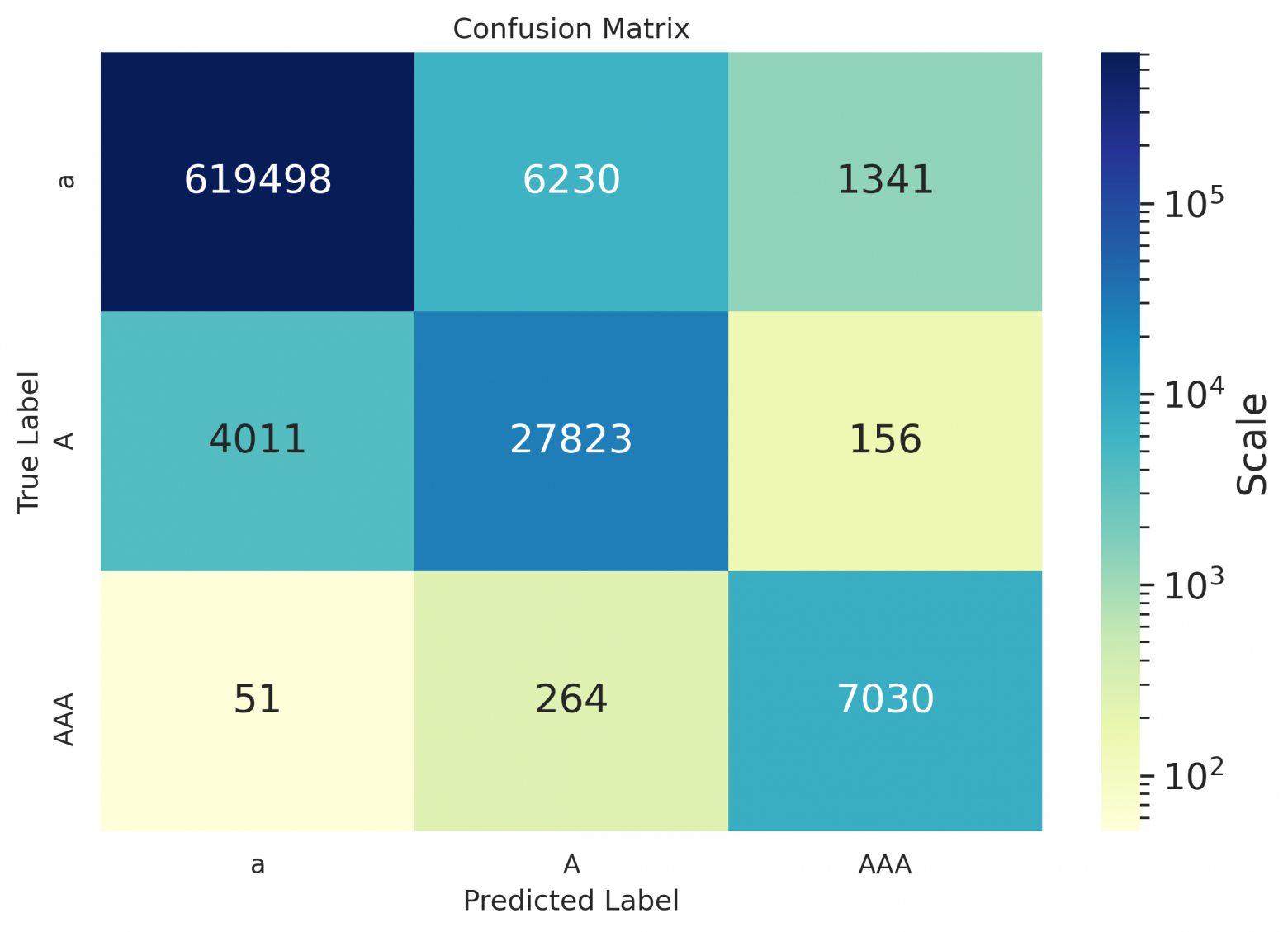
#### es
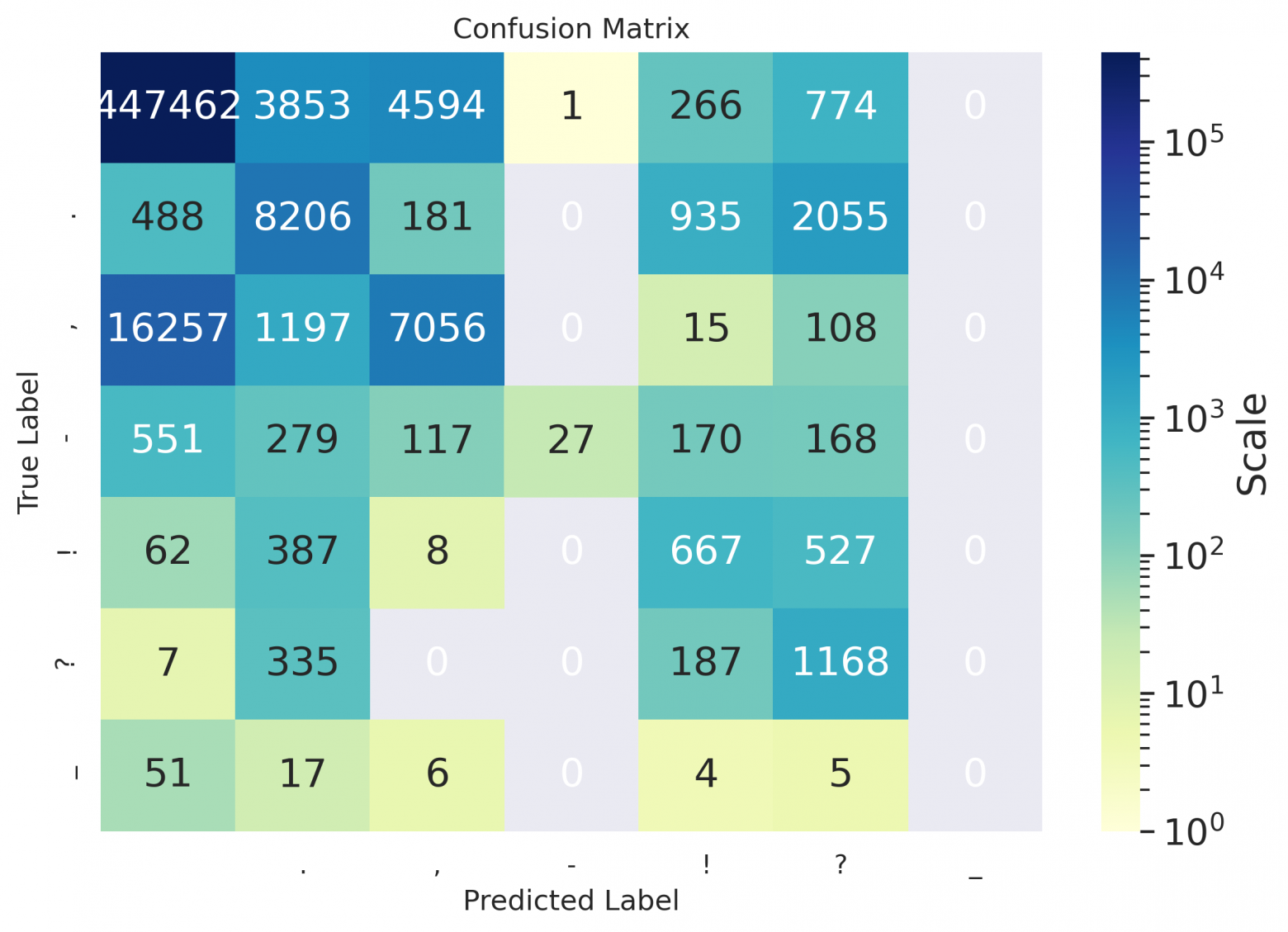
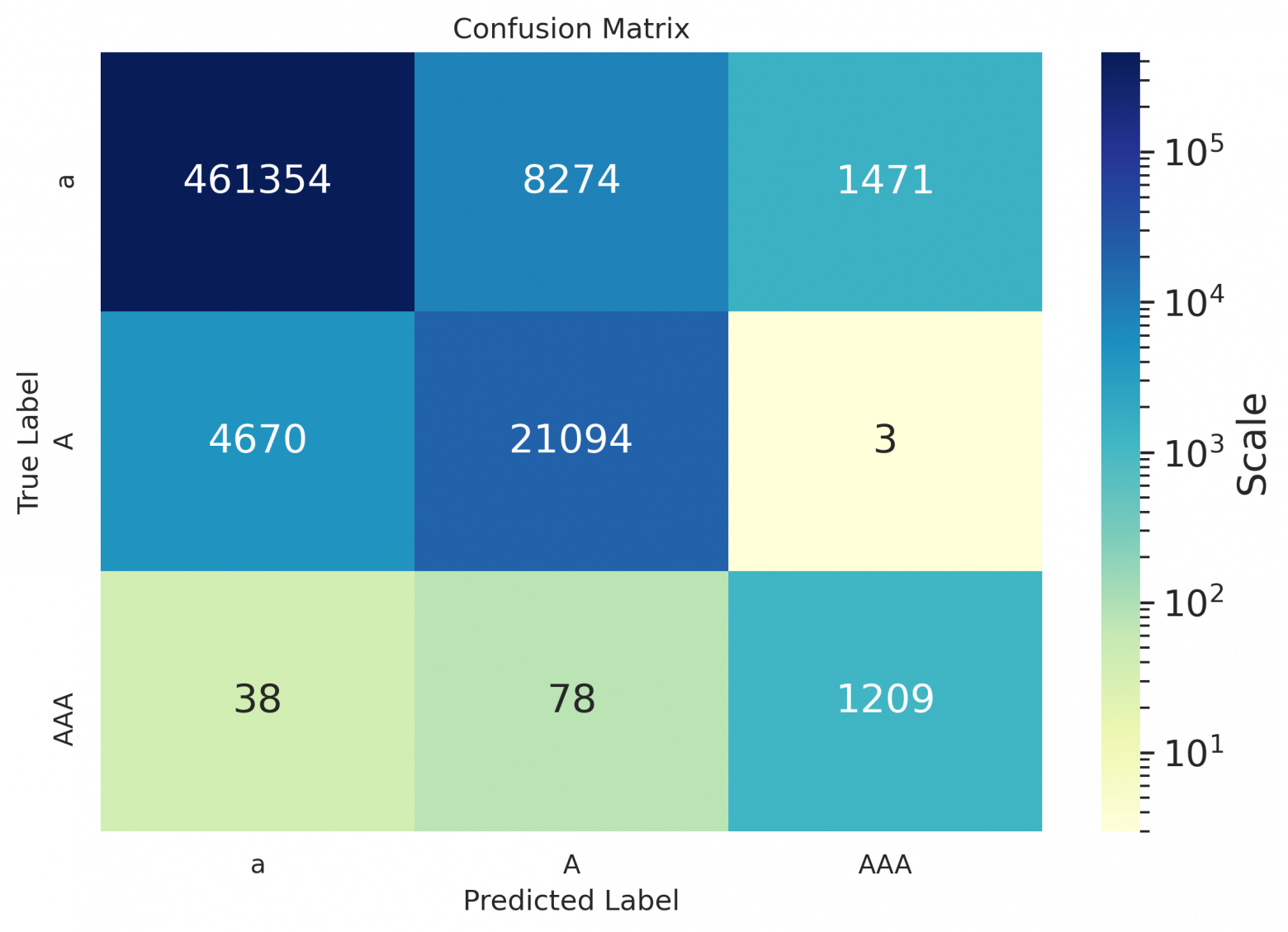
### Model output examples
| Original | Model |
| --- | --- |
| She heard Missis Gibson talking on in a sweet monotone, and wished to attend to what she was saying, but the Squires visible annoyance struck sharper on her mind. | She heard Missis Gibson talking on in a sweet monotone and wished to attend to what she was saying, but the squires visible annoyance struck sharper on her mind. |
| Yet she blushed, as if with guilt, when Cynthia, reading her thoughts, said to her one day, Molly, youre very glad to get rid of us, are not you? | Yet she blushed as if with guilt when Cynthia reading her thoughts said to her one day, Molly youre very glad to get rid of us, are not you? |
| And I dont think Lady Harriet took it as such. | And I dont think Lady Harriet took it as such. |
| -- | -- |
| Alles das in begrenztem Kreis, hingestellt wie zum Exempel und Experiment, im Herzen Deutschlands. | Alles das in begrenztem Kreis hingestellt, wie zum Exempel und Experiment im Herzen Deutschlands. |
| Sein Leben nahm die Gestalt an, wie es der Leser zu Beginn dieses Kapitels gesehen hat er verbrachte es im Liegen und im Müßiggang. | Sein Leben nahm die Gestalt an, wie es der Leser zu Beginn dieses Kapitels gesehen hat er verbrachte es im Liegen und im Müßiggang. |
| Die Flußpferde schwammen wütend gegen uns an und suchten uns zu töten. | Die Flußpferde schwammen wütend gegen uns an und suchten uns zu töten. |
| -- | -- |
| Пожалуйста, расскажите все это Бенедикту — послушаем, по крайней мере, что он на это ответит. | Пожалуйста, расскажите все это бенедикту, послушаем, по крайней мере, что он на это ответит. |
| Есть слух, что хороша также работа Пунка, но моя лучше. | Есть слух, что хороша также работа пунка, но моя лучше! |
| После восстания чехословацкого корпуса Россия зажглась от края до края. | После восстания Чехословацкого корпуса Россия зажглась от края до края. |
| -- | -- |
| En seguida se dirigió a cortar la línea por la popa del Trinidad, y como el Bucentauro, durante el fuego, se había estrechado contra este hasta el punto de tocarse los penoles, | En seguida se dirigió a cortar la línea por la popa del Trinidad y como el Bucentauro, durante el fuego se había estrechado contra este hasta el punto de tocarse los penoles. |
| Su propio padre Plutón, sus mismas tartáreas hermanas aborrecen a este monstruo Tantas y tan espantosas caras muda, tantas negras sierpes erizan su cuerpo! | Su propio padre, Plutón, sus mismas tartáreas hermanas, aborrecen a este monstruo tantas y tan espantosas caras muda tantas negras sierpes erizan su cuerpo. |
| Bien es verdad que quiero confesar ahora que, puesto que yo veía con cuán justas causas don Fernando a Luscinda alababa. | Bien, es verdad que quiero confesar ahora que puesto que yo veía con cuán justas causas, don Fernando a Luscinda Alababa? |
How to run it
-------------
The model is published in the repository [silero-models](https://github.com/snakers4/silero-models). And here is a simple snippet for model usage (more detailed examples can be found in [colab](https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_te.ipynb)):
```
import torch
model, example_texts, languages, punct, apply_te = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_te')
input_text = input('Enter input text\n')
apply_te(input_text, lan='en')
```
Limitations and future work
---------------------------
We had to put a full stop somewhere (pun intended), so the following ideas were left for future work:
* Support inputs consisting of several sentences;
* Try model factorization and pruning (i.e. attention head pruning);
* Add some relevant meta-data from the spoken utterances, i.e. pauses or intonations (or any other embedding); | https://habr.com/ru/post/581960/ | null | null | 2,509 | 56.35 |
Object.GetType Method ()
Assembly: mscorlib (in mscorlib.dll)
Because System.Object is the base class for all types in the .NET Framework type system, the GetType method can be used to return.
using System; public class Example { public static void Main() { int n1 = 12; int n2 = 82; long n3 =.
using System; public class MyBaseClass { }()); } } // The example displays the following output: // mybase: Type is MyBaseClass // myDerived: Type is MyDerivedClass // object o = myDerived: Type is MyDerivedClass // MyBaseClass b = myDerived: Type is MyDerivedClass
Available since 8
.NET Framework
Available since 1.1
Portable Class Library
Supported in: portable .NET platforms
Silverlight
Available since 2.0
Windows Phone Silverlight
Available since 7.0
Windows Phone
Available since 8.1 | https://msdn.microsoft.com/en-us/library/windows/apps/system.object.gettype(v=vs.110).aspx | CC-MAIN-2017-26 | refinedweb | 115 | 61.53 |
?"1 MM a M nana wwwBWwyV'1'"11 1AM J WLPKarWWWgrtft'gP
r. . i r"r.Vy t : i M TV I
! fV"'il " W 11 ' """ 'n'lTr-.y a aw leaf i'i l'o?-rv' TH" A ' "
ill)- :ltr ffi M JPp 0
t- 'M '- Wk "i .f.f.- - ;.:,". ?rt
7citj.iq r.-urfs 0
COLUMBUS, OHIO, THURSDAY MORNING, OCTOBER'8, 18G8. 1 ;
; :-' ; - ' l .- ' -.' ' ' ' . . .. I J . :.,il ! ' i- f , - - .............
"'NUMBKR'32.
3 "tw J--;-l L.!f,
mmmiMoi)MYm - ::::: 'XXH' h
.vrvriKiJ . .t as5iJfi rn-a-l t ' rtrri'i v' r-a J- IV." '' '
How We are Taxed and What
We are Taxed For.
SPEECH OF
JOHN H. JAMES,
At London, Ohio, Sept. 21, 1868.
Hi DMetintr of tb Democrmcy and other
Jt!etia of London' was beld at Toland
Hall, on Monday evening:, Septembei; 21st,
1968." The meeting was presided: over by
Colonel "WhJ IT. "who Introduced
Mr JAitfe,': who 8iX)k in gobstance, as fol
lows: . - .i.?..?. ... ..: j... :!. A
have been, announced tagpeak to you thl9
. evening-.on tii abject : 1 our- taxes and
flnancen.- It is a snbject that is, perhaps,
jrenerall J"'reffHrded as rather' dry and, un
- terstiM.-Ad in ordinary- -times,- per
haps, it is. But wnen times are hard, basl
esg doll od money ecarce;: when men
who ewe money find It difficult to pay, and
when creditors find it difficult to' collect,
few political questions possess so much in
terest as those which relate to these very
questions, of' finance; which- concern the
taxes we pay and the objects for which we
re required to pay them. i I is a matter
wbich eonaes dirccly home to -'men's busi
ness and bosoms." i When we approach it,
we leave the realm . of abstract political
discussion, and come to the -consideration
of a matter of business having a personal
interest to each one ol us. It Is to this sub
jeet therefore, that I Invite your attention
this evening. . .' . .
-! We are the most heavily taxed and debt
burthened people on the face of the earth.
