
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91 values | source stringclasses 1 value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 1
An Introduction to Python for UNIX/C Programmers
Guido van Rossum
CWI, P.O. Box 94079, 1090 GB Amsterdam
Abstract
Python is an interpreted, object-oriented language suitable for many purposes. It has a
clear, intuitive syntax, powerful high-level data structures, and a ßexible dynamic type
system. Python can be used interactively, in stand-alone scripts, for large programs, or
as an extension language for existing applications. The language runs on UNIX,
Macintosh, and DOS machines. Source and documentation are available by
anonymous ftp.
Python is easily extensible through modules written in C or C++, and can also be
embedded in applications as a library. Existing extensions provide access to most
standard UNIX library functions and system calls (including processes management,
socket and ioctl operations), as well as to large packages like X11/Motif. There are also
a number of system-speciÞc extensions, e.g. to interface to the Sun and SGI audio
hardware. A large library of standard modules written in Python also exists.
Compared to C, Python programs are much shorter, and consequently much faster to
write. In comparison with Perl, Python code is easier to read, write and maintain.
Relative to TCL, Python is better suited for larger or more complicated programs.
1. Introduction
Python is a new kind of scripting language, and as most scripting languages it is built around an inter-
preter. Many traditional scripting and interpreted languages have sacriÞced syntactic clarity to simplify
parser construction; consider e.g. the painful syntax needed to calculate the value of simple expressions
like a+b*c in Lisp, Smalltalk or the Bourne shell. Others, e.g. APL and Perl, support arithmetic expres-
sions and other conveniences, but have made cryptic one-liners into an art form, turning program main-
tenance into a nightmare. Python programs, on the other hand, are neither hard to write nor hard to read,
and its expressive power is comparable to the languages mentioned above. Yet Python is not big: the
entire interpreter Þts in 200 kilobytes on a Macintosh, and this even includes a windowing interface!
1
Python is used or proposed as an application development language and as an extension language for
non-expert programmers by several commercial software vendors. It has also been used successfully
for several large non-commercial software projects (one a continent away from the authorÕs institute). It
is also in use to teach programming concepts to computer science students.
The language comes with a source debugger (implemented entirely in Python), several windowing
interfaces (one portable between platforms), a sophisticated GNU Emacs editing mode, complete
source and documentation, and lots of examples and demos.
This paper does not claim to be a complete description of Python; rather, it tries to give a taste of
Python programming through examples, discusses the construction of extensions to Python, and com-
pares the language to some of its competitors.
1. Figures for modern UNIX systems are higher because RISC instruction sets and large libraries tend to cause
larger binaries. The Macintosh Þgure is actually comparable to that for a CISC processor like the VAX (remember
those? :-)
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 2
2. Examples of Python code
LetÕs have a look at some simple examples of Python code. For clarity, reserved words of the language
are printed in bold.
Our Þrst example program lists the current UNIX directory:
import os # operating system interface
names = os.listdir(Õ.Õ) # get directory contents
names.sort() # sort the list alphabetically
for n in names: # loop over the list of names
if n[0] != Õ.Õ: # select non-hidden names
print n # and print them
The Bourne shell script for this is simply ÒlsÓ, but an equivalent C program would likely require sev-
eral pages, especially considering the necessity to build and sort an arbitrarily long list of strings of
arbitrary length. Some explanations:
¥ The import statement is PythonÕs Òmoral equivalentÓ of CÕs#include statement. Functions and
variables deÞned in an imported module can be referenced by preÞxing them with the module name.
¥ Variables in Python are not declared before they are used; instead, assignment to an undeÞned vari-
able initializes it. (Use of an undeÞned variable is a run-time error however.)
¥ PythonÕsfor loop iterates over an arbitrary list.
¥ Python uses indentation for statement grouping (see also the next example).
¥ The module os deÞnes many functions that are direct interfaces to UNIX system calls, such as
unlink() and stat().The function used here,os.listdir(), is a higher-level interface to
the UNIX calls opendir(), readdir() and closedir().
¥.sort() is a method of list objects. It sorts the list in place (here in dictionary order since the list
items are strings).
And here is a simple program to print the Þrst 100 prime numbers:
primes = [2] # make a list of prime numbers
print 2 # print the first prime
i = 3 # initialize candidate
while len(primes) < 100: # loop until 100 primes found
for p in primes: # loop over known primes
if i%p == 0 or p*p > i: # look for possible divisors
break # cancel rest of for loop
if i%p != 0: # is i indeed a prime?
primes.append(i) # add it to the list
print i # and print it
i = i + 2 # consider next candidate
Some clariÞcations again:
¥ PythonÕs expression syntax is similar to that of C; however there are no assignment or pointer oper-
ations, and Boolean operators (and/or/not) are spelled as keywords.
¥ The expression [2] is a list constructor; it creates a new variable-length list object initially contain-
ing a single item with value 2.
¥ len() is a built-in function returning the length of lists and similar objects (e.g. strings).
¥.append() is another list object method; it modiÞes the list in place by appending a new item to
the end.
HereÕs another example, involving some simple I/O. It is intended as a shell interface to a trivial data-
base of phone numbers maintained in the Þle $HOME/.telbase. Each line is a free format entry; the
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 3
program simply prints the lines that match the command line argument(s). The program is thus more or
less equivalent to the Bourne shell script Ògrep -i "$@" $HOME/.telbaseÓ.
import os, sys, string, regex
def main():
pattern = string.join(sys.argv[1:])
filename = os.environ[ÕHOMEÕ] + Õ/.telbaseÕ
prog = regex.compile(pattern, regex.casefold)
f = open(filename, ÕrÕ)
while 1:
line = f.readline()
if not line:break # End of file
if prog.search(line) >= 0:
print string.strip(line)
main()
Some new Python features to be spotted in this example:
¥ Most code of the program is contained in a function deÞnition. This is a common way of structuring
larger Python programs, as it makes it possible to write code in a top-down fashion. The function
main() is run by the call on the last line of the program.
¥ The expression sys.argv[1:] slices the list sys.argv: it returns a new list with the Þrst ele-
ment stripped.
¥ The+ operator applied to strings concatenates its arguments.
¥ The built-in function open() returns an open Þle object; its arguments are the same as those for the
C standard I/O function fopen(). Open Þle objects have several methods for I/O operations, e.g.
the.readline() method reads the next line from the Þle (including the trailing Õ\nÕ character).
¥ Python has no Boolean data type. Extending CÕs use of integers for Booleans, any object can be used
as a truth value. For numbers, non-zero is true; for lists, strings and so on, values with a non-zero
length are true.
This program also begins to show some of the power of the standard and built-in modules provided by
Python:
¥ WeÕve already met theos module. The variable os.environ is a dictionary (an aggregate value
indexed by arbitrary values, in this case strings) providing access to UNIX environment variables.
¥ The module sys collects a number of useful variables and functions through which a Python pro-
gram can interact with the Python interpreter and its surroundings; e.g.sys.argv contains a
scriptÕs command line arguments.
¥ The string module deÞnes a number of additional string manipulation functions; e.g.
string.join() concatenates a list of strings with spaces between them;string.strip()
removes leading and trailing whitespace.
¥ The regex module deÞnes an interface to the GNU Emacs regular expression library. The function
regex.compile() takes a pattern and returns a compiled regular expression object; this object
has a method.search() returning the position where the Þrst match is found. The argument
regex.casefold passed to regex.compile() is a magic value which causes the search to
ignore case differences.
The next example is an introduction to using X11/Motif from Python; it uses two optional (and still
somewhat experimental) modules that together provide access to many features of the Motif GUI
toolkit. An equivalent C program would be several pages long...
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 4
import sys # Python system interface
import Xt # X toolkit intrinsics
import Xm # Motif
def main():
toplevel = Xt.Initialize()
button = toplevel.CreateManagedWidget(ÕbuttonÕ,
Xm.PushButton, {})
button.labelString = ÕPush meÕ
button.AddCallback(ÕactivateCallbackÕ, button_pushed, 0)
toplevel.RealizeWidget()
Xt.MainLoop()
def button_pushed(widget, client_data, call_data):
sys.exit(0)
main() # Call the main function
The program displays a button and quits when it is pressed. Just a few things to note about it:
¥ X toolkit intrinsics functions that have a widget Þrst argument in C are mapped to methods of widget
objects (here,toplevel and button) in Python.
¥ Most calls to XtSetValues() and XtGetValues() in C can be replaced to assignments or ref-
erences to widget attributes (e.g.button.labelString) in Python.
Much Python code takes the form of modules containing one or more class deÞnitions. Here is a (triv-
ial) class deÞnition:
class Counter:
def __init__(self): # constructor
self.value = 0
def show(self):
print self.value
def incr(self, amount):
self.value = self.value + amount
Assuming this class deÞnition is contained in module Cnt, a simple test program for it could be:
import Cnt
my_counter = Cnt.Counter() # constructor
my_counter.show()
my_counter.incr(14)
my_counter.show()
3. Extending Python using C or C++
It is quite easy to add new built-in modules (a.k.a.extension modules) written in C to Python. If your
Python binary supports dynamic loading (a compile-time option for at least SGI and Sun systems), you
donÕt even need to build a new Python binary: you can simply drop the object Þle in a directory along
PythonÕs module search path and it will be loaded by the Þrstimport statement that references it. If
dynamic loading is not available, you will have to add some lines to the Python MakeÞle and build a
new Python binary incorporating the new module.
The example below is written in C, but C++ can also be used. This is most useful when the extension
must interface to existing code (e.g. a library) written in C++. For this to work, it must be possible to
call C functions from C++ and to generate C++ functions that can be called from C. Most C++ compil-
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 5
ers nowadays support this through the extern"C" mechanism. (There may be restrictions on the use
of statically allocated objects with constructors or destructors.)
The simplest form of extension module just deÞnes a number of functions. This is also the most useful
kind, since most extensions are really ÒwrappersÓ around libraries written for use from C. Extensions
can also easily deÞne constants. DeÞning your own (opaque) data types is possible but requires more
knowledge about internals of the Python interpreter.
The following is a complete module which provides an interface to the UNIX C library function
system(3). To add another function, you add a deÞnition similar to that for demo_system(), and a
line for it to the initializer for demo_methods. The run-time support functions Py_ParseArgs()
and Py_BuildValue() can be instructed to convert a variety of C data types to and from Python
types.
1
/* File "demomodule.c" */
#include <stdlib.h>
#include <Py/Python.h>
static PyObject *demo_system(self, args)
PyObject *self, *args;
{
char *command;
int sts;
if (!Py_ParseArgs(args, "s", &command))
return NULL; /* Wrong argument list - not one string */
sts = system(command);
return Py_BuildValue("i", sts); /* Return an integer */
}
static PyMethodDef demo_methods[] = {
{"system", demo_system},
{NULL, NULL} /* Sentinel */
};
void PyInit_demo()
{
(void) Py_InitModule("demo", demo_methods);
}
4. Comparing Python to other languages
This section compares Python to some other languages that can be seen as its competitors or precursors.
Three of the most well-known languages in this category are reviewed at some length, and a list of
other inßuences is given as well.
4.1. C
One of the design rules for Python has always been to beg, borrow or steal whatever features I liked
from existing languages, and even though the design of C is far from ideal, its inßuence on Python is
considerable. For instance, CÕs deÞnitions of literals, identiÞers and operators and its expression syntax
have been copied almost verbatim. Other areas where C has inßuenced Python: the break,
1. In the current release, the run-time support functions and types have different names. In version 1.0, they will
be changed to those shown here in order to avoid namespace clashes with other libraries.
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 6
continue and return statements; the semantics of mixed mode arithmetic (e.g. 1/3 is 0, but 1/3.0 is
0.333333333333); the use of zero as a base for all indexing operations; the use of zero and non-zero for
false and true. (A more Òhigh-levelÓ inßuence of C on Python is also distinguishable: the willingness to
compromise the ÒpurityÓ of the language in favor of pragmatic solutions for real-world problems. This
is a big difference with ABC [Geurts], in many ways PythonÕs direct predecessor.)
On the other hand, the average Python program looks nothing like the average C program: there are no
curly braces, fewer parentheses, and absolutely no declarations (but more colons :-). Python does not
have an equivalent of the C preprocessor; the import statement is a perfect replacement for
#include, and instead of#define one uses functions and variables.
Because Python has no pointer data types, many common C ÒidiomsÓ do not translate directly into
Python. In fact, much C code simply vanishes into a single operation on PythonÕs more powerful data
types, e.g. string operations, data copying, and table or list management.
Since all built-in operations are coded in C, well-written Python programs often suffer remarkably few
speed penalties compared to the same code written out in C. Sometimes Python even outperforms C
because all Python dictionary lookup uses a sophisticated hashing technique instead, where a simple-
minded C program might use an algorithm that is easier to code but less efÞcient.
Surely, there are also areas where Python code will be clumsier or much slower than equivalent C code.
This is especially the case with tight loops over the elements of a large array that canÕt be mapped to
built-in operations. Also, large numbers of calls to functions containing small amounts of code will suf-
fer a performance penalty. And of course, scripts that run for a very short time may suffer an initial
delay while the interpreter is loaded and the script is parsed.
Beginning Python programmers should be aware of the alternatives available in Python to code that
will run slow when translated literally from C; thereÕs nothing like a regular look at some demo or stan-
dard modules to get the right ÒfeelingÓ (unless you happen to be a co-worker of the author :-).
In summary, on modern-day machines, where a programmerÕs time is often more at a premium than
CPU cycles or memory space, it is often worth while to write an application (or at least large portions
thereof) in Python instead of in C.
4.2. Perl
A well-known scripting language is Perl [Wall]. It has some similarities with Python: powerful string,
list and dictionary data types, access to high- and low-level I/O and other system calls, syntax borrowed
from C as well as other sources. Like Python, Perl is suited for small scripts or one-time programming
tasks as well as for larger programs. It is also extensible with code written in C (use as an embedded
language is not envisioned though).
Unlike Python, Perl has support for regular expression matching and formatted output built right into
the core of the language. PerlÕs type system is less powerful than PythonÕs, e.g. lists and dictionaries can
only contain strings and integers as elements. Perl preÞxes variable names with special characters to
indicate their type, e.g. Ò$fooÓ is a simple (string or integer) variable, while Ò@fooÓ is an array. Combi-
nations of special characters are also used to invoke a host of built-in operations, e.g. Ò$.Ó is the current
input line number.
In Perl, references to undeÞned variables generally yield a default value, e.g. zero. This is often touted
as a convenience, however it means that misspellings can cause nasty bugs in larger programs (this is
ÒsolvedÓ by an interpreter option to complain about variables set only once and never used).
Experienced Perl programmers often frown at Python: there is no built-in syntax for the use of regular
expressions, the language seems verbose, there is no implied loop over standard input, and the lack of
operators with assignment side effects in Python may require several lines of code to replace a single
Perl expression.
However, it takes a lot of time to gain sufÞcient Perl experience to be able to write effective Perl code,
and considerably more to be able to read code written by someone else! On the contrary, getting started
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 7
with Python is easy because there is a lot less ÒmagicÓ to learn, and its relative verbosity makes reading
Python code much easier.
There is lots of Perl code around using horrible ÒtricksÓ or ÒhacksÓ to work around missing features Ñ
e.g. Perl doesnÕt have general pointer variables, but it is possibly to create recursive or cyclical data
structures nevertheless; the code which does this looks contrived, and Perl programmers often try to
avoid using recursive data structures even when a problem naturally lends itself to their use (if they
were available).
In summary, Perl is probably more suitable for relatively small scripts, where a large fraction of the
code is concerned with regular expression matching and/or output formatting. Python wins for more
traditional programming tasks that require more structure for the program and its data.
4.3. TCL
TCL [Ousterhout] is another extensible, interpreted language. TCL (Tool Command Language) is espe-
cially designed to be easy to embed in applications, although a stand-alone interpreter (tcsh, the TCL
shell) also exists. An important feature of TCL is the availability of tk, an X11-based GUI toolkit whose
behavior can be controlled by TCL programs.
TCLÕs power is its extreme simplicity: all statements have the formkeyword argument argument ...
Quoting and substitution mechanisms similar to those used by the Bourne shell provide the necessary
expressiveness. However, this simplicity is also its weakness when it is necessary to write larger pieces
of code in TCL: since all data types are represented as strings, manipulating lists or even numeric data
can be cumbersome, and loops over long lists tend to be slow. Also the syntax, with its abundant use of
various quote characters and curly braces, becomes a nuisance when writing (or reading!) large pieces
of TCL code. On the other hand, when used as intended, as an embedded language used to send control
messages to applications (like tk), TCLÕs lack of speed and sophisticated data types are not much of a
problem.
Summarizing, TCLÕs application scope is more restricted than Python: TCL should be used only as
directed.
4.4. Other inßuences
Here is an (incomplete) list of Òlesser knownÓ languages that have inßuenced Python:
¥ ABC was one of the greatest inßuences on Python: it provided the use of indentation, the concept of
high-level data types, their implementation using reference counting, and the whole idea of an inter-
preted language with an elegant syntax. Python goes beyond ABC in its object-oriented nature, its
use of modules, its exception mechanism, and its extensibility, at the cost of only a little elegance
(Python was once summarized as ÒABC for hackersÓ :-).
¥ Modula-3 provided modules and exceptions (both the import and the try statement syntax were
borrowed almost unchanged), and suggested viewing method calls as syntactic sugar for function
calls.
¥ Icon provided the slicing operations.
¥ C++ provided the constructor and destructor functions and user-deÞned operators.
¥ Smalltalk provided the notions of classes as Þrst-class citizens and run-time type checking.
Python for Unix/C Programmers Copyright 1993 Guido van Rossum 8
5. Availability
The Python source and documentation are freely available by ftp. It compiles and runs on most UNIX
systems, Macintosh, and PCs and compatibles. For Macs and PCs, pre-built executables are available.
The following information should be sufÞcient to access the ftp archive:
Host: (IP number: 192.16.184.180)
Login: anonymous
Password: (your email address)
Transfer mode: binary
Directory: /pub/python
Files: python0.9.9.tar.Z (source, includes LaTeX docs)
pythondoc-ps0.9.9.tar.Z (docs in PostScript)
MacPython0.9.9.hqx (Mac binary)
python.exe.Z (DOS binary)
The Ò0.9.9Ó in the Þlenames may be replaced by a more recent version number by the time you are
reading this. Fetch the Þle INDEX for an up-to-date description of the directory contents.
The 0.9.9 release of Python is also available on the CD-ROM pressed by the NLUUG for its November
1993 conference. The next release will be labeled 1.0 and will be posted to a comp.sources news-
group before the end of 1993.
The source code for the STDWIN window interface is not included in the Python source tree. It can be
ftpÕed from the same host, directory/pub/stdwin, Þle stdwin0.9.8.tar.Z.
6. References
[Geurts] Leo Geurts, Lambert Meertens and Steven Pemberton, ÒABC ProgrammerÕs Hand-
bookÓ, Prentice-Hall, London, 1990.
[Wall] Larry Wall and Randall L. Schwartz, ÒProgramming perlÓ, OÕReilly & Associates, Inc.,
1990-1992.
[Ousterhout] John Ousterhout, ÒAn Introduction to Tcl and TkÓ, Addison Wesley, 1993.
Log in to post a comment | https://www.techylib.com/en/view/adventurescold/an_introduction_to_python_for_unixc_programmers | CC-MAIN-2017-51 | refinedweb | 3,799 | 54.52 |
Type: Posts; User: Joeman
this compiles
#include <utility>
#include <Windows.h>
int main()
{
RECT rc = {0};
std::pair <LONG,LONG> ControlSize;
You're welcome :).
Also my code made sure it didn't break the command:
EXENAME > echo.txt
To make sure your app doesn't break that command, you need to adapt IsAConsole at the least like:
...
This is what ~cConsoleInitializer did
~cConsoleInitializer()
{
if( File )
{
INPUT_RECORD InputRecord;
InputRecord.EventType = KEY_EVENT;
This seems like what you want:
#include <windows.h>
#include <iostream>
#include <cstdio>
bool IsAConsole( HANDLE Handle )
{
DWORD Mode;
return GetConsoleMode( Handle, &Mode ) != 0;...
To be more elaborate about trying &Class.myfunction from my previous post. The compiler will complain about trying to form a pointer by taking the address of a bound member function.
The correct...
Visual Studio 2010 c++ compiler:
Gcc 4.7.0:
This is incorrect since he only defined and declared a free standing function pointer, so you can assign any free standing function that...
I am confused about what you mean, but how about
class A{};
class B : public A{};
int main()
{
A* pA = new B;
B& pB1 = static_cast<B&>(*pA);
}
This is now possible with the new standard of c++ now called c++11 which was just finalized in August this year. c++11 is still being implemented in compilers. Gcc 4.7 and Clang 3.0 supports this...
#include <functional>
#include <algorithm>
#include <vector>
#include <string>
#include <locale>
#include <boost/algorithm/string/case_conv.hpp>
using namespace std;
using namespace...
I am sure you meant
template <class T>
Class1 < Class2 <T>>A problem that has now been fixed in the new c++11 standard. Any compiler that has been updated to conform will compile correctly.
You...
char n[29];Why not use std::string?
I think you quoted more than what you intended because you didn't fix the unsafe practice of calling delete by hand which can be fixed with raii design at the...
cout<<"Enter name :";
cin>>n;
cout<<"Enter shares :";
cin>>num;
cout<<"Enter share value :";
cin>>val;
s1[0].setName(n);
I want to point out the template way to determine the size which adds a little bit of safety as well.
template< typename TYPE, int Size >
size_t GetArrayLength( TYPE (&Array)[Size] )
{ ...
Why not learn from tutorials as well? Also read faqs. They can provide common pitfalls and how to avoid them. Googling your question first is even better if you can generalize it.
void...
Actually I was thinking of a user's point of view. I can see how you got confused, but as a programmer I haven't actually looked at windows 8 ... yet ...
So what if metro maybe the next big...
class UtilWindow
{
public:
Reshape(int width, int height);
~Reshape();
private:
};You should look at some tutorials about classes and see how they declare a constructor and...
I wouldn't inherit a shared_ptr since the destructor isn't virtual. Also shared_ptr only destroys the object it contains only after all shared_ptrs destruct, so if a user clicks the exit button, you...
I disagree. It is to make things easier by mapping one set of contexts to another and not to make things harder in general. I am fine with simplifying tools to make them more flexible and less ridged...
Well I am glad you revised your words because I really didn't read it that way the first time :). I won't argue that they are more prone to write horrible code, but at least it won't blow up so...
I disagree. A high level language should make it easier to write code since it abstracts away hardware dependency which abstracts away concepts related to hardware. For example, who aligns machine...
I agree knowing how things work and why is important. That is why I like computers in the first place :) They are quite complicated.
This is because of the c++ standard. The only type of polymorphic behavior that goes by its direct effect is class polymorphismThat is because c++ doesn't have another terminology for class...
example...
class cMainWindow
{
cWindow Window;
cButton SaveButton;
cButton CloseButton;
You could try CreateMDIWindow and if it fails, call GetLastError() and look at the system error codes.
Also don't forget to unregister your class since dlls do not unregister classes automatically.
Also are you sure there isn't a better way to pass HWND? Can you at least pass pointers? | http://forums.codeguru.com/search.php?s=37b34b0c058c3fc4e66f65b136ec37f0&searchid=967895 | CC-MAIN-2013-20 | refinedweb | 731 | 65.83 |
When you create a Google Cloud project, you are the only user on the project. By default, no other users have access to your project or its resources, including Google Kubernetes Engine resources. Google Kubernetes Engine supports multiple options for managing access to resources within your project and its clusters using role-based access control (RBAC).
These mechanisms have some functional overlap, but are targeted to different types of resources. Each is explained in a section below, but in brief:
Kubernetes RBAC is built into Kubernetes, and grants granular permissions to objects within Kubernetes clusters. Permissions exist as ClusterRole or Role objects within the cluster. RoleBinding objects grant Roles to Kubernetes users, Google Cloud users, Google Cloud service accounts, or Google Groups (beta).
If you primarily use GKE, and need fine-grained permissions for every object and operation within your cluster, Kubernetes RBAC is the best choice.
IAM manages Google Cloud resources, including clusters, and types of objects within clusters. Permissions are assigned to IAM members, which exist within Google Cloud, G Suite, or Cloud Identity.
There is no mechanism for granting permissions for specific Kubernetes objects within IAM. For instance, you can grant a user permission to create CustomResourceDefinitions (CRDs), but you can't grant the user permission to create only one specific CustomResourceDefinition, or limit creation to a specific Namespace or to a specific cluster in the project. An IAM role grants privileges across all clusters in the project, or all clusters in all child projects if the role is applied at the folder level.
If you use multiple Google Cloud components and you don't need to manage granular Kubernetes-specific permissions, IAM is a good choice.
Kubernetes RBAC
Kubernetes has built-in support for RBAC that allows you to create fine-grained Roles, which exist within the Kubernetes cluster. A Role can be scoped to a specific Kubernetes object or a type of Kubernetes object, and defines which actions (called verbs) the Role grants in relation to that object. A RoleBinding is also a Kubernetes object, and grants Roles to users. In a GKE user can be any of:
- Google Cloud user
- Google Cloud service account
- Kubernetes service account
- G Suite user
- G Suite Google Group (beta)
To learn more, refer to Role-Based Access Control.
IAM
IAM allows you to define roles and assign them to members. A role is a collection of permissions, and when assigned to a member, controls access to one or more Google Cloud resources. Roles fall into three broad categories:
- Basic roles provide coarse permissions limited to Owner, Editor, and Viewer.
- Pre-defined roles, such as the pre-defined roles for GKE, provide finer-grained access than basic roles and address many common use cases.
- Custom roles allow you to create unique combinations of permissions.
A member can be any of:
- Google account
- Service account
- Google group
- G Suite domain
- Cloud Identity domain
An IAM policy assigns a set of permissions to one or more Google Cloud members.
You can also use IAM to create and configure service accounts, which are Google Cloud accounts associated with your project that can perform tasks on your behalf. Service accounts are assigned roles and permissions in the same way as human users.
Service accounts provide other functionality as well. To learn more, refer to Creating IAM Policies.
IAM interaction with Kubernetes RBAC
IAM and Kubernetes RBAC work together to help manage access to your cluster. RBAC controls access on a cluster and namespace level, while IAM works on the project level. An entity must have sufficient permissions at either level to work with resources in your cluster.
What's next
- Read the GKE security overview.
- Learn how to use Kubernetes RBAC.
- Learn how to create IAM policies for GKE.
- Learn how to use IAM Conditions for load balancers. | https://cloud.google.com/kubernetes-engine/docs/concepts/access-control?hl=zh-Tw | CC-MAIN-2021-31 | refinedweb | 635 | 61.87 |
Hi, On Wed, 2006-07-19 at 00:27 +0100, Mukund wrote:
Advertising
#define GIMP_COPYRIGHT \ - _("Copyright © 1995-2006\n" \ - "Spencer Kimball, Peter Mattis and the GIMP Development Team") + _("Copyright © 1995-2006\n" \ + "Spencer Kimball, Peter Mattis\n" \ + "and the GIMP Development Team") Why is there a newline inserted here? I think it looked a lot better without it and there's no semantic reason why there should be a newline at this place. #define GIMP_LICENSE \ - _("GIMP is free software; you can redistribute it and/or modify it " \ + _("\n" \ + "GIMP is free software; you can redistribute it and/or modify it " \ "under the terms of the GNU General Public License as published by Please do not use newlines do adjust spacing. Especially not in translatable strings. The spacing in the about dialog is set to what the HIG suggests and should be fine without such hacks. If you really think it needs to be changed, please file a bug-report against GTK+. +#ifdef GIMP_UNSTABLE + gchar *comment = g_strconcat (GIMP_DESCRIPTION, "\n\n", + _("This is an unstable development release."), + "\n", NULL); +#endif Same comment applies here. Sven _______________________________________________ Gimp-developer mailing list Gimp-developer@lists.XCF.Berkeley.EDU | https://www.mail-archive.com/gimp-developer@lists.xcf.berkeley.edu/msg11437.html | CC-MAIN-2017-04 | refinedweb | 199 | 51.78 |
Hi,
I created an eps figure file with matplotlib. I can look at it via mac preview, but when I inserted it into a word document and printed it out, I got nothing except for the eps file information. So what's the problem? Here are all the packages I used in the python code. Does any of them impact the creation of the eps file? Thanks.
import numpy as np
import sys
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
from get_fbin import get_fbin
from matplotlib import mathtext
from matplotlib import rc
from matplotlib.font_manager import FontProperties
rc('font',**{'family':'sans-serif','sans-serif':['Helvetica']})
rc('text', usetex=True)
and I saved the code in this way:
fig.savefig('pfg1.eps') | https://discourse.matplotlib.org/t/cannot-print-out-eps-figures/15119 | CC-MAIN-2021-43 | refinedweb | 124 | 67.76 |
From: Jeremy Pack (rostovpack_at_[hidden])
Date: 2007-06-07 11:18:25
Johan,
>
> Yes, please don't make it a requirement to use UUIDs. I'll definitely have a
> need to use human-readable type names, which could also easily map to
> shared library names. This would allow for some automatic loading of shared
> libraries based upon the requested types.
>
One of the primary goals of the library is to keep the separate parts
as encapsulated as possible. As such, if the uuid specific header was
included, they could be used. Otherwise, there would be no
dependencies on uuid.
You can define any arbitrary mapping for your class's type
information. You could create a complicated struct to describe them,
as long as you provided a way to compare them (a less than operator).
So, I believe that what you propose should not be an issue. I or
Mariano will be writing an example soon showing the use of different
types of type info.
> [snip]
>
> >>
> >> 2. how else do you identify them if not with UUID ?
> >
> > RTTI. Some platforms (OS X) actually work fine just using the
> > type_info reference returned by typeid - other platforms (Windows, for
> > instance) only work with the full typeid(x).name(). But see above for
> > other options.
>
> Plain strings, e.g. equal to class names (including namespaces):
>
> "my::namespace::MyClass"
>
I'll make sure to detail that specific example in the tutorial.
>
> Why not provide a class loader with the library, which could be configured
> with e.g. :
>
> - Locations (i.e. directories) to use for loading, in prioritized order.
>
> - Type id => library name mappers, allowing the user to only provide the
> type id when loading classes.
>
> - Shared library extensions to use for the library loading (defaults to
> platform standard extension).
>
> - Explicit load functionality, where the user can specify the library
> name and the type id. As for cross-platform usage, the users should normally
> not include the file extensions or the paths to the libraries, only the
> canonical library names. It should still be _possible_ to provide the exact
> path and library extension.
>
Yes, this is planned - enough people have mentioned it, that we'll
definitely work it in. The basic design of it is done, and it will be
implemented "when we have time". Once again, it will be included in a
"convenience" header, and the code for it will only be included if its
header is included explicitly. Since not everyone will need this
functionality, it will be made optional.
> [snip]
>
> >>
> >> 7. can you explain shortly what Reflection is? Or some URL with
> >> explanation, please.
> >
> > I think of reflection as runtime type information about the methods of
> > a class for which you do not have access to any of its base classes.
> > As such, there are a lot of directions one could go with it - I'm not
> > sure which direction Mariano will choose. Some of these directions are
> > really hard in C++. I think we'll be discussing that a lot in about
> > three weeks - and will want lots of input from the community.
>
> I don't know what you intend to do, but please don't mix the two libraries
> into one. I'd even go as far as to suggest that the "dynamic (un-)loading of
> libraries/finding the entry points for specific methods" part of the
> Extension library should probably be a standalone library.
>
We will be posting the proposed reflection solution to this list
before implementing it. We'll do our best to avoid high coupling
between the plugin loading and reflection. I thought about this for a
while this morning, and I think that we can solve this in a way where
the reflection will work without including any of the plugin loading
headers, and vice versa. However, a "convenience" header will be
provided to make it easy to use them together. We'll definitely want
your input when we put forward the proposed design.
> I assume that it will always be possible to dynamic_cast the created
> instance to whatever types it actually implements, right? Example:
>
> boost::shared_ptr<base> pb = "load extension and create shared base
> instance";
> boost::shared_ptr<derived> pd = boost::dynamic_pointer_cast<derived>(pb);
>
Almost always - you of course can't cast it to a type that you don't
have defined in the current module. In addition, some compilers have
trouble doing dynamic casts across shared library boundaries. I do
know that an older version of the Borland C++ compiler had problems
with this, but am not sure about other compilers. I have done it
successfully with relatively recent versions of VS and gcc.
Thanks for the suggestions. We'll work on them!
Cheers,
Jeremy
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk | https://lists.boost.org/Archives/boost/2007/06/123042.php | CC-MAIN-2020-29 | refinedweb | 801 | 64.61 |
This!
The Turing test has been the de facto standard for testing a machine for intelligence. It's the way we try to figure out if our models are capable of responding to general-purpose questions the way a human would. The most efficient method for building a machine that has human-like responses is using neural networks and deep learning. These are new algorithms that have been made feasible through the recent advancements in hardware performance.
One aspect of humanity that is restricted to evolved primates is humor. In all fairness, there is no clear cut definition of humor, however, there is one theory that has gained quite a bit of popularity in recent years. The argument is that what makes us classify something as being funny falls under the "incongruity theory". The underlying mechanism of this theory builds on top of the inconsistency between what we are expecting to happen and what actually happens.
As it turns out the cognitive mechanisms that allow us to identify something as "funny" are quite complex, and it is only a few evolved primates that can find something funny.
For example Koko, the western lowland gorilla who understands more than 1,000 American Sign Language signs and 2,000 spoken words has been observed making prank jokes (IE: she would tie the instructor's shoelaces and then innocently make the sign for "chase". That's one tricksy gorilla :D !).
As a rule of thumb, the primates that can make laughing like sounds and are ticklish can be categorized as having a sense of humor.
Computers, on the other hand, are not ticklish, vocal cords are not yet a justified upgrade on any of the latest generation laptops, so, by all means, training a machine to understand humor needs to be trained by other means. The best way to train a neural network is by using an exhaustive text that contains as many jokes as possible in a specific format. You will notice that we already restricted the domain of humor to jokes (no pranks, ironic comedy with complex situations etc).
"If you're willing to restrict the flexibility of your approach, you can almost always do something better."
– John Carmack"
In our situation, we want to restrict the domain of the jokes to one-liners, question style comedy which would make the training of our model more focused, essentially what we are doing is gently nudging the machine in the right direction.
The machine intelligence we are building is for text generation, a deep learning neural network that can make jokes.
We will use the language with the most evolved ecosystem in terms of libraries, examples, and documentation, which in this case, is Python. I am a big fan of Python for its readability and because it is very closely evolving alongside JavaScript so many things feel familiar, it's also the other serverless language, and this makes it an excellent candidate to
write an Azure Function that tells us jokes.
The most popular approach to writing text generation applications are based on Andrej Karpathy's char-rnn architecture and blog post,
the example teaches a recurrent neural network to predict the next character in a sequence based on the previous n characters.
Based on Andrejs work Max Woolf built a python package that makes building a text generation bot very easy. It allows you to configure your neural network depth/layers/behavior etc.
The main method for training your joke model is textgenrnn. This object has a train_from_file method that allows you to consume a file with training data to teach your bot to figure out what punch line would be best suited to answer the joke.
The usage is quite straightforward, training a simple model would look something like this:
from textgenrnn import textgenrnn textgen = textgenrnn(name="new_model") textgen.train_from_file('jokes.txt', num_epochs=5)
After we have trained the data from the training data set, let's take it for a spin and try generating a test joke. We can do this by calling textgen.generate(). This will output the joke, but this simple call will not return the joke from the serverless function, which means we want to use a version of the method call that returns the data.
joke = textgen.generate(return_as_list=True)[0] # Grab the first generated joke in the list, in this case the only one
The script will create the model that is a serialized version of the dataset that will be used by tensorflow to help our function generate jokes based on the training data. This is the file with .hdf5 extension in your project's root folder.
Now the last piece of the puzzle is using the new model as a trigger to generate jokes in an Azure Function. Assuming you created a storage account that has a container named jokes, here's how your function will look like:
import azure.functions as func from textgenrnn import textgenrnn import tempfile import urllib.request import os import logging def main(myblob: func.InputStream, context: func.Context): tempFilePath = tempfile.gettempdir() jokesfile = os.path.join(tempFilePath,"jokes.hdf5") urllib.request.urlretrieve(myblob.uri, jokesfile) textgen = textgenrnn(jokesfile) joke = textgen.generate(return_as_list=True)[0] logging.info(f"joke: {joke}")
{ "scriptFile": "__init__.py", "bindings": [ { "name": "myblob", "type": "blobTrigger", "direction": "in", "path": "jokes/{name}", "connection": "AzureWebJobsStorage" } ] }
To test your function, upload the generated .hdf5 file to the joke container and see the generated joke in the functions logs.
Need more inspiration? You can find the source code in my github repository here.
Congrats
You now have an API with a sense of humor :D
Conclusions
You can notice that the API is not particularly funny in the classical sense, but it will surprise you. I think that what you would be expecting and what the endpoint is returning will definitely fall under the "theory of incongruity".
To improve results to match more traditional patterns, there are a few ways to improve the training method like:
- restrict the type of jokes
- increase training data set size
Want to submit your solution to this challenge? Build a solution locally and then submit an issue. If your solution doesn't involve code you can record a short video and submit it as a link in the issue desccription.!
Discussion (1)
Haha! This is pure gold! 🥇
Is there a live version of this? I would like to fiddle with it! | https://dev.to/azure/build-your-jokes-generator-using-machine-learning-and-serverless-5g4a | CC-MAIN-2021-43 | refinedweb | 1,067 | 60.85 |
An integrated development environment (IDE), like NetBeans or IntelliJ for Java, is a tool that enhances a computer programmer’s productivity.
A tool as in something that enables us to do quickly and easily something that would take us too long to do without assistance.
After a white-boarding interview exercise, one of my mentors said that an IDE can be a crutch.
A crutch as in something that we rely on so much that it atrophies our ability to do something we should be able to do without machine help.
In this article I will mostly only use examples from Java IDEs, specifically NetBeans and IntelliJ. But a lot of the concepts carry over to IDEs for other programming languages, like XCode for Objective-C and Swift, or VS Code for JavaScript and just about everything else.
And of course both NetBeans and IntelliJ can be used for programming languages other than Java. I’ve used NetBeans for C++ and have thought about using it for FORTRAN (curiousity, mostly). And IntelliJ is now what I mostly use for Scala.
Some people think that if you’re not using an editor like Vim you’re not a real programmer, you’re a pretender, an impostor.
A very good example of how much an IDE helps with refactoring comes from my reading of Building Maintainable Software: Java Edition by Joost Visser et al. With an IDE, making changes to several files at once is quite easy.
One of the recommendations in the book is that constructors (and other “methods”) should not take more than four parameters. And even just four parameters can often be too many.
In one of my projects, I had a constructor with five parameters. In another article I’ll delve into the details of that. For now, suffice it to say I realized the constructor ought to be able to infer the fifth parameter, otherwise it should throw an exception.
So I rewrote the constructor to only take four parameters. But now my project won’t compile, because I haven’t yet changed all the 5-parameter constructor calls to be 4-parameter constructor calls.
In Vim or some other plaintext editor, I can do a search for the relevant constructor calls. I might run the search on classes that don’t have the pertinent constructor call.
Of course a “real” programmer would just immediately know the location of all the constructor calls that need to be changed. The truth is, though, that computers are just better at keeping track of state than humans are.
So, in an IDE, I can simply rely on all the now-invalid 5-parameter constructor calls being flagged as compilation errors. Once my IDE’s error/warning indicator goes from red to yellow or (better yet) green, I know the problem is taken care of.
As I was writing this article, it occurred to me that I can further whittle this down to three constructor parameters for at least a simple majority of the use cases, if not a super majority.
This is a change that I intend to accomplish this with a chained constructor, so that the 4-parameter option is still available through the primary constructor when I need it.
This means that I will have to look at each constructor call and decide one by one whether it should remain as it is or if it should be rewritten to take advantage of the 3-parameter auxiliary constructor.
But again, the IDE gives me an easy way to quickly find the relevant constructor calls and take care of them on a case-by-case basis.
So I like to think that for me, the IDE is a tool, not a crutch. Most of the time, anyway. I think it is still necessary to do a little introspection and determine whether this is still the case. Hence this quiz.
Auto-complete
Java has a reputation for being verbose. The long names for some of the standard classes make some programmers give their variables excessively short names, as the following fictional example demonstrates all too well:
ClassWithLongName obj = new ClassWithLongName(param1, param2);
It is rare to see an exception instantiated in one line and then thrown in a later line. Java programmers instead generally prefer to have exceptions thrown in the very same line they’re instantiated. For example:
if (index > maxIndex) {
String msg = index + " is beyond maximum of " + maxIndex;
throw new IndexOutOfBoundsException(msg);
}
rather than
if (index > maxIndex) {
String msg = index + " is beyond maximum of " + maxIndex;
IndexOutOfBoundsException e =
new IndexOutOfBoundsException(msg);
throw e;
}
There is generally no good reason to do it the second way (the stack trace could be misleading), but it certainly doesn’t help that you would have to type
IndexOutOfBoundsException twice.
If you did want to do it that second way, though, you would certainly appreciate it if auto-complete kicked in and you only needed to type the first word, or even just a couple of letters.
In my experience, NetBeans will only auto-complete after a dot, but IntelliJ will offer auto-complete suggestions even for a single letter, if it recognizes the relevant class from either
java.lang or from the imported packages (or from packages in the overall project scope).
For example, if you have
java.awt.* imported, you might only need to type “
Mu” or even just “
M”in IntelliJ to give
MultipleGradientPaint as an auto-complete suggestion that you can accept by pressing Enter.
Then, if you want to access the
OPAQUE field of
MultipleGradientPaint, you might as well just go ahead and type the period, press Caps Lock and write that short word in full.
Whereas in NetBeans, you would have to type
MultipleGradientPaint in full and then the period before the auto-complete suggests
BITMASK,
OPAQUE and
TRANSLUCENT as possible completions.
You can customize how auto-complete works in both NetBeans and IntelliJ. Probably in Eclipse, too, after hunting through several preferences menus.
IntelliJ also tries to auto-complete Java keywords like “
instanceof” and “
extends.”
Quiz question: Do you use auto-complete only for things that would be too slow or error-prone to type? If so, your IDE is a tool. Or do you rely on auto-complete for things like “
catch” and “
true”? If so, your IDE is a crutch.
Quiz question: How do you feel when auto-complete lags behind or fails to offer any suggestions at all? It’s okay to feel a little annoyed, but if you’re angry, your IDE might be a crutch.
However… when your computer is overburdened with too many different programs running besides your IDE, you might have to let the auto-complete kick in even for the shorter keywords like “
else” and even “
if”.
But then your IDE is worse than a crutch, it’s a genuine nuisance. In that case it would probably be better to close some of the other programs, so that auto-complete can work more like it’s intended to work.
And also, it can happen that you neglected to import a necessary package, or an object is of a different type than the type you think it is. An apparent auto-complete failure might indicate a mistake on your part of this sort.
And then your IDE is a tool, helping you remember an important little detail. More proof that computers are better at keeping track of state than humans.
Auto-generate
One of the most touted features of both Scala and Kotlin is that getters and setters are generated automatically and behind the scenes. In Java you have to write a lot of lines like these:
private SomeType propertyA = new SomeType(initParam); public SomeType getPropertyA() {
return (SomeType) this.propertyA.clone();
} public void setPropertyA(SomeType setting) {
if (SomeType.isCurrentlyValid(setting)) {
this.propertyA = (SomeType) this.propertyA.clone();
} else {
throw new IllegalArgumentException("Bad setting");
}
}
Even if you don’t need your setter to do any validation, you still need something like ten lines (with standard formatting). That’s boilerplate, or worse, bloat, according to Java critics.
You can obtain the Java-style getter and setter in Scala with a single line:
@BeanProperty var propertyA: SomeType = SomeType(initParam)
This assumes
BeanProperty has been imported, and presumably you’re going to need it for other fields in the given class, because you need the given class to interoperate with Java classes expecting Java Beans.
This also assumes
SomeType has
apply(), but that’s outside the scope of this article. I’m guessing something very similar for Kotlin.
Maybe they got the idea from Lombok, a plugin for Java IDEs that needs to be specifically installed on your development system before you can start using it. The one-liner would be something like this:
@Getter @Setter SomeType propertyA = new SomeType(initParam);
(you also need to have the relevant Lombok packages imported). Presumably this will take care of the nuances of getters and setters for mutable types.
It is my understanding that, given a proper Lombok installation, a line like the above would lead the compiler to generate pretty much the same bytecode as if you had typed it all out in “vanilla Java,” but without having to worry about typos too much.
However, your IDE can generate getters and setters right out the box, no special plugins needed. Though you might think they’re still boilerplate eyesores, cluttering up your otherwise beautiful code.
In NetBeans, auto-generate for getters and setters is available through a contextual menu. In IntelliJ, you can use the Generate menu.
A much more dramatic example of auto-generate is the generation of
equals() and
hashCode(). You often need the former for unit testing, and then when you write it, your IDE offers to write
hashCode() for you.
You don’t even have to write the least bit of either, you can have your IDE generate both of them for you at once.
In NetBeans, the generated
equals() usually has a redundant if statement at the end, which triggers a warning. I guess the idea is to make sure you review the generated
equals().
I remember a long time ago I had NetBeans auto-generate
hashCode() for
ImaginaryQuadraticRing in my Algebraic Integer Calculator project (source and tests available from GitHub).
That was before the project grew to also include
RealQuadraticRing, and the abstract class
QuadraticRing. I don’t remember the exact form of the generated
hashCode(), but in shortening it to four lines, I did not change the logic of what NetBeans generated:
@Override
public int hashCode() {
return (219 + this.negRad);
}
I still don’t know where NetBeans got that number 219 from, but I’ve wondered about it since. And maybe I could have kept it without any problem when I expanded the project to include
RealQuadraticRing.
But I decided to come up with my own
hashCode() function, which now resides in
QuadraticRing:
@Override
public int hashCode() {
int hash = this.radicand;
if (this.d1mod4) {
hash--;
} else {
hash *= -1;
}
return hash;
}
It’s a tiny bit more complicated, but at least I can fully explain the thought process behind it.
And also I can more easily explain that it is guaranteed to give unique hash codes for any possible
ImaginaryQuadraticRing or
RealQuadraticRing object, (
radicand is of primitive type
int).
The logical extreme would be for me to say that you also need to examine the Java Virtual Machine (JVM) bytecode your IDE generates. But that’s not necessary, unless it interests you.
Java compiler optimization is something programmers like Scala inventor Martin Odersky have worked very hard to improve. As long as you understand your Java source and its efficiency or inefficiency, there’s probably no extra performance to be gained from scrutinizing and tweaking the byte code.
Quiz question: When you have your IDE auto-generate something, do you at least skim what was generated? If you make light edits to what was generated, your IDE is a tool.
But if you don’t even glance at what was generated, if you just assume it’s all good even when you haven’t had your IDE generate something like it before, your IDE is a crutch.
In particular, Java programmers should understand the nuances of getters and setters, and of
equals() and
hashCode(), even if they prefer to let the IDE, or a plugin like Lombok, write those for them.
Stylistic warnings
Remember the example above in which the
IndexOutOfBoundsException is instantiated in one line and thrown in the next? IntelliJ would certainly offer to “inline the variable.” Probably NetBeans, too.
The more you deviate from standard programming practices the more your IDE will offer to change your code to the more usual patterns. In my experience, IntelliJ is more opinionated about this than NetBeans.
It can be very helpful when you’re starting out programming Java, and in my case, IntelliJ has been very helpful as I learn Scala. Passing up easy opportunities for functional programming in Scala is one example of a deviation from common Scala practices.
In Java, constructing an exception in one line and throwing it in a later line is a deviation from common Java practices, and most of the time there is no good reason for it (this might indicate a need to wrap an already thrown exception in a new exception, but that’s a topic for another day).
There needs to be an understanding of when these deviations are ill-advised and when there is a good reason for them.
In some cases it may even be necessary to customize your IDE’s errors and warnings (though I would be very hesitant to demote errors to warnings, not to mention disabling them altogether).
Quiz question: Do you strive to make your IDE’s error/warning indicator be green most of the time? You should. But in so doing, do you question the reasons for the warnings? If you at least understand the reasons for the warnings, even if you don’t customize the warnings, your IDE is a tool.
Quiz question: Have you ever accepted a suggestion from your IDE without fully understanding it, but then followed that up with a question about it to a coworker, mentor, or on StackOverflow, Quora or some website like that? Then your IDE is a tool for learning.
Quiz question: Have you ever customized errors, warnings and/or inspections in your IDE? If you have, your IDE is a tool. But if you have not, and have not felt a need to do so, that’s okay, too, provided you’re aware than you can customize these if you need to.
In conclusion
It boils down to this: is your IDE taking care of tasks that would be too tedious for you to tackle one at a time? Then your IDE is a tool. Or are you letting it make decisions that you should be making? Then it’s a crutch.
I only barely mentioned the Eclipse IDE. I would appreciate comments about how Eclipse is helpful and when it gets in the way. I would also appreciate comments about IDEs for other programming languages. | https://alonso-delarte.medium.com/your-ide-tool-or-crutch-take-the-quiz-a6512e1af74c | CC-MAIN-2021-21 | refinedweb | 2,520 | 60.14 |
Creating a Face Swapping Model in 10 Minutes
January 13, 2021 | 4 min read | 313 views
Face swapping is now one of the most popular features of Snapchat and SNOW. In this post, I’d like to share a naive solution for face swapping, using a pre-trained face parsing model and some OpenCV functions.
I’m going to implement face swapping as follows:
- Parse the face into 19 classes.
- Swap every part of the face with the counterpart.
- Fill holes with local average colors.
The code is available at:.
Face Parsing
For face parsing, I used the pre-trained BiSeNet because it’s accurate and easy to use. This model parses a given face into 19 classes such as left eyebrow, upper lip, and neck.
For this case, I selected 8 classes: left eyebrow, right eyebrow, left eye, right eye, nose, upper lip, mouth, and lower lip. These were used to generate 6 types of masks:
- left eyebrow mask
- right eyebrow mask
- left eye mask
- right eye mask
- nose mask
- mouth mask (including lips)
Face swapping
Next, I swapped for each pair of parts. Since each part is in a different position in each picture, they are needed to be aligned. For example, the two right eyebrow masks below have slightly different positions.
This difference should be adjusted for the fine result, so I computed the shift in centroids with OpenCV’s
moments function.
def calc_shift(m0, m1): mu = cv2.moments(m0, True) x0, y0 = int(mu["m01"]/mu["m00"]), int(mu["m10"]/mu["m00"]) mu = cv2.moments(m1, True) x1, y1 = int(mu["m01"]/mu["m00"]), int(mu["m10"]/mu["m00"]) return (x0-x1, y0-y1)
Then I implemented the swapping part like:
def swap_parts(i0, i1, m0, m1, labels): m0 = create_mask(m0, labels) m1 = create_mask(m1, labels) i,j = calc_shift(m0, m1) l = i0.shape[0] h0 = i0 * m0.reshape((l,l,1)) # forground y = np.zeros((l,l,3)) # cancel the shift in centroids if i>=0 and j>= 0: y[:l-i, :l-j] += h0[i:, j:] elif i>=0 and j<0: y[:l-i, -j:] += h0[i:, :l+j] elif i<0 and j>=0: y[-i:, :l-j] += h0[:l+i, j:] else: y[-i:, -j:] += h0[:l+i, :l+j] h1 = i1 * (1-m1).reshape((l,l,1)) # background y += h1 * (y==0) return y
However, this left some holes (specifically,
m1 \ m0, using the notation of set operation) in the generated image.
Note: Throughout this experiment, I used randomly-sampled photos from.
Fill in the Holes
As a naive approach, I used the average color of the boundary region to fill in the holes. In computer vision, this boundary region is called morphological gradient, and it is computed by OpenCV’s
morphologyEx function.
def swap_parts(i0, i1, m0, m1, labels): ... h1 = i1 * (1-m1).reshape((l,l,1)) # background b = cv2.morphologyEx(m1.astype('uint8'), cv2.MORPH_GRADIENT, np.ones((5,5)).astype('uint8') ) # boundary region c = (np.sum(i1*b.reshape((l,l,1)), axis=(0,1)) / np.sum(b)).astype(int) # average color of the coundary # fill color in the hole h1 += c * m1.reshape((l,l,1)) y += h1 * (y==0) return y
Finally, I got the following result.
I have to admit that the result looks weird, but it means that this app is safe as it can’t be used for DeepFake😇
References
[1] OpenCV: Image Moments
[2] モルフォロジー変換 — OpenCV-Python Tutorials 1 documentation
[3] Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, Nong Sang. ”BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation“. ECCV. 2018.
Written by Shion Honda. If you like this, please share! | https://hippocampus-garden.com/face_swap/ | CC-MAIN-2022-27 | refinedweb | 612 | 64.91 |
# Memoization Forget-Me-Bomb

Have you heard about `memoization`? It's a super simple thing, by the way,– just memoize which result you have got from a first function call, and use it instead of calling it the second time - don't call real stuff without reason, don't waste your time.
Skipping some intensive operations is a very common optimization technique. Every time you might not do something — don’t do it. Try to use cache — `memcache`, `file cache`, `local cache` — any cache! A must-have for backend systems and a crucial part of any backend system of past and present.

Memoization vs Caching
======================
> Memoization is like caching. Just a bit different. Not cache, let's call it kashe.
Long story short, but memoization is not a cache, not a persistent cache. It might be it on a server side, but can not, and should not be a cache on a client side. It's more about available resources, usage patterns, and the reasons to use.
Problem - Cache need a" cache key"
----------------------------------
Cache is storing and fetching data using a **string** cache `key`. It's already a problem to construct a unique, and usable key, but then you have to serialise and de-serialise data to store in yet again string based medium… in short - cache might be not as fast, as you might think. Especially distributed cache.
Memoization does not need any cache key
---------------------------------------
In the same time - no key is needed for memoization. *Usually\** it uses arguments as-is, not trying to create a single key from them, and does not use some globally available shared object to store results, as cache usually does.
> The difference between memoization and cache is in **API INTERFACE**!
*Usually\** does not mean always. [Lodash.memoize](https://github.com/lodash/lodash/blob/4.17.11/lodash.js#L10547), by default, uses `JSON.stringify` to convert passed arguments into a string cache(is there any other way? No!). Just because they are going to use this key to access an internal object, holding a cached value. [fast-memoize](https://community.risingstack.com/the-worlds-fastest-javascript-memoization-library/), "the fastest possible memoization library", does the same. Both named libraries are not memoization libraries, but cache libraries.
> It worth to mention – JSON.stringify might be 10 times slower than a function, you gonna memoize.
Obviously - the simples solution to the problem is NOT to use a cache key, and NOT access some internal cache using that key. So - remember the last arguments you were called with. Like [memoizerific](https://github.com/thinkloop/memoizerific) or [reselect](https://github.com/reduxjs/reselect) do.
> Memoizerific is probably the only general caching library you would like to use.
The cache size
==============
The second big difference between all libraries is about the cache size and the cache structure.
Have you ever thought – why `reselect` or `memoize-one` holds only one, last result? Not to *"not to use cache key to be able to store more than one result"*, but because there are **no reasons to store more than just a last result**.
…It's more about:
* available resources - a single cache line is very resource friendly
* usage patterns - remembering something "in place" is a good pattern. "In place" you usually need only one, last, result.
* the reason to use -modularity, isolation and memory safety are good reasons. Not sharing cache with the rest of your application is just more safe in terms of cache collisions.
A Single Result?!
=================
Yes - the only one result. With one result memoized some **classical things**, like memoized fibonacci number generation(*you may find as an example in every article about memoization*) would be **not possible**. But, usually, you are doing something else - who needs a fibonacci on Frontend? On Backend? A real world examples are quite far from abstract *IT quizzes*.
But still, there are two **BIG** problems about a single-value memoization kind.
Problem 1 - it's "fragile"
--------------------------
By defaults - all arguments should match, exactly be the "===" same. If one argument does not match - the game is over. Even if this comes from the idea of memoization - that might not be something you want nowadays. I mean – you want to memoize as much, as possible, and as often, as possible.
> Even cache miss is a cache wiping headshot.
There is a little difference between "nowadays" from "yesterdays" - immutable data structures, used for example in Redux.
```
const getSomeDataFromState = memoize(state => compute(state.tasks));
```
Looking good? Looking right? However thestate might change when tasks did not, and you need only tasks to match.
**Structural Selectors** are here to save the day with their strongest warrior - **Reselect** – at your beck and call. Reselect is not only memoization library, but it's power comes from memoization **cascades**, or lenses(which they are not, but think about selectors as optical lenses).
```
// every time `state` changes, cached value would be rejected
const getTasksFromState = createSelector(state => state.tasks);
const getSomeDataFromState = createSelector(
// `tasks` "without" `state`
getTasksFromState, // <----------
// and this operation would be memoized "more often"
tasks => compute(state.tasks)
);
```
As a result, in case of immutable data - you always have to first **"focus"** into the data piece you really need, and then - perform calculations, or else cache would be rejected, and all the idea behind memoization would vanish.
This is actually a big problem, especially for newcomers, but it, as The Idea behind immutable data structures, has a significant benefit - **if something is not changed - it is not changed. If something is changed - probably it is changed**. That's giving us a super fast comparison, but with some false negatives, like in the first example.
> The Idea is about "focusing" into the data you depend on
There are two moments I should have - mentioned:
* `lodash.memoize` and `fast-memoize` are converting your data to a string to be used as a key. That means that they are 1) not fast 2) not safe 3) could produce false positives - some **different data** could have the **same string representation**. This might improve "cache hot rate", but actually is a VERY BAD thing.
* there is an ES6 Proxy approach, about tracking all the used pieces of variables given, and checking only keys which matter. While I personally would like to create myriads of data selectors - you might not like or understand the process, but might want to have proper memoization out of the box - then use [memoize-state](https://github.com/theKashey/memoize-state).
Problem 2- it's "one cache line"
--------------------------------
Infinite cache size is a killer. Any uncontrolled cache is a killer, as long as memory is quite finite. So - all the best libraries are "one-cache-line-long". That's a feature and strong design decision. I just written how right it is, and, believe me - it's a **really right thing**, but it's still a problem. A Big Problem.
```
const tasks = getTasks(state);
// let's get some data from state1 (function was defined above)
getDataFromTask(tasks[0]);
// Yep!
equal(getDataFromTask(tasks[0]), getDataFromTask(tasks[0]))
// Ok!
getDataFromTask(tasks[1]);
// a different task? What the heck?
// oh! That's another argument? How dare you!?
// TLDR -> task[0] in the cache got replaced by task[1]
you cannot use getDataFromTask to get data from different tasks
```
Once the same selector has to work with different source data, with more that one - everything is broken. And it is easy to run into the problem:
* As long as we were using selectors to get tasks from a state - we could use the same selectors to get something from a task. Intense comes from API itself. But it does not work then you can memoize only last call, but have to work with multiple data sources.
* The same problem is with multiple React Components - they all are the same, and all a bit different, fetching different tasks, wiping results of each other.
There are 3 possible solutions:
* in case of redux - use mapStateToProps factory. It would create per-instance memoization.
```
const mapStateToProps = () => {
const selector = createSelector(...);
// ^ you have to define per-instance selectors here
// usually that's not possible :)
return state => ({
data: selector(data), // a usual mapStateToProps
});
}
```
* the second variant is almost the same (and also for redux) - it's about using [re-reselect](https://github.com/toomuchdesign/re-reselect). It's a complex library, which could save the day by distinguishing components. It just could understand, that the new call was made for "another" component, and it might keep the cache for the "previous" one.
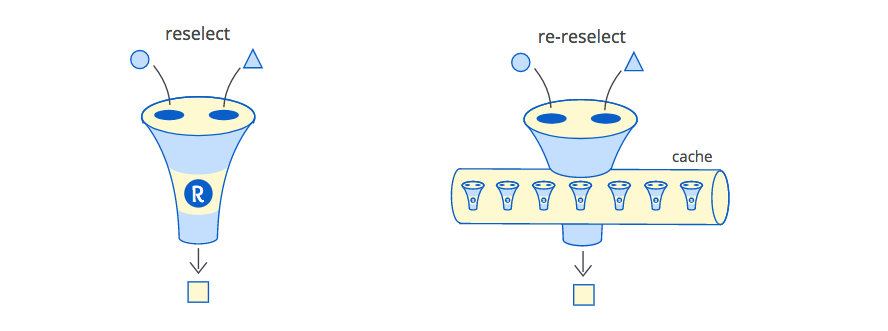
This library would help you "keep" the memoization cache, but not delete it. Especially because it is implementing 5(FIVE!) different cache strategies to fit any case. That's a bad smell. What if you choose the wrong one?
All the data you have memoized - you have to forget it, sooner or later. The point is not to remember last function invocation - the point is to FORGET IT at the right time. Not too soon, and ruin memoization, and not too late.
> Got the idea? Now forget it! And where is 3rd variant??
Let take a pause
================
Stop. Relax. Make a deep breath. And answer one simple question - What's the goal? What we have to do to reach the goal? What would save the day?
> TIP: Where is that f\*\*\* "cache" LOCATED!

Where is that "cache" LOCATED? Yes - that's the right question. Thanks for asking it. And the answer is simple - it is located in a closure. In a hidden spot inside\* a memoized function. For example - here is `memoize-one` code:
```
function(fn) {
let lastArgs; // the last arguments
let lastResult;// the last result <--- THIS IS THE CACHE
// the memoized function
const memoizedCall = function(...newArgs) {
if (isEqual(newArgs, lastArgs)) {
return lastResult;
}
lastResult = resultFn.apply(this, newArgs);
lastArgs = newArgs;
return lastResult;
};
return memoizedCall;
}
```
You will be given a `memoizedCall`, and it will hold the last result nearby, inside its local closure, not accessible by anyone, except memoizedCall. A safe place. "this" is a safe place.
`Reselect` does the same, and the only way to create a "fork", with another cache - create a new memoization closure.
But the (another) main question - when it(cache) would be "gone"?
> TLDR: It would be "gone" with a function, when the function instance would be eaten by Garbage Collector.
Instance? Instance! So - what's about per instance memoization? There is a whole article about it at [React documentation](https://reactjs.org/blog/2018/06/07/you-probably-dont-need-derived-state.html#what-about-memoization)
In short — if you are using Class-based React Components you might do:
```
import memoize from "memoize-one";
class Example extends Component {
filter = memoize( // <-- bound to the instance
(list, filterText) => list.filter(...);
// ^ that is "per instance" memoization
// we are creating "own" memoization function
// with the "own" lastResult
render() {
// Calculate the latest filtered list.
// If these arguments haven't changed since the last render,
// `memoize-one` will reuse the last return value.
const filteredList = this.filter(something, somehow);
return {filteredList.map(item => ...}
}
}
```
So - where **"lastResult"** is stored? Inside a local scope of memoized **filter**, inside this class instance. And, when it would be "gone"?
This time it would "be gone" with a class instance. Once component got unmounted - it gone without a trace. It's a real "per instance", and you might use `this.lastResult` to hold a temporal result, with exactly the same "memoization" effect.
What's about React.Hooks
------------------------
We are getting closer. Redux hooks have a few suspicious commands, which, probably, are about memoization. Like - `useMemo`, `useCallback`, `useRef`
> But the question - WHERE it is storing a memoized value this time?
In short - it stores it in "hooks", inside a special part of a VDOM element known as fiber associated with a current element. Within a parallel data structure.
Not so short - hooks are changing the way your program work, moving your function inside another one, with some variables in a *hidden spot inside a parent closure*. Such functions are known as *suspendable* or *resumable* functions — coroutines. In JavaScript they are usually known as `generators` or `async functions`.
But that a bit extreme. In a really short - useMemo is storing memoized value in this. It is just a bit different "this".
> If we want to create a better memoization library we should find a better "this".
Zing!
WeakMaps!
=========
Yes! WeakMaps! To store key-value, where the key would be this, as long as WeakMap does not accept anything except this, ie "objects".
Let's create a simple example:
```
const createHiddenSpot = (fn) => {
const map = new WeakMap(); // a hidden "closure"
const set = (key, value) => (map.set(key, value), value);
return (key) => {
return map.get(key) || set(key, fn(key))
}
}
const weakSelect = createHiddenSpot(selector);
weakSelect(todos); // create a new entry
weakSelect(todos); // return an existing entry
weakSelect(todos[0]); // create a new entry
weakSelect(todos[1]); // create a new entry
weakSelect(todos[0]); // return an existing entry!
weakSelect(todos[1]); // return an existing entry!!
weakSelect(todos); // return an existing entry!!!
```
It's stupidly simple, and quite "right". So "when it would be gone"?
* forget weakSelect and a whole "map" would be gone
* forget todos[0] and their weak entry would be gone
* forget todos - and memoized data would be gone!
> It's clear when something would "gone" – only when it should!
Magically - all the reselect issues are gone. Issues with aggressive memoization - also a goner.
This approach **REMEMBER** the data until it's time to **FORGET**. Its unbelievable, but to better remember something you have to be able to better forget it.
The only thing lasts - create a more robust API for this case
Kashe - is a cache
==================
[kashe](https://github.com/theKashey/kashe) is WeakMap based memoization library, which could save your day.
This library exposes 4 functions
* `kashe` -for memoization.
* `box` - for prefixed memoization, to *increase* chance of memoization.
* `inbox` - nested prefixed memoization, to *decrease* change of memoization
* `fork` - to *fork*(obviously) memoization.
kashe(fn) => memoizedFn(…args)
------------------------------
It's actually a createHiddenSpot from a previous example. It will use a first argument as a key for an internal WeakMap.
```
const selector = (state, prop) => ({result: state[prop]});
const memoized = kashe(selector);
const old = memoized(state, 'x')
memoized(state, 'x') === old
memoized(state, 'y') === memoized(state, 'y')
// ^^ another argument
// but
old !== memoized(state, 'x') // 'y' wiped 'x' cache in `state`
```
first argument is a key, if you called function again the same key, but different arguments - cache would be replaced, it is still one cache line long memoization. To make it work - you have to provide different keys for different cases, as I did with a weakSelect example, to provide different this to hold results. Reselect cascades A's still the thing.
Not all functions are kashe-memoizable. First argument *have* to be an object, array or a function. It should be usable as a key for WeakMap .
box(fn) => memoizedFn2(box, …args)
----------------------------------
this is the same function, just applied twice. Once for fn, once for memoizedFn, adding a leading key to the arguments. It might make any function kashe-memoizable.
> It is quite declarative – hey function! I will store results in this box.
```
// could not be "kashe" memoized
const addTwo = (a,b) => ({ result: a+b });
const bAddTwo = boxed(addTwo);
const cacheKey = {}; // any object
bAddTwo(cacheKey, 1, 2) === bAddTwo(cacheKey, 1, 2) === { result: 3}
```
If you will box already memoized function - you will increase memoization chance, like per instance memoization - you may create memoization cascade.
```
const selectSomethingFromTodo = (state, prop) => ...
const selector = kashe(selectSomethingFromTodo);
const boxedSelector = kashe(selector);
class Component {
render () {
const result = boxedSelector(this, todos, this.props.todoId);
// 1. try to find result in `this`
// 2. try to find result in `todos`
// 3. store in `todos`
// 4. store in `this`
// if multiple `this`(components) are reading from `todos` -
// selector is not working (they are wiping each other)
// but data stored in `this` - exists.
...
}
}
```
inbox(fn) => memoizedFn2(box, …args)
------------------------------------
this one is opposite to the box, but doing almost the same, commanding nested cache to store data into the provided box. From one point of view - it reduces memoization probability(there is no memoization cascade), but from another - it removes the cache collisions and help isolate processes if they should not interfere with each other by any reason.
> It's quite declarative - hey! Everybody inside! Here is a box to use
```
const getAndSet = (task, number) => task.value + number;
const memoized = kashe(getAndSet);
const inboxed = inbox(getAndSet);
const doubleBoxed = inbox(memoized);
memoized(task, 1) // ok
memoized(task, 2) // previous result wiped
inboxed(key1, task, 1) // ok
inboxed(key2, task, 2) // ok
// inbox also override the cache for any underlaying kashe calls
doubleBoxed(key1, task, 1) // ok
doubleBoxed(key2, task, 2) // ok
```
fork(kashe-memoized) => kashe-memoized
--------------------------------------
Fork is a real fork - it gets any kashe-memoized function, and return the same, but with another internal cache entry. Remember redux mapStateToProps factory method?
```
const mapStateToProps = () => {
// const selector = createSelector(...); //
const selector = fork(realSelector);
// just fork existing selector. Or box it, or don't do anything
// kashe is more "stable" than reselect.
return state => ({
data: selector(data),
});
}
```
Reselect
--------
And there one more thing you should know - kashe could replace reselect. Literally.
```
import { createSelector } from 'kashe/reselect';
```
It's actually the same reselect , just created with kashe as a memoization function.
Codesandbox
===========
Here is a [little example](https://codesandbox.io/s/v8953mz17l?from-embed) to play with. Also you may double [check tests](https://github.com/theKashey/kashe/tree/master/__tests__) — they are compact and sound.
If you want to know more about caching and memoization — check how [I wrote the fastest memoization library](https://itnext.io/how-i-wrote-the-worlds-fastest-react-memoization-library-535f89fc4a17) a year ago.
> PS: It worth to mention, than the simpler version of this approach - weak-memoize - is used in emotion-js for a while. No complaints. nano-memoize also uses WeakMaps for a single argument case.
Got the point? A more "weak" approach would help you to better remember something, and better forget it.
<https://github.com/theKashey/kashe>
Yeah, about forgetting something,– could you please look here?
 | https://habr.com/ru/post/446390/ | null | null | 3,055 | 58.18 |
A web framework is a so-called library that makes a developer’s life easier when building web applications. Most popular web frameworks encapsulate what developers across the globe have learnt over the past twenty years.
Most of you, when choosing a framework for a web application, firstly think of Django. No doubt, in lots of cases Django, with its everything-out-of-the-box and (killer feature) automatic database generation, is very suitable.
However, let's take a look around. There is a number of various Python frameworks and, surprisingly, they aren't clones of Django. Some of them are surely better to choose, or at least worth learning, for some specific usage.
There are more than 25 active Python web framework projects. Projects without stable releases during the last 365 days and web frameworks not supporting Python 3 were left out.
Let's develop a very simple application with each popular framework. An application must response "Hello world!" to
/hello/ request, and also templating must be used to pass "Hello world!" message dynamically. Database access is another important question regarding frameworks, but comparison of that would be too bulky for such brief overview. For API frameworks (Falcon, Hug and Sanic) a response must be
{'message': 'Hello world!'}.
The comparison of Python web frameworks includes
Another Python web frameworks comparison includes
Django
Github stars: 30164
Github forks: 12712
The main principle of Django ninjas is to develop everything of any complexity IN TIME. It's originally developed for content-management systems, but its rich features including but not limited to templating, automatic database generation, DB access layer, automatic admin interface generation - are well suitable for other kinds of web applications. Provides a web server for development use. Form serialization and validation, template system with inheritance of templates, caching in several ways, internationalization, serialization to XML or JSON. Django is contributed with applications for maintenance: an authorization system, a dynamic admin system, RSS and Atom generators, Google Sitemaps generator, and so on. Django is used by Instagram, Pinterest, The Washington Times, Disqus, Bitbucket and Mozilla.
When developing a microapplication, Django begins with complexity from the start. After installing the package (Django, literally), you must create a project with "django-admin startproject myproject" command. Then, you should configure the app in
myproject/myproject/settings.py - at least database access and templating. Django application is always unified in structure. It's excellent when you develop many boring applications. My application is:
myproject/myproject/views.py
from django.shortcuts import render def hello(request): return render(request, 'myproject/message.html', {'message': 'Hello world!'})
myproject/myproject/urls.py
from django.conf.urls import url from . import views urlpatterns = [ url(r'^hello/', views.hello, name='hello'), ]
Also, there are some obvious changes in myproject/myproject/settings.py and the template in myproject/templates/myproject/message.html.
pip freeze contains: appdirs, Django, packaging, pyparsing, six.
Official website | GitHub page | PyPI page
Flask
Github stars: 31543
Github forks: 9936
A microframework for Python based on Werkzeug and Jinja2 "with good intentions". Being a microframework, Flask is worth using when developing small applications with simple requirements, not like Django, Pyramid, et cetera. For example, you may operate your database in any way you like with Flask - by means of SQLAlchemy or anything else. Use it if you are going to develop a small application and configure everything by yourself. Other features: development web server, integrated unit testing support, Google App Engine compatibility. Flask is used by LinkedIn, Pinterest.
Flask example is very simple.
from flask import Flask, render_template app = Flask(__name__) @app.route("/hello") def hello(): return render_template('message.html', message="Hello world!") if __name__ == "__main__": app.run()
pip freeze contains: appdirs, click, Flask, itsdangerous, Jinja2, MarkupSafe, packaging, pyparsing, six, Werkzeug.
Official website | GitHub page | PyPI page
Tornado
Github stars: 14741
Github forks: 4349
Its main feature is non-blocking I/O. Thus, Tornado can be scaled to handle tens of thousands of open connections. An ideal framework for long polling, WebSockets and other usages with continuous connection. Tornado officially supports only Linux and BSD OS (Mac OS X and Microsoft Windows are recommended only for development use). The origin of Tornado is FriendFeed project, now owned by Facebook.
The task doesn't need any of the Tornado's key features - asynchrony. By the way, simple applications with Tornado are easy.
import tornado.ioloop import tornado.web class MainHandler(tornado.web.RequestHandler): def get(self): self.render('message.html', message='Hello world!') def make_app(): return tornado.web.Application([ (r"/hello", MainHandler), ]) if __name__ == "__main__": app = make_app() app.listen(8888) tornado.ioloop.IOLoop.current().start()
pip freeze lists: appdirs, packaging, pyparsing, six, tornado.
Official website | GitHub page | PyPI page
Falcon
Github stars: 4587
Github forks: 487
Falcon is a microframework for small applications, app backends and higher-level frameworks. It encourages to follow the REST concept, and thus, you should think of resources and state transitions mapped to HTTP methods when developing with Falcon. Falcon is one of the fastest web frameworks in Python. It's used by Cronitor, EMC, Hurricane Electric, OpenStack, Opera Software, Wargaming, Rackspace.
Falcon is not suitable for serving HTML pages at all. It is appropriate for RESTful APIs. Here is some code to response for a GET request with a JSON response.
import falcon import json class HelloResource: def on_get(self, request, response): """Handles GET requests""" data = {'message': 'Hello world!'} response.body = json.dumps(data) api = falcon.API() api.add_route('/hello', HelloResource())
As Falcon doesn't include a server, Waitress is suitable as one.
waitress-serve --port=8080 app:api
The response for is simple
{"message": "Hello world!"}
pip freeze contains: appdirs, falcon, packaging, pyparsing, python-mimeparse, six, waitress.
Official website | GitHub page | PyPI page
Hug
Github stars: 4793
Github forks: 252
One of the fastest web frameworks for Python. It's designed to build APIs. It supports providing of several API versions, automatic API documentation and annotation-powered validation. Also, hug is built on top of another JSON framework which is Falcon. Let's provide a JSON response via hug.
import hug @hug.get() @hug.local() def hello(): return {'message': 'Hello world!'}
Launched with the waitress by command "waitress-serve --port=8080 app:__hug_wsgi__"
pip freeze contains: appdirs, falcon, hug, packaging, pyparsing, python-mimeparse, requests, six, waitress.
Official website | GitHub page | PyPI page
Sanic
Github stars: 7462
Github forks: 406
A Flask-like web framework which is developed to be fast. It supports asynchronous request handlers, making your code non-blocking and speedy.
Code to response with
{'message': 'Hello world!'} JSON may be seen below.
from sanic import Sanic from sanic.response import json app = Sanic() @app.route("/hello") async def hello(request): return json({"message": "Hello world!"}) if __name__ == "__main__": app.run(host="0.0.0.0", port=8080)
pip freeze lists: aiofiles, appdirs, httptools, packaging, pyparsing, sanic, six, ujson, uvloop.
aiohttp
Github stars: 4184
Github forks: 733
Aiohttp is an asynchronous web framework which heavily utilizes Python 3.5+ async & await features. An example below shows only an obvious non-asynchronous functionality. aiohttp is not just a server web framework, but also the client one. It supports both WebSocket server and client. As it supports integration with Jinja2, the example uses this feature.
from aiohttp import web import aiohttp_jinja2 import jinja2 @aiohttp_jinja2.template('message.html') def hello(request): return {'message': 'Hello world!'} app = web.Application() aiohttp_jinja2.setup(app, loader=jinja2.FileSystemLoader('templates')) app.router.add_get('/hello', hello) web.run_app(app, port=8080)
pip freeze lists: aiohttp, aiohttp-jinja2, appdirs, async-timeout, cchardet, chardet, Jinja2, MarkupSafe, multidict, packaging, pyparsing, six, yarl.
Official website | GitHub page | PyPI page
Pyramid
Github stars: 2566
Github forks: 773
A framework for large applications. It aims to be flexible, unlike "everything-in-the-box" Django. For example, templating and database administration require external libraries. Pyramid web applications start from a single-file module and evolve into ambitious projects.
It took time to develop a single file application with Pyramid! Pyramid docs are cheating: if you want to response with a string, you have an example on their home page, but when you attempt to use templating... Docs are unclear, firstly because of unobvious proposed project structure. Pyramid_chameleon has been additionally installed to use Chameleon templating
(${} instead of Jinja's {{}}). Here is the code of the application.
from wsgiref.simple_server import make_server from pyramid.config import Configurator from pyramid.renderers import render_to_response def hello(request): return render_to_response('__main__:templates/message.pt', {'message':'Hello world!'}, request=request) if __name__ == '__main__': config = Configurator() config.include('pyramid_chameleon') config.add_route('hello', '/hello') config.add_view(hello, route_name='hello') app = config.make_wsgi_app() server = make_server('0.0.0.0', 6543, app) server.serve_forever()
pip freeze lists: appdirs, Chameleon, hupper, packaging, PasteDeploy, pyparsing, pyramid, pyramid-chameleon, repoze.lru, six, translationstring, venusian, WebOb, zope.deprecation, zope.interface.
Frameworks below are less popular. However, as they are still being developed, it's good to mention them.
Official website | GitHub page | PyPI page
Growler
Github stars: 692
Github forks: 27
Built atop asyncio, inspired by Connect and Express frameworks for Node.js. ORM, templating, etc. should be installed manually. Requests are handled by passing through a middleware chain.
CherryPy
Github stars: 557
Github forks: 151
Aims to be "a way between the programmer and the problem". A usual web application developed by means of CherryPy looks like an ordinary Python application, it works out of the box without a complicated setup and customization. Also, it supports different web servers like Apache, IIS, et cetera. CherryPy contains an embedded web-server, so your application may be deployed anywhere where Python is installed. CherryPy allows to launch multiple HTTP servers at once. Output compression, configurability of every part, flexible plugin system. CherryPy doesn't force you to use any certain template engine, ORM or JavaScript library, so you may use what you prefer.
Official website | GitHubPage | PyPI page
MorePath
Github stars: 340
Github forks: 35
A flexible model-driven web framework. Supports REST out-of-the-box. Its main concepts are reusability and extensibility.
Official website | GitHub page | PyPI page
TurboGears2
Github stars: 228
Github forks: 54
A MVC web framework.The Features include ORM with real multi-database support, support for horizontal data partitioning, widget system to simplify the development of AJAX apps. Template engine is Kajiki (must be additionally installed). You can develop with TurboGears as it's a microframework as well as it's a full-stack solution, installing additional components. Notice that TurboGears2's PyPI package is called tg.devtools.
Official website | GitHub page | PyPI page
Circuits
Github stars: 152
Github forks: 40
Circuits has similar features as CherryPy has. Unlike CherryPy, circuits are a highly efficient web framework for developing stand-alone multiprocess applications. It's event-driven, it supports concurrency, asynchronous I/O components. It's fully usable out-of-the-box.
Official website | GitHub page | PyPI page
Watson-framework
Github stars: 88
Github forks: 10
A component-based WSGI event-driven MVC web framework.
Pycnic
Github stars: 108
Github forks: 19
One of the fastest web frameworks for Python to develop JSON APIs.
Official website | GitHub page | PyPI page
WebCore
Github stars: 66
Github forks: 8
A light-weight full-stack framework. You can develop an application in a single file or structurize it as you wish.
Reahl
Github stars: 10
Github forks: 3
A web framework to develop web applications in pure Python. There are widgets which may be used, customized and composed in usual Python code. Those widgets describe a specific server-side and client-side behaviour.
Official pag | GitHub page | PyPI page
The following diagrams present the number of forks and stars on GitHub:
Summary
This concise overview leaves the best Python frameworks at your disposal. Try aiohttp or Tornado if you need asynchrony, when you develop something with continuous connections.
Try Django if you develop something rich.
Try Falcon, hug or Sanic if you develop JSON API.
Try Flask if you develop something simple.
Try Pyramid if you develop something rich, but extraordinary.
We can’t single out the best Python framework for web development since the choice of either framework depends on the specific needs of a project. Learn about the top 10 Python frameworks in 2018 and have different tools for different tasks in your toolbox. | https://steelkiwi.com/blog/best-python-web-frameworks-to-learn/ | CC-MAIN-2019-39 | refinedweb | 2,038 | 51.34 |
In this blog post, we’ll build a sample invoice in our React app using HTML and CSS, then generate a PDF file based on this content. Plus, we’ll control the generated page size exclusively through CSS.
Welcome to the Generating PDF in React blog post series! In Part 1 of this series, “Generating PDF in React: As Easy As 1-2-3,” we covered the basics around generating PDF in React by including a few basic HTML elements and seeing the quickest way we can generate a PDF file from HTML in React.
In today’s blog post, we will build further upon this by covering a very common scenario that the KendoReact team sees as a frequent request: how to export an HTML invoice to PDF. Beyond some fancier HTML and CSS, we are also going to see how to export SVG elements (via charts) and how even more advanced React components like DropDowns can be included in our generated PDF files.
Additionally, we will see how we can dynamically change the paper size of the generated PDF file just through CSS. As extra credit, we will also see how we can embed our own custom fonts in our PDF files to ensure proper Unicode support.
If You Like Video Tutorials
Everything I’m covering in the blog post today is also covered in the “Generating PDF in React: Part 2” video on YouTube, which is recreating this Kendo UI for jQuery demo in a React application. So, if you prefer a more visual medium, you can watch that here, or head on over to the KendoReact Video section, where you’ll find additional links.
How to Generate a PDF Document: Invoice Example
What we will be creating today is a sample layout of an invoice. If you’re not familiar with the terminology, it is essentially a document that highlights items purchased as a part of an order. While displaying these in our web apps makes a lot of sense, invoices are very often sent around in a PDF format when shared individuals who may not have access to said web app. This could include the company you are selling something to. So, generating a PDF from HTML to CSS becomes critical here.
The source code for everything we are doing here today, as well as the other parts of this series, can be found in this GitHub repo. Today’s blog post covers the code in the
LayoutSample component.
Let’s go ahead and copy in our HTML and CSS that we can use as a base to build upon. You can get a project up and running with
create-react-app, and then within your
App.js you can copy in the JSX section of the JS file, and you can copy the CSS in to
App.css and be off to the races.
For the sake of simplicity and to make it as easy as possible to share with everyone, here’s a StackBlitz project that shows off the HTML and JavaScript through
App.js and the CSS in
style.css. Since this can be a bit long, it’s just easier for you to fork this project, or copy and paste from each of the appropriate files.
Once you have this up and running, you can continue with the rest of the blog post. There are some details in the above markup that we will add to and cover in more detail, so don’t worry too much about what the CSS classes and HTML markup might be.
Now that we have this set, let’s continue by adding in some extra data visualizations in our React app.
Making Our Invoice Pop: Adding Data Visualization
In an attempt to make this invoice as fancy as possible, I want to add in some data visualization to make the end-result really pop. This lets me kill two birds with one stone. First, I get to add something that is visually pleasing to the example. And, second, I get to show off how to generate PDF files from HTML that include SVG elements.
Since we have been all about making things easy for us in these projects, I’ll lean on the KendoReact Charts library, as it lets me set up a chart with just a couple of lines of code instead of hand-coding SVG elements myself. Specifically, I want to add in a React Donut Chart in the invoice I’m setting up for PDF generation.
Looking at the KendoReact Chart Component Getting Started page, we can copy and paste the following command into our console and install the appropriate packages:
npm install --save @progress/kendo-react-charts @progress/kendo-drawing @progress/kendo-react-intl hammerjs @progress/kendo-licensing
We also have to install one of the KendoReact themes, which in this case will be the Material Theme. This can be done with the following
npm install:
npm install --save @progress/kendo-theme-material
And then we import the CSS file associated with the theme:
import "@progress/kendo-theme-material/dist/all.css";
Once this installation and setup is done, we have to import the proper pieces in to our React component:
import { Chart, ChartLegend, ChartSeries, ChartSeriesItem, ChartSeriesLabels, ChartCategoryAxis, ChartCategoryAxisItem } from "@progress/kendo-react-charts"; import "hammerjs"; import "@progress/kendo-theme-material/dist/all.css";
As a part of any chart, we need to have some sort of data as well, so let’s add this array somewhere in our application. In my case, I created
invoice-data.json and imported this file into my component, but feel free to add this wherever it feels natural for you.
[ { "product": "Chicken", "share": 0.175 }, { "product": "Pork", "share": 0.238 }, { "product": "Turkey", "share": 0.118 }, { "product": "Kobe Beef", "share": 0.052 }, { "product": "Pickled Herring", "share": 0.225 }, { "product": "Bison", "share": 0.192 } ]
This is also how imported the data into my component:
import sampleData from "./invoice-data.json";
Now, to add this in my project, I’m going to scan for the div with a
className="pdf-chart" prop set on it. From there, I will follow the KendoReact documentation to define my Donut Chart:
<div className="pdf-chart"> <Chart style={{ height: 280 }}> <ChartSeries> <ChartSeriesItem type="donut" data={sampleData} <ChartSeriesLabels color="#fff" background="none" /> </ChartSeriesItem> </ChartSeries> </Chart> </div>
The React donut chart is pretty flexible, but even so the markup can start feeling intuitive quickly. First off, we define a
<ChartSeriesItem> to define a single Donut chart (the KendoReact Data Visualization package can support multiple series at once) where we wire up our data in the
data prop, and set our two fields in
categoryField and
field to the two fields found in our sample data. The
<ChartSeriesLabel> item is just there to let us display labels in the donut chart—which will just be white text in our case.
To have a quick look at the current state of our project, here’s the full thing running in StackBlitz:
Next, we will cover how we can use CSS classes and a DropDown to control the paper size of our invoice and ultimately the PDF file we are generating.
Dynamic Paper Size via CSS
Let’s take some time and inspect the CSS we pasted at the beginning of this article or in one of the StackBlitz projects. Specifically this section right here:
.size-a4 { width: 6.2in; height: 8.7in; } .size-letter { width: 6.3in; height: 8.2in; } .size-executive { width: 5.4in; height: 7.8in; font-size: 12px; } .size-executive .pdf-header { margin-bottom: .1in; }
From this we can see that we have three different page sizes that we can operate within: A4, Letter and Executive. Normally when we generate a PDF in React we have to rely on the KendoReact PDF Generator’s paperSize prop to define our desired paper size. However, if we know the measurements for the desired output, we can actually customize this 100% through CSS!
In our invoice, this is the element that we need to adjust and set a new CSS class when we want to update the size of the invoice:
<div className="pdf-page size-a4">
For this application, we have a requirement from our users that they want to be able to customize what type of paper that the PDF should be generated to, so let’s give our users a DropDown that can select from the available sizes and change the paper size on the fly.
Whenever we have a finite list of available options that we want users to select from (without having the ability to enter custom text), a
select element is usually a great way to go. However, since we already have KendoReact included in our project, we may as well go for a fancier version of this element and upgrade to the React DropDownList. To get this added in our application, we need to install the package using the following npm install command, found on the React DropDown’s package overview page:
npm install --save @progress/kendo-react-dropdowns @progress/kendo-react-intl @progress/kendo-licensing
Once we have that installed, we can import the DropDownList in our React component:
import { DropDownList } from "@progress/kendo-react-dropdowns";
Now, we need to define the list of available options to bind to our React DropDownList. Here’s the variable we can use:
const ddData = [ { text: "A4", value: "size-a4" }, { text: "Letter", value: "size-letter" }, { text: "Executive", value: "size-executive" } ];
As you can see, we use the
text field to give us an easy-to-read string that we can present to the user, while the
value field for each item uses the CSS class name that we want to set for each option.
Something else that we need to set is some sort of state in our component that can keep track of the current value of the selected item—this is a React component, after all! So, we can do this by importing
useState from React and use it to define a variable. First, we do the proper import:
import { useRef, useState, useEffect } from 'react';
Then in our component we can set up the following:
const [layoutSelection, setLayoutSelection] = useState({ text: "A4", value: "size-a4"});
For those of you who haven’t used React Hooks yet, this may seem a bit confusing, but the
layoutSelection portion is the variable we can access in our app, and
setLayoutSelection can be called when we want to update our state. Additionally, so that we have a default item selected when our application loads, we set an initial state to be equal to that of our first option in our DropDownList, which is the A4 size.
Once we’ve done all of this, we can add the following code into the top of the application by finding the first
<div class="box-col"> element at the top of our HTML:
<div className="box-col"> <h4>Select a Page Size</h4> <DropDownList data={ddData} textField="text" dataItemKey="value" value={layoutSelection} onChange={updatePageLayout} > </DropDownList> </div>
As you can see, we pass in our
ddData variable to the DropDownList, then define the
textField to represent what the user will see and the
dataItemKey to be the underlying value. We set the initial value to our
layoutSelection variable, and finally we use the
onChange event to call a function which we will use to update our state. Since we haven’t defined that yet, let’s go ahead and do so:
const updatePageLayout = (event) => { setLayoutSelection(event.target.value); }
The last piece of the puzzle is to also update the CSS of the aforementioned div element that lets us control the dimensions of our invoice. Specifically, this element:
<div className="pdf-page size-a4">
In order to update the
className every time the state of
layoutSelection changes, we can set the className prop to be equal to a string literal which grabs the current value of
layoutSelection with the following:
<div className={ `pdf-page ${ layoutSelection.value }` }>
Now every time our state is updated, this part of our code will also update to be one of the following strings:
- pdf-page size-a4
- pdf-page size-letter
- pdf-page size-executive
Once we have compiled things and our app is up and running, you can select a value from the React DropDownList and see how the layout of the invoice changes with every choice!
Here’s an up-to-date StackBlitz project showcasing our progress so far.
The stage is set, so let’s move on to the last step in our journey and allow users to generate a PDF with varying sizes depending on the choice that our user has made!
Time to Generate our PDF from HTML
Now that we have the overall invoice HTML and CSS squared away, along with a DropDown that users can interact with to change the layout of the invoice, let’s add PDF generation to our React app!
To do this, I’ll need the KendoReact PDF Generation package, which we also used in Part 1 of this blog post series, and I’ll also toss in the KendoReact Button to give us a pretty button to press in order to generate a PDF file from the HTML of our React app.
To get started on this step, I’ll just go ahead and run the following npm install:
npm install --save @progress/kendo-react-pdf @progress/kendo-drawing @progress/kendo-react-buttons @progress/kendo-licensing
And then import both components by adding this at the top of my React component:
import { Button } from '@progress/kendo-react-buttons'; import { PDFExport, savePDF } from '@progress/kendo-react-pdf';
First things first, I’m going to take the easiest approach to exporting to PDF by just wrapping my desired content with a
<PDFExport> component. Yup, it’s really that simple! In this case, I need to wrap around the div element that we just used to dynamically update the page size, which should leave me with the following:
<div className="page-container hidden-on-narrow"> <PDFExport ref={pdfExportComponent}> <div className={ `pdf-page ${ layoutSelection.value }` }> ... </div> </PDFExport> ... </div>
We use the
ref prop above in order to let us quickly reference this element when we need to kick off our generation. Thanks to our previous import of
useRef from React, we can just add the following line of code to our component:
const pdfExportComponent = useRef(null);
Then we can go ahead and add our React Button somewhere on the page. In this case, I think it makes sense to add it under the DropDownList and give it an appropriate header, so let’s tweak the top of the page to look like this:
<div className="box wide hidden-on-narrow"> <div class="box-col"> <h4>Select a Page Size</h4> <DropDownList data={ddData} <h4>Export PDF</h4> <Button primary={true} onClick={handleExportWithComponent}>Export</Button> </div> </div>
I included the React DropDownList code as well to give you a reference, but the biggest piece to look at here is the
<Button> and its
onClick event toward the bottom of the markup.
Since we have wrapped around the appropriate elements with
<PDFExport>, the event handler we defined here is what does all the magic to generate a PDF file:
const handleExportWithComponent =(event) => { pdfExportComponent.current.save(); }
In the button’s
onClick event we find our
PDFExport component via the reference that we defined earlier and then use the
.save() function to take our HTML and generate a PDF file representing our content.
Here is the current version of the project in StackBlitz so you can see everything in a single project:
That’s all you need to do! Thanks to the KendoReact PDF Generator package, all we really have to do is identify our parent element for export, which can be anywhere in our markup as you just noticed, and wrap it with
<PDFExport> tags, and the React PDF Generator library takes care of all of the rest for us. Even the SVG element of the React donut chart is included without any additional code from our side.
One thing you may have noticed as you generate the PDF file and observe the end result in all its glory—and this is part of the extra credit—is that certain special characters (any letters with decoration in this example) may come out looking pretty odd. This is because, as a default, the KendoReact PDF Generator library relies on standard PDF fonts, which only support ASCII characters. This, however, is a problem we can work around by adding in our own fonts that support Unicode characters! Let’s do this now.
Rendering Special Characters in PDF
As the KendoReact embedded fonts in PDF files article mentions, we have to embed appropriate fonts in order to be able to handle characters that are not ASCII characters and instead require Unicode support to render.
A note to make here is that you need to ensure that you have the legal right to use the font that you are looking to embed. There are plenty of fonts with licensing that permits you to use them freely, but keep an eye out to ensure you’re not accidentally doing something you’re not supposed to do.
In our case, I’m going to import DejaVu Sans. My approach is to use the font found on the KendoReact CDN, but in your case you should either reference your own CDN or host the font files within your project.
When following the KendoReact PDF generator embedded fonts article, you’ll see that in order to take advantage of this font we need to use
@font-face within our CSS. We also need to find the
.pdf-page class and update this to use our new font in the
font-family CSS property.
Here’s the CSS that we can add to our component’s CSS file:
.pdf-page { position: relative; margin: 0 auto; padding: .4in .3in; color: #333; background-color: #fff; box-shadow: 0 5px 10px 0 rgba(0,0,0,.3); box-sizing: border-box; font-family: "DejaVu Sans", "Arial", sans-serif; } @font-face { font-family: "DejaVu Sans"; src: url("") format("truetype"); } @font-face { font-family: "DejaVu Sans"; font-weight: bold; src: url("") format("truetype"); } @font-face { font-family: "DejaVu Sans"; font-style: italic; src: url("") format("truetype"); } @font-face { font-family: "DejaVu Sans"; font-weight: bold; font-style: italic; src: url("") format("truetype"); }
With that added, we now have a font that supports Unicode characters. If we go ahead and generate a new PDF file, we see that all of our original characters are included, and the generated PDF file looks that much cleaner.
Here’s the final StackBlitz project in all its glory:
Go Forth and Generate PDFs!
This article was a little bit on the longer side, but as a quick recap we did the following:
- We created an invoice with a custom layout (a common requirement for generating PDF files).
- We added a SVG element to our content to make it extra fancy.
- We created a selector that allows users to change the paper size between A4, Letter and Executive through a DropDownList.
- We added support for Unicode characters by embedding a custom font.
- We generated a PDF file from all of our HTML and CSS by using a single React component and one line of code.
That’s quite the journey right there! Between “Generating PDF in React: As Easy As 1-2-3” and this blog post, I hope that you see just how flexible and powerful the KendoReact PDF Generator library can be. With a single line of code, you can also start generating PDF files in your React apps! | https://www.tefter.io/bookmarks/652527/readable | CC-MAIN-2021-43 | refinedweb | 3,282 | 54.15 |
Re: [soaplite] Re: non-qualified method calls in XMLRPC::Lite server?