Our debtts absolutely larger than that of
France or any other European nation ex
cept England, and comparing the popula
tion and wealth of the two countries, is
relatively' much greater than that of Eng
land,' while the rate of interest paid by us
-six per cent, nominally.; but as I will
Show, much more is vastly greater than
liers. ' As presented' by orators and editors
of-'thex-Radlcal party, 'I have -been-- led
to believe that it is the key note of their
present campaign .It: -was claimed that,
voder the- system of taxation established
by ttoe Republican party, and now in
force, that the taxes for the support of the
United States Government and its immense
expenditures, fall .mainly- on a few indi
viduals, and those of a class which can
best afiord to pay, while the mass of the
people were exempt; or, as Mr. Lawtence
remarked to his constituents In the neigh
boring county of Champaign, not one man
in thirty in the county paid any Federal
taxes at all; that the large manufacturers,
the men ' who owned distilleries, or were
engaged In- the manufacture and sale of
tobacco, "or who possessed large incomes,
paid the taxes.- This was coupled with the
charges which was certainly-entitled to
claim the merit' of originality, to say the
least), that because the platform of the Na
tional Democratic Convention- demands
equal taxation of all kinds of property, in
cluding Government bonds, that therefore
the party was in iavor of charging all the
taxes now raised from duties on imports
and other forms of indirect taxation upon
the land of the farmer and the property of
the country at large, and thus making the
farmers and others pay . large taxes, from
which they are now exempt. Now this
bas a specious appearance,' which' may
deceive some persons. . Some men may say
"these United States taxes don't concern
nfe especially? the collector' and assessor
don't come after . me. And they may
think that the United States taxes really
fall only on a:few: of the more wealthy
classes of the- community, and that they
are exempt from paying them. ; '. .-.
But the fallacy of all these arguments,
used to reconcile the people to the burdens
under which they labor, will be readily
seen, when our systems of State and Fed
eral taxation are once understood. A.nd I
am firmly convinced that the lack of a
ceneral understanding of the nature and
extent of our taxation, or our debt and our
expenditures,' bas been the main reason
that they have been so long acquiesced in,
and the party which is responsible for them
entrusted by the -people with any power
whatever. There' were, It Is true, other
causes which contributed to produce this
uatient acquiescence on the part of the
people Most of the debt was contracted
and the high taxes first imposed during the
war, when, every one expected large expen
ditures and hish taxes, and when very
many persons were deterred by patriotic
considerations and a fear of injuring the
pnblic credit, from looking too closely into
tne puoitc nnances. - men, too, is was a
period of expansion of the currency; money
was plenty and business active, and men
did not feel the pressure as they are begin
ning to now, and as they will more and
more But these causes have ceased to op
erated The war has been over for more than
three years. 'The "flush times' which ac
companied and immediately followed the
war. are over too. I am satisfied that the
only remaining cause for the apparent apa
thr of the Deoole on this subject is a ten
eral failure to understand and appreciate
how much money is year after year drawn
from- their pockets-end for-what it is ex
pended. . The taxes levied : by the United
States-are mainly ' indirect they are not
directly felt by those who pay them ? it was
not intended by those who laid them that
they should be, The system of taxation in
its details is an Intricate one, comprised in
voluminous statutes not generally accessi
ble." .Now, in brief, what is this system ? i
The taxes we pay are of two kinds
State and United States. The State taxes,
which we pay to our connty treasurers, are
the most familiar to us; so familiar indeed
that it is hardly worth while to refer to the
mode Of their collection. 'With' the ex
ception of the road tax,' which Is rather a
commutation for labor on the roads than
a tax, our State taxes, as you are aware,
are exclusively a tax on property or capi
tal every person paying in the same pro-i
portion on what he owns and is perhaps
as nearly equal and just a system as we can
expect to have. Periodical valuations are
made of , all the property of the people of
the real estate every six years and of the
personal ' property - annually- a sufficient
percentage of. taxation is levied upon It to
raise the amount needed for the use of the
State and municipal governments the sup
port of schools and other purposes, and
ypuTgo to the treasurer's office and pay the
amounts so levied annually or semi-annu-.
ally as you prefer. L. Now this system has
not been affected or changed since the war,
so far as the mode of collection is concern
ed. But let us see how the Federal -debt
and finances affect the amount of our State
taxet. .'1 i - :" -: '..
Before the war all the property In the
State, of every kind, (except eh urch, school
and public property aud a $50 exemption
to each taxpayer) was on the duplicate
for taxation.. No form of private proper
ty,' Whether owned by Individuals orcor
po0attoarwaa exempt.- All paid its share.
There was no privileged class of citizens
entitled to bold large amounts of property
exempt from tsxatton. Now what have
we? United States bonds have been is
sued to the amount of over $2,000,000,000,
exemnt from all State and municipal taxa
tion. Now, as I heard a very able speaker
remark the other evening, were is no mys
tery about the8e United States bonds. Au
impression seems to have been dissemina
ted that thev are different from Other prop
erty ; that there is something sacred about
tnem, mat they must not De taxea. y.&ow
they are simply private property just like
n your horse or your farm. Tnere Is no dif
ference In principle between public busi
ness or finance and private business. . II
you wish to borrow money you give your
note. r The note you give is property. The
holder can sell It, anditnassea (mm hand
to band like other property, and is subject
no auuiu uu ukusr property. . . xoe (xoy
ernment wants to borrow
its note which is a United States bond
A man sells his farm which was subject to
taxation anu ilyctu iuo price m United
States bonds. Why should ' the mere
change of- orm affect iw taxability But
these bonds, are exemnt from taxation. Ot
the total amount of them, Jl(l estimated
'
1
byrthe Auditor of State that about rone.
hundred million dollar, are. held in ! the.
State of Ohio. What is the result? This
Vast amount of property has been with
Irawn from the duplicate. It was former
ly Invested in real estate, loaned on bond
or mortgage, or employed In business; and
in each case- it' bore its? share of taxation
and at the same time contributed to swell
the "productive capital of the country.
Now it is converted into bonds and exempt
from taxation. On what-do -the burdens
It used to bear fall ? On your property and
mine on all the remaining property of the
conn'iy.
I Let us look for a moment at the practical
operation" of this thig-A farmer' has a
farm, worth say ten thousand dollars ; his,
taxes will' be in onnd ' numbers, not far
from two hundred dollars a year, according
to the rateot local taxation.' You know
the rate of taxation varies in different
townships and localities. I was looking
the other day in 'the Treasurer's office of
Champaign county, at the statement which r
the treasurer will shortly publish, as he
does every year, showing the rate of taxa
tion In each township And city in the coun
ty. In one township it was $2 55 on every
lOOOO of property, or over 2- per eent. &
in another it was about 2) per cent. I sup
pose the rates of taxation will not be very
different in this county from what they are
in Champaign. The taxes then on the farm
worth $10,000. will not be far from $200 00
a year, and this the farmer will have to
Day.-'Hienelghbor who has the same amonnt-
ln vested In bonds, rides over the same -
roads, sends his children to the same school,
receives the same protection and advan
tages from the' Governments, and on his ten t
thousand dollars pays no taxes at all.
Take the case of .a merchant, mechanic
or professional man living in town who
owns the store, shop or omce in wnien ne
carries on business and the house in which
he lives. - He must pay taxes, on them to
the State, and also to the town or city, for
the expenses of police, the ' fire .depart
ment, the lighting of the streets, and other
similar purposes. But the law exempts
bonds from all State, county, and munici
pal taxes, and enables-their owner toenjy
these advantages free of charge. .- This in.
equality manifests itself in all conditions
of society. Suppose a .lady of limited
means jhasv five' thousand dollars the
amount, Derhaps, of a life insurance policy
invested in notes or mortgages for
everybody can't hold Government bonds.
The income from it . at six. per cent.
(which is .all she can legally collect) will
be $300 per year in paper, and of this she
will have to pay annually for taxes to the
State from $50 to $150; depending on the
rate of taxation in the locality where she
lives. But her; neighbor,-: whose invest
ment is In bonds, may own double the
amount of her estate and draw six per
cent.-interest" In "gold equal to eight of
nine per cent. In paper and pay no taxes
at all.
Again : suppose the guardian of orphan
children has -t their property invested say
before trie war on a long loan at legal in
terest. From one-fourth to one-half of the
amount (according" to the rate of local '
taxation) intended for their support and
education must be paid yearly to the State
for taxes, v - - " '-----
And this is a matter in which we are all
interested. -Tne poor man's house how
ever poor, Is taxed ; his horse, his cow, his
furniture, his tools, and impliments, the
means of bis own and children's livelihood
if they exceed $50 in value, all are taxed.
How much they are taxed, depends on the
amount of the local taxation of the place of
his residence it varies, as I have said, in
different places and at . different times..
xne ' rate vanes irom one per cent,
or a little less, which is the mini
mum, to 3V3 per .cent, and .some times
more. The' average rate will notk vary
much from two per cent; that Is, for every"
$100 worth of property you have you
must pay an average of $2. If you have
a horse worth $100, the taxes on him, for
instance, would be about $2 a year. But
the bondholder, so tar as his bonds are con
cerned, is altogether independent of the
local taxation ot the county. ' It makes no -
difference to him whether the taxes are one
per cent.or three per cent. His bonds are
exempt by law from State or municipal
taxation.
But I anticipate the answer of my Re
publican friend. - He will say that the law
under which the bonds were issued pro
vided, that they should be exempt from
taxation, and that to tax them now would
be a breach of faith. But this is a mistake.
The htw-never- provided thatrthey should
be exempt from taxation.' .What the law
did provide was,' that they should bs ex
empt from State and municipal taxation.
And they could qpt have been so taxed if
the law -had . not so -enacted.- - The States
cannot tax the bonds of the United States,
becausi it they could they might tax them
to such an extent as to impair their -value
and destroy the constitutional power of the
United States to borrow money.' The Su-'
preme Court of the United States has deci
ded this point, and the provision of the law
was merely cumulative; merely affirmed;
what had been established by judicial de
cision. But the law nowhere provides that
the bonds shall not be taxed by Congress;
and Congress has twice exercised the pow
er of taxing them : First, in levying an
income tax of 3 per cent, on the income
derived from interest on United States se
curities (when income from, all -other
sources bore a tax of 5 per cent.), and sec
ond, when they raised that tax to 5 per
cent., in common with other incomes, or to
10 per cent.il the income exceeds ten'
thousand dollars a year. - The only diffi
culty is,' that ' Congress, ' legislating in
the -interest of the bondholders, has
laid upon the bonds (where they are taxed
at all) a tax so trifling in amount as to make
the taxation grossly unequal and unjust.
Let me explain. The rate of State and mu
nicipal taxation will average,as I remarked, .
about 1 to 2 per cent, on the capital or
principal of a person's property. - It you:
hold the note of a private individual for
$1,000, the Interest you will receive on it at
the legal rate of 6 per cent; will - be $60 00
a year, and of this yon will - have to pay
for taxes $15 to $20 a year, which is to
2 per cent, on the amount of the note" One-
thira or one-iourtu 01 your income men, or
25 to 33 per cent, goes for tax. But the,
holder ' of United States' bonds pays no ;
taxes upon them at all. unless .-the interest
from them amounts to $1,000 a year.or forms
part of an income of $1,000 a year, and
even then he only pays a tax of 5 per cent:
of the income, while your securities, subject ;
to State taxation, pay 20 to 3d per cent
While you pay one-third or one-fourth of
your income from such sources for taxes,
the bondholder (if be pays any at all) pays
one-twentieth ei his. It his income is less
than $10,000 a year, and If it is more than
that he only pays 10 per cent-, or one-tenth
of his income, while you. though your in-
cemB-msy not exceed $800 a year; pay one--"?
thira or yours.- ij- t: .'-
Is this equality before-the-law? 'Yet
this is the system you are asked to sustain
In voting the Republican ticket.- The posl--tloh-of
the two parties on this subject is'
substantially this : The Republican party
propose that one class of the people shall
bold the securities and draw the interest,
while another class pays the interest and
the taxes. '. The Democratic party propose -that
all men shall be taxed alike on what
thev own. "The very head and lro'nt of
our offending," in demanding equal taxa
tion for which we are so nercely denounced,
"hath tnis extent ; no more." . .
i So much for our State taxes and the way
In which they are affected by the exempt
ion of the Ualted States bonds from taxa
tion. -Now as to the, taxes which we pay
to the United States :
These taxes are mostly paid indirectly
and are of several kinds. And fiist duties
on imports. Before any kind of imported
goods or manufactures can be landed in this
country, they are required to pay at the
Custom House a duty in gold.-. This duty
is sometimes specific, as when a tax of so
much per pound, or per ton, is laid on cer
tain articles, but is generally a percentage
on the value of the imported fabrics, or,,
sometimes, both duties are laid on the
same article. For instance, imported
screws, such as yon buy at the hardware
stores, are required to pay aduty of eleven
cents per pound ; imported boots and shoes
pay a duty of 40 per cent, on their value.
On every pound ot tea imported, a tax of
25 costs U levied ; on every pound of su-jar
from 3 to 5 cents; on every gallon of
molasses 8 cents; on every spool of thread
a tax of about 51 percent, on its value,
and so on. I mention these merely as in-
stances of the duties on some of the most
com n:on articles ot dally nse. Now wh at
is the practical operation of these duties?
Hnw do thev affect the people ? Take lor
instance the' very common article of
1 tea.
The duty upon u -is zo cents
a pound, payable In gold. ' Who pays this
tax? The importer, In the first place, before
be can remove the goods from the custom
house. But does he pay this twenty-five
cents a pound out of his own' pocket and
sell the pound ot tea for the same as if he
had hot been required to pay anything? Of
uuu iuu uiignt as wen ex pee l mm
to pay the freight across the water without
getting it back. It simply adds that much
to the price of the tea Now when your
wholesale grocer goes to New Tork to buy
groceries,-.what will the Importer charge
him for tea?. First, the cost of the article
abroad; next, the freight and other ex
penses of importation, including his profits,
and third, the twenty-five cents duty in
gold, equivalent to at least thirty-five cents
In paper. The retail dealer pays the same
price to the wholesale dealer, with the ad
dition ot another profit, and when you go
Co the store to buv a pound of tea you pay
it all together. Now. what do you pay for
tea? From $125 to $2 00 per pound. Then
aboat one-fourth or one-filth of the price
you pay for every pound ot tea is tax to
the Government So with sugar. What
do you pay for sugar? " The cheapest you
can buy is i cents a pound; the best
about "0 cents. -
Well, if von turn to the" U. S. Statutes at
large, vol. 13, page 202, you will find that
the duty on sugar ranges from 3 to 5 cents
per pound in gold, according to its quality,
or from 411 to 7J cents per pound in paper
currency. Well, 4 cents, the lowest duty,
is more than one-tuird of the price of the
lowest priced article you can buy, and 1
cents, the highest duty, considerably more
than a third of what you pay for the high
est priced article. So on every pound ot
sugar you buy, whether cheap or dear, you
pay more than one-third ot Its price to the
Government for tax.
And it is one ot the peculiar beauties of
this system ot taxation devised by the Rad
ical party in Congress, that on many arti
cles the poorer a man is, the more he seeks
to economise and the cheaper the article he
buys, the more tax he has to pay In pro-
f onion. Take the article of tea, of which
just spoke. The retail price varies from
$1 25 to $2.00 per pound. The tax on all
kindsof tea is 25 cents in. gold, or about 36
cents in paper. If you buy tea at $2 00 the
tax is about 18 per cent.or its value, or
nearly 01 e-fiftb ; but if you buy a cheaper
tea at $1 25. the tax is about 30 per cent., or
nearly one-third.; - .
Coffee, tea and molasses, and pepper and
other articles of every day us in every
household, which in our state of society
have come to be regarded as among the ordinary-
necessaries of life,- are, taxed
through these import duties in the same
way. And these,- you will observe, are all
articles ot foreign growth or production
exclusively, for the only ones of those 1
have mentioned we ever produced, were
sugar and molasses, and that production
hnsibeen virtually destroyed by the war.
We have no choice but to import them and
pay these enormous duties, or to go with
out; we cannot produce them here. But
how is it with articles produced Doth at
home and abroad, such as manufactures?
Does not the tariff raise the price of the
domestic article as well as of the fureign?
The domestic manufacturer is relieved
from competition and can raise bH prices
as high as those at which the importer is
compelled by the duties to sell imported
goods. 11 a JNew England shoe manufac
turer knows that merchants cannot import
and sell shoes tor less than $2 25 per pair,
which they might, if the duties. were low,
import and sell for $1 50 per pair, he will
put tne pnee 01 nis snoes up to 92.20 per
pair. Many of these duties imposed, as
they nearly all are, with an eye sfugle to
the interests of the New England manu
facturer, are simply pronioitory and Dring
no revenue to the treasury, but operate
solely for the benefit of- the manufacturers
of the ' East. Let me give you
an example related - by -a promin
ent wholesale hardware merchant
in Cincinnati an intelligent and
reliable man and a member of the Repub
llcan party. The American Screw Com
puny, located somewhere In New England,
enjoys almost a monopoly of the manutac
ture of screws by holding most of the
patents under which they are made. It had
a capital of one million of dollars. My
friend ascertained during a vist to Eng
land that he could get them vastly cheaper
there, and belieye tried the importation
of a small amount. But Congress at the
instance, doubtless, of some loyal gentle
man from New England, seconded by such
vigilant guardians ot Western interests as
Mr. Sheliabarger and Judge -Lawrence
imposed a duty of 8 and 11 cents per pound
on imported screws which is 112 per cent,.,
on their value. This, of course, simply
prohibited importation, and the Govern
ment got nothing from the duty. But how
was it with the company? In the year
1S61, it declared a dividend of one million
ot dollars or 100 per cent.: in 1865 it declar
ed a dividend of $1,200 000 or 120 percent..
making a profit on its capital of 220 per
cent, in two years, or 110 per cent, -a year,
Men out here think they make a pretty
good profit if they make 10 per cent, on
their investments. But these gentlemen,
the special wards of Congress, are enabled
to make a profit of 110 per cent, and you,
gentlemen, when you go to the hardware
Btoree, pay, the bill. . -
How is it with the clothing you wear?
What are. your shirts made ot? -Cotton
flotb. What do you pay for the cotton ?.
From 18 to 25 cents per yard. ' Well, the
duty on such goods, as you will find by
turning to page vol. 14 ot tne U. s.
statutes at larite, is 5 or 5 cents in gold
per yard, according as you buy . bleached
or unbleached goods, which is equal to
1M. to 8 cents in greenbacks. So justabout
hue- third of the price of the cotton lor yonr
shirt is tax.
; But most of your shirts have linen bos
oms. What about linens? They, as you
know, are imported generally from Ire
land.-' The duty on them Is 35 and 40 per
cent-, according, to quality. This takes
between a third and a half, of the price of
the linen for tax. And on the spool cotton
with which the garment is sewed, the tax
amounts, to over 50 per cent. So you see
that overone-tbird of the price of the ma
terial In every shirt you wear is tax. :-
How is it with. the outer clothing which
vou will be buvintr as the cold weather ap
proaches. It will be almost universally of
some kind ot woolen goods. Now Congress
last year passed a new law laying increased
duties on. woolen goods of every descrip
tion. If you turn to the Statutes at large,
vol. 14, pace 561, you will find these duties
laid down: ua nanneis, Dianaets, wool
hats,' knit goods,' woolen cloths, woolen
Shawls,-and all manufactures ot wool of
every description, a duty of 35 per cent, on
their value,' and in addition thereto a spe
cific duty ot 20 to 00 cents per pound
weight in gold, equal to about 30 to 75
cents in paper; for gold is near 100 pre-
mium. To ascertaiu the taxes you pay on
woolen goods ot foreign Importation which
you buy, then, It Is Only necessary to weigh
the article, and then turning to the law,
see what the duty perpound is on that par
ticular class of goods, and count from 30 to
75 cents lor each pound weight, and then
add to that 35 percent- or a little over one-
third of the original price of the article,
and you have about tne portion 01 tne
price wnich is tax.
For instance, suppose a laboring ma i
wants to buv a shawl for his wife, worth,
say, $5 00. Such a shawl, I am informed,
will weigh aoout one anu a nan or two
pounds. Suppose it weighs one and a naif
nounds. The tax on such articles is fifty
cents per pound in gold, or about seventy-
five in paper, so tnere is l.tz ot the
price of the shawl, and in addition to this
. . 1 L o . r- . . .
there is a tax ui 00 per cent. 01 tne value
ol the shawl before St left the ship, which
would bring the tax up to about $1.75, or
over one-tuird ot the price ol the shawl.
And this reminds me that if vou look
through the tariff laws you will find duties
laid in tne same proportion on tne various
fabrics for ladies' and children's wear. And
so with hundreds of other articles, of less
universal use than those 1 have mentioned,
but still entering constantly into the cata
logue of necessary wants of the people, and
which it would be impossible to enumerate,
lhave merely referred to a few examples
among articles of the most common necessi
ty. I have done so for the purpose of show
ing you how these taxes press upon the
consumer, the people. From the crown of
your hat to the sole of your shoes, there is
not an article you wear, the price of which
is not enhanced by these duties. For when
you go to a store to purchase, you must
either buy foreign or domestic goods. If
you buy imported goods you pay the du
ties on them; and if you buy domestic
goods, you will find the price of them
raised by the absence of the foreign compe
tition ; pot, perhaps, In all casts to the full
price of the foreign article, with duties ad
ded, but it may be raised t this point with
out fear of foreign competition, and will
be so raised whenever there is not so much
domestic competition as to keep down the
price. -
, But we will be told that this is to pro
tect American Industry. Does it protect
American industry to-impose these enor
mous duties on tea, and coffee, and . sugar,
and pepper, things which .are not pro
duced on American soil (except sugar to a
trilling extent) and can't be ? Does it pro
tect American labor to tax Irish linens and
other fabrics of foreign production? But
even in the case ot manufactures, what
claim have the manufacturers of the East
to be built up at such enormous expense to
us? Why do they need so much more
protection now than in I860, whenthe du
ties on the most protected manufactures
would average 50 per cent, less than now.
Now I do not object to a reasonable amount
of protection. - But it should be merely in
cidental. The tariff should be merely suf
ficient to raise -what is needed for an
economical administration of the Govern
ment, and within this limit if you -wish to
discriminate in favor ol domestic manu
factures, to a reasonable extent,. I have
nothing to say. But the tariff we have
now is simply a piece of extortion in the
interest of certain manufacturers in New
England. - And just here you can
see one strong reason -for the opposi
tion - to . the. admission ot Southern
members. The Sooth, like the West's
mainly an agricultural and producing sec
tion.- Their interests in such matters would
be almost identical with our own. If they
were allowed to be represented by men
Identified with the interests of their States,
they would join the West in demanding the
repeal or modification of .these duties. So
it was sought to deprive theffcpf all repre
sentation, and .when this wm no longer
practicable, they now seek, by these recon
struction measures, to place the elections of
the Congressional delegations ot those
States in the hands of the negroes lust re
leased from slavery who are Ignorant and
who can be controlled by a lew adroit
managers, and made to return as members
of Congress, men from the North who
neither know nor care anything about the
interests of their States, and who will be
underthe control of Eastern capitalists, who
will thus be enabled, as the West wakes up
and sends men to Congress who will no
longer ignore the interests or their section
to overbalance their votes, and thus con
tinue to draw from our pockets and
direct into theirs the golden stream which
now enriches tnem.
This, then, is a brief stance at the tariff.
It is the great unseen tax-gatherer which
is at work every time you so to the store.
drawing from your pockets, unawares, a
large portion ot your snostance. Ten
f ears ago under a Democratic administra
lon we had no such tariff. Then our tea and
cjffee came in free of any duty whatever.
along wicn many other things now taxed,
and the duties which were levied were
much lower. The highest duty known was
30 per cent, and that on a short list of ar
ticles, none of them articles ot daily ne
cessity, while duties on other articles
ranged from 24 percent, downwards.
Now I do not mean to say that it the
Democratic party were placed in power
there would 110 longer be any duties on im
ports. ' It is the most convenient mode of
meeting - the necessary expenses of the
Government, and the one which has al
ways been In use under every party. But
I do mean to say that under an econnmical
administration of the Government, such as
the Democratic party is pledged to; under
such an administration of tt as they gave
us when last they were in power, and
which I propose to refer to presently, the
amount of these duties would be vastly re
duced, and the prices of articles to the peo
ple reduced In proportion.
But the duties on imported goods are by
no means the only taxes we pay to the
United States. A few years ago they were
the only ones. A few years ago almost the
only U. S. officer the people knew was the
postmaster, and be was only known as
bringing to them the advantage of com
munication with absent lriends. But now
we have grown upramong us a vast system
of taxation known as the Internal Reve
nue, having its head In Washington in the
person of the Commissioner, with a salary
of four thousand dollars, and more power
than any Cabinet minister formerly had
with deputy Commissioners, and a Cashier,
and a Soiicitor, and Clerks, and Revenue
Agents under him, and in each Congres
sional District a Collector and an Assessor
of Internal Revenue, and in nearly every
county an Assistant and Collector, besides
Inspectors, and Detectives, and whisky
and tobacco Inepectors a vast army of
oinciais drawing salaries irom the public
purse and for what ? To collect these new
taxes from the people. And what are these
taxes? They are various. In the- first
place stamps. If you sell your farm or
your house and lot In town, and make a
deed for it, you have to buy a stamp to put
upon it, ranging in price from 50 cents up
wards, aceording to the value of the prop
erty ; the law considerately providing that
not more than $10,000 of stamps shall ever
be required on any one deed. If you have
occasion to borrow money or purchase
property, and in so doing give your note,
you must put a stamp upon it; if to secure
the payment of it you give-a mortgage,
you must stamp It. If you receive money
to the amount ot twenty dollars or (to
wards, and are required to give a receipt
for it, you you must affix a stamp to the
receipt. If a merchant renders an ac
count and receipts it on payment, it re
quires a stamp. If you keep an acoount
at a bank, every check you draw requires
a stamp. And so with nearly every writ
ten instrument used in the business of so
ciety. ! But it Is not only papers which require
to De stamped. Tax is levied in this lorm
on many artl les ot commerce. If you
have your photograph taken you will find
a stamp on the back of it, for . which, of
course, you pay. On so common an arti
cle of daily use as matches, stamps are re
quired. I beard during a recent visit to
Cleveland of a rather forcible argument
made use of by a workman em
ployed - in one of the manufacto
ries of that - city, in a conversa
tion with the foreman of the establishment
The foreman was a Republican, and hav-
in2 heard probably an argument to that
effect fion Judge Lawrence, or some of
his colleagues, was endeavoring to per
suade the workman that the complaints
of the Democracy about the taxes were
' without any foundation ; that the taxes did
not amount to much after all, as they fell
only on a few who were able to pay. The
man in reply drew from bis pocket a box
ot matches. . "l lust oought this at tne
grocery," he said: "ten years ago the price
was one cent. Now I pay three cents for
it and there is a one cent stamp upon it
which is one-third of the price gone for
taxes." Is it only one man in thirty
In- Madison county who ever buys a box
of matches? Well, every time you buy a
box of matches you pay a stamp tax to the
Government
Then,agaln, before you can engage in al
most any business or profession, - which
men follow for a livelihood, you must pay
a special tax for the privilege of following
it The lawyer, the doctor, the dentist the
druggist the land agent the cattle dealer,
the photographer all must procure a li
cense and pay for tt every year. Merchants
and dealers, besides a fixed yearly sum;
must pay a per centage on sales above a
certain amount All these taxes are di
rectly on the industry of the country.
Then there is the income tax. This, it Is
said, only affects the rich; that all Incomes
less than $1,000 are exempt Well. It Is
true that only incomes of over $1,000 are
taxed. But does the tax only affect those
who nav it directly ? A very apt illustra
tion of the operation of the tax was given
by General Gary, in a recent speech deliv
ered at Springfield, in your District He
said that he had an income on which he
paid an income tax, derived from rent of
houses in Cincinnati. But when he paid
$5 on every $100 of bis rents, he simply
added it to the rent of the house, and the
tenant paid it. '
It Is so with the whole system of Federal
taxation. The great weight ot its burdens
rests - ultimately on the shoulders ot the
people, the laboring masses of the country.
Take the tax upon railroads. They are re
quired to pay a tax of 2 percent on their
gross receipts, besides the taxes they pay
in the increased price of everything they
buy. There is an import duty ot $2 in
gold, or about $3 in currency, on every ton
of railroad iron imported. These taxes ot
course simply add to the price the publio
pays for freight or passage over the roads.
So with steamboat transportation, which
is also taxed. So with telegraph and ex
press companies; they are taxed 3 percent
on their receipts. It simply adds to their
charges to the publio. So with Insurance
companies. So with gascompanies. They
are expressly authorized by the law to add
their tax to ihe price charged consumers,
and they would do it of -course, anyway.
The law of Congress merely. re-enacts the
the law of trade.- If you go to Cinclunati
and ride in the street cars, you will see
notice posted in each car, that the price ot
tickets by package (formerly one dollar) Is
one dollar and three cents. The three cents
Is the tax. In all these, and similar cases
the railroad companies, the express com
panies, the gas companies, the merchants,
wholesale or retail, are merely constituted
tax collectors by the Government The
tax-payers are the consumers the people.
1 This, then, is a brief view of how we
are taxed.. Now in all these various ways
how much is annually drawn from us and
for what is it expended? From statements
in a recent speech of Edward-Atkinson, ol
Boston, and published in the Cincinnati
Gazett,, which will certainly be regarded
as good Republican authority, and on the
principle ol admissions, may be held good
against them, and which he says are fur
Dished by David A. Wells, .Commissioner
of the Revenue, I find that there were
collected by the United States Government
for the fiscal year -ending June 30, 1868,
as follows : .
From Duties on Imports (gold). fies.soo.ooo
From Intamftl Re re hub 193,(MXJ.0U0
From Mi-eellanaons Sources (sales of
property, te.) 4S.800.000
' Total C406,300,000
Or, converting the whole into Curren
cy (435,000.000
The total expenses of the Government in
I860, the last year ot a Democratic admin,
istration, for all purposes, except payment
of principal of public debt were thirty
three millions of dollars, or in paper about
ninety-two millions ot dollars about one
fourth or one-fifth of what they .are now.
The expenses of the Government lu 1863.
in a time of profound peace, more than
four times as great as they were in I860 !
What makes this vast Increase? : How is
the money spent?
, In the first place for interest on- the Na
tional debt W e have a debt of about
2,600 millions of dollars, the great bulk of
wbich is In bonds bearing Interest. The
amount of this interest is about 130 millions
ot dollars per year iu gold, or In curreucy
about ISO millions. A portion, of the
bonds, those known as the 10 40 bonds, are
payable both principal and interest in gold.
About this there is, I believe, no contro
versy. It is admitted by both parties. -These,
however, constitute but a small part
of the bonds, only about 175 millions. The
great bulk of them are what are known as
5-20 bonds and these are payable in green
backs. Neither the bonds themselves, nor
the law under which they were issued re
quire anything else. This, I believe, was
admitted by Attorney General West In his
speech here a tew days ago, and it is now
generally conceded. . Tne amount of these
bonds is, iu round numbers, about 1,550
millions ot dollars. The rest ot the debt
is made up of the United States notes or
greenbacks and fractional currency, in cir
culation to the amount of over 400 millions
ot dollars and of bonds and securities ol
other forms not necessary to explain in
detail. You will remember that the great
bulk of our interest bearing debt more than
two-thirds of it is in the form of 5 20
bonds and payable in greenbacks. Now
what In brief, Is the plan proposed by each
of the two great parties tor dealing with
this debt. . .
: The Democratic party propose to pay
these bonds as fast as they become due, and
as last as it can be done without injury to
tho financial interests ot the country, in
greenbacks the ordinary currency of the
country, and that for which they were or
iginally sold. What does the Radical party
propose to dor
Just before its last adjournment, Con
gress passed a bill known as the funding
bill. By the provisions ot this bill, new
bonds were to De issued to an amount sut-
ficient to redeem all the present 5-20 bonds
and bearing Interest at 4 and 4 per
cent. These new bonds are to run for
thirtv and forty years, to be payable, prlu
cipal and interest, in gold, and be exempt
from all taxation, either by the State or
United States Government except such
trifling income tax as I have described.' In
other words, seeing the utter impossibility
of paving this enormous debt in gold, they
propose to simply postpone the payment of
It or, as the Kadieal speakers nave it turn
it over to posterity. Now how will this
plan operate ? Suppose the 1,550 millions
ot 5-20 bonds converted into these new
bonds, the annual interest on them would
be from 62 millions to 70 millions ot dol
lars in gold, according as the interest was
at 4 or 4J4- per cent- say 66. millions
Then in ten years we will have paid 660
millions In erold for interest: in twenty
years we will have paid 1,320 millions, in
thirty years l.aso millions, ana in xorty
years, supposing half the bonds to continue
unpaid that louir. I 300 millions ot dollars
in gold, or more than one and a half times
the entire principal ot the 5 M Donds, pain
in gold for interest upon them (besides the
interest yearly paid on the rest ot the pub
lic debt), and still the principal of the
bonds unpaid, and confronting us as large
as ever, and payable in sold ? What then?
Will It be any easier to pay it then, after
pavlnz interest on it lor forty years, tnan
it is now? Will posterity bo any better
able to pay It than we are? How do we
know what posterity can do. Who can
look into the future for forty years and tell
what then will , be the condition
of the country. " Posterity will
have - debts of its - own to pay.
A little over a hundred years ago Eogiaud
finished a long war-and entered into a
treaty wbich promised, historians tell us,
a peace of long duration.. Yet forty years
from that time found Englaud engaged In
the struggle with Napoleon tne most gi
srantic contest of arms the modern world
had seen: her debt vastly Increased and
constantly growing, so that now it has
become a permanent incubus upon her a
load ot debt never to he paid, nor liitea
irom tne snouiaers or tne people. Ana
this Is exactly what the Radical party by
this funding bill propose to make of our
debt - And they propose to do this with
out the slightest necessity or obligation to
. doit.' Good faith does not require it
Justice does not require it Neither the
bonds themselves nor the law under which
they were Issued require it It Is simply
for the interest and benefit ot the bond
holder, and with my consent It never shall
be done. I don't propose to place this
burden upon posterity, I havechildren of
my. own at home and whatever else I may
be able to leave them, I do not intend
that by any act of mine they shall receive a
legacy of debt and taxation.
! Nor is there any necessity for it. It
would, on the other hand, be a gross injus
tice to the people to pty these bonds in gold.
We have a great outcry against paying the
public creditors in a depreciated currency.'
But was not the debt contracted in the
same depreciated cu rrency. Did we receive
gold for these bonds? Did the men who
bought a hundred dollar bond in 18G3 give
us one hundred dollars in gold for it that
he should now ask to- he paid a hundred
dollars in gold? Did the-tlollander who
sent over and bought a hundred dollar bond,
send us over a hundred dollars in gold for
it? By no means. This was the operation :
These bonds were sold, the most of them
ia 1863 and 1864, when gold was at a hinh
premium, ranging as high - as 200
and even up to 200. In other words,
you could get for a gold dollar two dollars
or two dollars and a half, or more, in pa
per money, and it was for paper money
that the bonds were sold. Now, suppose a
man had one hundred dollars in gold which
he proposed to invest in bonds, when gold
was at 200. He would first convert his
gold into greenbacks, which would give
him $200. With this he would buy two
one hundred dollar bonds. On each of
them he receives 6 per cent, interest in
gold. Now, up to the present time, what
has he received for five years' use of his
hundred dollars In gold. 'On his two hun
dred dollars in bonds be has received
6 per cent, every year, which is $12 00 a year
in gold. He has been exempt from all
State taxation, which is equivalent to at
least 1 to 1 per cent, more, or $3.00 more
per annum. He has then - been receiving
for the last five years at the rate of 14 or 15
percent, interest for bis money. If he
bought his bonds when gold was at 200
he has for five years' use of his hundred
dollars in gold, recovered back sixty dol
lars in gold and been exempt from taxa
tion. If be bought when gold was at $2 50
he has received or will have received for
five yews' use of his hundred dollars, seventy-five
dollars back in gold, and been ex
empt from taxation. And if be bought
when gold was at the hishest . Doint ot
290, he will have been getting Interest
at the rate of about 20 per cent, ner annum
and will have received back at the end of
live years, about ninety dollars in gold, and
been exempt from taxation. And still this
Congress proposes to go on paying him In
terest in gold at 4 or 414 per cent, and
exempting him from taxation for thirty or
lorty years longer, and then paying him or
ins ucirs 1113 principal in fcoiu wnen ce
gave us paper. How will the account stand
(lien?:! .. .! 1. .:.;:
He invests one hundred dollars in crold.
Suppose be bought when gold was at $2 00.
(and It was higher than this a great part of
tne time;.
At the end of fire years he baa received beck ' T -'
in nold , .$ 00 00
He then converts his bonds into new bonds, '
1- at 4X percent .parable m thirty year;
b us nin Ktve 9, ou on eacn nunareaaoi ar - . .
bond, or 9 00 on his S200 00 of bonds,' ' '
I , wuicn ne got lor nis sioo 00 in cold, mak-
ins in thirtv VAitra VTli OA
S-t the end ef thirty years be re-elves, be- -
sides bis original hundred dol: ars. an- ,
other hundred dollars for the principal of "
his bonds., ............. 100 00
llakinia total, for the thirty-five -years' nse -.,
of bis hundred dollars, of.. ...... ........ S43S 00
In gold, or, about $12 28 a year, and ha bas
been exempt from all State taxes, equiva
lent to at least 4, per cent, more making
In all $13 78 per year, or nearly 14 per cent,
that the Government has been ' paying for.
money. The interest paid by England on
her national debt is 3 or 4 Per cent. These
are simple calculations, which you can all
worK out ior yourselves. -- ..!.-,
JNow, what is this but simply the -most
outrageous usury and extortion? What
would be thought of such a claim if nre-
ferred by a private individual in court?
Suppose a soldier on starting to the war
six or seven years ago, had. found it neces
sary to borrow a hundred dollars to re
move a lien, perhaps, from his house, that
be might leave a home tor his family. Sup
pose his creditor azreed to lend him a hun
dred dollars, if he would give him his note
ior zuu ana pay nttn 15 per cent per an
num on the $100 lent him, and secure the
whole by a mortgage on his house..- The
soldier comes back from the war after four
years and is unable to pay the note, and the
creditor, finding some Informality In his
mortgage, goes Into court to have his
mortgage reformed and made effectual.