Expand Messages
> namespace; all methods are mapped into one package. How can I getYou should be able to do that using dispatch_with method:
> the clients to use 'method' instead of 'Package.method'?
my $daemon = XMLRPC::Transport::HTTP::Daemon
-> dispatch_to('Foo')
-> dispatch_with({undef, 'Foo'})
# redirect all calls from package 'main' to package 'Foo'
;
You can also use ->dispatch_with({Bar => 'Foo'}) to do the same trick
for other packages.
Best wishes, Paul.
P.S. If that doesn't work for some reason, you should be able to do
that using on_dispatch method:
my $daemon = XMLRPC::Transport::HTTP::Daemon
-> dispatch_to('MyPackage')
-> on_dispatch(sub{return MyPackage => shift->method})
;
This code will resolve 'foo' as 'MyPackage::foo'. A little bit more
logic will allow to map any other package too:
-> on_dispatch(sub{
my $method = shift->method;
$method = s/.*\.//; # remove package name
return MyPackage => $method;
})
--- "askbjoernhansen <ask@...>" <ask@...>
wrote:
> --- In soaplite@yahoogroups.com, "al_shenkin" <ashenkin@q...>__________________________________________________
> wrote:
> > Hi Folks,
> > I've been asked by a client to implement an xmlrpc call on my
> server:
> >
> > <methodName>ourMethod</methodName>
> >
> > However, for obvious reasons, i can't just have "methodName"
> sitting
> available in the main namespace.
> >
> > I'm running apache, and have been using XMLRPC::Lite servers via
> a
> perl-script handler.
> >
> > Is there an easy way to implement this method without having the
> client rewrite their calls? I'd rather not ask the client to
> rewrite
> their calls to something like:
> >
>
> I don't see a reply to this in the archives. I am interested in
> the
> same thing. In my system the proxy is already specifying the
> internal
> namespace; all methods are mapped into one package. How can I get
> the
> clients to use 'method' instead of 'Package.method'?
>
>
> - ask
>
> --
>
>
>
> ------------------------. | https://groups.yahoo.com/neo/groups/soaplite/conversations/topics/2228?o=1&d=-1 | CC-MAIN-2015-11 | refinedweb | 295 | 64.41 |
Can you actually use the command-line arguements to call files?
The tutorial I'm reading is showing me code on how to use int main() but it isn't actually showing me how to open any files... I'm not sure if it's referencing files within the program or text files outside of the original source file.
This is the small bit of code he wrote with the comments:
} }
and then is the code I wrote, minus comments, plus cin.get(); so I can actually see the fruits of my labor before it closes.
#include <fstream> #include <iostream> using namespace std; int main ( int argc, char *argv[] ) { if ( argc != 2 ) cout<<"usage: " << argv[0] << " <filename>\n"; else { ifstream the_file ( argv[1] ); if ( !the_file.is_open() ) cout<<"Could not open file\n"; else { char x; while (the_file.get( x ) ) cout<< x; } } cin.get(); }
Is there some concepts that I missed? Because this is the second time file opening was reference and I wasn't actually able to open a file.
EDIT: Oops, i still had a mistake in the code here: cing.get should've been cin.get. I had already fixed that issue before, not sure how the g got back but at any rate, the code runs the same as I mentioned.
Edited by Savalric, 22 December 2012 - 02:52 PM. | https://www.gamedev.net/topic/636205-calling-files/ | CC-MAIN-2017-04 | refinedweb | 223 | 83.15 |
"Simon Peyton-Jones" <simonpj at microsoft.com> writes: > XML Schemas are extensible to future additions > XML Schemas are richer and more useful than DTDs > XML Schemas are written in XML > XML Schemas support data types > XML Schemas support namespaces Like XML in general, they also tend to be verbose and noisy, and difficult to read for a human. So if you want my opinion, I don't like them much, but then I don't like many of the directions XML is moving anyway. I'll accept it as a lost battle, and move on. :-) -kzm -- If I haven't seen further, it is by standing in the footprints of giants | http://www.haskell.org/pipermail/libraries/2003-October/001477.html | CC-MAIN-2014-41 | refinedweb | 111 | 67.08 |
I am an rather inexperienced junior-developer, working for a startup in germany. I am currently refactoring a highly scattered code base, trying to optimize the design a bit ...
Problem
When implementing the data access layer, we can choose to follow the principles of the DAO pattern. This works well as long as the entities we deal with are rather specific (eg. User, Invoice, Account, etc.). But when we have a more generic database model we may frequently feel the need to query for specific result sets that are compositions of several tables. Often it is not obvious which data access object we should assign query methods to.
Example
Take the OSM (openstreetmap.org) database: Effectively there are just Nodes, Ways and Relations that make up representations of many different objects (such as streets, buildings, traffic signs etc.). When querying for an amenity it may be represented by a single Node (a single point, e.g. a memorial), a Way (a path, lets say the outlines of museum) or collection of Ways (e.g. the buildings of a university campus).
Besides that I may only be interested in a fraction of the information available, and it might be overhead to fetch full entities. Or I may use database specific functions in my queries, which lead to results that abstract even further from the underlying entity model.
I give you an example in code (in java, using the spring-frameworks repository interface):
public class IWayRepository extends Repository<Way, Long> { ... @Query(value = "select distinct ways.tags->'addr:interpolation' as type," + "trim(both '{}' from text(ways.nodes)) as nodes from nodes, way_nodes, ways " + "where nodes.tags->'addr:street'=? and way_nodes.node_id=nodes.id " + "and ways.id=way_nodes.way_id " + "and st_intersects(st_geometryfromtext(?,4326),nodes.geom)" + "and exist(ways.tags,'addr:interpolation')=true", nativeQuery = true) List<Map<String, Object>> findAdressInterpolationInfoForStreetInBbox(String street, String bbox); ... }
The code queries over several tables, alters data with a function on the database-layer and returns an extract of data that hardly fits into the domain of the given entity.
Idea
To improve the design there are coming two options coming to my mind for now.
- Make up a more specific data access class: The AddressRepository, where I access bare result sets. But I dont really like that idea.
- Make up a more generic Service class: A LocalizationService for example.
Question
Are there any established practises to deal with such situations? How do I design the data access to generic database-models. Are there patterns that one should follow?
Thank you in advance! | http://www.howtobuildsoftware.com/index.php/how-do/ci5B/java-spring-architecture-software-engineering-dao-designing-the-data-access-layer-for-generic-database-models | CC-MAIN-2018-51 | refinedweb | 423 | 50.33 |
Odoo Help
Odoo is the world's easiest all-in-one management software. It includes hundreds of business apps:
CRM | e-Commerce | Accounting | Inventory | PoS | Project management | MRP | etc.
Web service API call
I have a method in a model with this signature:
@api.model
def do_stuff(self, arg1):
...
The method expects a singleton therefore I must pass an ID when calling it. How can I pass the object ID when in the web service calls?
About This Community
Odoo Training Center
Access to our E-learning platform and experience all Odoo Apps through learning videos, exercises and Quizz.Test it now | https://www.odoo.com/forum/help-1/question/web-service-api-call-101831 | CC-MAIN-2017-39 | refinedweb | 102 | 67.96 |
Definition of a paratereized ray. More...
#include <ray.h>
List of all members.
This ray is designed to be absolutely minimal. The purpose is so that the jBBox class can support intersection with a ray. For ray tracing libraries that use jBBox it would be useful to subclass jRay for a more full featured ray class.
Build a default ray whose origin is the world-space origin and whose direction is the negative z-axis.
Build a ray with the given origin and direction.
Return the origin of the ray.
Return the direction of the ray.
Set the origin of the ray.
Set the direction of the ray.
Returns the position in ray space for the given parameter, ie. o + d*t.
Returns the transformed ray.
[protected]
[protected] | http://pages.cpsc.ucalgary.ca/~jungle/software/jspdoc/jgl/class_jray.html | crawl-003 | refinedweb | 128 | 70.29 |
Hi Folks
I am copying files from Project1 to Project2. Some of those files are
modified in Project2 and then copied back to Project1. When I copy the files
back Project1 should now reflect the state of Project2 exactly.
Would the ant copy task copy back only those files that were changed in
Project 2 ?
And the tricky situation is, suppose I had files A,B,C in Project1 and were
copies to Project2. In Project2 I deleted the file C but added a new file D.
Now when I copy back, Ant would copy the new file D to Project1 and other
files that were modified but I need the file C that was deleted in Project2
to be deleted in Project1 also after the processing back in completed.
Project1 should be exactly the same as Project2 after the reverse copying.
Please guide.
Vik
-----Original Message-----
From: Jack Woehr [mailto:jax@purematrix.com]
Sent: Thursday, August 14, 2003 11:51 AM
To: Ant Users List
Subject: Re: Problem with new ant task
Aloizio Pereira da Silva wrote:
> > You have misspelled "diretorioSaida" either in your custom task source
> > or bel$
> >
> No, I have not.
> Below is my java task code:
> public class gerar_relatorio extends Task{
>
> private String diretorioSaida = "";
>
Then it appears you misspelled the attribute in your build.xml file, to
judge from the error message:
> > > file:M:/Aloizio/JAVADOC/NewAntTask/build.xml:24: The <gerar_relatorio>
> > > task doesn't support the "diretoriosaida" attribute.
.........................................^.............................
--
---------------------------------------------------------------------
To unsubscribe, e-mail: user-unsubscribe@ant.apache.org
For additional commands, e-mail: user-help@ant.apache.org | http://mail-archives.apache.org/mod_mbox/ant-user/200308.mbox/%3C8765557836794E4EADF7F31290F4C39F02AB3165@ns.suz.com%3E | CC-MAIN-2015-48 | refinedweb | 262 | 63.9 |
White House Website Switches To Open Source 219.'"
High profile target and popular CMS' (Score:4, Insightful)
I'm not sure how Drupal fares with bugs and patching speed (I know Wordpress seems to get some high profile holes discovered) but even if all vulns are patched before someone takes advantage of it, you're still going to need an admin who's going to be constantly alert to patching it.
I'm not arguing against closed source vs open, more about popular vs obscure.
Re: (Score:3, Insightful)
You could just as easily turn that argument around and say that because it's a popular CMS and has a lot of people looking through it's code for exploits, it's also a lot more secure than some other more obscure CMS which would have much less reviewed code.
Re:High profile target and popular CMS' (Score:5, Insightful)
Re: (Score:2)
[Not really, I'm just trying to be mildly humorous].
Re: (Score:2)
Re:High profile target and popular CMS' (Score:4, Insightful)
because it's a popular CMS and has a lot of people looking through it's code for exploits, it's also a lot more secure
As pointed out, Wordpress easily proves this long-believed mantra false. It's one of the mostly widely used blogging applications and it is consistently in the news for high-profile hacks and exploits. That, and Drupal hardly seems immune [google.com].
What's even more interesting is the possibility for intentional security flaws in the code. Interested parties can start submitting patches and changes to the Drupal codebase with inherent flaws. These might even be distributed (module A has a flaw that uses module B's flaw that uses module C's flaw...), which combined with submissions over a series of weeks or months and it seems unlikely they'll be easily spotted.
This is the real downside to using open source code in government applications -- In four months the White House website may be running code written by Chineses (or Russian or whoever) hackers (who may or may not be government employees) for the sole purpose of exploiting the site. Expand this into internally used applications like MediaWiki, Pidgin and it has even bigger implications for intelligence gathering and infiltration.
Major programs like these are big and complex. If the Debian OpenSSH fiasco taught us anything it should be that when you combine big and complex, don't be surprised if those many average eyes are insufficient to catch what the few skilled and experience hands put in the codebase.
Re: (Score:3, Insightful)
(okay, it's not that simple, but it's still a nice option to have)
Re: (Score:3, Insightful)
Perhaps you would also like to talk about all that closed source proprietary code that government espionage agencies all over the world have access to. In fact most governments are now refusing to you closed source proprietary code unless they have access to the code to scan for back doors not only put in by corporations for then own advantage but put in by governments via secret warrants and not disclosed for national security reasons.
The biggest difference between closed source and open source in gover
Re:High profile target and popular CMS' (Score:5, Interesting)
Re: (Score:3, Funny)
You're assuming an unusually high level of competence in government IT departments.
Re:High profile target and popular CMS' (Score:4, Insightful)
They picked Drupal, not Joomla or Wordpress
Re: (Score:3, Interesting)
...with the actual Drupal server locked down and disconnected from the internet.
How does the caching server get the original cache? Do you connect the actual server at some point, clear the cache, and let it answer requests, or do you push a cache?
Re:High profile target and popular CMS' (Score:5, Informative)
I run a fairly high profile drupal site - and this has always been a large concern for us.
Our solution was basically to disable user logins completely. An overwhelming number of the exploits require you to login, so by removing this prerequisite, we basically avoided the problem.
Security isn't exactly a priority for drupal either, it's almost added as an afterthought. To put things in perspective, their login page doesn't even support SSL by default in either drupal 5 or drupal 6. To me that's verging on pathetic.
We were lucky because user logins weren't a core part of our site concept when we implemented the site, but I am now thinking that it might be a good way to go in the future, but I'm mostly petrified of this problem.
On the bright side of things they include a large number of extensions, and things mostly work as advertised, so we found this to be our best option out of all the open source CMSes we tried.
Re:High profile target and popular CMS' (Score:4, Funny)
Security isn't exactly a priority for drupal either, it's almost added as an afterthought.
not any more!!
Re:High profile target and popular CMS' (Score:5, Informative)
Security is most certainly not an afterthought for Drupal.
Up though version 6 you needed to turn on a module like Securepages module to enable SSL logins.
The upcoming Drupal 7 has SSL login support in core.
See [crackingdrupal.com]
Incorrect on almost all points (Score:4, Informative)
It would appear that your experience doesn't stretch terribly far; off the top of my head I can name several much less secure systems. Finding, fixing and announcing vulnerabilities is a good thing: by your measure a hugely exploited CMS with no fixes would be better!
Regarding you assertion that the rewrite engine cannot be disabled; this is just plain wrong. The Apache rewrite engine can be disabled without any problem. If you do this, then you won't enjoy clean URLs, instead you'll have URLs like instead of. Internally Drupal always works with the first form. However, the rewrite engine is a widely used Apache module - with perhaps millions(?) of sites using it. It may very well have exploits - just as any software may - but it is trusted by lots of users.
Followsymlinks can be disabled too. It's required for rewriting and for one form of upload. Drupal works without problems without it. However, there's nothing inherently insecure in symlinks, and the default Drupal directory layout does not symlink to outside of the install tree.
Database load. I note that your assertion about load is without any reference to figures. I'm not certain which CMS you think is well written. However I'll note that there is a general problem with CMSs which are designed to be easily extensible: tightly integrated system usually use a single SQL statement to retrieve data - the designer knows all the constraints at design-time. A loosely coupled system is usually not able to do this: the designer has little idea of what will be present at run time. So it's in the nature of most loosely coupled system to run one query or more for each additional module. Drupal uses a loosely coupled callback orientated architecture. This means its very easy to extend. However the downside is that each module will usually include extra tables. Drupal is fairly smart about loading this extra data, but beyond that, to counteract the tendency for growth in queries, Drupal has a caching subsystem that is active in several layers. For anonymous users, Drupal only runs a few queries which determine where in the cache the data sits, and returns it.
Perhaps you'd like to elaborate with some firm figures and an example of a CMS that in your opinion does it right.
Regarding PHP security. Again - have you any firm facts to show that PHP is inherently less secure than any other language? The consensus in security circles is that openness is better for security. *You* are able to download the PHP source code and contribute patches. If you know of a security issue, I'd urge you to help fix it. Or is this opinion without facts to back it up?
Again, I'd be interested to know which CMS you do recommend to the person in the street. I would not at the moment recommend Drupal for most brochureware sites, though it is capable of brochureware, however for sites in excess of about 100 pages, for sites where there is a heavy community aspect, and for sites which hope to change and grow, Drupal is an excellent choice.
Re: (Score:2)
Re:High profile target and popular CMS' (Score:4, Insightful)
Re:High profile target and popular CMS' (Score:5, Insightful)
I'd argue it's the exact opposite: by choosing a popular, mature CMS, they're insuring a LOT of the vulnerabilities have been found, exploited and fixed. The major difference between the White House site and Joe Web Dev's site is that the former will probably only upgrade for security fixes and will be very careful with new features, since that's where the bugs and exploits can hide. With good sysadmins, proper security tools and good practices, the site can be very safe. I just don't see them using alpha versions of modules and such.
On the flip side, I'm hopeful that WhiteHouse.org's programmers and sysadmins will also contribute to the codebase with fixes and improvements of their own. This could end up being very beneficial for the Drupal community.
Re: (Score:3, Funny)
Actually, it's for the Obama administration. I'll let it slide though; as long as you don't confuse it with whitehouse.com - not linkified for a very special reason....
Re: (Score:2)
With a web based CMS you are constantly exposed and exploits can implemented and run in minutes (mod security only provides limited protection). You don't need to infect a webserver to do damage, you just need to be able run an sql query or upload a file with code.
There will always be a timelag between an exploit be
Re: (Score:2)
> I'm not arguing against closed source vs open, more about popular vs obscure.
Whatever they use is going to be a high-profile target just because they are using it. Security by obscurity doesn't work for such sites.
Re: (Score:3, Informative).
Re: (Score:3, Insightful)
You're certainly right the Drupal has a lot of visibility. On the other hand, is it the end of the world if Whitehouse.gov gets exploited? If we can assume that the site is reasonably managed, and does not have a direct pipeline from the front end web server into the CIA's servers, then the likely worst result would seem to be that misinformation would be published. This isnt' good, but it would probably get detected fairly quickly by partisans. We're not talking missle launch systems here.
If Drupal hel
Re:High profile target and popular CMS' (Score:5, Informative)
I think you are misinformed. Morpheus seemed to be targeted at a range of software, including Joomla, but not Drupal: as far as I can see, none of the URL's it scanned are Drupal-based. See [kulando.de] for example, but there are others out there.
In fact, Drupal has an excellent history of security. We find holes, fix them and issue patches. There is a security mailing list that anyone can sign up to. You will receive mail on the latest security fixes. Your Drupal installation will tell you when components are out of date, and when there are security updates. It will also email you on a regular basis if you don't care to look at your status, or ignore the status message at the top of the page when you log in as an administrator. Drupal will not download and install components without human intervention: components require manual installation.
Just like any software, I'm certain that Drupal has as yet undiscovered exploits. What's important is whether they are found and fixed, and we have a good track record of doing this.
Re:High profile target and popular CMS' (Score:4, Funny)
If your security beliefs are based on Googling " exploit" I hope you're not in charge of anything important.
Re: (Score:2, Informative)
Drupal really has not been known for its security in the past;
On the contrary. Drupal was one of the big open source projects to have a dedicated security team performing code audits and going through a security release process.
Drupal automatically checks for security updates (both in the core and in contributed modules) and can notify you immediately of updates. If, you know, you think that kind of thing is important.
Re:High profile target and popular CMS' (Score:5, Funny)
You're right. Block port 80, that'll stop 'em.
Re: (Score:3, Insightful)
Proper firewalls do more than simply block ports.
Clearly (Score:3, Interesting)
Huh. Now to me, this is a clear sign that they hired a new web guy who happens to have experience with and a preference for Drupal. I don't think there's a necessarily a political statement here.
Re:Clearly (Score:5, Insightful)
Re:Clearly (Score:4, Insightful)
The top of the government and especially the president are HR people first and foremost. They don't do much personally, but act through the agents they select, rely on their judgement and trust them to condense issues of importance for them. Sure, they also get to make some decisions, but they decide based on the information fed to them and the decisions are broad, policy decisions in most cases.
The point is, they didn't make a policy decision that "zomg, F/OSS ftw!", but they hired the guy who hired the guy who hired the guy who hired the web guy and the web guy seems competent enough to pick a F/OSS solution.
Re: (Score:2)
Sure, that's the way it works in theory. But how do you really know that a PHB looking to leverage some synergies didn't hand down this decision from on high? It's not like the private sector has a monopoly on incompetent management. (Yes, I know this applies equally well and probably moreso to "zomg $PROPRIETARY_SYSTEM ftw!" and even more likely to "zomg $SYSTEM_OWNED_BY_COMPANY_I_OWN_SHARES_IN ftw!")
PHP based? (Score:2, Funny)
I wish they used something Python based:
def askPresidentQuestion(q):
if president == "Bush":
misSpeak()
elif president == "Obama":
pass
Just wondering... (Score:2)
There's more to it than your personal preferences (Score:5, Insightful)
If some of the people who post here were as smart as they think they are, they'd figure out:
* Whitehouse.gov is not running Drupal on a ten-dollar shared server at GoDaddy.com.
* Building and maintaining a large, continuously updated website is not something you do in a weekend with Notepad, a giant bag of Cheetos, and a case of diet Coke.
* Any Drupal project of this scale involves layers of extremely high-performance caching and multiple firewalls.
* The site's administrative tools aren't available from the outside. (This is not difficult to implement.)
* Life does not begin and end with your personal favorite programming language, database server, etc., or with the boundaries of your parents' basement.
* Security reports are reports of vulnerabilities that have been fixed, not vulnerabilities that lie in wait to ambush your site. A properly run open-source project has a documented process [drupal.org] for handling security issues.."
Re: (Score:2)
You must be new here!
Re: (Score:3, Informative)."
I don't know where you came up with Varnish . . . there are lots of ways to get performance that's just as snappy. A CDN is a good start. And it's pretty easy to tell that that's exactly what's being used here:
$ dig +short.
e2561.g.akamaiedge.net.
96.16.18.135
They're using Akamai for most of their content, it seems. I get 35ms ping to from machines in New York, Denver, Holland, and Washington (the state). My Washington machine get
Re: (Score:3, Funny)
I work for the government, and uh, bullshit.
Open Source Education IT (Score:2, Interesting)
Re: (Score:2)
If you want to see a large part of the reason that this happens, look no farther than places like this: [oetc.org]
Seriously, at $2.30 per CAL for Exchange...
What was te old CMS (Score:2)
Hardly (Score:2).'"
Or, more likely, the PHB in charge is running with Drupal because it's popular and CMS's are
Awesome! (Score:2)
This is Awesome, now all the Drupal vulnerabilities will be highlighted on a daily basis!
I like Drupal, but security isn't really their strong point, nor is proper testing of their modules.
Oh well.
okay, so you guys don't like Drupal's security... (Score:2)
Do any of you have a recommendation on what to use instead? Preferably PHP-based, so it has a realistic shot of being supported on most hosting plans?
Re:okay, so you guys don't like Drupal's security. (Score:5, Insightful)
Actually most people have been praising Drupal for its excellent security. You aren't going to find a CMS with a much better track record than Drupal.
What they were mainly saying is that Drupal is extremely popular with lots of people looking to exploit it, so it might theoretically be a high risk. A less well known CMS would not have many people looking (well, that would definitely change overnight if whitehouse.gov chose it
:) and is therfore a lower risk, but also has tons of exploits not found yet.
Stick with Drupal if you want a tested, secure, and reliable CMS.
You know, a lot of people here are very silly. (Score:4, Insightful)
Yes, whitehouse.gov is a very attacked site, for all sorts of reasons, and I bet it will be the very first place to try out any new Drupal vulnerability, and at least one of those will succeed sometime in the next couple of years.
But, um...who cares if it does? It's not a mission critical web site. It's stupid fluff pieces about the president and his initiatives. If something goes wrong it gets flipped offline, restored from backup, patched, and brought back online.
It's interesting to see the government try OSS, and that might be an interesting discussion, but way too many people(1) here instantly leapt to the non-existence security implications, acting like important government computers were going to be exposed via any security issues in Drupal.
1) And half the remaining people appear to be morons talking about how CMS are useless. They haven't realized that stating 'people don't need CMSes' doesn't, like they think, show that they're some elite HTML coder, it just reveals them as someone who's never been hired to make a web site for someone else who then can add and remove content.
Re: (Score:2, Insightful)
Are you a troll, naive or stupid?
A CMS is required if you want content to be updatable by non-programmers, which is almost always a very requirement on larger corporates pages.
A CMS will also allow versioning of content, making it easy to publish new content at specific points in time.
Re:Why CMS (Score:4, Insightful)
A better question is why so many practically static web sites use online content management systems. Is it just for convenience? Lack of thought? A life content management system on the server is a serious security liability. Many web sites could just as well use an offline CMS and push the data to the server when an update is made. A typical web server can handle orders of magnitude more visitors when there is only static content. Even if you aggressively cache the CMS output, that still leaves the security aspect. I guess it takes a Slashdotting / Digg effect before most authors realize that having a web site which can't handle 10 concurrent visitors is rather pointless.
Re: (Score:2)
Are there many static-CMSes (for want of a better term) like that available?
Re: (Score:2)
Re: (Score:3, Informative)
Why reinvent the wheel?
Sure, you can program everything from scratch and that might even appeal to you if you're the CEO of a company that sells programming services, but in many cases it makes more sense to use off-the-shelf software (which drupal is - well, off an imaginery shelf where everything is free as long as you give back).
Re: (Score:3, Insightful))
Re: (Score:3, Insightful)
Businesses have come to accept the limitations of software, and will often adjust the way they do things to fit in with whatever the software requires, sad but true.
Re: (Score:3, Insightful)
It's not necessarily a bad thing. Yes, sometimes it cuts off new and creative ideas. Often, those are bad ideas, and everybody else is doing it the regular way for a reason.
This is especially true when a business is getting outside of its domain. If you're the best bottle-maker or book-binder on the block, do that. But your accounting and web site is almost certain to be identical to any other businesses, and crafting roll-your-own accounting or web management software specialized to your thing is quite
Re:Why CMS (Score:4, Insightful)
Re: (Score:2)
Forget the OS - do you reckon he designs and fabricates his own CPUs?
Screw that! (Score:4, Funny)
I make my own fucking ELECTRONS!
Re:Screw that! (Score:5, Funny)
Dude, why are you being so negative?
Re: (Score:2, Funny)
Do you know how fucking hard it is to make POSITRONS?
Re: (Score:2)
Re:Why CMS (Score:5, Informative)
"Did you guys forget how the web worked before CMSs came around?"
Yes: it did work slower, more expensive and less functional. I even remember why first intranet efforts used to fail: because content stagnated due to the fact that only programers that didn't produce the information in first place were the only ones allowed and/or with the knowledge to modify contents.
"Most CMS products are insecure pieces of shit. I would not use a CMS for a high profile target like that. They should be publishing static files with a custom system. Only pages that must be dynamic should be. It's just dumb?"
You do know you can have your CMS administrative backend opened only to your internal networks so from the Internet all you have access to is an static, pre-cached, read-only version, do you?
Re:Why CMS (Score:5, Informative)
That's your opinion and just because you have one doesn't make it the correct choice.
In fact, I do remember how the web was before CMS came around. I remember people handing me MS Word documents saved as 150KB+ HTML files. Or having to clean up sections of the corporate site where someone cut-and-pasted from MS Word into the site.
Heck, people made a living off writing software just to clean up the mess. Eliminate clutter in Microsoft Word generated HTML files with the Office 2000 HTML Filter [com.com]
And to Sopssa, He fails to realize that Drupal can be hardened and has the benefit of several years of testing and user feedback unlike a custom system.
I clearly remember the days before CMS and it looked like this.
<html xmlns: <head > <meta name=Title <meta name=Keywords <meta http-equiv=Content-Type <meta name=ProgId content=Word.Document > <meta name=Generator <meta name=Originator <link rel=File-List <title >This is normal unformatted text </title > <!--[if gte mso 9] > <xml > <o:DocumentProperties > <o:Author >Elizabeth Pyatt </o:Author > <o:Template >Normal </o:Template > <o:LastAuthor >Elizabeth Pyatt </o:LastAuthor > <o:Revision >1 </o:Revision > <o:TotalTime >1 </o:TotalTime > <o:Created >2003-10-22T19:05:00Z </o:Created > <o:LastSaved >2003-10-22T19:06:00Z </o:LastSaved > <o:Pages >1 </o:Pages > <o:Company >ETS </o:Company > <o:Lines >1 </o:Lines > <o:Paragraphs >1 </o:Paragraphs > <o:Version >10.2418 </o:Version > </o:DocumentProperties > </xml > <![endif]-- > <!--[if gte mso 9] > <xml > <w:WordDocument > :Compatibility > <w:SpaceForUL/ > <w:BalanceSingleByteDoubleByteWidth/ > <w:DoNotLeaveBackslashAlone/ > <w:ULTrailSpace/ > <w:DoNotExpandShiftReturn/ > <w:AdjustLineHeightInTable/ > </w:Compatibility > <:Palatino;
panose-1:0 2 0 5 0 0 0 0 0:Palatino;}
h3
{mso-style-next:Normal;
margin-top:12.0pt;
margin-right:0in;
margin-bottom:3.0pt;
margin-left:0in;
mso-pagination:widow-orphan;
page-break-after:avoid;
mso-outline-level:3;
font-size:13.0pt;
font-family:Helvetica;}
p.MsoBodyText, li.M
Re: (Score:3, Funny)
I clearly remember the days before CMS and it looked like this
Ha! The planetarium scheduler for the the school I work at has an HTML file she edits in Word to create the current month's calendar. This file has been used for some 2-3 years. Pulling it up right now, it is 682 KB in size and has over 6,000 lines of CSS at the top of the document. Here's a snippet:
Re:Why CMS (Score:4, Insightful)
theres alot of good reasons people use cms... and let me try and use your own words... say you wanted a website that looked like cisco's.
In a CMS, (such as drupal)... heres who does what:
1) designer writes a theme for the website (to give it the look)
2) content producers write the pages
3) codes do the bits the cms doesn't already do.
The point is, the CMS gives you alot to begin with without limiting you, sure you could code a website from scratch but something as powerfull as drupal is going to take a long time. You may not need everything drupal does so you can cut that down a bit. But ultimately you'll end up with something that allows people to do their jobs (i.e. content producers to write pages). Drupal CMS is also especially good at being extended (and there are virtually no limits that I can think of). So rather then writing a whole heap of code to do your website, your coders just write what they need to extend the CMS - "dang, drupal doesnt do rsa based two factor auth, we're going to have to code it in" as apposed to "ok, lets get started on coding a website - quick grab 15 people who know architecture".
Re: (Score:2)
Pretty sure noone in the world wants a website that looks like Cisco's. It's the worst site by a major technology company I've ever used. To get to anything I normally have to login 3-4 times because it randomly forgets your logged in, only to find out that what I was trying to get to was just a link back to where I started. And forget trying to download the software my account privileges say I should be entitled to, I always wind up using someone else's account because despite several attempts on Cisco'
Re:Why CMS (Score:4, Insightful)
So when you write your own code, you've written a CMS. But you just passed one up because it was too heavy-weight...
Re: (Score:3, Insightful)
"Both of those things can be accomplished on your own code too"
Yes, of course. And do you know how the internal app you developed so to allow non-programmers to update content, so PHBs can review the content prior to go public, so you can version contents and pre stablish the date it will go alive, etc. will be called? It will be called a "Content Management System".
So in the end you won't avoid the CMS you'll just develop your own internal one: reinventing the wheel, at a cost, and probably worse.
Re:Why CMS (Score:5, Informative)
Just a few reasons:
* You want to automatically use templates and not replicate formatting code
* You want different people that are not programmers to be able to update different parts of the website; you want to let them do it from their browser in a wysiwyg editor; you want to let them to easily first publish their articles on a staging host and then authorize somebody else to go online with it
* You want to allow commenting, feedback forms, registered users etc.
* You easily want to keep track of versions and revisions of published pages
* You want to automatically index the pages for searches
* You want to easily include dynamic(computed) data into your web pages
Re:Yes, but I don't want Whitehouse.gov doing that (Score:5, Insightful)
Yes, but I don't want Whitehouse.gov doing that. Allowing feedback on the high profile website is STUPID and ignorant.
Apparently, allowing feedback attracts the stupid and ignorant.
Re: (Score:2)
Re: (Score:3, Insightful)
Why do you assume they're not doing that?
Because he's a moron who doesn't understand how CMSes are actually used in the real world, and thinks the only point of them is for 'dynamic' content.
When in actual fact something like half of all CMS sites are mostly 'static', with maybe a forum and an RSS feed block being their sole 'automatically changing' area, and then rest is so that people who don't know a hell of a lot about web sites can fricking manage the site, or at least their area of it, and add and
Re:Why CMS (Score:5, Informative)
Especially for large websites, this can dramatically improve how fast you can update and improve your site.
Also, if you don't want to use a CMS, a framework like Django or Ruby on Rails is the way to go. These allow you to program everything yourself, but already have a lot of functionality built-in, to avoid reinventing the wheel.
Re: (Score:3, Informative)
Re:Why CMS (Score:5, Insightful)
With all due respect, are you a web developer?
For starters, a well-developed CMS and some competent IT people can produce a site every bit as quick as a static HTML site, because that's exactly what they'll be serving up with good server-side caching. Any "weight" in the backend is more than offset by the increased ease with which content can be updated.
Moreover, a CMS allows non-technical people to be involved in the process. Most likely, people from the press and communications offices are going to be the ones in charge of the content on this website, and it's not at all unreasonable to assume that most of them aren't going to be any good with HTML.
And why should they be? CMS is exactly what it says it is -- a content management system, letting people focus on content by hiding away the markup and technical nonsense they're not concerned with anyway. Sometimes it's fully inappopriate; sometimes a custom one is better than off-the-shelf. But you really can't see why anybody would want to use one? Ever?
Re:Great... (Score:5, Funny)
Now they're locked in to PHP.
It's part of Obama's economic recovery program. Just think how many IT jobs this will create: maintenance, debugging, modifications, and security. Maybe we could have a Slashdot poll on who will pwn the website first. I think it'll be the Chinese as payback for the tariffs on tires.
Re: (Score:2)
It's a significant step forward
It's quite a sad state of affairs when moving to one of the most common and widely used back-ends for a website is considered "a significant step forward".
Re: (Score:3, Insightful)
"It's quite a sad state of affairs when moving to one of the most common and widely used back-ends for a website is considered "a significant step forward"."
Bullshit - it's not a "step" anywhere.
This is ONE part of the government changing ONE system over to open source. That's it. The whole "since the Bush Administration" comment is a red herring:
a) Drupal only went Open Source in 2001. "Hey, it's time to update the Whitehouse.gov back end, and there's this new cool thing that just got released. It's ma
Re: (Score:3, Insightful)
Re: (Score:2)
Re: (Score:2)
I suspect your memory is a little faulty.
Akamai has been reverse proxying whitehouse.gov for quite some time.
So IIS on linux might have been reported, but all sites akamai proxies for show up as being on linux. See [netcraft.com] for example
of IIS/6.0 on linux.
Re:Something fishy. (Score:5, Funny)
In other words, what did they switch from.
They switched from capitalism to communism, silly.
Re: (Score:3, Insightful)
Re: (Score:2, Informative)
Re: (Score:2)
Re: (Score:2)
My first reaction to seeing this article was how long it will take for Fox News and friends to declare open source software as socialist and how comrade Obama has taken jobs away from hard working capitalist programmers. It's really not a stretch given their track record.
Take a look at the drupal logo. I think this calls for a big investigation to confirm that Obama is an alien!
My first take is (Score:4, Insightful)
does this even offset a Administration which takes all the bad habits of the last and compounds them with super sized bills that no one gets to review and a good dose of intimidation against any who speak up?
Re: (Score:3, Interesting)
My first reaction to seeing this article was how long it will take for Fox News and friends to declare open source software as socialist and how comrade Obama has taken jobs away from hard working capitalist programmers. It's really not a stretch given their track record.
foxnews.com's server runs on Linux according to Netcraft.
That's totally wrong. (Score:3, Insightful)
First off, most leaders of the left wing imagine a future where scarcity is the norm, largely because they see the consumption of natural resources by the West as unethical in a larger world view. In their eyes, Americans already have "too much" and therefor should have to make due with less. This faux-conservatism, coupled with the right wing's stupid devotion to "free trade", is the underlying cause of this current economic crisis. It is that people want more stuff, resources are capped by environmenta
Re: (Score:3, Informative)
Except you completely ignore externalities, systemic risks, and equity, which is what got us in various messes already. [wikipedia.org]
Consider the "True cost" of oil from various perspectives: [energyandcapital.com]
"""
Milton Copulus, the head of the National Defense Council Foundation, has a different view. And as the former principal energy analyst for the Heritage Foundation, a 12-year member of the National Petroleum Council, a Re
Re: (Score:2, Insightful)
Externalities, Concentrations of Wealth, etc... is a made up word excuse for socialism.
Re: (Score:2)
Really? I mean, I'm not saying you are wrong, but I am saying you've just made a direct statement of fact with no justification whatsoever. It's not even an argument.
Re: (Score:2, Insightful)
but I am saying you've just made a direct statement of fact with no justification whatsoever
Yes and no. I think your out would be that if you could address your concerns of concentrations of wealth and externalities without some of federal assumption of ownership, its pretty hard to avoid socialism.
The thing is, that, if you have a government to keep wealth from getting concentrated, it's wealth will get concentrated. If you make the government the sole arbiter of some bit of land or sky, then, it will be
Re:That's totally wrong. (Score:5, Insightful)
"If we all had our one acre of land, even if one of us screwed it up, humanity could continue. But if the King owned all the land, then, the King could screw up all the land, and frequently, will."
And if one of those people on their one acre of land makes a bioengineered plague, then everyone dies? Or, when the nuclear power plant next door melts down, we permanently evacuate Manhattan?
Here is something to consider,."
Manuel de Landa suggests we need a healthy balance between meshworks and hierarchies.
By the way, make sure you get enough Vitamin D while working inside on simulations, as I agree the public health agencies have dropped the ball on a lot of things: [vitamindcouncil.org] [vitamindcouncil.org] [blogspot.com]
Also, on "socialism": [digg me
Re: (Score:3, Informative)
"On the way out the door I deposit any mail I have to be sent out via the U.S. Postal Service and drop the kids off at the public school."
I should have caught that as a problem too. Someday, public schools may be much more like public libraries open to anyone to use than day prisons for children of working parents, but until then, consider:
"Links about alternative peer-oriented education" [p2pfoundation.net]
"The Underground History of American Education"
Re: (Score:3, Insightful)
The key really is, how do create a social mechanism to prevent excessive concentrations of wealth, without creating a defacto concentration of wealth?
I think you're framing the problem incorrectly. I think the question should be, how do we make sure that enough wealth is distributed such that society can reasonably function, and that we feel decent about how we are treating the least fortunate among us?
Focusing on the concentration at the top is just jealousy. The ethical concern is at the bottom of the pyramid, in my view.
If the wealthy are prudent, they will remember the lessons of the French Revolution and Russia in 1917, and make sure that they pas
Re: (Score:3, Informative)
From The American Conservative: [amconmag o
Re: (Score:2)
It will be interesting to see the first bug report from the White House. With all the layers of security they need, they are undoubtedly going to push Drupal's envelope in some novel ways.
Or maybe we will see evidence of a White House bug stomping party, or contributed code, first. I'm sure that the tech guys at whitehouse.gov will give back to the community somehow.
Is there a way to monitor drupal.org for White House activity? Can we see some "First sighting!" competitions? Or should we look for press re
Re: (Score:2)
Re: (Score:2)
Insightful post. Completely off-topic but, still, you make some damned good points.
Yeah, totally off topic, but inspired somewhat by the commentary that inevitably follows an FOSS product adoption decision made by a major enterprise..., it's like "the movement" won. Maybe the gov't just picked the better product? | https://news.slashdot.org/story/09/10/25/1126210/White-House-Website-Switches-To-Open-Source | CC-MAIN-2016-40 | refinedweb | 6,523 | 61.77 |
system("pause")... You can use the code I gave you there
"\n"instead of
endlbut it doesn't make much of a difference in this program.
int getRand();doesn't do anything as far as I know...
int total0=num0*0;if this returns 0 in the end anyway? And what about num7 if it isn't used anywhere?
#include <string>at the top (not all compilers need it, but some do)
using namespace std;
std::(which I already did in the code I wrote)
void clearscreen();at the top has to be there if the function is defined after the main, but in this case I don't think you need that... You'd certainly have to do it if you had multiple files. | http://www.cplusplus.com/forum/beginner/96040/ | CC-MAIN-2016-22 | refinedweb | 125 | 78.08 |
Max Kellermann <max@duempel.org> writes:
[...]
> I prefer Stas' idea of an Apache2::Request class, CGI::Request etc.
>
> DBI.pm is a single constructor for all database drivers for a reason
> which is not relevant for us: they want software to connect to any
> database only by replacing the connect string (from a config file?).
>
> At the time users of apreq are initializing an APR::Request object,
> they can't write abstract code anyways - either they're in a mod_perl
> script, then they have to pass the RequestRec, or they're in a CGI
> script, then it's an APR::Pool. After the APR::Request derivative is
> created, they are free to pass that to abstract functions.
>
> The arguments are the same as in the C API.
+1.
> btw. I'm unsure if the abstract base class should be named
> APR::Request. It's not part of APR, it only uses APR.
I don't see the harm in using APR::. Other third-party
APR:: apps will wind up in APR:: on CPAN, and I really
don't see the apr guys ever wanting to write a competing
request/cookie library. I believe it's more likely that
apreq could become an apr subproject, especially if httpd
decides they want to include mod_apreq in their distro.
So from that standpoint, I prefer we used the APR:: prefix.
> Apreq::Request? Apreq::Handle?
We've tossed around on a few of these namespace questions
before, but nothing stuck. Personally I'm more concerned
about how to carve up the API in trunk's Apache::Request.
I think we can remove all its non-mod_perl modes, but we
have to keep it being an Apache::RequestRec -derived class.
And so we must remove the defective args() and status() methods.
At that point body() doesn't make much sense anymore either,
and we still have to deal with the fact that Apache::Request
users expect to have a modifiable parameter table to
work with (which args and body will no longer provide
on the C level). So I think trunk's Apache::Request will
wind up looking a lot more like the 1.x API; in particular
instance() and new() will probably be different subs again.
Anyway, I suppose we'll cross these bridges once we
encounter them. I just wanted to start discussing
them now, so we don't paint ourselves into a corner
with the coming C API changes.
--
Joe Schaefer | http://mail-archives.apache.org/mod_mbox/httpd-apreq-dev/200502.mbox/%3C87r7jxn9u0.fsf@gemini.sunstarsys.com%3E | CC-MAIN-2013-48 | refinedweb | 409 | 70.33 |
CodePlexProject Hosting for Open Source Software
Can't seem to figure how to do this or if it's possible. This module does not use ContentItems at all.
I have a model that contains instances of other models:
public class MetricRecord
{
[ScaffoldColumn(true)]
public virtual int Id { get; set; }
[Required]
[DisplayName("Metric Type")]
public virtual MetricTypeRecord MetricType { get; set; }
[DisplayName("Qualifier")]
public virtual QualifierRecord Qualifier { get; set; }
[DisplayName("Scorecard")]
public virtual ScorecardRecord Scorecard { get; set; }
[Required]
[DisplayName("Metric ID Name")]
public virtual string MetricIdName { get; set; }
}
So, MetricRecord contains a MetricTypeRecord, QualifierRecord, and ScorecardRecord
I'd like QualifierRecord and ScorecardRecord optional on the MetricRecord so that they can be null.
I can't seem to figure out how to configure my Controller to allow for null values for these though.
I'm passing in a FormCollection to my Action so I can do this, since the controls for selecting these items are dropdowns:
metric.MetricType = _metrictypeService.Get(int.Parse(collection["MetricType.Id"]));
This one works great because it's required and I don't have the option in the dropdown to not select an item.
For Scorecard and Qualifier, the first item in the dropdown is "Select an item" which passes a null value. I thought I could do this in the Controller:
if (collection["Scorecard.Id"] != null)
metric.Scorecard = _scorecardService.Get(int.Parse(collection["Scorecard.Id"]));
else
metric.Scorecard = null;
but it gives me an error. I can select something from the dropdown list and it updates fine.
Any ideas on how I configure the Controller to leave Scorecard and Qualifier null if an item is not selected?
Thanks so much for the assistance.
What is the exact error you're getting, and on which line?
As an aside, you may want to consider using View Models instead of directly using Domain Models with model binding.
Having for example a "MetricViewModel" will enable you to work with nullable integers for the IDs: int? ScorecardId, int? QualifierId, etc. without having to manually parse them. It's just a thought though, and has probably nothing to do with the error.
Are you sure you want to delete this post? You will not be able to recover it later.
Are you sure you want to delete this thread? You will not be able to recover it later. | http://orchard.codeplex.com/discussions/356753 | CC-MAIN-2017-43 | refinedweb | 385 | 55.13 |
Turbo Borland C++ Introduction
Developer, PlayZion.com
Introduction to C++
Note: This tutorial is based on using Turbo C++ from Borland Software.
When you first start Turbo C++, you will see a blue screen with the title "
NONAME00.cpp". The main area is called the "
edit window". This is where you can type code for your programs. The flashing yellow thing is called a cursor. Type in the following code:
#include <iostream.h>
#include <conio.h>
// This is a comment
void main() { clrscr(): cout << "Hello World." << endl; }
As you can see, the text is different colours depending on what type of text it is, and what it's purpose is. This will be explained in greater detail later. If you want, you can use
F2 to save your program. To run it, you can either press
CTRL + F9, or choose "
Run" from the menu at the top of the screen.
If there are errors in your program, a little grey box will come up showing you the errors. Each line in the box shows you a different error for each line of your program.
If there aren't any errors, then your program has run properly. Why can't you see anything? Because you're still looking at the input window. In order to see what happened, select "
Window" from the menu at the top, and then pick "
Output". It will show you "
Hello World". You can switch back to the input window (or edit window) by pressing
F6.
Another way of seeing the output of your program is by typing:
#include <conio.h>
at the top of your program, and
getch();
at the very bottom. This will pause the program while the output window is visible until the user hits any key. | http://bytes.com/serversidescripting/c++/tutorials/introductiontoc++/index.html | crawl-002 | refinedweb | 293 | 84.88 |
I am in the middle of creating a IDE and Form Designer to run on Windows CE. It is about 75% finished. Is there any interest in me releasing it?(unlike IDLE, it is not writen in Python, but .NET CF v2.0) If there is more than just a few wanting it, I may even make it open source.
Luke Dunstan
2006-04-26
I am interested :-). What kind of output will the Form Designer produce? Python code for tkinter or something else?
because this post is hidden in the beggining help message, I think I'll post something to the mailing list. Does anyone know how to make a new post? I can't seem to find out how.(I can reply to one though)
Anton Orekhov
2006-04-27
os.startfile(), os.system(), os.startvfs() ???! Where they?
Tcl/Tk in Python CE 2.4 not work, not load.
(Create new subjects the user cannot? (could not find New Topic or similar))
Luke Dunstan
2006-04-28
To start a new thread, go here and then scroll down:
The Windows CE C library doesn't have a system() function therefore os.system() doesn't exist. It may be possible to work around this, but I'm not sure yet. Pocket PC doesn't have a cmd.exe by default so it is not obvious whether system() is a good idea.
os.startfile() should exist so that is a bug.
os.statvfs() (not startvfs) is documented as Unix only and is not available on Windows NT Python either.
Anton Orekhov
2006-04-28
Well that function startfile () worked.
Without this function I feel isolated. From Python I can not start not one other program. It is bad. startfile should work.
Now I use Python CE 2.3.5 (because in new it was not possible to start Tk, my programs with Tk interface).
If realize startfile make please this function in separate pyd the module that it(he) could be imported from Pocket Python 2.3.5.
Or update distribution Pocket Python 2.3.5 with this function please.
> (not startvfs) is documented as Unix only
Yes, it is valid so (I apologize:-))
Luke Dunstan
2006-04-29
os.startfile() will be in the next release of PythonCE 2.4.3. I don't really have time to support version 2.3 at the same time.
But before I make a release, can I ask what is the reason that you can't use version 2.4.3 with your Tk programs?
Luke Dunstan
2006-05-01
On second thought, I've created a new release already. Please try it. It also includes the headers and import library necessary for building C extension modules.
It began seems PythonCE to be started faster. Still at once has noticed, that the debugging information in a window of the interpreter is better given out.
I shall try to make C the module.
Many thanks! :-)
Works normally. Probably I have simply got confused. All works.
In PythonCE 2.3.5 I did(made) so:
import sys
if sys.platform == 'Pocket PC':
sys.path.append ('\\SD Card\\PythonCE Python\\python23.zip\\lib-tk')
Now it is not required! Ur!:-)
> that you can't use version 2.4.3 with your Tk programs?
Anton Orekhov
2006-04-28
How to create C the module for PythonCE?
(eVC 4.0, pyd files)
What it is necessary to install and adjust in eVC for this purpose?
Luke Dunstan
2006-04-28
Please post your question a new thread first. I told you how.
C compilation and uses pyd modules
Works well! Thanks :-)
- No enter in widgets non english chars (non english virtual keyboard work in unicode - 2 bytes symbols)
- Some messages stilus (<Motion>) every second erroneous.
event.x, event.y = -3, 14199456
In function event I do(make) so:
def run_Motion (event):
if x <0: return
...
But in the some widgets (Scale) this function inside. And it(he) works incorrectly.
At movement stilus widget jumps.
(IPAQ hx 2110 WM2003SE)
Anton Orekhov
2006-05-05
Buttons maximize/minimize a window in a line of heading.
they operate, but are not displayed
Anton Orekhov
2006-05-12
eVC 4 (DLL MFC include Python.h)
PythonCE-2.4.3-20060430
IPAQ hx2110 (WM2003SE)
I have tried to create the module for InputBox. (to enter not English text).
Source:
Test in PocketPC:
The text is entered normally. But there is one problem.
Sometimes PythonCE stop at an exit from the program.
The program is carried out normally, but at end PythonCE stops, blocked, hangs. (it(he) cannot be closed even through PanelControl/Memory)
It is a mistake in PythonCE or I have incorrectly made C the module?
> - No enter in widgets non english chars (non english virtual keyboard work in unicode - 2 bytes symbols) | http://sourceforge.net/p/pythonce/discussion/358834/thread/7804db7a | CC-MAIN-2015-40 | refinedweb | 803 | 78.35 |
Does anyone know how to connect to HTTPS?
I already tried the HTTPSConenction but it responds with an error code claiming httplib does not have attribute HTTPSConnection. I also don't have socket.ssl available.
I have installed Python 2.6.4 and I don't think it has SSL support compiled into it. Is there a way to integrate this suppot into the newer python without having to install it again.
I have installed OpenSSL and pyOpenSsl and I have tried the below code from one of the answers:
I have got an error:'
Does anyone know how to get this working?
-- UPDATE
I have found out what the problem was, the Python version I was using did not have support for SSL. I have found this solution currently at:.
The code will now work after this solution which is very good. When I import ssl and HTTPSConnection I know don't get an error.
Thanks for the help all.
Python 2.x: docs.python.org/2/library/httplib.html:
Note: HTTPS support is only available if the socket module was compiled with SSL support.
Python 3.x: docs.python.org/3/library/http.client.html:
Note HTTPS support is only available if Python was compiled with SSL support (through the ssl module).
#!>
To check for ssl support in Python 2.6+:
try: import ssl except ImportError: print "error: no ssl support"
import urllib2 | https://pythonpedia.com/en/knowledge-base/2146383/https-connection-python | CC-MAIN-2020-45 | refinedweb | 235 | 74.9 |
20 August 2008 15:02 [Source: ICIS news]
TORONTO (ICIS news)--Germany’s government under Chancellor Angela Merkel has agreed a draft law to change takeover and merger rules for bids from outside the European Union, it said on Wednesday.
?xml:namespace>
Under the new rules the Ministry of Economics would have the power to examine and block bids for stakes of 25% or more by bidders from non-EU countries.
The main test for approval was “public order and security” as defined under EU law, said Economics Minister Michael Glos.
The test had a high threshold and takeovers would likely fail only in exceptional cases.
“The bulk of foreign investments won't be affected by the draft law,” said Glos. “?xml:namespace>
Sovereign wealth funds, for example, typically acquired considerably less than 25%, he added.
The new review process would have to be initiated within three months after a takeover was agreed, thus providing high legal certainty for participants, Gl | http://www.icis.com/Articles/2008/08/20/9150542/german-govt-agrees-changes-to-takeover-rules.html | CC-MAIN-2014-41 | refinedweb | 161 | 57.61 |
Mark Dalrymple
Raise your hand if you wanna get paid.
It’s hard monetizing your apps, and as much as Apple has done to make in-app purchasing (aka IAP) easy, it’s still not easy. The code is the easy part. There are a bunch of things to get straight before we even get to the code. Today we’re going to walk through the process from start to finish.
If you’re the product owner or project manager, the first half of this article is for you. Keeping an eye on the lead time for launch means leaving adequate time for implementing and testing (ESPECIALLY testing!) these features. When the app is complete except for IAP, it’s especially painful because it’s done except for that all important “get the money” part.
Getting to the IAP testing stage with a test app is kind of a pain. It’s much easier to go through it “for real”. I would suggest that you do this work on an app you intend to monetize.
Also, you must make sure all the financial stuff is straight. Apple needs to know they have a way to send you money. They need to believe you have the legit right to sell what you’re selling (ie. you can’t call yourself Disney without proving that you really represent Disney.) And they need to know that stuff before they’ll even show you the products in the sandbox environment.
App Identifier or App ID: When Apple asks for these things, they mean the numeric Apple ID for your app, not the reverse-DNS bundle ID we use in the app. The Apple ID will be shown on the iTunes Connect App Information screen, under General Information, after we’ve created a record for your app.
Product ID is an string identifier you attach to your IAP record. If your
game sells a power-up for a buck, you’ll assign some unique ID to that
power-up such as, say,
powerUp.diamond_shields. In some organizations,
the product ID is provided by the accounting department so they can
tie purchases back to their system.
According to Apple,
you can use letters, numbers, periods and underscores.
Review is a many-faceted thing that, for the most part, we don’t deal with until we’re almost ready for release. There are three pieces of review: External TestFlight review, App Store Review, and In App Purchase Review.
The Sandbox is the test Apple purchase environment. When using a build that is sandboxed, all of the IAP screens will indicate that they are using the sandbox. Do not try to use real iTunes users in the sandbox, and don’t ever ever use a sandbox iTunes user for any kind of real login, such as the App Store or Apple ID management. Doing so renders the sandbox user permanently unusable. It’s too easy to slip up and make this mistake, so you should really be careful with your sandbox IDs.
TestFlight is Apple’s test deployment system. You use it to upload and distribute builds. You can use HockeyApp or other deployment services as well, but for ease of discussion, we’ll be using TestFlight.
You’ll need to flip the “In App Purchases” switch in Xcode, which will poke the relevant bits in the provisioning portal. (If you’re using source control, and you should be, this makes for a nice atomic commit. So do it.)
Then, log in to iTunes Connect. Go right into the Agreements, Tax and Banking module and make sure everything is set up, including the banking details. Seriously, cross every T and dot every I.
When you are all done, you must wait for Apple’s approval. They work fairly quickly when compared to app review, as it’s straightforward accounting and legal stuff. And remember, before you grouse about it, this is how Apple gets you paid. Agree with glee!
From time to time Apple updates their license agreements and you must log into iTunes Connect to re-agree to them. You should be logging in to view your reports, anyway, so periodically swing by the finance module and make sure we’re all still good with Apple.
While you’re waiting, go into the My Apps section and set that up. It’s in there that you will create your products for sale.
In order to get your app into the store, you need to create a record for it. This is pretty straightforward; select the Xcode managed app ID and take it from there. You don’t need to worry about all the descriptions and images just yet.
Once you’ve created your app record, switch to the “Features” tab. It starts on the In-App Purchases feature, so all you have to do is poke the ‘+’ to create a new product.
You’ll then be presented with a set of choices as to what sort of thing you’re selling:
Choose your item type and click Create, and then you’re on to the details. The Reference Name is just for your reports and Product ID is the value we’ll be searching for in the app. As mentioned above, you might use a value that maps back to your accounting system.
Warning: When you click Save here, you are creating a record that cannot be deleted. You can amend it, but not remove it. I give you this warning only because in learning about this, I cluttered up one of my apps and now will feel the shame forever.
import UIKit import StoreKit import Freddy class IAPProcessor: NSObject { static let shared = IAPProcessor() // Shared Secret for validation. This value comes from one of two // places in iTunes Connect: // // A) On your "My Apps", next to the plus, is an ellipsis (…). // In that menu, select 'In-App Purchase Shared Secret'. // B) On the In-App Purchases feature panel where you created your // IAP record, on the right side of the list, is 'View Shared Secret'. public var sharedSecret = "**yours here**" public var productIdentifier : String = "**yours here**" { didSet { searchForProduct() } } // We store the callback for the delegate calls var completionBlock: ((Bool, String?, Error?) -> Void)? let paymentQueue = SKPaymentQueue.default() var product : SKProduct? var runningRequest : SKProductsRequest? public var availableForPurchase : Bool { return !products.isEmpty } public func startListening() { paymentQueue.add(self) searchForProduct() } }
Also, go over to the App Delegate and add this line to the bottom of
...didFinishLaunching...:
IAPProcessor.shared.startListening()
The payment queue is the primary interface into
StoreKit. You send in your purchases, and then at some later point, you get
notified of transaction updates. The payment queue’s
add() method is
overloaded such that it can take an
SKPaymentTransactionObserver or an
SKPayment representing your purchase request.
We create this object and call
startListening() on it. This attempts to add
our
IAPProcessor to the payment queue.
Since we’re neither a payment or a transaction observer, Xcode will now
begin complaining. We’ll become an observer down below. First…
Before we offer our diamond shield up for purchase, we should probably make
sure that it’s available for sale. We do that for searching by product
identifier. The search is encapsulated in a
SKProductsRequest that is
meant to search for an entire array of product identifiers at one time. There
are code examples available that handle multiple, but for simplicity, we’re
asking for one, and expecting one reply.
extension IAPProcessor : SKProductsRequestDelegate, SKRequestDelegate { func searchForProduct() { let productIdentifiers = Set([productIdentifier]) let productsRequest = SKProductsRequest(productIdentifiers: productIdentifiers) productsRequest.delegate = self; productsRequest.start() runningRequest = productsRequest } func request(_ request: SKRequest, didFailWithError error: Error) { NSLog("Request fail \(error)") runningRequest = nil } func productsRequest(_ request: SKProductsRequest, didReceive response: SKProductsResponse) { let productsFromResponse = response.products NSLog("Search for Products received response, \(productsFromResponse.count) objects") if let product = productsFromResponse.first { self.product = product } runningRequest = nil } }
In this block of code, we encapsulate the search logic. Since we are only
searching for one
productIdentifier, we know we’ll get back one record or none
at all. The
SKProductRequest constructor takes a
Set containing only our
identifier, and
start() kicks off the product search as a background job.
Also, we must retain the request, or it is deallocated before it begins.
So once we have our
SKProduct object, we can ask the user to buy one! If he
does, here’s how we request the purchase, as well as restore them:
public func purchase(completion: @escaping (Bool, String?, Error?) -> Void) { if let product = product { if SKPaymentQueue.canMakePayments() { completionBlock = completion let payment = SKPayment(product: product) paymentQueue.add(payment); } else { completion(false, "User cannot make payments", nil) } } else { completion(false, "Product not found.", nil) } } public func restorePurchases(completion: @escaping (Bool, String?, Error?) -> Void) { self.completionBlock = completion paymentQueue.restoreCompletedTransactions() }
The
canMakePayments() method reports on whether the device has been restricted
from In-App Purchases. This is done in
Settings > General > Restrictions. In
your UI, you should disable your purchase controls and provide alternate
messaging if this returns
false.
When we add our payment to the payment queue, our app will be overlaid by system
dialogs completing the in-app purchase. The user may cancel the transaction or
complete it; we’ll find out later, in the
SKPaymentTransactionObserver
delegate calls. Let’s implement those now:
extension IAPProcessor : SKPaymentTransactionObserver { func paymentQueue(_ queue: SKPaymentQueue, updatedTransactions transactions: [SKPaymentTransaction]) { NSLog("Received \(transactions.count) updated transactions") var shouldProcessReceipt = false for trans in transactions where trans.payment.productIdentifier == self.productIdentifier { switch trans.transactionState { case .purchased, .restored: shouldProcessReceipt = true paymentQueue.finishTransaction(trans) case .failed: NSLog("Transaction failed!") if let block = completionBlock { block(false, "The purchase failed.", trans.error) } paymentQueue.finishTransaction(trans) default: NSLog("Not sure what to do with that") } } if(shouldProcessReceipt) { processReceipt() } }
At this point, Apple has completed the purchase transaction and written the
receipt data to the location in
Bundle.main.appStoreReceiptURL. For consumable
and non-consumable item purchases, you can implement a
processReceipt() that
looks like this:
func processReceipt() { completionBlock?(true, productIdentifier, nil) }
Your code might put an annotation in your database, or in the
UserDefaults, or
some other place. That’s it; we’re done with code. Jump down to the testing
section.
If you’re doing subscriptions, there is just a bit more to be done…
There are a number of reasons to validate the receipt with Apple, but chief among them is to find out the expiration date of the product your user just purchased. Many different configurations are possible. Not only may they be recurring, but there are also several options for free trial periods.
For many services – say, your fitness program or other content-driven app – it may make more sense to validate those receipts on the server. But if you have no backend, or your backend is just storing your content, then you’re going to have to validate the receipt yourself.
extension IAPProcessor { func processReceipt() { if let receiptURL = Bundle.main.appStoreReceiptURL, FileManager.default.fileExists(atPath: receiptURL.path) { expirationDateFromProd(completion: { (date, sandbox, error) in if let error = error { self.completionBlock?(false, "The purchase failed.", error) } else if let date = date, Date().compare(date) == .orderedAscending { self.completionBlock?(true, self.productIdentifier, nil) } }) } else { let request = SKReceiptRefreshRequest(receiptProperties: nil) request.delegate = self request.start() } } }
Apple doesn’t tell you, the app developer, whether a given purchase is a sandbox one or not. According to their Receipt Validation Programming Guide, you can find out if a purchase is a sandbox one by making a request to their production receipt validator; if it fails with a status code of 21007, it’s a sandbox purchase. Therefore we need to set up our code to check production, and on failure, to then check the sandbox.
Thankfully, the only difference is the URL, so it’s simple enough to reuse the
parsing code between them. We are using Freddy for our JSON parser, but it works just fine with
JSONSerialization.
My apologies, but it’s a bit of a code-dump. It’s pretty routine stuff.
enum RequestURL: String { case production = "" case sandbox = "" } extension IAPProcessor { func expirationDateFromProd(completion: @escaping (Date?, Bool, Error?) -> Void) { if let requestURL = URL(string: RequestURL.production.rawValue) { expirationDate(requestURL) { (expiration, status, error) in if status = 21007 { self.expirationDateFromSandbox(completion: completion) } else { completion(expiration, false, error) } }) } } func expirationDateFromSandbox(completion: @escaping (Date?, Bool, Error?) -> Void) { if let requestURL = URL(string: RequestURL.sandbox.rawValue) { expirationDate(requestURL) { (expiration, status, error) in completion(expiration, true, error) } } } func expirationDate(_ requestURL: URL, completion: @escaping (Date?, Int?, Error?) -> Void) { guard let receiptURL = Bundle.main.appStoreReceiptURL, FileManager.default.fileExists(atPath: receiptURL.path) else { NSLog("No receipt available to submit") completion(nil, nil, nil) return; } do { let request = try receiptValidationRequest(for: requestURL) URLSession.shared.dataTask(with: request) { (data, response, error) in var code : Int = -1 var date : Date? if let error = error { if let httpR = response as? HTTPURLResponse { code = httpR.statusCode } } else if let data = data { (code, date) = self.extractValues(from: data) } else { NSLog("No response!") } completion(date, code, error) }.resume() } catch let error { completion(nil, -1, error) } } func receiptValidationRequest(for requestURL: URL) throws -> URLRequest { let receiptURL = Bundle.main.appStoreReceiptURL! let receiptData : Data = try Data(contentsOf:receiptURL) let payload = ["receipt-data": receiptData.base64EncodedString().toJSON(), "password" : sharedSecret.toJSON()] let serializedPayload = try JSON.dictionary(payload).serialize() var request = URLRequest(url: requestURL) request.httpMethod = "POST" request.httpBody = serializedPayload return request } func extractValues(from data: Data) -> (Int, Date?) { var date : Date? var statusCode : Int = -1 do { let jsonData = try JSON(data: data) statusCode = try jsonData.getInt(at: "status") let receiptInfo = try jsonData.getArray(at: "latest_receipt_info") if let lastReceipt = receiptInfo.last { let formatter = DateFormatter() formatter.dateFormat = "yyyy-MM-dd HH:mm:ss VV" date = formatter.date(from: try lastReceipt.getString(at: "expires_date")) } } catch { } return (statusCode, date) } }
This one is pretty easy. Remember how we set up the listener in the App Delegate? That was because if a payment occurred while the app was not running, the transaction will be delivered right after the app comes up. You should treat this the same way and update your expiration dates.
Once you’ve got this code all lined up, and you’ve received confirmation from
Apple that they’ve done their bit, you should begin to see your
SKProduct
objects in the simulator. But you can’t purchase them yet, because you don’t
have a sandbox user.
Let’s go back to iTunes Connect, and go to the Users and Roles module:
There are three tabs here:
It’s vitally important that you don’t mess this one up: If you try to
log in to any other Apple service with a sandbox ID, it permanently borks
up that ID. You’ll have to toss it and start over. We recommend here that
you create a new e-mail address specifically for this (eg.
my_app_sandbox_1337@gmail.com) and use that
address for your Sandbox user. You will need to click a link in the email to
activate, so make sure it’s a real email address. (It is also possible to do plus-based email segmentation, ie.
myaddress+thisapp@mycompany.com.)
In order to see the builds in the TestFlight app, however, your device needs to be logged in to one of the accounts shown on the second tab. Thus the testing cycle becomes a bit of a hassle, going something like this:
Kind of ugly, isn’t it? Good reason to have a second device handy just for testing, too. Who wants to log their personal phone out of all that stuff?
Before going down the hole of device testing, you can be heartened by the news that the simulator now supports IAP. For the most part, you can proof out your process there. You should leave the account blank in the simulator’s Settings and force the app to sign you in.
When you do distribute builds to external testers via TestFlight, your app will be reviewed by Apple. This review tends to be fairly cursory, not on the order of an App Store review.
One last note: Automatically recurring subscriptions in the sandbox run on a compressed schedule and auto-expire after six transactions, allowing you to observe the complete lifecycle.
When you’re ready to go and you’ve tested your work not just in the simulator but also on a device, you’re ready to put it in the store. Each new IAP must be submitted to the store with a new app version, which should make sense. Your app will be reviewed and then your purchase will be reviewed separately. You will need to give directions on how to invoke the purchase.
After you’re reviewed and approved, you can launch. Now go make that money! | https://www.bignerdranch.com/blog/monetizing-your-apps-with-apples-in-app-purchases/ | CC-MAIN-2018-09 | refinedweb | 2,761 | 57.47 |
as one of the most professional top sell rechargeable led solar street light all in one led outdoor 200w motion sensor for street light manufacturers and suppliers in china, we're featured by customized products and competitive price. please rest assured to wholesale max3000lm commercial solar street light outdoor outdoor 200w motion sensor for street light in stock here from our factory. contact us for quotation.
kk.bol china manufacturer aluminum motion sensor street solar street light portable led light bulb solar panel powered rechargeable lantern lights lamps for pet house shed barn indoor outdoor emergency hiking tent reading camping night light (1600mah 150lm) brand: kk.bol. 4.1 out of 5 stars 2,082 ratings.
led sehl 60w ip65 integrated solar led street light ; led solar flood lights highly energy-efficient and durable these led lights will last you for at least 50,000 hours. this led fixture is a ul and dlc-approved product for safe and hazard-proof use. 50,000. hours. 100-277. voltage. 65. rated. 1-10v. dimmable. 5. years. features of led pole light 5700k universal
goldsuno - professional odm/oem manufacturer of solar street lights & solar landscape lighting goldsuno is a is a national high-tech enterprise and plays a leading role in outdoor solar lighting industry, specializing in 40w solar powered street light with time and light, solar landscape lights, solar wall lights, solar/p>
mar 25, 2021 solar fence post lightslohas hot sale integrated outdoor led solar street light 50w outdoor, solar fence post lights ip65 waterproof, 8leds solar light outdoor f
Solar Street Light 20 Watt All in One Hawk Series. Light / Solar Area Light / Solar Lampost / 10
About this item All-in-One Solar Street Light Solarellent as an area light, parking lot light, patio light or yard light, with 48 LEDs Professional quality, elegant and versatile -- Can be mounted onto a standard 2 3/8" pipe or a flat surface.
PolePalUSA Solar Street Light - 20 Watt - All in One
Amazon.com : PolePalUSA Solar Street Light - 20 Watt - All in One, Fully Integrated : Garden & Outdoor
20W All In One Solar Street Light | ILF
The LAR20 All-in-one solar LED Street Light fixtures are the perfect off-grid replacement for aging technology and fixtures. New installation require NO electrical service or connection to the local grid, providing a true "GREEN" lighting solution and 100% energy savings.
Loom Solar 20 Watt Solar Street light for Outdoor Lighting
20 Watt Solar Street light for Home, Gardens, Outdoor and High ways by Loom Solar - India's no. 1 company, Solar street light is completely off grid product which does not require electricity to power the lights during the night.
Solar Light Malaysia - Solar DIY Light Kit
RM498 US$199.20 Our 20 Watt solar power kit for do-it-yourselfers. Includes all the parts to build your own system to solar powered lighting. We've made it very easy to put together with complete instructions. The DIY System includes: 1) 20 Watt Solar Panel
Integrated All In One Solar Led Street Light Lamp 20 Watt
Integrated All In One Solar Led Street Light Lamp 20 Watt , Find Complete Details about Integrated All In One Solar Led Street Light Lamp 20 Watt,Integrated Solar Street Lamp,Solar Led Street Light 20 Watt,Solar Street Light 20 Watt from Street Lights Supplier or Manufacturer-Shenzhen Jinsdon Lighting Technology Co., Ltd.
Solar Street Light | BLUESWIFT
CCTV Camera Solar Panel All In One Waterproof Outdoor IP65 LED Road Lamp Sensor Outdoor Lighting Solar Street Light With 4G WIFI. FOB Price: US $284.7-307.47/ Piece. Min.Order Quantity: 50 Piece/Pieces. Supply Ability: 10000 Unit/Units per Day. Port:.
5,100 Lumen Donati II Series Solar Street Light - 170+ Lumen
Donati II Commercial Grade 30 Watt LED Solar Street Light - Over 5,100 Lumens - 170+ Lumens/Watt - All in One LED Solar Light - Motion Sensor - Professional Grade Street Solar Lighting - Solar Panel & Lithium Ion Battery Included - Slip Fit Mount
Solar Integrated Street Light 20 Watt - Solar Lights
Solar Street Light 20 Watt Hawk Series All in One – TTASL20W. View Product. Add to Wishlist. Compare. Solar Integrated Street Light 12 Watt; Solar Street Light 30 Watt Nightjars Series with MPPT Controller - TTSSIL30W Contact Info Tapetum India Solar #56, 21st A Main Road, Marenahalli, J.P Nagar 2nd Phase, Bengaluru, Karnataka 560078
All-In-One Solar Light - Fluent power and control electric
Electrical: Luminary Wattage: 20 W: Input Voltage: 11.1V DC: Driver Efficiency >85%: Dusk to Down & Charge Controller: The PV module itself will be used to sense the ambient light to switch ON / OFF the Lamp.
Eros Series LED Solar Street Light - 170+ Lumens per Watt
3,400 Lumen Donati II Series Solar Street Light - 170+ Lumens per Watt - 20 Watt - All in One LED Solar Street Light
Solar Street Light 20 Watt - TTISSL20W – tapetum.in …..
Catalog of Products - Solar Flagpole Lighting - Solar
20 Watt - Solar Street Light Our 20 WATT Solar Street Light turns on at dark, detect movement then illuminate to very bright. After the movement subsides, the lights return to normal power. $ 329.00. This is our powerful 8 Watt All-in-One Solar Security Light. Universal for many uses including street/path lighting or as a garden light
Tapetum, 56 21st A main Road, Marenahalli, 2nd Phase, JP
Solar street light is an effective outdoor lighting to illuminate the street or any open areas through the use of solar energy. Leaders in Manufacturing of Solar Garden Lights, All in one Integrated Solar Street Lights, Solar Emergency, Solar Wall Lights, Solar Flood Lights , LED Lights Bangalore , India . ISO 9001:2015 10002:2004 Certified
More Information About Solar Street Light - tapetum and …
Tapetum India Solar - Leaders in Solar Street Lights and
Solar Street Light 20 Watt Nightjars Series with MPPT Controller - TTSSIL20W Regular price Rs. 17,999.00 Rs. 15,499.00 Solar Street Light 20 Watt Hawk Series All in One - TTASL20W
Solar Street Light 30 Watt Hawk Series All in One - Tapetum.
control system ip65/ip68 solar led street light with 12/24v circuit
all in one 1000w de grow solar street light | digital greenhouse all in one 20w used for courtyards, parks, villages, parking lots, roads and other lighting places.
Solar Street Light 20 Watt All in One Hawk Series
we have 11 years experience in integrated solar street light high lumen abs 30w 60w 90w garden integrated all,50 watt all in one solar street light for outdoor design and all in one light led solar power pir motion sensor street light 40watts manufacturing
Solar Powered Commercial LED Street Light Systems
?? 5100lm super bright 100w high lumens buy graphene based lithium battery solar street light lvq3 supports up to 350 square meters lighting, like 4 to 5 units light up a basketball playground, 11 units light up a half football field.*?? energy saving and high performance high quality solar panel to the sun's light energy into electrical energy efficiency increased by 40. also, it work even on rainy days.only 4 to 5 hours on a full
Solar Street Light 20 Watt All in One Hawk Series
import china tiffany outdoor solar street light ideas for solar garden light from various high quality chinese tiffany high power all in one waterproof outdoor solar street light suppliers & manufacturers on globalsources.com. we use cookies to give you the best possible experience on our website. 12,609 tiffany 25w ce/rohs solar street light dusk to dawn factory price results from 1,605 china manufacturers.
Remote control
rotated 360 horizontally and 240 vertically
monocrystalline solar panel
better uniformity of illuminance
80w waterproof all in one solar street light in car parks
80w ip65 cctv camera integrated all in one solar street light in oman results history picture from jiangsu entai lighting group co., ltd. view photo of solar street light, all in one solar light, solar garden light.contact china suppliers for more products and price.
A108 Adam Street, NY 535022
+1 5589 55488 55 | https://www.ristorantedacarla.it/1b1389bcef8876082f9558aea15a6ece | CC-MAIN-2022-05 | refinedweb | 1,334 | 53.14 |
Introduction to Unity 3D
Unity 3D is a powerful game development engine. It is cross platform that is it allows you to create games for mobile, web, desktop and console, around 30 platforms in all. Unity 3D has many exciting features, a few of them are given below:
- Cost: Unity 3D’s personal version is free of cost for beginners, students and hobbyists. Unity Personal has all the core features of Unity. It also has core analytics, cloud build, ads, multiplayer, in-app purchases and cross platform features. Other than these features Unity personal has a few limitations too. Two other versions Unity Plus and Unity Pro are also available for serious creators and professionals, starting at the price of $35 per month.
- All In-one Editor: Unity is known as an all in one editor. The Unity editor has multiple artist friendly tools for designing impressive experiences. It has a strong suit of developer tools for implementing game logic and high end performing gameplay. Unity also allows you to create both 2D and 3D games. It also includes AI pathfinding tools based on a navigation system. It has an excellent built-in system to create eye catching user interfaces. Its Box2D physics engine allows us to create realistic motion, momentum, force and gameplay.
- Platforms: Unity supports many different platforms like Linux, IOS, Android, Windows, etc. totally nearly 30 platforms.
- Virtual and Augmented Reality: Unity supports for virtual and augmented reality development. It is most widely used engine for XR development. It has Microsoft HoloLens, Stream VR/Vive, Gear VR and PlayStation VR support in Unity Plus for virtual and augmented reality.
- Multiplayer: For real time networked and multiplayer games Unity is the best option. It provides servers for real time collaboration.
- Engine Performance: Unity’s engine performance is extraordinary. Multi-threaded compute system is coming for intensive scenarios. Unity engine has advanced profiling tools which determines if your game is CPU bound or not and also tells how to optimize it with better experience.
- Unity Asset Store: It is a massive catalog of free and paid content. You can increase your development time by downloading many built-in free models and assets. Even Unity asset store has complete projects both for free and paid.
- Graphics Rendering: Unity has one of the best graphics rendering system. It allows you to create environments like luminous day, gaudy glow of neon signs, dimly lit midnights and shadowy tunnels. It produces amazing visual effects. Although Unity supports multi-platform but still it tries to cover low level graphics API of every platform for better results and smother user experience.
- Team Collaboration: It has features that enable collaboration and simple workflow. Unity’s cloud storage allows you to save, share and sync your projects anywhere.
- Performance Reporting: Unity performance reporting system deals with issues in real time. High priorities issues are solved very efficiently. Finds application errors across devices and platforms.
Unity Interfaces
Let’s explore Unity editor’s interfaces, which are configurable. It is made up of tapped windows that you can rearrange according to your need. Let’s explore the default window settings. Here is the image how it looks
Hierarchy Window
The Hierarchy window represents every object in the scene. It shows how objects are linked with each other in the scene, so these two windows are related. In hierarchy window there is a drop down list named as Create. You can create an empty object, 3D objects, 2D objects, light, audio, video, particle system and camera objects very easily. The hierarchy window is shown below. ‘Untitled’ is the name of the scene. You can rename it as you want. You can see a drop down icon at the very right side of untitled (scene name). By clicking on this drop down you can see different options for Save Scene and Add New Scene.
Scene Window
Scene window is where you create your scene. It is where you can interact with your game objects and models. You can resize, reshape and reposition your scene objects. This is the window where you start working with Unity. Scene view can be 2D or 3D depending on the setting of your project. Here is a screen shot of how the scene window looks:
In scene window you can see another tab labeled Shaded, this is where you can select what type of view you want either shaded or wireframe. It has many other options like Miscellaneous, Global illumination, Real time GI, Baked GI and many others. You can view to 2D or 3D by using the button next to the Shaded drop down. Next is the toggle button for scene lighting. Similarly a toggle button for scene audio. Next is a drop down list to enable sky box, fog, animated material and image effects.
Game Window
Game window represents your final, published game in play mode. It is rendered from the cameras you used in your game. In game window you can see another tool bar as shown below in the screen shot:
Display 1 shows camera present in your game scene. By default it is set to Display 1 for main camera. If you have multiple cameras and you want to switch then you can select from drop down list. Next to this you can see a drop down for aspect ratios. You can select according to your target device monitor screen. Next you can see a Scale slider to zoom in. Scroll to the right and examine more details of your scene in play mode. Next is the button for Maximize On Play, when clicked, the game window size will be maximum on play mode. Mute Audio toggle is used for mute/unmute audio. Stats shows rendering statistics about your game’s audio and graphics.
Project Assets Window
As the name shows assets window has all the assets of your project which you can use. If you import something new it will appear in project assets window. Project asset window has two parts, the left panel and right panel as shown in the below screen shot:
Left pane shows the hierarchical structure of the project’s assets. When you click on any folder it will show the details in the right panel. For example in the given figure Prefabs folder is clicked in left panel so its details are showing in the right panel as it contains two game objects. In the left panel you can see a Favorites section, where you can drag items which you want to use very frequently to avoid time waste in searching for them. Above it you can see a Create drop down which enables you to create a C# script, a folder, a shader, a GUI skin, a scene, a prefab, a material and much more.
Console Window
Console window is the place where you can see your errors, warnings and messages. You can adjust them by clicking their toggle buttons. It also allows you to clear all the errors, warnings and messages. You can pause errors for a certain time. Here you can see in the following figure
The drop down icon at the very top right corner has options for Editor Log and Stack Trace Logging.
Inspector Window
Inspector window is one of the most interesting and useful window of the editor. It is the place where you can edit all the properties of the selected game object. Every game object has its own type so their properties will be different and inspector’s window can vary. Assets, scripts and game objects all vary in properties. Lets see the properties of a cube in inspector window. Here is the image:
You can rename your game object by just clicking on the previous name and typing a new one. Next you will see the transform section where you can adjust position, rotation and scaling of your selected game object. In the last you see a button name as Add Component, click on it to add new components to your game object, for example if you want to attach a script, just click on add component and type your script name.
Tool Bar
Last is the tool bar tab, it has many useful features. It contains some basic tools for manipulating the scene view and objects. In center there are buttons for play, pause and step control. The next two buttons shows your Unity cloud and Unity account. Here is the figure how it looks:
Getting Started With Unity
Let’s start creating a new project in Unity because it’s time to play with what we have learned. Double click on Unity icon following window will appear:
Enter Project Name, select a workplace Location and then select type of your project either 2D or 3D. Click on Create Project.
By default you will see an untitled scene containing a main camera and directional light in the scene. Let’s start creating an environment.
Building Environment
First of all create a plane by clicking on Create -> 3D Object and then select Plane. Or alternatively you can create it by clicking on GameObject -> Game Object and then select Plane. Go to hierarchy window and click on plane game object. Now go to inspector window and rename it as Ground. Now adjust transformation values so that this plane looks like a straight road. Just scale X to 6 and Z to 50. Here is the image how it looks
Now download a road texture and apply it on the ground object. Create a folder name as Texture. Drag downloaded road texture to Texture’s folder. Now select Ground and drag road texture in the scene view. Here is the image how it looks
This is the texture I downloaded
After applying texture on the ground, click on Ground and set tiling in inspector window. Here is how I set it.
Now you have created a road model, let’s create a ball model in unity.
Go to Create -> 3D object and then select Sphere, you will see a sphere object in scene window. Select it and go to the inspector window to rename it as Ball. Now adjust transformation values accordingly. Just scale it to 5 along all three axis and reposition it to the center of the road. Here is how it looks
Now create a fence or wall around the road.
Go to Create -> 3D Object and then select Cube. Select it and rename it to Wall1. Go to inspector window and set transformation values so that it looks like a wall around the road. Here is how it looks:
See these transformation values for Wall1. Scale Y to 6 and Z to 500. Then adjust its position so that it comes at the corners of road.
Now search for a wall texture download it and copy to the Texture folder in assets. Drag wall texture to the wall in the scene window. Adjust tilling so that it looks nice and smooth. I adjusted tiling as X to 50 and Y to 1.5. After adjusting tiling this is how it looks
This is the texture I used for wall
We have created wall for one side of the road. Now do the same thing for the other side of the road too. Instead of going through the all the process we can just copy Wall1 and rename it to Wall2.
Select Wall1 in hierarchy window and then right click and then select Duplicate option. It will create another game object having same size and transformation values. Click on Wall1(1) and rename it to Wall2. Now adjust position so that it comes to the other corner of the road.
See the following image how cool it looks
My position values for Wall2 are X to -29.6 Y to 2.6 and Z to 2.6.
Now create a material for Ball. Go to Project window and create a folder by right clicking on the mouse and then select Folder. Name it as Materials. Again right click on mouse and create a material. Name it as redBall. In inspector’s window select color of material. Go to Main Maps and select Albedo color to red. Increase the metallic texture by scrolling bar to the right. Drag this material to the Ball in the scene view. Here is how it looks
Here is how material looks:
So we are done with our environment development. Now time to do some coding. For this we have to create a script.
Scripting in Unity
To implement your own gameplay features and to control the behavior of the game Unity provides as a scripting mechanism. You can write your own script for the desired output of the game. With these scripts you can trigger game events, can change component’s properties and you can respond to user inputs. Basically Unity supports two different programming languages for scripting purpose, one is C# and other is JavaScript. Other than these two languages many other .NET languages can also be used with Unity. Scripts are known as behavior component in Unity.
Creating a Script
Let’s start creating a Unity script. For this go to the assets window and create a new folder named Scripts (you can skip creating new folders for every new type of asset but its good practice to keep things organized). Here is how my assets window looks now:
Now open the Scripts folder, right click, then go to Create and select C# script. Rename script to Movement. We are creating this script to move and roll the ball on the road. For now the ball is stationary, doing nothing, let’s create some movement in it.
Double click on the Movement script it will open in Mono Develop. If your script is a mono behavior then you will see some pre written code like this
using System.Collections; using System.Collections.Generic; using UnityEngine; public class MovementScript : MonoBehaviour { // Use this for initialization void Start () { } // Update is called once per frame void Update () { } }
You can see two functions Start() and Update().
Start(): Start function is used for initializing variables and objects. It is called only once when the script is enabled just before any other update function calls.
Update(): It is a mono behavior function, it is called once in every frame.
Other than these two there are many other mono behavior functions for example awake(), fixedUpdate(), lateUpdate() etc.
To move the ball on the road first of all you have to make it a rigid body (it is an ideal solid body in which deformation is neglected). Select Ball in hierarchy window and click on Add Component button in inspector window. Type rigid body and press Enter. A rigid body will attach to the Ball. Now go to script and create a private variable of type Rigidbody. Now assign rigid body of the Ball to this variable you just created in the script.
private Rigidbody rb; rb = GetComponent<Rigidbody> ();
Now write some code for the movement of this rigid body. What’s the idea? Ball should move when I press arrow keys of the key board. It should move forward when up key is pressed, backward when down key is pressed and so on.
So the input in coming from the keyboard, how should I get this input? Unity’s Input class has a function name GetAxis(), to returns the value of virtual axis identified by the axis name. Create two variables one for x-axis and one for y-axis input. Here is how it should be
float moveHorizontal = Input.GetAxis ("Horizontal");
Now create a Vector3 variable to get movement values.
Vector3 movement = new Vector3 (moveHorizontal, 0.0f,moveVerticle );
First parameter is the value of x-axis, second is the value of y-axis and third is the value of z-axis. As ball will not move in the direction of y-axis so assign zero to it. Lastly add this movement to rigid body and multiply with a constant number for speed or create another variable for speed. See the complete code below
using System.Collections; using System.Collections.Generic; using UnityEngine; public class Movement : MonoBehaviour { public float speed; private Rigidbody rb; // Use this for initialization void Start () { rb = GetComponent<Rigidbody> (); } // Fixed Update is called after fixed number of frame void FixedUpdate () { float moveHorizontal = Input.GetAxis("Horizontal"); float moveVerticle = Input.GetAxis("Horizontal"); Vector3 movement = new Vector3 (-1*moveHorizontal, 0.0f,-1*moveVerticle ); rb.AddForce (movement * speed); } }
As speed is a public variable so you can assign value in the inspector window. Attach this script to the ball by dragging it to the inspector window or by pressing Add Component button. Press play button and test your coding either ball is moving or not.
Setting Camera
Last thing you will notice is when you press forward button and ball starts moving it goes out of the camera as camera is stationary. What should we do? We should move camera too? Yes it is the simplest thing to do. Make the camera child of the ball by dragging main camera to the ball.
Conclusion
This was a basic introductory tutorial in which you learned many interesting features, environment building and scripting in Unity. Don’t hesitate, start creating your first game with Unity today and enjoy! | https://linuxhint.com/unity3d-tutorial/ | CC-MAIN-2020-10 | refinedweb | 2,879 | 65.93 |
SwiftRichString is a lightweight library which allows to create and manipulate attributed strings easily both in iOS, macOS, tvOS and even watchOS. It provides convenient way to store styles you can reuse in your app's UI elements, allows complex tag-based strings rendering and also includes integration with Interface Builder.
Main Features
Easy Styling
let style = Style { $0.font = SystemFonts.AmericanTypewriter.font(size: 25) // just pass a string, one of the SystemFonts or an UIFont $0.color = "#0433FF" // you can use UIColor or HEX string! $0.underline = (.patternDot, UIColor.red) $0.alignment = .center } let attributedText = "Hello World!".set(style: style) // et voilà!
XML/HTML tag based rendering
SwiftRichString allows you to render complex strings by parsing text's tags: each style will be identified by an unique name (used inside the tag) and you can create a
StyleXML (was
StyleGroup) which allows you to encapsulate all of them and reuse as you need (clearly you can register it globally).
// Create your own styles } let myGroup = StyleXML(base: normal, ["bold": bold, "italic": italic]) let str = "Hello <bold>Daniele!</bold>. You're ready to <italic>play with us!</italic>" self.label?.attributedText = str.set(style: myGroup)
That's the result!
Documentation
- Introduction to
Style,
StyleXML&
StyleRegEx
- The
StyleManager
- Assign style using Interface Builder
- All properties of
Style
Other info:
Introduction to
Style,
StyleXML,
StyleRegEx
The main concept behind SwiftRichString is the use of
StyleProtocol as generic container of the attributes you can apply to both
String and
NSMutableAttributedString.
Concrete classes derivated by
StyleProtocol are:
Style,
StyleXML and
StyleRegEx.
Each of these classes can be used as source for styles you can apply to a string, substring or attributed string.
Style: apply style to strings or attributed strings
A
Style is a class which encapsulate all the attributes you can apply to a string. The vast majority of the attributes of both AppKit/UIKit are currently available via type-safe properties by this class.
Creating a
Style instance is pretty simple; using a builder pattern approach the init class require a callback where the self instance is passed and allows you to configure your properties by keeping the code clean and readable:
let style = Style { $0.font = SystemFonts.Helvetica_Bold.font(size: 20) $0.color = UIColor.green // ... set any other attribute } let attrString = "Some text".set(style: style) // attributed string
StyleXML: Apply styles for tag-based complex string
Style instances are anonymous; if you want to use a style instance to render a tag-based plain string you need to include it inside a
StyleXML. You can consider a
StyleXML as a container of
Styles (but, in fact, thanks to the conformance to a common
StyleProtocol's protocol your group may contains other sub-groups too).
let bodyStyle: Style = ... let h1Style: Style = ... let h2Style: Style = ... let group = StyleXML(base: bodyStyle, ["h1": h1Style, "h2": h2Style]) let attrString = "Some <h1>text</h1>, <h2>welcome here</h2>".set(style: group)
The following code defines a group where:
- we have defined a base style. Base style is the style applied to the entire string and can be used to provide a base ground of styles you want to apply to the string.
- we have defined two other styles named
h1and
h2; these styles are applied to the source string when parser encounter some text enclosed by these tags.
StyleRegEx: Apply styles via regular expressions
StyleRegEx allows you to define a style which is applied when certain regular expression is matched inside the target string/attributed string.
let emailPattern = "([A-Za-z0-9_\\-\\.\\+])+\\@([A-Za-z0-9_\\-\\.])+\\.([A-Za-z]+)" let style = StyleRegEx(pattern: emailPattern) { $0.color = UIColor.red $0.backColor = UIColor.yellow } let attrString = "My email is hello@danielemargutti.com and my website is".(style: style!)
The result is this:
String & Attributed String concatenation
SwiftRichString allows you to simplify string concatenation by providing custom
+ operator between
String,
AttributedString (typealias of
NSMutableAttributedString) and
Style.
This a an example:
let body: Style = Style { ... } let big: Style = Style { ... } let attributed: AttributedString = "hello ".set(style: body) // the following code produce an attributed string by // concatenating an attributed string and two plain string // (one styled and another plain). let attStr = attributed + "\(username)!".set(style:big) + ". You are welcome!"
You can also use
+ operator to add a style to a plain or attributed string:
// This produce an attributed string concatenating a plain // string with an attributed string created via + operator // between a plain string and a style let attStr = "Hello" + ("\(username)" + big)
Finally you can concatente strings using function builders:
let bold = Style { ... } let italic = Style { ... } let attributedString = AttributedString.composing { "hello".set(style: bold) "world".set(style: italic) }
Apply styles to
String &
Attributed String
Both
String and
Attributed String (aka
NSMutableAttributedString) has a come convenience methods you can use to create an manipulate attributed text easily via code:
Strings Instance Methods
set(style: String, range: NSRange? = nil): apply a globally registered style to the string (or a substring) by producing an attributed string.
set(styles: [String], range: NSRange? = nil): apply an ordered sequence of globally registered styles to the string (or a substring) by producing an attributed string.
set(style: StyleProtocol, range: NSRange? = nil): apply an instance of
Styleor
StyleXML(to render tag-based text) to the string (or a substring) by producting an attributed string.
set(styles: [StyleProtocol], range: NSRange? = nil): apply a sequence of
Style/
StyleXMLinstance in order to produce a single attributes collection which will be applied to the string (or substring) to produce an attributed string.
Some examples:
// apply a globally registered style named MyStyle to the entire string let a1: AttributedString = "Hello world".set(style: "MyStyle") // apply a style group to the entire string // commonStyle will be applied to the entire string as base style // styleH1 and styleH2 will be applied only for text inside that tags. let styleH1: Style = ... let styleH2: Style = ... let StyleXML = StyleXML(base: commonStyle, ["h1" : styleH1, "h2" : styleH2]) let a2: AttributedString = "Hello <h1>world</h1>, <h2>welcome here</h2>".set(style: StyleXML) // Apply a style defined via closure to a portion of the string let a3 = "Hello Guys!".set(Style({ $0.font = SystemFonts.Helvetica_Bold.font(size: 20) }), range: NSMakeRange(0,4))
AttributedString Instance Methods
Similar methods are also available to attributed strings.
There are three categories of methods:
setmethods replace any existing attributes already set on target.
addadd attributes defined by style/styles list to the target
removeremove attributes defined from the receiver string.
Each of this method alter the receiver instance of the attributed string and also return the same instance in output (so chaining is allowed).
Add
add(style: String, range: NSRange? = nil): add to existing style of string/substring a globally registered style with given name.
add(styles: [String], range: NSRange? = nil): add to the existing style of string/substring a style which is the sum of ordered sequences of globally registered styles with given names.
add(style: StyleProtocol, range: NSRange? = nil): append passed style instance to string/substring by altering the receiver attributed string.
add(styles: [StyleProtocol], range: NSRange? = nil): append passed styles ordered sequence to string/substring by altering the receiver attributed string.
Set
set(style: String, range: NSRange? = nil): replace any existing style inside string/substring with the attributes defined inside the globally registered style with given name.
set(styles: [String], range: NSRange? = nil): replace any existing style inside string/substring with the attributes merge of the ordered sequences of globally registered style with given names.
set(style: StyleProtocol, range: NSRange? = nil): replace any existing style inside string/substring with the attributes of the passed style instance.
set(styles: [StyleProtocol], range: NSRange? = nil): replace any existing style inside string/substring with the attributes of the passed ordered sequence of styles.
Remove
removeAttributes(_ keys: [NSAttributedStringKey], range: NSRange): remove attributes specified by passed keys from string/substring.
remove(_ style: StyleProtocol): remove attributes specified by the style from string/substring.
Example:
let a = "hello".set(style: styleA) let b = "world!".set(style: styleB) let ab = (a + b).add(styles: [coupondStyleA,coupondStyleB]).remove([.foregroundColor,.font])
Fonts & Colors in
Style
All colors and fonts you can set for a
Style are wrapped by
FontConvertible and
ColorConvertible protocols.
SwiftRichString obviously implements these protocols for
UIColor/
NSColor,
UIFont/
NSFont but also for
String.
For Fonts this mean you can assign a font by providing directly its PostScript name and it will be translated automatically to a valid instance:
let firaLight: UIFont = "FiraCode-Light".font(ofSize: 14) ... ... let style = Style { $0.font = "Jura-Bold" $0.size = 24 ... }
On UIKit you can also use the
SystemFonts enum to pick from a type-safe auto-complete list of all available iOS fonts:
let font1 = SystemFonts.Helvetica_Light.font(size: 15) let font2 = SystemFonts.Avenir_Black.font(size: 24)
For Color this mean you can create valid color instance from HEX strings:
let color: UIColor = "#0433FF".color ... ... let style = Style { $0.color = "#0433FF" ... }
Clearly you can still pass instances of both colors/fonts.