He says in his plead inzs that he lent the
man $100 and took his note at five years
for $200; that the man has paid him inter
est every year at the rate of 15 per cent.,
buthe is unable to pay the note of $200.andl
want my mortgage reformed so that I can
continue to hold him to the payment of the
interest and the $200 note. ; Did any "court
ever sit in Madison county that would give
mm a decree? uouid a jury or. twelve
men be found to give him a verdict ? And
yet the claim now made In behalf of the
bondholder is precisely similar. Soldiers
by the, hundred thousand have returned
from the field to earn their living In the
occupations of civil lite. The country is
staggering under a load of debt. And at
this juncture the bondholder, who bas been
receiving lo per cent, on bis investment
comes and asks to be paid two dollars for
every one -ne lent And It we protest
against this extortion they raise the cry ot
repudiation. - -'
I can recall cases where they have not
been so sensitive. My friend Col. Squires,
who occupies the chair, will remember that
when the paymaster first came 'round to
us in Virginia in the latter part ot the year
1 sut, that he paid us partly in gold and sil
ver; that while the bulk ot the men's nav
was paid in treasury notes, the,' fractional
portions less than live dollars were paid in
gold dollars and silver change. The fact
marks the relative, value of the two cur
rencies at that time that there was but
little difference between them. Within the
next three years the premium on gold rose
to near 300. Ttie soldier who entered tne
army in 1861 at $13 a month, with the ex
pectation that that would suffice to support
his family at home, found the purchasing
value ot the dollar decreased from one-
hiilt to one-third of what it was when be
entered the service. It is true that towards
the latter part of the war bis pay was rais
ed to $16, and in some localities aid extend
ed to his family If needed,' but not to an
extent equal to the depreciation of the cur
rency. But we hear no Republican. speak
ers talking about this repudiation this de
preciation of the currency. -
1 But what do the Democracy'- propose to
do? we are a-ked. Would you flood the
country with a new issue of greenbacks
until they become so depreciated that all
values are unsettled. By no means. The
Democratic party propose to do nothing of
tne Kind, ihe o-zu bonds comprising the
great bulk of our interest bearing debt-
can be paid off and rapidly paid off", with-
outany undue inflation of the currency of
the country whatever. About 350 millions
of these bonds are beld by the- National
Banks, scattered over the . country to the
number of 1,600 and over, as a basis for
their circulating notes, which to-day form
a large part of the currency of the coun
try and the Government or rather the
people are actually, paying - these banks
the sum. in round numbers, of twenty mil
lions ot dollars a year. In gold, for the priv
ilege of indorsing and giving value to their
circulating notes. Now, the Government
can a treat deal better furnish this much
circulating medium itself by issuing green
backs in place of the National Bank notes,
and by so doing we will save the twenty
millions a year gold interest and - pay off
the 338 millionsof bonds held by the bauks
as the basis of their circulation. Here
would be near 350 millions of the debt paid
at one stroke, without increasing the cur
rency of the country a dollar.
But the currency will bear some expan
sion. It needs some. It has been con
tracted since the close of the war, and the
present financial stringency is largely
owing to this contraction. I am not pre
pared to state the exact amount of this
contraction, I have heard it stated at 500
millions. It is safe to say, however, that
with the whole of the Southern States
using our money as they did not during
the war and with the present hard times
and scarcity ot money at the west, that the
currency can be increased by two or three
hundred millions without the least-injury
to the business of the country. Say you
increase it 250 millions; 'this added to the
350 millions held by the national banks,
will make 600 millions of the debt more
than one third of the 5-20 bonds paid off,
and more than a third of the interest on
them saved annually.
But this 18 not an. Tne present immense
expenditures of the Government can be,
and must be, largely reduced. Look at
them:
For the year ending June 30, 186S, we
have seen that they are $435,000,000. De
ducting the interest on the public debt,
which in currency isabout$180,000 OOO.and
we have $255,000,000 for the annual ordi
nary expenditures ot the Government.
; In 1860, under a Democratic administra
tion, the total expenses of the Govern
ment exclusive of interest on the public
debt (which was ouly about $3,000,000)
were in round numbers $60,000,000 of dol
lars in gold or about $90,000 000 in cur
rency about one-third what they are
now.- - : i :. :'-.': . - - - '
In I860 our army numbered about twelve
or til teen thousand men and cost about
sixteen millons of dollars.' Our territory
was just as large then as now; our popu
lation about the same, for immigration has
not more than replaced the waste ot . war;
yet the army ot 15.000 men protected our
Indian frontier, garrisoned our seaboard
forts and performed all the services for
which we need an army. ; Now we have
an army ot fifty-five thousand men fitty
tive regiments of infantry, six of cavalry
and five of artillery with a numerous staff
of Brigadier and Major Generals, with
General Grant at their head with a salary
of twenty thousand dollars a year. .,
The cost of this army is officially esti
mated for the current fiscal year to be
$94,000,000. Now does any man in' this
house believe that there is , any necessity
tor such an army at such a cost We are
at peace with all the world. There is not
even any threatened trouble, foreign or
domestic Does any sane man believe there
is any danger of a renewal of the rebellion
at the South. Distrust their loyal ty as you
will, have the people there any power to
renew the contest If they should be ever
so much disposed ? Did they not fight till
they were wholly exhausted before giving
it up before? And will any man contend
that With the country full of veteran sol
diers, who could be had by the hundred
thousand at the appearance of danger from
any foe, foreign or domestic there is any
necessity for keeping up this great stand
ing army in a time ot profound peace and
when the country is laboring under such a
Jisd of. debts and taxes. "There 1s no ne-
cessity for it. Itls kept up simply for the?"
purpose of forcing upon the peopiefbM
Southern States new Governments based
on the very thing that has been rejected in
every Northern State In which it has recent
ly been sul mi ted to the people negro suf
frage. And what are these new Govern
ments which you are paying, to establish?
What Is the character of their Constitu
tions? i In Alabama they" hive a Constitu
tion under which the great majority of the
people of Ohio1 would, if they went there,
be disfranchised; forthe people of Ohio
voted by a majority" of 50,000 last v fall
against conlerrlng the right of suffrage on,
negroes, but iu Alabama no one is allowed;
to vote without taking.' -an- oath that
he accepts and always will uphold the civil
and political equality of all men; -So' any
one of the fifty thousand Republlcanawhd
defeated negro suffrage In Ohio last year
(I say Republicans, because while the
amendment was defeated the Republican
elected their State ticket), if he should gd
to Alabama, would bedisfranchised, though
be served in the Union army all through'
the war. In many of the new Southern;"
Constitutions nearly all, I believe I re-,
member certainly as to Arkansas and tber
Carolina,! and I think Alabama also a'
system of schools is established open to.!
both white and colored children, Attend-i
ance on which is compulsory. Every man
is to be compelled by law-to send bis chil
dren to these schools, nnless he Is able to
educate them at his own expense. Is this
the kind ot State Governments yoa 'want
to pay for keeping up? It was one of the
strong arguments ued in favor ef the war,
that we had an Interest in the territory -of
the Southern States, and had a right to em
igrate to them if we wished.- Are thet e the
Governments you wish to emigrate to and 4
live ni derf . ? i- - -- . ,
A similar saving of expense might be ef
fected in the N aw Department. .1 hazard
nothing in saying that- with pnpw
economy, - a saving ,of . .-nearly ai
hundred millions of dollar, , mluut -be
made, annually ln " the "War
and Navy Departments' alone.'- And like
retrenchments might be made in the ex
travagant expenditures ot other branches .
of the Government iiow. we have seen:1
that the total expenses of the Government
for the past year were 435 millions (in cur
rency), of which about 180 millions was In
terest on the public debt But if 600 mil
lions of the 5-20 bonds were paid off in the
manner I have referred to, this iuteresft t
would be reduced to about 125 millions a
year (stated in currency.) Then, as to the
; other expenses of Government they should;o
! not exceed 125 millions at the most. The
;only legitimate item ot Increase of anyirn
portar.ee since the administration of Mr
; Buchanan (when the expenses, as we have
' seen, were 60 millions In gold, or less tban J
; 90 millions in paper)71s the pension list of
I the late war, and that was reported) about
a -year ago at only about 15 millions. The
total expenses ot the Government then,..
. IiiAliirlinir Infamct chrtftM nnf 0Vfpfrl
250
millions
year.!v ''Soppesersl
we raised in' addition? 10U millions more
each year and applied it-to the redemption'
in legal tender'nbtes ot the 6-20 bauds. Iar
Lless than ten year they would all be. .paid
'and the immense amount of gold .interest '
upon them stopped, and still our expendi
tures would be 85 millions less than tht
are now. The debt would then be reduced; 3
to such a small compass that its payment,
in a very few years even those portions of
it which are payable' In coin would be 1
easily managed. And as the Interest by j
these successive payments would bs,,ds- ,
creasing every year, the amount paid on the"
debt might be increased, or the taxes di- ,
tninished, as might be thought best.J Now,"'
which Is the better course to pay. off in,!
this way these 5-20 bonds now, as rapidly,
as possible, or to go on paying interest in
gold for thirty and forty years, and then,
pay two dollars In gold where we received
;one.' ;'i'i -vji- . i:n i u ;--,-;: .f y
: I have thus attempted to give you, gentle- s
men, a brief outline of the financial ques
tions before us. The details and figures
may be dry, but the facts " are -worthy of
our serious consideration. As I remarked :
in opening, the matter is. entirely in your,j
own hands. It you wish to perpetuate the
present high taxes and extravagant expei
ditures, you can do it If you wish'toconwJi
tinue to pay taxes, as I have endeavored to i
describe, on the clothing you wear and the
tea and coffee you drink ; if you want to J
continue. to give every third pound of su-'-'
gar you buy for tax s, you ean do so by )
yonr votes. Judge Winans and General, ,
Grant if elected, will continue in substance 7
the policy of the party now in power. But
it you wish sometime' to see an end of this "
oppressive taxation ; if you don't 'want toh
have this debt entailed on yoa and your
children, go up to the polls . this fall audr
elect a Democratic Congress, and Horatio"
Seymeur to be ' President of the United I
State. - ; 1 " v r-t
J
1 '---'. MISCELLANEOUS. rn.r-
A New Article of. Food,;
tll.i--iO:V
' " f Trantlatton.1 5 u i f si
' It was M. BriVat Savarinv the celebrate! Frenelnd
Gastronome, who ntsaid .that "the man whoin-.
eotj a new dish doe3 more tor Society than the i
man who disooveis a Planet." Tb;.'. );)o.v ,r
, C ACIO 1)1 M lCCARoAl '
or Italian prepared Cheese MaoesronK-iS now of
fared as a most delicious, wholesome aad eiqa&nt
comestible (convenient lunch) for the use of Fam--ilie?.
Bachelors, Excursions (Pionics), Travelers',
and for use in Beer 8 loons. Bar or Sample .Rooms, o
It is eaten on Bread. Biscuit or Toast. . .
It is ruitablefor Sandwiches Clnglese "28 ef
tine di pane condentro." Especially is tt adapted
for those climates where the article of eheese can-'-i
not be kept in a sound eondition for anv length of w
time - - . .: f . ,
It ma; be used as a seasoning for Soups, Hash or
Stews and warmed upon a stove, after the aa
bas been opened, it makes, without further prep-s I
paration, a Delicious Welsh Raribit. - . - v(
For Travelers and others, it is far more oo&otn-;.
ical and convenient than Sardines, Deviled or Pot- .
ted Meats. ----- --.
The proprietors and Patentee cannot bat ask for
it a trial. - ., ?
Send as for s nurLX dozen a lb Cans, and rich
ly gilded show oard, securely packed, an.l ship
ped per express to any aidress.. liberal discount
made to the trade. ,
H. B. The Oaciodi Macearoni hi put- up in i
boxes, and packed in cases of two doien at (8 per 3
ease, net cash.
For sale by all respectable Grocers and at the
Fruit Stores. - .-..
; Re-ponsible agents wanted everywhere. fBJ
' All orders aud communications should be ad- .f
dressed to ' J.
THE LIVINGSTON CACIO COMPANY; 0 -7
88 Liberty Street, Haw York,
: VNT-sp29-deod6mos ... ..i.a
, 3 - ..'.-.-!:- 1 : -. 1 -t " ' i-j
-- - . .K;.V.
atrona Saleratus?
A. WORD .WITH YOinJ
BRFAD II THE STtFF OF LIFE-''
your most important artioleof diet. The health ;t
of your family largely depends upon its being f j
LICHT AND WHOLESOME.' -
Vonld yon have it so?. Then nse only s -J
NATRONA , S ALER A JUS ! J
3-IT IS ABSOLUTELY PORK. "S 1
Whiter ' than snow : makes Bread always light
white and beautiful. Take a pound home
to your wife to-night. She will be ,,,CT
. , . delighted with it. , . 1. . n ,0 -.
Buyers of Soda should try our -,
BI-CARBOMTE OF SODA. ;
-Ve guarantee it rot only fsr superior to anrotber '
Amerioan make, but even purer than the best Aesria
CasUe or English Soda. '- snn.,iH
j " MANUFACTURED BY THB .. ,
epiimi Mail- BSAkiiirin 'nrt'lj
rtnrvA oft!., mnnur ij :1vu.f
(
PITTSBURGH, PA.- iJd
vNT-auglO-eodly-r ,'.V '"
i - Tha : $ldMi: f fi Man's :;l
OF THE SFRINGS, KECENTt OF '
Somerset, Perrr oounty. will open tbeu? large
..j : - fn tfc retention of DOOMS on
. IUWIUIUW ,11. UV ,
WL. ROSE. BapX ;ua
partmentef the pupil
- Address oox ia.
t'V .-- ?&
i Ii--i ;,it; .r--:v- Hi "ttt l.-9-ut
i '-, ITOXl SA-IE. -
A PAIR OF "JOE GOD WIS" COLTS. FIVE ,
and six tears' old. very handsome, kind and '
(N
.x - -
1
xml | txt | http://chroniclingamerica.loc.gov/lccn/sn84028645/1868-10-08/ed-1/seq-1/ocr/ | CC-MAIN-2017-26 | refinedweb | 11,503 | 76.76 |
Ok im having trouble with my Tic-Tac-Toe program. I am currently working on the part where the computer reads what move the user did and then moves according to the rules. Now I havn't wrote all of the computers rules yet because I dont know if this is how to do it. When I try to run the program it messes up. Here is the source. I hope Yall can find the problem.
Code:#include <iostream> #include <fstream> #include <string> using namespace std; int x=1; int o=2; void startgame(); void xturn(); void oturn(); int moves[9] = {1,2,3,4,5,6,7,8,9}; int main() { int xx; cout << "Would you like to play a game of Tic-Tac-Toe?" << endl; cout << "1 for yes, and 2 for no" << endl; cin >> xx; if (xx == 1) startgame(); else if ( xx == 2) cout << "Looseer!!!!" << endl; return 0; } void startgame() { int win = 0; int count = 0; int victory = 0; int mover; cout << "Lets play." << endl; cout << "You are X. Press 1-9 to make a move." << endl; for ( count=1; count<=9; count++) { moves[9] = count; // This part of the code is used to deturmine whos move it is. if (moves[1] != false) xturn(); if (moves[2] != false) oturn(); if (moves[3] != false) xturn(); if (moves[4] != false) oturn(); if (moves[5] != false) xturn(); if (moves[6] != false) oturn(); if (moves[7] != false) xturn(); if (moves[8] != false) oturn(); if (moves[9] != false) xturn(); if (count==9) { if (!victory) cout << "DRAW!!" << endl; else if (victory != false) cout << mover << " WINS!!" << endl; } } } void xturn() { cin >> x; cout << "You moved to square " << x; cout << endl; } void oturn() { if (x==1) { o==5; } else if (x==5) o==1; cout << "The computer moved to square " << o; cout << endl; } | https://cboard.cprogramming.com/cplusplus-programming/26328-need-help-source.html | CC-MAIN-2017-22 | refinedweb | 297 | 94.66 |
Here it is with a notification. I have notifications for volume change, download completions, and other misc. stuff.
<screenshot>
sorry for going off topic but what is the name of that beautiful font?
(op: awesome script btw)
Offline
sorry for going off topic but what is the name of that beautiful font?
Looks like Envy Code R to me...
Online
BetterLeftUnsaid wrote:
Here it is with a notification. I have notifications for volume change, download completions, and other misc. stuff.
<screenshot>
sorry for going off topic but what is the name of that beautiful font?
Terminal font is Terminus, the font in the bottom and title bar is Cure, part of the artwiz-fonts package
Last edited by BetterLeftUnsaid (2010-02-17 07:58:01)
Offline
Apparently statnot doesn't work for me. I don't get any notifications printed when I send some using notify-send. I'm using the AUR version. I don't have notification-daemon installed.
Offline
I think it would be better if statnot just printed its output to stdout. It would make it suitable for other uses without modifying the source, for instance in dzen or dvtm's status bar.
Then, to get it to work in dwm, just pipe it to a script like this:
#!/bin/sh while read -r LINE; do xsetroot -name "$LINE" done
Assuming it's named dwmstatus:
statnot | dwmstatus
By the way, I'm writing a similar program that should be done pretty soon. Instead of using libnotify though, it uses a file directory similar to the way wmii handles its status bar. Then you have a separate application to feed it libnotify stuff...
Last edited by fflarex (2010-03-16 02:54:28)
Offline
I've changed statnot's update_text function to a simple "print text," in hopes of being able to pipe the output into wmii's statusbar, via something like
statnot | while read -r LINE; do wmiir xwrite /rbar/status "$LINE" done
However, even though "statnot" prints the messages normally when run by itself, for some reason, the output is entirely unpipeable. Even running "statnot | cat" does nothing. I've also tried using
subprocess.call(["wmiir", "xwrite", "/rbar/status", text])
inside update_text, but this also produces an empty status bar.
Any ideas on this issue? Is this a bug, or am I doing something wrong here?
Edit: I was being stupid and didn't have it set up right in wmiirc
it's fixed and works fine now
Last edited by decibelmute (2010-03-27 23:14:15)
Offline
I've ended up writing to a file and then reading from there with xmonad, and xmobar. Obviously not optimal, but it works.
archlinux|xmonad
++++++++++[>++++++++>+++++++>+++<<<-]>+++.>---.<----.+++++..>>++.<++++++++.--.-----..+.<--.
Offline
This is great
And how this can be shown in dzen?
It looks like theres a server error, i cant edit this post until now :s
Last edited by YamiFrankc (2010-03-26 00:53:18)
Thanks and greetings.
Offline
* Is this a project worth doing at all?
I can see such a thing being useful for my project,. We've been recommending LXDE, particularly for the older, smaller netbooks like the original model 4G and have supported all models of Eee PC with an eeepc-acpi-scripts package that has its own kludged-together OSD using aosd_cat but not libnotify. We're at the point where we'd like to rip this out and replace it with something better, probably using notify-send to generate the messages and therefore we want to know what to recommend to LXDE users or other users of plain WMs to receive and display the notifications.
* Is python OK or rewrite in e.g. C?
Rewriting in C seems better to keep dependencies light. Dragging in the whole python stack is a bit excessive, though python is nice for prototyping.