Derivating a
Style
Sometimes you may need to infer properties of a new style from an existing one. In this case you can use
byAdding() function of
Style to produce a new style with all the properties of the receiver and the chance to configure additional/replacing attributes.
let initialStyle = Style { $0.font = SystemFonts.Helvetica_Light.font(size: 15) $0.alignment = right } // The following style contains all the attributes of initialStyle // but also override the alignment and add a different foreground color. let subStyle = bold.byAdding { $0.alignment = center $0.color = UIColor.red }
Conforming to
Dynamic Type
To support your fonts/text to dynammically scale based on the users preffered content size, you can implement style's
dynamicText property. UIFontMetrics properties are wrapped inside
DynamicText class.
let style = Style { $0.font = UIFont.boldSystemFont(ofSize: 16.0) $0.dynamicText = DynamicText { $0.style = .body $0.maximumSize = 35.0 $0.traitCollection = UITraitCollection(userInterfaceIdiom: .phone) } }
Render XML/HTML tagged strings
SwiftRichString is also able to parse and render xml tagged strings to produce a valid
NSAttributedString instance. This is particularly useful when you receive dynamic strings from remote services and you need to produce a rendered string easily.
In order to render an XML string you need to create a compisition of all styles you are planning to render in a single
StyleXML instance and apply it to your source string as just you made for a single
Style.
For example:
// The base style is applied to the entire string let baseStyle = Style { $0.font = UIFont.boldSystemFont(ofSize: self.baseFontSize * 1.15) $0.lineSpacing = 1 $0.kerning = Kerning.adobe(-20) } let boldStyle = Style { $0.font = UIFont.boldSystemFont(ofSize: self.baseFontSize) $0.dynamicText = DynamicText { $0.style = .body $0.maximumSize = 35.0 $0.traitCollection = UITraitCollection(userInterfaceIdiom: .phone) } } let italicStyle = Style { $0.font = UIFont.italicSystemFont(ofSize: self.baseFontSize) } // A group container includes all the style defined. let groupStyle = StyleXML.init(base: baseStyle, ["b" : boldStyle, "i": italicStyle]) // We can render our string let bodyHTML = "Hello <b>world!</b>, my name is <i>Daniele</i>" self.textView?.attributedText = bodyHTML.set(style: group)
Customize XML rendering: react to tag's attributes and unknown tags
You can also add custom attributes to your tags and render it as you prefer: you need to provide a croncrete implementation of
XMLDynamicAttributesResolver protocol and assign it to the
StyleXML's
.xmlAttributesResolver property.
The protocol will receive two kind of events:
applyDynamicAttributes(to attributedString: inout AttributedString, xmlStyle: XMLDynamicStyle)is received when parser encounter an existing style with custom attributes. Style is applied and event is called so you can make further customizations.
func styleForUnknownXMLTag(_ tag: String, to attributedString: inout AttributedString, attributes: [String: String]?)is received when a unknown (not defined in
StyleXML's styles) tag is received. You can decide to ignore or perform customizations.
The following example is used to override text color for when used for any known tag:
// First define our own resolver for attributes open class MyXMLDynamicAttributesResolver: XMLDynamicAttributesResolver { public func applyDynamicAttributes(to attributedString: inout AttributedString, xmlStyle: XMLDynamicStyle) { let finalStyleToApply = Style() xmlStyle.enumerateAttributes { key, value in switch key { case "color": // color support finalStyleToApply.color = Color(hexString: value) default: break } } attributedString.add(style: finalStyleToApply) } } // Then set it to our's StyleXML instance before rendering text. let groupStyle = StyleXML.init(base: baseStyle, ["b" : boldStyle, "i": italicStyle]) groupStyle.xmlAttributesResolver = MyXMLDynamicAttributesResolver()
The following example define the behaviour for a non known tag called
rainbow.
Specifically it alter the string by setting a custom color for each letter of the source string.
open class MyXMLDynamicAttributesResolver: XMLDynamicAttributesResolver { public override func styleForUnknownXMLTag(_ tag: String, to attributedString: inout AttributedString, attributes: [String : String]?) { super.styleForUnknownXMLTag(tag, to: &attributedString, attributes: attributes) if tag == "rainbow" { let colors = UIColor.randomColors(attributedString.length) for i in 0..<attributedString.length { attributedString.add(style: Style({ $0.color = colors[i] }), range: NSMakeRange(i, 1)) } } } } }
You will receive all read tag attributes inside the
attributes parameter.
You can alter attributes or the entire string received as
inout parameter in
attributedString property.
A default resolver is also provided by the library and used by default:
StandardXMLAttributesResolver. It will support both
color attribute in tags and
<a href> tag with url linking.
letwebpage</b> is really <b>cool</b>. Take a look <a href=\"\">here</a>" let styleBase = Style({ $0.font = UIFont.boldSystemFont(ofSize: 15) }) let styleBold = Style({ $0.font = UIFont.boldSystemFont(ofSize: 20) $0.color = UIColor.blue }) let groupStyle = StyleXML.init(base: styleBase, ["b" : styleBold]) self.textView?.attributedText = sourceHTML.set(style: groupStyle)
The result is this:
where the
b tag's blue color was overriden by the color tag attributes and the link in 'here' is clickable.
Custom Text Transforms
Sometimes you want to apply custom text transforms to your string; for example you may want to make some text with a given style uppercased with current locale.
In order to provide custom text transform in
Style instances just set one or more
TextTransform to your
Style's
.textTransforms property:
let allRedAndUppercaseStyle = Style({ $0.font = UIFont.boldSystemFont(ofSize: 16.0) $0.color = UIColor.red $0.textTransforms = [ .uppercaseWithLocale(Locale.current) ] }) let text = "test".set(style: allRedAndUppercaseStyle) // will become red and uppercased (TEST)
While
TextTransform is an enum with a predefined set of transform you can also provide your own function which have a
String as source and another
String as destination:
let markdownBold = Style({ $0.font = UIFont.boldSystemFont(ofSize: 16.0) $0.color = UIColor.red $0.textTransforms = [ .custom({ return "**\($0)**" }) ] })
All text transforms are applied in the same ordered you set in
textTransform property.
Local & Remote Images inside text
SwiftRichString supports local and remote attached images along with attributed text.
You can create an attributed string with an image with a single line:
// You can specify the bounds of the image, both for size and the location respecting the base line of the text. let localTextAndImage = AttributedString(image: UIImage(named: "rocket")!, bounds: CGRect(x: 0, y: -20, width: 25, height: 25)) // You can also load a remote image. If you not specify bounds size is the original size of the image. let remoteTextAndImage = AttributedString(imageURL: "http://...") // You can now compose it with other attributed or simple string let finalString = "...".set(style: myStyle) + remoteTextAndImage + " some other text"
Images can also be loaded by rending an XML string by using the
img tag (with
named tag for local resource and
url for remote url).
rect parameter is optional and allows you to specify resize and relocation of the resource.
let This other is loaded from remote URL: <img url=""/> """ self.textView?.attributedText = taggedText.set(style: ...)
This is the result:
Sometimes you may want to provide these images lazily. In order to do it just provide a custom implementation of the
imageProvider callback in
StyleXML instance:
let has done!" let xmlStyle = StyleXML(base: { /// some attributes for base style }) // This method is called when a new `img` tag is found. It's your chance to // return a custom image. If you return `nil` (or you don't implement this method) // image is searched inside any bundled `xcasset` file. xmlStyle.imageProvider = { (imageName, attributes) in switch imageName { case "check": // create & return your own image default: // ... } } self.textView?.attributedText = xmlText.set(style: x)
The
StyleManager
Register globally available styles
Styles can be created as you need or registered globally to be used once you need. This second approach is strongly suggested because allows you to theme your app as you need and also avoid duplication of the code.
To register a
Style or a
StyleXML globally you need to assign an unique identifier to it and call
register() function via
Styles shortcut (which is equal to call
StylesManager.shared).
In order to keep your code type-safer you can use a non-instantiable struct to keep the name of your styles, then use it to register style:
// Define a struct with your styles names public struct StyleNames { public static let body: String = "body" public static let h1: String = "h1" public static let h2: String = "h2" private init { } }
Then you can:
let bodyStyle: Style = ... Styles.register(StyleNames.body, bodyStyle)
Now you can use it everywhere inside the app; you can apply it to a text just using its name:
let text = "hello world".set(StyleNames.body)
or you can assign
body string to the
styledText via Interface Builder designable property.
Defer style creation on demand
Sometimes you may need to return a particular style used only in small portion of your app; while you can still set it directly you can also defer its creation in
StylesManager.
By implementing
onDeferStyle() callback you have an option to create a new style once required: you will receive the identifier of the style.
Styles.onDeferStyle = { name in if name == "MyStyle" { } return (StyleXML(base: normal, ["bold": bold, "italic": italic]), true) } return (nil,false) }
The following code return a valid style for
myStyle identifier and cache it; if you don't want to cache it just return
false along with style instance.
Now you can use your style to render, for example, a tag based text into an
UILabel: just set the name of the style to use.
Assign style using Interface Builder
SwiftRichString can be used also via Interface Builder.
UILabel
UITextView
UITextField
has three additional properties:
styleName: String(available via IB): you can set it to render the text already set via Interface Builder with a style registered globally before the parent view of the UI control is loaded.
style: StyleProtocol: you can set it to render the text of the control with an instance of style instance.
styledText: String: use this property, instead of
attributedTextto set a new text for the control and render it with already set style. You can continue to use
attributedTextand set the value using
.set()functions of
String/
AttributedString.
Assigned style can be a
Style,
StyleXML or
StyleRegEx:
- if style is a
Stylethe entire text of the control is set with the attributes defined by the style.
- if style is a
StyleXMLa base attribute is set (if
baseis valid) and other attributes are applied once each tag is found.
- if style is a
StyleRegExa base attribute is set (if
baseis valid) and the attribute is applied only for matches of the specified pattern.
Typically you will set the style of a label via
Style Name (
styleName) property in IB and update the content of the control by setting the
styledText:
// use `styleName` set value to update a text with the style self.label?.styledText = "Another text to render" // text is rendered using specified `styleName` value.
Otherwise you can set values manually:
// manually set the an attributed string self.label?.attributedText = (self.label?.text ?? "").set(myStyle) // manually set the style via instance self.label?.style = myStyle self.label?.styledText = "Updated text"
Properties available via
Style class
The following properties are available:
Requirements
- Swift 5.1+
- iOS 8.0+
- macOS 11.0+
- watchOS 2.0+
- tvOS 11.0+
Installation
CocoaPods
CocoaPods is a dependency manager for Cocoa projects. For usage and installation instructions, visit their website. To integrate Alamofire into your Xcode project using CocoaPods, specify it in your Podfile:
pod 'SwiftRichString': "", from: "3.5.0") ]
Carthage
Carthage is a decentralized dependency manager that builds your dependencies and provides you with binary frameworks.
To integrate SwiftRichString into your Xcode project using Carthage, specify it in your
Cartfile:
github "malcommac/SwiftRichString"
Run
carthage to build the framework and drag the built
SwiftRichString.framework into your Xcode project.
Contributing
Issues and pull requests are welcome! Contributors are expected to abide by the Contributor Covenant Code of Conduct.
SwiftRichString is available under the MIT license. See the LICENSE file for more info.
Daniele Margutti: hello@danielemargutti.com, @danielemargutti | https://swiftpackageindex.com/malcommac/SwiftRichString | CC-MAIN-2021-04 | refinedweb | 3,392 | 56.45 |
?
gcov is a test coverage tool. When built with an application, the gcov utility monitors an application under execution and identifies which source lines have been executed and which have not and also it can identify the number of times a particular line has been executed, making it useful for performance profiling to help discover where the optimization efforts will best affect the code and also along with the other profiling tool, gprof, to assess which parts of your code use the greatest amount of computing time.
Since gcov is bundled along with GCC [sometimes it may not be] I will be just using the gcc compiler throughout this post. To use gcov test coverage tool to produce coverage information about your application source code, you must
- Compile your source code using a GCC compiler.The gcov application might not[Not sure if there are any ports available for other compilers] be compatible with embedded coverage and analysis information produced by any other compiler.
- Use -fprofile-arcs and -ftest-coverage options when compiling your code with a GCC compiler.
- Avoid using any of the optimization options provided by the GCC compiler.These options might modify the execution order or grouping of your code, which would make it difficult or impossible to map coverage information into your source files.
- Let the programming style be simple.Basically.
#include <stdio.h> int main (void) { int i; for(i=1;i<13;i++) { if(i%2 == 0) printf("%d is divisible by 2 \n",i); if(i%5==0) printf("%d is divisible by 5 \n",i); if (i%14==0) printf("%d is divisible by 14 \n",i); } return 0; }NOTE: Checkout GCC version with gcc -v command. Because I had some problems regarding the types of files that are generated when compiling the code to support code coverage option. So I decided to use both the older version of GCC and a newer one to notify different types of files that are created.
Let us enable code coverage and compile the source code
[bash]$ gcc -Wall -fprofile-arcs -ftest-coverage test.c
Once compiled successfully along with the executable file 'a.out' other files are also created.
For GCC version 2.95 cygwin special two new files namely test.bb & test.bbg with .bb & .bbg file extensions are created in the current directory.
For GCC version 3.4.4 cygwin special a file named test.gcno with .gcno file extension is created in the current directory.
Run the executable file created.
[bash]$ ./a.out 2 is divisible by 2 4 is divisible by 2 5 is divisible by 5 6 is divisible by 2 8 is divisible by 2 10 is divisible by 2 10 is divisible by 5 12 is divisible by 2
For GCC version 2.95 cygwin special a new file named test.da with file extension .da is created in the current directory.
For GCC version 3.4.4 cygwin special a new file named test.gcda with .gcda file extension is created.
We have to use gcov command with the name of the sourcefile i.e. test.c in our case to perform code coverage.
[bash]$ gcov test.c File `test.c' Lines executed:90.00% of 10 test.c:creating `test.c.gcov'The gcov command produces an annotated version of the original source file, with the file extension ‘.gcov’, containing counts of the number of times each line was executed. In our case a file named 'test.c.gcov' is created..
[bash]$cat test.c.gcov -: 0:Source:test.c -: 0:Graph:test.gcno -: 0:Data:test.gcda -: 0:Runs:1 -: 0:Programs:1 -: 1:#include <stdio.h> -: 2: -: 3:int main (void) function main called 1 returned 100% blocks executed 91% 1: 4:{ -: 5: 1: 6:int i; -: 7: 13: 8:for(i=1;i<13;i++) -: 9:{ 12: 10:if(i%2 == 0) 6: 11:printf("%d is divisible by 2 \n",i); -: 12: 12: 13:if(i%5==0) 2: 14:printf("%d is divisible by 5 \n",i); -: 15: 12: 16:if (i%14==0) #####: 17:printf("%d is divisible by 14 \n",i); -: 18:} -: 19: 1: 20:return 0; -: 21:}
The line counts can be seen in the first column of the output (Indicated in red box in the image) and the line which is not executed is marked with hashes ‘######’.
NOTE: grep '######' *.gcov can be used to find parts of a program which have not been used.
Using gcov’s -b (--branch-probabilities) option when running gcov on an instrumented source module writes branch frequencies and branch summary information into the annotated filename.c.gcov module produced by gcov.
[bash]$ gcov -b test.c File `test.c' Lines executed:90.00% of 10 Branches executed:100.00% of 8 Taken at least once:87.50% of 8 Calls executed:75.00% of 4 test.c:creating `test.c.gcov'New output file test.c.gcov is shown below.Branch - Annotated Source Code Showing Branch Percentages.
$cat test.c.gcov -: 0:Source:test.c -: 0:Graph:test.gcno -: 0:Data:test.gcda -: 0:Runs:1 -: 0:Programs:1 -: 1:#include <stdio.h> -: 2: -: 3:int main (void) function main called 1 returned 100% blocks executed 91% 1: 4:{ call 0 returned 100% -: 5: 1: 6:int i; -: 7: 13: 8:for(i=1;i<13;i++) branch 0 taken 92% (fallthrough) branch 1 taken 8% -: 9:{ 12: 10:if(i%2 == 0) branch 0 taken 50% (fallthrough) branch 1 taken 50% 6: 11:printf("%d is divisible by 2 \n",i); call 0 returned 100% -: 12: 12: 13:if(i%5==0) branch 0 taken 17% (fallthrough) branch 1 taken 83% 2: 14:printf("%d is divisible by 5 \n",i); call 0 returned 100% -: 15: 12: 16:if (i%14==0) branch 0 taken 0% (fallthrough) branch 1 taken 100% #####: 17:printf("%d is divisible by 14 \n",i); call 0 never executed -: 18:} -: 19: 1: 20:return 0; -: 21:}Note that the output file still identifies basic blocks and provides line execution counts, but now also identifies the line of source code associated with each possible branch and function call. The annotated source code also displays the number of times that branch is executed.
Compiling the source code with the -fprofile-arcs option enables GCC compiler to build a call graph for the application and generates a call graph file in the same directory where the source file is located. This call graph file has the same name as the original source file, but replaces the original file extension with the .gcno extension. For e.g. compiling the program test.c with the -fprofile-arcs option created the file test.gcno in the working directory. This file is created at compile time, rather than at runtime.
A call graph is a list identifying which basic blocks are called by other functions, and which functions call other functions. The representation of each call from one function to another in a call graph is known as a call arc, or simply an arc. The .gcno file contains information that enables the gcov program to reconstruct the basic block call graphs and assign source line numbers to basic blocks.On running the application executable compiled with -fprofile-arcs created a file with the same name as the original source file but with the .gcda extension (GNU Compiler arc data) in the same directory. For e.g. on executing a.out executable that was compiled with the -fprofile-arcs option created the file test.gcda in current directory. The file with the .gcda extension contains call arc transition counts and some summary information.
References
1. GCC/gcov - link
2. Man page - gcov.
3. An Introduction to GCC - for the GNU compilers gcc and g++ - link.
4. The Definitive Guide to GCC - Amazon link.
5. Code coverage - wiki
There is a tool called Trucov, which builds upon Gcov to output Control Flow Graphs with coverage information.
The homepage is
The wiki page is
In an embedded system like a router where will the .da for each of the source files be created. Will it be on the router or on the host system that built the code and is connected to the router?
Don't bother with the Trucov -- the cmakelists.txt is fail and it don't build. Gave up trying to fix it.
hi | http://codingfreak.blogspot.com/2009/02/gcov-analyzing-code-produced-with-gcc.html | CC-MAIN-2017-47 | refinedweb | 1,403 | 65.22 |
Recognize text from picture
This script recognizes text from a camera or photo library picture. Sharing it since iOS 13 has made it this easy, and Apple Shortcuts do not have support for it (yet, I bet).
Adjust languages on the first row.') ui_image = None if selection == 1: pil_image = photos.capture_image() if pil_image is not None: ui_image = pil2ui(pil_image) elif selection == 2: ui_image = photos.pick_asset().get_ui_image() if ui_image is not None: print('Recognizing...\n') req = VNRecognizeTextRequest.alloc().init().autorelease() req.setRecognitionLanguages_(language_preference) handler = VNImageRequestHandler.alloc().initWithData_options_(ui_image.to_png(), None).autorelease() success = handler.performRequests_error_([req], None) if success: for result in req.results(): print(result.text()) else: print('Problem recognizing anything') ```
I think VNRecognizeText works only for English.
@pavlinb, works perfectly for Finnish, too.
But the version above is slower than it needs to be, due to an unnecessary roundtrip to ui.Image. Here’s a faster version:') pil_image = None if selection == 1: pil_image = photos.capture_image() elif selection == 2: pil_image = photos.pick_asset().get_image() if pil_image is not None: print('Recognizing...\n') buffer = io.BytesIO() pil_image.save(buffer, format='PNG') image_data = buffer.getvalue() req = VNRecognizeTextRequest.alloc().init().autorelease() req.setRecognitionLanguages_(language_preference) handler = VNImageRequestHandler.alloc().initWithData_options_(image_data, None).autorelease() success = handler.performRequests_error_([req], None) if success: for result in req.results(): print(result.text()) else: print('Problem recognizing anything')
@pavlinb, ah, but you were right. This does not recognize the scandinavian letters ä and ö, substituting them with a and o. @cvp, are you getting é, ô and all the others?
@cvp, checked, usesLanguageCorrection is true and recognitionLevel set to ”accurate” by default, so no help there.
Doesn’t work for Cyrillic (Bulgarian).
Eh.
revision = VNRecognizeTextRequest.currentRevision() supported = VNRecognizeTextRequest.supportedRecognitionLanguagesForTextRecognitionLevel_revision_error_(0, revision, None)
Returns ”en-US”.
BTW, I'm impressed from accuracy ( for Latin based texts ).
@mikael @cvp have you tried setting
customWordsattrib of the request? Or, turn off
usesLanguageCorrection? (Since the language is en-US you DON'T want language correction when trying to detect other languages!)
I gather they are looking for words you'd find in an English dictionary. So perhaps façade, or tête-à-tête might recognize, while other examples wouldn't?
@JonB I didn't try but we are not alone with this problem, see here.
I've tried with unknown language codes like xx and yy in setRecognitionLanguages_ and the result is the same. It seems that characters are recognized in any languages.
My last test on a French text was entirely correct
Asie-Pacifique La mission économique belge en Chine cible de cyberattaques massives
usesLanguageCorrection
Tried with False: à still recognized as a
Edit : even with
req.setCustomWords_(['à'])
Is there any code examples of how to recognize text with ios 12.4.3 for the i pad mini 2 that would be cool to add it to my sodoku app game
@sodoku, yes, but it seems a bit more involved. Check this thread where @cvp does all kinds of magic.
def pil2ui(pil_image): buffer = io.BytesIO() pil_image.save(buffer, format='PNG') return ui.Image.from_data(buffer.getvalue())
is memory leaking buffer which has been proven to crash Pythonista when multiple images are processed. A better approach is to use a context manager to force the .close().
def pil2ui(pil_image): with io.BytesIO() as buffer: pil_image.save(buffer, format='PNG') return ui.Image.from_data(buffer.getvalue())
Revisiting this.
Regardless of language restrictions, I have found the simple and reliable ability to pick text from paper to be useful for me almost weekly - URLs, email addresses, reservation codes, laptop serial numbers, etc.
With the use, I noted that the original script had some issues:
- Difficult to find and open when quickly needed.
- Slow to get from the picked photo to recognized text.
- Results are a pain to copy from the Console as it likes to jump around just as you’ve selected the text to copy.
Point #1 was fixed with a simple Apple Shortcuts shortcut to make the script easy to run.
Point #3 was resolved by presenting the recognized text in a TableView, with tap to copy.
Point #2 took a bit more doing.
Pythonista
photosmodule wants to return PIL images, and that results in two very slow conversions - first the module converts the UIImage to PIL, and then I converted that back to a PNG image for recognition. I found some @cvp code in this thread and replaced
photosmodule with
objc_utilpickers, which return PNG data almost directly.
And hey presto! Not just faster recognition, but instantaneous - and with much better quality than with the only contender app I could find (Prizmo Go).
Question for a specialist of this forum.
In the last post of @mikael , I see my user as @cvp but as a black text and not clickable blue, although I've received a notification "Mikael mentioned you...".
How is that possible?
Happy last day of the decade to everyone who shares my calendar!
I finessed the script a bit with the ability to select, copy or share multiple items, and nicer icons.
@cvp, noted and wondered about the lack of the link for your handle, no idea why. | https://forum.omz-software.com/topic/6016/recognize-text-from-picture | CC-MAIN-2021-17 | refinedweb | 846 | 51.55 |
Note:
This functionality is currently only supported in Map Viewer Classic (formerly known as Map Viewer). It will be available in a future release of the new Map Viewer.
The Describe Dataset tool provides an overview of your big data. By default, the tool outputs a table layer containing summaries of your field values and an overview of your geometry and time settings for the input layer. Optionally, the tool can output a feature layer representing a sample of your input features, or a single polygon feature layer that represents the extent of your input features. You can choose to output one, both, or none.:
- Verify that you correctly registered time and geometry with your big data file share.
- Understand attribute values with summarized field statistics.
- Visualize your big data with a sample layer. Instead of drawing a million features, draw a sample.
- Run workflows using a sample of the data before scaling for longer and larger processing.
- Determine where a dataset is by calculating the geographical extent.
Usage notes
Browse to the tabular, point, line, or area feature layer or big data file share dataset you want to describe using the Choose dataset to describe option.
Output a subset of your data by clicking the Sample layer button and specifying the number of features in the value picker that appears. The output subset will always have the same schema, geometry, and time settings as the input features. Use the subset to understand how your big data appears when added to a map or visualized in an attribute table. Additionally, you can run analysis on the sample dataset to determine the best inputs for larger analysis on your entire dataset.
Output a boundary feature that describes the extent of your input dataset by selecting Extent layer. The output will always be a single rectangle feature representing the geographic extent of the input features. Use the extent layer to understand where your data is located, or use it as input elsewhere in your workflow. For example, use it as the area layer to clip features to using the Clip Layer GeoAnalytics tool.
If Use current map extent is checked, only the features that are within the current map extent will be analyzed. If it's not checked, all input features in the input layer will be analyzed, even if they are outside the current map extent. For example, if you chose to output a sample layer and Use current map extent is not checked, the entire dataset will be used for sample results. If you chose to output an extent layer with Use current map extent checked, the output boundary will represent the map extent.
By default, the tool will output a table containing summary statistics for each field and a JSON describing the properties of the input layer. To access the JSON string, click the Show Result button
that appears when you hover over the summary statistics table layer in the table of contents.
The JSON string includes the following information:
- datasetName—The name of the dataset being described.
- datasetSource—The storage location of the input dataset. This value can be ArcGIS Data Store — Relational, ArcGIS Data Store — Spatiotemporal, or Big Data File Share - <your_bdfs_name>.
- recordCount—The total number of records in the input dataset.
- geometry—The geometry settings of the input layer.
- geometryType—The type of geometry the input features represent. This value can be Point, Line, Polygon, or Table.
- sref—The spatial reference the input features use. For example, this value could be {"wkid": 26972}, in which 26972 is the spatial reference ID.
- countNonEmpty—The number of features with a valid geometry.
- countEmpty—The number of features without a valid geometry.
- spatialExtent—The geographical extent of the features represented by the minimum and maximum coordinate values.
- time—The time settings of the input layer.
- timeType—The type of time the input features represent. This value can be Instant, Interval, or None.
- countNonEmpty—The number of features with a valid time.
- countEmpty—The number of features without a valid time.
- temporalExtent—The temporal extent of the features represented by the minimum and maximum time values.
Learn more about time settings and big data file share datasets
Learn more about geometry settings and big data file share datasets
Limitations
The sample layer does not represent a truly random geographic selection and should not be used to understand the geographic extent or distribution of your data. For example, if you specify 230 features for Number of features to include, the result can contain 230 input features in any order or location.
How Describe Dataset works
Calculations
Summary statistics are calculated for each field in the input layer. Fields will have different statistics output depending on the field type. The following soil depth example outlines how statistics are calculated for each field type:
Note:
Results stored in the ArcGIS Data Store are always stored in milliseconds from epoch Coordinated Universal Time (UTC). For example, the UTC time of 1538713350000 milliseconds is the equivalent to Friday, October 5, 2018 04:22:30 PM in the GMT time zone.
Note:
The count statistic (for strings and numeric fields) counts the number of nonempty values. The count of [0, 1, 10, 5, null, 6] = 5. The count of [Primary, Primary, Secondary, null] = 3.
ArcGIS API for Python example
The Describe Dataset tool is available through ArcGIS API for Python.
This example describes a hurricane tracking dataset in a big data file share and outputs a subset of 200 hurricane features and an extent layer.
# Import the required ArcGIS API for Python modules
import arcgis
from arcgis import geoanalytics as ga
from arcgis.gis import GIS
#asters")
# Look through the big data file share for Hurricanes
hurricanes = next(x for x in bdfs_search.layers if x.properties.name == "Hurricanes")
# Run the Describe Dataset tool
result = ga.summarize_data.describe_dataset(input_layer=hurricanes, sample_size=200,
extent_output=true, output_name="Hurricanes_describe")
# Visualize the sample and extent layers if you are running Python in a Jupyter Notebook
processed_map = portal.map()
processed_map.add_layer(result)
processed_map
This example describes a hurricane tracking dataset in a big data file share and outputs a subset of 200 hurricane features and an extent layer.
Similar tools
Use Describe Dataset when you want to explore your data using samples, statistics, and summarization. Other tools may be useful in solving similar but slightly different problems.
Map Viewer Classic analysis tools
Aggregate your dataset into bins or areas and output summary statistics using the Aggregate Points ArcGIS GeoAnalytics Server tool.
Create a subset of your data within a certain area using the Clip Layer ArcGIS GeoAnalytics Server tool.
ArcGIS Desktop analysis tools
To run this tool from ArcGIS Pro, your active portal must be Enterprise 10.7 or later. You must sign in using an account that has privileges to perform GeoAnalytics Feature Analysis. | https://enterprise.arcgis.com/en/portal/latest/use/geoanalytics-describe-dataset.htm | CC-MAIN-2021-49 | refinedweb | 1,134 | 55.24 |
by John Goetz
The GISS Ts+dSST numbers are.
I will post up a plot later today, unless Anthony beats me to it (I like his format).
REPLY:.
In relation to the GISS figures and also Hadcrut I saw this over at realclimate
”
I am not sure about the significance or otherwise of this difference in treatment of the polar regions
GISTEMP anomaly at 250km smoothing:
June 1988 = 0.30 deg C
June 2008 = 0.29 deg C
GISTEMP anomaly at 1200km smoothing:
June 1988 = 0.38 deg C
June 2008 = 0.25 deg C
It’s cooler now than it was in 1988 no matter how they look at it.
JG, is it possible to plot the adjustments in some way so we can see what the scale and number of them is? Or has this already been done? Even a sample to show for a given station year, how the readings had varied over the last 20 years in consequence of the adjustments.
Or is the raw data simply not available any more?
Check out this GISS map: It shows the movement in GISS temperatures around the world from 1988 to 2008.
(This map is for the winter months. For some reason, GISS does not allow me to make the comparison for Spring or for June, and I have not yet understood the explanation of why. Of course, a reference to a GISS map is not be understood as an endorsement of GISS methodology.)
Here is a little exercise I did yesterday and you can play too!
Go to NOAA’sUnited States Climate Summary page (it says May but June’s numbers are in the database). Fill in the form as follows:
Leave “Data Type” at it’s default of Mean Temperature
Period: “Most Recent 12-month Period”
First Year To Display: 1998
Last Year To Display: 2008
Base Period Beg Yr: 1977
EndYr: 2007
Leave other data fields at their default and click the “Select” button to plot the graph.
And there you have it. A trend of -0.63C per decade or a cooling rate of 6 degrees per century since 1998. Now that looks to me like some significant “Global Cooling”. Keep in mind that those are only for North America, not global data.
Latest GISTEMP vs. UAH/RSS (Hadley not yet out for June), with adjusted baselines:
REPLY: Odd. GISS goes down while UAH and RSS go up slightly. – Anthony
I still have trouble with the idea that last months temperatures affect those recorded in 1927. I can see the need to make adjustments, but I would think that only one would be necessary, not readjustments every month.
This may be slightly OT but I have just been reading Steve McIntyre’s post of yesterday on Climate Audit – – and it seems pretty important to me, but as a layman fairly new to this debate, I should welcome a view from people here as to just how significant this is? It suggests to me, at least, that a key tenet of the IPCC argument may well be seriously flawed.
Maybe Hansen has bitten the dust. BTW there is no way NH ice is close to last years melting getting to 1 million Km2 above now
BTW La nina has gone too!
From CA, the response to Steve Mc’s request for Jones’ Russian station data:
.”
So, we cannot check their work or do our own (ok, not me, those of you who get these things done)? Does GISS then adjust adjusted data?
It is still unfathomable to me that historical data is revised every month. I can’t think of a real life analogy for this circumstance. The closest thing that comes to mind is the “fish that got away” whose size tends to be directly related to number of times the tale is told.
Imagine if stock charts were backward revised every month.
I believe someone recently referred to this as the worst scandal in science history going on right under our noses. Piltdown Man didn’t threaten to bankrupt entire economies. Its just waiting for a significant climate cool-down to expose it, I guess, they’re not even trying to hide their re-writing of temperature history.
Maybe they forgot that nature is going to do whatever its going to do no matter what mankind reaches consensus about.
It appears the continuous re-writing is not a conscious attempt at deception, but an artifact of the “adjustment” process.
Don’t confuse bias and group think with maliciousness.
Or as the famous quote goes:
Despite their many degrees and many “peer-reviewed” papers, the mob psychology that has infected the team is not unusual in the history of science.
Jeez, some executives at Northern Telecom tried that for a few years witth the company accounts.
Dittos to what jeez and Bill Marsh have said. As an economist, I’m very familiar with preliminary estimates being later revised into final figures. But that’s not what is taking place here, when recent data causes revisions to data going back decades and decades. There is obviously a serious methodological issue with this. Since this is “official US Government data,” why can we not get a Congressional investigation going to look into this? Is anybody in a position to plant a bug in Senator Inhofe or one of his staff and have somebody in a position of .gov influence to look into this?
To follow up to what jeez posted while I was writing, I realize that this is an artifact of the adjustment process used by GISS. Which is all the more reason why the adjustments need to be more transparent. What kind of adjustment process really justifies data revisions like this?
Can someone answer me this:
The “average” daily temperature is taken to be (highest + lowest )/2. Isn’t this, rather the median temperature? Isn’t the average a more important indicator, but would require integrating the temperature samples over the day and then dividing by the number of the samples. Wouldn’t this give a different result, more indicative of the heat of the day?
Hope everything goes okay re. the brush fires. Good fortune to you and yours.
Robert Wood,
No, it’s the average because only two temperatures are taken per day (the high and the low) using minimum and maximum thermometers. Technically it also is the median, but not in the sense you are thinking as in the case when more frequent reading are taken. Remember this process was started well over 100 years ago when readings were done manually. It took some effort just to get the high and low every day. Only with automated technology can you integrate a lot of reading over the course of a day.
But there can be a huge difference between the two techniques.
Isn’t this, rather the median temperature?
No, that would be like taking hourly samples and taking the 6th warmest (or coolest) as the measure and paying no attention to how much warmer or cooler anything else was.
Actually, the Min+Max/2 system seems to work quite well and compares favorably with systems that measure temperatures hourly and do the HourSum/24.
But having said that, it is obviously a better procedure to use the latter method. The new NOAA/CRN system is set up to do just that (it’s automated).
Oops. For median, I mean the 12th warmest or coolest!
What is interesting about the past data adjustments is that net total adjustment to date adds up to +0.7C which is essentially the amount that temperatures have increased since 1900.
So not only are temperatures increasing (falling lately actually) less than predicted by the global warming models, all of that increase is just Hansen and Hadley playing with the historical records (some of which might be justified if we could just find out what they actually did.)
Robert Wood,
(highest+lowest)/2 doesn’t have to be the mean or the median. Although it will be both if you assume a sinusoidal temperature function. The problem is that historically temperatures were not taken every minute or hour. Instead, they used two thermometers that would measure the minimum and maximum temperatures during a specific time period. An observer would check the thermometers once a day, and record them. Thus the best estimate of the mean daily temperature would be (highest+lowest)/2.
Or is the raw data simply not available any more?
It is. But NASA/GISS raw data = NOAA adjusted data.
NOAA raw data must be available because they show a before/after adjustment map. Not for public consumption, of course! (If the public could see it, they’d be marching up to Abbeville (or wherever the hell) with torches, flails, and pitchforks.) The Rev has it though, and posted it a couple of months ago.
Can someone please explain to me why they adjust temperatures every month? I understand them trying to adjust for the terrible placement of climate stations, but why adjust past data based on current data. Lastly, why adjust it every month?
Robert Wood, I couldn’t agree with you more. That is the mathematical definition of average. The problem, of course, is that with most of the historical data, all we have is the high and the low. No records of additional data points available. In order to be able to use same method comparisons for averages, they only worry about the high and low with the modern data. That allows them to say they are following historical trends. It isn’t necessarily reflective of reality, but it gives the illusion. You also have to remember that the temperature listings being used are monthly, seasonal, and annual averages, which even further skew data points.
I would much rather they put the data from 1902 to one side, and concentrate upon the more current data where we have more data points for a day to use. The trend length might not be as long, but temperature values would be more indicative of heat and we might get better predictive ability.
Bob Tilsdale,
LOL! Yes, and you’ll recall what Hansen was saying before Congress exactly 20 years ago. It’s just too amazing.
fred: As for NOAA/USHCN adjustment procedure, if you want to raise AGW by having your blood boil, check this out:
This is the USHCN-1 method.
Adjustments 1900-2000:
Results:
Map of Raw Temperature (USA)
Map of NOAA-Adjusted Temperature (USA)
Before you calm down, let me emphasize that the USHCN-2 is out now, and the adjustments are even worse. (Up to +.425°C trend adjustment from +.30°C) But they are MUCH too smart to provide a graph (or maps) this time around!
The best that I can put together is that they carefully account for the CRN1/2 to CRN4/5 differences–by “adjust” the CRN1/2 results to fit the others! Then they show a graph about how proud they are that their fine adjustment procedure “fixes” station quality, so go away, you denier, you!
Can someone please explain to me why they adjust temperatures every month?
I think it’s because they like to keep their options open? If they do it every month, then they can, effectively say anything at any time. And go, “…..What?” if anyone objects.
The story (poss. apoc.) is that the beastly Sovs used to send the British government a new Soviet Encyclopedia every year which included instructions as to what articles to add and cut out of the old ones.
Gary Gulrud:
Do these include those FUBARd Soviet-era weather stations that habitually exaggerated their wintertime lows in order to qualify for more fuel subsidies?
Don’t assume malice when stupidity will explain it.
Corollary: …Unless reputations and big, big bucks are involved.
Question: Does GISS provide the historical raw data along with the cooked data? If so, for how far back does their raw data go? Is it archived online?
Also, Gary mentions the old mercury thermometers [usually about 30"+/- long, with sliding magnifiers and 1/100th degree reticles] were by far the most accurate. They are more accurate than today’s thermocouple/datalogger setups, because thermocouples have inherent hysteresis; mercury thermometers don’t. Something to consider when tenths/hundreths of a degree matter.
– Paul Clark
Yes basically this is blowing up. Or this piece of it is, the UHI piece. No-one could assess Jones’ claims as long as the stations were kept secret. When they found the Chinese names out, after FOI proceedings in the UK last year, it turned out they likely were heavily contaminated with UHI. So now we have the Russian ones, and we must see whether they too are contaminated or are lacking adequate histories.
It always did seem odd that in studies the ROW station record showed so much more warming than the US station record. Now that the names of the stations have been revealed after 15 or 20 years, we can for the first time check into why this should be.
REPLY: I may need to go to Russia to solve this issue. -Anthony
Well, I’ve thrown up my monthly analysis and charts related to the GISS temps here:
Joe
Some people are asking why the past should change all the time. Well, you have to be a physicist to understand this, its a quantum mechanics matter, but here is a journalistic explanation for lay readers. You see, with temperatures, the act of observing affects them. This means that if you know when the temperature was recorded, you can only tell in a probabilistic way what it was. Obviously therefore the observation will change as surrounding data points are observed. You may not have quite followed this last step, but its as I say a quantum matter.
Its one of the things that makes climate science so difficult, and why we should particularly respect people like Hansen who struggle with this sort of thing every day.
Its almost as bad if you find you do know the temperature exactly. Then you can only tell in a probabilistic way when it was measured. This is why its so hard to establish what the warmest years of a given period were, and why it changes all the time. Its not the temperatures that were moving around, but the dates.
Its a bit like the husbands some of us used to have. If you knew where they were, you did not know what they were doing. If you knew what they were doing, you could only tell in probabilistic terms who they were doing it with. As to when they had done it, well, probably in the lunch hour. But not always.
Do you see now?
REPLY: For laymen readers, this is satire. -Anthony
“It is still unfathomable to me that historical data is revised every month.”
I can actually think of a reasonable reason to do so. I am not saying the GISS approach is reasonable, just that I can see a theoretical reason why it isn’t a problem.
Suppose you take measurements with a crude instrument until year X. In year X, you are able to take more accurate readings with a new instrument. Or, perhaps you used to take readings only twice a day, but the new instrument is able to take a proper 24-hour average. If you continue to take readings using both instruments from year X forward, each new month provides more information on how the crude instrument deviated from the new one. And, perhaps with further analysis, it can be shown that these deviations are of different magnitudes depending on certain conditions. With each new bit of information, then, the old data can be adjusted to give what can reasonably be considered to be a more accurate adjustment of the old readings to the current technology.
Again, I’m not saying that this is what has been done, or even if it is, that it has been done correctly. But it is a plausible argument in favor of making historical adjustments.
Their reasoning is something like that–JG knows it thoroughly, I’m just a dumb moderator.
In the article, Anthony ponders:
I wouldn’t be at all surprised that since the last release some late May data also arrived. If so, then that data would apply to the M-A-M GISS I-can’t-believe-they-do-that data adjustment for past M-A-Ms.
Just another uplifting GISS experience and yet another qualification in trying to keep track of data to reproduce past analyses.
What Diatribical Idiot is refering to is either a boostrap method or a Bayesian method. Both are common statistical treatises, but I would think that after a certain amount of time enough data form the new reliable statistical distribution would have been collected, resulting in very little change in the posterior (or newly estimated) result. It would be interesting to see if they were actually using this – perhaps John mentioned it in the preceeding post – I’ll have to go and look.
fred: You had me going.
leebert: Sorry, you’re beyond my pay grade.
Fred, to continue in all innocence, this is precisely the problem that Hansen has: climate is always changing, all over the place, all the time, in a probabalistic fashion.
He needs it to change upwards, all over the palce, all the time, so you can imagine the stress of his job and the fast-footedness of his statistical adjustments of data.
Fred, Anthony,
It made perfect sense to me.
It reads like something from “The Dancing Woo-Woo Masters”.
Unconcious bias is well documented and widespread in science. If you study science at university, you get drummed into you that you have to construct your experiments to minimize unconcious bias. Adjusting data is a big ‘no no’ for this reason.
Which is not to say the temperature adjustments aren’t justified, but they need to be done in a transparent auditable way.
And if you think the situation is bad in the USA, it’s worse in other countries where they won’t say whether they even adjust the data, never mind, by how much.
Actually, THIS may be Hansen’s problem.
@fred
Would that be the Hansenberg Uncertainty Principle???
I view GISS temperature record more like the cat in Schrodinger’s box and the current monthly temperature as the random quantum fluctuation that releases Hansen. The observer is unable to know the actually state of the GISS record until they open the box and GISS record collapses into a series of positive and negative adjustments.
Hey, thanks to thopse who answered my question re: median v. av erage temperature.
I was right (yeah :-)) but this measure is kept for historical reasons.
These measurement/data problems may be telltale of limits in our technological abilities. Perhaps observation of long-term trends in species distribution (altitude, latitude, temporal) are more revealing to actual trends. Could these highly evolved natural systems be more sensitive to climate trends than our timeframe-sensitive, technology-based perceptions? Maybe they are also too noisy; I guess we’ll find out.
Jd
Robert Wood (12:54:34) :
All this has been answered, but a personal empirical note applies. For a while I had a surplus thermograph that dad had rescued from work. (Nice big industrial style round charts with thermocouples and vacuum tube amplifiers. None of this search for an hour looking for the USB stick you dropped.) When I went to college I keypunched several months of data for each 3 hours and wrote various Algol programs to produce “ASCII art” graphs and whatnot.
One thing I did was to compare (max+min)/2 and average of 3 hour periods (half weighting each to the 0000 and 2400 readings). I was moderately surprised at how well they matched. Only in some of the obvious situations, e.g. winter cold front passing right after midnight so that 0000 had the high for the day was the data obviously bad.
The difference was typically a few tenths of a degree, IIRC, so I’d be very reluctant to mix both styles into any climate change analysis, but for producing climate atlases and other low precision documents, I decided it was close enough for government work.
All this data was from northeastern Ohio, but probably holds in most other areas. Perhaps not coastal with summer seabreezes, but perhaps it does.
40 year-old data. I know I don’t have the punch cards, but I might have it on listings still.
jeez (11:51:54) :
First, only missing data is adjusted in this pass. Second, temperature records from a single station are typically recorded by a single person and propagated to not too many other people. Company stock prices are recorded many times in many places and there is strong financial incentive to do that. OTOH, you might have trouble finding the stock price for DEC for, say July 9, 1968. DEC was bought by Compaq, that was bought by HP. DEC is no longer traded, so you probably can’t find it at your favorite online broker.
Questions. Is CO2 dispersed equally in the circumference of the globe? If it isn’t, where is it concentrated? I looked for actual numbers but all the web sites I went to gave me ……well garbage and interpretive language. Just wondering about the dynamics of the CO2 theory. If it does capture heat, and it is concentrated, shouldn’t we see warming where it is concentrated? If it is evenly dispersed, shouldn’t we see a smoother line in our global temps?
Yes, adjusting the value of missing days in 1927 because we had a cold June in 2008.
If we keep doing this for another thousand years, can we assume we will know better what the exact temperature was on some random day and random place in 1927 than we know it today? I see CRU temperatures for a 100 years ago stated in 1000’s of a degree. Does this remotely make any logical sense to you?
No more accuracy is being added by this process, only a false sense of sciency looking adjusting.
And what relevance is there to your DEC example? Just because information is obscure doesn’t mean it won’t be accurate and consistent when located. I don’t feel like subscribing to Hoovers just to find this information.
Does GISS then adjust adjusted data?
To be clear:
GISS uses fully adjusted NOAA data as its own raw data. It then adjusts it further.
Hey Evan, you live in SF right? Ok if I send you an email?
I see CRU temperatures for a 100 years ago stated in 1000’s of a degree.
Fischer is pleased to refer to this as “the fallacy of misplaced precision”.
When I was in high school science class it was called spurious accuracy–same thing.
Temperature data is a proxy for heat gain by the climate system. Some scientists like Pielke senior argue we should put more effort into directly measuring heat gain.
Using an average of min max is a poor way of trying to measure heat gain, because the difference from min to max to the next min is just a measure of how much heat is gained and then lost over the day and what we are interested in the net heat gain after the daily gain and loss. Hence we should use minimum temperatures only.
However, most people in most places are much more interested in the daily high temps than the lows and most people would consider rising minimum temps, ie less cold nights to be a good thing. So using just minimum temperatures would have a much weaker propaganda value.
Ric, how do you adjust missing data? I must be missing something.
Hey Evan, you live in SF right? Ok if I send you an email?
I live in NYC. But it’s still OK if you send me an email.
My email address is: [email snipped by jeez, now officially known as Charles the moderator]
Maybe I will, but I was looking for a potential drinking buddy. I’m mixing you up with someone else around here. I cut your email above. It’s never a good idea to leave it hanging out there.
I found this article interesting: “Mysterious California Glaciers Keep Growing Despite Warming”
I still like this one. Rising CO2 must be good for the Arctic Ice…….
That’s a good idea! Lets get the local groups together and have some beers. Jeez – you should begin to take a survey of where people live and figure out a few major beer drinking locations. I’m sure that survey software would be at least good for that!
Duct tape all attic, crawl space vents closed. That’s where embers get sucked in. Drape AC intake with wet cloth and keep wet. Park vehicles, lawnmower, other fuel tanks inside garage with the door closed. Sprinkler on roof. Keep vigil for embers. Most homes can withstand quite a bit if properly prepped.
Glenn (19:02:57) :
“Ric, how do you adjust missing data? I must be missing something.”
describes the process pretty well.
Suppose the observer for Penacook was on vacation for part of April 1933 and hence wasn’t able to come up with the 30 days of data to compute the average for the month. Averaging the days he was around for doesn’t work, escpecially if he was away during the beginning or end of the month when temperatures are usually furthest from the mean. Replacing the missing data with daily averages might work pretty well, and may be what should be done.
Instead, the missing month’s data is filled in by the other two months in the season and the average temperature of the month in that season for all other years. As the temperature record gets longer, the amount of data gets longer.
It would make a lot more sense, at least to me, to use something like the average of the preceding month, the following month, and the previous year’s month, and the following. Maybe a few other years too, but certainly no more than a few.
Probably some use of averages for the month and adjacent ones too.
There are some algorithms for doing this, I have one that’s used to take a collection of data samples and spread them out over an even matrix. If I ever have time, I want to try going from GPS traces to topographic map and I need that step to make some contour drawing software happy.
At the risk of stating the obvious, there is never any need or justification for infilling data that is missing for whatever reason.
This is a case where the computational algorithm is determining the data required, where it should be the other way around. And the algorithm should handle the data available. Calculating means and trends where data is missing from a time series isn’t a hard problem.
Amateur is too weak a word for this.
Ric, Thanks.”?
A few points…
I keep a local copy of Hadley/GISS/UAH/RSS at home. I also update the entire dataset, instead of merely adding the latest month. I was about to make a fool of myself by crowing about 12 consecutive months of temperatures falling year-over-year at GISS. Then I did a double-take. The GISS dataset with data to May 2008 showed March 2007 as 0.60 and March 2008 as 0.58, a 0.02 decline over 12 months. The GISS dataset with data to June 2008 shows March 2007 as 0.59 and March 2008 as 0.60, a rise of 0.01 over 12 months. They’re the only one showing a rise over the previous year for March 2008. Anything to deny the skeptic community a propaganda point.
The GISS 12-month running mean anomaly to June 2008 is 0.421. The GISS 12-month running mean anomaly to March 1998 was 0.422 (at least on the current GISS dataset :p ). So we’re back to where we were over 10 years ago, according to GISS.
Dr. Hansen should note that in the real world, corporate executives do not get thrown into prison for disagreeing with him, but rather for fiddling with corporate numbers. GISS restates previous years’ numbers more often than Nortel, fercryinoutloud.
Could just be noise, but it might slightly confirm my hunch that the satellite datasets react quicker and more strongly to short-term events (e.g. La Nina).
As a layman (relatively new to this debate – spurred by a feeling that not all is what it seems to be) I have tried to read widely from this and a number of other sites, on both sides of the debate, to get a handle on the key issues.
When dealing with issues in my working life I have always found the best question at the start is: “What is the problem we want to fix?” (BTW – the end game should always answer clearly the question – “why is this strategy/policy/plan the answer to that problem?”)
Therefore – my first question is – “Is the earth warming?” (Please stay with this point and do not get onto secondary issues such as – is it dangerous? can we forecast what will happen? – and what is causing it? – question ‘1′ has to be is the earth warming?)
Now, with all such issues as this my basic logic is to say there are 2 key factors (to me as a layman please understand)
1). what is the appropriate start point?
2). what is the data that shows this?
(Please understand I am trying to be purposefully simplistic here)
Now, depending on which side of the argument you are on you will naturally choose a start point that fits with the thesis you are trying to make. I would like to put that to one side for the moment and concentrate on getting clear in my mind an understanding of the data.
I have been singularly horrified by how much data manipulation may be going on in this area. I am not a scientist but I do suffer the consequences, as a citizen in my country, of decisions made by politicians on the basis of government policy formulations founded on the data produced about global warming/climate change.
So all I ask is:
1). ‘Is there a clear set of data that shows the average temperature of the earth over the last 100 hundred years?’
2). ‘Is this data available/reported (in its raw form as well as its adjusted form) in order that scientists around the world can evaluate it and have such assessments peer reviewed with rigour?’
Glenn (01:14:09) :
”?”
There are certainly limits, but science has always dealt with measurement errors and omissions. You certainly don’t want to throw out the entire 100 year history of a good site because someone lost a monthly data sheet or the tanscriber couldn’t make out a poorly written digit.
Stepping well beyond my statistics knowledge, one reason to fill in missing data with a good guess is that there are statistical methods that need a full history. One of them, (Principle components) was used in producing Mann’s hockey stick graph, though it had more problems with extrapolating data beyond a sample period than filling in holes. And many, many other problems to boot.
Some times the missing data can be omitted without much trouble, e.g. gaps in USHCN and COOP records during equipment relocations, Anthony frequently posts graphs with breaks in them. The breaks are convenient markers to see what short of shift in data occurs with the relocation.
Given all the other error sources in the data, filling in missing data with something close to neutral provides a lot of computational convenience at little cost.
Here’s an example – suppose a site had that April 1933 data missing. How would you compute the average temperature for that year? If you don’t, then that would suggest you couldn’t compute an annual average for the country that year because there ought to be at least one missing month somewhere for each month of the year. By splicing in neutral data, then all the simple averaging math (e.g. add up the monthly averages and divide by 12) still work.
There are several reasons for the discrepancies between GISS and HadCrut in particular. But the fact that the Arctic has cooled (anomaly wise) recently while the tropics have warmed might explain the relatively low GISS anomaly for June.
That’s possible, Paul, but then you also have to consider that all four metrics dropped sharply to about the same level in January. Then in March, the satellites stayed fairly cool, while Hadley and especially GISS jumped way up. The overall trends are somewhat clear, though…global temps dropped a lot in January, recovered somewhat through March, and since have cooled off again through June.
Therefore – my first question is – “Is the earth warming?”
I’ll have a shot at answering this.
First of all, there are 2 questions that need answering. One is, is the world’s climate warming and the second is, is it due to a global effect. Because we know peat fires in Indonesia, coal fires in China, etc, are excerting a warming influence on the climate.
The answer to the first question is, on average, probably yes.
The answer to the second question is more important. A global effect should show up equally in both hemispheres (north and south). Even though, ex tropics, the SH has less than 5% of the population of the NH.
There has been no significant warming over the entire satellite record for the SH (about 30 years).
So the obvious conclusion is that whatever warming that has occured in the NH is not due to a global effect and therefore greenhouse gases cannot be the cause because they are distributed moreorless equally across the hemispheres.
Paul Clark:
Excellent questions and the crux of the debate. Sorry to say that the answers are highly subjective and time sensitive. There are so many variables to take into account that a definitive answer to “are we warming” is impossible or incomplete at best. With the difference in measuring devices, locales, times of observations, changes in any of the these, and throw in the accuracy of the observer, to make any judgment is premature. As Anthony has pointed out with his auditing of stations and Steve McIntyre’s overall Climate Auditing, it becomes clear that the strict discipline needed in Science is regretfully absent in the field of Climate Science and makes answers highly suspect and open to question.
The reason GISS is so cool this month is the Antarctic. I’ll throw up the link to the GISS map for June 2008 again, just in case you missed it. Scroll down to the zonal mean plot. They have to lIve with the 1200km smoothing either way it leads them.
[This namespace collision is confusing even me! In case anyone hasn't realised, there are two Paul Clarks posting here - Paul H. Clark is the other one (Hi, namesake!). I've changed my display name to include 'woodfortrees' to try and make it more obvious who's who.]
To answer Paul H.’s question indirectly: Here is the HACRUT3 data for NH, SH and global, moderately smoothed:
So yes, it has warmed a bit, and may still be warming a bit, but there’s no evidence in these records yet of anything that looks like runaway positive feedback.
On the question of data manipulation, I personally think the different datasets tally pretty well, and since they’re all derived differently any adjustments are not having a great effect on long-term changes, which is all that really matters. So as an engineer if I ask myself “can I rely on this data?”, my answer would be “Yes, to a first approximation over long term trends”.
More notes on comparing different datasets, and in particular the baseline issue:
Cheers
Paul (R) Clark
With respect to datasets I have been playing with the UAH dataset and comparing the northern and southern hemisphere figures. I graphed them in Excel then created a third order polynomial trend line. The odd thing which came out is that the southern hemisphere has a lower variability than the north. Would this be because of the greater sea area in the south or just a statistical oddity.
Hadley is now out, BTW. It does occasionally do this on a Saturday! Also unusually Hadley is Higher that GISS for this month, coming in at +0.314C. Not sure if I’m reading it right, but there appears an awful lot of data missing from the SH, and Hadley doesn’t usually post quite this early in the month. | http://wattsupwiththat.com/2008/07/09/giss-tsdsst-numbers-are-in/ | crawl-002 | refinedweb | 6,187 | 72.26 |
Load password protected Excel files into Pandas DataFrame
When trying to read an Excel file into a Pandas DataFrame gives you the following error, the issue might be that you are dealing with a password protected Excel file.
pd.read_excel(PATH) [...] XLRDError: Can't find workbook in OLE2 compound document
There seems to be no way of reading password protected files with xlrd.
xlwings for the rescue
Fortunately, there is xlwings, which lets you interact with the Excel application itself (via
pywin32 or
appscript).
The following code will open your Excel file (if not open already, it will launch the Excel app, which then asks for your password) and turn a range selection of a sheet into a Pandas DataFrame.
Note: You need to have Excel installed. The code below was tested on macOS, but Windows should work the same.
import pandas as pd import xlwings as xw PATH = '/Users/me/Desktop/xlwings_sample.xlsx' wb = xw.Book(PATH) sheet = wb.sheets['sample'] df = sheet['A1:C4'].options(pd.DataFrame, index=False, header=True).value df
Output:
Your use case
A couple of things you might want to adjust for your case:
A1:C4is the selection you want to access (from cell A, first row, to cell C, fourth row), one-based index
index=Falsemeans you don’t want to use the cell values as index
header=Truemeans you want to use the first row cell values as header | https://davidhamann.de/2018/02/21/read-password-protected-excel-files-into-pandas-dataframe/ | CC-MAIN-2018-22 | refinedweb | 238 | 61.87 |
Become superuser on the global-cluster voting node whose namespace location you want to change.
On a local disk of the node, create a new partition that meets the following requirements:
Is at least 512 MByte in size
Uses the UFS file system
Add an entry to the /etc/vfstab file for the new partition to be mounted as the global-devices file system.
Determine the current node's node ID.
Create the new entry in the /etc/vfstab file, using the following format:
For example, if the partition that you choose to use is /dev/did/rdsk/d5s3, the new entry to add to the /etc/vfstab file would then be as follows: /dev/did/dsk/d5s3 /dev/did/rdsk/d5s3 /global/.devices/node@3 ufs 2 no global
Unmount the global devices partition /global/.devices/node@nodeID.
Remove the lofi device that is associated with the /.globaldevices file.
Delete the /.globaldevices file.
Disable and re-enable the globaldevices and scmountdev SMF services.
The partition is now mounted as the global-devices namespace file system.
Repeat these steps on other nodes whose global-devices namespace you might want to migrate from a lofi device to a partition.
From one node in the cluster, run the cldevice populate command to populate the global-devices namespace.
Ensure that the process completes on all nodes of the cluster before you perform any further action on any of the nodes.
The global-devices namespace now resides on the dedicated partition. | http://docs.oracle.com/cd/E19787-01/820-7358/gigjz/index.html | CC-MAIN-2014-35 | refinedweb | 247 | 52.8 |
snellspace
: a perfect world spoiled by reality
Simon Fell: "Sam & James have been debating this MSDN article by Scott Seely that discusses evolving SOAP / WSDL interfaces. I haven't had chance to read it yet, so will refrain from commenting, however past experience tells me that I could just agree with whatever Sam's saying, and save me the trouble of having to actually read it !" It's not a debate, Sam and I are just seeing the issue from two different points of view, both of which are equally valid. Given that his focus has been on runtime interoperability between toolkits and I'm coming more from a design/architecture point of view, the fact that we see things differently makes a lot of sense.
Fact: designing Web service interfaces is a different task than ensuring that the toolkits that implement those interfaces are compatible with one another.
Regardless, blind agreement with anybody is a bad idea in any context -- even if it is the great right-more-often-than-not Sam Ruby.
Sam Ruby: "cope with change just as the similar functions in other IDL languages do. Changing a namespace is not going to help when you realize that not all SOAP stacks dispatch on namespace." What you describe is a runtime issue, not a design time one. How a specific soap runtime dispatches messages is a separate issue than how a service interface is defined and evolved using WSDL. Example: I can create an IDL description of an object interface and implement that in either Java or COM. It's the same interface, but the dispatching mechanisms are going to be different. Regardless of the dispatching mechanism, the best practice rules of IDL design still apply. Where you run into problems is when WSDL is used as a means of dispatching requests which is why I also advocate that a clearer distinction be made between the abstract definition of a service (the message, portType and binding elements) and the concrete reference to a service implementation (the service element).
Sam Ruby: " Personally, I am a big advocate of adding inheritence to the WSDL interface definitions (and have been ever since I did this). Doing so would make it easier to cope with change just as the similar functions in other IDL languages do. One challenge, however, is that WSDL's role as an IDL has never been fully developed. I'd say that this is definitely something that needs to be dealt with in the WSDL's second coming.
Main point: WSDL needs to be treated like IDL, and must conform to the basic principles of IDL design.
Regarding the ASP.NET question: There is a distinct difference between identifying a best practice and implementing a best practice. The tools, over time, will start to line up, but at least we know what to strive towards. Regarding ASP.NET specifically, I would not be able to address that question as I'm not very familiar with ASP.NET in detail.
Evolving an Interface
Scott is right on in his discussion of how WSDL should be treated over multiple versions of a Web service interface.
I would add a couple more:
(ok, so the first two are a bit of a stretch) | http://radio.weblogs.com/0101915/2002/04/10.html | crawl-002 | refinedweb | 543 | 59.43 |
a bit confused by your description.
Your data file contains a special character that's outside the "normal" characterset and this character is causing a problem.
You could just copy the string to another buffer and skip all of the special characters.
char *CleanLine (char *Buffer)
{
char *Temp;
char *Source;
char *Dest;
Temp = (char *)malloc (strlen (Buffer) + 1);
Source = Buffer;
Dest = Temp;
while (*Source)
if (*Source >= 0x20 && *Source < 0x80)
*(Dest++) = *(Dest++);
else
Source++;
*Dest = 0;
return (Temp);
}
Kent
char *CleanLine (char *Buffer)
{
char *Temp;
char *Source;
char *Dest;
Temp = (char *)malloc (strlen (Buffer) + 1);
Source = Buffer;
Dest = Temp;
while (*Source)
if (*Source >= 0x20 && *Source < 0x80)
*(Dest++) = *(Source++);
else
Source++;
*Dest = 0;
return (Temp);
}
> I'd like to bypass only this character since I know there aren't any other like this.
what do you mean by bypass? Would you like to have this character replaced by some other character at all instances? Or is it that you want to process input char by char and skip processsing this char?
If your approach is latter, then it might be niteresting to see some more code ... You are using comparison of ASCII value to be <40 ... are you sure it is not the end of string character '\0' or just 0 which is causing you the pain
As a small hint, former can be achieved by strchr in a loop
temp2 = string;
temp1 = strchr (temp2, '<bad_char>' );
while ( temp1 != NULL )
{
*temp1 = '<good_char>';
temp2 = temp1 +1;
temp1 = strchr (temp2, '<bad_char>');
}
Make sure that your bad_char is not end-of-string or the code may segfault
For the latter approach, you can depend on && check ... Though it is not guaranteed to work on every C compiler but it should work on almost any C compiler currently in use
if ( *p != '<bad_char>' && <furthur processing>)
condition after && is generally executed only if first condition is true
Few more details about the problem and desired solution will be very useful for further discussion.
cheers
sunnycoder
Broken down into practical pointers and step-by-step instructions, the IT Service Excellence Tool Kit delivers expert advice for technology solution providers. Get your free copy now.
out you trivial typographical error:
if(str[i]="Ë")
should be
if(str[i] == "Ë")
(note == for comparison of equality)
Now look at your code
for(i=0; str[i] != '\t' && str[i] != '\n' && i < 40;i++)
if(str[i]="Ë") <-- "Ë": this will return a pointer and assign to str[i], it will be truncated to a char and str[i] will
eventually contain some weird character.
{out->author[i]="E";} <-- so will this.
How do u know there is a special character in your file?in case there is please modify above as follows.
for(i=0; str[i] != '\t' && str[i] != '\n' && i < 40;i++)
if(str[i]== 'Ë')
{out->author[i]='E';}
hope this helps.
van_dy
Use the isprint() function. It returns 0 for special characters, 1 otherwise:
#include <ctype.h>
[...]
for(i=0; str[i] != '\t' && str[i] != '\n' && i < 40;i++)
if(!isprint(str[i]))
out->author[i]="?";
Another alternative is a translation array, like:
char tr[256]={ '.', /* \0 */
[...]
'A', /* Ä */
'E', /* Ë */
[...]
};
and then
for(i=0; str[i] != '\t' && str[i] != '\n' && i < 40;i++)
out->author[i]=tr[(unsigne
...just be careful that you need to cast your (signed) char to unsigned before using it on the array, otherwise you'll get negative indices.
Cheers!
Stefan
> out you trivial typographical error:
>
> if(str[i]="Ë")
>
> should be
>
> if(str[i] == "Ë")
>
> (note == for comparison of equality)
Correct. But even Brett overlooked this one - it should be
if(str[i] == 'E') /* single quote, not double */
Regards
int i;
for(i=0; str[i] && str[i] != '\t' && str[i] != '\n' && i < 40;i++) {
if(str[i]=="Ë")
out->author[i] = 'E';
else
out->author[i] = str[i];
}
out->author[i] = 0; /* needs this ending null character */
Good luck,
Jaime.
int i;
for(i=0; str[i] && str[i] != '\t' && str[i] != '\n' && i < 40;i++) {
if(str[i]=='Ë') /* my correction here replace the " with ' */
out->author[i] = 'E';
else
out->author[i] = str[i];
}
out->author[i] = 0;
/should work if compiler supports unicode char set */
But the problem is the character Ë . Will the line
if(str[i]=='Ë')
work if the compiler is not working in an environment that does not support this character ?
Avik.
Experts Exchange Solution brought to you by
Facing a tech roadblock? Get the help and guidance you need from experienced professionals who care. Ask your question anytime, anywhere, with no hassle.Start your 7-day free trial
Sorry , working in an environment that does not support this character
Avik's accepted comment is just a typo correction of my solution, so I think more than one deserve points in this question.
If you don't know how to split points we can help you.
BR,
Jaime. | https://www.experts-exchange.com/questions/21185554/How-can-I-handle-a-special-character-using-a-if.html | CC-MAIN-2018-30 | refinedweb | 816 | 70.33 |
Coding for life cycle in threads
Coding for life cycle in threads program for life cycle in threads
Life cycle of Servlet
Life cycle of Servlet
This article is discussing about the Life cycle of Servlet and teaches you
the Servlet Life cycle methods. As a beginner you should understand
? A thread start its life from Runnable state. A thread first enters runnable state...Thread What is multi-threading? Explain different states of a thread.
Java Multithreading
Multithreading is a technique that allows
JSF Life Cycle
JSF Life Cycle
In this we will understand the life cycle
of JSF application.
Life... properties, the life cycle proceeds directly to the render response phase
System Development Life Cycle (SDLC)
Among all the models System Development Life Cycle (SDLC) Model is one... Life Cycle Model or Linear Sequential Model or Waterfall Method.
This model... should be based on the analysis of end-user information needs. This phase is also
Bean life cycle in spring
Bean life cycle in spring
This example gives you an idea on how to Initialize
bean in the program... to retrieves the values of the bean using java file. Here in the file given
below i.e.
System Development Life Cycle
cycle of Software Development Life Cycle. The information systems...
System Development Life Cycle
... Development life cycle. Advantages of using the SDLC also include efficient work
JSP Life Cycle
JSP Life Cycle
In this section we will discuss about life cycle of JSP.
Like the each Java based web technology JSP also follows a life cycle.... In
the core of the JSP, Java Servlet technology is executed therefore, JSP life
cycle
Java Thread
and then
the other thread having priority less than the higher one.
Life cycle of thread :
Diagram - Here is pictorial representation of thread life
cycle.
State of Thread Life cycle -
New : This is the state where new thread is created
Java Threads - Java Beginners
the thread that makes resource available to notify other threads...:
http...Java Threads Why we use synchronized() method? Hi Friend
Stateful and Stateless Session Bean Life Cycle
Understanding Stateful and
Stateless Session Bean Life Cycle... Bean Life cycle
There are two stages in the Lifecycle of Stateless
Session Bean... the bean into Does Not
Exist state.
Following Diagram shows the Life cycle
Servlet Life Cycle
Servlet Life Cycle Servlet Life Cycle
servlet life cycle
servlet life cycle What is the life cycle of a servlet
threads in java
threads in java how to read a file in java , split it and write into two different files using threads such that thread is running twice
threads - Java Interview Questions
threads what is thread safe.give one example of implementation of thread safe class? hi friend,
Thread-safe code is code that will work even if many Threads are executing it simultaneously. Writing it is a black
write a program in java to demonstrate the complete life cycle of servlet:
write a program in java to demonstrate the complete life cycle of servlet: ... for this program. my question is :Write a program in Java to demonstrate the complete life cycle of a Servlet
SCJP Module-8 Question-4
Given a sample code:
public class Test3 {
public static void main(String args[]) {
Test1 pm1 = new Test1("Hi");
pm1.run();
Test1 pm2 = new Test1("Hello");
pm2.run();
}
}
class Test1 extends Thread {
private
Threads - Java Beginners
Threads hi,
how to execute threads prgm in java? is it using...;
private volatile int curFrame;
private Thread timerThread;
private...("/home/vinod/amarexamples:9090/" + "amarexamples/Threads/applet
threads and events
threads and events Can you explain threads and events in java for me. Thank you.
Java Event Handling
Java Thread Examples
Chapter 4. Session Bean Life Cycle
Bean Life CycleIdentify correct and incorrect statements or examples about the life cycle of a
stateful or stateless session bean instance...
Chapter 4. Session Bean Life CyclePrev Part I.
Thread
Thread Write a Java program to create three theads. Each thread should produce the sum of 1 to 10, 11 to 20 and 21to 30 respectively. Main thread....
Java Thread Example
class ThreadExample{
static int
Threads on runnable interface - Java Beginners
:// on runnable interface need a program.....please reply asap
Create 2 threads using runnable interface.First threads shd print "hello
Flex Component Life Cycle
Flex Component Life Cycle hi....
please tell me about
What is Flex Component Life Cycle?
Thanks Ans:
There are following pase of flex component life cycle.
1. Initialization phase
2. Update phase
3
Chapter 7. CMP Entity Bean Life Cycle
or examples about the life cycle of
a CMP entity bean....
The following steps describe the life cycle of an entity bean...
Chapter 7. CMP Entity Bean Life CyclePrev Part
Demon thread
.
For more information, visit the following link: thread What is demon thread? why we need Demon thread?
Daemon threads are the service providers for other threads running
Hibernate Life Cycle
This tutorial contains full description of Hibernate life cycle
Threads on runnable interface - Java Beginners
");
}
}
-----------------------------------------------
Read for more information. on runnable interface need a program.....please reply asap
Create 2 threads using runnable interface.First threads shd print "hello
bean life cycle methods in spring?
bean life cycle methods in spring? bean life cycle methods in spring
interfaces,exceptions,threads
:
Exception Handling in Java
Threads
A thread is a lightweight process which... with multiple threads is referred to as a multi-threaded process.
In Java Programming...interfaces,exceptions,threads SIR,IAM JAVA BEGINER,I WANT KNOW
Life-Cycle of flex application
Life-Cycle of flex application hi.....
Please tell me What is LifeCycle of Flex-Application?
please give me the answer ASAP.
Thanks LifeCycle of flex application:
When we create a flex application in Adobe
Five disciplines in the Iterative Life Cycle
Five disciplines in the Iterative Life Cycle hello,
What are the Five disciplines in the Iterative Life Cycle?
hii,
These are the Five Disciplines in the Iterative Life Cycle:-
Requirements
Analysis and Design
Sync Threads
://
Thanks...Sync Threads "If two threads wants to execute a synchronized method in a class, and both threads are using the same instance of the class to invoke
Daemon thread - Java Beginners
information, visit the following link: thread Hi,
What is a daemon thread?
Please provide me... thread which run in background. like garbadge collection thread.
Thanks
Threads
Threads class Extender extends Thread
{
Extender(Runnable...();}
public void run(){
System.out.println("Extender Thread is Started :");
//new Thread(new Implementer()).start
Threads
Threads public class P3 extends Thread{
void waitForSignal() throws InterruptedException {
Object obj = new Object... in thread "main" java.lang.IllegalMonitorStateException
Extending thread - Java Beginners
visit to :
Thanks...Extending thread what is a thread & give me the programm of exeucte the thread
Hi friend,
Thread :
A thread is a lightweight
threads in java - Java Beginners
threads in java what is the difference between preemptive scheduling and time slicing?
hi friend,
In Preemptive scheduling, a thread... the waiting or dead states or the higher priority thread comes into existence
Java Thread Context
of threads to execute. In java this is achieved through the
ThreadContext class....
The ThreadContext
class is required for thread specific debugging information to be stored...
Thread Context
The Life cycle of An Applet
The Life cycle of An Applet
... of the applet.
stop(): This method can be called multiple times in
the life cycle of an Applet.
destroy(): This method is called only once in the
life cycle
Green Thread - Java Beginners
of Green Thread in java.
Thanks in advance... Hi friend
Green threads are simulated threads within the VM and were used prior to going to a native OS... for more information
Synchronized Threads
;
In Java, the threads are executed independently to each
other. These types....
Java's synchronized is used to ensure that only one thread is in a critical... operations. For Example if several threads were sharing a stack, if
one thread
java threads - Java Beginners
java threads What is Thread in Java and why it is Beginners
for more information.
Thanks...JAVA THREAD hii
i wrote a pgm to print the numbers from 0 to 9 in 2 threads. but it couldn't work pls help me int it.
the code is given below
Thread and Process - Java Beginners
space; a thread doesn't. Threads typically share the heap belonging to their parent..., threads have their own stack space.
This is thread code,
public class...Thread and Process Dear Deepak Sir,
What is the diffrence between
java thread - Java Beginners
java thread PROJECT WORK:
Create a application using thread...
CustomerAccount.java
The CustomerAccount class is used to store the information... .
AccountManager.java
The AccountManager class demonstrates creation of Thread objects using
Product Life Cycle Diagram
Product life cycle diagram is the graphical representation of four stages... life cycle also called PLC is a concept of marketing that tells about... stages in the Product life cycle diagram indicates:
Introduction
Java thread What method must be implemented by all threads
Daemon Threads
Daemon Threads
In Java, any thread can be a Daemon thread. Daemon threads are
like a service... thread. Daemon threads are used for background supporting tasks and are only
Count Active Thread in JAVA
Count Active Thread in JAVA
In this tutorial, we are using activeCount() method of
thread to count the current active threads.
Thread activeCount... of active threads in the current thread group.
Example :
class ThreadCount
Java thread
Java thread Can we have run() method directly without start() method in threads
Threads - Java Beginners
Threads Hi all,
Can anyone tell me in detail about the following question.
when we start the thread by using t.start(),how it knows that to execute run()method ?
Thanks in advance.
Vinod
Daemon Threads
Daemon Threads
This section describe about daemon thread in java. Any thread can be a daemon
thread. Daemon thread are service provider for other thread running in same
process, these threads are created by JVM for background task
Java Thread Synchronization - Development process
Java Thread Synchronization Hi,Please help me with this coding.
I have created two threads in my program.After the threads have started when I...: ");
t2.start();
}
}
For more information on Java visit to :
http
Product Life Cycle
Product life cycle is an important concept of marketing which shows the stages... of a product life cycle including introduction to growth, maturity and decline... and marketing mix accordingly.
The four stages of a product life cycle
java threads - Java Interview Questions
java threads How can you change the proirity of number of a thread... the priority of thread.
Thanks Hi,
In Java the JVM defines priorities for Java threads in the range of 1 to 10.
Following is the constaints defined
Thread - Java Beginners
Thread creation and use of threads in JAVA Can anyone explain the concept of thread, thread creation and use of threads in JAVA application? Thread creation and use of threads in JAVA Java Resourcehttp
Java - Threads in Java
Java - Threads in Java
Thread is the feature of mostly languages including Java. Threads... be increased
by using threads because the thread can stop or suspend a specific
Thread Priorities
;
In Java, thread scheduler can use the thread priorities... schedule of threads . Thread gets the ready-to-run state
according... a Java thread is created, it inherits its priority
from the thread
Spring Bean Life Cycle methods, Spring Bean Life Cycle
Spring Bean Life Cycle methods
In this example you will know about spring bean life cycle and how a bean is
initialized in the program. The bean factory container search for bean
definition and also instantiates the bean
Java Exception Thread
Java Exception Thread
... Thread
There are method to create thread
1)Extends the Threads Class( java.lang.thread)
2)Implement Runnable interface( java .lang. thread)
Understand | http://www.roseindia.net/tutorialhelp/comment/88649 | CC-MAIN-2014-52 | refinedweb | 1,950 | 65.12 |
PyQt Tips and Tricks] Identifying the Sender of a Signal
There are two main approaches for this. The first is to wrap the slot with a lambda to pass in any additional arguments:
def notifyMe(foo) print foo f = QPushButton("Click me!") x = lambda: notifyMe("they call him tim") self.connect(f, SIGNAL("clicked()"), x)
The second and more general solution is to use the QSignalMapper[3]
[edit] Learning to use Qt CSS
Much like web development, CSS is also available within Qt. There's a list of examples that can be tried out just using Qt Designer. If you're using custom CSS, using palette() in your CSS definitions will allow you to use colors that the theme already knows about. As an example, this is an easy way to get the default blue color on your buttons when you want that color.
Depending on your needs, there's a number of built-in icons that are available for use.[4]
Style sheets and the native
QMaemo5Style do not mix very well, since Maemo 5 lays out and draws some widgets very differently (e.g.
QRadioButton). We recommend using local style sheets on specific widgets only, instead of setting one via
QApplication::setStyleSheet().[5]
[edit] QString and Python
I've had some Unicode-related issues when moving strings between Python datatypes and Qt datatypes. Somehow, the Unicode stuff would get lost. So, it's likely easiest (At least when you're new to Python and Qt) to use
QString and
QStringList than their pure Python counterparts.
If you're not bringing in data from anywhere else, this isn't that big of a deal, but if you're interacting with data from any other source, Unicode is a pretty likely scenario these days.[6]
Just to note that, in my experience, locales fail to work with PyQt -
QTextCodec.codecForLocale() does not return the correct codec, which also means
QString's
toLocal8Bit() and
fromLocal8Bit() fail.
The Python locale stuff works fine, but then you have the joy of converting between
QString and Python strings (which works perfectly when it does it implicitly, but an explicit conversion seems to go via ASCII unless you specifically tell it to use UTF-8 instead). 21,117 times. | http://wiki.maemo.org/index.php?title=PyQt_Tips_and_Tricks | CC-MAIN-2015-18 | refinedweb | 374 | 67.69 |
Implementing Time Windowing in an Evented Streaming System
Implementing Time Windowing in an Evented Streaming System
In this post, a software engineer uses the Wallaroo open source big data platform to perform evented streaming on data taken from the Twitter API.
Join the DZone community and get the full member experience.Join For Free
How to Simplify Apache Kafka. Get eBook.
Hi there! Welcome to the second and final installment of my trending Twitter hashtags example series. In Part 1, we covered the basic dataflow and logic of the application. In part 2, we are going to take a look at how windowing for the "trending" aspect of our application is implemented.
When implementing any sort of "trending" application, what we are really doing is implementing some kind of windowing. That is, for some duration of time, we want to know what was popular, what was "trending" during that period of time. To do that, we need to implement an appropriate windowing algorithm. We'll start by taking a look at a few different types of windowing and then proceed to dive into how windowing was implemented in our Twitter Trending Hashtags example application.
Types of Windowing
There are a few types of windowing that can be implemented, and it is crucial that we clarify the distinctions.
External Event-Based Windowing
External event-based windowing is the most arbitrary kind of windowing. The boundaries of each window are determined outside of Wallaroo and can be triggered by any event. Event-based windowing is also the simplest kind of windowing to think about: when we are told that a window ends, we perform any end-of-window computation that our application requires, then we update the aggregate state to be ready for new events that arrive during the new window.
Internally Triggered Windowing
Internally triggered windowing is very similar to event-based windowing, except that the window is triggered from within the computation. Triggering is usually based on the internal state of the computation, and it is the responsibility of the computation itself to determine when a window has finished and when to start a new one. The code we will be looking at in this post is an example of internally triggered windowing.
Time-Based Windowing (Wall Clock)
A new window is started at regular intervals based on the current wall clock. For example, every 5 minutes we start a new window. Time-based windowing is currently not supported in Wallaroo.
Time-Based Windowing (Event Clock)
The time element is taken from information from the message rather than a timer, and windows are created accordingly. To implement this type of windowing, multiple windows have to be accumulated simultaneously as all events are not guaranteed to arrive during the same window. It's possible to implement event clock based windowing in Wallaroo in combination with internally triggered windowing.
The windowing in our trending twitter hashtags code is an example of internally triggered windowing. Let's dive into the code and take a look at how it's implemented.
We have a state object class HashtagCounts that keeps track of counts for hashtags over a window of time. There are multiple
HashtagCounts state objects within the application, but for the rest of this post, we are only interested in how any individual instance works.
HashtagCounts'
increment method is called each time we intend to increment the count for a given hashtag.
def increment(self, hashtag): """ Increment the count for `hashtag` """ mse = self.__minutes_since_epoch() window_gap = int(mse % TRENDING_OVER) # have we rolled over? if self.__window[window_gap][0] < mse: self.__rollover(hashtag, window_gap, mse) else: self.__increment(hashtag, window_gap) # did our top ten change? new_top_tags = self.__calculate_top_tags() if new_top_tags != self.__top_tags: self.__top_tags = new_top_tags return self.__top_tags.copy() else: return None
The core of our windowing logic is in the first few lines of
increment:
mse = self.__minutes_since_epoch() window_gap = int(mse % TRENDING_OVER) # have we rolled over? if self.__window[window_gap][0] < mse: self.__rollover(hashtag, window_gap, mse) else: self.__increment(hashtag, window_gap)
Alrighty, so what is going on here? The first thing to know is that we store our counts per hashtag on a per minute basis in the
__window variable. If our window is 5 minutes then
__window would have a length of 5.
We need to determine if the current time is outside of an existing window or within a current window. First, we need to get which
window_gap that our time is in. That is, which bucket in our
__window array are we in. We do this by getting the minutes since the Unix epoch and then taking the modulus of that over our
TRENDING_OVER time period:
mse = self.__minutes_since_epoch() window_gap = int(mse % TRENDING_OVER)
The default value of
TRENDING_OVER is 5 minutes. So if our minutes since epoch was 31 and we are trending over 5 minutes, then our "window gap" would 1.
The question is, is that "window gap" current or is it a new window? That we address with this bit of code:
# have we rolled over? if self.__window[window_gap][0] < mse: self.__rollover(hashtag, window_gap, mse) else: self.__increment(hashtag, window_gap)
So, what exactly are we storing in
__window anyway? Without knowing that, the "have we rolled over" logic is pretty opaque. Each element in
__window is a tuple. The tuple is:
(minutes_since_epoch, map_of_hashtags_to_counts)
This is most clearly seen in our
__rollover method:
def __rollover(self, hashtag, gap, mse): self.__window[gap] = (mse, {hashtag: 1})
So, back to our "is this a new window" logic...
# have we rolled over? if self.__window[window_gap][0] < mse: self.__rollover(hashtag, window_gap, mse) else: self.__increment(hashtag, window_gap)
When we check
self.__window[window_gap][0] < mse, what we are checking is if the minutes since epoch stored in __window is less than the one we are currently processing. If yes, then we have worked our way around
__window's various indexes and are back at
window_gap at a later point in time. When that happens, we want to roll over our window by getting rid of the existing data in our window gap and starting fresh with the hashtag we are processing:
def __rollover(self, hashtag, gap, mse): self.__window[gap] = (mse, {hashtag: 1})
and if the minutes since epoch stored in __window isn't less than one we are currently processing, that means we are within the same minute window and should augment our current counts:
def __increment(self, hashtag, gap): current_count = self.__window[gap][1].get(hashtag, 0) self.__window[gap][1][hashtag] = current_count + 1
And that is a complete windowing solution for our trending hashtags example app.
Windowing, What's Coming
Our approach with Wallaroo has been to provide programmers with core primitives for building event-by-event applications that give them the flexibility to implement the business logic their domain requires. Our current approach to windowing is an example of this. We have left windowing entirely in the hands of the Wallaroo user. You can implement any sort of windowing that is triggered by an event, from internally triggered, to externally triggered, to the handling of out of order or late arriving data.
We also know, that with this power and flexibility comes a cost. You have to implement windowing yourself, and for common use cases, it would be nice if Wallaroo provided APIs to make those common cases as easy as an API call. Such APIs (including time-based windowing) are on our roadmap. If you have interesting windowing use-cases, we'd love to talk to you. Talking to our users both current and future helps us build better solutions. Please, . And, in the meantime, we have the Twitter Trending Hashtags code available for you to clone, inspect, and play around with.
12 Best Practices for Modern Data Ingestion. Download White Paper.
Published at DZone with permission of Sean Allen , DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}{{ parent.urlSource.name }} | https://dzone.com/articles/implementing-time-windowing-in-an-evented-streamin | CC-MAIN-2019-09 | refinedweb | 1,333 | 56.05 |
Here is my program so far in Python 2.7:
def menu():
....print "Welcome to my bitchin' calculator!"
....print " "
....return raw_input("Would you like to add, subtract, multiply, or divide? ")
def add(add1,add2):
....print add1, "+", add2, "=", add1 + add2
def sub(sub1,sub2):
....print sub1, "-", sub2, "=", sub1 - sub2
def redo(a):
....if a == "yes":
........print "OK!"
....else:
........loop = 0
loop = 1
choice = 0
while loop == 1:
....choice = menu()
....if choice == "add":
........add(input("add this: "),input("to this: "))
........redo(raw_input("Would you like to start over? "))
print "Bye bye!"
*Note that the .... was added to indicate indention, due to this forum removing my indentions. in the actual program, the indentions are present
I can choose to add, and then it successfully adds the numbers and starts the redo function as defined above. However when I type "no", it should set loop to 0 and stop running the while loop, but it doesn't! after I type no, it runs menu again and starts over. It never prints "Bye bye!" Can someone help a rookie out? | http://forums.devshed.com/python-programming-11/help-defined-function-loop-937581.html | CC-MAIN-2017-09 | refinedweb | 175 | 79.77 |
- Advertisement
WunderStrudelMember
Content Count24
Joined
Last visited
Community Reputation162 Neutral
About WunderStrudel
- RankMember
Recent Profile Visitors
The recent visitors block is disabled and is not being shown to other users.
New Game Development Team / Network
WunderStrudel posted a topic in Hobby Project ClassifiedsGeneral Idea. Okay so the general idea here is to either make a little team of developers wanting to learn 3D game development in OpenGL but if there is any experienced developers out there wanting to spread they knowlegde, i gladly sit down, shutup and listen. If any of you out there is open for creating a new little team/community of new/experienced game devs let me know. You can either PM me or write me a mail at "JonasKristoffersen@ghostmail.com" and we will figure something out. I hope this is something people would find interresting and also i gladly share my web dev experience so you are welcome to ask any question. About me. I'm a pretty serious programmer with a background mainly in web development. For a long time i have been wanting to start 3D web development with OpenGL and i actually started my programming "carrier" with game development but quickly moved onto web development since it is a lot easier making a livin off. Now that i know all my ins and outs of web development and have a lot more programming experience i feel a lot more confident jumping into 3D game develpoment. Skills: HTML & CSS (expert). Javascript (expert). PHP & MYSQL (expert). C (some experience. was my first language but havent used since). C# (developed a couple of unity games in it). C++ (pretty experienced. developed my first couple of 2D games with c++ and opengl/sdl). Java (not so experience. made a couple of small progams with it). Python (used it alot for game plugin programming). Pawn (also used it a lot for game plugin programming). Shell/bat (I have used a fair amount managing my dedicated server).
Unity 2D tiled maps
WunderStrudel replied to SonicD007's topic in For Beginners's Forum.
Web Games/Apps - Kick starting help needed!
WunderStrudel posted a topic in General and Gameplay ProgrammingHi Guys! (: I have been web developing for a little while now, and i have earlier done a lot of 2d game programming in opengl. And then i figured why not mix them together? But my problem is that i did opengl in C++, and i have no idea how it works programming wise and "format" wise, when it is web based. So if there is anybody out there that think he got something that can lead me forward, please leave a comment. Thanks! Sincerly WunderStrudel!
C / C++ --> Need help with some text input.
WunderStrudel posted a topic in For Beginners's ForumHii guys (: I've been programming in c/c++ for about 6 - 8 month now, mostly game stuff, which might be why i'm asking this newbie question ^^ I got tired of playing around with SDL and Opengl efter a while, and i thought to myself "What do you want to achive with programming?", and i guess my answer was "it all" But right now i'm making my own little kinda cmd chat, right now just for localhost. My problem is getting the keystrokes converted to strings/words, so that it does not just buffer a single letter at the time, but submit the whole word or sesntence. i just deleted my whole project and started from scratch so this is all my code so far; #include <iostream> #include <windows.h> #include <Winuser.h> #include <time.h> using namespace std; int main() { TCHAR pcName [250]; TCHAR userName [250]; DWORD pcSize = 20; DWORD userSize = 20; SYSTEMTIME st; GetLocalTime(&st); if(!GetComputerName(pcName,&pcSize)) { cout << "Size: " << pcSize << "\tError Code: " << GetLastError() << std::endl; } if(!GetUserName(userName,&userSize)) { cout << "Size: " << userSize << "\tError Code: " << GetLastError() << std::endl; } cout << "("; cout << st.wDay; cout << "/"; cout << st.wMonth; cout << "/"; cout << st.wYear; cout << " - "; cout << st.wHour; if((int)st.wMinute < 10) { cout << ":0"; } else cout << ":"; cout << st.wMinute; cout << ":"; cout << st.wSecond; cout << ")"; cout << " -> "; cout << pcName; cout << " -> "; cout << userName << endl; system ("PAUSE"); return 0; } And in the other runs/tests i'v been using GetAsyncKeyState() to detect the keystrokes. Anybody have any lessons to teach me? Thanks a lot on advantage. Sincerly Wunder..
C++ / opengl/glut - Text rendering
WunderStrudel replied to WunderStrudel's topic in For Beginners's ForumOhhhh (: Actualy started out using "string", but then it didn't work with displaying the variables, so i though that maybe they had to be "char" becos those you loop through, if that makes any sense :D
C++ / opengl/glut - Text rendering
WunderStrudel replied to WunderStrudel's topic in For Beginners's ForumThank you for anwsering, although i'm not sure really sure which approach to take from here. Just cant figur out how to cheat it into displaying that freakin variable d; Btw. sry for my bad english, i'm kinda sleep "depribed"? idk, have been lookin at this freakin code in like 18 - 24 hours now d:
C++ / opengl/glut - Text rendering
WunderStrudel posted a topic in For Beginners's ForumHiii guys (: I dont know if this is the right place, but i thought of it as pretty basic, which just makes this more embaresing d: i have tried some functions for displaying text, and i made a couple of them work. Cant remember excatly how i wrote it but something like; void DrawText(float x, float y, char *string, ...) { int len = (int)strlen(string); for (int i = 0; i < len; i++) { glutBitmapCharacter(Thefont, (int)string[i]); } } u should get the idea ^^ Anyways i made it work "kinda", it shows the text, but i cant make it show my vars' like; DrawText(200, 200, "MouseX; %d", mouseX); Then it just types "MouseX %d" on the screen (: Anyfixes? ^^ Sincerly Wunder..
C++ 2D Isometric map problem
WunderStrudel replied to WunderStrudel's topic in General and Gameplay ProgrammingThanks you very much, those are some awesome links!!!
C++ 2D Isometric map problem
WunderStrudel replied to WunderStrudel's topic in General and Gameplay ProgrammingOhh thanks man (: I'll try with this one, and see if i can make it work d;
C++ 2D Isometric map problem
WunderStrudel replied to WunderStrudel's topic in General and Gameplay ProgrammingOhh yeah, i could have been more specific i guess, sry about that d: My problem is getting to "draw" / making the tile grid. in the isometric / diamond shaped way. And ofcos getting my "64x32" sprites fittet over the grid (: I cant really remember the function in my head, but what i'v seen so far was something like: For(int index = 0; index < Max_rows; index++) { for(int indey = 0; indey < Max_Cols; indey++) { Drawx = (This Algorithm is where my problem lies) Drawy = (This Algorithm is where my problem lies) } } and i'm not even sure that that is even remotely correct d:
C++ 2D Isometric map problem
WunderStrudel posted a topic in General and Gameplay Programming :D So i reeeeeallly need help guys :D Thanks for your time, sincerly Wunderstrudel.
I Need Help Getting Started
WunderStrudel replied to naughtyusername's topic in For Beginners's ForumHi you (: I just started myself, about 3 days ago. The way i do it is: I found some tuts and websites about "Console app programming", then i played around with that for a day, and created a program with a "Login, App Menu with a "Calculator, Text based game, Guessing Game and kinda logic conversation answer thingy, kinda like cleverbot" not as advanced though d; then i started looking in to the basic C and C++ coding language, learning the basic keywords like, if, else if, else, while, for and so on and so on. Then today, "Currently". i am making games. Earlier i made a "Packman game" and now i am making a Tic Tac Toe. The way i do it, is that i watch tuts on how to do it, and then i use "His code" but rewritten, so no copying, just "Reforming" the code, and "U HAVE TO UNDERTSAND WHAT EVERYTHING IN YOUR CODE MEANS AND DOES!!". Then tomorrow i'm gonna look in to texturing / skinning, and maybe alittle bit about game databases and such (: If you are engaged in learning C++. You can write to me here, or on steam or something. I could use someone to learn it with. Could also make it more fun with making the games, and testing them (:
C++ Minigame textures
WunderStrudel posted a topic in General and Gameplay ProgrammingHi guys (: I'm am quite new to C++, have only been coding it for a couple of days now (: Bur still i have managed to code myself a little game of "Catch me if you can". But now i have the problem "Textures" / Sprites. I can only really find explanations on how to do it with 3D, which i'm am not using Can any one tell me how, or refere me to a website or something? ^^ (Also how to display "Text / Messages" in my window. Like Scores, names and so on) (I would like them for my char, background and so on) (: Thanks ^^
Need help with "Calling"
WunderStrudel replied to WunderStrudel's topic in General and Gameplay ProgrammingThanks alot man! :D Haha i will d;
Need help with "Calling"
WunderStrudel replied to WunderStrudel's topic in General and Gameplay ProgrammingThanks for you post (: And yeah maybe, though the beginner forum was more generel question than coding questions, and didn't wanna place it in the wrong forum d; And well, i'm not rly sure i understand what you mean with the "Calling" can you make a quick line of code, with your ex. or something? Thanks a lot on advance mate (:
- Advertisement | https://www.gamedev.net/profile/211848-wunderstrudel/ | CC-MAIN-2019-22 | refinedweb | 1,625 | 66.88 |
Try with sql load data infile.
Example:
LOAD DATA INFILE 'data.txt' INTO TABLE db2.my_table;
Try this code->
String str =
"USI;1;3056090866;06/16/58/06/24/13;CN25.48,WN86.957;CN34.931,WN16.656";
StringBuilder b = new StringBuilder(str);
b.replace(str.lastIndexOf("CN") - 1, str.lastIndexOf("CN") + 2, "CO" );
b.replace(str.lastIndexOf("WN") - 1, str.lastIndexOf("WN") + 2, "WO" );
str = b.toString();
It will work..
The type of node is called processing-instruction so use
<xsl:template match="processing-instruction()[starts-with(name(),
'mso-')]"/>
together with the identity transformation template
<xsl:template
<xsl:copy>
<xsl:apply-templates
</xsl:copy>
</xsl:template>
That way the processing instructions where the name starts with mso- will
not be copied.
I will show a complete stylesheet:
<xsl:stylesheet version="1.0"
xmlns:
<xsl:template
<xsl:copy/>
</xsl:template>
<xsl:template match="processing-instruction()[starts-with(name(),
'mso-')]"/>
<xsl:template
<xsl:elem
I find this somewhere that I do not know where it was.
strings `which info` | grep /info
This would print out some default info directories that had been compiled
with the info command. One can also export a shell variable called INFOPATH
with info directories you want.
What you want to do is called as screen scrapping. You can use Watin for
this. Or else you can use WebResponse and WebRequest to achieve this also.
You get the text of the cells via the DataGridViewRow's Cells property.
The following example would get the text from the first cell in each
selected row:
Dim strContents As String = String.Empty
For Each selectedItem As DataGridViewRow In selectedItems
strContents += " First Cell's Text: " & selectedItem.Cells(0).Text
Just put
@echo off
in the first line of your batch file. This will prevent output of the
command's invocation when they are run (as does prepending a command with
@), so it eliminates all the lines that bother you.
Taken from.
Sounds like you want:
var hashAlgorithm = certificate.PrivateKey.SignatureAlgorithm;
var encryptionAlgorithm = certificate.PrivateKey.KeyExchangeAlgorithm;
They may not be exactly the sample values you've given, but that would be
my starting point...
As announced the "visual refresh" is now live for the Google Maps
Javascript API v3 if you are using the "experimental" version (no version
number in the API load).
In PHP use
header("Location: TARGETURL");
Create the TARGETURL using the information sent from the form.
The Location Header makes the server to generate 302 Moved temporarily HTTP
return code. The browser then sends the user to the TARGETURL transparently
without any further interaction.
Bundle extras = new Bundle();
when you do this you create a new Bundle named extras and not the extras
that you added to the activivty.
instead try:
contactId = getIntent().getIntExtra("contactId",0);
Youre mixing mysqli and mysql... they are two completely different and
incompatible interfaces. Secondly, your $query_get_referral_id is not an id
value... it is a mysqli_result object. You need to then extract the value
from that object.
And lastly... DONT use mysql... stick with mysqli, or use PDO
Also you should use a prepared statement for this:
$stmt = $this->db_connection->query("SELECT user_id From users WHERE
user_name = ?");
$stmt->bind_param('s', $referralname);
$stmt->execute();
if($stmt->num_rows) {
$stmt->bind_result($userId);
while($stmt->fetch()) {
// do something with $userId...
// each iteration of this loop is a
// row of the result set, it will automatically
// load the value of the user_id into $userId
It is getElementById not getElementsById, although your code shows the
correct version.
Just because IE is not busy doesn't mean that the page has finished
If IE.ReadyState = READYSTATE_COMPLETE Then '4
You should also use a Sleep method, or some other method to prevent .Busy
being read constantly.
Added: A Win-API call can call be used for the Sleep method:
Option Explicit
'Declare Sleep API
Private Declare Sub Sleep Lib "kernel32" (ByVal nMilliseconds As Long)
Sub UseIE()
Dim ie As Object
Dim thePage As Object
Dim strTextOfPage As String
Set ie = CreateObject("InternetExplorer.Application")
ie.FullScreen = True
With ie
.Visible = True
.Navigate ""
While Not .ReadyState = READYSTAT
Subnets work differently for IPv6, so the rogue 64 you are seeing is the
IPv6's subnet mask - not the IPv4's.
The prefix-length in IPv6 is the equivalent of the subnet mask in IPv4.
However, rather than being expressed in 4 octets like it is in IPv4, it is
expressed as an integer between 1-128. For example:
2001:db8:abcd:0012::0/64
See here:
In order to remove it you can try the following (massive assumption made
that IPv4 always comes first, but in all my experimenting it hasn't come
second yet ;))
ForEach($NIC in $env:computername) {
$intIndex = 1
$NICInfo = Get-WmiObject -ComputerName $env:computername
Win32_NetworkAdapterConfi
GetWindowInfo isn't going to tell you anything specific to a progress bar -
only the standard window flags. Take a look at the documentation for
Progress Bar Messages for how to interact with a progress bar.
You need to use the PBM_GETPOS message to get the current position of a
progress bar as below:
const uint PBM_GETPOS = 0x0408;
[DllImport("user32.dll")]
private static extern IntPtr GetWindowInfo(IntPtr hwnd, uint msg, IntPtr
wParam, IntPtr lParam);
uint pos = (uint)SendMessage(hwnd, PBM_GETPOS, IntPtr.Zero, IntPtr.Zero);
Is there a way to get info on an Android application (e.g., publisher name)
if you know the name of the package?
1) get application name from package name
2) Find package name for Android apps to use Intent to launch Market app
from web questions.
You may get some details using PackageManager and ApplicationInfo. The
first one seems to answer that. Hope this is of some use to you.
Your HTML is incorrect, you have no name on the first input and your second
input the name value is incorrect as it starts like [], try this.
<input id="<?php echo $catkey; ?>_addone_friendly_1"
name="friendly[<?php echo $catkey; ?>]" type="text" class="auto"
size="9" /><span> - Friendly Name</span><br />
<input id="<?php echo $catkey; ?>_addone_1" name="actual[<?php
echo $catkey; ?>][]" type="text" class="auto" size="9" /><span>
- Actual Name</span><br />
A Google+ URL generally contains the Google+ ID for a user. You can parse
out that ID, and then make a people.get API call using the ID. The response
will only contain information that is publicly available on the user's
profile, though. Also, if a user is verified, their URL will not contain
their ID, but rather their verified name, but this will also work as an ID.
In PHP, the call looks like: $me = $plus->people->get('{{ID}}');
You can learn more about the people.get API call and see a full example at.
Here is your query (formatted so I can read it better):
SELECT t1.id, t1.username, t1.password, t1.email,
t2.image, t3.intValue, t3.textValue, t3.dateValue
FROM table1 t1 LEFT JOIN
table2 t2
ON t1.id = t1.userId LEFT JOIN
table3 t3
ON t1.id = t3.userId AND
columnName='sex' OR columnName='birthdate' OR columnName='realname'
WHERE t1.email = $username OR t1.username = $username ;
One problem is the OR condition on table3. This is evaluated as:
ON (t1.id = t3.userId AND columnName='sex') OR columnName='birthdate'
OR columnName='realname';
SQL doesn't read mind. It invokes precedence rules. The condition would
be best stated as:
ON t1.id = t3.userId AND
columnName in ('sex', 'birthdate', 'realname');
However, I don't think that i
If I right
sql update like this -
update yourTable set nombre=?,apellido=?,username=? where cedula='$cedula';
sql insert like this -
insert into yourTable(nombre,username,apellido) values(?,?,?);
try this with the sql sysntax. thanks
You need to be accessing the main bundle instead of no bundle. The
instantiation of your storyboard should look like this:
UIStoryboard *iPhone4Storyboard = [UIStoryboard
storyboardWithName:@"iPhone4.storyboard" bundle:[NSBundle mainBundle]];
The following code should do the job.
var JSON =
{"name":"CRS_LOG_LEVEL","children":[{"name":"CRS_LOG","children":[{"name":"LOG_DESC","size":7,"type":"column"},{"name":"LOG_ID","size":7,"type":"column"},{"name":"LOG_TMSTMP","size":7,"type":"column"},{"name":"LOG_LEVEL_NBR","size":7,"type":"column"},{"name":"LOG_EVENT_CD","size":7,"type":"column"}],"size":100,"type":"table"}],"size":100,"type":"root"}
for (var i = 0; i<JSON.children.length; i++) {
for (var j = 0; j<JSON.children[i].children.length; j++) {
var parentIndex = JSON.children[i].children.indexOf(d);
if (parentIndex !== -1) {
var parentName = JSON.children[i].children[parentIndex].name;
}
}
}
The variable parentName should contain the name that you where looking for.
Note that
A valid token will start with T1==, the token you've shown does not. Can
you go back to the Dashboard, create a new token for that session, paste
the entire string into your application code, and try again?
Did you check the below class?
System.IO.DriveInfo
What detailed information are you looking for in addition to the ones
provided by this class?
You can check other classes in this namespace.
Edit based on the comment:
If you want to detect the device at runtime, you may use:
ManagementEventWatcher & WqlEventQuery
Below is an example:
WqlEventQuery _q = new WqlEventQuery("__InstanceOperationEvent",
"TargetInstance ISA 'Win32_USBControllerDevice' ");
_q.WithinInterval = TimeSpan.FromSeconds(1);
_usbWatcher = new ManagementEventWatcher(_q);
_usbWatcher.EventArrived += new
EventArrivedEventHandler(OnUSBDetectedOrDetached);
_usbWatcher.Start();
and in the event handler:
voi
As you are subscribing to Calendar-Folder only, then instead you can
directly bind it to Appointment object ::
Appointment appointment = Appointment.bind(service, itemEvent.getItemId()
,
new PropertySet( AppointmentSchema.Subject,
AppointmentSchema.Body,AppointmentSchema.IsRecurring ) );
Looking at the book’s source code on GitHub, it seems to be mostly static
HTML, CSS, and JavaScript. However, it uses Python, Java, and shell code
too, as you can see in the Makefile. (Makefiles are run with make.)
The Makefile contains a lot of shell code doing things like substitution,
file copying, and concatenation. It also calls the Python and Java code,
which is all in the util folder. The Python and Java programs compress the
HTML and CSS, build the table of contents from the headings in each file,
and do a few other things.
Firstly , this form definition might not work :
<form name="txtForm" action="Main.java" method="post">
In the action attribute you need to specify an URL such as form.do etc...
Then map the Servlet Main.java to this specific URL in the web.xml.
Try using the PrintStream to print it to the response.
response.getWriter.println("The name you enter is:" + text + "at the time :
" + d);
When you do this , the response will be sent back to the browser.
Though ideally you should use a JSP for view .
You can send the request to a JSP and then print the request parameters
using EL ${param.parameterName}.
i want is to take the info from the jsp thru my class then print it out
back on a the jsp
This will be a bit lengthy exercise though . You need to dispatch the
request from your
I don't really think you can do that. Check following situation:
Your predicate is set to be Func<T, bool> predicate, so you can call
it like that:
Accounts = _data.Filter(p => true);
What would you like to get from that kind of call?
(p) => true satisfies Func<T, bool>, because it takes T as input
and returns bool value.
Just 2 steps:
get "manage_pages" permission from user
Get all account information by calling FB.api(/me/accounts)
Way two, get it from Fql query:
SELECT page_id, type from page_admin WHERE uid=me()
page_admin documentation here
Generally speaking, just take the whole URL path and rewrite it into the
query string. The value will be available to your PHP scripts in
$_GET['roomName'].
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.*)$ /room.php?roomName=$1
The RewriteCond lines are checking to make sure the URL does not point at
an actual file/directory (otherwise, you would not be able to access such
files/directories).
If this isn't what you want, please explain your goals further.
You need to had an infoWindow for each marker!
Supposing you have 10 different messages, stored in 10 variables (message0,
message1, message2,...), you should write:
var infoWindow0 = new google.maps.InfoWindow({
content: message0
});
google.maps.event.addListener(marker0, 'click', function () {
infoWindow0.open(map, marker0);
});
var infoWindow1 = new google.maps.InfoWindow({
content: message1
});
google.maps.event.addListener(marker1, 'click', function () {
infoWindow1.open(map, marker1);
});
var infoWindow2 = new google.maps.InfoWindow({
content: message2
});
google.maps.event.addListener(marker2, 'click', function () {
infoWindow2.open(map, marker2);
});
...(and so on until marker1
Add: xmlns:w3="" to the xsl:stylesheet element.
and add the w3 prefix to the elements in your select statement:
<td><xsl:value-of</td>
<td><xsl:value-of</td>
Your xml is in the default namespace "",
but the xpaths in your xsl select is in the null namespace.
They don't match. Namespace match is not by prefix ( or lack of prefix )
but by the namespaces that the prefixes are bound to.
{}/Xboxspellen != {}/Xboxspellen
See this for more: XML Namespaces and How They Affect XPath and XSLT
Also: The perils of default namesp
why using Share Kit , Use Twitter Api V1.1 to Fetch Complete User Info
check below Links ...
Hope its HelpFull..
Yes, couple of ways to do this
Read assembly info
Usually as part of your CI build steps, you would add versioning numbers,
company details, sign libraries etc. You will be able to read this info
when a request comes from the library with updated metadata. Code snippet
to try, make sure to find correct dll though, as on IIS it may not be the
executing assembly.
Embed custom app config values
Similarly as part of the build process you may do xml-poke or xml-transform
to insert some values into the web.config, for example into the
<appsettings> section. MS build sample. You would likely to use
ConfigurationManager.AppSettings from the web application.
Your Object should implement Serializable interface
HINT: For clone the object, far better to implement Cloneable interface and
use the object.clone() method
Do i understand you correctly, that your array looks like this?!
[0] => array(
"your_super_long_product_key" => array(),
"another_super_long_product_key" => array(),
"awesome_super_long_product_key" => array(),
)
So you could access the data like this:
foreach(array_keys($array[0]) as $key) {
echo $key . "
";
}
This will give you:
your_super_long_product_key
another_super_long_product_key
awesome_super_long_product_key
To loop through your whole array like this use:
foreach($array as $dataset) {
foreach(array_keys($dataset) as $key) {
echo $key . "
";
}
}
If you want add manifest to project use it like this
win32 {
RC_FILE = c:/app.rc
-manifest c:/app.exe.manifest
}
or don't use full path if it on project home dir.
A Map maps one key to one value. You're overriding the value many times.
This
if (myStores.getStoreNumber().equals(myStores.getStoreNumber())) {
myCache.put(myStores, hardware.getHardwareInfo_East()); //myCache is a
static map.
myCache.put(myStores, hardware.getHardwareInfo_West());
myCache.put(myStores,hardware.getHardwareInfo_South());
myCache.put(myStores,hardware.getHardwareInfo_North());
break;
}
is the same as
if (myStores.getStoreNumber().equals(myStores.getStoreNumber())) {
myCache.put(myStores,hardware.getHardwareInfo_North());
break;
}
If you want to combine all the lists, you could do this:
if (myStores.getStoreNumber().equals(myStores.getStoreNumber())) {
myCache.put(mySt
What commits do they have in stage/master that I don't have locally:
git log ...stage/master --graph --decorate --cherry --name-status
What commits do I have locally that I haven't pushed to stage/master:
git log stage/master... --graph --decorate --cherry --name-status
--decorate -- shows tag and branch names beside commits
--cherry -- shows "=" instead of "*" on commits that are merged.
What's the symmetric difference, in term of commits, between the two:
git log ...stage/master --cherry-pick --left-right --name-status
--left-right -- shows "<" and ">" on commits to indicate whether
commits are from left of ..., or right, respectively.
Also look at: git-log
Maybe you want something like this
<article>
<p>Description and price</p>
<img src="" alt="amazing item" />
</article>
<style type="text/css">
article{
float: left;
}
article p{
float: left;
width: 0px;
-webkit-transition: width .5s ease;
-moz-transition: width .5s ease;
-ms-transition: width .5s ease;
-o-transition: width .5s ease;
transition: width .5s ease;
}
img{
float: left;
}
article:hover p{
width: 150px;
}
</style> | http://www.w3hello.com/questions/-asp-net-info- | CC-MAIN-2018-17 | refinedweb | 2,672 | 58.79 |
ResourceState
Since: BlackBerry 10.0.0
#include <bb/cascades/ResourceState>
Exposes resource state enum to QML.
Overview
Public Types Index
Public Types
Definitions of the resource states.
BlackBerry 10.0.0
- Unknown
The state is not known.
The resource is being loaded (for example, it's downloading or decoding, etc).Since:
BlackBerry 10.0.0
- Loaded
The resource is loaded and is ready to be used.Since:
BlackBerry 10.0.0
- ErrorNotFound
The resource is not found (for example, the given path is invalid).Since:
BlackBerry 10.0.0
- ErrorInvalidFormat
The resource is found but could not be recognized (for example, the data is corrupt or has an unhandled format).Since:
BlackBerry 10.0.0
- ErrorMemory
There's not enough memory to decode the resource.Since:
BlackBerry 10.0.0
Got questions about leaving a comment? Get answers from our Disqus FAQ.comments powered by Disqus | http://developer.blackberry.com/native/reference/cascades/bb__cascades__resourcestate.html | CC-MAIN-2014-42 | refinedweb | 146 | 55.71 |
Mathias Weinert wrote:
> In libsvn_subr/io.c there is macro called WIN32_RETRY_LOOP used to do
> several retries of some file commands like rename. As the problem which
> this macro shall solve - or at least soothe - also exists under cygwin
> I would like this macro to also be used if under cygwin.
>
> The following patch is just quick and dirty (indeed it's very dirty)
> but it shows what I mean (and it works and helps).
>
> Are there any objections against such a change (in principal)?
After doing some more tests I found out that in my cygwin environment
the rename failed several times with an error code of 13 which is
ERROR_INVALID_DATA. After adding this error to the WIN32_RETRY_LOOP
macro it worked without any problems.
So here is a new version of the patch (which is at least not as dirty
as the last one ;-) ). Maybe the ERROR_INVALID_DATA only applies for
cygwin. In that case two separate macros should be defined.
Mathias
--- subversion/libsvn_subr/io.c.orig 2005-11-17 00:05:43.000000000 +0100
+++ subversion/libsvn_subr/io.c 2006-05-04 16:21:12.701822100 +0200
@@ -30,6 +30,9 @@
#include <errno.h>
#endif
#endif
+#ifdef CYGWIN
+#include <winerror.h>
+#endif
#ifndef APR_STATUS_IS_EPERM
#ifdef EPERM
@@ -71,7 +74,7 @@
goes a long way towards minimizing it. It is not an infinite
loop because there might really be an error.
*/
-#ifdef WIN32
+#if defined(WIN32) | defined(CYGWIN)
#define WIN32_RETRY_LOOP(err, expr) \
do \
{ \
@@ -80,6 +83,7 @@
int retries; \
for (retries = 0; \
retries < 100 && (os_err == ERROR_ACCESS_DENIED \
+ || os_err == ERROR_INVALID_DATA \
|| os_err == ERROR_SHARING_VIOLATION); \
++retries, os_err = APR_TO_OS_ERROR (err)) \
{ \
---------------------------------------------------------------------
To unsubscribe, e-mail: dev-unsubscribe@subversion.tigris.org
For additional commands, e-mail: dev-help@subversion.tigris.org
Received on Thu May 4 18:14:25 2006
This is an archived mail posted to the Subversion Dev
mailing list. | http://svn.haxx.se/dev/archive-2006-05/0092.shtml | CC-MAIN-2014-42 | refinedweb | 303 | 58.28 |
NewFunction-macro
Counts the number of datasets that begin with the letter F (function datasets) and opens the function's Plot Details dialog box to create a new function named Fn where n is one more than the number of datasets counted. If the FUNCTION.OTP graph template is not opened before executing NewFunction, then the function dataset Fn is created but not plotted.
Def NewFunction {
list -sn F B;create %B -f 10;
def ErrorProc [del %B];set %B;del -m ErrorProc;
};
The following script creates a new graph window from the FUNCTION.OTP template and then creates and plots a new function named F1 (assuming that no other function datasets already exist).
GetEnumWin Function;
NewFunction; | http://cloud.originlab.com/doc/LabTalk/ref/NewFunction-macro | CC-MAIN-2020-16 | refinedweb | 117 | 61.36 |
To.
(In reply to Dima Voytenko from comment #0)
> To.
Hi Dima. I can confirm the bug on macOS and GTK. A quick debug in WebCore::DOMWindow::allowPopUp shows that UserGestureIndicator::processingUserGesture() returns false for "Channel Message" because UserGestureIndicator::currentToken() is null, so indeed it seems the user gesture context is not propagated somehow.
If there are no other reasons, it'd be great if it did. IMHO MessageChannel, while essentially the same, is an improvement over plain window messaging: I see a lot fewer security bugs with code relying on it.
(In reply to Dima Voytenko from comment #2)
> If there are no other reasons, it'd be great if it did. IMHO MessageChannel,
> while essentially the same, is an improvement over plain window messaging: I
> see a lot fewer security bugs with code relying on it.
I'm not sure why you say there's fewer security bugs with message channels vs. postMessage
MessageChannels can cross browsing contexts in newly radical ways (e.g. web page -> service worker context), making the bug surface significantly larger.
The fallout from "blessing" them with the user gesture flag should be carefully considered.
Port can be exchanged only once and post-handshake the continuous message is more secure: I'm seeing few bugs with constant origin/source/target verification.
Created attachment 342800 [details]
Patch
Here is a quick proof-of-concept patch that just propagates the current user gesture via MessageWithMesagePorts. That seems to make Dima's test case work as expected.
(In reply to Brady Eidson from comment #3)
> MessageChannels can cross browsing contexts in newly radical ways (e.g. web
> page -> service worker context), making the bug surface significantly larger.
>
> The fallout from "blessing" them with the user gesture flag should be
> carefully considered.
I agree, I think we would need feedback from security reviewers to be sure whether this change of behavior is acceptable.
It seems Chromium developers are considering allowing that (cf see also link) once they enable their new refactored code. Maybe they could give us their stance on this.
Comment on attachment 342800 [details]
Patch
View in context:
> Source/WebCore/dom/MessagePort.cpp:276
> + UserGestureIndicator gestureIndicator(ProcessingUserGesture);
Oops, this is not what I wanted to do!
Created attachment 342918 [details]
Patch
This new version now properly sets the current gesture in MessagePort::dispatchMessages and adds the missing IPC encoding/decoding of the gesture.
I've written a new test case, based on Dima's:
The difference is that the frame tries to automatically send the channel message 5 seconds after page load.
With this patch, WebKit allows to open the popup when you click "Channel Message" but not for the automatic channel message.
@beidson, it looks like there's a patch. How would we go about "The fallout from "blessing" them with the user gesture flag should be carefully considered."? What are possible scenarios with user gesture propagation w.r.t. service workers or web workers? To note, this bit is not exposed to the APIs anywhere, but it seems that having an additional context that directly lead to this message would be an overall good thing?
(In reply to Dima Voytenko from comment #4)
> Port can be exchanged only once
I'm unclear on what you mean here.
Can you rephrase?
(In reply to Brady Eidson from comment #9)
> (In reply to Dima Voytenko from comment #4)
> > Port can be exchanged only once
>
> I'm unclear on what you mean here.
>
> Can you rephrase?
You mention that there might be some concerns about merging the patch. I wanted to ask how you'd go about verifying/addressing these concerns?
Created attachment 343234 [details]
Patch (more restricted version)
This is a new version that is much stricter about how user gesture context is passed by postMessage. Basically, now:
- DOMWindow::postMessage always passes the user gesture context (that's already the case now)
- MessagePort::postMessage passes the user gesture context as long as it is not used in a worker context (currently, it never passes the user gesture context hence Dima's use case fails).
- Worker::postMessage will never pass the user gesture context (that's already the case now).
I have not tested it extensively yet, but at least it makes Dima's use case work.
@Brady Eidson: Do you think this would be an acceptable change from a security point of view?
@Dima: Do you think that would address your use cases?
If that sounds good, I'll try writing tests and prepare a patch for formal review.
Maybe relaxing the conditions for postMessage can be done in follow-up patches, if that's what we want.
Adding a few security people in cc.
(In reply to Frédéric Wang (:fredw) from comment #11)
> Created attachment 343234 [details]
> Patch (more restricted version)
>
> @Dima: Do you think that would address your use cases?
Thanks, Frédéric! It does solve the use case and makes window/channel messaging APIs more compatible. I'm definitely ok starting with a more strict version and expanding if other use cases emerge.
<rdar://problem/45836796>
Created attachment 354837 [details]
Patch
@Brent: Can you please review this patch?
Created attachment 363084 [details]
Patch
Rebasing...
Review ping?
Created attachment 369470 [details]
Patch
Rebasing...
Comment on attachment 369470 [details]
Patch
Attachment 369470 [details] did not pass win-ews (win):
Output:
New failing tests:
js/dom/custom-constructors.html
Created attachment 369478
Hi! Is there any response here from security folk or otherwise?
Comment on attachment 369470 [details]
Patch
View in context:
> LayoutTests/ChangeLog:9
> + tests message posting via Window, MessageChannel, BroadcastChannel although the latter is
We TEST message posting
> LayoutTests/ChangeLog:11
> + from a subframe.
"We also verify that the message is coming from the same window or from a subframe." ?
> LayoutTests/ChangeLog:19
> + * http/tests/messaging/postMessage-triggered-by-user-activation.html: Added.
Are these not in WPT because we use a different user interaction construct? Is there no way to just keep this in WPT to make future merge/updates easier?
> Source/WebCore/dom/MessagePort.cpp:159
> + bool contextIsWorker = is<WorkerGlobalScope>(*m_scriptExecutionContext);
What about WorkletGlobalScope? Do we need to do something different for them?
> Source/WebCore/dom/UserGestureIndicator.h:66
> +
Please remove this extra whitespace.
@fredw, is there a spec that describes the behavior of this patch?
We are reviewing this concept. We haven't decided if we agree this is a good approach yet.
Comment on attachment 369470 [details]
Patch
View in context:
What is the motivation for this? Firefox is even more restrictive than WebKit currently is, and Chrome is quite lenient in this case. "Chrome does it so we should too" is not sufficient motivation to make this change.
> LayoutTests/ChangeLog:4
> +
#c3 should be removed.
> Source/WebCore/dom/UserGestureIndicator.h:155
> +template<typename> struct EnumTraits;
> +template<typename E, E...> struct EnumValues;
> +
> +enum class UserGestureType { EscapeKey, Other };
All this should be deleted. You don't want to declare another enum class in namespace WTF, and Forward.h already has the forward declarations necessary.
> Source/WebCore/dom/UserGestureIndicator.h:170
> + WebCore::UserGestureType::EscapeKey,
> + WebCore::UserGestureType::Other
Since there are only two of these, you should instead use a bool as the storage type for the UserGestureType enum class and the traits are unneeded.
I don't think this should be a decision based on how Firefox or Chrome do it. And I wouldn't qualify Chrome as more lenient in this case. But it does, imho, have a more semantically consistent interpretation: if an iframe is activated and a gesture can be passed to the parent window, it doesn't matter which API is used. From most of points of view, the difference between `window.postMessage` and `MessageChannel.postMessage` is minimal.
This problem does not have to be solved by propagating the "user gesture" bit via postMessage - that's the implementation detail. Since this was the WebKit's approach, the idea was to extend it to message channel as well. But, as an example, Chrome does not use post messages for this.
(In reply to Dima Voytenko from comment #27)
> From most of points of view, the difference
> between `window.postMessage` and `MessageChannel.postMessage` is minimal.
In order to allow a change like this, we must consider those "minimal" differences from all points of view. Justifications like "most developers won't take advantage of a way to abuse something" are how we introduce bad security bugs and design issues into the web platform.
Totally agree. Hence I'm looking if there's any feedback from the security folk on this use.
Sorry for the delay replying to this. Some quick replies below about what I remember ; to be honest I haven't checked the details for a while so apologies if it's not accurate.
(In reply to Brent Fulgham from comment #23)
> Are these not in WPT because we use a different user interaction construct?
> Is there no way to just keep this in WPT to make future merge/updates easier?
I had opened a PR for this:
However, an automated test in upstream WPT is not really useful, given that the WPT runner basically disables the tests. Hence the PR currently adds a manual test but it won't be imported into browsers anyway. Plus the spec is not clear. So I didn't push too hard on this until other browser vendors can comment.
(In reply to youenn fablet from comment #24)
> @fredw, is there a spec that describes the behavior of this patch?
Hi Youenn. I don't remember any explicit mention in the spec last time I checked, but I had relied on this definition of triggered by user activation:
"The task in which the algorithm is running was queued by an algorithm that was triggered by user activation, and the chain of such algorithms started within a user-agent defined timeframe."
( )
I'll try to ask with someone who has better knowledge of the HTML5 spec, but I'm not sure why tasks queued by window.top.postMessage or channel.port1.postMessage should behave differently.
The popup blocking config and "triggered by user activation" are mentioned here:
(In reply to Alex Christensen from comment #26)
> What is the motivation for this? Firefox is even more restrictive than
> WebKit currently is, and Chrome is quite lenient in this case. "Chrome does
> it so we should too" is not sufficient motivation to make this change.
Talking only about WebKit, we have inconsistent behavior: User gesture is passed via window.top.postMessage but not via MessageChannel channel.port1.postMessage so the popup is only blocked in the latter case. Firefox and Chromium have their own interpretation of the spec but at least they handle these two cases consistently.
I was expecting to get Apple's feedback on this experimental patch before raising this to the WhatWG but as I understand correctly you don't have any concrete security concern besides "if there is no reason to relax security we shouldn't take any risk". So I guess we can move the discussion to the WhatWG now, so we can clarify the spec, write WPT tests etc | https://bugs.webkit.org/show_bug.cgi?id=186593 | CC-MAIN-2019-39 | refinedweb | 1,847 | 55.64 |
Associate a value with an object
with an object in Java util.
Here, you
will know how to associate the value... of the several extentions
to the java programming language i.e. the "...;}
}
Download this example
java - JSP-Servlet
java example of session tracking in servlet
Servlet - JSP-Servlet
Servlet and Java Code Example and source code in Servlet and JSP
Java hasNext
Java hasNext()
This tutorial discusses how to use the hasNext() method... Iterator. We are going to use
hasNext()
method of interface Iterator
in Java... through the following java program. True is return by this method in case
Java servlet
Java servlet What is servlet
java - JSP-Servlet
Java Servlet Config means What is Servlet Config means ? ServletContext and ServletConfig Tutorials And Example CodeServletConfighttp...:// Servlet Config means
@WebListener Annotation Servlet Example
and
servlet 3.0 (Java EE6). The example given
below will demonstrate you how to implement a listener interface in servlet.
In this example I will use...@WebListener Annotation Servlet Example
In this tutorial you will learn what
java - JSP-Servlet
java Java example for database connectivity
java servlet programming - JDBC
java servlet programming how to insert value in a column of datatype - datetime in sql 2000
using java servlets????
can ne 1 help me out??? ...: '11-Jul-2008'.
Example query:
insert into table_name values('"+dateTime
Getting Previous, Current and Next Day Date
current and next date in java. The java util package provides...;+ nextDate);
}
}
Download this example.
Output...
C:\vinod\Math_package>java GetPreviousAndNextDate
Java Servlet : Get URL Example
Java Servlet : Get URL Example
In this tutorial, You will learn how to get url of servlet.
Servlet getRequestURL :
getRequestURL() method reconstruct... can add query
string parameters.
Example : In this example we are using
Java : Servlet Tutorials - Page 2
Java : Servlet Tutorials
...
We are providing you an example. In the given example, an object of Servlet...;
Upload Image using Servlet
In this example program a form
JSON and Servlet example
JSON and Servlet example
In the previous section of JSON-Java example you
have learned how to create a java class by using JSON classes. Now in
this example
Response Filter Servlet Example
Response Filter Servlet Example
This Example shows how to use of response filter in Java Servlet.
Filter reads
own initial parameters and adds its value
Java servlet
Java servlet What is the difference between an applet and a servlet
java servlet - Servlet Interview Questions
java servlet i use tomcat server and eclipse as ide for j2ee environment when i tries the example for sevlet context in roseindia to make entry in server log file ( context.log method to log entry) but could not see the log
java (servlet) - JSP-Servlet
java (servlet) how can i disable back button in brower while using servlet or JSP
servlet prog - Java Interview Questions
with one java code example? Thanks in advance...servlet prog how to forward or redirect the client request from servlet to jsp? how a thread or request pass from one servlet prog to one jsp prog
java - JSP-Servlet
/java/example/java/io/DeleteFile.shtml
Thanks...\build\web\WEB-INF\lib\servlet-api.jar hi guys i am getting this error can any
Java(Servlet) - Servlet Interview Questions
Java Servlet examples Java and Servlet programming examples
java servlet
java servlet im using ubuntu 12.04 and ialready installed eclipse but i dont know how to run the servlet programs please give brief procedure to run the servlet program in eclipse
servlet - Java Beginners
()method in servlet if yes how???????????????????? give me one example... in an HTTP Servlet routes the request to another method based on the HTTP transfer method (POST, GET, etc.) For example, HTTP POST requests are routed to the doPost
Logging Filter Servlet Example
Logging Filter Servlet Example
Example program to demonstrate Logging Filter
This example illustrates how one can write Logging Filter servlet to provide
Map | Business Software
Services India
Java Servlet Tutorial Section... |
Snooping Headers |
Dice Roller in Java Servlet
|
Getting Init Parameter...
value Using Servlet |
Hit Counter Servlet
Java Servlet Tutorial Section
java - Java Beginners
java write a programme to to implement queues using list interface Hi Friend,
Please visit the following link:
Thanks
Roseindia Java Servlet
World Example
Java Servlet : Setting Attribute...This tutorial will teach you how to use Java servlet to develop your web-based... of Java API’s.
The Roseindia.net servlet tutorials have been designed
MVC architecture example - Java Beginners
u give me some example of login authentication using JSP+Servlet+Javabeans...")
2.Then create a servlet page name like login.java
3.Then create another java...MVC architecture example hi..
I would like to ask the example
java - Applet
://
Thanks...java what is the use of java.utl Hi Friend,
The java
Context Log Example Using Servlet
Context Log Example Using Servlet
This example illustrates about how to use of Context Log in servlet. Context
Log is used to write specified message
@WebFilter Servlet Example
@WebFilter Servlet Example
In this tutorial you will learn what the difference is in the registration of
Filter in older version and servlet 3.0 (Java EE6). The example given
below will demonstrate you how to use a @WebFilter
servlet - Java Beginners
the data from the postgres database using servlet . Is there any working sample or example which I can look at? Hi Friend,
We are providing you a code...* ;
import org.jfree.data.jdbc.JDBCCategoryDataset;
public class Servlet
java persistence example
java persistence example java persistence example
JSP Paging Example in Datagrid - JSP-Servlet
JSP Paging Example in Datagrid Hi,
I have tested JSP Paging Example in Datagrid which is available at the following url which i am able to run... to customize its Java file with required fields from the database of my web application
JAVA - JSP-Servlet
JAVA i browsed a picture in a html page then i want to use the path in the jsp then what i to do ?
in java the the path of a file takes the two slashes instead of one
example for c:\vinay\ghaf.gif we must use c:\\vinay
java servlet - Java Beginners
java servlet how to use java servlet? and what the purpose of servlet? Hi Friend,
Please visit the following link:
Hope that it will be helpful for you.
Thanks
java servlet programming - JDBC
java servlet programming Hii!
frnds
My reqiurement... download file example.
New Document...));
// Read from file into servlet output stream
ServletOutputStream
java - JSP-Servlet
example code for JSP and MySql Database Connectivity Need an example code for JSP and MySql Database Connectivity Hi here i am giving you a link that is having a example code for JSP and MySql Database Connectivity
java
java can you give an example of how to use servlet context
Hi,
You can get the servlet context in your java application using... be used to save the value in servlet context:
context .setAttribute("furniture
Java from JSP - JSP-Servlet
Calling Java from JSP Does anyone have an example of Calling Java from JSP
Servlet service method - Java Beginners
way to send the path from servlet to normal java class this is very urgent...://
Thanks...Servlet service method Hi EveryOne ,
I have a simple
Bit torrent technology code example - JSP-Servlet
to start implementing it to a code so please send me a sample code in java or jsp... the following example which asks user to upload an image on the server and then you
J2ME Servlet Example
J2ME Servlet Example
This is the simple servlet tutorial. In this tutorial we shows... it with .java extension.
Mapping your servlet in the web.xml file.
Compile the java
JSP Paging Example in Datagrid - JSP-Servlet
JSP Paging Example in Datagrid Hello,
This is with refernece...
standard.jar
taglibs-datagrid.jar
The Java File is as follows
package...
=========================================
Paging Example Using Datagrid
th a:link
stack and queue - Java Beginners
://
Hope...stack and queue write two different program in java
1.) stack
2
java - JSP-Servlet
java what is meant by response.sendRedirect().
what is the difference between response.getRequestDispatcher() and getRequestDispatcher
what is meant by absolute path and relative path.give me a small example
Java Client Application example
Java Client Application example Java Client Application example
Java - JSP-Servlet
JSP Example in Eclipse How to run my JSP page example in Eclipse? To run JSP page in Eclipse Please.1. Internally Eclipse supports open with Browser page, there u can directly can type the required URL whiich
java - JSP-Servlet
java how can we perform treeview by using jsp.
for example:
+EMPLOYE
ADD
DELETE
MODIFY
VIEW
if i click on EMPLOYEE all fields should expand and if i click perticuler
java - JSP-Servlet
java can u send me an example of jsp plugin action to illustrate that how the applet is embeded into this plugin Hi friend,
I am sending you a link. I hope that, This link will help you.
Visit for more
STACK&QUEUE - Java Interview Questions
://
Hope that it will be helpful for you
Java Servlet - JSP-Servlet
Java Servlet Hello Sir
Could you help me in understanding directory Structure for servlet page in eclipse (IDE).
I save my Sevlet in WEB-INF but it is not displaying, it is displaying code of servlet.
Process used
java sql - JSP-Servlet
java sql I need to diplay only 10 records per page from my resultset.
while(rs.next())loops through entire rs. How can I use a for loop...("MySQL Connect Example.");
Connection conn = null;
String url = "jdbc
Java Servlet - JSP-Servlet
Java Servlet 3-tier structures of servlets
java - JSP-Servlet
,
--------------------------------
Read for more information with example.
java - JSP-Servlet
java I have to make a JSP PAGE where i have to collect the data from database and give the different format to different columns from different rows
for example suppose i have database having records like
Section SubSection
Servlet & Jsp - Java Interview Questions
briefly with one java code example? Thanks in advance. Hi Friend,
Try...Servlet & Jsp how to forward or redirect the client request from servlet to jsp? how a thread or request pass from one servlet prog to one jsp prog
servlet
servlet I want a fully readymade project on online voting system with code in java servlet and database backend as msaccess.can u plz send me as soon as possible
Java - Java Interview Questions
://
Thank you for posting - JSP-Servlet
("MySQL Connect Example.");
Connection conn = null;
String url = "jdbc
Java compilation error - JSP-Servlet
Java compilation error Hi, im trying to do a report creation using... is working.. Please help to solve this problem.. I've tried the example given... to my problem, but having some error as below..
Generated servlet error:
C
Java Servlet : Reading Form Data Example
Java Servlet : Reading Form Data Example
In this tutorial, we are discussing about reading form data of a servlet.
Reading Form Data :
There are three methods of servlet to handle the form data. These are listed
below
Example of HashMap class in java
Example of HashMap class in java.
The HashMap is a class in java collection framwork. It stores values in the
form of key/value pair. It is not synchronized
Java Servlet addCookie Example
Java Servlet addCookie Example
In this tutorial you will learn how to add..., sent by a client with the request.
Example :
Here I am giving a simple example which will demonstrate you to how to use
these methods. In this example I am
Example of HashSet class in java
Example of HashSet class in java.
In this part of tutorial, we... unique. You can not store duplicate value.
Java hashset example.
How....
Example of Hashset iterator method in java.
Example of Hashset size() method program example - Java Beginners
java program example can we create java program without static and main?can u plzz explain with an example
calling java beans - JSP-Servlet
calling java beans Sir,
I want to know where to place the java beans java file and class file inside tomcat web server. and how to call them from jsp file. Hi Friend,
Java Bean is placed in classes\form
Java FTP Client Example
Java FTP Client Example How to write Java FTP Client Example code?
Thanks
Hi,
Here is the example code of simple FTP client in Java which downloads image from server FTP Download file example.
Thanks
login example
login example 1.Loginpage.jsp
<%@ page language="java...;
2.invalidLogin.jsp
<%@ page language="java"
contentType="text/html; charset...;/html>
3.userlogged.jsp
<%@ page language="java"
contentType
Java Servlet
Java Servlet how to create the login form using servlets and how to validate the username and password?
Please visit the following link:
Servlet doubt2 - Java Interview Questions
Servlet doubt2 Dear sir,
thanks for your response?
my question is
how can i develop a chatting application using servlets?
like can we use socket programming in servlets?
can you give me an example?
Hi
Servlet
the same error
<web-app>
<servlet>
<servlet-name>InsertServlet</servlet-name>
<servlet-class>InsertServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>
java - JSP-Servlet
java why is required to write both jsp and servlet in a application of java
JAVA - JSP-Servlet
Java servlets sessions session tracking How to track the session in Servlet Servlet : Get URI Example
Java Servlet : Get URI Example
In this section, we will discuss about... string in the first line of the
HTTP request.
Example : In this example...;ServletExample</display-name>
<!--GetURL servlet mapping-->
<servlet> servlet with jsp on sql server
Java servlet with jsp on sql server How to delete a user by an admin with check box in Java Servlet with jsp on Sql Server?
Here is a jsp example that can delete the multiple record from the database by selecting
Java servlet - Java Beginners
Java servlet Thank you for your kind reply.
please send
Servlet with JDBC connection code Hi Friend,
We are providing you a code that will connect the servlet to database and insert the data.
import
Java script in servlet
Java script in servlet Hi. How to use javascript inside java servlet? Thanks in advance
Servlet Annotation Hello World Example in Eclipse
Servlet Annotation Hello World Example in Eclipse
In this tutorial you will learn how to create an annotated servlet in web
applications. In this example I... is given at the time of servlet
creation by separating comma( , ).
Example
Advertisements
If you enjoyed this post then why not add us on Google+? Add us to your Circles | http://www.roseindia.net/tutorialhelp/comment/51391 | CC-MAIN-2015-18 | refinedweb | 2,408 | 54.32 |
Data is the new oil. It is the most valuable resource in the world. And like oil, it needs to be extracted, processed, and transported to where it can be used. This is where TensorFlow comes in. TensorFlow is an open source platform that allows you to build models and algorithms to process and interpret data.
Introduction
This tutorial helps you to get started with TensorFlow. It covers how to feed data into TensorFlow and how to train a simple model. The salient features are:
– TensorFlow offers APIs for beginners and experts to develop for desktop, mobile, web, and cloud
– You can use eager execution with TensorFlow
– TensorFlow provides multiple levels of APIs
TensorFlow Data Types
TensorFlow supports several types of data. The most common are:
-Tensors
-Variables
-Constants
Tensors are the basic data structure of TensorFlow. Tensors are essentially multidimensional arrays, and can represent anything from a single number to complex linear algebra equations. You can think of them as a generalization of matrices.
Variables are used to store data that can beChanged, such as weights in a neural network. Constants are used to store data that will never change, such as the bias in a neural network.
TensorFlow Data Structures
TensorFlow uses a data structure called a tensor to represent all the data that flows through the graph. The tensor has a static type but can hold values of different types. The following table shows the different types of Tensors:
TensorFlow Data Input
TensorFlow is a powerful tool for machine learning, but it can be difficult to get started. This guide will show you how to feed data to TensorFlow so that you can train your own models.
TensorFlow accepts data in a variety of formats, so you will need to choose the one that best suits your data. The most common formats are CSV, TFRecords, and HDF5.
CSV
CSV is the most common format for training data. It is easy to read and understand, and you can use any spreadsheet program to edit it. To use CSV with TensorFlow, you will need to convert your data into a format that TensorFlow can understand. The tf.contrib.learn library has a function that will do this for you:
from tensorflow.contrib import learn
learn.preprocessing.text_dataset_csv()
This function takes as input a filename, vocabulary size, and other parameters, and returns a TextDataset object that can be used with the TensorFlow library functions.
TFRecords
TFRecords is the native format for TensorFlow data. It is designed to be efficient and easy to use with TensorFlow programs. To convert your data into TFRecords, you will need to first convert it into a format that TensorFlow can understand, then use the tfrecord write() function to write it out to disk in the TFRecord format:
TensorFlow Data Output
Data is the bread and butter of machine learning. In this section, we will cover the various ways data can be formatted for TensorFlow.
TensorFlow supports two types of data output:
-Tensors: A tensor is a vector or matrix of n-dimensions that represents all types of data. Tensors are the fundamental data structure of TensorFlow and are used to represent all types of data.
-Sparse Tensors: A sparse tensor is a tensor that has only a few non-zero values. Sparse tensors are useful for representing data that is not entirely dense, such as images or text.
TensorFlow also supports two types of input:
– placeholder: A placeholder is a variable that will be assigned a value later. Placeholders are used to feed input data into TensorFlow when training a model.
– feeding_dict: A feeding_dict is a dictionary that maps input names (strings) to input values (tensors). Feeding_dicts are used to feed input data into TensorFlow when making predictions with a trained model.
When working with Tensors it is important to keep in mind the following:
– All Tensors are immutable (cannot be changed)
– All Tensors have a fixed size
– All Tensors have a defined data type
TensorFlow Data Preprocessing
Preprocessing data is an essential step in machine learning. TensorFlow has a handy function called tf.transform to help with preprocessing data inputs. This function is particularly well suited for organizations that need to do Machine Learning at scale, since it integrates with the TensorFlow Data Validation library.
To use tf.transform, you need to define a preprocessing_fn function. This function takes in raw data, performs some computation, and returns transformed data:
def preprocessing_fn(inputs):
# compute transformations
return transformed_inputs
The preprocessing_fn function can do anything you want, but there are a few common things you might want to do, like:
-Normalize an input feature
-Convert categorical features into numerical representations (one-hot encoding)
-Generate new features by combining existing features
You can read more about the tf.transform function here:
TensorFlow Data Augmentation
TensorFlow’s data augmentation capabilities are one of its key features. Data augmentation is the process of artificially increasing the size of a dataset by creating modified copies of existing data. This is especially useful when training machine learning models, as it can help reduce overfitting by providing more training data.
TensorFlow offers a variety of functions for data augmentation, including image distortions, cropping, and flipping. In order to use these functions, you first need to have your data in the form of a TensorFlow Dataset object. This tutorial will show you how to convert your data into a TensorFlow Dataset object, and then how to apply some of the most common data augmentation techniques.
TensorFlow Data normalization
TensorFlow offers a variety of ways to normalize your data. The most common method is to rescale your data so that it’s between 0 and 1, but other methods include standardization (rescaling so that the mean is 0 and the standard deviation is 1) and quantile normalization. Each method has its own advantages, so you’ll need to choose the right one for your data and your purposes.
To rescale your data to be between 0 and 1, you can use the tf.keras.utils.normalize() function. This function takes in an array of numbers and returns a new array that is rescaled so that all the values are between 0 and 1.
To standardize your data, you can use the tf.image.per_image_standardization() function. This function rescales each image in your dataset so that the mean pixel value is 0 and the standard deviation is 1. This is a common preprocessing step for image classification tasks.
If you want to quantile normalize your data, you can use the tf.contrib.learn.quantile_normalize() function. This function will rescale your data so that it has the same distribution as a reference dataset of known distribution. This can be useful if you want to compare two datasets that have different overall distributions but share some common features.
TensorFlow Data Visualization
Data is the fuel that drives machine learning. TensorFlow, Google’s open source machine learning platform, uses data to train artificial intelligence models to improve performance. When working with TensorFlow, it’s important to understand how the platform uses data and how you can optimize data input to get the most out of your models.
TensorFlow Data Visualization is a suite of tools that helps you understand and visualize your data. The suite includes a series of visualizations, each of which is designed to help you understand a different aspect of your data.
The first visualization in the suite is the Data Table. The Data Table shows you all the data that TensorFlow has collected about your training runs. You can use the Data Table to understand how TensorFlow is using your data and to troubleshoot problems with your data input.
The second visualization in the suite is the Graph Explorer. The Graph Explorer shows you the structure of your TensorFlow graph. You can use the Graph Explorer to understand how TensorFlow is using your data and to optimize your graph for performance.
The third visualization in the suite is the Run Metadata Viewer. The Run Metadata Viewer shows you information about your training runs, including input pipeline statistics and performance metrics. You can use the Run Metadata Viewer to understand how TensorFlow is using your data and to troubleshoot problems with your training runs.
The fourth visualization in the suite is the Session Logger. The Session Logger shows you information about your TensorFlow session, including run times and memory usage. You can use the Session Logger to understand how TensorFlow is using your resources and to troubleshoot performance problems.
TensorFlow Data Summary
TensorFlow is a powerful tool for machine learning, but it can be challenging to get started. In this article, we’ll show you how to feed data to TensorFlow so that you can train and build models with the library.
TensorFlow takes in data as a tensor, which is a multidimensional array. When you create a TensorFlow graph, you need to specify the shape of the tensor that will flow through the graph. The simplest way to do this is through the tf.placeholder() function, which creates a placeholder for a tensor that will be fed at run time.
In order to feed data to a placeholder, you need to use the tf.Session() function. This function allows you to run your TensorFlow graph in a session. A session takes care of all the details of running your graph, including managing variables and executing operations.
When you use tf.Session(), you need to specify which placeholder you want to feed data to. You do this by using the feed_dict argument. The feed_dict argument is a dictionary that maps placeholders to values. For example, if you have a placeholder for a tensor that has shape [3], you can map it to a NumPy array with three elements:
“`
import numpy as np # NumPy is a library for working with arrays
# Create an array with three elements
array = np .array([1 , 2 , 3])
print(array) # [1 2 3]
# Use the dictionary feed_dict to map placeholders to values (x : array) :map placeholder x to value array
with tf .Session () as sess : # Start a session
# Feed data into placeholder x output = sess .run(x ,feed_dict = {x : array }) print(output ) # [1 2 3] “` | https://reason.town/how-to-feed-data-to-tensorflow/ | CC-MAIN-2022-40 | refinedweb | 1,693 | 53.71 |
This is the new Thread about the OpenHR20 Firmware from .
For generic Questions about the HR20, please look&ask in
Beitrag "Honeywell Rondostat HR20E per AVR steuern und konfigurieren"
Please write in English, thanks!
SVN revision 100
- improve motor control
- check EEPROM layout on startup
From this version EEPROM layout is fixed. This mean that you can enable
"preserve EEPROM" fuse and your setting can be saved.
Change EEPROM layout case is tested on code. You will see "EEPr" on LCD
after restart, startup is blocked. With empty EEPROM you will see same
*I don't know any missing functionality or bug at this moment.*
Permanet problem is missing documentation generated from sources. We
need it to document "magic indexes" on setting (Gxx and Sxxxx commands)
or watches (Txx command)
Changelog:...
Known problem for Rev100:
After change of PID constants you must change wanted temperature.
Problem is teoretical internal value overload. I never saw this problem,
but I found it on code review.
SVN revision 101
- optimizations
- overload check in pid.c
- change default setting for PID
SVN revision 103
- motor stop threshold for calibration / runtime can be different
EEPROM layout is changed, you can't preserve old contend.
@jdobry:
very busy weekend! gonna try your latest release tomorrow when i have a
JTAG-adapter again.
gonna give you feedback about how the firmware works.
will try to get familiar with the general firmware architecture then,
for example questions like "how can i issue a task evry sixty seconds"
which shall be the RFM's staus broadcast in sooner future...
so long!
@ Mario Fischer:
execute task every second:
add it into "if (task & TASK_RTC)" section on main.c
execute it every 60 second have many choices
- use own counter inside "if (task & TASK_RTC)" (worst)
- same section as before, but inside new "if (minute)" condition
(better)
- same section, add condition "if (RTC_GetSecond() ==
config.network_addreess)" (best)
For interrupt from RFM you must add code inside "ISR (TIMER0_OVF_vect)"
and set "task |=TASK_RFM12" inside. Make code inside interrupt small as
is possible and move real functionality inside main.c "if (task &
TASK_RFM12) task&=~TASK_RFM12; ....."
f you have some code sniplets, please contact me by email. It have big
priority for me at this moment.
Hi Jdobri!
(what is your first name? I dont know if "Hi Jdobri" is correct ;)
ok, ive downloaded the OpenHR20-rev 103 and started to play with it...
I will try to integrate a RFM status sender for first approach.
I can say now, i will have to make changes in several files. For example
main.c in
if (task & TASK_RTC) { ... if (RTC_GetSecond() == g_RFM_devaddr) ...
and so on.
I would try to encapsulate all RFM-stuff in #ifdef RFM-blocks, so a
project-fork wouldnt be neccesary.
But im not sure if i can guarantee that it will be possible to
distinguish RFM and notRFM-code clearly in all future.
So, what do you want to do?
Can you give me an SVN-Account for the project? Im sure you will be
anoyed very soon if i start to mail you my code all the time...
So, tell me your plans!
Greets from Munich,
Mario
PS: First Request: I'd like to have the global variable uint8_t
g_RFM_devaddr to be adjustable by menu (1-254, others reserved for
broadcast or future usage) and storable in EEPROM. Since youre master
of the menue it shouldnt be too difficult? ;)
Plan is keep latest STABLE version in main trunk and create branch for
next development. By this way we can made anything include crazy ideas.
You don't need change anything on menu. Simple add line into eeprom.h
structure config_t and line into ee_config array. Don't forget change
eeprom layout map version to something for development (exaple #define
EE_LAYOUT (0xd0) ).
You can read it by config.g_RFM_devaddr and change it by service menu
(long press all buttons -select configuration press PROG change value
and press PROG)
Question about the Config-Menue:
Did i get this right?
I can edit the Variables in eeprom.h via:).
now its getting unclear: it looks like if i push [PROG] i'm back in
selecting a XX again. is the other value now stored? or how can i cancel
it (i guess via AUTOMANU] )? and what's happening if i push
[TEMPSUNMOON] ? hourbar except one bar blinks, scroller selects a
horbar, XX:YY shows thigs i dont understand...
[AUTOMANU] always exits eeprom-edit-mode?
regards!
Feature Request:
in normal mode, [TEMPSUNMOON] shows current temp, valvepos, RTCtime,
default display. i think that the RTCdate would also be interesting for
a common user.
regards!
Service mode:)
4. press PROG save selected value and go to step 2
any where on service menu:
AUTO - escape service menu without save
C - change service menu from EEPROM setting <-> watched variables and
back
Watched variables - see to watch.c. In this mode ALL segments are on,
except 16-bit hex value on numbers and except one blinking segment on
hourbar. Blinking segment indicate with values is on view. Ekvivalent
COM command is "Txx<enter>"
RFM Pin wiring:
you wired yor RFM like ths:
rfm_sck = atmega169_pf1 //solder direct to atmega :-(
rfm_sdi = atmega169_pf0 //solder direct to atmega :-(
rfm_nsel = atmega169_pa3 //solder direct to atmega :-(
rfm_sdo = atmega169_pe6 //crop via on backside of PCB as shown in
picture
rfm_nirq = open
as discussed yesterday, rfm_nirq = open, because rfm_sdo can serve as
irq-notifier. we will read the sdo-state after we drove rfm_nsel low.
i assume that it will be high when the rfm is still busy sending, and
edging low when ready (irq-event like "byte sent over radio in txmode or
fifo-filled in rxmode). we need to clarify when we go into the sleep
mode then and how we wake up/resume in main-loop.
... ive looked once again on pCB and schematic, it really looks like
that there is no other way than soldering 3 pins directly to the
atmega169? this is really a VERY sophisticated soldering job.
is it possible to disable the atmega's jtag-interface during runtime
only?
that would make the soldering job really easy, we could even wire the
RFM externally so that people dont have to open the HR20. of course,
disabling jtag via fuses requires a working bootloader and is (as far as
i know) not reversible...
are there any alternatives than soldering to those tiny nasty
atmega-pins?
RFM Wake up will be done by interrupt PCINT9 and setting task|=TASK_RFM.
When we process this event, we must to do task&=~TASK_RFM and it will
allow sleep in main loop.
Connection RFM to ATmega we have only by 2 ways and both is similar, can
be changed by compile option (different is only signal names).
1) connect wire directly to ATMEGA as in my pictures
2) use JTAG pins. JTAG is possible disable in runtime and it is also
possible to use it for programming but for it we must hold reset signal.
It is not problem. But it is no possible share this pins for debug.
Therefore it can be possible way for end-user, not for development.
Benefit is that it can be connected outside without open HR20.
JTAG disable by fuses is not reversible by JTAG interface because it is
disconnected. But this configuration can be changed later in runtime and
we can reenable it by hold reset signal.
Hi,
disable JTAG:
i have googled it but couldnt find something useful. the only rumor i
read was that "disabling JTAG at runtime doesnt mean setting the
DisableJtagFuse" which would be very good because this could really
cause trouble when the frmware crashes and cant execute any "ReEnable
the JtagFuse again" command.
do you have a sniplet how to use JTAG-Pins as IOpins at runtime without
messing with the fuses?
I would like to get this working soon, because i cant solder my RFM to
the Atmega's pins directly - these ones are too small for me :(
Idea:
Is a "mixed version" of RFM wiring (JATG vs. internal pins) possible as
well?
That eans using JTAGpins<=>RFM except RFM's nSEL, which we wire to PE6 -
that is the pin that is reachable by cropped via on PCB, so its possible
to solder.
Idea:
In JTAGmode PE6 is HighZ => RFM's nSEL is not tied to GND and not
SELected => RFM's other pins should be HighZ (gotta look that up...)
which means the RFM shouldnt disturb the Programming Traffic between
JTAGprogrammer and Atmega => no need to unplug the RFM when JTAGging.
Security:
I checked in a security.c module. mainly uses XTEA (yet written in C)
for en/decryption in cipher feedback mode. has the nice side effect,
that we dont need the code for XTEA-decipher (see...
).
i also abused the XTEA-code for a hash function in for
chall-resp-authentication. code not yet tested but function interface
shouldnt change.
Disable JTAG only for runtime: write one to the JTD bit in MCUCSR.
Datasheet chapter 9.8.7
We don't have any reason to mixed version of wiring. In this case we
will lost JTAG and we must solder inside HR20. It is not possible share
one pin on JTAG interface. JTAG can be completly disabled, nothing more.
Problem with share JTAG pins it not programing, but debug.
Security:
Yes, we can use XTEA encryptor on feedback mode to generate key to
encrypt data. see to...
But it have problem. Cipher on RX and TX side must by synchronized
otherwise is not possible to decrypt data. On wirelless is usual lost
same data, therefore in this case we can lost synchronization. It is
complication.
Hi!
Disable JTAG: ok will check that register in the atmegas manual. thanks!
mixed wiring: yes youre right, JTAG-firmwareupload is possible (if RFM's
pins are really HighZ when nSEL=High) but debugging is not possible.
i think it's ok as it is - you can use your directly soldered pins and i
the JTAG (and cant JTAGdebug, but i dont need that often).
its just pin definitions (see my rfm code its completely adjustable with
some #defines).
security:
dont worry about the syncing! the CFB resets with every sent-out
datagram again. it is just feedbacking within one datagram. otherwise it
would be impossible for a receiver who was offline for several datagrams
to resynchronize. id suggest this data format:
payload = [rand,currtemp,wantedtemp,valepos]
enc_payload = security_encrypt(payload)
packet_nocrc = [deviceID,enc_payload]
length = sizeof(packet_nocrc) + 1 // + 1 for crc
crc= crc8([length,packet_nocrc])
rfm_send([length,packet_nocrc,crc])
if you want to you can encrypt the deviceID as well. but point is that
we must use additional crc for checking air damage (crc is better for
that than any hashes). rand is a random number that "salts" our
security_encrypt => equal payload (except different randoms) will
produce completely different enc_payloads. so its not possible to create
a codebook. this salting rand could be also used for chall-resp-authes.
i was just thinking ...
do we need a hash-function at all?
if the master authenticates via sending the rand value back within an
encrypted message, then the master has proofen that he knows the shared
key.
so scenario:
1. hr20 status broadcast every minute
(length,devID,encrypted[rand,currtemp,wantedtemp,valepos],crc)
2. master receives that, decrypts packet and has rand in plain format.
when master wnts to send a command to the HR20 he sends (within one
second after HR20's broadcast):
(length,devID,encrypted[rand,CommandTotheHR20],crc)
3. HR20 unpacks that datagram, checks rand, and if it is equal to the
rand from (1.), CommandTotheHR20 is executed
4. HR20 sends back
(length,devID,encrypted[ResultCommandTotheHR20],crc)
5. HR20 listens another second for a further command (again with rand
included), and if not occuring, HR20 waits a minute till (1.)
what do you think? rand is encrypted in all air messages and different
in every (1.)
@Mario Fischer:
Your proposal looks good. I would like want only this modifications:
- use upper bit of length or devID to indicate HR20->master or
master->HR20 communication (benefit: we can reject unwanted packes
before decoding)
- remove step 5. After step 4 we can go back to 2. It have benefit that
we don't need keep receiver alive 1 second. Timeout can be smaller (max
aprox 100ms)
- use SYNC byte before communication, RFM support it in HW. It can
filter possible noise from others wireless comunications. I am sure that
you know this RFM feature but you forget write it in proposal.
And some technical notes:
- If you wan't, I can integrate RFM SPI layer into current code
(interrupts, create task etc.)
- It will be nice reuse/modify current COM code (same commands, same
results).
-- We can modify numbers in commands/responses to "compressed" version
(not use hex coding but raw format)
-- wireles layer will encapsulate COM packets and manage encryption.
-- it not need \n as command termination char (size of wirelles packet
is known)
We need hash or XTEA feedback hash.
Without this it is easy decrypt ((packets) xor (fixed key)).
Therefore we cant restart hash function for each "status" packed from
HR20. It is just variant of fixed key.
What we can to do:
step 2 on master: we must reply to HR20 with command or empty packed
(length,devID,encrypted[rand],crc)
step 2 on HR20: after success on receive calculate next step of hash
function to generate packed key
What can happen (success):
-step 1: HR20 will transmit packet with packet key generated from hash
(PK1)
-step 1: master receive it and decrypt it with PK1
-step 2: master transmit packet with PK1 and calculate PK2
-step 2: HR20 receive packet, decode it by PK1 and calculate PK2
What can happen next (fail):
-step 3: HR20 will transmit packet with packet key generated from hash
step 2 (PK2)
-step 3: master receive it and decrypt it with PK2
-step 4: master transmit packet with PK2 and calculate PK3
-step 4: HR20 fail to receive packet, PK3 is NOT calculated
-step 5: HR20 will transmit packet with PK2
-step 5: master receive it and try to decrypt it with PK3 it fail, but
will be successfuly decrypted with PK2
-step 6: master transmit packet with PK2 ( calculation of PK3 not
needed)
-step 6: HR20 receive packet, decode it by PK3 and calculate PK3
What can happen next (another fail):
-step 7: HR20 will transmit packet with PK3
-step 7: master fail to receive
-step 8: HR20 will transmit status packet next minute with PK3
-step 8: master receive it and decrypt it with PK3
-step 9: master transmit packet with PK3 and calculate PK4
-step 9: HR20 receive packet, decode it by PK3 and calculate PK3
......
I hope that it is clear. PK numbers is not significnt
(PK[n+1]=hash(PK[n])). But we need to solve resync after HR20 or master
is restarted (some initial fixed key)
I thinking.
(some initial fixed key) must not be fixed. It can be fixed part +
something from user for every init.
In this case, user must read one or two bytes from master and enter it
manualy into HR20.
It just only idea .....
Hi!
well, SPI is not the problem, the SPI-function itself is very very fast,
Problem is as discussed the waiting between SPI and SPI.
if you could write some code where i could integrate something, would be
fine!
Air-Protocol: In my implementation i had an additional byte "flags"
with several useful values (contains ReceiverAddress, LoBatt,
IsEncrypted...).
I left that away in my sketch but a concrete implementation will contain
sth like that.
"1 second" is of course a too long time period. we could shorten it.
Dont let us mix up all those SYNCS: you meant the sync-pattern the RFM
sniffs to
(and when he detects it he loads everything following into the RxFIFO) -
Yes the Sender must Send Sync and 0xAA0xAA-Preamble before (and trailing
0xAA as well!).
i also left that away in the sketch for keeping it simple.
Commands: yes com-proto-reuse would be nice but ascii-over-air makes
datagrams too long -
too dangerus. we must compress/binarize it somehow. also sending
multiple commands
without delimiter if fixed length in one packet is good - then we can
leave away the relisten for one second
from step 5.
Ok, gonna handle your latest post with security leak now...
Hi
i was quite busy in the last days, so i had no time to answer.
I don't have much time, but my business is embedded security.
Also i am often in das-labor.org, which is located near my home
(about 5 minutes walk)
Mario Fischer wrote:
> do we need a hash-function at all?
> if the master authenticates via sending the rand value back within an
> encrypted message, then the master has proofen that he knows the shared
> key.
Encryption != Authentication.
I will show you the error in your proposal:
An Attacker would receive from HR20
> (length,devID,encrypted[rand,currtemp,wantedtemp,valepos],crc)
He is not able to dencrypt this, but the master will anser e.g.:
> (length,devID,encrypted[rand,CommandTemp=20],crc)
Note: the attacker is not able to dencrypt this.
But he can se, which part of both encrypted parts is the same.
So he knows enc(rand).
Now what the attacker can do some days later:
The HR20 sends:
> (length,devID,encrypted[randnew,currtemp,wantedtemp,valepos],crc)
The attacker can replay the old command:
> (length,devID,encrypted[randnew,CommandTemp=20],crc)
There are many ways to avoid this. This can be done by using different
keys for encryption on both sides (key_H2M: HR20=enc Master=dec,
key_M2H: Master=enc HR20=dec).
Better it would be to use a MAC like CMAC[1], which can be done with
the Block-Cipher.
If you have some requirements, i can assist you in designing the
secutity functionality.
For cipher i would consider to think about using XTEA. Alternatives are
AES (about 1000 Words) or (better) PRESENT [2]. PRESENT is optimized
for very small hardware, but I think it should also be quite small on
the AVR. Nevertheless also XTEA would be OK.
[1]
[2]...
Hi guys,
ok im also thinking about the auth&encrypt stuff again.
some facts:
- we already decided for XTEA, seems secure "enough" (yes sounds sleazy
but code must be short => XTEA is excellent trade off)
- and we cant use long keys, digests or random numbers over air since
radio packets MUST be short. the counterpart to short key is that our
"slave" only accepts auth-tries every minute at all, so we must primary
defend offline-attacks.
- the amount of packet-ping-pong between auth/chal/comd/reply must be
short for battery.
- we can not use any circulating P[n] -> P[n+1] tokens because master or
slave can be offline for a while. Token or n might get lost.
- yes encryption alone doesnt replace auth or protects from playback.
let me ask you guys again about the leak here, i still dont see it:
1. Slave sends (simplified):
Encrypt( [rand1,statusinfo] )
2. Master sends
Encrypt( [rand2,rand1,command] )
3. Slave sends (if rand1 was recognized)
Encrypt( [rand3,rand2,result] )
i agree with dario that attacker could see enc(rand).
so i putted a rand2 on start of message in 2 which will scramble all the
rest of the packet (->CFB mode) (lesson learnd ;)
beside, even if the attacker could catch a rand/enc(rand)-pair, then he
couldnt offline-calc the key: rand is shorter than the key so many keys
would produce the same rand.
and the attacker would have to run thru the key-span (big) and not thru
the random-span (small).
ok, whats the weakness in this protocol?
we have lots of power/packetsize/battery/pingpong-constraints guys, we
must keep it simple!
Another thing:
to distribute the keys in HR20 (Slaves) and Master
we should think about the possible solutions:
a) Keys are compiled in the Software
b) Keys in EEPROM
- can be entered using serial interface
- can be entered using Service mode
I would prefer to enter the keys in EEPROM.
For maxium Security the key must at least 64 Bit,
better 80 Bit. So it would consume 8 to 10 Bytes
in Configuration Memory.
A key exchange between Master and Slave is only
possible, when we would use asymmetric functions
like Diffie-Hellman. All other key exchanges are
not secure, when they all use the same (master)key
for all HR20s.
Dario
@dario:
key distribution: already done. its stored in eeprom and
changeable via HR20's LCD/Button/Wheel-interface.
Jiri did a great job with his extensible interface!
=> key distribution is no problem.
i coded the keysize variable length. if shorter than xtea-key it will be
padded (no user wants to enter a 16-byte key in every HR20 so i think
padding is ok. it's not home-banking ;)
i think i see now the point you wanted to show with your "a few days
later":
but thats a tradeoff we have to accept: if the rand is only one or two
bytes long than it will some day repeat. again a trade-off for
short-radio-packets.
but even if the attacker has an old packet with matching rand. then he
could inject a packet of which he doesnt know what it will do.
@dario:
if you are interested, you can look at the current state-of-the-code in
the
branch of the project. new files are rfm.* and security.*
security is as mentioned still in a draft state.
i will think about the "do we need hash function if we have
symetric-cfb-encryption?" again... i still think we dont need hash
because cfb-enc kills all plain-cipher-pair-recognition-possibillities
...
@Dario C:
You are right.
For clarify: If attacker have 2 encrypted data with some KEY and know
information that it contain common par of source data (rand) it is
security hole. Attacker can easier calculate key. And from PK(n) can
calculate PK(n+m) (with hash it is simple, with XTEA in feedbak it can
be nightmare). (Example in history is repeat random part of KEY in
encrypted communication used at ENIGMA - decrypted in Poland 1934 by
Rejevski)
we must have something like protocol specification before coding. From
my side exist only small chance to do something till Xmas (I am quite
busy).
Therefore we have time to thinking about it.
Mario Fischer wrote:
> let me ask you guys again about the leak here, i still dont see it:
> 1. Slave sends (simplified):
> Encrypt( [rand1,statusinfo] )
> 2. Master sends
> Encrypt( [rand2,rand1,command] )
> 3. Slave sends (if rand1 was recognized)
> Encrypt( [rand3,rand2,result] )
I think you gonne send many data, which is not needed.
You saied, that radio packets MUST be short.
1. Keysize does not affect packetsize.
2. How long would your random mumbers be?
3. I think there are many better solutions,
when we think a bit about it.
4. Security can be added later, you can implement
2 Dummy functions on each side generate_msg and
verify_msg, which can be filled later.
I have to think about it, but for me it seems to be
a "Homebrewn" sollution which is not the best we
can have.
Also XTEA is very old, PRESENT is much newer and provides
better security. I think it should not be bigger than XTEA;
> we have lots of power/packetsize/battery/pingpong-constraints
> guys, we must keep it simple!
I Agree, but we should keep it smart, and simple.
And in your proposal i see that many random numbers are send,
which leads in big overhead, at least double rate
Overhead
============
Security
Let me ask a Question, befor i start to think about
a better solution:
Who is the Master?
- How much memory
- What computational power
If the HR20 shall talk to each other without a master,
than we have a problem. If not i think that the Master
can recover missing sync information, so that we don't
need to send the useless rand information. We would
need to send some additional Bits (32 to 80) for
authentication.
But I have to think about it.
Dario
Mario: "we can not use any circulating P[n] -> P[n+1]"
NOT we can't do it like this. It big secutity hole. When one of station
is offline it is not problem. See to my comments from 09.12.2008 23:48
But Dario is right, we cant repeat same data with 2 packet with same
key.
Mario Fischer wrote:
> i think i see now the point you wanted to show with your "a few days
> later":
No, when a few days later another rand (randnew) is send, i can replay
the old command, which was the response to the old rand.
I think when we use 1 or 2 Byte rands, than it is better to use
no security at all, because it can be very easy broken.
But I think by adding 4 Byte additional data to the frame, than
we can get the security of 4*8=32 Bit and by adding 8 Byte we have
64 Bit security.
But i have to think about it, i will write a purposal document for
security when i am not so busy (during the holidays).
Dario
@dario
- i diddnt know PRESENT but a first google shows me that it has s-boxes
... thats way to expensive!
- xtea is old, but look at known weaknes of it ...
- are there any other well-known and analyzed algorithms as short as
xtea?
- no hr20-hr20 communication.
- only hr20->master->hr20 talks
- master ... dont know... a linux-box, a atmega32, ... but doesnt play a
role: the computing-power-bottleneck is the HR20.
- random number lengths: i would guess 1 or 2 bytes. i know its short.
but be realistic: anyance over a shorter living battery from long radio
packets is more likely than someone who records about 256 or 65536
commands (there is NOT a command EVERY minute!)
> But Dario is right, we cant repeat same data with 2 packet with same
key.
do you really want some session-key-generation-protocol? this requires
lots of traffic!
the whole send encrypted random vice and versa is not my idea. i thik
its occuring similar in kerberos (let me look it up) but its not my
invention...
Dario C:
I know about PRESENT but it is too expensive
PRESENT - AVR C implementation - 1514 bytes of flash and 256bytes in
RAM
XTEA - AVR C implementation - 754bytes of flash, 0 bytes in RAM
XTEA - AVR ASM implementation - 504bytes of flash 0 bytes in RAM
source:
We have aprox 3kB of free flash in current SW. Save every byte is fine.
Mario: you dont need any session-key-generation-protocol
It is simple. You have key for packet (PK) , and master key (MK)
And you ca to do:
//have function encrypt(data,key)
PK(n+1) = encrypt (PK(n), MK);
You can calculate it on both sides withou any
session-key-generation-protocol
You must only keep synchronization you cant decrypt PK(324245) encrypted
packet by PK(6756324)
Jiri: im still trying to understand your post from 09.12.2008 23:48 -
could you summarize that all a little please?
how many transmissions each minute?
what is transmitted in every packet?
and im still insisting, that after one minute everything must be reset.
there may be no references to any randoms or packetkeys that occured one
minute before.
master or slave can be offline always and the other doesnt know it!
so after one minute, everything has to start from scratch.
so long guys, i fall asleep now!
Mario Fischer wrote:
> - i diddnt know PRESENT but a first google shows me that it has s-boxes
> ... thats way to expensive!
Yes one 4Bit-to-4Bit S-Box = 16 Byte.
> - random number lengths: i would guess 1 or 2 bytes. i know its short.
> but be realistic: anyance over a shorter living battery from long radio
> packets is more likely than someone who records about 256 or 65536
> commands (there is NOT a command EVERY minute!)
But when we use 1 Byte an attacker needs 128 tries for the chance
of 50% to change the next random number and so to destroy any
further communication.
The attack is on: Encrypt( [rand2,rand1,command] )
The attacker would send some random data, to the HR20 as response.
When the HR20 decrypts this data and the second byte is accidently
rand1 (which is 50% for 128 Tries), it would save rand2 as new value,
which the master (and the attacker) does not know.
=> After that no further communication is possible.
I will think about a solution to provide security with additional
4 to 8 Byte each packet.
> do you really want some session-key-generation-protocol? this requires
> lots of traffic!
I asked how the keys will be distributed, as they are in the
EEPROM this is not an issue anymore.
im almost in bed, but let me shot comment
> destroy any further communication.
thats why i insist on "reset everything every minute"
destroy any further communication would otherwise also be possible if
only one minute's session fails - then both wouldnt be synced.
let me clarify: all my rand0,rand1,2,3.... are diced every minute from
new!
in general, it is always possible that an attacker records a packet and
playbacks it every minute - after latest 256 or 65536 minutes it will be
considered as valid.
i can accept the threatof such an scenario, since long packets are very
battery-consuming. i measured the rfm's current consumption during
sending with shunt+osci, thats why 4byte-randoms are too expensive to
me.
Mario:
how many transmissions each minute?
- not change from your proposal
what is transmitted in every packet?
- not change from your proposal
You don't need sedn any aditional data for key change. Becasuse you can
calculate PK(n+1) from PK(n) if you know master key (stored in EEPROM)
You only must try for decryption use PK(n) and when you have not success
PK(n-1). If you have not success with PK(n), it mean that one or more
packets was lost and second side not change PK
Hi guys,
i followed this and the other threads a long time.
what i read out since now is that in between there is an open firmware
available. now, you want to get/send data from/to the HR20 via a rfm
module. but why should this be encrypted? the WHY is here missing. since
now i thought it should be an OPEN firmware? Maybe i didnt understand a
block or i missed one?
cu,
olly...
Open: The firmware's source code including encryption algorithms is open
source. The encryption key is selectable by the user.
Encrypted radio Traffic is to protect your HR20-valves from unauthorized
people to control your room temperature or even detect from outside that
your room temperature is cold (so you might not be at home and they
could break in).
No fundamental discussions about "who is interested in controlling my
valves?" please! Protecting the system is not much code but always worth
some thoughts about!
Guys, one Question:
If our radio packets are always smaller than a XTEA blocksize, then the
whole CFB or OFB modes dont make sense:
Because in both modes, the first plainblock is just XORed with
XTEAencrypt(Key,Initvector).
This means that the whole plainblock is just XORed with a constant
bitpattern.
This would mean that even one captured Plain/Cipher-Pair would disclose
this constant Key.
So i would suggest CBC mode or no modes at all if all radio telegrams
are < 17 bytes (what i would recommend). on the other hand, telegrams
smaller than 16 bytes would have to be blown up to a XTEA-block.
@Mario Fischer Datum: 10.12.2008 16:19
plainblock is just XORed with a bitpattern.
But this bit pattern is different for each packet.
Hi Jiri and OpenHR20-Team,
today I managed to make the HR20 send a radio frame with the RFM12
Module connected to the outside-accessible JTAG-Pins and PE2.
Well, almost -
I saw that quite often bytes are swallowed. For testing i let the HR20
send a bigger frame with increasing bytes
<preamble> <fifo start patt> 0x01, 0x02, ... 0x13 <dummy byte>
on the receiver side i saw things like
0x01 0x02 .. 0x04 0x50 0x60 ...
^^
in other words, sporadically swallowed bytes or nibbles and some noise.
Im quite sure its not the receiver which is swallowing the bytes, this
device im using for long time and it always worked.
I also looked at with the scope to the distances between the
SPI-16bit-Trains, their distances were not equal!
I suspect rather that the SDO line indicates the "ready to send next
byte" (TX flow control) event to early, multiple times, ... or the
InterruptRoutine sensing for SDO Edges somehow raises the "send next
byte" codition too often or to early ...
Im not sure where the problem is. In my other applications, I flow
controlled always with the IRQ line, which works fine.
The RFM datasheet tells us that the SDO line also is usamble for flow
control, so we want to use this line (to save IOports).
For test purpose i will connect the RFM's IRQ to the ATmegas IRQ (PE6)
and check wheather this is the cause of the stumbling TX flow control.
But im not sure, could be many sources
SDO not relieable for Flow Control,
OpenHR20's PinCHange-ISR has an error
main-task-loop has an error.
Updates will follow ...
Hi,
I have a problem with my HR20E ordered at Conrad, it is the same problem
at all three of them:
They work fine in the Full-stroke mode. Yet, in the default-stroke mode,
radiators stay cold after about three days, even though the HR20E shows
a higher target-temperature. Removing the Rondostat and turning the blue
wheel by hand, the radiators get warm. When it gets above the
target-temperature, they are turned of properly and the Rondostat will
work fine for another three days or so.
This should not be a battery problem. The batteries are new and
brand-products, and the Rondostat makes no sign of having a power
shortage at any point. It should neither be a problem with the valves
since the radiators get warm when I turn the blue wheel by my self, and
since the problem does not occur in the full-stroke mode.
It seems to me, that after a few days in the default-stroke mode, the
Rondostat does not know anymore at which position it is, and does not
open the valve as it thinks the valve is already open.
Does anyone know a solution for this? In the Full-stroke mode, the
temperature deviations from the target-temperature are too high since my
radiators heat up very fast.
Thanks for your answers,
Robert
Hi
just managed to flash the first HR20. I used the Atmel Eval Boarad from
Pollin modified according to the Evertool LIGHT by Rainer Rakow.
Starting test now...
Is there any readable user manual or anyone working on it?
Robert, i ordered 8 HR20 from CONRAD and had no problems found. Did you
rewind the blue weel before installing the head? But carefull - its easy
to overwind!
I read about similar problems in another thread - in one case some coins
helped to reduce the distance between the nozzle of the valve and the
regulator pin.
Frank
@Robert:
I have 5 valves (exacly same) and only one of them have same broblem. It
not depend to HR20 unit, but on valve. With original SW you can only use
"full stroke" mode. You not able change anything or discover it.
And it is one of reason why I wrote another SW for HR20. In my case it
is solved.
@Mario Fischer:
I will try discover where it problem tomorow.
@jdobry:
meanwhile i looked a little closer at the distances of the
SPI-RFM-SendByte-Commands. I let every time such a write-command occured
toggle a pin and looked at it with the osci, and their distances looked
good.
im not sure if the problem is in the receiver. it might have been false
what i wrote in my last posting, sorry. but i will test it a little more
today and know more.
Full-Stroke-Issue:
I have a general question:
The HR20's Manual sais, that the HR20 knows a Default and a
Full-Stroke-Mode of turning the Valves off and on. When coming out of
the Box, HR20 is in Default-Mode. What is the use of this so called
"Default-Mode"?
I thought, the HR20 works like this:
* When HR20 is screwed on Valve (detected by switch), then ...
* HR20 turns on Motor to rotate left,
until the light eye doesnt pulse any more (gearwheels block)
* Set a lighteye_pulsecounter=0
* Turn on Motor to rotate right,
until light eye doesnt pulse anymore and count pulses in between.
Then set lighteye_pulsesmax = lighteye_pulsecounter
* Now the mechanic is in a defined state (valve=100%)
and we know that
[Valve0% .. Valve100%] <=proportional=> [0 .. lighteye_pulsesmax]
Which this knowledge and pulsecounting,
we can put the Valve to any % we want.
I guess this is the full-stroke mode. So, whats the Default-Mode?
What would be the meaning/benefit of it?
Whats the use of having a water tap that you dont open or close
completely?
@Jiri:
My Description of the Valve-Calibration - is this like your Calibration
Algorithm? And if so, how do the described Phases correspondend with
your "C-1" "C-2" "C-3" Calibration Messages?
Your Code looks like if there is a "Manual Calibration" and a "Auto
Calibration", but i couldnt find out when which mode is driven, and
what's Manual at the manual Calibration.
And what are you working with PWM with the Motor?
I thought only the direction of the Motor is important when Setting a
Valve-Position (which is selected by the 4 H-Bridge Transistors next to
the Motor i guess), but why is Motorspeed interesting?
Could you tell us some words about these things? We will need this text
snipplet later probably for the User Documentation.
Thanks!
Mario
Hi at all,
today I finished the first (Christmas) release V 0.2.2.25740 for the
openHR20 Suite which allows comfortable managing of the module settings.
Since I was very busy adding functionality, not all things are well done
and some problems may arise (if you find some, please report).
The SW is based on .NET Framework 3.5 and uses WPF instead of Windows
Forms windowing. It was developed on a Vista notebook but should also
work with XP. The 3.5 .NET Framework is not contained in the installer.
If you don't have it already installed, you must obtain it from MS.
Basically WPF GUIs are very pale but the design can be changes
tremendously. If anybody here has Expression Blend and has experience
with good design, may contact me.
Only one hardware platform was used, so I can't say which problems may
arise on others.
Unzip the attached setup and install the SW. Connect the HR20 via serial
Port (or USB to Serial adapter as I did it), choose the correct COM Port
and connect to it. You may read or set all/single Timers or Eeprom Data
and save/load it to/from a File. You can also send manual commands, sync
the date/time with the PC or log the traffic to a log file. The other
functions are self describing I think.
The SW works with REV 103 of the HR20, but may also operate with elder
versions.
Have fun with it.
Karim
A picture of the user interface is attached. At first I would like to
make the SW stable before I add functions if I don't lose mood (e.g.
script executing, graphical data logging, several Tabs for each
connected module, connection via WEB Service, and what ever ideas
comes).
Wow this looks good!
Will try it soon!
Karim, could you assure in your code, that the COM-port-stuff is not too
much nested to the GUI-stuff.
This would make it easy to port your application to wireless HR20
control.
Would probably require some Addressing-Layer in your Programm.
Communication would the go to a "RFM-Gateway"
(= FTDI<=>Atmel<=>RFM), which would probably not be totally transparent
to your Programm.
The RFM-Gateway could do of course the HR20-comm totally transparent
(especially since FTDI is a Comport) but a more generic firmware in the
Radiomodem could make it a litte more flexible (use it as
remote-therometer-receivre as well etc).
But your Screenshot looks good! Will try it soon, wish i could code in
.NET ;-)
I wrote a short Status-Update about the Wireless-Branch in the Project's
Artice Page....
(@Jiri: sorry it is in german, but it contains nothing you do not
already know anyway)
Hi
Thank you for your answers.
@Frank:
I am sure the wheel was on the "all open" position, before I mounted it
on the valve. I am not sure whether the problem can be solved by coins.
If the distance would be too large, the pin of the valve would be out
and the valve open. In my case the valve is closed after three days. But
still I can give it a try.
@jdobry:
I am not sure I correctly understood what you ment. What is a SW? And
how did you change it?
Thanks a lot,
Robert
@Robert:
Original software in valve is 2.04 from Honeywell. We don't know how to
set it via serial line, how to bugug problematic situation etc.
Therefore we wrote complete different SW for this valve. It have some
extensions for debug and some more functionality. And don't have "cold
valve" problem as is discoverd by you.
For change SW you needd JTAG programer, see to this thread history.
@Karim L.
I was try your SW 0.2.2.25740 version. And this is result:
- not able to run under MONO, It use too many non implemented functions
in mono.
- it always use anti-aliased fonts and don't respect setting in windows.
It is hard to read on hudge monitor with high resolution
- layout have fix size, unable to use bigger window
- About dialog contain information about GPL II license, but where it
sources?
Thanks for this SW, it can be useful. It's pitty that it can run only
under MS Windows. Many of us have another system.
@Robert: If you dismount the head you can check the position of the blue
weel - is the pin all in or all out or in between? You can get mor
Information when you connect yor PC to the serial port of the HR20. But
keep in ´mind that ist side is in 3,3V-logic.
By the way, what is the easyest way to connect the HR20 to the serial
port of a PC? Found this Beitrag "1 Transitor + 2 Widerstände = Verwirrung",
intended for I2C but should work on RS232 too (?).
@Karim: very fine - it runs on my XP but not yet connected (s.a.).
Could your progy also work on an I2C-bus? I have 25 m cable going along
every radiator in my flat. It would save me from laying my hands on
every HR20 twice on each holyday :)
Frank
@Frank:
easyest way to connect the HR20 is use MAX232 for serial line or another
cheap solution is use USB cable with USB->serial convertor for mobile
phones. (Ulder mobile phones don't have USB and this cable not contain
level changer for RS232 line, but use 3.3V logic). Example is (tested)
KQ-U8A cable ( ). I buy each by
aprox 3.20 EUR
I2C-bus is not supported on OpenHR20 software. Except this I can't
recomend I2C bus over all valves. This bus is not protected to noise and
cables will be too long.
Hey Karim
first look on your tools is all great. It works fine - but: were can i
select the temperature for each on/off-time pair (snow/moon/sun on LCD)?
Great work!
Frank
@Mario,
the COM Interface is placed in an one class. I will add an SW interface
to it, which all communication classes has to implement, so that a
seamless integration of any interface will be possible.
@Jiri,
the Suite is for me also an interesting technology project, since I have
not written until yet a WPF application and I did like to use other
technology stuff like reflection, data binding, user controls, which the
.NET Framework offers, because I will need it at work next year.
- MONO is always behind the latest technology. It takes a while until a
full implementation is available but if I interpret it right, as I even
so they offer already the .NET 3.0 function set. I reduced the level of
.NET in the project to 3.0 and until some minor changes, it works as
before.
So the next release will require only .NET 3.0. Hope this helps for the
Mono user. But I have no experience with Mono.
- The code will be made public after I have added comments and
reorganized the code a bit. May I add the code into a new folder in the
SF openHR20 project? Would that be ok for you?
- The size of the windows is currently fixed, because I don't know how
to change it yet. It is different from Windows Forms but I think still
not difficult. But that is on my list for change as soon as I know how
to do it.
What monitor resolution do you use. My one has 1680x1050 and I can read
it well.
Windows is the most used OS platform and .NET is quite powerful. Since I
know how to program in .NET, it is the fastest way for me with
acceptable effort to get a complex program although it is still a lot of
work. And with Mono, even if it might not be possible yet, will open the
door for other platforms. Hope you can live with that point of view.
@Frank,
the level shifter would allow to connect the RS-232 in parallel, but a
special protocol would be required for communication which the I²C Bus
(TWI-Two Wire Interface) has already implemented (master/slave, clock,
addressing, collegian handling...). But in principle not a bad idea to
use a level shifter plus a special protocol. I have also installed a
cable ring to all heaters but planned to use I²C bus. The Atmel
controller supports I²C bus. And the nice thing is, the needed TWI Pins
(SCL (same as TCK, pin 4 of the connector), and SDA (TMS pin 3)) are
already routed to the module outside connector. What we need is an
interrupt routine which roots the traffic and at the PC a TWI to Serial
or USB converter. An additional option is the 3 wire USI connection. But
Jiri might be right, that long wires can be a problem for the signal
edges although the overall speed can be as slow as wished. We will see.
The temperature can be set in the eeprom block (temperature0-3), but it
is not a nice way because of the required calculation of the necessary
value. Also missing is the possibility to assign this temps to the
switching time. I will add both later.
@Karim
An I²C-Bus slave for Attiny was in the last issue of Elektor in germany:...
The best is, no special port is needed for it. We could use any line -
especially the serial lines, replacing the RS232 by the I²C.
By the way, in the same issue there is an article about to conntect a
RFM12 to AtMega.
@jdobry
I²C-Bus as a house-bus you find in Funkschau 9/2004 or at. It seems very simple.
My idea was to connect each rondostat with a power-line instad of
batterys, I²C-Bus for Comunication and a PIR-switch. The later is to
overide energy-save-mode if a person is in the room (e.g. school ends
earlyer). PE2 is still free!?
I2C have some problems. Generaly it have open-collector bus. This mean
that logical "1" is defined by resistor. On long cables, it have slow
edges and mainly it have zero protection for noise. This problem can be
fixed by active current injection on level change, but it need special
chipset. Except this we can't use hardware support on HR20, because it
need pins PE5 and PE6. Pin PE5 on HR20 is connected to ground, and it is
not possible disconnect it without remove chip. SW implemented I2C is
possible but I thing that RS485 is better for cables in home. RS485 HW
is extremely simple, see to...
But you can to do anything that you want, Source is GPL and you don't
have any restriction. But because I have not cables, I must use wireless
comunication.
Experience after 4 weeks on 4 valves
- valve have more actions compare to original SW. It must be improved.
Have anybody any idea?
- battery low detector is not sufficient. At low battery SW usualy
detect flase Error3 before battery low. I have some ideas how to imrove
it, but your ideas is also welcome.
- current temperature measure convert each measure to tempereture and
calculate average from last minute. Result after average have better
precision than is measured (overscan). But it can be reason to many
action on valve. I will try prepare version with average from RAW ad
data and calculate temperature from result. Overscan can be used or not,
i don't know what is better.
HI @ all,
i have some questions.
is there an bootloader also implementated, so it is possible to flash a
new Firmware over the Uart? The problem is, that i have the
JTAG-Ice-MKII debugger only for the next seven days, and than i have to
give it back.
The next think, i want to know. Is there a posibility to use the SPI,
i want to connect a can tranceiver to it, i saw that the pins PB0 to PB6
are use for the buttons and the engine.
wbr
Peppe
@peppe: It is possible use bootloader to flash this device. But I am do
not use it.
SPI: It is near ti impossible reconnect buttons to other pins. Therefore
only one chance is SW implementation of SPI protocol. See to branch for
RFM12 wireless communication (on development, not work now)
Idea: PE2 is free to use and avail on the connector. I'll try to connect
it to a PIR motion sensor.
If there are some events (PE2 is PCINT1 and can serve as an interrupt
source) within a given time, the room is known as used and the
temperature will be set to "comfort". If no motion is detected,
temperature wil go to normal value given by timer.
I will modify a cheap motion detector whith a relay.
I think i will need a timer for it - Timer1 is not used yet?
By the way - how are you using the simulator? Is it possible to simulate
the switches too? I only reach "E2" due to PB0 is always going back to
0.
@Frank E.
If you are not using RS485, PE2 is free. (used for debug, disable it on
debug.h)
Timer1 is free and it is disabled (you must remove this power save
feature)
I am not using simulator, just JTAGICE debuger connected to real HW. But
on simulator you can manualy change pin status when SW is stoppend, or
you can create input files, see to atmel docs. But I thing, that it is
too complicated.
Jiri
Hello Jiri and all,
in my holidays I modified the code to work with the Thermotronic
thermostats. I did this by using #if - #endif stuctures to make the code
working for HR20 as well. Maybe you want to include my modifications in
the SVN - a new branch should be unnecessary.
The important differences between HR20 and Thermotronic are:
-different pins for switches etc. (scheme of TT can be found in another
thread)
-no enable-pin for motor-pwm
-hardware USART used for motorencoder (so i actually disabled all debug
functions)
-different thermistor - I modified the values but I´m not sure they are
correct. Maybe the have to be updated in future. The Thermotronic doesnt
show the measured temp so I cannot analyze as described in doc.
Thomas
@Thomas V
Modification for Thermotronic would be nice. Please contact me by email
for access to SVN or send me patch set.
Schematic is here...
Hi,
first I want to thank you for creating this project! I do some
home-automation and this is just what I was looking for.
Yesterday I bought me a HR20, connected my spi-programmer to the
corresponding pins and set the fuses to l:0xe2, h:0x9b and e:0xfd.
Then I uploaded the firmware I compiled out of the current SVN rev. It
worked immediately but very unstable (random hangups). So i took the hex
and eep files from the repository and it works like a charm.
Do you have any idea why my self-compiled version fails? I used the
Makefile from the repo with only one little modification: my avrdude
doesnt know the atmega169p so I hardcoded the atmega169 for avrdude (not
avr-gcc).
Environment is Linux with avr-gcc version 4.3.0.
Best wishes
Björn
Hallo!
Das hier ist ja mal höchst interessant. Bin mittlerweile auch im Besitz
eines solchen Reglers.
Ich habe verdammt lange nichts mehr mit einem AVR gemacht!
Wie bekomme ich mein Rondostat umprogrammiert?
Mir steht ein STK500 zu Verfügung. So wie ich das hier gelesen habe kann
ich das ganze nur mit einem JTAG programmieren, den das STK500 nicht
hat?
Bekomme ich das doch noch recht spontan programmiert?
Gibt es eine Schritt für Schritt Anleitung?
Gruß,
gammla
@gammla
Sorry, keine Anleitung bis jetzt - ist auch kaum möglich, da stark von
dem vorhandenen Gerätepark abhängig.
Ich bin so vorgegangen:
1.) JTAG Programer gebaut. Ich habe dazu ein ATMEL-Eval-Board von Pollin
angepasst. Anleitung findest Du bei Evertool-Light... Dort
ist auch die Beschreibung, wie man die Firmware und die PC-Software
beschafft und installiert. Achtung: Es muss ein anderer Quarz ins Board!
Du brauchst auch nur den Teil fürs JTAG nachbauen - 1 Quarz, paar
Widerstände, 1 LED und 1 Kondensator.
Die Steckerbelegung am HR20 findest Du in der Analyse. Ich habe 2 5-polige
Platinenstecker benutzt, wie sie in PC für die Gehäuseanschlüsse oft
verwendet werden.
2.) Aktuelle Toolchain für den Compiler installiert (Win-AVR) und
danach das Atmel-Studio 4 (Nicht Studio 32!). Hinweise dazu auf der
Seite von ATMEL.
3.) Das Repository mit den Sources geholt -> siehe dazu...
4.) Anleitung zum Übersetzen und Übertragen im Repository unter
Open HR20\trunk\doc\Anleitung AVR Studio HR20.pdf
Das Device im Studio festgelegt als JTAG ICE.
Aufwand: Recherche 4 Tage (kannst Du Dir hiermit sparen), Löten 2
Stunden, Software 3 Stunden (aber nur wegen der alten Version von
Win-AVR).
Sieht nicht gut aus, tuts aber...
Hi,
I've written a little tool for the linux/*nix console to communicate
with openhr20. It's very basic, just for my needs, but if there is
interest, I will extend it. With it, you can set the current date/time,
the wanted temperature and the mode. You can also get the status.
To compile it, you need cmake. If chosen this as it makes it easy to
compile software for different architectures.
Björn
@ Björn Biesenbach
nice tool! Do you wan't to place this project into SVN? If yes contact
me by email.
Ok the tool can now be found in the svn under tools/
I made hudge experimental change in motor controller. Version before
this revision use constant PWM for open and another constant for close.
This experimental revision try to use constant speed and try to control
PWM.
Benefits:
- we can use slower movement and it is more quite
- I hope that it will more resistant to false "Error3" detections
- speed is independent to battery voltage
Second experimental change: limitation of "P" part of valve position
controller. "I" part of this controller will found valve position inside
regulation area. I hope that it will reduce motor movement outside valve
regulation area. It save battery. It use config.P_max eeprom constant
and it can be improved.
Because it is EXPERIMENTAL, it is not in SVN main trunk. If you want to
test it, please use "Rev 152" from rfmsrc branch. Change "#define RFM 1"
to "#define RFM 0" in config.h
If you want to help with development, PLEASE SEND ME LOGFILE FROM YOUR
VALVE. Thans.
Jiri
I forget to one warning. Rev 152 have changed numbers of settings in
eeprom. Please see to eeprom.h
Hello Jiri and Forum!
@Jiri:
PWM: could you explain a little about, what the use PWM in motor control
is at all?
I thought, motor speed is not important at all because the valve
position is not calculated by motorspeed (==PWM?) and motor's runtime -
it is calculated (much more exact) by lighteye pulse counting - which is
speed independant.