* Anything else?
Would you be interested in hacking on to reduce dependencies? Maybe do without dbus, and replace gconf with some xdg config instead? I know it's a different approach (not text-only) but it would be easier to drop in on top of *any* WM without having to integrate it, and would meet the "lightweight" criteria.
Ben
Offline
Thank you for this excellent piece of software! Had never imagined I would be able to get notifications in dwm... now, I wonder, how did I ever live without them? This has replaced conky for me
.
Here's my .statusline.sh in case anyone is interested (there's probably a better way to get the memory data from ps_mem):
#!/bin/sh battime=`~/.scripts/ibam.sh` bat0=`acpi -b | awk -F " " 'NR==1 {print $4}' | tr -d ,` bat1=`acpi -b | awk -F " " 'NR==2 {print $4}' | tr -d ,` ram=`sudo ps_mem | awk -F " " '{print $2}' | sed '/^$/d'` #uptime=`uptime | awk -F " " '{print $3}' | tr -d ,` time=`date +%H:%M` echo "BATT ["$bat0"] ["$bat1"] ["$battime"] RAM ["$ram"] ALERTS [$1] "$time"";
I especially love seeing the sound changes from the status bar (I used to always fire up alsamixer just for a visual interface, but now, with statnot, this is not necessary), and I have cron jobs that print visual alerts into the status bar using the notify-send command (e.g. for new mail).
Registed Linux User 483618
Offline
And here's mine
I'm using the statuscolors patch to highlight certain notifications (the \x01 and \x02 characters). Any chance statnot will be upgraded to use a configuration file?
Scott
#!/bin/sh function netstatus { eth=`ifconfig|grep eth0` wlan=`ifconfig|grep wlan0` status=`ping -qc1 google.com 2> /dev/null` if [ -n "$status" ]; then if [ `ifconfig|grep wlan0|wc -l` -ne "0" ]; then link=wlan0; elif [ `ifconfig|grep eth0|wc -l` -ne "0" ]; then link=eth0; fi else link=down; fi sshstatus=`ps aux|grep 'ssh -f'|wc -l` if [ "$sshstatus" -ge 2 ]; then sshstatus='S' else sshstatus='\x02S\x01' fi } function netspeed { # # displays download / upload speed by checking the /proc/net/dev with # 2 second delay # netstatus if [ "$link" == "down" ]; then echo -e "\x02Network Down\x01" exit 1 fi old_state=$(cat /proc/net/dev | grep ${link}) sleep 1 new_state=$(cat /proc/net/dev | grep ${link}) old_dn=`echo ${old_state/*:/} | awk -F " " '{ print $1 }'` new_dn=`echo ${new_state/*:/} | awk -F " " '{ print $1 }'` dnload=$((${new_dn} - ${old_dn})) old_up=`echo ${old_state/*:/} | awk -F " " '{ print $9 }'` new_up=`echo ${new_state/*:/} | awk -F " " '{ print $9 }'` upload=$((${new_up} - ${old_up})) d_speed=$(echo "scale=0;${dnload}/1024" | bc -lq) u_speed=$(echo "scale=0;${upload}/1024" | bc -lq) echo -e -${d_speed}k +${u_speed}k "$sshstatus" } function topproc { echo "`ps -e -o pcpu,args --sort pcpu | tail -1| sed 's/\/.*\///g' |awk '{print $2" "$1}'`" } function memory { USED=`free -m | awk '$1 ~ /^-/ {print $3}'` TOTAL=`free -m | awk '$1 ~ /^Mem/ {print $2}'` echo "100*$USED/$TOTAL" | bc } function diskuse { ## Usage - diskuse {mount point} USED=`df -hP|grep $1|awk '{print $5}'|sed 's/\%//'` echo "$USED" } function mailcount { m=`ls ~/mail/INBOX/new|wc -l` if [ "$m" == "0" ]; then echo "::" else echo -e ":: \x02Mail\x01::" fi } function weather { ## Only print .weather if network is up. Weather.sh is run by cron netstatus if [ "$link" == "down" ]; then echo "Weather N/A" exit 1 else cat ~/.weather|head -1 fi } function batt { perc=`acpi | awk '{print $4}'|sed 's/,//'` state=`acpi | awk '{print $3}'` if [ "$state" = "Discharging," ]; then echo -e "\x02$perc\x01" else echo "$perc" fi } function music { ## Print currently playing artist tmp=`mpc |grep "\[playing\]" | wc -l` if [ "$tmp" == "1" ]; then vis=`mpc current | awk -F "-" '{print $1}'` echo ":: $vis" fi } function date_mute { # Print Date, Time. Highlight it all if volume is muted d=`date +'%a %d %b %H:%M'` dm=`date +'%H:%M'` vol=`amixer|head -n6|tail -n1|awk '{print $7}'` if [ "$vol" = "[off]" ]; then echo -e "\x02--Mute--\x01 $dm" else echo "$d" fi } if [ $# -eq 0 ]; then echo " $(topproc) $(music):: $(netspeed):: M $(memory) :: / $(diskuse `mount |grep ' / '|awk '{print $1}'|sed -e 's/\/dev\///'`) :: $(batt)$(mailcount) $(weather):: $(date_mute) ::" else echo -e " $(topproc) $(music):: $(netspeed):: M $(memory) :: / $(diskuse `mount |grep ' / '|awk '{print $1}'|sed -e 's/\/dev\///'`) :: $(batt)$(mailcount) $(weather):: \x02$1\x01 ::" fi
Offline
I'm happy some keep using this old sin of mine! I got inspired enough to write 0.0.3 - only a year and a half after 0.0.2. Changes:
* Support for configuration (see statnot -h or , section Configuration)
* Fixed PKGBUILD, so python2 is used
If you hacked the old statnot file to configure, your changes will be lost. Sorry.
Actually, he's posted a solution for this at his website. Here's the pertinent stuff:
notify-send can also be used for other, more direct messages. For exampe, I call a script called dwm-volume when my volume media buttons on the keyboard are pressed. This script adjusts the volume and sends a notification containing e.g. vol [52%] [on].
#!/bin/sh if [ $# -eq 1 ]; then amixer -q set Master $1 fi notify-send -t 0 "`amixer get Master | awk 'NR==5 {print "vol " $4, $6}'`"
As you can see, I use the option -t 0 to notify-send, i.e. I request that the notification should show for zero milliseconds. For statnot, this means that the message should show for a regular status tick, by default two seconds, but if other notifications arrive, like a second press on the volume button, it goes away. This setup allows my audio volume to show only when I change it, while it updates instantly when I press the media buttons.
So in short, if you do
notify-send -t 0
you'll get the desired effect. Happily, not hackish at all
.
Last edited by Sara (2010-11-02 15:32:49)
Registed Linux User 483618
Offline
So in short, if you do
notify-send -t 0
you'll get the desired effect. Happily, not hackish at all
..
I just tried this and found that the notifications NEVER timed out and stayed up on the screen forever until closed
Offline
@Sara -- ah, thanks! That actually works quite well for the volume control. However...
I'm still playing with my weechat notifications -- I have them stay in the status bar for longer: about a minute, so this trick of setting -t0 doesn't work. It would be ideal for the most recent notification to supersede the existing one.
Scott
Offline
Sara wrote:
So in short, if you do
notify-send -t 0
you'll get the desired effect. Happily, not hackish at all
..
I just tried this and found that the notifications NEVER timed out and stayed up on the screen forever until closed
Really? And the regular updates are working when you dont try the -t 0 stuff?
Try
# notify-send -t 5000 "five seconds"; notify-send -t 0 "should not see"; notify-send -t 0 "for a tick";'
You should see the "five seconds" for five seconds, next "for a tick" for two seconds, and then back to your normal statusbar.
I'm happy to take a look at your ~/.statusline.sh if you think another set of eyes can help.
Offline
firecat53: Impressive statusline!
It would be ideal for the most recent notification to supersede the existing one.
That this is not the case, is by design. Notifications can come from many places at the same time and build a queue, where each one should show for a certain amount of time if it asks to. I can't think of a way to handle both queue-able notifications and lower priority ones at the same time without adding unproportional complexity. I could add a configuration option to ignore queueing and always show only the most recent one, for the amount of time it asks to be shown.
Example:
* 12:00:00 You receive a chat message that should show for 60 seconds.
* 12:00:15 You receive another message, which replaces the old and shows for 60 seconds
* 12:01:15 The regular status line shows
Example 2:
* 12:00:00 You receive a chat message that should show for 60 seconds
* 12:00:02 A volume update comes along with -t 0, and replaces the chat message
* 12:00:04 The regular status line shows
Would that be useful to you?
Offline
halhen: Thanks! Actually yes, that would be useful to me. Since my notification usage is pretty limited, that would actually be perfect for my workflow. If I'm playing with the volume, I'm going to see a notification sitting in the statusbar anyways, so it's ok to cancel it and show the volume notification.
Scott
Offline
There, a new version is in AUR.
To disable queueing, i.e. showing the most recent notification, configure as such:
QUEUE_NOTIFICATIONS=False
The project moved from my domain to github, so the few added lines of documentation is at.
Let me know if I screwed up somewhere.
Offline
Hm, I found wmii a couple of days ago, and it didn't handle libnotify events (I use pidgin - there's a hackish way to view notifications, but I really wanted to use the "proper" libnotify way)
Anyway, the default way you use statnot has functionality which is duplicated in wmii, so I thought I might share my setup.
I launch statnot as:
statnot ~/.config/statnot/config.py &
~/.config/statnot/config.py contains:
def update_text(text): import os file = open("%s/.config/statnot/notification" % os.getenv("HOME"),"w") file.write(text) file.close()
~/.statusline.sh contains:
if [ $# -ge 1 ]; then echo "NOTIFICATION: $1 | "; fi
And somewhere in my wmiirc is:
status() { echo -n $(cat ~/.config/statnot/notification) 'Wireless' $(iwconfig wlan0 | sed 's/ /\n/g' | grep Quality) '|' $(date) }
So any notifications found by statnot are put at the start of the wmii status line.
Amazing script, saved me reinventing the wheel (again)
Snark1994
Offline
Awesome tool. I found that it reacts bad to the clock adjusting, but i don't know if it can be called a "bug".
However i want to share my setup with 2 windows managers and 1 config file:
This is my statnot.conf
DEFAULT_NOTIFY_TIMEOUT = 5000 # milliseconds MAX_NOTIFY_TIMEOUT = 7000 # milliseconds NOTIFICATION_MAX_LENGTH = 100 # number of characters STATUS_UPDATE_INTERVAL = 3.0 # seconds # export WMNAME in ~/.xinitrc before the windows manager start import os STATUS_COMMAND = ['/bin/bash', '%(HOME)s/scripts/%(WMNAME)s/statnot-statusline.sh' % {'HOME': os.getenv('HOME'), 'WMNAME': os.getenv('WMNAME')}] USE_STATUSTEXT=True QUEUE_NOTIFICATIONS=True
WMNAME needs to be exported in .xinitrc. My scripts are placed in $HOME/scripts/$WMNAME/statnot-statusline.sh
--------------------------
My statnot scripts are used in conjunction with dzen2. This is one of my statnot-statusline.sh script that plays well with dzen2 using a named pipe:
# Create the named pipe [ ! -p /tmp/statnot ] && mkfifo /tmp/statnot if [ $# -eq 0 ]; then # Get date date=$(echo "^fg(grey)"$(date '+%A %d %B %Y') ; echo "^fg(cyan)"$(date '+%H:%M')) # Echo results echo $date >> /tmp/statnot else # Echo notification echo "NOTIFICATION: $1" >> /tmp/statnot; fi
Obviusly, dzen2 must be started somewhere like this:
tail -n1 -f /tmp/statnot | dzen2
Last edited by cyrusza (2011-06-10 16:35:51)
Offline
Quick question: short of rewriting my status script, is there any way to get statusline.sh to work with bashisms like process substitution?
# edit: nvm: missed it in the conf file...
Last edited by jasonwryan (2011-09-02 09:20:06)
Online
Anyone else seeing dropbox crash with statnot?
process 7632: Array or variant type requires that type string be written, but end_dict_entry was written. The overall signature expected here was 'susssasa{ss}' and we are on byte 10 of that signature. D-Bus not built with -rdynamic so unable to print a backtrace
Online | https://bbs.archlinux.org/viewtopic.php?pid=846917 | CC-MAIN-2017-04 | refinedweb | 2,584 | 60.75 |
I need to set a directory and then read all the filenames of the files inside and store the whole path in a variable. I need to use this this variable later , to open the file and read it. I don't want use
QDir
boost/filesystem.hpp
$ g++ -o test test.cpp -lboost_filesystem -lboost_system
$ ./test
g++ -o test test.cpp
root_dir = 'abc'
img_dir = os.path.join(root_dir,'subimages')
img_files = os.listdir(img_dir)
for files in img_files:
img_name = os.path.join (img_dir,files)
img = cv2.imread(img_name)
Your choices are to use boost, QDir, roll your own, or use a newer compiler which has adopted some of the TR2 features that are staged for C++17. Below is a sample which roughly should iterate over files in a system agnostic manner with the C++17 feature.
#include <filesystem> namespace fs = std::experimental::filesystem; ... fs::directory_iterator end_iter; fs::path subdir = fs::dir("abc") / fs::dir("subimages"); std::vector<std::string> files; for (fs::directory_iterator dir_iter(subdir); dir_iter != end_iter; dir_iter++) { if (fs::is_regular_file(dir_iter->status())) { files.insert(*dir_iter); } } | https://codedump.io/share/Tw1VkmQtcMRU/1/the-ospath-equivalent-in-c-without-qt | CC-MAIN-2017-09 | refinedweb | 176 | 62.04 |
WritableComparator subclasses that rely on deserialization for each
compare are already not threadsafe, but if you don't use the static
define, you'll get a new instance for each call to get, but *only for
the ordering defined by the WritableComparable type.* This is the
intent, I think: that the comparators registered with the cache in
WritableComparator are low-level comparators matching the semantics of
the WritableComparable type.
Other comparators with state are odd beasts; if it is required, then a
ThreadLocal instance of whatever you need is probably easier to reason
about. If you just want to change the ordering for the sort, the
registry doesn't enter into it. As a side-node (I think you're clear
on this), JobConf will return the same instance if it comes from the
registry. It only creates new instances for user-defined comparators.
For the (vast, vast) majority of RawComparators, there shouldn't be
any state, so sharing an instance is a modest, but clear win. Is there
something special about your use case that makes a new instance
necessary? Is there a particular reason why a ThreadLocal instance of
its members wouldn't be more appropriate? Can you define your
serialized format in a way that would make defining the raw compare()
simpler? -C
On Sep 3, 2008, at 6:53 AM, Igor Maximchuk wrote:
> Hello,
>
> We have experienced thread safety issues when subclassing
> WritableComparator and subsequently calling WritableComparator.define.
> It seems that same comparator instance has its methods called from
> different threads. This makes the following code failing from time
> to time due to race condition
>
> public class PComparator extends WritableComparator {
>
> ....
>
> private DataInputBuffer buf = new DataInputBuffer();
> public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2,
> int l2) {
>
> ... [do something that modifies buf]
> }
> }
> ...
> static {
> WritableComparator.define(PKey.class, new PComparator());
> }
>
> So, no member variables can be modified in compare without the
> explicit synchronization.
>
> On the other hand, when comparator class is specified in JobConf,
> each thread recieives it's own instance and no race condition occurs.
>
> I think this case should be mentioned in documentation
>
> I can also suggest to implement another version
> WritableComparator.define(Class c, Class comparatorClass) which
> registers the comparaator class, not comparator class instance and
> make WritableComparator.get to instantiate comparators registered in
> such a way and declare old defile method deprecated | http://mail-archives.apache.org/mod_mbox/hadoop-common-user/200809.mbox/%3C372CA05A-00C6-4BB9-A047-C9293E793355@yahoo-inc.com%3E | CC-MAIN-2017-39 | refinedweb | 392 | 52.49 |
Patterns
Many atoms vs. one large store
Legend-State can be used however you want. If your team prefers one large state object containing all app state, that's great! Or you may prefer to have multiple different individual atoms in their own files, which works too. Here's some examples of ways to organize your state.
One large global state
const store = observable({ UI: { windowSize: undefined as { width: number, height: number }, activeTab: 'home' as 'home' | 'user' | 'profile', ... }, settings: { theme: 'light' as 'light' | 'dark', fontSize: 14, ... }, todos: [] as TodoItem[] })
Multiple individual atoms
// settings.ts export const theme = observable('light') export const fontSize = observable(14) // UIState.ts export const uiState = observable({ windowSize: undefined as { width: number, height: number }, activeTab: 'home' as 'home' | 'user' | 'profile', })
Within React components
You can use
useObservable to create state objects within React components, then pass them down to children through either props or Context.
function App() { const store = useObservable({ profile: { name: 'hi' } }) return ( <div> <Profile profile={store.profile} /> </div> ) } function Profile({ profile }) { return ( <div>{profile.name}</div> ) } | https://legendapp.com/dev/state/patterns/ | CC-MAIN-2022-40 | refinedweb | 171 | 57.98 |
ok so ive been working on the code for weeks now for class and i dont know how to start inputing a function this is what i have
#include <iostream> using namespace std; int main() { //declare variable// const double g = 9.8; double s =1; double d; cout<<"Seconds "<< " Distance" <<endl; cout<<"========================" <<endl; for(s=1; s <= 10; s++) { //equation for distance falling// d = ((.5)* g * s * s); cout << s << " " << d << endl; } #pragma region wait cout<<" Press Enter to Quit"; cin.ignore(); cin.get(); #pragma end region return 0; }
the code does what i want it to but how do i get the equation "d = ((.5)* g * s * s)" as the function? | https://www.daniweb.com/programming/software-development/threads/321579/functions | CC-MAIN-2017-47 | refinedweb | 112 | 75.34 |
We are planning our trip to Galway in May. We are not renting a car, would it be better for us to fly into Dublin and take the train to Galway or fly into Shannon and then take a bus to Galway?
I'd go for Shannon due to it's proximity , You can get a City Link bus from the airport which will take you direct to Galway (You can also get this bus from Dublin) But the journey time from Shannon would be consideribly less. You can fly to Galway airport from Dublin using Aer Arann.
Hope this helps!
Shannon is your best bet for ease of travel.
Going from Dublin, you will have to take a long bus journey and if you opt for the train from Dublin, you need to get a bus to Dublin City Centre and a bus to the train station, then the train to Galway.
You could get a taxi but it would be a costly way to travel across Dublin City Centre.
It is cheaper to fly into Shannon from the US most of the time.
Thank you for your suggestions!
There is a direct bus from Dublin Airport to Dublin Heuston Station. It is route 748 and is an express service. There is no need to take 2 buses if choosing this way to travel
1. Fly to Galway Direct
2.You can fly to Dublin with Ryanair or Aer Lingus (good deals). There is a coach park at Dublin airport where you will find Citylink coaches which go direct to Galway city at €18 single €28 return (so don't bother going into Dublin first). If you do want to take the train, then you can take a bus from the airport to Heuston train station - this goes from just outside the arrivals hall, go left and take bus number 848 at €5 each way - see Bus Eireann.