Could you tell me/us a little about meaning of PWM in motor control?
RFM: sorry, i did not have time for working with RFM last weeks. I hope
i will find some time next week and/or the followings.
Rev 152 and 153 in branch rfmsrc is buggy (measure wrong motor
calibration, will be fixed today, please wait.)
Motor speed is not significant for valve position. But old versions use
constatnt pwm for control motor speed. This has this problems:
- high pwm constants are noisly
- high pwm constatns have hard touch on the end of motor movement range
- low pwm have problem with false "Error3" detection (motor can be too
slow)
- speed depend to actual battery voltage, therefore is near to
impossible find this constants for open/close
Jiri
Bug on motor calibration is on "manual callibration". It is fixed for
rfmsrc branch in Rev 155
New motor speed controller looks nice and better than original constant
PWM.
!!! Bug is not fixed on main trunk now !!!
I wan't to find maintainer for version 1.00 (main trunk)
We need to integrate changes from Rev 155 (bug fix)
We need to integrate changes from Rev 152,153 (motor speed controller)
Any volunteer?
Hello,
Motor speed controller is in SVN (Rev 158 in trunk / Rev 157 in rfmsrc).
If you can, send me log frou your valve/HR20 combination.
- If you will have problems (heating still cold or too hot) try to
increase config 0x0b
- If your motor speed is too high decrease config 0x12.
- If your motor speed is too low increase config 0x12.
Jiri
I have best results with "I" constatnt = 1
You can set it in service menu or by COM (S0601<enter>)
Current default value is 3
Can you confirm this result? I will change default value.
Jiri
Hi Jiri,
ok the hex file from trunk/source 158 seems to work here. What log do
you want to get? The output while adjusting or just any motor movement?
I still have the problem that my self-compiled hex does not work :-(
Don't you have any idea what the reason could be? Which compiler version
do you exactly use?
Bjoern
@Bjoern:
I need complete log (motor calibration, and all motor movement, both
have some significant information)
About compilation: I know only gcc version, but significant is also
version of AVR lib. Version? Distribution? You can try to disable
"#define TASK_IS_SFR 1" to 0 (disable interrupt optimizations) and
replace "OPT = s -mcall-prologues" to simple "OPT = 2" in Makefile
Jiri
If you want to use rev 152-158 please change configuration 0b to 0x32
(hex) It contain bug (Valve can still close, same bug as original SW see
Datum 21.12.2008 13:28 in this thread). I know why and I have solution.
It will be fixed later.
Jiri
Hi Jiri,
thanks for your unrestless effort. Propably tomorrow I can send you a
log file.
In rfmsrc you moved some files but didn't check in the appropriate AVR
Studio aps project file. The Studio claims about missing files.
openHR20 Suite:
Unfortuantely MONO does not support WPF (only Windows Forms) and there
are no plans yet to do so although parts of the community see high need
for that (otherwise MONO is ded on the long run).
It would be possible to rewrite the Suite to run under Windows Forms
instead of WPF, but since there is a Linux SW now available, it is not
needed and the more flexible solution would be a WEB application.
Nevertheless I extended the Suite between christmas and new year and
this could be released in a few days, if anybody likes to have it. New
is a script sending feature (for ease use, can be derived from log
file), the assignments of switching time and temperature (0..3) can be
done now, the temperatures can be set with more comfort and a bug fix
was done.
May I add the code to the SVN?
You have been right, the pins for TWI are not routet out, I did look at
the wrong port. Using RS485 is a good idea.
@Karim L:
I thing that your tool in SVN will be welcome. Please add it into
"tools" folder.
@All:
Please try Rev 159 and send me log. Current default "P" limiter (config
0b) in SVN is 100 (0x64 hex). But I want to test it with smaller value
(ex 32 = 0x20 hex). Please change it. This will reduce motor movement
outside live regulation arrea, but it is not fully tested. Bug from last
rev is fixed (I hope).
I want to have log file from 10 hours or more (integration of controller
error is slow)
Jiri
@Jiri,
Yesterday I flashed REV 159, changed 0b to 32 and logged a calibration,
window open/close and temp regulation over night. Log is still recording
and I will send it to you in the evening today when I am back from work.
But what I found in the morning is, that the switching times I set are
not used. I can set them and read them back which shows the correct
values but they are not used. Is this a bug or is there anything else to
set?
I have also a Thermotronic module and the code shows adjustments for
this module which can be enabled per compiler switch. Is this
implementation complete and does it work?
Regards,
Karim
@Karim L: switching times working without problem for me on all 4 walves
with OpenHR20 SW. It has not in MANU mode? Strange, it may be new bug?
Thermotronic: I thing that it works, but I haven't this HW to confirm
it. This modification is done by Thomas V. and I only review it. Main
difference from HR20 is missing communication (pin is used for something
else) and no PWM control for motor (haven't support in HW).
Can somebody confirm to me that original SW in Thermotronic not use SW
implementation of motor pwm (HW is not possible)?
Jiri
Hi Jiri,
I will try to find out if the Thermotronic uses software PWM next week.
At the moment i have less time. I hope I can finish my modification for
new timeroptions next week, too.
@Karim: except for missing communication and missing PWM my Thermotronic
works quite well. I think modification for RFM12 will be possible. The
RX-Pin of hardware usart isn´t used, too. So maybe it will be possible
to implement an unidirectional communication over RS232 for
configuration and so on. Another solution would be a software-uart, but
this would need much memory...
Thomas
@Jiri,
I don't think that manual mode is set, but may be you are rigth. I will
check that later.
@Thomas,
Thermotronic schematic diagram can be seen here
Beitrag "elektronische Heizungsregelung mit Thermotronic", but you may know that
already. Would it be possible, to release tx pin an use instead one of
PE4..PE7? It would enable full communication as HR20.
Hi there,
I'm going to try all the stuff as soon as my JTAG Adapter arrives!
So far it sounds soooo nice.
Meanwhile ...
Do you think it's possible to take a new software branch for
having more than 4 switching times, let's say 6 or 8 switching times per
day?
Additionally I'd like to have more than 2 temperatures, say 4
temperatures,
e.g.
07:00-09:00 21 Celsius
09:00-16:00 19 Celsius
16:00-22:30 21 Celsius
22:30-07:00 18 Celsius
How can this be achieved so that it doesnt conflict with all the
radio/wireless approaches there are?
Please gimme some helping hand, for what I've seen so far, I can change
the software in C with some version of the AVR studio... Am I right?
Having more than 4 switching times, together with more than 2
temperatures
will surley let me reprogramm all the setup stuff etc.
What do you think?
Kind regards
Thomas Reifferscheid
@reiffert,
this work is already done. Thanks to Jiri and Dario, the OpenHR20 SW
allows 8 switching times per day and 4 temperatures they can be assigned
to.
Ok, the original Thermotronic doesn´t use PWM. I think it is possible to
change pinconfiguration to use hw-uart but you have to do changes on the
pcb so I think this would be a solution for only a few people. A better
way would be to use a rfm12 wireless connection.
Thomas
To integrate a rfm12 module, a user has to open the Thermotronic module
an solder wires as well. Although it meight be a bit less complex than
to cut a strip on the board and rearange a connection, still some
wouldn't be able to do neither of both.
Here is an updated version of the hr20cmd tool. It has the ability to
get and set the timer slots now.
Björn
Hello Jiri, Dario and the other guys from HR20 wireless!
I read Jiri&Darios Wireless Spec and have some annotations about it, i'd
like to give now.
I hope it doesnt sound inpolite, it's for sure not meant that way!
Ok, nice evening!
*** ***
4.2. Sync Packets
Did i get this right? the Master sends regulary Sync-Frames containing
the current DateTime every :00 and :30 second? (:00 is enough anyway i
think).
Here i see a bootstrap problem:
If a slave hasnt a synced clock yet (regardless if he knows that his
clock isnt synced), he doesnt know when the time Slot 00 occurs:
So he has to switch on the RFM receiver for about a whole minute, hoping
he receives a Sync Frame, which is battery consuming and costing program
space.
I would rather suggest, that a Sync-Packet is just a
SETDATETIME-Command, the Master sends to the Slave,
after the Slave sent a BroadcastStatus packet (in his Timeslot with
Second=OwnAddress).
Then the slave's clock can be synced as well.
I dont agree with your statement that Date&Time is needed for preventing
replay attacks:
A Timestamp is worse for replay prevention than a random number.
4 byte MAC Code is totally overkill! This is wasting battery!
Beside, longer packets have a higher propability to get lost over the
air.
5.2 Keys
I agree that it isnt recommended using Masterkeys in encrypted
Communication.
But derived Keys like Kmac and Kenc make ONLY sense, if they are derived
from the Master Key more than one time within the life time of the
Masterkey!!!
Otherwise it doesnt have any impact on security.
If Kmac or Kenc is broken, Km is worthless as well!
I think you mixed that with the idea of session keys.
General Critic: The packets are too long, too many syncs from master the
slave might not hear anyway, derived Keys that dont improve security.
A nonce derived from a datetime and a packet counter is predicatable!
A nonce = rand() is much better.
What is the CRT ? did you mean CTR?
Does all this fit into HR20 left codespace anyway?
@Mario:
4.2.
- We need broadcast date/time for encryption also.
- boot strap is not problem. It happen only ONCE afret battery change
and price is 15mA on 30 second (maximum) It mean 0.002mAh - not problem
- sync packet on 00 and 30 is not exactly same. It is needed for force
communication from selected slave. Time slot 31-59 can be used as block
for one slave long communication.
- use random number rater than time is worst because it complicate
protocol, try it and you can see. For security is ony byte random number
nothing. Two bytes looks better, but if false feeling
()
- 4 byte MAC code is nothing, you must calculate energy. Cost is
4.6e-5mAh per packet. This mean that 132000 status packets (one year
average) take 6mAh. It is nothing.
- For save energy we MUST have very accurate time synchronization.
Enable receiver for 1 second have same cost like send 360 bytes!
5.2 I can't agree, that it not improve security. It is no way how to
calculate Km from Kenc or Kmac. This mean that if you have Kmac you are
not abble calculate Kenc nad vice versa.
CRT is misstyping
Jiri
PS: It is not pollite for others discus this document on this thread
when it is not public now. (it is not secret, we will add it on SVN
later)
New revision 175:
Changes:
- controler use new configuration for linear "P" gain
- controler configuration for quadratic "P" gain
- new config option (0a) for min valve position (default 30%)
- new config option (0b) for max valve position (default 80%)
- optimization
Improvemets:
- linear/quadratic controller have best result for me (send me your log)
- valve min/max setting save batteries because not all range of valve is
active. If you have problems (valve still open or close) please change
it. I am not abble to find algorithm to find it automaticaly (every idea
have some condition when must fail. I belive that range 30%-80% is
correct for major part of valves, but you can set narrower range and
save more battery energy.
If nobody found any problem I plan release Rev 175 as STABLE version
1.00.
If you want to do something:
- doxygen comments need improvement to generate USER DOCUMENTATION
- create Thermotronic patch for rfmsrc branch
- create schematics picture for RFM12 master HW (text specification is
in SVN)
- I want to find maintainer for stable 1.xx version. I have last one
HR20 without RFM12 modification and I will not have HW for test this SW.
Hello Jiri and OpenHR20 Team,
first of all, sorry if my comments on HR20 wireless spec were misplaced
and sounded inpolite, both wasnt meant so!
today i checked out the openhr20 from svn and tested the rfmsrc-branch:
i could verify, that the (interrupt driven) RFM packet sending now works
correctly, even for long packets (either my receiver was programmed
wrong some months ago, or the old openhr20's sending code (non interrupt
driven) swallowed some bytes), but anyway this looks good to me!
but i got one strange compiler message, saying that this code
// rfm_config.h
#define RFM_INT_EN() (PCMSK0 |= _BV(RFM_SDO_PCINT), PCINT0_vect())
#define RFM_INT_DIS() (PCMSK0 &= ~_BV(RFM_SDO_PCINT))
creates this warning:
main.c:223: warning: implicit declaration of function '__vector_2'
it looks to me like a typo (PCINT0 is hard coded beside that) and i
wrote
// rfm_config.h
#define RFM_INT_EN() PCMSK0 |= _BV(RFM_SDO_PCINT);
#define RFM_INT_DIS() PCMSK0 &= ~_BV(RFM_SDO_PCINT);
instead, raising no warnings, and running correctly ...
until i mounted the valve for the motor calibration to start, which
makes the HR20 reboot in infinite loop every few seconds. (reboot,
running till blinking "2008", reboot, ...).
it also showed this reboot loop with #define RFM 0
could this be a consequence that moror control isnt via PWM?
any ideas? sorry i have no logs about that (yet).
regards,
Mario
This code:
// rfm_config.h
#define RFM_INT_EN() (PCMSK0 |= _BV(RFM_SDO_PCINT), PCINT0_vect())
#define RFM_INT_DIS() (PCMSK0 &= ~_BV(RFM_SDO_PCINT))
is correct:
1) please don't remove branches around macro body or use ";" on end, it
make problems if you use macro in expression
2) PCINT0_vect() is dummy call interrupt to insurance that no interrupt
will be lost (signal is level based, interrupts is on edge)
3) If you want to remove this false warning, add this
void PCINT0_vect(void);
into rfm_config.h
Reboots: I thing that you are use external power not bateries. Right?
Problem is that old code has problem with motor movement with older
batteries and create false positive "E3". Therefore from Rev153 motor
have "I" controller for speed stabilize and motor startup use
config.motor_pwm_max value. This works amazing on batteries, but worst
with external power (HR20 have not any capacitor for absorb power shock
from motor start because it is not needed with batteries) With external
power you must add big capacitor into power lines. If you use USB as
power source it is worst, because USB have current limitter (USB
specification) and power line shock is hudge.
New release candidate for ver 1.00 is Rev 180.
Please test it.
Changes:
- fix setting to AUTO mode
Information about wirelles:
Rev 181 is just proof of concept for bi-directional communication. It is
not usable for real live, I must refactor some code and add real
functionality.
Jiri
PS: I am not abble maintain 1.00 versions after release. I have not Hw
and I have not time also. Any volunteer for maintain it?
Hello Jiri and the other guys from the 'development team'.
Fantastic project, the code worked more or less 'out of the box' for me.
No problems with compiling and exactly the features added to the
original code that I missed.
I have also been using the RFM12 in other projects and have tried that
modification during the last days (external RFM12 connected via JTAG
pins). After adding some code to get the necessary information like set
value and measured value for temperature and the valve position sent via
RF I can now at least log the data from one thermostat without cables or
a notebook in the bathroom. I hope that this will help me to fix some
problems I have with the regulation characteristics using the default
settings.
I use two HR20 in quite small rooms (toilet ~3m² and bathroom~10m²) and
the regulation with OpenHR20 and default settings works much worse for
me than with the original HR20 firmware. When heating up in the morning
(step from 15°C to 21°C) this happens much slower than with the original
software but there is also a big overshoot. Than i quite often see a big
permanent difference between set value and real temperature without any
reaction on the valve setting. Strange, but as already said I will now
first log the data before telling too much nonsense. And I know that
these small rooms are very complicated in terms of regulation compared
to larger ones. The doors and windows are also permanently (or at least
quite often) opened and closed in these rooms and this makes everything
even worse. But as already said, the original software seemed to handle
this much better.
To correct problems like this or workon them, I first have to understand
the code and function of the controller better.
One comment on the 'RFM' version: I have a blank display after some
seconds only with this software. When changing the set value with the
wheel, the changed value is displayed correctly again and then after
some seconds it disappears again. The 'normal' version without RFM12
works ok.
That's it for now, keep on the good work. And maybe someone has a
suggestion, which parameters I could touch to improve the regulation.
BR,
Jörg.
Hello Jörg,
I can confirm, that the software does not regulate the desired value
exact (about 0,8°C lower than set) and also it does not open the valve
wide enough in my opinion to reach fast the desired temperature. In my
30m² living room I have no overshot of the temp. The current setup might
be ok for a large heater in a midsized room, but it is not optimal yet.
Problem may also be the different valves (where is it completely open
and closed?). The SW was optimized by Jiri for less movements and saving
battery energy. Further work is required.
It would be good to have an algorithm, which adopts automatically to
some parameter and may be also predict the temperature which will be
reached on a valve setting. For that, a pulse response characteristic
could help.
Open the valve 100% for a short time close it completely. Measure how
long it takes until the temp rises, until it reaches the maximum and how
it does fall. Calculate the mathematical formula and use it ;-).
Regards,
Karim
@Jörg Becker: thank you for feedback. I know that default setting after
last modification is not perfect. It works for me (used on 4 rooms,
bathroom still use original SW for comparation)
Karim have true, we have to many different conditions (valves rooms etc)
but too less data for final setting (send me you log).
You can try change setting:
PP_Factor (05): proportional gain for quadratic error
P_Factor (06): proportional gain for linear error
I_Factor (07): gain for integrated error
Try increase I_Factor, it can solve problems with small rooms. If you
can, send me log file.
RFM12: this state still in pre-apha state. Too many parts is changed,
but not finished. Could you send me your modification on RFM12? May be I
can use some part from it. Current code will need some special SW/HW
called "master" to control wireless network and for encryption. It make
it incompatible with simple wireless listening and loging.
@Karim L.: I fully agree, that current controller part can be improved,
but it need some suficient matematical model. We not have it.
Jiri,
I am sorry, I simply do not have enough time at the moment. My logging
attempts were not successful partly because I have problems with my
circulation pump not working correctly (no, not with mine, but with that
of my heating system :-) ).
When the pump works ok and the water temperature is not too high
(dependant on outside temperature) the regulation with default values is
not so bad, although I still sometimes (?) see permanent differences of
nearly one degree like Karim.
One of the reasons why I want to have the RFM12 solution is, that I want
the thermostats to do the regulation only when the circulation pump is
running. And this is 'intelligently' controlled by my heating controller
(Schäfer Domoxxx something). In times when the pump is stopped (variable
interval at night with start time in the morning depending on outside
temperature) the thermostats shall go into off position. The same goes
for times when the pump is completely stopped due to high outside
temperatures (programmable, set to >17°C in my case).
Regarding code with RFM12, I used your code nearly 100% and just added
some extra bytes for sending set temperature, real temperature and valve
position every two seconds. Worked ok more or less as I did not 'know'
(or understand the code enough) that this software does not switch the
temperatures to the preset values like the normal software does in
automatic mode. It seems to be waiting for a master command to set a new
value? So my remote (RF) logging attempts were not successful. Have to
dig deeper into that code first (or wait for your solution :-) ).
BR,
Jörg.
I have a problem with version 180.
I had the valve behind a curtain. So it was very hot but the valve was
full open! The temperature was shown at 9 °C (I measured about 40°C with
another thermometer).
I pulled off the HR20-head and watched the temperature, while it cooled
down. It decreases from 9 to 0.0 °C and then it jumps to 25.5°C (in my
opinion the real temperature at this time).
Is there a problem with high temperature measuring?
Ronny
@rhb: thanks for bug report. I was repeat it and this bug is real. I
will fix it.
Hello Jiri,
on last Sunday I flashed REV 180, but couldn't log long enough to make
some effects clear. Today I discovered also a jump in the temperature,
which I couldn't explain (within a few minutes from 16,76 to 17,26 then
back to 16,76, 17,76, 17,30 and 16,82 which looked strange to me.
I have the feeling, that the temperature send to rs-232 and internally
used are different, which could be the reason for the temp difference of
about 1°C which I still can see.
When I increase the set temp from 17,5 to 18,5 °C the valve will be set
to about 50 which still does not open the valve (at least not much) and
even after 30min the valve will only be opened slightly to 52 or 53
which is still not enough. As I have that logged more clearly I will
send you a log.
Concerning a new regulator model, I have unfortunately no experience and
would have to do a lot of experimenting and development work to get
something reasonable to work.
Regards,
Karim
Rev 192 is bug fix for measured temperature > 25.5.
- temperature was measured correctly
- Rev192 is new release candidate for 1.00 version
@rhb: I was found bug only on LCD value, can you explain it better? What
was valve value on LCD on "%".
Jiri
@Karim L: internaly used temperature and RS232 log is SAME values. It is
past 15 second average.
Only one exeption is debug output (DEBUG_PRINT_MEASURE). This is RAW
values before 15second average. This debug is DISABED in default
compilation.
@Jiri:
Please take a look to the following source code lines.
From my point of view the type of the variable valve is changed too
often and may force neagative effects.
controller.c line 57:
static uint8_t pid_Controller(int16_t setPoint, int16_t processValue, int8_t old_result);
controller.c line 70:
int8_t CTL_update(bool minute_ch, int8_t valve) {
controller.c line 137:
valve = (int16_t)pid_Controller(calc_temp(temp),temp_average,valve);
controller.c line 225:
static uint8_t pid_Controller(int16_t setPoint, int16_t processValue, int8_t old_result)
Artax
@ Artax:
All this lines is correct:
temperature can be measured - unit is 1/100 degree(int16_t)
temperature can be wanted - unit 0.5 degree (uint8_t) - calc_temp()
macro change it into 1/100deg unit and int16_t type.
valve position have int8_t variable and range 0-100
PS: I know that it is not best practice change types often. But we don't
have a choice, because it was save many bytes in RAM and Flash. Current
situation : incomplete RFM code take 15102bytes form 16KB Flash. This is
one of many "ugly" parts of code. Most ugly is non existed division into
layers and interfaces between this layers. We dont have space for it.
@ Artax:
signed values on valve is remaining code from old valve renage (-50 to
+50).
It can be cahnged to uint8_t
Ex:
uint8_t CTL_update(bool minute_ch, uint8_t valve);
And it can save 4 bytes in flash.
@jdobry
measured temp is ok in rev. 192, thanks for your very fast response!
The overheating was my fault, your question was the right hint: the
default min. valve position in eeprom (30%) was to high for this small
room and valve. Now I set it to 5% and everything is ok.
Ronny
@rhb
Valve limitation is not depend to room size but only on valve type.
Every valves have wider range than active part. This is for my valves.
0-45 - valve is closed, when I try go from 45 to 0 force for movement
growing and this have not efect for regulation but big effect to battery
live and gears abrasion.
45-70 - this is active part of valve, in this change valve position
have effect to water stream
70-100 - valve is open, movement of valve have effect near to nothing.
All this values are not exact and it depend to valve type.
"All this values are not exact and it depend to valve type."
Not only valve type but even more on the pressure the water pump for the
heating water builds up.
Especially modern self adjustable water pumps can be a real nightmare in
this sence as the pressure in smaller rooms can be quite different
depending on how the other rooms behave.
I had the situation where the water pump would detect night shutdown for
some reason and reduce its power significantly without obvious reason.
Turning this feature off reduced my problems, however I did not even
know it had this feature as I had to open the pump to get to some small
dip switches to control this.
Axel
Hello
I have buy an other HR20
I will draw a new circuit diagramm for this.
@Thomas Peterson:
It looks like Thermotronic.
Compare it with this picture:...
Schematics is here:
Beitrag "elektronische Heizungsregelung mit Thermotronic"
Hello Jiri, Karim L. and the other team-members from the 'development
team'.
Very good, phantastic project, I´m not a electronic specalist and a
managed to flash 3 hr20 (original v2.04) with the guidance in this
forum, (currently I use the latest F0.97 rev.192 without rfm) for me it
works fine so far. But i have also an older hr20 (original v1.xx) and
with the same interface cable it was not possible to get a connection,
it works only with the newer HR20.
For setting the hr20 i used the openHR20suite dated 22.12.2008) from
Karim L. The program works in general fine, sometimes I have a longer
waiting time for read / write the data’s but maybe this is related to my
interface cable.
If a new version of openHR20suite is available I would be interested to
test it. I had some problems with the valve range adjustment (30-80%) in
openHR20suite, this I could not find in the openHR20suite.
many thanks and best regards
reinis
@Reinis,
since the eeprom data arrangement did change, the first openHR20 Suite
release is not fully compatible. But I have a newer version, which I can
offer next week (I will return on Monday evening home, so that hopefully
till Thursday a new release can be provided). It has several new
features and supports the latest eeprom layout.
Karim
Karim,
it seems that you activate RTS as well as DTR in your openHR20 Suite
(both lines show ~+12V). Would it be a big deal to make these settings
variable with maybe two check boxes?
I am using a 'standard' RS232 to TTL converter with optical isolation,
which draws the power from the RS232 lines and needs RTS activated and
DTR deactivated. Maybe I am not the only one with such a special wish
:-)
BR,
Jörg.
@karim,
that would be very nice if you can provide an updated Version of
openHR20suite matching the latest eeprom layout.
Can you give me a hint how i can log the data's from HR20 (Valve Pos.,
SW Temp. and Act. Temp.)i saw some recordings?
Was this done with openHR20suite (e.g. i have a recorder which would
work with DDE-Link if you provide this to other applications) or is it a
other program?
thx + br Reinis
Hello,
I'm new to this forum and I have been playing around with the new
firmware for the HR20E for some time. I just want to say that you've
done a really good job. But I've also found some minor problems:
- the parameter of the RTC_Setxxx functions has changed from int8_t
to uint8_t. At least for hours and seconds this was not a good idea.
The parameter can be negative if you set the values with the wheel
and turn it anti-clockwise. E.g. for minutes you get the sequence
01-00-15 instead of 01-00-59.
- setting of DEBUG_IGNORE_MONT_CONTACT to 1 doesn't work. In line 196
of keyboard.c ( mont_contact= 1; ) the value should be 0. The 1 is
forcing the E2-Error instead of ignoring it.
- After a reset setting of the year manually is sometimes wrong:
If you don't touch the wheel and confirm the standard value of 2009
with the PROG key the stored value is sometimes 2008 and sometimes
2009. It depends on the current position of the wheel. At one position
PB5 and PB6 are both LOW and at the next position both are HIGH. The
variable state_wheel_prev is initialized with zero and so it doesn't
reflect the HIGH values of PB5 and PB6. In this case when you press
the PROG key a wrong KB_EVENT_WHEEL_MINUS is detected.
I've found a solution for this but I'm not very happy with it.
But here it goes:
I've added the line
state_wheel_prev = (~PINB & KBI_ROT1);
to the end of the init function in main.c. It must go behind the
call of task_keyboard() in order to not being overwritten. I've also
defined state_wheel_prev as extern in keyboard.h.
Regards, Ulrich
@Ulrich Wilkens:
Thanks for bug report!
1) RTC_Setxxx and overflow: It look like bug in compiller. I know that
code mix signed and usigned types. And it is correct for 8-bit
aritmetics. For example minute 00-1 is 255 and
(uint8_t)255+(uint8_t)60=59. But compiler use 16 bit aritmetic to add 60
and I don't know why ((255+60)%60=15). This function:
void RTC_SetMinute(int8_t minute)
{
RTC_mm = ((uint8_t)minute+(uint8_t)60)%(uint8_t)60;
}
is compiled wrong to:
37 .global RTC_SetMinute
39 RTC_SetMinute:
40 .LFB8:
41 .LM3:
42 /* prologue: frame size=0 */
43 /* prologue end (size=0) */
44 .LVL2:
45 .LM4:
46 000e 90E0 ldi r25,lo8(0)
47 .LVL3:
48 0010 CC96 adiw r24,60
49 .LVL4:
50 0012 6CE3 ldi r22,lo8(60)
51 0014 70E0 ldi r23,hi8(60)
52 0016 0E94 0000 call __divmodhi4
53 001a 8093 0000 sts RTC_mm,r24
54 /* epilogue: frame size=0 */
55 001e 0895 ret
56 /* epilogue end (size=1) */
57 /* function RTC_SetMinute size 9 (8) */
Compiler use 16 bit aritmetic to adition
but this code
void RTC_SetMinute(int8_t minute)
{
RTC_mm = (uint8_t)(minute+60)%60;
}
create correct result:
37 .global RTC_SetMinute
39 RTC_SetMinute:
40 .LFB8:
41 .LM3:
42 /* prologue: frame size=0 */
43 /* prologue end (size=0) */
44 .LVL2:
45 .LM4:
46 000e 845C subi r24,lo8(-(60))
47 .LVL3:
48 0010 6CE3 ldi r22,lo8(60)
49 0012 0E94 0000 call __udivmodqi4
50 0016 9093 0000 sts RTC_mm,r25
51 /* epilogue: frame size=0 */
52 001a 0895 ret
53 /* epilogue end (size=1) */
54 /* function RTC_SetMinute size 7 (6) */
Could me somebody tell WHY?
2) DEBUG_IGNORE_MONT_CONTACT - fixed, thanks
3) wheel error, I was know about this bug, but it has not priority.
Thanks for bug fix.
*****************************
fixed in Rev 195 version 0.98
*****************************
This fixed code is not tested, tell me if it solve problem.
Since I had my notebook with me and a bit time, I finished the next
release of the openHR20 Suite V 0.2.4.23954 today. See the readme.txt
for the made changes after installation or the text below.
@Jörg, you may change the RTS/DTR signal state via the
openHR20suite.cfg. Install the program, chut it, modify the new cfg and
restart the program. Currently I did not like to add this settings to
the GUI.
Report problems and errors please.
23.02.2009, V 0.2.4.X
Current day in switching time table has style bold instead of italic
With # in command window, comments can be added for better documentation
of the log file
A detected open window will be shown in status bar
For com interface DTR and RTS signal state can be changed via
openHR20Suite.cfg XML File.
Log File can be renamed as *.scp and used as script file
Readme.txt added to installation
New eeprom layout of REV 180 supported (Attention: Incompatible to old
layout)
If an expected response is not received, an error comment is displayed
in terminal
28.12.2008, V 0.2.3.X Not released
IsTemp progress bar is green when Target Temp is range +-0.5°C, below
blue and above red.
Aktive day is shown in italic
Bugfixes on loading an saving data
Resizebale window, application starts with last size
Temp 0..3 can be set
Temp assignment to switching time possible
script execution added (see tooltip of command box)
Data names in data files changed -> incompatible
22.12.2008, V 0.2.2.25760
First release
@Karim,
i just tried your latest version of openHR20suite, excelent !!!
It works much faster with read/write as the older one i used and data-tx
is now much more reliable.
Also your idea with the red error line is good.
thanks and br
Reinis
Karim,
thanks, works perfect for me!!!
BR,
Jörg.
Hello Jiri,
I've tested your fixes and they are working for me. Thanks a lot.
Regarding your compiler question: I'm not a compiler expert but I've
found this one:
Beitrag "Re: reihenfolge der bits in einem byte umdrehen"
In short, it states out that gcc is doing calculations in a way that
intermediate results are at least of type int (16bit). This is requested
by the C standard and casting the parameters to 8bit types doesn't
change this behaviour.
Another thing is that avr-gcc is working internally like a virtual 16bit
machine and treating with 8bit values is defined specially.
This could be the reason that your second example with casting of the
end result is working.
Regards, Ulrich
Karim,
I found some problems with your OpenHR20Suite, but maybe this is just
because I do not use it correctly or I do not understand something.
If I read out temperature values, i get the reading 68:15 for empty
entries (--:--) in the thermostat. If I enter --:-- in the program and 0
0 for the temperature settings, the program just closes if I press
'set'.
Next, if I enter new values directly in the thermostat and then read the
timer settings again, nothing is changed on the screen. But the new
settings are clearly present in the thermostat.
Any idea what I am doing wrong?
BR,
Jörg.
Karim,
now I see that you only show the timer entries for the individual days
and not for settings the whole week (I use setting 1-7 on the
thermostat). I thought that the settings for (1-7) would be copied to
the individual days.
BR,
Jörg.
Hello Jörg,
thanks for the hints.
Week mode operation is not well supported in the program. That is one of
the open points for the next release.
If I don't want to use a switching timer, --:-- is to be set at the
module by the wheel. If I read then the time via program, I get x5A0,
where x stays for the temps 0..3 to be used and 5A0=24:00, which marks
not to use this switch setting.
The default in eeprom (see ee_timers in eeprom.h) after flashing is for
not used switching timers xFFF=68:15 which is different from above after
manual setting. 68:15 is not replaced by the suite with --:-- yet. And
even worse, if you try to enter an invalid time, the program crashes.
But I know that and in the About window I made a hint to not enter wrong
values.
I plan to add a check for all entries and I would like to use masked
text, but here MS made it not very easy to have a nice implementation.
This subject is more complex to solve as you would assume and I need
time to acquire a solution.
So don't enter an invalid time, only this range is allowed
[00:00...23:59, --:--]. Don't try to set a displayed 68:15 red from
device, because it lets the program crash.
You can switch from week to day mode by setting the timer_mode from 0 to
1 in the eeprom data block.
The week times can be set via R00..R07 command. But I will make that
available by direct setting in GUI.
@Jiri, is it required to have xFFF as default in ee_timers for not used
switches and could this values be changed to x5A0?
BR,
Karim
@Karim L.
For not used timers I need any invalid time. x5a0 is also correct.
@Jiri,
ok, I will do a fix for that in the next release.
Hi Jiri,
I still see some permanent differences in set value and real value
without any reaction of the controller. Now I took a HR20 with newest
firmware on my desk and waited until the real temperature reading
stabilized to 18.32°C (with a set value of 19.0). Then I made some
changes on the I value. But i do not understand the result. Do you have
an explanation?
20:38:54.515> D: d4 26.02.09 20:38:54 A V: 51 I: 1851 S: 1900 B: 3312 Is: ff03 I value = 3 (default)
20:40:54.515> D: d4 26.02.09 20:40:54 A V: 52 I: 1845 S: 1900 B: 3312 Is: ff3a
20:42:54.421> D: d4 26.02.09 20:42:54 A V: 54 I: 1838 S: 1900 B: 3312 Is: ff78
20:44:54.421> D: d4 26.02.09 20:44:54 A V: 54 I: 1838 S: 1900 B: 3312 Is: ff78
20:46:54.421> D: d4 26.02.09 20:46:54 A V: 54 I: 1838 S: 1900 B: 3312 Is: ff78
20:48:54.453> D: d4 26.02.09 20:48:54 A V: 55 I: 1832 S: 1900 B: 3312 Is: ffbc changed I value to 6
20:50:54.453> D: d4 26.02.09 20:50:54 A V: 55 I: 1832 S: 1900 B: 3312 Is: ffbc nothing happens
20:52:54.453> D: d4 26.02.09 20:52:54 A V: 55 I: 1832 S: 1900 B: 3312 Is: ffbc nothing happens, change I to 10
20:54:54.593> D: d4 26.02.09 20:54:54 A V: 51 I: 1832 S: 1900 B: 3312 Is: ffbc valve closes!!!
20:56:54.593> D: d4 26.02.09 20:56:54 A V: 51 I: 1832 S: 1900 B: 3312 Is: ffbc no change
20:58:54.593> D: d4 26.02.09 20:58:54 A V: 51 I: 1832 S: 1900 B: 3312 Is: ffbc no change
I thought that increasing the I value would help the controller to get
rid of the permanent difference by opening up the valve, but the
opposite happens.
Ok, I wanted to watch this a bit longer, but after some minutes the
automatic timer changed to 15.0°C and the valve closed down completely.
I am a bit puzzled.
BR,
Jörg.
I was try the best algoritmus with my valves in my flat. From feedback I
know, that it is not perfect for everybody. (info from Karim L.) I will
be changed soon (this wekend probably).
I will describe better current situation:
e = error = current_temp - wanted_temp
temperatures is in fixed point, unit is 1/100 degree
abs(e)*e*PP_Factor/256 + e*P_Factor + Is*I_Factor
valve = ------------------------------------------------ + 50
256
where "Is" is integrator with this limitter:
256*50
maximum Is change in one step = --------
P_Factor
if ( ((current_temp<last_temp) && (current_temp<wanted_temp))
||((current_temp>last_temp) && (current_temp>wanted_temp))) {
// update integrator
Is+=e;
}
You can see consequences:
- if current temperature is not changed from last, integrator is not
updated
- if temperature grow and current_temp<wanted_temp (and vice versa),
integrator is not updated
This limitation I was add to limit motor movement around wanted
position. Without this, near to every 4 minutes SW will move motor back
and forth. It have devastation consequence for battery live.
Another reason is hijacking of integrator. Why? Please fancy this
situation: wanted temperature is 17 degree, real temperature is 19
degree, we have opened door from heated space. In this situation, valve
is fully closed. But without limitation, error value must be -3 (-300 in
1/100 deg unit) and integrator will integrate this value every step.
Result after few hours is clear. Integrator will be on limit and not
allow motor movement when you change wanted_temp.
Valve changes < (pid_hysteresis/265) is ignored (noise protection)
(default pid_hysteresis is 120)
At this moment I thing that this limit conditions is too hard.
----------------------------------------------------------------
@Jörg Becker:
Is: is integrated value
ffbc mean -68 decadic. If you increase I_Factor, valve must be closted,
see up to formula. Small changes of I_Factor needn't change of valve
because it's smaller than (pid_hysteresis/265) Try calculate formula
from up.
----------------------------------------------------------------
What I can do? (and probably will do):
- I can change comparation in "i" change consequences from ">" to ">="
(and vice versa) After this it will be more sensitive to hijacking of
integrator.
- Itegrator can be reset after every change of wanted_temp. It is usual
in numeric PID controllers. But after this change temperature
stabilization take more time. It can be improved with default "zero
error" position in EEPROM (current value is hardcoded 50% - see to
formula, new default value can be around 55%) (@Karim L. > it need
change of EEPROM layout)
----------------------------------------------------------------
PS: If this explanation is not clear don't worry ask me.
Jiri
I forget in "What I can do?" part: (update)
- I can change comparation in "i" change consequences from ">" to ">="
(and vice versa) After this it will be more sensitive to hijacking of
integrator when valve is fully closed or open. And it will better to
repair temperature offset. It can be abble repair hijack, but it take
long time.
- Itegrator can be reset after every change of wanted_temp. It is usual
in numeric PID controllers. But after this change temperature
stabilization can take more time. It can be improved with default "zero
error" position in EEPROM (current value is hardcoded 50% - see to
formula, new default value can be around 55%) (@Karim L. > it need
change of EEPROM layout)
Reset interator will solve part of hijacking problem. After this
"hijacking" is possible only for constant wanted_temp without any
changes in long time when valve is fully closed or open. I don't have
any idea to solve this. Motor calibration on Saturday 10:00AM will
cancel this hijack, but it can be too late in some situations.
Hi Jiri,
I will take a closer look at it at the weekend.
Don't worry about eeprom layout change. I do only have to copy the new
Layout into my code, the rest is don't automatically per reflection
mechanism. The only disadvantages are, I have to release a new version
and that stored eeprom data in a file can't be used without problems.
Maybe I add a feature to load the eeprom structure from a file to have
more flexibility for different versions.
If not already implemented, you could add a hysteresis, which allows
lets say 0,2°C deviation before trying to regulate, to reduce motor
movements.
And the Is value should be limited for keeping the contoller responsive
even if it is what you call hijacked.
During the day (from 7:20 on), the wanted temp is set to 15,5°C, but my
living room is always warmer, because of good isolation, solar radation
and heat comming through the wall and floor of my neighbors ;-). The
temp during the day can go up even in cold winter day to 21°C without
having heater on. But in the evening it is getting colder, but most of
the days not below 16°C when heater keeps off. Thats to cold for me.
Therefor I programmed my controller to heat up to 17,5°C at 17:30 till
midnight which results in about 19-20°C where I sit.
Under this conditions the integrator will sum up to the rangellimit when
wanted temp is 15,5 during the day and after midnight.
So far that to the conditions I have.
@Karim L.
I was try to add hysteresis which allows deviation before trying to
regulate. But is was unstable solution. System was overregulated for any
constant setting. (I can't remember if I commit this try or not, but I
was try it)
I will try to use same "hysteresis" but only for integrator update
condition. Do you remember to ">" or ">=" in my text from 2009-02-27
10:35? We can use ">" around wanted temperature +- tolerance and ">=" or
none condition outsite tolerance. I would be better.
Is value is already limited to (256*50/I_Factor). This mean that maximum
effect is +-50% on valve. I can move this setting to EEPROM, but I don't
belive that it is major problem.
PS: You have perfect conditions to "hijack" integrator. Well isolated
room, where is external source of heat. And lower wanted temperature
than natural in long time.
Jiri
"ffbc mean -68 decadic. If you increase I_Factor, valve must be closted,
see up to formula."
I see from the formula that this is the way it works, but does this make
any sense? As you wrote, a negativ value means that the real temperature
is lower than the wanted temperature. In this case Is becomes more and
more negativ with time and the valve closes more and more. This is not
really the desired effect. Is this a bug in the formula or a
misinterpretation from my side?
BR,
Jörg.
@Jörg Becker
I thing that is correct:
ff03 is -253
ff3a is -198
ff78 is -136
ffbc is -68
Negative values can be calculated by (dec(value)-dec(0x10000))
Jiri
Jiri,
i know about representation of negative values. The problem is that your
description in the mail from 10:35 is not 100% correct and is not the
same as in the program code and that mislead me.
you wrote "e = error = current_temp - wanted_temp"
and that means that e is negative if the set value is higher than the
real value.
Together with the term "Is+=e" this would mean that in my example the
negative value of Is should get more and more negative, what it
obviously does not do!
In the program code we find that:
" error16 = setPoint - processValue;"
which has opposite sign than e
and
" sumError += error16;"
which leads to the correct behavior that Is gets more and more positive
over time if the real value is lower than the set value. So the code is
correct.
The only problem is, as you explained, that you only change Is if the
temperature value changes. So, in my example, if I only had waited some
minutes longer and the temperature would have changed just a bit, Is
would have become positive and the valve would have opened.
Thanks for your help to understand the code a bit better!
BR,
Jörg.
@Jörg Becker:
OPPS!
I was make mistake in my test. You are right. Correct error formula is
e = error = wanted_temp - current_temp
Jiri
Hello
How can i resive the data from termotronic?
@Thomas:
Thermotronic version of SW don't support serial communication due to
hardware limitation. Serial line pin is used for another function.
You can have two choices:
- wireless comunication - rfm12 - now exist on pre-alpha state, it is
not prepared for end user, wait aprox 1 month
- prepare another type of communication or simulate serial line on SW
(not exist now)
Jiri
@jdobry
Ok when i buy the rfm12 and connect it, what must i do on the receiver
site?
Have you an Link?
Thanks for all :)
@Thomas:
On receiver side you need another rfm12 and simple board with ATMEGA16.
Sorry but I don't have better documentation than text specification in
SVN now.
Jiri
OK special thx :)
Rev203 have improved integrator consequences. It can be less sensitive
to ingegrator "hijack". Please test it.
***********************************************************
It is no fully tested now, last stested version is Rev 192.
***********************************************************
Hi Jiri,
I tried the new version with temp-tolerance set to 0.3°C and it works
really nice for me. No big permanent deviations any more, that's good.
Congrats!
I still have problems with my very small toilet room with oversized
radiator. The temperature overshoots very much. One thing that helps is
to decrease the PID interval (I have set it to 1 minute now). But I have
no logging data, so I am still very uncertain about the effect.
After playing around with the various versions for some time now, I have
one remark (not complaining, just asking for your opinion :-) ):
- After a reset (e.g. battery exchange) I have to 'type in' the whole
date and time setting starting from the default value (01.01.2009). I
would like it much more if at least the year, the month and the day
would be stored to eeprom on every change (even for the day that means
just 365 write accesses per year and the time and Ah needed are
negligible). I have done this on a project where I want to be sure that
after an erroneous reset (spikes, ESD) the system still has a date/time
that is at least nearly ok. I also store the last hour value to eeprom
and have the minute and second value uninitialized at startup (I just
test if the value is reasonable, means in 0..60), so that in most cases
I only loose some seconds.
BR,
Jörg.
@Jörg Becker:
Toilet room: without log I can tell nothing. But log from this extreme
situation can be helpful.
Date in EEPROM: nice idea, you can me send patch. For me it is not
significant, because I am use date/time setting from wireless network
(rfm12). But it can be useful for others.
PS: I haven't erroneous reset. Do you use batteries or external power?
Jiri
I am just going through the RTC routines:
bool RTC_IsLastSunday(void)
{
if (RTC_DOW == 7){ // sunday ?
return 0; // not sunday
}
....
shouldn't that be:
bool RTC_IsLastSunday(void)
{
if (RTC_DOW != 7){ // sunday ?
return 0; // not sunday
}
....
Regarding your question:
No, I did not experience resets with this project except during battery
exchange.
BR,
Jörg.
@Jorg:
OPPS! Thanks for bugfix. You are right, it is bug.
Jiri
Just for your info, this is my (very simple) routine for RTC from one of
my other projects:
void RTC_add_one_second(void)
{
static const uint8_t days_per_month[12] = \
{31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if (++sec>59)
{
sec = 0;
if (++min>59)
{
min = 0;
if (++hour>23)
{
hour = 0;
// recognize leap year (correct until 2099!!!)
if (((year&0x03)==0) && (month==2)) // if year can be divided by 4
{
days = 29; // it's a leap year with 29 days in Febr.
}
else
{
days = days_per_month[month-1];
}
if (++day>days)
{
day = 1;
if (++month>12)
{
month = 1;
year++;
EEPROMwriteB(13, year);
}
EEPROMwriteB(12, month);
}
EEPROMwriteB(11, day);
}
EEPROMwriteB(10, hour);
}
}
}
BR,
Jörg.
@Jorg:
I know that current implementation isn't optimal. This was not my code
and abble to see many point to optimize (some function can be "static"
and more). But I has many more significant tasks.
RTC_IsLastSunday bug was fixed in Rev 207
thx: Jörg Becker
Jiri
Hello,
Schematic for RFM12 "master" board communication can be found here in
SVN:...
First alpha version of wireless comunication SW can be released very
soon.
If somebody will be create PCB for this, please send me one. Notes: not
all supply pins (5,6,17,18,38,39) must be used. LED can be moved to
another pin than PD7(16) but tell me it. RFM12 DATA pullup PB0(40) can
be moved to another pin or we can use pull-up resistor, but tell me it.
Jiri
Hi Jiri,
it would not be a big problem to do a pcb for the master. But it would
be nice if you could explain what the exact function or way of use of
the master is.
- Is it used as a stand-alone unit? What does it do then and how is the
master itself configured?
- Is it used as a sort of RF gateway for a PC?
- Does it completely override the settings in all the connected HR20s?
- It does not have any inputs (keys, door or window open detection, ...)
at all, no display, (no power supply), no temperature sensor, no RTC
Would be nice to understand that.
BR,
Jörg.
"master" have 2 functions:
- It control wireles network access to shared media (air) and broadcast
real time
- it is gateway for Linux/Windows PC or linux based router (see to)
I will completly control all connected HR20.
It have not any input (it is not needed). It is gateway between serial
line and RFM12.
I have same pinout like HR20, it mean that we can use same programming
cable and same serial level or serial USB convertor. Power supply must
be wired to connector.
SW on PC side have 2 parts: one is small daemon, second is web
interface. Both is in PHP. It can run under Linux or Windows. Including
Linux on small routers. It have amazing benefit for me, this router run
24/7 and need small power (7W). You can control heating from anywhere
24/7 including access from PDA.
Wireless RFM12 modification documentation is available on SVN...
- internal version is inside HR20. It allow to use debbugger. It is more
compact. It is safer for childen etc. But it need expert skill of
soldering. Solder wires "touch" to MLF package is nightmare.
- external version is outside HR20 on system connector. It not need open
HR20, easy to install. But not allow connect debuger to HR20. And it can
be mechanicaly damaged. (thx to Mario)
Jiri
Jiri,
thank you for your explanation of the master functionality.
I want to use the wireless HR20s a bit differently then you. Most of the
time the units shall work independently with their own settings and I
just want to override these settings occasionally, e.g. if I want to
switch off the heating completely or the circulation pump is not
running.....
Then I want to add small wireless nodes that monitor windows and doors
with a small reed contact. This is first just for monitoring and second
to switch on and off the HR20s in the same room where I see an open
window or door (for some minimum time off course).
Next thing I already started is the wireless remote control of most of
the internal and external lights and also some other electronic devices,
all with the same RFM12 receivers (433MHz in my case).
When all this is completed, I also need a gateway between PC and this
wireless network. And then a WEB interface would be nice, too.
These are the plans, I hope to find the time for it.
BR,
Jörg.
PS: Since some weeks I have a very small problem compiling the
'wireless' version of the firmware. If I double-click the .aps file, I
get a message about missing files and I see that the file path of these
files is 'C:\jirik\hr20\rfmsrc\...'. Am I doing something wrong with the
SVN update? I know that I can simply 'locate' these files on my HR20
folder, but every time I update I have to do it again.
@Jorg:
Don't worry about missing file.
.aps file is not used for compilation, just for debug and edit (I use
Kate and PSpad for edit). Compilation use Makefile.
Jiri
Information about RFM12 SW:
It is still incomplete and it is not prepared to use.
I hope that first "Alpha" version will be prepared around 20.3.
If you will want to use it, it is right time to buy/prepare HW. I will
need testers ;-)
Jiri
Apologies if this is in the wrong forum, but I would like to load up the
software to my HR20.
What is the easiest way to connect to pc? and what are the details of
each of the pins which I must connect to RS232? thanks
@Bronco:
To load up the software you need a Programmer that supports JTAG, e.g.
AVR Dragon:...
The details of the pins are described in the documentation.
Great. I will look up JTAG. I presume then I will need a JTAG to Rs232
if I want to communicate from pc to rondostat?
The software is not downloadable from sourceforgenet. Has the project
been moved elsewhere?
thanks.
Project is not moved. But we not release any final version. You must
download it from SVN.
Hi Jiri and all the other HR20 users,
I have just recognized a strange problem with on of my HR20s with one of
the latest firmware versions.
After mounting the HR20 and after the calibration run, I found that the
valve opened at a readout value of about 41% valve position. I then
corrected the minimum valve position to 38%. After a week or so I found
that the temperature in the room was always to high and the valve
already at its minimum position of 38. I could hear that the valve was
still open. I therefor corrected the minimum valve position to 30%
(default value) again. Yesterday evening I found that the valve was
again wide open (24°C in the room) although the valve was at 30%
position. After a calibration run the minimum position where the valve
opened was again ~41%.
(Strange thing is that this behavior is very similar to what I
experienced with my very old HR20s from time to time.)
Is there any chance that the controller misses pulses from the postion
encoder? Did anyone else experience the same problems? Is this perhaps
hardware dependent?
BR,
Jörg.
@Jörg Becker:
Have you log file? I could be more than one reason.
- you have some "noise" on impulse conter input and current noise filter
fail (create log file it is helpful)
- it is +-1 problem on ends. It can count false +1 on motor start or not
count first pulse on movement. On worst situation after 100 movements
you will have 100 impulses error on position but it is not probbaly (win
in lotery it absolute sure compare to this :-) ).
I would like to found where is bug. Because it can be problem on code.
Can you create log (calibration + minimum 20 movements)
Because we can't mesasure position without any error (motor start can
create false pulse very easy), valve use automatic calibration on Sun
10:00AM.
To break this problem, current SW don't stop motor inmediately after
wanted pulses but it will stop motor with delay. Idea was stop motor
ouside problematic position around motor pulse edge. You can tune this
value (config.motor_eye_noise_protect, position 0x15 on trunk), default
value is 40% of motor pulse cycle.
Jiri
ok. got the avr dragon.
could someone guide me on the steps to connect to the HR20?
I assume
a) connect JTAG cable from AVR Dragon to HR20
b) use AVR Studio (not sure how)
c) load up hex file from svn repository to flash HR20
could someone help me with some details:
a) do I need to set some JTAG pins?
b) If I want to communicate with HR20 without flashing to getState is
this possible? or do I need to flash (basically I am scared of flashing
until I know exactly what I am doing).
regards
@Jörg Becker:
I saw the same situation, but I thought, that was my fault, because I
played with the sources and sent the log/debug messages every second. So
I thought because of this the motor loose steps.
Unfortunately I don´t have any logs, because everything was fine until
after a new calibration...
Ronny
PS: Has anyone also my (strange) situation:
I have long-distance heating, but without a heat exchanger in my house
- only a valve, that closes the whole system (every heater in every
room), if the temperatur of the recirculation water is too high. That
means, if one heater (in my case in the bath-room) produces too high
temperature in the recirculation tube, the valve closes and also the
heater in the the living room gets cold. I cannot change this behavior,
because we rented this flat.
So I tried the following: I putted a second temperatur sensor to the
HR20 and tried to control the recirculation temperatur of any heater
independently.
Has anybody suggestions how/where this can be done? My idea: decrease at
the end of the function CTL_update the valve value proportional to the
recirculation temperatur. the various subroutines.
Ulf of the various subroutines.
Ulf
Most probaly is that SW not count one pulse add one false pulse when
motor stop and run back later. WE NEED LOG FILE. A am not able replay
this situation now.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!
!WARNING! Do not use "On" setting but some temperature only. It will
pull valve position to physical limit every second
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!
It will be fixed very soon.
Touched Revisions on main trunk is 175-221
Update to Rev 222 is RECOMENDED.
It was fix problem with "On" setting.
PS: Motor position measure will be improved later
Hello,
@Jiri Dobry
here are a logfile about the loss of pulses problem. I measured it from
22nd march at 00:00 till 23rd of march ~21:00. The valve was calibrated
at the beginning of the measure. Now the log says 5% valve position, but
the service menu (pressing 2 times -C-) says 10%.
The environment: a small bathroom with a big heater and a strong spring
in the valve (means: if I pull the head from the valve the valve opens
itself - I have other valves in my flat, where the valve stays at the
momentary position, if I remove the head). I have very agressive
settings at this valve: update every 1,5 minutes and a small differenz
between wanted/actual temperature.
hope this helps to find the problem
Ronny
what I forgot:
this is release 198
Ronny
Thanks for LOG file to everybody.
At this moment I have new valve position measurement. It works, but need
some cleanups. It will be prepared for SVN tomorrow (I hope).
@Ronny: Can you send me your valve range? You can get it by command
"T08" and absolute valve position (command "T09").
Valve position on log is what you want to have (can't be change live on
motor movements), valve position on LCD is calculated from absolute
position and show live position. It use near to same equation, but 16bit
fixed point aritmetic have some +-1 error. It is strange, that diffence
between this two values is bigger than 1.
Jiri
Hello,
You can test latest method to count motor pulses. Any LOGs will be
Revision with change is 225. This version is not tested on all
conditions.
If you want stable version on this moment, please use Rev222.
Jiri
EDIT: new pulses calculation - minor bug fix in Rev225
Hello Jiri,
at first: thanks for your incredible work at this project!
I´m not so familiar with microcontroller programming and it´s hard to
understand for me what you did in the program - but I´m learning... And
so I have to show respect to your work.
Unfortunately I had to recalibrate my bathroom HR20 before I read your
posting, so that the error isnt there now. I made a T08 and got
T[08]=01dc and for T[09]=00e5.
A log line is now
D: d2 24.03.09 20:25:04 A V: 48 I: 2349 S: 2400 B: 3052 Is: 10aa
and the valve position is identical in the service menu. Maybe I have to
wait until the error occurs again, for my experience this will be in 2
days. Therefore I didn´t flashed your new version, because another
hidden problem could be there
Ronny
Hello,
here is the problem on Version 198 again:
Log-File says 5% valve position and service menu says 10%!
D: d3 25.03.09 22:43:21 A V: 05 I: 2525 S: 2500 B: 3047 Is: ef56 X
T[08]=01f0
T[09]=0033
D: d3 25.03.09 22:44:00 A V: 05 I: 2585 S: 2500 B: 3044 Is: ef56
D: d3 25.03.09 22:45:20 A V: 05 I: 2548 S: 2500 B: 3048 Is: ef56
Ronny
@Ronny:
Strange. T08 and T09 values look correct for 10% (10.28%).
Can you update SW to rev 225? I will look to this problem later. Do you
change some values in EEPROM?
Jiri
Hello Jiri,
I will update to 225 now.
I changed the following eeprom-value:
/* 08 */ temp_tolerance; to 50h
/* 09 */ PID_interval; //!< PID_interval*5 to 10h
/* 0a */ valve_min; // valve position limiter min ;to 30h
/* 0c */ valve_max; // valve position limiter max; to 3ch
and s:ome strange settings - I cannot remember, that I changed this
values
/* 0d */ motor_pwm_min; //!< min PWM for motor; to fah
/* 0e */ motor_pwm_max; //!< max PWM for motor; to 1e
Ronny
I would like to inform you, that wireles communication works.
Rev 227 is ALPHA version
()
Some notes:
- PHP&sqlite is needed
- It can run on PC or Linux based routers (for 24/7 access, low powered
devices see to OpenWRT project)
- linux instalation is without problem. Windows users must use
"Serproxy" and connect daemon.php to localhost TCP port.
- daemon.php come from communication test code. It is buggy and
sometimes lost some request. User must make another request. I will not
fix it but I will create complete new daemon.
- It is need to setup serial port to 38400/8/1 (linux machines have
"start" file)
PS: it need to write HowTo setup document. (volunteer?)
Jiri
PS: When somebody will create PCB for wireles "master", please send me
one. Thanks.
My current master is nest of wires.
Jiri
Window open function looks buggy. See to my log. It have false "close"
detection. I will try it improve. PS: table is from wireless extension,
it is nice to monitor all valves near to real time. See to attachment
addr time mode valve real wanted battery error window force
17 2009-03-28 09:45:15 - 30 15.03 4.5 2.668 0 0 0
17 2009-03-28 09:44:55 - 30 14.78 4.5 2.663 0 0 0
17 2009-03-28 09:42:53 - 30 14.7 4.5 2.667 0 1 0
17 2009-03-28 09:41:15 - 30 15.13 4.5 2.663 0 0 0
17 2009-03-28 09:40:02 - 30 15.29 4.5 2.662 0 0 0
17 2009-03-28 09:37:14 - 30 15.44 4.5 2.661 0 1 0
17 2009-03-28 09:36:11 - 30 15.7 4.5 2.668 0 1 0
17 2009-03-28 09:33:14 - 30 16.29 4.5 2.668 0 0 0
17 2009-03-28 09:31:23 - 30 16.54 4.5 2.662 0 0 0
17 2009-03-28 09:30:15 - 30 16.5 4.5 2.668 0 1 0
17 2009-03-28 09:29:14 - 30 16.8 4.5 2.668 0 0 0
17 2009-03-28 09:25:34 - 30 16.99 4.5 2.662 0 0 0
17 2009-03-28 09:25:14 - 30 16.92 4.5 2.663 0 1 0
17 2009-03-28 09:24:17 - 30 17.13 4.5 2.669 0 1 0
17 2009-03-28 09:21:22 - 30 17.47 4.5 2.666 0 0 0
17 2009-03-28 09:21:15 - 30 17.43 4.5 2.666 0 1 0
17 2009-03-28 09:19:44 - 30 17.54 4.5 2.668 0 1 0
17 2009-03-28 09:17:15 - 30 17.97 4.5 2.663 0 0 0
17 2009-03-28 09:16:36 AUTO 45 17.77 17 2.667 0 0 0
17 2009-03-28 09:15:47 AUTO 30 17.6 17 2.669 0 1 0
Wireless aplication screenshot
Wireless aplication screenshot (false window close detection problem)
Wireless aplication screenshot #3 (timers)
Hello jiri,
your last inputs are very interesting. I think i have to upgrade to a
wireless version now....
I use at the moment Rev. 192 and since 3-4 days i have problems with the
time, each day the time changes with one additional hour (issue with
sommertime ?? the actual time is e.g. 10:00 but HR20 shows 11:00 ,next
day 12:00 and so on).
regards
reinis
@reinis: it look like bad XTAL. I have 6x HR20 and usual precision is
better than +-2sec/day except one (8 sec/day).
But with wireless extension it is not problem it is syncronized from
master. And master can be syncronized from internet.
@jiri, regarding the 1 hour timeshift, i think it has something to do
with the follwing function:
void RTC_AddOneSecond (void)
Add one second to clock variables
Note:
* calculate overflows, regarding leapyear, etc.
* process daylight saving
o last sunday in march 1:59:59 -> 3:00:00
o last sunday in october 2:59:59 -> 2:00:00
ONLY ONE TIME -> set FLAG RTC_DS
reset FLAG RTC_DS on November 1st
over a longer time/several weeks the time was always correct on all of
my hr20. The problem started only last week and on all of the three
hr20. I resetted the time on the next day i had again a 1 hour offset
but only until today (summertime change). This morning the 1 hour
timeshift was not there anymore and i did a manual set to summertime
(daylight saving).
regards
reinis
reinis,
before Rev207 there was a bug in the daylight saving routine (see our
postings on 2009-03-04). As you are using Rev192, it is very likely that
you hit that problem.
BR,
Jörg.
@Jorg & reinis: Jorg have true. This bug was fixed and I was not abble
to see that you are use too old version before bugfix.
Wireles extension: New Rev 228 with graphs. I was not abble to find any
library for lightweight XY grapg. All was too havy for embeded router.
Therefore I was create one oprimized for this project. I will improve
look&feel but you can see result from Rev 228 on attachment.
Hi Jiri,
regarding the wireless version (Rev207), I have some questions:
- when I compile it, I get
Program: 16478 bytes (100.6% Full)
is this ok?
- how does the HR20 with this version behave, if I do not have a master
running? Does it use its individual settings then? Does it send the 4
minute reports wireless instead of via RS232?
BR,
Jörg.
PS: I quite regularly (but not always!) see that the temperature reading
changes by some degrees (1.5 to 2?)while the motor is running (all
firmware revisions). Is there any explanation for this? Can this cause
any trouble? I am asking because yesterday morning the bathroom was cold
and the display showing 'OPen' without any cause. Nobody had opened the
window nor the door and half an hour earlier the temperature had been
ok. I have never managed to get this response ('Open') by really opening
the window (not even with the original firmware). In most cases when I
tried this (open window), the temperature did not fall fast enough. So
it is even more strange what I saw yesterday.
@Jörg:
Please use recomended compiler WinAVR-20071221 or disable something on
debug.h
Q: how does the HR20 with this version behave, if I do not have a master
running?
A: you can use RS232 connection in same way as before this modification.
But if you use only wireless and master not runnig, software will save 4
minutes report to buffer, after buffer overload (it is small for maximum
7 reports) data will be lost.
Q: Does it use its individual settings then?
A: yes, setting is individual for each valve. But you can manualy change
AUTO/MANU mode or wanted temperature easily from one page.
Q: Does it send the 4 minute reports wireless instead of via RS232?
A: yes, you can see example on screenshots
Jiri
Jorg: Temperature reading during motor run: You are right, motor measure
too big noise for exact measure. We will must change it.
But till now I was not have any accident from this, because we are use
15 second average for temperature controler. But window open detector
have noise filter only from 5 values. You can try change this filter
setting it is config.window_open_noise_filter setting (0x23
configuration).
But I wrote request to disable measure during motor run into TODO list.
Jiri
Jiri,
first of all, I saw your graph from Rev228. This is very nice!
- Regarding the wireless version, I want to have reports via RFM12
without using a master, e.g. for logging. Means that the HR20 works
exactly as with the normal version but with wireless reports instead of
RS232. Have to find out how this works.
The other question was whether the wireless version will use its own
(stored in the HR20!) settings, if the master fails working (or is not
present at all). I understand that if the master is running, it takes
full control.
- Regarding the temperature measurement, I do not understand why the ADC
buffer is 60 entries long and only 15 are used for the average (compile
time options, not changeable during runtime). Does this make any sense?
BR,
Jörg.
PS: I still have a lot of questions concerning the code and
unfortunately not enough time to go through it and understand it in
detail. I am just busy working on my remote switches with RFM12. Got
first PCBs and will try getting these to work during the next time.
Jorg: you are not abble use current wireless code without master. Simply
before master syncronize communication an without master you are not
abble use encryption. But I thing that master is extremely simple and
cheap. If master fail, you are not abble communicate. Current code don't
support communication between two valves (and we have not free flash).
And mainly: "master" is interface between computer and valve wireless
network. How you want to control this network without this interface?
60 measured items on table is used for window open detection. We need to
compare current value and 1 minute old value.
For clarification. CurrentSW can be modified to direct communication
between valves or between remote thermometer to valve. But it still need
"master" for manage network and encryption.
For direct communication without valve you need some caint of "MESH"
network. It is possible if you disable some existing part of SW to save
flash space (for example rs232 com). But it is more complicate than
current communication. It need complete new protocol, complete different
SW layer. And volume of work for RFM12 is sufficient university
dissertation for few peoples (it is not only few lines of code). Another
chance is buy some existing solution (and use another more expensive
wireless modules).
New improvements for 1.00 version are in rev 229:
- configuration for disable/enable ADC measure when motor run
- bug fix for false positive window close detection
Jiri
I have until now the problem with loss of steps (original version 225).
I think that because of the strong spring in the valve the real valve
position shifts a little bit every time the valve is closed.
So I want to correct these "shift values" by a "partial" calibration to
save battery.
That means: I want to correct the actual valve position only by driving
the valve to the real open position (until the motor stops).
Has somebody a hint for me?
Ronny
PS: I have solved my problem of the recirculation temperature (see Post
on: 2009-03-17 13:38)
at the beginning of CTL_update I save lastProcessValue and sumError.
After calling of pid_Controller I compare the recirculation temperature
with a value stored in eeprom. If the temperature is too high (with
hysteresis) , I close the valve and restore lastProcessValue and
sumError from the saved values. This works for me in a reasonable way...
But the problem of loosing steps exists also with the original software
from the SVN.
@rhb: It is unbelivable for me, that Rev 225 can lost some motor steps.
Absolutly strange.
You don't want to use "partial" calibration, you can use current manual
calibration mode. (Unmount head from valve, manualy close valve, this
position will be saved as "close", press "C" and mount head to valve
back - keep "C" pressed during this operation) After this calibration
proccess on LCD will not show "Ad 1" etc but "A 1" etc. Motor
recalibration will only touch to "open end" and go back to wanted
position because know "closed position" - saved in EEPROM.
Recalibration is done automaticaly every Sunday on 10:00, you can change
it on main.c
Return to automatic mode is same, butt preess and hold "PROG" button not
"C".
PS: I trust you this problem but I can imagine where is problem, it need
LONG log file from Rev 225 or up.
PSS: how you measure second temperature?
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
All: we still have problem with window open close detection. After last
change it is better, but it can be false positive or negative again. I
will completly rewrite this part later this week, I have idea how.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Hello Jiri,
my "partial calibration" was only a thought for a workaround to
automatically correct the actual position. I saw the part of the
program, were the full recalibration is done on sunday 10am, but I
wanted to save battery power...
(Thank you for the explanation of the manual calibration, I didn´t
figured out this from the source code - as I said, I´m learning)
My theory is, that the the motor doesn´t lose steps, but because of the
strong spring in the valve the motor is turned back a little bit AFTER
it (and the "photo eye") was switched off and so the actual position is
distorted. So maybe it would help to deactivate the "photo eye" a little
bit later - what do you think?
I started a new log today with original version 229, what do you mean
with LONG time? 1,2 or more days? Or until the valve isn´t closed? Now
this will takes longer because of the warm weather and mainly closed
valve...
Ronny
PS: I measure in my "recirculation temp version" the second temperature
by adding a second thermistor to pin 60 (ADC1) of the ATMEGA and GND (I
don´t need the wireless part) and a resistor between pin 60 and pin 58.
I know, that I decrease the precision of the measurement of the room
temperature with this modification.
@rhb: manual calibration is almost equal to "partial calibration" as you
want. Because range of valve is defined, every calibration in this mode
is simple (go to "open end" and it's done)
@Jiri
here are the long log. At this evening the error happens again. The
valve seems closed (30%), but the heater is warm.
At the beginning (after the calibration) the valve is real closed at 40%
and now the valve is a little bit open at 30%.
The log was made with original version 229. I changed only the
pid-interval to 120 seconds.
Ronny
Due to problems with window detection I made completly new window open
detection.
You can test in Rev 232
Configuration options:
/* 22 */ uint8_t window_open_detection_diff; //!< threshold for window open detection unit is 0.1C
/* 23 */ uint8_t window_close_detection_diff; //!< threshold for window close detection unit is 0.1C
/* 24 */ uint8_t window_open_detection_time;
/* 25 */ uint8_t window_close_detection_time;
How it works:
Program save temperature AVG every 15 seconds. For window open
detection, program compare current actual value with higest value in
selected interval.
Interval is in 15sec unit in window_close_detection_time and detection
threshold value is in window_close_detection_diff.
Window open detection is similar.
Default values is 0,5degC difference on 2 minutes interval. Maybe that
we will need change it.
Jiri
PS to @rhb: thanks for log, I will analyze it today or tommorow.
@rhb: Strange, your log looks perfect. No problem. Where is your
position where valve start opening? (normaly after restart)
On start or end of movement you can found x/X and y/Y chars. This is
signalization where motor stop (logical level). It must be "x" and "y"
every time because we want to stop on low level. When motor move
sometimes during eye is off, sometimes we will see "Y" after x. But it
never happen. (except calibration, but it is due to HW movement limit)
Rev 234 contain paranoid filter for temperature measure (noise
cancelation)
You can try it
Jiri
Hello Jiri,
I think, that I have a log with the error. At this evening the valve was
open at 30% (after calibration it is closed at 40%, so the error is
greater than 10). I set the eeprom valve_max to 90 and then I set the
wanted temperature to 30° (see 06.04.09 20:12:38). The valve wants to
open to 90%, but at nearly 86% the valve blocked and the scale jumps
from 86 to 100% and went then to 90%.
Ronny
@hrb:
- I am surprised, you are realy losing pulses. But it is not on log.
- Jump from 86->100 is correct and I wrote this behavior into SW. In
this situation calculated position is 86%, but valve stop on hard break.
This hard break must be 100% by definition, therefore SW fix current
position to 100% and will continue go to wanted position 90%. This is
partial recalibration initiated by error detection.
Main question is WHY you losing pulses? Have you only one HR20? Can you
try mount this HR20 into another valve?
I have 5x HR20 with my SW byt never see situation like this. Strange.
Problem is that your log looks perfect. Any pulse during motor run can't
be lost becasuse in this condition we can see in log longer time for one
pulse. (second column is time for one pulse) and it looks perfectly
stable without glitches.
Only one idea is, that your valve is too strong and it is abble change
position when motor is stopped. Probably after opening. But in this case
we will see sometimes "X" after "y" but it newer happen in your log.
Strange, strange, strange.
Jiri
Wireless extension: Have somebody "master" hardware already? I would
like ask, before I will change used MCU from ATMEGA16 to ATMEGA32.
Reason is RAM size needed for buffers. If somebody have deprecated
hardware with ATMEGA16, please tell me it !!!NOW!!! (if it is not
possible replace MCU in socket)
Jiri
Hello Jiri,
sorry for the delay, but I tried a second (different) HR20 on the
bathroom valve. But for the warm weather it tooks a little bit longer,
because the valve was closed most of the time. But now I saw the same
situation: I set the max position to 90% - the valve wants to set to 88%
and came to the hard break and jumps to 100 - see the log. I have the
same theory as you: the valve (or the valve spring) is too strong and
can change the position, if the motor is stopped, maybe only a few
seconds after the motor stops. Do you have an idea how this can be
solved?
Ronny
rhb: I have idea to keep motor eye enabled few secons after motor stop.
But it will be done after few weeks, today I have more urgent tasks.
Jiri
Hi,
the RF-Modul sends at 433 MHz and you need a master to controll the
units?
Maybe the "Betty Remote" can be used to control the single units (or
all).
It has a cc1100 included.
Take a loot at (german only):
Greets
torrz
I am using 868Mhz modules but it is easy use same modules but for 433.
Problem can be that current SW realy need "master" board. Current
communication protocol is simple and not support some "MESH"
functionlity.
!But! it is open project and your idea with "betty remote" is nice.
Everybody can modify it to this way, but it is lot of work.
Jiri
Hello,
first a big respect to all members in this forum which do a great job to
developing the new firmware.
I was looking for an alternative and found a way to control my HR20 by
my iPhone.
Here a brief description:
I use a master (ATiny2313) and a slave (ATiny2313) which communicate per
radio (RFM12 modules) bidirectional.
The HR20 is connected to the slave and the iPhone communicates via the
master with the HR20. To set the temperature on the HR20 the uC (slave)
is connected parallel to the encoder-pins of the HR20. To display the
set and the current temperature the uC (slave) receives the information
via the HR20-RS232-connector. Then the slave transmits the values to the
master and then to the iPhone.
For a better understanding watch:
Youtube-Video "How to control a HR20 thermostat per iPhone"
It's only the first experimental step and the development is going on
(pcb layout, control more then one HR20 and so on). But it works.
Many greetings,
puchti
@puchti100:
I thing that control with WEB interface is more comfortable. Please find
snapshots in this thread (example). It also works on iPhone,
I was test it. It need any PC or embeded linux based router (it is cheap
and power efficient)
But you can create complete another solution, it is your choice and your
time.
Alternate SW you can drive directly via serial line; you don't need
connect wires to encoder (It can work only on one encoder position as
you know)
PS: How you connect "master" (ATiny2313) and iPhone?
Jiri
At my home I've been controling all my audio and video equipments and
also lights per iPhone since one year. I use the iPhone app "CF iViewer"
and the controller of the manufacturer Crestron. It could also be a
PC-application, web interface or a Touchpanel-PC.
In the past I had the wish to integrate the HR20 into "my system".
That's why I looked for a way to do this.
I added a schematic to show how the communication works.
puchti100
sorry! here the schematic...
sorry again... to fast...
here the correct schematic (copy-and-paste mistake in the HR20-symbol)
@puchti100:
nice, it is solution.
I have few technical notes:
- RFM12 can be connected directly to valve but it will need modification
to your wireless protocol
- be careful if you use battery power, wireles communication is hungry
- alternate SW have public protocol on RS232, you can drive it direcly
without connection to encoder.
good evening everyone,
Can someone please tell me where a user can find generic celebrex online
without a prescription? I've been referred to but I'm unsure how to determine whether
their site is trustworthy.
Hi,
I have connected the rondostat to avrisp, via JTAG cable.
I am trying to use AVR Studio.
Which Amtel chip does the rondostat have? How can I check?
thanks
Chip is ATmega169P. Programmer can read and check chip signature without
programming.
I'm about to buy some HR20s to join this very interesting HR20
development. However, I got a few questions.
1) there is HR20E and HR20N. The HR20N seems cheaper. What's the
difference? Are they both ok for OpenHR20?
2) are there different versions of HR20? are they all ok for OpenHR20?
(like the Linksys WRT54G with a lot hardware difference for different
versions)
3) I plan to add a Zigbee tranceiver. Has anyone already done this? The
PCB size is about 20mm x 30mm x 3mm. Is there such room inside the
valve?
Many thanks
David
Hi,
This thread seems a bit quiet recently, maybe, because the weather is
still warm and there is not much need for heating.
Anyway, after a few days research, I plan to do the following based on
the current code/design;
- Add a different wireless transceiver (client). It is going to be an
A7105 based transceiver. The reason for different transceiver is that it
works at 2.4G and hence smaller antenna and faster data rate. Also, it
takes 3 wire SPI instead of 4. So I can use the PE2 (Sorry about the PIR
idea. But I think it can go with another A7105 transceiver.), RXD and
TXD. They are a lot easier to solder.
- Build a, maybe too ambitious, server. The server will have,
1. Graphic LCD 128x64;
2. A keypad and dial;
3. AVR MCU; (can be ARM but I do not want to involve another different
tool chain)
4. Two A7105 tranceivers: one for normal using; one for alternative
channel when there is jam;
5. One Blutooth module with the RS232 profile, which can be used to
connect a PC;
6. It's going to be powered from main through an adaptor.
- Build a boilder switch (another client). This switch has an A7105
transceiver and a simple AVR. It is going to be powered by batteries
only.
Each client will have to register with the server. The server Assign a
key and a device ID to the client. The A7105 can help to filter the
device ID. However, the communication packet will be encrypted with the
key.
Periodically the client will connect to the server to post its own
status and check out command. The detail of the protocol has not been
decided yet.
If a client, after certain retries, can not connect to the server, it
will switch to the alternative channel.
Time for bed now. I'll post more later.
David
@davidfat:
2.4GHz is not good idea for this. Many building have steel/concrete
parts and this building have BIG problem with wifi from room to room
communication. It is same wavelength. Except this, in city center I can
found over 50 wifi networks and it make communication near to
impossible, noise is too big.
Data speed is not critical, battery life is bigger broblem. Antena
length is not problem on 868MHz (RFM12 modules, antena fits inside valve
I will post photos), and wavelength is better for comunication throw
walls.
For "server" I has another goal. For me is not critical direct
connection to computer, but connection to internet. It can be maintained
remotely. Therefore I was use minimal AVR based protocol translator and
mips/linux based small router.
But stand alone server is significat for many others people, I hope that
@Others:
I have some small changes in code on todo list, It come from real
usage.
- battery warning or error will be one way. When battery is on end of
life and not on drain it measure too opimistic values.
- less communication. Enable slave receivers twice every minute for few
miliseconds is too expensive (battery life). Current plan: communicate
on changes or every 2(4) minutes or twice every minute if user activity
is detected.
- improvements on WWW interface.
@jdobry
868MHz has better path loss. However, given similar size, its antenna
may be not as efficient as a 2.4GHz one. I'm interested to see your
antenna inside the HR20.
Higher throughput for a network is still good, at least, a) it takes
less time to transmit, hence saving power; b) the channel is less used,
so better latency.
I also feel the bandwidth can be used in 868MHz is actually just 1MHz
(868MHz~869MHz). When there is interference, there is less space to
maneuver. Although 2.4G band is quite busy, the protocols there can
normally use FHSS or DSSS to make robust link.
One more thing worries me about the RFM12 is that, according to its
datasheet, its lowest working voltage is 2.2V. If the HR20 is powered by
NiMh batteries, the voltage may be blow that when there is still half
capacity left. Have you got chance to test an RFM12 at something like
2.0V?
The server sounds better to be made with a PoE interface, and it'll need
an ARM.
Re the transceiver power consuming. Suppose a short heart-beat packet is
sent from a client to the server every 10 second. The heart-beat packet
consists of 4 byte preamble, 4 byte server ID, 4 byte client ID and 2
byte CRC. The packet is FEC encoded, hence take 7/4 of the raw length.
So it has (4 + 4 + 4 + 2) 8 7/4 = 196bits. Given 250kbps, it takes
0.784ms. The client will also try to receive a wake-up packet from the
server, which is of same size. So roughly the whole procedure will take
about 2ms. A7105 has RX current 16mA and TX 19mA. One heart-beat costs
about 35mAmS. In one day there are 24*3600/10 = 8640 such communication,
and it costs 0.084mAh. A good battery gives ideally 2000mAh, which means
65 years. Let me know if this is possible or I did my calculation wrong.
I don't see RFM12 consumes more power. Why you can't do it twice every
minute?
When there is need to post server any status from the client, the client
will wake up by itself. Or if the server wants to talk to the client, it
sends a wake-up right after the client heart-beat. The client
transceiver goes to sleep after certain time no RF activity.
@davidfat:
You calculation about battery life is bad. Problem is not energy for
send data (it is small). Problem is here:
- internal PLL loop for frequency syntetizer need some time to
stabilization, it is more time than for TX data.
- current for RX is near to same as for TX, and because timing can't be
perfect, you need enable it few ms before packet.
- "heart-beat" packet must be also encrypted. Reason is potential
synchronization poisoning from attacker.
PS: Where is datasheet for A7105?
Jiri
@jiri
At 2.4G the PLL seems to lock faster. According to the datasheet I think
the extra overhead would be about 200us. However, without testing, I
can't confirm. I would say bad programming if you can only get real-time
response in a few ms. It is quite possible to get sub-100us timing
accuracy, or even better with a simple device like AVR, for example, the
heart-beat proceding can totally be done in the ISP. You don't need to
identify someone before he/she can knock at your door. You just need to
do the checking/encryption before letting him/her in.
The datasheet is here...
@david:
- Oscilator start-up overhead is 2mS (page 7 of datasheet)
- timing precision cant be better than 3.9mS Reason is 32768Hz x-tal and
prescaler /128 . If you will use smaller prescaler you will increase
volume of CPU wake-ups and it is not good for bateries. Use internal RC
oscilator for this situations is also possible, but battery hungry.
@jdobry
- Even if it's 2ms, it only lowers the battery life for transceiver from
65years to 32.5 years. Also, the standby state consumes much less power
than TX/RX state. The 2ms is the time from sleep to standby. Interestly,
although in the table it gives 2ms, in the diagram on page 38, it is
0.9ms (from sleep to PLL).
- Absolute timing does not matter. When sending the heart-beat, MCU a)
wakes up at certain time, b) disables all other request (for better
determinstic timing), c) changes to 1MHz or so, d) wakes up the
tranceiver, e) goes to idle/sleep(if possible) for 2ms, f) sets up the
PLL, and idle for 80us, g) triggers the heart-beat sending, (the
heart-beat packet can be stored inside the transceiver, so everytime you
only need to trigger it), h) sleep/idle 0.7ms, i) keeps checking until
TX finish, j) sets transceiver to RX, k) sleep/idle 1ms, l) checks if
any wake up packet received, m) transceiver goes to sleep. I think
that's pretty much the whole heart-beat procedure.
Hi
Build environment?
Just found this project and is very eager to try to build the software
and hack my HR20 thermostats. I have more than 10 in my house.
Unfortunately I'm not very good at German so I have some troubles
understanding the "Heizungssteuerung mit Honeywell HR20" page. Is it
correct that I need WinAVR or "AVR Studio 4" to compile and they are
both Windows only tools?
I am not wery experienced with Windows and have no license so I really
would prefer a Linux based development platform. From the discussion
above I see that some of you prefer *nix as well. Is it possible to
build and download the project on a linux platform?
@Mr_Manor:
AVR Studio is needed only for debugging, not for compilation.
For compilation WinAVR-20071221 compiler is recomended. Reason is that
newest GCC produce significantly longer code and it can be too big into
flash. But it depend to configuration. Linux distributions usualy
contain AVR GCC and avr-libc. You must try it.
Or you can use precompiled HEX from repository.
For programming use avrdude tool.
Jiri
PS: from where are you?
@jdobry
ok, thanks for your answer. I have installed VirtualBox and XP within so
I hope that will enable me to compile. I'm very interested in the
Wireless branch - several years ago I was into hardware so I think I am
able the build the radio into the device. Is the project state as
described on on the wiki page up to date?
I will most likely return with more questions when/if I get a build
environment working ;-)
I'm from Ugerløse,Denmark.
@Mr_Manor:
Information in wiki is not 100% up to date. But information in SVN is
up2date. SVN contain schematics and photos for wireless modification.
And if you want know communication protocols you must read source files,
it contain human readable documentation. Low level wireles layer have
documentation file in SVN (PDF and OpenOffice file).
Many greetings from Czech rep. Jiri
PS: I also use Linux at home, 100% in desktop and 80% in laptop.
Remaining 20% of laptop time is WinVista because linux have not comfort
tools for AVR debug :-(
Hi,
Is it possible to switch between full-stroke/default-stroke mode on a
"not-hacked" HR20? (I don't have the necessary hardware).
BR, Thomas Fogh
@Thomas Fogh: It is for ORIGINAL SW:
FULL stroke mode: unmount valve, press and hold "C" button, mount valve
and you will see "FULL" on LCD
DEFault stroke mode: unmount valve, press and hold "PROG" button, mount
valve and you will see "DEF" on LCD
@jdobry:
Thanks! But what's the "C" button?
I have the "auto/man", "prog" and the day/night temperatur buttons.
BR, Thomas Fogh
I mean day/night middle button. Because moon looks like "C" :-)
Any news on the development?
I'm going to move during the turn of the year and then would like to use
some RFM-enhanced HR20.
At the moment, I've only got two with the stock firmware, because I
couldn't get my USBprog JTAG to work yet :(
But I would buy a "real" JTAG adapter if I need to :)
@Marco G." RFM12 sotware simply works on my home. I have plan to some
improvemnts, but nothing critical.
Hi jdobry,
I guess you mean the firmware compiled from the repo/rfmsrc/OpenHR20
directory?
And you are using the "internal_RFM12" hardware modification? Is it
difficult to use the external one?
And what's your master? A HR20 with a special firmware or an extra piece
of hardware?
Please excuse my pile of questions, if there is any documentation please
point me to it :)
I hope I'll be able to improve the documentation soon :)
My answer from yesterday evening didn't make it into the forum :(
By reading through the thread I found out that the master is an
ATmega+RFM12, connected to an OpenWRT router.
@Marco G.
Diferrences between internal and externel RFM12
- with external RFM 12 you can't use ICE debugger
- external module can be easily damaged or accidenataly disconnected. It
is significant if you have childens.
- internal version need expert skill for soldering, chiset pins is
extremely small.
And you are right. "Master" is RFM12 + Atmega connected to OpenWRT based
router (I was test it with Asus GL500-deluxe and Buffallo WHR-G54S) It
provide web interface for valves ( Yes, it can be used by iPhone :-) or
any bother browser )
Hmm, you're right about the risks of an external module, but I thought
it could be easier to connect a cable to the 10-pin connector but put
the module inside.
Can both - internal and external - be used? There are preprocessor
defines, but also a warning message in
\rfmsrc\doc\external_RFM12\README.txt.
Warning in \rfmsrc\doc\external_RFM12\README.txt is little bit
obsolete.
You can not use it with birary files in SVN, it need recompilation where
you change hardware type.
jdobry, do you already have a PCB for master hardware?
Or does anyone else have a layout?
If not, I would design one and order some PCBs...
No I don't have PCB. Just prototype on universal PCB and wires. If you
will have it, please send me one.
Ok, that will be my task for the weekend :)
Maybe we should start a new thread for designing the PCB:
But I'm unsure about the connection to a router. Does yours have a
serial interface?
@Marco G.:
My router have serial interface inside. (3V3 logic levels)
Hello!
Hello,
I use my HR20 (currently one) with an external 433MHz RFM12 module from
Pollin. I modified the initialization of the RFM. I set the Band to
433MHz and the capacitor to 12.5pF. The frequency is 434MHz and the
range limit is set to +3-4 for 433MHz band ,respective to the
programming guide. My master is an ATMEGA32 on an prototype PCB powered
via USB. Now my problem: I start the master and the daemon and the first
5minutes all work well .Then I receive only errors for hours, sometimes
it work for a few packet and then the same problem. If I restart the
master , the first minutes it work well. What´s wrong ? Have somebody an
helpful hint ? Maybe is there an wrong initialization value for 433MHz.
Thanks in advance!
Ronny
@Ronny Kunze:
Can you send me any log? One of possible problems is time
synchronization. Master broadcast real time and slaves enable receiver
for synchronization packet. Real time is one of parameter to encrypt
packet and if master have another time than slaves, encryption not work
and it can't decrypt packages.
Master clock is not from XTAL but from RFM12 clock output (10MHz). Maybe
that you change it on init sequence.
What happen when sync is lost?
- Master normaly send SYNC packet on 00 and 30 second in every minute
- Slave show "E4" error
1) Slave try enable receiver for 4 minutes till receive SYNC
2) When SYNC is not found, receiver will be disabled for 40minutes
(save batteries) and after go to step 1)
Jiri
Hello Jiri,
did you mean the Debug log in the database or the log from the daemon ?
The Masterclock is from RFM and it is 10MHz , i have veryfied it whit an
oscilloscope. THe Slave doesn't show E4 and if i change the time on my
HR it will set back automaticly to the time of the master.
Here a short dump :
2009-12-08 12:38:07 @07.48 ERR04df 24 06 3f e4 44 43 b5 0f 87 1d...
2009-12-08 12:37:07 @07.49 ERR04de 24 06 18 e5 38 f7 08 55 b7 b0...
2009-12-08 12:37:01 ?
2009-12-08 12:36:07 @07.50 ERR04dd 24 06 63 38 37 91 0e 06 60 c5...
2009-12-08 12:35:07 @07.49 ERR04dc 1a 06 9f 7b 8a e8 dc 5e b7 c3...
2009-12-08 12:34:07 @07.49 ERR04db 1a 06 51 80 12 51 cf e8 0a c6...
2009-12-08 12:33:07 @07.49 ERR04da 1a 06 7c d0 06 01 67 d6 97 c3...
2009-12-08 12:32:07 @07.48 ERR04d9 1a 06 ee 43 5d 7e cf f9 22 47...
2009-12-08 12:31:07 @07.49 ERR04d8 10 06 f1 b3 10 9a 73 b1 5a ca...
2009-12-08 12:30:07 @07.47 ERR04d7 10 06 38 65 40 95 3d 99 6e 17...
2009-12-08 12:30:01 ?
2009-12-08 12:29:07 @07.48 ERR04d6 10 06 80 aa d5 32 4d b3 48 ec...
2009-12-08 12:28:30 @30.11 ERR04d5 8c 70 ec 16 26 33 de ad 7c 2e...
2009-12-08 12:28:07 @07.48 ERR04d4 10 06 9e 84 0f 48 e1 6f 7b 6b...
2009-12-08 12:27:07 @07.45 ERR04d3 06 06 e7 f5 fd 16
2009-12-08 12:27:01 1)?
2009-12-08 12:26:01 @58.57 ERR04d2 3f b7 3d 45 91 08 04 55 ac 3c...
2009-12-08 12:25:07 <06> -D m32 s03 - V46 I1884 S1900 B2941 E00
2009-12-08 12:25:07 <06> -D m27 s49 - V45 I1885 S1900 B2940 E00
2009-12-08 12:25:07 <06> -D m23 s39 - V45 I1890 S1900 B2947 E00
2009-12-08 12:25:07 <06> -D m19 s28 - V45 I1890 S1900 B2956 E00
2009-12-08 12:25:07 <06> -D m15 s16 - V45 I1890 S1900 B2953 E00
2009-12-08 12:25:07 <06> -D m11 s06 - V45 I1890 S1900 B2946 E00
2009-12-08 12:25:07 <06> -D m06 s55 - V44 I1897 S1900 B2956 E00
2009-12-08 12:25:07 <06> (06){
2009-12-08 12:25:07 }
2009-12-08 12:25:07 @06.13 PKT04d1
2009-12-08 12:24:07 @07.54 ERR04d0 4c 06 86 c7 c2 14 5c b1 10 b0...
2009-12-08 12:23:07 @07.54 ERR04cf 4c 06 5e bf 45 ae c3 c4 b3 11...
2009-12-08 12:23:01 )?
2009-12-08 12:22:07 @07.53 ERR04ce 4c 06 50 de 31 23 24 86 62 0a...
2009-12-08 12:21:07 @07.54 ERR04cd 4c 06 b9 c1 c0 35 56 74 1b c9...
2009-12-08 12:20:07 @07.54 ERR04cc 4c 06 25 9d bf 22 22 ec fd 52...
2009-12-08 12:19:07 @07.54 ERR04cb 4c 06 9d 3e 1f 97 a3 ec c6 d8...
2009-12-08 12:18:10 @09.95 ERR04ca 4c 06 e0 24 03 12 bb 1f 4a bb...
2009-12-08 12:17:07 @07.54 ERR04c9 4c 06 f7 2d 46 33 e2 67 88 d2...
2009-12-08 12:16:07 @07.53 ERR04c8 4c 06 23 54 02 7b ac 24 e9 80...
2009-12-08 12:15:07 @07.55 ERR04c7 4c 06 9b 1e 10 aa ad 18 d2 aa...
2009-12-08 12:14:07 @07.53 ERR04c6 4c 06 38 b1 45 f5 7d a7 87 b9...
2009-12-08 12:13:07 @07.54 ERR04c5 4c 06 2d a6 5d 22 18 c0 7d 07...
2009-12-08 12:12:07 @07.54 ERR04c4 4c 06 d1 e3 50 72 91 a3 f1 97...
2009-12-08 12:11:07 @07.54 ERR04c3 4c 06 11 38 b5 a1 64 fd 0c 98...
2009-12-08 12:10:07 @07.54 ERR04c2 4c 06 96 e8 a5 af 38 3e f1 a6...
Ronny
How often is the Time of the Master synced whit the PC ?
The timedrift on my ALIX2 is very strong , so i update the Time from a
NTP server every 10 minutes. Could this problem influence the decryption
?
Ronny
It looks like lost SYNC.
"Master" ask daemon on computer for time every minute and daemon tell
time in 1/100 precision. Do you use Windows or Linux? I am not sure if
Win&PHP combination can use this precision. Part of encryption key is
created from time. Therefore key in 0.99 second is not same as 0.01
second. If daemon is not abble te tell time in this presisoon, time in
master must float over +- 1 sec adn it is not abble to comunicate. It is
just idea.
PS: I use NTP for real time in router where runs daemon. But absolute
value is not significant.
Hi!
I'm looking for - Iowa City Real Estate
@Ronny Kunze:
I read the log ant it is definitively lost of SYNC. See too log and
follow my sentences:
- Log is in reverse order
- You have slave with address 6. This means that timeslot for
communication is from 6.00 to 6.99 second
2009-12-08 12:25:07 @06.13 PKT04d1
- Is correct packet received in 6.13
2009-12-08 12:24:07 @07.54 ERR04d0 4c 06 86 c7 c2 14 5c b1 10 b0...
- Correct packet from 06 (see to second byte) but received too late on
7.54
- Packet like this can't be accepted, because encryption key is expired
and normaly this is possible only on "replay attack"
- This means that master receive from daemon wrong time. Maybe without
correct 1/100 second and "jumping" around correct time.
If you want to have better verbose log (include time sending
daemon->master) you can start daemon without redirect to /dev/null
because it generate verbose log compare to log stored in database
(database engine is too slow for it on embeded routers)
I apologise to code qality on current "daemon". This peace of code was
hang together as proof of concept when I need to debug code in master
and slave. I was plan to rewrite it completely, but it not happen (have
not time and urgent motivation). But it works.
Hello Jiri,
I think i found the problem. I tried following on my server :
voyage:~# ntpdate ptbtime3.ptb.de;sleep 60;ntpdate ptbtime3.ptb.de
9 Dec 09:29:38 ntpdate[30871]: step time server 192.53.103.103 offset -0.749543 sec
9 Dec 09:30:37 ntpdate[31034]: step time server 192.53.103.103 offset -1.480186 sec
Lo and behold! The drift whitin 1 minute is around 1,5 seconds.
Then i tried to update the clock every minute , it looks better. At
least i tried to update via ntp every 10 seconds and every packet is OK
...
It seems i should fix the problem on my Server ...
Regards,
Ronny
Can you use ntpd (daemon) and not ntpclient? It is abble to compensate
drift.
Hello,
is there a how-to-file or wiki for beginners/dummies?
Peter
Hi Peter,
I've started one, but haven't got further than flashing yet :(
Hello Jiri,
Yes I use ntpd , but it was not precise enough. Now i found a other
solution. I have modified the handling of the time update at the
master.The request is send every minute , but it ignore the the answer
if onsync greather than 0xe1. This should be a time of 1 hour.
I found a other problem in the daemon. The serial connection will only
work if the system set the right baudrate. I add a
exec('stty -F /dev/ttyUSB0 38400 '); to the daemon. Now it is anytime
the right baudrate.
Ronny
Hello,
i have just converted my 2. Hr20 to the Open Hr20 with an RFM12 module.
when i measure the current, the Hr20 takes around 1 mA. This current
consumption seems a little bit high.
Ludger
Ludger: I know that we have some problem with wireless and power. Normal
cheap alcaline batteries is empty after 2-3 months. I will try fix it on
xmas vacation.
Till now I has feeling, that nobody except me use use wireles in HR20,
but it slowly changes in last two months. :-)
Hi Jiri,
now that we are back in heating period again :-(, I have changed two of
my HR20 running older versions of the OpenHR20 firmware (still without
wireless) to the newest (?) version 234.
Experience so far: both failed miserably, showing 'Open' for hours and
both rooms cold this morning and again this afternoon (my wife is not
amused).
Best thing for me at the moment would be to disable the window open
detection completely (any hint how to do that easily by changing
parameters ?).
Regarding your last post about wireless. I think one of the reasons why
this is not used by so many people is:
- the lack of an easily available master unit
- the way you are using it (with a router as master control, maybe too
complicated for most of us ???)
What I would love to do is have the individual units run on their own
with their own sets of parameters and monitor these units via wireless
with a master unit most of the time. Only in some special situations I
want to control the units remotely, e.g.:
- if the circulation pump is not running (at night)
- if i leave the house for a weekend holiday
- .....
BR,
Jörg.
Hi Jörg,
i have had the same Problem with my HR20. Here are my settings to
disable the window open detection.
next try
Hello Jiri,
I think the problem with the current consumption, ist the crystal
oscilator of the RFM module, it's always on. I can measure the output
frequency of 10Mhz. You can switch off the the oscilator output to save
some energy.
Ludger
Hi Ludger,
thanks a lot for this info regarding window open detection. I will try
that immediately.
BR,
Jörg.
Why don´t you switch off the RFM completely with a little transistor, if
it has nothing to do? I would implement short time slots in the
protocol, where the module is active and waiting for incoming data or
transmitting.
Opps, RFM oscillator must be enabled only in master (it is used as clock
for ATMEGA) but not in valves. I will fix it early (I hope today). We
don't need switch off RFM by transistor, it can be switched off by
command, I don't know where is problem for now, but I will find it.
Window: In current SW is this third version for window detection, and I
have similar problem. Do you have anybody idea to improve window
detection algorithm? For next version I will prepare window open timeout
( from 1-255 minutes ) When HR20 clear window open flag automatically.
Current detection is too sensitive, and today during change from 21 ->
17 degree detect window open in 3 rooms. Temperature decreasing too fast
(outside temperature was -16)
Master: It can be connected directly to PC, not to router. It is less
complicated, but you can not set valves remotely. Remote control is
fundamental feature for me, sorry. This SW can be installed on PC but is
is not optimal. If you have not permanently enabled PC, you will not
have logging.
GPL: it is GPL SW, this mean that everybody can modify it by own felling
what is better :-)
Today outside temperature in my location.
>We don't need switch off RFM by transistor, it can be switched off by
>command,
Sure, but how big is the quiescent current consumption in power down
mode? Is it noticeable, compared to the Mega169, or not?
@ TravelRec
Hi,
i have running to RFM12 + SHT75 + Tiny45 for almost a year now. And the
batteries ( 2 Alkaline AA ) are the first. The current consumption quit
low
Ludger
Ahh, okay. In my tests the Mega169P needs around 25µA during sleep with
LCD active and cyclic main calls 4 times a second. If the RFM takes more
than 10µA all the time, then the battery life will decrease
dramatically.
Jiri,
I think the idea with a programmable timeout after window open detection
is the best , because I can not imagine how it COULD work automatically
regarding the huge variety of circumstances (we have the same -15°C here
at the moment as you and the room temperature falls extremely fast and
never recovers. Temperature regulation is also not nearly perfect.
Because of the low temperatures outside and high heating water
temperature I see extreme overshoot in very small rooms with
comparatively big radiators whereas in other rooms temperature increases
very slowly with valves full open).
One other (maybe optional) possibility if the HR20 is located near to
the window/door would be to use one of the cheap reed contacts for
burglar alarm and cable this directly to the HR20 interface connector.
And, yes, I know that everyone is allowed to change the sources :-), but
there is simply not enough time for me to do that.
BR,
Jörg.
@ Jiri,
i know about the GPL, but i have some problems to compile the source
file correctly for a running HEX file. The compiler has the right
version and use the makefile for compiling. Do you use AVR studio for
building the HEX ?
I got always a lot of compiler warnings.
regards
Ludger | https://embdev.net/topic/118781?page=1 | CC-MAIN-2017-43 | refinedweb | 29,706 | 73.98 |
Hi Friend, Here We will create MVC application with the help of Model ,view and controller components.This components are helpful to create asp.net mvc application easily and secure.Here i will show you working of each components with an example. In this tutorial,we will learn "how to pass data from model to controller and vice versa ,as well as how to pass data from controller to view in ASP.NET MVC Framework". Now i am going to to explain this whole concepts on visual studio 2010 with MVC 2 framework. Every MVC Framework(eg. mvc 2 ,mvc 3 ,mvc 4,mvc 5 and mvc 6) can be used to create this simple application.
There are some steps to implement this whole concepts on your visual studio as given below:-
Step 1 :- First open your visual studio --> File --> Project -->Select Web --> Select ASP.NET MVC 2 Empty application --> OK,as shown below:-
There are some steps to implement this whole concepts on your visual studio as given below:-
Step 1 :- First open your visual studio --> File --> Project -->Select Web --> Select ASP.NET MVC 2 Empty application --> OK,as shown below:-
Step 2 :- Now open Solution Explorer --> Right click on Model folder -->Add -->New -->Item --> Select Class (Student.cs) -->Add ,as shown below:-
Step 3 :- Now create property for student class members as given below:-
using System; using System.Collections.Generic; using System.Linq; using System.Web; namespace Student_MVC_Application.Models { public class Student { public int sid { get; set; } public string Name { get; set; } public int Age { get; set; } public double Fee { get; set; } } }
Step 4 :- Now Open Solution Explorer -->Right click on Controller Folder --> Add -->Controller (Mystudent.cs) --> Add ,as shown below:-
Step 5 :- Now Add Model Class Namespace on above of your controller class as given below:-
Using Student_MVC_Application.Models;
Note :- This namespace is present in student class (model layer). For this see step 3.
Step 6 :- Now open class ( MystudentController .cs ) --> Create the object of student class --> and define the student's members here --> and pass the student class object in View function as an argument as shown below:-
Step 7 :- Now Right click on ActionResult -->Add View --> Check Create strongly -typed view Box --> Select View data class from dropdown list ,as shown below:-Step 7 :- Now Right click on ActionResult -->Add View --> Check Create strongly -typed view Box --> Select View data class from dropdown list ,as shown below:-
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Web.Mvc; using Student_MVC_Application.Models; namespace Student_MVC_Application.Controllers { public class MystudentController : Controller { // // GET: /Mystudent/ public ActionResult Index() { Student obj_st = new Student(); obj_st.sid = 10012; obj_st.Name = "Abhishek Patel"; obj_st.Age = 25; obj_st.Fee =4200.80; return View(obj_st); } } }
Note:- If you want to attached master page with your application then tick on Select master page box as shown above image.
Step 8 :- Now write the codes in index.aspx page as given below:-
Step 9 :- Now Run the application (Press F5) --> You will see following error message as shown below:-Step 9 :- Now Run the application (Press F5) --> You will see following error message as shown below:-
<%@ Page <html xmlns="" > <head runat="server"> <title>Index</title> <style type="text/css"> .style1 { color: #FF0000; } </style> </head> <body> <div> <span class="style1"><strong>Welcome to MY.NET Tutorials</strong></span> <br /> The student ID is :<b><%=Model.sid %> </b><br /> The student Name is :<b><%=Model.Name %> </b><br /> The student Age is :<b><%=Model.Age %> </b><br /> The student Fee is :<b><%=Model.Fee %></b> <br /> </div> </body> </html>
Note:- This error comes because we didn't invoke any Actions.
Step 10 :- Now Put any Action (Mystudent) in browser URL -->press Enter Button -->You will see following output as shown below:-
Step 11 :- If you want to open web page directly without typing Url parameter in browser --> open your solution Explorer window --> Open Global.asax file --> write your controller name and action name as shown in below image.
Note :-
- You will see same output as shown in step 10.
- I will explain URL Routing concepts in coming post.This is the main part of MVC Application.
For More...
- HTTP and state management concepts in asp.net application
- Threading concepts in c#
- Transaction concepts in sql server
- Web forms control in asp.net
- How to host asp.net website free on server
- .NET Interview questions and answers
- Delegate concepts in c#
- Stored procedure in ms sql server
Download | https://www.msdotnet.co.in/2015/02/how-to-create-aspnet-mvc-complete.html | CC-MAIN-2022-05 | refinedweb | 742 | 57.77 |
Dave Ihnat < ... at dminet dot com> wrote:
Aaron Konstam < ... at sbcglobal dot net> wrote:
Never had this happen in the many years of using Gnome. What specifically is happening to your system?
Please provide details on your computer, CPU, memory, bitness, video card and memory (and if it is out of the memory pool, or on the card.)
James McKenzie
Hiisi < ... at gmail dot com> wrote:
Ah, the Beta tester crying "Wolf, Wolf". Thanks for the warning, but should this not go to the developers?
Why doesn't Fedora/KDE tell you that you can "safely remove" a USB device
when you click on the icon on the right of the little window for the device?
Is it just reluctance to follow Bill Gates?
I would have thought it was courteous to tell you that.
Hello,
On a fedora 13 machine, after a recent release (around dec. 22nd), I
lost the possibility to move from the graphic mode to the text mode
by using the Atl+Ctl Fx command.
The graphic mode switch off, but no text appears.
How can I log/debug this problem ?
thank.
To have the same shell running twice a week, I am using crond and
anacron if I understand correctly. I have a file in /etc/cron.weekly
(file.cron)
and I also schedule the same file from crontad -e.
However, it appears that I have the same file command
(/etc/cron.weekly/file.cron) started at 2 slightly different times
started at Sun Dec 26 03:04:01 GMT 2010
and at:
started at Sun Dec 26 03:00:01 GMT 2010
according to my log files. This is a real problem.
How, can I run a cron file twice a week ?
Thank.
I was hoping to use anaconda's GUI interface to repartition my
hard drive while installing F14, but I ran into a problem with
anaconda's custom layout option. (I currently have F9 installed.)
After I resize the partition then re-edit the partition and choose the
Format option, anaconda tends to forget the size I entered and resets
it to the original size. After playing with this a while, I chose to
continue with installation .
Hi all;
I'm thinking about buying a Lenovo IdeaPad S10-3t and running Fedora14
on it. Anyone know if it's compatible? Web searches seem to indicate
that the wireless may be an issue. Any thoughts on if Fedora14 works
well with this card:
BCM 4313 BGN Wireless
Thanks in advance...
/Kevin
I am an ex kde 3.5 user - I switched to gnome after the 4.0 mess ...
With the impending advent of gnome-shell - I decided to take a look at
kde4 again on f14 - after a brief revisit I found it to be a
look-dont-touch GUI ...
I have live media running respins of F14 on machines where F14 is
installed, and doing better with my monitor than the hard drive has been
doing. (One is currently running the Fusion release candidate; the other
has the plain F14 Live.)
I want to figure out what is different, and edit the
corresponding file on the hard drive to match.
But for some reason, I can't seem to remember nor reconstruct any
way to get to the hard drive. What am I not seeing??
hi,
I have installed the java (by searching at the net) and just did as
directed.
If you logout or shutdown while in in Gnome Shell your menus under
Applications in Gnome will be changed. So to fix this you be out of Gnme
Shell when you logoff, and then login again.
Found that .xsession-error file had somehow grown to over 2GB.
Found a large number of lines linked to Package kit update applet, so have
disable it.
Noticed that used space on / had gone from normal 14GB used size to
16GB. Didn't quickly find where the space was until using the option to list
the . files. Haven't noticed this in the past, so wondering if others have seen
this?
+----------------------------------------------------------+
Michael D.
Hi guys :), i am using server web with apache, mysql and phpmyadmin as
front-end, with local host it is running, but with ip i can't see the
web 192.168.1.10/phpmyadmin, only with 127.0.0.1/phpmyadmin, in
/etc/phpMyadmin/config.inc.php i changed localhost by
ip(192.168.1.10), but i can't see 127.0.0.1/phpmyadmin, returned to
localhost and it is correct, in /etc/hosts i have:
127.0.0.1 localhost.localdomain localhost
192.168.1.10 fedora.org fedora
in /etc/sysconfig/network
i put in hosts fedora.org
i want to access of other pc of my network to phpmyadmin..., what is
the correct configuration
Same here.
As someone earlier let me know about the encrypting of passwords, I did the
following:
after becoming the root, used the command:
md5crypt
to get the encrypted string of passwords for using in /boot/grub/grub.conf
This is the password which is NOT the password of the user who logs-in.
I cannot find in 'Add to Panel' Nautilus to add it to the panel as I
have done in all previous versions of Fedora (well at least 10,11, and 12).
Where is it hiding this time?
Hi,
I just rebooted my FC14 x86_64 desktop, and there's no networking. I
have a bridge set up with eth0, and despite my best efforts, can't get
eth0 to be "active" in "Network Device Control". The activate/deactive
buttons are greyed out.
At one point I was able to click Activate, but even then it wouldn't
actually activate it.
Since moving from f13 to f14 (fresh install) on my laptop (lenovo T61p)
using nouveau driver - I have found that leaving the laptop plugged in
and with mail and browser running via wifi -
Once in a while (3 times so far) it will just freeze - when I return to
it the only response I can get is to power cycle it hard.
The lights are on - the wifi light is blinking - the disk light is off.
The /var/log/messages stops recording from the freeze point till i
hard reboot.
smart says disk seems ok - machine has never crashed under 12 or 13.
Very odd ...
gene/
If you know that it is possible to evaluate the GNOME3 under F14 stop
reading here.
You can get a look at Gnome3 by doing:
yum install gnome-shell
Then go to System->Preferences->Desktop Effects and choose GNOME Shell
This is described in the February 2010 issue of Linux Journal in an
article, "Coming Soon to Linux Desktops", by Charles Olsen. Except he
gives you bad advice on how to start the Gnome3 Shell.
I have something strange and quite annoying happening with my F14 x86_64
desktop system. I changed my desktop background in Gnome to something I
like - I use Digital Blasphemy (<a href="" title=""></a>) for most of
my backgrounds, and I usually change it almost every time he releases
something new.
Of late, whenever I change my background, if I logoff and log back on
again, the background I selected first displays momentarily, but then it
changes by itself to something I used to use a while ago.
After I upgraded my Fedora 14 from 13 with a local ISO image on my local drive,
I noticed that only some info such as one in "System->About this computer" was
turned to indicate something about Fedora14 while "uname -r" didn't show info
about fedora 14 instead of the previous one and no new source directories in
/usr/src/ were created. I am wondering whether my fedora13 was upgraded to 14?
Cricket
Hi;
I have been using TVTime through six or seven versions of Fedora. it
was working until recently. I don't exactly when it quit. Some time in
the last two weeks. I have been doing a lot of messing with my computer
in that time. Before dumping a whole pile of data on here;
TVTime starts with blue screen; then shifts to green screen after a few
seconds delay.
Is anyone familiar with this problem?
I am using cable TV in Canada, so NTSC.
Does.
I ran firstaidkit as root and got the following warning:
Grub_IMAGE Detected 'bad grub stage1 image'. Fix doesn't fix.
Googled and got either way out of date messages or lots of Grub2 stuff.
I posted a question here a couple of days ago with lots of info. Will
repost if it is helpful.
What is this firstaidkit warning telling me?
I installed the skype RPM on my 64-bit Fedora 14 machine and ran into
all kinds of problems with missing libs like:
skype: error while loading shared libraries: libasound.so.2: cannot open
shared object file: No such file or directory
skype: error while loading shared libraries: libXv.so.1: cannot open
shared object file: No such file or directory
skype: error while loading shared libraries: libXss.so.1: cannot open
shared object file: No such file or directory
skype: error while loading shared libraries: libQtDBus.so.4: cannot open
shared object file: No such file or directory
skype: err
*This is a fairly new Fedora 14 install and I did have the wireless
working for quite awhile, so all the fwcutter and other
pre-configuration stuff was done.
*This install was for a friend and he says it worked fine for awhile and
then stopped when he took his computer to the office and back home.
*I ran yum update and installed lots of updates yesterday, and after
that, it started working and stayed working through multiple reboots.
*When my friend arrived to pick it up, we did one final reboot and it
came up dead again, with no evidence of the adapter in the network
manager applet
*We'
I need to develop a schedule for a couple parties.
In the past we did it manually on a paper calendar.
I'd like to do it with a piece of software such that we can print out a
calendar with activities on it. Some of the people involved run
Windows.
Any ideas ?
Thanks
I just installed F14 on my notebook. I cannot find Nautilus anywhere in
the Gnome menus. In F12 it was in the Applications -> System Tools. It
is not there.
When I run Nautilus from a command line, I do not get the side window
with the directory tree, nor the location field and the view table does
not show this as options.
So how do I fix Nautilus?
The Gallium update to the ATI driver seems to have made X performance
much worse on my system. Obviously though, "feels slower" isn't exactly
specific. Is there a program out there that will measure X performance?
(I do know about glxgears, and it does report a 20X lower frame-rate on
Fedora 14 that it did on Fedora 13, but it also says that it is "Running
synchronized to the vertical refresh", so I don't think it's a valid
metric.)
Thanks!
I don't seem to be able to chainload to WindowsXP anymore.
My grub.conf in /boot/grub/ includes:
...
title WindowsXP SP3
rootnoverify (hd0,0)
chainloader +1
makeactive
]# fdisk -l
Disk /dev/sda: 41.0 GB, 40981069312 bytes
255 heads, 63 sectors/track, 4982 cylinders, total 80041151 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0xa6a9a6a9
Device Boot Start End Blocks Id System
/dev/sda1 * 63 63649529 31824733+ c W95 FAT32 (L
I have an sshd server running on a machine in Ireland.
Can I configure it so that it only accepts connection
from certain machines, wherever they may be in the world?
Last time I even looked at KDE, it was release 2 or 3, more
likely the former. It didn't appeal to me, and I abandoned it.
Now at least two distributions (Kororaa and PC-BSD) run KDE4 by
default -- and it bewilders me.
Ten to one I never really get serious -- I have too much hard-
earned experience invested in Gnome -- but I do want to manage well
enough, if I can, to explore my interest in those and maybe other
choices.
I've been trying various things, mostly Fedora variants, for
various reasons lately, and haven't kept good track. One machine has been
running for days, maybe a week or more, on some live medium, calling me
"liveuser."
I like it, whatever it is; but I don't want to interrupt it (by
shutting down and ejecting the disk, for instance) till I've tried a few
more things. (Most of what I've done so far is more setting up than
using.)
"uname -a" says only that it's F14. I *think* it's Fusion. How do
I get it to tell me for sure?
I have noticed that there are packages in fedora-updates which are not
being updated on my machine when I run yum update. I have the updates
repo enabled and I disabled yum-priority and yum-protectbase. I have
don a yum clean all and when I run yum update it downloads the
updates/primary_db. As an example I have bacula-5.0.2 installed on my
machine. I see in
<a href="" title=""></a>
that the bacula version is bacula-5.0.3-2 with a date of 10-Dec-2010.
Am I missing something or am I not getting all of the updates I should
be?
Fedora 14 / Kde
BSD-games-2.16
GNUmakefile:1220: wump/wump.d: No such file or directory
./mkdep wump/wump.c wump/wump.d gcc -g -O2 -Wall -W -Wstrict-prototypes
-Wmissing-prototypes -Wpointer-arith -Wcast-align -Wcast-qual
-Wwrite-strings -Iinclude -Iwump
./mkdep worms/worms.c worms/worms.d gcc -g -O2 -Wall -W
-Wstrict-prototypes -Wmissing-prototypes -Wpointer-arith -Wcast-align
-Wcast-qual -Wwrite-strings -Iinclude -Iworms
worms/worms.c:65:20: fatal error: curses.h: No such file or directory
compilation terminated.
make: *** [worms/worms.d] Error 1
What is it missing ?
I recently turned on the Compiz desktop effects and suspend stopped
working. At least I think this is the correlation. The PC just hangs
until I use the power switch. Has any one else observed this?
uname -a: Linux rwells-f14 2.6.35.10-74.fc14.x86_64 #1 SMP Thu Dec 23
16:04:50 UTC 2010 x86_64 x86_64 x86_64 GNU/Linux
machine is Lenovo X200 (Intel graphics)
Fedora x86_64 14 freeze up or reboot immediately, when running Virtualbox
3.2 or 4.0. I have installed the repo from Virtualbox. And now it's the same
problem like this guy had:
<a href="" title=""></a>
CPU: AMD Athlon(tm) 64 X2 Dual-Core Processor TK-53
Graphics: ATI Technologies Inc RS690M [Radeon X1200 Series]
How do I tell which update tree for Fedora 14 a system uses?
I have maintained a repo tree for i386 locally for some time. I have
always had 'older' equipment.
Well I just picked up an HP dc5000 and I noticed after the install, that
the upload profile stated it was an 686 platform (Intel P4 3.2Ghz). I
see i686 rpms on the system and there are i686 rpms in both the i386 and
x86_64 update trees.
Hi Guys,
Currently I see my project well and running - thanks to Pitivi (and
their debuggers, devs) - but I would like to have some help from our
Fedora community. I have an small audioclip what has been released by
an BR musician namely Carlos Amoyan (huge thanks), and received
permission from NASA itself (Goddard Space Center) to use their videos
to our AD marketing clip. I have my project stalled at in the middle
of planning, because of Pitivi wasn't so stable to make the cuts, and
the rendering.
For some reason I couldn't find a package for Processing in Fedora repos
(and in RPMFusion)..
How come it's not there?
The only RPMs I see (via rpm.pbone.net) are an older version for
OpenSuSE and just one current version for PCLinuxOS
I am trying to figure out if there is a way to configure a network
interface using /etc/sysconfig/network-scripts without creating the
corresponding static route..
I suspect not but wanted to ask before doing anything else.
I hesitate to shut this computer off, It comes on sounding like a
jet engine in my quiet room, fans running full bore and does not
I have Fedora 14 installed on a Dell Inspiron 1545, with the integrated
webcam and digital microphone array.
The camera picks up fine and runs well with vlc. But from the
microphones--silence.
I am also using KDE. I've looked in KMix and Phonon. Not a word about
those microphones.
The laptop does have a 3.5-mm external mic jack. Before I go out and get
a microphone (or a combination headset), should I expect that external
jack to work?
Thanks in advance.
Temlakos
I've installed F14 on a box that was running F8 (I know, I know...) and
DNS is not working properly.
nslookup and dig can both find google.com quite successfully, but any
other method of trying to connect to remote site (http, telnet, ftp) all
fail with the same error that they cannot resolve the name. I have
disabled SElinux, the firewall, and the iptables and ip6tables services.
Whether I configure the ethernet connection with DHCP or a static IP
address the results are the same, as they are if I'm using 64-bit or
32-bit F14.
Hi everybody
In fedora 10 and below, When I was at Terminal and attached a USB device
to my computer, It prints the device info in the Terminal such as
Manufacture, Device driver in use and so on...
but in fedora 12 and 13 It doesn't work
How can I enable it?
I use the
KB SSL Enforcer
<a href="" title="">...</a>
so i could browse the net safer [i mean webserver <-> me] with using https, if available.
The problem is: e.g.: facebook...
if i go to
<a href="" title=""></a>
that's ok, it's https.
But all the links are "http" on the site..
if i click on a "http" link, it will request the page on "http", and THEN it switches to "https". Heres the problem.
How/where could i write a privoxy rule, to rewrite all the "http" links to "https"?
I have tried to cut my videos to pieces, and stream back them together
to have the best moments that I have recorded - but it seems that I
couldn't.... The newest pitivi at last works, not crashing, but I
couldn't control the audio part of the clips - however would be fine
for this case, but rendering the project doesn't saves ANY audio....
Ok, have installed Avidemux, where I have more control. Same result,
and more because crashes, freezing as should.... I have tried bunch of
softwares - but right now, I sitting here on pile of recorded home
movies - and couldn't do anything....
I am using compiz under KDE and the shiftswitcher plugin, but it allways skips
a window, jumping in steps of two at a tiem.
anyone else seeing this?
compiz-0.8.6-1.fc13.i686
KDE 4.5.4
Thanks in advance,
YB.
Hi everyone,
Happy New Year :-)
I've just released a minimalistic version of Kororaa (KDE based Fedora
Remix), which is designed to provide a basic KDE system with Internet
connectivity. The idea is that users can take this and then install
what they want on top - or not (if they just need a browser). It still
includes the tweaks found in the full Kororaa release, etc.
It's a 670MB download via SourceForge or bittorrent. If that interests
you, please give it a try and let me know what I can do to make it
better :-)
See <a href="" title=""></a> for more details.
Thanks,
Chris.
Hi!
I just installed kile on my F14 box, and am unsure how to proceed with
integrating latexmk with it. I've google'd around but there's not much out
there.
Anyone have any experience with this?
TIA!
Kirk
I just upgraded my netbook from F13 to F14 (i386). Can't say
it went smoothly. Netbook is a Gateway (by Asus) with n450
and 250G HD.
First, before the preupgrade, updates to moddle were failing.
Preupgrade did not detect this when it did its check so when
it did the upgrade, it failed after a few hours of upgrading. I
switched to the virtual term, did a chroot /mnt/sysimage
and then rpm -e moddle, followed by a restart of the update
and the update finished.
Second, after preupgrade successfully ran (the second time),
the netbook failed to boot on the new kernel.
Fedora 14.
emma-0.6.tar.gz
Trying to compile emma frontend for MySQL but I get Error below and I
don't see a python2.4 in Fedora
# ./setup.py
/usr/bin/env: python2.4: No such file or directory
# cat setup.py
#!/usr/bin/env python2.4
import os
import os.path
import sys
from glob import glob
from distutils.core import setup
from emmalib import version
icon_data = glob('icons/*.png')
glade_data = ['emmalib/emma.glade',
'emmalib/plugins/table_editor/table_editor.glade']
theme_data = ["theme/README.html"]
theme_gtk_data = glob("theme/gtk-2.0/*")
other_data = ['changelog']
setup(name="emm
I dont know what I did but suddenly my sound is broken.
I'm running Fedora 14 (x86-64) on a Dell Latitude E6410. The problem is
as soon as I plug in my headphones I loose the sound. If I unplug the
headphones I get sound out of the built in speakers of the laptop.
After I lost sound I started experimenting with the settings in sound
preferences and I'm pretty sure I have tested all possible combinations
without success.
Has anyone seen something like this before?
PS: Happy new year!
sir i want to install oracle10g R2 in fedora 12 kindly give me the details to install the same
and how can i get the following packages
rpm
-Uvh setarch-*
rpm
-Uvh --force tcl-*
rpm
-Uvh compat-db-*
rpm
-Uvh --force libXau-devel-*
yum
install libXp libaio
yum
install compat-libstdc++* compat-libf2c* compat-gcc* compat-libgcc*
kindly help me to solve the problem
I have <a href="" title=""></a> as my home page.
There are about 100 errors in parsing the html code, and I captured the
unique ones, which are 20. The highest repeat is this one:
Warning: Expected declaration but found '*'..
I have Fedora 14 installed and now discover that between Fedora 12 and
Fedora 14, the resolution of my HP L2045W monitor has changed from
1600x1200 down to 800x600. How do I reconfigure the resolution to 1600x1200?
Hello there
I just a had a big surprise when I got a shiny new Nvidia 460 GTX for
Christmas.
I tried to get the Cuda device working under Fedora 14 x86_64 and there is
no support out yet for Cuda 3.2
All the Video works ok under the Nvidia 260 driver package but getting Cuda
to work is another thing all together.
Has anyone out there had similar problems with this card.
This is one hot damn card and the only real support is with Windows 7 x64
I am running Windows now and everything works flawlessly but I miss the
security under Fedora.
I am seeing now that I have to wait | http://www.devheads.net/linux/fedora/user | CC-MAIN-2018-17 | refinedweb | 3,953 | 72.87 |
Oops - Accidentally broke second instance checking (running PTK twice) in previous release this fixes it.
New release of changes that have been in svn for a while. New Features/Improvements include:
Editor changes
- Cell separators in editor.
Using #%% comments string to divide code.
Execute current cell via F9
Console
- New console auto-completes
Auto-completes for files paths (Ctrl+space in string), tab/right arrow to
navigate folders
Auto-completes for call args (Ctrl+space in call bracket) and names.
Auto-completes for string keys in dict-like objects.
Plus type icon displayed in list, and speed improvements.... read more
New release is now available. Only some minor changes to fix problems on MacOS plus new support for the gtk3 (PyGObject) toolkit.
Pretty major ommision in the 12.08 source release with the PTKengine.pyw file missing completely - a revised zip has been uploaded. Windows installer should be good though.
Long.... read more
Fixes a few bugs that slipped through the net.
1) New integrated debugger.
2) Stopping running code - keyboard interupt added to allow running code to be stopepd even if not debugging
3) Added PySide (Qt4) engine.
See updated webpages for details.
Mainly)... read more
Just noticed a major bug in the current release when reading from stdIn - e.g. input()/ raw_input() .
Fixed in the new version 10.07.23
- New engines:
GTKExternal - Allowing interactive use of the pygtk library .
Qt4External - Allowing interacive use of the pyQt4 library.
- Added engine enviroment options:
to use the __future__ imports (division etc)
to execute the python startup script specified by the environmental
variable PYTHONSTARTUP found in
Preferences>EngineManager
- New command: view('objname') command to engines to open a gui view of the object.... read more
- New improved calltips - scrollable for long tips, check option to prevent autoclose when typing command.
- Modified engine interface to allow extensions and simplify structure, allows control of GUI interface from commmand line:
ptk_help() - key help function
clear() - clears the console
edit('filename') - open the filename in the ptk editor
inspect('objectname') - inpsect the object in the Inspector tool... read more
Some major changes behind the scenes and new features:
>External engines - simple python and python with wxpython mainloop
>GUI Viewers added for lists,arrays and strings (double click in NSBrowser to open)
>Improved command history with history stored between sessions
>New Tool: Command History viewer
>Program preferences dialog added.
NEW)
The second release is available:
- Improved namespace browser (try browsing the wx module)
- New InfoBrowser tool to view object info.
- Bug fixes, code clean-up
The next release will probably be late April as I'm planning some internal changes which may take some time.
Python toolkit (ptk) is a matlab style gui / integrated development environment for python. It is designed to allow scientists and engineers to explore their data and interactively develop their software. Please remember that this is a work in progress so not all menu items (help>help,edit>preferences etc) do something! | http://sourceforge.net/p/pythontoolkit/news/?page=1 | CC-MAIN-2015-35 | refinedweb | 490 | 55.74 |
First I need some data to expose as JSON, so I will create a small service class that generates some data based on the following entity:
public class Car { public int Id { get; set; } public string Make { get; set; } public string Model { get; set; } public int Year { get; set; } public int Doors { get; set; } public string Colour { get; set; } public decimal Price { get; set; } }
The simple service will have one method that conforms to an interface, generating and returning a list of cars:
public interface ICarService { List<Car> ReadAll(); } public class CarService : ICarService { public List<Car> ReadAll() { List<Car> cars = new List<Car>{ new Car{Id = 1, Make="Audi",Model="R8",Year=2014,Doors=2,Colour="Red",Price=79995}, new Car{Id = 2, Make="Aston Martin",Model="Rapide",Year=2010,Doors=2,Colour="Black",Price=54995}, new Car{Id = 3, Make="Porsche",Model=" 911 991",Year=2016,Doors=2,Colour="White",Price=155000}, new Car{Id = 4, Make="Mercedes-Benz",Model="GLE 63S",Year=2017,Doors=5,Colour="Blue",Price=83995}, new Car{Id = 5, Make="BMW",Model="X6 M",Year=2016,Doors=5,Colour="Silver",Price=62995}, }; return cars; } }
This service is registered with the ASP.NET Core Dependency Injection system so that it can be made available throughout the application:
public void ConfigureServices(IServiceCollection services) { services.AddMvc(); services.AddTransient<ICarService, CarService>(); }
JsonResult in a Razor Page
Because Razor Pages is built on top of the ASP.NET Core MVC framework,
primitives from MVC are available to PageModel files.
One of those primitives is the
JsonResult action result which serialises data to
JSON and returns is as a response with the content type set to
application/json. Therefore you can configure a Razor Page to
deliver JSON. The following example shows the PageModel file content for a
simple Razor Page (GetCars.cshtml) that is designed solely to return JSON:
using Microsoft.AspNetCore.Mvc; using Microsoft.AspNetCore.Mvc.RazorPages; using RazorJSON.Services; namespace RazorJSON.Pages { public class GetCarsModel : PageModel { private readonly ICarService _carService; public GetCarsModel(ICarService carService) { _carService = carService; } public JsonResult OnGet() { return new JsonResult(_carService.ReadAll()); } } }
The service is injected into the PageModel constructor and the data is
returned as a JsonResult. To make the JsonResult type available to the PageModel
file, you need to add
using Microsoft.AspNetCore.Mvc; to the top of
the file. You add a place in a different page for the results to appear:
<ul id="car-list"></ul>
And a snippet of jQuery to make the call to the page:
@section scripts{ <script type="text/javascript"> $(function () { $.get('/GetCars/').done(function (cars) { $.each(cars, function (i, car) { var item = `<li> <strong>${car.make} ${car.model}</strong> (£${car.price})</li>`; $('#car-list').append(item); }); }); }); </script> }
When you run the page, the list of cars appears:
This works fine but creating a Razor Page just to serve JSON doesn't feel
right. Razor Pages are intended to generate UI, not act as a data service. You
could instead use an existing page and add a
named handler to deliver JSON. Let's alter the method in the example page to
adopt this approach by renaming
OnGet to
OnGetCarList:
public JsonResult OnGetCarList() { return new JsonResult(_carService.ReadAll()); }
Then we change the actual Razor Page so that the special
handler parameter becomes a
route parameter rather than a querystring parameter:
@page "{handler?}"
Now we can call this method from client-side code:
$.get('/GetCars/carlist').done(function (cars) { $.each(cars, function (i, car) { var item = `<li> <strong>${car.make} ${car.model}</strong> (£${car.price})</li>`; $('#car-list').append(item); }); });
This is a bit better in that we are not creating a bunch of Razor Pages purely to serve data, but this kind of piggy-backing of a resource that is intended to generate UI still feels a bit like the old PageMethods approach that Web Forms offered.
JsonResult from an MVC Controller
Since MVC primitives are available to a Razor Pages application, you can use an MVC Controller to deliver JSON. You can try this out by adding a folder named Controllers to the application and then right click on the folder and choose Add... Controller (if using Visual Studio). Then choose the Empty Controller option from the resulting dialogue and name it CarsController (plural). Replace the content with the following:
using Microsoft.AspNetCore.Mvc; using RazorAPI.Services; namespace RazorAPI.Controllers { public class CarsController : Controller { private readonly ICarService _carService; public CarsController(ICarService carService) { _carService = carService; } public JsonResult Index() { return Json(_carService.ReadAll()); } } }
Once again, you inject the CarService into the controller via its constructor. The car data is obtained in the Index method and returned as JSON to the callee. The same client side code is use but the URL is changed:
@section scripts{ <script type="text/javascript"> $(function () { $.get('/Cars/').done(function (cars) { $.each(cars, function (i, car) { var item = `<li> <strong>${car.make} ${car.model}</strong> (£${car.price})</li>`; $('#car-list').append(item); }); }); }); </script> }
This certainly feels like an improvement, but there is still another (possibly better) option.
Web API
The final option is to use a Web API controller. Web API is designed specifically to provide data services over HTTP. It is also easy to work with in ASP.NET Core as its part of the framework, unlike previous versions of ASP.NET. Finally, in the context of this discussion, the default data format that Web API works with is JSON.
Web API provides RESTful services, that is resources available over HTTP that respond in specific ways depending on the HTTP verb that is used for the request. The HTTP verbs typically map to standard CRUD operations as follows:
To test this out, right click on the Controllers folder and choose Add... Controller. This time, choose API Controller - Empty and name the controller CarController (singular). Amend the existing code as follows:
using Microsoft.AspNetCore.Mvc; using RazorAPI.Models; using RazorAPI.Services; using System.Collections.Generic; namespace RazorAPI.Controllers { [Produces("application/json")] [Route("api/Car")] public class CarController : Controller { private readonly ICarService _carService; public CarController(ICarService carService) { _carService = carService; } // GET: api/Car [HttpGet] public IEnumerable<Car> Get() { return _carService.ReadAll(); } } }
The controller is decorated with a couple of attributes. The
Produces
attribute specifies the content type that the controller works with, and the
Route attribute specifies the URL at which the service is available.
This controller only contains one method which responds to all
GET requests,
resulting in the collection of Cars being returned as JSON. You can see examples
of other operations at Working With JSON on
learnrazorpages.com. And this is
the key point about Web API resources- they are designed ot work with a variety
of CRUD operations and so are much more suitable if you want to do more than
just produce read-only data to be consumed by client code.
Once again, the only alteration required to the existing client code to make it work with the Web API approach is a change in the URL that's called:
@section scripts{ <script type="text/javascript"> $(function () { $.get('/api/car/').done(function (cars) { $.each(cars, function (i, car) { var item = `<li> <strong>${car.make} ${car.model}</strong> (£${car.price})</li>`; $('#car-list').append(item); }); }); }); </script> }
Summary
This article has looked at a number of ways to work with JSON in a Razor Pages application. The first option was a Razor Page handler method producing a JsonResult. While this works, it's not recommended - unless you are providing a small number of read-only operations. If that's the case, you should look to re-use existing pages with named handlers rather than cluttering your Pages folder with files that will invariably add routes to your application but are not intended to be navigated to.
An MVC Controller providing JsonResults offers an improvement over a Razor Page, in that you can work with them without having to add superfluous view files to the application. Web API really shines if you want to offer a full range of CRUD services in a RESTful manner - especially if you want to expose those services to third parties. | https://www.mikesdotnetting.com/article/318/working-with-json-in-razor-pages | CC-MAIN-2021-43 | refinedweb | 1,342 | 53.41 |
This is a compilation of common porting problems and their solutions.
Additionally to this page, also see the section General Porting Issues of, as well as further Debian-specific porting information.
There is a separate page about System API Limitations.
You may ask on the bug-hurd mailing list for details or questions about fixing bugs.
GNU build system
For a good overview of the components in the GNU build system, see and.
The GNU build system distinguishes between 'build', 'host' and 'target' machines. The 'build' machine is where compilers are run, the 'host' machine where the package being built will run, and for cross compiling the 'target' machine, on which the compiler built will generate code for.
When using GNU autotools to configure a package config.guess and config.sub from autotools-dev are used to find out the build machine identity: CPU_TYPE-MANUFACTURER-OPERATING_SYSTEM. For GNU/Hurd config.guess gives 'i686-unknown-gnu0.3'. Sometimes a quadruple is used adding KERNEL, e.g. for Linux on an amd64: 'x86_64-unknown-linux-gnu'. This is however actually a triple, it just happens that the operating system part unfortunately contains a '-'. config.sub is used to canonicalize on these triplets, e.g. config.sub i686-gnu gives 'i686-pc-gnu'.
On Debian systems the build Makefile is debian/rules and some Debian packages will set $host to 'i486-pc-gnu'. This is accomplished with the 'dpkg-architecture -qDEB_HOST_GNU_TYPE' construct forwarded to configure in debian/rules, e.g. configure --host=$DEB_HOST_GNU_TYPE. Another way to set $build, $host etc is via the Debian dh_auto_configure script from the debhelper package which uses the Perl code autoconf.pm to find out these variables.
Fixing configure.{ac,in}
The GNU/Hurd (and GNU/kFreeBSD) toolchain is extremely close to the GNU/Linux toolchain. configure.ac thus very often just needs to be fixed by using the same cases as Linux, that is, turn
switch "$host_os" in case linux*)
into
switch "$host_os" in case linux*|k*bsd-gnu*|gnu*)
for a host_os case statement, or
switch "$host" in case *-linux*)
into
switch "$host" in case *-linux*|*-k*bsd-gnu*|*-gnu*)
If separate case is needed, make sure to put -gnu after -linux:
switch "$host" in case *-linux*|*-k*bsd-gnu*) something;; case *-gnu*) something else;;
because else -gnu would catch i386-pc-linux-gnu for instance...
Note: some of such statements are not from the source package itself, but from aclocal.m4 which is actually from libtool. In such case, the package simply needs to be re-libtoolize-d.
Preprocessor Define
IRC, freenode, #hurd, 2013-10-23
<C-Keen> Is there a preprocessor define gcc sets for hurd which I can check in my code? <braunr> __GNU__ <braunr> glibc sets it if i'm right <C-Keen> I also see that __MACH__ gets set <azeem> that's also set on Mac OS X <C-Keen> right, which uncovered a bug in the code <braunr> the microkernel doesn't always implies what operating system runs on top of it <C-Keen> braunr: but __GNU__ is the correct define for hurd specific code? <braunr> yes
Undefined
bits/confname.h macros (
PIPE_BUF, ...)
If macro
XXX is undefined, but macro
_SC_XXX or
_PC_XXX is defined in
bits/confname.h, you probably need to use
sysconf,
pathconf or
fpathconf to obtain it dynamicaly.
The following macros have been found in this offending situation (add more if you find them):
PIPE_BUF
An example with
sysconf: (when you find a
sysconf offending macro, put a better example)
#ifndef XXX #define XXX sysconf(_SC_XXX) #endif /* offending code using XXX follows */
An example with
fpathconf:
#ifdef PIPE_BUF read(fd, buff, PIPE_BUF - 1); #else read(fd, buff, fpathconf(fd, _PC_PIPE_BUF) - 1); #endif /* note we can't #define PIPE_BUF, because it depends on the "fd" variable */,
MAX_PATH,
MAXPATHLEN,
_POSIX_PATH_MAX
Every unconditionalized use of
PATH_MAX,
MAX_PATH or
MAXPATHLEN is a POSIX incompatibility. If there is no upper limit on the length of a path (as its the case for GNU),. Usually it is thus simpler to just use dynamic allocation. Sometimes the amount is actually known. Else, a geometrically growing loop can be used: for instance, see Alioth patch or Pulseaudio patch. Note that in some cases there are GNU extensions that just work fine: when the
__GLIBC__ macro is defined,
getcwd() calls can be just replaced by
get_current_dir_name() calls.
Note: constants such as
_POSIX_PATH_MAX are only the minimum required value
for a potential corresponding
PATH_MAX macro. They are not a replacement for
PATH_MAX, just the minimum value that one can assume.
Note 2: Yes, some POSIX functions such as
realpath() actually assume that
PATH_MAX is defined. This is a bug of the POSIX standard, which got fixed in
the latest revisions, in which one can simply pass
NULL to get a dynamically
allocated buffer.
ARG_MAX
Same rationale as
PATH_MAX. There is no limit on the number of arguments.
IOV_MAX
Same rationale as
PATH_MAX. There is no limit on the number of iovec items.
MAXHOSTNAMELEN
Same as
PATH_MAX. When you find a
gethostname() function, which acts on a static buffer, you can replace it with Neal's xgethostname function which returns the hostname as a dynamic buffer. For example:
Buggy code:
char localhost[MAXHOSTNAMELEN]; ... gethostname(localhost, sizeof(localhost));
Fixed code:
#include "xgethostname.h" ... char *localhost; ... localhost = xgethostname(); if (! localhost) { perror ("xgethostname"); return ERROR; } ... /* use LOCALHOST. */ free (localhost);
NOFILE
Replace with
getrlimit(RLIMIT_NOFILE,...)
GNU specific
#define
If you need to include specific code for GNU GNU,. Unfortunaly coreutils (the above is a simplified version of what I found there.) Patches should of course be sent to upstream maintainers, this is very useful even for systems with a working
sys_errlist[].
Of course, if you don't care about broken systems (like MS-DOG) not supporting
strerror() you can just replace
sys_errlist[] directly (upstream might not accept your patch, but debian should have no problem)
C++,
error_t and
E*
On the Hurd,
error_t is an enumeration of the
E* constants. However, C++
does not like
E* integer macros being directly assigned to that enumeration. In short, replace
error_t err = EINTR;
by
error_t err = error_t(EINTR);
Missing
termio.h
Change it to use
termios.h (check for it properly with autoconf
HAVE_TERMIOS_H or the
__GLIBC__ macro)
Also, change calls to
ioctl(fd, TCGETS, ...) and
ioctl(fd, TCSETS, ...) with
tcgetattr(fd, ...) and
tcsetattr(fd, ...).
AC_HEADER_TERMIO
The autoconf check for
AC_HEADER_TERMIO tryes to check for termios, but it's only really checking for termio in
termios.h. It is better to use
AC_CHECK_HEADERS(termio.h termios.h)
missing
_IOT
This comes from ioctls. Fixing this is easy if the structure members can be expressed by using the _IOT() macro, else it's simply impossible... See
bits/termios.h for an instance:
#define _IOT_termios /* Hurd ioctl type field. */ \
_IOT (_IOTS (tcflag_t), 4, _IOTS (cc_t), NCCS, _IOTS (speed_t), 2)
The rationale behind is that on the Hurd ioctl numbers actually encode how the
data should be transferred via RPC: here
struct termios holds 4 members of
type
tcflag_ts, then
NCCS members of type
cc_tsi and finaly 2 members of
type
speed_ts, so the RPC mecanism will know how to transfer them.
As you can see, this limits the number of contiguous kinds of members to 3, and
in addition to that (see the bitfield described in
ioctls.h), the third kind
of member is limited to 3 members. This is a design limitation, there is no way
to overcome it at the moment.
Note: if a field member is a pointer, then the ioctl can't be expressed this way, and that makes sense, since the server you're talking to doesn't have direct access to your memory. Ways other than ioctls must then be found.
SA_SIGINFO
Implemented by Jérémie Koenig, pending upload in Debian eglibc 2.13-19.
SA_NOCLDWAIT
Not implemented yet.
SOL_IP
Not implemented yet.
HZ
Linuxish and doesn't even make sense since the value may vary according to the running kernel. Should use
sysconf(_SC_CLK_TCK) or
CLK_TCK instead.
SIOCDEVPRIVATE
Oh, we should probably provide it.
MAP_NORESERVE
Not POSIX, but we could implement it. See mmap.
O_DIRECT
Long story to implement.
PTHREAD_ERRORCHECK_MUTEX_INITIALIZER_NP
We could easily provide it;
PTHREAD_STACK_MIN
We should actually provide it.
linux/types.h or
asm/types.h
These are not POSIX,
sys/types.h and
stdint.h should be used instead.
iopl
Not supported and actually very dangerous (permits userland to completely disable interruptions...). Replace with
ioperm(0, 65536, 1).
semget,
sem_open
Not implemented, will always fail. Use
sem_init() instead if possible.
net/if_arp.h,
net/ethernet.h, etc.
Not implemented, not POSIX. Try to disable the feature in the package.
There is no programming interface for the parallel port on GNU/Hurd yet.
Use instead.
CBAUD
This is not actually standard; cfsetspeed, cfsetispeed, or cfsetospeed should be used instead.
IUCLC
IUCLC is a GNU extension. `#define GNUSOURCE' thus has to be used to get the definition (even if Linux unconditionally provides it, it should not).
errno values
When dealing with
errno, you should always use the predefined error codes defined with the
E* constants, instead of manually comparing/assigning/etc with their values.
For example (C/C++):
/* check whether it does not exist */ if (errno == 2) ...
or Python:
# check whether it does not exist try: ... except OSError, err: err.errno == 2: ...
This is wrong, as the actual values of the
E* are unspecified (per POSIX). You must always use the predefined constants for the possible errors.
For example (C/C++):
/* check whether it does not exist */ if (errno == ENOENT) ...
With Python, you can use the
errno module for the various constants:
# check whether it does not exist try: ... except OSError, err: import errno err.errno == errno.ENOENT: ...
undefined reference to
dlopen,
dlsym,
dlclose
Configure script often hardcode the library that contains dlopen & such (
-ldl), and only for Linux. Simply add the other GNU OS cases: replace
linux* with
linux*|gnu*|k*bsd*-gnu*
struct sockaddr,
sa_len/sa_family
IRC, freenode, #hurd, 2014-02-18
<braunr> if there is someone here that can help, i've traced the https issue in iceweasel down to nspr <braunr> the problem being that the hurd uses the old 4.4bsd sockaddr structure that includes sa_len before sa_family, and nspr directly maps that into its own structure, assuming the internal layout is the same <braunr> i need to change a configure script so that a macro is defined for the hurd <braunr> let's see if that works <braunr> better :) <braunr> there, ssl now works <braunr> \o/ <braunr> it's still the experimental one <braunr> and there are other minor issues <braunr> (like no logo on the about panel :p) <cluck> that's a feature^TM <braunr> maybe it's not a mistake <braunr> i haven't seen that version on linux to actually compare *** rbraun_hurd (c3445c23@gateway/web/freenode/ip.195.68.92.35) has joined channel #hurd <rbraun_hurd> webchat from freenode :) <teythoon> :D <rbraun_hurd> there is also this weird :"Failed to truncate cookie file: Invalid argument Failed to write cookie file: Unknown error (os/kern) 303" error <rbraun_hurd> but i guess it's simply a matter of supporting an option in glibc/hurd somewhere <braunr> 18:06 CTCP VERSION reply from rbraun_hurd: qwebirc v0.91, copyright (C) 2008-2011 Chris Porter and the qwebirc project -- Mozilla/5.0 (X11; GNU i686-AT386; rv:27.0) Gecko/20100101 Firefox/27.0 Iceweasel/27.0 <braunr> hm, i didn't version the iceweasel packages :/ <braunr> i'll rebuild them properly and put them on my repository <braunr> oh, the freenode webchat actually runs in gnash oO
IRC, freenode, #hurd, 2014-02-19
<braunr> <braunr> in short: nsprt has its own struct sockaddr, which it assumes to have the same layout as the native one <youpi> doesn't kfreebsd also have sockaddr_len ? <braunr> and of course, that's not the case on the hurd, because we use an old 4.4bsd header that defines sa_len before sa_family, making all sorts of tests fail in nspr <braunr> hm <braunr> i don't know <braunr> we could discuss that with them <braunr> but i doubt they don't use iceweasel :) <youpi> it really seems kfreebsd has sa_len etc. <youpi> kfreebsd really has sa_len <youpi> so put it in the new case too :) <braunr> i'll ask them first <braunr> something in nspr might already take care of the bsd case elsewhere <braunr> nspr knows more about bsd systems than it knows about the hurd :) <braunr> but with all these fixed, i could run iceweasel for a whole day at work, multiple tabs, gnash running (things like youtube and freenode web chat client among other things)
Missing
linux/types.h,
asm/types.h,
linux/limits.h,
asm/byteorder.h,
sys/endian.h,
asm/ioctl.h,
asm/ioctls.h,
linux/soundcard.h
These are often used (from lame rgrep results) instead of their standard equivalents:
sys/types.h (or
stdint.h for fixed-size types),
limits.h,
endian.h,
sys/ioctl.h,
sys/soundcard.h
Missing
sys/*.h,
linux/*.h
These are linuxish things, they may not have Hurd equivalents yet, better disable the code. | https://www.gnu.org/software/hurd/hurd/porting/guidelines.html | CC-MAIN-2014-23 | refinedweb | 2,176 | 63.39 |
In This Chapter
GDI+ Basics
Advanced Drawing
Custom Drawing in Windows Forms
Graphics Printing
Summary
The biggest gain that an object-oriented framework gives us is productivity. It's not necessarily that we can accomplish a greater variety of things with Graphics Device Interface (GDI+); rather, it's that we can be more productive in a shorter period of time. This productivity increase is provided to the framework developers too, resulting in a growing productivity for them as well.
You can walk from New York to Los Angeles, but you can get there a lot faster by car, or fastest of all by plane. Think of the 5- hour trip by plane from LaGuardia to LAX as a productivity gain of about 40 hours. (I am guessing here because I have made the trip from Michigan to Los Angeles and Michigan to New York several times but never coast to coast . I know with authority that you can listen to 30 hours of Ken Follett's The Pillars of the Earth while traveling from Las Vegas to Lansing by car.)
Is a 40-hour productivity gain valuable ? Let me rephrase that. Is a 90% reduction in travel timefrom 45 hours to 5worth the effort it takes to get that savings? You better believe it. A good object-oriented framework may not provide any more technical opportunities than assembly language does, but a good framework will provide a significant productivity gain. A big productivity gain is what Visual Basic .NET and GDI+ do for us.
GDI+ wraps API calls into tidy namespaces and classes and makes it easier to work with what is euphemistically referred to as a canvas, the device context (DC). Instead of requiring the individual developer to carefully manage the DC, the Graphics object provided by GDI+ is stateless and is easier to use than disjointed API calls. In this chapter you will find out how much easier it is to perform custom painting and drawing and create shaped and opaque forms, and how the GDI+ namespaces make it easier to render graphics on other objects like printers. | https://flylib.com/books/en/1.488.1.170/1/ | CC-MAIN-2020-34 | refinedweb | 350 | 59.43 |
Re: [PATCH 8/12] generic hweight{32,16,8}()
- From: linux@xxxxxxxxxxx
- Date: 31 Jan 2006 11:49:49 -0500
This is an extremely well-known technique. You can see a similar version
that uses a multiply for the last few steps at
whch refers to
"Software Optimization Guide for AMD Athlon 64 and Opteron Processors"
It's section 8.6, "Efficient Implementation of Population-Count Function
in 32-bit Mode", pages 179-180.
It uses the name that I am more familiar with, "pop***" (population count),
although "Hamming weight" also makes sense.
Anyway, the proof of correctness proceeds as follows:
b = a - ((a >> 1) & 0x55555555);
c = (b & 0x33333333) + ((b >> 2) & 0x33333333);
d = (c + (c >> 4)) & 0x0f0f0f0f;
#if SLOW_MULTIPLY
e = d + (d >> 8)
f = e + (e >> 16);
return f & 63;
#else
/* Useful if multiply takes at most 4 cycles */
return (d * 0x01010101) >> 24;
#endif
The input value a can be thought of as 32 1-bit fields each holding
their own hamming weight. Now look at it as 16 2-bit fields.
Each 2-bit field a1..a0 has the value 2*a1 + a0. This can be converted
into the hamming weight of the 2-bit field a1+a0 by subtracting a1.
That's what the (a >> 1) & mask subtraction does. Since there can be no
borrows, you can just do it all at once.
Enumerating the 4 possible cases:
0b00 = 0 -> 0 - 0 = 0
0b01 = 1 -> 1 - 0 = 1
0b10 = 2 -> 2 - 1 = 1
0b11 = 3 -> 3 - 1 = 2.
After this point, the masking can be delayed. Each 4-bit field holds
a population count from 0..4, taking at most 3 bits. These numbers can
be added without overflowing a 4-bit field, so we can compute
c + (c >> 4), and only then mask off the unwanted bits.
This produces d, a number of 4 8-bit fields, each in the range 0..8.
>From this point, we can shift and add d multiple times without overflowing
an 8-bit field, and only do a final mask at the end.
The number to mask with has to be at least 63 (so that 32 on't be truncated),
but can also be 128 or 255. The x86 has a special encoding for signed
immediate byte values -128..127, so the value of 255 is slower. On
other processors, a special "sign extend byte" instruction might be faster.
On a processor with fast integer multiplies (Athlon but not P4), you can
reduce the final few serially dependent instructions to a single integer
multiply. Consider d to be 3 8-bit values d3, d2, d1 and d0, each in the
range 0..8. The multiply forms the partial products:
d3 d2 d1 d0
d3 d2 d1 d0
d3 d2 d1 d0
+ d3 d2 d1 d0
----------------------
e3 e2 e1 e0
Where e3 = d3 + d2 + d1 + d0. e2, e1 and e0 obviously cannot generate
any carries.
-
To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
the body of a message to majordomo@xxxxxxxxxxxxxxx
More majordomo info at
Please read the FAQ at
- Follow-Ups:
- Re: [PATCH 8/12] generic hweight{32,16,8}()
- From: Grant Grundler
- Prev by Date: Re: CD writing in future Linux try #2
- Next by Date: Re: [PATCH 0/11] LED Class, Triggers and Drivers
- Previous by thread: [2.6 patch] wrong firmware location in IPW2100 Kconfig entry
- Next by thread: Re: [PATCH 8/12] generic hweight{32,16,8}()
- Index(es): | http://linux.derkeiler.com/Mailing-Lists/Kernel/2006-01/msg11467.html | crawl-001 | refinedweb | 577 | 77.57 |
2009/9/15 Bas Wijnen <address@hidden>: > On Tue, Sep 15, 2009 at 08:19:19PM +0200, Michal Suchanek wrote: >> 2009/9/15 Bas Wijnen <address@hidden>: >> > I have written a toy kernel for x86 some time ago, in the spirit of >> > discussions I had on this list with Shapiro and others. That kernel was >> > written in C. It worked, and I am still quite happy about it. If >> > others would have joined, it might have become a serious kernel, maybe >> > even the basis for the Hurd. >> > >> > However, nobody did, and I moved on as well. Recently, I started >> > writing a new kernel[0], for a mips-based mini-pc, mostly with the same >> > ideas, but now in C++[1]. Of course I'm not using any libraries, so no >> > new, virtual member functions, exceptions, or any other fancy things. >> > But I do sort my code in classes with normal member functions and >> > namespaces, and I do use default function arguments and a few templates >> > (but not the STL, because it uses new). >> > >> >> When you announced that you are writing this kernel you said something >> along the lines that it will be a sort of proof-of-concept >> implementation of some not-yet-finished ideas. > > It was. That was the toy kernel I was talking about. ;-) If one or two > people would have really liked it and helped me improve it, it might > have become more than a toy. For me to like a kernel I would need some information about properties or concepts the kernel implements that I find interesting. The posts I read were vague at best. > > However, I currently prefer to focus on Iris, because with her target > hardware, it is more likely that people will actually want to use it. I > don't see any way to get people to change their desktop system. After > all, a new system will for quite some time have problems such as missing > drivers. I would rather work on system that runs on x86 because it's easier to find hardware for testing once the system can run. However, I think I can get at some arm based access points or a SGI O2 easily (iirc you said the target is arm and mips) so this is not that much of a problem, especially similar access points should be easy to get anywhere. > >> I was somewhat curious about the results because the kernel was >> supposed to have a resource management which was based on ideas that I >> could not imagine working. > > Well, it can run nethack. ;-) That does mean it is almost completely > functional. What do you mean by "not working"? That is doesn't run, or > that it is extremely slow? I didn't do any benchmarks, and obviously > nethack isn't a heavy application, so not having performance issues > there doesn't mean anything. Also, as I wrote in the announcement, I > didn't even try to make my libc fast; it was only intended to make > nethack run so I could see (and show) that the kernel worked. Performance is quite relative because there are many measurements that can be applied which are relevant to different cases. For one startup time is important for desktops and 24/7 services. However, systems with long startup time but short resume time and suspend support would rate better than systems with mediocre startup time and no suspend support for this purpose. Similarly a 24/7 service that runs on reliable system that needs very few restarts and does not crash may rate better than service on a less reliable system with shorter startup time. CPU performance is important for batch processing but desktops and many other application may be more interested in event latency - the time it takes to process a keypress or a packet received from the network. So extremely slow is relative. You should be able to find an application for which the kernel performs decently. For the kernel to be interesting for me I would want to see something different from the other kernels available. The resource management was supposed to be such thing. From what I read on the list I never get a clear idea how that is supposed to work and never saw an update on that. So is the resource management finished and working somehow? Is it documented somewhere? Or does it work without one? It's certainly possible to run a system without one, most popular systems work like that these days. Thanks Michal | http://lists.gnu.org/archive/html/l4-hurd/2009-09/msg00012.html | CC-MAIN-2016-30 | refinedweb | 752 | 69.52 |
My main track on the PDC will be Indigo. What Indigo exactly is, is officialy a mystery but I do have an idea I use as a working hypothesis. To me Indigo is a way to route (xml-based) messages through any (inter-)network, where the hops from network node to network node and the means of transport used are just a property of the message itself. This theory has been fed by Keith Ballinger's msdn tv talk on WSE 2.0 and the session list for the PDC. As a preparation to the PDC I am now studying the WSE "technology preview".
In the current asp.net you can build webservices which are always hosted by IIS and where the invocation of a webservice by a consumer boils down to making a (remote) procedure call. In WSE you can not only use HTTP but also TCP to access a web (soap) service. Hosting a service which can be accessed over TCP is far simpler (and faster). You don't need (to configure) IIIS. Instead of the webservice baseclass, you use the soapservice base-class. An attribute publishes the method
public class MyDocService : SoapService{ [SoapMethod(MyDocCenter.ActionSend)] public void SendDoc(MyDocument doc) { // Implementation here }}
Register the method as being accessible, like this :
SoapReceivers.Add(new Uri(string.Format("soap.tcp://{0}/MySoapBox", System.Net.Dns.GetHostName())), new MyDocService());
And now everybody can send messages to your method using the TCP protocol. The most promising thing in this approach is that the protocol to use is a parameter to the listener started. In WSE 2 you can choose between tcp and http, in Indigo I expect message queues (and maybe smtp/pop) to be a possible choice as well. In the consumer is an interesting point as well. A consumer inherits from the SoapClient base class. This class has two methods two send the soap-message, SendRequestResponse and SendOneWay, pushing the metaphor of "making a call" to "sending a message".
In the current asp.net the consumer of the service has to know the endpoint address of the machine who is going to service the request. WSE introduces routing. A web service router receives requests from consumers and can route these request to another address which will service it. This routing is quite basic, the request can only be routed to an endpoint which provides the service. To keep up the networking analogy I would call this a web-services-switch. But the potential of all of this is gigantic. Imagine a real router which can route a message to another router and switches transport protocols as needed. In what I think (hope) will be Indigo we don't have to care to much about this and can fully concentrate on the content of the messages. In a month we'll all know more, for the moment I will browse some more in the WSE stuff, I don't think that will | http://codebetter.com/blogs/peter.van.ooijen/archive/2003/10/01/1969.aspx | crawl-002 | refinedweb | 492 | 64.3 |
RE: .net framework version, visual studio '03
- From: Charlie <c2farr@xxxxxxxxx>
- Date: Thu, 27 Sep 2007 20:11:01 -0700
You can use a config file to direct the runtime to use a particular version
of the framework.
The config file must be named the same as the dll or the exe, but with
..config at the end...
MyApp.exe.config
MyAppLib.dll.config
You can write the config file, if it does not already exist, in notepad, and
add it to the project.
Here is an example of a config file
<?xml version ="1.0"?>
<configuration>
<startup>
<supportedRuntime version="v1.1.4322" />
</startup>
</configuration>
Just name the file as stated above, and use one of these files for each
project in the solution. Also...get the exact version number for 3.0 and
insert it in place of version="v1.1.4322" as shown above.
Caution: AT DESIGN TIME, when attempting to use a later version of the
framework using an older version of VB.net, your design-time views of forms
may not be available. To alleviate this, use the compatible framework that
your design environment was intended for. When you compile for runtime, you
can switch out the referenced assemblies and add the config file. (Actually,
I think you only have to switch one reference for each project, and the rest
happen automatically.)
This is a tricky proposition, because you are actually writing code as
though it will be compiled against the expected framework. I would only
suggest doing this if you have a distinct reason for doing so.
Recently, I needed the System.Net.Mail namespace instead of the
System.Web.Mail namespace due to an additional method that I needed. Except
when I was testing for that method, I still was running the compatible
framework. When compiling the release, I did the switch. (You need to be
sure the config file is properly directed, or only present when compiling to
the "mis-matched" framework).
You should do serious beta testing for compatibility issues.
By default, I think that the compiled exe and dll's, whatever framework they
are compiled to run under, will find the closest framework available on the
system they are running on (unless the config file provides distinct
direction).
"jroozee@xxxxxxxxx" wrote:
I am developing in VS '03. I have all of the current framework.
versions installed on my PC, 1.1, 2.0, and 3.0.
How can I make sure the code I am developing in is using the 3.0
framework version? Or do I need to be using the latest version of
Visual Studio to do so?
Thanks,
Jason
- References:
- .net framework version, visual studio '03
- From: jroozee
- Prev by Date: Re: How to use WaitforSingleObject on events
- Next by Date: Re: .net framework version, visual studio '03
- Previous by thread: .net framework version, visual studio '03
- Next by thread: Re: .net framework version, visual studio '03
- Index(es): | http://www.tech-archive.net/Archive/DotNet/microsoft.public.dotnet.languages.vb/2007-09/msg01409.html | crawl-002 | refinedweb | 491 | 67.65 |
The future is here, and you’re loving every single second of writing your React code with Hooks. You’re all like “useThis” and “useThat” and are having the time of your life implementing cross-cutting concerns with this new React feature.
Then, out of nowhere, your manager tells you to fix a bug in some existing code. You know, that legacy crap you wrote in December of 2018? You realize you have to touch class components with lifecycles and
this. That hook you wrote yesterday would fix the bug in a second, but since class components don’t support hooks, you’re stuck doing it “the old way”. What should you do?
This article is going to show you two techniques to deal with these situations — creating HOCs from your hooks, and creating hooks from your HOCs.
Wait, what’s a HOC?
A HOC — or a higher order component — is a function that accepts a component, and returns a component that renders the passed component with a few extra props or capabilities. The React docs does a great job explaining them in more detail.
Creating HOCs from your Hooks
Why would you ever want to make your fancy, sleek Hooks into clunky, ol’ HOCs? Sounds like we’re going backwards, right? Well, not really. We’re providing a migration path that lets us use our hook logic in class components. This way, we can start using new code in old components without rewriting potentially complex logic.
Implementing a HOC that provide your Hook API is pretty straight forward.
const withMyHook = Comp => () => { const hookData = useMyHook(); return <Comp ...{hookData} {...props} />; }
In the code shown above, we create a function that receives a component as an argument and returns a new function component. This function component calls our hook and passes any return values to the passed component.
If your hook implementation requires static data, you can pass it in as an argument:
const withMyHook = hookArgs => Comp => () => { const hookData = useMyHook(hookArgs); return <Comp {...hookData} {...props} />; }
Here, we pass our static data to our HOC, which returns another HOC. It’s known as currying, and it’s basically functions returning functions. You’d use it like this:
const MyDecoratedComponent = withMyHook({ some: ‘value’ })(MyComponent);
If your hook needs data based on props, you might want to consider using the render prop pattern instead:
const MyHook = (props) => { const hookData = useMyHook(props.relevantData); return props.children(hookData); }
Your implementation may vary — but you can put different implementations into the module you store your hook in, and export the HOC version or render prop version as named exports.
You would use these HOCs the same way you’d use any HOC — wrap the component you want to enhance with it.
class MyComponent extends React.Component { … }; const MyEnhancedComponent = withMyHook(MyComponent);
Creating Hooks from your HOCs
If you’re working with any non-trivial app, your code base is most likely going to contain a few HOCs and render props components. As you continue to refactor your app, you might want to migrate away from these and recreate your existing shared logic as hooks.
The biggest challenge in rewriting your HOCs and render prop based components to hooks is the change in paradigms. Previously, you thought in terms of lifecycle methods — now you’ll have to think about renders and how props are changing.
The always great Donavon created this nice chart that tries to map the two paradigms together:
There aren’t any generic patterns to follow here, but instead, I’ll show an example. By the end, you’ll have a few ideas for your own rewrites.
withScreenSize => useScreenSize
withScreenSize is a utility that provides the current screen size to our component. It’s implemented like this:
import React from ‘react’; import debounce from ‘debounce’; const withScreenSize = Comp => { return class extends React.Component { state = { width: null, height: null }; updateScreenSize = debounce(() => { this.setState({ width: window.screen.width, height: window.screen.height }); }, 17); componentDidMount() { window.addEventListener(‘resize’, this.updateScreenSize); } componentWillUnmount() { window.removeEventListener(‘resize’, this.updateScreenSize); } render() { return <Comp {...this.props} screenSize={this.state} /> } }; }
We can implement this with Hooks like so:
import React from ‘react’; import debounce from ‘debounce’; const useScreenSize = () => { const [screenSize, setScreenSize] = React.useState({ width: window.innerWidth, height: window.innerHeight, }); const updateScreenSize = debounce(() => { setScreenSize({ width: window.innerWidth, height: window.innerHeight, }); }, 17); React.useEffect(() => { window.addEventListener(‘resize’, updateScreenSize); return () => { window.removeEventListener(‘resize’, updateScreenSize); }; }, []); return screenSize; };
We store the width and height via the
useState hook, and initialize it to be the window dimensions while mounting the component. Then, we re-implement the
updateScreenSize method by using the setter from the
useState call above. Finally, we apply the resize listener by using the
useEffect hook. Notice that we’re passing an empty dependency array — that means it’ll only run once.
Remember — if you want to keep supporting class components, you can write a wrapper HOC:
const withScreenSize = Comp => props => { const screenSize = useScreenSize(); return <Comp {…props} screenSize={screenSize} />; };
Jump on the bandwagon, already!
Hooks are here to stay, and they’re about to simplify your code base in a big way. In order to migrate away from existing patterns, however, you’re going to have to compromise at times.
This article shows how you can write wrappers around your existing HOCs and render props components, as well as how you can get started refactoring your existing HOCs to be Hooks.
What challenges have you faced while migrating away from HOCs?.
3 Replies to “How to migrate from HOCs to Hooks”
Great article.
Featured at
Nice article, i’m a react newbie i was wondering where should be placed the HOC (withScreenSize) and the custom hook, i mean should i create a folder called “hocs” and “hooks” to place these files in the project?
Hi!
If it’s a one-off hook, i would place it in the component file it was used. If it’s reused a lot, I’d pull it out into it’s own file and perhaps place that file in a utils folder.
To be honest, how you place your files doesn’t matter all that much. Do what feels right to you. 🤗 | https://blog.logrocket.com/how-to-migrate-from-hocs-to-hooks-d0f7675fd600/ | CC-MAIN-2019-39 | refinedweb | 1,018 | 56.35 |
C# 3.0 Features That Support LINQ
Updated: September 2008
The following section introduces the new language constructs in C# 3.0. Although these new features are all used to a degree with LINQ queries, they are not limited to LINQ and can be used in any context where you find them useful.
Queries expressions use a declarative syntax similar to SQL or XQuery to query over IEnumerable collections. At compile time query syntax is converted to method calls to a LINQ provider's implementation of the standard query operator extension methods. Applications control the standard query operators that are in scope by specifying the appropriate namespace with a using directive. The following query expression takes an array of strings, groups them according to the first character in the string, and orders the groups.
For more information, see LINQ Query Expressions (C# Programming Guide).
Instead of explicitly specifying a type when you declare and initialize a variable, you can use the var modifier to instruct the compiler to infer and assign the type, as shown here:
Variables declared as var are just as strongly-typed as variables whose type you specify explicitly. The use of var makes it possible to create anonymous types, but it can be used for any local variable. Arrays can also be declared with implicit typing.
For more information, see Implicitly Typed Local Variables (C# Programming Guide).
Object and collection initializers make it possible to initialize objects without explicitly calling a constructor for the object. Initializers are typically used in query expressions when they project the source data into a new data type. Assuming a class named Customer with public Name and Phone properties, the object initializer can be used as in the following code:
For more information, see Object and Collection Initializers (C# Programming Guide).
An anonymous type is constructed by the compiler and the type name is only available to the compiler. Anonymous types provide a convenient way to group a set of properties temporarily in a query result without having to define a separate named type. Anonymous types are initialized with a new expression and an object initializer, as shown here:
For more information, see Anonymous Types (C# Programming Guide).
An extension method is a static method that can be associated with a type, so that it can be called as if it were an instance method on the type. This feature enables you to, in effect, "add" new methods to existing types without actually modifying them. The standard query operators are a set of extension methods that provide LINQ query functionality for any type that implements IEnumerable<T>.
For more information, see Extension Methods (C# Programming Guide).
A lambda expression is an inline function that uses the => operator to separate input parameters from the function body and can be converted at compile time to a delegate or an expression tree. In LINQ programming, you will encounter lambda expressions when you make direct method calls to the standard query operators.
For more information, see:
Auto-implemented properties make property-declaration more concise. When you declare a property as shown in the following example, the compiler will create a private, anonymous backing field that is not accessible except through the property getter and setter.
For more information, see Auto-Implemented Properties (C# Programming Guide). | http://msdn.microsoft.com/en-us/library/bb397909(v=vs.90).aspx | CC-MAIN-2014-41 | refinedweb | 550 | 50.36 |
Products and Services
Downloads
Store
Support
Education
Partners
About
Oracle Technology Network
Name: mc57594 Date: 02/06/97
A program which calls the static method getDefaultToolkit()in
class Toolkit won't terminate. The following is a simplest
java source code for this bug.
import java.awt.*;
class Test {
public static void main(String[] args) {
Toolkit.getDefaultToolkit();
}
}
After starting this program, it should return to OS. However,
it hangs there forever.
I use Window 95. I have tried this program on several different
machines, e.g, standalone ones and network-attached ones, the
problem is the same.
company - dept of comp. sci. King's College London , email - ###@###.###
======================================================================
Name: tb29552 Date: 02/08/99
When java.awt.SystemColor is loaded, it calls Toolkit.getDefaultToolkit(), which
creates two AWT threads. These threads never stop, and they are not daemon
threads, so the program hangs.
The following code demonstrates this problem:
public class SimplCon {
public SimplCon() {
}
static public void main(String args[]) {
java.awt.Color color = java.awt.SystemColor.window;
}
}
Note: I have reproduced this problem on a Windows 98 and NT 4.0
machine. It only happens when you use JDK 1.2. It works fine in JDK 1.1.7A.
======================================================================
Name: vi73552 Date: 06/14/99
The AWT threads are *still* not Daemon threads (reported as bug 4030718).
I have presented Sun with a fix for this, which they've had for 7 months.
It's not that the problem is not fixable - so how come no-one has even
evaluated the bug/fix? The report shows up as useless.
(Review ID: 84317)
======================================================================
Name: tb29552 Date: 04/03/2000
java version "1.3.0rc2"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.3.0rc2-Y)
Java HotSpot(TM) Client VM (build 1.3.0rc2-Y, interpreted mode)
In developing a system which needs to shutdown the grapics environment, I have
found that it is impossible to cleanly close down the awt. The natively
implemented event loop thread never checks for Java exceptions or any other
exit condition, and as Thread.stop() is now deprecated, it is impossible to
cleanly bring down the display. Here is the excerpt from awt_Motif.c as it
stands - the possiblity of exitting has been considered by the authors, but not
implemented...
...
/*
* ACTUALLY PROCESS EVENTS
*/
while(True) {
...
waitForEvents(env, fdXPipe, AWT_READPIPE);
...
} /* while(True) */
/* If we ever exit the loop, must unlock the toolkit */
...
(Review ID: 103193)
======================================================================
SUGGESTED FIX
Date: Fri, 6 Nov 1998 10:40:57 +0000 (GMT)
From: Alex Blewitt <###@###.###>
To: Tom Ball <Thomas.Ball@Eng>
cc: ###@###.###, ###@###.###
Subject: 100% pure way of closing applications
MIME-Version: 1.0
Folks,
I have written a solution to the problem, and am enclosing it with this
e-mail. I have tested it under Solaris 5.6/JDK 1.1 and it seems to work.
To demonstrate the problem, I have created a new EventDispatch thread and
a new Window class (in alex.awt.*). This demonstrates the feasibility
without requiring me to hack around with the internal JVM stuff itself.
It uses a blocker thread to prevent the JVM from quitting whilst there is
still 'active' processing to be done, but does have the processing thread
as a daemon one.
Javaworld: I'm copying you on this, because I'm sure that Bill Venners or
Mark Johnson would love to write an article on the use of a BlockerThread.
It's quite appropriate for command line tasks and other non-AWT related
tasks where you need to have a Daemon server thread processing events.
I've enclosed just the Java source file (contains 3 classes in alex.awt
package). I've written JavaDoc comments for the source code, and checked
that it a) compiles b) runs and c) generates nice(ish) JavaDoc stuff about
what's going on. (If you're generating JavaDoc, make sure you've got the
-private flag on :)
To test it:
java alex.awt.Example
-> creates a test thread, starts it, and will quit (expected)
java alex.awt.Example 1
-> creates a window, makes it visible, and will hang (expected)
java alex.awt.Example 1 2
-> creates a window, hides it, and will quit (expected)
java alex.awt.Example 1 2 3
-> creates an event and puts it in the queue, and will hang (expected)
java alex.awt.Example 1 2 3 4
-> creates an event, puts it in the queue, processes it, and quits
(expected)
There you go. You wanted a solution, you got one :-)
I'll be happy to defend this solution against any problems that are
presented about it. I will stake my reputation on it working for over 95%
of the existing apps :-)
NB: Copyright and use of the software are up for grabs to be put in either
an article, or merged into Java source code. All I ask is that it is
acknowledged somewhere.
I look forward to hearing your feedback about this,
Alex.
/***************************************************************|* Alex Blewitt * Hug, and the world hugs with you *|
|* ###@###.### * *|
|* Mobile: + 44 966 158647 * Spread a little happiness *|
\***************************************************************/
package alex.awt;
/**
* Example code to show the ExampleWindow objects.
* <p>
* This tests the principles behind the ExampleDispatchThread,
* and easily shows that it is possible to overcome the 'bug' which
* stops the JVM from working nicely.
* <p>
* Usage:
* <p>
* Run with different numbers of arguments (can be any values)
* to see different effects.
* <dl>
* <dt>No arguments
* <dd>Creates and runs the Thread, but doesn't generate any AWT-like events. Quits.
* <dt>One argument
* <dd>Creates a window and makes it visible. Hangs.
* <dt>Two arguments
* <dd>Generates a window, shows it, and then closes it. Quits.
* <dt>Three arguments
* <dd>Generates an event, and puts it in the event queue. Hangs.
* <dt>Four arguments
* <dd>Generates an event, inserts it into the queue, processes it. Quits.
* </dl>
*/
class Example {
public static void main(String args[]) {
// system would set up the AWT Thread normally
ExampleDispatchThread edt = new ExampleDispatchThread();
edt.setDaemon(true);
edt.start();
switch(args.length) {
case 0:
// quits
System.out.println("No windows created; running to end of loop");
break;
case 1:
// hangs until the 'user' closes it
System.out.println("Generating a window and making it visible");
new ExampleWindow().setVisible(true);
break;
case 2:
// quits
System.out.println("Generating a window, and closing it again");
ExampleWindow ew = new ExampleWindow();
ew.setVisible(true);
ew.setVisible(false);
break;
case 3:
// hangs until 'event' is processed
System.out.println("Generating an event, and putting it in the Queue");
edt.insertEvent("an event");
break;
case 4:
// quits
System.out.println("Generating an event, putting it in and processing it");
edt.insertEvent("an event");
edt.removeEvent();
break;
}
}
}
/**
* This is a representation of a Window object.
* (Do not use the real Window to prevent the AWTThread kicking in).
* The only important methods that are provided here is the setVisible()
* method. Could equally be used for the Constructor/dispose() instead of
* the setVisible true/false. Obviously call super.setVisible() if
* you're using a real component.
*/
class ExampleWindow {
private static int numberOfVisibleWindows = 0;
private boolean visible;
/**
* Sets the Window to be visible (true) or not (false). When no visible
* windows are left, the AWT will quit.
*/
public void setVisible(boolean visible) {
// super.setVisible();
if (this.visible != visible) {
// it's changed
if (visible) {
numberOfVisibleWindows++;
ExampleDispatchThread.setVisibleWindows(true);
} else {
numberOfVisibleWindows--;
if (numberOfVisibleWindows == 0) {
ExampleDispatchThread.setVisibleWindows(false);
}
}
}
this.visible = visible;
}
}
/**
* A pseudo DispatchThread. Kind of rolls the event queue and
* Thread into one for the purposes of this example, although in
* the real AWT they are different.
* <p>
* Also uses a static based resolver instead of a singleton type
* method. Again, to get the point across in a succint a way possible.
* @see #anyVisibleWindows
* @see #anyRemainingEvents
* @see BlockingThread
*/
class ExampleDispatchThread extends java.lang.Thread {
// used to block the JVM from quitting
private static BlockingThread blockingThread;
// used to store a single event object, for purposes of example
private static Object eventQ;
// used to store a copy of the # visible windows. Could equally be
// well implemented directly using the Window class.
private static boolean visibleWindows;
/**
* Called by the Window class to tell the EventDispatchThread that
* there are visible windows. Must do this so that a BlockingThread
* is created.
* @see #update
*/
static void setVisibleWindows(boolean visible) {
visibleWindows = visible;
update();
}
/**
* Called internally to find out if there are any visible windows.
* Could be re-written at a later stage to enquire from the Window
* class directly; however, the Window class must still notify the
* EDT to let it know when a Window is created/disposed.
* @see ExampleWindow
* @see #update
*/
private static boolean anyVisibleWindows() {
return visibleWindows;
}
/**
* Called internally to find out if there are any remaining events.
* Could be re-written at a later stage to enquire from the EventQueue
* class directly; however, the EventQueue class must still notify the
* EDT to let it know when an Event is inserted/removed.
* @see #update
*/
private static boolean anyRemainingEvents() {
return (eventQ != null);
}
/**
* Inserts a dummy event into the queue. If EventQueue is being used,
* must have some kind of callback so that update() can be called.
* @see #update
*/
public static void insertEvent(Object o) {
eventQ = o;
update();
}
/**
* Removes (processes) an event from the queue. If EventQueue is being used,
* must have some kind of callback so that update() can be called.
* @see #update
*/
public static Object removeEvent() {
Object result = eventQ;
eventQ = null;
update();
return result;
}
/**
* Makes sure that the system only blocks the JVM iff there are no
* more events and no more windows.
* <p>
* Must be called whenever there is a change in anyVisibleWindows()
* or anyRemainingEvents().
* @see #anyRemainingEvents
* @see #anyVisibleWindows
* @see #setVisibleWindows
* @see #insertEvent
* @see #removeEvent
*/
private static void update() {
if (anyVisibleWindows() || anyRemainingEvents()) {
createBlockingThread();
} else {
destroyBlockingThread();
}
}
/**
* Helper method to create a BlockingThread. If one exists
* already, this method has no effect.
* <p>
* This method is effectively class synchronized if a blocking thread
* does not exist. However, this lock is only obtained if necessary.
*/
private static void createBlockingThread() {
if (blockingThread == null) {
synchronized(ExampleDispatchThread.class) {
if (blockingThread == null) {
blockingThread = new BlockingThread();
blockingThread.start();
yield();
}
}
}
}
/**
* Helper method to remove the BlockingThread.
* Kills it off by sending it the die() request,
* and then nullifying the (static) reference.
*/
private static void destroyBlockingThread() {
blockingThread.die();
blockingThread = null;
yield();
}
/**
* Demo processing loop. In a real situation, this
* would be calling requests to getNextEvent() or similar.
* Currently indefiniately blocks to show that the AWT Daemon
* thread is running.
*/
public void run() {
// demo loop; just hangs to prove a point
while(true) {
try {
synchronized(this) { wait(); }
} catch (Exception e) {
}
}
}
}
/**
* Blocker thread.
* <p>
* Once started, this thread will continue to run in the background
* using the wait primitive. As a result, will take up minimal resources
* once running.
* <p>
* The purpose of this thread is to prevent the JVM from accidentally
* quitting before the time is ripe. Once told to die(), the BlockingThread
* will tidy itself up and allow the JVM to quit (providing that there
* are no more non-Daemon threads).
* <p>
* Example:
* <pre>
* BlockingThread bt = new BlockingThread();
* bt.start(); // will cause the JVM to not quit
* // some time later
* bt.die(); // the JVM is now free to quit
* </pre>
* @see #die
*/
class BlockingThread extends java.lang.Thread {
private boolean running = true;
/**
* Asks this BlockingThread to tidy itself up.
* Cleanly finishes by running off the bottom of the
* run method, so is lock-safe.
*/
public void die() {
running = false;
this.interrupt();
}
/**
* Runs in a resource friendly perpetual loop.
* <p>
* Will terminate on two conditions:
* <ol>
* <li>If an Error is generated whilst the Thread is wait()ing
* <li>If the die() method has been called
* </ol>
*/
public void run() {
while(running) {
try {
synchronized(this) { wait(); }
} catch (Exception e) {
}
}
}
}
WORK AROUND
Name: tb29552 Date: 10/27/99
Call System.exit() when it is time to shut down the app.
(Review ID: 97019)
======================================================================
EVALUATION
Commit for Kestrel.
eric.hawkes@eng 1999-06-22
Any fix which involves changing the EventDispatchThread, PostEventQueue, and
Toolkit threads to daemon suffers from a major design problem.
Recall that a new, child thread inherits the daemon status of its parent
thread. By making the EventDispatchThread daemon, we would change the deafult
daemon state of all threads spawned by client code in event handlers. This
is a fairly common thing to do (e.g., Swing worker threads). Previously,
daemon-ness didn't matter in an AWT application, because the app would never
exit anyways. If this bug were fixed, it definitely would matter. That's okay,
as long as the default for client code threads is non-daemon. Changing this
default breaks the class of applications which relies on the current
default daemon state. It is unlikely that every developer has been careful
enough to set the daemon status of all of their threads explicitly.
We are continuing to consider other options, including minor API changes, more
complicated fixes, and command-line switches.
david.mendenhall@eng 1999-09-10
Customer indicates that their product will ship before Kestrel is released.
It appears that more substantial changes are necessary to address this
issue correctly. We will continue to investigate this for Merlin.
eric.hawkes@eng 1999-10-05
Another report that is similar: 4291432 should also be addressed for Merlin.
eric.hawkes@eng 1999-11-16
I am recategorizing this as an RFE, since it is a request for a rearchitecture
of the AWT, and requires new public APIs. We have committed to fix this in Merlin.
eric.hawkes@eng 2000-03-08
Apparently, this fix was broken late in Merlin. 4515058 has been filed
about it. It is probably too late to fix the problem in Merlin, but we
will try to fix it as soon as we can.
###@###.### 2001-11-09
No, I'm wrong. It isn't broken. We just found one case that doesn't exit.
All the other tests I tried exit just fine.
###@###.### 2001-11-15
The solution is
1) to make the toolkit thread daemon and
2) to start an AWT event dispatch thread only when the first java event appears
in its associated event queue and
3) to stop all the event dispatch threads when all three conditions become true:
1. There are no displayable AWT or Swing components.
2. There are no events in the native event queue.
3. There are no events in java event queues.
When all the event dispatch threads are terminated, the VM will exit
if there are no other alive non-daemon threads.
This solution implies that normally if an application uses AWT, the
only legal cases for VM to not terminate are as follows:
1. There is an alive non-daemon thread that doesn't belong to AWT
(see Thread.isAlive() and Thread.isDaemon()).
2. There is a displayable component (see Component.isDisplayable()).
3. An AWT event is processed on one of AWT event dispatch threads.
To write an AWT application that will terminate without System.exit(),
one should do the following:
1. Stop all non-daemon threads that the application has started.
2. Make all components undisplayable.
3. Make sure that the application doesn't continuously post synthetic
AWT events to the AWT event queue or that it doesn't post an AWT event
which processing cannot complete (e.g. an ActiveEvent that
starts an infinite loop in its dispatch() method).
###@###.###
###@###.### 2002-04-15
CONVERTED DATA
BugTraq+ Release Management Values
COMMIT TO FIX:
merlin
FIXED IN:
merlin-beta
INTEGRATED IN:
merlin-beta | http://bugs.sun.com/view_bug.do?bug_id=4030718 | CC-MAIN-2013-48 | refinedweb | 2,538 | 58.28 |
.
Downloaded your source and ran into a bug..
the constants in the CRMOnlineCOnnector (show below) are different than the property values gen'd in the xml file for the BDC application
public class CRMOnlineConnector : ISystemUtility, IAdministrableSystem
{
const string crmProxyServiceUrlPropertyName = "CRMProxyServiceReferenceUrl";
const string crmServerPropertyName = "CRMServer";
//the need to be changed to this – or update the xml values gend for the bdc file to import
const string crmProxyServiceUrlPropertyName = "CRMProxyServiceUrl";
const string crmServerPropertyName = "CRMServerUrl";
The /createdevicecredentials switch doesn't exist on the crmbcsutil.exe command. How do you generate the required device credentials? I was following the directions in the provide word document in the zip file. Thanks!
Mike,
I'll investigate it when I get a chance. The code is essentially using the DeviceIdManager class to create the device credentials. You can modify the code to do it pretty easily. Please see here for reference: msdn.microsoft.com/…/gg328147.aspx
You can also use this tool (created by one of our MVPs) to create the device credentials: archive.msdn.microsoft.com/…/ProjectReleases.aspx.
Thanks,
-Girish.
Hi Girish, I was able to run the deviceregistration tool from SDK. However, I'm still having issues getting this to work. I'm able to generate the out.bdcm file just fine.'.
Any ideas on what I need to do get this to work? Thanks
I was able to solve the import failed issue. For some reason all the .DLLs did not get put into the GAC during the .wsp upload. I copied both CRMEntityService.SharePoint and CRMEntityService.SharePoint.Connector dlls into the GAC and then did a iisreset on all the sharepoint servers and it worked.
Now the only issue is that I'm getting all the records back that I think I should be. So I'm looking into what might be causing records to be filtered.
Otherwise this thing is pretty cool. Sure hope it gets more support moving forward.
Glad that you're able to get it working Mike.
Regarding the list of records, we're doing a simple pull of data for the current user. You can certainly modify the query to bring the data you need.
Thanks,
-Girish.
Looks like there is a limit filter setup by default that only retreives 30 rows which is causing the result. Anyway should be able to remove this from the bdcm file and be good to go.
Girish,
First I would like to thak you for a very nice presentation and the code.
I have gotten to the point where the web part in SharePoint asks me to authenticate against CRM. Once the authentication goes trhough, I get the following error:
Unable to display this Web Part. To troubleshoot the problem, open this Web page in a Microsoft SharePoint Foundation-compatible HTML editor such as Microsoft SharePoint Designer. If the problem persists, contact your Web server administrator.
Correlation ID:182cac5d-a2f8-4a47-bb56-e2f62bc0b8e0
I found some posts about the item limit and changed it up, but I'm still getting the error. Any ideas?
Thanks,
Dick M.
Addendum to my previous question-
It seems that the external content type can't recognize identity columns or null values. I saw a few online posts about this.
I've created a profile page for "Account" and the page returns the following error:
Item not found in CRM Online (Steward).
Correlation ID:f3268b95-e903-43cd-b461-7ed9439893b3
The query could not be executed because one or more identifier values could not be converted to the proper type. The exception was: 'System.IO.InvalidDataException: Found invalid data while decoding. at Microsoft.BusinessData.Runtime.Identity.DecodeElement(String s, Int32& index) at Microsoft.BusinessData.Runtime.Identity.Deserialize(String serializedIdentity) at Microsoft.SharePoint.Portal.WebControls.BdcUtility.FindEntity(IEntity entity, String finderName, Object[] userValues, ILobSystemInstance lobSystemInstance)'.
Do you have any insight on this?
Thanks,
Dick
The generated BCDM appears to have some superfluous tags, I had to remove all instances of <TypeDescriptors/> for the BCDM file to pass validation.
@Dick
I'm getting exactly the same error message. Can you share tips on how you solved it?
Thanks
I checked out the ULS logs and there seems to be some exception in the *CRMEntityService.SharePoint.Connector.CRMOnlineConnector.ExecuteStatic* method. I just uploaded the logs here on <a href="pastebin.com/…/a>. Can you go through it once and tell me where exactly things are going wrong?
Hi all
If you get an error regarding "Entity xy does not contain attribute StateCode", you have to change EntityService.cs, line 147 to:
if(entityMetadata.Attributes.Keys.Contains("statecode"))
{
qe.Criteria.AddCondition(new ConditionExpression("statecode", ConditionOperator.Equal, new object[] { 0 }));
}
or remove the condition altogether and do the filtering (if desired at all) on the SharePoint side of things.
Regards
How to implement the security trim in the search results for the external conten source. Using the above connector i have created a ECT and searching fine. But i need to implent the securit part – how to implement the checkaccess or securitydescriptor methond in the bdcm file for the above connector. is there any articles to follow up by steps.
Is there a way to filter the results in the finder with a wildcard filter?
Today we have 500 accounts and only the first 30 is retrieved. I tried changing the limit filter, but SharePoint still limits it to 200.
Hi Girish I'm able to generate the out.bdcm file but'.
I already have CRMEntityService.SharePoint and CRMEntityService.SharePoint.Connector dlls into the GAC and already did a iisreset on the Sharepoint Server,
Do you have any ideas, or is there a final release of this code and the one in this post is outdated?
Thank you very much
@Kevin,
Can you try changing the list of entities/attributes for which you are generating the model. I'm not sure what the culprit might be.
Hi Girish,
I am unable to authenticate the CRM Online. I am getting the following error
"Error: An unsecured or incorrectly secured fault was received from the other party.". Do you have any idea?
Hi Girish,
why my service proxy can't talk with crm service, I alwasys get the error when the call from connector response = (RetrieveEntityResponse)serviceProxy.Execute(request); even I tried serviceProxy.Execute(new WhoAmIRequest()); also get internal error, and no error message cameback because that I don't know how to turn the crm servcie errow message on.
Thanks,
Hi Giresh,
I'm getting this error when trying to import the bdcm file into Office365 SharePoint 2013:
Application definition import failed. The following error occurred: Cannot find file with Type described by a TypeName on the LobSystem (External System). Parameter name: systemUtilityTypeName Error was encountered at or just before Line: '40' and Position: '20'.
I've seen your fix to deploy the “CRMEntityService.SharePoint.Connector.dll” to the GAC – but pretty sure I can't do that on o365??
Any ideas?
Cheers – MC
Hi Girish,
I cannot run your code because the solution is not under source control: I would have to connect to your server. Can you tell me how to do it? Hereafter the error message I got.
TF400324: Team Foundation services are not available from server wlgtfs2.intergen.org.nz.
Technical information (for administrator):
The remote name could not be resolved: 'wlgtfs2.intergen.org.nz'
Francois,
You should be able to disconnect it from TFS using visual studio. Unfortunately I don't have an environment at the moment to do that and repost the code.
Hi Girish,
This project has support for CRM field type "Option Set"?
Can you give an exemple of the xml file including one entity with one field of this type?
Thanks. | https://blogs.msdn.microsoft.com/girishr/2011/05/16/source-code-from-my-teched-osp309-session/ | CC-MAIN-2016-50 | refinedweb | 1,276 | 58.18 |
Hello!
I'm working on a Breakout style game, and after much testing I've pinpointed my exact problem. Sprites that I've given the .kill() command to and removed from all groups are still persistent in memory and causing issues. Below are a few excerpts of my code, and I'd appreciate if someone could point me in the direction of a better command to use, or perhaps a logic error in my coding.
(Note:
spell = ball
shield = paddle)
The root of the problem
I decided to add some simple items to enhance gameplay. This particular item is supposed to split your ball into three:
def itemEffects(self): if len(self.spellSprites) == 1: if self.spell.angle == 30 or self.spell.angle == 45 or self.spell.angle == 60: tempSpellx = self.spell.rect.x tempSpelly = self.spell.rect.y tempSpellSpeed = self.spell.speed tempSpellAngle = self.spell.angle self.spellSprites.empty() j = 30 for i in range (0,3): self.spell = Spell(self.shield) self.spell.setStats(True, tempSpellx, tempSpelly, tempSpellSpeed, j) self.spell.setVelX(self.spell.angle) self.spell.setVelY(self.spell.angle) self.spellSprites.add(self.spell) j += 15
Directional movement is locked on 12 seperate angles, 3 for each quadrant. This code checks the quadrant, saves the current balls relevant stats to a temporary variable, clears the entire ball sprite group, then creates three new balls given the saved stats with the three angles for that quadrant. I believe the problem is that the first sprite created in this group remains in memory even after it's .kill() function is invoked.
Ball Death
Here is the code for when a ball meets it's untimely demise:
for theSpell in self.spellSprites: if theSpell.rect.centery > 540: if len(self.spellSprites) <= 1: LIVES -= 1 self.loadLives() self.shield.reset() theSpell.kill() self.spellSprites.empty() self.spell = Spell(self.shield) self.spellSprites.add(self.spell) self.itemSprites.empty() if LIVES < 0: SCORE = 0 LIVES = 2 self.showTextScreen('Game Over!', 'Press Escape to Quit or Any Key to Play Again.', 2) else: theSpell.kill()
I thought this would be sufficient to destroy a ball and make everything work ok. Instead, it would appear that the first ball stays in memory.
I came to this conclusion because when there is one ball remaining, and the length of the spellSprites group is equal to 1, occasionally when I obtain a power up to split the balls, the current ball will disappear and a life will be lost as if the ball was out of bounds. It is my belief that the extra balls are spawning off of the primary spell who's location is far below paddle, thus instantly trigerring a loss of life as all balls are lost.
The Question
Is there a way to permenantly delete a sprite out of memory? If not, is there a way that I can access specific sprite objects within the sprite group when they all share the same name? If that's not possible either, is there some other way I can go about trying to solve this problem that I may have overlooked?
If there is any other information or code necessary to provide in order to solve this issue, let me know. Thank you for your time and I greatly appreciate any help you are able to give! | http://www.gamedev.net/user/152794-paladinjohn/?tab=topics | CC-MAIN-2015-14 | refinedweb | 555 | 65.93 |
From our sponsor:
Sell access to courses, classes, and community with Squarespace.