3. Fly to Shannon and take either the Bus Eireann bus or the direct Citylink bus to Galway city
Avail of some bus tours to the Burren, Connemara, visit the Aran Islands, trip up the Corrib. Hang out at the old part of town - Quay street and if you like fish, then do not miss Mc Donagh's restaurant on Quay Street. | http://www.tripadvisor.com/ShowTopic-g186609-i429-k401036-Best_Airport_for_Galway-Galway_County_Galway_Western_Ireland.html | CC-MAIN-2014-52 | refinedweb | 381 | 85.22 |
Introduction: Debug Joomla PHP With Eclipse and LAMP on Ubuntu 16.04
The purpose of this Instructable is to setup a LAMP web server on Ubuntu, install a Joomla! Content Management System and finally debug PHP scripts with Eclipse.
A Windows Instructable with XAMPP is located here.
You'll get a quick installation guide in 10 detailed steps. At the end of this Instructable, you're ready to debug your own website. Only freeware software will be used.
Question: Do you need a PHP debugger?
Answer: When you're developing websites in PHP, then the answer is YES.
A debugger can save you a lot of time to find bugs in your PHP scripts, such as Joomla! components, modules or plugins. It allows you to step through the code, set breakpoints, watch variables and many more.
Prerequisites:
- Ubuntu 16.04 clean installation. (32-bit or 64-bit)
- At least 2GB free disk space.
- Internet connection.
Steps:
- Install Apache
- Install MySQL
- Install PHP with phpmyadmin
- Configure Apache Xdebug module
- Install Joomla
- Test Joomla installation
- Install Java
- Download and configure Eclipse
- Create a new PHP project with Eclipse
- Basic Eclipse debugging
Several commands should be executed in a terminal. You can open a terminal with the [CTRL+ALT+T] shortcut. (See screenshot) All commands are executed as a normal user, displayed with a $ prompt. For example:
$ whoami
Note: Copy and paste the commands without the $ character and press [ENTER].
I could not find good tutorials on the web, so I decided to share my experiences with you, step by step. The first step is to setup a LAMP web server which stands for: Linux Apache MySQL PHP.
Let's continue and have fun! :-)
Step 1: Install Apache
Install the web server Apache:
$ sudo apt-get install apache2
You can check the Apache installation by opening a web browser at. A welcome message "It works!" will be displayed when the installation is successful.
The root directory of the Apache web server is write protected by default:
$ ls -la /var/www/html total 20 drwxr-xr-x 2 root root 4096 aug 9 20:54 . drwxr-xr-x 3 root root 4096 aug 9 17:26 .. -rw-r--r-- 1 root root 11321 aug 9 17:26 index.html
Add your user to the "www-data" group to add write permission:
$ sudo adduser $USER www-data
Logout and login:
$ gnome-session-quit
Change owner to the group "www-data":
$ sudo chown -R www-data:www-data /var/www
Add group write permission:
$ sudo chmod -R g+rwX /var/www
Now you can create a new file as normal user (without sudo):
$ cd /var/www/html $ touch test.html $ ls test.html test.html
Step 2: Install MySQL
Install the MySQL database server:
$ sudo apt-get install mysql-server
During the installation, you'll be asked to set a root password.
Step 3: Install PHP With Phpmyadmin
phpmyadmin is a web based MySQL administration tool which is a powerful tool for web developers. Frequently used operations such as managing databases, tables, columns, relations, indexes, users, permissions, etc can be performed via a web interface.
Installing phpmyadmin will automatically install and configure PHP.
Note: I could not get phpmyadmin up and running when PHP is already installed.
Install phpmyadmin with the command:
$ sudo apt-get install phpmyadmin
During the installation, you'll be asked to configure the web server automatically. Press [SPACE] to select apache2 and press [ENTER]. (Use [TAB] or arrow keys to navigate).
Answer "Configure database for phpmyadmin with dbconfig-common?" with Yes. ([LEFT ARROW], [ENTER])
Enter the MySQL root password.
Install mcrypt for phpmyadmin:
$ sudo apt-get install mcrypt
Restart Apache:
$ sudo service apache2 restart
Check your installed PHP version with the command:
$ php -v Copyright (c) 1997-2016 The PHP Group Zend Engine v3.0.0, Copyright (c) 1998-2016 Zend Technologies with Zend OPcache v7.0.8-0ubuntu0.16.04.2, Copyright (c) 1999-2016, by Zend Technologies
To check the phpmyadmin installation, open in your web browser.
Login with user name root and your MySQL phpmyadmin password.
Step 4: Configure Apache Xdebug Module
Xdebug will be used to debug PHP scripts. It should be configured manually in the Apache web server.
Install Xdebug:
$ sudo apt-get install php-xdebug
To find your Apache php.ini configuration file, enter the following command:
$ find /etc/php -name php.ini /etc/php/7.0/cli/php.ini /etc/php/7.0/apache2/php.ini
The Apache PHP configuration file on Ubuntu 16.04 is located in
/etc/php/7.0/apache2/php.ini, but depends on the installed PHP version.
Open php.ini in a text editor, for example:
$ sudo gedit /etc/php/7.0/apache2/php.ini
Add the following lines to the end of the file. Then save the file:
[Xdebug] zend_extension=xdebug.so xdebug.remote_enable=1 xdebug.remote_port=9000
Restart Apache:
$ sudo service apache2 restart
Check the Xdebug installation which should display " with Xdebug...":
$ php -v PHP 7.0.8-0ubuntu0.16.04.2 (cli) ( NTS ) Copyright (c) 1997-2016 The PHP Group Zend Engine v3.0.0, Copyright (c) 1998-2016 Zend Technologies with Zend OPcache v7.0.8-0ubuntu0.16.04.2, Copyright (c) 1999-2016, by Zend Technologies with Xdebug v2.4.0, Copyright (c) 2002-2016, by Derick Rethans
Create a new info.php file in the Apache web server root directory:
$ gedit /var/www/html/info.php
Add the following lines and save the file:
<?php phpinfo(); ?>
Note: Please refer to Step 1 Install Apache to fix the permission of the /var/www/html directory when you can't save the file.
Now open a web browser at.
A new xdebug configuration should be displayed. (See screenshot)
Step 5: Install Joomla
Now you're ready to install Joomla.
Download Joomla from.
In my case, it is saved to ~/Downloads/Joomla_3.6.2-Stable-Full_Package.zip.
Extract the zip file in the /var/www/html directory:
$ cd /var/www/html $ unzip ~/Downloads/Joomla*
Remove the index.html example:
$ rm index.html
Set Apache permission for the Joomla directory:
$ mv htaccess.txt .htaccess
Set user and group "www-data" permission:
$ sudo chown -R www-data:www-data /var/www
Add group write permission:
$ sudo chmod -R g+rwX /var/www
Open in a web browser to start the Joomla installation.
Set Main Configuration:
- Site Name
- Description
- Administrator Email
- Administrator Username
- Administrator Password
- ConfirmAdministrator Password
Click Next
Set Database Configuration:
- Database Type: MySQLi
- Host Name: localhost
- Username: root
- Database Name: joomla
- Table Prefix: jos_
- Database Process: Remove
Click Next
Finalization:
Make sure Pre-Installation Check column is green.
Check the /var/www/html permission above when configuration.php Writable is set to No.
Click Install
Congratulations! Joomla! is now installed.
Click Remove installation folder
Step 6: Test Joomla Installation
Open in a web browser.
Login with your user name and password.
Step 7: Install Java
Java is required to run Eclipse. must agree with the license agreement by selecting: <Yes>.
[LEFT ARROW], [ENTER]
Check the Java installation, for example:
$ java -version java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
Step 8: Download and Configure Eclipse
Download Eclipse PDT (PHP Development Tools) from: > Download 32 bit or 64 bit version.
To check if you're using Ubuntu 32 or 64 bit:
$ uname -i x86 < This is 32 bit x86_64 < This is 64 bit
Extract the eclipse-php-neon-R-linux-gtk-x86_64.tar.gz file:
$ cd ~/Downloads $ tar -zxvf eclipse-php*
Start Eclipse:
$ cd eclipse $ ./eclipse
Accept default workspace and click OK.
Close the Welcome tab (by clicking the X).
Click in the toolbar Window > Preferences:
- Click PHP > Interpreter:
This should be set to your PHP version.
- Click PHP > PHP Executables > Add:
- PHP executable tab:
- Name: PHP
- Executable path: /usr/bin/php
- PHP ini file (optional): /etc/php/7.0/apache2/php.ini
- SAPI type: CLI
- Debugger: XDebug
- Port: 9000
Click Finish > OK.
Step 9: Create a New PHP Project With Eclipse
Now we're ready to create and configure a new PHP project and use existing Joomla sources.
Click in the toolbar: File > New > PHP project:
- Project name: joomla
- Check: Create project at existing location (from existing source)
- Directory: /var/www/html
Click Finish.
Click in the toolbar Window > Preferences > Servers >
Select Default PHP Web Server > Click Edit:
- Click Server tab:
- Server Name: Default PHP Web Server
- Base URL:
- Document Root: /var/www/html
- Debugger: XDebug
- Port: 9000
- Path on Server:
- Path in File System: /var/www/html
Click OK > Finish > OK.
Let's continue to debug your fist Joomla PHP project!
Step 10: Basic Eclipse Debugging
Now you're ready to start debugging.
- Expand the joomla project directory.
- Double click index.php to open it in the editor.
- Set a breakpoint on line 12 (left of the line number).
- Click in the toolbar debug button (small down arrow) >
Debug As > PHP Web Application.
Next time you can click the Debug button in the toolbar instead.
Set Launch URL to: > click OK.
You'll be asked to switch to Debug perspective. Answer with Yes. You can switch back to PHP project perspective by clicking the small PHP button in the upper right corner.
Your default web browser such as Firefox will be opened at:. You can change this for example to Chrome in the Preferences dialog box > General > Web Browser.
The web browser displays a blank white page, because the breakpoint in Eclipse should be reached on index.php line 12.
Now you should be able to step through the code with shortcuts:
- [F5] Step into
- [F6] Step over
- [F7] Step return (or out)
- [F8] Resume (or continue)
Now press 3x [F6].
The $startTime variable is displayed in the Variables tab. Hover over the variable to see the contents of the variable.
Press [F8] to resume. The entire website is now displayed in your web browser.
Refresh your web page in the web browser to reload the page. The breakpoint in index.php line 12 is reached again.
Notes:
- Use the debug button to start a debug session once.
- Use the terminate button [CTRL]+[F2] to stop the debugger.
Step 11: Finally
Congratulations! Now you're completely up and running when you reached this final step.
Feedback is welcome.
Please leave a message when this tutorial was helpful for you.
Thanks!
Be the First to Share
Recommendations
3 Discussions
2 years ago
Also Codeloobster IDE works great on Ubuntu:
4 years ago
Very nice, thanks for sharing! :)
Reply 4 years ago
Thanks, seamster! In the meantime I've added more screenshots and updated some steps. Success! | https://www.instructables.com/Debug-Joomla-PHP-With-Eclipse-and-Xdebug-With-LAMP/ | CC-MAIN-2020-50 | refinedweb | 1,778 | 67.35 |
-850
Java Standard Edition 5 and 6
Demo Product - For More Information - Visit:
Edition = DEMO
ProductFull Version Features:
90 Days Free Updates
30 Days Money Back Guarantee
Instant Download Once Purchased
24/7 Online Chat Support
Page | 1 Preparation: C,D
Question: 2
Which two are associated with the web tier in a J2EE web-based application? (Choose two.)
A. servlets
B. JAX-RPC
C. JMS
D. entity beans
E. JSP
Answer: A,E
Question: 3
Given:
1. class Test {
2. public static void main(String args[]) {
3. int num1 = 10, num2 = 20, result;
4. result = calc(num1, num2);
5. System.out.println(result);
6. }
7.
8. // insert code here
9. }
Which, inserted at line 8, produces the output 30?
A. static int calc(int n1, int n2) { return; }
B. public int calc(int n1, int n2) { return n1 + n2; }
C. public int calc(int n1, int n2) { return; }
D. static int calc(int n1, int n2) { return n1 + n2; }
E. static void calc(n1, n2) { return (n1 + n2); }
F. static int calc(int n1, n2) { return n1, n2; };
Answer: D
Question: 4
Page | 2 Preparation Material
Given:
1. public abstract class Wow {
2. private int wow;
3. public Wow(int wow) {
4. this.wow = wow;
5. }
6. public void wow() { }
7. private void wowza() { }
8. }
Which is true about the class Wow?
A. It does NOT compile because an abstract class must have at least one abstract method.
B. It does NOT compile because an abstract class CANNOT have instance variables.
C. It compiles without error.
D. It does NOT compile because an abstract class CANNOT have private methods.
E. It does NOT compile because an abstract class must have a constructor with no arguments.
Answer: C
Question: 5
Given:
1. class X {
2. private Y y;
3. public X(Y y) { this.y = y; }
4. }
5. class Y {
6. private X x;
7. public Y() { }
8. public Y(X x) { this.x = x; }
9. }
The instance variable y is intended to represent the composition relationship "X is composed of Y."
Which code correctly maintains this meaning?
A. X x1 = new X(new Y());
X x2 = new X(new Y());
B. X xx = new X(null);
Y y1 = new Y(xx);
Y y2 = new Y(xx);
C. Y yy = new Y();
X x1 = new X(yy);
X x2 = new X(yy);
D. Y y1 = new Y(new X(null));
Y y2 = new Y(new X(null));
Answer: A
Question: 6
Which type of J2EE component is used to store business data persistently?
Page | 3 Preparation Material
A. stateless session beans
B. JavaBeans
C. stateful session beans
D. entity beans
E. JavaServer Pages
Answer: D
Question: 7
What is the purpose of JNDI?
A. to access native code from a Java application
B. to parse XML documents
C. to access various directory services using a single interface
D. to register Java Web Start applications with a web server
Answer: C
Question: 8
Which two are true about HTML? (Choose two.)
A. HTML can set up hypertext links between documents.
B. HTML uses tags to structure text into headings, paragraphs, and lists.
C. HTML is an object-oriented programming language.
D. HTML documents CANNOT be browsed by a text editor.
Answer: A,B
Question: 9
Given:
4. class Example {
5. int x = 50;
6. int y = 100;
7. public static void main(String args[]) {
8. int x = 0, y = 10;
9. Example ex = new Example();
10. while (x < 3) {
11. x++; y--;
12. }
13. System.out.println("x = " + x + " , y = " + y);
14. }
15. }
What is the result?
A. Compilation fails because of an error at line 8.
B. x = 3 , y = 7
C. Compilation fails because of an error at line 11.
Page | 4 Preparation Material
D. Compilation fails because of an error at line 9.
E. x = 53 , y = 97
F. Compilation fails because of an error at line 10.
Answer: B
Question: 10
You have developed a MIDlet that runs on a Java-enabled Personal Digital Assistant (PDA) device. Now, your
employer has asked you to port the MIDlet to run on other Java platforms. Which is true?
A. The MIDlet is 100% portable across all J2ME devices.
B. The MIDlet can run within a standard web browser.
C. The MIDlet is guaranteed to run correctly under J2SE.
D. The MIDlet is NOT guaranteed to run on a Java technology-enabled phone.
Answer: D
Question: 11
Which statement is true?
A. JMS enables an application to provide flexible, asynchronous data exchange.
B. JMS provides interfaces to naming and directory services.
C. The JMS API is located in the java.jms package.
D. JMS enables an application to provide tightly coupled, distributed communication.
Answer: A
Question: 12
Which two are true about stateless session beans? (Choose two.)
A. They are used to represent data stored in an RDBMS.
B. They implement the JMS API.
C. They are used to implement business logic.
D. They CANNOT hold client state.
Answer: C,D
Question: 13
Which two are true about javax.swing? (Choose two.)
A. It includes classes for creating buttons and panels.
B. It is used to create MIDlets.
C. It is used to create applications that have the same user interface on different platforms.
Page | 5 Preparation Material
D. It uses the native GUI components of each platform.
Answer: A,C
Question: 14
Which two are true? (Choose two.)
A. An interface CANNOT be extended by another interface.
B. An abstract class CANNOT be extended by an abstract class.
C. An interface can be extended by an abstract class.
D. An abstract class can implement an interface.
E. An abstract class can be extended by a concrete class.
F. An abstract class can be extended by an interface.
Answer: D,E
Question: 15
Click the Exhibit button.
Which relationships, referenced by the class names involved, are drawn using valid UML notation?
A. AB, AC, BD, and CD
B. only AC, BD, and CD
C. only AB, AC, and BD
D. only AB and AC
E. only BD and CD
Answer: A
Question: 16
Given:
12. String s = "abcdefgabc";
13. char c = s.charAt(2);
14.
15. if (c == 'c')
16. s = s.replace('c', 'X');
17. else if (c == 'b')
18. s = s.replace('b', 'O');
Page | 6 Preparation Material
19. else
20. s = s.replace('c', 'O');
21. System.out.println(s);
What is the result?
A. aOcdefgabc
B. Compilation fails.
C. abOdefgabc
D. abXdefgabc
E. abOdefgabO
F. aOcdefgaOc
G. abXdefgabX
Answer: G
Question: 17
Which package contains classes used to create data collections, such as maps or queues?
A. java.lang
B. java.io
C. java.awt
D. java.net
E. javax.swing
F. java.util
Answer: F
Question: 18
Given:
1. interface A { }
2. interface B { void b(); }
3. interface C { public void c(); }
4. abstract class D implements A,B,C { }
5. class E extends D {
6. void b() { }
7. public void c() { }
8. }
Which is true?
A. Compilation fails due to an error in line 6.
B. The code compiles without error.
C. Compilation fails due to an error in line 2.
D. Compilation fails due to an error in line 4.
E. Compilation fails due to an error in line 1.
Answer: A
Question: 19
Page | 7 Preparation Material
What type of relationship is needed to represent the relationship between students and the courses they are
enrolled in at a university?
A. a one-to-one composition
B. a one-to-one association
C. a many-to-many composition
D. a one-to-many composition
E. a one-to-many association
F. a many-to-many association
Answer: F
Question: 20
Which two are features of JNDI? (Choose two.)