Recently, I release my brand new portfolio, home to my projects that I have worked on in the past couple of years:
As I was doing experimentations for the portfolio, I tried to reproduce this kind of effect I found on the web:
I really like these 2D grain effects applied to 3D elements. It kind of has this cool feeling of cray and rocks and I decided to try and reproduce it from scratch. I started with a custom light shader, then mixed it with a grain effect and by playing with some values I got to this final result:
In this tutorial I’d like to share with you what I’ve done to achieve this effect. We’re going to explore two different ways of doing it.
Note that I won’t get into too much detail about Three.js and WebGL for simplicity, so it’s good to have some solid knowledge of JavaScript, Three.js and some notions about shaders before starting with this tutorial. If you’re not very familiar with shaders but with Three.js, then the second way is for you!
Summary
Method 1: Writing our own custom ShaderMaterial (That’s the harder path but you’ll learn about how light reflection works!)
- Creating a basic Three.js scene
- Use ShaderMaterial
- Create a diffuse light shader
- Create a grain effect using 2D noise
- Mix it with light
Method 2: Starting from MeshLambertMaterial shader (Easier but includes unused code from Three.js since we’ll rewrite the Three.js LambertMaterial shader)
- Copy and paste MeshLambertMaterial
- Add our custom grain light effect to the fragmentShader
- Add any Three.js lights
1. Writing our own custom ShaderMaterial
Creating a basic Three.js scene
First we need to set up a basic Three.js scene with a simple sphere in the center:
Here is a Three.js basic scene with a camera, a renderer and a sphere in the middle. You can find the code in this repository in the file
src/js/Scene.js, so you can start the tutorial from here.
Use ShaderMaterial
Let’s create a custom shader in Three.js using the
ShaderMaterial class. You can pass it uniforms objects, and a vertex and a fragment shader as parameters. The cool thing about this class is that it’s already giving you most of the necessary uniforms and attributes for a basic shader (positions of the vertices, normals for light, ModelViewProjection matrices and more).
First, let’s create a uniform that will contain the default color of our sphere. Here I picked a light blue (#51b1f5) but feel free to pick your favorite color. We’ll use a
new THREE.Color() and call our uniform
uColor. We’ll replace the material from the previous code l.87:
const material = new THREE.ShaderMaterial({ uniforms: { uColor: { value: new THREE.Color(0x51b1f5) } } });
Then let’s create a simple vertex shader in
vertexShader.glsl, a separated file that will display the sphere vertices at the correct position related to the camera.
void main(void) { gl_Position = projectionMatrix * modelViewMatrix * vec4(position, 1.0); }
And finally, we write a basic fragment shader
fragmentShader.glsl in a separated file as well, that will use our uniform uColor vec3 value:
uniform vec3 uColor; void main(void) { gl_FragColor = vec4(uColor, 1.); }
Then, let’s import and link them to our ShaderMaterial.
import vertexShader from './vertexShader.glsl' import fragmentShader from './fragmentShader.glsl' ... const material = new THREE.ShaderMaterial({ vertexShader: vertexShader, fragmentShader: fragmentShader, uniforms: { uColor: { value: new THREE.Color(0x51b1f5) } } });
Now we should have a nice monochrome sphere:
Create a diffuse light shader
Creating our own custom light shader will allow us to easily manipulate how the light should affect our mesh.
Even if that seems complicated to do, it’s not that much code and you can find great articles online explaining how light reflection works on a 3D object. I recommend you read webglfundamentals if you would like to learn more details on this topic.
Going further, we want to add a light source in our scene to see how the sphere reflects light. Let’s add three new uniforms, one for the position of our spotlight, the other for the color and a last one for the intensity of the light. Let’s place the spotlight above the object, 5 units in Y and 1 unit in Z, use a white color and an intensity of 0.7 for this example.
... uLightPos: { value: new THREE.Vector3(0, 5, 3) // position of spotlight }, uLightColor: { value: new THREE.Color(0xffffff) // default light color }, uLightIntensity: { value: 0.7 // light intensity },
Now let’s talk about normals. A
THREE.SphereGeometry has normals 3D vectors represented by these arrows:
For each surface of the sphere, these red vectors define in which direction the light rays should be reflected. That’s what we’re going to use to calculate the intensity of the light for each pixel.
Let’s add two varyings on the vertex shader:
- vNormals, the normals vectors of the object related to the world position (where it is in the global scene).
- vSurfaceToLight, this represents the direction of the light position minus the direction of each surface of the sphere.
uniform vec3 uLightPos; varying vec3 vNormal; varying vec3 vSurfaceToLight; void main(void) { vNormal = normalize(normalMatrix * normal); gl_Position = projectionMatrix * modelViewMatrix * vec4(position, 1.0); // General calculations needed for diffuse lighting // Calculate a vector from the fragment location to the light source vec3 surfaceToLightDirection = vec3( modelViewMatrix * vec4(position, 1.0)); vec3 worldLightPos = vec3( viewMatrix * vec4(uLightPos, 1.0)); vSurfaceToLight = normalize(worldLightPos - surfaceToLightDirection); }
Now let’s generate colors based on these light values in the Fragment shader.
We already have the normals values with
vNormals. To calculate a basic light reflection on a 3D object we need two values light types: ambient and diffuse.
Ambient light is a constant value that will give a global light color of the whole scene. Let’s just use our light color for this case.
Diffuse light is representing the value of how strong the light is depending on how the object reflects it. That means that all surfaces which are close to and facing the spotLight should be more enlightened than surfaces that are far away and in the same direction. There is an amazing math function to calculate this value called the
dot() product. The formula for getting a diffuse color is the dot product of
vSurfaceToLight and
vNormal. In this image you can see that vectors facing the sun are brighter than the others:
Then we need to addition the ambient and diffuse light and finally multiply it by a lightIntensity. Once we got our light value let’s multiply it by the color of our sphere. Fragment shader:
uniform vec3 uLightColor; uniform vec3 uColor; uniform float uLightIntensity; varying vec3 vNormal; varying vec3 vSurfaceToLight; vec3 light_reflection(vec3 lightColor) { // AMBIENT is just the light's color vec3 ambient = lightColor; //- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - // DIFFUSE calculations // Calculate the cosine of the angle between the vertex's normal // vector and the vector going to the light. vec3 diffuse = lightColor * dot(vSurfaceToLight, vNormal); // Combine return (ambient + diffuse); } void main(void) { vec3 light_value = light_reflection(uLightColor); light_value *= uLightIntensity; gl_FragColor = vec4(uColor * light_value, 1.); }
And voilà:
Feel free to click and drag on this sandbox scene to rotate the camera.
Note that if you want to recreate MeshPhongMaterial you also need to calculate the specular light. This represent the effect you can observe when a ray of light gets directly into our eyes when reflected by an object, but we don’t need that precision here.
Create a grain effect using 2D noise
To get a 2D grain effect we’ll have to use a noise function that will display a gray color from 0 to 1 for each pixel of the screen in a “beautiful randomness”. There are a lot of functions online for creating simplex noise, perlin noise or others. Here we’ll use glsl-noise for a 2D simplex noise and glslify to import the noise function directly at the beginning of our fragment shader using:
#pragma glslify: snoise2 = require(glsl-noise/simplex/2d)
Thanks to the native WebGL value
gl_FragCoord.xy we can easily get the UVs (coordinates) of the screen. Then we just have to apply the noise to these coordinates
vec3 textureNoise = vec3(snoise2(uv)); This will create our 2D noise. Then, let’s apply these noise colors to our
gl_FragColor:
#pragma glslify: snoise2 = require(glsl-noise/simplex/2d) ... // grain vec2 uv = gl_FragCoord.xy; vec3 noiseColors = vec3(snoise2(uv)); gl_FragColor = vec4(noiseColors, 1.0);
What a nice old TV noise effect:
As you can see, when moving the camera, the texture feels like it’s “stuck” to the screen, that’s because we matched our simplex noise effect to the coordinates of the screen to create a 2D style effect. You can also adjust the size of the noise like so
uv /= myNoiseScaleVal;
Mixing it with the light
Now that we got our noise value and our light let’s mix them! The idea is to apply less noise where the light value is stronger (1.0 == white) and more noise where the light value is weaker (0.0 == black). We already have our light value, so let’s just multiply the texture value with that:
colorNoise *= light_value.r;
You can see how the light affects the noise now, but this doesn’t look very strong. We can accentuate this value by using an exponential function. To do that in GLSL (the shader language) you can use
pow(). It’s already included in shaders, here I used the exponential of 5.
colorNoise *= pow(light_value.r, 5.0);
Then, let’s enlighten the noise color effect like so:
vec3 colorNoise = vec3(snoise2(uv) * 0.5 + 0.5);
To gray, right? Almost there, let’s re-add our beautiful color that we got from the start. We can say that if the light is strong it will go white, and if the light is weak it will be clamped to the initial channel color of the sphere like this:
gl_FragColor.r = max(textureNoise.r, uColor.r); gl_FragColor.g = max(textureNoise.g, uColor.g); gl_FragColor.b = max(textureNoise.b, uColor.b); gl_FragColor.a = 1.0;
Now that we have this Material ready, we can apply it to any object of the scene:
Congrats, you finished the first way of doing this effect!
2. Starting from MeshLambertMaterial shader
This way is simpler since we’ll directly reuse the
MeshLambertMaterial from Three.js and apply our grain in the fragment shader. First let’s create a basic scene like in the first method. You can take this repository, and start from the
src/js/Scene.js file to follow this second method.
Copy and paste MeshLambertMaterial
In Three.js all the Materials shaders can be found here. They are composed by shunks (reusable GLSL code) that are included here and there in Three.js shaders. We’re going to copy the MeshLambertMaterial fragment shader from here and paste it in a new
fragment.glsl file.
Then, let’s add a new ShaderMaterial that will include this fragmentShader. However, for the vertex, since we’re not changing it, we can just pick it directly from the lib
THREE.ShaderLib.lambert.vertexShader.
Finally, we need to merge the Three.js uniforms with ours, using
THREE.UniformsUtils.merge(). Like in the first method, let’s use the sphere color uColor, uNoiseCoef to play with the grain effect and a uNoiseScale for the grain size.
import fragmentShader from './fragmentShader.glsl' ... this.uniforms = THREE.UniformsUtils.merge([ THREE.ShaderLib.lambert.uniforms, { uColor: { value: new THREE.Color(0x51b1f5) }, uNoiseCoef: { value: 3.5 }, uNoiseScale: { value: 0.8 } } ]) const material = new THREE.ShaderMaterial({ vertexShader: THREE.ShaderLib.lambert.vertexShader, fragmentShader: glslify(fragmentShader), uniforms: this.uniforms, lights: true, transparent: true })
Note that we’re importing the fragmentShader using glslify because we’re going to use the same simplex noise 2D from the first method. Also, the lights parameter needs to be set to true so the materials can reuse the value of all source lights of the scene.
Add our custom grain light effect to the fragmentShader
In our freshly copied fragment shader, we’ll need to import the 2D simplex noise using the glslify and glsl-noise libs.
#pragma glslify: snoise2 = require(glsl-noise/simplex/2d).
If we look closely at the MeshLambertMaterial fragment we can find a
outgoingLight value. This looks very similar to our
light_value from the first method, so let’s apply the same 2D grain shader effect to it:
// grain vec2 uv = gl_FragCoord.xy; uv /= uNoiseScale; vec3 colorNoise = vec3(snoise2(uv) * 0.5 + 0.5); colorNoise *= pow(outgoingLight.r, uNoiseCoef);
Then let’s mix our uColor with the colorNoise. And here is the final fragment shader:
#pragma glslify: snoise2 = require(glsl-noise/simplex/2d) ... uniform float uNoiseScale; uniform float uNoiseCoef; ... // write this the very end of the shader // grain vec2 uv = gl_FragCoord.xy; uv /= uNoiseScale; vec3 colorNoise = vec3(snoise2(uv) * 0.5 + 0.5); colorNoise *= pow(outgoingLight.r, uNoiseCoef); gl_FragColor.r = max(colorNoise.r, uColor.r); gl_FragColor.g = max(colorNoise.g, uColor.g); gl_FragColor.b = max(colorNoise.b, uColor.b); gl_FragColor.a = 1.0;
Add any Three.js lights
No light? Let’s add some
THREE.SpotLight in the scene in
src/js/Scene.js file.
const spotLight = new THREE.SpotLight(0xff0000) spotLight.position.set(0, 5, 4) spotLight.intensity = 1.85 this.scene.add(spotLight)
And here you go:
You can also play with the alpha value in the fragment shader like this:
gl_FragColor = vec4(colorNoise, 1. - colorNoise.r);
And that’s it! Hope you enjoyed the tutorial and thank you for reading. | https://tympanus.net/codrops/2022/03/07/creating-a-risograph-grain-light-effect-in-three-js/ | CC-MAIN-2022-40 | refinedweb | 2,281 | 57.06 |
try netbeans
try netbeans
It's possible to be a problem with Eclipse IDE and the way of using libraries with:
This solves something I think:
package GGG;
import java.util.Scanner; // used for console input (from the keyboard)
// Declare the class
public class toothpickPuzzle {
// Fields that can...
Try this:
package LoopPb;
import java.io.*;
import java.util.*;
class AminoToken
{
I'm confuzed because of this comment:
where is the body of mainLoop?
box.setBounds(5, 10, 5 * width, 5 * height);
how to insert formated code?
I'm new.
You don't call
wrd.FileToArray();
so you don't initialize wrd.
Try:
public void PlayGame() {
try {
wrd.FileToArray();
} catch (IOException e) {
// TODO Auto-generated catch block... | http://www.javaprogrammingforums.com/search.php?s=3a66fbe96d32739885e522b16636ba4b&searchid=1724639 | CC-MAIN-2015-35 | refinedweb | 116 | 68.47 |
I'm writing a program that simulates a game of Bunko for my compSci class, but I'm having issues getting the function
scoreCalc
playerScore
playerScore
dieList = []
sixCount = 0
playerScore = 0
def rollDice():
global sixCount
sixCount = 0
dieList.clear()
die1 = random.randint(1,6)
die2 = random.randint(1,6)
die3 = random.randint(1,6)
dieList.append(die1)
dieList.append(die2)
dieList.append(die3)
print(dieList)
for x in dieList:
if x == 6:
sixCount += 1
print("sixCount:", sixCount)
return
def scoreCalc(x):
if sixCount == 1:
x += 1
elif sixCount == 2:
x += 5
elif sixCount == 3:
x += 21
return x
print()
print("Player's turn!")
print('*' * 30)
input("Press ENTER to roll the dice")
print()
rollDice()
print("Score:", scoreCalc(playerScore))
You clearly know how to modify a global variable, which you did for sixCount. You probably used to do that with playerScore, but changed it when trying to make the function useful for calculating anybody's score (stated goal in the OP).
In order to make the function work like a function, it needs to be ... a function. Meaning that it takes an input and gives an output, and nothing else matters. You then just need to use that output.
def scoreCalc(sixCount): x = 0 if sixCount == 1: x += 1 elif sixCount == 2: x += 5 elif sixCount == 3: x += 21 return x # now use it playerScore += scoreCalc(sixCount)
Notice how scoreCalc doesn't care about any global variables. It just gives the score for its input. You then apply that score where it belongs.
These functions might also be useful. It's better not to give them any global variables. Handle the results where they matter, and just let these functions do their job, and nothing else.
# return a list of d6 outputs def rollDice(number_of_dice): return [random.randint(1,6) for _ in range(number_of_dice)] # takes a list of d6 outputs and returns the count of sixes def countSixes(dieList): return sum([1 for x in dieList if x==6]) | https://codedump.io/share/cwmAgrSgvA6a/1/function-not-updating-global-variable | CC-MAIN-2018-09 | refinedweb | 329 | 63.59 |
The article below tackles!
Understanding Progressive Web Apps
Progressive Web Apps (PWA) are experiences that combine the best of the web and the best of apps. Native app store apps have become hugely popular in the past through features such as push notifications, working offline, smooth animations and transitions, loading on the homescreen and so on.
Mobile Web Apps are JavaScript applications that worked in the browser and attempted to bring some of the native apps features to the web, but weren’t able to provide push notifications for example. With the mobile introduction of new Web APIs, Progressive Web Apps are now closing the gap, providing the full app-like experience on the mobile web.
Google describes them as being:
Reliable – Load instantly
Fast – Quickly respond to user interactions
Engaging – Behaving like a native app
To hit all of these points, a Progressive Web App must have the following capabilities:
- Work offline or on poor network conditions
- Web App Install Banners or Add to Homescreen
- Use Web Push Notifications. With the introduction of the Web Push API, we can now send Push Notifications to our users, even when the browser is closed.
- Implement HTTPS
- Use an application shell (or app shell) architecture that instantly loads on the users’ screens, similar to native applications.
In essence, a PWA is a Single Page Application written in JavaScript. Offline mode, Add to Homescreen and Web Push Notifications are all implemented using service workers.
Progressive Web Apps vs. Responsive Web Design
Progressive Web Apps should not be confused with Responsive Web Design. Progressive Web Apps have responsive capabilities because they can adapt to different screen sizes, but their unique value proposition are the features that make them app-like.
In the last years, RWD has been the go-to solution for mobile web solutions, but a Forrester report from last year identified that RWD has reached saturation – 87% of digital experience makers embrace it – and that a shift in customer expectations to prefer app-like experiences on the web is taking place before our eyes.
Are PWAs the solution for engaging mobile web users?
Building a high-quality Progressive Web App has incredible benefits, making it easy to delight users, grow engagement and increase conversions. There are several examples of companies, particularly from the e-commerce industry, that have successfully used Progressive Web Apps to improve their metrics, a lot of them are listed on Google’s Developers website.
For example, Alibaba.com built a PWA that led to a fast, effective, and reliable mobile web experience. The new strategy delivered a 76% increase in total conversions across browsers and a four times higher interaction rate from Add to Homescreen.
In another use case, OLX wanted to re-engage mobile web users by using Add to Homescreen and Push Notifications. They increased engagement by 250% and improved other metrics too: the time until the page became interactive fell by 23%, with a corresponding 80% drop in bounce rates. Monetization also improved, with clickthrough rate (CTR) rising 146%.
How do we know that a mobile web app is progressive?
First of all, being progressive is a score, not a Yes or No, and there’s a Chrome plugin called Lighthouse that you can use to measure this score. This plugin is really easy to use and generates a report with all the PWA capabilities, basically it lets us know what we need to change for a web app to become fully progressive. For our alpha version of the WooCommerce PWA, we managed to hit a 91 score on Lighthouse.
How can we build a PWA?
Google’s PWA standard doesn’t list any particular technology or framework for creating Progressive Web Apps. It can be anything as long as the checklist is followed. Many PWAs are built using Angular JS or React, which are the most popular JavaScript frameworks at the moment.
Both AngularJS and React have their advantages:
The Angular / Ionic combination is pretty popular nowadays. Ionic is a great framework that was originally built for mobile apps, but has expanded to Progressive Web Apps and even desktop applications.
React is really intuitive and easy to understand. It benefits from a great boilerplate, create-react-app, which comes with PWA support by default.
Besides these two, VueJS is also gaining in popularity.
Next, we’re going to see some code samples from an e-commerce application built with React on top of the WordPress and WooCommerce REST API.
Understanding WooCommerce REST API
When it comes to building an e-commerce application, the first thing we need is an API from where we can retrieve the data. Fortunately, the inclusion of the REST API in the core has opened the door for using WordPress as a backend. In addition, for e-commerce apps we can use the REST API from the popular WooCommerce plugin.
WooCommerce also has an NPM package (WooCommerce API) for making API calls, but unfortunately this package requires both the consumer key and consumer secret in order to authenticate requests. We would have a security issue if we used the consumer secret in a frontend app.
Also, when creating keys from the WooCommerce admin section, it’s not possible to specify permissions at the route level, for example allowing view access for products and write access for orders.
So, we had to create a proxy in our WordPress plugin, that allows access to a restricted set of API endpoints. As a base, we used the WooCommerce REST API PHP wrapper, as you can see in the below example:
<?php use Automattic\WooCommerce\Client; class Custom_Endpoints_Woocommerce_API { protected function get_client() { return new Client( get_site_url(), 'woocommerce_consumer_key', 'woocommerce_consumer_secret', [ 'wp_api' => true, 'version' => 'wc/v1', ] ); } public function register_woocommerce_routes() { register_rest_route( 'customroutes', '/products', array( 'methods' => 'GET', 'callback' => array( $this, 'view_products' ) )); } public function view_products( WP_REST_Request $request ) { $woocommerce = $this->get_client(); return $woocommerce->get( 'products/categories' ); } }
We first initialize the WooCommerce client using the consumer key and secret. The second and third methods are creating a custom route called products and map that route to the products/categories endpoint from the WooCommerce API.
In this way, we can allow access to reading categories and products, but allow only the create operation for an order.
Creating new React app in four simple steps
Once we have set up the API, we can start working on our React application. After installing NodeJS and NPM globally, you can use the create-react-app package to quickly generate a React JS app that has PWA support by default.
Install NodeJS and NPM globally
Install create-react-app boilerplate
npm install create-react-app -g
Generate new React application
create-react-app my-app
Start application
cd my-app & npm start
Below is a screenshot of the application that is generated by create-react-app, it has everything that we need, so we can start coding, including live reload:
There are a few things to keep in mind when starting a new app:
1) Organizing app files
There are several good tutorials out there about how to best structure the app. I prefer folders-by-feature, because it allows better scalability. You can find a really good explanation here.
2) Linters and coding standards
Coding standards can be annoying if you’re not used to them, but do not skip this step. They help clean up unused dependencies and make sure that data is properly validated at the component level. In addition, if you install a prettier editor plugin that automatically formats your code, using coding standards becomes a breeze. As for the standard itself, I prefer the popular one created by Airbnb.
3) Small components
Keeping components files small makes them easier to test and manage. You can start writing code in a single component and, once it gets bigger, divide it into smaller component. For UI/UX components, there are several libraries that are compatible with React, such as Material UI, Semantic UI or even Bootstrap, just to give a few examples.
These libraries contain a set of ready-made components, such as grids, menus, cards, buttons and so on. Here is an example of an e-commerce application interface built with basic Semantic UI elements:
You can see a list of categories, a list of products and a side menu. Let’s dive into the code – you’ll see how easy it is to use React to create such an example.
Diving into ReactJS
Below is a React component that reads a set of product categories from the API. The component’s state is initialized with an empty list of categories. In the componentWillMount method that is automatically called by React before render we make a request to fetch the categories and we add them to the state after receiving the response:
import React, { Component } from "react"; import config from "./config"; import CategoriesList from "./CategoriesList"; class Categories extends Component { constructor(props) { super(props); this.state = { categories: [] }; } componentWillMount() { fetch(config.API_CATEGORIES_URL) .then(response => response.json()) .then(json => this.setState({ categories: json })) .catch(() => { console.log("An error occured"); }); } render() { return <CategoriesList categories={this.state.categories} />; } } export default Categories;
As you can see, we don’t need to call the render method when the categories are received, React takes care of that for us and re-renders the component. The render method just returns another custom component called CategoriesList that receives the categories data and looks like this:
import React from "react"; import CategoryCard from "./CategoryCard"; const CategoriesList = props => ( <div> {props.categories.map(element => ( <CategoryCard key={element.id} categId={element.id} src={element.image.src} name={element.name} /> ))} </div> ); export default CategoriesList;
The above component iterates over the list of categories that it receives as a prop and calls another custom component called CategoryCard to render a single category element.
All these components communicate by passing props between them. The main Categories component calls the API and passes down a list of categories to CategoriesList, which in turn passes a category’s details to the Category Cards.
Managing the global app state using Redux
The problem with the above approach is that sometimes we have data that needs to be managed at the top application level, for example a list of products that were added to the shopping cart. The number of products is shown in the shopping cart icon from the header bar, but these are also displayed as a list on the checkout page.
If we add all this data in the parent application component, it will become very difficult to manage on larger applications. This is where libraries such as ReduxJs come in. Just to clarify, Redux can be used in combination with any JavaScript framework, it is not specific to React.
Also, using Redux doesn’t mean that we can’t use state or props at the component level. Redux should be used only for retaining data that makes sense at the application level.
Let’s see how we can read products from the API and render them in a list, similar to what we need with categories, but this time using Redux. First, we need to make the connection with Redux by wrapping our main app component into a global store:
import { createStore, combineReducers, applyMiddleware } from "redux"; import thunk from "redux-thunk"; import categories from "./views/Categories/reducer"; import products from "./views/Products/reducer"; const rootReducer = combineReducers({ categories, products }); const defaultState = {}; const store = createStore(rootReducer, defaultState, applyMiddleware(thunk)); export default store;
In this example, the global app store will contain a list of categories and a list of products, which are merged together using the combineReducers method from Redux.
Then, we continue by defining Redux actions, which are very simple functions that return objects that must contain a type property. Since JS is asynchronous, we’ll need two actions: one for signaling when a request is sent and the other for signaling when a response is received. The whole app will know when these actions take place.
Below, we have also added a function called fetchProducts. As you can see, this function:
- dispatches the request products action,
- calls the API for retrieving products,
- dispatches the receiveProducts action when a result is received.
import config from "./config"; export const requestProducts = () => ({ type: "REQUEST_PRODUCTS" }); export const receiveProducts = products => ({ type: "RECEIVE_PRODUCTS", products }); export const fetchProducts = () => dispatch => { dispatch(requestProducts()); return fetch(config.API_PRODUCTS_URL) .then(response => response.json()) .then(json => dispatch(receiveProducts(json))) .catch(() => { dispatch(receiveProducts([])); }); };
To modify the app state, we’ll add a so-called Redux “reducer”. The reducer is just a function that listens to particular actions and changes a portion of the global state, in this case the list of products.
This reducer doesn’t do anything when receiving a request products action, it always returns the current state. For the receive products action, the reducer returns the data that is passed to it, in this case it will be a list of products.
import { combineReducers } from "redux"; const productsReducer = (state = [], action) => { switch (action.type) { case "REQUEST_PRODUCTS": return state; case "RECEIVE_PRODUCTS": return action.products; default: return state; } }; export default productsReducer;
To wrap things up, we use these actions and reducer in a new Products component.
import React from "react"; import { connect } from "react-redux"; import { fetchProducts } from "./actions"; import ProductsList from "./ProductsList"; class Products extends React.Component { componentWillMount() { const { dispatch } = this.props; dispatch(fetchProducts()); } render() { return <ProductsList />; } } export default connect(null, { fetchProducts })(Products);
This component is wrapped in the connect method from Redux, and just dispatches fetchProducts in its componentWillMount method. Also, the component includes a products list, but as you can see the products list component doesn’t directly receive the products data. That’s because the product list component is directly linked to the global app state, also using Redux.
In this way, it can access the products data directly from the app store, iterate over the list of products and use a ProductCard component to render a single product element.
import React from "react"; import { connect } from "react-redux"; import ProductCard from "./ProductCard"; class ProductsList extends React.Component { render() { const list = this.props.products.map(element => ( <ProductCard key={element.id} src={element.images[0].src} name={element.name} price={element.price} /> )); return <div>{list}</div>; } } const mapStateToProps = state => ({ products: state.products }); export default connect(mapStateToProps)(ProductsList);
So far, we have seen some examples on how to display data, but what if we wanted to add user interaction, for example adding a product to cart?
In this case, when the user clicks the “Add to cart” button, we will dispatch an action that will modify the global app state. The header bar, which displays the number of cart products, will be connected with Redux. It will count the number of products saved in the application’s cart and update itself accordingly.
Linking the app with WordPress
These are all basic examples to get you started, and you’re probably wondering how exactly we can link this app with WordPress.
Well, we can host the app on a subdomain and let it connect to the API, or we can use it as a WordPress theme – meaning creating a very basic theme with an index.php file that will just load a JavaScript / CSS file. The create-react-app boilerplate includes commands for creating the application’s build, so we can get the production files immediately.
<html manifest="" <?php language_attributes(); ?>> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no" /> <!-- load other meta tags here --> <title><?php echo get_bloginfo("name");?></title> <link rel="stylesheet" href="<?php echo get_template_directory_uri();?>/style.css" /> <script src="<?php echo get_template_directory_uri();?>/js/bundle.js" type="text/javascript"> </script> <script> if('serviceWorker' in navigator) { navigator.serviceWorker .register('/sw.js') .then(function() { console.log("Service Worker Registered"); }); } </script> </head> <body> <noscript> You need to enable JavaScript to run this app. </noscript> <div id="root" style="height:100%"></div> </body> </html>
Where to use service workers
For offline mode, we can add a service worker that will display the app shell even when users are offline. The service worker is just a JavaScript file that registers itself in the browser.
<script> if('serviceWorker' in navigator) { navigator.serviceWorker .register('/sw.js') .then(function() { console.log("Service Worker Registered"); }); } </script>
There are several strategies that you can use for offline mode, such as network first or cache first, and you can read about these in Google’s offline cookbook.
Caching the application’s shell has benefits even when we have a network connection, because the app will load much faster.
If you want to go even further and start caching the data that comes from the API, you can use NPM packages like redux-persist and modify your app to save / retrieve data from the browser’s local storage.
For web push notifications, we recommend taking a look at the One Signal free WordPress plugin. This plugin also works with responsive themes, so you should definitely check it out immediately.
What’s next?
You can find the demo for the above WooCommerce PWA here.
We’re already working on the beta version and here’s just a part of our roadmap:
- Add offline mode capabilities
- Add push notifications
- Finalize the checkout process If you want to contribute or customize it for your own needs, you can find the alpha version of the e-commerce progressive web application on GitHub.
What do you think of Progressive Web Apps and the role they can have on the mobile WordPress landscape? Are you considering following this path with your next project?
The article was originally published on CodeinWP.com
Written by Alexandra Anghel, co-founder and CTO at Appticles.com
Discussion (0) | https://dev.to/codeinwp/want-to-build-progressive-web-apps-based-on-wordpress-and-woocommerce-here-s-how-w-code-examples-20f7 | CC-MAIN-2022-33 | refinedweb | 2,941 | 52.6 |
Blobs are described as spheres and cylinders covered with "goo" which stretches to smoothly join them
(see section "Blob").
Ideal for modeling atoms and molecules, blobs are also powerful tools for creating many smooth flowing
"organic" shapes.
A slightly more mathematical way of describing a blob would be to say that it is one object made up of two or more
component pieces. Each piece is really an invisible field of force which starts out at a particular strength and falls
off smoothly to zero at a given radius. Where ever these components overlap in space, their field strength gets added
together (and yes, we can have negative strength which gets subtracted out of the total as well). We could have just
one component in a blob, but except for seeing what it looks like there is little point, since the real beauty of
blobs is the way the components interact with one another.
Let us take a simple example blob to start. Now, in fact there are a couple different types of components but we
will look at them a little later. For the sake of a simple first example, let us just talk about spherical components.
Here is a sample POV-Ray code showing a basic camera, light, and a simple two component blob:
#include "colors.inc"
background{White}
camera {
angle 15
location <0,2,-10>
look_at <0,0,0>
}
light_source { <10, 20, -10> color White }
blob {
threshold .65
sphere { <.5,0,0>, .8, 1 pigment {Blue} }
sphere { <-.5,0,0>,.8, 1 pigment {Pink} }
finish { phong 1 }
}
The threshold is simply the overall strength value at which the blob becomes visible. Any points within the blob
where the strength matches the threshold exactly form the surface of the blob shape. Those less than the threshold are outside
and those greater than are inside the blob.
We note that the spherical component looks a lot like a simple sphere object. We have the sphere keyword, the
vector representing the location of the center of the sphere and the float representing the radius of the sphere. But
what is that last float value? That is the individual strength of that component. In a spherical component, that is
how strong the component's field is at the center of the sphere. It will fall off in a linear progression until it
reaches exactly zero at the radius of the sphere.
Before we render this test image, we note that we have given each component a different pigment. POV-Ray allows
blob components to be given separate textures. We have done this here to make it clearer which parts of the blob are
which. We can also texture the whole blob as one, like the finish statement at the end, which applies to all
components since it appears at the end, outside of all the components. We render the scene and get a basic kissing
spheres type blob.
The image we see shows the spheres on either side, but they are smoothly joined by that bridge section in the
center. This bridge represents where the two fields overlap, and therefore stay above the threshold for longer than
elsewhere in the blob. If that is not totally clear, we add the following two objects to our scene and re-render. We
note that these are meant to be entered as separate sphere objects, not more components in the blob.
sphere { <.5,0,0>, .8
pigment { Yellow transmit .75 }
}
sphere { <-.5,0,0>, .8
pigment { Green transmit .75 }
}
Now the secrets of the kissing spheres are laid bare. These semi-transparent spheres show where the components of
the blob actually are. If we have not worked with blobs before, we might be surprised to see that the spheres we just
added extend way farther out than the spheres that actually show up on the blobs. That of course is because our
spheres have been assigned a starting strength of one, which gradually fades to zero as we move away from the sphere's
center. When the strength drops below the threshold (in this case 0.65) the rest of the sphere becomes part of the
outside of the blob and therefore is not visible.
See the part where the two transparent spheres overlap? We note that it exactly corresponds to the bridge between
the two spheres. That is the region where the two components are both contributing to the overall strength of the blob
at that point. That is why the bridge appears: that region has a high enough strength to stay over the threshold, due
to the fact that the combined strength of two spherical components is overlapping there.
The shape shown so far is interesting, but limited. POV-Ray has a few extra tricks that extend its range of
usefulness however. For example, as we have seen, we can assign individual textures to blob components, we can also
apply individual transformations (translate, rotate and scale) to stretch, twist, and squash pieces of the blob as we
require. And perhaps most interestingly, the blob code has been extended to allow cylindrical components.
Before we move on to cylinders, it should perhaps be mentioned that the old style of components used in previous
versions of POV-Ray still work. Back then, all components were spheres, so it was not necessary to say sphere or
cylinder. An old style component had the form:
component Strength, Radius, <Center>
This has the same effect as a spherical component, just as we already saw above. This is only useful for backwards
compatibility. If we already have POV-Ray files with blobs from earlier versions, this is when we would need to
recognize these components. We note that the old style components did not put braces around the strength, radius and
center, and of course, we cannot independently transform or texture them. Therefore if we are modifying an older work
into a new version, it may arguably be of benefit to convert old style components into spherical components anyway.
Now for something new and different: cylindrical components. It could be argued that all we ever needed to do to
make a roughly cylindrical portion of a blob was string a line of spherical components together along a straight line.
Which is fine, if we like having extra to type, and also assuming that the cylinder was oriented along an axis. If
not, we would have to work out the mathematical position of each component to keep it is a straight line. But no more!
Cylindrical components have arrived.
We replace the blob in our last example with the following and re-render. We can get rid of the transparent spheres
too, by the way.
blob {
threshold .65
cylinder { <-.75,-.75,0>, <.75,.75,0>, .5, 1 }
pigment { Blue }
finish { phong 1 }
}
We only have one component so that we can see the basic shape of the cylindrical component. It is not quite a true
cylinder - more of a sausage shape, being a cylinder capped by two hemispheres. We think of it as if it were an array
of spherical components all closely strung along a straight line.
As for the component declaration itself: simple, logical, exactly as we would expect it to look (assuming we have
been awake so far): it looks pretty much like the declaration of a cylinder object, with vectors specifying the two
endpoints and a float giving the radius of the cylinder. The last float, of course, is the strength of the component.
Just as with spherical components, the strength will determine the nature and degree of this component's interaction
with its fellow components. In fact, next let us give this fellow something to interact with, shall we?
Beginning a new POV-Ray file, we enter this somewhat more complex example:
#include "colors.inc"
background{White}
camera {
angle 20
location<0,2,-10>
look_at<0,0,0>
}
light_source { <10, 20, -10> color White }
blob {
threshold .65
sphere{<-.23,-.32,0>,.43, 1 scale <1.95,1.05,.8>} //palm
sphere{<+.12,-.41,0>,.43, 1 scale <1.95,1.075,.8>} //palm
sphere{<-.23,-.63,0>, .45, .75 scale <1.78, 1.3,1>} //midhand
sphere{<+.19,-.63,0>, .45, .75 scale <1.78, 1.3,1>} //midhand
sphere{<-.22,-.73,0>, .45, .85 scale <1.4, 1.25,1>} //heel
sphere{<+.19,-.73,0>, .45, .85 scale <1.4, 1.25,1>} //heel
cylinder{<-.65,-.28,0>, <-.65,.28,-.05>, .26, 1} //lower pinky
cylinder{<-.65,.28,-.05>, <-.65, .68,-.2>, .26, 1} //upper pinky
cylinder{<-.3,-.28,0>, <-.3,.44,-.05>, .26, 1} //lower ring
cylinder{<-.3,.44,-.05>, <-.3, .9,-.2>, .26, 1} //upper ring
cylinder{<.05,-.28,0>, <.05, .49,-.05>, .26, 1} //lower middle
cylinder{<.05,.49,-.05>, <.05, .95,-.2>, .26, 1} //upper middle
cylinder{<.4,-.4,0>, <.4, .512, -.05>, .26, 1} //lower index
cylinder{<.4,.512,-.05>, <.4, .85, -.2>, .26, 1} //upper index
cylinder{<.41, -.95,0>, <.85, -.68, -.05>, .25, 1} //lower thumb
cylinder{<.85,-.68,-.05>, <1.2, -.4, -.2>, .25, 1} //upper thumb
pigment{ Flesh }
}
As we can guess from the comments, we are building a hand here. After we render this image, we can see there are a
few problems with it. The palm and heel of the hand would look more realistic if we used a couple dozen smaller
components rather than the half dozen larger ones we have used, and each finger should have three segments instead of
two, but for the sake of a simplified demonstration, we can overlook these points. But there is one thing we really
need to address here: This poor fellow appears to have horrible painful swelling of the joints!
A review of what we know of blobs will quickly reveal what went wrong. The joints are places where the blob
components overlap, therefore the combined strength of both components at that point causes the surface to extend
further out, since it stays over the threshold longer. To fix this, what we need are components corresponding to the
overlap region which have a negative strength to counteract part of the combined field strength. We add the following
components to our blob.
sphere{<-.65,.28,-.05>, .26, -1} //counteract pinky knucklebulge
sphere{<-.65,-.28,0>, .26, -1} //counteract pinky palm bulge
sphere{<-.3,.44,-.05>, .26, -1} //counteract ring knuckle bulge
sphere{<-.3,-.28,0>, .26, -1} //counteract ring palm bulge
sphere{<.05,.49,-.05>, .26, -1} //counteract middle knuckle bulge
sphere{<.05,-.28,0>, .26, -1} //counteract middle palm bulge
sphere{<.4,.512,-.05>, .26, -1} //counteract index knuckle bulge
sphere{<.4,-.4,0>, .26, -1} //counteract index palm bulge
sphere{<.85,-.68,-.05>, .25, -1} //counteract thumb knuckle bulge
sphere{<.41,-.7,0>, .25, -.89} //counteract thumb heel bulge
Much better! The negative strength of the spherical components counteracts approximately half of the field strength
at the points where to components overlap, so the ugly, unrealistic (and painful looking) bulging is cut out making
our hand considerably improved. While we could probably make a yet more realistic hand with a couple dozen additional
components, what we get this time is a considerable improvement. Any by now, we have enough basic knowledge of blob
mechanics to make a wide array of smooth, flowing organic shapes! | http://www.povray.org/documentation/view/3.6.1/71/ | CC-MAIN-2014-42 | refinedweb | 1,882 | 72.66 |
CodePlexProject Hosting for Open Source Software
Hi,
First of all, congratulations for the excellent job! Your library is so easy to use!
Despite the ease of use, I ran into a few difficulties when trying to create a Google Earth Tour.
First, as stated on, this URI: "xmlns:gx="" must be added to the <kml> element, in order to get
this:
<kml xmlns=""
xmlns:
Second, all elements that have the gx-prefix (see, again) appear without the "gx:" prefix, although they are not part of the OGC KML standard.
Without the "gx:" prefix added to the extension tags and the namespace URI added to the <kml> element, Google Earth does not play the tours properly (i.e. not at all), although it does not complain about wrong syntax (even if configured to
do so).
How can I add the URI and the prefixes without having to post-process the kml files I'm generating?
Best regards,
Andrei
Thanks for the kind comments.
The library should support some of the Google extensions in the SharpKml.Dom.GX namespace. Looking at the example from the
TourPrimitive (which doesn't actually work in Google Earth 6.0.3.2197, perhaps because the namespace for
gx isn't specified in the example?) I was able to get the following to work in Google Earth (though maybe not the best example of how to organise your code - I tried to copy the example as close as I could).
SharpKml.Dom.GX
TourPrimitive
gx
using System;
using SharpKml.Base;
using SharpKml.Dom;
using SharpKml.Engine;
class Program
{
static void Main(string[] args)
{
var animationUpdate = new SharpKml.Dom.GX.AnimatedUpdate();
animationUpdate.Duration = 6.5;
animationUpdate.Update = new Update();
animationUpdate.Update.AddUpdate(new ChangeCollection
{
new IconStyle { TargetId = "iconstyle", Scale = 10.0 }
});
var flyTo = new SharpKml.Dom.GX.FlyTo();
flyTo.Duration = 4.1;
flyTo.View = new Camera
{
Longitude = 170.157,
Latitude = -43.671,
Altitude = 9700,
Heading = -6.333,
Tilt = 33.5,
Roll = 0
};
var wait = new SharpKml.Dom.GX.Wait();
wait.Duration = 2.4;
var tour = new SharpKml.Dom.GX.Tour();
tour.Name = "Play me!";
tour.Playlist = new SharpKml.Dom.GX.Playlist();
tour.Playlist.AddTourPrimitive(animationUpdate);
tour.Playlist.AddTourPrimitive(flyTo);
tour.Playlist.AddTourPrimitive(wait);
var document = new Document();
document.Name = "gx:AnimatedUpdate example";
document.Open = true;
document.AddStyle(
new Style
{
Icon = new IconStyle
{
Id = "iconstyle",
Scale = 1.0
}
});
document.AddFeature(
new Placemark
{
Id = "mountainpin1",
Name = "New Zealand's Southern Alps",
StyleUrl = new Uri("#style", UriKind.Relative),
Geometry =
new Point
{
Coordinate = new Vector(-43.605, 170.144, 0)
}
});
document.AddFeature(tour);
// Quick way to save the output
var kml = new Kml { Feature = document };
KmlFile.Create(kml, false).Save("output.kml");
}
}
Sam, thanks for your quick answer. You're faster than a normal helpdesk :-)
The sample code from the
TourPrimitive you mentioned is indeed not working. They miss what I mentioned in my first post, namely the second attribute of the <kml> element, which comes on the second line in this snippet:
Another thing they're missing is the "id" attribute for the style. Their declaration should look like this:
<Style id = "style">
If you add these two modifications their example will work. In fact I remember I encountered the same example in their tutorials and it worked at that time, so I looked back and I found it
here, where they teach about tour updates.
The code given there contains the two corrections I mentioned and works properly. They just forgot to also update the example in the reference documentation.
Coming to your C# code, I compiled/ran it and the output suffers more or less from the same problem as my outputs.
First of all, there are the two problems mentioned above.
Second, all Google extension elements miss the "gx:" prefix. For example, your program outputs <Tour> instead of <gx:Tour>
Third, your code adds an xmlns attribute to the <Tour> element, making it <Tour xmlns=""> . The tour will work only after deleting the xmlns attribute.
There is also a fourth problem I encountered with SharpKML, but not in this code. Namely, the <gx:flyToMode> element is written as <gx:FlyToMode>, which is incorrect, as KML is case sensitive. The tour won't work with capital F, unfortunately.
My questions remain therefore the same:
1) How to add the xmlns:gx attribute to the <kml> element?
2) How to add the "gx:" prefixes to the non-standard Google extensions?
3) This is new, but it's still a problem: How to avoid adding the xmlns attribute to the <gx:Tour> element?
4) I put this here again, for the record: How can I correct the <gx:FlyToMode> element to start with lower case: <gx:flyToMode>?
I ran the output of the C# code that I posted though Google Earth (6.0.3.2197) and it worked fine as it is valid KML, though it might look a bit different to what you're expecting. KML extends XML, which has namespaces. The
xmlns attribute specifies the default namespace for the element (and children) if no prefixes are found. However, if you're determined to use the
gx prefix then you've got a couple of options (though they're both the same really). You can either change the
Namespaces property of the Element class (Dom/Element.cs, line 51) from
internal to public or you can use reflection to get hold of it (shown here).
xmlns
Namespaces
Element
Dom/Element.cs
internal
public
using System;
using System.Reflection;
using System.Xml;
using SharpKml.Base;
using SharpKml.Dom;
class Program
{
static void Main(string[] args)
{
var flyTo = new SharpKml.Dom.GX.FlyTo();
flyTo.Mode = SharpKml.Dom.GX.FlyToMode.Bounce;
var tour = new SharpKml.Dom.GX.Tour();
tour.Playlist = new SharpKml.Dom.GX.Playlist();
tour.Playlist.AddTourPrimitive(flyTo);
var kml = new Kml();
kml.Feature = tour;
AddNamespace(kml, "gx", "");
Serializer serializer = new Serializer();
serializer.Serialize(kml);
Console.WriteLine(serializer.Xml);
}
static void AddNamespace(Element element, string prefix, string uri)
{
// The Namespaces property is marked as internal.
PropertyInfo property = typeof(Element).GetProperty(
"Namespaces",
BindingFlags.Instance | BindingFlags.NonPublic);
var namespaces = (XmlNamespaceManager)property.GetValue(element, null);
namespaces.AddNamespace(prefix, uri);
}
}
This will output the elements with the gx prefix (and also shows that when the
FlyToMode enum is serialized it will change its case)
FlyToMode
<?xml version="1.0" encoding="utf-16"?>
<kml xmlns:
<gx:Tour>
<gx:Playlist>
<gx:FlyTo>
<gx:flyToMode>bounce</gx:flyToMode>
</gx:FlyTo>
</gx:Playlist>
</gx:Tour>
</kml>
Hope it helps to answer your questions.
Thanks a lot, this answers my questions, indeed.
As a side note, the code from your first post does not work properly, although I have the same version of Google Earth (6.0.3.2197). I tried it on two computers, one of which having a fresh install of Google Earth. Only the FlyTo part works. If
one also wants to see the pin growing (which is part of the tour, too), he has to make the modifications I indicated in my previous posts.
A very curious thing that happened yesterday was that Google Earth was not sensitive to the gradual changes I manually made to the KML output of your code from the first post (the "output.kml" file). I already had another similar file elsewhere which
I knew it was ok, and I was gradually modifying "output.kml" to see which minimal changes needed to be done in order to make it work. At some point I made all the changes, so the two files were identical, but Google Earth wouldn't play "output.kml"
properly. Restarting Google Earth (without saving "output.kml" to My Places) had no effect. Copying "output.kml" outside bin/Debug was the only move that made Google Earth accept the file...
Yet another thing happened yesterday: after freshly installing Google Earth, I turned on the error handling (Tools->Options->General->"KmL Error Handling") and restarted GE. Upon restarting, GE complained (if I remember correctly) that a "<styleUrl>"
belonging to "My Places" (which was generated on the first run) was an "unknown element". I inspected the file where "My Places" was saved and indeed there was this bogus <styleUrl> element wrongly placed either right before or right after a "</FlyTo>"
element, so I deleted it and GE did not complain anymore after restart. The same error also happened before in the non-fresh install of GE, when turning on the error handling. At that time I thought it was my fault as I had already added other stuff
to "My Places" (but not manually, so I was still a bit surprised).
All this reminds me of some other case, where I had to load the same file twice before being able to play the tour.
I suspect GE does not clean its internal memory properly, so things can still hang in which affect consequent operations, though a restart should normally reset everything. This hypothesis makes sense when thinking that GE needs to cache a lot of data
for efficiency reasons. Who knows, maybe it also preserves some cache on the disk, between two starts...
Well, maybe some things also happened because of my limited experience with XML/KML, but I'm still pretty sure that GE is not always behaving consistently. Otherwise it's a great product, no question about that.
Sorry for this long post, I just wanted to share you some of my experiences with GE while using SharpKML.
Thank you again for your prompt and helpful answers, and for sharing SharpKML with us. Kudos!
No need to apologise for the post - all feedback is welcome.
I've never used Google Earth so when I loaded the file I saw it had loaded the "Play Me!" (which I didn't see in the original example on the KML Reference page) so assumed it had worked, sorry about the confusion.
I've just been playing with it and the only way to get it to enlarge the icon is to use the
gx prefix you mentioned. I'm pretty confident this is an issue with how Google Earth handles namespaces in XML - SharpKml uses the built in XML library of the .NET Framework so I don't think the problem is there. Therefore, I won't be making any
changes to the library to accommodate this as I want to keep it compliant with the Open Geospatial Consortium KML 2.2 standard, though I might add an extension method that will let you add namespaces and prefixes to an element (I tried to get the Google extension
elements to register and use the gx prefix but it doesn't seem to help unless the prefix is registered on the root Kml element, so I don't think there's an automatic process of adding the prefix when needed.)
Thanks so much for all your effort.
This is indeed a very usefull library.
As an update.
I've discovered that the original problem with the code sample was a missing style ID.
document.AddStyle(
new Style
{
Id = "style0",
Icon = new IconStyle
{
Id = "iconstyle",
Scale = 1.0
}
});
document.AddFeature(
new Placemark
{
Id = "mountainpin1",
Name = "New Zealand's Southern Alps",
StyleUrl = new Uri("#style0", UriKind.Relative),
Geometry =
new Point
{
Coordinate = new Vector(-43.605, 170.144, 0)
}
});
This works fine for me with proper animation of the pin size.
Are you sure you want to delete this post? You will not be able to recover it later.
Are you sure you want to delete this thread? You will not be able to recover it later. | http://sharpkml.codeplex.com/discussions/262185 | CC-MAIN-2017-30 | refinedweb | 1,912 | 65.73 |
Chart.js is a popular JavaScript charting library and
ng2-charts is a wrapper for Angular 2+ to integrate Chart.js in Angular.
In this tutorial, you will use Chart.js and
ng2-charts to create sample charts in an Angular application.
To complete this tutorial, you will need:
This tutorial was verified with Node v14.13.1,
npm v6.14.8,
angular v10.1.6,
chart.js v2.9.4, and
ng2-charts v2.4.2.
You can use
@angular/cli to create a new Angular Project.
In your terminal window, use the following command:
- npx @angular/cli new angular-chartjs-example --style=css --routing=false --skip-tests
This will configure a new Angular project with styles set to “CSS” (as opposed to “Sass”, Less", or “Stylus”), no routing, and skipping tests.
Navigate to the newly created project directory:
- cd angular-chartjs-example
From your project folder, run the following command to install
chart.js:
- npm install chart.js@2.9.4 ng2-charts@2.4.2
Next, add
chart.js to your Angular application by opening
angular.json in your code editor and modifying it to include
Chart.min.js:
{ // ... "projects": { "angular-chartjs-example": { // ... "architect": { "build": { // ... "options": { // ... "scripts": [ "node_modules/chart.js/dist/Chart.min.js" ], "allowedCommonJsDependencies": [ "chart.js" ] }, // ... }, } }}, // ... }
Note: Adding
chart.js to
allowedCommonJsDependencies will prevent the “
CommonJS or AMD dependencies can cause optimization bailouts.” warning.
Then, open
app.module.ts in your code editor and modify it to import
ChartsModule:
import { BrowserModule } from '@angular/platform-browser'; import { NgModule } from '@angular/core'; import { ChartsModule } from 'ng2-charts'; import { AppComponent } from './app.component'; @NgModule({ declarations: [ AppComponent ], imports: [ BrowserModule, ChartsModule ], providers: [], bootstrap: [AppComponent] }) export class AppModule { }
With this scaffolding set in place, you can begin work on the chart component.
Let’s begin with an example that uses some of the options to pass-in as inputs to plot values associated with three different accounts over the course of four months.
ng2-charts gives you a
baseChart directive that can be applied on an HTML
canvas element.
Open
app.component.html in a code editor and replace the content with the following lines of code:
<div style="width: 40%;"> <canvas baseChart > </canvas> </div>
Then, modify the canvas to pass in
chartType and
legend:
<div style="width: 40%;"> <canvas ... [chartType]="'line'" [legend]="true" > </canvas> </div>
chartType: This sets the base type of the chart. The value can be
pie,
doughnut,
bar,
line,
polarArea,
radar, or
horizontalBar.
legend: A boolean for whether or not a legend should be displayed above the chart.
Then, modify the canvas to pass in
datasets:
<div style="width: 40%;"> <canvas ... [datasets]="chartData" > </canvas> </div>
Next, open
app.component.ts in a code editor to define the array you referenced in the template:
// ... export class AppComponent { // ... chartData = [ { data: [330, 600, 260, 700], label: 'Account A' }, { data: [120, 455, 100, 340], label: 'Account B' }, { data: [45, 67, 800, 500], label: 'Account C' } ]; }
datasets: This should be an array of objects that contain a data array and a label for each data set.
data: Alternatively, if your chart is simple and has only one data set, you can use
datainstead of
datasetsand pass-in an array of data points.
Now, revisit
app.component.html and modify the canvas to pass in
labels:
<div style="width: 40%;"> <canvas ... [labels]="chartLabels" > </canvas> </div>
Next, re-open
app.component.ts in a code editor to define the array you referenced in the template:
// ... export class AppComponent { // ... chartLabels = [ 'January', 'February', 'March', 'April' ]; }
labels: An array of labels for the X-axis.
Now, revisit
app.component.html and modify the canvas to pass in
options:
<div style="width: 40%;"> <canvas ... [options]="chartOptions" > </canvas> </div>
Next, re-open
app.component.ts in a code editor to define the object you referenced in the template:
// ... export class AppComponent { // ... chartOptions = { responsive: true }; }
options: An object that contains options for the chart. You can refer to the official Chart.js documentation for details on the available options.
Recompile your application:
- npm start
When visiting your application in a web browser (typically
localhost:4200), you will observe a chart with data plotted out for
Account A,
Account B, and
Account C over the months of
April,
February,
March,
April:
There are additional properties and options that are available to Chart.js that are covered in the official documentation.
chartClickand
chartHover
Two events are emitted,
chartClick and
chartHover, and they provide a way to react to the user interacting with the chart. The currently active points and labels are returned as part of the emitted event’s data.
Let’s create an example of adding these to the canvas.
Open
app.component.html and add
chartHover and
chartClick:
<div style="width: 40%;"> <canvas ... (chartHover)="onChartHover(($event)" (chartClick)="onChartClick(($event)" > </canvas> </div>
Open
app.component.ts and add the custom functions you referenced from the template:
// ... export class AppComponent { // ... onChartHover = ($event: any) => { window.console.log('onChartHover', $event); }; onChartClick = ($event: any) => { window.console.log('onChartClick', $event); }; }
After recompiling your application, you will observe
onChartHover and
onChartClick logged in your developer tools.
One of the highlights of using Chart.js is the ability to dynamically update or respond to data received from a backend or from user input.
Let’s continue to build off the previous example with the 3 account values plotted across 4 months and add new data points for the month of May.
Open
app.component.ts and defined the custom function:
// ... export class AppComponent { // ... newDataPoint(dataArr = [100, 100, 100], label) { this.chartData.forEach((dataset, index) => { this.chartData[index] = Object.assign({}, this.chartData[index], { data: [...this.chartData[index].data, dataArr[index]] }); }); this.chartLabels = [...this.chartLabels, label]; } }
[100, 100, 100] is provided as the default value if no array is passed to
newDataPoint().
There is also no mutation being performed on the dataset array. Object.assign is used to return new objects containing the previous data with the new data.
Then, open
app.component.html and use the custom function in a
button after the
canvas:
<div style="width: 40%;"> ... <button (click)="newDataPoint([900, 50, 300], 'May')"> Add data point </button> </div>
After recompiling your application, you will observe that the chart will plot values for
Account A,
Account B,
Account C for the month of
May when you interact with the Add data point button.
In this tutorial, you used Chart.js and
ng2-charts to create a sample chart in an Angular application.
Together, these libraries provide you with the power to present data in a way that is modern and dynamic. | https://www.digitalocean.com/community/tutorials/angular-chartjs-ng2-charts | CC-MAIN-2022-21 | refinedweb | 1,082 | 50.33 |
weight of animation.
This calculates the blend weights for one curve.
Weights are distributed so that the top layer gets everything. If it doesn't use the full weight then the next layer gets to distribute the remaining weights and so on. Once all weights are used by the top layers, no weights will be available for lower layers anymore Unity uses fair weighting, which means if a lower layer wants 80% and 50% have already been used up, the layer will NOT use up all weights. instead it will take up 80% of the 50%.
Example: a upper body which is affected by wave, walk and idle a lower body which is affected by only walk and idle.
- Blend weights can change per animated value because of mixing. Even without mixing, sometimes a curve is just not defined. Still you want the blend weights to add up to 1. Most of the time weights are similar between curves.
using UnityEngine; using System.Collections;
public class ExampleScript : MonoBehaviour { public Animation anim;
void Start() { // Set the blend weight of the walk animation to 0.5 anim["Walk"].weight = 0.5f; } } | https://docs.unity3d.com/ScriptReference/AnimationState-weight.html | CC-MAIN-2021-43 | refinedweb | 189 | 74.08 |
If you ever wondered how to animate snow, follow this tutorial to know how.
Table of contents
What We Will Be Building
We’re going to build an app that has an image of a Christmas Tree and snowfall. That’s how it’s going to look like.
For your reference, the final code for the app we’re building can be found in this GitHub repo.
Outlining the App Structure
It’s always a good idea to plan you app code structure in advance. Let’s list the files that we’re going to need to build all of the components for the app.
index.ios.jsor
index.android.js. Entry points into the app for iOS or Android platforms respectively. Both are going to render just one component called
Tree.
Tree.js. A component that renders a background image and flakes using multiple instances of
Flakecomponent.
Flake.js. A component that renders a flake of given size and position.
Let’s Get Started
Let’s start off by creating a new app. Open Terminal App and run these commands to initialize a new project and run it in the simulator.
react-native init ChristmasTree; cd ChristmasTree; react-native run-ios;
Enable Hot Reloading
Once your app is up and running, press ⌘D and select Enable Hot Reloading. This will save you some time having to reload the app manually every time you make a change.
Flake Component
Let’s start off by creating
Flake component, which is a pure render component. It doesn’t have state and just renders a flake taking in
radius,
density and
x,
y coordinates as props.
Create a new file with the following code and call it
Flake.js.
import React, { Component } from 'react'; import { Animated, Dimensions, Easing } from 'react-native'; // Detect screen size const { width, height } = Dimensions.get('window'); export default class Flake extends Component { // Angle of falling flakes angle = 0 componentWillMount() { // Pull x and y out of props const { x, y } = this.props; // Initialize Animated.ValueXY with passed x and y coordinates for animation this.setState({ position: new Animated.ValueXY({ x, y }) }); } getStyle = ({ radius, x, y } = this.props) => ({ position: 'absolute', backgroundColor: 'rgba(255,255,255,0.8)', borderRadius: radius, width: radius * 2, height: radius * 2, }) render() { return <Animated.View style={[this.getStyle(), this.state.position.getLayout()]} />; } }
Index Files
Next, let’s update our index files. Since we’re going to re-use the same code for both, iOS and Android, so we don’t need two different index files. We’ll be using the same
Tree component in both index files.
Open
index.ios.js file and scrap all of the React Native boilerplate code to start from scratch. Do the same for
index.android.js. And add the following code to both of index files.
import { AppRegistry } from 'react-native'; import Tree from './Tree'; AppRegistry.registerComponent('ChristmasTree', () => Tree);
This code imports
Tree component from
Tree.js file and registers it as main app container. If you took at look at the simulator at this point, you would see an error screen. That’s because
Tree.js doesn’t exist yet, and therefore can’t be imported. So, let’s fix it.
Tree Component
Next, let’s build
Tree component. It takes in
flakesCount prop with the default value of
50 flakes on the screen and renders that amount of flakes distributed randomly on the screen. To render each flake, it uses
Flake component we built in the previous step. It also renders a background image we’re about to download.
Download Background Image
Create a new folder called
assets inside your project and download this image into that folder.
Create Tree.js
Create a new file with the following code and call it
Tree.js.
import React, { Component } from 'react'; import { Dimensions, Image, StyleSheet, View } from 'react-native'; import Flake from './Flake'; // Detect screen size const { width, height } = Dimensions.get('window'); export default class Tree extends Component { static defaultProps = { flakesCount: 50, // total number of flakes on the screen } render({ flakesCount } = this.props) { return <View style={styles.container}> {/* Christmas Tree background image */} <Image style={styles.image} source={require('./assets/tree.jpg')} > {/* Render flakesCount number of flakes */} {[...Array(flakesCount)].map((_, index) => <Flake x={Math.random() * width} // x-coordinate y={Math.random() * height} // y-coordinate radius={Math.random() * 4 + 1} // radius density={Math.random() * flakesCount} // density key={index} />)} </Image> </View>; } } const styles = StyleSheet.create({ container: { flex: 1, }, image: { flex: 1, resizeMode: 'cover', width: width, position: 'relative', }, });
Bring up the simulator window and see what we’ve got so far. We have our Christmas Tree and a bunch of snowflakes. If you press ⌘R you can see that they’re distributed randomly every time. That’s great, but snowflakes are static and do not move. Let’s make them fall in the next step.
Make Them Fall
To make the snowflakes fall, we’re going to need to add
animate() method that will update flake coordinates and use React Native core module
Animated to animate their falling.
So, open up
Flake.js file and add the following code inside
Flake class definition between
export default class Flake extends Component { and
}.
export default class Flake extends Component { // ...exisiting code componentDidMount() { this.animate(); } animate = () => { // Animation duration let duration = 500; // Pull x and y out of Animated.ValueXY object in this.state.position const { x: { _value: x }, y: { _value: y } } = this.state.position; // Pull radius and density out of props const { radius, density } = this.props; this.angle += 0.02; let newX = x + Math.sin(this.angle) * 10; let newY = y + Math.cos(this.angle + density) + 10 + radius / 2; // Send flakes back from the top once they exit the screen if (x > width + radius * 2 || x < -(radius * 2) || y > height) { duration = 0; // no animation newX = Math.random() * width; // random x newY = -10; // above the screen top // Send 2/3 of flakes back to the top if (Math.floor(Math.random() * 3) + 1 > 1) { newX = Math.random() * width; newY = -10; // Send the rest to either left or right } else { // If the flake is exiting from the right if (Math.sin(this.angle) > 0) { // Enter from the left newX = -5; newY = Math.random() * height; } else { // Enter from the right newX = width + 5; newY = Math.random() * height; } } } // Animate the movement Animated.timing(this.state.position, { duration, easing: Easing.linear, toValue: { x: newX, y: newY, } }).start(() => { // Animate again after current animation finished this.animate(); }); } // ...exisiting code }
And now they’re falling.
Wrapping Up
I hope you enjoyed the tutorial. If you have any questions or ideas for next tutorials, just leave a comment. | https://rationalappdev.com/christmas-tree-animation-with-react-native/ | CC-MAIN-2020-40 | refinedweb | 1,092 | 59.8 |
#include <MIDI.h>const int RecButtonPin = 7;const int StopButtonPin = 8; //Init button pinsconst int RecLedPin = 13;const int StopLedPin = 12;int RecLedState = LOW;int RecButtonState;int lastRecButtonState = LOW;int StopLedState = LOW;int StopButtonState;int lastStopButtonState = LOW;void setup() { // Set MIDI baud rate: pinMode(RecButtonPin, INPUT); pinMode(StopButtonPin, OUTPUT); pinMode(RecLedPin, OUTPUT); pinMode(StopLedPin, OUTPUT); digitalWrite(RecLedPin, RecLedState); digitalWrite(StopLedPin, StopLedState); Serial.begin(31250);}void loop() { int previousRecState; int previousStopState; // check if the pushbutton is pressed. // if it is, the buttonState is HIGH: RecButtonState = digitalRead(RecButtonPin); StopButtonState = digitalRead(StopButtonPin); if (RecButtonState != previousRecState){ if (RecButtonState = HIGH){ //Note on channel 1 (0x90), value 0, middle velocity (0x45): MIDI.sendNoteOn(0, 64, 1); } } if (StopButtonState != previousStopState){ if (StopButtonState = HIGH){ //Note on channel 1 (0x90), value 4, middle velocity (0x45): MIDI.sendNoteOn(4, 64, 1); } } previousRecState = RecButtonState; previousStopState = StopButtonState; }
pinMode(StopButtonPin, INPUT);
void StopPlaying(int StopReading){ // If the switch state changed, reset the debounce timer if (ButtonStopState != LastStopState){ StopDebounceTime = millis(); } // If the reading has been active for more than the DebounceDelay time, // it is the new state if ((millis() - StopDebounceTime) > DebounceDelay){ //if the button state has changed if (StopReading != ButtonStopState){ ButtonStopState = StopReading; // only send MIDI if the new state is HIGH if(ButtonStopState == HIGH){ MIDI.sendControlChange(85,64,1); // Send MIDI CC #85 value 64 channel 1 changeLoopMode(3); } } } // Save the reading LastStopState = StopReading; }
// this is not code, more like pseudo-code to give you an idea... ;)When a buttonState != lastButtonState and the button is pressed { reset button's counter and start counting.}when a buttonState != lastButtonState and the button is released { //check the button's counter: if button's counter is smaller than holdInterval { // so this is a simple click do this... } if button's counter is bigger than holdInterval { // so this is a button hold do that... }}
Here's the code snippet, it all works as it should within the main loop.
void StopPlaying(int StopReading)
ButtonStopState = StopReading;
to you know the ClickButton library? is very easy to use and it gives you simple clicks, double and triple click, simple hold and double and triple click+hold.I have used it in the past and it worked great.
I my latest project i also used a click and click+hold function (without the library) and i had some trouble doing it (i'm not so experienced!!).The way i got it working was to always send the message on button release, instead of button push!i made something like this:
Do you really need it outside the main loop?
why are you using like this:Code: void StopPlaying(int StopReading)or this:Code: ButtonStopState = StopReading;('im not saying it is wrong. i don't know so much code and i'm trying to understand so i can help you).Do you need to "report" the button state and use it also somewhere else in the code, or do you just need it to send that midi command and change the loopMode? Maybe you can make the bit of code more simple...
I've tried something similar but it didn't work. But I have to send the message on button press, not release, so that's not an option for me.
ButtonStopState = StopReading;
StopReading = ButtonStopState;
How will you then do the hold? You cannot send that on click.You could make something like you have done, on click record the millis at that point into a variable.Then maybe you can always check how much time as passed. If passed time is equal to hold time (let's say 2000ms), send midi message.Maybe that would work...
something i just though...here:Code: ButtonStopState = StopReading;wouldn't it be betterCode: StopReading = ButtonStopState;or is it the same?
Please enter a valid email to subscribe
We need to confirm your email address.
To complete the subscription, please click the link in the
Thank you for subscribing!
Arduino
via Egeo 16
Torino, 10131
Italy | http://forum.arduino.cc/index.php?topic=176559.msg1312294 | CC-MAIN-2017-13 | refinedweb | 650 | 56.35 |
The topic you requested is included in another documentation set. For convenience, it's displayed below. Choose Switch to see the topic in its original location.
createAttributeNS method
Creates a reference to an attribute object that is associated with an XML namespace.
Syntaxvar ppAttribute = document.createAttributeNS(pvarNS, bstrAttrName);
Parameters
- pvarNS [in]
Type: Variant
A Variant value that contains the name of the desired namespace or a null value if no namespace is desired.
- bstrAttrName [in]
A String value that contains the name of the desired attribute.
- ppAttribute [out, retval]
Type: IHTMLDOMAttribute
A reference to an attribute object that contains the new attribute.
Return value
Type: IHTMLDOMAttribute
A reference to an attribute object that contains the new attribute.
Standards information
Remarks
The createAttributeNS method is supported only for XML documents.
See also
Show: | https://msdn.microsoft.com/en-us/library/windows/apps/ff975211.aspx | CC-MAIN-2016-50 | refinedweb | 132 | 51.14 |
On Fri, Oct 28, 2011 at 02:52:09PM +0300, Stanislav Kinsbursky wrote:> This patch-set was created in context of clone of git branch:> git://git.linux-nfs.org/projects/trondmy/nfs-2.6.git> and rebased on tag "v3.1".> > v7:> 1) Implemented "goto pattern" in __svc_create().> 2) Pathes 5 and 6 from perious patch-set were squashed to make things looks> clearer and to allow safe bisecting of the patch-set.This series looks fine to me; thanks!--b.> > v6:> 1) Fixes in rpcb_clients management.> > v4:> 1) creation and destruction on rpcbind clients now depends on service program> versions "vs_hidden" flag.> > This patch is required for further RPC layer virtualization, because rpcbind> clients have to be per network namespace.> To achive this, we have to untie network namespace from rpcbind clients sockets.> The idea of this patch set is to make rpcbind clients non-static. I.e. rpcbind> clients will be created during first RPC service creation, and destroyed when> last RPC service is stopped.> With this patch set rpcbind clients can be virtualized easely.> > The following series consists of:> > ---> > Stanislav Kinsbursky (7):> | 88 ++++++++++++++++++++++++++++---------------> net/sunrpc/sunrpc_syms.c | 3 -> net/sunrpc/svc.c | 57 ++++++++++++++++++++++++----> 6 files changed, 113 insertions(+), 40 deletions(-)> > --> To unsubscribe from this list: send the line "unsubscribe linux-nfs" in> the body of a message to majordomo@vger.kernel.org> More majordomo info at | https://lkml.org/lkml/2011/10/28/211 | CC-MAIN-2016-22 | refinedweb | 230 | 67.25 |
First module of the year!
Posted on Wed 13 January 2016 in blog>
The
sfxnode argument tells maya which sfx shader to work on. The
command flag indiciates an action and the
node id specifies an node in the network. Nodes are assigned an id in order of creation, with the firstnode after the root ordinarily being number 2 and so on – however the ids are not recycled so a network which has been edited extensively can have what look like random ids and there is no guarantee that the nodes will form a neat, continuous order.
Many commands take additional arguments as well. Those extra always follow the main command; thus
shaderfx -n "StingrayPBS1" -edit_int 19 "uiorder" 1;
sets the value of the
uiorder field on node 19 to a value of 1.
The
shaderfx command can also return a value: to query the
uiorder field in the example above you’d issue
shaderfx -n "StingrayPBS1" -getPropertyValue 19 "uiorder"; // Result: 1 //
So, the good news is that the
shaderfx command is actually pretty capable: so far, at least, I have not found anything I really needed to do that the command did not support. For some reason the help documentation on the mel command is pretty sparse but the python version of the help text is actually quite verbose and useful.
Still, it’s kind of a wonky API: a single command for everything, and no way to really reason over a network as a whole. Worse, the different types of nodes are identified only by cryptic (and undocumented) numeric codes: for example a
Cosine node is 20205 – but the only way to find that out is to use the
getNodeTypeByClassName command (and, by the way, the node type names are case and space sensitive).
Cleanup crew
With all that baggage I was pretty discouraged about actually getting any work done using shaderfx programmatically. However a little poking around produced what I hope is a somewhat more logical API, which I’m sharing on github.
The
sfx module is a plain python module - you can drop it into whatever location you use to story your Maya python scripts. It exposes two main classes:
SFXNetwork represents a single shader network – it is a wrapper around the Maya shader ball. The
SFXNetwork contains and
pbsnodes. These make it easier to work with the zillions of custom node ids: Instead of remembering that a
Cosine node is type 20205, you reference
sfxnodes.Cosine. I’ll be using the
StingrayPBSNetwork class and the
pbsnodes submodule in my examples, since most of my actual use-case involves the Stingray PBS shader. The syntax and usage, however, are the same for the vanilla
SFXNetwork and
sfxnodes – only the array of node types and their properties.
Here’s a bit of the basic network functionality.
Create a network
To create a new shaderfx network, use the
create() classmethod:
from sfx import StingrayPBSNetwork import sfx.pbsnodes as pbsnodes network = StingrayPBSNetwork.create('new_shader')
That creates a new shaderball (note that it won’t be connected to a shadingEngine by default – that’s up to you).
Listing nodes
show node IDs toggle in the ShaderFX window.
The values of the node dictionary are
SFXNode objects.
Adding new nodes
To add a node to the network use its
add() method and pass a class from either the
sfxnodes or
pbsnodes submodule to indicate the type.
if_node = network.add(pbsnodes.If) # creates an If node and adds it to the network var_node = network.add(pbsnodes.MaterialVariable) # creates a MaterialVariable node and adds it to the network
Connecting nodes
Connecting nodes in shaderfx requires specifying the source node the source plug, the target node and the target plug. Unforunately the plugs are indentifited by zero-based index numbers: the only way to know them by default is to count the slots in the actual shaderfx UI. Output plugs are usually (not always) going to be index zero but the target plugs can be all over the map.
To make this cleaner, each
SFXNode object exposes two fields called
inputs and
outputs, which have named members for the available plugs. So to connect the ‘result’ output of the
var_node object to the input named ‘B’ on the
if_node:
network.connect(var_node.outputs.result, if_node.inputs.b)
If the connection can’t be made for some reason, a
MayaCommandError will be raised.
In any shader system it’s common to have to ‘swizzle’ the connections: to connect the x and z channels of a 3-pronged output to channels of an input, for example. Mismatched swizzles are a common cause of those
MayaCommandErrors. You can set the swizzle along with the connection by passing the swizzle you need as a string
network.connect(var_node.outputs.result, if_node.inputs.b, 'z') # connects the 'x' output of var_node to the b channel of the input
Setting node properties
Nodes often have editable properties. There are a lot of different ones so it is often necessary to inspect a node and find out what properties it has and what type of values those properties accept. Every
SFXNode object has a read-only member
properties, which is a dictionary of names and property types. Thus:
print node.properties # { 'min': 'float', 'max': 'float', 'method': 'stringlist' }
If you know that a property exists on an object you can query it or set it using typical python dot syntax:
node = network.properties[5] # get the node at index 5 in this network print node.properties: # { 'min': 'float', 'max': 'float', 'method': 'stringlist' } print node.min # 1.0 # getting a named property returns its value. node.min = 2.0 # sets the node value print node.min # 2.0
If you try to access a property that doesnt exist, an error will be raised:
print node.i_dont_exist # AttributeError: no attribute named i_dont_exist node.i_dont_exist = 99 # MayaCommandError
Help wanted!
So, there’s the basics. This module is pretty simple but I’ve found it extremely helpful in workign with SFX nodes. It will be much easier to work with, of course, if you already know your way around ShaderFX. Please let me know how it works for you – and as always bug reports and pull requests are very welcome! | https://theodox.github.io/2016/sfx_module | CC-MAIN-2021-31 | refinedweb | 1,034 | 60.35 |
:
- 608
- John McGrath
- May 30, 2005
#include <boost/shared_ptr.hpp> or #include "boost/shared_ptr.hpp"?Colin Caughie, Aug 29, 2006, in forum: C++
- Replies:
- 1
- Views:
- 957
- Shooting
- Aug 29, 2006
Difference between *.hxx and *.h header files?Mark Sullivan, May 17, 2008, in forum: C++
- Replies:
- 27
- Views:
- 5,910
- James Kanze
- May 21, 2008
What is the difference between .cpp + .h vs .cxx and .hxx ?Patrick Brehmer, Nov 27, 2008, in forum: C++
- Replies:
- 9
- Views:
- 8,825
- $B3Y?.L@(B
- Dec 5, 2008
REGEX (Not allowing file extenstions) or the dotGuest, Oct 4, 2003, in forum: Perl Misc
- Replies:
- 8
- Views:
- 249
- sts
- Oct 5, 2003 | http://www.thecodingforums.com/threads/c-standard-and-file-extenstions-hpp-h-hxx.676353/ | CC-MAIN-2016-18 | refinedweb | 109 | 82.54 |
.
So, I've settled on a pattern that I found somewhere on the web to safely override Equals. I don't remember where I found it, and there are certainly many other good implementations (probably better than mine). Regardless, I found that I do have a repeating pattern. I decided to set out to limit this duplication if I could. Here is what I came up with.
1: public static bool SafeEquals<T>( this T left, object right, Predicate<T> test )
3: if( right != null && right.GetType().Equals( left.GetType() ) )
5: return test( (T)right );
7: return false;
This is meant as a utility extension to help me override Equals in my classes without having to write that if condition over and over again. Also, it takes care of casting to my type as well.
Here is an example of how it is used. Suppose you have a class that should demonstrate equality if the Key property is equal:
1: public override bool Equals( object obj )
3: return this.SafeEquals( obj, test => test.Key == this.Key );
or
3: return this.SafeEquals( obj, test => object.Equals( test.Key, this.Key ) );
Let me know what you guys think.
The string.Join method can come in handy when you want a comma separated list of strings. However, there's a major limitation. To use it, you must provide a one-dimensional string array. What if you have a collection of objects and you want to "Join" a property on the objects (e.g., a comma separated list of IDs). Well, since I couldn't find anything within the framework that would do this for me, I wrote an extension method that meets my need. Updated from James Curran's suggestion in the comments.
1: public static string Join<T>( this IEnumerable<T> target, Func<T, object> valueSelector )
3: StringBuilder result = new StringBuilder();
4: foreach( T item in target )
5: {
6: result.Append( valueSelector( item ).ToString() );
7: result.Append( "," );
8: }
9: result.Length--;
10: //remove the trailing comma
11: return result.ToString();
12: }
This will take any Generic Enumerable and Join the string representation based on the value selector you provide.
Here is an example of how to use it:
1: public class Child
3: public int Id { get; set; }
4: public string Name { get; set; }
5: // ...
6: }
7: public class Parent
8: {
9: public int Id { get; set; }
10: public string Name { get; set; }
11: public List<Child> Children;
12: // ...
13: public string ChildIds
14: {
15: get { return Children.Join( child => child.Id ); }
16: }
17: public string ChildNames
18: {
19: get { return Children.Join( child => child.Name ); }
20: }
21: }
Cheers.
[Update.
I've had a few people ask me about my custom GridView and whether I can help them with theirs. Though, I cannot share my code directly, I can provide some guidelines. In the coming weeks I plan to post segments stepping through customizing a GridView. My customizations are by no means perfect, and I have had to tweak things as I encounter issues. I look forward to sharing my experiences. I will probably post a multi-part article that walks through customizing a GridView. Again, I will not be posting any large chunks of code. Mainly, I will provide guidelines that should meet the needs of most customizations. | http://geekswithblogs.net/WillSmith/archive/2008/06.aspx | CC-MAIN-2015-11 | refinedweb | 547 | 76.01 |
Swift Algorithm Club: Heap and Priority Queue Data Structure
The Swift Algorithm Club is an open source project on implementing data structures and algorithms in Swift.
Every month, Kelvin Lau, Vincent Ngo and I feature a cool data structure or algorithm from the club in a tutorial on this site. If you want to learn more about algorithms and data structures, follow along with us!
In this tutorial, you’ll learn how to implement a heap in Swift 3. A heap is frequently used to implement a priority queue.
The Heap data structure was first implemented for the Swift Algorithm Club by Kevin Randrup, and has been presented here for tutorial form.
You won’t need to have done any other tutorials to understand this one, but it might help to read the tutorials for the Tree and Queue data structures, and be familiar with their terminology.
Getting Started
The heap data structure was first introduced by J. W. J. Williams in 1964 as a data structure for the heapsort sorting algorithm.
In theory, the heap resembles the binary tree data structure (similar to the Binary Search Tree). The heap is a tree, and all of the nodes in the tree have 0, 1 or 2 children.
Here’s what it looks like:
Elements in a heap are partially sorted by their priority. Every node in the tree has a higher priority than its children. There are two different ways values can represent priorities:
- maxheaps: Elements with a higher value represent higher priority.
- minheaps: Elements with a lower value represent higher priority.
The heap also has a compact height. If you think of the heap as having levels, like this:
…then the heap has the fewest possible number of levels to contain all its nodes. Before a new level can be added, all the existing levels must be full.
Whenever we add nodes to a heap, we add them in the leftmost possible position in the incomplete level.
Whenever we remove nodes from a heap, we remove the rightmost node from the lowest level.
Removing the highest priority element
The heap is useful as a priority queue because the root node of the tree contains the element with the highest priority in the heap.
However, simply removing the root node would not leave behind a heap. Or rather, it would leave two heaps!
Instead, we swap the root node with the last node in the heap. Then we remove it:
Then, we compare the new root node to each of its children, and swap it with whichever child has the highest priority.
Now the new root node is the node with the highest priority in the tree, but the heap might not be ordered yet. We compare the new child node with its children again, and swap it with the child with the highest priority.
We keep sifting down until either the former last element has a higher priority than its children, or it becomes a leaf node. Since every node once again has a higher priority than its children, the heap quality of the tree is restored.
Adding a new element
Adding a new element uses a very similar technique. First we add the new element at the left-most position in the incomplete level of the heap:
Then we compare the priority of the new element to its parent, and if it has a higher priority, we sift up.
We keep sifting up until the new element has a lower priority than its parent, or it becomes the root of the heap.
And once again, the ordering of the heap is preserved.
Practical Representation
If you’ve worked through the Binary Search Tree tutorial, it might surprise you to learn the heap data structure doesn’t have a Node data type to contain its element and links to its children. Under the hood, the heap data structure is actually an array!
Every node in the heap is assigned an index. We start by assigning 0 to the root node, and then we iterate down through the levels, counting each node from left to right:
If we then used those indices to make an array, with each element stored in its indexed position, it would look like this:
A bit of clever math now connects each node to its children. Notice how each level of the tree has twice as many nodes as the level above it. We have a little formula for calculating the child indices of any node.
Given the node at index
i, its left child node can be found at index
2i + 1 and its right child node can be found at index
2i + 2.
This is why it’s important for the heap to be a compact tree, and why we add each new element to the leftmost position: we’re actually adding new elements to an array, and we can’t leave any gaps.
Implementing a Swift Heap
That’s all the theory. Let’s start coding.
Start by creating a new Swift playground, and add the following struct declaration:
struct Heap<Element> { var elements : [Element] let priorityFunction : (Element, Element) -> Bool // TODO: priority queue functions // TODO: helper functions }
You’ve declared a struct named
Heap. The
syntax declares this to be a generic struct that allows it to infer its own type information at the call site.
The
Heap has two properties: an array of
Element types, and a priority function. The function takes two
Elements and returns
true if the first has a higher priority than the second.
You’ve also left some space for the priority queue functions – adding a new element, and removing the highest priority element, as described above – and for helper functions, to help keep your code clear and readable.
Simple functions
All the code snippets in this section are small, independent computed properties or functions. Remove the
TODO comment for priority queue functions, and replace it with these.
var isEmpty : Bool { return elements.isEmpty } var count : Int { return elements.count }
You might recognize these property names from using arrays, or from the
Queue data structure. The
Heap is empty if its
elements array is empty, and its count is the
elements array’s count. We’ll be needing to know how many elements are in the heap a lot in the coming code.
Below the two computed properties, add this function:
func peek() -> Element? { return elements.first }
This will definitely be familiar to you if you’ve used the
Queue. All it does is return the first element in the array – allowing the caller to access the element with the highest priority in the heap.
Now remove the
TODO comment for helper functions, and replace it with these four functions:
func isRoot(_ index: Int) -> Bool { return (index == 0) } func leftChildIndex(of index: Int) -> Int { return (2 * index) + 1 } func rightChildIndex(of index: Int) -> Int { return (2 * index) + 2 } func parentIndex(of index: Int) -> Int { return (index - 1) / 2 }
These four functions are all about taking the formula of calculating the array indices of child or parent nodes, and hiding them inside easy to read function calls.
You might have realised that the formula for calculating the child indices only tell you what the left or right child indices should be. They don’t use optionals or throw errors to suggest that the heap might be too small to actually have an element at those indices. We’ll have to be mindful of this.
You might also have realised that because of the left and right child index formula, or because of the tree diagrams above, all left children will have odd indices and all right children will have even indices. However, the
parentIndex function doesn’t attempt to determine if the
index argument is a left or right child before calculating the parent index; it just uses integer division to get the answer.
Comparing priority
In the theory, we compared the priorities of elements with their parent or children nodes a lot. In this section we determine which index, of a node and its children, points to the highest priority element.
Below the
parentIndex function, add this function:
func isHigherPriority(at firstIndex: Int, than secondIndex: Int) -> Bool { return priorityFunction(elements[firstIndex], elements[secondIndex]) }
This helper function is a wrapper for the priority function property. It takes two indices and returns
true if the element at the first index has higher priority.
This helps us write two more comparison helper functions, which you can now write below
isHigherPriority:
func highestPriorityIndex(of parentIndex: Int, and childIndex: Int) -> Int { guard childIndex < count && isHigherPriority(at: childIndex, than: parentIndex) else { return parentIndex } return childIndex } func highestPriorityIndex(for parent: Int) -> Int { return highestPriorityIndex(of: highestPriorityIndex(of: parent, and: leftChildIndex(of: parent)), and: rightChildIndex(of: parent)) }
Let’s review these two functions. The first assumes that a parent node has a valid index in the array, checks if the child node has a valid index in the array, and then compares the priorities of the nodes at those indices, and returns a valid index for whichever node has the highest priority.
The second function also assumes that the parent node index is valid, and compares the index to both of its left and right children – if they exist. Whichever of the three has the highest priority is the index returned.
The last helper function is another wrapper, and it’s the only helper function which changes the
Heap data structure at all.
mutating func swapElement(at firstIndex: Int, with secondIndex: Int) { guard firstIndex != secondIndex else { return } swap(&elements[firstIndex], &elements[secondIndex]) }
This function takes two indices, and swaps the elements at those indices. Because Swift throws a runtime error if the caller attempts to swap array elements with the same index, we
guard for this and return early if the indices are the same.
Enqueueing a new element
If we’ve written useful helper functions, then the big and important functions should now be easy to write. So, first we’re going to write a function which enqueues a new element to the last position in the heap, and then sift it up.
It looks as simple as you would expect. Write this with the priority queue functions, under the
peek() function:
mutating func enqueue(_ element: Element) { elements.append(element) siftUp(elementAtIndex: count - 1) }
count - 1 is the highest legal index value in the array, with the new element added.
This won’t compile until you write the
siftUp function, though:
mutating func siftUp(elementAtIndex index: Int) { let parent = parentIndex(of: index) // 1 guard !isRoot(index), // 2 isHigherPriority(at: index, than: parent) // 3 else { return } swapElement(at: index, with: parent) // 4 siftUp(elementAtIndex: parent) // 5 }
Now we see all the helper functions coming to good use! Let’s review what you’ve written.
- First you calculate what the parent index of the index argument is, because it’s used several times in this function and you only need to calculate it once.
- Then you
guardto ensure you’re not trying to sift up the root node of the heap,
- or sift an element up above a higher priority parent. The function ends if you attempt either of these things.
- Once you know the indexed node has a higher priority than its parent, you swap the two values,
- and call
siftUpon the parent index, in case the element isn’t yet in position.
This is a recursive function. It keeps calling itself until its terminal conditions are reached.
Dequeueing the highest priority element
What we can sift up, we can sift down, surely.
To dequeue the highest priority element, and leave a consistent heap behind, write the following function under the
siftUp function:
mutating func dequeue() -> Element? { guard !isEmpty // 1 else { return nil } swapElement(at: 0, with: count - 1) // 2 let element = elements.removeLast() // 3 if !isEmpty { // 4 siftDown(elementAtIndex: 0) // 5 } return element // 6 }
Let’s review what you’ve written.
- First you
guardthat that the heap has a first element to return. If there isn’t, you return
nil.
- If there is an element, you swap it with the last node in the heap.
- Now you remove the highest priority element from the last position in the heap, and store it in
element.
- If the heap isn’t empty now, then you sift the current root element down the heap to its proper prioritized place.
- Finally you return the highest priority element from the function.
This won’t compile without the accompanying
siftDown function:
mutating func siftDown(elementAtIndex index: Int) { let childIndex = highestPriorityIndex(for: index) // 1 if index == childIndex { // 2 return } swapElement(at: index, with: childIndex) // 3 siftDown(elementAtIndex: childIndex) }
Let’s review this function too:
- First you find out which index, of the argument index and its child indices, points to the element with the highest priority. Remember that if the argument index is a leaf node in the heap, it has no children, and the
highestPriorityIndex(for:)function will return the argument index.
- If the argument index is that index, then you stop sifting here.
- If not, then one of the child elements has a higher priority; swap the two elements, and keep recursively sifting down.
One
last first thing
The only essential thing left to do is to check the
Heap‘s initializer. Because the
Heap is a struct, it comes with a default init function, which you can call like this:
var heap = Heap(elements: [3, 2, 8, 5, 0], priorityFunction: >)
Swift’s generic inference will assume that
heap has a type of
Heap, and the comparison operator
> will make it a maxheap, prioritizing higher values over lower values.
But there’s a danger here. Can you spot it?
Write this function at the beginning of the
Heap struct, just below the two properties.
init(elements: [Element] = [], priorityFunction: @escaping (Element, Element) -> Bool) { // 1 // 2 self.elements = elements self.priorityFunction = priorityFunction // 3 buildHeap() // 4 } mutating func buildHeap() { for index in (0 ..< count / 2).reversed() { // 5 siftDown(elementAtIndex: index) // 6 } }
Let's review these two functions.
- First, you've written an explicit init function which takes an array of elements and a priority function, just as before. However, you've also specified that by default the array of elements is empty, so the caller can initialise a
Heapwith just the priority function if they so choose.
- You also had to explicitly specify that the priority function is
@escaping, because the struct will hold onto it after this function is complete.
- Now you explicitly assign the arguments to the
Heap's properties.
- You finish off the
init()function by building the heap, putting it in priority order.
- In the
buildHeap()function, you iterate through the first half of the array in reverse order. If you remember that the every level of the heap has room for twice as many elements as the level above, you can also work out that every level of the heap has one more element than every level above it combined, so the first half of the heap is actually every parent node in the heap.
- One by one, you sift every parent node down into its children. In turn this will sift the high priority children towards the root.
And that's it. You wrote a heap in Swift!
A final thought
Let me leave you with a final thought.
What would happen if you had a huge, populated heap full of prioritised elements, and you kept dequeueing the highest priority element until the heap was empty?
You would dequeue every element in priority order. The elements would be perfectly sorted by their priority.
That's the heapsort algorithm!
Where To Go From Here?
I hope you enjoyed this tutorial on making a heap data structure!
Here is a Swift playground with the above code. You can also find alternative implementations and further discussion in the Heap! | https://www.raywenderlich.com/160631/swift-algorithm-club-heap-and-priority-queue-data-structure | CC-MAIN-2017-26 | refinedweb | 2,642 | 60.65 |
want to delete character in console by using write method
here are methods to delete character
Console.Write("\b") or Console.Write("\0");
these methods does not work in mono
is there a way to delete character?
Console.Write("\b") work
Console.Write("\0") does not work
Console.Write("123");
Console.Write("\b");
does not delete character '3';
but after using Console.BufferWidth Property, it does work
var text = string.Empty.PadRight(Console.BufferWidth - 1, '1');
Console.Write("123");
Console.Write("\b");
and another bug.
after deletion character '3'
selectall and copy text in terminal
paste them to text editor
i think text must be "12"
but result is "12 "
is this right?
`\b` only controls cursor you need to overwrite the character. Following repro works for me as expected
using System;
class X
{
public static void Main ()
{
Console.Write("Abc");
Console.Write("\b ");
}
} | https://xamarin.github.io/bugzilla-archives/57/57471/bug.html | CC-MAIN-2019-43 | refinedweb | 144 | 69.89 |
Archives
Areas vs. Sites
This is like the SharePoint version of Freddy vs. Jason (or Aliens vs. Predator if that's your sort of thing). It's a debate that, IMHO, has been asked and answered a thousand times over in the newsgroups and emails but people still are confused. Bill English said it best to me once (and continues with this position which I completely share).
- SharePoint Areas are for aggregation.
- SharePoint Sites are for collaboration.
Read this. Learn this. Live this.
True, you can use the portal to create document libraries, check-in/out and all that good stuff but it becomes a bit of a nightmare in organization from what I've found. Moving it down to a WSS site and letting the user manage access and all that works much better. Also you can create public areas for the information and let users “publish“ information up to the portal into that area which lets them decide what they want to show. They'll go on in their WSS site adding documents and only pushing up to the portal what others need to see.
SharePoint Wrapper Assembly and Migration Tool
I've completed a tool to migrate our documents with version histories from 2001 to 2003. I know SPIN/SPOUT do this en-masse but for our needs, there wasn't a 1:1 mapping with old portal directory structure and new portal. There were some other tools in this space, but I had some fun writing an assembly that bridges between the two. Also the new assembly comes in handy when I want to access SharePoint 2003 and do things without having to deploy web parts or executables on the server (everything is done through SharePoint web services).
The tool has gone off to QA for our own migration so I'll put together a small spike project with examples on how to use it. I'll include some samples on using the SharePoint wrapper assembly as it's handy to be able to bring up a treeview of all of your sites. I used it for another tool we created for deploying web parts to all sites or deleting lists. It can easily be extended to perform more functions but this was all we needed right now.
If there's any specific requests for functionality in the assemblies let me know and I'll include them before a release later this week. Just have to package up the code and put together some examples then release everything in a day or so.
Do we really need version history of documents?
This is something that's been bugging me for awhile so I thought I would throw it out there. "Is it really worth keeping version history of documents?". Other than legal reasons, I can't see why any would need version history of a document. Source code. Sure. Absolutely. A document? I'm beginning to think that there's no real reason why history is that important.
Look at a document. Okay, so you'll be able to go back in time and see that Joe added a paragraph or something. If you use Office, this feature is already built into the product. If it's a binary file of some kind (like a PDF) you really can't compare or track revisioning in the document (yes, Adobe had this feature but you need special tools to use it). The only case I can see is a text file where you can do diffs of the versions, but then why would I really care?
Retaining history seems to be so important to some, but I wonder if that's really the case? Maybe take a look at your documents and try to justify why you think you need a complete version history. Is it really worth keeping in the long run?
SharePoint Wrappers
As part of my migration tool that I broke down and wrote, I've created a .NET assembly for accessing both SharePoint 2001 and 2003 systems. It uses PKMCDO internally to talk to the Web Storage System and get information about folder and documents and .NET web services to talk to 2003 servers and sites to perform basic stuff like adding web parts, deleting lists, etc. All you need to do is point it at your SharePoint server so you can build desktop apps or non-SharePoint web apps to do SharePoint functionality. I'll clean up the assembly and make it available this weekend for anyone interested. It's not the perfect solution (using web services it's somewhat limited) but at least you can deal with a SharePoint site as a real object.
User Control Container Web Part
I found a great tip and component that strangely enough has been around for a couple of months. Fons Sonnemans over at Reflection IT created a nice simple SharePoint Web Part that acts like a container for normal ASP.NET User Controls (.ascx files). This makes it dead simple to customize a portal page by adding normal ASP.NET controls to it.
You simply deploy the web part into your SharePoint environment and then create a custom control (his example uses a simple calculator). Deploy the user control to your web server (not sure if it has to be the SharePoint server) and then specify it in the wrapper web part. Presto. Instant Web Part without having to do all that funky Render code. Very nice.
There's an updated version of the component here. You can find the original information and v1.0 of the web part here.
Got ideas?
I have some spare cycles coming up and would like to offer my services for anyone looking for "small" web parts or .NET apps that interact and perform
some function directly with SharePoint Portal Server or the WSS. These are things I want to add to the community so who better to provide ideas than well, the community. A couple of caveats to this:
1. These are small spike projects not giant enterprise solutions so don't ask the world of me (i.e. I'm not going to build a business automation process engine for you).
2. I cannot make SPS/WSS do things it's not designed for (like providing a web part that grants folder level security) so don't ask.
3. There are no guarantees on the work done here and any creations are released to the community with source code for anyone to use. You're just there to get something directly and spark the ideas.
4. This is not contract work so nothing in return is expected.
5. Please send me your ideas, wants, desires to bsimser@shaw.ca only please.
Bring it.
Wrapping PKMCDO and Adding documents via HTTP PUT
/// <summary>
/// Gets the document root for a given workspace on the server.
/// Will load it on demand if it hasn't been created yet.
/// </summary>
/// <param name="workspaceName"></param>
/// <returns><;
}
/// <summary>
/// Connects to a SharePoint server for accessing
/// workspaces, folders, and items.
/// </summary>
/// <returns></returns>,
null);
return rc;
}
}
/// <summary>
/// This represents a wrapper class to more easily
/// use the PKMCDO KnowledgeFolders object for accessing
/// Sharepoint 2001 items. It uses COM interop so it's
/// slooow but it works and at least you can use C# iterators.
/// </summary>
public class SharePointFolder
{
private string folderUrl;
private KnowledgeFolder folder = new KnowledgeFolder();
private ArrayList subFolders = new ArrayList();
/// <summary>
/// Constructs a SharePointFolder object and opens
/// the datasource (via a url). COM interop so its
/// ugly and takes a second or so to execute.
/// </summary>
/// <param name="url"></param>
public SharePointFolder(string url)
{
folderUrl = url;
folder.DataSource.Open(
folderUrl,
null,
PKMCDO.ConnectModeEnum.adModeRead,
PKMCDO.RecordCreateOptionsEnum.adFailIfNotExists,
PKMCDO.RecordOpenOptionsEnum.adOpenSource,
null,
null);
}
/// <summary>
/// This loads the subfolders for the class
/// if there are any available.
/// </summary>();
}
}
}
#region Accessors
public ArrayList SubFolders
{
get { return subFolders; }
}
public bool HasSubFolders
{
get { return folder.HasChildren; }
}
public string Name
{
get { return folder.DisplayName.ToString(); }
}
#endregion
}:
/// <summary>
/// This function uploads a local file to a remote SharePoint
/// document library using regular HTTP responses. Can be
/// included in a console app, windows app or a web app.
/// </summary>
/// .
Working on a simple document migration tool
I'm kinda fed up at the migration tools for SharePoint (and maybe I'm just still steamed at the fiasco I went through yesterday). Using SPIN and SPOUT was to get everything (with history) from 2001 to 2003. My plan was, once migrated into the SharePoint Document Libraries, to just copy these things down to where they belong. Now I'm on the warpath to write a proper migration tool. One step read from 2001 to write into 2003. It's all there via Web Services and the old SharePoint 2001 OM. Why is this so difficult? All the tools that Microsoft gives you are for mass migrations and assume you want to maintain security and copy all the profiles, etc. 2003 is a completely different beast architecturally and makes you think differently about the way your organize your information. Yes, there are some other commerical tools that might do this but again these are just not quite right. And to top it off, nothing ever seems to work from your desktop. You have to be running right on the SharePoint servers directly. This is just not right and I'm out to fix it (somehow). Back later with the results of my madness...
One other note from yesterdays blog, Addy Santo has posted a commont about an an excellent deployment tool which assists both in migrations and deployments, and can take most of the pain out of the process. There wasn't much to check out but I'm going to investigate this and see if this can assist with what I'm trying to do here.
Share.
Remembering Design Principles
After taking a look at NDepend and running it on a few projects at work, most of the assemblies seem to either be living in the Zone of Pain or the Zone of Uselessness. While I'm not using NDepend as the silver bullet to tell me who's been naughty or nice, I am wondering how many basic design principles have been forgotten (or some cases never learned in the first place).
The common ones that I keep going back to (and evangelise to those that care) are:
- The single responsibility principle (a class should have only one reason to change)
- The common reuse principle (the classes in a component are reused together. If you reuse one of the classes in a component, you reuse them all)
- The interface segregation principle (clients should not be forced to depend upon methods that they don’t use. Interfaces belong to clients, not to type hierarchies)
- The abstract factory pattern (to trim down dependencies between concrete types)
- The separated interface pattern
There are others, but these are usually the most common and most violated as I keep looking at other peoples code (and my own for that matter).
Design Quality Metrics for .NET Applications
I've been struggling with a concept at work. How to measure the quality of an application? It's typical to ask and there are some basic things you can look at, but for the most part you're doing code reviews or looking through architecture diagrams trying to figure out what someone built and is it good.
Now along comes NDepend. It analyses .NET assemblies and generates design quality metrics around them. You can measure the quality of a design in terms of extensibility, reusability, and maintainability. Prety nice stuff and of course, open source (yay for OSS!). You can check out the latest version of NDepend here and check out a sample report of NDepend run against NUnit here. Neat stuff.
Unit Testing with SharePoint Web Parts
In my experiences, one of the best things you can do (if you do any XP practice at all) is to write Unit Tests. These are a small, focused set of tests that perform some specific testing of the system. For an overview of Unit Tests check out this link here. In the .NET space, NUnit is my preferred Unit Test framework. Your milage may vary.
When writing Web Parts for SharePoint, you can apply the same practice to your web part and exercise the Unit Tests using the NUnit GUI (or NUnit command line if you prefer). First download NUnit from here and install it to your development environment and on the SharePoint server.
How you setup your tests are up to you (and what dependancies your web parts will need) but try to position the Test Fixture up as high as you can on the SharePoint tree, holding whatever information you need. Get a reference to the entire web collection if you want so that way your tests don't have to tax the SharePoint server too much when running. Then just manipulate the collection during your tests. As long as you clean up after yourself (like deleting a site after creating it) everything should be fine.
Here's a sample test for a custom webpart that creates new sites (using the SPWebCollection class). The Test counts the number of existing sites and stores it and then adds a new site and tests the count (you could also find the test using a query or something but this is a simple example). The test uses data from the web part for input into the site creation process (name, description, etc.):;
using NUnit.Framework;
using CustomWebPart;
namespace CustomWebPart.Test
{
// This is our custom web part which
// has some public properties for the new site
private CustomWebPart webPart;
private SPWeb webSite;
private SPWebCollection siteCollection;
private string currentTemplate;
[TestFixtureSetUp]
public void Init()
{
webPart = new CustomWebPart();
webSite = new SPWeb(““);
siteCollection = webSite.Webs;
currentTemplate = webSite.WebTemplate;
}
[Test]
public void TestAddSite()
{
string siteName = webPart.SiteName;
string siteDescription = webPart.SiteDescription;
string siteUrl = webPart.SiteUrl;
int siteCount = siteCollection.Count;
// Add the new site
siteCollection.Add(siteUrl, siteName, siteDescription, Convert.ToUInt32(1033), currentTemplate, True, False);
int newCount = siteCollection.Count;
Assert.AreEqual(siteCount+1, newCount, “Invalid site count“);
// delete the site we just created
siteCollection.Delete(siteName);
}
}
You can reference any part of your Web Part or invoke a method on it to help with your tests as needed. As well, once you create a connection to a SPSiteCollection or SPWebCollection you can iterate through sites or get individual sites and perform any tests on them. Just keep your tests clean and simple and only test what you need to as it relates to your Web Part. | https://weblogs.asp.net/bsimser/archive/2004/6 | CC-MAIN-2018-30 | refinedweb | 2,430 | 62.68 |
Break, Continue and Pass
Break Statement
Python break Statement uses for the conditionally exit from the loop flow according to the user, Break rapidly terminates the area of the loop.
If the loop is used in a nested loop at that time, the nested loop will be terminated and come into the outer loop, here is the diagram of the break statement.
Diagram
Syntax
break
Program
for x in "salesforcedrillers": if(x=="c"): break print(x,end=" ")
When the condition is true then loop has terminated.
Output:
s a l e s f o r
Break using in the nested loop
Program:
for x in range(1): for y in range(1,10): if(y==5): print("Break Point") break print("Inner Loop") print("Outer Loop")
Here you can see that when inner loop terminated by the break it come out at outer loop
Output:
Inner Loop Inner Loop Inner Loop Inner Loop Break Point Outer Loop
Break using with while loop
Program:
i=1 while(i<=10): if(i==9): print("Break Point") break print(i,end=" ") i+=1
Output:
1 2 3 4 5 6 7 8 Break Point
Continue Statement
Continue statement is used for the skipping the value if the conditional will be satisfy, basically this statement has used when we want to skip the any condition. Here is the diagram which will clearly show the function of the Continue
Diagram
Program:
for x in "salesforcedrillers": if(x=="l"): continue print(x,end=" ")
Output:
= RESTART: C:/Users/laptop/AppData/Local/Programs/Python/Python38-32/break.py s a e s f o r c e d r i e r s >>>
Program:
for x in range(1,100): if(x%2!=0): continue print(x,end=" ,")
Output:
= RESTART: C:/Users/laptop/AppData/Local/Programs/Python/Python38-32/break.py 2 ,4 ,6 ,8 ,10 ,12 ,14 ,16 ,18 ,20 ,22 ,24 ,26 ,28 ,30 ,32 ,34 ,36 ,38 ,40 ,42 ,44 ,46 ,48 ,50 ,52 ,54 ,56 ,58 ,60 ,62 ,64 ,66 ,68 ,70 ,72 ,74 ,76 ,78 ,80 ,82 ,84 ,86 ,88 ,90 ,92 ,94 ,96 ,98 >>>
Pass Statement
Pass statement is like null if you do not want to do anything then declare it as Pass. it is like a comment, but in the case of comment is ignore by the interpreter but pass is not ignored by the interpreter.
Syntax
pass
Program:
a=[1,2,3,4,5] for x in a: pass
Output:
>>> = RESTART: C:/Users/Manish/AppData/Local/Programs/Python/Python38-32/break.py >>>
Program :
def abc() pass | https://salesforcedrillers.com/learn-python/break-continue-and-pass/ | CC-MAIN-2022-40 | refinedweb | 427 | 55.2 |
Inherits fltk::Image.
Draws inline XPM data. This is a text-based 256-color image format designed for X11 and still very useful for making small icons, since the data can be easily inserted into your source code:
#include "image_name.xpm" static xpmImage image_name(image_name_xpm);
FLTK recognizes a few extensions to the xpm color map: Setting the number of colors negative means the second line in the array is a "compressed" colormap, which is 4 bytes per color of character,r,g,b. If all colors are grays and there is no transparent index, it instead makes a MASK image, where black draws the current color and white is transparent, and all other grays are partially transparent. This allows you to put antialiased glyphs into images.
This is called by the draw() functions once after the Image is created or after refetch() has been called. This allows subclasses to defer reading files and calling setpixels() calls until the first draw() or measure(). This should return true if successful, false on any error (though fltk does not do anything useful with errors).
The base class does nothing and returns true, thus leaving the image unchanged.
Sample implementation:
bool MyImage::fetch() { setsize(get_width(file), get_height(file)); setpixeltype(my_pixeltype); for (int y=0; y<height(); y++) { uchar* buffer = linebuffer(y); get_line_of_pixels(file, buffer, y); setpixels(buffer, y); } return true; }
Reimplemented from fltk::Image. | http://www.fltk.org/doc-2.0/html/classfltk_1_1xpmImage.html | CC-MAIN-2017-51 | refinedweb | 230 | 50.06 |
This)?
Latest posts made by Olivier Van Parys
- RE: Bid-Ask Data to OHLC
- RE: Escape from OHLC Land
One last question on this, as mentionned, I did use a csv file with the exact same column structure as in your example (columns=[bid, ask, datetime in last position]). The original file however come with the following structure [symbol, datetime, bid, ask] as show here:
EUR/USD,20180201 00:00:00.125,1.24171,1.24173 EUR/USD,20180201 00:00:00.262,1.24172,1.24173 EUR/USD,20180201 00:00:00.695,1.24172,1.24175 EUR/USD,20180201 00:00:00.838,1.24173,1.24178 EUR/USD,20180201 00:00:00.848,1.24174,1.24177
Thus modifing the BidAskCSV class:
class BidAskCSV(btfeeds.GenericCSVData): linesoverride = True # discard usual OHLC structure # datetime must be present and last lines = ('PAIR','datetime','bid', 'ask') # datetime (always 1st) and then the desired order for params = ( ('PAIR', 0), # inherited from parent class ('datetime', 1), # inherited from parent class ('bid', 2), # default field pos 1 ('ask', 3) # default field pos 2 )
The above won't work due to lines = ('PAIR','datetime','bid', 'ask') however replacing the section below instead is not returning an error message and so seems to be working fine:
lines = ('datetime','bid', 'ask')
I understand that the field 'PAIR' being a string is what is causing the error (code section below from -loadline), thus my questions:
- What is the underlying rationale ? Is it because "lines" should only refers to preset categories defined in BT (datetime, OHLV, volume, etc...)?
- What is the impact of simply not mentioning "PAIR" in the "lines" list (if any)?
for linefield in (x for x in self.getlinealiases() if x != 'datetime'): # Get the index created from the passed params csvidx = getattr(self.params, linefield) if csvidx is None or csvidx < 0: # the field will not be present, assignt the "nullvalue" csvfield = self.p.nullvalue else: # get it from the token csvfield = linetokens[csvidx] if csvfield == '': # if empty ... assign the "nullvalue" csvfield = self.p.nullvalue # get the corresponding line reference and set the value line = getattr(self.lines, linefield) line[0] = float(float(csvfield))# Why is the expectation to ALWAYS have a float - can it be changed for more flexibility? (cg 'PAIR' filed in TruFX import - Error message return True
- RE: Escape from OHLC Land
@backtrader - This is really helpful. I looked into dateintern.py to better grasb where rounding is occuring, I now understand why adding (timespec='milliseconds') brought more confusion, I have therefore removed it as it was truncating as opposed to rounding to nearest .001s. However to your point this was only a display issue - in the background the actual rounding is much less insignificant and clearly not a source of concern. See relevant code here for those with an interest:
def num2date(x, tz=None, naive=True): # Same as matplotlib except if tz is None a naive datetime object # will be returned. """ :class:`datetime` instance in timezone *tz* (default to rcparams TZ value). If *x* is a sequence, a sequence of :class:`datetime` objects will be returned. """ ix = int(x) dt = datetime.datetime.fromordinal(ix) remainder = float(x) - ix hour, remainder = divmod(HOURS_PER_DAY * remainder, 1) minute, remainder = divmod(MINUTES_PER_HOUR * remainder, 1) second, remainder = divmod(SECONDS_PER_MINUTE * remainder, 1) microsecond = int(MUSECONDS_PER_SECOND * remainder) if microsecond < 10: microsecond = 0 # compensate for rounding errors if True and tz is not None: dt = datetime.datetime( dt.year, dt.month, dt.day, int(hour), int(minute), int(second), microsecond, tzinfo=UTC) dt = dt.astimezone(tz) if naive: dt = dt.replace(tzinfo=None) else: # If not tz has been passed return a non-timezoned dt dt = datetime.datetime( dt.year, dt.month, dt.day, int(hour), int(minute), int(second), microsecond) if microsecond > 999990: # compensate for rounding errors dt += datetime.timedelta(microseconds=1e6 - microsecond) return dt
Going deep into your code really helped me appreciate how much work was put into this, (and I know I am only scratching the surface , this is humbling - I wish I could code like you do :-).
For newbies like myself - it is probably worth mentioning the F7 button in Pycharm Debuging facility to execute line by line. This is a real life saver. Hope that helps some people.
- RE: Escape from OHLC Land
I did shout "Victory" too early indeed. Below is the tail end of my dataset
Original csv input (last 5 lines): 1.2192,1.21923,20180228 23:59:47.750 1.21918,1.21922,20180228 23:59:51.024 1.21917,1.2192,20180228 23:59:51.029 1.21916,1.2192,20180228 23:59:51.087 1.21915,1.21919,20180228 23:59:58.725
Indeed we can spot a few discrepencies when I look at the output of the backtrader script:
3916973: 2018-02-28T23:59:47.749 - Bid 1.21920 - 1.21924 Ask 3916974: 2018-02-28T23:59:51.023 - Bid 1.21918 - 1.21922 Ask 3916975: 2018-02-28T23:59:51.028 - Bid 1.21917 - 1.21920 Ask 3916976: 2018-02-28T23:59:51.087 - Bid 1.21916 - 1.21920 Ask 3916977: 2018-02-28T23:59:58.725 - Bid 1.21915 - 1.21919 Ask
I have tried date2num function which I noticed you use a few times across background files, but it isn't working either:
At this stage, I am at a loss as to where it would make sense to apply any modification so as not to corrupt the input (Tick data from TrueFX)
dtstr = self.data.datetime.datetime().isoformat(timespec='milliseconds') txt = '%4d: %s - Bid %.5f - %.5f Ask' % ((len(self), date2num(dtstr)/1000, self.data.bid[0], self.data.ask[0])) ````
- RE: Escape from OHLC Land
Thanks so much! That was as simple as modifying this line:
dtstr = self.data.datetime.datetime().isoformat(timespec='milliseconds')
WOuld it be fair to say that this fix is only cosmetic and the the 3 extra random digits that were added at the back of the micorseconds are still occuring in the background?
Just wondering if I would get consistent results should we process those micorsecond ticks (for instance in terms of count within 5ms OHLC bars)
- RE: Escape from OHLC Land
Thanks for this example
I am trying to adapt it to a dataset with the same colum structure for simplicity, the only difference is that the datetime field also has millisconds (eg 3 digits after the dot (like so: 02/03/2010 16:53:50.158).
As such I have made a slight modification to the code as per below, the problem I have is that I then get 3 extra random digits at the back of those millisecond (e.g. instead of 02/03/2010 16:53:50.158 I get 02/03/2010 16:53:50.158003) :
parser.add_argument('--dtformat', '-dt',
required=False, default='%Y%m%d %H:%M:%S.%f',
help='Format of datetime in input')
I have tried to replace the above code with "default='%Y%m%d %H:%M:%S.%fff'" but that doesn't work .
Any help would be greatly appreciated. | https://community.backtrader.com/user/olivier-van-parys | CC-MAIN-2021-21 | refinedweb | 1,173 | 64.3 |
Search found 49 matches
- Sun Dec 30, 2007 3:07 pm
- Forum: Volume 113 (11300-11399)
- Topic: 11374 - Airport Express
- Replies: 15
- Views: 7161
my idea was to first find the sp from start to all other vertices (say its d0[]) and end to all other vertices( say it is d1[]). then for each edge(u,v) in the commercial express i checked wheather i hav a smaller d0 + w(u,v) + d1[v] lenght(i cheked it for bothe (u,v) and (v,u) ), if a smaller lengt...
- Sat Dec 01, 2007 6:23 pm
- Forum: Volume 110 (11000-11099)
- Topic: 11015 - 05-2 Rendezvous
- Replies: 48
- Views: 18034
- Tue May 22, 2007 10:25 pm
- Forum: Volume 9 (900-999)
- Topic: 988 - Many Paths, One Destination
- Replies: 9
- Views: 7648
getting WA
a simple graph problem. but getting wa. i don no why. plz somebody provide some suggetions, i/o. #include <stdio.h> #include <vector> #include <queue> #include <string.h> using namespace std; #define MAXN 1000 vector <int> adj[MAXN]; int path[MAXN]; bool visited[MAXN]; int v; int BFS() { int i,u,nex...
- Sat May 19, 2007 9:45 pm
- Forum: Volume 111 (11100-11199)
- Topic: 11175 - From D to E and Back
- Replies: 18
- Views: 9265
- Fri May 18, 2007 11:24 pm
- Forum: Volume 109 (10900-10999)
- Topic: 10917 - Walk Through the Forest
- Replies: 19
- Views: 10861
lots of WA
What i've done is: 1. Find shortest path from 2 to all vertex using dijkstra 2. build another di graph with edges (u,v) such that d > d[v] in the original graph. that is length of any path from v to 2 is shorter than length of any path from u to 2; 3. count the number of paths from 1 to 2 in the new...
- Mon Feb 05, 2007 11:00 pm
- Forum: Volume 108 (10800-10899)
- Topic: 10804 - Gopher Strategy
- Replies: 39
- Views: 24081
So many WA's in this prob
I am doing bin search on distance and running mbm. I'm getting wa in this. #include <stdio.h> #include <queue> #include <vector> #include <string.h> #include <algorithm> #include <math.h> using namespace std; #define NIL -1 #define MAXN 110 typedef struct Point_ { double x,y; } Point_; double maxDis...
- Thu Jan 18, 2007 9:58 pm
- Forum: Volume 9 (900-999)
- Topic: 928 - Eternal Truths
- Replies: 11
- Views: 5534
Getting WA in 928. Hlp
Hi all, i'm getting WA in 928 with my BFS code. Can some1 provide hlp plz (suggetions,i/o......) #include <stdio.h> #include <queue> #include <string.h> using namespace std; #define MAXN 300 #define _min(a,b) (a) < (b) ? (a) : (b) typedef struct state_ { int r,c,nm; } state_; int row,col; char maze[...
- Fri Nov 24, 2006 3:12 pm
- Forum: Volume 4 (400-499)
- Topic: 408 - Uniform Generator
- Replies: 48
- Views: 5369
Can somenone plz give explanation or proof why STEP and MOD are good choices if gcd(STEP,MOD) == 1.
-Shihab
-Shihab
- Wed Aug 23, 2006 3:59 pm
- Forum: Volume 100 (10000-10099)
- Topic: 10061 - How many zero's and how many digits ?
- Replies: 43
- Views: 22603
- Tue Aug 22, 2006 9:30 pm
- Forum: Volume 100 (10000-10099)
- Topic: 10061 - How many zero's and how many digits ?
- Replies: 43
- Views: 22603
WA in 10061
Getting WA in this prob. My code passed all the inputs posted in the prev posts. I still don't know my fault. I'm giving my code.
Code: Select all
Cut after AC
- Mon Aug 21, 2006 10:09 pm
- Forum: Volume 103 (10300-10399)
- Topic: 10354 - Avoiding Your Boss
- Replies: 47
- Views: 22609
WA in 10354
Getiing WA in this problem. Here's the code: #include<stdio.h> #include<vector> #include<string.h> using namespace std; #define NIL 0 #define MAX 500 #define INF 99999999 typedef struct Node_ { int id,d; } Node_; bool visited[MAX+1]; bool visitedByBoss[MAX+1]; vector<Node_> adj[MAX+1]; int d[MAX+1],...
- Thu Aug 17, 2006 11:02 pm
- Forum: Volume 103 (10300-10399)
- Topic: 10330 - Power Transmission
- Replies: 43
- Views: 17100
10330 - Getting WA. Plz Hlp
Hi all, I'm getting WA in this prob. I've used EKarp MaxFlow to solve it. I've splitted each vertex(other than source and sink) in two and have places a edge between them having capacity equal to the given node capacity. I've tested my code with several inputs (also the ones given in prev posts), an...
- Tue Aug 15, 2006 10:13 pm
- Forum: Volume 103 (10300-10399)
- Topic: 10344 - 23 out of 5
- Replies: 81
- Views: 29573
10344
Hi all, I'm getting TLE in 10344. I've used recursion to denerate all possible strings of "+*-". since there are 4 slots for operators and 5 operands. so there can be at most 3^4 * 5! or 9720 possible expressions. I think this can be evaluated within time. But i'm getting TLE.some1 plz hlp...
- Sun Jul 23, 2006 10:06 pm
- Forum: Volume 110 (11000-11099)
- Topic: 11051 - Dihedral groups
- Replies: 8
- Views: 2687
- Sun Jul 23, 2006 8:39 pm
- Forum: Volume 110 (11000-11099)
- Topic: 11051 - Dihedral groups
- Replies: 8
- Views: 2687
11051 - Dihedral groups
Hi all,
I'm getting WA in this problem. Can some1 give me some I/O.
-Thanx in advance
I'm getting WA in this problem. Can some1 give me some I/O.
-Thanx in advance | https://onlinejudge.org/board/search.php?author_id=5296&sr=posts | CC-MAIN-2021-10 | refinedweb | 910 | 81.43 |
There’s no doubt Moment.js is one of the most popular libraries in the JavaScript ecosystem, but now that it’s considered a legacy project in maintenance mode and its use is discouraged, you may be looking for some alternatives.
At first, looking for an alternative library may not seem like an easy task because there’s a lot of things you can do with Moment.js. For example:
- Add any amount of time, from milliseconds to years
- Check if a date is after another date
- Display a moment in time in relation to any other time
- Show a date using a specific locale
However, most projects don’t need all this functionality. While some projects may use Moment.js to format dates and times in a particular way (relative dates and times are popular), for other projects it may be more important to check if a date is before, after, or between other dates or displaying dates according to the locale of the user.
So probably, many projects can satisfy their requirements by using a combination of native JavaScript objects (such as Date and Intl) and optionally, one lightweight library for specific purposes.
Last year, I wrote an article reviewing alternatives to Moment.js in the context of internationalization. The libraries reviewed in that article (luxon, date-fns, day.js) are still good alternatives to Moment.js, but in this article, I’ll review the functionality of three more libraries:
Also, I’ll revisit the Intl.RelativeTimeFormat object, which reached Stage 4 at the beginning of 2020 and is now supported by more browsers.
Let’s get started.
js-joda
If you have worked with Java, you won’t have a hard time learning how to use this library because it’s a port of the Date/Time API that was introduced in Java 8 (which in turn, is based on the library Joda-Time, hence the name).
js-joda is organized into a set of immutable core classes. The main ones are:
- LocalDate, which represents a date without time information. For example,
2020-12-01
- LocalTime, which represents time. For example,
10:00:01.999999999
- LocalDateTime, which represents a date with time information. For example,
2020-12-01T10:00:01.999999999
These classes don’t provide time zone information. For this, you have to use ZonedDateTime, which stores the date, time, and time zone information, and ZoneId or ZoneOffset to work with particular time zones (you’ll also need to import the package
@js-joda/timezone).
The library also provides other classes (such as ChronoField) and types to represent portions of a date or time (such as Month). In particular, there’s a set of classes that represent amounts and points in time:
- Duration, which represents an amount of time from nanoseconds to days. For example, 2 hours
- Period, which represents a date-based amount of time using days, months, and years. For example, 2 years and 5 days
- Instant, which represents a single point in time measured from
1970-01-01T00:00:00Z(including time zone information). For example,
2020-12-01T10:00:47.202Z
Most of these classes have a common interface so they can implement the same methods in different ways. For example, Temporal provides a contract with methods for manipulating date-time fields (such as days or seconds) that are implemented by classes such as
Instant,
LocalTime, and
ZonedDateTime, among others.
This way, for parsing or creating date-time objects, all the classes have variations of the methods
of,
from,
parse, and
now. Here are some examples:
// Creates a LocalDate object from a year, month, and dayOfMonth value const ld1 = LocalDate.of(2020, Month.DECEMBER, 1); // Creates a LocalTime object from an ISO 8601 string const lt1 = LocalTime.parse("10:01:00.123456789"); // Creates a LocalDateTime object from the current datetime in UTC time const ldt1 = LocalDateTime.now(ZoneOffset.UTC); // Creates a ZonedDateTime ojbect from from a local date, time, and a time zone const zdt1 = ZonedDateTime.of(ld1, lt1, ZoneId.of("Europe/Paris")); // Creates an instant from the ZonedDateTime object const i1 = Instant.from(zdt1); // Creates a Period object from a text string such as PnYnMnD const p1 = Period.parse("P1Y10M"); // Creates a Duration object from a number of standard hours (positive or negative) const d1 = Duration.ofHours(-48);
The
with* methods can be used as setters (creating a new instance since everything is immutable):
// Returns a copy of the LocalDate with the value 2020/12/3 const ld2 = ld1.withDayOfMonth(3); // Returns a copy of the Instant object with the specified seconds but without changing the nanoseconds part const i2 = i1.withFieldValue(ChronoField.INSTANT_SECONDS, 923232434);
Or you can use the
at* methods to combine two instances of different types:
// Combines a LocalDate and a LocalTime object to create a new LocalDateTime const ldt2 = ld1.atTime(lt1); // Combines a LocalDateTime object and a time zone to create a ZonedDateTime object const zdt2 = ldt1.atZone(ZoneId.of("+04:00"));
In a similar way, the methods to query and check for conditions start with
is:
console.log(ld1.isLeapYear()); console.log(ldt1.isBefore(ldt2));
And there are
plus and
minus method to manipulate the date/time information of the objects:
// Add 10 minutes: 10:11:00.123456789 const lt2 = lt1.plusMinutes(10); // Add a duration const ldt3 = ldt1.plus(d1); // Subtract one hour: 09:01:00.123456789 const lt3 = lt1.minus(1, ChronoUnit.HOURS); // Substract a period const zdt3 = zdt1.minusAmount(p1);
Regarding date formatting, js-joda doesn’t have as many options as moment.js, but it does have a set of pattern strings (the same patterns used in Java) for custom formats. Here are some examples:
// 10:00 console.log(lt2.format(DateTimeFormatter.ofPattern("h:m"))); // 2019, 1 console.log(zdt3.format(DateTimeFormatter.ofPattern("y, Q")));
However, if your pattern contains text, you’ll have to use a locale.
To do so, import the package
@js-joda/timezone along with
@js-joda/locale to import all locales, or an individual locale package (
@js-joda/locale_de, for example):
import "@js-joda/timezone"; import { Locale } from "@js-joda/locale_de"; // ... // Formatting text with the DE locate: Okt. 1 2:52 PM console.log( ldt3.format( DateTimeFormatter.ofPattern("MMM d h:m a").withLocale(Locale.GERMAN) ) );
You can try all the examples in this sandbox.
Sugar
Sugar is a library that provides many utility functions to work with arrays, numbers, objects, and dates, among other types.
The library contains many modules and polyfills, with a total size of around 38k gzip. However, if you don’t plan to use the complete set of functionality, you have three options:
- Create a custom build through the download page
- Install the complete package with npm or bower, which allows you to require methods and entire modules individually
- Install just the package(s) of the module(s) you’re going to use. In this case, the sugar-date package
Sugar has three modes of use:
- Default, which uses the
Sugarglobal object, organized into namespaces that correspond to the modules that extend the native classes. The methods are called directly on the object. For example,
Sugar.Date.create("2020-01-01")
- Chainable, which uses the Sugar namespaces as constructors to build an instance. For example,
new Sugar.Date("2020-01-01").isLeapYear().raw
- Extended, which maps the methods directly on the native types:
Sugar.Date.extend(); console.log(new Date().isLeapYear());
Here I’ll use the default mode.
To create an instance use the
create() method passing a variety of formats, many of them unconventional:
const d1 = Sugar.Date.create("last month"); const d2 = Sugar.Date.create("in 2 hours"); const d3 = Sugar.Date.create("20th of May"); const d4 = Sugar.Date.create("13 Jan 2014 11:00:00 CST"); const d5 = Sugar.Date.create("the 2nd Friday of October 2009"); const d6 = Sugar.Date.create("6-2017"); // months are zero-based, this is actually May, 2017 const d7 = Sugar.Date.create("5 minutes ago");
You can see a lot of examples of how to create dates in the unit tests of the library.
Once you have created a Sugar instance, you can manipulate the date using the
set method, which also accepts a boolean parameter to reset the units more specific than those passed (just remember that months are zero-based):
// Sets month to January Sugar.Date.set(d1, { month: 0 }); // Sets day to 10 and reset hours to midnight Sugar.Date.set(d2, { day: 10 }, true);
In Sugar, not all methods are immutable. Here you can find the list of methods that mutate the date object.
There are also methods to shift the date forward and backwards (
advance() and
rewind() respectively), add single units of time
add*() methods) and moving the date to the beginning or end of a unit of time (
beginningOf*() and
endOf*() respectively):
// Shifts the date forward one month Sugar.Date.advance(d3, { months: 1 }); // Keys can be singular too: month // Shifts the date backwards 2 hours Sugar.Date.rewind(d4, { hours: 2 }); // Adds 1 month Sugar.Date.addMonths(d5, 1); // Sets the date to Jan 1st at midgnight of the same year Sugar.Date.beginningOfYear(d6); // Sets the time to 11:59:59 Sugar.Date.endOfDay(d7);
Methods beginning with
is allow us to compare or test dates:
// Is the year of d1 2020? Sugar.Date.is(d1, '2020'); // Is d1 before January 2nd, 2020? Sugar.Date.isBefore(d1, 'January 2nd, 2020'); // Is d1 after December 2018? Sugar.Date.isAfter(d1, 'December 2018'); // Is d1 Friday? Sugar.Date.isFriday(d1); // Is d1 a date in the future? Sugar.Date.isFuture(d1); // Is d1 a weekday? Sugar.Date.isWeekday(d1);
Sugar also provides a way to get time differences in many units with the methods
*Since,
*Ago,
*Until, and
*FromNow:
// How many months have passed since d4? Sugar.Date.monthsSince(d4); // How many years have passed between d4 and d5? Sugar.Date.yearsSince(d4, d5); // How many days ago was d4) Sugar.Date.daysAgo(d4); // How many hours aga from d5 was d4? Sugar.Date.hoursAgo(d5, d4); // How many weeks from d4 until now? Sugar.Date.weeksUntil(d4); // How many seconds until d5 from d4? Sugar.Date.secondsUntil(d5, d4); // How many ms from now to d4) Sugar.Date.millisecondsFromNow(d4);
But what I like most about Sugar is all the options it provides for formatting. The
format method supports two types of tokens, LDML, and strftime.
LDML, which are formats that are both short and easy to remember (search for a list of tokens here):
Sugar.Date.format(d3, "{Weekday}, {hours}:{mm}:{ss}{TT}"); // e.g. Saturday, 12:00:00AM
And strftime, which is used in other programming languages, such as Python (search for a list of tokens here):
Sugar.Date.format(d3, "{Weekday}, {hours}:{mm}:{ss}{TT}"); // e.g. Saturday, 12:00:00AM
In addition, there are four predefined format patterns (
short,
medium,
long, and
full):
Sugar.Date.short(d6); // 01/01/2017 Sugar.Date.medium(d6); // January 1, 2017 Sugar.Date.long(d6); // January 1, 2017 12:00 AM Sugar.Date.full(d6); // Sunday, January 1, 2017 12:00 AM
And two methods for relative time (
relative and
relativeTo) that automatically choose the most appropriate unit:
Sugar.Date.relative(d2); // 2 weeks ago Sugar.Date.relativeTo(d2, d5); // 10 years
English is the default locale included automatically. At the time of this writing, Sugar supports 17 locales, which are included in the official build or added separately via the downloads page.
A locale can be set globally with the
setLocale method, or passed as an argument to locale dependent methods such as
isLastWeek (so it can know the beginning of the week),
create(), or
relative():
import "sugar-date/locales"; // Sets the locale to italian globaly // Sugar.Date.setLocale("it"); // Parse the string with the spanish locale const d8 = Sugar.Date.create("hace 5 dias", "es"); // Uses the default locale, english (or the one set with setLocale) // It doesn't use the locale used to create the instance Sugar.Date.full(d8); // Uses the french locale Sugar.Date.full(d8, "fr");
You can try all the examples in this sandbox.
Spacetime
Spacetime is a library to parse, manipulate, compare, and format dates with a special focus on time zones and daylight saving time (DST) to avoid errors when manipulating times in time zones with different DST rules.
You have to be aware of some considerations, however, spacetime has an API very similar to Moment.js (with some nice additions), with the difference that all its methods are immutable.
For example, you can create a Spacetime instance using many input formats and some helper methods:
/ ISO Format const s1 = spacetime("2020-12-01"); // As long date const s2 = spacetime("Dec 02 2020 17:50"); // As epoch in ms const s3 = spacetime(1606975200000); // As an array (months are zero-based) const s4 = spacetime([2020, 0, 1, 20, 0]); // As an object (months are zero-based) const s5 = spacetime({year:2020, month:0, date:1}); // Current time const s6 = spacetime.now(); // Today at midgnight const s7 = spacetime.today(); // Tomorrow at midnight const s8 = spacetime.tomorrow();
Getters and setters are handled in the same way that Moment.js is, with a few helpful additions such as
season(),
hourFloat(), and
progress():
// Sets a new date based on s1 with 400 milliseconds const s9 = s1.millisecond(400); // Get milliseconds: 400 console.log("s9.milliseconds(): " + s9.millisecond()); // Get month (zero-based): 11 console.log("s9.month(): " + s9.month()); // Get day of year: 336 console.log("s9.dayOfYear(): " + s9.dayOfYear()); // Get day of year: winter console.log("s9.season(): " + s9.season()); // Set the hour + minute in decimal form const s10 = s2.hourFloat(16.5); // Get the time: 4:30pm console.log("s10.time(): " + s10.time()); // How far the moment lands between the start and end of the day/week/month/year (percentage-based) console.log("s3.progress('year'): " + s3.progress('year'));
The same happens with query or comparison methods:
// s3: 2020-12-03 // s4: 2020-01-01 console.log("s3.isAfter(s4): " + s3.isAfter(s4)); console.log("s3.isBefore(s4): " + s3.isBefore(s4)); console.log("s3.isEqual(s4): " + s3.isEqual(s4)); console.log("s3.leapYear(): " + s3.leapYear()); // Detect if two date/times are the same day, week, or year, etc console.log("s3.isSame(s4, 'year'): " + s3.isSame(s4, "year")); // Given a date amd a unit, count how many of them you'd need to make the dates equal console.log("s3.diff(s4, 'day'): " + s3.diff(s4, "day")); // Is daylight-savings-time activated right now, for this timezone? console.log("s3.inDST(): " + s3.inDST()); // Does this timezone ever use daylight-savings? console.log("s3.hasDST(): " + s3.hasDST()); // The current, DST-aware time-difference from UTC, in hours console.log("s3.offset(): " + s3.offset()); // Checks if the current time is between 10pm and 8am console.log("s3.isAsleep(): " + s3.isAsleep());
As well as with manipulation methods:
// s5: 2020-01-10 1:31pm // Move to the first millisecond of the day, week, month, year, etc. const s11 = s5.startOf('month'); // 2020-01-01 12:00am // Move to the last millisecond of the day, week, month, year, etc. const s12 = s5.endOf('week'); // 2020-01-12 11:59pm // Increment the date/time by a number and unit const s13 = s5.add(1, 'season') // 2020-05-10 1:31pm // Decrease the date/time by a number and unit const s14 = s5. subtract(2, 'years') // 2018-01-10 1:31pm // Move forward/backward to the closest unit const s15 = s5.nearest('hour'); // 2020-01-10 2:00pm // Go to the beginning of the next unit const s16 = s5.next('quarter'); // 2020-01-04 12:00am // Go to the beginning of the previous unit const s17 = s5.last('month'); // 2019-12-01 12:00am
To format dates and times, Spacetime has some predefined formats:
s11.format('numeric-uk') // 01/01/2020 s12.format('iso-utc') // 2020-01-13T05:59:59.999Z s13.format('mm/dd') // 05/10 s14.format('nice') // Jan 10th, 1:31pm s15.format('quarter') // Q1 // They can be combined using this syntax s16.format('{day} {date-ordinal}, {month-short} {year}')); // Sunday 1st, Dec 2019
But you can also use more standard date format patterns:
s17.unixFmt('yyyy/MM/dd h a')); // 2019/12/01 12 AM
Or the
since() function for relative times. For example, when you execute:
spacetime('September 1 2020').since('September 30 2020')
It will return the following object:
{ "diff": { "years": 0, "months": 0, "days": -29, "hours": 0, "minutes": 0, "seconds": 0 }, "rounded": "in 29 days", "qualified": "in 29 days", "precise": "in 29 days" }
About time zones, when you create an instance, you can pass an additional parameter to specify the time zone (the use of IANA names is recommended):
const s18 = spacetime(1601521200000, "Europe/Paris"); const s19 = spacetime([2020, 0, 1, 20, 0], "Lima"); // America/Lima const s20 = spacetime.now("-4h");
But once you have an instance, you can also easily change it to another time zone with
goto() (once again, the use of IANA names is recommended):
const s21 = s18.goto("Australia/Sydney"); // Oct 1 2020, 1:00pm const s22 = s18.goto("GMT-5"); //-5 is actually +5
Also, you can get an array containing all the time zones within a range of hours using your local time as a reference:
spacetime.whereIts('12:00pm', '2:00pm') // ["asia/seoul", "asia/tokyo", "pacific/palau", "australia/adelaide", ...] spacetime.whereIts('10am') // Within an hour, from 10am to 11am
And get the metadata of the time zone of an instance:
s21.timezone(); /* Returns: { "name": "Australia/Sydney", "hasDst": true, "default_offset": 10, "hemisphere": "South", "current": { "offset": 10, "isDST": false }, "change": { "start": "04/05:03", "back": "10/04:02" } } */
You can try all the examples in this sandbox.
Intl.RelativeTimeFormat
One of the most helpful features of Moment.js is the ability to display dates as relative time:
const start = moment('2020-12-01'); const end = moment('2020-12-04'); start.to(end); // "in 3 days" start.to(end, true); // "3 days"
Not all libraries provide this functionality, but now that
Intl.RelativeTimeFormat is fully supported by most browsers, this is not a problem anymore.
Intl.RelativeTimeFormat is a standard built-in object that allows you to format numbers as relative times in a localized way.
The constructor optionally takes two arguments, a BCP 47 language tag (or an array of such strings) and an object with properties to configure the locale matching algorithm, the format, and the length of the output message:
const rtf = new Intl.RelativeTimeFormat("es", { localeMatcher: "best fit", numeric: "auto", style: "short" });
Once you have an instance of this object, you can use the
format() method passing the numeric value to use in the message as the first argument, and the unit (like days or hours, in either singular or plural forms) as the second argument:
rtf.format(-4, 'second'); // hace 4 s rtf.format(-1, 'week'); // la semana pasada rtf.format(3, 'quarter'); // dentro de 3 trim. rtf.format(2, 'year'); // dentro de 2 a
Or
formatToParts() to get an array with the parts of the message separated:
rtf.formatToParts(-4, 'second'); /* Returns: [ { "type": "literal", "value": "hace " }, { "type": "integer", "value": "4", "unit": "second" }, { "type": "literal", "value": " s" } ] **/
And if you’re wondering how to get the numeric part, in other words, the elapsed time between two dates, check out this StackOverflow answer that shares the following function:
// in miliseconds var units = { year : 24 * 60 * 60 * 1000 * 365, month : 24 * 60 * 60 * 1000 * 365/12, day : 24 * 60 * 60 * 1000, hour : 60 * 60 * 1000, minute: 60 * 1000, second: 1000 }; var rtf = new Intl.RelativeTimeFormat('en', { numeric: 'auto' }); var getRelativeTime = (d1, d2 = new Date()) => { var elapsed = d1 - d2; // "Math.abs" accounts for both "past" & "future" scenarios for (var u in units) if (Math.abs(elapsed) > units[u] || u == 'second') return rtf.format(Math.round(elapsed/units[u]), u); }
You can try all the examples in this sandbox.
Conclusion
There’s no doubt there are a lot of alternatives to Moment.js. In this article, we have reviewed three libraries that provide similar functionality and a few useful additions in some cases.
In my opinion, each of those libraries is better at different use cases:
- js-joda works great as a general-purpose library, in particular, if you have a Java background
- Sugar is particularly good for formatting dates, and since it provides many methods for types other than dates, it can be useful for other parts of your application
- Spacetime is particularly good for when you have to support multiple time zones due to the way it calculates remote times and the methods for changing between time zones.
Also, now the JavaScript Internationalization API is more widely supported by browsers, consider the combination of a lightweight library and native features or even if you need an external library at all.
Happy coding!. | https://blog.logrocket.com/more-alternatives-to-moment-js/ | CC-MAIN-2021-04 | refinedweb | 3,460 | 55.95 |
I have this project:
.txt
Let's tackle this one step at a time...
Getting the data:
string readText = File.ReadAllText("path to my file.txt");
Now that we have it in a string we can parse it
List<string> listStrLineElements = List<string> listStrLineElements = line.Split(new string[] { Environment.NewLine }, StringSplitOptions.None).ToList();// You need using System.Linq at the top.
More options for splitting at a new line can be found here
Now, you need to split each element into its own row; you said you had it tab delimited which is good (something like comma seperated (CSV) is more common modernly, but tabs will work!)... For that we can do something like this:
List<string> rowList = listStrLineElements.SelectMany(s => s.Split('\t')).ToList();// The \t is an *escape character* meaning tab.
now, you need something like a loop to go through each one of these entries and insert it into the database, which means we now need our database connection...
Connecting to the database
Make sure you are using the SQL namespace...
using System.Data.SqlClient;
private void sqlCon(List<string> x) { //Replace with your server credentials/info SqlConnection myConnection = new SqlConnection("user id=username;" +"password=password;server=serverurl;" +"Trusted_Connection=yes;" +"database=database; " + "connection timeout=30"); try { myConnection.Open(); for (int i = 0; i <= x.Count -4; i += 4)//Implement by 3... { //Replace table_name with your table name, and Column1 with your column names (replace for all). SqlCommand myCommand = new SqlCommand("INSERT INTO table_name (Column1, Column2, Column3, Column4) " + String.Format("Values ('{0}','{1}','{2}','{3}')", x[i], x[i + 1], x[i + 2], x[i + 3]), myConnection); myCommand.ExecuteNonQuery(); } } catch (Exception e){Console.WriteLine(e.ToString());} try{myConnection.Close();} catch (Exception e){Console.WriteLine(e.ToString());} }
Note, you may very likely have to change/edit my loop; the logic behind it is to implement i by 4 so you can read each of your columns, so the columns Count (number of entries) must be 4 less so you don't get an index out of bounds (typing this all in notepad I'm not sure if I got all the logic right, but again, if it's wrong that is something you will have to fix, we don't just write code for people).
PLEASE NOTE!
things like string.format() leave you open for an SQL injection, you really should lookup SQL parameters, but this will get the job done. Here are some posts that I consider a must read:
Preventing SQL Injections in C#
What is an SQL Injection (W3-schools) | https://codedump.io/share/GEG85VDfTwwR/1/how-to-import-text-file-and-save-data-into-database | CC-MAIN-2016-50 | refinedweb | 424 | 65.22 |
IntelliJ and Spark is the best combination for doing the real Big Data development. IntelliJ IDEA is the best IDE for Spark, whether your are using Scala, Java or Python. In this guide we will be setting up IntelliJ, Spark and Scala to support the development of Apache Spark application in Scala language.
Install IntelliJ Scala plugins
First of all we need to install the required plugins into our IntelliJ. Go to File -> Settings -> Plugins and look for both Scala and Sbt.
After installing them, you might need to restart your IDE. Do that if prompted.
Create Spark with Scala project
No we can start creating our first, sample Scala project. Go to File -> New -> Project and then Select Scala / Sbt
On the next screen choose the right version of Scala. Your chosen version should be compatible with the version of Spark you will be using. In my case it was Scala 2.12
Add Spark libraries to Sbt
Now in our newly created project, find build.sbt file, and add the following lines:
name := "SparkTest" version := "0.1" scalaVersion := "2.12.8" libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "2.3.3", "org.apache.spark" %% "spark-sql" % "2.3.3" )
After that, IntelliJ should ask if you want to download new dependencies. If prompted, click yes. In a situation when IDE is not asking you about that, you might have automatic downloading of dependencies turned on, which is totally fine. These two libraries will add support for Spark code we will be writing in a moment.
Run the Spark Scala application in IntelliJ
Let’s create a basic application and test if everything runs properly. Create an object named FirstSparkApplication and paste in the code below:
import org.apache.spark.sql.SparkSession object FirstSparkApplication extends App { val spark = SparkSession.builder .master("local[*]") .appName("Sample App") .getOrCreate() val data = spark.sparkContext.parallelize( Seq("I like Spark", "Spark is awesome", "My first Spark job is working now and is counting down these words") ) val filtered = data.filter(line => line.contains("awesome")) filtered.collect().foreach(print) }
Now just execute it, and in the run console, you should see a string Spark is awesome.
Summary
I hope you have found this post useful. If so, don’t hesitate to like or share this post. Additionally you can follow me on my social media if you fancy so :)
Bartosz Gajda
Setting up @intellijidea for @ApacheSpark and @scala_lang language. Improve your #BigData workflow, by automating compilation and #testing in #Spark.
bartoszgajda.com/2019/07/05/set…
#intellij #intellijidea #apache #apachespark #bigdata #scala #programming #softwareengineering20:12 PM - 06 Feb 2020
Discussion (0) | https://practicaldev-herokuapp-com.global.ssl.fastly.net/bartoszgajda55/setting-up-intellij-idea-for-apache-spark-and-scala-development-4ne2 | CC-MAIN-2021-21 | refinedweb | 436 | 58.89 |
Chuck Geiger wrote: . . . Cannot make a static reference to the non-static field Data.var (this was why my original post had "static" on the first line. . . .
I got it wrong when I wrote: . . . . . .
public final class GeogData
{
. . .
@Override public int hashCode()
{
long bits = Double.doubleToLongBits(longitude);
int longHash = (int)(bits >> 0x20 ^ bits);
bits = Double.doubleToLongBits(latitude);
int latHash = (int)(bits >> 0x20 ^ bits);
return (((name.hashCode()
+ currencyName.hashCode()) * 31
+ altitude) * 31
+ longHash) * 31
+ latHash;
}
. . .
}
Chuck Geiger wrote:I am writing a program that is much less predictable. The data file being read in could contain any number of rows AND any number of columns (separated by commas, *.csv fashion). Each column will always have the same kind of information (like yours) BUT the values in any of those positions can be any kind of data (numerical or text). That's why I am preserving a string version of each data value, so that I can process it elsewhere to determine what kind of data it is and what other statistical tests it's suited for. The ones that are numbers will be stored as numbers as well. When I need strings, such as for output purposes, I'll have the .valStrValue field ready for that.
Thanks again for your patience.
Chuck Geiger wrote: . . . we are talking at cross-purposes a bit. Your model is based on the assumption that the data being read in will always be in the same format: name, latitude, longitude, etc. I am writing a program that is much less predictable. . . . | http://www.coderanch.com/t/586493/java/java/Accessing-Object-properties | CC-MAIN-2015-18 | refinedweb | 255 | 68.36 |
Quoting Peter Astrand astrand@lysator.liu.se:
Your examples don't work with call either, right?
They work with call if you use a string argument. That's the core of the problem: The callv function doesn't support passing a string-type args argument to the Popen constructor.
Their call() equivalents:
subprocess.call(["somewindowsprog.exe some strange command line"]) subprocess.call(["somewindowsprog.exe", "some", "strange", "command",
"line"])
are just as broken, no?
Yes. You'll need to do:
subprocess.call("somewindowsprog.exe some strange command line")
Given that call is only a shortcut function, wouldn't the following suffice?:
def call(*args, **kwds): if len(args) <= 1: return Popen(*args, **kwds) else: return Popen(args, **kwds)
With that implementation, a single string, a list, a sequence of strings and Popen keywords only would all work as arguments to call. That is:
call("ls -l") -> Popen("ls -l") call("ls", "-l") -> Popen(["ls", "-l"]) call(["ls", "-l"]) -> Popen(["ls", "-l"]) call(args="ls -l") -> Popen(args="ls -l")
All it would mean is that if you want to use the optional arguments to Popen, you either don't use call, or you use keywords.
Cheers, Nick. | https://mail.python.org/archives/list/python-dev@python.org/message/UTPJCHINQTM2IPFZQCT4I7IIIVFPI6BT/ | CC-MAIN-2021-21 | refinedweb | 196 | 64.91 |
function getPay(employeeID) // note: this is not meant to nec. be good code, only to illustrate concept record = getEmployeeByID(employeeID) pay = base_pay_constant if record.isManager pay = pay * 1.4 else pay = pay * 1.1 endif ... return(pay) end functionHere, the caller may have no idea whether the employee is a manager or not. Further, I don't see where the plurality matters. Also, the above definition depends on the definition of "object", which is what we are trying to define in the first place, and thus the definition appears to be recursive. One is trying to use polymorphism to define objects, but also using objects to define polymorphism. Isn't the "if record.isManager" line requiring the caller to know whether an employee is a manager and selecting one of two possible operations? No. That is possibly determined at run time, not a programming time. For an employee's status may change between programming and running. Aren't do_something() and do_something_else() different names? {That was originally to simplify the illustration, so I rewrote as to not make it an issue.} "Manager" is an attribute. There are multiple orthogonal attributes that can be assigned to an "employee" entity. Yes, you can artificially make any given attribute into a "type", but whether that is good or not is another matter. Note the difference if we rewrite to a polymorphic class. The getEmployeeByID(employeeID) function is also assumed to become a class factory that returns either a Manager or Employee class derived from a record class.
function getEmployeeByID(employeeID) if isManager return new Manager(employeeID) else return new Employee(employeeID) endif end function function Manager::getPay() ... //equivalent operation to do_something(...) end function function Employee::getPay() ... //equivalent operation to do_something_else(...) end functionI don't see how this relates to the original definition and example. I am seeking a clearer text-based definition, not a "how-to" coding lesson, I would note. Under languages with different characteristics than the typical "object.method" syntax, it can become an issue. Otherwise, one would seem to be suggesting that polymorphism is only a syntax convention. Maybe the definition should say "code things" instead of "physical things". In other words, polymorphism is different code things answering the same message in a way that is appropriate to the given thing. (I use "thing" instead of "object" to avoid making the definition recursive, but still need to define "code thing".) However, that still does not distinguish from two different functions which can take the same parameter. | http://c2.com/cgi/wiki?NobodyAgreesOnWhatOoIs | CC-MAIN-2014-15 | refinedweb | 415 | 50.53 |
What's New in ASP.NET 4.5 and Visual Web Developer 11 Developer Preview
-
- ASP.NET Web Pages 2
- Visual Web Developer 11 Developer Preview.
-, but in between each iteration of an asynchronous read loop.
ASP.NET 4.5 has also added a new's say that you want to use this asynchronous method in an asynchronous ASP.NET HTTP module. ASP.NET 4.5 includes a helper method (EventHandlerTaskAsyncHelper) and a new delegate type (TaskEventHandler) that you can use to easily Task-based return signature of ProcessRequestAsync with the older asynchronous programming model used by the ASP.NET pipeline.
The following example shows how you can easily } }! ASP.NET 4.5 added the unvalidated request properties and collections to make it easier for you to tightly scope access to unvalidated request data. However, you must still perform custom parsing and validation on the raw request data to ensure that dangerous text is not rendered back to customers.
Anti-X real upstream client have successfully completed a WebSockets handshake, ASP.NET calls your delegate and the WebSockets application starts running. The following code example shows a simple echo application that uses the built-in low-level WebSockets support in ASP.NET:
public async Task MyWebSocket.
The bundling feature hooks into the ASP.NET routing mechanism and makes it possible to reference an entire folder instead of individual files. Suppose you have the following file structure.
You might want to bundle all .js files in the Scripts folder. To do that, you can now reference the folder and append /js to the path, as in this example:
You can do the same to bundle all the .css files in the Styles folder, but instead you append /css to the path: as shown above will be as follows:
- reset.css
- content.css
- forms.css
- globals.css
- menu.css
- styles.css
The sorting algorithm is customizable.
You can register your own bundles in the Global.asax file in order to specify which files go into each bundle and what the exact URL will be. The following code shows how:
The custom bundle can now be referenced as in this example:
You can even override the default CSS and JavaScript bundles in order to call custom post-processing routines for the bundled files. In the following example, the built-in minification transforms are replaced with custom MyJsTransform and MyCssTransform types. The types derive from the CSS and JavaScript minifier routines, respectively, and add custom functionality.
The bundling and minification feature is built with extensibility in mind, and every part of the process can be extended or replaced.. In Web Forms controls in previous versions of ASP.NET, you use Eval and a data-binding expression to display a data-bound value:
HTML. This approach makes it easy to data bind against arbitrary, unshaped data.
However, data-binding expressions doesn't features like IntelliSense for these member names, support for navigation (like Go To Definition), or compile-time checking of these names.
To address this issue, ASP.NET 4.5 adds the ability to declare what type of data a control is bound to. You do this using the new ModelType property. When you set this property, two new typed variables are available in the scope of data-binding expressions: Item and BindItem. Because the variables are strongly typed, you get the full benefits of the Visual Studio development experience.
The following example shows how IntelliSense works for the Item member:>
For example, if you make a mistake, Visual Studio can offer immediate feedback:
Most controls in the ASP.NET Web Forms framework that support data binding have been updated to support the Model <Columns> <asp:BoundField <asp:BoundField <asp:BoundField <asp:TemplateField <ItemTemplate><%#Item.Products.Count %></ItemTemplate> </asp:TemplateField> </Columns> </asp:GridView>
You create the GetCategories method in the page's code. For a simple select operation, the method needs no parameters and should return an IEnumerable or IQueryable object. If the new ModelType property is also set to enable strongly typed data-binding expressions, the generic versions of these interfaces should be returned — IEnumerable<T> or IQueryable<T>, with the T parameter matching the type of the ModelType property (for example, IQueryable<Category>).
The following example shows the actual GetCategories, which can involve performing type conversion. <Columns> <asp:BoundField <asp:BoundField <asp:BoundField <asp:BoundField </Columns> ; }
Now when the page runs is rendered, users can select a category from the drop-down list, and the GridView control is automatically rebound to show the filtered data. This is possible because model binding tracks the values of parameters for select methods and detects whether any parameter value has changed after a postback. If so, model binding forces the associated data control to rebind
Some improvements have been made to.
Support was added for).
The UpdatePanel control has been fixed to support posting HTML5 input fields.
ASP.NET MVC 4
ASP.NET MVC 4 Beta is not included with Visual Studio 11 Developer Preview. You can get the ASP.NET MVC 4 Beta release by using the Web Platform Installer. For more information, see the ASP.NET MVC 4 Release Notes.
ASP.NET Web Pages 2
ASP.NET Web Pages 2 Developer Preview is not included with the Visual Studio 11 Developer Preview. Installation details will be available soon. For more information, see the ASP.NET Web Pages 2 Release Notes.
This section describes new and enhanced features in ASP.NET Web Pages 2 Developer Preview.
New and Updated Site Templates
Web Pages 2 updates all the existing templates from Web Pages 1 so that they run on Web Pages 2.
The Starter Site template includes the following new capabilities:
- Mobile-friendly page rendering that uses CSS styles to render pages for smaller displays.
- Membership and authentication enhancements. You can use OAuth and OpenID providers to let users log into your site with their Google, Yahoo, Facebook, Windows Live, or Twitter accounts.
- A new Personal Site template. The site is easy for developers to customize and for end users to personalize. The home page of the site lets the user set up a blog, a Twitter page, and a photos page.
Improved Input Validation
Web Pages provides improved tools for validating user input. Some of the new options include:
- Client-side validation, which lets you validate user input using JavaScript. This avoids round trips to the server for validation and improves the performance of your application.
- New validation classes. Classes such as System.Web.WebPages.ValidationHelper and System.Web.WebPages.Validator enable you to specify validation rules with very little code.
To validate user input using these new features, you can use an approach like the following.
- Reference the required jQuery files. You can do this in a page or in a _Layout.cshtml page. The jQuery files can be local or on a remote site (including a CDN, as here).
<script src=""></script> <script src=""> </script> <script src="@Href("~/Scripts/jquery.validate.unobtrusive.min.js")"></script>
- In the input form, include calls to display validation messages.
<form method="post" action=""> <!-- Display a summary message about any validation issues at top of form. --> @Html.ValidationSummary() <!-- The Validation.GetHtml("lastName") call adds validation attributes to the input element. --> <input type="text" name="lastName" value="@Request["lastName"]" @Validation.GetHtml("lastName") /> <!-- Display a field-specific message about validation -- for instance, if a required field is empty. --> @Html.ValidationMessage("lastName")
- Specify what fields in the form are required. For example, you can specify that an input field named lastName is required by using this code at the top of the page:
Validation.Required("lastName");
- Specify what type of data must go in an input field. For example, to specify that a field named quantity should contain only numbers, use code like this:
Validation.Add("quantity", Validator.Integer());
- Wrap your form-processing logic inside a call to your validation rules. You typically process form input in page postback code, and this is where you can check the result of validation:
if(IsPost) { // Wrap the postback code with a validation check. if (Validation.IsValid()) { // Do form processing here. Validation issues are flagged // automatically. } }
The following example uses validation logic similar to the code in the previous examples. Here, the user has not filled in a required field:
Resource Management
Web Pages 2 includes new resource management functions that make it easy to work with scripts when you have a complex site that includes layout pages, content pages, and other source files such as helper files. The resource manager coordinates among the source files to make sure that script files are referenced correctly and efficiently on the rendered page, regardless of where scripts are called from or how many times they are called. The resource manager also renders <script> tags in the right place on a page to avoid errors that can occur if scripts are called before rendering is complete.
For example, this can be very useful if you create a helper that other developers use in their web pages. Suppose that your helper must reference a script. Instead of requiring other developers to register a script on each page that contains the helper, you can register the script in the helper file itself. The resource manager will then make sure that the script is rendered correctly when the page runs.
To use resource management features, do this:
- In the code that needs to reference a script file, call the Scripts.Add method and pass it the path of the script. This registers the script.
- In a page that will reference the code that contains the script, add a call to Scripts.GetScriptTags, which renders the <script> tags. A good place to add this call is at the end of the <body> section of the _Layout.cshtml page, if your site uses a layout page. That way, all required scripts will be referenced when pages that depend on the layout page are rendered.
Enhanced Membership and Authentication
Web Pages 2 includes new authentication options that let visitors log into your site using their credentials from social networking sites such as Google, Yahoo, Facebook, Twitter, and Windows Live. After users log in, they can associate their logins with a single account on your website. New built-in providers for OAuth and OpenID authentication make it possible to add these features to your site with just a few lines of code. If you create a site based on the Starter Site template, most of this functionality is built in and all you have to do is add and uncomment a few lines of code.
The following illustration shows the Login page of the Starter Site template. Notice that users can log in with an existing account or with an external account.
To support login from Facebook, Twitter, or Windows Live accounts, create a site using the Starter Site template and then follow these steps.
- Go to the application developer website for Windows Live, Facebook, or Twitter, create an application, and then record the key and "consumer secret" values.
- In your site, edit the _AppStart.cshtml page and uncomment the code block for the provider you want to use. The following example shows the uncommented code block for the Facebook provider in _AppStart.cshtml:
OAuthWebSecurity.RegisterOAuthClient( BuiltInOAuthClient.Facebook, consumerKey: "", // For FB, consumerKey is called AppID consumerSecret: "");
- Assign the key value from your application to the consumerKey parameter, and assign the secret value from your application to the consumerSecret parameter.
- Edit the ~/Account/Login.cshtml file and uncomment the <fieldset> element near the end of the file that wraps the input buttons for Facebook, Twitter, and Windows Live. This will enable users to see these input buttons on the Login page and submit their logins to those sites. The uncommented <fieldset> element looks like this:
<fieldset> <legend>Log in using another service</legend> <input type="submit" name="provider" id="facebook"value="Facebook" title="Log in using your Facebook account." /> <input type="submit" name="provider" id="twitter" value="Twitter" title="Log in using your Twitter account." /> <input type="submit" name="provider" id="windowsLive" value="WindowsLive" title="Log in using your Windows Live account." /> </fieldset>
- Edit the ~/Account/AssociateServiceAccount.cshtml file and uncomment the same <fieldset> element that you uncommented in the Login file. This lets users associate a login with an existing account on your website.
The following image shows the Facebook login page after you've done these steps and after a user has clicked the Facebook icon on the login page:
Side-by-side Execution
Web Pages 2 lets you run Web Pages 1 applications and Web Pages 2 applications on the same computer. Note the following:
- By default, new websites based on the site templates run on Web Pages 2.
- Existing Web Pages 1 websites continue to run on Web Pages 1.
To run a Web Pages 1 site as a Web Pages 2 site, you have these options:
- Copy all the Web Pages 2 assemblies from the installation folder (for example, C:\Program Files (x86)\Microsoft ASP.NET\ASP.NET Web Pages\v2.0\Assemblies) to the bin folder of your website. This is the simplest approach and is recommended for most users.
-or-
- Update the web.config file of your website with an entry like the following one:
<?xml version="1.0"?> <configuration> <appSettings> <add key="webPages:Version" value="2.0"/> </appSettings> </configuration>
Mobile Device Rendering
Increasingly, visitors view your sites using different devices and display sizes, often on mobile devices. Web Pages 2 adds features for rendering content on mobile (or other non-desktop) devices.
The System.Web.WebPages namespace contains the following classes that let you work with display modes: DefaultDisplayMode, DisplayInfo, and DisplayModes. You can use these classes directly and write code that renders the right output for specific devices. For example, you can write code in your web page code that responds differently based on what kind of device is making a request. You can also create custom display modes that are tailored to recognize specific devices.
Alternatively, you can create mobile-specific pages by using a file-naming pattern like this: FileName.Mobile.cshtml. For example, you can create two versions of a page, one named MyFile.cshtml and one named MyFile.Mobile.cshtml. At run time, when a mobile device requests MyFile.cshtml, Web Pages renders the content from MyFile.Mobile.cshtml. Otherwise, MyFile.cshtml is rendered.
The following two screen shots show a file named Page1.cshtml rendered in a desktop browser and in a mobile-browser simulator.
A desktop browser requests Page1.cshtml:
An Apple iPhone simulator requests Page1.cshtml, but Page1.Mobile.cshtml is rendered:
The Maps Helper
The Maps helper (that is, a new class named Microsoft.Web.Helpers.Maps
) is included with the updated ASP.NET Web Helpers Library. You can use the Maps class to render maps on your website based on the Bing, Google, Yahoo, or MapQuest mapping engines.
To use the Maps class, you must first install the version 2 of the Web Helpers Library, which will be available soon through the Nuget package manager.
The basic process for using the Maps class is to make a call to the mapping engine that you want to use. You pass parameters like a street address or map coordinates, a key value (if the map engine requires it), and optional parameters to configure the appearance of the rendered map.
The following example shows how to call the Google maps provider. In this case, the only required parameter is a street address; all other parameters are optional.
@Maps.GetGoogleHtml("One Microsoft Way, Redmond, WA 98052");
The other map provider calls work similarly (@Maps.GetBingHtml, @Maps.GetYahooHtml, @Maps.GetMapQuestHtml).
The following image shows a map rendered by a call to the Google maps engine:
Visual Web Developer 11 Developer Preview
This section provides information about improvements for web development in Visual Web Developer 11 Developer Preview and Visual Studio 11 Developer Preview.
HTML Editor
Smart Tasks
In Design view, complex properties of server controls often have associated dialog boxes and wizards to make it easy to set them. For example,,Tab when the element is selected in IntelliSense:
This produces a snippet that you can easily 11 Developer Preview a has forced developers to code for specific browsers by using vendor-specific syntax., will show is not included with Visual Studio 11 Developer Preview. To get Page Inspector Developer Preview, install it using Web Platform Installer. For more information, see Page Inspector v1 Developer Preview Release Notes.
Publishing
Publish profiles
In Visual Studio 2010, publishing information for Web application projects is not stored in version control and is not designed for sharing with others. In Visual Studio 11 Developer Preview, 11 Developer Preview Developer Preview is very similar to using it in Visual Studio 2010 SP1.. | http://www.asp.net/web-pages/overview/whats-new/whats-new-in-aspnet-45-and-visual-web-developer-11-developer-preview | CC-MAIN-2013-20 | refinedweb | 2,795 | 56.45 |
Components and supplies
Necessary tools and machines
Apps and online services
About this project
Arduinolibrary for 16-bit IO port
Turnyour Arduino board into 16-bit IO port
Title sounds interesting? or no?
You all will wonder, Arduino UNO or NANO (or other such similar arduino boards)have ATMega328 onboard microcontroller and that is an 8 bit device. Then how it can generate 16-bit output or take 16-bit input?
Also we all know that, the arduino gives digital output using “digitalWrite()”function and gets digital input through “digitalRead()” function. But using these two functions, it can give output or get input from any one pin - means at a time it can give output to or take input from single pin only. Then how it can give output or take input from 16 pins simultaneously?
What if we can club (combine) 16 Arduino board pins together? Means, with onboard 8-bit microcontroller, arduino can give 16-bit output and/or can get 16-bit input.
Now I think this sounds interesting?
So, here I present 16-bit IO Port (input-output port) library for arduino. Using this library one can send direct 16 bit data to any arduino board pins configured as a combined 16-bit port or can get 16-bit input from these configured pins. This library clubs any 16 pins of arduino together to work as 16-bit IO port. Just one has to select any 16 arduino pins to be combined as 16-bit port and it has to configure its data direction as input or output. Data direction is set by character ‘O’ for output or ‘I’ for input.
The library has only 5 functions. There are two constructors that will create port object(s), one function to send 16-bit digital output to port pins, one function to get 16-bit digital input from port pins and one additional function to alter / set IO direction of port. Here all 5 functions are explained in brief and there after some examples are given with explanations.
So just use this library to interface any 16 bit device like ADC, DAC, MUX, or any digital device get 16-bit input or give 16-bit output, char dir)
This is constructor. It will create object(s) of this class and thus it will create one or many 16-bit port(s) by combining distinct arduino pins. One has to specify 16 different arduino pins to be combined as port along with data direction as input or output - means port works as either input or output. The last argument dir in this constructor defines port works as input or output. If dir='O' means port work as output and if dir='I', port works as input. The same port cannot work as input and output both simultaneously or even alternatively. Also it indicates error if data direction is not selected)
This is another constructor. It will also create object(s) of this class and thus it will create one or many 16-bit port(s) by combining distinct arduino pins. One has to specify 16 different arduino pins to be combined as port. But it does not specify the data direction as input or output. After creating port object using this constructor, one has to set the port direction using set_IO_direction function. So this constructor allows programmer to alter port data direction in run time using this constructor, the same port can work as input or output alternatively (but not simultaneously)
3. set_IO_direction(char dir)
This function specifies the input/output direction of port. It has one character argument that can be 'I' for port as input or 'O' for port as output. If data direction is not selected, it displays error on serial monitor of arduino
4. send_16bit_data(unsigned int byt)
This function sends 16 bit data to specified pins. Just give int data (must be < 65535) as an argument that is directly given to 16 different pins. If data is >65535 it displays error on serial monitor of arduino.
5. get_16bit_data(void)
This function gets 16 bit data from specified pins. It returns 16-bit unsigned int data by reading status of 16 different pins
Example1: take 16-bit input and display it on serial monitor
#include<IO_Port_16bit.h>
IO_Port_16bit my16bitport(2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17);
int i;
long input_double_byte;
void setup()
{
// put your setup code here, to run once:
my16bitport.set_IO_direction('I');
Serial.begin(9600);
}
void loop()
{
input_double_byte =my16bitport.get_16bit_data();
Serial.print("input data: ");
Serial.println(input_double_byte);
delay(1000);
}
Example2: 16 LED chaser program
#include <IO_Port_16bit.h>
IO_Port_16bitmy16bitport(2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17);
void setup()
{
// declareport direction as output specifying ‘O’
my16bitport.set_IO_direction('O');
}
void loop()
{
unsigned int i;
for(i=1;i<65535;i*=2)
{
my16bitport.send_16bit_data(i); //send data as 2, 4, 8, 16
delay(200); // 32,..,..,...65534
}
}
Code
16-bit IO port libraryC/C++
No preview (download only).
Schematics
Author
Published onNovember 3, 2019
you might like | https://create.arduino.cc/projecthub/ambhatt/turn-your-arduino-board-into-16-bit-io-port-ec31ab | CC-MAIN-2019-47 | refinedweb | 847 | 62.68 |
5 of the Best Android ORMs
If you are developing an Android application, you will likely need to store data somewhere. You may choose a Cloud service (in which case, using a SyncAdapter would be a good idea), or to store your data in the embedded SQLite database. If you take the second option, you will have to decide between writing SQL queries, using a Content Provider (useful if you want to share your data with other apps), or using an ORM.
In this article, I will discuss some of the Android ORMs you may consider using in your application.
OrmLite
OrmLite is the first Android ORM that comes to my mind. However OrmLite is not an Android ORM, it’s a Java ORM with SQL databases support. It can be used anywhere Java is used, such as JDBC connections, Spring, and also Android.
It makes heavy usage of annotations, such as
@DatabaseTable for each class that defines a table, or
@DatabaseField for each field in the class.
A simple example of using OrmLite to define a table would be something like this:
@DatabaseTable(tableName = "users") public class User { @DatabaseField(id = true) private String username; @DatabaseField private String password; public User() { // ORMLite needs a no-arg constructor } public User(String username, String password) { this.username = username; this.password = password; } // Implementing getter and setter methods public String getUserame() { return this.username; } public void setName(String username) { this.username = username; } public String getPassword() { return this.password; } public void setPassword(String password) { this.password = password; } }
OrmLite for Android is open source and you can find it on GitHub. For more information read its official documentation here.()).
Configure your application to use SugarORM by adding these four
meta-data tags to your apps
AndroidManifest.xml:
<meta-data android: <meta-data android: <meta-data android: <meta-data android:
Now you may use this ORM by extending it in the classes you need to make into tables, like this:
public class User extends SugarRecord<User> { String username; String password; int age; @Ignore String bio; //this will be ignored by SugarORM public User() { } public User(String username, String password,int age){ this.username = username; this.password = password; this.age = age; } }
So adding a new user would be:
User johndoe = new User(getContext(),"john.doe","secret",19); johndoe.save(); //stores the new user into the database
Deleting all the users of age 19 would be:
List<User> nineteens = User.find(User.class,"age = ?",new int[]{19}); foreach(user in nineteens) { user.delete(); }
For more, read SugarORM’s online documentation.
GreenDAO
When it comes to performance, ‘fast’ and GreenDAO are synonymous. As stated on its website, “most entities can be inserted, updated and loaded at rates of several thousand entities per second”. If it wasn’t that good, these apps wouldn’t be using it. Compared to OrmLite, it is almost 4.5 times faster.
Speaking of size, it is smaller than 100kb, so doesn’t affect APK size very much.
Follow this tutorial, which uses Android Studio to show the usage of GreenDAO in an Android application. You can view the GreenDAO source code on GitHub, and read the GreenDAO official documentation.
Active Android
Much like other ORMs, ActiveAndroid helps you store and retrieve records from SQLite without writing SQL queries.
Including ActiveAndroid in your project involves adding a
jar file into the
/libs folder of your Android project. As stated in the Getting started guide, you can clone the source code from GitHub and compile it using Maven. After including it, you should add these
meta-data tags into your app’s
AndroidManifest.xml:
<meta-data android: <meta-data android:
After adding these tags, you can call
ActiveAndroid.initialize() in your activity like this:
public class MyActivity extends Activity { @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); ActiveAndroid.initialize(this); //rest of the app } }
Now that the application is configured to use ActiveAndroid, you may create Models as Java classes by using
Annotations:
@Table(name = "User") public class User extends Model { @Column(name = "username") public String username; @Column(name = "password") public String password; public User() { super(); } public User(String username,String password) { super(); this.username = username; this.password = password; } }
This is a simple example of ActiveAndroid usage. The documentation will help you understand the usage of ActiveAndroid ORM further.
Realm
Finally Realm is a ‘yet-to-come’ ORM for Android which currently only exists. It is built on C++, and runs directly on your hardware (not interpreted) which makes it really fast. The code for iOS is open source, and you can find it on GitHub.
On the website you will find some use cases of Realm in both Objective-C and Swift, and also a Registration form to get the latest news for the Android version.
Final Words
These are not the only Android ORMs on the market. Other examples are Androrm and ORMDroid.
SQL knowledge is a skill that every developer should have, but writing SQL queries is boring, especially when there are so many ORMs out there. When they make your job simpler, why not use them in the first place?
How about you? What Android ORM do you use? Comment your choice below | https://www.sitepoint.com/5-best-android-orms/ | CC-MAIN-2018-13 | refinedweb | 861 | 56.25 |
I’ve noticed a trend among C# programmers which is to avoid the use of the
static keyword. It seems I’m not the only one who’s noticed this either [Twitter]. It’s not inherently limited to C# programmers as C++ can be written in a similar manner, but the terminology bias (functions vs. methods) and its clearer multi-paradigm stance means it’s probably less susceptible.
There is a perception that ‘static’ things – data and methods – are bad. In the wrong hands that can be true, but by throwing the proverbial baby out with the bathwater we have closed the door on embracing some of the goodness that functional-style programming brings.
This article attempts to dispel the myths by illustrating which uses of
static are bad and which are actually beneficial.
Shared mutable state
My guess is that the
static keyword has got a bad rap because of past transgressions caused by functions that were designed decades ago in a time when re-entrancy and multi-threading were something only specialist programmers had to worry about. Yes
strtok() I’m looking at you.
This old C function which is used to tokenise a string has some serious side-effects. Behind the scenes it keeps track of the string being tokenised (which it also modifies) so that you can keep calling it without supplying the original input string when fetching the next token:
char input[] = "unit test "; char separators[] = " "; assert(strcmp(strtok(input, separators), "unit") == 0); assert(strcmp(strtok(NULL, separators), "test") == 0);
In a single-threaded environment you have to be careful not to ‘nest’ use of it (e.g. tokenise a token), and in a multi-threaded environment this kind of behaviour is a disaster waiting to happen. Fortunately many C implementations managed to avoid ruining a programmer’s day due to spurious errors by utilising thread-local storage, but this was a courtesy and not standards-defined behaviour.
The anti-pattern, for want of a better term, which can lead to this kind of sorry state of affairs, is to take a simple function that only depends on its inputs and then find you need to add new behaviour without changing its interface. In a waterfall-esque development process the new behaviour could be the need to cache results, and the inability to change the interface might come from discovering this very late during The Testing Phase. Of course adding a cache and then accidentally making it non-thread-safe is only going to exacerbate your woes at this point of the cycle. More likely it doesn’t need to be thread-safe initially but does later; only no one notices it's not. The C# example in Listing 1 shows how easy it can be to naively add a cache to an existing class.
Sharing mutable state via global variables (
public static properties) is definitely a very bad smell and has been for many years, but also sharing it implicitly across threads can be dangerous too. It’s not just a matter of ensuring our own types are safe, it’s the whole object graph, so any 3rd party collection types have to be checked too.
Although I’ve focused on complex types above, it should be noted that primitive values are not immune from this problem either. If anything they are likely to ‘appear to work’ more than a complex type due to their small footprint. Use of
volatile and the various
Interlocked helper methods are required to keep them behaving properly.
Sometimes sharing mutable state is a necessary evil but there should be precious few times when we need to enter those murky waters. If possible we should look to change the interface or find some other design to make the problem disappear altogether and keep the code simple.
Before moving on let’s just go back to the procedural world of C to look at how we might tackle this problematic function. Putting aside for the moment the fact that
strtok() is a published function specified by a standards process, we could avoid its state problem by changing the interface to allow the state to passed back in by the caller. Also we’d tackle the mutation of the input string to restrict the side-effects to just the state object. (See Listing 2.)
There is still more that could be done to improve matters, such as using two separate functions (e.g.
firsttok()/
nexttok()). But this is C and combining state and functions into a more cohesive package is exactly what object-orientation allows us to do more cleanly in languages like C++ and C#. Hence in OO you might choose to present a
strtok-style class in C# like Listing 3.
Shared immutable state
When talking about the pitfalls of ‘shared state’ it’s important to qualify what sort of state you’re talking about. As we just discussed, shared mutable state can be dangerous when done badly. In contrast shared immutable state is much safer; at least once the potentially tricky initialisation phase is complete. Once we have a read-only data structure it can be used concurrently without the need for any kind of locking. Even if it can be referenced globally, which may still be another smell; it cannot be changed behind our backs.
For example, imagine you’re writing a simple XML parser in C#. To handle the translation of entity references, such as
& to their equivalents you might decide to use a lookup table. This table will likely be immutable and so it requires no additional locking in the event that two threads attempt to parse separate XML documents concurrently. (See Listing 4.)
The initialisation issue is handled for us by the C# language which guarantees that type constructors are thread-safe. That said we need to be especially careful inside a type constructor because if it throws things start going horribly wrong as the type can’t be loaded.
Static classes
C#, unlike C++, does not allow methods to exist outside of classes (often called free functions in C++). Consequently you are forced into defining a class even when all you want to write is a simple function. I suspect this has an undesirable side-effect on C# programmers because I’ve seen them create classes that hold no state, or only hold compile-time immutable state (i.e. constants), e.g.:
public class ConfigurationSettings { public string DatabaseName { get { return ". . . "; } } }
It’s not always as obvious as this and it might be returned as a property of another class. These extra levels of indirection make it harder for a static code analysis tool to spot it and suggest a refactoring.
public class Configuration { public ConfigurationSettings Settings { get { return _settings; }} private readonly ConfigurationSettings _settings = new ConfigurationSettings(); }
In a managed environment like C#, classes such as the
ConfigurationSettings class above are quite literally garbage – the objects just get created and then destroyed again and their behaviour can be determined entirely at compile-time. As with free functions, constants in C# need to be defined as part of a class too:
public static class ConfigurationSettings { public const string DatabaseName = ". . . "; }
The C# answer to classes which shouldn’t be instantiated is to declare them ‘static’. In essence the class is now acting as merely a namespace, albeit one that you can’t elide with a
using declaration at the top.
The canonical example in C# for a static class of ‘pure’ functions (deterministic functions that only depend on their inputs and have no side-effects) is probably the
Math class which plays hosts to fundamentals like
Abs() and
Min().
public static class Math { public static int Abs (int value) { return (value < 0) ? -value : value; } }
Static functions
Right back at the beginning I suggested one reason why there might be a fear of static functions is because of where their implementation could end up. I’d also suggest that programmers find it easier to pass parameters to functions by making them implicit, i.e. through class members accessible via
this.
Back in the 1980s, Meilir Page-Jones wrote a book called The Practical Guide to Structured System Design. He goes into detail about the various types of coupling we might see in code, with each category being viewed as a less desirable form from a maintenance perspective. Whilst the most serious forms of coupling should be avoided, Page-Jones suggests that the weaker forms can be used effectively in the right hands, but also have the potential to cause grief in the wrong ones.
At the farthest end of the spectrum we have Content Coupling which is of little concern in today’s languages. Back in the days of assembler programming you could jump from the middle of one ‘function’ right into the middle of another, meaning you couldn’t ever be sure where you’d come from. Next up is Common Coupling, i.e. global variables. As the name implies they have the ability to affect any and every part of the code-base in unanticipated ways.
Then we come to Control Coupling. This is where one function passes some kind of flag or signal to tell another how to behave. Depending on the direction of the signal either a child is telling its parent how to behave or the parent might know too much about the child’s implementation, either way it’s a symptom of low cohesion.
Moving onwards we come to Stamp Coupling. This oddly named formed of coupling is about passing excessive input to functions that don’t need it. For example, if you had a function that formatted a customer’s full name from their first and last names, you should consider only passing those two arguments, not an entire Customer record. By passing the entire type you make the function (appear to be) dependent on attributes it doesn’t use.
Finally we reach Data Coupling which is analogous to a ‘pure’ function. What Page-Jones tells us is that the easiest code to reason about is this style of function which, as mentioned earlier, has a deterministic output solely based on its direct inputs with no side-effects. In essence, given that some form of coupling is a necessity to do anything useful, then Data Coupling is the most preferable.
Member coupling
His book was published in a time before Object-Orientated Programming was A Big Thing. He is also concerned more with inter-module coupling rather than intra-module coupling, such as between methods of the same class. As the size of a class grows it becomes more common to rely further and further on data being passed between methods via its own state, i.e. its members. I believe there is a form of Stamp Coupling going on here as any method might use its input arguments plus any aspect of the object’s current state or per-class state, and so it is impossible to know what that is without looking at the implementation of an instance method. And that is what coupling is all about – being able to reason about the knock-on effects of a change to other parts of the code.
The over reliance of implied state makes it harder to refactor code later because pulling that state out to another data structure may require lots of unexpected fixing up of other methods. I’ve found that taking Page-Jones’s advice to favour Data Coupling right into the heart of classes has made code easier to read because simple methods start looking like simple black boxes again.
As a simple example consider the class-based OO version of the
strtok() function I mentioned earlier. In the implementation, when it comes to finding the next token we could rely solely on the implied state held in the member variables and code it up as one method (see Listing 5).
One alternative would be to hand-off the finding off the end of the token to a separate little method that is only dependent on its inputs (Listing 6).
Although the first implementation of
NextToken() is quite small there is perhaps a temptation to put a comment above the bit of code that finds the end of the token because it’s not immediately apparent due to the overloaded use of the
_position member (initial start of the next token and then the end of next token). Whenever I find myself wanting to write a comment I consider that to be a sign I should use the Extract Method or Introduce Explaining Variable [Fowler] refactorings instead.
There might be a knee-jerk reaction that splitting code up into so many simple methods would create a big hit on performance. It is possible, but then we all know that premature optimisation is a dangerous pastime. The JIT compiler in .Net and modern C++ compilers can do a pretty good job these days of inlining methods so you’ll probably not notice it in the vast majority of your code.
Exception safety
Whilst it’s highly unlikely that any client code would attempt to recover directly from an OutOfMemory exception thrown from our
StringTokeniser class, it is a library function and they often get used in mysterious ways. Writing exception safe code is hard, especially when it’s so easy to mutate state at an unsafe moment.
A common example I’ve seen of this is when two-phase construction is used and the second phase throws an exception, leaving a member mutated by accident (see Listing 7).
Here, if
ExecuteJob() throws when the
Start() method is called the
_process member will be left pointing to a partially initialised object. When the second call to
ExecuteJob() comes in it will assume the
_process member is fully initialised and will try and to use it.
The general pattern for writing exception safe code is to perform all code that might throw off to the side and then commit the changes locally with non-throwing operations. In this example we could have written it like Listing 8.
Internal factory methods are a good fit for being static because object creation and initialisation is often full of code likely to throw that you might want to keep at arms length until you know you’re dealing with fully constructed objects. By factoring the creation out into a static method you also convey to both the compiler and the reader that they shouldn’t be messing with any of
this object’s state at that point of its lifecycle (Listing 9).
Extension methods
Whilst C# might not support ‘free functions’, it does have Extension Methods and these often embody the practice of writing small independent methods. They are members of a static class and are themselves declared static, despite the fact that they appear to be called as instance methods. If you ever wished that the C# String class had an instance method that could tell you whether a string was empty or just contained white-space, you can make it happen yourself (see Listing 10).
This is often how I find extension methods come about. Initially they start as a simple static method in a class that looks suspiciously as though the first argument really wants to be
this. Once reuse rears its head, it’s a simple step to factor it out into a common extension method. Alternatively it could be pulled out as a formal extension method, but left defined inside a private static class of the current consumer to avoid publishing it formally as that comes with the possible burden of needing to write separate unit tests.
Building classes from static methods
The Object-Orientated paradigm is good for creating types that represent things, but when it comes to algorithms and processes it can start to get ugly. Take the process of parsing a string of XML into a DOM for example. Whilst the input string can be an object, and the output is a tree of objects, the algorithm used to process the characters in the string and create the tree of objects feels much less object-like. It feels to me more like a function that transforms one to the other. Yes, there will be some temporal state involved during the processing, but by-and-large the decomposition of the problem has more of a focus on functions.
If I was using Test-Driven Development to tackle a problem like this my initial tests would very likely start out with just a simple function (Listing 11). You can argue about whether it should be a member of a class called
XmlDocument, or
XmlReader, etc. but either way I wouldn’t start out expecting to create a class like Listing 12.
Anyone who uses FizzBuzz [FizzBuzz] or the Roman Numerals kata in their interview process to separate the ‘wheat from the chaff’ will probably see this kind of thing. It’s not wrong, per se, but it can lead to the kind of ‘empty’ classes described above.
From a Design Pattern’s perspective what my eventual function will become is akin to a façade over a bunch of other functions. As the number of tests grow, so will the number of internal functions. Internal refactoring will start to push some of those out into separate (internal) classes which in turn will likely receive their own more focused unit tests. The handling of XML entity references earlier was very simplistic, just a lookup table, but as more scenarios are discovered so the complexity of that aspect of the implementation will likely increase.
The state required during parsing is entirely transient from the perspective of the caller. It could be held inside an instance of the
XmlParser class, where the public class gets a private constructor because it just becomes an implementation detail of the static
ParseDocument() method. But why even expose that, why not create an internal class, say,
XmlParserImpl and treat
ParseDocument() as a sort of top-level factory method? (See Listing 13.)
If the implementation class is internal then the entire type is encapsulated and so we could hold the state as a Dumb Data Object [DDO] and access it in our static methods via public fields (so long as we promise never to expose it). Then again we could hold the state entirely on the stack by passing it as parameters to recursion functions.
Methods on immutable types
Jon Skeet raised a question at the Norfolk Developers Conference [Norfolk] about how to make methods on immutable types more intention revealing. His canonical example in C# involves the
DateTime class like this:
DateTime date = DateTime.Today; date.AddDays(1);
The method name
AddDays suggests that it will add 1 day to
date and give us the date for tomorrow. Only it won’t. It will create a new
DateTime value based on
date (with an offset) which will subsequently be thrown away by the caller. It’s an easy mistake to make and one of the reasons why writing tests is such a worthy pursuit. The example should have been:
DateTime date = DateTime.Today; DateTime tomorrow = date.AddDays(1);
Jon went on to question whether there is a way to name methods to make this pattern (returning a new value instead of mutating the existing one) more revealing. He proposed this for the example above:
DateTime tomorrow = date.PlusDays(1);
It is an improvement, but I would posit that it’s just too subtle a change in language to really make a difference. Part of the problem is that mutability is the default position in C#; for example the object initializer syntactic sugar relies on the class having writable properties.
My own stance is that once again we can draw from the functional side and use static methods (aka functions) to more clearly suggest that a new value will be created from an existing one and some adjustment:
DateTime tomorrow = Date.AddDays(date, 1);
If you started making the same mistake above with this style, would it be any more obvious?
Date.AddDays(date, 1);
At least this way you start by invoking a static method and so that should tell you something extra that you don’t get by invoking an instance method.
Summary
The
static keyword is in need of a public relations exercise in C# to try and overcome prejudices caused by misunderstanding its role. C# might have started out with a heavy bias towards the object-orientated paradigm but over the years its audience and the language have tried to embrace a multi-paradigm world. This means a stronger focus on immutability and the use of functions instead of objects and mutable state, at least for those problems where it’s beneficial.
The natural outcome of this is code that is easier to reason about and inherently thread-safe. Whilst another language such as F# might be a better tool for the job by removing some of the ceremony, there is no reason why you cannot adopt some of their practices to improve a C# codebase.
Acknowledgements
A debt of gratitude is owed to Ric Parkin and Roger Orr for helping me polish this article.
References
[DDO]
[FizzBuzz]
[Fowler]
[Norfolk]
[Twitter] | https://accu.org/index.php/journals/1900 | CC-MAIN-2020-29 | refinedweb | 3,539 | 56.69 |
Truffle 3 is out, and it switched to a less opinionated build process. In Truffle 2, the default app from
truffle init included a frontend example with build process. Now, there's nothing other than a
build folder for your JSON contract artifacts. This opens up the door for testing and building other (cough command line cough) types of applications!
This is written for those familiar with Truffle and Ethereum, who want to learn how to create a testable, Ethereum-enabled command line application with Truffle.
For this tutorial, we'll be building a command line tool that interacts with the Ethereum Name Service (ENS).
If you were using Truffle beta 3.0.0-9 or below, do not immediately upgrade. Read these release notes and the upgrade guide first. Next, make a new folder and run the following command:
$ truffle init
You should see the
test,
build, and
migrations directories were created for you -- but no
app. Additionally, the build step in the
truffle.js file is mysteriously absent. That's ok! This means Truffle is getting out of your way and letting you control the build process.
Check out the example app as a reference. I'll be referring to it often so give it a look over if you haven't already.
The first thing to look at is the build process. Since Truffle now puts us in control of the build, I've added some custom scripts within
package.json to handle building for us:
... "description": "CLI for ENS deployment", "scripts": { "ens": "babel-node ./bin/ensa.js", "lint": "eslint ./" }, "author": "Douglas von Kohorn", "license": "MIT", ...
I've defined two scripts here:
lint for linting my Javascript to keep my codebase so fresh and so clean, and
ens for transpiling my Javascript command line tool (using Babel) and running it. That's it! That's the build process. You can run it via
npm run lint and
npm run ens. Now that that's out of the way, let's dig into how and why I structured my app this way.
In order to take advantage of all parts of Truffle while building this tool, we need to separate our code into two distinct pieces. First, we need to write a library which will constitute the bulk of the app, and allow us to perform actions against the ENS contracts quickly and easily from Javascript. Next is the CLI; the CLI will take advantage of the library itself, and will be the user's interface to our application.
The library is lib/ens_registrar.js. Let's take a look at the constructor:
... constructor (AuctionRegistrar, Deed, registrarAddress, provider, fromAddress) { this.web3 = new Web3(provider) this.Deed = Deed this.Deed.setProvider(provider) AuctionRegistrar.setProvider(provider) AuctionRegistrar.defaults({ from: fromAddress, gas: 400000 }) this.registrar = AuctionRegistrar.at(registrarAddress) } ...
The library constructor requires a few things:
AuctionRegistrar&
Deed)
It's crucial that the library remain ignorant of the creation of these variables if we want to take advantage of both Truffle's testing pipeline and a CLI. As I see it, there are two ways to use the library:
Let's take a look at how the library is used in both cases.
Here's test/ENS.js, a Truffle test that uses the library:
import { default as ENSAuctionLib } from '../lib/ens_registrar' const Registrar = artifacts.require('./Registrar.sol') const Deed = artifacts.require('./Deed.sol') contract('ENS integration', (accounts) => { let auctionRegistrar before('set up auction registrar', (done) => { Registrar.deployed().then((instance) => { auctionRegistrar = new ENSAuctionLib( Registrar, Deed, instance.address, web3.currentProvider, accounts[0] ) }).then(() => done()) }) it('demonstrates that the domain name is available', (done) => { auctionRegistrar.available('test') .then((isAvailable) => { assert.isTrue(isAvailable) done() }) }) ... }
Truffle injects a global
artifacts.require function, a helper for finding the right compiled contract artifacts within the test environment. The test then finds a deployed instance of the Registrar on the test network via
Registrar.deployed(). Now, with the addition of
accounts, which is passed in via the
contract wrapper (see here), we have enough to instantiate the library and use it to test that the domain name
'test' is available for auction.
Here's index.js, which provides our command line tool, using the library:
import { default as ENSAuctionLib } from './lib/ens_registrar' import { default as Web3 } from 'web3' import { default as contract } from 'truffle-contract' const AuctionRegistrar = contract(require('./build/contracts/Registrar.json')) const Deed = contract(require('./build/contracts/Deed.json')) export default function (host, port, registrarAddress, fromAddress) { let provider = new Web3.providers.HttpProvider(`http:\/\/${host}:${port}`) return new ENSAuctionLib( AuctionRegistrar, Deed, registrarAddress, provider, fromAddress ) }
Here I'm using the same library,
truffle-contract, that
artifacts.require uses under the hood. Because I can't rely on the Truffle framework within the CLI, I have to include the compiled contract artifacts manually. The rest is passed in through the CLI in
bin/ensa.js:
import { default as initializeLib } from '../index' ... let command = argv._[0] if (command === 'bid') { let { name, host, max, port, registrar, account, secret } = argv let auctionRegistrar = initializeLib(host, port, registrar, account) auctionRegistrar.createBid(name, account, max, secret) .then(() => console.log('Created bid for ' + name)) }
You can use the command line tool against any network that has an ENS registrar deployed. First, choose a command:
$ npm run -s ens Usage: bin/ensa.js [command] [options] Commands: winner Current winner of bid bid Place a bid on a domain name reveal Reveal your bid on a domain name Options: --help Show help
Then specify the correct options, including the
account and
registrar:
$ npm run -s ens -- winner -n 'NewDomain' bin/ensa.js winner Options: --help Show help [boolean] --host, -h HTTP host of Ethereum node [default: "testrpc"] --port, -p HTTP port [default: "8545"] --registrar, -r The address of the registrar [string] [required] --name, -n The name you want to register [string] [required] --account, -a The address to register the domain name [string] [required] Missing required arguments: account, registrar
You might be thinking to yourself, "That was a short tutorial". That's because it doesn't need to be much longer: Creating a command line application with Truffle is very similar to creating a web application, but you have to do things a bit differently. For instance, instead of a build process, your command line tool needs to grab your contract artifacts and make them ready for use. Additionally, if you want to take advantage of Truffle's tests, you need to separate your code into a command line interface and a library -- a good practice anyway -- so you can use Truffle's testing framework to test your code.
Truffle 3.0 now makes it easier than ever to write any Ethereum-enabled application, and not just web apps. Stay tuned for more examples in the future where we explore Desktop and Mobile applications, too. Cheers! | https://www.truffleframework.com/tutorials/creating-a-cli-with-truffle-3 | CC-MAIN-2019-22 | refinedweb | 1,127 | 56.05 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.