A. an interface to store and retrieve named Java objects of any type
B. an interface to search for objects using attributes
C. a defined common set of messaging concepts and programming strategies
D. connectivity to databases and other tabular data sources
Answer: A,B
Page | 8 Preparation Material
Demo Product - For More Information - Visit:
20% Discount Coupon Code:
20off2016
Page | 9 | http://www.slideserve.com/certschief3/1z0-850-exam-certification-test | CC-MAIN-2017-22 | refinedweb | 1,347 | 71 |
1,1
Also, solutions to phi(n + 2) = sigma(n). - Conjectured by Jud McCranie, Jan 03 2001; proved by Reinhard Zumkeller, Dec 05 2002
The set of primes for which the weight as defined in A117078 is 3 gives this sequence except for the initial 3. - Rémi Eismann, Feb 15 2007
The set of lesser of twin primes larger than three is a proper subset of the set of primes of the form 3n - 1 (A003627). - Paul Muljadi, Jun 05 2008
It is conjectured that A113910(n+4) = a(n+2) for all n. - Creighton Dement, Jan 15 2009
I would like to conjecture that if f(x) is a series whose terms are x^n, where n represents the terms of sequence A001359, and if we inspect {f(x)}^5, the conjecture is that every term of the expansion, say a_n * x^n, where n is odd and at least equal to 15, has a_n >= 1 . This is not true for {f(x)}^k, k = 1, 2, 3 or 4, but appears to be true for k >= 5. - Paul Bruckman (pbruckman(AT)hotmail.com), Feb 03 2009
A164292(a(n)) = 1; A010051(a(n)-2) = 0 for n > 1. - Reinhard Zumkeller, Mar 29 2010
From Jonathan Sondow, May 22 2010: (Start)
About 15% of primes < 19000 are the lesser of twin primes. About 26% of Ramanujan primes A104272 < 19000 are the lesser of twin primes.
About 46% of primes < 19000 are Ramanujan primes. About 78% of the lesser of twin primes < 19000 are Ramanujan primes.
A reason for the jumps is in Section 7 of "Ramanujan primes and Bertrand's postulate" and in Section 4 of "Ramanujan Primes: Bounds, Runs, Twins, and Gaps". (End)
Primes generated by sequence A040976. - Odimar Fabeny, Jul 12 2010
Primes of the form 2*n - 3 with 2*n - 1 prime n > 2. Primes of the form (n^2-(n-2)^2)/2 - 1 with (n^2-(n-2)^2)/2 + 1 prime so sum of two consecutive odd numbers/2 - 1. - Pierre CAMI, Jan 02 2012
Solutions of the equation n' + (n+2)' = 2, where n' is the arithmetic derivative of n. - Paolo P. Lava, Dec 18 2012
Conjecture: For any integers n >= m > 0, there are infinitely many integers b > a(n) such that the number sum_{k = m}^n a(k)*b^(n-k) (i.e., (a(m), ..., a(n)) in base b) is prime; moreover, when m = 1 there is such an integer b < (n+6)^2. - Zhi-Wei Sun, Mar 26 2013
Except for the initial 3, all terms are congruent to 5 mod 6. One consequence of this is that no term of this sequence appears in A030459. - Alonso del Arte, May 11 2013
Aside from the first term, all terms have digital root 2, 5, or 8. - J. W. Helkenberg, Jul 24 2013
The sequence provides all solutions to the generalized Winkler conjecture (A051451) aside from all multiples of 6. Specifically, these solutions start from n = 3 as a(n) - 3. This gives 8, 14, 26, 38, 56, ... An example from the conjecture is solution 38 from twin prime pairs (3, 5), (41, 43). - Bill McEachen, May 16 2014
Conjecture: a(n)^(1/n) is a strictly decreasing function of n. Namely a(n+1)^(1/(n+1)) < a(n)^(1/n) for all n. This conjecture is true for all a(n) <= 1121784847637957. - Jahangeer Kholdi and Farideh Firoozbakht, Nov 21 2014
a(n) are the only primes, p(j), such that (p(j+m)-p(j)) divides (p(j+m)+p(j)) for some m>0, where p(j) = A000040(j). For all such cases m=1. It is easy to prove, for j>1, the only common factor of (p(j+m)-p(j)) and (p(j+m)+p(j)) is 2, and there are no common factors if j = 1. Thus, p(j) and p(j+m) are twin primes. Also see A067829 which includes the prime 3. - Richard R. Forberg, Mar 25 2015
Primes prime(k) such that prime(k)! == 1 (mod prime(k+1)) with the exception of prime(991) = 7841 and other unknown primes prime(k) for which (prime(k)+1)*(prime(k)+2)*...*(prime(k+1)-2) == 1 (mod prime(k+1)) where prime(k+1) - prime(k) > 2. - Thomas Ordowski and Robert Israel, Jul 16 2016
Milton Abramowitz and Irene A. Stegun, eds., Handbook of Mathematical Functions, National Bureau of Standards Applied Math. Series 55, 1964 (and various reprintings), p. 870.
T. M. Apostol, Introduction to Analytic Number Theory, Springer-Verlag, 1976, page 6.
N. J. A. Sloane, A Handbook of Integer Sequences, Academic Press, 1973 (includes this sequence).
N. J. A. Sloane and Simon Plouffe, The Encyclopedia of Integer Sequences, Academic Press, 1995 (includes this sequence).
Chris K. Caldwell, Table of n, a(n) for n = 1..100000
Milton Abramowitz and Irene A. Stegun, eds., Handbook of Mathematical Functions, National Bureau of Standards, Applied Math. Series 55, Tenth Printing, 1972 [alternative scanned copy].
Chris K. Caldwell, First 100000 Twin Primes
Chris K. Caldwell, Twin Primes
Chris K. Caldwell, Largest known twin primes
Chris K. Caldwell, Twin primes
Chris K. Caldwell, The prime pages
Harvey Dubner, Twin Prime Statistics, Journal of Integer Sequences, Vol. 8 (2005), Article 05.4.2.
Andrew Granville and Greg Martin, Prime number races, Amer. Math. Monthly, 113 (No. 1, 2006), 1-33.
Thomas R. Nicely, Home page, which has extensive tables.
Thomas R. Nicely, Enumeration to 10^14 of the twin primes and Brun's constant, Virginia Journal of Science, 46:3 (Fall, 1995), 195-204.
Omar E. Pol, Determinacion geometrica de los numeros primos y perfectos.
Fred Richman, Generating primes by the sieve of Eratosthenes
P. Shiu, A Diophantine Property Associated with Prime Twins, Experimental mathematics 14 (1) (2005)
Jonathan Sondow, Ramanujan primes and Bertrand's postulate, Amer. Math. Monthly, 116 (2009) 630-635.
Jonathan Sondow, J. W. Nicholson, and T. D. Noe, Ramanujan Primes: Bounds, Runs, Twins, and Gaps, J. Integer Seq. 14 (2011) Article 11.6.2
Jonathan Sondow and Emmanuel Tsukerman, The p-adic order of power sums, the Erdos-Moser equation, and Bernoulli numbers, arXiv:1401.0322 [math.NT], 2014; see section 4.
Terence Tao, Obstructions to uniformity and arithmetic patterns in the primes, arXiv:math/0505402 [math.NT], 2005.
Eric Weisstein's World of Mathematics, Twin Primes
Index entries for primes, gaps between
a(n) = A077800(2n-1).
A001359 = { n | A071538(n-1) = A071538(n)-1 } ; A071538(A001359(n)) = n. - M. F. Hasler, Dec 10 2008
A001359 = { prime(n) : A069830(n) = A087454(n) }. - Juri-Stepan Gerasimov, Aug 23 2011
a(n) = prime(A029707(n)). - R. J. Mathar, Feb 19 2017
select(k->isprime(k+2), select(isprime, [$1..1616])); # Peter Luschny, Jul 21 2009
A001359 := proc(n)
option remember;
if n = 1
then 3;
else
p := nextprime(procname(n-1)) ;
while not isprime(p+2) do
p := nextprime(p) ;
end do:
p ;
end if;
end proc: # R. J. Mathar, Sep 03 2011
Select[Prime[Range[253]], PrimeQ[# + 2] &] (* Robert G. Wilson v, Jun 09 2005 *)
a[n_] := a[n] = (p = NextPrime[a[n - 1]]; While[!PrimeQ[p + 2], p = NextPrime[p]]; p); a[1] = 3; Table[a[n], {n, 51}] (* Jean-François Alcover, Dec 13 2011, after R. J. Mathar *)
nextLesserTwinPrime[p_Integer] := Block[{q = p + 2}, While[NextPrime@ q - q > 2, q = NextPrime@ q]; q]; NestList[nextLesserTwinPrime@# &, 3, 50] (* Robert G. Wilson v, May 20 2014 *)
(PARI) A001359(n, p=3) = { while( p+2 < (p=nextprime( p+1 )) || n-->0, ); p-2}
/* The following gives a reasonably good estimate for any value of n from 1 to infinity; compare to A146214. */
A001359est(n) = solve( x=1, 5*n^2/log(n+1), 1.320323631693739*intnum(t=2.02, x+1/x, 1/log(t)^2)-log(x) +.5 - n)
/* The constant is A114907; the expression in front of +.5 is an estimate for A071538(x) */ \\ M. F. Hasler, Dec 10 2008
(MAGMA) [n: n in PrimesUpTo(1610) | IsPrime(n+2)]; // Bruno Berselli, Feb 28 2011
(Haskell)
a001359 n = a001359_list !! (n-1)
a001359_list = filter ((== 1) . a010051' . (+ 2)) a000040_list
-- Reinhard Zumkeller, Feb 10 2015
(Python)
from sympy import primerange, isprime
print [n for n in primerange(1, 2001) if isprime(n + 2)] # Indranil Ghosh, Jul 20 2017
Subsequence of A003627.
Cf. A006512 (greater of twin primes), A014574, A001097, A077800, A002822, A040040, A054735, A067829, A082496, A088328, A117078, A117563, A074822, A071538, A007508, A146214.
Cf. A104272 Ramanujan primes, A178127 Lesser of twin Ramanujan primes, A178128 Lesser of twin primes if it is a Ramanujan prime.
Cf. A010051, A000040.
Sequence in context: A093326 * A096292 A181747 A078864 A208574 A023218
Adjacent sequences: A001356 A001357 A001358 * A001360 A001361 A001362
nonn,nice,easy,changed
N. J. A. Sloane, Apr 30 1991
approved | http://oeis.org/A001359 | CC-MAIN-2017-30 | refinedweb | 1,454 | 83.05 |
Before you start
For many Perl programmers, the typical development environment is probably an editor like Emacs coupled with a command-line environment. The problem is you tend to spend most of your day switching between Emacs and the command line, and it gets worse if you are doing Web development, as you have to switch between Emacs, your command line, and your Web browser as you write, execute, and check logs for information. Surprisingly, there are few IDEs that have really captured the Perl programmer's imagination over the years, which is why EPIC and Eclipse fills such a void.
EPIC is a complete plug-in suite that supports a new "nature" within Eclipse. The EPIC plug-in incorporates extensions to the editor so that it understands Perl structure and layout. The plug-in also adds additional views and interfaces to your code, and related information enables you to view documentation, execute your Perl applications, and debug them.
About this tutorial
This tutorial will look at the basics of the EPIC plug-in before moving on to an examination of the EPIC system using a real-world example, developing a small module and script entirely within Eclipse that supports RSS parsing. You'll use this as an opportunity to examine other areas, such as the integration with Perldoc, code folding and refactoring -- all of which can make the application development process run more smoothly. By the end, you will have a good understanding of how the EPIC plug-in can be used to develop your Perl applications within Eclipse.
Prerequisites
You will need the following tools before you can make good use of EPIC:
- Eclipse V3.0 or 3.1
- Java technology V1.3, 1.4, or higher
- Perl V5.8.6 or higher. A version of Perl is included with most UNIX® and Linux® installations, and Mac OS X. On Windows®, use ActivePerl.
- PadWalker Perl module at CPAN.
- EPIC (Eclipse Perl Integration), an open source Perl IDE for the Eclipse platform at SourceForge.
Why use an IDE?
This section will examine the reasons behind using an Integrated Development Environment (IDE) over more traditional methods.
Tasks during development
Before looking at the reasons behind using an IDE over more traditional methods, it is worth considering all the tasks you tend to perform when developing with a scripted language. There are differences from the typical compiled language. You generally don't need to compile the source into the final application, but some of the tasks remain constant:
- Writing the code -- This includes getting the format right so it is readable.
- Checking the validity -- Although you won't compile the code, there is still a formal structure, and you can still introduce bugs and problems into the code that can be identified by running some simple checks on the code.
- Access documentation -- No matter how good a programmer you are, it is almost inevitable that you will need to look up some aspect of documentation.
- Write comments/documentation -- Adding commentary to your code makes it readable, and adding documentation as you go helps to make it portable.
- Executing the code -- Often, perhaps more so with scripted languages, you tend to try out the code you are writing.
- Debugging -- Any problems during execution will normally need to be investigated through a determined period of debugging.
How you perform each of these tasks will depend on what environment you use. Let's look at the typical non-IDE based environment first.
Existing environments
Ask a typical Perl programmer what he uses for editing and working with Perl scripts, and it's likely that he will simply return the name of his favorite editor -- perhaps vi, maybe even Notepad. At a push, he might be using a more extensive and intelligent editor like Emacs or oXygen that provides built-in markup, highlighting, and intelligent formatting.
The ability to use a standard editor and execute the program directly through the command line is one of the major benefits and advantages of scripting languages like Perl and other scripted languages like Python, PHP, and Ruby.
There are some obvious benefits to the editor approach. For example, you can easily edit and create the scripts pretty much everywhere, with or without a specific editor, so there are no limits on when and where you can program.
Some aspects, though, are less than perfect. Looking up documentation, for example, often needs to be handled in another application or terminal window. Execution of the application will also require dropping to a shell or terminal to execute. Also there is no management of the project as a whole. A typical Perl project will consist of Perl scripts, modules, and probably other data, as well, like XML files or other data sources. They may all exist in the same folder, but their relationship to each other and their significance might be less clear.
IDE benefits
The key element to any IDE is directly related to that first word: integrated. All the steps outlined in Tasks can generally be performed within an IDE without ever having to leave or switch from the application.
For example, code can be written and automatically formatted. Errors and typos in your code can be highlighted as you type, and you can use the hot links to documentation to verify the functions or modules you need to use, without separately looking up that information.
Usually, you can also execute -- and monitor the execution -- of your application so you determine whether it works correctly, and you can debug its operation in the process.
You can use the information generated, and output during the execution and debugging process in your application directly. For example, generated errors and warnings will provide a link that will take you directly back to the appropriate line of your source code.
Overall, the main benefit of the integrated system is to save you time. You no longer have to spend time switching between applications, or finding and locating the code that generated problems. All of the information is not only highlighted but linked and accessible, making it easier to work within the code structure.
Many of these abilities are unfamiliar to the typical script programmer who is used to the simple editor approach. But it's time to move on to a more coherent environment.
Installation and setup
Let's take a look at how to install the EPIC plug-in so you can use the IDE features to write Perl applications.
Installing the EPIC plug-in
Before looking at EPIC, you need to install the plug-in. Before you get there, you will obviously need a Perl interpreter. I'm using Mac OS X, which, being based on BSD, comes with the UNIX-based Perl interpreter that you might otherwise have access to on any other UNIX/Linux host. On Windows, you can use the ActivePerl interpreter (from ActiveState) or the Perl interpreter provided as part of the Cygwin system. I prefer ActivePerl, but the choice is yours.
Once you have a Perl interpreter handy, use the Software Update component of Eclipse to install it:
- Choose Help > Software Update > Find and Install, and you'll be presented with a window for configuring downloads, as shown in Figure 1.
Figure 1. The Software Update window
- Click Next.
- Click New Remote Site. Give the new site a name and enter the source URL ("), as shown in Figure 2.
Figure 2. Creating a new site
- Then follow the on-screen process to find, select, and install the plug-in.
Quick configuration
You'll take a closer look at the preferences and their effect on how you use and work with the EPIC plug-in later, but you can benefit from a brief look at the preferences panel to get an idea of the sort of facilities that are available when using the plug-in.
To access the preferences for EPIC, open the standard Eclipse Preferences Window and choose the Perl EPIC folder from the navigation panel on the left, as shown here in Figure 3.
Figure 3. EPIC Preferences
The preferences are split into sections, starting with the general preferences for the plug-in:
- General Preferences -- Sets the location of the Perl executable, interpreter, execution model, and the period to wait before the code is checked in the background.
- Code Assist -- Sets the characters that trigger auto-completion.
- Editor -- Sets editor preferences, including the colors used for highlighting different components, annotation formats, and so on.
- Source Formatter -- Sets formatting preferences.
- Task Tags -- Sets task tags, which are quick notes that take you back to a specific location.
- Templates -- Sets up templates of code that can be inserted directly into your code to speed development time.
When these options affect the way you work, I'll mention how to adjust the action in this tutorial. We'll also look at some specific elements, such as task tags and templates, in their own sections later.
Windows notes
When using the EPIC plug-in within Eclipse under Windows, there are some tricks that will improve your interaction between components.
If you are using ActiveState's ActivePerl distribution, change the Perl executable (as set in the General Preference panel) to the wperl.exe executable. This will prevent a command prompt window being displayed each time the code is being checked. It is also a good idea (but not essential) to add the Perl binary directory to your path. It should have been added automatically when ActivePerl was installed.
If you are using the Cygwin version of Perl, ensure that the mount command, part of the standard Cygwin installation, is available through your system path. You can verify this by checking the values of environment variables. To do this:
- Open the System Control Panel (usually in Start > Control Panels > System, or right-click on My Computer and select Properties).
- Switch to the Advanced panel.
- Click Environment Variables. You should be presented with a window like that shown in Figure 4.
Figure 4. System and user environment variables in Windows
Check the value of the PATH variable. If the Perl or Cygwin binary directories are not listed, add them to the path value. Individual directories are separated by a semicolon.
Creating projects and files
To write Perl applications within Eclipse using the EPIC plug-in, you need to understand the roles of the Perl project and the Perl file.
Creating a new project
Let's create a new Perl project. Because EPIC provides a new nature, you can create a new project to build your Perl application. For this demonstration, you'll be building a Really Simple Syndication (RSS) application that will download an RSS file from the Internet, parse it, and dump a summary of the information. You'll then extend this basic functionality.
You can do all of this by creating a new project to contain your RSS project files. Create a new project by selecting it from the list of available project types. Choose New > Perl Project, or New > Other and select Perl Project from the list. You can see the resulting window in Figure 5.
Figure 5. Creating a new Perl project
Give the project a name (RSS Feeder) and specify the workspace for the project, or simply use the default workspace.
Eclipse should change to the Perl perspective automatically when you create a new Perl project. The Perl perspective includes a number of specific panels that will help you as you start to write Perl script.
The Perl perspective
If Eclipse does not automatically switch to the Perl perspective, you can switch to it using Window > Open Perspective and selecting Perl from the list of perspectives. You can see an example of this perspective in Figure 6, here with some open and active files and views.
Figure 6. The Perl perspective
You can see from Figure 6 that the perspective includes many different panels (called Views in Eclipse), including:
- Package explorer view -- This shows the layout of your project (files, modules, and scripts).
- Outline view for the current file -- This shows the list of modules imported and the list of functions defined within the current file.
- Standard editor/file interface -- This will show the source individual files in the project.
- Tasks view -- This shows a list of registered tasks.
- Console view -- This is the standard output from your application.
- Problems -- This view highlights and provides links to errors in your code within the current project.
You'll be using the information contained in most of these views within this tutorial. Remember that you can add and remove views at any time by selecting Show View from the Window menu, and either selecting a view directly or choosing the Other menu item and choosing from a more extensive list.
Creating a new file
Once you've created a new project, the first job is to create a new file. Files within EPIC can be either scripts or Perl modules. As far as EPIC is concerned, there is no difference between the two, although of course Perl treats them differently. Because EPIC doesn't specifically differentiate between the two, you have to rely on the file extension to differentiate between the files in a given project.
You can do all of this by creating a new project to contain your RSS project files. Create a new project by selecting it from the list of available project types. Choose New > File > Other and select Perl File from the list, shown in Figure 7.
Figure 7. Selecting a Perl file
You can see the resulting window Perl file properties window in Figure 8.
Figure 8. Setting Perl file properties
You'll need to specify the folder (or project) where the file should be created and the file name. You can optionally associate the file with an existing file on the filesystem by clicking the Advanced button and setting preferences.
Click Finish to create the new file. You'll then be presented with an editor window for the file.
Editor features and Perldoc integration
The bulk of any programming endeavor is actually writing the code, so it is no surprise that the bulk of the EPIC functionality is related to improving the environment of the editor.
The Perl editor
Actually generating code is basically a case of typing the code you want to write into the editor. There's very little difference here from any other editor. The primary difference is in the additional functionality that you gain as you use it.
The first feature you'll look at is the syntax coloring. Basically, this colors different elements of the source code (according to the settings) to make it easier to identify components in the code.
For example, if you type the following:
use strict; use warnings;
The
use keyword will be highlighted in a different color to the names of the modules you are loading. Syntax highlighting applies to a wide range of elements, and each has its own color. You can change these by modifying the preferences. Sample elements include functions, arguments, static strings and variables, and key terms like those seen here.
The second feature that is directly obvious during editing is the highlighting of errors in your code that can be identified during the standard checks performed before execution. For example, type the following, exactly as it is here:
use XML:RSS;
When you pause (the amount of time you have to pause is configurable), the EPIC plug-in checks the format and syntax of your code and reports any errors it finds. The offending error lines are highlighted, and if you switch to the Problems view, you can see a description of the error, and the file and line in which the error occurs. You can see an example of this in Figure 9.
Figure 9. Highlighted errors in the code
In this example, the code is highlighted automatically because that code is wrong. It needs a double colon for Perl to identify the module. To get more detailed help, right-click on the error line and choose Explain Errors/Warnings for a more complete description of the problem and possible resolution.
Note that it is not EPIC checking the validity of the code. It checks the code through Perl, then parses the output. This ensures that the code is valid Perl and also means that pragmas in the code (such as the warnings and strict pragmas defined earlier) will also be applied.
Simple code completion
Although useful, syntax and error highlighting don't speed up the rate at which you can create code, although they do help reduce the amount of errors and typos you introduce.
For improving the speed at which you generate code and its quality, EPIC will complete common elements for you automatically. For example, if you type:
my $feeds = {" What you actually get is: my $feeds = {""}
EPIC has automatically completed the closing brace and quote.
Add a semicolon to the previous line and type:
$ on a new line.
After a short pause, EPIC will bring up a list of possible variables. You've only defined one, but the system can automatically suggest possible variable completions with any of the variable types, scalar ($), array (@) or hash (%).
To continue building your RSS parser, let's populate the hash with some information about some feeds. For the purposes of the demonstration, you'll just define one:
my $feeds = {"MCslp" => ""};
To download an RSS feed, you need to use the Lib WWW Perl library (LWP) that handles all of the download for you by whatever method is specified in the URL. You need to create a new UserAgent object. Add the
LWP::UserAgent module to the start of the script. Then type:
$ua = LWP::UserAgent->
As you can see in Figure 10, EPIC will provide a list of possible functions you can use to complete the line. This interactive completion works as a sort of combination of documentation lookup and code completion, reminding you about the functions or methods applicable to an object or class and allowing you to select it.
Figure 10. Interactive method completion
Note that for this system to work correctly on objects, you must create the object using
$ua = LWP::UserAgent->new();, rather than
$ua = new LWP::UserAgent;. This is because of the way EPIC determines this information.
Basic Perldoc integration
Let's return to the RSS feeder example. When you parse a feed, you want to make a note of the date and time the feed was processed. The built-in Perl
localtime() functions returns a list of variables containing the time information. However, despite programming in Perl for 10 years, I can never remember the order of the information.
What I can do with Eclipse and EPIC is type the name of the function, double-click to select it, then hover over it to get a quick view of the contents. Again this information is pulled from Perldoc. I can now see what the return values are. You can see an example of this in Figure 11.
Figure 11. Getting inline documentation help
Let's try it by typing
localtime. Now highlight the word and hover over it.
The information is pulled directly from the Perl documentation (Perldoc). For those not aware, Perldoc is a command-line interface that extracts the documentation embedded into Perl scripts and modules.
Looking up full definitions in Perldoc
You can also use, browse, and search for information from the Perldoc library. If you press Control-Shift-H or right-click within your editor, you'll be prompted for a Perldoc fragment to look for (module, built-in function, or FAQ search). You can also highlight an item and right-click or use the keyboard shortcut. In both cases, the information is displayed in a special Perldoc view. You can see the Perldoc view, here showing the
LWP::UserAgent module, in Figure 12.
Figure 12. Full Perldoc integration
Again, like the syntax checking, the information is being accessed through the standard Perl tools. Rather than EPIC replacing their functionality, it is using it as a way of obtaining the information you need and which is most useful to you. That means that the same information (and formatting) that are available to you through Emacs or the command line are also available through EPIC and Eclipse.
In terms of Perldoc, that means you have access to the entire range of standard Perl pages (such as perlre or perlfunc), individual access to specific areas (for example, you can get the definition of a single function, as demonstrated with localtime), and you can get information on all of the installed modules within a given Perl installation.
Power-user functionality
There are a few additional areas of functionality useful to people working on large projects or who spend a frequent amount of time in Eclipse developing Perl applications.
Task tags
Let's say you need to parse the RSS just downloaded, but you want to write a separate function for that. You don't want to worry about actually writing that particular piece of code yet. Within a standard editor and environment, you might do this in a number of ways -- using a special comment in the source code that you can search and locate during a later session, for example.
EPIC (and actually Eclipse) supports this. You can search for an individual item or piece of code just like any other. However, EPIC and Eclipse extend this functionality by supporting specific task tags. These are comments with a specific format. For example, type the following into your source code:
#TODO Write the function to parse the RSS raw code
If you then open the Tasks view (select it or add it through the Window > Show View menu item) you can see that you've just added a task, with a description, into a list of things to do. You can see this, both the source and the resulting view, in Figure 13.
Figure 13. Task tags in action
The Tasks view is project-specific, which means that you will be shown such tags and their descriptions across all of the files in your project, not just the current file. This makes it a great way of highlighting tasks and to-dos in your code right across your project.
The standard installation comes with a two recognized tags: TODO and TASK. You can configure additional task tags using the Task Tags preferences for EPIC. You can see the preferences window in Figure 14.
Figure 14. Setting task tag preferences
To create a new task tag: click New and specify the text to be identified as the tag.
Incidentally, since tags work through comments, you should know that
Control-/ (Control slash) comments the current line and
Control-\ uncomments a particular line. If you've selected multiple lines, the operation comments or uncomments each individual line.
Code formatting
There are lots of ways in which you can format Perl code, and getting the format correct makes a big difference to the readability of the code you are working with. EPIC will automatically format certain elements of your code. You've seen some evidence of this already with the way in which EPIC automatically lays out different components during auto-completion using parentheses and quote marks. You can also force EPIC to reformat the code into a readable format by pressing Control-Shift-F or by choosing Format from the Source menu.
The exact format will depend on your preferences, set through the Source Formatting pane in the Eclipse preferences (see Figure 15). The formatting is performed by Perltidy, which reads and reformats code according to some agreed-upon standards (mostly those detailed in Programming Perl from O'Reilly).
Figure 15. Setting source formatting preferences
The main options affect the formatting as follows. Cuddle else changes the behavior for an
else statement, shown in Listing 1:
Listing 1.
else statement
} else { to } else {
The opening brace on the new line forces Perltidy to place the opening brace to a block on a new line. See Listing 2 for an example.
Listing 2. Forcing Perltidy to place brace to a block on a new line
if ($a == 1) { becomes if ($a == 1) {
Lining up parentheses ensures that parentheses line up when split across lines. Finally, Swallow optional blank lines deletes any blank lines that serve no purpose. For example, blank lines before comments are kept, but blank lines after are not. Blank lines are retained between major blocks (for example functions, loops and tests).
Any additional options can be configured by adding arguments to the command line called when Perltidy is executed. See Resources for more information on Perltidy.
Refactoring
Refactoring code adapts the source code without changing its behavior. In the case of EPIC, refactoring can convert a block of code into a function, making the functionality accessible to any part of the code. EPIC will extract the variables required for input to the block of code, determine the outputs, and convert them into arguments and return values respectively. To use refactoring, let's consider the code fragment you use to download and parse an RSS feed URL into an RSS object (see Listing 3).
Listing 3. Code fragment used to download and parse an RSS feed URL into an RSS object
foreach my $feed ( sort keys %{$feeds} ) { my $response = $ua->get( $feeds->{$feed} ); if ( $response->is_success ) { my $rss = XML::RSS->new(); $rss->parse( $response->{_content} ); } }
If you select the contents of this
foreach loop (the contents of the entire block, not including the
foreach statement and the parentheses), right-click and choose the Refactor > Extract subroutine, EPIC will convert the code into the following fragment, instead (see Listing 4):
Listing 4. Extract subroutine
foreach my $feed ( sort keys %{$feeds} ) { my ($response, $rss) = parse_rss_fromurl ($feeds, $ua, $feed); } sub parse_rss_fromurl { my $feeds = shift; my $ua = shift; my $feed = shift; my $response = $ua->get( $feeds->{$feed} ); if ( $response->is_success ) { my $rss = XML::RSS->new(); $rss->parse( $response->{_content} ); } return ( $response, $rss ); }
You can see that EPIC has determined the variables it needs in the new subroutine and the response values. The actual code remains the same, but the entire block has been rebuilt into a new subroutine. Also note that the
foreach loop now contains the required subroutine call and arguments.
Templates and modules
A lot of source code is based on similar elements. For example, although subroutines may be different, the same basic content remains the same: You need the same keywords, parentheses, and the same structure for extracting subroutine arguments. Templates enable you to quickly insert this into your code.
Creating templates
Templates are defined through the Templates pane in the Eclipse Preferences. At face value, a template is exactly that: a fragment of code that can be inserted quickly and easily into your source code.
To create a new template:
- Open the Preferences window and choose Templates from the Perl EPIC section. You should get a preference panel like the one shown here in Figure 16.
Figure 16. Template preferences
- Click the New button and you'll be prompted with the window in Figure 17.
Figure 17. Creating a new template
- Enter a new name for the template. Try to keep it to a single word, as it will be used when you want to insert the code.
- Enter a description for the code.
- Enter the code for the template. The code you enter here will be inserted exactly as you enter it, as if you had cut and pasted the content.
- Click OK to close the template definition.
- Click OK to close the Preferences window.
To actually use the template, type the name of the template into your code and press Control-Space. The code you entered for your template will be inserted at the current location, replacing the template name you had specified.
While templates like this are useful, you still have to go back and set certain elements. For example, in a
for loop, you still have to edit and enter the name of the loop variable, the test value, and the increment. You can simplify this process even further by using dynamic templates.
Creating dynamic templates
Dynamic templates are created just like standard templates. The difference is the code entered into the definition. EPIC supports the notion of variables in a template. These have nothing to do with variables in your code. Instead, they provide an easy way for you to customize the inserted code with simple elements.
For example, in the
for loop example just given, you might enter code like this into the template:
for($i;$i<10;$i++) { }
Even though
$i may not be the variable you want to use, or 10 the value you want to compare against. Using a dynamic template, define a variable element that can easily be replaced when the template is inserted. To do this, specify the name of a template variable using the form
${varname}. If you use the same name multiple times, you only have to type the variable once, and you can create multiple template variables in a single template. Use a double dollar sign ($$) to insert the dollar symbol into your template.
For example, you can change the
for loop definition to:
for($$${var};$$${var}<=${maxvalue};$$${var}++) { }
Now, when you insert the template, the cursor will automatically by highlighted across the first instance of
${var}. Type the name of the variable, and every instance of
${var} will be replaced with the variable name. Press Tab and the highlight will move to
${maxvalue}.
This is a piece of functionality that probably makes more sense in the flesh, so try out the above example to get a feel for how flexible the template system is with variable substitution.
Summary
There you have it. The EPIC plug-in provides a complete environment for writing and developing Perl code. EPIC does this in a variety of ways, mostly related to how you edit, create, and format the code for it to be used within your applications. Although EPIC doesn't help actually generate the code (although templates almost provide that functionality), it does make it easier for you to navigate your source code, and you can format and auto-complete elements to reduce the amount of typing you have to do.
Resources
Learn
- Perl.com provides information and tutorials on using the Perl language.
- For help on the basics of using Eclipse, read Get started now with Eclipse.
- For more details about Eclipse, be sure to visit Eclipse.org.
- There are some interesting technical articles at the Eclipse Corner.
- To find out more about events, resources and projects happening in the Eclipse community, check out the Eclipse Corner Developer Community Resources.
- For insight into the world of Eclipse hackers, check out Planet Eclipse.
- Visit the developerWorks Open source zone for extensive how-to information, tools, and project updates to help you develop with open source technologies and use them with IBM's products.
Get products and technologies
- The EPIC plug-in is hosted on Sourceforge. You can find downloads for the EPIC system, supporting extensions and software, tutorials, documentation, and the FAQ for the system.
- Perltidy is used by EPIC to format the code to make it more readable.
- Eclipse can be obtained at Eclipse.org.
- Get ActivePerl, an interpreter for Windows (and also now for Linux and Mac OS X).
- Get PyDev, a plug-in for developing Python applications within Eclipse, which provides similar functionality to EPIC.
- Innovate your next open source development project with IBM trial software, available for download or on DVD.
Discuss
- Ask technical questions about Eclipse on the Eclipse mailing lists.
- If you are new to Eclipse, it is worth taking a look at the Eclipse newsgroups.
-. | http://www.ibm.com/developerworks/opensource/tutorials/os-perlecl/ | CC-MAIN-2015-06 | refinedweb | 5,283 | 60.85 |
What are Access Modifiers?
In Java, access modifiers are used to set the accessibility (visibility) of classes, interfaces, variables, methods, constructors, data members, and the setter methods. For example, methods.
Types of Access Modifier
Before you learn about types of access modifiers, make sure you know about Java Packages.
There are four access modifiers keywords in Java and they are:
Default Access Modifier
If we do not explicitly specify any access modifier for classes, methods, variables, etc, then by default the default access modifier is considered. For example,
package defaultPackage; class Logger { void message(){ System.out.println("This is a message"); } }
Here, the Logger class has the default access modifier. And the class is visible to all the classes that belong to the defaultPackage package. However, if we try to use the Logger class in another class outside of defaultPackage, we will get a compilation error.
Private Access Modifier
When variables and methods are declared
private, they cannot be accessed outside of the class. For example,
class Data { // private variable private String name; } public class Main { public static void main(String[] main){ // create an object of Data Data d = new Data(); // access private variable and field from another class d.name = "Programiz"; } }
In the above example, we have declared a private variable named name and a private method named
display(). When we run the program, we will get the following error:
Main.java:18: error: name has private access in Data d.name = "Programiz"; ^
The error is generated because we are trying to access the private variable and the private method of the Data class from the Main class.
You might be wondering what if we need to access those private variables. In this case, we can use the getters and setters method. For example,("Programiz"); System.out.println(d.getName()); } }
Output:
The name is Programiz
In the above example, we have a private variable named name. In order to access the variable from the outer class, we have used methods:
getName() and
setName(). These methods are called getter and setter in Java.
Here, we have used the setter method (
setName()) to assign value to the variable and the getter method (
getName()) to access
When methods and data members are declared
protected, we can access them within the same package as well as from subclasses. For example,
When methods, variables, classes, and so on are declared
public, then we can access them from anywhere. The public access modifier has no scope restriction. For example,
//. To learn more about encapsulation, visit Java Encapsulation. | https://www.programiz.com/java-programming/access-modifiers | CC-MAIN-2021-04 | refinedweb | 422 | 54.83 |
uplevel #0 $callback [list $arg1] [list $arg2] ..This works well, but is a bit hard to read if you are not familiar with the idiom. This is where invoke comes in: it handily packages up this familiar idiom into a single command:
proc invoke {level cmd args} { if {[string is integer -strict $level]} { incr level } uplevel $level $cmd $args } invoke #0 $callback $arg1 $arg2 ...To be a bit more efficient, we can ensure uplevel is passed a single list, which avoids any possibility of string concatenation (Tcl_UplevelObjCmd does its best to avoid this, but cannot always do so):
proc invoke {level cmd args} { if {[string is integer -strict $level]} { incr level } # Note 8.5ism uplevel $level [linsert $cmd end {*}$args] }I'm not sure if this really makes a noticeable impact on performance in typical cases, though. (If $cmd doesn't have a string rep, then uplevel does this automatically, from my reading of the source code).Lars H: As I sort-of remarked in "data is code", a built-in alternative to the #0 case
uplevel #0 $callback [list $arg1] [list $arg2] ..is
namespace inscope :: $callback $arg1 $arg2 ..This is no good for callbacks that expect to access local variables in their calling context, though; the context is still available (which it wouldn't be with [uplevel #0]), but it's at [uplevel 2], not [uplevel 1] as it would be after a normal call.Also, in 8.5 the plain case
invoke 0 $callback $arg1 $arg2 ..is just
{*}$callback $arg1 $arg2 ..NEM: All callbacks I know of in Tcl use the uplevel #0 semantics, so any namespace or callframe context is not available. The callback should take care of restoring any such context by for instance using namespace code or providing any variable values it needs as part of the callback (e.g. [list $callback $var1 $var2...]).Lars H: Most callbacks called from C tend to have eval semantics, e.g. the lsort -command option:
proc mycompare {args} { for {set n 0} {$n + [info level] > 0} {incr n -1} { puts "Level $n: [info level $n]" } eval [list string compare] $args } proc wrap {script} {eval $script} wrap {wrap {lsort -command mycompare {b c a}}}writes
Level 0: mycompare b c Level -1: wrap {lsort -command mycompare {b c a}} Level -2: wrap {wrap {lsort -command mycompare {b c a}}} Level 0: mycompare b a Level -1: wrap {lsort -command mycompare {b c a}} Level -2: wrap {wrap {lsort -command mycompare {b c a}}}This is sometimes useful, but other times surprising. (I recently tried to understand why
trace add execution someProc leave {lappend L}didn't add any data to L although the someProc clearly was being called. It worked much better when I made it {lappend ::L}.)Promising a caller that a callback will be evaluated in the calling context can get tricky if you need to pass it on to a helper proc though, so aiming for uplevel #0 semantics in code you design yourself is probably a good idea. However, it is sometimes very convenient to go non-functional and communicate via direct access to the context. | http://wiki.tcl.tk/18024 | CC-MAIN-2016-50 | refinedweb | 521 | 64.14 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.